Третье издание познакомит вас с интегрированной средой Android Studio, которая сильно облегчает разработку приложений. Вы не только изучите основы программирования, но и узнаете о возможностях самых распространенных версий Android; новых инструментах, таких как макеты с ограничениями и связывание данных; модульном тестировании; средствах доступности; архитектурном стиле MVVM; локализации; новой системе разрешений времени выполнения. Все учебные приложения были спроектированы таким образом, чтобы продемонстрировать важные концепции и приемы программирования под Android и дать опыт их практического применения.
Под катом более подробно о книге и отрывок из книги «Множественные загрузки»
Структура книги
В этой книге мы напишем восемь приложений для Android. Два приложения очень просты, и на их создание уходит всего одна глава. Другие приложения часто оказываются более сложными, а самое длинное приложение занимает 13 глав. Все приложения спроектированы так, чтобы продемонстрировать важные концепции и приемы и дать опыт их практического применения.
• GeoQuiz — в первом приложении мы исследуем основные принципы создания проектов Android, активности, макеты и явные интенты.
• CriminalIntent — самое большое приложение в книге, предназначено для хранения информации о проступках ваших коллег по офису. Вы научитесь использовать фрагменты, интерфейсы «главное-детализированное представление», списковые интерфейсы, меню, камеру, неявные интенты и многое другое.
• BeatBox — наведите ужас на своих врагов и узнайте больше о фрагментах, воспроизведении мультимедийного контента, архитектуре MVVM, связывании данных, тестировании, темах и графических объектах.
• NerdLauncher — нестандартный лаунчер, раскроет тонкости работы системы интентов и задач.
• PhotoGallery — клиент Flickr для загрузки и отображения фотографий из общедоступной базы
Flickr. Приложение демонстрирует работу со службами, многопоточное программирование, обращения к веб-службам и т. д.
• DragAndDraw — в этом простом графическом приложении рассматривается обработка событий касания и создание нестандартных представлений.
• Sunset — в этом «игрушечном» приложении вы создадите красивое представление заката над водой, а заодно освоите тонкости анимации.
• Locatr — приложение позволяет обращаться к сервису Flickr за изображениями окрестностей вашего текущего местонахождения и отображать их на карте. Вы научитесь пользоваться сервисом геопозиционирования и картами.
Множественные загрузки
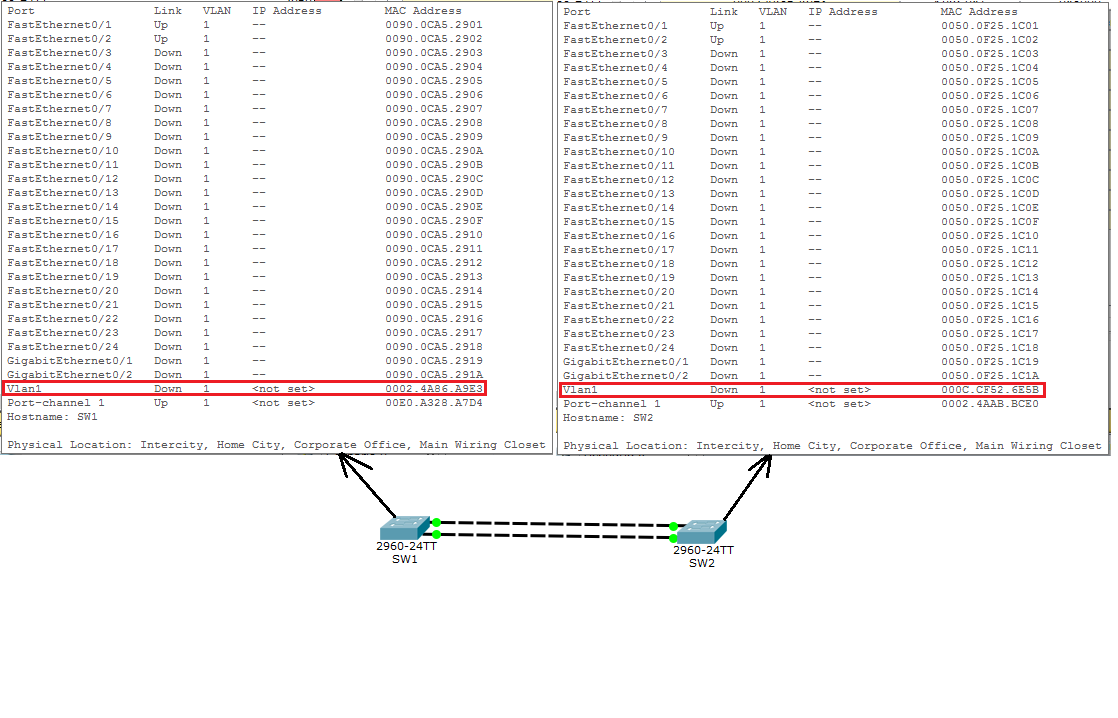
В настоящее время сетевая часть PhotoGallery работает следующим образом: PhotoGalleryFragment запускает экземпляр AsyncTask, который получает JSON от Flickr в фоновом потоке, и разбирает JSON в массив объектов GalleryItem. В каждом объекте GalleryItem теперь хранится URL, по которому находится миниатюрная версия фотографии.
Следующим шагом должна стать загрузка этих миниатюр. Казалось бы, дополнительный сетевой код можно просто добавить в метод doInBackground() класса FetchItemsTask. Массив объектов GalleryItem содержит 100 URL-адресов для загрузки. Изображения будут загружаться одно за одним, пока у вас не появятся все сто. При выполнении onPostExecute(…) они все вместе появятся в RecyclerView.
Однако единовременная загрузка всех миниатюр создает две проблемы. Во-первых, она займет довольно много времени, а пользовательский интерфейс не будет обновляться до момента ее завершения. На медленном подключении пользователям придется долго рассматривать стену из Биллов.
Во-вторых, хранение полного набора изображений требует ресурсов. Сотня миниатюр легко уместится в памяти. Но что, если их будет 1000? Что, если вы захотите реализовать бесконечную прокрутку? Со временем свободная память будет исчерпана.
С учетом этих проблем реальные приложения часто загружают изображения только тогда, когда они должны выводиться на экране. Загрузка по мере надобности предъявляет дополнительные требования к RecyclerView и его адаптеру. Адаптер инициирует загрузку изображения как часть реализации onBindViewHolder(…).
AsyncTask — самый простой способ получения фоновых потоков, но для многократно выполняемых и продолжительных операций этот механизм изначально малопригоден. (О том, почему это так, рассказано в разделе «Для любознательных» в конце этой главы.)
Вместо использования AsyncTask мы создадим специализированный фоновый поток. Это самый распространенный способ реализации загрузки по мере надобности.
Взаимодействие с главным потоком
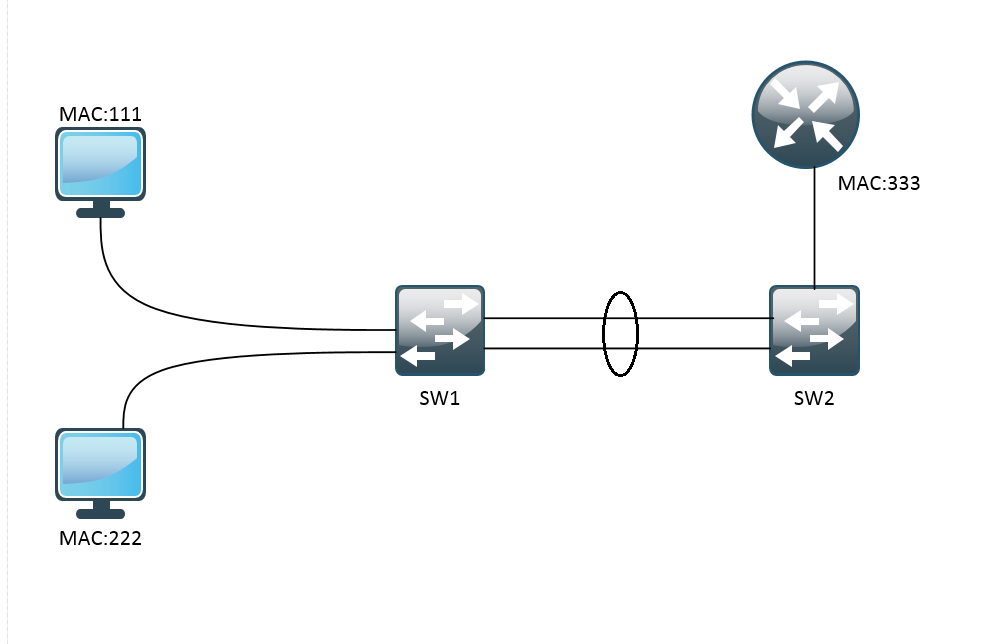
Специализированный поток будет загружать фотографии, но как он будет взаимодействовать с адаптером RecyclerView для их отображения, если он не может напрямую обращаться к главному потоку?
Вспомните пример с обувным магазином и двумя продавцами-Флэшами. Фоновый Флэш завершил свой телефонный разговор с поставщиком, и теперь ему нужно сообщить Главному Флэшу о том, что обувь была заказана. Если Главный Флэш занят, Фоновый Флэш не может сделать это немедленно. Ему придется подождать у стойки и перехватить Главного Флэша в свободный момент. Такая схема работает, но не слишком эффективно.
Лучше дать каждому Флэшу по почтовому ящику. Фоновый Флэш пишет сообщение о том, что обувь заказана, и кладет его в ящик Главного Флэша. Главный Флэш делает то же самое, когда он хочет сообщить Фоновому Флэшу о том, что какой-то товар закончился.
Идея почтового ящика чрезвычайно полезна. Возможно, у продавца имеется задача, которая должна быть выполнена скоро, но не прямо сейчас. В таком случае он кладет сообщение в свой почтовый ящик и обрабатывает его в свободное время.
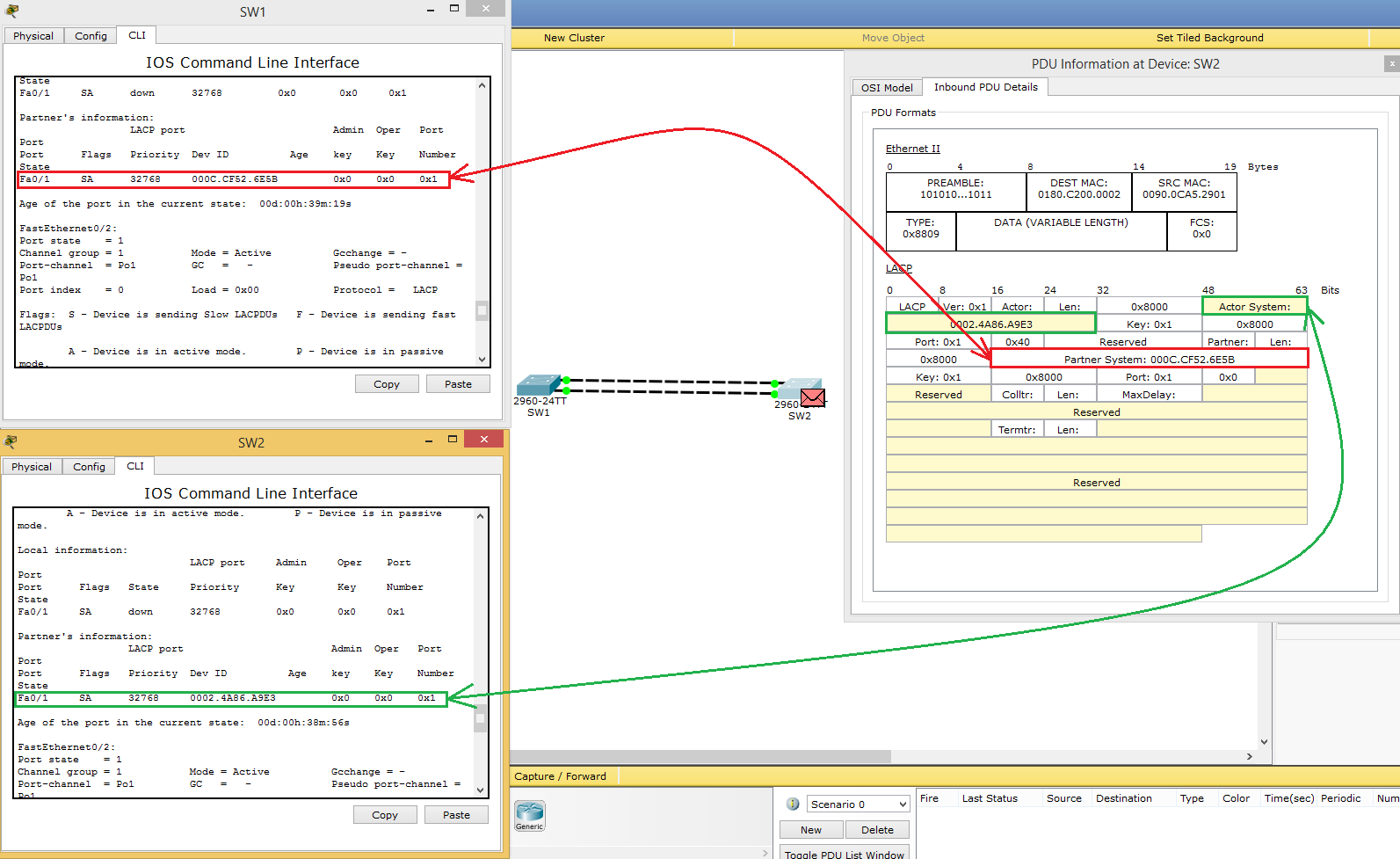
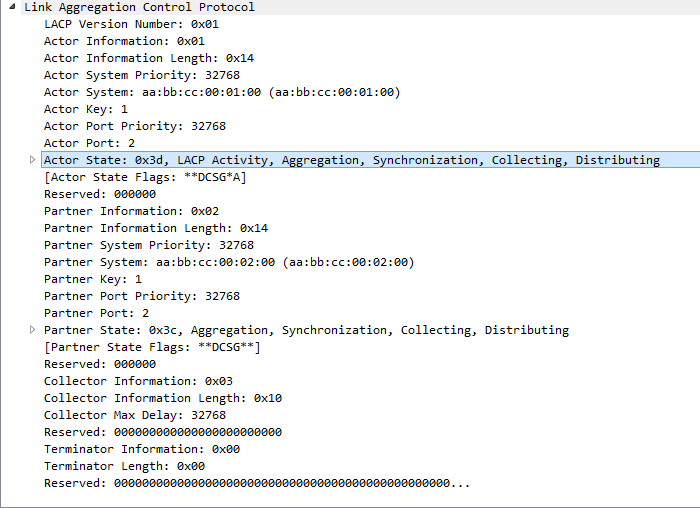
В Android такой «почтовый ящик», используемый потоками, называется очередью сообщений (message queue). Поток, работающий с использованием очереди сообщений, называется циклом сообщений (message loop); он снова и снова проверяет новые сообщения, которые могли появиться в очереди (рис. 26.3).
Цикл сообщений состоит из потока и объекта Looper, управляющего очередью сообщений потока.
Главный поток представляет собой цикл сообщений, и у него есть управляющий объект, который извлекает сообщения из очереди сообщений и выполняет задачу, описанную в сообщении.
Мы создадим фоновый поток, который тоже использует цикл сообщений. При этом будет использоваться класс HandlerThread, который предоставляет готовый объект Looper.
Создание фонового потока
Создайте новый класс с именем ThumbnailDownloader, расширяющий HandlerThread. Определите для него конструктор и заглушку реализации метода с именем queueThumbnail() (листинг 26.4).
Листинг 26.4. Исходная версия кода потока (ThumbnailDownloader.java)
public class ThumbnailDownloader extends HandlerThread {
private static final String TAG = "ThumbnailDownloader";
private boolean mHasQuit = false;
public ThumbnailDownloader() {
super(TAG);
}
@Override
public boolean quit() {
mHasQuit = true;
return super.quit();
}
public void queueThumbnail(T target, String url) {
Log.i(TAG, "Got a URL: " + url);
}
}
Классу передается один обобщенный аргумент . Пользователю ThumbnailDownloader понадобится объект для идентификации каждой загрузки и определения элемента пользовательского интерфейса, который должен обновляться после завершения загрузки. Вместо того чтобы ограничивать пользователя одним конкретным типом объекта, мы используем обобщенный параметр и сделаем реализацию более гибкой.
Метод queueThumbnail() ожидает получить объект типа T, выполняющий функции идентификатора загрузки, и String с URL-адресом для загрузки. Этот метод будет вызываться PhotoAdapter в его реализации onBindViewHolder(…).
Откройте файл PhotoGalleryFragment.java. Определите в PhotoGalleryFragment поле типа ThumbnailDownloader. В методе onCreate(…) создайте поток и запустите его. Переопределите метод onDestroy() для завершения потока.
Листинг 26.5. Создание класса ThumbnailDownloader (PhotoGalleryFragment.java)
public class PhotoGalleryFragment extends Fragment {
private static final String TAG = "PhotoGalleryFragment";
private RecyclerView mPhotoRecyclerView;
private List mItems = new ArrayList<>();
private ThumbnailDownloader mThumbnailDownloader;
...
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setRetainInstance(true);
new FetchItemsTask().execute();
mThumbnailDownloader = new ThumbnailDownloader<>();
mThumbnailDownloader.start();
mThumbnailDownloader.getLooper();
Log.i(TAG, "Background thread started");
}
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
...
}
@Override
public void onDestroy() {
super.onDestroy();
mThumbnailDownloader.quit();
Log.i(TAG, "Background thread destroyed");
}
...
}
В обобщенном аргументе ThumbnailDownloader можно указать любой тип. Однако вспомните, что этот аргумент задает тип объекта, который будет использоваться в качестве идентификатора для загрузки. В данном случае в качестве идентификатора удобно использовать объект PhotoHolder, так как он заодно определяет место, куда в конечном итоге поступят загруженные изображения.
Пара примечаний: во-первых, обратите внимание на то, что вызов getLooper() следует после вызова start() для ThumbnailDownloader (вскоре мы рассмотрим объект Looper более подробно). Тем самым гарантируется, что внутреннее состояние потока готово для продолжения, чтобы исключить теоретически возможную (хотя и редко встречающуюся) ситуацию гонки (race condition). До вызова getLooper() ничто не гарантирует, что метод onLooperPrepared() был вызван, поэтому существует вероятность того, что вызов queueThumbnail(…) завершится неудачей так как ссылка на Handler равна null.
Во-вторых, вызов quit() завершает поток внутри onDestroy(). Это очень важный момент. Если не завершать потоки HandlerThread, они никогда не умрут, словно зомби. Или рок-н-ролл.
Наконец, в методе PhotoAdapter.onBindViewHolder(…) вызовите метод queueThumbnail() потока и передайте ему объект PhotoHolder, в котором в конечном итоге будет размещено изображение, и URL-адрес объекта GalleryItem для загрузки.
public class PhotoGalleryFragment extends Fragment {
...
private class PhotoAdapter extends RecyclerView.Adapter {
...
@Override
public void onBindViewHolder(PhotoHolder photoHolder, int position) {
GalleryItem galleryItem = mGalleryItems.get(position);
Drawable placeholder = getResources().getDrawable
(R.drawable.bill_up_close);
photoHolder.bindDrawable(placeholder);
mThumbnailDownloader.queueThumbnail(photoHolder, galleryItem.getUrl());
}
...
}
...
}
Запустите приложение PhotoGallery и проверьте данные LogCat. При прокрутке RecyclerView в LogCat появляются строки, сообщающие о том, что ThumbnailDownloader получает все запросы на загрузку.
Теперь, когда наша реализация HandlerThread заработала, следующим шагом становится создание сообщения с информацией, переданной queueThumbnail(), и его размещение в очереди сообщений ThumbnailDownloader.
Немало статей написано и переписано о том, как защитить MODX, но в этой статье я опишу не только стандартные рекомендации по защите инстанса MODX Revolution (далее я буду писать просто MODX, потому что ветка MODX Evolution — это тупиковая ветвь «эволюции» являющаяся рудиментом не заслуживающим внимания современных разработчиков), но и некоторые новые методы «заметания следов».
Итак, начнем самого важного.
Существует две разновидности установщика MODX — это Traditional и Advanced.
Какая между ними разница?
Advanced — версия для парней, которые, как минимум «смотрели кино про нидзей». Этот вид установщика позволяет разместить ядро MODX вне публичной папки, спрятав его от посягательств злоумышленников. Для серьезных проектов это рекомендуемый вариант, но лично я его использую всегда.
Защита ядра
Защитить ядро можно двумя способами:
1. На нормальном хостинге — вынести ядро из публичной папки и можно его не переименовывать и не настраивать .htaccess лежащий в этом каталоге (на VDS не стоит забывать о настройке прав доступа пользователя, от которого запускается Apache).
2. На дурацком хостинге — переименовать каталог ядра воспользовавшись, например, генератором паролей (без спецсимволов, конечно же — только буквы и цифры) И во время установки указать физический путь к каталогу ядра. Именно по этому лучше использовать Advanced установщик.
Защита служебных каталогов
Не секрет, что кроме каталога ядра, другие служебные каталоги должны остаться в публичной папке сервера.
Что нам сделать для защиты от попыток взлома через коннекторы и попыток проникнуть в админку? Стандартные наименования каталога коннекторов /connectors, а для админки — /manager, и это палево.
Во время установки вам будет предложено изменить эти названия. В этом нам поможет, правильно, — генератор паролей и, как ни странно, в случае с админкой собственная голова. Название каталога админки лучше сделать человекопонятным, но не /admin, конечно же :)
Возможно, вы захотите спросить: Почему мы не прячем /assets?
И, возможно, я отвечу: А зачем? Все картинки и скрипты лежат в /assets, а в коде страницы есть все ссылки на картинки и скрипты :)
Защита таблиц БД
Во время установки, в настройках БД, по умолчанию предлагается префикс таблиц «modx_». Так дело не пойдет. И вновь нам поможет генератор паролей (Помнишь, товарищ? Только из букв и цифр!). Меняем стандартный префикс на кракозябры, в конце которых ставим нижнее подчеркивание. Например, «IU1xbp4_».
Защита от определения CMS
Сервисы автоматического определения CMS сайтов, конечно, не в курсе, что MODX — это CMF, но это не мешает им определить, что контентом на сайте рулит именно MODX. Казалось бы, мы уже спрятали всё что надо. А вот и нет.
Кроме описанных приёмов, можно применить небольшую хитрость, чтобы увести возможных злоумышленников по ложному следу. Некоторые «попсовые» CMS добавляли метатэги с указанием названия CMS:
Можно смело добавить в свой код такой тэг, и создать фэйковую стандартную страницу входа в админку указанной версии имитируемой CMS.
Автоопределялки будут интерпретировать наш MODX как Wordpress, а если хулиганы захотят залезть в админку, то будут долго и нудно пытаться подобрать отмычки от простого замка к сканеру сетчатки глаза ( это метафора :) ).
А что, если сайт уже установлен?
В час наименьшей нагрузки, переименуйте все указанные каталоги (/core, если позволяет хостинг, лучше вынести из паблика).
Смените префикс существующих, с помощью phpMyAdmin:
в левой части phpMyAdmin кликаете на название нужной базы;
в основной области появится список всех таблиц, внизу которого надо отметить чекбокс «Отметить все»;
справа от чекбокса комбобокс «С отмеченными:» в котором надо выбрать «Заменить префикс таблицы»;
в новом окне указать старый префикс и новый префикс, на который надо заменить старый.
Затем, если у вас Traditional, но вы хотите заменить на Advanced, то поверх содержимого /core (или как вы его по-новому назвали) надо записать содержимое каталога /core из архива Advanced установщика, а в корень сайта поместить /setup.
Проверить права и доступ (на каталоги 755, на файлы 644).
Запустить процесс установки.
Во время установки вам надо будет указать физический путь до каталога ядра.
ВАЖНО выбрать вариант установки «Расширенное обновление (с настройкой параметров базы данных)», потому что после ввода данных БД, появится диалог переименования каталогов.
Можно, конечно, было залезть в config.inc.php и отредактировать всё там. Но зачем что-то делать, если этого можно не делать? :)
На этом всё. Если информация из этой статьи окажется Вам полезной — супер. Если захотите что-то спросить, добавить или просто поумничать — вэлкам в коменты!
Несколько дней назад мы выпустили первую версию JetBrains Rider — новой кроссплатформенной IDE для .NET-разработки на базе IntelliJ-платформы и ReSharper. Rider теперь можно не только загрузить, но и купить. Rider входит в подписку All Products Pack, так что если она у вас есть — загружайте и пользуйтесь, ничего не доплачивая.
Что еще за Rider?
Rider — это IDE для .NET-разработки, которой можно пользоваться на Windows, Mac и Linux. Rider подходит для многих видов .NET-приложений, в том числе ASP.NET, .NET Core, .NET Framework, Xamarin и Unity.
Rider сочетает возможности ReSharper в части анализа .NET-кода с функциональностью IntelliJ-платформы. Например, в Rider доступно большинство возможностей WebStorm для разработки фронтенда и DataGrip для написания SQL и работы с базами данных. Мы надеемся, что Rider вам понравится, особенно если у вас есть опыт работы с ReSharper в Visual Studio или использования IDE от JetBrains: IntelliJ IDEA, PhpStorm, PyCharm, CLion и других.
Среди языков, которые поддерживаются в Rider, — C#, VB.NET, F#, синтаксис Razor в ASP.NET, JavaScript, TypeScript, XAML, HTML, CSS, SCSS, LESS, JSON и SQL.
Функциональность Rider внушительна: более 2000 инспекций кода, около 500 рефакторингов и автоматических трансформаций, прямая и контекстная навигация по коду, юнит-тестирование, отладчик, работа с системами контроля версий и многое другое.
Какая нужна лицензия?
Rider применяет стандартную для JetBrains модель лицензирования: мы предлагаем месячные и годовые подписки для компаний и индивидуальных разработчиков. При непрерывном обновлении подписок можно накопить скидку до 40%.
Rider можно купить отдельно, но он также входит в состав двух более широких лицензий:
All Products pack: если у вас уже есть лицензия на комплект наших индивидуальных продуктов, используйте Rider, ничего не доплачивая;
ReSharper Ultimate + Rider: это новый вид подписки, который позволяет получить Rider, сохранить доступ к другим нашим .NET-инструментам (ReSharper, dotTrace, dotMemory, dotCover, ReSharper C++) и при этом сэкономить, избежав перехода на All Products pack.
Некоторым категориям клиентов Rider предоставляется бесплатно: это Microsoft MVP, ASP.NET Insiders, студенты, преподаватели и некоммерческие OS-проекты.
