Наш опыт с Kubernetes в небольших проектах (обзор и видео доклада) |


apiVersion: v1
kind: Pod
metadata:
name: manual-bash
spec:
containers:
- name: bash
image: ubuntu:16.04
command: bash
args: [-c, "while true; do sleep 1; date; done"]apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: backend
spec:
replicas: 3
selector:
matchLabels:
tier: backend
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: fpm
image: myregistry.local/backend:0.15.7
command: php-fpm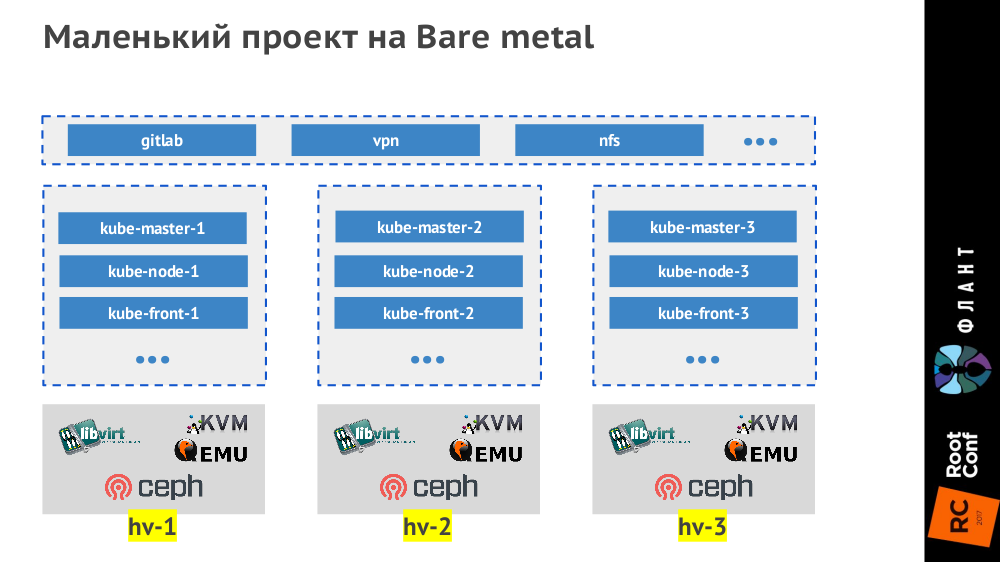
kube-front-X):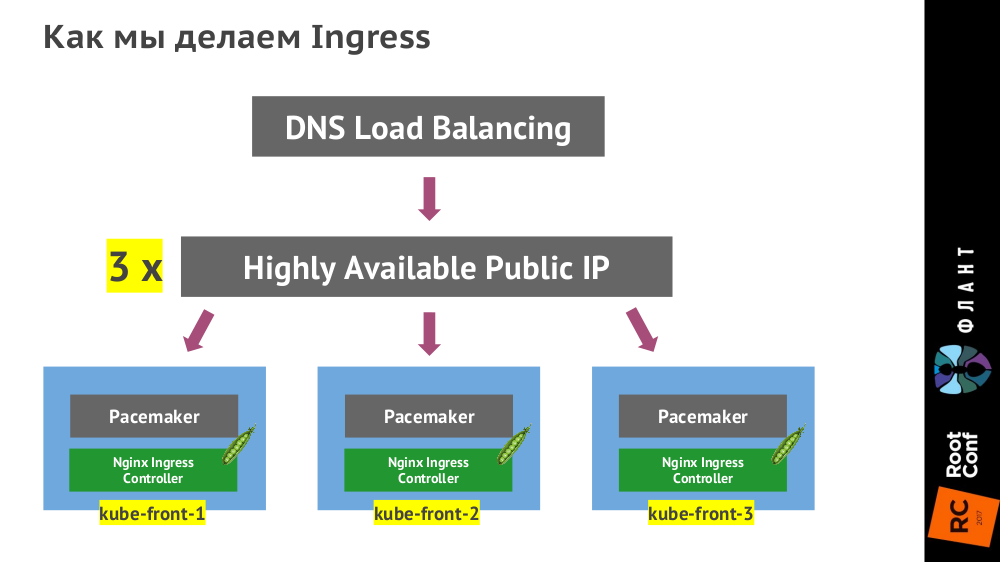
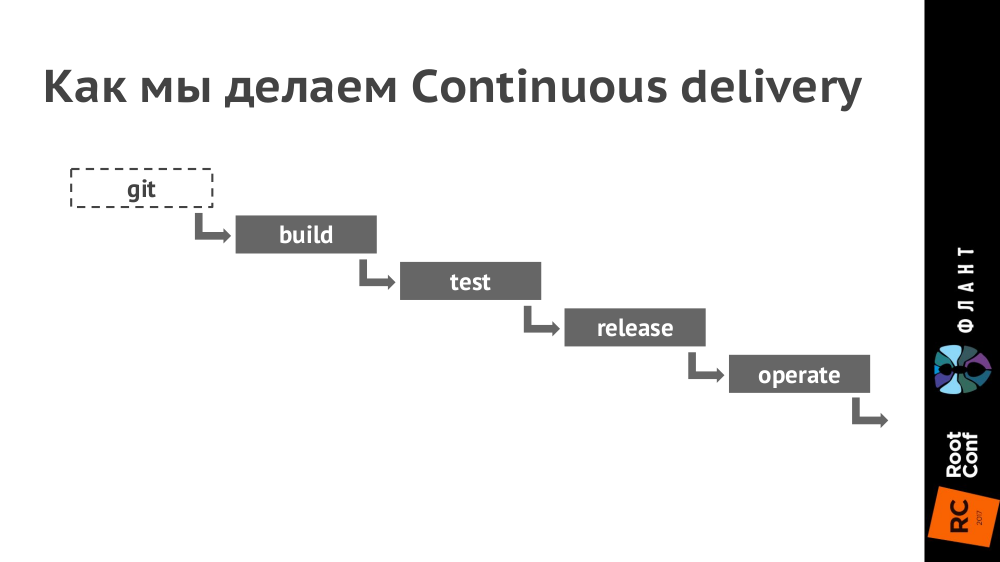


|
|
Биробиджан на светлой стороне: как мы за свои деньги город осветили |
|
Метки: author Artem_Rimer it- инфраструктура блог компании гк ланит уличное освещение проектирование инженерные работы ланит освещение системная интеграция |
[Перевод] CSS: введение в единицу длины 'fr' |

.grid {
display: grid;
grid-template-columns: repeat(4, 25%);
grid-column-gap: 10px;
}
.grid {
display: grid;
grid-template-columns: repeat(4, 1fr);
grid-column-gap: 10px;
}
.grid {
display: grid;
grid-template-columns: 250px repeat(12, 1fr);
grid-column-gap: 10px;
}
.container {
/* ... */
grid-template-columns: 1fr 1fr 40px 2fr;
grid-template-rows: 100px 200px 100px;
/* ... */
}


|
Метки: author gprokofyeva разработка веб-сайтов css fr unit верстка единица fr перевод |
Как выигрывать в конкурсах репостов Вконтакте? |
|
Метки: author mmvds вконтакте api python vkontakte api конкурсы социальные сети бот |
Пример синтеза асинхронных SI схем в двухходовой элементной базе: C-элемент |









|
Метки: author ajrec fpga асинхронные схемы |
Современные конвергентные технологии на рынке в РФ — попробуем сравнить? «Ипортозамещение», Ceph + OpenStack, Nutanix |





