Redux Business Logic |
Как-то раз в Телеграмм-чате React_JS (кстати, русскоязычный чат, присоединяйтесь) обсуждали вопрос: "где в React-приложении должен быть расположен код, отвечающий за бизнес-логику". Вариантов несколько, мнения разделились. Ну а я решил записать подкаст (автор @PetrMyazin).
Рассмотрим частный пример с бизнес-логикой исключительно на клиенте. Приложение "кредитный калькулятор". Пользователь вводит в форму исходные данные: сумму, срок кредита, еще какие-то параметры; и на лету получает результат, например, сумму переплаты. Весь хитрый алгоритм расчёта суммы переплаты известен и уже реализован в виде JS-функции, назовём её f, которая принимает несколько параметров — те самые данные из формы, пусть будут a-b-c-d, а возвращает эта функция числовой результат (сумму переплаты, обозначим её как x) — это наша бизнес-логика.
Обратите внимание, что функция чистая. Её результат зависит только от входящих параметров. Она не производит никаких side-эффектов, не читает из глобальных переменных. Также эту функцию можно назвать независимой от фреймворка, ведь она одинаково будет работать и в React-приложении, и в Angular, и в Ember, и в jQuery, и даже на VanillaJS.
Но мы решили строить интерфейс на React+Redux, так что теперь возник вопрос: "в какой момент запускать вычисление нашей бизнес-логики". Ещё раз подчеркну, что в этом подкасте мы рассмотрим только упрощённый пример — все вычисления на клиенте, никаких запросов к серверу. В реальном приложении у нас навернка будет часть логики завязана на общение с сервером, но будет и такая часть, которая полностью может быть вычислена на клиенте по уже имеющимся данным. Так что все дальнейшие рассуждения применимы именно ко второй части — вычислениям на клиенте.
Что же, взглянем на форму. Она состоит: из пары текстовых полей, из слайдеров, выпадающих списков, чекбоксов. Введённые пользователем значения этих полей станут входящими параметрами в функцию f. Первый вопрос: "где и как будем хранить значения полей". Вариантов всего два: либо в локальном состоянии самих компонент (чекбоксов, слайдеров и тому подобных), либо в Redux-store.
Локальный state, размазанный по нескольким компонентам, в данном случае неудобен, т.к. нам в итоге нужно получить все значения одновременно, чтобы передать их параметрами a-b-c-d в функцию бизнес-логики. Нам хотелось бы хранить всё в одном месте: либо в неком общем предке (помните lifting state up), либо в Redux-store. Поскольку темой этого подкаста является обзор бизнес-логики в Redux-приложении, будем хранить в Redux.
Пройдём по шагам всю цепочку событий и попробуем прикинуть, в какой же момент лучше всего вызвать функцию бизнес-логики f.
Итак, пользователь меняет что-то на форме, вводит новую цифру в текстовое поле ввода, или двигает слайдер. Срабатывает некий обработчик handleChange — это первое место для вызова бизнес-логики. Но в обработчике handleChange мы можем прочитать значение только текущего измененного поля ввода из event.target.value, а остальные данные формы нам пока недоступны. Напомню, функция f — чистая, она не читает никаких данных из глобальных переменных. Она только принимает параметры a-b-c-d, и возвращает результат x. Значит сам по себе обработчик handleChange не подходит.
Следующий шаг — это функция action-creator. Здесь, с помощью Redux-thunk, мы можем получить весь объект состояния, т.е. получить a-b-c-d для вызова f. Action-creator — хороший претендент, запомним его.
Идём дальше. Поток выполнения переходит к запуску всех редюсер-функций. Редюсеры можно реализовать по-разному. Например, заготовим четыре отдельных функций для поля a, для поля b, для поля c и для поля d. В этом случае каждый из редюсеров имеет доступ к предыдущему состоянию своего поля ввода и к объекту action. Нам же, для запуска функции f, нужны все значения a-b-c-d одновременно. При такой организации редюсеров, единственный шанс — это если мы пробросим все четыре значения a-b-c-d внутри объекта action. По сути, мы таким образом передаем в объект action почти полную копию store. Звучит не очень, не хочется так делать.
Другой способ организации редюсеров — это единый редюсер, который будет обновлять все поля формы сразу, этакий formData-редюсер. Он принимает предыдущее состояние полей формы в виде объекта, содержащего a-b-c-d, обновляет изменившееся значение, а затем запускает функцию бизнес-логики f. Но постойте, а куда мы будем складывать результат вычислений, ту самую сумму переплаты x? Находясь внутри formData-редюсер, единственное место, куда мы можем сохранить x — в тот же самый объект, который теперь у нас будет иметь пять полей: a-b-c-d и x. Впору переименовать этот редюсер в formDataAndResult-редюсер. Он делает всё: и изменение формы запоминает, и результат вычисления бизнес-логики запоминает. Всё в одном большом объекте из пяти полей. Звучит тоже не очень. Слишком жирный редюсер, слишком много всего. Redux настраивает нас на функциональные подходы, на композицию редюсеров. А мы тут пишем одну большую функцию для управления всем сразу.
Дальше у нас запускаются селекторы в container components. Селекторы — это функции в mapStateToProps. Нас интересует селектор для компонента отображающего финальный результат х. Да, здесь можно сделать вызов функции бизнес-логики, т.к. селектор имеет доступ ко всему state, причем к уже обновленному state со свежими значениями a-b-c-d (сделаю на этом небольшой акцент); а результат вычисления функции f, вызванной внутри селектора, попадает в props компонента, отображающего сумму переплаты — вполне рабочее решение.
Если же не в селекторе, то последний шанс вызвать бизнес-логику — это вызвать функцию f непосредственно в методе render компонента x, того самого, который отображает сумму переплаты. Для этого в props придётся прокинуть все четыре требуемые значения a-b-c-d. На мой взгляд это менее изящное решение, чем предыдущее. Селекторы представляются более правильным местом, чтобы запустить вычисления, и передать уже готовый x для отображения.
Мы рассмотрели все варианты. Ну почти все. Можно было обсудить стрёмные способы, типа запуска расчётов в компонент will receive props, или ещё что-нибудь придумать. Но не будем тратить время.
Итого, у нас есть два явных кандидата на запуск бизнес-логики — это action creator и селектор компонента x.
Взглянем на action creator подробнее. Сначала ответим себе на вопрос: "у нас будет один action creator на все поля формы, или по отдельной функции на каждое из полей". Если мы сделаем отдельные функции, то получим четыре action creater-а: changeA, changeB, changeC и changeD; которые на самом деле будут похожи друг на друга, как две капли воды. Если мы хотим вызвать функцию f внутри action creator, эти вызовы придётся скопировать в код всех четырёх функций. Много копипасты. Хотя, кто плотно работает с Redux, boilerplate-кода не боится. Здесь можно организовать фабрику — create action creator, чтобы избежать копирования кода.
Но я предлагаю не углубляться в этом направлении, давайте лучше опишем одну функцию action creator, она будет принимать fieldName и newValue. fieldName — это строковая переменная, обозначающее поле ввода, в которое пользователь что-то ввёл. Используя Redux-thunk, мы можем получить доступ ко всему текущему state внутри нашего action creator-а, что нам и нужно для вызова функции f.
Но обратите внимание, что функция f должна получить самые свежие значения a-b-c-d, а тот state, который мы получим благодаря Redux-thunk, это уже устаревший state. Одно из полей имеет старое значение. Перед тем, как вызывать функцию f, нам нужно понять, в какой именно параметр подставить newValue. С точки зрения JS-синтаксиса, тут можно придумать с десяток элегантных и не очень решений. Но факт остаётся фактом, если мы хотим вызвать f внутри action creator, нам нужно взять текущий state, т.е. уже немного устаревший, и объединить его с только что пришедшим newValue. Не напоминает ли это нам редюсер-функцию, которая занимается ровно тем же самым? Получается, что нам придётся продублировать логику редюсера внутри action creater-а, чтобы сформировать самые свежие значения a-b-c-d.
Дальше-больше. Допустим мы получили результат вызова функции бизнес-логики внутри action creater-а, но теперь нам надо довести результирующее значение x до компонента, отображающего сумму переплаты. Придётся пробрасывать через Redux store, написав соответствующий редюсер и селектор. Сделав это, обратим внимание, что store теперь хранит и данные формы a-b-c-d, и одновременно результат вычисления x. Store получился избыточним. Помимо исходных данным, в нём ещё и результат производных вычислений. Это нехорошо по многим причинам. Некоторые из них мы обсуждали в предыдущих выпусках. Вывод: action creator — плохой выбор для вызова функции бизнес-логики.
