[Перевод] Moby/Docker в продакшене. История провала |
Примечание переводчика: в предыдущей статье о подготовке к девопс-конференциям, Gryphon88 задал резонный вопрос: как отличить cutting-edge и хайп? Нижеследующая статья наполнена сочной незамутненной истерикой, которую так приятно читать с утра, попивая чашечку кофе. Минус в том, что она написана в ноябре 2016, но нетленка не стареет. Если после прочтения захочется добавки, есть комментарии на Hacker News. А у тебя, юзернейм, такой же ад? Пиши в комментариях. Итак, начнем.
В первый раз я встретился с Докером в начале 2015. Мы экспериментировали с ним, чтобы понять, для чего бы его можно употребить. В то время нельзя было запустить контейнер в фоне, не было команд чтобы посмотреть что запущено, зайти под дебагом или SSH внутрь контейнера. Эксперимент оказался быстрым, Докер был признан бесполезным и более похожим на альфу или прототип, чем на релиз.
Промотаем нашу историю до 2016. Новая работа, новая компания, и хайп вокруг докера поднялся безумный. Разработчики уже выкатили докер в продакшен, так что сбежать с него не удастся. Хорошая новость в том, что команда run наконец-то заработала, мы можем запускать и останавливать контейнеры. Оно шевелится!
У нас 12 докеризованных приложений, бегающих на проде прямо в момент написания этой заметки, размазанные на 31 хост на AWS (по одному приложению на хост, дальше объясню — почему).
Эта заметка рассказывает, как мы путешествовали вместе с Докером — путешествие полное опасностей и неожиданных поворотов.

Мы использовали следующие версии (или по крайней мере, попытались это сделать):
1.6 => 1.7 => 1.8 => 1.9 => 1.10 => 1.11 => 1.12
Каждая новая версия что-нибудь да ломала. В начале гда на докере 1.6 мы запустили одно приложение.
И обновились только через 3 месяца, потому что необходим был фикс, доступный только в свежих версиях. Ветка 1.6 оказалась уже заброшеной.
Версии 1.7 и 1.8 не запускались. Мы перешли на 1.9 только чтобы спустя две недели найти критический баг в этой версии, поэтому пришлось (снова!) обновляться до 1.10.
Между версиями Докера постоянно случаются небольшие регрессии. Он постоянно ломается непредсказуемым способом в неожиданных местах.
Большая чатсь хитрых регрессий, на которые мы напоролись, оказалась связанной с сетью. Докер полностью абстрагирует хостовую сеть. От этого случается большая заваруха с пробросом портов, хаками DNS и виртуальных сетей.
Бонус: Докер убрали из официальных репозиториев Debian, поэтому покет переименовался из docker.io в docker-engine. Документация созданная до этого изменения — устарела.
Наиболее желаемая, и болезненно отсутствующая фича — команда для удаления старых образов (старше чем X дней, или не используемых Х дней, неважно). Дисковое пространство — это критическая проблема, учитывая что образы часто обновляются и могут занимать более 1 Gb.
Единственный способ очищать место — это запускать следующий хак каждый день, скорей всего по крону:
docker images -q -a | xargs --no-run-if-empty docker rmi Она перебирает все образы и удаляет их. Остаются только те, которые прямо сейчас используются в работающих контейнерах, она не может удалить их и валится с ошибкой. Грязный способ, но дело делает.
Путешествие по миру докера начинается с очищающего скрипта. Это — ритуал инициации, сквозь который должна пройти любая организация.
В интернете можно найти множество попыток сделать это, ни одна из них не работает хорошо. Нет никакого API чтобы показывать образы с датами, иногда есть но они устаревают за 6 месяцев. Например, часто используемая стратегия — читать аттрибут "дата" из файла образа и запускать docker rmi. Но она не работает, когда меняется имя. Другая стратегия — вычитывать дату и удалять файлы напрямую, но она приводит к повреждением если прошла неидеально, и это просто нельзя сделать идеально никому кроме самого Докера.
Бесконечное количество проблем, посвященных взаимодействию ядра, дистрибутива, докера и файловой системы.
Мы используем Debian Stable c backports в проде. Мы начали с Debian Jessie 3.16.7-ckt20-1 (ее релизнули в ноябре 2015). У нее был большой критичный баг, из-за которого хаотично крашились хосты (в среднем, каждые несколько часов).
У докера есть куча драйверов для подсистемы хранения. Единственный (якобы) ревностно поддерживаемый — AUFS.
Драйвер AUFS нестабилен. Включая критические баги, приводящие к панике ядра и повреждениям данных.
Он сломан (как минимум) на всех ядрах linux-3.16.x. Лечения не существует.
Мы часто обновляемся вслед за Дебианом и ядром. Дебиан выложил специальные патчи вне обычного цикла. Был один большой багфикс AUFS где-то в марте 2016. Мы думали, что это ТОТ САМЫЙ ФИКС, но нет. После него паники начали случаться реже (каждую неделю вместо каждого дня), но баг никуда не исчез.
Однажды летом случилась реграессия прямо в мажорном обновлении, которая притащила с собой предыдущий критичный баг. Он начал убивать сервера CI один за другим, со средним перерывом в 2 часа между умерщвлениями.
В 2016 случилось множество фиксов AUFS. Некоторые критичные проблемы починилсь, но куча других всё еще существует. AUFS нестабилен как минимум на всех ядрах linux-3.16.x.
Широко известен факт, что у AUFS бесконечно проблем, что разработчики считают ее мертвым грузом. Ради будущих поколений, AFUS выбросили из четвертого ядра.
Не существует никакого неофициального патча для ее поддержки, нет никакого опционального модуля, бэкпорта или чего-то такого, ничего. AUFS полностью исчезла.
(драматическая пауза)
.
.
.
Как тогда докер работает без AUFS? Ну, он не работает.
(драматическая пауза)
.
.
.
Поэтому чуваки из докера написали новую файловую систему, называющуюся overlay.
"OverlayFS — это современная union файловая система, похожая на AUFS. В сравнении с AUFS, OverlayFS спроектирована проще, присутствует в мейнлайне ядра Linux с версии 3.18, и потенциально работает быстрее". — Docker OverlayFS driver
Заметьте, что ее не бэкпортнули в существующие дистрибутивы. Докер не то чтобы заботится об обратной совместимости.
Кстати, "overlay" — это имя как для модуля ядра (разработанного мантейнерами Linux), и для докерного драйвера, который ее использует (является частью докера и разрабатывается докером). Они — два совершенно разных компонента (возможно, с пересечением в истории и списке разработчиков). Проблемы в основном относятся к драйверу, а не к файловой системе как таковой.
Драйвер файловой системы — это сложное программное обеспечение, и оно требует огромного уровня надежности. Старички помнят, как Linux мигрировал с ext3 на ext4. Его не сразу написали, еще больше времени дебажили, и в конце концов ext4 стал основной файловой системой во всех популярных дистрибутивах.
Сделать новую файловую систему за 1 год — невыполнимая миссия. Это даже забавно, учитывая что задача легла не на кого-нибудь, а на Докер, с его послужным списком из нестабильностей и жутких поломманных обновлений — в точности того, чего не хочется видеть в файловой системе.
Короче. В этой истории всё пошло не так. Жуткие истории до сих пор населяют кэш Гугла.
Разработку Overlay бросили в течение года после первого релиза.
драматическая пауза
.
.
.
Время для Overlay2!
"Драйвер overlay2 призван решить ограничения overlay, но он совместим только с ядрами Linux 4.0 и старше, и docker 1.12" — статья "Overlay vs Overlay2 storage drivers"
Сделать файлуху за год — всё еще невыполнимая миссия. Докер попытался и опростоволосился. Тем не менее, они продолжают пробовать! Посмотрим, как это обернется на дистанции в несколько лет.
Сейчас она не поддерживается ни на каких используемых нами системах. Не то что использовать, даже протестировать ее мы не можем.
Выводы: как мы видим на примере Overlay и Overlay2. Нет бэкпортов. Нет патчей. Нет совместимости со старыми версиями. Докер просто идет вперед и ломает вещи :) Если вы хотите использовать Докер, придется тоже двигаться вперед, успевая за релизами докера, ядра, дистрибутива, файловых систем, и некоторых зависимостей.
2 июня 2016, примерно в 9 утра (по Лондонскому времени). Новые ключи пушатся в публичный репозиторий докера.
Прямым следствием этого является то, что любой apt-get update (или аналог) на системе, в которую подключен сломанный репозиторий, падает с ошибкой "Error https://apt.dockerproject.org/ Hash Sum mismatch".
Это проблема случилась по всему миру. Она повлияла на ВСЕ системы на планете, к которым подключен репозиторий Докера. На всех версиях Debian и Ubuntu, вне запвисимости от версии операционной системы и докера.
Все пайплайны непрерывной интеграции в мире, основывающиеся на установке/обновлении докера или установке/обновлении системы — сломались. Невозможно запустить обновление или апгрейд существующей системы. Невозможно сделать новую систему, на которую устанавливался бы докер.
Через некоторое время. Новость от сотрудника докера: "Есть новости. Я поднял этот вопрос внутри компании, но люди, которые могут это починить, находятся в часовом поясе Сан Франциско (8 часов разницы с Лондоном — прим. автора), поэтому их еще нет на работе."
Я лично рассказываю эту новость разработчикам внутри нашей компании. Сегодня не будет никакого CI на Докере, мы не сможем делать новые системы, или обновлять старые, у которых есть зависимость на Докер. Вся наша надежда — на чувака из Сан-Франциско, который сейчас спит.
Пауза, в ходе которой мы употребили всю наличную еду и выпивку.
Новость от чувака из Докера во Флориде, примерно 3 часа дня по Лондонскому времени. Он проснулся, обнаружил ошибку, и работает над фиксом.
Позже были переопубликованы ключи и пакеты.
Мы попробовали и подтвердили работоспособность фикса примерно в 5 дня (по Лондону).
По сути случилось 7 часовое общемировое падение систем, исключительно по причине поломки Докера. Всё что осталось от этого события — несколько сообщений на страничке бага на GitHub. Никакого постмортема. Немного (или вообще никаких?) технических новостей или освещения в прессе, несмотря на катастрофичность проблемы.
Реестр хранит и обслуживает образы докера.
Автоматическая сборка CI ===> (при удаче) заливка образа в ===> docker registry
Команда на разворачивание <=== залить образ из <=== docker registry
Существует публичный реестр, обслуживаемый докером. Как организация, у нас тоже есть наш внутренний реестр. Он является образом докера, запущенным внутри докера на докерном хосте (это прозвучало довольно метауровнево!). Образ реестра докера является наиболее часто используемым докерным образом.
Существует 3 версии реестра:
Реестр v2 — это полностью переписанный софт. Реестр v1 был отправлен на пенсию сразу же после выпуска v2.
Мы обязаны установить новую штуку (снова!) просто чтобы докер продолжал работать. Они поменяли конфигурацию, урлы, пути, ендпоинты.
Переход к v2 был не бесшовным. Нам пришлось починить нашу установку, билды, скрипты развертывания.
Выводы: не доверяй никакому инструменту или API из докера. Они постоянно забрасываются и ломаются.
Одна из целей реестра v2 была в создании более качественного API. Это задокументировано здесь, 9 месяцев назад существовала документация, о которой мы уже и не помним.
Невозможно удалять образы из реестра докера. Нет сборки мусора — документация о ней упоминает, но она не существует. (Образы действительно умеют в компрессию и дедупликацию, но это совершенно другая вещь).
Реестр просто растёт вечно. Наш реестр может расти на 50 GB в неделю.
У нас нет сервера с бесконечным размером диска. Наш реестр несколько раз переполнял свободное место, превращая пайплайн сборки в ад, а потом мы перешли на S3.
Выводы: Необходимо использовать S3 для хранения образов (это поддерживается из коробки).
Мы делали ручную зачистку всего 3 раза. Во всех случаях нам приходилось остановить реестр, стереть всё на диске и запустить новый контейнер. (К счастью, мы можем пересобирать последние докерные образы с помощью CI).
Выводы: ручное удаление любого файла или директории с диска реестра ПОВРЕДИТ его.
И на сегодняшний день всё так же невозможно удалить образ из реестра. Никакого API тоже нет. (Одна из главных целей создания v2 была в дизайне хорошего API. Миссия провалилась).
Релизный цикл докера является единственной константой в экосистеме Докера:
Релизный цикл применим, но не ограничивается следующим: докер, фичи, файловые системы, реестр, всё API…
Судя по истории Докера, мы можем оценить время жизни чего угодно из Докера полураспадом в 1 год, считая что половина того, что сейчас существует, будет заброшена (и уничтожена) в течение года. Будет существовать замена, не полностью совместимая с тем, что предназначена заменять, и это может (или может не) выполняться на той же экосистеме (если она вообще сохранится).
"Мы делаем софт не для того, чтобы его кто-то использовал, а потому что нам нравится делать новые вещи" — будущая эпитафия Докера
Докер впервые появился через веб-приложение. В то время, это был простой путь разработчику запаковать и развернуть его. Они попробовали и быстро научились применять. Как только мы начали использовать микросервисную архитектуру, докер распространился и на микросервисы.
Веб-приложения и микросервисы — похожи. Они не имеют состояния, они могут быть запущены, остановлены, убиты, перезапущены, совершенно без раздумий. Вся тяжелая работа делегируется внешним системам (базам данных и бэкендам).
Применение докера началось с небольших новых сервисов. Вначале, всё нормально работало в деве, и в тестинге, и в продакшене. По мере докеризации всё большего количества веб-сервисов и веб-приложений, понемногу начали случаться паники ядра. Чем больше мы росли, тем большее явными и важными становились проблемы со стабильностью.
В течение года появилось несколько патчей и регрессий. С тех пор мы начали играться с поиском проблем Докера и методами их обхода. Это боль, но не похоже чтобы она оттолкнула людей от внедрения Докера. Внутри компании постоянно существует запрос на использование Докера, и на его поддержку.
Заметка: никакие из этих проблем не коснулись наших клиентов и их денег. Мы довольно успешно сдерживаем буйство Докера.
Имеются критические приложения, написанные на Эрланге, поддерживаемые и управляемые несколькими ребятами из команды "core".
Они попробовали запускать некоторые из них в Докере. Это не сработало. По какой-то причине, приложения на Эрланге и Докер вместе не сосуществуют.
Это делалось очень давно, и мы не помним всех подробностей. У Эрланга есть конкретные идеи на тему, как должна работать система и сеть, и ожидаемая нагрузка была в тысячах запросов в секунду. Любая нестабильность или несовместимость может считаться выдающейся неудачей. (Мы точно знаем, что в версиях, которые мы использовали для тестирования, присутствовала куча важных проблем со стабильностью).
Тестирование запустило тревожный звонок. Докер не готов ни для чего критичного. Это был правильный звоночек. В дальнейшем, краши и баги подтвердили это.
Мы используем Эрланг только для критичных приложений. Например, его юзают чуваки из ядра, которые отвечают за систему оплаты, которая провела в этом месяце 96 миллионов баксов. Кроме того, на нем работает парочка приложений и баз данных, находящихся под их ответственностью.
Докер — это опасный актив, за который приходится отвечать, и который может поставить на кон миллионы баксов. Поэтому он забанен во всех системах ядра.
Докер задуман быть stateless. Контейнеры не имеют хранилища на диске, всё что происходит — эфемерно и уходит, когда контейнер останавливатеся. Не подразумевается, что контейнеры будут хранить данные. На самом деле, они спроектированы чтобы НЕ ХРАНИТЬ данные. Любоая попытка действовать против этой философии приводит к несчастьям.
Более того. Докер прячет процессы и файлы с помощью своих абстракций, они недоступны как если бы вообще не существовали. Это позволяет предотвращает использования любой процедуры восстановления в случае, если что-то пошло не так.
Короче. Докер НЕ ДОЛЖЕН ЗАПУСКАТЬ базы данных в продакшене, by design.
Всё хуже. Помните постоянные паники ядра при использовании докера?
Краш уничтожит базу данных и повлияет на все системы, которые с ней соединены. Этот баг случается хаотически, но срабатывает чаще при интенсивном использовании. База данных — это предельно интенсивная по IO нагрузка, и значит — гарантированная паника ядра. Плюс, существует другой баг, который может поломать маунт докера (уничтожая все данные) и, возможно, системную файловую систему хоста (если они находятся на одном диске).
Фильм ужасов: хост покрашился, диски развалились, вместе с ними умерла операционная система хоста, и все данные, которые в данный момент находятся в обработке.
Заключение: Вы ОБЯЗАНЫ НЕ ЗАПУСКАТЬ на Докере базы данных в продакшене, НИКОГДА.
Время от времени, всегда находится человек, который подойдет и спросит: "почему бы нам не засунуть эти базы данных в докере", и мы в ответ рассказываем одну из многих боевых историй. Пока что никто не подходил дважды.
Заметка: мы начали рассказывать историю внедрения Докера как часть курса молодого бойца для новых сотрудников. Это — новая философия контроля повреждений: убить любую идею использования докера прежде, чем эта идея вырастет, и у нее появится шанс убить нас.
Докер получил импульс, ему оказывается безумная фантастическая поддержика. Хайп вокруг докера больше не является ответственностью исключительно технарей, он эволюционировал в социалогическую проблему.
В данный момент периметр контролируется, охраняется, ограниченный несколькими stateless веб-приложениями и микросервисами. Это всё неважные вещи, они могут докеризовываться и крашиться каждый день, мне наплевать.
До сих пор, все люди, которые хотели использовать докер для важных вещей, останавливались сразу же после короткой дискуссии. Мой ночной кошмар в том, что однажды какой-то докерный фанатик не послушает голоса рассудка, и продолжит проталкивать своё. Мне придется защищаться, и это будет выглядеть некрасиво.
Сценарий кошмара: обновление кластера с бухгалтерским софтом, сейчас держащего на себе 23M денег клиентов (M — сокращение для миллионов долларов). Люди постоянно спрашивают архитектора, почему бы не переложить эту базу в докер, и лицо архитектора в такие моменты словами не передать.
Мой долг — перед клиентами. Защищать их, и их деньги.
Как Докер хочет выглядеть:

