[Перевод] Продвинутые перечисления с Ruby |
def my_printer
puts "Hello World!"
end
def thrice
3.times do
yield
end
end
thrice &method(:my_printer)
# Hello World!
# Hello World!
# Hello World!
thrice { puts "Ruby" }
# Ruby
# Ruby
# Ruby
def simple_enum
yield 4
yield 3
yield 2
yield 1
yield 0
end
simple_enum do |value|
puts value
end
# 4
# 3
# 2
# 1
# 0
Array.ancestors
# => [Array, Enumerable, Object, Kernel, BasicObject]
Hash.ancestors
# => [Hash, Enumerable, Object, Kernel, BasicObject]
Hash.method_defined? :each
# => true
require "set"
Set.ancestors
# => [Set, Enumerable, Object, Kernel, BasicObject]
class Thing
def each
yield "winning"
yield "not winning"
end
end
a = Thing.new.to_enum.lazy
Thing.include Enumerable
b = Thing.new.lazy
a.next
# => "winning"
b.next
# => "winning"
Вызов to_enum возвращает объект, который является как Enumerator так и Enumerable, и который будут иметь доступ ко всем их методам.
x = (0..Flot::INFINITY)
y = x.chunk(&:even?)
# => #:each>>
y.next
# => [true, [0]]
y.next
# => [false, [1]]
y.next
#=> [true, [2]]
z = x.lazy.select(&:even?)
# => #:select>
z.next
# => 0
z.next
# => 2
z.next
# => 4
(0..Float::INFINITY).take(2)
# => [0, 1]
def divisible_by?(num)
->input{ (input % num).zero? }
end
def fizzbuzz_from(value)
Enumerator::Lazy.new(value..Float::INFINITY) do |yielder, val|
yielder << case val
when divisible_by?(15)
"FizzBuzz"
when divisible_by?(3)
"Fizz"
when divisible_by?(5)
"Buzz"
else
val
end
end end
x = fizzbuzz_from(7)
# => #
9.times { puts x.next }
# 7
# 8
# Fizz
# Buzz
# 11
# Fizz
# 13
# 14
# FizzBuzz
require "prime"
x = (0..34).lazy.select(&Prime.method(:prime?))
x.next
# => 2
x.next
# => 3
x.next
# => 5
x.next
# => 7
x.next
# => 11
[0,1,2,3,4,5,6,7,8].group_by.with_index {|_,index| index % 3 }.values
# => [[0, 3, 6], [1, 4, 7], [2, 5, 8]]
0 3 6
1 4 7
2 5 8
threes = (0..2).cycle
[0,1,2,3,4,5,6,7,8].slice_when { threes.next == 2 }.to_a
# => [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
0 1 2
3 4 5
6 7 8
x = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
x = x.transpose
# => [[0, 3, 6], [1, 4, 7], [2, 5, 8]]
x = x.transpose
# => [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
[1,2,3].reduce(:+)
# => 6
[1,2,3].inject(:+)
# => 6
class AddStore
def add(num)
@value = @value.to_i + num
end
def inspect
@value
end
end
[1,2,3].each_with_object(AddStore.new) {|val, memo| memo.add(val) }
# => 6
# As of Ruby 2.4
[1,2,3].sum
# => 6
collection = [:a, 2, :p, :p, 6, 7, :l, :e]
collection.reduce("") { |memo, value|
memo << value.to_s if value.is_a? Symbol
memo # Note the return value needs to be the object/collection we're building
}
# => "apple"
collection.each_with_object("") { |value, memo|
memo << value.to_s if value.is_a? Symbol
}
# => "apple"
class Pair < Struct.new(:first, :second)
def same?; inject(:eql?) end
def add; inject(:+) end
def subtract; inject(:-) end
def multiply; inject(:*) end
def divide; inject(:/) end
def swap!
members.zip(entries.reverse) {|a,b| self[a] = b}
end
end
x = Pair.new(23, 42)
x.same?
# => false
x.first
# => 23
x.swap!
x.first
# => 42
x.multiply
# => 966
Заросли данных — это когда две или более переменных всегда используются в группе, но при этом они бы не имели никакого смысла если бы использовались по отдельности. Эта группа переменных должна быть сгруппирована в объект/класс.
|
Метки: author houk ruby on rails ruby перечисления enumerators enumerations lambdas blocks перечислители |
[Из песочницы] Централизованное хранилище логов для Squid Proxy или как мы логи в базу заворачивали |

yum install perl perl-Readonly* perl-URI perl-YAML perl-DBI perl-Carp perl-DBD-mysqlcp log_mysql_daemon.pl /usr/libexec/squid/log_mysql_daemon.plchmod +x /usr/libexec/squid/log_mysql_daemon.pl
chown squid:squid /usr/libexec/squid/log_mysql_daemon.plvi /etc/squid/log_mysql_daemon.conf
host: ""
database: "squid_log"
table: "access_log"
user: "squid"
pass: ""mysql -p
create database squid_log;
CREATE USER 'squid'@'%' IDENTIFIED BY '';
GRANT ALL PRIVILEGES ON squid_log.* TO 'squid'@'';
GRANT ALL PRIVILEGES ON squid_log.* TO 'squid'@'';
GRANT ALL PRIVILEGES ON squid_log.* TO 'squid'@'';
GRANT ALL PRIVILEGES ON squid_log.* TO 'squid'@'';
GRANT ALL PRIVILEGES ON squid_log.* TO 'squid'@'';
exit
cat log_mysql_daemon-table.sql log_mysql_daemon-views.sql | mysql -p squid_logvi /etc/squid/squid.conf
acl dontLog http_status 403 407
logformat squid_mysql %ts.%03tu %6tr %>a %Ss %03Hs %
access_log /var/log/squid/access.log squid
access_log daemon:/etc/squid/log_mysql_daemon.conf squid_mysql !dontLog
logfile_daemon /usr/libexec/squid/log_mysql_daemon.pl # fields that we should have in the database table
# this list depends on the log format configuration
my @required_fields = qw(
id
time_since_epoch
response_time
client_src_ip_addr
squid_request_status
http_status_code
reply_size
request_method
request_url
username
squid_hier_status
server_ip_addr
mime_type
squid_server
);squid reconfigure
squid -k reconfigure
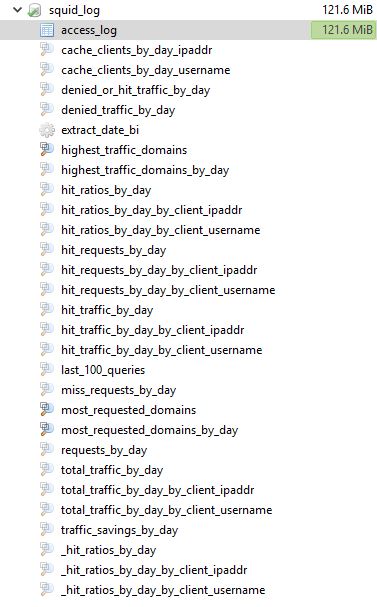
|
Метки: author iRandom хранение данных системное администрирование настройка linux администрирование баз данных *nix squid3 proxy db perl system administration |
И снова Huawei Cloud Fabric: что такое SDN-архитектура и с чем её едят |

|
Метки: author Huawei_Russia сетевые технологии серверное администрирование облачные вычисления виртуализация it- инфраструктура sdn- архитектура huawei |
[Перевод] Криптовалюта Dash приглашает… взломать свой блокчейн |

|
Метки: author zapp управление сообществом управление проектами развитие стартапа венчурные инвестиции бизнес-модели dash криптовалюта блокчейн взлом |
За глобальные переменные замолвите слово? |
Мне, как и многим другим, в университете, рассказали про то, что глобальные переменные использовать плохо. Конечно, я пытался задавать вопрос: "Почему?", на который получил пространное объяснение про плохо структурированный код. Ответ я не понял до конца, но инстинкт самосохранения мне подсказал, что надо делать как говорят. Только спустя много лет, я нашел в статье E. M. Clarke Programming Language Constructs for Which It Is Impossible To Obtain Good Hoare Axiom Systems теорему, которая, на мой взгляд, проясняет ситуацию с глобальными переменными.