Переходим к варианту с вызовом функции бизнес-логики из селектора. Его механику я уже упомянул выше. Селектор компонента, отображающего сумму переплаты, имеет доступ ко всему store. Причём к самым актуальным значениям a-b-c-d. Никакого дублирования кода редюсера. Имея a-b-c-d внутри селектора, мы вызываем f, а результат x передаём в качестве props в компонент, отображающий сумму переплаты. Просто, логично, без дублирования кода и без избыточного состояния. Селектор — отличное место для вызова функции бизнес-логики, которое представлено чистой функции от данных.
Заострю внимание на последней фразе, что мы рассматривали исключительно вычисление на клиенте. Если же ваша бизнес-логика — это не чистая функция, а целый процесс, с походом на сервер, т.е. с некими side-эффектами, то это уже тема отдельного разговора. Тут как раз надо обратить внимание и на action creator, и на middleware. Но обсудим это в другой раз.
Пишите на React, и процветайте!
|
Метки: author comerc разработка веб-сайтов reactjs вискас |
LibGDX + Scene2d (программируем на Kotlin). Часть 0 |
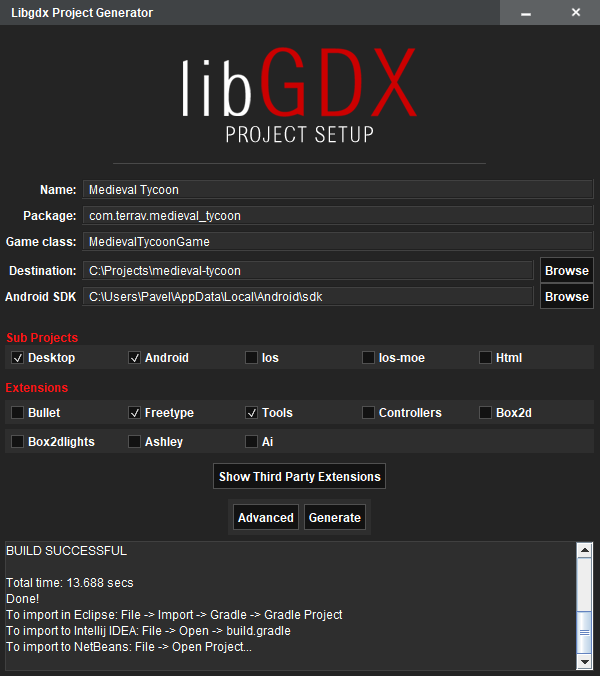
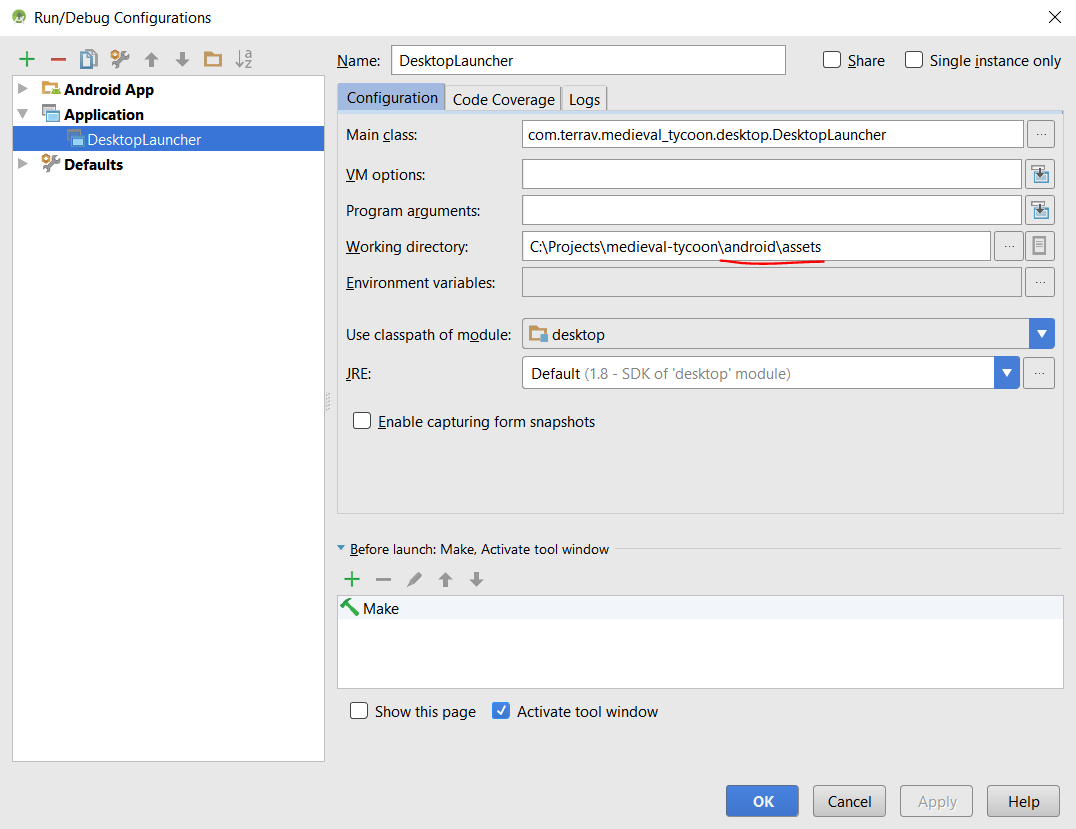

mavenCentral()
maven { url "https://oss.sonatype.org/content/repositories/snapshots/" }
jcenter()
+
+ maven { url 'https://maven.google.com' }
}
+
+ ext.kotlin_version = '1.1.3'
+
dependencies {
- classpath 'com.android.tools.build:gradle:2.2.0'
-
-
+ // uncomment for desktop version
+ // classpath 'com.android.tools.build:gradle:2.3.2'
+ classpath 'com.android.tools.build:gradle:3.0.0-alpha5'
+ classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
}
}
@@ -37,7 +43,7 @@
}
project(":desktop") {
- apply plugin: "java"
+ apply plugin: "kotlin"
dependencies {
@@ -74,13 +80,13 @@
}
project(":core") {
- apply plugin: "java"
+ apply plugin: "kotlin"
dependencies {
compile "com.badlogicgames.gdx:gdx:$gdxVersion"
compile "com.badlogicgames.gdx:gdx-freetype:$gdxVersion"
-
+ compile "org.jetbrains.kotlin:kotlin-stdlib-jre8:$kotlin_version"
}
}
public class MedievalTycoonGame extends ApplicationAdapter {
SpriteBatch batch;
Texture img;
@Override
public void create () {
batch = new SpriteBatch();
img = new Texture("badlogic.jpg");
}
@Override
public void render () {
Gdx.gl.glClearColor(1, 0, 0, 1);
Gdx.gl.glClear(GL20.GL_COLOR_BUFFER_BIT);
batch.begin();
batch.draw(img, 0, 0);
batch.end();
}
@Override
public void dispose () {
batch.dispose();
img.dispose();
}
}
class MedievalTycoonGame : ApplicationAdapter() {
internal var batch: SpriteBatch // ошибка тут <- следует заменить на private lateinit var batch: SpriteBatch
internal var img: Texture // ошибка тут <- следует заменить на private lateinit var img: Texture
override fun create() {
batch = SpriteBatch()
img = Texture("badlogic.jpg")
}
override fun render() {
Gdx.gl.glClearColor(1f, 0f, 0f, 1f)
Gdx.gl.glClear(GL20.GL_COLOR_BUFFER_BIT)
batch.begin()
batch.draw(img, 0f, 0f)
batch.end()
}
override fun dispose() {
batch.dispose()
img.dispose()
}
}private val batch = SpriteBatch()
private val img = Texture("badlogic.jpg")

config.width = 576
config.height = 1024
config.resizable = false
config.vSyncEnabled = false
class MedievalTycoonGame : Game() {
val viewport: FitViewport = FitViewport(AppConstants.APP_WIDTH, AppConstants.APP_HEIGHT)
override fun create() {
screen = LoadingScreen(viewport)
}
}
class LoadingScreen(val viewport: Viewport) : ScreenAdapter() {
private val loadingStage = LoadingStage(viewport)
override fun render(delta: Float) {
Gdx.gl.glClearColor(0f, 0f, 0f, 0f)
Gdx.gl.glClear(GL20.GL_COLOR_BUFFER_BIT)
loadingStage.act()
loadingStage.draw()
}
override fun resize(width: Int, height: Int) {
viewport.update(width, height)
}
}
class LoadingStage(viewport: Viewport) : Stage(viewport) {
init {
val backgroundImage = Image(Texture("backgrounds/loading-logo.png"))
addActor(backgroundImage.apply {
setFillParent(true)
setScaling(Scaling.fill)
})
}
}
init {
val backgroundImage = Image(Texture("backgrounds/loading-logo.png"))
addActor(backgroundImage.apply {
setFillParent(true)
setScaling(Scaling.fill)
})
}
public LoadingStage() {
Image backgroundImage = new Image(new Texture("backgrounds/loading-logo.png"));
backgroundImage.setFillParent(true);
backgroundImage.setScaling(Scaling.fill);
addActor(backgroundImage);
}
|
Метки: author TerraV разработка игр kotlin графика интерфейс libgdx я пиарюсь |
Посещение конференции — чеклист |




|
Метки: author olegchir devops конференция |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №269 (26 июня — 2 июля 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Занимательное |
 Веб Разработка
Веб Разработка Визуальное регрессионное тестирование (как быстро продвигаться в разработке и ничего не ломать) Валидация форм, Часть 1: Проверка ограничений в HTML, Часть 2: API проверки достоверности (JavaScript), Часть 3: Validity State API Polyfill, Part 4: Валидация формы подписки MailChimp
Визуальное регрессионное тестирование (как быстро продвигаться в разработке и ничего не ломать) Валидация форм, Часть 1: Проверка ограничений в HTML, Часть 2: API проверки достоверности (JavaScript), Часть 3: Validity State API Polyfill, Part 4: Валидация формы подписки MailChimp Прогрессивная деградация — HTML Шорты Запись стрима Юрия Артюха ALL YOUR HTML #5: Sexy Fragment Shader and throttle-debounce Полная компиляция видео с React Amsterdam 2017 + бонус JS Foundation: Episode #0 – sonar: инструмент линтинга для веба 8 свойств CodePen, о которых вы не знаете Полноразмерные скриншоты страниц нативными средствами браузеров GreenSock для начинающих: руководство по веб-анимации (часть 1) Анимация органической формы с помощью SVG clipPath
Прогрессивная деградация — HTML Шорты Запись стрима Юрия Артюха ALL YOUR HTML #5: Sexy Fragment Shader and throttle-debounce Полная компиляция видео с React Amsterdam 2017 + бонус JS Foundation: Episode #0 – sonar: инструмент линтинга для веба 8 свойств CodePen, о которых вы не знаете Полноразмерные скриншоты страниц нативными средствами браузеров GreenSock для начинающих: руководство по веб-анимации (часть 1) Анимация органической формы с помощью SVG clipPath  Я решил отключить Google AMP на своём сайте Любой сайт может стать PWA – но мы должны делать это лучше Создание m.uber: разработка высокопроизводительного веб-приложения для глобального маркета