Наконец, на Rider, как и на все остальные продукты JetBrains, распространяется 50% скидка для стартапов.
Узнать подробнее о лицензиях, ценах и возможностях получить Rider бесплатно можно здесь.
Что будет дальше?
Команда Rider рассчитывает выпустить как минимум еще два релиза до конца года: неминуемый багфикс 2017.1.1 в августе и полноценный релиз 2017.2 осенью. Мы намерены работать над популярными запросами, в том числе над поддержкой MSTest и .NET Core 2.0, а параллельно будем следить за развитием событий в поддержке и трекере, чтобы понимать, что еще нужно улучшить в первую очередь.
Предлагаем вам загрузить Rider для Windows, macOS или Linux и попробовать его в действии. Имейте в виду, что если вы устанавливали Rider 2017.1 RC или один из последующих предрелизных билдов, то вам, возможно, придется вручную сбросить пробный период.
12 июля компания Intel представила новую линейку серверных процессоров под кодовым названием Skylake-SP. Буквы SP в названии линейки — это сокращение от Scalable Processors («масштабируемые процессоры» в переводе на русский). Такое название не случайно: Intel реализовали много интересных нововведений и, как было отмечено в одном обзоре, «попытались угодить чуть ли не всем».
Процессоры линейки SP являются частью серверной платформы Purley, которую называют «платформой десятилетия».
Какие нововведения реализованы в Intel Skylake-SP? Каковы технические характеристики этих процессоров? В чём заключаются их преимущества по сравнению с предыдущими моделями? Обо всём этом мы подробно расскажем в этой статье.
Новые процессоры — новые имена
Предыдущие линейки процессоров Xeon получали имена вида Exvx: E3v3, E3v5 и т.п. В линейке SP используется другая схема именования: все процессоры делятся на четыре серии под кодовыми названиями Bronze, Silver, Gold и Platinum. Все эти серии отличаются между собой числом ядер и набором технологий.
Bronze — это самые простые процессоры: они могут иметь до 8 ядер и не поддерживают hyper-threading. Platinum, как и следует из названия, рассчитаны на работу под высокими нагрузками и обладают наибольшим (до 28) числом ядер.
В именах некоторых моделей появились новые индексы. Так, литера F указывает на наличие встроенного контроллера Omni-Path, M — на поддержку большего объёма памяти (до 1,5 ТБ на сокет), а T — на поддержку стандарта NEBS (Network Equipment Building System). Процессоры с индексом T в имени выдерживают большие температурные нагрузки, и срок службы по сравнению с другими моделями у них гораздо больше.
Технические характеристики
Для наших конфигураций мы выбрали Intel Xeon Silver 4114 и Intel Xeon Gold 6140. Их основные технические характеристики представлены в таблице ниже.
Характеристика
Intel Xeon Silver 4114
Intel Xeon Gold 6140
Технологический процесс
14 нм
14 нм
Количество ядер
10
18
Количество потоков
20
36
Базовая частота
2,20 ГГц
2,30 ГГц
Максимальная частота Turbo
3,00 ГГц
3,70 ГГц
Кэш L3
13,75 МБ
24,75 МБ
Количество линий UPI
2
3
TDP (thermal design power)
85 Вт
140 Вт
Основные нововведения
Приведём список наиболее значительныx нововведений, реализованных в процессорах Skylake-SP:
благодаря набору инструкций AVX-512 существенно улучшена производительность целочисленных вычислений и вычислений с плавающей точкой;
наличие шестиканального контроллера памяти (в предыдущей линейке был четырехканальный);
ускорена связь между ядрами благодаря технологии UPI (Ultra Path Interconnect);
увеличено количество линий PCI (до 48);
модифицирована топология: на смену кольцевой шине пришла сетчатая (mesh) архитектура.
Микроархитектура
Базовая структура ядра у процессоров линейки SP осталась точно такой же, как и у Skylake предыдущих моделей. Тем не менее, некоторые отличия и усовершенствования есть. Увеличился объём L2-кэша: он составляет 1 МБ. Объём L3-кэша составляет 13,75 МБ на ядро. L2-кэш заполняется напрямую из оперативной памяти, а затем неиспользуемые линии вытесняются в L3. Данные, общие для нескольких ядер, хранятся в L3.
Обратим внимание на ещё один момент: объём L3-кэша не зависит от числа ядер. Кэшем на 24,75 МБ оснащены как восьмиядерные, так и двенадцати- и даже восемнадцатиядерные (см. таблицу выше) модели.
Как отмечено во многих обзорах (см., например, здесь), упор сделан именно на работу с L2-кэшем. Встраиваемая память eDRAM в процессорах Skylake вообще отсутствует.
Новая топология
Важным нововведением в процессорах Intel Skylake-SP является отказ от внутрипроцессорной кольцевой шины, которая использовалась для связи между ядрами на протяжении почти 10 лет.
Впервые кольцевая шина появилась в 2009 году в восьмиядерных процессорах Nehalem-EX. Она работала очень быстро (до 3 ГГц). Задержки L3-кэша были минимальными. Если ядро находило данные в своём фрагменте кэша, требовался только один дополнительный цикл. Для получения кэш-линии из другого фрагмента требовалось до 12 циклов (6 циклов в среднем).
Впоследствии технология кольцевой шины претерпела множество изменений и усовершенствований. Так, в процессорах Ivy Bridge, представленных в 2012 году, три ряда ядер были объединены двумя кольцевыми шинами. Они перемещали данные в двух направлениях (по часовой стрелке и против часовой стрелки), что позволяло обеспечить их доставку по кратчайшему маршруту и снизить время задержки. После поступления данных в кольцевую структуру требовалось скоординировать их маршрут во избежание смешение с предыдущими данными.
В процессорах Intel Xeon E5v3 (2014 год) всё стало куда более сложным: четыре ряда ядер, две независимые друг от друга кольцевые шины, буферный переключатель (подробнее об этом см. в статье по только что приведённой ссылке).
Технология кольцевой шины получила распространение, когда у процессоров было максимум 8 ядер. А когда ядер стало больше 20, стало ясно: предел её возможностей близок. Конечно, можно было бы пойти самым простым путём и добавить ещё одно, третье, кольцо. Но в Intel решили пойти другим путём и перейти к новой топологии строения шин — ячеистой (mesh). Такой подход уже был опробован на процессорах Xeon Phi (более подробно об этом можно прочитать в этой статье.
Схематично ячеистую топологию строения шин можно представить так:
Благодаря новой топологии удалось значительно увеличить скорость взаимодействия между ядрами, а также повысить эффективность работы с памятью.
Новый набор инструкций AVX-512
Повысить производительность вычислительных операций в процессорах Skylake-SP удалось благодаря использованию нового набора инструкций AVX-512. Он расширяет 32-битные и 64-битные AVX инструкции с использованием 512-битных векторов.
Программы теперь могут упаковать или 8 чисел с плавающей запятой с двойной точностью, или 16 чисел с плавающей запятой с единичной точностью, или 8 64-битных целых чисел, или 16 32-битных целых чисел внутри 512-битного вектора. Это позволяет увеличить количество обрабатываемых элементов данных за одну инструкцию в два раза по сравнению с Intel AVX/AVX2 и в четыре раза — по сравнению с Intel SSE.
AVX-512 полностью совместим с набором инструкций AVX. Это, в частности, означает, что оба набора инструкций можно использовать в одной программе без ущерба производительности (такая проблема наблюдалась при совместном использовании SSE и AVX). Регистры AVX (YMM0—YMM15) ссылаются на младшие части регистров AVX-512 (ZMM0—ZMM15) по аналогии с SSE и AVX регистрами. Поэтому в процессорах с поддержкой AVX-512 инструкции AVX и AVX2 выполняются на младших 128 или 256 битах первых 16 регистров ZMM.
Тесты производительности
Тесты sysbench
Описание возможностей новых процессоров было бы неполным без результатов тестов производительности. Мы провели такие тесты и сравнили два сервера: на базе процессора Intel Xeon 8170 Platinum и на базе процессора Intel Xeon E5-2680v4. На обоих серверах была установлена OC Ubuntu 16.04.
Начнём с тестов из популярного пакета sysbench.
Первый бенчмарк, который мы провели — это тест по поиску простых чисел.
На обоих серверах мы установили sysbench и выполнили команду:
sysbench --test=cpu --cpu-max-prime=200000 --num-thread=1 run
В ходе выполнения теста мы увеличивали количество потоков (параметр --num-threads) с 1 до 100.
Результат теста наглядно представлен на графике (чем ниже цифра, тем лучше результат):
По мере увеличения числа потоков Intel Xeon Platinum 8170 показывает лучшие результаты.
Рассмотрим теперь результаты теста на скорость операций чтения-записи из буфера памяти (чем ниже цифра, тем лучше результат):
Здесь мы наблюдаем аналогичную картину: c увеличением количества потоков Intel Xeon 8170 Platinum выходит в лидеры.
Тест threads проверяет работу с большим количеством конкурирующих потоков. В ходе наших экспериментов мы увеличивали количество потоков с 1 до 120.
Результаты этого теста представлены ниже (чем меньше цифры, тем лучше результат):
Как видно из графика, по мере увеличения количества потоков у результаты у Intel Xeon Skylake-SP Platinum выше.
Тест Linpack
Следующий тест, который мы провели — это Linpack. Этот тест используется для измерения производительности вычислений с плавающей точкой и де-факто является стандартом в области тестирования вычислительных систем. Именно по его результатам составляется список самых производительных систем в мире.
Смысл теста заключается в решении плотной системы линейных алгебраических уравнений (СЛАУ) методом LU-декомпозиции. Производительность измеряется в флопсах — это сокращение от floating point per second, то есть число операций с плавающей точкой в секунду. Об алгоритме, лежащем в основе Linpack, можно подробнее прочитать здесь.
Тест-бенчмарк Linpack можно скачать с сайта Intel. В ходе теста программа решает 15 систем уравнений с матрицей разной размерности (от 1000 до 45000). Результаты проведённого нами теста наглядно представлены на графике (чем выше цифра, тем лучше результат):
Как видим, новый процессор показывает гораздо более высокие результаты. В тесте с максимальным размером матрицы (45 000) производительность Intel Xeon E5-2680v4 составляет 948.9728 ГФлопс, а Intel Xeon Platinum — 1233.2960 Гфлопс.
Сборка Boost на скорость
Для оценки производительности процессоров очень желательно проводить не только бенчмарки, но и тесты, максимально приближенные к реальной практике. Поэтому мы решили посмотреть, с какой скоростью наши серверы соберут из исходного кода набор библиотек С++ Boost.
Мы использовали последнюю стабильную версию Boost — 1.64.0; архив с иcходным кодом мы скачали с официального сайта.
На сервере с процессором Intel Xeon E5-2680v4 сборка заняла 12 минут 25 секунд. Cервер на базе Intel Xeon Platinum справился с задачей ещё быстрее — за 9 минут 16 секунд.
Заключение
В этой статье мы проделали обзор важнейших нововведений, которые появились в процессорах Intel Skylake-SP. Для желающих узнать больше приводим подборку полезных ссылок по теме:
Серверы на базе новых процессоров уже доступны для заказа в дата-центрах Петербурга и Москвы.
Мы предлагаем следующие конфигурации:
Процессор
Память
Диски
Intel Xeon Silver 4114
96 ГБ DDR4
2 x 480 ГБ SSD + 2 x 4 ТБ SATA
Intel Xeon Silver 4114
192 ГБ DDR4
2 x 480 ГБ SSD
Intel Xeon Silver 4114
384 ГБ DDR4
2 x 480 ГБ SSD
Intel Xeon Gold 6140 2.1
384 ГБ DDR4
2 x 800 ГБ SSD
Чтобы арендовать серверы на базе новых процессоров, нужно оформить предварительный заказ, но в скором времени они будут доступны и на постоянной основе.
Наличие коммерческой недвижимости – бизнес-центра, гостиницы или здания завода – подразумевает наличие регламента управления. Ну да, у кого нет регламента? Но сегодня мы не будем говорить о его совершенстве. Мы остановимся на вопросах исполнения этого регламента. Увы, на практике, обслуживание далеко не всегда производится даже на 50% от запланированного, что ведет к значительным потерям (или затратам) со стороны владельца недвижимости. Эту проблему нужно решить с помощью современных средств автоматизации. Но внедряя их, нельзя забывать, что мы работаем в России, и у любых процессов есть свой национальный колорит.
Системы управления недвижимостью носят общее название FM (Facility Management). И хотя аббревиатура английская, в России подобные решения воплощаются не совсем в классическом виде и с другими акцентами. Так какие же преимущества они дают собственникам или управляющим лицам? Помимо общих целей сокращения затрат и оптимизации работы, которые так или иначе ставит перед собой любая организация, существуют частные позитивные аспекты внедрения систем FM.
Они помогают контролировать сроки исполнения заявок, учитывая договорные обязательства, гарантировать исполнение технического обслуживания по регламентам, наличие реальных обходов по маршрутным картам и с заданной периодичностью, а также оптимизировать наличие нужного количества расходных материалов на складе, избегая излишних запасов. Для бизнеса все это – деньги, а для информационных систем – информация, которую нужно соответствующим образом собирать и анализировать.
Кто выполняет работы по эксплуатации объектов недвижимости? Обычно это подрядные организации. Не важно, идет ли речь о единой компании с комплексными компетенциями, которая будет привлекать узкоспециализированные субподрядные организации, либо о нескольких эксплуатирующих организациях, отвечающих за различные виды работ. Даже на одном достаточно крупном объекте недвижимости традиционно возникает масса неразберихи, связанной с исполнением регламентов.
А к чему приводит ведение планов капительных ремонтов в MS Project и отчетность в Excel? Кто сможет разобраться, куда делись лишние 5 км трубы, 10 кубов бетона и целое футбольное поле террасной доски? В условиях полного неведения, управленческие решения могут приниматься на основании несуществующих фактов, ведь у подрядчиков возникает соблазн «умолчать» об ошибочных действиях, заявить заказчику о выполнении несуществующих работ и заодно с офисом отремонтировать парочку коттеджей. Поэтому без инструмента автоматизированного контроля на местах оказывается сложно.
Пример. На одном машиностроительном заводе по регламенту обходы специализированных помещений должны были совершаться раз в неделю, о чем подрядчик отчитывался регулярно. Когда дело дошло до проверки, выяснилось, что в эти помещения не заходили БОЛЕЕ ГОДА, поставив под угрозу работу инженерных систем.
На самом деле на рынке представлено не так много систем, которые способны обеспечить поддержку всего функционала FM, который необходим сегодня российским компаниям без дополнительной разработки программного кода. В своей практике мы используем продукты IBM Maximo и IBM Tririga. Но это не значит, что их можно просто установить и воспользоваться «наработанными лучшими практиками», чтобы оптимизировать управление недвижимостью по западному образцу. Увы, в России такой подход не работает, впрочем, как и в других странах с отличными от запада традициями ведения деятельности. Плюсом в данном случае выступает гибкость используемой платформы и возможность ее настройки для реальных требований заказчика, а также удобный интерфейс для оператора и руководителя.
См. ниже скриншот интерфейса
Искусство управления недвижимостью в России
На протяжении 20 лет работы по направлению FM, мы убедились в том, что помимо использования проверенных рынком инструментов, успешность проектов определяется 6 факторами, которые необходимо учитывать изначально.
1. Адаптация к существующим регламентам
Если взять западную модель в чистом виде, то компании придется целиком принять логику ново информационной системы. Это может потребовать изменения организационной структуры, статей бюджета по эксплуатации, форматов корпоративной отчетности и так далее. К такому готовы далеко не все российские компании, если не сказать больше – не готов почти никто. Вместо попытки скопировать чужие правила нужно вложить в логику системы уже существующую модель управления, с частичной оптимизацией и внесениями изменений, которые помогут повысить эффективность операционной деятельности, но не нарушат сложившуюся схему работы.
2. Удобство в приоритете
Бизнес-пользователи систем управления на западе и в России по-разному подходят к вопросам удобства интерфейса. Если западные менеджеры стремятся к оптимизации производительности системы, и во многих корпорациях это стандарт де-факто, то в российских компаниях более успешными оказываются проекты, которые помогают работать удобнее. Даже в тендерных заявках часто указывается пожелание выполнять задачи «в меньше кликов». Таким образом снимается сопротивление внедрению новых систем, а предпочтительным оказываются инструменты с интуитивным гроафическим интерфейсом.
3. Контроль на уровне работ
Еще одно очень важное отличие между сложившимися схемами работ по управлению недвижимостью в разных странах – это разный предмет контроля. Например, в США многие сервисные контракты отслеживаются на уровне предмета договора – постгарантийное обслуживание рефрижераторов, регулярный ремонт коммуникаций и так далее. В нашей стране из-за большой вероятности низкого качества исполнения рутинных процедур контроль необходимо реализовывать на уровне самих работ. То есть – осмотр станка А, замена прокладок в установке Б и так далее.
4. Использование мобильных технологий
Мобильные технологии создают возможность для нового уровня контроля исполнения работ. Например, мы создавали системы, в которых сотрудник подрядчика не может отчитаться об обходе объекта без считывания RFID-меток, нанесенных на самих установках, а также без загруженных на сервер фотографий выполненных работ. Можно также использовать и QR-метки, но помните – их можно сфотографировать, распечатать и сканировать, сидя дома на диване.
5. Интеграция с системами бюджетирования и бухучета
Закупки материалов и их учет – больная тема для многих компаний. Поэтому интеграция с системами бюджетирования и учета позволяет не допустить растрат корпоративных средств, а также доказать окупаемость системы руководству. При наличии четкого понимания о соотношении потраченных средств, закупленных и использованных материалов, подрядчик не сможет построить себе дачу вместо ремонта подвальных помещений, завысить стоимость закупаемых материалов и так далее.
6. Отказ от старых стандартов принятия решений
Наконец, нередко проекты внедрения новых информационных систем класса FM заходят в тупик просто из-за того, что не меняется логика управления процессами. Опыт показывает, что при переходе на работу в новой автоматизированной системе, необходимо убедить руководителей всех уровней отказаться от привычных совещаний и коллективных обсуждений – только перенося все процессы в режим онлайн можно добиться повышения эффективности работы сервисных организаций.
Только через год…
Сколько придется переходить на «новые рельсы?» В среднем внедрение системы FM занимает 8-12 месяцев, потому что проект требует тщательной подготовки. Нужно определить направления планирования, включая определения состава контролируемых показателей и допустимы диапазон их значений. Кроме этого нужно формализовать организационную структуру подразделения по эксплуатации, ответственность отдельных лиц, порядок взаимодействия системы с подрядчиками и центральным офисом. Чтобы система могла работать требуется определить состав отчетных форм, правила и порядок их формирования, процедуры рассмотрения и систему аудита объектов. Наконец, все это теряет смысл без выделенных объектов учета с заданной степенью детализации затрат, порядка анализа исторических данных и создания графических представлений для принятия управленческих решений.
Но после завершения процесса компания получает инструмент, предлагающий способ выставления обоснованных претензий подрядчикам, формирования мотивации штатного персонала, в том числе за счет премий и построения сводных отчетов для руководства с возможностью детализации.
В следующих постах мы расскажем о том, как подобные задачи были решены на площадках некоторых российских заказчиков. Поэтому просим в комментариях отметить, какие именно аспекты внедрения систем FM вам было бы интереснее всего обсудить?
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Доброго времени суток! В этой статье хотел бы поделиться решением неожиданной проблемы, возникшей в одном из проектов, над которым я сейчас работаю.
Что может быть опасного в обновлении .net 4.6.1 до .net 4.6.2? Я считал что для процесса обновления минорной версией достаточно прочитать release notes, чтобы избежать серьезных проблем. Однако, как выяснилось, Microsoft может привнести очень интересные и занимательные изменения в обход release notes, которые смогут вас занять в «скучные летние вечера и выходные дни».
Под катом будет описание одной проблемы возникшей из-за обновления и пути её решения, а так же немного исходников .net.
С чего началось?
Штатное обновление .net. Зачем? Да просто потому что. Можно долго рассуждать на тему «работает — не трогай», но я считаю что на активных проектах всегда необходимо хоть сколько-нибудь регулярно обновлять компоненты стека. Иначе в какой-то момент обновления через несколько десятков версий превратятся в такую боль, что будет проще навсегда заморозить старую версию, чем пытаться обновить и разгребать проблемы, которые коммюнити лечила несколько лет назад и никто уже не помнит, с чем там приходилось сталкиваться.
Вообще говоря, плановое обновление должно было быть на .net 4.7, но поскольку Microsoft очень дружелюбно уже полгода перестраивает систему партнерства и до сих пор не может предоставить способа его нормально продлить в наших условиях, то VS 2017 нам так и не явился пока. Поэтому временно было решено догнать версию хотя бы до 4.6.2.
Сказано — сделано. Обновили, выкатили на тестовый контур, протестировали, потом на боевой. Полет нормальный.
Проблемы
System.Web.HttpException (0x80004005): The request queue limit of the session is exceeded.
Эм, wat? Ежедневно проводимый анализ наиболее частых ошибок выявил на несильно нагруженном сервере 600+ таких ошибок. Хорошо, начинаем копать.
Параллельно была включена поддержка http/2 на мобильных устройствах и в стеке оказался старый мобильный asmx сервис, поэтому следы слегка запутались. Появилось подозрение на то, что банально запросы стали приходить слишком часто и это перегружало очередь.
asmx
Да, у нас не всё на webApi2, по-прежнему есть некоторое количество asmx сервисов, которые в силу размера проекта мигрируются постепенно.
Начали отрабатывать этот кейс. Поскольку все мобильные сервисы с сессией работали readonly, переводим сессию в соответствующий режим.
Global.asax:
if (<Запрос на падающий сервис>)
{
Context.SetSessionStateBehavior(SessionStateBehavior.ReadOnly);
}
Обновляем контур. Проблемы с мобильными устройствами исчезают. Но возникают с другим asmx сервисом, который используется из web.
Это наводит подозрения, что первичное предположение скорее всего ведёт не в ту сторону.
Что мы видим? Рекомендации увеличить requestQueueLimit (размер очереди на сервер), пробуем — толку нет. Да и как-то по нагрузке не похоже, что мы можем этот лимит пробить каким-то образом.
Вторая ссылка — если у вас проблемы с очередью — «не трожьте очередь, увеличивайте ресурсы!» Понятно, проехали.
Больше никакой информации. Чтож, остается еще один проверенный способ. Исходники.
Я на самом деле очень благодарен MS за открытие исходников. Иначе бы многие проблемы решались бы в десятки раз дольше, эмпирическим способом, а может так и остались бы нерешенными. (А еще для путешествия по исходным кодам очень удобен Resharper).
Вводные данные:
System.Web.HttpException (0x80004005): The request queue limit of the session is exceeded.
at System.Web.SessionState.SessionStateModule.QueueRef()
at System.Web.SessionState.SessionStateModule.PollLockedSession()
at System.Web.SessionState.SessionStateModule.GetSessionStateItem()
at System.Web.SessionState.SessionStateModule.BeginAcquireState(Object source, EventArgs e, AsyncCallback cb, Object extraData)
Проходим по всей цепочке. В целом, ничего сильно подозрительного. Доходим до конечного метода:
private void QueueRef() {
if (!IsRequestQueueEnabled || _rqId == null) {
return;
}
//
// Check the limit
int count = 0;
s_queuedRequestsNumPerSession.TryGetValue(_rqId, out count);
if (count >= AppSettings.RequestQueueLimitPerSession) {
throw new HttpException(SR.GetString(SR.Request_Queue_Limit_Per_Session_Exceeded));
}
//
// Add ref
s_queuedRequestsNumPerSession.AddOrUpdate(_rqId, 1, (key, value) => value + 1);
}
Хм. А что это за настройка RequestQueueLimitPerSession которая упоминается почему-то только в .net 4.7, но при этом распространяется фиксами вплоть до .net 3.5?
Переходим для изучения настройки в AppSettings.cs. Бинго!
internal const int UnlimitedRequestsPerSession = Int32.MaxValue;
internal const int DefaultRequestQueueLimitPerSession = 50;
if (settings == null || !int.TryParse(settings["aspnet:RequestQueueLimitPerSession"], out _requestQueueLimitPerSession) || _requestQueueLimitPerSession < 0)
_requestQueueLimitPerSession = BinaryCompatibility.Current.TargetsAtLeastFramework463 ? DefaultRequestQueueLimitPerSession : UnlimitedRequestsPerSession;
Если у вас версия .net 4.6.3 (что по всей видимости есть системное название 4.6.2) или старше, то длина очереди на каждого пользователя оказывается обрублена 50 запросами, что достигается достаточно легко в определённых случаях использования. Увеличиваем лимит, заливаем, тестируем — happy end.
Надеюсь, что это статья на хабре поможет кому-нибудь, кто столкнется с той же проблемой, т.к. в интернете поиском информации по этой проблеме найти тяжело.
P.S.: Странно, что такие изменения идут в обход release notes. Видимо, дело именно в том, что это распространяли апдейтами и фиксами из 4.7. Но с моей точки зрения это явный breaking change, который на некоторое время частично свалил приложение и как-то более явно хотелось бы видеть такие изменения.
В данном цикле статей я буду рассказывать о моем опыте сборки «умной» автоматической системы для кормления домашнего питомца, в моем случае – кота.
Хочу сразу отметить, что на первом шаге речь пойдет только об "автоматической" кормушке, а "умной" она станет на следующих этапах (если повезет, и все пойдет по плану).
Итак, начнем с концепции и целей:
Сделать систему, которая освободит меня от обязанности кормить кота сухим кормом (шаг 1)
Оснастить систему датчиком веса под миской и осуществлять кормежку в соответствии с показаниями весов: если миска пустая – подсыпать, иначе – ждать пока миска не станет пустой (шаг 2)
Добавить в систему вай-фай модуль и видеокамеру для передачи фотографий с любимым котом, а также обеспечить контроль кормежки удаленно. Кроме того, собирать данные о том сколько кот съел и строить аналитику (шаг 3)
На первом шаге не требуется большое количество датчиков и манипуляторов, достаточно одного серводвигателя (например, Micro Servo Towerpro SG90 9 г), поэтому все управление происходит с платы ArdruinoUno, которая идеально подходит для задач такого рода.
Системы кормления так или иначе содержат некоторый контейнер, в котором лежит сухой корм, и вращающийся механизм, дозирующий его количество. Изучив опыт других "изобретателей", я бы выделила три основных механизма:
Используется контейнер и сама система из под диспенсера мюслей (наверняка видели в отелях). Внизу в горлышке контейнера установлен стержень с лопостями. Ось стержня лежит вдоль плоскости горлышка. К нему прикреплен мотор, который прокручивает лопасть на одно деление один раз в заданный промежуток времени Такой механизм выглядит довольно аккуратно, его легко собрать (собственно и собирать почти ничего не надо), но, увы, очень уж дорогой. Но тут на вкус и цвет.