Итак, собственно, теорема Clarke:
It is impossible to obtain a system of Hoare axioms H which is sound and
complete in the sense of Cook for a programming language which allows:
(I) procedures as parameters of procedure calls,
(II) recursion,
(III) static scope,
(IV) global variables,
(V) internal procedures.
небольшие пояснения по тексту:
Попробую объяснить смысл простым языком, без глубокого погружения в терминологию.
Если использовать все пять перечисленных конструкций языка программирования, то можно
При этом, в той же статье показано, что если изменить/отказаться от одного из предложенных пунктов, то система аксиом существует.
Если перебрать все пять пунктов, то окажется, что наименее ценное, от чего можно отказаться — глобальные переменные.
Другими словами, глобальные переменные — это не зло, а жертва, которую пришлось принести, чтобы избежать проблем с отладкой, верификацией программ, возможностью реализации задачи.
|
Метки: author etyumentcev программирование математика hoare logic global variables soundness completness clarke |
Сайты интернет-магазинов и промышленных компаний наиболее уязвимы для хакерских атак |
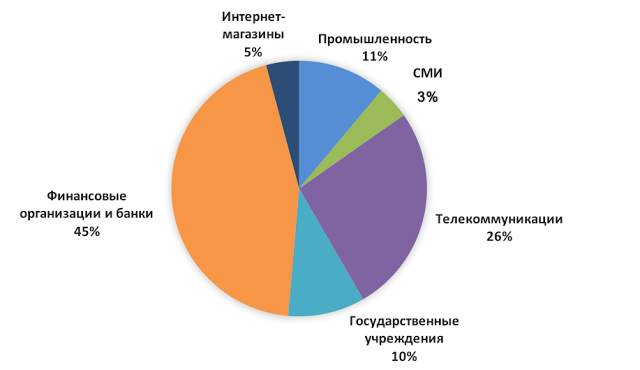
Полная версия исследования: blog.ptsecurity.ru/2017/08/web-attacks.html
|
Метки: author ptsecurity информационная безопасность блог компании positive technologies исследование статистика уязвимости |
[Из песочницы] ML Boot Camp V, история решения на 3 место |
with gzip.open('../run/local/pred_1.pickle.gz', 'wb') as f:
pickle.dump((x, y), f)
|
Метки: author ifilonov машинное обучение ml boot camp |
Очень легкая система мониторинга с Телеграмом и Консулом |
|
Метки: author LeshiyUrban программирование go docker docker-compose consul telegram |
Асинхронный дешифратор |


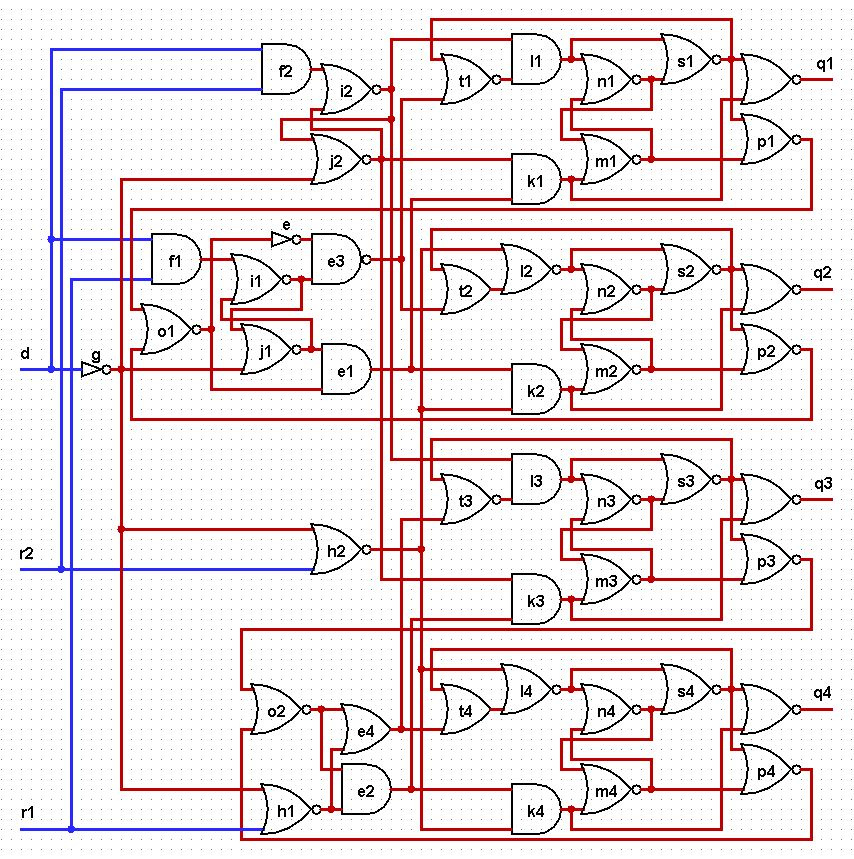
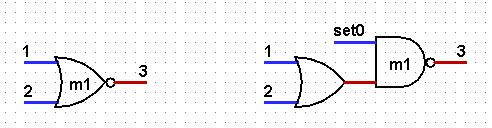
|
Метки: author ajrec fpga асинхронные схемы асинхронный дешифратор |
[Перевод - recovery mode ] Применение PowerShell для ИТ-безопасности. Часть I: отслеживание событий |

классов WMI. Разумеется, язык запросов называется WQL.Win32_Process, содержащий информацию о текущем запущенном процессе.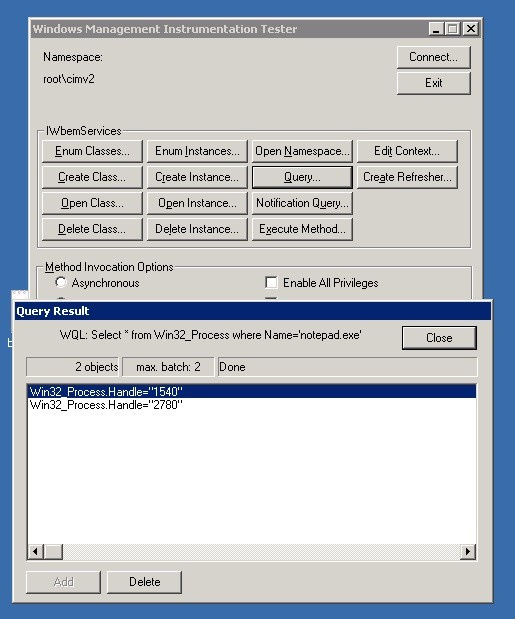
Get-WMIObject. Он позволяет отправлять запрос WQL непосредственно в виде параметра.select Name, ProcessId, CommandLine from Win32_Process в тестовой среде AWS.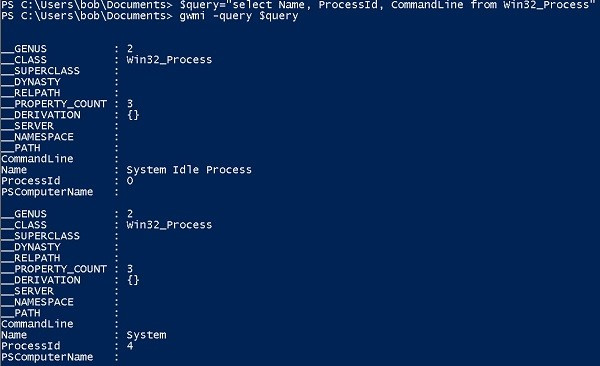
Out-GridView — командлет PowerShell, который форматирует данные в аккуратную таблицу на основе графического интерфейса.
