Как ритейл-компании оценивают эффективность внедрения систем лояльности в России и за рубежом |

Подробнее о технической стороне организации систем лояльности мы рассказывали в этом материале: «Почему не взлетает «облако»: как работают системы лояльности в магазинах».
|
Метки: author pilot-retail повышение конверсии монетизация it-систем блог компании пилот системы лояльности ритейл |
[Перевод] Одинарная или двойная точность? |
|
Метки: author m1rko программирование математика float double плавающая запятая плавающая точка одинарная точность двойная точность |
«Проект Ironman». Как подготовиться к «Железному человеку» за 500 часов, используя скиллы PM’а |

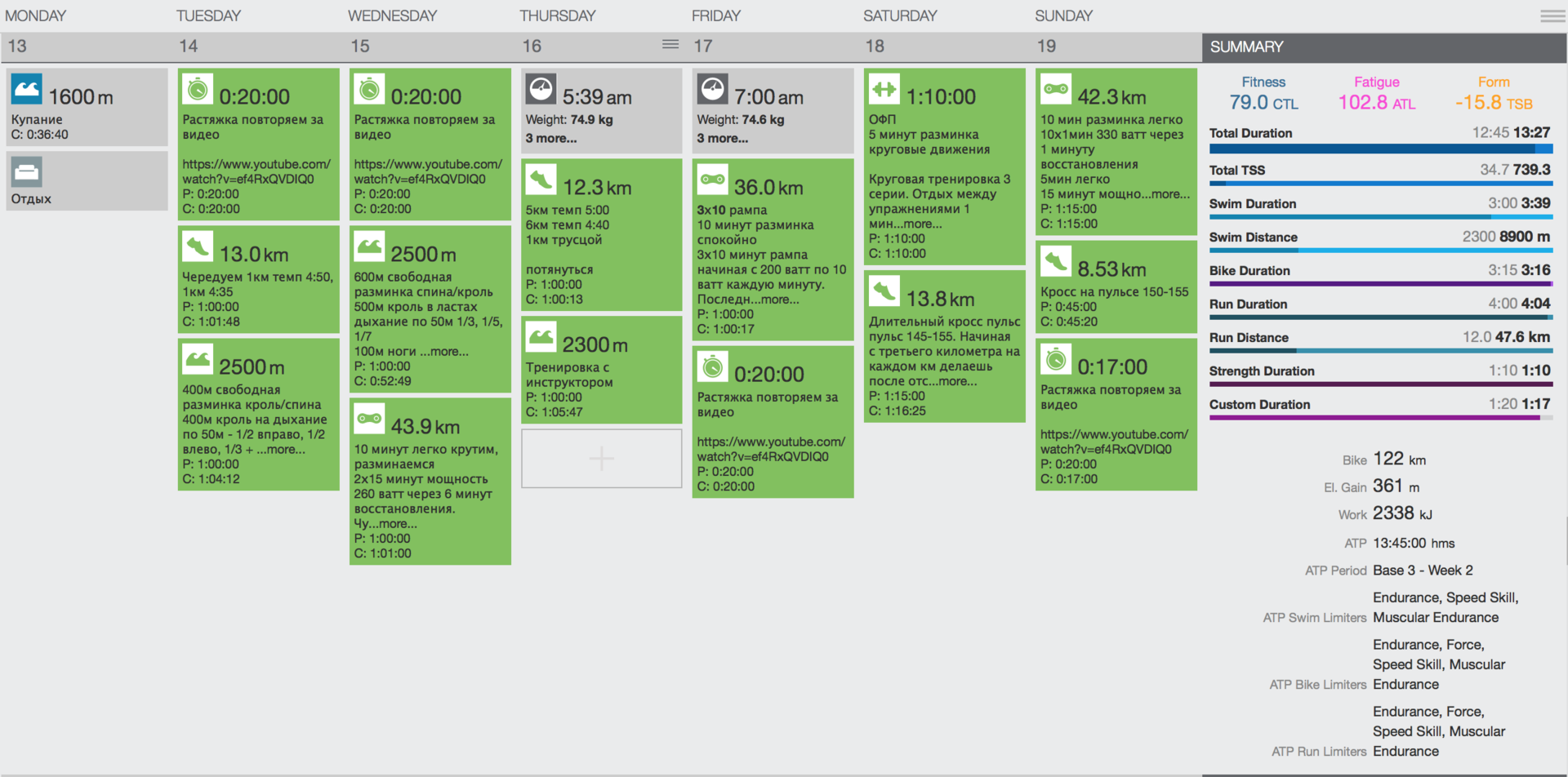
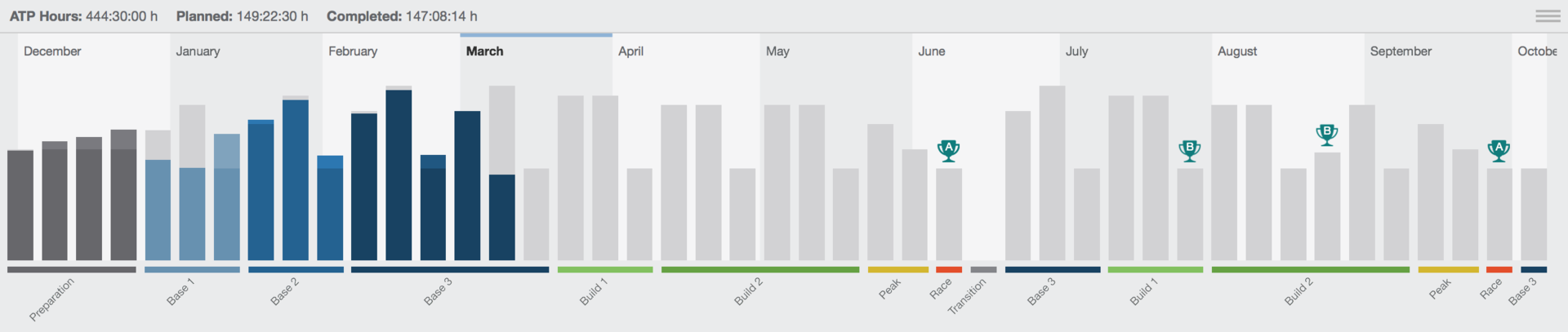
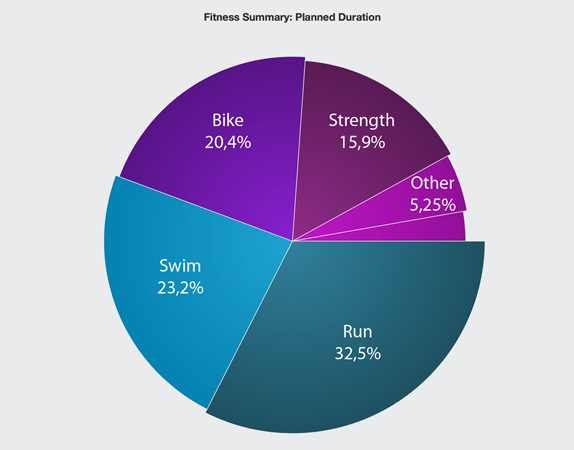
|
Метки: author Softliner управление проектами управление персоналом блог компании softline pm проектный менеджмент ironman project management |
[Перевод] Как превратить увлечение программированием в работу |

«Мы все ученики в ремесле, в котором никто никогда не становится мастером».


