Начинаем публиковать материалы с
форума «Совместная безопасность облачных решений для бизнеса», который мы провели совместно с «Лабораторией Касперского» и HUAWEI 31 мая в Москве. Одноименная пленарная сессия оказалась центральным событием и мы решили начать с нее. Участники дискуссии представили свои решения по обеспечению безопасности в облаке, а присутствующие потребители услуг оценили их по существу. Что получилось в итоге — читайте, смотрите.
Участники:
Модератор дискуссии: Никита Цаплин, управляющий партнер RUVDS
Владимир Островерхов, эксперт поддержки корпоративных продаж «Лаборатория Касперского»
Михаил Сергеев, директор по корпоративным коммуникациям ГАРС телеком
Данила Чежин, директор по продажам Variti
Сергей Слукин, руководитель отдела DMA и алгоритмической торговли АО «ФИНАМ»
Станислав Погоржельский, продакт менеджер HOSTKEY
Александр Мисюрев, директор по развитию AIG
Александр Миляр, эксперт по информационной безопасности HUAWEI
Франк Харцхайм, CEO, Deltalis
Лидия Шрейдер-Стрюб, руководитель продаж Deltalis
Видеозапись:
Пригласив спикеров, дискуссию открыл модератор, Никита Цаплин, Управляющий партнер RUVDS
Для начала я хотел бы, опять же, провести некоторую параллель с прошлогодним форумом, там в преддверье форума обсуждалось то что американский банк J.P. Morgan заявил о переносе части своих сервисов в публичное облако и мы обсуждали, как раз таки на форуме, на сколько возможны такие сценарии для российского рынка информационных услуг. А вот за несколько месяцев до проведения текущего форума, технический директор J.P. Morgan, господин Дизи провёл рабочий завтрак на котором он уже продемонстрировал результаты переноса нескольких приложений в публичное облако Amazon. То есть мы видим, что тенденции по переносу в облако, они действительно сбываются. И при том что J.P. Morgan — это финансовое учреждение, это крупнейший банк по активам в мире. А финансовые учреждения они наиболее чувствительны для переносов в облака и даже по самым оптимистичным прогнозам, не более 15% данных финансовых компаний к девятнадцатому году могут быть перенесены в облако. В то время как, например, такие компании как Джонсон и Джонсон заявляют о готовности перенести 85% в течении ближайших двух лет. То, что мы видим — это как бы действительно сильный тренд. Он конечно же происходит… Локомотив всего этого — это конечно западный рынок. Мы как бы видим что там всё хорошо, мы за них рады, но мы хотели бы поговорить больше о ситуации в России непосредственно. О ситуации как осуществляется подобные прогнозы в России, по переносам в облако и насколько предложения вендоров соответствуют ожиданиям потребителей здесь. Я хотел бы что бы мы поговорили не о таких крупных компаниях как J.P. Morgan, здесь, а о тех компаниях которые составляют наш рынок, которые создают спрос — это компании малого и среднего бизнеса, на которые мы, как провайдеры и наши коллеги из других провайдеров которые здесь присутствуют, вендоров, ориентируются. Поэтому я бы хотел что бы мы поговорили именно о данном секторе.
— Поскольку вектор для дискуссии задан, в плане масштаба по компаниям малого и среднего бизнеса, я хотел бы спросить у присутствующих здесь вендоров, в первую очередь оборудования — насколько для вас этот сегмент, малого и среднего бизнеса, для вашей компании значим? Что ваша компания предлагает подобным клиентам и готовы ли вы отвечать на запросы данных компаний, или они ещё довольно малы для того что бы задавать какой-то специфический спрос, как вы считаете?
Александр Миляр, эксперт по информационной безопасности HUAWEI:
— Добрый день, коллеги. Меня зовут Миллер Александр. Я занимаюсь информационной безопасностью компании HUAWEI. И если ответить, то если мы говорим в разрезе тонких клиентов и когда у нас инфраструктура в облаке, включая пользователей, то всё равно, необходимо соблюдение корпоративной политики. В том числе и доступа в интернет. Если у нас, например, межсетевые экраны, прокси-сервера, которые находятся у нас в компании, мы на них настраиваем политики, то что будет в облаке? На самом деле — тоже самое. Наши продукты готовы как для применения в облаке, так и для локальных… Здесь для себя, в предприятиях. Они одни и те же, разница лишь в том, что настаивается либо администраторами здесь, либо в облаке. И мы подключаем все наши те же самые ресурсы, которые используем здесь, то есть — политика доступа в интернет, защита серверов, которые находятся в облаке, при помощи IPS, URL-фильтрации, идентификации приложений, гранулярный доступ к интернету так же и в облаке. С точки зрения малого бизнеса, как мы рассматривали сегодня кейс по… Если малый бизнес готов идти в облако, то для них всё сохраняется, с этой точки зрения. HUAWEI видит, что малый бизнес будет использовать облако немного иначе. То есть будет использовать больше как подписка к управлению локальными девайсами. То есть не устанавливать себе решения локально по управлению множество, допустим коммутаторов или WI-FI сетей, то всё это мы видим что уйдёт в облако. К примеру, к 20-му году, у нас есть понимание что более половины точек доступа которые сейчас будут продаваться, будут управляться из облака. И 35% коммутаторов и маршрутизаторов будут использовать облачное управление. То есть не только наши десктопы уйдут в облако но и локальные сети, которые мы строим, управление всеми политиками, устройствами, конфигурациями, всё так же будет происходить из облака. Если мы говорим про малый бизнес, то малый бизнес в частности хочет, это размеры от, допустим, 10ти человек, которые в компании и до 500. Вот это, грубо говоря, наш малый бизнес. Хотя у нас часто говорят, малый бизнес 500 — это уже средний бизнес, но на самом деле — нет. Это всё-таки относятся к сегменту малого бизнеса. И когда у нас есть филиальная сеть, нам нужно управлять, допустим, настройками, нужно использовать администраторов у себя в штате, которые разбираются — как построить VPN-ы, как соединить наши сети, как построить доступ в интернет. Через облако это реализуется через VM-интерфейс, то есть идёт и упрощение к настройке и использованию ресурсов структуры предприятий.
Никита Цаплин (Модератор): — Спасибо. Теперь я хотел бы задать похожий вопрос представителям хостинг-провайдеров, но прежде давайте не много расскажу про нашу компанию и наших клиентов. Для проекта RUVDS 90% клиентов — это физический лица и лишь 10% юридические лица. Правила 20 на 80, где 20% клиентов делают 80% прибыли, нашей компанией не выполняется. Между тем мы видим сегмент малого и среднего бизнеса очень важным для нас в плане дальнейшего масштабирования и развития технологий. Я хотел бы спросить у Станислава, как у нашего коллеги по цеху — какая ситуация, насколько ваша компания следует запросам малого и среднего бизнеса и на сколько для вас важен этот сегмент, и есть ли какие-то специфические запросы с их стороны?
Станислав Погоржельский, продакт менеджер HOSTKEY:
— Добрый день, меня зовут Станислав. Я представляю компанию HOSTKEY. Что касается малого и среднего бизнеса, вот этих клиентов кто приходит к нам. Для нас это очень интересный сегмент. И мы стараемся привлечь их как можно больше в свою сторону, собственно говоря почему. Наша цель — дать клиенту инфраструктуру. Это как обычно — железо, сервера, так и виртуализация облака. При чём важный момент, облака максимально автоматизированы, то есть клиент приходит на сайт, клиент сам регистрируется, клиент там сам себе двигает ползунки, купил услуги и радуется, сам оплачивает, мы даже фактически с ним не общаемся, только в случае крайней необходимости технической помощи. Отвечаю на ваш вопрос, дословно, что малый и средний сегмент нам очень интересен. Это самостоятельные люди, это компании которые ценят финансовые затраты и им требуются обычно услуги вот сейчас. Вот они зашли на сайт и им нужно услуги прямо сейчас купить. Они готовы оплатить своей карточкой и они это у нас и получают. Очень актуально.
Никита Цаплин (Модератор): — Вот вопрос ещё интересный. Часто ли бывает такая ситуация когда приходит клиент, образно, представитель малого и среднего бизнеса и вопрос окончательный именно о переходе, о принятии облачного решения, касается вопроса безопасности. У нас вот нередкая ситуация, когда к нам приходит большой коммерческий банк или другая структура, которая запрашивает коммерческое предложение, начинают его изучать, смотреть, долго думают и в конце говорят — нет, мы всё-таки возьмём выделенный сервер. Мы такие услуги тоже предоставляем, но тем не менее, вот как бы интересен именно вот данный момент.
