[Перевод] Математический детектив: поиск положительных целых решений уравнения |
«Я экспериментировал с задачами кубического представления в стиле предыдущей работы Эндрю и Ричарда Гая. Численные результаты были потрясающими…» (комментарий на MathOverflow)Вот так ушедший на покой математик Аллан Маклауд наткнулся на это уравнение несколько лет назад. И оно действительно очень интересно. Честно говоря, это одно из лучших диофантовых уравнений, которое я когда-либо видел, но видел я их не очень много.
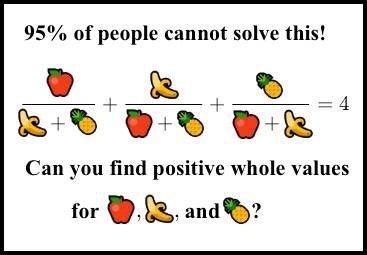
9P=(-66202368404229585264842409883878874707453676645038225/13514400292716288512070907945002943352692578000406921,
58800835157308083307376751727347181330085672850296730351871748713307988700611210/1571068668597978434556364707291896268838086945430031322196754390420280407346469)a=154476802108746166441951315019919837485664325669565431700026634898253202035277999,
b=36875131794129999827197811565225474825492979968971970996283137471637224634055579,
c=4373612677928697257861252602371390152816537558161613618621437993378423467772036

|
Метки: author PatientZero математика занимательные задачки диофантовы уравнения |
Несколько слов о тестировании сложных аппаратных комплексов |





















|
Метки: author asmolenskiy тестирование it-систем блог компании yadro тестирование ошибки правда жизни аппаратное обеспечение |
Model-View-Intent и индикатор загрузки/обновления |
Добрый день! Многие Android-приложения загружают данные с сервера и в это время показывают индикатор загрузки, а после этого позволяют обновить данные. В приложении может быть с десяток экранов, практически на каждом из них нужно:
ProgressBar) в то время, как данные грузятся с сервера;SwipeRefreshLayout);Snackbar).При разработке приложений я использую архитектуру MVI (Model-View-Intent) в реализации Mosby, подробнее о которой можно почитать на Хабре или найти оригинальную статью о MVI на сайте разработчика mosby. В этой статье я собираюсь рассказать о создании базовых классов, которые позволили бы отделить описанную выше логику загрузки/обновления от остальных действий с данными.
Первое, с чего мы начнем создание базовых классов, это создание ViewState, который играет ключевую роль в MVI. ViewState содержит данные о текущем состоянии View (которым может быть активити, фрагмент или ViewGroup). С учетом того, каким может быть состояние экрана, относительно загрузки и обновления, ViewState выглядит следующим образом:
// Здесь и далее LR используется для сокращения Load-Refresh.
data class LRViewState>(
val loading: Boolean,
val loadingError: Throwable?,
val canRefresh: Boolean,
val refreshing: Boolean,
val refreshingError: Throwable?,
val model: M
) Первые два поля содержат информацию о текущем состоянии загрузки (происходит ли сейчас загрузка и не произошла ли ошибка). Следующие три поля содержат информацию об обновлении данных (может ли пользователь обновить данные и происходит ли обновление в данный момент и не произошла ли ошибка). Последнее поле представляет собой модель, которую подразумевается показывать на экране после того, как она будет загружена.
В LRViewState модель реализует интерфейс InitialModelHolder, о котором я сейчас расскажу.
Не все данные, которые будут отображены на экране или будут еще как-то использоваться в пределах экрана, должны быть загружены с сервера. К примеру, имеется модель, которая состоит из списка людей, который загружается с сервера, и нескольких переменных, которые определяют порядок сортировки или фильтрацию людей в списке. Пользователь может менять параметры сортировки и поиска еще до того, как список будет загружен с сервера. В этом случае список — это исходная (initial) часть модели, которая грузится долго и на время загрузки которой необходимо показывать ProgressBar. Именно для того, чтобы выделить, какая часть модели является исходной используется интерфейс InitialModelHolder.
interface InitialModelHolder {
fun changeInitialModel(i: I): InitialModelHolder
} Здесь параметр I показывает какой будет исходная часть модели, а метод changeInitialModel(i: I), который должен реализовать класс-модель, позволяет создать новый объект модели, в котором ее исходная (initial) часть заменена на ту, что передана в метод в качестве параметра i.
То, зачем нужно менять какую-то часть модели на другую, становится понятно, если вспомнить одно из главных преимуществ MVI — State Reducer (подробнее тут). State Reducer позволяет применять к уже имеющемуся объекту ViewState частичные изменения (Partial Changes) и тем самым создавать новый экземпляр ViewState. В дальнейшем метод changeInitialModel(i: I) будет использоваться в State Reducer для того, чтобы создать новый экземпляр ViewState с загруженными данными.
Теперь настало время поговорить о частичных изменениях (Partial Change). Частичное изменение содержит в себе информацию о том, что именно нужно изменить в ViewState. Все частичные изменения реализуют интерфейс PartialChange. Этот интерфейс не является частью Mosby и создан для того, чтобы все частичные изменения (те, которые касаются загрузки/обновления и те, что не касаются) имели общий "корень".
Частичные изменения удобно объединять в sealed классы. Далее Вы можете видеть частичные изменения, которые можно применить к LRViewState.
sealed class LRPartialChange : PartialChange {
object LoadingStarted : LRPartialChange() // загрузка началась
data class LoadingError(val t: Throwable) : LRPartialChange() // загрузка завершилась с ошибкой
object RefreshStarted : LRPartialChange() // обновление началось
data class RefreshError(val t: Throwable) : LRPartialChange() // обновление завершилось с ошибкой
// загрузка или обновления завершились успешно
data class InitialModelLoaded(val i: I) : LRPartialChange()
} Следующим шагом является создание базового интерфейса для View.
interface LRView> : MvpView {
fun load(): Observable
fun retry(): Observable
fun refresh(): Observable
fun render(vs: LRViewState)
} Здесь параметр K является ключем, который поможет презентеру определить какие именно данные нужно загрузить. В качестве ключа может выступать, например, ID сущности. Параметр M определяет тип модели (тип поля model в LRViewState). Первые три метода являются интентами (в понятиях MVI) и служат для передачи событий от View к Presenter. Реализация метода render будет отображать ViewState.
Теперь, когда у нас есть LRViewState и интерфейс LRView, можно создавать LRPresenter. Рассмотрим его по частям.
abstract class LRPresenter, V : LRView>
: MviBasePresenter>() {
protected abstract fun initialModelSingle(key: K): Single
open protected val reloadIntent: Observable = Observable.never()
protected val loadIntent: Observable = intent { it.load() }
protected val retryIntent: Observable = intent { it.retry() }
protected val refreshIntent: Observable = intent { it.refresh() }
...
...
} Параметры LRPresenter это:
K ключ, по которому загружается исходная часть модели;I тип исходной части модели;M тип модели;V тип View, с которой работает данный Presenter.Реализация метода initialModelSingle должна возвращать io.reactivex.Single для загрузки исходной части модели по переданному ключу. Поле reloadIntent может быть переопределено классами-наследниками и используется для повторной загрузки исходной части модели (например, после определенных действий пользователя). Последующие три поля создают интенты для приема событий от View.
Далее в LRPresenter идет метод для создания io.reactivex.Observable, который будет передавать частичные изменения, связанные с загрузкой или обновлением. В дальнейшем будет показано, как классы-наследники могут использовать этот метод.
protected fun loadRefreshPartialChanges(): Observable = Observable.merge(
Observable
.merge(
Observable.combineLatest(
loadIntent,
reloadIntent.startWith(Any()),
BiFunction { k, _ -> k }
),
retryIntent
)
.switchMap {
initialModelSingle(it)
.toObservable()
.map { LRPartialChange.InitialModelLoaded(it) }
.onErrorReturn { LRPartialChange.LoadingError(it) }
.startWith(LRPartialChange.LoadingStarted)
},
refreshIntent
.switchMap {
initialModelSingle(it)
.toObservable()
.map { LRPartialChange.InitialModelLoaded(it) }
.onErrorReturn { LRPartialChange.RefreshError(it) }
.startWith(LRPartialChange.RefreshStarted)
}
) И последняя часть LRPresenter это State Reducer, который применяет к ViewState частичные изменения, связанные с загрузкой или обновлением (эти частичные изменения были переданы из Observable, созданном в методе loadRefreshPartialChanges).
@CallSuper
open protected fun stateReducer(viewState: LRViewState, change: PartialChange): LRViewState {
if (change !is LRPartialChange) throw Exception()
return when (change) {
LRPartialChange.LoadingStarted -> viewState.copy(
loading = true,
loadingError = null,
canRefresh = false
)
is LRPartialChange.LoadingError -> viewState.copy(
loading = false,
loadingError = change.t
)
LRPartialChange.RefreshStarted -> viewState.copy(
refreshing = true,
refreshingError = null
)
is LRPartialChange.RefreshError -> viewState.copy(
refreshing = false,
refreshingError = change.t
)
is LRPartialChange.InitialModelLoaded<*> -> {
@Suppress("UNCHECKED_CAST")
viewState.copy(
loading = false,
loadingError = null,
model = viewState.model.changeInitialModel(change.i as I) as M,
canRefresh = true,
refreshing = false
)
}
}
} Теперь осталось создать базовый фрагмент или активити, который будет реализовывать LRView. В своих приложениях я придерживаюсь подхода SingleActivityApplication, поэтому создадим LRFragment.
Для отображения индикаторов загрузки и обновления, а также для получения событий о необходимости повторения загрузки и обновления был создан интерфейс LoadRefreshPanel, которому LRFragment будет делегировать отображение ViewState и который будет фасадом событий. Таким образом фрагменты-наследники не обязаны будут иметь SwipeRefreshLayout и кнопку "Повторить загрузку".
interface LoadRefreshPanel {
fun retryClicks(): Observable
fun refreshes(): Observable
fun render(vs: LRViewState<*>)
} В демо-приложении был создан класс LRPanelImpl, который представляет собой SwipeRefreshLayout с вложенным в него ViewAnimator. ViewAnimator позволяет отображать либо ProgressBar, либо панель ошибки, либо модель.
С учетом LoadRefreshPanel LRFragment будет выглядеть следующим образом:
abstract class LRFragment, V : LRView, P : MviBasePresenter>> : MviFragment(), LRView {
protected abstract val key: K
protected abstract fun viewForSnackbar(): View
protected abstract fun loadRefreshPanel(): LoadRefreshPanel
override fun load(): Observable = Observable.just(key)
override fun retry(): Observable = loadRefreshPanel().retryClicks().map { key }
override fun refresh(): Observable = loadRefreshPanel().refreshes().map { key }
@CallSuper
override fun render(vs: LRViewState) {
loadRefreshPanel().render(vs)
if (vs.refreshingError != null) {
Snackbar.make(viewForSnackbar(), R.string.refreshing_error_text, Snackbar.LENGTH_SHORT)
.show()
}
}
} Как видно из приведенного кода, загрузка начинается сразу же после присоединения презентера, а все остальное делегируется LoadRefreshPanel.
Теперь создание экрана, на котором необходимо реализовать логику загрузки/обновления становится несложной задачей. Для примера рассмотрим экран с подробностями о человеке (гонщике, в нашем случае).
Класс сущности — тривиальный.
data class Driver(
val id: Long,
val name: String,
val team: String,
val birthYear: Int
)Класс модели для экрана с подробностями состоит из одной сущности:
data class DriverDetailsModel(
val driver: Driver
) : InitialModelHolder {
override fun changeInitialModel(i: Driver) = copy(driver = i)
} Класс презентера для экрана с подробностями:
class DriverDetailsPresenter : LRPresenter() {
override fun initialModelSingle(key: Long): Single = Single
.just(DriversSource.DRIVERS)
.map { it.single { it.id == key } }
.delay(1, TimeUnit.SECONDS)
.flatMap {
if (System.currentTimeMillis() % 2 == 0L) Single.just(it)
else Single.error(Exception())
}
override fun bindIntents() {
val initialViewState = LRViewState(false, null, false, false, null,
DriverDetailsModel(Driver(-1, "", "", -1))
)
val observable = loadRefreshPartialChanges()
.scan(initialViewState, this::stateReducer)
.observeOn(AndroidSchedulers.mainThread())
subscribeViewState(observable, DriverDetailsView::render)
}
} Метод initialModelSingle создает Single для загрузки сущности по переданному id (примерно каждый 2-й раз выдается ошибка, чтобы показать как выглядит UI ошибки). В методе bindIntents используется метод loadRefreshPartialChanges из LRPresenter для создания Observable, передающего частичные изменения.
Перейдем к созданию фрагмента с подробностями.
class DriverDetailsFragment
: LRFragment(),
DriverDetailsView {
override val key by lazy { arguments.getLong(driverIdKey) }
override fun loadRefreshPanel() = object : LoadRefreshPanel {
override fun retryClicks(): Observable = RxView.clicks(retry_Button)
override fun refreshes(): Observable = Observable.never()
override fun render(vs: LRViewState<*>) {
retry_panel.visibility = if (vs.loadingError != null) View.VISIBLE else View.GONE
if (vs.loading) {
name_TextView.text = "...."
team_TextView.text = "...."
birthYear_TextView.text = "...."
}
}
}
override fun render(vs: LRViewState) {
super.render(vs)
if (!vs.loading && vs.loadingError == null) {
name_TextView.text = vs.model.driver.name
team_TextView.text = vs.model.driver.team
birthYear_TextView.text = vs.model.driver.birthYear.toString()
}
}
...
...
} В данном примере ключ хранится в аргументах фрагмента. Отображение модели происходит в методе render(vs: LRViewState фрагмента. Также создается реализация интерфейса LoadRefreshPanel, которая отвечает за отображение загрузки. В приведенном примере на время загрузки не используется ProgressBar, а вместо этого поля с данными отображают точки, что символизирует загрузку; retry_panel появляется в случае ошибки, а обновление не предусмотрено (Observable.never()).
Демо-приложение, которое использует описанные классы, можно найти на GitHib.
Спасибо за внимание!
|
|
Разрушители легенд — Gentoo Linux |
Дочка Убунту прибежала к Дебиану и, весело смеясь, поцеловала его в лоб: "С днём рождения, папа!". Затем она окинула радостным взглядом сидящих за столом гостей и спросила своим звонким голосом:
— Папа, а где Gentoo, разве он ещё не пришёл?
— Нет, он ещё только собирается.
Среди прочих Linux дистрибутивов Gentoo выделяется тем, что его окружает множество мифов, светлой и темной окраски. Я его использую более 10 лет в качестве домашней и офисной рабочей станции и хочу с вами разоблачить несколько мифов и создать парочку новых.
Также хотелось бы рассказать о достоинствах и недостатках дистрибутива, дабы помочь сомневающимся и беженцам с systemd принять верное решение. Пользуясь случаем также хочу здесь разместить несколько полезных советов, которые помогут избежать многочасовых поисков в интернетах и повторной компиляции монструозных пакетов.
Gentoo Linux дает прирост производительности за счет того, что все программы компилируются под конкретное пользовательское железо. На этапе зарождения и становления дистрибутива этот тезис звучал с лютой настойчивостью.
Это на самом деле не совсем миф, но вы скорее всего не заметите прироста производительности, если не ставите целью доказать это статистически, вооружившись Phoronix Test Suite или чем-то подобным. Возможно исключение для FireFox, собранного с профилированием, USE="pgo".
На чем основан этот миф? Действительно узкий круг вычислительных программ можно ускорить при компиляции под определенную платформу, задавая компилятору включение инструкций SIMD, AESNI, или AVX. Бинарные дистрибутивы из-за чрезмерной заботы о совместимости со старой архитектурой базой зачастую приносят подобные оптимизации в жертву. Вернее будет сказать, что так было раньше, а сейчас это не играет большой роли.
Определенно, не за это адепты ценят Gentoo.
Технически это верно, таки да, иногда программы обновляются долго, но обходные пути очень хорошо проторены, что и делает этот тезис мифом. Вот мои рекордсмены.
(5:515)$ sudo qlop -t libreoffice firefox qtwebengine
libreoffice: 15028 seconds average for 20 merges
firefox: 3127 seconds average for 32 merges
qtwebengine: 8884 seconds average for 5 mergesВо-первых никто не мешает долгоиграющие обновления запускать ночью. Во-вторых в любой момент задание emerge и компиляцию исходников можно поставить на паузу (Ctrl+Z), возобновив позже в фоновом режиме (bg) или явно (fg). В-третьих можно задать автоматическое обновление через небольной скрипт, например такой.
# Part 1
layman -S
emerge --sync
eix-update
# Part 2
emerge -avuND --with-bdeps=y --complete-graph=y --backtrack=30 --keep-going --verbose-conflicts --exclude "gentoo-sources firefox libreoffice chromium glibc perl python gcc" world
smart-live-rebuild -- -av --with-bdeps=y --complete-graph=y
emerge -av --exclude "gentoo-sources firefox libreoffice chromium glibc perl python gcc" @preserved-rebuild
eclean distfilesКонечно, если сравнивать с Debian Linux, то в целом это так, однако и тут бывают исключения. Тот же Debian раньше стал использовать Grub 2 в стабильной ветке и Perl какое-то время был более новой версии, нежели в Gentoo. Если же сравнивать стабильные ветки менее консервативных дистрибутивов с таковыми в Gentoo, то результат может быть каким угодно. Все зависит от кучи обстоятельств, насколько данный пакет обеспечен мейнтейнером и волонтерами. Например QEMU обновляется почти одновременно со стабильной веткой Github, а MATE — застрял в Gentoo на версии 1.12.2 из-за того, что у него мало разработчиков.
(5:499)$ eix -ce qemu;eix -ce mate
[I] app-emulation/qemu (2.9.0-r2@19.05.2017): QEMU + Kernel-based Virtual Machine userland tools
[N] mate-base/mate (1.12-r1): Meta ebuild for MATE, a traditional desktop environmentПоговорим теперь немного о достоинствах Gentoo Linux. Гибкость и возможность настроить очень многие аспекты ОС под себя это то, чем блещет дистрибутив. Вот всего лишь несколько таких примеров.
Systemd или OpenRC, решайте сами.Pulseaudio ставить или нет, думайте.dri3 в mesa и Xorg или оставить dri2?ffmpeg, mpv, vlc?emerge и portage вас не устраивают?Для меня это одно из основных преимуществ дистрибутива. Из-за того, что вы невнимательно читали RSS ленту вашего дистрибутива вы не окажетесь в ситуации, когда вам на голову свалился новый инит, файловая система или принцип работы сетевых интерфейсов.
Все важные изменения изменения доносят до пользователей заблаговременно через механизм рассылки новостей. Прочитать последние актуальные новости дистрибутива можно командой eselect news read.
(5:501)$ sudo eselect news read
No news is good news.Это действительно так. Установку ОС значительно облегчает подробнейшее руководство, но есть также крайне полезные вики и форум.
Туда же входят упомянутые рассылки новостей и сообщения elog в специальных файлах /var/log/portage/elog.
Основная система управления пакетами portage и штатное средство управления пакетами emerge являются очень мощным и функциональным в руках опытного и внимательного к докам пользователя. Именно благодаря системе portage возможны тонкие и гибкие настройки операционной систему и пользовательского ПО (см. выше в +1). Даже беглое описание возможностей emerge/portage заслуживает отдельного поста, поэтому ограничусь общим описанием.
USE флагами, которые транслируются в --enable-<опция> и --disable-<опция> инструкции .configure скрипта установки из исходников.python или gcc, придется затем скачивать бинарные пакеты, так как emerge впадет в ступор и будет не в состоянии собрать программу из исходников.Из-за чего могут возникать такие ситуации? По самым разным причинам, изменения в лицензировании продукта, необходимость замаскировать, или наоборот размаскировать пакет, изредка ляпы разработчиков. Тут наблюдается обратная зависимость от частоты обновлений, поэтому рекомендуется регулярно и по возможности часто обновлять систему, чтобы накопленная энтропия в древе портов не порождала цепной реакции.
Полная ерунда, вот установка с помощью однострочника.
wget goo.gl/5Y2Gj -O install.sh && sh install.shА если серьезно, то действительно весь процесс займет времени намного больше, чем при установки бинарных дистрибутивов, таких как Дебиан, или Убунту. Однако трудности более чем преодолимы, ввиду следующих обстоятельств.
gentoolkit позволяет безболезненно пройти самый запутанный и неформализуемый процесс конфигурации и сборки ядра. Другие утилиты из набора portage-utils, eix, eselect и другие позволят хорошо ориентироваться в порядке и зависимостях установленных пакетов и избежать состояний блокировки.Если по каким-то причинам компиляция пакета прервалась (выключился свет, завис компьютер и т. д.), но технически может быть возобновлена, можно продолжить процесс с этого самого места. Это особенно ценно для LibreOffice, Chromium или qt-webengine, которые собираются не один час.
ebuild /usr/portage/cate-gory/prog/prog-x.y.z.ebuild compileebuild /usr/portage/cate-gory/prog/prog-x.y.z.ebuild installebuild /usr/portage/cate-gory/prog/prog-x.y.z.ebuild qmergeСмонтируйте /var/tmp/portage и /usr/portage на SSD, а если у вас немерено оперативной памяти, то можно и на tmpfs, это даст заметный прирост скорости работы emerge.
Можно сделать бинарный бэкапы системных пакетов на всякий пожарный случай.
quickpkg --include-config y <установленная программа>|
Метки: author temujin системное администрирование настройка linux it- инфраструктура *nix gentoo linux мифы и реальность |
[Из песочницы] Как повысить шансы при поиске работы и получить максимум приглашений на перспективные собеседования при минимуме времени |
|
Метки: author Alina_Alexandrovna управление персоналом карьера в it-индустрии поиск работы hr- процесс собеседования |
12 полезных сайтов для творческих коллективов |
|
Метки: author Logomachine читальный зал блог компании логомашина логомашина команда полезные ресурсы совет подборка |
[Перевод] Как Discord масштабировал Elixir на 5 млн одновременных пользователей |
def handle_call({:publish, message}, _from, %{sessions: sessions}=state) do
Enum.each(sessions, &send(&1.pid, message))
{:reply, :ok, state}
endsend/2 может варьироваться от 30 мкс до 70 мкс из-за дешедулинга процесса вызова Erlang. Это означало, что в пиковые часы публикация одного события с большого guild'а может занять от 900 мс до 2,1 с! Процессы Erlang полностью однопоточные, и единственным вариантом параллелизации представлялись шарды. Такое мероприятие потребовало бы немалых сил, и мы знали, что найдётся лучший вариант.send/2 максимум столько раз, сколько вовлечено удалённых нодов. Manifold делает это, сначала группируя PID'ы по их удалённым нодам, а затем отправляя их в «разделитель» Manifold.Partitioner на каждой из этих нод. Затем разделитель последовательно хеширует PID'ы, используя :erlang.phash2/2, группирует их по количеству ядер и отправляет на дочерние воркеры. В конце концов, воркеры рассылают сообщения в реальные процессы. Это гарантирует, что разделитель не перегружен и продолжает обеспечивать линеаризуемость, как send/2. Такое решение стало эффективной заменой send/2:Manifold.send([self(), self()], :hello)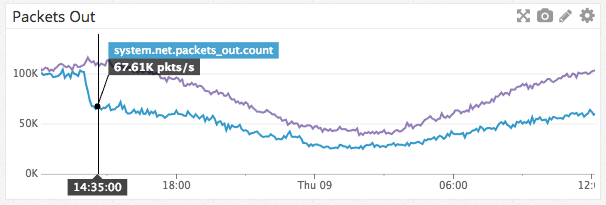

