«Как это работает»: Классификация ЦОД Tier |
 / фото Arthur Caranta CC
/ фото Arthur Caranta CC
|
Метки: author it_man it- стандарты блог компании ит-град ит-град tier дата-центр |
Smart IDReader SDK — добавляем распознавание в Android приложения |
 Привет, Хабр! В одной из прошлых наших статей изучался вопрос встраивания ядра распознавания Smart IDReader в iOS приложения. Пришло время обсудить эту же проблему, но для ОС Android. Ввиду большого количества версий системы и широкого парка устройств это будет посложнее, чем для iOS, но всё же вполне решаемая задача. Disclaimer – приведённая ниже информация не является истинной в последней инстанции, если вы знаете как упростить процесс встраивания/работы с камерой или сделать по другому – добро пожаловать в комментарии!
Привет, Хабр! В одной из прошлых наших статей изучался вопрос встраивания ядра распознавания Smart IDReader в iOS приложения. Пришло время обсудить эту же проблему, но для ОС Android. Ввиду большого количества версий системы и широкого парка устройств это будет посложнее, чем для iOS, но всё же вполне решаемая задача. Disclaimer – приведённая ниже информация не является истинной в последней инстанции, если вы знаете как упростить процесс встраивания/работы с камерой или сделать по другому – добро пожаловать в комментарии!
Допустим, мы хотим добавить функционал распознавания документов в своё приложение и для этого у нас есть Smart IDReader SDK, который состоит из следующих частей:
bin – сборка библиотеки ядра libjniSmartIdEngine.so для 32х битной архитектуры ARMv7bin-64 – сборка библиотеки ядра libjniSmartIdEngine.so для 64х битной архитектуры ARMv8 bin-x86 – сборка библиотеки ядра libjniSmartIdEngine.so для 32х битной архитектуры x86bindings – JNI обёртка jniSmartIdEngineJar.jar над библиотекой libjniSmartIdEngine.sodata – файлы конфигурации ядраdoc – документация к SDKНекоторые комментарии по содержанию SDK.
Наличие трех сборок библиотеки под разные платформы – плата за большое разнообразие устройств на ОС Android (сборку для MIPS не делаем по причине отсутствия устройств данной архитектуры). Сборки для ARMv7 и ARMv8 являются основными, версия для x86 обычно используется нашими клиентами для конкретных устройств на базе мобильных процессоров Intel.
Обёртка JNI (Java Native Interface) jniSmartIdEngineJar.jar требуется для вызова C++ кода из Java приложений. Сборка обёртки у нас автоматизирована с помощью инструментария SWIG (simplified wrapper and interface generator).
Итак, как говорят французы, revenons `a nos moutons! У нас есть SDK и нужно с минимальными усилиями встроить его в проект и начать использовать. Для этого потребуются следующие шаги:
Для того чтобы каждый мог поиграться с библиотекой мы подготовили и выложили исходный код Smart IDReader Demo for Android на Github. Проект сделан для Android Studio и демонстрирует пример работы с камерой и ядром на основе простого приложения.
Рассмотрим данный процесс на примере проекта приложения под Android Studio, для пользователей других IDE процесс не особо отличается. По умолчанию в каждом проекте Android Studio создает папку libs, из которой сборщик Gradle забирает и добавляется к проекту JAR файлы. Именно туда скопируем JNI обёртку jniSmartIdEngineJar.jar. Для добавления библиотек ядра существует несколько способов, проще всего это сделать с помощью JAR архива. Создаем в папке libs архив с именем native-libs.jar (это важно!) и внутри архива подпапки lib/armeabi-v7a и lib/arm64-v8a и помещаем туда соответствующие версии библиотек (для x86 библиотеки подпапка будет lib/x86).
В этом случае ОС Android после установки приложения автоматически развернёт нужную версию библиотеки для данного устройства. Сопутствующие файлы конфигурации движка добавляем в папку assets проекта, если данная папка отсутствует, то её можно создать вручную или с помощью команды File|New|Folder|Assets Folder. Как видим, добавить файлы к проекту очень просто и занимает совсем немного времени.
Итак, мы добавили необходимые файлы к приложению и даже успешно его собрали. Руки так и тянутся попробовать новый функционал в деле, но для этого нужно ещё немного поработать :-) А именно сделать следующее:
Чтобы библиотека могла получить доступ к файлам конфигурации необходимо перенести их из assets в рабочую папку приложения. Достаточно сделать это один раз при запуске и затем обновлять только при выходе новой версии. Проще всего такую проверку сделать, основываясь на версии кода приложения, и если она изменилась то обновить файлы.
// текущая версия кода приложения
int version_code = BuildConfig.VERSION_CODE;
SharedPreferences sPref = PreferenceManager.getDefaultSharedPreferences(this);
// версия кода из настроек
int version_current = sPref.getInt("version_code", -1);
// если версии отличаются нужно обновить данные
need_copy_assets = version_code != version_current;
// обновляем версию кода в настройках
SharedPreferences.Editor ed = sPref.edit();
ed.putInt("version_code", version_code);
ed.commit();
…
if (need_copy_assets == true)
copyAssets();Сама процедура копирования не сложна и заключается в получении данных из файлов, находящихся в assets приложения, и записи эти данных в файлы рабочего каталога. Пример кода функции, осуществляющей такое копирование, можно посмотреть в примере на Github.
Осталось только загрузить библиотеку и инициализировать ядро. Вся процедура занимает определённое время, поэтому разумно выполнять её в отдельном потоке, чтобы не затормаживать основной GUI поток. Пример инициализации на основе AsyncTask
private static RecognitionEngine engine;
private static SessionSettings sessionSettings;
private static RecognitionSession session;
...
сlass InitCore extends AsyncTask {
@Override
protected Void doInBackground(Void... unused) {
if (need_copy_assets)
copyAssets();
// конфигурирование ядра
configureEngine();
return null;
}
@Override
protected void onPostExecute(Void aVoid) {
super.onPostExecute(aVoid);
if(is_configured)
{
// устанавливаем ограничения на распознаваемые документы (например, rus.passport.* означает подмножество документов российского паспорта)
sessionSettings.AddEnabledDocumentTypes(document_mask);
// получаем полные наименования распознаваемых документов
StringVector document_types = sessionSettings.GetEnabledDocumentTypes();
...
}
}
}
…
private void configureEngine() {
try {
// загрузка библиотеки ядра
System.loadLibrary("jniSmartIdEngine");
// путь к файлу настроек ядра
String bundle_path = getFilesDir().getAbsolutePath() + File.separator + bundle_name;
// инициализация ядра
engine = new RecognitionEngine(bundle_path);
// инициализация настроек сессии
sessionSettings = engine.CreateSessionSettings();
is_configured = true;
} catch (RuntimeException e) {
...
}
catch(UnsatisfiedLinkError e) {
...
}
}Если ваше приложение уже использует камеру, то можете спокойно пропустить этот раздел и перейти к следующему. Для оставшихся рассмотрим вопрос использования камеры для работы с видео потоком для распознавания документов посредством Smart IDReader. Сразу оговоримся, что мы используем класс Camera, а не Camera2, хотя он и объявлен как deprecated начиная с версии API 21 (Android 5.0). Это осознанно сделано по следующим причинам:
Чтобы добавить поддержку камеры в приложение нужно прописать в манифест следующие строки:
Хорошим тоном является запрос разрешения на использование камеры, реализованные в Android 6.x и выше. К тому же пользователи этих систем всегда могут отобрать разрешения у приложения в настройках, так что проверку все равно проводить нужно.
// если необходимо - запрашиваем разрешение
if( needPermission(Manifest.permission.CAMERA) == true )
requestPermission(Manifest.permission.CAMERA, REQUEST_CAMERA);
…
public boolean needPermission(String permission) {
// проверка разрешения
int result = ContextCompat.checkSelfPermission(this, permission);
return result != PackageManager.PERMISSION_GRANTED;
}
public void requestPermission(String permission, int request_code)
{
// запрос на разрешение работы с камерой
ActivityCompat.requestPermissions(this, new String[]{permission}, request_code);
}
@Override
public void onRequestPermissionsResult(int requestCode, String permissions[], int[] grantResults)
{
switch (requestCode) {
case REQUEST_CAMERA: {
// запрос на разрешение работы с камерой
boolean is_granted = false;
for(int grantResult : grantResults)
{
if(grantResult == PackageManager.PERMISSION_GRANTED) // разрешение получено
is_granted = true;
}
if (is_granted == true)
{
camera = Camera.open(); // открываем камеру
....
}
else
toast("Enable CAMERA permission in Settings");
}
default:
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
}
}Важной частью работы с камерой является установка её параметров, а именно режима фокусировки и разрешения предпросмотра. Из-за большого разнообразия устройств и характеристик их камер этому вопросу следует уделить особое внимание. Если камера не поддерживает возможности фокусировки, то приходится работать с фиксированным фокусом или направленным на бесконечность. В таком случае особо ничего сделать нельзя, получаем изображения с камеры as is. А если нам повезло и фокусировка доступна, то проверяем, поддерживаются ли режимы FOCUS_MODE_CONTINUOUS_PICTURE или FOCUS_MODE_CONTINUOUS_VIDEO, что означает постоянный процесс фокусировки на объектах съемки в процессе работы. Если эти режимы поддерживаются, то выставляем их в параметрах. Если же нет, то можно сделать следующий финт – запустить таймер и самим вызывать функцию фокусировки у камеры с заданной периодичностью.
Camera.Parameters params = camera.getParameters();
// список поддерживаемых режимов фокусировки
List focus_modes = params.getSupportedFocusModes();
String focus_mode = Camera.Parameters.FOCUS_MODE_AUTO;
boolean isAutoFocus = focus_modes.contains(focus_mode);
if (isAutoFocus) {
if (focus_modes.contains(Camera.Parameters.FOCUS_MODE_CONTINUOUS_PICTURE))
focus_mode = Camera.Parameters.FOCUS_MODE_CONTINUOUS_PICTURE;
else if (focus_modes.contains(Camera.Parameters.FOCUS_MODE_CONTINUOUS_VIDEO))
focus_mode = Camera.Parameters.FOCUS_MODE_CONTINUOUS_VIDEO;
} else {
// если нет автофокуса то берём первый возможный режим фокусировки
focus_mode = focus_modes.get(0);
}
// установка режима фокусировки
params.setFocusMode(focus_mode);
// запуск автофокуса по таймеру если нет постоянного режима фокусировки
if (focus_mode == Camera.Parameters.FOCUS_MODE_AUTO)
{
timer = new Timer();
timer.schedule(new Focus(), timer_delay, timer_period);
}
…
// таймер периодической фокусировки
private class Focus extends TimerTask {
public void run() {
focusing();
}
}
public void focusing() {
try{
Camera.Parameters cparams = camera.getParameters();
// если поддерживается хотя бы одна зона для фокусировки
if( cparams.getMaxNumFocusAreas() > 0)
{
camera.cancelAutoFocus();
cparams.setFocusMode(Camera.Parameters.FOCUS_MODE_AUTO);
camera.setParameters(cparams);
}
}catch(RuntimeException e)
{
...
}
} Установка разрешения предпросмотра достаточно проста, основные требования чтобы соотношения сторон preview камеры соответствовали сторонам области отображения для отсутствия искажений при просмотре, и желательно чтобы разрешение было как можно выше, так как от него зависит качество распознавания документа. В нашем примере приложение отображает preview на весь экран, поэтому выбираем максимальное разрешение, соответствующее соотношениям сторон экрана.
DisplayMetrics metrics = new DisplayMetrics();
getWindowManager().getDefaultDisplay().getMetrics(metrics);
// соотношение сторон экрана
float best_ratio = (float)metrics.heightPixels / (float)metrics.widthPixels;
List sizes = params.getSupportedPreviewSizes();
Camera.Size preview_size = sizes.get(0);
// допустимое отклонение от оптимального соотношения при выборе
final float tolerance = 0.1f;
float preview_ratio_diff = Math.abs( (float) preview_size.width / (float) preview_size.height - best_ratio);
// выбираем оптимальное разрешение preview камеры по соотношению сторон экрана
for (int i = 1; i < sizes.size() ; i++)
{
Camera.Size tmp_size = sizes.get(i);
float tmp_ratio_diff = Math.abs( (float) tmp_size.width / (float) tmp_size.height - best_ratio);
if( Math.abs(tmp_ratio_diff - preview_ratio_diff) < tolerance && tmp_size.width > preview_size.width || tmp_ratio_diff < preview_ratio_diff)
{
preview_size = tmp_size;
preview_ratio_diff = tmp_ratio_diff;
}
}
// установка размера preview в настройках камеры
params.setPreviewSize(preview_size.width, preview_size.height);Осталось совсем немного – установить ориентацию камеры и отображение preview на поверхность Activity. По умолчанию углу 0 градусов соответствует альбомная ориентация устройства, при поворотах экрана её нужно соответственно менять. Тут можно еще вспомнить добрым словом Nexus 5X от Google, матрица которого установлена в устройстве вверх ногами и для которого нужна отдельная проверка на ориентацию.
private boolean is_nexus_5x = Build.MODEL.contains("Nexus 5X");
SurfaceView surface = (SurfaceView) findViewById(R.id.preview);
...
// портретная ориентация
camera.setDisplayOrientation(!is_nexus_5x ? 90: 270);
// отображение preview на поверхность приложения
camera.setPreviewDisplay(surface.getHolder());
// начало процесса preview
camera.startPreview();Итак, камера подключена и работает, осталось самое интересное – задействовать ядро и получить результат. Запускаем процесс распознавания, начав новую сессию и установив callback для получения кадров с камеры в режиме preview.
void start_session()
{
if (is_configured == true && camera_ready == true) {
// установка параметров сессии, например тайм-аут
sessionSettings.SetOption("common.sessionTimeout", "5.0");
// создании сессии распознавания
session = engine.SpawnSession(sessionSettings);
try {
session_working = true;
// семафоры готовности кадра к обработке и ожидания кадра
frame_waiting = new Semaphore(1, true);
frame_ready = new Semaphore(0, true);
// запуск потока распознавания в отдельном AsyncTask
new EngineTask().execute();
} catch (RuntimeException e) {
...
}
// установка callback для получения изображений с камеры
camera.setPreviewCallback(this);
}
}Функция onPreviewFrame() получает текущее изображение с камеры в виде массива байт формата YUV NV21. Так как она может вызываться только в основном потоке, чтобы его не замедлять вызовы ядра для обработки изображения помещаются в отдельный поток с помощью AsyncTask, синхронизация процесса происходит с помощью семафоров. После получения изображения с камеры даём сигнал рабочему потоку начать его обработку, по окончании — сигнал на получение нового изображения.
// текущее изображение
private static volatile byte[] data;
...
@Override
public void onPreviewFrame(byte[] data_, Camera camera)
{
if(frame_waiting.tryAcquire() && session_working)
{
data = data_;
// семафор готовности изображения к обработке
frame_ready.release();
}
}
…
class EngineTask extends AsyncTask
{
@Override
protected Void doInBackground(Void... unused) {
while (true) {
try {
frame_ready.acquire(); // ждем новый кадр
if(session_working == false) // остановка если сессия завершена
break;
Camera.Size size = camera.getParameters().getPreviewSize();
// передаём кадр в ядро и получаем результат
RecognitionResult result = session.ProcessYUVSnapshot(data, size.width, size.height, !is_nexus_5x ? ImageOrientation.Portrait : ImageOrientation.InvertedPortrait);
...
// семафор ожидания нового кадра
frame_waiting.release();
}catch(RuntimeException e)
{
... }
catch(InterruptedException e)
{
...
}
}
return null;
}После обработки каждого изображения ядро возвращает текущий результат распознавания. Он включает в себя найденные зоны документа, текстовые поля со значениями и флагами уверенности, а также графические поля, такие как фотографии или подписи. Если данные распознаны корректно или произошел тайм-аут, то устанавливается флаг IsTerminal, сигнализирующий о завершении процесса. Для промежуточных результатов можно производить отрисовку найденных зон и полей, показывать текущий прогресс по качеству распознавания и многое другое, все зависит от вашей фантазии.
void show_result(RecognitionResult result)
{
// получаем распознанные поля с документа
StringVector texts = result.GetStringFieldNames();
// получаем изображения с документа, такие как фотография, подпись и так далее
StringVector images = result.GetImageFieldNames();
for (int i = 0; i < texts.size(); i++) // текстовые поля документа
{
StringField field = result.GetStringField(texts.get(i));
String value = field.GetUtf8Value(); // данные поля
boolean is_accepted = field.IsAccepted(); .. статус поля
...
}
for (int i = 0; i < images.size(); i++) // графические поля документа
{
ImageField field = result.GetImageField(images.get(i));
Bitmap image = getBitmap(field.GetValue()); // получаем Bitmap
...
}
...
}После этого нам остается только остановить процесс получения изображений с камеры и прекратить процесс распознавания.
void stop_session()
{
session_working = false;
data = null;
frame_waiting.release();
frame_ready.release();
camera.setPreviewCallback(null); // останавливаем процесс получения изображений с камеры
...
}Как можно убедиться на нашем примере, процесс подключения Smart IDReader SDK к Android приложениям и работа с камерой не являются чем-то сложным, достаточно всего лишь следовать некоторым правилам. Целый ряд наших заказчиков успешно применяют наши технологии в своих мобильных приложениях, причем сам процесс добавления нового функционала занимает весьма небольшой время. Надеемся, с помощью данной статьи и вы смогли убедиться в этом!
P.S. Чтобы посмотреть, как Smart IDReader выглядит в нашем исполнении после встраивания, вы можете скачать бесплатные полные версии приложений из App Store и Google Play.
|
|
[Перевод] Непрерывная интеграция: CircleCI vs Travis CI vs Jenkins |

