Для чего используется SBC на границе сетей |

|
Метки: author AUDC-SP разработка систем связи информационная безопасность asterisk sbc voip виртуализация приложений голосовая связь безопасность пакетная передача |
Когда IP-адресов будет хватать всем? |

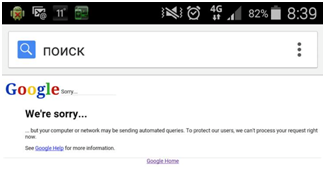
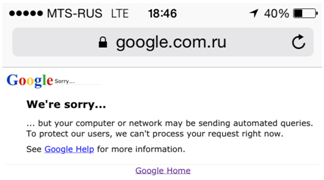


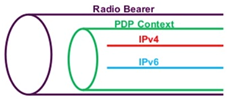
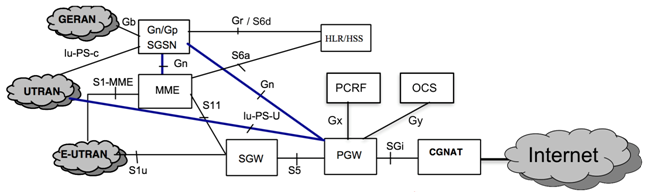
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author info_habr тестирование it-систем блог компании мтс мтс ipv6 pv4v6 dualstack |
Разбор доклада Артёма Гавриченкова о масштабировании TLS |





|
Метки: author p0b0rchy криптография блог компании jug.ru group презентация разбор сертификаты безопасности tls |
ИТ на стадионе «Открытие Арена». Когда адреналина в проекте не меньше, чем во время матча |





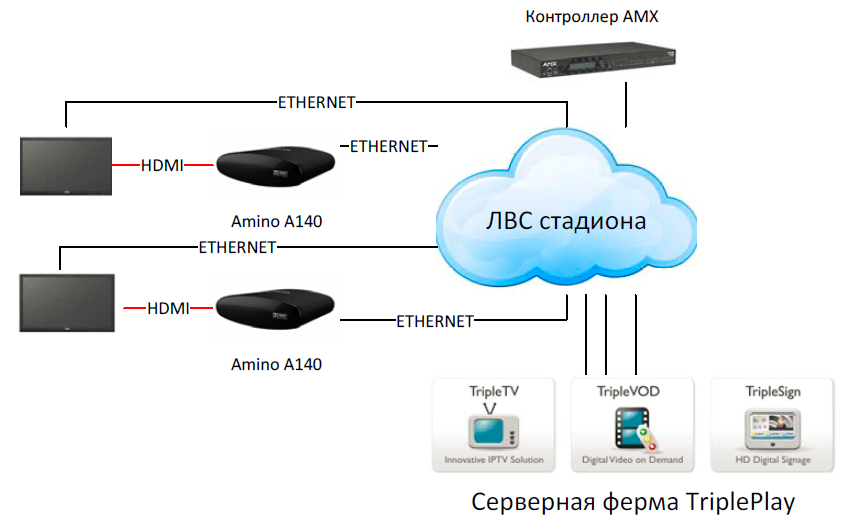









|
Метки: author Raccooon системное администрирование сетевые технологии it- инфраструктура блог компании гк ланит интернет связь |
Что может и чего не может нейросеть: пятиминутный гид для новичков |
 / Фотография Jun / CC-SA
/ Фотография Jun / CC-SAКак правило, это делают с помощью метода обратного распространения ошибки: для каждого из обучающих примеров веса корректируются так, чтобы уменьшить ошибку. Считается, что при правильно подобранной архитектуре и достаточном наборе обучающих данных сеть рано или поздно обучится.
Механизм этого явления примерно такой: исходные данные нередко сильно многомерны (одна точка из обучающей выборки изображается большим набором чисел), и вероятность того, что наугад взятая точка окажется неотличимой от выброса, будет тем больше, чем больше размерность. Вместо того, чтобы «вписывать» новую точку в имеющуюся модель, корректируя веса, нейросеть как будто придумывает сама себе исключение: эту точку мы классифицируем по одним правилам, а другие — по другим. И таких точек обычно много.

Более того, нейросети обладают определенной особенностью, которую называют катастрофической забывчивостью (catastrophic forgetting). Она сводится к тому, что нейросеть нельзя последовательно обучить нескольким задачам — на каждой новой обучающей выборке все веса нейронов будут переписаны, и прошлый опыт будет «забыт».
|
Метки: author IgorLevin блог компании neurodata lab neurodata lab нейронные сети нейросети |
Клиент у руля, или почему провайдеру следует передать штурвал |
 / Flickr / Carla Wosniak / CC
/ Flickr / Carla Wosniak / CC
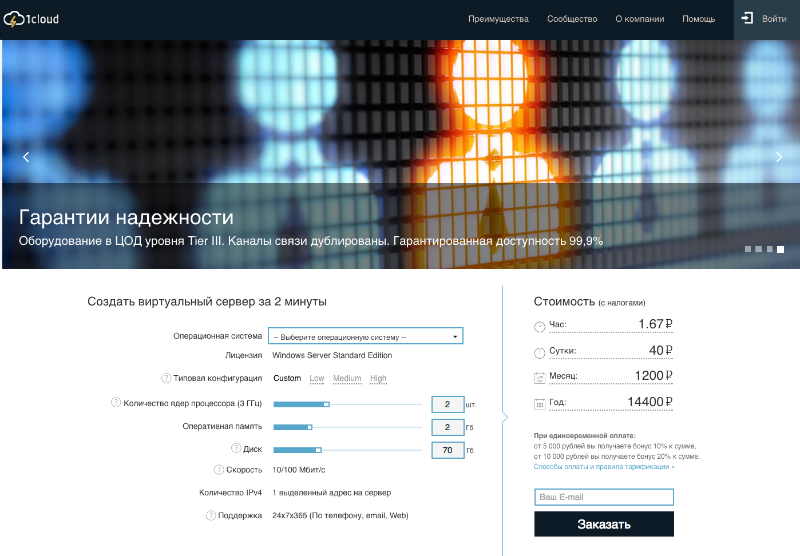
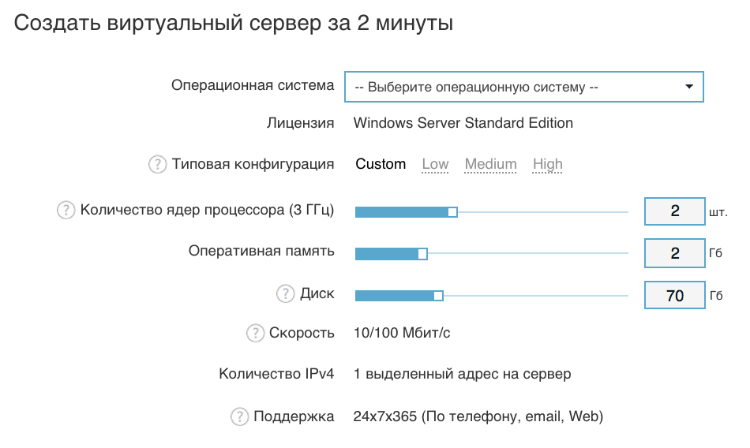
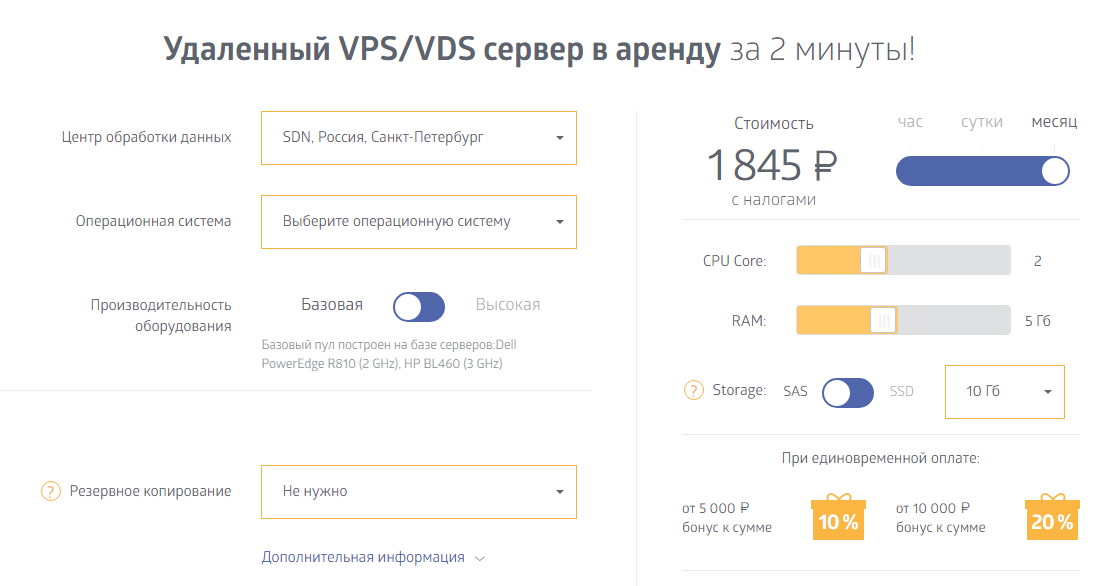
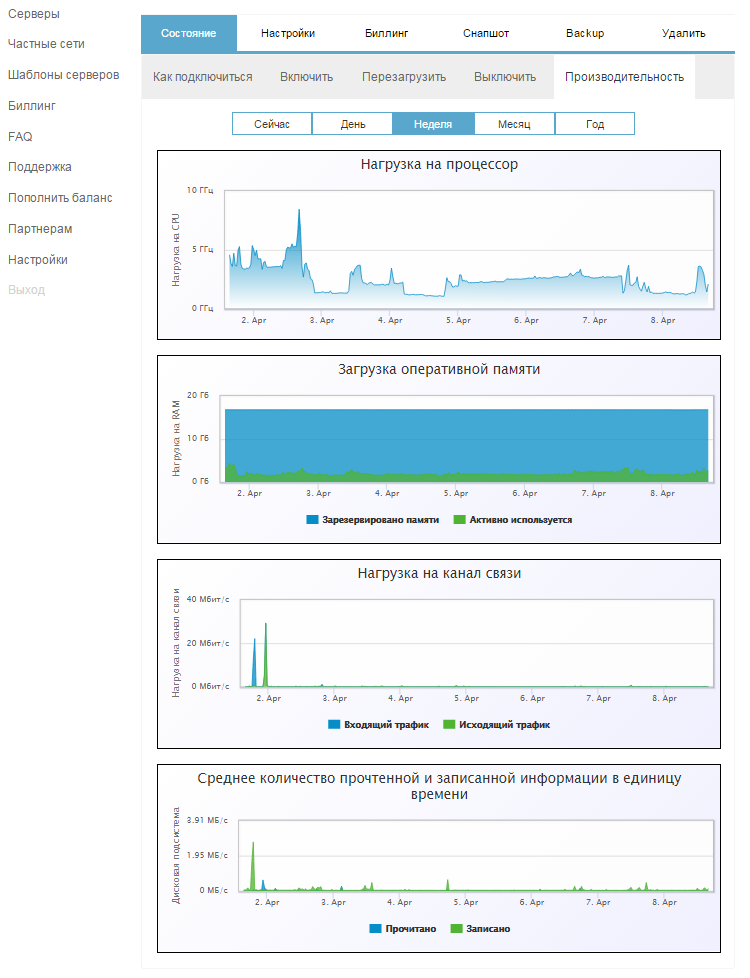
curl -X POST -H 'Content-Type: application/json' -H 'Authorization: Bearer 75bb9805c018b1267b2cf599a38b95a3a811e2ef7ad9ca5ed838ea4c6bafaf50' "https://api.1cloud.ru/Server" -d '{"Name":"testAPI","CPU":1,"RAM":1024,"HDD":40,"imageID":1,"HDDType":"SSD","IsHighPerformance":true}'|
Метки: author 1cloud развитие стартапа блог компании 1cloud.ru 1cloud iaas iaas- провайдер |
[Из песочницы] Практическое руководство по использованию CSS Modules в React приложениях |
.select {}
.select__item {}
.select__item__icon {}
.select--loading {}CSS модуль — это CSS файл, в котором все имена классов и анимаций имеют локальную область видимости по умолчанию.
/* select.css */
.select {}
.loading {}
.item {}
.icon {}/* select.js */
import styles from "./select.css";
console.log(styles.select, styles.loading);npm install -g create-react-app
create-react-app css-modules
cd css-modules/
npm start
import React, { Component } from 'react';
import logo from './logo.svg';
import './App.css';
class App extends Component {
render() {
return (