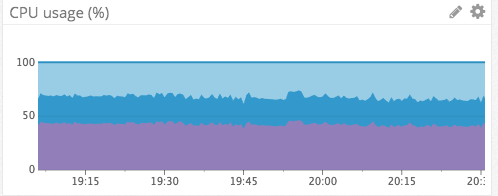
guild_pid в нодах guild стали давать задний ход. Медленный поиск нод раньше защищал их. Новая проблема заключалась в том, что около 5 000 000 сессионных процессов пытались давить на десять из этих процессов (по одному на каждой ноде guild). Здесь ускорение обработки не решало проблему; фундаментальной причиной было то, что обращения сессионных процессов к этому реестру guild'ов вываливались в таймаут и оставляли запрос в очереди к реестру. После некоторого времени запрос повторялся, но постоянно накапливаемые запросы переходили в неустранимое состояние. Получая сообщения из других сервисов, сессии блокировали бы эти запросы до тех пор, пока они не уйдут в таймаут, что приводило к раздуванию очереди сообщений и, в итоге, к OOM всей Erlang VM, результатом чего становятся каскадные перебои в обслуживании.:ets.update_counter/4, который выполняет атомарные операции с обусловленных приращением на числе, которое находится в ключе ETS. Поскольку нужна была хорошая параллелизация, можно было запустить ETS в режиме write_concurrency, но по-прежнему считывать значение, поскольку :ets.update_counter/4 возвращает результат. Это дало нам фундаментальную основу для создания библиотеки Semaphore. Её исключительно легко использовать, и она очень хорошо работает с высокой пропускной способностью:semaphore_name = :my_sempahore
semaphore_max = 10
case Semaphore.call(semaphore_name, semaphore_max, fn -> :ok end) do
:ok ->
IO.puts "success"
{:error, :max} ->
IO.puts "too many callers"
end
|
|
Комиксы Даниэля Стори (часть 2) |