Register-WmiEvent в PowerShell 2.0 позволяет реагировать на события в более приемлемой манере. Иными словами, когда происходит событие, срабатывает вызов, который можно зарегистрировать.CIM_DataFile. Вместо получения доступа к процессам, как мы делали ранее, Боб использует этот класс для соединения с метаданными основного файла.
Register-WmiEvent, который будет отправлять уведомления в консоль при создании большого файла в основном каталоге.Register-WmiEvent -Query "SELECT * FROM __InstanceModificationEvent WITHIN 5 WHERE TargetInstance isa 'CIM_DataFile' and TargetInstance.FileSize > 2000000 and TargetInstance.Path = '\\Users\\bob\' and targetInstance.Drive = 'C:' "-sourceIdentifier "Accessor3" -Action { Write-Host "Large file" $EventArgs.NewEvent.TargetInstance.Name "was created”}CIM_DataFile, превышающего 2 млн байтов. При создании файла, соответствующего условиям, появится уведомление, для которого активируется InstanceModificationEvent.
|
Метки: author Alexandra_Varonis хранение данных системное администрирование powershell блог компании varonis systems varonis информационная безопасность |
[Из песочницы] Атака клонов. Как бороться с дублированием кода? |
Несмотря на то, что проблемы, связанные с дублированием кода, упоминаются довольно часто, актуальность этих проблем из года в год остается почти неизменной. Во многих популярных проектах количество клонов измеряется сотнями или даже тысячами.
В рамках данной статьи мне бы хотелось напомнить, что такое программные клоны, какие они влекут за собой проблемы и как с ними можно бороться. В статье приводятся примеры рефакторинга реальных клонов из популярного фреймворка Spring. В качестве инструментов используются Java 8, IDE IntelliJ IDEA 2017.1 и плагин Duplicate Detector 1.1.
По сути, клоны — это просто схожие фрагменты исходного кода. В основном они появляются при копировании, даже не смотря на то, что копирование является общеизвестно плохой практикой. Конечно, это не единственная возможная причина появления клонов, существуют и другие, более объективные. Например, сам язык программирования может быть недостаточно выразительным, или у разработчика может не быть возможностей для соответствующего изменения исходного кода.
Можно выделить следующие основные причины возникновения клонов:
С одной стороны, дублированный код обладает рядом очевидных недостатков. Такой код труднее изменять и развивать, из-за дубликатов увеличивается размер проекта и усложняется его понимание. Кроме того, при копировании также возникают риски распространения ошибок из исходных фрагментов.
С другой стороны, удаление дубликатов также может привести к ошибкам, особенно, если для этого необходимо вносить существенные изменения в текст программы. Однако главным аргументом против удаления клонов является то, что такое удаление часто приводит к увеличению числа зависимостей. Довольно интересно про это написано в статье "Redundancy vs dependencies: which is worse?".

С моей точки зрения, клоны являются признаком не очень качественного исходного кода и, соответственно, влекут за собой те же проблемы. К сожалению, их не всегда можно эффективно удалить, да и не всегда именно они являются настоящей проблемой. В некоторых случаях они могут указывать на неудачный выбор архитектуры или на чрезмерную захламленность функции.
В конечном счете, удалять клоны или нет — зависит от конкретной ситуации. Однако, в любом случае, дублированный код — это всегда повод задуматься.
Существует довольно много инструментов для поиска клонов: PMD, CCFinder, Deckard, CloneDR, Duplicate finder (maven plugin), и многие другие.
К сожалению, в основном эти инструменты не интегрированы со средой разработки. Отсутствие интеграции значительно затрудняет навигацию и рефакторинг клонов. При этом, инструментов, встроенных в среду разработки, оказывается не так много. Например, в случае IntelliJ IDEA выбор стоит только между стандартными инспекциями и двумя плагинами (PMD и Duplicate Detector).
Данная статья преследует две цели. С одной стороны, с ее помощью мне бы хотелось внести свой скромный вклад в борьбу с дублированием исходного кода. С другой стороны, я бы хотел познакомить читателя с плагином Duplicate Detector, разработчиком которого я и являюсь. На данный момент, по сравнению со стандартными инспекциями, этот плагин обнаруживает в 3-4 раза больше клонов, предоставляет более удобный интерфейс и доступен для некоммерческой версии IntelliJ IDEA.
Основные возможности плагина Duplicate Detector:
По сути, существует лишь один способ удаления клонов — обобщить схожую функциональность. Для этого можно создать вспомогательный метод или класс, или попробовать выразить один дубликат через другой. При этом не стоит забывать, что рефакторинг делается для повышения качества кода. Поэтому к нему лучше подходить творчески, так как иногда проблема может быть шире или уже, или вообще заключаться в чем-то другом.
Давайте рассмотрим несколько конкретных примеров из популярного фреймворка Spring. Для этого воспользуемся средой разработки IntelliJ IDEA и плагином Duplicate Detector.
Среда разработки IntelliJ IDEA и плагин Duplicate Detector предоставляют множество возможностей, которые упростят рефакторинг клонов. Например, довольно много функций можно найти в контекстном меню Refactor или в подсказках к инспекциям кода (Alt + Enter в рамках инспекции).