Станислав Погоржельский: — Я понял вопрос, да, вопрос отличный, хороший. На самом деле самым первым уровнем оценки хостинг-компании с точки зрения клиента, они смотрят — а где будут размещаться данные. И смотрят, в каком дата-центре размещается хостинг-провайдер. Был замечательный дата-центр презентовал до этого презентацию. Вот есть как бы клиенты которые хотят размещать там свои данные, потому что им так хочется. В нашем же случае они смотрят где мы размещаемся, мы размещаемся в хорошем дата-центре, сертификацией TIER в Москве, это локация в России и есть локация в Нидерландах. Собственно все достойные. В первую очередь клиент спрашивает — в каком центре размещаетесь? Дальше он смотрит — а как мои данные размещаются на ваших серверах? Как мы это обеспечиваем, а мы обеспечиваем следующим образом. Данные клиента они именуются цифирным значением. Системный администратор наш, который управляет облаком, они не имеют привязки конкретно взятого клиента и отдельного вот этого сторожа хранилища пользователя. Они не знают чьи это данные. Наши данные размещаются на многих серверах в нашем дата-центре. В тоже время есть система хранения данных. То есть целенаправленно системный администратор не может залезть в данные клиента и нарушить безопасность, требования. Плюс, мы можем рекомендовать клиентам такую услугу как поставить их персональное сетевое оборудование и сделаем только там вход, линки через это оборудование. Например, CISCO K9 или ещё какое то шифровальное оборудование.
Никита Цаплин (Модератор): — Я так понимаю речь идёт об индивидуальных решениях, они не предлагаются всем клиентам в качестве какого-то пакета.
Станислав Погоржельский: — Да, абсолютно верно, дополнительный контур сетевой безопасности строится в эксклюзивном варианте, когда есть запрос от клиента. Самый главный вопрос безопасности людей, компаний которые к нам приходят и хотят автоматизированного облака, они спрашивают — где данные будут размещаться? Всё, это всё что их волнует в первую очередь. Эта информация доступна сразу из сайта. Клиент может с нами не общаться и не получать лично от нас информацию.
Никита Цаплин (Модератор): — По поводу расположения дата-центра всё понятно. Это вопрос номер 1 и всё же хотелось бы понять, возможно есть какие-то услуги для безопасности клиентов в облаке, если среди этих услуг защита от DDoS-атаки, антивирусная защита, что-то такое? И на сколько они востребованы? Вот по опыту нашей компании, эти инновационные решения, они медленно распространяются, в целом рынок хочет, но это точечные решения, которые не могут быть массовой тенденцией. Хотелось бы узнать, какие услуги безопасность в облаке вы предлагаете и насколько они востребованы?
Станислав Погоржельский: — Начнём с первого который вы назвали — защита от DDoS, вообще я считаю что это стандартная услуга которая должна предоставляться хостинг-провайдером. Потому что, когда клиент размещается на серверах компании, любой DDoS может затронуть соседнего клиента, в этом же канале связи. Поэтому защита DDoS как базовая услуга. Если клиент хочет персонально, я не знаю, чистить его канал связи, и он целенаправленно знает, что у него будет DDoS. Когда, естественно эта услуга предоставляется, но это отдельно. В базовом варианте DDoS защита есть и если мы увидим DDoS-атаку, мы говорим клиенту — у тебя проблемы с безопасностью, у тебя идёт атака, давай придумаем что то хорошее и правильное и такой опыт есть. Если говорим об антивирусной защите, запросов больших нету, но я слежу за рынком, люди в принципе хотят, но не понимают до конца эту услугу. У людей есть виртуальная машина, они поставили себе какой-то антивирус, они понимают, они отчёт получили — столько-то вирусов и всё хорошо. А вот по нашему антивирусу они считают, что данные будут сканированы и это уязвимость безопасности. Это мнение людей с которыми я общался. Поэтому эту услугу мы предоставляем только в кастомном варианте.
Никита Цаплин (Модератор): — Защита от DDoS-атаки предлагается всем клиентам как встроенная услуга?
Станислав Погоржельский: — Она есть в любом случае.
Никита Цаплин (Модератор): — Часто бывают атаки? Есть какая-то закономерность, что пострадавшие фирмы или физические лица больше?
Станислав Погоржельский: — Так как у нас на сайт может зайти кто угодно и купить виртуальную машину и арендовать сервера, многие компании покупают как физ. лица и мы не можем их идентифицировать. По количеству DDoS — минимальный идёт каждый день. Большой DDoS, наверное раз в месяц. Нету возможности сортировать, большие это компании или физ. лица.
Никита Цаплин (Модератор): — Часто ли приходится сталкиваться с новыми видами атак? У нас изобретательные клиенты, они регулярно придумывают что-то новое.
Станислав Погоржельский: — Интересный вопрос. Но так как мы предоставляем только инфраструктуру, мы только можем видеть верхнеуровневый трафик. А тот трафик что пришёл заказчику, на его сервер, он сам анализирует. Мы даём инфраструктуру, а именно глубокий анализ того что приходит клиенту это всё доп услуги.
Никита Цаплин (Модератор): — Понятно. Спасибо. Мне кажется было бы интересно услышать вендоров по безопасности которые здесь присутствуют. Начнём с вопроса к Даниле, компания VARITY. Кто ваши основные клиенты, приобретающее защиту от DDoS-атак, продукты в этом направлении, планируете ли вы их расширять?
Данила Чежин, директор по продажам Variti:
— Добрый день коллеги, меня зовут Данила. Отвечаю за взаимодействие с клиентами и за работу с партнёрами компании. Пару слов о нас. Мы разработали собственную технологию защиты от своевременных угроз. Мы это делаем не на уровне, как многие привыкли защищаться на уровне каналов и защищать периметр сети или контур информационной безопасности, как здесь прозвучало. Мы защищаем конкретные сервисы и это сервисы которые приносят бизнесу деньги. Вот мои коллеги с компании HUAWEI, компании HOSTKEY, да и многие другие сидящие рядом, они продают свои сервисы путём регистрации своих клиентов, само регистрацией в своих личных кабинетах. Всё это вэб. И мы фокусируемся как раз на защите вэб-сервисов, и в отличии от привычного подхода, когда многие покупают защиту на уровне каналов, мы защищаем помимо инфраструктурного уровня L3-L4, мы защищаем и на прикладном уровне. Мы хорошо разбираемся в http, https, и это даёт ряд технологических преимуществ, мы это делаем немного по-другому. В целом если отвечать на вопрос. Мы компания тоже молодая, нам меньше даже чем компании RUVDS, и мы так же сталкиваемся с тем что клиенты не готовы сразу перейти на облачные сервисы, будь то инфраструктура или сервис очистки, фильтрации DDoS- атак, здесь имеет место такой подход клиента, когда у них не было таких случаев и мы заниматься не будем. Есть подход когда люди понимают, что то что они делают это важно для бизнеса и если это интернет-магазин, то веб это для них основной источник выручки и прибыли и они понимают, что помимо того что бы этот ресурс просто работал, он должен работать хорошо. И он должен давать возможность любому человеку, даже если ресурс под атакой, и даже если устройство человека в этот момент атакует ресурс, защита должна дать возможность этому человеку всё равно зайти и заплатить какие-то деньги за сервис или за товары. Мы это умеем, нам приходится это рассказывать и объяснять и в рамках встреч, конференций и силами наших партнёров, которые продают технологии, мы вас здесь хорошо понимаем, и если я что-то упустил, давайте…
Никита Цаплин (Модератор): — Появился другой вопрос. Давайте представим, у нас хостинг-провайдер, если у нас, например, есть какой либо сбой, по нашей вине то есть соглашение по которому мы возвращаем средства. Например, происходит DDoS-атака, которая всё равно, не смотря на подключенную услугу защиты, прервала работу вэб-сервиса, что в таком случае делает вендор?
Данила Чежин: — Мы как все игроки на этом рынке предлагаем определённый уровень обслуживания и мы готовы нести ответственность в рамках этого SLA и это может быть какой то типовой вариант, у нас есть ряд тарифов, которые зависят от гарантированной доступности нашего сервиса, но мы готовы обсуждать и индивидуально в рамках каких то отдельных проектов, какие-то отдельные условия. Но нам было бы интересно изучить и ваш опыт, когда вы работали с компанией AIG, и вот…
Никита Цаплин (Модератор): — Я к этому и веду. Какие-то сбои, они происходят у всех вендоров, что бы они там не говорили. Вопрос — как эти ситуации обрабатывать? Понятно что есть SLA, но мало кого устроит что возместят стоимость услуг за месяц, при этом потери пострадавшей стороны могут превышать значительно стоимость этих услуг, по сколько мы видим тенденцию снижения цен на подобные услуги. То данная компенсация, она не устроит клиента. Клиент уйдёт, это сложная и не приятная ситуация. Мы начали думать над тем что придумать в данном направлении и тут как раз мы с нашими партнёрами с AIG, придумали такое решение, точнее они его придумали задолго до нас, потому что программа CyberEdge существует толи с 2007, толи с 2008 года. Мы с партнёрами с кампании AIG разработали данную программу страхования рисков и я хотел бы что бы Александр поделился некоторым опытом со стороны своей компании по страховке рисков потери данных, прерывании работы сети по причине DDoS-атак, или влияния извне.

