Всё, что вам нужно знать про Windows Server 2016 |

 Книга «Введение в Windows Server 2016» посвящена разбору ключевых функций системы и вполне может стать настольной книгой для тех, кто постоянно работает с Windows Server 2016. Вы также найдёте в ней описание сценариев развертывания системы и особенностей миграции. Введение не подразумевает погружение в детали той или иной технологии, но в книге приведены ссылки на дополнительные источники информации по темам.
Книга «Введение в Windows Server 2016» посвящена разбору ключевых функций системы и вполне может стать настольной книгой для тех, кто постоянно работает с Windows Server 2016. Вы также найдёте в ней описание сценариев развертывания системы и особенностей миграции. Введение не подразумевает погружение в детали той или иной технологии, но в книге приведены ссылки на дополнительные источники информации по темам.Windows Server 2016: эволюция или революция?
Защита привилегированных учетных записей в Windows Server 2016
Какие технологии Microsoft Azure реализованы в Windows Server 2016
|
Метки: author ashapo блог компании microsoft microsoft windows server 2016 hyper-v sdn контейнеры nano server |
Короткий чеклист по созданию миров |

Итак, первое что нам нужно, это направление развития нашей цивилизации (под цивилизацией мы будем подразумевать конкретное соcтояние общества в нашем мире). Например наша цивилизация — человечество, в данный момент развивает технологию и в меньшей степени, биологию), но никто нас не ограничивает выбрать другое направление или сразу несколько направлений. Для себя я выделил следующие возможные втеки развития:
Определив направление(я) развития нашей цивилизации мы должны выбрать уровень ее развития. Иными словами нам нужно установить ее прогресс. Для этого я предпочитаю определить ключевые достижения цивилизации которые коренным образом меняют уклад жизни всего населения. Я выбрал самые важные, конечно на мой весьма спорный взгляд, достижения в каждой ветке развития (события отсортированы условно):
*А вот здесь есть нюанс. Если вы выбрали что у вас мир пошел по ветви развития магии, это значит, что ее плоды должны быть общедоступны. Т.е., грубо говоря, если у вас в мире есть магия, но она доступна единицам, то магия у вас находится в зачаточной стадии, несмотря на ее уровень. Кроме того, помимо степени развития магия, стоит так же подумать о ее направлении, так как уж слишком та разносторонняя. Это может быть некромантия, призыв, трансформация, и так далее и тому подобное. Главное, если Вы выбрали направление, постарайтесь сделать на нем акцент, что бы игроки это заметили.
**А здесь нюанс еще больше. С одной стороны эта ветвь развития не выглядит как самодостаточная. С другой стороны она
а) прекрасно дополняет другие ветви (кроме пожалуй магии) и б) при должном усилии вполне способна раскрыться как standalone ветвь. Вспомните ту же цивилизацию протосов, например.
Возраст цивилизации коррелирует с уровнем развития цивилизации, но не только. Как и человек, цивилизация рождается, проходит пубертатный период, этап зрелости, стареет и умирает. И вы должны четко понимать, на какой стадии ваш мир находится сейчас.
Многие, интуитивно выбирают «возраст подростка» для своего сеттинга, поскольку он более близок нашей собственной цивилизации и располагает к агрессивным действиям (а значит больше экшена).
Но осознанное решение может принести сеттингу гораздо больше пользы добавив миру глубину. Представьте ваш любимый сеттинг и посмотрите на него через призму упадка цивилизации. Или наоборот, ее пика, когда все вершины покоримы и нет предела возможностям. Совсем другой акцент получается, не так ли?
Как правило, молодые цивилизации более агрессивны, взрослые направляют развитие вовне, а старые наоборот внутрь. Конечно, это не догма. Так цивилизация эпохи упадка может бросить все силы на поиск «свежего» мира, а цивилизация в рассвете сил, запечатать к себе все входы и заняться самоанализом. Но если это произошло, Вы как гейммастер, должны знать причины такого не типичного поведения. Этот совет, кстати подходит к любому не стандартному факту. Если что-то пошло не так, вы а) должны знать причину, б) оставить объяснение этого для игроков. Если ружье висит, оно должно выстрелить. Или, если оно все же не стреляет, это должно быть демонстративно.
Теперь давайте поговорим о государственном устройстве. Если действие вашей игры не слишком размазано по времени, скорее всего Вы захотите выбрать политическое устройство Вашей цивилизации. Выбрав его, вы добавите еще больше инструментов для детализации. Я предлагаю попробовать выбрать что-то из следующего списка:
Для того, что бы мир выглядел более живым, мы можем выделить еще несколько дополнительных особенностей на которых можно сделать акцент.
Как пример:
Возможно, покажется, что тема конфликта не совсем подходит к созданию сеттинга, но, это не так. Чаще всего персонажи/мир раскрывается именно в конфликте и чем он более продуман, обоснован и логичен тем лучше. Так что мотивы и основные сюжетные ветки (пусть даже игроки и не будут на них влиять) стоит определить заранее. Кроме того, конфликт никогда не ходит один. Разноплановость мира (и конфликтов в нем) это если и не залог успеха то вполне весомый вклад в этот самый успех. Только учтите, что не стоит вываливать на игрока сразу все что у вас есть. Если мир продуман глубоко, то скорее всего игрок просто утонет. Информацию нужно подавать дозированно, оставляя возможность заинтересовавшимся самостоятельно узнать больше о Вашем мире. А то, что по вашему миру является ключевым, стоит вплести в сюжет.
Черт побери, как же это важно. И как жалко когда игроки пропускают ее мимо ушей. Но очень часто история и фольклор добавляют миру ту маленькую крупицу, благодаря которой он оживает. Если вы уже дошли сюда, не поленитесь, опишите, почему ваш мир пошел именно по такому пути. Что подтолкнуло его к текущей системе управления. Кто именно изобрел радио. Почему цивилизация отказалась от создания «таблетки бессмертия». И, конечно, оставьте возможность игрокам как то об этом узнать. Что-то можно предложить как вводную. Что-то обозначить мотивами и поступкам. А что-то будет явно влиять на сюжет. Те, кому это будет интересно, с благодарностью раскопают предложенную подноготную. А те, кому это не интересно, все равно будут ощущать, что мир логичен и детален, а не «болтается в воздухе», что только улучшит их игровой опыт. Кстати, история сеттинга это еще один способ проверить его на полноту и логичность. Если у Вас есть время, не стоит этим принебрегать.
Набросав примерный чеклист, попробуйте найдите музыку, которая бы наиболее полно подходила к выбранному вами сеттингу. Если вы сможете правильно ее подобрать, это станет якорем который позволит вам выдержать не только стилистику но и настроение вашего сеттинга, во время всего процесса.
Вот небольшой набросок мира, попробуйте сами найти в нем пункты из чеклиста:
|
Метки: author Drag13 разработка игр game development gamedev amp;d настолки !42 |
DevOops 2017 Piter: Новая конференция от JUG.ru Group, поговорим про DevOps |

 Барух jbaruch Садогурский — один из наиболее заметных DevOps-инженеров, говорящих по-русски. Отличный спикер, developer advocate из JFrog, постоянный закадыка подкаста «Разбор Полетов».
Барух jbaruch Садогурский — один из наиболее заметных DevOps-инженеров, говорящих по-русски. Отличный спикер, developer advocate из JFrog, постоянный закадыка подкаста «Разбор Полетов». Леонид Игольник — опытный спикер, разработчик из CA Technologies с двадцатилетним бэкграундом, венчурный инвестор. Чтобы понять, насколько Леонид крут, достаточно просто послушать 133 выпуск «Разбора Полетов».
Леонид Игольник — опытный спикер, разработчик из CA Technologies с двадцатилетним бэкграундом, венчурный инвестор. Чтобы понять, насколько Леонид крут, достаточно просто послушать 133 выпуск «Разбора Полетов». Олег m0nstermind Анастасьев – злой гений, заставляющий без малого десяток тысяч серверов безостановочно обрабатывать миллионы сообщений в минуту без падений и тормозов. Олег расскажет об Облачном хранилище, которое пилят в Одноклассниках, и, знаете, я уверен, это будет круто.
Олег m0nstermind Анастасьев – злой гений, заставляющий без малого десяток тысяч серверов безостановочно обрабатывать миллионы сообщений в минуту без падений и тормозов. Олег расскажет об Облачном хранилище, которое пилят в Одноклассниках, и, знаете, я уверен, это будет круто.  Сергей bsideup Егоров – ведущий DevOps-подкаста 2d1o, хардкорщик, каких поискать, и, кстати, первый человек, который смог внятно мне объяснить, что такое DevOps.
Сергей bsideup Егоров – ведущий DevOps-подкаста 2d1o, хардкорщик, каких поискать, и, кстати, первый человек, который смог внятно мне объяснить, что такое DevOps.  Николай Рыжиков – Технический лидер команды «Health Samurai», которая успешно создает медицинскую систему нового поколения для автоматизации деятельности врачей и другого медицинского персонала в США. Активист питерских Ruby & Clojure сообществ и мета-сообщества «PiterUnited». Огненно выступал на Joker и HolyJS. Гуру и человек-оркестр, идеально для DevOps!
Николай Рыжиков – Технический лидер команды «Health Samurai», которая успешно создает медицинскую систему нового поколения для автоматизации деятельности врачей и другого медицинского персонала в США. Активист питерских Ruby & Clojure сообществ и мета-сообщества «PiterUnited». Огненно выступал на Joker и HolyJS. Гуру и человек-оркестр, идеально для DevOps! Paul Stack – Разработчик из HashiCorp (разработчики Vagrant, Vault, Consul, Terraform, Otto) поделится адским хардкором про разработку инструментов для DevOps-инженеров.
Paul Stack – Разработчик из HashiCorp (разработчики Vagrant, Vault, Consul, Terraform, Otto) поделится адским хардкором про разработку инструментов для DevOps-инженеров. Erno Aapa – девопсер уже 6 лет, активный спикер и независимый консультант, основатель Финского DevOps-коммьюнити.
Erno Aapa – девопсер уже 6 лет, активный спикер и независимый консультант, основатель Финского DevOps-коммьюнити. 