Другой вариант — наоборот, конструкция делается своими руками из акрила, а вращающийся дозатор из CD дисков. Довольно понятно о том, как сделать такую кормушку рассказано в этом видео https://www.youtube.com/watch?v=C_ezRywtVg4&t=20s. Если есть под рукой акрил, резак для него, ну и в принципе есть какой-то опыт в сборке такого рода вещей, то это дов
ольно бюджетный вариант. Но не для таких как я — самостоятельно все спроектировать, вырезать и ровненько соединить требует другого уровня аккуратности.
Для третьего варианта потребуется: обычная банка, которая будет играть роль контейнера, что-то, из чего можно вырезать небольшой сектор (подойдет, например, крышка какой-нибудь пластмассовой икеевской коробки), ну и пара магнитов для крепежа конструкции. Этот вариант мы и разберем подробней, он не требует инженерного образования и большого количества вложений, в общем, как раз то, что нужно.
Все материалы, которые мне были нужны для сборки кормушки на первом этапе:
Стеклянная банка
ArduinoUno
MicroServo (у меня разрешенный угол поворота 180, но это не принципиально)
кусок пластика
магниты
пины для соединении платы с серводигателем
Usb зарядка на 5V
Логика работы механизма проста: в крышке банки делается дырка типа сектор (центр крышки не вырезается), такой же сектор вырезается из пластмассы. Внутрь крышки прикрепляется серводвигатель, например, скотчем. На ось двигателя насаживается сначала крышка, а с внешней стороны вырезанный сектор. Так, при повороте оси серводвигателя вырезанный сектор смещается относительно дырки в крышке банки.
Также надо не забыть сделать дырочку под вывод провода серводвигателя наружу для подключения к плате. На шаге 1 кормежка происходит по таймеру, кот у меня не обжора, поэтому открытие сектора происходит раз в день на короткое время, ниже код для Arduino:
Для крепежа банки к стене я использовала вот такие магниты, каждый на 4кг (мне кажется лучше использовать более мощные). К банке магниты крепятся просто клеем, к стене — винтами.
Плата прикреплена к банке при помощи такой липучки, ее удобно снимать и крепить обратно. Липучка такая продается в любом хозяйственном, используется для крепежа картин.
Поскольку у меня единственным внешним модулем является серводвигатель, то дополнительного питания не надо, достаточно запитать плату, ее можно подключить напрямую к сети через usb зарядку на 5V.
Вот как все выглядит в собранном состоянии:
"Ниже я набросала несколько идей дальнейшего развития кормушки, их много и пока непонятно, что именно будет делаться дальше, эта часть для обсуждения.
установка датчиков движения, фотографирование кота в тот момент, когда он появляется в зоне видимости. Интеграция датчика веса и датчика движения позволяет определять, когда кот просто прогуливается мимо кормушки, а когда пришел покушать. Соответственно, можно прикрутить аналитику, когда котэ предпочитает кушать и как много.
можно добавить датчик веса в сам контейнер с кормом, чтобы кормушка определяла момент, когда становится пустой и присылала предупреждение хозяину, что, мол, пусто, надо пополнить. Потом, как вариант, прикрутить возможность автозаказа корма с любимого сайта с доставкой.
Можно добавить возможность кормушки работать на двух котов:
Либо это будут две разные кормушки, каждая из которых умеет отпугивать “чужого” кота
Либо это одна, но как-то модифицированная
Надо подумать как реализовать поилку и синтегрировать ее с кормушкой, добавить систему фильтрации.
Привет, Хабр! В этом посте речь пойдет об интересной разработке для Oracle Business Intelligence под названием Visual Plugin Pack.
Один из продуктов в составе пакета Oracle BI — интерактивные панели (Interactive Dashboard) — основан на web-интерфейсе и поддерживает комплекс средств визуализации: шкалы, диаграммы, сводные отчеты, сценарии анализа на базе условий. В нем также реализован механизм drilldown, который может быть настроен и как иерархия в OBIEE, и как ссылка на другое действие. Таким образом, обеспечивается неограниченная детализация отчетных показателей.
Стандартные средства визуализации в OBIEE
Наиболее популярными среди стандартных средств визуализации, по моему мнению, являются несколько представлений.
Таблица и таблица среза, столбчатая и круговая диаграмма.
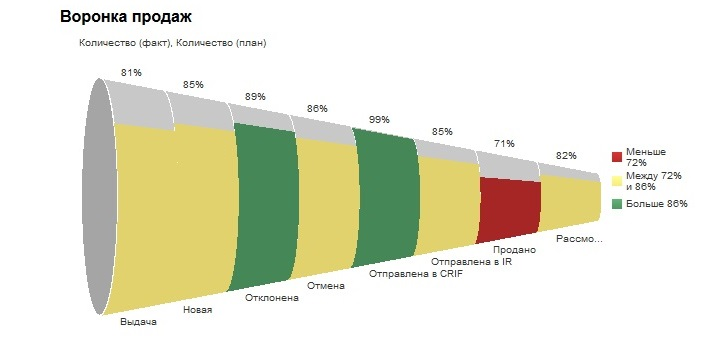
Воронка продаж. Очень удобный аналитический инструмент, позволяющий получить информацию о том, как потенциальный клиент проходит путь от первой заинтересованности в покупке продукта или услуги до момента совершения покупки.
Мозаика производительности. Этот элемент нужен для вывода наиболее значимых показателей на информационную панель. Представление мозаики производительности содержат один фрагмент агрегата данных. На приведенной ниже иллюстрации показана информационная панель с несколькими элементами мозаики производительности.
Карты дерева. Организуют данные, группируя их в прямоугольники (известные как плитки). Карты дерева отображают плитки на основе размера одного показателя и цвета другого показателя.
Что дает Visual Plugin Pack?
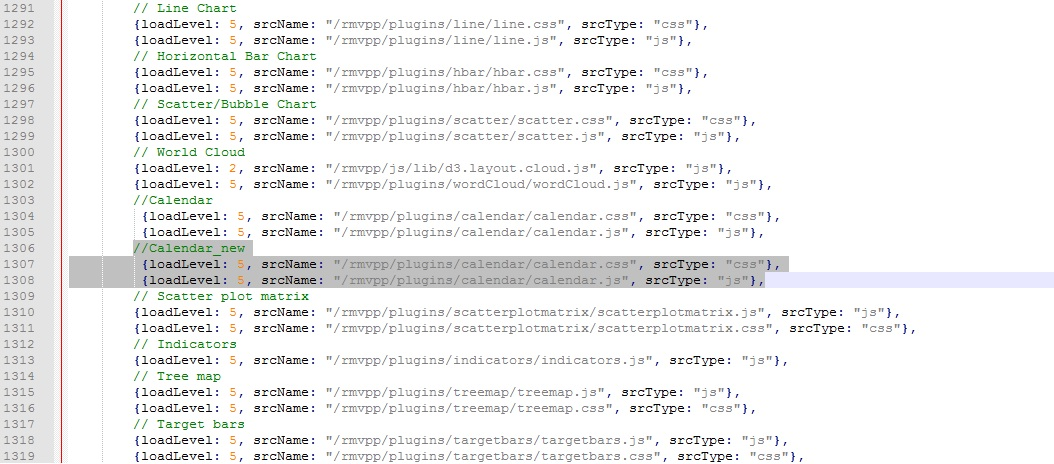
Visual Plugin Pack (VPP) расширяет визуальные возможности OBIEE, добавляя 18 новых представлений. Наиболее интересные из них — ниже.
Calendar — отображает календарь за год, в котором подсвечиваются значения max\min. Например: количество продаж в каждый день за год. Лучшие\худшие дни.
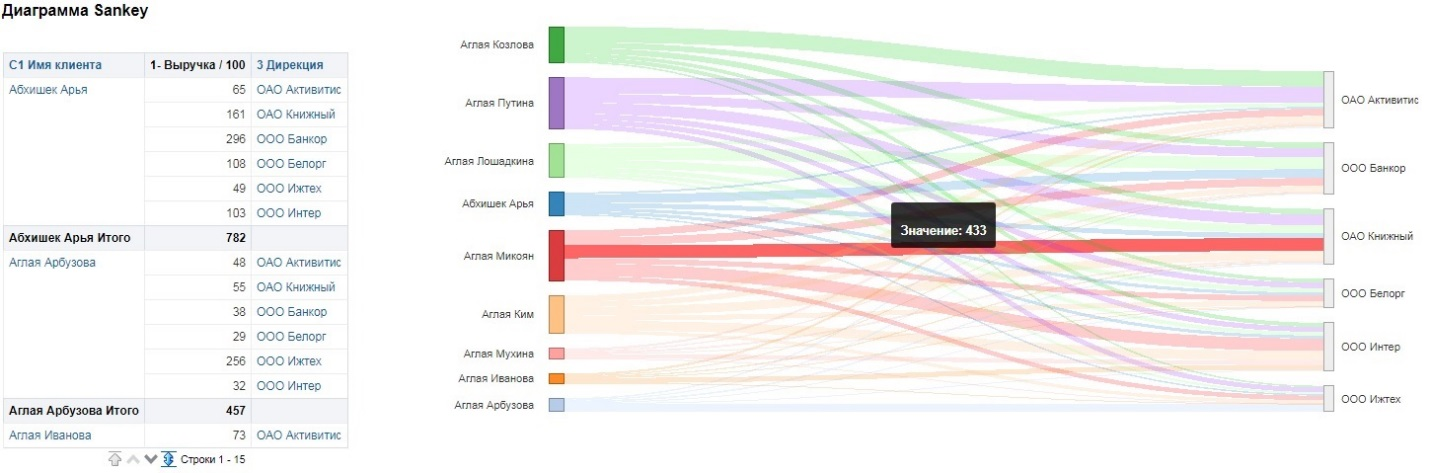
Sankey diagram — представление позволяет отслеживать различные потоки. Например, у нас есть крупные клиенты-юрлица, которые работают с разными менеджерами. Менеджеры, в свою очередь, также работают с разными клиентами. Можно посмотреть какие продажи (ширина потока) наиболее эффективны. Аналогичное представление существует в Visual Analyzer.
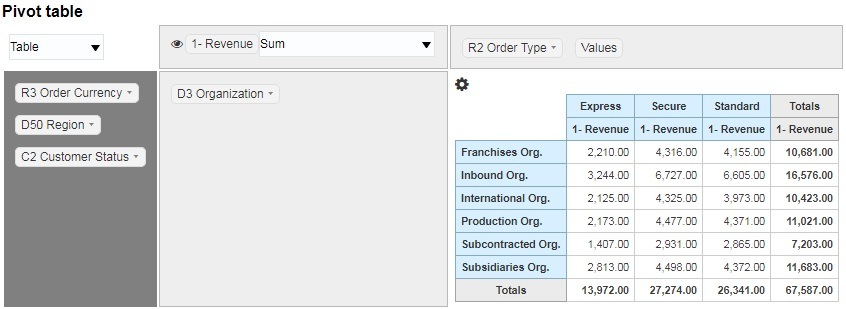
Pivot table — сводная таблица. Аналогичное по смыслу представление есть и в OBIEE. Основное отличие — пользователь имеет новый user-friendly интерфейс для работы с таблицей среза. Можно исключать ненужные столбцы, потом возвращать их обратно, менять способы агрегирования показателей, изменять представление. И все это без использования редактора построения отчетов.
Word Cloud. Облако слов составляется из атрибутов, наиболее часто использующихся в анализе. Уровни ориентации, цвета и размеры показателей настраиваются в параметрах представления.
Indicators. Индикаторы отлично подходят для демонстрации превышения трудозатрат либо других аналогичных показателей.
Установка VPP
Для установки Visual Plugin Pack в OBIEE 12c необходимо выполнить следующие подготовительные условия:
Некоторые подкаталоги, следующие за папкой Analytics, могут иметь случайно сгенерированные имена, поэтому файлы придется искать вручную.
Вставляем в начало каждого файла следующую строку: var src = document.createElement('script');src.setAttribute("type", "text/JavaScript");src.setAttribute("src", "/rmvpp/rmvpp.js");parent.document.getElementsByTagName("head")[0].appendChild(src);
Сохраняем изменения и перезапускаем OBIEE. В OBIEE появится кнопка Visual Plugin Pack.
Добавление собственных плагинов
Можно начать с малого и попробовать дополнить уже существующие представления своими доработками. Для этого создаем папку по пути $VPP_HOME\plugins, копируем в нее скрипты представления, которое хотим отредактировать и добавляем информацию о местоположении новых скриптов в файл rmvpp.js.
В целом разработка новых плагинов — достаточно глубокая тема со своими нюансами и подводными камнями, заслуживающая отдельного материала. Но, думаю, в нем нет необходимости, поскольку основные моменты отлично описаны в статье разработчика VPP. И в дополнение — руководство по установке.
Заключение
Рассмотренные выше представления являются малой частью набора, доступного для использования в VPP. Остальные представления также интересны по-своему и могут прийтись по душе вам или вашему заказчику, однако, главная фишка VPP в другом.
Visual Plugin Pack — это целая структура, которая позволяет разработчикам создавать свои собственные плагины визуализации на Javascript, которые затем разработчики отчетов смогут использовать и настраивать с помощью пользовательского интерфейса OBIEE.
Так, например, в календарь, представленный выше, мы добавили отображение дней месяца, а начало недели адаптировали к российскому стандарту (понедельник вместо воскресенья). Все эти приятные для восприятия мелочи были «допилены» добавлением пары строк кода в исходные скрипты представления.
Кроме того, можно добавлять новые элементы привязок столбцов, а также компоненты конфигурации, которые будут определять масштаб/цвет/сами_придумайте_что вашего будущего представления. Потенциал у инструмента огромен и ограничивается лишь вашей фантазией.
Олег Земнухов, разработчик Центра внедрения бизнес-систем компании «Инфосистемы Джет»
Многие из нас постоянно думают о производительности веб-приложений: добиваются 60 FPS на медленных телефонах, загружают свои ассеты в идеальном порядке, кэшируют всё что можно, и много чего ещё.
Но не является ли такое представление о производительности веб-приложений слишком ограниченным? С позиции пользователя все эти действия — лишь крошечный кусок большого пирога производительности.
В этой статье мы пройдёмся по всем этапам использования сайта, как если бы это делал обычный человек, измерив длительность каждого из них. И особое внимание уделим конкретному шагу на одном конкретном сайте, который может быть ещё больше оптимизирован. Хочется верить, что решение (которым будет машинное обучение) может быть использовано во многих различных случаях на разных сайтах.
Проблема
В качестве примера возьмём сайт, на котором одни пользователи могут продавать лишние для них вещи, чтобы другие могли купить себе новое сокровище.
Когда пользователь регистрирует новый товар для продажи, он выбирает категорию, затем требуемый рекламный пакет, заполняет подробности, просматривает объявление, а затем его публикует.
Смущает первый шаг — выбор категории.
Во-первых, есть 674 категории, и пользователь может встать в тупик, в какую из них «засунуть», скажем, разбитый каяк (Стив Круг прекрасно сказал: не заставляйте меня думать).
Во-вторых, даже когда становится ясно, какой категории / подкатегории / подподкатегории принадлежит товар, процесс всё равно занимает около 12 секунд.
Если сказать, что можно сократить время загрузки страницы на 12 секунд, вы бы вполне ожидаемо удивились. Ну почему бы не сойти с ума настолько, чтобы сэкономить 12 секунд в другом месте, а?
Как сказал Юлий Цезарь: «12 секунд — это 12 секунд, чувак».
Первым делом приходит в голову, что если скормить заголовок, описание и цену товара правильно обученной модели машинного обучения, то она определит, к какой категории принадлежит товар.
Так что вместо того, чтобы тратить время на выбор категории, пользователь мог бы потратить 12 дополнительных секунд, глядя на двухъярусные самодельные кровати на reddit.
Машинное обучение — почему вы должны перестать его бояться
Что обычно делает разработчик, который абсолютно ничего не знает о машинном обучении, кроме того, что программы на нём могут играть в видеоигры и превзойти лучших в мире игроков в шахматы?
Погуглить «Machine Learning».
Покликать по ссылкам.
Обнаружить Amazon Machine Learning.
Понять, что не нужно ничего знать о машинном обучении.
Расслабиться.
Процесс, как он есть
Он полностью описан в ML-документации Amazon. Если вы заинтересовались этой идеей, то запланируйте ~ 5 часов и прочитайте документацию, здесь мы не будем её рассматривать.
После прочтения документации можно сформулировать такой план:
Запишите данные в CSV-файл. Каждая строка должна быть элементом (например, каяком), столбцы должны быть заголовками, описаниями, ценами и категориями.
Загрузите в AWS S3.
«Обучите» машину на этих данных (всё делается с помощью визуального мастера со встроенной помощью). Маленький облачный робот должен знать, как предсказать категорию на основе названия, описания и цены.
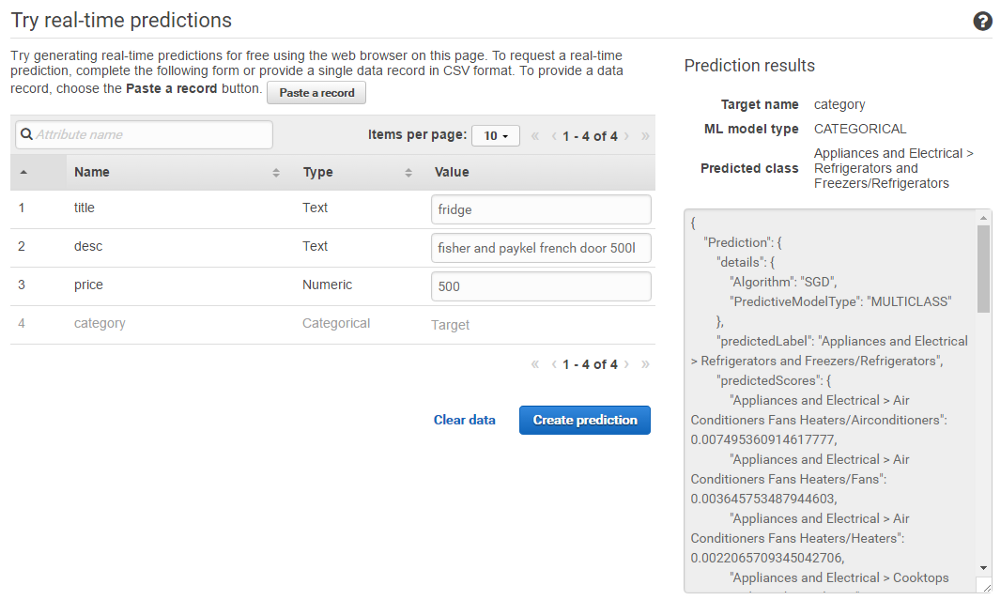
Добавьте код к приведённому ниже фронтенду, который берёт заголовок / описание / цену, введённые пользователем, отправляет их в конечную точку предсказания (она автомагически создаётся Amazon) и показывает прогнозируемую категорию на экране.
Пример сайта
Можете воспользоваться прекрасной формой, которая имитирует ключевые аспекты этого процесса.
Эти захватывающие результаты не позволят вам потерять интерес во время предстоящих скучных объяснений. Просто поверьте, что предлагаемая категория действительно была предсказана на основе машинного обучения.
Давайте попробуем продать холодильник:
Как насчёт аквариума:
Маленький облачный робот знает, что такое аквариум!
Очень здорово, правда?
(Форма создана с помощью React/Redux, jQuery, MobX, RxJS, Bluebird, Bootstrap, Sass, Compass, NodeJS, Express и Lodash. И WebPack для сборки. Готовая вещь чуть больше 1 MB — #perfwin).
Хорошо, а теперь о менее впечатляющих вещах.
Поскольку вначале было просто баловство, то теперь нужно получить откуда-то реальные данные. Например, 10 000 предметов в нескольких десятках категорий. Был взят локальный торговый сайт, и написан небольшой парсер, который сохранял URL-адреса и DOM в CSV. Это заняло около четырёх часов: половина времени, затраченного на весь эксперимент с машинным обучением.
Готовый CSV был загружен на S3 и проведён через мастер, чтобы настроить и обучить программу. Общее время CPU для обучения составило 3 минуты.
Интерфейс работает в реальном времени, поэтому можно проверить, действительно ли он вернёт мне то, что нужно, если передать ему определённые параметры,.
ОК, работает.
А теперь не хочется дёргать API Amazon напрямую из браузера, чтобы он не был общедоступным. Поэтому удалим его с Node-сервера.
Бэкенд-код
Общий подход довольно прост. Передаём API идентификатор и данные, а он присылает прогноз.
const AWS = require('aws-sdk');
const machineLearning = new AWS.MachineLearning();
const params = {
MLModelId: 'some-model-id',
PredictEndpoint: 'some-endpoint',
Record: {},
};
machineLearning.predict(params, (err, prediction) => {
// у нас есть предсказание!
});
record, извините, имеется в виду Record, является объектом JSON, где свойства — это то, на чём обучена модель (название, описание и цена).
Чтобы не оставлять в статье незаконченный код, вот весь файл server.js, который предоставляет конечную точку /predict:
Вот и всё. Это 100% кода, требуемого для того, чтобы облачный робот использовал данные пользователя и предсказывал категорию, к которой относится элемент.
Замолчи и возьми мои деньги
Держите свои шляпы друзья, всё это волшебство не приходит бесплатно…
Модель, которую мы использовали для примера (обучалась на 10 000 строк / 4 столбцах), занимает 6,3 Мб. Поскольку у нас есть конечная точка, ожидающая получения запросов, то расход памяти можно считать на уровне 6,3 Мб. Стоимость составляет $0,0001 / час. Или около восьми баксов в год. За каждый прогноз также взимается плата в размере $0,0001. Так что не используйте предсказания понапрасну.
Конечно, не только Amazon, предлагает подобные услуги. У Google есть TensorFlow, но у них с первых же строк совершенно убойное руководство по началу работы. Microsoft также предлагает модель машинного обучения. Microsoft Azure Machine Learning значительно превосходит Amazon. Итерация намного быстрее, потому что вы можете добавлять / удалять столбцы, не загружая файлы повторно. Наше обучение, занимающее 11 минут на Amazon, занимает 23 секунды на Azure. И, между прочим, их «студийный» интерфейс — очень хорошо сделанное веб-приложение.
Что дальше?
Вышеприведённый пример, безусловно, надуман. И тут не выложен скриншот, где программа приняла тостер за лошадь. И всё равно это чертовски потрясающе. Обычный человек может попробовать машинное обучение и, возможно, сделать некоторые улучшения для пользователей.
Можно было бы перечислить все возможные проблемы, но будет куда интереснее, если вы сами их найдёте. Так что идите, пробуйте, и добивайтесь успеха.
В статье под катом мы поговорим о том, как бороться с энтропией в конфигурационных файлах.
Рождение файлов конфигурации
Давным-давно один разработчик написал простое веб-приложение для хранения данных о размерах зарплат сотрудников компании. Он использовал две базы: рабочую с настоящими сотрудниками и зарплатами и тестовую с выдуманными данными.
Однажды поздно ночью он перенес в рабочую базу новую функцию и забыл поменять жестко вбитую ссылку на тестовую базу:
Следующим утром босс зашел в систему и обнаружил, что там вместо сотрудников таинственным образом появились герои диснеевских мультиков.
Босса это не порадовало.
Твердо намереваясь больше никогда не повторить эту ошибку, разработчик решил заменить жестко вбитое имя хоста на переменную.
Так родился первый файл конфигурации.
; Не хранить в SVN
[db]
host = db1.example.com
dbname = payrolls
user = admin
pass = s3cur3
Прошло несколько лет, и настройки подключения к базам данных все еще остаются первым, что люди стараются поместить в файлы конфигурации. Но теперь у нас также есть API-ключи, токены сторонних систем и другие всевозможные виды необходимой информации, обладающей неприятной особенностью периодически меняться.
Раньше у нас в buildo веб-приложения использовали 2 файла конфигурации.
Серверные API на Scala читали конфигурационные данные из файла application.conf. Это выглядело следующим образом:
app {
db = {
url = "jdbc:postgresql://localhost:5432/app"
user = "postgres"
password = ""
driver = org.h2.Driver
keepAliveConnection = true
queriesTimeoutSeconds = 1
connectionTimeout = 1000
numThreads = 1
}
interface = "0.0.0.0"
port = 8082
allowedHostnames = ["localhost"]
allowedHeaders = ["Content-Type", "Authorization", "Cache-Control", "Pragma"]
#Timeout for reading routine time from file
routineTimeDataTimeout = 1
localBackupPath = "/Users/fra/buildo/app/backup"
serviceEndpoint = "http://localhost:8083"
maximumItemsNumber = 100000000
#Wait 5 seconds before killing all connections
waitBeforeKillingConnectionsMillis = 5000
#Size of the buffer used to read and write files
streamBufferSize = 4096
}
Оба файла добавлялись в .gitignore и никогда не попадали в Git.
Постойте, вам же нужно использовать переменные окружения!
Возможно, вы знакомы с манифестом Twelve-Factor App, в котором рекомендуется хранить конфигурационную информацию в переменных окружения, а не в файлах конфигурации. Однако, несмотря на то что это удобный, независимый от языка способ хранения конфигурационной информации, он не решает основную проблему. Если приложению нужно несколько параметров конфигурации, вы в итоге создаете файл примерно следующего содержания:
export MY_APP_VAR1="foo"
export MY_APP_VAR2="bar"
Поздравляю, вы только что создали универсальный файл конфигурации! Вы также открыли первый закон конфигодинамики:
Значения параметров конфигурации не могут быть созданы или уничтожены, они лишь переходят из одного вида в другой.
Обычно я задаю вопрос в Slack, и другой разработчик скидывает мне рабочую версию конфига в личный чат (это, конечно, глупо, но доподлинно известно, что мы не единственные, кто так делает).
Еще раз взглянув на два предыдущих примера, можно отметить, что они довольно длинные. Это обусловлено вторым законом конфигодинамики:
Общая длина файла конфигурации со временем может только возрастать.
На самом деле я пропустил несколько значений из реальных файлов конфигурации, которые пересылал по Slack несколько месяцев назад. Но всегда ли можно быть уверенным, что это правильные настройки, а не какой-то тестовый конфиг?
