Время чудес, или Тормоза для конца света |

Когда говорят «конец света», значит, хотят продать кукурузные хлопья,
а вот если говорят «без паники», тут уж дело серьезнее.
Стивен Кинг. «Буря столетия»
Говорят, что наиболее оптимистичные пессимисты верят в счастливый конец света. Применительно к телекому эта мысль имеет второе дно. Все учебные пособия по телекоммуникациям сходятся в одном: когда взамен медных линий стали применяться волоконно-оптические линии связи (ВОЛС) вкупе с лазерами, для отрасли наступило долгожданное и практически вечное счастье, по крайней мере в части обеспечения высокой пропускной способности для почти мгновенной (буквально со скоростью света) доставки множества информационных потоков. Так в отрасли началось время чудес. Да будет свет!
Однако сегодня пропускная способность оптических транспортных сетей стремительно приближается к своему пределу. Дальнейшее ее наращивание потребует организации новой инфраструктуры ВОЛС и – новых инвестиций. Об этом и предлагаем поговорить ниже.
Меж тем природа регулярно напоминает нам, что ничего вечного в ней нет. И «пределы беспредельности» оптического транспорта также не за горами, хотя дату «конца света» в ВОЛС удавалось не единожды отодвигать.
Конечно, такую простую неприятность, как отключение электричества, связисты научились преодолевать в первую очередь. Следующая неприятность, а именно непрерывное сокращение безрегенерационного (без промежуточных оптических регенераторов) промежутка на магистральных ВОЛС по мере увеличения скорости передачи, грозила было серьезными проблемами всей отрасли. Спасение пришло в лице когерентных систем класса N x 100 Гбит/с. Системы плотного спектрального волнового уплотнения (DWDM) позволили справиться с этой убийственной для отраслевого бизнеса неприятностью, обеспечив безрегенерационную дальность порядка 5–6 тыс. км в наземных линиях связи и более 10 тыс. км – в подводных (в зависимости от применяемых схем модуляции и кодирования – QPSK, QAM и пр.).

Ныне на очереди – физические пределы пропускной способности оптического волокна вкупе с ростом в них задержек распространения сигнала. И это на фоне текущего и грядущего роста информационных потоков, вызванного развитием интернета вещей и сетей мобильной связи пятого поколения (5G). Стоит напомнить, что сети 5G должны будут иметь не только сверхвысокие скорости передачи информации (до 1 Гбит/с и выше), но и чрезвычайно малые задержки передачи сигнала (порядка 1 мс и менее). Наиболее сильное влияние на суммарное значение задержки оптического сигнала в системе передачи оказывает длина оптоволокна. С учетом того, что в современном мире практически не осталось транспортных и магистральных сетей, организованных не на базе ВОЛС, получение сверхмалых задержек, если речь идет о чем-либо протяженном за границы стран, регионов и даже городов, становится невозможным.
Прежде всего, повышение эффективности ВОЛС с помощью DWDM значительно увеличивает задержки непосредственно в элементах сети DWDM, где сигнал подвергается различным преобразованиям. Также в канальном слое DWDM большое внимание с необходимостью уделяется дисперсионным характеристикам оптической линии, заставляя прибегать к компенсаторам дисперсии, которые в своем нынешнем исполнении вносят дополнительную задержку. К счастью, использование когерентных систем класса N x 100 Гбит/с позволило от компенсаторов дисперсии отказаться. Это существенно улучшило качество оптического тракта и снизило потери в нем, что благотворно сказалось на предельных дистанциях передачи сигнала. Вместе с тем вопреки утвердившемуся мнению, скорость распространения оптического сигнала в оптоволокне существенно ниже скорости распространения электрических сигналов в медных линиях связи и радиосигналов в атмосфере*.
Собственно, поэтому МСЭ-T и разработал рекомендации по допустимым уровням задержки. В большинстве случаев она не должна превышать 150 мс в одну сторону, что вполне приемлемо, например, для VoIP. Задержки от 150 до 400 мс также могут быть приемлемыми, если принимать в расчет и экономические характеристики (в первую очередь стоимость разговора).
Таким образом, с точки зрения минимальных задержек современные ВОЛС не могут считаться чем-то особенным, что существенно повлияет на физическую и логическую топологии оптических транспортных сетей будущего. Уже сегодня динамика роста наземных и подводных кабельных сетей различается – в силу разницы в стоимости права прохода и строительства, а также вносимых задержек сигнала.
Приход в отрасль связи таких глобальных «возмутителей спокойствия», как Google и Facebook, создал дополнительный стимул для развития инфраструктуры оптических систем передачи континентального и межконтинентального классов, обладающих предельной пропускной способностью «на вырост», с учетом очень высоких темпов роста интернет-трафика вообще и доли видеотрафика в нем в частности. Поэтому отраслевая литература пестрит победными реляциями о запуске новых линий, очередных рекордах пропускной способности, создании международных консорциумов для прокладки новых трансокеанских подводных кабельных систем и т.п.
Стремительная динамика ИКТ-отрасли заставила также говорить и о «смерти волокна», поскольку стало понятно, что недалек тот день, когда развитие связи на базе ВОЛС упрется в физические пределы пропускной способности оптических линий. А это означает, что на уже проложенных ВОЛС нельзя будет сделать ничего нового, кроме как уплотнить их по максимуму, и следует прокладывать новые кабели, что весьма недешево. Всяческие технологические улучшения сделали сегодня «обычной» возможность создавать системы связи, позволяющие передать поток 100 Гбит/с и даже 400 Гбит/с (4 х 100 Гбит/с) по одной оптической несущей («лямбде»). Однако далее дело застопорилось, поскольку эмпирический предел спектральной эффективности для подобных оптических систем составляет примерно 5 бит/с/Гц и он уже практически достигнут, вследствие чего одно оптическое волокно имеет предельную пропускную способность порядка 25–50 ТБод в зависимости от задействованных оптических диапазонов. Впрочем, практический предел символьной скорости передачи по одному оптическому волокну, определяемый физическими характеристиками используемого материала, сейчас равняется 12–25 ТБод в зависимости от типа модуляции и пр.

С появлением систем 100 Гбит/с с когерентным приемом была достигнута почти предельная эффективность использования независимых параметров светового излучения (фазы и поляризации), и усложнение модуляции неизбежно приведет к существенному падению дальности передачи**. То есть снова встает проблема безрегенерационной дальности. Впрочем, новых успехов в системах DWDM можно добиться уплотнением каналов, расширением спектрального диапазона (т.е. подбором других оптопрозрачных материалов), более изощренными методами модуляции и детектирования (называемыми пробабилистическими), а также применением «фотонных кристаллов», многосердцевидных волокон и пр. Нетрудно видеть, что большинство этих решений сопряжено с организацией новой инфраструктуры ВОЛС и соответственно с новыми инвестициями. Разве что помудрить еще со способами модуляции.
Таким образом, в скором времени во всей отрасли дальней связи начнутся серьезные перемены, обусловленные исчерпанием ресурса проложенных кабельных линий. Этот «ползучий» процесс исчерпания емкости наследованной оптической инфраструктуры вкупе с падением тарифов и маржинальности магистрального бизнеса в целом может в ближайшие годы создать новую интригу в развитии этого сегмента и запустить «качели» «спрос – предложение». Ожидаемый результат – интенсификация работ по уплотнению уже существующего оптического волокна и строительству новых оптических линков всех классов.
Так что, господа, без паники!
*Салифов И. Расчет и сравнение сред передачи современных магистральных сетей связи по критерию латентности (задержки). T-Comm № 4 2009 с. 42.
**Трещиков В., Наний О., Леонов А. особенности разработки DWDM-систем высокой емкости. T-Comm № 9 2014 с. 83.
Авторы публикации:
Александр ГОЛЫШКО, системный аналитик ГК «Техносерв»
Виталий ШУБ, заместитель генерального директора, бизнес-направление «Телеком», IPG Photonics Russia (НТО «ИРЭ-Полюс»)
|
Метки: author TS_Telecom стандарты связи сжатие данных сетевые технологии блог компании техносерв волс линии связи кабельные линии оптическое волокно |
Что такое DevOps: подход, который может изменить всё |
|
Метки: author Dmitry21 тестирование веб-сервисов программирование блог компании отус отус otus devops linux администрирование тестирование |
[Перевод] Система перемотки времени в стиле Prince of Persia |






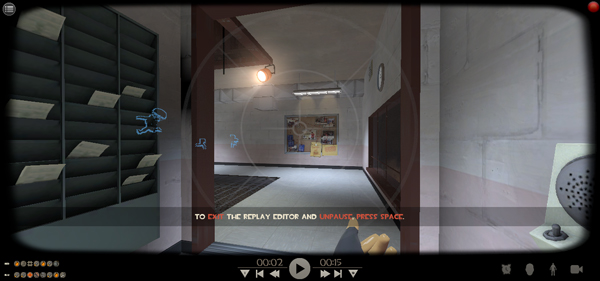
Player.cs и добавьте в функцию Update() следующее:void Update()
{
transform.Translate (Vector3.forward * 3.0f * Time.deltaTime * Input.GetAxis ("Vertical"));
transform.Rotate (Vector3.up * 200.0f * Time.deltaTime * Input.GetAxis ("Horizontal"));
}
TimeController.cs и добавлим его к новому пустому GameObject. Он будет управлять записью и перемоткой игры.public GameObject player;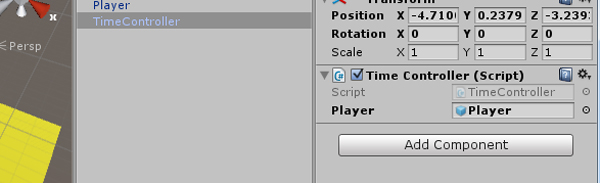
public ArrayList playerPositions;
void Start()
{
playerPositions = new ArrayList();
}void FixedUpdate()
{
playerPositions.Add (player.transform.position);
}FixedUpdate() мы записываем данные. Используется FixedUpdate(), потому что она выполняется с постоянной частотой 50 циклов в секунду (или любое выбранное значение), что позволяет нам записывать данные с фиксированным интервалом. Функция Update() же выполняется с той частотой, которую обеспечить процессор, что усложнило бы нам работу.public bool isReversing = false;Update():void Update()
{
if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
}
else
{
isReversing = false;
}
}void FixedUpdate()
{
if(!isReversing)
{
playerPositions.Add (player.transform.position);
}
else
{
player.transform.position = (Vector3) playerPositions[playerPositions.Count - 1];
playerPositions.RemoveAt(playerPositions.Count - 1);
}
}TimeController будет выглядеть следующим образом:using UnityEngine;
using System.Collections;
public class TimeController: MonoBehaviour
{
public GameObject player;
public ArrayList playerPositions;
public bool isReversing = false;
void Start()
{
playerPositions = new ArrayList();
}
void Update()
{
if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
}
else
{
isReversing = false;
}
}
void FixedUpdate()
{
if(!isReversing)
{
playerPositions.Add (player.transform.position);
}
else
{
player.transform.position = (Vector3) playerPositions[playerPositions.Count - 1];
playerPositions.RemoveAt(playerPositions.Count - 1);
}
}
}player проверку того, выполняется ли в TimeController перемотка, чтобы выполнять движение только если оно не воспроизводится. В противном случае поведение может стать странным:using UnityEngine;
using System.Collections;
public class Player: MonoBehaviour
{
private TimeController timeController;
void Start()
{
timeController = FindObjectOfType(typeof(TimeController)) as TimeController;
}
void Update()
{
if(!timeController.isReversing)
{
transform.Translate (Vector3.forward * 3.0f * Time.deltaTime * Input.GetAxis ("Vertical"));
transform.Rotate (Vector3.up * 200.0f * Time.deltaTime * Input.GetAxis ("Horizontal"));
}
}
}
TimeController и проверять его в процессе выполнения. Мы можем управлять персонажем только тогда, когда перемотка не выполняется.using UnityEngine;
using System.Collections;
public class TimeController: MonoBehaviour
{
public GameObject player;
public ArrayList playerPositions;
public ArrayList playerRotations;
public bool isReversing = false;
void Start()
{
playerPositions = new ArrayList();
playerRotations = new ArrayList();
}
void Update()
{
if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
}
else
{
isReversing = false;
}
}
void FixedUpdate()
{
if(!isReversing)
{
playerPositions.Add (player.transform.position);
playerRotations.Add (player.transform.localEulerAngles);
}
else
{
player.transform.position = (Vector3) playerPositions[playerPositions.Count - 1];
playerPositions.RemoveAt(playerPositions.Count - 1);
player.transform.localEulerAngles = (Vector3) playerRotations[playerRotations.Count - 1];
playerRotations.RemoveAt(playerRotations.Count - 1);
}
}
}
public int keyframe = 5;
private int frameCounter = 0;keyframe — это кадр в методе FixedUpdate, в который мы будем записывать данные игрока. В настоящий момент ей присвоено значение 5, то есть данные будут записываться на каждом пятом цикле выполнения метода FixedUpdate. Поскольку FixedUpdate выполняется 50 раз в секунду, то за секунду будет записываться 10 кадров. Переменная frameCounter будет использоваться как счётчик кадров до следующего ключевого кадра.FixedUpdate, чтобы он выглядел вот так:if(!isReversing)
{
if(frameCounter < keyframe)
{
frameCounter += 1;
}
else
{
frameCounter = 0;
playerPositions.Add (player.transform.position);
playerRotations.Add (player.transform.localEulerAngles);
}
}frameCounter, чтобы не записывать данные, а воспроизводить их.private int reverseCounter = 0;FixedUpdate должна выглядеть так:void FixedUpdate()
{
if(!isReversing)
{
if(frameCounter < keyframe)
{
frameCounter += 1;
}
else
{
frameCounter = 0;
playerPositions.Add (player.transform.position);
playerRotations.Add (player.transform.localEulerAngles);
}
}
else
{
if(reverseCounter > 0)
{
reverseCounter -= 1;
}
else
{
player.transform.position = (Vector3) playerPositions[playerPositions.Count - 1];
playerPositions.RemoveAt(playerPositions.Count - 1);
player.transform.localEulerAngles = (Vector3) playerRotations[playerRotations.Count - 1];
playerRotations.RemoveAt(playerRotations.Count - 1);
reverseCounter = keyframe;
}
}
}private Vector3 currentPosition;
private Vector3 previousPosition;
private Vector3 currentRotation;
private Vector3 previousRotation;void RestorePositions()
{
int lastIndex = keyframes.Count - 1;
int secondToLastIndex = keyframes.Count - 2;
if(secondToLastIndex >= 0)
{
currentPosition = (Vector3) playerPositions[lastIndex];
previousPosition = (Vector3) playerPositions[secondToLastIndex];
playerPositions.RemoveAt(lastIndex);
currentRotation = (Vector3) playerRotations[lastIndex];
previousRotation = (Vector3) playerRotations[secondToLastIndex];
playerRotations.RemoveAt(lastIndex);
}
}if(reverseCounter > 0)
{
reverseCounter -= 1;
}
else
{
reverseCounter = keyframe;
RestorePositions();
}
if(firstRun)
{
firstRun = false;
RestorePositions();
}
float interpolation = (float) reverseCounter / (float) keyframe;
player.transform.position = Vector3.Lerp(previousPosition, currentPosition, interpolation);
player.transform.localEulerAngles = Vector3.Lerp(previousRotation, currentRotation, interpolation);if(firstRun)
{
firstRun = false;
RestorePositions();
}firstRun:private bool firstRun = true;if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
}
else
{
isReversing = false;
firstRun = true;
}if(playerPositions.Count > 128)
{
playerPositions.RemoveAt(0);
playerRotations.RemoveAt(0);
}FixedUpdate после кода записи и воспроизведения.public class Keyframe
{
public Vector3 position;
public Vector3 rotation;
public Keyframe(Vector3 position, Vector3 rotation)
{
this.position = position;
this.rotation = rotation;
}
}keyframes = new ArrayList();playerPositions.Add (player.transform.position);
playerRotations.Add (player.transform.localEulerAngles);keyframes.Add(new Keyframe(player.transform.position, player.transform.localEulerAngles));