Я решил отключить Google AMP на своём сайте Любой сайт может стать PWA – но мы должны делать это лучше Создание m.uber: разработка высокопроизводительного веб-приложения для глобального маркета CSS Применение стилей для фокуса с клавиатуры Выбираем, как структурировать наши CSS компоненты Как определить и использовать пользовательские свойства CSS Пять основных этапов развития CSS Наложение шрифтов, или как переименовать шрифт в CSS Отзывчивая типографика с помощью calc(), vw, и суперспособности Sass reproCSS — CSS репроцессор, использующий теги
CSS Применение стилей для фокуса с клавиатуры Выбираем, как структурировать наши CSS компоненты Как определить и использовать пользовательские свойства CSS Пять основных этапов развития CSS Наложение шрифтов, или как переименовать шрифт в CSS Отзывчивая типографика с помощью calc(), vw, и суперспособности Sass reproCSS — CSS репроцессор, использующий теги |
|
Продажи через App Store. Неутешительные выводы по-прошествии 4-х лет |
|
Метки: author Elis767 разработка под ios xcode swift objective c заработок в appstore заработок в google play |
Один бит сломал, другой потерял: задачка по передаче данных |
 Картинка отсюда
Картинка отсюдаОбщаются между собой две машины. Шлют друг другу цифровые данные, натурально нули и единицы. Только канал между ними не очень: биты регулярно то искажаются, то пропадают вовсе. Допустим, наш канал из 20 бит в среднем один бит ломает, другой теряет. А теперь пишем алгоритм, наиболее оптимально эти данные передающий.
var runs = this.counter();var frame = this.getPayload(n);n бит полезной нагрузки.this.write(frame);frame, являющийся массивом бит, другой машине. Проходя по каналу передачи, сообщение, возможно, будет искажено.var frame = this.read(n);n бит. Если ничего нет, вернет пустой массив.this.acceptPayload(frame);frame в результирующий массив.true, значит она хочет быть вызвана еще раз в будущем. Иначе, машина завершает свое исполнение. На принимающей машине вызовется проверка целостности принятых данных, а также подсчитается оверхед.|
Метки: author augur программирование ненормальное программирование занимательные задачки алгоритмы задачки выходные |
Метод оптимизации Нелдера — Мида. Пример реализации на Python |
|
Метки: author FUNNYDMAN программирование машинное обучение математика алгоритмы python |
[Из песочницы] Практическое использование в Go: организация доступа к базам данных |
Несколько недель назад кто-то создал топик на Reddit с просьбой:
Что бы Вы использовали в качестве лучшей практики Go для доступа к базе данных в (HTTP или других) обработчиках, в контексте веб-приложения?
Ответы, которые он получил, были разнообразными и интересными. Некоторые люди посоветовали использовать внедрение зависимостей, некоторые поддержали идею использования простых глобальных переменных, другие предложили поместить указатель пула соединений в x/net/context.
Что касается меня? Думаю что правильный ответ зависит от проекта.
Какова общая структура и размер проекта? Какой подход используется вами для тестирования? Какое развитие проект получит в будущем? Все эти вещи и многое другое частично влияют на то, какой подход подойдет для вас.
В этом посте рассматрим четыре разных подхода к организации вашего кода и структурирование доступа к пулу соединений к базе данных.
Данный пост является вольным переводом оригинальной статьи. Автор статьи предлагает четыре подхода по организации доступа к БД в приложении написанном на golang
Первый подход, который мы рассмотрим является общим и простым — возьмем указатель на пул соединений к базе данных и положим в глобальную переменную.
Что бы код выглядел красивым и соответствовал принципу DRY (Don't Repeat Yourself — рус. не повторяйся), вы можете использовать функцию инициализации, которая будет устанавливать глобальный пул соединений из других пакетов и тестов.
Мне нравятся конкретные примеры, давайте продолжим работу с базой данных онлайн магазина и кодом из моего предыдущего поста. Мы рассмотрим создание простых приложений с MVC (Model View Controller) подобной структурой — с обработчиками HTTP в основном приложении и отдельным пакетом моделей содержащей глобальные переменные для БД, функцию InitDB(), и нашу логику по базе данных.
bookstore
+-- main.go
+-- models
+-- books.go
+-- db.goFile: main.go
package main
import (
"bookstore/models"
"fmt"
"net/http"
)
func main() {
models.InitDB("postgres://user:pass@localhost/bookstore")
http.HandleFunc("/books", booksIndex)
http.ListenAndServe(":3000", nil)
}
func booksIndex(w http.ResponseWriter, r *http.Request) {
if r.Method != "GET" {
http.Error(w, http.StatusText(405), 405)
return
}
bks, err := models.AllBooks()
if err != nil {
http.Error(w, http.StatusText(500), 500)
return
}
for _, bk := range bks {
fmt.Fprintf(w, "%s, %s, %s, lb%.2f\n", bk.Isbn, bk.Title, bk.Author, bk.Price)
}
}File: models/db.go
package models
import (
"database/sql"
_ "github.com/lib/pq"
"log"
)
var db *sql.DB
func InitDB(dataSourceName string) {
var err error
db, err = sql.Open("postgres", dataSourceName)
if err != nil {
log.Panic(err)
}
if err = db.Ping(); err != nil {
log.Panic(err)
}
}File: models/books.go
package models
type Book struct {
Isbn string
Title string
Author string
Price float32
}
func AllBooks() ([]*Book, error) {
rows, err := db.Query("SELECT * FROM books")
if err != nil {
return nil, err
}
defer rows.Close()
bks := make([]*Book, 0)
for rows.Next() {
bk := new(Book)
err := rows.Scan(&bk.Isbn, &bk.Title, &bk.Author, &bk.Price)
if err != nil {
return nil, err
}
bks = append(bks, bk)
}
if err = rows.Err(); err != nil {
return nil, err
}
return bks, nil
}Если вы запустите приложение и выполните запрос на /books вы должны получить ответ похожий на:
$ curl -i localhost:3000/books
HTTP/1.1 200 OK
Content-Length: 205
Content-Type: text/plain; charset=utf-8
978-1503261969, Emma, Jayne Austen, lb9.44
978-1505255607, The Time Machine, H. G. Wells, lb5.99
978-1503379640, The Prince, Niccol`o Machiavelli, lb6.99Использование глобальных переменных потенциально подходит, если:
В примере выше использование глобальных переменных замечательно подходит. Но что произойдет в более сложных приложениях, когда логика базы данных используется в нескольких пакетах?
