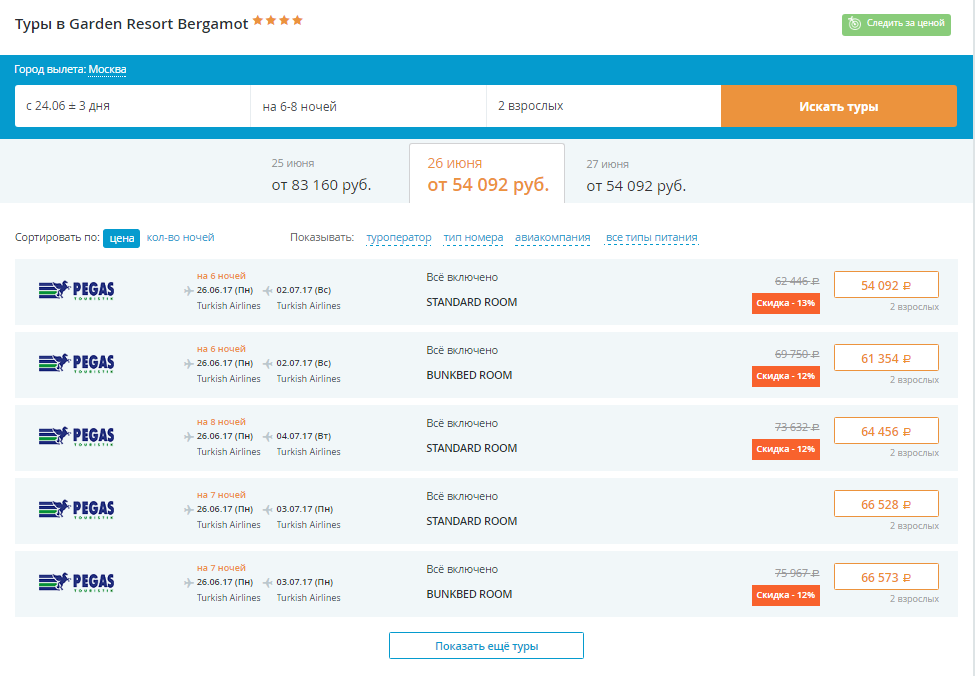
Гумано-ориентированное программирование. Часть первая |
DISKPART> create partition /?
Microsoft DiskPart, версия 10.0.14393.0
EFI - Создание системного раздела EFI.
EXTENDED - Создание расширенного раздела.
LOGICAL - Создать логический диск.
MSR - Создание резервного раздела Майкрософт.
PRIMARY - Создание основного раздела.
DISKPART> create partition logical /?
Для этой команды указаны недопустимые аргументы.
Чтобы получить дополнительные сведения о данной команде, введите HELP CREATE PARTITION LOGICALcd c:\ && dir /b/s | findstr "\.docx$" > list.txt && list.txt|
Метки: author stranger777 учебный процесс в it человек |
Ищу команду для создания простой игры с целью изучения Unreal Engine 4 |

|
Метки: author norlin разработка игр хобби unreal engine 4 ue4 c++ никто не читает теги обучение |
Повседневный C++: изолируем API в стиле C |
Мы все ценим C++ за лёгкую интеграцию с кодом на C. И всё же, это два разных языка.
Наследие C — одна из самых тяжких нош для современного C++. От такой ноши нельзя избавиться, но можно научиться с ней жить. Однако, многие программисты предпочитают не жить, а страдать. Об этом мы и поговорим.
Не так давно я случайно заметил в своём любимом компоненте новую вставку. Мой код стал жертвой Tester-Driven Development.
Согласно википедии, Tester-driven development — это антиметодология разработки, при которой требования определяются багрепортами или отзывами тестировщиков, а программисты лишь лечат симптомы, но не решают настоящие проблемы
Я сократил код и перевёл его на С++17. Внимательно посмотрите и подумайте, не осталось ли чего лишнего в рамках бизнес-логики:
bool DocumentLoader::MakeDocumentWorkdirCopy()
{
std::error_code errorCode;
if (!std::filesystem::exists(m_filepath, errorCode) || errorCode)
{
throw DocumentLoadError(DocumentLoadError::NotFound(), m_filepath, errorCode.message());
}
else
{
// Lock document
HANDLE fileLock = CreateFileW(m_filepath.c_str(),
GENERIC_READ,
0, // Exclusive access
nullptr, // security attributes
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL,
nullptr //template file
);
if (!fileLock)
{
CloseHandle(fileLock);
throw DocumentLoadError(DocumentLoadError::IsLocked(), m_filepath, "cannot lock file");
}
CloseHandle(fileLock);
}
std::filesystem::copy_file(m_filepath, m_documentCopyPath);
}Давайте опишем словесно, что делает функция:
Вам не кажется, что кое-что тут выпадает из уровня абстракции функции?

Не смешивайте слои абстракции, код с разным уровнем детализации логики должен быть разделён границами функции, класса или библиотеки. Не смешивайте C и C++, это разные языки.
На мой взгляд, функция должна выглядеть так:
bool DocumentLoader::MakeDocumentWorkdirCopy()
{
boost::system::error_code errorCode;
if (!boost::filesystem::exists(m_filepath, errorCode) || errorCode)
{
throw DocumentLoadError(DocumentLoadError::NotFound(), m_filepath, errorCode.message());
}
else if (!utils::ipc::MakeFileLock(m_filepath))
{
throw DocumentLoadError(DocumentLoadError::IsLocked(), m_filepath, "cannot lock file");
}
fs::copy_file(m_filepath, m_documentCopyPath);
}Начнём с того, что они родились в разное время и у них разные ключевые идеи:
В C++ ошибки обрабатываются с помощью исключений. Как они обрабатываются в C? Кто вспомнил про коды возврата, тот неправ: стандартная для языка C функция fopen не возвращает информации об ошибке в кодах возврата. Далее, out-параметры в C передаются по указателю, а в C++ программиста за такое могут и отругать. Далее, в C++ есть идиома RAII для управления ресурсами.
Мы не будем перечислять остальные отличия. Просто примем как факт, что мы, C++ программисты, пишем на C++ и вынуждены использовать API в стиле C ради:
Но использовать не значит "пихать во все места"!
Если вы используете ifstream, то с обработкой ошибок попытка открыть файл выглядит так:
int main()
{
try
{
std::ifstream in;
in.exceptions(std::ios::failbit);
in.open("C:/path-that-definitely-not-exist");
}
catch (const std::exception& ex)
{
std::cout << ex.what() << std::endl;
}
try
{
std::ifstream in;
in.exceptions(std::ios::failbit);
in.open("C:/");
}
catch (const std::exception& ex)
{
std::cout << ex.what() << std::endl;
}
}Поскольку первый путь не существует, а второй является директорией, мы получим исключения. Вот только в тексте ошибки нет ни пути к файлу, ни точной причины. Если вы запишете такую ошибку в лог, чем это вам поможет?
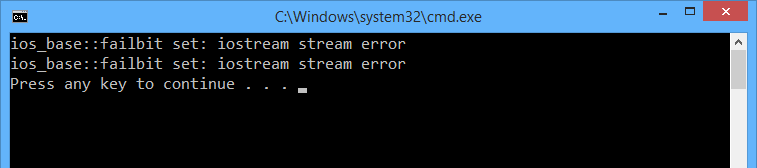
Типичный код, использующий API в стиле C, ведёт себя хуже: он даже не даёт гарантии безопасности исключений. В примере ниже при выбросе исключения из вставки // .. остальной код файл никогда не будет закрыт.
// Держи это, если ты вендовоз
#if defined(_MSC_VER)
#define _CRT_SECURE_NO_WARNINGS
#endif
int main()
{
try
{
FILE *in = ::fopen("C:/path-that-definitely-not-exist", "r");
if (!in)
{
throw std::runtime_error("open failed");
}
// ..остальной код..
fclose(in);
}
catch (const std::exception& ex)
{
std::cout << ex.what() << std::endl;
}
}А теперь мы возьмём этот код и покажем, на что способен C++17, даже если перед нами — API в стиле C.
Валяйте, попробуйте. У вас получится ещё один iostream, в котором нельзя просто взять и узнать, сколько байт вам удалось прочитать из файла, потому что сигнатура read выглядит примерно так:
basic_istream& read(char_type* s, std::streamsize count);А если вы всё же хотите воспользоваться iostream, будьте добры вызвать ещё и tellg:
// Функция читает не более чем count байт из файла, путь к которому задан в filepath
std::string GetFirstFileBytes(const std::filesystem::path& filepath, size_t count)
{
assert(count != 0);
// Бросаем исключение, если открыть файл нельзя
std::ifstream stream;
stream.exceptions(std::ifstream::failbit);
// Маленький фокус: C++17 позволяет конструировать ifstream
// не только из string, но и из wstring
stream.open(filepath.native(), std::ios::binary);
std::string result(count, '\0');
// читаем не более count байт из файла
stream.read(&result[0], count);
// обрезаем строку, если считано меньше, чем ожидалось.
result = result.substr(0, static_cast(stream.tellg()));
return result;
}Одна и та же задача в C++ решается двумя вызовами, а в C — одним вызовом fread! Среди множества библиотек, предлагающих C++ wrapper for X, большинство создаёт подобные ограничения или заставляет вас писать неоптимальный код. Я покажу иной подход: процедурный стиль в C++17.
Джуниоры не всегда знают, как создавать свои RAII для управления ресурсами. Но мы-то знаем:
namespace detail
{
// Функтор, удаляющий ресурс файла
struct FileDeleter
{
void operator()(FILE* ptr)
{
fclose(ptr);
}
};
}
// Создаём FileUniquePtr - синоним специализации unique_ptr, вызывающей fclose
using FileUniquePtr = std::unique_ptr;Такая возможность позволяет завернуть функцию ::fopen в функцию fopen2:
// Держи это, если ты вендовоз
#if defined(_MSC_VER)
#define _CRT_SECURE_NO_WARNINGS
#endif
// Функция открывает файл, пути в Unicode открываются только в UNIX-системах.
FileUniquePtr fopen2(const char* filepath, const char* mode)
{
assert(filepath);
assert(mode);
FILE *file = ::fopen(filepath, mode);
if (!file)
{
throw std::runtime_error("file opening failed");
}
return FileUniquePtr(file);
}У такой функции ещё есть три недостатка:
Если вызвать функцию для несуществующего пути и для пути к каталогу, получим следующие тексты исключений:

