Canvas — почти как SVG |

// так же понадобится найти факториал
function factorial (number) {
var result = 1;
while(number){
result *= number--;
}
return result;
}
function getPointOnCurve (shift, points) {
var result = [0,0];
var powerOfCurve = points.length - 1;
shift = shift/100;
for(var i = 0;points[i];i++){
var polynom = (factorial(powerOfCurve)/(factorial(i)*factorial(powerOfCurve - i))) *
Math.pow(shift,i) *
Math.pow(1-shift,powerOfCurve - i);
result[0] += points[i][0] * polynom;
result[1] += points[i][1] * polynom;
}
return result;
}
getPointOnCurve(60, [[0,0],[100,0],[100,100]]); // -> [84, 36]
[[0,0],[100,0],[100,100,true],[200,100],[200,0]]function getCenterToPointDistance (coordinates){
return Math.sqrt(Math.pow(coordinates[0],2) + Math.pow(coordinates[1],2));
}
function getLengthOfCurve (points, step) {
step = step || 1;
var result = 0;
var lastPoint = points[0];
for(var sift = 0;sift <= 100;sift += step){
var coord = getPointOnCurve(sift,points);
result += getCenterToPointDistance([
coord[0] - lastPoint[0],
coord[1] - lastPoint[1]
]);
lastPoint = coord;
}
return result;
};
function getMapOfSpline (points, step) {
var map = [[]];
var index = 0;
for(var i = 0;points[i];i++){
var curvePointsCount = map[index].length;
map[index][+curvePointsCount] = points[i];
if(points[i][2] && i != points.length - 1){
map[index] = getLengthOfCurve(map[index],step);
index++;
map[index] = [points[i]];
}
}
map[index] = getLengthOfCurve(map[index],step);
return map;
};
function getPointOnSpline (shift, points, services) {
var shiftLength = services.length / 100 * shift;
if(shift >= 100){
shiftLength = services.length;
}
var counter = 0;
var lastControlPoint = 0;
var controlPointsCounter = 0;
var checkedCurve = [];
for(;
services.map[lastControlPoint] &&
counter + services.map[lastControlPoint] < shiftLength;
lastControlPoint++
){
counter += services.map[lastControlPoint];
}
for(
var pointIndex = 0;
points[pointIndex] && controlPointsCounter <= lastControlPoint;
pointIndex++
){
if(points[pointIndex][2] === true){
controlPointsCounter++;
}
if(controlPointsCounter >= lastControlPoint){
checkedCurve.push(points[pointIndex]);
}
}
return getPointOnCurve(
(shiftLength - counter) / (services.map[lastControlPoint] / 100),
checkedCurve
);
};
var points = [[0,0],[100,0],[100,100,true],[200,100],[200,0]];
var services = {};
services.map = getMapOfSpline(points);
services.length= 0;
for(var key in services.map){
services.length += services.map[key];
}
getPointOnSpline(60, points, services); // -> [136, 95.(9)]
A rx ry x-axis-rotation large-arc-flag sweep-flag x y[
[x1,y1],
[x2,y2],
[x3,y3],
[radiusX,radiusY,startRadian,endRadian,tilt], // tilt - optional
[x5,y5],
...
[xN,yN]
]
function getPointOnEllipse (radiusX,radiusY,shift,tilt,centerX,centerY){
tilt = tilt || 0;
tilt *= -1;
centerX = centerX || 0;
centerY = centerY || 0;
var x1 = radiusX*Math.cos(+shift),
y1 = radiusY*Math.sin(+shift),
x2 = x1 * Math.cos(tilt) + y1 * Math.sin(tilt),
y2 = -x1 * Math.sin(tilt) + y1 * Math.cos(tilt);
return [x2 + centerX,y2 + centerY];
}
function getLengthOfEllipticArc (radiusX, radiusY, startRadian, endRadian, step) {
step = step || 1;
var length = 0;
var lastPoint = getPointOnEllipse(radiusX,radiusY,startRadian);
var radianPercent = (endRadian - startRadian) / 100;
for(var i = 0;i<=100;i+=step){
var radian = startRadian + radianPercent * i;
var point = getPointOnEllipse(radiusX,radiusY,radian);
length += getCenterToPointDistance([point[0]-lastPoint[0],point[1]-lastPoint[1]]);
lastPoint = point;
}
return length;
};
function getMapOfPath (points, step) {
var map = [[]];
var index = 0;
var lastPoint = [];
for(var i = 0;points[i];i++){
var point = points[i];
if(point.length > 3){
map[index] = getLengthOfEllipticArc(point[0], point[1], point[2], point[3], step);
if(!points[i+1]){continue}
var centerOfArc = getPointOnEllipse(point[0], point[1], point[2] + Math.PI, point[4], lastPoint[0], lastPoint[1]);
var endOfArc = getPointOnEllipse(point[0], point[1], point[3], point[4], centerOfArc[0], centerOfArc[1]);
index++;
map[index] = [endOfArc];
lastPoint = endOfArc;
continue;
}
map[index].push(point);
if(point[2] === true || (points[i+1] && points[i+1].length > 3)){
map[index] = getLengthOfCurve(map[index],step);
index++;
map[index] = [point];
}
lastPoint = point;
}
if(typeof map[index] !== 'number'){map[index] = getLengthOfCurve(map[index],step);}
return map;
};
function getPointOnPath (shift, points, services) {
var shiftLength = services.length / 100 * shift;
if(shift >= 100){
shiftLength = services.length;
}
var counter = 0;
var lastControlPoint = 0;
var controlPointsCounter = 0;
var checkedCurve = [];
for(; services.map[lastControlPoint] && counter + services.map[lastControlPoint] < shiftLength; lastControlPoint++){
counter += services.map[lastControlPoint];
}
var lastPoint = [];
for(var pointIndex = 0; points[pointIndex] && controlPointsCounter <= lastControlPoint; pointIndex++){