— День добрый. Меня зовут Александр. Отвечаю за развитие бизнеса в компании AIG, Никита, опытом всегда интересно делится, его очень много, может есть смысл рассказать не много о самом продукте, как он устроен, либо как то конкретизировать?
Никита Цаплин (Модератор): — Мы вот обсуждали конкретную ситуацию. Вот происходит DDoS-атака, она такой силы что защита по каким то причинам не выдержала. Какие есть предложения у компании AIG, я бы хотел, чтобы вы рассказали зрителям, мы то это знаем. По тому что можно с этим сделать, что можно предложить и как можно получить компенсацию сверх SLA.
Александр Мисюрев: — Теперь задача более понятна. Как сказал Майк Тайсон — «У вас всегда есть хороший план до первого удара в челюсть». Действительно сейчас все провайдеры предоставляют какие-то SLA, предоставляют гарантии, кто-то возмещает стоимость обслуживания за месяц. Но гражданский кодекс и вообще возмещение по законодательству никто не отменял, и плюс ко всему у вас ещё существует такой риск, когда происходит DDoS-атака, это перерыв в производстве. Это если вы представляете интернет-магазин, скажем, либо ваша критическая инфраструктура построена на каких-то it решениях и это всё падает и вы не можете обслуживать клиентов, то вы неминуемо теряете деньги, как бы вы этого не хотели. Что здесь делает AIG. Мы занимаемся в мире этим порядка 15 лет, в Россию в 2013 году этот продукт принесли и он называется CyberEdge, он по факту делится на 3 составляющие. Первая составляющая — это расходы на, она называется сервисная, расходы на специалистов, которые помогают вам посмотреть и минимизировать возможный убыток, потому что Cyber — это в первую очередь защита данных, и всё что с этим связано. То есть когда произошла DDoS-атака, привлекается некие специалисты, это могут быть специалисты из компании Касперский, это могут быть специалисты из компании Group-IB, какие-то другие специалисты, которые помогают отследить, что же произошло, какое количество информации утекло, куда это всё ушло, и как с этим дальше работать что бы в дальнейшем не получить претензию по второй секции. Потому что вы как компании которые обрабатываете данные ваших клиентов, вы за эти данные отвечаете. И не зависимо от того, кому бы вы эти данные не передавали, вы можете отдать в любой клауд или ещё, если я работаю с вами как с компанией, покупаю эту услугу, я приду к вам за требованием и буду от вас просить компенсацию а не от кого то. Здесь очень важно подумать о том какую ответственность вы по-настоящему несёте, не зависимо от того как вы выстроили всю инфраструктуру, и отдали ответственность другим подрядчикам.
Стоит не забывать такой момент, что разработчики разрабатывают очень защищённые инструменты и оборудование каждый раз всё защищеннее и защищеннее, есть ребята которые помогают, дают правильную консультацию, как правильно построить защиту. Но самым уязвимым являются ваши сотрудники и социальный инженерия и хакеры в целом, они всегда на шаг вперёд вас. Мы всегда опаздываем, потому что мы боимся делится данными, мы боимся обмениваться опытом. Кто расскажет как у кого построена безопасность в этой студии, я сомневаюсь что все секреты сейчас расскажете. Использование страховщика позволяет привлечь специалистов, которые помогают преодолеть этот кризис и помогают заплатить суму того требования которое к вам придёт если данные вашего пользователя утекут, то есть данные утекли, скажем из-за DDoS-атаки. К вам приходит какое то количество клиентов, это могут быть физические, юридические лица и предъявляет вам требования. Это требование необходимо по законодательству оплатить. И третья часть это перерыв в производстве. Если ваша компания не работает из-за DDoS-атаки неделю или 3 дня, не важно. Вы терпите убытки, вот эта сумма убытка может быть компенсирована по полюсу CyberEdge, в рамках условий которые предусмотрены по договору. Один из хороших примеров где, казалось бы, ничего не могло произойти. Всё знают авиаперевозчика Дельта. В прошлом году из-за технических сбоев они не могли обслуживать клиентов на протяжении 2 или 3 дней. Хотя казалось что это авиакомпания которая должна лучше всего заботится о своих данных, так же как и Yahoo, больше 1 миллиона учётных записей утекло. Я думаю что там явно не дураки работают в этих компаниях и они выстаивают свою систему безопасности. Но тем не менее у того же Yahoo, например, 4.86 миллиарда долларов сделка, она не сорвалась, она отложилась до выяснения обстоятельств. Они потратили больше 10 миллионов долларов только на то что бы пройти первичную стадию кризиса, понять что произошло, уведомить своих клиентов ну и понести дополнительные расходы.
Никита Цаплин (Модератор): — Ну а всё же, мы говорим про какие-то такие крупные компании. Среди покупателей полисов CyberEdge, среди ваших клиентов кто преобладает, кто эти покупатели. Мы стали первым провайдером в России кто застраховал свою ответственность, но программа довольно не новая и у неё как бы много различий есть, просто хотелось бы, чтобы вы рассказали кто ваши клиенты по этой программе, всё-таки это предприятие среднего бизнеса или более крупные игроки. Покупают они коробочные решения или какая то кастомизация требуется?
Александр Мисюрев: — Я не отвечу на вопрос, наверное, если скажу что наши клиенты — это все наши клиенты которые работают с данными. Кто их покупает и кто активно интересуется. Ну конечно финансовые учреждения. Потому что они больше всего данных обрабатывают. Их информация наиболее критична. У нас есть клиенты, которые являются разработчиками софта, и в силу контрактных обязательств они этот полис покупают. У нас есть клиенты, которые являются интернет магазинами. Это небольшие интернет магазины, скажу сразу- это компании с оборотом в 100 миллионов рублей условно, это копейки по сравнению с онлайн бизнесом. Так как AIG глобальный страховщик, у нас есть глобальные клиенты, которые в Россию начинают адаптировать свои международные программы.
Скажем сеть гипермаркетов международная, европейская они имеют этот полис в России в том числе. Вот когда была атака WannaCry, они обратились к нам, у них перестали работать платёжные терминалы, например. То есть это один из кейсов. Есть так же обычные ритейлеры, которые уже по полису Cyber заявляли такие убытки как например шантаж. То есть к ним приходит письмо по факсу, что если вы не заплатите мне деньги, я сделаю вашу жизнь адом, я скомпрометирую вашу отчётность, я проведу вам проверку, и всё будет у вас ужас. Это как раз покрытие, виртуальное вымогательство, оно покрывается по Cyber’у. Поэтому решения разные, у нас есть коробочные решения, которые мы разработали для малого и среднего бизнеса с лимитом до 3 миллионов долларов, извините, мы привыкли всё считать в долларах, поэтому 3 миллиона долларов. И в принципе это решение начинается от 500 долларов за полис годовой, если это небольшая компания. Ну а дальше увеличивается, полис для банка будет стоить уже сотни тысяч долларов.
Никита Цаплин (Модератор): — Спасибо. Я думаю все зрители ознакомились с программой CyberEdge. В конце после пленарной сессии вы сможете задать вопросы. Сейчас я хотел бы задать вопрос Владимиру Островерху из «Лаборатории Касперского». Я хотел спросить, какие продукты вы предлагаете помимо антивирусной защиты, начнём с других продуктов. И какие продукты вы предлагаете вашим клиентам, предприятиям малого и среднего бизнеса в области обеспечения безопасности? И в чём их преимущество перед другими вендорами данных решений.
Владимир Островерхов, эксперт поддержки корпоративных продаж «Лаборатория Касперского»:
— Всем добрый день. Меня зовут Владимир Островерхов, «Лаборатория Касперского». По поводу списка продуктов. У нас сейчас их порядка 40 видов. Все перечислим или…
Никита Цаплин (Модератор): — Я Думаю начнём с самых востребованных. Хотел бы узнать что востребовано у предприятий малого и среднего бизнеса? Что они покупают?
Владимир Островерхов: — У малого и среднего бизнеса виртуальные технологии, они выходят в облака, соответственно здесь есть резервная защита для конкретной индустриализации для конкретных технологий. Малый и средний бизнес потихоньку перетекает в хранение информации на специализированное хранение данных. Есть специализированная система хранения данных. Есть огромное количество сервисов, которые предлагаем. По расследованию инцидентов, по выявлению инцидентов, сервисы по рекомендации безопасности, огромное количество продуктов. Та же самая DDoS защита, тоже предлагается с нашей стороны.
