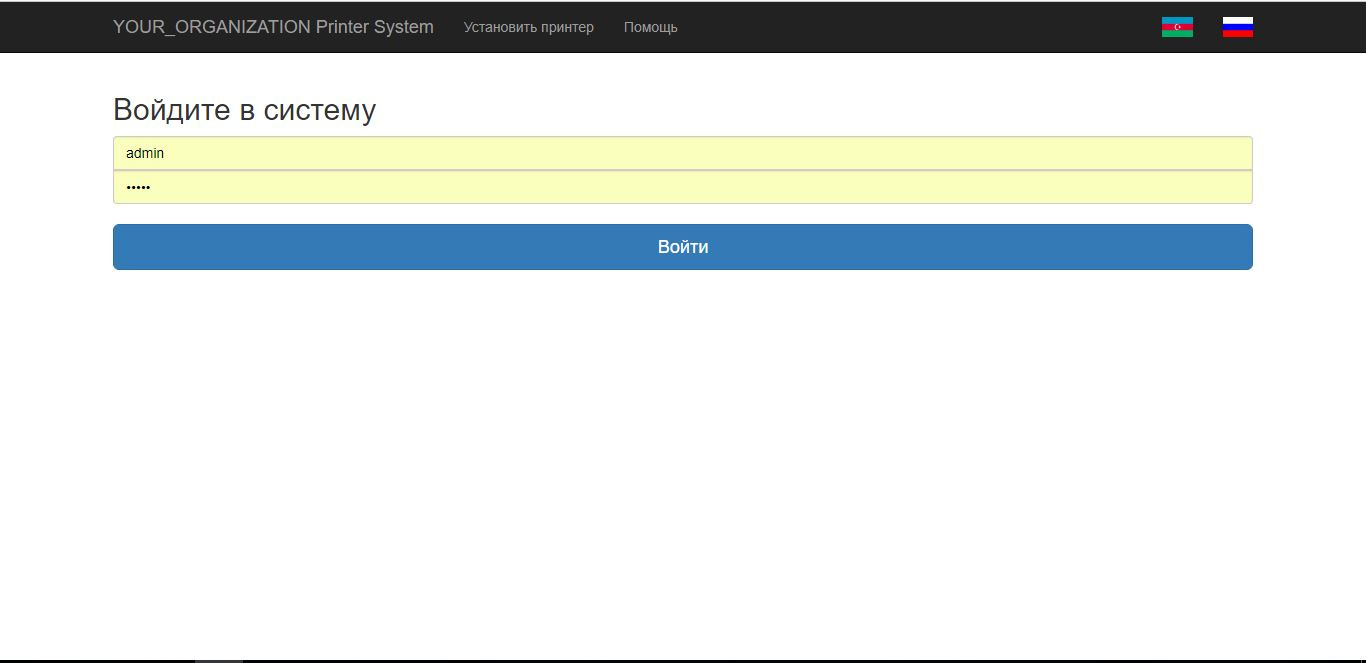
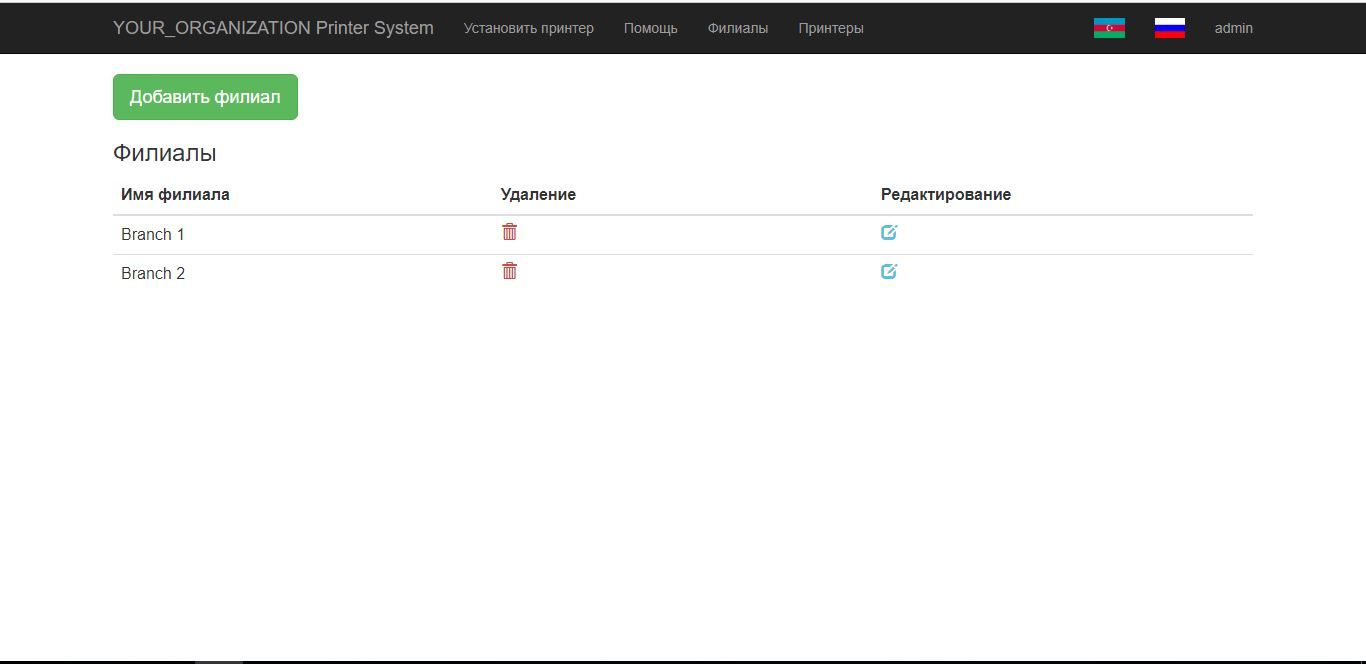
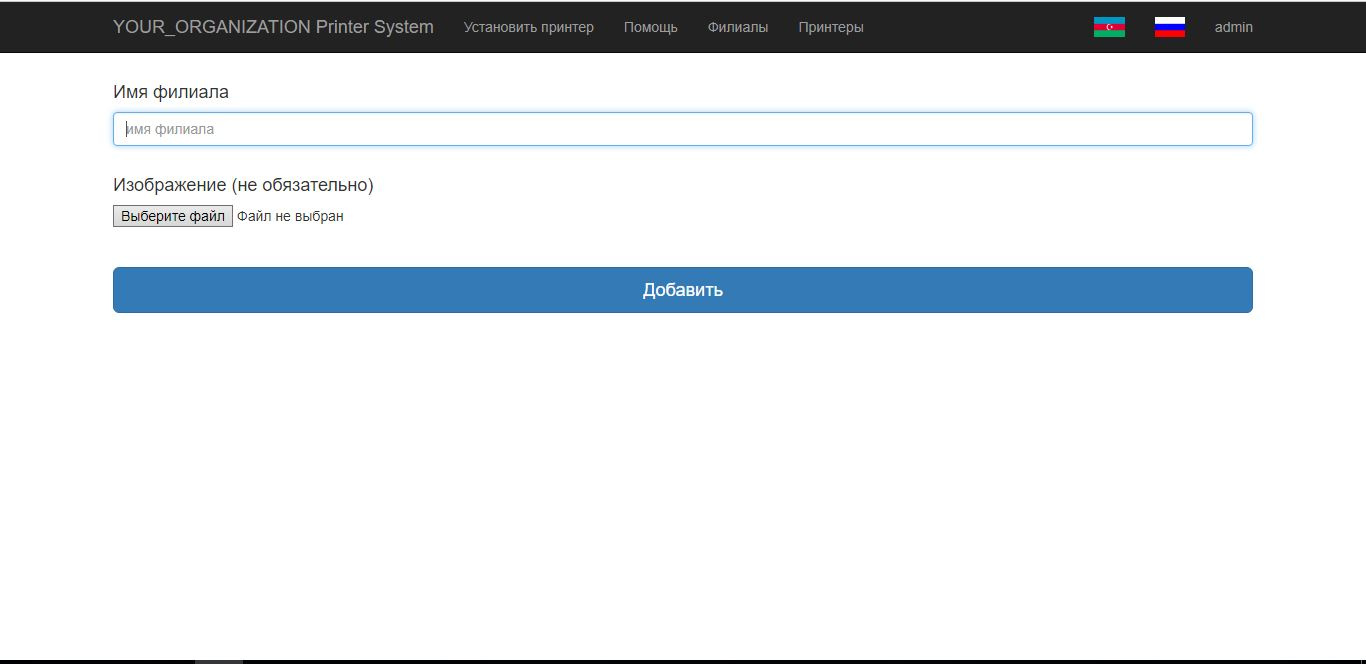
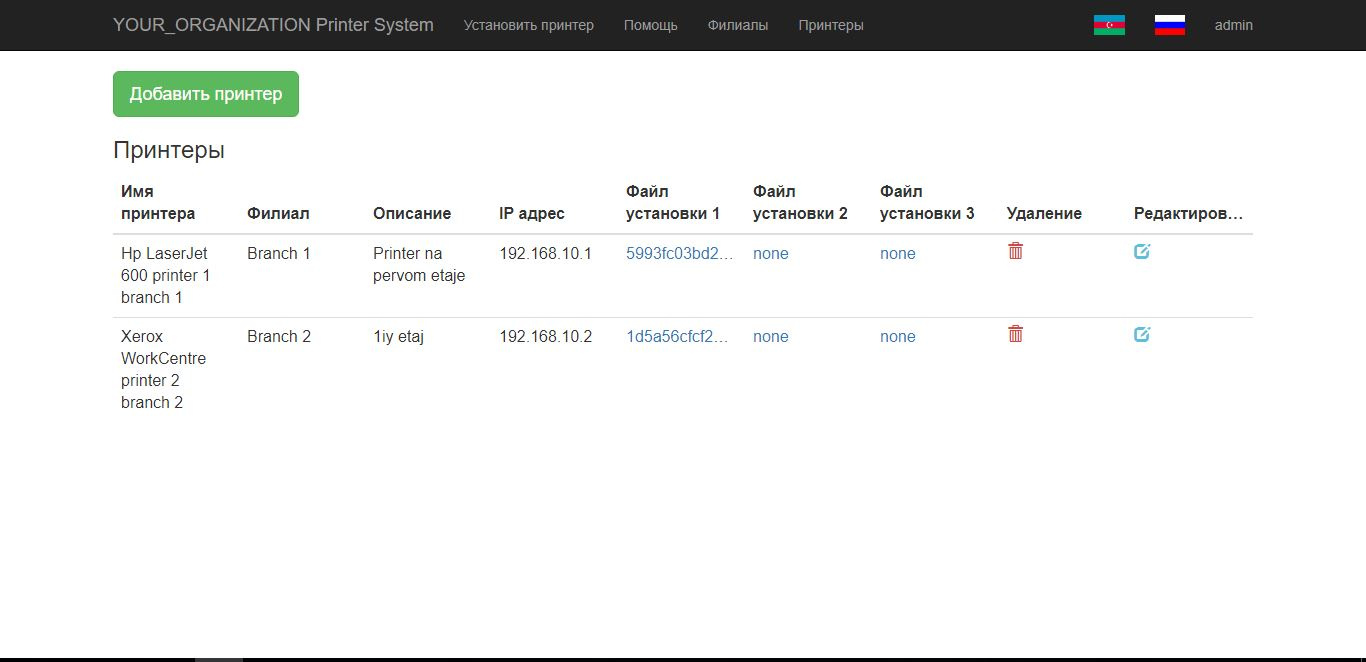
[Из песочницы] Как я создал систему установки принтеров на работе |

