[Из песочницы] Сборка модуля ядра Linux без точных заголовочных файлов |

/proc/version. Если, как я, вы собираете модуль для устройства Android, попробуйте ядра Android от Code Aurora, Cyanogen или Android, те, что наиболее ближе к вашему устройству. В моем случае, это было ядро msm-3.0. Заметьте, вам не обязательно необходимо искать в точности ту же версию исходников, что и версия вашего образа ядра. Небольшие отличия версии, наиболее вероятно, не станут помехой. Я использовал исходники ядра 3.0.21, в то время как версия имеющегося образа ядра была 3.0.8. Не пытайтесь, однако, использовать исходники ядра 3.1, если у вас образ ядра 3.0.x. /proc/config.gz, вы можете начать с этого, в противном случае, вы можете попытаться начать с конфигурацией по умолчанию, но в этом случае нужно быть крайне аккуратным (хотя я и не буду углубляться в детали использования дефолтной конфигурации, поскольку мне посчастливилось не прибегать к этому, далее будут некоторые детали относительно того, почему правильная конфигурация настолько важна).arm-eabi-gcc у вас доступен по одному из путей в переменной окружения PATH, и что терминал открыт в папке с исходными файлами ядра, вы можете начать конфигурацию ядра и установку заголовочных файлов и скриптов:$ mkdir build
$ gunzip config.gz > build/.config # или что угодно, для того, чтобы приготовить .config
$ make silentoldconfig prepare headers_install scripts ARCH=arm CROSS_COMPILE=arm-eabi- O=build KERNELRELEASE=`adb shell uname -r`
silentoldconfig, наиболее вероятно, спросит, хотите ли вы включить те или иные опции. Вы можете выбрать умолчания, но это вполне может и не сработать.KERNELRELEASE, однако это должно совпадать в точности с версией ядра, с которого вы планируете подгружать модуль.Makefile. Расположите следующий код в файле hello.c, в некоторой отдельной директории:#include Makefile в той же директории:obj-m = hello.o
hello.mod.c, содержимое которого может создать различные проблемы:MODULE_INFO(vermagic, VERMAGIC_STRING);
VERMAGIC_STRING определяется макросом UTS_RELEASE, который располагается в файле include/generated/utsrelease.h, генерируемом системой сборки ядра. По умолчанию, это значение определяется версией ядра и статуса git-репозитория. Это то, что устанавливает KERNELRELEASE при конфигурации ядра. Если VERMAGIC_STRING не совпадает с версией ядра, загрузка модуля приведет к сообщению подобного рода в dmesg:hello: version magic '3.0.21-perf-ge728813-00399-gd5fa0c9' should be '3.0.8-perf'
struct module __this_module
__attribute__((section(".gnu.linkonce.this_module"))) = {
.name = KBUILD_MODNAME,
.init = init_module,
#ifdef CONFIG_MODULE_UNLOAD
.exit = cleanup_module,
#endif
.arch = MODULE_ARCH_INIT,
};
struct module, определенная в include/linux/module.h, несет в себе неприятный сюрприз:struct module
{
(...)
#ifdef CONFIG_UNUSED_SYMBOLS
(...)
#endif
(...)
/* Startup function. */
int (*init)(void);
(...)
#ifdef CONFIG_GENERIC_BUG
(...)
#endif
#ifdef CONFIG_KALLSYMS
(...)
#endif
(...)
(... plenty more ifdefs ...)
#ifdef CONFIG_MODULE_UNLOAD
(...)
/* Destruction function. */
void (*exit)(void);
(...)
#endif
(...)
}
init оказался в правильном месте, CONFIG_UNUSED_SYMBOLS должен быть определен в соответствии с тем, что использует наш образ ядра. Что же насчет указателя exit, — это CONFIG_GENERIC_BUG, CONFIG_KALLSYMS, CONFIG_SMP, CONFIG_TRACEPOINTS, CONFIG_JUMP_LABEL, CONFIG_TRACING, CONFIG_EVENT_TRACING, CONFIG_FTRACE_MCOUNT_RECORD и CONFIG_MODULE_UNLOAD. static const struct modversion_info ____versions[]
__used
__attribute__((section("__versions"))) = {
{ 0xsomehex, "module_layout" },
{ 0xsomehex, "__aeabi_unwind_cpp_pr0" },
{ 0xsomehex, "printk" },
};
Module.symvers, который генеруется в соответствии с заголовочными файлами. module_layout, зависит от того, как выглядит struct module, то есть, зависит от того, какие опции конфигурации, упомянутые ранее, включены. Второй, __aeabi_unwind_cpp_pr0, — функция, специфичная ABI ARM, и последний — для наших вызовов функции printk.printk, даже совместимым путем, модули, собранные изначально, не загрузятся с новым ядром.hello: disagrees about version of symbol symbol_name
Module.symvers, которым мы не располагаем. bool each_symbol_section(bool (*fn)(const struct symsearch *arr,
struct module *owner,
void *data),
void *data)
{
struct module *mod;
static const struct symsearch arr[] = {
{ __start___ksymtab, __stop___ksymtab, __start___kcrctab,
NOT_GPL_ONLY, false },
{ __start___ksymtab_gpl, __stop___ksymtab_gpl,
__start___kcrctab_gpl,
GPL_ONLY, false },
{ __start___ksymtab_gpl_future, __stop___ksymtab_gpl_future,
__start___kcrctab_gpl_future,
WILL_BE_GPL_ONLY, false },
#ifdef CONFIG_UNUSED_SYMBOLS
{ __start___ksymtab_unused, __stop___ksymtab_unused,
__start___kcrctab_unused,
NOT_GPL_ONLY, true },
{ __start___ksymtab_unused_gpl, __stop___ksymtab_unused_gpl,
__start___kcrctab_unused_gpl,
GPL_ONLY, true },
#endif
};
if (each_symbol_in_section(arr, ARRAY_SIZE(arr), NULL, fn, data))
return true;
(...)
struct symsearch {
const struct kernel_symbol *start, *stop;
const unsigned long *crcs;
enum {
NOT_GPL_ONLY,
GPL_ONLY,
WILL_BE_GPL_ONLY,
} licence;
bool unused;
};
each_symbol_section — три (или пять, когда конфиг CONFIG_UNUSED_SYMBOLS включен) поля, каждое из которых содержит начало таблицы символов, ее конец и два флага.integer из определений в each_symbol_section, мы можем определить расположение таблиц символов и сигнатур, и воссоздать файл Module.symvers из бинарника ядра.zImage), так что простой поиск по сжатому образу невозможен. Сжатое ядро на самом деле представляет небольшой бинарник, следом за которым идет сжатый поток. Можно просканировать файл zImage с тем, чтобы найти сжатый поток и получить из него распакованный образ.dmesg:$ adb shell dmesg | grep "\.init"
<5>[01-01 00:00:00.000] [0: swapper] .init : 0xc0008000 - 0xc0037000 ( 188 kB)
0xc0008000.$ python extract-symvers.py -B 0xc0008000 kernel-filename > Module.symvers
Module.symvers для ядра, из которого мы хотим загрузить модуль, мы наконец можем собрать модуль (опять, полагая, arm-eabi-gcc доступно из PATH, и что терминал открыт в директории с исходниками):$ cp /path/to/Module.symvers build/
$ make M=/path/to/module/source ARCH=arm CROSS_COMPILE=arm-eabi- O=build modules
$ adb shell
# insmod hello.ko
# dmesg | grep insmod
<6>[mm-dd hh:mm:ss.xxx] [id: insmod]Hello world
# lsmod
hello 586 0 - Live 0xbf008000 (P)
# rmmod hello
# dmesg | grep rmmod
<6>[mm-dd hh:mm:ss.xxx] [id: rmmod]Goodbye world
|
Метки: author RadicalDreamer разработка под linux разработка под android android module linux hack |
Немного о ServiceNow, ITSM и ServiceDesk в формате подборки полезных материалов |
 Изображение Dennis Skley CC
Изображение Dennis Skley CC5 шагов для успешного внедрения ServiceNow
Тактика лучшего внедрения Service Desk — 7 шагов
Внедрение ServiceNow. 7 ошибок, которые нельзя допустить
6 интересных фактов о компании ServiceNow
Что такое ServiceNow, или Как не сесть в тюрьму и заработать миллиард
Лучшие бесплатные ресурсы для специалиста ServiceNow
Искусственный интеллект для классификации запросов в ServiceNow
GRC — управление ИТ, управление рисками и соответствие требованиям в ServiceNow
Что читать в 2017 году для успешного внедрения ServiceNow
В чем причина популярности ServiceNow
Инновационные способы использования ServiceNow
Интервью с CTO ServiceNow об инновациях, приоритетах и развитии ИТ
ServiceNow — релиз Istanbul
Как не надо внедрять ITSM в компании
ITSM в облако. 9 преимуществ SaaS-платформы для ITSM
6 различий между Helpdesk и ServiceDesk
Тактика лучшего внедрения Service Desk — 7 шагов
В чем разница между инцидентом и проблемой
Правильно внедряем «Управление финансами в ИТ» (ITFM)
Что такое Управление портфелем проектов?
5 причин внедрения управления HR
Как управлять эксплуатацией объекта недвижимости
Управлять активами (ITAM) или вести амбарную книгу
10 фактов, которые вы должны знать об ITIL
Как сделать ITIL более клиентоориентированной
|
Метки: author it-guild help desk software блог компании ит гильдия ит-гильдия servicenow itsm servicedesk дайджест |
[Перевод - recovery mode ] Страны Юго-Восточной Азии переходят на гибридную модель хранения данных |

|
Метки: author ICLServices хранилища данных облачные вычисления блог компании icl services облачные технологии схд облачные хранилища гибридная модель |
ZFS on Linux: вести с полей 2017 |


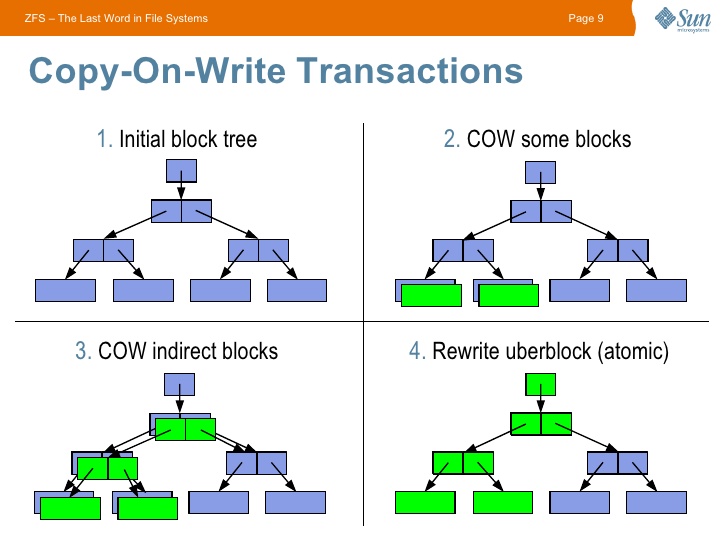
copies);- pool
-- vdev (virtual device) - объединяет носители (в mirror, stripe и др.)
--- block device - диск, массив, файлzdb -S название_пула для симуляции на существующем пуле) или ~ 5гб на каждый 1 тб. В ОЗУ хранится т.н. Dedup table (DDT), при недостатке ОЗУ каждая операция записи будет упираться в IO носителя (DDT будет читаться каждый раз с него).compression=lz4xattr=saatime=offrecordsize=1M файл размером 1.5мб будет записан как 2 блока по 1мб, в то время как файл 0.5мб будет записан в блок размером 0.5мб). Больше — лучше для компрессии:recordsize=128Kecho "options zfs zfs_arc_max=половина_ОЗУ_в_байтах" >> /etc/modprobe.d/zfs.conf
echo половина_ОЗУ_в_байтах >> /sys/module/zfs/parameters/zfs_arc_maxdestroy будьте бдительны!|
|
Борьба за время сборки iOS-приложений |

xcodebuild -workspace App.xcworkspace -scheme App clean build OTHER_SWIFT_FLAGS="-Xfrontend -debug-time-function-bodies" | grep .[0-9]ms | grep -v ^0.[0-9]ms | sort -nr > functions_build_analysis.txtlet object = Object(param1: param1Value ?? defaultParam1Value,
param2: param2Value ?? defaultParam2Value)

App was compiled with optimization - stepping may behave oddly; variables may not be available.
|
Метки: author ToyoApps разработка под ios xcode swift objective c блог компании tinkoff.ru ios development ios разработка objective-c compile-time время компиляции |
Частоты и емкость сети — все, о чем вы хотели спросить |






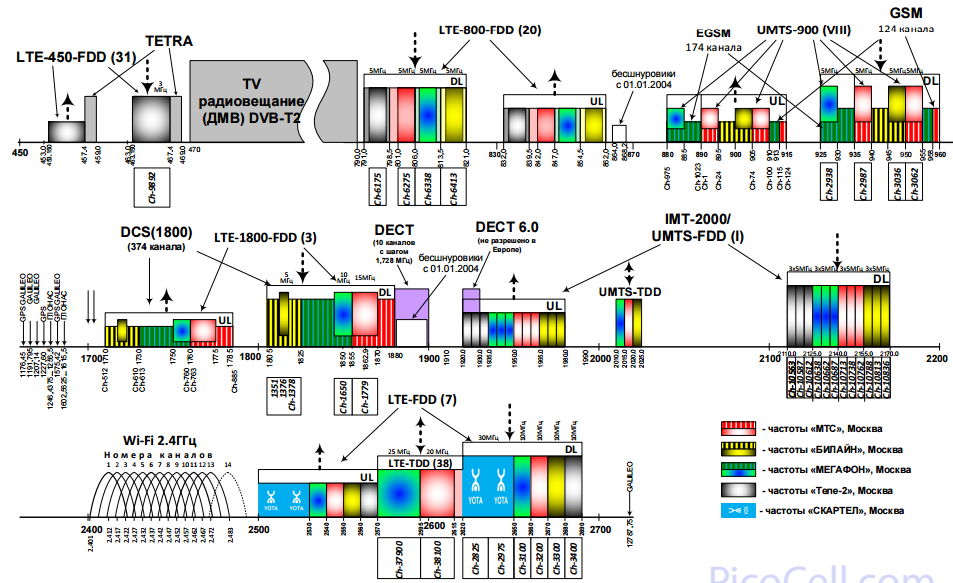


|
Метки: author MegaFon стандарты связи беспроводные технологии блог компании «мегафон» частоты |
Индексы в PostgreSQL — 4 |



demo=# select * from aircrafts;
aircraft_code | model | range
---------------+---------------------+-------
773 | Boeing 777-300 | 11100
763 | Boeing 767-300 | 7900
SU9 | Sukhoi SuperJet-100 | 3000
320 | Airbus A320-200 | 5700
321 | Airbus A321-200 | 5600
319 | Airbus A319-100 | 6700
733 | Boeing 737-300 | 4200
CN1 | Cessna 208 Caravan | 1200
CR2 | Bombardier CRJ-200 | 2700
(9 rows)
demo=# create index on aircrafts(range);
CREATE INDEX
demo=# set enable_seqscan = off;
SET
demo=# explain(costs off) select * from aircrafts where range = 3000;
QUERY PLAN
---------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: (range = 3000)
(2 rows)
demo=# explain(costs off) select * from aircrafts where range < 3000;
QUERY PLAN
---------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: (range < 3000)
(2 rows)
demo=# explain(costs off) select * from aircrafts where range between 3000 and 5000;
QUERY PLAN
-----------------------------------------------------
Index Scan using aircrafts_range_idx on aircrafts
Index Cond: ((range >= 3000) AND (range <= 5000))
(2 rows)
demo=# create index on aircrafts(range desc);
demo=# create view aircrafts_v as
select model,
case
when range < 4000 then 1
when range < 10000 then 2
else 3
end as class
from aircrafts;
CREATE VIEW
demo=# select * from aircrafts_v;
model | class
---------------------+-------
Boeing 777-300 | 3
Boeing 767-300 | 2
Sukhoi SuperJet-100 | 1
Airbus A320-200 | 2
Airbus A321-200 | 2
Airbus A319-100 | 2
Boeing 737-300 | 2
Cessna 208 Caravan | 1
Bombardier CRJ-200 | 1
(9 rows)
demo=# create index on aircrafts(
(case when range < 4000 then 1 when range < 10000 then 2 else 3 end), model);
CREATE INDEX
demo=# select class, model from aircrafts_v order by class, model;
class | model
-------+---------------------
1 | Bombardier CRJ-200
1 | Cessna 208 Caravan
1 | Sukhoi SuperJet-100
2 | Airbus A319-100
2 | Airbus A320-200
2 | Airbus A321-200
2 | Boeing 737-300
2 | Boeing 767-300
3 | Boeing 777-300
(9 rows)
demo=# explain(costs off) select class, model from aircrafts_v order by class, model;
QUERY PLAN
--------------------------------------------------------
Index Scan using aircrafts_case_model_idx on aircrafts
(1 row)
demo=# select class, model from aircrafts_v order by class desc, model desc;
class | model
-------+---------------------
3 | Boeing 777-300
2 | Boeing 767-300
2 | Boeing 737-300
2 | Airbus A321-200
2 | Airbus A320-200
2 | Airbus A319-100
1 | Sukhoi SuperJet-100
1 | Cessna 208 Caravan
1 | Bombardier CRJ-200
(9 rows)
demo=# explain(costs off)
select class, model from aircrafts_v order by class desc, model desc;
QUERY PLAN
-----------------------------------------------------------------
Index Scan Backward using aircrafts_case_model_idx on aircrafts
(1 row)
demo=# explain(costs off)
select class, model from aircrafts_v order by class asc, model desc;
QUERY PLAN
-------------------------------------------------
Sort
Sort Key: (CASE ... END), aircrafts.model DESC
-> Seq Scan on aircrafts
(3 rows)
demo=# create index aircrafts_case_asc_model_desc_idx on aircrafts(
(case when range < 4000 then 1 when range < 10000 then 2 else 3 end) asc, model desc);
CREATE INDEX
demo=# explain(costs off)
select class, model from aircrafts_v order by class asc, model desc;
QUERY PLAN
-----------------------------------------------------------------
Index Scan using aircrafts_case_asc_model_desc_idx on aircrafts
(1 row)

demo=# create index on aircrafts(
model, (case when range < 4000 then 1 when range < 10000 then 2 else 3 end));
CREATE INDEX