Под катом вы найдете перевод статьи ознакомительного характера, в которой сравниваются три системы непрерывной интеграции: CircleCI, Travis CI и Jenkins.
Непрерывная интеграция (CI, Continuous Integration) — это практика разработки программного обеспечения, при которой изменения кода с высокой частотой интегрируются в общий репозиторий и проверяются с помощью автоматической сборки.
Непрерывная интеграция нацелена на ускорение и облегчение процесса выявления проблем, возникающих в процессе разработки программного обеспечения. При регулярной интеграции изменений единовременный объем проверок уменьшается. В результате на отладку тратится меньше времени, которое можно перераспределить на добавление новых функций. Также возможно добавить проверку стиля кода, цикломатической сложности (чем ниже сложность, тем легче тестировать) и другие виды контроля. Это упрощает рецензирование кода (code review), экономит время и улучшает качество кода.

Надеюсь, теперь процесс непрерывной интеграции в общих чертах нам понятен, и мы можем перейти к сравнению нескольких популярных в настоящее время CI-платформ, у каждой из которых есть свои преимущества и недостатки. Давайте начнем с CircleCI.

Функции:
CircleCI совместима с:
Достоинства CircleCI:
Недостатки CircleCI:
Также, несмотря на то что у облачных систем есть несомненные преимущества, нужно быть готовым к тому, что в любой момент необходимая вам функция может быть убрана, и вы ничего с этим поделать не сможете.

Travis CI и CircleCI очень похожи
Обе системы:
Что есть в TravisCI и нет в CircleCI?
language: python
python:
- "2.7"
- "3.4"
- "3.5"
env:
- DJANGO='django>=1.8,<1.9'
- DJANGO='django>=1.9,<1.10'
- DJANGO='django>=1.10,<1.11'
- DJANGO='https://github.com/django/django/archive/master.tar.gz'
matrix:
allow_failures:
- env: DJANGO='https://github.com/django/django/archive/master.tar.gz'Build matrix — это инструмент, который дает возможность выполнять тесты, используя разные версии языков и пакетов. Он обладает богатыми возможностями по настройке. Например, при неудачных сборках в некоторых окружениях система может выдать предупреждение, но сборка целиком не будет считаться неудачной (это удобно при использовании dev-версий пакетов).
Если вы предпочитаете какую-либо другую CI-платформу, то Build Matrix можно создать с помощью Tox.
[tox]
envlist = py{27,34,35}-django{18,19,110,master}
[testenv]
deps =
py{27,34,35}: -rrequirements/test.txt
django18: Django>=1.8,<1.9
django19: Django>=1.9,<1.10
django110: Django>=1.10,<1.11
djangomaster: https://github.com/django/django/archive/master.tar.gz
commands = ./runtests.py
[testenv:py27-djangomaster]
ignore_outcome = TrueTox — это универсальный консольный инструмент по управлению пакетами и их тестированию в virtualenv. Его можно установить с помощью pip install tox или easy_install tox.
Достоинства Travis CI:
Недостатки Travis CI:

Возможности:
Достоинства Jenkins:
Недостатки Jenkins:
Какую систему CI выбрать? Это зависит от ваших потребностей и планируемого способа использования этого инструмента.
CircleCI хорошо подходит для небольших проектов, где основная задача — запустить непрерывную интеграцию как можно быстрее.
Travis CI рекомендуется в первую очередь для open-source проектов, которые необходимо тестировать в различных окружениях.
Jenkins я бы посоветовал для больших проектов, при работе над которыми потребуется серьезная настройка системы (в случае Jenkins выполняется с помощью плагинов). В Jenkins можно изменить практически что угодно, но на это потребуется время. Если вы хотите побыстрее запустить CI-цепочку, Jenkins может не подойти.
Ссылки:
|
Метки: author olemskoi devops блог компании southbridge circleci travis jenkins continuous integration continuous delivery |
Расширяем экосистему Skyeng, открыв API словаря — первые участники конкурса |

Месяц назад мы открыли API нашего словаря, предложили всем желающим использовать его в своих приложениях и сервисах и даже объявили конкурс среди разработчиков. За прошедшее время мы получили 18 конкурсных заявок, среди них несколько готовых решений. Сегодня мы решили в своем блоге дать авторам четырех из них возможность рассказать о своем продукте (а мы прокомментируем).
Если вы пропустили пост о нашей экосистеме, где был объявлен конкурс – вот ссылка. На тот момент у нас еще не были готовы условия конкурса — вот и они. Призовой фонд нашего конкурса составляет 200 тысяч рублей — деньги для разработчика нового приложения или сервиса не бывают лишними!
Ну а теперь — к знакомству с первыми участниками.
 Lenny — это чатбот, который помогает пользователям пополнять их словарный запас по 10 слов в день. ЦА — это люди, которые изучают английский прямо сейчас или изучали его ранее. Большой словарный запас нужен для того, чтобы хорошо говорить, легко читать, понимать других и просто думать.
Lenny — это чатбот, который помогает пользователям пополнять их словарный запас по 10 слов в день. ЦА — это люди, которые изучают английский прямо сейчас или изучали его ранее. Большой словарный запас нужен для того, чтобы хорошо говорить, легко читать, понимать других и просто думать.
Чтобы слова не забывались, их нужно регулярно «освежать» в памяти. Далеко ходить мы не стали и построили алгоритм повторения на основе кривой забывания Эббингауза. На деле это значит, что пользователь повторяет слова через 30 минут, 1 день, 1 неделю, 1 месяц и 1 год. Таким образом слова закрепляются долговременной памяти. А в нужный момент их можно оттуда достать и применить.
Теперь о контенте. Перед началом конкурса у нас уже была база из 10 000 слов. И когда Skyeng предоставляет возможность сделать базу еще лучше, ей надо пользоваться. Мы так и сделали, получив и сохранив в отдельные файлы все необходимое.
А именно:
import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
ids = response.json()[0]['meanings'][0]['id']
return skyeng_meaning(ids)
except:
return None
def skyeng_meaning(ids):
url = "http://dictionary.skyeng.ru/api/public/v1/meanings?_format=json&ids={}".format(ids)
response = requests.get(url)
return response.json()[0]['examples'][0]['text']
def get_example(word):
example = skyeng_word(word)
if example is not None:
return example
else:
return '!!! {} !!!'.format(word)
def add_example():
i = 1
while i <= 10000:
time.sleep(1)
example = get_example(dictionary[i]['word'])
with open('examples.py', 'a') as file:
file.write("{}: \"{}\"\n".format(i, example))
print(i)
i += 1
if __name__ == '__main__':
add_example()import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
ids = response.json()[0]['meanings'][0]['id']
return skyeng_meaning(ids)
except:
return None
def skyeng_meaning(ids):
url = "http://dictionary.skyeng.ru/api/public/v1/meanings?_format=json&ids={}".format(ids)
response = requests.get(url)
return response.json()[0]['definition']['text']
def get_definition(word):
definition = skyeng_word(word)
if definition is not None:
return definition
else:
return '!!! {} !!!'.format(word)
def add_definition():
i = 1
while i <= 10000:
time.sleep(1)
definition = get_definition(dictionary[i]['word'])
with open('definitions.py', 'a') as file:
file.write("{}: \"{}\"\n".format(i, definition))
print(i)
i += 1
if __name__ == '__main__':
add_definition()import requests
import time
from content import dictionary
def skyeng_word(word):
url = "http://dictionary.skyeng.ru/api/public/v1/words/search?_format=json&search={}".format(word)
response = requests.get(url)
try:
voice_url = "http:{}".format(response.json()[0]['meanings'][0]['soundUrl'])
return requests.get(voice_url)
except:
return None
def get_voice():
i = 1
while i <= 10000:
time.sleep(1)
voice = skyeng_word(dictionary[i]['word'])
file_name = '{}.ogg'.format(i)
if voice is not None:
with open(file_name, 'wb') as file:
file.write(bytes(voice.content))
print(i)
i += 1
if __name__ == '__main__':
get_voice()Далее мы просто обновили текущую базу всем сохраненным.
Думаю, не стоит объяснять, почему мы сохранили контент у себя вместо того, чтобы каждый раз обращаться к API. Такой способ быстрее. А чем быстрее работает бот, тем довольнее пользователи.
Закончить свой дебют на Хабре хотелось бы афоризмом. Он отражает философию нашей небольшой команды — «Words can inspire and words can destroy. They are important to learn».
Благодарим школу Skyeng за возможность сделать продукт лучше. Спасибо всем, удачи!
Skyeng: Нам очень нравится бот LennyEnglishBot, он минималистичный и ненавязчивый, а работает на трех платформах – Telegram, Facebook и Viber. Для тех, кто не хочет или не может ставить лишнее приложение в телефон – самое оно, порог вхождения минимальный. В нашей экосистеме такой продукт очень был нужен.
Проблема, однако, в том, что этот бот не до конца интегрирован в нашу экосистему. Автор загнал туда фиксированный набор из 10 тысяч слов и подтянул к этому набору наши определения. Нет возможности тренировать произвольные слова и, главное для нас, нет возможности тренировать слова, взятые на изучение в Vimbox. Надеемся, что в будущих версиях бота все это будет учтено, потому что, повторимся, он нам очень-очень нравится.
readore — это коллекция книг, синхронизированных с аудио-дорожкой. Каждой книге присвоен уровень сложности, что позволяет легко подобрать литературу для своего уровня владения языком. При чтении можно мгновенно переводить незнакомые слова и добавлять в список слов для запоминания. Начиная с этого момента во всех книгах это слово будет выделено, а в течение дня мы будем отправлять ему уведомление "слово-перевод".