Во-первых мы должны узнать у ОС причину ошибки, во-вторых мы должны указать, по какому пути она возникла, чтобы не потерять контекст ошибки в процессе полёта по стеку вызовов.
И тут надо признать: не только джуниоры, но и многие мидлы и синьоры не в курсе, как правильно работать с errno и насколько это потокобезопасно. Мы напишем так:
// Держи это, если ты вендовоз
#if defined(_MSC_VER)
#define _CRT_SECURE_NO_WARNINGS
#endif
// Функция открывает файл, пути в Unicode открываются только в UNIX-системах.
FileUniquePtr fopen3(const char* filepath, const char mode)
{
using namespace std::literals; // для литералов ""s.
assert(filepath);
assert(mode);
FILE *file = ::fopen(filepath, mode);
if (!file)
{
const char* reason = strerror(errno);
throw std::runtime_error("opening '"s + filepath + "' failed: "s + reason);
}
return FileUniquePtr(file);
}Если вызвать функцию для несуществующего пути и для пути к каталогу, получим более точные тексты исключений:

C++17 принёс множество маленьких улучшений, и одно из них — модуль std::filesystem. Он лучше, чем boost::filesystem:
boost::filesystem содержит опасные игры с разыменованием указателей, в ней много Undefined BehaviorДля нашего случая filesystem принёс универсальный, не чувствительный к кодировкам класс path. Это позволяет прозрачно обработать Unicode пути на Windows:
// В VS2017 модуль filesystem пока ещё в experimental
#include
#include
#include
#include
#include
namespace fs = std::experimental::filesystem;
FileUniquePtr fopen4(const fs::path& filepath, const char* mode)
{
using namespace std::literals;
assert(mode);
#if defined(_WIN32)
fs::path convertedMode = mode;
FILE *file = ::_wfopen(filepath.c_str(), convertedMode.c_str());
#else
FILE *file = ::fopen(filepath.c_str(), mode);
#endif
if (!file)
{
const char* reason = strerror(errno);
throw std::runtime_error("opening '"s + filepath.u8string() + "' failed: "s + reason);
}
return FileUniquePtr(file);
} Мне кажется очевидным, что такой код трудно написать и что писать его должен один раз кто-то из опытных инженеров в общей библиотеке. Джуниорам в такие дебри лезть не стоит.
Сейчас я покажу вам код, который в июне 2017 года, скорее всего, не скомпилирует ни один компилятор. Во всяком случае, в VS2017 constexpr if ещё не реализован, а GCC 8 почему-то компилирует ветку if и выдаёт следующую ошибку:

Да-да, речь пойдёт о constexpr if из C++17, который предлагает новый способ условной компиляции исходников.
FileUniquePtr fopen5(const fs::path& filepath, const char* mode)
{
using namespace std::literals;
assert(mode);
FILE *file = nullptr;
// Если тип path::value_type - это тип wchar_t, используем wide-функции
// На Windows система хочет видеть пути в UTF-16, и условие истинно.
// примечание: wchar_t пригоден для UTF-16 только на Windows.
if constexpr (std::is_same_v)
{
fs::path convertedMode = mode;
file = _wfopen(filepath.c_str(), convertedMode.c_str());
}
// Иначе у нас система, где пути в UTF-8 или вообще нет Unicode
else
{
file = fopen(filepath.c_str(), mode);
}
if (!file)
{
const char* reason = strerror(errno);
throw std::runtime_error("opening '"s + filepath.u8string() + "' failed: "s + reason);
}
return FileUniquePtr(file);
}Это потрясающая возможность! Если в язык C++ добавят модули и ещё несколько возможностей, то мы сможем забыть препроцессор из языка C как страшный сон и писать новый код без него. Кроме того, с модулями компиляция (без компоновки) станет намного быстрее, а ведущие IDE будут с меньшей задержкой реагировать на автодополнение.
Хотя в индустрии правит ООП, а в академическом коде — функциональный подход, фанатам процедурного стиля пока ещё есть чему радоваться.
fopen4 по-прежнему использует флаги, mode и другие фокусы в стиле C, но надёжно управляет ресурсами, собирает всю информацию об ошибке и аккуратно принимает параметрыЯ рекомендую все функции стандартной библиотеки C, WinAPI, CURL или OpenGL завернуть в подобном процедурном стиле.
На C++ Russia 2016 и C++ Russia 2017 замечательный докладчик Михаил Матросов показывал всем желающим, почему не нужно использовать циклы и как жить без них:
Насколько известно, вдохновением для Михаила служил доклад 2013 года "C++ Seasoning" за авторством Sean Parent. В докладе было выделено три правила:
Я бы добавил ещё одно, четвёртное правило повседневного C++ кода. Не пишите на языке Си-Си-Плюс-Плюс. Не смешивайте бизнес-логику и язык C.
Причины прекрасно показаны в этой статье. Сформулируем их так:
Только настоящий герой может написать абсолютно надёжный код на C/C++. Если на работе вам каждый день нужен герой — у вас проблема.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author sergey_shambir c++ c++17 повседневный c++ |
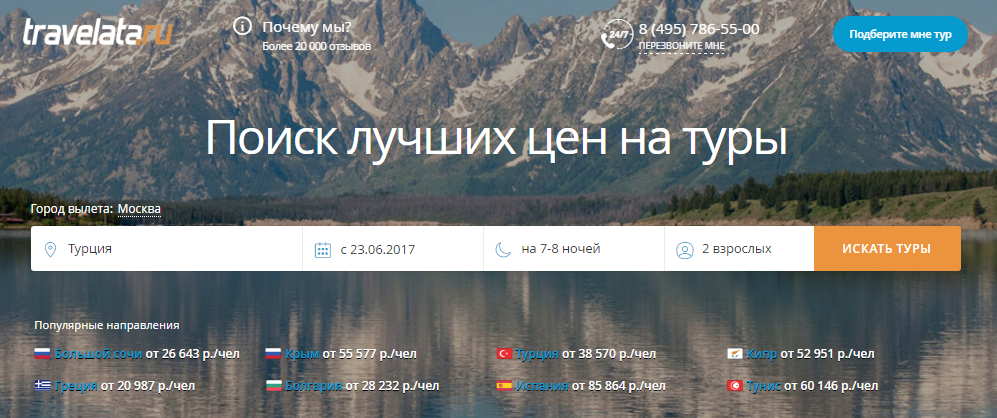
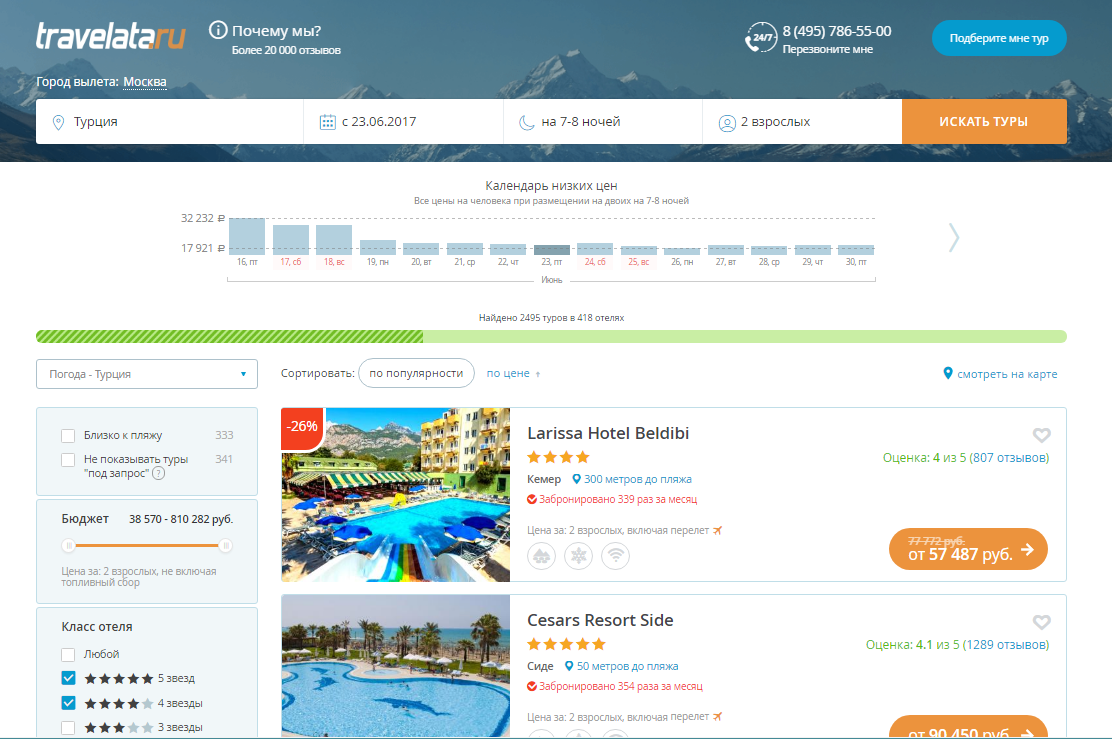
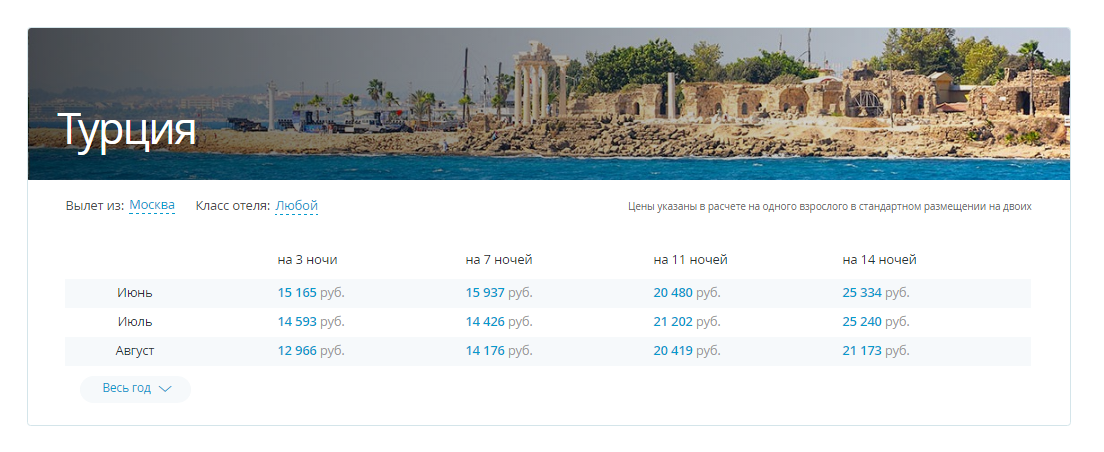
Что может пойти не так на сайте метапоисковика и что с этим делать? Часть 2 |



|
Метки: author zalexis управление разработкой управление продуктом управление e-commerce блог компании травелата api туризм интерфейсы ui базы данных |
Лучше один раз услышать чем семь раз прочитать |




Аккорды
“Mary Had a Little Lamb”
Это известная детская песня с узнаваемой простой мелодией. Вот одноголосая мелодия в тональности Фа-мажор.
открыть http://tinyurl.com/y9k93o3r
Но если мы гармонизируем мелодию с помощью нескольких аккордов, у нас получится полноценное произведение.
Этот пример показывает простую прогрессию (последовательность) аккордов. В большинстве стилей музыки прогрессия аккордов используется для создания напряжения или завершённости и т.п. Для этого аккорды могут как совпадать с основной тональностью, так и противостоять ей.
http://tinyurl.com/y8r9xabu
Как используются аккорды?
Мы добавили трезвучия Фа-мажоре и в До-мажоре. Но почему мы добавили именно эти аккорды?
Обратите внимание на совпадение нот мелодии с нотами аккомпанирующих аккордов. Например, в первом такте ноты Фа и Ля мелодии входят в трезвучие Фа-мажор. Ноты Соль не входят в это трезвучие, но они используются в мелодии как «соединение» между Фа и Ля.
Попробуйте поэкспериментировать поменяв аккорды в композиции.
|
Метки: author musicriffstudio работа со звуком интерфейсы web audio api sound web |
Тестируем возможности ARKit. Создаем игру с дополненной реальностью |

