Let’s Encrypt: раздаем видео по HTTPS в один клик |

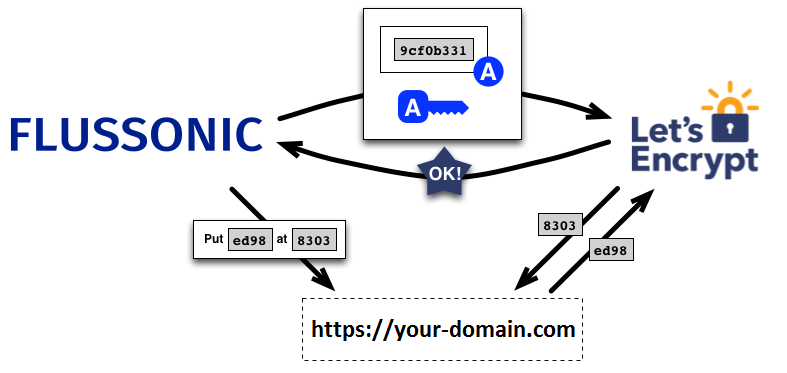
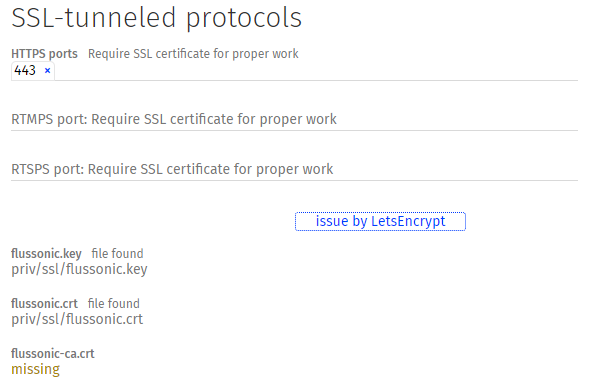
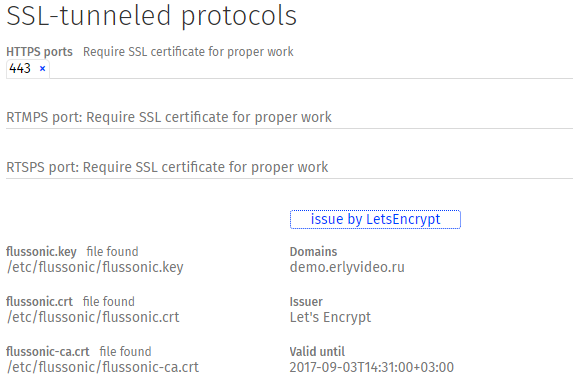
|
|
Настройка среды разработки: кружок рукоделия (Часть 1) |

$ sudo add-apt-repository ppa:ondrej/php
$ sudo apt-get install php5.6 php7.0 php7.1 php7.1-fpm
$ sudo apt-get install php-bcmath php-curl php-dev php-fpm php-gd php-intl php-json php-mbstring php-mcrypt php-mysql php-readline php-soap php-sqlite3 php-tidy php-xml php-zip php-codecoverage php-codesniffer php-common php-geoip php-igbinary php-imagick php-memcache php-memcached php-redis php-ssh2 php-xdebug php-xhrpof
$ sudo apt-get install php5.6-bcmath php5.6-curl php5.6-dev php5.6-fpm php5.6-gd php5.6-intl php5.6-json php5.6-mbstring php5.6-mcrypt php5.6-mysql php5.6-opcache php5.6-readline php5.6-soap php5.6-sqlite3 php5.6-tidy php5.6-xml php5.6-zip
$ sudo apt-get install php7.0-bcmath php7.0-curl php7.0-dev php7.0-fpm php7.0-gd php7.0-intl php7.0-json php7.0-mbstring php7.0-mcrypt php7.0-mysql php7.0-opcache php7.0-readline php7.0-soap php7.0-sqlite3 php7.0-tidy php7.0-xml php7.0-zip
$ sudo apt-get install php7.1-opcache
$ sudo apt-get install memcached redis-server redis-tools nginx mysql-server-5.7 mysql-client-5.7 composer npm curl nodejs nodejs-legacy ruby-full
$ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
$ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list
$ sudo apt-get update && sudo apt-get install yarn
$ sudo gem update --system
$ sudo gem install compass
$ composer global require hirak/prestissimo
$ sudo npm install -g grunt-cli
$ sudo apt-get install bind9 samba
 Первое, к чему я потянулся — Samba-сервер, который настроил для того, чтобы моя IDE могла работать непосредственно с файловой системой гостевой OS.
Первое, к чему я потянулся — Samba-сервер, который настроил для того, чтобы моя IDE могла работать непосредственно с файловой системой гостевой OS. [global]
workgroup = WORKGROUP
server string = %h server (Samba, Ubuntu)
dns proxy = no
# few changes to speed up smbd
strict allocate = Yes
read raw = Yes
write raw = Yes
strict locking = No
socket options = TCP_NODELAY IPTOS_LOWDELAY SO_RCVBUF=131072 SO_SNDBUF=131072
min receivefile size = 16384
use sendfile = true
aio read size = 16384
aio write size = 16384
max log size = 1000
syslog only = no
syslog = 0
server role = standalone server
usershare allow guests = yes
[www]
path = /var/www
available = yes
valid users = oxcom
read only = no
browsable = yes
public = yes
writable = yes
executable = yes
@echo off
@title Local UBUNTU Network Drive
net use q: \\172.16.126.130\www {user-password} /USER:oxcom
Unmount local drive
@echo off
@title Local UBUNTU Network Drive
net use q: /delete
 Дорогой читатель может представить насколько трудно в большой компании запросить небольшие изменения в настройках сети. И даже если вы успешно пройдете первый этап объяснения для чего вам это нужно, то второй этап (реализация) может затянуться на очень большой срок, что проще все сделать самому.
Дорогой читатель может представить насколько трудно в большой компании запросить небольшие изменения в настройках сети. И даже если вы успешно пройдете первый этап объяснения для чего вам это нужно, то второй этап (реализация) может затянуться на очень большой срок, что проще все сделать самому.172.16.126.130 project1.lo
172.16.126.130 project2.lo
;
; BIND data file for local loopback interface
;
$TTL 604800
@ IN SOA lo. root.lo. (
0000119 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS lo.
@ IN A 172.16.126.130
@ IN AAAA ::1
* IN CNAME @
;
; BIND data file for local loopback interface
;
$TTL 604800
;
; BIND reverse data file for local loopback interface
;
$TTL 604800
@ IN SOA ns.lo. root.lo. (
0000112 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS lo.
zone "lo" {
type master;
file "/etc/bind/db.lo";
check-names ignore;
allow-query { any; };
allow-transfer { any; };
};
zone "126.16.172.in-addr.arpa" {
type master;
file "/etc/bind/db.126.16.172";
allow-query { any; };
allow-transfer { any; };
};
options {
directory "/var/cache/bind";
forwarders {
8.8.8.8;
8.8.4.4;
};
recursion yes;
listen-on { any; };
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
; <<>> DiG 9.10.3-P4-Ubuntu <<>> example.lo
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32204
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 1, ADDITIONAL: 2
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;example.lo. IN A
;; ANSWER SECTION:
example.lo. 604800 IN CNAME lo.
lo. 604800 IN A 172.16.171.130
;; AUTHORITY SECTION:
lo. 604800 IN NS lo.
;; ADDITIONAL SECTION:
lo. 604800 IN AAAA ::1
;; Query time: 0 msec
;; SERVER: 172.16.171.130#53(172.16.171.130)
;; WHEN: Mon Jul 17 11:09:52 CEST 2017
;; MSG SIZE rcvd: 111
Pinging lo [172.16.171.130] with 32 bytes of data:
Reply from 172.16.171.130: bytes=32 time<1ms TTL=64
Reply from 172.16.171.130: bytes=32 time<1ms TTL=64
 Вроде все работает. Теперь необходимо приступить к настройке PHP для каждого из проектов.
Вроде все работает. Теперь необходимо приступить к настройке PHP для каждого из проектов.; Start a new pool
; the variable $pool can we used in any directive and will be replaced by the
; pool name ('www' here)
[{project-name}-{project-subname}]
user = www-data
group = www-data
listen = /run/php/php7.0-$pool-fpm.sock
listen.owner = www-data
listen.group = www-data
pm = dynamic
pm.max_children = 20
pm.start_servers = 5
pm.min_spare_servers = 3
pm.max_spare_servers = 7
php_admin_value[xdebug.idekey] = key-$pool
cryengine.d/www.conf
cryengine.d/shop.conf
cryengine.d/forum.conf
warface.d/www.conf
www.conf
php5.6-cryengine-www-fpm.sock
php5.6-cryengine-shop-fpm.sock
php5.6-cryengine-forum-fpm.sock
php5.6-warface-www-fpm.sock
php5.6-fpm.sock
php7.0-cryengine-www-fpm.sock
php7.0-cryengine-shop-fpm.sock
php7.0-cryengine-forum-fpm.sock
php7.0-warface-www-fpm.sock
php7.0-fpm.sock Настройка сервера довольно проста. Для каждого проекта создается отдельный файл конфигурации в 'sites-available', который описывает конфигурацию vhost. В конфигурации мы подключаем соответствующие файлы конфигурации для каждого проекта.
Настройка сервера довольно проста. Для каждого проекта создается отдельный файл конфигурации в 'sites-available', который описывает конфигурацию vhost. В конфигурации мы подключаем соответствующие файлы конфигурации для каждого проекта.cryengine.d/
- www.conf
- forum.conf
- shop.conf
- ssl.conf
warface.d/
- www.conf
- ssl.conf
sites-available/
- www.cryengine.conf
- forum.cryengine.conf
- shop.cryengine.conf
- www.warface.conf
nginx.conf
server {
listen 443 ssl http2;
server_name {project-subname}.{project-name}.lo;
root /var/www/{project-subname}.{project-name}.com/wwwroot;
index index.php;
error_log /var/www/{project-subname}.{project-name}.com/log/nginx.error.log error;
access_log /var/www/{project-subname}.{project-name}.com/log/nginx.access.log;
# configuration related to sub-project
include {project-name}.d/www.conf;
# global configuration for projects
include {project-name}.d/ssl.conf;
}|
Метки: author OxCom разработка веб-сайтов php virtual machine development environment |
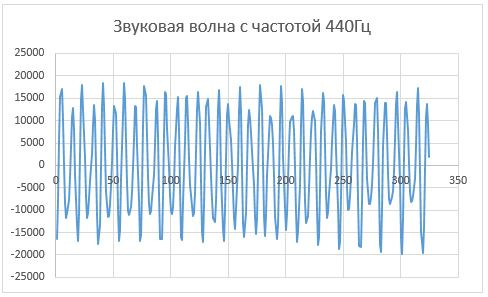
[Из песочницы] Применение преобразования Фурье для создания гитарного тюнера на Android. Часть 1 |