TimeController эффекты изображения. Добавляем их в самое начало:using UnityStandardAssets.ImageEffects;TimeController, добавим эту переменную:private Camera camera;Start:camera = Camera.main;void Update()
{
if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
camera.GetComponent().enabled = true;
camera.GetComponent().enabled = true;
}
else
{
isReversing = false;
firstRun = true;
camera.GetComponent().enabled = false;
camera.GetComponent().enabled = false;
}
} TimeController должен выглядеть следующим образом:using UnityEngine;
using System.Collections;
using UnityStandardAssets.ImageEffects;
public class Keyframe
{
public Vector3 position;
public Vector3 rotation;
public Keyframe(Vector3 position, Vector3 rotation)
{
this.position = position;
this.rotation = rotation;
}
}
public class TimeController: MonoBehaviour
{
public GameObject player;
public ArrayList keyframes;
public bool isReversing = false;
public int keyframe = 5;
private int frameCounter = 0;
private int reverseCounter = 0;
private Vector3 currentPosition;
private Vector3 previousPosition;
private Vector3 currentRotation;
private Vector3 previousRotation;
private Camera camera;
private bool firstRun = true;
void Start()
{
keyframes = new ArrayList();
camera = Camera.main;
}
void Update()
{
if(Input.GetKey(KeyCode.Space))
{
isReversing = true;
camera.GetComponent().enabled = true;
camera.GetComponent().enabled = true;
}
else
{
isReversing = false;
firstRun = true;
camera.GetComponent().enabled = false;
camera.GetComponent().enabled = false;
}
}
void FixedUpdate()
{
if(!isReversing)
{
if(frameCounter < keyframe)
{
frameCounter += 1;
}
else
{
frameCounter = 0;
keyframes.Add(new Keyframe(player.transform.position, player.transform.localEulerAngles));
}
}
else
{
if(reverseCounter > 0)
{
reverseCounter -= 1;
}
else
{
reverseCounter = keyframe;
RestorePositions();
}
if(firstRun)
{
firstRun = false;
RestorePositions();
}
float interpolation = (float) reverseCounter / (float) keyframe;
player.transform.position = Vector3.Lerp(previousPosition, currentPosition, interpolation);
player.transform.localEulerAngles = Vector3.Lerp(previousRotation, currentRotation, interpolation);
}
if(keyframes.Count > 128)
{
keyframes.RemoveAt(0);
}
}
void RestorePositions()
{
int lastIndex = keyframes.Count - 1;
int secondToLastIndex = keyframes.Count - 2;
if(secondToLastIndex >= 0)
{
currentPosition = (keyframes[lastIndex] as Keyframe).position;
previousPosition = (keyframes[secondToLastIndex] as Keyframe).position;
currentRotation = (keyframes[lastIndex] as Keyframe).rotation;
previousRotation = (keyframes[secondToLastIndex] as Keyframe).rotation;
keyframes.RemoveAt(lastIndex);
}
}
} |
Метки: author PatientZero разработка игр unity3d c# time rewind перемотка времени prince of persia |
С/С++ на Linux в Visual Studio Code для начинающих |

sublime (или gedit/kate/emacs), а запускать в терминале — так себе решение, ошибку при работе с динамическим распределением памяти вряд ли найдёшь с первого раза. А если проект трудоёмкий? У меня есть более удобное решение. Да и ещё поддержка Git в редакторе, одни плюсы.sudo dpkg -i (имя пакета).deb
sudo apt-get install -fsudo rpm --import https://packages.microsoft.com/keys/microsoft.asc
sudo sh -c 'echo -e "[code]\nname=Visual Studio Code\nbaseurl=https://packages.microsoft.com/yumrepos/VScode\nenabled=1\ntype=rpm-md\ngpgcheck=1\ngpgkey=https://packages.microsoft.com/keys/microsoft.asc" > /etc/zypp/repos.d/VScode.repo'sudo zypper refresh
sudo zypper install code


printf.
command). Поэтому для компиляции .cpp, понадобится в поле command указать g++ или c++, а для .c gcc.args прописываем аргументы, которые будут переданы на вход вашему компилятору. Напоминаю, что порядок должен быть примерно таким: -g, <имя файла>.-g(а лучше даже -g3). Иначе вы не сможете отладить программу.makefile, то в поле command введите make, а в качестве аргумента передайте директиву для сборки.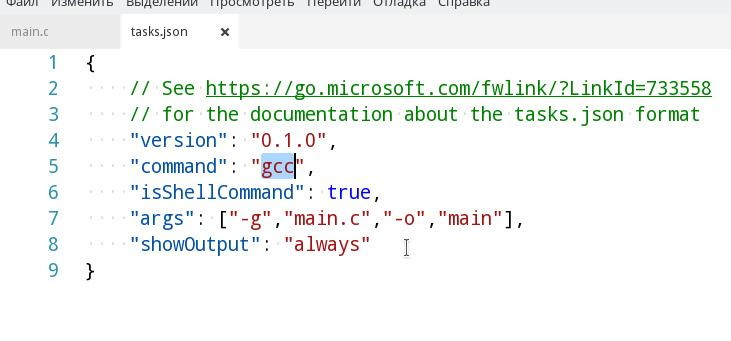

${workspaceRoot}/a.out, но я в своем файле сборки указал флаг -o и переименовал файл скомпилированной программы, поэтому у меня путь до программы: ${workspaceRoot}/main.

main, значит все в порядке и сборка прошла без ошибок. У меня не слишком большая программа, но выполняется она моментально. Одним словом, провал чистой воды, потому что отладка идет в отдельном терминале, который закрывается после того, как программа дошла в main() до "return 0;".
"return 0;" и нажимаем F9.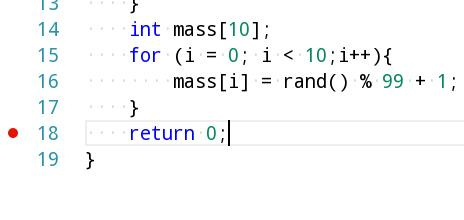




|
Метки: author Schvepsss разработка под linux visual studio c++ блог компании microsoft microsoft с++ linux visual studio code |
Сказ о проектном менеджере в банке и как он решил проблемы с удаленным подрядчиком |
Коллеги, здравствуйте
Не знаю как вам, но мне кажется, что мы сейчас рассинхронизированы и нынешнее положение вещей это только усугубляет. В перспективе это обязательно скажется на качестве задач, сроках которые будут увеличиваться. В свою очередь вы будете не довольны тем, что нами оплачено одно время, а вы затратили на задачи совсем другое. В итоге всё это может привести к нашему расставанию, что не выгодно для наших компаний.
Чтобы избежать все вышеизложенное, я подготовил небольшой список принципов и правил нашего с вами взаимодействия.
- Встать на сторону заказчика. Это значит, что нужно одевать на себя шапку заказчика и будучи в его шкуре представить мотивы его требований и задач. Мотивы могут быть очевидные, а могут быть и скрытые. Если чувствуете, что в задаче нет дополнительной информации для полного понимания – надо о ней спрашивать и фиксировать в исходном документе о задаче, который размещен на гугл диске. Все должно быть прозрачно ясно.
- для пээмов: если в процессе получения задачи или юзер стори вы чувствуете спорные моменты или что-то упускаете, то постарайтесь получить всю информацию, чтобы быть с заказчиком on the same page. Заказчик может говорить одно, подразумевать другое, а ожидать третье.
- для остальных: для ребят разработчиков/дизайнеров тоже полезно перед началом работы над задачей представить себя заказчиком и понять его мотивы. Это такой простой и недолгий мысленный эксперимент и он поможет вам глубоко и ясно понять задачу. Если же вы получили задачу и она, в принципе, понятна, но вы не видите общей картины и не чувствуете как она в целом повлияет на процесс – обязательно сообщите об этом пээму.
- Честность, уважение и сдержанность.
- честность: своевременно говорите о проблемах и о отставаниях, чтобы заказчик на своей стороне успел мобилизоваться. От ошибок никто не застрахован, но их замалчивание расценивается как не профессионализм.
- уважение: заказчик может быть со своими тараканами в голове, может иногда тупить. Но раз уж он работает с вами, это что-то значит.
- сдержанность: старайтесь сдерживать свои эмоции в общении и в переписке.
- Коммуникация! Коммуникация! Коммуникация! (хотелось бы сразу заметить, что под коммуникацией ни в коем разе не подозревается пустая болтовня и бездумные переговоры). Ниже приведу выдержки из книги Remote, так как мы с вами работаем удаленно:
- Почаще рассказывайте клиенту, что сделано по проекту. Это лучший способ избавить его от вполне естественной тревоги. Послушайте, он же платит вам приличные деньги, и некоторое беспокойство, которое он ощущает с момента расставания с авансом, вполне понятно. Так что показывайте ему то, за что он платит. Когда клиенты регулярно видят результаты ваших усилий, они гораздо лучше себя чувствуют. Но для того чтобы избежать постоянных созвонов, НУЖНО четко и структурированно вести работу над задачами в нашем инструменте – Трак:
- Задача должна быть оформлена полностью по шаблону (что нужно сделать, как это сделать, критерии готовности и прочее)
- У задачи должны быть проставлены все пункты (milestone, планируемый срок исполнения, компоненты, номер релиза, дата и прочее)
- У задачи должен быть виден прогресс, то есть если разработчик проставил задачу в статус inProgress и работает над ней, то я ожидаю увидеть, что он по ней сделал в течении дня (это минимум 2 комментария к задаче в день, которые понятно раскроют суть сделанного)
- Будьте подчеркнуто доступны для общения. Поскольку у нас нет возможности встречаться лично, лучше вовремя перезванивать, отвечать на электронную почту, отзываться в мессенджерах и так далее. Это азы деловой этики, и их важность десятикратно усиливается в случае удаленной работы. Если вы работаете удаленно, клиенты более подозрительно относятся к оставшимся без ответа звонкам и «потерянной» почте. Будьте на связи, это в ваших интересах. Для того чтобы плыть в одном русле теперь каждый день у нас с вами в 9:30 будет видеоконференция (это будет стенд-ап не больше чем на 10 минут, чтобы сверить часы, услышать проблемы и понять куда движемся). Присутствие всей команды обязательно.
- Подключайте заказчика к работе, пусть он видит весь процесс. Пусть чувствует, что это и его проект тоже. Да, вас наняли из-за вашего опыта, но и у него опыта хватает. Показывайте полусырой, еле двигающийся прототип или сервис, лучше на начальном этапе понять что не так и потратить меньше ресурсов и сил на переделку. Я как заказчик понимаю, что такое прототип и на какие вещи не стоит обращать внимание, здесь важно базовое понимание работы, а детали это детали.
|
Метки: author Gen1us2k управление разработкой управление проектами управление персоналом управление людьми управление проектами и командой |
Книга «Python. Уроки» |
 Добрый день, коллеги!
Добрый день, коллеги!|
Метки: author marat_ab python уроки python |
Как я был обманут, связавшись с дизайнером Ramin Nasibov (Berlin, Germany) |

12 июня через Twitter я получил сообщение с предложением о сотрудничестве:
Are looking for a freelance designer and social media manager? Professional Branding and Social Media Design. Porfolio: nasibov.me If you have any questions please email me: ramin@nasibov.me
Я нуждался в обновлении изображений на моем сайте vialatm.com. Познакомившись с его представительством в соц. сетях, я обратился с вопросом о стоимости работ. Практически сразу я получил предложение обсудить все в Skype митинге. Через 30 минут мы провели переговоры в Skype. Оказалось что дизайнер свободно говорит на русском. Мы пришли к соглашению, что в течении недели он подготовит оригинальные изображения для моего сайта. Он запросил оплату в размере 50% от общей стоимости работ. Я предлагал провести оплату через PayPal, но он настоял на оплате через Payoneer.
Через два часа я получил запрос на оплату работ и сразу произвел оплату:

После этого общаться с ним стало весьма проблематично. То он не отвечал потому, что был далеко от компьютера, то он не появлялся на оговоренных Skype митингах из-за проблем с интернетом.
22 июня, в связи с отсутствием каких-либо результатов и неудачных попыток связаться и пообщаться с ним, я попросил его вернуть авансовый платеж.
23 июня, не получив никаких ответов, я предупредил его что буду пытаться разрешить возникшую ситуацию по другим каналам.
Полное молчание. Я был вынужден приобрести дизайн сайта в другой компании и купить изображения на iStock.
25 июня я направил жалобу в платежную систему Payoneer. И вот после этого он объявился. Через Skype от него было получено сообщение:
Hello Andrey. As a result of the action of the group by the scammer and the burglars, I lost access to my own social networks, mail and Skype. Unfortunately you had to communicate with scammers on my behalf. As a result, not only you, but also other users were deceived. The criminals professionally mimicked my content in social networks and in contacting clients requested advances. At the moment, with the help of a lawyer and right services, I was able to return access to my social networks and Skype. After gaining access back I was shocked by the correspondence and the number of cheated people. At the moment, I draft an application to the relevant authorities and contact the deceived customers. Since the fraudsters in a certain way managed to get money, I have to work for clients for free and without any fees. I’m really sorry Andrey. Are you interested in receiving your order?
Вкратце суть его в том, что его акаунтами завладели мошенники, общался я с мошенниками, с помощью адвокатов он вернул доступ к своим социальным сетям и прочая чушь!:
Все это время, в Twitter он публиковал свои новые работы, а в Facebook делился фотографиями (кошки, кресла, ...). А я все свои последние сообщения ему дублировал по эл. почте, в Twitter и Skype.
28 июня он предложил в течении 1-2 дней выполнить работы.
Но я отказался и потребовал возвращения денег (в течении двух недель после оплаты я даже никакого эскиза не получил, и он откликнулся только после моего обращения в Payoneer).
После этого он окончательно исчез.
Я еще раз решил взглянуть на работы этого дизайнера и мое внимание привлекло публикация в Twitter — работы для компании «Coffeepolitan» https://twitter.com/RaminNasibov Никакого труда не составило найти подобную картинку с картой мира на кофе на сайте — Shutterstoc