|
|
[Перевод] Осознанные ошибки: как добавить глупость в код ИИ |
|
Метки: author PatientZero разработка игр искусственный интеллект геймдизайн |
Обзор основных секций конференции PG Day'17 Russia |





|
Метки: author rdruzyagin блог компании pg day'17 russia postgresql oracle ms sql server mysql innodb java conference конференция greenplum elasticsearch mongodb |
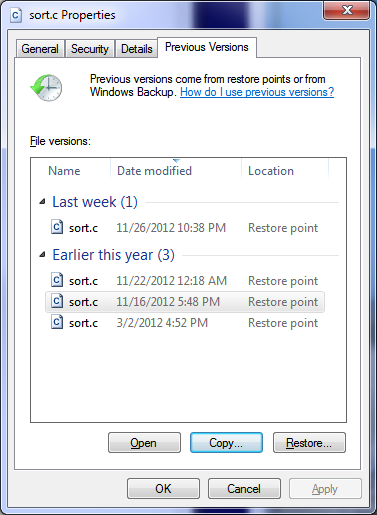
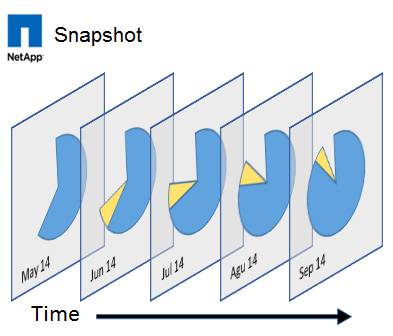
Как защитить корпоративный NAS от вирусов RansomWare |
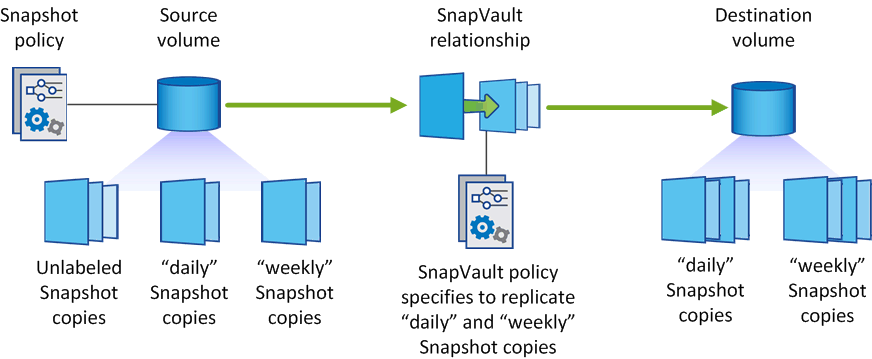
|
|
«Теперь он и тебя сосчитал» или Наука о данных с нуля (Data Science from Scratch) |