На WWDC 2017 Apple анонсировала ARKit — SDK для работы с дополненной реальностью. Благодаря ему порог вхождения в эту технологию стал значительно ниже. Можно ожидать появления большого количества качественных игр и приложений.
Если вы смотрели Keynote, то, вероятно, вы уже в восторге от увиденного. Игровой мир, который инженеры Apple смогли развернуть на обычном столе при помощи ARKit, не может оставить равнодушными даже самых искушенных геймеров. Это был не просто прототип, а хорошо работающая технология, над которой действительно потрудились. В этом легко убедиться, запустив несколько демо или попробовав самим привнести что-либо виртуальное в наш мир.
Вынужден расстроить счастливых обладателей iPhone 6 и ниже. На данных девайсах все эти прелести жизни будут недоступны. Для использования всех ключевых функций ARKit необходим процессор А9 и выше. Apple, конечно, даст урезанный доступ к функциональности, но это уже совсем не то.
Дополненная реальность (augmented reality, AR) — это виртуальная среда, которая накладывается на реальный мир для придания ему большей выразительности, информативности или просто ради развлечения. Термин, предположительно, был предложен исследователем компании Boeing Томасом Коделлом еще в 1990 году. Уже тогда начали появляться первые примеры устройств с применением данной технологии. Впервые дополненная реальность была реализована на электронных шлемах летчиков для вывода информации о полете и радаре.
Хочется спросить, чем же все занимались почти 20 лет и почему масштабное развитие эта технология получила лишь сейчас. Все предельно просто. Появление хороших камер в телефонах, сенсоров и развитие технологий компьютерного зрения сделали это возможным.
Что же можно сделать полезного и чего ждать в ближайшее время на полках AppStore? На самом деле все ограничивается лишь фантазией разработчиков. Можно с уверенностью назвать несколько отраслей, где AR произведет революцию с выходом нового фреймворка от Apple:
ARKit — не волшебная палочка Гарри Поттера, а инструмент, который умеет грамотно обрабатывать большое количество данных, полученных от устройства. Благодаря камере и датчикам движения фреймворк отслеживает движение, находит поверхности и определяет освещенность. После анализа данных мы получаем конкретное представление об окружающем мире в виде точек пересечения, координат поверхностей и положении камеры в пространстве.
Основой задачей ARKit является слежение за окружающим миром (World Tracking) для создания виртуальной модели реального мира. Фреймворк распознает особенности видеокадров, отслеживает изменения их положения и сравнивает эту информацию с данными от датчиков движения. Результатом является виртуальная модель реального мира. Отдельная возможность — распознавание плоских горизонтальных поверхностей. ARKit находит плоскости и сообщает об их расположении и размерах.
Слежение за окружающим миром требует анализа картинки, получаемой от камеры. Для достижения наилучшего результата, необходимо хорошее освещение.
Основой ARKit являются ARSCNView и ARSKView. Они служат для отображения live видео и рендеринга 3D и 2D изображений. Как все уже догадались, это наследники от SCNView и SKView. Следовательно, ARKit не привносит каких-то невероятных особенностей в отображении данных. Это все те же движки для работы с 2D и 3D графикой, с которыми уже все знакомы. Поэтому порог вхождения в данную технологию будет достаточно низким. Apple знаменита любовью к своим технологиям и продуктам, но несмотря на это разработчики ARKit сделали поддержку Unity и Unreal Engine. Это положительно скажется на количестве качественных приложений, которые появятся в ближайшее время.
ARSCNView и ARSKView содержат в себе сердце ARKit — ARSession. Именно этот класс содержит в себе все необходимое для работы с дополненной реальностью. Для запуска ARSession необходимо передать конфигурацию работы сессии.
Тип конфигурации определяет стиль и качество работы AR, которое может быть достигнуто:
ARWorldTrackingSessionConfiguration. Именно эта конфигурация дает возможность воспользоваться всей мощью нового фреймворка. Для вас будет создана модель окружающего мира в виртуальной реальности и предоставлена информация о плоскостях в поле видимости камеры. Это поможет расположить виртуальные объекты с максимальной точностью.ARSessionConfiguration. Базовый класс предоставляет только информацию о движении устройства в пространстве, но не строит виртуальных моделей. Это не даст необходимого эффекта и не позволит насладиться всем качеством новой технологии. Вам будет недоступна возможность фиксации виртуальных объектов относительно объектов реального мира.После выбора типа конфигурации необходимо создать ее экземпляр, произвести настройку и запустить сессию:
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
// Create a session configuration
let configuration = ARWorldTrackingSessionConfiguration()
// Run the view's session
sceneView.session.run(configuration)
}Важно помнить, что ARKit потребляет довольно много энергии для расчетов. Если View с контентом не отображается в данный момент на экране, то имеет смысл приостановить сессию на это время, используя session.pause().
После запуска сессии можно начинать работать с виртуальным контентом. Если хотите, чтобы ARKit распознавал плоскости, не забудьте установить значение planeDetection у конфигурации в значение horizontal. Изначально распознавание горизонтальных поверхностей выключено. Будем надеяться, что в будущем появится возможность находить и вертикальные поверхности, но пока только горизонтальные.
Способ получения информации об окружающей среде зависит от того, какой вид отображения данных вы будете использовать ARSCNView, ARSKView или Metal. Единицей информации, которую предоставляет ARKit, является ARAnchor. Если у вас включено распознавание поверхностей, то вы столкнетесь с сабклассом ARPlaneAnchor. Он содержит в себе информацию о найденных плоскостях. Благодаря данным якорям есть возможность ориентироваться в пространстве. В случае использования Metal вам придется вручную заниматься рендерингом. Тогда можете подписаться на обновления, используя делегат ARSessionDelegate у класса ARSession, и получать якоря от сессии. Если используете один из Apple движков для рендеринга объектов, тогда есть возможность воспользоваться более удобными делегатами ARSCNViewDelegate или ARSKViewDelegate.
На первый взгляд все довольно просто. Почти всю сложную работу делает ARSession. Давайте попробуем сделать тестовое приложение.
Дополненная реальность сейчас у всех ассоциируется с игрой Pok'emon GO, которая взорвала рынок игровой индустрии. Попробуем сделать нечто похожее.
Для создания тестового приложения мы воспользуемся ARSCNView для создания и рендеринга 3D моделей. Наша игра будет состоять из 2 этапов. Сначала мы будем расставлять мишени по комнате, а после пытаться как можно быстрее попасть по ним всем. Игра довольна примитивна, но продемонстрирует простоту создания игр с дополненной реальностью.
Начнем с того, что растянем на весь ViewController ARSCNView и создадим IBOutlet. Далее будем работать с ней, как с обычной SCNView. Произведем первоначальную настройку. Сделаем контроллер делегатом контактов физического мира и выведем статистику. Настроим запуск и паузу сессии при появлении и скрытии контроллера.
override func viewDidLoad() {
super.viewDidLoad()
sceneView.scene.physicsWorld.contactDelegate = self
// Show statistics such as fps and timing information
sceneView.showsStatistics = true
}
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
// Create a session configuration
let configuration = ARSessionConfiguration.isSupported ?
ARWorldTrackingSessionConfiguration() : ARSessionConfiguration()
// Run the view's session
sceneView.session.run(configuration)
}
override func viewWillDisappear(_ animated: Bool) {
super.viewWillDisappear(animated)
// Pause the view's session
sceneView.session.pause()
}Выбор конфигурации сессии зависит от модели устройства, на котором запустили приложение. Крайне важно сделать эту проверку. Иначе, в случае неверной конфигурации, сессия пришлет ошибку и игра не запустится вообще.
ARKit настолько прост, что мы больше не будем использовать никакие его настройки. Единственное, что еще понадобится — это расположение камеры в пространстве виртуального мира. Остальное — дело техники и немного SceneKit.
Мы не будем здесь описывать обработку нажатий или подсчет очков. Это не так важно, и вы можете это увидеть сами в ДЕМО, представленном в конце статьи.
Наша игра содержит две модели объектов: шарик, которым мы будем стрелять, и летающие логотипы Touch Instinct. Для добавления этих моделей на экран, необходимо создать их, используя SCNNode.
Что понадобится, чтобы создать физический объект:
Пример реализации классов патрона в виде шара и логотипа в виде куба с нужными текстурами.
class ARBullet: SCNNode {
override init() {
super.init()
let arKitBox = SCNSphere(radius: 0.025)
self.geometry = arKitBox
let shape = SCNPhysicsShape(geometry: arKitBox, options: nil)
self.physicsBody = SCNPhysicsBody(type: .dynamic, shape: shape)
self.physicsBody?.isAffectedByGravity = false
self.physicsBody?.categoryBitMask = CollisionCategory.arBullets.rawValue
self.physicsBody?.contactTestBitMask = CollisionCategory.logos.rawValue
// add texture
let material = SCNMaterial()
material.diffuse.contents = UIImage(named: "art.scnassets/ARKit_logo.png")
self.geometry?.materials = [material]
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
}class Logo: SCNNode {
override init() {
super.init()
let logo = SCNBox(width: 0.1, height: 0.1, length: 0.1, chamferRadius: 0)
self.geometry = logo
let shape = SCNPhysicsShape(geometry: logo, options: nil)
self.physicsBody = SCNPhysicsBody(type: .dynamic, shape: shape)
self.physicsBody?.isAffectedByGravity = false
self.physicsBody?.categoryBitMask = CollisionCategory.logos.rawValue
self.physicsBody?.contactTestBitMask = CollisionCategory.arBullets.rawValue
// add texture
let material = SCNMaterial()
material.diffuse.contents = UIImage(named: "art.scnassets/logo-mobile.png")
self.geometry?.materials = Array(repeating: material, count: 6)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
}Хочется обратить внимание на CollisionCategory. Это структура используется для определения типа объекта при контакте.
struct CollisionCategory: OptionSet {
let rawValue: Int
static let arBullets = CollisionCategory(rawValue: 1 << 0)
static let logos = CollisionCategory(rawValue: 1 << 1)
}Это стандартная тактика для определения контакта. Свойство categoryBitMask задает маску конкретного объекта, а contactTestBitMask настраивает все контакты, которые нам будут интересны и о которых мы хотим получать уведомления.
Раз мы заговорили про обработку контактов, давайте посмотрим, как это выглядит в контроллере. Во viewDidLoad мы уже подписались на события контактов физического мира. Осталось реализовать одну функцию.
extension ViewController: SCNPhysicsContactDelegate {
func physicsWorld(_ world: SCNPhysicsWorld, didBegin contact: SCNPhysicsContact) {
guard let nodeABitMask = contact.nodeA.physicsBody?.categoryBitMask,
let nodeBBitMask = contact.nodeB.physicsBody?.categoryBitMask,
nodeABitMask & nodeBBitMask == CollisionCategory.logos.rawValue & CollisionCategory.arBullets.rawValue else {
return
}
contact.nodeB.removeFromParentNode()
logoCount -= 1
if logoCount == 0 {
DispatchQueue.main.async {
self.stopGame()
}
}
DispatchQueue.main.asyncAfter(deadline: .now() + 0.5, execute: {
contact.nodeA.removeFromParentNode()
})
}
}Самое интересное — это первая проверка того, что произошло именно соударение патрона и мишени в виде куба. Она выполняется на основе битовой маски. Это очень удобно и избавляет от большого количества других проверок.
При соударении мы убавляем счетчик оставшихся логотипов и удаляем оба объекта. Второй объект удаляется с небольшой задержкой для визуализации столкновения.
Две основные игровые функции — это добавление мишени и выстрел. Добавление происходит на небольшом расстоянии от экрана в той стороне, куда направлена камера. Мы просто создаем уже сконфигурированный объект куба, добавляем его на сцену и настраиваем его расположение относительно камеры в пространстве.
private func addLogo() {
guard let currentFrame = sceneView.session.currentFrame else {
return
}
let logo = Logo()
sceneView.scene.rootNode.addChildNode(logo)
var translation = matrix_identity_float4x4
translation.columns.3.z = -1
logo.simdTransform = matrix_multiply(currentFrame.camera.transform, translation)
logoCount += 1
if logoCount == ViewController.logoMaxCount {
startGame()
}
}При выстреле мы также создаем объект шара. Добавляем его на сцену. Но теперь нам необходимо не просто его добавить, но и придать ему ускорение. Для этого мы определяем позицию посередине экрана и придаем ускорение, приложив силу в нужном направлении.
private func shoot() {
let arBullet = ARBullet()
let (direction, position) = cameraVector
arBullet.position = position
arBullet.physicsBody?.applyForce(direction, asImpulse: true)
sceneView.scene.rootNode.addChildNode(arBullet)
}Вот так всего за пару десятков строк мы создали простую игру.
Как видите, Apple потрудились на славу. Благодаря новому фреймворку ARKit создание приложений с дополненной реальностью — так же просто, как сделать приложение с несколькими контроллерами. При этом вам не нужно беспокоиться о красивых декорациях. Эта технология точно изменит наше представление о мобильных приложениях.
Скачивайте новый Xcode 9, и создавайте приложения, которые добавят в наш мир виртуальной магии. Будущее уже здесь. Ну или будет здесь ближе к сентябрю, после очередной презентации Apple.
Скачивайте в репозитории Touch Instinct
|
Метки: author GrigoryUlanov разработка под ios разработка под ar и vr xcode swift блог компании touch instinct ios wwdc wwdc 2017 ar arkit |
[Перевод] Как добиться того, чтобы обучение в играх не раздражало |