| Имя | Тип | Дополнительно |
|---|---|---|
| Id | int(6) | AUTO_INCREMENT, PRIMARY, UNIQUE |
| branch_name | varchar(255) | |
| image | varchar(255) |
| Имя | Тип | Дополнительно |
|---|---|---|
| Id | int(6) | AUTO_INCREMENT, PRIMARY, UNIQUE |
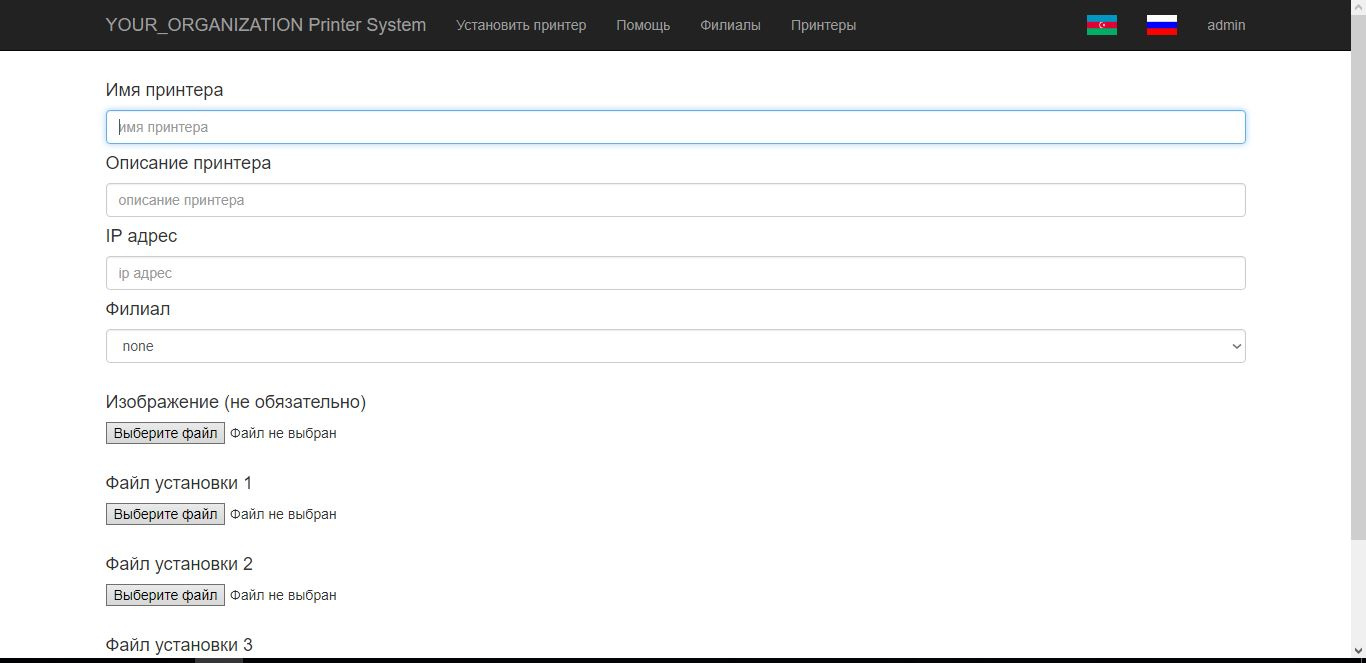
| Name | varchar(255) | |
| branchid | int(6) | По умолчанию значение: 1 |
| description | text | |
| ipaddress | varchar(255) | |
| image | varchar(255) | |
| File1 | varchar(255) | |
| File2 | varchar(255) | |
| File3 | varchar(255) |
| Имя | Тип | Дополнительно |
|---|---|---|
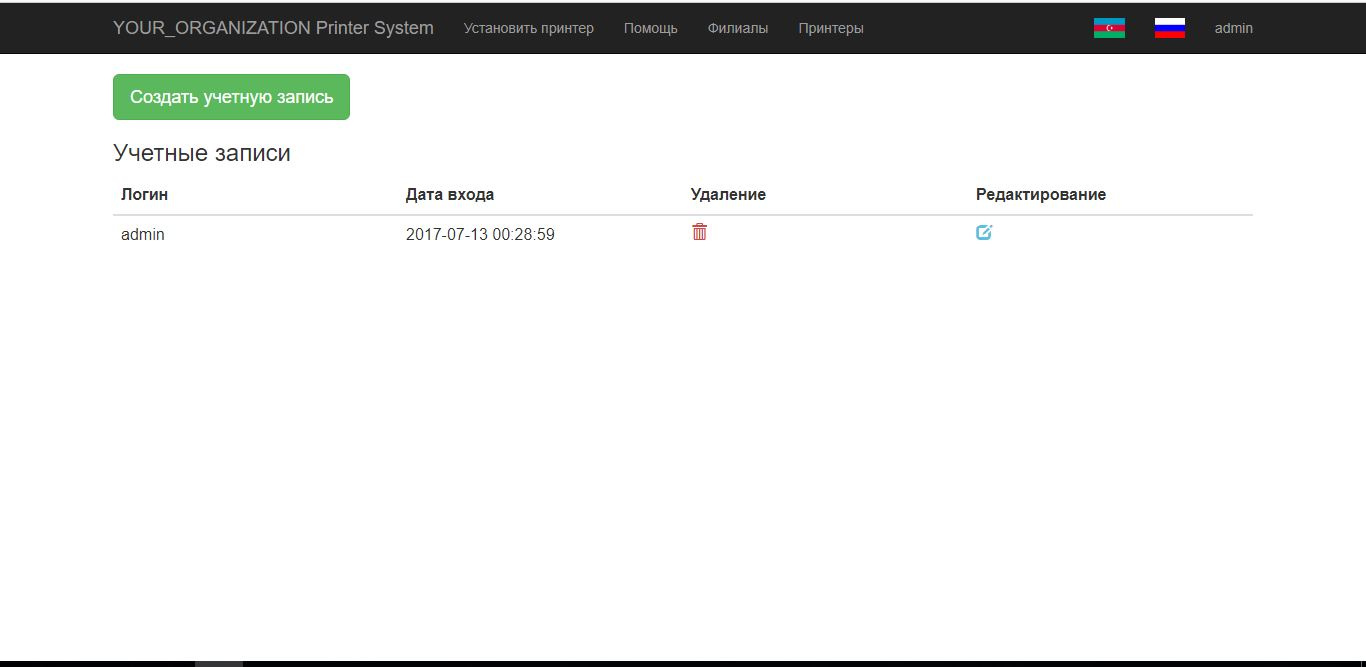
| Id | int(6) | AUTO_INCREMENT, PRIMARY, UNIQUE |
| Login | varchar(128) | |
| Token | varchar(128) | |
| password | varchar(128) | |
| lang | varchar(10) | |
| logindate | varchar(255) |
$views = new Views;
$views->addView('header', 'header.php');
$views->addView('menu', 'menu.php');
$views->addView('dashboard', 'dashboard.php');
$views->addView('footer', 'footer.php');
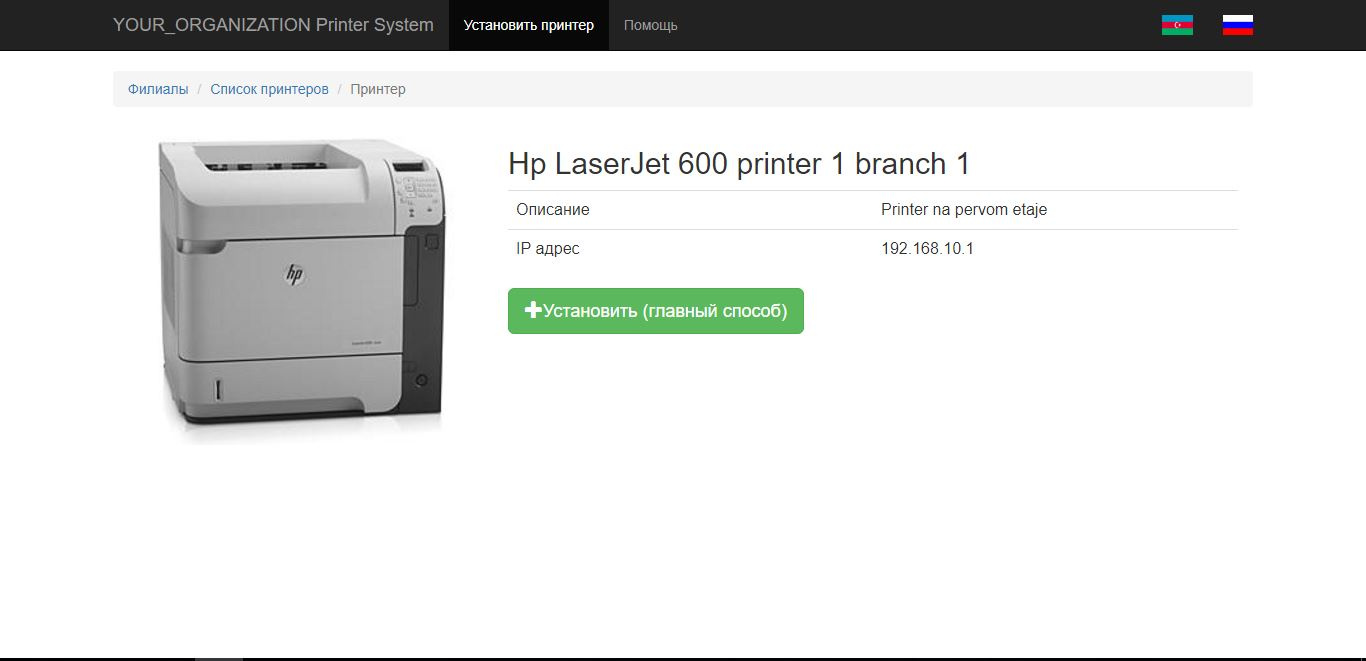
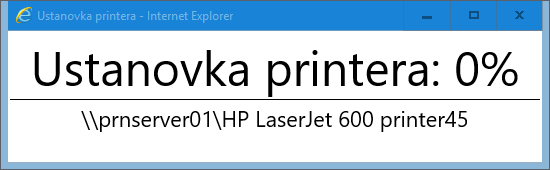
printerName = "\\prnserver01\HP LaserJet 600 printer1 branch1"
Set WshNetwork = CreateObject("WScript.Network")
WshNetwork.AddWindowsPrinterConnection printerName
WSHNetwork.SetDefaultPrinter printerName
'Задаем путь принтера
printerName = "\\prnserver01\HP LaserJet 600 printer1"
'Создаем окно Internet Explorer
Set objExplorer = CreateObject("InternetExplorer.Application")
'Задаем настройки окна - длину, ширину, позицию на экране
objExplorer.Navigate "about:blank"
objExplorer.ToolBar = 0
objExplorer.StatusBar = 0
objExplorer.Left = 500
objExplorer.Top = 250
objExplorer.Width = 550
objExplorer.Height = 170
objExplorer.Visible = 1
'Задаем заголовок
objExplorer.Document.Title = "Ustanovka printera"
'Задаем html код страницы, со своим крутым дизайном
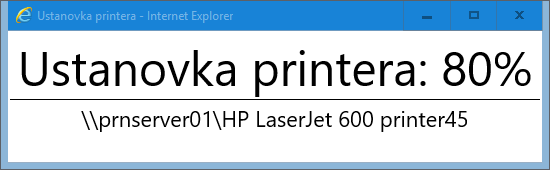
objExplorer.Document.Body.InnerHTML = " Ustanovka printera: 0% " & printerName & "
"
'Ждем 500 миллисекунд, находим на странице объект с id progress и меняем его значение. Психологический фактор для юзверя, толку от этого 0
Wscript.Sleep 500
objExplorer.document.getElementById("progress").innerText = " Ustanovka printera: 10%"
'Создаем объект для установки принтера, устанавливаем принтер и ставим его по умолчанию. Скрипт не продолжит выполнятся пока принтер не установится или выйдет ошибка
Set WshNetwork = CreateObject("WScript.Network")
WshNetwork.AddWindowsPrinterConnection printerName
WSHNetwork.SetDefaultPrinter printerName
'Психологический фактор на 200 миллисекунд, хотя принтер уже установился или вышла ошибка
Wscript.Sleep 200
objExplorer.document.getElementById("progress").innerText = " Ustanovka printera: 20%"
'Ещё один психологический фактор на 200 миллисекунд
Wscript.Sleep 200
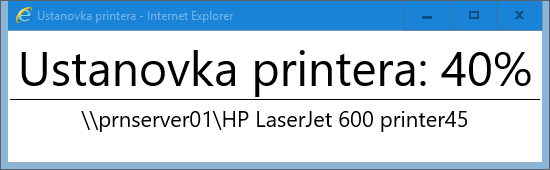
objExplorer.document.getElementById("progress").innerText = " Ustanovka printera: 40%"
'Ещё один, это же такой кайф когда проценты быстро идут
Wscript.Sleep 200
objExplorer.document.getElementById("progress").innerText = " Ustanovka printera: 60%"
'В этом моменте можно уже откинуться
Wscript.Sleep 200
objExplorer.document.getElementById("progress").innerText = " Ustanovka printera: 80%"
'О свершилось чудо, наконец!
Wscript.Sleep 100
objExplorer.document.getElementById("progress").innerText = " Printer ustanovlen!"
'Получим на 3 секунды еще кайфа от того, что установили принтер и прощаемся
Wscript.Sleep 3000
objExplorer.Quit



|
Метки: author AkshinM разработка веб-сайтов php html css printer setup system программирование |
Нейротеатр: технологии Университета ИТМО помогают создавать «искусство новых медиа» |
 / Фотография Университета ИТМО
/ Фотография Университета ИТМО
Весь этот хайп вокруг нейроинтерфейсов хорош тем, что люди вспоминают о том, что у них есть мозг. И что его возможности стоит использовать и развивать более активно
– Юрий Дидевич, медиахудожник, один из создателей NEU-theatre

Было бы здорово, чтобы ученые, в том числе, российские, перестали относиться к искусству как к чему-то ущербному. Это очень хорошее сочетание — ученого и его научного подхода и художников, людей, воспринимающих мир несколько иначе. Это может привести к очень интересным результатам
– Юрий Дидевич

|
Метки: author itmo визуализация данных блог компании университет итмо университет итмо neu-theatre |
[Из песочницы] WPF и Box2D. Как я делал физику c WPF |

public class MyModel3D
{
public Vector3D Position { get; set; } // Позиция квадрата
public Size Size { get; set; } // Размер квадрата
private TranslateTransform3D translateTransform; // Матрица перемещения
private RotateTransform3D rotationTransform; // Матрица вращения
public MyModel3D(Model3DGroup models, double x, double y, double z, string path, Size size, float axis_x = 0, double angle = 0, float axis_y = 0, float axis_z = 1)
{
this.Size = size;
this.Position = new Vector3D(x, y, z);
MeshGeometry3D mesh = new MeshGeometry3D();
// Проставляем вершины квадрату
mesh.Positions = new Point3DCollection(new List
{
new Point3D(-size.Width/2, -size.Height/2, 0),
new Point3D(size.Width/2, -size.Height/2, 0),
new Point3D(size.Width/2, size.Height/2, 0),
new Point3D(-size.Width/2, size.Height/2, 0)
});
// Указываем индексы для квадрата
mesh.TriangleIndices = new Int32Collection(new List { 0, 1, 2, 0, 2, 3 });
mesh.TextureCoordinates = new PointCollection();
// Устанавливаем текстурные координаты чтоб потом могли натянуть текстуру
mesh.TextureCoordinates.Add(new Point(0, 1));
mesh.TextureCoordinates.Add(new Point(1, 1));
mesh.TextureCoordinates.Add(new Point(1, 0));
mesh.TextureCoordinates.Add(new Point(0, 0));
// Натягиваем текстуру
ImageBrush brush = new ImageBrush(new BitmapImage(new Uri(path)));
Material material = new DiffuseMaterial(brush);
GeometryModel3D geometryModel = new GeometryModel3D(mesh, material);
models.Children.Add(geometryModel);
translateTransform = new TranslateTransform3D(x, y, z);
rotationTransform = new RotateTransform3D(new AxisAngleRotation3D(new Vector3D(axis_x, axis_y, axis_z), angle), 0.5, 0.5, 0.5);
Transform3DGroup tgroup = new Transform3DGroup();
tgroup.Children.Add(translateTransform);
tgroup.Children.Add(rotationTransform);
geometryModel.Transform = tgroup;
}
// Утсанавливает позицию объекта
public void SetPosition(Vector3D v3)
{
translateTransform.OffsetX = v3.X;
translateTransform.OffsetY = v3.Y;
translateTransform.OffsetZ = v3.Z;
}
public Vector3D GetPosition()
{
return new Vector3D(translateTransform.OffsetX, translateTransform.OffsetY, translateTransform.OffsetZ);
}
// Поворачивает объект
public void Rotation(Vector3D axis, double angle, double centerX = 0.5, double centerY = 0.5, double centerZ = 0.5)
{
rotationTransform.CenterX = translateTransform.OffsetX;
rotationTransform.CenterY = translateTransform.OffsetY;
rotationTransform.CenterZ = translateTransform.OffsetZ;
rotationTransform.Rotation = new AxisAngleRotation3D(axis, angle);
}
public Size GetSize()
{
return Size;
}
}



public class Physics
{
private World world;
public Physics(float x, float y, float w, float h, float g_x, float g_y, bool doSleep)
{
AABB aabb = new AABB();
aabb.LowerBound.Set(x, y); // Указываем левый верхний угол начала границ
aabb.UpperBound.Set(w, h); // Указываем нижний правый угол конца границ
Vec2 g = new Vec2(g_x, g_y); // Устанавливаеи вектор гравитации
world = new World(aabb, g, doSleep); // Создаем мир
}
}
private const string PATH_CIRCLE = @"Assets\circle.png"; // Изображение круга
private const string PATH_RECT = @"Assets\rect.png"; // Изображение квадрата
public MyModel3D AddBox(float x, float y, float w, float h, float density, float friction, float restetution)
{
// Создается наша графическая модель
MyModel3D model = new MyModel3D(models, x, -y, 0, PATH_RECT, new System.Windows.Size(w, h));
// Необходим для установи позиции, поворота, различных состояний и т.д. Советую поюзать свойства этих объектов
BodyDef bDef = new BodyDef();
bDef.Position.Set(x, y);
bDef.Angle = 0;
// Наш полигон который описывает вершины
PolygonDef pDef = new PolygonDef();
pDef.Restitution = restetution;
pDef.Friction = friction;
pDef.Density = density;
pDef.SetAsBox(w / 2, h / 2);
// Создание самого тела
Body body = world.CreateBody(bDef);
body.CreateShape(pDef);
body.SetMassFromShapes();
body.SetUserData(model); // Это отличная функция, она на вход принемает объекты типа object, я ее использовал для того чтобы запихнуть и хранить в ней нашу графическую модель, и в методе step ее доставать и обновлять
return model;
}
public MyModel3D AddCircle(float x, float y, float radius, float angle, float density,
float friction, float restetution)
{
MyModel3D model = new MyModel3D(models, x, -y, 0, PATH_CIRCLE, new System.Windows.Size(radius * 2, radius * 2));
BodyDef bDef = new BodyDef();
bDef.Position.Set(x, y);
bDef.Angle = angle;
CircleDef pDef = new CircleDef();
pDef.Restitution = restetution;
pDef.Friction = friction;
pDef.Density = density;
pDef.Radius = radius;
Body body = world.CreateBody(bDef);
body.CreateShape(pDef);
body.SetMassFromShapes();
body.SetUserData(model);
return model;
}
public MyModel3D AddVert(float x, float y, Vec2[] vert, float angle, float density,
float friction, float restetution)
{
MyModel3D model = new MyModel3D(models, x, y, 0, Environment.CurrentDirectory + "\\" + PATH_RECT, new System.Windows.Size(w, h)); // Данный метод нужно заменить на рисование многоугольников
BodyDef bDef = new BodyDef();
bDef.Position.Set(x, y);
bDef.Angle = angle;
PolygonDef pDef = new PolygonDef();
pDef.Restitution = restetution;
pDef.Friction = friction;
pDef.Density = density;
pDef.SetAsBox(model.Size.Width / 2, model.Size.Height / 2);
pDef.Vertices = vert;
Body body = world.CreateBody(bDef);
body.CreateShape(pDef);
body.SetMassFromShapes();
body.SetUserData(model);
return info;
}
public void Step(float dt, int iterat)
{
// Параметры этого метода управляют временем мира и точностью обработки коллизий тел
world.Step(dt / 1000.0f, iterat, iterat);
for (Body list = world.GetBodyList(); list != null; list = list.GetNext())
{
if (list.GetUserData() != null)
{
System.Windows.Media.Media3D.Vector3D position = new System.Windows.Media.Media3D.Vector3D(
list.GetPosition().X, list.GetPosition().Y, 0);
float angle = list.GetAngle() * 180.0f / (float)System.Math.PI; // Выполняем конвертацию из градусов в радианы
MyModel3D model = (MyModel3D)list.GetUserData();
model.SetPosition(position); // Перемещаем нашу графическую модель по x,y
model.Rotation(new System.Windows.Media.Media3D.Vector3D(0, 0, 1), angle); // Вращаем по координате x
}
}
}
public partial class MainWindow : Window
{
private Game.Physics px;
public MainWindow()
{
InitializeComponent();
px = new Game.Physics(-1000, -1000, 1000, 1000, 0, -0.005f, false);
px.SetModelsGroup(models);
px.AddBox(0.6f, -2, 1, 1, 0, 0.3f, 0.2f);
px.AddBox(0, 0, 1, 1, 0.5f, 0.3f, 0.2f);
this.LayoutUpdated += MainWindow_LayoutUpdated;
}
private void MainWindow_LayoutUpdated(object sender, EventArgs e)
{
px.Step(1.0f, 20); // тут по хорошему нужно вычислять дельту времени, но лень :)
this.InvalidateArrange();
}
}