Единственный способ борьбы со вторым законом — это взять немного энергии (разработчика) и заняться поиском параметров конфигурации, которые меняются достаточно редко. Возможно, вы не хотите жестко вбивать их в код, но никто не запретит залить эти значения в репозиторий в какой-нибудь другой форме.
Для приложений на Scala мы используем Lightbend Config. Он позволяет определить reference.conf с параметрами конфигурации по умолчанию, которые можно спокойно поместить в репозиторий.
Не так давно мы начали обращать более пристальное внимание на то, что происходит в файле reference.conf. Мы хотим быть уверены, что это не просто каркас, а полноценный файл конфигурации, в котором есть все необходимые значения для запуска приложения.
При желании перезаписать эти значения можно либо установить локальные переменные окружения, либо создать файл application.conf, который не будет попадать в коммиты, так как добавлен в .gitignore.
Вот начало нашего reference.conf, оформленного в новом стиле:
# This is the reference config file that contains all the default settings.
# Make your edits/overrides in your application.conf.
app {
interface = "0.0.0.0"
interface = ${?SERVICE_INTERFACE}
port = 8080
port = ${?SERVICE_PORT}
...
}
Похожая ситуация складывается и с клиентской частью, где мы теперь всегда создаем файл development.json (попадает в коммит), содержащий значения по умолчанию, которые могут быть переопределены в необязательном файле local.json (не попадает в коммит). Мы также создаем файл production.json, в котором находятся настройки для production. В этом случае мы не используем какую-либо open-source-библиотеку, а написали собственную простую реализацию.
Она позволяет нам преобразовать, например, вот такой старый сборочный CI-скрипт:
Следует стремиться к тому, чтобы у вас была одна загруженная в репозиторий дефолтная конфигурация, которой достаточно для запуска приложения в локальном окружении разработчика.
Отсюда формулируется третий закон конфигодинамики:
Длина идеального файла конфигурации в окружении разработчика равняется нулю.
А как же другие окружения? Вы, возможно, захотите развернуть приложение в production. Также вполне вероятно, что у вас есть staging-сервер с небольшими отличиями (например, более подробное логирование).
Сначала нужно сократить количество необязательных различий. Если для окружений подходят одинаковые настройки, их, скорее всего, нужно объединить.
Далее необходимо для каждого окружения создать файлы с их специфическими настройками, перезаписывающими установленные по умолчанию. Храните их в Git в репозитории приложения или в отдельном репозитории “infrastructure”. У ваших разработчиков должна быть возможность быстро найти конфигурации для различных окружений и в случае необходимости применить их в своих окружениях разработки.
Наконец, обеспечьте автоматическое развертывание на серверы своих артефактов, которые версионированы в Git. Всячески сопротивляйтесь искушению зайти на сервер по SSH и поправить конфиг вручную. Используйте Ansible, Chef или другой инструмент управления конфигурацией; или берите Packer, собирайте новые AMI и разворачивайте их с помощью Terraform. Используйте наиболее удобный для себя инструмент, но всегда держите свои файлы в синхронизированном состоянии.
Мощь Docker
Мы используем Docker для упаковки приложений, и это упрощает работу с файлами конфигурации за счет уменьшения различий между окружениями.
Следующий файл Docker Compose нормально отработает и на MacBook, и на production-сервере. Имя API-хоста всегда будет api, хоста с базой — db, а Docker позаботится о связывании этих имен с правильными контейнерами. Теперь не нужно прописывать разные имена хостов для разных окружений!
services:
web:
image: quay.io/buildo/app-frontend
ports:
- "80:5000"
links:
- api
api:
image: quay.io/buildo/app-backend
links:
- db
db:
image: postgres
Чтобы собирать специфические для окружений настройки в один файл, мы используем функциональность множественных compose-файлов Docker. Взглянув на testing.yml, можно сразу заметить, что тестовое окружение использует нестандартные HTTP-порты, включает development-токен и загружает другую конфигурацию базы данных.
Таким образом, наши Docker-образы абсолютно одинаковы для всех окружений, и мы используем Compose-файлы для установки специфичных для окружений настроек с помощью переменных окружения или файлов конфигурации.
В большинстве случаев лучше использовать переменные окружения, поскольку значения параметров конфигурации для разных (микро)сервисов могут быть с легкостью включены в один Compose-файл, который затем сохраняется в Git. Как показано в примере выше, если вы считаете, что файл конфигурации в каком-то случае лучше, его можно подключить с помощью Docker-тома. Но не забывайте, что все файлы конфигурации, которые упомянуты в Compose-файле, должны быть также сохранены в Git.
Как хранить секреты
Иногда параметры файлов конфигурации слишком чувствительны для того, чтобы их можно было хранить в Git даже в том случае, если это частный репозиторий. Это могут быть, например, ключи для AWS, токены production API и т. д. Diogo Monica недавно заявил, что эти данные также не стоит хранить в переменных окружения.
В buildo для шифрования конфиденциальной информации мы чаще всего пользуемся git-crypt, поэтому эту информацию можно сохранять в Git, но доступ к ней без PGP-ключа из белого списка получить невозможно.
Более навороченные решения типа Vault или Docker secrets обладают определенными преимуществами. Однако эти инструменты пока находятся у нас в разработке, и, возможно, мы напишем о них в будущих статьях…
Заключение
Пожалуйста, запомните следствия трех законов конфигодинамики:
перемещение параметров конфигурации в переменные окружения не решает проблему;
необходимо регулярно проводить поиск необязательных настроек;
важно обеспечить запуск приложения без файлов конфигурации.
Знание этих законов позволяет уменьшить конфигурационную энтропию и в итоге сэкономить значительное количество времени.
Следующее утверждение иногда зовется нулевым законом конфигодинамики:
Если конфигурация A сохранена в Git и скачана двумя разработчиками B и C, тогда B и C будут находиться в состоянии конфигурационного равновесия.
Проверка на наличие определенного контента на сайте — одна из наиболее востребованных функций сервиса мониторинга сайтов ХостТрекер. Под катом мы расскажем, в каких случаях и почему это важно и рассмотрим несколько реальных ситуаций.
Как оно работает?
Проверять регулярно контент — значит убеждаться в наличии определенных ключевых слов или фраз на проверяемых страницах. Выбрав эти слова правильным образом, можно быть уверенным, что правильно отработали нужные серверные скрипты, данные с базы успели подгрузиться куда надо, и вообще все происходит вовремя и по замыслу создателя.
Практика применения
Много чему мы учимся у наших клиентов. Нередко наблюдение за использованием наших функций преподносит нам сюрпризы из разряда «а что и так можно было?»
Вирусы и нерадивый хостинг.
Не все хостинги вовремя закрывают дыры в безопасности, даже довольно известные. И уж тем более не все хостинги оперативно решают вопросы клиентской поддержки, особенно если они сложнее за перезагрузку сервера. Были случаи, когда на сайте регулярно появлялся вирус. Конечно, мы рекомендуем с такими хостингами вообще дело не иметь, но ситуации бывают разные. Клиенту удалось с помощью функции проверки контента отслеживать появление этого вируса и оперативно удалять его вручную, пока хостер все же не закрыл дыру. Кстати, на это ушли месяцы.
Проверка всего и вся.
Некоторые клиенты не довольствуются тем, что есть. Например, можно создать страницу, на которую выводятся важные внутренние параметры системы с помощью скриптов на стороне сервера, а затем страница проверяется ХостТрекером извне, наравне с «внешними» сайтами клиента. В случае инцидентов приходят оповещения и о сайте, и о проблемах с системой — сразу понятно куда бежать и кого пинать. Кстати, мы эту практику тоже переняли.
Цензор из костылей.
Кое-кто занимается даже таким! Проверка контента может быть как «прямая», так и «обратная» — можно проверять страницу на отсутствие заданных фраз. Некоторые ресурсы, за нежеланием прикручивать более традиционный антимат, используют ХостТрекер для выявления нежелательных фраз. Плюс — мгновенная настройка и отсутствие надобности что-либо устанавливать на свой сервер.
Нюансы настройки и пользования
Продолжим тему быстрой настройки:
Как видим, все довольно просто и интуитивно понятно. Но есть несколько интересных «галочек». Например, можно заставить бота считывать всю строку, которая включает в себя найденный ключевик, и отправлять ее в сообщении. Таким образом, если ключевое слово — «error», а фраза, которая появилась на сайте — «server 11 connection error», то с этой галочкой вся фраза и придет, вместо обычного оповещения о появлении нежелательного ключевого слова. Более полное описание функций ХостТрекера можно найти здесь.
Как упоминалось выше, клиенты очень часто дают нам пример и стимул для дальнейшего развития. Поэтому будем рады замечаниям и пожеланиям.
От переводчика: «Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. Уже сейчас эти инструменты предоставляют качественный доступ к технологиям реального времени для веб-приложений. Сайты с повышенной интерактивностью, многопользовательские браузерные игры, микросервисы — те направления, в которых данные технологии сослужат хорошую службу. Далее представлен перевод серии из 11 статей, подробно описывающих аспекты разработки на фреймворке Феникс казалось бы такой тривиальной вещи, как блоговый движок. Но не спешите кукситься, будет действительно интересно, особенно если статьи побудят вас обратить внимание на Эликсир либо стать его последователями.»
В этой части речь больше пойдёт о вёрстке, чем непосредственно об Эликсире, однако статья будет полезна тем, что расскажет о взаимодействии с ассет-пайплайном Phoenix.
На чём мы остановились
В прошлой части мы закончили с написанием тестов для всего, связанного с каналами. На этот раз будет значительно меньше кода на Elixir, вместо которого мы научимся использовать сторонние библиотеки внутри Phoenix-приложений. Как правило, Phoenix встречает вас с очень-очень базовой версией Bootstrap, оптимизированной под него. Давайте немного отойдём от этого подхода и заменим его на другой CSS-фреймворк (а также будет использовать Sass).
Предупреждение. Автор статьи точно не является дизайнером. Результат может вас напугать, так что попробуйте менять всё на свой вкус.
Почему Foundation?
Не хотелось бы начинать спор на тему Bootstrap против Foundation. Вместо этого давайте просто возьмём Foundation, потому что внешний вид сайта на нём выглядит интереснее. Также для него нужно делать чуть меньше шаблонных вещей, по сравнению с Bootstrap. Кроме того, не так много людей пробовали использовать Foundation, так что будет тем интереснее!
Примечание. Обратите внимание, что для избежания проблем совместимости jQuery и Foundation, здесь устанавливается конкретная версия jQuery (v2.2.4). Для дополнительной информации посмотрите эту статью.
Также нужно поправить brunch-config.js, чтобы учесть изменения. А именно подключение Foundation к Brunch, включая загрузку Sass-директорий, конфигурацию модуля Sass, и установка jQuery в качестве глобальной зависимости для Npm.
exports.config = {
// See http://brunch.io/#documentation for docs.
files: {
javascripts: {
joinTo: "js/app.js"
},
stylesheets: {
joinTo: "css/app.css",
order: {
after: ["web/static/css/app.css"] // concat app.css last
}
},
templates: {
joinTo: "js/app.js"
}
},
conventions: {
// This option sets where we should place non-css and non-js assets in.
// By default, we set this to "/web/static/assets". Files in this directory
// will be copied to `paths.public`, which is "priv/static" by default.
assets: /^(web\/static\/assets)/
},
// Phoenix paths configuration
paths: {
// Dependencies and current project directories to watch
watched: [
"web/static",
"test/static"
],
// Where to compile files to
public: "priv/static"
},
// Configure your plugins
plugins: {
babel: {
// Do not use ES6 compiler in vendor code
ignore: [/web\/static\/vendor/]
},
sass: {
options: {
includePaths: [
'node_modules/foundation-sites/scss',
'node_modules/motion-ui/src',
]
}
}
},
modules: {
autoRequire: {
"js/app.js": ["web/static/js/app"]
}
},
npm: {
enabled: true,
globals: {
$: 'jquery',
jQuery: 'jquery',
}
}
};
Затем, нам нужно добавить директорию для Sass-файлов. Создайте директорию web/static/scss с 3 файлами внутри:
application.scss;
_settings.scss;
_custom.scss.
В файл web/static/scss/application.scss добавьте:
// Only put imports and things here
@import "settings";
@import "foundation";
@include foundation-everything;
@import "motion-ui";
@include motion-ui-transitions;
@import "custom";
В файл web/static/scss/_settings.scss добавьте содержимое файла по ссылке.
Вам также потребуется загрузить картинку и кинуть его в директорию web/static/assets/images/computer-bg.png, чтобы файл стилей мог использовать его в качестве фонового изображения.
Устанавливаем иконки и шрифты для Foundation
Если вы захотите подключить шрифт с иконками из набора Foundation, выполните следующие шаги:
Скопируйте следующие файлы в директорию web/static/assets/fonts: foundation-icons.eot, foundation-icons.svg, foundation-icons.ttf, foundation-icons.woff.
Скопируйте следующий файл в директорию web/static/css: foundation-icons.css.
Наконец, измените файл foundation-icons.css, чтобы пути для каждого шрифта соответствовали путям ассетов Phoenix:
/* Rest of the file */
@font-face {
font-family: "foundation-icons";
src: url("/fonts/foundation-icons.eot");
src: url("/fonts/foundation-icons.eot?#iefix") format("embedded-opentype"),
url("/fonts/foundation-icons.woff") format("woff"),
url("/fonts/foundation-icons.ttf") format("truetype"),
url("/fonts/foundation-icons.svg#fontcustom") format("svg");
font-weight: normal;
font-style: normal;
}
/* Rest of the file */
Теперь иконки должны быть полностью установлены.
Удаляем стандартные стили
Откройте файл web/static/css/phoenix.css и удалите всё, что в нём есть! Нам ничего из этого не понадобится, но могло бы пригодиться, если бы мы решили использовать стандартный CSS.
Изменяем работу с текущим пользователем
Перед тем как продолжить, хотелось бы сделать ещё одну вещь – улучшить написанный ранее код. Например, способ работы с текущим пользователем немного ненадёжен и требует писать один и тот же код снова и снова. Давайте добавим коду, связанному с текущим пользователем, возможность повторного использования. Сначала создадим новый плаг, который расположим в файле web/controllers/current_user_plug.ex:
defmodule Pxblog.CurrentUserPlug do
import Plug.Conn
def init(default), do: default
def call(conn, _opts) do
if current_user = get_session(conn, :current_user) do
assign(conn, :current_user, current_user)
else
conn
end
end
end
Что здесь происходит? Сначала импортируется Plug.Conn внутрь нашего модуля (так что можно легко получить доступ к функциям assign и get_session). Далее описывается функция init, принимающая и тут же возвращающая переменную default. Самая суть плага находится в функции call. Любой плаг должен реализовывать две функции – init и call. Функция call должна принимать conn и необязательные опции, а возвращать conn (изменённый или нет).
Если current_user есть в текущей сессии, то достаём его и закидываем внутрь conn, чтобы можно было отовсюду получать доступ к текущему пользователю. Если достать его нельзя, то просто возвращаем неизменённый conn. Затем, чтобы использовать плаг current_user глобально, откройте файл web/router.ex и вставьте его в стандартный пайплайн браузера:
pipeline :browser do
plug :accepts, ["html"]
plug :fetch_session
plug :fetch_flash
plug :protect_from_forgery
plug :put_secure_browser_headers
plug Pxblog.CurrentUserPlug
end
Вот и всё! Теперь, когда потребуется обратиться к текущему пользователю внутри разметки, мы можем просто вызвать @conn.assigns[:current_user]. Замечательно!
Улучшаем основной макет
Приступаем к рефакторингу основного макета приложения, чтобы было проще вносить изменения и легче повторно использовать общие элементы. Начнём с раздела head (всё что между тегами ). Создайте файл web/templates/layout/head.html.eex и перенесите в него тег head вместе с содержимым:
css/app.css") %>">
По большей части мы просто скопировали контент тега head, но при этом немного упростили работу с текущим пользователем и добавили немного информации в теги description, author и title. Вместо предыдущего подхода, когда использовался хелпер из LayoutView, теперь проверяется есть ли current_user внутри assigns, и если он есть, то текущий пользователь берётся в качестве параметра для метатега канала.
Теперь переходим к рефакторингу разметки верхней навигационной панели. Создайте файл web/templates/layout/navigation.html.eex:
Phoenix Tech Blog
Это первый большой участок кода, в котором по полной используется Foundation. Здесь есть класс top-bar, а также различные вариации меню и сдвигов вправо/влево. Мы полностью вырезаем стандартные логотип Phoenix и навигационную панель и вместо этого используем простой текст в качестве логотипа. Ради простоты будем называть наш проект Phoenix Tech Blog. Также построим немного простого HTML с парой встроенных в Foundation стилей и компонентов. Ещё раз, в любом месте, где используется старый способ получения текущего пользователя, нужно заменить его на новый подход с использованием плага.
Краткое описание представленных классов
В последнем примере используются описанные ниже классы:
top-bar – верхняя навигационная панель, как и ожидалось. (Документация)
Теперь возьмёмся за блок оповещения, который также являются достаточно часто используемым кодом. Давайте создадим файл web/templates/layout/alerts.html.eex:
Здесь нам нужно сделать чуть больше правок, так как у Phoenix по умолчанию есть конкретные ожидания относительно используемых классов CSS. Эти изменения сделают код блока предупреждений и стили чуть более платформонезависимыми.
Если мы можем достать сообщение из conn, то соответственно отображаем его внутри div. Если нет, то не отображаем ничего. В исходном HTML-коде всё равно появится пустой div, но он никак не повлияет на отображение.
callout – стандартный контейнер с флеш-сообщением. (Документация)
success – приятный светло-зеленый стиль для успешного сообщения. (Документация)
alert – приятный светло-красный стиль для сообщений об ошибках. (Документация)
Заканчиваем с рефакторингом макета
У нас осталось 2 паршла, которые нужно доработать. Первый – основной контент. Обернём внутренности дива в классы row и content:
Второй – шаблон для включение стандартного кода Javascript внизу. Создайте файл web/templates/layout/script.html.eex:
js/app.js") %>">
Основная доработка здесь – это замыкание которое включается для вызова функции foundation() на объекте документа. Это требуется для встроенных в Foundation JS-хелперов.
Добавляем паршлы в макет
Наконец, давайте взглянем на макет приложения после нашего рефакторинга и на общий контент. Давайте изменим файл web/templates/layout/app.html.eex:
Как вы можете заметить, макет приложения теперь выглядит куда более аккуратнее. Будет КРАЙНЕ удобно, если мы добавим новый макет для действия index из PageController, который назовём "splash page", что значит приветственная страница.
Создаём новый макет
Создайте файл нового макета `web/templates/layout/splash.html.eex:
What Powers This Blog
This blog is powered by Elixir and Phoenix Framework to
give us a super fast, super clean, and super fun to modify blog engine!
We Support Live Comments
By using the latest and greatest in client and server technology, we're able to offer a live, realtime commenting system with nearly no impact
to performance!
We Support Markdown
We allow you to use Markdown in all of your posts, which will make it simple to write
up each post in the program of your choice and import it into this blog!
This is an example design for the Phoenix Blog Engine project detailed in my series of
Medium posts.
This design is merely a starting template; you may want to go out and find your own
as well to make it look truly original! You're welcome to use the source code for this
project as well as the design as you wish! If you're interested in more, please find me
on the internet via:
Здесь делается много всего, но по сути это просто контент с парой стилей здесь и там. Давайте взглянем ещё на несколько классов из Foundation:
expanded – разворачивает row на всю ширину страницы. (Документация)
text-center – говорит сам за себя: выравнивает текст по центру. Схожим образом text-left и text-right выравнивает текст влево и вправо, соответственно. (Документация)
fi-comments, fi-pencil, fi-like – иконки из набора Foundation. (Документация)
columns – сообщает о том, что мы хотим использовать блок в качестве отдельной колонки. (Документация)
medium-12, large-4 – примеры использования адаптивной модели сетки. На экранах размера medium разметка займёт 12 колонок, а на экранах размера large только 4 колонки. (Вы также увидите пример использования small-N, где N некоторое число между 1 и 12). (Документация)
Наконец, сообщим Phoenix, что будем использовать новый макет для приветственного экрана в PageController. Откройте файл web/controllers/page_controller.ex и добавьте следующую строчку:
plug :put_layout, "splash.html"
Создаём экран постов для гостей
Нам также нужно дать гостям возможность просмотреть последние N постов, так как было бы глупо делать прикольный блог, который никто не сможет читать. Для начала откройте файл web/router.ex и добавьте ресурс для постов с одним действием index.
И затем откройте файл web/controllers/post_controller.ex, измените функцию index и добавьте ещё одну функцию index с использованием сопоставления с образцом. Но для начала измените плаг assign_user вверху файла:
plug :assign_user when not action in [:index]
А теперь измените функцию index:
def index(conn, %{"user_id" => _user_id}) do
conn = assign_user(conn, nil)
if conn.assigns[:user] do
posts = Repo.all(assoc(conn.assigns[:user], :posts)) |> Repo.preload(:user)
render(conn, "index.html", posts: posts)
else
conn
end
end
def index(conn, _params) do
posts = Repo.all(from p in Post,
limit: 5,
order_by: [desc: :inserted_at],
preload: [:user])
render(conn, "index.html", posts: posts)
end
Первый вызов проверяет наличие user_id в параметрах. Таким образом мы знаем, что получаем определённый пост для определённого пользователя. Если мы попали в эту функцию, то необходимо повторно использовать плаг assign_user для присвоения пользователя в conn. Чтобы не загружать пользователей для пустого массива, мы заранее проверяем наличие пользователя в assigns. Иначе просто возвращаем conn, который будет содержать переадресацию для несуществующего пользователя, флеш-сообщение и остановку запроса.
Вторая функция index немного отличается. Нам нужно достать 5 самых свежих постов, так что ограничим их количество и предзагрузим пользователей в каждый пост. Не стоит волноваться по поводу комментариев, ведь их не нужно отображать на странице со списком постов. Здесь также нужно немного оптимизировать использование current_user. Для этого откройте файл web/templates/post/index.html.eex:
Posts
Posted on by
Всё, что мы делали до – это там и сям прибирали стили. На всякий случай, код этих уроков находится здесь, так что можете посмотреть на все проделанные изменения, если хотите, чтобы у вас было всё один-в-один.
Исправляем тесты
Мы изменили часть разметки и функциональности, так что тесты упали. Чтобы их исправить, откройте файл test/controllers/page_controller_test.exs и измените проверку на “Phoenix Tech Blog”.
Заключение
Когда всё будет готово, вы должны увидеть подобную приветственную страницу:
А вот что увидит гость, решив взглянуть на список постов:
Теперь блог выглядит гораздо более профессионально. Плюс ко всему мы воспользовались Zurb Foundation 6 через Sass, а также jQuery и кучей других мелких бонусов.
Ура! Проделана огромная работа, которая наконец-то подошла к концу. Теперь у всех интересующихся Эликсиром и Фениксом есть довольно неплохой вводный курс, который поможет познакомиться с технологиями.
Спасибо всем, кто прошёл данный обучающий курс до конца, кто сообщал об ошибках, а также автору оригинальных статей. Лучшей благодарностью от вас за то, что я нашёл силы и довёл работу до конца, будет плюс этой статье, пусть она не самая интересная в цикле, но выводя её в топ, мы поможем узнать об этом курсе куче новых людей, так что, пожалуйста, не пожалейте времени и рейтинга для этого.
Задача резервирования основного шлюза — одна из самых популярных в сетевом администрировании. У нее есть целый ряд решений, которые реализуют механизмы приоритезации или балансировки исходящих каналов для абсолютного большинства современных маршрутизаторов, в том числе и маршрутизаторов на базе Linux.
В статье об отказоустойчивом роутере мы вскользь упоминали свой корпоративный стандарт для решения этой задачи — Open Source-продукт NetGWM — и обещали рассказать об этой утилите подробнее. Из этой статьи вы узнаете, как устроена утилита, какие «фишки» можно использовать в работе с ней и почему мы решили отказаться от использования альтернативных решений.
Почему NetGWM?
Классическая схема резервирования основного шлюза в Linux, реализуемая средствами iproute2, выглядит практически во всех источниках примерно одинаково:
Дано: 2 провайдера.
Создаем для каждого оператора свою таблицу маршрутизации.
Создаем правила (ip rule), по которым трафик попадает в ту или иную таблицу маршрутизации (например, по источнику и/или по метке из iptables).
Метриками или ifupdown-скриптами определяем приоритет основного шлюза.
Подробности этой схемы легко гуглятся по запросу «linux policy routing». На наш взгляд, схема имеет ряд очевидных недостатков, которые и стали основным мотиватором создания утилиты NetGWM:
Сложность внесения изменений в схему, плохая управляемость.
Если количество шлюзов 3 и более, логика скриптов усложняется, как и реализация выбора шлюза на основе метрик.
Проблема обнаружения пропадания канала. Зачастую, физический линк и даже шлюз оператора могут быть доступны, при этом из-за проблем внутри инфраструктуры оператора или у его вышестоящего поставщика услуг реально сеть оказывается недоступной. Решение этой проблемы требует добавление дополнительной логики в ifupdown-скрипты, а в маршрутизации на основе метрик она нерешаема в принципе.
Проблема «шалтай-болтай». Такая проблема проявляется, если на высокоприоритетном канале наблюдаются кратковременные частые перерывы в связи. При этом шлюз успешно переключается на резервный. Откуда здесь, казалось бы, может взяться проблема? Дело в том, что ряд сервисов, таких как телефония, видеосвязь, VPN-туннели и другие, требуют некоторого таймаута для определения факта обрыва и установления нового сеанса. В зависимости от частоты обрывов это приводит к резкому снижению качества сервиса или его полной недоступности. Решение этой проблемы также требует усложнения логики скриптов и тоже совершенно нерешаема метриками.
Мы посмотрели, что поможет нам решить все 4 проблемы: простое и управляемое средство с поддержкой 2 и более шлюзов по умолчанию, умеющее диагностировать доступность канала и тестировать его на стабильность. И не нашли такого варианта. Именно так и появился NetGWM.
Установка из GitHub и репозитория «Флант»
NetGWM (Network GateWay Manager) — это небольшая утилита приоритезации основного шлюза, написанная на Python и распространяемая под свободной лицензией GNU GPL v3. Автор первоначальной версии — driusha (Андрей Половов).
Исходный код и документация на английском языке доступны на GitHub, а краткая документация и описание на русском языке — здесь.