Чашка и деревянный фон на картинках отличаются (но чашек и фона из деревяшек найти вообще труда не составляет), а вот картинки карты мира на кофе совпадают до мелочей.
Очень интересно какое изображение является оригиналом, а какое копией?
Между прочим этот дизайнер имеет два сайта http://nasibov.me/ и http://pixelin.me/ с impressum
Выводы из всего этого — договоры на работы должны сопровождаться четкими юридическими документами. В них должны быть предусмотрены санкции не только за срыв сроков, но и ответстсвенность за получение изображений, к которым могут быть предявлены права третьих лиц.
|
Метки: author Euler2012 блог компании euler2012.com дизайн жулики и воры |
Доработки шаблонизатора DoT.js |
_.template() в Underscore/Lodash, но с улучшенным синтаксисом, при котором необходимость писать JS в шаблонах встречается нечасто, а в Underscor-овском — нужна всегда. Этим скобкам со скриптами даже придумали специальный термин: javascript encapulated sections (JES), и от них, в основном, избавились.var rw = unescape(...). В общем, всё сделано для неразберихи. Поэтому считаем, что самая новая версия — 1.1.1, в которой учтём отличие из ветки 2.0. Ветка 2.0 своего звания не заслуживает._.template(), в котором внутри скобок "{{ ... }}" можем писать любой JS-код, включая незакрытые фигурные и операторные скобки, а снаружи скобок — HTML-фрагменты текста.'it' тоже переопределить можно, как и 4 логических настройки поведения;'doT');_.template(), имеет 2 этапа шаблонизации (каррирования параметров) — в функцию и затем в HTML (или другой) код;_.template() — 3.4 К в сжатом не зипованном виде.test/index.html. По умолчанию она сравнивает одинаковость результатов в развёрнутой и минифицированной версиях файлов. И второй движок может работать лишь с клоном, т.к. у него возможно глобальное имя, отличное от 'doT'. Вместо минифицированной можно поставить клон, а на первом месте, например, оригинальный DoT.js 1.1.1 и смотреть различия в парсинге.)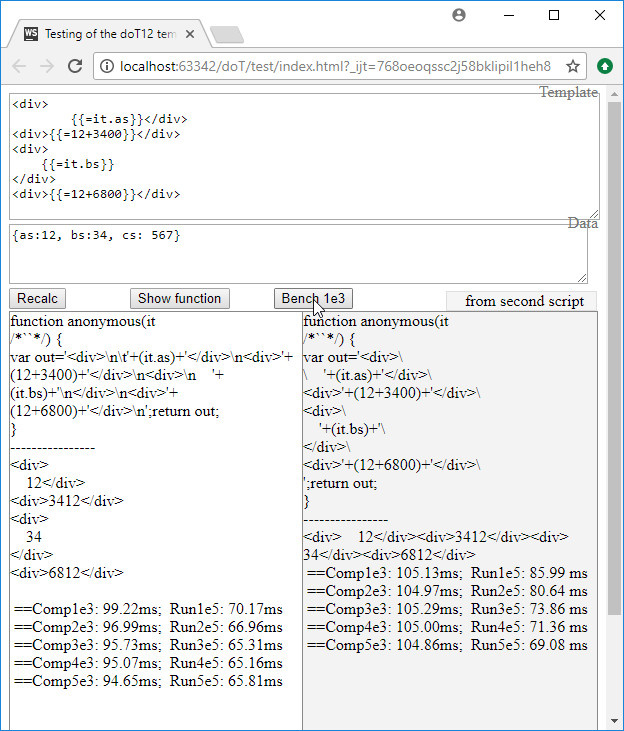
globalName:'doTmin'.doT на doTmin (даже если не minimized). По умолчанию выставлены DoT.js 1.1.1 оригинал и DoT12.js 1.2.1 — клон.'~' и '@' по массиву. Вторая тоже работать может, но значительно медленнее — на 10-15% (проверяется кнопкой «Bench»). Это связано с необходимостью использовать более медленный цикл for-in во втором случае. Тем не менее, без for-in для структур не обойтись, чтобы не иметь необходимости подготовки массивов из структур для оригинальной версии, не имеющей команды '@'.Comp1e3: 99.22ms" означает: «1000 полных компиляций проведены за время 99.22ms». "Run5e5: 69.08 ms" в 5-й строчке означает: «50 тысяч быстрых генераций HTML по шаблону проведены за усреднённое время 69.08ms на каждые 10 тысяч генераций».DoT12.js названо регулярное выражение, отвечающее за данную функцию (команду) шаблонизации.{{ часть выражения и операторов JS }}{{= выражение JS }}"
" в значении выражения, если будет выложен в страницу браузера, будет вести себя не как текст, а как тег — приведёт к переносу строки по правилам HTML.{{! выражение JS }}&...;) символы превращаются в текст;{{? if-выражение }} then-шаблон {{?}}{{? if-выражение }} then-шаблон {{?? [if-else-выражение]}} [if-]else-шаблон {{?}}'it', в которую передаётся параметр при шаблонизации.{{# выражение, выдающее строку }}{{# ...}} можно внести в шаблон текст другого шаблона через переменную. Но задумана команда была для более простых и конкретных дел, в паре с командой «define».{{## def.defin1 :что_угодно_до_скобки#}}
или {{## def.defin1 =что_угодно_до_скобки#}} - имеет другой смысл (функция){{##foo="bar"#}}{{#def.foo}}{{ операторы JS }}{{~...}} — это пробежка по массиву циклом while. (Выбирали, очевидно, из всего и выбрали самое быстрое на тот момент в браузерах.) Работает быстрее на 10-15%, чем её альтернатива {{@...}} на for-in-шаблоне, которая может пробегать по массиву или по струкутуре. 4-й параметр — фильтрация элементов по выражению. В оригинальной версии поддерживается только массив и без фильтрации. Не устраивает — всегда есть "{{ ... }}" (писать удобно, читать — нет, как Perl или машинный код).{{~ it : value : index : filter-expression }} while-шаблон {{~}}it — слово 'it' (или другое), означающее первый аргумент, или глобальное имя массива, или выражение, возвращающее массив; value — любое имя, например, 'v' или 'value' без кавычек, которое будет использоваться в for-шаблоне на месте подставляемого значения элемента массива, например, в выражении {{= value+1}}; index — аналогично, любое имя, определяющее индекс элемента массива.index можно опускать, если не нужен в шаблоне, вместе с двоеточием.templateSettings.varname), у остальных тоже есть умолчания, но они очень технические, незапоминаемые.{{@ it : value : index : expression }} for-in-шаблон {{@}}"if(1)"? это — плата за баланс.){{@::i}} for-in-шаблон {{@}}{{@::i}} {{=it[i]}} {{@}}{{@:v}} {{=v}} {{@}}"@"-командах. Но наоборот, в "~"-командах (в массивах) — структуры — нельзя, ради совместимости с оригиналом.varname: 'it',doT.template(), в локальных настройках текущей команды. (Есть ещё способ «статической» смены настроек, добравшись к ним по window.doT.templateSettings.)test/index.html. Это имена: out, arr1, arr2, ..., ll (две малые L), v, i (при проходе по массивам. Они экранируют такие же внешние имена. Но it — на особом счету, без неё — никуда, поэтому вынесена в настройки.strip: true,strip: false.append: true,log: true,selfcontained: false,doT.template(...) может быть подготовлена в одном общем окружении (_globals) и тут же исполнена как doT.template(...)(...), а может — отдельно (прийти по ajax или из файла). В последнем случае нужно true (удлиняет функцию doT.template(...)), а обычно, в первом случае — false. Тогда не приходится в ней генерировать лишнего, а подсчитанное сохраняется в _globals._encodeHTML, генерируемой из _globals.doT.encodeHTMLSource(), но не всегда, а лишь при наличии команд {{! выражение}} в шаблонах.selfcontained = true — значит, что функцию шаблона doT.template() будут использовать отдельно от doT.js, поэтому она должна содержать в себе всё для выполнения шаблонизации. Всё — это значит лишь особый случай кодирования HTML-символов командами {{!}}. Если они есть, в функцию нужно включить определение функции кодирования — строку doT.encHtmlStr при её создании (так сделано в клоне 1.2.1, а в оригинале функция encodeHTMLSource преобразуется в строку).selfcontained = false, это пришлось исправить. Ещё эта функция занимается связыванием параметра doNotSkipEncoded постоянно, хотя это нужно только при создании функции шаблона.var encHt = '_'+dS.globalName + doT.version.replace(/\./g,'').
...
encHtmlStr:'var encodeHTML=typeof '+ encHt +'!="undefined"?'+ encHt +':function(c){return((c||"")+"").replace('
+ (dS.doNotSkipEncoded ?'/[&<>"'\\/]/g':'/&(?!#?\\w+;)|[<>"'/]/g')
+',function(s){return{"&":"&","<":"<",">":">",'"':""","'":"'","/":"/"}[s]||s})};'selfcontained = false и есть {{! выражение}}, то ограничиваемся выполнением её в глобальном объекте, чтобы из него использовать encodeHTML().doNotSkipEncoded: false,doT.encodeHTMLSource(). Работает для функций {{! выражение}} — выдачи безопасного (без исполняемых тегов) HTML-кода. Если они есть в любом шаблоне окружения, первый раз определяется функция _globals._encodeHTML генерации безопасных символов для экономии повторных её вызовов. Сделано для решения таких багов: github.com/olado/doT/issues/106. Если true, то не кодируются все коды вида "&....;", и главный результат — некодирование амперсенда в '&' в таких выражениях.selfcontained = true. Остальные части doT оптимизированы хорошо, выбраны в среднем самые быстрые решения. Скорость версий зависит от конкретного вида шаблонов, поэтому утверждение о скорости может быть лишь усреднённым по кругу задач.performance.now() полифиллится.|
Метки: author spmbt node.js javascript html dot.js шаблонизаторы handlebars mustache |
Стоимость хранения данных: «игра с нулевой суммой» |
 / Flickr / William Hook / CC
/ Flickr / William Hook / CCВсе это — дело уже самого ближайшего времени, значимость данных отраслей и специфика не оставляют сомнений в постепенном изменении критериев, к которым «привык» рынок хранения данных
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author 1cloud хранение данных блог компании 1cloud.ru сloud |
[Перевод] Work-stealing планировщик в Go |
Задача планировщика в Go — распределять запущенные горутины между потоками ОС, которые могут исполняться одним или большим количеством процессоров. В многопоточных вычислениях, возникли две парадигмы в планировании: делиться задачами (work sharing) и красть задачи (work stealing).
Миграция потоков происходит реже при work stealing подходе, чем при work sharing. Когда все процессоры заняты, потоки не мигрируют. Как только появляется простаивающий процессор, рассматривается вариант миграции.
В Go начиная с версии 1.1 планировщик реализован по схеме work stealing и был написан Дмитрием Вьюковым. Эта статья подробно объясняет устройство work stealing планировщиков и как он устроен в Go.
Планировщик Go выполнен по M:N схеме и может использовать несколько процессоров. В любой момент M горутин должны быть распределены между N потоками ОС, которые бегут на максимум GOMAXPROCS процессорах. В Go планировщике используется следующая терминология для горутин, потоков и процессоров:
Далее у нас есть две очереди, специфичные для P. Каждый M должен быть назначен к своему P. P-ы могут не иметь M, если они заблокированы или ожидают окончания системного вызова. В любой момент может быть максимум GOMAXPROCS процессоров — P. В любой момент только один M может исполняться на каждый P. Больше M может создаваться планировщиком, если это требуется.

Каждый цикл планирования заключается в поиске горутины, которая готова к тому, чтобы быть запущенной и её исполнения. При каждом цикле поиск присходит в следующем порядке:
runtime.schedule() {
// только 1/61 от всего времени, проверить глобальную очередь G
// если не найдено, проверить локальную очередь
// если не найдено, то:
// попытаться украсть у других P
// если не вышло, проверить глобальную очередь
// если всё равно не вышло, поллить (poll) сеть
}Как только готовая к исполнению G найдена, она исполняется, пока не будет заблокирована.
Заметка: Может показаться, что глобальная очередь имеет преимущество перед локальной, но регулярная проверка глобальной очереди критична для избежания M использования только горутин из локальной очереди.
Когда новая G создается или существующая G становится готовой к исполнению, она помещается в локальную очередь готовых к исполнению горутин текущего P. Когда P заканчивается исполнение G, он пытается вытащить (pop) G из своей очереди. Если список пуст, P выбирает случайным образом другой процессор (P) и пытается украсть половину горутин из его очереди.

В примере выше, P2 не может найти готовых к исполнению горутин. Поэтому он случайно выбирает другой процессор (P1) и крадёт три горутины в свою очередь. P2 теперь сможет их запустить и работа будет более равномерно распределена между процессорами.
Планировщик всегда хочет распределить как можно больше готовых к исполнению горутин на много M, чтобы использовать все процессоры, но, в тоже время, мы должны уметь приостанавливать (park) сильно прожорливые процессы, чтобы сохранять ресурсы CPU и энергию. И при этом, планировщик должен также уметь масштабироваться для задач, которые действительно требуют много вычислительной мощности процессора и большую производительность.
Постоянное упреждение (preemption) одновременно и дорогое и проблематичное для высоко-производительных программ, где производительность критичней всего. Горутины не должны постоянно прыгать между потоками ОС, поэтому это приводит к повышенной задержки (latency). В добавок ко всему, когда вызываются системные вызовы, поток должен быть постоянно блокироваться и разблокироваться. Это дорого и приводит к большим накладным расходам.
Чтобы уменьшить эти прыжки горутин туда-сюда, планировщик Go реализует так называемые зацикленные потоки (spinning threads). Эти поток используют чуть больше процессорной мощности, но уменьшают упреждение потоков. Поток считается зациклен, если:
В любой момент времени может быть максимум GOMAXPROCS зацикленных M. Когда зацикленный поток находит работу, он выходит из зацикленного состояния.
Простаивающие поток, назначенные на какой-либо P не блокируются, если есть другие M, не назначенные на P. Если создается новая горутина или блокируется M, планировщик проверяет и гарантирует, что есть хотя бы один зацикленный M. Это гарантирует, что все горутины могут быть запущены, если есть возможность и позволяет избежать излишних блокировок/разблокировок M.
Планировщик Go делает много всего для избежания избыточного упреждения потоков, распределяя их по недоиспользованным процессорам методом "кражи", и также реализацией "зацикленных" потоков, чтобы избежать частых переходов из блокирующего в неблокирующее состояние и обратно.
События планирования можно отслеживать с помощью execution tracer-а. Вы можете детально докопаться до всего, что происходит внутри планировщика, особенно если считаете, что в вашем случае происходит не эффективное использование процессоров.
Если у вас есть предложения или комментарии, пишите @rakyll.
|
Метки: author divan0 go scheduler |
[Из песочницы] Рынок 5D. Проекционные системы |




