Как накрутить рейтинг на хабре и уйти незамеченным |

Как-то пятничным вечером я сидел за домашним компом с чашкой черного чая, писал статью и думал о жизни. Работа спорилась, но голова начинала к тому времени заметно притормаживать. И вот когда за окном стало уже совсем темно, я решил отправить статью отдыхать до завтрашнего дня, да и самому пойти спать. Но вместо того, чтобы сохранить все в черновик, как полагается, сонный мозг на автопилоте её зачем-то опубликовал...
Понял я это не сразу, а только спустя несколько минут, зайдя напоследок обновить свой профиль. Ощущение было, как будто не выключил газ на кухне и все вот-вот умрут. Я молился, чтобы ее можно вернуть в черновики или хотя бы удалить. Кстати, последнего, как оказалось, сделать уже нельзя, если материал попал в общее обозрение. Впоследствии говорил на этот счет с тех поддержкой, но мне порекомендовали просто смириться с провалом)
Не буду томить — статья в итоге успешно вернулась в гнездо — но какой-то добрый самаритянин уже успел поставить ей плюс. Но что самое интересное, несмотря на то, что статьи больше не было на сайте, рейтинг, полученный за нее, остался у меня в профиле.
Это не могло не натолкнуть на мысль воспроизвести ситуацию в промышленных масштабах.

У меня тогда как раз накопился один инвайт, которым я решил поделиться с другом и заодно проверить теорию. Разумеется, кликать по одной статье за раз — это скучно и, тем более, не подобает уважающему себя разработчику. К тому же, не слишком безопасно, потому что есть риск просто попасться.
Будем автоматизировать.
Нам надо получить следующие методы: создание статьи, публикация, голосование и скрытие статьи в черновиках.
Процесс авторизации проходить не будем, поскольку он сложный, с кучей переадресаций, да и достаточно просто вытащить все cookie и прикинуться ветошью браузером.
В качестве веб прокси будем использовать Charles для Mac. Крайне удобная вещь. Если вы разработчик, то рекомендую иметь её в своем джентельменском наборе. Позволяет также слушать трафик с любого подручного девайса, если вы, например, отлаживаете мобильное приложение.
В рамках одной сессии успешно получаем все необходимые нам методы.

Как оказалось, за создание, публикацию и удаление статей отвечает один и тот же запрос, но с разными параметрами. Можно создать пост в качестве черновика или сразу его опубликовать. И именно здесь прописывается будет ли ваш пост в песочнице, переводом или ходовой публикацией. Может быть, это даст возможность обойти требования к публикации в песочнице, но не проверял. Скорее всего, сервер просто развернет домой с какой-нибудь забавной ошибкой.
Уже практически праздную победу, делаю запрос на создание поста:
params = {
:id => '',
:post_type => 'simple',
:flow => 5,
:hubs => [20742],
:title => 'test1',
:text => 'test1',
:tags_string => 'test1'
}
response = HTTParty.post('https://habrahabr.ru/json/topic/?action=save', headers: headers, body: params)
# Получаем id поста для последующего использования
params[:id] = JSON.parse(response.body)['redirect'].split('/')[2]Flow равное 5 и Hubs равное 20742 — это не случайные числа, а вполне осознанно выбранный наименее популярный поток 'Разное' и хаб 'Читальный зал', чтобы снизить вероятность быть уличенным в афере.
Но тем не менее, Habr нам почему-то отвечает отказом:
{
"system_errors": [
"Неизвестный тип публикации"
]
}Странно. Ведь все параметры верны, post_type установлен и точно совпадает с нужным и все поля на месте. Проверяем запрос из прокси — работает. А из кода — ошибка.
Как оказалось после веселой отладки, если отсутствует заголовок Referer, то любой запрос к API падает. Юзабилити на высоте. И еще один забавный случай: независимо от того какое значение указано в поле draft, публикация все равно будет создаваться черновиком:

Даже если стоит 0 или вообще абракадабра.
Но если поля вообще нет, то статья уже публикуется в общий поток.
Хорошо, пост создали, можно голосовать. Тут все тоже довольно просто и завелось с первого раза:
vote_headers = {
'Cookie' => HTTP::Cookie.cookie_value(vote_jar.cookies(habr_uri)),
'User-Agent' => 'Mozilla/5.0',
'Referer' => 'https://habrahabr.ru/top/',
'Content-Type' => 'application/x-www-form-urlencoded',
'Accept' => 'application/json'
}
vote_body = {
# Помните прошлый запрос?
'ti' => params[:id],
'tt' => 2,
'v' => 1
}
uri = URI.parse('https://habrahabr.ru/json/vote/')
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true
request = Net::HTTP::Post.new(uri.path, vote_headers)
request.body = URI.encode_www_form(vote_body)
# Только для отладки
puts http.request(request).bodyЗапрос через HTTParty отчаянно отказывался работать с голосованием, пришлось пилить его через net/http. Аргументы, конечно, не самые говорящие в API, но в целом все понятно: id публикации и два магических параметра. Элементарно.
Теперь все вместе. Достаем через прокси наши Cookies, сначала для одного аккаунта, с которого будем постить, а потом для второго, с которого будем голосовать.
Запускаем запросы последовательно друг за другом и все, вроде как, хорошо. И тут я понял, что для смены аккаунтов мне пришлось явно разлогиниться на сайте. Но при этом моя сессия все равно продолжала работать из кода.
То есть, мои куки никто и не думал обнулять на бэкенде. Хабр, как-то нехорошо так поступать со своими пользователями. Не секьюрно.
Оставим все как есть, и запустим процедуру в цикле. Крутим без какого-либо delay, но на второй же итерации натыкаемся на забавную ошибку с пасхалкой:
{
"system_errors": [
"Повтор на втором игроке!"
]
}Кто постарше помнит, что раньше была такая передача 'Пойми меня', где дети по цепочке объясняли друг другу слова. И если двое сделали это одинаково, то ведущий говорил: 'повтор на таком-то игроке!'. Ссылка на запись игры.
Мне кажется, это многое говорит о возрасте тех, кто разрабатывал хабр.
Постепенно увеличиваем задержку, и методом перебора выясняем, что таймаут на создание постов стоит 30 секунд. Запускаем цикл и уходим пить любимый кетчуп чай.
Не будем наглеть, остановимся на 30 баллах, исчеркав все черновики хабра:

122 место, неплохо. Осталось чуть-чуть до первой сотни. А вот и сами тестовые посты:

Как можно заметить, на сайте нет никакого упоминания о вашей деятельности, посты никто не видел, кроме вас самих, но рейтинг при этом присутствует.
Вот таким нехитрым способом можно незаметно накрутить своему товарищу рейтинг.
Возможно, хабру стоит поставить ограничение на несколько публикаций в день, чтобы этой особенностью не злоупотребляли. И я бы еще все-таки сделал сброс сессии при логауте.
Спасибо за внимание.
P.S. Не баньте меня, пожалуйста. Баньте его — sp1nfox, это ему рейтинг накручивали.
|
Метки: author Mehdzor информационная безопасность api habrahabr api habrahabr.ru рейтинг хакер_от_бога |
Проблема непрерывной защиты веб-приложений. Взгляд со стороны исследователей и эксплуатантов |


http://apex.app:8090/apex/f?p=30:180:3426793174520701::::P180_ARTICLE_ID:5024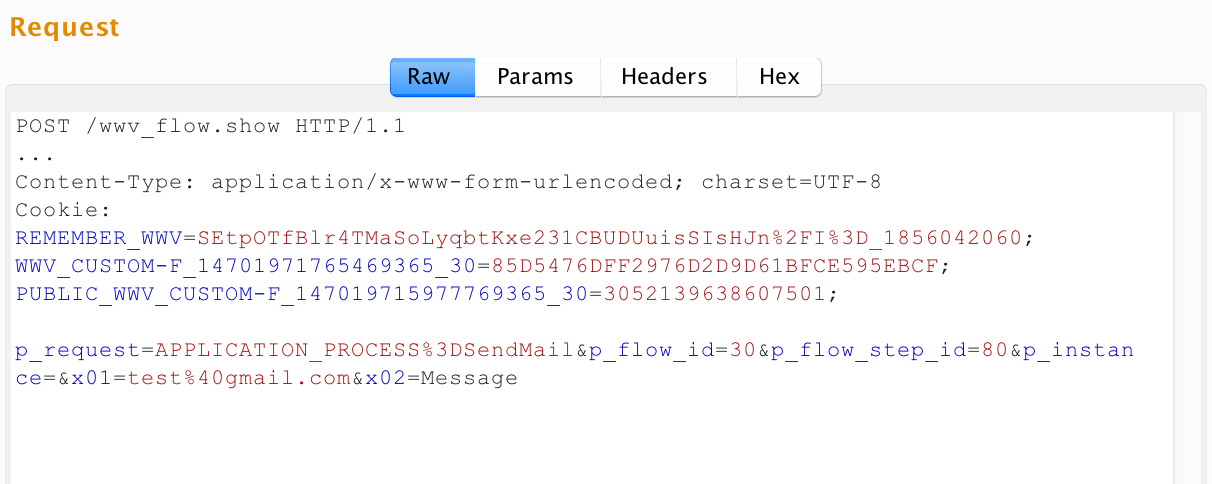
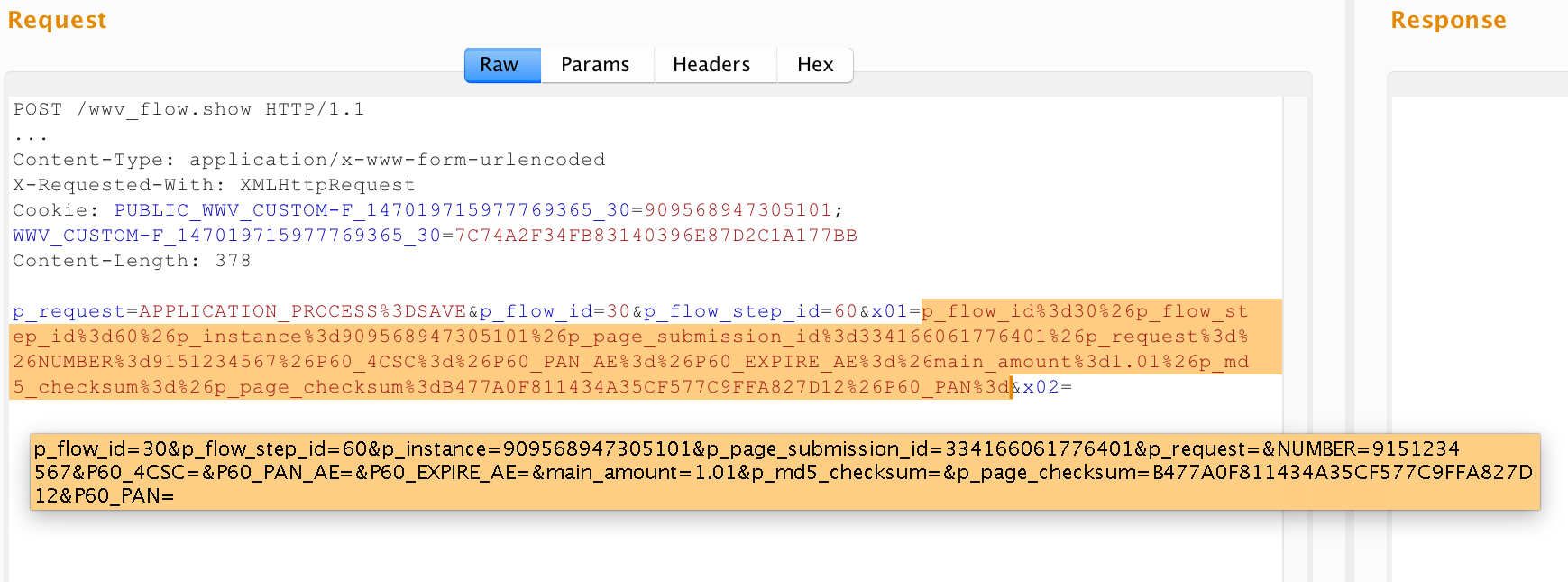
|
Метки: author SolarSecurity тестирование веб-сервисов информационная безопасность анализ и проектирование систем saas / s+s блог компании solar security soc waf защита веб-приложений |
Имитируем управление устройствами с помощью акторов |
Корни SObjectizer берут свое начало в теме автоматизированных систем управления технологическими процессами (АСУТП). Но использовали мы SObjectizer в далеких от АСУТП областях. Поэтому иногда возникает ностальгия из категории «эх, давно не брал в руки шашек...» Однажды из-за этого в составе SObjectizer появился один из самых объемных примеров — machine_control. Уж очень тогда захотелось «тряхнуть стариной», смоделировать задачку управления оборудованием на современном SObjectizer-е. Ну и под шумок запихнуть в пример разные вкусные фичи SObjectizer-а вроде фильтров доставки, шаблонных агентов и диспетчера с поддержкой приоритетов. Сегодня попробуем рассказать и показать, как это все работает.

Photo by Mike Boening
Предположим, что мы имеем дело с какой-то машиной или со станком на производстве, у которого внутри есть двигатель. Ну, скажем, привод ленты конвейера. Или это насос, качающий воду. Не суть важно. Важно то, что когда двигатель работает, он нагревается. А когда он нагревается, его нужно охлаждать. Поэтому рядом с двигателем установлен охлаждающий вентилятор. Этот вентилятор нужно включить, если двигатель разогрелся свыше 70 градусов. Вентилятор следует выключить, если в результате охлаждения двигатель остыл до 50 градусов. Если же двигатель, не смотря на охлаждение, продолжает нагреваться и его температура достигает 95 градусов, то двигатель вовсе нужно выключить и подождать, пока он не остынет до 50 градусов.
Естественно, что нам бы хотелось видеть, как все это происходит в динамике. Нам нужно видеть работает ли сейчас двигатель, какова температура у двигателя, включен ли охлаждающий вентилятор. Для этого в реализации machine_control мы используем простую периодическую печать всей этой информации на консоль.
Ну и для того, чтобы нам было интереснее, сделаем работу не с одним двигателем, а с несколькими. Все они работают одинаковым образом, но их свойства отличаются. Какой-то из них нагревается быстрее, какой-то медленнее. Поэтому если наблюдать за работой, скажем, четырех двигателей, то будет казаться, что каждый из них живет своей жизнью.
Понятно, что любую задачу можно решить несколькими способами. Описываемый ниже способ всего лишь один из возможных. Его выбрали не столько из-за соображений простоты и практичности, сколько из-за возможности продемонстрировать разные фичи SObjectizer-а. Поэтому лучше относиться к последующему тексту как к демонстрации. Тем более, что в продакшен все будет гораздо серьезнее и страшнее ;)
Есть несколько агентов-машин, есть специальный общий почтовый ящик. Агенты-машины время от времени посылают в этот общий почтовый ящик сообщения о своем текущем статусе.

Из общего почтового ящика сообщения о статусе агента-машины попадают к двум совершенно разным агентам. Первый из них, total_status_dashboard, собирает информацию о статусах агентов-машин и периодически отображает информацию о происходящем на стандартный поток вывода. Благодаря чему запустив пример мы видим приблизительно вот такую картинку:
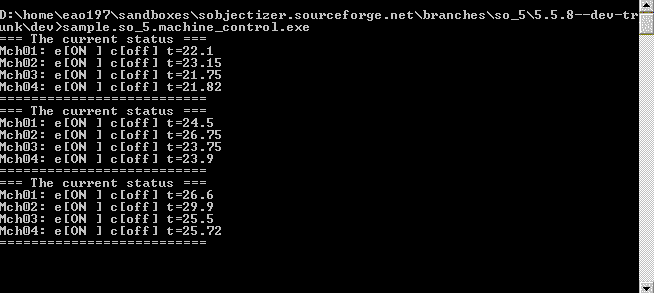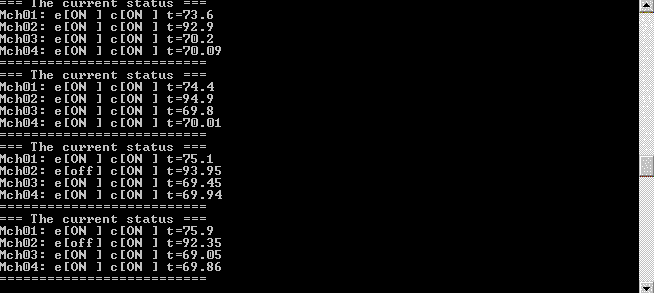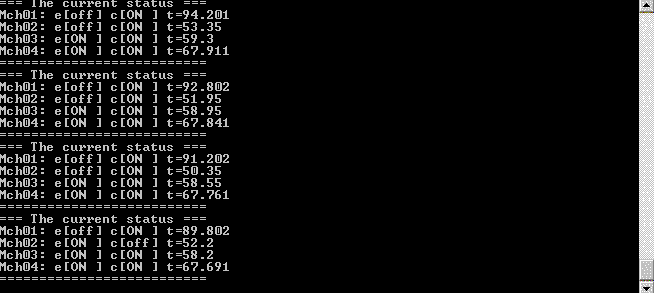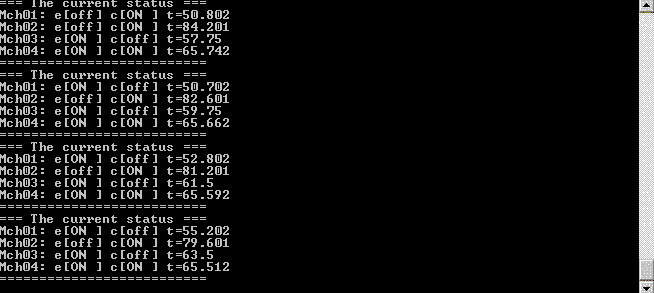
Второй агент — это statuses_analyser. Он получает информацию о статусах для того, чтобы контролировать происходящее с машинами и определять моменты, когда какой-то из машин требуется внешнее воздействие. Когда воздействие требуется, агент statuses_analyser отсылает еще одно сообщение в этот же общий почтовый ящик. На это сообщения реагируют агенты machine_controller. Они уже решают какое именно управляющее воздействие должно быть применено к конкретной машине и отсылают соответствующее сообщение напрямую соответствующему агенту-машине.
Вот, собственно, и все. Остальные моменты в деталях постараемся рассмотреть ниже по тексту.
Начнем разбор реализации нашего примера «от печки», т.е. от самой машины с двигателем и охлаждающим вентилятором. В реальной жизни у нас было бы какое-то настоящее «железо», к которому были бы подключены какие-то датчики и управляторы. И со всей этой кухней нужно было бы работать из программы через тот или иной интерфейс, а может быть и через несколько разных интерфейсов.
Но у нас вымышленный пример, поэтому нам не нужно опрашивать никаких портов и считывать данные с реального оборудования. Нам нужно что-то изображающее из себя работающую машину. Для этого у нас есть агент a_machine_t, который:
Не смотря на то, что данный агент занимается имитацией, в свое время, в задачах АСУТП, доводилось использовать похожую логику. Агент по событию таймера обращался через некоторый интерфейс к оборудованию и собирал информацию с датчиков. После чего преобразовывал снятую информацию в нужный вид и отсылал ее тем, кто мог эту информацию должным образом обработать.
Посмотрим на то, как выглядит этот самый агент a_machine_t, но сперва введем несколько определений, которые нам понадобятся в реализации a_machine_t:
// Специальный тип для обозначения состояния двигателя.
enum class engine_state_t { on, off };
// Специальный тип для обозначения состояния вентилятора.
enum class cooler_state_t { on, off };
// Управляющие сообщения-сигналы для включения и выключения двигателя.
struct turn_engine_on : public so_5::signal_t {};
struct turn_engine_off : public so_5::signal_t {};
// Управляющие сообщения-сигналы для включения и выключения вентилятора.
struct turn_cooler_on : public so_5::signal_t {};
struct turn_cooler_off : public so_5::signal_t {};
// Описание текущего состояния машины.
struct machine_status
{
// Уникальное название-идентификатор для машины.
// Необходимо для того, чтобы отличать машины друг от друга.
const std::string m_id;
// Статус двигателя машины.
const engine_state_t m_engine_status;
// Статус вентилятора машины.
const cooler_state_t m_cooler_status;
// Текущая температура двигателя.
const float m_engine_temperature;
};Соответственно, наш агент a_machine_t будет получать управляющие команды в виде сообщений-сигналов turn_engine_on/turn_engine_off и turn_cooler_on/turn_cooler_off, а о своем состоянии будет извещать посредством отсылки сообщения machine_status.
Теперь уже можно перейти к рассмотрению самого агента a_machine_t. Начнем с самых потрохов:
class a_machine_t : public so_5::agent_t
{
// Этот сигнал будет использоваться для периодического информирования
// о текущем статусе машины.
struct update_status : public so_5::signal_t {};
// Агент-машина может находиться в двух состояниях:
// состояние, когда двигатель включен,
const state_t st_engine_on{ this, "on" };
// состояние, когда двигатель выключен.
const state_t st_engine_off{ this, "off" };
// Уникальный идентификатор-название этой машины.
const std::string m_id;
// В этот почтовый ящик будет отсылаться сообщение machine_status.
const so_5::mbox_t m_status_distrib_mbox;
// Уникальные параметры конкретной машины:
// начальная температура,
const float m_initial_temperature;
// шаг изменения температуры двигателя во время нагревания,
const float m_engine_heating_step;
// шаг изменения температуры двигателя во время охлаждения.
const float m_cooler_impact_step;
// Текущая температура двигателя.
float m_engine_temperature;
// Текущие состояния двигателя и вентилятора.
engine_state_t m_engine_status = engine_state_t::off;
cooler_state_t m_cooler_status = cooler_state_t::off;
// ID таймера для периодического сообщения update_status.
// В SO-5 для периодических сообщений ID таймера нужно сохранять
// в течении всего времени работы, иначе произойдет автоматическая
// отмена периодического сообщения.
so_5::timer_id_t m_update_status_timer;Агент a_machine_t представляет из себя очень простой конечный автомат с двумя состояниями: «двигатель включен» и «двигатель выключен». В каждом из них он реагирует на некоторые сообщения по-разному. Для того, чтобы представить агента в виде конечного автомата в SObjectizer нам и потребовались два отдельных атрибута st_engine_on и st_engine_off.
При своем старте агент инициирует периодическое сообщение update_status. Каждый раз, когда он получает это сообщение, агент пересчитывает значение m_engine_temperature с учетом того, работают ли сейчас двигатель и вентилятор или нет. После чего в почтовый ящик m_status_distrib_mbox отсылается сообщение machine_status с текущими показаниями.
Конструктор агента выглядит объемным из-за обилия начальных параметров, но на самом деле он тривиален, поэтому мы его рассматривать не будем.
А вот дальше уже интереснее. Во-первых, это специальный метод so_define_agent(), который используется для того, чтобы агент мог настроить себя для работы внутри SObjectizer. Нашему a_machine_t нужно перейти в свое начальное состояние и подписаться на нужные ему сообщения. Вот как это выглядит:
virtual void so_define_agent() override
{
this >>= st_engine_off;
st_engine_on
.event< turn_engine_off >( &a_machine_t::evt_turn_engine_off )
.event< turn_cooler_on >( &a_machine_t::evt_turn_cooler_on )
.event< turn_cooler_off >( &a_machine_t::evt_turn_cooler_off )
.event< update_status >( &a_machine_t::evt_update_status_when_engine_on );
st_engine_off
.event< turn_engine_on >( &a_machine_t::evt_turn_engine_on )
.event< turn_cooler_on >( &a_machine_t::evt_turn_cooler_on )
.event< turn_cooler_off >( &a_machine_t::evt_turn_cooler_off )
.event< update_status >( &a_machine_t::evt_update_status_when_engine_off );
}Можно обратить внимание, что на сигнал update_status агент в разных состояниях реагирует посредством разных обработчиков. Также можно увидеть, что в состоянии st_engine_on сигнал turn_engine_on игнорируется, поскольку нет смысла включать уже работающий двигатель. Аналогично и с turn_engine_off в состоянии st_engine_off.
По поводу метода so_define_agent() нельзя не сделать маленького лирического отступления: на первый взгляд этот метод выглядит избыточным и кажется, что без него можно было бы обойтись. Ведь можно все настройки агента выполнить прямо в конструкторе.
Действительно, можно. В простейших случаях так и делается. Но вот если используется наследование для агентов, то настройка агента в so_define_agent() оказывается более удобной, чем в конструкторе. Классы наследники получают простой и удобный способ вмешательства в настройки базового класса (например, можно просто не вызывать so_define_agent() для базового класса, тогда все настройки будут сделаны производным классом).
Кроме того, по нашему опыту, отдельный метод so_define_agent() начинает себя оправдывать в больших проектах, написанных разными людьми: открываешь чужой код, сразу же заглядываешь в so_define_agent() чужого агента и видишь все в одном месте. Сильно экономит время и силы.
Следующий важный метод — это so_evt_start(). SObjectizer автоматически вызывает его у всех агентов, которые начинают работать внутри SObjectizer-а. Наш a_machine_t использует so_evt_start() для того, чтобы начать отсылку периодического сообщения update_status:
virtual void so_evt_start() override
{
// Запускаем периодическое сообщение типа update_status и сохраняем
// ID таймера, чтобы сообщение продолжало отсылаться до тех пор,
// пока агент существует.
m_update_status_timer = so_5::send_periodic< update_status >(
// Указываем себя в качестве получателя сообщения.
*this,
// Нет задержки перед появлением сообщения в первый раз.
std::chrono::milliseconds(0),
// Далее сообщение будет отсылаться каждые 200ms.
std::chrono::milliseconds(200) );
}Далее идут обработчики событий агента a_machine_t. Обработчиком события называется метод, который SObjectizer вызовет когда агент получит соответствующее сообщение-инцидент. Соответствие между сообщением-инцидентом и обработчиком задается при подписке на сообщение. Так, подписка вида:
st_engine_on
.event< turn_engine_off >( &a_machine_t::evt_turn_engine_off )указывает SObjectizer-у, что когда агенту приходит сообщение типа turn_engine_off, то у агента нужно вызвать метод evt_turn_engine_off().
У агента a_machine_t есть четыре простых обработчика, пояснять работу которых нет смысла:
void evt_turn_engine_off()
{
// Меняем текущее состояние агента.
this >>= st_engine_off;
// Обновляем соответствующий статус.
m_engine_status = engine_state_t::off;
}
void evt_turn_engine_on()
{
this >>= st_engine_on;
m_engine_status = engine_state_t::on;
}
void evt_turn_cooler_off()
{
// Состояние агента менять не нужно.
// Поэтому просто обновляем соответствующий статус.
m_cooler_status = cooler_state_t::off;
}
void evt_turn_cooler_on()
{
m_cooler_status = cooler_state_t::on;
}А вот по поводу реакций на периодическое сообщение update_status нужно будет дать несколько пояснений. Сперва посмотрим на реакцию на update_status когда двигатель работает:
void evt_update_status_when_engine_on()
{
m_engine_temperature += m_engine_heating_step;
if( cooler_state_t::on == m_cooler_status )
m_engine_temperature -= m_cooler_impact_step;
distribute_status();
}Поскольку двигатель у нас работает, а значит и нагревается, то мы должны увеличить текущую температуру. Однако, если включен охлаждающий вентилятор, то температуру нужно откорректировать с учетом влияния охлаждения.
Когда сигнал update_status обрабатывается в состояние st_engine_off, т.е. когда двигатель отключен, нам нужно только учесть влияние охлаждение, если оно сейчас включено:
void evt_update_status_when_engine_off()
{
if( cooler_state_t::on == m_cooler_status )
{
m_engine_temperature -= m_cooler_impact_step;
// В данной имитации мы не позволяем температуре двигателя
// опуститься слишком низко.
if( m_engine_temperature < m_initial_temperature )
m_engine_temperature = m_initial_temperature;
}
distribute_status();
}Ну а вспомогательный метод distribute_status() имеет совсем тривиальную реализацию, т.к. его единственная задача — это отсылка сообщения machine_status в специально предназначенный для этого почтовый ящик:
void distribute_status()
{
// Внутри send-а создается экземпляр типа machine_status,
// который инициализируется параметрами из вызова send.
// После чего этот экземпляр будет отослан в почтовый ящик
// m_status_distrib_mbox.
so_5::send< machine_status >(
// Куда направляется сообщение.
m_status_distrib_mbox,
// Все остальные аргументы используются для конструирования
// экземпляра сообщения machine_status.
m_id,
m_engine_status,
m_cooler_status,
m_engine_temperature );
}Возможно, у кого-то из читателей возник вопрос: а почему же a_machine_t сам не принимает решения по поводу включения/выключения вентилятора и двигателя? Почему вместо того, чтобы самостоятельно анализировать происходящее и предпринимать соответствующие действия, a_machine_t лишь периодически отсылает куда-то сообщения о своем текущем состоянии?
Это потому, что декомпозиция :)
Когда мы проектируем какую-то систему на основе объектно-ориентированного подхода, то мы стремимся к тому, чтобы каждый объект отвечал за свою задачу и нужный нам эффект достигался бы за счет их комбинирования. Точно так же происходит и при проектировании системы на базе акторов (агентов): пусть каждый актор отвечает за свою задачу, а мы сформируем решение за счет их комбинации.
Поэтому агент a_machine_t решает только одну задачу: реализует интерфейс с оборудованием (в нашем примере он имитирует этот интерфейс). В реальной задаче a_machine_t бы занимался выставлением/сбросом битиков, чтением-записью байтиков в какой-то коммуникационный порт с проверками успешности операций ввода-вывода, контролем скорости передачи данных, тайм-аутов и пр. низкоуровневыми вещами.
Так что задача a_machine_t — это получить от устройства осмысленную информацию, пригодную для дальнейшей обработки, отдать эту информацию кому-то наверх, принять сверху команду для устройства, преобразовать эту команду в последовательность понимаемых устройством воздействий. Что a_machine_t в меру ограничений конкретной имитации и делает.
Агент a_total_status_dashboard_t должен собирать сообщения machine_status, агрегировать информацию из этих сообщений и периодически отображать агрегированную информацию в стандартный поток вывода.
Для выполнения своей работы a_total_status_dashboard_t подписывается на два сообщения:
virtual void so_define_agent() override
{
so_subscribe( m_status_distrib_mbox )
.event( &a_total_status_dashboard_t::evt_machine_status );
so_subscribe_self().event< show_dashboard >(
&a_total_status_dashboard_t::evt_show_dashboard );
}Первое сообщение, machine_status, агент ожидает из специального почтового ящика, в который агенты a_machine_t отсылают свои machine_status-сообщения. А второе сообщение, show_dashboard, агент a_total_status_dashboard_t отсылает себе сам в виде периодического сообщения:
virtual void so_evt_start() override
{
// Запускаем периодический сигнал для отображения
// текущей информации на консоль.
const auto period = std::chrono::milliseconds( 1500 );
m_show_timer = so_5::send_periodic< show_dashboard >( *this,
period, period );
}Здесь a_total_status_dashboard_t использует тот же самый подход, как и агент a_machine_t — инициирует периодическое сообщение в своем методе so_evt_start(), который SObjectizer автоматически вызывает в самом начале работы a_total_status_dashboard_t.
Обработка machine_status очень простая: нужно всего лишь сохранить очередную порцию информации в ассоциативный контейнер:
void evt_machine_status( const machine_status & status )
{
m_machine_statuses[ status.m_id ] = one_machine_status_t{
status.m_engine_status, status.m_cooler_status,
status.m_engine_temperature
};
}Да и обработчик show_dashboard не содержит ничего сложного: всего лишь итерация по содержимому ассоциативного контейнера с печатью на стандартный поток вывода:
void evt_show_dashboard()
{
auto old_precision = std::cout.precision( 5 );
std::cout << "=== The current status ===" << std::endl;
for( const auto & m : m_machine_statuses )
{
show_one_status( m );
}
std::cout << "==========================" << std::endl;
std::cout.precision( old_precision );
}Поскольку агент a_total_status_dashboard_t не представляет большого интереса и его реализация весьма проста, то углубляться дальше в его реализацию мы не будем. Кому интересно, полный исходный код a_total_status_dashboard_t можной увидеть здесь.
В данной реализации примера machine_control анализом информации от агентов a_machine_t и выдачей управляющих команд агентам-машинам занимается связка из нескольких агентов.
Во-первых, это агент a_statuses_analyser_t, который получает сообщения machine_status, анализирует их и определяет, что конкретный a_machine_t нуждается в каком-то воздействии.
Во-вторых, есть группа агентов-шаблонов типа a_machine_controller_t, которые реагируют на сигналы от a_statuses_analyser_t и выдают то или иное воздействие на конкретную машину. Так, один агент a_machine_controlle_t реагирует на ситуацию, когда следует включить охлаждающий вентилятор и отсылает сообщение turn_cooler_on соответствующему агенту a_machine_t. Другой агент a_machine_controller_t реагирует на ситуацию, когда следует отключить двигатель и отсылает сообщение turn_engine_off. И т.д.
Вообще говоря, такое деление на a_statuses_analyser_t и a_machine_controller_t — это явное усложнение нашего примера. Можно было бы вполне обойтись всего одним агентом a_statuses_analyser_t, который бы сам мог и информацию анализировать, и управляющие команды отсылать. Хотя, скорее всего, агент a_statuses_analyser_t сильно бы увеличился в объеме при этом.
Изначально в machaine_control хотелось показать разнообразные фичи SObjectizer-а, в частности, использование агентов-шаблонов и приоритетов агентов, поэтому мы пошли на разделение логики между a_statuses_analyser_t и a_machine_controller_t.
Итак, суть взаимодействия a_machine_t, a_statuses_analyser_t и a_machine_controller_t в следующем:

Сообщение machine_needs_attention имеет следующий вид:
// Перечисление, которое определяет какую именно ситуацию диагностировали.
enum class attention_t
{
none,
engine_cooling_done,
engine_cooling_needed,
engine_overheat_detected
};
// Сообщение о том, что с конкретной машиной что-то произошло.
struct machine_needs_attention
{
// Уникальный идентификатор-название машины.
const std::string m_id;
// Что именно диагностировали.
const attention_t m_attention;
// Текущий статус двигателя у машины (включен/выключен).
const engine_state_t m_engine_status;
// Текущий статус охлаждающего вентилятора (включен/выключен).
const cooler_state_t m_cooler_status;
};Агент a_statuses_analyser_t хранит прошлую информацию о каждой машине и сравнивает ее с новой информацией, поступающей с сообщением machine_status. Если обнаруживается, что двигатель требует охлаждения или что двигатель перегрелся, или что двигатель достиг безопасной температуры, то a_statuses_analyser_t генерирует сообщение machine_needs_attention. Это сообщение подхватывается соответствующим a_machine_controller_t и нужному агенту a_machine_t будет отослана нужная команда.
Потроха у агента a_statuses_analyser_t довольно объемные. Но большая их часть относится к тому, чтобы хранить и анализировать текущее состояние агентов-машин. Разбирать эту часть в деталях мы не будем (если возникнут какие-то вопросы, то я на них отвечу в комментариях), просто поясним в двух словах:
В коде все это занимает приличное количество строк, но ничего сложного там нет.
А вот та часть агента a_statuses_analyser_t, которая относится к взаимодействию с SObjectizer-ом, вообще минимальна: всего лишь подписка на одно-единственное сообщение в so_define_agent() и одно-единственное событие для этого сообщения:
virtual void so_define_agent() override
{
so_subscribe( m_status_distrib_mbox ).event(
&a_statuses_analyzer_t::evt_machine_status );
}
void evt_machine_status( const machine_status & status )
{
auto it = m_last_infos.find( status.m_id );
if( it == m_last_infos.end() )
// Об этой машине мы еще информацию не получали.
// Добавим информацию в наше хранилище.
it = m_last_infos.insert( last_info_map_t::value_type {
status.m_id,
last_machine_info_t {
attention_t::none,
status.m_engine_temperature
} } ).first;
handle_new_status( status, it->second );
}Где метод handle_new_status(), который вызывается внутри evt_machine_status(), это уже часть той прикладной логики контроля за статусом агента-машины, о которой мы коротко рассказали ранее.
В наличии нескольких экземпляров агентов a_machine_controller_t есть следующий смысл: когда агент a_statuses_analyser_t определяет, например, что двигатель у машины остыл до безопасной температуры, то в нам может потребоваться сделать несколько разных действий. Во-первых, выключить охлаждающий вентилятор. Во-вторых, может оказаться, что двигатель был предварительно отключен и нам нужно включить его вновь.
Если бы мы разместили всю эту логику внутри a_statuses_analyser_t, то его код бы разросся и понимать его было бы труднее. Вместо этого мы просто заставили a_statuses_analyser_t объявлять на что именно следует обратить внимание в работе агента-машины. А уже реагировать на это объявление будут агенты a_machine_controller_t. И каждый a_machine_controller_t сам определяет, нужно ли ему реагировать или нет. Если нужно, то a_machine_contoller_t получает сообщение machine_needs_attention и инициирует соответствующую команду агенту-машине. Если не нужно, то a_machine_controller_t сообщение machine_needs_attention просто игнорирует.
Код агента-шаблона a_machine_controller_t небольшой, поэтому для простоты работы с ним приведем весь код этого агента полностью:
template< class LOGIC >
class a_machine_controller_t : public so_5::agent_t
{
public :
a_machine_controller_t(
context_t ctx,
so_5::priority_t priority,
so_5::mbox_t status_distrib_mbox,
const machine_dictionary_t & machines )
: so_5::agent_t( ctx + priority )
, m_status_distrib_mbox( std::move( status_distrib_mbox ) )
, m_machines( machines )
, m_logic()
{}
virtual void so_define_agent() override
{
so_set_delivery_filter( m_status_distrib_mbox,
[this]( const machine_needs_attention & msg ) {
return m_logic.filter( msg );
} );
so_subscribe( m_status_distrib_mbox )
.event( [this]( const machine_needs_attention & evt ) {
m_logic.action( m_machines, evt );
} );
}
private :
const so_5::mbox_t m_status_distrib_mbox;
const machine_dictionary_t & m_machines;
const LOGIC m_logic;
};Итак, это шаблонный класс, который параметризуется одним параметром: типом прикладной логики, которую должен иметь конкретный a_machine_controller_t. Этот тип LOGIC должен быть типом с двумя методами следующего вида:
struct LOGIC
{
bool filter( const machine_needs_attention & msg ) const;
void action(
const machine_dictionary_t & machines,
const machine_needs_attention & evt ) const;
};Если бы в C++11 были концепты, то можно было бы объявить соответствующий концепт для того, чтобы проще было определять, какой тип может быть параметром для шаблона a_machine_controller_t, а какой — нет. Но, т.к. в C++11 концепты не завезли, то приходится полагаться на утиную типизацию.
Агент a_machine_controller_t создает у себя внутри экземпляр типа LOGIC и делегирует все свои действия этому экземпляру. И этот экземпляр есть не что иное, как контроллер, который выдает управляющие воздействия агенту-машине.
Действий же у контроллера всего два:
Во-первых, нужно отфильтровать сообщения, которые конкретному контроллеру не интересны. Для этого a_machine_controller_t назначает фильтр доставки сообщений:
so_set_delivery_filter( m_status_distrib_mbox,
[this]( const machine_needs_attention & msg ) {
return m_logic.filter( msg );
} );Фильтр доставки — это специальный механизм SObjectizer-а. Он нужен в ситуациях, когда агент подписывается на некоторое сообщение типа T из почтового ящика M, но хочет получать не все сообщения типа T, а только те, внутри которых содержится интересная агенту информация.
В этих случаях агент посредством своего метода so_set_delivery_filter() задает фильтр, лямбда-функцию, которую почтовый ящик M будет автоматически вызывать каждый раз, когда в него приходит сообщение типа T. Если фильтр возвращает true, значит экземпляр сообщения агенту интересен и доставка сообщения до агента выполняется. Если же фильтр возвращает false, то сообщение этому агенту не доставляется, тем самым агент не отвлекается на то, что ему не интересно.

Наглядная схема работы фильтра доставки. Агент Subscriber-1 не использует фильтр доставки и поэтому получает все сообщения из mbox-а. Тогда как агент Subscriber-2 установил фильтр доставки и получает только те сообщения, которые проходят через фильтр.
Вот метод LOGIC::filter() и должен играть роль фильтра доставки, он пропускает только те экземпляры machine_needs_attention, которые интересны контроллеру.
Во-вторых, контроллер должен что-то предпринять при получении сообщения machine_needs_attention, в котором уже точно лежит информация, интересная для контроллера.
За это отвечает метод LOGIC::action(). Агент a_machine_controller_t вызывает этот метод в своем обработчике machine_needs_attention:
so_subscribe( m_status_distrib_mbox )
.event( [this]( const machine_needs_attention & evt ) {
m_logic.action( m_machines, evt );
} );Ну а для того, чтобы было понятнее, как же именно работают a_machine_controller_t, приведем пару примеров контроллеров. Первый очень простой, он отвечает за выдачу команды turn_engine_off, если обнаружили перегрев двигателя:
struct engine_stopper_t
{
bool filter( const machine_needs_attention & msg ) const
{
return msg.m_attention == attention_t::engine_overheat_detected;
}
void action(
const machine_dictionary_t & machines,
const machine_needs_attention & evt ) const
{
so_5::send< turn_engine_off >( machines.find_mbox( evt.m_id ) );
}
};Т.е. фильтруются только те сообщения machine_needs_attention, которые говорят о перегреве двигателя. Когда же такое сообщение поступает, то соответствующему агенту-машине отсылается сигнал turn_engine_off.
А вот этот контроллер уже посложнее:
struct cooler_starter_t
{
bool filter( const machine_needs_attention & msg ) const
{
return (msg.m_attention == attention_t::engine_overheat_detected ||
msg.m_attention == attention_t::engine_cooling_needed) &&
msg.m_cooler_status == cooler_state_t::off;
}
void action(
const machine_dictionary_t & machines,
const machine_needs_attention & evt ) const
{
so_5::send< turn_cooler_on >( machines.find_mbox( evt.m_id ) );
}
};Он отвечает за включение охлаждающего вентилятора. Этот вентилятор нужно включать только если на данный момент вентилятор отключен, а двигатель либо просто нуждается в охлаждении, либо уже перегрелся.
Всего таких контроллеров в примере четыре:
Это означает, что и агентов a_machine_controller_t будет четыре — по одному на каждый тип контроллера.
При работе примера machine_control может случиться так, что один и тот же экземпляр machine_needs_attention будет получен несколькими контроллерами. Например, если в machine_needs_attention передается attention_t::engine_overheat_detected и cooler_status_t::off, то такое сообщение будет получено двумя контроллерами: и контроллером engine_stopper_t, и контроллером cooler_starter_t.
И тут нам важно, в каком порядке эти контроллеры обработают сообщение. Логично же, чтобы в ситуации engine_overheat_detected сперва была дана команда turn_engine_off, а уже затем команда turn_cooler_on. Ведь выполнение команды будет занимать какое-то время, скажем несколько секунд. Если сперва потратить эти секунды на включение вентилятора, то двигатель перегреется еще больше. Поэтому лучше сразу выключить двигатель, а потом уже тратить время на все остальное.
Каким же образом в SObjectizer-е можно управлять порядком обработки сообщений?
Вопрос совсем непростой. Есть опасение, что попытка развернуто ответить на него потребует написания еще одной статьи. Если говорить коротко, то гарантии очередности обработки сообщений могут быть только для диспетчеров с одной рабочей нитью. Но и этого еще недостаточно. Нужно, чтобы очередь сообщений на этой рабочей нити упорядочивалась с учетом приоритетов агентов, которым сообщения адресуются.
В SObjectizer есть такой тип диспетчера: он запускает всех привязанных к нему агентов на одной общей рабочей нити, при этом агенты с более высоким приоритетом обрабатывают свои сообщения перед агентами с более низкими приоритетами. Это диспетчер so_5::disp::prio_one_thread::strictly_ordered. Именно к нему привязываются агенты a_machine_controller_t в данном примере.
При этом приоритеты для агентов-контроллеров распределены следующим образом:
Следы того, как задаются приоритеты для агентов a_machine_controller_t можно найти в конструкторе:
a_machine_controller_t(
...,
so_5::priority_t priority,
... )
: so_5::agent_t( ctx + priority )
, ...
{}И при непосредственном создании таких агентов:
coop.make_agent_with_binder< a_machine_controller_t< engine_stopper_t > >(
disp->binder(),
so_5::prio::p4,
status_distrib_mbox,
machines );
coop.make_agent_with_binder< a_machine_controller_t< cooler_starter_t > >(
disp->binder(),
so_5::prio::p3,
status_distrib_mbox,
machines );Здесь значения so_5::prio::p4 и so_5::prio::p3 — это и есть приоритеты агентов.
Можно было обратить внимание, что агенты a_machine_t начинают свою работу в состоянии st_engine_off, т.е. двигатель считается выключенным. Но запустив пример можно увидеть, что у машин двигатель сразу же включается. Как же так происходит, если ни a_machine_t, ни a_machine_controller_t изначально никаких команд на включение двигателя не выдают?
Для того, чтобы у агентов-машин заработал двигатель используется отдельный агент-стартер, единственной задачей которого является выдача команды turn_engine_on каждому агенту-машине.
Этот агент настолько прост, что для него мы даже не делаем отдельный C++ класс, как это происходило у нас с a_machine_t, a_total_status_dashboard_t, a_statuses_analyser_t и a_machine_controller_t. Вместо этого мы используем такую штуку, как ad-hoc агент. Т.е. агент, который создается из набора заданных пользователем лямбда-функций. В примере machine_control это делается следующим образом:
coop.define_agent().on_start( [&dict] {
dict.for_each(
[]( const std::string &, const so_5::mbox_t & mbox ) {
so_5::send< turn_engine_on >( mbox );
} );
} );Метод define_agent() создает пустого ad-hoc агента, которого пользователь может наполнить нужной функциональностью. Здесь мы задаем всего лишь реакцию на начало работы ad-hoc агента внутри SObjectizer-а: при старте всем агентам просто отсылается turn_engine_on.
Одной из самых важных возможностей SObjectizer-а, которая постоянно используется на практике, является возможность задать рабочую нить для агента через привязку агента к тому или иному диспетчеру.
Каждому агенту нужно обрабатывать доставленные ему сообщения. Делать это нужно на контексте какой-то рабочей нити. В SObjectizer рабочую нить агентам предоставляют диспетчеры. Поэтому программист при создании своего агента должен привязать агента к тому диспетчеру, который обеспечит агенту нужный режим работы.
В примере machine_control используются несколько диспетчеров, благодаря чему происходит следующее распределение агентов по рабочим нитям:

В статье мы не стали рассматривать одну важную для реализации вещь, которая, однако, никак не влияет на поведение агентов в примере: это machine_dictionary. Специальный ассоциативный словарь, в котором сохранено соответствие между уникальным названием-идентификатором агента-машины и его персональным почтовым ящиком.
Этот словарь используется для того, чтобы по имени агента-машины (которое присутствует в сообщениях machine_status и machine_needs_attention) получить доступ к почтовому ящику соответствующего агента. Ведь сообщения в SObjectizer отсылаются в почтовые ящики, поэтому, для того, чтобы отослать turn_engine_on, нужно по имени получить почтовый ящик. Что и делается посредством machine_dictionary.
Теперь же, как в любом уважающем себя произведении, вслед за долгим прологом должна последовать основная часть, никакого отношения к прологу не имеющая.
Если читатель подумал, что статья была написана для того, чтобы показать, как можно разрабатывать агентов, похожих на a_machine_t или a_machine_controller_t, то он оказался не совсем прав.
Демонстрация конкретных фич SObjectizer-а, вроде привязки агентов к разным диспетчерам или использование ad-hoc агентов для простых действий — это лишь одна из задач данной статьи. Мы надеемся, что знакомство с тем, как может выглядеть более-менее объемный код на SObjectizer, поможет читателям лучше понять, нравится ли им то, что они видят или нет, возникнет ли у них желание разрабатывать свои программы в таком стили или же лучше пойти «другим путем». В конце-концов, примеры чуть посложнее, чем ставший классическим и совершенно бесполезным ping-pong, дают намного лучшее представление о том, как будет выглядеть продакшен код. И захочется ли связываться после подобного знакомства с таким фреймворком, как SObjectizer.
Однако, есть у данного примера и другая задача, не менее важная. Эта задача состоит в том, чтобы показать, как посредством Actor Model и Publish/Subscribe организовать взаимодействие между независимыми сущностями в программе.
Ключевой момент в рассмотренном примере machine_control в том, что взаимодействующие сущности (т.е. агенты) не имеют никакого понятия друг о друге и о взаимосвязях между собой.
Действительно, агент a_machine_t просто отсылает сообщение machine_status в некоторый почтовый ящик и понятия не имеет, кто стоит за этим ящиком, куда реально попадает сообщение и что с этим сообщением происходит дальше. Просто агент a_machine_t выполняет свою работу (имитирует периодический опрос оборудования) и выдает результат своей работы во внешний мир. Все, больше его ничего не интересует.
Даже когда к агенту a_machine_t приходит внешняя команда (вроде turn_engine_on), он не представляет, кто именно эту команду ему прислал. От a_machine_t требуется лишь выполнить поступившую команду, если в этом есть смысл. А уж из каких соображений эта команда возникла, через что она прошла по дороге — все это для a_machine_t не имеет никакого значения.
Кстати говоря, когда кто-то выдает команду вроде turn_engine_on конкретному агенту a_machine_t, то это классическое взаимодействие в рамках Actor Model, где акторы общаются в режиме 1:1.
Но вот в случае с сообщениями machine_status и machine_needs_attention мы уже оказываемся за рамками Actor Model, т.к. у нас образуется взаимодействие 1:N. И тут мы пользуемся моделью Publish/Subscribe. Специальный почтовый ящик, куда агенты отсылают сообщения machine_status и machine_needs_attention, играет роль брокера. Отсылка сообщения в этот ящик — это просто-напросто операция Publish. А для получения сообщения из ящика необходимо выполнить операцию Subscribe, что, собственно, агенты a_total_status_dashboard_t, a_statuses_analyser_t и a_machine_controller_t и делают в своих so_define_agent().
И тут можно увидеть еще одну важную штуку, которую дает разработчику SObjectizer: возможность использовать один и тот же экземпляр сообщения для совершенно разных целей. Происходит это как раз благодаря тому, что в SObjectizer есть multi-producer/multi-consumer почтовые ящики, через которые и происходит общение агентов в режиме 1:N.
Действительно, сообщение machine_status, например, получают и обрабатывают два разных агента, решающих совершенно разные задачи и ничего не знающие друг о друге. Агент a_total_status_dashboard_t использует machine_status для периодического отображения хода работы примера на консоль. Тогда как a_statuses_analyser_t использует machine_status для контроля за агентами a_machine_t.
В этом заложена большая гибкость. Мы совершенно спокойно можем добавить еще одного агента, который мог бы собирать информацию о температуре двигателей для построения графиков изменения температуры. И наличие этого агента никак не повлияет на работу a_total_status_dashboard_t и a_statuses_analyser_t. Или же мы можем заменить агента a_total_status_dashboard_t на какого-нибудь a_gui_status_dashboard_t, который будет отображать ход работы примера не на std::cout, а в графическое окно. И это, опять же, никак не повлияет на других агентов приложения, которые работают с сообщениями machine_status.
Так что разработка приложений на SObjectizer — это все про создание агентов, каждый из которых выполняет свою независимую часть работы, и про каналы связи между агентами. А каналы связи в SObjectizer представляют из себя почтовые ящики и сообщения, посредством которых информация распространяется (хотя есть и CSP-шные каналы).
И как раз основная сложность разработки приложений на SObjectizer состоит в том, чтобы выделить в предметной области те сущности, которые в программе могут быть выражены в виде агентов. А также в выделении и формировании каналов связи (т.е. наборов сообщений и почтовых ящиков), посредством которых агенты будут взаимодействовать друг с другом.
Ну а уже внешний вид самих агентов, их привязка к диспетчерам и пр. технические детали — это всего лишь детали. Но детали, которые оказывают важное влияние на привлекательность конкретного фреймворка. Ну вот не понравится кому-то, что для объявления сообщения-сигнала нужно сделать структуру, отнаследованную от типа с именем so_5::signal_t, и ничего уже не поделать. Хотя суть вовсе не в том, нужно ли наследоваться от чего-то или что наследоваться нужно от типа, название которого не отвечает чьим-то эстетическим представлениям. А в том, чтобы выделить в предметной области сущности, для какого-то взаимодействия между которыми вот такое сообщение-сигнал будет необходимо.
В финале статьи хочется поблагодарить самых настойчивых читателей за терпение, прекрасно понимаем, что дочитать до заключения было непросто.
Заодно хотим похвастаться тем, что для SObjectizer-а появился сопутствующий проект so_5_extra, который будет содержать дополнения и расширения для SObjectizer. Смысл в том, чтобы в SObjectizer включать только самую базовую функциональность, без которой ну никак не обойтись, и которая будет нужна большинству пользователей. Тогда как so_5_extra может содержать в том числе и экзотические вещи, необходимые лишь узкому кругу пользователей. Так что если вам чего-то не хватает в SObjectizer, то скажите чего именно. Если мы не увидим смысла добавления этого в SObjectizer, то место вполне может найтись в so_5_extra.
|
Метки: author eao197 программирование open source c++ библиотеки multithreading actor model concurrency |
Как использовать implicit'ы в Scala и сохранить рассудок |