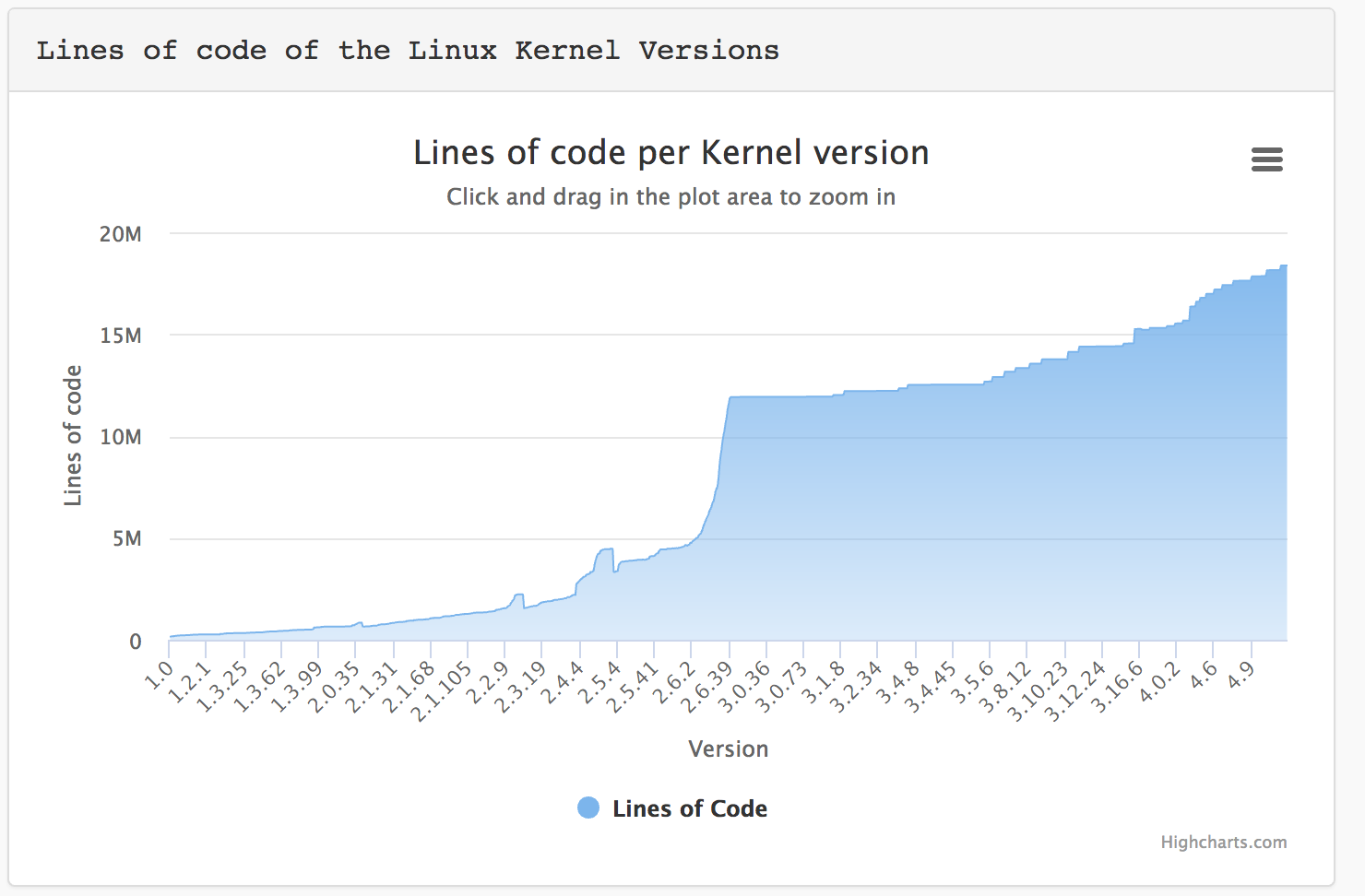


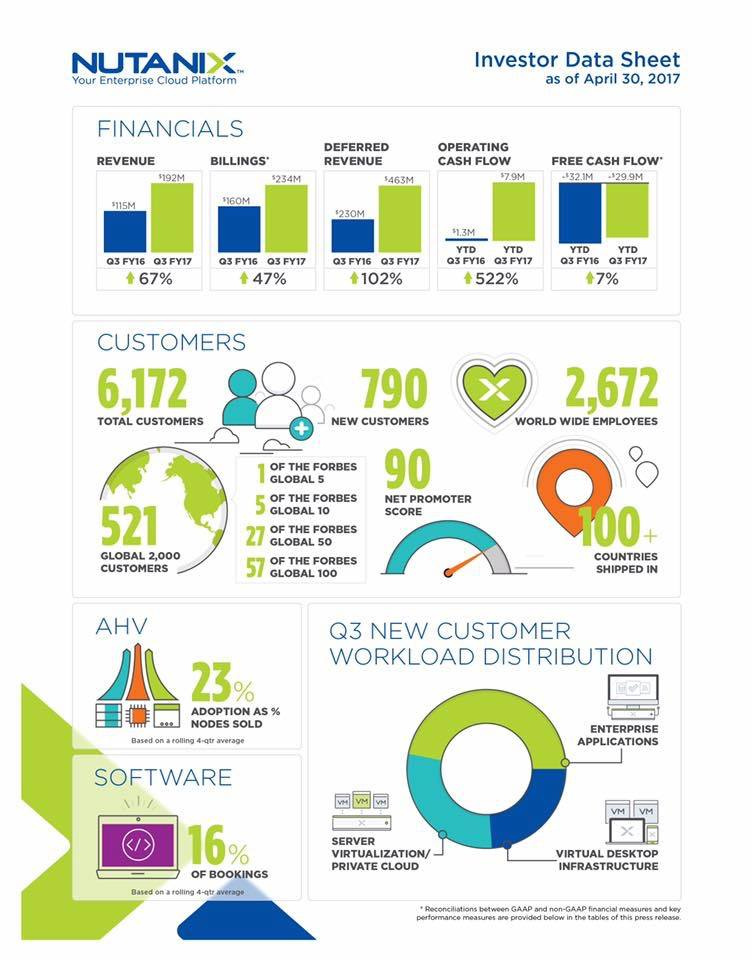
| СКАЛА-Р / Росплатформа / Virtuozzo |
Nutanix | CEPH + OpenStack | |
|---|---|---|---|
| Программная архитектура В случае работы на уровне хоста / ядра ОС, потенциальные проблемы безопасности и отказоустойчивости. |
Ядро / хост | Изолированный виртуальный контроллер | Ядро / хост |
| “Заточенность” решения | Сервис провайдеры | Энтерпрайз (корпорации), правительственные службы, военные, медицина, промышленность, ресурсодобывающие компании, финансовые структуры. |
Сервис провайдеры |
| HCI (гиперконвергентное) решение. Дата сервисы и виртуализация работают на серверах одновременно. |
да | да | нет |
| Отсутствие узких мест / точек отказа (централизованные сервисы, например cервера метаданных или сервера управления) |
нет | да | нет |
| STIG политики (Security Technical Implementation Guide) | Отсутствуют, рекомендация производителя — ручной поиск rootkit и обнаружение взломов | да | Отсутствуют, есть масса разрозненных рекомендаций и методик |
| Расположение компании, разрабатывавшей основную часть ПО | США (Parallels -> Virtuozzo -> Росплатформы->”СКАЛА-Р”) |
США | США (основная разработка), производится множеством компаний. Публично доступны полные исходные коды |
| Встроенный полноценный мониторинг (все аппаратные и программные компоненты) и самодиагностика | Частично, Скала-Р применяет дополнительные средства мониторинга |
да | Частично |
| Интеллектуальный автоматический Data Tiering — перемещение блоков данных между холодным и горячими уровнями в случае изменения частоты запросов к этим данным (“нагрев” или “охлаждение”) | нет | да | нет |
| Встроенный портал самообслуживания | нет | да | да |
| Локализация данных VM (data locality) — активные данные VM находятся на том-же сервере где работает виртуальная машина. Кардинальное ускорение операций чтения и снижение нагрузки на сеть в разы. |
нет | да | нет |
| Репликация на уровне VM | нет | да | нет |
| Восстановление целостности данных | Ручной запуск в случае потери крупного домена | Автоматический старт | Автоматический старт |
| Дедупликация данных | нет | да | нет |
| Компрессия данных | нет | да | нет |
| Erasure Code (помехоустойчивое кодирование) | нет | да | да |
| Поддержка All Flash | нет | да | да |
| Микс All Flash и Hybrid в едином кластере | нет | да | да |
| Обработка отказов SSD дисков с метаданными | Временная потеря части узлов с данными и долгое восстановление | Автоматическая отработка, не влияет на производительность кластера, все узлы с данными продолжают работу | Автоматическая отработка, может влиять на производительность кластера |
| Поддержка VAAI и ODX (протоколы «разгрузки» операций ввода-вывода на систему хранения данных) | нет | да | нет |
| Поддержка Application Consistent Snapshots (провайдер VSS для Windows Server и имплементация для Linux) | нет | да | нет |
| Неограниченное количество снапшотов VM, без влияния на производительность и возможностью манипуляций (в т.ч. удаления) снапшотов на любом уровне | нет | да | нет |
| Теневые клоны (shadow disk) — создание локальной копии дисков VM для кардинальной акселерации загрузки и работы | нет | да | нет |
| Встроенный бэкап на Amazon / Azure | нет | да | нет |
| Наличие Best Practice для ключевых типовых приложений (Oracle RAC, MSSQL, Postgres, SAP NetWeaver, MongoDB, Microsoft Exchange, Cisco Unified Communications и другие) | нет | да | нет |
| Распределенный отказоустойчивый cтек управления (management plane) без использования централизованных баз данных | нет | да | нет |
| Не требуются выделенные сервера управления | нет | да | нет |
| Автоматические апгрейды аппаратных прошивок (биос, прошивки дисков и флеш, контроллеры и тд) | нет | да | нет |
| Прозрачное обновление без перезапуска клиентских сервисов при смене основной версии ПО | нет | да | да |
| Поддержка гипервизоров | KVM (несертифицированные патчи), Virtuozzo (устарел, в новой версии перешли на KVM) | AHV (KVM совместим, сертифицирован Microsoft, SAP и другими), XenServer, vSphere, HyperV | KVM. Возможно использование vSphere и HyperV с подключением через iSCSI, не рекомендуется для продуктива ввиду отсуствия поддержки VAAI / ODX Не является HCI решением. |