Приложение было реализовано еще до конкурса, когда для изучения испанского я купил Маркеса в бумажном переплете. Тогда и пришла идея изучать иностранный язык с любимыми книгами.
С помощью API SkyEng наше приложение теперь снова будет работать в Украине (до этого мы использовали Яндекс.Словарь), я как раз искал бесплатную альтернативу. Ну и теперь по многочисленным просьбам пользователей, readore может похвастаться offline-словарем.
Skyeng: Нам это приложение понравилось. Симпатичное, похоже на Bookmate. В некоторых книжках есть встроенная озвучка. Встроен словарь и переводчик, можно отмечать слова на изучение. И самое приятное, что в ближайшее время у учеников нашей школы появится возможность добавлять слова на изучение в нашем мобильном приложении Words.
Изучаю английский уже года три, до этого мечтал смотреть фильмы и читать литературу в оригинале. Мечта сбылась, но запоминание новых слов дается с трудом, постоянно попадаются слова, которые я не знаю.
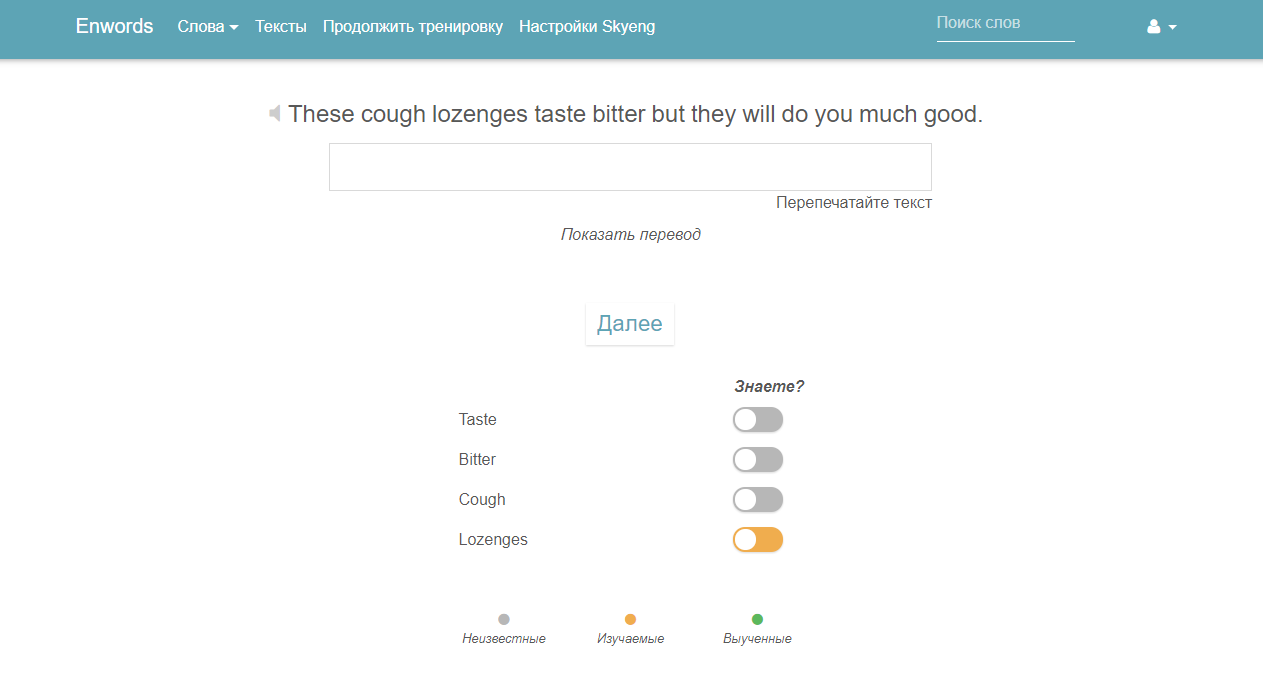
Прочитал когда-то статью на geektimes, из которой узнал про сайт tatoeba.org. Выгрузил оттуда список предложений, распарсил и выбрал самые часто встречающиеся слова, а дальше решил не ограничиваться только английским языком. В итоге была создана своя база, состоящая из 3.5 миллионов предложений, 500 тысяч слов на 30 языках, включая даже эсперанто. Создал web-приложение, в котором можно добавлять слова для изучения и отмечать выученные. Запоминание слов происходит при повторении их в небольших фразах.
Есть режим тренировок, где фразу нужно полностью перепечатать (заодно можно тренировать слепую печать). Можно загрузить текст для изучения, обычно использую тексты из уроков A.J. Hoge, он парсится, на выходе получается список слов, отсортированный по частоте встречаемости в этом тексте. Приложение не подойдет совсем новичкам в иностранных языках, грамматических уроков здесь нет.
Недавно подключил Skyeng API в связке с jQuery плагином qtip, теперь по клику на английское слово отправляется ajax запрос в Skyeng, и появляется перевод слова с озвучкой. Я давно хотел подключить такой функционал, руки не доходили, но со Skyeng это заняло буквально час. В ближайшее время позволю своим пользователям изучать слова, которые они добавили в учетной записи Skyeng, надеюсь это повысит конверсию.
Проект opensource, полностью бесплатный, если будет много пользователей, придется вводить платные функции, сервера нужно оплачивать, но основа все равно будет доступна для всех.
Написан на Ruby on Rails, любой желающий может предлагать свои идеи по функционалу, дизайну, маркетингу, вообще от product manager’а я бы не отказался.
Skyeng: Enwords предоставляет возможность самостоятельно составлять списки слов для изучения, это функционал, который активно просят пользователи нашего приложения Words. Однако текстовый парсер, в отличие от нашего Wordset Generator, не умеет сортировать слова по уровню сложности, поэтому на выходе получается очень большой список, начинающийся с артиклей, местоимений и заведомо всем известных слов; таким образом, надо потратить время на извлечение нужной для изучения лексики. Важная фишка Enwords – открытый исходный код.
UPD: новая важная фишка — возможность добавлять слова из своего аккаунта в Skyeng, достаточно указать e-mail в поле "Настройки Skyeng". Отлично!
 Идея приложения следующая: создать онлайн переводчик слов (фраз) с сохранением вариантов перевода (оффлайн) для детального изучения полученных значений. Т.е. подразумевается "бессистемное" расширение словарного запаса.
Идея приложения следующая: создать онлайн переводчик слов (фраз) с сохранением вариантов перевода (оффлайн) для детального изучения полученных значений. Т.е. подразумевается "бессистемное" расширение словарного запаса.
API Skyeng в настоящий момент используется в виде реализации запроса (метод "search": dictionary.skyeng.ru/api/public/v1/words/search). Порадовало то, что работает без авторизации, а результаты предоставляются как для русских, так и английских слов. Из структуры результатов запроса возникла простая реализация приложения в виде двух фрагментов: «список полученных (по запросу) слов» и «отображение значений (вариантов перевода)». Полученные значения отображаются в виде «визуальных карточек» с возможностью загрузки аудио-файлов для воспроизведения транскрипции. Результаты поискового запроса сохраняются в БД приложения (состоит из двух связанных таблиц, используется ORM Lite), аудио-файлы и изображения хранятся в директории приложения.
Каждому слову (результаты запроса) назначается одна из категорий:
1) "Для изучения",
2) "Изученное",
3) "Избранное",
4) "Просмотренное" (назначается при выборе слова для просмотра значений перевода);
при перемещении в "Изученное" формируется тестовое задание: выбрать верный из пяти предложенных вариантов перевода, случайная выборка из таблицы "значения" при совпадении поля "часть речи" (Part of speech).
Skyeng: «Больше Слов» — по сути упрощенный аналог нашего приложения Words. Хотя он не очень вписывается в нашу экосистему, мы рады его существованию: мы за разнообразие и возможность выбора.
Конкурс Skeyng продолжается, мы надеемся увидеть еще больше интересных разработок, использующих наш API. Если у вас есть идея или готовое приложение — заполните заявку.
Ну а если вы хотите разрабатывать приложения внутри Skyeng — у нас, как всегда, есть интересные вакансии.
|
Метки: author Ontaelio разработка мобильных приложений разработка веб-сайтов api блог компании skyeng экосистема конкурс идея для стартапа ридер словарь переводчик |
«Ультимативный» блокчейн-дайджест: полезные материалы на Хабре и другие источники по теме |
 / изображение Ron Mader CC
/ изображение Ron Mader CC«C чем это едят»: что такое блокчейнКомпания BitFury принимает участие в развитии блокчейна с 2011 года. Здесь мы рассказываем об истории данной технологии, даем простое объяснение принципов работы и знакомим с основными составляющими. Этот материал стоит использовать в качестве отправной точки и рекомендовать к прочтению всем, кто хотел бы понять, что такое блокчейн.
Что такое эксклюзивные блокчейныПростыми словами об особенностях эксклюзивных блокчейнов, их задачах, сферах применения и возможностях. В этом материале мы постарались привести как можно больше примеров и дать полезные ссылки на первоисточники. Кроме того, здесь вы найдете подраздел, посвященный фреймворкам для эксклюзивных блокчейнов.
Объяснение блокчейна для веб-разработчиковХабражитель Ratix подготовил перевод материала «The Blockchain Explained to Web Developers, Part 1: The Theory» за авторством Франсуа Занинотто (Francois Zaninotto). Это очередная попытка разобраться в теме с помощью самостоятельного перевода первоисточника. В этой статье вы найдете базовое определение блокчейна, краткий рассказ о криптовалютах, майнинге, блоках и контрактах.
Кто нужен блокчейн-проектам, где их искать и сколько платят специалистамКрупнейшие международные организации начинают активное внедрение в свою деятельность технологии построения цепочки блоков транзакций. Здесь вы сможете увидеть экспертное мнение о том, какие специалисты нужны прямо сейчас, кто в них заинтересован и какие вам потребуются знания для работы с блокчейном.
Кладбище блокчейн-проектовЭто — сборник 43 инцидентов, негативно отразившихся на тех или иных криптовалютах. Беглый анализ основных причин произошедшего говорит, что основные проблемы связаны с применением методов социальной инженерии, перехватом аккаунтов облачного хранилища данных и базовых уязвимостей на уровне приложений.
Как майнить с помощью бумаги и ручкиmark_ablov подготовил перевод занимательной заметки Кена Ширриффа (Ken Shirriff), которую тот написал еще в 2014 году. Этот материал будет интересен тем, кто хотел бы перейти от слов к практике и разобраться в сути технологии. Помимо времени на решение задачи Кен предполагает и свое энергопотребление, хотя затраты на бумагу и ручки он исключил из общего обоснования экономической эффективности процесса.
Как масштабировать биткойн-блокчейнЗдесь мы разбираемся с тем, как устранить самый большой недостаток биткойн-блокчейна. Из этой статьи вы узнаете о тех решениях, которые предлагает мировое сообщество, и о том, какое из них станет частью биткойн-сети. Для тех, кто уже успел немного погрузиться в тему: речь пойдет о Segregated Witness и Lightning Network.
Как работать с метаданными блокчейнаПошаговый анализ того, что можно сделать на уровне метаданных. От биткоин-адреса до Transaction ID и возможных параметров метаданных, их передачи и необходимых для этого ресурсов.
Как запустить надстройку над биткойн-блокчейномЗдесь мы приводим чуть более детальный разбор того, что из себя представляет Lightning Network. Плюс рассказываем о том, как можно настроить двунаправленный платежный канал, немного о работе в сети, трехстороннем обмене и маршрутизации в Lightning Network.
«Алгоритмы консенсуса»: Подтверждение доли и доказательство работыРаспределенный и децентрализованный характер архитектуры блокчейна ставит перед сообществом задачу распределенного консенсуса. В этой статье мы начинаем со структуры блокчейн-сетей, говорим о консенсусе и «доказательстве работы». Помимо этого — приводим альтернативы для PoW. Этот материал мы рекомендуем «продвинутым пользователям».
«Криптография в блокчейнах»: о хеш-функциях и цифровых подписяхРазбираемся с тем, что лежит в основе блокчейна. Здесь вы сможете узнать, что дает защиту от коллизий, познакомиться с «эффектом лавины» и найти «живые» примеры, которые наглядно иллюстрируют рассматриваемые понятия. В этом нам помогли Алиса и Боб, активные пользователи биткойна.
Различия, плюсы и минусы: публичные и приватные блокчейныКрупнейшие банковские структуры и другие организации активно изучают возможности построения собственных приватных блокчейнов. Мы решили разобраться с соответствующей терминологией и характерными особенностями публичных и приватных блокчейнов.
Обзор децентрализованных технологий. Часть 1 и Часть 2Александр Стрелов pokupo написал серию обзорных материалов и постарался коротко осветить самые интересные проекты из области блокчейна. Его основная задача заключалась в том, чтобы начать рассказывать о революционной технологии, которая открывает новые возможности для построения принципиально иных систем и программных продуктов.
Погружение в блокчейн: Быстрые и безопасные транзакцииКорпоративный блог Microsoft повествует о проектах, разработанных на основе технологии блокчейн. В этом материале вы найдете краткий анализ проблем, которые решает новая технология, и практический туториал на тему выполнения задачи по развёртыванию, в том числе и распределенного варианта, сети блокчейн. Продолжение цикла статей — здесь.
200 строк на блокчейнЛаури Хартикка (Lauri Hartikka) поможет разобраться с реализацией простейшего блокчейна на самописном примере, который он назвал NaiveChain. Сам проект написан на Javascript, а в материале Лаури рассказывает о его основных составляющих и архитектуре. Дополнительно для интересующихся: репозиторий на GitHub.
Как с помощью блокчейна защитить свои данныеКомпания Acronis рассказывает в своем корпоративном блоге о том, каким образом новую технологию возможно применить в сфере обеспечения безопасности данных. Здесь кратко рассмотрена техническая сторона задачи и поставлены юридические вопросы, которые влияют на применение подобных решений на территории России.
Иное применение блокчейнов: Смарт-контрактыВ одном их материалов блога Bitfury Group на Хабрахабре мы решили разобраться с тем, что из себя представляют смарт-контракты. Здесь мы кратко затронули примеры платформ для смарт-контрактов (Rootstock) и поговорили о будущем и практическом применении умных контрактов.
Разработки Университета ИТМО: Управление дронами на блокчейнеУниверситет ИТМО рассказывает об одном из точечных экспериментов своего сообщества. Сфера применения — управление беспилотниками. Платформа — Ethereum.
Блокчейн для управления городом: властям Дубая поможет IBMПравительство Дубая планирует запустить управление инфраструктурой города на базе блокчейна уже в следующем году. Создаваемая платформа будет открытой и для других регионов. В своем корпоративном блоге на Хабре компания IBM (партнер проекта) подчеркивает, что возможности новой технологии должны и будут применяться не только в сфере финансовых услуг.
Регистрация прав на землю с помощью блокчейнаBitfury Group поможет правительству Грузии вести регистрацию прав собственности на земельные участки с помощью технологии блокчейн. Об этом кейсе мы рассказывали в своем англоязычном блоге на Medium.
Электронное правительство на основе блокчейн-технологийЕще один кейс применения блокчейна вне финансового сектора — сотрудничество Bitfury Group и правительства Украины. Первый этап программы — интеграция технологии в платформу электронного правительства. Первоначальные области для внедрения: реестры, социальный сектор, сферы здравоохранения и энергетики. По мере завершения пилотного проекта программа охватит все сферы правительственной компетенции, включая информационную безопасность.
ТОП 10 ошибок при создании блокчейн-проектов от Gartner IncВладимир>Menaskop подготовил перевод материала, который предлагает взглянуть не только на технологическую, но и на управленческую составляющую блокчейн-проектов. Оригинал — в блоге Gartner на английском.
Блокчейн для ИИТрент МакКонахи (Trent McConaghy) поделился со своей аудиторией видением того, каким образом блокчейн может повлиять на развитие ИИ. Трент рассмотрел этот вопрос с точки зрения «стратегии голубого океана» и проанализировал возможности для работы с большими данными.
Для чего подойдет блокчейнБлог Digital Chains на Medium представляет аудитории интересный англоязычный материал на тему практического применеия блокчейна. Здесь вы сможете найти 30 use-кейсов с примерами уже существующих проектов: от сервиса для доставки товаров и до методов управления медицинской историей пациентов.
Что может блокчейнЖурнал Эксперт заинтересовался возможностями блокчейна и привел собственный разбор проблем и решений в таких сферах как регистрация прав на собственность, заключение контрактов, гарантирование свободы информации и ряда других. Получился великолепный аналитический материал, который мы рекомендуем к прочтению.
Где и как применять блокчейнМайк Голдин (Mike Goldin), разработчик блокчейн-решений, записал тематический подкаст на тему возможностей новой технологии и проблем, которые приходится решать. Здесь вы сможете найти текстовый транскрипт выпуска.
17 use-кейсов для блончейнаЕще одна англоязычная подборка с огромным количеством примеров уже запущенных проектов (в среднем по 3-4 примера на каждый use-кейс). Данный материал подойдет тем, кто только начинает разбираться в теме.
27 отраслей для применения блокчейнаCB Insights, одна из наиболее авторитетных аналитических компаний, публикует свою подборку сфер применения блокчейна. Этот материал дополняет предыдущие новыми примерами реализованных проектов.
|
Метки: author alinatestova программирование блог компании bitfury group bitfury мегаподборка блокчейн blockchain |
QML: как легко получать футболки в конкурсах mail.ru по машинному обучению |
|
Метки: author quantum программирование машинное обучение python mlbootcamp |
Нагрузочное тестирование Web-систем. Продолжаем подготовку |