Ивата: Если вы играете в первый раз, не имея никаких знаний об игре, то наткнётесь на первого гумбу и умрёте.
Миямото: Да, и поэтому нам нужно было естественным образом обучить игрока… чтобы он перепрыгивал и избегал их.
Ивата: Тогда при попытке избежать их иногда будет происходить так, что игрок ошибается и случайно падает на гумбу сверху. Таким образом, он в процессе игры узнаёт, что можно победить их, запрыгивая им на голову.
Миямото:… Когда вы играете, то прямо с самого начала видите гумбу, и он похож на гриб. Когда вы ударяете по ящику и из него вылетает что-то, похожее на гумбу…
Ивата: Вы убегаете.
Миямото: Правильно, убегаете. Это стало для нас серьёзной проблемой. Нам нужно было как-то дать понять игроку, что на самом деле это что-то хорошее.
Ивата: Если игрок избежит первого гумбу, а потом подпрыгнет и ударит ящик над головой, то из него выскочит гриб и игрок удивится. Но потом он увидит, что гриб уползает вправо и подумает, что находится в безопасности. «Появилось что-то странное, но со мной всё в порядке!» Но потом, конечно же, ударившись об трубу, гриб вернётся назад! (смеётся)
Миямото: Верно! (смеётся)
Ивата: В этот момент, даже если игрок запаникует и попытается отпрыгнуть с его пути, то ударится об ящик. И в ту секунду, когда он поймёт, что с ним покончено, Марио неожиданно затрясётся и увеличится в размерах! Может быть, игрок сначала и не поймёт, что произошло, но по крайней мере, он не потерял жизнь.


|
Метки: author PatientZero разработка игр обучение в играх туториалы tutorials |
Security Week 24: 95 фиксов от Microsoft, роутер сливает данные светодиодами, для MacOS появился рансомвар-сервис |
 Этот вторник патчей – просто праздник какой-то! Microsoft решила порадовать админов и выпустила 95 фиксов для Windows всех поддерживаемых версий, Office, Skype, Internet Explorer и Edge. 18 из них – для критических уязвимостей, включая три RCE. Кто не знает, это дыры, позволяющие удаленно запускать код без аутентификации, то есть самые опасные из всех. Первые две, согласно Microsoft, уже под атакой.
Этот вторник патчей – просто праздник какой-то! Microsoft решила порадовать админов и выпустила 95 фиксов для Windows всех поддерживаемых версий, Office, Skype, Internet Explorer и Edge. 18 из них – для критических уязвимостей, включая три RCE. Кто не знает, это дыры, позволяющие удаленно запускать код без аутентификации, то есть самые опасные из всех. Первые две, согласно Microsoft, уже под атакой. Новость. Исследование. Когда исследователям нечего делать, они изобретают причудливые способы взлома всяких защищенных систем. Высший пилотаж у этих сумрачных гениев – ломануть компьютер, не подключенный к Интернету. Это вполне реализуемо, спасибо двуногим переносчикам инфекций, сующим флешки куда попало, но внедрить на систему троянца – это только половина дела. Еще надо как-то извлечь украденные данные, и вот тут безопасники свою фантазию не сдерживают.
Новость. Исследование. Когда исследователям нечего делать, они изобретают причудливые способы взлома всяких защищенных систем. Высший пилотаж у этих сумрачных гениев – ломануть компьютер, не подключенный к Интернету. Это вполне реализуемо, спасибо двуногим переносчикам инфекций, сующим флешки куда попало, но внедрить на систему троянца – это только половина дела. Еще надо как-то извлечь украденные данные, и вот тут безопасники свою фантазию не сдерживают.


