Автоэнкодеры в Keras, Часть 5: GAN(Generative Adversarial Networks) и tensorflow |
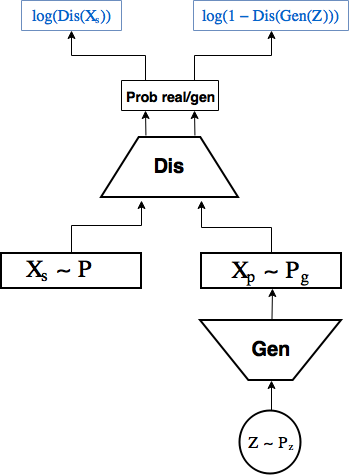
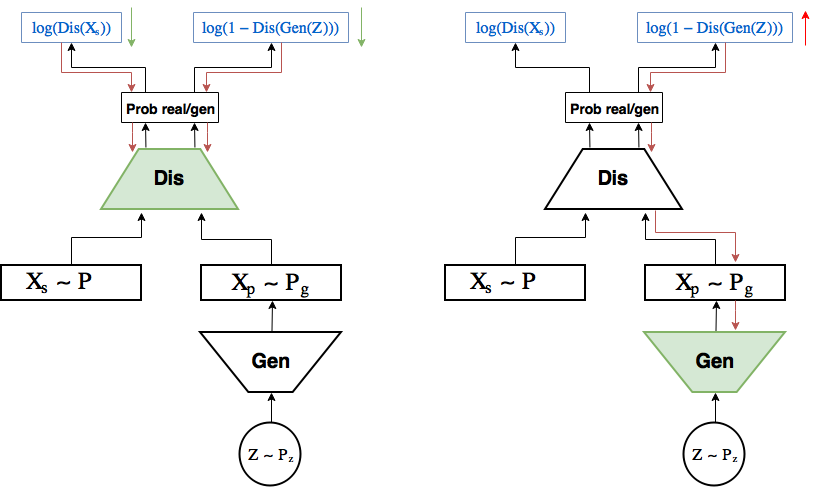
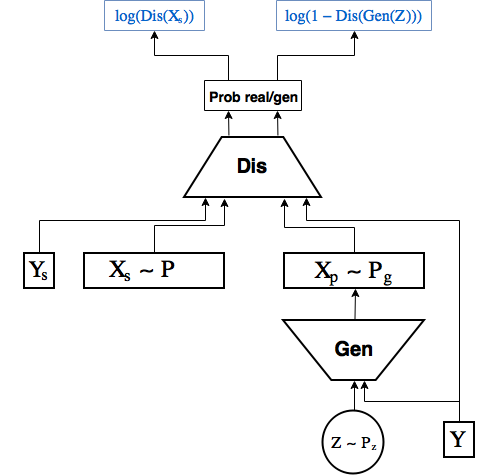
При заданном генераторе оптимальный дискриминатор выдает вероятность что почти очевидно, предлагаю задуматься об этом немножно.

from IPython.display import clear_output
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from keras.layers import Dropout, BatchNormalization, Reshape, Flatten, RepeatVector
from keras.layers import Lambda, Dense, Input, Conv2D, MaxPool2D, UpSampling2D, concatenate
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Model, load_model
from keras.datasets import mnist
from keras.utils import to_categorical
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test .astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
y_train_cat = to_categorical(y_train).astype(np.float32)
y_test_cat = to_categorical(y_test).astype(np.float32)
from keras import backend as K
import tensorflow as tf
sess = tf.Session()
K.set_session(sess)
batch_size = 256
batch_shape = (batch_size, 28, 28, 1)
latent_dim = 2
num_classes = 10
dropout_rate = 0.3
def gen_batch(x, y):
n_batches = x.shape[0] // batch_size
while(True):
for i in range(n_batches):
yield x[batch_size*i: batch_size*(i+1)], y[batch_size*i: batch_size*(i+1)]
idxs = np.random.permutation(y.shape[0])
x = x[idxs]
y = y[idxs]
train_batches_it = gen_batch(x_train, y_train_cat)
test_batches_it = gen_batch(x_test, y_test_cat)
x_ = tf.placeholder(tf.float32, shape=(None, 28, 28, 1), name='image')
y_ = tf.placeholder(tf.float32, shape=(None, num_classes), name='labels')
z_ = tf.placeholder(tf.float32, shape=(None, latent_dim), name='z')
img = Input(tensor=x_)
lbl = Input(tensor=y_)
z = Input(tensor=z_)
with tf.variable_scope('generator'):
x = concatenate([z, lbl])
x = Dense(7*7*64, activation='relu')(x)
x = Dropout(dropout_rate)(x)
x = Reshape((7, 7, 64))(x)
x = UpSampling2D(size=(2, 2))(x)
x = Conv2D(64, kernel_size=(5, 5), activation='relu', padding='same')(x)
x = Dropout(dropout_rate)(x)
x = Conv2D(32, kernel_size=(3, 3), activation='relu', padding='same')(x)
x = Dropout(dropout_rate)(x)
x = UpSampling2D(size=(2, 2))(x)
generated = Conv2D(1, kernel_size=(5, 5), activation='sigmoid', padding='same')(x)
generator = Model([z, lbl], generated, name='generator')
def add_units_to_conv2d(conv2, units):
dim1 = int(conv2.shape[1])
dim2 = int(conv2.shape[2])
dimc = int(units.shape[1])
repeat_n = dim1*dim2
units_repeat = RepeatVector(repeat_n)(lbl)
units_repeat = Reshape((dim1, dim2, dimc))(units_repeat)
return concatenate([conv2, units_repeat])
with tf.variable_scope('discrim'):
x = Conv2D(128, kernel_size=(7, 7), strides=(2, 2), padding='same')(img)
x = add_units_to_conv2d(x, lbl)
x = LeakyReLU()(x)
x = Dropout(dropout_rate)(x)
x = MaxPool2D((2, 2), padding='same')(x)
l = Conv2D(128, kernel_size=(3, 3), padding='same')(x)
x = LeakyReLU()(l)
x = Dropout(dropout_rate)(x)
h = Flatten()(x)
d = Dense(1, activation='sigmoid')(h)
discrim = Model([img, lbl], d, name='Discriminator')
generated_z = generator([z, lbl])
discr_img = discrim([img, lbl])
discr_gen_z = discrim([generated_z, lbl])
gan_model = Model([z, lbl], discr_gen_z, name='GAN')
gan = gan_model([z, lbl])
log_dis_img = tf.reduce_mean(-tf.log(discr_img + 1e-10))
log_dis_gen_z = tf.reduce_mean(-tf.log(1. - discr_gen_z + 1e-10))
L_gen = -log_dis_gen_z
L_dis = 0.5*(log_dis_gen_z + log_dis_img)
optimizer_gen = tf.train.RMSPropOptimizer(0.0003)
optimizer_dis = tf.train.RMSPropOptimizer(0.0001)
# Переменные генератора и дискриминаторы (отдельно) для оптимизаторов
generator_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "generator")
discrim_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, "discrim")
step_gen = optimizer_gen.minimize(L_gen, var_list=generator_vars)
step_dis = optimizer_dis.minimize(L_dis, var_list=discrim_vars)
sess.run(tf.global_variables_initializer())
# Шаг обучения генератора
def step(image, label, zp):
l_dis, _ = sess.run([L_dis, step_gen], feed_dict={z:zp, lbl:label, img:image, K.learning_phase():1})
return l_dis
# Шаг обучения дискриминатора
def step_d(image, label, zp):
l_dis, _ = sess.run([L_dis, step_dis], feed_dict={z:zp, lbl:label, img:image, K.learning_phase():1})
return l_dis
# Массивы, в которые будем сохранять результаты, для последующей визуализации
figs = [[] for x in range(num_classes)]
periods = []
save_periods = list(range(100)) + list(range(100, 1000, 10))
n = 15 # Картинка с 15x15 цифр
from scipy.stats import norm
# Так как сэмплируем из N(0, I), то сетку узлов, в которых генерируем цифры, берем из обратной функции распределения
grid_x = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
grid_y = norm.ppf(np.linspace(0.05, 0.95, n))
def draw_manifold(label, show=True):
# Рисование цифр из многообразия
figure = np.zeros((28 * n, 28 * n))
input_lbl = np.zeros((1, 10))
input_lbl[0, label] = 1.
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.zeros((1, latent_dim))
z_sample[:, :2] = np.array([[xi, yi]])
x_generated = sess.run(generated_z, feed_dict={z:z_sample, lbl:input_lbl, K.learning_phase():0})
digit = x_generated[0].squeeze()
figure[i * 28: (i + 1) * 28,
j * 28: (j + 1) * 28] = digit
if show:
# Визуализация
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys')
plt.grid(False)
ax = plt.gca()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
return figure
n_compare = 10
def on_n_period(period):
clear_output() # Не захламляем output
# Рисование многообразия для рандомного y
draw_lbl = np.random.randint(0, num_classes)
print(draw_lbl)
for label in range(num_classes):
figs[label].append(draw_manifold(label, show=label==draw_lbl))
periods.append(period)
batches_per_period = 20 # Как часто сохранять картинки
k_step = 5 # Количество шагов, которые могут делать дискриминатор и генератор во внутреннем цикле
for i in range(5000):
print('.', end='')
# Достанем новый батч
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
# Шаги обучения дискриминатора
for j in range(k_step):
l_d = step_d(b0, b1, zp)
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
if l_d < 1.0:
break
# Шаги обучения генератора
for j in range(k_step):
l_d = step(b0, b1, zp)
if l_d > 0.4:
break
b0, b1 = next(train_batches_it)
zp = np.random.randn(batch_size, latent_dim)
# Периодическое рисование результата
if not i % batches_per_period:
period = i // batches_per_period
if period in save_periods:
on_n_period(period)
print(l_d)
from matplotlib.animation import FuncAnimation
from matplotlib import cm
import matplotlib
def make_2d_figs_gif(figs, periods, c, fname, fig, batches_per_period):
norm = matplotlib.colors.Normalize(vmin=0, vmax=1, clip=False)
im = plt.imshow(np.zeros((28,28)), cmap='Greys', norm=norm)
plt.grid(None)
plt.title("Label: {}\nBatch: {}".format(c, 0))
def update(i):
im.set_array(figs[i])
im.axes.set_title("Label: {}\nBatch: {}".format(c, periods[i]*batches_per_period))
im.axes.get_xaxis().set_visible(False)
im.axes.get_yaxis().set_visible(False)
return im
anim = FuncAnimation(fig, update, frames=range(len(figs)), interval=100)
anim.save(fname, dpi=80, writer='imagemagick')
for label in range(num_classes):
make_2d_figs_gif(figs[label], periods, label, "./figs4_5/manifold_{}.gif".format(label), plt.figure(figsize=(10,10)), batches_per_period)






















|
Метки: author iphysic обработка изображений машинное обучение математика алгоритмы python keras mnist deep learning machine learning gan |
Переход в двоичную систему |




|
Метки: author Schvepsss блог компании microsoft microsoft |
Как начинать тушить огонь до пожара или наш список общих принципов IT безопасности |

|
Метки: author MazayZaycev сетевые технологии серверное администрирование антивирусная защита it- инфраструктура ваня петя информационная защита превентивные меры |
Сравниваем #NotPetya и #Petya — реально ли расшифровать свои файлы? |
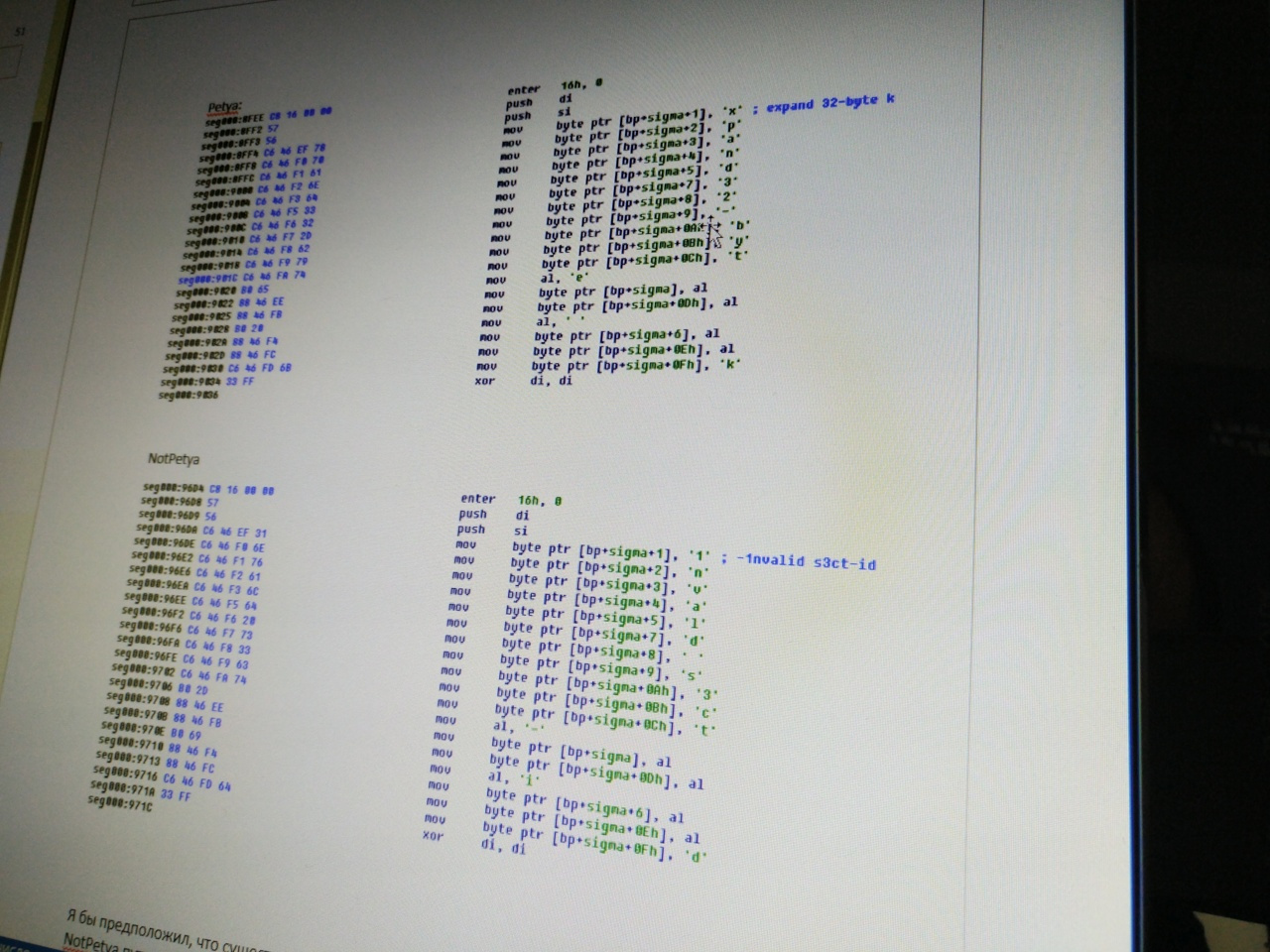