|
Метки: author Nick-Monk тестирование веб-сервисов высокая производительность нагрузочное тестирование web- сайт |
Бесплатные, линейные иконки для вашего сайта или приложения |

|
Метки: author nikitamarcius0 разработка веб-сайтов css awesomeicons fontawesomeicons linear icons линейные иконки иконки шрифтов бесплатные иконки |
[Из песочницы] Электронная демократия или как собрать и обработать данные по голосованию (и явке) за реновацию в Москве |
Что касается популярности этих сервисов, то центры госуслуг «Мои документы» привлекли чуть больше половины всех проголосовавших, незначительно уступив порталу «Активный гражданин»как-то возникают лёгкие сомнения. Так что — приступим к сбору информации! А потом будем её анализировать. Для этого нам понадобится какой-нибудь язык (скажем, питон), какая-нибудь бд (скажем, sqlite) и какой-нибудь веб-скраппер, благо для питона их множество. Сразу говорю, в конце дам ссылку на получившуюся базу данных, можно сделать с ней что угодно.
https://www.mos.ru/otvet-stroitelstvo/itogi-golosovaniya-zhitelej-po-proektu-programmy-renovacii/?u=121import requests
r = requests.get('https://www.mos.ru/otvet-stroitelstvo/itogi-golosovaniya-zhitelej-po-proektu-programmy-renovacii/?u=121')
print(r.text)
{
"execTime": 0.044450044631958,
"errorMessage": "",
"result": {
"table": "Код квартиры Идентификатор голоса Решение Дата Выбор квартиры 0G6O4 bf659227e8e3
5f9403659209
За
За
18.05
18.05
За
0G6O5 3f12be5cea77
За
15.05
За
... 0G6V1 5acd126a410ea1a842e67066ea68fa8f
За
24.05
За
",
"total": {
"und": 0,
"za": 100,
"protocol_res": 0,
"protiv": 0,
"gorod_mark": 0,
"protocol_date": null,
"house_status": 1,
"gorod": 0
},
"und_table": "Код квартиры Идентификатор голоса Решение Дата Выбор квартиры
",
"address": "Авиационная улица, дом 63, корпус 2"
},
"request_id": "empty_requestid",
"errorCode": 0
}import requests
from concurrent.futures import ProcessPoolExecutor
import concurrent.futures
def check(url):
#try тут нужен, потому что гет-реквест, не смотря на таймаут, иногда плохо себя ведёт
#мы же не хотим в конце перебора миллиона страничек получить краш с ошибкой
try:
r = requests.get('https://www.mos.ru/altmosprx/api/1/renovation/house_result/' + str(url) + '/', timeout=10)
print(url)
r.encoding = 'utf-8'
if '400: Bad Request' not in r.text:
return str(url)
except:
#ошибок будет немного, но лучше эти номера потом пробить ещё раз, для этого пишем и их
woops = str(url) + ' failed'
return woops
results = []
with ProcessPoolExecutor(max_workers=6) as executor:
future_results = {executor.submit(check, url): url for url in range(0, 1000000)}
#если нужны конкретные номера, то просто берём их из списка: url in somelist
for future in concurrent.futures.as_completed(future_results):
results.append(future.result())
results[:] = [item for item in results if item or item == 0]
#check возвращает None, если дома нет, убираем; а вот ноль нам нужен, не забудем о нём
with open('/home/deb/mosres.txt', 'w') as f:
for item in results:
f.write('{}\n'.format(item))import sqlite3
schema = "CREATE TABLE `houses` (\
`id` INTEGER PRIMARY KEY,\
`street` TEXT NOT NULL ,\
`house_nbr` TEXT NOT NULL,\
`house_additional` TEXT,\
`total_votes` INTEGER,\
`total_za` INTEGER,\
`meeting` INTEGER DEFAULT '0',\
`flats` INTEGER\
);"
conn = sqlite3.connect('renovation.db')
cur = conn.cursor()
db = cur.execute(schema)
conn.commit()
conn.close()
import requests
import re
import sqlite3
def gethouseinfo(idd):
print(idd)
urly = 'https://www.mos.ru/altmosprx/api/1/renovation/house_result/' + str(idd) + '/'
try:
r = requests.get(urly)
r.encoding = 'utf-8'
results = r.json()
adress = results['result']['address']
print(adress)
if re.match('(.*), (дом.*), (.*)', adress):
adress_street = re.match('(.*), (дом.*), (.*)', adress).group(1)
adress_house = re.match('(.*), (дом.*), (.*)', adress).group(2)
adress_building = re.match('(.*), (дом.*), (.*)', adress).group(3)
else:
adress_street = re.match('(.*), (дом.*)', adress).group(1)
adress_house = re.match('(.*), (дом.*)', adress).group(2)
adress_building = ''
totalvotes = len(re.findall('apartment-id', results['result']['table'])) + len(re.findall('apartment-id', results['result']['und_table']))
aye = results['result']['total']['za']
meetinghappened = bool(results['result']['total']['protocol_res'])
iddlist = []
iddlist.append(idd)
check = cur.execute('SELECT * FROM houses WHERE id=?', iddlist)
res = check.fetchone()
if res:
print('already exists')
else:
insert = cur.execute('INSERT INTO houses (id, street, house_nbr, house_additional, total_votes, total_za, meeting) values (?, ?, ?, ?, ?, ?, ?)', [idd, adress_street, adress_house, adress_building, totalvotes, aye, meetinghappened])
print('added ' + str(idd))
except ValueError:
print('no data for id '+ str(idd))
jsonerror.append(idd)
except:
print('unknown eggog')
unknownerror.append(idd)
jsonerror = []
unknownerror = []
with open('/home/deb/mosres.txt') as fc:
mosres = fc.read().splitlines()
conn = sqlite3.connect('/home/deb/renovation.db')
cur = conn.cursor()
for house in mosres:
gethouseinfo(house)
conn.commit()
conn.close()
if jsonerror:
with open('/home/deb/jsonerror.txt', 'w') as f:
for item in jsonerror:
f.write('{}\n'.format(item))
if unknownerror:
with open('/home/deb/unknownerror.txt', 'w') as f:
for item in unknownerror:
f.write('{}\n'.format(item))


http://tvoyadres.ru/js/street.php?region=81&city=Москва&count=2073&_=1499809159225 Critical Error
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '-1, 100' at line 1
def getstreets(num):
r = requests.get(url + str(num))
results = r.json()
result = results['string']
return(result)
for i in range(1, 2272, 100):
totalres += getstreets(i)
sids = re.findall('ulitsy\/(.*?)">(.*?)<\/a>', totalres)
#sids = streets with ids
streetsdict = {}
for i in range(len(sids)):
key = sids[i][1]
value = sids[i][0]
streetsdict[key] = valueimport re
from bs4 import BeautifulSoup
def gethouses(num):
r = requests.get('http://tvoyadres.ru/moskovskaya-oblast/moskva/ulitsy/' + str(num) + '/')
results = r.text
soup = BeautifulSoup(results, 'html.parser')
ul = soup.find("ul", {"class": "next"})
houses = []
try:
for li in ul.find_all("li"):
urly = li.a['href']
urly = re.search('doma\/(.*)\/', urly).group(1)
houses.append([li.get_text(), urly])
return(houses)
except:
print('None')
return('None')
totalyres = {}
for key in sids:
num = sids[key]
totalyres[num] = gethouses(num)
for key in totre:
urlo = 'http://tvoyadres.ru/moskovskaya-oblast/moskva/ulitsy/' + key + '/'
ra = requests.get(urlo)
try:
streetname = re.search('- /docs.python.org/3/library/difflib.html">difflib, благо в питон он встроен. Но мало надеяться на диффлиб, нужно будет сделать проверку пользователем, потому что частотность и схожесть это, конечно, хорошо, но нам нужно избежать глупых ошибок. В общем, смотрим на форматы, замечаем, что где-то нет букв ё как класс, где-то слово «улица» из названия улицы убрано, и делаем такое вот:
conn = sqlite3.connect('renovation.db')
cur = conn.cursor()
streets = cur.execute('SELECT DISTINCT street FROM houses order by street asc')
streeets = streets.fetchall()
conn.close()
exactmatches = {}
keyslist = []
for key in sids.keys():
keyslist.append(key)
def glue(maxres=3, freq=0.6):
for each in streeets:
eachnoyo = each[0].replace('ё', 'е')
diffres = difflib.get_close_matches(eachnoyo, keyslist, maxres, freq)
if each[0] not in exactmatches.keys():
if len(diffres) == 1:
print(each[0] + ': ' + diffres[0])
notcompleted = False
while notcompleted == False:
inp = input('Correct? y/n ')
if inp == 'y':
notcompleted = True
exactmatches[each[0]] = sids[diffres[0]]
elif inp == 'n':
notcompleted = True
else:
print('Incorrect input, try again')
elif len(diffres) == 0:
print('No matches for ' + each[0])
elif len(diffres) > 1:
print(each[0] + ': ' + str(diffres))
notcompleted = False
while notcompleted == False:
inp = input('List number? Or n ')
try:
listnum = int(inp)
except:
listnum = None
if inp == 'n':
notcompleted = True
elif listnum in range(0, len(diffres)):
notcompleted = True
exactmatches[each[0]] = sids[diffres[0]]
else:
print('Incorrect input, try again')
with open('exactmatches.json', 'w') as f:
json.dump(exactmatches, f, ensure_ascii=False)
Сидим в консоли, смотрим выдачу, нажимаем кнопки. Когда прошли весь цикл — запускаем функцию с более щадящими параметрами, например, glue(10, freq=0.4).