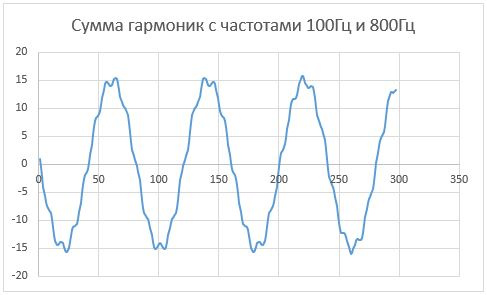
private double someFun(int index, int sampleRate) {
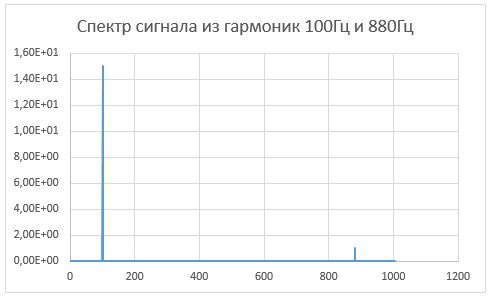
final int amplitudeOfFirstHarmonic = 15;
final int amplitudeOfSecondHarmonic = 1;
final int frequencyOfFirstHarmonic = 100;
final int frequencyOfSecondHarmonic = 880;
return amplitudeOfFirstHarmonic * Math.cos((frequencyOfFirstHarmonic * 2 * Math.PI * index ) / sampleRate)
+ amplitudeOfSecondHarmonic *Math.cos((frequencyOfSecondHarmonic * 2 * Math.PI * index) / sampleRate);
}final int sampleRate = 8000;
final int someFuncSize = 8000;
double[] someFunc = new double[someFuncSize];
for (int i = 0; i < someFunc.length; i++) {
someFunc[i] = someFun(i, sampleRate);
}
private double cos(int index, int frequency, int sampleRate) {
return Math.cos((2 * Math.PI * frequency * index) / sampleRate);
}
private double sin(int index, int frequency, int sampleRate) {
return Math.sin((2 * Math.PI * frequency * index) / sampleRate);
}private double[] dft(double[] frame, int sampleRate) {
final int resultSize = sampleRate / 2;
double[] result = new double[resultSize * 2];
for (int i = 0; i < result.length / 2; i++) {
int frequency = i;
for (int j = 0; j < frame.length; j++) {
result[2*i] +=frame[j] * cos(j, frequency, sampleRate);
result[2*i + 1] +=frame[j] * sin(j, frequency, sampleRate);
}
result[2*i] =result[2*i] / resultSize;
result[2*i + 1] = result[2*i + 1] / resultSize;
}
return result;
}double[] result;
long start = System.currentTimeMillis();
result = dft(someFunc, sampleRate);
long finish = System.currentTimeMillis();
long timeConsumedMillis = finish - start;
System.out.println("Time's dft: " + timeConsumedMillis);
double[] amplitude = new double[sampleRate/2];
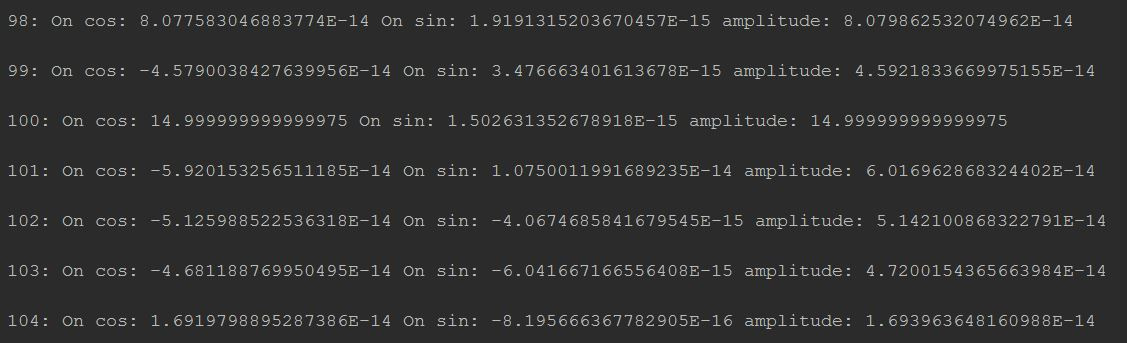
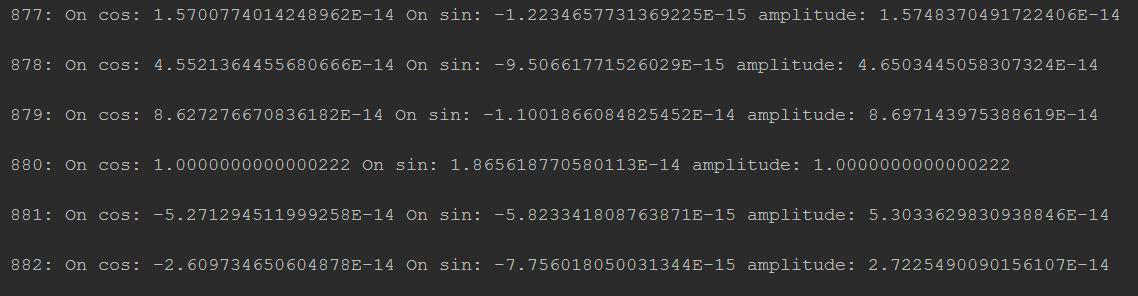
for (int i = 0; i < result.length / 2; i++) {
amplitude[i] = Math.sqrt(result[2*i]*result[2*i] + result[2*i+1]*result[2*i+1]);
System.out.println(i + ": " + "Projection on cos: " + result[2*i] + " Projection on sin: " + result[2*i + 1]
+ " amplitude: "+ amplitude[i] + "\n");
}
|
Метки: author ByArt разработка мобильных приложений алгоритмы java бпф дпф гармоника тюнер для гитары андроид преобразование фурье звуковая волна частота дискретизации |
[Перевод] CSS — это не чёрная магия |