var point = points[pointIndex];
if(point.length > 3){
var centerOfArc = getPointOnEllipse(point[0], point[1], point[2] + Math.PI, point[4], lastPoint[0], lastPoint[1]);
if(controlPointsCounter === lastControlPoint){
var percent = (shiftLength - counter) / (services.map[lastControlPoint] / 100);
var resultRadian = point[2] + ((point[3] - point[2])/100*percent);
return getPointOnEllipse(point[0], point[1], resultRadian, point[4], centerOfArc[0], centerOfArc[1]);
}
lastPoint = getPointOnEllipse(point[0], point[1], point[3], point[4], centerOfArc[0], centerOfArc[1]);
controlPointsCounter++;
if(controlPointsCounter === lastControlPoint){
checkedCurve.push(lastPoint);
}
continue
}
if(point[2] === true || (points[pointIndex+1] && points[pointIndex+1].length > 3)){
controlPointsCounter++;
}
if(controlPointsCounter >= lastControlPoint){
checkedCurve.push(point);
}
lastPoint = point;
}
return getPointOnCurve(
(shiftLength - counter) / (services.map[lastControlPoint] / 100),
checkedCurve
);
};
var points = [[0,0],[100,0],[100,100],[20,20,0,Math.PI],[200,100],[200,0]];
var services = {};
services.map = getMapOfPath(points);
services.length= 0;
for(var key in services.map){
services.length += services.map[key];
}
getPointOnPath(60, points, services); // -> [96.495, 98.036]
|
Метки: author takovoy javascript canvas |
Сказ о том, как Android-разработчика спамеры задолбали, и что и из этого вышло |
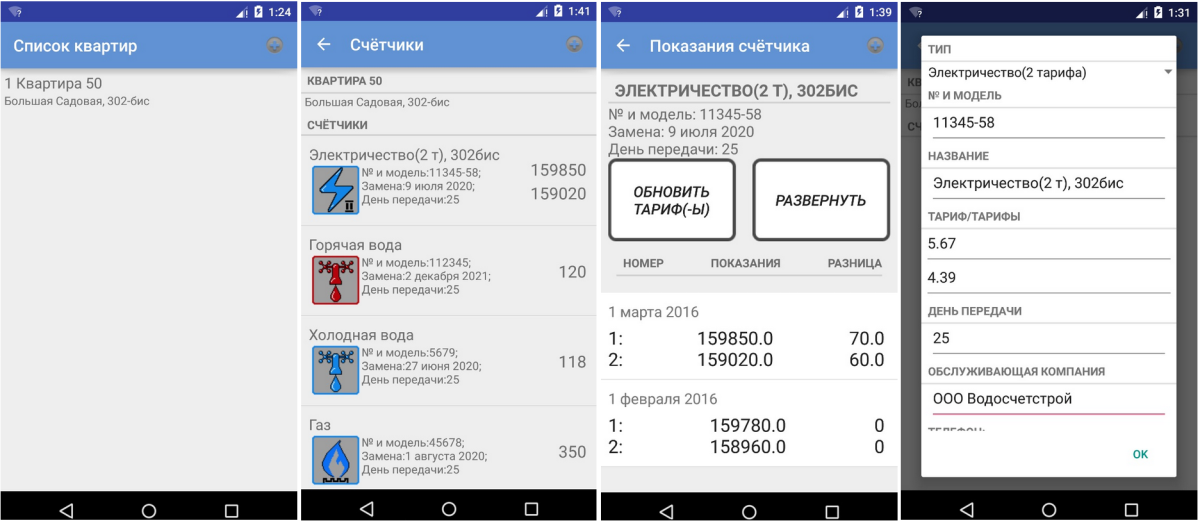
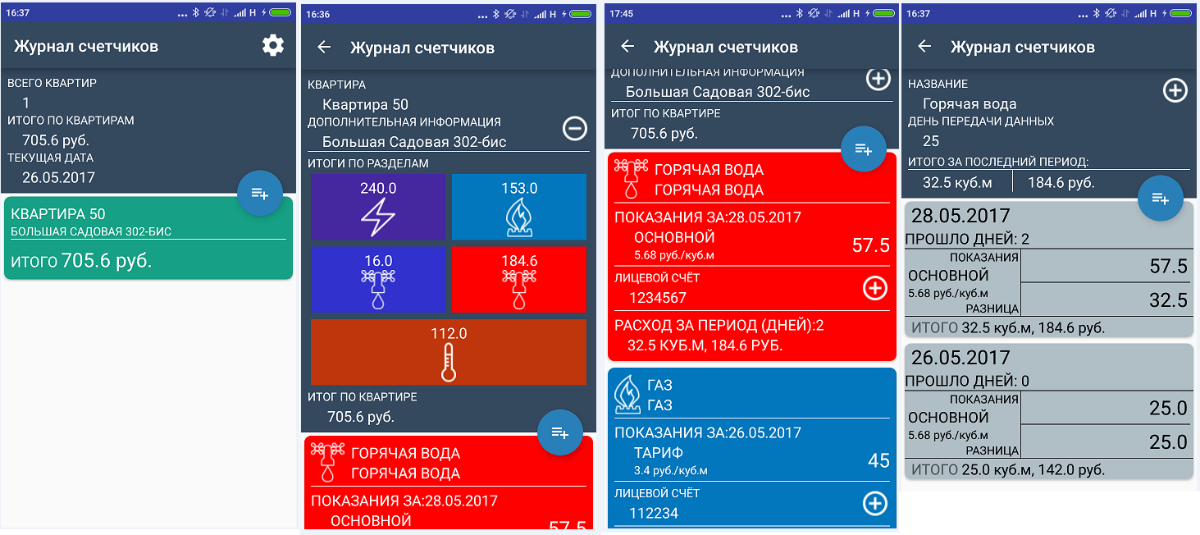
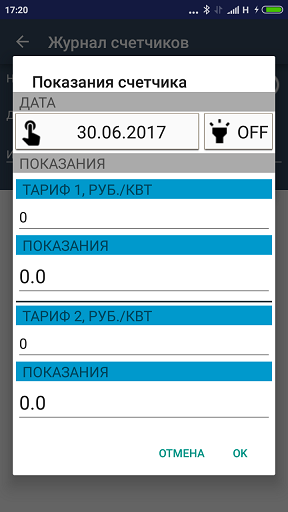
ListView lvAmounts = (ListView)mView.findViewById(R.id.lv_newAmount_Amount); insertAmountAdapter insertAmountAdapter = new insertAmountAdapter(getActivity(), amountList);
lvAmounts.setAdapter(insertAmountAdapter);
public class insertAmountAdapter extends BaseAdapter {
Context mContext;
ArrayList amountList;
LayoutInflater mLayoutInflater;
EditText etAmount, etTariff;
TextView tvTariffTitle;
public insertAmountAdapter(Context mContext, ArrayList amountList) {
this.mContext = mContext;
this.amountList = amountList;
mLayoutInflater = (LayoutInflater)mContext.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
}
@Override
public int getCount() {
return amountList.size();
}
@Override
public Object getItem(int position) {
return amountList.get(position);
}
@Override
public long getItemId(int position) {
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
View view = convertView;
if(view == null){
view = mLayoutInflater.inflate(R.layout.item_insertamount, parent, false);
etTariff = (EditText)view.findViewById(R.id.et_amount_tariffInfo);
etTariff.addTextChangedListener(new AmountTextWatcher(view, etTariff, amountList));
etAmount = (EditText)view.findViewById(R.id.et_amount_Amount);
etAmount.addTextChangedListener(new AmountTextWatcher(view, etAmount, amountList));
}
etAmount.setTag(position);
etAmount.setText(String.valueOf(amountList.get(position).getAmount()));
etAmount.setFilters(new InputFilter[]{new DigitalFilter(3)});
tvTariffTitle = (TextView)view.findViewById(R.id.tv_amount_tariffTitle);
tvTariffTitle.setText(amountList.get(position).getTariffTitle()+", "+amountList.get(position).getUnit());
etTariff.setTag(position);
etTariff.setText(amountList.get(position).getTariffValue());
etTariff.setFilters(new InputFilter[]{new DigitalFilter(2)});
return view;
}
}
class AmountTextWatcher implements TextWatcher {
private View view;
private EditText editText;
private ArrayList amountList;
public AmountTextWatcher(View view, EditText editText, ArrayList amountList) {
this.view = view;
this.editText = editText;
this.amountList = amountList;
}
@Override
public void beforeTextChanged(CharSequence s, int start, int count, int after) {
}
@Override
public void onTextChanged(CharSequence s, int start, int before, int count) {
}
@Override
public void afterTextChanged(Editable s) {
if(editText.equals(view.findViewById(R.id.et_amount_Amount))){
amountList.get(Integer.parseInt(editText.getTag().toString())).setAmount(Double.valueOf(s.toString().isEmpty()?"0":s.toString()));
} else if(editText.equals(view.findViewById(R.id.et_amount_tariffInfo))){
amountList.get(Integer.parseInt(editText.getTag().toString())).setTariffValue(s.toString().isEmpty()?"0":s.toString());
}
return;
}
}
String instructionHTML = getString(R.string.instructionText);
TextView tvInstruction = (TextView)findViewById(R.id.tv_instruction);
tvInstruction.setText(Html.fromHtml(instructionHTML, htmlImageGetter, null));
Html.ImageGetter htmlImageGetter = new Html.ImageGetter() {
public Drawable getDrawable(String source) {
int resId = getResources().getIdentifier(source, "drawable", getPackageName());
Drawable ret = InstructionActivity.this.getResources().getDrawable(resId);
ret.setBounds(0, 0, ret.getIntrinsicWidth(), ret.getIntrinsicHeight());
return ret;
}
};
|
Метки: author Snakecatcher разработка под android android счетчики жэк спамеры |
Три дня как все кассы в стране должны стать онлайн (на самом деле нет) |