Один из вариантов это вызывать InitDB несколько раз, но такой подход быстро может стать неуклюжим и это выглядит немного странным (легко забыть инициализировать пул коннектов и получить панику вызова пустого указателя во время выполнения). Второй вариант это создание отдельного конфигурационного пакета с экспортируемой переменной БД и импортировать "yourproject/config" в каждый файл, где это необходимо. Если не понятно о чем идет речь, Вы можете посмотреть пример.
Во втором подходе мы рассмотрим внедрение зависимости. В нашем примере, мы явно хотим передать указатель в пул соединений, и в наши обработчики HTTP и затем в нашу логику базы данных.
В реальном мире приложения имеют вероятно дополнительный уровень (конкурентно безопасный), в котором находятся элементы, к которым ваши обработчики имеют доступ. Такими могут быть указатели на логгер или кэш, а также пул соединений с базой данных.
Для проектов, в которых все ваши обработчики находятся в одном пакете, аккуратный подход состоит в том, чтобы все элементы находились в пользовательском типе Env:
type Env struct {
db *sql.DB
logger *log.Logger
templates *template.Template
}… и затем определить ваши обработчики и методы там же, где и Env. Это обеспечивает чистый и характерный способ для создания пула соединений (и для других элементов) для ваших обработчиков.
Полный пример:
File: main.go
package main
import (
"bookstore/models"
"database/sql"
"fmt"
"log"
"net/http"
)
type Env struct {
db *sql.DB
}
func main() {
db, err := models.NewDB("postgres://user:pass@localhost/bookstore")
if err != nil {
log.Panic(err)
}
env := &Env{db: db}
http.HandleFunc("/books", env.booksIndex)
http.ListenAndServe(":3000", nil)
}
func (env *Env) booksIndex(w http.ResponseWriter, r *http.Request) {
if r.Method != "GET" {
http.Error(w, http.StatusText(405), 405)
return
}
bks, err := models.AllBooks(env.db)
if err != nil {
http.Error(w, http.StatusText(500), 500)
return
}
for _, bk := range bks {
fmt.Fprintf(w, "%s, %s, %s, lb%.2f\n", bk.Isbn, bk.Title, bk.Author, bk.Price)
}
}File: models/db.go
package models
import (
"database/sql"
_ "github.com/lib/pq"
)
func NewDB(dataSourceName string) (*sql.DB, error) {
db, err := sql.Open("postgres", dataSourceName)
if err != nil {
return nil, err
}
if err = db.Ping(); err != nil {
return nil, err
}
return db, nil
}File: models/books.go
package models
import "database/sql"
type Book struct {
Isbn string
Title string
Author string
Price float32
}
func AllBooks(db *sql.DB) ([]*Book, error) {
rows, err := db.Query("SELECT * FROM books")
if err != nil {
return nil, err
}
defer rows.Close()
bks := make([]*Book, 0)
for rows.Next() {
bk := new(Book)
err := rows.Scan(&bk.Isbn, &bk.Title, &bk.Author, &bk.Price)
if err != nil {
return nil, err
}
bks = append(bks, bk)
}
if err = rows.Err(); err != nil {
return nil, err
}
return bks, nil
}Если вы не хотите определять ваши обработчики и методы в Env, альтернативным подходом будет использование логики обработчиков в замыкании и закрытие переменной Env следующим образом:
File: main.go
package main
import (
"bookstore/models"
"database/sql"
"fmt"
"log"
"net/http"
)
type Env struct {
db *sql.DB
}
func main() {
db, err := models.NewDB("postgres://user:pass@localhost/bookstore")
if err != nil {
log.Panic(err)
}
env := &Env{db: db}
http.Handle("/books", booksIndex(env))
http.ListenAndServe(":3000", nil)
}
func booksIndex(env *Env) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
if r.Method != "GET" {
http.Error(w, http.StatusText(405), 405)
return
}
bks, err := models.AllBooks(env.db)
if err != nil {
http.Error(w, http.StatusText(500), 500)
return
}
for _, bk := range bks {
fmt.Fprintf(w, "%s, %s, %s, lb%.2f\n", bk.Isbn, bk.Title, bk.Author, bk.Price)
}
})
}Внедрение зависимостей является хорошим подходом, когда:
Еще раз, вы можете использовать этот подход, если ваши обработчики и логика базы данных будут распределены по нескольким пакетам. Один из способов добиться этого — создать отдельный конфигурационный пакет, экспортируемый тип Env. Один из способов использования Env в примере выше. А так же простой пример.
Мы будем использовать пример внедрения зависимостей немного позже. Давайте изменим пакет моделей так, что бы он возвращал пользовательский тип БД (который включает sql.DB) и внедрим логику базы данных в виде типа DB.
Получаем двойное преимущество: сначала мы получаем чистую структуру, но что еще важнее он открывает потенциал для тестирования нашей базы данных в виде юнит тестов.
Давайте изменим пример и включим новый интерфейс Datastore, который реализовывает некоторые методы, в нашем новом типе DB.
type Datastore interface {
AllBooks() ([]*Book, error)
}Мы можем использовать данный интерфейс во всем нашем приложении. Обновленный пример.
File: main.go
package main
import (
"fmt"
"log"
"net/http"
"bookstore/models"
)
type Env struct {
db models.Datastore
}
func main() {
db, err := models.NewDB("postgres://user:pass@localhost/bookstore")
if err != nil {
log.Panic(err)
}
env := &Env{db}
http.HandleFunc("/books", env.booksIndex)
http.ListenAndServe(":3000", nil)
}
func (env *Env) booksIndex(w http.ResponseWriter, r *http.Request) {
if r.Method != "GET" {
http.Error(w, http.StatusText(405), 405)
return
}
bks, err := env.db.AllBooks()
if err != nil {
http.Error(w, http.StatusText(500), 500)
return
}
for _, bk := range bks {
fmt.Fprintf(w, "%s, %s, %s, lb%.2f\n", bk.Isbn, bk.Title, bk.Author, bk.Price)
}
}File: models/db.go
package models
import (
_ "github.com/lib/pq"
"database/sql"
)
type Datastore interface {
AllBooks() ([]*Book, error)
}
type DB struct {
*sql.DB
}
func NewDB(dataSourceName string) (*DB, error) {
db, err := sql.Open("postgres", dataSourceName)
if err != nil {
return nil, err
}
if err = db.Ping(); err != nil {
return nil, err
}
return &DB{db}, nil
}File: models/books.go
package models
type Book struct {
Isbn string
Title string
Author string
Price float32
}
func (db *DB) AllBooks() ([]*Book, error) {
rows, err := db.Query("SELECT * FROM books")
if err != nil {
return nil, err
}
defer rows.Close()
bks := make([]*Book, 0)
for rows.Next() {
bk := new(Book)
err := rows.Scan(&bk.Isbn, &bk.Title, &bk.Author, &bk.Price)
if err != nil {
return nil, err
}
bks = append(bks, bk)
}
if err = rows.Err(); err != nil {
return nil, err
}
return bks, nil
}Из-за того, что наши обработчики теперь используют интерфейс Datastore, мы можем легко создать юнит тесты для ответов от базы данных.
package main
import (
"bookstore/models"
"net/http"
"net/http/httptest"
"testing"
)
type mockDB struct{}
func (mdb *mockDB) AllBooks() ([]*models.Book, error) {
bks := make([]*models.Book, 0)
bks = append(bks, &models.Book{"978-1503261969", "Emma", "Jayne Austen", 9.44})
bks = append(bks, &models.Book{"978-1505255607", "The Time Machine", "H. G. Wells", 5.99})
return bks, nil
}
func TestBooksIndex(t *testing.T) {
rec := httptest.NewRecorder()
req, _ := http.NewRequest("GET", "/books", nil)
env := Env{db: &mockDB{}}
http.HandlerFunc(env.booksIndex).ServeHTTP(rec, req)
expected := "978-1503261969, Emma, Jayne Austen, lb9.44\n978-1505255607, The Time Machine, H. G. Wells, lb5.99\n"
if expected != rec.Body.String() {
t.Errorf("\n...expected = %v\n...obtained = %v", expected, rec.Body.String())
}
}Наконец-то давайте посмотрим на использование контекста в области видимости запроса и передачи пула подключений к базе данных. В частности мы будем использовать пакет x/net/context.