Никита Цаплин (Модератор): — А если говорить о защите систем виртуализации, кто в данном сегменте основные потребители? Всё равно есть какие-то тенденции, либо это крупные компании которые владеют своими цодами, либо это провайдеры, либо это могут быть не большие предприятия которые не могут позволить себе свой цод, но хотят обезопасить свой сервер находящейся в каком-то дата центре, либо виртуальный сервер, кто ваш клиент?
Владимир Островерхов: — На данный момент по тенденции именно, наиболее популярный и используемые решение для защиты и виртуализации приходится на компании которые осознали себя в этой индустрии, осознали себя в рынке виртуализации, поняли что они активно пользуются облаками, поняли что они активно мигрируют туда, поняли что сервис-провайдеры это крупные компании со своими центрами обработки данных. Для рынка СМБ не могу сказать что это инновация, года три назад сказал бы, что только появилось. Сейчас это переходит на формат обязательного тренда, потому что все переезжают, все строят себе виртуальный цод, Все начинают потихоньку пользоваться виртуальными машинами и все начинают понимать что традиционные антивирусы, поставленные внутрь виртуальной машины, часто выступает дополнительным условием угрозы и дополнительным уровнем угрозы.
Никита Цаплин (Модератор): — Вот расскажите в чём именно угроза, если например я арендовал виртуальный сервер и поставил на него обычный десктопный антивирус?
Владимир Островерхов: — У меня впереди будет презентация на эту тему как раз.
Никита Цаплин (Модератор): — Тогда давай без спойлеров.
Владимир Островерхов: — Без спойлеров, если очень коротко — это огромное количество потребления данных и не правильный их анализ в том плане что требуется рассчитывать их, требуется защищается внутри каждой из виртуальных машин, без общения нескольких антивирусов между собой, без предоставления информации другому антивирусу. Соответственно каждая виртуальная машина защищает сама себя. Это очень сильно просаживает ресурсы. У нас есть пара кейсов, в телеком провайдерах крупных, в телеком провайдерах Европы, порядка 60-70 тысяч виртуальных машин одновременно которые пришли к нам после того как у них был негативный опыт использования традиционного антивируса. Не буду говорить о конкурентах, называть бренды, но без наличия вирусной атаки у них упала половина инфраструктуры, просто спасибо антивирусу. Надо понимать тенденцию о том что, вопрос есть ресурсы или нет их, уходит на второй план. Сейчас о том на сколько просадка может повлиять на способности инфраструктуры целиком без вирусов, без атаки. Ну и о наболевшем- это WannaCry.
Никита Цаплин (Модератор): — Если говорить о защите виртуализации, каких основных конкурентов вы видите на этом рынке?
Владимир Островерхов: — Основные конкуренты защиты виртуализации, наверное хакеры.
Никита Цаплин (Модератор): — Я о компаниях, хакеры всегда с другой стороны конкуренты.
Владимир Островерхов: — Они с обеих сторон. Сейчас очень активно в мире представляется hack-as-a-service. Сейчас любая компания которая заинтересована во взломе соседней компании может обратиться в некоторые компании, которые предоставляют взлом, DDoS, разрушение баз данных, компрометации за определённую сумму.
Никита Цаплин (Модератор): — Интересная бизнес модель. Это как software-as-a-service, только специфический software. Какой порядок цен на подобные услуги?
Владимир Островерхов: — Да смешной. Берём DDoS, о которых говорили, минимальный DDoS компании стоит 200 долларов.
Никита Цаплин (Модератор): — 200 долларов, понимаете, за 200 долларов сервис может остановится как я понимаю
Владимир Островерхов: — Задедосить Пентагон можно тысячи за 4 долларов.
Никита Цаплин (Модератор): — Сбор средств на DDoS Пентагона начнётся чуть позже.
Владимир Островерхов: — Здесь вопрос в том, что выявляются заранее эти целенаправленные атаки, они заранее перехватываются, заранее отсекаются потоки этих атак. Коллеги из отдела защиты интересней и подробней расскажут. Но а сам факт стоимости DDoS-атаки- он копеечный.
Никита Цаплин (Модератор): — Почему так дёшево получается? Надо обладать определённой инфраструктурой для этого.
Владимир Островерхов: — Потому что очень просто. На самом деле с развитием технологий все всегда играют в гонку вооружений, щит против ракеты и так далее. Чем дешевле становятся технологии, тем дешевле становится взлом. Наверное, самый дорогой в наше время- это социальная инженерия. Потому что её ускорить нельзя и избавится нельзя. Взлом людей.
Никита Цаплин (Модератор): — От неё не спасёт даже наличие собственного сервера который можно пощупать в соседней комнате. Сотрудник можно воткнуть флешку, понимая ценность информации, которая на сервере находится, и кому эта информация может потребоваться.
Владимир Островерхов: — Да но здесь есть бдительность и мнительность сотрудников, её надо развивать и повышать, потому что сколько кейсов было что левая страничка фэйсбука приходит на почту со словами от какого то знакомого, который даже не знает об этой почте, все открывают, смотрит, стандартный, легальный фэйсбук, прошедший все фаерволы, запретов нету, но в ней какая то ссылка есть. Фейсбук разрешён, значит ссылка разрешена, давайте посмотрим. И начинается эпидемия. Тот же WannaCry так же зашёл.
Никита Цаплин (Модератор): — Интересно узнать на счёт защиты виртуализации, есть ли какие-то конкуренты у «Лаборатории Касперского», либо это какое-то уникальное решение?
Владимир Островерхов: — Конкуренты всегда есть. Но все мы думаем по-разному, подходим к защите с разных сторон. У нас есть на наши технологии свои патенты, у конкурентов свои патенты. Из основных вендоров, это из самых крупных, но на российском рынке кроме нас не представлены, это Trend Micro, Symantec, которые действительно интересны нам, с которыми интересно сталкиваться и соревноваться в развитии технологий, решений.
Никита Цаплин (Модератор): — Возможно есть какие-либо преимущества ваших решений перед конкурентами?
Владимир Островерхов: — А о них уже на презентации.
Никита Цаплин (Модератор): — Ладно не будем забегать вперёд, если суммировать то что мы услышали от Владимира, то что невозможно защитить от человеческого инжиниринга. Но здесь на помощь может прийти AIG, и компенсировать эти риски.
Владимир Островерхов: — Надеюсь.
Никита Цаплин (Модератор): — Теперь хотелось бы спросить другого вендора безопасности, по факту это провайдер цод, Франк Хаймхарф, он выступил с докладом, это провайдер цод но в какой-то степени этот дата-центр таков, что по факту это провайдер безопасности. И я хотел бы спросить у Франка, кто ваши клиенты, традиционный вопрос, кто больше всего обеспокоен безопасностью данных, это какие-то международные холдинговые компании, или это не большие, локальные игроки, что вы предлагаете им, что не могут предложить конкуренты?
Франк Харцхайм, CEO, Deltalis (перевод с английского): — Наши клиенты это как международные компании, так и швейцарские клиенты конечно. Любая ИТ-инфраструктура требует хранения данных, места, где эти данные будут храниться физически. Не существует ничего виртуального в природе. Существуют физические сервера и они должны где-то размещаться. Мы, простыми словами, предлагаем лучшее место для их размещения, наиболее защищенное, которое вы можете себе представить, в лучшей стране для этого. Многие люди и компании начинают беспокоиться насчет безопасности размещения своих ИТ-платформ и данных, и это как раз является предметом нашей компетенции.
Любой международный клиент нуждается надежной защите своих данных, и такими являются наши клиенты, если вы посмотрите на список наших клиентов- там будут компании из Среднего Востока, США, Южной Америки, Европы, конечно Швейцарии- таким образом довольно широкий круг. Услуги, которые мы предлагаем- это очень гибкие услуги по предоставлению инфраструктуры. Мы не соприкасаемся с данными наших клиентов, например, сервера RUVDS, размещенные у нас в дата-центре- только сотрудники RUVDS имеют доступ к гермозоне, где они расположены. Мы заботимся о физической безопасности, электричестве, охлаждении- все, чтобы вы не заботились о внешних факторах- это наша работа.
Никита Цаплин (Модератор): — По поводу доступности дата-центров действительно не стоит сомневаться, я там был, действительно, это выдолбленный в горе бункер, предназначенный для вооружённых сил Швейцарии, был на боевом дежурстве, теперь она находится в распоряжении клиентов Deltalis обеспечен по всем стандартам Тier 4, пожалуй, действительно самый центр который я видел. Но тем не менее, интересен вопрос юридической стороны. Случалось ли такое, что по каким-то из ваших клиентов интересуются государственные службы других стран, как в таком случае происходит обработка запросов? На сколько мне известно расположение Швейцарии, оно обеспечивает некоторую юридическую защиту, хотелось бы узнать подробнее об этом.