| Поддержка основных стеков виртуализации рабочих мест (VDI) – Citrix, VMware | нет | Citrix, VMware, Workspot и другие | нет |
| Возможность запуска Microsoft Windows Server с полной поддержкой от Microsoft (SVVP — Server Virtualization Validation Program) | Нет, SVVP сертификация присутствует для старой версии американского продукта с другим гипервизором. Виртуализация Windows Server — на свой страх и риск |
Полная SVVP сертификация | Есть для RedHat OpenStack и Canonical (Ubuntu) OpenStack, отсутствует для большинства других вариантов. |
| Контейнерная виртуализация | Virtuozzo | Docker | Docker, LXD |
| Встроенные бэкапы (без применения стороннего ПО) с пофайловым восстановлением и самообслуживанием | нет | да | нет |
| Метро кластер (распределённый кластер с синхронным реплицированием) | нет | да | нет |
| Встроенная поддержка аварийного мульти-цод восстановления (many to many DR) | нет | да | <нет |
| Поддержка кросс-гипервизорного DR | нет | да | нет |
| Автоматическая конвертация гипервизора и всех VM на кластере (например, ESXi->AHV/KVM) | нет | да | нет |
| Встроенный SDN стек с интеграцией в аппаратное сетевое обеспечение | нет | да | нет |
| Поддержка Affinity / Anti-Affinity, для оптимизации лицензирования ПО. При отсутствии поддержки необоснованные лицензионные затраты могут составлять миллионы долларов |
нет | да | нет |
| Поддержка RESTful API (стандарт индустрии) | нет | да | нет |
| Бесплатный апгрейд ПО на новые версии (минорные и глобальные обновления версий) при наличии действующей базовой техподдержки |
Скала-Р — платно Росплатформа — бесплатно Virtuozzo — платно |
да | нет |
| Ценообразование (для РФ) на готовые коммерческие решения (ПАК — программно аппаратный комплекс) | Стартовая цена от 136000$ Кластер минимум из 4-х узлов |
Стартовая цена от 35000$ Кластер минимум из 3-х узлов |
Стартовая цена от 45000$ Необходимый минимум: 3 сервера ceph, 3 сервера виртуализации, ~5$k в год за каждый сервер виртуализации (поддержка OpenStack). Поддержка ceph не учтена. |
|
Метки: author nutanix хранение данных системное администрирование виртуализация it- инфраструктура devops nutanix openstack росплатформа скала-р |
Работа с API КОМПАС-3D -> Урок 2 -> Оформление чертежа |



KompasObjectPtr kompas;
//Запускаем КОМПАС
kompas.CreateInstance(L"KOMPAS.Application.5");
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type= lt_DocSheetStandart;//Чертеж на стандартном листе
SheetParPtr SheetPar;
SheetPar = (SheetParPtr)DocumentParam->GetLayoutParam();
SheetPar->layoutName[0] = L'0';
SheetPar->shtType = 1; //Тип документа
//Подготавливаем параметры листа
StandartSheetPtr StandartSheet;
StandartSheet = (StandartSheetPtr)SheetPar->GetSheetParam();
StandartSheet->direct = false; //надпись вдоль короткой стороны
StandartSheet->format = 4; //А4
StandartSheet->multiply = 1; //кратность
//Создаем чертеж
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();
KompasObjectPtr kompas;
//Запускаем КОМПАС
kompas.CreateInstance(L"KOMPAS.Application.5");
//Подготавливаем параметры документа
DocumentParamPtr DocumentParam;
DocumentParam=(DocumentParamPtr)kompas->GetParamStruct(ko_DocumentParam);
DocumentParam->Init();
DocumentParam->type = lt_DocSheetUser; //Чертеж на нестандартном листе
SheetParPtr SheetPar;
SheetPar = (SheetParPtr)DocumentParam->GetLayoutParam();
SheetPar->layoutName[0] = L'0';
SheetPar->shtType = 1; //Тип документа
//Подготавливаем параметры листа
SheetSizePtr SheetSize;
SheetSize = (SheetSizePtr)SheetPar->GetSheetParam();
SheetSize->Init();
SheetSize->width = 300;
SheetSize->height = 300;
//Создаем чертеж
Document2DPtr Document2D;
Document2D = (Document2DPtr)kompas->Document2D();
Document2D->ksCreateDocument(DocumentParam);
//Делаем КОМПАС видимым
kompas->Visible = true;
kompas.Unbind();

 Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
Сергей Норсеев, автор книги «Разработка приложений под КОМПАС в Delphi».
|
Метки: author kompas_3d разработка под windows cad/cam c++ api блог компании аскон компас 3d компас компас-3d приложения библиотеки |
Уязвимость Stack Clash позволяет получить root-привилегии в Linux и других ОС |

|
Метки: author ptsecurity информационная безопасность блог компании positive technologies stack clash linux unix уязвимости |
Лекции Технотрека. Администрирование Linux |