Scala богата выразительными средствами, за что ее и не любят опытные программисты на классических ООП-языках. Неявные параметры и преобразования — одна из самых спорных фич языка. Слово "неявные", уже как-бы намекает на что-то неочевидное и сбивающее с толку. Тем не менее, если с ними подружиться, implicit'ы открывают широкие возможности: от сокращения объема кода до возможности многие проверки делать в compile-time.
Хочу поделиться своим опытом по работе с ними и рассказать о том, о чем пока умалчивает официальная документация и блоги разработчиков. Если вы уже знакомы со Scala, пробовали использовать неявные параметры, но все еще испытываете некоторые сложности при работе с ними, либо хотя-бы о них слышали, то этот пост может оказаться вам интересен.
Содержание:
Ключевое слово implicit имеет отношение к трем понятиям в Scala: неявные параметры, неявные преобразования и неявные классы.
Неявные параметры — это параметры, которые могут быть автоматически переданы в функцию из контекста ее вызова. Для этого в нем должны быть однозначно определены и помечены ключевым словом implicit переменные соответствующих типов.
def printContext(implicit ctx: Context) = println(ctx.name)
implicit val ctx = Context("Hello world")
printContextВыведет:
Hello worldВ методе printContext мы неявно получаем переменную типа Context и печатаем содержимое ее поля name. Пока не страшно.
Механизм разрешения неявных параметров поддерживает обобщенные типы.
case class Context[T](message: String)
def printContextAwared[T](x: T)(implicit ctx: Context[T]) = println(s"${ctx.message}: $x")
implicit val ctxInt = Context[Int]("This is Integer")
implicit val ctxStr = Context[String]("This is String")
printContextAwared(1)
printContextAwared("string")Выведет:
This is Integer: 1
This is String: stringЭтот код эквивалентен тому, как если бы мы явно передавали в метод printContextAwared параметры ctxInt в первом случае и ctxString во втором.
printContextAwared(1)(ctxInt)
printContextAwared("string")(ctxStr)Что интересно, неявные параметры не обязательно должны быть полями, они могут быть методами.
implicit def dateTime: LocalDateTime = LocalDateTime.now()
def printCurrentDateTime(implicit dt: LocalDateTime) = println(dt.toString)
printCurrentDateTime
Thread.sleep(1000)
printCurrentDateTimeВыведет:
2017-05-27T16:30:49.332
2017-05-27T16:30:50.476Более того, неявные параметры-функции могут, в свою очередь, принимать неявные параметры.
implicit def dateTime(implicit zone: ZoneId): ZonedDateTime = ZonedDateTime.now(zone)
def printCurrentDateTime(implicit dt: ZonedDateTime) = println(dt.toString)
implicit val utc = ZoneOffset.UTC
printCurrentDateTimeВыведет:
2017-05-28T07:07:27.322ZНеявные преобразования позволяют автоматически преобразовывать значения одного типа к другому.
Чтобы задать неявное преобразование вам нужно определить функцию от одного явного аргумента и пометить ее ключевым словом implicit.
case class A(i: Int)
case class B(i: Int)
implicit def aToB(a: A): B = B(a.i)
val a = A(1)
val b: B = a
println(b)Выведет:
B(1)Все что справедливо для неявных параметров-функций, справедливо также и для неявных преобразований: поддерживаются обобщенные типы, должен быть только один явный, но может быть сколько угодно неявных параметров и т. п.
case class A(i: Int)
case class B(i: Int)
case class PrintContext[T](t: String)
implicit def aToB(a: A): B = B(a.i)
implicit val cContext: PrintContext[B] = PrintContext("The value of type B is")
def printContextAwared[T](t: T)(implicit ctx: PrintContext[T]): Unit = println(s"${ctx.t}: $t")
val a = A(1)
printContextAwared[B](a)Ограничения
Scala не допускает применение нескольких неявных преобразований подряд, таким образом код:
case class A(i: Int)
case class B(i: Int)
case class C(i: Int)
implicit def aToB(a: A): B = B(a.i)
implicit def bToC(b: B): C = C(b.i)
val a = A(1)
val c: C = aНе скомпилируется.
Тем не менее, как мы уже убедились, Scala не запрещает искать неявные параметры по цепочке, так что мы можем исправить этот код следующим образом:
case class A(i: Int)
case class B(i: Int)
case class C(i: Int)
implicit def aToB(a: A): B = B(a.i)
implicit def bToC[T](t: T)(implicit tToB: T => B): C = C(t.i)
val a = A(1)
val c: C = aСтоит заметить, что если функция принимает значение неявно, то в ее теле оно будет видимо как неявное значение или преобразование. В предыдущем примере для объявления метода bToC, tToB является неявным параметром и при этом внутри метода работает уже как неявное преобразование.
Ключевое слово implicit перед объявлением класса — это более компактная форма записи неявного преобразования значения аргумента конструктора к данному классу.
implicit class ReachInt(self: Int) {
def fib: Int =
self match {
case 0 | 1 => 1
case i => (i - 1).fib + (i - 2).fib
}
}
println(5.fib)Выведет:
5Может показаться, что неявные классы это всего лишь способ примешивания функционала к классу, но на самом это понятие несколько шире.
sealed trait Animal
case object Dog extends Animal
case object Bear extends Animal
case object Cow extends Animal
case class Habitat[A <: Animal](name: String)
implicit val dogHabitat = Habitat[Dog.type]("House")
implicit val bearHabitat = Habitat[Bear.type]("Forest")
implicit class AnimalOps[A <: Animal](animal: A) {
def getHabitat(implicit habitat: Habitat[A]): Habitat[A] = habitat
}
println(Dog.getHabitat)
println(Bear.getHabitat)
//Не скомпилируется:
//println(Cow.getHabitat)Выведет:
Habitat(House)
Habitat(Forest)Здесь в неявном классе AnimalOps мы объявляем что тип значения, к которому он будет применен, будет виден нам как A, затем в методе getHabitat мы требуем неявный параметр Habitat[A]. При его отсутствии, как в строчке с Cow, мы получим ошибку компиляции.
Не прибегая к помощи неявных классов, достичь такого же эффекта нам бы мог помочь F-bounded polymorphism:
sealed trait Animal[A <: Animal[A]] { self: A =>
def getHabitat(implicit habitat: Habitat[A]): Habitat[A] = habitat
}
trait Dog extends Animal[Dog]
trait Bear extends Animal[Bear]
trait Cow extends Animal[Cow]
case object Dog extends Dog
case object Bear extends Bear
case object Cow extends Cow
case class Habitat[A <: Animal[A]](name: String)
implicit val dogHabitat = Habitat[Dog]("House")
implicit val bearHabitat = Habitat[Bear]("Forest")
println(Dog.getHabitat)
println(Bear.getHabitat)Как видно, в этом случае у типа Animal существенно усложнилось объявление, появился дополнительный рекурсивный параметр A, который играет исключительно служебную роль. Это сбивает с толку.
Этот вопрос рассмотрен в официальном FAQ: http://docs.scala-lang.org/tutorials/FAQ/chaining-implicits.html.
Как я уже говорил в разделе про неявные преобразования, компилятор не умеет рекурсивно применять неявные преобразования. Тем не менее, он поддерживает рекурсивное разрешение неявных параметров.
Пример ниже добавляет для тех типов, для которых неявно определены соответствующие тайп-классы, метод describe, который будет возвращать их описание на неком подобии человеческого языка (как мы знаем, в runtime в JVM определить точный тип невозможно, так что мы его определяем в compile-time):
sealed trait Description[T] {
def name: String
}
case class ContainerDescr[P, M[_]](name: String)
(implicit childDescr: Description[P]) extends Description[M[P]] {
override def toString: String = s"$name of $childDescr"
}
case class AtomDescr[P](name: String) extends Description[P] {
override def toString: String = name
}
implicit class Describable[T](value: T)(implicit descr: Description[T]) {
def describe: String = descr.toString
}
implicit def listDescr[P](implicit childDescr: Description[P]): Description[List[P]] =
ContainerDescr[P, List]("List")
implicit def arrayDescr[P](implicit childDescr: Description[P]): Description[Array[P]] =
ContainerDescr[P, Array]("Array")
implicit def seqDescr[P](implicit childDescr: Description[P]): Description[Seq[P]] =
ContainerDescr[P, Seq]("Sequence")
implicit val intDescr = AtomDescr[Int]("Integer")
implicit val strDescr = AtomDescr[String]("String")
println(List(1, 2, 3).describe)
println(Array("str1", "str2").describe)
println(Seq(Array(List(1, 2), List(3, 4))).describe)Выведет:
List of Integer
Array of String
Sequence of Array of List of IntegerDescription — базовый тип.
ContainerDescr — рекурсивный класс, который, в свою очередь, требует существования неявного параметра Description для типа описываемого контейнера.
AtomDescr — терминальный класс, описывающий простые типы.

Cхема разрешения неявных параметров.
При разработке с использованием цепочек из неявных параметров, время от времени вы будете получать ошибки времени компиляции, с довольно туманными названиями, как правило, это будут: ambiguous implicit values и diverging implicit expansion. Чтобы понимать, что от вас хочет компилятор, необходимо разобраться, что же значат эти сообщения.
Как правило это ошибка означает что есть несколько конфликтующих неявных значений подходящего типа в одной области видимости, и компилятор не может решить которому отдать предпочтение (о том в каком порядке компилятор проходит области видимости в поиске неявных параметров можно прочитать в этом ответе).
implicit val dog = "Dog"
implicit val cat = "Cat"
def getImplicitString(implicit str: String): String = str
println(getImplicitString)При попытке скомпилировать этот код, мы получим ошибку:
Error:(7, 11) ambiguous implicit values:
both value dog in object Example_ambigous of type => String
and value cat in object Example_ambigous of type => String
match expected type String
println(getImplicitString)Решаются эти проблемы довольно очевидно — необходимо оставить только один неявный параметр этого типа в контексте, чтобы компилятор мог определить его однозначно.
Эта ошибка означает бесконечную рекурсию при поиске неявного значения.
implicit def getString(implicit str: String): String = str
println(getString)Ошибка:
Error:(5, 11) diverging implicit expansion for type String
starting with method getString in object Example_diverging
println(getString)Такого рода ошибки сложнее отслеживать. Убедитесь что у вашей рекурсии есть терминальная ветка. Часто помогает попробовать явно подставить всю цепочку параметров и убедиться, что этот код компилируется.
Попробуйте также использовать флаг компилятора -Xlog-implicits — с ним scalac будет логировать шаги разрешения неявных параметров и причины неудач.
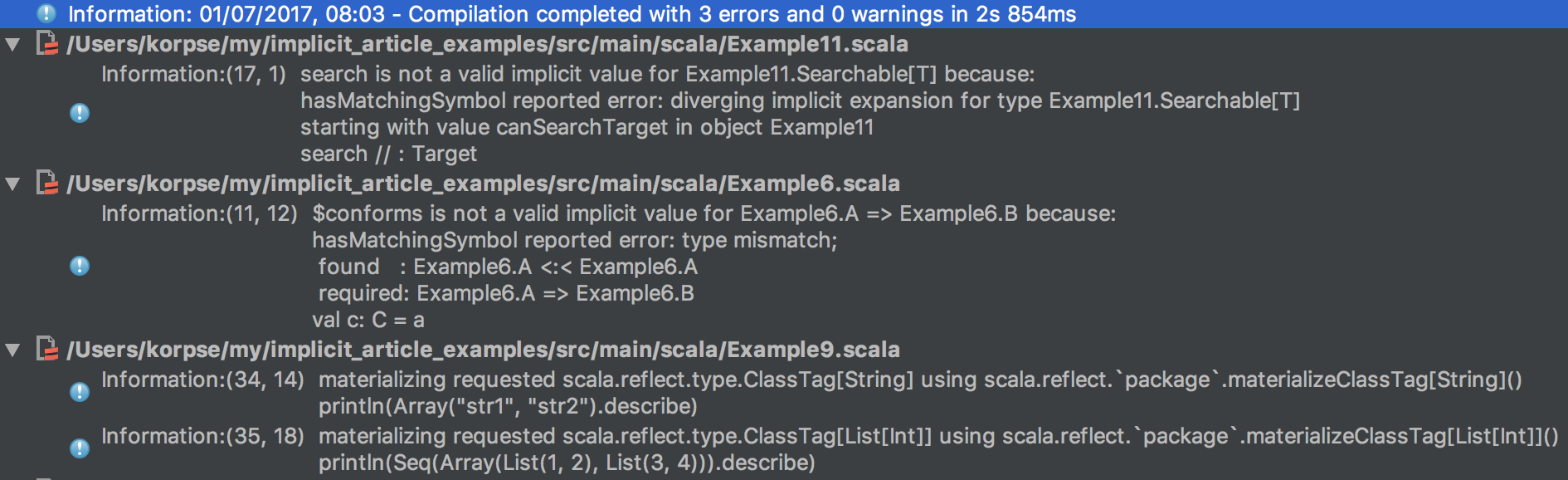
Cообщения компилятора о кандидатах для неявных параметров.
Вы можете помечать свои классы и трейты аннотацией @implicitNotFound чтобы сделать более человечными сообщения компилятора о том, что неявное значение этого типа не было найдено.
@implicitNotFound("No member of type class NumberLike in scope for ${T}")
trait NumberLike[T] {
def plus(x: T, y: T): T
def divide(x: T, y: Int): T
def minus(x: T, y: T): T
}Описания этого аспекта не удалось найти в интернете и пришлось прояснить его экспериментально.
Порядок объявления неявных параметров функции имеет принципиальное значение.
Это значит что мы можем использовать одни неявные параметры для ограничения видимости других. Например, если в области видимости оказалось два значения подходящих типов и нам необходимо выбрать одно из них, не прибегая к уточнению искомого типа.
sealed trait BaseSought
class Target extends BaseSought
class Alternative extends BaseSought
trait Searchable[T <: BaseSought]
implicit def search[T <: BaseSought](implicit canSearch: Searchable[T], sought: T): T = sought
implicit val target = new Target()
implicit val alt = new Alternative()
implicit val canSearchTarget = new Searchable[Target] {}
search // : TargetВ области видимости находятся два параметра, подходящих по искомому типу [T <: BaseSought], но из-за того, что неявный параметр Searchable[T] определен только для одного из них, мы можем его определить однозначно и не получаем ошибки компиляции.

Успешное разрешение неявных параметров.
Если бы мы определили неявные параметры в другом порядке:
implicit def search[T <: BaseSought](implicit sought: T, canSearch: Searchable[T]): T = soughtто получили бы ошибку:
Error:(17, 1) ambiguous implicit values:
both value target in object Example11 of type => Example11.Target
and value alt in object Example11 of type => Example11.Alternative
match expected type T
search // : Target
Oops...
В заключении я хочу сразу ответить на вопрос, который неизбежно будет задан в комментариях: "Зачем нам нужны такие сложности? На Go вообще без дженериков живут, не говоря уже о такой черной магии."
Да, может быть и не нужны. Совершенно точно имплиситы не нужны, если вы с их помощью хотите сделать ваш код сложнее. После таких языков как, например, Java, программисты думают, что если в языке много инструментов, то они должны их все использовать. На самом же деле следует использовать сложные инструменты только для сложных задач.
Если вы можете красиво решить задачу без имплиситов — сделайте это, если нет — подумайте еще раз.
Если вы понимаете, что на освоение какого-либо инструмента у ваших коллег может уйти существенное время, но вам без него вот здесь никак не обойтись, ограничьте его область применения, сделайте библиотеку с простым интерфейсом, обеспечьте ее качество. И тогда люди дорастут до нее сами к тому моменту, как им придет в голову в ней что-то менять.

|
Метки: author xkorpsex функциональное программирование scala implicit functional programming type level programming |
[Перевод] Вебинар про Petya: Вспышка еще одного шифровальщика |


|
Метки: author PandaSecurityRus антивирусная защита блог компании panda security в россии petya шифровальщики вебинар panda security |
Перевод Redmine-плагинов с TelegramCLI на Webogram |

Ранее мы уже писали о наших плагинах redmine_chat_telegram и redmine_intouch, предназначенных
для того, чтобы ваша работа с Redmine и Telegram была продуктивнее.
А сегодня мы хотели бы рассказать о том, как избавились от TelegramCLI.
Это большой апдейт, призванный упростить работу с нашими telegram-плагинами.
В процессе эксплуатации у нас неоднократно возникали проблемы с настройкой TelegramCLI, поэтому мы решили упростить работу наших плагинов. Для этого мы сочли необходимым избавиться от зависимости TelegramCLI, добавили вместо него Webogram и модифицировали под свои нужды. Это позволило больше не запускать на сервере сервис TelegramCLI.
Webogram — официальный веб-клиент к Telegram, написанный на AngularJS. Поэтому, чтобы работать с Webogram через скрипты, приходится использовать headless browser, в нашем случае это PhantomJS.
Мы модифицировали код Webogram, чтобы отдавать ему запросы на нужные действия без необходимости работать с интерфейсом. В форме специального запроса плагин отправляет на URL модифицированного Webogram инструкцию сделать некую операцию в Telegram.
Сначала плагин дает команду произвести какую-то операцию в Telegram.
telegram = TelegramCommon::Telegram.new
result = telegram.execute('Test')Далее формируется строка запуска PhantomJS.
module TelegramCommon
class Telegram
...
def make_request
@api_result = `#{cli_command}`
debug(api_result)
api_result
end
def cli_command
cmd = "#{phantomjs} #{config_path} \"#{api_url}\""
debug(cmd)
cmd
end
end
endЗатем PhantomJS выполняет запрос и ожидает 10 секунд, чтобы элемент #api-status
получил класс ready, который свидетельствовал бы о том, что Webogram завершил обработку.
// plugins/redmine_telegram_common/config/phantom-proxy.js
...
page.open(url, function() {
waitFor(
function () {
return page.evaluate(function () {
return $('#api-status').hasClass('ready');
});
},
function () {
exit()
}, 10000);
});AngularJS-контроллер AppApiController занимается обработкой запросов, и когда он заканчивает работу, то на странице у блока #api-status меняется класс на "ready", тем самым уведомляя PhantomJS о завершении операции.
// plugins/redmine_telegram_common/app/webogram/app/js/controllers.js
$scope.promiseStatus = false;
var args = {};
if (typeof $routeParams.args !== 'undefined') {
args = JSON.parse($routeParams.args)
}
$scope.handle = function () {
var command = $routeParams.command;
var handlerName = $scope['api' + command];
if (typeof handlerName === 'function') {
handlerName(args)
} else {
console.error('There is no ' + handlerName + ' api function.')
}
};
$scope.apiTest = function () {
$scope.successApi('api test')
};
...
$scope.successApi = function (msg) {
console.log('success: ' + msg);
$scope.resolveApi()
};
$scope.failedApi = function (msg) {
console.log('failed: ' + msg);
$scope.resolveApi()
};
$scope.resolveApi = function () {
$scope.promiseStatus = true
};Вскоре запрос выполняется, и плагин получает ответ, с которым можно работать.
В итоге, чтобы начать работать с нашими плагинами, которые ранее зависели от TelegramCLI, теперь достаточно установить новые зависимости, перейти на страницу настройки плагина redmine_telegram_common и пройти простенькую процедуру авторизации, в процессе которой PhantomJS запомнит, под каким логином отправлять запросы на Telegram.
Telegram-боты в наших плагинах redmine_chat_telegram и redmine_intouch научились работать не только через getUpdates (как ранее фоновые процессы через rake), но и через WebHooks (достаточно инициализировать ботов в настройках соответствующих плагинов, однако необходим HTTPS на Redmine). Таким образом, мы избавились от дополнительных фоновых процессов, которые раньше могли быть преградой для установки плагина неопытными пользователями.
Если вы встретили какие-то ошибки, у вас есть предложения по улучшению плагина или вы желаете принять участие в развитии плагинов, мы будем рады вашим откликам. Наши репозитории перечислены ниже.
|
Метки: author olemskoi ruby on rails блог компании southbridge redmine redmine plugin telegram webogram telegram-cli |
[Перевод] Как принципы HumanOps применяются в Sever Density |