demo=# create index on flights(actual_arrival);
CREATE INDEX
demo=# explain(costs off) select * from flights where actual_arrival is null;
QUERY PLAN
-------------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (actual_arrival IS NULL)
-> Bitmap Index Scan on flights_actual_arrival_idx
Index Cond: (actual_arrival IS NULL)
(4 rows)
demo=# explain(costs off) select * from flights order by actual_arrival nulls last;
QUERY PLAN
--------------------------------------------------------
Index Scan using flights_actual_arrival_idx on flights
(1 row)
demo=# explain(costs off) select * from flights order by actual_arrival nulls first;
QUERY PLAN
----------------------------------------
Sort
Sort Key: actual_arrival NULLS FIRST
-> Seq Scan on flights
(3 rows)
demo=# create index flights_nulls_first_idx on flights(actual_arrival nulls first);
CREATE INDEX
demo=# explain(costs off) select * from flights order by actual_arrival nulls first;
QUERY PLAN
-----------------------------------------------------
Index Scan using flights_nulls_first_idx on flights
(1 row)
demo=# \pset null NULL
Null display is "NULL".
demo=# select null < 42;
?column?
----------
NULL
(1 row)
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
btree | can_order | t
btree | can_unique | t
btree | can_multi_col | t
btree | can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | t
index_scan | t
bitmap_scan | t
backward_scan | t
name | pg_index_column_has_property
--------------------+------------------------------
asc | t
desc | f
nulls_first | f
nulls_last | t
orderable | t
distance_orderable | f
returnable | t
search_array | t
search_nulls | t
demo=# explain(costs off)
select * from aircrafts where aircraft_code in ('733','763','773');
QUERY PLAN
-----------------------------------------------------------------
Index Scan using aircrafts_pkey on aircrafts
Index Cond: (aircraft_code = ANY ('{733,763,773}'::bpchar[]))
(2 rows)
demo=# \d bookings
Table "bookings.bookings"
Column | Type | Modifiers
--------------+--------------------------+-----------
book_ref | character(6) | not null
book_date | timestamp with time zone | not null
total_amount | numeric(10,2) | not null
Indexes:
"bookings_pkey" PRIMARY KEY, btree (book_ref)
Referenced by:
TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
demo=# create unique index bookings_pkey2 on bookings(book_ref) include (book_date);
CREATE INDEX
demo=# begin;
BEGIN
demo=# alter table bookings drop constraint bookings_pkey cascade;
NOTICE: drop cascades to constraint tickets_book_ref_fkey on table tickets
ALTER TABLE
demo=# alter table bookings add primary key using index bookings_pkey2;
ALTER TABLE
demo=# alter table tickets add foreign key (book_ref) references bookings (book_ref);
ALTER TABLE
demo=# commit;
COMMIT
demo=# \d bookings
Table "bookings.bookings"
Column | Type | Modifiers
--------------+--------------------------+-----------
book_ref | character(6) | not null
book_date | timestamp with time zone | not null
total_amount | numeric(10,2) | not null
Indexes:
"bookings_pkey2" PRIMARY KEY, btree (book_ref) INCLUDE (book_date)
Referenced by:
TABLE "tickets" CONSTRAINT "tickets_book_ref_fkey" FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
demo=# explain(costs off)
select book_ref, book_date from bookings where book_ref = '059FC4';
QUERY PLAN
--------------------------------------------------
Index Only Scan using bookings_pkey2 on bookings
Index Cond: (book_ref = '059FC4'::bpchar)
(2 rows)
postgres=# select amop.amopopr::regoperator as opfamily_operator,
amop.amopstrategy
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'btree'
and opf.opfname = 'bool_ops'
order by amopstrategy;
opfamily_operator | amopstrategy
---------------------+--------------
<(boolean,boolean) | 1
<=(boolean,boolean) | 2
=(boolean,boolean) | 3
>=(boolean,boolean) | 4
>(boolean,boolean) | 5
(5 rows)
postgres=# select amop.amopopr::regoperator as opfamily_operator
from pg_am am,
pg_opfamily opf,
pg_amop amop
where opf.opfmethod = am.oid
and amop.amopfamily = opf.oid
and am.amname = 'btree'
and opf.opfname = 'integer_ops'
and amop.amopstrategy = 1
order by opfamily_operator;
opfamily_operator
----------------------
<(integer,bigint)
<(smallint,smallint)
<(integer,integer)
<(bigint,bigint)
<(bigint,integer)
<(smallint,integer)
<(integer,smallint)
<(smallint,bigint)
<(bigint,smallint)
(9 rows)
postgres=# create type complex as (re float, im float);
CREATE TYPE
postgres=# create table numbers(x complex);
CREATE TABLE
postgres=# insert into numbers values ((0.0, 10.0)), ((1.0, 3.0)), ((1.0, 1.0));
INSERT 0 3
postgres=# select * from numbers order by x;
x
--------
(0,10)
(1,1)
(1,3)
(3 rows)
postgres=# create function modulus(a complex) returns float as $$
select sqrt(a.re*a.re + a.im*a.im);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create function complex_lt(a complex, b complex) returns boolean as $$
select modulus(a) < modulus(b);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create function complex_le(a complex, b complex) returns boolean as $$
select modulus(a) <= modulus(b);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create function complex_eq(a complex, b complex) returns boolean as $$
select modulus(a) = modulus(b);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create function complex_ge(a complex, b complex) returns boolean as $$
select modulus(a) >= modulus(b);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create function complex_gt(a complex, b complex) returns boolean as $$
select modulus(a) > modulus(b);
$$ immutable language sql;
CREATE FUNCTION
postgres=# create operator #<#(leftarg=complex, rightarg=complex, procedure=complex_lt);
CREATE OPERATOR
postgres=# create operator #<=#(leftarg=complex, rightarg=complex, procedure=complex_le);
CREATE OPERATOR
postgres=# create operator #=#(leftarg=complex, rightarg=complex, procedure=complex_eq);
CREATE OPERATOR
postgres=# create operator #>=#(leftarg=complex, rightarg=complex, procedure=complex_ge);
CREATE OPERATOR
postgres=# create operator #>#(leftarg=complex, rightarg=complex, procedure=complex_gt);
CREATE OPERATOR
postgres=# select (1.0,1.0)::complex #<# (1.0,3.0)::complex;
?column?
----------
t
(1 row)
postgres=# create function complex_cmp(a complex, b complex) returns integer as $$
select case when modulus(a) < modulus(b) then -1
when modulus(a) > modulus(b) then 1
else 0
end;
$$ language sql;
CREATE FUNCTION
postgresx=# create operator class complex_ops
default for type complex
using btree as
operator 1 #<#,
operator 2 #<=#,
operator 3 #=#,
operator 4 #>=#,
operator 5 #>#,
function 1 complex_cmp(complex,complex);
CREATE OPERATOR CLASS
postgres=# select * from numbers order by x;
x
--------
(1,1)
(1,3)
(0,10)
(3 rows)
postgres=# select amp.amprocnum,
amp.amproc,
amp.amproclefttype::regtype,
amp.amprocrighttype::regtype
from pg_opfamily opf,
pg_am am,
pg_amproc amp
where opf.opfname = 'complex_ops'
and opf.opfmethod = am.oid
and am.amname = 'btree'
and amp.amprocfamily = opf.oid;
amprocnum | amproc | amproclefttype | amprocrighttype
-----------+-------------+----------------+-----------------
1 | complex_cmp | complex | complex
(1 row)
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select * from bt_metap('ticket_flights_pkey');
magic | version | root | level | fastroot | fastlevel
--------+---------+------+-------+----------+-----------
340322 | 2 | 164 | 2 | 164 | 2
(1 row)
demo=# select type, live_items, dead_items, avg_item_size, page_size, free_size
from bt_page_stats('ticket_flights_pkey',164);
type | live_items | dead_items | avg_item_size | page_size | free_size
------+------------+------------+---------------+-----------+-----------
r | 33 | 0 | 31 | 8192 | 6984
(1 row)
demo=# select itemoffset, ctid, itemlen, left(data,56) as data
from bt_page_items('ticket_flights_pkey',164) limit 5;
itemoffset | ctid | itemlen | data
------------+---------+---------+----------------------------------------------------------
1 | (3,1) | 8 |
2 | (163,1) | 32 | 1d 30 30 30 35 34 33 32 33 30 35 37 37 31 00 00 ff 5f 00
3 | (323,1) | 32 | 1d 30 30 30 35 34 33 32 34 32 33 36 36 32 00 00 4f 78 00
4 | (482,1) | 32 | 1d 30 30 30 35 34 33 32 35 33 30 38 39 33 00 00 4d 1e 00
5 | (641,1) | 32 | 1d 30 30 30 35 34 33 32 36 35 35 37 38 35 00 00 2b 09 00
(5 rows)
|
Метки: author erogov sql postgresql блог компании postgres professional postgres index indexing |
Первая подборка материалов о цифровизации страхования |
 Фото: GotCredit / CC
Фото: GotCredit / CCАтаки, вирусы, ИБ-фейлы сотрудников — есть множество причин для утечки критически значимой информации, включающей ПД пользователей. Все эти риски можно компенсировать не только грамотной организацией внутренних процессов, но и страховкой. В этом материале идет речь о продукте CyberEdge, который разработала компания AIG.
Попытка рассуждения на тему наступления такого страхового случая как «кибер-вымогательство». Мнения экспертов, мысли автора и комментарии хабражителей.
Редакция Хабра пишет о новом кейсе в российском венчуре, который реализовала компания AIG. Ряд сотрудников фонда застрахованы от управленческих ошибок на сумму в 300 миллионов рублей — сюда входят в том числе и расходы на защиту в суде.
Переводной материал в блоге компании GVA. Здесь рассмотрены основные тренды и новые веяния на страховом рыке. Основной акцент — на страховании ИТ-рисков и потребности в соответствующей экспертизе со стороны страховщиков.
Компания убеждена в надежности своего продукта и готова предложить рынку одну цену за все: автомобиль, техническое обслуживание и страховой пакет.
Компания Wirex рассказывает о возможных сценариях использования блокчейна в сфере страхования, описывает возможные ограничения и дает прогноз для отрасли и отдельных страховых компаний на основе отчета консалтинговой компании McKinsey.
Блокчейн на практике и в сфере страховых услуг — реальность. Основная ниша для начала работ — киберстрахование. Ранее Bitfury уже реализовала блокчейн-проекты для правительства Украины и Грузии (ссылка на блог Bitfury на Хабре).
Заметка по теме на Techcrunch. Здесь рассмотрены: P2P-страхование, параметрическое страхование и микрострахование. Помимо общих слов для каждого пункта приведены примеры использования блокчейна.
Обсуждение проблем сбора и анализа данных вместе с примерами разработок Университета ИТМО в сфере страхования и транспортной экосистемы города.
Достаточно известный кейс, который в очередной раз ставит перед индустрией ряд вопросов, связанных с мошенничеством. Помогут ли здесь ИТ и кому? Будем надеяться, что силам добра, конечно.
Онлайн-агрегаторы, брокеры, что дальше? Компания Wirex подготовила перевод по этой теме и рассказала о будущем сферы Insurtech (тренды Insurtech).
Когнитивная система IBM Watson обладает возможность анализа текста, аудио и видео, что в целом могло бы пригодится в работе страховых компаний. В этом материале есть пара примеров тех, кто уже сотрудничает с IBM по этому направлению (вот еще заметка на английском по теме).
Крупнейший страховщик Великобритании будет внедрять анализ социальных медиа, чтобы профилировать клиентов. В соответствии с внутренним регламентом будут выставлять оценки и определять итоговый балл, который и повлияет на стоимость страховки.
 Фото: franchise opportunities / CC
Фото: franchise opportunities / CCРазбор мифов, анализ условий оформления и особенностей Е-ОСАГО, которое появилось еще в 2015 году, но на самом деле — только совсем недавно.
Как проблемы есть вокруг темы покупки полисов онлайн, что из этого уже решено и какие нюансы стоит знать. Материал пригодится обывателям и тем, кто разрабатывает сервисы в этой сфере.
Экспертная колонка в Forbes. Здесь разобран западный опыт и дана аналитическая оценка того, что будет происходить на российском рынке страховых услуг.
Критика на тему того, почему на сегодняшний день сложно говорить о рабочем применении систем телематики и снижении затрат на КАСКО.
История нового тематического стартапа в формате интервью.
Зачем понадобилось очередное новшество, как все это реализовать, каких результатов ждать и как к этому относиться.
Переход на новую систему замедляет отсутствие необходимых нормативных актов. Немного о том, какие изменения произойдут на авторынке после полного перехода на электронные ПТС.
|
Метки: author KatbertW бизнес-модели дайджест страхование цифровые технологии |
Производительность lambda-выражений в Java 8 |

public static final int WARMUP_ITERATIONS_COUNT = 10;
public static final int ITERATIONS_COUNT = 10;
public static final int ITERATION_DURATION_MSEC = 1000;
| for | iterate | guava | jdk8 lambda | |||||
|---|---|---|---|---|---|---|---|---|
| time, ns | heap, Mb | time, ns | heap, Mb | time, ns | heap, Mb | time, ns | heap, Mb | |
| Extract cars original cost | 220.4 | 313 | 200.6 | 324 | 188.1 | 302 | 266.2 | 333 |
| Age of youngest who bought for > 50k | 6367 | 260 | 4245 | 271 | 6367 | 260 | 6157 | 278 |
| Find buys of youngest person | 6036 | 270 | 6411.4 | 259 | 6206 | 260 | 6235 | 288 |
| Find most bought car | 2356 | 167 | 2423 | 171 | 5882 | 193 | 2971 | 190 |
| Find most costly sale | 49 | 71 | 58.1 | 66 | 431.6 | 297 | 196.1 | 82 |
| Group sales by buyers and sellers | 12144 | 250 | 12053 | 254 | 8259 | 206 | 18447 | 242 |
| Index cars by brand | 263.3 | 289 | 275.0 | 297 | 2828 | 226 | 307.5 | 278 |
| Print all brands | 473.2 | 355 | 455.3 | 365 | 540.3 | 281 | 514.2 | 337 |
| Select all sales of a Ferrari | 199.3 | 66 | 265.1 | 53 | 210.4 | 111 | 200.2 | 65 |
| Sort sales by cost | 1075 | 74 | 1075 | 74 | 1069 | 72 | 1566 | 124 |
| Sum costs where both are males | 67.0 | 63 | 72.9 | 58 | 215.9 | 88 | 413.7 | 114 |
| for | iterate | guava | jdk8 lambda | |||||
|---|---|---|---|---|---|---|---|---|
| time | heap | time | heap | time | heap | time | heap | |
| Extract cars original cost | 117% | 104% | 107% | 107% | 100% | 100% | 142% | 110% |
| Age of youngest who bought for > 50k | 150% | 100% | 100% | 104% | 150% | 100% | 145% | 107% |
| Find buys of youngest person | 100% | 104% | 106% | 100% | 103% | 100% | 103% | 111% |
| Find most bought car | 100% | 100% | 103% | 102% | 250% | 116% | 126% | 114% |
| Find most costly sale | 100% | 108% | 119% | 100% | 881% | 450% | 400% | 124% |
| Group sales by buyers and sellers | 147% | 121% | 146% | 123% | 100% | 100% | 223% | 117% |
| Index cars by brand | 100% | 128% | 104% | 131% | 1074% | 100% | 117% | 123% |
| Print all brands | 104% | 126% | 100% | 130% | 119% | 100% | 113% | 120% |
| Select all sales of a Ferrari | 100% | 125% | 133% | 100% | 106% | 209% | 100% | 123% |
| Sort sales by cost | 101% | 103% | 101% | 103% | 100% | 100% | 147% | 172% |
| Sum costs where both are males | 100% | 109% | 109% | 100% | 322% | 152% | 617% | 197% |
|
Метки: author blutovi тестирование it-систем программирование java java lambda тестирование |
Интерактивная кредитка для ввода платежа |





|
Метки: author kamushken разработка под e-commerce разработка веб-сайтов платежные системы кредитка карточка axure анимация flip оплата e-commerce |
[Из песочницы] Занимательная вёрстка с единицами измерения области просмотра |
Единицы измерения области просмотра используются вот уже несколько лет. Они практически полностью поддерживаются основными браузерами. Тем не менее я продолжаю находить новые и любопытные способы их применения. Я подумала, что было бы здорово сначала вспомнить базовые вещи, а затем затронуть некоторые из моих любимых вариантов использования этих единиц.
Между 2011 и 2015 годами в спецификациях CSS, разработанных W3C, в 3-ем уровне модуля Значения и единицы CSS, появились четыре новые единицы, которые связаны непосредственно
с параметрами области просмотра. Новые единицы — vw, vh, vmin, и vmax — работают аналогично существующим единицам длины, таким как px или em, но представляют собой процентные величины от текущей области просмотра браузера.
В то время как значение этих единиц зависит от высоты или ширины области просмотра, они могут использоваться везде применительно к длине, будь то размер шрифта, полей, отступов, теней, границ и т. д. или позиционирование элемента. Давайте посмотрим, что мы можем делать с их помощью!
Стало популярным использовать единицы измерения области просмотра в отзывчивой типографике — настраивать размер шрифта таким образом, чтобы он увеличивался и уменьшался в зависимости от текущего размера области просмотра. Использование единиц измерения области просмотра для определения размера шрифта имеет интересный (опасный) эффект. Как вы видите, шрифты масштабируются очень быстро — от нечитабельно-мелкого до крайне крупного размера в очень малом диапазоне.
html {
font-size: 3vw;
margin: .5em;
}
h1 {
font-size: 4vmax;
}
h2 {
font-size: 4vmin;
}
h1, h2 {
font-weight: bold;
}
h1, h2, p {
margin: .5em 0;
}