Welcome to React
To get started, edit {gfm-js-extract-pre-1} and save to reload.
);
}
}
export default App;npm run eject 
{
test: /\.css$/,
use: [
require.resolve('style-loader'),
{
loader: require.resolve('css-loader'),
options: {
importLoaders: 1,
},
},
{
loader: require.resolve('postcss-loader'),
options: {
// Necessary for external CSS imports to work
// https://github.com/facebookincubator/create-react-app/issues/2677
ident: 'postcss',
plugins: () => [
require('postcss-flexbugs-fixes'),
autoprefixer({
browsers: [
'>1%',
'last 4 versions',
'Firefox ESR',
'not ie < 9', // React doesn't support IE8 anyway
],
flexbox: 'no-2009',
}),
],
},
},
],
},{
test: /\.css$/,
use: [
require.resolve('style-loader'),
{
loader: require.resolve('css-loader'),
options: {
importLoaders: 1,
modules: true,
localIdentName: "[name]__[local]___[hash:base64:5]"
},
},
{
loader: require.resolve('postcss-loader'),
options: {
// Necessary for external CSS imports to work
// https://github.com/facebookincubator/create-react-app/issues/2677
ident: 'postcss',
plugins: () => [
require('postcss-flexbugs-fixes'),
autoprefixer({
browsers: [
'>1%',
'last 4 versions',
'Firefox ESR',
'not ie < 9', // React doesn't support IE8 anyway
],
flexbox: 'no-2009',
}),
require('postcss-modules-values'),
],
},
},
],
},postcss-loader применяет autoprefixer к CSS.
style-loader преобразовывает CSS в JS модули, которые инжектят теги
|
Метки: author Alexey_Solomatin reactjs javascript css react postcss css modules bem перевод |
Умные магазины, омниканальная аналитика и бесконечная лояльность: 6 трендов ритейла в 2017 году |



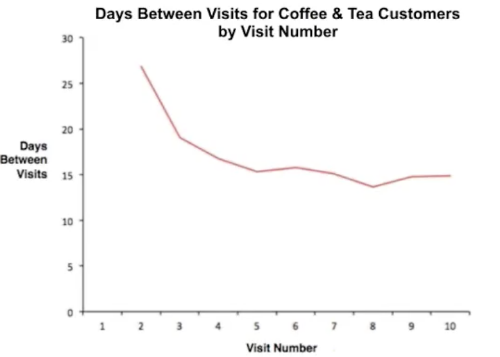

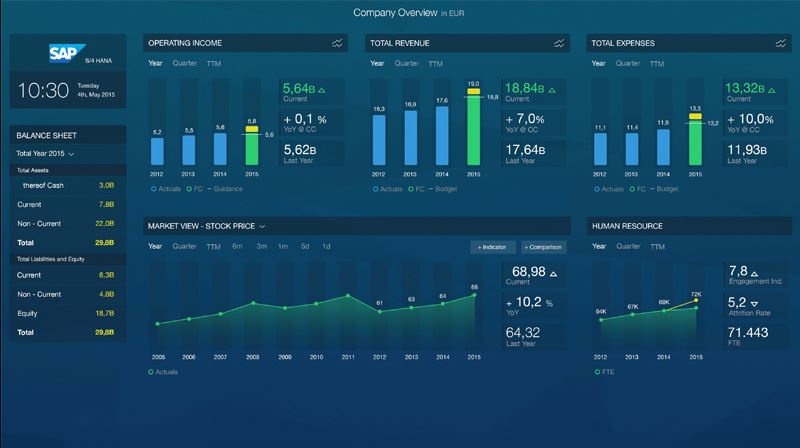


|
Метки: author pilot-retail монетизация it-систем блог компании пилот ритейл инфраструктура тренды умные магазины омниканальная аналитика автоматизация маркетинг |
Как сервис push-уведомлений помог нам сделать более посещаемым портал техподдержки |


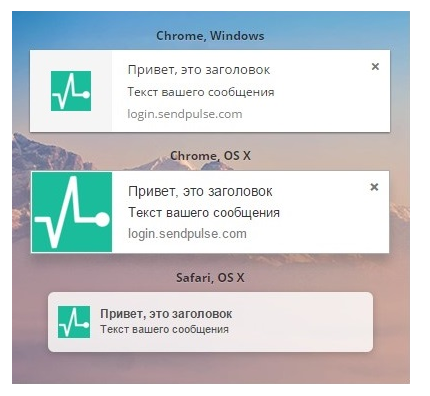
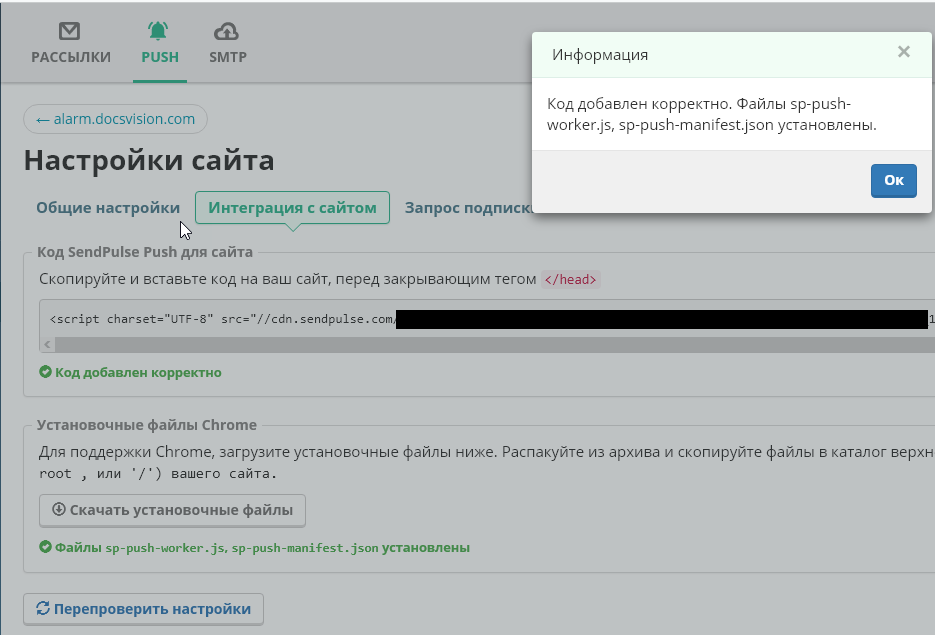
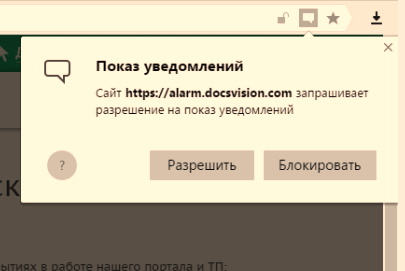
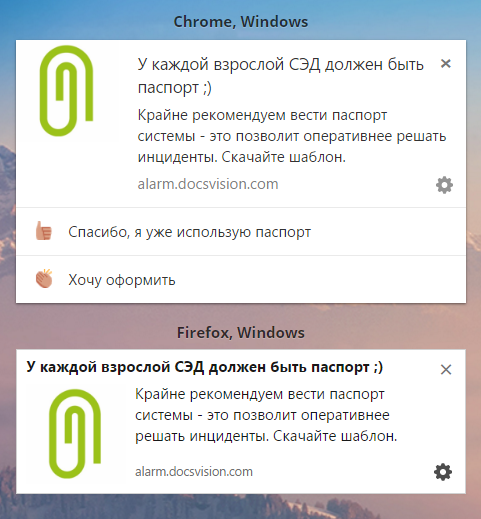
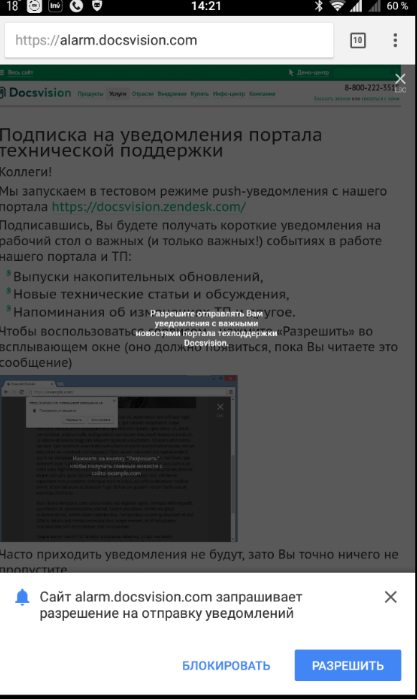