|
Метки: author ptsecurity информационная безопасность блог компании positive technologies notpetya petya вирус-вымогатель |
Использование GAP-анализа для выявления и согласования задач по проекту |
 Существует множество методов оценки эффективности работы компании в целом или на уровне определенных бизнес-процессов, которые включают в себя выявление «узких мест», описание непосредственно проблематики, выявление разницы между желаемым уровнем эффективности и реальной ситуацией. Я уже рассказывал о том, как на практике можно использовать использовать различные методы для выявления проблемных «узких мест», для планирования работы, для взаимодействия с заказчиком и демонстрации предложенных решений. Все это и многое другое вы можете прочитать в статьях Краткое описание BPMN с примером и Знакомство с нотацией IDEF0 и пример использования.
Существует множество методов оценки эффективности работы компании в целом или на уровне определенных бизнес-процессов, которые включают в себя выявление «узких мест», описание непосредственно проблематики, выявление разницы между желаемым уровнем эффективности и реальной ситуацией. Я уже рассказывал о том, как на практике можно использовать использовать различные методы для выявления проблемных «узких мест», для планирования работы, для взаимодействия с заказчиком и демонстрации предложенных решений. Все это и многое другое вы можете прочитать в статьях Краткое описание BPMN с примером и Знакомство с нотацией IDEF0 и пример использования.|
Метки: author JustRamil управление проектами управление продажами бизнес-модели gap- анализ gap графические нотации постановка задач консалтинговый проект |
Безопасная флешка. Миф или реальность |

Привет, Хабр!
Сегодня мы расскажем вам об одном из простых способов сделать наш мир немного безопаснее.
Флешка — привычный и надежный носитель информации. И несмотря на то, что в последнее время облачные хранилища все больше и больше их вытесняют, флешек все равно продается и покупается очень много. Все-таки не везде есть широкий и стабильный интернет-канал, а в каких-то местах и учреждениях интернет вообще может быть запрещен. Кроме того, нельзя забывать, что значительное количество людей по разным причинам с недоверием относятся к разного рода «облакам».
К флешкам мы все давно уже привыкли и многие из нас помнят, как сначала робко появилась поддержка usb mass storage в Windows 2000, а потом, немного погодя и в Windows Me. Многие понимают, насколько удобно сейчас пользоваться флешками и помнят, как раньше мы все мучались с ненадежными дискетами и непрактичными оптическими дисками.
Автор этих строк примерно в 2004-м году был счастливейшим обладателем симпатичного 128-мегабайтного носителя в моднейшем корпусе с металлической вставкой. Он был моим верным спутником и хранителем ценной для меня информации долгие годы, пока я наконец не потерял его вместе со связкой ключей, к которой он был прицеплен.
И, казалось бы, потеря ключей — это довольно рядовое событие, которое наверняка происходило с каждым, но меня оно заставило срочным образом поменять все замки в доме.
Все дело в том, что в дебрях файловой системы моей флешки лежали сканы моего паспорта, сделанные на всякий случай (кто же знает, когда могут пригодиться сканы паспорта?). А в сочетании с настоящими ключами от реальной квартиры, данные о прописке превращаются в заманчивую возможность даже для тех людей, которые раньше может быть и не помышляли о квартирных кражах.
В первую очередь — бережнее относиться к своим вещам, а во вторую — тому, что любую информацию, которую хоть каким-либо даже косвенным образом можно использовать во вред тебе, необходимо защищать.
Первый, самый очевидный вариант, флешки с аппаратной защитой и без внешнего программного управления, у них обычно клавиатура на корпусе — все в них вроде бы неплохо, но стоят они в большинстве своем совершенно диких денег, может быть за счет своей малосерийности, а может быть и жадности продавцов. Очевидно, ввиду высокой стоимости, особого распространения не нашли.
Второй вариант — навесная программная защита для обычной флешки.
Вариантов много (их можно легко нагуглить), но все они имеют явный плюс в виде почти нулевой стоимости и неизбежные ограничения, связанные с необходимостью установки специального программного обеспечения на компьютер. Но главный минус навесной защиты — это ее слабость.
В чем же слабость — спросите вы.
А дело в том, что любая шифрующая диски программа использует в качестве ключа шифрования последовательность полученную по особому алгоритму, например PBKDF, из пароля, который вы будете использовать для разблокировки. И что-то мне подсказывает, что вряд ли пароль, который придется часто набирать, будет длинным и сложным.
А если пароль короткий и простой, то подобрать его по словарю будет не таким уж и сложным делом.
Злоумышленник, завладев вашей зашифрованной флешкой даже на короткое время, может скопировать с нее криптоконтейнер. Вы так и будете думать, что данные по-прежнему в безопасности. А на самом деле все это время кто-то усиленно подбирает ключ к вашему контейнеру и с каждой минутой подходит все ближе к своей цели.
Поэтому, если вы не враг самому себе, то пароль должен быть «стойким». Но поскольку вам же потом этот же «стойкий» пароль придется многократно набирать — это начинает противоречить утверждению на предыдущей строке.
Что же делать — спросите вы.
Можно ли поставить между защищаемой флеш-памятью и компьютером аппаратную защиту так, чтобы это было удобно, надежно и более-менее доступно? Чтобы хотя бы можно было обойтись без монструозного корпуса с аппаратными кнопками.
Оказывается, да, можно, если вы российский производитель устройств электронной подписи (токенов и смарт-карт).
В устройствах Рутокен ЭЦП 2.0 Flash флеш-память подключена через специальный защищенный контроллер, прошивка которого, карточная операционная система Рутокен, целиком и полностью разработана специалистами компании «Актив» (карточная ОС Рутокен находится в реестре отечественного ПО Минкомсвязи).

В эту прошивку встроен специальный управляющий модуль, который контролирует потоки данных, входящие на флешку и выходящие из нее.
А так как в карточной операционной системе Рутокен испокон веков есть функциональность, обеспечивающая доступ к криптографическим ключам электронной подписи по PIN-кодам, мы реализовали в ней своего рода «вентиль», который может быть открыт, закрыт или открыт в одностороннем режиме (например, только для чтения). Вентиль этот как раз и управляется PIN-кодом. Не зная его, этот вентиль невозможно повернуть.
Теперь представьте, что такой вентиль по умолчанию находится в положении «закрыт». А чтобы открыть его, нужно предъявить PIN-код, который знаете только вы. Причем, вентиль автоматически закрывается при извлечении устройства из компьютера. И количество попыток ввода неправильного PIN-кода жестко ограничено. Причем, устройство защищено от физического взлома и извлечения флеш-карты.
Получается вполне безопасная, надежная и удобная система. Мы реализовали ее в виде небольшой управляющей программы, которая называется — «Рутокен Диск».
Флеш-память устройства Рутокен ЭЦП 2.0, на котором работает «Рутокен Диск», разбита на 2 области: одна служебная, для эмулирующего CD-ROM раздела с управляющей программой; вторая — для пользовательских данных.
При подключении такого устройства к компьютеру вы увидите два физических диска. CD-ROM раздел сразу доступен для чтения и автоматически монтируется, а в операционных системах Windows еще и всплывает симпатичное окошко.

Защищенный раздел выглядит как ридер карт памяти, но без вставленной в него карты, доступа к данным нет.
Однако, запустив приложение и введя простой PIN-код, вы моментально получаете доступ к своим файлам.