public class Solver : ContactListener
{
public delegate void EventSolver(MyModel3D body1, MyModel3D body2);
public event EventSolver OnAdd;
public event EventSolver OnPersist;
public event EventSolver OnResult;
public event EventSolver OnRemove;
public override void Add(ContactPoint point)
{
base.Add(point);
OnAdd?.Invoke((MyModel3D)point.Shape1.GetBody().GetUserData(), (MyModel3D)point.Shape2.GetBody().GetUserData());
}
public override void Persist(ContactPoint point)
{
base.Persist(point);
OnPersist?.Invoke((MyModel3D)point.Shape1.GetBody().GetUserData(), (MyModel3D)point.Shape2.GetBody().GetUserData());
}
public override void Result(ContactResult point)
{
base.Result(point);
OnResult?.Invoke((MyModel3D)point.Shape1.GetBody().GetUserData(), (MyModel3D)point.Shape2.GetBody().GetUserData());
}
public override void Remove(ContactPoint point)
{
base.Remove(point);
OnRemove?.Invoke((MyModel3D)point.Shape1.GetBody().GetUserData(), (MyModel3D)point.Shape2.GetBody().GetUserData());
}
}
public void SetSolver(ContactListener listener)
{
world.SetContactListener(listener);
}
Game.Solver solver = new Game.Solver();
px.SetSolver(solver);
solver.OnAdd += (model1, model2) =>
{
// Произошло столкновение тел model1 и model2
};
public Joint AddJoint(Body b1, Body b2, float x, float y)
{
RevoluteJointDef jd = new RevoluteJointDef();
jd.Initialize(b1, b2, new Vec2(x, y));
Joint joint = world.CreateJoint(jd);
return joint;
}
public Joint AddDistanceJoint(Body b1, Body b2, float x1, float y1, float x2, float y2,
bool collideConnected = true, float hz = 1f)
{
DistanceJointDef jd = new DistanceJointDef();
jd.Initialize(b1, b2, new Vec2(x1, y1), new Vec2(x2, y2));
jd.CollideConnected = collideConnected;
jd.FrequencyHz = hz;
Joint joint = world.CreateJoint(jd);
return joint;
}
|
Метки: author Win332 разработка игр программирование c# .net wpf box2d |
Код высших достижений |


Уверен, что соревнования по программированию — увлекательный и эффективный способ научиться кодить, разобраться в структурах данных и выработать алгоритмическое мышление. Пробуйте участвовать, раунды на Codeforces открыты для всех и проходят каждую неделю. Наша цель — предложить интересные задачи для каждого участника!
Михаил Мирзаянов, основатель Codeforces


|
Метки: author dmitryegorov спортивное программирование блог компании вконтакте вконтакте vk cup acm icpc |
Yubikey 4 — покупка, доставка и получение |

*no shipping to: Afghanistan, North Korea, Iran, Russia, Sudan, Syria
This item does not ship to Russian Federation.
|
Метки: author ElderMan криптография информационная безопасность github yubico yubikey 2fa amazon well shaped nails |
Вышел Upsource 2017.2 с поддержкой внешних инспекций кода, Python, NPM и многим другим |
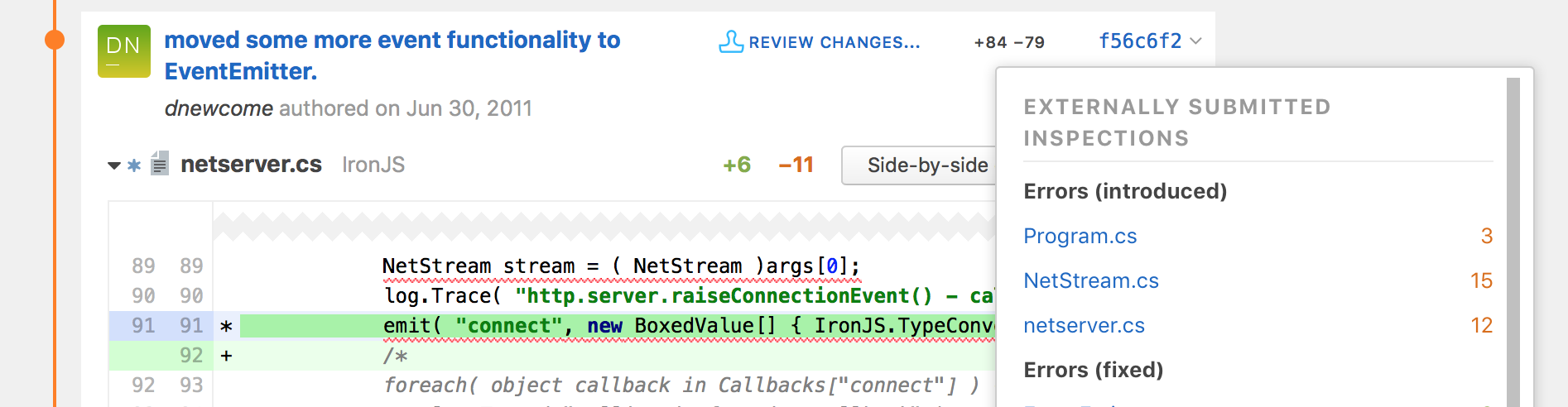
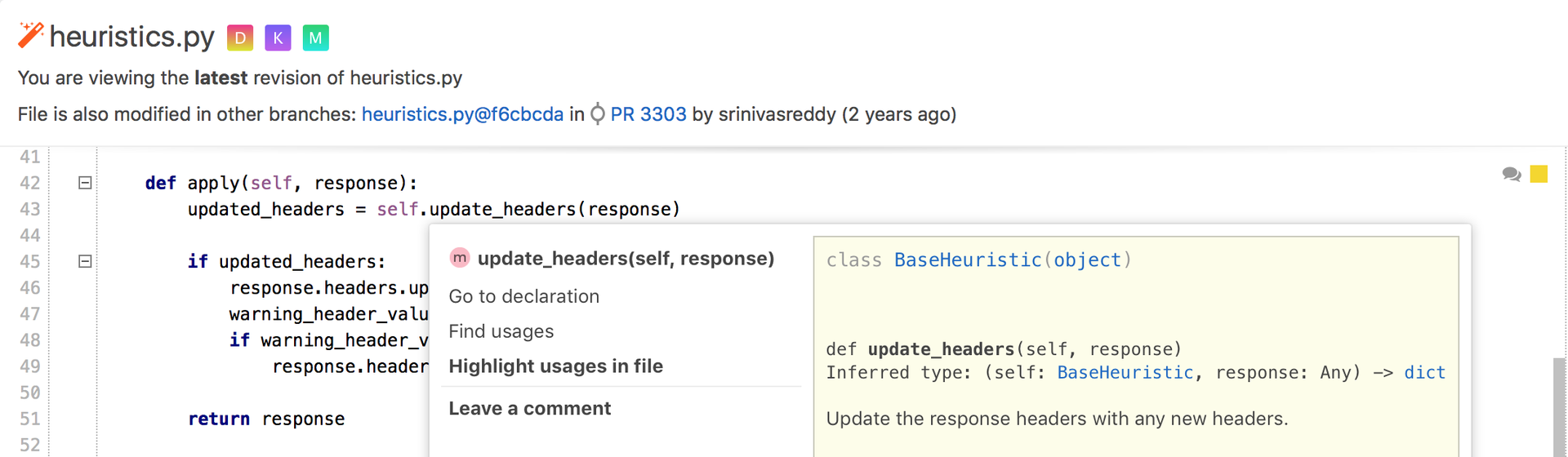
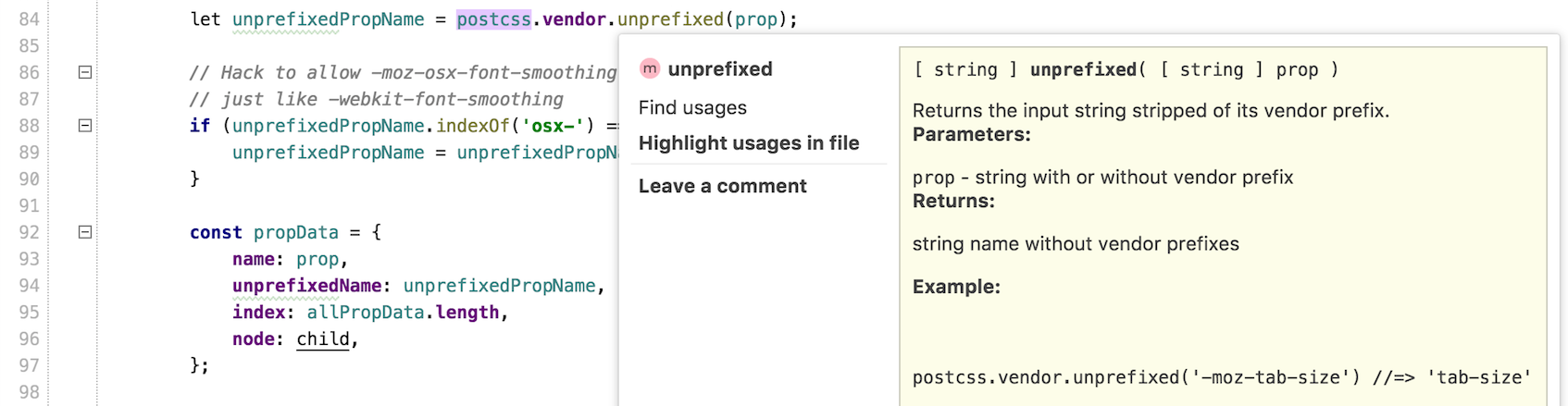

|
Метки: author kafooster python javascript java блог компании jetbrains release code review php kotlin code analysis jetbrains code quality tools .net resharper |
Почему руководство не принимает agile и что вы можете с этим сделать |

|
Метки: author vkalenov agile перевод matthew heusser enterprise agility executives |
Как мы упоролись и откалибровали кофе-машину на спектрофотометре |











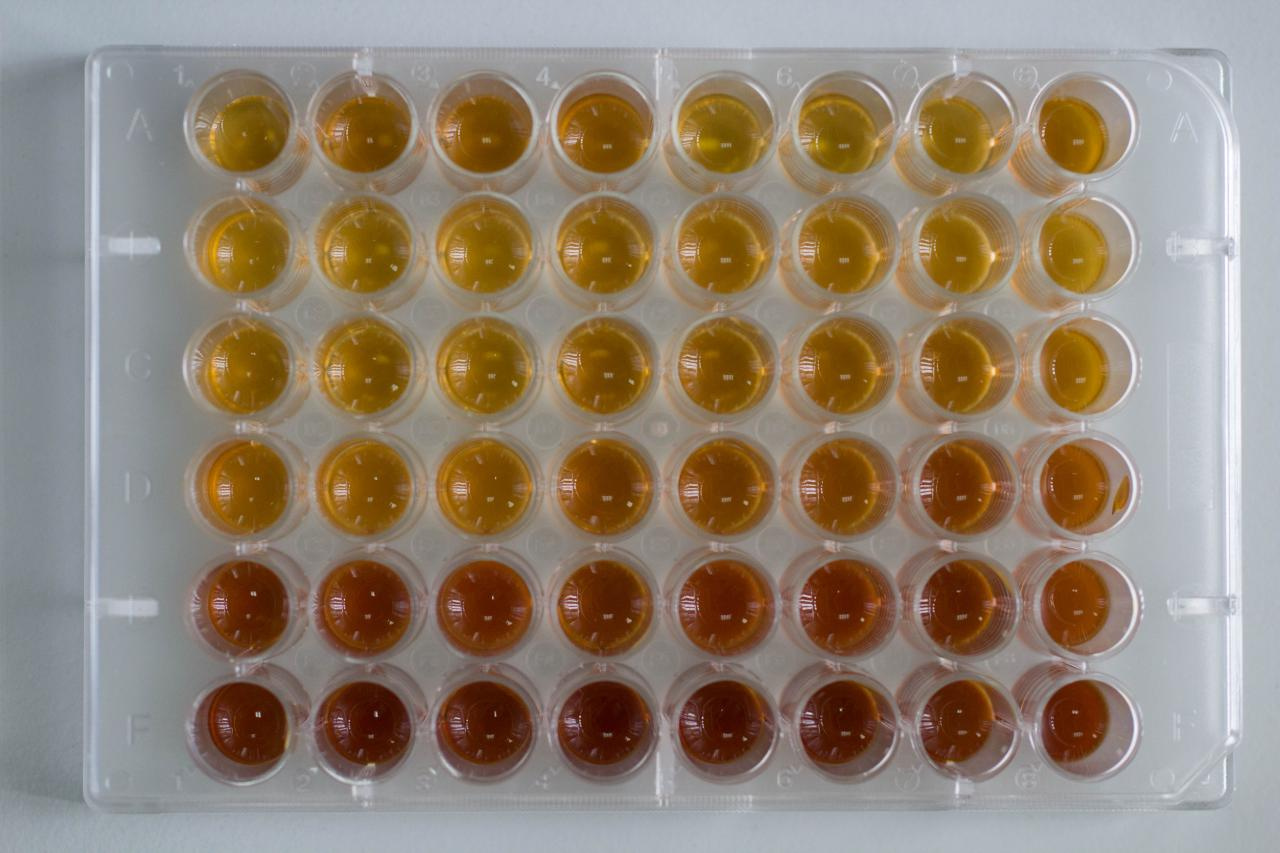


import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv("data.csv")
sns.set()
sns.set_style("whitegrid")
sns.set_context("talk")
ax = sns.barplot(x="Compression", y="Absorbance", hue="Roast", data=df, palette="Paired")
ax.set(ylim=(0, 100), xlabel='Compression level', ylabel='Absorbance at 450 nm, %')
plt.axhline(32, alpha=0.4, color='black', linestyle='dashed', label='Optimal concentration')
plt.legend(loc='upper left')
plt.savefig("plot.png", dpi=300)
plt.show()
# Subtract optimal value
df['Absorbance'] = df['Absorbance'] - 32

import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
df = pd.read_csv("data.csv")
# Subtract optimal value
df['Absorbance'] = df['Absorbance'] - 32
sns.set()
sns.set_style("whitegrid")
sns.set_context("talk")
ax = sns.barplot(x="Compression", y="Absorbance", hue="Roast", data=df, palette="Paired")
ax.set(xlabel='Compression level', ylabel='Deviation from optimal concentration')
plt.legend(loc='upper left')
plt.savefig("plot_diverging.png", dpi=300)
plt.show()
|
Метки: author Meklon ненормальное программирование визуализация данных python кофе мы можем в любой момент бросить |
Рано закапывать Java |

float dp = getResources().getDisplayMetrics().density;
FrameLayout root = new FrameLayout(this);
root.setBackgroundColor(RED);
root.setLayoutParams(
new ViewGroup.LayoutParams(
MATCH_PARENT,
(int)(100f*dp)));
FrameLayout child = new FrameLayout(this);
child.setBackgroundColor(GREEN);
FrameLayout.LayoutParams childParams =
new FrameLayout.LayoutParams(
(int)(50f*dp),
(int)(50f*dp));
childParams.gravity = CENTER;
child.setLayoutParams(childParams);
root.addView(child);
frameLayout {
backgroundColor = RED
frameLayout {
backgroundColor = GREEN
}.lparams(dip(50), dip(50)) {
gravity = CENTER
}
}.lparams(matchParent, dip(100))new frameLayout(this) {{
new lparams(this) {{
width = MATCH_PARENT;
height = dip(100);
}}._();
backgroundColor = RED;
new frameLayout(this) {{
new lparams(this) {{
width = dip(50);
height = dip(50);
gravity = CENTER;
}}._();
backgroundColor = GREEN;
}}._();
}}._();class A {
// block
{
// some code
}
}new imageView(this) {{
new lparams(this) {{
width = dimen(R.dimen.avatarSide);
height = dimen(R.dimen.avatarSide);
}}._();
}}._();
new textView(this) {{
new lparams(this) {{
width = dimen(R.dimen.avatarSide) + dip(10);
height = WRAP_CONTENT;
}}._();
}}._();
object : frameLayout(this) {
init {
object : lparams(this) {
init {
width = MATCH_PARENT
height = dip(100f)
}
}.`_`()
backgroundColor = RED
object : frameLayout(this) {
init {
object : lparams(this) {
init {
width = dip(50f)
height = dip(50f)
gravity = CENTER
}
}.`_`()
backgroundColor = GREEN
}
}.`_`()
}
}.`_`()Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author adev_one разработка под android java android пятничный пост |
Bare words в JavaScript |

with(bareWords) {
alert(Иван + Ургант)
console.log(We, can, use, bare, words)
}
try {
let self = this
window.bareWords = new Proxy({}, {
has: function(target, name) {
return !(name in self)
},
get: function(target, name) {
return name
},
})
} catch(e) {
console.error('Your browser doesn't support bare words.')
}

|
Метки: author mitinsvyat javascript wat |
[Перевод] Создание движка для блога с помощью Phoenix и Elixir / Часть 10. Тестирование каналов |

