[Из песочницы] Послевкусие от Kotlin |

class UserWithField(param: String) {
@NotEmpty var field: String = param
}
class UserWithConstructor(
@NotEmpty var paramAndField: String
)
class UserWithFixedConstructor(
@field:NotEmpty var paramAndField: String
)
class NotDefaultSetterTest {
@Test fun customSetter() {
val ivan = User("Ivan")
assertEquals("Ivan", ivan.name)
ivan.name = "Ivan"
assertEquals("IVAN", ivan.name)
}
class User(
nameParam: String
) {
var name: String = nameParam
set(value) {
field = value.toUpperCase()
}
}
}
class User(
nameParam: String
) {
var name: String = nameParam.toUpperCase()
set(value) {
field = value.toUpperCase()
}
}
fun getBalance(group: ClassGroup, month: Date, payments: Map>): Balance {
val errors = mutableListOf()
fun tryGetBalanceItem(block: () -> Balance.Item) = try {
block()
} catch(e: LackOfInformation) {
errors += e.message!!
Balance.Item.empty
}
val credit = tryGetBalanceItem {
creditBalancePart(group, month, payments)
}
val salary = tryGetBalanceItem {
salaryBalancePart(group, month)
}
val rent = tryGetBalanceItem {
rentBalancePart(group, month)
}
return Balance(credit, salary, rent, errors)
}
val result: String
try {
//some code
result = "first"
//some other code
} catch (e: Exception) {
result = "second"
}
data class User (
val name: String,
val birthDate: Date,
val created: Date = Date()
)
fun usageVersion1() {
val newUser = User("Ivan", SEPTEMBER_1990)
val userFromDto = User(userDto.name, userDto.birthDate, userDto.created)
}
data class User (
val name: String,
val birthDate: Date,
val created: Date = Date(),
val disabled: Boolean = false
)
fun usageVersion2() {
val newUser = User("Ivan", SEPTEMBER_1990)
val userFromDto = User(userDto.name, userDto.birthDate, userDto.created, userDto.disabled)
}
val months: List = ...
val hallsRents: Map> = months
.map { month ->
month to halls
.map { it.name to rent(month, it) }
.toMap()
}
.toMap()
val months: List = ...
val hallsRents: Map> = months
.map { it to rentsByHallNames(it) }
.toMap()
|
Метки: author gnefedev kotlin |
Как программист машину покупал. Часть III |

|
Метки: author nikitos18 я пиарюсь машинное обучение data mining predictive analytics покупка автомобиля продажа авто поиск выгодных автомобилей robasta.ru |
Время смелых. Как мигрировать в облака, не нарушая требований регуляторов? |

Сегмент финансовых услуг — один из самых технологичных. В то же время в России он один из самых зарегулированных. Банкиры вынуждены принимать в расчет «гору» требований, поэтому очень внимательно относятся ко всем новым инициативам госорганов, которые могут отразиться на их бизнесе.
Несмотря на то, что в мире банковский сектор стал одним из первых использовать облачные технологии, в РФ к ним, из-за принятия ряда новых законов (Закона «О персональных данных» и сопутствующих документов), финансовые учреждения относятся осторожно. И если рынка частных облаков законодательные акты не коснулись, то публичных компании опасаются. Ведь использование «внешних» сервисов всегда требовало повышенного внимания к вопросам информационной безопасности, все-таки банковская отрасль. Кроме того, за последние годы существенно увеличилось количество киберугроз и хакерских атак, и теперь на участников финансового рынка накладываются ужесточенные требования законодательства РФ в области защиты информации и акты регулирующих органов.
Итак, ниже разберем отношение регуляторов к использованию банками облаков под управлением сторонних провайдеров. А также нормативные требования по защите информации, которые эти провайдеры должны соблюдать.
Начнем с главного – с требований законодательства и регулирующих органов.
Список документов внушительный. Давайте разбираться. Если не рассматривать информацию, отнесенную к государственной тайне, то запрета по размещению в публичных облаках любых банковских информационных систем нет. В том числе нет запретов на использование информационных систем (ИС), обрабатывающих персональные данные (ПДн). Единственное законодательное ограничение содержится в Федеральном Законе №242-ФЗ и касается физического размещения средств обработки и хранения ПДн на территории РФ при сборе ПДн.
Документы ЦБ, ФСТЭК и ФСБ предъявляют требования по защите информации в рамках всего жизненного цикла информационных систем. Требования федерального законодательства и документов, указанных выше регуляторов, достаточно понятно как соблюдать при размещении банковских ИС на собственной площадке банка. Но, когда идет речь об информационных системах в облаке, появляются некоторые особенности реализации тех или иных технических и организационных мер защиты, а вместе с ними и множество вопросов по реализации конкретных мер. Большая часть вопросов относится к разграничению зон ответственности по обеспечению информационной безопасности между провайдером облачных услуг и банком. Это связано с тем, что при размещении системы в облаке управлением системы защиты занимаются как работники банка, так и представители провайдера облачных услуг.
В результате, ввиду необходимости использования нетривиальных решений по выполнению тех или иных требований законодательства и регуляторов, а также ввиду необходимости детальной проработки матрицы зон ответственности по обеспечению ИБ, наиболее часто встречаются аргументы против передачи банковских ИС в публичное облако, мол, невозможно их всех соблюсти. Но так ли это?
Реализовать комплекс мер и исполнять законодательные требования в облаке сложно, согласимся, но все же – возможно. Выходом для банков при переносе своей инфраструктуры на площадку стороннего провайдера в этих условиях является решение не только организационно-технических, но и правовых вопросов.
ФСТЭК со своей стороны не предъявляет дополнительных требований по защите информации при использовании публичных облаков. Есть требования по защите среды виртуализации, но конкретно по защите облаков – нет. Приказ ФСТЭК №21, непосредственно посвященный обеспечению безопасности ПДн, говорит о необходимости защиты ключевого элемента облачных вычислений — «среды виртуализации» (ч.2, п.8), не запрещая напрямую или косвенно использовать внешние сервисы. Также данный приказ содержит конкретные меры по защите среды виртуализации, которые должны быть реализованы в зависимости от уровня защищенности персональных данных и наличия актуальных угроз (ЗСВ.1 – ЗСВ.10).
Кстати, об угрозах. Если посмотреть банк данных угроз, пользоваться которым при моделировании угроз активно призывает ФСТЭК (а в случае с госсистемами — явно требует), то в данном банке можно обнаружить множество угроз, реализация которых возможна исключительно в системах, расположенных в облаках.
ФСБ пока молчит. В ее документах отсутствует упоминание облаков.
Исходя из вышесказанного, можно сделать вывод, что ФСТЭК и ФСБ допускают использование облачных технологий для обработки защищаемой информации.
Свое видение по облачным технологиям, помимо вышеуказанных документов, есть и у регулятора финансовой отрасли – Центробанка (ЦБ). К тестированию облачных технологий финансовый регулятор приступил в 2011 году. Уже тогда ИТ-специалисты Банка России говорили, что в «облаке» должны быть защита от вредоносного кода, контроль и разграничение доступа на сетевом уровне, на уровне доступа к различным приложениям и виртуальным машинам. В 2014 году была создана рабочая группа, задачей которой стала разработка предложений по внесению необходимых изменений в законодательство, позволяющих более широко использовать электронный документооборот (ЭДО). По сути, тогда ЦБ стал готовиться к проведению финансовых операций в облачных сервисах. В мае 2016 года участники финрынка перешли на обязательный ЭДО с Банком России. Летом прошлого года на Международном финансовом конгрессе зампред ЦБ Ольга Скоробогатова объявила, что крупнейшие банки и ИТ-компании во главе с Банком России создают консорциум по внедрению новых технологий. Сообщество поставило целью изучить и затем внедрять технологии распределенных регистров (blockchain), облачных технологий, управления большими данными (big data) и развитие системы упрощенной идентификации.
В «Основных направлениях развития финансового рынка Российской Федерации на период 2016–2018 годов» говорится, что Банк России намерен «проработать подходы по предоставлению сервисов для малых поднадзорных финансовых организаций, позволяющих вести учет хоздеятельности без обязанности сдавать отчетность при предоставлении ЦБ права непосредственного использования данных бухгалтерского учета, в том числе с использованием облачных технологий». В рамках этого, согласно «Основным мероприятиям по развитию финансового рынка Российской Федерации на период 2016–2018 годов», в 2016 году был определен подход (план) работы ЦБ по созданию для малых поднадзорных организаций единой технологии по ведению учета хоздеятельности без обязанности сдавать отчетность. Иных мероприятий по «облачному» направлению в документе не значится.
Собственно, сам ЦБ уже использует облачные продукты в своей деятельности. К примеру, в марте этого года «Ведомости» со ссылкой на данные электронной торговой площадки сообщили, что Банк России намерен приобрести около 45 тыс. лицензии на облачный офисный продукт Office 365. ЦБ объяснял покупку продлением лицензий. В планах у финансового регулятора и создание с банками, входящими в ассоциацию «Финтех», платформы моментальных платежей (p2p). И понятно, что без облачных технологий здесь не обойтись.
Выполнение требований стандарта PCI DSS становятся актуальными для банка при размещении в публичном облаке систем, осуществляющих обработку данных держателей платежных карт. Требования и взаимоотношения организаций финансового сектора при использовании облачных технологий регулируются п. 12.8 PCI DSS, и уже давно распространена практика использования PCI DSS-хостинга у сторонних сервис-провайдеров.