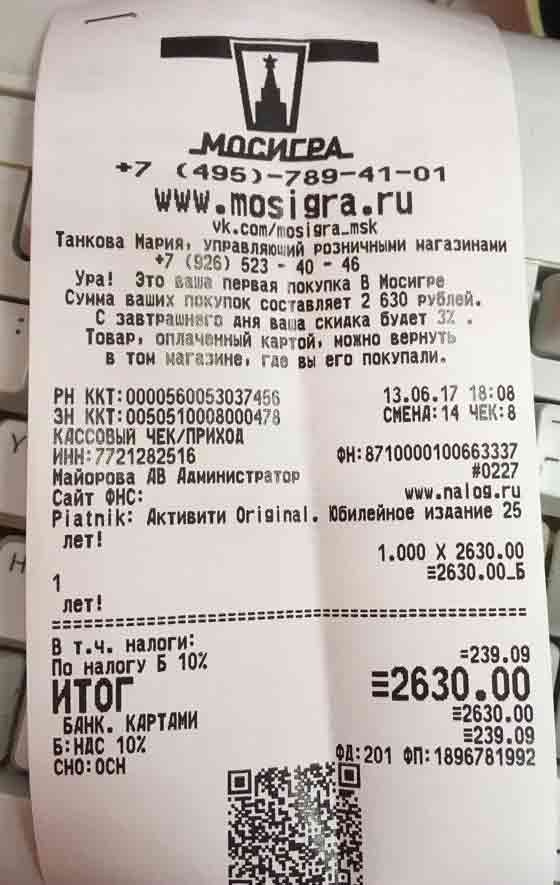



«В целях установления факта принятия исчерпывающих мер по соблюдению указанных выше требований законодательства Российской Федерации может быть исследован заключенный пользователем договор поставки фискального накопителя на предмет разумного срока до окончания действия блока ЭКЛЗ или до определенного законодательством Российской Федерации о применении контрольно-кассовой техники предельного срока возможности его использования.»
|
Метки: author Milfgard управление проектами управление продажами управление e-commerce блог компании мосигра кассы будущее чек продажи |
4 популярные ошибки в дизайне визиток |








|
Метки: author Logomachine типографика графический дизайн логомашина дизайн студия дизайн бизне визитка |
Как обеспечить безопасность в эпоху AI и облачных платформ. Интервью с профессором Малковым |
|
Метки: author megapost microsoft azure информационная безопасность |
Как быстро удалить множество строк из большой базы в MySQL |

---TRANSACTION 1 4141054098, ACTIVE 191816 sec, OS thread id 36004918272 updating or deleting, thread declared inside InnoDB 84
mysql tables in use 1, locked 1
686063 lock struct(s), heap size 88520688, undo log entries 229144332
MySQL thread id 56087872, query id 2202164550 1.1.1.2 database updating
DELETE
FROM table
WHERE UNIX_TIMESTAMP(moment) < 1498712335 - 365 * 86400
AND UNIX_TIMESTAMP(moment) > 0pt-archiver --source h=127.0.0.1,D=build4,t=b_iblock_element \
--optimize s --purge --where 'TAGS LIKE "%САПР%"' \
--limit 1000 --commit-each --progress 500 --charset "CP1251"В принципе, ключи довольно очевидны, тем не менее, пройдусь по ним:--source — описывает подключение. Хост, база и таблица. При необходимости можно дописать логин и пароль (в примере я использую креды из ~/.my.cnf);
--optimize — оптимизирует исходную таблицу, либо ту, в которую переносятся данные. Поскольку в данном случае я не переношу, а удаляю данные, оптимизирую именно исходную (s) таблицу. В принципе, делать это необязательно;
--purge — изначально утилита предназначена для переноса данных в другую таблицу (или в файл). Но можно и просто удалять строки;
--where — обычное SQL-условие, по которому будут отбираться строки для удаления;
--limit 1000 — обрабатывать за раз 1000 строк (можно больше, зависит от производительности вашего сервера);
--commit-each — делать коммит после количества строк, указанного в --limit;
--progress 500 — выводить прогресс каждые 500 строк (опять же, имеет смысл подобрать этот параметр индивидуально);
--charset — кодировка. Если будет использоваться только ASCII-кодировка, проще указать --no-check-charset. Отдельно упомяну, что необходимо чтобы локаль консоли совпадала с указанным charset'ом, иначе ошибка не выведется, но и строки обработаны не будут.
|
Метки: author StraNNicK системное администрирование администрирование баз данных mysql innodb |
Как искать людей в числе Пи и причем тут Python |
emails = pandas.read_csv("emails.csv")
emails.sample(NUM_WINNERS, random_state=SEED)
def pi_digits():
"""generator for digits of pi"""
q, r, t, k, n, l = 1, 0, 1, 1, 3, 3
while True:
if 4 * q + r - t < n * t:
yield n
q, r, t, k, n, l = (10*q, 10*(r-n*t), t, k, (10*(3*q+r))/t-10*n, l)
else:
q, r, t, k, n, l = (q*k, (2*q+r)*l, t*l, k+1, (q*(7*k+2)+r*l)/(t*l), l+2)
np.random.seed(SEED)
emails["num"] = np.random.randint(10 ** (NUM_DIGITS - 1), 10 ** NUM_DIGITS - 1, size=len(emails))
class _Num(object):
def __init__(self, n):
self.n = n
self.s = str(n)
self.p = 0 # pointer in number string representation
self.l = len(self.s)
def move_p(self, d):
if d == self.s[self.p]:
self.p += 1
else:
self.p = 0
def find_nums_in_pi(nums, first_n=None):
MAX_POS = 10 ** 6
pi_gen = pi_digits()
first_n = first_n if first_n is not None else len(nums)
_nums = [_Num(n) for n in nums]
nums_pos = {}
for pos in itertools.count():
if pos % 1000 == 0:
print "Current Pi position: %s. Nums found: %s" % (pos, len(nums_pos))
if pos == MAX_POS:
raise RuntimeError("Circuit breaker!")
d = str(pi_gen.next())
for cur_num in _nums:
cur_num.move_p(d)
# whole number found
if cur_num.p == cur_num.l:
nums_pos[cur_num.n] = pos - cur_num.l + 1
# found enough numbers
if len(nums_pos) == first_n:
return nums_pos
# create new search array without found number
_nums = [num for num in _nums if num.n != cur_num.n]
break
|
Метки: author Rumpelstiltskin программирование python блог компании отус online education online- курс lottery |
Как компьютерные профи раскалывают хакеров |