Установка из GitHub:
## Предварительно в системе требуется установить:
## iproute2, conntrack, модуль python-yaml
## После этого клонируем репозиторий:
$ git clone git://github.com/flant/netgwm.git netgwm
## И устанавливаем (понадобятся права суперпользователя):
$ cd netgwm && sudo make install
## Добавим служебную таблицу маршрутизации, которая будет использоваться NetGWM
$ sudo sh -c "echo '100 netgwm_check' >> /etc/iproute2/rt_tables"
## Добавляем в cron пользователя root вызов netgwm с той частотой,
## с которой вам бы хотелось проверять доступность основного шлюза
## (например, раз в минуту):
$ sudo crontab -e
*/1 * * * * /usr/lib/netgwm/newtgwm.py
Кроме того, готовый DEB-пакет с NetGWM можно установить из репозитория для Ubuntu компании «Флант». Установка для Ubuntu 14.04 LTS выглядит так:
## Установим репозиторий:
$ sudo wget https://apt.flant.ru/apt/flant.trusty.common.list \
-O /etc/apt/sources.list.d/flant.common.list
## Импортируем ключ:
$ wget https://apt.flant.ru/apt/archive.key -O- | sudo apt-key add -
## Понадобится HTTPS-транспорт — установите его, если не сделали это раньше:
$ sudo apt-get install apt-transport-https
## Обновим пакетную базу и установим netgwm:
$ sudo apt-get update && sudo apt-get install netgwm
Добавлять служебную таблицу маршрутизации и настраивать cron в Ubuntu не потребуется. Таблица автоматически добавится при установке пакета. Кроме того, при установке будет зарегистрирована служба netgwm, init-скрипт которой стартует в качестве демона небольшой shell-скрипт /usr/bin/netgwm, который, в свою очередь, читает из файла /etc/default/netgwm значение параметра INTERVAL (в секундах) и с указанной периодичностью сам вызывает netgwm.py.
Настройка
В основе работы NetGWM также лежит policy-роутинг, и нам придется предварительно настроить таблицы маршрутизации для каждого оператора.
Допустим, есть 3 оператора, и необходимо сделать так, чтобы основным оператором был оператор 1, в случае отказа — использовался оператор 2, а в случае отказа из обоих — оператор 3.
Пусть первый оператор у нас подключен к интерфейсу eth1, второй — к eth2, третий — к eth3. Первый оператор имеет шлюз 88.88.88.88, второй оператор — шлюз 99.99.99.99, третий — 100.100.100.100.
Мы почти всегда при настройке сети с несколькими основными шлюзами используем маркировку пакетов и модуль conntrack из NetFilter. Это хорошая практика, помогающая распределять пакеты по таблицам маршрутизации с учетом состояния, но не являющаяся обязательной.
2. Добавим правила маршрутизации для промаркированных пакетов. Мы это делаем с помощью скрипта, который вызывается из /etc/network/interfaces при событии post-up на интерфейсе lo:
3. Объявим таблицы маршрутизации в /etc/iproute2/rt_tables:
# Зарезервированные значения:
255 local
254 main
253 default
0 unspec
# Служебная таблица, которую мы (или dpkg) добавили ранее:
100 netgwm_check
# Таблицы для операторов, которые мы должны добавить сейчас:
101 operator1
102 operator2
103 operator3
4. Настроим NetGWM. По умолчанию, netgwm.py будет искать конфигурационный файл по адресу /etc/netgwm/netgwm.yml, однако вы можете переопределить это с помощью ключа -c. Настроим работу утилиты:
# Описываем маршруты по умолчанию для каждого оператора и приоритеты
# Меньшее значение (число) имеет больший приоритет. 1 - самый высокий приоритет
# Обратите внимание, что для смены шлюза по умолчанию на другой достаточно просто
# изменить значения приоритетов в этом файле. И уже при следующем запуске (через
# минуту в нашем случае) шлюз изменится на более приоритетный (если он доступен).
# Наименование оператора должно совпадать с именем таблицы маршрутизации из
# /etc/iproute2/rt_tables
gateways:
operator1: {ip: 88.88.88.88, priority: 1}
operator2: {ip: 99.99.99.99, priority: 2}
operator3: {ip: 100.100.100.100, priority: 3}
# Этот параметр решает проблему «шалтай-болтай», когда приоритетного
# оператора (из доступных) «штормит».
# Параметр определяет время постоянной доступности (в секундах),
# после которого netgwm будет считать, что связь стабильна
min_uptime: 900
# Массив удаленных хостов, которые будут использоваться netgwm для
# проверки работоспособности каждого оператора. Здесь стоит указать либо важные
# для вас хосты в интернете, либо общедоступные и стабильно работающие ресурсы,
# как сделано в примере. Шлюз считается недоступным, если netgwm НЕ СМОГ
# установить через него связь до ВСЕХ (условие AND) указанных хостов
check_sites:
- 8.8.8.8 # Google public DNS
- 4.2.2.2 # Verizon public DNS
# По умолчанию netgwm проверяет доступность только для самого
# приоритетного шлюза. Если тот недоступен — до второго по приоритетности и т.д.
# Данная опция, будучи установленной в true, заставит netgwm проверять
# доступность всех шлюзов при каждом запуске
check_all_gateways: false
5. Настроим действия при переключении.
Если произойдет переключение, то после смены основного шлюза будут выполнены все исполняемые файлы из каталога /etc/netgwm/post-replace.d/*. При этом каждому файлу будут переданы 6 параметров командной строки:
$1 — наименование нового оператора;
$2 — IP вновь установленного шлюзе или NaN, если новый шлюз установить не удалось;
$3 — имя устройства нового шлюза или NaN, если шлюз установить не удалось;
$4 — наименование старого оператора или NaN, если шлюз устанавливается впервые;
$5 — IP старого оператора или NaN, если шлюз устанавливается впервые;
$6 — имя устройства старого оператора или NaN, если шлюз устанавливается впервые.
В скрипте можно на основании этих переменных описать логику действий в зависимости от подключаемого оператора (добавить или удалить маршруты, отправить уведомления, настроить шейпинг и т.п.). Для примера приведу скрипт на shell, отправляющий уведомления:
#!/bin/bash
# Определяем, что произошло: переключение или старт netgwm
if [ "$4" = 'NaN' ] && [ "$5" = 'NaN' ]
then
STATE='start'
else
STATE='switch'
fi
# Отправляем уведомление дежурным инженерам о произошедшем
case $STATE in
'start')
/usr/bin/flant-integration --sms-send="NetGWM on ${HOSTNAME} has been started and now use gw: $1 - $2"
;;
'switch')
/usr/bin/flant-integration --sms-send="NetGWM on ${HOSTNAME} has switched to new gw: $1 - $2 from gw: $4 - $5"
;;
*)
/usr/bin/logger -t netgwm "Unknown NetGWM state. Try restarting service fo fix it."
;;
esac
exit
6. Стартуем сервис netgwm в Ubuntu, если вы установили DEB-пакет:
$ sudo service netgwm start
Если вы получили NetGWM из GitHub, то установленное ранее задание в cron уже и так проверяет доступность вашего основного шлюза, дополнительных действий не требуется.
Журналирование
События по переключению NetGWM регистрирует в журнале /var/log/netgwm:
$ tail -n 3 /var/log/netgwm.log
2017-07-14 06:25:41,554 route replaced to: via 88.88.88.88
2017-07-14 06:27:09,551 route replaced to: via 99.99.99.99
2017-07-14 07:28:48,573 route replaced to: via 88.88.88.88
Сохраненная история переключений помогает произвести анализ инцидента и определить причины перерыва в связи.
Проверено в production
Уже около 4 лет NetGWM используется в нашей компании на 30+ маршрутизаторах Linux разных масштабов. Надежность утилиты многократно проверена в работе. Для примера, на одной из инсталляций, с мая 2014 года NetGWM обработал 137 переключений операторов без каких-либо проблем.
Стабильность, покрытие всех наших потребностей и отсутствие проблем в эксплуатации в течение длительного времени привели к тому, что мы практически не занимаемся развитием проекта. Код NetGWM написан на Python, поэтому отсутствует и необходимость в адаптации утилиты к новым версиям операционных систем. Тем не менее, мы будем очень рады, если вы решите принять участие в развитии NetGWM, отправив свои патчи в GitHub или просто написав feature request в комментариях.
Заключение
С NetGWM мы имеем стабильную, гибкую и расширяемую (с помощью скриптов) утилиту, которая полностью закрывает наши потребности в управлении приоритетом основного шлюза.
Любые вопросы по использованию NetGWM также приветствуются — можно прямо здесь в комментариях.
И снова всем привет! После небольшого перерыва, продолжаем грызть гранит сетевой науки. В данной статье речь пойдет о протоколе Etherchannel. В рамках данной темы поговорим о том, что такое агрегирование, отказоустойчивость, балансировка нагрузки. Темы важные и интересные. Желаю приятного прочтения.
Итак, начнем с простого.
Etherchannel — это технология, позволяющая объединять (агрегировать) несколько физических проводов (каналов, портов) в единый логический интерфейс. Как правило, это используется для повышения отказоустойчивости и увеличения пропускной способности канала. Обычно, для соединения критически важных узлов (коммутатор-коммутатор, коммутатор-сервер и др.). Само слово Etherchannel введено компанией Cisco и все, что связано с агрегированием, она включает в него. Другие вендоры агрегирование называют по-разному. Huawei называет это Link Aggregation, D-Link называет LAG и так далее. Но суть от этого не меняется.
Разберем работу агрегирования подробнее.
Есть 2 коммутатора, соединенных между собой одним проводом. К обоим коммутаторам подключаются сети отделов, групп (не важен размер). Главное, что за коммутаторами сидят некоторое количество пользователей. Эти пользователи активно работают и обмениваются данными между собой. Соответственно им ни в коем случае нельзя оставаться без связи. Встает 2 вопроса:
Если линк между коммутаторами откажет, будет потеряна связь. Работа встанет, а администратор в страхе побежит разбираться в чем дело.
Второй вопрос не настолько критичен, но с заделом на будущее. Компания растет, появляются новые сотрудники, трафика становится больше, а каналы все те же. Нужно как-то увеличивать пропускную способность.
Первое, что приходит в голову — это докинуть еще несколько проводов между коммутаторами. Но этот поход в корне не верен. Добавление избыточных линков приведет к появлению петель в сети, о чем уже говорилось в предыдущей статье. Можно возразить, что у нас есть замечательное семейство протоколов STP и они все решат. Но это тоже не совсем верно. Показываю на примере того же Packet Tracer.
Как видим, из 2-х каналов, активен только один. Второй будет ждать, пока откажет активный. То есть мы добьемся некой отказоустойчивости, но не решим вопрос с увеличением пропускной способности. Да и второй канал будет просто так простаивать. Правилом хорошего тона является такой подход, чтобы элементы сети не простаивали. Оптимальным решением будет создать из нескольких физических интерфейсов один большой логический и по нему гонять трафик. И на помощь приходит Etherchannel. В ОС Cisco 3 вида агрегирования:
1) LACP или Link Aggregation Control Protocol — это открытый стандарт IEEE.
2) PAgP или Port Aggregation Protocol — проприетарный протокол Cisco.
Ручное агрегирование.
Все 3 вида агрегирования будут выполнены только в следующих случаях:
Одинаковый Duplex
Одинаковая скорость интерфейсов
Одинаковые разрешенные VLAN-ы и Native VLAN
Одинаковый режим интерфейсов (access, trunk)
То есть порты должны быть идентичны друг другу.
Теперь об их отличии. Первые 2 позволяют динамически согласоваться и в случае отказа какого-то из линков уведомить об этом.
Ручное агрегирование делается на страх и риск администратора. Коммутаторы не будут ничего согласовывать и будут полагаться на то, что администратор все предусмотрел. Несмотря на это, многие вендоры рекомендуют использовать именно ручное агрегирование, так как в любом случае для правильной работы должны быть соблюдены правила, описанные выше, а коммутаторам не придется генерировать служебные сообщения для согласования LACP или PAgP.
Начну с протокола LACP. Чтобы он заработал, его нужно перевести в режим active или passive. Отличие режимов в том, что режим active сразу включает протокол LACP, а режим passive включит LACP, если обнаружит LACP-сообщение от соседа. Соответственно, чтобы заработало агрегирование с LACP, нужно чтобы оба были в режиме active, либо один в active, а другой в passive. Составлю табличку.
Режим
Active
Passive
Active
Да
Да
Passive
Да
Нет
Теперь перейдем к лабораторке и закрепим в практической части.
Есть 2 коммутатора, соединенные 2 проводами. Как видим, один линк активный (горит зеленым), а второй резервный (горит оранжевым) из-за срабатывания протокола STP. Это хорошо, протокол отрабатывает. Но мы хотим оба линка объединить воедино. Тогда протокол STP будет считать, что это один провод и перестанет блокировать.
Заходим на коммутаторы и агрегируем порты.
SW1(config)#interface fastEthernet 0/1 - заходим на интерфейс
SW1(config-if)#shutdown - выключаем его (чтобы не было проблем с тем, что STP вдруг его заблокирует)
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
SW1(config-if)#channel-group 1 mode active - создаем интерфейс port-channel 1 (это и будет виртуальный интерфейс агрегированного канала) и переводим его в режим active.
Creating a port-channel interface Port-channel 1 - появляется служебное сообщение о его создании.
SW1(config-if)#no shutdown - включаем интерфейс.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
SW1(config)#interface fastEthernet 0/2 - заходим на второй интерфейс
SW1(config-if)#shutdown - выключаем.
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if)#channel-group 1 mode active - определяем в port-channel 1
SW1(config-if)#no shutdown - включаем.
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
На этом настройка на первом коммутаторе закончена. Для достоверности можно набрать команду show etherchannel port-channel:
SW1#show etherchannel port-channel
Channel-group listing:
----------------------
Group: 1
----------
Port-channels in the group:
---------------------------
Port-channel: Po1 (Primary Aggregator)
------------
Age of the Port-channel = 00d:00h:08m:44s
Logical slot/port = 2/1 Number of ports = 2
GC = 0x00000000 HotStandBy port = null
Port state = Port-channel
Protocol = LACP
Port Security = Disabled
Ports in the Port-channel:
Index Load Port EC state No of bits
------+------+------+------------------+-----------
0 00 Fa0/1 Active 0
0 00 Fa0/2 Active 0
Time since last port bundled: 00d:00h:08m:43s Fa0/2
Видим, что есть такой port-channel и в нем присутствуют оба интерфейса.
Переходим ко второму устройству.
SW2(config)#interface range fastEthernet 0/1-2 - переходим к настройке сразу нескольких интерфейсов.
SW2(config-if-range)#shutdown - выключаем их.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW2(config-if-range)#channel-group 1 mode passive - создаем port-channel и переводим в режим passive (включится, когда получит LACP-сообщение).
Creating a port-channel interface Port-channel 1 - интерфейс создан.
SW2(config-if-range)#no shutdown - обратно включаем.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
После этого канал согласуется. Посмотреть на это можно командой show etherchannel summary:
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) LACP Fa0/1(P) Fa0/2(P)
Здесь видно группу port-channel, используемый протокол, интерфейсы и их состояние. В данном случае параметр SU говорит о том, что выполнено агрегирование второго уровня и то, что этот интерфейс используется. А параметр P указывает, что интерфейсы в состоянии port-channel.
Все линки зеленые и активные. STP на них не срабатывает.
Сразу предупрежу, что в packet tracer есть глюк. Суть в том, что интерфейсы после настройки могут уйти в stand-alone (параметр I) и никак не захотят из него выходить. На момент написания статьи у меня случился этот глюк и решилось пересозданием лабы.
Теперь немного углубимся в работу LACP. Включаем режим симуляции и выбираем только фильтр LACP, чтобы остальные не отвлекали.
Видим, что SW1 отправляет соседу LACP-сообщение. Смотрим на поле Ethernet. В Source он записывает свой MAC-адрес, а в Destination мультикастовый адрес 0180.C200.0002. Этот адрес слушает протокол LACP. Ну и выше идет «длинная портянка» от LACP. Я не буду останавливаться на каждом поле, а только отмечу те, которые, на мой взгляд, важны. Но перед этим пару слов. Вот это сообщение используется устройствами для многих целей. Это синхронизация, сбор, агрегация, проверка активности и так далее. То есть у него несколько функций. И вот перед тем, как это все начинает работать, они выбирают себе виртуальный MAC-адрес. Обычно это наименьший из имеющихся.
И вот эти адреса они будут записывать в поля LACP.
С ходу это может не сразу лезет в голову. С картинками думаю полегче ляжет. В CPT немного кривовато показан формат LACP, поэтому приведу скрин реального дампа.
Выделенная строчка показывает для какой именно цели было послано данное сообщение.
Вот суть его работы. Теперь это единый логический интерфейс port-channel. Можно зайти на него и убедиться:
SW1(config)#interface port-channel 1
SW1(config-if)#?
arp Set arp type (arpa, probe, snap) or timeout
bandwidth Set bandwidth informational parameter
cdp Global CDP configuration subcommands
delay Specify interface throughput delay
description Interface specific description
duplex Configure duplex operation.
exit Exit from interface configuration mode
hold-queue Set hold queue depth
no Negate a command or set its defaults
service-policy Configure QoS Service Policy
shutdown Shutdown the selected interface
spanning-tree Spanning Tree Subsystem
speed Configure speed operation.
storm-control storm configuration
switchport Set switching mode characteristics
tx-ring-limit Configure PA level transmit ring limit
И все действия, производимые на данном интерфейсе автоматически будут приводить к изменениям на физических портах. Вот пример:
SW1(config-if)#switchport mode trunk
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
Стоило перевести port-channel в режим trunk и он автоматически потянул за собой физические интерфейсы. Набираем show running-config:
SW1#show running-config
Building configuration...
Current configuration : 1254 bytes
!
version 12.2
no service timestamps log datetime msec
no service timestamps debug datetime msec
no service password-encryption
!
hostname SW1
!
!
!
!
!
spanning-tree mode pvst
!
interface FastEthernet0/1
channel-group 1 mode active
switchport mode trunk
!
interface FastEthernet0/2
channel-group 1 mode active
switchport mode trunk
!
***************************************
interface Port-channel 1
switchport mode trunk
!
И действительно это так.
Теперь расскажу про такую технологию, которая заслуживает отдельного внимания, как Load-Balance или на русском «балансировка». При создании агрегированного канала надо не забывать, что внутри него физические интерфейсы и пропускают трафик именно они. Бывают случаи, что вроде канал агрегирован, все работает, но наблюдается ситуация, что весь трафик идет по одному интерфейсу, а остальные простаивают. Как это происходит объясню на обычном примере. Посмотрим, как работает Load-Balance в текущей лабораторной работе.
SW1#show etherchannel load-balance
EtherChannel Load-Balancing Operational State (src-mac):
Non-IP: Source MAC address
IPv4: Source MAC address
IPv6: Source MAC address
На данный момент он выполняет балансировку исходя из значения MAC-адреса. По умолчанию балансировка так и выполняется. То есть 1-ый MAC-адрес она пропустит через первый линк, 2-ой MAC-адрес через второй линк, 3-ий MAC-адрес снова через первый линк и так будет чередоваться. Но такой подход не всегда верен. Объясняю почему.
Вот есть некая условная сеть. К SW1 подключены 2 компьютера. Далее этот коммутатор соединяется с SW2 агрегированным каналом. А к SW2 поключается маршрутизатор. По умолчанию Load-Balance настроен на src-mac. И вот что будет происходить. Кадры с MAC-адресом 111 будут передаваться по первому линку, а с MAC-адресом 222 по второму линку. Здесь верно. Переходим к SW2. К нему подключен всего один маршрутизатор с MAC-адресом 333. И все кадры от маршрутизатора будут отправляться на SW1 по первому линку. Соответственно второй будет всегда простаивать. Поэтому логичнее здесь настроить балансировку не по Source MAC-адресу, а по Destination MAC-адресу. Тогда, к примеру, все, что отправляется 1-ому компьютеру, будет отправляться по первому линку, а второму по второму линку.
Это очень простой пример, но он отражает суть этой технологии.
Меняется он следующим образом:
SW1(config)#port-channel load-balance ?
dst-ip Dst IP Addr
dst-mac Dst Mac Addr
src-dst-ip Src XOR Dst IP Addr
src-dst-mac Src XOR Dst Mac Addr
src-ip Src IP Addr
src-mac Src Mac Addr
Здесь думаю понятно. Замечу, что это пример балансировки не только для LACP, но и для остальных методов.
Заканчиваю разговор про LACP. Напоследок скажу только, что данный протокол применяется чаще всего, в силу его открытости и может быть использован на большинстве вендоров.
Тем, кому этого показалось мало, могут добить LACP здесь, здесь и здесь. И вдобавок ссылка на данную лабораторку.
Теперь про коллегу PAgP. Как говорилось выше — это чисто «цисковский» протокол. Его применяют реже (так как сетей, построенных исключительно на оборудовании Cisco меньше, чем гетерогенных). Работает и настраивается он аналогично LACP, но Cisco требует его знать и переходим к рассмотрению.
У PAgP тоже 2 режима:
Desirable — включает PAgP.
Auto — включиться, если придет PAgP сообщение.
Режим
Desirable
Auto
Desirable
Да
Да
Auto
Да
Нет
Собираем аналогичную лабораторку.
И переходим к SW1:
SW1(config)#interface range fastEthernet 0/1-2 - выбираем диапазон интерфейсов.
SW1(config)#shutdown - выключаем.
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if-range)#channel-group 1 mode desirable - создаем port-channel и переключаем его в режим desirable (то есть включить).
Creating a port-channel interface Port-channel 1
Теперь переходим к настройке SW2 (не забываем, что на SW1 интерфейсы выключены и следует после к ним вернуться):
SW2(config)#interface range fastEthernet 0/1-2 - выбираем диапазон интерфейсов.
SW2(config-if-range)#channel-group 1 mode auto - создаем port-channel и переводим в auto (включиться, если получит PAgP-сообщение).
Creating a port-channel interface Port-channel 1
Возвращаемся к SW1 и включаем интерфейсы:
SW1(config)#interface range fastEthernet 0/1-2
SW1(config-if-range)#no shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
Вроде как все поднялось. Проверим. SW1:
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) PAgP Fa0/1(P) Fa0/2(P)
SW2:
SW2#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) PAgP Fa0/1(P) Fa0/2(P)
Теперь переходим в симуляцию и настраиваемся на фильтр PAgP. Видим, вылетевшее сообщение от SW2. Смотрим.
То есть видим в Source MAC-адрес SW2. В Destination мультикастовый адрес для PAgP. Повыше протоколы LLC и SNAP. Они нас в данном случае не интересуют и переходим к PAgP. В одном из полей он пишет виртуальный MAC-адрес SW1 (выбирается он по тому же принципу, что и в LACP), а ниже записывает свое имя и порт, с которого это сообщение вышло.
В принципе отличий от LACP практически никаких, кроме самой структуры. Кто хочет ознакомиться подробнее, ссылка на лабораторную. А вот так он выглядит реально:
Последнее, что осталось — это ручное агрегирование. У него с агрегированием все просто:
Режим
On
On
Да
При остальных настройках канал не заработает.
Как говорилось выше, здесь не используется дополнительный протокол согласования, проверки. Поэтому перед агрегированием нужно проверить идентичность настроек интерфейсов. Или сбросить настройки интерфейсов командой:
Switch(config)#default interface faX/X
В созданной лабораторке все изначально по умолчанию. Поэтому я перехожу сразу к настройкам.
SW1(config)#interface range fastEthernet 0/1-2
SW1(config-if-range)#shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to administratively down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
SW1(config-if-range)#channel-group 1 mode on - создается port-channel и сразу включается.
Creating a port-channel interface Port-channel 1
SW1(config-if-range)#no shutdown
%LINK-5-CHANGED: Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINK-5-CHANGED: Interface FastEthernet0/2, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
И аналогично на SW2:
SW2(config)#interface range fastEthernet 0/1-2
SW2(config-if-range)#channel-group 1 mode on
Creating a port-channel interface Port-channel 1
%LINK-5-CHANGED: Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel 1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/1, changed state to up
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to down
%LINEPROTO-5-UPDOWN: Line protocol on Interface FastEthernet0/2, changed state to up
Настройка закончена. Проверим командой show etherchannel summary:
SW1#show etherchannel summary
Flags: D - down P - in port-channel
I - stand-alone s - suspended
H - Hot-standby (LACP only)
R - Layer3 S - Layer2
U - in use f - failed to allocate aggregator
u - unsuitable for bundling
w - waiting to be aggregated
d - default port
Number of channel-groups in use: 1
Number of aggregators: 1
Group Port-channel Protocol Ports
------+-------------+-----------+----------------------------------------------
1 Po1(SU) - Fa0/1(P) Fa0/2(P)
Порты с нужными параметрами, а в поле протокол "-". То есть дополнительно ничего не используется.
Как видно все методы настройки агрегирования не вызывают каких-либо сложностей и отличаются только парой команд.
Под завершение статьи приведу небольшой Best Practice по правильному агрегированию. Во всех лабораторках для агрегирования использовались 2 кабеля. На самом деле можно использовать и 3, и 4 (вплоть до 8 интерфейсов в один port-channel). Но лучше использовать 2, 4 или 8 интерфейсов. А все из-за алгоритма хеширования, который придумала Cisco. Алгоритм высчитывает значения хэша от 0 до 7.
4
2
1
Десятичное значение
0
0
0
0
0
0
1
1
0
1
1
3
1
0
0
4
0
0
1
1
1
0
1
5
1
1
0
6
1
1
1
7
Данная таблица отображает 8 значений в двоичном и десятичном виде.
На основании этой величины выбирается порт Etherchannel и присваивается значение. После этого порт получает некую «маску», которая отображает величины, за которые тот порт отвечает. Вот пример. У нас есть 2 физических интерфейса, которые мы объединяем в один port-channel. Значения раскидаются следующим образом:
В результате получим, что половину значений или паттернов возьмет на себя fa0/1, а вторую половину fa0/2. То есть получаем 4:4. В таком случае балансировка будет работать правильно (50/50).
Теперь двинемся дальше и объясню, почему не рекомендуется использовать, к примеру 3 интерфейса. Составляем аналогичное сопоставление:
Здесь получаем, что fa0/1 возьмет на себя 3 паттерна, fa0/2 тоже 3 паттерна, а fa0/3 2 паттерна. Соответственно нагрузка будет распределена не равномерно. Получим 3:3:2. То есть первые два линка будут всегда загруженнее, чем третий.
Все остальные варианты я считать не буду, так как статья растянется на еще больше символов. Можно только прикинуть, что если у нас 8 значений и 8 линков, то каждый линк возьмет себе по паттерну и получится 1:1:1:1:1:1:1:1. Это говорит о том, что все интерфейсы будут загружены одинаково. Еще есть некоторое утверждение, что агрегировать нужно только четное количество проводов, чтобы добиться правильной балансировки. Но это не совсем верно. Например, если объединить 6 проводов, то балансировка будет не равномерной. Попробуйте посчитать сами. Надеюсь алгоритм понятен.