Франк Харцхайм, CEO, Deltalis (перевод с английского): — В Швейцарии у нас страна с очень строгими законами и правилами по защите данных. Государственные структуры не имеют права доступа к какой-либо информации, находящейся на серверах в этой стране, до вступления соответствующего законного решения местных властей. Если вы являетесь подозреваемым и существует решение суда по запросу информации — тогда данные будут запрошены, но данный запрос должен быть отправлен самому клиенту, не нам. В данном случае дата-центр никак не является посредником в этом вопросе и не в праве предоставлять данные клиента, не вступает в сотрудничество с правоохранительными органами. У нас в Швейцарии очень строгие законы по защиет конфиденциальной информации и данных, поэтому нет такой процедуры, чтобы правительственные структуры запрашивали данные у дата-центров или провайдеров без ведома клиента.
Никита Цаплин (Модератор): — Я так понимаю что для того, чтобы был предоставлен доступ к данным кроме клиента к серверу, то Швейцарское правительство должно признать клиента в какой то мере виновным по Швейцарскому законодательству, правильно? Если, например, приходит запрос. Представим ситуацию, находится у вас клиент, гражданин РФ или Великобритании, а ещё лучше США, он располагает там своё оборудование и размещает какие-то сервисы, которые в стране его гражданства признаются незаконными. Я так понимаю, что бы вы предоставили доступ к оборудованию, Швейцария должна признать факт виновности данного человека или как?
Франк Харцхайм, CEO, Deltalis (перевод с английского): — Правильно.
Никита Цаплин (Модератор): — Расскажите подробнее, какая процедура, чтобы вы предоставили доступ к дата-центру, я видел, я был в этом дата-центре, туда так просто нельзя попасть. Но понятно, что если будет ордер локальных властей… Хотелось бы понять как это может произойти.
Франк Харцхайм, CEO, Deltalis (перевод с английского): — У нас очень защищенный дата-центр. Очень безопасное место. Никто не будет хранить свои данные в небезопасном месте разумеется. И многие провайдеры и дата-центры это предлагают, но мы предоставляем нечто большее. У нас модульная система защита, многопараметрическая, точки входа, права доступа, несколько периметров безопасности, фиксация всех действий гостей и персонала, идентификация по венам рук- более надежная чем отпечатки пальцев, строгие регламенты безопасности, сертифицированные ISO, все системы аудируются ежегодно. Это не так, что сделано один раз и все- мы проходим сертификацию ежегодно и у нас есть доказательства этого, что все соответствует стандартам, что все процессы проходят правильно, все сотрудники проходят обучены и сертифицированы- сотрудники это очень важная часть.
Никита Цаплин (Модератор): — Здесь понятно, я всё таки хотел узнать, я попробую задать вопрос на английском, прошу прощения за мой английский.
Никита Цаплин (перевод с английского): — В каких случаях дата-центр должен предоставить доступ локальным правоохранительным органам или международным доступ к серверам клиента?
Франк Харцхайм, CEO, Deltalis (перевод с английского): — Это возможно только в случае если будет доступ к этим серверам и наличие решения местных властей, только при решении соответствующих органов власти. Никакие другие запросы, от каких-либо правоохранительных органов других стран, включая США, не признаются. У нас Швейцарская компания и мы не имеем каких-либо обязательств по выполнению распоряжений каких-либо властей, включая международных, за исключением швейцарского правительства.
Никита Цаплин (Модератор): — Я думаю это было как раз интересно, когда человек размещает данные в такой стране как Швейцария. Спасибо большое, я теперь хотел бы перевести вопросы с вендоров на потребителей. Сегодня у нас здесь нет непосредственно потребителей услуг среди спикеров. Но есть представители потребителей, здесь среди нас. Присутствует Сергей из компании ФИНАМ, которая активно предлагает своим клиентам облачные услуги на основе VPS-серверов, среди нас есть и представитель компании HOSTKEY, также представитель ГАРС телеком- Михаил, которые в своём перечне своих услуг имеют услуги VPS/VDS. Вот я хотел бы задать вопрос им. Насколько те решения, которые мы сейчас обсуждали, нужны клиентам. Начнём с Михаила.
Михаил Сергеев, директор по корпоративным коммуникациям ГАРС телеком:
— Здравствуйте, Михаил Сергеев – ГАРС телеком. ГАРС телеком с 99 года оказывает услуги корпоративным клиентам и наши сети объединяет все точки обмена данными плюс более 30 дата центров только в столице, поэтому понятно, что облако не облако, без канективити, поэтому рано или поздно вы все приходите к нам. Я хотел обратить снимание на первый вопрос, который задавали нашему коллеге из Швейцарии, этот вопрос же, давайте честно, про маски шоу. Я хотел внести новую струю, понимаете какая история, в России по-своему относятся к понятию безопасности, маски шоу остаётся чуть ли не приоритетным у собственников и первых лиц бизнеса, когда речь идёт о безопасности. Мы за 20 лет обслуживания клиентов, предоставления конективити, про это знаем многое, например, курьёзный случай, но это живой кейс и этот кейс не один. Наш клиент, крупная инвестиционная компания в топ-10 заказала следующий сервис, они очень беспокоились что придут и будут обыскивать и тд. И хотя, казалось бы, кейсу меньше 10 лет, то есть было уже куда отправить данные, можно было арендовать что то за границей, но нет — своя рубашка ближе к телу. У нас на территории одного из наших офисов был организован полноценный дата центр на одну стойку. Задублирована электроэнергия, охлаждение, всё серьёзно. В стойке был один сервер. Перед дата-центром стоял стул, стол, на столе телефон. Это было рабочее место сотрудника. Это был когда-то кадровый офицер ФСБ, явно с высшим образованием с хорошими физическими данными. Его работа была в том, что он приходил и сидел за столом. Телефон никогда не звонил, работа заключалась в том, что если телефон зазвонит, он быстро должен вскочить, вынуть сервер и очень быстро убежать. Это смешно, но это очень у многих в нашей стране про безопасность так. Этот несчастный человек, было видно, что человек с высшим образованием, делать было нечего, читать газеты было нельзя, он брал бумагу и вспоминал что-то, какие-то формулы, было видно, что в голове что-то есть. У нас лет пять где-то он просидел.
Никита Цаплин (Модератор): — Эту услугу вы предоставили клиенту получается?
Михаил Сергеев: — Клиент сказал — мне нужна безопасность, вы сможете мне обеспечить безопасность моего сервера. Мы говорим — а как вы хотите? А вот мы так хотим. У нас Швейцария вроде близко, но, как мы знаем, у нас в Москве есть 2 точки: в районе Киевской есть дата-центр, который выдерживает прямое попадание атомной бомбы, и дата-центр в при Курчатовском институте, который для нашего менталитета может поспорить с этими возможностями доступа, потому что в Курчатовский институт маски шоу прийти может, но нужно за неделю подать заявления вот- заказать пропуск. Поэтому те, кто говорят, в Швейцарии не надёжно, они спокойно в Курчатовке ставят и им кажется, что хорошо. Я хочу завершить свой спич тем что безопасность- она в голове. Если у нас жёлтые тараканы, то у нас такая безопасность, если она зелёные, то чуть иная, и мне кажется, что так будет всегда. Поэтому хочешь- не хочешь, менталитет никуда не денется.
Никита Цаплин (Модератор): — Согласен. Как в фильме, что предоставили швейцарские коллеги прозвучала фраза «Its all about the trust», вопрос безопасности- это вопрос того, доверяете вы или не доверяете компании. Но хотелось бы подробнее узнать насколько, кроме вопросов физического доступа к оборудованию, какие вопросы безопасности: DDoS- атаки или какие-то вирусные атаки беспокоят клиентов. Вопросы частые или это редкость? Бывает, что клиент приходит и говорит — я хочу облако. Вы – хорошо, вот. Он говорит — я боюсь, тогда не пойду.
Михаил Сергеев: — Я не просто так про маски шоу сказал, в принципе получить качественный сервис – вообще не проблема. Я считаю, что уровень инфраструктуры, который обеспечиваете и сервис сегодня, который предлагаете вы, да ещё и начав работать вместе во Швейцарцами и Касперким- это планка, которой вполне достаточно. Я не помню, чтобы кто-то говорил — ой, знаете нам такого мало. Всё достаточно хорошо, более того, к счастью рынок облачного дошёл до такого уровня технологического развития, что конкуренции как таковой нет, все используют существующее решения. И у нас на практике не было случаев, когда клиент говорил, знаете, меня тут задедосили, мне недостаточен тот уровень инфраструктуры, который вы предоставляете. Как то всё идет спокойно, но может надо перекрестится.