От переводчика: «Elixir и Phoenix — прекрасный пример того, куда движется современная веб-разработка. Уже сейчас эти инструменты предоставляют качественный доступ к технологиям реального времени для веб-приложений. Сайты с повышенной интерактивностью, многопользовательские браузерные игры, микросервисы — те направления, в которых данные технологии сослужат хорошую службу. Далее представлен перевод серии из 11 статей, подробно описывающих аспекты разработки на фреймворке Феникс казалось бы такой тривиальной вещи, как блоговый движок. Но не спешите кукситься, будет действительно интересно, особенно если статьи побудят вас обратить внимание на Эликсир либо стать его последователями.»
В этой части мы научимся тестировать каналы.
В конце прошлой части мы доделали классную систему «живых» комментариев для блога. Но к ужасу, на тесты не хватило времени! Займёмся ими сегодня. Этот пост будет понятным и коротким, в отличие от чересчур длинного предыдущего.
Прежде, чем перейти к тестам, нам нужно подтянуть несколько мест. Во-первых, давайте включим
флаг approved в вызов broadcast. Таким образом мы сможем проверять в тестах изменение состояния подтверждения комментариев.
new_payload = payload
|> Map.merge(%{
insertedAt: comment.inserted_at,
commentId: comment.id,
approved: comment.approved
})
broadcast socket, "APPROVED_COMMENT", new_payloadТакже нужно изменить файл web/channels/comment_helper.ex, чтобы он реагировал на пустые данные, отправляемые в сокет запросами на одобрение/удаление комментариев. После функции approve добавьте:
def approve(_params, %{}), do: {:error, "User is not authorized"}
def approve(_params, nil), do: {:error, "User is not authorized"}А после функции delete:
def delete(_params, %{}), do: {:error, "User is not authorized"}
def delete(_params, nil), do: {:error, "User is not authorized"}Это позволит сделать код проще, обработку ошибок – лучше, а тестирование – легче.
Будем использовать фабрики, которые написали с помощью ExMachina ранее. Нам нужно протестировать создание комментария, а также одобрение/отклонение/удаление комментария на основе авторизации пользователя. Создадим файл test/channels/comment_helper_test.exs, а затем добавим подготовительный код в начало:
defmodule Pxblog.CommentHelperTest do
use Pxblog.ModelCase
alias Pxblog.Comment
alias Pxblog.CommentHelper
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
fake_socket = %{assigns: %{user: user.id}}
{:ok, user: user, post: post, comment: comment, socket: fake_socket}
end
# Insert our tests after this line
endЗдесь используется модуль ModelCase для добавления возможности использования блока setup. Ниже добавляются алиасы для модулей Comment, Factory и CommentHelper, чтобы можно было проще вызывать их функции.
Затем идёт настройка некоторых основных данных, которые можно будет использовать в каждом тесте. Также как и раньше, здесь создаются пользователь, пост и комментарий. Но обратите внимание на создание "фальшивого сокета", который включает в себя лишь ключ assigns. Мы можем передать его в CommentHelper, чтобы тот думал о нём как о настоящем сокете.
Затем возвращается кортеж, состоящий из атома :ok и словарь-список (также как и в других тестах). Давайте уже напишем сами тесты!
Начнём с простейшего теста на создание комментария. Так как комментарий может написать любой пользователь, здесь не требуется никакой специальной логики. Мы проверяем, что комментарий действительно был создан и… всё!
test "creates a comment for a post", %{post: post} do
{:ok, comment} = CommentHelper.create(%{
"postId" => post.id,
"author" => "Some Person",
"body" => "Some Post"
}, %{})
assert comment
assert Repo.get(Comment, comment.id)
endДля этого вызываем функцию create из модуля CommentHelper и передаём в неё информацию, как будто это информация была получена из канала.
Переходим к одобрению комментариев. Так как здесь используется немного больше логики, связанной с авторизацией, тест будет чуть более сложным:
test "approves a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, socket)
assert comment.approved
end
test "does not approve a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
endСхожим с созданием комментария образом, мы вызываем функцию CommentHelper.approve и передаём в неё информацию "из канала". Мы передаём "фальшивый сокет" в функцию и она получает доступ к значению assign. Мы тестируем их оба с помощью валидного сокета (с вошедшим в систему пользователем) и невалидного сокета (с пустым assign). Затем просто проверяем, что получаем комментарий в положительном исходе и сообщение об ошибке в отрицательном.
Теперь о тестах на удаление (которые по сути идентичны):
test "deletes a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, socket)
refute Repo.get(Comment, comment.id)
end
test "does not delete a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
endКак я упоминал ранее, наши тесты практически идентичны, за исключением положительного исхода, в котором мы убеждаемся что комментарий был удалён и больше не представлен в базе данных.
Давайте проверим, что мы покрываем код тестами должным образом. Для этого запустите следующую команду:
$ mix test test/channels/comment_helper_test.exs --coverОна создаст в директории [project root]/cover отчёт, который скажет нам какой код не покрыт тестами. Если все тесты зелёные, откройте файл в браузере ./cover/Elixir.Pxblog.CommentHelper.html. Если вы видите красный цвет, значит этот код не покрыт тестами. Отсутствие красного цвета означает 100% покрытие.
Полностью файл с тестами хелпера комментариев выглядит следующим образом:
defmodule Pxblog.CommentHelperTest do
use Pxblog.ModelCase
alias Pxblog.Comment
alias Pxblog.CommentHelper
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
fake_socket = %{assigns: %{user: user.id}}
{:ok, user: user, post: post, comment: comment, socket: fake_socket}
end
# Insert our tests after this line
test "creates a comment for a post", %{post: post} do
{:ok, comment} = CommentHelper.create(%{
"postId" => post.id,
"author" => "Some Person",
"body" => "Some Post"
}, %{})
assert comment
assert Repo.get(Comment, comment.id)
end
test "approves a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, socket)
assert comment.approved
end
test "does not approve a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.approve(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
test "deletes a comment when an authorized user", %{post: post, comment: comment, socket: socket} do
{:ok, comment} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, socket)
refute Repo.get(Comment, comment.id)
end
test "does not delete a comment when not an authorized user", %{post: post, comment: comment} do
{:error, message} = CommentHelper.delete(%{"postId" => post.id, "commentId" => comment.id}, %{})
assert message == "User is not authorized"
end
endГенератор уже создал для нас основу тестов каналов, осталось наполнить их мясом. Начнём с добавления алиаса Pxblog.Factory для использования фабрик в блоке setup. Собственно, всё как и раньше. Затем необходимо настроить сокет, а именно, представиться созданным пользователем и подключиться к каналу комментариев созданного поста. Оставим тесты ping и broadcast на месте, но удалим тесты, связанные с shout, поскольку у нас больше нет этого обработчика. В файле test/channels/comment_channel_test.exs:
defmodule Pxblog.CommentChannelTest do
use Pxblog.ChannelCase
alias Pxblog.CommentChannel
alias Pxblog.Factory
setup do
user = Factory.create(:user)
post = Factory.create(:post, user: user)
comment = Factory.create(:comment, post: post, approved: false)
{:ok, _, socket} =
socket("user_id", %{user: user.id})
|> subscribe_and_join(CommentChannel, "comments:#{post.id}")
{:ok, socket: socket, post: post, comment: comment}
end
test "ping replies with status ok", %{socket: socket} do
ref = push socket, "ping", %{"hello" => "there"}
assert_reply ref, :ok, %{"hello" => "there"}
end
test "broadcasts are pushed to the client", %{socket: socket} do
broadcast_from! socket, "broadcast", %{"some" => "data"}
assert_push "broadcast", %{"some" => "data"}
end
endУ нас уже написаны довольно полноценные тесты для модуля CommentHelper, так что здесь оставим тесты, непосредственно связанные с функциональностью каналов. Создадим тест для трёх сообщений: CREATED_COMMENT, APPROVED_COMMENT и DELETED_COMMENT.
test "CREATED_COMMENT broadcasts to comments:*", %{socket: socket, post: post} do
push socket, "CREATED_COMMENT", %{"body" => "Test Post", "author" => "Test Author", "postId" => post.id}
expected = %{"body" => "Test Post", "author" => "Test Author"}
assert_broadcast "CREATED_COMMENT", expected
endЕсли вы никогда раньше не видели тесты каналов, то здесь всё покажется в новинку. Давайте разбираться по шагам.
Начинаем с передачи в тест сокета и поста, созданных в блоке setup. Следующей строкой мы отправляем в сокет событие CREATED_COMMENT вместе с ассоциативным массивом, схожим с тем, что клиент на самом деле отправляет в сокет.
Далее описываем наши "ожидания". Пока что вы не можете определить список, ссылающийся на любые другие переменные внутри функции assert_broadcast, так что следует выработать привычку по определению ожидаемых значений отдельно и передачу переменной expected в вызов assert_broadcast. Здесь мы ожидаем, что значения body и author совпадут с тем, что мы передали внутрь.
Наконец, проверяем, что сообщение CREATED_COMMENT было транслировано вместе с ожидаемым ассоциативным массивом.
Теперь переходим к событию APPROVED_COMMENT:
test "APPROVED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
push socket, "APPROVED_COMMENT", %{"commentId" => comment.id, "postId" => post.id, approved: false}
expected = %{"commentId" => comment.id, "postId" => post.id, approved: true}
assert_broadcast "APPROVED_COMMENT", expected
endЭтот тест в значительной степени похож на предыдущий, за исключением того, что мы передаём в сокет значение approved равное false и ожидаем увидеть после выполнения значение approved равное true. Обратите внимание, что в переменной expected мы используем commentId и postId как указатели на comment.id и post.id. Это выражения вызовут ошибку, поэтому нужно использовать разделение ожидаемой переменной в функции assert_broadcast.
Наконец, взглянем на тест для сообщения DELETED_COMMENT:
test "DELETED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
payload = %{"commentId" => comment.id, "postId" => post.id}
push socket, "DELETED_COMMENT", payload
assert_broadcast "DELETED_COMMENT", payload
endНичего особо интересного. Передаём стандартные данные в сокет и проверяем, что транслируем событие об удалении комментария.
Подобно тому, как мы поступали с CommentHelper, запустим тесты конкретно для этого файла с опцией --cover:
$ mix test test/channels/comment_channel_test.exs --coverВы получите предупреждения, что переменная expected не используется, которые можно благополучно проигнорировать.
test/channels/comment_channel_test.exs:31: warning: variable expected is unused
test/channels/comment_channel_test.exs:37: warning: variable expected is unusedЕсли вы открыли файл ./cover/Elixir.Pxblog.CommentChannel.html и не видите ничего красного, то можете кричать "Ура!". Полное покрытие!
Финальная версия теста CommentChannel полностью должна выглядеть так:
defmodule Pxblog.CommentChannelTest do
use Pxblog.ChannelCase
alias Pxblog.CommentChannel
import Pxblog.Factory
setup do
user = insert(:user)
post = insert(:post, user: user)
comment = insert(:comment, post: post, approved: false)
{:ok, _, socket} =
socket("user_id", %{user: user.id})
|> subscribe_and_join(CommentChannel, "comments:#{post.id}")
{:ok, socket: socket, post: post, comment: comment}
end
test "ping replies with status ok", %{socket: socket} do
ref = push socket, "ping", %{"hello" => "there"}
assert_reply ref, :ok, %{"hello" => "there"}
end
test "broadcasts are pushed to the client", %{socket: socket} do
broadcast_from! socket, "broadcast", %{"some" => "data"}
assert_push "broadcast", %{"some" => "data"}
end
test "CREATED_COMMENT broadcasts to comments:*", %{socket: socket, post: post} do
push socket, "CREATED_COMMENT", %{"body" => "Test Post", "author" => "Test Author", "postId" => post.id}
expected = %{"body" => "Test Post", "author" => "Test Author"}
assert_broadcast "CREATED_COMMENT", expected
end
test "APPROVED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
push socket, "APPROVED_COMMENT", %{"commentId" => comment.id, "postId" => post.id, approved: false}
expected = %{"commentId" => comment.id, "postId" => post.id, approved: true}
assert_broadcast "APPROVED_COMMENT", expected
end
test "DELETED_COMMENT broadcasts to comments:*", %{socket: socket, post: post, comment: comment} do
payload = %{"commentId" => comment.id, "postId" => post.id}
push socket, "DELETED_COMMENT", payload
assert_broadcast "DELETED_COMMENT", payload
end
endТак как отчёт о покрытии тестами можно легко создать с помощью Mix, то не имеет смысла включать его в историю Git, так что откройте файл .gitignore и добавьте в него следующую строчку:
/coverВот и всё! Теперь у нас есть полностью покрытый тестами код каналов (за исключением Javascript-тестов, которые представляют собой отдельный мир, не вписывающийся в эту серию уроков). В следующей части мы перейдём к работе над UI, сделаем его немного симпатичнее и более функциональнее, а также заменим стандартные стили, логотипы и т.п., чтобы проект выглядел более профессионально. В дополнение, удобство использования нашего сайта сейчас абсолютно никакое. Мы поправим и это, чтобы людям хотелось использовать нашу блоговую платформу!
А вы, уважаемые читатели, подписывайтесь на нашу рассылку, читайте другие интересные статьи, задавайте вопросы в чате, присоединяйтесь к каналу, ходите на митапы и пишите классный код на Эликсире! Ваш Вунш.
|
Метки: author jarosluv функциональное программирование разработка веб-сайтов ruby on rails erlang/otp elixir/phoenix elixir phoenix wunsh |
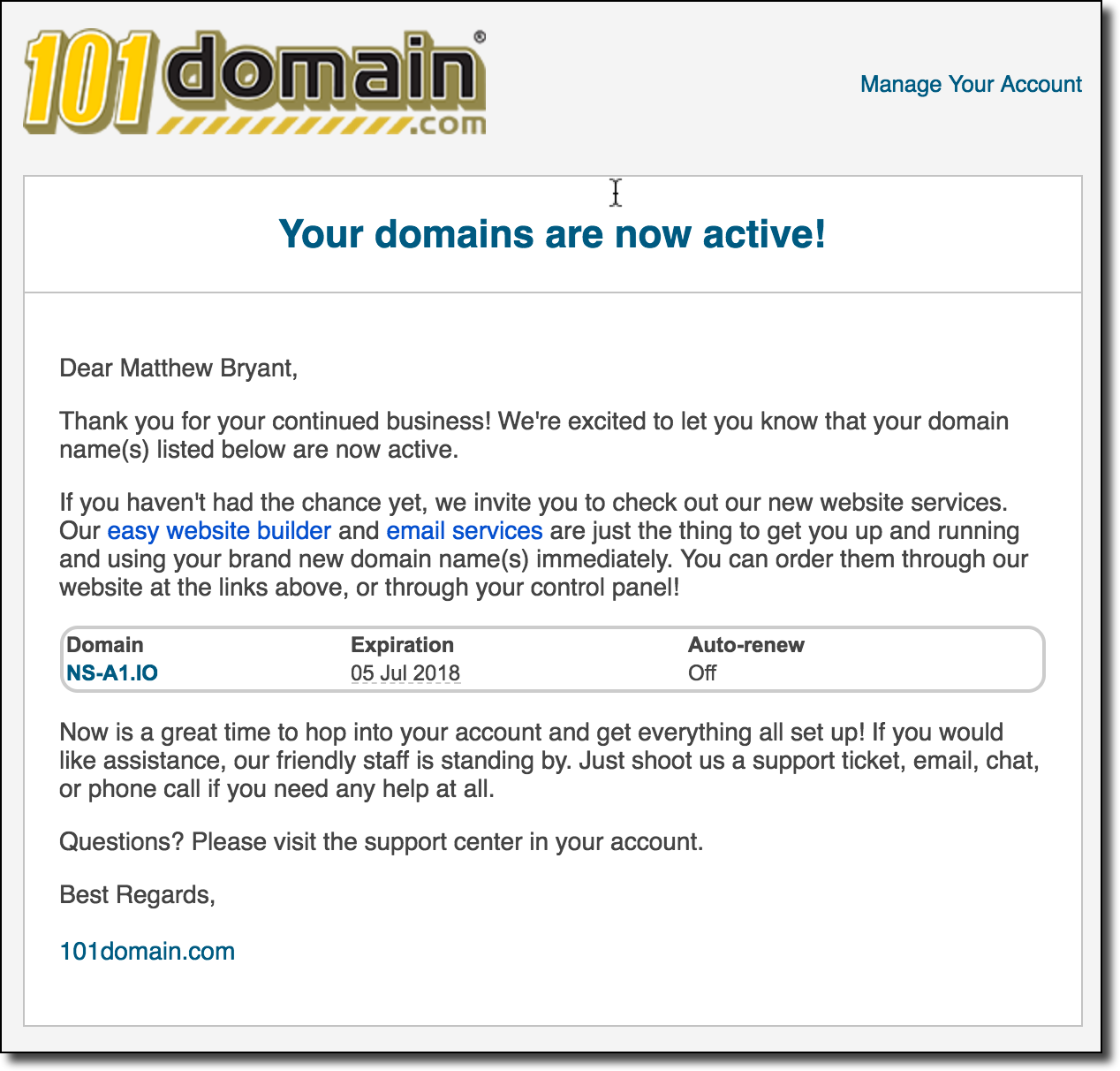
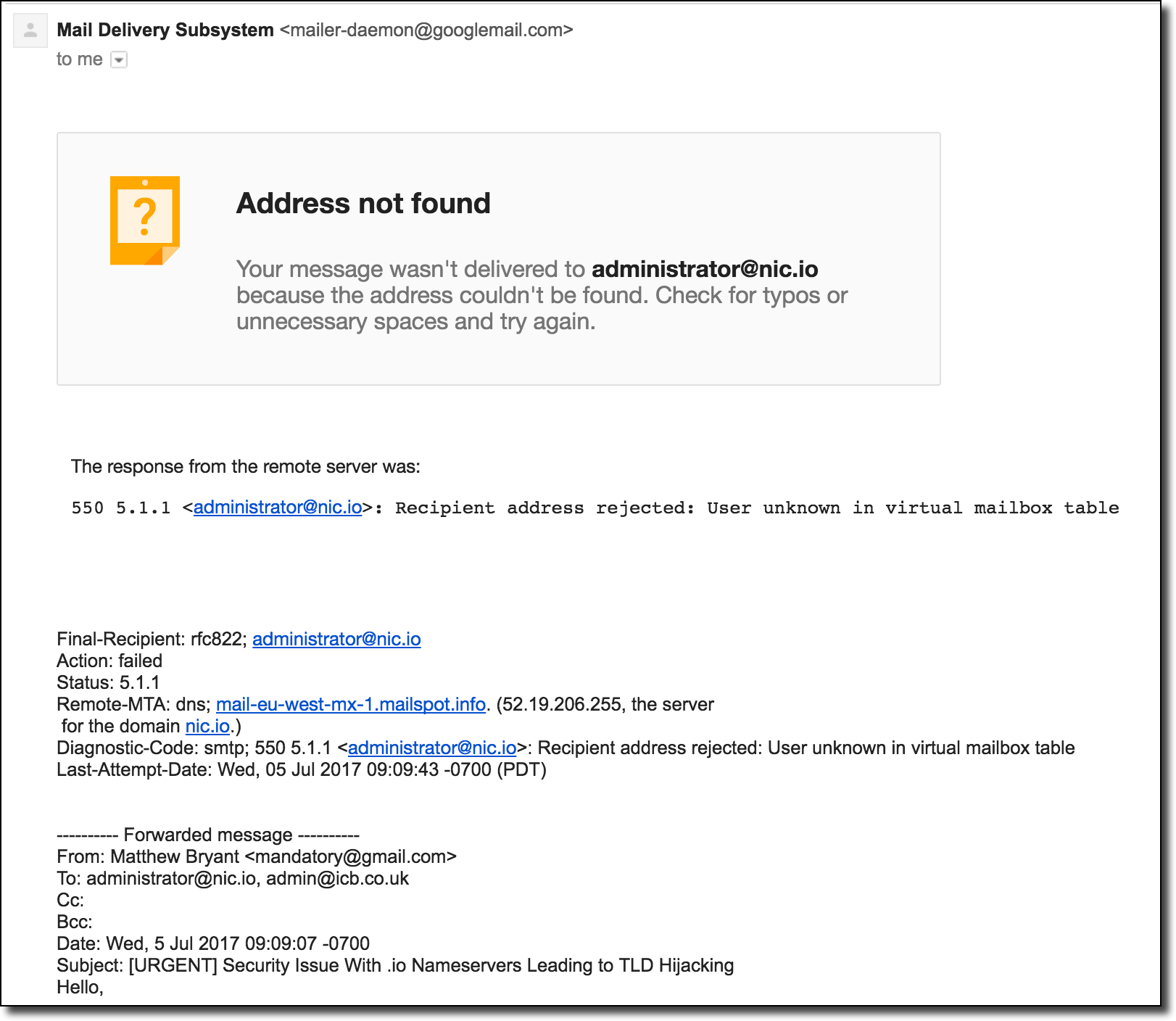
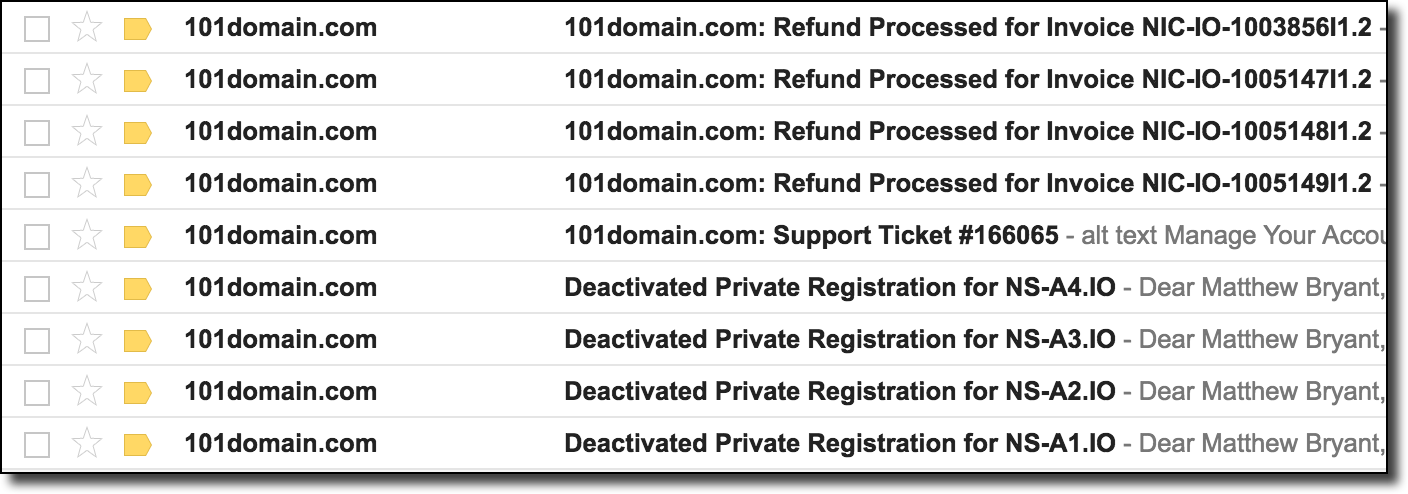
[Перевод] Захват всех доменов .io с помощью таргетированной регистрации |
 В предыдущей статье мы обсуждали захват доменных расширений .na, .co.ao и .it.ao разными хитростями с DNS. Сейчас рассмотрим угрозу компрометации домена верхнего уровня (TLD) и как нужно действовать злоумышленнику, чтобы достичь поставленной цели. Одним из довольно простых методов видится регистрация доменного имени одного из авторитативных серверов имён этой TLD. Поскольку в TLD авторитативные серверы могут размещаться на произвольных доменах, то есть вероятность зарегистрировать такой домен, воспользовавшись ошибкой из-за неправильной конфигурации, истечения срока действия или других ошибок. Затем этот сервер можно использовать для выдачи новых DNS-записей в целой доменной зоне.
В предыдущей статье мы обсуждали захват доменных расширений .na, .co.ao и .it.ao разными хитростями с DNS. Сейчас рассмотрим угрозу компрометации домена верхнего уровня (TLD) и как нужно действовать злоумышленнику, чтобы достичь поставленной цели. Одним из довольно простых методов видится регистрация доменного имени одного из авторитативных серверов имён этой TLD. Поскольку в TLD авторитативные серверы могут размещаться на произвольных доменах, то есть вероятность зарегистрировать такой домен, воспользовавшись ошибкой из-за неправильной конфигурации, истечения срока действия или других ошибок. Затем этот сервер можно использовать для выдачи новых DNS-записей в целой доменной зоне.Такой вариант казался верной дорогой к победе, так что я потратил много времени на разработку инструментария для проверки ошибок этого типа. По сути, этот процесс состоит в записи всех хостов серверов имён для данного домена — и проверке, когда истечёт срок регистрации какого-нибудь из корневых доменов и он станет доступен для регистрации. Основная проблема в том, что многие регистраторы не говорят, что домен полностью свободен, пока вы реально не попробуете его купить. Кроме того, было несколько случаев, когда у сервера заканчивался срок регистрации, но по какой-то причине домен был недоступен для регистрации, хотя не был помечен как зарезервированный. В результате такого сканирования удалось зафиксировать много перехватов доменов в закрытых зонах (.gov, .edu, .int и др.), но не самих TLD.