# -*- coding: utf-8 -*-
# linear_algebra.py
import re, math, random # regexes, math functions, random numbers
import matplotlib.pyplot as plt # pyplot
from collections import defaultdict, Counter
from functools import partial, reduce
#
# functions for working with vectors
#
def vector_add(v, w):
"""adds two vectors componentwise"""
return [v_i + w_i for v_i, w_i in zip(v,w)]
def vector_subtract(v, w):
"""subtracts two vectors componentwise"""
return [v_i - w_i for v_i, w_i in zip(v,w)]
def vector_sum(vectors):
return reduce(vector_add, vectors)
def scalar_multiply(c, v):
return [c * v_i for v_i in v]
def vector_mean(vectors):
"""compute the vector whose i-th element is the mean of the
i-th elements of the input vectors"""
n = len(vectors)
return scalar_multiply(1/n, vector_sum(vectors))
def dot(v, w):
"""v_1 * w_1 + ... + v_n * w_n"""
return sum(v_i * w_i for v_i, w_i in zip(v, w))
def sum_of_squares(v):
"""v_1 * v_1 + ... + v_n * v_n"""
return dot(v, v)
def magnitude(v):
return math.sqrt(sum_of_squares(v))
def squared_distance(v, w):
return sum_of_squares(vector_subtract(v, w))
def distance(v, w):
return math.sqrt(squared_distance(v, w))
#
# functions for working with matrices
#
def shape(A):
num_rows = len(A)
num_cols = len(A[0]) if A else 0
return num_rows, num_cols
def get_row(A, i):
return A[i]
def get_column(A, j):
return [A_i[j] for A_i in A]
def make_matrix(num_rows, num_cols, entry_fn):
"""returns a num_rows x num_cols matrix
whose (i,j)-th entry is entry_fn(i, j)"""
return [[entry_fn(i, j) for j in range(num_cols)]
for i in range(num_rows)]
def is_diagonal(i, j):
"""1's on the 'diagonal', 0's everywhere else"""
return 1 if i == j else 0
identity_matrix = make_matrix(5, 5, is_diagonal)
# user 0 1 2 3 4 5 6 7 8 9
#
friendships = [[0, 1, 1, 0, 0, 0, 0, 0, 0, 0], # user 0
[1, 0, 1, 1, 0, 0, 0, 0, 0, 0], # user 1
[1, 1, 0, 1, 0, 0, 0, 0, 0, 0], # user 2
[0, 1, 1, 0, 1, 0, 0, 0, 0, 0], # user 3
[0, 0, 0, 1, 0, 1, 0, 0, 0, 0], # user 4
[0, 0, 0, 0, 1, 0, 1, 1, 0, 0], # user 5
[0, 0, 0, 0, 0, 1, 0, 0, 1, 0], # user 6
[0, 0, 0, 0, 0, 1, 0, 0, 1, 0], # user 7
[0, 0, 0, 0, 0, 0, 1, 1, 0, 1], # user 8
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0]] # user 9
|
Метки: author BosonBeard учебный процесс в it python data science самоучитель новичкам kaggle статистика математика |
IT&City Android хакатон в Нижнем Новгороде |
1-2 июля в Нижнем Новгороде пройдет хакатон для андроид разработчиков IT&City hackathon. Специально для его организации комьюнити Google Developers Group Nizhny Novgorod впервые объединило свои усилия с Yandex. Приглашаем Android-разработчиков и дизайнеров из Нижнего Новгорода и других городов попробовать свои силы в создании приложений, которые могут быть полезны городу, его жителям и представителям местных IT-сообществ.
В течение дня участники будут работать над социально-полезными приложениями, пробовать новые технологии, искать решения, обсуждать идеи и задавать вопросы. Цель хакатона – не только создание прототипов проектов, но и возможность поделиться знаниями о новейших технологиях и попробовать их на практике, обсудить последние новости в сфере IT с единомышленниками и получить ответы на актуальные вопросы от приглашенных экспертов.
Помогать участникам будут эксперты из Яндекса и GDG Nizhny Novgorod,. Какие именно технологии использовать в приложении — решать разработчикам. Главное, чтобы была реализована изначальная идея.
На хакатоне не будет ни лекций, ни докладов. А принять участие могут все желающие, знакомые с разработкой под андроид – как опытные разработчики, так и начинающие специалисты. Главное требование — взять с собой ноутбук ;)
Можно участвовать самостоятельно, подать командную заявку или объединиться с другими участниками на месте. В команде может быть от одного до четырех человек.
Хакатон пройдет в нижегородском офисе Яндекса. В субботу участники будут работать над проектами, а в воскресенье презентовать свои решения. Созданные участниками приложения будут оцениваться в номинациях:
• Самый полезный проект
• Лучший UX
• Самый фановый проект
• Самый инновационный проект (за использование новейших технологий)
• Приз зрительских симпатий
Победители получат памятные сувениры от Яндекса и GDG.
Подробнее ознакомиться с мероприятием и оставить заявку на участие можно на сайте.
Будем рады видеть вас! До встречи!
|
Метки: author Developers_Relations хакатоны блог компании google google android hackathon yandex gdg gdgnn |
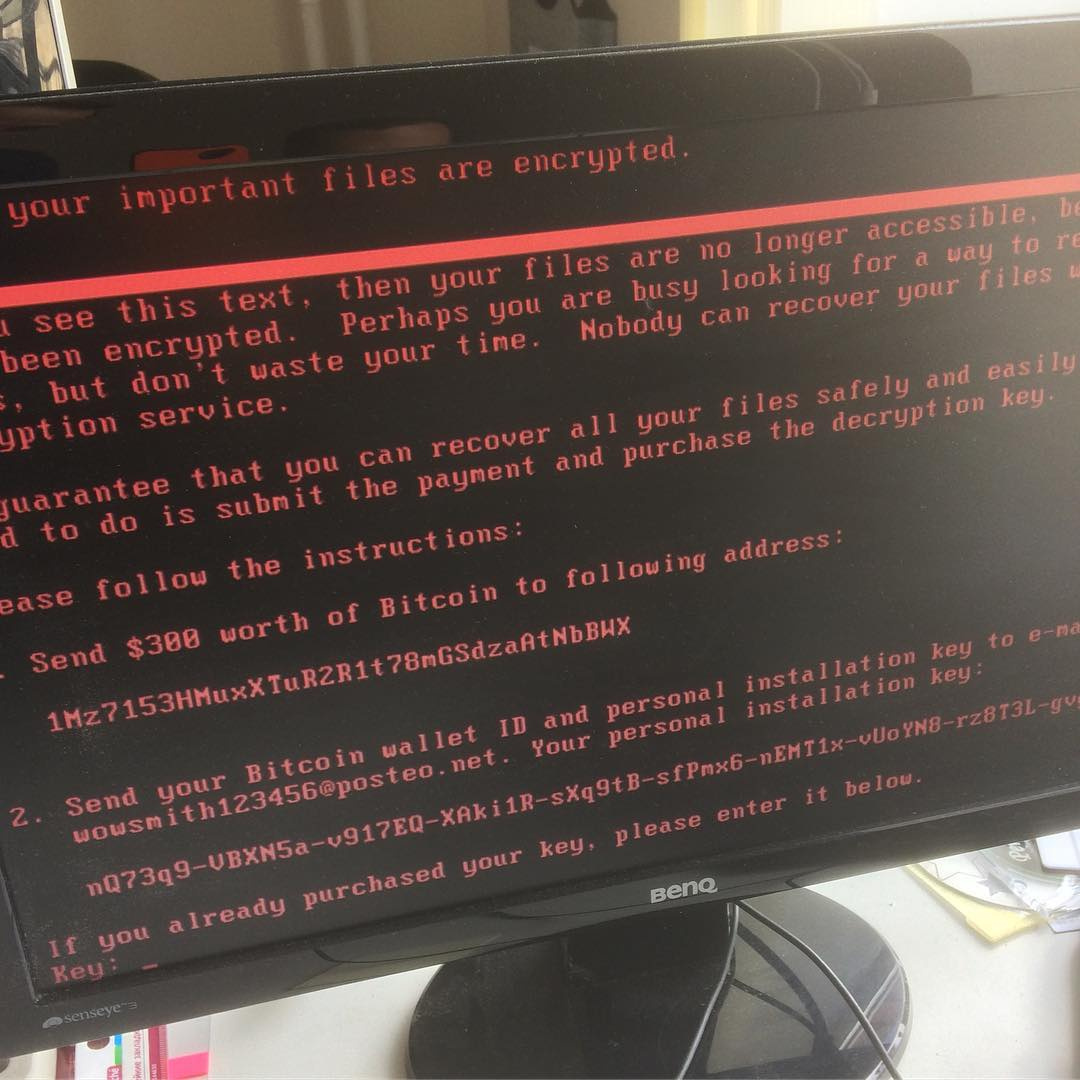
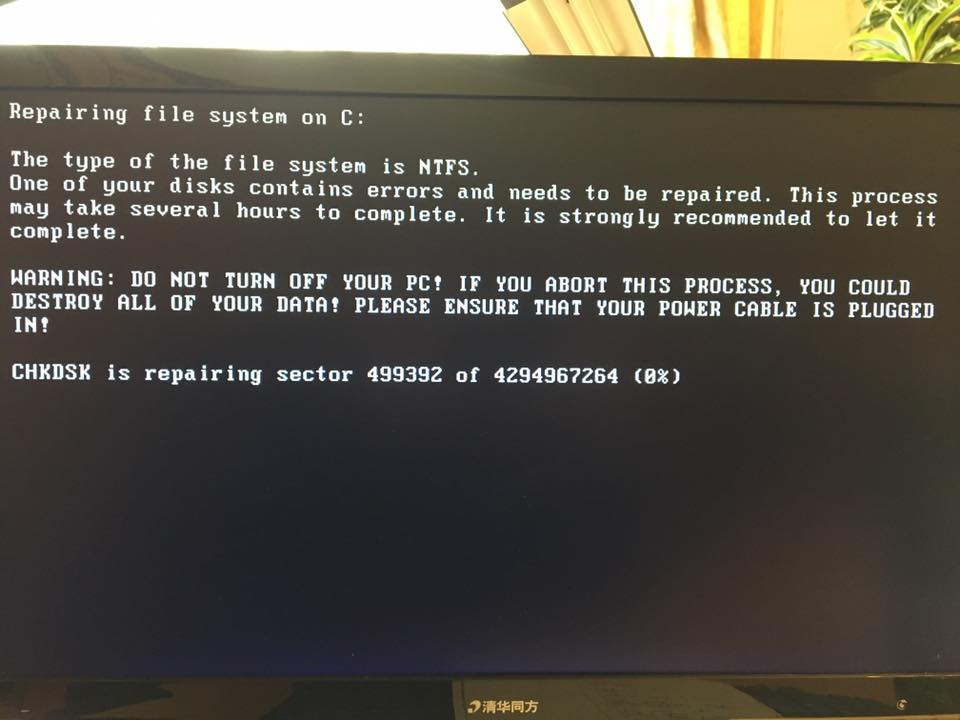
Petya.A, Petya.C, PetrWrap или PetyaCry? Новая вирусная угроза для компаний России и Украины |
|
|
Как мы писали стратегический кликер на хакатон ReactRiot |
Привет. Не так давно мы с rjericho увидели статью Как я участвовал в хакатоне Angular Attack, и что из этого вышло. У нас в Барнауле хакатоны начали проводиться всего год назад. При этом они больше были ориентированы на быстрый старт IT-стартапа. Поэтому на них не получалось насладиться использованием всяких прикольных хипстерских библиотек, а приходилось пилить продукт на старых добрых PHP или Java. Однако нам давно хотелось поучаствовать в каком-нибудь фановом мероприятии, где можно просто запилить то, что душе угодно и не придумывать, как это монетизировать.
Был найден хакатон от тех же организаторов, что и AngularAttack: ReactRiot. То, что о реакте мы знали только по статьям на хабре только добавляло интерес к данному мероприятию.
Для начала нужно было побольше узнать о самом реакте. В этом помогли хабр, официальные доки и codesandbox.io. На данном сайте были некоторые примеры, которые и помогли определиться с выбором основных библиотек.
Для менеджмента состояния был выбран MobX. Redux также выглядел интересно, однако показалось, что для хакатона он не подходит, так как требует больше времени на продумывание архитектуры и добавление actions, что не очень подходит для формата хакатона, когда через сутки после начала придумываешь гениальную фичу, которая никак не влезает в архитектуру.
Для стилизации компонентов был взят glamorous и сам glamor. Понравилось, что весь код одного компонента может быть в одном файле, а не раскидан по папкам css и js и не влияет на другие компоненты.
Самое трудное в хакатоне — это идея :). Так как для нас целью этого хакатона было изучение новой технологии и получение фана, то было решено делать игру. А чтобы она ещё и красиво ложилась в принципы реакта и mobx, т. е. можно было создать компонент и использовать его много раз на странице, а также при действиях пользователя всё реактивненько обновлялось, то решили делать что-нибудь, похожее на кликер.
Изначальной идеей был симулятор шахтёрского поселка с различными видами шахтёров, шахт и вспомогательных зданий, которые влияют на шахтёров (вроде увеличения производительности и т.п). Однако когда я начал делать мокап под это дело, оказалось, что вместить такое на один экран так, чтобы сразу было понятно что делать тут делать, очень непросто. Поэтому идея была полностью переделана.
От первоначальной идеи осталось только наличие у населения показателя недовольства, при увеличении которого они начинают бунт (англ. riot — отсылка к названию хакатона).
Если вкратце:
Полное описание идеи с которой мы начинали хакатон можно посмотреть тут. Правда она отличается от того, что в итоге получилось, так как на некоторые фичи не хватило времени. Про другие фичи вспоминали только в середине хакатона, когда вставить их было уже затруднительно.
И тут бы возникла ещё одна проблема команды из двух программистов — графическая составляющая проекта. Однако по примеру stickytape подходящие иконки юнитов, ресурсов и зданий были взяты из твиттер-пака эмодзи (Кроме лого топора. Оказывается его нет в юникоде и соответственно в эмодзи. Поэтому подходящий по стилистике топор пришлось искать в другом месте).