|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw macransom ddwrt rce air-gapped |
[Перевод] Сокращаем использование Redux кода с помощью React Apollo |
Всем привет! Хочу поделиться своим переводом интересной статьи Reducing our Redux code with React Apollo автора Peggy Rayzis. Статья о том, как автор и её команда внедряли технологию GraphQL в их проект. Перевод публикуется с разрешения автора.
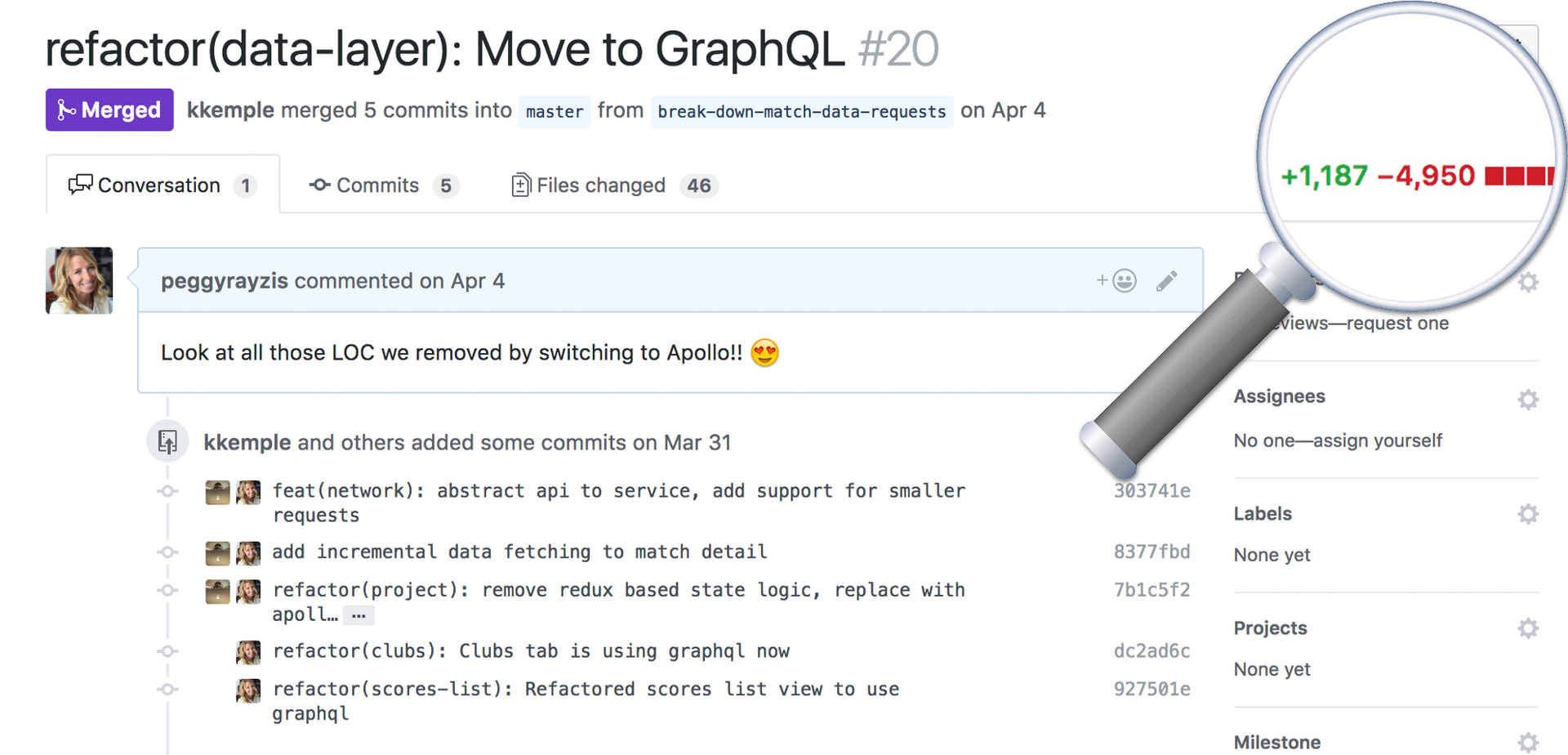
Переключаемся на декларативный подход в Высшей Футбольной Лиге
Я твёрдо убеждена, что лучший код — это отсутствие кода. Чем больше кода, тем больше вероятности для появления багов и тем больше тратится времени на поддержку такого кода. В Высшей Футбольной Лиге у нас совсем небольшая команда, поэтому мы принимаем этот принцип близко к сердцу. Мы стараемся оптимизировать всё, что нам по силам, либо путём увеличения переиспользуемости кода, либо просто перестав обслуживать определённую часть кода.
В данной статье вы узнаете о том, как мы передали контроль над получением данных в Apollo, что позволило нам избавиться от почти 5,000 строчек кода. К тому же, после перехода на Apollo наше приложение стало не только намного меньше по объёму, оно также стало более декларативным, поскольку теперь наши компоненты запрашивают только те данные, которые им нужны.
Что я подразумеваю под декларативным и почему это так здорово? Декларативное программирование фокусируется на конечной цели, в то время как императивное программирование сосредоточено на шагах, которые требуются для её достижения. React же сам по себе декларативный.
Давайте взглянем на простой компонент Article:
import React from 'react';
import { View, Text } from 'react-native';
export default ({ title, body }) => (
{title}
{body}
);Предположим, мы хотим отрендерить в подключённом мог бы быть таким:
Так много шагов, чтобы просто получить данные для ! Без клиента GraphQL наш код становится намного более императивным, поскольку нам приходится концентрироваться на том, как мы получаем данные. Но что, если мы не хотим передавать все данные матча для простого рендеринга ? Вы могли бы построить другой endpoint и создать отдельный набор action creators для получения от него данных, но такой вариант очень легко может стать неподдерживаемым.
Давайте сравним, как бы мы могли сделать то же самое с помощью GraphQL:
query Article($id: Float!) {
match(id: $id) {
article {
title
body
}
}
}… и это всё! Как только клиент получает данные, он передаёт их в props, которые могут быть далее переданы в . Это намного более декларативно, поскольку мы фокусируемся только на том, какие данные нам нужны для рендеринга компонента.
В этом вся прелесть делегирования получения данных GraphQL клиенту, будь то Relay или Apollo. Когда вы начнёте "думать в концепциях GraphQL", вы станете заботиться только о том, в каких props нуждается компонент для рендеринга, вместо того, чтобы беспокоиться о том, как получить эти данные.
В какой то момент вам придётся подумать об этом "как", но это уже забота серверной части, и, соответственно, сложность для front-end резко снижается. Если вы новичок в серверной архитектуре GraphQL, то попробуйте graphql-tools, библиотеку Apollo, которая поможет вам более модульно структурировать вашу схему. Для краткости мы сегодня остановимся только на front-end части.
И хотя этот пост о том, как сократить использование вашего Redux кода, вы не избавитесь от него полностью! Apollo использует Redux под капотом, поэтому вы всё ещё сможете извлекать выгоду из иммутабельности и все клёвые возможности Redux Dev Tools, типа time-travel debugging, так же будут работать. Во время конфигурирования вы можете подключить Apollo к существующему store в Redux, чтобы поддерживать единый "источник правды". Как только ваш store сконфигурирован, вы передаёте его в ApolloClient через свойство client.
Прежде, чем мы начнём резать наш Redux код, я бы хотела назвать одну из лучших фукнциональных особенностей GraphQL: поэтапная настройка (incremental adoption). Вам не обязательно совершать рефакторинг всего приложения сразу. После интеграции Apollo с вашим существующим Redux store, вы можете переключаться с ваших reducers постепенно. То же самое применимо и к серверной части — если вы работаете над большим масштабным приложением, вы можете использовать GraphQL бок о бок с вашим текущим REST API, до того момента, пока вы не будете готовы для полного перехода. Справедливое предупреждение: как только вы попробуете GraphQL, вы можете влюбиться в эту технологию и захотить переделать всё ваше приложение.
Перед переходом от Redux к Apollo, мы тщательно подумали о том, отвечает ли Apollo нашим потребностям. Вот на что мы обратили внимание перед тем, как принять решение:
fetchMore, которая проделывает за нас всю тяжёлую работу? Надо сказать, что Apollo удовлетворял не только всем нашим текущим требованиям, он также охватывал и некоторые наши будущие потребности, особенно учитывая то, что в наш roadmap включена расширенная персонализация. И хотя наш сервер в настоящее время доступен "только для чтения", нам в будущем может потребоваться ввести мутации (mutations) для сохранения пользователями их любимых команд. На случай, если мы решим добавить комментирование в режиме реального времени или взаимодействия с фанатами, которые не могут быть решены с помощью поллинга (polling), то в Apollo есть поддержка подписок (subscriptions).
Момент, которого все ждали! Изначально, когда я только задумалась о написании этой статьи, я собиралась лишь привести примеры кода до и после, но я думаю, что было бы трудно сравнивать вот так напрямую эти два подхода, особенно для новичков в Apollo. Вместо этого я собираюсь подсчитать количество удалённого кода в целом и провести вас через знакомые вам концепции Redux, которые вы сможете применить при создании контейнерных компонентов с помощью Apollo.
fetchPolicy из Apollo и использования redux-persist в reducer.Если вы умеете пользоваться connect, тогда компонент высшего порядка graphql из Apollo вам покажется очень знакомым! Точно так же, как connect возвращает функцию, которая принимает компонент и подключает его к вашему Redux store, также и graphql возвращает функцию, которая принимает компонент и "подключает" его к клиенту Apollo. Давайте посмотрим на это в действии!
import React, { Component } from 'react';
import { graphql } from 'react-apollo';
import { MatchSummary, NoDataSummary } from '@mls-digital/react-components';
import MatchSummaryQuery from './match-summary.graphql';
// here we're using the graphql HOC as a decorator, but you can use it as a function too!
@graphql(MatchSummaryQuery, {
options: ({ id, season, shouldPoll }) => {
return {
variables: {
id,
season,
},
pollInterval: shouldPoll ? 1000 * 60 : undefined,
};
};
})
class MatchSummaryContainer extends Component {
render() {
const { data: { loading, match } } = this.props;
if (loading && !match) {
return Первый аргумент, переданный в graphql это MatchSummaryQuery. Это данные, которые мы хотим получить от сервера. Мы используем загрузчик Webpack для парсинга нашего запроса в GraphQL AST, но если вы не используете Webpack, то вам нужно обернуть ваш запрос в шаблонные строки (template string) и передать его в функцию gql, экспортированную из Apollo. Вот пример запроса на получение данных, необходимых для нашего компонента:
query MatchSummary($id: String!, $season: String) {
match(id: $id) {
stats {
scores {
home {
score
isWinner: is_winner
}
away {
score
isWinner: is_winner
}
}
}
home {
id: opta_id
record(season: $season)
}
away {
id: opta_id
record(season: $season)
}
}
}Отлично, у нас есть запрос! Чтобы корректно его выполнить, нам нужно передать в него две переменные $id и $season. Но откуда мы возьмём эти переменные? Вот здесь то и вступает в игру второй аргумент функции graphql, представленный в виде объекта конфигурации.
Этот объект имеет несколько свойств, которые вы может указать для настройки поведения компонента высшего порядка (HOC). Одно из самых важных свойств — это options, принимающее функцию, которая получает props вашего контейнера. Эта функция возвращает объект со свойствами типа variables, что позволяет вам передавать ваши переменные в запрос, и pollInterval, который позволяет настраивать поведение поллинга (polling) у компонента. Обратите внимание, как мы используем props нашего контейнера для передачи id и season в наш MatchSummaryQuery. Если эта функция становится слишком длинной, чтобы писать её прямо в декораторе, то мы разбиваем её на отдельную функцию под названием mapPropsToOptions.
Наверняка вы использовали функцию mapStateToProps в ваших Redux контейнерах, передавая эту функцию в connect для передачи данных из state приложения в props данного контейнера. Apollo позволяет вам определять похожую функцию. Помните конфигурационный объект, который ранее мы передавали в функцию graphql? У этого объекта есть ещё одно свойство — props, которое принимает функцию, получающую на вход props и обрабатывающую их перед передачей в контейнер. Вы, конечно, можете определить её прямо в graphql, но нам нравится определять её как отдельную функцию mapResultsToProps.
Зачем вам переопределять ваши props? Результат запроса GraphQL всегда присваивается к свойству data. Иногда вам может потребоваться подкорректировать эти данные перед тем, как отправить их в компонент. Вот один из примеров:
import React, { Component } from 'react';
import { graphql } from 'react-apollo';
import { MatchSummary, NoDataSummary } from '@mls-digital/react-components';
import MatchSummaryQuery from './match-summary.graphql';
const mapResultsToProps = ({ data }) => {
if (!data.match)
return {
loading: data.loading,
};
const { stats, home, away } = data.match;
return {
loading: data.loading,
home: {
...home,
results: stats.scores.home,
},
away: {
...away,
results: stats.scores.away,
},
};
};
const mapPropsToOptions = ({ id, season, shouldPoll }) => {
return {
variables: {
id,
season,
},
pollInterval: shouldPoll ? 1000 * 60 : undefined,
};
};
@graphql(MatchSummaryQuery, {
props: mapResultsToProps,
options: mapPropsToOptions,
})
class MatchSummaryContainer extends Component {
render() {
const { loading, ...matchSummaryProps } = this.props;
if (loading && !matchSummaryProps.home) {
return Теперь объект с данными содержит не только результат запроса, но также и свойства типа data.loading, чтобы дать вам знать, что запрос ещё не возвратил ответ. Это может быть полезным, если в подобной ситуации вы хотите отобразить другой компонент вашим пользователям, как мы сделали это с
Compose это функция, использующаяся не только в Redux, но я всё же хочу обратить ваше внимание, что Apollo содержит её. Она очень удобна, если вы хотите скомпоновать несколько graphql функций для использования в одном контейнере. В ней вы даже можете использвать функцию connect из Redux вместе с graphql! Вот как мы используем compose для отображения различных состояний матча:
import React, { Component } from 'react';
import { compose, graphql } from 'react-apollo';
import { NoDataExtension } from '@mls-digital/react-components';
import PostGameExtension from './post-game';
import PreGameExtension from './pre-game';
import PostGameQuery from './post-game.graphql';
import PreGameQuery from './pre-game.graphql';
@compose(
graphql(PreGameQuery, {
skip: ({ gameStatus }) => gameStatus !== 'pre',
props: ({ data }) => ({
preGameLoading: data.loading,
preGameProps: data.match,
}),
}),
graphql(PostGameQuery, {
skip: ({ gameStatus }) => gameStatus !== 'post',
props: ({ data }) => ({
postGameLoading: data.loading,
postGameProps: data.match,
}),
}),
)
export default class MatchExtensionContainer extends Component {
render() {
const {
preGameLoading,
postGameLoading,
gameStatus,
preGameProps,
postGameProps,
...rest
} = this.props;
if (preGameLoading || postGameLoading)
return compose отлично помогает, когда ваш контейнер содержит множественные состояния. Но что, если вам нужно выполнять отдельный запрос только в зависимости от его состояния? Здесь нам поможет skip, который вы можете увидеть в конфигурационном объекте выше. Свойство skip принимает функцию, которая получает props и позволяет вам пропустить выполнение запроса, если он не соответствует необходимым критериям.
Все эти примеры демонстрируют, что если вы знаете Redux, то вы быстро вольётесь в разработку на Apollo! Его API вобрало в себя многое из концепций Redux, при этом уменьшая количество кода, которое вам нужно написать для достижения такого же результата.
Я надеюсь, что опыт перехода Высшей Футбольной Лиги на Apollo поможет вам! Как и в случае с любыми решениями относительно различных библиотек, лучшее решение по контролю над получением данных в вашем приложении будет зависеть от конкретных требований вашего проекта. Если у вас есть какие-либо вопросы касательно нашего опыта, пожалуйста, оставляйте комментарии здесь или стучитесь ко мне в Twitter!
Спасибо за прочтение!
|
Метки: author KarafiziArthur reactjs node.js javascript api graphql react redux |
Неглубокое погружение или восстановление данных с жесткого диска после затопления офиса |