Мне терпения хватило на 506 улиц из 700 с копейками — по-моему, отличный результат, а главное, статистически значимый (скорее всего).
А теперь нужно сделать то же самое для домов, а также взять, собственно, их количество квартир. И поместить в базу данных.
conn = sqlite3.connect('renovation.db')
cur = conn.cursor()
allhouses = cur.execute('SELECT * FROM houses WHERE flats IS NULL ORDER BY id')
allhousesres = allhouses.fetchall()
url2 = 'http://tvoyadres.ru/moskovskaya-oblast/moskva/'
def getnumberofflats(streetname, houseid):
urlo = url2 + str(streetname) + '/doma/' + str(houseid) + '/'
r = requests.get(urlo)
results = r.text
numbe = re.search('Количество квартир<\/span> (\d*)<', results).group(1)
return numbe
def gluehousesnumbers(freq=3, ratio=0.6):
for house in allhousesres:
if house[1] in exactmatches.keys():
housenbr = house[2].replace('дом', '')
if house[3]:
housenbr = housenbr + ' ' + house[3]
housenbr = housenbr.lower()
diffres = difflib.get_close_matches(housenbr, totre[exactmatches[house[1]]].keys(), freq, ratio)
if len(diffres) == 1:
print(housenbr + ': ' + diffres[0])
notcompleted = False
while notcompleted == False:
inp = input('Correct? y/n ')
if inp == 'y':
notcompleted = True
try:
flatsnumber = getnumberofflats(totre[exactmatches[house[1]]]['streetname'], totre[exactmatches[house[1]]][diffres[0]])
insertion = cur.execute('UPDATE houses SET flats = ? WHERE id = ?', [flatsnumber, house[0]])
except:
print('weird, no flat number for ' + str(house))
elif inp == 'n':
notcompleted = True
else:
print('Incorrect input, try again')
elif len(diffres) > 1:
print(housenbr + ': ' + str(diffres))
notcompleted = False
while notcompleted == False:
inp = input('List number? Or n ')
try:
listnum = int(inp)
except:
listnum = None
if inp == 'n':
notcompleted = True
elif listnum in range(0, len(diffres)):
notcompleted = True
try:
flatsnumber = getnumberofflats(totre[exactmatches[house[1]]]['streetname'], totre[exactmatches[house[1]]][diffres[0]])
insertion = cur.execute('UPDATE houses SET flats = ? WHERE id = ?', [flatsnumber, house[0]])
except:
print('weird, no flat number for ' + str(house))
else:
print('Incorrect input, try again')
conn.commit()
conn.close()
Продолжаем развлекаться. Главное — не забывать закоммитить изменения после каждого прогона функции. Я не стал добавлять коннект и коммит в сами функции, чтобы не теребить постоянно базу данных.
Да, это довольно утомительно. Но, опять же, если отдать всё на откуп диффлибу — будут дурацкие ошибки, как на скриншоте, где он считает «35б» ближе к «35», чем к «35 'б'». Это, конечно, не ошибка диффлиба, но, если честно, я потратил бы больше времени на поск идеального запроса, а потом бы всё равно где-нибудь споткнулся. Лучшее с подтверждением пользователя, увереннее.

Итого: количество квартир есть для 3592 из примерно 4500 домов! Отличный результат (сам себя не похвалишь — никто не похвалит). Но, конечно, если подтверждать так много совпадений — будут ошибки.

Уберём 43 квартиры, в которых проголосовало больше квартир, чем квартир вроде бы есть всего. Ясно, что там либо ошибся я при подтверждении совпадений, либо были заведомо неверные данные.
Ну а с оставшимися уже можно развлекаться. Явка очевидно считается как количество проголосовавших, поделённое на количество квартир. Графики тоже рисуются очевидно, единственное, для каждой точки данных по явке нет смысла рисовать график, т.к. он будет похож на заштрихованную бумагу, лучше округлить данные по явке и брать средние данные по результатам для этой точки данных.
Округляем до ближайшего целого:

Округляем до ближайшего, кратного пяти:

В общем и целом, за исключением пары антипиков в районе 80% явки, или, если смотреть с округлением пожиже, в районах 30%, 40% и 80%, в целом, явка на результат не влияла. Разве что 100%-ая явка удивительным образом всегда давала 100%-й результат. А в среднем явка была 58,7%.
Стоило ли оно того? Для меня да, узнал много нового. А для читателя? Ну, читателю я выкладываю саму базу данных.
Может быть, вы сможете сделать с этими данными что-то поинтереснее.

|
Метки: author Abyrvalgov кодобред sqlite python difflib sqlite3 bs4 реновация статистика |
Разработка для Sailfish OS: Тестирование QML-кода, зависящего от C++ в Sailfish OS |
// counter.h
#include
class Counter : public QObject {
Q_OBJECT
Q_PROPERTY(int count READ count NOTIFY countChanged)
private:
int m_count = 0;
public:
int count();
Q_INVOKABLE void incrementCount();
Q_INVOKABLE void resetCount();
signals:
void countChanged();
};
// counter.cpp
int Counter::count() {
return m_count;
}
void Counter::incrementCount() {
m_count++;
emit countChanged();
}
void Counter::resetCount() {
m_count = 0;
emit countChanged();
}
TEMPLATE = lib
TARGET = core
CONFIG += qt plugin c++11
QT += qml\
quick\
HEADERS += \
counter.h
SOURCES += \
counter.cpp
DISTFILES += qmldir
uri = counter.cpp.application.Core
qmldir.files = qmldir
installPath = /usr/lib/counter-cpp-application/$$replace(uri, \\., /)
qmldir.path = $$installPath
target.path = $$installPath
INSTALLS += target qmldir
module counter.cpp.application.Core
plugin core
TARGET = counter-cpp-application
CONFIG += sailfishapp \
sailfishapp_i18n \
c++11
SOURCES += src/counter-cpp-application.cpp
OTHER_FILES += qml/counter-cpp-application.qml \
qml/cover/CoverPage.qml \
translations/*.ts \
counter-cpp-application.desktop
TRANSLATIONS += translations/counter-cpp-application-de.ts
SAILFISHAPP_ICONS = 86x86 108x108 128x128 256x256
DISTFILES += \
qml/CounterCppApplication.qml \
qml/pages/CounterPage.qml
TEMPLATE = subdirs
OTHER_FILES += $$files(rpm/*)
SUBDIRS += \
app \
core
app.depends = core
qmlRegisterType(uri, 1, 0, "Counter");
int main(int argc, char *argv[]) {
return SailfishApp::main(argc, argv);
}
int main(int argc, char *argv[]) {
QGuiApplication* app = SailfishApp::application(argc, argv);
QQuickView* view = SailfishApp::createView();
view->engine()->addImportPath("/usr/lib/counter-cpp-application/");
view->setSource(SailfishApp::pathTo("qml/counter-cpp-application.qml"));
view->showFullScreen();
QObject::connect(view->engine(), &QQmlEngine::quit, app, &QGuiApplication::quit);
return app->exec();
}
import counter.cpp.application.Core 1.0
Counter {
id: counter
}
QML2_IMPORT_PATH=/usr/lib/counter-cpp-application/ /usr/lib/qt5/bin/qmltestrunner -input /usr/share/counter-cpp-application/tests/
********* Start testing of qmltestrunner *********
Config: Using QtTest library 5.2.2, Qt 5.2.2
PASS : qmltestrunner::Counter tests::initTestCase()
PASS : qmltestrunner::Counter tests::test_counterAdd()
PASS : qmltestrunner::Counter tests::test_counterReset()
PASS : qmltestrunner::Counter tests::cleanupTestCase()
Totals: 4 passed, 0 failed, 0 skipped
********* Finished testing of qmltestrunner *********
|
Метки: author FRUCT тестирование мобильных приложений разработка мобильных приложений qt sailfish os qml testing |
Книга «Автостопом по Python» |
 Привет, Хаброжители! Мы издали книгу, составленную на основе одноименного онлайнового руководства и содержащую наработки многочисленных профессионалов и энтузиастов, знающих, что такое Python и чего вы от него хотите.
Привет, Хаброжители! Мы издали книгу, составленную на основе одноименного онлайнового руководства и содержащую наработки многочисленных профессионалов и энтузиастов, знающих, что такое Python и чего вы от него хотите.$ pip install toxlanguage: python
python:
- "2.6"
- "2.7"
- "3.3"
- "3.4"
script: python tests/test_all_of_the_units.py
branches:
only:
- masterinstall:
- pip install tox
script:
- tox$ pip install buildbot|
Метки: author ph_piter профессиональная литература python блог компании издательский дом «питер» книги |
[Перевод] Кроссплатформенный IoT: Использование Azure CLI и Azure IoT Hub |