Что такое Докер на самом деле:

Внимательно следите за версиями и ченжлогами для ядра, операционной системы, дистрибутива, докера, и всего в промежутке между ними. Изучайте баги, описания как люди ждут патчи, читайте всё что можете максимально внимательно.
ansible '*' -m shell -a "uname -a"
Позвольте докеру умирать. Не требует пояснений.
Время от времени мы мониторим сервера, находим мертвые и перезапускаем с форсом.
Требование высокой доступности подразумевает, что у вас есть хотя бы 2 инстнаса каждого сервиса, чтобы пережить падение одного из них.
Когда докер используется для чего-то хотя бы приблизительно важного, мы должны иметь по 3 инстанса этой штуки. Докер умирает постоянно, и мы обазаны переживать хотя бы 2 краша одного и того же сервиса подряд.
Большую часть времени, крашатся CI и тестовые инстансы. (На них работает куча интенсивных тестов, и проблемы там возникают особо адовые). У нас их много. Бывают вечера, когда они крашатся по 3 штуки одновременно.
Сервисы, которые держат в себе данные, не докеризуются.
Докер спроетирован так, чтобы НЕ ХРАНИТЬ данные. Не пытайтесь идти против этого, это рецепт боли и унижений.
Прямо сейчас существуют баги, которые приводят к тому, что при убийстве сервера уничтожаются и данные, и это уже достаточная причина чтобы не пытаться так делать.
Докер ОБЯЗАТЕЛЬНО сломается. Докер УНИЧТОЖИТ всё, к чему притронулся.
Использовать его можно только в приложениях, краши которых не приводят к даунтайму. Это значит, в основном stateless приложения, которые можно перезапустить где-нибудь еще.
Докеризованные приложения должны работать на автомасштабирующихся группах. (Заметка: у нас это сделано всё еще не до конца.)
Каждый раз, когда инстанс крашится, он автоматически заменяется новым в течение 5 минут. Не должно быть никаких ручных действий. Автоматическая починка.
Невероятное испытание при использовании Докера — прийти к работающей комбинации ядро + дистрибутив + версия докера + файловая система.
Прямо сейчас. Мы не знаем, НИКАКОЙ комбинации, которая является действительно стабильной (может быть, такой не существует?). Мы активно ищем её, постоянно тестируя новые системы и патчи.
Цель: найти стабильную экосистему для запуска докера.
Требуется 5 лет чтобы сделать хороший, стабильный софт, а Docker v1.0 имеет возраст всего лишь 28 месяцев, и у него не было времени повзрослеть.
Время обновления железа — 3 года, цикл релизов дистрибутив — 18-36 месяцев. Докер не существовал на предыдущем цикле, поэтому мы не можем оценить совместимость с ним. Хуже того, он зависит от множества продвинутых внутренних систем, которые довольно новы и тоже не успели ни повзрослеть, ни добраться до дистрибутивов.
Он может стать хорошим продуктом лет через 5. Подождем и посмотрим.
Цель: подождать, пока ситуцация станет лучше. В это время заняться делами, и постараться не обанкротиться.
Докер ограничен stateless приложениями. Если приложения может быть пакетизировано в Docker Image, оно может быть пакетизировано в AMI (Amazon Machine Image — прим. пер.). Если приложение может запускаться в докере, оно также может запускаться в автоматически масштабирующейся группе.
Большинство людей игнорируют это, но Docker бесполезен на AWS, и на самом деле это шаг назад.
Во-первых, смысл контейнеров — в экономии ресурсов, благодаря запуску множества контейнеров на одном (большом) хосте. (Давайте проигнорирует на минутку, что у текущего докера есть баг, который крашит и хост, и все контейнеры на нем, заставляя нас запускать лишь 1 контейнер на хост из соображений надежности).
Контейнеры бесполезны на облачных провайдерах. Всегда существует инстанс правильного размера. Просто создайте его с тем количеством памяти/процессора, которое реально нужно приложению. (Минимально на AWS можно сделать t2.nano, который стоит 5 баксов в месяц за 512MB и 5% CPU).
Во-вторых, наибольшее преимущество контейнеров проявляется в системах с системой полной оркестрации всего, позволяющей автоматически управлять всеми командами (create/stop/start/rolling-update/canary-release/blue-green-deployment). Таких систем оркестрации в данный момент не существует. (В этот момент на сцену выходят всякие Nomad/Mesos/Kubernetes, но они пока недостаточно хороши).
AWS предоставляет автоматически масштабирующиеся группы, которые управляют оркестрацией и жизненным циклом инстансов. Этот инструмент совершенно никак не связан с экосистемой Докера, и при позволяет достигать куда лучшего результата без всех этих проблем и факапов.
Создавайте автоматически масштабирующиеся группы для каждого сервиса, и собирайте AMI на каждую версию (совет: используйте Packer чтобы собирасть AMI). Люди уже знакомы с управлением AMI и инстансами на AWS, здесь нечего особо изучать, и тут нет никакого подвоха. В результате развертывание получается преотличное и полностью автоматизированное. Автомасштабируемые группы года на три опередили экосистему Докера.
Цель: класть докерные сервисы в автомасштабируемые группы для того, чтобы отказы обрабатывались автоматически.
Важно: Docker and CoreOS созданы различными компаниями, это нужно учитывать.
Чтобы еще раз пнуть Докер, он зависит от кучи новых внутренних подсистем. Классический дистрибутив не может обновлять их вне выпуска мажорных релизов, даже если бы очень хотел.
Для докера имеет смысл иметь специальную операционную систему (или быть ей?) с соответствующим циклом обновлений. Возможно, это вообще единственный способ иметь рабочий набор из ядра и операционной системы, которые могли бы хорошо выполнять Докер.
Цель: проверить стабильность экосистемы CoreOS.
Во всеобщей схеме всего, возможно отделить сервера для запуска контейнеров (на CoreOS) от обычных серверов (на Debian). Не предполагается, что контейнеры должны знать (или беспокоиться) о том, на какой операционной системе они выполняются.
Буча случится при попытке управлять новым семейством операционных систем (установка, провиженинг, обновление, учетки пользователей, логирование, мониторинг). Пока никаких идей, как мы с этим справимся, и сколько вообще будет работы.
Цель: исследовать разворачивание CoreOS в целом.
Один из (будущих) крупных прорывов в возможности управлять флотами контейнеров, абтрагированно от машин, на которых они в конце концов оказываются, с автоматическим стартом, стопом, роллинг-апдейтом, изменением мощности, итп.
Проблема с Докером в том, что он ничего из этого не делает. Это просто тупая контейнерная система. Она имеет все недостатки контейнеров без каких-либо преимуществ.
Сейчас не существует ни одной хорошей, проверенной в бою, готовой для продакшена системы оркестрации.
Kubernetes — единственный из этих проектов, предназначенный для решения сложных проблем с контейнерами. У него есть ресурсы, которых нет ни у кого больше (например, Google имеет долгую историю использования контейнеров на больших масштабах, они имеют гугол денег и других ресурсов в собственном пользовании, и они знают, как писать работающий софт).
В данный момент Kubernetes молод и экспериментален, и у него не хватает документации. Порог входа болезненный, и ему очень далеко от совершенства. Тем не менее, это уже хоть что-то работающее, и уже сослужило добрую службу куче людей.
В долгосрочной перспективе, Kubernetes — это будущее. Он — главный технологический прорыв этого времени (или чтобы поаккуратней, это последний кирпичик, которого не хватает контейнерам, чтобы стать важной (р)еволюцией в инфраструктурном управлении).
Вопрос не в том, стоит ли внедрять Kubernetes. Вопрос в том, когда это делать?
Задача: продолжать наблюдать за Kubernetes.
Заметка: Kubernetes требует для своего запуска докер. Он будет подвержен всем проблемам докера. (Например, не пытайтесь запустить Kubernetes ни на чем, кроме CoreOS).
Как мы говорили раньше, не существует никакой известной стабильной комбинации: операционная система + дистрибутив + версия докера, поэтому не существует стабильной экосистемы для запуска на ней Kubernetes. Это — проблема.
Но существует потенциальный вокрэраунд: Google Container Engine. Он хостится на Kubernetes (и Docker) как сервис, часть Google Cloud.
Google должен был решить проблемы Докера, чтобы предлагать то, что они предлагают, других вариантов нет. Внезапно, они могут оказаться единственными людьми, разобравшимися как найти стабильную экосистему для Докера, починить баги, и продать это готовое решение как облачный сервис. Получается, однажды у нас были общие цели.
Они уже предлагают этот серивис, что означает — они придумали обходные пути для починки проблем Докера. Поэтому самым простым способом иметь контейнеры, которые будут работать в продакшене (ну, или будут работать вообще), может оказаться использование Google Container Engine.
Цель: перейти на Google Cloud, начиная с филиалов, не привязанных к AWS. Игнорирвать оставшуюся часть перечисленных здесь задач, т.к. они становятся нерелевантными.
Google Container Engine: еще одна причина, почему Google Cloud — это будущее, и AWS — это прошлое (в т.ч. на 33% более дешевые инстансы со в 3 раза большей скоростью и IOPS в среднем).
Небольшой кусочек контекста потерялся где-то между строк. Мы — небольшая контора с несколькими сотнями серверов. По сути, мы делаем финансовую систему, которая перемещает миллионы долларов в день (или миллиарды — в год).
Честно сказать, у нас были ожидания выше среднего, и мы воспринимаем проблемы с продакшеном довольно (слишком?) серьезно.
В общем, это "нормально", что у вас никогда не было этих проблем, если вы не используете докер на больших масштабах в продакшене, или не использовали его достаточно долго.
Хочется отдельнро отметить, что все эти проблемы и обходные пути были пройдены за период более года, а сконцентрированы в заметке, которую вы успели прочитать отсилы за 10 минут. Это сильно нагнетает градус драматизма, и боль от прочитанного.
В любом случае, чтобы ни случилось в прошлом — прошлое уже в прошлом. Наиболее важная часть — план на будущее. Это то, что вам точно нужно знать, если собираетесь внедрять Докер (или использовать Амазон вместо этого).
|
Метки: author olegchir devops docker kubernetes aufs overlay |
«Доктор Веб»: M.E.Doc содержит бэкдор, дающий злоумышленникам доступ к компьютеру |