|
Метки: author ARG89 системное администрирование облачные вычисления it- инфраструктура devops блог компании jug.ru group devoops |
[Перевод] Как видео может изменить вашу стратегию контент-маркетинга |
|
|
[Перевод] 10 базовых принципов визуального дизайна |










|
Метки: author m1rko типографика графический дизайн визуальный дизайн текстуры фрейминг масштаб баланс ритм контраст |
[Перевод] Реализация алгоритма A* |
|
Метки: author PatientZero разработка игр алгоритмы алгоритмы поиска пути поиск в ширину алгоритм дейкстры a* |
[Перевод] Волшебное введение в алгоритмы классификации |


pandas и requests. Первые будут использоваться для упорядочивания данных, а последние — для запросов к API на получение данных.info и затем положим их во фрейм данных (Data Frame) Pandas.# Импортирует модули
import pandas as pd
import requests
# Получает статьи из категории Рэйвенклоу
category = 'Ravenclaws'
url = 'http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=' + category
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
ravenclaw_df = pd.DataFrame(info)
print('Number of articles: {}'.format(len(info)))
print('')
ravenclaw_df.head()

ravenclaw_df не указаны содержания статей… только описания. Чтобы получить содержания, придётся воспользоваться другим видом запроса к API и запрашивать данные на основе ID статей.# Задаём переменные
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
mydf = pd.DataFrame()
# Получаем ID статей, URL статей и факультеты
for house in houses:
url = "http://harrypotter.wikia.com/api/v1/Articles/List?expand=1&limit=1000&category=" + house + 's'
requested_url = requests.get(url)
json_results = requested_url.json()
info = json_results['items']
house_df = pd.DataFrame(info)
house_df = house_df[house_df['type'] == 'article']
house_df.reset_index(drop=True, inplace=True)
house_df.drop(['abstract', 'comments', 'ns', 'original_dimensions', 'revision', 'thumbnail', 'type'], axis=1, inplace=True)
house_df['house'] = pd.Series([house]*len(house_df))
mydf = pd.concat([mydf, house_df])
mydf.reset_index(drop=True, inplace=True)
# Выводим результаты
print('Number of student articles: {}'.format(len(mydf)))
print('')
print(mydf.head())
print('')
print(mydf.tail())

# Циклически проходим по статьям и извлекаем разделы " Личность и черты характера " по каждому студенту
# Если в статье про какого-то студента такого раздела нет, то оставляем пустую строку
# Это займёт несколько минут
text_dict = {}
for iden in mydf['id']:
url = 'http://harrypotter.wikia.com/api/v1/Articles/AsSimpleJson?id=' + str(iden)
requested_url = requests.get(url)
json_results = requested_url.json()
sections = json_results['sections']
contents = [sections[i]['content'] for i, x in enumerate(sections) if sections[i]['title'] == 'Personality and traits']
if contents:
paragraphs = contents[0]
texts = [paragraphs[i]['text'] for i, x in enumerate(paragraphs)]
all_text = ' '.join(texts)
else:
all_text = ''
text_dict[iden] = all_text
# Помещаем данные в DataFrame и вычисляем длину раздела "Личность и черты характера"
text_df = pd.DataFrame.from_dict(text_dict, orient='index')
text_df.reset_index(inplace=True)
text_df.columns = ['id', 'text']
text_df['text_len'] = text_df['text'].map(lambda x: len(x))
# Снова объединяем текст с информацией о студентах
mydf_all = pd.merge(mydf, text_df, on='id')
mydf_all.sort_values('text_len', ascending=False, inplace=True)
# Создаём новый DataFrame только с теми студентами, про которых есть разделы "Личность и черты характера"
mydf_relevant = mydf_all[mydf_all['text_len'] > 0]
print('Number of useable articles: {}'.format(len(mydf_relevant)))
print('')
mydf_relevant.head()
trait_dict = {}
trait_dict['Gryffindor'] = ['bravery', 'nerve', 'chivalry', 'daring', 'courage']
trait_dict['Slytherin'] = ['resourcefulness', 'cunning', 'ambition', 'determination', 'self-preservation', 'fraternity',
'cleverness']
trait_dict['Ravenclaw'] = ['intelligence', 'wit', 'wisdom', 'creativity', 'originality', 'individuality', 'acceptance']
trait_dict['Hufflepuff'] = ['dedication', 'diligence', 'fairness', 'patience', 'kindness', 'tolerance', 'persistence',
'loyalty']
Когда он был моложе, Невил был неуклюж, забывчив, застенчив, и многие считали, что он плохо подходит для факультета Гриффиндор, потому что он казался робким.
Благодаря поддержке друзей, которым он был очень предан; вдохновению профессора Римуса Люпина предстать перед лицом своих страхов на третьем году обучения; и тому, что мучители его родителей разгуливают на свободе, Невил стал храбрее, увереннее в себе, и самоотверженным в борьбе против Волан-де-Морта и его Пожирателей Смерти.
(When he was younger, Neville was clumsy, forgetful, shy, and many considered him ill-suited for Gryffindor house because he seemed timid.
With the support of his friends, to whom he was very loyal, the encouragement of Professor Remus Lupin to face his fears in his third year, and the motivation of knowing his parents’ torturers were on the loose, Neville became braver, more self-assured, and dedicated to the fight against Lord Voldemort and his Death Eaters.)
synsets из WordNet, лексической базы данных английского языка, включённой в модуль nltk (NLTK — Natural Language Toolkit). “Synset” — это «synonym set», коллекция синонимов, или «лемм». Функция synsets возвращает наборы синонимов, которые ассоциированы с конкретными словами.from nltk.corpus import wordnet as wn
# Наборы синонимов из разных слов
foo1 = wn.synsets('bravery')
print("Synonym sets associated with the word 'bravery': {}".format(foo1))
foo2 = wn.synsets('fairness')
print('')
print("Synonym sets associated with the word 'fairness': {}".format(foo2))
foo3 = wn.synsets('wit')
print('')
print("Synonym sets associated with the word 'wit': {}".format(foo3))
foo4 = wn.synsets('cunning')
print('')
print("Synonym sets associated with the word 'cunning': {}".format(foo4))
foo4 = wn.synsets('cunning', pos=wn.NOUN)
print('')
print("Synonym sets associated with the *noun* 'cunning': {}".format(foo4))
print('')
# Выводим синонимы ("леммы"), ассоциированные с каждым synset
foo_list = [foo1, foo2, foo3, foo4]
for foo in foo_list:
for synset in foo:
print((synset.name(), synset.lemma_names()))wn.synsets('bravery') связано с двумя наборами синонимов: один для courage.n.01 и один для fearlessness.n.01. Давайте посмотрим, что это означает:crafty.s.01 и clever.s.03 (прилагательные). Они появились тут потому, что слово «cunning» может быть и существительным, и прилагательным. Чтобы оставить только существительные, можно задать wn.synsets('cunning', pos=wn.NOUN).synset может предоставлять нежелательные наборы синонимов. Например, со словом 'fairness' также ассоциированы наборы paleness.n.02 («иметь от природы светлую кожу») и comeliness.n.01 («хорошо выглядеть и быть привлекательным»). Эти черты явно не ассоциируются с Хаффлпаффом (хотя Невил Лонгботтом и вырос красавчиком), так что придётся вручную исключать такие наборы из нашего анализа.
# Выводим разные леммы (синонимы), антонимы и производные словоформы для наборов синонимов к "bravery"
foo1 = wn.synsets('bravery')
for synset in foo1:
for lemma in synset.lemmas():
print("Synset: {}; Lemma: {}; Antonyms: {}; Word Forms: {}".format(synset.name(), lemma.name(), lemma.antonyms(),
lemma.derivationally_related_forms()))
print("")# Вручную выбираем наборы, которые нам подходят
relevant_synsets = {}
relevant_synsets['Ravenclaw'] = [wn.synset('intelligence.n.01'), wn.synset('wit.n.01'), wn.synset('brain.n.02'),
wn.synset('wisdom.n.01'), wn.synset('wisdom.n.02'), wn.synset('wisdom.n.03'),
wn.synset('wisdom.n.04'), wn.synset('creativity.n.01'), wn.synset('originality.n.01'),
wn.synset('originality.n.02'), wn.synset('individuality.n.01'), wn.synset('credence.n.01'),
wn.synset('acceptance.n.03')]
relevant_synsets['Hufflepuff'] = [wn.synset('dedication.n.01'), wn.synset('commitment.n.04'), wn.synset('commitment.n.02'),
wn.synset('diligence.n.01'), wn.synset('diligence.n.02'), wn.synset('application.n.06'),
wn.synset('fairness.n.01'), wn.synset('fairness.n.01'), wn.synset('patience.n.01'),
wn.synset('kindness.n.01'), wn.synset('forgivingness.n.01'), wn.synset('kindness.n.03'),
wn.synset('tolerance.n.03'), wn.synset('tolerance.n.04'), wn.synset('doggedness.n.01'),
wn.synset('loyalty.n.01'), wn.synset('loyalty.n.02')]
relevant_synsets['Gryffindor'] = [wn.synset('courage.n.01'), wn.synset('fearlessness.n.01'), wn.synset('heart.n.03'),
wn.synset('boldness.n.02'), wn.synset('chivalry.n.01'), wn.synset('boldness.n.01')]
relevant_synsets['Slytherin'] = [wn.synset('resourcefulness.n.01'), wn.synset('resource.n.03'), wn.synset('craft.n.05'),
wn.synset('cunning.n.02'), wn.synset('ambition.n.01'), wn.synset('ambition.n.02'),
wn.synset('determination.n.02'), wn.synset('determination.n.04'),
wn.synset('self-preservation.n.01'), wn.synset('brotherhood.n.02'),
wn.synset('inventiveness.n.01'), wn.synset('brightness.n.02'), wn.synset('ingenuity.n.02')]
# Функция, получающая разные словоформы из леммы
def get_forms(lemma):
drfs = lemma.derivationally_related_forms()
output_list = []
if drfs:
for drf in drfs:
drf_pos = str(drf).split(".")[1]
if drf_pos in ['n', 's', 'a']:
output_list.append(drf.name().lower())
if drf_pos in ['s', 'a']:
# Наречия + "-ness" существительные + сравнительные & превосходные прилагательные
if len(drf.name()) == 3:
last_letter = drf.name()[-1:]
output_list.append(drf.name().lower() + last_letter + 'er')
output_list.append(drf.name().lower() + last_letter + 'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-4:] in ['able', 'ible']:
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name()[:-1].lower()+'y')
elif drf.name()[-1:] == 'e':
output_list.append(drf.name().lower()+'r')
output_list.append(drf.name().lower()+'st')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
elif drf.name()[-2:] == 'ic':
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ally')
elif drf.name()[-1:] == 'y':
output_list.append(drf.name()[:-1].lower()+'ier')
output_list.append(drf.name()[:-1].lower()+'iest')
output_list.append(drf.name()[:-1].lower()+'iness')
output_list.append(drf.name()[:-1].lower()+'ily')
else:
output_list.append(drf.name().lower()+'er')
output_list.append(drf.name().lower()+'est')
output_list.append(drf.name().lower()+'ness')
output_list.append(drf.name().lower()+'ly')
return output_list
else:
return output_list
# Создаём копию словаря черт характера
# Если этого не сделать, то мы сразу же обновим словарь, по которому проходим циклически, что приведёт к бесконечному циклу
import copy
new_trait_dict = copy.deepcopy(trait_dict)
antonym_dict = {}
# Добавляем синонимы и словоформы в (новый) словарь черт характера; также добавляем антонимы (и их словоформы) в словарь антонимов
for house, traits in trait_dict.items():
antonym_dict[house] = []
for trait in traits:
synsets = wn.synsets(trait, pos=wn.NOUN)
for synset in synsets:
if synset in relevant_synsets[house]:
for lemma in synset.lemmas():
new_trait_dict[house].append(lemma.name().lower())
if get_forms(lemma):
new_trait_dict[house].extend(get_forms(lemma))
if lemma.antonyms():
for ant in lemma.antonyms():
antonym_dict[house].append(ant.name().lower())
if get_forms(ant):
antonym_dict[house].extend(get_forms(ant))
new_trait_dict[house] = sorted(list(set(new_trait_dict[house])))
antonym_dict[house] = sorted(list(set(antonym_dict[house])))
# Выводим некоторые результаты
print("Gryffindor traits: {}".format(new_trait_dict['Gryffindor']))
print("")
print("Gryffindor anti-traits: {}".format(antonym_dict['Gryffindor']))
print("")# Проверяем, что словарь черт характера и словарь антонимов не содержат повторов внутри факультетов
from itertools import combinations
def test_overlap(dict):
results = []
house_combos = combinations(list(dict.keys()), 2)
for combo in house_combos:
results.append(set(dict[combo[0]]).isdisjoint(dict[combo[1]]))
return results
# Выводим результаты теста; должно получиться "False"
print("Any words overlap in trait dictionary? {}".format(sum(test_overlap(new_trait_dict)) != 6))
print("Any words overlap in antonym dictionary? {}".format(sum(test_overlap(antonym_dict)) != 6))
# Импортируем "word_tokenize", разбивающий предложение на слова и пунктуацию
from nltk import word_tokenize
# Функция, распределяющая студентов
def sort_student(text):
text_list = word_tokenize(text)
text_list = [word.lower() for word in text_list]
score_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
score_dict[house] = (sum([True for word in text_list if word in new_trait_dict[house]]) -
sum([True for word in text_list if word in antonym_dict[house]]))
sorted_house = max(score_dict, key=score_dict.get)
sorted_house_score = score_dict[sorted_house]
if sum([True for i in score_dict.values() if i==sorted_house_score]) == 1:
return sorted_house
else:
return "Tie!"
# Тестируем функцию
print(sort_student('Alice was brave'))
print(sort_student('Alice was British'))# Отключаем предупреждение
pd.options.mode.chained_assignment = None
mydf_relevant['new_house'] = mydf_relevant['text'].map(lambda x: sort_student(x))
mydf_relevant.head(20)
print("Match rate: {}".format(sum(mydf_relevant['house'] == mydf_relevant['new_house']) / len(mydf_relevant)))
print("Percentage of ties: {}".format(sum(mydf_relevant['new_house'] == 'Tie!') / len(mydf_relevant)))