Представляем вашему вниманию очередную порцию лекций Технотрека. В рамках курса будут рассмотрены основы системного администрирования интернет-сервисов, обеспечения их отказоустойчивости, производительности и безопасности, а также особенности устройства ОС Linux, наиболее широко применяемой в подобных проектах. В качестве примера будут использоваться дистрибутивы семейства RHEL 7 (CentOS 7), веб-сервер nginx, СУБД MySQL, системы резервного копирования bacula, системы мониторинга Zabbix, системы виртуализации oVirt, балансировщика нагрузки на базе ipvs+keepalived. Курс ведёт Сергей Клочков, системный администратор в компании Variti.
Список лекций:
В начале лекции вы узнаете об истории появления и развития Linux. Затем проводится экскурс по экосистеме Linux, рассказывается о некоторых различиях между дистрибутивами. Далее обсуждается иерархия файловой системы, рассматривается основной рабочий инструмент в этой ОС — командная строка. Подробно рассказывается о Bash-скриптах, о двух основных сущностях в системе — пользователях и группах. Затем обсуждаются регулирование прав доступа к файлам и директориям, рассматриваются привилегии пользователей и в завершение лекции затрагивается тема удалённого доступа.
Сначала подробно рассказывается об этапах загрузки системы и ОС, обсуждается ядро Linux. Объясняется, что собой представляет «процесс», как он использует оперативную память. Вы узнаете, что такое дескрипторы и для чего они нужны, как процессор потребляет ресурсы. Затем рассматриваются системные вызовы, сигналы, лимиты процессов, переменные окружения. Обсуждается вопрос размножения процессов и подробно анализируется работа процесса. В завершение вы узнаете о подсистеме perf и логах.
Вы узнаете, что такое сетевой стек и модель OSI. Вспомните, что такое Ethernet и как с ним работает Linux. Дальше будут освежены ваши знания об использовании IPv4, особенностях IPv4-пакетов и сетей. Затем рассматривается ICMP, мультикаст в IPv4. Далее переходим к IPv6, обсуждаются заголовки IPv6-пакетов, UDP, TCP-соединения. Затрагивается тема TCP congestion control. Потом рассказывается о NAT, протоколах уровня приложения, DNS, NTP, HTTP и URL. Разбираются коды HTTP-ответа (успешные ответы и ошибки).
Вы узнаете о том, что такое менеджер пакетов RPM и как его использовать. Далее рассматривается классический init, системный менеджер systemd. Разбирается пример init-файла. Обсуждаются основные типы Unit’ов, рассказывается про системный логгер и ротацию логов. В заключение вы узнаете об основах конфигурации сетевых интерфейсов.
Сначала рассматривается типовая архитектура веб-сервиса. Рассказывается о том, что такое фронтенд, что такое сервер приложений. Разбирается вопрос хранения данных веб-приложениями. Подробно разбирается работа и использование протокола HTTP. Обсуждаются виды HTTP-запросов. Затрагивается тема создания шифрованных туннелей с помощью SSL. Затем рассматриваются примеры установки СУБД MySQL с созданием БД и пользователя. Разбирается работа с PHP-FPM, конфигурирование nginx, установка и настройка wiki-движка.
Перечисляются основные проблемы хранения данных, рассматриваются достоинства и недостатки разных устройств хранения, их интерфейсы. Затем вы узнаете, как определять состояние жёсткого диска, какова его производительность, что такое RAID, какие бывают RAID-массивы и как их создавать. Сравниваются разные типы RAID, а также программные и аппаратные массивы. Обсуждаются LVM-снепшоты, рассматриваются разные файловые системы. Затрагивается вопрос удалённого хранения данных и использование протокола ISCSI.
Рассматривается DNS-сервер bind, NTP-сервер. Обсуждается централизованная аутентификация на основе LDAP. Разбирается DHCP, задача установки ОС по сети с помощью kickstart, а в завершение рассматривается система управления конфигурацией Salt.
Начало лекции посвящено продолжению рассказа о системе управления конфигурацией Salt. Рассказывается, как её установить, как осуществляется управление конфигурацией Linux, разбирается её пример. Вы узнаете, что такое «зёрна» и зачем они нужны. Далее переходим к теме резервного копирования: какие данные нужно копировать, каковы основные трудности, какие бывают виды резервных копий. Обсуждается задача резервного копирования ОС. Рассказывается об использовании системы резервного копирования bacula.
В начале лекции рассказывается о резервном копировании БД. Обсуждаются различные стратегии резервного копирования — mysqldump, mylvmbackup. Вы узнаете, для чего нужен мониторинг и как его выполнять, какие есть средства мониторинга. Рассматриваются разные виды проверок. Обсуждаются шаблоны проверок. В заключение рассказывается об элементах данных, о выполнении веб-мониторинга.
Вы узнаете, что такое электронная почта, познакомитесь с основными понятиями. Затем рассматривается процесс доставки и выдачи почты. Обсуждается использование протоколов SMTP, POP3 и IMAP. Разбирается применение SMTP-сервера postfix, IMAP-сервера Dovecot. Рассказывается о том, как ходят письма по сети и что такое MX-записи. Наконец, обсуждается защита от спама, разбираются SPF-записи, DKIM и Spamassassin.
Лекция посвящена продвинутым вопросам администрирования Linux. Сначала вы узнаете, как управлять параметрами ядра ОС. Затем рассматриваются модули ядра, как ими управлять. Обсуждается выделение ресурсов приложения. Далее рассказывается о планировщике задач, об алгоритмах шедулинга, о приоритетах процессов. Разбирается шедулер CFS, политики шедулинга. Вы узнаете, что такое NUMA и как с ней работать. Познакомитесь с планировщиками ввода/вывода. Далее рассказывается о контрольных группах, об управляемых ресурсах, об управлении контрольными группами и лимитами ввода/вывода.
Плейлист всех лекций находится по ссылке. Напомним, что актуальные лекции и мастер-классы о программировании от наших IT-специалистов в проектах Технопарк, Техносфера и Технотрек по-прежнему публикуются на канале Технострим.
Другие курсы Технотрека на Хабре:
Информацию обо всех наших образовательных проектах вы можете найти в недавней статье.
|
Метки: author Olga_ol системное администрирование настройка linux *nix блог компании mail.ru group администрирование linux технотрек |
[Из песочницы] Динамический рендеринг компонентов в Angular 2 |
marker.bindPopup(`
Leaflet PopUp
Some text
Should be deleted from DOM if it was angular component because of ngIf = false
`);

@Component({
selector: 'custom-popup',
template: require('./custom-popup.component.html')
})
export class CustomPopUpComponent {
public inputData: any;
private title: string = 'Angular component';
private array: Array = ['this', 'array', 'was viewed', 'by', 'ngFor!'];
}
{{title}}
{{inputData}}
{{text}}
Should be deleted from DOM if it was angular component because of ngIf = false
@Injectable()
export class RenderService {
private componentRef: ComponentRef;
constructor(private ngZone: NgZone,
private injector: Injector,
private appRef: ApplicationRef,
private componentFactoryResolver: ComponentFactoryResolver) { }
public attachCustomPopUpsToMap(map: Map) {
this.ngZone.run(() => {
map.on("popupopen",
(e: any) => {
const popup = e.popup;
const compFactory = this.componentFactoryResolver.resolveComponentFactory(popup.options.popupComponentType);
this.componentRef = compFactory.create(this.injector);
this.componentRef.instance.geoObject = popup.options.object;
this.appRef.attachView(this.componentRef.hostView);
let div = document.createElement('div');
div.appendChild(this.componentRef.location.nativeElement);
popup.setContent(div);
});
});
}
}
this.appRef.attachView(this.componentRef.hostView);
if (this.appRef['attachView']) {
this.appRef['attachView'](this.componentRef.hostView);
this.componentRef.onDestroy(() => {
this.appRef['detachView'](this.componentRef.hostView);
});
}
else {
this.appRef['registerChangeDetector'](this.componentRef.changeDetectorRef);
this.componentRef.onDestroy(() => {
this.appRef['unregisterChangeDetector'](this.componentRef.changeDetectorRef);
});
}
this.renderService.attachCustomPopUpsToMap(this.mapService.getMap());
let options = {
data: 'you can provide here anything you want',
popupComponentType: CustomPopUpComponent
};
let myPopUp = L.popup(options);
marker.bindPopup(myPopUp);

|
Метки: author bodryi разработка веб-сайтов angularjs angular 2 angular 4 leaflet typescript |
Рынок приложений для касс: первая конференция CHANGE |

|
Метки: author RoboForm конференции конференция разработка приложений россия |
[Из песочницы] Google Play и 2K установок в сутки без денежных вложений (+ статистика и доходы) |