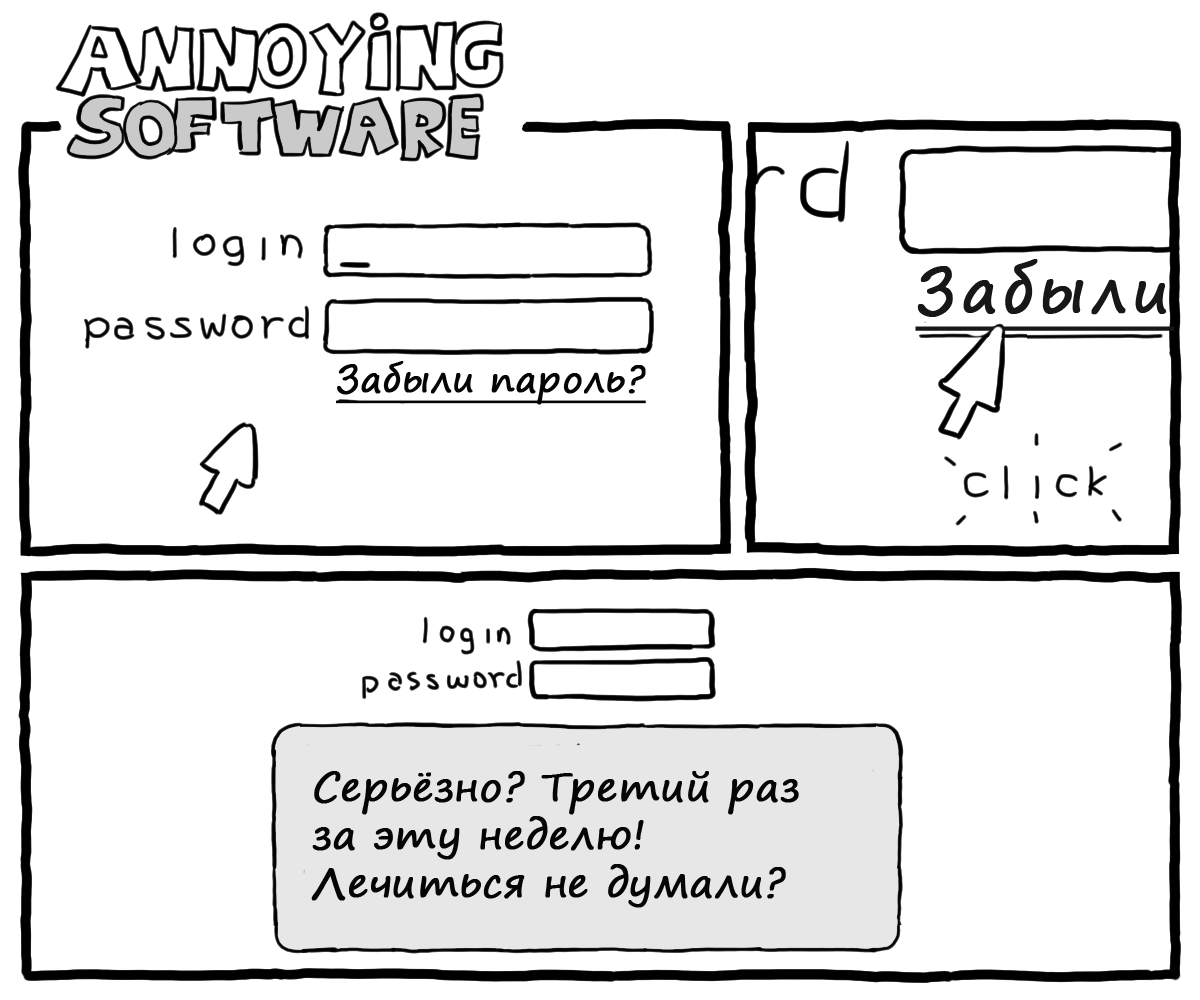
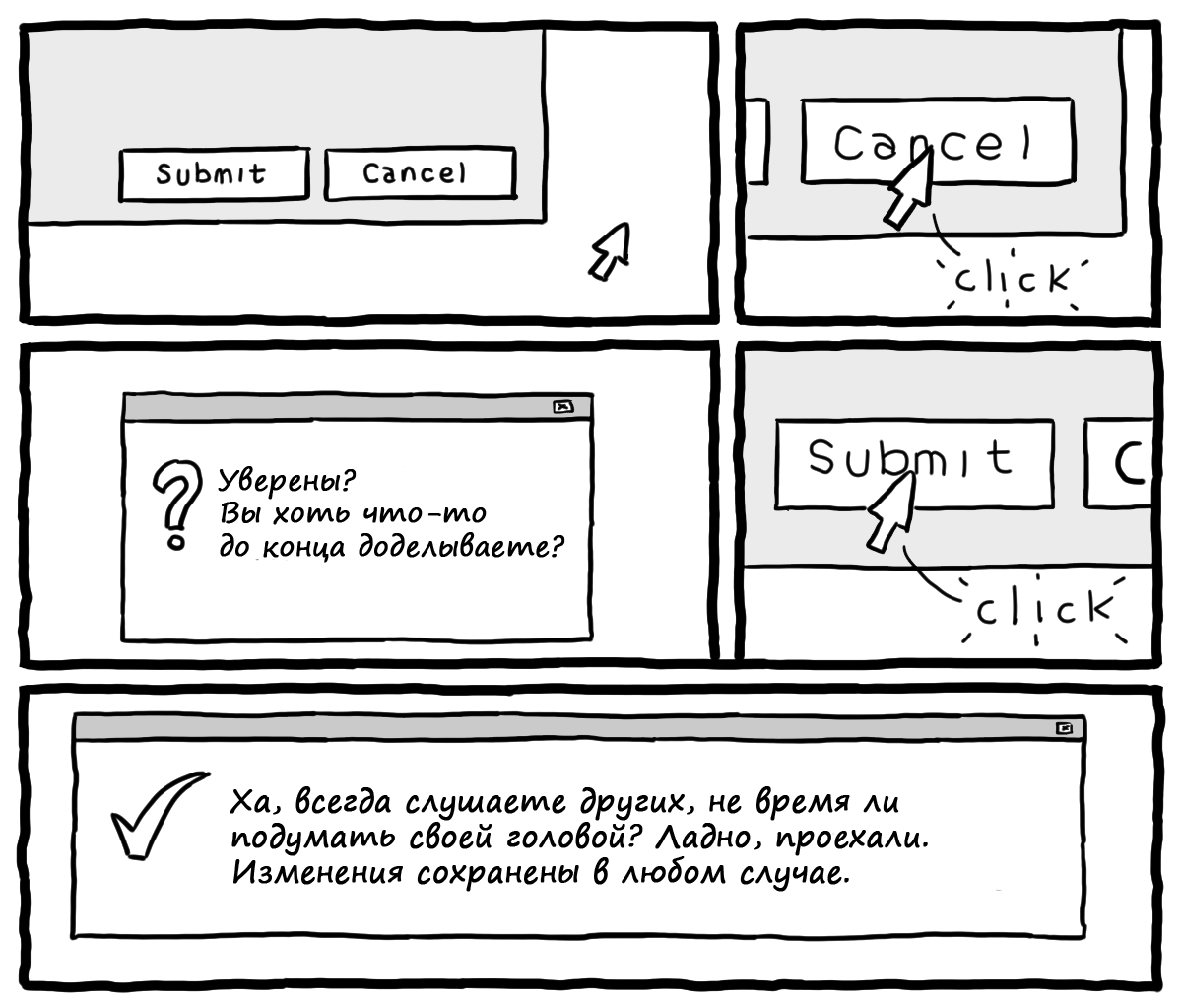
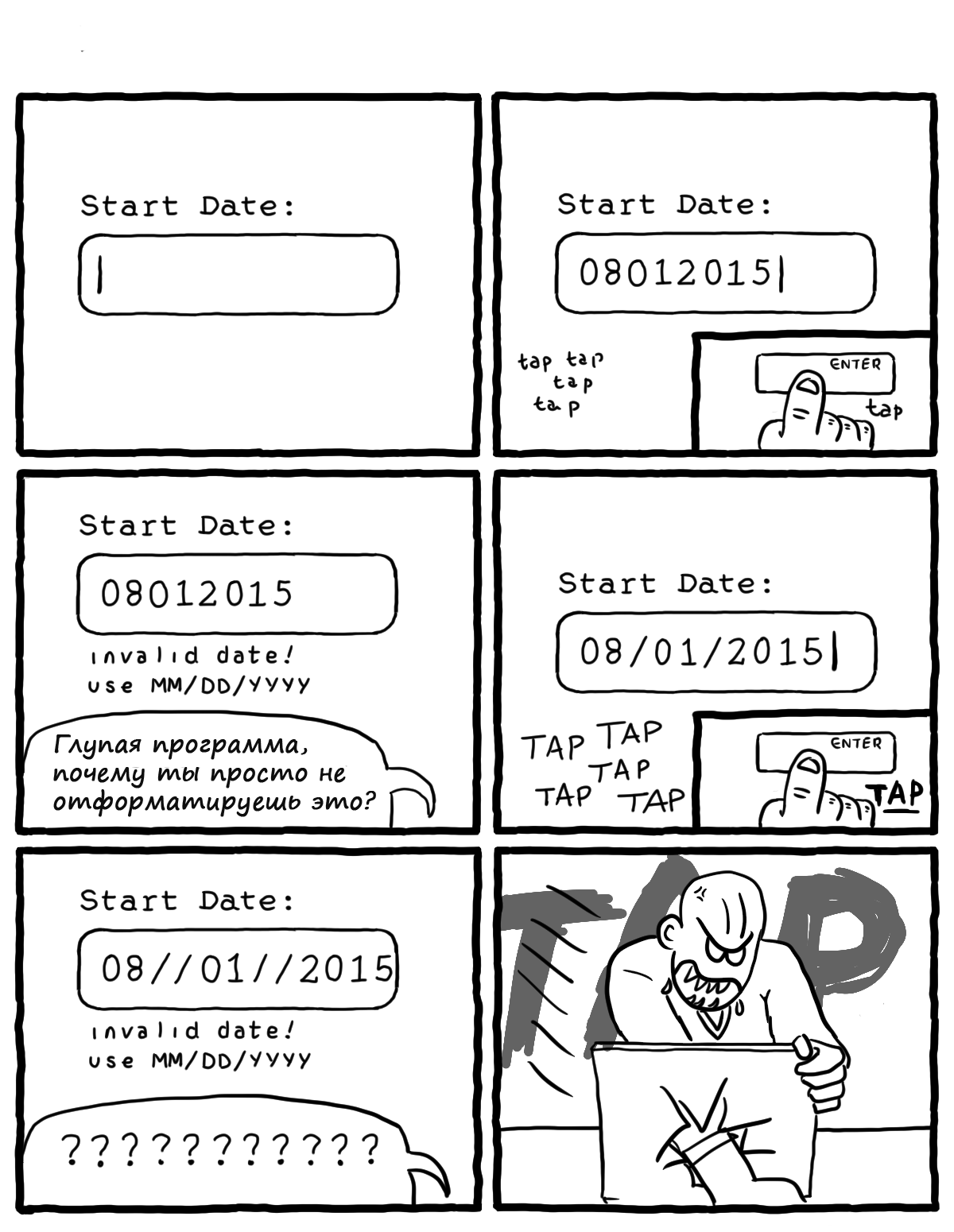


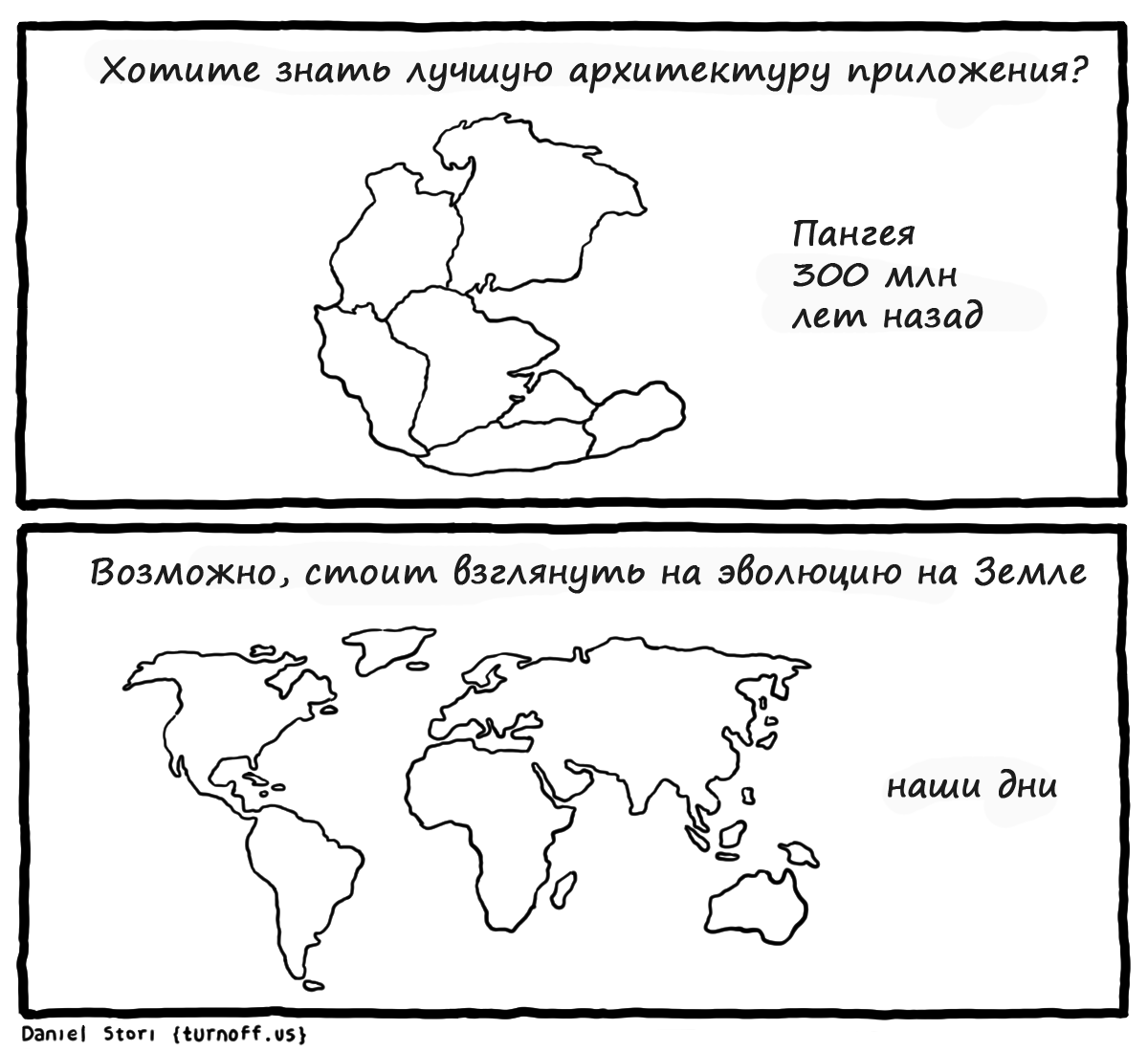






|
Метки: author Cloud4Y читальный зал учебный процесс в it блог компании cloud4y комиксы юмор монолит cloud программисты шутят микросервисы java |
Как workflow разработки влияет на декомпозицию задач |

Одним из самых важных факторов, влияющих на скорость разработки и успех запуска проекта, является правильная декомпозиция идеи продакт-менеджера в задачи для непосредственно программирования. Как правильно это делать? Взять сценарий работы новой фичи от продакта и сразу начать кодить? Сначала написать приёмочные тесты, а потом – код, который будет обеспечивать их прохождение? А, может, переложить всё на плечи разработчиков – и пусть они в ходе скрам-покера сами решают?
Давайте подумаем и обозначим проблемы, которые могут возникнуть в процессе разделения задач, и способы их решения. В этом посте будут рассмотрены основные принципы декомпозиции задач при работе в команде. Меня зовут Илья Агеев, я – глава QA в Badoo. Сегодня расскажу, как workflow влияет на декомпозицию, насколько отличаются тестирование и выкладка задач, которые появляются в результате декомпозиции, и каких правил стоит придерживаться, чтобы процесс разработки проходил гладко для всех участников.
Необходимо помнить о том, что процесс разработки – это не только непосредственно сеанс написания кода. Когда мы говорим о разработке, я призываю смотреть на весь процесс целиком, начиная от постановки задачи и заканчивая стабильной работой фичи у наших пользователей. Если не брать в расчёт все этапы, которые предшествуют кодированию и следуют за ним, то очень легко можно попасть в ситуацию, когда все что-то делают, выполняют свои KPI, получают бонусы, а результат получается плачевный. Бизнес загибается, конкуренты «душат», но при этом все – молодцы.
Почему так происходит? Всё просто: человеческая психология заставляет людей смотреть на ситуации с точки зрения собственного комфорта. Разработчику не всегда хочется думать о том, что будет с кодом после его написания. Решил задачу – и хорошо. Его крайне редко это интересует (именно поэтому мы, айтишники, и работаем в этой отрасли – наша мотивация в основном держится на интересности задач), ведь в отношениях с людьми столько неопределённости. Гораздо более комфортно многие разработчики чувствуют себя, сидя за компьютером и сосредоточившись на решении своей собственной интересной задачи – блокчейнах с нейросетями – им совсем не хочется отвлекаться и думать о каких-то продакт-менеджерах, дедлайнах, пользователях, которые потом будут использовать их гениальное произведение (а то ещё и критиковать начнут!).
Это не плохо и не хорошо – мы ценим разработчиков именно за вдумчивое и грамотное решение технических задач. Но узкий взгляд на проблемы часто останавливает развитие. И речь о развитии не только конкретных людей, но и компании в целом. Ведь рост компании и совершенствование корпоративной культуры возможны только с ростом каждого сотрудника. Поэтому нам важно иногда вылезать из «кокона» и заставлять себя смотреть на проблемы шире, чтобы этот рост стимулировать.
И, разумеется, если такой важный этап, как декомпозиция, поручить человеку, который смотрит на всё исключительно с точки зрения собственного удобства, есть реальный риск огрести кучу проблем на последующих этапах: при слиянии результатов его работы с результатами других, при code review, при тестировании, выкладке в продакшн, и т. д.
Таким образом, определяя для себя, как правильно разбить ту или иную задачу, прикидывая, с чего следует начать и куда в итоге прийти, важно учитывать как можно больше факторов, а не смотреть на проблему только «со своей колокольни». Иногда для того чтобы всё работало быстрее и эффективнее на следующих этапах, приходится делать что-то сложнее и медленнее на том этапе, за который отвечаете вы.
Хороший пример – написание юнит-тестов. Зачем мне тратить своё драгоценное время на написание тестов, если у нас есть тестировщики, которые потом и так всё протестируют? А затем, что юнит-тесты необходимы не только для облегчения процесса кодинга – они нужны также и на последующих этапах. И нужны как воздух: с ними процесс интеграции и проверки регрессии ускоряется в десятки, сотни раз, на них базируется пирамида автоматизации. И это даже если не брать в расчёт ускорение вашей собственной работы: ведь «потрогав» код в каком-то месте, вам самому нужно убедиться в том, что вы ненароком что-нибудь не сломали. И один из самых быстрых способов это сделать – прогнать юнит-тесты.
Многие команды, чтобы как-то формализовать отношения между участниками процесса, договариваются о правилах работы в коллективе: согласовывают стандарты кодирования, общий workflow в системе контроля версий, устанавливают расписание релизов и т. д.
Стоит ли говорить, что если изначально договориться о процессе, не принимая во внимание весь жизненный цикл фичи, то можно получить замедление и «грабли» в будущем? Особенно если учесть рост проекта и компании. О преждевременной оптимизации не забываем, но если есть процесс, который хорошо работает на разных масштабах, то почему бы его не использовать изначально?
Говоря о workflow разработки, многие, кто использует Git, сразу вспоминают (всуе) о некоем «стандартном git-flow», считая его идеальным, правильным, и часто внедряют его у себя. Даже на конференциях, где я выступал, рассказывая про workflow в Badoo, меня несколько раз спрашивали: «Зачем вы изобрели своё, почему не используете стандартный git-flow?» Давайте разбираться.