Час до хакатона — самое время начать думать об архитектуре проекта :). Однако успели только придумать структуру папок.

В components находятся jsx компоненты реакта. В logic — модели — стейты MobX.
В static собирался бандл вебпака, были вставлены сторонние css, шрифты и картинки.
В styles.js были некоторые общие стили, которые использовались в нескольких компонентах, вроде такого:
import { css } from 'glamor'
export const boldBorder = css({
border: '3px solid'
})Не уверен насчёт правильно организованной работы с такими стилями. Было бы неплохо, если в комментариях подсказали что-нибудь по этому поводу.
Разработка началась с создания небольших информационных компонентов. Были написаны компоненты по отображению информации по одному юниту, зданию и ресурсу.

После чего был сверстан основной трёхколоночный вид и добавлены ещё пара компонентов. Тут хорошо помогли библиотеки react-bootstrap и react-rangeslider.
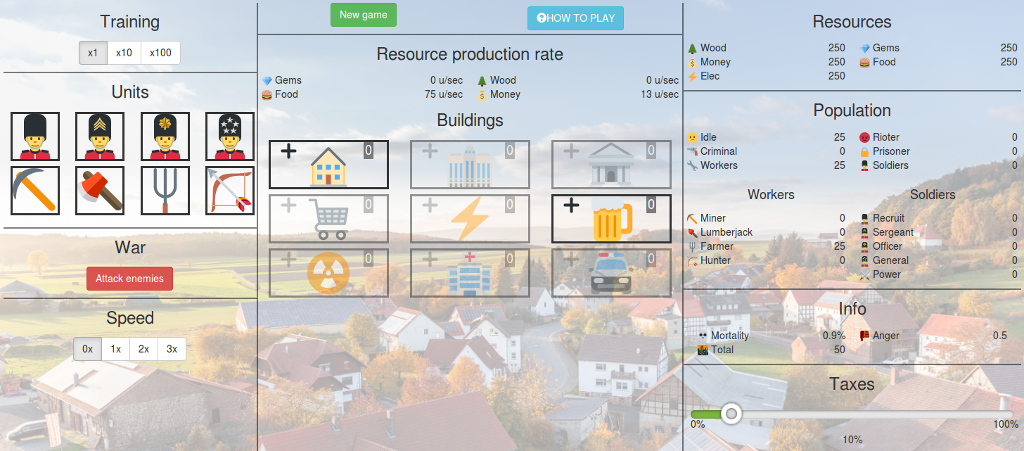
В итоге получилось вот так:

Затем был написан компонент отображения сетки юнитов и зданий и добавлены некоторые иконки.
Наконец настало время писать логику. Первым было написано приращение ресурсов за юнитов и постройка новых юнитов. Тут и случился первый wtf.
Обновление игры у нас идёт по тикам: основные тики — по одной секунде. Также были введены более мелкие тики обучения для более плавного отображения прогресса обучения. При клике на юнита начиналась анимация его постройки и если с одним юнитом всё было ещё хорошо, то при клике сразу на нескольких начинались лаги. Даже не так — ЛАГИ. Всё начинало так дико тормозить, что я уже думал просто убрать эту анимацию. Однако время было уже позднее и, решив что утро вечера мудренее, мы пошли спать.
Утро второго дня началось с осознания нашей главной ошибки: мы неправильно готовим MobX. Наши минимальные компоненты, отображающие основную информацию не являются observer'ами, а тупо принимают информацию о том, что показывать через props. А это в корне противоречит методу работы MobX.
Было:
> this.props.onTrain(unit)} /> После исправления данной ошибки, скорость приложения стабилизировалась.
Стало:
> this.props.onTrain(unit)} /> Также в процессе исправления данного просчёта было обнаружено, что динамически использовать glamor.css внутри render() это не очень хорошо. На каждое изменение стиля, используемого при анимации он создавал новое правило в таблице стилей, что возможно тоже просаживало производительность.
После исправления вчерашних косяков была добавлена сетка постройки зданий

Затем была доделана логика смертности населения и накопления недовольства, отправка солдат на войну, а также добавлена нулевая скорость игры для создания паузы.
После чего настала пора балансировать все коэффициенты, цены и эффекты зданий так, чтобы и нельзя было играть просто тыкая на всё подряд, но и так, чтобы она была не слишком хардкорной. Это была пожалуй самая весёлая часть. Из-за придуманной от балды формулы смертности было интересно наблюдать, как обучающиеся по очереди лесорубы срубали одно дерево и сразу же умирали, из-за высокого коэффициента преступности только что обученные фермеры сразу же становились преступниками, съедали все запасы и от голода начинали бунтовать. Однако если смертность была отбалансирована ещё довольно легко, то при калибровке преступности мы долго не могли найти такой баланс, чтобы при небольшом стартовом количестве людей они не становились сразу же преступниками. В итоге пришлось ввести механизм превращения преступников обратно в безработных тоже с некоторым коэффициентом.

После наведения баланса оставалось добавить уведомления о бунте и случайных событиях (миграциях и наводнениях), а также добавить плашку голосования от организаторов. Причём плашку эту они сделали за 6 часов до конца хакатона и когда она добавилась, нам пришлось один блок переносить с правой части интерфейса в левую, чтобы по высоте всё входило.
В процессе хакатона были, хоть и на начальном уровне, но изучены реакт и MobX. Самостоятельно были опробованы некоторые грабли :). Один из главных наших выводов: архитектуру лучше всё таки хоть немного продумать заранее. Так конечно получается больше рофлов, но на второй день код сменил цвет на коричневый и некоторые вещи делались ужасными костылями. Код можно найти здесь. Потыкать саму игру можно по адресу town.surge.sh
|
|
SD-WAN «на пальцах»: плюсы, минусы, подводные камни |


|
Метки: author sergx71 системное администрирование сетевые технологии it- инфраструктура sd-wan программно-определяемые сети решения для управления сетью |
Кассовые аппараты выходят онлайн: налоговая России открыла новый рынок для разработчиков приложений |

|
Метки: author andorro я пиарюсь моя налоговая меня бережет сначала сосчитает потом пострижет фнс evotor |
МФТИ запустил первую в России онлайн-магистратуру по технологическому предпринимательству |