Никита Цаплин (Модератор): — Спасибо за комментарий. Также я хотел спросить у Сергея. Сергей- представитель компании ФИНАМ, помимо прочих брокерских услуг она предоставляет клиентам также услуги VPS-серверов для торговли, то есть именно там, на стыке тех технологий, где любая секунда простоя может принести прямой финансовый убыток. Вот я хотел спросить, на сколько ваши клиенты чувствительны к вопросам безопасности? Или когда мы говорим о финансовых компаниях, тут важна надёжность, в плане сбоев по техническим причинам. Всё-таки вопросы безопасности более актуальны?
Сергей Слукин, руководитель отдела DMA и алгоритмической торговли, АО «ФИНАМ»:
— Добрый день, меня зовут Сергей. Я руковожу отделом торговли в ФИНАМ — это самый большой брокер в России по количеству клиентов. У нас есть представительство в каждом крупном городе России. Несколько десятков тысяч клиентов России и за рубежом. Наш отдела помогает клиентам строить собственную структуру, для того что бы их алгоритмы работали успешно, что бы они зарабатывали деньги. В том числе мы предоставляем клиентам железные решения, то есть предоставляем клиентам свои сервера, покупаем сервера, если им это нужно, представляем облака в партнерстве с компанией RUVDS. Как с точки зрения подключения в интернет в московской бирже, так и в периметре московской зоны локации биржи Dataspace. По поводу безопасности, на самом деле если говорить о периметре интернета, то и о клиентах, которые пользуются виртуальными машинами, то те услуги безопасности что сейчас предоставляются, их достаточно. Если говорить о периметре локации то это не много другой круг клиентов и их требования выше. Но мы не ограничиваемся только тем что нам даёт провайдер. Мы используем симбиоз облачных и наших собственных биржевых решений, стоят наши фаерволы и фаерволы биржи. Разрешаем доступ с определённых статических ip. Мы мониторим трафик, биржа тоже мониторит трафик на своём периметре, мы относимся серьёзно к безопасности, это в первую очередь волнует клиентов. Но если говорить о том, что важнее безопасность или устойчивость, это на одном уровне.
Никита Цаплин (Модератор): — Это синонимы, согласен. А случалось ли, когда клиенты подвергались взлому, атаке, в таком плане? Или это не про вашу категорию клиентов.
Сергей Слукин: — Это не про этих клиентов. Мы видим? что иногда прилетают пакеты из Китая, видим что пытается проводить DDoS’ы и пытается положить каналы, серваки. Естественно ничего не получается потому что опять же из-за симбиоза систем защиты. Если бы у нас всё было в облаке, тогда, наверное, у этих клиентов были бы проблемы. В этом плане, мы пока не готовы переносить всю инфраструктуру в облако, здесь еще долгое время будет работать симбиоз решений.
Никита Цаплин (Модератор): — Как я и говорил что финансовый сектор- самый тяжёлый для переноса, потому что там взаимодействие напрямую с финансовыми потоками. Хотелось бы услышать ваше мнение о AIG, насколько интересно вашим клиентам страхование на случай, если клиент фонд — который управляет средствами, подвергнется DDoS-атаке, например, и будет невозможно осуществлять сделки. Кто-то получит не санкционированный доступ к серверу, который управляет транзакциями- в результате чего могут быть получены колоссальные убытки.
Сергей Слукин: — Вопрос сложный, потому что оценить убытки достаточно сложно. Естественно что, возмещать стоимость услуг за месяц по SLA, этого недостаточно.
Никита Цаплин (Модератор): — Мы говорим не о недополученной прибыли.
Сергей Слукин: — Явно речь идёт не о недополученной прибыли. Если клиент говорит — у меня упал сервак, у меня висит заявка я не смог её вовремя снять у меня убыток миллион рублей, это сложно доказать и тд. Если речь о краже какого-то алгоритма то тоже сложно, потому что невозможно оценить в судебном порядке стоимость алгоритма клиента. С точки зрения базовых функций, если доказано. что с сервера клиента что-то украдено, что-то слито или, что его сервер подвергся атаке, и он не смог торговать, то если страховая компания может возместить больше, чем нам предлагает SLA, то это будет интересно.
Никита Цаплин (Модератор): — Об этом и речь, потому что понятно, что возмещение возможно только в случае подтверждения данного события иначе эта услуга потеряла бы смысл. Должно быть подтверждение несанкционированного доступа, иначе любой убыток горе-трейдеры могут списать на страховой случай.
Сергей Слукин: — Мы не предлагали эту услугу клиентам, потому что она новая. Но в принципе в течении недели мы готовы запустить акцию. Если продукт поможет клиентам, если поймём, как можно применять продукт, то можем активно пиарить.
Никита Цаплин (Модератор): — А что думаете о инструктуре Швейцарии? Швейцария является столицей банковского дела. Это близкий вопрос к финансовым рынкам, понимаю, что территориально это не лучшее расположение с точки зрения скорости доступа к финансовым рынкам, но насколько вы видите интересным предложение по размещению клиентских сервисов вот в таком безопасном месте, где невозможно событие запроса локальных властей. Насколько интересна юридическая безопасность клиентам? Я знаю, что большинство фондов, которые оперируют в том числе и на московской бирже, они не принадлежат российской юрисдикции, и тем не менее, размещая оборудование в нашей стране, они несут риск локальных властей. Насколько этот вопрос интересен клиенту?
Сергей Слукин: — Зависит от типа клиента, если клиент готов, иностранный фонд готов иметь инфраструктуру в России, 90-99% будет размещаться в биржевой локации, в России. Швейцария- это хорошо, но с точки зрения торговли это не совсем хорошо применимо именно к клиенту, которому важна скорость доступа. С той же Швейцарии сигнал будет идти несколько десятков миллисекунд. А клиенты уже соревнуются по наносекундам. Если клиент может сэкономить 200 наносекунд, то это уже большой плюс. Если речь о хранении данных бэкофиса, какую-то маркет дату, то да это может быть интересно, но если сервисы, которые принимают решения, обрабатывают маркет дату, то они должны находиться там, где торговая площадка. Но я не вижу ничего такого в разделении сервисов клиента. Когда сервис здесь, а бэк и база данных в другом месте.
Никита Цаплин (Модератор): — Спасибо. Сейчас я хотел бы опять вернутся с вопросом к Александру из AIG. Есть ли у вас опыт взаимодействия с компаниями из ИТ-сектора по вопросам страхования. Есть какие-то проекты или кейсы? Я понимаю, что эта область она конфиденциальная и, как и в случае с Deltalis, они не могут показывать своих клиентов, потому что, во многом, клиенты туда идут именно за конфиденциальностью. Но тем не менее, может есть интересные кейсы взаимодействия с ИТ-компаниями, о которых можно было здесь рассказать? Как провайдер, мы первые, кто застраховался от этих рисков, но возможно есть какие-то другие проекты, тех же компаний-вендоров по безопасности? Мне кажется страхование это единственный выход. Вопрос доверия — понятно. Вопрос физической безопасности, надёжности, всё это так или иначе решается, защита DDoS. Но всё равно может случится какой-то сбой, и в любом случае и от него можно защитится только страховкой и никак больше, по этому такой вопрос к вам.
Александр Мисюрев, директор по развитию AIG:
Про клиентов рассказывать не буду, потому что всё-таки это конфиденциальная информация. Так как я занимаюсь адаптацией тех или иных продуктов, в России, самое сложное — кто ваши клиенты, кто покупает? И все привыкли что как правило все российские страховщики показывают в своих презентациях миллион логотипов, вот все они купили. У нас другой подход, у нас, мы изначально работаем с корпоративными клиентами, крупными, сейчас развиваем малый и средний бизнес. Если говорить о том, где Cyber есть как встроенный продукт, который позволяет защищаться клиентам, и в этом видим большую перспективу с точки зрения развития, когда существует не только финансовое решение как страхование, финансовая защита страхование, но и ещё некая сигнализация на ваше оборудование. Вот с нашим партнёром, Group-IB, мы сделали продукт, который называется Group-IB TDS и CyberEdge, этот продукт как раз о том что Cyber даёт свой сенсор клиенту, а дальше если сенсор не справляется со своей задачей, работают определённые части нашего полиса. Из интересных ИТ- решений, могу сказать, что порядка трех провайдеров, которые предоставляют защиту от DDoS-атак- мы ведем с ними переговоры в этой части. Изначально идея появилась из этого, когда DDoS все же проходит и компания несёт убытки, тогда должна работать страховка, понятно что мы стремимся предоставить 99.9% защиты, поскольку под 100% защиты я сомневаюсь, что кто-либо подпишется, это нереально. Но вот после того как вышел наш пресс-релиз с RUVDS, Никита, к нам ещё один клауд-сервис обратился- раз это можно страховать, давайте работать.