# Текст о Волан-де-Морте
tom_riddle = word_tokenize(mydf_relevant['text'].values[0])
tom_riddle = [word.lower() for word in tom_riddle]
# Вместо вычисления баллов выведем список слов в тексте, совпадающих со словами из словарей черт характера и антонимов
words_dict = {}
anti_dict = {}
houses = ['Gryffindor', 'Hufflepuff', 'Ravenclaw', 'Slytherin']
for house in houses:
words_dict[house] = [word for word in tom_riddle if word in new_trait_dict[house]]
anti_dict[house] = [word for word in tom_riddle if word in antonym_dict[house]]
print(words_dict)
print("")
print(anti_dict)
|
Метки: author NIX_Solutions программирование алгоритмы блог компании nix solutions алгоритм классификации классификационный алгоритм |
Как смотреть кино и сериалы с пользой: умные субтитры |





|
Метки: author Ontaelio расширения для браузеров алгоритмы php блог компании skyeng субтитры кино на английском сериалы nlp токенизация экосистемы |
Настройка сервера для проекта (Nginx, PHP-FPM, Elasticsearch, RabbitMQ) |
[remi]
name=Les RPM de remi pour Enterprise Linux $releasever - $basearch
#baseurl=http://rpms.famillecollet.com/enterprise/$releasever/remi/$basearch/
mirrorlist=http://rpms.famillecollet.com/enterprise/$releasever/remi/mirror
enabled=1
priority=10
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-remi
failovermethod=priority
root# rpm --import http://rpms.famillecollet.com/RPM-GPG-KEY-remi
root# yum install epel-release -y
root# yum update -y
root# yum groupinstall 'Development tools' -y
root# yum install gcc gcc-c++ glibc-devel make ncurses-devel openssl-devel autoconf java-1.8.0-openjdk-devel git wget wxBase.x86_64
root# yum install java-1.8.0-openjdk -y
root# java -version
root# echo $JAVA_HOME
root# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
root# yum install elasticsearch -y
root# firewall-cmd --permanent --add-port=9200/tcp
root# firewall-cmd --permanent --add-port=9300/tcp
root# firewall-cmd --reload
root# systemctl start elasticsearch
root# systemctl enable elasticsearch
root# systemctl status elasticsearch
root# wget http://packages.erlang-solutions.com/erlang-solutions-1.0-1.noarch.rpm
root# rpm -Uvh erlang-solutions-1.0-1.noarch.rpm
root# yum update
root# yum install erlang
root# wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.10/rabbitmq-server-3.6.10-1.el7.noarch.rpm
root# rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
root# yum install rabbitmq-server-3.6.10-1.el7.noarch.rpm
root# firewall-cmd --permanent --add-port=4369/tcp
root# firewall-cmd --permanent --add-port=25672/tcp
root# firewall-cmd --permanent --add-port=5671-5672/tcp
root# firewall-cmd --permanent --add-port=15672/tcp
root# firewall-cmd --permanent --add-port=61613-61614/tcp
root# firewall-cmd --permanent --add-port=8883/tcp
root# firewall-cmd --reload
root# systemctl start rabbitmq-server
root# systemctl enable rabbitmq-server
root# rabbitmqctl status
root# rabbitmq-plugins enable rabbitmq_management
root# chown -R rabbitmq:rabbitmq /var/lib/rabbitmq/
http://ip-address:15672/
root# rabbitmqctl add_user mqadmin mqadmin
root# rabbitmqctl set_user_tags mqadmin administrator
root# rabbitmqctl set_permissions -p / mqadmin ".*" ".*" ".*"
root# wget http://nginx.org/packages/centos/7/noarch/RPMS/nginx-release-centos-7-0.el7.ngx.noarch.rpm
root# rpm -Uvh nginx-release-centos-7-0.el7.ngx.noarch.rpm
root# yum install nginx -y
root# systemctl enable nginx
root# yum install php70-php php70-php-cli php70-php-fpm php70-php-bcmath php70-php-devel php70-php-gd php70-php-json php70-php-mbstring php70-php-mcrypt php70-php-opcache php70-php-pecl-amqp php70-php-pecl-event -y
systemctl enable php70-php-fpm
root# setenforce 0
root# systemctl restart nginx
root# systemctl restart php70-php-fpm
http://ip-address/
|
Метки: author GHostly_FOX серверное администрирование настройка linux nginx *nix centos php-fpm elasticsearch rabbitmq |
Законы и проекты, которые изменят лицо российского IT. Часть II |

У нас сейчас сложилось представление, что майнер – тот кто сидит на своей криптоферме, дома или в своей конторе ночью и майнит, на самом деле это ещё и товарищи, которые обеспечивают консенсус, которые занимаются администрированием сетей.Взаимодействие между различными типами систем, тоже важный вопрос. Как юристы будут заниматься этим? Мы должны найти некий переходничок, как и приезжая в другую страну мы понимаем – не факт, что наш телефон будет заряжаться от их сети, идём в магазин и покупаем переходник.Такая же система должна быть и здесь, этот переходник должен быть найден, но не в ближайшем магазине, а в ближайшем ЦБ.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Организация коммутационного поля СКС высокой плотности |
























|
Метки: author Orest_ua хранилища данных хранение данных системное администрирование серверная оптимизация блог компании мук комутационное поле сервера |
Перевод книги Appium Essentials. Глава 2 |
| Инструмент | Т1 | Т2 | Т3 | Т4 |
| Calabash | - | - | - | + |
| iOS Driver | + | + | + | - |
| Robotium | - | - | + | - |
| Selendroid | - | + | + | - |
| Appium | + | + | + | + |
echo %JAVA_HOME% //выведется добавленное содержимоеecho %PATH% //значение должно будет содержать текст из %JAVA_HOME% + "\bin"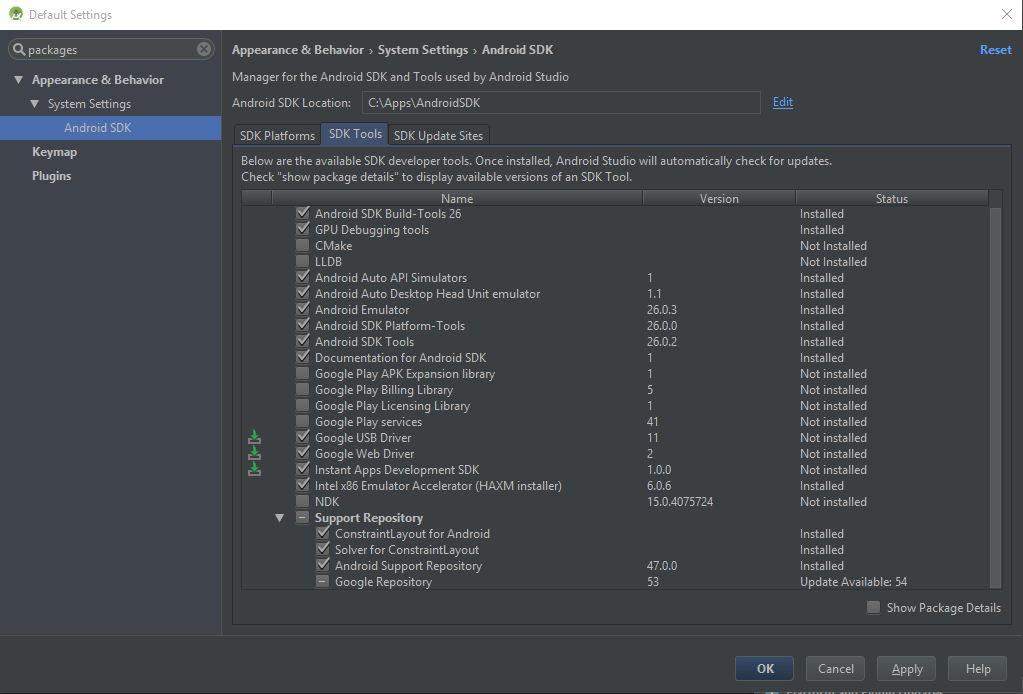
.bash_profiletouch ~/.bash_profileopen ~/.bash_profilejava –versionruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"brew doctorbrew install nodenode Appium-doctor [если чего-то будет не хватать, утилита об этом сообщит и даст советы, как исправить ситуацию].npm install –g appiumsudo authorize_iosandroid list targetsandroid create avd –n -t --abi 

|
Метки: author EreminD читальный зал appium automation testing |
Особенности организации ИТ-инфраструктуры для видеонаблюдения |