|
Метки: author KateVo учебный процесс в it техпред технологическое предпринимательство предпринимательство онлайн-магистратура магистратура мфти образование обучение онлайн |
[Из песочницы] Плагин jQuery — jdDialog. Принцип «транзитных вызовов» |
if(confirm('') ) {...}$('#test').click(function() { ...$(this).jdDialogs('confirm',1,['Текст?','Заголовок'],fncname)
if(! $(this).jdDialogs('confirm',1,['Текст?','Заголовок']) ) return;
if( $(this).jdDialogs('confirm',1,['Текст?','Заголовок']) ) {
...
}
switch( $(this).jdDialogs('confirm',1,['Текст?','Заголовок']) ) {
case 1: ...;
default: return;
}
$(this).jdDialogs('alert',0,['Сделано!','Project'])
if(! $(this).jdDialogs('alert',0,['Сделано!',project]) ) return;
alert('Код выполнен');
$(id).data(fname,value);$('.jdModalBg').detach().fadeIn(10,function() { if(!!fncdo) window[fncdo]();methods.jdReclick(id);$(this).jdDialogs('confirm2bttn',0,['Мы на перепутье','Действие шаг 3','Идти налево','Идти направо'])
confirm2bttn : function(fid,data,fname) {
return methods.jdDialog('Confirm2bttn',fid,data,$(this),fname);
}
case 'Confirm2bttn':
var bttntext1 = data[2];
var bttntext2 = data[3];
jdBttns = ''+
''+
'';
clClass = 'jdClose0';
break; .on('click','.jdOk2', function() {
methods.jdSetAnswer(2,$(this));
})switch($(this).jdDialogs('confirm2bttn',0,['Мы на перепутье','Действие шаг 3','Идти налево','Идти направо'])) {
case 0: return;
case 1:
alert('Идём налево');
break;
case 2:
alert('Идём направо');
break;
default:.jdDialogConfirm2bttn {
min-width:380px;
max-width:450px;
}
.jdDialogConfirm2bttn .jdText {
min-height:60px;
}
.jdDialogConfirm2bttn .jdHeader{
background-color: hsl(115,63%,15%);
color:#F0C800;
}
.jdDialogConfirm2bttn .jdHeader .jdClose{
background-color: hsl(114,58%,22%);
color:#F5DA50;
}|
Метки: author drtropin javascript плагин jquery транзитный вызов диалоговые окна |
[Перевод] ArrayBuffer и SharedArrayBuffer в JavaScript, часть 2: знакомство с новыми объектами языка |