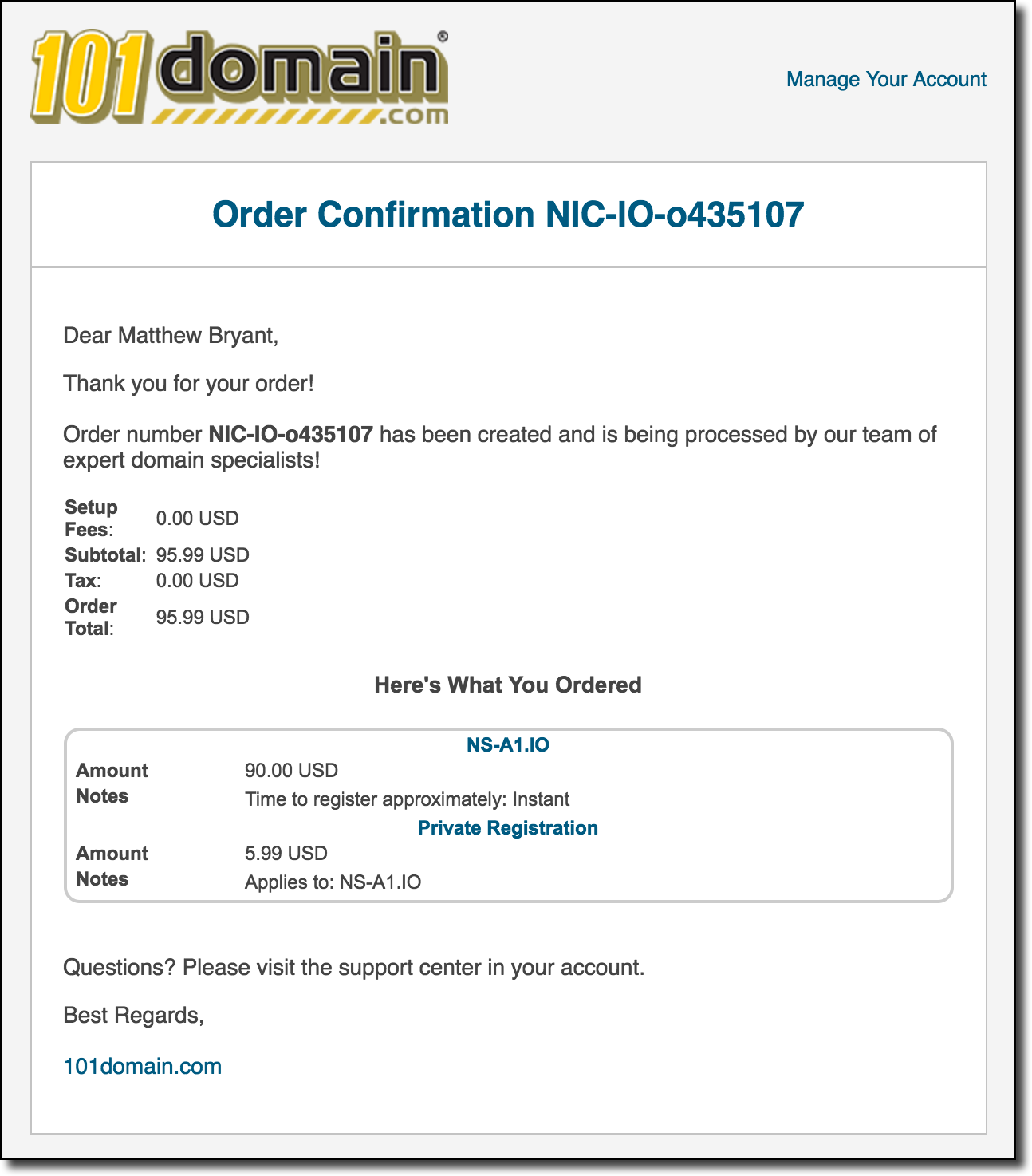
dig для домена — и убедился, что мои тестовые серверы имён DNS (ns1/ns2.networkobservatory.com ) действительно записаны на ns-a1.io:bash-3.2$ dig NS ns-a1.io
; <<>> DiG 9.8.3-P1 <<>> NS ns-a1.io
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 8052
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;ns-a1.io. IN NS
;; ANSWER SECTION:
ns-a1.io. 86399 IN NS ns2.networkobservatory.com.
ns-a1.io. 86399 IN NS ns1.networkobservatory.com.
;; Query time: 4 msec
;; SERVER: 2604:5500:16:32f9:6238:e0ff:feb2:e7f8#53(2604:5500:16:32f9:6238:e0ff:feb2:e7f8)
;; WHEN: Wed Jul 5 08:46:44 2017
;; MSG SIZE rcvd: 84
bash-3.2$bash-3.2$ dig NS io. @k.root-servers.net.
; <<>> DiG 9.8.3-P1 <<>> NS io. @k.root-servers.net.
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 19611
;; flags: qr rd; QUERY: 1, ANSWER: 0, AUTHORITY: 7, ADDITIONAL: 12
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;io. IN NS
;; AUTHORITY SECTION:
io. 172800 IN NS ns-a1.io.
io. 172800 IN NS ns-a2.io.
io. 172800 IN NS ns-a3.io.
io. 172800 IN NS ns-a4.io.
io. 172800 IN NS a0.nic.io.
io. 172800 IN NS b0.nic.io.
io. 172800 IN NS c0.nic.io.
;; ADDITIONAL SECTION:
ns-a1.io. 172800 IN AAAA 2001:678:4::1
ns-a2.io. 172800 IN AAAA 2001:678:5::1
a0.nic.io. 172800 IN AAAA 2a01:8840:9e::17
b0.nic.io. 172800 IN AAAA 2a01:8840:9f::17
c0.nic.io. 172800 IN AAAA 2a01:8840:a0::17
ns-a1.io. 172800 IN A 194.0.1.1
ns-a2.io. 172800 IN A 194.0.2.1
ns-a3.io. 172800 IN A 74.116.178.1
ns-a4.io. 172800 IN A 74.116.179.1
a0.nic.io. 172800 IN A 65.22.160.17
b0.nic.io. 172800 IN A 65.22.161.17
c0.nic.io. 172800 IN A 65.22.162.17
;; Query time: 70 msec
;; SERVER: 2001:7fd::1#53(2001:7fd::1)
;; WHEN: Wed Jul 5 08:46:14 2017
;; MSG SIZE rcvd: 407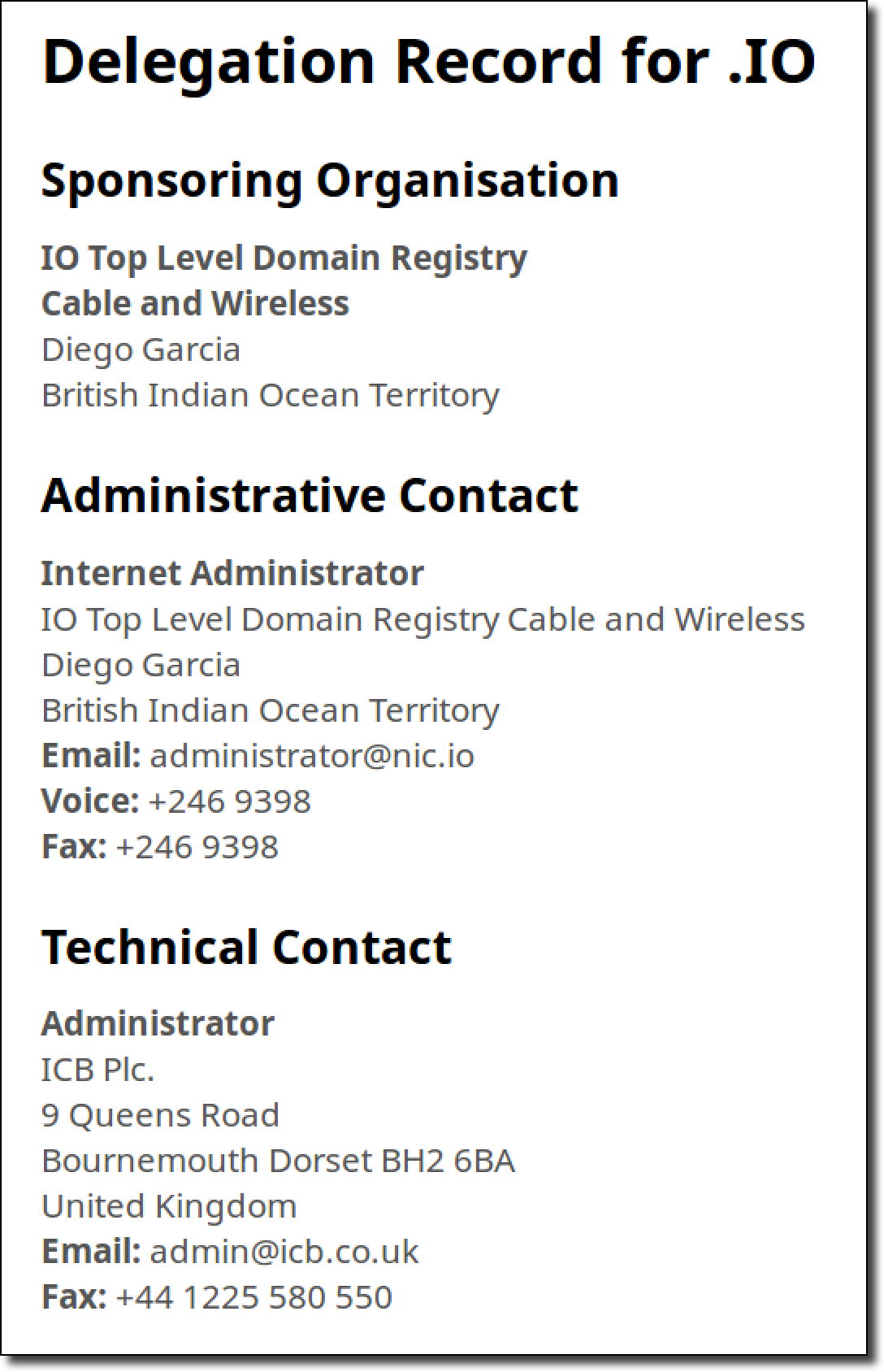


