[Перевод] AWS DeepLearning AMI — почему (и как) его стоит использовать |
Иногда хорошие вещи приходят бесплатно ...
Для тех из вас, кто не знает, что такое AMI, позвольте мне процитировать официальную документацию по этому вопросу:
Amazon Machine Image (AMI) предоставляет данные, необходимые для запуска экземпляра виртуального сервера в облаке. Вы настраиваете AMI при запуске экземпляра, и вы можете запустить столько экземпляров из AMI, сколько вам нужно. Вы также можете запускать экземпляры виртуальных машин из множества различных AMI, сколько вам нужно.
Этого должно быть достаточно, чтобы понять остальную часть статьи, однако я бы посоветовал потратить некоторое время на официальную документацию об AMI.
Глубокое обучение или глубинное (англ. Deep learning) — набор алгоритмов машинного обучения, которые пытаются моделировать высокоуровневые абстракции в данных, используя архитектуры, состоящие из множества нелинейных преобразований
Глубокое обучение является частью более широкого семейства методов машинного обучения, которые подбирают представление данных. Наблюдение (например, изображение) может быть представлено многими способами, такими как вектор интенсивности значений на пиксель, или (в более абстрактной форме) как множество примитивов, областей определенной формы, и т. д.
С другой стороны есть и мнения, что глубокое обучение — не что иное, как модное слово или ребрендинг для нейронных сетей. Wiki.
Обучение (тренировку) нейронных сетей можно делать 2-мя путями: с использование CPU или с использованием GPU. Думаю ни для кого не секрет что обучение с помощью GPU показывает лучшие результаты, с точки зрения скорости(а как следствие и затрат), чем обучение с помощью CPU, поэтому все современные системы машинного обучения поддерживают GPU. Однако, чтобы использовать все преимущества GPU мало просто иметь этот самый GPU, вам необходимо еще "по приседать":
Так что же нужно сделать что бы решить все эти 4 незадачи? Есть 2 варианта:
Оба случая имеют разные плюсы и минусы, однако есть один большой минус для этих вариантов — оба требуют от пользователя некоторых технических знаний. Это основная причина, по которой не так много людей, как хотелось бы, тренируют нейронные сети на GPU.
Как DLAMI может решить эту проблему? Да легко, дело в том, что DLAMI, это первое бесплатное решение, включающее все, что необходимо прямо из коробки:
Аль, к слову, список фреймворков, которые работают из коробки:
DLAMI можно использовать с GPU-совместимым машинами на AWS, например P2 или G2:
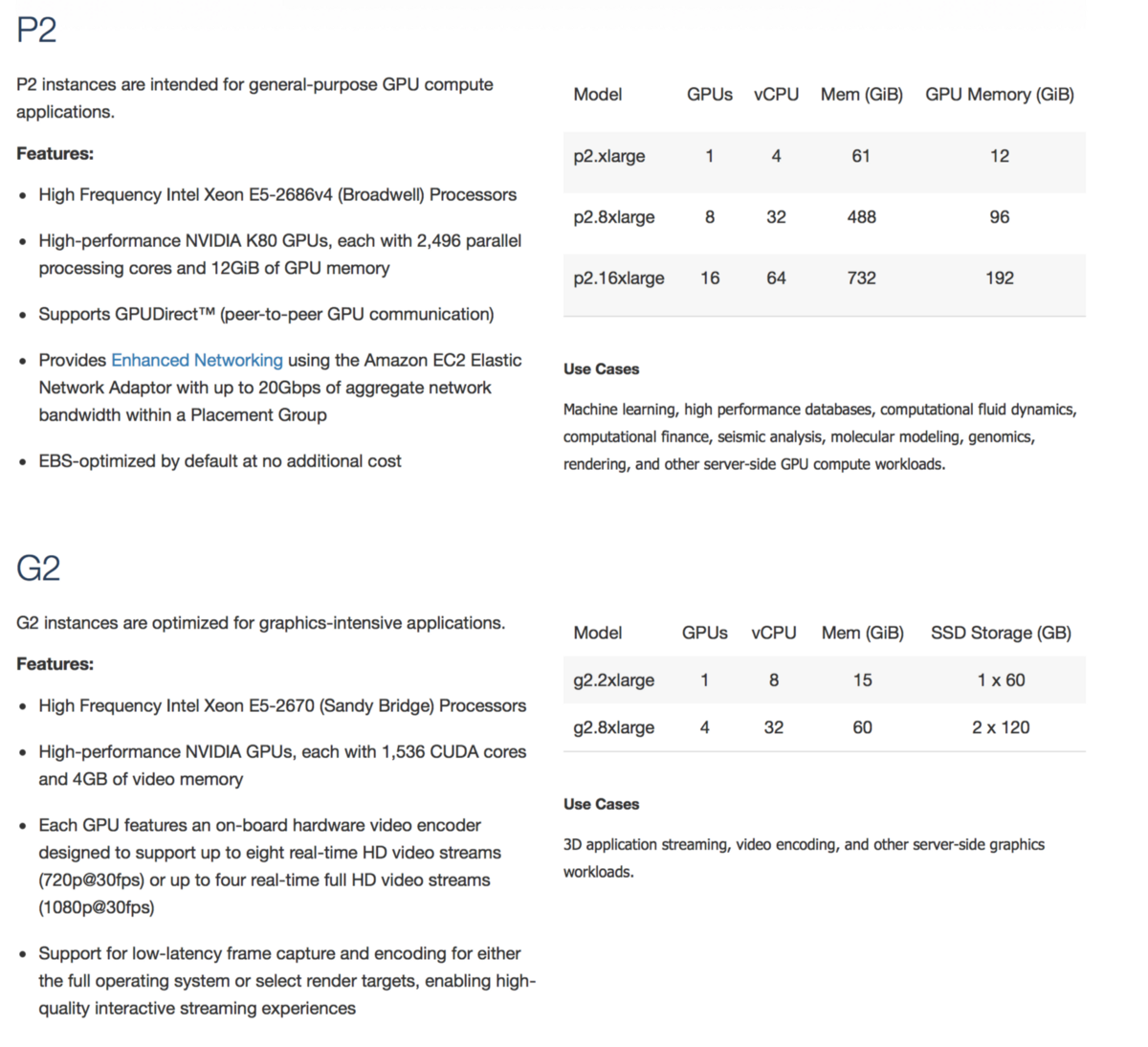
Можете, кстати, попробовать поиграться со свеже выпущенными G3
Надеюсь, теперь у нас есть ответ на вопрос: почему и кому нужно использовать DLAMI. Теперь давайте обсудим ответ на следующий вопрос ...
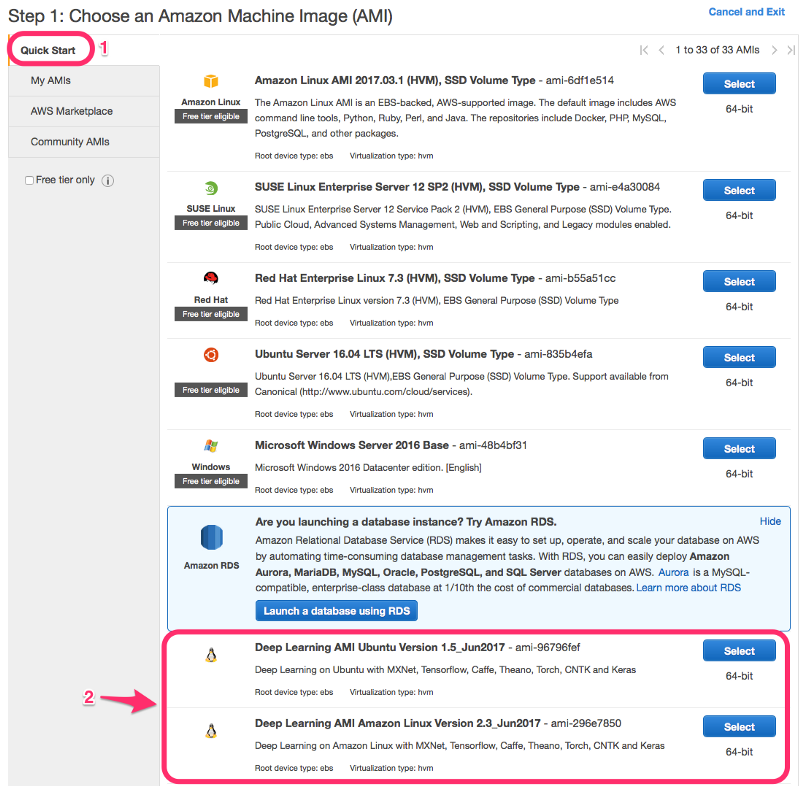
Для этого сначала нужно выбрать, какой вариант DLAMI более предпочтителен:
Если с типом DLAMI определились то перейдем с способам создания машин на базе DLAMI:
Консоль EC2 фактически предоставляет два способа ее создания, обычное создание:
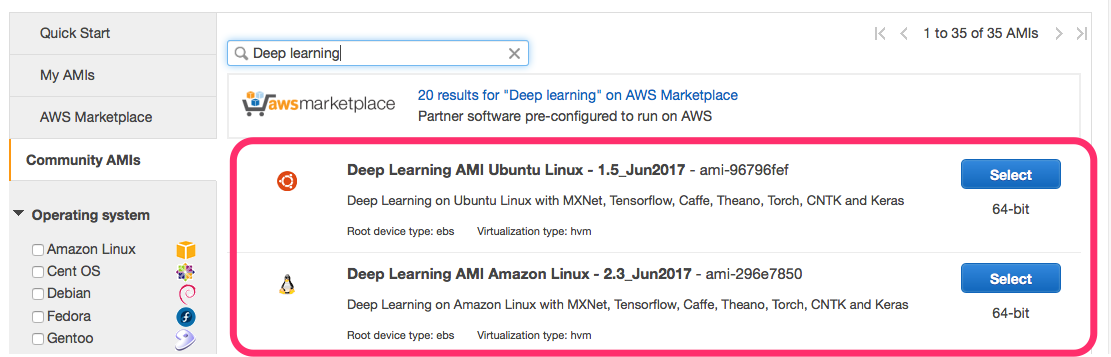
И ускоренное создание консоли EC2, применяя конфигурацию по умолчанию:
Существует одна оговорка, которую необходимо обсудить. Поскольку все фреймворки построены с нуля, вы не можете просто так взять и обновить их до последней версии, есть риск получить версию фреймворка, которая не собрана с поддержкой GPU (или не совместима с версией CUDA). Так что обновляйте пакеты на свой страх и риск!
Согласен, это затрудняет переход на новые версии фреймворков, поскольку вам нужно перейти на новый AMI, а не просто обновить пакет. В свою очередь переход на новую AMI может быть болезненным. Поэтому имейте это в виду, создавая новый экземпляр виртуальной машины, я бы посоветовал вам создать отдельную EBS для хранения ваших данных, которую вы можете легко отмонтировать и использовать с новым экземпляром виртуальной машины с обновленной версией AMI. Ну или храните данные в репозитории.
На практике я обнаружил, что это не такая уж большая проблема для машин которые используется не продолжительно в исследовательских целях. Плюс DLAMI, обычно, включает в себя достаточно свежие версии фреймворков.
|
Метки: author b0noII машинное обучение amazon web services aws mxnet deep learning aws ec2 dlami |
IBM и ВВС США разрабатывают нейроморфный суперкомпьютер нового поколения |


|
Метки: author ibm машинное обучение высокая производительность блог компании ibm нейромфорный компьютер компьютеры |
Security Week 28: а Petya сложно открывался, в Android закрыли баг чипсета Broadcomm, Copycat заразил 14 млн девайсов |
 Прошлогодний троянец-криптолокер Petya, конечно, многое умеет – ломает MBR и шифрует MFT, но сделаться столь же знаменитым как его эпигоны, у него не вышло. Но вся эта история с клонами – уничтожителями данных, видимо, настолько расстроила Януса, автора первенца, что тот взял и выложил закрытый ключ от него.
Прошлогодний троянец-криптолокер Petya, конечно, многое умеет – ломает MBR и шифрует MFT, но сделаться столь же знаменитым как его эпигоны, у него не вышло. Но вся эта история с клонами – уничтожителями данных, видимо, настолько расстроила Януса, автора первенца, что тот взял и выложил закрытый ключ от него.Congratulations!
Here is our secp192k1 privkey:
38dd46801ce61883433048d6d8c6ab8be18654a2695b4723
We used ECIES (with AES-256-ECB) Scheme to encrypt the decryption password into the "Personal Code" which is BASE58 encoded.
 Помимо Broadpwn в cвежее обновление Google попали патчи еще для 11 критических дыр, в том числе для RCE-бага CVE-2017-0540, который позволяет через специально созданный файл запускать код в контексте привилегированного процесса. Присутствует эта “черная дыра” в Android 5.0.2, 5.1.1, 6.0, 6.0.1, 7.0, 7.1.1 и 7.1.2. Патчи получат владельцы Nexus и Pixel, остальные – как повезет. В общем, то самое чувство, когда Google при очередном апдейте устраняет сразу несколько RCE-уязвимостей, но ты понимаешь, что на твой смартфон, выпущенный год назад, патча не будет никогда.
Помимо Broadpwn в cвежее обновление Google попали патчи еще для 11 критических дыр, в том числе для RCE-бага CVE-2017-0540, который позволяет через специально созданный файл запускать код в контексте привилегированного процесса. Присутствует эта “черная дыра” в Android 5.0.2, 5.1.1, 6.0, 6.0.1, 7.0, 7.1.1 и 7.1.2. Патчи получат владельцы Nexus и Pixel, остальные – как повезет. В общем, то самое чувство, когда Google при очередном апдейте устраняет сразу несколько RCE-уязвимостей, но ты понимаешь, что на твой смартфон, выпущенный год назад, патча не будет никогда.

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw petya expetr android google copycat broadpwn |
[Перевод] Реверс-инжиниринг одной строчки JavaScript |