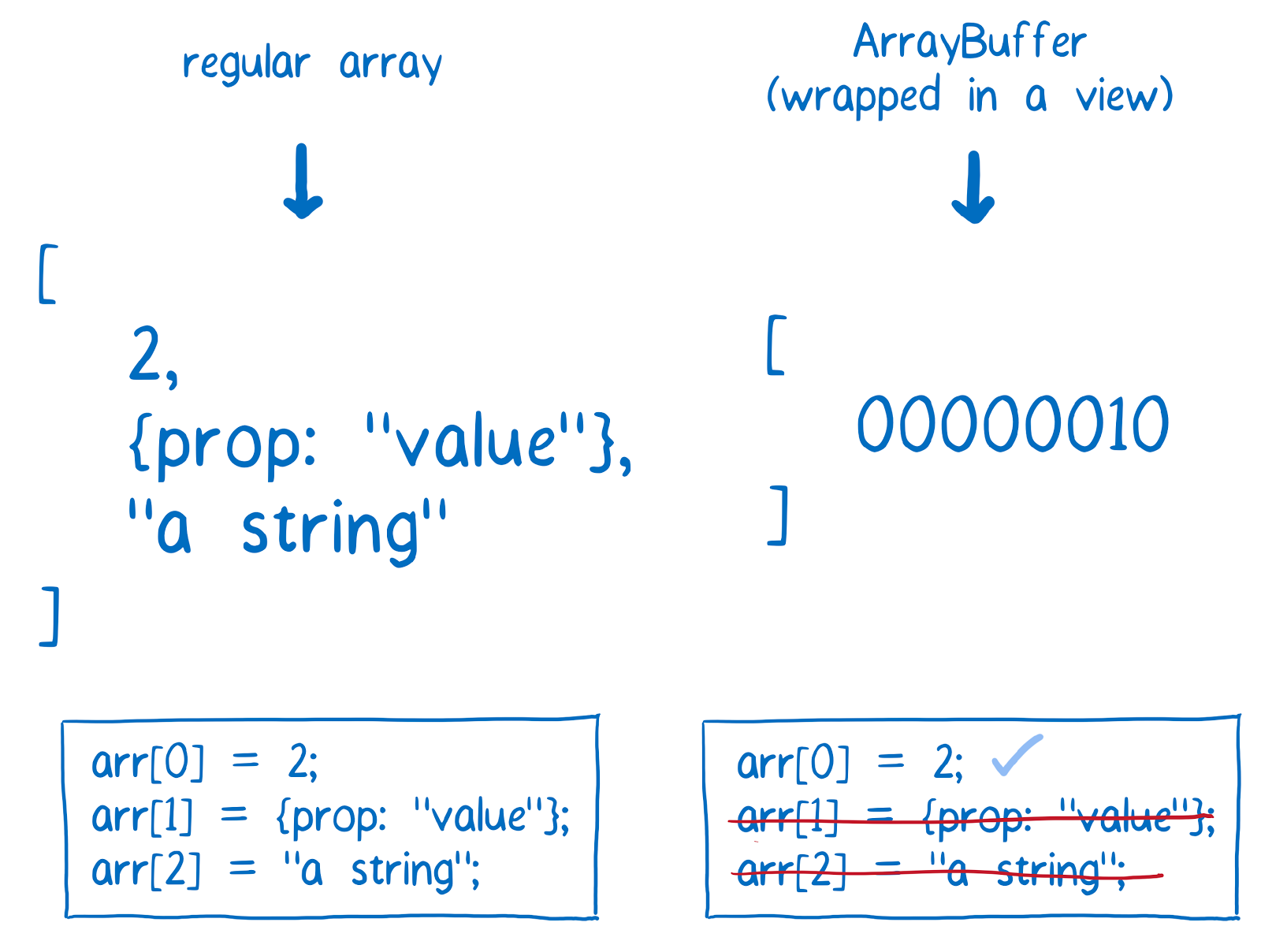


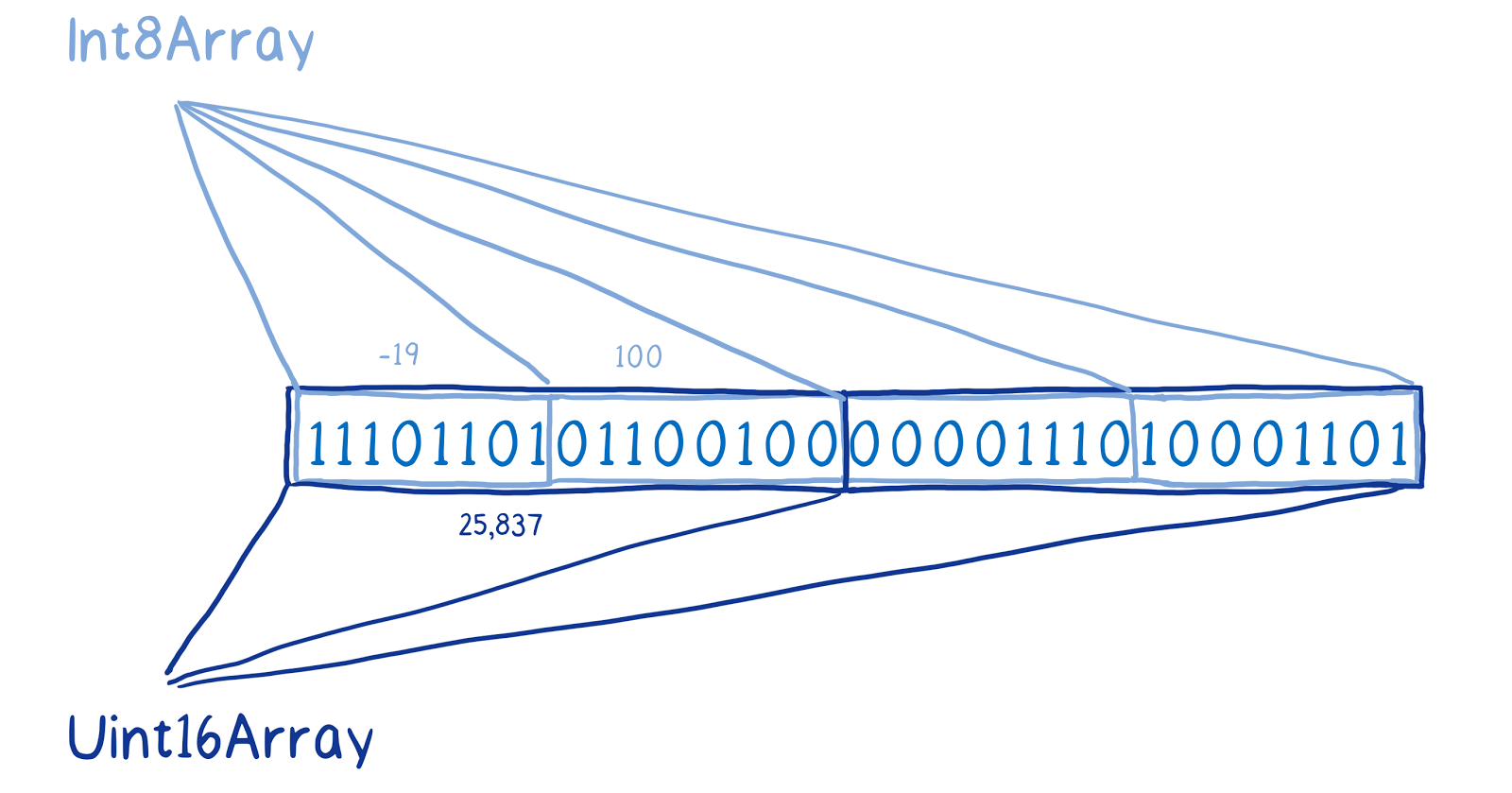
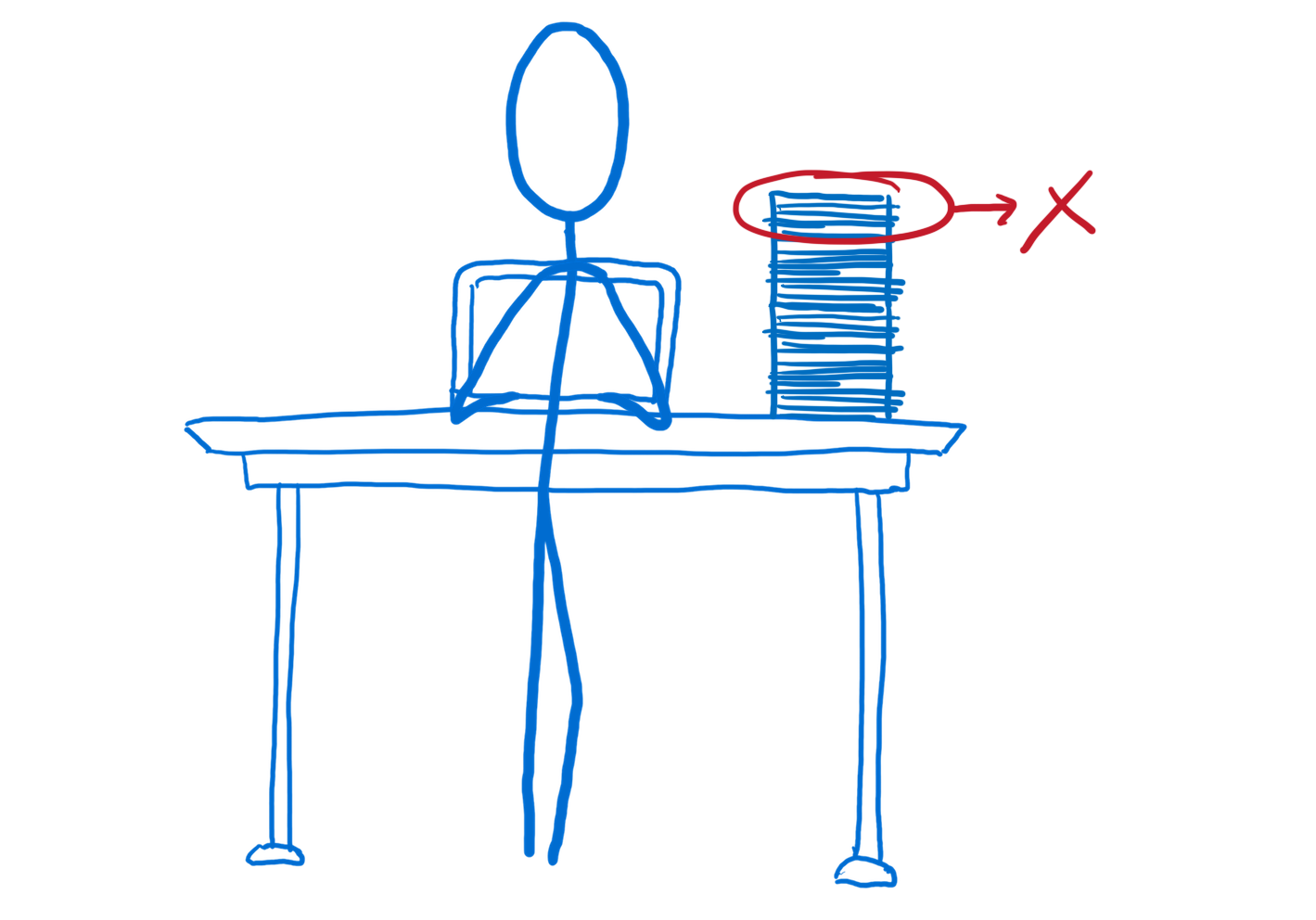