Никита Цаплин (Модератор): — Вопрос в том что многие не знают, что такое можно страховать. У нас есть представитель компании по защите от DDoS. Насколько вы считаете, что дострахование услуг защиты целесообразно предлагать клиентам? Или вы придерживаетесь парадигмы, что мы обеспечиваем 100% защита и не можем допустить мыли о том, что может что-то произойти? Есть такая точка зрения, действительно, что не хотят предлагать страховку, потому что это ломает парадигму, вносит сомнение, что может что-то сломаться.
Данила Чежин, директор по продажам Variti:
— Всё что создаётся человеком, человек несовершенен и, к сожалению, кто-то рано или поздно какие-то ошибки допускает, это видно из утечек постоянных каких то. Какие-то дырки в самом разнообразном ПО находятся. И они находятся спустя достаточно длительное время. Уязвимости в SSL, например, которые несли достаточно серьёзную угрозу. И всё это говорит о том, что какое количество девяток после запятой вы у себя в вебсайте не написали, что бы вы не написали в контракте- всё равно, конечно же, вероятность того что что-то случится она есть. Вопрос в том какое количество ресурсов злоумышленник должен потратить на достижение цели.
Никита Цаплин (Модератор): — Владимир заверил, что суммы доступные.
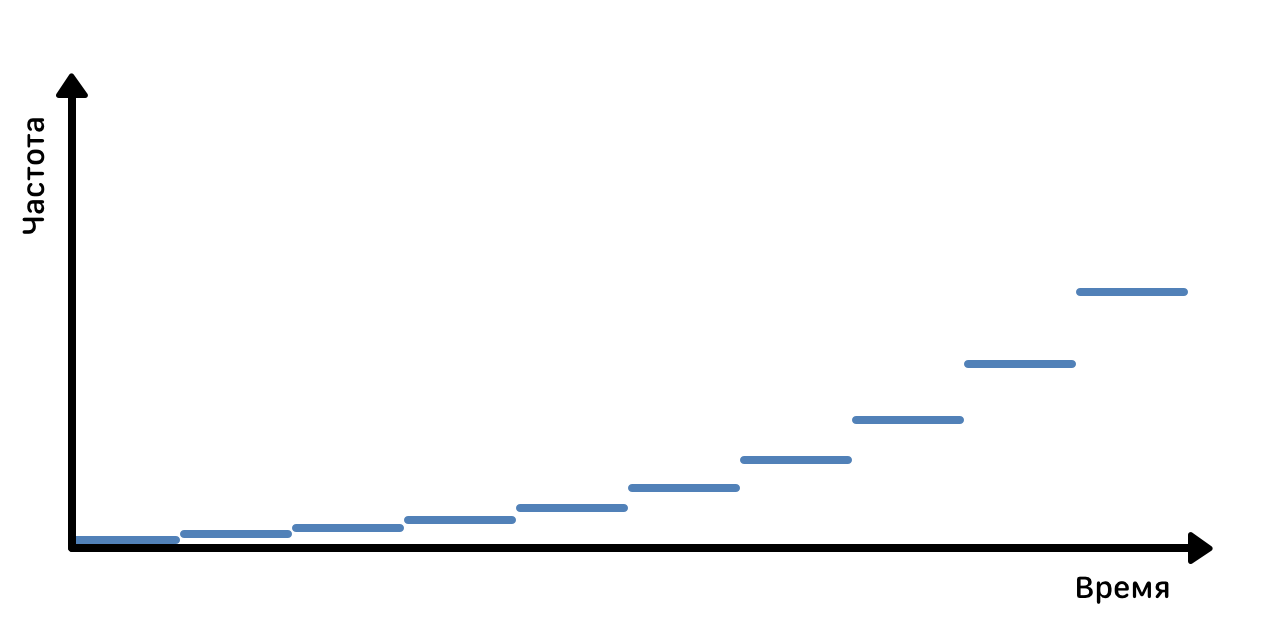
Данила Чежин: — Мы такие атаки видим, они выглядят в форме прямоугольника, на графиках- это эффект каналов полки. У атаки есть четкие параметры, как правило, атаки выскакивают высокочастотные, это какой-то флуд, и такие дешёвые атаки они как правило заказываются, я предполагаю, не знаю сам не заказывал, но если раз сработало, почему бы ещё раз не повторить если недорого. Есть другой подход, когда заказывают атаки не просто с какими-то параметрами по объёму и длительности, а есть заказ на результат. Не думаю что 200 долларов для каких-то хороших ресурсов, это совсем другие деньги. И здесь злоумышленник, он совсем в творчестве никак не ограничен, он думает, это мы видим в том числе по графикам, пробует разные методы уходит покурить, возвращается, пробует что-то еще, опять не получатся и тд. Там тоже живые люди и поскольку у них задача выполнить заказ, они прикладывают максимальные усилия. Если я скажу, что мы от всего всегда будем защищать, что бы ни случилось, мне кажется, это будет некоторым допущением и не очень честным по отношению к клиенту, поэтому то, что предлагает AIG, это интересно. Здесь всегда вопрос баланса, потому что есть страховая премия, она понятна, и есть стоимость страховки для конечного клиента. И если мы говорим о каком то не очень большом бизнесе, новом, на фоне Morgan Stanley многие будут небольшими. Для бизнеса в тех реалиях, в которых мы живем, в той стране в которой мы живём, для него любые дополнительные затраты, они тяжёлые. У населения уже достаточно длительное время падает покупательская способность. У бизнеса та же ситуация. У них нет заказов, становится меньше, они получают меньше прибыли, и естественно тот бюджет расходов который имеют, они стараются как то оптимизировать. И покупая страховку у AIG, очевидно мы будем перекладывать как-то на клиента, закладывать в стоимость, если будет существенное увеличение услуг, это просто не будет востребованным у такого небольшого бизнеса. Для корпораций это будет востребованным, это то, что они хотят видеть. Действительно они говорят, что компенсация SLA за месяц-два, это всё не для нас.

— Верно, на самом деле как бы это не парадоксально не звучало, мы не стремимся продать наши решения, мы стремимся помочь нашим клиентам и здесь нужно найти золотую середину на самом деле. Все попались на КАСКО на таких вещах, когда нам предлагали — ребята, давайте страховаться без франшизы, а когда случился скачок валюты, определенное количество убытков- все резко начали страховать с франшизой что бы удержать премию, потому что стоимость страховки, она колоссальна. Вот тот месседж, который я хочу донести до клиента, когда мы общаемся: что страхование должно помогать в сложной ситуации, с лёгкими чихами, с простудой, вы сами можете справится, страховка должна помогать бизнесу там где есть угроза, когда происходят такие вещи как WannaCry, когда всё падает, здесь и должна помогать страховка. Но и плюс ещё добавлю, вот мы с Владимиром из Лаборатории Касперского по поводу промышленной безопасности общались: есть уже определенное количество решения и библиотека знаний, как закрыть уязвимости. И стоит не забывать, что котиков лайкают все, и приходят такие сообщения, сколько бы не выстраивали техническую безопасность. Вам не стоит забывать работать с вашими сотрудниками, проводить тесты, рассылать сообщения, в которых будет ссылочки, что угодно, что будет не так опасно для организации, но будет выявлять те слабые звенья, которые в дальнейшем смогут принести определенных проблем.

— Мы тут говорим с одной стороны о DDoS, потом об утечках информации- это все-таки немного разные истории. Я просто что хотел уточнить: насколько я понимаю, бизнес любой страховой компании он построен на эффективной оценке рисков, рисков наступления страхового события, и если говорить о DDoS, то на мой взгляд стоимость полиса должна зависеть от оттого есть там защита или нет. Бизнес, наверное, может застраховаться и не имея подобной защиты, может прийти к вам и сказать, я хочу застраховаться от потери данных, от недоступности. И вы как эксперты должны посмотреть, что у клиента с защищенностью, провести аудит. Или просто посмотрев на договор с вендором защиты и увидя какое-то название знакомое сказать и какой-то уровень SLA, сказать «окей, тебе это будет стоить на 40% дешевле, потому что у тебя хорошее решение по защите». Есть ли у вас подобные подходы, как вы обычно действуете здесь?