Итак, каких-либо преград или запрета на использование публичных облаков банками, находящихся на территории РФ, в нормативных документах и требованиях для организаций финансовой отрасли нет. В случае использования банком инфраструктуры из публичного облака сторонний провайдер должен в своем облаке реализовать и выполнять нормативные требования (в рамках своей зоны ответственности) и требования банка по информационной безопасности. Зона ответственности облачного провайдера должна быть закреплена в соответствующем соглашении между сторонами.
Конечно же, опасения от использования публичных облаков банками никуда не деваются. Хотя, как известно, специализированные провайдеры облачных сервисов одними из первых изучают свежие нормативные акты и максимально оперативно приводят свои предложения в полное соответствие с требованиями отечественного законодательства.

Например, сейчас при размещении ИС банка в облаке Техносерв Cloud обе стороны обязательно составляют полный реестр требований по ИБ, предъявляемых к банку и банком и разграничивают зоны ответственности. Как правило, провайдер облачных услуг ответственен за защиту периметра от внешних угроз (межсетевое экранирование, защита от сетевых этак) и за защиту виртуальной инфраструктуры, а банк ответственен за обеспечение информационной безопасности внутри предоставленных ему провайдером виртуальных машин. При этом, провайдер безусловно обеспечивает защиту рабочих станций своих администраторов и предоставление им защищенного доступа к средствам администрирования инфраструктуры облачной платформы.
Далее начинается работа над подготовкой или актуализацией внутренних документов банка, необходимых для успешного прохождения аудитов по СТО БР ИББС, положению ЦБ РФ №382-П, стандарту PCI DSS v.3.2 и др. с учетом новой модели потребления инфраструктурных ресурсов. Параллельно идет перенос ИС банка в облачную платформу.
В целом, мировая практика показывает, что компании, специализирующиеся на облачных сервисах, чаще всего, создают более качественную инфраструктуру и сервисы, чем это могут позволить себе большинство не профильных организаций. К примеру, Техносерв Cloud развернута на площадке дата-центра категории Tier III. Платформа состоит из двух физически изолированных частей (VDC и VDC.152; для государственных и финансовых организаций):
Сегмент «Закрытый» реализован с использованием решений VMware. Инфраструктура соответствует требованиям приказов №17 и №21 ФСТЭК для обеспечения до 1-го класса защиты ГИС и 1-го уровня защищенности ПДн включительно. Собственно говоря, решение позволяет, в том числе, государственным органам размещать ИС с наивысшими требованиями к информационной безопасности, что подтверждается наличием аттестата соответствия требованиям защиты информации, установленным ФСТЭК России.
В сухом остатке – не так страшно облако, «как его малюют». Что до регуляторов, то облачным провайдерам соблюсти их требования вполне реально.
|
Метки: author TS_Cloud облачные вычисления блог компании техносерв публичные облака банки регулятор фстэк pci dss техносерв cloud |
Материальная мотивация персонала в отделе интернет-маркетинга |

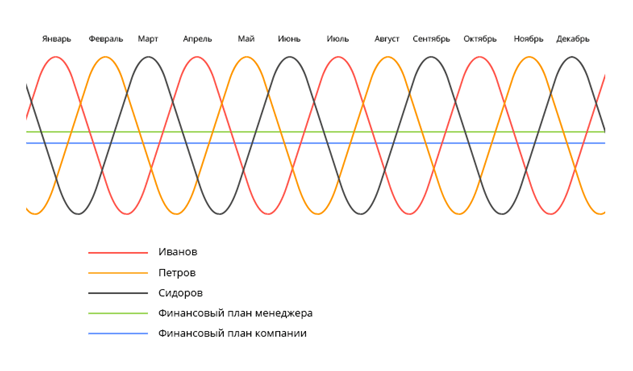



| Процент выполнения суммарного плана по итогам месяца | Размер премии в % от потенциальной |
| Менее 90% от поставленного плана | премия не выплачивается |
| 90,00–99,99% от поставленного плана | 60% |
| 100,00–109,99% от поставленного плана | 100% |
| 110,00% и более от поставленного плана | 120% |

| Процент выполнения суммарного плана по итогам месяца | Размер премии в % от потенциальной |
| Менее 90% от поставленного плана | премия не выплачивается |
| 90,00–99,99% от поставленного плана | 60% |
| 100,00–109,99% от поставленного плана | 100% |
| 110,00% и более от поставленного плана | 120% |

| Процент выполнения суммарного плана по итогам месяца | Размер премии в % от потенциальной |
| Менее 90% от поставленного плана | премия не выплачивается |
| 90,00–99,99% от поставленного плана | 60% |
| 100,00–109,99% от поставленного плана | 100% |
| 110,00% и более от поставленного плана | 120% |
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author vasyay управление персоналом блог компании webcanape мотивация персонала работа в команде интернет-маркетинг управление командой управление людьми |
Скорочтение: работает или нет? Часть 1 |
 / Фото Craig Sunter / CC
/ Фото Craig Sunter / CCПросматривание – это не чтение. Если вы ранее не читали текст, который просматриваете, вы упустите массу информации. А курсы скорочтения учат именно просматриванию, а не чтению, хотя (в большинстве своем) и не признают этого
– Тимоти Ноа (Timothy Noah), писатель, редактор Politico, ведущий автор в Slate (2000–2011гг.)
Я окончил курсы скорочтения – нас заставляли водить пальцем вдоль страниц, – и прочел «Войну и мир» за двадцать минут. Там что-то про Россию
– Вуди Аллен
|
Метки: author itmo gtd блог компании университет итмо университет итмо скорочтение |
[Перевод] HTTP/2 Server Push не так прост, как я думал |

Фото найдено на просторах Википедии
Привет! Меня зовут Макс Матюхин, я работаю PHP-программистом в Badoo. Мы постоянно изучаем различные возможности по ускорению работы нашего приложения и самыми интересными находками, конечно, делимся в нашем блоге на Хабре.
Вторая версия протокола HTTP обещает нам много улучшений, и одной из любопытных особенностей HTTP/2 является поддержка push. Теоретически эта возможность позволяет ускорить загрузку приложения. Недавно Jake Archibald написал большую статью, в которой проанализировал особенности реализации push в различных браузерах, и оказалось, что таких особенностей довольно много.
Мы уже публиковали пост, описывающий базовый функционал HTTP/2 Server Push, а этот будет хорошим дополнением, рассказывающим, как в реальности обстоят дела с поддержкой HTTP/2 Server Push в различных браузерах.
Я много раз слышал фразу «HTTP/2 Server Push справится с этим», когда дело касалось проблем с загрузкой страницы, но я мало что понимал в этой теме и потому решил разобраться подробнее.
HTTP/2 Server Push оказалась более сложной и низкоуровневой, чем я думал, но по-настоящему меня удивило то, насколько отличается её взаимодействие с различными браузерами – я-то всегда считал, что это полностью отработанная фича, готовая к использованию в production.
Я не хочу сказать, что HTTP/2 Server Push – это бесполезная ерунда; думаю, это действительно мощный инструмент, который со временем станет лучше. Но я уже не считаю его «серебряной пулей из золотого ружья».
Между вашей страницей и целевым сервером есть целая серия кешей и функций, которые могут перехватить запрос:

Указанная выше модель напоминает блок-схемы, которые используются для описания Git или её характерных признаков. Те, кто знаком с темой, убеждаются в правильности своих знаний, остальные – только пугаются. Прошу прощения, если это так, и надеюсь, следующие разделы помогут вам разобраться.