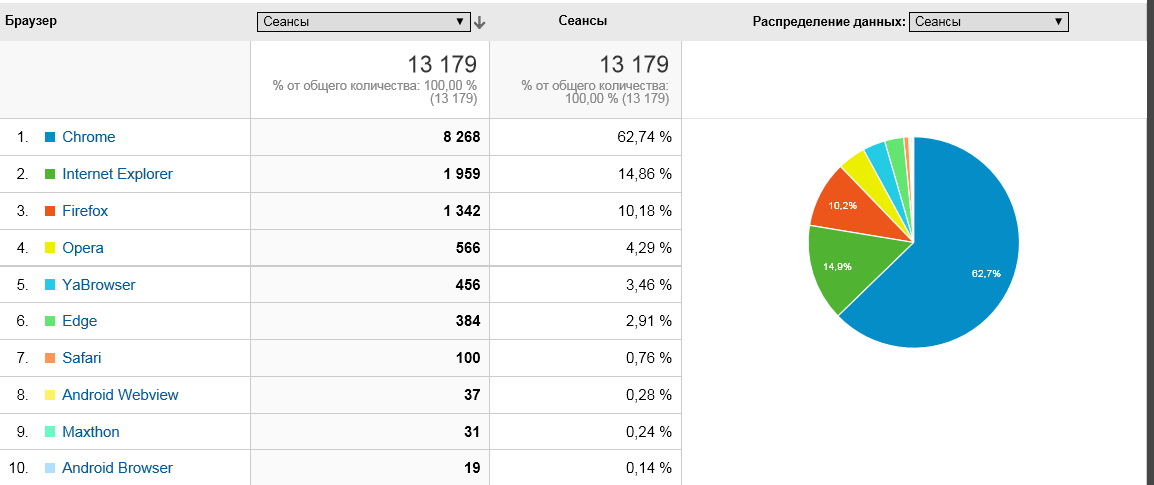



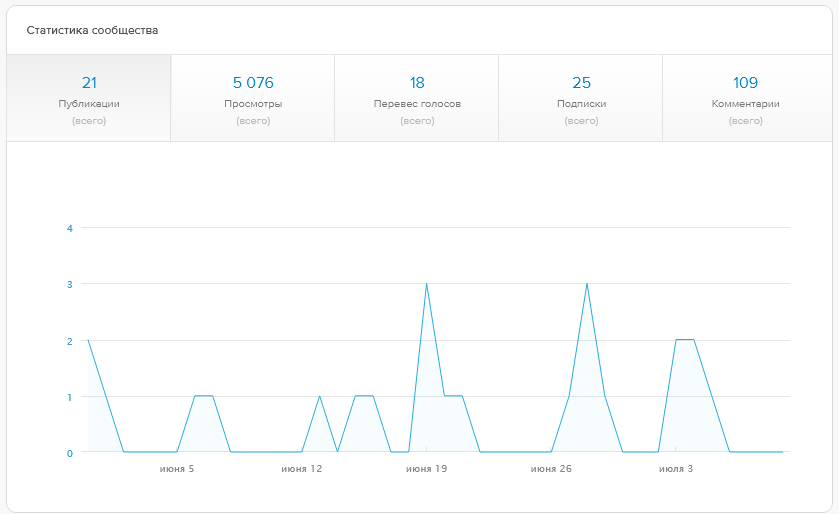
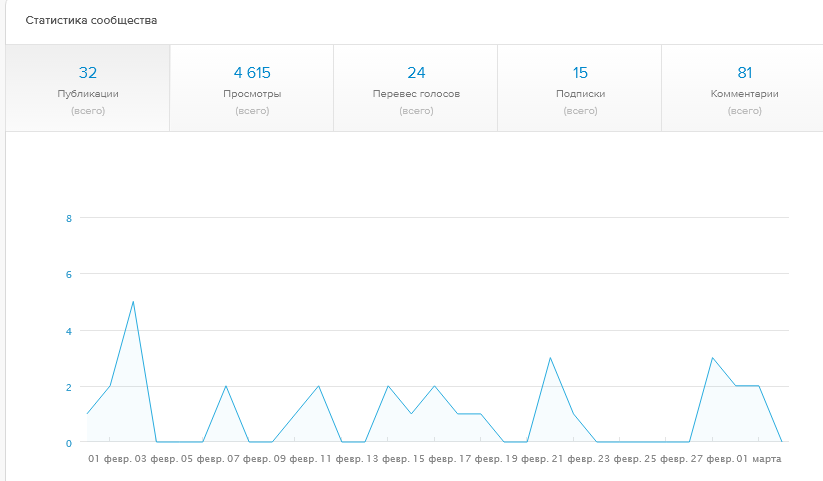
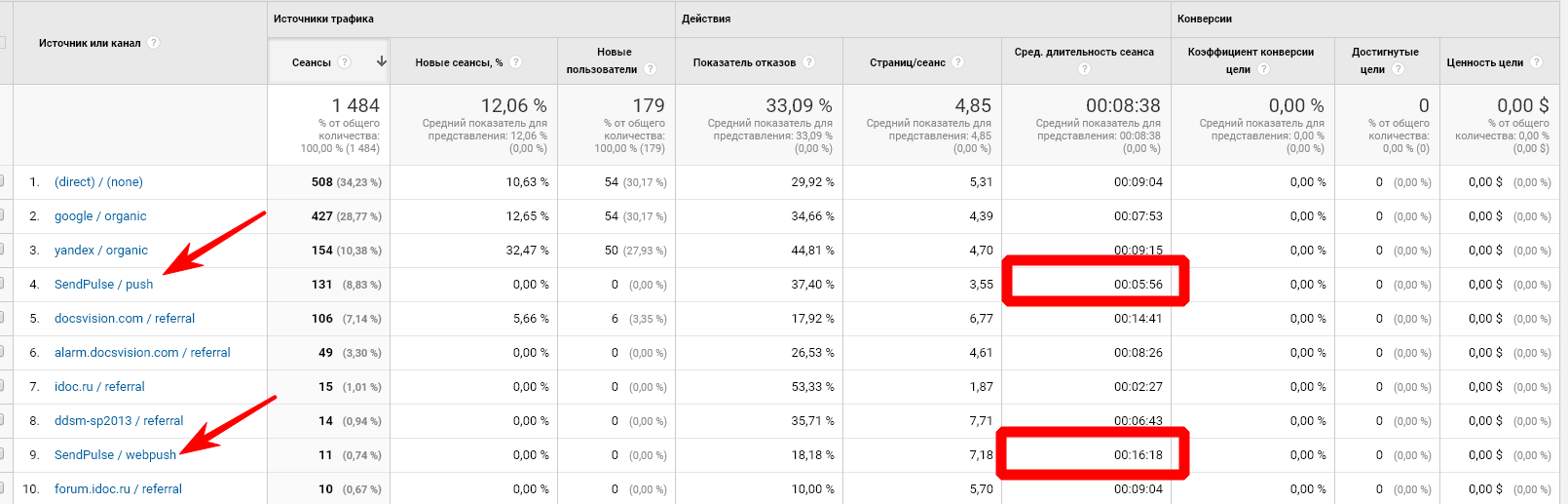