z-index, мы остановимся на этом подробнее. Для тех, кто хорошо воспринимает визуальную информацию, вот отличная демонстрация процесса формирования графического представления страницы.will-change, умелое использование которого позволяет ускорить вывод страниц. Например, при использовании CSS-трансформаций, свойство will-change позволяет подсказать браузеру, что элемент DOM будет трансформирован в ближайшем будущем. Выглядит это как will-change: transform. Это позволяет передать GPU некоторые операции по отрисовке и сведению слоёв, что способно значительно повысить производительность страниц, содержащих много анимированных элементов. Улучшить производительность с помощью will-change можно, воспользовавшись конструкциями will-change: scroll-position, will-change: contents, will-change: opacity, will-change: left, top.div с классом container. В этот тег вложен ещё один div, id которого — main. Внутри main имеется тег p, в котором содержится тег a.a.#main a {
color: green;
}
p a {
color: yellow;
}
.container #main a {
color: pink;
}
div #main p a {
color: orange;
}
a {
color: red;
}div #main p a: 1,0,3#main a: 1,0,1p a: 2a: 1[type="text"], [rel="nofollow"]) и псевдоклассов (:hover, :visited).::before, ::after)#header .navbar li a:visitedli и a). Это значение можно прочитать и так, как будто в нём нет запятых, вместо 1,2,2 — 122. Запятые тут имеются только для того, чтобы подчеркнуть, что перед нами не десятичное число из трёх цифр, а три числа. Это особенно важно для теоретически возможных результатов вроде 0,1,13. Если переписать это в виде 0113, неясно будет, как вернуть его в исходное состояние.z-index. На первый взгляд кажется, что говорить тут особо не о чем. Каждый элемент в HTML-документе может быть либо перед другими, либо позади них. Кроме того, это работает только для позиционированных элементов. Если установить свойство z-index для элемента, позиционирование которого явно не задано, это ничего не изменит.z-index, заключается в понимании идеи контекстов наложения. Поиск неполадок всегда начинается с корневого элемента контекста наложения. Контекст наложения — это концепция расположения HTML-элементов в трёхмерном пространстве, в частности — вдоль оси Z, относительно пользователя, находящегося перед монитором. Другими словами — это группа элементов с общим родителем, которые вместе перемещаются по оси Z либо ближе к пользователю, либо дальше от него.z-index не используются, правила взаимодействия элементов просты. Порядок наложения элементов соответствует порядку их появления в HTML.z-index, и вот тут уже всё становится сложнее. Среди них — свойство opacity, когда это значение меньше единицы, filter, когда значение этого свойства отличается от none, и mix-blend-mode, значение которого не normal. Эти свойства, на самом деле, создают новые контексты наложения. На всякий случай хочется напомнить, что режим наложения (blend mode) позволяет задать то, как пиксели на некоем слое взаимодействуют с видимыми пикселями на слоях, расположенных ниже этого слоя.transform тоже вызывает создание нового контекста наложения в тех случаях, когда оно отличается от none. Например, scale(1) и translate3d(0,0,0). Опять же, как напоминание, свойство scale используется для изменения размера элемента, а translate3d позволяет задействовать GPU для CSS-переходов, повышая качество анимации.|
Метки: author ru_vds разработка веб-сайтов css блог компании ruvds.com веб-разработка |
Машинное обучение и поиск темной материи: соревнование от ЦЕРНа и Яндекса |
|
Метки: author nau4no программирование машинное обучение python big data блог компании яндекс kaggle data science physics |
[Перевод] Как создать виртуальную машину в Google Таблицах |
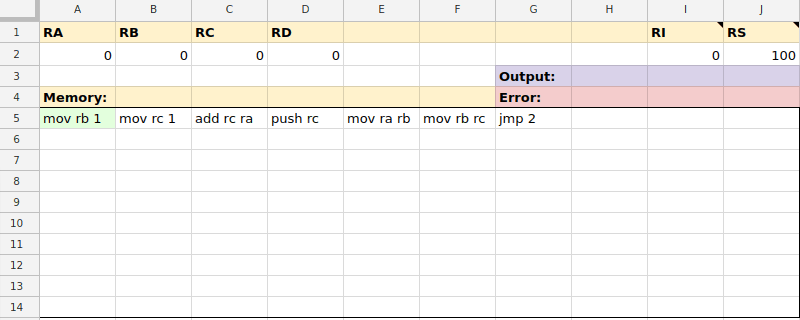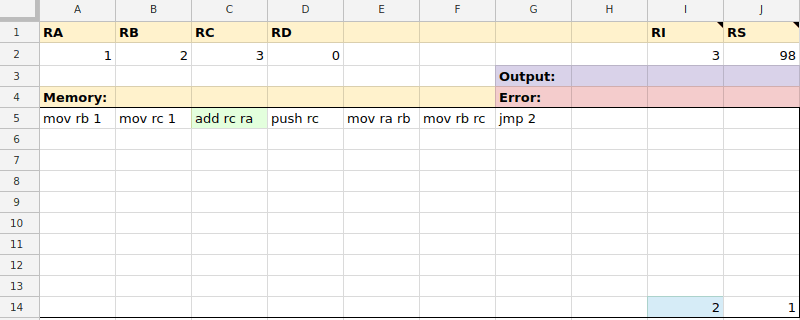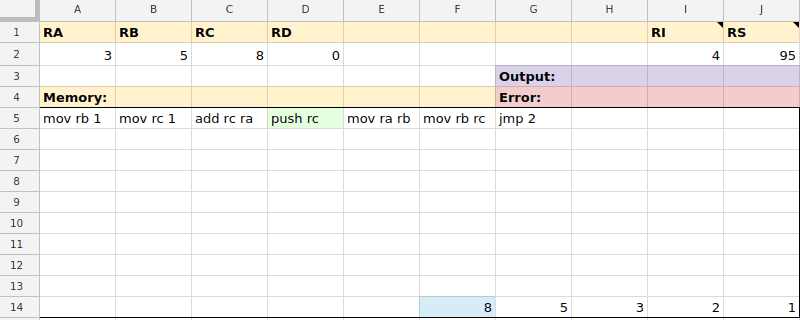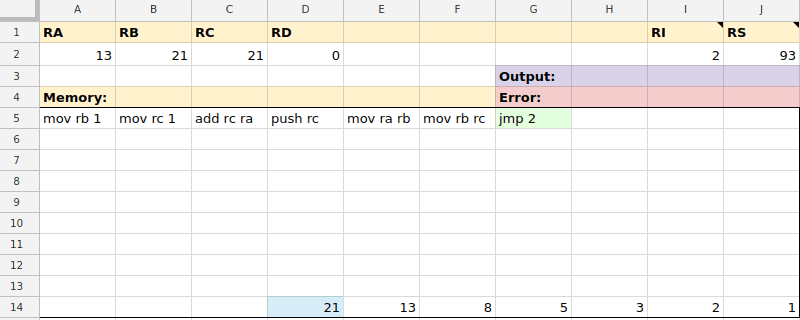
mov ra 7mov rb rcmov $0 ramov rd $99mov ra @10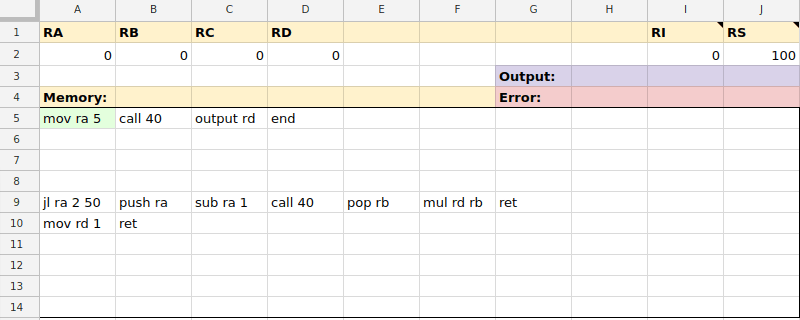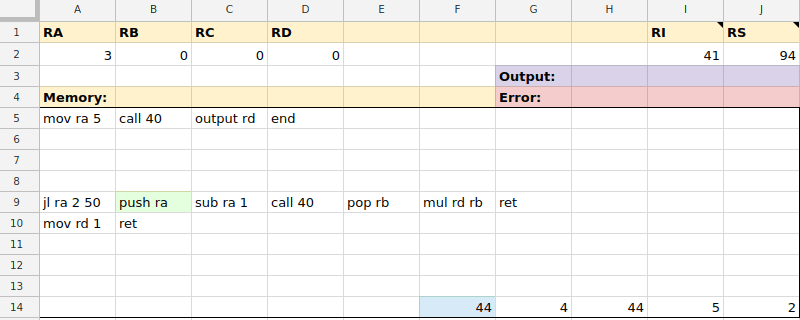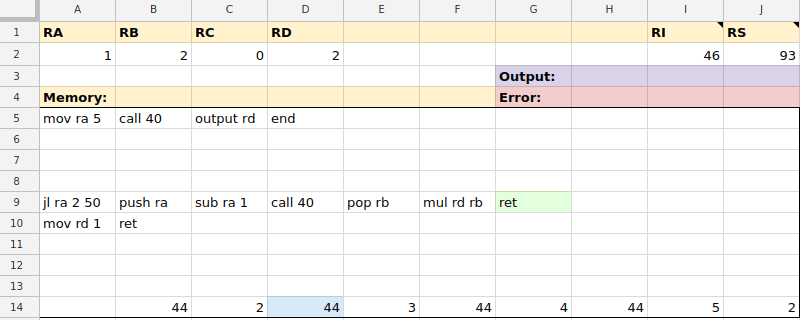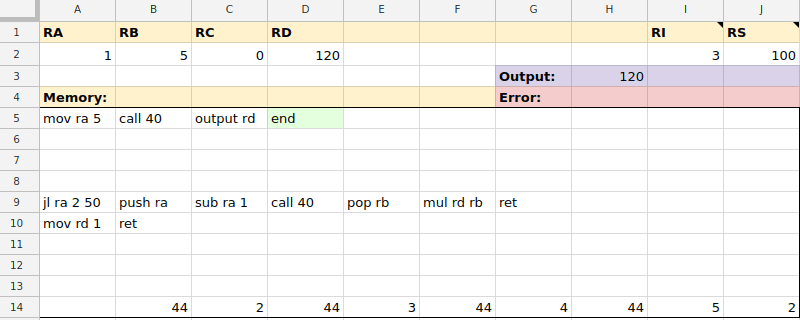