Понятие HumanOps родилось в Server Density в результате накопления значительного опыта работы по мониторингу компьютерных систем и, соответственно, пребывания команды в состоянии постоянной готовности. В первые годы существования компании я долгое время был на связи в режиме 24/7. Однако по мере роста команды мы внедряли процессы и политики, целью которых было распределение нагрузки и снижение негативного влияния случаев, когда сотрудников отрывают от текущей работы или звонят во внеурочное время, в том числе и ночью.
В процессе создания и распространения продукта, предназначенного для того, чтобы будить людей, мы обратили внимание, что наши клиенты испытывают схожие с нашими проблемы, связанные с пребыванием в состоянии постоянной готовности. Общение с клиентами убедило нас, что такие проблемы характерны для индустрии, и поэтому мы решили критически взглянуть на применяемые подходы, а также изучить лучшие практики, используемые другими участниками рынка. В итоге это привело к созданию сообщества по выработке и обсуждению ряда принципов, которые получили название HumanOps.
Мы надеемся, что аналогично практикам DevOps, ускоряющим развертывание, приносящим новые инструменты, а также объединяющим команды разработки и эксплуатации, HumanOps поможет организациям в освоении более «человечного» подхода к построению систем и работе с ними.
Под катом вы найдете 12 принципов HumanOps и описание их работы на примере Server Density.
В центре внимания HumanOps находятся люди, которые создают, используют и поддерживают системы. Для кого-то это может показаться очевидным, но все же крайне важно сформулировать эту идею в качестве первого принципа, поскольку без признания того, что работа систем невозможна без участия людей, слишком легко начать думать только о серверах, сервисах и API.
На практике это означает, что при проектировании систем вы с самого начала учитываете людей, которые будут так или иначе с ними взаимодействовать.
Что нужно принимать во внимание:
С этого надо начинать проработку улучшения процессов. Используя компьютеры, мы небезосновательно ожидаем, что они будут работать одинаково независимо от времени суток. Это, безусловно, одно из ключевых преимуществ компьютерных систем — они могут, не уставая, надежно выполнять поставленные задачи.
Однако многие ошибочно пытаются применять такую же логику по отношению к людям. Важно учитывать, что люди в разных ситуациях действуют по-разному. Эмоции, стресс и усталость снижают предсказуемость поведения системы, поэтому эти факторы необходимо принимать во внимание при проектировании.
В качестве примера рассмотрим человеческий фактор. Компьютеры не совершают ошибок. Они не нажимают на не ту кнопку по причине усталости. Люди на такое способны, и даже, скорее всего, где-то ошибутся, если не была проведена должная подготовка, а в систему не встроена соответствующая защита. Человеческий фактор — это неотъемлемая часть системы, которую надо очень хорошо понимать. Этот феномен необходимо рассматривать скорее как симптом, нежели как проблему саму по себе, а его проявления должны побуждать к более внимательному изучению ситуации, в которой человек принял неправильное решение.
Один из путей улучшения ситуации — это обучение. Обучение должно быть максимально приближено к реальности, чтобы в тот момент, когда проблема произошла в действительности, она воспринималась бы так же, как и при обучении. Таким образом снижается стресс, поскольку сотрудники знают, что нужно делать. Стресс возникает из-за неуверенности вкупе с осознанием того, что система не работает, поэтому нужно всячески стараться смягчать подобное влияние нештатных ситуаций на психику. Для моделирования различных сценариев сбоев мы проводим военные игры. Таким образом, все сотрудники в любой из отработанных ситуаций знают, что нужно делать.
Соглашение об уровне предоставления услуги (SLA) — это отработанный метод определения того, что вы можете ожидать от определенного сервиса или API. У вас должна быть возможность легко определить, соответствует ли сервис SLA, а также что делать, если не соответствует.
Аналогично принципу № 2, в отличие от компьютеров, которые могут безостановочно работать месяцами и годами, людям требуется отдых. Реагируя на нештатные ситуации и имея дело со сложными системами, люди быстро устают, поэтому время на отдых и восстановление должно быть неотъемлемой частью процессов. Человек может сохранять концентрацию лишь в течение 1,5–2 часов, после этого ему потребуется перерыв. В противном случае работоспособность начинает снижаться.
В Server Density мы решаем эту проблему с помощью ротации дежурств. Первичная и вторичная (primary/secondary) роли по очереди переходят членам команды, и у нас есть документы, определяющие время реакции в зависимости от роли. Это позволяет уменьшить ощущение невозможности отойти от своего компьютера. Например, специалист на подстраховке (secondary) не обязан реагировать мгновенно, поэтому ему не нужно постоянно быть рядом с компьютером.
Более того, время на отдых после работы во внеурочные часы у нас выделяется автоматически. Сотрудник по желанию может отказаться от него, но компания никогда не просит это сделать. Таким образом, мы уверены, что у сотрудников есть достаточно времени на восстановление и на них никто не давит с целью вынудить отказаться от него. Например, это достигается за счет именно автоматического предоставления отдыха — сотруднику не надо ничего делать, чтобы его получить.
Может показаться, что мы даем нашим сотрудникам отдохнуть после реагирования на инциденты во внеурочное время только лишь из хорошего человеческого к ним отношения. Однако здесь есть и бизнес-логика: переутомленные люди делают ошибки, и мы знаем много примеров крупных аварий, которые были усугублены или спровоцированы усталостью операторов.
Как и со страховкой, которой вы надеетесь никогда не воспользоваться, бывает тяжело рассчитать прямую выгоду такого подхода. Смысл снижения вероятности совершения человеческой ошибки в том, чтобы избежать чего-то плохого. Это сложно измерить, но, без сомнения, есть железная логика в том, чтобы стремиться к хорошему самочувствию операторов, поскольку в этом случае они будут принимать более качественные решения.
Тревожная усталость (alert fatigue) возникает от получения слишком большого количества сигналов тревоги. Этих сигналов так много, что оператор начинает их игнорировать, рискуя пропустить что-то важное. Это явление значительно снижает эффективность системы оповещения, которая должна срабатывать в редких случаях, ставя людей в известность о том, что произошло что-то действительно серьезное.
Для решения этой проблемы необходимо проводить аудит системы мониторинга, проверяя, требуют ли генерируемые сигналы тревоги совершения каких-либо действий, а также что эти действия на самом деле совершаются.
Этот принцип связан с предыдущим, поскольку сигналы тревоги должны передаваться людям только в тех случаях, когда система не может починить себя сама. Не нужно будить человека, чтобы перезагрузить сервер или выполнить другое простое действие. Если что-то может быть автоматизировано, то лучше так и поступить. Люди должны привлекаться лишь для оценки сложных ситуаций и выполнения нестандартных действий.
К сожалению, после сдачи системы в промышленную эксплуатацию дальше что-то автоматизировать достаточно проблематично. Это происходит по той причине, что, используя такие современные технологии, как Kubernetes и облачные API, можно настроить автоматическое восстановление после практически любого сбоя, но при этом требуется очень много усилий для адаптации новых технологий к старым системам. Безусловно, и использование избыточности, и внедрение чего-то нового стоят денег, но эти затраты окупаются за счет экономии времени работы человека и увеличения общей надежности систем.
Правильный подход к построению инфраструктуры заключается в том, что ничего в условиях промышленной эксплуатации не должно делаться вручную. Все должно быть шаблонизировано, оформлено в виде сценариев и выполняться автоматически.
При модернизации старой инфраструктуры необходимо соблюдать баланс, поскольку, например, контейнеризация основных компонентов системы может оказаться нецелесообразной. Однако есть пути по достижению схожих целей, например, перенос размещенной на собственном оборудовании базы данных в управляемый сервис типа AWS RDS.
В реальной жизни никто не любит писать документацию, но по мере роста команды и усложнения системы это быстро становится необходимостью. Вам нужно достаточное количество документации, которую сможет использовать человек с ограниченным пониманием внутренних механизмов системы. Для решения проблем с помощью документации могут применяться контрольные списки (checklists) и плейбуки.
Обучение не менее важно. Оно в числе прочего помогает выявить недостатки документации. Также жизненно необходимо проводить реалистичные симуляции с участием сотрудников, отвечающих на инциденты, и объяснять им как работает система.
Чтобы сделать документацию удобной для поиска и легкодоступной для всех сотрудников компании, мы в Server Density используем Google Drive. Однако существует еще немало других вариантов по ее размещению.
При поиске причины возникновения проблемы практически всегда будет найден сотрудник, который совершил ошибку, не запланировал все возможные сценарии, сделал неверное предположение или написал плохой код. Это нормально, и людей не нужно за это стыдить, поскольку в следующий раз они вряд ли захотят помогать в расследовании инцидента.
Идеальных людей нет. Каждый из нас хоть раз ломал что-то в production. Здесь важно не обвинять конкретного человека, а суметь сделать систему лучше и устойчивее к подобного рода проблемам. Такого практически никогда не бывает, чтобы система была сломана сознательно, поэтому люди не должны испытывать проблем в признании своих ошибок сразу же после осознания содеянного. Это важно для быстрой ликвидации последствий. Неудачи должны рассматриваться как возможность научиться и сделать команду лучше.
Этого можно добиться с помощью никого не обвиняющего анализа причин сбоя, в процессе которого выясняются детали и основная причина произошедшего, но люди, совершившие ошибку, не называются.
Существует тенденция рассматривать проблемы людей и проблемы систем по отдельности. Гораздо проще обосновать дополнительные затраты на увеличение производительности серверов и отказоустойчивость, нежели на вопросы, связанные с персоналом. Все вышеперечисленные принципы призваны подчеркнуть, что вопросы, связанные с людьми, не менее важны и им нужно уделять соответствующее время на рассмотрение и бюджет.
В Server Density при планировании циклов разработки мы часто приоритезируем задачи на основе их потенциала по уменьшению количества нештатных ситуаций, требующих участия людей во внеурочное время. Реализация исправлений проблем, выявленных в ходе анализа причин сбоя, получает более высокий приоритет, если в процессе реагирования на ситуацию пришлось поднимать с постели людей или у проблемы, по крайней мере, есть такой потенциал.
Поскольку здоровье и благополучие людей влияет на их работу, в том числе на способность вносить вклад в общее дело по решению возникающих проблем, а проблемы системы приводят к уменьшению прибыли и порче репутации, здоровье людей имеет прямое влияние на здоровье бизнеса. Процесс поиска новых сотрудников отнимает много времени и сил, поэтому забота о людях выгодна для бизнеса.
Несмотря на то что, несомненно, важно рассматривать людей и системы находящимися на одном уровне по степени влияния друг на друга и бизнес в целом, по большому счету люди все же важнее. Ведь для чего существует бизнес? Чтобы продавать товары и услуги другим людям! И зачем люди делают определенную работу, как не для получения средств к существованию?
Улучшение условий работы вашей команды достаточно легко обосновать. Чтобы иметь возможность нанимать и удерживать лучших специалистов, ваши рабочие процессы должны быть хорошо отлажены. Когда людей постоянно поднимают с постели, стыдят за ошибки и не исправляют проблемы, это негативно сказывается на их состоянии. Стресс, испытываемый на протяжении продолжительных периодов времени, может вызвать повышенное кровяное давление, заболевания сердца, ожирение и диабет. Таким образом, многие организации, не уделяя достаточного внимания вопросам благополучия персонала, могут непреднамеренно подрывать здоровье своих сотрудников, причем иногда очень серьезно.
Мы в Server Density считаем, что это недопустимая цена успешности бизнеса.
Ссылки:
|
Метки: author olemskoi управление разработкой управление проектами блог компании southbridge humanops hr |
Нативные переменные в CSS. Уже пора… |

:root {
--body-background: #ccc;
}
body {
background-color: var(--body-background);
}
.title {
--wrapper-width: 50%;
width: var(--wrapper-width);
}
@media (max-width: 320px) {
--wrapper-width: 100%;
}
.title {
--background: blue;
background-color: var(--background);
}
changeColor() {
this.setState({
style: {'--background': 'green'}
});
}
Title
html {
--a: #ccc;
}
body {
--b: #a3a3a3;
}
.title {
--title-width: 300px;
width: calc(var(--title-width) + 150px);
}
.title {
--title-width: 300;
/* так не сработает */
width: var(--title-width)px;
/* так сработает */
width: calc(var(--title-width) * 1px);
}
|
Метки: author CodeViking html css javascript variables development разработка css3 css variables |
Xamarin.Forms для WPF и UWP разработчиков |

using Xamarin.Forms;
namespace App1
{
public class MainPage : ContentPage
{
public MainPage()
{
Label lblIntro = new Label
{
Text = "Welcome to Xamarin Forms!",
VerticalOptions = LayoutOptions.Center,
HorizontalOptions = LayoutOptions.Center,
};
Content = lblIntro;
}
}
}using Xamarin.Forms.Xaml[assembly: XamlCompilation(XamlCompilationOptions.Compile)]
public static readonly BindableProperty HeaderTextProperty =
BindableProperty.Create("HeaderText", typeof(string), typeof(MainPage), "Заголовок");
public string HeaderText
{
get { return (string)GetValue(HeaderTextProperty); }
}
MessagingCenter.Subscribe(this, "SomeIdText", GetMessage); private void GetMessage(object sender, string args)
{
// здесь можно что-то сделать
} MessagingCenter.Subscribe(this, "SomeIdText", (sender, arg) =>
{
// и здесь тоже можно что-то сделать
});MessagingCenter.Send(this, "SomeIdText", "значение, которое можно получить в args");MessagingCenter.Unsubscribe(this, "SomeIdText");#if __ANDROID__
// код, который использует возможности Android
#endifinternal class Alert
{
internal static void Show(string title, string message)
{
new AlertDialog.Builder(Application.Context).SetTitle(title).SetMessage(message);
}
} Alert.Show("Сообщение", "Привет Xamarin!"); public interface ITextToSpeech
{
void Speak(string text);
} public class TextToSpeechImplementation : ITextToSpeech
{
public TextToSpeechImplementation() { }
public async void Speak(string text)
{
MediaElement ml = new MediaElement();
SpeechSynthesizer synth = new SpeechSynthesizer();
SpeechSynthesisStream stream = await synth.SynthesizeTextToStreamAsync(text);
ml.SetSource(stream, stream.ContentType);
ml.Play();
}
}[assembly: Xamarin.Forms.Dependency(typeof(AppName.UWP.TextToSpeechImplementation))]
namespace AppName.UWP
TextToSpeech _speaker;
string _toSpeak;
public TextToSpeechImplementation() { }
public void OnInit([GeneratedEnum] OperationResult status)
{
if (status.Equals(OperationResult.Success))
{
var p = new Dictionary();
_speaker.Speak(_toSpeak, QueueMode.Flush, p);
}
}
public async void Speak(string text)
{
var ctx = Forms.Context;
_toSpeak = text;
if (_speaker == null)
{
_speaker = new TextToSpeech(ctx, this);
}
else
{
var p = new Dictionary();
_speaker.Speak(_toSpeak, QueueMode.Flush, p);
}
}
}[assembly: Xamarin.Forms.Dependency(typeof(TextToSpeechImplementation))]
namespace AppName.DroidDependencyService.Get().Speak("Hello from Xamarin Forms"); public static class TextToSpeech
{
public static ITextToSpeech Instance { get; set; }
} TextToSpeech.Instance = new TextToSpeechImplementation(); TextToSpeech.Instance.Speak("Hello! How are you?"); if (Device.RuntimePlatform == Device.Android) Margin = new Thickness(0, 20, 0, 0);
0
0,20,0,0
public class MyEntry : Entry
{
}using Xamarin.Forms.Platform.iOS;
[assembly: ExportRenderer (typeof(MyEntry), typeof(MyEntryRenderer))]
namespace YourAppName.iOS
{
public class MyEntryRenderer : EntryRenderer
{
protected override void OnElementChanged (ElementChangedEventArgs e)
{
base.OnElementChanged (e);
if (Control != null) {
Control.BackgroundColor = UIColor.FromRGB (204, 153, 255);
}
}
}
} if (Control != null) {
Control.SetBackgroundColor (global::Android.Graphics.Color.LightGreen);
} if (e.OldElement != null) {
// Отписаться от событий и очистить ресурсы (если необходимо)
} if (e.NewElement != null) {
// Здесь можно настроить вид контрола и подписаться на события
}|
Метки: author asommer разработка под windows phone разработка под windows разработка мобильных приложений xamarin uwp .net xamarin.forms quickstart |
Законы и проекты, которые изменят лицо российского IT. Часть III. Заключительная? |

Согласно закону, Минкомсвязи России по поступающей информации принимает мотивированное решение о признании сайта копией заблокированного сайта и направляет данное решение владельцу такого сайта и в Роскомнадзор для принятия мер по ограничению доступа к копии заблокированного сайта, которое будет осуществляться во внесудебном порядке
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Menaskop терминология it патентование законодательство и it-бизнес законодательство и ит абсурд законов закон о vpn закон о мессенджерах it- юрист |
[Перевод] Golem: децентрализация нового уровня |
|
Метки: author Menaskop финансы в it исследования и прогнозы в it golem голем p2p блокчейн blockchain whitepaper it- юрист |
[Перевод] Полное руководство по переходу с HTTP на HTTPS |
example.com, действительно является example.com. Некоторые сертификаты даже проверяют правовую идентичность владельца веб-сайта, так что вы знаете, что yourbank.com принадлежит YourBank, Inc.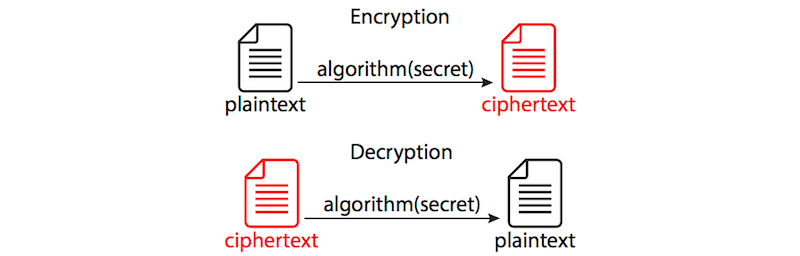

example.com (уникальный идентификатор) связано с публичным ключом XXX. В некоторых случаях (с сертификатами EV и OV — см. ниже) CA также проверяет, что конкретная компания контролирует этот домен. Эта информация гарантирована (то есть сертифицирована) центром сертификации Х, и эта гарантия действует не раньше, чем дата Y (то есть сертификат начинает действовать с этой даты), и не позже чем дата Z (то есть сертификат заканчивает своё действие в эту дату). Вся эта информация включена в один документ, который называется сертификат HTTPS. Чтобы привести легко понимаемую аналогию — это как ID или паспорт, который выдаёт правительство страны (то есть третья сторона, которой все доверяют) — и все, кто доверяют правительству, будут также доверять сертификату (паспорту) его владельца и самому владельцу. Предполагается, конечно, что паспорт не поддельный, но подделка сертификатов выходит за рамки данной статьи.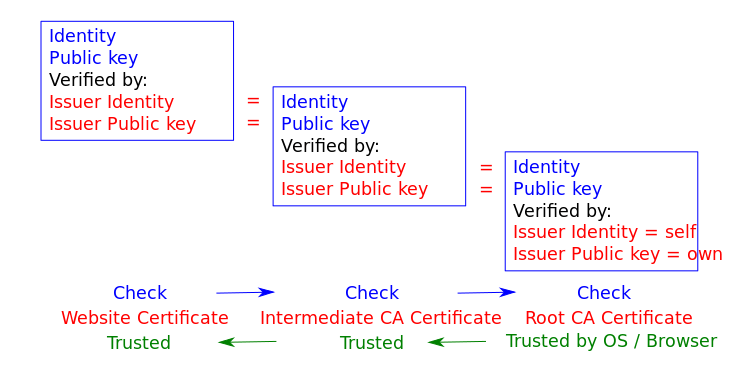
www этого домена). Однако многие продавцы по историческим причинам по-прежнему продают сертификаты HTTPS на один и несколько доменов.example.com и www.example.com.*.example.com) — например, example.com, www.example.com, mail.example.com, ftp.example.com и т. д. Ограничение в том, что он покрывает только поддомены основного домена.| Тип сертификата | Подтверждённый домен (DV) | Подтверждённая организация (OV) | Расширенное подтверждение (EV) |
|---|---|---|---|
| HTTPS | HTTPS Проверенный правообладатель |
HTTPS Проверенный правообладатель Информация о владельце отображается в браузере |
|
| Один домен | example.com, www.example.com |
||
| Несколько доменов | example.com, www.example.com, mail.example.com, example.net, example.org и др.Определённый заранее список, до некоторого лимита (обычно 100) |
||
| Поддомены | *.example.comПодходит для любого поддомена |
Недоступно — все имена должны быть явно включены в сертификат и проверены центром сертификации | |
ECDHE-RSA-AES256-GCM-SHA384 означает, что обмен ключами будет производиться по алгоритму Elliptic Curve Diffie-Hellman Ephemeral (ECDHE); центр сертификации подписал сертификат при помощи алгоритма Rivest-Shamir-Adleman (RSA); симметричное шифрование сообщений будет использовать шифр Advanced Encryption Standard (AES) с 256-битным ключом и будет работать в режиме GCM; целостность сообщений будет обеспечивать алгоритм безопасного хеширования SHA, с использованием 384-битных дайджестов. (Доступен полный список комбинаций алгоритмов).example.com.key.key не является стандартом, так что кто-то может использовать его, а кто-то нет. Файл должен быть защищён и доступен только для суперпользователя.example.com.pubexample.com.csrexample.com.crt.crt не является стандартом; часто используются другие расширения, в том числе .cert и .cer.-----BEGIN RSA PRIVATE KEY-----
MIIEowIBAAKCAQEAm+036O2PlUQbKbSSs2ik6O6TYy6+Zsas5oAk3GioGLl1RW9N
i8kagqdnD69Et29m1vl5OIPsBoW3OWb1aBW5e3J0x9prXI1W/fpvuP9NmrHBUN4E
S17VliRpfVH3aHfPC8rKpv3GvHYOcfOmMN+HfBZlUeKJKs6c5WmSVdnZB0R4UAWu
Q30aHEBVqtrhgHqYDBokVe0/H4wmwZEIQTINWniCOFR5UphJf5nP8ljGbmPxNTnf
b/iHS/chjcjF7TGMG36e7EBoQijZEUQs5IBCeVefOnFLK5jLx+BC//X+FNzByDil
Tt+l28I/3ZN1ujhak73YFbWjjLR2tjtp+LQgNQIDAQABAoIBAEAO2KVM02wTKsWb
dZlXKEi5mrtofLhkbqvTgVE7fbOKnW8FJuqCl+2NMH31F1n03l765p4dNF4JmRhv
/+ne4vCgOPHR/cFsH4z/0d5CpHMlC7JZQ5JjR4QDOYNOpUG51smVamPoZjkOlyih
XGk/q72CxeU6F/gKIdLt6Dx03wBosIq9IAE8LwdMnioeuj18qaVg195OMeIOriIn
tpWP4eFya5rTpIFfIdHdIxyXsd6hF/LrRc9BMWTY1/uOLrpYjTf7chbdNaxhwH7k
buvKxBvCvmXmd6v/AeQQAXbUkdSnbTKDaB9B7IlUTcDJyPBJXvFS1IzzjN6vV+06
XBwHx5ECgYEAyRZLzwnA3bw8Ep9mDw8JHDQoGuQkFEMLqRdRRoZ+hxnBD9V9M0T6
HRiUFOizEVoXxf6zPtHm/T7cRD8AFqB+pA/Nv0ug6KpwUjA4Aihf5ADp0gem0DNw
YlVkCA6Bu7c9IUlE0hwF7RLB7YrryJVJit9AymmUTUUHCQTWW2yBhC8CgYEAxoHS
HGXthin5owOTNPwLwPfU2o7SybkDBKyW69uTi0KxAl3610DjyA/cV2mxIcFlPv1y
HualGd9eNoeCMBy/AUtjzI0K77yeRpjj321rj6k8c8bYWPHH539SiBXLWTY/WQ0w
pxfT3d/Z4QMh5d6p+p5f3UIrXESYQd+fAaG5tNsCgYEAksTdTB4YUT9EsWr6eN9G
jPlclFQUKV3OMvq77bfYvg8EJORz32nnDDmWS7SUjoOtemwutBlMeWbaKk25aMp3
5JNMXuV6apeMJ9Dd8GU7qBUqlIvVK31/96XPvzmnYzWZPqRVwO2HPcRFG3YcJmkg
JmZQyexJvCQ3wFNxiYUm+y0CgYBXQSMhFnCUg4jWbbDcHlnwRT+LnjHrN2arPE3O
eKLfGL6DotmqmjxFaStaRPv2MXMWgAMUsB8sQzG/WEsSaOBQaloAxJJlFIyhzXyE
bi1UZXhMD8BzQDu1dxLI/IN4wE6SDykumVuocEfuDxlsWDZxEgJjWD2E/iXK9seG
yRa+9wKBgEydVz+C1ECLI/dOWb20UC9nGQ+2dMa+3dsmvFwSJJatQv9NGaDUdxmU
hRVzWgogZ8dZ9oH8IY3U0owNRfO65VGe0sN00sQtMoweEQi0SN0J6FePiVCnl7pf
lvYBaemLrW2YI2B7zk5fTm6ng9BW/B1KfrH9Vm5wLQBchAN8Pjbu
-----END RSA PRIVATE KEY----------BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAm+036O2PlUQbKbSSs2ik
6O6TYy6+Zsas5oAk3GioGLl1RW9Ni8kagqdnD69Et29m1vl5OIPsBoW3OWb1aBW5
e3J0x9prXI1W/fpvuP9NmrHBUN4ES17VliRpfVH3aHfPC8rKpv3GvHYOcfOmMN+H
fBZlUeKJKs6c5WmSVdnZB0R4UAWuQ30aHEBVqtrhgHqYDBokVe0/H4wmwZEIQTIN
WniCOFR5UphJf5nP8ljGbmPxNTnfb/iHS/chjcjF7TGMG36e7EBoQijZEUQs5IBC
eVefOnFLK5jLx+BC//X+FNzByDilTt+l28I/3ZN1ujhak73YFbWjjLR2tjtp+LQg
NQIDAQAB
-----END PUBLIC KEY----- -----BEGIN CERTIFICATE REQUEST-----
MIICzjCCAbYCAQAwgYgxFDASBgNVBAMMC2V4YW1wbGUuY29tMQswCQYDVQQLDAJJ
VDEPMA0GA1UECAwGTG9uZG9uMRIwEAYDVQQKDAlBQ01FIEluYy4xIDAeBgkqhkiG
9w0BCQEWEWFkbWluQGV4YW1wbGUuY29tMQswCQYDVQQGEwJHQjEPMA0GA1UEBwwG
TG9uZG9uMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAm+036O2PlUQb
KbSSs2ik6O6TYy6+Zsas5oAk3GioGLl1RW9Ni8kagqdnD69Et29m1vl5OIPsBoW3
OWb1aBW5e3J0x9prXI1W/fpvuP9NmrHBUN4ES17VliRpfVH3aHfPC8rKpv3GvHYO
cfOmMN+HfBZlUeKJKs6c5WmSVdnZB0R4UAWuQ30aHEBVqtrhgHqYDBokVe0/H4wm
wZEIQTINWniCOFR5UphJf5nP8ljGbmPxNTnfb/iHS/chjcjF7TGMG36e7EBoQijZ
EUQs5IBCeVefOnFLK5jLx+BC//X+FNzByDilTt+l28I/3ZN1ujhak73YFbWjjLR2
tjtp+LQgNQIDAQABoAAwDQYJKoZIhvcNAQELBQADggEBAGIQVhXfuWdINNfceNPm
CkAGv4yzpx88L34bhO1Dw4PYWnoS2f7ItuQA5zNk9EJhjkwK8gYspK7mPkvHDbFa
Um7lPSWsm3gjd3pU7dIaHxQ+0AW9lOw5ukiBlO4t3qgt+jTVZ3EhMbR0jDSyjTrY
kTgfuqQrGOQSmLb5XviEtCcN0rseWib3fKIl8DM69JiA2AALxyk7DCkS1BqLNChT
pnbgvtlUhc4yFXNCtwPGskXIvLsCn2LRy+qdsPM776kDLgD36hK0Wu14Lpsoa/p+
ZRuwKqTjdaV23o2aUMULyCRuITlghEEkRdJsaXadHXtNd5I5vDJOAAt46PIXcyEZ
aQY=
-----END CERTIFICATE REQUEST----- example.com.-----BEGIN CERTIFICATE-----
MIIDjjCCAnYCCQCJdR6v1+W5RzANBgkqhkiG9w0BAQUFADCBiDEUMBIGA1UEAwwL
ZXhhbXBsZS5jb20xCzAJBgNVBAsMAklUMQ8wDQYDVQQIDAZMb25kb24xEjAQBgNV
BAoMCUFDTUUgSW5jLjEgMB4GCSqGSIb3DQEJARYRYWRtaW5AZXhhbXBsZS5jb20x
CzAJBgNVBAYTAkdCMQ8wDQYDVQQHDAZMb25kb24wHhcNMTYwNDE5MTAzMjI1WhcN
MTcwNDE5MTAzMjI1WjCBiDEUMBIGA1UEAwwLZXhhbXBsZS5jb20xCzAJBgNVBAsM
AklUMQ8wDQYDVQQIDAZMb25kb24xEjAQBgNVBAoMCUFDTUUgSW5jLjEgMB4GCSqG
SIb3DQEJARYRYWRtaW5AZXhhbXBsZS5jb20xCzAJBgNVBAYTAkdCMQ8wDQYDVQQH
DAZMb25kb24wggEiMA0GCSqGSIb3DQEBAQUAA4IBDwAwggEKAoIBAQCb7Tfo7Y+V
RBsptJKzaKTo7pNjLr5mxqzmgCTcaKgYuXVFb02LyRqCp2cPr0S3b2bW+Xk4g+wG
hbc5ZvVoFbl7cnTH2mtcjVb9+m+4/02ascFQ3gRLXtWWJGl9Ufdod88Lysqm/ca8
dg5x86Yw34d8FmVR4okqzpzlaZJV2dkHRHhQBa5DfRocQFWq2uGAepgMGiRV7T8f
jCbBkQhBMg1aeII4VHlSmEl/mc/yWMZuY/E1Od9v+IdL9yGNyMXtMYwbfp7sQGhC
KNkRRCzkgEJ5V586cUsrmMvH4EL/9f4U3MHIOKVO36Xbwj/dk3W6OFqTvdgVtaOM
tHa2O2n4tCA1AgMBAAEwDQYJKoZIhvcNAQEFBQADggEBABwwkE7wX5gmZMRYugSS
7peSx83Oac1ikLnUDMMOU8WmqxaLTTZQeuoq5W23xWQWgcTtfjP9vfV50jFzXwat
5Ch3OQUS53d06hX5EiVrmTyDgybPVlfbq5147MBEC0ePGxG6uV+Ed+oUYX4OM/bB
XiFa4z7eamG+Md2d/A1cB54R3LH6vECLuyJrF0+sCGJJAGumJGhjcOdpvUVt5gvD
FIgT9B04VJnaBatEgWbn9x50EP4j41PNFGx/A0CCLgbTs8kZCdhE4QFMxU9T+T9t
rXgaspIi7RA4xkSE7x7B8NbvSlgP79/qUe80Z7d8Oolva6dTZduByr0CejdfhLhi
mNU=
-----END CERTIFICATE----- 




example.com); центр сертификации обычно сам добавляет поддомен www (то есть www.example.com). По окончании нажмите кнопку “Generate”.