Reverse Engineering One Line of JavaScript : https://t.co/QsTzYBvWbu cc @akras14
— Binni Shah (@binitamshah) July 13, 2017
code.js, а p закавычил в id="p".
k — просто константа, так что убрал её из строчки и переименовал в delay.var delay = 64;
var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var n = setInterval(draw, delay);var draw был просто строкой, которая исполнялась как функция eval с периодичностью setInterval, поскольку setInterval может принимать и функции, и строки. Я перенёс var draw в явную функцию, но сохранил изначальную строку для справки на всякий случай.p в действительности ссылался на элемент DOM с идентификатором p, объявленным в HTML, который я недавно закавычил. Оказывается, на элементы в JavaScript можно ссылаться по их идентификатору, если id состоит только из букв и цифр. Я добавил document.getElementById("p"), чтобы сделать код понятнее.var delay = 64;
var p = document.getElementById("p"); // < --------------
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
for (n += 7, i = delay, P = 'p.\n'; i -= 1 / delay; P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2]) {
j = delay / i; p.innerHTML = P;
}
};
var n = setInterval(draw, delay);i, p и j и перенёс их в начало функции.var delay = 64;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
var i = delay; // < ---------------
var P ='p.\n';
var j;
for (n += 7; i > 0 ;P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2]) {
j = delay / i; p.innerHTML = P;
i -= 1 / delay;
}
};
var n = setInterval(draw, delay);for и преобразовал его в цикл while. Из трёх частей прежнего for осталась только одна часть CHECK_EVERY_LOOP, а всё остальное (RUNS_ONCE_ON_INIT; DO_EVERY_LOOP) перенёс за пределы цикла.var delay = 64;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
var i = delay;
var P ='p.\n';
var j;
n += 7;
while (i > 0) { // <----------------------
//Update HTML
p.innerHTML = P;
j = delay / i;
i -= 1 / delay;
P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2];
}
};
var n = setInterval(draw, delay);( condition ? do if true : do if false) in P += P[i % 2 ? (i % 2 * j - j + n / delay ^ j) & 1 : 2];.i%2 проверяет, является переменная i чётной или нечётной. Если она четная, то просто возвращает 2. Если нечётная, то возвращает «магическое» значение magic (i % 2 * j - j + n / delay ^ j) & 1; (подробнее об этом чуть позже).index и превратим строку в P += P[index];.var delay = 64;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
var i = delay;
var P ='p.\n';
var j;
n += 7;
while (i > 0) {
//Update HTML
p.innerHTML = P;
j = delay / i;
i -= 1 / delay;
let index;
let iIsOdd = (i % 2 != 0); // <---------------
if (iIsOdd) { // <---------------
index = (i % 2 * j - j + n / delay ^ j) & 1;
} else {
index = 2;
}
P += P[index];
}
};
var n = setInterval(draw, delay);& 1 из значения index = (i % 2 * j - j + n / delay ^ j) & 1 в ещё один оператор if.& — это побитовый оператор AND. Он работает так:something & 1 преобразует "something" в двоичное представление, а также добивает перед единицей необходимое количество нулей, чтобы соответствовать размеру "something", и возвращает просто результат AND последнего бита. Например, 5 в двоичном формате равняется 101, так что если мы применим на ней логическую операцию AND с единицей, то получится следующее: 101
AND 001
0010 & 1 // 0 - even return 0
1 & 1 // 1 - odd return 1
2 & 1 // 0 - even return 0
3 & 1 // 1 - odd return 1
4 & 1 // 0 - even return 0
5 & 1 // 1 - odd return 1index в magic, так что код с развёрнутым &1 будет выглядеть следующим образом:var delay = 64;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
var i = delay;
var P ='p.\n';
var j;
n += 7;
while (i > 0) {
//Update HTML
p.innerHTML = P;
j = delay / i;
i -= 1 / delay;
let index;
let iIsOdd = (i % 2 != 0);
if (iIsOdd) {
let magic = (i % 2 * j - j + n / delay ^ j);
let magicIsOdd = (magic % 2 != 0); // &1 < --------------------------
if (magicIsOdd) { // &1 <--------------------------
index = 1;
} else {
index = 0;
}
} else {
index = 2;
}
P += P[index];
}
};
var n = setInterval(draw, delay);P += P[index]; в оператор switch. К этому моменту стало понятно, что index может принимать только одно из трёх значений — 0, 1 или 2. Также понятно, что переменная P всегда инициализируется со значениями var P ='p.\n';, где 0 указывает на p, 1 указывает на ., а 2 указывает на \n — символ новой строкиvar delay = 64;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
var draw = function() {
var i = delay;
var P ='p.\n';
var j;
n += 7;
while (i > 0) {
//Update HTML
p.innerHTML = P;
j = delay / i;
i -= 1 / delay;
let index;
let iIsOdd = (i % 2 != 0);
if (iIsOdd) {
let magic = (i % 2 * j - j + n / delay ^ j);
let magicIsOdd = (magic % 2 != 0); // &1
if (magicIsOdd) { // &1
index = 1;
} else {
index = 0;
}
} else {
index = 2;
}
switch (index) { // P += P[index]; <-----------------------
case 0:
P += "p"; // aka P[0]
break;
case 1:
P += "."; // aka P[1]
break;
case 2:
P += "\n"; // aka P[2]
}
}
};
var n = setInterval(draw, delay);var n = setInterval(draw, delay);. Метод setInterval возвращает целые числа, начиная с единицы, увеличивая значение при каждом вызове. Это целое число может использоваться для clearInterval (то есть для отмены). В нашем случае setInterval вызывается всего один раз, а переменная n просто установилась в значение 1.delay в DELAY для напоминания, что это всего лишь константа.i % 2 * j - j + n / DELAY ^ j для указания, что у ^ (побитового XOR) меньший приоритет, чем у операторов %, *, -, + и /. Другими словами, сначала выполнятся все вышеупомянутые вычисления, а уже потом ^. То есть получается (i % 2 * j - j + n / DELAY) ^ j).p.innerHTML = P; //Update HTML в цикл, так что я убрал его оттуда.const DELAY = 64; // approximately 15 frames per second 15 frames per second * 64 seconds = 960 frames
var n = 1;
var p = document.getElementById("p");
// var draw = "for(n+=7,i=delay,P='p.\\n';i-=1/delay;P+=P[i%2?(i%2*j-j+n/delay^j)&1:2])j=delay/i;p.innerHTML=P";
/**
* Draws a picture
* 128 chars by 32 chars = total 4096 chars
*/
var draw = function() {
var i = DELAY; // 64
var P ='p.\n'; // First line, reference for chars to use
var j;
n += 7;
while (i > 0) {
j = DELAY / i;
i -= 1 / DELAY;
let index;
let iIsOdd = (i % 2 != 0);
if (iIsOdd) {
let magic = ((i % 2 * j - j + n / DELAY) ^ j); // < ------------------
let magicIsOdd = (magic % 2 != 0); // &1
if (magicIsOdd) { // &1
index = 1;
} else {
index = 0;
}
} else {
index = 2;
}
switch (index) { // P += P[index];
case 0:
P += "p"; // aka P[0]
break;
case 1:
P += "."; // aka P[1]
break;
case 2:
P += "\n"; // aka P[2]
}
}
//Update HTML
p.innerHTML = P;
};
setInterval(draw, 64);i установлено на 64 посредством var i = DELAY;, а затем каждый цикл оно уменьшается на 1/64 (0,015625) через i -= 1 / DELAY;. Цикл продолжается, пока i больше нуля (код while (i > 0) {). Поскольку за каждый проход i уменьшается на 1/64, то требуется 64 цикла, прежде чем оно уменьшится на единицу (64/64 = 1). В целом уменьшение i произойдёт 64x64 = 4096 раз, чтобы уменьшиться до нуля.i может быть чётным (не нечётным let iIsOdd = (i % 2 != 0);), если i является строго чётным числом. Такое произойдёт 32 раза, когда оно равняется 64, 62, 60 и т. д. Эти 32 раза index примет значение 2 index = 2;, а к строке добавится символ новой строки: P += "\n"; // aka P[2]. Остальные 127 символов в строке примут значения p или ..p, а когда .?. при нечётном значении let magic = ((i % 2 * j - j + n / DELAY) ^ j);, или установить p, если «магия» чётная.var P ='p.\n';
...
if (magicIsOdd) { // &1
index = 1; // second char in P - .
} else {
index = 0; // first char in P - p
}magic чётное, а когда нечётное? Это вопрос на миллион долларов. Перед тем как перейти к нему, давайте определим ещё кое-что.+ n/DELAY из let magic = ((i % 2 * j - j + n / DELAY) ^ j);, то получится статическая картинка, на которой вообще ничего не двигается:
magic без + n/DELAY. Как получилась эта красивая картинка?(i % 2 * j - j) ^ j j = DELAY / i;
i -= 1 / DELAY;j через конечное i как j = DELAY/ (i + 1/DELAY). Но поскольку 1/DELAY слишком малое число, то для этого примера можно отбросить + 1/DELAY и упростить выражение до j = DELAY/i = 64/i.(i % 2 * j - j) ^ j как i % 2 * 64/i - 64/i) ^ 64/i.i%2.
64/i, то получим такой график:


(i % 2 * j - j) ^ j принимает чётное значение, то нужно добавить p, а для нечётного числа нужно добавить ..i имеет значения от 64 до 32.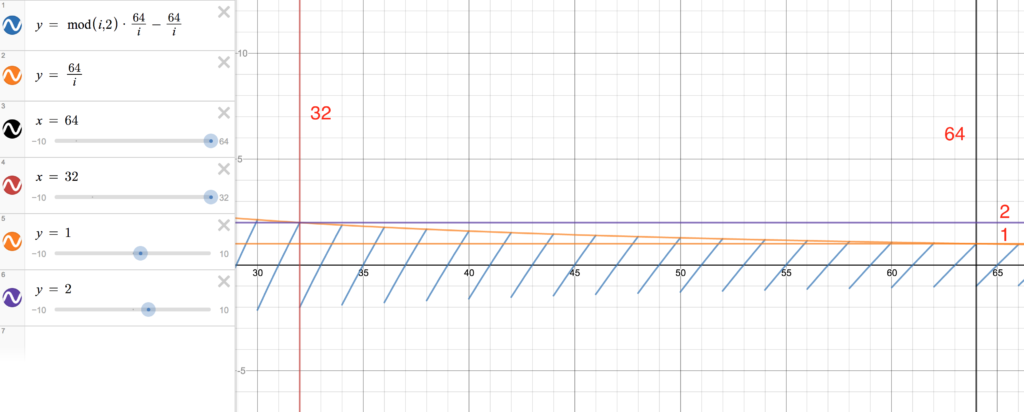
Math.floor, который округляет число в меньшую сторону.j начинается с единицы и медленно продвигается к двойке, останавливаясь прямо около неё, так что можем считать её всегда единицей при округлении в меньшую сторону (Math.floor(1.9999) === 1), и нам нужна ещё одна единица с левой стороны, чтобы получить в результате ноль и дать нам p.(i % 2 * j - j) ^ j, она же i % 2 * i/64 — i/64, то есть зелёная диагональ, тоже будет выше 1 или ниже -1.1 ^ 1 // 0 - even p
1.1 ^ 1.1 // 0 - even p
0.9 ^ 1 // 1 - odd .
0 ^ 1 // 1 - odd .
-1 ^ 1 // -2 - even p
-1.1 ^ 1.1 // -2 - even pp). Следующая выходит чуть дальше за эти границы, третья — ещё чуть дальше и т. д. Линия номер 16 едва удерживается в границах между 2 и -2. После линии 16 мы видим, что наш статический график меняет свой характер.
j пересекает лимит 2, так что меняется ожидаемый результат. Теперь мы получим чётное число, если зелёная диагональная линия выше 2 или ниже -2, или внутри рамок 1 и -1, но не соприкасается с ними. Вот почему мы видим на картинке две или больше групп символов p начиная с 17-й строки.+ n/DELAY. В коде мы видим, что значение n начинается с 8 (1 от setInteval и плюс 7 на каждый вызов метода). Затем оно увеличивается на 7 при каждом срабатывании setInteval. 
j по-прежнему находится около единицы, но теперь левая половина красной диагонали в пределах примерно 62-63 находится примерно около нуля, а правая половина в пределах примерно 63-64 — около единицы. Поскольку наши символы появляются в убывающем порядке от 64 к 62, то можно ожидать, что правая половина диагонали в районе 63-64 (1 ^ 1 = 0 // even) добавит кучку символов p, а левая половина диагонали в районе 62-63 (1 ^ 0 = 1 // odd) добавит кучку точек. Всё это будет нарастать слева направо, как обычный текст.n в редакторе CodePen и посмотреть). Это совпадает с нашими ожиданиями.
p выросло до постоянной величины. Например, в первом ряду половина всех значений всегда будут чётными. Теперь символы p и . будут только меняться местами.n увеличивается на 7 на следующем вызове setInterval, график немного изменится.

n будет равняться 64+9x7.
j по-прежнему равняется 1. Теперь верхняя половина красной диагонали около отметки 64 примерно упирается в два, а нижний конец около единицы. Это переворачивает картинку в другую сторону, поскольку теперь 1^2 = 3 // odd - . и 1 ^ 1 = 0 //even - p. Так что можно ожидать кучу точек, за которыми пойдут символы p.
|
Метки: author m1rko реверс-инжиниринг ненормальное программирование занимательные задачки визуализация данных javascript обратная разработка минимализм демо |
Цикл стартапа: как (в общем) работает венчурное инвестирование |
|
Метки: author Roman_Yankovskiy законодательство и it-бизнес венчурные инвестиции бизнес-модели цикл стартапа книга стартапы; финансирование; инвесторы |
Чемпионы мира — о спортивном программировании |