Во-первых, обычно, говоря про этот флоу, имеют в виду вот эту картинку. Я взял её из статьи Vincent Driessen “A successful Git branching model”, в которой описывается схема, довольно успешно работавшая на нескольких его проектах (было это в далёком 2010 году).
Сегодня некоторые крупные игроки на рынке хостинга кода вообще предлагают свой флоу, критикуя «стандартный git-flow» и описывая его недостатки; дают свои схемы, рекомендации, приёмы.
Если же поискать на git-scm.com (хорошо бы вообще погуглить), то с удивлением можно обнаружить, что никакого рекомендованного (и уж тем более «стандартного») workflow не существует. Всё потому, что Git – это, по сути, фреймворк для систем хранения версий кода, и то, как вы организуете это самое хранение и совместную работу, зависит только от вас самих. Всегда нужно помнить о том, что, если какой-то флоу «взлетел» на каких-то проектах, это вовсе не означает, что вам он тоже полностью подойдёт.
Во-вторых, даже у нас в компании у разных команд разный флоу. Флоу разработки серверного кода на PHP, демонов на С/ С++ и Go, флоу мобильных команд – они разные. И пришли мы к этому не сразу: пробовали разные варианты, прежде чем остановиться на чём-то конкретном. К слову, отличается в этих командах не только workflow, но ещё и методологии тестирования, постановки задач, релизы и сам принцип доставки: то, что поставляется на ваши личные серверы и на компьютеры (смартфоны) конечных пользователей, не может разрабатываться одинаково по определению.
В-третьих, даже принятый workflow является скорее рекомендацией, чем непререкаемым правилом. Задачи у бизнеса бывают разные, и хорошо, если вам удалось выбрать процесс, покрывающий 95% случаев. Если же ваша текущая задача не вписывается в выбранный флоу, имеет смысл посмотреть на ситуацию с прагматической точки зрения: если правила мешают вам сделать эффективно, к чёрту такие правила! Но обязательно посоветуйтесь с вашим менеджером перед принятием окончательного решения – иначе может начаться бардак. Вы можете банально не учесть какие-то важные моменты, которые известны вашему руководителю. А, возможно, всё пойдёт как по маслу – и вы сумеете изменить существующие правила так, что это приведёт к прогрессу и станет залогом роста для всех.
Если всё так сложно, да ещё и флоу – это не догма, а всего лишь рекомендация, то почему бы не использовать одну ветку для всего: Master для Git или Trunk для SVN? Зачем усложнять?
Тем, кто смотрит на проблему однобоко, этот подход с одной веткой может показаться очень удобным. Зачем мучиться с какими-то ветками, париться со стабилизацией кода в них, если можно написать код, закоммитить (запушить) в общее хранилище – и радоваться жизни? И правда, если в команде работает не очень много человек, это может быть удобно, поскольку избавляет от необходимости слияния веток и организации веток для релиза. Однако данный подход имеет один очень существенный недостаток: код в общем хранилище может быть нестабильным. Вася, работающий над задачей №1, может легко сломать код других задач в общем хранилище, залив свои изменения; и пока он их не исправит/ не откатит, код выкладывать нельзя, даже если все остальные задачи готовы и работают.
Конечно, можно использовать теги в системе контроля версий и код-фриз, но очевидно, что подход с тегами мало отличается от подхода с ветками, как минимум потому что усложняет изначально простую схему. А уж код-фриз тем более не добавляет скорости работе, вынуждая всех участников останавливать разработку до стабилизации и выкладки релиза.
Так что первое правило хорошей декомпозиции задач звучит так: задачи нужно разбивать так, чтобы они попадали в общее хранилище в виде логически завершённых кусочков, которые работают сами по себе и не ломают логику вокруг себя.
При всём многообразии вариантов workflow у нас в компании у них есть общая черта – они все основаны на отдельных ветках для фич. Такая модель позволяет нам работать независимо на разных этапах, разрабатывать разные фичи, не мешая друг другу. А ещё мы можем тестировать их и сливать в общее хранилище, только убедившись, что они работают и ничего не ломают.
Но и такой подход имеет свои недостатки, основанные на самой природе фичебранчей. В конце концов, после изоляции результат вашей работы нужно будет слить в общее для всех место. На этом этапе можно огрести немало проблем, начиная от мерж-конфликтов и заканчивая очень длительным тестированием/ багфиксингом. Ведь отделяясь в свою ветку кода, вы изолируете не только общее хранилище от ваших изменений, но и ваш код – от изменений других разработчиков. В результате, когда приходит время слить свою задачу в общий код, даже если она проверена и работает, начинаются «танцы с бубном», потому что Вася и Петя в своих ветках затронули одни и те же строки кода в одних и тех же файлах – конфликт.
Современные системы хранения версий кода имеют кучу удобных инструментов, стратегий слияния и прочее. Но избежать конфликтов всё равно не удастся. И чем больше изменений, чем они витиеватее, тем сложнее и дольше эти конфликты разрешать.
Ещё опаснее конфликты, связанные с логикой кода, когда SCM сливает код без проблем (ведь по строкам в файлах конфликтов нет), но из-за изоляции разработки какие-то общие методы и функции в коде изменили своё поведение или вообще удалены из кода. В компилируемых языках проблема, как может показаться, стоит менее остро – компилятор валидирует код. Но ситуации, когда сигнатуры методов не поменялись, а логика изменилась, никто не отменял. Такие проблемы сложно обнаруживать, и они ещё более отдаляют счастливый релиз и заставляют перетестировать код много раз после каждого слияния. А когда разработчиков много, кода много, файлов много и конфликтов много, всё превращается в сущий ад, ибо пока мы исправляли код и перепроверяли его, основная версия кода уже ушла далеко вперёд, и надо всё повторять заново. Вы всё ещё не верите в юнит-тесты? Хе-хе-хе!
Чтобы этого избежать, многие стараются как можно чаще сливать результаты общей работы в свою ветку. Но даже соблюдение этого правила, если фичебранч будет достаточно большим, не поможет избежать проблем, как бы мы ни старались. Потому что чужие изменения вы к себе в код получаете, но ваши изменения при этом никто не видит. Соответственно, необходимо не только почаще заливать чужой код в свою ветку, но и свой код в общее хранилище – тоже.
Отсюда – второе правило хорошей декомпозиции: фичебранчи должны содержать как можно меньше изменений, чтобы как можно быстрее попадать в общий код.
Хорошо, но как же тогда работать в отдельных ветках, если несколько программистов трудятся над одной и той же задачей, разбитой на части? Или если им нужны изменения в общих для разных задач частях кода? И Петя, и Вася используют общий метод, который в рамках задачи Пети должен работать по одному сценарию, а в задаче Васи – по другому. Как им быть?
Тут многое зависит от вашего цикла релизов, потому что моментом завершения задачи мы считаем момент попадания её на продакшн. Ведь только этот момент гарантирует нам, что код стабилен и работает. Если не пришлось откатывать изменения с продакшна, конечно.
Если цикл релизов быстрый (несколько раз в день вы выкладываетесь на свои серверы), то вполне можно сделать фичи зависимыми друг от друга по стадиям готовности. В примере с Петей и Васей выше создаём не две задачи, а три. Соответственно, первая звучит как «меняем общий метод так, чтобы он работал в двух вариантах» (или заводим новый метод для Пети), а две другие задачи – это задачи Васи и Пети, которые могут начать работу после завершения первой задачи, не пересекаясь и не мешая друг другу.
Если же цикл релизов не позволяет вам выкладываться часто, то пример, описанный выше, будет непомерно дорогим удовольствием, ведь тогда Васе и Пете придётся ждать дни и недели (а в некоторых циклах разработки и года), пока они смогут начать работать над своими задачами.
В этом случае можно использовать промежуточную ветку, общую для нескольких разработчиков, но ещё недостаточно стабильную, чтобы быть выложенной на продакшн (Master или Trunk). В нашем флоу для мобильных приложений такая ветка называется Dev, на схеме Vincent Driessen она называется develop.
Важно иметь в виду, что любое изменение в коде, даже слияние веток, вливание общих веток в стабильный Master и т. д., обязательно должно быть протестировано (помните про конфликты по коду и логике, да?). Поэтому если вы пришли к выводу, что вам необходима общая ветка кода, то нужно быть готовым к ещё одному этапу тестирования – после момента слияния необходимо тестировать, как фича интегрируется с другим кодом, даже если она уже протестирована в отдельной ветке.
Тут вы можете заметить, что можно ведь тестировать только один раз – после слияния. Зачем тестировать до него, в отдельной ветке? Верно, можно. Но, если задача в ветке не работает или ломает логику, этот неработоспособный код попадёт в общее хранилище и мало того, что помешает коллегам работать над своими задачами, ломая какие-то участки продукта, так ещё и может подложить бомбу, если на неправильных изменениях кто-то решит базировать новую логику. А когда таких задач десятки, очень тяжело искать источник проблемы и чинить баги.
Также важно понимать, что, даже если мы используем промежуточную разработческую ветку кода, которая может быть не самой стабильной, задачи или их кусочки в ней должны быть более-менее завершёнными. Ведь нам необходимо в какой-то момент зарелизиться. А если в этой ветке код фич будет ломать друг друга, то выложиться мы не сможем – наш продукт работать не будет. Соответственно, протестировав интеграцию фич, нужно как можно скорее исправить баги. Иначе мы получим ситуацию, похожую на ту, когда используется одна ветка для всех.
Следовательно, у нас появляется третье правило хорошей декомпозиции: задачи должны разделяться так, чтобы их можно было разрабатывать и релизить параллельно.
Но как же быть в ситуации, когда новое изменение бизнес-логики – большое? Только на программирование такой задачи может уйти несколько дней (недель, месяцев). Не будем же мы сливать в общее хранилище недоделанные куски фич?
А вот и будем! В этом нет ничего страшного. Подход, который может быть применён в этой ситуации, – feature flags. Он основан на внедрении в код «выключателей» (или «флагов»), которые включают/ выключают поведение определённой фичи. К слову, подход не зависит от вашей модели ветвления и может использоваться в любой из возможных.
Простым и понятным аналогом может быть, например, пункт в меню для новой страницы в приложении. Пока новая страница разрабатывается по кусочкам, пункт в меню не добавляется. Но как только мы всё закончили и собрали воедино, добавляем пункт меню. Так же и с фичефлагом: новую логику оборачиваем в условие включённости флага и меняем поведение кода в зависимости от него.
Последней задачей в процессе разработки новой большой фичи в этом случае будет задача «включить фичефлаг» (или «добавить пункт меню» в примере с новой страницей).
Единственное, что нужно иметь в виду, используя фичефлаги, – это увеличение времени тестирования фичи. Ведь продукт необходимо протестировать два раза: с включённым и выключенным фичефлагом. Сэкономить тут можно, но действовать следует крайне деликатно: например, тестировать только то состояние флага, которое выкладывается пользователю. Тогда в процессе разработки (и выкладки по частям) задачи её тестировать вообще не будут, а проведут тестирование только во время проверки последней задачи «включить фичефлаг». Но тут надо быть готовым к тому, что интеграция кусков фичи после включения флага может пройти с проблемами: могут обнаружиться баги, допущенные на ранних этапах, и в этом случае поиск источника проблемы и устранение ошибок могут дорого стоить.
Итак, при декомпозиции задач важно помнить три простых правила:
Куда уж проще? Кстати, независимая выкладка, на мой взгляд, — самый важный критерий. Из него так или иначе проистекают остальные пункты.
Желаю удачи в разработке новых фич!
|
Метки: author uyga управление разработкой управление проектами блог компании badoo декомпозиция разработка программного обеспечения |
«Есть плюсы как для админов, так и для разработчиков»: Олег Анастасьев про облако Одноклассников |