float cc=log(color)*kj;
float4 c2=rgb*exp(cc);
return c2;
procedure TCam_Geometry_frm.CalcPixelRegion(x,y:integer);
var
StartP:TPoint;
I: Integer;
J: Integer;
StaPo,EnPo:integer;
begin
StartP.X := x * InternalBitmap.Width div Image1.Width;
StartP.Y := y * InternalBitmap.Height div Image1.Height;
SetLength(CheckingMask,InternalBitmap.Height);
for I := 0 to InternalBitmap.Height - 1 do
begin
SetLength(CheckingMask[i],InternalBitmap.Width);
for J := 0 to InternalBitmap.Width-1 do
begin
CheckingMask[i][j].IsCheckPoint := false;
CheckingMask[i][j].IsPointChecked := false;
CheckingMask[i][j].typ := 0;
CheckingMask[i][j].texX := -1;
CheckingMask[i][j].texY := -1;
end;
end;
SetLength(TempFireBuf,InternalBitmap.Width * InternalBitmap.Height * 4);
StaPo := 0;
EnPo := 1;
TempFireBuf[0].XPos := StartP.X;
TempFireBuf[0].YPos := StartP.Y;
CheckingMask[StartP.Y][StartP.X].IsPointChecked := true;
CheckingMask[StartP.Y][StartP.X].IsCheckPoint := true;
while StaPo <> EnPo do
begin
if (abs(InternalPic.GetRED(TempFireBuf[StaPo].XPos, TempFireBuf[StaPo].YPos)-
InternalPic.GetRED(TempFireBuf[TempFireBuf[StaPo].pripos].XPos, TempFireBuf[TempFireBuf[StaPo].pripos].YPos)) 0 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos][TempFireBuf[StaPo].XPos-1].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos-1;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if TempFireBuf[StaPo].XPos < InternalBitmap.Width - 1 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos][TempFireBuf[StaPo].XPos+1].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos+1;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if TempFireBuf[StaPo].YPos > 0 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos-1][TempFireBuf[StaPo].XPos].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos-1;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
if (TempFireBuf[StaPo].YPos < 5) or (TempFireBuf[StaPo].YPos < 5) then
begin
ShowMessage('Область выделения подошла опасно к краю. Пордолжение не возможно.');
exit;
end;
if TempFireBuf[StaPo].YPos < InternalBitmap.Height - 1 then
begin
if not CheckingMask[TempFireBuf[StaPo].YPos+1][TempFireBuf[StaPo].XPos].IsPointChecked then
begin
TempFireBuf[EnPo].XPos := TempFireBuf[StaPo].XPos;
TempFireBuf[EnPo].YPos := TempFireBuf[StaPo].YPos+1;
TempFireBuf[EnPo].pripos := StaPo;
CheckingMask[TempFireBuf[EnPo].YPos][TempFireBuf[EnPo].XPos].IsPointChecked := true;
inc(EnPo);
end;
end;
end;
inc(StaPo);
end;
SetLength(TempFireBuf,0);
end;procedure TCam_Geometry_frm.CreateFrame;
var
nn:array [1..10] of integer;
i,j,k,l,tmp:integer;
rasts:array [1..4]of extended;
rad:extended;
begin
for I := 1 to 10 do
nn[i] := GetMinY(i);
for k := 0 to 5 do
for I := 11 to InternalPic.PicX - 1 do
begin
if (nn[1] > 0) and (nn[5] > 0) and (nn[10] > 0) and (abs(nn[10]-nn[1])< 7) then
begin
tmp := 0;
for l := 1 to 10 do
tmp := tmp + nn[l];
tmp := tmp div 10;
while nn[5] < tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := false;
inc(nn[5]);
end;
while nn[5] > tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := true;
dec(nn[5]);
end;
end;
for j := 2 to 10 do
nn[j-1] := nn[j];
nn[10] := GetMinY(i);
end;
for I := 1 to 10 do
nn[i] := GetMaxY(i);
for k := 0 to 5 do
for I := 11 to InternalPic.PicX - 1 do
begin
if (nn[1] > 0) and (nn[5] > 0) and (nn[10] > 0) and (abs(nn[10]-nn[1])< 7) then
begin
tmp := 0;
for l := 1 to 10 do
tmp := tmp + nn[l];
tmp := tmp div 10;
while nn[5] <= tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := false;
inc(nn[5]);
end;
while nn[5] > tmp do begin
CheckingMask[nn[5]][i-6].IsCheckPoint := true;
dec(nn[5]);
end;
end;
for j := 2 to 10 do
nn[j-1] := nn[j];
nn[10] := GetMaxY(i);
end;
rasts[1] := 0;rasts[2] := 0;rasts[3] := 0;rasts[4] := 0;
Center.X := 0;Center.Y := 0;
k := 0;
for I := 11 to InternalPic.PicY - 1 do
for J := 11 to InternalPic.PicX - 1 do
if CheckingMask[i][j].IsCheckPoint then
begin
Center.X := Center.X + J;
Center.Y := Center.Y + I;
inc(k);
end;
Center.X := Center.X div k;
Center.Y := Center.Y div k;
for I := 11 to InternalPic.PicY - 1 do
for J := 11 to InternalPic.PicX - 1 do
begin
if CheckingMask[i][j].IsCheckPoint then
begin
rad := (J-Center.X)*(J-Center.X)+(I-Center.Y)*(I-Center.Y);
if i < Center.Y then
begin
if j < Center.X then
begin
if (rasts[1] < rad) then
begin
rasts[1] := rad;
X1Y1.X := J;
X1Y1.Y := I;
end;
end
else
begin
if (rasts[2] < rad) then
begin
rasts[2] := rad;
X2Y1.X := J;
X2Y1.Y := I;
end;
end;
end
else
begin
if j < Center.X then
begin
if (rasts[3] < rad) then
begin
rasts[3] := rad;
X1Y2.X := J;
X1Y2.Y := I;
end;
end
else
begin
if (rasts[4] < rad) then
begin
rasts[4] := rad;
X2Y2.X := J;
X2Y2.Y := I;
end;
end;
end;
end;
end;
LeftSetkaSide.IsHorisontOnScreen := false;
LeftSetkaSide.CoordVal := 0;
LeftSetkaSide.IsHorisontVals := false;
LeftSetkaSide.x[1] := X1Y1.X;
LeftSetkaSide.y[1] := X1Y1.Y;
LeftSetkaSide.x[2] := X1Y2.X;
LeftSetkaSide.y[2] := X1Y2.Y;
LeftSetkaSide.y[3] := (LeftSetkaSide.y[1]+LeftSetkaSide.y[2]) / 2;
LeftSetkaSide.x[3] := GetMinX(Round(LeftSetkaSide.y[3]));
LeftSetkaSide.y[4] := (LeftSetkaSide.y[1] + LeftSetkaSide.y[3]) / 2;
LeftSetkaSide.x[4] := GetMinX(Round(LeftSetkaSide.y[4]));
LeftSetkaSide.y[5] := (LeftSetkaSide.y[2] + LeftSetkaSide.y[3]) / 2;
LeftSetkaSide.x[5] := GetMinX(Round(LeftSetkaSide.y[5]));
RightSetkaSide.IsHorisontOnScreen := false;
RightSetkaSide.CoordVal := 0;
RightSetkaSide.IsHorisontVals := false;
RightSetkaSide.x[1] := X2Y1.X;
RightSetkaSide.y[1] := X2Y1.Y;
RightSetkaSide.x[2] := X2Y2.X;
RightSetkaSide.y[2] := X2Y2.Y;
RightSetkaSide.y[3] := (RightSetkaSide.y[1]+RightSetkaSide.y[2]) / 2;
RightSetkaSide.x[3] := GetMaxX(Round(RightSetkaSide.y[3]));
RightSetkaSide.y[4] := (RightSetkaSide.y[1] + RightSetkaSide.y[3]) / 2;
RightSetkaSide.x[4] := GetMaxX(Round(RightSetkaSide.y[4]));
RightSetkaSide.y[5] := (RightSetkaSide.y[2] + RightSetkaSide.y[3]) / 2;
RightSetkaSide.x[5] := GetMaxX(Round(RightSetkaSide.y[5]));
UpSetkaSide.IsHorisontOnScreen := true;
UpSetkaSide.CoordVal := 0;
UpSetkaSide.IsHorisontVals := false;
UpSetkaSide.x[1] := X1Y1.X;
UpSetkaSide.y[1] := X1Y1.Y;
UpSetkaSide.x[2] := X2Y1.X;
UpSetkaSide.y[2] := X2Y1.Y;
UpSetkaSide.x[3] := (UpSetkaSide.x[1]+UpSetkaSide.x[2]) / 2;
UpSetkaSide.y[3] := GetMinY(Round(UpSetkaSide.x[3]));
UpSetkaSide.x[4] := (UpSetkaSide.x[1]+UpSetkaSide.x[3]) / 2;
UpSetkaSide.y[4] := GetMinY(Round(UpSetkaSide.x[4]));
UpSetkaSide.x[5] := (UpSetkaSide.x[2]+UpSetkaSide.x[3]) / 2;
UpSetkaSide.y[5] := GetMinY(Round(UpSetkaSide.x[5]));
DownSetkaSide.IsHorisontOnScreen := true;
DownSetkaSide.CoordVal := 0;
DownSetkaSide.IsHorisontVals := false;
DownSetkaSide.x[1] := X1Y2.X;
DownSetkaSide.y[1] := X1Y2.Y;
DownSetkaSide.x[2] := X2Y2.X;
DownSetkaSide.y[2] := X2Y2.Y;
DownSetkaSide.x[3] := (DownSetkaSide.x[1]+DownSetkaSide.x[2]) / 2;
DownSetkaSide.y[3] := GetMaxY(Round(DownSetkaSide.x[3]));
DownSetkaSide.x[4] := (DownSetkaSide.x[1]+DownSetkaSide.x[3]) / 2;
DownSetkaSide.y[4] := GetMaxY(Round(DownSetkaSide.x[4]));
DownSetkaSide.x[5] := (DownSetkaSide.x[2]+DownSetkaSide.x[3]) / 2;
DownSetkaSide.y[5] := GetMaxY(Round(DownSetkaSide.x[5]));
end;procedure TCam_Geometry_frm.AddLograngeKoeffs(n:integer;byX:boolean;coord:integer);
var
I, J: integer;
possx,possy,ccou:integer;
srX1,srY1:extended;
lfid:integer;
foundPoints:arrpo;
Center:TPoint;
Clct,Clct2,Clct3,last:TPoint;
dy,sry,ddy,y:extended;
// CheAr:array of array of boolean;
begin
possx := 0;
possy := 0;
ccou := 0;
SetLength(foundPoints,0);
for I := 0 to Length(ProjSetka[n]) - 1 do
for J := 0 to Length(ProjSetka[n][i]) - 1 do
begin
if (byX and (ProjSetka[n][i][j].ProjX = coord) and IsPossHere(n,j,i,byX,20, 20,srX1,srY1))or
((not byX) and (ProjSetka[n][i][j].ProjY = coord) and IsPossHere(n,j,i,byX,20, 20,srX1,srY1))then
begin
possx := possx + j;
possy := possy + i;
inc(ccou);
SetLength(foundPoints,ccou);
foundPoints[ccou-1].X := J;
foundPoints[ccou-1].Y := I;
end;
end;
if ccou < 10 then
begin
possx := -3;
exit;
end;
possx := possx div ccou;
possy := possy div ccou;
Center.X := possx; Center.Y := possy;
lfid := length(LograngeFuncs[n]);
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])+1);
LograngeFuncs[n][lfid].IsHorisontOnScreen := false;
LograngeFuncs[n][lfid].CoordVal := coord;
LograngeFuncs[n][lfid].IsHorisontVals := byX;
i := GetMinLengthFromArr(foundPoints,Center);
if i < 0 then
begin
ShowMessage('Не нашли ни одной точки для интерполяции Лагранжа!');
exit;
end;
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[1] := srX1;
LograngeFuncs[n][lfid].Y[1] := srY1;
foundPoints[i].X := -1;
i := GetMaxLengthFromArr(foundPoints,Center);
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[5] := srX1;
LograngeFuncs[n][lfid].Y[5] := srY1;
foundPoints[i].X := -1;
Clct.X := round(srX1);
Clct.Y := round(srY1);
i := GetMaxLengthFromArr(foundPoints,Center);
while abs(GetAngleFrom3Points(Center,Clct,foundPoints[i])) < Pi / 2 do
begin
foundPoints[i].X := -1;
i := GetMaxLengthFromArr(foundPoints,Center);
if i < 0 then
begin
ShowMessage('Не нашли точки для интерполяции Лагранжа!');
exit;
end;
end;
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[4] := srX1;
LograngeFuncs[n][lfid].Y[4] := srY1;
Clct2.X := round(srX1);
Clct2.Y := round(srY1);
LograngeFuncs[n][lfid].x[2] := -1;
LograngeFuncs[n][lfid].x[3] := -1;
while (LograngeFuncs[n][lfid].x[2] < 0) or (LograngeFuncs[n][lfid].x[3] < 0) do
begin
i := GetNearestFromArr(foundPoints,Center,min(GetLengthBW2P(Center,Clct),GetLengthBW2P(Center,Clct2)) div 2);
if LograngeFuncs[n][lfid].x[2] < 0 then
begin
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[2] := srX1;
LograngeFuncs[n][lfid].Y[2] := srY1;
foundPoints[i].X := -1;
Clct3.X := round(srX1);
Clct3.Y := round(srY1);
end
else
begin
if i < 0 then
begin
LograngeFuncs[n][lfid].x[3] := last.X;
LograngeFuncs[n][lfid].Y[3] := last.Y;
end
else
if abs(GetAngleFrom3Points(Center,Clct3,foundPoints[i])) > Pi / 2 then
begin
IsPossHere(n,foundPoints[i].X,foundPoints[i].Y,byX,20, 20,srX1,srY1);
LograngeFuncs[n][lfid].x[3] := srX1;
LograngeFuncs[n][lfid].Y[3] := srY1;
end;
end;
if i >= 0 then
begin
last := foundPoints[i];
foundPoints[i].X := -1;
end;
end;
if abs(LograngeFuncs[n][lfid].x[1]-LograngeFuncs[n][lfid].x[5]) > abs(LograngeFuncs[n][lfid].y[1]-LograngeFuncs[n][lfid].y[5]) then
begin
LograngeFuncs[n][lfid].IsHorisontOnScreen := true;
end
else
LograngeFuncs[n][lfid].IsHorisontOnScreen := false;
if LograngeFuncs[n][lfid].IsHorisontOnScreen then
begin
sry := 0;
for I := 1 to 5 do
sry := sry + LograngeFuncs[n][lfid].y[i];
sry := sry / 5;
dy := 0;
for I := 1 to 5 do
if dy < abs(sry - LograngeFuncs[n][lfid].y[i]) then
dy := abs(sry - LograngeFuncs[n][lfid].y[i]);
dy := dy * 3 + 5;
for I := 10 to 1000 do
begin
y := CalcPointByPolinom(n,lfid,i,-1);
if (y > 0) and(dy < abs(sry - y)) then
begin
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])-1);
exit;
end;
end;
end
else
begin
sry := 0;
for I := 1 to 5 do
sry := sry + LograngeFuncs[n][lfid].x[i];
sry := sry / 5;
dy := 0;
for I := 1 to 5 do
if dy < abs(sry - LograngeFuncs[n][lfid].x[i]) then
dy := abs(sry - LograngeFuncs[n][lfid].x[i]);
dy := dy * 3+5;
for I := 10 to 1000 do
begin
y := CalcPointByPolinom(n,lfid,-1,i);
if (y > 0) and(dy < abs(sry - y)) then
begin
SetLength(LograngeFuncs[n],length(LograngeFuncs[n])-1);
exit;
end;
end;
end;
end;procedure TCam_Geometry_frm.sButton3Click(Sender: TObject);
var
I, couu: Integer;
geom_frms:array of Tcam_geomery_lines_ouput_frm;
j,l: Integer;
k, pos: Integer;
begin
if not sButton1.Enabled then begin FlagStop:=true;exit;end;
FlagStop:=false;
SetLength(geom_frms,g_MonitorsCount);
SetLength(ProjSetka,g_MonitorsCount);
SetLength(LograngeFuncs,g_MonitorsCount);
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i] := Tcam_geomery_lines_ouput_frm.Create(self);
geom_frms[i].PosX := g_MonitorsSetup[i+1].ScreenPosition.x;
geom_frms[i].PosY := g_MonitorsSetup[i+1].ScreenPosition.y;
Application.ProcessMessages;
SetLength(ProjSetka[i],length(CheckingMask));
SetLength(LograngeFuncs[i],0);
for J := 0 to length(CheckingMask)-1 do
begin
SetLength(ProjSetka[i][j],length(CheckingMask[j]));
for k := 0 to length(CheckingMask[j]) - 1 do
begin
ProjSetka[i][j][k].ProjX := -1;
ProjSetka[i][j][k].ProjY:= -1;
end;
end;
end;
sButton2.Enabled := false;
sButton1.Enabled := false;
sButton17.Enabled := false;
sButton4.Enabled := false;
sButton5.Enabled := false;
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i].Show;
geom_frms[i].SetBlack;
end;
for L := 0 to 40 do
begin
Application.ProcessMessages;
Sleep(20);
end;
GetBitmapFromCam(blackBitmap);
InitPicBuffer(blackPic,blackBitmap.Width,blackBitmap.Height);
CopyToPic(blackBitmap,0,0,blackPic);
for I := 0 to g_MonitorsCount-1 do
begin
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
GetBitmapFromCam(blackBitmap);
CopyToPic(blackBitmap,0,0,blackPic);
couu := 16;
if FlagStop then break;
for j := 0 to couu do
begin
pos := j*geom_frms[i].Width div couu;
if pos < 4 then pos := 4;
if pos >= geom_frms[i].Width - 4 then pos := geom_frms[i].Width - 4;
geom_frms[i].PaintLine(pos,0,pos,geom_frms[i].Height);
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
if not SaveProjLineCoords(i,pos,-1) then FlagStop := true;
AddLograngeKoeffs(i,true,pos);
pos := j*geom_frms[i].Height div couu;
if pos < 4 then pos := 4;
if pos >= geom_frms[i].Height - 4 then pos := geom_frms[i].Height - 4;
geom_frms[i].PaintLine(0,pos,geom_frms[i].Width,pos);
for L := 0 to 70 do
begin
Application.ProcessMessages;
Sleep(20);
end;
if not SaveProjLineCoords(i,-1,pos) then FlagStop := true;
AddLograngeKoeffs(i,false,pos);
if FlagStop then break;
end;
geom_frms[i].SetBlack;
// geom_frms[i].hide;
SaveProjSsetka(i);
end;
if not FlagStop then
SetCaptSetkaWidthToOne;
if not FlagStop then
CreateProjSetka;
for I := 0 to g_MonitorsCount-1 do
begin
geom_frms[i].Free;
end;
if not FlagStop then
SaveGeometry;
sButton2.Enabled := true;
sButton1.Enabled := true;
sButton17.Enabled := true;
sButton4.Enabled := true;
sButton5.Enabled := true;
end;