Такое резкое масштабирование явно не подходит для повседневного использования. Нам нужно что-то более тонкое — минимальные и максимальные значения. Также нужно больше контроля над диапазонами увеличения показателя. Тут нам поможет функция calc(). Для определения базового размера шрифта мы можем использовать более стабильные единицы (скажем, 16px). Мы также можем уменьшить диапазон подстраивания значения под размер области просмотра (0.5vw). Таким образом, браузер будет выполнять следующие математические вычисления: calc(16px + 0.5vw)
Изменяя зависимость между базовым размером и размером, рассчитываемым относительно параметров области просмотра, мы можем менять скорость увеличения последнего. Попробуйте для заголовков определить большие значения единиц измерения области просмотра, нежели для остального текста, и вы увидите, насколько быстрее их размер будет увеличиваться в сравнении с окружающим текстом. Это позволяет использовать более динамичную типографику на больших экранах, в то же время ограничивая размер шрифта на мобильных устройствах. При этом не требуется никаких медиа-запросов. Этот метод также можно применить к высоте строки, что позволит корректировать междустрочный интервал со скоростью, отличной от скорости масштабирования размера шрифта.
body {
// размер шрифта увеличивается на 1px через каждые 100px ширины области просмотра
font-size: calc(16px + 1vw);
// междустрочный интервал увеличивается вместе со шрифтом
// и получает дополнительный прирост на 0.1em + 0.5px через каждые 100px ширины области просмотра
line-height: calc(1.1em + 0.5vw);
}
На мой взгляд, больше усложнять здесь не надо. Если нам потребуется ограничить верхнее значение для быстро растущих заголовков, мы можем сделать это с помощью одного медиа-запроса для разрешений, на которых их размер уже слишком велик:
h1 {
font-size: calc(1.2em + 3vw);
}
@media (min-width: 50em) {
h1 {
font-size: 50px;
}
}
Тут я поняла, что было бы здорово, если бы существовало такое свойство, как max-font-size.
Наши коллеги разработали более сложные расчеты и миксины Sass для определения точных диапазонов масштабирования размера текста через конкретные медиа-запросы. Есть несколько статей на CSS Tricks, в которых объясняется этот метод. Там же представлены фрагменты кода, которые помогут попробовать его в деле.
Я думаю, в большинстве случаев это излишне, но у вас может быть другое мнение.
Существует великое множество вариаций вёрстки во всю высоту окна (или подразумевающей ограничение по высоте) — от интерфейсов в стиле рабочего стола до hero images, широких макетов и прилипающих футеров. Единицы измерения области просмотра помогут вам со всем перечисленным.
В интерфейсе в полную высоту в стиле рабочего стола страница часто разбивается на разделы, которые скроллятся по отдельности. Такие элементы, как хедер, футер, боковые панели, остаются на месте при любом размере окна. Сегодня это обычная практика для многих веб-приложений, а единицы vh делают реализацию такого интерфейса гораздо проще. Ниже приведен пример с использованием нового синтаксиса CSS Grid:
Одно правило для body — height: 100vh — задает высоту вашему приложению равной высоте области просмотра. Убедитесь, что для элементов внутри body заданы значения overflow, чтобы их содержимое не обрезалось. Такой же вёрстки можно добиться, используя flexbox или плавающие элементы. Заметьте, что с вёрсткой в полную высоту в некоторых мобильных браузерах могут возникать проблемы. Есть хороший фикс для Safari на iOS, который мы используем для наиболее часто встречающихся нестандартных случаев.
Прилипающие футеры можно создать аналогичным образом. Все, что нужно — правило для body height: 100vh заменить на min-height: 100vh, и футер будет зафиксирован внизу экрана, до тех пор пока не сместится контентом вниз.
Используйте единицы vh для определения свойств height, min-height или max-height различных элементов и создавайте полноэкранные разделы, hero images и многое другое. В новом редизайне OddBird мы ограничили высоту hero images правилом max-height: 55vh, чтобы они не вытесняли заголовки со страницы. На моем собственном сайте я использовала правило max-height: 85vh, чтобы больше выделить изображения. На других сайтах я применила минимальную высоту — min-height: 90vh — к разделам.
Этот пример демонстрирует сразу и hero image котика, ограниченное максимальной высотой, и раздел с минимальной высотой. Используя все эти приемы, вы можете максимально управлять тем, как контент будет заполнять окно браузера и реагировать на различные размеры области просмотра.
Также может быть полезно ограничить отношение высоты элемента к его ширине. Это особенно полезно для встраиваемого содержимого, например видео. Крис ранее писал об этом. В старые добрые времена мы делали это с помощью %-ого отступа для контейнера и абсолютного позиционирования для внутреннего элемента. Теперь в некоторых случаях для достижения того же эффекта мы можем использовать единицы измерения области просмотра, и уже нет необходимости создавать дополнительные контейнеры.
Если мы хотим растянуть наше видео на весь экран, мы можем задать его высоту относительно ширины области просмотра:
/* во всю ширину * соотношение высоты и ширины */
.full-width {
width: 100vw;
height: calc(100vw * (9/16));
}
Такие расчеты не обязательно выполнять именно в браузере с поддержкой функции calc. Если вы используете препроцессор, как, например, Sass, того же эффекта можно добиться с помощью подобного расчета: height: 100vw * (9/16). Если вам нужно ограничить максимальную ширину, вы также можете ограничить максимальную высоту:
/* максимальная ширина * соотношение высоты и ширины */
.full-width {
width: 100vw;
max-width: 30em;
height: calc(100vw * (9/16));
max-height: calc(30em * (9/16));
}
Данный пример демонстрирует оба варианта с использованием кастомных свойств CSS (переменных), позволяющим придать расчету больше семантики. Поиграйтесь с цифрами, и вы увидите, как элементы масштабируются, сохраняя при этом правильное соотношение:
Крис идет дальше в своей статье, и мы последуем его примеру. Что если нам нужно, чтобы обычное текстовое содержимое HTML масштабировалось в пределах установленного соотношения, как часто бывает, например, со слайдами презентаций?
Мы можем задать значения всем свойствам шрифтов и размерам элементов, используя все те же единицы области просмотра, как и для контейнера. В этом случае я использовала vmin для всего, поэтому содержимое будет масштабироваться с изменениями как высоты, так и ширины контейнера:
Уже многие годы мы используем текстовые блоки ограниченного размера на пару с фонами на всю ширину. В зависимости от разметки или CMS, здесь могут возникать проблемы. Как уйти от необходимости ограничивать содержимое размером контейнера, но обеспечить при этом точно такое же заполнение им окна браузера?
И снова нам помогут единицы измерения области просмотра. Вот еще один прием, который мы использовали на новом сайте OddBird, где генератор статического сайта иногда ограничивает наш контроль над разметкой. Для реализации данного замысла требуется всего несколько строк кода.
.full-width {
margin-left: calc(50% - 50vw);
margin-right: calc(50% - 50vw);
}
Есть более подробные статьи, посвященные данной технике, как на Cloud Four, так и здесь, на CSS Tricks.
Конечно, если вы попробуете поэкспериментировать, то с помощью единиц измерения области просмотра вы сможете сделать гораздо больше. Вот, например, этот индикатор прокрутки страницы (созданный неким Майком) сделан на чистом CSS и с применением единиц измерения области просмотра на фоновом изображении:
А что еще интересного вы слышали о единицах измерения области просмотра или как еще использовали их в своей работе? Попробуйте подключить воображение в своей работе и покажите нам свои результаты!
|
Метки: author gprokofyeva разработка веб-сайтов css viewport units перевод верстка |
Программируем в мире Minecraft |

Установка
Несмотря на четкое следование инструкции, вы можете столкнуться с целым рядом проблем в процессе установки. Мои проблемы в основном были связаны с тем, что некоторые компоненты у меня уже были поставлены, но версия отличалась. Все проблемы лечатся с помощью всем известного сайта.
Поддержка ОС и языков программирования
Несмотря на смелое заявление о поддержке всех трех популярных ОС, мне показалось, что тестирование было как следует проведено лишь для ОС Windows. Победив проблемы с установкой, ваша головная боль на ОС Windows обещает закончиться. На Linux проблемы, скорее всего, продолжатся, так как поднятый сервер периодически падает, не сообщая причин. Если вы продолжите мои эксперименты – обязательно пишите в комментарях о вашем опыте.
Авторы постарались поддержать большое число популярных языков и сделали обвязки для C#, C++, Lua, Python2 и Java. Я выбрала Python.
./Minecraft/launchClient.*. После того, как сервер поднялся, в другом окне вы можете запустить код с основной логикой для управления персонажем. Как узнать, что сервер поднялся? Все крайне логично: вы увидите запущенный экземпляр Minecraft с начальным меню внутри, а в терминале будет гордо красоваться надпись Building 95%.launchClient. В таком случае первый запущенный экземпляр будет являться сервером, а также клиентом, представляющим из себя одного персонажа. Все последующие экземпляры будут подключаться к уже поднятому серверу, добавляя дополнительного персонажа в мир. agent_host.sendCommand("move 1")"move 1", вы сделаете не один шаг. Вы будете бежать, пока не дадите команду "move 0". Такой код на практике не сдвинет человечка с места:agent_host.sendCommand("move 1")
agent_host.sendCommand("move 0")"time.sleep(X)". Я уверена, что вы знаете, где брать информацию об остальных командах (хотя, по моему опыту, проще по диагонали просмотреть туториал и затем искать нужное в исходниках).
grid = observations.get(u'floor3x3', 0)floor3x3: ['lava', 'obsidian', 'obsidian', 'lava', 'obsidian', 'obsidian', 'lava', 'obsidian', 'obsidian']

|
Метки: author telezhnaya машинное обучение python open source блог компании microsoft microsoft machine learning artificial intelligence искусственный интеллект |
[Перевод] Исходный код Quake III |

renderer.lib и статично связан с quake3.exe: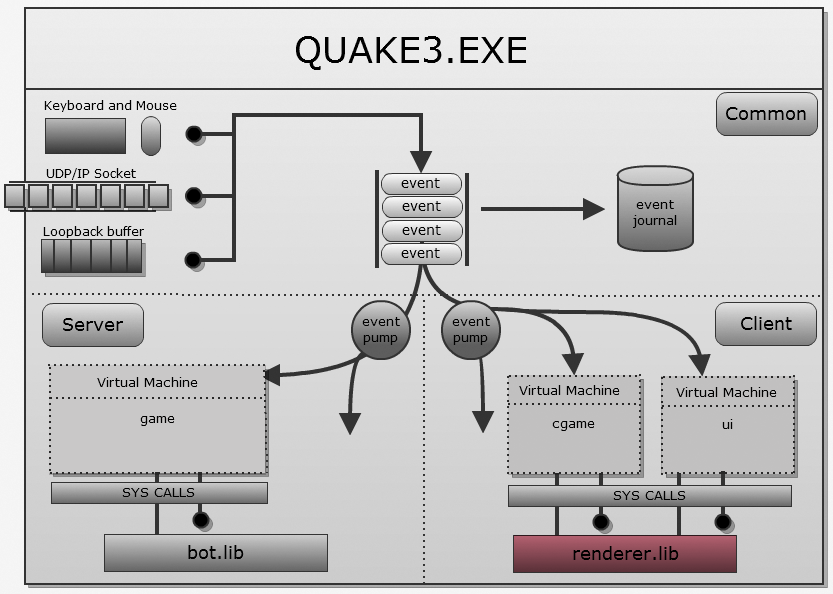
q3vis.exe использует систему порталов и генерирует PVS (потенциально видимый набор) для каждого листа. Каждый PVS сжимается и хранится в файле bsp, как описано в предыдущей статье.q3light.exe вычисляет освещение для каждого полигона на карте и сохраняет результат как текстуры карт освещённости в файле bsp.
q3light.exe:


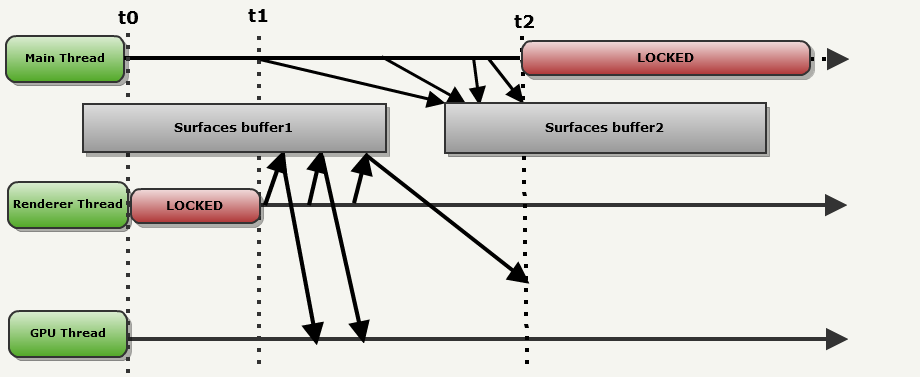
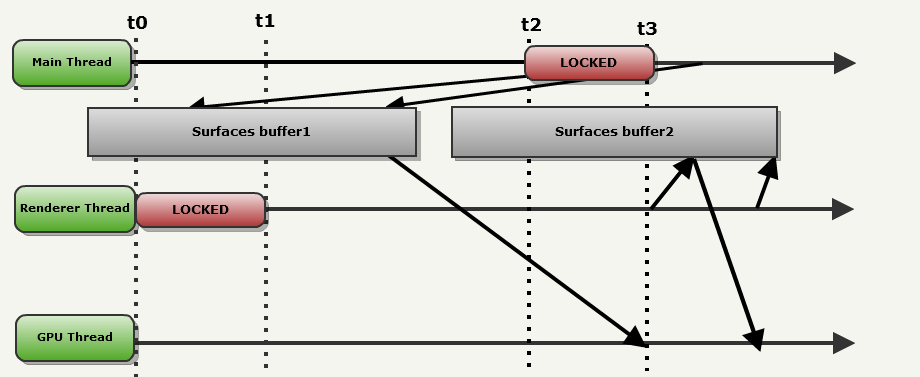
r_smp. Фронтэнд и бекэнд обмениваются информацией через стандартную схему Producer-Consumer. Когда r_smp имеет значение 1, рисуемые поверхности попеременно сохраняются в двойной буфер, расположенный в ОЗУ. Фронтэнд (который называется в этом примере Main thread (основным потоком)), попеременно выполняет запись в один из буферов, в то время как из другого выполняет чтение бекэнд (в этом примере называемый Renderer thread (потоком рендерера)).

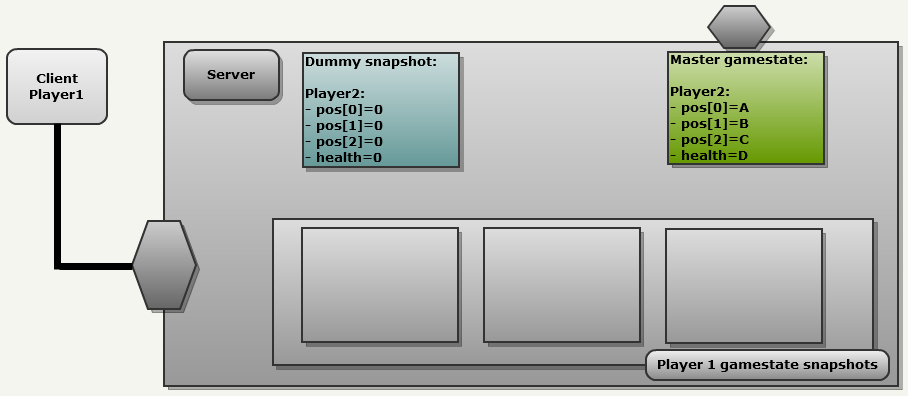
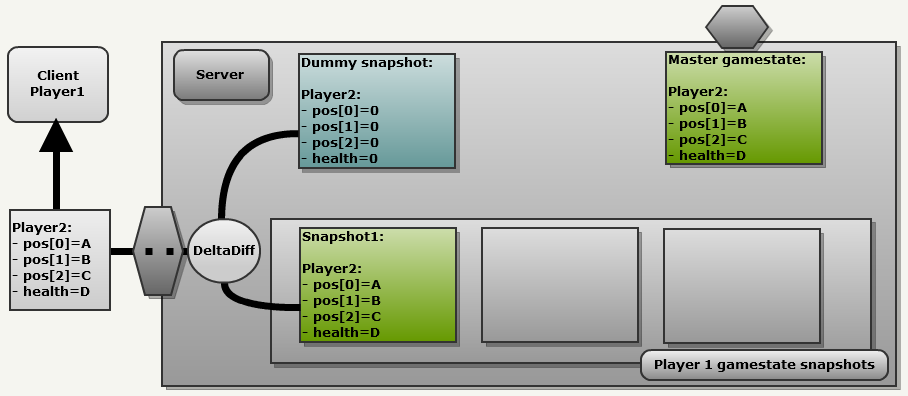
[1 A_on32bits 1 B_on32bits 1 B_on32bits 1 C_on32bits].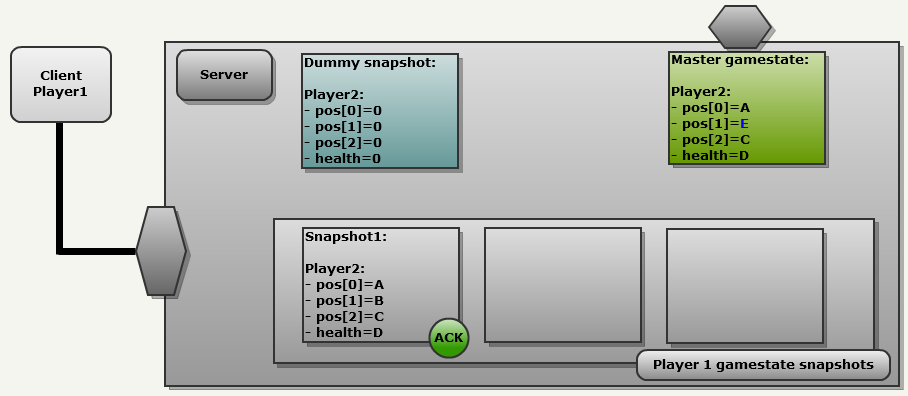
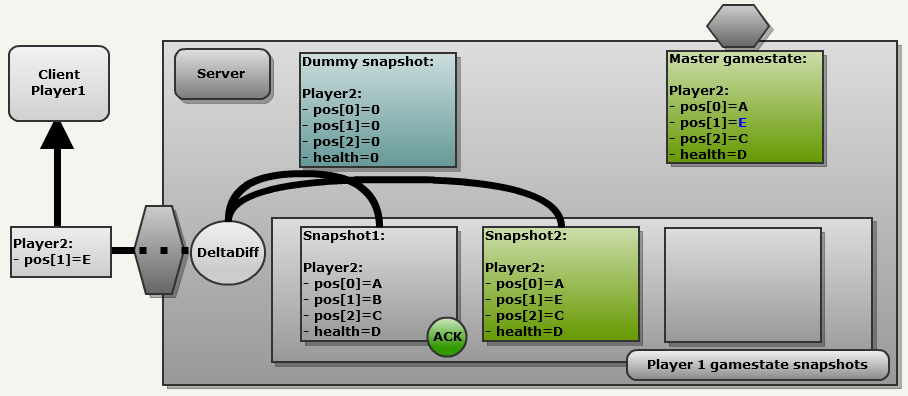
[0 1 32bitsNewValue 0 0]. 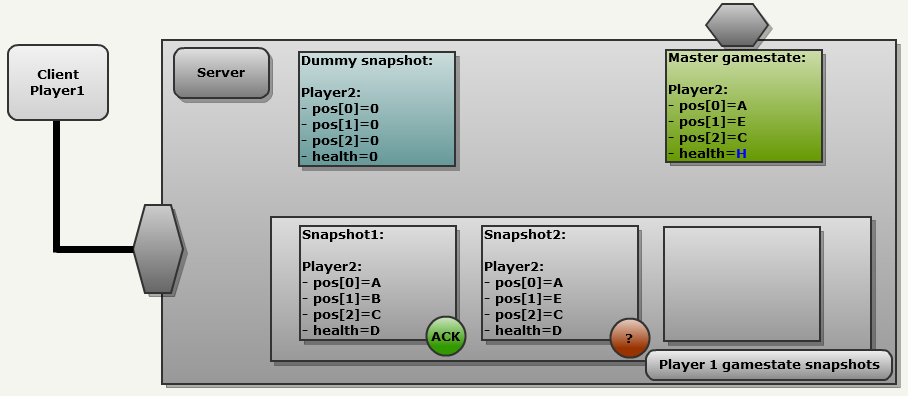
netField_t создаётся предварительно с помощью массива и умных директив предварительной обработки: typedef struct {
char *name;
int offset;
int bits;
} netField_t;
// используем оператор преобразования в строку для сохранения типизации...
#define NETF(x) #x,(int)&((entityState_t*)0)->x
netField_t entityStateFields[] =
{
{ NETF(pos.trTime), 32 },
{ NETF(pos.trBase[0]), 0 },
{ NETF(pos.trBase[1]), 0 },
...
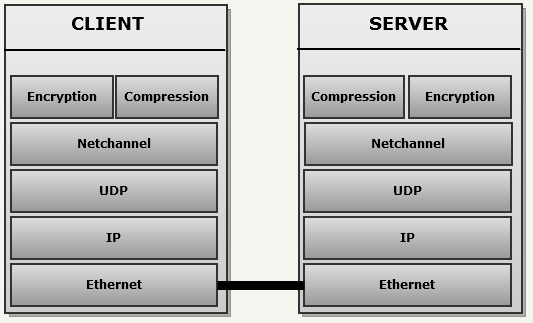
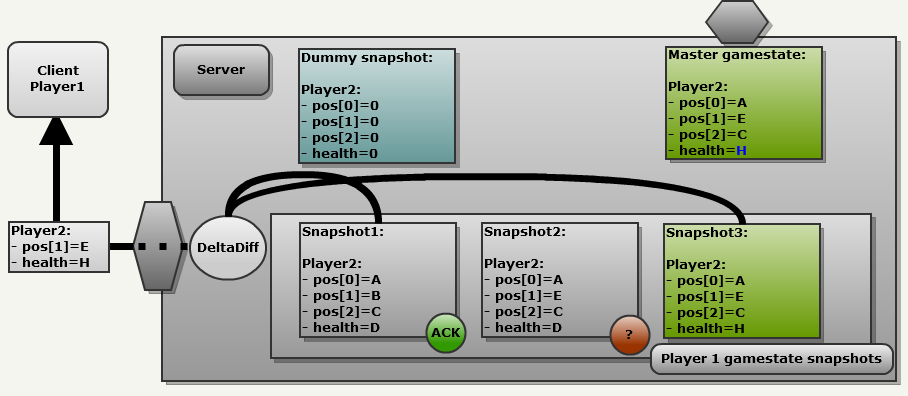
}MSG_WriteDeltaEntity из snapshot.c. Quake3 даже не знает, что сравнивает: он слепо использует индекс, смещение и размер entityStateFields и отправляет по сети различия.Netchan_Transmit), даже несмотря на то, что максимальный размер датаграммы UDP составляет 65507 байт. Так движок избегает разбивания пакетов роутерами при передаче через Интернет, потому что у большинства сетей максимальный размер пакета (MTU) равен 1500 байтам. Избавление от фрагментации в роутерах очень важно, потому что:
cgame: получает сообщения в фазе боя. Выполняет только отсечение невидимой графики, предсказания и управляет renderer.lib.q3_ui: получает сообщения в режиме меню. Использует системные вызовы для отрисовки меню.game: всегда получает сообщения, выполняет игровую логику и использует bot.lib для работы ИИ.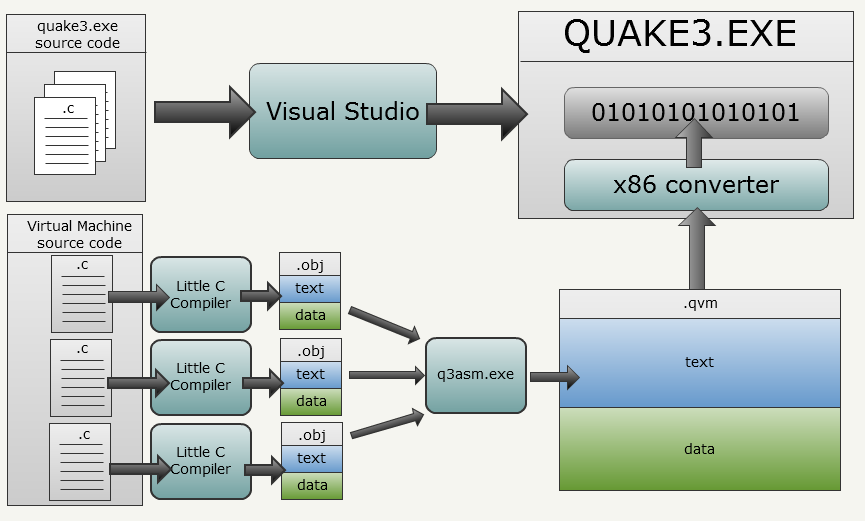
quake3.exe и его интерпретатор байт-кода сгенерированы с помощью Visual Studio, но в байт-коде ВМ применяется совершенно другой подход:text, data и bss с экспортом и импортом символов.q3asm.exe получает все текстовые файлы сборок и собирают их вместе в файл .qvm. Кроме того, он преобразует всю информацию из текстового в двоичный вид (ради скорости, на случай, если невозможно применить нативные преобразованные файлы). Также q3asm.exe распознаёт вызываемые системой методы.quake3.exe преобразует его в команды x86 (не обязательно требуется). extern int variableA;
int variableB;
int variableC=0;
int fooFunction(char* string){
return variableA + strlen(string);
}module.c lcc.exe вызывается со специальным флагом, чтобы избежать генерации объекта Windows PE и выполнить вывод в промежуточное представление. Это файл вывода .obj LCC, соответствующий представленной выше функции C: data
export variableC
align 4
LABELV variableC
byte 4 0
export fooFunction
code
proc fooFunction 4 4
ADDRFP4 0
INDIRP4
ARGP4
ADDRLP4 0
ADDRGP4 strlen
CALLI4
ASGNI4
ARGP4 variableA
INDIRI4
ADDRLP4 0
INDIRI4
ADDI4
RETI4
LABELV $1
endproc fooFunction 4 4
import strlen
bss
export variableB
align 4
LABELV variableB
skip 4
import variableAtext, data и bss): мы чётко видим bss (неинициализированные переменные), data (инициализированные переменные) и code (обычно называемую text)proc, endproc.ARGP4, ADDRGP4, CALLI4...). Каждый параметр и результат передаётся в стек.import strlen, потому что ни q3asm.exe, ни интерпретатор ВМ не обращаются к стандартной библиотеке C, strlen считается системным вызовом и выполняется виртуальной машиной.q3asm.exe получает текстовые файлы промежуточного представления LCC и собирает их вместе в файл .qvm:
vmMain, потому что это диспетчер вводимых сообщений. Кроме того, он должен находиться в 0x2D текстового сегмента байт-кода.
VM_Call( vm_t *vm, int callnum, ... ).VMCall может получать до 11 параметров и записывает каждое 4-битное значение в байт-код ВМ (vm_t *vm) с 0x00 по 0x26.VMCall записывает идентификатор сообщения в 0x2A.q3asm.exe записал vmMain).vmMain используется для диспетчеризации и маршрутизации сообщения к соответствующему методу байт-кода.VM_CallInterpreted).CALLI4, то проверяет индекс метода в int.int (*systemCall)( int *parms )).systemCall, используется для диспетчеризации и маршрутизации системного вызова к нужной части quake3.exe