У Cisco на сайте по этому делу есть хорошая статья с табличкой. Можно почитать по данной ссылке. Если все равно останутся вопросы, пишите!
Раз уж так углубились, то расскажу про по увеличение пропускной способности. Я специально затронул эту тему именно в конце. Бывают случаи, что срочно нужно увеличить пропускную способность канала. Денег на оборудование нет, но зато есть свободные порты, которые можно собрать и пустить в один «толстый» поток. Во многих источниках (книги, форумы, сайты) утверждается, что соединяя восемь 100-мегабитных портов, мы получим поток в 800 Мбит/с или восемь гигабитных портов дадут 8 Гбит/с. Вот кусок текста из «цисковской» статьи.
Теоретически это возможно, но на практике почти недостижимо. Я по крайней мере не встречал. Если есть люди, которые смогли этого добиться, я буду рад услышать. То есть, чтобы это получить, нужно учесть кучу формальностей. И вот те, которые я описывал, только часть. Это не значит, что увеличения вообще не будет. Оно, конечно будет, но не настолько максимально.
На этом статья подошла к концу. В рамках данной статьи мы научились агрегировать каналы вручную, а также, при помощи протоколов LACP и PAgP. Узнали, что такое балансировка, как ею можно управлять и как правильно собирать Etherchannel для получения максимального распределения нагрузки. До встречи в следующей статье!
Если у вас появилась потребность добавить React в Wagtail CMS, да еще и с использованием GraphQL, то это руководство должно помочь вам в этом.
Это перевод статьи из официального блога Wagtail, автор Brent Clark.
Возможность интегрировать Wagtail CMS с существующими моделями сайта на уровне GraphQL означает, что мы могли бы использовать наши существующие вызовы API внутри статей блога используя немного больше, чем ForeignKey и небольшой преобразователь.
Понедельник, 07 Августа 2017 г. 20:01
+ в цитатник
Как строить рекомендательные системы? Какие модели машинного обучения можно применять? Какие проблемы решают интерактивные рекоммендеры, а какие – нет? Какие инструменты могут быть полезны для e-commerce портала? Об этом – в докладе Big Data-инженера ЕРАМ Екатерины Сотенко «Обзор подходов построения интерактивных рекоммендеров», с которым она выступила на самарском ITsubbotnik этой весной. Ниже – видеозапись доклада, еще ниже – его краткое содержание.
С чего все началось
К EPAM обратился известный британский модный дом, которому нужен был интерактивный рекоммендер для e-commerce портала. До этого EPAM представил имплементацию обычного offline рекоммендера. Теперь заказчик хотел узнавать о желаниях пользователей в реальном времени, а не постфактум. Чтобы решить эту задачу, мы изучили портал заказчика и выбрали следующие элементы в работу:
1. Главная страница
Это страница, где пользователь – даже если он еще не залогинился – видит каталог. Какой бы пользователь не пришел – уже зарегистрированный или новый – нам нужно его заинтересовать с самого начала. Для этого мы предложили концепцию с категориальными фильтрами: вы можете выбирать из предложенного набора категорий по принципу «я хотел бы больше это, нежели это», а не точно указывать («хочу именно это»). В этом и отличие от обычного поиска: пользователю дается инструмент, с помощью которого можно быстро обнаружить что-то интересное ему, даже если человек четко не сформулировал свои пожелания. Здесь интерактивные рекоммендеры уместны, так как нам нужно понять, ищет пользователь что-то новое или уже привычное. Эту задачу можно решить с помощью группы алгоритмов «многорукие бандиты» (multi-armed bandits).
2. Основной каталог
Традиционно пользователь может отбирать элементы из каталога с помощью фильтров по цвету, размеру и другим критериям. Если нам уже известны предпочтения человека, можно сразу представить каталог с наиболее релевантным для него подбором элементов. Алгоритмы, использующие информацию о пользователе, – это demographic based рекоммендеры.
Но тут возникает вопрос: что, если мы не знаем о контексте пользователя и не понимаем, чем определяется его выбор? Здесь нам помогут context based рекоммендеры. Более того, мы можем строить рекомендации интерактивно: например, если пользователь начинает скроллить экран, мы понимаем, что он продолжает искать, и подбрасываем ему новые продукты. Мы учитываем, что варианты, которые уже были представлены, оказались неинтересны. Здесь можно снова использовать модель multi-armed bandits.
3. Корзина
Если пользователь определился с выбором, можно попробовать заинтересовать его чем-то еще. Это реализуется с помощью линейки товаров вида «С этим таже покупают». Для построения этой линейки используются learning to rank или sequential pattern mining алгоритмы.
4. Подарки
Основная проблема этого раздела в том, что подарки пользователь выбирает не себе. Нужно использовать информацию не о вас, а о том, кому достанется подарок. Тут не помогут ни знания о пользователе, ни коллаборативная фильтрация. Нам нужна информация, с кем дружит пользователь, есть ли у него дети и т.д. Здесь нам поможет demographic based рекоммендер, использующий информацию об отношениях пользователя, и sequential pattern mining.
Конверсия
Когда мы определились с задачами и инструментами, нужно понять, какие инструменты принесут наибольшую конверсию. Рассмотрим пример apparel stores. В Германии провели исследование о поведении пользователей во время онлайн-шопинга, при покупке одежды. В нем участвовало около 50 женщин. Им нужно было подобрать себе образ на встречу выпускников в ресторане. В рамках эксперимента они могли купить любое количество вещей, но поратить не больше 300 евро. Основываясь на даных о доходах, возрасте, привычке следить за модой, исследователи разделили участниц на несколько групп и начали собирать статистику.
Результаты исследования показали: чаще всего участницы использовали фильтры и поиск (71%). Среди фильтров активнее всего пользовались фильтром по цвету, далее идут фильтры по размеру и стоимости. Если говорить о рекоммендерах, то чаще всего использовали коллаборативную фильтрацию, а другие инструменты – гораздо реже.
При этом основную долю конверсии сгенерировал поиск (62%) и навигация с помощью фильтров (83%). Это значит, что, если пользователь ищет, он знает, чего хочет, и не нужно мешать ему. Коллаборативная фильтрация, рекомендация «надеть с этим», style guide дали меньше 50% конверсии. Это объясняется тем, что люди не хотят выглядеть как другие и стремятся подчеркнуть свою индивидуальность. С другой стороны, 50% – это неплохо, и при уместном использовании такие рекоммендеры могут быть очень эффективными. Например, раздел Occasion/event принес 100% конверсию.
Отдельно стоит отметить, что разделы Top seller’s list, New in, сезонные предложения принесли 0% конверсии. Это не стоит воспринимать как абсолютные показатели, так как нужно помнить о задаче: женщины выбирали не повседневную одежду, кроме того, выбор не зависел от сезона. Значит, в других условиях такие рекомендации могли сработать.
Теория. Типы рекомендательных систем
Кратко рассмотрим, как можно реализовать те или иные рекоммендеры.
1. Коллаборативная фильтрация
Идея этого подхода в том, что есть пользователи и элементы, которые люди оценивают несколькими способами: ставят лайки, оценки и т.д. На их основе строится матрица оценок пользователей. Но поскольку далеко не все ставят лайки, эта матрица разряженная, и задача заключается в регрессии недостающих оценок.
Есть два типа алгоритмов, которые реализуют эту концепцию:
• Neighborhood-based (Memory-Based) методы. Они помогают восстановить оценки явно, при этом храня полную матрицу отношений, которая, как правило, очень большая. Главный недостаток этих методов – низкая эффективность из-за того, что они не дают действительно персонализованную оценку. Примеры алгоритмов: User-Based Filtering (UBCF), Item-Based Filtering (IBCF), Slope-One.
• Model Based методы. Их идея в том, чтобы определить скрытые факторы (интересы пользователей), на основе которых люди ставят оценки. Примеры алгоритмов: o Matrix Factorization (MF): Singular Value Decomposition (SVD, SVD++, timeSVD++, MSVD), Non-Negative MF (ALS), Factorization Machines, Probabilistic Matrix Factorization (PMF)
o RBM (Restricted Bolzman Machines).
o Incremental CF via Co-clustering (COCL, ECOCL)
o Probabilistic Principle Component Analysis (pPCA), Probabilistic Latent Semantic Analysis (pLSA), Latent Dirichlet Allocation (LDA) and etc.
Достоинство коллаборативной фильтрации заключается в том, что для построения рекомендаций не нужны знания о предметной области вообще, не требуется знать деталей об айтемах и пользователях. Они кластеризуются между собой в режиме самоорганизации.
Недостаток: проблема холодного старта (cold start problem): если появляется новый пользователь или айтем, они не будут рекомендованы, так как нет информации и оценок.
2. Сontent based рекоммендеры
Чтобы решить проблему холодного старта и рекомендовать новые элементы, коллаборативную фильтрацию иногда интегрируют с content based рекоммендерами. При этом подходе нужно описать все айтемы. Но их свойства не всегда получается собрать по юридическим или техническим причинам.
3. Demographic based рекоммендеры
Если холодный старт произошел для пользователя, то нам нужно собрать о нем информацию и описать его.
Общая проблема группы методов, связанных с коллаборативной фильтрацией, заключаеся в следующем. Они работают хорошо, только если речь идет о большом количестве данных. Эти методы подходят для рекомендации объектов, выбор которых зависит от вкуса пользователя, например, для рекомендации фильмов или музыки. Но этот подход не эффективен, когда нужно рекомендовать такие сложные объекты, как машины, недвижимость и т.д. В этом случае можно использовать knowledge based recommenders.
4. Knowledge based рекоммендеры
Здесь требуются эксперты, которые оценивают предлагаемые объекты и описывают критерии, по которым их выбирают пользователи. Считается, что эти эксперты знают все: к какому типу пользователей вы принадлежите, сколько хотите потратить, какими характеристиками должны обладать товары, чтобы привлечь вас. Таким образом решается проблема и для пользователей, и для айтемов. Но тут есть недостаток: эксперты – очень дорогие и ненадежные люди, поэтому не всегда возможно описать все правила для вашего каталога.
5. Сontext-aware рекоммендеры
Оффлайн оценки экспертов могут быть ошибочны и неполны, так как на этапе оценки неизвестен контекст, в котором пользователь выбирает айтем. Контекст со временем может меняться. Например, вы все время смотрели фильмы ужасов, но вдруг начали искать мультики, потому что ваши дети захотели их посмотреть. С точки зрения рекоммендера вы сошли с ума, и он продолжит рекомендовать вам фильмы ужасов, предполагая, что однажды вы придете в себя. Что с вами случилось на самом деле? Изменился контекст, и на это нужно реагировать, что и позволяют сделать context-aware рекоммендеры.
Чтобы эффективно делать контекстные рекомендации, нужно решать задачу Change Point Detection в смысле временных рядов. Когда поведение пользователя резко меняется, это значит, что резко изменился контекст. Есть различные методы, которые позволяют нам учитывать контекст: factorization machines, Byesian Probablistic Tensor Factorization.
6. Интерактивные рекоммендеры
Их главная цель – в режиме текущей сессии пользователя выбрать варианты, наиболее релевантные его пожеланиям.
Жизненный пример
Вспомним себя в баре. Вы хотите отлично провести время. Видите краны от пива и начинаете выбирать, что выпить. В этот момент вы решаете задачу: пить незнакомое (exploration) или знакомое (exploitation) пиво? Это Exploration vs. Exploitation problem. Ее должны решать интерактивные рекоммендеры. Подходы к решению этой проблемы:
1. Active learning (AL) позволяет осуществить редукцию пространства поиска
2. Multi-armed bandits (MAB) algorithms: E-greedy, UCB, LinUCB, Tomson Sampling, Active Thompson Sampling (ATS)
3. Markov Decision Process (MDP)/Reinforcement Learning (RL)
4. Hybrid scoring approaches could be considered – models composition used.
Основные виды MAB алгоритмов
1. E-greedy – это просто частотная оценка: мы выбираем ту или иную руку нашего бандита на основе частоты ее использования. Вспоминаем краны в баре: чем чаще мы используем тот или иной кран, тем больше мы любим это пиво.
2. Upper Confidence Bound (UCB) – стремимся оценить удовольствие, которое получит пользователь от выбора определенного айтема. Задача – достаточно точно оценить это удовольствие для каждой из ручек. Для новых айтемов в этом алгоритме присваивается потенциально максимальная оценка вознаграждения. Каждый раз, когда бандиту дергают ручку, актуализируется оценка вознаграждения. Этот алгоритм будет всегда больше склоняться к exploration, нежели к exploitation, и не может поддерживать вычисление слишком большого числа рук.
3. Tomson Sampling (TS) может представлять каждую из рук бандита в виде вероятностного распределения и каждый раз просто пересчитывать вероятность при взаимодействии с каждой из рук. Каждая рука выбирается на основе ее истории, и наша цель – минимизировать общее разочарование, которое может испытывать пользователь при взаимодействии с MAB.
Как правило, интерактивные рекоммендеры не используют сами по себе, а сочетают, например, с коллаборативной фильтрацией. На практике себя хорошо показали линейный UCB и Tompson Sampling + Probablistic Matrix Factorization.
Немного о фичах
Чтобы построить рекоммендеры, нужен дата-сет. Там должны быть фичи, описывающие нашу модель. Есть два вида фич, о которых стоит знать: implicit и explicit feedback. Implicit feedback – это когда пользователь делает скроллы, склики и так далее. А explicit feedback – это когда они явно ставят лайки или дизлайки. Что опасного кроется во втором? Explicit feedback – рейтинги, лайки, которые ставят пользователи, – сильно шумит. При этом implicit feedback – скроллы, клики, просмотры – работает гораздо круче для рекомендаций. Он менее шумный, потому что никак не связан с предпочтениями пользователей, не зависит от их настроения и понимания, что такое «оцени от нуля до пяти». Чтобы не решать проблемы смещений, можно работать с implicit фидбеком. Понятно, что только с ним работать нельзя, и нужно учитывать оба сигнала. Поэтому есть модели, которые позволяют учитывать и тот, и другой подход.
Пример рекоммендра у Spotify
У Spotify есть рекоммендер музыки. В качестве основы они используют коллаборативную фильтрацию: следят за предпочтениями пользователей, кластеризуют их между собой. Они также делают проекцию интента пользователя в данный момент времени на пространство музыкальных интересов пользователей. Кроме того, Spotify использует NLP-методы (natural language processing) для анализа плейлистов. Он собирает данные о всех плейлистах пользователей и говорит, что ваш плейлист – это такой же текстовый документ. Здесь можно использовать классические для NLP инструменты, когда мы просто работаем с текстом и извлекаем, например, топики для плейлиста. Помимо этого они используют глубокое обучение, чтобы извлекать контент. Они берут трек, пропускают его через глубокую нейросеть, извлекают фичи, которые ценят пользователи в песне. Это content based рекоммендер, сделанный на основе deep learning. Так компания собирает данные о самих айтемах.
Библиотеки и системы для создания рекоммендеров
Что нам дарит open source? Есть два уровня технических предложений: технические библиотеки и системы.
Что нам дарит open source? Есть два уровня технических предложений: технические библиотеки и системы.
Наиболее мощные библиотеки – Spark MLLib, RankSys, LensKit. Есть Waffles, библиотека на С++.
Есть более высокоуровневые инструменты, чем одна библиотека, – machine learning серверы. Самым интересным мне кажется PredictionIO.
Тем, кто хочет заниматься рекоммендерами, стоит прочитать «Recommendation System Handbook, 2nd Edition», где речь идет о разных подходах к построению рекоммендеров, алгоритмах и их практическом применении.
Понедельник, 07 Августа 2017 г. 19:32
+ в цитатник
Недавно решил добавить встроенные покупки в одно из самых популярных моих приложений для изучения английского языка. Не нашел ни одного вменяемого урока по добавлению встроенных покупок на Objective C. Все уроки либо очень старые, либо на Swift. Здесь хочу предложить вашему вниманию довольно простое решение, которое я использовал в своем приложении, сделанном на Objective C в Xcode 8.
Необходимо сделать следующее:
1. Перейдите на сайт itunes.connect.apple.com и войдите в систему.
2. Нажмите «Мои приложения», затем нажмите приложение, которое вы хотите добавить
3. Щелкните заголовок «Функции», а затем справа от надписи «Встроенные покупки» нажмите значок +
4. Для этого примера мы делаем покупку для удаления рекламы «Нерасходуемая покупка». Если вы собираетесь отправить физический элемент пользователям или дать им что-то, что они могут купить более одного раза, то используйте «Расходуемая покупка»
5. Оригинальное название может быть любым, но понятным для вас.
6. В качестве идентификатора продукта рекомендуется использовать Bundle ID и через точку название, например, вы можете использовать ru.yourdomen.removeads
7. Выберите Доступно для продажи, а затем уровень цен.
8. Отображаемое название и описание будут видны клиенту.
9. Нажмите «Сохранить»
Для вашего идентификатора продукта может потребоваться несколько часов для регистрации в iTunesConnect, поэтому придется подождать.
Теперь, когда вы установили информацию о покупке своего приложения в iTunesConnect, зайдите в свой проект Xcode и добавьте StoreKit.framework (Build Phases --> Link Binary With Libraries --> +). Если вы этого не сделаете, покупка в приложении НЕ будет работать!
Теперь перейдем непосредственно к кодировке.
Добавьте следующий код в ваш .h-файл:
Далее вам нужно импортировать ваш StoreKit framework в ваш .m файл, так же, как и добавить SKProductsRequestDelegate и SKPaymentTransactionObserver после interface:
#import StoreKit.h>
//напишите название вашего view controller вместо MyViewController
@interface MyViewController()
@end
@implementation MyViewController //название вашего view controller (такое же, как выше)
//здесь код вашего приложения
@end
И теперь добавьте следующее в ваш .m-файл.
//Если у вас больше, чем одна встроенная покупка, вы можете объявить их обе здесь
//Например kRemoveAdsProductIdentifier
//и kBuyCurrencyProductIdentifier к каждому свой идентификатор
//
//для этого примера мы используем только один продукт
#define kRemoveAdsProductIdentifier @"ваш product id (который мы создавали в iTunesConnect) напишите здесь"
- (IBAction)tapsRemoveAds{
NSLog(@"Пользователь запросил удаление рекламы");
if([SKPaymentQueue canMakePayments]){
NSLog(@"Пользователь может совершить покупку");
//Если у вас больше чем одна встроенная покупка, и вы хотели бы
//чтобы пользователь купил другой продукт просто объявите
//другую функцию и измените kRemoveAdsProductIdentifier на
//id другого продукта
SKProductsRequest *productsRequest = [[SKProductsRequest alloc] initWithProductIdentifiers:[NSSet setWithObject:kRemoveAdsProductIdentifier]];
productsRequest.delegate = self;
[productsRequest start];
}
else{
NSLog(@"Пользователь не может производить платежи из-за родительского контроля");
}
}
- (void)productsRequest:(SKProductsRequest *)request didReceiveResponse:(SKProductsResponse *)response{
SKProduct *validProduct = nil;
int count = [response.products count];
if(count > 0){
validProduct = [response.products objectAtIndex:0];
NSLog(@"Продукты доступны!");
[self purchase:validProduct];
}
else if(!validProduct){
NSLog(@"Нет доступных продуктов");
//Это вызывается, если ваш идентификатор продукта недействителен.
}
}
- (void)purchase:(SKProduct *)product{
SKPayment *payment = [SKPayment paymentWithProduct:product];
[[SKPaymentQueue defaultQueue] addTransactionObserver:self];
[[SKPaymentQueue defaultQueue] addPayment:payment];
}
- (IBAction) restore{
//Это называется, когда пользователь восстанавливает покупки, вы должны подключить это к кнопке
[[SKPaymentQueue defaultQueue] addTransactionObserver:self];
[[SKPaymentQueue defaultQueue] restoreCompletedTransactions];
}
- (void) paymentQueueRestoreCompletedTransactionsFinished:(SKPaymentQueue *)queue
{
NSLog(@"Получены восстановленные транзакции: %i", queue.transactions.count);
for(SKPaymentTransaction *transaction in queue.transactions){
if(transaction.transactionState == SKPaymentTransactionStateRestored){
//вызывается когда пользователь успешно восстанавливает покупку
NSLog(@"Transaction state -> Restored");
// если у вас более одного продукта для покупки в приложении,
// вы восстанавливаете правильный продукт для идентификатора.
// Например, вы можете использовать
// if (productID == kRemoveAdsProductIdentifier)
// для получения идентификатора продукта для
// восстановленных покупок, вы можете использовать
//
//NSString *productID = transaction.payment.productIdentifier;
[self doRemoveAds];
[[SKPaymentQueue defaultQueue] finishTransaction:transaction];
break;
}
}
}
- (void)paymentQueue:(SKPaymentQueue *)queue updatedTransactions:(NSArray *)transactions{
for(SKPaymentTransaction *transaction in transactions){
// если у вас несколько покупок в приложении,
// вы можете получить идентификатор продукта для этой транзакции
// с помощью transaction.payment.productIdentifier
//
// затем, проверьте идентификатор для продукта
//, который вы определили для проверки какой продукт пользователь
// только что купил
switch(transaction.transactionState){
case SKPaymentTransactionStatePurchasing: NSLog(@"Transaction state -> Purchasing");
//Вызывается, когда пользователь находится в процессе покупки, не добавляйте свой код.
break;
case SKPaymentTransactionStatePurchased:
//Это вызывается, когда пользователь успешно приобрел продукт
[self doRemoveAds]; //Вы можете добавить свой код для того, что вы хотите, чтобы произошло, когда пользователь совершает покупку, для этого урока мы используем удаление объявлений
[[SKPaymentQueue defaultQueue] finishTransaction:transaction];
NSLog(@"Transaction state -> Purchased");
break;
case SKPaymentTransactionStateRestored:
NSLog(@"Transaction state -> Restored");
//добавьте сюда тот же код, что вы делали для SKPaymentTransactionStatePurchased
[[SKPaymentQueue defaultQueue] finishTransaction:transaction];
break;
case SKPaymentTransactionStateFailed:
//вызывается когда транзакция не закончена
if(transaction.error.code == SKErrorPaymentCancelled){
NSLog(@"Transaction state -> Cancelled");
//пользователь отменил покупку ;(
}
[[SKPaymentQueue defaultQueue] finishTransaction:transaction];
break;
}
}
}
Теперь вы должны добавить свой код для того, что произойдет, когда пользователь завершит транзакцию. Для этого урока мы используем удаление рекламы.
- (void)doRemoveAds{
ADBannerView *banner;
[banner setAlpha:0];
areAdsRemoved = YES;
removeAdsButton.hidden = YES;
removeAdsButton.enabled = NO;
[[NSUserDefaults standardUserDefaults] setBool:areAdsRemoved forKey:@"areAdsRemoved"];
// используем NSUserDefaults, чтобы мы могли узнать, купил ли пользователь это или нет.
// было бы лучше использовать доступ KeyChain или что-то более безопасное
// для хранения пользовательских данных, поскольку NSUserDefaults можно изменить.
// Обычный пользователь, не сможете легко его изменить, но
// лучше использовать что-то более безопасное, чем NSUserDefaults.
// Для этого урока мы будем использовать NSUserDefaults
[[NSUserDefaults standardUserDefaults] synchronize];
}
Теперь, где-нибудь в методе viewDidLoad, вам нужно добавить следующий код:
areAdsRemoved = [[NSUserDefaults standardUserDefaults] boolForKey:@"areAdsRemoved"];
[[NSUserDefaults standardUserDefaults] synchronize];
if(areAdsRemoved){
//если вы удаляете рекламу или делаете еще что-то, вам нужно разместить соответствующий код здесь
}
Теперь, когда вы добавили весь код, зайдите в ваш .xib или storyboard файл и добавьте две кнопки, одну «Куплю», а другую — «Восстановить покупки». Подсоедините tapsRemoveAds IBAction к кнопке «Куплю», которую вы только что создали, и restore IBAction к кнопке «Восстановить покупки». По кнопке «Восстановить покупки» будет проверено, делал ли пользователь ранее эту покупку и если да, то она будет восстановлена.
По-хорошему нужно еще добавить различные алерты, объясняющие пользователю что происходит в процессе покупки или восстановления, а также после их завершения, здесь вам простор для творчества. Как тестировать покупки здесь объяснять не буду, так как этого материала достаточно в сети. Наверное не все еще перешли на Swift, да и много еще Objective C приложений дорабатываются, поэтому думаю, что кому-нибудь моя статья будет полезной.
Понедельник, 07 Августа 2017 г. 19:12
+ в цитатник
Доброго времени суток!
Недавно я решил познакомиться с API крупнейшей социальной сети Европы — ВКонтакте. В разделе «Для разработчиков» содержится довольно подробная документация, а в интернете существует немалое количество статей, помогающих освоиться с VK API, поэтому я решил, что серьезных проблем в изучении быть не должно. Однако, когда я добрался до LongPoll сервера, обнаружилось, что статей по работе с ним практически нет, а официальная документация не настолько полна, чтобы полностью понять изучаемый материал. Пришлось методом проб и ошибок пытаться понять принцип работы LongPoll-а, что через некоторое время мне сделать все-таки удалось. Я решил поделиться изученным материалом с другими людьми, чтобы сократить их время изучения нового. Ниже вы можете ознакомиться с разделами, про которые мне удалось написать.
Основы работы с API (те, кто знаком с базовыми методами и запросами к ним, могут пропустить этот пункт)
Что же такое API ВКонтакте? Вот как трактует это официальная документация:
Callback API — это инструмент для отслеживания активности пользователей в Вашем сообществе ВКонтакте.
Другими словами, это способ отправлять запросы на серверы ВКонтакте, чтобы получить ответ, содержащий некоторую информацию. С помощью VK API можно сделать практически все: отправить сообщение пользователю, изменить пароль учетной записи, создать альбом с фотографиями и так далее. Лично я для работы с API использую библиотеку vk_api, но можно обойтись и библиотекой requests. Сейчас мы рассмотрим базовые принципы работы. Если вы решили использовать библиотеку vk_api, то пример запроса будет выглядеть так:
Этой строкой мы авторизируемся через access token (способы его получения доступно описаны в документации и интернете, я не буду заострять на них внимание). Заметьте: не для всех методов нужна авторизация. О том, когда она требуется, будет написано в документации метода на сайте ВКонтакте.