|
|
Вебинар Крикета Ли и Пола Викси о методах защиты сети с использованием DNS RPZ |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Homas информационная безопасность rpz dns |
Без заголовка |
|
Метки: author zuborg системное администрирование сетевые технологии серверное администрирование серверная оптимизация *nix freebsd tcp ddos highload dpi |
Почему подключаться под атакой к сервису нейтрализации DDoS уже слишком поздно |
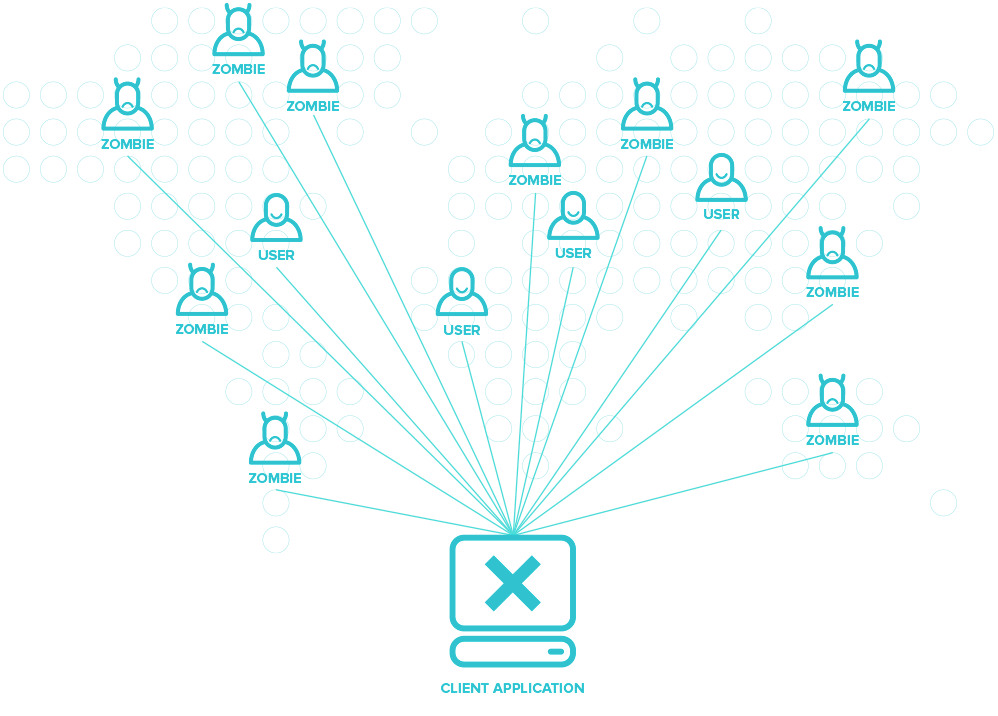
Постскриптум.
Коллеги, доводим до вашего сведения следующую важную новость: www.ietf.org/mail-archive/web/idr/current/msg18258.html
Инициатива о внедрении механизма автоматической защиты от возникновения «утечек маршрутов» (route leaks), непосредственное участие в создании которой принимали инженеры Qrator Labs, успешно прошла этап «принятия» (adoption call) и перешла в рабочую группу по Interdomain Routing (IDR).
Следующий этап — доработка документа в рамках IDR и, в дальнейшем, проверка руководящей группой (IESG www.ietf.org/iesg). В случае успешного прохождения этих этапов черновик станет новым сетевым стандартом RFC (https://www.ietf.org/rfc.html).
Авторы: Александр Азимов, Евгений Богомазов, Рэнди Буш (Randy Bush, Internet Initiative Japan), Котикалапуди Шрирам (Kotikalapudi Sriram, US NIST) и Кейур Пател (Keyur Patel, Arrcus Inc.) осознают, что в индустрии есть острый спрос на предлагаемые изменения. Однако спешка в данном процессе также неприемлема, и авторы приложат максимум усилий, чтобы сделать предлагаемый стандарт удобным как для транснациональных операторов, так и небольших домашних сетей.
Мы благодарим технических специалистов, выразившим свою поддержку в рамках adoption call. При этом отдельная благодарность тем, кто не просто выразил свое мнение, но и прислал свои замечания. Мы постараемся учесть их при последующих изменениях данного черновика.
Мы также хотим донести до сведения заинтересованных инженеров, что у вас всё ещё есть возможность выразить собственные пожелания к внесению дополнений и уточнений через рассылку IETF (draft-ymbk-idr-bgp-open-policy@ietf.org) или на через сайт инициатив Qrator Labs.
Важно также отметить, что к моменту принятия финального решения у стандарта должно быть две рабочих реализации. Одна из них уже доступна — это наша разработка на базе раутингового демона Bird, доступная на Github: github.com/QratorLabs/bird. Мы приглашаем вендоров и open source сообщество присоединиться к данному процессу.
|
|
“Коллеги, всё упало!” Что может пойти не так на сайте и что с этим делать? Часть 1 |