~/.bashrc, что, как я заметил, плохо взаимодействует с терминалом MacOS. Чтобы вы могли использовать псевдоним «az» для всех команд Azure CLI, нужно добавить следующую переменную среды в вашу конфигурацию ~/.bash_profile. Для изменения конфигурации вводим в bash nano ~/.bash_profile, после чего сохраняем настройки:export PATH=\~/bin:$PATHcd ~/
touch .bash_profileaz --versionacs (2.0.0)
appservice (0.1.1b5)
batch (0.1.1b4)
cloud (2.0.0)
component (2.0.0)
configure (2.0.0)
container (0.1.1b4)
core (2.0.0)
documentdb (0.1.1b2)
feedback (2.0.0)
keyvault (0.1.1b5)
network (2.0.0)
nspkg (2.0.0)
profile (2.0.0)
redis (0.1.1b3)
resource (2.0.0)
role (2.0.0)
sql (0.1.1b5)
storage (2.0.1)
vm (2.0.0)
Python (Darwin) 2.7.10 (default, Jul 30 2016, 19:40:32)
[GCC 4.2.1 Compatible Apple LLVM 8.0.0 (clang-800.0.34)]az login
az account set --subscription
az component update --add iot
az provider register -namespace Microsoft.Devicesaz –version должен дать результат с новым модулем.acs (2.0.0)
appservice (0.1.1b5)
......
iot (0.1.1b3)
......device и hub:az iot device -h или az iot hub -h.az group create --name yourresourcegroupname --location westus
az iot hub create --name youriothubname --location yourlocation --sku S1 --unit 1 --resource-group yourresourcegroupname SKU S1, но IoT Hub можно использовать в бесплатном режиме – F1 (доступные значения: {F1,S1,S2,S3}). Кроме того, unit обозначает количество юнитов, которые вы хотите создать с помощью IoT Hub. Также указывается регион, в котором будет создан IoT Hub. Вы можете пропустить этот пункт — IoT Hub будет размещён в регионе с группой ресурсов. Список доступных регионов (на момент написания данного текста): {westus,northeurope,eastasia,eastus,westeurope,southeastasia,japaneast,japanwest,australiaeast,australiasoutheast,westus2,westcentralus}.{
"etag": "AAAAAAC2NAc=",
"id": "/subscriptions/yournamespace/providers/Microsoft.Devices/IotHubs/youriothubname",
"location": "westus",
"name": "youriothubname",
"properties": {
....
}
},
...
'' "type": "Microsoft.Devices/IotHubs"
}az iot hub list -g yourresourcegroupname — должен появиться список всех IoT Hub, созданных в вашей группе ресурсов. Если вы опустите группу ресурсов, отобразятся все инстансы IoT Hub в подписке. Для просмотра подробной информации о конкретном IoT Hub укажите: az iot hub show -g yourresourcegroupname --name yourhubname.az iot hub policy list --hub-name youriothubname. Политики — это важный элемент работы IoT Hub. Всегда придерживайтесь принципа «наименьших привилегий» и выбирайте политику, соответствующую текущей операции. Например, политика iothubowner предоставляет права администратора IoT Hub и не должна использоваться, в частности, для подключения устройства.az iot hub show-connection-string -g yourresourcegroupname.iothubowner, которая предоставляет полное управление вашим IoT Hub. Рекомендуется задавать детализированные политики. Они гарантируют наименьшие права доступа. Для этого воспользуйтесь опцией --policy-name и укажите название политики.az iot device для создания device; вместо этого для демонстрации этих функций мы воспользуемся IoT Hub Explorer. IoT Hub Explorer предоставляет несколько дополнительных команд. Мне кажется, что все функциональные возможности IoT Hub Explorer войдут в будущую версию IoT-компонента для Azure CLI.-debug, которая предоставляет трассировку всех производимых вызовов и любых сопутствующих исключений, которые могли произойти во время обработки. Например, для команды такого типа:az iot hub show-connection-string -g yourresourcegroupname --debug"Command arguments ['iot', 'hub', 'show-connection-string', '-g', 'yourrgname']
Current active cloud 'AzureCloud'
{'active_directory': 'https://login.microsoftonline.com',
'active_directory_graph_resource_id': 'https://graph.windows.net/',
'active_directory_resource_id': 'https://management.core.windows.net/',
'management': 'https://management.core.windows.net/',
.......
'storage_endpoint': 'core.windows.net'}
Registered application event handler 'CommandTableParams.Loaded' at
Registered application event handler 'CommandTable.Loaded' at
Successfully loaded command table from module 'iot'.
..........
g': 'gzip, deflate'
msrest.http_logger : 'Accept': 'application/json'
msrest.http_logger : 'User-Agent': 'python/2.7.10 (Darwin-16.4.0-x86_64-i386-64bit) requests/2.13.0 msrest/0.4.6 msrest_azure/0.4.7 iothubclient/0.2.1 Azure-SDK-For-Python AZURECLI/2.0.0'
msrest.http_logger : 'Authorization': 'Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiIsIng1dCI6ImEzUU4wQlpTN3M0bk4tQmRyamJGMFlfTGRNTSIsImtpZCI6ImEzUU4wQlpTN3M0bk4tQmRyamJGMFlfTGRNTSJ9.eyJhdWQiOiJodHRwczovL21hbmFnZW1lbnQuY29yZS53aW5kb3dzLm5ldC8iLCJpc3MiOiJodHRwcz0cy53aW5kb3dzLm5ldC83MmY5ODhiZi04NmYxLTQxYWYtOTFhYi0yZDdjZDAxMWRiNDcvIiwiaWF0IjoxNDg5NjEzODc5LCJuYmYiOjE0ODk2MTM4NzksImV4cCI6MTQ4OTYxNzc3OSwiX2NsYWltX25hbWVzIjp7Imdyb3VwcyI6InNyYzEifSwiX2NsYWltX3NvdXJjZXMiOnsic3JjMSI6eyJlbmRwb2ludCI6Imh0dHBzOi8vZ3JhcGgud2luZG93cy5uZXQvNzJmOTg4YmYtODZmMS00MWFmLTkxYWItMmQ3Y2QwMTFkYjQ3L3VzZXJzL2UyZTNkNDdlLTRiYzAtNDg1Yy04OTE1LWYyMDVkYzRlODY5YS9nZXRNZW1iZXJPYmplY3RzIn19LCJhY3IiOiIxIiwiYWlvIjoiQVFBQkFBRUFBQURSTllSUTNkaFJTcm0tNEstYWRwQ0pwWnVGcnREQ05QTTBrNjB1NVl0RElLTjZ5cklUVHJna0Fod3JuQXJBd2NMQXFqczlNQ0RhazRtM0E2cjN3T09YZ1FxaWZlUVFIRC1TQ0JXOVVJdjNabzFnMERXMElvYWRLRWgtQ0R3X01XY2dBQSIsImFtciI6WyJwd2QiLCJtZmEiXSwiYXBwaWQiOiIwNGIwNzc5NS04ZGRiLTQ2MWEtYmJlZS0wMmY5ZTFiZjdiNDYiLCJhcHBpZGFjciI6IjAiLCJlX2V4cCI6MTA4MDAsImZhbWlseV9uYW1lIjoiU2FjaGRldmEiLCJnaXZlbl9uYW1lIjoiTmlrIiwiaW5fY29ycCI6InRydWUiLCJpcGFkZHIiOiI2NS4zNi44OC4xNjYiLCJuYW1lIjoiTmlrIFNhY2hkZXZhIiwib2lkIjoiZTJlM2Q0N2UtNGJjMC00ODVjLTg5MTUtZjIwNWRjNGU4NjlhIiwib25wcmVtX3NpZCI6IlMtMS01LTIxLTEyNDUyNTA5NS03MDgyNTk2MzctMTU0MzExOTAyMS0xMzUwMDI4IiwicGxhdGYiOiI1IiwicHVpZCI6IjEwMDM3RkZFODAxQjZCQTIiLCJzY3AiOiJ1c2VyX2ltcGVyc29uYXRpb24iLCJzdWIiOiI2Z3d4WUFKem4zM3h6WVhfVWM4cHpNcGc4dzk1NVlHYTJ2VnlpazMtVDZ3IiwidGlkIjoiNzJmOTg4YmYtODZmMS00MWFmLTkxYWItMmQ3Y2QwMTFkYjQ3IiwidW5pcXVlX25hbWUiOiJuaWtzYWNAbWljcm9zb2Z0LmNvbSIsInVwbiI6Im5pa3NhY0BtaWNyb3NvZnQuY29tIiwidmVyIjoiMS4wIn0.jEAMzSd4bV0x_hu8cNnQ7fActL6uIm97U7pkwCz79eaSfEnBdqF8hXEJlwQh9GYL0A3r8olNdjr1ugiVH6Y0RFutn7iD8E-etkVI9btE1aseZ3vvZqYeKPhA1VytBsTpb4XO2ZI094VynTeALoxe7bbuEzl5YaeqtbC5EM0PMhPB04o7K1ZF49nGKvA385MHJU3G-_JT3zV-wdQWDj5QKfkEJ0a9AsQ9fM7bxyTdm_m5tQ4a-kp61r92e1SzcpXgCD7TXRHxrZ2wa65rtD8tRmHt6LOi7a4Yx2wPFUpFoeQAcN7p7RKW6t_Cn8eyyvWrrUXximBcTB4rtQTgXCfVUw'--debug будет следующим:[
{
"connectionString": "HostName=youriothub.azure-devices.net;SharedAccessKeyName=iothubowner;SharedAccessKey=yourkey=,
"name": "youriothub"
}
]output. Она позволяет форматировать конечное значение, используя различные средства синтаксического анализа. Например, применяя ту же команду, что была задействована выше, мы можем поменять формат конечного значения с JSON (по умолчанию) на таблицу.az iot hub show-connection-string -g yourresourcegroupname -o table"ConnectionString -------------------------------------------------------------------------------------------------------------------------------------- --------------
HostName=youriothub.azure-devices.net;SharedAccessKeyName=iothubowner;SharedAccessKey=yourkey=
Name
youriothubaz iot hub list --query "[?contains(location,'westus')].{Name:name}" -o tsv|
Метки: author Schvepsss разработка для интернета вещей microsoft azure блог компании microsoft microsoft azure cli azure iot hub python |
[Из песочницы] Снимаем “4D видео” с помощью depth-сенсора и триангуляции Делоне |
|
|
Постквантовая реинкарнация алгоритма Диффи-Хеллмана: вероятное будущее (изогении) |
|
Метки: author Crittografo криптография информационная безопасность алгоритмы блог компании «актив» изогении |
[Из песочницы] Как тысячи игроков Eve Online помогают в расшифровке человеческого тела |
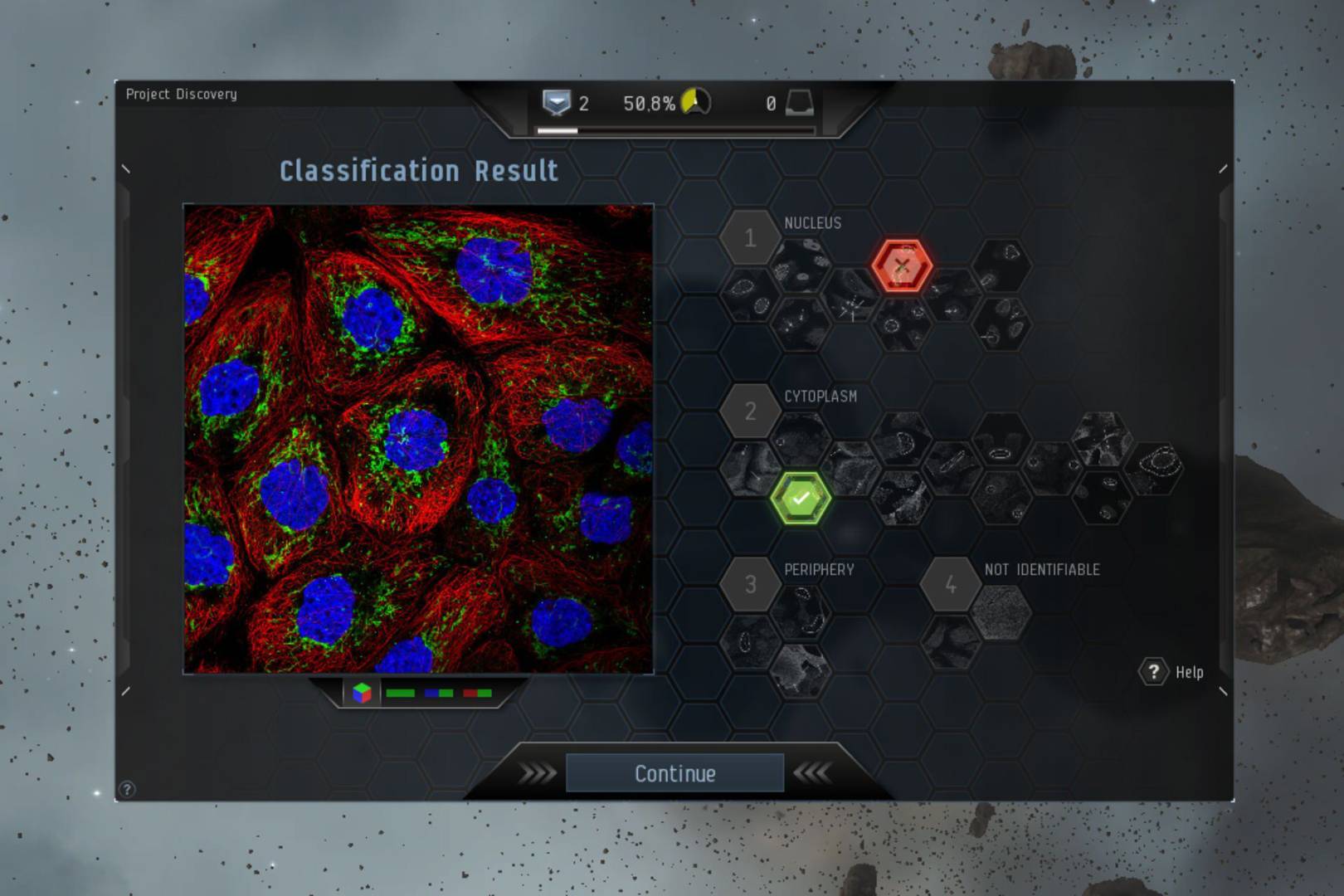
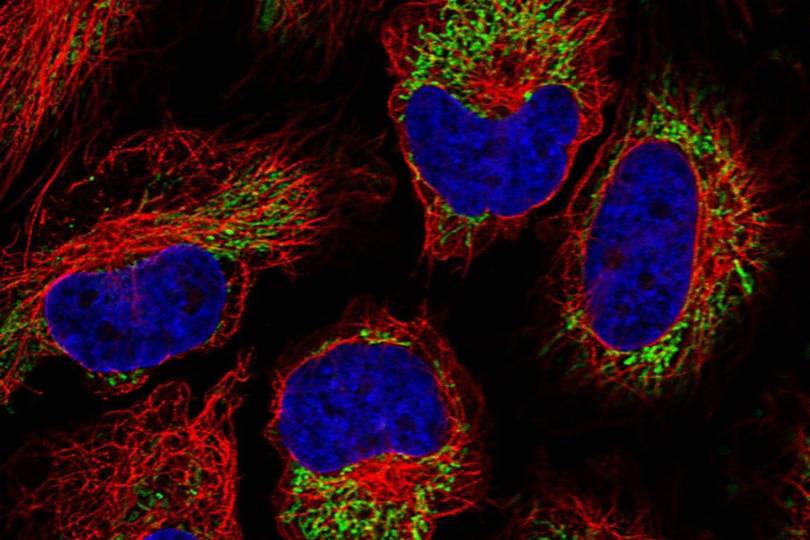
«Но мы даже близко не знаем этого, поэтому вот что мы делаем — составляем карту того, где находятся протеины. Если мы знаем, что белок находится в печени, в митохондриях, тогда хорошо — он может быть смоделирован в этих процессах, что даст подсказки исследователям. Исследователи могут сказать: «Хорошо, я изучаю печень — каковы все белки, расположенные в печени?.. Меня интересует энергетический метаболизм. Каковы митохондриальные белки в печени?» — так это могут использовать другие исследователи».
|
Метки: author ruslanjf разработка игр data mining big data перевод атлас белков человека human protein atlas mmo science eve online |
[Перевод - recovery mode ] SDN с платформой Red Hat OpenStack: интеграция с OpenDaylight |

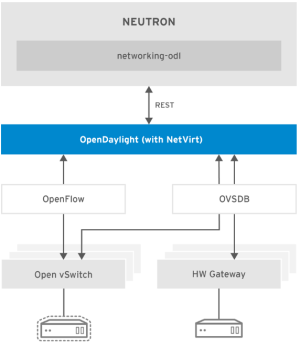
|
Метки: author ICLServices разработка под linux open source api блог компании icl services red hat linux foundation openstack виртуализация сетей |
React Native с колокольни Android разработки часть 2 |