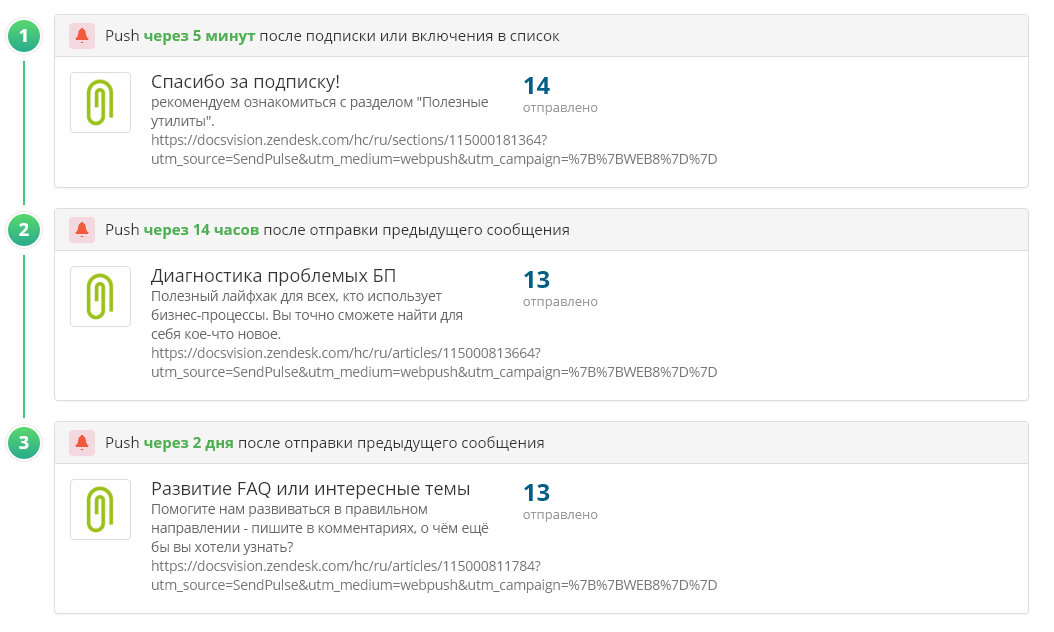


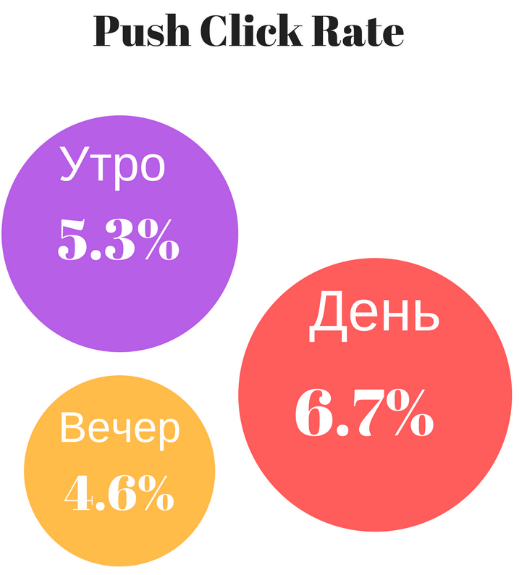
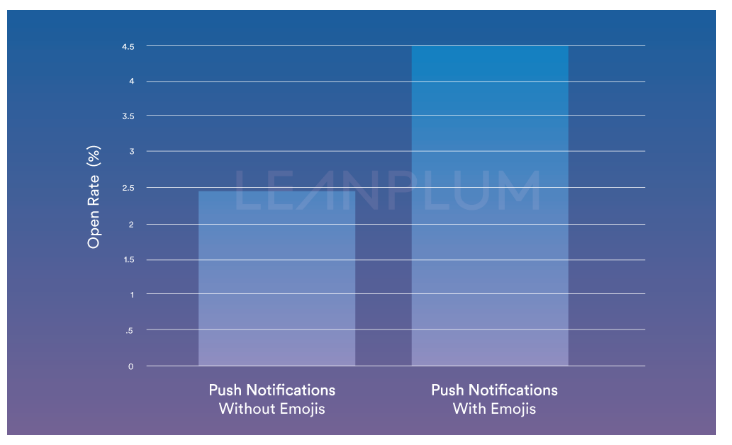
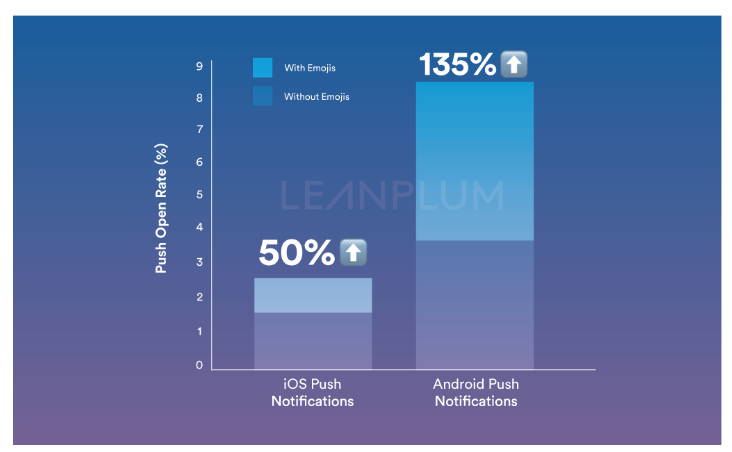
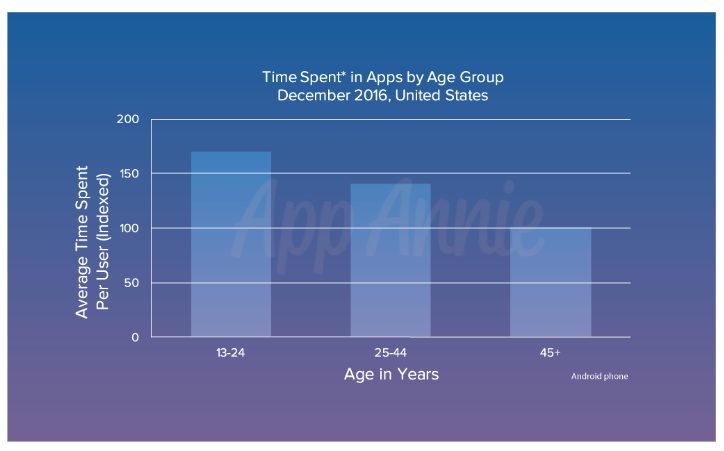

|
|
Эти токсичные, токсичные собеседования |

Hello, my name is David. I would fail to write bubble sort on a whiteboard. I look code up on the internet all the time. I don't do riddles.
— DHH (@dhh) February 21, 2017
@dhh Hello, I'm Rebecca. Whiteboards suck. I can't hold a marker for over a few minutes, I can type nonstop. I wrote Bard's Tale III.
— Rebecca Heineman (@burgerbecky) February 28, 2017
Hi, I'm Yonatan. I'm one of Google's most senior engineers, and I'll be damned if I can remember how quicksort works. https://t.co/yvofJHgCvG
— (((Yonatan Zunger))) (@yonatanzunger) March 1, 2017
.@mxcl Didn't you know? Being able to memorize & recite your algo homework for the last 4 years is more important than building real things.
— Shayan Mohanty (@shayanjm) June 10, 2015

Mastering the technical interview pic.twitter.com/14RlUgX0zU
— The Practical Dev (@ThePracticalDev) January 12, 2017
Проекты проваливаются не из-за того, что кто-то не может сделать RB дерево, а от того что люди не умеют общаться и работать вместе.
— Разработчик бэкенда (@backendsecret) April 10, 2017

Я как-то к вам пробовался, но не прошёл ) Очень рад, а то всё по-другому сложилось бы.
— Dan Abramov (@dan_abramov) July 6, 2017
The best software developers I know are always hacking over the holidays.
— Joe McCann (@joemccann) December 24, 2016
True story.
You can start a sentence with "All the best developers I know," as long as you end it with "& that's a great example of survivorship bias."
— Sarah Mei (@sarahmei) December 25, 2016
Valid response to any interview question: "can you tell me an example where you've run into this issue in day-to-day work at the company?"
— Justin Searls (@searls) July 18, 2017
|
Метки: author nazarov_tech управление разработкой карьера в it-индустрии блог компании exante собеседования собеседование |
Как мы ищем (и почему находим) крутых разработчиков. Опыт HR и советы соискателям |