Сам токен уже много лет продается и возможность реализации защищенной флешки в нем была изначально. Но сейчас мы написали удобное приложение и если у кого-то из читателей уже есть такое устройство – программное обеспечение «Рутокен Диск» можно загрузить с нашего сайта и инсталлировать на устройство по инструкции.
Если вы доверяете свою информацию обычной флешке — храните ее, как зеницу ока. В случае же с Рутокеном ЭЦП 2.0 Flash и Рутокен.Диском — можно быть гораздо спокойнее за конфиденциальность своих данных. Хотя и полностью расслабляться никогда не стоит.
Заранее отвечу на некоторые вопросы, которые обязательно у кого-нибудь появятся:
Остальные вопросы, пожелания и замечания оставляйте в комментариях — постараемся ответить на все вопросы.
|
Метки: author aktiv_company криптография информационная безопасность блог компании «актив» флешка с паролем |
Baking Boards или секретный ингредиент идеальной Agile кухни |
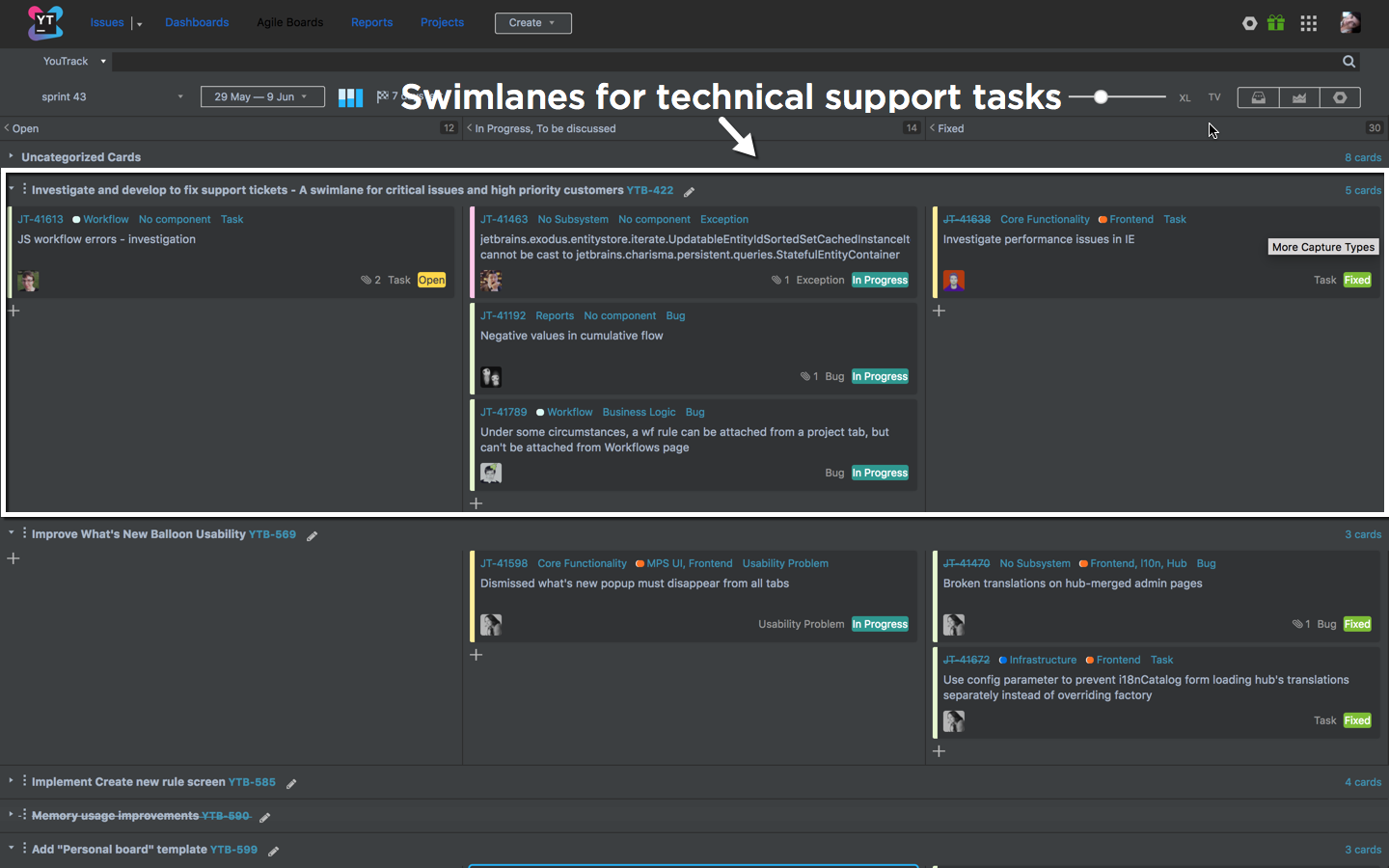
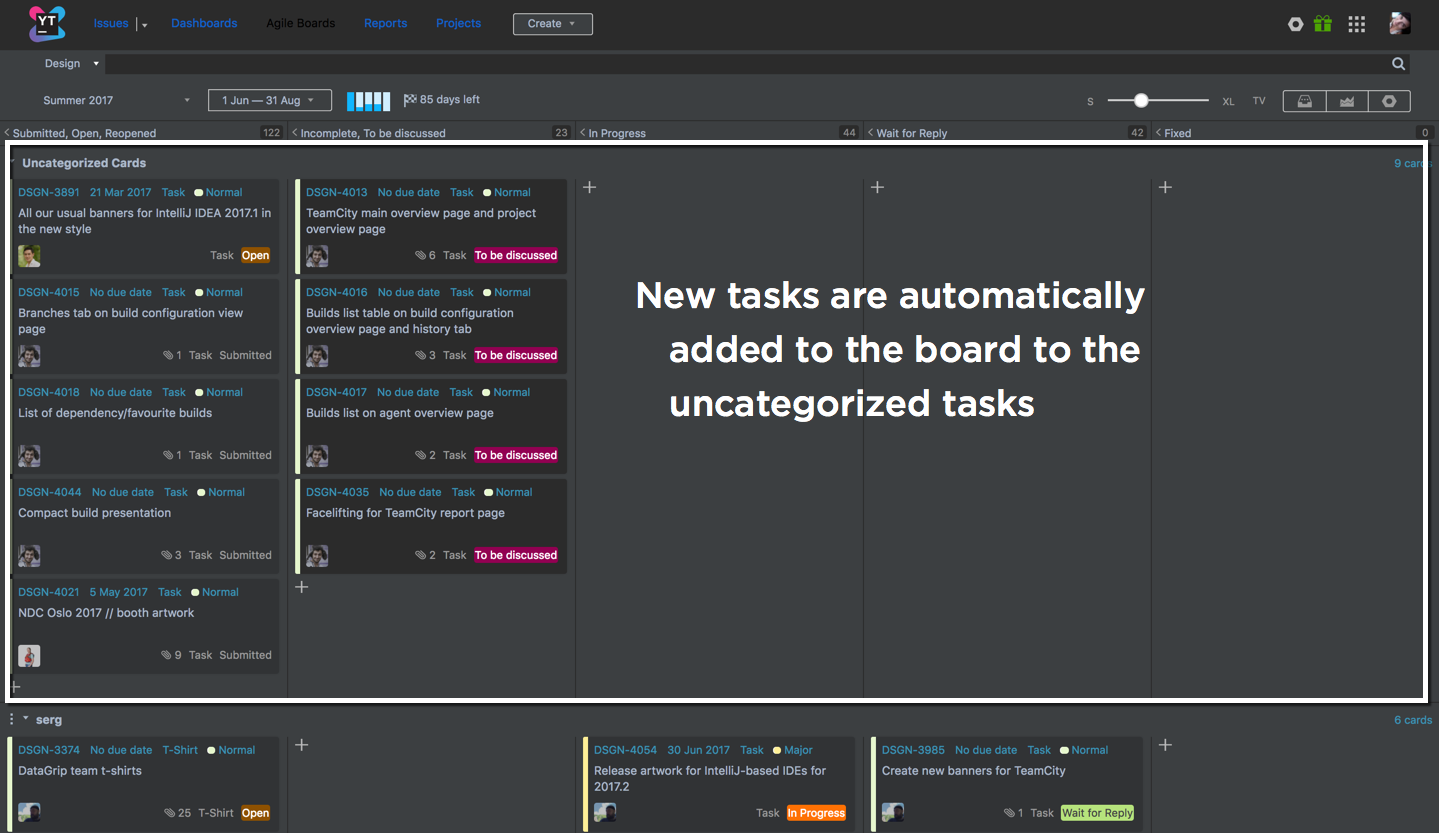
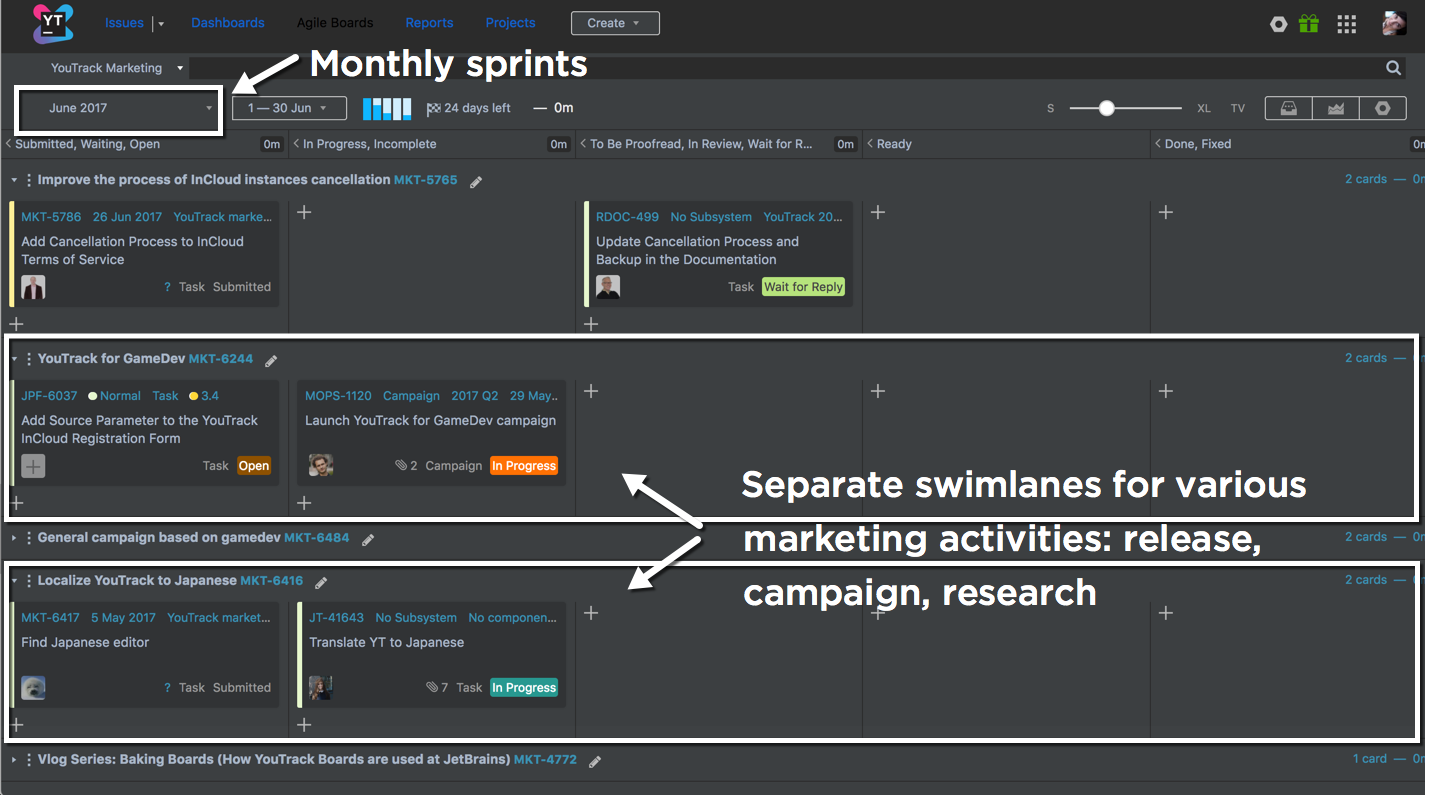
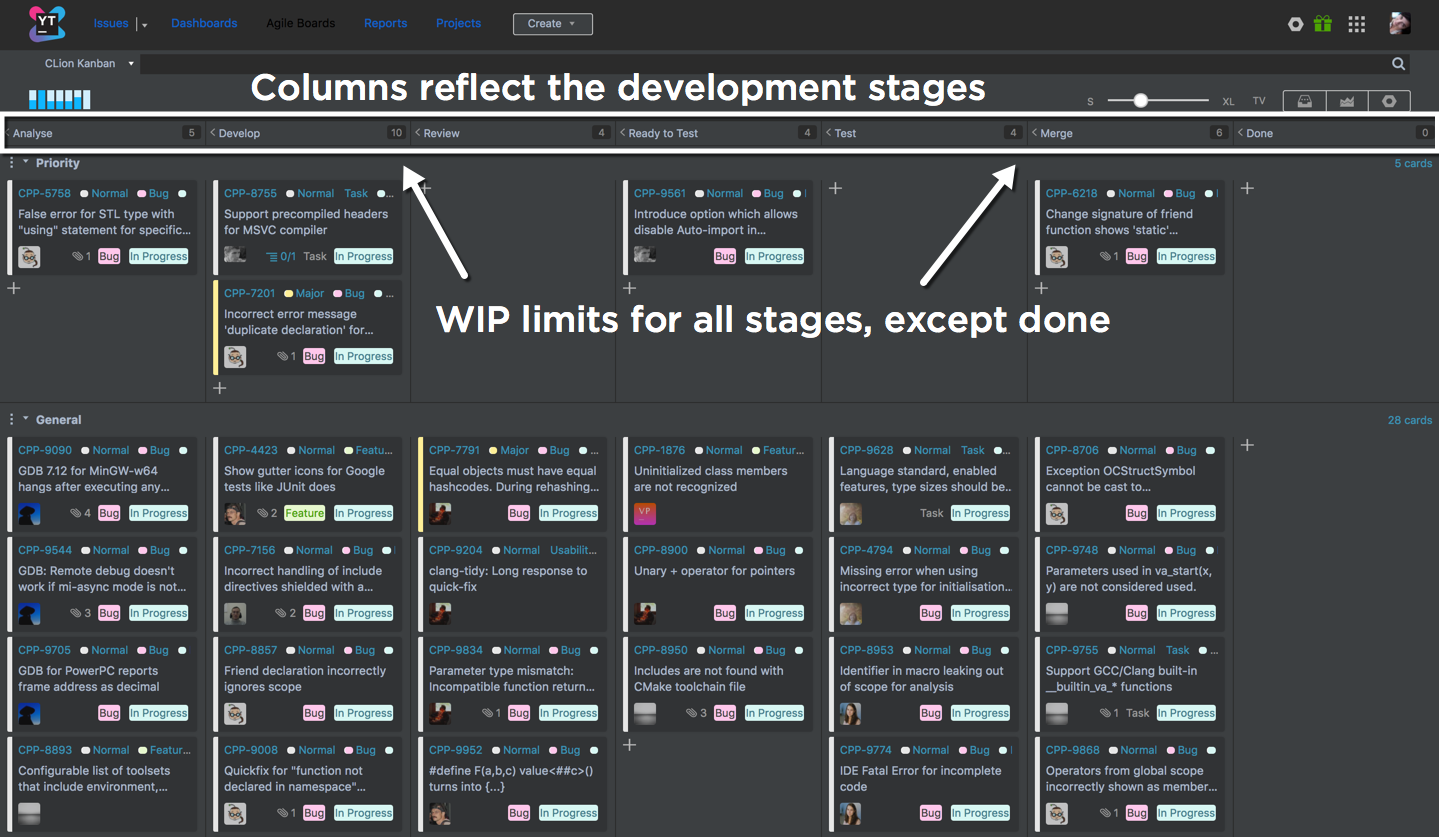