|
Метки: author DataArt спортивное программирование алгоритмы c++ блог компании dataart icpc acm icpc итмо олимпиадное программирование |
[Перевод] Scala коллекции: секреты и трюки |
Представляю вашему вниманию перевод статьи Павла Фатина Scala Collections Tips and Tricks. Павел работает в JetBrains и занимается разработкой Scala плагина для IntelliJ IDEA. Далее, повествование идет от лица автора.
В этой статье вы найдете упрощения и оптимизации, характерные для повседневного использования API Scala коллекций.
Некоторые советы основаны на тонкостях реализации библиотеки коллекций, однако большинство рецептов — это разумные преобразования, которые на практике часто упускаются из виду.
Этот список вдохновлен моими попытками разработать практичные инспекции для Scala коллекций, для Scala плагина IntelliJ. Сейчас мы внедряем эти инспекции, так что, используя Scala плагин в IDEA, вы автоматически выигрываете от статического анализа кода.
Тем не менее, эти рецепты ценны сами по себе. Они могут помочь вам углубить понимание стандартной библиотеки коллекций Scala и сделать ваш код быстрее и выразительнее.
Обновление:
Если вы испытываете тягу к приключениям,
вы можете узнать, как помочь в развитии IntelliJ плагина для Scala и попробовать свои силы в реализации, подобрав подходящую инспекцию.
Содержание:
1. Легенда
2. Композиция
3. Побочные эффекты
4. Последовательности (Sequences)
4.1. Создание
4.2. Длина
4.3. Равенство
4.4. Индексация
4.5. Существование
4.6. Фильтрация
4.7. Сортировка
4.8. Свертка
4.9. Сопоставление
4.10. Перерабатываем
5. Множества (Sets)
6. Option-ы
6.1. Значение
6.2. Null
6.3. Обработка
6.4. Перерабатываем
7. Таблицы
8. ДополнениеВсе примеры кода доступны в репозитории на GitHub.
Чтобы сделать примеры кода понятней, я использовал следующие обозначения:
seq — экземпляр основанной на Seq коллекции, вроде Seq(1, 2, 3)set — экземпляр Set, например Set(1, 2, 3)array — массив, такой как Array(1, 2, 3)option — экземпляр Option, например, Some(1)map — экземпляр Map, подобный Map(1 -> "foo", 2 -> "bar")??? — произвольное выражениеp — предикат функции типа T => Boolean, например _ > 2n — целочисленное значениеi — целочисленный индексf, g — простые функции, A => Bx, y — некоторые произвольные значенияz — начальное или значение по умолчаниюP — паттернПомните, вопреки тому, что рецепты изолированы и самодостаточны, их можно скомпоновать для последующего постепенного превращения в более продвинутые выражения:
seq.filter(_ == x).headOption != None
// от seq.filter(p).headOption к seq.find(p)
seq.find(_ == x) != None
// от option != None к option.isDefined
seq.find(_ == x).isDefined
// от seq.find(p).isDefined к seq.exists(p)
seq.exists(_ == x)
// от seq.exists(_ == x) к seq.contains(x)
seq.contains(x)Так, мы можем полагаться на "заменяющую модель применения рецептов" (аналогично SICP), и использовать ее для упрощения сложных выражений.
"Побочный эффект" (Side effect) это основное понятие, которое стоит рассмотреть перед тем, как мы перечислим основные преобразования.
По сути, побочный эффект — любое действие, которое наблюдается за пределами функции или выражения помимо возврата значения, например:
О функциях или выражениях, содержащих любое из вышеперечисленных действий, говорят, что они имеют побочные эффекты, в противном случае их называют «чистыми».
Почему побочные эффекты так важны? Потому что с ними порядок исполнения имеет значение. Например, два «чистых» выражения, (связанных с соответствующими значениями):
val x = 1 + 2
val y = 2 + 3Так как они не содержат побочных эффектов (т.е. эффектов, наблюдаемых вне выражений), мы можем вычислить эти выражения в произвольном порядке — сначала x, а затем y или сначала y, а затем x — это не повлияет на корректность полученных результатов (мы можем даже закешировать результирующие значения, если того захотим). Теперь рассмотрим следующую модификацию:
val x = { print("foo"); 1 + 2 }
val y = { print("bar"); 2 + 3 }А это уже другая история — мы не можем изменить порядок выполнения, потому что в нашем терминале будет напечатано "barfoo" вместо "foobar" (и это явно не то, чего хотелось).
Так, присутствие побочных эффектов сокращает число возможных преобразований (как упрощений, так и оптимизаций), которые мы можем применить к коду.
Схожие рассуждения применимы и к родственным коллекциям, выражениям. Представим, что где-то за пределами области видимости у нас есть некий builder:
seq.filter(x => { builder.append(x); x > 3 }).headOptionВ принципе, вызов seq.filter(p).headOption упрощается до seq.find(p), впрочем, наличие побочного эффекта не дает нам это сделать:
seq.find( x => {builder.append(x); x > 3 })Хотя эти выражения и эквивалентны с позиции конечного значения, они не эквивалентны касательно побочных эффектов. Первое выражение добавит все элементы, а последнее отбросит все элементы, как только найдет первое совпадающее с предикатом значение. Поэтому такое упрощение сделать нельзя.
Что можно сделать для того, чтобы автоматическое упрощение стало возможным? Ответ — это золотое правило, которого следует придерживаться по отношению ко всем побочным эффектам в нашем коде (включая тот, где коллекций нет в принципе):
Поэтому нам нужно либо избавиться от builderа (вместе с его API, в котором есть побочные эффекты), либо отделить вызов builderа от чистого выражения. Предположим, что этот builder является неким сторонним объектом, изжить который мы не можем, так что нам остается лишь изолировать вызов:
seq.foreach(builder.append)
seq.filter(_ > 3).headOptionТеперь мы можем благополучно выполнить преобразование:
seq.foreach(builder.append)
seq.find(x > 3)Чисто и красиво! Изоляция побочных эффектов сделала возможным автоматическое преобразование. Дополнительная выгода еще и в том, что из-за присутствия четкого разделения, человеку легче понять получившийся код.
Наименее очевидным и при этом наиболее важным преимуществом изоляции побочных эффектов будет улучшение надежности нашего кода вне зависимости от других возможных оптимизаций. Касательно примера: первоначальное выражение может порождать различные побочные эффекты, зависящие от текущей реализации Seq. Для Vector, например, оно добавит все элементы, для Stream оно пропустит все элементы после первого удачного сопоставления с предикатом (потому что стримы «ленивы» — элементы вычисляются только тогда, когда это необходимо). Отделение побочных эффектов позволяет нам избежать этих неопределенностей.
Хотя советы в этом разделе и относятся к наследникам Seq, некоторые преобразования допустимы и для других типов коллекций (и не коллекций), например: Set, Option, Map и даже Iterator (потому что все они предоставляют похожие интерфейсы с монадическими методами).
// До
Seq[T]()
// После
Seq.empty[T]Некоторые неизменяемые (immutable) классы коллекций имеют синглтон-реализацию метода empty. Однако, далеко не все фабричные методы проверяют длину созданных коллекций. Так что, обозначив пустоту на этапе компиляции, вы можете сохранить либо место в куче (путем переиспользования экземпляра), либо такты процессора (которые могли бы быть потрачены на проверки размерности во время выполнения).
Также применимо к: Set, Option, Map, Iterator.
length вместо size// До
array.size
// После
array.lengthХотя size и length по существу синонимы, в Scala 2.11 вызовы Array.size по-прежнему выполняются через неявное преобразование (implicit conversion), таким образом создавая промежуточные объекты-обертки для каждого вызова метода. Если вы, конечно, не включите эскейп анализ для JVM, временные объекты станут обузой для сборщика мусора и ухудшат производительность кода (особенно внутри циклов).
// До
!seq.isEmpty
!seq.nonEmpty
// После
seq.nonEmpty
seq.isEmptyПростые свойства содержат меньше визуального шума, чем составные выражения.
Также применимо к: Set, Option, Map, Iterator.
// До
seq.length > 0
seq.length != 0
seq.length == 0
// После
seq.nonEmpty
seq.nonEmpty
seq.isEmptyС одной стороны, простое свойство воспринимается гораздо легче, чем составное выражение. С другой стороны, наследникам LinearSeq (таким как List) может потребоваться O(n) времени на вычисление длины списка (вместо O(1) для IndexedSeq), таким образом мы можем ускорить наш код, избегая вычисления длины, когда нам, вобщем-то, это значение не очень-то и нужно.
Имейте также в виду, что вызов .length для бесконечных стримов может никогда не закончиться, поэтому всегда проверяйте стрим на пустоту явно.
Также применимо к: Set, Map.
// До
seq.length > n
seq.length < n
seq.length == n
seq.length != n
// После
seq.lengthCompare(n) > 0
seq.lengthCompare(n) < 0
seq.lengthCompare(n) == 0
seq.lengthCompare(n) != 0Поскольку расчет размера коллекции может быть достаточно «дорогим» вычислением для некоторых типов коллекций, мы можем сократить время сравнения с O(length) до O(length min n) для наследников LinearSeq (которые могут быть спрятаны под Seq-подобными значениями). Кроме того, такой подход незаменим, когда имеем дело с бесконечными стримами.
exists для проверки на пустоту// До
seq.exists(_ => true)
seq.exists(const(true))
// После
seq.nonEmptyРазумеется, такой трюк будет совсем излишним.
Также применимо к: Set, Option, Map, Iterator.
== для сравнения содержимого массивов// До
array1 == array2
// После
array1.sameElements(array2)Проверка на равенство всегда будет выдавать false для различных экземпляров массивов.
Также применимо к: Iterator.
// До
seq == set
// После
seq.toSet == setПроверки на равенство могут быть использованы для сравнения коллекций и различных категорий (например List и Set).
Прошу вас дважды подумать о смысле данной проверки (касательно примера выше — как рассматривать дубликаты в последовательности).
sameElements для сравнения обыкновенных коллекций// До
seq1.sameElements(seq2)
// После
seq1 == seq2Проверка равенства — это способ, которым следует сравнивать коллекции одной и той же категории. В теории это может улучшить производительность из-за наличия возможных низлежащих проверок экземпляра (eq, обычно намного быстрее).
// До
seq1.corresponds(seq2)(_ == _)
// После
seq1 == seq2У нас уже есть встроенный метод, который делает тоже самое. Оба выражения принимают во внимание порядок элементов. И мы опять-таки сможем выиграть пользу от повышения производительности.
// До
seq(0)
// После
seq.headДля некоторых классов коллекций обновленный подход может быть немного быстрее (ознакомьтесь с кодом List.apply, например). К тому же, доступ к свойству намного проще (как синтаксически, так и семантически), чем вызов метода с аргументом.
// До
seq(seq.length - 1)
// После
seq.lastПоследнее выражение будет понятней и позволит избежать ненужного вычисления длины коллекции (а для линейных последовательностей это может занять немало времени). Более того, некоторые классы коллекций могут извлекать последний элемент более эффективно в сравнении с доступом по индексу.
// До
if (i < seq.length) Some(seq(i)) else None
// После
seq.lift(i)Семантически второе выражение эквивалентно, однако более выразительно
// До
if (seq.nonEmpty) Some(seq.head) else None
seq.lift(0)
// После
seq.headOptionУпрощенное выражение более лаконично.
lastOption// До
if (seq.nonEmpty) Some(seq.last) else None
seq.lift(seq.length - 1)
// После
seq.lastOptionПоследнее выражение короче (и потенциально быстрее).
indexOf и lastIndexOf// До
Seq(1, 2, 3).indexOf("1") // скомпилируется
Seq(1, 2, 3).lastIndexOf("2") // скомпилируется
// После
Seq(1, 2, 3).indexOf(1)
Seq(1, 2, 3).lastIndexOf(2)Из-за особенностей работы вариантности, методы indexOf и lastIndexOf принимают аргументы типа Any. На практике это может приводить к труднонаходимым багам, которые невозможно обнаружить на этапе компиляции. Вот где будут к месту вспомогательные инспекции вашей IDE.
// До
Range(0, seq.length)
// После
seq.indicesУ нас есть встроенный метод, который возвращает диапазон из всех индексов последовательности.
// До
seq.zip(seq.indices)
// После
seq.zipWithIndexВо-первых, последнее выражение короче. Кроме того, мы можем ожидать некоторый прирост производительности, из-за того, что мы избегаем скрытого вычисления размера коллекции (что в случае линейных последовательностей может обойтись недешево).
Дополнительное преимущество последнего выражения в том, что оно хорошо работает с потенциально бесконечными коллекциями (например Stream).
// До (seq: IndexedSeq[T])
Seq(1, 2, 3).map(seq(_))
// После
Seq(1, 2, 3).map(seq)Поскольку экземпляр IndexedSeq[T] также является Function1[Int, T], вы можете использовать его как таковой.
// До
seq.exists(_ == x)
// После
seq.contains(x)Второе выражение семантически эквивалентно, при этом более выразительно. Когда эти выражения применяются к Set, производительность может разительно отличаться, потому что поиск у множеств стремится к O(1) (из-за внутреннего индексирования, не использующегося при вызове exists).
Также применимо к: Set, Option, Iterator.
contains// До
Seq(1, 2, 3).contains("1") // компилируется
// После
Seq(1, 2, 3).contains(1)Так же как методы indexOf и lastIndexOf, contains принимает аргументы типа Any, что может привести к труднонаходимым багам, которые не обнаруживаются на этапе компиляции. Будьте с ними осторожны.
// До
seq.forall(_ != x)
// После
!seq.contains(x)И снова последнее выражение чище и, вероятно, быстрее (особенно для множеств).
Также применимо к: Set, Option, Iterator.
// До
seq.count(p) > 0
seq.count(p) != 0
seq.count(p) == 0
// После
seq.exists(p)
seq.exists(p)
!seq.exists(p)Очевидно, когда нам нужно знать, находится ли соответствующий условию элемент в коллекции, подсчет количества удовлетворяющих элементов будет излишним. Упрощенное выражение выглядит чище и работает быстрее.
p должен быть чистой функцией.Set, Map, Iterator.// До
seq.filter(p).nonEmpty
seq.filter(p).isEmpty
// После
seq.exists(p)
!seq.exists(p)Вызов filter создает промежуточную коллекцию, которая занимает место в куче и нагружает GC. К тому же, предшествующие выражения находят все вхождения, в то время как требуется найти только первое (что может замедлить код в зависимости от возможного содержимого коллекции). Потенциальный выигрыш в производительности менее значим для ленивых коллекций (таких как Stream и, в особенности, Iterator).
p должен быть чистой функцией.Set, Option, Map, Iterator.// До
seq.find(p).isDefined
seq.find(p).isEmpty
// После
seq.exists(p)
!seq.exists(p)Поиск определенно лучше фильтрации, однако и это далеко не предел (по крайней мере, с точки зрения ясности).
Также применимо к: Set, Option, Map, Iterator.
// До
seq.filter(!p)
// После
seq.filterNot(p)Последнее выражение синтактически проще (при том, что семантически они эквивалентны).
Также применимо к: Set, Option, Map, Iterator.
// До
seq.filter(p).length
// После
seq.count(p)Вызов filter создает промежуточную (и не очень-то нужную) коллекцию, которая будет занимать место в куче и нагружать GC.
Также применимо к: Set, Option, Map, Iterator.
// До
seq.filter(p).headOption
// После
seq.find(p)Конечно, если seq не является ленивой коллекцией (как, например, Stream), фильтрация найдет все вхождения (и создаст временную коллекцию) при том, что требовался только первый элемент.
Также применимо к: Set, Option, Map, Iterator.
// До
seq.sortWith(_.property < _.property)
// После
seq.sortBy(_.property)Для этого у нас есть свой метод, более ясный и выразительный.
// До
seq.sortBy(identity)
seq.sortWith(_ < _)
// После
seq.sortedИ для этого тоже есть метод.
// До
seq.sorted.reverse
seq.sortBy(_.property).reverse
seq.sortWith(f(_, _)).reverse
// После
seq.sorted(Ordering[T].reverse)
seq.sortBy(_.property)(Ordering[T].reverse)
seq.sortWith(!f(_, _))Таким образом, мы можем избежать создания промежуточной коллекции и исключить дополнительные преобразования (чтобы сберечь место в куче и циклы процессора).
// До
seq.sorted.head
seq.sortBy(_.property).head
// После
seq.min
seq.minBy(_.property)Последний подход более выразителен. Кроме того, из-за того что не создается дополнительная коллекция, работать он будет быстрее.
// До
seq.sorted.last
seq.sortBy(_.property).last
// После
seq.max
seq.maxBy(_.property)Объяснение совпадает с предыдущим советом.
// До
seq.reduce(_ + _)
seq.fold(z)(_ + _)
// После
seq.sum
seq.sum + zПреимущества этого подхода — ясность и выразительность.
reduceLeft, reduceRight, foldLeft, foldRight.z равняется 0.Set, Iterator.// До
seq.reduce(_ * _)
seq.fold(z)(_ * _)
// После
seq.product
seq.product * zПричины те же, что и в предыдущем случае.
z равняется 1.Set, Iterator.// До
seq.reduce(_ min _)
seq.fold(z)(_ min _)
// После
seq.min
z min seq.minОбоснование такое же, как и в предыдущем случае.
Также применимо к: Set, Iterator.
// До
seq.reduce(_ max _)
seq.fold(z)(_ max _)
// После
seq.max
z max seq.maxВсе как и в предыдущем случае.
Также применимо к: Set, Iterator.
forall// До
seq.foldLeft(true)((x, y) => x && p(y))
!seq.map(p).contains(false)
// После
seq.forall(p)Цель упрощения — ясность и выразительность.
p должен быть чистой функцией.Set, Option (для второй строки), Iterator.exists// До
seq.foldLeft(false)((x, y) => x || p(y))
seq.map(p).contains(true)
// После
seq.exists(p)При всей ясности и выразительности, последнее выражение может работать быстрее (оно останавливает последующую обработку элементов, как только найдет первый подходящий элемент), что может работать для бесконечных последовательностей.
p должен быть чистой функцией.Set, Option (для второй строки), Iterator.map// До
seq.foldLeft(Seq.empty)((acc, x) => acc :+ f(x))
seq.foldRight(Seq.empty)((x, acc) => f(x) +: acc)
// После
seq.map(f)Это «классическая» в функциональном программировании реализация отображения (map) через свертку. Бесспорно, она поучительна, но нужды ее использовать нет. Для этого у нас есть встроенный и выразительный метод (который еще и быстрее, так как в своей реализации использует простой цикл while).
Также применимо к: Set, Option, Iterator.
filter// До
seq.foldLeft(Seq.empty)((acc, x) => if (p(x)) acc :+ x else acc)
seq.foldRight(Seq.empty)((x, acc) => if (p(x)) x +: acc else acc)
// После
seq.filter(p)Причины те же, что и в предыдущем случае.
Также применимо к: Set, Option, Iterator.
reverse// До
seq.foldLeft(Seq.empty)((acc, x) => x +: acc)
seq.foldRight(Seq.empty)((x, acc) => acc :+ x)
// После
seq.reverseИ опять-таки встроенный метод быстрее и чище.
Также применимо к: Set, Option, Iterator.
Вот несколько обособленных советов, посвященных сопоставлению с образцом в Scala и частичным функциям.
// До
seq.map {
_ match {
case P => ??? // x N
}
}
// После
seq.map {
case P => ??? // x N
}Обновленное выражение дает сходный результат и выглядит при этом проще.
Описанные выше преобразования можно применить к любым функциям, а не только к аргументам функции map. Этот совет относится не только к коллекциям. Однако, в виду вездесущести функций высшего порядка в API стандартной библиотеки коллекций Scala, он будет весьма кстати.
flatMap с частичной функцией collect// До
seq.flatMap {
case P => Seq(???) // x N
case _ => Seq.empty
}
// После
seq.collect {
case P => ??? // x N
}Обновленное выражение дает аналогичный результат и выглядит намного проще.
Также применимо к: Set, Option, Map, Iterator.
match к collect, когда результатом является коллекция// До
v match {
case P => Seq(???) // x N
case _ => Seq.empty
}
// После
Seq(v) collect {
case P => ??? // x N
}Учитывая, что все case-операторы создают коллекции, можно упростить выражение, заменив match на вызов collect. Так мы создаем коллекцию всего один раз, опустив при этом явные ветки case для дефолтных случаев.
Лично я обычно использую этот трюк с Option, а не с последовательностями как таковыми.
Также применимо к: Set, Option, Iterator.
collectFirst// До
seq.collect{case P => ???}.headOption
// После
seq.collectFirst{case P => ???}Для такого случая у нас есть особый метод, который работает быстрее для неленивых коллекций.
Set, Map, Iterator.filter// До
seq.filter(p1).filter(p2)
// После
seq.filter(x => p1(x) && p2(x))Так мы можем избежать создания промежуточной коллекции (после первого вызова filter), чем облегчим участь сборщика мусора.
Мы так же можем использовать обобщенный подход, который полагается на представления (смотрите ниже), получив: seq.view.filter(p1).filter(p2).force.
p1 и p2 должны быть чистыми функциями.Set, Option, Map, Iterator.map// До
seq.map(f).map(g)
// После
seq.map(f.andThen(g))Как и в предыдущем случае, мы сразу создаем конечную коллекцию без создания промежуточной.
Мы так же можем применить обобщенный подход, который полагается на view (смотрите ниже), получив: seq.view.map(f).map(g).force.
f и g должны быть чистыми.Set, Option, Map, Iterator.// До
seq.sorted.filter(p)
// После
seq.filter(p).sortedСортировка — процедура затратная. Поэтому нет нужды сортировать элементы, которые на следующем шаге могут быть отфильтрованы.
sortWith и sortBy.p должен быть чистой функцией.map// До
seq.reverse.map(f)
// После
seq.reverseMap(f)Первое выражение создает промежуточную (перевернутую) коллекцию перед преобразованием элементов, что иногда бывает достаточно разумно (например для List). В других случаях, что будет более эффективно, можно сразу выполнить требуемые преобразования, не создавая промежуточную коллекцию.
// До
seq.reverse.iterator
// После
seq.reverseIteratorК тому же последнее выражение проще и может быть более эффективным.
Set для нахождения отдельных элементов// До
seq.toSet.toSeq
// После
seq.distinctНет нужды создавать временное множество (во всяком случае явно), чтобы найти отдельные элементы.
slice// До
seq.drop(x).take(y)
// После
seq.slice(x, x + y)Для линейных последовательностей, ничего кроме ясно выраженных мыслей и намерений мы не получим. Однако, в случае с индексированными последовательностями мы можем ожидать потенциальный прирост производительности.
Также применимо к: Set, Map, Iterator.
splitAt// До
val seq1 = seq.take(n)
val seq2 = seq.drop(n)
// После
val (seq1, seq2) = seq.splitAt(n)Для линейных последовательностей (как для List, так и для Stream), упрощенные выражения будут выполняться быстрее из-за того, что результаты вычисляются за один проход.
Также применимо к: Set, Map.
span// До
val seq1 = seq.takeWhile(p)
val seq2 = seq.dropWhile(p)
// После
val (seq1, seq2) = seq.span(p)А так мы можем пройти последовательность и проверить предикат не два, а всего один раз.
p не должен иметь побочных эффектов.Set, Map, Iterator.partition// До
val seq1 = seq.filter(p)
val seq2 = seq.filterNot(p)
// После
val (seq1, seq2) = seq.partition(p)Опять-таки, преимуществом будет вычисление в один проход
p не должен иметь побочных эффектов.Set, Map, Iterator.takeRight// До
seq.reverse.take(n).reverse
// После
seq.takeRight(n)Последнее выражение более выразительно и потенциально более эффективно (как для индексированных, так и для линейных последовательностей).
flatten// До (seq: Seq[Seq[T]])
seq.reduce(_ ++ _)
seq.fold(Seq.empty)(_ ++ _)
seq.flatMap(identity)
// После
seq.flattenНет необходимости делать это вручную: у нас уже есть встроенный метод.
Также применимо к: Set, Option, Iterator.
flatMap// До (f: A => Seq[B])
seq.map(f).flatten
// После
seq.flatMap(f)Опять-таки незачем писать велосипед. Улучшится не только выразительность, дополнительная коллекция создаваться тоже не будет.
Также применимо к: Set, Option, Iterator.
map если результат игнорируется// До
seq.map(???) // результат игнорируется
// После
seq.foreach(???)Когда вам нужны именно побочные эффекты, оправданий вызову map нет. Такой вызов вводит в заблуждение, при том еще и менее эффективен.
Также применимо к: Set, Option, Map, Iterator.
unzip для извлечения единственного элемента// До (seq: Seq[(A, B]])
seq.unzip._1
// После
seq.map(_._1)Незачем создавать дополнительные коллекции, когда требуется всего-навсего один элемент.
unzip3.Set, Option, Map, Iterator.Этот рецепт разбит на три части (в зависимости от конечного результата преобразования).
1) Преобразование сокращает коллекцию до единственного значения.
// До
seq.map(f).flatMap(g).filter(p).reduce(???)
// После
seq.view.map(f).flatMap(g).filter(p).reduce(???)Вместо reduce может быть любой метод, который сокращает коллекцию до единственного значения, например: reduceLeft, reduceRight, fold, foldLeft, foldRight, sum, product, min, max, head, headOption, last, lastOption, indexOf, lastIndexOf, find, contains, exists, count, length, mkString, и т.д.
Точный порядок преобразований не столь важен — важно то, что мы создаем одну, а то и несколько промежуточных коллекций не очень-то и нужных, при этом они будут занимать место в куче и нагружать GC. Это происходит потому, что по умолчанию все преобразователи коллекций (map, flatMap, filter, ++, и т.д.) являются «строгими» (за исключениемStream) и, как результат, порождают новую коллекцию со всеми ее элементами.
Здесь на помощь приходят представления (view) — о которых вы можете думать, как о своего рода итераторах, позволяющих повторную итерацию:
Stream).Чтобы перейти от коллекции к ее представлению, используйте метод view.
2) Преобразование, порождающее коллекцию того же типа.
Представления можно использовать и тогда, когда конечный результат преобразования по-прежнему остается коллекцией — метод force построит коллекцию первоначального типа (при этом все промежуточные коллекции созданы не будут):
// До
seq.map(f).flatMap(g).filter(p)
// После
seq.view.map(f).flatMap(g).filter(p).forceЕсли фильтрация — единственное промежуточное преобразование, то, как вариант, вы можете рассмотреть метод withFilter:
seq.withFilter(p).map(f)Первоначально этот метод предназначался для использования внутри "for comprehensions". Он работает так же, как и представление — создает временный объект, который ограничивает область последующих преобразований коллекции (так, что он реорганизует возможные побочные эффекты). Однако, нет нужды явно преобразовывать коллекцию к (или наоборот) от временного представления (вызвав veiw и force)
Хоть основанный на представлениях подход и будет более универсальным в этом конкретном случае, withFilter из-за лаконичности может быть более предпочтительным.
3) Преобразование порождает коллекцию другого типа.
// До
seq.map(f).flatMap(g).filter(p).toList
// После
seq.view.map(f).flatMap(g).filter(p).toListВ этот раз вместо обобщенного вызова force мы используем подходящий метод-конвертер, поэтому результатом будет коллекция другого типа.
Также существует альтернативный способ совладать с «преобразованием + конверсией». И случай этот полагается на breakOut:
seq.map(f)(collection.breakOut): List[T]Функционально выражение эквивалентно использованию представления, однако:
map, flatMap, filter, fold, и т.д.),Так что, скорее всего, лучше заменить breakOut на более гибкое и выразительнее представление.
Представления наиболее целесообразны при относительно большом размере коллекций.
f и g) и предикаты (p) должны быть чистыми функциями (так как представление может задерживать, пропускать, а то и вовсе переупорядочивать вычисления).Set, Map.// До
seq = seq :+ x
seq = x +: seq
seq1 = seq1 ++ seq2
seq1 = seq2 ++ seq1
// После
seq :+= x
seq +:= x
seq1 ++= seq2
seq1 ++:= seq2Scala предлагает «синтаксический сахар», известный как «операторы присваивания» (“assignment operators”) — он автоматически приводит операторы типа x к виду x = x , где: +, -, и т.д). Обратите внимание, что если :, то он считается право-ассоциативным (т.е. вызывается для правого выражения, вместо левого). Для списков и стримов также существует особый синтаксис:
// До
list = x :: list
list1 = list2 ::: list
stream = x #:: list
stream1 = stream2 #::: stream
// После
list ::= x
list1 :::= list2
stream #::= x
stream1 #:::= stream2Упрощенные выражения лаконичны.
Также применимо к Set, Map, Iterator (учитывая специфику операторов).
// До
seq.foldLeft(Set.empty)(_ + _)
seq.foldRight(List.empty)(_ :: _)
// После
seq.toSet
seq.toListДля этого существуют встроенные методы, которые и чище, и быстрее. А если вам нужно преобразовать или отфильтровать значения во время преобразования, рассмотрите использование представлений или схожих техник, описанных выше.
Также применимо к: Set, Option, Iterator.
toSeq для нестрогих коллекций.// До (seq: TraversableOnce[T])
seq.toSeq
// После
seq.toStream
seq.toVectorИз-за того, что Seq(...) создает строгую коллекцию (а именно, Vector), мы можем захотеть использовать toSeq для преобразования нестрогой сущности (как Stream, Iterator или view) к строгой коллекции. Однако TraversableOnce.toSeq на самом деле возвращает Stream, являющийся ленивой коллекцией, что может привести к труднонаходимым багам и проблемам с производительностью. Даже если вы изначально ожидали стрим, подобное выражение может ввести в заблуждение тех, кто читает ваш код.
А вот и типичный пример ловушки:
val source = Source.fromFile("lines.txt")
val lines = source.getLines.toSeq
source.close()
lines.foreach(println)Такой код выбросит IOException, сетующий на то, что стрим уже закрыт.
Чтобы ясно обозначить наши намерения, лучше добавить toStream явно или, если нам после всего потребуется строгая коллекция, использовать toVector вместо toSeq.
// До (seq: Seq[String])
seq.reduce(_ + _)
seq.reduce(_ + separator + _)
seq.fold(prefix)(_ + _)
seq.map(_.toString).reduce(_ + _) // seq: Seq[T]
seq.foldLeft(new StringBuilder())(_ append _)
// После
seq.mkString
seq.mkString(prefix, separator, "")Последний подход чище и потенциально быстрее, так как внутри он использует единственный StringBuilder.
reduceLeft, reduceRight, foldLeft, foldRight.Set, Option, Iterator.Большинство советов для последовательностей так же хорошо работают и для множеств. Более того, для множеств есть несколько специфичных советов.
sameElements для сравнения неупорядоченных коллекций// До
set1.sameElements(set2)
// После
set1 == set2Ранее мы уже ознакомились с этим правилом (на примере последовательностей), однако для множеств обоснование будет наиболее логичным.
Метод sameElements может возвращать недетерминированные результаты для неупорядоченных коллекций, потому что этот метод принимает во внимание порядок элементов, на который мы не можем полагаться в случае с множествами.
Исключениями из правила будут классы, которые явно гарантируют предсказуемый порядок итерации: например, LinkedHashSet.
Также применимо к: Map.
// До (set: Set[Int])
Seq(1, 2, 3).filter(set(_))
Seq(1, 2, 3).filter(set.contains)
// После
Seq(1, 2, 3).filter(set)Так как Set[T] также явялется экземпляром Function1[T, Boolean], вы можете использовать его в этом качестве.
// До
set1.filter(set2.contains)
set1.filter(set2)
// После
set1.intersect(set2) // или set1 & set2При схожей производительности, последнее выражение будет яснее и выразительней.
Такое преобразование применимо и к последовательностям, однако стоит учесть, что в таком случае в работе с повторяющимися элементами потребуется особый подход.
// До
set1.filterNot(set2.contains)
set1.filterNot(set2)
// После
set1.diff(set2) // или set1 &~ set2Опять же, при схожей производительности, обновленное выражение будет более ясными выразительным.
Потенциально, такое преобразование можно применить и к последовательностям, однако нам следует принять во внимание наличие дубликатов.
Технически Option не является частью Scala коллекций, однако предоставляет похожий интерфейс (с монадическими методами и т.д.) и даже ведет себя как специальный тип коллекций, который может иметь, а может и не иметь какое-то значение.
Многие из приведенных советов для последовательностей применимы и к Option. Кроме того, здесь представлены советы, характерные для Option API.
None// До
option == None
option != None
// После
option.isEmpty
option.isDefinedПри том, что сравнение является вполне законным, есть более простой способ, который позволяет проверить объявлен ли Option.
Еще одно преимущество данного упрощения в том, что если вы решите изменить тип от Option[T] к T, scalac скомпилирует предшествующее выражение (выдав только одно предупреждение), тогда как компиляция последнего справедливо закончится ошибкой.
Option с Some// До
option == Some(v)
option != Some(v)
// После
option.contains(v)
!option.contains(v)Этот совет дополняет предыдущий.
isInstanceOf для проверки наличия элемента// До
option.isInstanceOf[Some[_]]
// После
option.isDefinedВ подобном трюкачестве нет нужды.
// До
option match {
case Some(_) => true
case None => false
}
option match {
case Some(_) => false
case None => true
}
// После
option.isDefined
option.isEmptyОпять же, первое выражение и является корректным — оправдывать подобную экстравагантность не стоит. Более того, упрощенное выражение будет работать быстрее.
Также применимо к: Seq, Set.
// До
!option.isEmpty
!option.isDefined
!option.nonEmpty
// После
seq.isDefined
seq.isEmpty
seq.isEmptyПричина та же, что и для последовательностей — простое свойство добавит меньше визуального шума, нежели составное выражение.
Заметьте, что у нас есть синонимы: isDefined (специфичный для option) и nonEmpty (специфичный для последовательностей). Возможно, было бы разумно отдать предпочтение первому для явного отделения Option и последовательностей.
null, чтобы создать Option// До
if (v != null) Some(v) else None
// После
Option(v)Для этого у нас есть более подходящий синтаксис.
null как явную альтернативу// До
option.getOrElse(null)
// После
option.orNullВ этом случае мы можем полагаться на предопределенный метод, делая выражение короче.
Можно выделить группы советов, связанные с тем, как обрабатываются значения Option.
В документации, посвященной интерфейсу Option, говорится, что «самый идиоматичный способ использования экземпляра Option — это рассмотрение его в качестве коллекции или монады на ряду с использованием map, flatMap, filter или foreach». Основной принцип здесь заключается в том, чтобы избегать "check & get" (проверь и возьми) цепочек, которые обычно реализуются через оператор if или сопоставлением с образцом.
Цель — надежность, выразительность и «монадический» код:
NoSuchElementException и MatchError ислючений во время выполненияЭто объяснение объединяет все последующие случаи.
getOrElse// До
if (option.isDefined) option.get else z
option match {
case Some(it) => it
case None => z
}
// После
option.getOrElse(z)orElse// До
if (option1.isDefined) option1 else option2
option1 match {
case Some(it) => Some(it)
case None => option2
}
// После
option1.orElse(option2)exists// До
option.isDefined && p(option.get)
if (option.isDefined) p(option.get) else false
option match {
case Some(it) => p(it)
case None => false
}
// После
option.exists(p)forall// До
option.isEmpty || (option.isDefined && p(option.get))
if (option.isDefined) p(option.get) else true
option match {
case Some(it) => p(it)
case None => true
}
// После
option.forall(p)contains// До
option.isDefined && option.get == x
if (option.isDefined) option.get == x else false
option match {
case Some(it) => it == x
case None => false
}
// После
option.contains(x)foreach// До
if (option.isDefined) f(option.get)
option match {
case Some(it) => f(it)
case None =>
}
// После
option.foreach(f)filter// До
if (option.isDefined && p(option.get)) option else None
option match {
case Some(it) && p(it) => Some(it)
case _ => None
}
// После
option.filter(p)map// До
if (option.isDefined) Some(f(option.get)) else None
option match {
case Some(it) => Some(f(it))
case None => None
}
// После
option.map(f)flatMap// До (f: A => Option[B])
if (option.isDefined) f(option.get) else None
option match {
case Some(it) => f(it)
case None => None
}
// После
option.flatMap(f)map и getOrElse в fold// До
option.map(f).getOrElse(z)
// После
option.fold(z)(f)Приведенные выражения семантически эквиваленты (в обоих случаях z будет вычислен лениво — по требованию), однако последнее выражение короче. Преобразование может требовать дополнительного указания типа (из-за особенностей работы вывода типов в Scala), и в таких случаях предыдущее выражение предпочтительнее.
Имейте в виду, что упрощение это весьма противоречиво из-за того, что последнее выражение выглядит менее ясно, особенно если вы к нему не привыкли.
exists// До
option.map(p).getOrElse(false)
// После
option.exists(p)Мы представили довольно похожее правило для последовательностей (которое применимо и к Option). Нетипичное преобразование для вызова getOrElse.
flatten// До (option: Option[Option[T]])
option.map(_.get)
option.getOrElse(None)
// После
option.flattenПоследнее выражение смотрится чище.
Option в Seq вручную// До
option.map(Seq(_)).getOrElse(Seq.empty)
option.getOrElse(Seq.empty) // option: Option[Seq[T]]
// После
option.toSeqДля этого есть специальный метод, который делает это кратко и наименее затратно.
Как и с другими типами коллекций, многие советы для последовательностей применимы и к таблицам, поэтому перечислим только характерные для таблиц.
// До
map.find(_._1 == k).map(_._2)
// После
map.get(k)В принципе, первый фрагмент кода будет работать, однако производительность будет неоптимальной из-за того, что Map не является простой коллекцией пар (ключ, значение) — она может выполнять поиск куда более эффективным способом. Более того, последнее выражение проще и легче для понимания.
get, когда необходимо сырое значение// Before
map.get(k).get
// After
map(k)Нет необходимости плодить промежуточный Option, когда необходимо сырое (raw) значение.
lift вместо get// Before
map.lift(k)
// After
map.get(k)Незачем рассматривать значение таблицы, как частичную функцию для получения опционального результата (что полезно для последовательностей), потому что у нас есть встроенный метод с такой же функциональностью. Хотя lift отлично работает, он выполняет дополнительное преобразование (от Map доPartialFunction) и может выглядеть весьма запутанным.
get и getOrElse раздельно// До
map.get(k).getOrElse(z)
// После
map.getOrElse(k, z)Единственный вызов метода проще как синтаксически, так и с точки зрения производительности. В обоих случаях z вычисляется лениво, по требованию.
// До (map: Map[Int, T])
Seq(1, 2, 3).map(map(_))
// После
Seq(1, 2, 3).map(map)Так как экземпляр Map[K, V] также является Function1[K, V], вы можете использовать его как функцию.
// До
map.map(_._1)
map.map(_._1).toSet
map.map(_._1).toIterator
// После
map.keys
map.keySet
map.keysIteratorОптимизированные выражения являются более понятными (и потенциально более быстрыми).
// До
map.map(_._2)
map.map(_._2).toIterator
// После
map.values
map.valuesIteratorУпрощенные выражения понятней (и потенциально быстрее).
filterKeys// До
map.filterKeys(p)
// После
map.filter(p(_._1))Метод filterKeys обертывает исходную таблицу без копирования каких-либо элементов. В этом нет ничего плохого, однако вы вряд ли ожидаете от filterKeys подобного поведения. Поскольку оно неожиданно ведет так же, как представление, производительность кода может быть существенно снижена для некоторых случаев, например, для filterKeys(p).groupBy(???).
Другой вероятной неприятностью является неожиданная «ленивость» (по умолчанию, фильтры коллекций должны быть строгими) – при вызове самого метода предикат вообще не вычисляется, из-за чего возможные побочные эффекты могут быть переупорядочены.
Метод filterKeys, скорее всего, следовало бы объявить устаревшим, из-за невозможности сделать его строгим, не сломав обратную совместимость. Более подходящим именем для текущей реализации будет withKeyFilter (по аналогии с withFilter).
В общем, наиболее разумно будет следовать Правилу наименьшего удивления и фильтровать ключи вручную.
Тем не менее, поскольку схожая с представлением функциональность filterKeys потенциально полезна (когда доступ будет только к небольшому числу записей,
|
Метки: author ppopoff функциональное программирование программирование алгоритмы scala коллекции |
Баланс между устройствами безопасности в режиме прокси и влиянием на производительность сети |