|
Метки: author phillennium java блог компании jug.ru group одноклассники облако частное облако олег анастасьев joker devoops конференция |
[Из песочницы] Digitalization и что это за зверь |
|
Метки: author DanilovaVikVik бизнес-модели digital digitalization customer centricity |
Как математическая библиотека КОМПАС-3D превратилась в C3D Toolkit для разработчиков САПР -> часть 1 |
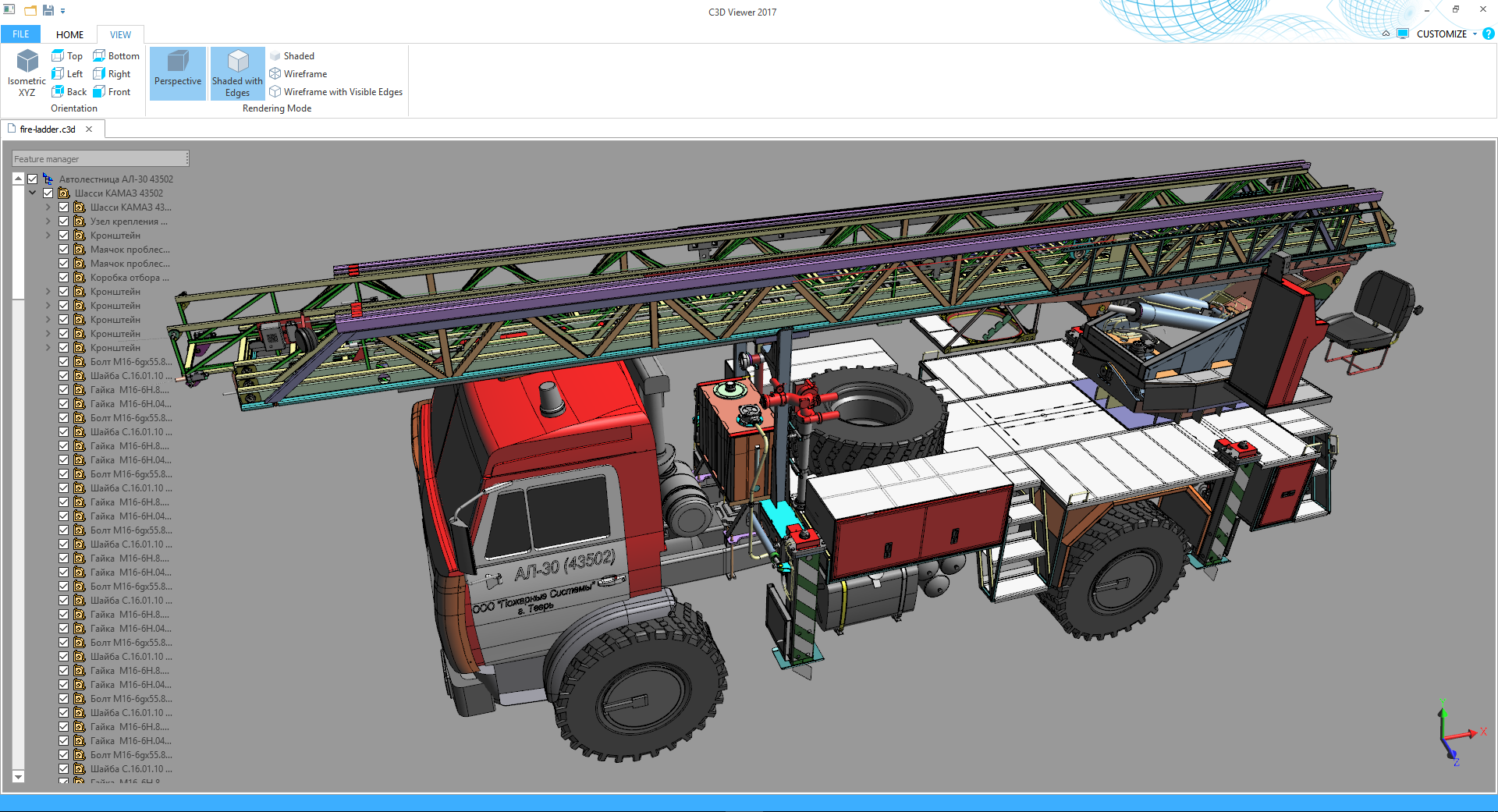










 Аркадий Камнев, Менеджер по продукту C3D.
Аркадий Камнев, Менеджер по продукту C3D.
|
|
Linux Kernel Extension for Databases |























Кстати, мы выложили в открытый доступ видеозаписи последних пяти лет конференции разработчиков высоконагруженных систем HighLoad++. Смотрите, изучайте, делитесь и подписывайтесь на канал YouTube.





























Этот доклад — расшифровка одного из лучших выступлений на профессиональной конференции разработчиков высоконагруженных систем HighLoad++.
Сейчас мы уже вовсю готовим конференцию 2017-года — самый большой HighLoad++
в истории. Если вам интересно и важна стоимость билетов — покупайте сейчас, пока цена ещё не высока!
Кстати, мы обязательно позовём в докладчики Александра Крижановского — на сегодняшний день это один из лучших профессионалов отрасли.
|
|
Как избежать ошибок при смене CRM |
В этой статье мы разберем основные ошибки при уходе от Saas-решений к разработке на платформе, а также способы, с помощью которых эти ошибки можно не допускать вообще.

Далее, когда проблема принята и четко обозначена, а также известны причины ее возникновения — предприятие встает перед выбором: подобрать ли другое коробочное решение, конфигурацию на платформе, или разработать систему с нуля.
Пожалуй, самые бессмысленные затраты произойдут в результате перехода «из коробки в коробку». В целях экономии, некоторые компании могут найти альтернативу старой системе: систему побольше, — уже решающую все текущие задачи бизнеса.
На первый взгляд это выгодно, — не нужно тратить деньги на разработку, минимальный период адаптации персонала, множество готовых решений и способов автоматизации. Да, в целом все супер — однако нужно понимать, что если у вас не студия из нескольких фотографов — вы будете расти, и этот переход лишь отсрочит неизбежное повторение истории.

Выходом из этих трудностей может стать правильный выбор платформы, определиться с чем действительно непросто.
Еще один очень важный момент — это прототипирование. Возможность накидать быстрый прототип системы для тестирования, — это действительно круто. С помощью такого инструмента вы проверите свои гипотезы и будете точно знать, как сформулировать ТЗ без ошибок.
Неплохо реализован визуальный редактор у платформы «КлиК»: он позволяет сделать прототип для тестирования еще перед началом работы с системой. Степень настройки всех составляющих без программирования — крайне высокая, что тоже приятно, особенно для экономии средств на разработке системы под свой бизнес.
1 — Найти «идеолога»
С вашей стороны необходим человек, который может точно отразить текущие бизнес-процессы компании и формализовать их. Этот человек будет контролировать весь процесс разработки учитывая удобство пользователей, и постоянно сверяться с «картой» — направляя проект в нужную сторону.
2 — Создать прототип
Даже те компании, которые пережили неэффективные коробочные системы не всегда могут сформулировать те или иные задачи к новой системе. В этом лежат риски, связанные с тем, что при создании нового CRM-проекта можно заложить ошибки заранее, уже на уровне ТЗ. Поэтому, важным пунктом тут будет отлаживание — то есть вам надо не просто выстроить пробную модель, но и испытать ее на практике. Если визуальный редактор платформы позволяет накидать первую рабочую версию — обязательно воспользуйтесь такой возможностью и поиграйтесь с прототипом вместе в бизнес-аналитиком. Это сократит множество ошибок в разработке, которые вы могли допустить.
3 — Отделаться от вендора
Довольно спорный момент, который подойдет не во всех ситуациях, но поможет значительно сократить инвестиции в систему. Хитрость в том, что если вы используете по-настоящему адаптивную платформу — для вас будет гораздо выгодней нанять фрилансера, и настроить систему своими силами отдельно от разработчиков вендора.
4 — Подготовить сотрудников
Если бизнес вырос из системы — достаточно объяснить сотрудникам: «Ребята, мы выросли, давайте переходить на новую систему». При этом, используя платформу вы можете подготовить интерфейс системы таким образом, чтобы он был похож на старый — это снизит дискомфорт от перехода. Чем больше удобство пользователей — тем легче приживется система.
|
Метки: author vei_cw управление разработкой erp- системы crm- бизнес-модели crm open source crm sdk crm доработка асу кис на коленке |
[Перевод] Увольнять, нанимать, повышать — культура вашей компании. Анатомия редиски |




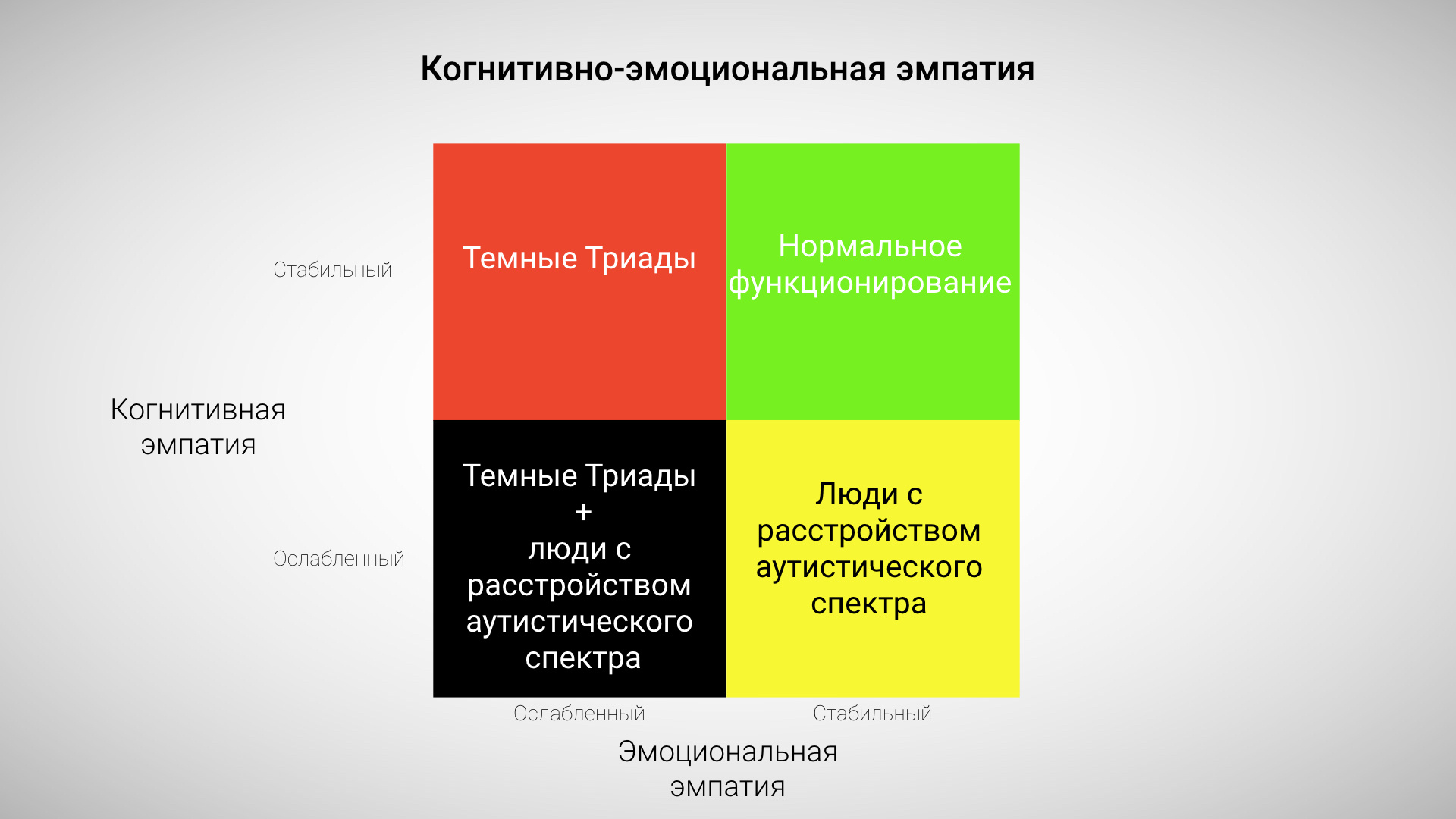
Люди с расстройством аутистического спектра сосредоточены на «создании лучшей коробки»: как она сконструирована, как ее можно улучшить, как ее можно использовать. Часто они хотят, чтобы другие люди слушали их объяснения про эту коробку и связанные с ней идеи, разделяли их энтузиазм, или хотя бы понимали или уважали их энтузиазм в отношении «коробки».
Представители Темной Триады сосредоточены на получении одобрения на «создание лучшей коробки» (независимо от того, сделали они ее или нет). Они хотят выглядеть как «строитель коробки», получить статус «Главного эксперта по созданию коробок», измышляют, как можно использовать эту коробку для зарабатывания денег, стараются скрыть факт, что кто-то еще делает коробку.
|
Метки: author Sherbinin управление проектами управление персоналом карьера в it-индустрии блог компании райффайзенбанк управление людьми управление персонал нарциссизм психология карьера |
Мультипротокольный NAS-доступ к Netapp-ресурсам c ACLs |
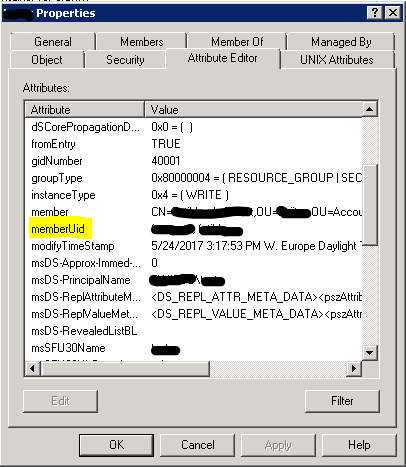
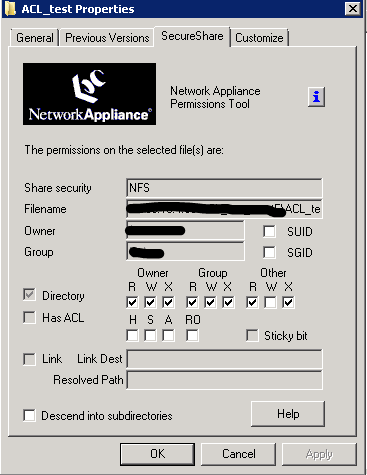
 Небольшое предисловие к статье. Заказчик выставил требование организовать доступ по CIFS (SMB) к некоторым NFS-экспортам, которые лежат на NetApp. Звучит вроде бы несложно: нужно создать CIFS-шару на уже экспортированном qtree. Позже было выставлено требование, что нужно гранулярно управлять доступом на эти шары. Опять-таки задача выглядит решаемой: это можно контролировать и с NetApp и через оснастку Shared Folders (share permissions). Затем выяснилось, что нужно варьировать доступ к различным подпапкам на CIFS-шаре. Это уже оказалось нетривиальной задачей. Так как нужно было настроить списки контроля доступа (ACL) и для CIFS и для NFS к одним и тем же данным.
Небольшое предисловие к статье. Заказчик выставил требование организовать доступ по CIFS (SMB) к некоторым NFS-экспортам, которые лежат на NetApp. Звучит вроде бы несложно: нужно создать CIFS-шару на уже экспортированном qtree. Позже было выставлено требование, что нужно гранулярно управлять доступом на эти шары. Опять-таки задача выглядит решаемой: это можно контролировать и с NetApp и через оснастку Shared Folders (share permissions). Затем выяснилось, что нужно варьировать доступ к различным подпапкам на CIFS-шаре. Это уже оказалось нетривиальной задачей. Так как нужно было настроить списки контроля доступа (ACL) и для CIFS и для NFS к одним и тем же данным. 