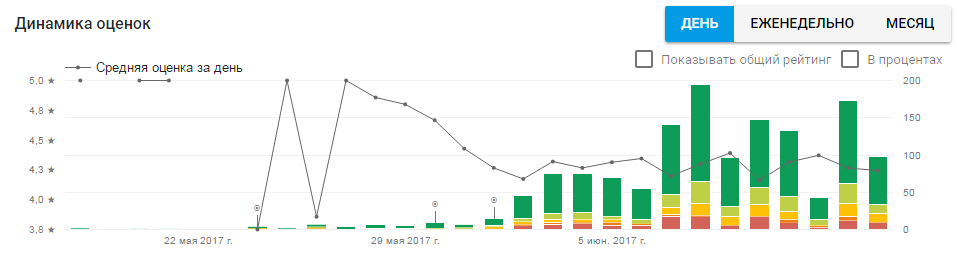
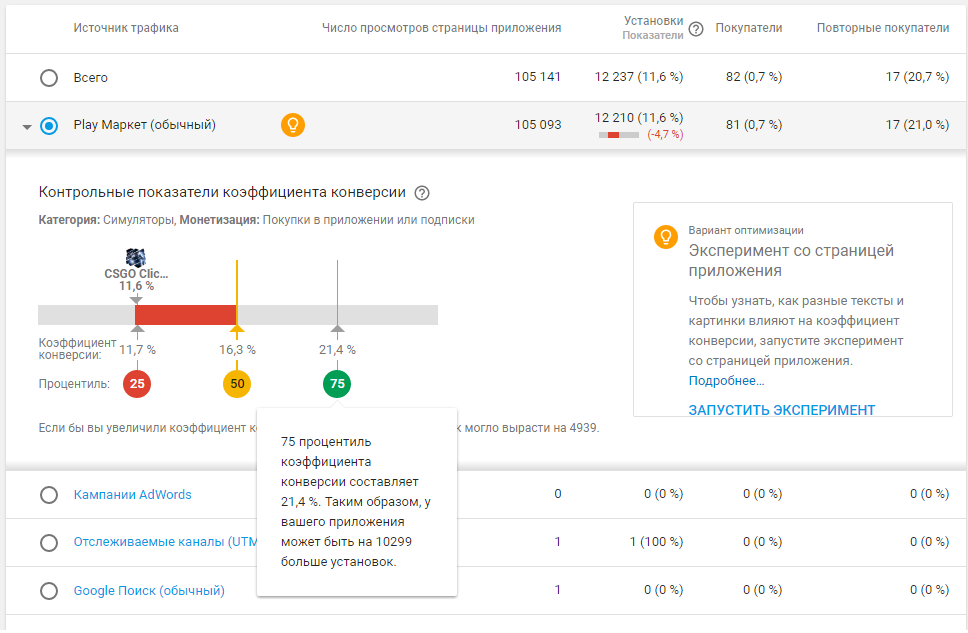
Статистика, указанная в статье, собрана с нового приложения, которое живет с 24 мая 2017
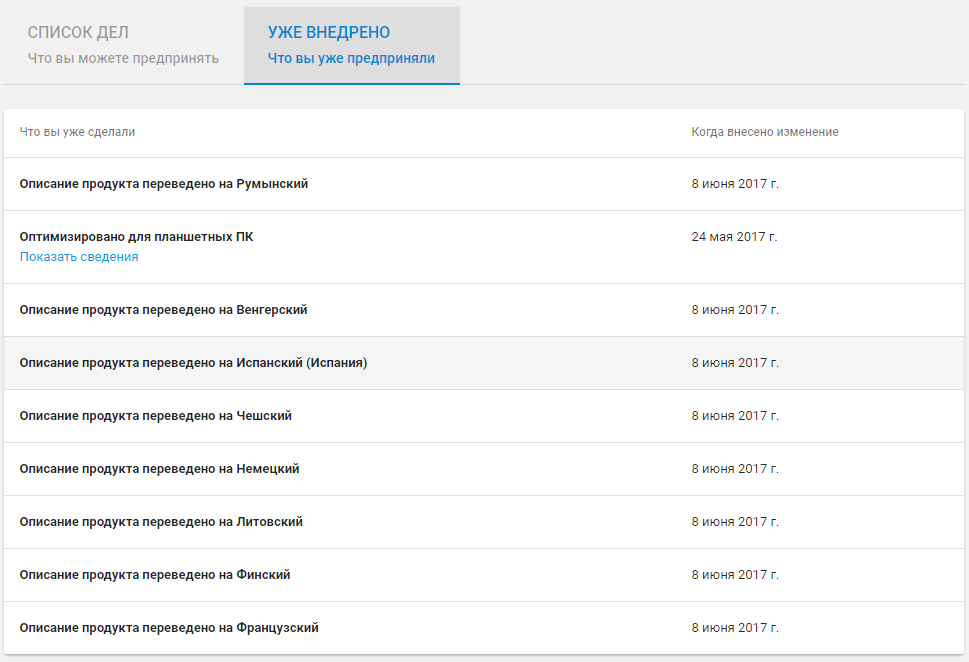
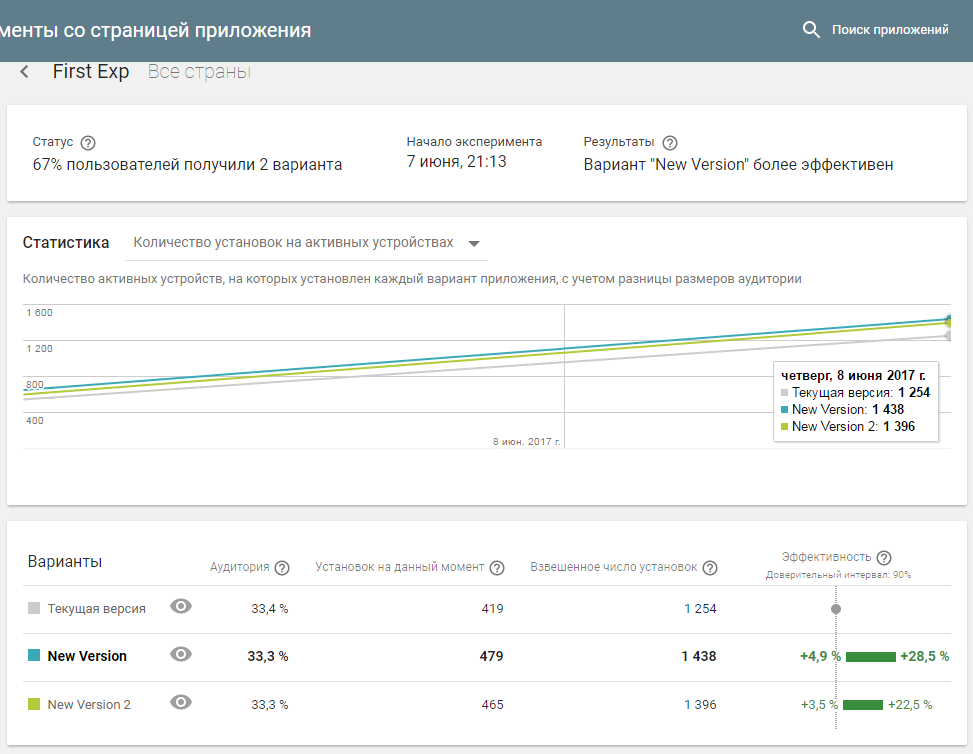
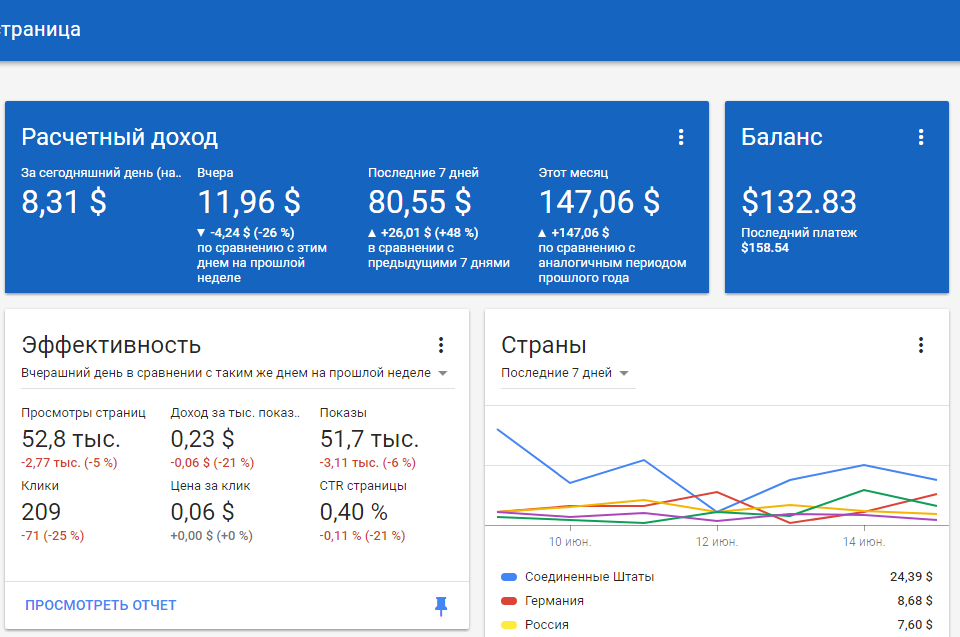
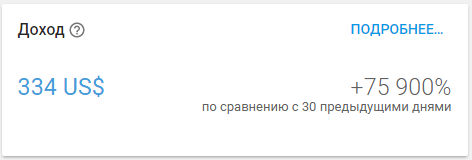