|
|
Дни открытых дверей перед запуском нового курса по Python |

|
Метки: author Tully программирование python блог компании отус otus otus.ru обучение |
[Из песочницы] Пример создания WCF-сервиса, работающего внутри службы Windows |
using System.ServiceModel;
namespace WCFMyServiceLibrary
{
[ServiceContract]
public interface IMyService
{
[OperationContract]
string Method1(string x);
[OperationContract]
string Method2(string x);
}
}
namespace WCFMyServiceLibrary
{
public class MyService : IMyService
{
public string Method1(string x)
{
string s = $"1 You entered: {x} = = = 1";
return s;
}
public string Method2(string x)
{
string s = $"2 you entered: {x} = = = 2";
return s;
}
}
}
using System.ServiceModel;
using System.ServiceModel.Description;
private ServiceHost service_host = null;
protected override void OnStart(string[] args)
{
if (service_host != null) service_host.Close();
string address_HTTP = "http://localhost:9001/MyService";
string address_TCP = "net.tcp://localhost:9002/MyService";
Uri[] address_base = { new Uri(address_HTTP), new Uri(address_TCP) };
service_host = new ServiceHost(typeof(WCFMyServiceLibrary.MyService), address_base);
ServiceMetadataBehavior behavior = new ServiceMetadataBehavior();
service_host.Description.Behaviors.Add(behavior);
BasicHttpBinding binding_http = new BasicHttpBinding();
service_host.AddServiceEndpoint(typeof(WCFMyServiceLibrary.IMyService), binding_http, address_HTTP);
service_host.AddServiceEndpoint(typeof(IMetadataExchange), MetadataExchangeBindings.CreateMexHttpBinding(), "mex");
NetTcpBinding binding_tcp = new NetTcpBinding();
binding_tcp.Security.Mode = SecurityMode.Transport;
binding_tcp.Security.Transport.ClientCredentialType = TcpClientCredentialType.Windows;
binding_tcp.Security.Message.ClientCredentialType = MessageCredentialType.Windows;
binding_tcp.Security.Transport.ProtectionLevel = System.Net.Security.ProtectionLevel.EncryptAndSign;
service_host.AddServiceEndpoint(typeof(WCFMyServiceLibrary.IMyService), binding_tcp, address_TCP);
service_host.AddServiceEndpoint(typeof(IMetadataExchange), MetadataExchangeBindings.CreateMexTcpBinding(), "mex");
service_host.Open();
}
protected override void OnStop()
{
if (service_host != null)
{
service_host.Close();
service_host = null;
}
}
using System.ServiceProcess;
public MyServiceInstaller()
{
// InitializeComponent();
serviceProcessInstaller1 = new ServiceProcessInstaller();
serviceProcessInstaller1.Account = ServiceAccount.LocalSystem;
serviceInstaller1 = new ServiceInstaller();
serviceInstaller1.ServiceName = "WindowsServiceHostForMyService";
serviceInstaller1.DisplayName = "WindowsServiceHostForMyService";
serviceInstaller1.Description = "WCF Service Hosted by Windows NT Service";
serviceInstaller1.StartType = ServiceStartMode.Automatic;
Installers.Add(serviceProcessInstaller1);
Installers.Add(serviceInstaller1);
}
C:\Windows\Microsoft.NET\Framework\v4.0.30319\InstallUtil.exe WindowsServiceHostForMyService.exe
SvcUtil http://localhost:9001/MyService /out:MyServiceProxy.cs /config:App.config
SvcUtil net.tcp://localhost:9002/MyService /out:MyServiceProxy.cs /config:App.config
using System.ServiceModel в файле формы.
namespace ServiceReference1
{
using System.Runtime.Serialization;
using System;
… затем идёт содержимое файла MyServiceProxy.cs …
и конечно, не забываем поставить завершающую скобку для namespace
} using ServiceReference1;
namespace ServiceReference1
{
using System.Runtime.Serialization;
using System;
[System.CodeDom.Compiler.GeneratedCodeAttribute("System.ServiceModel", "3.0.0.0")]
[System.ServiceModel.ServiceContractAttribute(ConfigurationName="IMyService")]
public interface IMyService
{
[System.ServiceModel.OperationContractAttribute(Action="http://tempuri.org/IMyService/Method1", ReplyAction="http://tempuri.org/IMyService/Method1Response")]
string Method1(string x);
[System.ServiceModel.OperationContractAttribute(Action="http://tempuri.org/IMyService/Method2", ReplyAction="http://tempuri.org/IMyService/Method2Response")]
string Method2(string x);
}
[System.CodeDom.Compiler.GeneratedCodeAttribute("System.ServiceModel", "3.0.0.0")]
public interface IMyServiceChannel : IMyService, System.ServiceModel.IClientChannel
{
}
[System.Diagnostics.DebuggerStepThroughAttribute()]
[System.CodeDom.Compiler.GeneratedCodeAttribute("System.ServiceModel", "3.0.0.0")]
public partial class MyServiceClient : System.ServiceModel.ClientBase, IMyService
{
public MyServiceClient()
{
}
public MyServiceClient(string endpointConfigurationName) :
base(endpointConfigurationName)
{
}
public MyServiceClient(string endpointConfigurationName, string remoteAddress) :
base(endpointConfigurationName, remoteAddress)
{
}
public MyServiceClient(string endpointConfigurationName, System.ServiceModel.EndpointAddress remoteAddress) :
base(endpointConfigurationName, remoteAddress)
{
}
public MyServiceClient(System.ServiceModel.Channels.Binding binding, System.ServiceModel.EndpointAddress remoteAddress) :
base(binding, remoteAddress)
{
}
public string Method1(string x)
{
return base.Channel.Method1(x);
}
public string Method2(string x)
{
return base.Channel.Method2(x);
}
}
} using System;
using System.ServiceModel;
using System.Windows.Forms;
using ServiceReference1;
namespace WindowsFormsApplication1
{
public partial class Form1 : Form
{
MyServiceClient client = null;
public Form1()
{
InitializeComponent();
}
private void Print(string text)
{
richTextBox1.Text += text + "\n\n";
richTextBox1.SelectionStart = richTextBox1.Text.Length;
richTextBox1.ScrollToCaret();
}
private void Print(Exception ex)
{
if (ex == null) return;
Print(ex.Message);
Print(ex.Source);
Print(ex.StackTrace);
}
private void Create_New_Client()
{
if (client == null)
try { Try_To_Create_New_Client(); }
catch (Exception ex)
{
Print(ex);
Print(ex.InnerException);
client = null;
}
else
{
Print("Cannot create a new client. The current Client is active.");
}
}
private void Try_To_Create_New_Client()
{
try
{
NetTcpBinding binding = new NetTcpBinding(SecurityMode.Transport);
binding.Security.Message.ClientCredentialType = MessageCredentialType.Windows;
binding.Security.Transport.ClientCredentialType = TcpClientCredentialType.Windows;
binding.Security.Transport.ProtectionLevel = System.Net.Security.ProtectionLevel.EncryptAndSign;
string uri = "net.tcp://192.168.1.2:9002/MyService";
EndpointAddress endpoint = new EndpointAddress(new Uri(uri));
client = new MyServiceClient(binding, endpoint);
client.ClientCredentials.Windows.ClientCredential.Domain = "";
client.ClientCredentials.Windows.ClientCredential.UserName = "Vasya";
client.ClientCredentials.Windows.ClientCredential.Password = "12345";
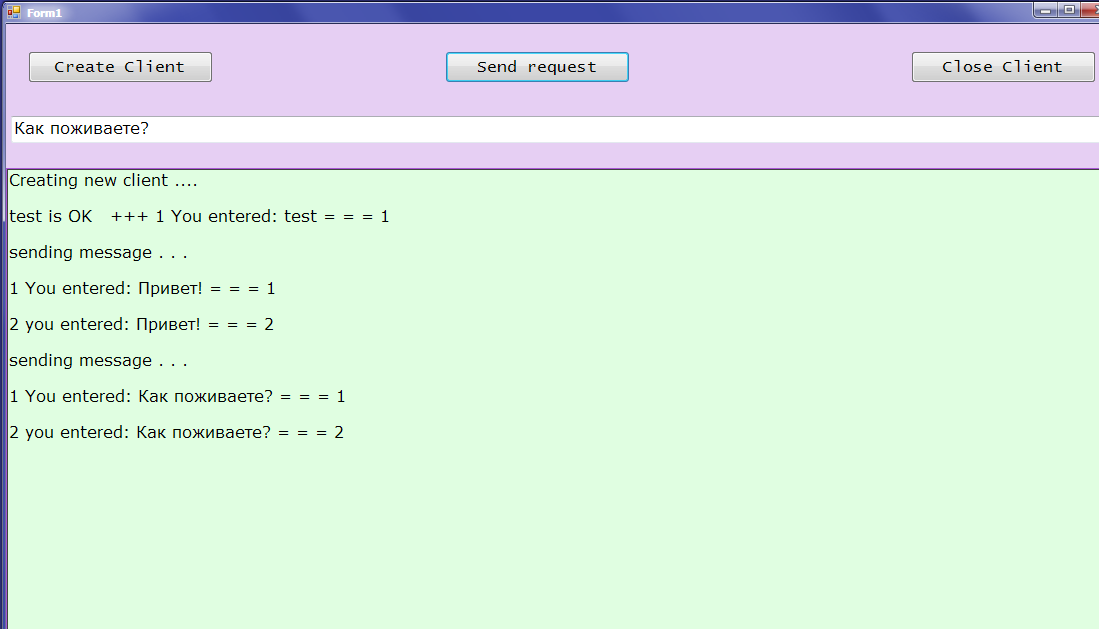
Print("Creating new client ....");
Print(endpoint.Uri.ToString());
Print(uri);
string test = client.Method1("test");
if (test.Length < 1)
{
throw new Exception("Проверка соединения не удалась");
}
else
{
Print("test is OK ! " + test);
}
}
catch (Exception ex)
{
Print(ex);
Print(ex.InnerException);
client = null;
}
}
private void btn_Start_Click(object sender, EventArgs e)
{
Create_New_Client();
}
private void btn_Send_Click(object sender, EventArgs e)
{
Print("sending message . . .");
string s = textBox1.Text;
string x = "";
if (client != null)
{
x = client.Method1(s);
Print(x);
x = client.Method2(s);
Print(x);
}
else
{
Print("Error! Client does not exist!");
}
}
private void btn_Close_Click(object sender, EventArgs e)
{
if (client != null)
{
Print("Closing a client ...");
client.Close();
client = null;
}
else
{
Print("Error! Client does not exist!");
}
this.Close();
}
}
}
http://localhost:9001/MyServicenet.tcp://localhost:9002/MyService|
Метки: author user4000 .net wcf windows service |
Что делать, если в PK Identity закончились значения? |