{true && Я существую }
{false && Я НЕ существую }
const text = this.props.text;
{text && {text}
{this.props.text}
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
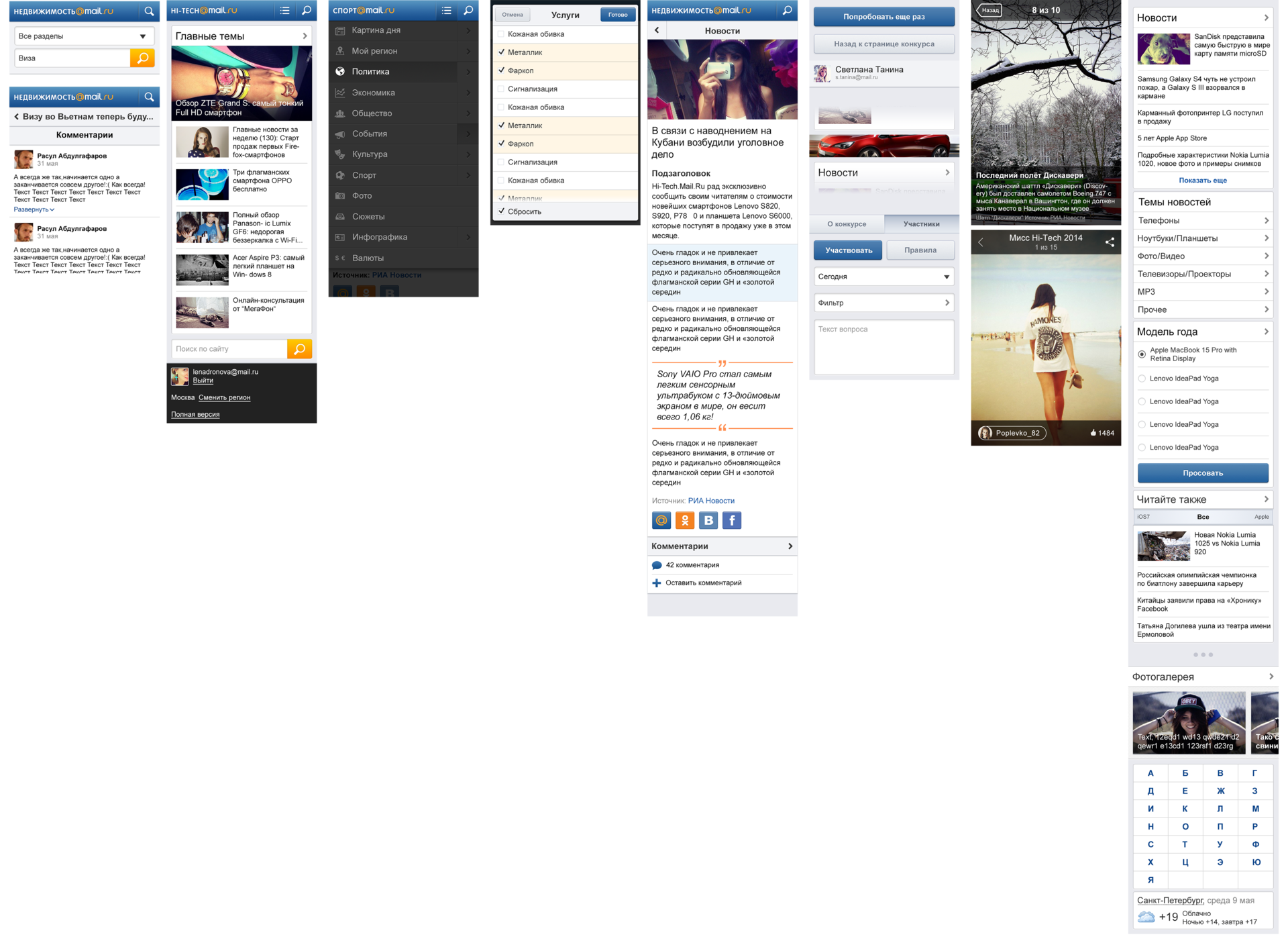
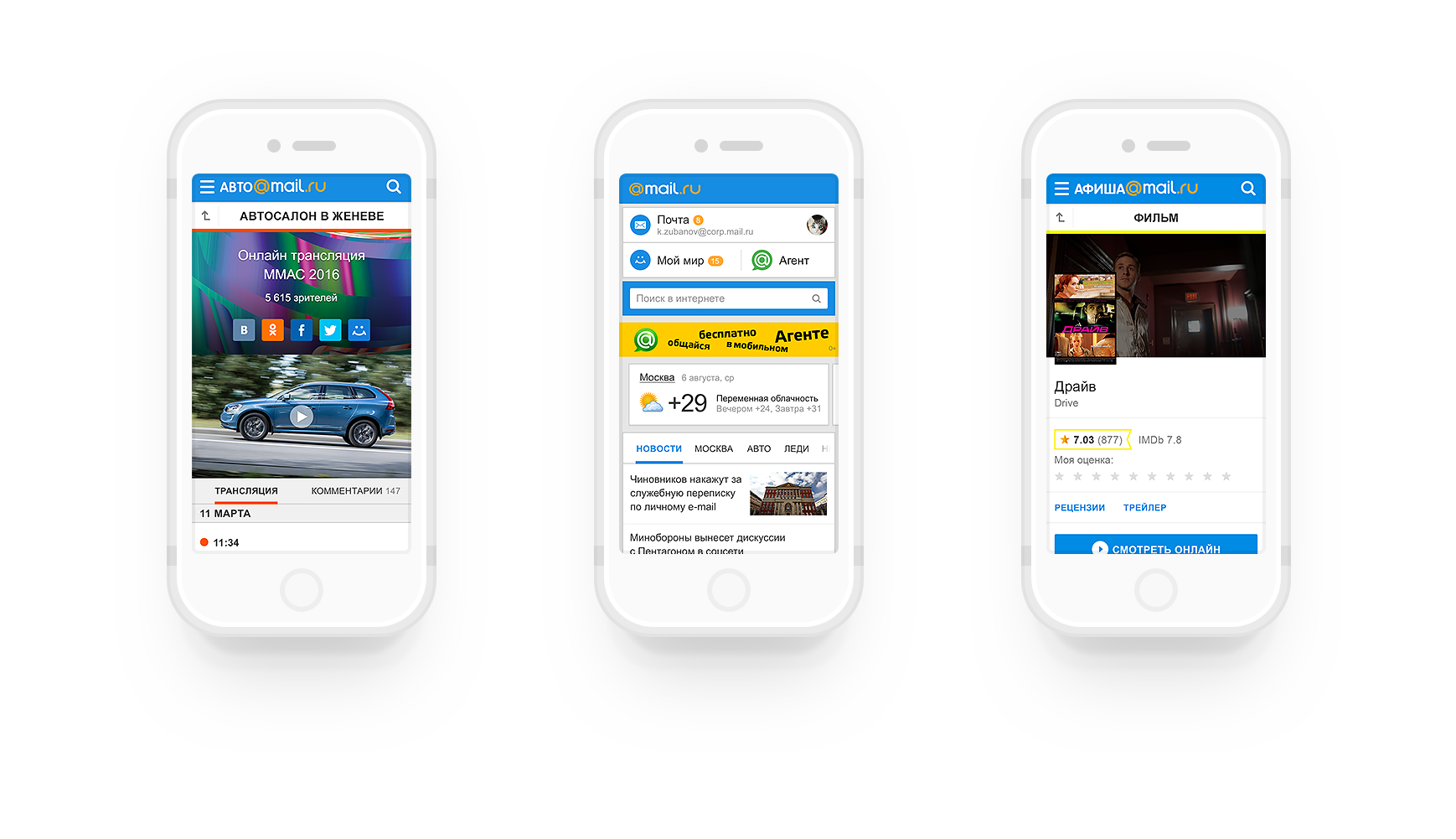
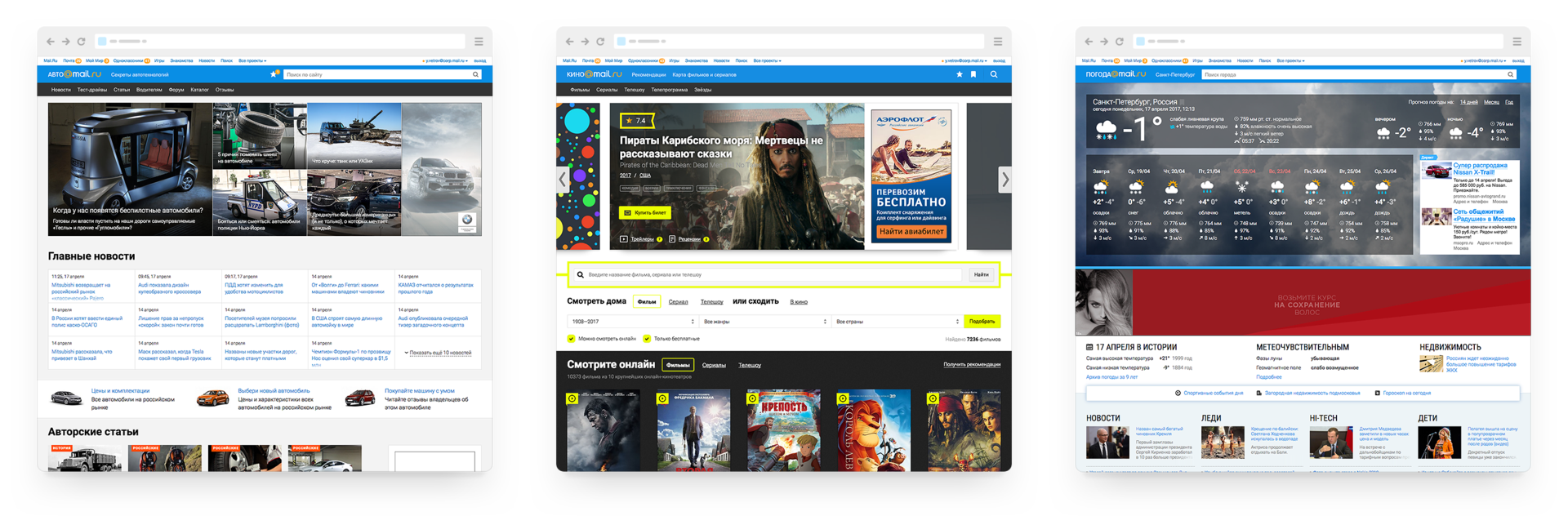
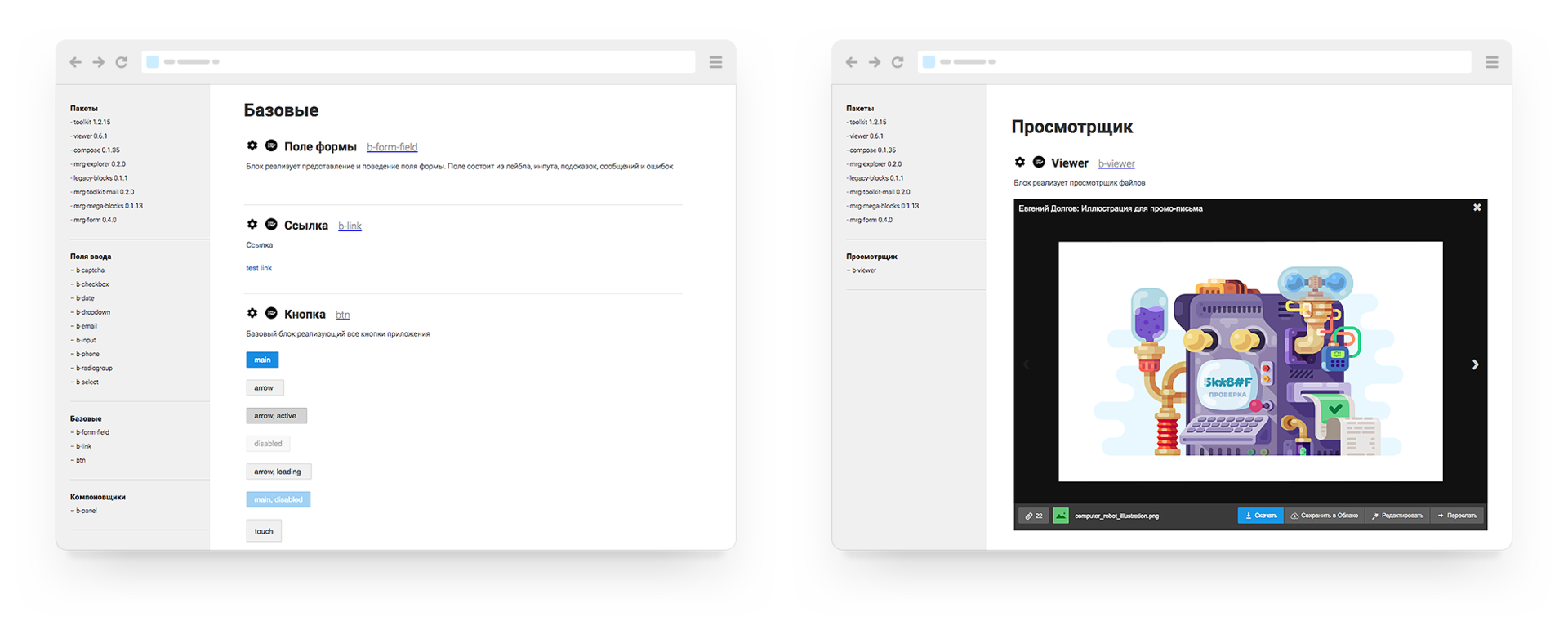
Paradigm — Дизайн-система Mail.Ru Group, часть 1: Визуальный язык |