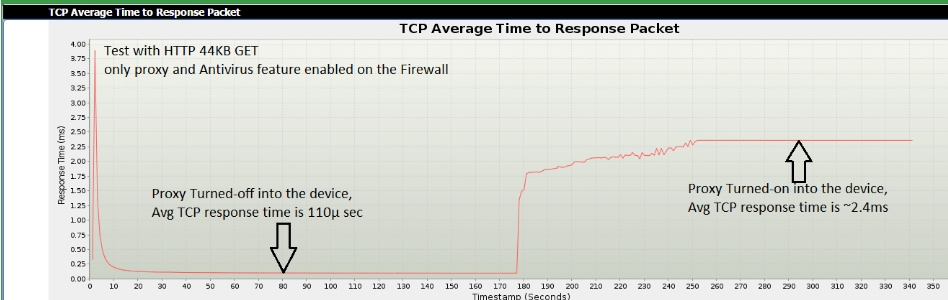




|
Метки: author Orest_ua системное администрирование сетевые технологии серверная оптимизация it- инфраструктура блог компании мук прокси безопасность оптимизация |
[Из песочницы] Решето Эратосфена, попытка минимизировать память |

import java.util.ArrayList;
import java.util.List;
public class SieveEratosthenes {
static class PrimePair {
Integer prime;
Integer lastCrossed;
PrimePair(Integer prime, Integer lastCrossed) {
this.prime = prime;
this.lastCrossed = lastCrossed;
}
}
private List primes;
private SieveEratosthenes() {
primes = new ArrayList<>();
primes.add(new PrimePair(2, 2));
primes.add(new PrimePair(3, 3));
}
private void fillNPrimes(int n) {
while (primes.size()/restart
candidate+=2;
i=-1;
}
}
System.out.println(candidate);
primes.add(new PrimePair(candidate, candidate));
}
public static void main(String[] args) {
SieveEratosthenes test = new SieveEratosthenes();
test.fillNPrimes(1000);
}
}
primes = [2, 3]
last_crossed = [2, 3]
def add_next_prime():
candidate = primes[-1] + 2
i = 0
while i < len(primes):
while last_crossed[i] < candidate:
last_crossed[i] += primes[i]
if last_crossed[i] == candidate:
candidate += 2
i = 0
i += 1
primes.append(candidate)
last_crossed.append(candidate)
def fill_primes(n):
while len(primes) < n:
add_next_prime()
fill_primes(1000)
print(primes)
|
Метки: author StanislavL алгоритмы простые числа решето эратосфена |
Что такое Display Rate и как он влияет на доход вашего приложения? |



|
|
Куда пойти, что читать, с кем общаться на профессиональные темы: дорожная карта для iOS-разработчика |

|
Метки: author YourDestiny разработка под ios блог компании avito ios telegram |
[Перевод] На пути к Go 2 |
Перевод блог поста и доклада Russ Cox с GopherCon 2017, с обращением ко всему Go сообществу помочь в обсуждении и планировании Go 2. Видео доклада будет добавлено сразу после опубликования.

25 сентября 2007 года, после того как Роб Пайк, Роберт Грисмайер и Кен Томпсон несколько дней обсуждали идею создания нового языка, Роб предложил имя "Go".

В следующем году, Ян Лэнс Тейлор и я присоединились к команде и мы впятером создали два компилятора и стандартную библиотеку, которые были публично открыты 10 ноября 2009.

В следующие два года, с помощью нового open-source сообщества гоферов, мы экспериментировали и пробовали различные идеи, улучшая Go и ведя его к запланированному релизу Go 1, предложенному 5 октября 2011.

С ещё более активной помощью Go сообщества, мы пересмотрели и реализовали этот план, в итоге выпустив Go 1 28 марта 2012.