ALTER TABLE TableWithPKViolation ALTER COLUMN TableWithPKViolationId BIGINT;DBCC CHECKIDENT (TableWithPKViolation, - 2147483647, reseed) CREATE TABLE [dbo].[TableWithPKViolation](
[TableWithPKViolationId] [int] IDENTITY(1,1) NOT NULL
) ON [PRIMARY]
CREATE TABLE [dbo].[NewIds](
[NewId] [int] NOT NULL,
[DateUsedUtc] [datetime] NULL
) ON [PRIMARY]
CREATE PROCEDURE [dbo].[spNewIDPopulateInsertFromGaps]
@batchsize INT = 10000,
@startFrom INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX([NewId])
FROM dbo.NewIds;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT;
SELECT @maxId = MAX(TableWithPKViolationId)
FROM dbo.TableWithPKViolation;
WHILE @startId < @maxId
BEGIN
INSERT INTO dbo.NewIds
([NewId])
SELECT id
FROM (
SELECT TOP (@batchsize)
@startId + ROW_NUMBER()
OVER(ORDER BY TableWithPKViolationId) AS id
FROM dbo.TableWithPKViolation --any table where you have @batchsize rows
) AS genids
WHERE id < @maxId
AND NOT EXISTS
(
SELECT 1
FROM [dbo].[TableWithPKViolation] as Tb WITH (NOLOCK)
WHERE Tb.TableWithPKViolationId = genids.id
);
SET @rowscount = @@ROWCOUNT;
SET @startId = @startId + @batchsize;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
CREATE TABLE [dbo].[IntRange](
[Id] [int] NOT NULL
) ON [PRIMARY]
CREATE PROCEDURE [dbo].[spNewIDPopulateInsert]
@batchsize INT = 10000,
@startFrom INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX(id)
FROM dbo.IntRange;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT = 2147483647;
WHILE @rowscount = @batchsize
BEGIN
INSERT INTO dbo.IntRange
(id)
SELECT id
FROM (
SELECT TOP (@batchsize)
@startId + ROW_NUMBER()
OVER(ORDER BY TableWithPKViolationId) AS id
FROM dbo.TableWithPKViolation --any table where you have @batchsize rows
) AS genids
WHERE id < @maxId;
SET @rowscount = @@ROWCOUNT;
SET @startId = @startId + @rowscount;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
exec dbo.spNewIDPopulateInsert
@batchsize = 10000000
ALTER TABLE [dbo].[IntRange] ADD PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = OFF) ON [PRIMARY]
CREATE PROCEDURE [dbo].[spNewIDPopulateInsertFiltered]
@batchsize INT = 10000,
@startFrom INT = NULL,
@endTill INT = NULL
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @startFrom IS NULL
BEGIN
SELECT @startFrom = MAX([NewId])
FROM dbo.NewIds;
END;
DECLARE @startId INT = ISNULL(@startFrom,0);
DECLARE @rowscount INT = @batchsize;
DECLARE @maxId INT = ISNULL(@endTill,2147483647);
DECLARE @endId INT = @startId + @batchsize;
WHILE @startId < @maxId
BEGIN
INSERT INTO [NewIds]
([NewId])
SELECT IR.id
FROM [dbo].[IntRange] AS IR
WHERE IR.id >= @startId
AND IR.id < @endId
AND NOT EXISTS
(
SELECT 1
FROM [dbo].[TableWithPKViolation] as Tb WITH (NOLOCK)
WHERE Tb.TableWithPKViolationId = IR.id
);
SET @rowscount = @@ROWCOUNT;
SET @startId = @endId;
SET @endId = @endId + @batchsize;
IF @endId > @maxId
SET @endId = @maxId;
PRINT CONVERT(VARCHAR(50),GETDATE(),121)+' '+ CAST(@startId AS VARCHAR(50));
END
END
-----Run each part in separate window in parallel
-----
--part 1
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1, @endTill= 500000000
--end of part 1
--part 2
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 500000000, @endTill= 1000000000
--end of part 2
--part 3
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1000000000, @endTill= 1500000000
--end of part 3
--part 4
DECLARE @maxId INT
SELECT @maxId = MAX(TableWithPKViolationId)
FROM dbo.TableWithPKViolation
exec dbo.spNewIDPopulateInsertFiltered @batchsize = 10000000,
@startFrom = 1500000000, @endTill= @maxId
--end of part 4
ALTER TABLE [dbo].[NewIds] ADD CONSTRAINT [PK_NewIds] PRIMARY KEY CLUSTERED
(
[NewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [IX_NewIds_DateUsedUtc] ON [dbo].[NewIds]
(
[DateUsedUtc] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = OFF)
GO
ALTER TABLE [dbo].[NewIds] SET ( LOCK_ESCALATION = DISABLE )
GO
declare @maxId INT
select @maxId = max(TableWithPKViolationId)
from [dbo].[TableWithPKViolation]
IF EXISTS (select 1 from [dbo].[NewIds] WHERE [NewId] > @maxId)
BEGIN
PRINT 'PROBLEM. Wait for cleanup';
declare @batchsize INT = 10000
DECLARE @rowcount int = @batchsize;
while @rowcount = @batchsize
begin
delete top (@batchsize)
from [dbo].[NewIds]
where DFVId > @maxId;
SET @rowcount = @@rowcount;
end;
END
ELSE
PRINT 'OK';
declare @command VARCHAR(4096),
@dbname VARCHAR(255),
@path VARCHAR(1024),
@filename VARCHAR(255),
@batchsize INT
SELECT @dbname = DB_NAME();
SET @path = 'D:\NewIds';
SET @filename = 'NewIds-'+@dbname+'.txt';
SET @batchsize = 10000000;
SET @command = 'bcp "['+@dbname+'].dbo.NewIds" out "'+@path+@filename+'" -c -t, -S localhost -T -b '+CAST(@batchsize AS VARCHAR(255));
PRINT @command
exec master..xp_cmdshell @command
create PROCEDURE [dbo].[spGetTableWithPKViolationIds]
@batchsize INT = 1
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
DECLARE @rowcount INT,
@now DATETIME = GETUTCDATE();
BEGIN TRAN
UPDATE TOP (@batchsize) dbo.NewIds
SET DateUsedUtc = @now
OUTPUT inserted.[NewId]
WHERE DateUsedUtc IS NULL;
SET @rowcount = @@ROWCOUNT;
IF @rowcount != @batchsize
BEGIN
DECLARE @msg NVARCHAR(2048);
SET @msg = 'TableWithPKViolationId out of ids. sp spGetTableWithPKViolationIds, table NewIds. '
+'Ids requested '
+ CAST(@batchsize AS NVARCHAR(255))
+ ', IDs available '
+ CAST(@rowcount AS NVARCHAR(255));
RAISERROR(@msg, 16,1);
ROLLBACK;
END
ELSE
BEGIN
COMMIT TRAN
END;
END
CREATE TABLE #tmp_Id (Id INT);
INSERT INTO #tmp_Id
EXEC spGetTableWithPKViolationIds @batchsize=@IDNumber;
SELECT @newVersionId = Id
FROM #tmp_Id;
SET IDENTITY_INSERT [dbo].[TableWithPKViolation] ON;
create PROCEDURE dbo.spCleanupNewIds @batchSize INT = 4999
AS
BEGIN
SET NOCOUNT ON
DECLARE @minId INT
DECLARE @maxId INT
SELECT @minId = Min([NewId]), @maxId = MAX([NewId])
FROM dbo.NewIds WITH (NOLOCK)
WHERE DateUsedUtc IS NOT NULL;
DECLARE @totRowCount INT = 0
DECLARE @rowCount INT = @batchSize
WHILE @rowcount = @batchsize
BEGIN
DELETE TOP (@batchsize)
FROM dbo.NewIds
WHERE DateUsedUtc IS NOT NULL AND [NewId] >= @minId AND [NewId] <= @maxId
SET @rowcount = @@ROWCOUNT
SET @totRowCount = @totRowCount + @rowcount
END
PRINT 'Total records cleaned up - ' + CAST(@totRowCount AS VARCHAR(100))
END
|
Метки: author KristinaMyLife sql microsoft sql server arithmetic overflow identity workaround sql server ужас |
[Перевод] Получаем фотографии NASA с Марса с помощью aiohttp |
pip install aiohttpfrom aiohttp import web
async def get_mars_photo(request):
return web.Response(text='A photo of Mars')
app = web.Application()
app.router.add_get('/', get_mars_photo, name='mars_photo')
web.run_app(app, host='127.0.0.1', port=8080)python nasa.py
pip install aiohttp-devtools
adev runserver -p 8080 nasa.py
import random
from aiohttp import web, ClientSession
from aiohttp.web import HTTPFound
NASA_API_KEY = 'DEMO_KEY'
ROVER_URL = 'https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos'
async def get_mars_image_url_from_nasa():
while True:
sol = random.randint(0, 1722)
params = {'sol': sol, 'api_key': NASA_API_KEY}
async with ClientSession() as session:
async with session.get(ROVER_URL, params=params) as resp:
resp_dict = await resp.json()
if 'photos' not in resp_dict:
raise Exception
photos = resp_dict['photos']
if not photos:
continue
return random.choice(photos)['img_src']
async def get_mars_photo(request):
url = await get_mars_image_url_from_nasa()
return HTTPFound(url)

async def get_mars_photo_bytes():
while True:
image_url = await get_mars_image_url_from_nasa()
async with ClientSession() as session:
async with session.get(image_url) as resp:
image_bytes = await resp.read()
if await validate_image(image_bytes):
break
return image_bytes
async def get_mars_photo(request):
image = await get_mars_photo_bytes()
return web.Response(body=image, content_type='image/jpeg')
pip install pillowimport io
from PIL import Image
async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024

async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024 and image.mode != 'L'


#!/usr/bin/env python3
import io
import random
from aiohttp import web, ClientSession
from aiohttp.web import HTTPFound
from PIL import Image
NASA_API_KEY = 'DEMO_KEY'
ROVER_URL = 'https://api.nasa.gov/mars-photos/api/v1/rovers/curiosity/photos'
async def validate_image(image_bytes):
image = Image.open(io.BytesIO(image_bytes))
return image.width >= 1024 and image.height >= 1024 and image.mode != 'L'
async def get_mars_image_url_from_nasa():
while True:
sol = random.randint(0, 1722)
params = {'sol': sol, 'api_key': NASA_API_KEY}
async with ClientSession() as session:
async with session.get(ROVER_URL, params=params) as resp:
resp_dict = await resp.json()
if 'photos' not in resp_dict:
raise Exception
photos = resp_dict['photos']
if not photos:
continue
return random.choice(photos)['img_src']
async def get_mars_photo_bytes():
while True:
image_url = await get_mars_image_url_from_nasa()
async with ClientSession() as session:
async with session.get(image_url) as resp:
image_bytes = await resp.read()
if await validate_image(image_bytes):
break
return image_bytes
async def get_mars_photo(request):
image = await get_mars_photo_bytes()
return web.Response(body=image, content_type='image/jpeg')
app = web.Application()
app.router.add_get('/', get_mars_photo, name='mars_photo')
web.run_app(app, host='127.0.0.1', port=8080)
|
Метки: author TyVik python aiohttp nasa asyncio photos |
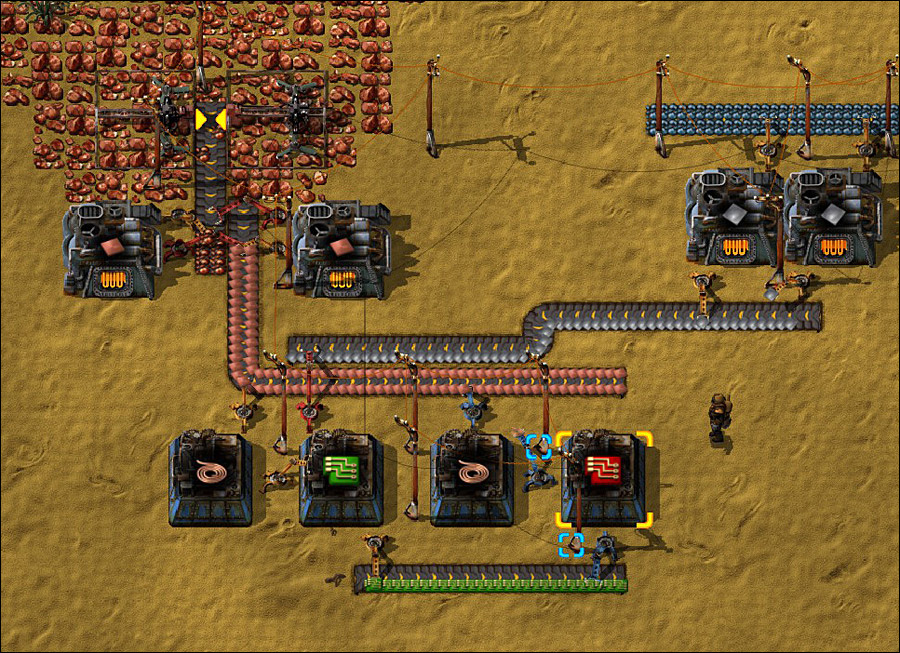
Интересный этюд Factorio: симулятор завода |











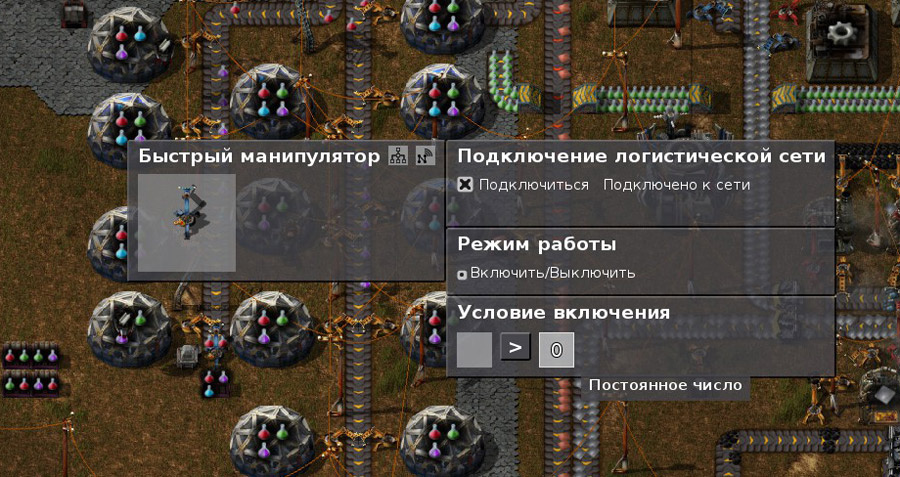
|
Метки: author Milfgard разработка игр блог компании мосигра factorio игра бета механика разбор обучение |
Дайджест IT событий на июль |




|
Метки: author EverydayTools хакатоны учебный процесс в it блог компании everyday tools конференции митапы баркемп it- сообщество |
Руководство: как использовать Python для алгоритмической торговли на бирже. Часть 2 |