К тому же не был готов фундаментальный ингредиент игры — боты. Боты — это персонажи, управляемые компьютером. Правильный бот должен хорошо вписываться в игру, дополнять уровни и взаимодействовать с игроком. Для Quake III, которая была исключительно многопользовательской игрой, боты оказались неотъемлемой частью игры в одиночку. Они должны были стать безусловно сложными и действовать подобно человеку.
Кармак впервые решил передать задачу создания ботов другому программисту компании, но потерпел неудачу. Он снова посчитал, что все, как и он, целеустремлённы и преданы работе. Но Кармак ошибался.
Когда Грэм попытался остановить работу, обнаружилось, что боты совершенно неэффективны. Они не вели себя, как люди, и были просто ботами. Команда начала паниковать. Это был март 1999 года, и причины для страха конечно же были.
bot.lib: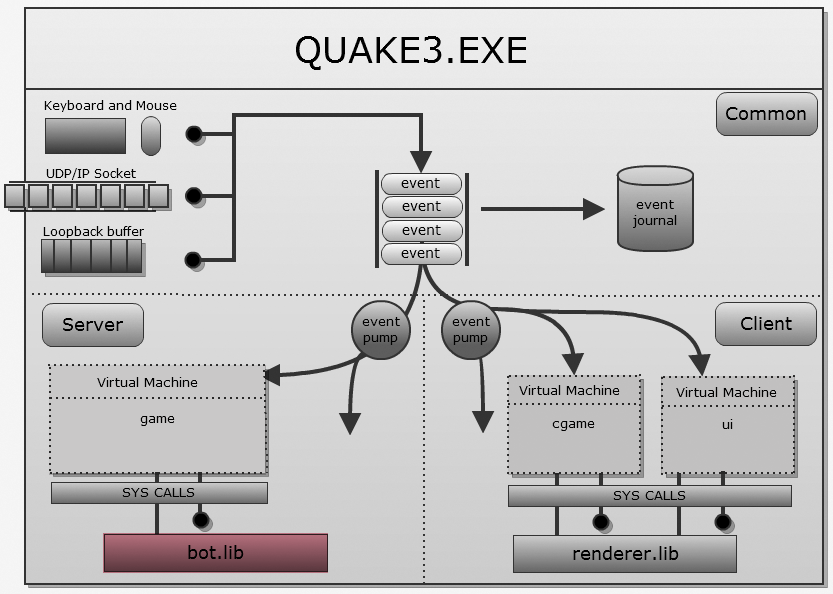
|
Метки: author PatientZero реверс-инжиниринг разработка игр quake 3 multiplayer обратная разработка |
Механическая Коробка и моя Success Story |










|
|
Software Defined Radio руками шестнадцатилетнего подростка |
SDR, или программно-определяемая радиосистема – это устройство для работы с радио, в котором работает мини-компьютер со специальным программным обеспечением. Он заменяет традиционные аппаратные компоненты: фильтры, усилители, модуляторы и демоуляторы. Это позволяет создать радиоприемник, работающий с самыми разными протоколами. Вообразите себе радиолу, которая кроме «ХитFM» может принимать аналоговое и цифровое телевидение, связываться по Wi-Fi, Bluetooth и GPS, а также засекать излучение пульсаров.
А теперь представьте себе американского девятиклассника, который решил сделать такую радиолу, заказал через интернет ПЛИС, радиомодуль, развёл шестислойную плату, а потом своими руками смонтировал на неё почти 300 компонентов. И через три ревизии это всё у него заработало!
Кому может понадобиться такая радиола? Радиолюбителям, которые здорово эволюционировали! Двадцать лет назад увлеченный человек покупал сложный приёмник и часами сидел в наушниках, вращая частоты в поисках интересных сигналов. В современном мире радиоэфир переполнен информацией, но вся она цифровая. Слушать в наушниках пакеты Wi-Fi не представляет никакого интереса. Сегодня радиолюбитель находит в эфире интересные цифровые радиостанции, а потом подбирает софт, который разбирает протокол передачи и преобразует информацию. К примеру, можно принимать данные телеметрии гражданской авиации – на основе такого рода информации от множества радиолюбителей по всему миру сайт flightradar публикует данные о воздушных судах.
Вы можете прямо сейчас своими глазами увидеть работу Software Defined Radio. Университет Твенте содержит увлекательный проект онлайн SDR-приёмника, который принимает сразу кусок спектра шириной в 29MHz, после чего радиолюбители могут параллельно прослушивать различные несущие этого диапазона. Каталог подобных радиопроектов собран на сайте
Большую роль в популярности любительского SDR играет небольшая стоимость минимального комплекта оборудования. Обнаружились недорогие TV-тюнеры, реализованные на Software-Defined Radio, и в интернете немедленно появились инструкции о том, как перепрашивать такие тюнеры, чтобы прослушивать с их помощью не только телевизионный сигнал. Специализированный комплект на китайском рынке стоит всего 35$ правда, он приходит разобранным (в необходимости предварительно спаять и заключается его шарм) и поддерживает диапазон только 100KHz-1.7GHz. Конечно, аппетит приходит во время еды, и очень скоро радиолюбитель начинает смотреть в сторону оборудования, которое может принимать широкие частотные диапазоны на высокой скорости. Давайте рассмотрим, какие серьёзные приборы сейчас наиболее популярны.
| Название | Диапазон | Макс. ширина канала | ADC Sample Rate | Цена |
|---|---|---|---|---|
| hackRF One | 1MHz — 6MHz | 20MHz | 20MSPS | $299 |
| bladeRF x40 | 300MHz — 3.8GHz | 28MHz | 38.4MSPS | $420 |
| USRP B205mini-i | 70 MHz — 6 GHz | 56MHz | 61.44MSPS | $750 |
| LimeSDR (coming soon) | 100 kHz — 3.8 GHz | 61.44MHz | 61.44MSPS | $299 |
| RTL-SDR (receive only) | 22 MHz — 3.8 GHz | 3.2MHz | 3.2MSPS | $10 |
| Per Vices Crimson | 0 MHz — 6 GHz | 1200MHz | 370MSPS | $6500 |
В двух словах: начинать знакомство с SDR можно с дешёвых вариантов типа RTL-SDR. Когда аппетит исследователя превысит небольшие возможности устройства, придётся искать замену подороже. Устройства типа Per Vices Crimson используются очень серьёзными специалистами, чьи компьютеры достаточно производительны для обработки таких потоков информации. LimeSDR на данный момент только-только закончил сбор средств на Kickstarter. Выглядит очень заманчиво: частота семплирования максимальна для USB3.0, а ширина канала достаточна для поднятия шести 10MHz сот LTE.
Однако, ещё недавно выбор не был так велик, и если не устраивал hackRF за $300, то следующим вариантом был USRP сразу за $750, и никакого компромисса. В связи с этим, шестнадцатилетний Лукас Лао Бейер решил самостоятельно разработать SDR-плату и недавно опубликовал отчёт о своём проекте. Сказать, что мы были поражены – ничего не сказать, лучше просто промолчать.
"Да что эти американские школьники себе позволяют!" — кричат в комментариях к статье Лукаса. Люди годами совершенствуют своё мастерство, а этот мальчишка сделал всё между уроками! Мы решили, что так это оставлять нельзя, и связались с Лукасом. В этой серии статей мы рассмотрим все аспекты создания подобного устройства, чтобы российские школьники перенимали опыт и делали не менее восхитительные вещи. Начнём с перевода на русский язык дневника Лукаса, в котором можно пронаблюдать ход проекта и его переживания в связи с ним. Затем мы разберём выбранные решения и попробуем изготовить такое устройство в российских условиях.
Из дневника Лукаса Лао Байер
FreeSRP – доступная программно-определяемая радиосистема. Я ее разработал, потому что не нашел устройств с более высокой пропускной способностью, чем HackRF за 300$, но дешевле более производительной USRP за 700$. Некоторые компоненты еще требуют доработки, но система будет полностью соответствовать философии Open Source.
FreeSRP основана на трансивере Analog Devices AD9364. Ключевые возможности:
Несмотря на то, что есть другие альтернативы типа LimeSDR, я считаю, что FreeSRP будет востребован. Разработка, как и ожидалось, была невероятно познавательной.
Я начал работу над системой два года назад, летом 2014, когда мне было 16. На тот момент у меня не было опыта серьезной работы с железом, не считая низкопроизводительных плат для моего проекта High Altitude Balloon. Поэтому я понимал, что разработка FreeSRP будет непростой во всех аспектах: скоростные шины (100MHz), USB3.0, сигнальные дорожки с производительностью до 6GHz, сложные схемы питания с семью различными напряжениями… Очень хотелось собрать компактную систему на современных компонентах, так что пришлось познакомиться с такими компонентами, как BGA или QFN.

Сравните мою предыдущую плату и нынешнюю
Что и говорить, амбициозность проекта колоссальна. Однако, меня это нисколько не пугало, и я начал с чистого листа, исходя лишь из того, что я точно буду использовать трансивер AD9346, а мост между трансивером и USB3.0 реализую на ПЛИС. Недолгие поиски привели меня к Xilinx Artix 7 и контроллеру Cypress EZ-USB FX3. Эти игрушки показались мне оптимальными рещениями в плане цены.
На основе даташитов и референсных дизайнов я постепенно подготовил принципиальную схему, в которой решил вопросы по всем остальным компонентам. Для разработки я использовал Altium Designer. Хотя он и не open source, для меня это был наиболее интуитивно понятный пакет дизайна печатных плат. Многие его прекрасные функции весьма помогли мне в разработке: жизнь становится гораздо проще, если у тебя есть инструменты для отрисовки параллельных шин или дорожек с конкретным сопротивлением. Впрочем, когда я закончу устранение недочётов в дизайне, я перерисую всё в KiCad, чтобы большему числу людей было удобнее пользоваться моими разработками.
От дизайна к прототипу

Когда схема готова, пора выпускать шаблон платы. Для прототипа очень важна цена изготовления, и в мой бюджет еле-еле умещалась четырёхслойная плата от нашего американского сервиса OSH Park, который славится низким ценником на штучные заказы. Пусть у них есть только четырёхслойки, параметры изготовления весьма хороши — дорожки 5 mil с такими же промежутками, 10 mil для отверстий, а также прекрасный субстрат Isola FR408, от качества которого зависит радиосигнал.
Самое важное в разработке платы — удобно расположить компоненты. Я старался сделать так, чтобы соединения между компонентами были как можно меньше. Конечно, я изо всех сил стремился сделать плату минимального размера, что сильно влияет на цену. Я начал рисовать прохождения сигнала с одной стороны — от USB — и постепенно добавлял компоненты по ходу этого пути, пока не дошёл до радиоинтерфейса. Компоненты вне этого пути (регуляторы напряжения) были добавлены в оставшиеся свободные места на плате.

С первого раза, разумеется, вышло не идеально, и довольно долго я увлеченно переделывал плату, пока наконец не понял, что уже всё хорошо. Самая сильная боль наступила, когда я начал разводить BGA на своей четырёхслойной плате. Тем не менее, я справился. Дизайн прошёл все проверки, и я ещё на несколько раз проверил всё вручную. Совершенно не хотелось рвать на себе волосы после изготовления платы с ошибкой, потому что это, конечно, было бы уже никак не исправить.
Изготовление прототипа
После долгих треволнений, я всё же заказал три платы, и в январе 2015 они — УРА! — приехали. Я намеревался самостоятельно собирать плату, поэтому дополнительно заказал шаблон монтажа на пленке для паяльной пасты. Для монтажа я использовал галогеновую печку и контроллер собственной разработки.

Так как FreeSRP основан на двухсторонней плате, я сначала монтировал нижний слой. В дизайне я расположил снизу только маленькие компоненты: когда я буду запекать плату второй раз при монтаже верхнего слоя, маленькие компоненты удержатся на плате даже вверх ногами.

Частичная сборка
У меня было три печатные платы, поэтому я сначала собрал прототип лишь частично. На одной плате установил только регуляторы напряжения, и благодаря этому обнаружил проблему с регулятором на 1.8В. Ничего страшного, я заменил его внешним источником питания. А вот проблему с регулятором на 1.3В я устранить не смог, потому что здесь уже проблема заключалась в ошибке проектирования, так что в первой ревизии я не смог запустить радио.