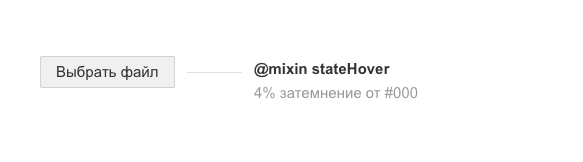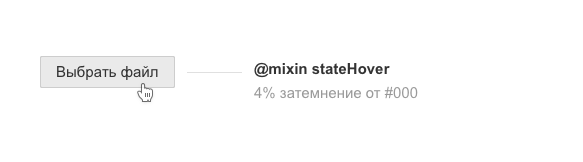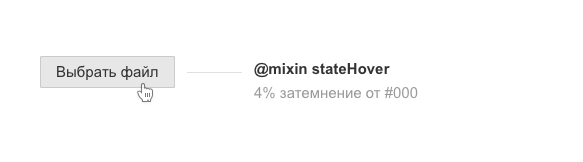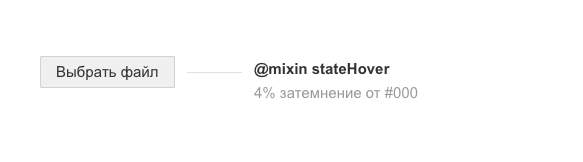
@mixin stateHover ($colorBgSecondary) {
background: mix($colorBgSecondary, $colorAccent, 4%);
}
@mixin stateActive ($colorBgSecondary) {
background: mix($colorBgSecondary, $colorAccent, 8%);
box-shadow: $zIndex-1;
}


height: $sizeControlHeight; // 32px
padding: 0 $paddingControlButton; // 0 16px
background-color: $colorBgSecondary; // #f0f0f0
border-radius: $sizeBorderRadius; // 2px
border: $sizeBorderWidth solid $colorBorder; // 1px solid rgba(0,0,0,.12)
box-shadow: $zIndex1; // 0 2px 0 0 rgba(0,0,0,.04)
color: $colorBody; // #333333
font-size: $fontBody; // 15px
line-height: $fontBodyLine; // 20px@include stateHover ($colorBgSecondary);@include stateActive ($colorBgSecondary);opacity: .48;

background-color: $colorAccent; // #168de2
color: $colorBody; // #ffffff
height: $sizeControlHeight; // 40px
padding: 0 $paddingControlButton; // 0 20px
background-color: $colorAccent; // #5856d6
color: $colorBody; // #333333
border-radius: $sizeBorderRadius; // 4px
font-size: $fontBody; // 17px
line-height: $fontBodyLine; // 24px
height: $sizeControlHeight; // 40px
padding: 0 $paddingControlButton; // 0 20px
background-color: $colorAccent; // #00abf2
color: $colorBody; // #333333
border-radius: $sizeBorderRadius; // 4px
font-size: $fontBody; // 17px
line-height: $fontBodyLine; // 24px
text-transform: $fontBodyCase // uppercase
height: $sizeControlHeight; // 48px
padding: 0 $paddingControlButton; // 0 20px
background-color: $colorAccent; // #168de2
color: $colorBody; // #333333
border-radius: $sizeBorderRadius; // 2px
font-size: $fontBody; // 15px
line-height: $fontBodyLine; // 20px
text-transform: $fontBodyCase // uppercase

|
Метки: author ASundiev интерфейсы веб-дизайн usability блог компании mail.ru group дизайн-системы унификация |
Обновление систем хранения Fujitsu ETERNUS DX начального уровня |


|
Метки: author FeeAR хранилища данных системное администрирование it- инфраструктура блог компании fujitsu fujitsu схд eternus dx |
СУБД для 1С Fresh. Быстро. Надежно. Бесплатно |

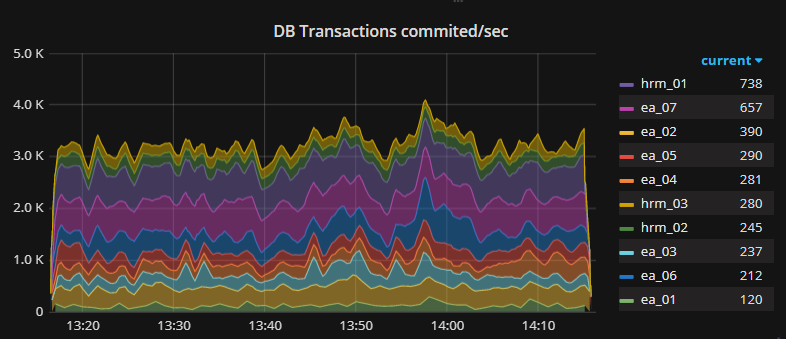
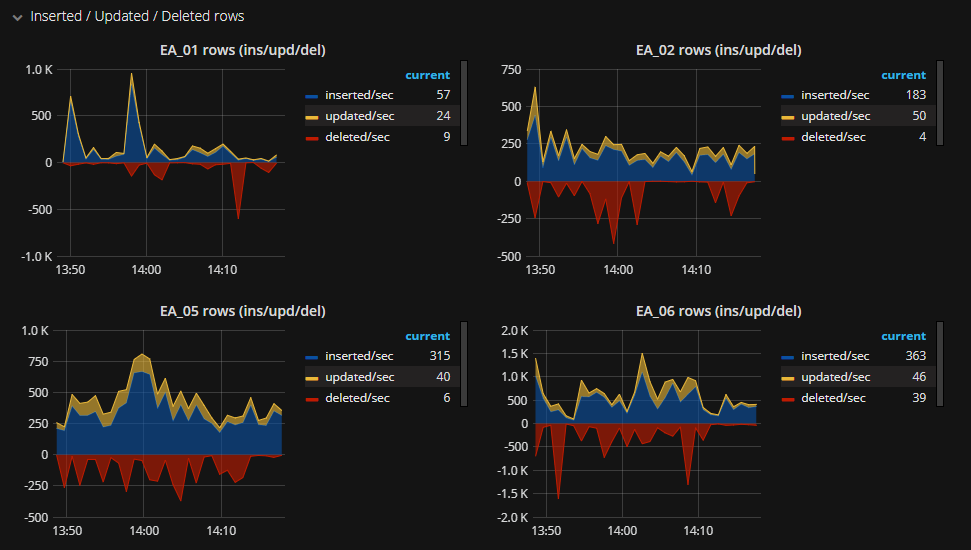
# pg_createcluster 9.6 -p 5433 -d /databases/db_01# pg_lsclusters# -----------------------------
# PostgreSQL configuration file
# -----------------------------
#------------------------------------------------------------------------------
# FILE LOCATIONS
#------------------------------------------------------------------------------
data_directory = '/db/disk_database_db_01/db_01'
hba_file = '/etc/postgresql/9.6/db_01/pg_hba.conf'
ident_file = '/etc/postgresql/9.6/db_01/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.6-db_01.pid'
#------------------------------------------------------------------------------
# CONNECTIONS AND AUTHENTICATION
#------------------------------------------------------------------------------
listen_addresses = '*'
port = 5433
max_connections = 100
unix_socket_directories = '/var/run/postgresql'
ssl = true
ssl_cert_file = '/etc/ssl/certs/ssl-cert-snakeoil.pem'
ssl_key_file = '/etc/ssl/private/ssl-cert-snakeoil.key'
#------------------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#------------------------------------------------------------------------------
shared_buffers = 1536MB
work_mem = 7864kB
maintenance_work_mem = 384MB
dynamic_shared_memory_type = posix
shared_preload_libraries = 'online_analyze, plantuner,pg_stat_statements'
#------------------------------------------------------------------------------
# WRITE AHEAD LOG
#------------------------------------------------------------------------------
wal_level = replica
wal_buffers = 16MB
max_wal_size = 2GB
min_wal_size = 1GB
checkpoint_completion_target = 0.9
#------------------------------------------------------------------------------
# REPLICATION
#------------------------------------------------------------------------------
max_wal_senders = 2
wal_keep_segments = 32
#------------------------------------------------------------------------------
# QUERY TUNING
#------------------------------------------------------------------------------
effective_cache_size = 4608MB
#------------------------------------------------------------------------------
# RUNTIME STATISTICS
#------------------------------------------------------------------------------
stats_temp_directory = '/var/run/postgresql/9.6-db_01.pg_stat_tmp'
#------------------------------------------------------------------------------
# CLIENT CONNECTION DEFAULTS
#------------------------------------------------------------------------------
datestyle = 'iso, dmy'
timezone = 'localtime'
lc_messages = 'ru_RU.UTF-8' # locale for system error message
# strings
lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting
lc_numeric = 'ru_RU.UTF-8' # locale for number formatting
lc_time = 'ru_RU.UTF-8' # locale for time formatting
default_text_search_config = 'pg_catalog.russian'
#------------------------------------------------------------------------------
# LOCK MANAGEMENT
#------------------------------------------------------------------------------
max_locks_per_transaction = 300 # min 10
#------------------------------------------------------------------------------
# VERSION/PLATFORM COMPATIBILITY
#------------------------------------------------------------------------------
escape_string_warning = off
standard_conforming_strings = off
#------------------------------------------------------------------------------
# CUSTOMIZED OPTIONS
#------------------------------------------------------------------------------
online_analyze.threshold = 50
online_analyze.scale_factor = 0.1
online_analyze.enable = on
online_analyze.verbose = off
online_analyze.min_interval = 10000
online_analyze.table_type = 'temporary'
plantuner.fix_empty_table = false
# pg_ctlcluster 9.6 db_01 starthostname port=5433listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
wal_keep_segments = 128postgres=# CREATE ROLE replica WITH REPLICATION PASSWORD 'MyBestPassword' LOGIN;# TYPE DATABASE USER ADDRESS METHOD
host replication replica 192.168.0.0/24 md5
# pg_ctlcluster 9.6 db_01 restart
# pg_ctlcluster 9.6 db_01 stop
hot_standby = on
# cd /databases/db_01
# rm -Rf /databases/db_01
# su postgres -c "pg_basebackup -h master.domain.local -p 5433 -U replica -D /databases/db_01 -R -P --xlog-method=stream"
standby_mode = 'on'
primary_conninfo = 'user=replica password=MyBestPassword host=master.domain.local port=5433 sslmode=prefer sslcompression=1 krbsrvname=postgres'# pg_ctlcluster 9.6 db_01 start
SELECT *,pg_xlog_location_diff(s.sent_location,s.replay_location) byte_lag FROM pg_stat_replication s;
SELECT now()-pg_last_xact_replay_timestamp();archive_command = 'test ! -f /wal_backup/db_01/%f && cp %p /wal_backup/db_01/%f'#!/bin/bash
db="db_01"
wal_arch="/wal_backup"
datenow=`date '+%Y-%m-%d %H:%M:%S'`
mkdir /tmp/pg_backup_$db
su postgres -c "/usr/bin/pg_basebackup --port=5433 -D /tmp/pg_backup_$db -Ft -z -Xf -R -P"
test -e ${wal_arch}/$db/base.${datenow}.tar.gz && rm ${wal_arch}/$db/base.${datenow}.tar.gz
cp /tmp/pg_backup_$db/base.tar.gz ${wal_arch}/$db/base.${datenow}.tar.gz
# pg_ctlcluster 9.6 db_01 stop
# rm -Rf /databases/db_01
restore_command = 'cp /wal_backup/db_01/%f %p'
recovery_target_time = '2017-06-12 21:33:00 MSK'
recovery_target_inclusive = true
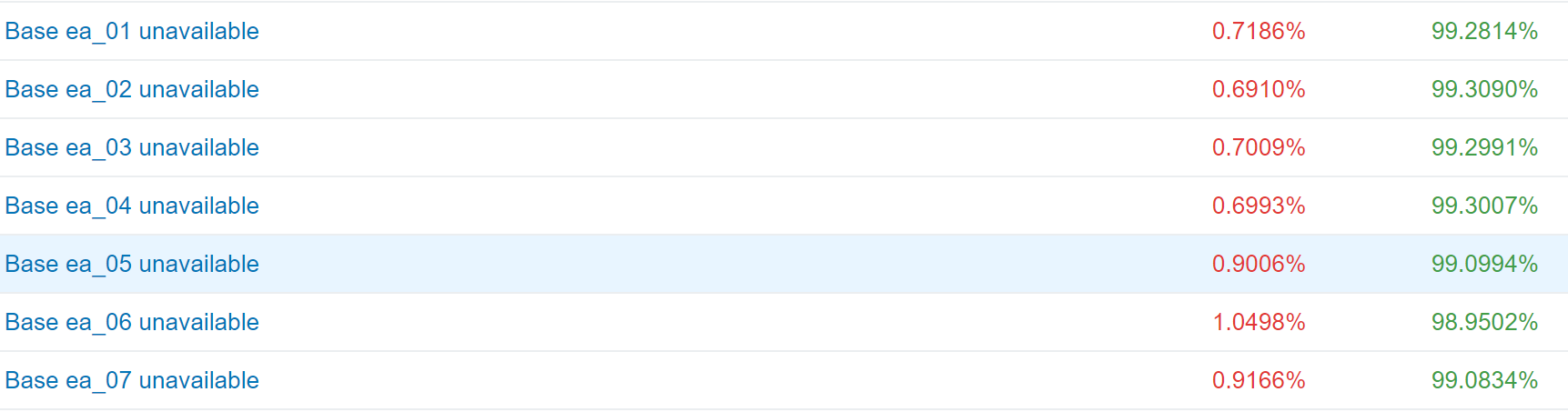
|
Метки: author sinyakov_sergey системное администрирование администрирование баз данных блог компании кнопка 1c 1cfresh субд postgresql базы данных |