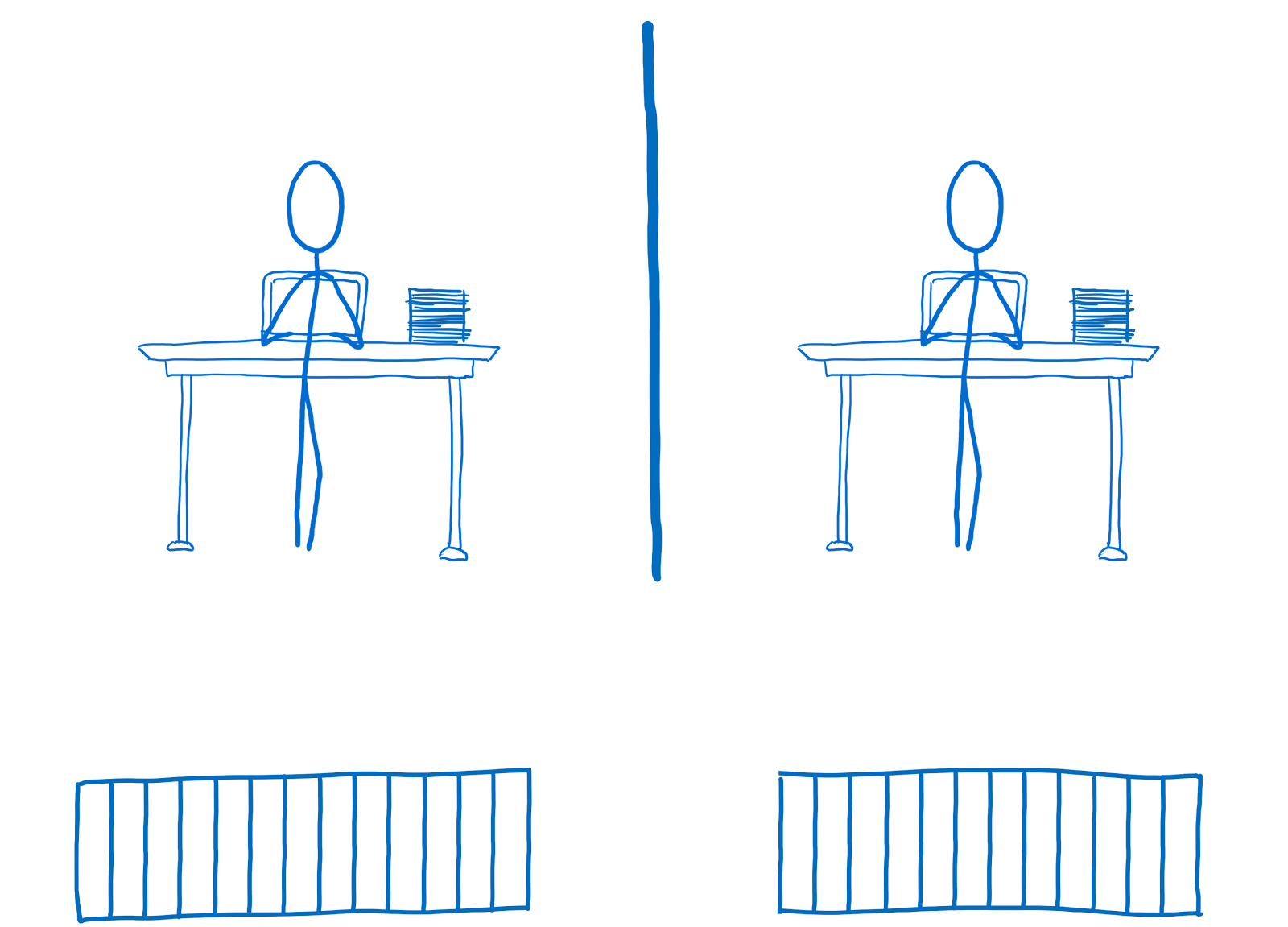
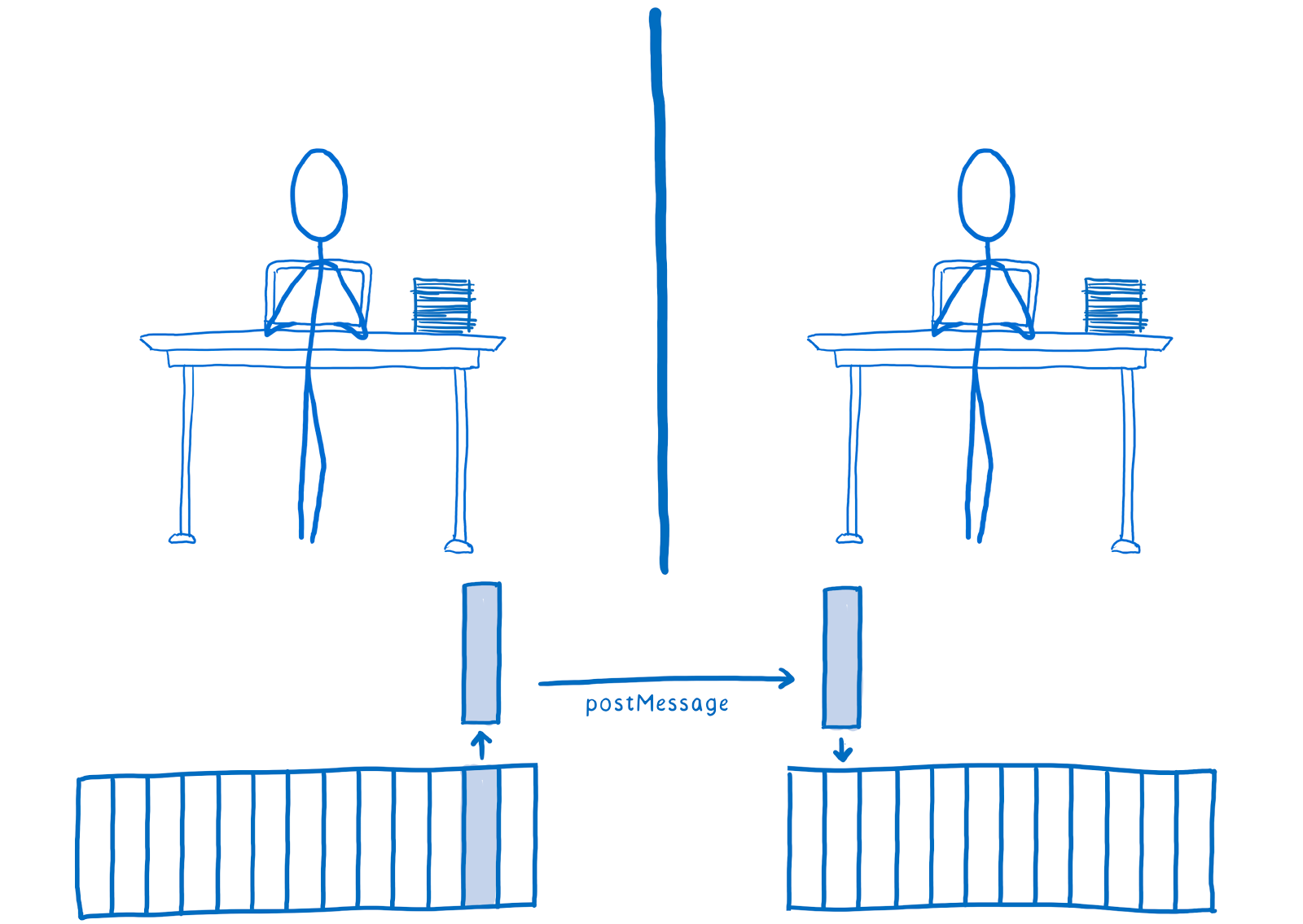
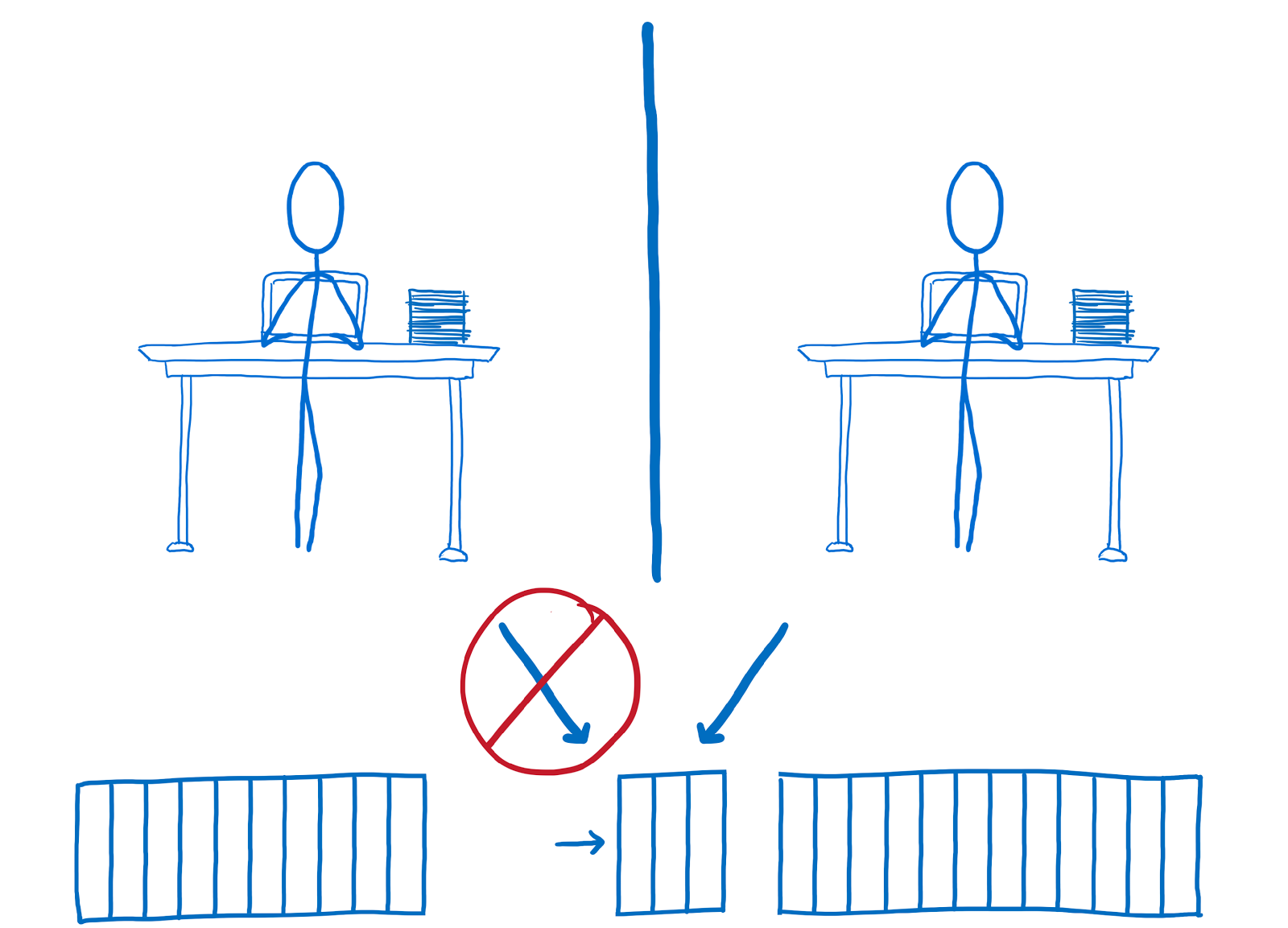