id: 425036, timestamp: 15:41:42.606, type: PsCreate (16), flags: 1 (wait: 1), cid: 1184/5796:\Device\HarddiskVolume3\ProgramData\Medoc\Medoc\ezvit.exe
source context: start addr: 0x7fef06cbeb4, image: 0x7fef05e0000:\Device\HarddiskVolume3\Windows\Microsoft.NET\Framework64\v2.0.50727\mscorwks.dll
created process: \Device\HarddiskVolume3\ProgramData\Medoc\Medoc\ezvit.exe:1184 --> \Device\HarddiskVolume3\Windows\System32\cmd.exe:6328
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 1, new: 1, dbg: 0, wsl: 0
curdir: C:\Users\user\Desktop\, cmd: "cmd.exe" /c %temp%\wc.exe -ed BgIAAACkAABSU0ExAAgAAAEAAQCr+LiQCtQgJttD2PcKVqWiavOlEAwD/cOOzvRhZi8mvPJFSgIcsEwH8Tm4UlpOeS18o EJeJ18jAcSujh5hH1YJwAcIBnGg7tVkw9P2CfiiEj68mS1XKpy0v0lgIkPDw7eah2xX2LMLk87P75rE6 UGTrbd7TFQRKcNkC2ltgpnOmKIRMmQjdB0whF2g9o+Tfg/3Y2IICNYDnJl7U4IdVwTMpDFVE+q1l+Ad9 2ldDiHvBoiz1an9FQJMRSVfaVOXJvImGddTMZUkMo535xFGEgkjSDKZGH44phsDClwbOuA/gVJVktXvD X0ZmyXvpdH2fliUn23hQ44tKSOgFAnqNAra
status: signed_microsoft, script_vm, spc / signed_microsoft / clean
id: 425036 ==> allowed [2], time: 0.285438 ms
2017-Jun-27 15:41:42.626500 [7608] [INF] [4480] [arkdll]
id: 425037, timestamp: 15:41:42.626, type: PsCreate (16), flags: 1 (wait: 1), cid: 692/2996:\Device\HarddiskVolume3\Windows\System32\csrss.exe
source context: start addr: 0x7fefcfc4c7c, image: 0x7fefcfc0000:\Device\HarddiskVolume3\Windows\System32\csrsrv.dll
created process: \Device\HarddiskVolume3\Windows\System32\csrss.exe:692 --> \Device\HarddiskVolume3\Windows\System32\conhost.exe:7144
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 0, new: 0, dbg: 0, wsl: 0
curdir: C:\windows\system32\, cmd: \??\C:\windows\system32\conhost.exe "1955116396976855329-15661177171169773728-1552245407-149017856018122784351593218185"
status: signed_microsoft, spc / signed_microsoft / clean
id: 425037 ==> allowed [2], time: 0.270931 ms
2017-Jun-27 15:41:43.854500 [7608] [INF] [4480] [arkdll]
id: 425045, timestamp: 15:41:43.782, type: PsCreate (16), flags: 1 (wait: 1), cid: 1340/1612:\Device\HarddiskVolume3\Windows\System32\cmd.exe
source context: start addr: 0x4a1f90b4, image: 0x4a1f0000:\Device\HarddiskVolume3\Windows\System32\cmd.exe
created process: \Device\HarddiskVolume3\Windows\System32\cmd.exe:1340 --> \Device\HarddiskVolume3\Users\user\AppData\Local\Temp\wc.exe:3648
bitness: 64, ilevel: high, sesion id: 1, type: 0, reason: 1, new: 1, dbg: 0, wsl: 0
curdir: C:\Users\user\Desktop\, cmd: C:\Users\user\AppData\Local\Temp\wc.exe -ed BgIAAACkAABSU0ExAAgAAAEAAQCr+LiQCtQgJttD2PcKVqWiavOlEAwD/cOOzvRhZi8mvPJFSgIcsEwH8Tm4UlpOeS18oE JeJ18jAcSujh5hH1YJwAcIBnGg7tVkw9P2CfiiEj68mS1XKpy0v0lgIkPDw7eah2xX2LMLk87P75rE6U GTrbd7TFQRKcNkC2ltgpnOmKIRMmQjdB0whF2g9o+Tfg/3Y2IICNYDnJl7U4IdVwTMpDFVE+q1l+Ad92 ldDiHvBoiz1an9FQJMRSVfaVOXJvImGddTMZUkMo535xFGEgkjSDKZGH44phsDClwbOuA/gVJVktXvDX 0ZmyXvpdH2fliUn23hQ44tKSOgFAnqNAra
fileinfo: size: 3880448, easize: 0, attr: 0x2020, buildtime: 01.01.2016 02:25:26.000, ctime: 27.06.2017 15:41:42.196, atime: 27.06.2017 15:41:42.196, mtime: 27.06.2017 15:41:42.196, descr: wc, ver: 1.0.0.0, company: , oname: wc.exe
hash: 7716a209006baa90227046e998b004468af2b1d6 status: unsigned, pe32, new_pe / unsigned / unknown
id: 425045 ==> undefined [1], time: 54.639770 ms
|
|
Bitfury Group провела первую успешную multi-hop-транзакцию в сети Lightning Network |
 / изображение Vadim Kurland CC
/ изображение Vadim Kurland CC|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury lightning network |
[Из песочницы] Интеграция TI SensorTag, Eclipse kura и веб части через Apache Camel |

Привет всем. В данной статье я бы хотел показать пример использования связки TI SensorTag, Raspberry PI, Apache Camel с выводом в веб часть. В результате будет веб приложение, отображающее в реальном времени данные с сенсоров и бд хранящая показания, с промежуточным связующим узлом в виде Apache Camel приложения.
Устанавливаем Raspbian на Raspberry PI отсюда.
Eclipse Kura — это фреймворк для создания приложений, работающих с IoT на таких платформах как Raspberry PI. Позволяет настраивать приложения через веб интерфейс или через API. Приложения разворачиваются через OSGi. Так же берет на себя заботу об работе с mqtt брокером. [1]
Для простоты станем рутом и обновим список пакетов sudo -i && apt-get update. Установим Java (лучше использовать Oracle java, apt-get install oracle-java8-jdk). Скачаем Kura версии Raspbian (Model 2) — Stable отсюда (скачать последную версию на момент статьи: wget http://mirror.onet.pl/pub/mirrors/eclipse//kura/releases/3.0.0/kura_3.0.0_raspberry-pi-2-3_installer.deb) и установим: dpkg -i kura_*_installer.deb && apt-get install -f. Перезапускаем Raspberry PI: shutdown -r now.
Теперь можно открыть Kura WEB UI по адресу http://\ c логином и паролем admin/admin. Здесь можно настроить сеть, wi-fi точку доступа, имя устройства и другие параметры.
Версия из менеджера пакетов должна вполне подойди. Поэтому выполняем:
apt-get install -y libusb-dev libdbus-1-dev libglib2.0-dev libudev-dev libical-dev libreadline-devapt-get install bluezЗапустим и добавим в автозагрузку bluetooth сервис: systemctl enable bluetooth && systemctl start bluetooth. Включим беспроводной интерфейс: hciconfig hci0 up. Проверим, что интерфейс включился и все работает: hciconfig -a. При возникновении ошибок в bluez, можно попробовать скачать и скомпилировать последнюю версию, например по статье [3][4].
Mosquitto — опенсорный брокер сообщений по протоколу MQTT. Он нам нужен для отправки данных с SensorTag на Camel backend приложение.
Его можно установить, как на Rasperry PI, так и на другую машину, или использовать облачные решения (IBM, Azure). Но для работы web части, необходимо, чтобы mosquitto был настроен на работу через mqtt over websockets (Это можно сделать на другом экземпляре брокера, а не на локальном брокере).
Версия из стандартного репозитория
apt-get install mosquitto
systemctl enable mosquittoЧтобы включить websocket в mosquitto добавим следующие строки в /etc/mosquitto/mosquitto.conf
# Websocket
listener 1883
listener 9001
protocol websocketsи запустим systemctl start mosquitto. Чтобы установить самую новую версию mosquttio с поддержкой websockets. [2]
wget http://repo.mosquitto.org/debian/mosquitto-repo.gpg.key
apt-key add mosquitto-repo.gpg.key
cd /etc/apt/sources.list.d/
wget http://repo.mosquitto.org/debian/mosquitto-jessie.list
apt-get update
apt-get install mosquittoKura содержит пример приложения для работы с TI SensorTag. Оно раз в n секунд подключается по BLE к устройству, считывает данные с помощью Generic Attribute Profile (GATT) и отправляет их в брокер. Получается довольно медленно, но для начала пойдет.
Для начала склонируем репозиторий с kura. Можете воспользоваться или оригинальным https://github.com/eclipse/kura или форкнутым проектом https://github.com/leadex/kura, в котором добавлено считывание метрики температуры с барометра.
Выкачиваем:
git clone https://github.com/leadex/kura
cd kuraУ меня скомпилировать код удалось только на linux. Для сборки выполняем ./build-all.sh. Для последующей сборки только ble example:
cd kura/kura/examples/org.eclipse.kura.example.ble.tisensortag
mvn clean install -Dmaven.test.skip=trueДалее скопируем полученный jar на Raspberry PI.
cd kura/examples/org.eclipse.kura.example.ble.tisensortag
scp target/org.eclipse.kura.example.ble.tisensortag-*-SNAPSHOT.jar pi@:/tmpПодключаемся к OSGi console из Raspberry PI telnet localhost 5002 или удаленно telnet 5002. Вводим команду на установка нашего скомпилированного приложения install file:///tmp/org.eclipse.kura.example.ble.tisensortag-1.0.3-SNAPSHOT.jar и потом вводим для проверки ss. Видим установленный, но не запущенный bundle в конце: 75 INSTALLED org.eclipse.kura.example.ble.tisensortag.
Запустим командой start 75, где 75 — id приложения с предыдущего шага. Теперь он запущен: 75 ACTIVE org.eclipse.kura.example.ble.tisensortag и можно просмотреть логи на Raspberry PI: tail -f /var/log/kura.log [5].
В Kura web UI появился новый сервис BluetoohLe. Откроем и настроим его.
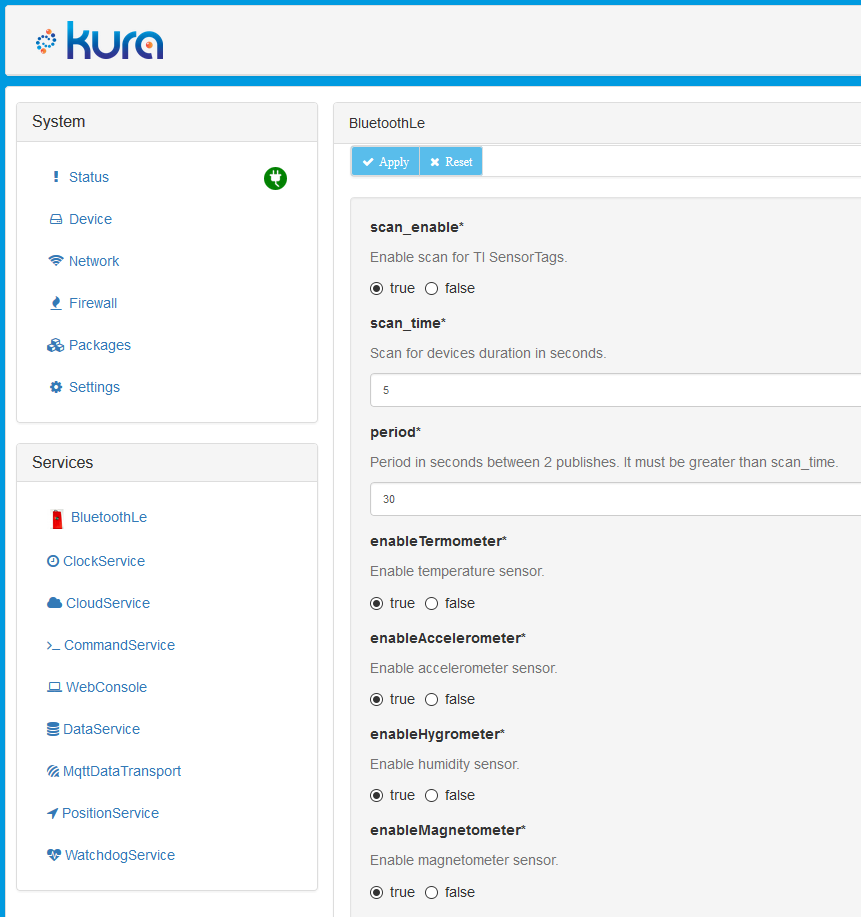
После перезапуска Kura, наш развернутый бандл пропадет, поэтому можно воспользоваться инструкцией по постоянной работе бандла.
Для быстрого запуска MongoDB + Mosquitto + Webview можно выполнить docker-compose up -d в корне проекта. Это создаст 3 контейнера и забиндит mqtt, websocket, http (8081) порты на localhost. Сразу после этого будет доступна веб часть по адресу http://localhost:8081. И mqtt broker на localhost:1883, поэтому можно будет указать в Kura MqttDataTransport ваш IP.
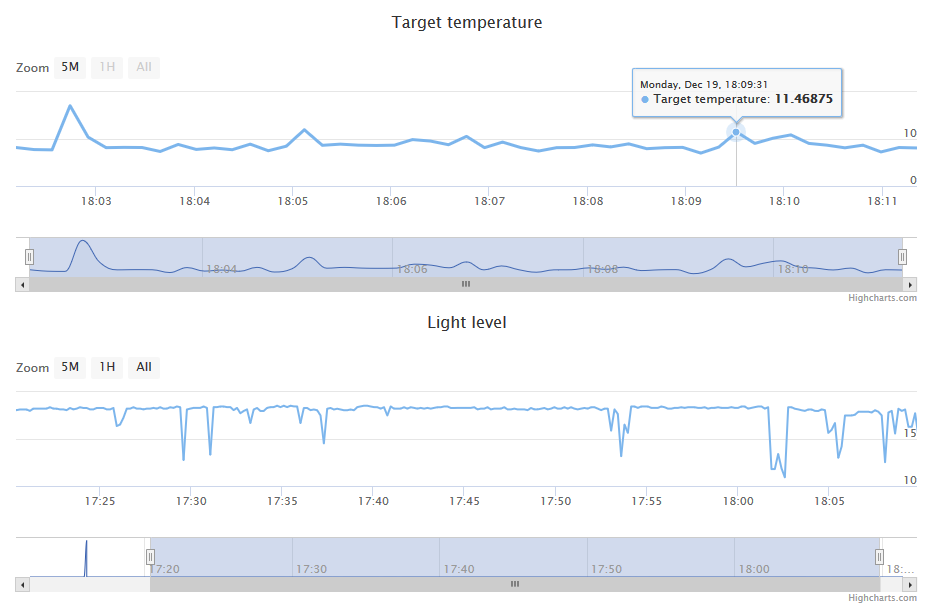
Пример веб части:
iot-backend-camel содержит Apache Camel проект, который подписывается к брокеру сообщений и получает KuraPayload.
EclipseKura сообщения передаются в закодированном формате Google Protobuf. Поэтому нам понадобится библиотека от Google для декодирования com.google.protobuf:protobuf-java.
Далее из сообщения достаются метрики, сериализуются в json и отправляются подписчикам веб части в брокер, а так же сохраняются в базу MongoDB.
Для запуска Camel приложения выполним: gradlew clean build и java -jar ./build/libs/iot-backend-camel-1.0.0-SNAPSHOT.jar.
webview содержит докер образ на основе nginx с html & js. Веб часть использует mqtt over websocket Paho библиотеку и highcharts для динамического отображения значения сенсоров (Температура с ИК сенсора и уровень освещения).
Сайт подписывается у брокера на обновления данных. Вероятно для работы, вам придется сменить mqtt хост в webview. Это можно сделать в webview/dist/view.js. В строке:
// Create a client instance
client = new Paho.MQTT.Client("localhost", Number(9001), "webview_" + parseInt(Math.random() * 1000000, 10));Перезапустить webview можно с помощью docker-compose up -d --build. Это пересобирет docker образ и перезапустит, если он изменился.
|
Метки: author quckly разработка под linux разработка для интернета вещей eclipse kura raspberry pi apache camel texas instruments bluez sensortag mosquitto |
Создаем UWP приложение на языке SPL |
#.output("Hello, world!")w,h = #.scrsize()
sfx = -2.5; sfy = -2*h/w; sfs = 4
#.aaoff()
:again
end,redo,update = 0
-> draw() 'посчитаем фрактал в отдельном потоке
>
moved = 0
> #.pan() 'мультитач навигация
moved = 1
x,y,s = #.pan(3)
x -= (s-1)/2*w
y -= (s-1)/2*h
#.drawoff(x,y,s)
<
? moved 'пересчитаем фрактал заново
sfs /= s
sfx -= x*sfs/w
sfy -= y*sfs/w
again -> end
redo = 1
.
? update & !redo 'отобразим фрактал
update = 0
#.drawoff(0,0)
.
wn,hn = #.scrsize()
? wn!=w | hn!=h 'изменился размер экрана
w = wn; h = hn
again -> end
redo = 1
.
<
draw()=
:loop
#.offon() 'рисуем в закадровом буфере
#.scrclear(0,0,0)
.redo = 0
sfx = .sfx; sfy = .sfy; fs = .sfs/.w
> y, 1...h
> x, 1...w
fx = sfx + x*fs
fy = sfy + y*fs
#.drawpoint(x,y,color(fx,fy):3)
<
loop -> .redo
.update = 1
<
.end = 1
.
color(x,y)=
zr = x; zi = y; n = 0
maxn = #.int(200*(1-#.log10(.sfs/4)))
> zr*zr+zi*zi<4 & n