|
Метки: author akadone алгоритмы delphi многопроекторные системы 5d |
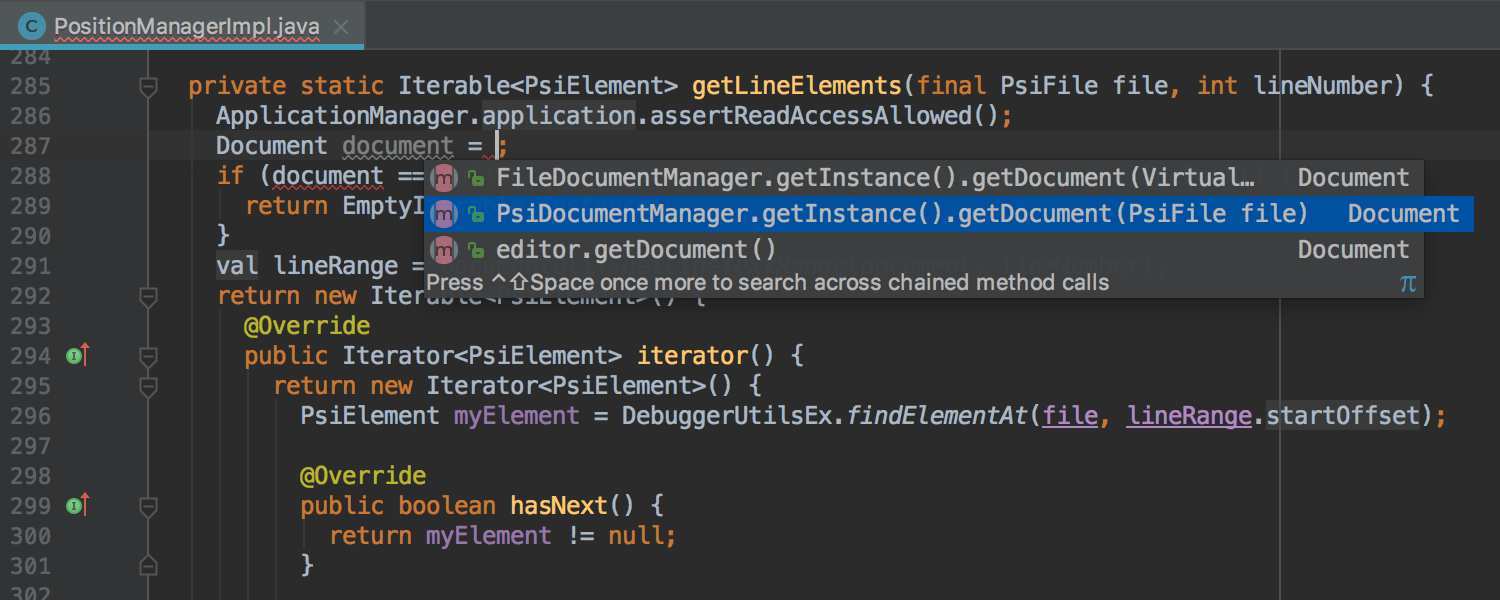
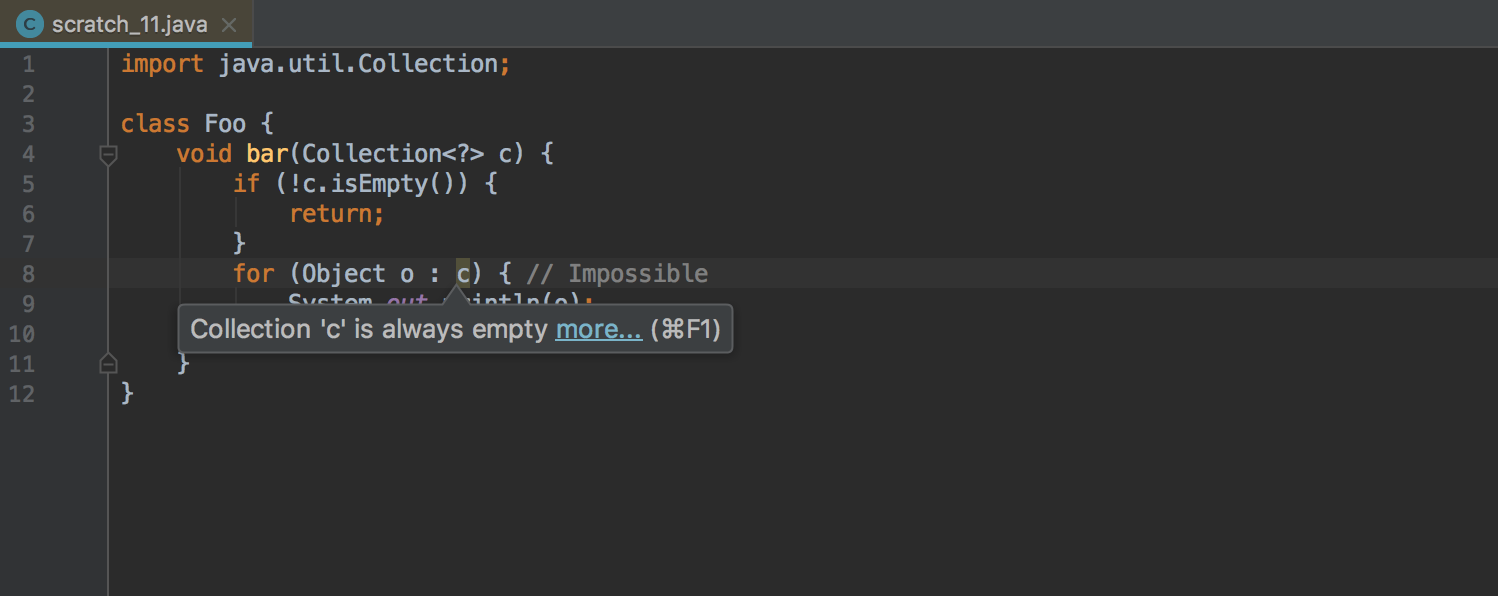
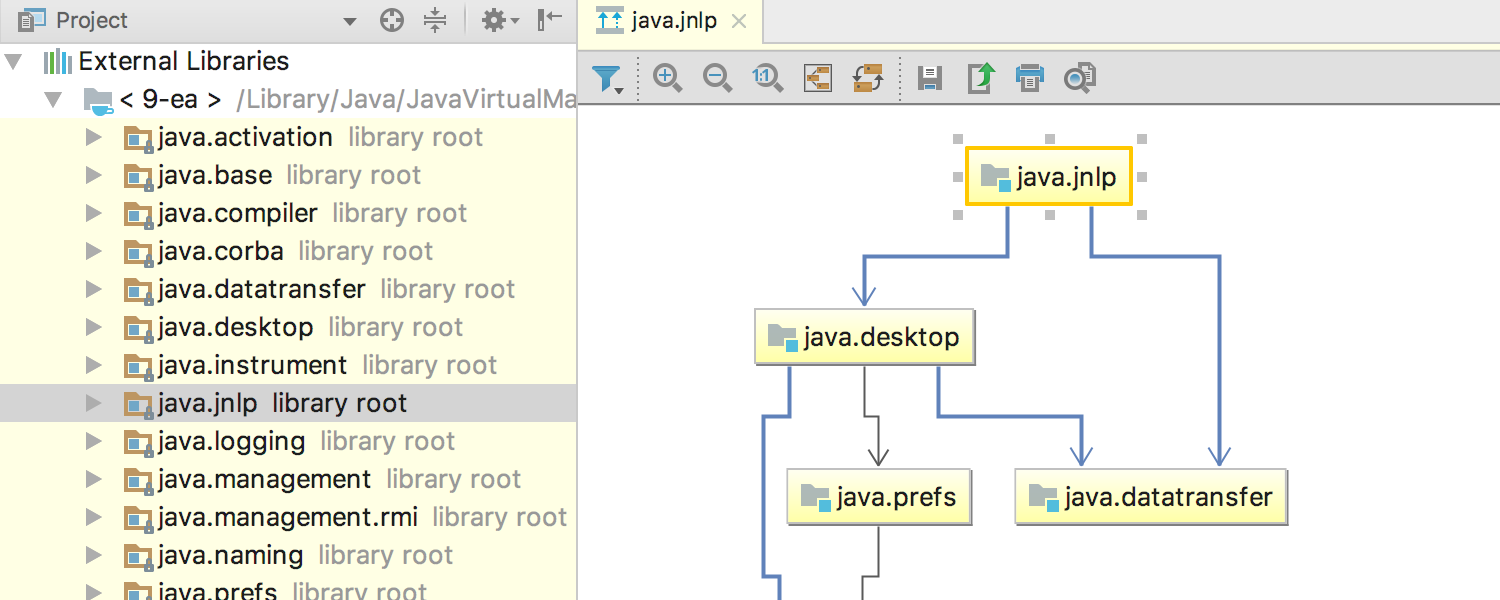
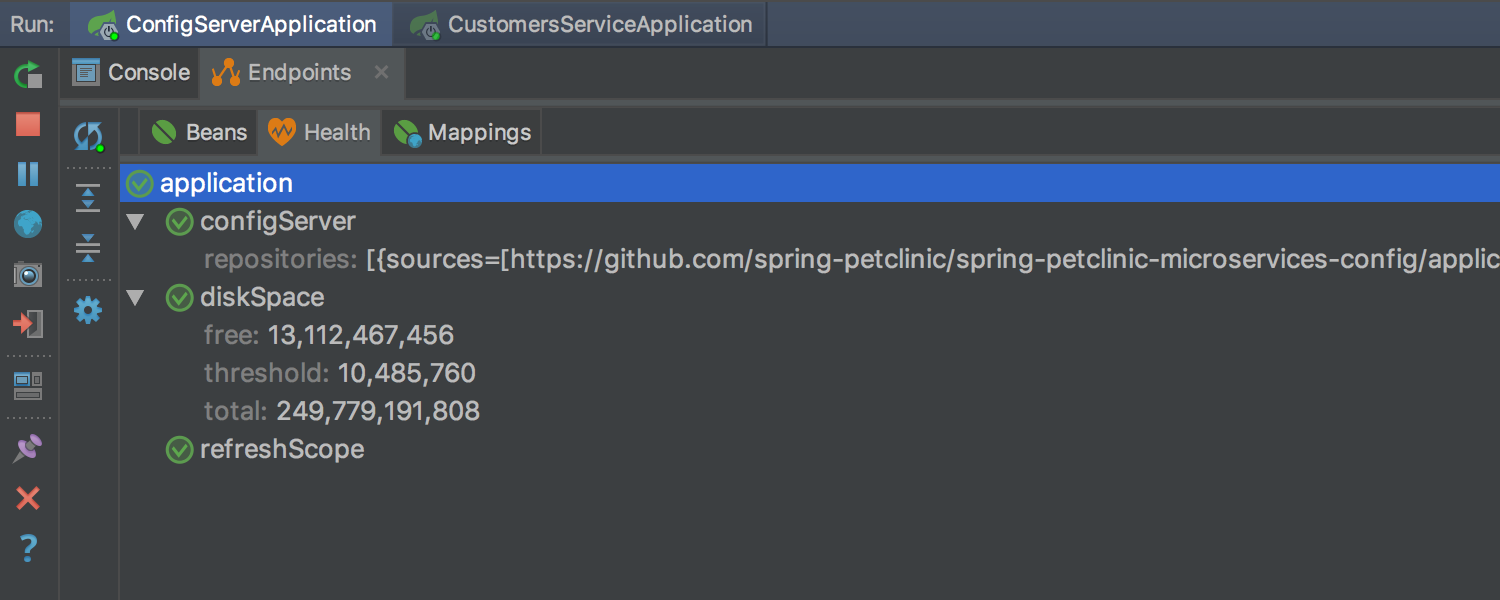
Что нового в IntelliJ IDEA 2017.2 |

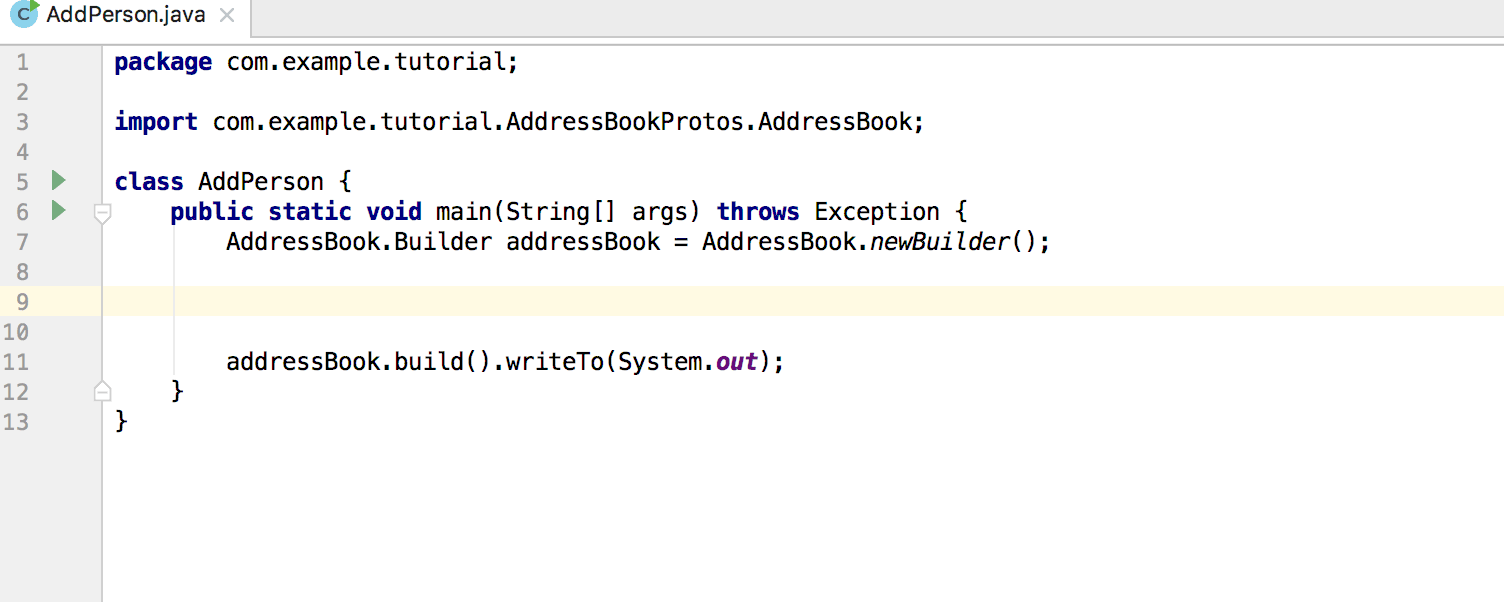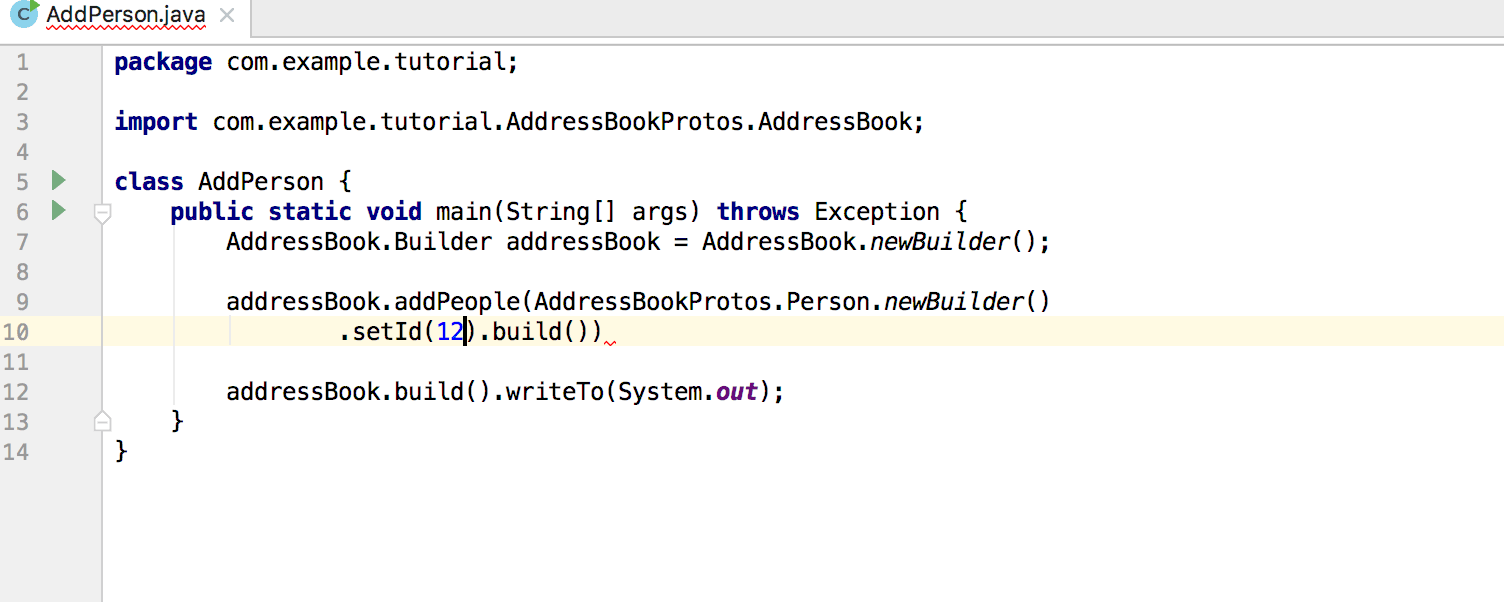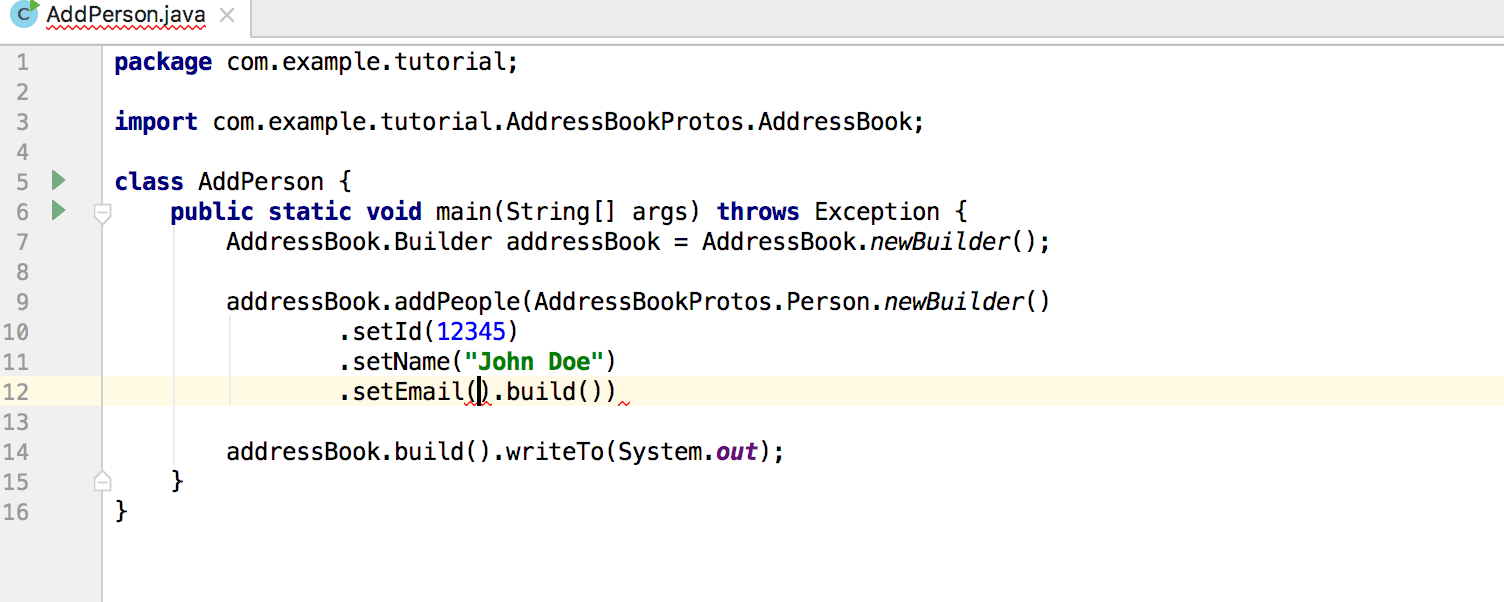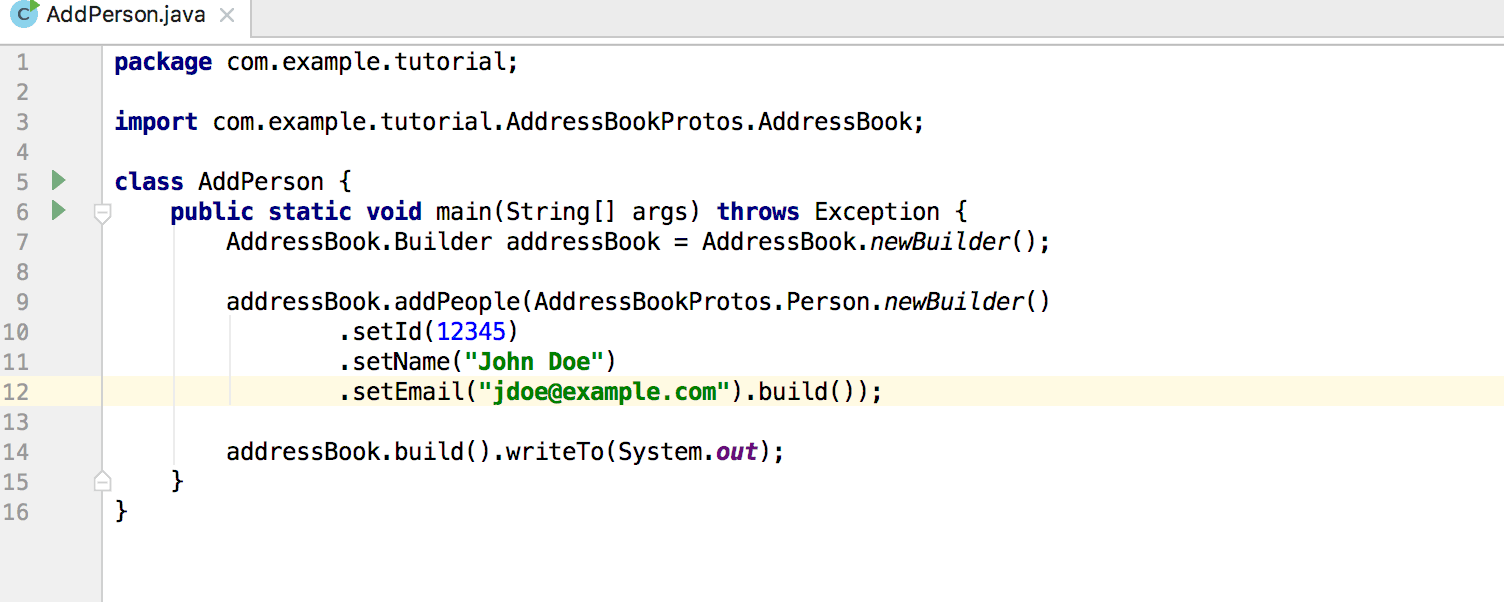