Релиз Go 1 ознаменовал кульминацию почти пяти полных лет креативных и неистовых усилий, которые привели нас от выбора имени и обсуждения идей до стабильного готового языка. Он также знаменовал явный переход от изменений и непостоянства к стабильности.
В годы, предшествующие Go 1, мы меняли язык ломая чужие Go программы практически еженедельно. Мы понимали, что это удерживало Go от использования в продакшене, где программы никто не будет переписывать каждую неделю, синхронизируя с изменениями в языке. Как написано в блог посте с анонсом Go 1, главной мотивацией языка было предоставить стабильный фундамент для создания надёжных продуктов, проектов и публикаций (блогов, туториалов, докладов и книг), дав пользователям уверенность, что их программы будут компилироваться и работать без необходимости их менять даже через много лет.
После того, как Go 1 был выпущен, мы знали, что мы должны провести какое-то время в реальном использовании Go в продакшн среде, для которой он и был создан. Мы явно перешли от изменений языка к использованию Go в наших проектах и улучшения реализации: мы портировали Go на множество новых систем, мы переписали практически все критичные к производительности части, чтобы сделать Go ещё более эффективным и добавили ключевые инструменты вроде race-детектора.
На сегодня у нас есть 5 лет реального опыта использования Go для создания огромных, качественных продакшн-систем. Это дало нам чувство того, что работает, а что нет. И сейчас самое время начать новый этап в эволюции и развитии Go. Сегодня я прошу вас всех, сообщество Go разработчиков, будь вы сейчас тут в зале GopherCon или смотрите видео или читаете это в Go блоге, работать вместе с нами по мере того, как мы будем планировать и реализовывать Go 2.
Далее я расскажу и объясню задачи, которые стоят перед Go 2; наши ограничения и препятствия; сам процесс в целом; важность описания вашего опыта с Go, особенно если он относится к проблемами которые мы можем пытаться решить; возможные варианты решений; как мы будем внедрять Go 2 и как вы все можете в этом помочь.
Задачи перед Go сегодня стоят точно такие же, какими были в 2007 году. Мы хотим сделать программистов более эффективными в управлении двумя видами масштабируемости: масштабируемости систем, особенно многопоточных(concurrent) систем, взаимодействующих со многими другими серверами — широко представленными в виде серверов для облака, и масштабируемость разработки, особенно большие кодовые базы, над которыми работают множество программистов, часто удалённо — как, например, современная open-source модель разработки.
Эти виды масштабируемости сегодня присутствуют в компаниях всех размеров. Даже стартап из 5 человек может использовать большие облачные API сервисы, предоставленные другими компаниями и использовать больше open-source софта, чем софта, который они пишут сами. Масштабируемость систем и масштабируемость разработки также актуальны для стартапа, как и для Google.
Наша цель для Go 2 — исправить основные недочёты в Go, мешающие масштабируемости.
(Если вы хотите больше узнать про эти задачи, посмотрите статью Роба Пайка 2012 года “Go at Google: Language Design in the Service of Software Engineering” и мой доклад с GopherCon 2015 “Go, Open Source, Community”.)
Наши задачи перед Go не изменились, но изменились препятствия. Главное из них это уже существующее использование Go. По нашим оценкам, сейчас в мире есть, как минимум, пол миллиона Go программистов, что означает порядка миллиона файлов с исходным кодом на Go и не менее миллиарда строк Go кода. Эти программисты и этот исходный код представляет собой успех Go, но в тоже время является главным препятствием для Go 2.
Go 2 должен способствовать всем этим разработчикам. Мы должны просить их разучить старые привычки и выучить новые только если выгода от этого действительно того стоит. Например, перед Go 1, метод интерфейсного типа error назывался String. В Go 1 мы переименовали его в Error, чтобы отличить типы для ошибок от других типов, который просто могут иметь отформатированное строчное представление. Однажды я реализовывал тип, удовлетворяющий error интерфейсу, и, не думая, называл метод String, вместо Error, что, конечно же, не скомпилировалось. Даже через 5 лет я всё ещё не до конца разучил старый способ. Этот пример проясняющего переименования было важным и полезным изменением для Go 1, но был бы слишком разрушительным для Go 2 без действительно очень весомой причины.
Go 2 должен также хорошо дружить с существующим Go 1 кодом. Мы не должны расколоть Go экосистему. Смешанные программы, в которых пакеты написаны на Go 2 и импортируют пакеты на Go 1 или наоборот, должны безпрепятственно работать в течении переходного периода в несколько лет. Нам ещё предстоит придумать, как именно этого достичь; инструментарий для автоматического исправления и статического анализа вроде go fix определённо сыграют тут свою роль.
Чтобы уменьшить разрушительный эффект, каждое изменение потребует очень бережного обдумывания и планирования, также как и инструментария, что, в результате, ограничит количество изменений, которые мы вообще сможем сделать. Возможно мы можем сделать два или три, но точно не больше пяти.
При этом я не считаю мелкие вспомогательные изменения, как, возможно, разрешение идентификаторов на большем количестве натуральных языков или добавления литералов для чисел в двоичной форме. Подобные мелкие изменения также важны, но их гораздо проще сделать правильно. Сегодня я буду концентрироваться на возможных крупных изменениях, таких как дополнительная поддержка обработки ошибок или добавление неизменяемых (immutable) или read-only значений, или добавления какой-нибудь формы generics, или ещё какой-нибудь важной пока не озвученной темы. Мы сможем сделать только несколько таких крупных изменений. И мы должны будем выбрать их очень внимательно.
Это поднимает важный вопрос. Какой процесс разработки Go в целом?
В ранние дни Go, когда нас было всего пятеро, мы работали в паре смежных офисов, разделённых стеклянной стеной. Было очень просто собрать всех в одной комнате, обсудить какую-то проблему, вернуться на свои места и тут же реализовать решение. Если во время реализации возникало какое-то затруднение, было легко снова собраться и обсудить. В офисе Роба и Роберта был маленький диванчик и белая доска, и обычно кто-то из нас заходил и начинал писать пример на доске. Как правило к моменту, когда пример был написан, все остальные находили момент, на котором можно было сделать паузу в текущей задаче, и были готовы сесть и обсудить код. Такой неформальный подход, само собой, невозможно масштабировать на размер Go сообщества сегодня.
Частью нашей работы после релиза Go в open-source было портирование этого неформального процесса в более формальный мир почтовых рассылок и трекеров задач для полумиллиона пользователей, но мне кажется, мы никогда явно не рассказывали, как устроен весь процесс. Возможно, мы даже никогда полностью сознательно не думали об этом. Впрочем, оглядываясь назад, я думаю, что базовый план процесса, которому Go следовал с самого зарождения выглядит примерно так:

Первый шаг — использовать Go, чтобы наработать опыт работы с ним.
Второй шаг — идентифицировать проблему в Go, которая, вероятно, нуждается в решении и выразить её, объяснить другим, представить её в письменном виде.
Третий шаг — предложить решение проблемы, обсудить его с другими и пересмотреть решение, основываясь на этом обсуждении.
Четвертый шаг — реализовать решение, проверить его и улучшить, основываясь на результатах проверки.
И, наконец, пятый шаг — внедрить решение, добавив его в язык или стандартную библиотеку или в набор инструментов, которые люди используют каждый день.
Один и тот же человек не обязательно должен делать все эти шаги сам. На самом деле, обычно как раз на каждом шагу вовлечено много разных людей и много решений может быть предложено для одной и той же проблемы. Также, на каждом этапе мы можем решить не идти дальше и вернуться на шаг назад.
И хотя я не думаю, что мы когда-либо рассказывали про этот процесс целиком, но мы объясняли его по частям. В 2012, когда мы выпустили Go 1 и сказали, что настало время начать использовать Go и перестать изменять, мы объясняли первый шаг. В 2015, когда мы представили изменения в процесс предложений (proposals) для Go, мы объясняли шаги 3, 4 и 5. Но мы никогда не объясняли второй шаг подробно, и я бы хотел сделать это сейчас.
(Более подробно про разработку Go 1 и про прекращение изменений в языке, посмотрите доклад Роба Пайка и Эндрю Герранда на OSCON в 2012 году “The Path to Go 1.”. Более детально про процесс предложений можно посмотреть в докладе Эндрю Герранда на GopherCon в 2015 “How Go was Made” и в документации к самому процессу)

Объяснение проблемы состоит из двух частей. Первая часть — лёгкая — это просто озвучить, в чём, собственно, проблема заключается. Мы, разработчики, в целом достаточно хорошо это умеем. В конце концов, каждый тест, который мы пишем это формулировка проблемы, которая должна быть решена, причём написанная на таком точном языке, который поймёт даже компьютер. Вторая часть — сложная — заключается в том, чтобы описать важность проблемы достаточно хорошо, чтобы все остальные поняли, почему мы должны тратить время на её решение и его поддержку. В отличие от точной формулировки проблемы, мы не так часто описываем их важность и мы не слишком это хорошо умеем. Компьютер никогда нас не спросит “Почему этот случай для теста важен? А ты уверен, что это именно та проблема, которую ты должен решать? Точно ли решение этой проблемы это самая важная задача, которой ты должен заниматься?”. Возможно, однажды так и будет, но точно не сегодня.
Давайте взглянем на старый пример из 2011. Вот, что я написал про переименование os.Error в error.Value, когда мы планировали Go 1.
error.Value
(rsc) Проблема, которую мы имеем в низкоуровневых библиотеках заключается в том, что всё зависит от “os” из-за os.Error, поэтому сложно делать вещи, которые пакет os сам мог бы использовать (как пример с time.Nano ниже). Если бы не os.Error, не было было бы столько других пакетов, которые зависят от пакета os. Сугубо вычислительные пакеты вроде hash/* или strconv или strings или bytes могли бы обойтись без него, к примеру. Я планирую исследовать (пока что ничего не предлагая) определить пакет error примерно с таким API:
package error
type Value interface { String() string }
func New(s string) Value
Он начинается с краткой однострочной формулировки проблемы: в низкоуровневых библиотеках всё импортирует “os” ради os.Error. Далее идут 5 строк, которые я подчеркнул, описывающие значимость проблемы: пакеты, которые “os” использует не могут использовать тип error в своих API, и другие пакеты зависят от os по причинам никак не связанным с работой операционной системы.
Убедят ли вас эти 5 строк, что проблема стоит внимания? Это зависит от того, насколько хорошо вы можете заполнить контекст, который я оставил за рамками: чтобы быть понятым, нужно уметь предугадать, что другие люди знают. Для моей аудитории в то время — десять других людей в команде Google работающей над Go, которые читали этот документ — этих 50 слов было достаточно. Чтобы представить ту же самую проблему аудитории на конференции GothamGo прошлой осенью — аудитории с гораздо более разнообразным опытом — я должен быть предоставить больше контекста, и я использовал уже 200 слов, плюс примеры реального кода и диаграмму. И это факт, что современное Go сообщество, которое пытается объяснить важность какой-либо проблемы, должно добавлять контекст, причём проиллюстрированный конкретными примерами, который можно было бы исключить в беседе с вашими коллегами, например.
Убедить других, что проблема действительно важна — это ключевой шаг. Если проблема кажется не такой уж важной, то практически любое решение выглядит слишком дорогостоящим. Но для действительно важной проблемы, почти всегда есть несколько не таких уж и дорогих решений. Когда мы расходимся во мнениях о том, принимать или нет какое-то решение, обычно это означает, что мы расходимся в оценке важности решаемой проблемы. Это настолько важный момент, что я хочу показать два недавних примера, хорошо иллюстрирующих его, по крайней мере, в ретроспективе.
Мой первый пример связан с временем.
Представьте, что вы хотите замерить, сколько времени занимает некое событие. Вы сначала запоминаете время начала, запускаете событие, записывает время конца и затем вычитаете время начала из времени конца. Если событие заняло 10 миллисекунд, операция вычитания вернёт вам ровно 10 миллисекунд, возможно плюс-минус маленькую погрешность измерения.
start := time.Now() // 3:04:05.000
event()
end := time.Now() // 3:04:05.010
elapsed := end.Sub(start) // 10 msЭта очевидная процедура может не сработать во время “високосной секунды” (leap second). Когда наши часы не совсем точно синхронизированы с дневным вращением Земли, специальная високосная секунда — официально это секунды 23:59 и 60 — вставляется прямо перед полуночью. В отличие от високосного года, у високосных секунд нет легко предсказуемого паттерна, что затрудняет автоматизацию их учета в программах и API. Вместо того, чтобы ввести специальную, 61-ю, секунду, операционные системы обычно реализуют високосную секунду переводя часы на секунду назад аккурат перед полуночью, так что при этом 23:59 происходит дважды. Такой сдвиг часов выглядит, как поворот времени вспять, и наш замер 10-миллисекундного события теперь может оказаться отрицательным значением в 990 миллисекунд.
start := time.Now() // 11:59:59.995
event()
end := time.Now() // 11:59:59.005 (really 11:59:60.005)
elapsed := end.Sub(start) // –990 msПоскольку обычные часы оказываются неточными для измерений длительности событий во время подобных сдвигов времени, операционные системы предоставляют второй тип часов — монотонные часы, которые просто считают секунды и никогда не изменяются и не сдвигаются.
Только при этом нестандартном сдвиге часов, монотонные часы не особо лучше обычных часов, которые, в отличие от монотонных, умеют показывать текущее время. Поэтому, ради простоты API пакета time в Go 1 доступ есть только к обычным часам компьютера.
В октябре 2015 появился баг-репорт о том, что Go программы некорректно возвращают длительность событий во время подобных сдвигов часов, особенно в случае с високосной секундой. Предложенное решение было также и заголовком репорта: “Добавить новый API для доступа к монотонным часам”. Тогда я утверждал, что проблема не была достаточно значима, чтобы ради неё создавать новый API. Несколько месяцев перед этим, для високосной секунды в середине 2015 года, Akamai, Amazon и Google научились замедлять свои часы таким образом, что эта дополнительная секунда “размазывалась” по всему дню и не нужно было переводить часы назад. Всё шло к тому, что повсеместное использовать этого подхода “размазывания секунды” позволило бы избавиться от перевода часов вообще и проблема исчезнет сама собой. Для контраста, добавление нового API в Go добавило бы две новые проблемы: мы должны были бы объяснять про эти два типа часов, обучать пользователей когда использовать какой из них и конвертировать массу существующего кода, и всё лишь для ситуации, когда очень редка и, скорее всего, вообще исчезнет сама.
Мы поступили так, как делаем всегда, когда решение проблемы не очевидно — мы стали ждать. Ожидание даёт нам больше времени, чтобы накопить больше опыта и углубить понимание проблемы, плюс больше времени на поиски хорошего решения. В этом случае, ожидание добавило понимание серьёзности проблемы, в виде сбоя в работе Cloudflare, к счастью незначительного. Их Go код замеряющий длительность DNS запросов во время високосной секунды в конце 2016 года возвращал негативное значение, подобное примеру с -990 миллисекундами выше, и это приводило к панике на их серверах, поломав около 0.2% всех запросов в самом пике проблемы.
Cloudflare это именно тот тип облачных систем, для которых Go и создавался, и у них случился сбой в продакшене из-за того, что Go не мог замерять время правильно. Дальше, и это ключевой момент тут, Cloudflare написали про свой опыт — Джон Грэхем-Камминг опубликовал блог-пост “Как и почему високосная секунда повлияла на DNS Cloudflare”. Рассказав конкретные детали и подробности инцидента и их опыт работы с Go, Джон и Cloudflare помогли нам понять, что проблема неточного замера во время високосной секунды была слишком важной, чтобы оставлять её не решенной. Через два месяца после публикации статьи, мы разработали и реализовали решение, которое появится в Go 1.9 (и, кстати, мы сделали это без добавления нового API).
Мой второй пример о поддержке алиасов в Go.
За последние несколько лет, Google собрал команду, сфокусированную на крупномасштабных изменениях в коде, вроде миграций API и исправлений багов по всей кодовой в базе, состоящей из миллионов файлов исходных кодов и миллиардов строк кода, написанных на C++, Go, Java, Python и других языках. Одна из вещей, которую я усвоил из их трудов, было то, что при замене в API старого имени на новое, важно иметь возможность делать изменения шаг за шагом, а не всё за один раз. Чтобы это сделать, должна быть возможность задекларировать, что под старым именем, подразумевается новое. В C++ есть #define, typedef и использование деклараций позволяют это сделать, но в Go такого механизма не было. И поскольку одной из главных задача перед Go стоит умение масштабироваться в больших кодовых базах, было очевидно, что нам нужен какой-то механизм перехода от старых имён к новым во время рефакторинга, и что другие компании также упрутся в эту проблему по мере роста их кодовых баз на Go.
В марте 2016 я начал обсуждать с Робертом Грисмайером и Робом Пайком то, как Go мог бы справляться с многошаговым рефакторингом кодовых баз, и мы пришли к идее алиасов (alias declarations), которые были именно тем механизмом, что нужно. В тот момент я был очень доволен тем, как Go развивался. Мы обсуждали идею алиасов ещё с ранних дней Go — на самом деле первый черновик спецификации Go содержит пример, использующий алиасы — но, каждый раз при обсуждении алиасов, и, чуть позже, алиасов типов, мы не сильно понимали для чего они могут быть важны, поэтому мы отложили идею. Теперь же мы предлагали добавить алиасы в язык не потому что они были прямо элегентным концептом, а потому что они решали очень серьезную практическую проблему, к тому же помогающая Go лучше решать поставленную перед ним задачу масштабируемости разработки. Я искренне надеюсь это послужит хорошей моделью для будущих изменений в Go.
Чуть позднее той же весной Роберт и Роб написали предложение, и Роберт предоставил его на коротком докладе (lightning talk) на GopherCon 2016. Следующие несколько месяцев были достаточно смутными, и точно не могут быть примером того, как делать изменения в Go. Один из многих уроков, который мы тогда вынесли была важность описания значимости проблемы.
Минуту назад я объяснил вам суть проблемы, дав некоторую минимальную информацию о том, как и почему эта проблема может возникнуть, но не дав конкретных примеров о том, как вам вообще решить, коснётся ли эта проблема вас когда-нибудь или нет. То предложение и доклад оперировали абстрактными примерами, включающими пакеты C, L, L1 и C1..Cn, но ничего конкретного, с чем программисты могли ассоциировать проблему. В результате, большая часть ответной реакции от сообщества была основана на идее того, что алиасы решают проблему Google, и которая не актуальна для остальных.
Аналогично тому, как мы в Google поначалу не понимали важности в корректной обработкой високосной секунды, также мы и не донесли эффективно Go сообществу важность и необходимость уметь справляться с постепенной миграцией и исправлением кодовых баз во время крупномасштабного рефакторинга.
Осенью мы начали заново. Я выступил с докладом и написал статью, подробно объясняющую проблему, используя множество конкретных примеров из реальных open-source проектов, показывающих, что эта проблема актуальна для всех, а не только для Google. Теперь, после того как больше людей поняли проблему и могли оценить её важность, мы смогли начать продуктивное обсуждение о том, какое решение подойдёт лучше всего. Результатом этого стало то, что алиасы типов будут включены в Go 1.9 и помогут Go лучше масштабироваться во всё более крупных кодовых базах.
Один из уроков тут в том, что это сложно, но критически важно описывать важность проблемы понятным способом, чтобы другие люди, работающие в другой среде и условиях, могли понять. Для обсуждения крупных изменений в Go в сообществе, мы должны будем уделять особое внимание этому процессу подробного описания важности каждой проблемы, которую мы будем пытаться решить. Самый хороший способ сделать это — показать как проблема влияет на реальные программы или реальные системы, как в блог посте Cloudflare или моей статье про рефакторинг.
Такие рассказы об опыте использования превращают проблемы из абстрактной в конкретную и позволяют нам понять её значимость. Они также выступают в роли тестовых примеров: любое предложение решение можно проверить на этих примерах и оценить эффект.
К примеру, недавно я изучал проблему дженериков (generics), и пока что я не вижу в голове чёткой картины подробного и детального примера проблемы, для решения которой пользователям Go нужны дженерики. Как результат, я не могу чётко ответить на вопрос о возможном дизайне дженериков — например, стоит ли поддерживать generic-методы, тоесть методы, которые параметризованы отдельно от получателя (receiver). Если бы у нас был большой набор реальных практических проблем, мы бы смогли отвечать на подобные вопросы, отталкиваясь от них.
Или, другой пример, я видел предложения расширить error интерфейс несколькими различными способами, но я не видел ещё ни разу рассказа об опыте больших проектов на Go с попыткой понять обработку ошибок, и уж тем более не видел статей о том, как текущее решение Go затрудняет эту попытку. Эти рассказы и статьи могли бы помочь нам понять детали и важность проблемы, без чего мы не можем даже начать её решать.
Я могу продолжать долго. Каждое потенциально крупное изменение в Go должно быть мотивировано одним или несколькими рассказами о практическом опыте использования, документирущими то, как люди используют Go сегодня и как что-то не работает для них достаточно хорошо. Для очевидных тем, которые мы можем рассматривать для Go, я пока что не вижу этих рассказов, особенно подробных статей, проиллюстрированными реальными примерами использования.
Эти статьи и рассказы будут служить сырым материалом для процесса подачи предложений для Go 2, и мы нуждаемся в вас, чтобы помочь понять нам ваш опыт с Go. Вас около полумиллиона, работающих в разных окружениях, и совсем немного нас. Напишите блог пост в своем блоге или на Medium, или Github Gist (добавив расширение .md для Markdown), или в Google doc, или любым другим удобным вам способом. Написав пост, пожалуйста, добавьте его в эту новую страницу Wiki: https://golang.org/wiki/ExperienceReports