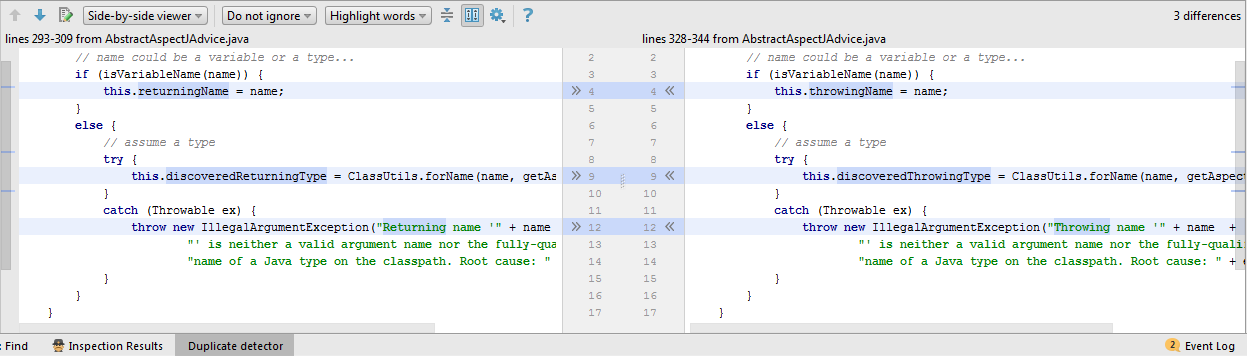
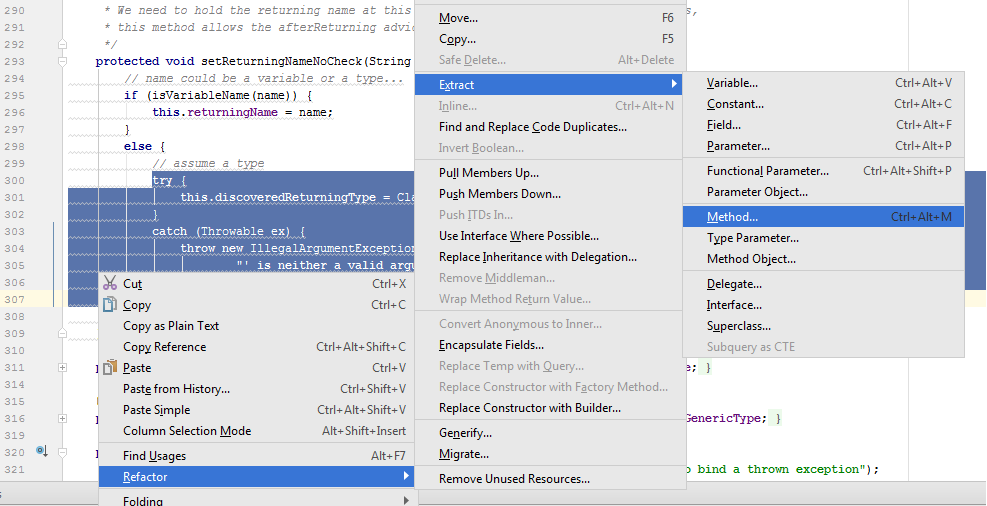
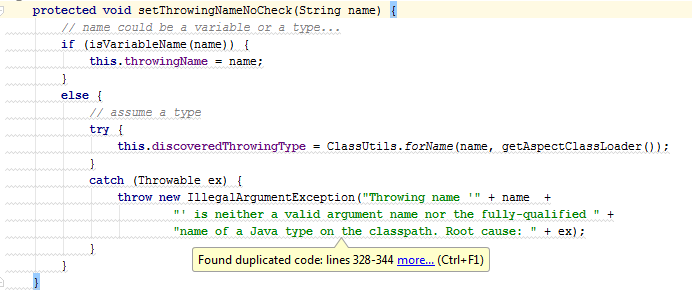
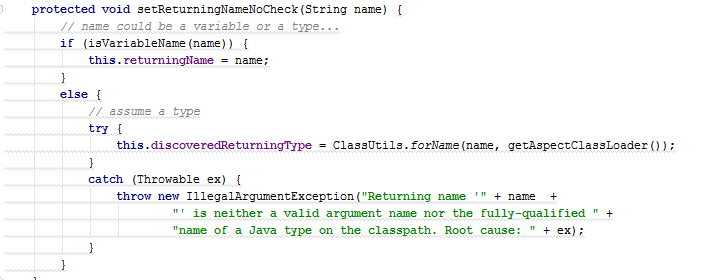
В данном примере фрагменты кода почти идентичны. Главные отличия касаются только строк 4 и 9, в которых изменяются значения полей. В таких случаях на практике мало что можно сделать. Как вариант, можно попробовать выделить функциональные интерфейсы и использовать лямбды. Однако при таком рефакторинге код не обязательно станет короче, а главное, понятнее.
void setVariableNameOrType(String name, Consumer setName, Consumer> setType) {
if (isVariableName(name)) {
setName.accept(name);
}
else {
try {
setType.accept(ClassUtils.forName(name, getAspectClassLoader()));
}
catch (Throwable ex) {
throw new IllegalArgumentException("Class name '" + name +
"' is neither a valid argument name nor the fully-qualified " +
"name of a Java type on the classpath. Root cause: " + ex);
}
}
} void setThrowingNameNoCheck(String name) {
setVariableNameOrType(name, variableName -> this.throwingName = name, type -> this.discoveredThrowingType = type);
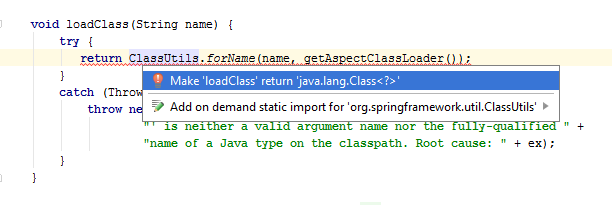
}Вместо этого давайте еще раз внимательно рассмотрим код дубликатов. Судя по всему, главная задача ветки else — это загрузка класса. Было бы логичным, для начала, выделить такую загрузку в виде отдельного метода.
Class|
Метки: author crazy_llama совершенный код java intellij idea чистый код клоны дублирование кода |
Что творится с HEVC (h265) |
|
Метки: author erlyvideo разработка систем связи разработка систем передачи данных блог компании эрливидео h265 hevc |
[Перевод] Программирование /= информатика |
|
Метки: author m1rko программирование математика алгоритмы разработка по информатика тезис черча-тюринга |
[Из песочницы] Полиморфизм и указатели на функции |
const int n = 15;
string cities[n] = {
"Красноярск", "Москва", "Новосибирск", "Лондон", "Токио",
"Пекин", "Волгоград", "Минск", "Владивосток", "Париж",
"Манчестер", "Вашингтон", "Якутск", "Екатеринбург", "Омск"
};typedef bool(*CompareFunction) (int i, int j);bool compareUp(int i, int j) {
return cities[i] < cities[j];
}
bool compareDown(int i, int j) {
return cities[i] > cities[j];
}
bool compareLengthUp(int i, int j) {
return cities[i].length() < cities[j].length();
}
bool compareLengthDown(int i, int j) {
return cities[i].length() > cities[j].length();
}
CompareFunction compares[] = {compareUp, compareDown, compareLengthUp, compareLengthDown};void sortCities(CompareFunction compare) {
for (int i = 0; i < n - 1; i++) {
int j_min = i;
for (int j = i+1; j < n; j++) {
if (compare(j, j_min)) {
j_min = j;
}
}
string temp = cities[i];
cities[i] = cities[j_min];
cities[j_min] = temp;
}
}int _tmain(int argc, _TCHAR* argv[]) {
setlocale(LC_ALL, "Russian");
for (;;) {
int choice;
cout << "Ваш выбор: ";
cin >> choice;
sortCities(compares[choice]);
printCities();
}
system("pause");
return 0;
}|
Метки: author pestunov ооп c++ полиморфизм указатель на функцию сортировка |
Оптимизация и автоматизация тестирования веб-приложений |

В этой статье я расскажу о том, как оптимизировать и автоматизировать процессы тестирования на проникновение с помощью специализированных утилит и их расширений.
Тестирование на проникновение условно можно разделить на два этапа:
Плюсы:
При автоматизированном тестировании, как правило, значительно экономится время тестирования, можно покрыть большую площадь веб-приложения за меньшее время.
Большое количество проверок. Автоматизированные системы содержат огромное количество паттернов атак, признаков уязвимостей, и, как правило, расширяемы.
Перебор файлов и папок, подбор паролей — тут, я думаю все понятно и так.
Регламентное сканирование и процедуры инвентаризации — для этих целей автоматизированные системы подходят лучше всего.
Минусы:
False positive срабатывания. Очень часто сканеры руководствуясь формальными признаками выявляют уязвимости, которых нет. Классика жанра — при сканировании Single Page Application сканер получает код ответа 200 на все свои запросы и выводит длинный список уязвимостей, которых на самом деле нет.