w,h = #.scrsize()
sfx = -2.5; sfy = -2*h/w; sfs = 4
#.aaoff()
:again
end,redo,update = 0
-> draw() 'посчитаем фрактал в отдельном потокеmoved = 0
> #.pan() 'мультитач навигация
moved = 1
x,y,s = #.pan(3)
x -= (s-1)/2*w
y -= (s-1)/2*h
#.drawoff(x,y,s)
<? moved 'пересчитаем фрактал заново
sfs /= s
sfx -= x*sfs/w
sfy -= y*sfs/w
again -> end
redo = 1
.? update & !redo 'отобразим фрактал
update = 0
#.drawoff(0,0)
.wn,hn = #.scrsize()
? wn!=w | hn!=h 'изменился размер экрана
w = wn; h = hn
again -> end
redo = 1
.draw()=
:loop
#.offon() 'рисуем в закадровом буфере
#.scrclear(0,0,0)
.redo = 0
sfx = .sfx; sfy = .sfy; fs = .sfs/.w
> y, 1...h
> x, 1...w
fx = sfx + x*fs
fy = sfy + y*fs
#.drawpoint(x,y,color(fx,fy):3)
<
loop -> .redo
.update = 1
<
.end = 1
.color(x,y)=
zr = x; zi = y; n = 0
maxn = #.int(200*(1-#.log10(.sfs/4)))
> zr*zr+zi*zi<4 & n

|
Метки: author Mr_Kibernetik программирование spl |
Проведение ретроспективы по методу шести шляп |


Как я уже отметила выше, синяя шляпа — организация и обсуждение процесса, в нашем случае ретроспективы. В контексте аджаила синяя шляпа — шляпа скрам-мастера на время всей ретроспективы (именно он организует процесс обсуждения и следит за его последовательностью и эффективностью).
Важно, чтобы вся полученная на ретроспективе информация была зафиксирована, а при использовании метода шести шляп, ещё и структурирована. С этой целью я вывела на маркерную достку слайд:
— предполагается, что все озвученные мысли будут записываться под каждой из шляп (в зависимости от того, в какой шляпе мысль была сгенерирована).

|
Метки: author arwres agile ретроспектива мозговой штурм командная работа |
Про Гауди — разработчика из девятнадцатого века, добившегося всего, чего может добиться разработчик |






















|
Метки: author Milfgard прототипирование usability гауди проекты юзабилити эргономика геометрия сопромат |
Видеозаписи с Avito Data Science meetup |

|
Метки: author rafinirovannoe машинное обучение data mining блог компании avito рекомендательные системы рекомендации рекомендательный сервис avito яндекс.дзен ozon.ru |
[Перевод] Мемоизация в JS и ускорение функций |

factorial, которая вычисляет и возвращает факториал числа. Если не вдаваться в детали её реализации, выглядеть она будет так:function factorial(n) {
// Вычисления: n * (n-1) * (n-2) * ... (2) * (1)
return factorial
}factorial(50). Она, как и ожидается, найдёт и возвратит факториал числа 50. Всё это хорошо, но давайте теперь найдём с её помощью факториал числа 51. Компьютер снова выполнит вычисления, и то, что нам надо, будет найдено. Однако, можно заметить, что, при повторном вызове, функция выполняет массу вычислений, которые уже были выполнены ранее. Попытаемся функцию оптимизировать. Подумаем, как, имея значение factorial(50) перейти к factorial(51) без повторного вызова функции. Если следовать формуле вычисления факториала, окажется, что factorial(51) это то же самое, что и factorial(50) * 51.factorial() производится полная цепочка вычислений для нахождения факториала 50, а потом то, что получилось, умножается на 51. То есть, при использовании подобной функции, вычисление факториала для числа 51 в любом случае выглядит как перемножение всех чисел от 1 до 51.factorial() умела запоминать результаты вычислений, выполненных при её предыдущих вызовах и использовать их при следующих вызовах для ускорения производительности.Мемоизация — сохранение результатов выполнения функций для предотвращения повторных вычислений. Это один из способов оптимизации, применяемый для увеличения скорости выполнения компьютерных программ.
// простая функция, прибавляющая 10 к переданному ей числу
const add = (n) => (n + 10);
add(9);
// аналогичная функция с мемоизацией
const memoizedAdd = () => {
let cache = {};
return (n) => {
if (n in cache) {
console.log('Fetching from cache');
return cache[n];
}
else {
console.log('Calculating result');
let result = n + 10;
cache[n] = result;
return result;
}
}
}
// эту функцию возвратит memoizedAdd
const newAdd = memoizedAdd();
console.log(newAdd(9)); // вычислено
console.log(newAdd(9)); // взято из кэшаmemoizeAdd возвращает другую функцию, которую мы можем вызвать тогда, когда нужно. Такое возможно потому что функции в JavaScript — это объекты первого класса, что позволяет использовать их как функции высшего порядка и возвращать из них другие функции.cache может хранить данные между вызовами функции, так как она определена в замыкании.cache ведёт себя именно так, как ожидается.// простая чистая функция, которая возвращает сумму аргумента и 10
const add = (n) => (n + 10);
console.log('Simple call', add(3));
// простая функция, принимающая другую функцию и
// возвращающая её же, но с мемоизацией
const memoize = (fn) => {
let cache = {};
return (...args) => {
let n = args[0]; // тут работаем с единственным аргументом
if (n in cache) {
console.log('Fetching from cache');
return cache[n];
}
else {
console.log('Calculating result');
let result = fn(n);
cache[n] = result;
return result;
}
}
}
// создание функции с мемоизацией из чистой функции 'add'
const memoizedAdd = memoize(add);
console.log(memoizedAdd(3)); // вычислено
console.log(memoizedAdd(3)); // взято из кэша
console.log(memoizedAdd(4)); // вычислено
console.log(memoizedAdd(4)); // взято из кэшаmemoize способна превращать другие функции в их эквиваленты с мемоизацией. Конечно, этот код не универсален, но его несложно переделать так, чтобы функция memoize могла бы работать с функциями, имеющими любое количество аргументов._.memoize(func, [resolver])@memoize из decko.memoize, или функции _.memoize из Lodash, то, что получится, будет работать неправильно, так как рекурсивные функции вызывают сами себя, а не то, что получается после добавления возможностей по мемоизации. Как результат, переменная cache в такой ситуации не выполняет своего назначения. Для того, чтобы решить эту проблему, рекурсивная функция должна вызывать свой вариант с мемоизацией. Вот как можно добавить мемоизацию в рекурсивную функцию вычисления факториала. Код, как обычно, можно найти на CodePen.// уже знакомая нам функция memoize
const memoize = (fn) => {
let cache = {};
return (...args) => {
let n = args[0];
if (n in cache) {
console.log('Fetching from cache', n);
return cache[n];
}
else {
console.log('Calculating result', n);
let result = fn(n);
cache[n] = result;
return result;
}
}
}
const factorial = memoize(
(x) => {
if (x === 0) {
return 1;
}
else {
return x * factorial(x - 1);
}
}
);
console.log(factorial(5)); // вычислено
console.log(factorial(6)); // вычислено для 6, но для предыдущих значений взято из кэшаfactorial рекурсивно вызывает свою версию с мемоизацией.factorial(5).|
Метки: author ru_vds javascript блог компании ruvds.com программирование функции мемоизация |
Как повторить сервис anyroom.io в несколько строк JS и без бэкенда |

|
Метки: author mdnsresponder разработка мобильных приложений разработка веб-сайтов программирование javascript блог компании voximplant |
Как защитить ЦОД от DDoS-атак? |

Что такое DDoS-атаки – сегодня знают, кажется, даже весьма далёкие от IT-сферы люди. На случай, если на Хабр вдруг попал человек, ничего об этом не слышавший, всё же скажем пару слов о базовом. Итак, DDoS – это Distributed Denial of Service, «распределенный отказ в обслуживании»: большое количество машин, заражённых вредоносным ПО, одновременно начинает отправлять на сервер запросы.
В итоге сервер, разумеется, «падает». Техника атаки достаточно проста, и весьма эффективна – так что пользуются ею все, от простых «киберхулиганов», которым по каким-то причинам не нравится атакуемый сайт, до правительств государств с серьёзными политическими целями. А уж в России, где борьба с киберпреступностью ведётся весьма вяло, практика и вовсе широко распространена.
Заказать подобную атаку на конкурента – проще простого, вы легко можете убедиться в этом сами. По запросу «заказать DDoS» любой поисковик выдаст сотни ссылок – и среди них будет полно самых настоящих киберпреступников, которые действительно оказывают подобную услугу.
К чему же мы обо всём этом говорим?