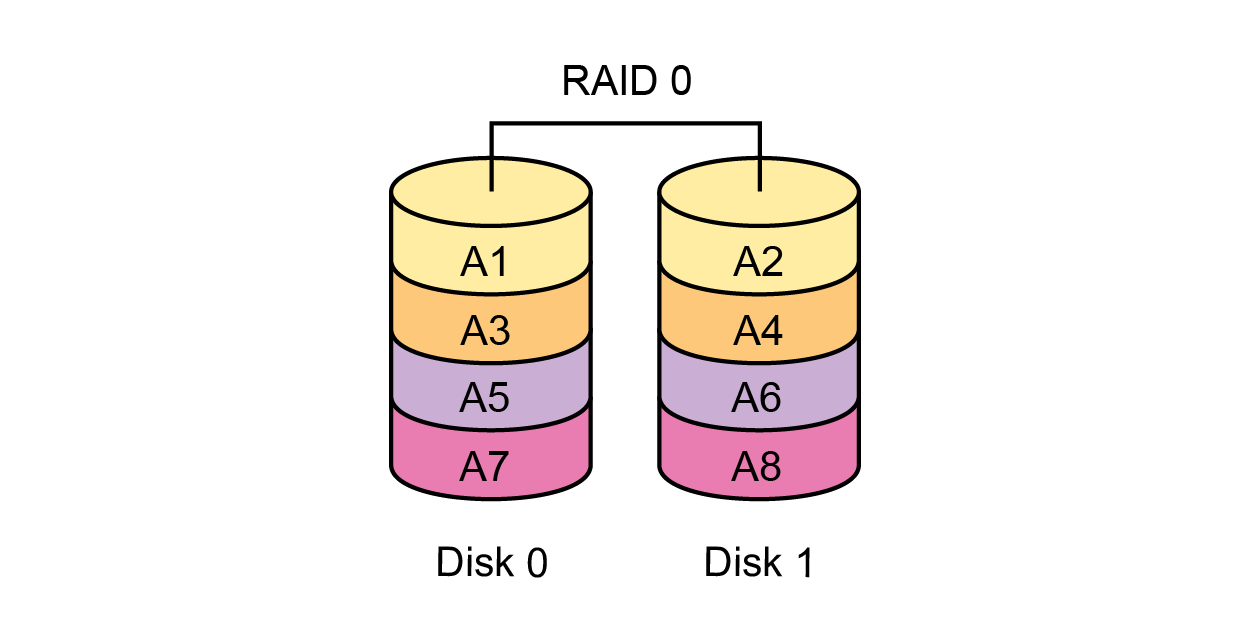
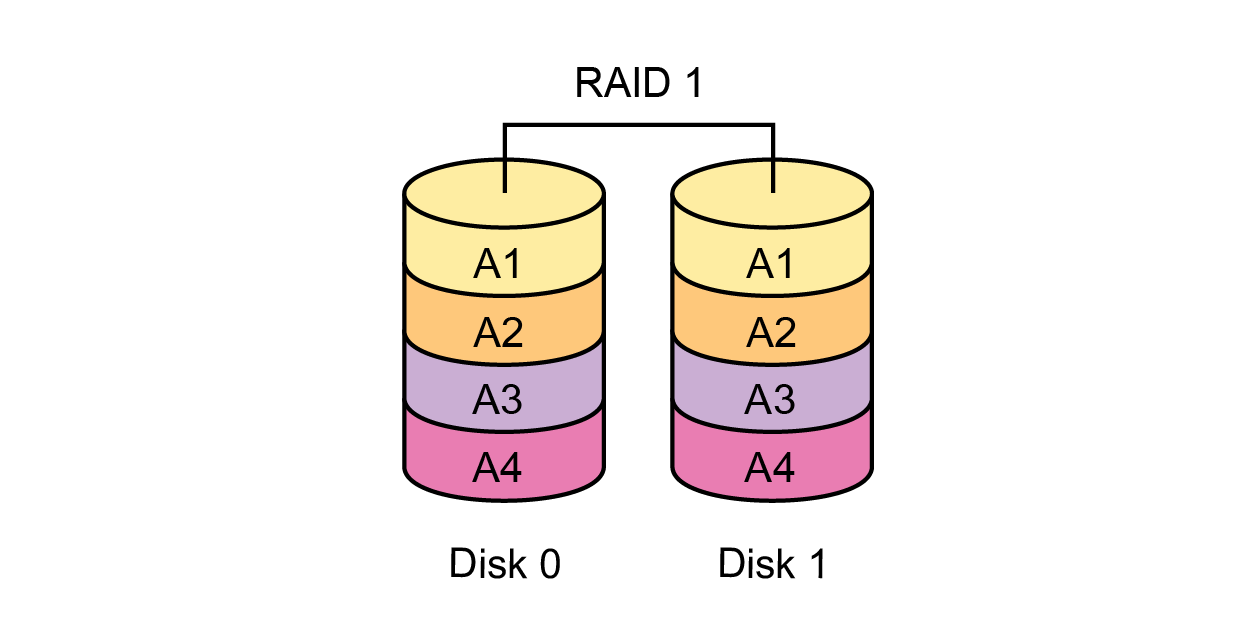
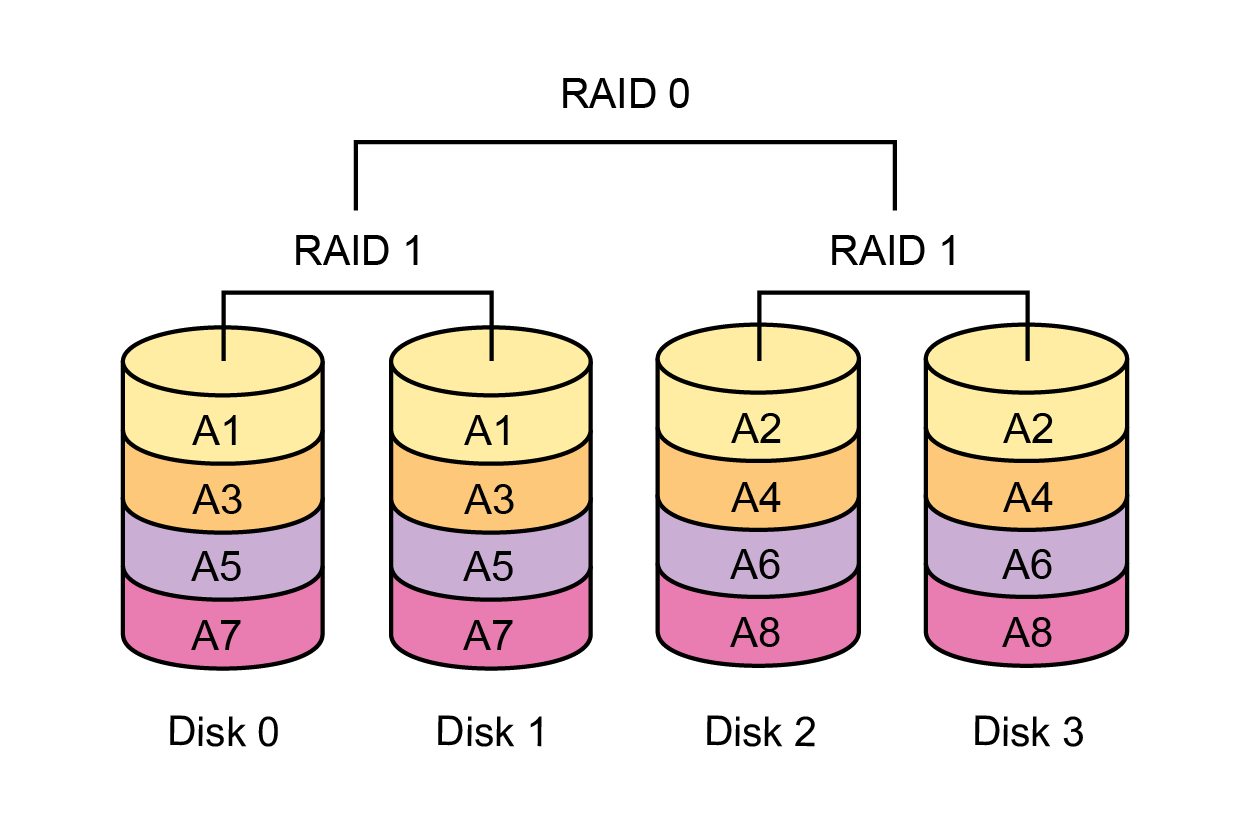
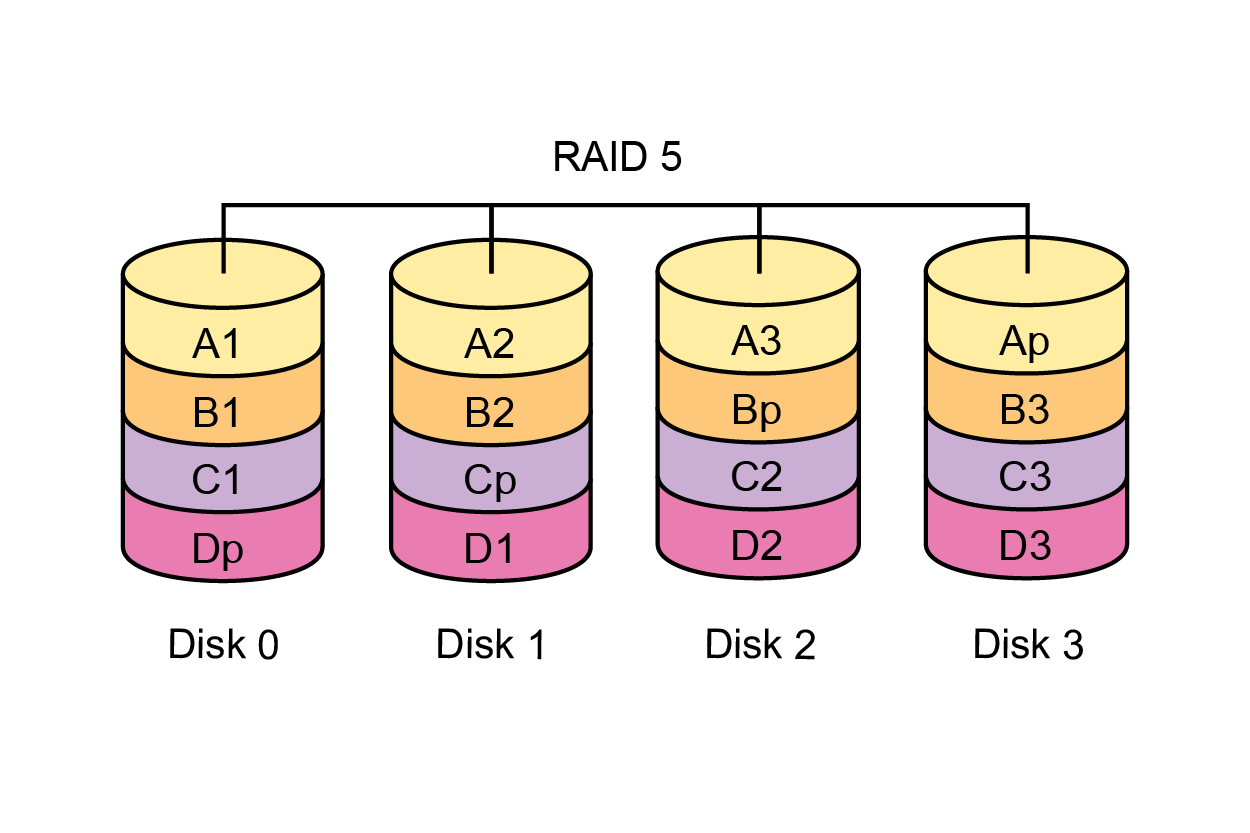