Страница: Привет, example.com, могу я получить твою домашнюю страницу? 10:24
Сервер: Конечно! О, пока она отправляется, вот ещё таблица стилей, изображения, JavaScript и JSON. 10:24
Страница: Вау, класс! 10:24
Страница: Я читаю HTML, и, похоже, мне понадобится таблица сти… О, ты уже отправил мне её, круто! 10:25
Отвечая на запрос, сервер может включить дополнительные ресурсы, такие как заголовки запросов, которые браузер сможет сопоставить позже. Они находятся в кеше до тех пор, пока браузер не запросит ресурс, соответствующий описанию.
Повышение производительности происходит благодаря тому, что ресурсы отправляются ещё до того, как браузер запросит их. Теоретически это означает, что страница должна загружаться быстрее.
Вот практически всё, что я знал об HTTP/2 Server Push. Звучало это довольно легко, но на деле всё оказалось совсем не так просто…
HTTP/2 Server Push – это низкоуровневая сетевая фича: всё, что использует сетевой стек, может использовать и её.
Но любая фича полезна, если она непротиворечива и предсказуема. Я протестировал HTTP/2 Server Push по этим показателям, запушив ресурсы и попробовав их собрать с помощью:
fetch()XMLHttpRequest|
Метки: author max_m разработка веб-сайтов программирование javascript html блог компании badoo http2 server push |
[Из песочницы] GraphicsJS – графическая JavaScript библиотека |

// создаем рабочую область
var stage = acgraph.create('stage-container');
// рисуем прямоугольник
var stage.rect(25, 50, 350, 300);// создаем рабочую область
var stage = acgraph.create('stage-container');
// рисуем рамку
var frame = stage.rect(25, 50, 350, 300);
// рисуем дом
var walls = stage.rect(50, 250, 200, 100);
var roof = stage.path()
.moveTo(50, 250)
.lineTo(150, 180)
.lineTo(250, 250)
.close();
// рисуем человечка
var head = stage.circle(330, 280, 10);
var neck = stage.path().moveTo(330, 290).lineTo(330, 300);
var kilt = stage.triangleUp(330, 320, 20);
var rightLeg = stage.path().moveTo(320, 330).lineTo(320, 340);
var leftLeg = stage.path().moveTo(340, 330).lineTo(340, 340);stage.path().moveTo(320, 330).lineTo(320, 340);), что позволяет сократить код. Использовать эту возможность нужно аккуратно, но при правильном подходе цепной вызов действительно делает код более компактным и легко читаемым.// раскрашиваем картинку
// элегантная рамка
frame.stroke(["red", "green", "blue"], 2, "2 2 2");
// кирпичные стены
walls.fill(acgraph.hatchFill('horizontalbrick'));
// соломенная крыша
roof.fill("#e4d96f");
// клетчатый килт
kilt.fill(acgraph.hatchFill('plaid'));// 169 - символьный код значка копирайта
var text = acgraph.text().text(String.fromCharCode(169)).opacity(0.2);
var pattern_font = stage.pattern(text.getBounds());
pattern_font.addChild(text);
// заполняем паттерном все изображение
frame.fill(pattern_font);// создаем рабочую область
var stage = acgraph.create("stage-container");
// цветовые палитры для листьев
var palette_fill = ['#5f8c3f', '#cb9226', '#515523', '#f2ad33', '#8b0f01'];
var palette_stroke = ['#43622c', '#8e661b', '#393b19', '#a97924', '#610b01'];
// счетчик
var leavesCounter = 0;stage.layer создадим слой для всей рабочей области и назначим последнему более низкий zIndex, чем у надписи.// создаем надпись для отображения счетчика
var counterLabel = stage.text(10,10, "Swiped: 0", {fontSize: 20});
// слой для листьев
var gameLayer = stage.layer().zIndex(counterLabel.zIndex()-1);function drawLeaf(x, y) {
// выбираем произвольный цвет из палитры
var index = Math.floor(Math.random() * 5);
var fill = palette_fill[index];
var stroke = palette_stroke[index];
// генерируем произвольные масштабирующий коэффициент и угол поворота
var scale = Math.round(Math.random() * 30) / 10 + 1;
var angle = Math.round(Math.random() * 360 * 100) / 100;
// создаем новый путь (лист)
var path = acgraph.path();
// задаем раскраску и рисуем лист
path.fill(fill).stroke(stroke, 1, 'none', 'round', 'round');
var size = 18;
path.moveTo(x, y)
.curveTo(x + size / 2, y - size / 2, x + 3 * size / 4, y + size / 4, x + size, y)
.curveTo(x + 3 * size / 4, y + size / 3, x + size / 3, y + size / 3, x, y);
// применяем произвольные трансформации
path.scale(scale, scale, x, y).rotate(angle, x, y);
return path;
};drawLeaf, перед оператором return:path.listen("mouseover", function(){
path.remove();
counterLabel.text("Swiped: " + leavesCounter++);
if (gameLayer.numChildren() < 200) shakeTree(300);
});if (gameLayer.numChildren() < 200) shakeTree(300); function shakeTree(n){
stage.suspend(); // приостанавливаем рендеринг
for (var i = 0; i < n; i++) {
var x = Math.random() * stage.width()/2 + 50;
var y = Math.random() * stage.height()/2 + 50;
gameLayer.addChild(drawLeaf(x, y)); // добавляем лист
}
stage.resume(); // возобновляем рендеринг
}// первый раз сбрасываем все листья
shakeTree(500);shakeTree().|
|
Фреймворк Jobs-To-Be-Done: наш опыт использования |
|
Метки: author Wriketeam управление разработкой управление проектами управление продуктом развитие стартапа блог компании wrike jtbd wrike wriketechclub odi jobstobedone |
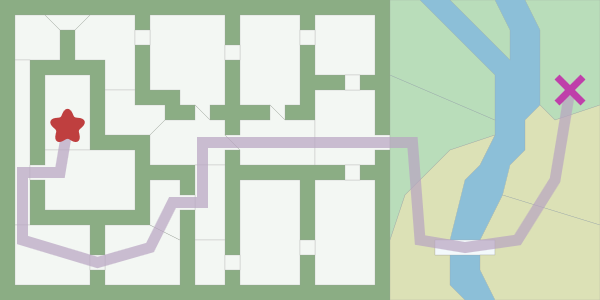
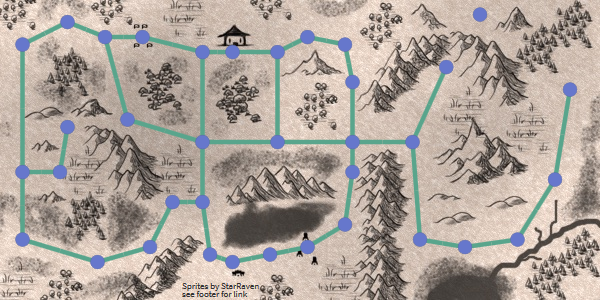
[Перевод] Введение в алгоритм A* |