|
Метки: author myevolove unity3d google api unity google play |
Умеют ли коты строить регрессию? |

trait GeneralizedLinearModel {
def getWeights(): Vector[Real]
def apply(v: Vector[Real]): Real = getWeights().dot(v + bias)
def apply(vectors: Seq[Vector[Real]]): Seq[Real] = vectors.map(this.apply(_))
def convertToTransformation(): InhomogeneousTransformation[Vector[Real], Real] =
new InhomogeneousTransformation[Vector[Real], Real](v => this.apply(v))
}
object GeneralizedLinearModel {
val bias = Vector("bias" -> Real(1.0))
object Metrics {
def RSS(generalizedLinearModel: GeneralizedLinearModel, input: Seq[Vector[Real]], output: Seq[Real]): Real = {
val predictions = generalizedLinearModel(input)
predictions.zip(output)
.map { case (pred, real) => (pred - real) ^ 2.0 }
.reduce(_ + _) / input.length
}
}
}
case class OrdinaryLeastSquaresRegression(w: Vector[Real]) extends GeneralizedLinearModel {
override def getWeights(): Vector[Real] = w
}
object OrdinaryLeastSquaresRegression {
class Task(input: Seq[Vector[Real]], output: Seq[Real]) extends General.Task {
def toOptimizationTask(searchArea: Map[String, (Double, Double)]): (Optimization.Real.Task, InhomogeneousTransformation[Vector[Real], OrdinaryLeastSquaresRegression]) = {
val vectorToRegressor =
new InhomogeneousTransformation[Vector[Real], OrdinaryLeastSquaresRegression]((w: Vector[Real]) => OrdinaryLeastSquaresRegression(w))
val task = new Optimization.Real.Task(
new Function[Real]((w: Vector[Real]) =>
GeneralizedLinearModel.Metrics.RSS(vectorToRegressor(w), input, output)), searchArea)
(task, vectorToRegressor)
}
}
}
class RidgeRegression(w: Vector[Real], alpha: Double) extends OrdinaryLeastSquaresRegression(w) { }
object RidgeRegression {
class Task(input: Seq[Vector[Real]], output: Seq[Real]) extends General.Task {
def toOptimizationTask(searchArea: Map[String, (Double, Double)], alpha: Double): (Optimization.Real.Task, InhomogeneousTransformation[Vector[Real], RidgeRegression]) = {
val vectorToRegressor =
new InhomogeneousTransformation[Vector[Real], RidgeRegression]((w: Vector[Real]) => new RidgeRegression(w, alpha))
val task = new Optimization.Real.Task(
new Function[Real]((w: Vector[Real]) =>
GeneralizedLinearModel.Metrics.RSS(vectorToRegressor(w), input, output) +
alpha * w.components.filterKeys(_ != "bias").values.map(_ ^ 2.0).reduce(_ + _)), searchArea)
(task, vectorToRegressor)
}
}
}class LassoRegression(w: Vector[Real], alpha: Double) extends OrdinaryLeastSquaresRegression(w) { }
object LassoRegression {
class Task(input: Seq[Vector[Real]], output: Seq[Real]) extends General.Task {
def toOptimizationTask(searchArea: Map[String, (Double, Double)], alpha: Double): (Optimization.Real.Task, InhomogeneousTransformation[Vector[Real], LassoRegression]) = {
val vectorToRegressor =
new InhomogeneousTransformation[Vector[Real], LassoRegression]((w: Vector[Real]) => new LassoRegression(w, alpha))
val task = new Optimization.Real.Task(
new Function[Real]((w: Vector[Real]) =>
GeneralizedLinearModel.Metrics.RSS(vectorToRegressor(w), input, output) / (2.0 * input.length) +
alpha * w.components.filterKeys(_ != "bias").values.map(Algebra.abs(_)).reduce(_ + _)), searchArea)
(task, vectorToRegressor)
}
}
}Шаг 1. Инициализировать популяцию из N котов.
Шаг 2. Определить приспособленность каждого кота на основе его позиции в исследуемом пространстве. Запомнить "лучшего" кота (в терминологии задачи минимизации, ему будет соответствовать наименьшее значение функции).
Шаг 3. Переместить котов в соответствии с их процедурой смещения (поиск или погоня).
Шаг 4. Заново присвоить котам режимы перемещения в соответствии с параметром MR.
Шаг 5. Проверить условие окончания работы. В случае его невыполнения перейти к шагу 2.
class CatSwarmOptimization(numberOfCats: Int, MR: Double,
SMP: Int, SRD: Double, CDC: Int, SPC: Boolean,
velocityConstant: Double, velocityRatio: Double,
generator: DiscreteUniform with ContinuousUniform = Kaimere.Tools.Random.GoRN) extends Algorithm
case class Cat(location: Vector[Real], velocity: Vector[Real])(implicit generator: DiscreteUniform with ContinuousUniform) {
def getFromSeries[T](data: Seq[T], n: Int, withReturn: Boolean): Seq[T] =
withReturn match {
case true => Seq.fill(n)(generator.getUniform(0, data.size - 1)).map(x => data(x))
case false => data.sortBy(_ => generator.getUniform(0.0, 1.0)).take(n)
}
def seek(task: Task, SPC: Boolean, SMP: Int, CDC: Int, SRD: Double): Cat = {
val newLocations = (if (SPC) Seq(location) else Seq()) ++
Seq.fill(SMP - (if (SPC) 1 else 0))(location)
.map { loc =>
val ratio =
getFromSeries(task.searchArea.keys.toSeq, CDC, false)
.map { key => (key, generator.getUniform(1.0 - SRD, 1.0 + SRD)) }.toMap
(loc * ratio).constrain(task.searchArea)
}
val fitnessValues = newLocations.map(task(_)).map(_.value)
val newLocation =
if (fitnessValues.tail.forall(_ == fitnessValues.head)) newLocations(generator.getUniform(0, SMP - 1))
else {
val maxFitness = fitnessValues.max
val minFitness = fitnessValues.min
val probabilities = fitnessValues.map(v => (maxFitness - v) / (maxFitness - minFitness))
val roulette =
0.0 +: probabilities.tail
.foldLeft(Seq(probabilities.head)) { case (prob, curr) => (curr + prob.head) +: prob }
.reverse
val chosen = generator.getUniform(0.0, roulette.last)
val idChosen = roulette.sliding(2).indexWhere{ case Seq(a, b) => a <= chosen && chosen <= b}
newLocations(idChosen)
}
new Cat(newLocation, newLocation - this.location)
}
def updateVelocity(bestCat: Cat, velocityConstant: Double, maxVelocity: Map[String, Double]): Vector[Real] = {
val newVelocity = this.velocity + (bestCat.location - this.location) * velocityConstant * generator.getUniform(0.0, 1.0)
Vector(newVelocity.components
.map { case (key, value) =>
if (value.value > maxVelocity(key)) (value, Real(maxVelocity(key)))
if (value.value < -maxVelocity(key)) (value, Real(-maxVelocity(key)))
(key, value)
})
}
def trace(task: Task, bestCat: Cat, velocityConstant: Double, maxVelocity: Map[String, Double]): Cat = {
val newVelocity = this.updateVelocity(bestCat, velocityConstant, maxVelocity)
val newLocation = (location + newVelocity).constrain(task.searchArea)
new Cat(newLocation, newVelocity)
}
def move(mode: Int, task: Task, bestCat: Cat, SPC: Boolean, SMP: Int, CDC: Int, SRD: Double, velocityConstant: Double, maxVelocity: Map[String, Double]): Cat = mode match {
case 0 => seek(task, SPC, SMP, CDC, SRD)
case 1 => trace(task, bestCat, velocityConstant, maxVelocity)
}
}