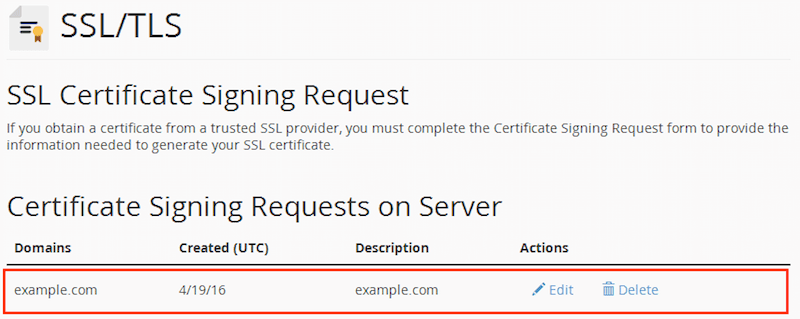
openssl version sudo apt-get install openssl sudo yum install openssl make -C /usr/ports/security/openssl install cleanopenssl req -newkey rsa:2048 -nodes -keyout example.com.key -out example.com.csr Generating a 2048 bit RSA private key
........................+++
................................................................+++
writing new private key to 'example.com.key'
-----
You are about to be asked to enter information that will be incorporated
into your certificate request.
What you are about to enter is what is called a Distinguished Name or a DN.
There are quite a few fields but you can leave some blank
For some fields there will be a default value,
If you enter ‘.', the field will be left blank. example.com); центр сертификации обычно сам добавляет поддомен www (то есть www.example.com):Country Name (2 letter code) [AU]:GB
State or Province Name (full name) [Some-State]:London
Locality Name (eg, city) []:London
Organization Name (eg, company) [Internet Widgits Pty Ltd]:ACME Inc.
Organizational Unit Name (eg, section) []:IT
Common Name (e.g. server FQDN or YOUR name) []:example.com
Email Address []:admin@example.com
Please enter the following 'extra' attributes
to be sent with your certificate request
A challenge password []:
An optional company name []: 
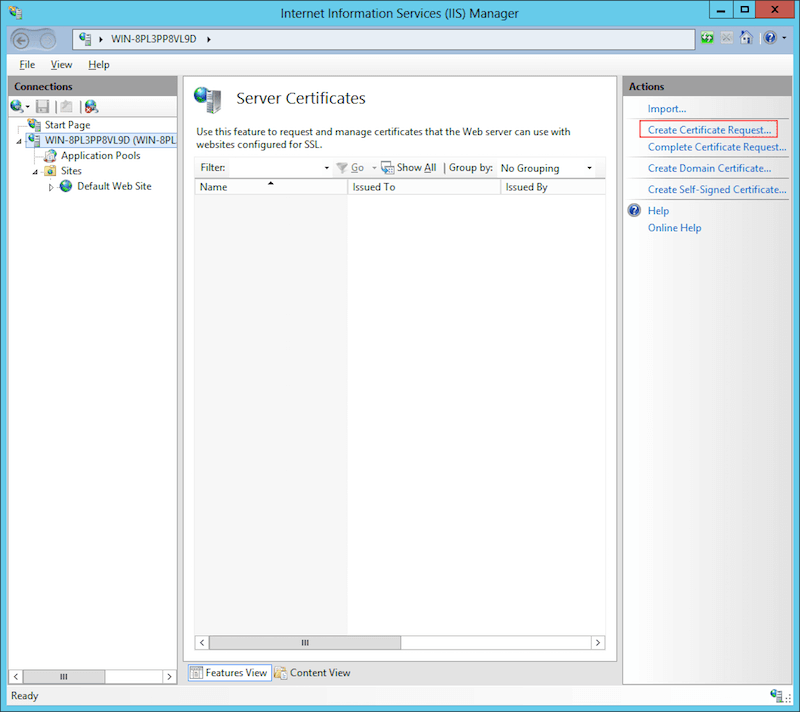

2048. Нажмите “Next”.
2048. (см. большую версию)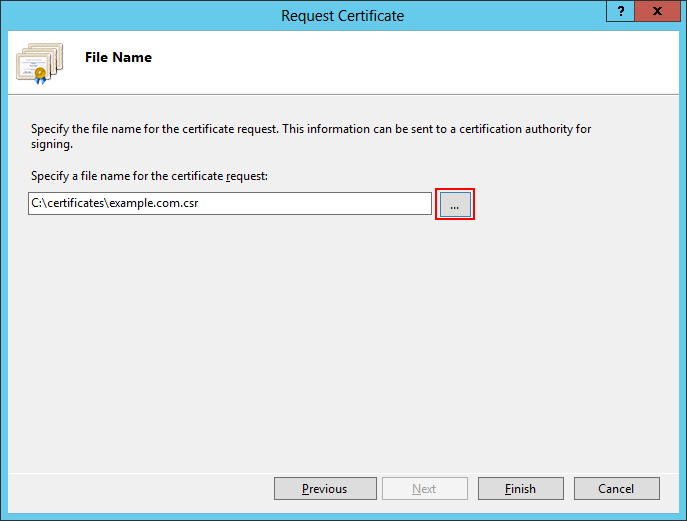
-----BEGIN CERTIFICATE REQUEST----- и -----END CERTIFICATE REQUEST-----. Если вам нужен сертификат EV или OV, то нужно будет указать юридическое лицо, для которого вы запрашиваете сертификат. У вас также могут попросить дополнительные документы, подтверждающие тот факт, что вы представляете эту компанию. Затем регистратор сертификатов проверит ваш запрос (и все сопутствующие документы) и выдаст подписанный сертификат HTTPS.TXT к своему файлу доменной зоны (на основе DNS). Следуйте инструкциям по указанному методу DCV для утверждения.example.com, и он будет работать в течение своего срока действия.openssl x509 -signkey example.com.key -in example.com.csr -req -days 365 -out example.com.crt 




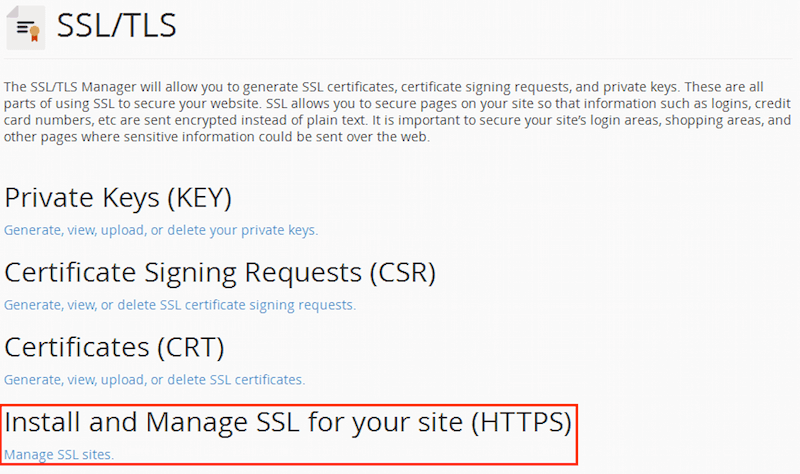

https://www.example.com. Если всё работает нормально, то вы, вероятно, захотите поставить постоянный редирект HTTP-трафика на HTTPS. Для этого нужно добавить несколько строчек в файл .htaccess (если у вас веб-сервер Apache) в корневой директории на своём сервере.RewriteEngine On
RewriteCond %{HTTPS} off
RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301] .htaccess уже существует, то вставьте только строчки RewriteCond и RewriteRule сразу после существующей директивы RewriteEngine On.example.com.key), запрос на подпись сертификата (example.com.csr) и действительный сертификат HTTPS (example.com.crt):cp example.com.crt /etc/ssl/certs/
cp example.com.key /etc/ssl/private/
cp example.com.csr /etc/ssl/private/ cp example.com.crt /etc/pki/tls/certs/
cp example.com.key /etc/pki/tls/private/
cp example.com.csr /etc/pki/tls/private/
restorecon -RvF /etc/pki 600.chown -R root. /etc/ssl/certs /etc/ssl/private
chmod -R 0600 /etc/ssl/certs /etc/ssl/private chown -R root. /etc/pki/tls/certs /etc/pki/tls/private
chmod -R 0600 /etc/pki/tls/certs /etc/pki/tls/private chown -R root:wheel /etc/ssl/certs /etc/ssl/private
chmod -R 0600 /etc/ssl/certs /etc/ssl/private .crt),mod_ssl. В зависимости от операционной системы, должен работать один из вариантов:apache2 -M | grep ssl httpd -M | grep ssl mod_ssl установлен, то вы получите такой ответ…ssl_module (shared)
Syntax OK sudo a2enmod ssl
sudo service apache2 restart sudo yum install mod_ssl
sudo service httpd restart make -C /usr/ports/www/apache24 config install clean
apachectl restart /etc/apache2/apache2.conf /etc/httpd/conf/httpd.conf /usr/local/etc/apache2x/httpd.conf Listen 80
Listen 443
ServerName example.com
ServerAlias www.example.com
Redirect 301 / https://www.example.com/
ServerName example.com
Redirect 301 / https://www.example.com/
ServerName www.example.com
...
SSLEngine on
SSLCertificateFile/path/to/signed_certificate_followed_by_intermediate_certs
SSLCertificateKeyFile /path/to/private/key
# Uncomment the following directive when using client certificate authentication
#SSLCACertificateFile /path/to/ca_certs_for_client_authentication
# HSTS (mod_headers is required) (15768000 seconds = 6 months)
Header always set Strict-Transport-Security "max-age=15768000"
...
# intermediate configuration, tweak to your needs
SSLProtocol all -SSLv3
SSLCipherSuite ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS
SSLHonorCipherOrder on
SSLCompression off
SSLSessionTickets off
# OCSP Stapling, only in httpd 2.3.3 and later
SSLUseStapling on
SSLStaplingResponderTimeout 5
SSLStaplingReturnResponderErrors off
SSLStaplingCache shmcb:/var/run/ocsp(128000)www на домен с www (полезно для задач SEO).nginx.conf):/etc/nginx/nginx.conf /usr/local/etc/nginx/nginx.confserver {
listen 80 default_server;
listen [::]:80 default_server;
# Redirect all HTTP requests to HTTPS with a 301 Moved Permanently response.
return 301 https://$host$request_uri;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
# certs sent to the client in SERVER HELLO are concatenated in ssl_certificate
ssl_certificate /path/to/signed_cert_plus_intermediates;
ssl_certificate_key /path/to/private_key;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_session_tickets off;
# Diffie-Hellman parameter for DHE ciphersuites, recommended 2048 bits
ssl_dhparam /path/to/dhparam.pem;
# intermediate configuration. tweak to your needs.
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers 'ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS';
ssl_prefer_server_ciphers on;
# HSTS (ngx_http_headers_module is required) (15768000 seconds = 6 months)
add_header Strict-Transport-Security max-age=15768000;
# OCSP Stapling ---
# fetch OCSP records from URL in ssl_certificate and cache them
ssl_stapling on;
ssl_stapling_verify on;
## verify chain of trust of OCSP response using Root CA and Intermediate certs
ssl_trusted_certificate /path/to/root_CA_cert_plus_intermediates;
resolver ;
....
} 
example.com.crt), который вы получили от центра сертификации. Введите какое-нибудь название в поле “Friendly name”, чтобы различать сертификаты впоследствии. Поместите новый сертификат в хранилище сертификатов “Personal” (IIS 8+). Нажмите “OK”.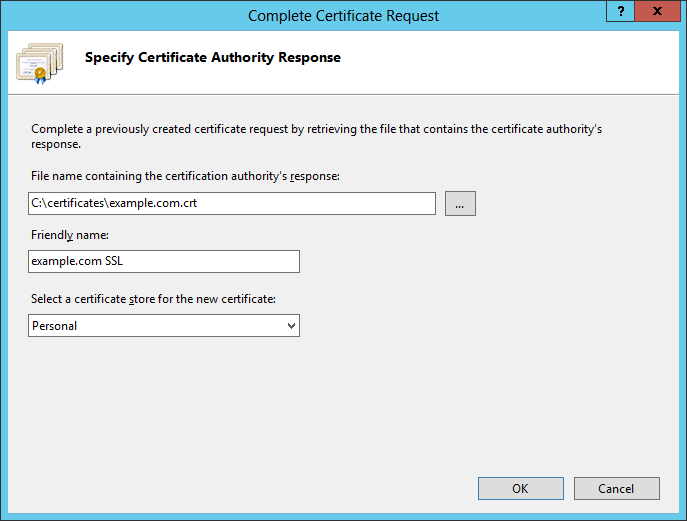

|
|
IBM Watson и кибербезопасность: как когнитивная система защищает ценные данные |

|
Метки: author ibm машинное обучение информационная безопасность блог компании ibm watson кибербезопасность watson for cybersecurity |
Шесть мифов о Big Data |

Новые области знаний рождают новые профессии.
Контролировать и мониторить процессы всегда должен человек.
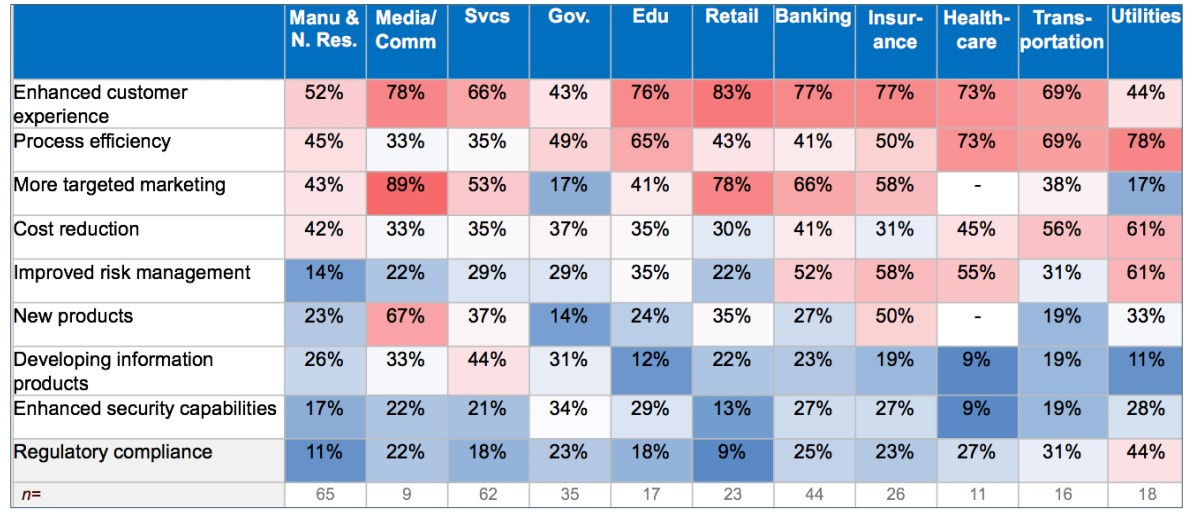
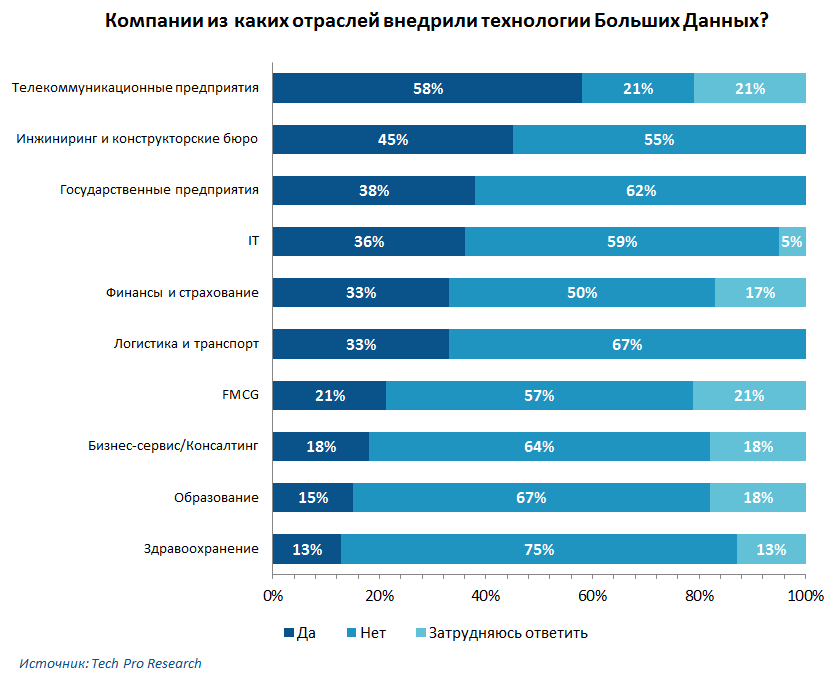
Больше не значит лучше.
Главная задача — встроить модели в бизнес-процессы в продакшене и выгодно использовать найденные решения.
|
Метки: author shapovalowa-netology data mining big data блог компании нетология bigdata data data science биг дата нетология |
[Из песочницы] Решение задачи коммивояжера алгоритмом Литтла с визуализацией на плоскости |
Известная как минимум с 19 века задача коммивояжера имеет множество способов решения и неоднократно описана. Ее оптимизационная версия является NP-трудной, поэтому оптимальное решение можно получить либо полным перебором, либо оптимизированным полным перебором — методом ветвей и границ.
Пытаясь запрограммировать алгоритм Литтла (частный случай метода ветвей и границ), я понял, что в рунете крайне трудно найти его правильное описание понятным языком и разобранную программную реализацию. Однако имеющиеся в изобилии описания обманчиво правдоподобны на данных малого размера и с трудом проверяются без визуализации.