|
Метки: author yakovasavr хранение данных системное администрирование блог компании icl services linux nas netapp shared folders |
Взгляд снизу вверх или Ubuntu Server для разработчика электроники. Часть 2 |
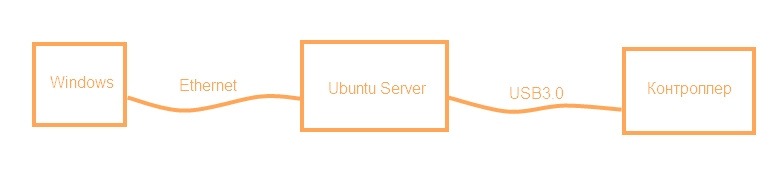
sudo lshw -C network logical name: enp3s0sudo nano /etc/network/interfaces # This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# My local network.
allow-hotplug enp3s0
iface enp3s0 inet static
address 172.16.55.1
netmask 255.255.255.0
gateway 172.16.55.1
service networking restartsudo nano /etc/default/isc-dhcp-serverINTERFACES=""INTERFACES="enp3s0"sudo nano /etc/dhcp/dhcpd.confsubnet 172.16.55.0 netmask 255.255.255.0{
range 172.16.55.2 172.16.55.100;
}sudo nano /etc/hosts127.0.0.1 localhost
172.16.55.1 ubuntusudo cat /etc/hostnameservice networking restartd:\"Program Files"\PuTTY\pscp.exe ubuntu@172.16.55.1:/home/ubuntu/tool/* "F:/WORK/SERVER/tool/"d:\"Program Files"\PuTTY\pscp.exe "F:/WORK/SERVER/tool/*" ubuntu@172.16.55.1:/home/ubuntu/tool/tar -xvf d3xx-linux-i686-0.5.0.tar.bz2cd linux-i686
sudo rm -f /usr/lib/libftd3xx.so
sudo cp -f libftd3xx.so /usr/lib
sudo cp -f libftd3xx.so.0.5.0 /usr/lib
sudo cp -f 51-ftd3xx.rules /etc/udev/rules.d
sudo udevadm control --reload-rules
CC=g++
UNAME := $(shell uname)
ifeq ($(UNAME), Darwin)
DEPENDENCIES := -lpthread -ldl -lobjc -framework IOKit -framework CoreFoundation
else
DEPENDENCIES := -lpthread -ldl -lrt
endif
CFLAGS=$(DEPENDENCIES) -Wall -Wextra -std=c++11
STATLIB=libftd3xx.a
APP = prgr
all: $(APP)
$(APP): main.o
$(CC) -o $(APP) main.o $(STATLIB) $(CFLAGS)
main.o: main.cpp
$(CC) -c -o main.o main.cpp $(CFLAGS)
clean:
rm -f *.o ; rm $(APP)
makeps -elvoid SetPidFile(char* Filename)
{
FILE* f;
f = fopen(Filename, "w+");
if (f)
{
fprintf(f, "%u", getpid());
fclose(f);
}
}
int main( int argc, char** argv )
{
char toolfile[32];
char folder[32];
intptr_t ret;
FILE* logfile;
if( argc!=3 )
{
printf( "Write address of the program and name: /home/ubuntu/tool/ tool\n");
return -1;
}
pid_t pid, sid;
pid = fork();
if (pid < 0)
{
sleep(1);
return -1;
}
//We got a good pid, Close the Parent Process
if (pid > 0) {
return 0;
}
//Create a new Signature Id for our child
sid = setsid();
if (sid < 0)
{
return -1;
}
//Change File Mask
umask(0);
//Save PID
memcpy( toolfile, argv[0], strlen(argv[0]) );
memcpy( toolfile + strlen(argv[0]), ".log", 4 );
memset( toolfile + strlen(argv[0]) + 4, 0, 1 );
printf( "Daemon:: log to:%s\n", toolfile );
logfile = fopen( toolfile, "w" );
fprintf( logfile, "Daemon:: started with 0=%s 1=%s 2=%s\n", argv[0], argv[1], argv[2] );
memset( toolfile, 0, 32 );
memcpy( toolfile, argv[0], strlen(argv[0]) );
memcpy( toolfile + strlen(argv[0]), ".pid", 4 );
memset( toolfile + strlen(argv[0]) + 4, 0, 1 );
SetPidFile( toolfile );
fprintf( logfile, "Daemon:: PID=%u saved in the %s\n", getpid(), toolfile );
memset( folder, 0, 32 );
memcpy( folder, argv[1], strlen(argv[1]) );
fflush ( logfile );
memset( toolfile, 0, 32 );
memcpy( toolfile, folder, strlen(argv[1]) );
memset( toolfile + strlen(argv[1]), '/', 1 );
memcpy( toolfile + strlen(argv[1]) + 1, argv[2], strlen(argv[2]) );
//Change Directory
//If we cant find the directory we exit with failure.
if ((chdir(folder)) < 0)
{
fprintf( logfile, "Daemon:: Program folder was not found:%s\n", folder );
fclose( logfile );
return -1;
}
//Close Standard File Descriptors
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
fprintf( logfile, "Daemon:: Program started\n" );
fflush ( logfile );
ret = execl( toolfile, folder, NULL );
if( ret==-1 )
{
fprintf( logfile, "Daemon:: execl error: %s. File=%s Folder=%s\n", strerror(errno), toolfile, folder );
fclose( logfile );
return -1;
}
fprintf( logfile, "Daemon:: closed\n" );
fclose( logfile );
return 0;
}
sudo chmod 755 ./tool
sudo chmod 755 ./daemonsudo nano /etc/systemd/system/mydaemon.service[Unit]
Description=my service
After=network.target
After=isc-dhcp-server.service
[Service]
Type=forking
PIDFile=/home/ubuntu/daemon/daemon.pid
ExecStartPre=/bin/sh /home/ubuntu/daemon/prgr.strt
ExecStart=/home/ubuntu/daemon/daemon /home/ubuntu/daemon/prgr prgr
ExecStop=/bin/sh /home/ubuntu/daemon/prgr.stop
Restart=always
TimeoutSec=5
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl status mydaemonsystemctl start mydaemonsystemctl enable mydaemon|
Метки: author akhrapotkov разработка под linux программирование c++ ftdi ubuntu server ethernet usb3.0 daemon |
[Из песочницы] Социальная сеть для киноманов или как не закопаться, разрабатывая еще одну соцсеть |