|
Метки: author ru_vds javascript блог компании ruvds.com программирование управление памятью |
О чем говорили на Avito.iOS? Отчет, отзывы гостей и видеозаписи |

Было интересно и смотреть, и слушать, и иногда смеяться.
Это главный доклад, ради которого я шёл на митап.
Очень интересная тема, люблю такие проекты. Фактически — вот вам и инновационный проект!
Я не использую “реактив”, но доклад был качественным и интересным, появился большой интерес перевести хотя бы один модуль на эту технологию.
Надеюсь увидеть доклад во снах!
Классный доклад, тема актуальная. Наша команда тоже столкнулась с этой проблемой, примерно так же пытаемся её решить.
Много важной, открытой информации.
Неожиданно был очарован манерой доклада. Предмет актуальный и доложен шикарно. Так держать! Отлично!
|
Метки: author rafinirovannoe тестирование мобильных приложений разработка под ios блог компании avito ios тестирование интерфейсы дизайн |
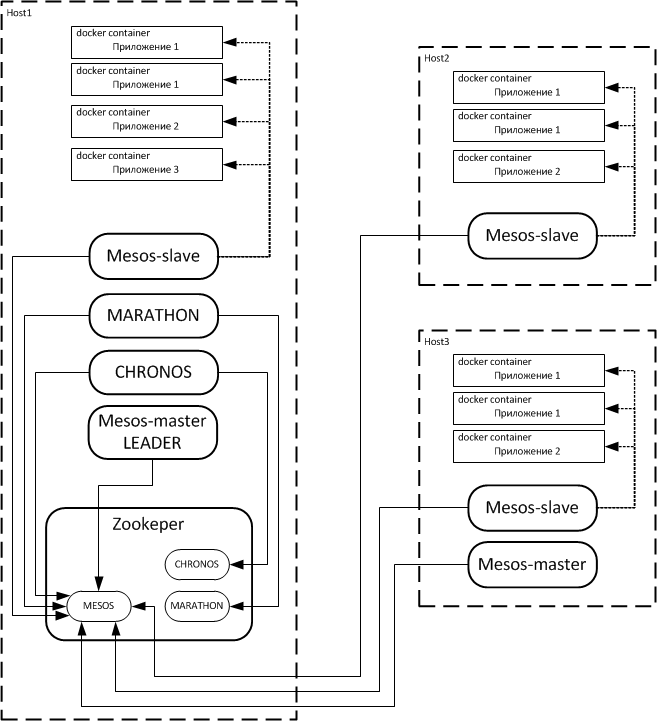
Построение систем управления приложениями в распределенной кластерной инфраструктуре на базе технологии MESOS |


|
|
Закрытый хакатон по технологиям машинного обучения от Microsoft |
|
Метки: author el777 машинное обучение хакатон cognitive toolkit microsoft azure thequestion python anaconda |
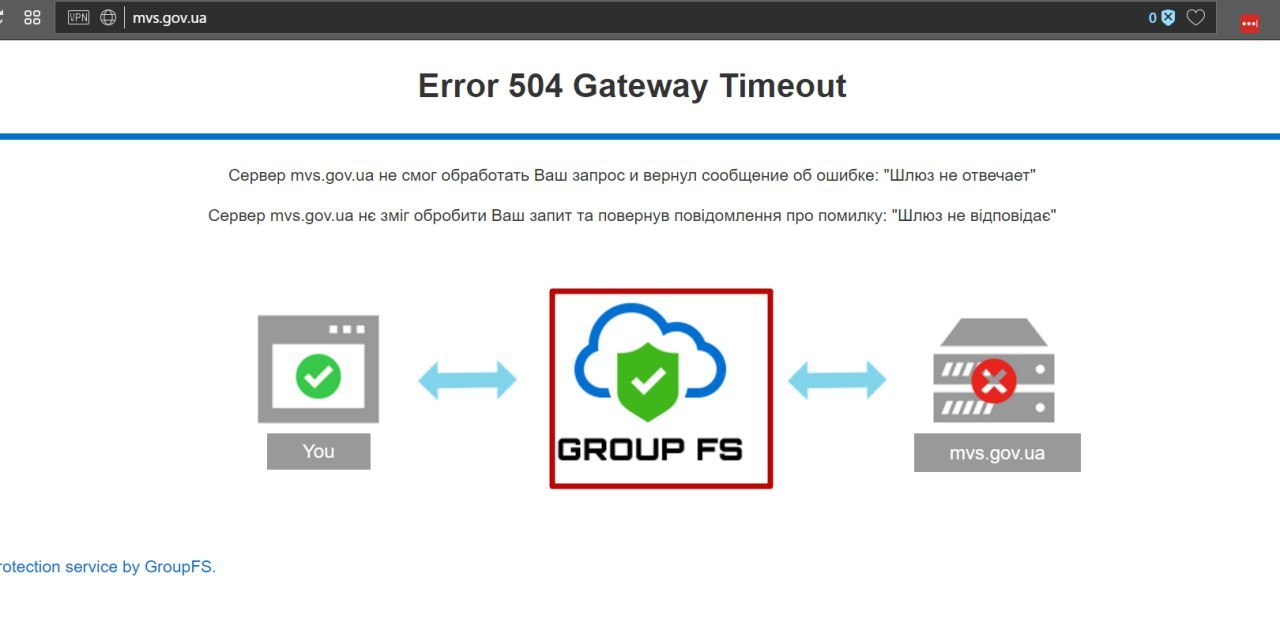
Украина подверглась самой крупной в истории кибератаки вирусом Petya |


|
Метки: author combonik информационная безопасность petya ransomware misha |