# Import `numpy` as `np`
import numpy as np
# Assign `Adj Close` to `daily_close`
daily_close = aapl[['Adj Close']]
# Daily returns
daily_pct_change = daily_close.pct_change()
# Replace NA values with 0
daily_pct_change.fillna(0, inplace=True)
# Inspect daily returns
print(daily_pct_change)
# Daily log returns
daily_log_returns = np.log(daily_close.pct_change()+1)
# Print daily log returns
print(daily_log_returns)# Resample `aapl` to business months, take last observation as value
monthly = aapl.resample('BM').apply(lambda x: x[-1])
# Calculate the monthly percentage change
monthly.pct_change()
# Resample `aapl` to quarters, take the mean as value per quarter
quarter = aapl.resample("4M").mean()
# Calculate the quarterly percentage change
quarter.pct_change()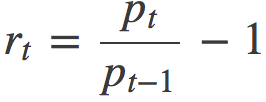 ,
,# Import matplotlib
import matplotlib.pyplot as plt
# Plot the distribution of `daily_pct_c`
daily_pct_change.hist(bins=50)
# Show the plot
plt.show()
# Pull up summary statistics
print(daily_pct_change.describe())
# Calculate the cumulative daily returns
cum_daily_return = (1 + daily_pct_change).cumprod()
# Print `cum_daily_return`
print(cum_daily_return)# Import matplotlib
import matplotlib.pyplot as plt
# Plot the cumulative daily returns
cum_daily_return.plot(figsize=(12,8))
# Show the plot
plt.show()
# Resample the cumulative daily return to cumulative monthly return
cum_monthly_return = cum_daily_return.resample("M").mean()
# Print the `cum_monthly_return`
print(cum_monthly_return)def get(tickers, startdate, enddate):
def data(ticker):
return (pdr.get_data_yahoo(ticker, start=startdate, end=enddate))
datas = map (data, tickers)
return(pd.concat(datas, keys=tickers, names=['Ticker', 'Date']))
tickers = ['AAPL', 'MSFT', 'IBM', 'GOOG']
all_data = get(tickers, datetime.datetime(2006, 10, 1), datetime.datetime(2012, 1, 1))
# Import matplotlib
import matplotlib.pyplot as plt
# Isolate the `Adj Close` values and transform the DataFrame
daily_close_px = all_data[['Adj Close']].reset_index().pivot('Date', 'Ticker', 'Adj Close')
# Calculate the daily percentage change for `daily_close_px`
daily_pct_change = daily_close_px.pct_change()
# Plot the distributions
daily_pct_change.hist(bins=50, sharex=True, figsize=(12,8))
# Show the resulting plot
plt.show()
# Import matplotlib
import matplotlib.pyplot as plt
# Plot a scatter matrix with the `daily_pct_change` data
pd.scatter_matrix(daily_pct_change, diagonal='kde', alpha=0.1,figsize=(12,12))
# Show the plot
plt.show()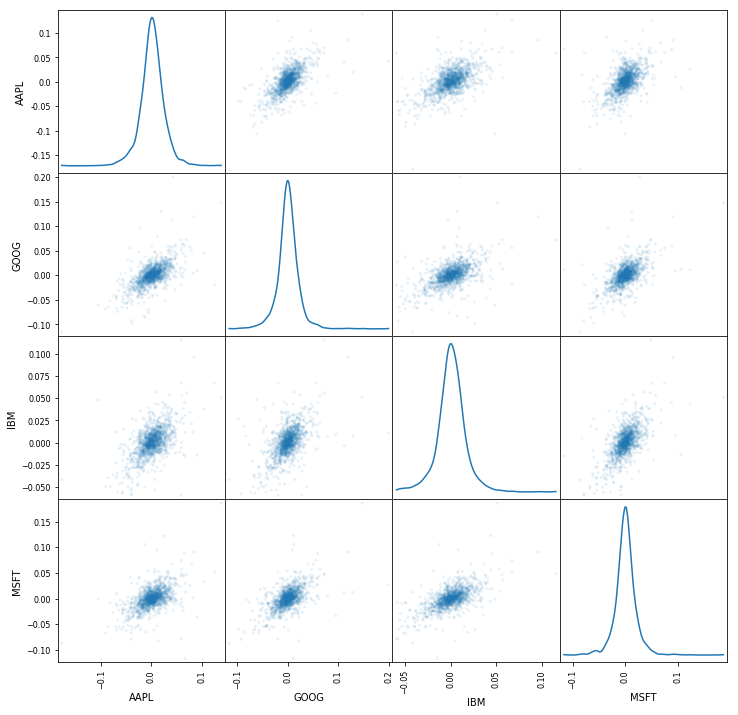
|
Метки: author itinvest python блог компании itinvest финансы разработка торговля на бирже |
Настройка Dockerfile для создания и запуска контейнера Docker с вашей программой на Go |
В данной заметке я рассматриваю способ компиляции Вашей программы внутри образа, на этапе его сборки. Это самый очевидный способ для начинающих.
#имя базового образа
FROM golang:latest
#создаем папку, где будет наша программа
RUN mkdir -p /go/src/app
#идем в папку
WORKDIR /go/src/app
#копируем все файлы из текущего пути к файлу Docker на вашей системе в нашу новую папку образа
COPY . /go/src/app
#скачиваем зависимые пакеты через скрипт, любезно разработанный командой docker
RUN go-wrapper download
#инсталлируем все пакеты и вашу программу
RUN go-wrapper install
#запускаем вашу программу через тот же скрипт, чтобы не зависеть от ее скомпилированного имени
#-web - это параметр, передаваемый вашей программе при запуске, таких параметров может быть сколько угодно
CMD ["go-wrapper", "run", "-web"]
#пробрасываем порт вашей программы наружу образа
EXPOSE 8000
docker build -t my-golang-app .docker ps -adocker run -it --rm --name my-running-app my-golang-app|
Метки: author pfihr go golang docker dockerfile |
Как создать альтернативу Google Disk и Dropbox за 3700 часов |
|
Метки: author AndyKy анализ и проектирование систем алгоритмы блог компании гк ланит sendfile ланит передача файлов файлообменник artezio |
[Перевод] Изучите все языки программирования |
Не будьте разработчиками шаблонного ширпотребного софта. Вместо этого, постарайтесь разрабатывать новые инструменты для пользователей и других программистов. Если провести историческую аналогию, то кем бы вам больше хотелось быть: работником за ткацким станком, ежедневно выполняющим рутинные операции или разработчиком новых моделей таких станков?

Выучите хотя бы 5 языков программирования. В ваш багаж знаний должен входить хотя бы один язык с классической абстракцией «классов» (это может быть Java или С++), один функциональный язык (вроде Lisp, ML или Haskell), один язык с поддержкой синтаксической абстракции (вроде Lisp), один язык декларативный язык (Prolog или шаблоны С++), один язык с продвинутой поддержкой параллелизма (Clofure или Go).