|
Метки: author Ontaelio управление персоналом развитие стартапа карьера в it-индустрии блог компании skyeng найм персонала работа в it поиск разработчиков |
[Перевод] Запросы GraphQL без подключения к сети с помощью Redux Offline и Apollo |
Забавно, но с распространением интернета в мире все больше востребованы веб-приложения, работающие без подключения к сети. Пользователи (и клиенты) хотят функциональные интернет-приложения в онлайн, офлайн и в зонах с неустойчивой связью.
А это… не просто.
Посмотрим, как создать эффективное решение, работающее без подключения к сети, на React и слое данных GraphQL с применением Apollo Client. Статья разбита на две части. На этой неделе разберем оффлайновые запросы. На следующей неделе примемся за мутации.
За спиной Apollo Client все тот же Redux. А это значит, вся экосистема Redux с многочисленными инструментами и библиотеками доступна в приложениях на Apollo.
В сфере поддержки офлайн у Redux два основных игрока: Redux Persist и Redux Offline.
Redux Persist прекрасный, но дающий лишь основу, инструмент для загрузки хранилища redux в localStorage и восстановления обратно (поддерживаются и другие места хранения). По принятой терминологии, восстановление также называется регидрацией.
Redux Offline расширяет возможности Redux Persist дополнительным слоем функций и утилит. Redux Offline автоматически узнает о разрывах и восстановлениях связи и при разрыве позволяет ставить в очередь действия и операции, а при восстановлении – автоматически воспроизводит эти действия вновь.
Redux Offline – это «заряженый» вариант для работы без сетевого подключения.
Apollo Client и сам неплохо справляется с краткосрочными перебоями сетевых подключений. Когда сделан запрос, его результат помещается в собственное хранилище Apollo.
Если тот же запрос делается повторно, результат немедленно берется из хранилища на клиенте и отдается запрашивающему компоненту, кроме случая, когда параметр fetchPolicy имеет значение network-only. Это значит, что при отсутствии сетевого подключения или недоступности сервера повторные запросы будут возвращать последний сохраненный результат.
Однако стоит пользователю закрыть приложение, и хранилище пропадет. Как не потерять хранилище Apollo на клиенте между перезапусками приложения?
На помощь приходит Redux Offline.
Apollo держит свои данные в хранилище Redux (в ключе apollo). Записывая хранилище целиком в localStorage и восстанавливая при следующем запуске приложения, можно переносить результаты прошлых запросов между сеансами работы с приложением даже при отсутствии подключения к интернету.
Использование Redux Offline и Apollo Client не обходится без нюансов. Посмотрим, как заставить работать вместе обе библиотеки.
Обычно клиент Apollo создается довольно просто:
export const client = new ApolloClient({
networkInterface
});Конструктор ApolloClient автоматически создает хранилище Apollo (и косвенно – хранилище Redux). Полученный экземпляр client подается в компонент ApolloProvider:
ReactDOM.render(
,
document.getElementById('root')
);При использовании Redux Offline необходимо вручную создавать хранилище Redux. Это позволяет подключить к хранилищу промежуточный обработчик (middleware) из Redux Offline. Для начала просто повторим то, что делает сам Apollo:
export const store = createStore(
combineReducers({ apollo: client.reducer() }),
undefined,
applyMiddleware(client.middleware())
);Здесь хранилище store использует редьюсер и промежуточный обработчик (middleware) из экземпляра Apollo (переменная client), а в качестве исходного состояния указано undefined.
Теперь можно подать store в компонент ApolloProvider:
Превосходно. Создание хранилища Redux под контролем, и можно продолжать с Redux Offline.
В простейшем случае добавление Redux Offline заключается в добавлении еще одного промежуточного обработчика к хранилищу.
import { offline } from 'redux-offline';
import config from 'redux-offline/lib/defaults';
export const store = createStore(
...
compose(
applyMiddleware(client.middleware()),
offline(config)
)
);Без дополнительных настроек обработчик offline начнет автоматически записывать хранилище Redux в localStorage.
Не верите?
Откройте консоль и получите из localStorage эту запись:
localStorage.getItem("reduxPersist:apollo");Выводится большой объект JSON, представляющий полное текущее состояние приложения Apollo.
Великолепно!
Теперь Redux Offline автоматически делает снимки хранилища Redux в сохраняет их в localStorage. При каждом запуске приложения сохраненное состояние автоматически берется из localStorage и восстанавливается в хранилище Redux.
На все запросы, результаты которых находятся в этом хранилище, будут возвращены данные даже при отсутствии подключения к серверу.
Увы, восстановление хранилища происходит не мгновенно. Если приложение делает запрос в то время, как Redux Offline восстанавливает хранилище, могут происходить Странные Вещи(tm).
Если в Redux Offline включить логирование для режима autoRehydrate (что само по себе заставляет понервничать), при первоначальной загрузке приложения можно увидеть ошибки, на подобии:
21 actions were fired before rehydration completed. This can be a symptom of a race condition where the rehydrate action may overwrite the previously affected state. Consider running these actions after rehydration: …
Выполнено 21 действие прежде чем завершилось восстановление. Это признак конкуренции, из-за чего при восстановлении может быть потеряно ранее настроенное состояние. Рассмотрите возможность выполнять эти действия после восстановления: …Разработчик Redux Persist признал проблему и предложил рецепт отложенного рендеринга приложения после восстановления. К сожалению, его решение основано на ручном вызове persistStore. Однако Redux Offline делает такой вызов автоматически.
Посмотрим на другое решение.
Создадим Redux action с названием REHYDRATE_STORE, а также соответствующий редьюсер, устанавливающий значение true для признака rehydrated в хранилище Redux:
export const REHYDRATE_STORE = 'REHYDRATE_STORE';
export default (state = false, action) => {
switch (action.type) {
case REHYDRATE_STORE:
return true;
default:
return state;
}
};Подключим созданный редьюсер к хранилищу и настроим Redux Offline так, чтобы по окончанию восстановления выполнялось новое действие.
export const store = createStore(
combineReducers({
rehydrate: RehydrateReducer,
apollo: client.reducer()
}),
...,
compose(
...
offline({
...config,
persistCallback: () => {
store.dispatch({ type: REHYDRATE_STORE });
},
persistOptions: {
blacklist: ['rehydrate']
}
})
)
);Превосходно! Когда Redux Offline закончит восстанавливать хранилище, вызовет функцию persistCallback, которая запустит действие REHYDRATE_STORE и в конечном счете установит признак rehydrate в хранилище.
Добавление rehydrate в массив blacklist гарантирует, что эта часть хранилища не будет записана в localStorage и восстановлена из него.
Теперь, когда в хранилище есть сведения об окончании восстановления, разработаем компонент, реагирующий на изменения поля rehydrate и визуализирующий дочерние компоненты, только если rehydrate равно true:
class Rehydrated extends Component {
render() {
return (
{this.props.rehydrated ? this.props.children : Наконец, поместим компонент
Уфф.
Теперь приложение будет беспечно ждать, пока Redux Offline восстановит хранилище из localStorage, и только потом продолжит отрисовку и будет делать все последующие запросы или мутации GraphQL.
Есть несколько странностей и требующих пояснения вещей при использовании Redux Offline вместе с клиентом Apollo.
Во-первых, надо заметить, что в примерах этой статьи используется версия 1.9.0-0 пакета apollo-client. Для Apollo Client версии 1.9 заявлены исправления некоторых странных проявлений при работе с Redux Offline.
Другая странность этой пары в том, что Redux Offline, кажется, не слишком хорошо уживается с Apollo Client Devtools. Попытки использовать Redux Offline с установленным Devtools иногда приводят к неожиданным и, казалось бы, бессвязным ошибкам.
Такие ошибки можно легко исключить, если при создании Apollo client не подключать его к Devtools.
export const client = new ApolloClient({
networkInterface,
connectToDevTools: false
});Redux Offline дает приложению на Apollo основые механизмы для выполнения запросов даже при перезагрузке приложения после отключения от сервера.
Через неделю погрузимся в обработку офлайновых мутаций с помощью Redux Offline.
Будьте на связи!
Перевод статьи. Автор оригинала Pete Corey.
|
Метки: author teux разработка веб-сайтов api graphql redux react-offline |
Игра с номерами: как алгоритмическая торговля изменит сферу финансов |


«Сбои, подобные тем, что имели место в августе 2015 года, поколебали доверие отдельных инвесторов, которые полагаются на публичные рынки, чтобы диктовать фундаментальную ценность компании» – заявил бывший сенатор США Тед Кауфман.
|
Метки: author itinvest блог компании itinvest алгоритмы финансы алгоритмическая торговля hft биржа |
[Из песочницы] ML Boot Camp V, история решения на 2 место |
В данной статье я расскажу историю о том, как решал конкурс ML Boot Camp V “Предсказание сердечно-сосудистых заболеваний” и занял в нём второе место.
Данные содержали 100 000 пациентов, из которых 70% были в обучающей выборке, 10% для публичного лидерборда (public) и финальных 20% (private), на которых и определялся результат соревнования. Данные представляли собой результат врачебного осмотра пациентов, на основании которого нужно было предсказать, есть ли у пациента сердечно-сосудистое заболевание (ССЗ) или нет (данная информация была доступна для 70% и нужно было предсказать вероятность ССЗ для оставшихся 30%). Другими словами – это классическая задача бинарной классификации. Метрика качества – log loss.
Результат врачебного осмотра состоял из 11 признаков:
Так как субъективные признаки были основаны на основании ответов пациентов (могут быть недостоверными), организаторы конкурса скрыли 10% каждого из субъективных признаков в тестовых данных. Выборка была сбалансирована. Рост, вес, верхнее и нижнее давление нуждались в чистке, так как содержали опечатки.
Первый важный момент – это правильная кросс-валидация, так как тестовые данные имели пропущенные данные в полях smoke, alco, active. Поэтому, в валидационной выборке 10% данных полей тоже были скрыты. Используя 7 фолдов кросс-валидации (CV) с изменённым валидационным множеством, я рассмотрел несколько различных стратегий улучшения предсказаний на smoke, alco, active:
Также была рассмотрена стратегия взвешивания обучающих примеров по близости к валидации\тестовым данным, которая, однако, не давала прироста ввиду одинакового распределения train-test.
Скрытие в обучении почти всегда показывало лучшие результаты CV, причём оптимальная доля скрытых значений в обучении тоже получалась 10%.
Хотелось бы добавить, что если использовать стандартную кросс-валидацию без скрытия значений в валидации, то CV получался лучше, однако завышенным, так как тестовые данные в данном случае не похожи на локальную валидацию.
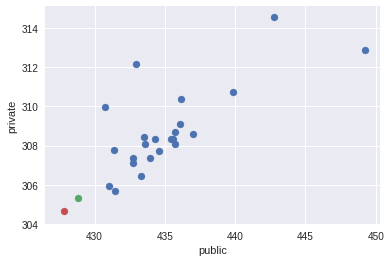
Интересный вопрос, который всегда волнует участников, это корреляция между CV и тестовыми данными. Уже имея полные данные после завершения конкурса (ссылка), я провёл небольшой анализ данной корреляции. Почти для всех сабмитов я записывал в описание результаты CV. Имея также результат на public и private, построим попарные графики сабмитов для значений CV, public, private (Так как все значения logloss начинаются на 0.5, для наглядности я опустил первые цифры, например 370 – это 0.5370, а 427.78 – 0.542778):

Чтобы получить численную оценку корреляции, я выбрал коэффициент Спирмана (другие тоже подойдут, но в данном случае важна именно монотонная зависимость).
| Spearman rho | CV | Public | Private |
|---|---|---|---|
| CV | 1 | 0.723 | 0.915 |
| Public | - | 1 | 0.643 |
| Private | - | - | 1 |
Можно сделать вывод, что введённая в предыдущей секции кросс-валидация хорошо коррелировала с private для моих сабмитов (в течении всего конкурса), когда как корреляция public с CV или private слабая.
Небольшие замечания: не ко всем сабмитам я подписывал результат CV, причём среди данных CV имеются результаты с не самыми лучшими стратегиями для работы с NaN (но подавляющее большинство с лучшей стратегией, описанной в предыдущей секции). Также, на данных графиках не присутствуют два моих финальных сабмита, о которых я расскажу далее. Их я изобразил отдельно в пространстве public-private красной и зелёной точкой.
В течении данного конкурса я использовал следующие модели с соответствующими библиотеками:
Поэксперементировав с различными моделями, и получая лучшие результаты путём смешивания 2-3 xgb (кросс-валидация занимала 3-7 минут), я решил сконцентрироваться больше на чистке данных, преобразовании признаков и тщательном тюнинге 1-5 различных множеств гиперпараметров xgb.
Гиперпараметры я попробовал искать с помощью Байесовской оптимизации (библиотека bayes_opt), но в основном опирался на случайный поиск, который служил инициализацией для Баейсовской оптимизации. Также, помимо банального оптимального количества деревьев, после такого поиска я старался попеременно подтягивать параметры (в основном регуляризационные параметры деревьев min_child_weight и reg_lambda) — метод, который некоторые называют graduate student descent.
Первый вариант чистки данных, вариант которого в той или иной мере реализовывали участники, состоял в простом применении правил на обработку выбросов:
Используя несколько простых правил для очистки, я смог добиться в среднем CV ~0.5375 и public ~0.5435, что показывало совсем средненький результат.
На рисунках изображён последовательный процесс обработки экстремальных значений и выбросов с приходом к очищенным значениям верхнего и нижнего давления на последнем изображении.