|
Метки: author wol4aravio программирование машинное обучение математика алгоритмы scala методы оптимизации эвристические алгоритмы линейная регрессия |
[Из песочницы] Автоматизация тестирования Windows-приложений с использованием Winium |
ProcessBuilder pro = new ProcessBuilder(windriverPath + windriverName, windriverParam);
shell = pro.start();
//<наш код>
shell.destroy();DesiredCapabilities cap = new DesiredCapabilities();
cap.setCapability("app",""); //если хотим сразу запускать какую-либо программу
cap.setCapability("launchDelay","5"); //задержка после запуска программы
WebDriver driver = new RemoteWebDriver(new URL("http://localhost:9999"),cap); //на этом порту по умолчанию висит Winium драйвер
WebElement wrk = driver.findElement(By.name("Значение поля Name")); //один элемент, поиск по полю Name
List wrkL = driver.findElements(By.className("Значение поля ClassName")); //список элементов с заданным полем ClassName
WebElement wrk1 = wrk.findElement(By.name("Значение поля Name"));
WebElement field = wrk.findElement(By.xpath("*[@HasKeyboardFocus='True']")); //найдёт элемент у wrk, на котором стоит фокус
String xpathStr = "*[(@AutomationId='" + autId + "') and (@IsOffscreen='False')]"; //будем искать элемент у текущего окна с каким-то заданным AutomationId = autId и у которого свойство IsOffscreen = False
log("Performing xpath search: " + xpathStr);
WebElement tWrk = wrk1.findElement(By.xpath(xpathStr));
Actions builder = new Actions(driver);
Action enter = builder
.moveToElement(wrk)
.moveByOffset(x,y)
.click()
.build();
enter.perform();
|
Метки: author P-Ray тестирование it-систем разработка под windows winium qa automation windows java |
Новые технотренды в сфере финансов: зачем нужны чат-боты |