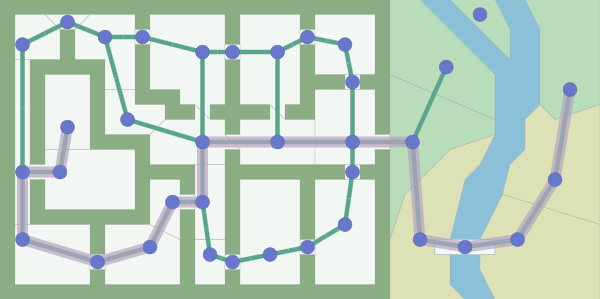

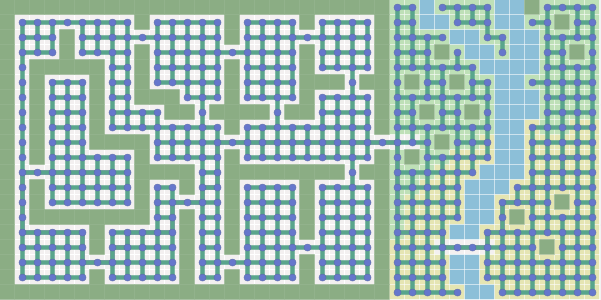



frontier = Queue()
frontier.put(start )
visited = {}
visited[start] = True
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in visited:
frontier.put(next)
visited[next] = Truevisited в came_from:frontier = Queue()
frontier.put(start )
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current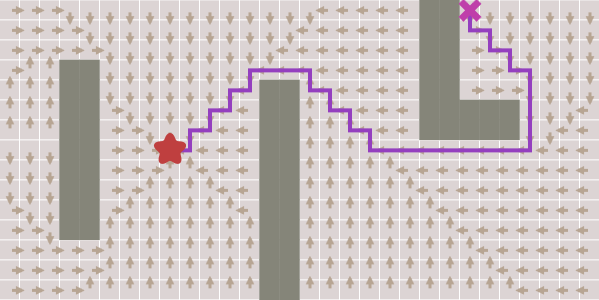
current = goal
path = [current]
while current != start:
current = came_from[current]
path.append(current)
path.append(start) # optional
path.reverse() # optional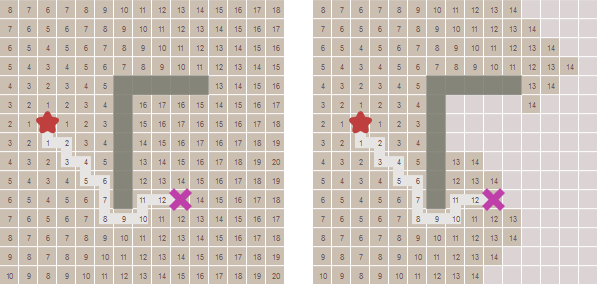
frontier = Queue()
frontier.put(start )
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
if next not in came_from:
frontier.put(next)
came_from[next] = current
cost_so_far, чтобы следить за общей стоимостью движения с начальной точки. При оценке точек нам нужно учитывать стоимость передвижения. Давайте превратим нашу очередь в очередь с приоритетами. Менее очевидно то, что у нас может получиться так, что одна точка посещается несколько раз с разной стоимостью, поэтому нужно немного поменять логику. Вместо добавления точки к границе в случае, когда точку ни разу не посещали, мы добавляем её, если новый путь к точке лучше, чем наилучший предыдущий путь.frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost
frontier.put(next, priority)
came_from[next] = currentdef heuristic(a, b):
# Manhattan distance on a square grid
return abs(a.x - b.x) + abs(a.y - b.y)cost_so_far из алгоритма Дейкстры:frontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
came_from[start] = None
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
if next not in came_from:
priority = heuristic(goal, next)
frontier.put(next, priority)
came_from[next] = currentfrontier = PriorityQueue()
frontier.put(start, 0)
came_from = {}
cost_so_far = {}
came_from[start] = None
cost_so_far[start] = 0
while not frontier.empty():
current = frontier.get()
if current == goal:
break
for next in graph.neighbors(current):
new_cost = cost_so_far[current] + graph.cost(current, next)
if next not in cost_so_far or new_cost < cost_so_far[next]:
cost_so_far[next] = new_cost
priority = new_cost + heuristic(goal, next)
frontier.put(next, priority)
came_from[next] = current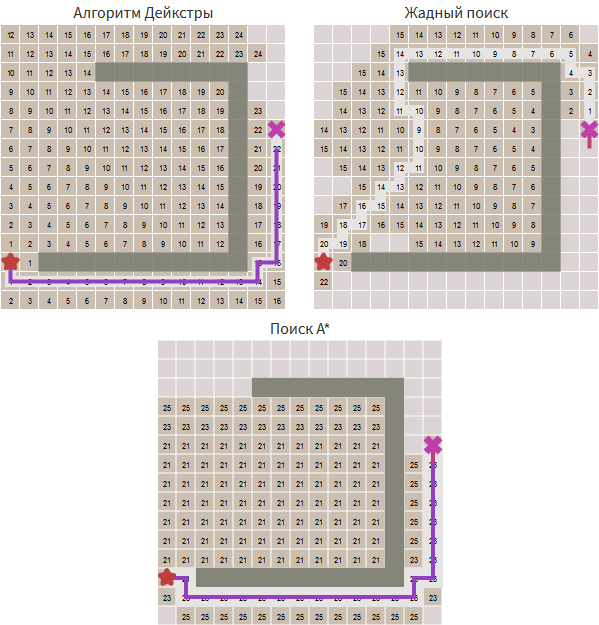
|
Метки: author PatientZero разработка игр алгоритмы алгоритмы поиска пути поиск в ширину алгоритм дейкстры a* |
Надстройка над биткойн-блокчейном — Lightning Network |
 / изображение Iraia Mart'inez CC
/ изображение Iraia Mart'inez CC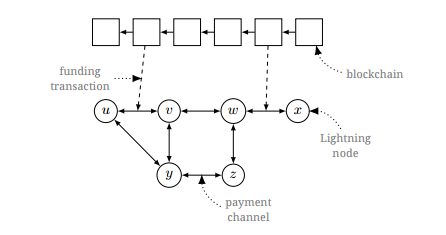
|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury lightning network |
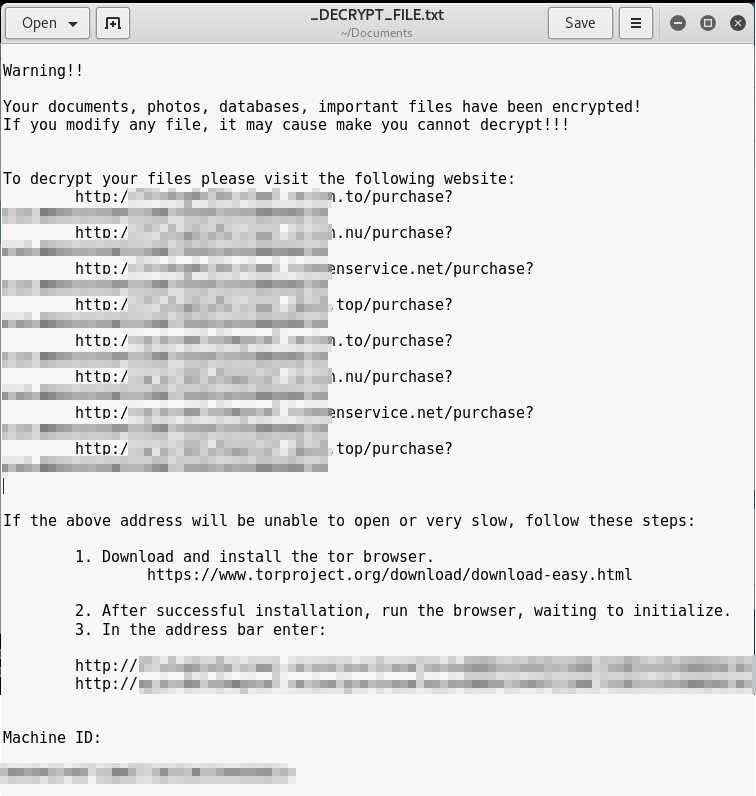
[Перевод] Хостинг-провайдер заплатил миллион долларов хакерам-вымогателям |

Мой босс сказал мне дать вам хорошую цену, так как вы покупаете много машин,
550 BTC
Если у вас недостаточно денег, вам нужно взять кредит
У вас 40 сотрудников,
Годовой оклад каждого сотрудника 30 000 долларов США
Все сотрудники 30 000 * 40 = $ 1 200 000
Все сервера 550BTC = $ 1,620,000
Если вы не можете заплатить, вы банкрот.
Вам придётся смотреть в глаза своим детям, жене, клиентам и сотрудникам.
Также вы потеряете вашу репутацию и бизнес.
Вы получите множество судебных исков.