|
Метки: author SmirkinDA разработка под windows программирование криптография информационная безопасность блог компании parallels parallels иб wanna cry petya |
Конкурс по программированию: JSDash |

A — это вы. Можно перемещаться через пустое пространство или землю (:), толкать камни (O) по горизонтали в пустое пространство и собирать алмазы (*). Через кирпичи (+) и сталь (#) пройти невозможно. Камни и алмазы падают, когда остаются без опоры, а также скатываются вбок друг с друга и с кирпичей. Падающие предметы убивают игрока. Бабочки (анимация /|\-) взрываются при соприкосновении с игроком, от удара падающим предметом, а также будучи запертыми без возможности передвижения. Взрыв бабочки поглощает любые материалы, кроме стали, и может убить игрока. После взрыва образуются алмазы, которые можно собрать.play(screen)
play один раз, передав начальное состояние игры в качестве параметра screen. Оно представляет собой массив строк, по одной на каждую строку экрана с верхней до нижней, включая строку состояния. Строки будут содержать в точности то, что вы видите на экране, только без раскраски в ANSI-цвета (игру можно увидеть в таком режиме на консоли, если запустить её с параметром --no-color). Функция play должна быть генератором. Чтобы сделать ход, она должна сгенерировать (yield) значение 'u', 'd', 'r' или 'l' для шага вверх, вниз, вправо или влево соответственно. Ещё можно сгенерировать 'q' или просто завершить работу генератора (return), чтобы окончить игру досрочно (набранные очки при этом не теряются). Если сгенерировать любое другое значение, это означает ход «остаться на месте». Пытаться идти в направлении, в котором двигаться невозможно (например, в стену) не запрещено: персонаж просто останется на месте. После каждого yield содержимое массива screen обновляется, и ваш код может снова его проанализировать для принятия дальнейших решений.play будет генерировать команды быстрее, то персонаж будет двигаться 10 раз в секунду. После каждой команды генератор будет блокироваться на инструкции yield до конца рануда длиной в 100 мс. Если функция «думает» над ходом дольше, чем 100 мс, она начинает пропускать ходы, и тогда персонаж будет оставаться на месте в те раунды, когда функция не успела сделать ход. В этом случае генератор также не увидит некоторых промежуточных состояний экрана. Например, если скрипт «задумается» на 250 мс между двумя инструкциями yield, то не увидит двух состояний экрана, а персонаж останется неподвижным на два раунда; таким образом, будут упущены две возможности сделать ход, которые были бы, если бы программа работала быстрее. После этого генератор будет заблокирован на 50 мс до конца раунда, и сгенерированная им команда будет выполнена.--help, чтобы узнать обо всех его возможностях.jsdash.js --ai=submission.js --log=log.json
jsdash.js --replay=log.json
|
|
[Из песочницы] Обновление document.title в фоновой вкладке |
tab
int Document::requestAnimationFrame(Ref&& callback)
{
if (!m_scriptedAnimationController) {
#if USE(REQUEST_ANIMATION_FRAME_DISPLAY_MONITOR)
m_scriptedAnimationController = ScriptedAnimationController::create(*this, page() ? page()->chrome().displayID() : 0);
#else
m_scriptedAnimationController = ScriptedAnimationController::create(*this, 0);
#endif
// It's possible that the Page may have suspended scripted animations before
// we were created. We need to make sure that we don't start up the animation
// controller on a background tab, for example.
if (!page() || page()->scriptedAnimationsSuspended())
m_scriptedAnimationController->suspend();
if (page() && page()->isLowPowerModeEnabled())
m_scriptedAnimationController->addThrottlingReason(ScriptedAnimationController::ThrottlingReason::LowPowerMode);
if (!topOrigin().canAccess(securityOrigin()) && !hasHadUserInteraction())
m_scriptedAnimationController->addThrottlingReason(ScriptedAnimationController::ThrottlingReason::NonInteractedCrossOriginFrame);
}
return m_scriptedAnimationController->registerCallback(WTFMove(callback));
}
requestAnimationFrame(function handler() {
document.title += 'R'
requestAnimationFrame(handler);
});

|
Метки: author samsdemon javascript requestanimationframe |
Многопользовательская игра на Go через telnet |

telnet towel.blinkenlights.nl
stty -icanon && nc
if player.Car.Borders.intersects(&opponent.Car.Borders) {
switch player.Car.Borders.nextTo(&opponent.Car.Borders, 0) {
case LEFT:
// Игрок слева
switch player.Car.Direction {
...
case RIGHT:
// Удар сзади
player.Health -= DAMAGE_BACK * (maxSpeed - player.Car.Speed)
...
case RIGHT:
// Игрок справа
switch player.Car.Direction {
case RIGHT:
// Удар спереди
player.Health -= DAMAGE_FRONT * player.Car.Speed
...
...
}
telnetOptions := []byte{
255, 253, 34, // IAC DO LINEMODE
255, 250, 34, 1, 0, 255, 240, // IAC SB LINEMODE MODE 0 IAC SE
255, 251, 1, // IAC WILL ECHO
}
_, err := conn.Write(telnetOptions)
type Round struct {
Players []Player
FrameBuffer Symbols
...
}
func (p *Player) checkBestRoundForPlayer(compileRoundChannel chan Round) {
foundRoundForUser := false
for i := 0; i < len(compileRoundChannel); i++ {
select {
case r := <-compileRoundChannel:
// Есть ожидающий раунд
if len(r.Players) < maxPlayersPerRound && !p.searchDuplicateName(&r) {
...
r.Players = append(r.Players, *p)
compileRoundChannel <- r
foundRoundForUser = true
break
} else {
compileRoundChannel <- r
}
default:
}
}
if !foundRoundForUser {
// Создаём новый раунд
...
r := Round{...}
r.Players = append(r.Players, *p)
compileRoundChannel <- r
}
}
type Symbol struct {
Color int
Char []byte
}
type Symbols []Symbol
telnet protury.info 4242
telnet protury.info 4243|
Метки: author leoleovich разработка игр программирование golang development telnet system administration |
Цифровой датчик температуры TSic: адреса, пароли, явки |
|
|
Как мы унифицируем аналитическую деятельность в CUSTIS |
Мы писали в блоге о технологиях в привычном айтишному миру понимании — о наших лучших практиках в разработке информационных систем. Сегодняшний пост посвящен технологиям другого толка — управленческим: мы поговорим об унификации аналитической деятельности в CUSTIS. Эта история о том, как изменить огромную и стабильную систему сложившихся с годами практик и направить ее навстречу проектам развития.
Когда наша компания занималась в основном заказной разработкой и создавала уникальные продукты, над проектом для каждого клиента трудилась одна команда на всем жизненном цикле системы.
Такой подход хорошо отвечал потребностям заказчиков, поскольку аналитик:
Эта модель стала неэффективной, когда мы начали переходить к созданию тиражируемых решений и работать одновременно над большим количеством проектов. Нам потребовалось быстро ротировать аналитиков между проектами и повторно использовать их артефакты, а из-за того, что один описывал действия пользователя в системе Visio, а другой — в Archi, возникали дублирование описаний и неразбериха с нотациями.
Мы поставили перед собой задачу выбрать и внедрить для всех проектных команд одну методику или набор методик, которые будут отвечать новым бизнес-задачам. В посте мы расскажем, как разрабатываем эту методическую основу.
Мы начали с того, что выделили три трека, в рамках которых будем проводить унификацию:
Затем мы проанализировали аналитическую деятельность в разных проектных командах и определили, что необходимо унифицировать:
В следующих разделах подробнее расскажем о результатах методического трека работ.
Мы выделили четыре типа проектов в компании, на которых нам важно уметь перемещать аналитиков:
Далее мы приступили к выделению тех понятий, в которых аналитики будут описывать создаваемые системы.
На UML-диаграмме (см. ниже) показаны концепты аналитической деятельности, которые мы выделили. Используя их, аналитики создают описание IT-системы и общаются.
Схема состоит из следующих элементов:

Подробно остановимся на основных концептах.
Чтобы использовать на практике концепты, нужно выбрать единый для всех инструмент моделирования. О нем — в следующем разделе.
О достоинствах и недостатках инструментов, обеспечивающих аналитическую деятельность, можно спорить бесконечно. Например, кому-то нравится развивать мелкую моторику на примере вот таких решений для моделирования бизнес-процессов.
Наша компания много лет использовала гибкие методики разработки DDD (Domain Driven Design) [7] и инструменты Wiki [6]. Мы опирались на этот опыт и искали новые рыночные методики и инструменты аналитической деятельности.
Мы выписали возможные кейсы использования инструмента, опробовали их на нескольких проектах [9], пообщались с коллегами из других компаний и в итоге остановили выбор на Enterprise Architect.
Для нас были критичными такие параметры, как:
То, что мы предпочли этот инструмент, совсем не значит, что он подойдет и вам. При выборе своего инструмента постарайтесь собрать все ограничения и требования к нему, рассмотреть как можно больше сценариев того, как его используют ваши коллеги, и определить, насколько хорошо аналитики, разработчики, тестировщики и инженеры знают стандарты и нотации. Тогда в краткосрочной перспективе вам не придется переходить на новый инструмент.
Чтобы аналитик каждый раз не перечислял артефакты, которые нужно создать, мы разработали шаблон проекта в Enterprise Architect. Следующий раздел про него.
Когда мы создавали шаблон проекта, мы руководствовались потребностями разработчиков, тестировщиков, инженеров и заказчиков, а также распространенными в IT-отрасли стандартами и нотациями.
Существует несколько вариантов описаний требований. Узнать о них подробнее вы можете из материалов, указанных в списке литературы в конце статьи [1–4]. Мы постарались взять только варианты, необходимые для решения наших задач, и оставили те артефакты, которые используют в работе два и более человек в проекте с учетом жизненного цикла разработки системы.
В шаблоне проекта мы зафиксировали структуру папок и диаграмм в них, а также технологию наполнения диаграмм для различных видов проектов. Еще мы приводили не только перечень нотаций, но и их необходимые модификации, например, для выгрузки документации по ГОСТ, маппинга объектов одного уровня описания с другим.
Набор артефактов в шаблоне меняется в зависимости от типа проекта.
Желающие могут пройти по ссылкам ниже и посмотреть, что это за артефакты. В описании папок и диаграмм есть пояснения.
Еще раз напомню, для чего все мы здесь сегодня собрались.
Представленный методический трек — часть большой работы по унификации аналитической деятельности в компании CUSTIS. На момент написания статьи мы уже испытали методику на некоторых типах проектов.
На проектах типа RFI мы увидели несомненную пользу данной методики: она позволила повторно использовать функциональную и компонентную декомпозицию работ, а также методику оценки трудозатрат.
Впервые работая по предложенной схеме, мы создавали функции, компоненты системы и другие необходимые элементы и оценивали трудозатраты. При получении аналогичных RFI мы копировали уже созданные диаграммы и при необходимости делали небольшие корректировки, например изменяли состав функций и (или) компонент. Таким образом, нам удалось повторно использовать созданные артефакты и минимизировать время на оценку трудозатрат по аналогичным RFI.
На проектах по доработке существующих и разработке новых систем время создания аналитических артефактов «по-новому» оказалось меньше времени их разработки «по-старому» на 25–40%.
Мы сравнивали время, затраченное на разработку артефакта в новой методике, и экспертную оценку временных затрат каждого из работающих в проекте аналитиков на разработку артефакта «по-старому». Аналитик, впервые работавший по новым правилам, тратил больше времени на освоение методики, лучших практик и примеров, консультировался с более опытными коллегами, но после двух-трех итераций время на разработку диаграмм существенно уменьшалось.
Это продемонстрировано на диаграмме:

Мы не ставили перед собой цель уменьшить трудозатраты на разработку артефактов — нам было важно, чтобы это время не увеличилось критично и методика прижилась в компании. Тем отраднее было видеть, что затраты ресурсов стали снижаться, а люди разделяли ценности наших изменений.
Актуальной для нас остается задача обеспечить перемещение аналитиков внутри компании по подразделениям, которые работают с заказчиками из разных предметных областей. Мы поделимся успехами этой части, когда наберем достаточно наглядных примеров, на основе которых с уверенностью можно сказать, что трек внедрения начал приносить первые существенные результаты.
В следующих статьях мы также расскажем о том, как проверяем методологию: на какие параметры смотрим, чтобы понять, подходит ли выбранный метод к нашей работе — и поделимся опытом внедрения работы «по-новому» в действующих проектах.
|
Метки: author oleolke управление проектами блог компании custis инструменты аналитика методика аналитическая деятельность анализ и проектирование систем |
[Из песочницы] Три года успешного предоставления услуг публичного сервиса аренды виртуальных машин с Apache CloudStack |
|
Метки: author ivankudryavtsev системное администрирование виртуализация it- инфраструктура apache cloudstack публичное облако опыт внедрения опыт использования я пиарюсь |
Стартап дня (июнь 2017-го) |

Продолжая серию дайджестов «Стартап дня», сегодня я представляю самые интересные проекты за июнь. Если хотите ознакомиться с остальными, то прошу в мой блог. Записи доступны в Facebook, ICQ и Телеграм.
Yext помогает бизнесу быть лучше представленным на картах. В идеале, как только у банка открывается новое отделение, оно должно сразу появиться в десятках мест: от очевидных карт Google и Яндекса (Google и Bing в американских реалиях) до местного аналога banki.ru и, например, сайта Western Union. В реальности десятками мест никто, конечно, не занимается: везде, кроме самых крупных и раскрученных источников, надолго остается неправильная или неполная информация; клиенты идут не туда, деньги теряются.