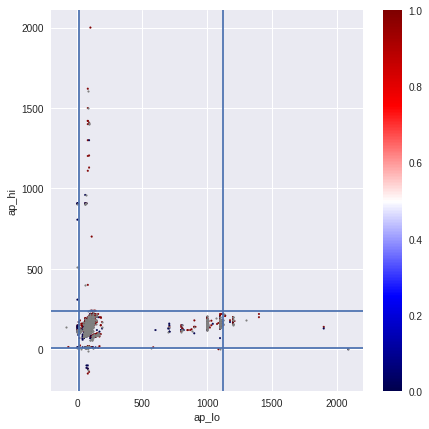
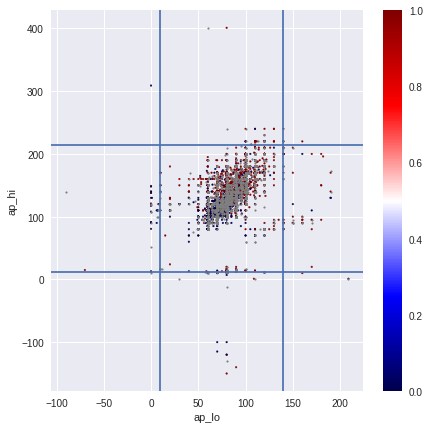

В моих экспериментах удаление выбросов не приводило к улучшению CV.
Предыдущая чистка данных вполне адекватная, однако, после долгих попыток улучшения моделей я её пересмотрел более тщательно, что позволило значительно улучшить качество. Последующие модели с данной чисткой показали прирост CV до ~0.5370 (с ~0.5375), public до ~0.5431 (с ~0.5435).
Основная идея – к каждому правилу есть исключение. Мой процесс поиска таких исключений был довольно рутинным – для небольшой группы (например, людей с с верхним давлением между 1100 и 2000) я смотрел на значения в train и test. Для большинства, конечно, правило “разделить на 10” срабатывало, но всегда существовали исключения. Данные исключения было проще изменить отдельно для примеров, чем искать общую логику исключений. Например, такие выбивающиеся из общей группы давления, как 1211 и 1620, я заменял на 120 и 160.
В некоторых случаях правильно обработать исключения удавалось, лишь включая информацию с других полей (например, по связке верхнего и нижнего давления). Таким образом, давления вида 1/1099 и 1/2088 заменялись на 110/90 и 120/80, а 14900/90 заменялись на 140/90. Самые сложные случаи были, например, при замене давления 585 на 85, 701 на 170, 401 на 140.
В сложных менее однозначных случаях я проверял, насколько исправления похожи на обучение и тест. Например, случай 13/0 я заменял на 130/80, так как он самый вероятный. Для исключений из обучающей выборки мне также помогало знание поля ССЗ.
Очень важный момент – это различить шум от сигнала, в данном случае – опечатку от настоящих аномальных значений. Например, после чистки у меня осталась небольшая группа людей с давлением вида 150/60 (имеют ССЗ в обучении, их давление вписывается в одну из категорий ССЗ) или ростом около 90 см с небольшим весом.
Добавлю, что основной прирост дала очистка давления, тогда как с ростом и весом было много неоднозначностей (обработка роста-веса тоже основана на поиске исключений с дальнейшим применением общего правила).
Пользуясь выложенным полным датасетом после соревнования, получаем, что данная очистка затронула 1379 объектов в обучении (1.97%), 194 в public (1.94%), 402 в private (2.01%). Конечно, исправления аномальных значений для 2% датасета была не идеальной и можно её сделать лучше, однако даже в этом случае наблюдался самый большой прирост CV. Стоит отметить только, что после чистки или работы с признаками необходимо находить более оптимальные гиперпараметры алгоритмов.
Изначально возраст был поделён на 365.25, чтобы работать с годами. Распределение возраста было периодичным, где пациентов с чётными годами было гораздо больше. Возраст представлял собой гауссовскую смесь с 13 центрами в чётных годах. Если просто округлить по годам, то улучшалось CV в четвёртом знаке на ~1-2 единицы по сравнению с исходным возрастом. На рисунках показан переход от исходного возраста к округлённому до года.

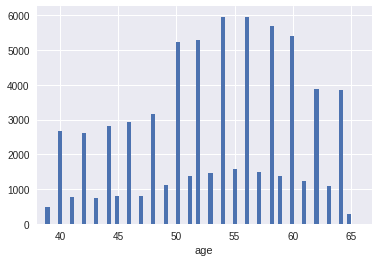
Однако, я также использовал другую дискретизацию с целью улучшения распределения по годам, которую и включил в последнюю простую модель. Вершины распределений в гауссовской смеси были найдены с помощью гауссовского процесса, и «год» определился как половина гауссовского распределения (справа и слева). Таким образом новое распределение по «годам» выглядело более равномерным. На рисунках показан переход от исходного возраста (с найденными вершинами гауссовской смеси) к новому распределнию по «годам»
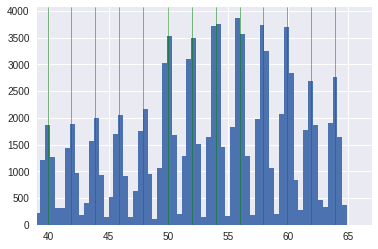
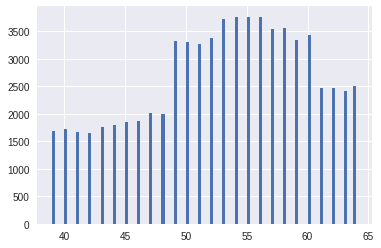
BMI ( индекс массы тела = ) появлялся первым в важности признаков. Добавление исходного BMI улучшало результат, однако, наибольшего улучшения модели достигли после дискретизации его значений. Порог дискретизации был выбран на основании квартилей, а количество определялось на основании cv, визуальной валидации распределений. На рисунках показан переход от исходного BMI к дискретизированному BMI.

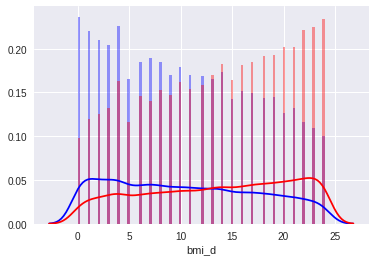
Аналогично, к росту и весу была применена дискретизация с малым количеством категорий, а давление и пульс были округлены c точностью до 5.
Поиск новых признаков и их отбор производился вручную. Лишь небольшое количество новых признаков смогли улучшить CV, причём все они показывали относительно небольшой прирост:
Итоговую важность признаков (с дискретизацией) для одной модели xgb можно увидеть на графике:
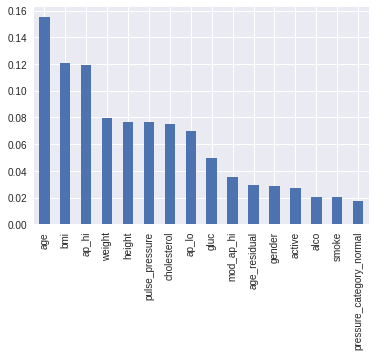
За час до окончания у меня была довольно простая модель из 2 xgb с использованием последней чистки данных и дискретизации признаков. Код доступен на github ( показывал CV 0.5370, public 0.5431, private 0.530569 — тоже 2 место).
Имея усреднения двух или трёх xgb на последней предобработке данных, я решил попробовать усреднить результаты последних моделей с некоторыми предыдущими (различные преобразования и набор признаков, чистка данных, модели) и на удивление, усреднение с весами 8 предыдущих предсказаний дало улучшение на public с 0.5430-31 до 0.54288. Стратегия с весами была зафиксирована сразу — обратно пропорционально округлённой 4й цифре на public (к примеру, у 0.5431 вес 1, 0.5432 — 1/2, 0.5433 — 1/3), что вполне хорошо коррелировало с тем, что модели с последней чисткой данных показывали также лучшие значения CV. Эти 8 предсказаний были получены с помощью одного, двух, трёх (большинство), а также 9 различных моделей xgb. Все, кроме одной, были на основании последней чистки данных, различаясь набором новых признаков, дискретизацией или её отсутствием, гиперпараметрами, а также стратегией с NaN. Далее, с той же схемой весов добавление сабмитов похуже (с весами меньше 1/4) помогло улучшить public до 0.542778 (всего 17 предсказаний, описание можно найти на github).
Конечно же, по-хорошему необходимо было хранить результаты предыдущих кросс-валидаций, чтобы правильно оценить качество такого усреднения. Могло ли быть здесь переобучение? Руководствуясь тем, что более 90% веса в усреднении было у моделей со стабильными CV 0.5370-0.5371, можно было ожидать, что модели послабее могли помочь в экстремальных ошибках лучших простых моделей, однако в целом предсказания мало отличались от лучших моделей. Учитывая также, что public значительно улучшился, я выбрал в качестве финальных именно два этих усреднения, которое и вылилось в лучшую модель, показавшую 2 место с private 0.5304688. Можно заметить, что простое решение, описанное выше, и которое было базой в данном усреднении, показало бы тоже 2 место, однако оно менее стабильно.
Финальное усреднение показало, что использование комбинации относительно простых моделей на разных признаках/предобработке может дать лучшие результаты, чем использование множества моделей на одних и тех же данных. К сожалению, в течении конкурса я искал именно одну «идеальную» очистку данных, одно преобразование признаков и т.д.
Также, для себя я заметил, что кроме частых коммитов в git, желательно хранить результаты кросс-валидации предыдущих моделей, чтобы можно было быстро оценить, смешивание каких различных признаков\предобработки\моделей даёт наибольший прирост. Однако же, исключения к правилам бывают, например, если остаётся лишь час до конца конкурса.
Судя по результатам других участников, мне необходимо было продолжить свои эксперименты с включением нейронных сетей, стекингом. Они, однако, присутствовали у меня в финальном сабмите, но лишь косвенно с незначительным весом.
В заключение, выступление автора доступно здесь, а презентация также на github.
|
Метки: author shayakhmetov машинное обучение mlbootcamp python спортивный анализ данных |
Уязвимость в Альфа-Банк Украина: получение ФИО клиента по номеру телефона |
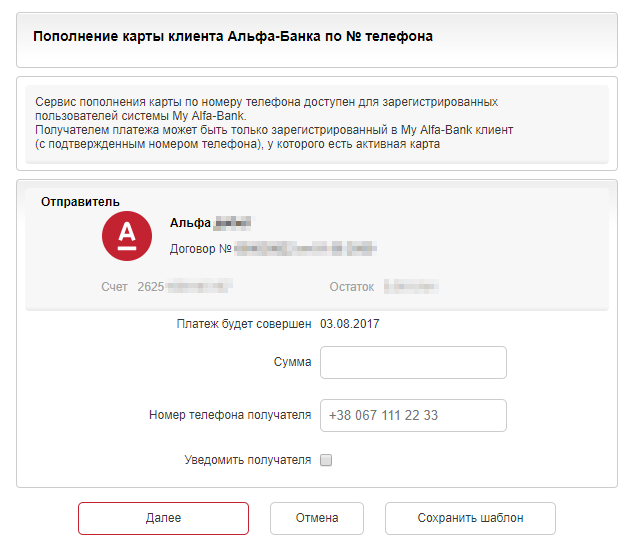
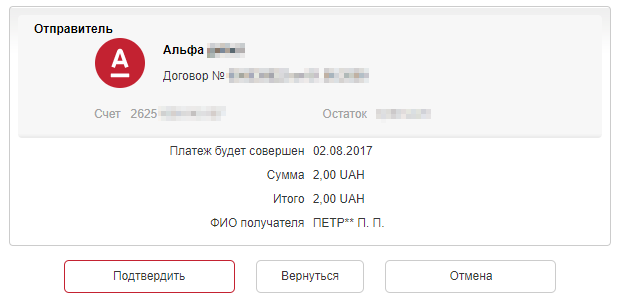