Теперь, после того, как мы познакомились с тем, как мы будем находить и объяснять проблемы, которые должны быть решены, я хочу кратко отметить, что не все проблемы решаются лучше всего изменением языка, и это нормально.
Одна из проблем, которую мы, возможно, будем решать, это то, что компьютеры часто при базовых арифметических вычислениях выдают дополнительные результаты, но в Go нет прямого доступа к этим результатам. В 2013 Роберт предложил, что мы можем расширить идею двойных выражений (“comma-ok”) на арифметические операции. Например, если x и y, скажем, uint32 значения, lo, hi = x * y вернет не только обычные нижние 32 бита, но и верхние 32 бита умножения. Эта проблема не выглядела особо важной, поэтому мы записали потенциальное решение, но не реализовывали его. Мы ждали.
Совсем недавно, мы разработали для Go 1.9 новый пакет math/bits, в котором находятся различные функции для манипулирования битами:
package bits // import "math/bits"
func LeadingZeros32(x uint32) int
func Len32(x uint32) int
func OnesCount32(x uint32) int
func Reverse32(x uint32) uint32
func ReverseBytes32(x uint32) uint32
func RotateLeft32(x uint32, k int) uint32
func TrailingZeros32(x uint32) int
...Пакет содержит качественные реализации каждой функции, и компилятор задействует специальные инструкции процессоров, там где это возможно. Основываясь на опыте с math/bits мы оба, Роберт и я, пришли к выводу, что делать дополнительные результаты арифметических операций в виде изменения языка это не лучший путь, и, взамен, мы должны оформить их в виде функций в пакете вроде math/bits. Лучшим решением тут будет изменение в библиотеке, а не в языке.
Другая проблема, которую мы могли бы хотеть решить после выхода Go 1 был факт того, что горутины и разделённая (shared) память позволяли слишком легко создать ситуацию гонки (races) в Go программах, приводящих к падениям и прочим проблемам в работе. Решение, основанное на изменении языка, могло бы заключаться в том, чтобы найти какой-то способ гарантировать отсутствие ситуаций гонки, сделать так, чтобы такие программы не компилировались, например. Как это сделать для такого языка, как Go пока что остается открытым вопросом в мире языков программирования. Вместо этого мы добавили базовый инструмент, который очень просто использовать — этот инструмент, детектор гонок (race detector) стал неотъемлемой частью опыта работы с Go. В этом случае наилучшим решением оказалось изменение в runtime и в инструментарии, а не изменение языка.
Конечно, изменения языка также будут иметь место, но не все проблемы лучше всего решаются именно этим.

В заключение, как же мы будем выпускать Go 2?
Я думаю, наилучший план будет выпускать обратно-совместимые части Go 2 постепенно, шаг за шагом, по ходу обычного плана релизов Go 1. У такого подхода есть несколько важных свойств. Во-первых, это сохраняет привычный график релизов Go 1, позволяя своевременно планировать исправления ошибок и улучшения, от которых зависят пользователи. Во-вторых, это позволяет избежать разделения усилий на Go 1 и Go 2. В-третьих, это спасает от расхождения между Go 1 и Go 2, облегчая в итоге всем жизнь при миграции. В-четвертых, это позволяет нам сконцентрироваться на работе над одним изменением за раз, что позволит сохранять качество. В-пятых, это будет заставлять нас выбирать решения, которые обратно-совместимы.
Нам потребуется время и планирование перед тем, как какие-либо изменения вообще начнут попадать в релизы Go 1, но, вполне вероятно, что мы можем увидеть мелкие изменения уже где-то через год, в Go 1.12 или около того. Это также даст нам время завершить сначала проект с менеджментом зависимостей.
Когда все обратно-совместимые изменения будут внедрены, допустим в Go 1.20, тогда мы сможем приступить к обратно-несовместимым изменениям в Go 2. Если окажется так, что не будет обратно-несовместимых изменений, то мы просто объявим, что Go 1.20 это и есть Go 2. В любом случае, на том этапе мы плавно перейдем от работы над Go 1.X релизами к Go 2.X, возможно с более продлённым окном поддержки для финальных Go 1.X релизов.
Это всё пока немного спекулятивно, и только что упомянутые номера релизов это всего лишь заглушки для грубой оценки, но я хочу явно донести, что мы не оставляем Go 1 в стороне, и, на самом деле, мы будем способствовать продлению периода разработки Go 1 настолько долго, насколько это максимально возможно.
Обсуждение Go 2 начинается сегодня, и оно будет вестись публично, на открытых площадках вроде почтовой рассылки или трекера проблем. Пожалуйста, помогайте нам на каждом шагу на этом пути.
Сегодня мы больше всего нуждаемся в вашем опыте использования. Пожалуйста, расскажите и напишите о том, как Go работает для вас, и, что более важно, где и как он не работает. Напишите блог пост, покажите реальные примеры, конкретные детали и поделитесь своим опытом. И не забудьте добавить в вики-страничку. Это то, как мы начнём говорить о том, что мы, Go сообщество, можем захотеть изменить в Go.
Спасибо.
Russ Cox, 13 июля 2017
|
Метки: author divan0 go go 2 |
[Из песочницы] Измеряя Telegram |
«Пока что возможности по полноценной аналитике каналов
ограничены, в первую очередь, возможностями BotAPI Telegram»
канал «Телеграм-маркетинг», 28 июня 2016
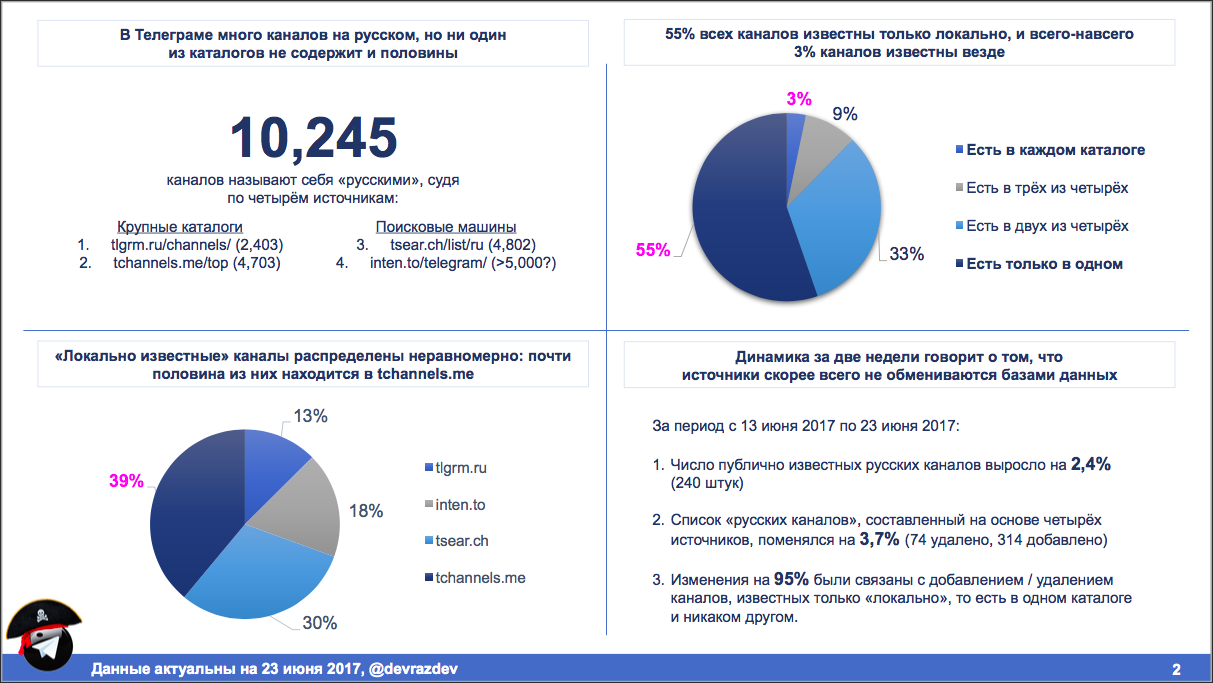


|
|
Делаем сервис по распознаванию изображений с помощью TensorFlow Serving |

Всегда наступает то самое время, когда обученную модель нужно выпускать в production. Для этого часто приходится писать велосипеды в виде оберток библиотек машинного обучения. Но если Ваша модель реализована на Tensorflow, то у меня для Вас хорошая новость — велосипед писать не придется, т.к. можно использовать Tensorflow Serving.
В данной статье мы рассмотрим как использовать Tensorflow Serving для быстрого создания производительного сервиса по распознаванию изображений.
Tensorflow Serving — система для развертывания Tensorflow-моделей с такими возможностями как:
Дополнительным плюсом является возможность перегнать модель из Keras в Tensorflow-модель и задеплоить через Serving (если конечно в Keras используется Tensorflow бэкенд).

Основной частью Tensorflow Serving является сервер моделей (Model Server).
Рассмотрим схему работы сервера моделей. После запуска сервер моделей загружает модель из пути, указанном при запуске, и начинает слушать указанный порт. Сервер общается с клиентами через вызовы удаленных процедур, используя библиотеку gRPC. Это позволяет создать клиентское приложение на любом языке, поддерживающем gRPC.
Если сервер моделей получает запрос, то он может выполнить следующие действия:
--enable_batching) активирована при запуске. Обработка батчами является более эффективной (особенно на GPU), поэтому эта функция позволяет увеличить количество обрабатываемых запросов на единицу времени.Как уже было упомянуто ранее Tensorflow Serving поддерживает горячую замену моделей. Сервер моделей постоянно сканирует указанный при запуске путь на наличии новых моделей и при нахождение новой версии автоматически загружает эту версию. Это позволяет выкладывать новые версии моделей без необходимости остановки сервера моделей.
Таким образом, Tensorflow Serving имеет достаточный функционал для полноценной работы в production. Поэтому использование таких подходов, как создание собственной обертки над моделью, выглядит неоправданно, т.к. Tensorflow Serving предлагает те же возможности и даже больше без необходимости писать и поддерживать самописные решения.
Сборка Tensorflow Serving наверное самая сложная часть использования этого инструмента. В принципе ничего сложно нет, но есть несколько подводных граблей. Именно про них я и расскажу в этом разделе.
Для сборки используется система сборки bazel.
Установка Tensorflow Serving описана на официальном сайте https://tensorflow.github.io/serving/setup. Я не буду расписывать подробно каждый шаг, а расскажу о проблемах, которые могут возникнуть при выполнении установки.
Со всеми шагами до конфигурации Tensorflow (./configure) не должно возникнуть проблем.
При конфигурации Tensorflow почти для всех параметров можно оставлять дефолтные значения. Но если вы выберете установку с CUDA, то конфигуратор спросит версию cuDNN. Надо вводить полную версию cuDNN (в моем случае 5.1.5).
Доходим до сборки (bazel build tensorflow_serving/...).
Для начала надо определить какие оптимизации доступны вашему процессору и указать их при сборке, т.к. bazel не может распознать их автоматически.
Таким образом, команда сборки усложняется до следующей:
bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both --copt=-msse4.2 tensorflow_serving/...
Проверьте, что все эти оптимизации доступны вашему процессору. У меня процессор не поддерживает AVX2 и FMA поэтому я собирал следующей командой:
bazel build -c opt --copt=-mavx --copt=-mfpmath=both --copt=-msse4.2 tensorflow_serving/...
По дефолту сборка Tensorflow потребляет много памяти, поэтому если у Вас ее не слишком много, то надо ограничить потребление ресурсов. Сделать это можно следующим флагом --local_resources availableRAM,availableCPU,availableIO (RAM in MB, CPU in cores, available I/O (1.0 being average workstation), например, --local_resources 2048,.5,1.0).
Если вы хотите собрать Tensorflow Serving с поддержкой GPU, то надо добавить флаг --config=cuda. Получится примерно такая команда.
bazel build -c opt --copt=-mavx --copt=-mfpmath=both --copt=-msse4.2 --config=cuda tensorflow_serving/...
При сборке может возникнуть следующая ошибка.
ERROR: no such target '@org_tensorflow//third_party/gpus/crosstool:crosstool': target 'crosstool' not declared in package 'third_party/gpus/crosstool' defined by /home/movchan/.cache/bazel/_bazel_movchan/835a50f8a234772a7d7dac38871b88e9/external/org_tensorflow/third_party/gpus/crosstool/BUILD.
Чтобы исправить эту ошибку, надо в файле tools/bazel.rc заменить @org_tensorflow//third_party/gpus/crosstool на @local_config_cuda//crosstool:toolchain
Еще может появиться следующая ошибка.
ERROR: /home/movchan/.cache/bazel/_bazel_movchan/835a50f8a234772a7d7dac38871b88e9/external/org_tensorflow/tensorflow/contrib/nccl/BUILD:23:1: C++ compilation of rule '@org_tensorflow//tensorflow/contrib/nccl:python/ops/_nccl_ops.so' failed: crosstool_wrapper_driver_is_not_gcc failed: error executing command external/local_config_cuda/crosstool/clang/bin/crosstool_wrapper_driver_is_not_gcc -U_FORTIFY_SOURCE '-D_FORTIFY_SOURCE=1' -fstack-protector -fPIE -Wall -Wunused-but-set-parameter ... (remaining 80 argument(s) skipped): com.google.devtools.build.lib.shell.BadExitStatusException: Process exited with status 1. In file included from external/org_tensorflow/tensorflow/conERROR: /home/movchan/.cache/bazel/_bazel_movchan/835a50f8a234772a7d7dac38871b88e9/external/org_tensorflow/tensorflow/contrib/nccl/BUILD:23:1: C++ compilation of rule '@org_tensorflow//tensorflow/contrib/nccl:python/ops/_nccl_ops.so' failed: crosstool_wrapper_driver_is_not_gcc failed: error executing command external/local_config_cuda/crosstool/clang/bin/crosstool_wrapper_driver_is_not_gcc -U_FORTIFY_SOURCE '-D_FORTIFY_SOURCE=1' -fstack-protector -fPIE -Wall -Wunused-but-set-parameter ... (remaining 80 argument(s) skipped): com.google.devtools.build.lib.shell.BadExitStatusException: Process exited with status 1. In file included from external/org_tensorflow/tensorflow/contrib/nccl/kernels/nccl_manager.cc:15:0: external/org_tensorflow/tensorflow/contrib/nccl/kernels/nccl_manager.h:23:44: fatal error: external/nccl_archive/src/nccl.h: No such file or directory compilation terminated.
Чтобы ее исправить надо удалить префикс /external/nccl_archive в строчке #include "external/nccl_archive/src/nccl.h" в следующих файлах:
tensorflow/tensorflow/contrib/nccl/kernels/nccl_ops.cc tensorflow/tensorflow/contrib/nccl/kernels/nccl_manager.h
Ура! Собрали наконец!
Экспорт модели из Tensorflow подробно описан на https://tensorflow.github.io/serving/serving_basic в разделе "Train And Export TensorFlow Model".
Для экспорта используется класс SavedModelBuilder. Я же использую Keras для тренировки Tensorflow-моделей, т.ч. я опишу процесс экспорта модели из Keras в Serving с помощью этого модуля.
Код экспорта ResNet-50, обученного на ImageNet.
import os
import tensorflow as tf
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
from tensorflow.contrib.session_bundle import exporter
import keras.backend as K
# устанавливаем режим в test time.
K.set_learning_phase(0)
# создаем модель и загружаем веса
model = ResNet50(weights='imagenet')
sess = K.get_session()
# задаем путь сохранения модели и версию модели
export_path_base = './model'
export_version = 1
export_path = os.path.join(
tf.compat.as_bytes(export_path_base),
tf.compat.as_bytes(str(export_version)))
print('Exporting trained model to', export_path)
builder = tf.saved_model.builder.SavedModelBuilder(export_path)
# создаем входы и выходы из тензоров
model_input = tf.saved_model.utils.build_tensor_info(model.input)
model_output = tf.saved_model.utils.build_tensor_info(model.output)
# создаем сигнатуру для предсказания, в которой устанавливаем входы и выходы модели
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': model_input},
outputs={'scores': model_output},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))
# добавляем сигнатуры к SavedModelBuilder
legacy_init_op = tf.group(tf.tables_initializer(), name='legacy_init_op')
builder.add_meta_graph_and_variables(
sess, [tf.saved_model.tag_constants.SERVING],
signature_def_map={
'predict':
prediction_signature,
},
legacy_init_op=legacy_init_op)
builder.save()Вместо 'images' и 'scores' при установке входов и выходов можно указать любые названия. Эти названия будут использоваться далее.
Если модель имеет несколько входов и/или выходов, то нужно указать это в tf.saved_model.signature_def_utils.build_signature_def. Для этого нужно использовать model.inputs и model.outputs. Тогда код установки входов и выходов будет выглядеть следующим образом:
# создаем входы и выходы из тензоров
model_input = tf.saved_model.utils.build_tensor_info(model.inputs[0])
model_output = tf.saved_model.utils.build_tensor_info(model.outputs[0])
model_aux_input = tf.saved_model.utils.build_tensor_info(model.inputs[1])
model_aux_output = tf.saved_model.utils.build_tensor_info(model.outputs[1])
# создаем сигнатуру для предсказания
prediction_signature = (
tf.saved_model.signature_def_utils.build_signature_def(
inputs={'images': model_input, 'aux_input': model_aux_input},
outputs={'scores': model_output, 'aux_output': model_aux_output},
method_name=tf.saved_model.signature_constants.PREDICT_METHOD_NAME))Еще стоит заметить, что в signature_def_map указываются все доступные методы (сигнатуры), которых может быть больше чем 1. В примере выше добавлен только один метод — predict. Название метода будет использоваться позже.
Запуск сервера моделей осуществляется следующей командой:
./bazel-bin/tensorflow_serving/model_servers/tensorflow_model_server --enable_batching --port=9001 --model_name=resnet50 --model_base_path=/home/movchan/ml/serving_post/model
Рассмотрим, что означают флаги в данной команде.
enable_batching — флаг активации автоматического батчинга, позволяет Tensorflow Serving объединять запросы в батчи для более эффективной обработки.port — порт, который модель будет прослушивать.model_name — имя модели (будет использоваться далее).model_base_path — путь до модели (туда, куда вы ее сохранили на предыдущем шаге).Для начала поставим пакет grpcio через pip.
sudo pip3 install grpcio
Вообще по туториалу на официальном сайте предлагается собирать python-скрипты через bazel. Но мне эта идея не нравится, т.ч. я нашел другой способ.
Для использования python API можно скопировать (сделать софтлинк) директорию bazel-bin/tensorflow_serving/example/inception_client.runfiles/tf_serving/tensorflow_serving. Там содержится все необходимое для работы python API. Я обычно просто копирую в директорию, в которой лежит скрипт, использующий это API.
Рассмотрим пример использования python API.
import numpy as np
from grpc.beta import implementations
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2
# Создаем канал и заглушку для запроса к Serving
host = '127.0.0.1'
port = 9001
channel = implementations.insecure_channel(host, port)
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
# Создаем запрос
request = predict_pb2.PredictRequest()
# Указываем имя модели, которое было указано при запуске сервера (флаг model_name)
request.model_spec.name = 'resnet50'
# Указываем имя метода, которое было указано при экспорте модели (см. signature_def_map).
request.model_spec.signature_name = 'predict'
# Копируем входные данные. Названия входов такие же как при экспорте модели.
request.inputs['images'].CopyFrom(
tf.contrib.util.make_tensor_proto(image, shape=image.shape))
# Выполняем запрос. Второй параметр - timeout.
result = stub.Predict(request, 10.0)
# Извлекаем результаты. Названия выходов такие же как при экспорте модели.
prediction = np.array(result.outputs['scores'].float_val)import time
import sys
import tensorflow as tf
import numpy as np
from grpc.beta import implementations
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
def preprocess_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
def get_prediction(host, port, img_path):
image = preprocess_image(img_path)
start_time = time.time()
channel = implementations.insecure_channel(host, port)
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'resnet50'
request.model_spec.signature_name = 'predict'
request.inputs['images'].CopyFrom(
tf.contrib.util.make_tensor_proto(image, shape=image.shape))
result = stub.Predict(request, 10.0)
prediction = np.array(result.outputs['scores'].float_val)
return prediction, (time.time()-start_time)*1000.
if __name__ == "__main__":
if len(sys.argv) != 4:
print ('usage: serving_test.py ')
print ('example: serving_test.py 127.0.0.1 9001 ~/elephant.jpg')
exit()
host = sys.argv[1]
port = int(sys.argv[2])
img_path = sys.argv[3]
for i in range(10):
prediction, elapsed_time = get_prediction(host, port, img_path)
if i == 0:
print('Predicted:', decode_predictions(np.atleast_2d(prediction), top=3)[0])
print('Elapsed time:', elapsed_time, 'ms') Сравним скорость работы Tensorflow Serving c Keras-версией.
import sys
import time
from keras.applications.resnet50 import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
def preprocess_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
def get_prediction(model, img_path):
image = preprocess_image(img_path)
start_time = time.time()
prediction = model.predict(image)
return prediction, (time.time()-start_time)*1000.
if __name__ == "__main__":
if len(sys.argv) != 2:
print ('usage: keras_test.py ')
print ('example: keras_test.py ~/elephant.jpg')
exit()
img_path = sys.argv[1]
model = ResNet50(weights='imagenet')
for i in range(10):
prediction, elapsed_time = get_prediction(model, img_path)
if i == 0:
print('Predicted:', decode_predictions(np.atleast_2d(prediction), top=3)[0])
print('Elapsed time:', elapsed_time, 'ms')Все замеры производились на CPU.
Для тестирования возьмем эту фотографию кота с Pexels.com, которую я нашел через https://everypixel.com.