|
Метки: author tangro совершенный код программирование ненормальное программирование компиляторы блог компании инфопульс украина programming languages |
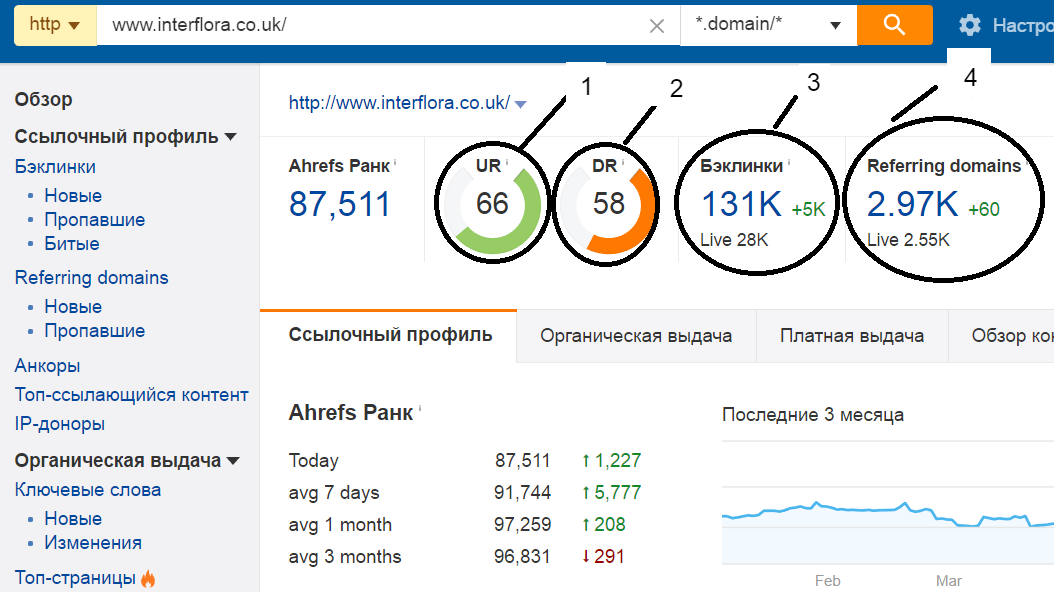
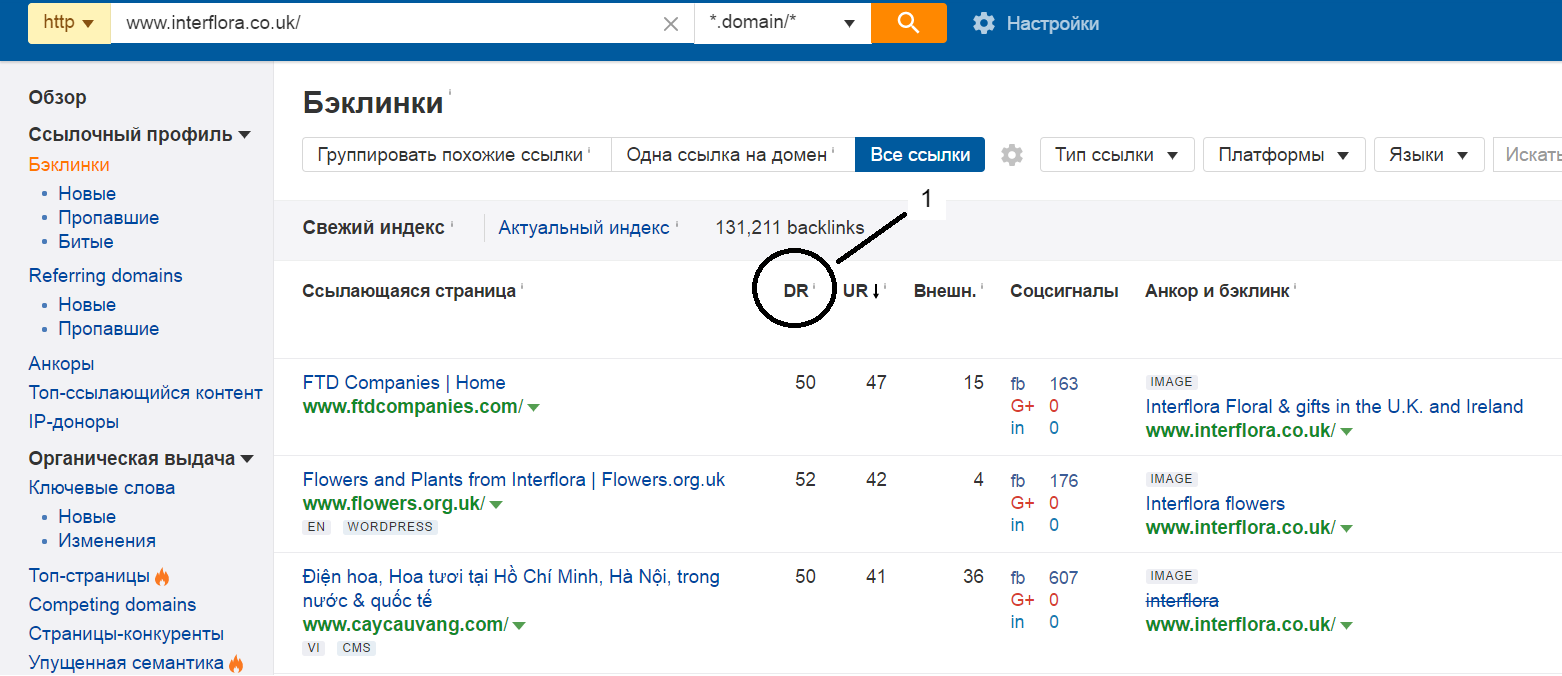
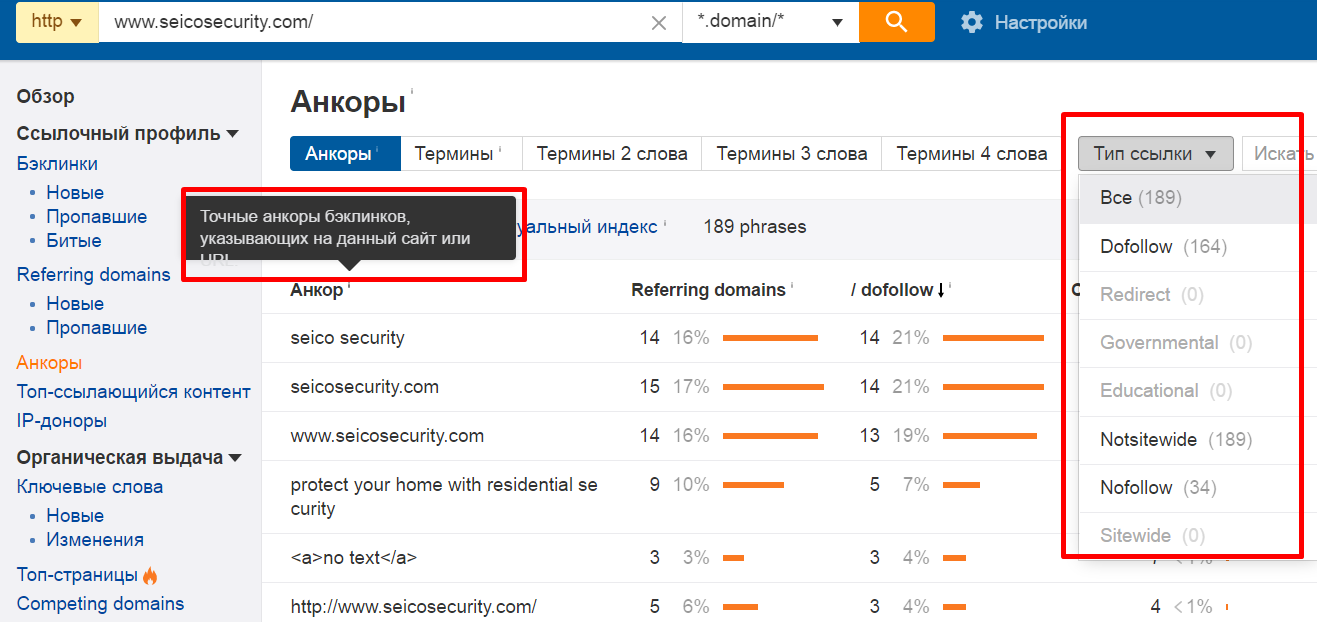
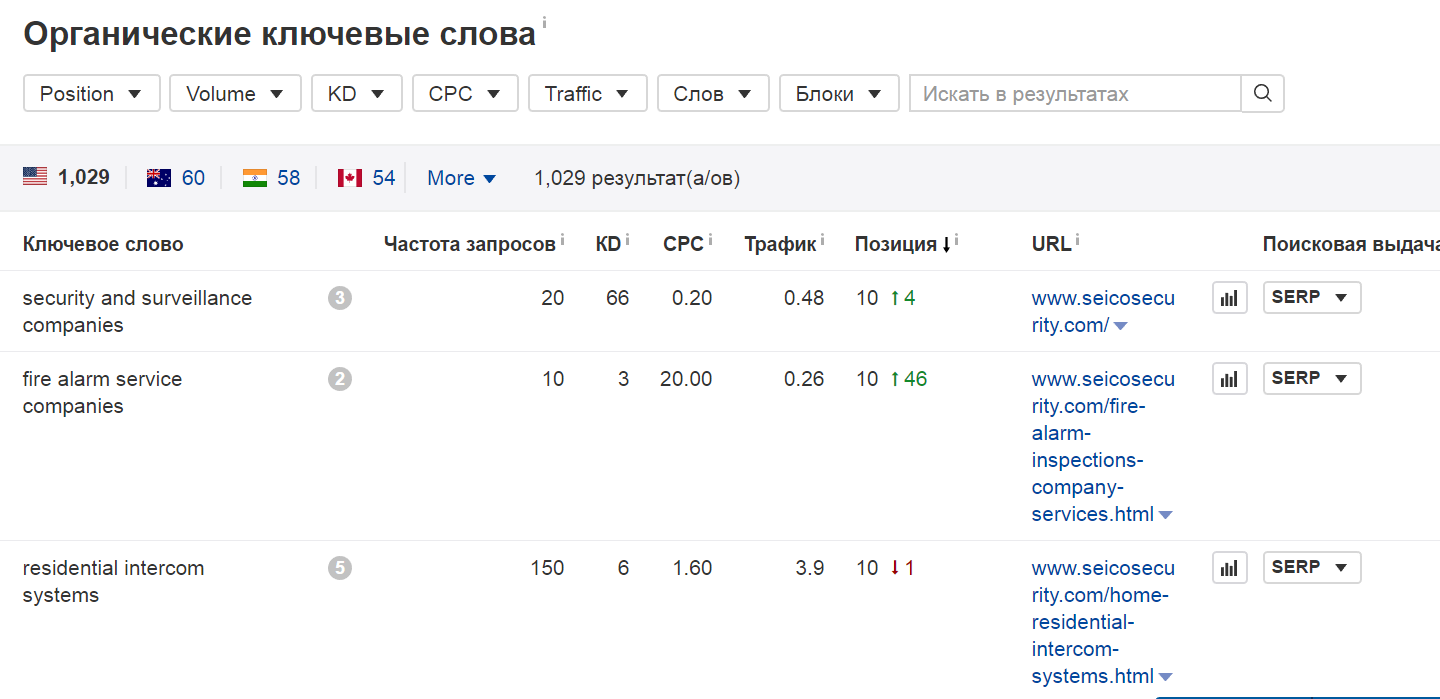
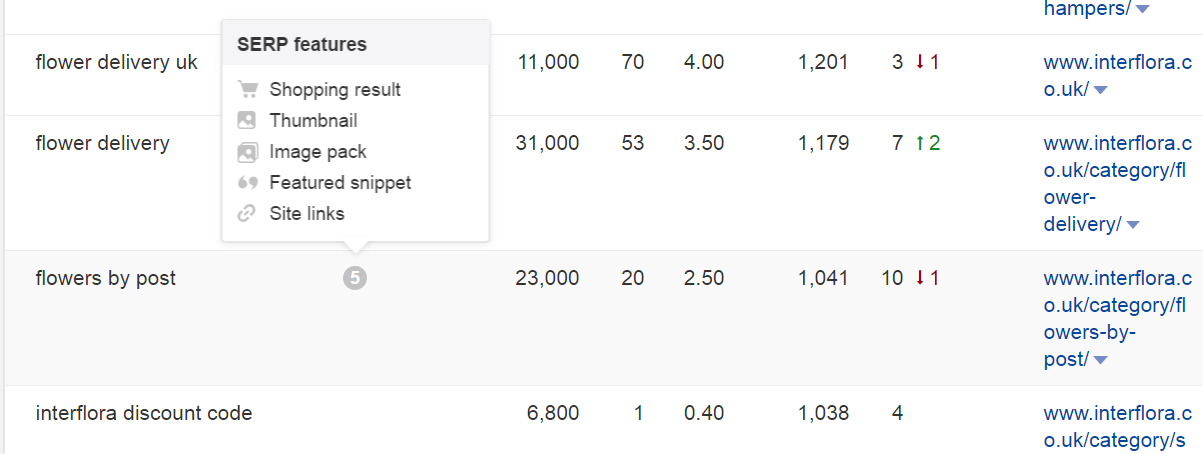
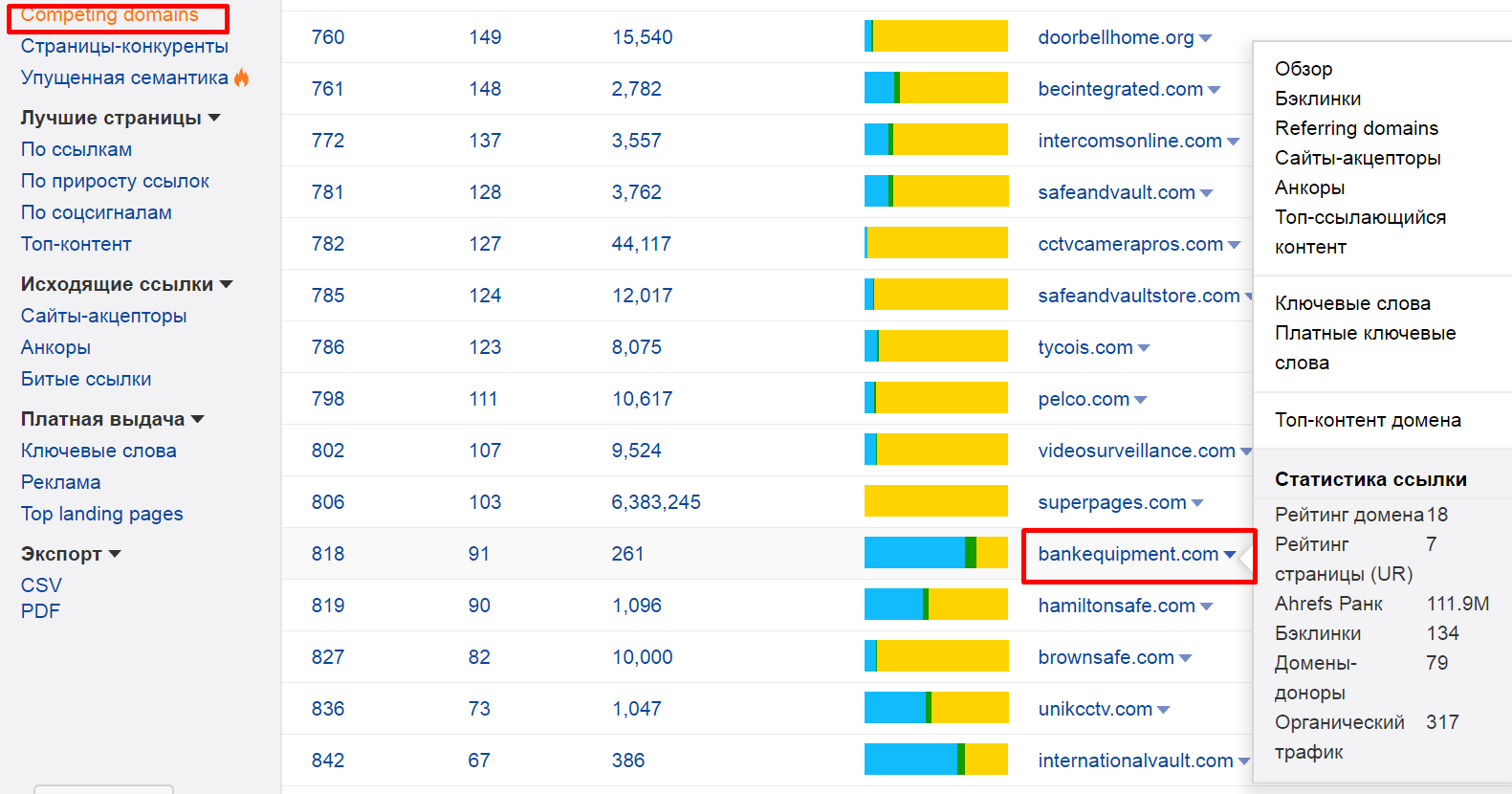
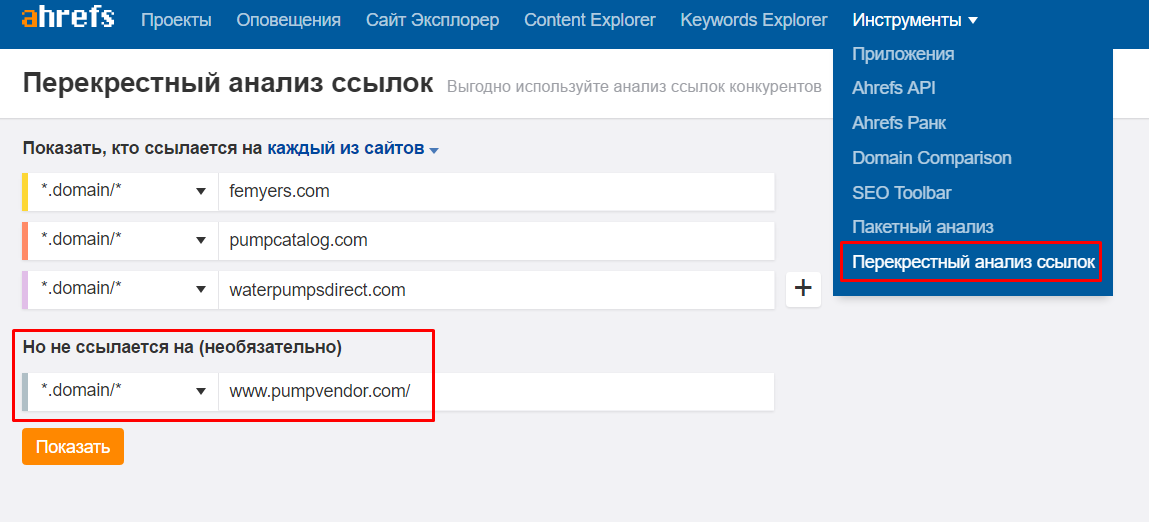
[Из песочницы] N способов использовать Ahrefs при проведении поискового аудита |
– Что он читает? – спросил соседа путник.
– Вступление для своей книги. Мы собираемся здесь каждое
воскресенье и показываем наброски.
– Вы писатели?
– Мы начинаем.
Мария Фариса. Авантюрин
Меня, напротив, больше интересует начало – в начале всегда столько надежд. У финала нет достоинств, кроме одного – показать, насколько ошибочны были те надежды.
Майнет Уолтерс. Уздечка для сварливых
Всё – сплошная банальность.
Ссылка на ссылку к ссылке.
– Главный вопрос, который теперь задают себе люди,
это не «В чём смысл существования?». – говорят губы.
– Главный вопрос – это «Откуда эта цитата?».
Чак Паланик. Уцелевший










Ключевые слова «Свинья», «Оружие» и «Сейф» напрягли мои нервы. Наф-Наф решил ограбить банк, чтобы оплатить ипотеку Ниф-Нифу и Нуф-Нуфу?
Из игры «The Missing: A Search and Rescue Mystery»


– У вас там конкурент возле крыльца устроился.
– Конкурент? Мои конкуренты раков в реке кормят.
Артем Каменистый. Самый странный нуб
– Дживс, – говорю я, – знаете что?
– Нет, сэр.
– Знаете, кого я видел вчера вечером?
– Нет, сэр.
– Дж. Уошберна Стоукера и его дочь Полину.
– В самом деле, сэр?
– Должно быть, они в Англии.
– Такое заключение напрашивается, сэр.
Пэлем Гринвел Вудхауз. Дживс, Вы гений!
|
Метки: author Kytin поисковая оптимизация ahrefs аудит сайта |
Эксплуатация дата-центра: что нужно делать самим |