Лично я не фанат переменных уровня приложения в контексте области видимости запроса — он выглядит неуклюжим и обременительным для меня. Документация пакета x/net/context так же советует:
Используйте значения контекста только для области видимости данных внутри запроса, которые передают процессы и точки входа API, а не для передачи необязательных параметров функции.
Тем не менее, люди используют данный подход. И если ваш проект содержит множество пакетов, и использование глобальной конфигурации не обсуждается, то это довольно привлекательное решение.
Давайте адаптируем пример книжного магазина в последний раз, передавая контекст для наших обработчиков, используя шаблон, предложенный в замечательной статье от Joe Shaw
File: main.go
package main
import (
"bookstore/models"
"fmt"
"golang.org/x/net/context"
"log"
"net/http"
)
type ContextHandler interface {
ServeHTTPContext(context.Context, http.ResponseWriter, *http.Request)
}
type ContextHandlerFunc func(context.Context, http.ResponseWriter, *http.Request)
func (h ContextHandlerFunc) ServeHTTPContext(ctx context.Context, rw http.ResponseWriter, req *http.Request) {
h(ctx, rw, req)
}
type ContextAdapter struct {
ctx context.Context
handler ContextHandler
}
func (ca *ContextAdapter) ServeHTTP(rw http.ResponseWriter, req *http.Request) {
ca.handler.ServeHTTPContext(ca.ctx, rw, req)
}
func main() {
db, err := models.NewDB("postgres://user:pass@localhost/bookstore")
if err != nil {
log.Panic(err)
}
ctx := context.WithValue(context.Background(), "db", db)
http.Handle("/books", &ContextAdapter{ctx, ContextHandlerFunc(booksIndex)})
http.ListenAndServe(":3000", nil)
}
func booksIndex(ctx context.Context, w http.ResponseWriter, r *http.Request) {
if r.Method != "GET" {
http.Error(w, http.StatusText(405), 405)
return
}
bks, err := models.AllBooks(ctx)
if err != nil {
http.Error(w, http.StatusText(500), 500)
return
}
for _, bk := range bks {
fmt.Fprintf(w, "%s, %s, %s, lb%.2f\n", bk.Isbn, bk.Title, bk.Author, bk.Price)
}
}File: models/db.go
package models
import (
"database/sql"
_ "github.com/lib/pq"
)
func NewDB(dataSourceName string) (*sql.DB, error) {
db, err := sql.Open("postgres", dataSourceName)
if err != nil {
return nil, err
}
if err = db.Ping(); err != nil {
return nil, err
}
return db, nil
}File: models/books.go
package models
import (
"database/sql"
"errors"
"golang.org/x/net/context"
)
type Book struct {
Isbn string
Title string
Author string
Price float32
}
func AllBooks(ctx context.Context) ([]*Book, error) {
db, ok := ctx.Value("db").(*sql.DB)
if !ok {
return nil, errors.New("models: could not get database connection pool from context")
}
rows, err := db.Query("SELECT * FROM books")
if err != nil {
return nil, err
}
defer rows.Close()
bks := make([]*Book, 0)
for rows.Next() {
bk := new(Book)
err := rows.Scan(&bk.Isbn, &bk.Title, &bk.Author, &bk.Price)
if err != nil {
return nil, err
}
bks = append(bks, bk)
}
if err = rows.Err(); err != nil {
return nil, err
}
return bks, nil
}P.S. Автор перевода будет благодарен за указанные ошибки и неточности перевода.
|
Метки: author KosToZyB go перевод golang database dba |
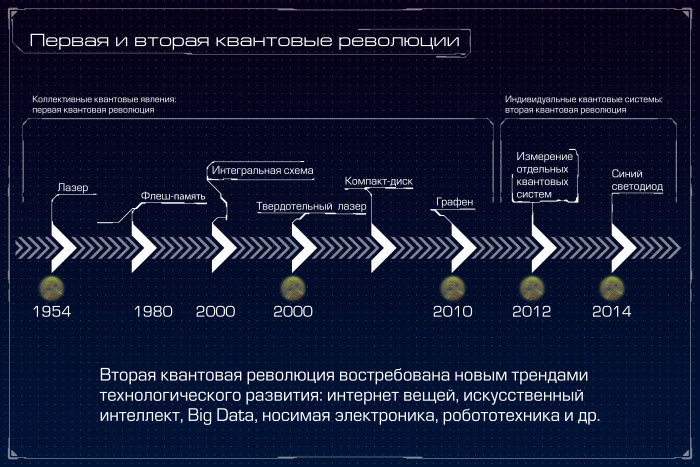
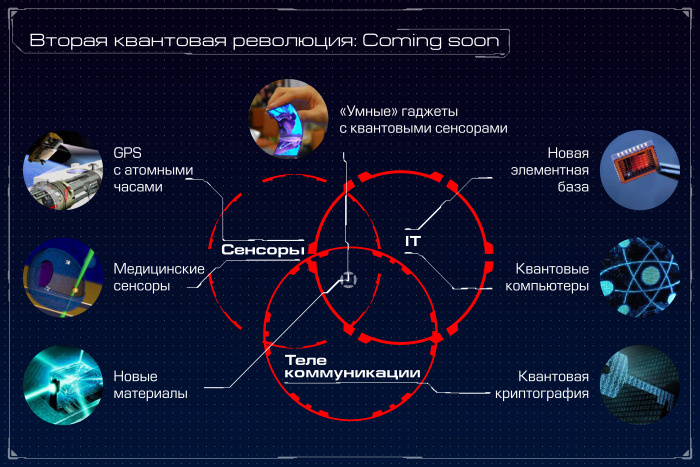
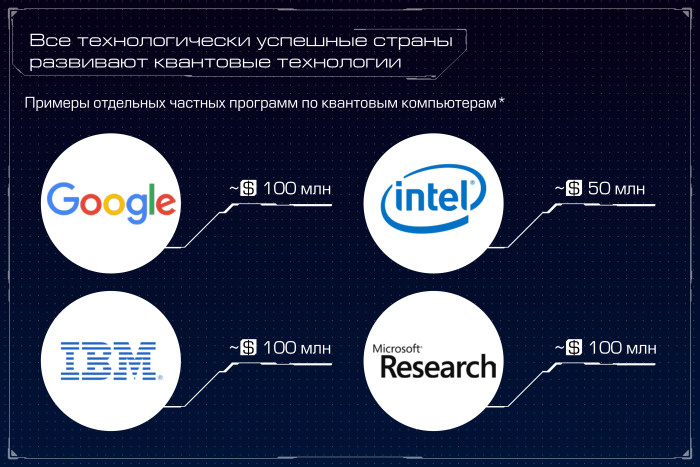
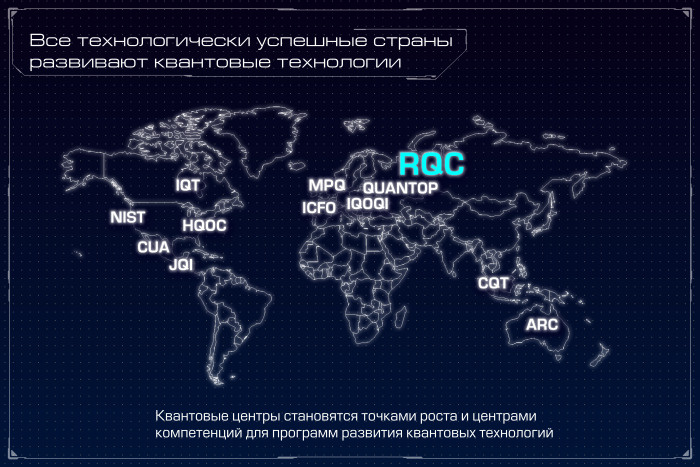
Квантовый компьютер: большая игра на повышение. Лекция в Яндексе |


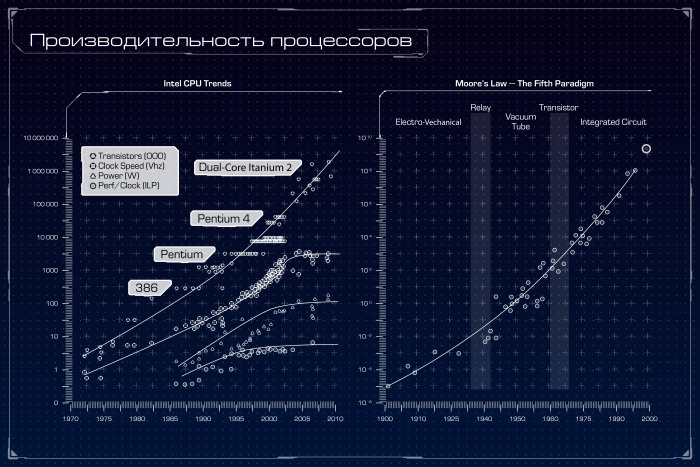
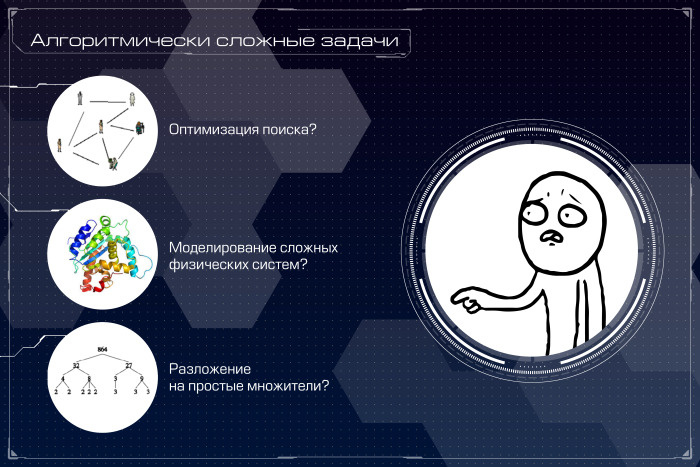

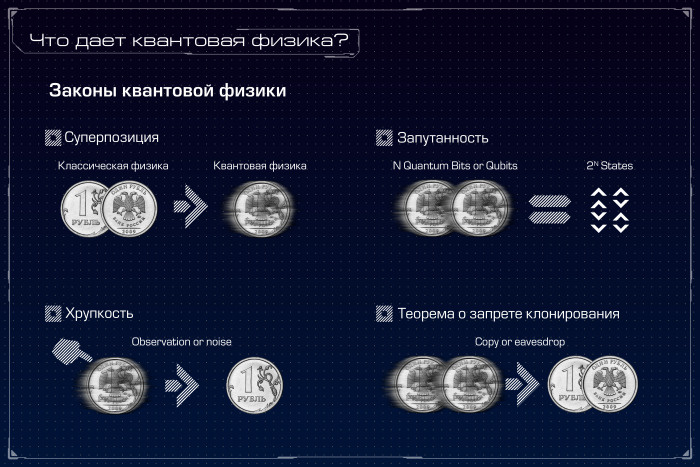

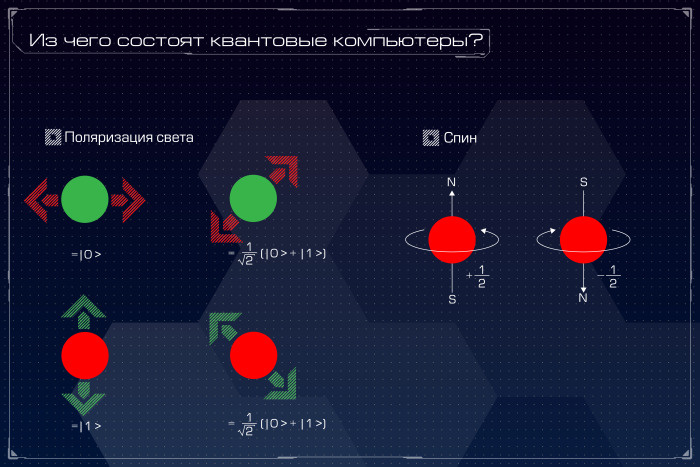
|
Метки: author Leono исследования и прогнозы в it блог компании яндекс квантовый компьютер квантовые алгоритмы квантовые вычисления квантовая криптография кубиты закон мура d-wave |
[Из песочницы] Mocking в swift при помощи Sourcery |
В ходе разработки ios-приложения, перед разработчиком может встать задача unit-тестирования кода. Именно с такой задачей столкнулся я.