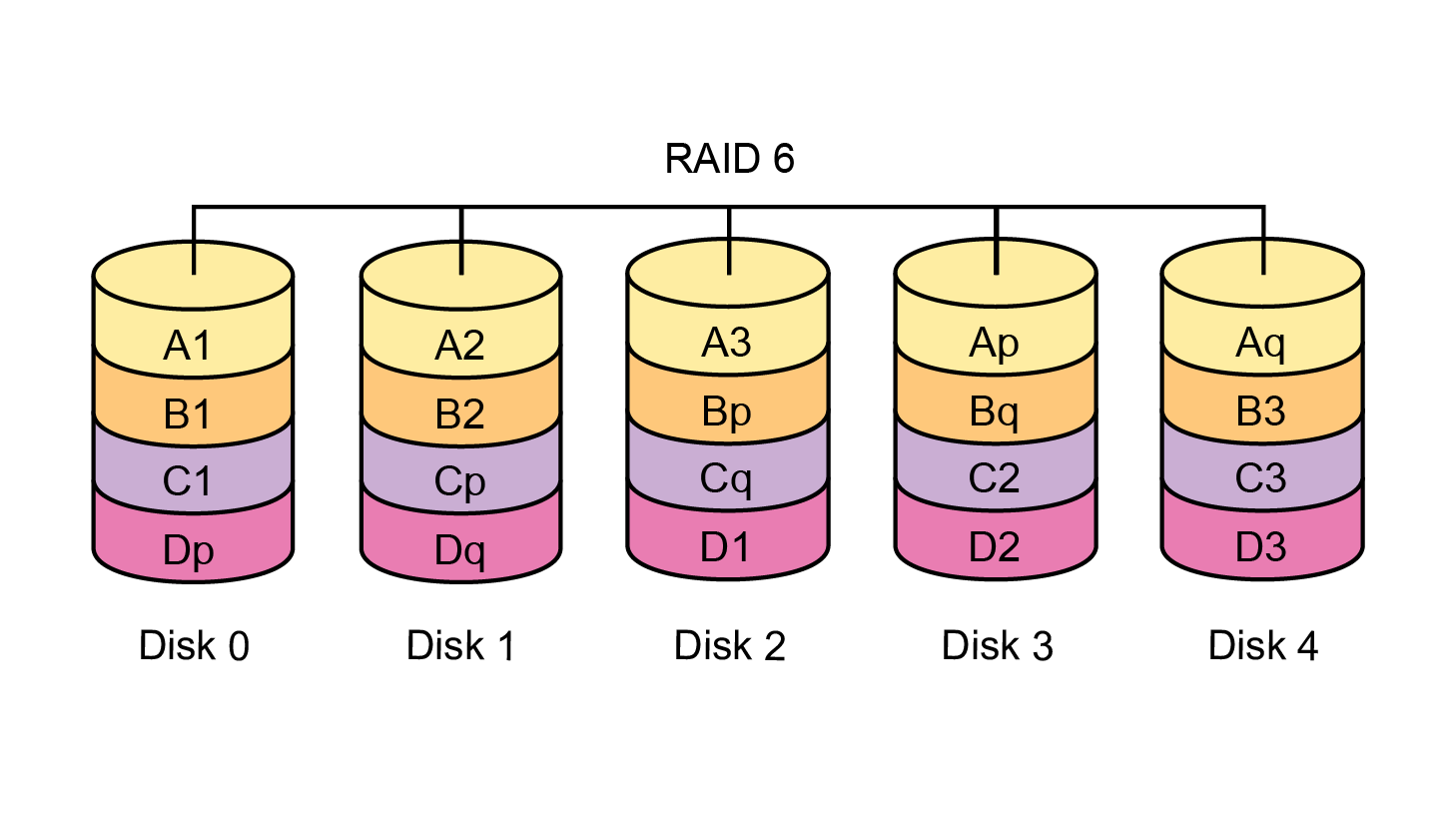
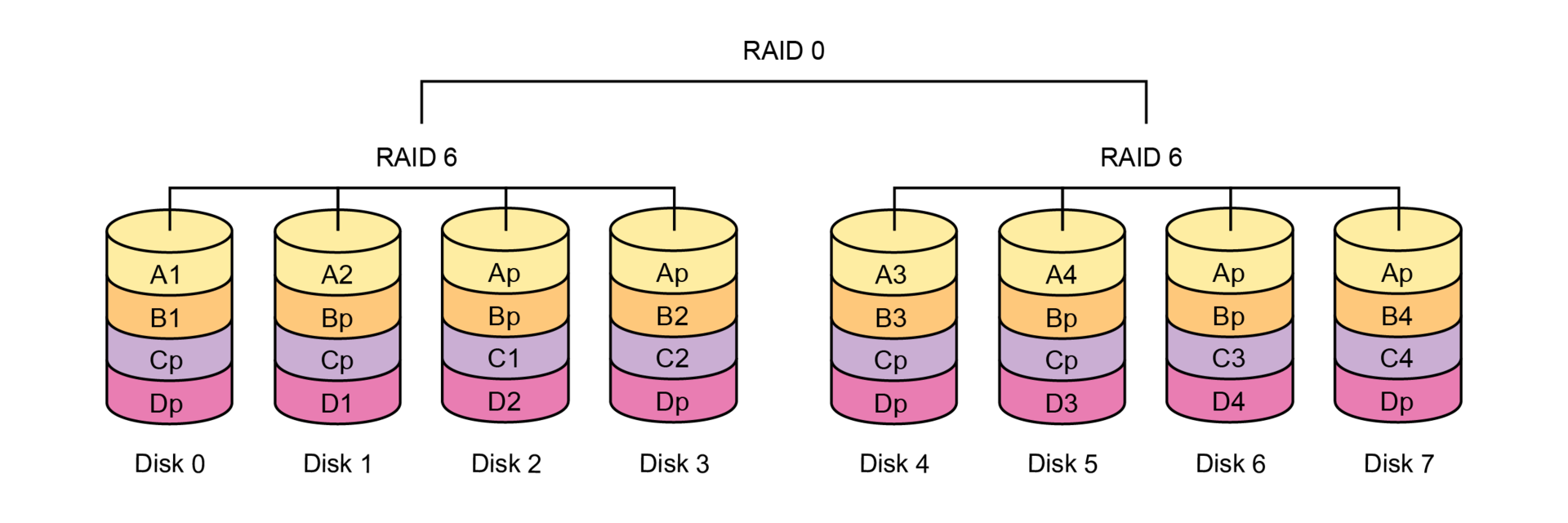
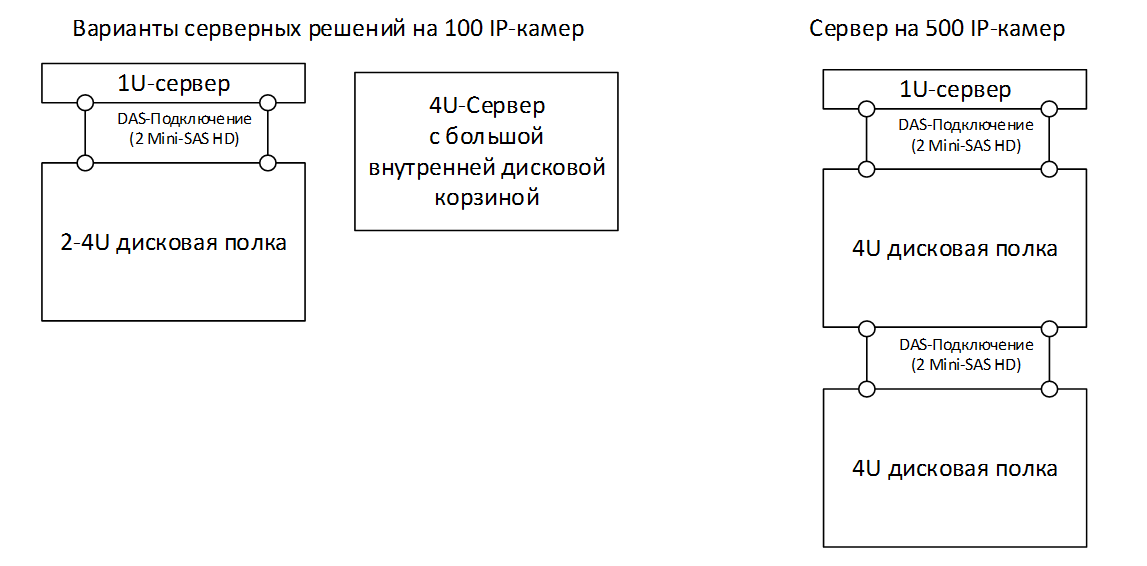
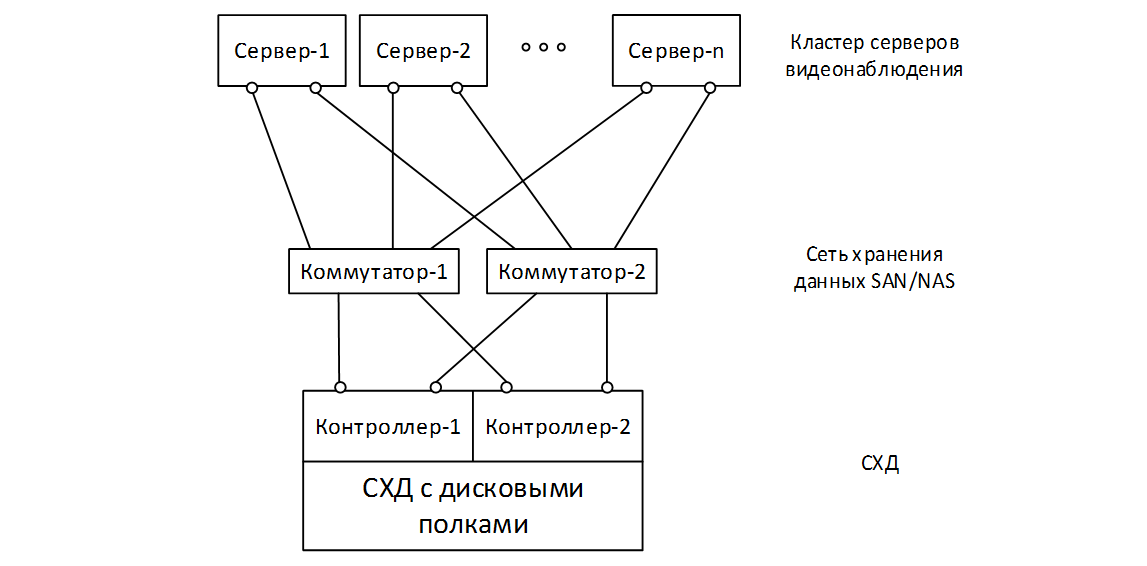
|
|
[Перевод] Российские студенты доминируют на олимпиадах по программированию и американские студенты этому не удивлены |

|
Метки: author zarytskiy учебный процесс в it образование олимпиады по программированию |
История разработки приложения для чтения статей Forbes |






|
Метки: author Pashkevich я пиарюсь yii2 ionic framework forbes android история |
Полезные функции Google Таблиц, которых нет в Excel |