Эта часть кода заслуживает отдельного внимания. Что же здесь происходит? Мы вызываем метод method, передавая ему два аргумента: первый — название метода API, второй — словарь из параметров этого метода. Список всех методов и их параметров находится в документации API. В данном случае мы вызываем метод «users.get» и передаем следующие параметры: «user_ids» — список id пользователей, для которых мы хотим получить данные, «fields»: дополнительную информацию о пользователях: аватарку и город проживания. Результатом выполнения программы будет следующая выведенная строка: [{'id': 210700286, 'first_name': 'Lindsey', 'last_name': 'Stirling', 'city': {'id': 5331, 'title': 'Los Angeles'}, 'photo_50': 'https://pp.userapi.com/c636821/v636821286/38a75/Ay-bEZoJZw8.jpg'}]
Если допустить какую-либо ошибку, например, указать неправильное название вызываемого метода, будет возбуждено исключение: vk_api.exceptions.ApiError: [5] User authorization failed: no access_token passed..
Примечание: если ошибка допущена в названии необязательного параметра, исключение сгенерировано не будет, а неизвестный параметр будет проигнорирован.
Если вы решили использовать библиотеку requests, придется немного углубиться в документацию API, чтобы узнать формат запроса и ответа.
Запрос должен выглядеть так: https://api.vk.com/method/{METHOD_NAME}?{PARAMS}&v={API_VERSION}, где {METHOD_NAME} — название метода, {PARAMS} — параметры вызываемого метода, а {API_VERSION} — версия API, которую должен использовать сервер при формировании ответа.
В качестве ответа нам будет возвращен JSON объект с информацией о результатах вызова метода. Давайте реализуем запрос к API с помощью библиотеки requests:
data = requests.get('https://api.vk.com/method/{METHOD_NAME}'.format(METHOD_NAME='users.get'),
params={'user_ids': 210700286, 'fields': 'photo_50, city'}).json()
Эта строка записывает в переменную data ответ сервера. Мы передаем функции get два аргумента: адрес, к которому нужно сделать запрос (в нашем случае — форматированную строку), и словарь из параметров этого метода. Если метод не вызывается без access token-а, нужно добавить его в словарь с ключем 'access_token'. Параметр «v» (версия API) не является обязательным, так как по умолчанию будет использоваться последняя версия, но, если нужно использовать иную версию, ее тоже нужно добавить в словарь с ключом 'v'. К пришедшему от сервера ответу применяется метод json(), который обрабатывает JSON-объекты.
Последняя строка выводит результат работы, в нашем случае — {'response': [{'uid': 210700286, 'first_name': 'Lindsey', 'last_name': 'Stirling', 'city': 5331, 'photo_50': 'https://pp.userapi.com/c636821/v636821286/38a75/Ay-bEZoJZw8.jpg'}]}.
Если передать неправильное название метода, будет выведено следующее: {'error': {'error_code': 5, 'error_msg': 'User authorization failed: no access_token passed.', 'request_params': [{'key': 'oauth', 'value': '1'}, {'key': 'method', 'value': 'user.get'}, {'key': 'user_ids', 'value': '210700286'}, {'key': 'fields', 'value': 'photo_50, city'}]}}.
Что такое LongPoll?
Для начала обратимся за помощью к документации:
Long Polling — это технология, которая позволяет получать информацию о новых событиях с помощью «длинных запросов». Сервер получает запрос, но отправляет ответ на него не сразу, а лишь тогда, когда произойдет какое-либо событие (например, поступит новое входящее сообщение), либо истечет заданное время ожидания.
Другими словами, получая от вас запрос, сервер ждет, когда произойдет событие, о котором он должен вас уведомить, и, когда оно происходит, Long Poll сервер отправляет ответ на ваш запрос, содержащий информацию о случившемся событии.
Мы напишем программу, которая будет уведомлять пользователя о некоторых изменениях в его аккаунте, которые мы будем получать от Long Poll сервера. Чтобы начать получать ответы от сервера, необходимо получить три обязательных параметра, необходимых для работы Long Poll-a: server, key и ts.
key — секретный ключ сессии;
server — адрес сервера;
ts — номер последнего события, начиная с которого нужно получать данные.
Их не нужно получать каждый раз, вызывая Long Pooll, — будет достаточно одного вызова. Из документации следует, что эти значения можно получить, вызвав метод messages.getLongPollServer. Напишем программу, которая сделает запрос с этим методом и будем использовать полученные данные для получения к Long Pooll.
import requests
token = '' # здесь вы должны написать свой access_token
data = requests.get('https://api.vk.com/method/messages.getLongPollServer',
params={'access_token': token}).json()['response'] # получение ответа от сервера
print(data)
Если вы все сделали правильно, программа выведет словарь с тремя ключами: {'key': '###############################', 'server': 'imv4.vk.com/im####', 'ts': 0000000000}
Запрос к Long Pooll серверу
Теперь, используя значения, хранящиеся в словаре, который был создан в предыдущей части, мы можем сделать запрос к Long Poll серверу! Чтобы это сделать, нужно сделать запрос к следующему адресу: https://{$server}?act=a_check&key={$key}&ts={$ts}&wait=25&mode=2&version=2, где {$server}, {$key} и {$ts}- значения из словаря с ключами 'server', 'key' и 'ts' соответственно, wait — время, которое Long Poll сервер будет ожидать обновлений, а mode — дополнительные опции ответа. Напишем программу, которая сделает один запрос на Long Poll сервер
import requests
token = '' # здесь вы должны написать свой access_token
params = requests.get('https://api.vk.com/method/messages.getLongPollServer',
params={'access_token': token}).json()['response'] # получение ответа от сервера
response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=90&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json() # отправление запроса на Long Poll сервер со временем ожидания 90 секунд и опциями ответа 2
print(response)
Если за 90 секунд произошло какое-либо событие, которое попадает в список обрабатываемых Long Pooll сервером, на экран выведется нечто похожее: {'ts': 0000000000, 'updates': [[9, -999999999, 0, 1501588841]]}. Что же значит пришедший ответ и как с ним дальше можно работать?
Во-первых, вы могли заметить, что в ответе содержится параметр 'ts', который мы использовали при отправлении запроса. Он здесь неспроста. Все события, попадающие в список обрабатываемых Long Poll сервера, нумеруются. Когда вы создаете новый аккаунт, первое такое событие имеет номер 1, второе — 2 и так далее. При отправлении запроса на Long Poll, нужно передавать этот параметр для того, чтобы сервер знал, начиная с какого номера нужно присылать обновления. В каждом ответе сервера также приходит этот параметр, чтобы вы использовали его при следующем вызове Long Poll сервера.
Во-вторых, в словаре содержится ключ 'updates' с говорящим названием. Не трудно догадаться, что значение по этому ключу хранит обновления, случившиеся после отправления запроса. Формат обновлений — массив массивов. Каждый массив в массиве — произошедшее обновление, которое нужно обработать. Если в первом массиве массивов больше одного, это значит, что несколько событий произошли одновременно. Параметр 'ts' содержит номер последнего из них. Если массив, доступный по ключу 'updates', пуст, то за время wait не произошло ни одного события. Вы спросите: «А что это за непонятные цифры в массивах?». Ответ довольно прост — это информация о случившемся событии, которую можно преобразовать в более понятный вид. Их обработкой мы займемся позже, а в следующей части напишем программу, которая будет постоянно обращаться к Long Poll серверу.
Циклические запросы к Long Pooll и коды событий
Для того, чтобы постоянно отправлять запросы к Long Pooll, я решил использовать цикл, чтобы не переполнять стек рекурсией. Ниже приведена реализация программы, которая обращается к Long Pooll и выводит обновления на экран
import requests
token = '' # здесь вы должны написать свой access_token
data = requests.get('https://api.vk.com/method/messages.getLongPollServer',
params={'access_token': token}).json()['response'] # получение ответа от сервера
while True:
response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=20&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json() # отправление запроса на Long Poll сервер со временем ожидания 20 и опциями ответа 2
updates = response['updates']
if updates: # проверка, были ли обновления
for element in updates: # проход по всем обновлениям в ответе
print(element)
data['ts'] = response['ts'] # обновление номера последнего обновления
Данная программа циклически посылает запросы к Long Pooll-у, проверяет, были ли обновления, и выводит пришедшие обновления на экран. Но выходные данные этой программы в том виде, в котором они есть сейчас, никуда не годятся. Сейчас вывод программы выглядит подобным образом: [8, -999999999, 1, 1501592696]
[8, -999999999, 7, 1501592862]
[9, -999999999, 0, 1501592882]
[9, -999999999, 1, 1501592583]
[8, -999999999, 4, 1501592893]
[9, -999999999, 0, 1501592900]
Первая цифра в каждом массиве означает код события. Используя ее, можно понять, какое событие произошло. Вот список кодов событий с кратким описанием (из официальной документации):
1 — Замена флагов сообщения (FLAGS:=$flags);
2 — Установка флагов сообщения (FLAGS|=$mask);
3 — Сброс флагов сообщения (FLAGS&=~$mask);
4 — Добавление нового сообщения;
6 — Прочтение всех входящих сообщений в $peer_id, пришедших до сообщения с $local_id.
7 — Прочтение всех исходящих сообщений в $peer_id, пришедших до сообщения с $local_id.
8 — Друг $user_id стал онлайн. $extra не равен 0, если в mode был передан флаг 64. В младшем байте (остаток от деления на 256) числа extra лежит идентификатор платформы $timestamp — время последнего действия пользователя $user_id на сайте;
9 — Друг $user_id стал оффлайн ($flags равен 0, если пользователь покинул сайт (например, нажал выход) и 1, если оффлайн по таймауту (например, статус away)). $timestamp — время последнего действия пользователя $user_id на сайте;
10 — Сброс флагов диалога $peer_id. Соответствует операции (PEER_FLAGS &= ~$flags). Только для диалогов сообществ;
11 — Замена флагов диалога $peer_id. Соответствует операции (PEER_FLAGS:= $flags). Только для диалогов сообществ;
12 — Установка флагов диалога $peer_id. Соответствует операции (PEER_FLAGS|= $flags). Только для диалогов сообществ;
13 — Удаление всех сообщений в диалоге $peer_id с идентификаторами вплоть до $local_id;
14 — Восстановление недавно (менее 20 дней назад) удаленных сообщений в диалоге $peer_id с идентификаторами вплоть до $local_id;
51 — Один из параметров (состав, тема) беседы $chat_id были изменены. $self — 1 или 0 (вызваны ли изменения самим пользователем);
61 — Пользователь $user_id набирает текст в диалоге. Событие приходит раз в ~5 секунд при постоянном наборе текста. $flags = 1;
62 — Пользователь $user_id набирает текст в беседе $chat_id;
70 — Пользователь $user_id совершил звонок с идентификатором $call_id;
80 — Счетчик непрочитанных в левом меню стал равен $count;
112 — Изменились настройки оповещений. $peer_id — идентификатор чата/собеседника.
Таким образом, если первое число в массиве — 8, то кто-то из ваших друзей стал онлайн, если 9 — оффлайн и так далее. Остальные числа в массиве тоже имеют значение, но к ним мы подберемся позже, так как их значение зависит от кода события.
Обработка приходящих событий
В этой части мы реализуем обработку событий, которые приходят нам в качестве ответа. Напомню, что эти события представлены в виде массивов с информацией, которую нужно обработать. Начать предлагаю с кода 80 — обновление счетчика непрочитанных сообщений, так как по моему мнению это событие является наименее сложным. Вот пример событий с кодом 80: [80, 0, 0]
[80, 1, 0]
Первый параметр, как вы уже знаете, — код события. Остаются 2 элемента: 0 и 0 в первом случае и 1 0 во втором. Последний параметр при коде 80 должен быть всегда равен нулю, поэтому его можно игнорировать; для нас важен лишь второй. Во втором параметре указано, сколько на данный момент у пользователя непрочитанных сообщений. Минимальное значение — 0 (нет новых сообщений), максимальное — не ограничено. Этого достаточно, чтобы обрабатывать все события с кодом 80. Реализуем это в код:
# часть кода в этом примере опущена для сокращения места, без нее код работать не будет
while True:
response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=20&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json() # отправление запроса на Long Poll сервер со временем ожидания 20 и опциями ответа 2
updates = response['updates']
if updates: # проверка, были ли обновления
for element in updates: # проход по всем обновлениям в ответе
action_code = element[0] # запись в переменную кода события
if action_code == 80: # проверка кода события
print('количество непрочитанных сообщений стало равно', element[1]) # вывод
data['ts'] = response['ts'] # обновление номера последнего обновления
Если запустить эту программу, она будет выводить на экран сообщения об изменении количества непрочитанных сообщений. Следующие относительно несложные обновления имеют коды 8 и 9 — друг стал онлайн и оффлайн соответственно. Дополним нашу программу, чтобы она смогла обрабатывать и их. Начнем с кода 9. Напишем строку, которая будет проверять код события:
elif action_code == 9:
Далее рассмотрим формат приходящих обновлений, имеющих код 9: [9, -000000000, 1, 1501744865]
С индексом 0, как вы уже знаете, хранится код обновления — 9. Далее идет отрицательное id пользователя, ставшего оффлайн (чтобы получить действительное id, нужно умножить на -1, дабы избавиться от минуса). Элемент с индексом 3 может принимать лишь 2 значения: 0 или 1. 1 означает, что отметка «оффлайн» поставлена по истечении тайм-аута неактивности, а 0 — что пользователь покинул сайт явно, например, нажав кнопку «выход». Последнее значение в ответе — время последнего действия пользователя на сайте в Unix time. Запишем все полученные сведения в переменные:
user_id = element[1] * -1 # id пользователя, ставшего оффлайн
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя, фамилия и пол пользователя с id = user_id
timeout = bool(element[2]) # был ли поставлен статус оффлайн по истечении тайм-аута
last_visit = element[3] # время последнего действия пользователя на сайте в Unix time
Как вы могли заметить, помимо имени и фамилии пользователя, мы получаем еще и его пол. Это нужно, чтобы программа правильно использовала рода в предложениях и не писала что-то вроде «Иван Иванов вышела из ВКонтакте». Переменная timeout хранит False, если пользователь явно покинул сайт, и True, если истекло время тайм-аута. Теперь можно вывести на экран полученные данные:
# не забудьте написать вначале "import time", здесь используется эта библиотека
if user['sex'] == 1:
verb = ['стала', 'вышла']
else:
verb = ['стал', 'вышел']
if timeout:
print(user['first_name'], user['last_name'], verb[0], 'оффлайн по истечении тайм-аута. Время последнего действия на сайте:', time.ctime(last_visit).split()[3])
else:
print(user['first_name'], user['last_name'], verb[1], 'из ВКонтакте. Время последнего действия на сайте:', time.ctime(last_visit).split()[3])
Единственное, что я вижу неочевидным в этом коде — вывод времени:
time.ctime(last_visit).split()[3]
Давайте разберемся с этой частью кода. Функция ctime библиотеки time принимает в качестве аргумента число — время в Unix time и возвращает строку вида 'Thu Jan 1 03:00:00 1970' . Так как нам нужно лишь время последнего действия на сайте, мы разбиваем эту строку методом split по пробелам и получаем массив, где в индексе 0 хранится день недели, в индексе 1 — месяц, 2 — число, 3 — время, а 4 — год. Мы извлекаем элемент с индексом 3, то есть время.
Теперь напишем реализацию обработки обновлений с кодом 8. Их формат выглядит так: [8, -6892937, 4, 1501750273]. Второй элемент в массиве — отрицательное id пользователя, ставшего онлайн, третий — платформа, с которой зашел пользователь, а четвертый — время последнего действия пользователя на сайте в Unix time. Реализуем полученные данные в код:
user_id = element[1] * -1 # id пользователя, ставшего онлайн
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя, фамилия и пол пользователя с id = user_id
platform = element[2] # код платформы пользователя
last_visit = element[3] # время последнего визита в Unix time
if user['sex'] == 1:
verb = 'стала'
else:
verb = 'стал'
Здесь мы записали данные из ответа в переменные, а также поставили глагол в нужный род. Параметр platform сейчас содержит число в диапазоне от 1 до 7 включительно. Каждое число обозначает платформу, с которой пользователь совершил действие. Переведем это число в текст:
# определение платформы по ее коду
if platform == 1:
platform = 'официальную мобильную версию web-сайта VK'
elif platform == 2:
platform = 'официальное приложение VK для iPhone'
elif platform == 3:
platform = 'официальное приложение VK для iPad'
elif platform == 4:
platform = 'официальное приложение VK для Android'
elif platform == 5:
platform = 'официальное приложение VK для Windows Phone'
elif platform == 6:
platform = 'официальное приложение VK для Windows'
elif platform == 7:
platform = 'официальную web-версию VK'
Далее мы рассмотрим коды 61 и 62. Они сообщают о том, что кто-то набирает сообщение. Разница в том, что обновления с кодом 61 оповещают о наборе текста в личных сообщениях, а 62 — в беседах. Обновления с кодом 62 выглядят так: [62, 000000000, 000]. Второй элемент массива — id пользователя, набирающего сообщения, а третий — идентификатор беседы. Обновления с кодом 61 имеют следующий вид: [61, 000000000, 1]. Здесь значение имеет лишь второй элемент — id пользователя, набирающего сообщение. Напишем обработчик этих событий:
elif action_code == 61:
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': element[1]}).json()['response'][0] # получение имени и фамилии пользователя
print(user['first_name'], user['last_name'], 'набирает сообщение')
elif action_code == 62:
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': element[1]}).json()['response'][0] # получение имени и фамилии пользователя, набирающего сообщение
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': element[2], 'access_token': token}).json()['response']['title'] # получение названия беседы
print(user['first_name'], user['last_name'], 'набирает сообщение в беседе "{}"'.format(chat))
В следующей теме мы напишем обработчик входящих сообщений и рассмотрим флаги сообщений.
Обработка сообщений и флаги
Наиболее интересные обновления, как мне кажется, — добавление сообщений. Эти обновления имеют код 4 и возвращают информацию о входящих и исходящих сообщений. Вот пример обновления с кодом 4: [4, $ts, $flag, $id, $unixtime, $text, {'title': ' ... '}]. Здесь $ts — номер пришедшего события, $flag — флаги сообщения, $id — id собеседника или 2000000000 + id беседы (в случае с коллективными диалогами), $unixtime — время добавления сообщения в Unix time, а последний элемент — словарь, содержащий информацию о вложениях, отправителе и изменениях в настройках беседы. Для начала разберемся с тем, где было добавлено сообщение: в личной переписке или беседе. Если сообщение было отправлено в беседе, то, как я уже написал, в поле $id будет указано число, получившиеся при сложении 2000000000 и chat_id (идентификатор беседы). Если сообщение было добавлено в личной переписке, в поле $id будет значиться id собеседника, которое всегда меньше, чем 2000000000 + chat_id любой беседы. Из этого можно сделать вывод, что, если $id — 2000000000 > 0, то сообщение было отправлено в беседе, если меньше, то в личной переписке. Если сообщение было отправлено в беседе, то id пользователя, написавшего сообщение, будет указано в словаре под ключем 'from'. Напишем обработчик сообщений:
elif action_code == 4:
if element[3] - 2000000000 > 0: # проверяем, было ли отправлено сообщение в беседе
user_id = element[6]['from'] # id отправителя
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
if text: # проверяем, что сообщение содержит текст
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'], 'в беседе "{}"'.format(chat) + ':', text)
else:
user_id = element[3] # id собеседника
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
if text: # проверяем, что сообщение содержит текст
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'] + ':', text)
Однако, у данной программы довольно много недостатков. Вот некоторые из них:
Неумение отличить исходящие сообщения от входящих;
игнорирования медиа-вложений;
игнорирование сообщений, сигнализирующих об изменении настроек беседы;
неумение обработать специальные сиволы в сообщениях
Две из четырех проблем можно решить, используя флаги сообщений, которые хранятся в массиве обновления под индексом 2. Этот элемент массива — число, получившиеся в результате сложения некоторых параметров, приведенных ниже (из официальной документации):
+1: сообщение не прочитано
+2: исходящее сообщение
+4: на сообщение был создан ответ
+8: помеченное сообщение
+16: сообщение отправлено через чат
+32: сообщение отправлено другом. Не применяется для сообщений из групповых бесед
+64: сообщение помечено как «Спам»
+128: сообщение удалено (в корзине)
+256: сообщение проверено пользователем на спам
+512: сообщение содержит медиаконтент
+65536: приветственное сообщение от сообщества. Диалог с таким сообщением не нужно поднимать в списке (отображать его только при открытии диалога напрямую). Флаг недоступен для версий <2.
Теперь нужно научить программу отличать исходящие сообщения от входящих. Чтобы проверить, есть ли среди слагаемых флага сообщения нужное нам число, мы будем использовать побитовое И. Создадим массив, в котором будут храниться слагаемые флага:
summands = [] # массив, где мы будем хранить слагаемые
flag = element[2] # флаг сообщения
for number in [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 65536]: # проходим циклом по возможным слагаемым
if flag & number: # проверяем, является ли число слагаемым с помощью побитового И
summands.append(number) # если является, добавляем его в массив
Выводить на экран информацию об исходящих сообщениях, как мне кажется, бессмысленно, поэтому мы добавим строку
if 2 not in summands:
Сейчас часть программы, работающая с сообщениями, выглядит так:
elif action_code == 4:
summands = [] # массив, где мы будем хранить слагаемые
flag = element[2] # флаг сообщения
for number in [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 65536]: # проходим циклом по возможным слагаемым
if flag & number: # проверяем, является ли число слагаемым с помощью побитового И
summands.append(number) # если является, добавляем его в массив
if 2 not in summands:
if element[3] - 2000000000 > 0: # проверяем, было ли отправлено сообщение в беседе
user_id = element[6]['from'] # id отправителя
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
if text: # проверяем, что сообщение содержит текст
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'], 'в беседе "{}"'.format(chat) + ':', text)
else:
user_id = element[3] # id собеседника
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
if text: # проверяем, что сообщение содержит текст
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'] + ':', text)
Теперь научимся работать с медиа-вложениями. Вот пример обновления, говорящего о том, что пришло сообщение с прикрепленными фотографией, песней, видео, документом и гео-позицией: [[4, $ts, $flag, $id, $unixtime, $text, {'attach1_type': 'photo', 'attach1': '$photoId', 'attach2_type': 'video', 'attach2': '$videoId', 'attach3_type': 'audio', 'attach3': '$audioId', 'attach4_type': 'doc', 'attach4': '$docId', 'geo': '2_SVK-le', 'geo_provider': '4', 'title': ' ... '}]. Чтобы получить доступ к этим вложениям, нужно будет обращаться к API для получения ссылки на файл. Методы для выполнения этого действия (photos.getById и docs.getById) нашлись лишь для фотографий и документов (аудиосообщения приходят как документы, поэтому ссылку для их прослушивания получить удастся). Для музыки с недавних пор недоступен ни один метод из-за авторских прав, а для видео нужный метод попросту отсутствует. Для дальнейшей работы с вложениями напишем код, который создаст два массива (для фото и для документов) со ссылками на просмотр вложений.
if 512 in summands: # проверка, есть ли медиа-вложения
index = 1
photos = [] # массив для хранения id фотографий
docs = [] # массив для хранения id документов
media_type = 'attach1_type'
while media_type in element[6].keys(): # проверка, существует ли медиа-вложение с таким индексом
media_type = element[6]['attach{}_type'.format(index)] # если существует, сохраняем его тип
if media_type == 'photo': # является ли вложение фотографией
photos.append(element[6]['attach{}'.format(index)]) # добавляем id фотографии в массив
elif media_type == 'doc': # является ли вложение документом
docs.append(element[6]['attach{}'.format(index)]) # добавляем id документа в массив
index += 1 # увеличиваем индекс
media_type = 'attach{}_type'.format(index)
change = lambda ids, type_: requests.get('https://api.vk.com/method/{}.getById'.format(type_), params={type_: ids, 'access_token': token}).json() # функция, возвращающаяся ссылки на объекты
if photos: # проверка, были ли во вложениях фотографии
photos = change(', '.join(photos), 'photos') # если были, то перезаписываем переменную photos на словарь
if 'response' in photos.keys():
photos = [attachment['src_xbig'] for attachment in photos['response']] # перезаписываем на ссылки
print('сообщение содержит следующие фотографии:', ', '.join(photos))
else:
pass # скорее всего, возникла ошибка доступа
if docs: # проверка, были ли во вложениях документы
docs = change(', '.join(docs), 'docs') # если были, то перезаписываем переменную docs на словарь
if 'response' in docs.keys():
docs = [attachment['url'] for attachment in docs['response']] # перезаписываем на ссылки
print('сообщение содержит следующие документы:', ', '.join(docs))
else:
pass # скорее всего, возникла ошибка доступа
Уберем строки
if text:
, чтобы при выводе данных было понятно, какие медиа-вложения к каким сообщениям относятся.