Они "очень шумные". При сканировании сайта создается очень много событий в журналах веб-сервера, по которым легко определить атаку.
Нагрузка на веб-сервер. Иногда автоматизированное сканирование может дать ощутимую нагрузку на веб-сервер, что может привести к нестабильной работе веб приложения (хотя этот минус относится к конфигурированию веб-сервера).
Блокирование средствами защиты. Как правило, признаки автоматизированных систем хорошо знакомы разработчикам и они учитывают их при проектировании. Как итог — происходит блокировка (по User Agent, маркерам сканера или частоте запросов).
Не учитывают ошибки логики.
Требуют ручной валидации уязвимостей.
Для того, чтобы автоматизированная система была максимально эффективна, она должна обладать следующими возможностями:
Эти факторы позволят построить систему, отвечающую вашим требованиям и целям.
В качестве примера "готовой системы" могу привести описанную мной ранее Sparta. Для того, чтобы тестирование было максимально эффективным, контролируемым, а также для комфортной валидации уязвимостей необходимо учитывать все компоненты системы, архитектуру тестируемого приложения и связность решений.
В качестве оптимальной основы предлагаю остановится на двух кроссплатформенных системах для тестирования веб-приложений (как в ручном, так и в автоматизированном режиме): OWASP ZAP (free версия) и BurpSuite (free + платная версии).
Самое важное отличие этих систем от классических сканнеров — это принцип работы: сканнер "долбит по сайту" напрямую, выявляя те или иные признаки уязвимостей, зачастую пропуская огромные участки веб-приложения. А Zap и Burp работают в качестве проксирующего механизма, позволяющего добавить все области сайта (как встроенным "пауками", так и при ручном серфинге приложения). Также, важной особенностью является возможность "на лету" разбирать каждый запрос.
Огромным плюсом этих приложений является возможность расширения с помощью плагинов/компонентов:
В качестве примера приложения предлагаю рассмотреть уязвимое веб-приложение со следующими характеристиками:
Исходя из этих данных нам необходимо выбрать и использовать следующие компоненты (минимальный набор).
Owasp ZAP:
Установленные:
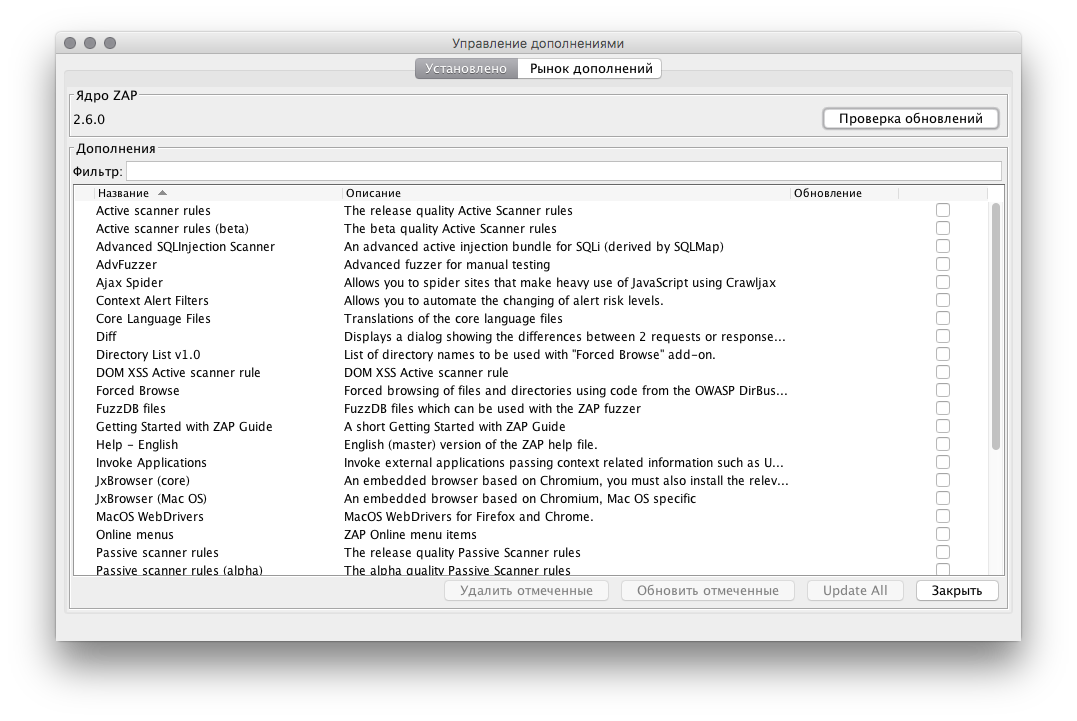
Необходимо установить:
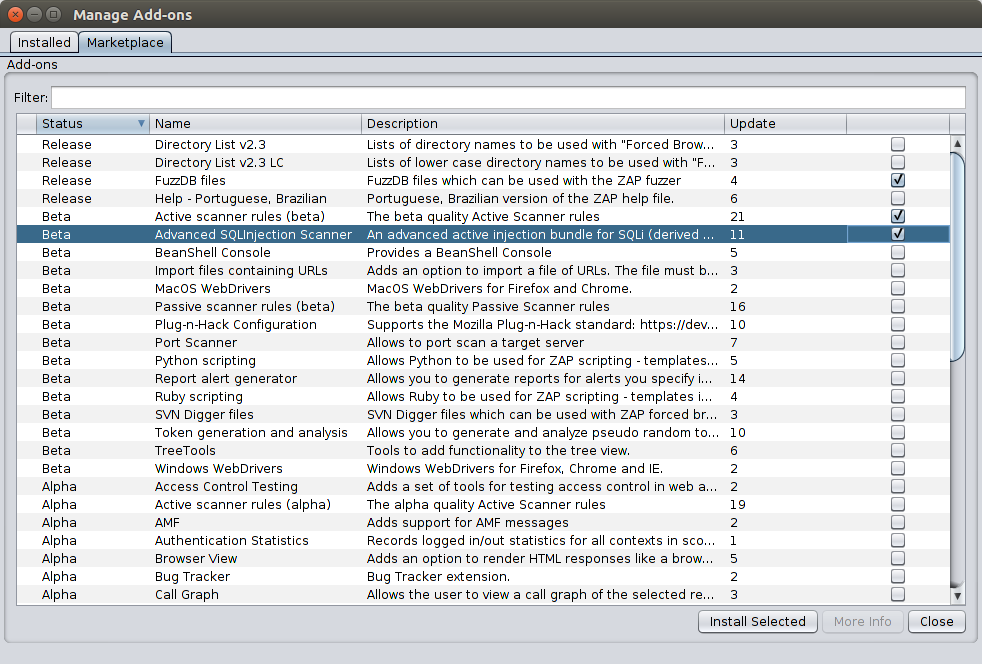
Здесь необходимо выбрать те инструменты, которые помогут выявлять и эксплуатировать уязвимости, обозначенные в списке выше.
Burp Suite:
Честно признаюсь, Burp мне нравится больше чем Owasp Zap, поэтому остановлюсь на нем подробнее.
Нам необходимо выполнить задачу по идентификации CMS и установленных компонентов, выявить устаревшие версии, попытаться обойти WAF и проэксплуатировать SQL-инъекцию.