|
|
Направо пойдешь — стажировку найдешь, налево пойдешь — в стартап попадешь |



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author ksusha_icc развитие стартапа карьера в it-индустрии карьера карьера в it начало карьеры стажировка работа поиск работы icanchoose.ru |
[Перевод] Туториал по AsyncDisplayKit 2.0 (Texture): автоматическая компоновка |
|
Метки: author PolyaLA разработка под ios разработка мобильных приложений блог компании mobileup asyncdisplaykit ios разработка фреймворк autolayout objective-c |
[Перевод] Edge computing заменит Cloud computing? |


|
Метки: author mary_guba исследования и прогнозы в it блог компании mclouds.ru edge cloud computing тренды |
Вышел Firefox 54, который наконец получил поддержку многопроцессного режима |
 / фото Dees Chinniah CC
/ фото Dees Chinniah CC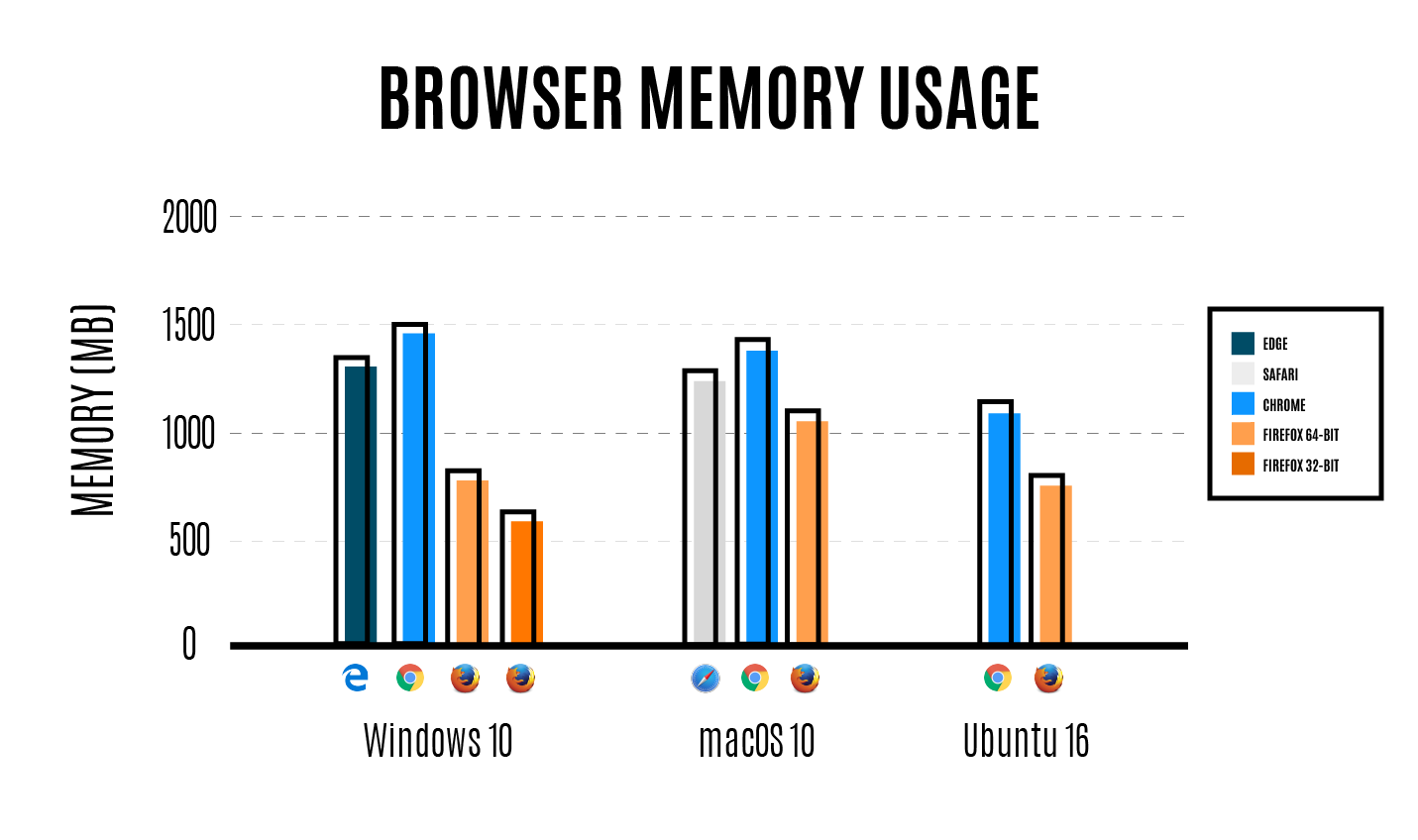
|
Метки: author it_man браузеры блог компании ит-град ит-град firefox |
[Из песочницы] RESTful API: мы всё делаем неправильно |
books, я же считал (и считаю), что это нелогично, и отстаивал вариант book. Признаюсь, мы оба пошли неправильным путем — вместо того, чтобы найти оригинальную документацию к архитектуре REST, написанную её создателем Р. Филдингом ещё в 2000 году (ссылку приведу в конце), мы сначала начали придумывать логические обоснования нашим позициям, а после просто стали смотреть, как это делается в больших компаниях и, перебрав несколько вариантов, установили, что мой встречается чаще, на чем и порешили спор завершить.books! REST uses a resource identifier to identify the particular resource involved in an interaction between components. REST connectors provide a generic interface for accessing and manipulating the value set of a resource, regardless of how the membership function is defined or the type of software that is handling the request. The naming authority that assigned the resource identifier, making it possible to reference the resource, is responsible for maintaining the semantic validity of the mapping over time (i.e., ensuring that the membership function does not change).
In regards to «untold hours wasted in debate», that is close to the goal of my dissertation — to introduce a way of thinking about software architecture that promotes honest debate about the properties that are desired and actual thought applied to the constraints chosen to achieve them (and their resulting trade-offs). It is almost never wasted, even when it is poorly informed.
…
...at best all you will get is a committee that has some vague notion
of what they consider to be design to write down the least common
denominator of misinformed «best practice» based upon whatever Microsoft
chose to implement in its last release. The IETF has made a habit of
that recently.
|
Метки: author feakuru it- стандарты api rest |
Как личная жизнь влияет на работу – этапы развития Unified Communications |



|
|