|
Метки: author m1rko администрирование доменных имен it- инфраструктура dns 101domain .io tld доменная зона серверы имен dnssec |
Yet another tutorial: запускаем dotnet core приложение в docker на Linux |

dotnet new -alldotnet new webapidotnet restoredotnet runhttp://localhost:5000/api/values и наслаждаемся работой C# кода на LinuxProgram.cs и в настройке хоста добавляем .UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(Directory.GetCurrentDirectory())
.UseUrls("http://*:5000") // listen on port 5000 on all network interfaces
.UseStartup()
.Build();
host.Run();
}
http://localhost:5000. Проблема в том, что localhost является loopback-интерфейсом и при запуске приложения в контейнере доступен только внутри контейнера. Соответственно, докеризовав dotnet core приложение с дефолтной настройкой прослушиваемых url можно потом довольно долго удивляться, почему проброс портов не работает, и перечитывать свой docker-файл в поисках ошибок.Startup.cs publicpublic Startup(IHostingEnvironment env) и смотрим, что у нашего ConfigurationBuilder вызван метод AddEnvironmentVariables().ConfigurationBuilder вызываем .AddInMemoryCollection(new Dictionary
{
{"InstanseId", Guid.NewGuid().ToString()}
})
public Startup(IHostingEnvironment env) будет выглядеть примерно так:public Startup(IHostingEnvironment env)
{
var builder = new ConfigurationBuilder()
.SetBasePath(env.ContentRootPath)
.AddJsonFile("appsettings.json", optional: false, reloadOnChange: true)
.AddJsonFile($"appsettings.{env.EnvironmentName}.json", optional: true)
.AddInMemoryCollection(new Dictionary
{
{"InstanseId", Guid.NewGuid().ToString()}
})
.AddEnvironmentVariables();
Configuration = builder.Build();
}
public class ValuesControllerSettings
{
public string MyTestParam { get; set; }
public string InstanseId { get; set; }
}
Startup.cs и вносим изменения в ConfigureServices(IServiceCollection services) // This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
//регистрируем экземпляр IСonfiguration
//откуда будет заполняться наш ValuesControllerSettings
services.Configure(Configuration);
// Add framework services.
services.AddMvc();
}
ValuesController и пишем инжекцию через конструктор private readonly ValuesControllerSettings _settings;
public ValuesController(IOptions settings)
{
_settings = settings.Value;
}
using Microsoft.Extensions.Options;.dotnet publish./bin/Debug/[framework]/publish Dockerfile и напишем туда примерно следующее
# базовый образ для нашего приложения
FROM microsoft/dotnet:runtime
# рабочая директория внутри контейнера для запуска команды CMD
WORKDIR /testapp
# копируем бинарники для публикации нашего приложения(напомню,что dockerfile лежит в корневой папке проекта) в рабочую директорию
COPY /bin/Debug/netcoreapp1.1/publish /testapp
# пробрасываем из контейнера порт 5000, который слушает Kestrel
EXPOSE 5000
# при старте контейнера поднимаем наше приложение
CMD ["dotnet","ИмяВашегоСервиса.dll"]
Dockerfile написан, запускаем docker build -t my-cool-service:1.0 . docker imagesdocker run -p 5000:5000 my-cool-service:1.0http://localhost:5000/api/values и наслаждаемся работой C# кода на Linux в dockerdocker imagesdocker psdocker run с флагом -ddocker inspect имя_или_ид_контейнераdocker stop имя_или_ид_контейнера# Delete all containers
docker rm $(docker ps -a -q)
# Delete all images
docker rmi $(docker images -q)
docker-compose.docker-compose.yml, который будет поднимать контейнер нашего приложения и контейнер с nginx (не знаю, зачем он мог понадобиться нам локально при разработке, но для примера сойдет) и настраивать последний, как reverse proxy для нашего приложения.
# версия синтаксиса docker-compose файла
version: '3.3'
services:
# сервис нашего приложения
service1:
container_name: service1_container
# имя образа приложения
image: my-cool-service:1.0
# переменные окружения, которые хотим передать внутрь контейнера
environment:
- MyTestParam=DBForService1
# nginx
reverse-proxy:
container_name: reverse-proxy
image: nginx
# маппинг портов для контейнера с nginx
ports:
- "777:80"
# подкладываем nginx файл конфига
volumes:
- ./test_nginx.conf:/etc/nginx/conf.d/default.conf
docker-compose поднимает при старте между сервисами, описанными в docker-compose файле, локальную сеть и раздает hostname в соотвествии с названиями сервисов. Это позволяет таким сервисам удобно между собой общаться. Воспользуемся этим свойством и напишем простенький файл конфигурации для nginxupstream myapp1 {
server service1:5000; /* мы можем обратится к нашему приложению по имени сервиса из docker-compose файла*/
}
server {
listen 80;
location / {
proxy_pass http://myapp1;
}
}
docker-compose up
docker-compose.yml и получаем nginx, как reverse proxy для нашего приложения. При этом рекомендуется представить, что тут вместо nginx что-то действительно вам полезное и нужное. Например база данных при запуске тестов.dotnet core приложение на Linux, научились собирать и запускать для него docker-образ, а также немного познакомились с docker-compose. dotnet core в продакшене на Linux (не обязательно в docker, хотя в docker особенно интересно) — поделитесь, пожалуйста, впечатлениями от использования в комментариях. Особенно будет интересно услышать про реальные проблемы и то, как их решали.
|
Метки: author Frank59 разработка под linux c# .net asp.net core docker linux |
Тестирование в Openshift: Автоматизированное тестирование |
Это заключительная часть серии из трех статей, которые посвящены автоматизированному тестированию программных продуктов в Openshift Origin. В данной статье будут рассмотрены аспекты тестирования в контейнерах и особенности выстраивания CI/CD при участии таких продуктов как:
Robot Framework — как framework для написания тестов.
Для лучшей репрезентативности я подготовил образ Vagrant, который содержит содержит преднастроенную среду из вышеперечисленных продуктов (все перечисленные в данной статье объекты и механизмы могут быть легко проинспектированы). Чтобы повысить градус понимания материала я создал две задачи: задачу сборки, задачу тестирования. Обе задачи разбиты на этапы и детально описаны.
vagrant box add --name viewshift viewshift-1.0.box && vagrant upСоздание полноценного окружения не входило в мои планы, но проиграв несколько сценариев со связыванием minishift c docker контейнерами пришло понимание, что это категорически неудобно и чревато ошибками. Тренировать воображение читателей с помощью одного текста считаю бесполезным занятием.
По умолчанию окружение стартует в графическом режиме. Сделано это для того, чтобы обойти проблему с доступом к продуктам извне. Настроен автоматический вход пользователя. Пользовательский Firefox содержит сохраненные закладки и учетные данные для доступа к продуктам.
Системные пользователи user и vagrant имеют неограниченный sudo доступ.
Задействованное ПО:
| Название | Версия | Учетные данные |
|---|---|---|
| Openshift | 1.5.1 | admin:admin |
| Jenkins | 2.60.1 | admin:admin |
| Testlink | 1.9.16 | admin:admin |
| Gogs | 0.11.19.0609 | git:git |
| Mariadb | 5.5.52 | root:root |
| OpenShift Pipeline Jenkins Plugin | 1.0.47 | - |
| TestLink Plugin | 3.12 | - |
| Robot Framework plugin | 1.6.4 | - |
| Post-Build Script Plug-in | 0.17 | - |
| system | - | root:root |
| system | - | user:user |
| system | - | vagrant:vagrant |
SHA1:
0992d621809446e570be318067b70fe2b8e786b2 viewshift-1.0.box
Задача сборки подразумевает под собой сборку образа Docker с приложением "curl", которое в последующем будет участвовать в задаче тестирования.
Примечание: в качестве корневого процесса (PID 1) в контейнере используется supervisord. supervisord и другие похожие инструменты очень полезны в тех случаях, когда нужно завершить работу приложения полностью или управлять процессами удаленно.
Принципиальная схема:

Этапы:
Определяем переменные, которые будут задействованы в задаче:
PROJECT — название проекта Openshift. Для данного проекта был создан ServiceAccount "jenkins", который обладает правами администратора в проекте. Данный ServiceAccount используется для доступа к проекту из Jenkins (данный аккаунт также используется в задаче тестирования).
APP_NAME и APP_VERSION — условное название и версия приложения, которые, тем не менее, фигурируют в нескольких местах: название и таг результирующего образа Docker, название запускаемого Build и т.д.
После того, как требуемые переменные были определены (продумана гранулярность/отличимость задач в проекте), требуется разнести их по всем YAML конфигурациям Openshift и другим шагам Jenkins.
На данном этапе создается объект BuildConfig, на базе которого будет создан и выполнен объект Build.
Происходит запуск процесс сборки на основе созданного BuildConfig. В случае успеха результирующий образ будет помещен во внутренний Docker регистр.
Под задачей тестирования подразумевается процесс тестирования приложения "curl", которое взаимодействует с сервисом "nginx" по протоколу HTTP. Мы хотим удостовериться, что приложение работает корректно и проходит заданные тесты.
Принципиальная схема:
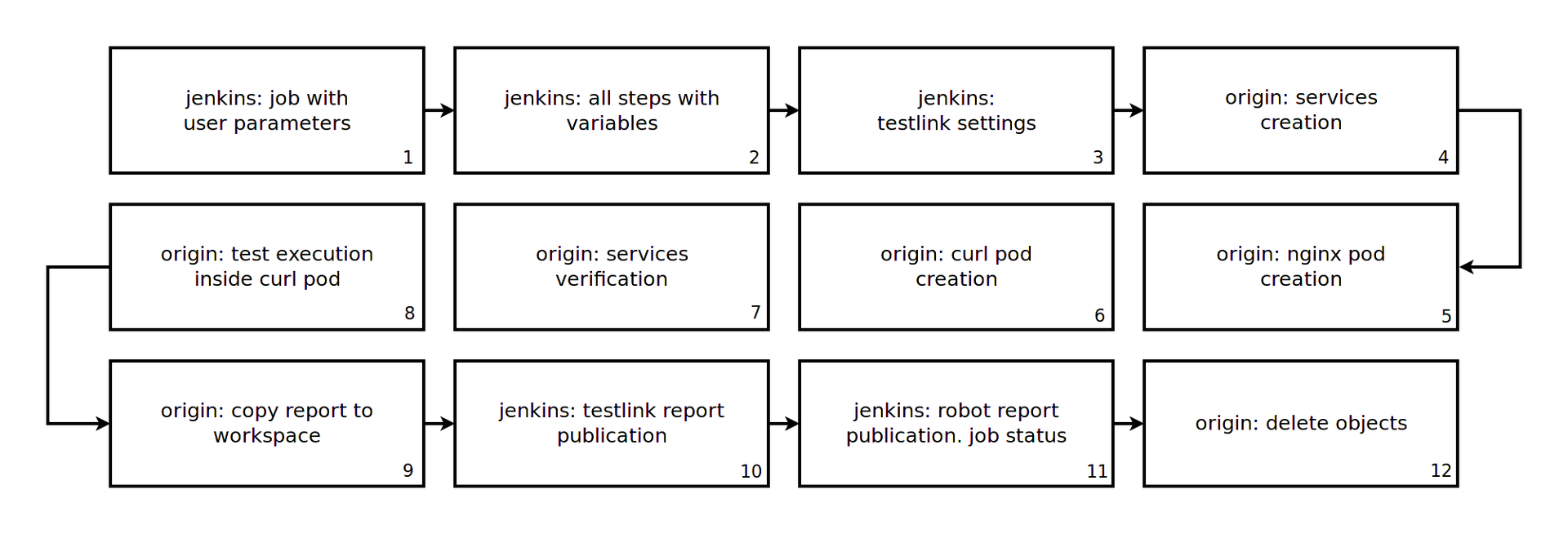
Этапы:
Определяем параметры, которые будут задействованы в задаче:
PROJECT — название проекта Openshift.
TESTPLAN — название тест-плана в Testlink. Задача завершится ошибкой, если указанный тест-план отсутствует в Testlink.
APP_NAME и APP_VERSION — условное название и версия приложения, которые аналогичным образом как и в задаче сборки.
TEST_CMD — переменная, которая содержит название исполняемого файла, который будет запущен внутри контейнера. Аргументы командной строки указаываются в соотвествующем шаге Jenkins.
TEST_TIMEOUT — численное выражение, которое задает время ожидания выполнения команды внутри контейнера. По истечении данного времени Jenkins задача завершает своё выполнение с ошибкой.
см. задачу сборки.
На данном этапе задается конфигурация Testlink, в которой указывается: с каким сервером будет установлена связь, какой тест-план будет использоваться (из тест-плана загружаются все назначенные данном тест-плану тесты для последующего сравнения), под какой платформой проводилось тестирование и т.д. Всё это требуется для последующей публикации пройденных тестов обратно в Testlink и отображения отчета тестирования непосредственно в Jenkins.
Данный этап предназначен для создания Service. Создаваемые сервисы будут указывать на приложения, которые будут запущены позднее. Через данные сервисы осуществляется проверка доступности приложений.
На данном этапе создается Pod для приложения "nginx".
На данном этапе создается Pod для приложения "curl". Образом для данного контейнера является образ, который создается в процессе задачи сборки. В отличии от "nginx", в данный образ добавлен том данных "share", который позволит контейнеру коммуницировать с файловой системой рабочего узла.
После того, как все Pod созданы, требуется проверка доступности приложений через опубликованные раннее сервисы.
На данном этапе происходит запуск команды тестирования в Pod с последующим ожиданием завершения выполнения данной команды.
После прохождения всех тестов происходит копирование отчета о тестировании в workspace задачи для последующего иморта в Testlink.
На данном этапе указывается стратегия (может быть не одна) сопоставления пройденных тестов с тем, что было получено из указанного раннее тест-плана. В данном случае идет простое сравнение названий тест-кейсов. После всех операции происходит публикация отчета о тестировании в Testlink.
Помимо отчета Teslink в формате Junit присутствует отчет о тестировании в формате Robot Framework, который установит статус выполненной задачи исходя из пороговых значений пройденных тестов.
Недостатки:
Плюсы:
Openshift Origin в связке с другими инструментами позволяет добиться впечатляющей гибкости и эффективности. Продуманная схема именования проектов/объектов позволяет избежать возникновения ошибок при массовых запусках задач тестирования.
Хочу выразить благодарность сотрудникам компании Google за то, что сделали такую замечательную платформу.
Хочу выразить благодарность сотрудникам компании Red Hat, которые сделали из замечательной платформы законченный продукт.
|
Метки: author livelace анализ и проектирование систем openshift тестирование |
Тестирование в Openshift: Внутреннее устройство кластера |
Это продолжение серии из трех статей об автоматизированном тестировании программных продуктов в Openshift Origin. В данной статье будут описаны основные объекты Openshift, а также описаны принципы работы кластера. Я осознано не делаю попытку описать все возможные объекты и их особенности, так как это очень трудоемкая задача, которая выходит за рамки данной статьи.
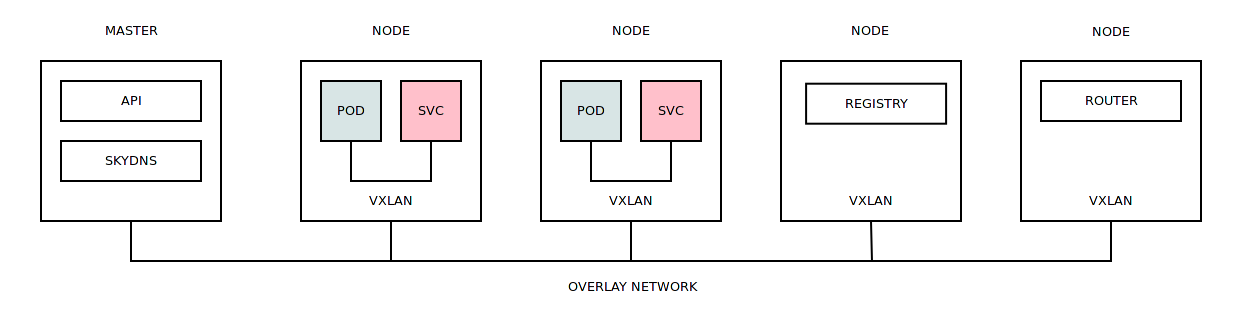
В целом работа кластера Openshift Origin не сильно отличается от других решений. Поступающие задачи распределяются по рабочим узлам на основе их загруженности, данное распределение берет на себя планировщик.
Для запуска контейнеров требуется Docker образа, которые могут быть загружены из внутреннего или внешнего регистра. Непосредственно запуск контейнеров происходит в различных контекстах безопасности (политики безопасности, которые ограничивают доступ контейнера к различным ресурсам).
По умолчанию контейнеры из разных проектов могут коммуницировать друг с другом с помощью overlay сети (выделяется одна большая подсеть, которая разбивается на более мелкие подсети для всех рабочих узлов кластера). Запущенному на рабочем узле контейнеру выделяется IP-адрес из той подсети, которая была назначена данному узлу. Сама overlay сеть построена на базе Open vSwitch, который использует VXLAN для связи между рабочими узлами.
На каждом рабочем узле запускается выделенныё экземпляр Dnsmasq, который перенаправляет все DNS запросы контейнеров на SkyDNS во внутреннюю сервисную подсеть.
Если контейнер аварийно завершил свою работу или просто не может быть проинициализирован, то задача по его развертыванию передается на другой рабочий узел.
Стоит отметить что:
SELinux не является строгим условием работы кластера. Отключение оного (не рекомендуется по соображениям безопасности) привнесет некое увелечение скорости (равно как и отключение мониторинга, кстати) при работе с контейнерами. Если SELinux мешает работе приложения в контейнере, присутствует возможность добавления исключения SELinux непосредственно на рабочем узле кластера.
По умолчанию используется LVM в качестве хранилища Docker Engine. Это далеко не самое быстрое решение, но можно использовать любой другой тип хранилища (BTRFS, например).
Стоит иметь ввиду, что название сервиса (см. Service) — это DNS имя, которое влечет за собой ограничения на длину и допустимые символы.
Чтобы сократить временные и аппаратные издержки при сборке Docker образов можно использовать так называемый "слоистый" подход (multi-stage в Docker). В данном подходе используются базовые и промежуточные образа, которые дополняют друг друга. Имеем базовый образ "centos:7" (полностью обновлен), имеем промежуточный образ "centos:7-tools" (установлены иструменты), имеем финальный образ "centos:7-app" (содержит "centos:7" и "centos:7-tools"). То есть вы можете создавать задачи сборки, которые основываются на других образах (см. BuildConfig).
Достаточно гибким решением является подход, когда существует один проект, который занимается только сборкой Docker образов с последующей "линковкой" данных образов в другие проекты (см. ImageStream). Это позволяет не плодить лишних сущностей в каждом проекте и приведет к некой унификации.
Большинству объектов в кластере можно присвоить произвольные метки, с помощью которых можно совершать массовые операции над данными объектами (удаление определенных контейнеров в проекте, например).
Если приложению требуется некий ядерный функционал ядра Linux, то тогда требуется загрузить данный модуль на всех рабочих узлах, где требуется запуск данного приложения.
Стоит сразу побеспокоиться об удалении старых образов и забытых окружений. Если первое решается с помощью сборщика мусора/oadm prune, то второе требует проработки и ознакомлении всех участников с правилами совместной работы в Openshift Origin.
Любой кластер ограничен ресурсами, поэтому очень желательно организовать мониторинг хотя бы на уровне рабочих узлов (возможен мониторинг на уровне приложения в контейнере). Сделать это можно как с помощью готового решения Openshift Metrics, так и с помощью сторонних решений (Sysdig, например). При наличии метрик загруженности кластера (в целом или по проектно) можно организовать гибкую диспетчерезацию поступающих задач.
Project — объект является Kubernetes namespace. Верхний уровень абстракции, который содержит другие объекты. Созданные в проекте объекты не пересекаются с объектами в других проектах. На проект могут быть выставлены квоты, привилегии, метки узлов кластера и т.д. Вложенная иерархия и наследование между проектами отсутствуют, доступна "плоская" структура проектов. Существуюет несколько системных проектов (kube-system, openshift, openshift-infra), которые предназначены для нормального функционирования кластера.
Создание нового проекта:
oc adm new-project project1 --node-selector='node_type=minion'Редактирование настроек проекта:
oc edit namespace project1# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Namespace
metadata:
annotations:
openshift.io/description: ""
openshift.io/display-name: ""
openshift.io/node-selector: node_type=minion
...Pod — объект, который стал одним из решающих факторов, так как позволяет запускать произвольные команды внутри контейнера с помощью специальных хуков (и не только). Pod является основной рабочей единицей в кластере. Любой запущенный в кластере контйенер — Pod. По своей сути — группа из одного и более контейнеров, которые работают в единых для этих контейнеров namespaces (network, ipc, uts, cgroup), используют общее хранилище данных, секреты. Контейнеры, из которых состоит Pod, всегда запущены на одном узле кластера, а не распределены в одинаковых пропорциях по всем узлам (если Pod будет состоять из 10 контейнеров, все 10 будут работать на одном узле).
Pod:
apiVersion: "v1"
kind: "Pod"
metadata:
name: "nginx-redis"
spec:
containers:
-
name: "nginx"
image: "nginx:latest"
-
name: "redis"
image: "redis:latest"Статус Pod:
NAME READY STATUS RESTARTS AGE
nginx-redis 2/2 Running 0 7sSecret — может являться строкой или файлом, предназначен для проброса чувствительной (хранится в открытом виде в etcd (поддержка шифрования в Kubernetes 1.7)) информации в Pod. Один Secret может содержать множество значений.
Создание Secret:
oc secrets new gitconfig .gitconfig=/home/user/.gitconfigИспользование Secret в BuildConfig:
apiVersion: "v1"
kind: "BuildConfig"
metadata:
name: "nginx-bc"
spec:
source:
type: "Git"
git:
uri: "https://github.com/username/nginx.git"
sourceSecret:
name: "gitconfig"
strategy:
type: "Docker"
dockerStrategy:
dockerfilePath: docker/nginx-custom
noCache: true
output:
to:
kind: "ImageStreamTag"
name: "nginx-custom:latest"ServiceAccount — специальный тип объекта, который предназначен для взаимодействия с ресурсам кластера. По своей сути является системным пользователем.
По умолчанию новый проект содержит три ServiceAccount:
Перечисленные служебные аккаунты:
ServiceAccount:
apiVersion: "v1"
kind: "ServiceAccount"
metadata:
name: "jenkins"Свойства ServiceAccount:
Name: jenkins
Namespace: project1
Labels:
Image pull secrets: jenkins-dockercfg-pvgsr
Mountable secrets: jenkins-dockercfg-pvgsr
jenkins-token-p8bwz
Tokens: jenkins-token-p8bwz
jenkins-token-zsn9p Добавление прав администратора проекта ServiceAccount:
oc policy add-role-to-user admin system:serviceaccount:project1:jenkinsDeploymentConfig — это объект, который оперирует всё теми же Pod, но при этом привносит ряд дополнительных механизмов для управления жизненным циклом запущенных приложений, а именно:
DeploymentConfig:
apiVersion: "v1"
kind: "DeploymentConfig"
metadata:
name: "nginx-dc"
spec:
template:
metadata:
labels:
name: "nginx-dc"
spec:
containers:
-
name: "nginx"
image: "nginx:latest"
replicas: 3
selector:
name: "nginx-dc"Статус DeploymentConfig:
NAME READY STATUS RESTARTS AGE
nginx-dc-1-1wl8m 1/1 Running 0 7s
nginx-dc-1-k3mss 1/1 Running 0 7s
nginx-dc-1-t8qf3 1/1 Running 0 7sImageStream — по своей сути является "контейнером" для "ссылок" (ImageStreamTag), которые указывают на Docker образа или другие ImageStream.
ImageStream:
apiVersion: "v1"
kind: "ImageStream"
metadata:
name: "third-party"Создание тага/ссылки на Docker образ между проектами:
oc tag project2/app:v1 project1/third-party:appСоздание тага/ссылки на Docker образ, который расположен на Docker Hub:
oc tag --source=docker nginx:latest project1/third-party:nginxBuildConfig — объект является сценарием того, как будет собран Docker образ и куда он будет помещен. Сборка нового образа может базироваться на других образах, за это отвечает секция "from:"
Источники сборки (то место, где размещены исходные данные для сборки):
Стратегии сборки (каким образом следует интерпретировать источник данных):
Назначение сборки (куда будет выгружен собранный образ):
BuildConfig:
apiVersion: "v1"
kind: "BuildConfig"
metadata:
name: "nginx-bc"
spec:
source:
type: "Git"
git:
uri: "https://github.com/username/nginx.git"
strategy:
type: "Docker"
dockerStrategy:
from:
kind: "ImageStreamTag"
name: "nginx:latest"
dockerfilePath: docker/nginx-custom
noCache: true
output:
to:
kind: "ImageStreamTag"
name: "nginx-custom:latest"Какие операции выполнит данный BuildConfig:
Service — объект, который стал одним из решающих факторов при выборе системы запуска сред, так как он позволяет гибко настраивать коммуникации между средами (что очень важно в тестировании). В случаях с использованием других систем требовались подготовительные манипуляции: выделить диапазоны IP-адресов, зарегистрировать DNS имена, осуществить проброс портов и т.д. и т.п. Service может быть объявлен до фактического развертывания приложения.
Что происходит во время публикации сервиса в проекте:
Service:
apiVersion: v1
kind: Service
metadata:
name: "nginx-svc"
spec:
selector:
name: "nginx-pod"
ports:
- port: 80
targetPort: 80
name: "http"
- port: 443
targetPort: 443
name: "https"Разрешение DNS имени:
root@nginx-pod:/# ping nginx-svc
PING nginx-svc.myproject.svc.cluster.local (172.30.217.250) 56(84) bytes of data.Переменные окружения:
root@nginx-pod:/# env | grep -i nginx
NGINX_SVC_PORT_443_TCP_ADDR=172.30.217.250
HOSTNAME=nginx-pod
NGINX_VERSION=1.13.1-1~stretch
NGINX_SVC_PORT_80_TCP_PORT=80
NGINX_SVC_PORT_80_TCP_ADDR=172.30.217.250
NGINX_SVC_SERVICE_PORT=80
NGINX_SVC_PORT_80_TCP_PROTO=tcp
NGINX_SVC_PORT_443_TCP=tcp://172.30.217.250:443
NGINX_SVC_SERVICE_HOST=172.30.217.250
NGINX_SVC_PORT_443_TCP_PROTO=tcp
NGINX_SVC_SERVICE_PORT_HTTPS=443
NGINX_SVC_PORT_443_TCP_PORT=443
NGINX_SVC_PORT=tcp://172.30.217.250:80
NGINX_SVC_SERVICE_PORT_HTTP=80
NGINX_SVC_PORT_80_TCP=tcp://172.30.217.250:80Заключение:
Все объекты кластера можно описать с помощью YAML, это, в свою очередь, дает возможность полностью автоматизировать любые процессы, которые протекают в Openshift Origin. Вся сложность в работе с кластером заключается в знании приципов работы и механизмов взаимодействия объектов. Такие рутинные операции как инициализация новых рабочих узлов берут на себя сценарии Ansible. Доступность API открывает возможность работать с кластером напрямую минуя посредников.
|
Метки: author livelace анализ и проектирование систем openshift тестирование |
Интеграция 3D-мыши в Renga |