И тут на сцену выходит Yext. За суммы, начинающиеся с $4 в неделю, он дает бизнесам единую точку управления своими локациями на всех релевантных площадках: один клик — и данные обновились везде. В одиночку такой сервис не работает: жадный покупатель мог бы включать его только ради каких-то изменений, но для большинства клиентов это событие довольно редкое, можно заметно сэкономить, поэтому стартап «заодно» предлагает и постоянные услуги. Для популярных сетей это мониторинг отзывов на всех тех сайтах, данные на которых Yext приводит в порядок, а для маленьких, кому это неактуально, есть функция геостраниц. Красивые, правильно сверстанные и SEO-оптимизированные страницы про каждую локацию один раз встраиваются в основной сайт и дальше управляются из общего дашборда вместе с внешними ресурсами.
Сейчас у стартапа больше 40 тысяч клиентов, выручка за сотню миллионов долларов в год, пару месяцев назад прошло IPO, капитализация компании больше миллиарда. В Россию не выйдет, наверное, никогда, вполне можно делать своё.
Американский August Home делает для обычных домов и квартир электронные дверные замки, управляемые через приложение на смартфоне, и эта идея куда глубже, чем может показаться: всё, что связано с доставкой, сейчас в тренде, а проект во многом именно про неё. Основной продвигаемый бонус — отсутствие необходимости встречать курьеров и других людей, которым на самом деле нужно место, а не человек. Дверь можно открыть откуда угодно, где есть интернет, не надо никого ждать. Курьер может приехать, когда ему удобно, а вы быть там, где удобно вам. Восьмичасовой интервал доставки становится вполне комфортным, логистические услуги дешевеют, ВВП растет, благолепие… У жителя России может возникнуть вопрос про воровство, но в Штатах ответ настолько очевиден, что даже в промоматериалах не упоминается: с одной стороны, и воровать в современных квартирах особенно нечего, а с другой, курьера при входе фотографируют, откуда он взялся — более-менее известно. Возможное преступление просто идеально для раскрытия, люди не до такой степени идиоты.
Остальные возможные сценарии кажутся куда более надуманными. Ну да, можно отобрать ключ у бывшего парня одним нажатием кнопки и быть уверенным, что он дубликат не сделал. Но заботиться о такой ситуации заранее и ставить для этого специальный замок?.. Разве что в квартирах под посуточную аренду это актуально. Или, например, возможность для уборщицы заходить в дом только по средам с 10 до 12 — а зачем? Потому что можем? А уж логирование входов и push-уведомления о них кажутся вообще вредными для нормальной семейной жизни.
Что касается риска разрядившегося телефона, то он решается максимально просто: замок можно открыть не только из приложения, но и введя код. Потерянный же телефон кажется менее опасным, чем потерянный железный ключ: перепрограммировать коды существенно проще и дешевле, чем сменить замок. Но хакерам в будущем в любом случае будет раздолье, да.
Если говорить о текущих масштабах, то проданы сотни тысяч устройств, поднято порядка пятидесяти миллионов долларов инвестиций, за четыре года жизни железячного стартапа — довольно много.