Алгоритм Литтла является частным случаем МВиГ, т.е. в худшем случае его сложность равна сложности полного перебора. Теоретическое описание выглядит следующим образом:
Имеется множетво S всех гамильтоновых циклов рафа. На каждом шаге в S ищется ребро (i, j), исключение которого из маршрута максимально увеличит оценку снизу. Далее происходит разбиение множества на два непересекающихся S1 и S2. S1 — все циклы, содержащие ребро (i, j) и не содержащие (j, i). S2 — все циклы, не содержащие (i, j). Далее вычисляется оценка снизу для длины пути каждого множества и, если она превышает длину уже найденного решения, множество отбрасывается. Если нет — множества S1 и S2 обрабатываются так же, как и S.
Имеется матрица расстояний M. Диагональ заполняется бесконечными значениями, т.к. не должно возникать преждевременных циклов. Также имеется переменная, хранящая нижнюю границу.
Стоит оговориться, что нужно вести учет двух видов бесконечностей — одна добавляется после удаления строки и столбца из матрицы, чтобы не возникало преждевременных циклов, другая — при отбрасывании ребер. Случаи будут рассмотрены чуть позже. Первую бесконечность обозначим как inf1, вторую — inf2. Диагональ заполнена inf1.
Эвристика состоит в том, что у матрицы M1 нижняя граница не больше, чем у матрицы M2 и в первую очередь рассматривается ветвь, содержащая ребро (i, j).
Примеров в интернете огромное количество, но действительно интересный находится в этой статье с хорошо иллюстированными деревьями (единственная найденная мной статья, в которой также указано про распространенную ошибку, но, к сожалению, в ней недостаточно алгоритмическое описание алгоритма — сначала про матрицы, потом про множества). Интересен пример тем, что если рассматривать только ветки с ребрами с максимальным штрафом, будет получен неверный результат.
Так что приведу шаги поиска оптимального пути для этой матрицы.
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | inf | 20 | 18 | 12 | 8 |
| 1 | 5 | inf | 14 | 7 | 11 |
| 2 | 12 | 18 | inf | 6 | 11 |
| 3 | 11 | 17 | 11 | inf | 12 |
| 4 | 5 | 5 | 5 | 5 | inf |
0 1 2 3 4
0 inf1 20.00 18.00 12.00 8.00
1 5.00 inf1 14.00 7.00 11.00
2 12.00 18.00 inf1 6.00 11.00
3 11.00 17.00 11.00 inf1 12.00
4 5.00 5.00 5.00 5.00 inf1
After subtracting:
0 1 2 3 4
0 inf1 12.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 12.00 inf1 0.00 5.00
3 0.00 6.00 0.00 inf1 1.00
4 0.00 0.00 0.00 0.00 inf1
edge (4, 1)
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 2.00 inf1
2 6.00 inf1 0.00 5.00
3 0.00 0.00 inf1 1.00
After subtracting:
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 2.00 inf1
2 6.00 inf1 0.00 5.00
3 0.00 0.00 inf1 1.00
edge (3, 2)
0 3 4
0 inf1 4.00 0.00
1 0.00 2.00 inf1
2 6.00 inf1 5.00
After subtracting:
0 3 4
0 inf1 2.00 0.00
1 0.00 0.00 inf1
2 1.00 inf1 0.00
edge (0, 4)
0 3
1 inf1 0.00
2 1.00 inf1
candidate solution(4 1) (3 2) (0 4) (1 3) (2 0)
cost: 43; record: 1.79769e+308
NEW RECORD
0 3 4
0 inf1 2.00 0.00
1 0.00 0.00 inf1
2 1.00 inf1 0.00
not edge (0, 4)
0 3 4
0 inf1 2.00 inf2
1 0.00 0.00 inf1
2 1.00 inf1 0.00
After subtracting:
0 3 4
0 inf1 0.00 inf2
1 0.00 0.00 inf1
2 1.00 inf1 0.00
limit: 44; record:43
DISCARDING BRANCH
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 2.00 inf1
2 6.00 inf1 0.00 5.00
3 0.00 0.00 inf1 1.00
not edge (3, 2)
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 2.00 inf1
2 6.00 inf1 0.00 5.00
3 0.00 inf2 inf1 1.00
After subtracting:
0 2 3 4
0 inf1 1.00 4.00 0.00
1 0.00 0.00 2.00 inf1
2 6.00 inf1 0.00 5.00
3 0.00 inf2 inf1 1.00
limit: 44; record:43
DISCARDING BRANCH
0 1 2 3 4
0 inf1 12.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 12.00 inf1 0.00 5.00
3 0.00 6.00 0.00 inf1 1.00
4 0.00 0.00 0.00 0.00 inf1
not edge (4, 1)
0 1 2 3 4
0 inf1 12.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 12.00 inf1 0.00 5.00
3 0.00 6.00 0.00 inf1 1.00
4 0.00 inf2 0.00 0.00 inf1
After subtracting:
0 1 2 3 4
0 inf1 6.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 6.00 inf1 0.00 5.00
3 0.00 0.00 0.00 inf1 1.00
4 0.00 inf2 0.00 0.00 inf1
edge (3, 1)
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 inf1 6.00
2 6.00 inf1 0.00 5.00
4 0.00 0.00 0.00 inf1
After subtracting:
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 inf1 6.00
2 6.00 inf1 0.00 5.00
4 0.00 0.00 0.00 inf1
edge (0, 4)
0 2 3
1 0.00 9.00 inf1
2 6.00 inf1 0.00
4 inf1 0.00 0.00
After subtracting:
0 2 3
1 0.00 9.00 inf1
2 6.00 inf1 0.00
4 inf1 0.00 0.00
edge (0, 0)
2 3
2 inf1 0.00
4 0.00 inf1
candidate solution(3 1) (0 4) (1 0) (2 3) (4 2)
cost: 41; record: 43
NEW RECORD
0 2 3
1 0.00 9.00 inf1
2 6.00 inf1 0.00
4 inf1 0.00 0.00
not edge (1, 0)
0 2 3
1 inf2 9.00 inf1
2 6.00 inf1 0.00
4 inf1 0.00 0.00
After subtracting:
0 2 3
1 inf2 0.00 inf1
2 0.00 inf1 0.00
4 inf1 0.00 0.00
limit: 56; record:41
DISCARDING BRANCH
0 2 3 4
0 inf1 10.00 4.00 0.00
1 0.00 9.00 inf1 6.00
2 6.00 inf1 0.00 5.00
4 0.00 0.00 0.00 inf1
not edge (0, 4)
0 2 3 4
0 inf1 10.00 4.00 inf2
1 0.00 9.00 inf1 6.00
2 6.00 inf1 0.00 5.00
4 0.00 0.00 0.00 inf1
After subtracting:
0 2 3 4
0 inf1 6.00 0.00 inf2
1 0.00 9.00 inf1 1.00
2 6.00 inf1 0.00 0.00
4 0.00 0.00 0.00 inf1
limit: 50; record:41
DISCARDING BRANCH
0 1 2 3 4
0 inf1 6.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 6.00 inf1 0.00 5.00
3 0.00 0.00 0.00 inf1 1.00
4 0.00 inf2 0.00 0.00 inf1
not edge (3, 1)
0 1 2 3 4
0 inf1 6.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 6.00 inf1 0.00 5.00
3 0.00 inf2 0.00 inf1 1.00
4 0.00 inf2 0.00 0.00 inf1
After subtracting:
0 1 2 3 4
0 inf1 0.00 10.00 4.00 0.00
1 0.00 inf1 9.00 2.00 6.00
2 6.00 0.00 inf1 0.00 5.00
3 0.00 inf2 0.00 inf1 1.00
4 0.00 inf2 0.00 0.00 inf1
limit: 47; record:41
DISCARDING BRANCH
Solution tour:
0 4 2 3 1 0
Tour length:
41Получение нулей в каждой строке и каждом столбце.
double LittleSolver::subtractFromMatrix(MatrixD &m) const {
// сумма всех вычтенных значений
double subtractSum = 0;
// массивы с минимальными элементами строк и столбцов
vector minRow(m.size(), DBL_MAX),
minColumn(m.size(), DBL_MAX);
// обход всей матрицы
for (size_t i = 0; i < m.size(); ++i) {
for (size_t j = 0; j < m.size(); ++j)
// поиск минимального элемента в строке
if (m(i, j) < minRow[i])
minRow[i] = m(i, j);
for (size_t j = 0; j < m.size(); ++j) {
// вычитание минимальных элементов из всех
// элементов строки, кроме бесконечностей
if (m(i, j) < _infinity) {
m(i, j) -= minRow[i];
}
// поиск минимального элемента в столбце после вычитания строк
if ((m(i, j) < minColumn[j]))
minColumn[j] = m(i, j);
}
}
// вычитание минимальных элементов из всех
// элементов столбца, кроме бесконечностей
for (size_t j = 0; j < m.size(); ++j)
for (size_t i = 0; i < m.size(); ++i)
if (m(i, j) < _infinity) {
m(i, j) -= minColumn[j];
}
// суммирование вычтенных значений
for (auto i : minRow)
subtractSum += i;
for (auto i : minColumn)
subtractSum += i;
return subtractSum;
} Увеличение нижней границы и сравнение ее с рекордом.
// вычитание минимальных элементов строк и столбцов
// увеличение нижней границы
bottomLimit += subtractFromMatrix(matrix);
// сравнение верхней и нижней границ
if (bottomLimit > _record) {
return;
}Расчет коэффициентов.
double LittleSolver::getCoefficient(const MatrixD &m, size_t r, size_t c) {
double rmin, cmin;
rmin = cmin = DBL_MAX;
// обход строки и столбца
for (size_t i = 0; i < m.size(); ++i) {
if (i != r)
rmin = std::min(rmin, m(i, c));
if (i != c)
cmin = std::min(cmin, m(r, i));
}
return rmin + cmin;
}Поиск всех нулевых элементов и вычисление их коэффициентов.
// список координат нулевых элементов
list> zeros;
// список их коэффициентов
list coeffList;
// максимальный коэффициент
double maxCoeff = 0;
// поиск нулевых элементов
for (size_t i = 0; i < matrix.size(); ++i)
for (size_t j = 0; j < matrix.size(); ++j)
// если равен нулю
if (!matrix(i, j)) {
// добавление в список координат
zeros.emplace_back(i, j);
// расчет коэффициена и добавление в список
coeffList.push_back(getCoefficient(matrix, i, j));
// сравнение с максимальным
maxCoeff = std::max(maxCoeff, coeffList.back());
} Отбрасывание нулевых элементов с немаксимальными коэффициентами.
{ // область видимости итераторов
auto zIter = zeros.begin();
auto cIter = coeffList.begin();
while (zIter != zeros.end()) {
if (*cIter != maxCoeff) {
// если коэффициент не максимальный, удаление элемента из списка
zIter = zeros.erase(zIter);
cIter = coeffList.erase(cIter);
}
else {
++zIter;
++cIter;
}
}
}
return zeros;Переход к множеству, содержащему ребро с максимальным штрафом.
auto edge = zeros.front();
// копия матрицы
auto newMatrix(matrix);
// из матрицы удаляются строка и столбец, соответствующие вершинам ребра
newMatrix.removeRowColumn(edge.first, edge.second);
// ребро iter добавляется к пути
auto newPath(path);
newPath.emplace_back(matrix.rowIndex(edge.first),
matrix.columnIndex(edge.second));
// добавление бесконечности для избежания преждевремнного цикла
addInfinity(newMatrix);
// обработка множества, содержащего ребро edge
handleMatrix(newMatrix, newPath, bottomLimit);Переход к множеству, не содержащему ребро с максимальным штрафом.
// переход к множеству, не сожержащему ребро edge
// снова копирование матрицы текущего шага
newMatrix = matrix;
// добавление бесконечности на место iter
newMatrix(edge.first, edge.second) = _infinity + 1;
// обработка множества, не сожержащего ребро edge
handleMatrix(newMatrix, path, bottomLimit);Несмотря на то, что метод ветвей и границ в худшем случае ничем не лучше полного перебора, в большинстве случаев он значительно выигрывает во времени благодаря эвристике для поиска начального решения и отбрасыванию заведомо плохих множеств.
Ниже представлены графики сравнения МВиГ с полным перебором и среднее время работы реализованного мной алгоритма на различном количестве городов. Тестировалось на матрицах для случайно сгенерированных точек.
Сравнение метода ветвей и границ с полным перебором.
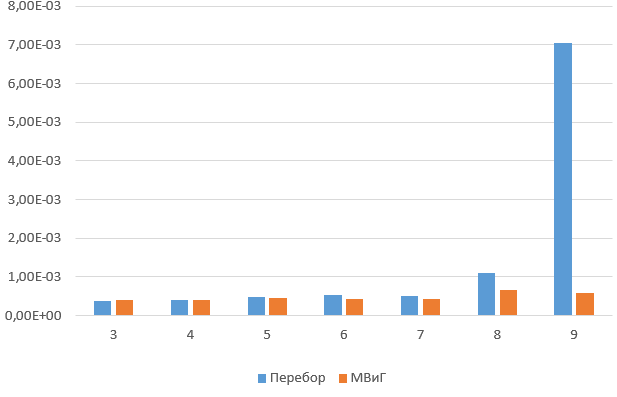
Начиная с 9 городов полный перебор заметно проигрывает МВиГ. Начиная с 13 городов полный перебор занимает больше минуты.
Время работы МВиГ на различном количестве городов.
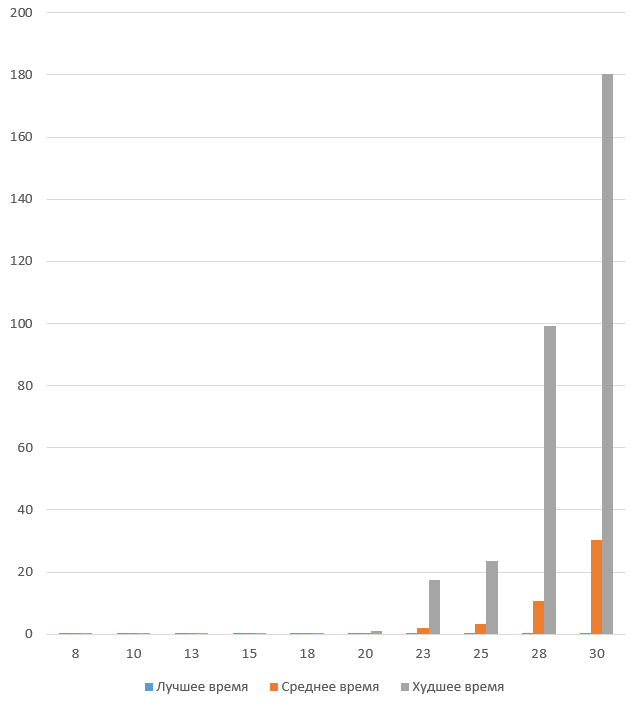
Также был сделан графический интерфейс на Qt с возможностью динамически смотреть на процесс решения. Как раз его рабочая область на гифке в шапке статьи. Итересующиеся могут скомпилировать и потрогать прогу руками.
Желтым цветом обозначен наилучший найденный путь и его длина находится в поле "Tour length".
Черным обозначены ребра, находящиеся в последнем просмотренном наборе.
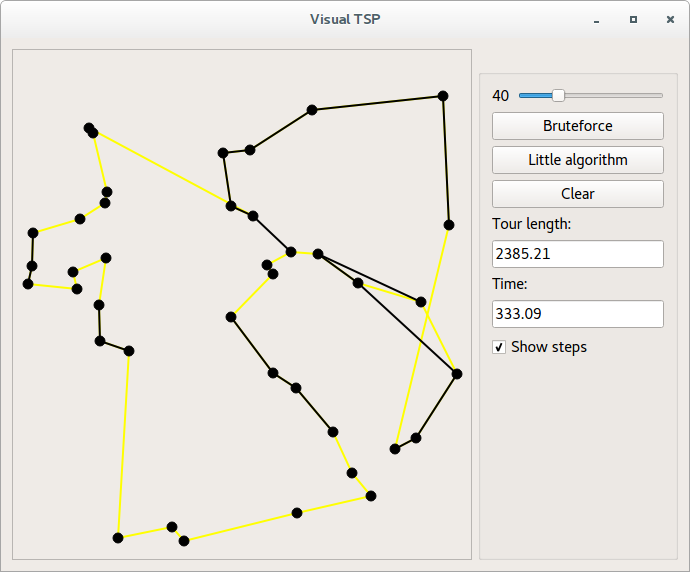
Для динамического отображения задача должна решаться либо пошагово, либо в параллельном с графическим интерфейсом потоке. Т.к. основная функция решения рекурсивна, был выбран второй вариант, из-за чего в решающий класс пришлось добавить мьютекс, а переменную рекорда сделать атомарной и в некоторых методах позаботиться о потокобезопасности.
Надеюсь, эта статья поможет тем, кто захочет реализовать данный алгоритм или уже реализовал и не понимает, почему он дает неверный результат.
-> Исходный код
|
Метки: author scidev алгоритмы c++ литтл коммивояжер |
[Перевод] Вышел GitLab 9.3: Code Quality и межпроектные графики конвейеров |

В GitLab 9.3 мы представляем Code Quality, межпроектные графики конвейеров, индекс совместной разработки, улучшения локализации, описания сниппетов и многое другое!
GitLab представляет собой интегрированный продукт для всего цикла разработки. С выходом каждого ежемесячного релиза мы стремимся добавлять новые аспекты совместного написания кода, непрерывной интеграции, автоматизации релизов и мониторинга. Так, в GitLab 9.3 мы внесли функциональность, позволяющую улучшить качество кода, сократить время цикла разработки, а также упростить управление большими проектами.
В GitLab 9.3 добавлены отчеты Code Quality (качества кода), которые отображаются прямо в виджете мерж-реквеста. Эти отчеты позволяют мгновенно оценить влияние предложенных изменений на состояние вашего кода и проекта в целом. Благодаря этому сокращается время на ревью, а также появляется возможность находить ошибки перед мержем.
Современное production-level ПО, особенно то, что использует архитектуру микро-сервисов, зачастую состоит из множества различных проектов. В таком ПО очень важно понимать взаимодействие проектов. В GitLab 9.3 вы можете увидеть взаимосвязь upstream и downstream конвейеров при помощи межпроектных графиков конвейеров.
Также GitLab 9.3 предоставляет возможность оценить, как вы используете каждый элемент GitLab в сравнении с другими людьми. Для этого используется индекс совместной разработки. С помощью данного индекса можно легко оценить насколько эффективно вы используете систему по сравнению с другими пользователями, а также увидеть, какие элементы вашего рабочего процесса вы могли бы улучшить.
Мы создали небольшое видео, позволяющее оценить возможности GitLab и его новую функциональность, а также убедиться в том, что GitLab позволяет уместить весь процесс разработки на одной платформе.
Huang внес значительный вклад в локализацию GitLab на несколько новых языков. Спасибо, Huang!
Сложно переоценить важность правильного код-ревью. При обзоре внесенных изменений важно обращать внимание на качество кода, реализацию, форматирование и многое другое. Даже если ревью проводится качественно, достичь постоянства в этом процессе невозможно без какой-либо оценки качества кода.
Мы создали GitLab Code Quality для того, чтобы ускорить процесс код-ревью и предоставить пользователям возможность проводить сравнительную оценку качества кода и создавать соответствующие отчеты прямо в окне мерж-реквеста. Теперь, если качество вашего кода ухудшится, GitLab укажет вам на это, и вы сможете исправить ситуацию еще до мержа.
Больше информации о GitLab Code Quality в нашей документации
В больших проектах, особенно в тех, что используют архитектуру микро-сервисов, конечный продукт зачастую состоит из набора взаимозависимых компонентов. Из-за этого временами нелегко понять, почему произошел запуск определенного конвейера или почему произошла сборка одного проекта после коммита в другом.
В GItLab 9.3 появилась возможность отображения связей upstream и downstream проектов прямо на графиках конвейеров, благодаря чему можно легко увидеть статус всей цепочки в одном окне. Теперь для отображения связей между проектами не нужно использовать переменную $CI_JOB_TOKEN с триггерами — графики создаются автоматически.
Больше информации о межпроектных графиках конвейеров в нашей документации
В прошлом сентябре мы анонсировали принципы совместной разработки (Conversational Development — ConvDev). Внедрение этой методологии ускоряет процесс разработки ПО от идеи до внедрения.
В GitLab 9.3 включен индекс совместной разработки, который предоставляет численное отображение использования данной методологии. При помощи этого индекса вы можете оценить вашу производительность по сравнению с другими пользователями GitLab, а также увидеть элементы вашего рабочего процесса, которые вы могли бы улучшить.
В данной версии этот индекс доступен только системным администраторам. Индекс формируется на основе деятельности всех активных пользователей вашего инстанса GitLab.
Больше информации об индексе совместной разработки в нашей документации
Секретные переменные полезны в тех случаях, когда определенную информацию нужно скрыть от внешних пользователей, однако при этом для пользователей с доступом на внесение изменений в проект она открыта. При таком подходе возможны ситуации, когда в среду разработки вносят изменения те пользователи, которые в идеале этого делать не должны; у них даже может не быть доступа на запись в master.
В GitLab 9.3 с введением защищенных переменных появляется дополнительный уровень безопасности для секретной информации, такой как полномочия развертывания. Теперь в Settings -> CI/CD Pipelines можно отметить переменную как «защищенную» (“protected”). Такая переменная будет доступна только для задач, выполняемых на защищенных ветках, благодаря чему доступ к ней будет открыт только для пользователей с соответствующими правами доступа.
Больше информации о защищенных секретных переменных в нашей документации
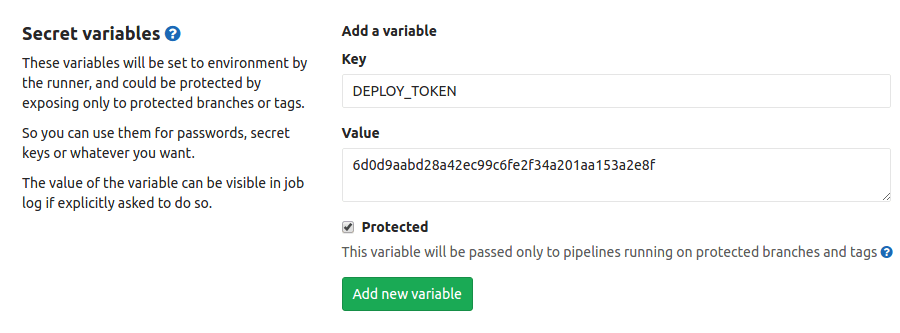
Множество компаний нуждаются в отчетах изменений прав доступа по ходу всего цикла разработки. В GitLab 9.3 у каждого системного администратора появляется доступ к улучшенному централизованному логу пользовательских действий, в котором содержатся все соответствующие события групп, проектов и действий отдельных пользователей.
Кроме того, в данном логе можно проводить фильтрацию событий по типу и названию, благодаря чему можно легко находить события определенных групп, проектов или пользователей.
Больше информации о логах ревизий в нашей документации
С течением времени мы добавили много новой функциональности и вариантов конфигурации проектов и групп, и, как следствие, количество настроек GitLab значительно увеличилось.
В GitLab 9.3 мы начинаем работу по упрощению страниц настроек. Первым шагом стало улучшение читаемости страницы настроек репозиториев.
Мы стремимся улучшить группирование настроек и добавить обзор всех настроек для каждой секции.
В данном релизе мы улучшили настройки интеграции JIRA, что упрощает установку и тестирование соединения между проектом GitLab и сервером JIRA. Также добавлены отдельные поля Web URL и JIRA API URL. Такое разделение полезно в тех случаях, когда JIRA REST API и задачи JIRA находятся на разных адресах.
Больше информации об интеграции JIRA в нашей документации
Пользователи с правами Reporter, Developer, Master и Owner вдобавок к ярлыкам проектов теперь могут создавать и редактировать ярлыки групп. Ранее это могли делать только Master and Owner.
Больше информации о модели прав доступа GitLab в нашей документации
Описание задачи является опорной точкой и главным источником информации при совместной работе нескольких команд. В GitLab 9.3 мы убрали переход на отдельную страницу при редактировании описания задачи. Просто нажмите Edit, внесите изменения и нажмите Save changes — все это время вы остаетесь на странице задачи. Поскольку перенаправление на другую страницу теперь отсутствует, во время редактирования вы можете пролистать комментарии к задаче и даже скопировать и вставить в описание текст GFM
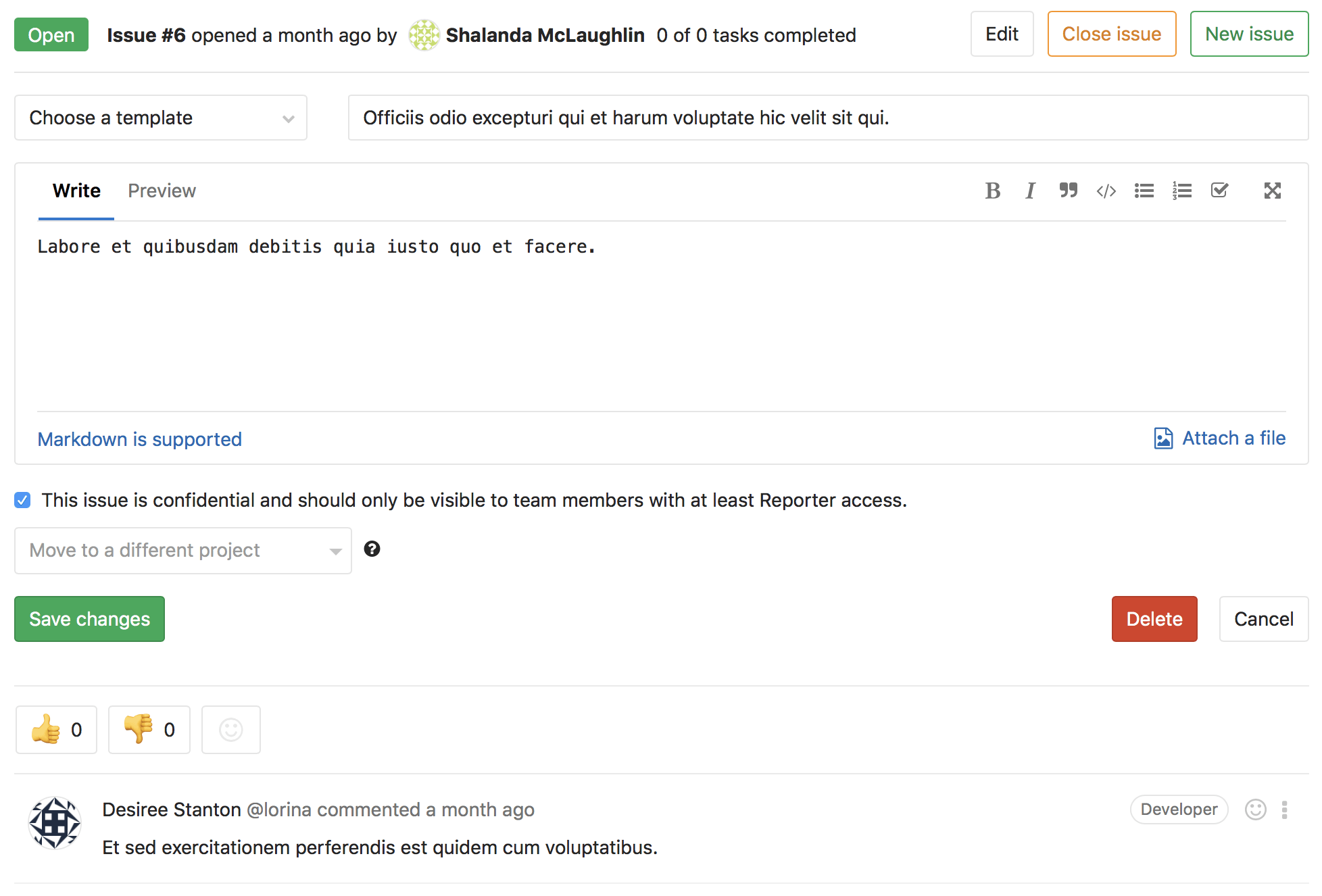
Больше информации о задачах GitLab в нашей документации
Мы понимаем, что у различных команд свои подходы к использованию досок задач. Для упрощения взаимодействия с ними мы добавили возможность сворачивать столбцы Backlog и Closed. Также мы внесли изменения в процесс добавления новых задач на доску: при нажатии на + задача автоматически добавляется в начало списка, что серьезно упрощает работу с длинными списками.
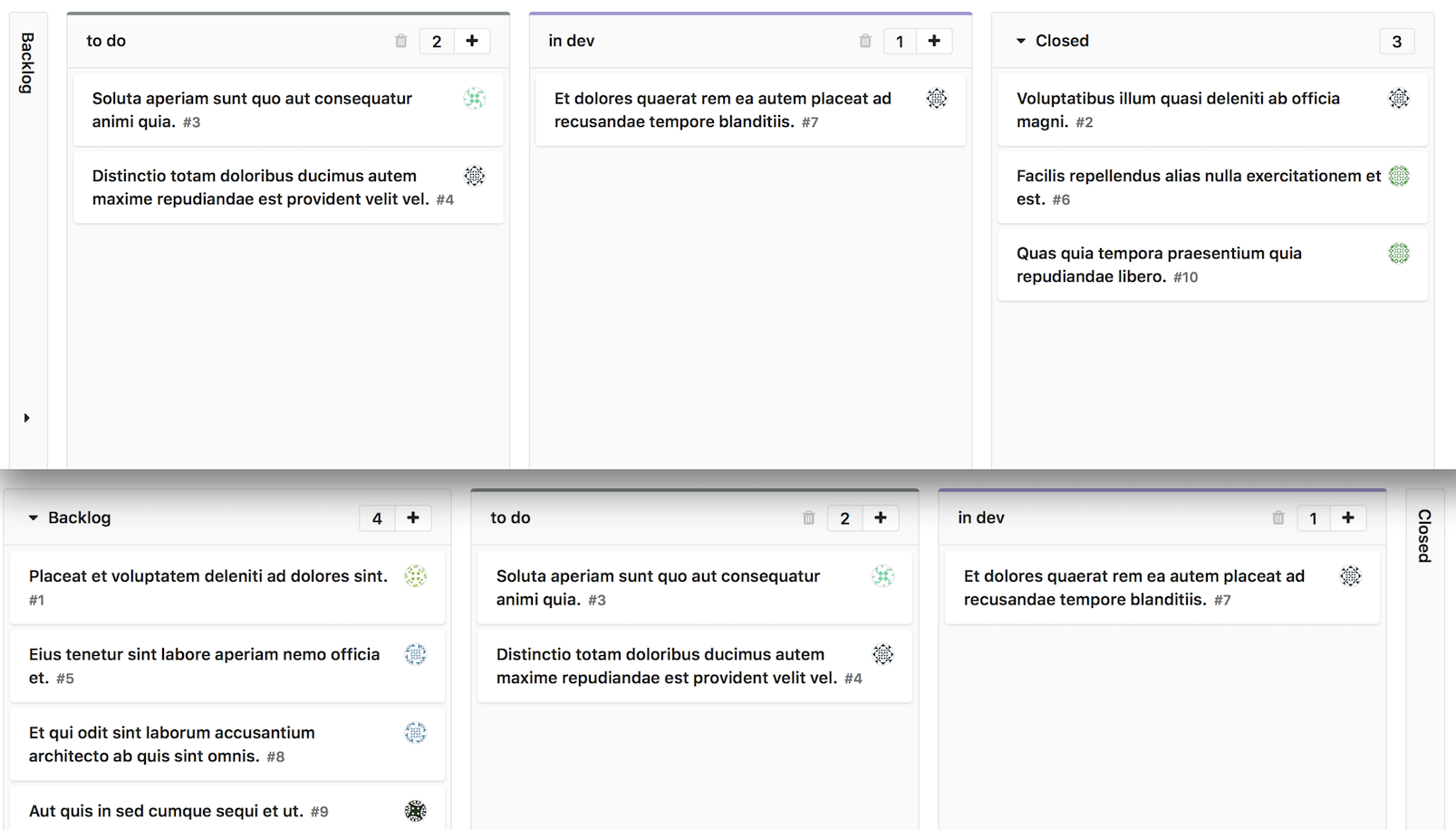
Больше информации о досках задач GitLab в нашей документации
В GitLab 9.2 мы начали процесс локализации с перевода страницы аналитики цикла разработки на немецкий и испанский. В GitLab 9.3 мы перевели самые часто используемые страницы: домашнюю страницу проекта и страницу файлов репозитория.
Сообщество GitLab уже начало добавлять другие языки — китайский, болгарский и бразильский португальский. Вы можете наблюдать за изменениями и взглянуть на их гайдлайны, если хотите подключиться.
Узнайте, как построено взаимодействие сообщества по переводу GitLab
Когда вы разворачиваете проект, основанный на Docker, вам нужно подтягивать образ каждый раз, когда окружению нужно его запустить. Поскольку встроенный реестр контейнеров GitLab является очевидным выбором для хранения ваших контейнеров, в GitLab 9.3 вы сможете использовать его и для их распространения.
Создайте токен личного доступа с новой областью read_registry, и у вас будет постоянный токен развертывания, который смогут использовать внешние сервисы вроде Kubernetes, чтобы при необходимости получить доступ к вашим образам — без ввода всех ваших данных или использования фиктивного пользователя для этой задачи.
Побробнее вы можете узнать в документации о токенах личного доступа
На протяжении ревью кода мерж-реквеста мы постоянно изменяем код и комментируем эти изменения. Зачастую это сложно отследить. В частности, когда мы начинаем комментировать определенную строчку кода, и кто-то другой одновременно вносит туда изменения. Может закончиться тем, что вы обсуждаете что-то, что уже изменили.
В этом релизе мы добавили системную заметку — индикатор того, что строка уже изменилась. Если вы участвуете в обсуждении конкретной строки, вы узнаете, что ее уже изменили, и сможете посмотреть изменения, нажав на нее.
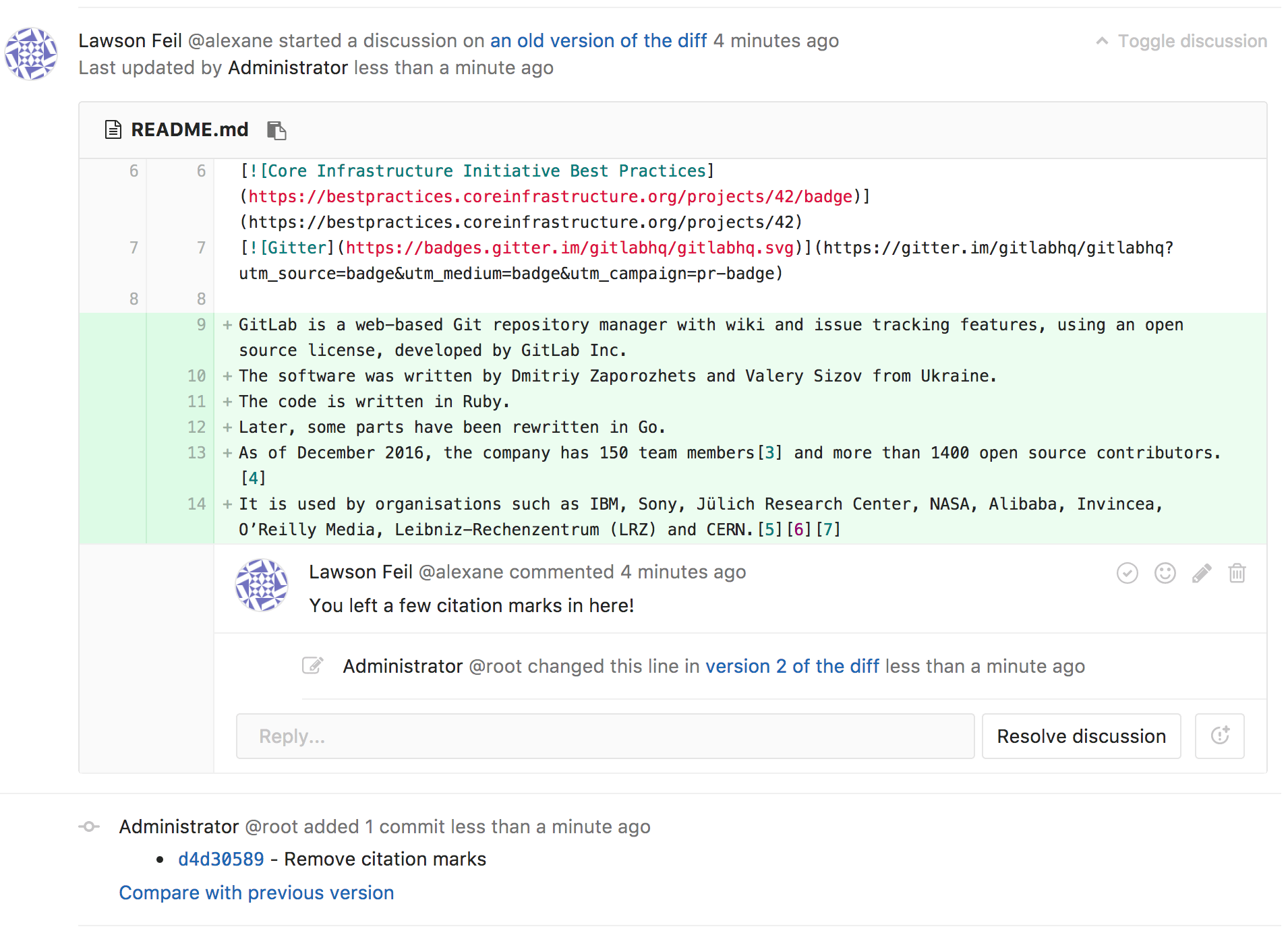
Чтобы извлечь максимум пользы из автоматической отмены лишних конвейеров и сэкономить множество часов разработки, GitLab 9.3 распространяет это поведение на все существующие и новые проекты.
Если вам не нужно отменять лишние конвейеры, вы можете настроить соответствующие параметры под свои нужды.
В рамках предстоящего релиза GitLab 9.4 мы обновим версию nginx, входящую в Omnibus, до новой стабильной версии 1.12. В эту версию включается несколько улучшений предыдущей стабильной версии. Например, появилась возможность фильтровать вывод лога.
Для пользователей это обновление должно быть понятным, но если вы изменяли настройки в конфигурации nginx, пожалуйста, после обновления до 1.12 удостоверьтесь, что они работают корректно.
Доступна поддержка последнего релиза Debian 9. Вы можете скачать официальные пакеты Omnibus для GitLab 9.3 из раздела установки.
GitLab 9.3 включает Mattermost 3.10, альтернативу Slack с открытым исходным кодом. В этой версии появилась поддержка турецкого языка, новые горячие клавиши и многое другое.
Подробнее об изменениях GitLab Mattermost читайте в документации
Обновились связанные с ним пакеты Git и PostgreSQL. Git обновился до версии 2.13.0, а Postgres до 9.6.3.
Документация об Omnibus GitLab
У сниппетов теперь есть описания. Это касается только персональных сниппетов, которые мы добавили в предыдущем релизе. Сниппеты — мощный инструмент для быстрой и непринужденной совместной работы над кодом. В этом релизе совместно работать над ними стало так же просто, как и над мерж-реквестами.
Документация о сниппетах GitLab
Мы продолжаем улучшать производительность GitLab с каждым релизом. Это не только сделает каждый инстанс GitLab еще быстрее, но также увеличит производительность инстанса с миллионом пользователей — GitLab.com.
В GitLab 9.3 мы продолжаем ускорять вывод списка проектов, а также в целом улучшаем производительность сервера за счет изменений в том, как мы зеркалируем репозитории. Синтаксическая подсветка файлов теперь кэшируется, это повышает общую производительность и ускоряет отображение коммитов.
В GitLab 9.3 есть еще множество других улучшений производительности, которые не только сделают GitLab быстрее, но и снизят влияние на инфраструктуру сервера в целом.
Мы сделали массовое редактирование задач проще и понятнее, чем в последнем релизе. Теперь при одновременном обновлении нескольких задач используется такая же боковая панель, как и во многих других элементах GitLab.
Подробнее в нашей документации о задачах в GitLab
Мы продолжаем постепенно улучшать поиск и фильтрацию. Теперь вы сможете видеть пользовательские аватарки.
Также клик на фильтр вызывает выпадающее меню, позволяющее быстро менять фильтры.
Подробности вы сможете прочитать в документации о поиске по GitLab
В GitLab 9.0 мы добавили подгруппы, сделав управление группами и проектами более гибким. С каждым релизом мы продолжаем улучшать эту функциональность: в этот раз мы сделали более понятную навигацию по подгруппам. На странице групп вы сможете увидеть расширяемое дерево со всеми проектами и подгруппами — вместо того, чтобы искать и загружать по странице за раз.
Документация по подгруппам GitLab
При просмотре файлов в репозитории теперь на той же странице автоматически отображается дополнительная информация.
Начиная с версии 9.3 вы сможете видеть, действительны ли файлы .gitlab-ci.yml или .gitlab/route-map.yml, а также конкретные ошибки парсинга. Также анализируется файл LICENSE, что упрощает доступ к информации о конкретной лицензии, если вам нужны дополнительные детали. А чтобы понять, на что опираются проекты, можно изучить системы управления зависимостями, которые теперь тоже отображаются автоматически.
Ах, пакеты, эти драгоценные кусочки мудрости, собранные и готовые к использованию. GitLab теперь автоматически определяет и связывает директории в файловом обозревателе, сохраняя вам клики каждый день. Изящно, правда?
*.gemspec (Ruby)package.json (Node.js)composer.json (PHP)Podfile (Objective-C)*.podspec (Objective-C)*.podspec.json (Objective-C)Cartfile (Objective-C)Godeps.json (Go)requirements.txt (Python)
В GitLab 9.2 мы выпустили конвейеры по расписанию, которые можно настраивать с помощью пользовательского интерфейса. В GitLab 9.3 мы также добавили возможность создавать и управлять конвейерами по расписанию через набор API, чтобы сделать интеграцию с другими инструментами проще и эффективнее.
Подробнее в документации об API конвейеров по расписанию
В прошлой версии GitLab мы добавили возможность видеть влияние мерж-реквеста на память прямо на странице мерж-реквеста. В GitLab 9.3 мы решили пойти дальше: теперь мы замеряем изменения в среднем использовании памяти за 30 минут до мержа и через 30 минут после него.
Разработчикам стало проще чем когда-либо знать о влиянии их действий на производительность за счет прямой обратной связи от инструментов, которые они используют каждый день.
Подробнее в документации о мониторинге приложений с помощью Prometheus
Также с этим релизом мы выпустили GitLab Runner 9.3.
GIT_CHECKOUT, которая контролирует выполнение git checkout (мерж-реквест)cpus в Docker executor (мерж-реквест)userns в Docker executor (мерж-реквест)Список всех изменений вы найдете в CHANGELOG.
Полная документация о GitLab Runner.
В GitLab 9.0 был представлен мониторинг сервиса GitLab с помощью Prometheus, с помощью которого можно оценить производительность Redis, PostgreSQL, а также системы в целом.
В рамках GitLab 9.3 мы добавили экспериментальный сервис мониторинга кодовой базы ruby. Пока в нем отображаются только несколько показателей вроде статуса конвейера и авторизаций пользователей. В последующих релизах мы будем добавлять мониторинг и других частей GitLab.
Подробнее в документации о дополнительных метриках
Подробные release notes и инструкции по обновлению/установке можно прочитать в оригинальном англоязычном посте: https://about.gitlab.com/2017/06/22/gitlab-9-3-released/
Перевод с английского выполнен переводческой артелью «Надмозг и партнеры», http://nadmosq.ru. Над переводом работали rishavant и sgnl_05 .
|
|
Отечество амбиций: неповторимое путешествие по заводам TP-Link |
|
|
Как с помощью больших данных получить целевые лиды |