| Header (0x438 bytes) |
| RSA-2048-encrypted original filename |
| RSA-2048-encrypted AES key |
| AES-encrypted RC4 key |
| RC4-encrypted data |
| Included directories: | Excluded directories: |
| var/www/ | $/bin/ |
| Included files: | $/boot/ |
| ibdata0 | $/dev/ |
| ibdata1 | $/etc/ |
| ibdata2 | $/lib/ |
| ibdata3 | $/lib64/ |
| ibdata4 | $/proc/ |
| ibdata5 | $/run/ |
| ibdata6 | $/sbin/ |
| ibdata7 | $/srv/ |
| ibdata8 | $/sys/ |
| ibdata9 | $/tmp/ |
| ib_logfile0 | $/usr/ |
| ib_logfile1 | $/var/ |
| ib_logfile2 | /.gem/ |
| ib_logfile3 | /.bundle/ |
| ib_logfile4 | /.nvm/ |
| ib_logfile5 | /.npm/ |
|
|
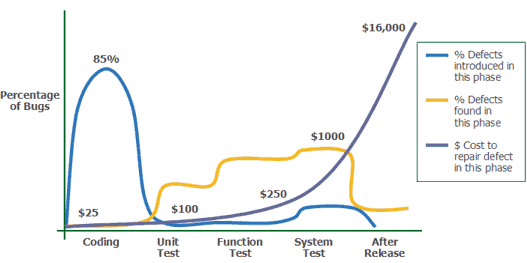
Как PVS-Studio может помочь в поиске уязвимостей? |


| CWE | PVS-Studio | CWE Description |
|---|---|---|
| CWE-14 | V597 | Compiler Removal of Code to Clear Buffers |
| CWE-36 | V631, V3039 | Absolute Path Traversal |
| CWE-121 | V755 | Stack-based Buffer Overflow |
| CWE-122 | V755 | Heap-based Buffer Overflow |
| CWE-123 | V575 | Write-what-where Condition |
| CWE-129 | V557, V781, V3106 | Improper Validation of Array Index |
| CWE-190 | V636 | Integer Overflow or Wraparound |
| CWE-193 | V645 | Off-by-one Error |
| CWE-252 | V522, V575 | Unchecked Return Value |
| CWE-253 | V544, V545, V676, V716, V721, V724 | Incorrect Check of Function Return Value |
| CWE-390 | V565 | Detection of Error Condition Without Action |
| CWE-476 | V522, V595, V664, V757, V769, V3019, V3042, V3080, V3095, V3105, V3125 | NULL Pointer Dereference |
| CWE-481 | V559, V3055 | Assigning instead of comparing |
| CWE-482 | V607 | Comparing instead of Assigning |
| CWE-587 | V566 | Assignment of a Fixed Address to a Pointer |
| CWE-369 | V609, V3064 | Divide By Zero |
| CWE-416 | V723, V774 | Use after free |
| CWE-467 | V511, V512, V568 | Use of sizeof() on a Pointer Type |
| CWE-805 | V512, V594, V3106 | Buffer Access with Incorrect Length Value |
| CWE-806 | V512 | Buffer Access Using Size of Source Buffer |
| CWE-483 | V640, V3043 | Incorrect Block Delimitation |
| CWE-134 | V576, V618, V3025 | Use of Externally-Controlled Format String |
| CWE-135 | V518, V635 | Incorrect Calculation of Multi-Byte String Length |
| CWE-462 | V766, V3058 | Duplicate Key in Associative List (Alist) |
| CWE-401 | V701, V773 | Improper Release of Memory Before Removing Last Reference ('Memory Leak') |
| CWE-468 | V613, V620, V643 | Incorrect Pointer Scaling |
| CWE-588 | V641 | Attempt to Access Child of a Non-structure Pointer |
| CWE-843 | V641 | Access of Resource Using Incompatible Type ('Type Confusion') |
| CWE-131 | V512, V514, V531, V568, V620, V627, V635, V641, V645, V651, V687, V706, V727 | Incorrect Calculation of Buffer Size |
| CWE-195 | V569 | Signed to Unsigned Conversion Error |
| CWE-197 | V642 | Numeric Truncation Error |
| CWE-762 | V611, V780 | Mismatched Memory Management Routines |
| CWE-478 | V577, V719, V622, V3002 | Missing Default Case in Switch Statement |
| CWE-415 | V586 | Double Free |
| CWE-188 | V557, V3106 | Reliance on Data/Memory Layout |
| CWE-562 | V558 | Return of Stack Variable Address |
| CWE-690 | V522, V3080 | Unchecked Return Value to NULL Pointer Dereference |
| CWE-457 | V573, V614, V730, V670, V3070, V3128 | Use of Uninitialized Variable |
| CWE-404 | V611, V773 | Improper Resource Shutdown or Release |
| CWE-563 | V519, V603, V751, V763, V3061, V3065, V3077, V3117 | Assignment to Variable without Use ('Unused Variable') |
| CWE-561 | V551, V695, V734, V776, V779, V3021 | Dead Code |
| CWE-570 | V501, V547, V517, V560, V625, V654, V3022, V3063 | Expression is Always False |
| CWE-571 | V501, V547, V560, V617, V654, V694, V768, V3022, V3063 | Expression is Always True |
| CWE-670 | V696 | Always-Incorrect Control Flow Implementation |
| CWE-674 | V3110 | Uncontrolled Recursion |
| CWE-681 | V601 | Incorrect Conversion between Numeric Types |
| CWE-688 | V549 | Function Call With Incorrect Variable or Reference as Argument |
| CWE-697 | V556, V668 | Insufficient Comparison |
Таблица N1 — Черновой вариант таблицы соответствий CWE и диагностик PVS-Studio



static int devzvol_readdir(....)
{
....
char *ptr;
....
ptr = strchr(ptr + 1, '/') + 1;
rw_exit(&sdvp->sdev_contents);
sdev_iter_datasets(dvp, ZFS_IOC_DATASET_LIST_NEXT, ptr);
....
}....
if (NasConfig.DoDaemon) { /* daemons use syslog */
openlog("nas", LOG_PID, LOG_DAEMON);
syslog(LOG_DEBUG, buf);
closelog();
} else {
errfd = stderr;
....void syslog(int priority, const char *format, ...);syslog(LOG_DEBUG, "%s", buf);vl->data = calloc(vl->size, sizeof(WORD));
temp_word = SwapWord((BYTE*)d, sizeof(WORD));
memcpy(vl->data, &temp_word, vl->size);
typedef char my_bool;
my_bool
check_scramble(const char *scramble_arg, const char *message,
const uint8 *hash_stage2)
{
....
return memcmp(hash_stage2, hash_stage2_reassured, SHA1_HASH_SIZE);
}
static OSStatus
SSLVerifySignedServerKeyExchange(SSLContext *ctx,
bool isRsa,
SSLBuffer signedParams,
uint8_t *signature,
UInt16 signatureLen)
{
OSStatus err;
....
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
....
fail:
SSLFreeBuffer(&signedHashes);
SSLFreeBuffer(&hashCtx);
return err;
}