Теперь научим нашу программу реагировать на изменения в беседе: создание новой беседы, обновления фотографии, изменения названий, добавления и исключения людей. Информация о подобных событиях хранится в словаре, находящемся под индексом 6 в обновлениях с кодом 4. Ниже приведены примеры событий:
Изменение названия беседы: [4, $ts, $flag, $chat_id, $unixtime, '', {'source_act': 'chat_title_update', 'source_text': 'Новое название', 'source_old_text': 'Старое название', 'from': '$id'}]
Исключение пользователя из беседы (выход пользователя из беседы): [4, $ts, $flag, $chat_id, $unixtime, '', {'source_act': 'chat_kick_user', 'source_mid': '&removed_user_id', 'from': '&remover_id'}]
Создание новой беседы: [4, $ts, $flag, $chat_id, $unixtime, '', {'source_act': 'chat_create', 'source_text': 'Название', 'from': '$creator_id'}]
Вот программа, которая обрабатывает изменения такого вида:
elif action_code == 4:
if 'source_act' not in element[6].keys():
# <код, обрабатывающий сообщения>
else:
source_act = element[6]
if source_act['source_act'] == 'chat_title_update': # было ли обновление вызвано изменением названия беседы
changer_id = source_act['from'] # id человека, изменившего названия
source_text = source_act['source_text'] # новое название беседы
source_old_text = source_act['source_old_text'] # старое название беседы
changer = requests.get('https://api.vk.com/method/users.get', params={'user_ids': changer_id, 'fields': 'sex'}).json()['response'][0] # получение имени и фамилии пользователя, изменившего название
if changer['sex']:
verb = 'изменила'
else:
verb = 'изменил'
print(changer['first_name'], changer['last_name'], verb, 'название беседы с "{}" на "{}"'.format(source_old_text, source_text))
elif source_act['source_act'] == 'chat_photo_update':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
user_id = source_act['from'] # id пользователя, обновившего фото
photo_id = source_act['attach1'] # id фотографии
photo = requests.get('https://api.vk.com/method/photos.getById', params={'photos': photo_id, 'access_token': token}).json() # ссылка на фотографию
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия пользователя, обновившего фото
if 'error' not in photo.keys(): # не возникло ли ошибок при получении ссылки
if user['sex']:
verb = 'обновил'
else:
verb = 'обновила'
print(user['first_name'], user['last_name'], verb, 'фотографию беседы "{}" на'.format(chat), photo['response'][0]['src_xbig'])
else:
pass # вероятнее всего, отсутствуют права для выполнения запроса
elif source_act['source_act'] == 'chat_invite_user':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
invited_id = source_act['source_mid'] # id приглашенного
inviter_id = source_act['from'] # id пригласившего
if invited_id == inviter_id: # вернулся ли пользователь в беседу или был добавлен кем-то из участников
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': inviter_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия вернувшегося
if user['sex']:
verb = 'вернулась'
else:
verb = 'вернулся'
print(user['first_name'], user['last_name'], verb, 'в беседу "{}"'.format(chat))
else:
inviter_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': inviter_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия добавившего
invited_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': invited_id, 'name_case': 'acc'}).json()['response'][0] # имя и фамилия добавленного
if inviter_user['sex']:
verb = 'добавила'
else:
verb = 'добавил'
print(inviter_user['first_name'], inviter_user['last_name'], verb, 'в беседу "{}"'.format(chat), invited_user['first_name'], invited_user['last_name'])
elif source_act['source_act'] == 'chat_kick_user':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
removed_id = source_act['source_mid'] # id исключенного
remover_id = source_act['from'] # id исключившего
if removed_id == remover_id: # вышел ли пользователь сам или был исключен
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': remover_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия вышедшего
if user['sex']:
verb = 'вышла'
else:
verb = 'вышел'
print(user['first_name'], user['last_name'], verb, 'из беседы "{}"'.format(chat))
else:
remover_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': remover_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия исключившего
removed_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': removed_id, 'name_case': 'acc'}).json()['response'][0] # имя и фамилия исключенного
if remover_user['sex']:
verb = 'исключила'
else:
verb = 'исключил'
print(remover_user['first_name'], remover_user['last_name'], verb, 'из беседы "{}"'.format(chat), removed_user['first_name'], removed_user['last_name'])
elif source_act['source_act'] == 'chat_create':
chat = source_act['source_text'] # название беседы
creator_id = source_act['from'] # id создателя
creator = requests.get('https://api.vk.com/method/users.get', params={'user_ids': creator_id, 'fields': 'sex'}).json()['response'][0] # имя, фамилия и пол создателя
if creator['sex']:
verb = 'создала'
else:
verb = 'создал'
print(creator['first_name'], creator['last_name'], verb, 'беседу "{}"'.format(chat))
Наводим красивости. Заключительная часть
В этой части мы рассмотрим лишь две детали: ошибку при запросе к Long Poll серверу и отображение спец. символов в сообщениях.
Об ошибке: если запустить программу в том виде, в котором она есть сейчас, через некоторое время возникнет ошибка KeyError на строке 8: response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=20&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json()['response'] # отправление запроса на Long Poll сервер со временем ожидания 20 и опциями ответа 2. Дело в том, что на наш запрос сервер вернул ошибку «error 2», что означает, что используемый параметр &key устарел и нужно получить новый. Для этого мы несколько изменим существующий код на:
response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=20&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json() # отправление запроса на Long Poll сервер со временем ожидания 20 и опциями ответа 2
try:
updates = response['updates']
except KeyError: # если в этом месте возбуждается исключение KeyError, значит параметр key устарел, и нужно получить новый
data = requests.get('https://api.vk.com/method/messages.getLongPollServer', params={'access_token': token}).json()['response'] # получение ответа от сервера
break # выходим из цикла, чтобы сделать повторный запрос
Теперь проблема решена! Остается последнее: спец. символы в сообщениях. Дело в том, что некоторые символы ВК возвращает не в привычном для нас виде. Так, например, если в сообщении есть амперсант, он будет заменен на &_amp (нижнее подчеркивание нужно, чтобы Хабр не заменил эту надпись на амерсант). Подобных символов много и всех их нужно вывести правильно. Для этого сохраним подобные символы и их коды в словарь, а затем заменим коды в сообщении на символы с помощью функции sub библиотеки re (не забудьте ее импортировать!).
import re
# <...>
symbols = {' ': '\n', '&': '&', '"': '"', '<': '<', '>': '>', '˜': '~', 'ˆ': '^', '–': '–', '—': '—', '€': '€', '‰': '‰'}
for code, value in symbols.items():
text = re.sub(code, value, text)
Разумеется, таких символов куда больше, чем я добавил в словарь, но переписать их всех очень сложно, тем более, что некоторые из них невыводимые. На этом создание нашей программы кончается, финальная ее версия выглядит так:
import re
import time
import requests
token = '' # здесь вы должны написать свой access_token
data = requests.get('https://api.vk.com/method/messages.getLongPollServer',
params={'access_token': token}).json()['response'] # получение ответа от сервера
while True:
response = requests.get('https://{server}?act=a_check&key={key}&ts={ts}&wait=20&mode=2&version=2'.format(server=data['server'], key=data['key'], ts=data['ts'])).json() # отправление запроса на Long Poll сервер со временем ожидания 20 и опциями ответа 2
try:
updates = response['updates']
except KeyError: # если в этом месте возбуждается исключение KeyError, значит параметр key устарел, и нужно получить новый
data = requests.get('https://api.vk.com/method/messages.getLongPollServer', params={'access_token': token}).json()['response'] # получение ответа от сервера
break # выходим из цикла, чтобы сделать повторный запрос
if updates: # проверка, были ли обновления
for element in updates: # проход по всем обновлениям в ответе
action_code = element[0]
if action_code == 80: # проверка кода события
print('количество непрочитанных сообщений стало равно', element[1]) # вывод
elif action_code == 9:
user_id = element[1] * -1 # id пользователя, ставшего оффлайн
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия пользователя с id = user_id
timeout = bool(element[2]) # был ли поставлен статус оффлайн по истечении тайм-аута
last_visit = element[3] # дата последнего действия пользователя на сайте
if user['sex'] == 1:
verb = ['стала', 'вышла']
else:
verb = ['стал', 'вышел']
if timeout:
print(user['first_name'], user['last_name'], verb[0], 'оффлайн по истечении тайм-аута. Время последнего действия на сайте:', time.ctime(last_visit).split()[3])
else:
print(user['first_name'], user['last_name'], verb[1], 'из ВКонтакте. Время последнего действия на сайте:', time.ctime(last_visit).split()[3])
elif action_code == 8:
user_id = element[1] * -1 # id пользователя, ставшего онлайн
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия пользователя с id = user_id
platform = element[2] # код платформы пользователя
last_visit = element[3] # время последнего визита в Unix time
if user['sex'] == 1:
verb = 'стала'
else:
verb = 'стал'
# определение платформы по ее коду
if platform == 1:
platform = 'официальную мобильную версию web-сайта VK'
elif platform == 2:
platform = 'официальное приложение VK для iPhone'
elif platform == 3:
platform = 'официальное приложение VK для iPad'
elif platform == 4:
platform = 'официальное приложение VK для Android'
elif platform == 5:
platform = 'официальное приложение VK для Windows Phone'
elif platform == 6:
platform = 'официальное приложение VK для Windows'
elif platform == 7:
platform = 'официальную web-версию VK'
print(user['first_name'], user['last_name'], verb, 'онлайн через', platform, 'в', time.ctime(last_visit).split()[3])
elif action_code == 61:
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': element[1]}).json()['response'][0] # получение имени и фамилии пользователя
print(user['first_name'], user['last_name'], 'набирает сообщение')
elif action_code == 62:
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': element[1]}).json()['response'][0] # получение имени и фамилии пользователя, набирающего сообщение
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': element[2], 'access_token': token}).json()['response']['title'] # получение названия беседы
print(user['first_name'], user['last_name'], 'набирает сообщение в беседе "{}"'.format(chat))
elif action_code == 4:
if 'source_act' not in element[6].keys():
summands = [] # массив, где мы будем хранить слагаемые
flag = element[2] # флаг сообщения
for number in [1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 65536]: # проходим циклом по возможным слагаемым
if flag & number: # проверяем, является ли число слагаемым с помощью побитового И
summands.append(number) # если является, добавляем его в массив
if 2 not in summands:
if element[3] - 2000000000 > 0: # проверяем, было ли отправлено сообщение в беседе
user_id = element[6]['from'] # id отправителя
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
symbols = {'&': '&', '"': '"', '<': '<', '>': '>', '&tilde': '~', '&circ': '^', '&ndash': '–', '&mdash': '—', '&euro': '€', '&permil': '‰'}
for code, value in symbols.items():
text = re.sub(code, value, text)
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'], 'в беседе "{}"'.format(chat) + ':', text)
else:
user_id = element[3] # id собеседника
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'name_case': 'gen'}).json()['response'][0] # получение имени и фамилии пользователя, отправившего сообщение
time_ = element[4] # время отправления сообщения
text = element[5] # текст сообщения
symbols = {' ': '\n', '&': '&', '"': '"', '<': '<', '>': '>', '˜': '~', 'ˆ': '^', '–': '–', '—': '—', '€': '€', '‰': '‰'}
for code, value in symbols.items():
text = re.sub(code, value, text)
print(time.ctime(time_).split()[3] + ':', 'Сообщение от', user['first_name'], user['last_name'] + ':', text)
if 512 in summands: # проверка, были ли медиа-вложения
index = 1
photos = [] # массив для хранения id фотографий
docs = [] # массив для хранения id документов
media_type = 'attach1_type'
while media_type in element[6].keys(): # проверка, существует ли медиа-вложение с таким индексом
media_type = element[6]['attach{}_type'.format(index)] # если существует, сохраняем его тип
if media_type == 'photo': # является ли вложение фотографией
photos.append(element[6]['attach{}'.format(index)]) # добавляем id фотографии в массив
elif media_type == 'doc': # является ли вложение документом
docs.append(element[6]['attach{}'.format(index)]) # добавляем id документа в массив
index += 1 # увеличиваем индекс
media_type = 'attach{}_type'.format(index)
change = lambda ids, type_: requests.get('https://api.vk.com/method/{}.getById'.format(type_), params={type_: ids, 'access_token': token}).json() # функция, возвращающаяся ссылки на объекты
if photos: # проверка, были ли во вложениях фотографии
photos = change(', '.join(photos), 'photos') # если были, то перезаписываем переменную photos на словарь
if 'response' in photos.keys():
photos = [attachment['src_xbig'] for attachment in photos['response']] # перезаписываем на ссылки
print('сообщение содержит следующие фотографии:', ', '.join(photos))
else:
pass # скорее всего, возникла ошибка доступа
if docs: # проверка, были ли во вложениях документы
docs = change(', '.join(docs), 'docs') # если были, то перезаписываем переменную docs на словарь
if 'response' in docs.keys():
docs = [attachment['url'] for attachment in docs['response']] # перезаписываем на ссылки
print('сообщение содержит следующие документы:', ', '.join(docs))
else:
pass # скорее всего, возникла ошибка доступа
else:
source_act = element[6]
if source_act['source_act'] == 'chat_title_update': # было ли обновление вызвано изменением названия беседы
changer_id = source_act['from'] # id человека, изменившего названия
source_text = source_act['source_text'] # новое название беседы
source_old_text = source_act['source_old_text'] # старое название беседы
changer = requests.get('https://api.vk.com/method/users.get', params={'user_ids': changer_id, 'fields': 'sex'}).json()['response'][0] # получение имени и фамилии пользователя, изменившего название
if changer['sex']:
verb = 'изменила'
else:
verb = 'изменил'
print(changer['first_name'], changer['last_name'], verb, 'название беседы с "{}" на "{}"'.format(source_old_text, source_text))
elif source_act['source_act'] == 'chat_photo_update':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
user_id = source_act['from'] # id пользователя, обновившего фото
photo_id = source_act['attach1'] # id фотографии
photo = requests.get('https://api.vk.com/method/photos.getById', params={'photos': photo_id, 'access_token': token}).json() # ссылка на фотографию
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': user_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия пользователя, обновившего фото
if 'error' not in photo.keys(): # не возникло ли ошибок при получении ссылки
if user['sex']:
verb = 'обновил'
else:
verb = 'обновила'
print(user['first_name'], user['last_name'], verb, 'фотографию беседы "{}" на'.format(chat), photo['response'][0]['src_xbig'])
else:
pass # вероятнее всего, отсутствуют права для выполнения запроса
elif source_act['source_act'] == 'chat_invite_user':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
invited_id = source_act['source_mid'] # id приглашенного
inviter_id = source_act['from'] # id пригласившего
if invited_id == inviter_id: # вернулся ли пользователь в беседу или был добавлен кем-то из участников
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': inviter_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия вернувшегося
if user['sex']:
verb = 'вернулась'
else:
verb = 'вернулся'
print(user['first_name'], user['last_name'], verb, 'в беседу "{}"'.format(chat))
else:
inviter_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': inviter_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия добавившего
invited_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': invited_id, 'name_case': 'acc'}).json()['response'][0] # имя и фамилия добавленного
if inviter_user['sex']:
verb = 'добавила'
else:
verb = 'добавил'
print(inviter_user['first_name'], inviter_user['last_name'], verb, 'в беседу "{}"'.format(chat), invited_user['first_name'], invited_user['last_name'])
elif source_act['source_act'] == 'chat_kick_user':
chat_id = element[3] - 2000000000 # id беседы
chat = requests.get('https://api.vk.com/method/messages.getChat', params={'chat_id': chat_id, 'access_token': token}).json()['response']['title'] # получение названия беседы
removed_id = source_act['source_mid'] # id исключенного
remover_id = source_act['from'] # id исключившего
if removed_id == remover_id: # вышел ли пользователь сам или был исключен
user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': remover_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия вышедшего
if user['sex']:
verb = 'вышла'
else:
verb = 'вышел'
print(user['first_name'], user['last_name'], verb, 'из беседы "{}"'.format(chat))
else:
remover_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': remover_id, 'fields': 'sex'}).json()['response'][0] # имя и фамилия исключившего
removed_user = requests.get('https://api.vk.com/method/users.get', params={'user_ids': removed_id, 'name_case': 'acc'}).json()['response'][0] # имя и фамилия исключенного
if remover_user['sex']:
verb = 'исключила'
else:
verb = 'исключил'
print(remover_user['first_name'], remover_user['last_name'], verb, 'из беседы "{}"'.format(chat), removed_user['first_name'], removed_user['last_name'])
elif source_act['source_act'] == 'chat_create':
chat = source_act['source_text'] # название беседы
creator_id = source_act['from'] # id создателя
creator = requests.get('https://api.vk.com/method/users.get', params={'user_ids': creator_id, 'fields': 'sex'}).json()['response'][0] # имя, фамилия и пол создателя
if creator['sex']:
verb = 'создала'
else:
verb = 'создал'
print(creator['first_name'], creator['last_name'], verb, 'беседу "{}"'.format(chat))
data['ts'] = response['ts'] # обновление номера последнего обновления
В этом руководстве я рассмотрел не все возможности Long Poll-a, такие интересные вещи, как замена флагов сообщений или отметки «прочитано» и «непрочитанно» остались незатронутыми, но вы всегда можете дописать программу.
На этом у меня все, надеюсь, вы узнали для себя что-то новое. До скорых встреч!
Понедельник, 07 Августа 2017 г. 18:51
+ в цитатник
Постановка задачи
Необходимость решения транспортных задач в связи с территориальной разобщённостью поставщиков и потребителей очевидна. Однако, когда необходимо решить транспортную задачу без дополнительных условий это как правило не является проблемой поскольку такие решения достаточно хорошо обеспечены как теоретически, так и программными средствами.
Решение закрытой транспортной задачи средствами Python с классическим условиями для поставщиков и потребителей товара приведено в моей статье “Решение задач линейного программирования с использованием Python” [1].
Реальная транспортная задача усложняется дополнительными условиями и вот некоторые из них. Ограниченная грузоподъёмность транспорта, не учитываемые задержки при оформлении груза на таможне, приоритеты и паритеты для поставщиков и потребителей. Поэтому решение закрытой транспортной задачи с учётом дополнительных условий и стало целью данной публикации.
Алгоритм решения транспортной задачи с классическими условиями
Рассмотрим пример исходных данных в виде таблицы (матрицы).
где C= [7,3,6,4,8,2,1,5,9]– список стоимости перевозки единицы товара от заказчиков к потребителям; X – список объёмов перевозимых товаров, обеспечивающих минимальные затраты; a= [74,40,36] – список объёмов однородных товаров на складах поставщиков; b= [20,45,30] – список объёмов спроса заказчиками однородных товаров.
Задача закрытая поскольку sum(a)> sum(b), поэтому для X из строк таблицы запишем неравенства ограниченные сверху, а для X из столбцов таблицы равенства. Для дальнейшей обработки возьмём полученные соотношения в скобки и приравняем их переменным.
Приведенная система из шести переменных является типовой для транспортной задачи, остаётся определить функцию цели, которая с учётом списка С для коэффициентов и переменных mass будит иметь вид:
Следует отметить возможности некоторых решателей по введению ограничений сразу на все переменные Х, например, добавлением к общим условиям условия не отрицательности –x_non_negative.
Формирование дополнительных условий для закрытой транспортной задачи
Причины этих условий могут быть различными, например, ограниченная грузоподъёмность транспорта, не учитываемые задержки при оформлении груза на таможне, приоритеты и паритеты для поставщиков и потребителей. Поэтому мы будем указывать только субъектов и характер ограничения.
Для дальнейшего использования пронумеруем следующие дополнительные условия к закрытой транспортной задаче.
1.Установка заданного объёма поставки товара от определённого поставщика определённому заказчику.
Для этого вводиться новая переменная с соответствующим ограничением. Например первый поставщик должен поставить второму заказчику ровно 30 единиц товара– mass7 = (x[1] == 30).
2.Изменение объёма поставки товара для определённого заказчика.
Для этого меняются условия на столбец таблицы объёмов доставок товаров. Например, для второго заказчика объём заказа уменьшился с 45 единиц товара до 30.
Строку условий mass5 = (x[1] +x[4] + x[7] == 45) следует заменить на mass5 = (x[1] +x[4] + x[7] == 30).
3. Установка верхней границы объёма поставок товара для поставщика.
Для этого меняются условия на строку таблицы объёмов доставок товаров. Например, для объёмов доставки товаров второго поставщика было ограничение сверху <= 40, а возникла необходимость доставки ровно 40 единиц товара. Переменную условий mass2 = (x[3] + x[4] +x[5] <= 40) заменим на mass2 = (x[3] + x[4] +x[5] == 40).
4. Паритет на поставки второго и третьего поставщиков
Для этого приравниваются объёмы поставок нескольких поставоких поставщиков, что обычно делается для улучшения бизнес климата. Например 6объёмы доставок товаров второго и третьего поставщика транспортных услуг соответственно ограничены сверху <=40 и <=36. Заменим строки mass2 = (x[3] + x[4] +x[5] <= 40) и mass3 = (x[6] + x[7] + x[8] <= 36) на mass2 = (x[3] + x[4] +x[5] == 30) и mass3 = (x[6] + x[7] + x[8] == 30).
Решение закрытой транспортной задачи с дополнительными условиями средствами решателя cvxopt Python
Полученные в публикации дополнительные условия к закрытой транспортной задаче позволяют получать решения, более приближенные к реальной ситуации по доставке товаров. Приведенные дополнения можно использовать по несколько в одной задаче применяя их в зависимости от возникшей ситуации. Исследован вопрос выбора решателя для транспортной задачи с условиями. Таким решателем является scipy. optimize, как более узко функциональный чем cvxopt и более быстрый чем pulp. Кроме того scipy. optimize имеет более компактную запись условий транспортной задачи, что облегчает его работу с интерфейсом.
 Третье издание познакомит вас с интегрированной средой Android Studio, которая сильно облегчает разработку приложений. Вы не только изучите основы программирования, но и узнаете о возможностях самых распространенных версий Android; новых инструментах, таких как макеты с ограничениями и связывание данных; модульном тестировании; средствах доступности; архитектурном стиле MVVM; локализации; новой системе разрешений времени выполнения. Все учебные приложения были спроектированы таким образом, чтобы продемонстрировать важные концепции и приемы программирования под Android и дать опыт их практического применения.
Третье издание познакомит вас с интегрированной средой Android Studio, которая сильно облегчает разработку приложений. Вы не только изучите основы программирования, но и узнаете о возможностях самых распространенных версий Android; новых инструментах, таких как макеты с ограничениями и связывание данных; модульном тестировании; средствах доступности; архитектурном стиле MVVM; локализации; новой системе разрешений времени выполнения. Все учебные приложения были спроектированы таким образом, чтобы продемонстрировать важные концепции и приемы программирования под Android и дать опыт их практического применения.
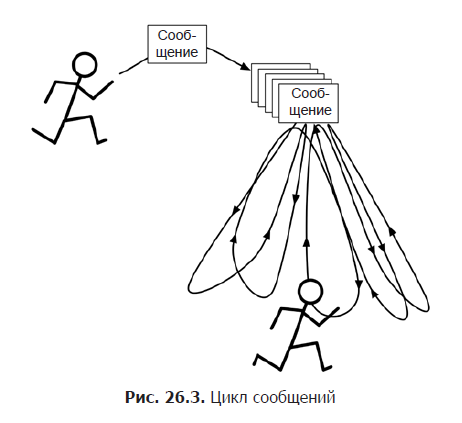



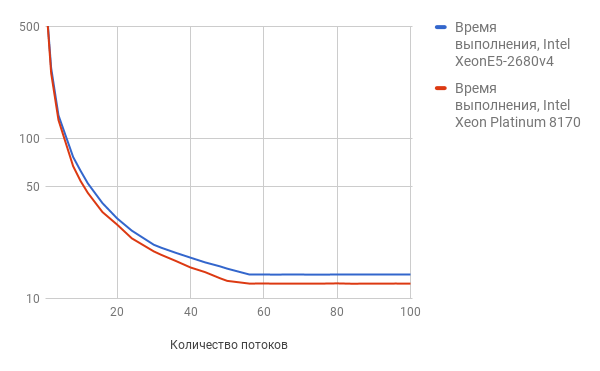
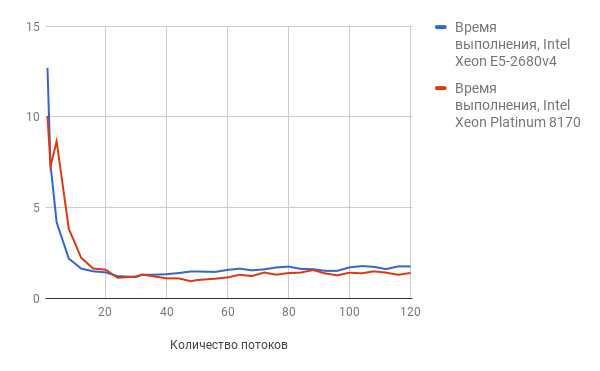
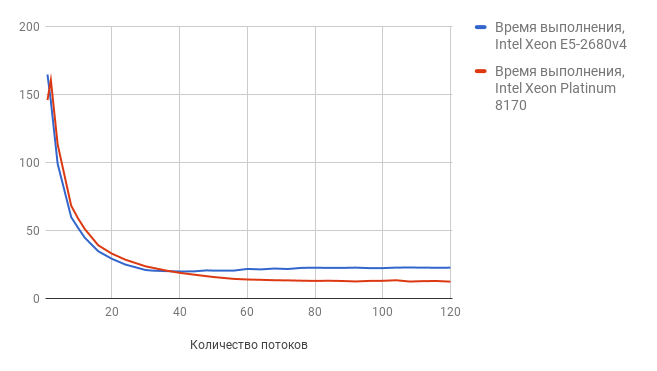
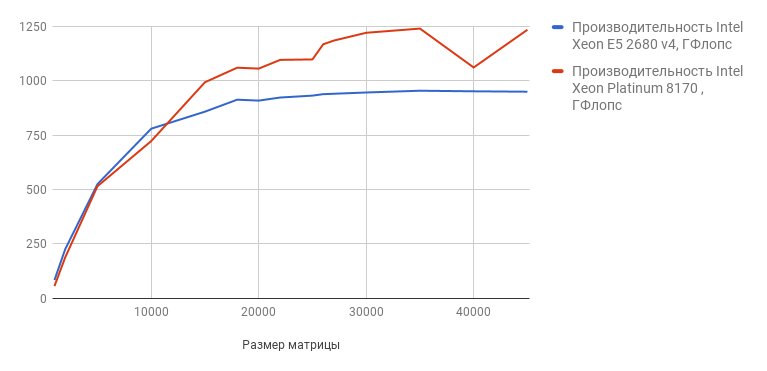






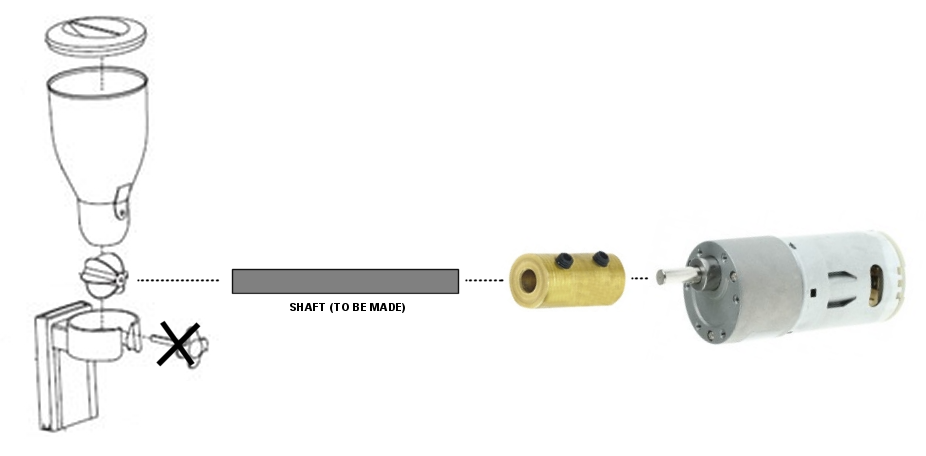 Такой механизм выглядит довольно аккуратно, его легко собрать (собственно и собирать почти ничего не надо), но, увы, очень уж дорогой. Но тут на вкус и цвет.
Такой механизм выглядит довольно аккуратно, его легко собрать (собственно и собирать почти ничего не надо), но, увы, очень уж дорогой. Но тут на вкус и цвет.