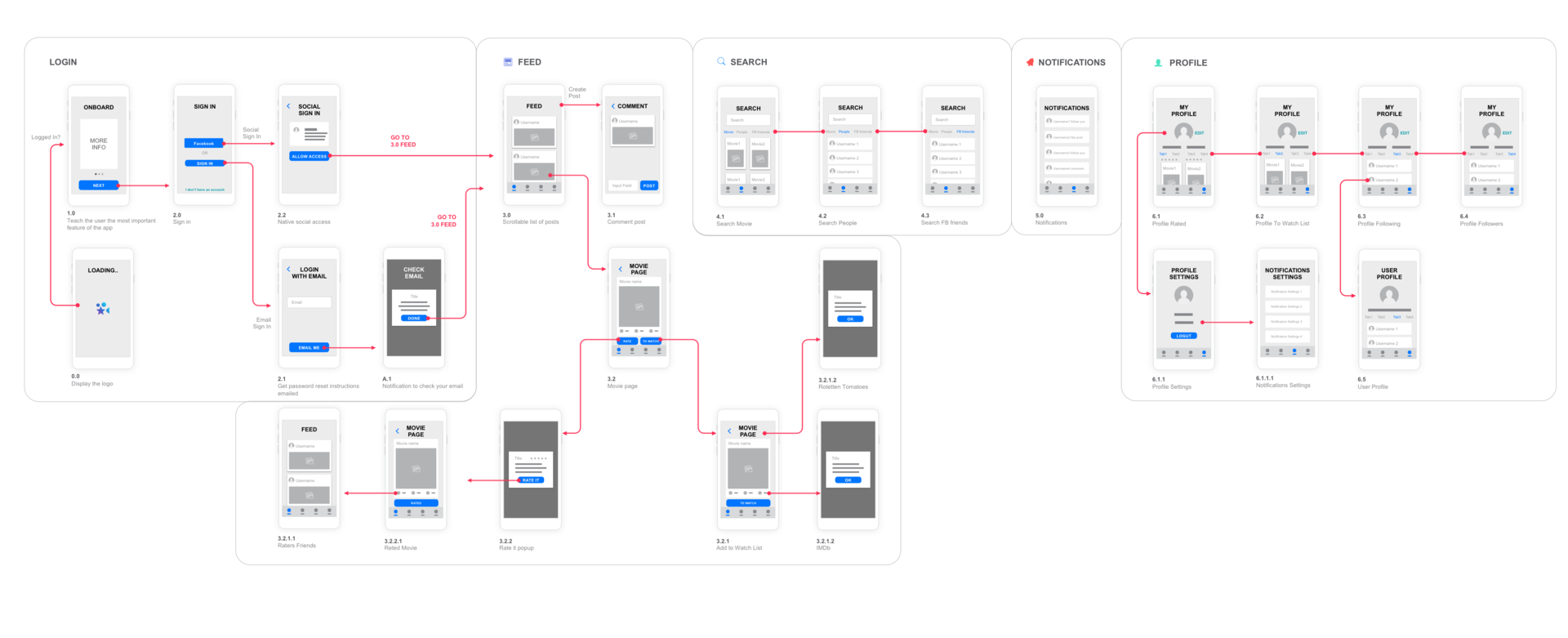

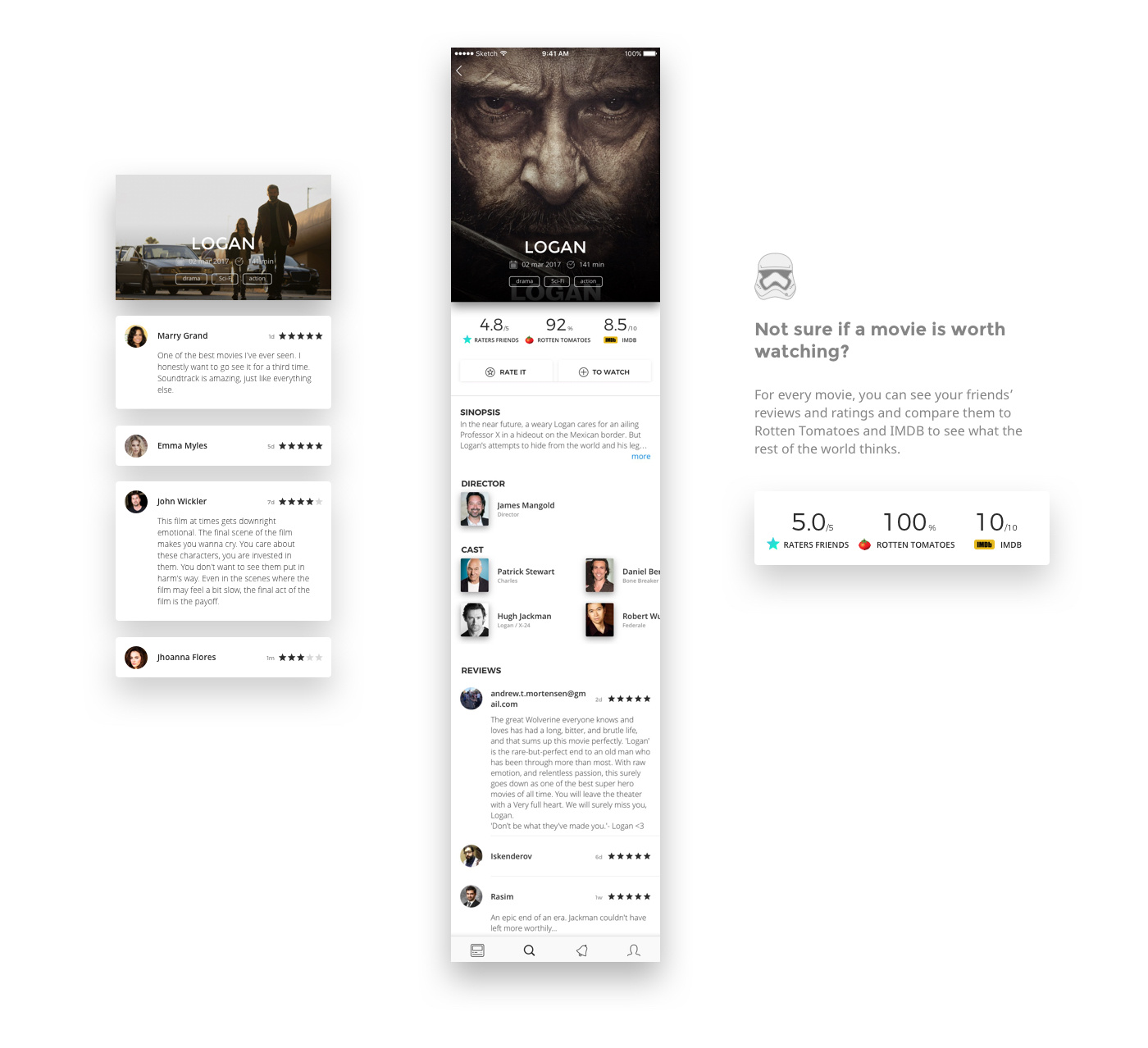

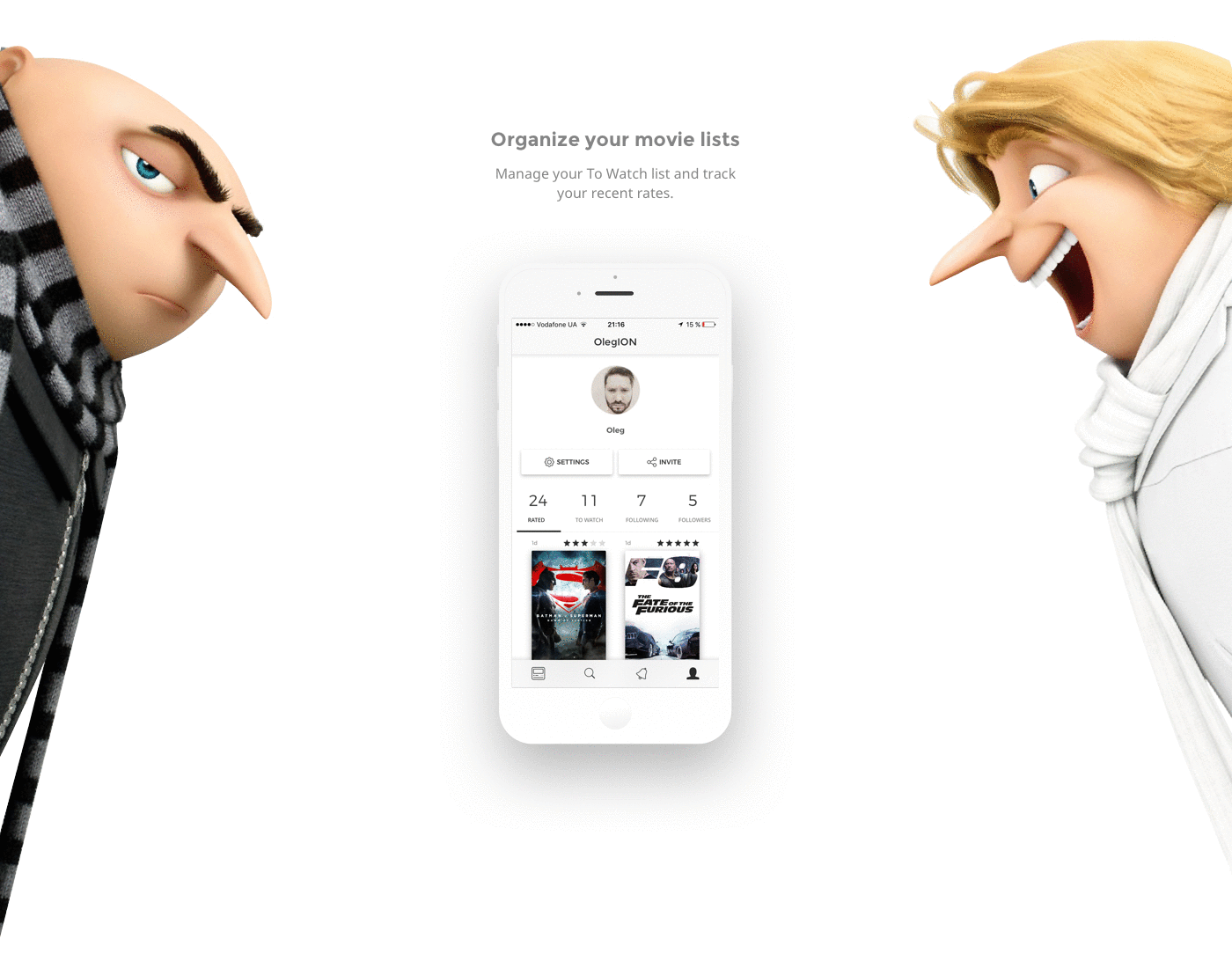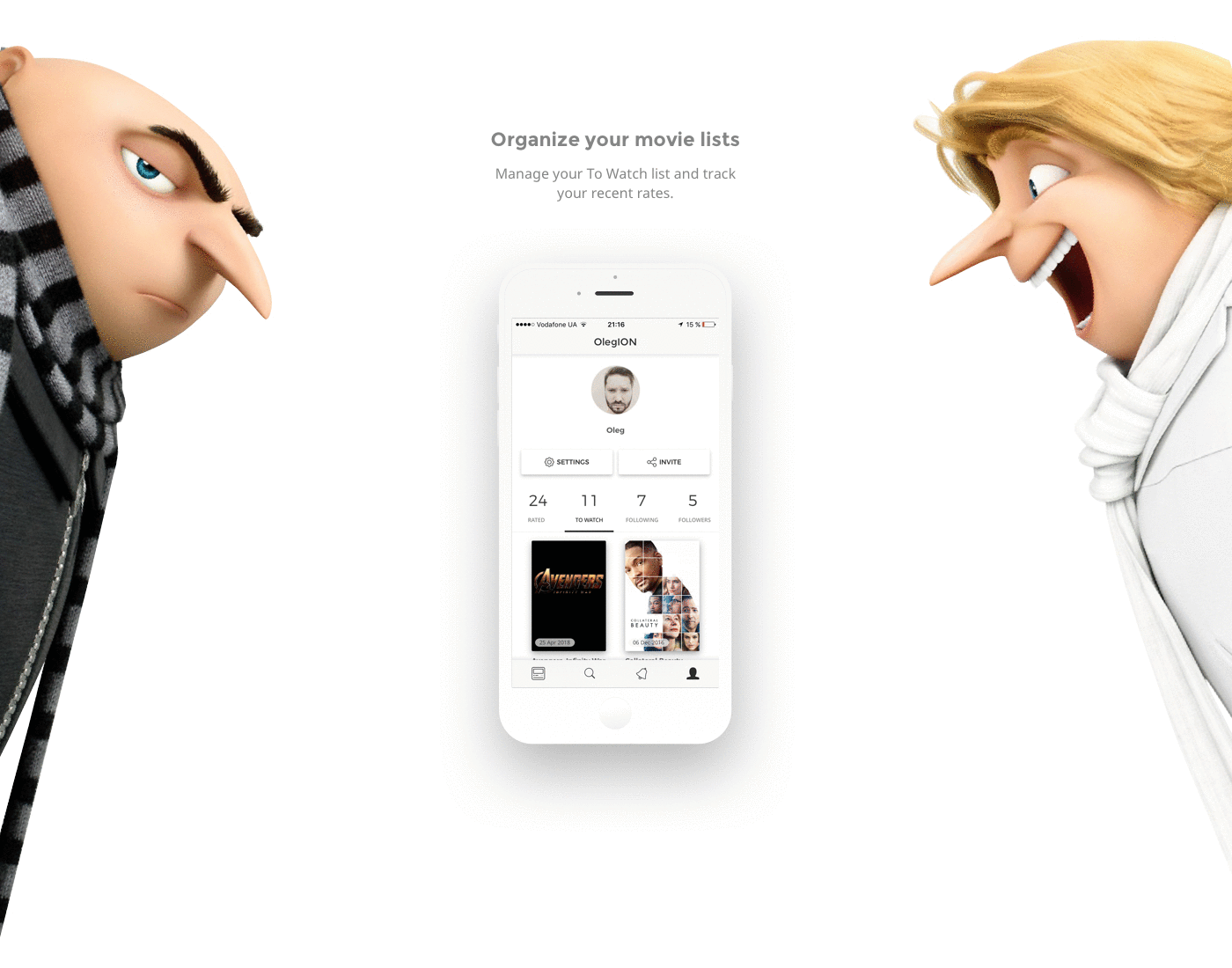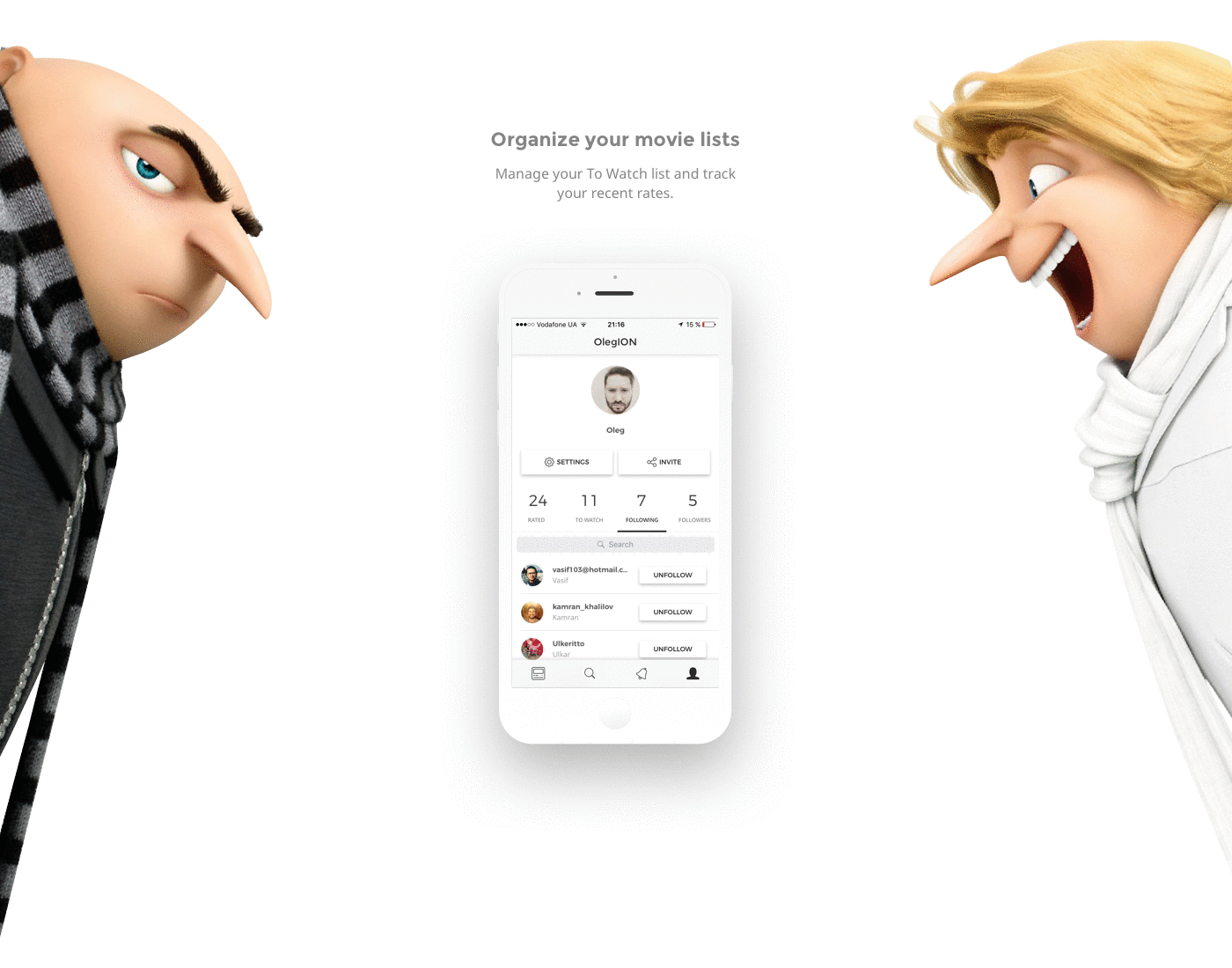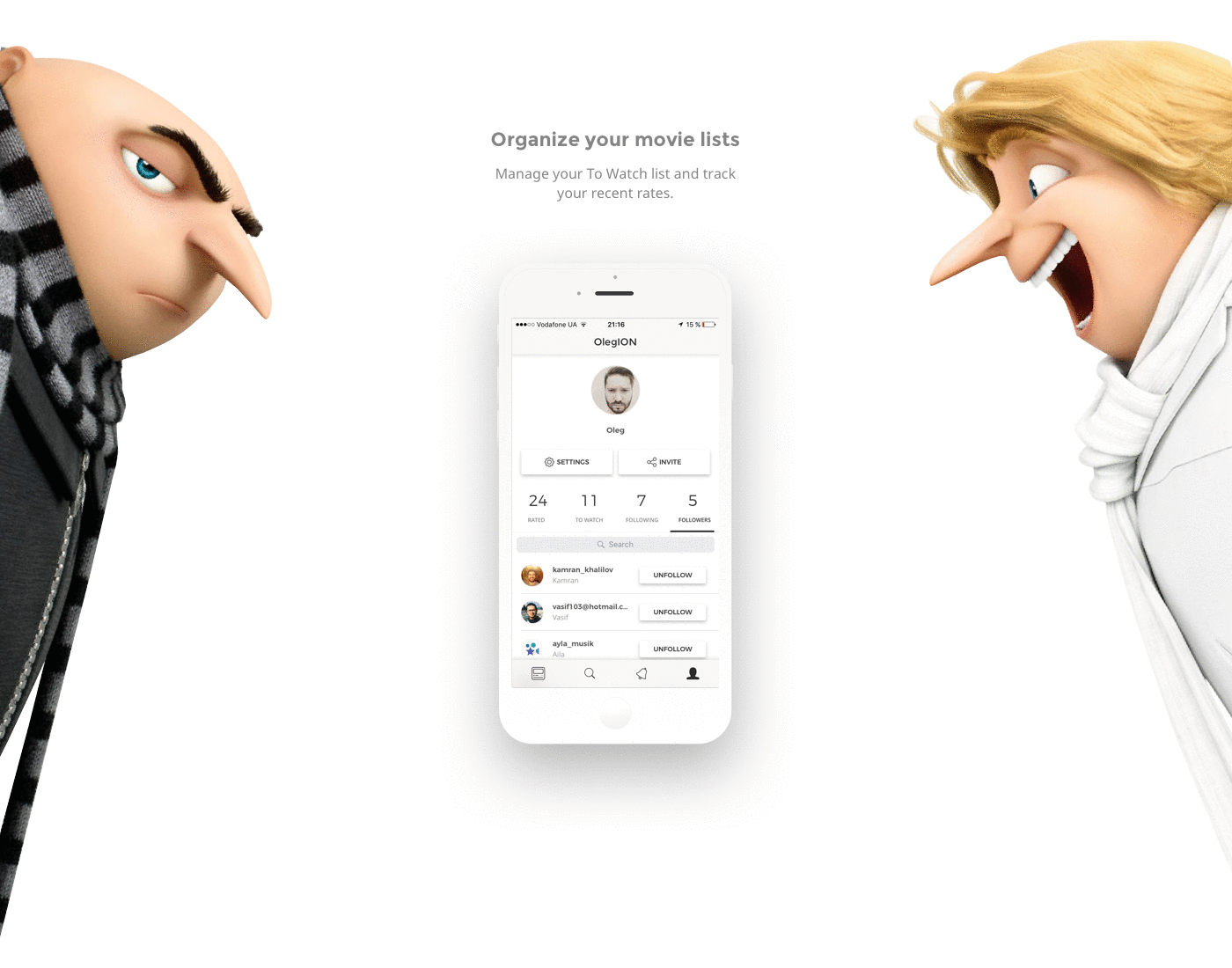