|
Метки: author PayOnline программирование javascript google app engine блог компании payonline google docs числа фибоначчиб payonline |
[recovery mode] Unity на Linux? Да без проблем |

sudo sh /path/to/*.shsudo apt-get updatesudo apt-get install monodevelopsudo apt-get install mono-reference-assemblies-3.5|
Метки: author DenisVladimirovich тестирование игр разработка под linux разработка игр linux unity3d linux game programming bash c# |
Дорога к С++20 |
 Сегодня завершилась летняя встреча комитета ISO WG21 C++, проходившая в Торонто с 10 по 15 июля. Вскоре нас наверняка ждёт подробный отчёт от РГ21, а сегодня уважаемой публике предлагается пост-«разогрев» с обсуждением самого интересного.
Сегодня завершилась летняя встреча комитета ISO WG21 C++, проходившая в Торонто с 10 по 15 июля. Вскоре нас наверняка ждёт подробный отчёт от РГ21, а сегодня уважаемой публике предлагается пост-«разогрев» с обсуждением самого интересного.#define LOG(msg, ...) printf(msg __VA_OPT__(,) __VA_ARGS__)
LOG("hello world") // => printf("hello world")
LOG("hello world", ) // => printf("hello world")
LOG("hello %d", n) // => printf("hello %d", n)[] (T t) { /* ... */ } [](auto x) { /* ... */ }
[](T x) { /* ... */ }
[](T* p) { /* ... */ }
[](T (&a)[N]) { /* ... */ }
shared_ptr p = make_shared(1024);enum class endian
{
little = __ORDER_LITTLE_ENDIAN__,
big = __ORDER_BIG_ENDIAN__,
native = __BYTE_ORDER__
};vector v{vector{1, 2}};
// Выведет vector вместо vector> |
Метки: author HotWaterMusic программирование it- стандарты c++ c++20 iso |
Разработка скриптов-обёрток с помощью инструмента Sparrow |
Доброе время суток! В данном посте я хочу рассказать как с помощью инструмента Sparrow лёгко и просто писать собственные обёртки к существующим скриптам и утилитам, а так же зачем вам это может понадобиться.
Очень часто мы имеем дело с различными скриптами, которые нам приходится запускать для разных задач и на разных серверах. Эти скрипты могут быть написанными нами самими же или устанавливаться как часть пакетов программного обеспечения. Так или иначе очень часто задача сводится к тому, что нужно просто запустить некий скрипт с набором параметров:
script Основной трудностью здесь может быть, то что аргументы скрипта могут быть достаточно развесистыми и сложными, и при этом, в зависимости от контекста задачи, ещё и разными. Это порождает ряд неудобств, конечно не таких критичных, но тем не менее о которых хочется упомянуть:
Приходится каждый раз вспоминать ( или искать в history ) аргументы передаваемые на вход скрипту, если запускаешь скрипт вручную.
Итак, здесь нас могут выручить скрипты-обёртки, которые будут инкапсулировать все, что связанно с логикой подготовки входных параметров для заданной скрипта, а затем запускать данный скрипт с данными параметрами.
Вместо того, что бы писать свои скрипты-обёртки можно воспользоваться инструментом Sparrow, и я покажу сейчас как легко и просто это можно сделать.
Sparrow — это CPAN модуль, поэтому ставим его соответственно:
$ cpanm Sparrow Так как это обучающая статья — выберу любой скрипт, в чисто ознакомительных целях, в реальной жизни, это будет скрипт или скрипты, которые вы используете в своей работе. Пусть это будет утилита speedtest-cli, предназначенная для тестирования скорости интернета на вашем локальном узле. Судя по документации, у скрипта достаточное большоеи количество настроек, задаваемых через аргументы командной строки — как раз тот самый случай, когда обёртка может быть уместна. Представим себе что мы хотим запускать данный скрипт по крону и отсылать отчёты что бы анализировать доступность интернета в течение определённого периода времени. Пердположим на интересуют два варианта вызова скрипта:
sppedtest-cli --no-download # не выполнять тест скачивания и
speedtest-cli --no-upload # не выполнять тест закачивания И в обоих случаях мы хотим всегда добавлять опцию
--bytes # выводить информацию в отчёте в байтах, а не в битах Также, допустим что в первом случае мы хотим указать тайм-аут ожидания при http запросах:
--timeout 10 # http тайм-аут Хорошо, таким образом у нас есть два отдельных запуска скрипта speedtest-cli с различными параметрами.
Создаём скрипт-историю:
$ nano story.bash
speedtest-cli $(args_cli)В данном случае всю работу делает предопределённая в Sparrow bash функция args_cli, котороя прозрачно передаст на вход скрипта speedtest-cli все входные параметры.
Определяем загрузчик утилиты speedtest-cli. Sparrow умеет ставить зависимости для скриптов, поддерживая ряд пакетных менеджеров, определённых для различных языков программирования, в том числе для Python. Утилита speedtest-cli ставится как pip модуль, так что просто определим файл зависимостей в стиле установщика pip:
$ nano requirements.txt
speedtest-cli==1.0.6Хорошо, идём дальше осталось определить файл с мета данными плагина и собственно загрузить его в репозиторий Sparrow плагинов:
$ nano sparrow.json
{
"name" : "speedtest-cli",
"description" : "Simple wrapper for speedtest-cli from https://github.com/sivel/speedtest-cli",
"version" : "0.0.1",
"url" : "https://github.com/melezhik/sparrow-plugins/tree/master/speedtest-cli",
"category": "utilities",
"python_version" : 2,
"sparrow_version": "0.2.45"
}Формат файла мета данных для Sparrow плагина подробно описан в документации по Sparrow, здесь мы его разбирать не будем, нам важно лишь то, что плагин называется аналогично скрипту, для которого он предоставляет обёртку.
Теперь у нас все готово, что бы загрузить плагин в репозитарий:
$ sparrow plg upload # запускаем из дериктории где лежат файлы плагинаЗдесь собственно начинается самое интересное. Это то, как мы будем использовать созданный нами плагин для запуска утилиты speedtest-cli, описанной ранее.
Допустим, мы хотим запускать данную утилиту на другом сервере. Не трудно догадаться, что сначала нам необходимо установить соответсвующий Sparrow плагин:
$ sparrow plg install speedtest-cliЕсли все пройдёт успешно мы получим установленный Sparrow плагин и собственно саму утилиту speedtest-cli вместе со всеми Python зависимостями.
Сделаем простую поверку, что плагин работает:
$ sparrow plg run speedtest-cli -- --helpЕсли все хорошо, то мы получим help от утилиты speedtest-cli.
Что бы связать запускаемый плагин с определёнными параметрами создадим задачи. Вспоминаем, что нам требуется запускать speedtest-cli с разными аргументами.
$ sparrow project create monitoring # создадим проект - это контейнер для задач
$ sparrow task add monitoring nettest-download speedtest-cli