В первую очередь необходимо придерживаться методологии тестирования веб-приложения. В этом нам поможет представленный на последнем Def Con HUNT Burp Suite Extension:
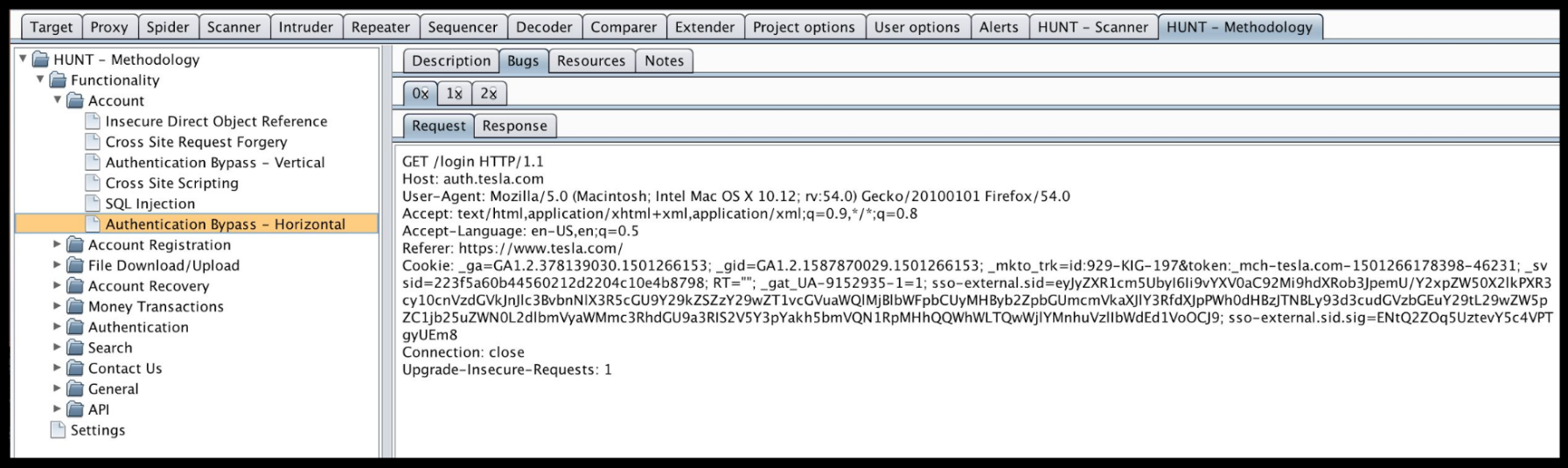
Далее нам пригодится плагин (уже добавленный в BApp store плагин от Vulners.com (@isox, avleonov — спасибо за замечательный инструмент).
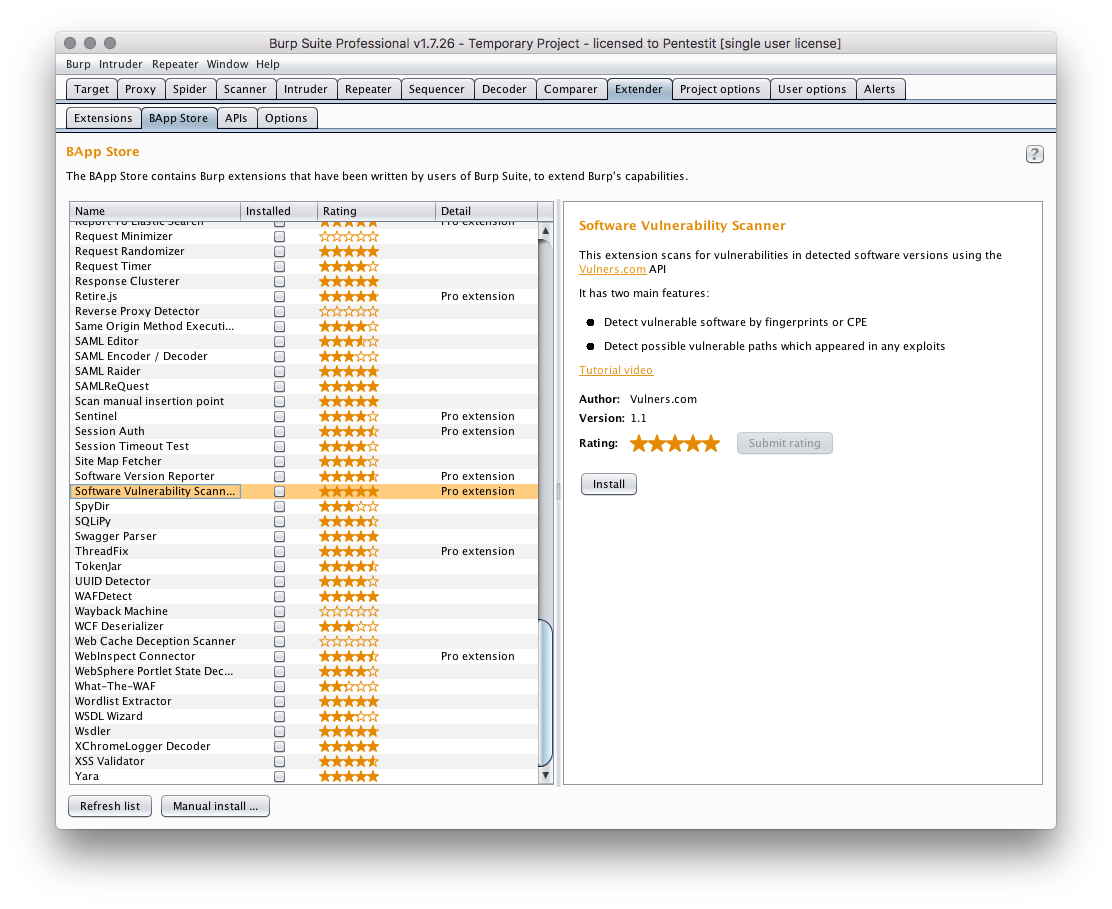
Также, может быть полезен расширенный набор фаззинга для sql-инъекций (которого нет в бесплатной версии — sql и не только.
Далее, ускорить "раскручивание" инъекции нам поможет sql map — для его интеграции необходимо воспользоваться плагином SQLiPy:
Нам известно, что веб-приложение защищено WAF — могут пригодится расширения What the WAF и Waf bypass.
Также рекомендую плагин от Владимира Иванова: burp-xss-sql-plugin.
В качестве средства автоматизации можно использовать встроенный сканнер, либо воспользоваться инструментом Burp Automator:
Требования:
Этот инструмент позволит автоматизировать проверки, использую в качестве основы Burp Suite:
$ python burpa.py -h
###################################################
__
/ /_ __ ___________ ____ _
/ __ \/ / / / ___/ __ \/ __ `/
/ /_/ / /_/ / / / /_/ / /_/ /
/_.___/\__,_/_/ / .___/\__,_/
/_/
burpa version 0.1 / by 0x4D31
###################################################
usage: burpa.py [-h] [-a {scan,proxy-config}] [-pP PROXY_PORT] [-aP API_PORT]
[-rT {HTML,XML}] [-r {in-scope,all}]
[--include-scope [INCLUDE_SCOPE [INCLUDE_SCOPE ...]]]
[--exclude-scope [EXCLUDE_SCOPE [EXCLUDE_SCOPE ...]]]
proxy_url
positional arguments:
proxy_url Burp Proxy URL
optional arguments:
-h, --help show this help message and exit
-a {scan,proxy-config}, --action {scan,proxy-config}
-pP PROXY_PORT, --proxy-port PROXY_PORT
-aP API_PORT, --api-port API_PORT
-rT {HTML,XML}, --report-type {HTML,XML}
-r {in-scope,all}, --report {in-scope,all}
--include-scope [INCLUDE_SCOPE [INCLUDE_SCOPE ...]]