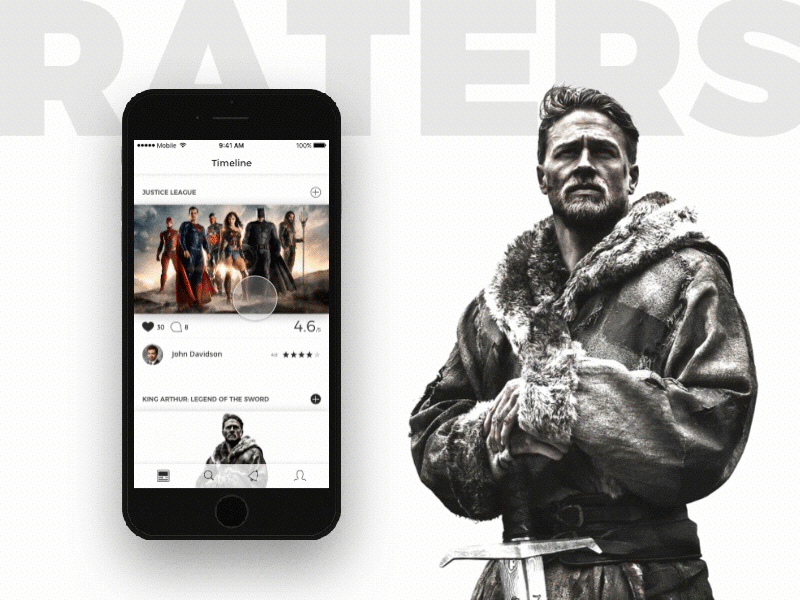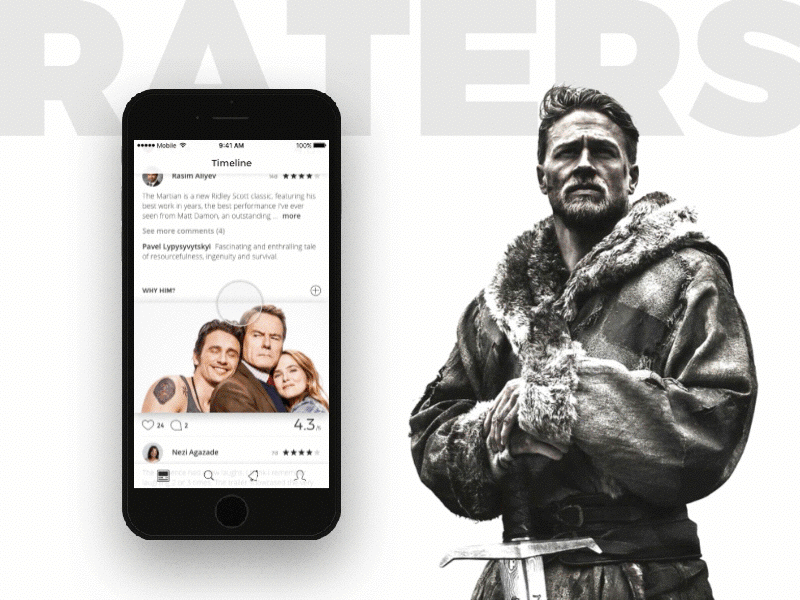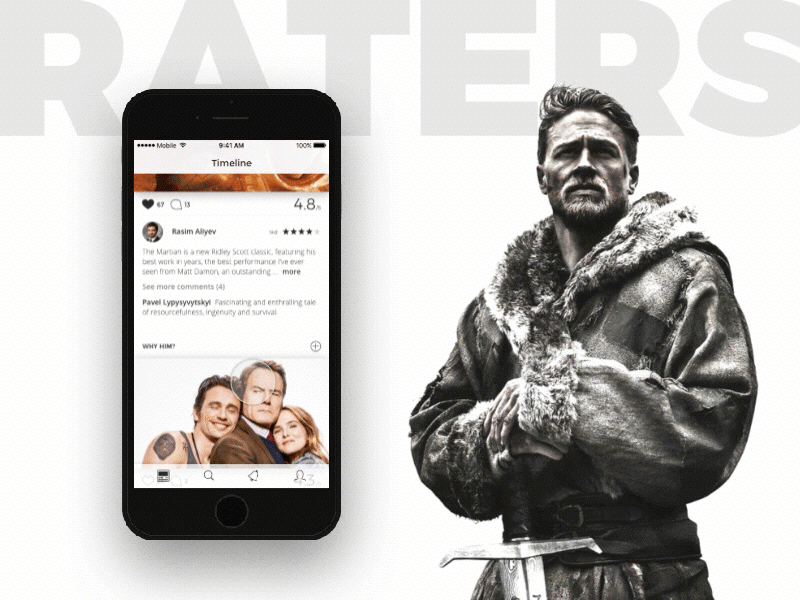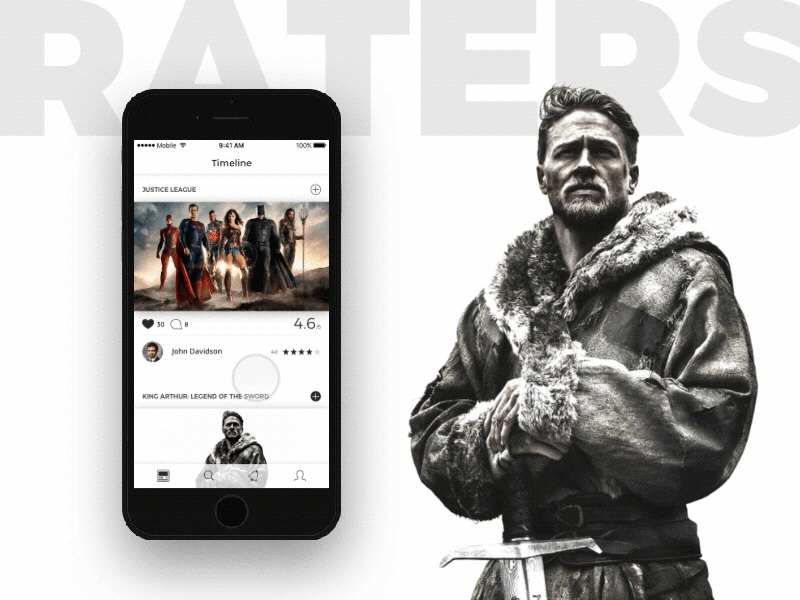
|
|
Расширение, изменение и создание элементов управления на платформе UWP. Часть 3 |







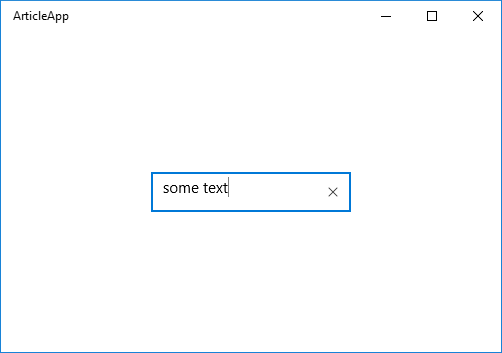
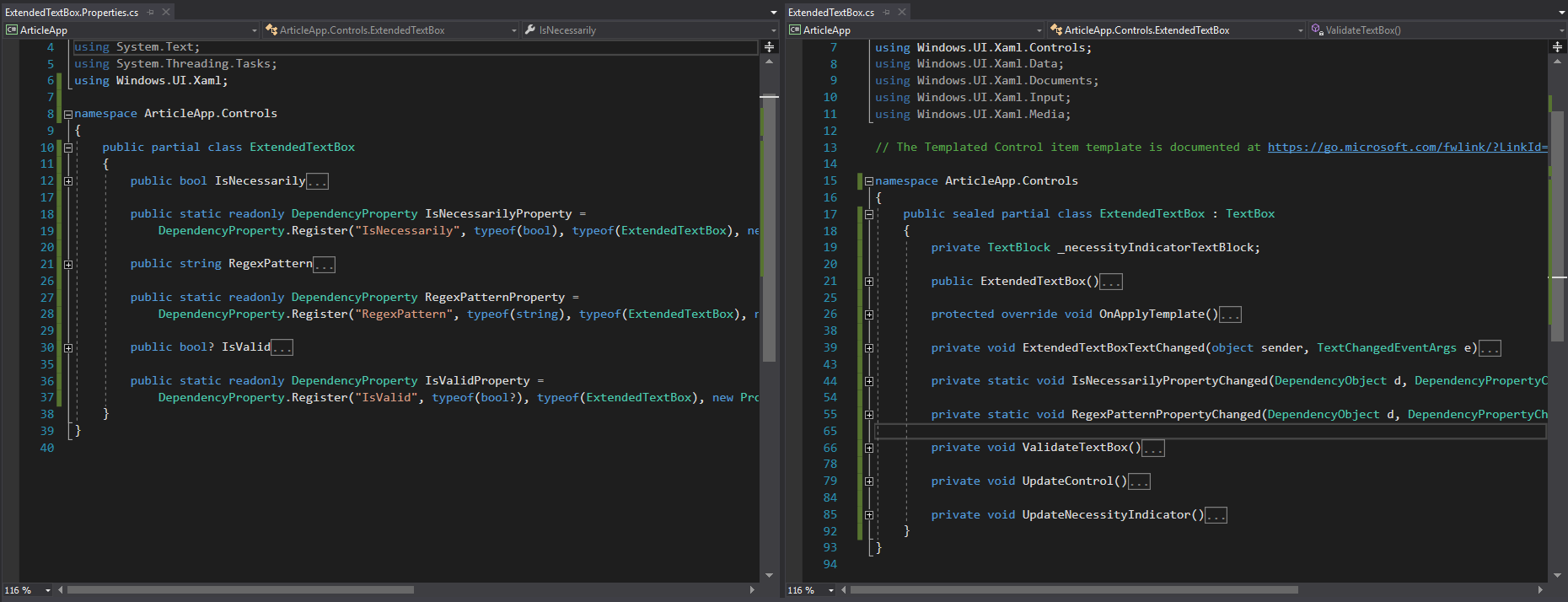
public sealed class ExtendedTextBox : TextBox
{
private TextBlock _necessityIndicatorTextBlock;
public ExtendedTextBox()
{
this.DefaultStyleKey = typeof(ExtendedTextBox);
}
protected override void OnApplyTemplate()
{
base.OnApplyTemplate();
_necessityIndicatorTextBlock = GetTemplateChild("NecessityIndicatorTextBlock") as TextBlock;
UpdateControl();
}
public bool IsNecessarily
{
get => (bool)GetValue(IsNecessarilyProperty);
set => SetValue(IsNecessarilyProperty, value);
}
public static readonly DependencyProperty IsNecessarilyProperty =
DependencyProperty.Register("IsNecessarily", typeof(bool), typeof(ExtendedTextBox), new PropertyMetadata(false, IsNecessarilyPropertyChanged));
private static void IsNecessarilyPropertyChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var textbox = d as ExtendedTextBox;
if (textbox == null || !(e.NewValue is bool))
{
return;
}
textbox.UpdateNecessityIndicator();
}
private void UpdateControl()
{
UpdateNecessityIndicator();
}
private void UpdateNecessityIndicator()
{
if (_necessityIndicatorTextBlock != null)
{
_necessityIndicatorTextBlock.Visibility = IsNecessarily ? Visibility.Visible : Visibility.Collapsed;
}
}
}

public sealed class ExtendedTextBox : TextBox
{
private TextBlock _necessityIndicatorTextBlock;
public ExtendedTextBox() ...
protected override void OnApplyTemplate()
{
base.OnApplyTemplate();
this.TextChanged -= ExtendedTextBoxTextChanged;
_necessityIndicatorTextBlock = GetTemplateChild("NecessityIndicatorTextBlock") as TextBlock;
this.TextChanged += ExtendedTextBoxTextChanged;
UpdateControl();
}
private void ExtendedTextBoxTextChanged(object sender, TextChangedEventArgs e)
{
ValidateTextBox();
}
//public bool IsNecessarily ...
//public static readonly DependencyProperty IsNecessarilyProperty = ...
//private static void IsNecessarilyPropertyChanged(DependencyObject d, DependencyPropertyChangedEventArgs e) ...
public string RegexPattern
{
get { return (string)GetValue(RegexPatternProperty); }
set { SetValue(RegexPatternProperty, value); }
}
public static readonly DependencyProperty RegexPatternProperty =
DependencyProperty.Register("RegexPattern", typeof(string), typeof(ExtendedTextBox), new PropertyMetadata(string.Empty, RegexPatternPropertyChanged));
private static void RegexPatternPropertyChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var textbox = d as ExtendedTextBox;
if (textbox == null || !(e.NewValue is string))
{
return;
}
textbox.ValidateTextBox();
}
private void ValidateTextBox()
{
IsValid = Regex.IsMatch(Text, RegexPattern);
if (this.Text.Length == 0 || !this.IsValid.HasValue)
{
VisualStateManager.GoToState(this, "Indeterminate", true);
return;
}
VisualStateManager.GoToState(this, this.IsValid.Value ? "Valid" : "Invalid", true);
}
public bool? IsValid
{
get { return (bool?)GetValue(IsValidProperty); }
private set { SetValue(IsValidProperty, value); }
}
public static readonly DependencyProperty IsValidProperty =
DependencyProperty.Register("IsValid", typeof(bool?), typeof(ExtendedTextBox), new PropertyMetadata(default(bool?)));
private void UpdateControl()
{
UpdateNecessityIndicator();
ValidateTextBox();
}
//private void UpdateNecessityIndicator() ...
}

public partial class Expander
{
public static readonly DependencyProperty HeaderProperty =
DependencyProperty.Register(nameof(Header), typeof(string), typeof(Expander), new PropertyMetadata(null));
public static readonly DependencyProperty IsExpandedProperty =
DependencyProperty.Register(nameof(IsExpanded), typeof(bool), typeof(Expander), new PropertyMetadata(false, OnIsExpandedPropertyChanged));
public string Header
{
get { return (string)GetValue(HeaderProperty); }
set { SetValue(HeaderProperty, value); }
}
public bool IsExpanded
{
get { return (bool)GetValue(IsExpandedProperty); }
set { SetValue(IsExpandedProperty, value); }
}
}
public sealed partial class Expander : ContentControl
{
public Expander()
{
this.DefaultStyleKey = typeof(Expander);
}
protected override void OnApplyTemplate()
{
base.OnApplyTemplate();
if (IsExpanded)
{
VisualStateManager.GoToState(this, "Expanded", true);
}
}
private void ExpandControl()
{
VisualStateManager.GoToState(this, "Expanded", true);
}
private void CollapseControl()
{
VisualStateManager.GoToState(this, "Collapsed", true);
}
private static void OnIsExpandedPropertyChanged(DependencyObject d, DependencyPropertyChangedEventArgs e)
{
var expander = d as Expander;
bool isExpanded = (bool)e.NewValue;
if (isExpanded)
{
expander.ExpandControl();
}
else
{
expander.CollapseControl();
}
}
}
|
Метки: author MobileDimension разработка под windows разработка мобильных приложений .net блог компании mobile dimension разработка приложений uwp |
Двухфакторная аутентификация в Check Point Security Gateway |




























*:disconnect_on_smartcard_removal (
gateway (
:default (true)
)
)* 


|
|