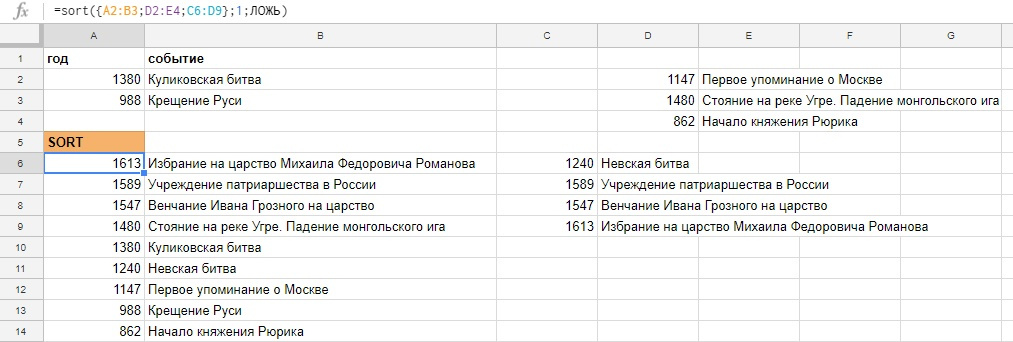
=SORT(сортируемые данные; столбец_для_сортировки; по_возрастанию; [столбец_для_сортировки_2, по_возрастанию_2; ...])
(здесь и далее — примеры для российских региональных настроек таблицы, рег. настройки меняются в меню файл-> настройки таблицы)

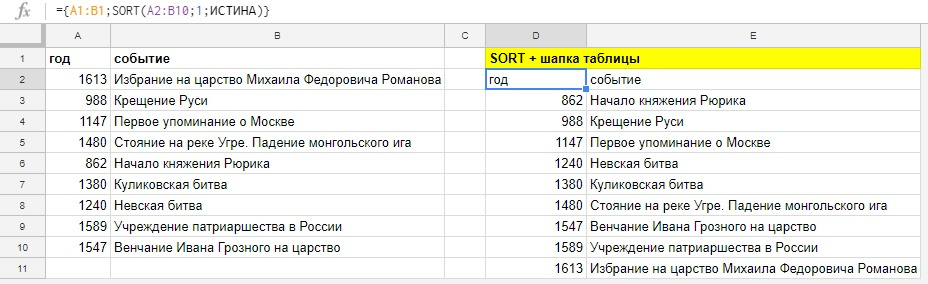


(точка с запятой и обратный слэш — это разделители элементов массива в российских региональных настройках, если у вас не работают примеры, то через файл — настройки таблицы, убедитесь, что у вас стоят именно они)
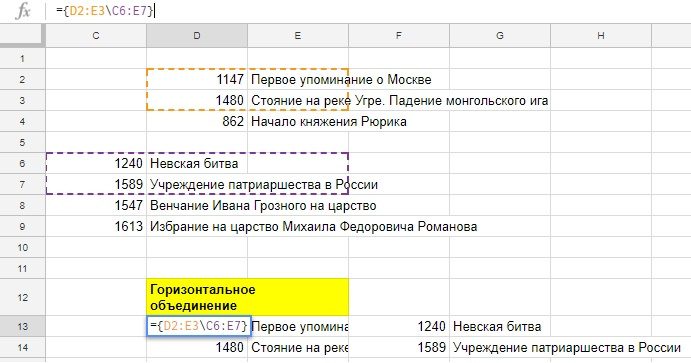
FILTER(диапазон; условие_1; [условие_2; ...])
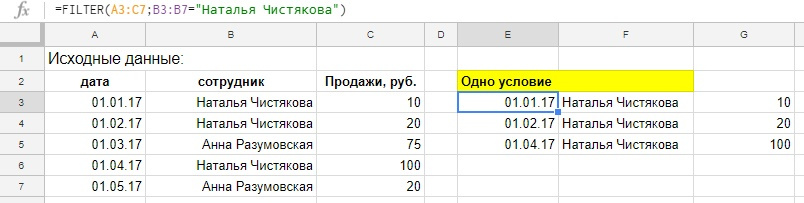
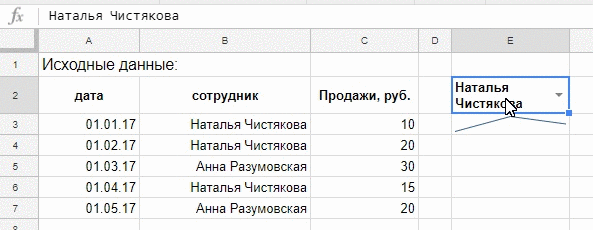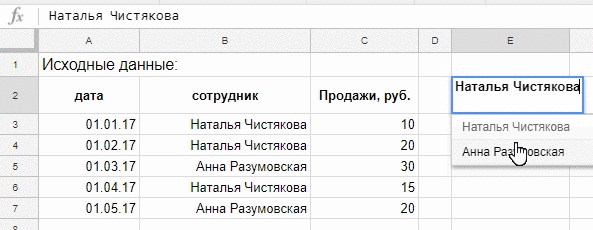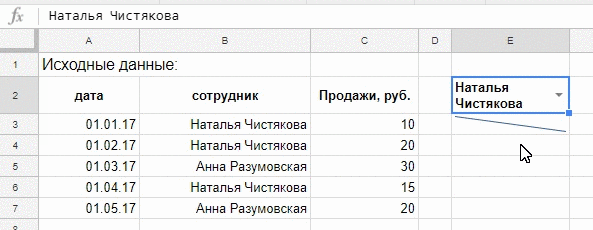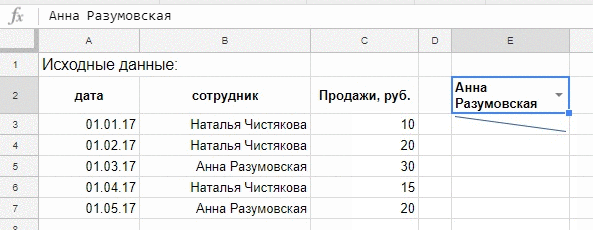
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»)
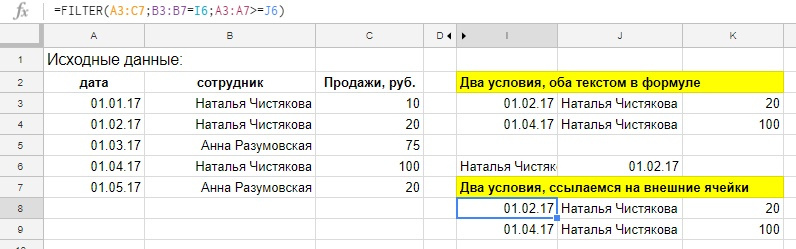
=FILTER(A3:C7;B3:B7=«Наталья Чистякова»;A3:A7>=ДАТАЗНАЧ(«01.02.17»))
=FILTER(A3:C7;B3:B7=I6;A3:A7>=J6)
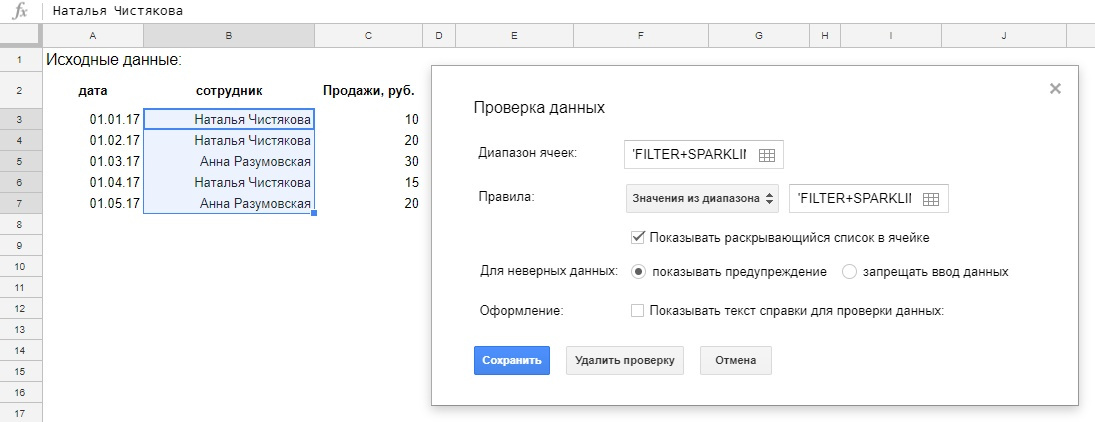
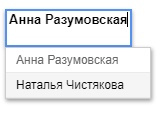
=FILTER(C3:C7;B3:B7=E2)
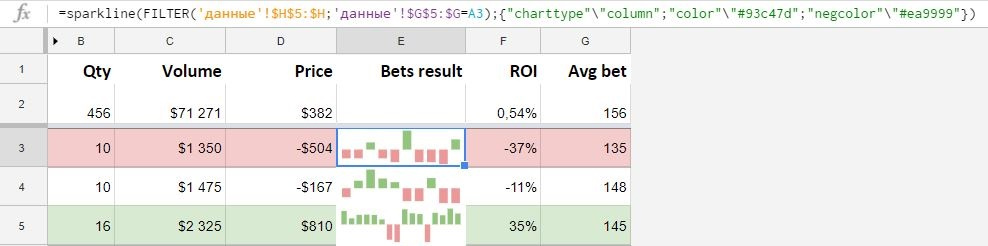
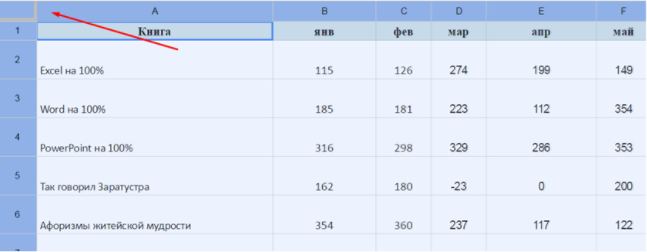
=sparkline(FILTER(C3:C7;B3:B7=E2))