|
|
Почему стоит полностью переходить на Ceylon или Kotlin (часть 2) |
Продолжаем рассказ о языке цейлон. В первой части статьи Сeylon выступал как гость на поле Kotlin. То есть брались сильные стороны и пытались их сравнить с Ceylon.
В этой части Ceylon выступит как хозяин, и перечислим те вещи, которые близки к уникальным и которые являются сильными сторонами Ceylon.
Поехали:
18# Типы — объединения (union types)
В большинстве языков программирования функция может может возвратить значения строго одного типа.
function f() {
value rnd = DefaultRandom().nextInteger(5);
return
switch(rnd)
case (0) false
case (1) 1.0
case (2) "2"
case (3) null
case (4) empty
else ComplexNumber(1.0, 2.0);
}
value v = f();Какой реальный тип будет у v? В Kotlin или Scala тип будет Object? или просто Object, как наиболее общий из возможных вариантов.
В случае Ceylon тип будет Boolean|Float|String|Null|[]|ComplexNumber.
Исходя из этого знания, если мы, допустим, попробуем выполнить код
if (is Integer v) { ...} //Не скомпилируется, v не может физически быть такого типа
if (is Float v) { ...} //Все нормально
Что это дает на практике?
Во первых, вспомним про checked исключения в Java. В Kotlin, Scala и других языках по ряду причин от них отказались. Однако потребность декларировать, что функция или метод может вернуть какое то ошибочное значение никуда не делась. Как и никуда не делась потребность обязать пользователя как то обработать ошибочную ситуацию.
Соответственно можно, например, написать:
Integer|Exception p = Integer.parse("56");И далее пользователь обязан как то обработать ситуацию, когда вместо p вернется исключение.
Можно выполнить код, и прокинуть далее исключение:
assert(is Integer p);Или мы можем обработать все возможные варианты через switch:
switch(p)
case(is Integer) {print(p);}
else {print("ERROR");}Все это позволяет писать достаточно лаконичный и надежный код, в котором множество потенциальных ошибок проверяется на этапе компиляции. Исходя из опыта использования, union types — это реально очень удобно, очень полезно, и это то, чего очень не хватает в других языках.
Также за счет использования union types в принципе можно жить без функционала перегрузки операторов. В Ceylon это убрали с целью упрощения языка, за счет чего удалось добиться весьма чистых и простых лямбд.
19# Типы — пересечения (Intersection types)
Рассмотрим код:
interface CanRun {
shared void run() => print("I am running");
}
interface CanSwim {
shared void swim() => print("I am swimming");
}
interface CanFly {
shared void fly() => print("I am flying");
}
class Duck() satisfies CanRun & CanSwim & CanFly {}
class Pigeon() satisfies CanRun & CanFly {}
class Chicken() satisfies CanRun {}
class Fish() satisfies CanSwim {}
void f(CanFly & CanSwim arg) {
arg.fly();
arg.swim();
}
f(Duck()); //OK Duck can swim and fly
f(Fish());//ERROR = fish can swim onlyМы объявили функцию, принимающую в качестве аргумента объект, который должен одновременно уметь и летать и плавать.
И мы можем без проблем вызывать соответствующие методы. Если мы передадим в эту функцию объект класса Duck — все хорошо, так как утка может и летать и плавать.
Если же мы передадим объект класса Fish — у нас ошибка компиляции, ибо рыба может только плавать, но не летать.
Используя эту особенность, мы можем ловить множество ошибок в момент компиляции, при этом мы можем пользоваться многими полезными техниками из динамических языков.
20# Типы — перечисления (enumerated types)
Можно создать абстрактный класс, и у которого могут быть строго конкретные наследники. Например:
abstract class Point()
of Polar | Cartesian {
// ...
}В результате можно писать обработчики в switch не указывая else
void printPoint(Point point) {
switch (point)
case (is Polar) {
print("r = " + point.radius.string);
print("theta = " + point.angle.string);
}
case (is Cartesian) {
print("x = " + point.x.string);
print("y = " + point.y.string);
}
}В случае, если в дальнейшем при развитии продукта мы добавим еще один подтип, компилятор найдет за нас те места, где мы пропустили явную обработку добавленного типа. В результате мы сразу поймаем ошибки в момент компиляции и их подсветит IDE.
С помощью данного функционала в Ceylon делается аналог enum в Java:
shared abstract class Animal(shared String name) of fish | duck | cat {}
shared object fish extends Animal("fish") {}
shared object duck extends Animal("duck") {}
shared object cat extends Animal("cat") {}В результате мы получаем функционал enum практически не прибегая к дополнительным абстракциям.
Если нужен функционал, аналогичный valueOf в Java, мы можем написать:
shared Animal fromStrToAnimal(String name) {
Animal? res = `Animal`.caseValues.find((el) => el.name == name);
assert(exists res);
return res;
}Соответствующие варианты enum можно использовать в switch и т.д, что во многих случаях помогает находить потенциальные ошибки в момент компиляции.
23# Алиасы типов (Type aliases)
Ceylon является языков с весьма строгой типизацией. Но иногда тип может быть довольно громоздким и запутанным. Для улучшения читаемости можно использовать алиасы типов:
Например можно сделать алиас интерфейса, в результате чего избавиться от необходимости указания типа дженерика:
interface People => Set; Для типов объединений или пересечений можно использовать более короткое наименование:
alias Num => Float|Integer;Или даже:
alias ListOrMap => List|Map; Можно сделать алиасы на интерфейс:
interface Strings => Collection; Или на класс, причем класс с конструктором:
class People({Person*} people) => ArrayList(people);
Также планируется алиас класса на кортеж.
За счет алиасов можно во многих местах не плодить дополнительные классы или интерфейсы и добиться большей читаемости кода.
21# Кортежи
В цейлоне очень хорошая поддержка кортежей, они органично встроены в язык. В Kotlin посчитали, что они не нужны. В Scala они сделаны с ограничениями по размеру. В Ceylon кортежи представляют собой связанный список, и соответственно могут быть произвольного размера. Хотя в реальности использование кортежей из множества разнотипных элементов это весьма спорная практика, достаточно длинные кортежи могут понадобиться, например, при работе со строками таблиц баз данных
Рассмотрим пример:
value t = ["Str", 1, 2.3];
Тип будет довольно читаемым — [String, Integer, Float]
А теперь самое вкусное — деструктуризация. Если мы получили кортеж, то можно легко получить конкретные значения. Синтаксис по удобству будет практически как в Python:
value [str, intVar, floatType] = t;
value [first, *rest] = t;
value [i, f] = rest;Деструктуризацию можно проводить внутри лямбд, внутри switch, внутри for — выглядит это достаточно читаемо. На практике за счет функционала кортежей и деструктуризации во многих случаях можно отказаться от функционала классов практически без ущерба читаемости и типобезопасности кода, это позволяет очень быстро писать прототипы как в динамических языках, но совершать меньше ошибок.
22# Конструирование коллекций (for comprehensions)
Очень полезная особенность, от которой сложно отказаться после того, как ее освоил.
Попробуем проитерировать от 1 до 25 с шагом 2, исключая элементы делящиеся без остатка на 3 и возведем их в квадрат.
Рассмотрим код на python:
res = [x**2 for x in xrange(1, 25, 2) if x % 3 != 0]На Ceylon можно писать в подобном стиле:
value res = [for (x in (1:25).by(2)) if ( (x % 3) != 0) x*x];
Можно тоже самое сделать лениво:
value res = {for (x in (1:25).by(2)) if ( (x % 3) != 0) x*x};
Синтаксис работает в том числе с коллекциями:
value m = HashMap { for (i in 1..10) i -> i + 1 };К сожалению пока нет возможности так элегантно конструировать Java коллекции. Пока из коробки синтаксис будет выглядеть как:
value javaList = Arrays.asList(*ObjectArray.with { for (i in 1..10) i}); Но написать функции, которые конструируют Java коллекции можно самостоятельно очень быстро. Синтаксис в этом случае будет как:
value javaConcurrentHashMap = createConcurrentHashMap {for (i in 1..10) i -> i + 1};22# Модульность и Ceylon Herd
Задолго до выхода Java 9 в Ceylon существовала модульность.
module myModule "3.5.0" {
shared import ceylon.collection "1.3.2";
import ceylon.json "1.3.2";
}Система модулей уже интегрирована с maven, соответственно зависимости можно импортировать традиционными средствами. Но вообще, для Ceylon рекомендуется использовать не Maven артефакторий, а Ceylon Herd. Это отдельный сервер (который можно развернуть и локально), который хранит артефакты. В отличие от Maven, здесь можно сразу хранить документацию, а также Herd проверяет все зависимости модулей.
Если все делать правильно, получается уйти от jar hell, весьма распространенный в Java проектах.
По умолчанию модули иерархичны, каждый модуль загружается через иерархию Class Loaders. В результате мы получаем защиту, что один класс будет по одному и тому же пути в ClassPath. Можно включить поведение, как в Java, когда classpath плоский — это бывает нужно когда мы используем Java библиотеки для сериализации. Ибо при десериализации ClassLoader библиотеки не сможет загрузить класс, в который мы десериализуем, так как модуль библиотеки сериализации не содержит зависимостей на модуль, в котором определен класс, в который мы десериализуем.
24# Улучшенные дженерики
В Ceylon нет Erasure. Соответственно можно написать:
switch(obj)
case (is List) {print("this is list of string)};
case (is List) {print("this is list of Integer)}; Можно для конкретного метода узнать в рантайме тип:
shared void myFunc() given T satisfies Object {
Type tclass = `T`;
//some actions with tClass Есть поддержка self types. Предположим, мы хотим сделать интерфейс Comparable, который умеет сравнивать элемент как с собой, так и себя с другим элементом. Попытаемся ограничить типы традиционными средствами:
shared interface Comparable
given Other satisfies Comparable {
shared formal Integer compareTo(Other other);
shared Integer reverseCompareTo(Other other) {
return other.compareTo(this); //error: this not assignable to Other
}
} Не получилось! В одну сторону compareTo работает без проблем. А в другую не получается!
А теперь применим функционал self types:
shared interface Comparable of Other
given Other satisfies Comparable {
shared formal Integer compareTo(Other other);
shared Integer reverseCompareTo(Other other) {
return other.compareTo(this);
}
} Все компилируется, мы можем сравнивать объекты строго одного типа, работает!
Также для дженериков гораздо более компактный синтаксис, поддержка ковариантности и контравариантности, есть типы по умолчанию:
shared interface Iterable ... В результате снова имеем гораздо лучшую и строгую типизацию по сравнению с Java. Правда некоторыми особенностями в узких местах программы пользоваться не рекомендуется, получение информации о типах в рантайме не бесплатно. Но в некритичных по скорости местах это может быть очень полезно.
24# Метамодель
В Ceylon мы в рантайме можем очень детально проинспектировать весьма многие элементы программы. Мы можем проинспектировать поля класса, мы можем проинспектировать атрибут, конкретный пакет, модуль, конкретный обобщенный тип и тому подобное.
Рассмотрим некоторые варианты:
ClassWithInitializerDeclaration v = `class Singleton`;
InterfaceDeclaration v =`interface List`;
FunctionDeclaration v =`function Iterable.map`;
FunctionDeclaration v =`function sum`;
AliasDeclaration v =`alias Number`;
ValueDeclaration v =`value Iterable.size`;
Module v =`module ceylon.language`;
Package v =`package ceylon.language.meta`;
Class,[String]> v =`Singleton`;
Interface> v =`List`;
Interface<{Object+}> v =`{Object+}`;
Method<{Anything*},{String*},[String(Anything)]> v =`{Anything*}.map`;
Function v =`sum`;
Attribute<{String*},Integer,Nothing> v =`{String*}.size`;
Class<[Float, Float, String],[Float, [Float, String]]> v =`[Float,Float,String]`;
UnionType v =`Float|Integer`; Здесь v — объект метамодели, который мы можем проинспектировать. Например мы можем создать экземпляр, если это класс, мы можем вызвать функцию с параметром, если это функция, мы можем получить значение, если это атрибут, мы можем получить список классов, если это пакет и т.д. При этом справа от v стоит не строка, и компилятор проверит, что мы правильно сослались на элемент программы. То есть в Ceylon мы по существу имеем типобезопасную рефлексию. Соответственно благодаря метамодели мы можем написать весьма гибкие фреймворки.
Для примера, найдем средствами языка, без привлечения сторонних библиотек, все экземпляры класса в текущем модуле, которые имплементят определенный интерфейс:
shared interface DataCollector {}
service(`interface DataCollector`)
shared class DataCollectorUserV1() satisfies DataCollector {}
shared void example() {
{DataCollector*} allDataCollectorsImpls = `module`.findServiceProviders(`DataCollector`);
}Соответственно достаточно тривиально реализовать такие вещи, как инверсия зависимостей, если нам это реально нужно.
#25 Общий дизайн языка
На самом деле, сам язык весьма строен и продуман. Многие достаточно сложные вещи выглядят интуитивно и однородно
Рассмотрим, например, синтаксис прямоугольных скобок:
[] unit = [];
[Integer] singleton = [1];
[Float,Float] pair = [1.0, 2.0];
[Float,Float,String] triple = [0.0, 0.0, "origin"];
[Integer*] cubes = [ for (x in 1..100) x^3 ];В Scala, эквивалентный код будет выглядеть следующим образом:
val unit: Unit = ()
val singleton: Tuple1[Long] = new Tuple1(1)
val pair: (Double,Double) = (1.0, 2.0)
val triple: (Double,Double,String) = (0.0, 0.0, "origin")
val cubes: List[Integer] = ... В язык очень органично добавлены аннотации synchronized, native, variable, shared и т.д — это все выглядит как ключевые слова, но по существу это обычные аннотации. Ради аннотаций, чтобы не требовалось добавлять знак @ в Ceylon даже пришлось пожертвовать синтаксисом — к сожалению точка с запятой является обязательной. Соответственно Ceylon сделан таким образом, чтобы код, предполагающий использование уже существующих распространенных Java библиотеки вроде Spring, Hibernate, был максимально приятным для глаз.
Например посмотрим как выглядит использование Ceylon с JPA:
shared entity class Employee(name) {
generatedValue id
shared late Integer id;
column { lenght = 50;}
shared String name;
column
shared variable Integer? year = null;
}Это уже заточено на промышленное использование языка с уже существующими Java библиотеками, и здесь мы получаем весьма приятный для глаза синтаксис.
Посмотрим как будет выглядеть код Criteria API:
shared List employeesForName(String name) {
value crit = entityManager.createCriteria();
return
let (e = crit.from(`Employee`))
crit.where(equal(e.get(`Employee.name`),
crit.parameter(name))
.select(e)
.getResultList();
} По сравнению с Java мы здесь получаем типобезопасность и более компактный синтаксис. Именно для промышленных приложений типобезопасность очень важна. Особенно для тяжелых сложных запросов.
Итого, в данной статье мы играли на поле Ceylon и рассмотрели некоторые особенности языка, которые выгодно выделяют его на фоне конкурентов.
В следующей, заключительной части, попробуем поговорить не о языке как таковом, а об организационных аспектах и возможностях использовать Ceylon и других JVM языков в реальных проектах.
Ceylon on android https://www.youtube.com/watch?v=zBtSimUYALU
Ceylon swarm https://ceylon-lang.org/community/presentations/ceylon-swarm.pdf
|
Метки: author elmal программирование kotlin java ceylon |
CocoaHeads Russia в офисе Туту.ру |