Проверяю по чек-листу техническое обслуживание ИБП, проведенное подрядчиком.
Привет, Хабр! Меня зовут Кирилл Шадский. Сейчас я проектирую и строю дата-центры и серверные. До этого долго руководил службой эксплуатации дата-центров DataLine (на тот момент около 3000 стоек). Вместе со своей командой проходил аудит Uptime по процессам эксплуатации (Management and Operations) с результатом 92 балла из 100 возможных, а также вместе с коллегами участвовал в сертификации NORD 4. Сегодня хочу рассказать, как грамотно поделить эксплуатацию дата-центра или серверной между своей командой и подрядчиками.
Рулить дата-центром только собственными силами или силами подрядчика сложно. За весь свой опыт мало встречал какой-то один вариант в чистом виде, в основном какой-то гибрид. Что будет делать своя команда, а что подрядчики — каждая компания определяет сама, исходя из финансов, удобства, наличия квалифицированных инженеров (попробуйте найти специалиста по ДДИБП в Туле), а иногда политики. Каким бы замечательным ни был ваш подрядчик, есть моменты, которые лучше оставить себе. О них и поговорим ниже.
Прежде, чем пойдем делить эксплуатацию между собственной командой и подрядчиком, вспомним, что входит в этот процесс. Не буду подробно расписывать по каждому пункту — на эту тему можно целые книги писать. Выделю лишь основные моменты, которые можно условно поделить технические и организационные.
Технические моменты:
Организационные моменты:
Все, что записано в технической части, можно и иногда нужно отдать на аутсорс. В этом случае у вас остается только функция управления и контроля над подрядчиками. Кто это должен делать с вашей стороны, расскажу чуть ниже.
С организационной составляющей сложнее. Почти все из этого списка придется делать самостоятельно. Давайте разберемся, почему так.
Ведение документации. Регламенты и инструкции нужны для того, чтобы у всей команды по эксплуатации было одинаковое представление о процессах и алгоритмах действий (например, о том, как надо тестировать ДГУ). А еще для того, чтобы «священное знание» не пропало вместе с заболевшим или уволившимся инженером Васей. В теории написание документации тоже можно доверить подрядчику, — тем более не каждый инженер серверной сможет или захочет заниматься бумажками. Но правда в том, что лучше вас ваши процессы никто не знает, а отслеживать все изменения и поддерживать актуальность документации, не работая постоянно на объекте, вовсе из разряда «миссия невыполнима». Как вариант, совместно с подрядчиком можно разработать документацию, а следить за ее актуальностью уже самим на месте.
Сбор и анализ статистики. Ситуация примерно такая же, как и в предыдущем пункте, поэтому берем ручку/клавиатуру и методично записываем «историю болезни» каждого кондиционера, ДГУ и дальше по списку оборудования. Раз в квартал, полгода или хотя бы год заглядываем туда, чтобы понять, что и как часто у нас ломается. Информация пригодится при составлении бюджета на эксплуатацию, планировании ЗИП, а также поможет выявить, есть ли оборудование, которому уже не помогут ремонты, и его нужно полностью менять.
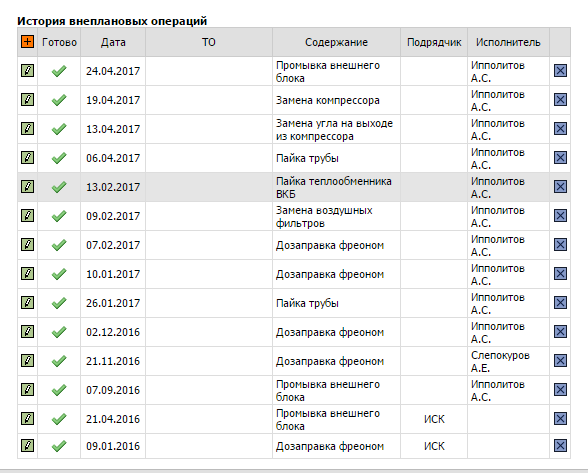
Список поломок и типов ремонта для одного из кондиционеров.
Контроль за установкой ИТ-оборудования и управление мощностью. Про это многие забывают, а зря. Айтишник увидел свободный юнит и воткнул оборудование, не посмотрев, хватает ли мощности в данной стойке, холода, и вообще правильно ли установил. А все претензии потом инженеру эксплуатации — за моргнувшее питание (из-за того, что сервер c одним блоком питания подключен без АВР или обоими блоками питания в одно PDU) или тормоза оборудования из-за локального перегрева.
Чтобы уменьшить количество проблем по этой части, делайте понятные инструкции, чек-листы для тех, кто занимается установкой оборудования, и периодически проверяйте, как установлено ИТ-оборудование (особенно внимательно если загрузка зала перевалила за 50%). Периодичность проверок будет зависеть от того, как часто в машинном зале появляется новое оборудование.
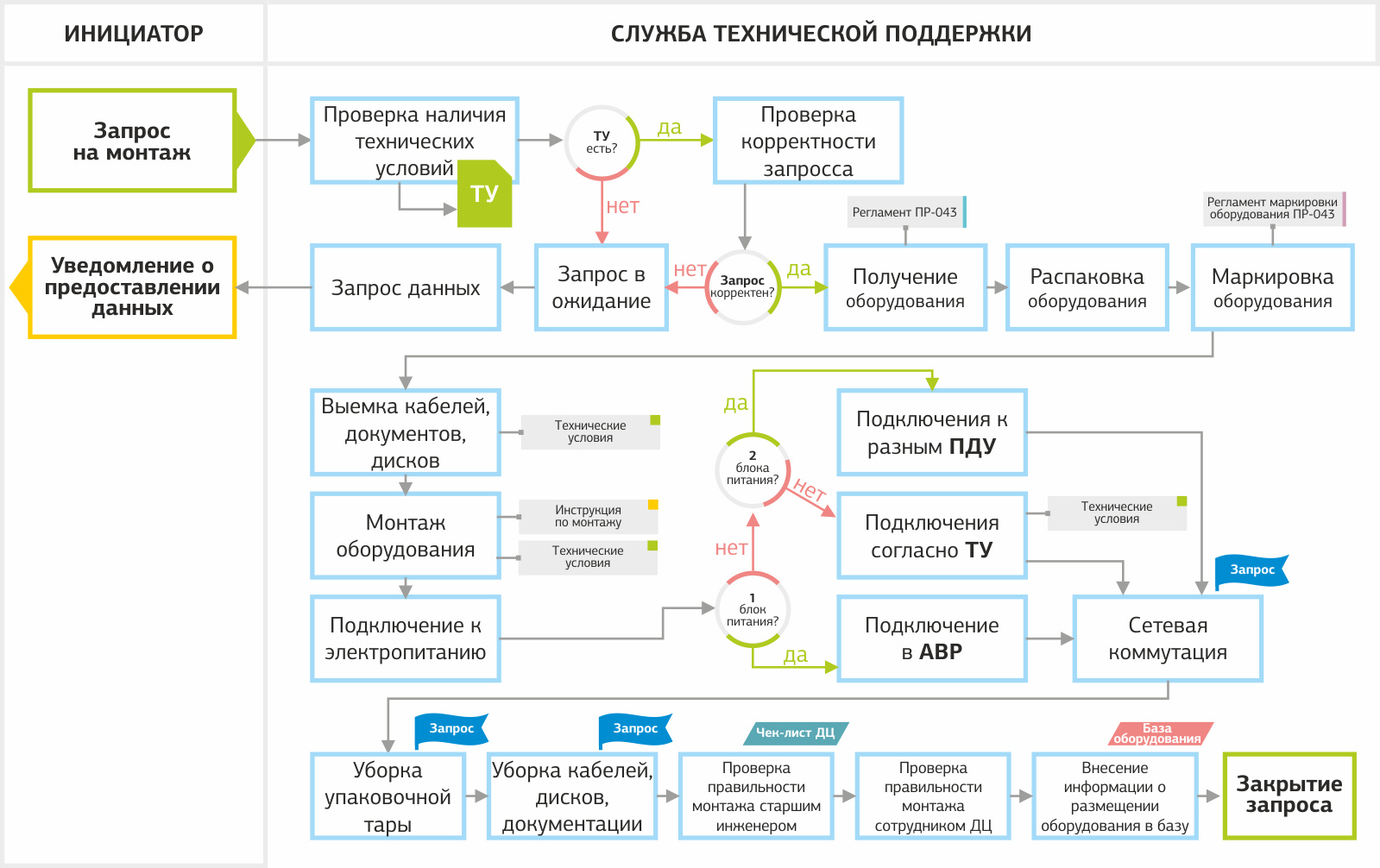
Алгоритм для отработки запроса на установку нового оборудования.
Планирование работ (ТО и наряды на работу). Совместно с подрядчиком согласовываем график работ, исходя из загрузки персонала (не должно быть работ по всем системам в одну неделю). Также выдаем наряды на работу и согласовываем с подрядчиком форму приема работ (акт, чек-лист и пр.).
Бюджетирование. Лучше делать самостоятельно. В зависимости от того, как заведено у вас — каждый месяц, квартал или сразу на год, операционное или инвестиционное. Про составление бюджета своими силами скоро напишу отдельно. Если отдать подрядчику, угадайте, что будет с бюджетом? Правильно, скорее всего, он вырастет. Произойдет это даже не из корыстного умысла подрядчика, а просто потому что он не будет так печься об экономии, как это делали бы вы.
Даже если как-то умудрились отдать подрядчику все описанное выше, то сидеть, закинув ноги на стол, и просто оплачивать счета не получится: подрядчиков нужно обучать и контролировать.
Учить подрядчиков, в первую очередь, нужно жизни правилам работы в дата-центре и серверной. Кроме,«не пить, не курить и не дебоширить», есть и технические нюансы. Например, от вас подрядчик должен узнать, что при ТО кондиционеров нельзя отключать больше одного за раз, а перед тем, как отключить, нужно проверить, что остальные кондиционеры работают исправно.
Контроль за доступом на объект тоже останется на ваших плечах. Проверять актуальность списков, график доступа на объект (круглосуточный или только в рабочие дни), наличие корочек по электробезопасности и прочих необходимых удостоверений — ваша и только ваша задача.
В общем помните, что за работоспособность серверной или дата-центра отвечаете в конечном итоге вы, а не подрядчик.

Выдержка из правил работы в наших дата-центрах для подрядчиков.
Количество людей в вашей службе эксплуатации будет зависеть от заявленного SLA, объема инфраструктуры и того, как много вы планируете делать собственными силами. Универсальной формулу не подскажу, но вот на что можно опереться.
В каком режиме предоставляем услуги? Если 24х7, нужна круглосуточная служба поддержки как минимум из четырех человек, которые будут работать в четыре смены — сутки через трое. Если 8x5, то людей понадобится вдвое меньше.
Сколько нужно инженеров? Здесь многое будет зависеть от функций. Если нужно просто следить за мониторингом, то хватит и одного, если нужно делать обходы — минимум два человека. Если придется что-то делать руками (тянуть кроссировки, монтировать оборудование, менять фильтры в кондиционерах), то понадобится уже трое.
Храните ли ЗИП и расходники у себя? Если храните почти все, то понадобится кладовщик или закупщик, который будет следить за остатками и заказывать новые.
Вот как выглядит команда нашей площадки NORD на 2720 стоек.

Название должностей и количество людей будет для каждого случая свое, но одна функция обязательно должна присутствовать при любом раскладе. Это функция “быть ответственным”. Условно я называю эту позицию «главный инженер». В нашей иерархии это руководитель службы эксплуатации. Главная его функция — принимать решения, которые не обсуждаются: нужно ли вызывать подрядчика по аварийному вызову, можно ли отложить ремонт резервного кондиционера. Он же дает команду на отключение оборудования на время ТО, согласовывает срочные ремонтные работы, внеплановые закупки, руководит операцией по спасению дата-центра в случае аварий. К нему можно обратиться как в третейский суд, если инженер эксплуатации или подрядчик вдруг не может договориться с энергетиком о тестовых запусках ДГУ.
В целом, «главный инженер» в конечном итоге отвечает за всю эксплуатацию и инженерную инфраструктуру перед бизнесом или клиентам.
Подведем итоги. Программа «минимум» для службы эксплуатации дата-центра или серверной выглядит следующим образом:
Если у вас есть вопросы, пишите в личку или приходите на мой ближайший семинар 4 июля, сможете обо всем спросить лично.
Другие статьи по управлению инженерной инфраструктурой дата-центра и серверной:
Путь электричества в дата-центре
Ошибки в проекте дата-центра, которые вы ощутите только на этапе эксплуатации
Как создавалась система холодоснабжения дата-центра NORD-4
О животрепещущем в эксплуатации дата-центра
Как тестируют ДГУ в дата-центре
Мониторинг инженерной инфраструктуры в дата-центре. Часть 1. Основные моменты
Мониторинг инженерной инфраструктуры в дата-центре. Часть 2. Система энергоснабжения
Обслуживание инженерных систем ЦОД: что должно быть в договоре подряда
Dumb ways to die, или отчего “падают” дата-центры
|
|
JaCarta Authentication Server и JaCarta WebPass для OTP-аутентификации в Linux SSH |


















# sudo -i
# apt-get install libpam-radius-auth # nano /etc/pam_radius_auth.conf
# The timeout field controls how many seconds the module waits before
# deciding that the server has failed to respond.
#
# server[:port] shared_secret timeout (s)
[SERVER IP] [Общий секрет] 3 # nano /etc/pam.d/sshd
# PAM configuration for the Secure Shell service
# Standard Un*x authentication.
auth sufficient pam_radius_auth.so
@include common-auth
# Disallow non-root logins when /etc/nologin exists. 


|
|