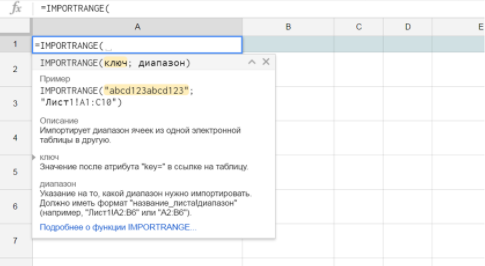
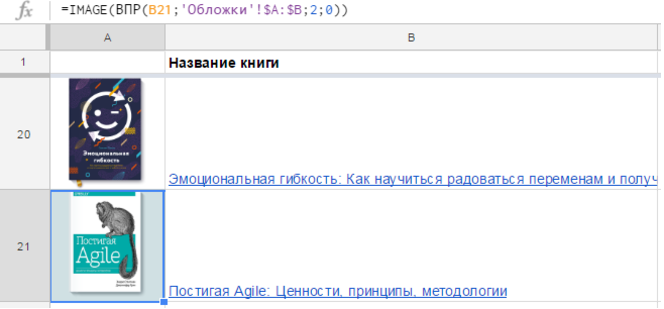
IMPORTRANGE(spreadsheet key; range string)
IMPORTRANGE(ключ; диапазон)
=IMPORTRANGE(«abcd123abcd123»; «sheet1!A1:C10»)
=IMPORTRANGE(«docs.google.com/a/company_site.ru/spreadsheet/ccc?key=0A601pBdE1zIzHRxcGZFVT3hyVyWc»; «Лист1!A1:CM500»)
Лист1!A1:CM (если будут добавляться строки)
Лист1!A1:1000 (если будут добавляться столбцы)
=IMPORTRANGE(A1;B1)

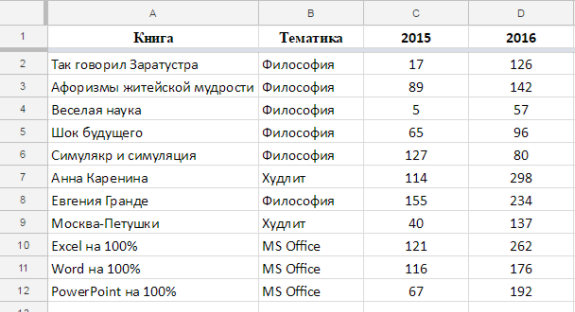
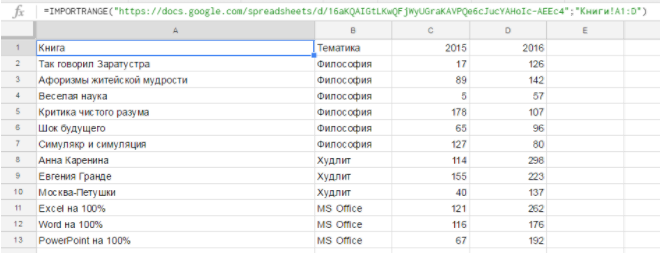
IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»)
=СРЗНАЧ(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))
=AVERAGE(IMPORTRANGE(«docs.google.com/spreadsheets/d/16aKQAIGtLKwQFjWyUGraKAVPQe6cJucYAHoIc-AEEc4»;«Книги!D2:D»))

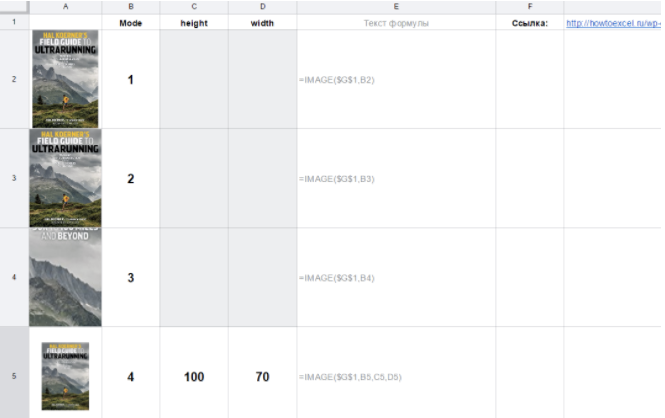
IMAGE(URL, [mode], [height], [width])
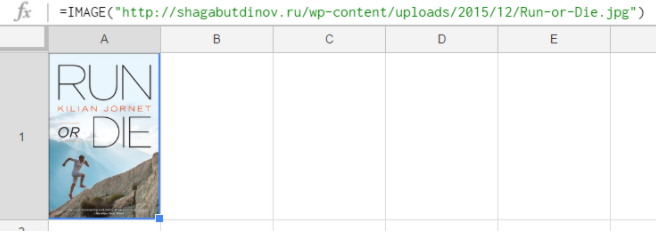
=IMAGE(“http://shagabutdinov.ru/wp-content/uploads/2015/12/Run-or-Die.jpg”)
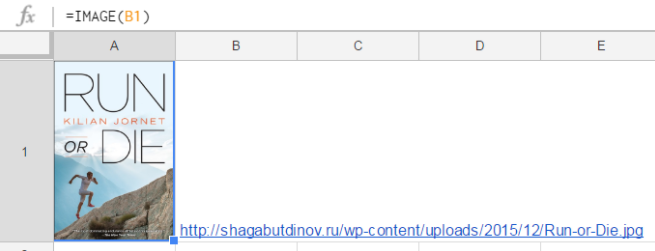
= IMAGE(B1)
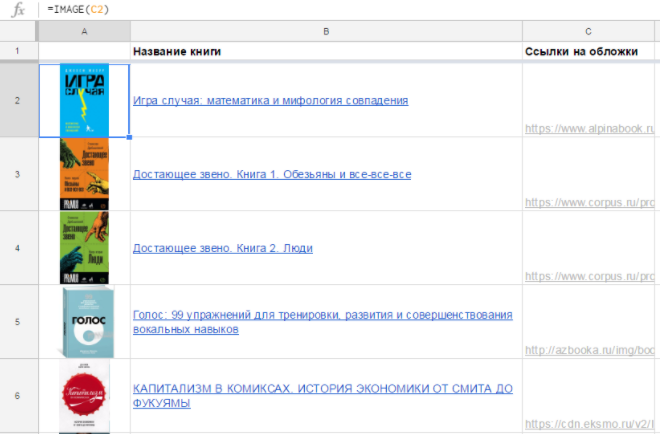
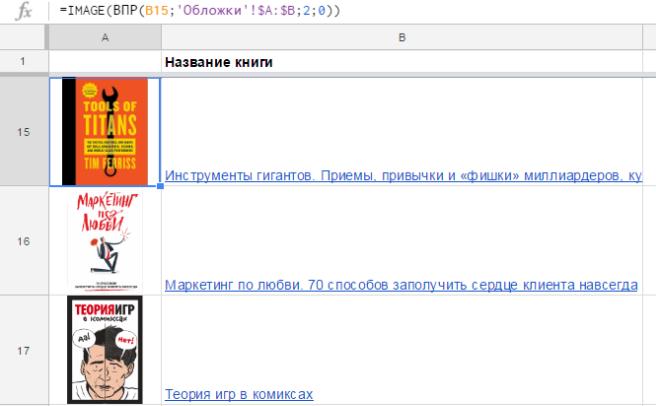

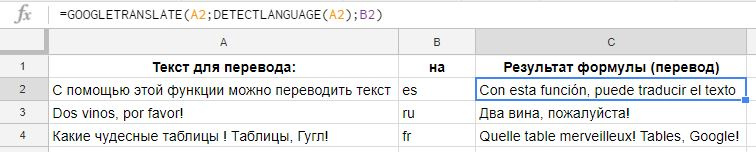
GOOGLETRANSLATE (text,[source_language], [target_language])