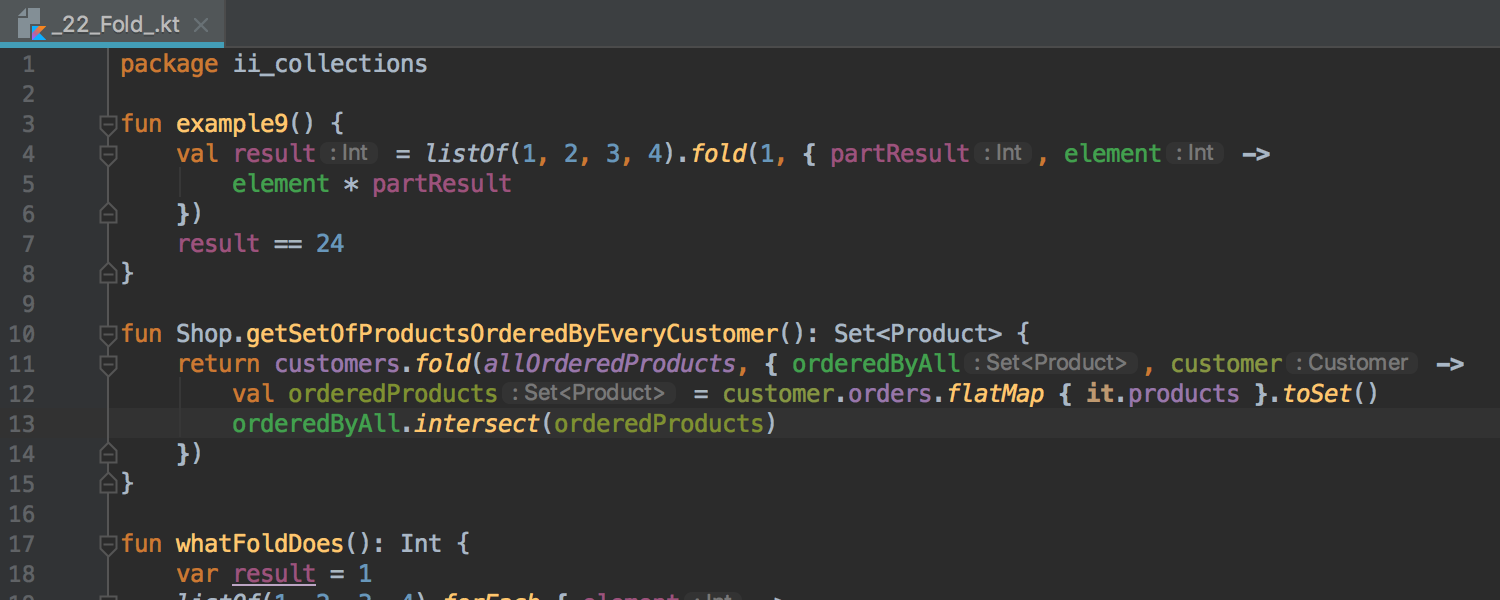




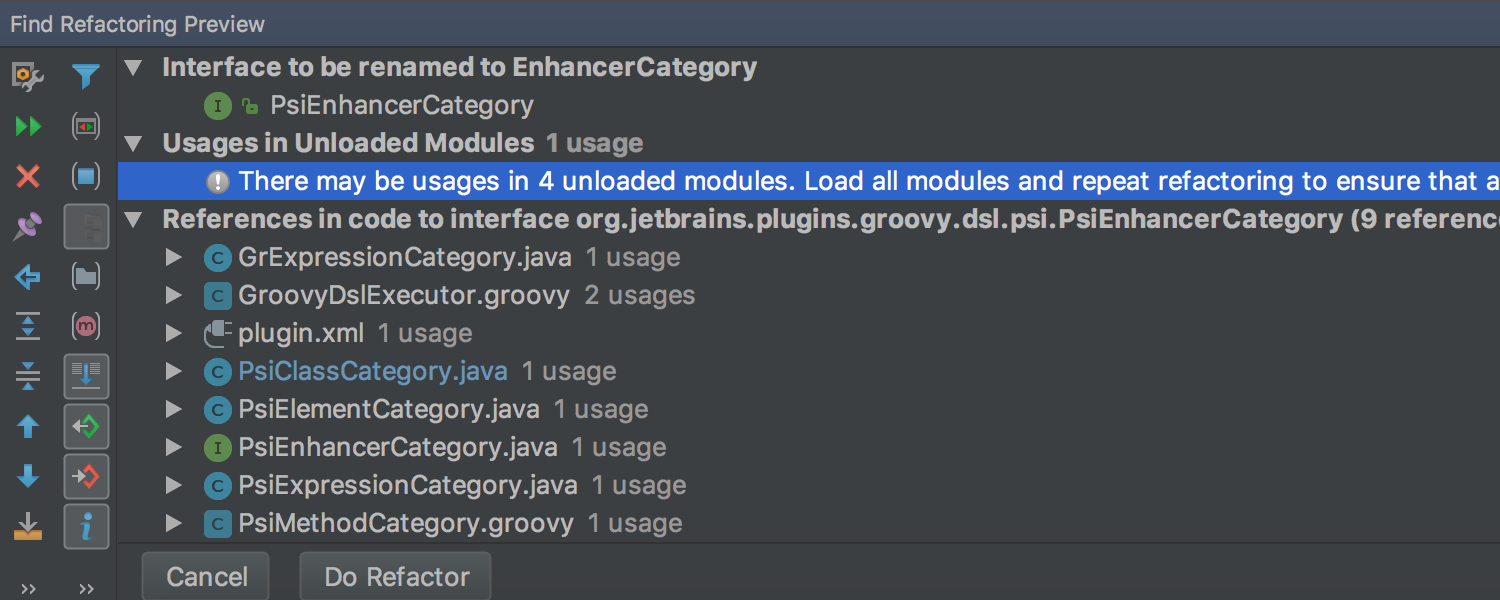
|
Метки: author andreycheptsov java блог компании jetbrains kotlin groovy spring boot mocha javascript typescript intellij intellij idea |
[Перевод] Применение принципа poka-yoke в программировании на примере PHP |
Всем привет! Я Алексей Грезов, разработчик Server Team Badoo. Мы в Badoo всегда стараемся сделать так, чтобы наш код было легко поддерживать, развивать и переиспользовать, ведь от этих параметров зависит, насколько быстро и качественно мы сможем реализовать какую-либо фичу. Одним из способов достижения этой цели является написание такого кода, который просто не позволит совершить ошибку. Максимально строгий интерфейс не даст ошибиться с порядком его вызова. Минимальное количество внутренних состояний гарантирует ожидаемость результатов. На днях я увидел статью, в которой как раз описывается, как применение этих методов упрощает жизнь разработчикам. Итак, предлагаю вашему вниманию перевод статьи про принцип "poka-yoke".
При совместной работе с кодом в команде среднего или большого размера иногда возникают трудности с пониманием и использованием чужого кода. У этой проблемы существуют различные решения. Например, можно договориться следовать определённым стандартам кодирования или использовать известный всей команде фреймворк. Однако зачастую этого недостаточно, особенно когда нужно исправить ошибку или добавить новую функцию в старый код. Трудно вспомнить, для чего были предназначены конкретные классы и как они должны работать как по отдельности, так и совместно. В такие моменты можно случайно добавить побочные эффекты или ошибки, даже не осознавая этого.
Эти ошибки могут быть обнаружены при тестировании, но есть реальный шанс, что они-таки проскользнут в продакшн. И даже если они будут выявлены, может потребоваться довольно много времени, чтобы откатить код и исправить его.
Итак, как мы можем предотвратить это? С помощью принципа «poka-yoke».
Poka-yoke – японский термин, который переводится на английский примерно как «mistake-proofing» (защита от ошибки), а в русском варианте более известен, как «защита от дурака». Это понятие возникло в бережливом производстве, где оно относится к любому механизму, который помогает оператору оборудования избежать ошибок.
Помимо производства, poka-yoke часто используется в бытовой электронике. Возьмём, к примеру, SIM-карту, которая благодаря своей асимметричной форме может быть вставлена в адаптер только правильной стороной.

Противоположным примером (без использования принципа poka-yoke) является порт PS/2, имеющий одинаковую форму разъёма и для клавиатуры, и для мыши. Их можно отличить только по цвету и поэтому легко перепутать.

Ещё концепция poka-yoke может использоваться в программировании. Идея в том, чтобы сделать публичные интерфейсы нашего кода как можно более простыми и понятными и генерировать ошибки, как только код будет использоваться неправильно. Это может показаться очевидным, но на самом деле мы часто сталкиваемся с кодом, в котором этого нет.
Обратите внимание, что poka-yoke не предназначен для предотвращения преднамеренного злоупотребления. Цель лишь в том, чтобы избежать случайных ошибок, а не в защите кода от злонамеренного использования. Так или иначе, пока кто-то имеет доступ к вашему коду, он всегда сможет обойти предохранители, если действительно этого захочет.
Прежде чем обсуждать конкретные меры, позволяющие сделать код более защищённым от ошибок, важно знать, что механизмы poka-yoke можно разделить на две категории:
Механизмы предотвращения ошибок полезны для исключения ошибок на раннем этапе. Максимально упростив интерфейсы и поведение, мы добиваемся того, чтобы никто не мог случайно использовать наш код неправильно (вспомните пример с SIM-картой).
С другой стороны, механизмы обнаружения ошибок находятся вне нашего кода. Они контролируют наши приложения, чтобы отслеживать возможные ошибки и предупреждать нас о них. Примером может быть программное обеспечение, которое определяет, имеет ли устройство, подключённое к порту PS/2, правильный тип, и, если нет, сообщает пользователю, почему оно не работает. Такое ПО не могло бы предотвратить ошибку, поскольку разъёмы одинаковые, но оно может обнаружить её и сообщить об этом.
Далее мы рассмотрим несколько методов, которые можно использовать как для предотвращения, так и для обнаружения ошибок в наших приложениях. Но имейте в виду, что этот список является лишь отправной точкой. В зависимости от конкретного приложения могут быть приняты дополнительные меры, чтобы сделать код более защищённым от ошибок. Кроме того, важно убедиться в целесообразности внедрения poka-yoke в ваш проект: в зависимости от сложности и размера вашего приложения некоторые меры могут оказаться слишком дорогостоящими по сравнению с потенциальной стоимостью ошибок. Поэтому вам и вашей команде решать, какие меры подходят вам лучше всего.
Ранее известное как Type Hinting в PHP 5, объявление типов – это простой способ защиты от ошибок при вызове функций и методов в PHP 7. Назначив аргументам функции определённые типы, становится сложнее нарушать порядок аргументов при вызове этой функции.
Например, давайте рассмотрим уведомление, которое мы можем отправить пользователю:
|
Метки: author Grezz тестирование веб-сервисов совершенный код программирование php блог компании badoo type hinting validation |
Обучение в онлайн-магистратуре как вариант профессионального и карьерного роста |

Меня зовут Роман Пилюгин, учусь в онлайн -магистратуре «Современная комбинаторика» МФТИ. Мой научный руководитель — Тренин Сергей Алексеевич. Мне очень повезло попасть к нему, он мне и предложил присоединится к организующейся лаборатории МФТИ-Сбертех. К этому моменту у меня появилось возможность посещать МФТИ по будням два раза в неделю без проблем с основным местом работы и я ею воспользовался. Поскольку только оформил документы в МФТИ, то пока рассказать о том как работает лаборатория не могу, но определенные ожидания у меня есть. Как я понимаю, помимо теоретических исследований тут есть четкий фокус на практическую сторону задач, решаются технические и технологические проблемы. Для меня это возможность применить полученные знания на практике и прикоснуться к задачам, взятым из жизни, с их сложными формулировками и подчас эвристическим подходом. К тому же, это редкая возможность поработать в одной команде с людьми, которые идут в авангарде науки в России. Думаю это будет бесценный опыт для меня.
|
Метки: author KateVo учебный процесс в it мфти образование магистратура онлайн-магистратура комбинаторика современная комбинаторика лаборатория мфти |
[Из песочницы] Emacs + удобный менеджер окон и буферов |