Допустим, у нас есть приложение с аутентификацией. За аутентификацию, в нём отвечает сервис аутентификации — AuthenticationService. Для примера, у него будут два метода, оба аутентифицируют пользователя, но один синхронный, а другой асинхронный:
protocol AuthenticationService {
typealias Login = String
typealias Password = String
typealias isSucces = Bool
/// Функция аутентификации пользователя
///
/// - Parameters:
/// - login: Учётная запись
/// - password: Пароль
/// - Returns: Успешность аутентификации
func authenticate(with login: Login, and password: Password) -> isSucces
/// Асинхронная функция аутентификации пользователя
///
/// - Parameters:
/// - login: Учётная запись
/// - password: Пароль
/// - authenticationHandler: Callback(completionHandler) аутентификации
func asyncAuthenticate(with login: Login, and password: Password, authenticationHandler: @escaping (isSucces) -> Void)
}Имеется viewController, который будет использовать этот сервис:
class ViewController: UIViewController {
var authenticationService: AuthenticationService!
var login = "Login"
var password = "Password"
/// Обработчик аутентификации, используется для асинхронной аутентификации
var aunthenticationHandler: ((Bool) -> Void) = { (isAuthenticated) in
print("\nРезультат асинхронной функции:")
isAuthenticated ? print("Добро пожаловать") : print("В доступе отказано")
}
override func viewDidLoad() {
super.viewDidLoad()
authenticationService = AuthenticationServiceImplementation() // Какая-то реализация сервиса аутентификации, нам не важно, т.к. тестировать мы будем viewController
performAuthentication()
performAsyncAuthentication()
}
func performAuthentication() {
let isAuthenticated = authenticationService.authenticate(with: login, and: password)
print("Результат синхронной функции:")
isAuthenticated ? print("Добро пожаловать") : print("В доступе отказано")
}
func performAsyncAuthentication() {
authenticationService.asyncAuthenticate(with: login, and: password, and: aunthenticationHandler)
}
}Нам нужно протестировать viewController.
Т.к. мы не хотим, чтобы наши тесты зависели от каки-либо ещё объектов, кроме класса нашего viewController'a, мы будем мокировать все его зависимости. Для этого сделаем заглушку сервиса аутентификации. Выглядела бы она примерно вот так:
class MockAuthenticationService: AuthenticationService {
var emulatedResult: Bool? // То, что вернёт синхронная функция аутентификации
var receivedLogin: AuthenticationService.Login? // Поле для проверки полученния логина
var receivedPassword: AuthenticationService.Password? // Поле для проверки полученния пароля
var receivedAuthenticationHandler: ((AuthenticationService.isSucces) -> Void)? // Обработчик, с помощью которого будем управлять возвращаемым значением при тестировании функции асинхронной аутентификации
func authenticate(with login: AuthenticationService.Login,
and password: AuthenticationService.Password) -> AuthenticationService.isSucces {
receivedLogin = login
receivedPassword = password
return emulatedResult ?? false
}
func asyncAuthenticate(with login: AuthenticationService.Login,
and password: AuthenticationService.Password,
and authenticationHandler: @escaping (AuthenticationService.isSucces) -> Void) {
receivedLogin = login
receivedPassword = password
receivedAuthenticationHandler = authenticationHandler
}
}В ручную писать столько кода для каждой зависимости, очень не приятное занятие (особенно приятно переписывать их, когда у зависимостей меняется протокол). Я начал искать решение данной проблемы. Думал найти аналог mockito(подсмотрел у коллег занимающихся android-разработкой). В ходе поиска узнал, что swift поддерживает read-only рефлексию (в рантайме, мы можем только узнавать информацию об объектах, менять поведение объекта, мы не можем). Поэтому подобной библиотеки нет. Отчаявшись, я задал вопрос на тостере. Решение подсказали: Вячеслав Бельтюков и Человек с медведем (ManWithBear).