Насколько я могу судить, я пишу по-русски достаточно грамотно; постоянным читателям блога, конечно, виднее, но самооценка у меня такая. И такая же самооценка была про английский язык: я понимал, что мои тексты очень упрощенные, без сложных конструкций и ярких идиом, но думал, что явных ошибок в них мало, тем более что и браузер с Word’ом подчеркивали что-то редко. Ха! Стоило установить себе плагин от Grammarly, и иллюзии развеялись как дым.
Это всего лишь проверка грамотности текста, но проверка хорошая. Grammarly не проверяет слова по словарю, а действительно знает английскую (только английскую) орфографию с пунктуацией, видит пропущенные запятые, несогласование времен, неправильные артикли, понимает, что player должен обязательно has, а не have, и замечает ещё огромную кучу разных проблем. Меня правит практически в каждом абзаце, при том, что, повторюсь, стандартные средства не подчеркивают почти ничего. Важно, что ошибки не просто отмечаются, но и полноценно разъясняются. В общем, действительно полезное применение технологий AI.
Технически в Grammarly есть три варианта реализации: плагин к Chrome/Safari/Firefox/IE, плагин к MS Office и самостоятельный текстовый редактор. Работоспособным кажется только вариант в браузере — менять привычный редактор, даже ради проверки английского, это чересчур, а в Word’е он почему-то ломает возможность Undo через Ctrl-Z (как?? кто так программирует??), что, конечно, полностью убивает возможность использования.
Модель монетизации, естественно, основана на подписке: бесплатно можно видеть только явные ошибки, а премиум-пользователи за примерно 20 долларов в месяц получают ещё и стилистические рекомендации в духе «a lot of тут не подходит, используйте лучше much». Платит за такое, скорее всего, очень маленький процент аудитории, но при текущих 7 миллионах DAU это должно быть несколько сот тысяч человек (то есть десятки миллионов годовой выручки).
Компания говорит, что она прибыльная, да и инвестиций до этого года не было, убытки покрывать было нечем, куда бы они делись без прибыльности. Но сейчас решили расти быстрее, взяли аж 110 миллионов долларов в недавнем раунде. Успеха им и спасибо за отличный продукт.
Самый «простой» способ сделать успешный интернет-магазин — продавать такую категорию товаров, на которую есть большой спрос и большой объём продаж в оффлайне, но она при этом плохо представлена в уже существующих онлайн-магазинах. Требуются-то самые пустяки: нужно только найти такую категорию.
Английский стартап LoveCrafts продает через интернет товары для вязания и шитья по самой обычной бизнес-модели, со своими складами, самой обыкновенной логистикой и остальными особенностями типового интернет-магазина. Фокус на единственной узкой категории позволил им добиться совершенно бесконечного выбора, запрограммировать удобные фильтры, ну и, конечно, вести более прицельный маркетинг. Показательно, что даже для вязания и шитья они сделали два отдельных сайта, хоть и связанных множеством перекрестных ссылок, но всё-таки разных. Целевой аудитории всё это, естественно, нравится, покупают на LoveCraft много.
Однако даже позиция специализированного магазина не гарантированно устойчива: и наглый конкурент может сделать клон, и у Амазона рано или поздно дойдут руки и до этой ниши, и тогда остаётся только ценовая конкуренция — а кому она нужна. Поэтому, чтобы закрепить свое текущее преимущество, LoveCraft хочет быть не только магазином, но и сообществом, и маркетплейсом. Раз уж он продает товары творческим людям, то пусть они и делятся своим творчеством через его площадку — это же должно быть удобно?
Ради денег авторы могут загружать на сайт придуманные ими схемы и дизайны и продавать их менее креативным пользователям. Если же хочется славы и уважения, а не дохода, то для этого служит раздел «сообщество»: там можно выставлять свои работы и лайкать чужие.
Дополнительный функционал не приносит LoveCraft денег напрямую, они даже комиссию за продажу схем не берут, но повышает лояльность пользователей, да и журналистам нравится. Впрочем, если сообщество в самом деле активно заведется (пока нет), там можно много разной монетизации придумать.
Английский рынок стартап занял практически без инвестиций, ради американского поднял порядка 30 миллионов долларов и сейчас в США примерно половина его бизнеса. В апреле был очередной раунд в 33 миллиона — хотят организовывать новые категории и выходить в новые страны.
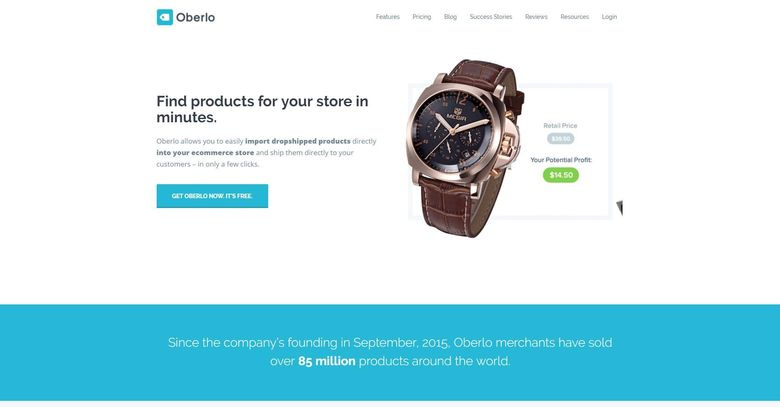
Идея этого стартапа — автоматизация прямой перепродажи с AliExpress. Интернет-бизнесмен со своим аккаунтом на Shopify подключается к Oberlo, выбирает в веб-интерфейсе те товары с AliExpress, которые нужно показывать на новой площадке, и вуаля, магазин готов. Осталось только описания на нужном языке поправить и правило для новых цен установить, +20 или +50 процентов к оригинальным, например. Всё равно ведь дешево останется.
Когда конечный покупатель закажет что-то на этой витрине, Oberlo автоматически создаст и оплатит заказ на AliExpress сразу с финальным адресом. Если что-то изменится на странице товара на Ali, цена увеличится или товар вообще пропадет, то Oberlo поправит и витрину. Владельцу магазина остается только привлекать клиентов и разбираться с претензиями: диспуты, увы, пока автоматически не проксируются.
Кроме чистых арбитражников с подходом «написал красивые описания, поставил наценку в 100 %, закупил рекламу в Таргете, профит» такая модель вполне логично может использоваться на тематических сайтах: почему бы и не продавать своей аудитории релеватную подборку товаров. Наверное, при разумной разнице в цене люди даже не слишком возмущены будут, если всю подноготную узнают. В конце концов, за них выбор сделали, это тоже чего-то стоит.
В дополнение к очевидной SaaS-подписке и потенциальному использованию маркетингового бюджета AliExpress, Oberlo ещё и берет комиссию за часть товаров. Идея состоит в том, что кроме обычных магазинов с Ali они в том же режиме предлагают перепродавать товары неких «проверенных» поставщиков, работающих напрямую с Oberlo. При настройке экспорта эта часть ассортимента всегда подсовывается повыше, и, конечно, регулярно попадает в финальные витрины. Не знаю, насколько это действительно прямые договоры: было бы очень красиво и вполне соответствовало духу проекта, если «проверенными» назывались бы просто обычные товары с Ali с измененными описаниями и увеличенной ценой.
Придумали эту замечательную модель совсем недалеко от России, в Литве. Стартап недавно куплен Shopify за 15 миллионов долларов.
|
Метки: author gornal развитие стартапа венчурные инвестиции бизнес-модели блог компании mail.ru group стартапы стартап дня startups |
Pygest #12. Релизы, статьи, интересные проекты из мира Python [20 июня 2017 — 03 июля 2017] |
 Всем привет! Это уже двенадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже двенадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python. |
Метки: author andrewnester разработка веб-сайтов программирование машинное обучение python django digest pygest machine learning flask дайджест web |
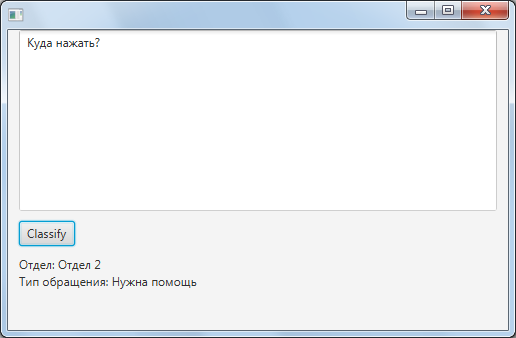
Классификация текста с помощью нейронной сети на JAVA |
| Текст | Униграмма | Биграмма | 3-символьная N-грамма |
|---|---|---|---|
| Этот текст должен быть разбит на части | [«этот», «текст», «должен», «быть», «разбит», «на», «части»] | [«этот текст», «текст должен», «должен быть», «быть разбит», «разбит на», «на части»] | [«Это», «т т», «екс», «т д», «олж», «ен », «быт», «ь р», «азб», «ит », «на », «час», «ти»] |
class Unigram implements NGramStrategy {
@Override
public Set getNGram(String text) {
if (text == null) {
text = "";
}
// get all words and digits
String[] words = text.toLowerCase().split("[ \\pP\n\t\r$+<>№=]");
Set uniqueValues = new LinkedHashSet<>(Arrays.asList(words));
uniqueValues.removeIf(s -> s.equals(""));
return uniqueValues;
}
}
public class FilteredUnigram implements NGramStrategy {
@Override
public Set getNGram(String text) {
// get all significant words
String[] words = clean(text).split("[ \n\t\r$+<>№=]");
// remove endings of words
for (int i = 0; i < words.length; i++) {
words[i] = PorterStemmer.doStem(words[i]);
}
Set uniqueValues = new LinkedHashSet<>(Arrays.asList(words));
uniqueValues.removeIf(s -> s.equals(""));
return uniqueValues;
}
private String clean(String text) {
// remove all digits and punctuation marks
if (text != null) {
return text.toLowerCase().replaceAll("[\\pP\\d]", " ");
} else {
return "";
}
}
}
class VocabularyBuilder {
private final NGramStrategy nGramStrategy;
VocabularyBuilder(NGramStrategy nGramStrategy) {
if (nGramStrategy == null) {
throw new IllegalArgumentException();
}
this.nGramStrategy = nGramStrategy;
}
List getVocabulary(List classifiableTexts) {
if (classifiableTexts == null ||
classifiableTexts.size() == 0) {
throw new IllegalArgumentException();
}
Map uniqueValues = new HashMap<>();
List vocabulary = new ArrayList<>();
// count frequency of use each word (converted to n-gram) from all Classifiable Texts
//
for (ClassifiableText classifiableText : classifiableTexts) {
for (String word : nGramStrategy.getNGram(classifiableText.getText())) {
if (uniqueValues.containsKey(word)) {
// increase counter
uniqueValues.put(word, uniqueValues.get(word) + 1);
} else {
// add new word
uniqueValues.put(word, 1);
}
}
}
// convert uniqueValues to Vocabulary, excluding infrequent
//
for (Map.Entry entry : uniqueValues.entrySet()) {
if (entry.getValue() > 3) {
vocabulary.add(new VocabularyWord(entry.getKey()));
}
}
return vocabulary;
}
}
| Текст | Отфильтрованная униграмма | Словарь |
|---|---|---|
| Необходимо найти последовательность 12 задач | необходим, найт, последовательн, задач | необходим, найт, последовательн, задач, для, произвольн, добав, транспозиц |
| Задачу для произвольных | задач, для, произвольн | |
| Добавить произвольную транспозицию | добав, произвольн, транспозиц |
class Bigram implements NGramStrategy {
private NGramStrategy nGramStrategy;
Bigram(NGramStrategy nGramStrategy) {
if (nGramStrategy == null) {
throw new IllegalArgumentException();
}
this.nGramStrategy = nGramStrategy;
}
@Override
public Set getNGram(String text) {
List unigram = new ArrayList<>(nGramStrategy.getNGram(text));
// concatenate words to bigrams
// example: "How are you doing?" => {"how are", "are you", "you doing"}
Set uniqueValues = new LinkedHashSet<>();
for (int i = 0; i < unigram.size() - 1; i++) {
uniqueValues.add(unigram.get(i) + " " + unigram.get(i + 1));
}
return uniqueValues;
}
}
| Слово в словаре | Вектор слова |
|---|---|
| привет | 1 0 0 0 |
| как | 0 1 0 0 |
| дела | 0 0 1 0 |
| тебе | 0 0 0 1 |
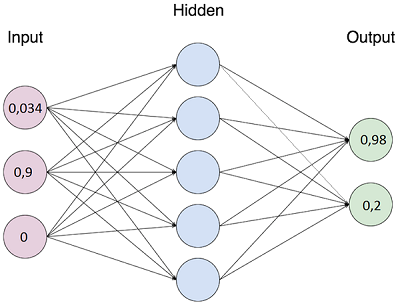
private double[] getTextAsVectorOfWords(ClassifiableText classifiableText) {
double[] vector = new double[inputLayerSize];
// convert text to nGram
Set uniqueValues = nGramStrategy.getNGram(classifiableText.getText());
// create vector
//
for (String word : uniqueValues) {
VocabularyWord vw = findWordInVocabulary(word);
if (vw != null) { // word found in vocabulary
vector[vw.getId() - 1] = 1;
}
}
return vector;
}
| N-грамма | Точность | Размер словаря (без редкоиспользуемых слов) |
|---|---|---|
| Униграмма | 58% | ~25 000 |
| Отфильтрованная униграмма | 73% | ~1 200 |
| Биграмма | 63% | ~8 000 |
| Отфильтрованная биграмма | 69% | ~3 000 |
|
Метки: author i11 проектирование и рефакторинг программирование машинное обучение open source java нейронные сети классификация текста шаблоны проектирования паттерны проектирования |
The incredible machine или мой самый лучший тест |
|
Метки: author antonsobolev тестирование it-систем программирование open source c++ openpapyrus тестирование штрихкод распознавание штрих-кода |
FinWin-2017: конкурс финтех-проектов и последние тенденции в банковской сфере |