На второй плате я собрал всю цифровую часть: USB и FPGA. Впервые мне довелось монтировать BGA, и я делал это вручную. После долгих часов напряжённого и кропотливого монтажа дорогущих компонентов без права на ошибку, я дрожащими руками аккуратно положил плату в печь. Ожидание было мучительным, и как же я ликовал, когда всё прошло идеально!
Первое включение

Конечно, я невероятно страшился первого включения платы. Хотя цепи питания были проверены на первой плате, я всё равно не исключал, что сейчас мои драгоценные компонентики вспыхнут синим пламенем. Возможно есть какой-то безопасный способ включать не тестированную плату. Мне ничего лучше не пришло в голову, как плавно повышать ток на блоке питания, и молиться, чтобы нигде не пошёл дым.
Тест на дым был пройден успешно, и лампочки загорелись. Ни ПЛИС, ни USB на ощупь не нагревались. Я подключил USB в компьютер, и операционка обнаружила чип Cypress. Затем я запустил приложения Xilinx, и они подключились к ПЛИС через JTAG. Похоже, всё заработало! Рассмотрев детальней, я конечно нашёл ошибку: криво развёл разьём USB3.0, так что заработала только вторая версия. Ничего страшного, начнём тестировать в таком виде, и исправим проблему позже.
Вторая ревизия
Во второй ревизии мне понадобилось устранить проблемы с питанием и разводкой USB3.0. В результате, я получил полностью рабочую цифровую часть платы, и пора было переходить к радиочасти.
Сначала я не стал трогать трансивер, и собрал все остальные компоненты. Параллельно, началась разработка программной части проекта. До этого я никогда не программировал ПЛИС, поэтому мне пришлось изучать Verilog с нуля. На этом этапе я решил реализовать параллельный интерфейс к USB-контроллеру. Хотя все части проекта были не тривиальны, разработка ПЛИС для меня стала самой жуткой частью проекта. Очень сложно найти документацию для чайников по использованию инструментов и IP-блоков. Сообщения, которые писала Vivado Design Suite, были для меня китайской грамотой, а включение готовых IP-блоков приводило к сотням непонятных уведомлений. Скорее всего, я просто не умею пока правильно готовить на этой кухне.Даже самые минимальные изменения в дизайне требовали мучительно долгого обсчёта программой, поэтому всё необходимо симулировать — а это еще больше усложняет вход в чудесный мир ПЛИС. А отладка! Без Integrated Logic Analyzer отлаживать что-либо совершенно невозможно, а он стал бесплатным только в 2016 году– до этого прайс был очень высоким. Поэтому пришлось при отладке передавать часть тестовой информации морганием диода, а часть — на ножки GPIO и смотреть сигнал осциллоскопом.

В вопрос по тактированию я вник до конца не сразу – только к третьей попытке пришло осознание, что тактовый сигнал трансивера нужно было обязательно завернуть в clock-inputs на ПЛИС.
Наигравшись с Verilog, я решил, что самое время впаивать трансивер. Я взял третью плату, вновь установил на неё три сотни компонентов, как и ранее, начав с нижней стороны. Но когда я паял верхнюю сторону, контроллер моей печки объявил забастовку и не выключил печь. Я не мог получать показания по температуре в печи, а контролировать агрегат удавалось только включая-выключая его или открывая дверцу. Никакие мои молитвы не помогли: на дорожках появилось КЗ. Я попытался починить, но тщетно: при включении ПЛИС нагревался. Увы, я только что сжег в печи четыре сотни баксов, и этот факт совсем не придавал мне уверенности.
Тем не менее, я был решительно настроен закончить проект, поэтому разбил копилку, вновь заказал компоненты и через несколько недель предпринял еще одну попытку всё собрать. Вы не представляете, как я потел в этот раз, словно в финале турнира по покеру! К счастью, всё прошло без сюрпризов.

Цифровая часть в новом прототипе работала идеально. А вот трансивер работать не хотел, его конфигурационный порт просто не отвечал. Потом я заметил, что трансивер на ощупь горячий. Почему он так нагрелся, было непонятно, ведь он должен спать без конфигурации. Я безуспешно пытался найти проблемы в питания. Излазил все схемы, перепроверил все на сто раз. И потом я обнаружил следующую вещь.
Оказывается, я по ошибке последовательно включил два резистора — 698Ом и 536ОМ (в сумме 1234Ом) вместо 14.3 килоомного резистора из документации! Я заменил резисторы, и чип перестал греться, но он всё равно не работал. Похоже, я его спалил.

В общем, в этот момент я решил, что сделано уже достаточно много для такого юного специалиста без глубоких знаний электроники, и пора проект отложить. Но у меня осталась работающая ПЛИС, поэтому я стал развлекаться с ней.
В результате долгих экспериментов, я прикрутил драйвер трансивера и справился с генерацией тестовых сигналов. У меня заработала цепочка передачи сигнала от ПЛИС к USB, так что дальше я мог управлять своей SDR с компьютера с помощью библиотеки на более знакомом мне C++. Затем я реализовал совместимость моей платы с GNURadio, так что теперь с этой платой могли работать все полезные программы, реализованные на базе GNURadio.
Третья ревизия

В какой-то момент я нашёл силы на ещё один рывок и сделал третью ревизию. Я исправил досадную ошибку с 14.3 килоомным резистором, соединил clock-inputs с FPGA, и заменил осциллятор трансивера на кристалл, чтобы упростить раздачу тактового сигнала и исключить дальнейшие проблемы.
Конечно, проект вышел за рамки срока и бюджета, но сейчас мне уже кажется, что иметь всего три ревизии до работающей платы — это совсем неплохо!
Также на этой ревизии я перешёл на шестислойную печатную плату. Прототипы стали стоить дороже, но расстояние между сигнальными дорожками значительно увеличились, и я достиг максимальной тактовой частоты в шинах.
Кроме того, я купил отличные шаблоны из нержавейки, которые, в отличие от каптоновых, гораздо проще использовать.

Раз софт у меня уже был готов, я сразу смог запустить трансивер на прием, и вот они долгожданные первые сэмплы в GNURadio!

Наконец-то вся тяжелая работа дала свои плоды. Еще через несколько недель я смог запустить передатчик, и убедился, что полнодуплексный режим у меня взлетел, пусть и не в полную ширину. И тут я нашёл новую проблему с усилком на передаче, поэтому сигнал получился очень слабым.
В любом случае, у меня есть полнофункциональная SDR-плата, ребята! Да, ещё много нужно доделать. Я хочу тщательно измерить производительность приемника и передатчика. Очень хочется запустить мелкосерийное производство, но перед этим мне нужно ещё немного оптимизировать дизайн и быть на 100% уверенным, что я не оставил в плате ещё каких-то сюрпризов.
Постановка задачи
Большое спасибо Лукасу за его подробный отчёт, а сейчас давайте рассмотрим его решения.
Итак, Лукас хотел сделать широкополосную программно-определяемую радиосистему с характеристиками лучше, чем у hackRF, и дешевле USRP. Давайте рассмотрим, как устроено оборудование конкурентов.
USRP



hackRF

Последнее изображение выглядит наиболее лаконично, однако все три устройства имеют одинаковую архитектуру: сигнал принимается из эфира, оцифровывается и передаётся в USB. Есть различия в деталях. В hackRF радиочасть реализована в виде нескольких компонент: сигнал после приёма с помощью миксера сдвигается в промежуточную частоту диапазона 2.3-2.7GHz, затем преобразуется в синфазную и квадратурную составляющую сигнала, которая уже оцифровывется. Другие устройства решают эту задачу одним компонентом — трансивером. Преобразование цифрового сигнала для передачи в USB, а также управление радиотрактом, осуществляется при помощи ПЛИС (FPGA) либо микроконтроллера.
Проектируя систему сверху вниз, мы разделим её на три части: RF, FPGA и USB, и сначала проработаем каждый блок по отдельности, а затем разберёмся, как связать их вместе.
RF-часть
Радиомодуль в такой системе — самое хрупкое дело. Дискретные биты должны превратиться в волну и с нужной мощностью полететь в антенну. Для этого раньше требовалась целая россыпь восхитительных штучек: фильтры, интерполяторы, дециматоры, цифро-аналоговые преобразователи, синтезаторы, миксеры и различные усилители. До сих пор существует класс людей, предпочитающих самостоятельно контролировать каждый аспект их радиомодуля и собирающих их из маленьких кусочков. Какое же решение предпочтёт школьник? Конечно, он будет рад, если один суперчип решит для него все эти проблемы. Вот какие есть варианты:
Как в hackRF
Майкл Оссманн, кстати говоря, тоже радиолюбитель, а не радиопрофессионал, и единственная причина, почему он не решил радиочасть в своём проекте в виде одного умного кусочка кремния — это доллары, которые для этого потребовались бы. Майкл выбрал компромисс: он использует три кусочка кремния и экономит примерно половину стоимости, что делает hackRF таким доступным по цене. Радиосигнал в hackRF приходит на RFFC5071, который понижает частоту до ~2.5GHz (это называется LO-синтез), затем этот сигнал попадает в узкополосный трансивер MAX2837, превращается в baseband и в таком виде идёт в MAX5864 — это как раз цифро-аналоговый (и обратно) преобразователь.
AD9364
Analog Devices выпускают отличные трансиверы, которые часто используются в различных SDR-проектах. Выше на схеме видно, что такой чип, к примеру, комфортно себя чувствует на устройствах USRP. У производителя можно купить чип на демонстрационной плате AD-FMCOMMS4-EBZ, которая в принципе является готовой примитивной SDR.
LMS6002D
Чипы Lime Micro используются во множестве систем (bladeRF, например), в том числе и в российской SDR-разработке umTRX, а в этом году они замахнулись на собственную SDR-систему и успешно собрали на Kickstarter средства для запуска LimeSDR в продакшн. В целом, Лукас вполне имел право использовать этот чип в своей работе, он прекрасен, и главный его недостаток — диапазон принимаемых частот вполовину уже, чем у AD9364.
Поэтому в итоге Лукас выбрал вариант с AD9364, и немедленно заказал его.
Выбор FPGA
Самое сложное при выборе ПЛИС — это определиться Altera или Xilinx. Эти компании словно Sony и Nintendo производят одинаково крутое железо, и дьявол лишь в деталях. Какая же разница между Altera и Xilinx?
Altera славится очень долгой поддержкой своих микросхем. Среда разработки Xilinx Vivado работает только с последней (седьмой) серией микросхем, тогда как Altera's Quartus поддерживает даже Flex 10K, которому пятнадцать лет исполнилось с момента первого выпуска. На момент старта проекта, софт для отладки Xilinx стоил 700$ (и стал бесплатным только в этом году), а у Altera он бесплатен. IP-блоки (готовые программные библиотеки) в Altera можно попробовать во время демо-периода с ограничениями. В итоге, для новичка-любителя Altera выглядит предпочтительней. Зато в Xilinx умнее DSP часть, в ней есть не только умножение (как в Altera), но и предсложение с аккумулятором, что уменьшает количество необходимых логических блоков для решения задачи.
Но Лукаc выбрал Xilinx. Он утверждает, что из-за цены, но я думаю, что наугад (сравните, Xilinx Aritx-7 и Altera Cyclone V).
Как выбрать конкретную модель микросхемы у Xilinx? Два года назад выбор стоял между Spartan-6 и Artix-7, которые считаются low-cost предложением Xilinx. Spartan-6 отпадает, потому что его не поддерживает программное обеспечение Vivado.
Все BGA семейства Artix-7 совместимы что называется pin-to-pin, поэтому дальше Лукас просто ткнул в модель 50T, решив определиться с конкретной моделью, когда софт будет готов и точно определятся требования к производительности микросхемы.
Какие FPGA используют в других аналогичных проектах?
| SDR | Модель FPGA | Logic Cells |
|---|---|---|
| USRP B200 | Xilinx Spartan 6 LX150 | 150k |
| USRP B210 | Xilinx Spartan 6 LX75 | 75k |
| bladeRF x40 | Altera Cyclone 4 | 40k |
| bladeRF x115 | Altera Cyclone 4 | 115k |
| hackRF | CPLD | xx |
Автор hackRF не стал ставить FPGA, а выбрал более дешёвую технологию — CPLD, что является, скажем так, упрощённой версией FPGA. В результате, он практически ничего полезного не может в ней делать и вообще планирует исключить ПЛИС из своего дизайна, переведя управление трансивером на чип USB-контроллера.
USB3.0
Осталось определиться с решением для USB3.0. Самое популярное решение здесь — микроконтроллер Cypress FX3, и сложно придумать причины не использовать его. Тем не менее, рассмотрим альтернативы.
Первым на ум приходит FTDI FT60x — микроконтроллер в корпусе QFN. Компания FTDI знаменита тем, что любит выпускать драйвера, которые намеренно убивают твой чип, если он является подделкой. Если для USB2.0 чипы этой компании считались стандартом де-факто, то в USB3.0 они, к сожалению, упустили свой рынок таким странным отношением к оборудованию конечного пользователя и низким качеством софта.
Другой вариант — взять трансивер от Texas Instruments TUSB1310A, а MAC-уровень реализовать в ПЛИС. Трансивер стоит на 20$ дешевле, чем микроконтроллер от Cypress FX3, и я затрудняюсь прокомментировать, почему Лукас не сделал именно так.
Изготовление печатной платы
Если вам больше хочется программировать, чем развлекаться с паяльником, я бы рекомендовал делать прототип на готовой плате. Хороший список готовых плат на разных ПЛИС можно найти на специальном сайте. Для этого конкретного проекта есть идеальный вариант готовой платы с USB3.0 и FPGA Artix 7 остаётся только скоммутировать трансивер и можно немедленно приступать к экспериментам.
Однако, Лукасу в этом проекте были интересны все этапы. Более того, он даже монтировать плату хотел сам. Прототипы Лукас изготовил в OSH Park — это очень популярный сервис среди американских студентов. Цена у них идёт от площади платы (10$ за квадратный дюйм), и с учётом расположения в США вся процедура занимает весьма короткий промежуток времени. Однако, сейчас, когда на плату есть заказы и её нужно изготавливать десятками, имеет смысл поискать самый оптимальный вариант для её изготовления. Ниже в таблице я привёл сравнение российских и зарубежных сервисов по изготовлению плат без монтажа на них.
Сравнение цен на изготовление печатной платы. Требования:
| Предприятие | Стоимость за пять штук шестислойки | Пять штук четырёхслойки |
|---|---|---|
| OSH Park | Шестислойную не делают | 123$ за три штуки, опт — от 150 квадратных дюймов |
| PCB tech | 614$ | - |
| Резонит | 153$ | - |
| EasyEDA | 284$ | - |
| seeedstudio.com | 158$ | - |
| pcbwing | 348$ | 299$ |
| PCB Offshore | 280$ / 4pcs | 140$ / 4pcs |
| PCBCart | 191$ | 93$ |
Часть российских заводов ответили отказом или выставили заградительные цены: не хотят связываться с мелкосерийным заказом. Хочу обратить внимание, что при текущем курсе доллара услуги российской компании Резонит оказываются даже предпочтительней китацев. Плюс, они готовы сами смонтировать платы, если вы предоставите им комплектующие. На данный момент, из этого списка я лично работал только с EasyEDA, и нареканий нет. Цены Резонита приятно удивили Лукаса, и сейчас мы планируем разместить там заказ платы по его проекту. Когда у нас всё получится, я обязательно расскажу вам детали взаимодействия с заводом, а также подготовлю статью о процессе проектирования печатной платы и подготовке проекта к изготовлению.
Из дневника Лукаса Лао Байер
Чтобы эта плата начала приносить пользу, необходимо разработать несколько компонент:
Для персонального компьютера я написал C++ библиотеку на основе libusb. Однако, чтобы не изобретать велосипед, я решил интегрироваться в какой-нибудь популярный фреймворк, и очевидным выбором была GNU Radio.
Сначала я собирался просто написать собственный блок для GNU Radio, но затем я натолкнулся на проект gr-osmosdr, который осуществляет поддержку многих популярных SDR. В комплекте с ним идёт анализатор спектра, генератора сигнала. Плюс, эта библиотека уже используется другими приложениями (например, Gqrx, AirProbe/gr-gsm). Соответственно, если я сделаю патч в этот проект, то моя плата автоматически появится в этих приложениях.
Потому я скопировал себе актуальную версию gr-osmosdr, и дальше просто смотрел какие правки делались для поддержки других SDR. В итоге, потребовались очень небольшие правки, чтобы библиотека увидела мою плату. Дальше появились функции для настройки частоты, ширины спектра и т.д. Ключевая функция — work — производит или потребляет данные из потока GNU Radio. Сначала я реализовал простую очередь, чтобы как можно быстрее начать играть с платой, но, конечно, это неэффективно. Сейчас я обновил алгоритм и сделал, как делают все папы: через обратные вызовы и синхронизацию с помощью условных переменных
В общем, теперь для работы с моей платой через gr-osmosdr нужно просто указать аргумент freesrp.
Проверяем корректность потока данных
Я начал баловаться с GNU Radio начиная со второй ревизии моей платы, когда трансивер ещё не очень-то работал. Я просто посылал сигнал и разворачивал его обратно в приёмный тракт. Так я мог проверить, что в цифровой части платы ничего не искажается.
Чтобы проверить частоту дискретизации платы, я гнал сигнал из блока GNU Radio "probe rate", а на ПЛИС собрал простой счётчик:

Сигнал генерируется в ПЛИС и принимается в GNU Radio. Частота дискретизации вбита прямо в код. Получаемая частота дискретизации выводится в отладочное окно.
Дальше тестировал цепь передачи сигнала. Теперь сигнал генерируется в GNU Radio и сливается в (sink block).

Теперь проверяем, что ПЛИС правильно декодирует данные: драйвер должен возвращать 32-битное слово, в котором будет два 12-битных сэмпла (I и Q) и выравнивающая пустота. С помощью программы Integrated Logic Analyzer я мог получить доступ к 12-битным сэмплам в ПЛИС и сравнить их с тем, что я вижу на моём компьютере.

I и Q сигналы на конце цепочки передачи данных в ПЛИС.
GNU Radio генерировал синусы и косинусы, но данные где-то портились. В итоге оказалось, что ошибка была в моей библиотеке freesrp, она неправильно форматировала данные. Когда я её починил, то собрал петлю в ПЛИС:

И всё почти работало. Только некоторые сэмплы терялись и заменялись на нули. На следующей картинке мы видим сгенерированный синий сигнал I, красный Q и сигнал, который прилетел обратно — зелёный I и чёрный Q:

Периодичность потери сигнала натолкнула меня на мысль, что проблема где-то в моём конечном автомате, который управляет чтением и записью в USB-контроллер: переход в состояние записи происходило за цикл до попадания данных в регистры, которые нужно записать. Я сдвинул этот переход на один такт, и всё стало гладенько:

На третьей ревизии платы я повторил все тесты, чтобы убедиться в полной работоспособности. Для лупбэка я использовал внутреннюю петлю AD9364, таким образом покрыв тестом всю цифровую часть прототипа.
Весёлые эксперименты с GNU Radio
Теперь мне очень хотелось попробовать декодировать реальные сигналы. Первыми моими жертвами стали GSM и Zigbee, потому что для них есть готовые библиотеки gr-gsm and gr-ieee802-15-4.
GSM
Внешние модули GNU Radio собираются через cmake, потому всё просто:
mkdir build # Creates a blank directory for the build to run in
cd build
cmake… # Load CMake build script in root of the module's directory and run it
make # Run the CMake-generated makefile
sudo make install # Install the module
sudo ldconfig
В пакете gr-gsm идёт некоторое количество пробных приложений. Самые интересные — grgsm_scanner and grgsm_livemon. С помощью первого можно поискать GSM вещание и вычленить из них какие-то идентификаторы, а также получить список базовых станций.