// Mouse 3D stuff
#include /* Common macros used by SpaceWare functions. */
#include /* Required for any SpaceWare support within an app.*/
#include /* Required for siapp.lib symbols */
#include "virtualkeys.hpp"
bool init3DMouse()
{
SiOpenData oData;
/*init the SpaceWare input library */
if (SiInitialize() == SPW_DLL_LOAD_ERROR)
return false;
SiOpenWinInit(&oData, (HWND)winId()); /* init Win. platform specific data */
SiSetUiMode(mouse3DHandle, SI_UI_ALL_CONTROLS); /* Config SoftButton Win Display */
/* open data, which will check for device type and return the device handle
to be used by this function */
if ( (mouse3DHandle = SiOpen ("HabrahabrAnd3DMouse", SI_ANY_DEVICE, SI_NO_MASK, SI_EVENT, &oData)) == NULL)
{
SiTerminate(); /* called to shut down the SpaceWare input library */
return false; /* could not open device */
}
else
{
return true; /* opened device succesfully */
}
}
typedef struct /* 3DxWare event */
{
int type; /* Event type */
union
{
SiSpwData spwData; /* Button, motion, or combo data */
SiSpwOOB spwOOB; /* Out of band message */
SiOrientation spwOrientation; /* Which hand orientation is the device */
char exData[SI_MAXBUF]; /* Exception data. Driver use only */
SiKeyboardData spwKeyData; /* String for keyboard data */
SiSyncPacket siSyncPacket; /* GUI SyncPacket sent to applications */
SiHWButtonData hwButtonEvent; /* V3DKey that goes with *
* SI_BUTTON_PRESS/RELEASE_EVENT */
SiAppCommandData appCommandData; /* Application command event function data that *
* goes with an SI_APP_EVENT event */
SiDeviceChangeEventData deviceChangeEventData; /* Data for connecting/disconnecting devices */
SiCmdEventData cmdEventData; /* V3DCMD_* function data that *
* goes with an SI_CMD_EVENT event */
} u;
} SiSpwEvent;
bool HabrahabrAnd3DMouse::nativeEventFilter(const QByteArray &eventType, void *msg, long *)
{
if(!mouse3DHandle)
return false;
MSG* winMSG = (MSG*)msg;
bool handled = SPW_FALSE;
SiSpwEvent Event; /* SpaceWare Event */
SiGetEventData EData; /* SpaceWare Event Data */
/* init Window platform specific data for a call to SiGetEvent */
SiGetEventWinInit(&EData, winMSG->message, winMSG->wParam, winMSG->lParam);
/* check whether msg was a 3D mouse event and process it */
if (SiGetEvent (mouse3DHandle, SI_AVERAGE_EVENTS, &EData, &Event) == SI_IS_EVENT)
{
if (Event.type == SI_MOTION_EVENT)
{
qDebug() << "delta by X coordinate = " << Event.u.spwData.mData[SI_TX] << "\n";
qDebug() << "delta by Y coordinate = " << Event.u.spwData.mData[SI_TY] << "\n";
qDebug() << "delta by Z coordinate = " << Event.u.spwData.mData[SI_TZ] << "\n";
qDebug() << "delta by Yaw = " << Event.u.spwData.mData[SI_RX] << "\n";
qDebug() << "delta by Pitch = " << Event.u.spwData.mData[SI_RY] << "\n";
qDebug() << "delta by Roll = " << Event.u.spwData.mData[SI_RZ] << "\n";
}
else if (Event.type == SI_ZERO_EVENT)
{
// ZERO event
}
else if (Event.type == SI_BUTTON_EVENT)
{
// misc button events
}
handled = SPW_TRUE; /* 3D mouse event handled */
}
return handled;
}
|
|
«Доктор Веб»: портал gosuslugi.ru скомпрометирован и может начать заражать посетителей или красть информацию |
На портале государственных услуг Российской Федерации (gosuslugi.ru) специалисты компании «Доктор Веб» обнаружили внедрённый неизвестными потенциально вредоносный код. В связи с отсутствием реакции со стороны администрации сайта gosuslugi.ru мы вынуждены прибегнуть к публичному информированию об угрозе.
Дату начала компрометации, а также прошлую активность по этому вектору атаки, установить на данный момент не представляется возможным. Вредоносный код заставляет браузер любого посетителя сайта незаметно связываться с одним из не менее 15 доменных адресов, зарегистрированных на неизвестное частное лицо. В ответ с этих доменов может поступить любой независимый документ, начиная от фальшивой формы ввода данных кредитной карточки и заканчивая перебором набора уязвимостей с целью получить доступ к компьютеру посетителя сайта.
В процессе динамического генерирования страницы сайта, к которой обращается пользователь, в код сайта добавляется контейнер , позволяющий загрузить или запросить любые сторонние данные у браузера пользователя. На текущий момент специалистами обнаружено не менее 15 доменов, среди которых: m3oxem1nip48.ru, m81jmqmn.ru и другие адреса намеренно неинформативных наименований. Как минимум для 5 из них диапазон адресов принадлежит компаниям, зарегистрированным в Нидерландах. За последние сутки запросы к этим доменам либо не завершаются успехом, так как сертификат безопасности большинства этих сайтов просрочен, либо не содержит вредоносного кода, однако ничего не мешает владельцам доменов в любой момент обновить сертификаты и разместить на этих доменах вредоносный программный код.
На данный момент сайт gosuslugi.ru по-прежнему скомпрометирован, информация передана в техническую поддержку сайта, но подтверждения принятия необходимых мер по предотвращению инцидентов в будущем и расследования в прошлом не получено. «Доктор Веб» рекомендует проявлять осторожность при использовании портала государственных услуг Российской Федерации до разрешения ситуации. ООО «Доктор Веб» рекомендует администрации сайта gosuslugi.ru и компетентным органам осуществить проверку безопасности сайта.
Любой пользователь может проверить наличие кода самостоятельно, использовав поисковый сервис и задав запрос о поиске следующей формулировки:
site:gosuslugi.ru "A1996667054"
|
Метки: author doctorweb хранение данных сетевые технологии серверное администрирование it- инфраструктура блог компании доктор веб gosuslugi dr.web iframe |
Авторизация OAuth для Xamarin-приложений |


Предполагается, что вы уже знакомы с тем, как работает OAuth, а если нет — рекомендуем вот эту хорошую статью на Хабре. Если коротко, то при авторизации OAuth пользователь перенаправляется с одной веб-страницы на другую (обычно 2-3 шага) до тех пор, пока не перейдет на конечный URL. Этот финальный переход и будет отловлен в приложении (если писать логику самому) на уровне WebView, а нужные данные (token и срок его валидности) будут указаны прямо в URL.
Небольшой список популярных сервисов, которые предоставляют возможность авторизации пользователей по OAuth: Одноклассники, Mail.ru, Dropbox, Foursquare, GitHub, Instagram, LinkedIn, Microsoft, Slack, SoundCloud, Visual Studio Online, Trello.
Для того, чтобы работать с OAuth в Xamarin мы остановимся на простой и удобной библиотеке Xamarin.Auth, которая развивается уже не первый год и имеет все необходимые для нас механизмы:
Также Xamarin.Auth поддерживает возможность хранения учетных данных пользователя в защищенном хранилище. В общем, зрелый и качественный компонент с необходимой функциональностью.
Рекомендуем устанавливать Xamarin.Auth из Nuget, так как версия в Xamarin Components уже давно устарела и не обновляется.

Напомню, что мы уже ранее рассказывали про авторизацию с помощью SDK от Facebook и ВКонтакте. В нашем примере мы вынесли всю логику авторизации в платформенные проекты, оставив в PCL только интерфейсы. Для OAuth мы пойдем тем же путем, несмотря на поддержку PCL в самом Xamarin.Auth.
Помимо Xamarin.Auth можем также порекомендовать библиотеку Xamarin.Forms.OAuth от Bruno Bernardo. Даже если вы используете классический Xamarin, в исходных кодах этого проекта можно найти множество готовых конфигураций для различных сервисов.
Мы же в качестве примера работы OAuth подключим авторизацию с помощью Microsoft. Первым делом создадим приложение на сайте https://apps.dev.microsoft.com и получим там Client ID (ИД клиента или приложения).
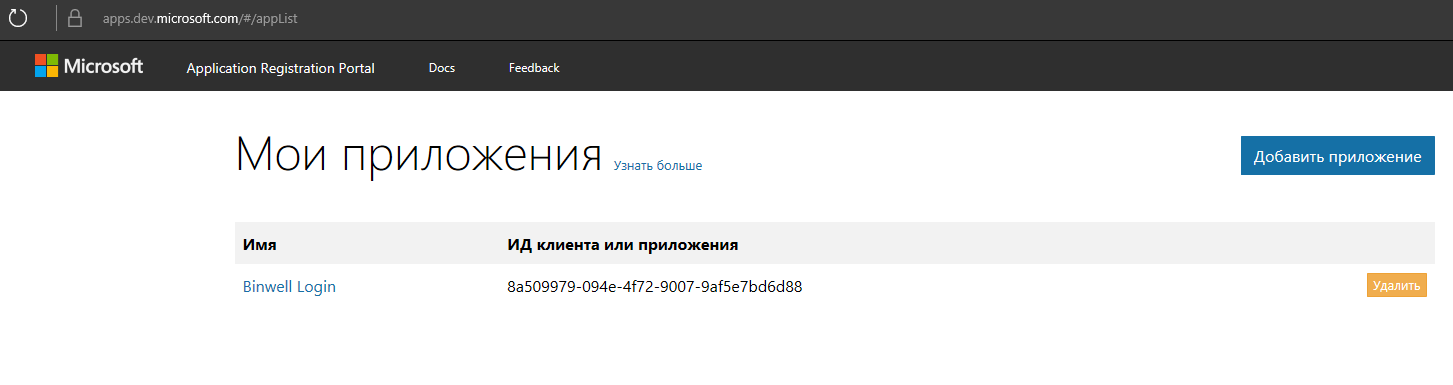
На уровне PCL все как обычно — делаем простой интерфейс IOAuthService для платформенного сервиса, никаких новых зависимостей в проект не добавляем.
public interface IOAuthService
{
Task Login();
void Logout();
} Ну и, конечно же, будет необходимо добавить обращение к методам DependencyService.Get и DependencyService.Get внутри нашей страницы авторизации.
Также нет проблем добавить поддержку нескольких OAuth-сервисов. Для этого можно добавить в методы Login() и Logout() аргумент providerName (тип string, int или enum) и в зависимости от его значения выбирать поставщика услуг.
Как уже отмечалось ранее, необходимо добавить библиотеки Xamarin.Auth из Nuget в каждый платформенный проект, в нашем случае — iOS и Android. Дальше пишем нашу реализацию IOAuthService для каждой платформы и регистрируем ее в качестве Dependency.
Теперь нам достаточно создать экземпляр класса OAuth2Authenticator с нужными параметрами:
var auth = new OAuth2Authenticator
(
clientId: "ВАШ_CLIENT_ID",
scope: "wl.basic, wl.emails, wl.photos",
authorizeUrl: new Uri("https://login.live.com/oauth20_authorize.srf"),
redirectUrl: new Uri("https://login.live.com/oauth20_desktop.srf"),
clientSecret: null,
accessTokenUrl: new Uri("https://login.live.com/oauth20_token.srf")
)
{
AllowCancel = true
};Теперь повесим обработчик завершения авторизации:
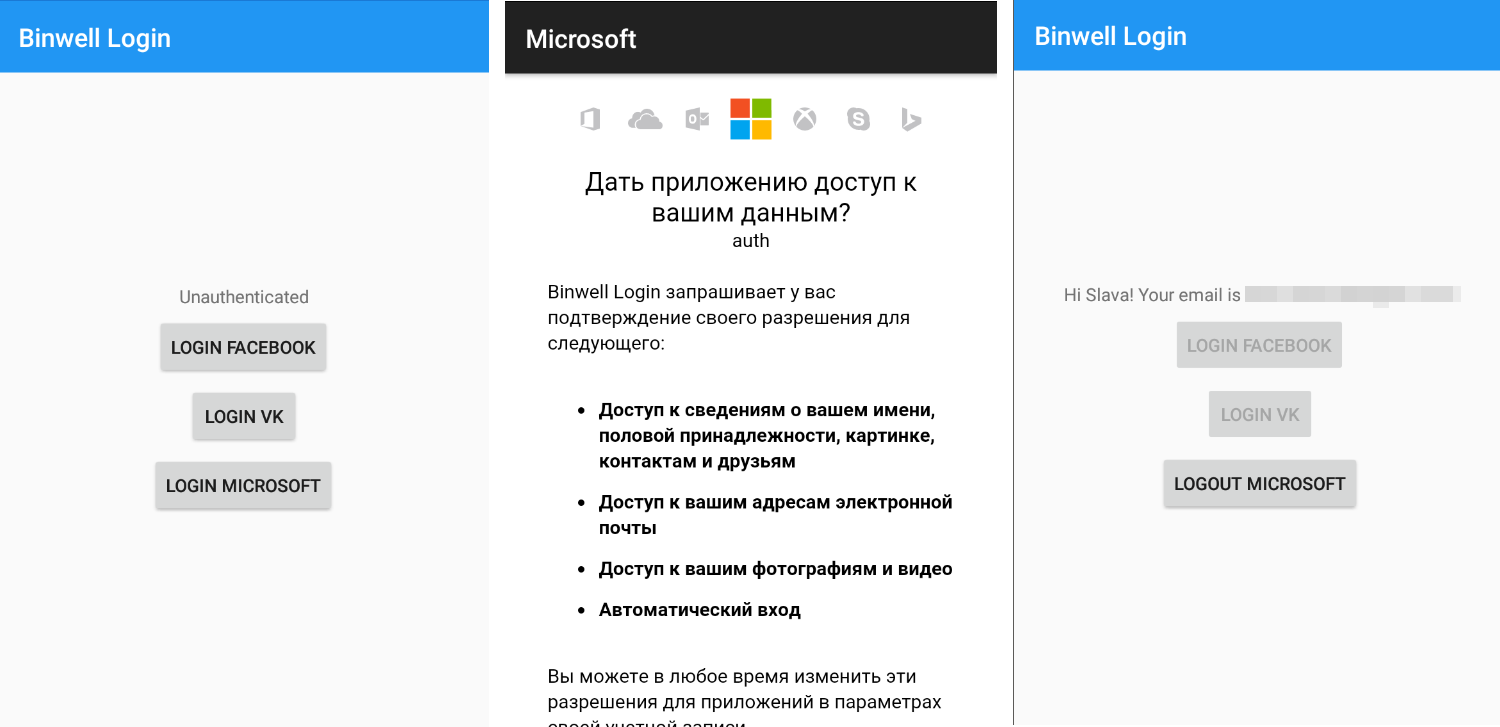
auth.Completed += AuthOnCompleted;Всё, можно показать модальное окно со встроенным веб-браузером для авторизации, получаемое через метод auth.GetUI(). На iOS это можно сделать примерно так:
UIApplication.SharedApplication.KeyWindow.RootViewController.PresentViewController(auth.GetUI(), true, null);На Android при использовании Xamarin.Forms код может получится следующим:
Forms.Context.StartActivity(auth.GetUI(Forms.Context));После успешной авторизации вызовется наш метод AuthOnCompleted(), и для iOS будет необходимо скрыть модальное окно с браузером (на Android само скроется):
UIApplication.SharedApplication.KeyWindow.RootViewController.DismissViewController(true, null);Теперь можно получать нужные данные (access_token и время его жизни в секундах — expires_in)
var token = authCompletedArgs.Account.Properties["access_token"];
var expireIn = Convert.ToInt32(authCompletedArgs.Account.Properties["expires_in"]);
var expireAt = DateTimeOffset.Now.AddSeconds(expireIn);И нам остался последний шаг — получить расширенную информацию из профиля пользователя, включая email и ссылку на аватарку. Для этого в Xamarin.Auth есть специальный класс OAuth2Request с помощью которого удобно делать подобные запросы.
var request = new OAuth2Request("GET", new Uri("https://apis.live.net/v5.0/me"), null, account);
var response = await request.GetResponseAsync();Теперь нам приходит JSON с данными пользователя, и мы можем их сохранить и отобразить в приложении.
if (response.StatusCode == HttpStatusCode.OK)
{
var userJson = response.GetResponseText();
var jobject = JObject.Parse(userJson);
result.LoginState = LoginState.Success;
result.Email = jobject["emails"]?["preferred"].ToString();
result.FirstName = jobject["first_name"]?.ToString();
result.LastName = jobject["last_name"]?.ToString();
result.ImageUrl = jobject["picture"]?["data"]?["url"]?.ToString();
var userId = jobject["id"]?.ToString();
result.UserId = userId;
result.ImageUrl = $"https://apis.live.net/v5.0/{userId}/picture";
}Как видим, ничего сложного нет. Вопрос в том, чтобы правильно прописать URL для процесса авторизации. Ну и помнить, что поле expires_in содержит время в секундах (это вызывает частые вопросы).
В реальных проектах также рекомендуем назначить обработчик ошибок на событие auth.Error, чтобы ни одна проблема не осталась без решения.
Сегодня мы завершили рассмотрение всех популярных способов авторизации пользователей и получения базовой информации о них через внешние сервисы. Описанные механизмы подходят как для Xamarin.Forms, так и для классического Xamarin iOS/Android. Полные исходные коды проекта со всеми примерами можно найти в нашем репозитории:
https://bitbucket.org/binwell/login
Задавайте ваши вопросы в комментариях к статье и оставайтесь на связи!
 Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.
Вячеслав Черников — руководитель отдела разработки компании Binwell, Microsoft MVP и Xamarin Certified Developer. В прошлом — один из Nokia Champion и Qt Certified Specialist, в настоящее время — специалист по платформам Xamarin и Azure. В сферу mobile пришел в 2005 году, с 2008 года занимается разработкой мобильных приложений: начинал с Symbian, Maemo, Meego, Windows Mobile, потом перешел на iOS, Android и Windows Phone. Статьи Вячеслава вы также можете прочитать в блоге на Medium.|
|
[Из песочницы] Noty.js V3 — шикарная javascript библиотека для создания уведомлений. А также готовый плагин для vuejs |
import Noty from 'noty';
new Noty({
text: 'Some notification text',
}).show();
new Noty({
text: 'Some notification text',
animation: {
open : 'animated fadeInRight',
close: 'animated fadeOutRight'
}
}).show();
// минимальным опцией для запуска уведомления является текст
this.$notice.info("New version of the app is available!")
// также, легко переопределить стандартные настройки
// они основаны на опциях плагина
this.$notice.info("Hey! Something very important here...", {
timeout: 6000,
layout: 'topLeft'
})
|
Метки: author nikitamarcius0 node.js javascript noty.js vuejs |
[recovery mode] 7 способов улучшить дизайн сайта |
Иллюстрации помогут сделать дружелюбным даже самый минималистичный дизайн.

У каждого шрифта свой характер. Постарайтесь выбрать тот шрифт, который передаст настроение текста за счет графического образа.








Чтобы выбрать цветовое решение, определите целевую аудиторию и сообщение, которое хотите до нее донести.





|
Метки: author blognetology интерфейсы веб-дизайн usability блог компании нетология дизайн сайтов типографика иллюстрации нетология |