Keras
Predicted: [('n02127052', 'lynx', 0.59509182), ('n02128385', 'leopard', 0.050437182), ('n02123159', 'tiger_cat', 0.049577814)]
Elapsed time: 419.47126388549805 ms
Elapsed time: 125.33354759216309 ms
Elapsed time: 122.70569801330566 ms
Elapsed time: 122.8172779083252 ms
Elapsed time: 122.3604679107666 ms
Elapsed time: 116.24360084533691 ms
Elapsed time: 116.51420593261719 ms
Elapsed time: 113.5416030883789 ms
Elapsed time: 112.34736442565918 ms
Elapsed time: 110.09907722473145 msServing
Predicted: [('n02127052', 'lynx', 0.59509176015853882), ('n02128385', 'leopard', 0.050437178462743759), ('n02123159', 'tiger_cat', 0.049577809870243073)]
Elapsed time: 117.71702766418457 ms
Elapsed time: 75.67715644836426 ms
Elapsed time: 72.94225692749023 ms
Elapsed time: 71.62714004516602 ms
Elapsed time: 71.4271068572998 ms
Elapsed time: 74.54872131347656 ms
Elapsed time: 70.8014965057373 ms
Elapsed time: 70.94025611877441 ms
Elapsed time: 70.58024406433105 ms
Elapsed time: 68.82333755493164 msКак видно, Serving работает даже быстрее, чем версия на Keras. Это будет еще заметнее при большом количестве запросов.
Сначала установим Flask.
sudo pip3 install flask
from flask import Flask
from flask import request
from flask import jsonify
import tensorflow as tf
from grpc.beta import implementations
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
application = Flask(__name__)
host = '127.0.0.1'
port = 9001
def preprocess_image(img):
img = image.load_img(img, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
return x
def get_prediction(img):
image = preprocess_image(img)
channel = implementations.insecure_channel(host, port)
stub = prediction_service_pb2.beta_create_PredictionService_stub(channel)
request = predict_pb2.PredictRequest()
request.model_spec.name = 'resnet50'
request.model_spec.signature_name = 'predict'
request.inputs['images'].CopyFrom(
tf.contrib.util.make_tensor_proto(image, shape=image.shape))
result = stub.Predict(request, 10.0)
prediction = np.array(result.outputs['scores'].float_val)
return decode_predictions(np.atleast_2d(prediction), top=3)[0]
@application.route('/predict', methods=['POST'])
def predict():
if request.files.get('data'):
img = request.files['data']
resp = get_prediction(img)
response = jsonify(resp)
return response
else:
return jsonify({'status': 'error'})
if __name__ == "__main__":
application.run()Запустим сервис.
python3 serving_service.py
Протестируем сервис. Отправим запрос через curl.
curl '127.0.0.1:5000/predict' -X POST -F "data=@./cat.jpeg"
Получаем ответ следующего вида.
[ [ "n02127052", "lynx", 0.5950918197631836 ], [ "n02128385", "leopard", 0.05043718218803406 ], [ "n02123159", "tiger_cat", 0.04957781359553337 ] ]
Замечательно! Оно работает!
В данной статье мы рассмотрели как можно использовать Tensorflow Serving для деплоймента моделей в production. Также рассмотрели как можно реализовать простой REST-сервис на Flask, обращающийся к серверу моделей.
Официальный сайт Tensorflow Serving
Код всех скриптов статьи
|
|
Какой firewall лучше всех? Лидеры среди UTM и Enterprise Firewalls (Gartner 2017) |
|
Метки: author cooper051 тестирование it-систем информационная безопасность блог компании ts solution check point cisco fortinet palo alto sophos sonicwall huawei |
Что такое ERP система |
 Многие компании по мере роста бизнеса приходят к понимаю, что им требуется какая-то ERP-система. Если в малом бизнесе удается обойтись без этого инструмента, то средний бизнес с каждым днем активнее пользуется подобными средствами. Но чтобы выбрать ERP-систему, и даже для того, чтобы понимать, требуется ли в бизнесе этот продукт и какие преимущества принесет его использование, важно правильно понимать, что это такое.
Многие компании по мере роста бизнеса приходят к понимаю, что им требуется какая-то ERP-система. Если в малом бизнесе удается обойтись без этого инструмента, то средний бизнес с каждым днем активнее пользуется подобными средствами. Но чтобы выбрать ERP-систему, и даже для того, чтобы понимать, требуется ли в бизнесе этот продукт и какие преимущества принесет его использование, важно правильно понимать, что это такое.ERP (англ. Enterprise Resource Planning, планирование ресурсов предприятия) — организационная стратегия интеграции производства и операций, управления трудовыми ресурсами, финансового менеджмента и управления активами, ориентированная на непрерывную балансировку и оптимизацию ресурсов предприятия посредством специализированного интегрированного пакета прикладного программного обеспечения, обеспечивающего общую модель данных и процессов для всех сфер деятельности[1][2]. ERP-система — конкретный программный пакет, реализующий стратегию ERP. Википедия
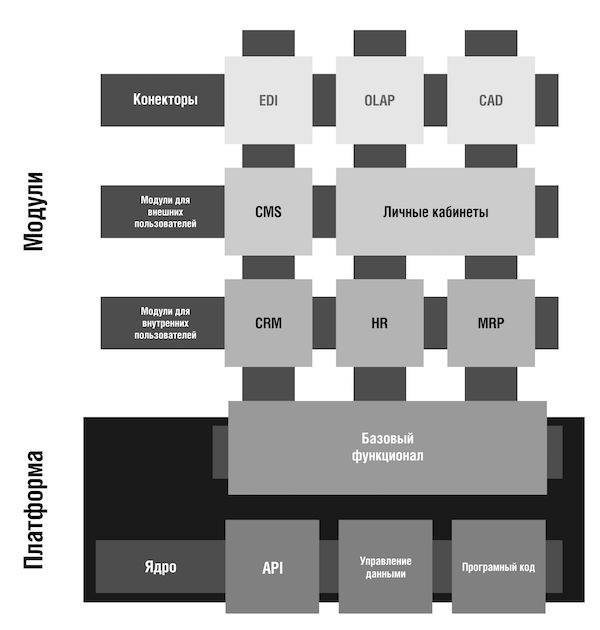
ERP – это продукт, который изначально создан, с одной стороны, для масштабируемости, а с другой – для обеспечения максимума возможностей.
|
Метки: author JustRamil терминология it erp- системы erp |
С новым (айтишным) «годом» Вас, други |
Как то прошло незамеченным, что где-то 8 часов назад началась новая "эра", как минимум на наших железках всех мастей.
Я не перепил, если что...
PoC (несколько часов назад):
$ date +%s
1500000000
$ date +%s
1500000001Маленький юбилей, ибо мы разменяли полтора лярда секунд с начала времен эпох.
Посему, с Праздником всех! Холодного и вкусного пива! Безбажного кода! Тихо шуршащего железа! И да обойдут вас вируса стороной!
Следующая новая эпоха (1600000000) состоится через три человеческих года, а именно "Sun Sep 13 12:26:40 GMT 2020".
Следующая же юбилейная секунда отсчитает только в "Wed May 18 03:33:20 GMT 2033" и разменяет уже два миллиарда.
Как оно все сложится...
|
Метки: author sebres системное администрирование серверное администрирование *nix с новым годом! |
[Перевод] Семантика exactly-once в Apache Kafka |

Всем привет! Меня зовут Юрий Лилеков, я работаю в Server Team Badoo. На днях мне попалась довольно интересная статья о новой семантике exactly-once в Apache Kafka, которую я с радостью для вас перевёл.
Наконец, свершилось то, что сообщество Kafka так долго ждало: в Apache Kafka версии 0.11 появилась семантика exactly-once («строго однократная доставка»). В этом посте я расскажу вам о следующих моментах:
– что представляет собой семантика exactly-once в Apache Kafka;
– почему эта проблема сложна;
– как новые свойства идемпотентности и транзакций позволяют корректно выполнять потоковую exactly-once-обработку с помощью Kafka Streams API.
Я догадываюсь, о чём каждый из вас сейчас подумал: доставка exactly-once невозможна. Для практического применения это слишком дорого (или поправьте меня, если я ошибаюсь). Вы не одиноки в таких мыслях. Некоторые из моих коллег признают, что доставка exactly-once – одна из самых сложных проблем в сфере распределённых приложений.

Итак, кое-кто недвусмысленно дал понять, что считает доставку exactly-once с большой вероятностью невозможной!