|
Метки: author 0xy разработка под ios блог компании туту.ру сходка cocoaheads tutu.ru митап |
«Мое самое главное испытание – не сломать драйвер» — Dave Cramer о разработке драйвера JDBC для PostgreSQL |

|
Метки: author rdruzyagin sql postgresql java блог компании pg day'17 russia jdbc logical decoding pl/java pl/j dave cramer interview интервью |
Yet another вариант отправки уведомлений от Asterisk в Telegram |

yum -y update
yum groupinstall -y 'development tools'
yum install -y zlib-dev openssl-devel sqlite-devel bzip2-devel
yum install xz-libswget http://www.python.org/ftp/python/2.7.6/Python-2.7.6.tar.xz
xz -d Python-2.7.6.tar.xz
tar -xvf Python-2.7.6.tarcd Python-2.7.6
./configure --prefix=/usr/local/bin (префикс можно ставить любой удобный вам, к примеру импортировать его из переменной $HOME)
make
make altinstallПеред установкой необходиом скачать и установить setuptools
wget --no-check-certificate https://pypi.python.org/packages/source/s/setuptools/setuptools-1.4.2.tar.gz
tar -xvf setuptools-1.4.2.tar.gz
cd setuptools-1.4.2
python2.7 setup.py install
и сам pip
curl https://bootstrap.pypa.io/get-pip.py | python2.7 -rpm -ivh http://dl.iuscommunity.org/pub/ius/stable/Redhat/6/x86_64/epel-release-6-5.noarch.rpm
rpm -ivh http://dl.iuscommunity.org/pub/ius/stable/Redhat/6/x86_64/ius-release-1.0-14.ius.el6.noarch.rpm
yum clean all
yum install python27
yum install python27-pippip2.7 install pyTelegramBotAPI==2.3.1
#!/usr/local/bin/python2.7
# -*- coding: utf-8 -*-
import telebot
import sys
token = 'INSERT_YOUR_TOKEN' # Вводим свой телеграм API токен
group_id = -123456789 # Вводим id группы, куда надо слать сообщения (обратите внимание, что id группы - отрицательное целое число)
bot = telebot.TeleBot(token, skip_pending=True)
# Ловим команду старта при старте без аргументов (первый старт)
@bot.message_handler(func=lambda message: True, commands=['start'])
def start(message):
if len(sys.argv) != 1:
return
bot.send_message(message.chat.id, "ID чата: " + str(message.chat.id))
print message.chat.id
sys.exit()
# Если были переданы три аргумента, то возвращаем в чат сообщение
if len(sys.argv) == 4:
callerid = str(sys.argv[1])
exten = str(sys.argv[2])
redirectnum = str(sys.argv[3])
bot.send_message(group_id, "Вызов с номера " + callerid + "\nна номер " + exten + "\nпереадресован на номер " + redirectnum)
# Если аргумента нет, то считаем первым стартом и запускаем в режиме полинга
if len(sys.argv) == 1:
bot.polling(none_stop=True) exten => 84951234567,1,Set(CALLERID(num)=+7${CALLERID(num)})
same => n,Answer()
same => n,Playback(hello)
same => n,Set(REDIRECTNUM=+79261234567)
same => n,System(/etc/asterisk/redirector/redirector.py ${CALLERID(num)} +7${EXTEN:1} ${REDIRECTNUM})
same =>n,Dial(SIP/mytrunk/mymobilenumer&SIP/mytrunk/mymobilenumber2,40,tTm(default))
same =>n,Hangup()
|
Метки: author sfw asterisk блог компании southbridge telegram python 2.7 telegram api telegram bots |
Мальта как новое направление для IT специалистов |