Поглядите, кстати, я в качестве аргумента указываю код своей платы freesrp — и всё работает. Это очень приятное чувство.
Второе приложение позволяет настроиться на один из GSM каналов, расшифровать данные и отправить их в твою локальную сеть, где их можно послушать через Wireshark. Я добавил в программу модуль gr-fosphor, чтобы скриншот стал более красочным:

802.15.4 (Zigbee)
У меня дома было несколько XBee модулей, и я решил с ними взаимодействовать. На этом примере я хотел проверить отправку данных.
Установка модуля настолько же проста, как и в случае с gr-gsm. Примеры, которые идут с библиотекой, сделаны для коммуникационного стека Rime, поэтому я отрезал от него всё, что не касается самого Zigbee, и добавил блок TCP Server, чтобы можно было по локальной сети подключаться и отправлять данные:

Для примера я написал два Python-скрипта: один подключается к XBee через USB, а другой цепляется на TCP порты в GNU Radio. И затем я просто передавал текстовые сообщения через протокол 802.15.4, как в чате.
О разработке драйвера
Дизайн ПЛИС и USB-контроллера
Сейчас моя ПЛИС ничего особого не делает, кроме как служит интерфейсом между трансивером и USB. Из-за простоты реализации, я запустил на MicroBlaze драйвер от AD9364, который производит настройку и калибровку. Драйвер взаимодействует с USB через UART. Вскоре я перенесу этот драйвер на контроллер USB.
AD9364 выдаёт семплы в 12-битный порт чередуя I и Q. Есть ещё один 12-битный порт, куда надо отправлять исходящией I\Q значения. Так же трансивер предоставляет DDR-клок в зависимости от выбранной частоты дискретизации. Во входной сигнальной цепи происходит обратное перемежение и складывание в 24битную очередь.
В контроллере USB есть механизм DMA, куда ПЛИС может напрямую писать (и оттуда же читать) данные через 32битную шину. Поэтому когда в очереди ПЛИС накопилось достаточно данных, а FX3 готова к приёму, конечный автомат перебрасывал данные.
Сейчас я использую только 24 бита из доступных 32. Влезает один I\Q семпл, и остальные 8 бит я просто отбрасываю. Но для полнодуплексной передачи данных нужно будет использовать все 32 бита.
USB контроллер предоставляет следующие контрольные точки:
После включения FPGA можно настроить через INTERRUPT OUT.
Libfreesrp
Библиотека взаимодействия с FreeSRP очень проста. Для приёма и отправки используется интерфейс libusb. Это позволяет накапливать в очередь данные для оптимальной обработки операционной системой. Пользователь указывает колбэк, который будет вызван если поступили новые данные или буферы отправки освободились.
Планы
Дмитрий Стольников из gr-osmosdr уже связался со мной и предложил слить мои изменения в основную ветку библиотеки. Я вскоре закончу её полировать и сделаю это.
Когда я избавлюсь от MicroBlaze и перенесу драйвер на FX3, ПЛИС почти полностью освободится. Я бы хотел воспользоваться этим для экспериментов с обработкой сигналов в реальном времени прямо на ПЛИС.
Очень хочется получить более точные характеристики производительности радиочасти. Я не приблизился к этому ни на шаг, потому что у меня нет приборов, да и других дел полно.
В апреле Лукас запустил краудфандинг для своего продукта и получил первую партию заказов на 20000$ (то есть, порядка пятидесяти экземпляров).
После отгрузки этой партии можно будет с уверенностью сказать, что прототип превратился в продукт, и это замечательный финал длинной трёхлетней истории шестандцатилетнего пацана, собравшего своими руками настоящее Software Defined Radio.
Справочные ссылки
Схематика FreeSRP
Исходники FPGA
Исходники USB Контроллера
Сайт проекта
|
Метки: author BAC51 разработка систем связи fpga sdr плис freesrp |
Наш рецепт отказоустойчивого Linux-роутера |
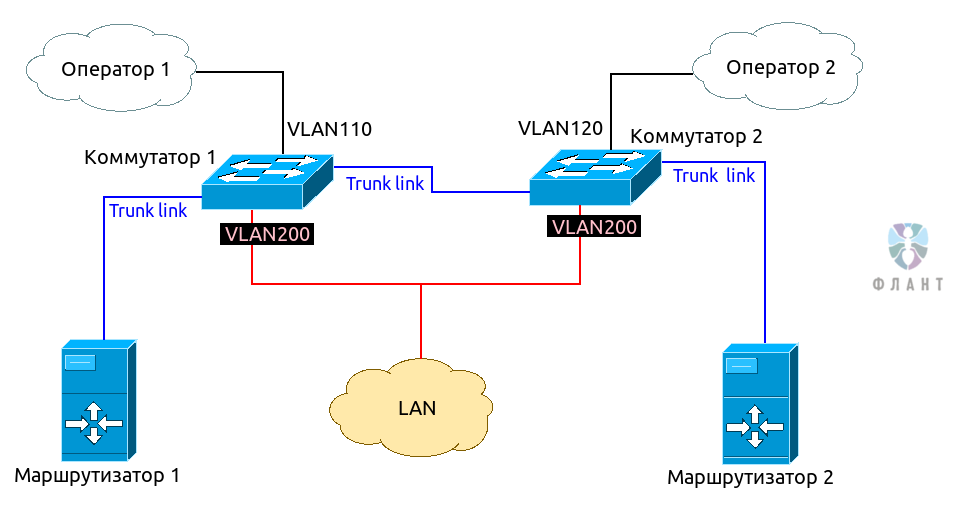
/etc/network/interfaces будет выглядеть примерно так:auto lo
iface lo inet loopback
post-up bash /etc/network/iprules.sh
post-up ip route add blackhole 192.168.0.0/16
dns-nameservers 127.0.0.1
dns-search dz
# lan, wan: trunk dot1q
auto eth0
iface eth0 inet manual
# lan
auto vlan200
iface vlan100 inet static
vlan_raw_device eth0
address 192.168.1.2
netmask 255.255.255.0
# Operator1
auto vlan110
iface vlan110 inet static
vlan_raw_device eth0
address 1.1.1.2
netmask 255.255.255.252
post-up ip route add default via 1.1.1.1 table oper1
post-up sysctl net.ipv4.conf.$IFACE.rp_filter=0
post-down ip route flush table oper1
# Operator2
auto vlan120
iface vlan120 inet static
vlan_raw_device eth0
address 2.2.2.2
netmask 255.255.255.252
post-up ip route add default via 2.2.2.1 table oper2
post-up sysctl net.ipv4.conf.$IFACE.rp_filter=0
post-down ip route flush table oper2
net.ipv4.conf.$IFACE.rp_filter=0 — необходим для корректной работы multi-wan;iptables -t mangle -A PREROUTING -i vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A PREROUTING -i vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A OUTPUT -o vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A OUTPUT -o vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iptables -t mangle -A OUTPUT -j CONNMARK --restore-mark --nfmask 0xffffffff --ctmask 0xffffffff
iptables -t mangle -A POSTROUTING -o vlan110 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x1/0x3
iptables -t mangle -A POSTROUTING -o vlan120 -m conntrack --ctstate NEW,RELATED -j CONNMARK --set-xmark 0x2/0x3
iprules.sh при выполнении ifup lo (смотри выше в /etc/network/interfaces). Внутри скрипта:#!/bin/bash
/sbin/ip rule flush
#operator 1
/sbin/ip rule add priority 8001 iif vlan110 lookup main
/sbin/ip rule add priority 10001 fwmark 0x1/0x3 lookup oper1
/sbin/ip rule add from 1.1.1.2 lookup oper1
#operator 2
/sbin/ip rule add priority 8002 iif vlan120 lookup main
/sbin/ip rule add priority 10002 fwmark 0x2/0x3 lookup operator2
/sbin/ip rule add from 2.2.2.2 lookup operator2
/etc/iproute2/rt_tables:# reserved values
255 local
254 main
253 default
0 unspec
# local
110 oper1
120 oper2
# Установим репозиторий
$ sudo wget https://apt.flant.ru/apt/flant.trusty.common.list -O /etc/apt/sources.list.d/flant.common.list
# Импортируем ключ
$ wget https://apt.flant.ru/apt/archive.key -O- | sudo apt-key add -
# Понадобится HTTPS-транспорт — установите его, если не сделали это раньше
$ sudo apt-get install apt-transport-https
# Обновим пакетную базу и установим netgwm
$ sudo apt-get update && sudo apt-get install netgwm/etc/netgwm/netgwm.yml, что у нас 2 оператора, маршруты по умолчанию для каждого из них, приоритезацию и настройки для контроля доступности:# Описываем маршруты по умолчанию для каждого оператора и приоритеты
# Меньшее значение (число) имеет больший приоритет
gateways:
oper1: {ip: 1.1.1.1, priority: 1}
oper2: {ip: 2.2.2.1, priority: 2}
# В ситуации, когда более приоритетного оператора начинает «штормить»
# и он то online, то offline, хочется избежать постоянных переключений
# туда-сюда. Этот параметр определяет время (в секундах), после которого
# netgwm будет считать, что связь стабильна
min_uptime: 900
# Массив удаленных хостов, которые будут использоваться netgwm для
# проверки работоспособности каждого оператора
check_sites:
- 192.5.5.241
- 198.41.0.4oper1 и oper2 — это названия таблиц маршрутизации из /etc/iproute2/ip_tables. Рестартнем сервис netgwm, чтобы он начал управлять шлюзом по умолчанию для системы:$ sudo service netgwm restart/etc/keepalived/keepalived.conf:! Глобальный блок можно настраивать под себя
! Configuration File for keepalived
global_defs {
notification_email {
admin@fromhabr.ru
}
notification_email_from keepalived@example.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MY_ROUTER
}
vrrp_instance VI_1 {
interface vlan200 # VRRP обслуживает VLAN локальной сети
virtual_router_id 17 # поставьте любое число, но одинаковое на Master и Backup
nopreempt # важный параметр, подробнее см. ниже
state MASTER # на резервном сервере установите state BACKUP
priority 200 # на резервном сервере число должно быть ниже, например 100
advert_int 1 # интервал рассылки сообщения “Я жив”
garp_master_delay 1
garp_master_refresh 60
authentication {
auth_type PASS
auth_pass qwerty # не забудьте поменять пароль
}
virtual_ipaddress {
# Виртуальный адрес, который будет шлюзом по умолчанию в локальной сети и
# заодно широковещательный адрес, в который будут рассылаться VRRP-анонсы
192.168.1.1/24 broadcast 192.168.1.255 dev vlan200
}
# Скрипты вызываются при переходе в соответствующее состояние Master, Backup, Fault и
# при остановке keepalived; используются нами для передачи уведомлений
notify_master /etc/keepalived/scripts/master.sh
notify_backup /etc/keepalived/scripts/backup.sh
notify_stop /etc/keepalived/scripts/stop.sh
notify_fault /etc/keepalived/scripts/fault.sh
}nopreempt. /etc/dhcp/dhcpd.conf:# Настраиваем DDNS для локальных адресов
ddns-updates on;
ddns-update-style interim;
do-forward-updates on;
update-static-leases on;
deny client-updates; # ignore, deny, allow
update-conflict-detection false;
update-optimization false;
key "update-key" {
algorithm hmac-md5;
secret "КЛЮЧ"; # про генерацию ключа см. ниже
};
zone 1.168.192.in-addr.arpa. {
primary 192.168.1.1;
key "update-key";
}
zone mynet. {
primary 192.168.1.1;
key "update-key";
# Настраиваем масштабирование
failover peer "failover-partner" {
primary; # на резервном сервере укажите здесь secondary
address 192.168.1.3; # адрес резервного сервера
port 519;
peer address 192.168.1.2; # адрес основного сервера
peer port 520;
max-response-delay 60;
max-unacked-updates 10;
load balance max seconds 3;
}
default-lease-time 2400;
max-lease-time 36000;
log-facility local7;
authoritative;
option ntp-servers 192.168.1.1, ru.pool.ntp.org;
# Настраиваем пул для нашего сервера
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.51 192.168.1.150; # на 100 адресов, например
option subnet-mask 255.255.255.0;
option broadcast-address 192.168.1.255;
option domain-name-servers 192.168.1.1;
option routers 192.168.1.1;
ddns-domainname "mynet.";
# … и пул для резервного. Они не должны пересекаться
pool {
failover peer "failover-partner";
range 192.168.1.151 192.168.1.250;
}
# … и статические leases
host printer { hardware ethernet 00:26:73:47:94:d8; fixed-address 192.168.1.8; }
}
update_key, с помощью которого мы будем обновлять зону mynet. Сгенерируем его и выведем на экран:$ dnssec-keygen -r /dev/urandom -a HMAC-MD5 -b 64 -n HOST secret_key
Ksecret_key.+157+64663
$ cat Ksecret_key.+*.private | grep ^Key | awk '{print $2}'
bdvkG1HcHCM=# Заходим в MySQL CLI
$ mysql -u root -p
# Создаем БД и назначаем права для пользователя, которым будем к ней подключаться
mysql> CREATE DATABASE IF NOT EXIST powerdns;
mysql> GRANT ALL ON powerdns.* TO 'pdns_admin'@'localhost' IDENTIFIED BY 'pdns_password';
mysql> GRANT ALL ON powerdns.* TO 'pdns_admin'@'localhost.localdomain' IDENTIFIED BY 'pdns_password';
mysql> FLUSH PRIVILEGES;
# Переходим в только что созданную БД и создаем структуру данных
mysql> USE powerdns;
mysql> CREATE TABLE IF NOT EXIST `domains` (
id INT auto_increment,
name VARCHAR(255) NOT NULL,
master VARCHAR(128) DEFAULT NULL,
last_check INT DEFAULT NULL,
type VARCHAR(6) NOT NULL,
notified_serial INT DEFAULT NULL,
account VARCHAR(40) DEFAULT NULL,
primary key (id)
);
mysql> CREATE TABLE `records` (
id INT auto_increment,
domain_id INT DEFAULT NULL,
name VARCHAR(255) DEFAULT NULL,
type VARCHAR(6) DEFAULT NULL,
content VARCHAR(255) DEFAULT NULL,
ttl INT DEFAULT NULL,
prio INT DEFAULT NULL,
change_date INT DEFAULT NULL,
primary key(id)
);
mysql> CREATE TABLE `supermasters` (
ip VARCHAR(25) NOT NULL,
nameserver VARCHAR(255) NOT NULL,
account VARCHAR(40) DEFAULT NULL
);
mysql> CREATE INDEX `domain_id` ON `records`(`domain_id`);
mysql> CREATE INDEX `rec_name_index` ON `records`(`name`);
mysql> CREATE INDEX `nametype_index` ON `records`(`name`,`type`);
mysql> CREATE UNIQUE INDEX name_index` ON `domains`(`name`);
quit;pdns-backend-mysql и изменить конфиг /etc/powerdns/pdns.conf:# Настраиваем доверенные сети
allow-axfr-ips=127.0.0.0/8,192.168.1.0/24
allow-dnsupdate-from=127.0.0.0/8,192.168.1.0/24
allow-recursion=127.0.0.0/8,192.168.1.0/24
# Базовые настройки демона
config-dir=/etc/powerdns
daemon=yes
disable-axfr=no
dnsupdate=yes
guardian=yes
local-address=0.0.0.0
local-address-nonexist-fail=no
local-port=53
local-ipv6=::1
# На втором маршрутизаторе такие же значения этих параметров
master=yes
slave=no
recursor=127.0.0.1:5353
setgid=pdns
setuid=pdns
socket-dir=/var/run
version-string=powerdns
webserver=no
# Настраиваем MySQL
launch=gmysql
# Хост с БД - тот самый, которым управляет keepalived
gmysql-host=192.168.1.1
gmysql-port=3306
# Имя и пароль пользователя, которого мы создавали в БД
gmysql-user=pdns_admin
gmysql-password=pdns_password
gmysql-dnssec=yes/etc/powerdns/recursor.conf:daemon=yes
forward-zones-file=/etc/powerdns/forward_zones
local-address=127.0.0.1
local-port=5353
quiet=yes
setgid=pdns
setuid=pdns
forward_zones вносим зоны intranet, которые обслуживают соседние серверы:piter_filial.local=192.168.2.1
2.168.192.in-addr.arpa=192.168.2.1pdns и pdns-recursor.|
|
Pygest #11. Релизы, статьи, интересные проекты из мира Python [6 июня 2017 — 19 июня 2017] |
 Всем привет! Это уже одиннадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python.
Всем привет! Это уже одиннадцатый выпуск дайджеста на Хабрахабр о новостях из мира Python. |
Метки: author andrewnester разработка веб-сайтов программирование машинное обучение python django digest pygest machine learning flask дайджест web |
О лицензиях Qt (и немного о компании) |
В предыдущей статье про Qt roadmap я обещал рассказать про Qt 3D Studio и текущую ситуацию с лицензиями. Qt 3D Studio уже было выпущено два (пока писал статью, вышел третий) внутренних релиза, но статьи про неё пока не будет, так что сегодня расскажу про лицензии.
Система лицензирования Qt и раньше не особо отличалась простотой, но сейчас она особенно усложнилась, так как добавились (и добавляются) новые продукты и вместе с ними дополнительные условия соответствующих лицензий. Официальный сайт не сильно помогает разобраться, хотя и содержит текст условий и соглашений.
Но речь пойдёт не сразу про лицензии, сначала я хочу рассказать немного о компании, чтобы было понятно, кто именно сейчас занимается разработкой/распространением фреймворка и вообще стоит за Qt.
Мне показалось важным начать с вводной части, потому что до сих пор есть “серые” места даже в таких простых вещах как правильное произношение (“кьют”) и написание ("Qt"). Что уж тут говорить, если и во внутренней переписке и звонках можно иногда услышать "ку-ти" и увидеть "QT" (от разработчиков — никогда).
Иногда на выставках задают вопросы вида: “Как, а вы ещё живы?” или “А разве Nokia не того?”. Да, компания вполне жива и не имеет ничего общего с Nokia уже несколько лет.
Вот вся история компании вкратце:
Вообще, в планах компании сейчас стоит цель достичь прибыли в 100 миллионов евро к 2021 году, потому сейчас идёт активный набор новых сотрудников, и помимо прочих вакансий особенно срочно нужен так называемый sales engineer в берлинский офис. Если кому-то интересно — напишите мне, я расскажу подробнее.
Говоря о Nokia, нельзя не упомянуть её вклад в распространение Qt — ведь именно Nokia сделала Qt доступным также и под лицензией LGPL. По понятным причинам, продажи лицензий её не интересовали — Nokia хотела “популяризировать” Qt, чтобы создавалось больше приложений для её мобильной платформы, а GPL этому очень мешала. И действительно, сразу же после этого начался взрывной рост сообщества Qt, так что спасибо Nokia за это. Но есть и обратная сторона: продавать ПО, лицензируемое одновременно под LGPL и коммерческой лицензией — это довольно непростая задача, так что в этом смысле LGPL-наследие Nokia "fucked up sales big time" (не буду переводить), как сказал сотрудник отдела продаж, пожелавший остаться неизвестным.
Что хочу отметить особо — при всех произошедших сменах владельцев разработчики Qt оставались те же (насколько это возможно за более чем 20 лет). Некоторые, включая нынешнего chief technology officer (CTO) Lars Knoll, работают в Qt и сегодня, а начинали ещё во времена Trolltech.
Вот вкратце об истории всё. Кстати, если будет интересно, расскажу, почему домен — qt.io, а не qt.com (спойлер: киберсквоттинг).
The Qt Company — международная компания с офисами в нескольких странах:

И хотя юридически главный офис сейчас находится в Финляндии, исторически самый большой офис — в Осло (Норвегия). В нём же сидит большинство разработчиков (и CTO).
Российское же представительство The Qt Company одно из самых маленьких (если не самое) — на всю страну только один небольшой офис в Санкт-Петербурге. Кстати говоря, после определённых событий питерский офис однажды получил такое письмо:
В связи с войной между [...] и Россией, для меня в настоящее время неприемлемо общение с российским офисом компании. Пожалуйста, переадресуйте мой запрос в какой-либо европейский или американский офис The Qt Company.В общем, наличие офисов в разных странах иногда пригождается довольно неожиданным образом.
Новые релизы выходят обычно два раза в год, но иногда даты съезжают и в каком-то году может оказаться всего один релиз, зато в другом — три.
Если рассмотреть сроки поддержки релизов, то пока ещё действует “старая” система, по которой минимальный поддерживаемый релиз — 5.4.
По новой же системе начиная с Qt 5.6 релизы теперь будут делиться на обычные и LTS (long-term support):
Таким образом, текущие поддерживаемые (сопровождаемые) версии:
Сопровождение включает в себя выпуск корректирующих релизов (x.x.1, x.x.2 и т.д.) а также техническую поддержку. Не следует путать техническую поддержку с баг-фиксами: корректирующие релизы и баг-фиксы, разумеется, доступны для всех, но техническая поддержка предоставляется только обладателям коммерческой лицензии (об этом будет ниже).
Пример с прекращением сопровождения релиза: если вы используете Qt 5.3 и по тем или иным причинам не можете/хотите обновляться до актуальной 5.9, то вы можете продолжать разработку с Qt 5.3 и выпускать свои продукты — но не ожидайте никаких обновлений/исправлений для этой версии. Даже если у вас есть доступ к тех.поддержке — обращаться с вопросами по Qt 5.3 вы не сможете, стандартная поддержка этого релиза также закончилась. Но если вам очень нужно, то есть возможность приобрести расширенную (extended) поддержку для устаревших версий, и тогда сопровождение этой версии будет возобновлено специально для вас.
Qt всегда был доступен под “двойной” (dual-license) лицензией: Open Source и коммерческой. С коммерческой всё понятно: компании нужны деньги, чтобы платить сотрудникам и развивать фреймворк. Но зачем делать свой продукт доступным под лицензиями Open Source?

На графике показан вклад сторонних компаний в разработку Qt. Нетрудно видеть, что хотя вклад The Qt Company и самый большой, немалая часть разработки ведётся силами Open Source сообщества. А в некоторых модулях вклад сторонних разработчиков даже больше — к примеру, появление Qt 3D является заслугой сервисной компании KDAB.
Поэтому важно, чтобы Qt был и оставался быть доступным не только под коммерческой лицензией, но и под Open Source. Далее ещё будет отдельно про KDE Free Qt Foundation.
Положительную роль играет и такая сторона Open Source — допустим, некоторая компания Chamomile решает использовать Qt в разработке своего нового продукта. Выделяются ресурсы, и разработка ведётся в течение какого-то времени. Затем компания Macrohard неожиданно покупает The Qt Company и, по своему обыкновению, уничтожает её (и продукт). Что это означает для компании Chamomile — проект обречён, все ресурсы потрачены впустую, ведь разработка Qt прекратилась? Нет — его исходники доступны, и разработка будет продолжаться независимо от существования того или иного юридического лица. Конечно, повисает вопрос с лицензиями, но самое главное — Qt как технология останется жив и будет продолжать развиваться.
При всём вышесказанном, неподготовленные сотрудники отдела продаж на ситуацию с Open Source смотрят с плохо скрываемым ужасом. Для них это означает только одно — мы раздаём наш продукт бесплатно! Точно так же на бизнес-модель The Qt Company смотрят и люди со стороны. Но на самом деле всё не так просто, и далее в статье я надеюсь это объяснить.
Для дальнейшего разбирательства с лицензиями (отличиями между ними) нужно рассказать о продуктах. Разные продукты имеют разные условия лицензирования (и разную стоимость).
Сейчас список продуктов такой:
Эти три продукта можно представить так:

То есть, с технической точки зрения последующий продукт включает в себя предыдущий и добавляет новые компоненты и инструменты.
Однако кроме технической есть и юридическая составляющая. Например, вы создаёте кофемашину и используете Qt в разработке ПО для неё. По условиям лицензии Qt for Application Development вы не можете распространять/продавать ваши кофемашины — для этого вы должны обладать лицензией Qt for Device Creation, потому как именно она лицензирует такое использование Qt (распространение в составе “устройства”, подробности чуть ниже.
Через некоторое время ожидается появление новых продуктов. Скорее всего, они тоже будут базироваться на Qt for Device Creation и расширять его дополнительным функционалом (и условиями лицензирования), специфичным для определённых индустрий (например, ТВ-приставки, медицина и т.п.).
Есть ещё один, обособленный продукт — лицензия на создание SDK на основе Qt. Этот пакет существует на случай если кто-то захочет взять Qt, внести в него свои изменения (добавить в состав новые библиотеки, расширить Qt Creator дополнительными плагинами, ещё что-то) и распространять/продавать как свой продукт на своих условиях (виртуальный оператор сотовой связи, как аналогия). Такой вариант лицензирования встречается очень редко (и стоит очень дорого).
Вероятно, пример с кофемашиной вызвал некоторое недоумение, а может и возмущение, потому хочу рассказать о “юридических“ отличиях между продуктами Qt for Application Development и Qt for Device Creation подробнее.
Qt for Application Development предназначен для разработки приложений на десктопах и мобильных платформах, где такое приложение будет лишь одним из множества других, использующихся в системе. Примеры: Telegram, VLC, VirtualBox и другие — то есть “обычные” приложения, которые могут быть установлены на любой компьютер (смартфон, планшет) или размещены в магазине приложений (App Store, Google Play, Windows Store). Условия этой лицензии покрывают следующие операционные системы: Windows, Linux, Mac OS, iOS, Android, Windows Phone — все они уже включены в стоимость лицензии (выкинуть “ненужные” нельзя).
Qt for Device Creation предназначен для создания “устройств”, когда продукт — это не просто приложение, но комбинация софта и железа, то есть приложение разрабатывается для конкретного устройства, и конечный продукт будет распространяться/продаваться именно в таком виде — устройство и предустановленное (или устанавливаемое позже) на него ПО, без которого устройство просто “не будет работать”. Это может быть графический интерфейс пользователя либо другая существенная функциональность устройства, реализованная с использованием Qt. Условия этой лицензии покрывают только одну операционную систему из списка: Embedded Linux (в общем-то, тот же Линукс, но на embedded платформе), Embedded Windows (UWP, WinRT, Windows EC/WinCE), QNX, VxWorks, INTEGRITY — в стоимость лицензии включена только одна из них, и каждая дополнительная ОС добавляется за дополнительную плату (со скидкой за каждую последующую). Кроме того, есть ещё так называемая “лицензия на распространение” — об этом будет далее.
На всякий случай хочу пояснить, что лицензирование ОС затрагивает только “конечную” (deployment) ОС. Разработку же можно вести в любой ОС, какая нравится (Windows, Linux, Mac OS).
Некоторое проекты могут требовать наличия лицензии Qt for Device Creation даже несмотря на то, что “устройство” представляет собой обычный настольный компьютер на Windows. Например, это может быть рабочая станция на каком-то заводе, на которой работает некоторое приложение для мониторинга каких-нибудь датчиков — и это единственное предназначение этой рабочей станции. С технической точки зрения здесь нет никакой нужды в компонентах из состава Qt for Device Creation (Boot to Qt, виртуальная клавиатура, эмулятор и т.д.), но юридически — это “устройство”, а значит требуется именно эта лицензия. Определение "устройства" дано в условиях и соглашениях.
Может быть и такая ситуация: у некоторой компании два разных проекта: медиа-плеер под Windows и погодная станция на Raspberry Pi и Linux. В этом случае ей нужно приобрести обе лицензии — так называемую “комбо-лицензию”: Qt for Application Development плюс Qt for Device Creation (стоит дешевле этих двух по отдельности). Опять же, с технической точки зрения вполне себе можно работать над проектом медиа-плеера используя версию Qt for Device Creation (ведь она содержит все библиотеки из Qt for Application Development), но “юридически” по условиям лицензии это не разрешается.
Для работы над проектом с использованием Qt каждый разработчик должен обладать лицензией. Она именная и привязывается к e-mail адресу (Qt Account). Несмотря на такую привязку, на самом деле лицензия принадлежит вашей компании, и потому когда разработчик с лицензией, например, уволится, вы сможете “переназначить” его лицензию на другого. Однако, это не означает, что у вас в руках “плавающая” лицензия, которую можно переключать между сотрудниками по несколько раз в день — переназначение лицензии регулируется The Qt Company.
Если команда большая, то есть возможность приобрести “массовую” (site license) лицензию на всю компанию, которая не будет зависеть от реального количества разработчиков и, соответственно, обойдётся дешевле.
Свою лицензию каждый разработчик может использовать на неограниченном количестве рабочих станций и операционных систем, при условии что пользоваться ими будет исключительно он. Пример: на работе у меня стоит десктоп с Windows 10 и ноутбук с Ubuntu, а дома я использую Mac — можно установить Qt на все три машины и спокойно работать над проектом на любой из них.
Часто задают вопрос про сервера сборки, нужна ли им отдельная лицензия? Нет, лицензия требуется только для “живых” разработчиков, которые работают с Qt (“touching the Qt code”).
Вообще, лицензии для разработчиков являются пожизненными (perpetual), но Qt for Application Development имеет опцию приобретения лицензии по подписке (subscription) (в том числе и “инди”-лицензия для стартапов). Такая лицензия оплачивается за каждый месяц использования.
Подписочная модель имела смысл для краткосрочных проектов, когда разработка длится, скажем, пару месяцев, после чего вы только распространяете своё приложение. Как только требуется возобновить разработку, выпустить новую версию приложения — вы оплачиваете новый месяц, осуществляете задуманное и опять останавливали подписку. Почему я "имела смысл"? Потому что какая-то светлая голова из менеджмента придумала сделать так, что с недавних пор (где-то с полгода назад) действующая подписка стала требоваться не только на период разработки, но и на распространение приложения. То есть теперь, если ваша подписка неактивна, то вы не можете не только заниматься разработкой, но и распространять/продавать своё уже готовое приложение.
Кстати, почему на сайте указана цена на подписку, но нигде нет цены на пожизненную? Руководство решило, что всю важную информацию в паре абзацев на сайте не уместить, и потому желающие приобрести коммерческую лицензию должны связаться с отделом продаж, который сначала объяснит систему лицензирования применимо к конкретному проекту, и только после этого объявит стоимость и условия соответствующей лицензии.
Qt for Device Creation (и все производные продукты, начиная с Automotive Suite) помимо лицензий для разработчиков имеет вторую составляющую — “лицензии на распространение” (distribution licenses или runtimes (не самый удачный термин)). То есть, компания-разработчик, распространяющая/продающая “устройства” с Qt внутри (ПО, разработанное с использованием Qt), должна пробрести эти самые рантаймы по числу распространяемых устройств. Например, пусть та же контора Chamomile продаёт 20 000 кофемашин в год, значит она должна приобрести “рантаймы” для как минимум 20 000 устройств (или сразу 100 000, чтобы на пять лет). Чем больше объём, тем меньше стоимость рантайма за одно устройство (и наоборот).
Более того, существует минимальный порог числа рантаймов — вы должны купить как минимум 5 000 рантаймов независимо от вашего реального плана поставок. Но некоторые компании (и необязательно стартапы) просто не нуждаются в таких объёмах — скажем, производитель МРТ-сканеров продаст от силы 500 сканеров за 10 лет, что ему делать с остальными 4 500 рантаймами? В общем, довольно странное требование (но к счастью не такое "жёсткое").
Лицензия для разработчика включает в свою стоимость один год технической поддержки и "получения"" новых версий Qt. Через год у вас есть выбор, “продлить” (renew) поддержку и обновления или нет. Если не продлевать, то вы по-прежнему можете вести разработку (лицензия же “пожизненная”) с последней версией Qt, которая была выпущена в течение этого года, но вы больше не можете обращаться в техническую поддержку а также использовать более новые версии Qt.
У лицензий на распространение (рантаймов) срока действия нет. Вы можете использовать их хоть пять лет, хоть пятьдесят — до тех пор, пока не исчерпаете приобретённый объём. Например, вы приобрели 10 000 рантаймов, и ежегодно вы выпускаете 1 000 единиц вашего продукта (кофемашин) — это означает, что новый пакет рантаймов вам понадобится только через 10 лет.
Чтобы не покупать кота в мешке, можно запросить “триальную” (evaluation) версию Qt. Это ознакомительный дистрибутив, ограниченный по времени (действует 30 дней) и который содержит все коммерческие компоненты, то есть вы можете собственноручно пощупать образы Boot to Qt, попробовать удалённую отладку и профилирование на устройстве, замерить эффект от использования Qt Quick Compiler, оценить удобство Qt Configuration Tool для Qt Lite и прочее. Также в течение этих 30 дней у вас будет доступ к специалистам тех.поддержки.
Триал доступен как для Qt for Application Development, так и для Qt for Device Creation. Что касается Automotive Suite, то этот продукт ориентирован на “крупных игроков” уровня BMW, Volvo и прочих, потому его заполучить будет не так просто.
Для получения ознакомительной версии нужно связаться с отделом продаж.
Одним из важных (а для некоторых — ключевым) отличием коммерческой лицензии от Open Source является наличие технической поддержки.
С Open Source версией вы можете либо бороться с проблемами самостоятельно, либо полагаться на Stack Overflow, форумы, IRC-каналы и т.д. Помогут вам или нет (а также насколько быстро) зависит исключительно от уровня альтруизма участников.
При наличии же технической поддержки вы можете использовать систему тикетов в вашем Qt Account. Вы получаете гарантированное время ответа (48 часов) и доступ к специалистам Qt. Можно даже выйти на разработчика той или иной библиотеки напрямую. Нет никакой “первой линии” с “маринками”, вы общаетесь сразу с техническими специалистами. Задавать можно любые вопросы, даже если они вам кажутся глупыми и "нубскими", без ограничения на их количество. Хотя если у вас всего одна лицензия, но при этом от вас поступают сотни тикетов в день — это вызовет определённые встречные вопросы.
Кроме тех.поддержки, ваши баг-репорты и фича-реквесты получают повышенный приоритет (и помечаются внутренним маркером “коммерческий клиент”).
Также есть возможность приобрести премиум поддержку: выделенный специально для вас специалист, время ответа снижается до 24 часов, ещё больший приоритет для баг-репортов и реквестов, не нужно предоставлять минимальный пример проекта для воспроизведения бага и даже возможность удалённого подключения.
Если и премиум поддержки недостаточно, то The Qt Company также оказывает сервисные (consultancy) услуги. Это вебинары/тренинги в офисе (обучение по стандартным программам или по вашему списку интересующих тем), семинары/воркшопы (анализ архитектуры вашего проекта, оптимизация производительности), изготовление proof-of-concept, срочная реализация фича-реквестов, а также просто аутсорс разработки.
Open Source пользователи тоже могут заказать сервисные услуги у The Qt Company. Однако для них этого будет стоить дороже, чем для обладателей коммерческой лицензии.
Ну и наконец про Open Source лицензии.
Текущая Open Source версия Qt доступна под условиями и ограничениями GPLv3 или LGPLv3. До Qt 5.7 это были GPLv2.1 и LGPLv2.1.
LGPL является менее “строгой” лицензией по сравнению с GPL, и в подавляющем большинстве компании, решившие пойти путём Open Source, выбирают именно её. Однако, кроме более “мягких” требований LGPL отличается от GPL тем, что не все компоненты Qt доступны под LGPL — например, Qt Charts, Qt Data Visualization и Qt Virtual Keyboard доступны только под GPL, то есть вы не можете использовать их в LGPL-проекте.
Другой момент, которому далеко не все придают должное значение, это необходимость соответствия полному тексту лицензии, то есть выполнение всех требований и соблюдение всех ограничений соответствующей лицензии (GPL/LGPL). Например, очень сильно распространено заблуждение, что достаточно линковать Qt динамически и на этом все требования LGPL будут выполнены — на самом же деле это всего лишь одно из многих (да и то не полностью, если не ошибаюсь).
Вообще, лицензии Open Source не принадлежат The Qt Company, потому она не может предоставить чёткий список требований и ограничений GPL/LGPL по пунктам — это личная ответственность каждой компании, которая хотела бы использовать Qt под той или иной лицензией Open Source. Если юристы компании, изучив текст соответствующей лицензии, выносят вердикт, что продукт компании соответствует требованиям лицензии — это их решение и их ответственность. Потому, если какая-то компания-разработчик заявляет, что им коммерческая лицензия не нужна, и они будут использовать Qt под LGPL, так как полностью ей соответствуют — мы даже не спорим. Может, они и правда соответствуют. Мы не юридическая фирма, и потому не можем консультировать по вопросам использования СПО. The Qt Company отвечает только за свою коммерческую лицензию. Выполнение требований лицензий Open Source регулируется не нами.
Пока что я почти не видел сколько-нибудь крупной компании, которая выбрала бы Qt под Open Source лицензией для своего коммерческого проекта. Если говорить, например, о Германии, то там отдел продаж вообще работает в режиме “алло — сколько, вы говорите, нужно лицензий — отправляю договор”. Мало кто хочет рисковать своим бизнесом, когда текст лицензий попросту не совершенен (переход с GPL/LGPLv2.1 на v3 из-за тивоизации, нечёткое определение “consumer product” и прочие “серые” места), а также когда судебные процессы в этой сфере выдают непредсказуемый результат (GPL внезапно рассматривается как договор).
Я представляю, да, в реалиях какой страны я тут расписываю за Open Source лицензии и их требования. Далеко не отходя за примерами — первые мои работодатели в России, где я начинал как раз-таки разработчиком C++/Qt, имели весьма слабое представление о каких-то там лицензиях-шмицензиях. Вот же страница загрузки, вот ссылка на установщик — всё ставится, ничего не просит, платить не надо, Далее — Далее — Принять — Далее — Готово, можно работать.
Кроме России таким же подходом к лицензиям Open Source отличаются Индия и некоторые страны юга Европы (Италия и Испания, например). Компаниям из этих регионов в подавляющем большинстве случаев бесполезно рассказывать про условия и ограничения Open Source лицензий — тебя выслушают, кивая головой, а в конце всё равно спросят про разницу в компонентах. Потому что это единственное, что для них важно — что есть в коммерческой версии, и чего нет в Open Source. Ну, я сам был таким, потому не могу осуждать. Однако, в других странах к вопросу лицензирования ПО относятся смертельно серьёзно.
А ещё вот кстати: одной из метрик анализа данных о посетителях сайта с недавних пор является количество загрузок Open Source версии. То есть, если в каком-то регионе активно грузят “свободный” Qt, то в глазах менеджмента этот регион является очень перспективным, и значит надо усилить в нём присутствие, потому что скоро начнут расти продажи коммерческих лицензий. Лишним будет говорить, что по числу загрузок лидируют Россия, Индия ну и далее по списку. Я пытался объяснять руководству, что цифры эти означают нечто совсем другое, но мне, скажем так, не совсем поверили. Для них это реально невообразимая ситуация — что кто-то может игнорировать текст лицензионного соглашения.
По условиям лицензионного соглашения нельзя смешивать коммерческий и Open Source код. К примеру, нельзя иметь одного разработчика с коммерческой лицензией и десять разработчиков с LGPL, и чтобы все они работали над одним проектом или использовали общие компоненты.
Также иногда встречаются ситуации, когда та или иная компания пару лет вела разработку своего проекта под Open Source лицензией, а перед релизом продукта “вдруг” узнала об её ограничениях и захотела приобрести коммерческую лицензию. Вообще, такое не допускается, лицензия должна выбираться на старте проекта, до начала разработки, и если вы взяли Open Source, то и распространение должно осуществляться в соответствии с требованиями GPL/LGPL. Но если такое всё-таки случилось не “вдруг”, а действительно по незнанию — свяжитесь с The Qt Company и опишите ситуацию.
Различия в доступных компонентах есть не только между коммерческой и Open Source версией Qt, но также и между GPL и LGPL (какие-то компоненты доступны только в GPL).
Вот тут надо сказать о KDE Free Qt Foundation. В 1998 году между сообществом KDE и тогда ещё Trolltech было заключено соглашение, что Qt всегда будет доступен как свободное ПО, и это соглашение соблюдалось и соответствующе обновлялось при смене владельцев Qt. Но относительно недавно условия соглашения были, скажем так, нарушены — в составе Qt появился ряд библиотек, которые были доступны только под коммерческой лицензией — это как раз-таки Qt Charts, Qt Data Visualization, Qt Virtual Keyboard и другие. В общем, отношения начали слегка портиться. К счастью, руководство всё-таки приняло решение сделать эти библиотеки доступными и в Open Source, что и произошло в релизе Qt 5.7 — они стали доступны под GPL.
Но кстати говоря, разрыв между GPL и LGPL в этом плане в дальнейшем будет только увеличиваться — новые фичи будут лицензироваться преимущественно под GPL (и коммерческой лицензией, конечно).
Кроме разницы в доступных компонентах отдельного внимания заслуживает техническая поддержка, которая, как уже говорилось, доступна только с коммерческой лицензией, а также необходимость (или её отсутствие) соблюдать требования и ограничения соответствующей Open Source лицензии.
И всё же, если ставить вопрос ребром, что доступно в какой лицензий, и в какой чего наоборот не хватает, то для начала можно ознакомиться с таблицей сравнения на сайте, но её актуальность оставляет желать: там содержится не полный перечень отличий, а некоторые пункты и вовсе просто повторяются, предлагая одно и то же разными словами. В общем, я попытался создать более подробную таблицу. Хотя не исключено, что и моя тоже окажется неполной — в фреймворк входит слишком много компонентов (положительный такой минус).