--exclude-scope [EXCLUDE_SCOPE [EXCLUDE_SCOPE ...]]Как результат вы получите отчет о проведенном сканировании:
Я намеренно не рассматривал готовые сканеры типа w3af (или платные аналоги), позволяющие проводить такие работы, где использование сводится к существующему функционалу (и установки чекбоксов у опций), а постарался раскрыть интересные плагины и доработки для проксирующей утилиты Burp Suite — как наиболее популярного и эффективного инструмента.
Для того чтобы максимально эффективно применять инструменты автоматизированного тестирования необходимо иметь базис ручной проверки, для более точной настройки системы.
|
Метки: author LukaSafonov информационная безопасность блог компании pentestit web penetration testing |
Мобильные приложения: как избежать бана от рекламной сети? |

|
|
[Из песочницы] Сравнение REST и GraphQL |
Перевод статьи Sashko Stubailo GraphQL vs. REST
GraphQL часто представляют как революционно новый путь осмысления API. Вместо работы с жестко определенными на сервере конечными точками (endpoints) вы можете с помощью одного запроса получить именно те данные, которые вам нужны. И да — GraphQL гибок при внедрении в организации, он делает совместную работу команд frontend- и backend-разработки гладкой, как никогда раньше. Однако на практике обе эти технологии подразумевают отправку HTTP-запроса и получение какого-то результата, и внутри GraphQL встроено множество элементов из модели REST.
Так в чем же на самом деле разница на техническом уровне? В чем сходства и различия между этими двумя парадигмами API? К концу статьи я покажу вам, что GraphQL и REST отличаются не так уж сильно, но у GraphQL есть небольшие отличия, которые существенно меняют процесс построения и использования API разработчиками.
Ключевое для REST понятие — ресурс. Каждый ресурс идентифицируется по его URL, и для получения ресурса надо отправить GET-запрос к этому URL. Скорее всего, ответ придет в формате JSON, так как именно этот формат используется сейчас в большинстве API. Выглядит это примерно так:
GET /books/1{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
"lastName": "Левин"
}
// ... другие поля
}Замечание: для рассмотренного выше примера некоторые REST API могут возвращать данные об авторе (поле «author») как отдельный ресурс.
Одна из заметных особенностей REST состоит в том, что тип, или форма ресурса, и способ получения ресурса сцеплены воедино. Говоря о рассмотренном выше примере в документации по REST API, вы можете сослаться на него как на «book endpoint».
GraphQL весьма отличается в этом аспекте, потому что в GraphQL эти два понятия полностью отделены друг от друга. В вашей схеме может быть два типа, Book и Author:
type Book {
id: ID
title: String
published: Date
price: String
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
books: [Book]
}
Заметьте: мы описали типы доступных нам данных, но это описание совершенно ничего не говорит вам о том, как эти объекты могут быть извлечены клиентом. Это одно из ключевых различий между REST и GraphQL : описание отдельного ресурса не связано со способом его получения.
Чтобы действительно получить доступ к отдельно взятой книге или автору, нам понадобится создать тип Query в нашей схеме:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
Теперь мы можем отправить запрос, аналогичный REST-запросу, рассмотренному выше, но на этот раз с помощью GraphQL:
GET /graphql?query={ book(id: "1") { title, author { firstName } } }
{
"title": "Блюз черных дыр и другие мелодии космоса",
"author": {
"firstName": "Жанна",
}
}
Отлично, это уже что-то! Мы немедленно видим несколько особенностей GraphQL, весьма отличающих его от REST, даже несмотря на то, что оба они могут быть запрошены через URL, и оба могут вернуть одну и ту же форму JSON-ответа.
Прежде всего, мы видим, что в GraphQL-запросе URL содержит как нужный нам ресурс, так и описание интересующих нас полей. Кроме того, уже не разработчик сервера решает за нас, что нужно включить в ответ связанный ресурс author, — это теперь решение клиента, использующего API.
Но, что более важно, сущности ресурсов, понятия Books и Authors, не привязаны к способу их извлечения. Мы могли бы извечь одну и ту же книгу с помощью запросов различного типа и с различным набором полей.
Мы уже обнаружили некоторые сходства и различия:
Если вы уже использовали GraphQL и/или REST, пока все было довольно просто. Если раньше вы не использовали GraphQL, можете поиграть на Launchpad с примером, подобным приведенному выше.
API бесполезен, если он непредсказуем. Когда вы используете API, вы обычно делаете это в рамках какой-то программы, и этой программе нужно знать, что она может вызвать и что ей ожидать в качестве результата такого вызова, чтобы этот результат мог быть обработан программой.
Итак, одна из важнейших частей API — это описание того, к чему возможен доступ. Это как раз то, что вы изучаете, читая документацию по API, а с помощью GraphQL-интроспекции или систем поддержки схем REST API вроде Swagger эта информация может быть получена прямо из программы.
В существующих сегодня REST API чаще всего API описывается как список конечных точек (endpoints):
GET /books/:id
GET /authors/:id
GET /books/:id/comments
POST /books/:id/comments
Можно сказать, что «форма» API линейна — это просто список доступных вам вещей. При извлечении данных или сохранении какой-либо информации первый вопрос, который вы задаете себе: «Какой endpoint мне следует вызвать»?
В GraphQL, как мы разобрались ранее, вы не используете URL-адреса для идентификации того, что вам доступно в API. Вместо этого вы используете GraphQL-схему:
type Query {
book(id: ID!): Book
author(id: ID!): Author
}
type Mutation {
addComment(input: AddCommentInput): Comment
}
type Book { ... }
type Author { ... }
type Comment { ... }
input AddCommentInput { ... }
Здесь есть несколько интересных особенностей по сравнению с маршрутами REST для аналогичного набора данных. Первое: вместо выполнения HTTP-запросов одного и того же URL-адреса с помощью разных методов (GET, PUT, DELETE и т.п.) GraphQL использует для различения чтения и записи разный начальный тип — Mutation или Query. В GraphQL-документе вы можете выбрать, какой тип операции вы отправляете, с помощью соответствующего ключевого слова:
query { ... }
mutation { ... }
Более детально язык запросов разбирается в более ранней моей статье «Анатомия запросов GraphQL» (англ.), перевод на Хабрахабре.
Как видите, поля типа Query довольно хорошо совпадают с маршрутами REST, рассмотренными выше. Это потому, что данный специальный тип является входной точкой для доступа к нашим данным, так что в GraphQL это наиболее близкий эквивалент понятию «URL конечной точки (endpoint URL)».
Способ получения начального ресурса от GraphQL API довольно похож на то, как это делается в REST: вы передаете имя и некоторые параметры; но главное отличие здесь в том, куда вы сможете двинуться после этого. В GraphQL вы можете отправить сложный запрос, который извлечет дополнительные данные согласно связям, определенным в схеме, а в REST вам для этого пришлось бы сделать несколько запросов, встроить связанные данные в начальный запрос, или же включить какие-то особые параметры в URL-запрос для модификации ответа.
В REST пространство доступных данных описывается как линейный список конечных точек (endpoints), а в GraphQL это схема со связями между ее элементами.