Александр Мисюрев: — Конечно, как и при продаже любого полиса, всегда есть процедура андеррайтинга, то есть некое коробочное решение, которое базируется на допущении и коробка, как любой финансовый продукт, она дороже стоит, потому что базируется на допущении. Конечно, мы просим заполнить вопросник, если это крупный клиент или финансовые учреждения, то мы проводим предстраховой сюрвей, привлекаем специалистов, которые смотрят, как всё это устроено. Это всё присутствует. И возвращаюсь к нашему решению с Group-IB, мы, прежде чем запустить какие-либо решения, мы понимаем тот эффект, который даёт их решение, и за счёт этого можем предоставить более выгодные условия, которые включены в этот совместный продукт. Поэтому андеррайтинг очень важен для страховщика, но куда важнее то, как клиент будете работать и действовать, если нас не будет. Если вы будете действовать разумно и целесообразно, то для вас премия будет явно дешевле, если у вас никаких степеней защиты нет, а вы хотите купить полис, мы его вам просто не продадим.
Никита Цаплин (Модератор): — Мы поняли, что предложений у рынка достаточно, есть совершенно разные предложения в области антивирусных защит, защит от DDoS, а там где и то, и то не помогает, есть и дата-центр в более безопасном месте и, наконец, страховая защита. Но хотелось бы также услышать какие-то вопросы из зала со стороны потенциальных потребителей этих услуг. Насколько доводы спикеров были убедительными и, какие, может быть, дополнительные риски в облачных решениях видите вы, которые не покрываются представленными решениями?
Шевченко Андрей, HOSTKEY:
— Добрый день, Шевченко Андрей компания HOSTKEY. Хотел бы немножко шаг в сторону сделать, если можно. Если мы говорим про облачные решения и можно ли там вообще обеспечить какую-ту безопасность, я бы, наверное, сказал, а можно ли вообще обеспечить эту безопасность на своей инфраструктуре? Приведу банальный пример. 152 ФЗ. Все его знают, все его понимают. Закон становится немного жёстче. И мы понимаем, что в своей инфраструктуре сделать правильное решение тяжело. Далеко не у всех есть лицензии ФСБ, ФСТЭК, чтобы поставить криптографию, да. Но на рынке присутствуют облачные решения за приемлемые деньги, которые вплоть до первого уровня- все позволяют перекрыть. Это может быть частное облако, может приватное облако- но всё можно решить. Второй момент, который тоже хотел сказать — относительно DDoS’ов- полностью соглашусь с к









 Александр Чистяков: Читайте планы запросов. Думайте быстрее, чем люди, которые эксплуатируют то, что вы написали. Занимайтесь спортом, хорошо спите по ночам.
Александр Чистяков: Читайте планы запросов. Думайте быстрее, чем люди, которые эксплуатируют то, что вы написали. Занимайтесь спортом, хорошо спите по ночам.
 Дмитрий Васильев: Не использовать ORM. На самом деле, скрывая простоту и общение с базой через ORM, вы в дальнейшем откладываете технический долг, который вам все равно придется восполнить. Все равно нужно знать SQL, и как работают базы данных внутри. Это основы, которых не так много, но их нужно изучить.
Дмитрий Васильев: Не использовать ORM. На самом деле, скрывая простоту и общение с базой через ORM, вы в дальнейшем откладываете технический долг, который вам все равно придется восполнить. Все равно нужно знать SQL, и как работают базы данных внутри. Это основы, которых не так много, но их нужно изучить.  Михаил Тюрин: Здесь все очень серьезно, никаких шуток, разработчикам приложений надо понимать, что работа с данными – это одна из основных задач, которая должна ими решаться. Надо подключать ДБА на ранних этапах.
Михаил Тюрин: Здесь все очень серьезно, никаких шуток, разработчикам приложений надо понимать, что работа с данными – это одна из основных задач, которая должна ими решаться. Надо подключать ДБА на ранних этапах.  Брюс Момжан: Я могу ответить относительно Постгреса: нужно проводить исследования и узнавать его разносторонние возможности. Многие, приходя из других СУБД, пользуются им по привычке: «Я всегда делал это так, буду делать как привык». В этом нет ничего плохого, но Постгрес – это намного больше, чем хранилище данных. Не обязательно использовать Постгрес так, как вы использовали БД до этого, изучайте современные нестандартные функции, относящиеся к консистентности данных, моделированию данных, они сделают ваше приложение проще и чище.
Брюс Момжан: Я могу ответить относительно Постгреса: нужно проводить исследования и узнавать его разносторонние возможности. Многие, приходя из других СУБД, пользуются им по привычке: «Я всегда делал это так, буду делать как привык». В этом нет ничего плохого, но Постгрес – это намного больше, чем хранилище данных. Не обязательно использовать Постгрес так, как вы использовали БД до этого, изучайте современные нестандартные функции, относящиеся к консистентности данных, моделированию данных, они сделают ваше приложение проще и чище.










































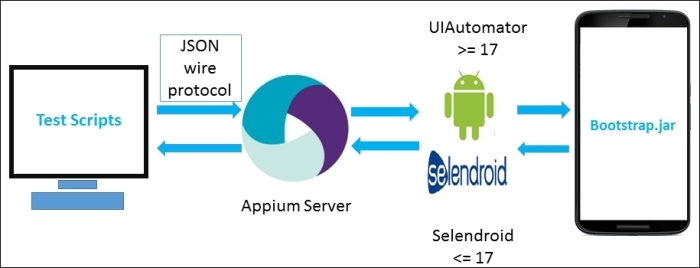
 В этой статье мы хотим рассказать о нашем продукте TOTPRadius. Это RADIUS сервер, спроектированный для применения в системах двухфакторной аутентификации. Помимо стандартного для этого протокола фунционала, TOTPRadius предоставляет несколько дополнительных функций, одной из которых является восзможность организации самостоятельной регистрации второго фактора для рядовых пользователей
В этой статье мы хотим рассказать о нашем продукте TOTPRadius. Это RADIUS сервер, спроектированный для применения в системах двухфакторной аутентификации. Помимо стандартного для этого протокола фунционала, TOTPRadius предоставляет несколько дополнительных функций, одной из которых является восзможность организации самостоятельной регистрации второго фактора для рядовых пользователей VoIP — это термин-зонтик. Набор технологий, протоколов и просто buzzword'ов, которые относятся к передаче голоса (и видео!) по компьютерным сетям (локальным или интернет) вместо телефонных. И да, большая часть телеком-провайдеров всё ещё использует для передачи голоса собственные сети вместо интернет. С недешевыми коробочками, куда втыкаются T1 и E1 провода.
VoIP — это термин-зонтик. Набор технологий, протоколов и просто buzzword'ов, которые относятся к передаче голоса (и видео!) по компьютерным сетям (локальным или интернет) вместо телефонных. И да, большая часть телеком-провайдеров всё ещё использует для передачи голоса собственные сети вместо интернет. С недешевыми коробочками, куда втыкаются T1 и E1 провода. А еще 20 лет назад, когда это всё создавалось, был очень печальный вопрос переподключения. Для UDP версии SIP клиентам достаточно время от времени (раз в час) посылать пакеты REGISTER, говоря «вот он я, готов принимать звонки». В случае перезагрузки или выключения сервера другой сервер за тем же IP-адресом может работать со всеми этими клиентам. А вот в случае TCP клиентам нужно будет переподключаться. Десять тысяч телефонов здания (обычная ситуация) пошли переподключаться и убили сервер…
А еще 20 лет назад, когда это всё создавалось, был очень печальный вопрос переподключения. Для UDP версии SIP клиентам достаточно время от времени (раз в час) посылать пакеты REGISTER, говоря «вот он я, готов принимать звонки». В случае перезагрузки или выключения сервера другой сервер за тем же IP-адресом может работать со всеми этими клиентам. А вот в случае TCP клиентам нужно будет переподключаться. Десять тысяч телефонов здания (обычная ситуация) пошли переподключаться и убили сервер… А в комбинации «SIP и UDP» есть беда. Собственно, этот пост про нее. Беда называется «фрагментация». Сама по себе фрагментация сетевых пакетов почти безвредна: есть настроенный для сетевой карты MTU, максимальный размер передаваемого за раз пакета. В большинстве случаев это 1500 байт. Для TCP и подавляющего большинства UDP протоколов это никак не влияет: они просто никогда не шлют пакеты больше MTU и используют внутренние механики, чтобы передавать большие объемы данных по кусочкам, терять эти кусочки и пересылать их повторно, если надо.
А в комбинации «SIP и UDP» есть беда. Собственно, этот пост про нее. Беда называется «фрагментация». Сама по себе фрагментация сетевых пакетов почти безвредна: есть настроенный для сетевой карты MTU, максимальный размер передаваемого за раз пакета. В большинстве случаев это 1500 байт. Для TCP и подавляющего большинства UDP протоколов это никак не влияет: они просто никогда не шлют пакеты больше MTU и используют внутренние механики, чтобы передавать большие объемы данных по кусочкам, терять эти кусочки и пересылать их повторно, если надо.