К тому, что хорошая защита от DDoS-атак в наше время – значимый критерий при выборе ЦОД. Этому есть две причины.
Во-первых, при достаточно мощной, хорошо организованной DDoS-атаке, сервер может получить нагрузку в несколько сотен Гбит/с (зафиксированы атаки в 300 Гбит/с и выше) – далеко не всякий дата-центр выдержит подобное. Во-вторых, всё чаще атакуют не отдельные сайты, а именно целые ЦОДы. Примерно 2/3 дата-центров подвергаются атакам с целью «забивания» их каналов связи.
А для крупных крупных ЦОД отражение попыток их «заddosить» уже превратилось в рутину – и, при этом, далеко не все центры научились с ними бороться. Примерно пятая часть случаев отключения ЦОД – это именно последствия DDoS, причём «поднять» центр после этого – сложнее, чем при каком-то ином сбое.
Скорее всего, количество подобных происшествий будет только увеличиваться. Далеко не все компании скрывают информацию о том, в каких дата-центрах распложены их серверы, а атаковать целый ЦОД технически не сложнее, чем конкретный ресурс.
Словом, даже если вы не ожидаете никакой атаки именно на ваш сервер (что, как мы уже выяснили, довольно самонадеянно), то всё равно можете стать жертвой DDoS. Но уже вместе с тысячами людей и организаций, которые пользуются услугами вашего дата-центра. Просто потому, что кто-то из «соседей» кому-то насолил.
Так что очень важно, насколько дата-центр защищён от DDoS-атак. Мы, в ЦОД «Контел», это отлично понимаем – и стараемся принимать все меры к предотвращению проблем (устранять которые после возникновения уже много тяжелее).
Как же сегодня защищают дата-центры?
Как водится, средства защиты от DDoS в тех ЦОДах, что хорошо о ней позаботились (вроде нашего), используются и программные, и аппаратные. Мы, конечно, говорим не только о банальных вещах, вроде той защиты, что реализована Microsoft в IIS.
Прекрасные комплексные решения для защиты как отдельных серверов, так и целых ЦОД от DDoS создаёт компания Cisco. Тут речь идёт о именно о программно-аппаратном комплексе. В первую очередь, работает Cisco Traffic Anomaly Detector – идёт пассивный мониторинг трафика, не вредящий производительности. Но зато позволяющий вовремя распознать начинающуюся атаку, и передать на Cisco Guard «сигнал тревоги».
Cisco Guard работает не «внешнем периметре» — устройство ставится на вышестоящем отрезке того пути, что проходит трафик. Кстати, сигнал от атаке необязательно должен поступать именно от Anomaly Detector – какой-то детектор вторжений, или даже обычный межсетевой экран тоже могут передать эту информацию. Поскольку Cisco Guard использует отдельный сетевой интерфейс, то его работа по «фильтрации» трафика во время DDoS не мешает остальным системам.
Cisco Guard на MVP-архитектуре, кстати, успешно масштабируются – так что это именно тот случай, когда можно создать оборону, явно превосходящую возможности атакующих. При этом, как выражается сама компания, защита осуществляется «с хирургической точностью» — то есть, Cisco подвергает тщательному анализу и фильтрации именно подозрительный трафик, а «нормальный» при этом продолжает совершенно свободное движение.
Но, конечно же, Cisco не является монополистом в сфере программно-аппаратной защиты ЦОД от DDoS-атак. Такие системы разрабатываются и в России (где, как мы уже отмечали выше, проблема DDoS стоит достаточно остро). Хороший пример тут – система «Периметр», но углубляться в её сравнение с продуктами Cisco мы не станем.
Ну, помимо очевидного «положитесь на надёжность наших услуг»?.. К примеру, может посоветовать отказаться от Windows Server и Apache. Сетевой экран «винды», мягко говоря, не очень хорошо справляется с подобными нагрузками. А что до Apache, то на уровне самой архитектуры кода он имеет ряд уязвимостей, которые успешно эксплуатируются годами – несмотря на любые патчи.
Ну, а главное – не бояться. Рано или поздно, с DDoS столкнётся практически каждый. Важно подготовиться к данной неприятности – практически неизбежной, чтобы свести возможные потери к минимуму. Мы поступаем именно так, и всем советуем.
Ну и как всегда немного вкусных дедиков с уже включенной защитой от DDOS
Заказать сервер с защитой от 3200 руб
|
Метки: author ondys сетевые технологии it- инфраструктура cisco блог компании контел ddos ddos- защита дата-центр |
AMD Strikes Back: Доля AMD на рынке CPU выросла до 31% |
 / фото halfrain CC
/ фото halfrain CC
|
Метки: author it_man высокая производительность блог компании ит-град ит-град ryzen amd |
Куда сходить в июле: подборка событий для интернет-маркетологов |

|
Метки: author EverydayTools конференции веб-аналитика блог компании everyday tools интенсивы мастер-классы семинары интернет-маркетинг smm |
Что же такое RQL |
eq(author,Перумов) или в обычном формате URL: author=Перумов.[
{ title: "Эльфийский клинок", year: 1993, series: "Кольцо тьмы" },
{ title: "Чёрное копьё", year: 1993, series: "Кольцо тьмы" },
{ title: "Адамант Хенны", year: 1995, series: "Кольцо тьмы" },
{ title: "Воин Великой Тьмы", year: 1995, series: "Летописи Хьёрварда" }
]db.users.find({series: "Кольцо тьмы"})eq(series, "Кольцо тьмы")series="Кольцо тьмы"db.users.find({series: "Кольцо тьмы", year: 1995})eq(series, "Кольцо тьмы"),eq(year, 1995){ title: "Воин Великой Тьмы", year: 1995, series: "Летописи Хьёрварда", translations: { language: "English", title: "Godsdoom" } }translations. И чтобы найти все книги переведенные на английский язык, нам надо использовать точку.db.users.find({"translations.language": "English"})eq(translations.language, "English")db.users.find().skip(10).limit(10)limit(10,10)db.users.find().sort({title: 1})sort(+title) | Функция | Описание | Примеры |
|---|---|---|
| in (,) | Выбирает объекты, у которых значение указанного свойства входит в заданный массив свойств. |
in(name,(Silver,Gold)) |
| out (,) | Выбирает объекты, у которых значение указанного свойства не входит в заданный массив свойств. | out(name,(Platinum,Gold)) |
| limit (,) | Возвращает заданное количество (number) объектов начиная с определённой (start) позиции. |
limit(0,2) |
sort (
|
Сортирует список объектов по заданным свойствам (количество свойств неограниченно). Сначала список сортируется по первому из заданных свойств, затем по второму, и так далее. Порядок сортировки определяется префиксом: + — по возрастанию, — — по убыванию. |
sort(+hardware.memory,-hardware.diskspace) |
select (
|
Обрезает каждый объект до набора свойств, определенных в аргументах. | elect(name,hardware.memory,user) |
| values() | Возвращает набор значений из указанного поля всех объектов | values(ve.name) |
| count() | Возвращает количество записей | in(name,(Silver,Gold))&count() |
| max() | Возвращает максимальное значение из указанного поля всех объектов | max(ve.memory) |
| min() | Возвращает минимальное значение из указанного поля всех объектов | min(ve.memory) |
| Функция | Описание | Примеры |
|---|---|---|
| like (, ) | Ищет заданный паттерн (pattern) в заданном свойстве (property). Эта функция аналогична оператору SQL LIKE, хоть и использует символ * вместо %. Чтобы определить в паттерне сам символ *, он должен быть процентно-кодированным, то есть надо писать %2A вместо *, см. примеры. Кроме того, в паттерне можно использовать символ ?, обозначающий, что любой символ в этой позиции является валидным. |
like(firstName,Jo*) |
| Функция | Описание | Примеры |
|---|---|---|
| implementing () | Возвращает список объектов (ресурсы и типы), реализующих базовый тип и включающих в себя сам базовый тип. | aps-standard.org/samples/user-mgmt/offer/1.0 |
| composing () | Возвращает список типов, которые реализованы производным типом (derived type), включая сам производный тип. | aps-standard.org/samples/user-mgmt/offer/1.0 |
| linkedWith () | Возвращает список ресурсов, которые связаны тем ресурсом, чей ID указан в качестве аргумента. APS-контроллер ищет все ссылки на ресурсы, включая внутренние системные ссылки. Например, актор admin/owner/referrer, имеющий доступ к ресурсу, тоже будет считаться «связанным» ресурсом. | linkedWith(220aa29a-4ff4-460b-963d-f4a3ba093a0a) implementing(http://aps-standard.org/types/core/user/service/1.0), linkedWith(220aa29a-4ff4-460b-963d-f4a3ba093a0a) |
| Оператор | Алиас | Примеры | Значение |
|---|---|---|---|
| and (,,...) | & , |
and (http://aps-standard.org/samples/user-mgmt/offer),like(name,*L*)) implementing(http://aps-standard.org/samples/user-mgmt/offer)&like(name,*L*)) implementing(http://aps-standard.org/samples/user-mgmt/offer),like(name,*L*)) |
Выбирает все предложения (offers), имена которых соответствуют нечувствительному к регистру паттерну *L* |
| or (,,...) | | ; |
implementing(http://aps-standard.org/samples/user-mgmt/offer1.0)&or(like(description,*free*),in(name,(Silver,Gold))) | Выбирает все предложения (offers), описания (description) которых соответствуют паттерну *free*, а также те, чьё имя Silver или Gold. |
| Оператор | Алиас | Примеры | Значение |
|---|---|---|---|
| not () | implementing(http://aps-standard.org/samples/user-mgmt/offer),not(like(name,*free*)) | Выбирает все предложения (offers), за исключением тех, чьё имя соответствует Хабр и Гиктаймс — RQL паттерну *free*. |
and является неявным RQL-оператором верхнего уровня. Например, выражение http://hosting.com?and(arg1,arg2,arg3) эквивалентно http://hosting.com?arg1,arg2,arg3.implementing(),(prop1=eq=1|prop2=ge=2).| Оператор | Алиас | Примеры | Значение |
|---|---|---|---|
| eq (,) | =eq= | eq(aps.status,aps:ready) |
Выбирает все объекты, чей aps.status имеет значение aps:ready. |
| ne (,) | =ne= | ne(aps.status,aps:ready) |
Выбирает все объекты, чей aps.status имеет значение aps:ready. |
| gt (,) | =gt= | implementing(http://aps-standard.org/samples/user-mgmt/offer),hardware.memory=gt=1024) | Выбирает все предложения (offers), предоставляющие hardware.memory больше 1024. |
| ge (,) | =ge= | implementing(http://aps-standard.org/samples/user-mgmt/offer),hardware.memory=ge=1024) | Выбирает все предложения (offers), предоставляющие hardware.memory больше или равно 1024. |
| lt (,) | =lt= | implementing(http://aps-standard.org/samples/user-mgmt/offer),hardware.CPU.number=lt=16) | Выбирает все предложения (offers), предоставляющие hardware.CPU.number меньше 16. |
| le (,) | =le= | implementing(http://aps-standard.org/samples/user-mgmt/offer),hardware.CPU.number=le=16) | Выбирает все предложения (offers), предоставляющие hardware.CPU.number меньше или равно 16. |
null, true, false или пустое строковое значение. Все они применимы к определённым типам данных.| Функция-значение | Применимые типы | Описания | Примеры |
|---|---|---|---|
| null() | Любой тип | Задаётся, если значение null |
name=eq=null() |
| true() false() |
Булевы | Задаётся, если значение true или false |
disabled=eq=false() |
| empty() | Строковые | Задаётся, если строковое значение является пустым (не null, но не содержит никаких символов) |
addressPostal.extendedAddress=eq=empty() |
|
Метки: author BuranLcme разработка веб-сайтов javascript блог компании odin (ingram micro) aps rql rest request data |
[recovery mode] Openstack. Детективная история или куда пропадает связь? Часть вторая. IPv6 и прочее |

Прежде всего скажу – ребята, я не понимаю, для чего нужен IPv6 на платформе, которая сама по себе никуда не привязана по этому самому протоколу и адреса она себе назначает какие хочет. Мы с коллегой решили – «нафига козе баян?» – и запретили IPv6. Основательно так запретили. В трёх местах, на уровне ядра и модулей. Заодно обновили софт до последней стабильной версии.
И тут упала у нас раздача адресов по DHCP. При этом, естественно, и пароли в новые машины перестали заводиться.
Что поменялось? Похоже, не запускается dnsmasq. Тогда я нашёл в бэкапах старые версии софта и подложил их. Но боже ж ты мой – всё равно не работает!
Что за чудеса? В логах много всего, но никаких конкретных указаний, что происходит. Начал шерстить все логи подряд, в том числе и системные. Случайно увидел, что на самом деле есть логи, говорящие что произошло – но они лежат вовсе не в /var/log, как можно было бы ожидать. Нет, их почему-то прячут в /var/lib/neutron/ha_confs и далее – в названии каталога участвует имя подсети. Там лежат сгенерированный нейтроном конфиг и логи запуска для keepalived. У нас же «устойчивая» конфигурация. Автоматом сгенерированный конфиг содержит IPv6 адреса. Демон keepalived не стартует – от системы он получает отбой. Мы же запретили IPv6? После этого уже не стартует на нужном адресе dnsmasq – потому что адреса нет, его должен был поднять keepalived. Пришлось вернуть обратно.
Вывод: Если мы запрещаем IPv6 на уровне ядра, то dnsmasq перестаёт запускаться.
Не запрещайте IPv6 в Openstack версии Mitaka!

Но старая история продолжается.
В некоторых случаях проблема возникает сразу после создания виртуальной машины, в некоторых – нет. Напомню: периодически начинает пропадать часть пакетов. И иногда это выглядит даже так, как на представленном рисунке.

Мы нашли относительно простой способ эту проблему обходить. Сейчас это делается отрыванием внутреннего IP адреса и назначением его из другой подсети – нам при этом приходится часто добавлять новые подсети. Проблема на какое-то время уходит. Часть машин при этом работают замечательно. Самые настоящие «танцы с бубном».