Я не отрицаю, что семантика доставки exactly-once (и поддержка потоковой обработки в этом же режиме) – действительно трудноразрешимая задача. Но также я больше года была свидетелем того, как талантливые инженеры Confluent совместно с open-source-сообществом усердно работали над решением этой проблемы в Apache Kafka. Так что давайте перейдём к обзору семантики передачи сообщений.
Компьютеры, образующие распределённую систему, всегда могут выйти из строя вне зависимости от других участников системы. В случае с Kafka из строя может выйти отдельный брокер, или может произойти сетевая ошибка, в то время как продюсер отправляет сообщение в топик. И в зависимости от действий продюсера по обработке сбоя, можно получить различные семантики.
Если продюсер получает подтверждение от брокера Kafka, и при этом acks=all, это означает, что сообщение было записано в топик Kafka строго однократно. Но если продюсер не получает подтверждение по истечении тайм-аута или получает ошибку, то он может попробовать снова отправить сообщение, считая, что оно не было записано в топик Kafka. Если брокер дал сбой непосредственно перед отправкой подтверждения, но после того, как сообщение было успешно записано в топик Kafka, эта повторная попытка отправки приведёт к тому, что сообщение будет записано и отправлено конечному потребителю дважды. Все будут довольны неутомимостью раздающего, но такой подход приводит к дублированию работы и некорректным результатам.
Если продюсер не производит повторную отправку сообщения по истечении тайм-аута или получения ошибки, то сообщение может не записаться в топик Kafka, и, следовательно, оно не будет доставлено потребителю. В большинстве случаев сообщения будут доставляться, но, чтобы избежать вероятности дублирования, мы допускаем, что иногда сообщения не доходят.
Даже при повторной попытке продюсера отправить сообщение, сообщение доставляется строго один раз. Семантика exactly once – наиболее желаемая гарантия, но при этом наименее понимаемая. Причина в том, что она требует взаимодействия между самой системой передачи сообщений и приложением, генерирующим и получающим сообщения. Например, если после удачного получения сообщения вы перемотаете Kafka-потребитель на предыдущее положение, то снова получите оттуда все до последнего сообщения. Это наглядно показывает, почему система обмена сообщениями и клиентское приложение должны взаимодействовать друг с другом, чтобы работала семантика exactly-once.
Описание трудностей поддержки семантики exactly-once начнём с простого примера.
Допустим, однопоточное приложение-продюсер отправляет сообщение “Hello, Kafka” в состоящий из одного раздела топик Kafka с именем “EoS” Далее, предположим, что единственный экземпляр приложения-потребителя на другом конце берёт данные из топика и выводит сообщение. Если повезёт и сбоев не будет, то всё сработает отлично, и сообщение “Hello, Kafka” будет однократно записано в раздел топика “EoS”. Потребитель получает сообщение, обрабатывает его и фиксирует его положение, тем самым сообщая о завершении обработки – и приложение-потребитель уже не получит это сообщение повторно даже в случае своего сбоя и перезагрузки.
Но всем нам хорошо известно, что нельзя всегда рассчитывать на удачу. По мере масштабирования периодически происходят даже самые маловероятные сценарии сбоев.
Сбой брокера. Kafka – это высокодоступная, устойчивая и надёжная система, в которой каждое сообщение, записанное в раздел, сохраняется и реплицируется n-ное кличество раз. Поэтому Kafka может выдержать n-1 сбоев брокера, а значит, раздел доступен до тех пор, пока доступен хотя бы один брокер. Протокол репликации Kafka гарантирует, что, если сообщение однажды было успешно записано в главную реплику, оно будет растиражировано по всем доступным репликам.
Сбой RPC «продюсер-брокер». Устойчивость Kafka зависит от продюсера, получающего от брокера подтверждение. Сбой при получении подтверждения не обязательно означает сбой самого запроса. Брокер может «упасть» уже после записи сообщения, но ещё до отправки подтверждения продюсеру. Также он может «упасть» ещё до записи сообщения в топик. Поскольку продюсеру неоткуда узнать причину сбоя, он вынужден предположить, что сообщение не было успешно записано, и сделает ещё одну попытку. В некоторых случаях это приведёт к дублированию сообщения в логе раздела Kafka, а конечный потребитель получит это сообщение более одного раза.
До версии 0.11.x Apache Kafka поддерживал для каждого раздела семантику доставки at least once и доставку с сохранением порядка. Как видно из вышеприведённого примера, это означает, что повторные попытки отправки сообщения продюсером могли привести к его дублированию. В новой семантике exactly-once мы усилили семантику обработки данных Kafka тремя различными, но взаимосвязанными способами.
Идемпотентная операция – это операция, которая при многократном выполнении даёт тот же результат, что и при однократном. Операция отправки продюсером теперь является идемпотентной. В случае ошибки, заставляющей продюсера повторить попытку, сообщение, которое многократно отправлялось продюсером, будет однократно записано в логе брокера Kafka. Применительно к одиночному разделу идемпотентные операции отправки продюсером избавляют нас от вероятности дублирования сообщений вследствие ошибок продюсера или брокера.
Для включения этой функции и получения семантики exactly-once для каждого раздела (то есть никакого дублирования, никакой потери данных и сохранение порядка доставки) просто укажите в настройках продюсера enable.idempotence=true.
Так как же работает эта функция? «Под капотом» она работает аналогично ТСР: каждый пакет сообщений, отправленный в Kafka, будет содержать порядковый номер, при помощи которого брокер сможет устранить дублирование данных. Но в отличие от ТСР, который гарантированно выполняет дедупликацию только в условиях временного соединения в памяти, порядковый номер сохраняется в реплицированный лог. Поэтому даже в случае сбоя главной реплики любой брокер, берущий на себя эту роль, также распознаёт, являются ли дублем заново отправленные данные.
Накладные расходы при таком подходе относительно невелики: всего лишь несколько дополнительных числовых полей для каждого пакета сообщений. Дальше вы увидите, что эта функция очень незначительно снижает производительность по сравнению с неидемпотентным продюсером.
Теперь Kafka поддерживает атомарную запись в нескольких разделах при помощи новых транзакционных API. Это позволяет продюсеру отправлять пакеты сообщений в несколько разделов так, что либо все сообщения из пакета будут видны любому потребителю, либо ни одно из них не будет видно никому. Данная функция также позволяет осуществлять смещение потребителя в одной транзакции с данными, которые вы обработали, а, следовательно, делает возможной сквозную семантику exactly-once. Вот сниппет с примером кода, который демонстрирует использование транзакционного API:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch(ProducerFencedException e) {
producer.close();
} catch(KafkaException e) {
producer.abortTransaction();
}Этот пример показывает, как можно использовать новый Producer API для атомарной отправки сообщений в набор разделов топика. Стоит отметить, что раздел топика Kafka может одновременно содержать сообщения, как являющиеся частью транзакции, так и не являющиеся.
Поэтому с точки зрения потребителя есть два способа чтения транзакционных сообщений, выраженных через isolation level — настройку потребителя:
read_committed: вдобавок к чтению сообщений, не являющихся частью транзакции, есть возможность считывать и те, что являются частью транзакции, после коммита транзакции.
read_uncommitted: считываются все сообщения в порядке смещения без ожидания коммита транзакции; эта опция аналогична существующей семантике Kafka-потребителя.Чтобы использовать транзакцию, необходимо сконфигурировать потребителя для задания нужного isolation level, использовать новые Producer API и задать в конфигурации продюсера параметр Transactional ID как некий уникальный ID (он нужен для обеспечения непрерывности транзакционного состояния при перезапусках приложения).
Благодаря Streams API в Apache Kafka теперь доступна потоковая exactly-once- обработка на основании идемпотентности и атомарности. Чтобы ваше потоковое приложение могло использовать эту семантику, достаточно указать в конфигурации processing.guarantee=exactly_once. В результате вся обработка будет выполняться строго однократно. Это относится как к обработке, так и к воссозданному состоянию, созданному заданием на обработку данных и записанному обратно в Kafka.
«Вот почему гарантии exactly-once-обработки, предоставляемые Streams API в Kafka, являются сильнейшими среди всех гарантий, предлагаемых сегодня системами потоковой обработки. Он обеспечивает сквозные exactly-once-гарантии для приложения потоковой обработки, начиная с чтения данных из Kafka, с любого состояния, воссозданного в Kafka потоковым приложением, до записи в Kafka финального результата. Системы потоковой обработки, в которых поддержка воссозданных состояний опирается лишь на внешние системы данных, ослабляют гарантии потоковой exactly-once-обработки. Даже когда они используют Kafka в качестве источника для обработки и должны восстановиться после сбоя, то могут лишь переключить свои Kafka-положения для перепотребления и переобработки сообщений. Но они не могут откатить ассоциированное состояние во внешней системе, что приводит к некорректным результатам в случае неидемпотентности обновления состояния».
Позволю себе добавить ещё немного подробностей. Обычно нас волнует, правильный ли ответ получает приложение потоковой обработки, даже если во время обработки падает один из инстансов. Правильное решение при восстановлении вышедшего из строя инстанса – продолжение обработки в том состоянии, которое было до сбоя.
Итак, потоковая обработка – это простая операция «чтение – обработка – запись» в топике Kafka. Потребитель считывает из топика сообщения, обрабатывающая логика преобразует их или меняет состояние, поддерживаемое обработчиком, а продюсер записывает результат в другой топик Kafka. Потоковая exactly-once-обработка – это просто возможность строго однократно выполнять операцию «чтение – обработка – запись». При таком раскладе получить правильный ответ означает лишь не пропустить какое-нибудь входящее сообщение или не продублировать выходные данные. И это как раз тот режим работы, который потребители ждут от потокового exactly-once-обработчика.
Помимо рассмотренного простейшего сценария сбоя есть и много других.
Потоковый обработчик может брать входные данные из нескольких исходных топиков, порядок которых отличается при многократных прогонах. Поэтому если вы перезапустите свой потоковый обработчик, который взял данные из нескольких исходных топиков, то можете получить другие результаты.
Потоковый обработчик может передавать выходные данные в несколько целевых топиков. Если продюсер не может выполнять атомарную запись в несколько топиков, то его выходные данные могут оказаться неверными в случае сбоя записи в некоторые (не во все) разделы.
Потоковый обработчик может агрегировать или объединять несколько входных данных при помощи средств управления состоянием, предоставляемых Streams API. Если один из экземпляров потокового обработчика даёт сбой, то у вас должна быть возможность откатиться к состоянию, воссозданному этим экземпляром потокового обработчика. При перезапуске инстанса вам также нужно иметь возможность продолжить обработку и воссоздать его состояние.
Потоковый обработчик может искать более полную информацию во внешней базе данных или посредством обращения к сервису, обновляемому извне. Зависимость от внешнего сервиса делает потоковый обработчик совершенно недетерминированным. Если внешний сервис изменит своё внутреннее состояние между двумя запусками, это приведёт к некорректной передаче результатов. Но при правильной обработке это не должно стать причиной получения полностью неправильных результатов – просто выходные данные потокового процессора будут относиться к допустимым выходным данным.
Сбой и перезапуск, особенно в сочетании с недетерминированными операциями и изменениями персистентного состояния, рассчитанного приложением, могут привести не только к дублированию, но и к неверным результатам. Например, если на одной стадии обработки рассчитывается количество увиденных событий, то дублирование может привести к неверному подсчёту на следующей стадии. Поэтому нам нужно определиться со смыслом фразы «потоковая exactly-once-обработка».
Это относится и к потреблению из топика, и к воссозданию промежуточного состояния в топике Kafka и отправке в него. Не все возможные вычисления в сообщении выполняются с помощью Streams API, некоторые из них (например, зависящие от внешнего сервиса или потребления из нескольких топиков-источников) в основе своей являются недетерминированными.
«Применительно к гарантиям потоковой exactly-once-обработки для детерминированных операций нужно убедиться, что выходные данные операции «чтение – обработка – запись» будут такими же, как если бы потоковый обработчик видел каждое сообщение строго однократно – как будто при условии бесперебойной работы».
Всё это имеет смысл для детерминированных операций, но что означает потоковая exactly-once обработка, когда сама логика обработки является недетерминированной? Допустим, тот же потоковый обработчик, подсчитывающий количество входящих событий, будет модифицирован для подсчёта только тех событий, которые удовлетворяют условиям, диктуемым внешним сервисом. Эта операция – недетерминированная по своей природе, поскольку внешние условия могут меняться от запуска к запуску потокового обработчика, что потенциально ведёт к различным результатам. Так как же нам понимать гарантии потоковой exactly-once-обработки применительно к таким операциям?
«Применительно к гарантиям потоковой exactly-once-обработки для недетерминированных операций нужно убедиться, что выходные данные операции «чтение – обработка – запись» принадлежат к подмножеству допустимых выходных данных, генерируемых комбинацией допустимых значений недетерминированных входных данных».
Итак, в нашем примере потокового обработчика при текущем значении счётчика 31 и значении входящего события 2 верными выходными данными в случае сбоя могут быть только 31 или 33: 31 – при условии, что входное событие отклонено, как указано внешними условиями, а 33 – если оно не отклонено.
Это статья лишь поверхностно касается вопросов потоковой exactly-once-обработки в Streams API. В следующем посте на эту тему будет подробнее рассказано о гарантиях, а также проведено сравнение гарантий exactly-once в других системах потоковой обработки.
Любая крупная работа вроде этой всегда вызывает вопрос «А работает ли эта фича так, как обещано?» Чтобы ответить на него, давайте рассмотрим её правильность (как мы спроектировали, построили и протестировали эту фичу) и производительность.
Корректность и производительность начинаются с надёжной архитектуры. Работу над ней и прототипами мы начали около трёх лет назад в LinkedIn. Также мы занимались этим более года в Confluent, пытаясь найти элегантный способ свести идемпотентность и транзакционные требования в целостный пакет. Мы составили 60-страничное описание, охватывающее все аспекты архитектуры, начиная с высокоуровневой передачи сообщений до рутинных подробностей реализации каждой структуры данных и RPC. Этот процесс шёл целых девять месяцев под пристальным вниманием общественности, за это время архитектура значительно улучшилась благодаря обратной связи сообщества.
Например, благодаря open-source-дискуссии мы заменили буферизацию транзакционных чтений со стороны потребителя на более умную фильтрацию в серверной части, избежав тем самым возможных больших проблем с производительностью. Также мы улучшили взаимодействие транзакций со сжатыми топиками и расширили возможности по обеспечению безопасности.
В результате мы пришли к простой архитектуре, которая во многом опирается на надёжные примитивы Kafka.
Эти простота, упор на эффективное использование и внимание к деталям дали нашей архитектуре большие шансы превратиться в хорошо работающую реализацию.
Мы разрабатывали фичу с открытым исходным кодом, чтобы каждый запрос на добавление кода подвергался интенсивной проверке. В результате отдельные запросы в течение месяцев проходили через несколько десятков итераций. Это позволило выявить некоторые недостатки архитектуры и бесчисленные тупиковые ситуации, о которых мы и не догадывались.
Для тестов мы написали более 15 000 строк кода, включая распределённое тестирование работы под нагрузкой с настоящими сбоями, и проводили их каждую ночь в течение нескольких недель в поисках багов. Тесты выявили самые разные проблемы: от базовых ошибок в коде до эзотерических проблем с NTP-синхронизацией в нашей тестовой обвязке. Также мы прогоняли распределённые случайные тесты: брали полный кластер Kafka с несколькими транзакционными клиентами, транзакционно создавали сообщения, считывали их в многопоточном режиме и жёстко «убивали» клиенты и серверы во время этого процесса, чтобы убедиться, что данные не теряются и не дублируются.
В результате получилась простая и надёжная архитектура с тщательно протестированной, высококачественной кодовой базой, которая и легла в основу нашего решения.
При создании этой фичи мы сосредоточились на производительности; мы хотели, чтобы наши пользователи могли использовать доставку exactly-once и семантику обработки не только в каких-то определённых случаях, но и имели возможность включать их по умолчанию. Мы отказались от множества более простых архитектурных решений, подразумевающих снижение производительности. После долгих раздумий мы остановились на схеме, имеющей минимальные накладные расходы на каждую транзакцию (~1 процедура записи на раздел и несколько дополнительных записей в центральном транзакционном логе). Это видно из результатов измерения производительности фичи. Для однокилобайтных сообщений и транзакций, длящихся 100 мс, пропускная способность продюсера снижается на:
3% по сравнению с его работой, когда он сконфигурирован на контролируемую (in-order) доставку at least once (acks=all, max.in.flight.requests.per.connection=1),
на 20% по сравнению с его работой, когда он сконфигурирован на at most once без соблюдения порядка сообщений (acks=1, max.in.flight.requests.per.connection=5), используется по умолчанию.
С момента выхода первого релиза семантики exactly-once появились планы по дальнейшему улучшению производительности. Например, как только мы решим задачу KAFKA-5494, улучшающую конвейеризацию в продюсере, то надеемся значительно снизить накладные расходы в производительности транзакционного продюсера даже по сравнению с продюсером, поддерживающим доставку at most once без соблюдения порядка сообщений. Мы также обнаружили, что идемпотентность оказывает ничтожно малое влияние на производительность продюсера. Если вам интересно, вот результаты наших бенчмарков, тестовая конфигурация и методика тестирования.
Помимо обеспечения низких накладных расходов при работе новых фич, нам хотелось не допустить регрессию производительности приложений, не использующих фичи exactly-once. Мы не только добавили поля в заголовки сообщений Kafka для внедрения exactly-once, но и доработали формат сообщений Kafka, чтобы ещё эффективнее сжимать их при передаче по сети или на диске. В частности, мы перенесли часть метаданных в заголовки пакетов и внедрили кодирование длин переменных для каждой записи в пакете. Это позволило значительно уменьшить размер сообщения. Например, пакет с семью записями по 10 байтов каждая в новом формате будет весить на 35% меньше. Это привело к улучшению чистой производительности Kafka в приложениях, использующих ввод/ вывод: при обработке маленьких сообщений до 20% ускоряется работа продюсера и до 50% – потребителя. Такой рост производительности доступен любому пользователю Kafka 0.11, даже если он не пользуется фичами exactly-once.
Мы также пересмотрели накладные расходы на потоковую exactly-once обработку с помощью Streams API. При коротком интервале коммита в 100 мс (что необходимо для поддержания низкой сквозной задержки) порисходит падение производительности от 15% (однокилобайтные сообщения) до 30% (стобайтные сообщения). Однако при большом интервале коммита в 30 с вообще не наблюдается повышения накладных расходов для сообщений размером 1 Кб и больше. В следующем релизе мы планируем внедрить спекулятивное исполнение, что позволит поддерживать низкую сквозную задержку даже при большом интервале коммита. То есть мы хотим добиться нулевых накладных расходов на транзакцию.
Наконец, кардинально переработав некоторые ключевые структуры данных, мы освободили пространство для построения идемпотентности и транзакционных фич с минимальным снижением производительности, чтобы Kafka стал ещё быстрее. Годы напряжённой работы – и мы невероятно рады выпустить фичи exactly-once для всего сообщества Apache Kafka. Благодаря усилиям, вложенным в создание семантики exactly-once, по мере её широкого распространения в сообществе будут внедряться и новые улучшения. С нетерпением ждём обратной связи и работаем над преобразованиями для предстоящих релизов Apache Kafka.
Нет, не совсем. Обработка данных exactly-once – это сквозная гарантия, и приложение должно быть спроектировано так, чтобы не нарушать это свойство. Если вы пользуетесь потребительским API, это значит, что вы фиксируете изменения состояния вашего приложения в соответствии со своими смещениями, как описано в этой статье.
Ситуация с потоковой обработкой немного лучше. Поскольку потоковая обработка – закрытая система, где входные и выходные данные, а также изменения состояний смоделированы в одной операции, то это действительно во многом похоже на волшебную пыль. Единственное изменение в конфиге обеспечит вам сквозные гарантии. Хотя вам всё ещё нужно получить данные из Kafka. Вы получите возможность потоковой обработки в сочетании с exactly-once коннектором.
Эта статья в основном посвящена описанию характера ориентированных на пользователей гарантий, обеспечиваемых грядущей exactly-once-фичей в Apache Kafka 0.11, а также тому, как вы можете её использовать.
Если вы хотите подробнее изучить гарантии exactly-once, рекомендую пройтись по KIP-98, чтобы узнать о свойствах транзакции, и KIP-129, чтобы узнать о потоковой exactly-once обработке. Если хотите ещё глубже узнать об архитектуре этих фич, вам в помощь этот дизайн-документ.
|
Метки: author lilek системы обмена сообщениями разработка систем передачи данных программирование высокая производительность блог компании badoo kafka apache kafka |
Information Security Europe: тренды мирового рынка ИБ, о которых вы не прочитаете у Gartner |
 В начале июня мы с моим другом и коллегой Андреем Данкевичем съездили на несколько дней в Лондон на Information Security Europe. Это крупнейшая выставка в Европе и «одна из» в мире. В этом году ее посетило более 15 000 человек, и проходила она уже в 22 раз.
В начале июня мы с моим другом и коллегой Андреем Данкевичем съездили на несколько дней в Лондон на Information Security Europe. Это крупнейшая выставка в Европе и «одна из» в мире. В этом году ее посетило более 15 000 человек, и проходила она уже в 22 раз. 
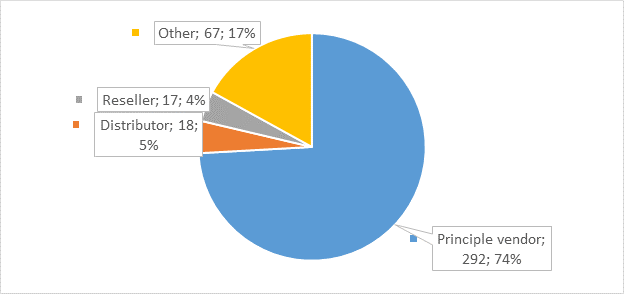



|
Метки: author SolarSecurity информационная безопасность блог компании solar security dlp soc. mssp mdr ueba grc iga мероприятие конференция выставка infosec |
Как построить маленькую, но хорошую сеть? |
|
Метки: author jandrian блог компании cisco wi-fi cisco wi-fi 802.11ac точки доступа беспроводные сети cisco mobility cisco wireless малый бизнес |