$ sparrow task add monitoring nettest-upload speedtest-cli Последними двумя командами мы создали задачи для разных запусков утилиты speedtest-cli, теперь настроим их:
$ sparrow task ini monitoring/nettest-download
---
args:
- timeout: 10
-
- bytes
- no-upload $ sparrow task ini monitoring/nettest-upload
---
args:
-
- bytes
- no-downloadТеперь нам просто отсатется запустить наши задачи:
$ sparrow task run monitoring/nettest-upload
$ sparrow task run monitoring/nettest-uploadНаши обёртки готовы и работают как надо.
Sparrow позволяет легко и просто писать обёртки для практически любых консольных утилит. Это избавляет от необходимости писать отдельные скрипты для запуска одной и той же утилиты с различными параметрами, для этого есть простой и мощный инструмент Sparrow задач. Sparrow плагины переносимы практически на любой Linux сервер, где установлен Perl. Также настройка скриптов в стиле Sparrow подразумевает генерацию входных данных в форматах YAML и JSON, что сильно упрощает запуск подобных скриптов из любых современных языков программирования и делает их автоматизацию более простой. Для примера можно посмотреть проект Sparrowdo, который позволяет настраивать и запускать Sparrow задачи удалённо по ssh.
С уважением, Алексей Мележик, автор Sparrow
|
Метки: author alexey_melezhik разработка под linux perl perl6 devops (*nix) автоматизация python |
Метод BFGS или один из самых эффективных методов оптимизации. Пример реализации на Python |
|
Метки: author FUNNYDMAN программирование машинное обучение математика алгоритмы python оптимизация bfgs |
А был ли взлом «Госуслуг»? Расследование расследования от ИБ Яндекса |


|
|
[Из песочницы] Рекомендации по безопасности при работе с Docker |
Docker ускоряет разработку и циклы развертывания и тем самым позволяет выдавать готовый код в невероятно короткие сроки. Но у этой медали есть и обратная сторона — безопасность. Стоит знать о ряде вещей, на безопасность которых влияет Docker, и именно о них пойдет речь в этой статье. Мы рассмотрим 5 типовых ситуаций, в которых образы, развернутые на Docker, становятся источником новых проблем с безопасностью, которые вы могли и не учитывать. Также мы рассмотрим крутые инструменты для решения этих проблем и дадим совет, которым вы можете воспользоваться, чтобы удостовериться, что все люки задраены при деплое.
Начнем с проблемы, которая является, пожалуй, неотъемлемой частью самой природы Docker — достоверность образа.
Если вы хоть когда-нибудь пользовались Docker, то вам должно быть известно, что с его помощью вы можете разместить контейнеры практически на любом образе — как на образе из официального списка поддерживаемых репозиториев, таких как NGINX, Redis, Ubuntu, или Alpine Linux, так и на любом другом.
В результате у нас есть огромный выбор.
Если один контейнер не решает всех ваших задач, вы можете заменить его на другой. Но разве такой подход самый безопасный?
Если вы со мной не согласны, давайте рассмотрим этот вопрос с другой стороны.
Когда вы разрабатываете приложение, менеджер пакетов позволяет с легкостью использовать чужой код, но стоит ли использовать чей попало код в разработке? Или к любому коду, который вы не анализировали, следует относиться со здоровым уровнем подозрительности? Если безопасность хоть что-то для вас значит, то я бы на вашем месте всегда тщательно проверял код, прежде чем интегрировать его в свое приложение.
Я прав?
Ну и с таким же подозрением надо относиться к Docker-контейнерам.
Если вы не знаете автора кода, как вы можете быть уверены в том, что выбранный вами контейнер не содержит бинарников другого вредоносного кода?
Верно, никакой уверенности тут быть не может.
При таких условиях я могу дать три совета.
Во-первых, можно использовать приватные или проверенные репозитории, вроде доверенных репозиториев Docker Hub.
В официальных репозиториях можно найти следующие образы:
Что выделяет Docker Hub из других репозиториев, помимо прочего, — это то, что образы всегда сканирует и просматривает Docker’s Security Scanning Service.
Если вы не слышали об этом сервисе, то вот цитата из его документации:
Docker Cloud и Docker Hub могут сканировать образы в приватных репозиториях, чтобы убедиться, что в них нет известных уязвимостей. После этого они отправляют отчет о результатах сканирования по каждому тэгу образа.
В итоге, если вы используете официальные репозитории, вы будете знать, что контейнеры безопасны и не содержат вредоносный код.
Опция доступна для всех платных тарифов. На бесплатном тарифе она тоже есть, но с ограничением по времени. Если вы уже на платном тарифе, то вы можете воспользоваться функцией сканирования, чтобы проверить, насколько безопасны ваши кастомные контейнеры и нет ли в них уязвимостей, о которых вы не знаете.
Таким образом, вы можете создать приватный репозиторий и использовать его внутри вашей организации.
Еще один инструмент, которым стоит воспользоваться — Docker Content Trust.
Это новая функция, доступная в Docker Engine 1.8. Она позволяет верифицировать владельца образа.
Цитата из статьи о новом релизе, автор Diogo M'onica, ведущий специалист по безопасности Docker:
Прежде чем автор публикует образ в удаленном реестре, Docker Engine подписывает этот образ приватным ключом автора. Когда вы загружаете к себе этот образ, Docker Engine использует публичный ключ для верификации, что этот образ именно тот, который выложил его автор, что это не подделка и что на нем есть все последние обновления.
Подведем итог. Сервис защищает вас от подделок, атак повторного воспроизведения и компрометирования ваших ключей. Очень сильно рекомендую ознакомиться с этой статьей и с официальной документацией.
Еще один инструмент, которым я недавно пользовался — это Docker Bench Security. Это большая подборка рекомендаций по развертыванию контейнеров в продакшене.
Инструмент основывается на рекомендациях из the CIS Docker 1.13 Benchmark, и применяется в 6 областях:
Чтобы его установить, клонируйте репозиторий при помощи
git clone git@github.com:docker/docker-bench-security.gitПотом введите cd docker-bench-secutity и запустите такую команду:
docker run -it --net host --pid host --cap-add audit_control \
-e DOCKER_CONTENT_TRUST=$DOCKER_CONTENT_TRUST \
-v /var/lib:/var/lib \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /etc:/etc --label docker_bench_security \
docker/docker-bench-securityТаким образом, вы соберете контейнеры и запустите скрипт, который проверит безопасность хост машины и ее контейнеров.
Ниже пример того, что вы получите на выходе.