Недавно я доказал себе, что эта проблема – в глубине OpenStack. Мы сооружали новую платформу по образу и подобию старой, при этом на тестовых диапазонах. Всё работало шикарно при заведении до 300 машин в ферме, и при этом никаких сбоев!
Обрадовались и стали готовить её в «продакшн». Это подразумевало введение «рваных» диапазонов ip адресов – так получилось. Мы очистили ферму, убрав эти самые триста машин. И вдруг на трёх тестовых виртуалках случилось то же, что и на старой ферме – стали пропадать пакеты, в большом количестве. Похоже, дело в самой сетевой настройке OpenStack.
Да, да! Всё дело в настройке виртуального роутера. К великому сожалению, примеров нормального построения сети более чем для 20 виртуальных машин, в сети не отыскать. Так что, похоже, продолжение следует…
|
Метки: author JohnSelfiedarum системное администрирование облачные вычисления ipv6 openstack neutron mitaka |
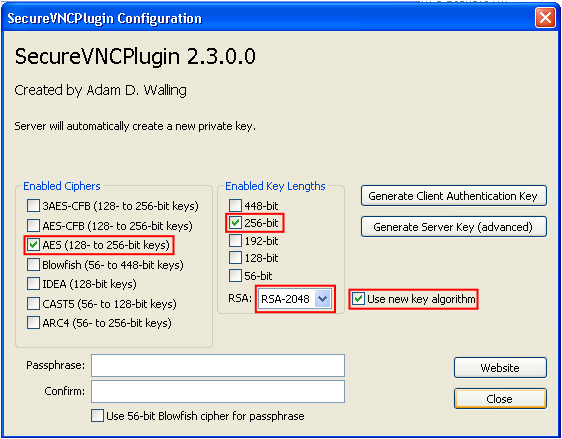
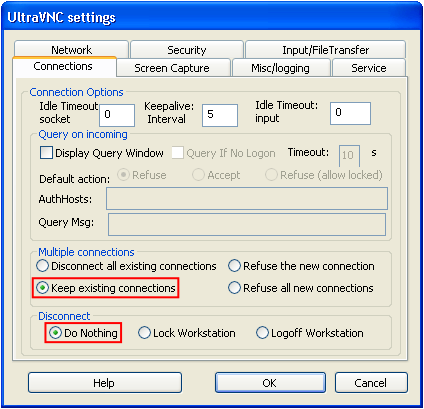
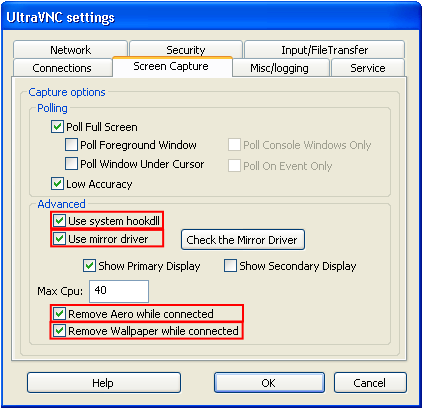
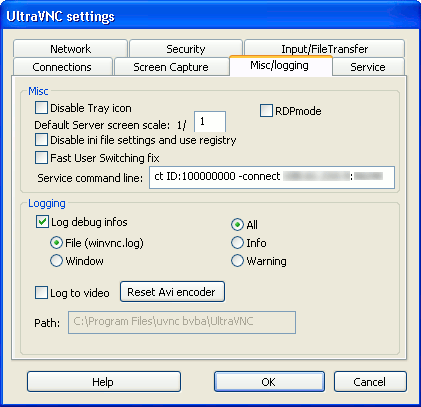
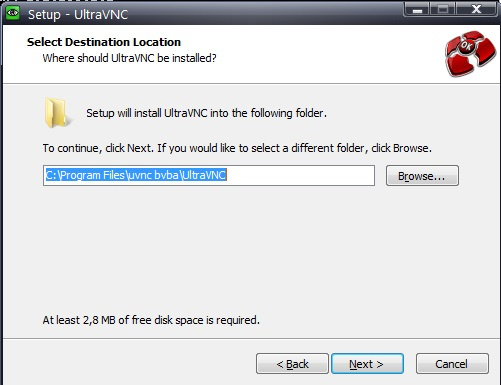
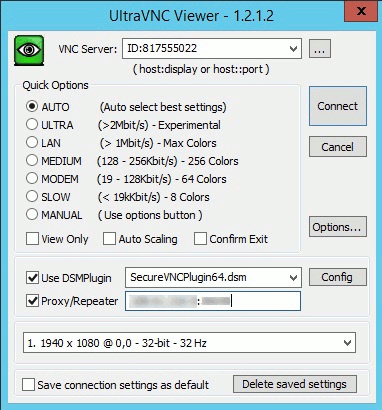
UltaVNC как замена TeamViewer |


sudo apt-get install build-essentialsudo useradd -c 'UltraVNC Repeater User' -M -s /sbin/nologin uvncrepwget http://www.wisdomsoftware.gr/download/uvncrep017-ws.tar.gztar -xzvf uvncrep017-ws.tar.gz && cd uvncrep017-wsmakesudo ./install.shviewerport = 5900logginglevel = 2allowedmodes = 2useeventinterface = falsesudo uvncrepeatersvc /etc/uvnc/uvncrepeater.iniUltraVnc Linux Repeater version 0.17
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): viewerPort : 5900
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): serverPort : 5500
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): maxSessions: 100
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): loggingLevel: 2
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): ownIpAddress (0.0.0.0 = listen all interfaces) : 0.0.0.0
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): runAsUser (if started as root) : uvncrep
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): Mode 1 connections allowed : No
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): Mode 2 connections allowed : Yes
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): Mode 1 allowed server port (0=All) : 0
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): Mode 1 requires listed addresses : No
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): Mode 2 requires listed ID numbers : No
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): useEventInterface: false
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): eventListenerHost : localhost
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): eventListenerPort : 2002
UltraVnc Sat Feb 11 16:48:29 2017 > listInitializationValues(): useHttpForEventListener : true
UltraVnc Sat Feb 11 16:48:29 2017 > dropRootPrivileges(): privileges successfully dropped, now running as user uvncrep
UltraVnc Sat Feb 11 16:48:29 2017 > routeConnections(): starting select() loop, terminate with ctrl+csudo systemctl start uvncrepeater$ ps ax | grep uvnc
11168 ? S 0:00 /usr/sbin/uvncrepeatersvc /etc/uvnc/uvncrepeater.ini
11170 pts/0 S+ 0:00 grep --color=auto uvnc







|
Метки: author binfini системное администрирование серверное администрирование блог компании business infinity group ultravnc teamviewer удаленное администрирование удаленный доступ |
Работа с VPC при помощи пакета ansible-selvpc-modules |

$ virtualenv --no-site-packages env
$ source env/bin/activate
$ pip install ansible-selvpc-modules
$ pip install shade jmespath
$ export SEL_URL=https://api.selectel.ru/vpc/resell/
// На момент написания статьи актуальной версией API является 2
$ export SEL_TOKEN=<ваш API-ключ полученный выше в панели>
$ export OS_PROJECT_DOMAIN_NAME=<ваш логин на my.selectel.ru>
$ export OS_USER_DOMAIN_NAME=<аналогично предыдущему>
$ export ANSIBLE_HOST_KEY_CHECKING=False
---
username: TestUser
password: 123456
project_name: TestProject
image: Ubuntu 16.04 LTS 32-bit
volumes:
- display_name: volume1
- display_name: volume2
- display_name: volume3
servers:
- name: vm1
- name: vm2
- name: vm3
---
- hosts: localhost
vars_files:
- example_vars.yaml
...
tasks:
- name: Create project
selvpc_projects:
project_name: "{{ project_name }}"
register: project_out
- name: Set quotas on created project
selvpc_quotas:
project_id: "{{ project_out.project.id }}"
quotas:
compute_cores:
- region: ru-1
zone: ru-1a
value: 3
compute_ram:
- region: ru-1
zone: ru-1a
value: 1536
volume_gigabytes_fast:
- region: ru-1
zone: ru-1a
value: 15
register: quotas_out
tasks:
...
- name: Create user
selvpc_users:
username: "{{ username }}"
password: "{{ password }}"
register: user_out
- name: Add created user to project
selvpc_roles:
project_id: "{{ project_out.project.id }}"
user_id: "{{ user_out.user.id }}"
tasks:
...
- name: Create public net
selvpc_subnets:
project_id: "{{ project_out.project.id }}"
subnets:
- region: ru-1
type: ipv4
quantity: 1
prefix_length: 29
register: public_net
- name: Get info about network
selvpc_subnets:
subnet_id: "{{ public_net|json_query(subnets[0].id') }}"
register: network_out
tasks:
...
- name: Create volumes
os_volume:
state: present
auth:
auth_url: https://api.selvpc.ru/identity/v3
username: "{{ username }}"
password: "{{ password }}"
project_name: "{{ project_name }}"
display_name: "{{ item.display_name }}"
image: "{{ image }}"
size: 5
region_name: ru-1
with_items: "{{ volumes }}"
register: volume
tasks:
...
- name: Create key
os_keypair:
state: present
auth:
auth_url: https://api.selvpc.ru/identity/v3
username: "{{ username }}"
password: "{{ password }}"
project_name: "{{ project_name }}"
name: ansible_key
region_name: ru-1
public_key_file: "{{ '~' | expanduser }}/.ssh/id_rsa.pub"
register: key
tasks:
...
- name: Create flavor
os_nova_flavor:
state: present
auth:
auth_url: https://api.selvpc.ru/identity/v3
username: "{{ username }}"
password: "{{ password }}"
project_name: "{{ project_name }}"
name: selectel_test_flavor
ram: 512
vcpus: 1
disk: 0
region_name: ru-1
is_public: False
register: flavor
tasks:
...
- name: Create servers
os_server:
state: present
auth:
auth_url: https://api.selvpc.ru/identity/v3
username: "{{ username }}"
password: "{{ password }}"
project_name: "{{ project_name }}"
name: "{{ item.1.name }}"
flavor: "{{ flavor }}"
boot_volume: "{{ item.0 }}"
nics: "net-id={{ network_out.subnet.network_id }}"
key_name: ansible_key
region_name: ru-1
with_together:
- "{{ volume|json_query('results[].id') }}"
- "{{ servers }}"
register: created_servers
- name: Add hosts to inventory
add_host:
name: "{{ item }}"
ansible_host: "{{ item }}"
ansible_ssh_user: root
groups: just_created
with_items: "{{ created_servers|json_query('results[].openstack.accessIPv4') }}"
- pause:
seconds: 60
tasks:
...
- hosts: just_created
tasks:
- name: Ping all instances
ping:
register: results
debug: msg={{ results }}
- hosts: localhost
gather_facts: False
vars_files:
- example_vars.yaml
tasks:
- name: Delete flavor
os_nova_flavor:
state: absent
auth:
auth_url: https://api.selvpc.ru/identity/v3
username: "{{ username }}"
password: "{{ password }}"
project_name: "{{ project_name }}"
name: "{{ flavor.flavor.name }}"
region_name: ru-1
register: out
- name: Delete user
selvpc_users:
user_id: "{{ user_out.user.id }}"
state: absent
register: out
- name: Delete project
selvpc_projects:
project_id: "{{ project_out.project.id }}"
state: absent
register: out
$ ansible-playbook example.yaml

TASK [Ping all instances]
*************************************************************************
ok: [95.213.234.211]
ok: [95.213.234.212]
ok: [95.213.234.210]
TASK [debug]
*************************************************************************
ok: [95.213.234.210] => {
"msg": {
"changed": false,
"ping": "pong"
}
}
ok: [95.213.234.211] => {
"msg": {
"changed": false,
"ping": "pong"
}
}
ok: [95.213.234.212] => {
"msg": {
"changed": false,
"ping": "pong"
}
}
PLAY [localhost]
*************************************************************************
TASK [Delete flavor]
*************************************************************************
changed: [localhost]
TASK [Delete user]
*************************************************************************
changed: [localhost]
TASK [Delete project]
*************************************************************************
changed: [localhost]
PLAY RECAP
*************************************************************************
95.213.234.210 : ok=3 changed=0 unreachable=0 failed=0
95.213.234.211 : ok=3 changed=0 unreachable=0 failed=0
95.213.234.212 : ok=3 changed=0 unreachable=0 failed=0
localhost : ok=25 changed=13 unreachable=0 failed=0
|
Метки: author rutskiy api блог компании селектел openstack vpc selectel selectel cloud howto |
[Перевод] Введение в процедурную анимацию |
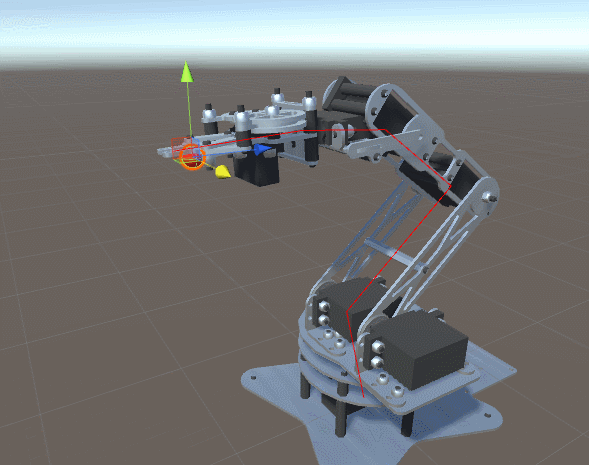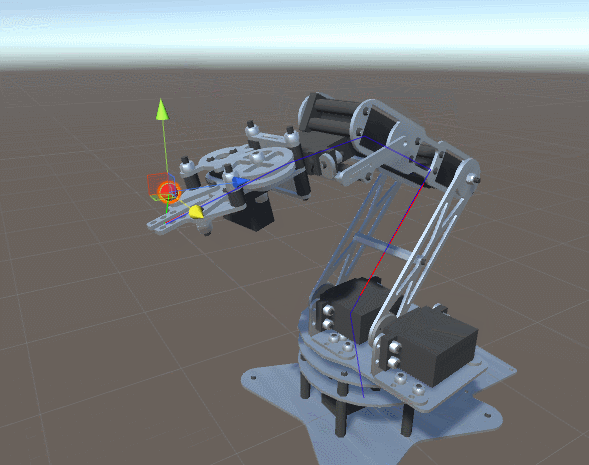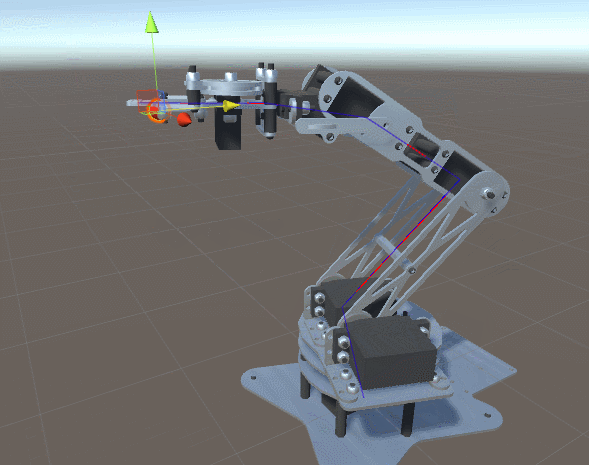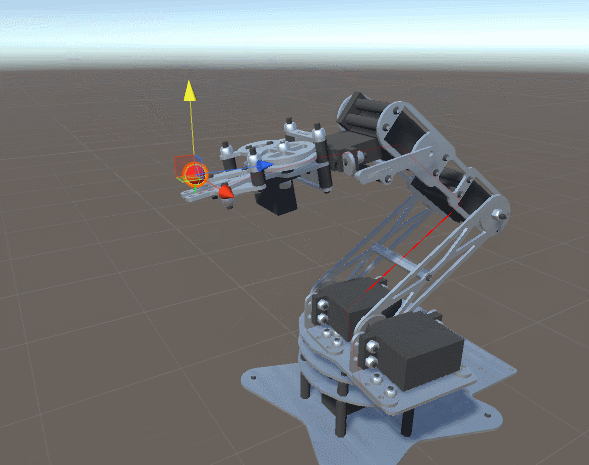