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author instam повышение конверсии медийная реклама контекстная реклама интернет-маркетинг блог компании маркетинговое агентство «инстам» лиды ца статистика dmp инстам |
[Перевод] ArrayBuffer и SharedArrayBuffer в JavaScript, часть 3: гонки потоков и Atomics |
-> ArrayBuffer и SharedArrayBuffer в JavaScript, часть 1: краткий курс по управлению памятью
-> ArrayBuffer и SharedArrayBuffer в JavaScript, часть 2: знакомство с новыми объектами языка
-> ArrayBuffer и SharedArrayBuffer в JavaScript, часть 3: гонки потоков и Atomics

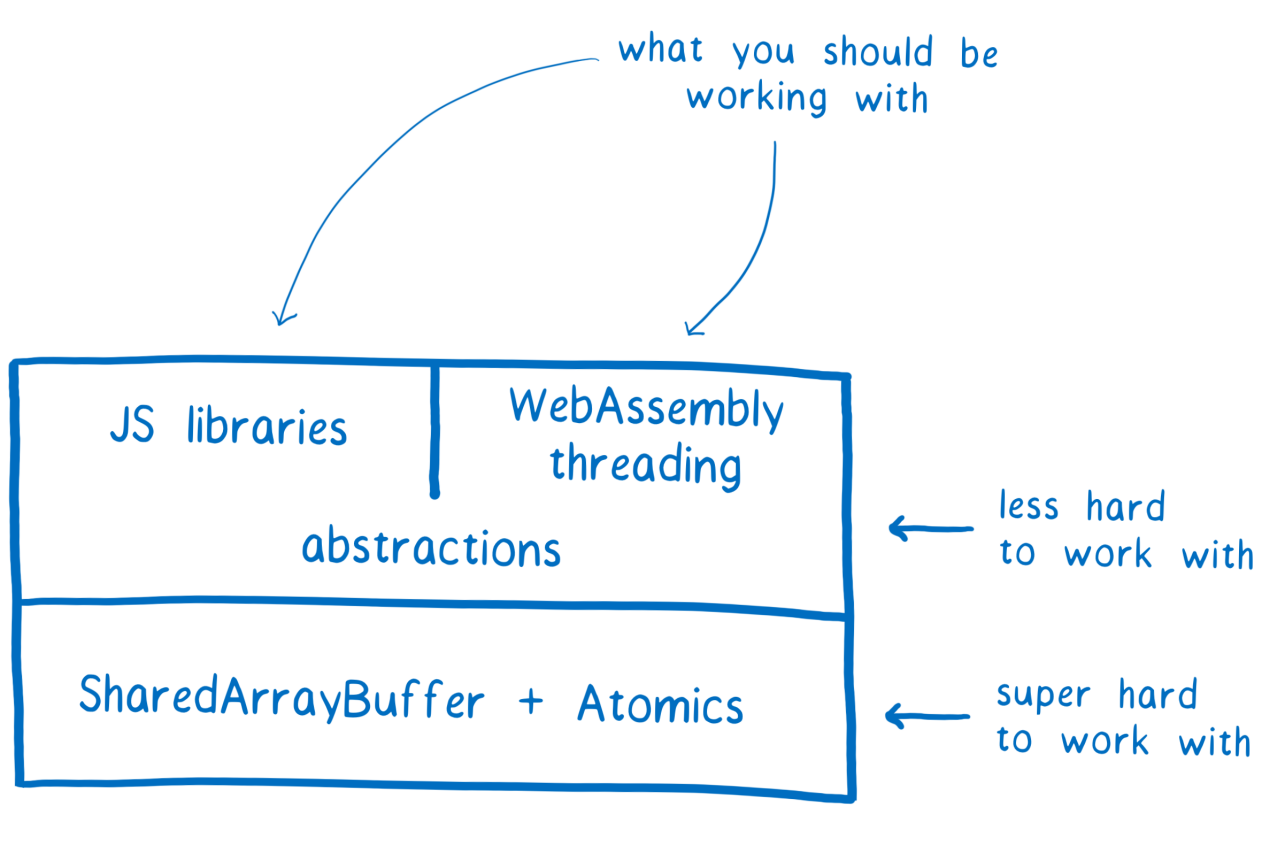
fileExists, загружает некий файл, а второй проверяет, существует ли файл, и, если это так, устанавливает эту переменную в значение true. В детали мы не вдаёмся, код проверки наличия файла опущен. false.