Как видите, на выходе получается четкая детализация с цветовым кодированием, в которой вы можете увидеть все проверки и их результаты.
В моем случае необходимы некоторые исправления.
Что мне особенно нравится в этой функции, так это то, что ее можно автоматизировать.
В результате вы получаете функцию, которая включена в цикл непрерывной документации и помогает проверять безопасность контейнеров.
Теперь следующий момент. Насколько я помню, вопрос лишних полномочий всегда имел место. Что во времена установки дистрибутивов Linux на bare-metal сервера, что сейчас, когда их устанавливают в качестве гостевых операционных систем внутри виртуальных машин.
То, что теперь мы их устанавливаем внутри Docker-контейнера, не значит, что они стали существенно безопаснее.
К тому же с Docker повысился уровень сложности, т.к. теперь граница между гостем и хостом неясна. В отношении Docker я концентрируюсь на двух вещах:
Что касается первого пункта: вы можете запустить Docker-контейнер с опцией privileged, после чего у этого контейнера будут расширенные полномочия.
Цитата из документации:
Контейнер получает доступ ко всем возможностям, а также снимаются все ограничения, вызванные cgroup-контроллером. Другими словами, контейнер теперь может делать почти все то же самое, что и хост. Такой прием позволяет осуществлять особые сценарии, такие как запуск Docker внутри Docker.
Если сама идея такой возможности не заставит вас притормозить, то я буду удивлен и даже обеспокоен.
Ну правда, я не представляю, зачем вам пользоваться этой опцией, пусть даже и с предельной осторожностью, если только у вас не совсем особый случай.
При таких данных, пожалуйста, будьте очень осторожны, если вы все же собираетесь его использовать.
Цитата из Armin Braun:
Не используйте привилегированные контейнеры, если только вы не обращаетесь с ними так же, как и с любым другим процессом, запущенным в корне.
Но даже если вы не запускаете контейнер в привилегированном режиме, один или несколько ваших контейнеров могут иметь лишние возможности.
По умолчанию Docker запускает контейнеры с довольно ограниченным набором возможностей.
Тем не менее, эти полномочия можно расширить при помощи кастомного профиля.
В зависимости от того, где вы хостите ваши Docker-контейнеры, включая таких вендоров как DigitalOcean, sloppy.io, dotCloud и Quay.io, их дефолтные настройки могут отличаться от ваших.
Вы также можете хоститься у себя, и в таком случае также важно валидировать привилегии ваших контейнеров.
Не важно, где вы хоститесь. Как говорится в руководстве Docker по безопасности:
Пользователям лучше всего отказаться от всех возможностей, кроме тех,
которые необходимы для их процессов.
Подумайте над этими вопросами:
Если нет, то отключите эти возможности.
Однако, нужны ли вашему приложению какие-то особые возможности, которые не требуются по умолчанию для большинства приложений? Если да, то подключите эти возможности.
Таким образом вы ограничите возможности злоумышленников повредить вашей системе, потому что у них попросту не будет доступа к этим функциям.
Чтобы это сделать, используйте опции --cap-drop and --cap-add.
Предположим, вашему приложению не надо изменять возможности процесса или биндить привилегированные порты, но требуется загружать и выгружать модули ядра. Соответствующие возможности можно удалить и добавить так:
docker run \
--cap-drop SETPCAP \
--cap-drop NET_BIND_SERVICE \
--cap-add SYS_MODULE \
-ti /bin/shБолее подробные инструкции можно изучить в документации Docker: “Runtime privilege and Linux capabilities”
Ну хорошо, вы используете проверенный образ и уменьшили или удалили лишние полномочия у ваших контейнеров.
Но насколько безопасен этот образ?
Например, какие права будут у злоумышленников, если они вдруг получат доступ к вашим контейнерам? Другими словами, насколько вы обезопасили свои контейнеры?
Если можно так легко попасть в ваш контейнер, то, значит, можно так же легко наворотить там всякого? Если это так, то пора укрепить ваш контейнер.
Docker, безусловно, безопасен по умолчанию, благодаря namespaceам и cgroupам, но не стоит беззаветно уповать на эти функции.
Вы можете пойти дальше и воспользоваться другими инструментами безопасности на Linux, такими как AppArmor, SELinux, grsecurity и Seccomp.
Каждый из этих инструментов хорошо продуман и проверен в боях, и поможет вам еще больше усилить безопасность хоста вашего контейнера.
Если вы никогда не пользовались этими инструментами, то вот краткий обзор на каждый из них.
Это модуль безопасности ядра Linux, который позволяет системному администратору ограничить возможности программы с помощью индивидуальных профилей программ. Профили могут выдавать разрешения на такие действия как read, write и execute для файлов on matching paths. AppArmor предоставляет обязательный контроль доступа (mandatory access control, MAC) и таким образом служит хорошим дополнением к традиционной модели контроля Unix (discretionary access control, DAC). AppArmor включен в основное ядро Linux, начиная с версии 2.6.36.
Источник: Википедия.
Security-Enhanced Linux (SELinux) — Linux с улучшенной безопасностью) — реализация системы принудительного контроля доступа, которая может работать параллельно с классической избирательной системой контроля доступа.
Источник — Википедия.
Это проект для Linux, который включает в себя некоторые улучшения связанные с безопасностью, включая принудительный контроль доступа, рандомизацию ключевых локальных и сетевых информативных данных, ограничения/procиchroot()jail, контроль сетевых сокетов, контроль возможностей и добавочные функции аудита. Типичной областью применения являются web-серверы и системы, которые принимают удалённые соединения из сомнительных мест, такие как серверы, которые обеспечивают shell-доступ для пользователей.
Источник — Википедия.
Это объект безопасности компьютера в ядре Linux. В версии 2.6.12, опубликованной 8 марта 2005 года, его объединили с основным ядром Linux. Seccomp позволяет перевести процесс в "безопасный" режим, из которого нельзя делать никаких системных вызовов, кромеexit(),sigreturn(),read()иwrite()уже открытых файловых дескрипторов. Если процесс пытается сделать какие-либо другие системные вызовы, то ядро убивает процесс сSIGKILL. Таким образом, Seccomp не виртуализирует системные ресурсы, а просто изолирует от них процесс.
Источник: Wikipedia.
Поскольку статья все же о другом, здесь не получится показать эти технологии на рабочих примерах и дать более подробное их описание.
Но все же я очень рекомендую побольше о них узнать и внедрить в свою инфраструктуру.
Что нужно вашему приложению?
Это совершенно легкое приложение, потребляющее не более 50Мb памяти? Тогда зачем давать ему больше? Выполняет ли приложение более интенсивный процессинг, которому требуется 4+ CPU? Тогда дайте ему к ним доступ, но не более того.
Если вы включаете анализ, профилирование и бенчмаркинг в непрерывный процесс разработки, тогда вы должны знать, какие ресурсы необходимы вашему приложению.
Поэтому когда вы разворачиваете контейнеры, убедитесь, что у них есть доступ только к самому необходимому.
Для этого используйте следующие команды для Docker:
-m / --memory: # Установить лимит памяти
--memory-reservation: # Установить мягкий лимит памяти
--kernel-memory: # Установить лимит памяти ядра
--cpus: # Ограничьте количество CPU
--device-read-bps: # Ограничьте пропускную способность чтения для конкретного устройстваВот пример конфига из официальной документации Docker:
version: '3'
services:
redis:
image: redis:alpine
deploy:
resources:
limits:
cpus: '0.001'
memory: 50M
reservations:
memory: 20MБольше информации можно найти при помощи команды docker help run или же в разделе “Runtime constraints on resources” документации Docker.
Последний аспект безопасности, который стоит рассмотреть, является прямым следствием того, как работает Docker — и это потенциально очень большая поверхность атаки. Таким рискам подвержена любая IT-организация, но особенно та, что полагается на эфемерную природу контейнерной инфраструктуры.
Поскольку Docker позволяет быстро создавать и разворачивать приложения и так же быстро их удалять, трудно уследить, какие именно приложения развернуты в вашей организации.
В таких условиях атакам может подвергнуться потенциально намного больше элементов вашей инфраструктуры.
Вы не в курсе статистики развертывания приложений в вашей организации? Тогда задайте себе следующие вопросы:
Надеюсь, вам не очень сложно ответить на эти вопросы. В любом случае, давайте рассмотрим, какие действия можно предпринять на практике.
Внутри приложения обычно ведется учет действий пользователя, таких как:
Помимо этих действий следует вести учет действий и по каждому контейнеру, который создается и разворачивается в вашей организации.
Не стоит этот учет излишне усложнять. Следует вести учет таких действий, как:
Большинство инструментов непрерывной разработки должны уметь записывать эту информацию — такая опция должна быть доступна либо в самом инструменте, либо при помощи кастомных скриптов на определенном языке программирования.
Вдобавок стоит внедрить уведомления по почте или любым другим способом (IRC, Slack или HipChat). Этот прием позволит убедиться, что все могут видеть, когда что разворачивается.
Таким образом, если случилось что-то неподобающее, спрятать это не получится.
Я не призываю перестать доверять своим сотрудникам, но лучше всегда быть в курсе того, что происходит. Прежде чем я закончу эту статью, пожалуйста, не поймите меня неправильно.
Я не предлагаю вам нырнуть за борт и увязнуть в создании множества новых процессов.
Такой подход, скорей всего, только лишит вас тех преимуществ, которые дает использование контейнеров, и будет совершенно ненужным.
И тем не менее, если вы хотя бы обдумаете эти вопросы и будуте регулярно уделять им время впоследствии, вы будете лучше информированы и сможете снизить количество белых пятен в вашей организации, которые могут подвергнуться атакам извне.
Итак, мы рассмотрели пять проблем безопасности Docker и ряд возможных решений для них.
Я надеюсь, что вы переходите или уже перешли на Docker, вы будете держать их в уме и сможете обеспечить нужный уровень защиты ваших приложений. Docker — удивительная технология, и как жаль, что она не появилась раньше.
Я надеюсь, что информация, представленная в этой статье, поможет вам защититься от всех неожиданных проблем.
Matthew Setter — это независимый разработчик и технический писатель. Он специализируется на создании тестовых приложений и пишет о современных методах разработки, включая непрерывную разработку, тестирование и безопасность.
Данная статья является переводом Docker Security Best Practices
|
Метки: author r-moiseev системное администрирование devops docker |
Стоимость качества в разработке программного обеспечения |