Query и Mutation, используемых в GraphQL API. Оба они являются точками входа для доступа к данным.Query и полями любого другого типа, за исключением того, что в корне запроса доступен только тип query. Например, у вас в запросе любое поле может иметь аргументы. В REST не существует понятия первого класса в случае вложенного URL.GET на что-то вроде POST. В GraphQL вы меняете ключевое слово в запросе.Из-за первого пункта в списке сходств, указанных выше, люди часто начинают воспринимать поля типа Query как «конечные точки» или «запросы» GraphQL. Хотя такое сравнение и имеет определенный смысл, оно может привести к искаженному восприятию, будто тип Query работает совершенно иначе, чем другие типы, а это совсем не так.
Итак, что происходит, когда вы вызываете API? Ну, обычно при этом на сервере выполняется какой-то код, получивший ваш запрос. Этот код может выполнять расчеты, загружать данные из базы, вызывать другой API, и вообще делать все, что угодно. Весь смысл в том, что вам снаружи нет необходимости знать, что именно делает этот код. Но и в REST, и в GraphQL есть стандартные способы реализации внутренней части API, и будет полезно сравнить их для понимания того, насколько различны эти технологии.
В этом сравнении я буду использовать код на JavaScript, потому что я знаю этот язык лучше всего, но вы, конечно же, можете использовать практически любой язык программирования для реализации и REST, и GraphQL API. Я также пропущу все подготовительные этапы, требуемые для поднятия и запуска сервера, потому что это не важно для рассматриваемых вопросов.
Рассмотрим пример реализации «Hello World» с помощью express, популярного фреймворка для построения API на Node:
app.get('/hello', function (req, res) {
res.send('Hello World!')
})
Как видите, мы создали конечную точку /hello, которая возвращает строку 'Hello World!'. Из этого примера становится понятен жизненный цикл HTTP-запроса на сервере REST API:
GET) и путь URLGraphQL работает очень похожим способом, и для того же примера код практически тот же самый:
const resolvers = {
Query: {
hello: () => {
return 'Hello world!';
},
},
};
Как видите, вместо предоставления функции для выбранного URL мы указываем функцию, которая сопоставляет отдельное поле типу, в нашем случае — поле hello типу Query. В GraphQL функция, реализующая такое сопоставление, называется распознавателем (resolver).
Чтобы получить данные, нам нужен запрос (query):
query {
hello
}
Итак, что происходит, когда наш сервер получает GraphQL-запрос:
hello, и ему соответствует тип Query.Вы получаете от сервера ответ:
{ "hello": "Hello, world!" }
Но есть один трюк: мы можем вызвать одно поле дважды!
query {
hello
secondHello: hello
}
В этом случае цикл обработки тот же, но так как мы запросили одно и то же поле дважды (используя псевдоним), распознаватель hello на самом деле будет вызван дважды. Пример соврешенно надуманный, но смысл в том, что множество полей могут выполняться в рамках одного запроса, а одно и то же поле может вызываться множество раз в разных местах запроса.
Объяснение не было бы полным без примера с вложенными распознавателями («nested» resolvers):
{
Query: {
author: (root, { id }) => find(authors, { id: id }),
},
Author: {
posts: (author) => filter(posts, { authorId: author.id }),
},
}
Эти распознаватели способны разрешить запрос вроде такого:
query {
author(id: 1) {
firstName
posts {
title
}
}
}
Итак, хотя список распознавателей на самом деле плоский, из-за прикрепления их к различным типам вы можете построить из них вложенные запросы. Подробнее о том, как работает выполнение GraphQL, читайте в статье «GraphQL Explained».
Можете посмотреть полный пример и протестировать его, запуская разные запросы!

Художественная интерпретация извлечения ресурсов: в REST множество данных гоняются туда и обратно, в GraphQL все делается одним-единственным запросом
На настоящий момент как REST, так и GraphQL API являются лишь причудливыми способами вызывать функции по сети. Если вам знакомо построение REST API, реализация GraphQL API не будет особо отличаться. Однако GraphQL имеет большое преимущество: возможность вызова нескольких взаимосвязанных функций в рамках одного запроса.
По сути, вы можете думать о GraphQL как о системе для вызова множества вложенных конечных точек в одном запросе. Почти как мультиплексированный REST.
Есть множество тем, на которые в данной статье не хватило места. Например, идентификация объектов, гипермедиа или кэширование. Возможно, это станет темой одной из следующих статей. Я надеюсь, теперь вы согласитесь, что если взглянуть на основные принципы, то окажется, что REST и GraphQL работают с понятиями, которые принципиально очень похожи.
Я думаю, некоторые из различий говорят в пользу GraphQL. В частности, мне кажется, действительно здорово иметь возможность реализовать свой API как набор небольших функций-распознавателей, а затем отправлять сложные запросы, которые предсказуемым способом извлекают множество ресурсов за один раз. Это ограждает разработчика API от необходимости создавать множество конечных точек с различной формой, а клиенту API позволяет избежать извлечения лишних данных, которые ему не нужны.
С другой стороны, для GraphQL пока нет такого множества инструментов и решений по интеграции, как для REST. Например, у вас не получится с помощью HTTP-кэширования кэшировать результаты работы GraphQL API так же легко, как это делается для результатов работы REST API. Однако сообщество упорно работает над улучшением инструментов и инфраструктуры, а для кэширования GraphQL вы можете использовать такие инструменты, как Apollo Client и Relay.
Если у вас есть еще мысли по поводу различий между REST и GraphQL — высказывайтесь в комментариях.
|
Метки: author bevalorous разработка веб-сайтов api graphql rest api |
Так кто вернулся, братиш? |

|
Метки: author nikitasius хабрахабр habr братиш |
[Перевод] Вредоносный код в npm-пакетах и борьба с ним |
|
Метки: author ru_vds разработка веб-сайтов информационная безопасность node.js javascript блог компании ruvds.com npm разработка безопасность |
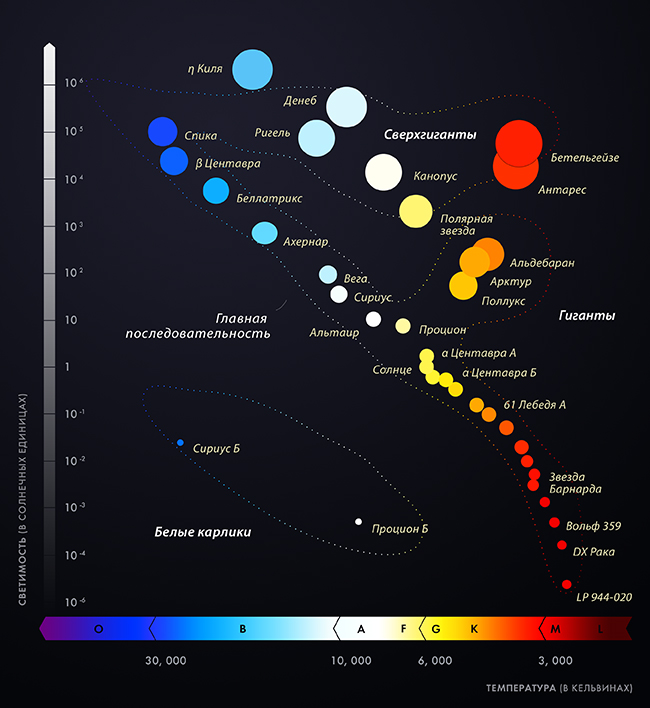
Генерация Галактики и обучение начальным знаниям астрономии |





|
Метки: author tas хабрахабр учебный процесс в it svg астрономия обучение идея |