(purpose-load-window-layout-file "~/.emacs.d/layouts/full-ide.window-layout")
(nil
(0 0 152 35)
(t
(0 0 29 35)
(:purpose dired :purpose-dedicated t :width 0.16 :height 0.5 :edges
(0.0 0.0 0.19333333333333333 0.5))
(:purpose buffers :purpose-dedicated t :width 0.16 :height 0.4722222222222222 :edges
(0.0 0.5 0.19333333333333333 0.9722222222222222)))
(t
(29 0 125 35)
(:purpose edit :purpose-dedicated t :width 0.6 :height 0.85 :edges
(0.19333333333333333 0.0 0.8266666666666667 0.85))
(:purpose misc :purpose-dedicated t :width 0.6 :height 0.1 :edges
(0.19333333333333333 0.8722222222222222 0.8266666666666667 0.9722222222222222))
)
(t
(125 0 152 35)
(:purpose ilist :purpose-dedicated t :width 0.15333333333333332 :height 0.6 :edges
(0.82666666666666667 0.0 0.9722222222222222 0.6))
(:purpose todo :purpose-dedicated t :width 0.15333333333333332 :height 0.372222222 :edges
(0.8266666666666667 0.6 0.9722222222222222 0.9722222222222222))
)
)
(defun load-purpose-mode ()
(interactive)
(purpose-load-window-layout-file "~/.emacs.d/layouts/full-ide.window-layout")
(purpose-x-code1-setup)
)
(global-set-key (kbd "M-L") 'load-purpose-mode)| misc purpose | todo purpose | edit purpose |
|---|---|---|
| inferior-python-mode | org-mode | css-mode |
| python-inferior-mode | yaml-mode | |
| gdb-inferior-io-mode | conf-unix-mode | |
| fundamental-mode | *magit* | |
| compilation-mode | ||
| shell-mode | ||
| eshell-mode | ||
| term-mode |
(add-to-list 'purpose-user-mode-purposes
'(YOUR_MODE . PURPOSE))
(defvar purpose-x-magit-single-conf
(purpose-conf "magit-single"
:regexp-purposes '(("^\\*magit" . misc)))
"Configuration that gives each magit major mode the same purpose.")
(purpose-x-magit-single-on)
(purpose-compile-user-configuration)
;; helper для получения первого буфера с определенным purpose. нужна для прямого переключения на нужный буфер. (ie, на специальный purpose буфер)
(defun get-only-one-buffer-with-purpose (purpose)
"Get buffers wih purpose"
(buffer-name (nth 0 (purpose-buffers-with-purpose purpose)))
)
;; переключитья на dired buffer, к сожалению, на каждую открытую директорию создается буфер, это значит что по прошествии нескольких часов у вас может быть открыто очень много dired буферов. Здесь есть один недостаток. А может можно проще ? Я не нашел как переключить просто на активный буфер с конкретным purpose. Итак, ты сможешь выбрать на какой буфер переключиться
(define-key purpose-mode-map (kbd "C-c C-f")
(lambda () (interactive) (purpose-switch-buffer-with-some-purpose 'dired))
)
;; переключиться на буфер со списком открытых файлов. Здесь все просто супер. Он один. Поэтому нет проблемы.
(define-key purpose-mode-map (kbd "C-c C-l")
(lambda () (interactive) (purpose-switch-buffer (get-only-one-buffer-with-purpose 'buffers)))
)
;; переключиться на один из файлов для редактирования. Та же проблемы что и с dired
(define-key purpose-mode-map (kbd "C-c C-c")
(lambda () (interactive) (purpose-switch-buffer-with-some-purpose 'edit))
)
;; переключиться на буфер с списком определений (функций, классов и тд и тп) в открытом файле для редактирования. Здесь все просто супер. Он один. Поэтому нет проблемы.
(define-key purpose-mode-map (kbd "C-c C-d")
(lambda () (interactive) (purpose-switch-buffer (get-only-one-buffer-with-purpose 'ilist)))
)
;; переключиться на буфер с списком todo вещей. Об этом расскажу чуть позже. Полезная вещь. И он тоже один
(define-key purpose-mode-map (kbd "C-c C-t")
(lambda () (interactive) (purpose-switch-buffer (get-only-one-buffer-with-purpose 'todo)))
)
(defconst todo-mode-buffer-name "*CodeTodo*"
"Name of the buffer that is used to display todo entries.")
;; когда процесс создания todo файла закончился, выполнится эта функция, фактически эта функция откроет файл в read only mode с списком @todo. Можно будет перейти к месту @todo и посмотреть что там за вопрос не решен.
(defun on-org-mode-todo-file-built (process event)
(find-file (concat (getenv "PWD") "/todo.org"))
(call-interactively 'read-only-mode)
)
;; функция отвечающая за генерацию todo файла для org-mode
(defun build-org-mode-file-for-todo ()
(start-process "Building todo things" "*CodeTodo*" "bash" "-ic" "source ~/.bashrc; collecttodotags")
(set-process-sentinel (get-process "Building todo things") 'on-org-mode-todo-file-built)
)
;; создание буффера если его еще нет, запуск функций приведенных выше
(defun todo-mode-get-buffer-create ()
"Return the todo-mode buffer.
If it doesn't exist, create it."
(or (get-buffer todo-mode-buffer-name)
(let ((buffer (get-buffer-create todo-mode-buffer-name)))
(with-current-buffer buffer
(org-mode)
(build-org-mode-file-for-todo)
(pop-to-buffer todo-mode-buffer-name))
buffer)))
alias collecttodotags="find `pwd` -type d \( -name .git -o -name myworkenv -o -name node_modules \) -prune -o -type f \( -name todo.org \) -prune -o -type f -print -exec grep -n '@todo' '{}' \; | create_org_mode_todo_file.py > ./todo.org"
(global-set-key "\C-c+" (lambda () (interactive) (enlarge-window +20)))
(global-set-key "\C-c_" (lambda () (interactive) (enlarge-window -20)))
|
Метки: author sergeyglazyrin python emacs linux ide |
[Перевод] XBRL: Просто о сложном - 1. Введение |
От переводчика
В 2015 году Центральный Банк РФ запустил проект перехода некредитных финансовых организаций (НФО) на электронный формат представления отчетных данных в формате XBRL с 01.01.2018. Сроки уже подходят, а НФО только начинают осознавать масштабы грядущих изменений. Качественных материалов про XBRL на русском языке достаточно мало (могу разве что рекомендовать книгу XBRL для чайников, перевод которой был инициирован ЦБ, правда выполнен не в лучшем виде). Хочу восполнить этот пробел и предлагаю вашему вниманию свою адаптацию неплохой брошюры XBRL in Plain English от компании Batavia, которая рассказывает об основах XBRL.
Перевод веду от лица автора, немного дополняю текст полезными ссылками. Стараюсь придерживаться терминологии ЦБ РФ со ссылкой на оригинальные термины. Начну с первых глав, и если тема будет вам интересна, завершу перевод. Комментируйте, задавайте вопросы - расскажу все, что знаю.
Роман Удальцов
В этой главе представлена сама книга и основные понятия XBRL
Если вы начали читать эту книгу, значит вы уже слышали о новом способе формирования бизнес-отчетности - XBRL. Если вы взглянули на спецификацию XBRL, то знаете, что она представляет собой 158-страничный документ, полный формальных определений. Такой документ нужен для корректного определения XBRL. Его можно считать расслабляющим чтивом на ночь для математиков. Но не для нас, нормальных людей.
Для нас, нормальных людей, эта книга передает суть спецификации XBRL простым русским языком. Она должна дать вам хорошее понимание того, что такое XBRL и как его можно использовать. В основном, книга фокусируется на представленной в спецификации функциональности XBRL.
Вы не погрузитесь в мельчайшие детали, прочитав эту книгу. Если вам нужен такой уровень понимания, напр. если вы хотите написать свое ПО для валидации XBRL, вам следует внимательно изучить формальную спецификацию. Но так или иначе, эта книга безусловно послужит введением в захватывающий мир XBRL.
Такими блоками будет обозначаться более глубокое погружение в детали (где это действительно необходимо)
Я также не буду дискутировать на тему таких базовых технических стандартов как XML, XML Schema, XLink, XPath, XPointer и т.д. Если вам не очень знакомы эти технологии, загляните на сайт W3C (World Wide Web Consortium) за списком рекомендованной литературы или в любую хорошую книжку по XML.
Эта книга основывается на спецификации XBRL 2.1 от 20.02.2013 с исправлениями от 25.04.2005. Если вдруг встретятся расхождения между книгой и официальной спецификацией, скромность требует от меня предположить, что это я ошибся, а авторы спецификации сделали все правильно. Я бы рекомендовал вам сделать аналогичное предположение.
За неимением богатых возможностей форматирования в Markdown и HFM, такими же блоками будут обозначаться примеры
XRBL расшифровывается как Extensible Business Reporting Language (расширяемый язык деловой отчетности), что само по себе неплохо описывает суть: это язык отчетности, используемый в бизнесе. И он расширяемый. Все просто, да? Ну, может быть, потребуется немного больше объяснений.
В этой главе вводятся некоторые связанные с XBRL термины, они будут выделяться жирным шрифтом. В следующих главах мы всё подробно разберем, поэтому не пугайтесь их.
Давайте прыгнем сразу в середину:… Business Reporting ...
Мы все знаем, что бизнес формирует кучу отчетности:
Каждый отчет - это данные, представляющие собой набор фактов про содержимое отчета, таких как:
В старые добрые времена такие отчеты создавались сбором всех соответствующих фактов и заполнением их в предварительно распечатанные бумажные формы. Затем заполненная форма отправлялась заинтересованным лицам, которые считывали факты из формы.
Звучит громоздко, но так оно и есть. Дальше - хуже… Разные заинтересованные лица требуют данные в разной форме, при этом содержащиеся в них факты могут быть одинаковыми. Для этого составитель отчета вынужден заполнять одни и те же факты в разные формы.
XBRL предлагает способ улучить процесс создания, распространения и использования данных в бизнес-отчетах. Он определяет электронный формат для отчетности, позволяющий компьютерам автоматически создавать, валидировать и обрабатывать отчетность. Он также определяет способ обеспечения единого смыслового значения передаваемых бизнес-фактов. Составитель отчета мог бы просто сделать один отчет со всеми фактами и передать его получателю, который выбирал бы нужные ему факты и представлял бы в любой удобной ему форме. Определение единого смыслового значения фактов гарантирует, что каждый получатель отчета интерпретирует полученные факты одинаково.
Другим интересным моментом является возможность разделения формы отчета и его содержания. Преднастроенная форма отчета представляет собой шаблон, который определяет состав фактов. Он создается получателем отчета один раз. А передаваемые факты - это содержание, которое создается каждый раз при формировании отчетности.
Стандарт XBRL также использует подобное разделение:
Похоже, настал неплохой момент для знакомства с примером, который я буду использовать на протяжении всей книги. Он иллюстрирует базовые принципы XBRL и показывает технические и формальные аспекты с практической стороны. Пример состоит из формы на бумажном носителе и рукописных данных.
Форма отчета выглядит следующим образом:
Отчетная форма может быть однозначно определена по своему уникальному идентификатору ФД-01. Она состоит из следующих элементов – наименование компании, отчетный период, количество сотрудников на начало и конец отчетного периода. Также, требуется разбить количество сотрудников на мужчин и женщин и распределить их по нескольким возрастным группам.
Пример заполненного отчета может выглядеть следующим образом:
Несложно заметить, что количество сотрудников увеличилось, но в компании работает как минимум один человек с недостатком математических навыков. В таком простом примере вряд ли кто-то посчитает 27 + 15 как 41, но в более сложных отчетах такие ошибки весьма вероятны, если все делается вручную.
Другая предпосылка XBRL заключается в том, что он расширяемый. Возвращаясь к старым добрым временам, давайте рассмотрим сценарий, в котором расширяемость была бы полезна.
Предположим, что Европейский Союз определяет требования к отчетности для любого бизнеса в рамках ЕС.
XBRL позволяет поддерживать такие требования. ЕС создаст одну таксономию для определения требований к отчетности. Перевод технических концептов в таксономии на понятные пользователю термины содержится в так называемой базе ярлыков (label linkbase). Каждый язык внутри ЕС может иметь свою собственную базу ярлыков или можно создать одну общую базу, содержащую ярлыки для каждого языка. Обратите внимание, что при этом фактическое определение концептов не требуется повторять для каждого языка.
Страна, желающая расширить таксономию ЕС, просто создаст свою собственную таксономию, которая будет ссылаться на таксономию ЕС в части общих концептов. Этой стране достаточно будет доопределить только специфичные концепты, не входящие в таксономию ЕС.
‘L’ в XBRL обозначает Язык. Язык XBRL обеспечивает способ выражения таксономий и отчетов XBRL в едином однозначном формате, что является необходимым требованием для обработки информации компьютером.
Язык XBRL основан на таких мировых стандартах как XML и соответствующих им спецификациях. В следующих главах об этом будет рассказано более подробно.
|
Метки: author r_udaltsov it- стандарты xbrl финансы отчетность цб рф |
Что такое SMT и как оно работает в приложениях — плюсы и минусы |
|
Метки: author RollNoir разработка под windows программирование машинное обучение winperst windows performance station оптимизация windows amd ryzen hyper-threading |
WebStorm 2017.2 – что нового в поддержке JavaScript, TypeScript, Angular и Sass и работе с ESLint, Karma и Mocha |
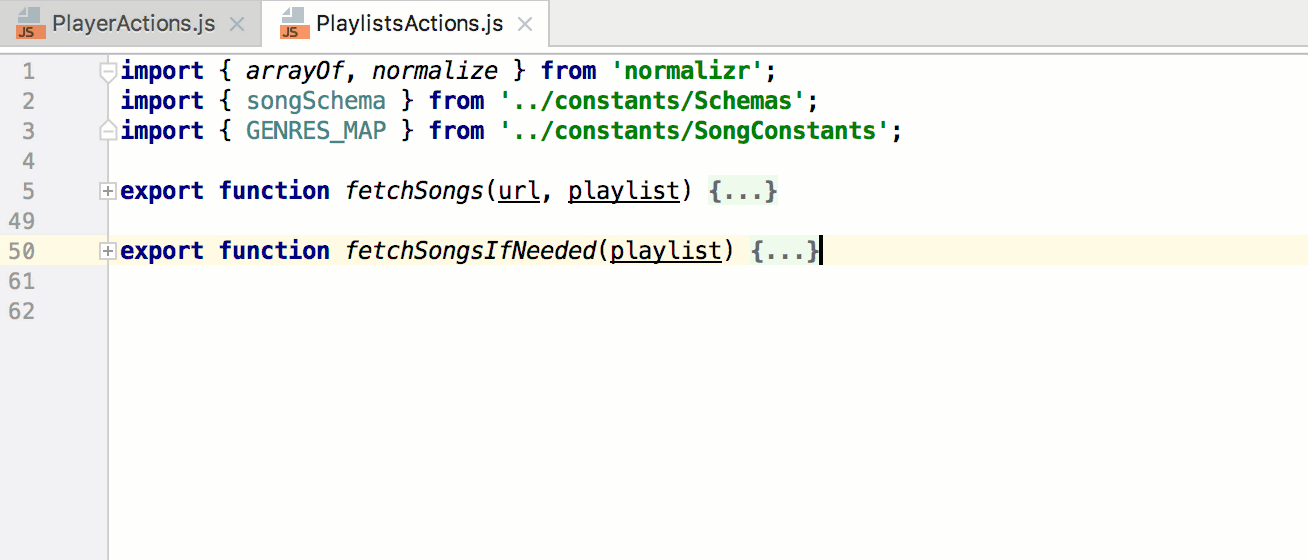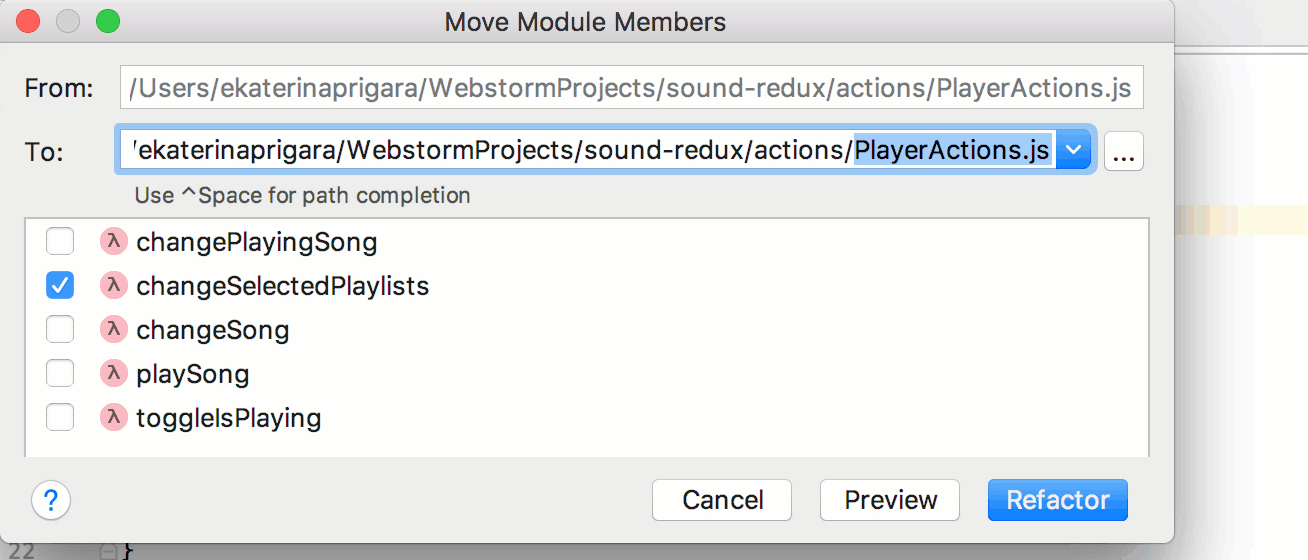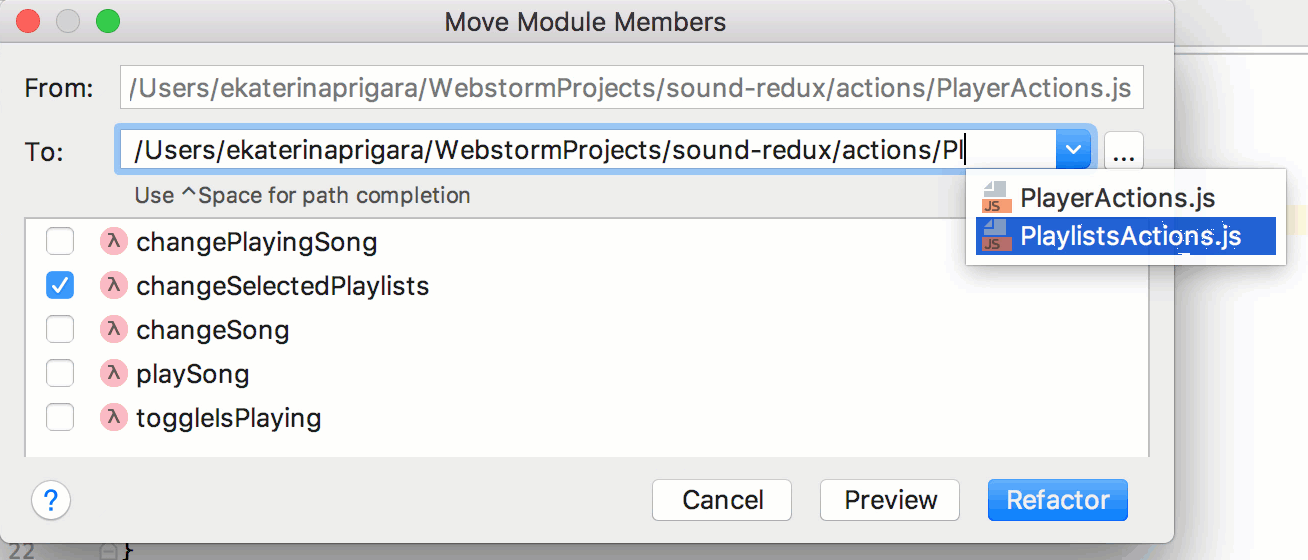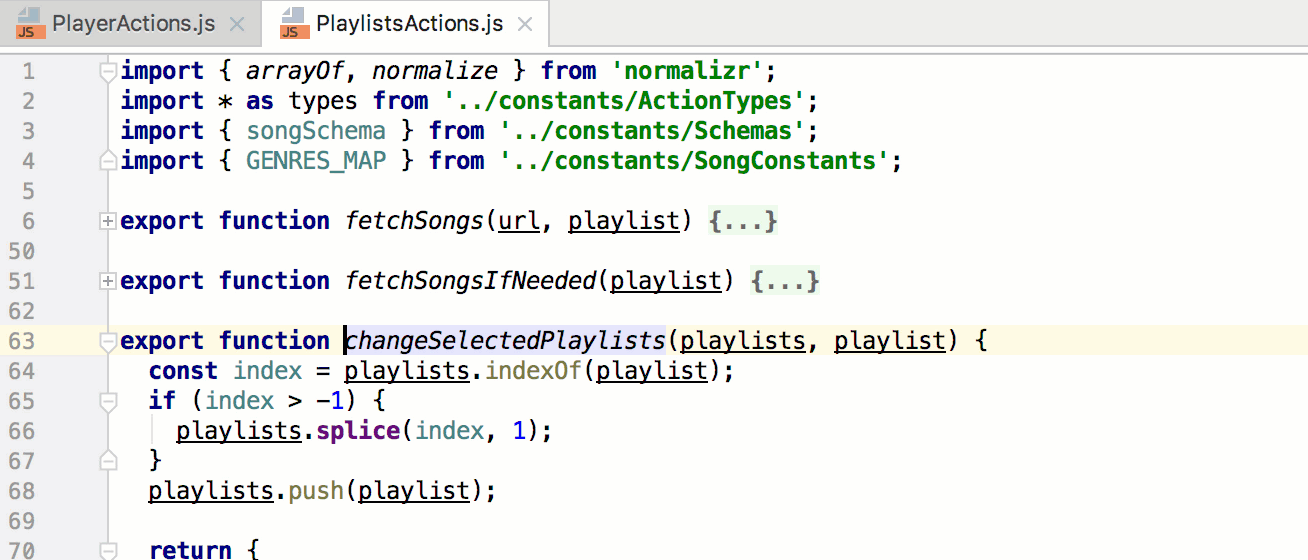