| Вид затрат | Часть 1 | Часть 2 | Часть 4 | Итого |
|---|---|---|---|---|
| Затраты времени Пользователя | 1 | - | - | 1 |
| Затраты времени Инженера СП | 2 | 1 | - | 3 |
| Затраты времени Владельца Продукта | 1 | - | - | 1 |
| Затраты времени Инженера-Разработчика | 1 | 1,5 | 1 | 3,5 |
| Затраты времени Заказчика | 1 | - | - | 1 |
| Затраты времени Инженера-Тестировщика | - | 1,5 | 1 | 2,5 |
| Ухудшение репутации | 1 | - | 1 | 2 |
| Потерянный доход | - | - | 2 | 2 |
| Итого | 7 | 4 | 5 | 16 |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Делаем сайт для виртуальной реальности. Встраиваем монитор в монитор и размышляем о будущем |



....
....
....
var scene = null,
camera = null,
renderer = null,
controls = null;
init();
render();
animate();
function init() {
initScene();
initRenderer();
initCamera();
initControls();
initAreas();
initCursor();
initEvents();
}
function initScene() {
scene = new THREE.Scene();
}
function initRenderer() {
renderer = new THREE.CSS3DStereoRenderer();
renderer.setSize(window.innerWidth, window.innerHeight);
renderer.domElement.style.position = 'absolute';
renderer.domElement.style.top = 0;
renderer.domElement.style.background = '#343335';
document.body.appendChild(renderer.domElement);
}
function initCamera() {
camera = new THREE.PerspectiveCamera(45,
window.innerWidth/window.innerHeight, 1, 1000);
camera.position.z = 1000;
scene.add(camera);
}
function initControls() {
controls = new DeviceOrientationController(camera, renderer.domElement);
controls.connect();
controls.addEventListener('userinteractionstart', function () {
renderer.domElement.style.cursor = 'move';
});
controls.addEventListener('userinteractionend', function () {
renderer.domElement.style.cursor = 'default';
});
}
function initAreas() {
var width = window.innerWidth / 2;
initArea('.vr-area.-left', [-width/2 -width/5.64,0,width/5.64], [0,Math.PI/4,0]);
initArea('.vr-area.-center', [0,0,0], [0,0,0]);
initArea('.vr-area.-right', [width/2 + width/5.64,0,width/5.64], [0,-Math.PI/4,0]);
}
function initArea(contentSelector, position, rotation) {
var element = document.querySelector(contentSelector),
area = new THREE.CSS3DObject(element);
area.position.x = position[0];
area.position.y = position[1];
area.position.z = position[2];
area.rotation.x = rotation[0];
area.rotation.y = rotation[1];
area.rotation.z = rotation[2];
scene.add(area);
}
function initEvents() {
window.addEventListener('resize', onWindowResize);
}
function onWindowResize() {
camera.aspect = window.innerWidth / window.innerHeight;
camera.updateProjectionMatrix();
renderer.setSize( window.innerWidth, window.innerHeight );
render();
}
function animate() {
controls.update();
render();
requestAnimationFrame(animate);
}
function render() {
renderer.render(scene, camera);
}