|
|
Краткое описание BPMN с примером |
 О том, что такое BPMN, написано очень много. Но проблема в том, что почти вся информация, которую можно найти в Интернет, ориентирована на людей, которые уже ранее сталкивались с BPMN или с другим стандартом моделирования бизнес-процессов. Я же предлагаю разобраться «с нуля» — что такое BPMN? В чем особенности и преимущества этой технологии и почему она появилась и оказалась столь востребованной, по крайней мере, за рубежом. Да и у нас в стране ей все больше и больше интересуются.
О том, что такое BPMN, написано очень много. Но проблема в том, что почти вся информация, которую можно найти в Интернет, ориентирована на людей, которые уже ранее сталкивались с BPMN или с другим стандартом моделирования бизнес-процессов. Я же предлагаю разобраться «с нуля» — что такое BPMN? В чем особенности и преимущества этой технологии и почему она появилась и оказалась столь востребованной, по крайней мере, за рубежом. Да и у нас в стране ей все больше и больше интересуются.Важно понимать: BPMN не является языком описания IT-систем. Эта нотация предназначена для описания предметной области реального бизнеса. И здесь могут быть задействованы как программные системы, так и люди (сотрудники компании, заказчики, поставщики). Это самое главное отличие этой нотации от графических инструментов для описания программ.





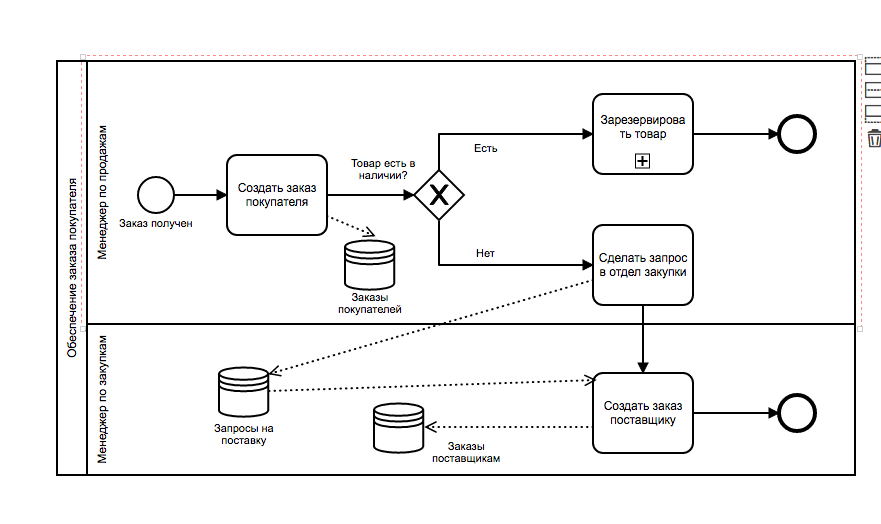
|
Метки: author JustRamil управление проектами терминология it бизнес-модели bpmn bpm bpm- системы |
История неожиданного «окирпичивания» и восстановления одного смартфона |

dd — это опечатка или ошибка при наборе пути к разделу. Сейчас мне только остается удивляться собственной неосторожности (или криворукости, называйте, как хотите), но именно это и произошло… Раздел EFS на данном девайсе – это /dev/block/mmcblk0p7, но я почему-то в тот момент не имел ни тени сомнения, что это, якобы, должен быть /dev/block/mmcblk0p6. Собственно, дальнейшее не требует особых объяснений, обо всей катастрофичности произошедшего я уже понял только тогда, когда dd вывел сообщение о том, что при записи был достигнут конец раздела. Вроде далеко не первый год пользуюсь устройством и являюсь одним из тех немногих оставшихся разработчиков под этот богом забытый девайс. Как же я мог оказаться в такой, с какой стороны не посмотри, дурацкой ситуации? Не спрашивате меня, самому хотелось бы знать… Так телефон с легкой руки стал если не «кирпичом», то «инвалидом» точно.root@:/ # cd ramdisk
root@:/ramdisk # ./cspsa-cmd
[CSPSA]: open CSPSA0
[CSPSA]:
[CSPSA]:
[CSPSA]: ls
Key Size
0 4
1 96
2 96
3 96
1000 38
66048 497
-8192 41
-4 4
-3 4
-2 4
-1 4
Number of keys in CSPSA : 11
Total size of all values: 884
[CSPSA]: read_to_file 3e8 /sdcard/1000.bin
[CSPSA]: (...)
static const struct {
const char *str;
cops_return_code_t (*func)(cops_context_id_t *ctx,
int *argc, char **argv[]);
} api_funcs[] = {
{"read_imei", cmd_read_imei},
{"bind_properties", cmd_bind_properties},
{"read_data", cmd_read_data},
{"get_nbr_of_otp_rows", cmd_get_nbr_of_otp_rows},
{"read_otp", cmd_read_otp},
{"write_otp", cmd_write_otp},
{"authenticate", cmd_authenticate},
{"deauthenticate", cmd_deauthenticate},
{"get_challenge", cmd_get_challenge},
{"modem_sipc_mx", cmd_modem_sipc_mx},
{"unlock", cmd_simlock_unlock},
{"lock", cmd_simlock_lock},
{"ota_ul", cmd_ota_simlock_unlock},
{"get_status", cmd_simlock_get_status},
{"key_ver", cmd_verify_simlock_control_keys},
{"get_device_state", cmd_get_device_state},
{"verify_imsi", cmd_verify_imsi},
{"bind_data", cmd_bind_data},
{"verify_data_binding", cmd_verify_data_binding},
{"verify_signed_header", cmd_verify_signed_header},
{"calcdigest", cmd_calcdigest},
{"lock_bootpartition", cmd_lock_bootpartition},
{"init_arb_table", cmd_init_arb_table},
{"write_secprofile", cmd_write_secprofile},
{"change_simkey", cmd_change_simkey},
{"write_rpmb_key", cmd_write_rpmb_key},
{"get_product_debug_settings", cmd_get_product_debug_settings}
};
(...)
cops_cmd read_imei — точно сейчас не вспомню, выдало, что-то вроде «error 13, device is tampered». Ага, конечно, чего еще можно было ожидать, с запоротым-то разделом CSPSA. Недолгое чтение исходников привело к команде «bind_properties»:static cops_return_code_t cmd_bind_properties(cops_context_id_t *ctx,
int *argc, char **argv[])
{
cops_return_code_t ret_code;
cops_imei_t imei;
(...)
usage:
(...)
fprintf(stderr,
"Usage: bind_properties imei (15 digits)\n"
"Usage: bind_properties keys (keys are space delimited)\n"
"Usage: bind_properties auth_data \n"
"Usage: bind_properties data \n");
return COPS_RC_ARGUMENT_ERROR;
}
#TA Loader to write default IMEI
service ta_load /system/bin/ta_loader recovery
user root
group radio
oneshot
/system/bin/ta_loader recovery
sed -i "s,<15_zeroes>,," /ramdisk/ta_loader
sed -i "s,0,<16_zeroes>," /ramdisk/ta_loader
|
Метки: author RadicalDreamer реверс-инжиниринг разработка под android android samsung кирпич brick восстановление |
Автомонтирование файловых систем с systemd |
/etc/systemd/system/media-nfs.mount:[Unit] Description=NFS share [Mount] What=server.url.example.com:/srv/nfs_share Where=/media/nfs Type=nfs4 Options=rw DirectoryMode=0755
/etc/systemd/system/media-nfs.automount:[Unit] Description=NFS share Requires=openvpn@vpn.service Requires=network-online.target [Automount] Where=/media/nfs TimeoutIdleSec=301 [Install] WantedBy=graphical.target
|
Метки: author amarao системное администрирование серверное администрирование настройка linux *nix systemd desktop linux howto fstab mount automount |