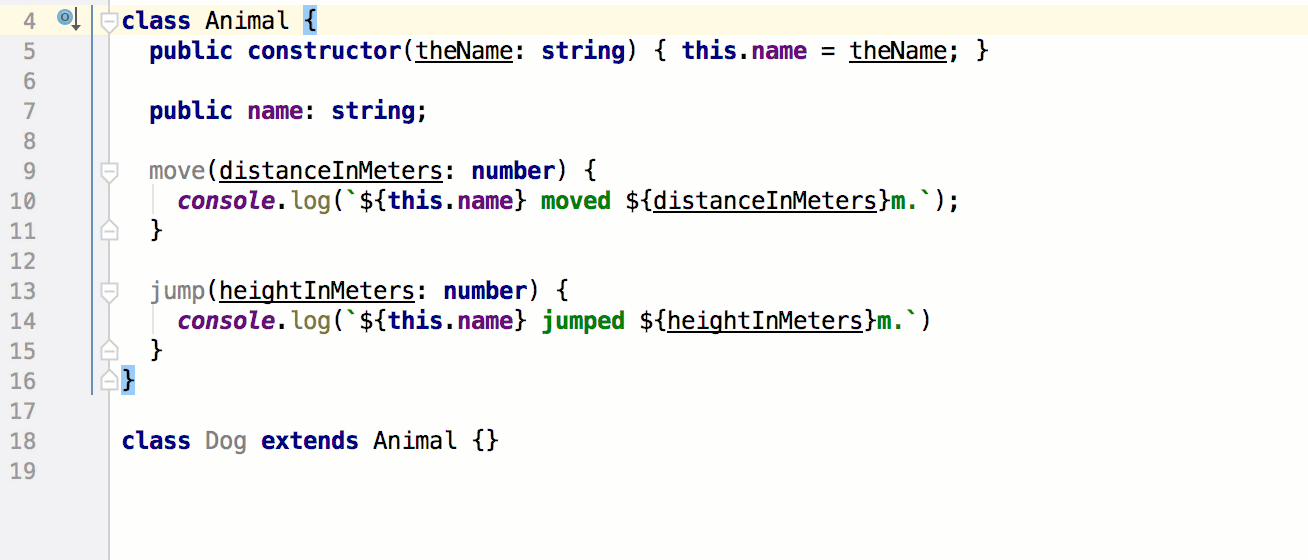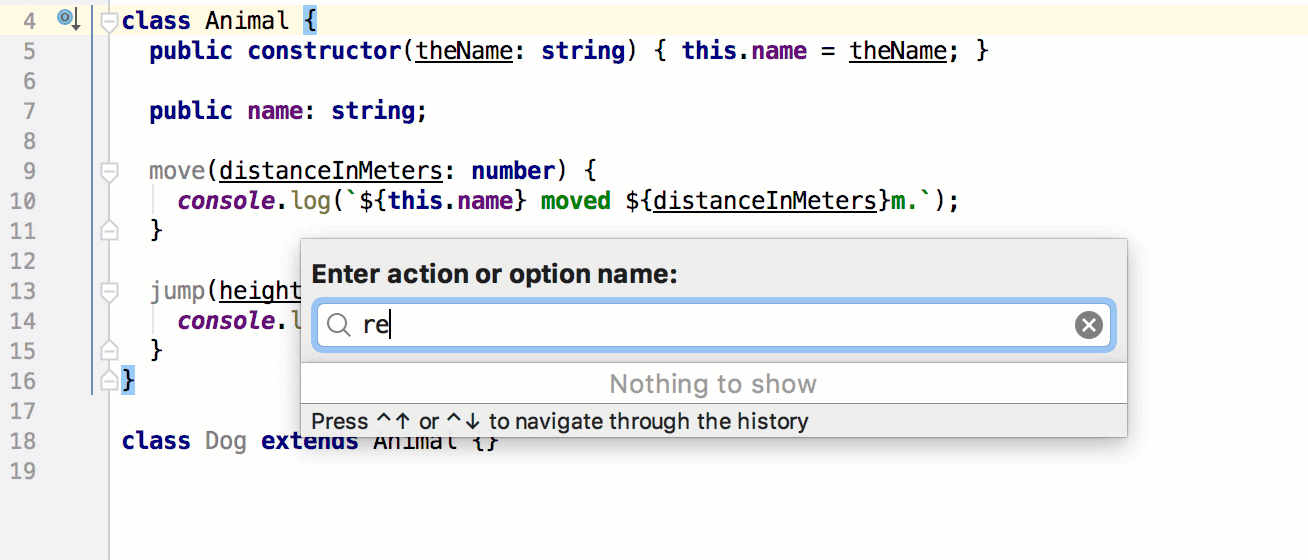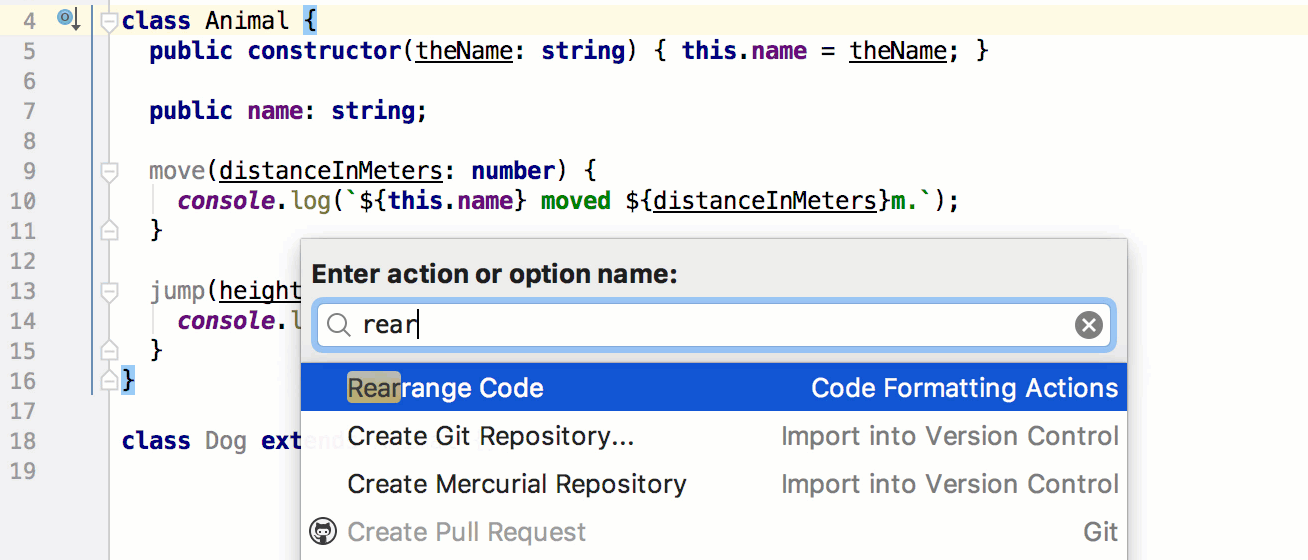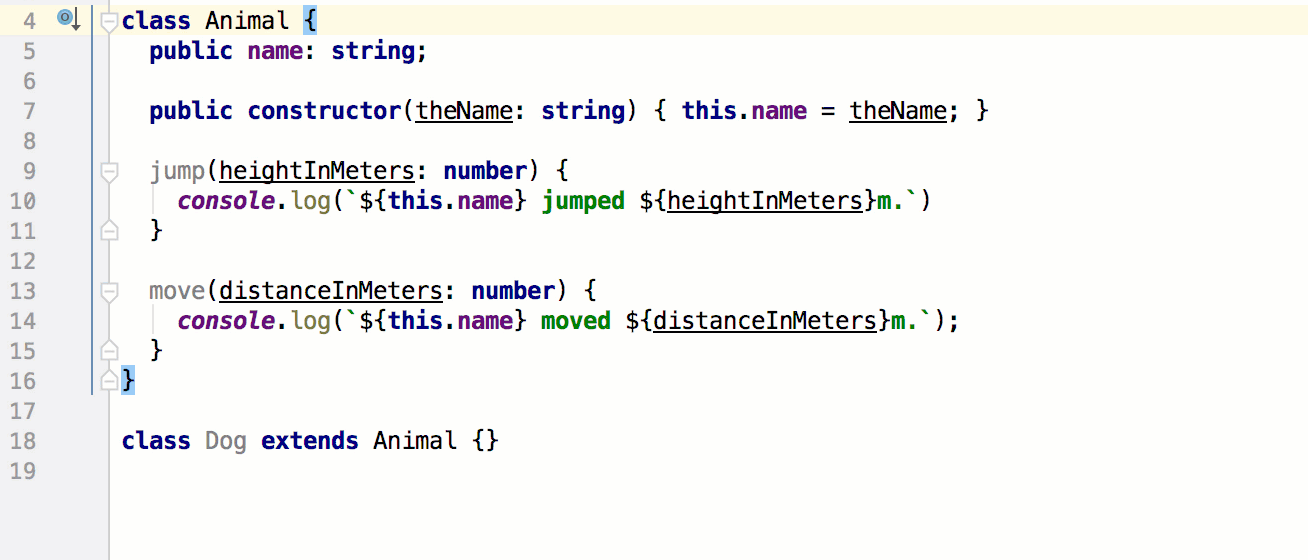



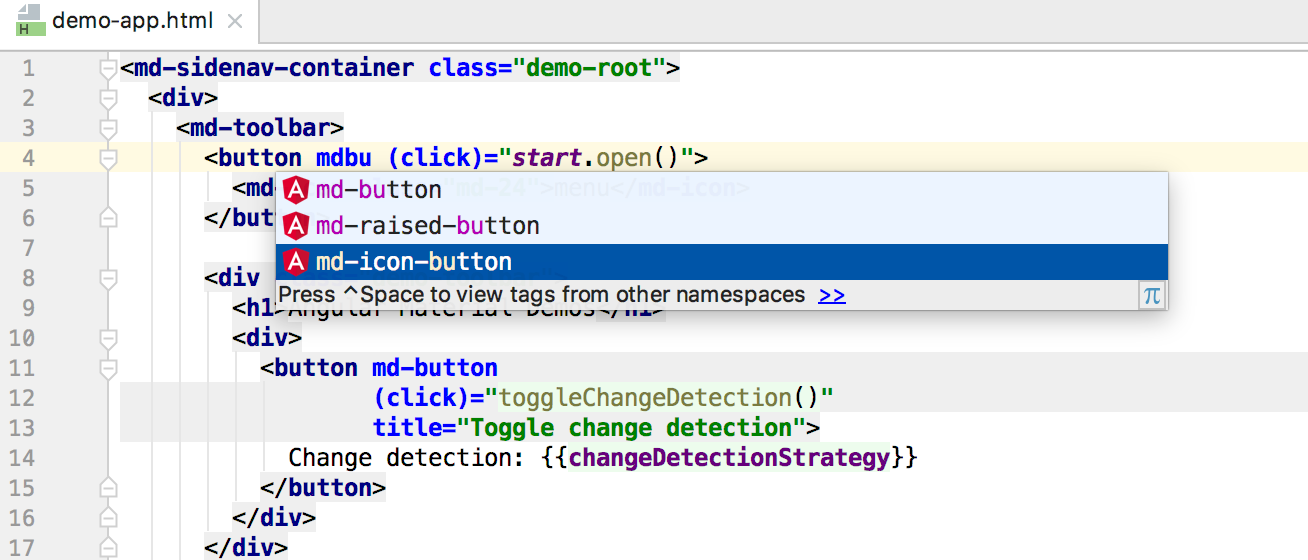
|
Метки: author prigara разработка веб-сайтов javascript html angularjs блог компании jetbrains webstorm ide angular react typescript webpack jetbrains |
Лидогенерация изнутри: от «сырого» трафика к реальному клиенту |

|
Метки: author instam повышение конверсии интернет-маркетинг веб-аналитика блог компании маркетинговое агентство «инстам» лидогенерация анализ данных трафик инстам |
Анализируем карьеру игроков NHL с помощью Survival Regression и Python |

df.head(3)| Name | Position | Points | Balance | Career_start | Career_length | Observed |
|---|---|---|---|---|---|---|
| Olli Jokinen | F | 419 | -58 | 1997 | 18 | 1 |
| Kevyn Adams | F | 72 | -14 | 1997 | 11 | 1 |
| Matt Pettinger | F | 99 | -44 | 2000 | 10 | 1 |
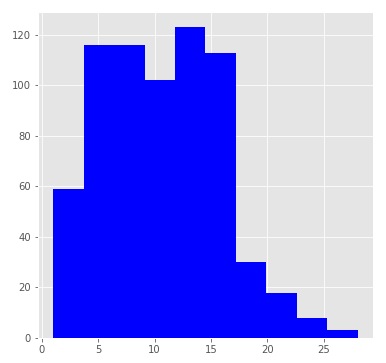
from lifelines import KaplanMeierFitter
kmf = KaplanMeierFitter()
kmf.fit(df.career_length, event_observed = df.observed)
Out:kmf.survival_function_.plot()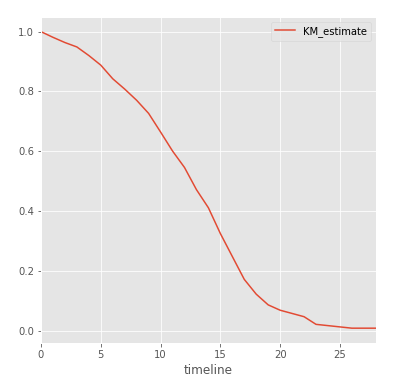
print(kmf.median_)
print(kmf.survival_function_.KM_estimate[20])
print(kmf.survival_function_.KM_estimate[5])Out:13.0
0.0685611305647
0.888063315225kmf.plot()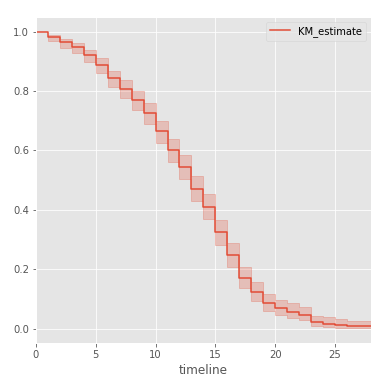
from lifelines import NelsonAalenFitter
naf = NelsonAalenFitter()
naf.fit(df.career_length,event_observed=df.observed)
naf.plot()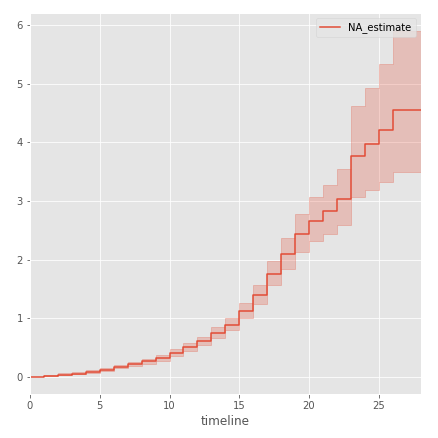
ax = plt.subplot(111)
kmf.fit(df.career_length[df.Position == 'D'], event_observed=df.observed[df.Position == 'D'],
label="Defencemen")
kmf.plot(ax=ax, ci_force_lines=True)
kmf.fit(df.career_length[df.Position == 'F'], event_observed=df.observed[df.Position == 'F'],
label="Forwards")
kmf.plot(ax=ax, ci_force_lines=True)
plt.ylim(0,1);
from lifelines.statistics import logrank_test
dem = (df["Position"] == "F")
L = df.career_length
O = df.observed
results = logrank_test(L[dem], L[~dem], O[dem], O[~dem], alpha=.90 )
results.print_summary()Results
t 0: -1
test: logrank
alpha: 0.9
null distribution: chi squared
df: 1
__ p-value ___|__ test statistic __|____ test result ____|__ is significant __
0.05006 | 3.840 | Reject Null | True from lifelines import AalenAdditiveFitter
import patsy # используем библиотеку patsy, чтобы создать design матрицу из факторов
# -1 добавляет столбец из единиц к матрице, чтобы обучить константу модели
X = patsy.dmatrix('Position + Points + career_start + Balance -1', df, return_type='dataframe')
aaf = AalenAdditiveFitter(coef_penalizer=1.0, fit_intercept=True) # добавляем penalizer, который делает регрессию более стабильной, в случае мультиколлинеарности или малой выборки)
X['L'] = df['career_length']
X['O'] = df['observed'] # добавляем career_length и observed к матрице факторов
aaf.fit(X, 'L', event_col='O')ix1 = (df['Position'] == 'F') & (df['Points'] == 360) & (df['career_start'] == 2010) & (df['Balance'] == +109)
ix2 = (df['Position'] == 'D') & (df['Points'] == 11) & (df['career_start'] == 2014) & (df['Balance'] == -12)
stepan = X.ix[ix1]
dahlbeck = X.ix[ix2]
ax = plt.subplot(2,1,1)
aaf.predict_cumulative_hazard(oshie).plot(ax=ax)
aaf.predict_cumulative_hazard(jones).plot(ax=ax)
plt.legend(['Stepan', 'Dahlbeck'])
plt.title('Функция угрозы')
ax = plt.subplot(2,1,2)
aaf.predict_survival_function(oshie).plot(ax=ax);
aaf.predict_survival_function(jones).plot(ax=ax);
plt.legend(['Stepan', 'Dahlbeck']);
from lifelines.utils import k_fold_cross_validation
score = k_fold_cross_validation(aaf, X, 'L', event_col='O', k=5)
print (np.mean(score))
print (np.std(score))Out:0.764216775131
0.0269169670161
|
Метки: author a-pichugin машинное обучение data mining big data блог компании new professions lab nhl кривые дожития survival analysis |