Возможности разметки таблиц небогаты, потому пришлось картинкой. Ссылки на компоненты, понятное дело, теперь в виде пикселей.
И несколько комментариев по таблице.
За Open Source лицензии не нужно платить в явном виде, однако следует понимать, что некоторые расходы всё-таки последуют, пусть они и неочевидны на первый взгляд:

Те самые компоненты, которые раньше были доступны только в коммерческой лицензии. Начиная с Qt 5.7 они доступны и под GPL (но по-прежнему недоступны под LGPL).
Qt Quick Compiler был (и остаётся) доступным только в коммерческой версии Qt. Его обещали отдать в Open Source с релизом 5.7, потом 5.8, потом 5.9, а сейчас вроде как больше не обещают, только предложили “взамен” механизм кэширования (который всё же не то же самое).
Этот модуль был раньше только коммерческий, потом стал доступен и в GPL, а после релиза 5.8 перестал быть отдельным модулем, и теперь интегрирован в Qt Quick и доступен также под LGPL.
Готовые "из коробки" наборы инструментов сборки для кросс-компиляции, отладки, деплоя и профилирования с хост-машины на присоединённом устройстве.
На скриншоте ниже показано меню выбора “таргета” для проекта в Qt Creator — под какую платформу компилировать (кросс-компилировать) и где запустить приложение. Конкретно тут я собираю проект под Raspberry Pi 3 и хочу запустить своё приложение на подключённом по сети устройстве:

А на этом скриншоте показан полный список устройств, для которых "из коробки" имеются готовые образы и инструменты сборки:

Разумеется, это не означает, что больше ни на каких устройствах разработку с Qt вести не получится. Свой образ Boot to Qt можно собрать для любой платформы, которая соответствует требованиям.
Существует также проект "образовательной" лицензии для преподавателей и студентов университетов. Подразумевается, что она будет бесплатной.
В состав такого дистрибутива входят не только Open Source компоненты, но и коммерческие тоже. Также предоставляется ограниченный доступ к тех.поддержке (пониженный приоритет, нет фиксированного времени ответа и т.д.) и некоторые обучающие материалы. Однако, следует ожидать ограничений в условиях использования.
Проект "образовательной" лицензии всё ещё в пилотном режиме, потому особо не афишируется. Я тоже в этом обзоре не стал её включать в общую лицензионную структуру. Как станет известно больше — добавлю новую информацию.
Глядя на весь этот километр текста, думаю, стоит показать лицензионную структуру Qt в виде картинки:

Иногда задают вопрос: “Каковы условия использования Qt без лицензии?”. Ответ содержится на картинке: нет таких условий — невозможно использовать Qt без лицензии. Вы либо приобретаете коммерческую лицензию, либо используете Qt под условиями соответствующей Open Source лицензии (GPL/LGPL).
После приобретения коммерческой лицензии ваше общение с The Qt Company не прекращается. Кроме продления лицензии, приобретения рантаймов, общения с технической поддержкой, заказом сервисных услуг, обучения и запросов новых фич, есть ещё два вида взаимодействия.
Первое — это маркетинговое сотрудничество. Например, у вас классный продукт, вы выходите на рынок и потому заинтересованы в продвижении. The Qt Company, разумеется, тоже заинтересована, чтобы появлялось больше классных продуктов на Qt, и была бы рада объявлять о новых у себя на сайте. На этой взаимовыгодной почве и пополняется галерея Built with Qt. Если же продвижение вам не сильно интересно, зато хотелось бы получить скидку на лицензии — это тоже возможно.
Второе — это compliancy check. Что-то вроде проверки соблюдения условий лицензии. Время от времени The Qt Company может (по условиям договора) проводить такие проверки, и если будут выявлены нарушения, то это чревато последствиями. Пример: вы описали свой проект как “просто приложение под винду” и приобрели Qt for Application Development, а на самом деле у вас хаб для “умного дома” на Windows 10 IoT, поставляемый на рынок в количестве нескольких тысяч устройств ежегодно — это весьма грубое нарушение. Или другой пример: компания заявляет, что в команде проекта будет всего один разработчик, но при этом в LinkedIn от имени этой же компании висит штук десять объявлений поиска программистов Qt — как-то не сходятся цифры.
Надеюсь, теперь система лицензий Qt стала немного понятнее. Если хотите, чтобы я рассказал о чём-то подробнее (например, таки перечислил хотя бы основные ограничения GPL/LGPL), напишите в комментариях — я дополню статью.
|
Метки: author abagnale qt open source licensing |
Сравнение систем мониторинга серверов. Заменяем munin на… |
server {
listen 80;
server_name munin.myserver.ru;
root /var/cache/munin/www;
index index.html;
}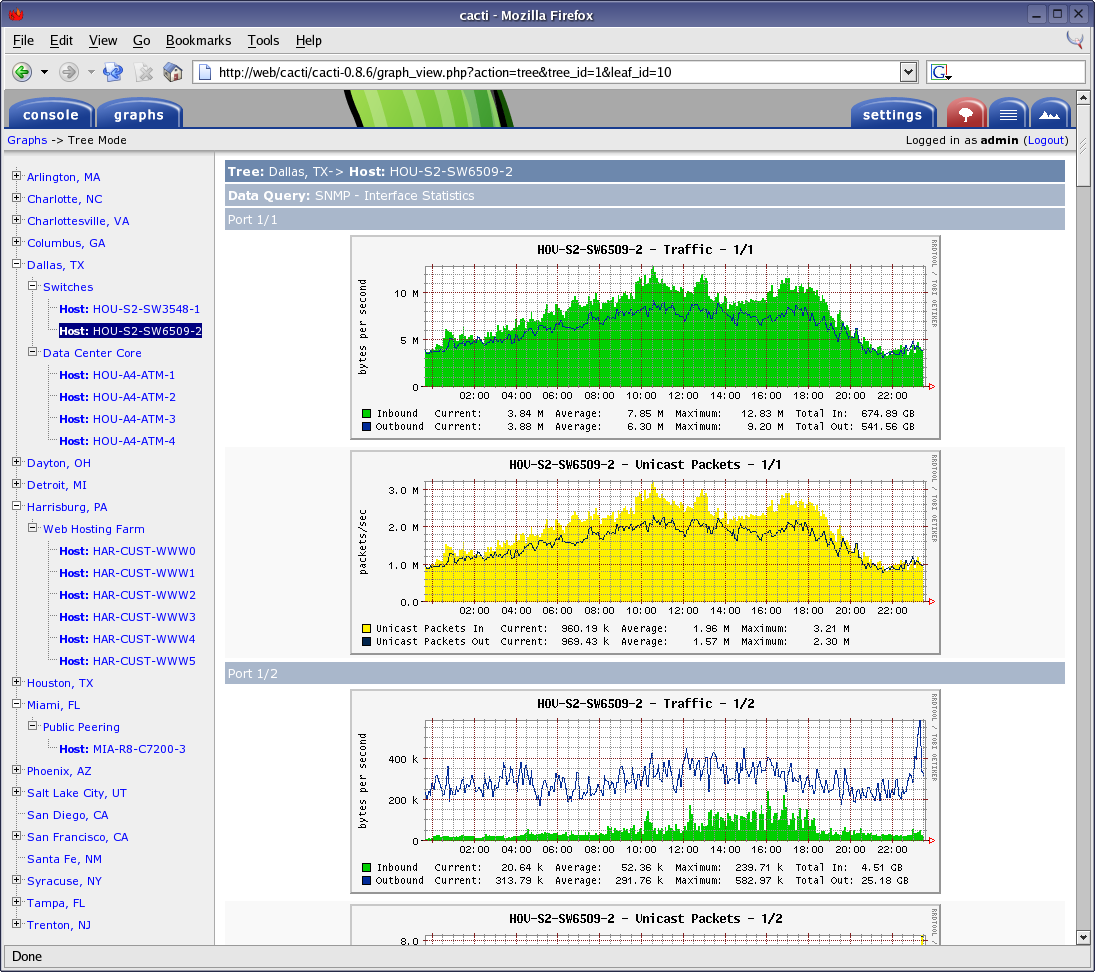


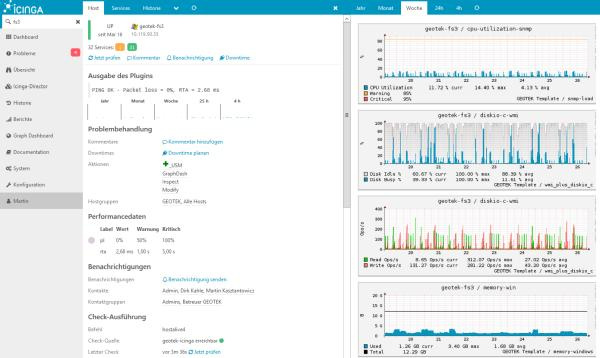
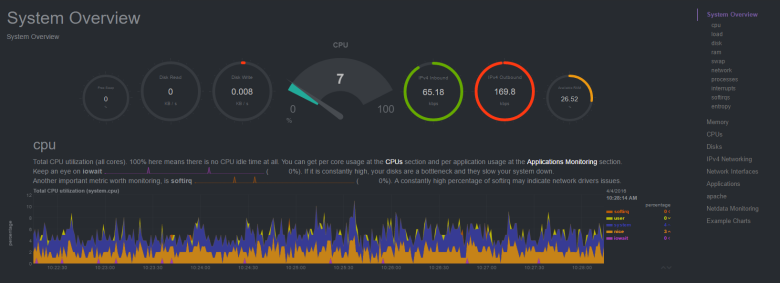
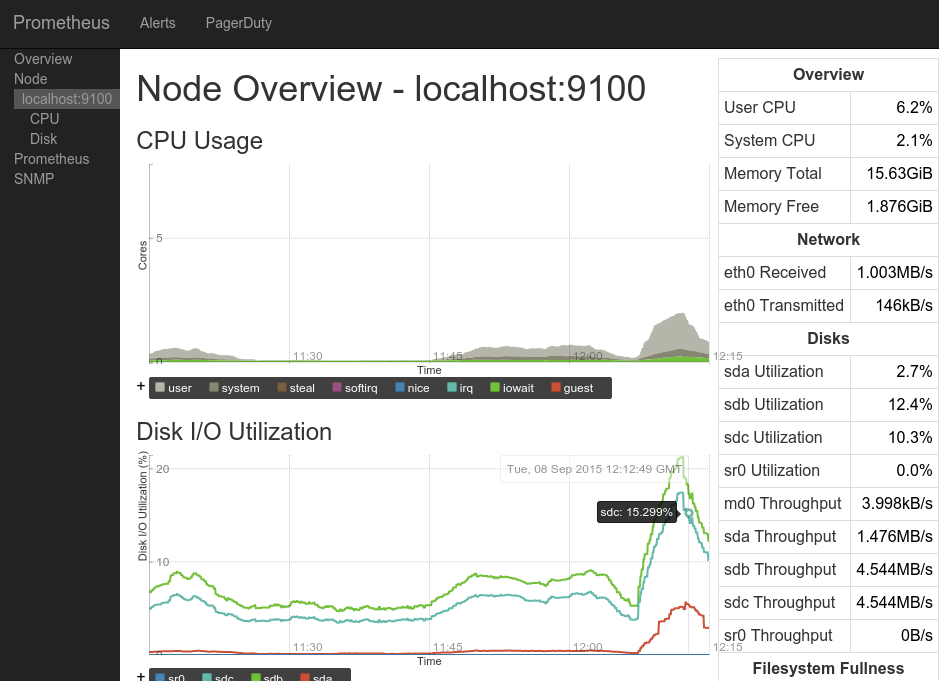
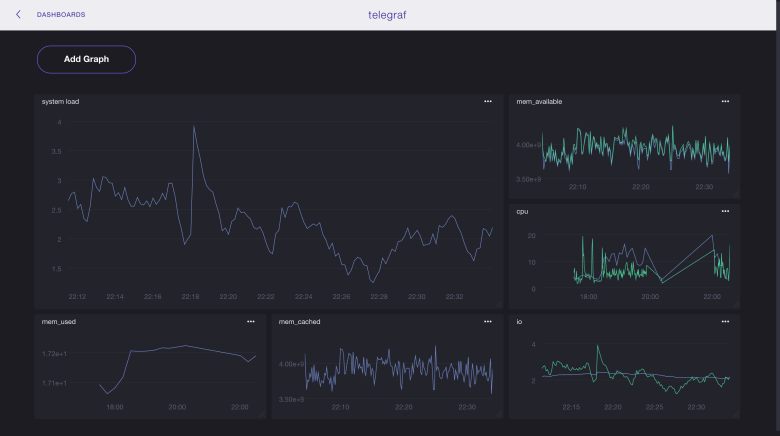
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.2.2.x86_64.rpm && yum localinstall influxdb-1.2.2.x86_64.rpm #centos
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.2.4_amd64.deb && dpkg -i influxdb_1.2.4_amd64.deb #ubuntu
systemctl start influxdb
systemctl enable influxdbhttp://localhost:8086/query?q=select+*+from+telegraf..cpuwget https://dl.influxdata.com/telegraf/releases/telegraf-1.2.1.x86_64.rpm && yum -y localinstall telegraf-1.2.1.x86_64.rpm #centos
wget https://dl.influxdata.com/telegraf/releases/telegraf_1.3.2-1_amd64.deb && dpkg -i telegraf_1.3.2-1_amd64.deb #ubuntu
#в случае установки на сервер отличный от того где находится influxdb необходимо в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] поменять параметр urls = ["http://localhost:8086"]:
sed -i 's| urls = ["http://localhost:8086"]| urls = ["http://myserver.ru:8086"]|g' /etc/telegraf/telegraf.conf
systemctl start telegraf
systemctl enable telegrafyum install https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.3.2-1.x86_64.rpm #centos
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.3.2_amd64.deb && dpkg -i grafana_4.3.2_amd64.deb #ubuntu
systemctl start grafana-server
systemctl enable grafana-server
http://myserver.ru:3000. Логин: admin, пароль: admin.#Создаём базу и пользователей:
influx -execute 'CREATE DATABASE telegraf'
influx -execute 'CREATE USER admin WITH PASSWORD "password_for_admin" WITH ALL PRIVILEGES'
influx -execute 'CREATE USER telegraf WITH PASSWORD "password_for_telegraf"'
influx -execute 'CREATE USER grafana WITH PASSWORD "password_for_grafana"'
influx -execute 'GRANT WRITE ON "telegraf" TO "telegraf"' #чтобы telegraf мог писать метрики в бд
influx -execute 'GRANT READ ON "telegraf" TO "grafana"' #чтобы grafana могла читать метрики из бд
#в конфиге /etc/influxdb/influxdb.conf в секции [http] меняем параметр auth-enabled для включения авторизации:
sed -i 's| # auth-enabled = false| auth-enabled = true|g' /etc/influxdb/influxdb.conf
systemctl restart influxdb#в конфиге /etc/telegraf/telegraf.conf в секции [[outputs.influxdb]] меняем пароль на созданный в предыдущем пункте:
sed -i 's| # password = "metricsmetricsmetricsmetrics"| password = "password_for_telegraf"|g' /etc/telegraf/telegraf.conf
systemctl restart telegrafAdmin -> profile -> change passwordТолько зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author morozovsk серверное администрирование настройка linux devops munin grafana influxdb telegraf tick influxdata rrdtool tig |
Нечеткий поиск по названиям |
|
Метки: author RussianDragon программирование алгоритмы c# алгоритмы поиска анализ данных |