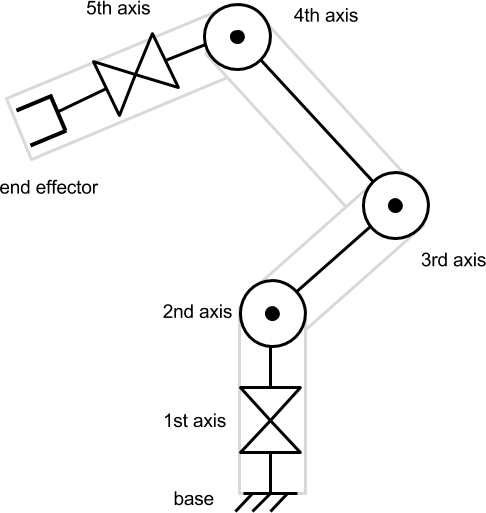
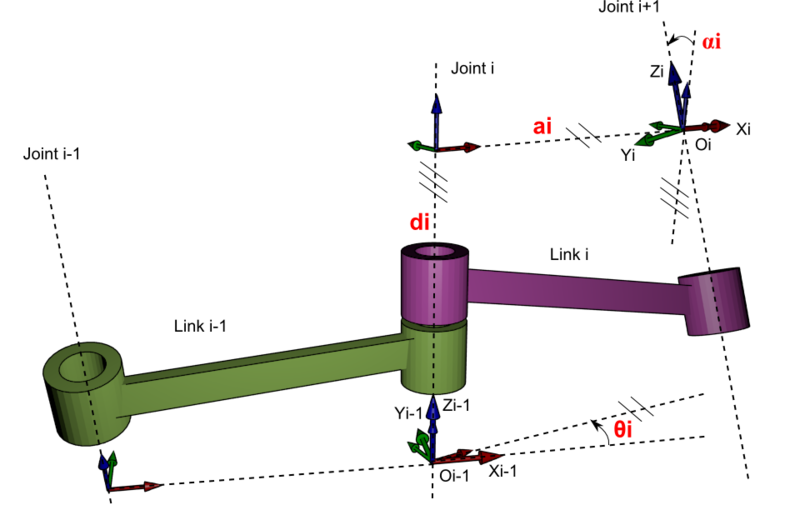
 на
на 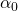 градусов. Он приводит к соответствующему перемещению всей цепочки сочленений и звеньев, прикреплённых к .
градусов. Он приводит к соответствующему перемещению всей цепочки сочленений и звеньев, прикреплённых к .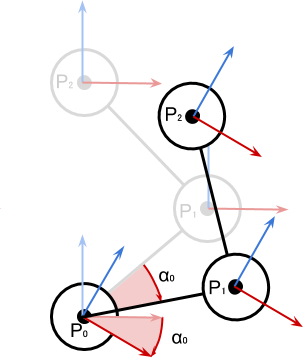
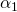 градусов.
градусов.
 определяет только , а на
определяет только , а на  воздействуют уже и , и . Система координат поворота (красная и синяя стрелки) ориентирована в соответствии с суммой поворотов более ранней цепи соединений, к которой она присоединена.
воздействуют уже и , и . Система координат поворота (красная и синяя стрелки) ориентирована в соответствии с суммой поворотов более ранней цепи соединений, к которой она присоединена. , как на схеме ниже:
, как на схеме ниже:
 не равен нулю, нам нужно просто повернуть вектор расстояния в точке опоры
не равен нулю, нам нужно просто повернуть вектор расстояния в точке опоры  вокруг на градусов:
вокруг на градусов: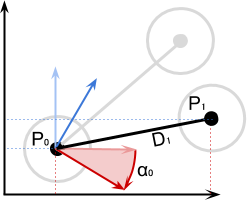
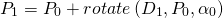
AngleAxis (документация Unity) без возни с тригонометрией.: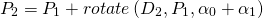

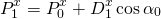
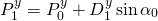
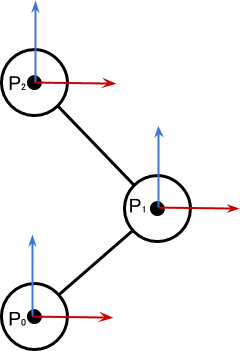
 на схеме представляют собой декартовы координаты, или
на схеме представляют собой декартовы координаты, или  -тое сочленение. Локальные углы, определяющие поворот относительно исходных положений, помечены как
-тое сочленение. Локальные углы, определяющие поворот относительно исходных положений, помечены как  .
. сочленения — это сумма поворотов всех предыдущих сочленений:
сочленения — это сумма поворотов всех предыдущих сочленений: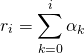 сочленения задаётся как:
сочленения задаётся как: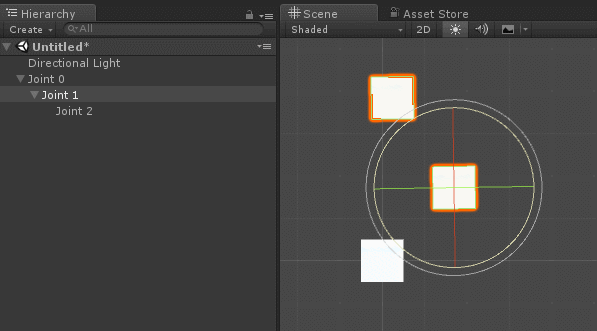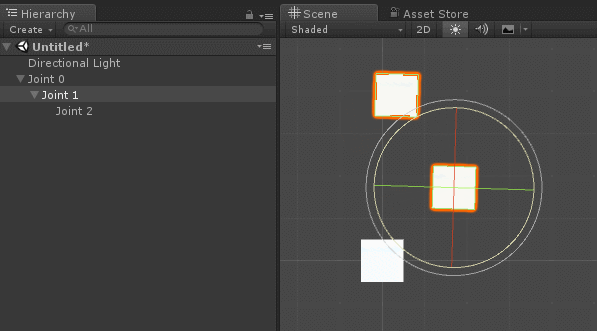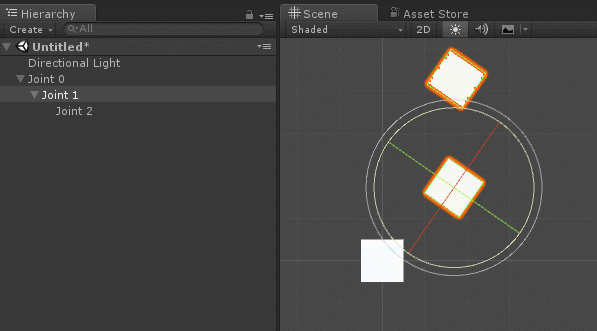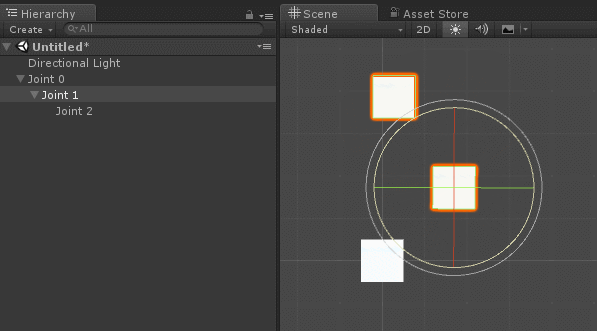
RobotJoint из следующего примера:using UnityEngine;
public class RobotJoint : MonoBehaviour
{
public Vector3 Axis;
public Vector3 StartOffset;
void Awake ()
{
StartOffset = transform.localPosition;
}
}Axis, которая принимает значение 1 для координаты относительно оси вращения. Если сочленение поворачивается по оси Y, то Axis будет иметь вид (0,1,0). Мы увидим, как это позволит нам избавиться от конструкций с IF.ForwardKinematics. Она получает массив angles чисел типа float. Имя говорит само за себя: angles[i] содержит значение локального поворота i-того сочленения. Функция возвращает положение конечного звена в глобальных координатах.public Vector3 ForwardKinematics (float [] angles)
{
...
}rotate реализуются через удобную функцию Quaternion.AngleAxis.Vector3 prevPoint = Joints[0].transform.position;
Quaternion rotation = Quaternion.identity;
for (int i = 1; i < Joints.Length; i++)
{
// Выполняет поворот вокруг новой оси
rotation *= Quaternion.AngleAxis(angles[i - 1], Joints[i - 1].Axis);
Vector3 nextPoint = prevPoint + rotation * Joints[i].StartOffset;
prevPoint = nextPoint;
}
return prevPoint;Quaternion.AngleAxis. Строка Quaternion.AngleAxis(angle, axis); создаёт кватернион, описывающий поворот вокруг оси axis на angle градусов. В этом контексте значение Axis может быть равно (1,0,0), (0,1,0) или (0,0,1), что обозначает, соответственно, X, Y или Z. Это объясняет, почему мы создали переменную Axis в классе RobotJoint.for переменная rotation умножается на текущий кватернион. Это значит, что она будет включать в себя все повороты всех сочленений.Vector3 nextPoint = prevPoint + rotation * Joints[i].StartOffset;|
Метки: author PatientZero разработка игр математика unity3d процедурные анимации инверсная кинематика прямая кинематика кватернионы углы эйлера |
Сравнение сервисов автоматизации контекстной рекламы (часть 2) |

Как я писал в первой части статьи-обзора сервисов автоматизации контекстной рекламы, если обзор наберёт более 50 плюсов, повешу вторую часть. Столько плюсов он не набрал, но, исходя из неподдельного интереса к теме, не поделиться второй частью исследования было бы не правильно. В этой части статьи подробно разобран функционал каждой из систем, а также выделены оригинальные решения в работе каждого. Надеюсь, вам будет интересно и полезно. Оценивайте и пишите комментарии.
Сервис «Рекомендатор»
Запускается при первом входе в систему, его можно запустить и позже.