Мы будем генерировать моки при помощи Sourcery. Sourcery использует шаблоны для генерации кода. Имеются несколько стандартных, для наших целей подходит AutoMockable.
Приступим к делу:
1) Добавляем в наш проект pod 'Sourcery'.
2) Настраиваем RunScript для нашего проекта.
$PODS_ROOT/Sourcery/bin/sourcery --sources . --templates ./Pods/Sourcery/Templates/AutoMockable.stencil --output ./SwiftMockingГде:
"$PODS_ROOT/Sourcery/bin/sourcery" — путь к исполняемому файлу Sourcery.
"--sources ." — Указание, что анализировать для кодогенерации (точка указывает на текущую папку проекта, то есть мы будем смотреть нужно ли сгенерировать моки для каждого файла нашего проекта).
"--templates ./Pods/Sourcery/Templates/AutoMockable.stencil" — путь к шаблону кодогенерации.
"--output ./SwiftMocking" — место, где будет хранится результат кодогенерации (наш проект называется SwiftMocking).
3) Добавлям файл AutoMockable.swift в наш проект:
/// Базовый протокол для протоколов, которые мы хотим мокировать
protocol AutoMockable {}4) Протоколы, которые мы хотим мокировать, должны наследоваться от AutoMockable. В нашем случае наследуемся AuthenticationService'ом:
protocol AuthenticationService: AutoMockable {5) Билдим проект. В папке путь к которой мы указали как параметр --ouput, сгенерируется файл AutoMockable.generated.swift, в котором будут лежать сгенерированные моки. Все последующие моки будут складываться в этот файл.
6) Добавляем этот файл в наш проект. Теперь мы можем использовать наши заглушки.
Давайте посмотрим, что сгенерировалось для протокола сервиса аутентификации.
class AuthenticationServiceMock: AuthenticationService {
//MARK: - authenticate
var authenticateCalled = false
var authenticateReceivedArguments: (login: Login, password: Password)?
var authenticateReturnValue: isSucces!
func authenticate(with login: Login, and password: Password) -> isSucces {
authenticateCalled = true
authenticateReceivedArguments = (login: login, password: password)
return authenticateReturnValue
}
//MARK: - asyncAuthenticate
var asyncAuthenticateCalled = false
var asyncAuthenticateReceivedArguments: (login: Login, password: Password, authenticationHandler: (isSucces) -> Void)?
func asyncAuthenticate(with login: Login, and password: Password, and authenticationHandler: @escaping (isSucces) -> Void) {
asyncAuthenticateCalled = true
asyncAuthenticateReceivedArguments = (login: login, password: password, authenticationHandler: authenticationHandler)
}
}
Прекрасно. Теперь мы можем использовать заглушки в наших тестах:
import XCTest
@testable import SwiftMocking
class SwiftMockingTests: XCTestCase {
var viewController: ViewController!
var authenticationService: AuthenticationServiceMock!
override func setUp() {
super.setUp()
authenticationService = AuthenticationServiceMock()
viewController = ViewController()
viewController.authenticationService = authenticationService
viewController.login = "Test login"
viewController.password = "Test password"
}
func testPerformAuthentication() {
// given
authenticationService.authenticateReturnValue = true
// when
viewController.performAuthentication()
// then
XCTAssert(authenticationService.authenticateReceivedArguments?.login == viewController.login, "Логин не был передан в функцию аутентификации")
XCTAssert(authenticationService.authenticateReceivedArguments?.password == viewController.password, "Пароль не был передан в функцию аутентификации")
XCTAssert(authenticationService.authenticateCalled, "Не произошёл вызова функции аутентификации")
}
func testPerformAsyncAuthentication() {
// given
var isAuthenticated = false
viewController.aunthenticationHandler = { isAuthenticated = $0 }
// when
viewController.performAsyncAuthentication()
authenticationService.asyncAuthenticateReceivedArguments?.authenticationHandler(true)
// then
XCTAssert(authenticationService.asyncAuthenticateCalled, "Не произошёл вызов асинхронной функции аутентификации")
XCTAssert(authenticationService.asyncAuthenticateReceivedArguments?.login == viewController.login, "Логин не был передан в асинхронную функцию аутентификации")
XCTAssert(authenticationService.asyncAuthenticateReceivedArguments?.password == viewController.password, "Пароль не был передан в асинхронную функцию аутентификации")
XCTAssert(isAuthenticated, "Контроллер не обрабтывает результат аутентификации")
}
}
Sourcery пишет за нас заглушки, экономя тем самым наше время. У этой утилиты имеются и другие применения: генерация Equatable расширений для структур в наших проектах (чтобы мы могли сравнивать объекты этих структур).
-> Проект
-> Sourcery на github
-> Документация sourcery
|
Метки: author Agranatmark разработка под ios swift mocking ios development ios разработка мобильные приложения unit testing unit- тестирование тесты unit-tests |
Практика применения технологий виртуальной и дополненной реальности |





|
Метки: author viacheslavnu разработка под ar и vr vr виртуальная реальность дополненная реальность ar |
[recovery mode] Установка 3CX на Debian Linux 9 Stretch, обновление Session Border Controller и Call Flow Designer |
echo 'deb http://ftp.de.debian.org/debian/ jessie main' | tee -a /etc/apt/sources.list apt-get update apt-get install libicu52 libssl1.0.0 libcurl3=7.38.0-4+deb8u5
wget -O- http://downloads.3cx.com/downloads/3cxpbx/public.key | apt-key add - echo "deb http://downloads.3cx.com/downloads/3cxpbx/ /" | tee /etc/apt/sources.list.d/3cxpbx.list apt-get update apt-get install 3cxpbx
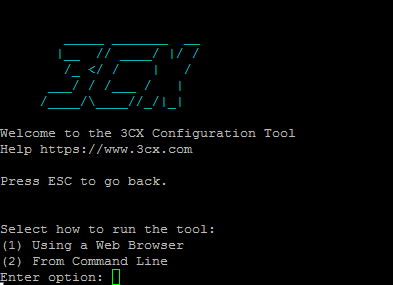

sudo apt-get update sudo apt-get install 3cxsbc
|
|
[Из песочницы] Доступ к ClickHouse с помоьщью JDBC |
/usr/local/etc/clickhouse-server/config.xml, так как я решил хранить базу данных на отдельном разделе. Запусить сервер я смог с помощью sudo /usr/local/bin/clickhouse-server --config /usr/local/etc/clickhouse-server/config.xml| Запрос | Время, с |
|---|---|
| какие направления были самыми популярными в 2015 году | 2.067 |
| из каких городов отправляется больше рейсов | 3.744 |
| из каких городов можно улететь по максимальному количеству направлений | 7.012 |
| как зависит задержка вылета рейсов от дня недели | 3.195 |
| из каких городов, самолёты чаще задерживаются с вылетом более чем на час | 3.392 |
| какие наиболее длинные рейсы | 12.466 |
| распределение времени задержки прилёта, по авиакомпаниям | 4.596 |
| какие авиакомпании прекратили перелёты | 1.653 |
| в какие города стали больше летать в 2015 году | 0.380 |
| перелёты в какие города больше зависят от сезонности | 8.806 |
ru.yandex.clickhouse
clickhouse-jdbc
${clickhouse-jdbc-version}
::. private static final String DB_URL = "jdbc:clickhouse://localhost:8123/default";
private final Connection conn;
/**
* Creates new instance
* @throws SQLException in case of connection issue
*/
public ClickHouseJDBCDemo() throws SQLException {
conn = DriverManager.getConnection(DB_URL);
}
/**
* Queries db to get most popular flight route for ths given year
* @param year year to query
* @throws SQLException in case of query issue
*/
public void popularYearRoutes(int year) throws SQLException {
String query = "SELECT " +
" OriginCityName, " +
" DestCityName, " +
" count(*) AS flights, " +
" bar(flights, 0, 20000, 40) AS bar " +
"FROM ontime WHERE Year = ? GROUP BY OriginCityName, DestCityName ORDER BY flights DESC LIMIT 20";
long time = System.currentTimeMillis();