function initCursor() {
var x1 = window.innerWidth * 0.25,
x2 = window.innerWidth * 0.75,
y = window.innerHeight * 0.50,
element1 = document.body,
element2 = document.body,
cursor = document.querySelector('.fake-cursor');
setInterval(function() {
if (element1 && element1.classList) {
element1.classList.remove('-focused');
}
if (element2 && element2.classList) {
element2.classList.remove('-focused');
}
element1 = document.elementFromPoint(x1, y);
element2 = document.elementFromPoint(x2, y);
if (element1 && element2) {
while (element1.tabIndex < 0 && element1.parentNode) {
element1 = element1.parentNode;
}
while (element2.tabIndex < 0 && element2.parentNode) {
element2 = element2.parentNode;
}
if (element1.tabIndex >= 0) {
element1.classList.add('-focused');
}
if (element2.tabIndex >= 0) {
element2.classList.add('-focused');
}
}
}, 100);
}
document.addEventListener('keydown', function(event) {
if (event.keyCode === 13) {
if (element1 && element2) {
element1.click();
element2.click();
cursor.classList.add('-active');
setTimeout(function() {
cursor.classList.remove('-active');
}, 100);
}
}
});
|
Метки: author sfi0zy разработка веб-сайтов программирование javascript виртуальная реальность ненормальное программирование |
[Из песочницы] PHP Reflection на замыканиях |
Привет, Habr! Сегодня хочу рассказать про свой костыль, который помог мне не погружаться в дебри PHP Reflection. Ведь все пишут костыли, просто кто-то пишет большие, а кто-то поменьше.

Я активно использую Laravel в своих проектах. Для тех, кто не знаком с этим framework'ом — не отчаивайтесь, потому что я объясню непонятные моменты.
В этот раз я писал некоторое расширение правил валидации:
Validator::extend('someRule', function ($attribute, $value, $parameters, $validator) {
// some code...
return $result; // boolean
}, ':attribute is invalid');И мне потребовалось получить список всех правил, передаваемых валидатору. Как оказалось, эта простая на первый взгляд задача заняла у меня немного больше времени, чем я планировал. Свойство было приватным. И никаких getter'ов для него в реализации класса не было. Изменять класс я конечно же не стал, ибо после composer update эта правка тут же слетит.
Следует сказать, что раньше я никогда не использовал Reflection, но слышал, для чего оно используется. Так вот, я начал читать документацию. Естественно, код из примера с первого раза не завелся и нужно было искать еще. И тут я подумал, что решение должно быть проще.
И я нашел таки простой и элегантный костыль. Все-таки так лучше не делать. Приватные свойства на то и приватные, чтобы туда не лазили. Но обстоятельства требуют, так что...
Validator::extend('someRule', function ($attribute, $value, $parameters, $validator) {
// Это функция-ниндзя. Она врывается в валидатор и крадет приватное свойство.
// Это очень коварно и подло но у меня нет другого выбора (есть, но там писать больше)
$ninja = function() {
// именно в этом свойстве хранится массив с нужными мне данными
return $this->initialRules;
};
$initialRules = $ninja->call($validator); // параметр $newThis
// some code
return $result;
}, ':attribute is invalid');Если кто-то еще не понял, объясню: я создал анонимную функцию, которая возвращает некоторое свойство. А потом просто подменил контекст на контекст валидатора (laravel передает экземпляр этого класса). Тоесть, замыкание теперь имеет доступ к этому объекту изнутри и может получить доступ к любому приватному свойству и методу.
Работает вся это красота, начиная с PHP 5.4
Это собственно все, что я хотел рассказать. Может до меня это уже изобрели, но в мою голову это идея пришла сама, поэтому я решил ею поделиться. Вдруг, это решение упростит коме-то жизнь.
Спасибо за внимание.
|
Метки: author HackerZhenya php reflection closure |
Акции Яндекса взлетели после сделки с Uber |


В этом нашем материале мы подробно рассказывали о том, как купить акции «Яндекса» на зарубежных биржевых площадках и Московской бирже. Открыть брокерский счет для этого можно дистанционно через «Госуслуги» (подробнее об этом в нашей статье).
|
Метки: author itinvest финансы в it блог компании itinvest яндекс uber финансы биржа акции |
Конкурс по программированию: JSDash (промежуточные результаты) |
|
|
[Из песочницы] История создания библиотеки для группового общения андроид-устройств через Wi-Fi Peer-to-Peer соединение |




final WifiP2pConfig config = new WifiP2pConfig();
config.deviceAddress = deviceAddress;
config.wps.setup = WpsInfo.PBC;
config.groupOwnerIntent = status.getIntent();
mWifiP2pManager.connect(mWifiP2pManagerChannel, config, null);
|
Метки: author chelsenok разработка систем передачи данных разработка под android android os android development wi-fi direct library wi-fi wi-fi peer-to-peer bicycle |
Безытеративное обучение однослойного персептрона. Задача классификации |

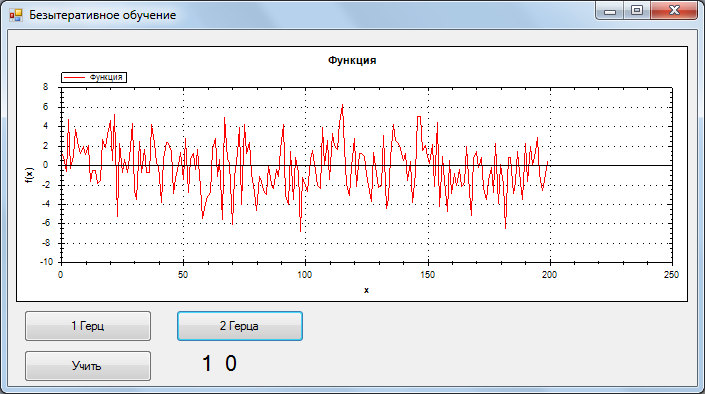
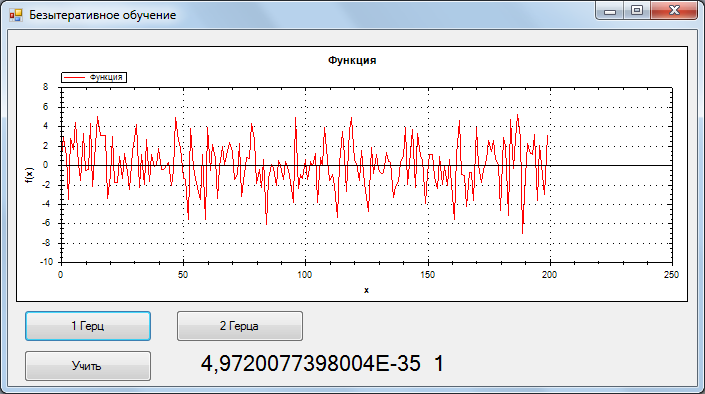
public void Train(Vector[] inp, Vector[] outp)
{
OutNew = new Vector[outp.Length];
In = new Vector[outp.Length];
Array.Copy(outp, OutNew, outp.Length);
Array.Copy(inp, In, inp.Length);
for (int i = 0; i < OutNew.Length; i++)
{
OutNew[i] = 2*OutNew[i]-1;
}
K = 4.6*inp[0].N*inp.Length;
double summ = 0;
for (int i = 0; i < inp.Length; i++)
{
summ += Functions.Summ(MathFunc.abs(In[i]));
}
K /= summ;
Parallel.For(0, _neurons.Length, LoopTrain);
}
void LoopTrain(int i)
{
for (int k = 0; k < In[0].N; k++) {
for (int j = 0; j < OutNew.Length; j++)
{
_neurons[i].B.Vecktor[k] += OutNew[j].Vecktor[i]*In[j].Vecktor[k];
}
}
_neurons[i].W = K*_neurons[i].B;
}|
Метки: author Zachar_5 машинное обучение математика c# .net нейронные сети персептрон |
[Из песочницы] Как крупные компании следят за работниками |




|
Метки: author Klausstrof управление персоналом безопасность контроль сотрудников менеджмент |