Рекомендации подразделяются на критичные и важные, баллов нет, в отчете есть кнопки (Настроить, Редактировать) для немедленного выполнения рекомендаций.
При клике по ссылке обучение запускается «слайд-шоу», Каждый слайд — всплывающее окно. Слайды показываются рядом с рекомендациями, выданными для клиентской РК. Каждый слайд поясняет одну из рекомендаций.
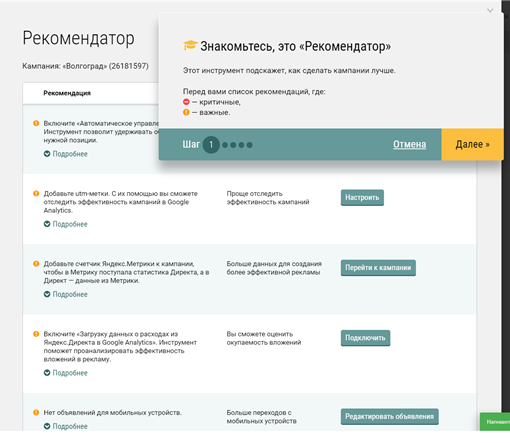
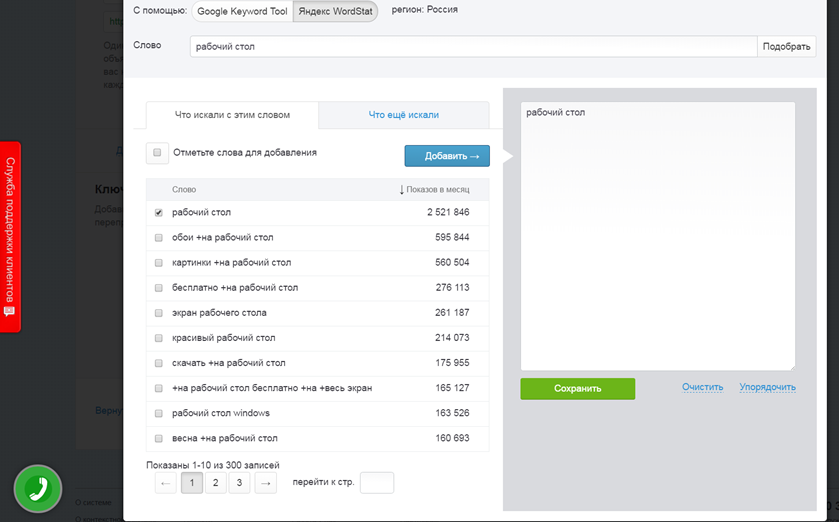
Работа с Wordstat.yandex.ru в интерфейсе Elama
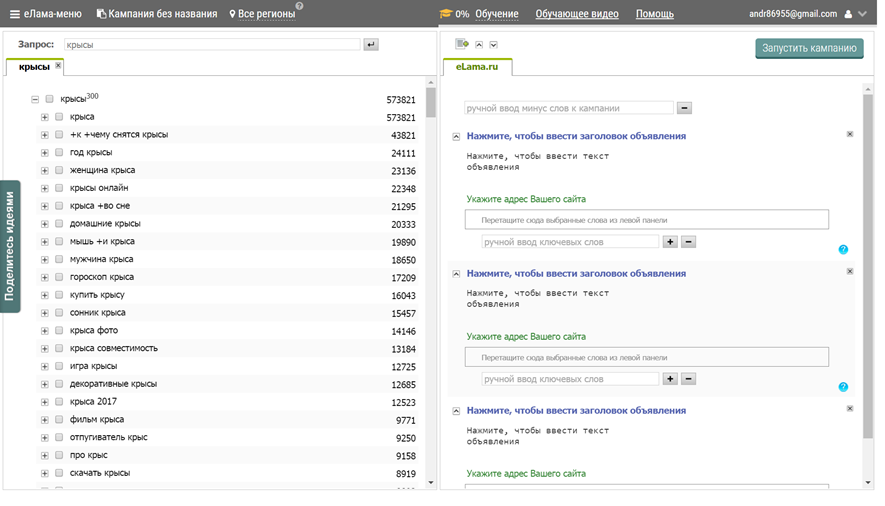
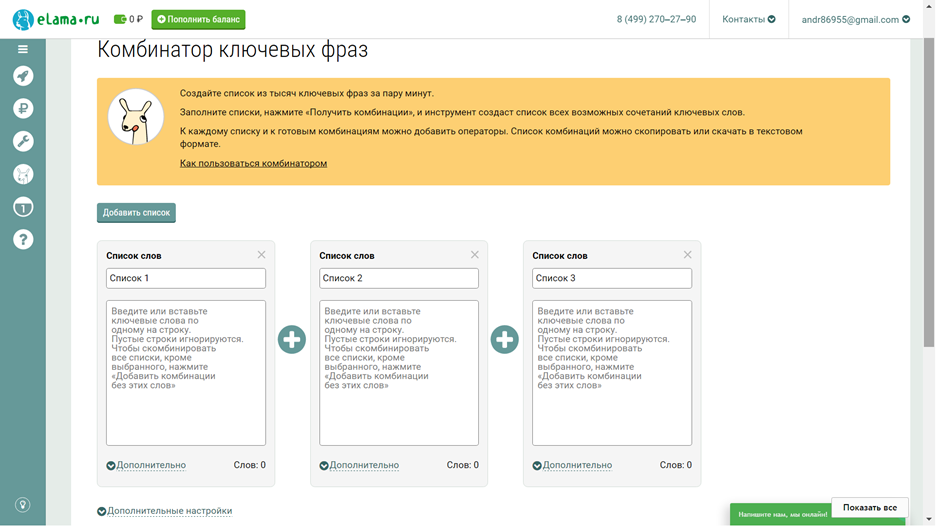
Комбинатор ключевых фраз: можно создать несколько списков слов, затем получить их комбинации.
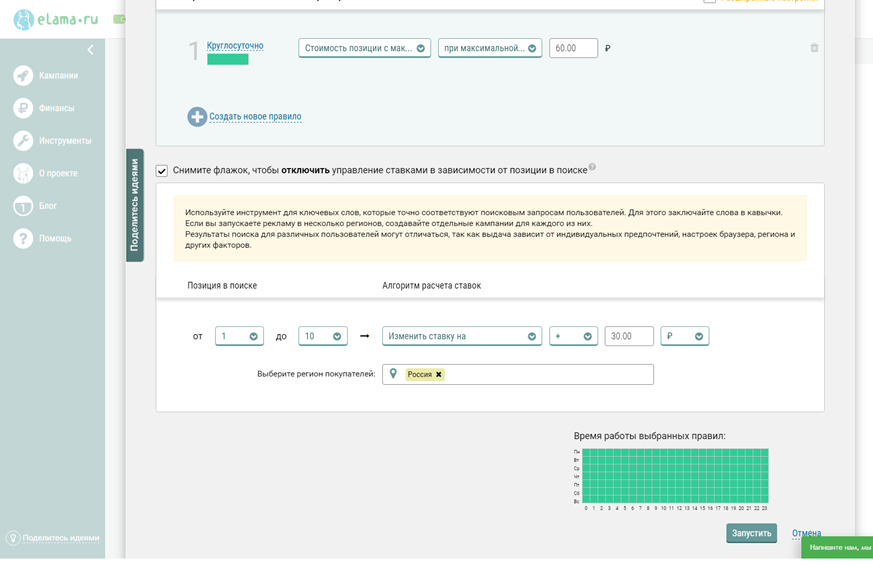
Управление ставками в зависимости от позиций сайта в поисковой выдаче
Другие особенности Elama
Подбор ключевиков с Яндекс WordStat и Google Keyword Tool
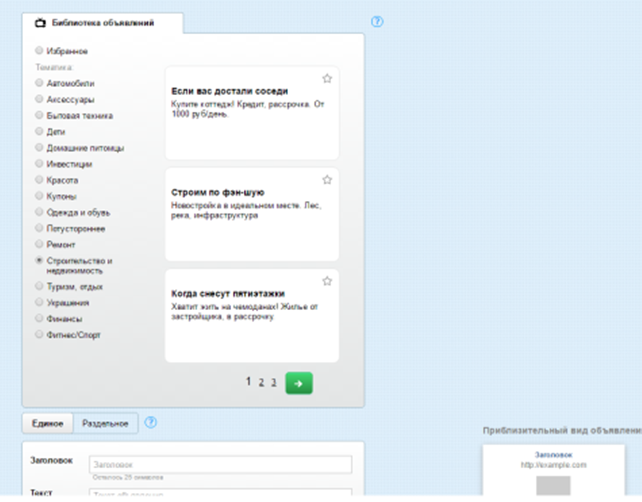
Бесплатная библиотека текстов объявлений
Бесплатная фототека

Магазин услуг

Другие особенности Aori
Несколько разных периодов в одной формуле
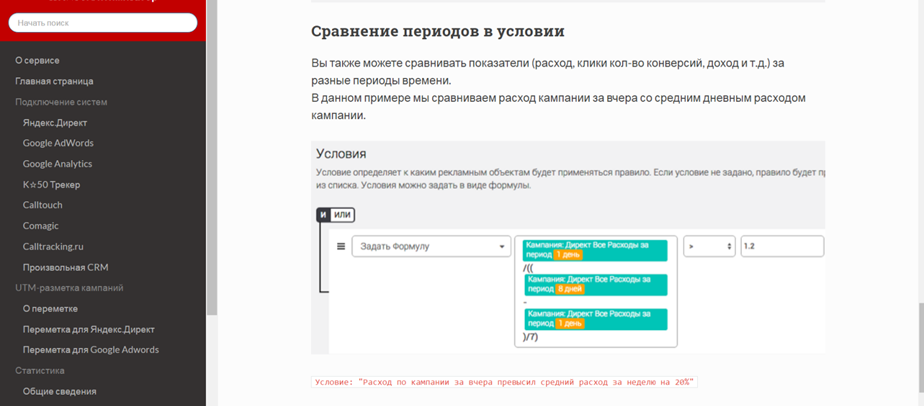
Другие особенности К50
Большой набор показателей, используемых в триггерах. Кроме стандартных показателей, присутствующих в других сервисах, используются:
Особенности генерации из YML у Alytics
Особенности генерации из YML у Origami
Особенности Origami
Особенности Marilyn

Оценка качества
У R-брокера мне понравился функционал, который называется «Оценка качества». Можно заказать такую оценку для рекламной кампании. Система выдает Excel файл с оценками по каждой фразе и с общими оценками по всей РК. В результате можно увидеть, какие недостатки есть у рекламной кампании. Например, в заголовке, тексте объявления или в быстрых ссылках мало слов из ключевой фразы, ссылка нерелевантна, нет минус-слов, посадочная страница долго загружается, у посадочной страницы высокий показатель отказов. Для каждой фразы выдается оценка (от «плохо» до «отлично»). Система даже предлагает свой вариант релевантной посадочной страницы с того же сайта. Для кампании выдаются 2 оценки: с учетом и без учета значимости отдельных фраз. Учет значимости означает следующее: чем больше доля фразы в кликах и расходах кампании, тем больше она влияет на суммарную оценку для кампании. Это правильно: если львиная доля расходов приходится на 2-3 некачественные фразы, то несколько сотен качественных объявлений, по которым никто не кликает, не спасут ситуацию.
Недостатком оценки качества от R-брокера является то, что в файле с отчетом мало пояснений, что означает каждый столбец. Правда, в разделе "Частые вопросы" мне удалось найти более подробные пояснения. Но хотелось бы получить всю информацию в файле с отчетом, а не искать ее самостоятельно.
Расчет R-max по CPC или CPO/CPA
Еще один любопытный функционал R-брокера – «Расчет R-max по CPC». Часто приходится решать такую задачу. Нужно чтобы стоимость клика (CPC) была близка к заданному значению. Какую ставку установить, чтобы добиться именно такой стоимости клика? Если выставить высокую ставку, клики будут слишком дорогими. Если назначить низкую ставку, купим дешевые клики, но кликов окажется слишком мало, план по трафику не будет выполнен. Директ не дает ответа на вопрос об оптимальной ставке, но «Расчет R-max по CPC» отвечает на этот вопрос. Можно выбрать ставку, которая обеспечит желаемую CPC. Система также дает прогноз, сколько будет получено кликов по этой цене. Если выяснится, что кликов слишком мало, можно скорректировать CPC и получить новую рекомендацию по ставке.
Аналогичным образом можно подобрать ставку (R-max), которая обеспечивает желаемую стоимость заказа (CPO) или стоимость достижения выбранной цели (CPA). R-брокер указывает в прогнозе количество заказов (или достигнутых целей), которое будет получено при данной ставке.
Автоуправление по CPC или CPA/CPO
Можно выставить ставки в кампании по рекомендациям R-брокера. Но реальная ситуация в Директе меняется ежедневно. Поэтому прогноз R-брокера нужно все время корректировать, после чего менять ставки. Чтобы не тратить время на эту однообразную работу, можно поставить кампанию на автоуправление. Тогда R-брокер будет сам корректировать ставки в Директе, чтобы обеспечить назначенное значение CPC или CPA/CPO.
Проекты
Удобный инструмент для работы с кампаниями в R-брокере – проекты. Можно объединить несколько кампаний в один проект и управлять этими кампаниями так, как будто все они объединены в одну кампанию. Например, можно создать набор сегментов, назначить ставки для проекта. Если нужно управлять сразу сотнями кампаний, это очень удобно. Не нужно сотни раз повторять одни и те же рутинные операции.
Индивидуальные тактики
В R-брокере можно использовать стандартные тактики вида "Только 3-я позиция в спецразмещении". Но многим специалистам по контекстной рекламе этого недостаточно. Нужны более сложные тактики. Например, если списываемая цена входа в спецразмещение превысила некоторый порог, нужно назначить ставку для входа на 1-е место в динамике. Если цена входа в спецразмещение ниже указанного порога, нужно выбрать другую ставку. Такую тактику можно создать, используя функционал создания индивидуальных тактик, имеющийся в R-брокере. Для создания тактик имеется удобный "Калькулятор". Можно создавать довольно сложные условия, используя операторы И и ИЛИ, а также различные ставки, имеющиеся в калькуляторе. Кроме ставок и списываемых цен различных позиций, можно использовать при создании тактик такие элементы как "текущая ставка", "прошлая ставка", "текущая списываемая цена", "прошлая списываемая цена".

Сегменты
В одной кампании имеется много фраз с разными показателями. Есть эффективные фразы с низкой стоимостью заказа и большим числом конверсий. Есть явно неэффективные фразы, по которым много кликали, но ничего не заказали. Есть "сомнительные" фразы, которые не принесли заказов, но по ним накоплено мало статистики, поэтому неизвестно, чего от них ждать. Некоторые из них могут оказаться эффективными, а другие — нет. Очевидно, что не следует назначать всем этим фразам одинаковые ставки. Поэтому разным категориям фраз следует назначить разные тактики. Состав этих категорий ежедневно меняется, так как фразы перемещаются из одной категории в другую по мере накопления статистики. Но в R-брокере не нужно вручную распределять фразы по категориям. Для этого имеется функционал "Сегменты". Пользователь может создать несколько сегментов, настроить условия для каждого сегмента (например, больше 3-х транзакций по фразе за последние 90 дней при стоимости заказа меньше 1000 руб.) Для каждого сегмента можно назначить ставку или тактику. После каждого обновления статистики R-брокер проверяет условия сегментов и при необходимости переводит фразу в другой сегмент.
|
Метки: author andreenkoff контекстная реклама |
Видео-инструкция по Check Point Security CheckUP R80.10. Аудит безопасности сети |

|
|