try (PreparedStatement statement = conn.prepareStatement(query)) {
statement.setInt(1, year);
try (ResultSet rs = statement.executeQuery()) {
Util.printRs(rs);
}
}
System.out.println("Time: " + (System.currentTimeMillis() - time) +" ms");
}org.hibernate.dialect.Dialect:public class ClickHouseDialect extends Dialect {
}
SELECT alias.column from tablename alias|
Метки: author grekon sql java big data clickhouse jdbc hibernate spring framework gcc-6 |
Дайджест интересных материалов для мобильного разработчика #210 (13 июня — 18 июня) |
 |
Как стать тимлидом и не взорваться |
 |
Как HBO делала приложение Not Hotdog для сериала «Кремниевая долина» |
 |
Ubuntu для мобильных устройств: посмертный анализ |
 iOS
iOS Жизнь, смерть и наследие джейлбрейка iPhone Сделано на ARKit Что нового в Metal 2 Прототипирование в Xcode
Жизнь, смерть и наследие джейлбрейка iPhone Сделано на ARKit Что нового в Metal 2 Прототипирование в Xcode Neural Network Playground GridView: табличная верстка
Neural Network Playground GridView: табличная верстка Android
Android Android Dev Подкаст. Выпуск 36. О подходе к разработке Увеличиваем встроенные покупки с помощью бесплатного триала Уроки перехода на Kotlin в Android Studio Fotoapparat: простая съемка изображений в Android От студента к Android-разработчику
Android Dev Подкаст. Выпуск 36. О подходе к разработке Увеличиваем встроенные покупки с помощью бесплатного триала Уроки перехода на Kotlin в Android Studio Fotoapparat: простая съемка изображений в Android От студента к Android-разработчику Разработка React Native: лучшие практики 20 вдохновляющих мобильных форм входа
Разработка React Native: лучшие практики 20 вдохновляющих мобильных форм входа Аналитика, маркетинг и монетизация Как создавать виральный контент Как отслеживать органические установки в iTunes и Play Console
Аналитика, маркетинг и монетизация Как создавать виральный контент Как отслеживать органические установки в iTunes и Play Console Устройства, IoT, AI Спуфинг данных в Fitbit
Устройства, IoT, AI Спуфинг данных в Fitbit|
|
Как защитить корпоративное хранилище от вирусов-шифровальщиков снэпшотами |
|
|
Путешествие в Японию самостоятельно. Стоит или нет? |
|
Метки: author vostokoved читальный зал туризм туры в японию самостоятельные путешествия |
[Из песочницы] Советы по использованию FactoryGirl без ORM |
it "supports building a PORO object" do
class User
attr_accessor :name
end
FactoryGirl.define do
factory :user do
name "Amy"
end
end
user = FactoryGirl.build(:user)
expect(user.name).to eq "Amy"
end
NoMethodError:
undefined method `save!' for #
class User
attr_reader :name
def initialize(data = {})
@name = data[:name]
end
end
NoMethodError:
undefined method `name=' for #
t "supports custom initialization" do
class User
attr_reader :name
def initialize(data)
@name = data[:name]
end
end
FactoryGirl.define do
factory :user do
name "Amy"
initialize_with { new(attributes) }
end
end
user = FactoryGirl.build(:user)
expect(user.name).to eq "Amy"
end
{
"name": "Bob",
"location": {
"city": "New York"
}
}
class Location
attr_reader :city
def initialize(data)
@city = data[:city]
end
end
class User
attr_reader :name, :location
def initialize(data)
@name = data[:name]
@location = Location.new(data[:location])
end
end
it "supports constructing nested models" do
class Location
attr_reader :city
def initialize(data)
@city = data[:city]
end
end
class User
attr_reader :name, :location
def initialize(data)
@name = data[:name]
@location = Location.new(data[:location])
end
end
FactoryGirl.define do
factory :location do
city "London"
initialize_with { new(attributes) }
end
factory :user do
name "Amy"
location { attributes_for(:location) }
initialize_with { new(attributes) }
end
end
user = FactoryGirl.build(:user)
expect(user.name).to eq "Amy"
expect(user.location.city).to eq "London"
end
puts FactoryGirl.attributes_for(:user)
# => {:name=>"Amy", :location=>{:city=>"London"}}
FactoryGirl::InvalidFactoryError: The following factories are invalid:
* user - undefined method `save!' for # (NoMethodError) FactoryGirl.define do
factory :location do
city "London"
skip_create
initialize_with { new(attributes) }
end
factory :user do
name "Amy"
location { attributes_for(:location) }
skip_create
initialize_with { new(attributes) }
end
end FactoryGirl.create(:user)namespace :factory_girl do
desc "Lint factories by building"
task lint_by_build: :environment do
if Rails.env.production?
abort "Can't lint factories in production"
end
FactoryGirl.factories.each do |factory|
lint_factory(factory.name)
end
end
private
def lint_factory(factory_name)
FactoryGirl.build(factory_name)
rescue StandardError
puts "Error building factory: #{factory_name}"
raise
end
end
class User
attr_reader :name
def initialize(data)
@name = data.fetch(:name) # <- Имя обязательно
end
end
FactoryGirl.define do
factory :user do
# name "Amy" <- Закомментируем
initialize_with { new(attributes) }
end
endError building factory: user
rake aborted!
KeyError: key not found: :name
/path/models.rb:5:in `fetch'
/path/models.rb:5:in `initialize'
/path/factories.rb:8:in `block (3 levels) in '
/path/Rakefile:15:in `lint_factory'
|
Метки: author eGGshke тестирование веб-сервисов ruby factorygirl перевод |
[Из песочницы] ReactJS — мое понимание тестирования |
|
Метки: author SlicerMrk тестирование веб-сервисов reactjs react.js unit-testing testing |
Никогда не пишите длинных if-ов |
static int ParseNumber(const char* tx)
{
....
else if (strlen(tx) >= 4 && (strncmp(tx, "%eps", 4) == 0
|| strncmp(tx, "+%pi", 4) == 0 || strncmp(tx, "-%pi", 4) == 0
|| strncmp(tx, "+Inf", 4) == 0 || strncmp(tx, "-Inf", 4) == 0
|| strncmp(tx, "+Nan", 4) == 0 || strncmp(tx, "-Nan", 4) == 0
|| strncmp(tx, "%nan", 4) == 0 || strncmp(tx, "%inf", 4) == 0
))
{
return 4;
}
else if (strlen(tx) >= 3
&& (strncmp(tx, "+%e", 3) == 0
|| strncmp(tx, "-%e", 3) == 0
|| strncmp(tx, "%pi", 3) == 0 // <=
|| strncmp(tx, "Nan", 3) == 0
|| strncmp(tx, "Inf", 3) == 0
|| strncmp(tx, "%pi", 3) == 0)) // <=
{
return 3;
}
....
}if (model.user && model.user.id) {
doSomethingWithUserId(model.user.id);
...
}let userExistsAndValid = model.user && model.user.id;
if (userExistsAndValid) {
doSomethingWithUser(model.user);
...
}if (this.profile.firstName && this.profile.lastName &&
(this.password ||
!!_.find(this.serviceAccounts, a => a.provider === 'slack' && a.accountId)) {
....
}const hasSlack = !!_.find(this.serviceAccounts, a => a.provider === 'slack' && a.accountId);
const hasSomeLoginCredentials = this.password || hasSlack;
const hasPersonalData = this.profile.firstName && this.profile.lastName;
if (hasPersonalData && hasSomeLoginCredentials) {
....
}if (err || !result || !result.length === 0) return callback(err);|
Метки: author osharper совершенный код программирование советы начинающим |
Задачи с собеседований. Три адекватные задачки на «подумать» |

Дана упорядоченная последовательность чисел от 1 до N. Из нее удалили одно число, а оставшиеся перемешали. Найти удаленное число.
У вас есть пятилитровый и трехлитровый кувшины и неограниченное количество воды. Как отмерить ровно 4 литра воды? Кувшины имеют неправильную форму, поэтому точно отмерить половину кувшина не получится.
Имеется два числа. Можно ли поменять их местами без использования дополнительной переменной?
|
Метки: author AnROm карьера в it-индустрии собеседование |