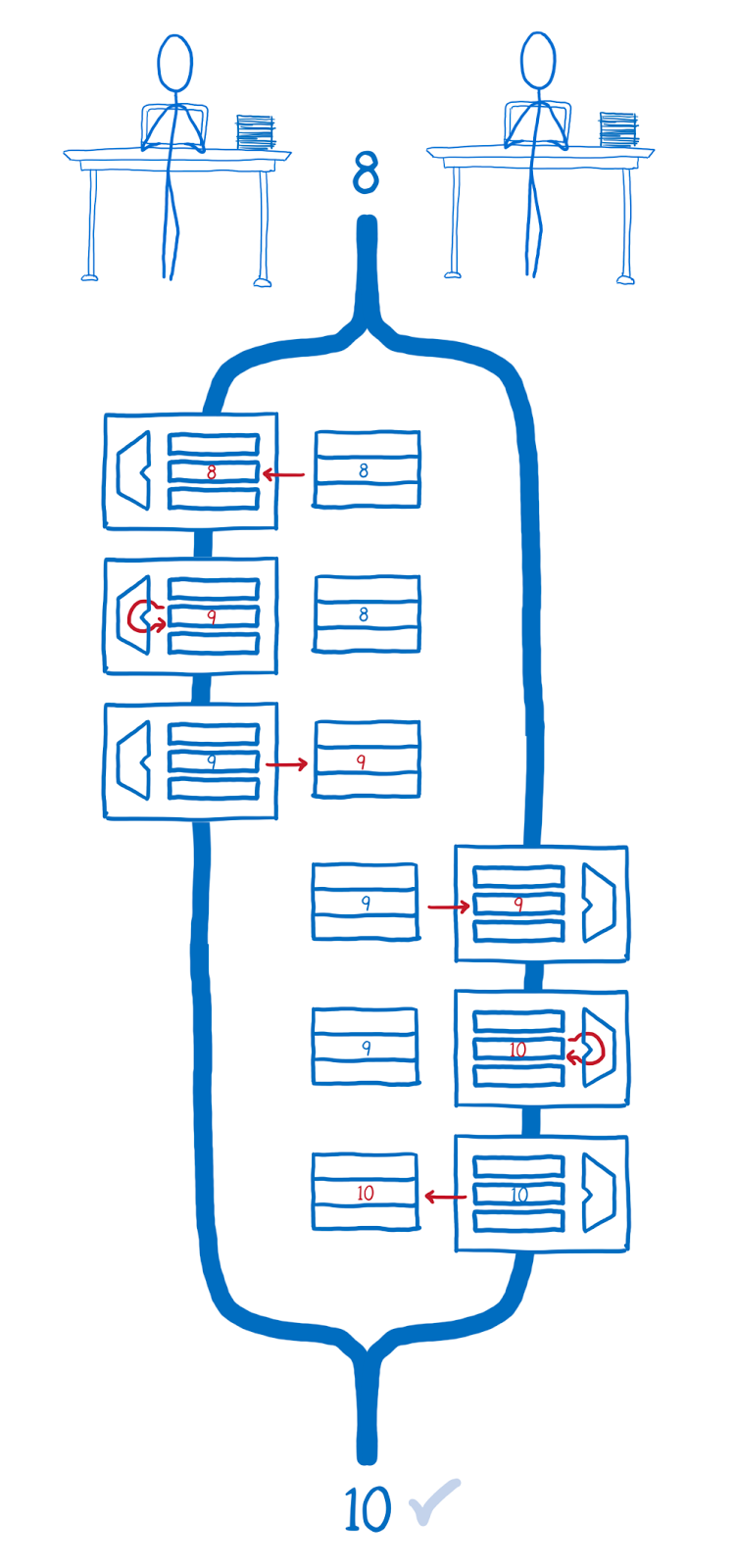
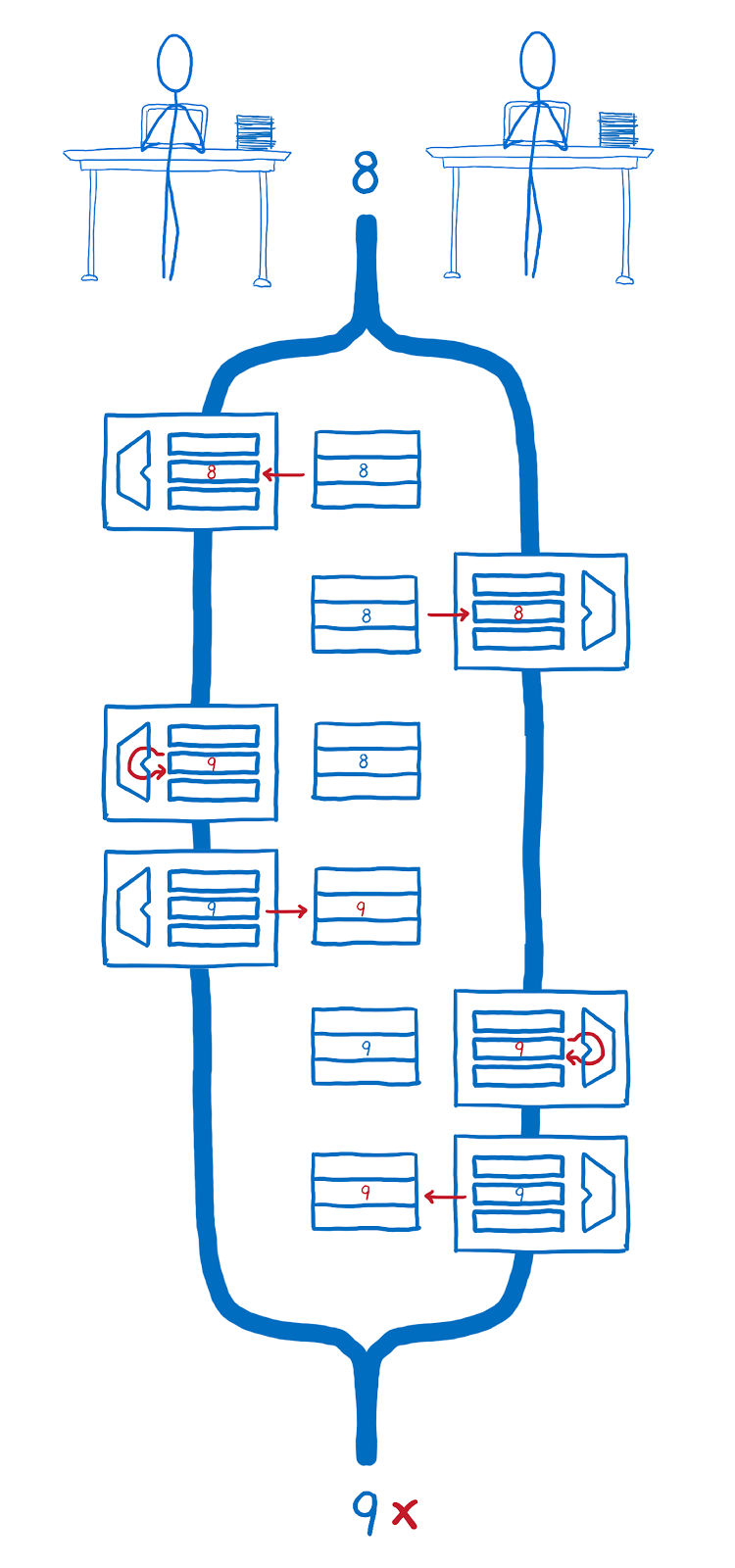
sharedVar++ это будет нечто вроде Atomics.add(sabView, index, 1). Первый аргумент метода add представляет собой структуру данных для доступа к SharedArrayBuffer (Int8Array, например). Второй — это индекс, по которому sharedVar находится в массиве. Третий аргумент — число, которое нужно прибавить к sharedVar.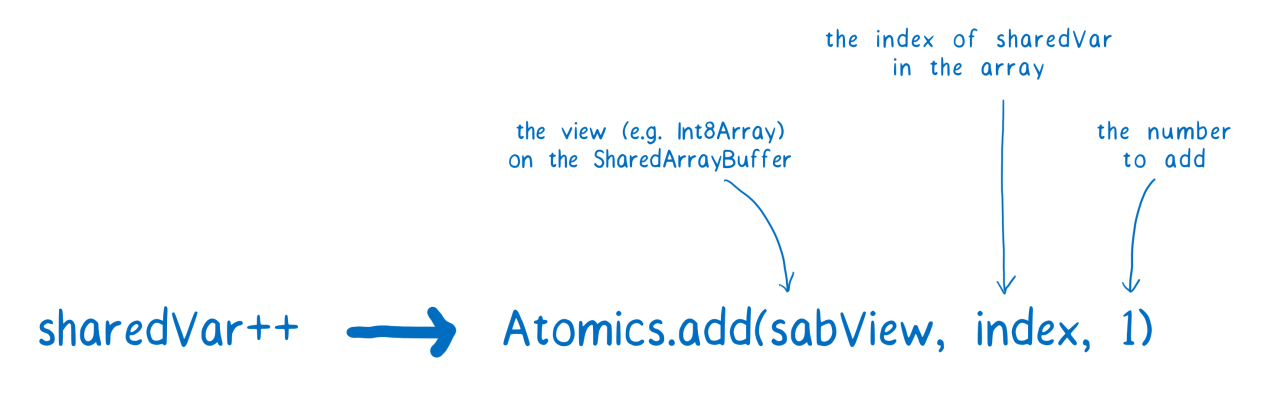
Atomics.add, действия процессора, связанные с инкрементированием переменной по команде из одного потока, не смешиваются с операциями, инициированными из другого потока. Вместо этого сначала все необходимые действия, в рамках одной атомарной операции, выполняются первым потоком, после чего выполняются операции второго потока, опять же, заключённые в атомарную операцию.
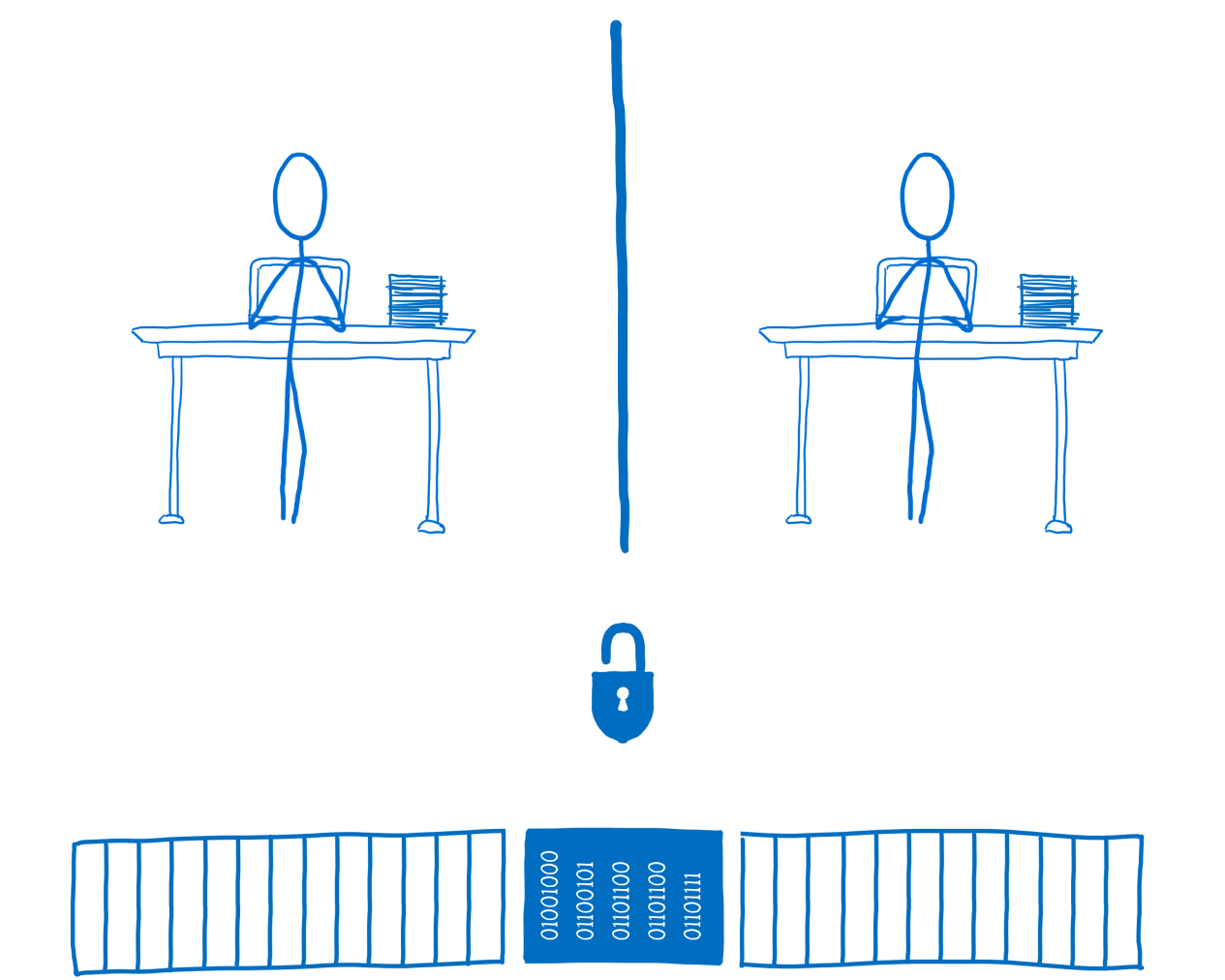
locked в true. Это означает, что поток №1 не сможет получить доступ к данным до тех пор, пока поток №2 их не разблокирует.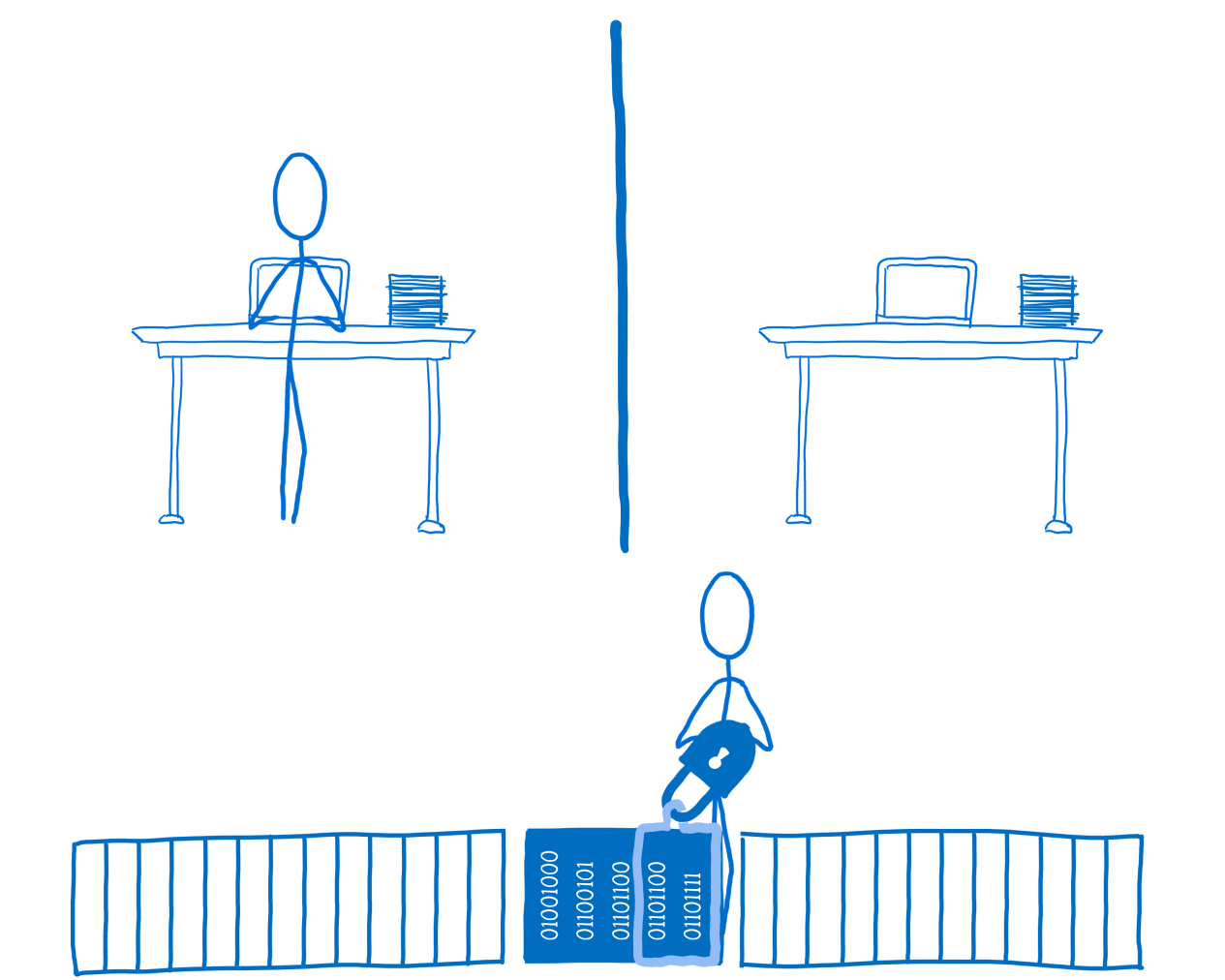
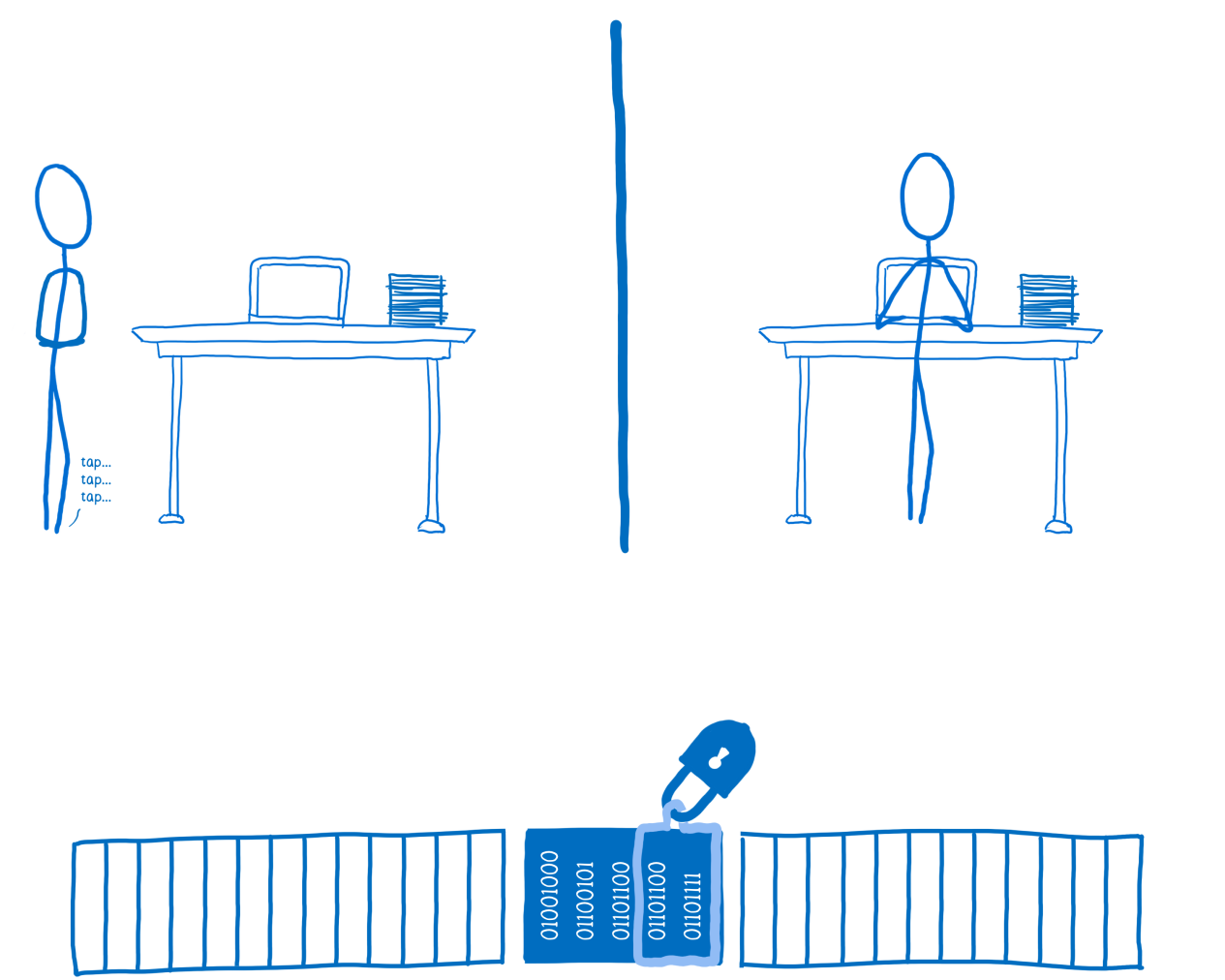
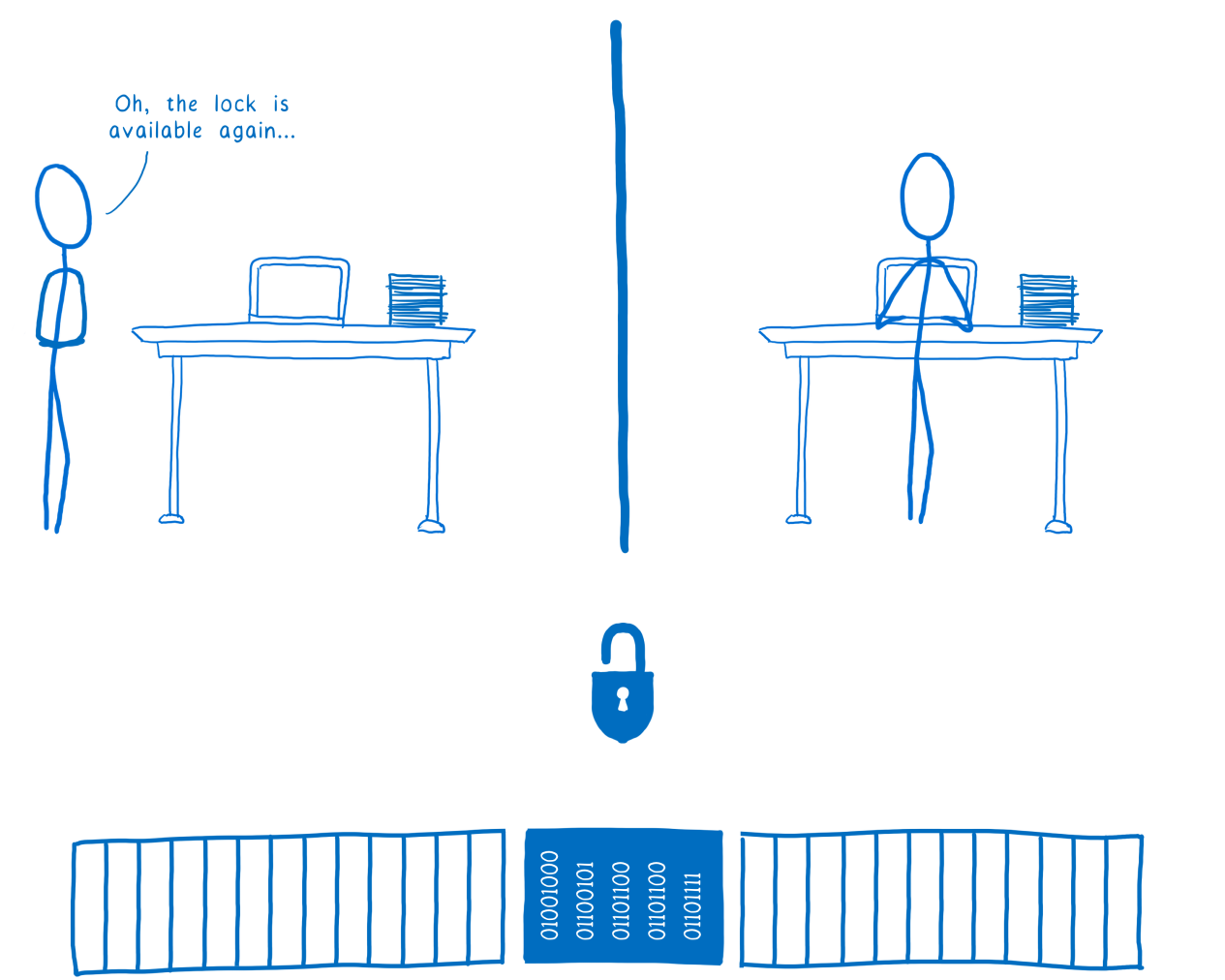
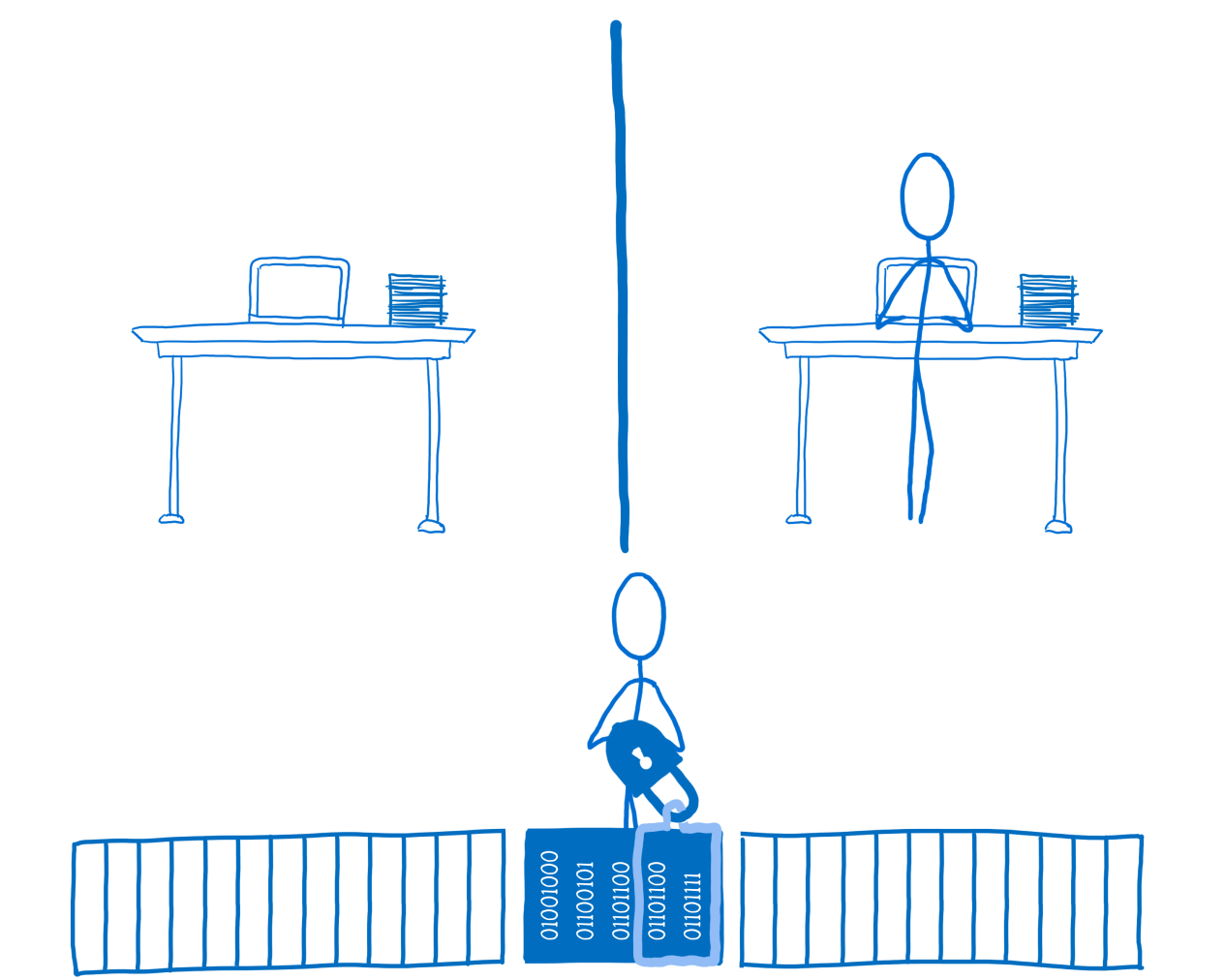


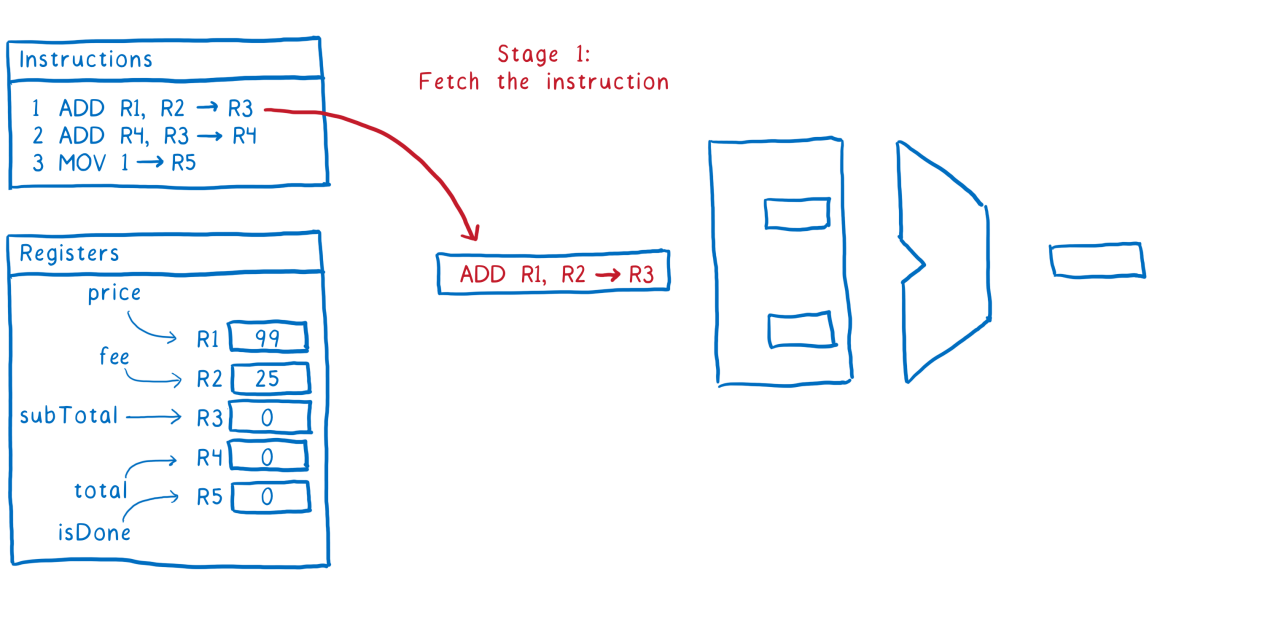
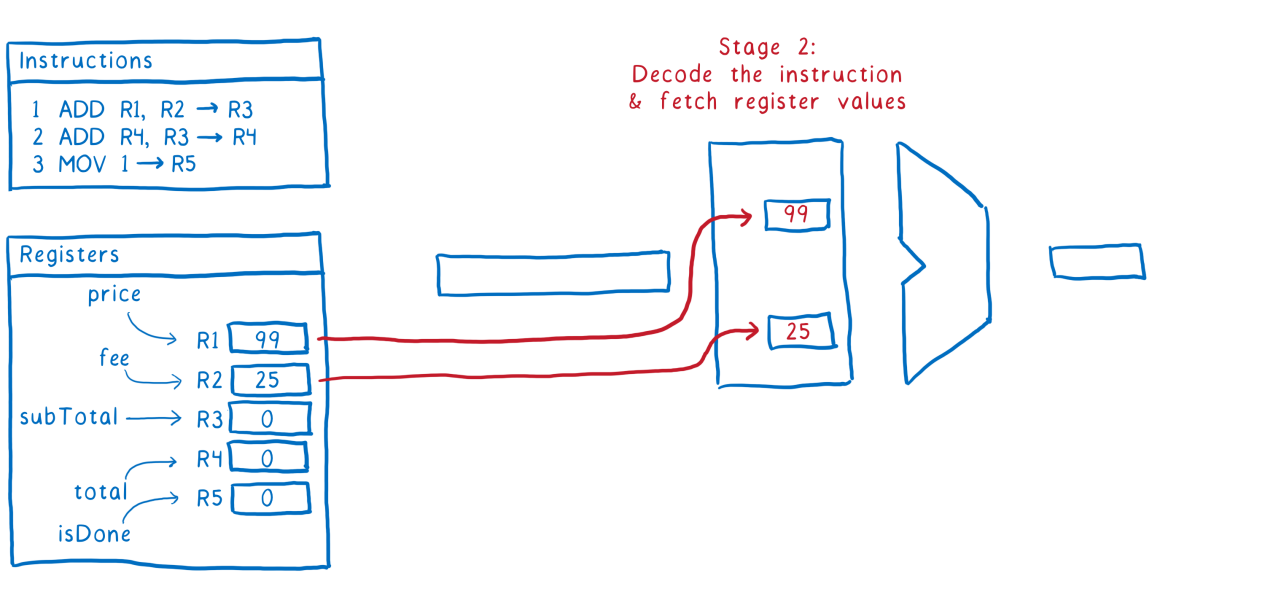
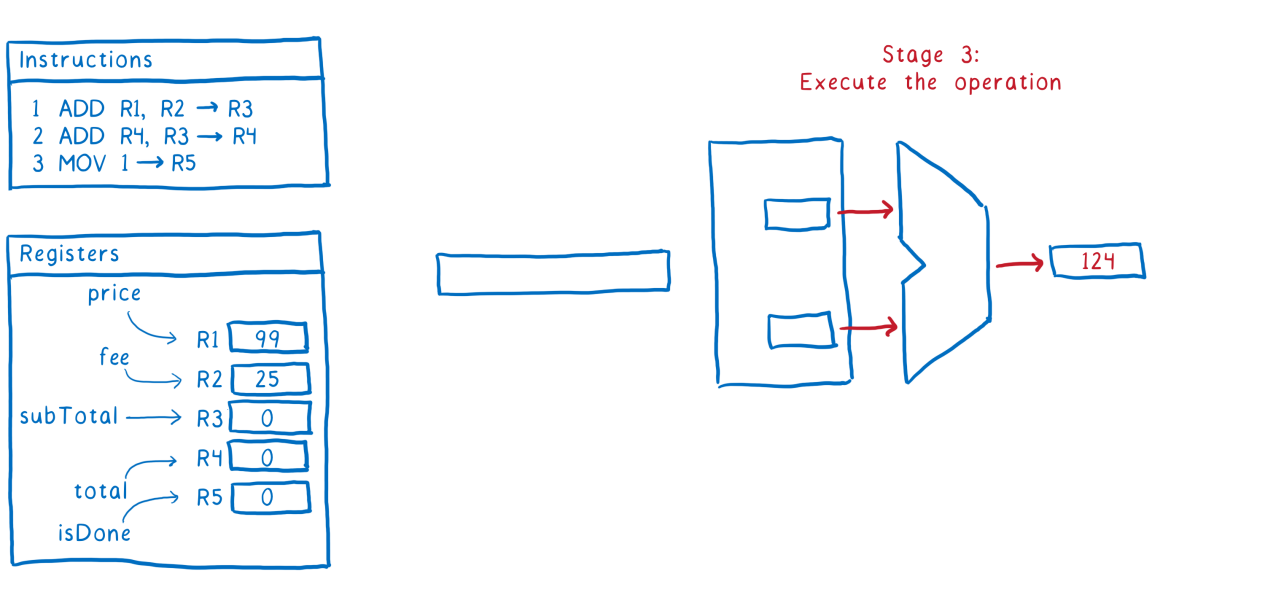


subTotal в регистре. Однако, при таком подходе пострадает производительность.subTotal и total, и выполнение этих инструкций между инструкциями №1 и №2, которые следуют в коде друг за другом.
isDone, видимый другому потоку, будет установлен до завершения вычислений. codeisDone как флаг, указывающий на то, что вычисление total завершено, и полученное значение готово к использованию в другом потоке, изменение порядка выполнения операций приведёт к состоянию гонки потоков.Atomics.store, оно гарантированно будет завершено до того, как Atomics.store сохранит значение переменной в памяти. Если даже порядок выполнения неатомарных инструкций будет изменён по отношению друг к другу, ни одна из них не будет перемещена ниже вызова Atomics.store, размещённого в нижней части кода.Atomics.load гарантированно будет выполнена после того, как Atomics.load прочтёт её значение. Опять же, если даже порядок выполнения неатомарных инструкций будет изменён, ни одна из них не будет перемещена так, что будет выполнена до Atomics.load, которая размещена в коде выше неё.
while из этого примера реализует циклическую блокировку, это весьма неэффективная конструкция. Если нечто подобное окажется в главном потоке приложения, программа может попросту зависнуть. В реальном коде, практически наверняка, циклическими блокировками пользоваться не стоит.
|
Метки: author ru_vds javascript блог компании ruvds.com программирование управление памятью многопоточность гонка потоков |