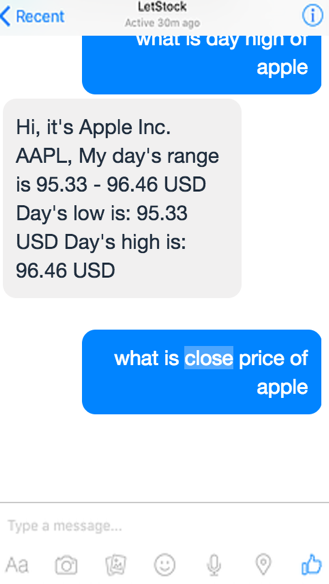


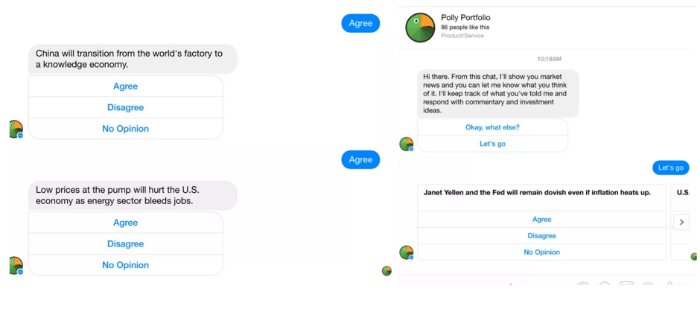
|
Метки: author itinvest системы обмена сообщениями блог компании itinvest чат-боты боты финансы разработка |
[Из песочницы] CameraTablet — как сделать графический планшет при помощи веб-камеры |
|
Метки: author dmitry_vlas обработка изображений python эмуляция мыши opencv |
Антипаттерны для поиска соискателей |
Привет, Хабр. В качестве тимлида я стою одновременно по обе стороны поиска соискателей — последние пять лет я активно участвую в собеседованиях своих разработчиков, а так же прохожу собеседования. Мне не стыдно писать, что я хожу по собеседованиям — это помогает понять, что сейчас востребовано на рынке, и где у тебя есть пробелы, которые хорошо было бы восполнить. Да и вообще любой специалист должен стремиться к росту, а не стагнации.
И за это время у меня накопилось огромное количество смешных и грустный историй взаимодействия с рекрутерами с обеих сторон, которые я решил систематизировать в общий сборник антипаттернов. Поехали!
Каждый поиск начинается с публикации вакансии, и очень важно её правильно оформить.
Для начала, никогда не указывайте зарплату — соискатель должен мечтать работать в вашем стартапе ООО "горим", и для него не должно быть важно, сколько денег ему заплатят. И вообще, зачем вам меркантильные сотрудники?
Далее, обязательно нужно искать фуллстека. Всё знают это модное слово, и зачем нанимать нескольких разработчиков, если всё может сделать один? Фронт, бэк, базы данных, архитектура, поддержка серверов, и лучше наличие транспорта, чтобы развозить продукт по клиентам.
Лучше написать, что это интересная работа с кучей перспектив и возможностей по самореализации — вот тогда соискатель точно клюнет на то, чтобы делать абсолютно всё в вашей компании.
Так же можно написать про ответственность, лидерские качества, и про то, что разработчик сам должен всё понимать и ставить себе задачи. В конце концов, у вас уже есть видение вашего продукта — осталось только его накодить, с этим и макака справится.
Ещё можно рассказать, что вы будете платить процентом от чего-нибудь там. Деньги обещать опасно, а процент от нуля всегда равен нулю, и вы ничем не рискуете.
Если вы не знаете ещё, какой стек будет использоваться в продукте, спросите у друзей или почитайте статьи в интернете — нужно, чтобы вы сразу определили, какого разработчика ищете. А в технологиях вы и сами разберётесь — легко. Например, вы можете понять, что чёткие пацаны пишут на go и при этом используют NoSQL — значит, вам точно нужен go разработчик со знанием NoSQL на ваш сайт по продаже шапок ушанок с полутора посетителями в день.
Обязательно напишите, что скоро вы переезжаете в США или куда-нибудь ещё, куда обычно хотят программисты. Это безопасно. "Скоро" — это понятие растяжимое, обычно означает "как только мы внезапно получим кучу денег и будем купаться в них как Скрудж Макдак". Ну и что, что это в лучшем случае в перспективе пары лет. Может же случиться. Везёт же некоторым! Так что ваш стартап — убийца Фейсбука и Гугла одновременно — обязательно взлетит.
Ни в коем случае не раскрывайте, над чем собственно придётся работать. У вас наверняка бесценная идея, и её может украсть коварный разработчик — молчите и загадочно намекайте на хайлоад, блокчейн, инстаграм, нейронные сети и SaaS.
В вакансии нужно сразу писать, что у вас все любят переработки и постоянные дедлайны. Плох и ленив тот разработчик, который не мечтает делать что-то хорошее хотя бы по 12 часов в сутки. Естественно, переработки никто не оплачивает — вы же команда и трудитесь ради продукта, а не за презренное золото.
Обязательно сделайте необходимым добавление сопроводительного письма, где разработчик напишет, почему хочет идти именно к вам. Он же идёт не просто деньги за свою работу получать, а к Вам! Пускай обоснует, хотя бы символов на 500. Тех, кто пишет "хочу работать, у вроде подходящая вакансия" можно сразу отфильтровывать.
Кроме сопроводительного письма так же неплохо сделать анкету с 20 или больше вопросами — чем больше вы знаете про соискателя, тем лучше! Не стесняйтесь давать эту анкету соискателю несколько раз подряд — расхождения в ответах могут вам о многом сказать.
Отдельная ремарка по поиску джуниоров. Если вы ищете начинающего разработчика, то у него обязательно должно быть минимум пять лет работы в аналогичной должности и опыт промышленных внедрений.
Ни в коем случае не уточняйте у соискателя, насколько ему важна белая зарплата. О том, что у вас только серая, он должен узнать только пройдя три собеседования, решив тестовые задачи и познакомившись со всеми, включая уборщика Ахмета. Уж наверняка после этого он будет так измучен рад работать с вами, что не обратит внимание на такие мелочи, как серая зарплата.
Не забудьте написать в описании вакансии, что у вас есть печеньки. А ещё Agile и Scrum. Это так оригинально!
Ура, вакансия готова! Что же делать дальше? В первую очередь нужно написать ответное письмо, которое приходит от автомата заинтересованным соискателям. Лучше всего указать там свой номер телефона и написать, чтобы соискатель звонил вам, если ему вдруг всё ещё интересна вакансия, на которую он откликнулся пять минут назад.
Вы наверняка знаете, что разработчики сами не знают, чего хотят, так что смотрите резюме по диагонали и присылайте приглашение, если совпало хоть одно слово.
В общем, у вас и так мало времени, а ваш KPI измеряется количеством соискателей, которые вы найдёте. Шлите всех, и пускай там уже высоколобые разработчики разбираются, подойдёт ли Javascript разработчик под Java, или 1C разработчик под C#.
Запомните — главный ваш рабочий инструмент — это телефон. Ничто не заменит старой доброй ламповой голосовой коммуникации. Даже если разработчик указал, что предпочтительно для него три других способа связи. Ну и что, что он скорее всего сейчас на предыдущей работе или дома. Наверняка он может найти 20 минут чтобы с вами пообщаться. Ему же вообще не каждый день звонят с предложением работы.
Отдельно замечу, что разработчики часто в резюме прикрепляют кучу всякого мусора — профили на каких-то сайтах, какой-то код… Нужно всё это отсечь, чтобы технарям ушла только нужная информация. ФИО и список мест работы — вот необходимый и достаточный набор данных.
Помните про тестовые задания! Надо же как-то людей фильтровать. Принято давать три категории тестовых заданий:
Есть несколько обязательных заповедей, которым нужно следовать при проведении собеседования, неважно, удалённое оно или нет.
Если вам понравился кандидат, и вы во всём сошлись, то не забудьте поторговаться. У вас ведь в описании вакансии указано “до ххх”. Так что вы никого не обманете, если предложите “ххх:2”. Люди — это как арбузы на рынке, только люди. Принципы торговли те же. Если после вашего предложения соискатель пропал — ну, значит, он просто не мотивирован с вами работать и сам виноват.
Ещё одна общая рекомендация — помните: вы — машина, вы — комбайн по переработке заявок в людей! Ко всем нужно применять один и тот же подход, чтобы соискатель понимал, что он — потенциальный винтик огромной машины, который должен знать своё место в ней. Веерные рассылки, обмен базами соискателей, беспорядочные связи в linkedin — всё это годится для поиска людей!
Ну и последнее. Если вам не понравился соискатель, то просто забейте на переписку. Зачем терять своё время на человека, который вам не подходит?
Следуйте этим советам, и вы обязательно не найдёте себе нужного разработчика!
Не хотелось бы, чтобы данный пост был принят за какое-то нытьё. Наоборот — мне хочется думать, что он дойдёт до многих рекрутеров, и они, заметив за собой некоторые пункты, будут над ними работать. Обе стороны (разработчики и рекрутеры) заинтересованы в том, чтобы работа искалась быстро и качественно.
Да, отдельный пост можно было бы написать про соискателей — я признаю, что на этой стороне тоже много всего забавного — но это будет не столь интересно и полезно.
Так же хотелось привести несколько примеров компаний с той и другой стороны, но решил, что это не совсем коректно. Кто-то себя просто узнает в этих примерах.
Указывайте в комментариях свои антипаттерны — давайте дополним список!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author jehy карьера в it-индустрии hr поиск работы |
Материалы студенческой школы «Recent Advances in Algorithms» |







|
Метки: author avsmal параллельное программирование математика алгоритмы big data блог компании спбау streaming параллельные алгоритмы |
Облачный хостинг PCI DSS: Детали предоставления услуги |
 / фото kuhnmi CC
/ фото kuhnmi CC 
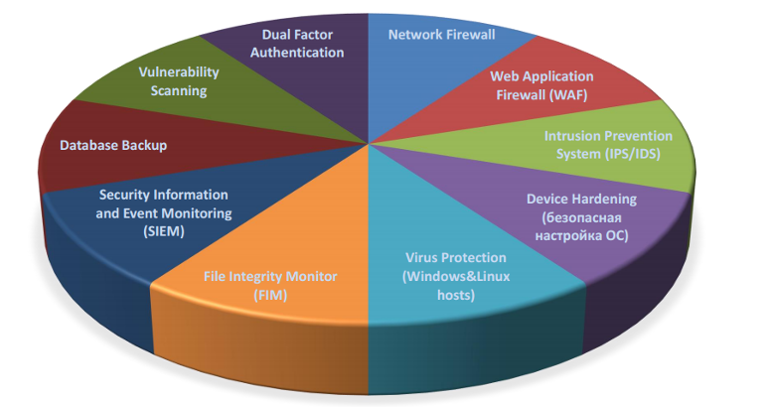
|
Метки: author it_man платежные системы блог компании ит-град ит-град pci dss сертификация |
Аналитические инструменты: обзор выгодных предложений |



|
Метки: author nanton веб-аналитика аналитика мобильных приложений блог компании everyday tools seo оптимизация поисковая оптимизация поведение пользователя kpi |