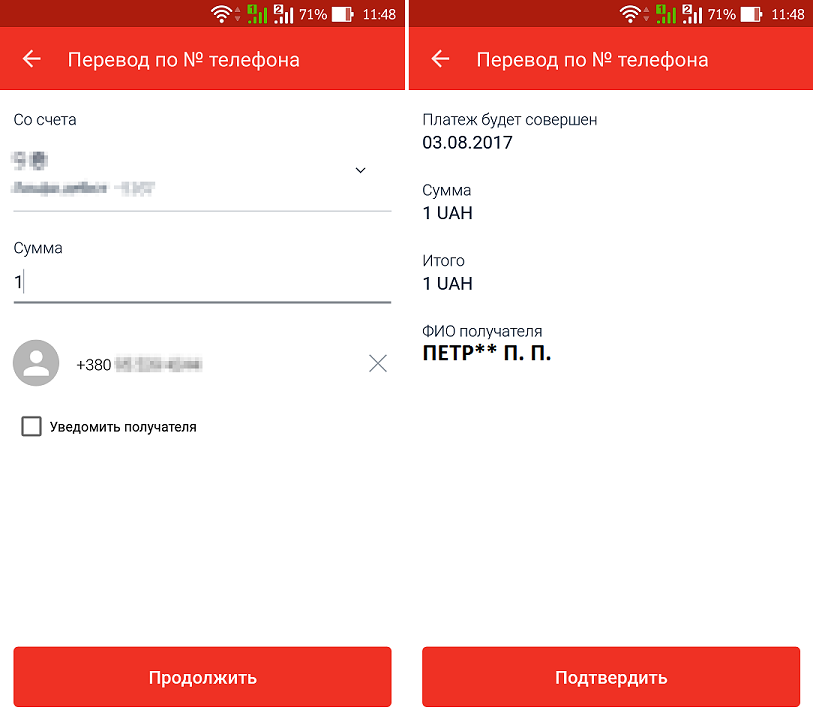
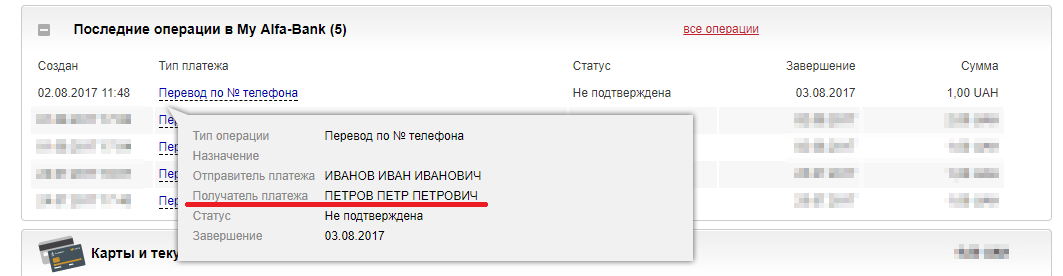
|
Метки: author Gorodnya тестирование мобильных приложений тестирование веб-сервисов платежные системы информационная безопасность банк уязвимость альфа-банк |
Асимметричная криптография и криптография с открытым ключом — это не одно и то же? |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author pestunov криптография информационная безопасность криптосистема криптоалгоритм шифр шифрование открытый ключ закрытый ключ |
Бесплатный аудит безопасности сети с помощью Fortinet. Часть 1 |
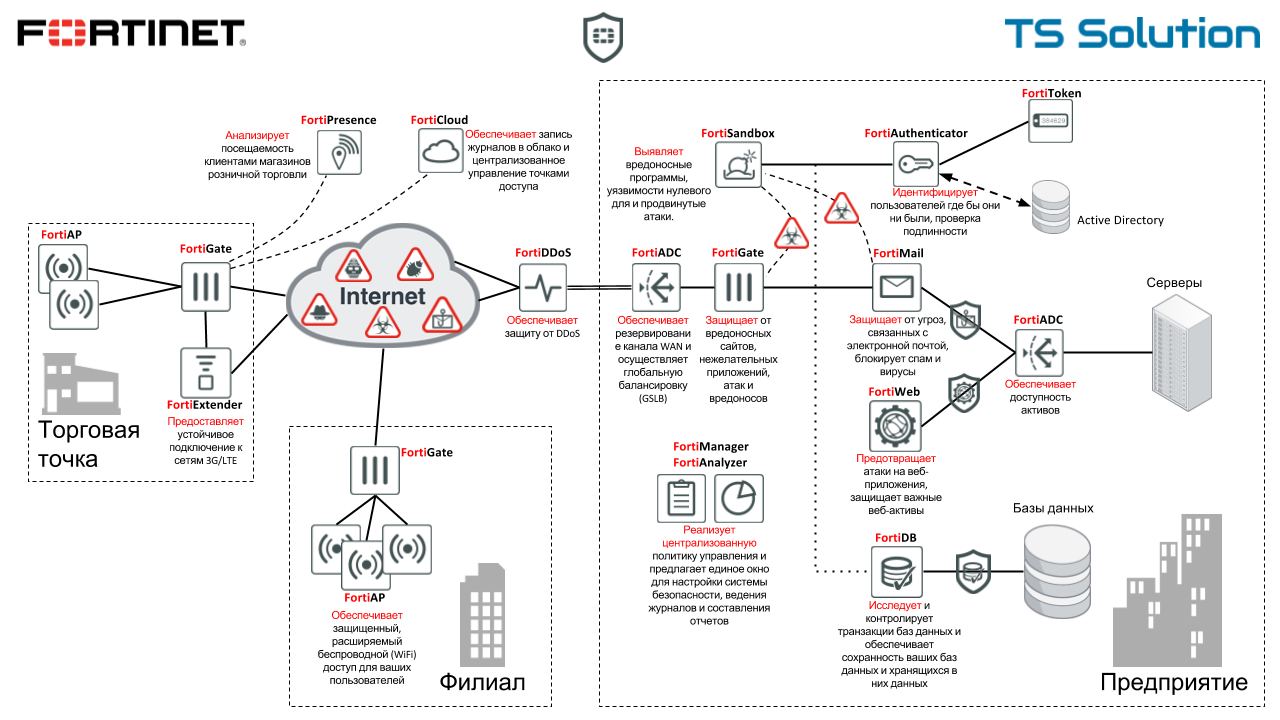
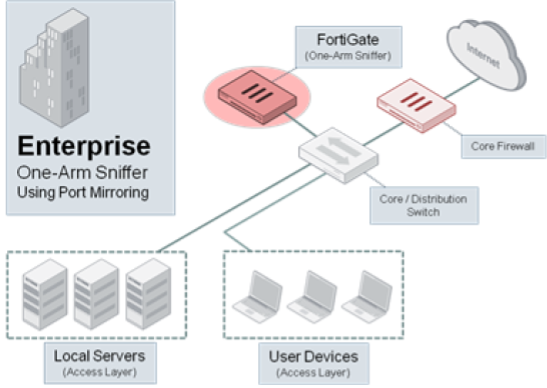
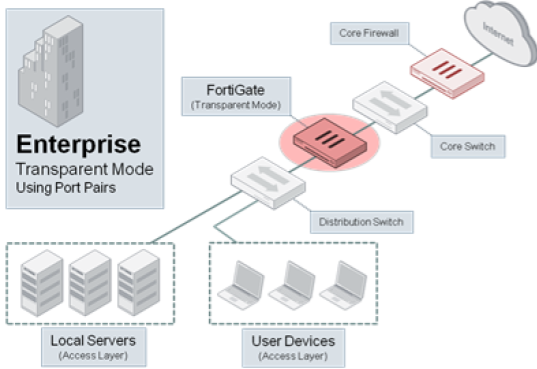











Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
«Паровозик, который смог!» или «Специализация Машинное обучение и анализ данных», глазами новичка в Data Science |

import pandas as pd
humor_rate=[(5/2575),(3/2098), (4/2667),(2/3051)]
days=[2,3,2,37]
df=pd.DataFrame(list(zip(humor_rate, days)), index=None, columns=['Humor rate', 'Days of study'])
print ('Таблица данных: \n', df)
print ('Корреляция между humor rate и days of study = ', df.corrwith(df['days of study'])[0])
Таблица данных:
.....Humor rate.....Days of study
0....0.001942............2
1....0.001430............3
2....0.001500............2
3....0.000656............37
Корреляция между humor rate и days of study = -0.912343823382

|
Метки: author BosonBeard учебный процесс в it data science coursera машинное обучение анализ данных новичкам статистика математика python онлайн обучение |
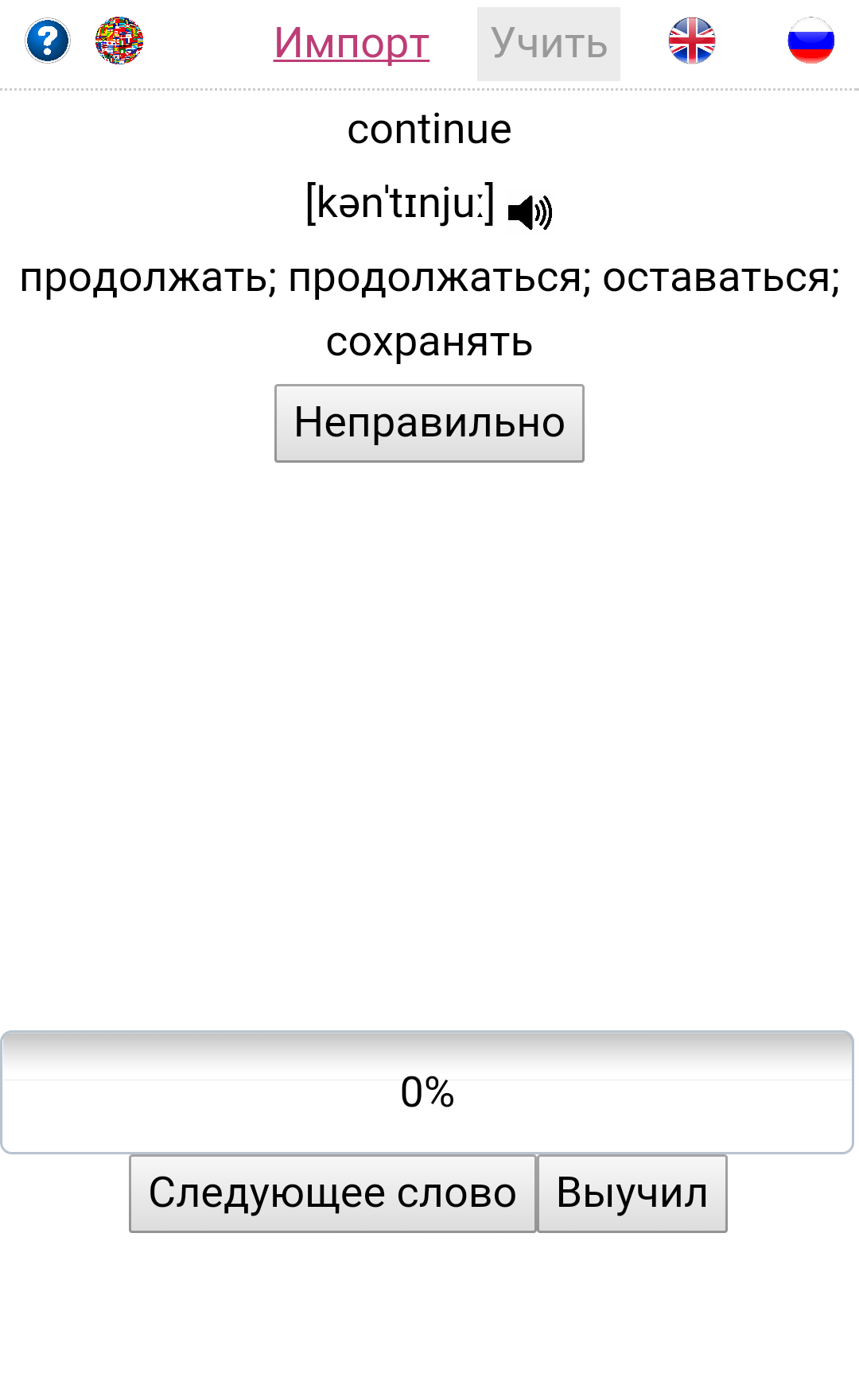
Алгоритм для запоминания иностранных слов |
var oneWord = function() {
$.post("https://dictionary.yandex.net/api/v1/dicservice.json/lookup",
{
key: apiKey,
lang: lang,
text: words[index].text
}, function(data)
{
words[index].tr = "";
words[index].ts = "";
for (var j = 0; j < data.def.length; j++) {
var def = data.def[j];
for (var k = 0; k < def.tr.length; k++) {
var tr = def.tr[k];
words[index].tr += tr.text + "; ";
}
if (def.ts)
words[index].ts = def.ts;
}
if (words[index].tr == "") {
translateWords();
tsWords();
return;
} else {
var str = words[index].tr;
words[index].tr = str.substring(0, str.length - 2);
}
complete();
},
"json");
};
var tsWords = function() {
var text = words[index].text;
var tsText = "";
var tsWords = text.match(/\S+/gi);
var tsIndex = 0;
var tsPost = function() {
$.post("https://dictionary.yandex.net/api/v1/dicservice.json/lookup",
{
key: apiKey,
lang: lang,
text: tsWords[tsIndex]
}, function(data)
{
var ts = "";
for (var j = 0; j < data.def.length; j++) {
var def = data.def[j];
if (def.ts)
ts = def.ts;
}
tsText += ts + " ";
if ((tsIndex < (tsWords.length - 1)) && (tsIndex < 5)) {
tsIndex++;
tsPost();
} else {
words[index].ts = tsText.trim();
complete(false, true);
}
},
"json");
};
tsPost();
};
var translateWords = function() {
$.post("https://translate.yandex.net/api/v1.5/tr.json/translate",
{
key: apiKeyTranslate,
lang: slang,
text: words[index].text
}, function(data)
{
words[index].tr = "";
for (var j = 0; j < data.text.length; j++) {
var text = data.text[j];
words[index].tr += text + "; ";
}
var str = words[index].tr;
words[index].tr = str.substring(0, str.length - 2);
complete(true, false);
},
"json");
};
var qu = function() {
if (!words[index].tr) {
oneWord();
} else {
complete();
}
};
qu();
var complete = function(tr, ts) {
if (ts == undefined) ts = true;
if (tr == undefined) tr = true;
var word = words[index];
if (tr) $("#text").html(word.text);
if (ts) $("#ts").html("[" + word.ts + "]");
$("#tr").hide();
$("#attempt").hide();
$("#show").show();
$("#tr").html(word.tr);
$("#tts").show();
};
var words = [],
patternCount = 5,
indexMemory = {},
indexMemoryCount = 0,
patternIndex = [],
lastIndex = -1,
lastIndexs = [],
lastIndexsCount = 2,
wasAttempt = false,
wasMemory = false,
deep = 0,
deepMax = 100;
var index = nextIndex();
var nextIndex = function() {
deep++;
if (lastIndexsCount - words.length >= 0) {
lastIndexsCount = 0;
}
if ((patternIndex.length < patternCount) && (indexMemoryCount < words.length)) {
if (deep > deepMax) {
var index = maxAttemptsIndex(true);
return index;
}
var index = Math.floor(Math.random() * words.length);
if (indexMemory[index]) {
return nextIndex();
}
indexMemory[index] = "do";
indexMemoryCount++;
patternIndex.push(index);
lastIndex = index;
pushIndex(lastIndex);
return index;
} else {
var index = Math.floor(Math.random() * (patternIndex.length + 1));
if (index == patternIndex.length || (patternIndex.length == 0)) {
wasMemory = true;
var ind = maxAttemptsIndex();
if (inArray(lastIndexs, ind))
{
if (deep > deepMax) {
ind = Math.floor(Math.random() * words.length);
lastIndex = ind;
pushIndex(lastIndex);
return ind;
}
return nextIndex();
}
lastIndex = ind;
pushIndex(lastIndex);
return ind;
}
if (inArray(lastIndexs, patternIndex[index])) return nextIndex();
lastIndex = patternIndex[index];
pushIndex(lastIndex);
return patternIndex[index];
}
};
var maxAttemptsIndex = function(notAttempts) {
var arr = sortMemoryIndexes(indexMemory);
var index = getRandomFishIndex(arr, notAttempts);
return index;
};
var pushIndex = function(index) {
if (lastIndexsCount == 0) return;
if (lastIndexs.length < lastIndexsCount) {
lastIndexs.push(index);
} else {
lastIndexs[0] = lastIndexs[1];
lastIndexs[1] = index;
}
};
var inArray = function(arr, elem) {
for (var i = 0; i < arr.length; i++) {
if (arr[i] == elem)
return true;
}
return false;
};
function getRandomFishIndex(arr, notAttempts) {
var fishForLevel = arr;
var fishTotalWeight = 0, fishCumWeight = 0, i;
// sum up the weights
for (i = 0; i < fishForLevel.length; i++) {
fishTotalWeight += fishForLevel[i].attempts;
}
if (notAttempts) {
fishTotalWeight = 0;
}
var random = Math.floor(Math.random() * fishTotalWeight);
// now find which bucket out random value is in
if (fishTotalWeight == 0) return fishForLevel[Math.floor(Math.random() * fishForLevel.length)].index;
for (i = 0; i < fishForLevel.length; i++) {
fishCumWeight += fishForLevel[i].attempts;
if (random <= fishCumWeight) {
return fishForLevel[i].index;
}
}
}
function sortMemoryIndexes(indexMemory) {
var arr = [];
for (var key in indexMemory) {
if (indexMemory[key] == "do") {
var word = jQuery.extend(true, {}, words[key]);
word.index = key;
arr.push(word);
}
}
var sAttempt = function(first, second) {
if (first.attempts < second.attempts)
return 1;
else if (first.attempts > second.attempts)
return -1;
else
return 0;
};
return arr.sort(sAttempt);
}
$("#attempt").click(function()
{
words[index].attempts++;
wasAttempt = true;
$("#attempt").hide();
});


|
Метки: author vladshow яндекс api разработка под android разработка мобильных приложений алгоритмы javascript иностранный язык английский язык android cordova |
[Из песочницы] Аутсорсинг: за и против |

|
Метки: author Novikova_Svetlana фриланс управление персоналом бизнес-модели аутсорсинг аутсорсинг деловых процессов стратегия развития стратегический маркетинг |