|
|
Docker 17.06 и Kubernetes 1.7: ключевые новшества |

Dockerfile несколько этапов сборки образа для того, чтобы в конечный образ не попадали промежуточные данные, которые не требуются. Очевидный пример, который приводят в Docker: Java-разработчики обычно используют Apache Maven для компиляции своих приложений, однако Maven не нужен в конечном контейнере (образе) для запуска этих приложений. Теперь можно оформить Dockerfile таким образом, что сам Maven будет использоваться в промежуточном образе (для сборки), но не попадёт в конечный (для запуска).Dockerfile для простого приложения на Java Spring Boot:FROM node:latest AS storefront
WORKDIR /usr/src/atsea/app/react-app
COPY react-app/package.json .
RUN npm install
COPY . /usr/src/atsea/app
RUN npm run build
FROM maven:latest AS appserver
WORKDIR /usr/src/atsea
COPY pom.xml .
RUN mvn -B -f pom.xml -s /usr/share/maven/ref/settings-docker.xml dependency:resolve
COPY . .
RUN mvn -B -s /usr/share/maven/ref/settings-docker.xml package -DskipTests
FROM java:8-jdk-alpine
WORKDIR /static
COPY --from=storefront /usr/src/atsea/app/react-app/build/ .
WORKDIR /app
COPY --from=appserver /usr/src/atsea/target/AtSea-0.0.1-SNAPSHOT.jar .
ENTRYPOINT ["java", "-jar", "/app/AtSea-0.0.1-SNAPSHOT.jar"]
CMD ["--spring.profiles.active=postgres"]$ docker plugin install --grant-all-permissions cpuguy83/docker-metrics-plugin-test:latest
$ curl http://127.0.0.1:19393/metrics
docker info. Кроме того, реализацию docker service logs, которая с прошлого релиза (17.05) может показывать и логи индивидуальных заданий (/task/{id}/logs в REST), перенесли из ветки Edge в Stable, поэтому теперь легко получить обобщённые логи для всего сервиса, запущенного в Swarm.[Wrk-node1]$ docker network create --config-only --subnet=10.1.0.0/16 local-config
[Wrk-node2]$ docker network create --config-only --subnet=10.2.0.0/16 local-config
[Mgr-node2]$ docker network create --scope=swarm --config-from=local-config -d macvlan
mynet
[Mgr-node2]$ docker service create --network=mynet my_new_service$ echo "This is a config" | docker config create test_config -
$ docker service create --name=my-srv --config=test_config …
$ docker exec -it 37d7cfdff6d5 cat test_config
This is a configdocker swarm ca --rotate);--datapath-addr для docker swarm init, указывающий сетевой интерфейс для изоляции заданий управления (control traffic) от данных приложений (data traffic) — полезно в случае приложений, производящих большую нагрузку на ввод/вывод;/var/run).StatefulSet, используемых для деплоя stateful-приложений. Стратегия обновлений определяется полем spec.updateStrategy, поддерживающим сейчас два значения: OnDelete и RollingUpdate.StatefulSets более быстрого масштабирования и запуска приложений, не требующих строгой очередности, настраиваемой теперь через Pod Management Policy. Такие приложения теперь могут запускаться параллельно и без ожидания получения подом определённых статусов (Running, Ready).StorageClasses внутри StatefulSets теперь можно получить доступ к локальному хранилищу через стандартный интерфейс PVC/PV.DaemonSets.APIService, который реализуется через extension-apiserver внутри пода, работающего в кластере Kubernetes.|
Метки: author shurup системное администрирование серверное администрирование it- инфраструктура devops блог компании флант docker kubernetes контейнеры микросервисы |