|
Метки: author Sianuk google api data mining big data google sheets |
Настройка веб-интерфейса TheOnionBox для мониторинга relay-ноды Tor'а |
The Onion Box — опенсорсный веб-интерфейс для мониторинга relay-нод, написанный на питоне.
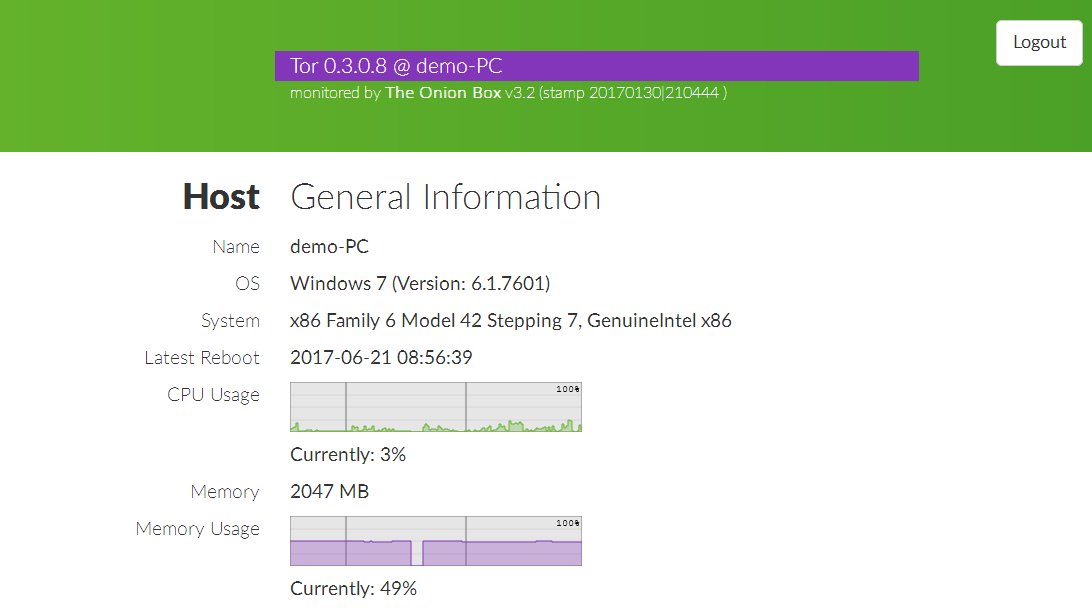
Он умеет отображать показатели загрузки диска, памяти, сети, а также статистику ноды, в том числе, получаемую через Onionoo (протокол для мониторинга статуса в сети Tor), и строить красивые графики.
Выглядит как-то так:
Под катом описание настройки.
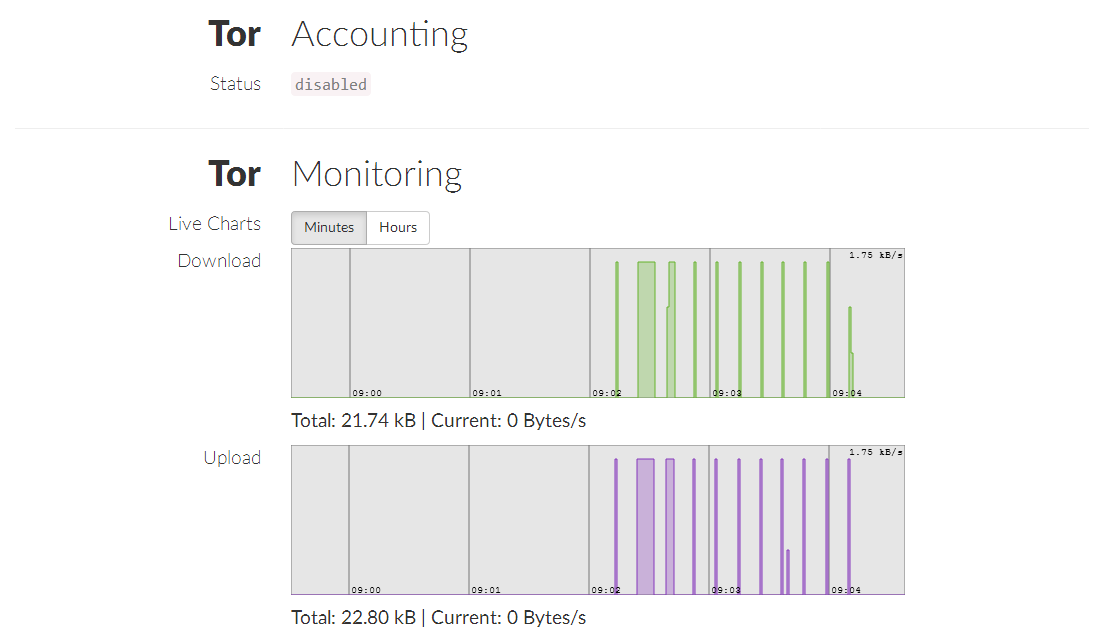
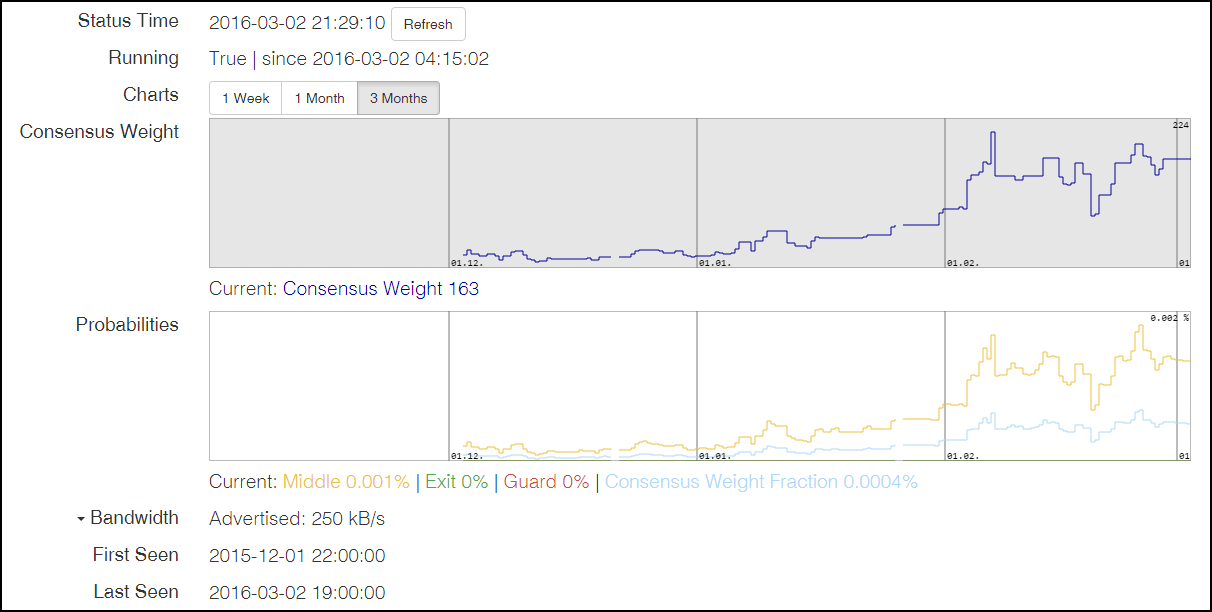
Сравнивая Tor-ноду и I2P-ноду (i2pd), в дружелюбности к неискушённому пользователю, на мой взгляд, Tor проигрывает, по крайней мере с точки зрения quick start. У i2pd есть хотя минимальный интерфейс для мониторинга и выполнения простейших команд, в то время как у Tor-ноды никакого интерфейса нет.
В свете последних событий держать у себя exit-ноду может быть чревато но, если вы хотите помочь сети Tor стать быстрее-лучше-безопаснее, при этом ничем не рискуя и с минимумом усилий, тогда relay-нода для вас! Более подробно о настройке можно почитать здесь. В этой статье я буду считать, что на вашей машине Tor relay-нода уже настроена.
Всё, что нужно, это включить управление нодой, указав порт управления. Также лучше добавить пароль на эту админку (по желанию, впрочем).
Для установки пароля получим его хеш. Переходим в папку с бинарником Tor'а, открываем cmd и выполняем:
tor --hash-password SUPER-PASSWORD > hash.txtВ той же папке должен появиться файл hast.txt с примерно таким содержимым:
Jun 21 18:26:33.023 [notice] Tor v0.2.4.24 (git-a8a38e5dd1fbb67a) running on Windows 7 with Libevent 2.0.21-stable and OpenSSL 1.0.1i.
Jun 21 18:26:33.025 [notice] Tor can't help you if you use it wrong! Learn how to be safe at https://www.torproject.org/download/download#warning
16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80Из этого нам понадобится последняя строчка, представляющая собой хеш нашего пароля: 16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80.
Затем открываем torrc-файл (обычно он лежит в /usr/local/etc/torrc или %appData%\Roaming\tor\torrc) и дописываем следующие строчки:
СontrolPort 9051
HashedControlPassword 16:5DC1FEEC60D990AB6081B9319FD29D850CBE07545B94055C1B5490EA80
CookieAuthentication 1И перезапускаем ноду, чтобы конфиг применился.
Для запуска OnionBox'а нужен питон. Любая версия (работает как с 2.7, так и с 3.х).
Под линуксом всё тривиально, а под Windows после установки нужно сделать logoff-login (или выполнить скрипт), чтобы изменения в PATH применились.
Проверим, что питон готов, открываем cmd и пишем: python -V
Должна отобразиться установленная версия.
Если не сработало, нужно добавить в PATH путь, куда установлен питон, например, C:\Python3.6 и C:\Python3.6\Scripts.
Скачиваем последний релиз с гитхаба, на момент написания статьи это 3.2.1. Распаковываем в папку, например, C:\Tor\UI.
Если вы установили в конфиге ноды Tor'а другой порт управления (не 9051), откройте конфиг (config\theonionbox.cfg), найти там строчку tor_control_port = 9051 и напишите тот же порт, что и в конфиге Tor'а.
После этого нужно установить необходимые зависимости для OnionBox'а.
Открываем cmd и первым делом ставим pip (пакетный менеджер для питона), если он ещё не установлен.
python get-pip.pypip -VДалее ставим необходимые модули:
pip install psutil stem bottle apscheduler requestsДля питона 2.7 нужно дополнительно поставить модуль configparser.
И запускаем сам сервис:
python theonionbox.pyЕсли всё в порядке, можно открыть в браузере админку (http://127.0.0.1:8080) и наслаждаться.
Также, для удобства, можно демонизировать этот сервис. Под Windows, в частности, это можно сделать через NSSM. Для этого переходим в папку с бинарником nssm, запускаем cmd, выполняем:
nssm install TorUI "path-to-python\python.exe" "path-to-onionbox\theonionbox.py"Запускаем сервис и готово!
Хабрастатья по настройке relay-ноды
Официальный ман Tor'а
TheOnionBox на гитхабе
|
Метки: author redmanmale it- инфраструктура tor tor relay the onion box onion box interface web-interface тор интерфейс веб-интерфейс |
Магия SSH |

host1# ssh -L 9999:localhost:5432 host2host1# psql -h localhost -p 9999 -U postgres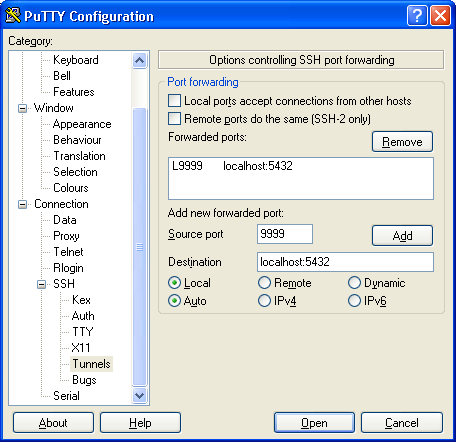
AllowTcpForwarding yes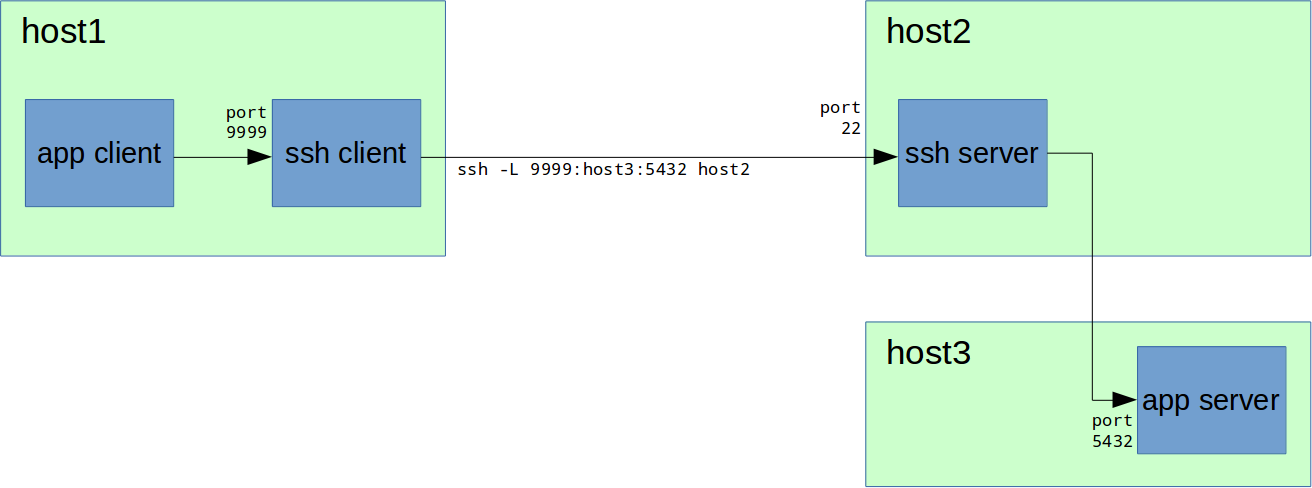
host1# ssh -L 9999:host3:5432 host2
ssh -L 0.0.0.0:9999:host3:5432 host2
ssh -R 9999:localhost:5432 host1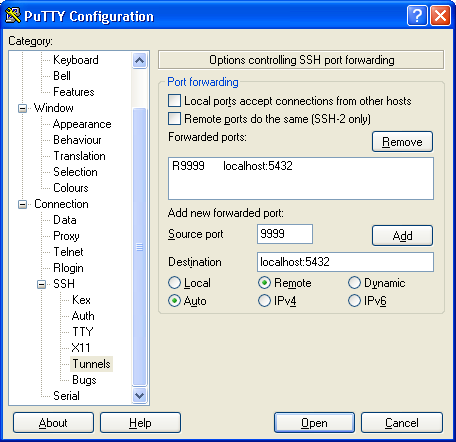
host1# ssh host2
host2# ssh host3
host3# ssh host4
host4# echo hello host4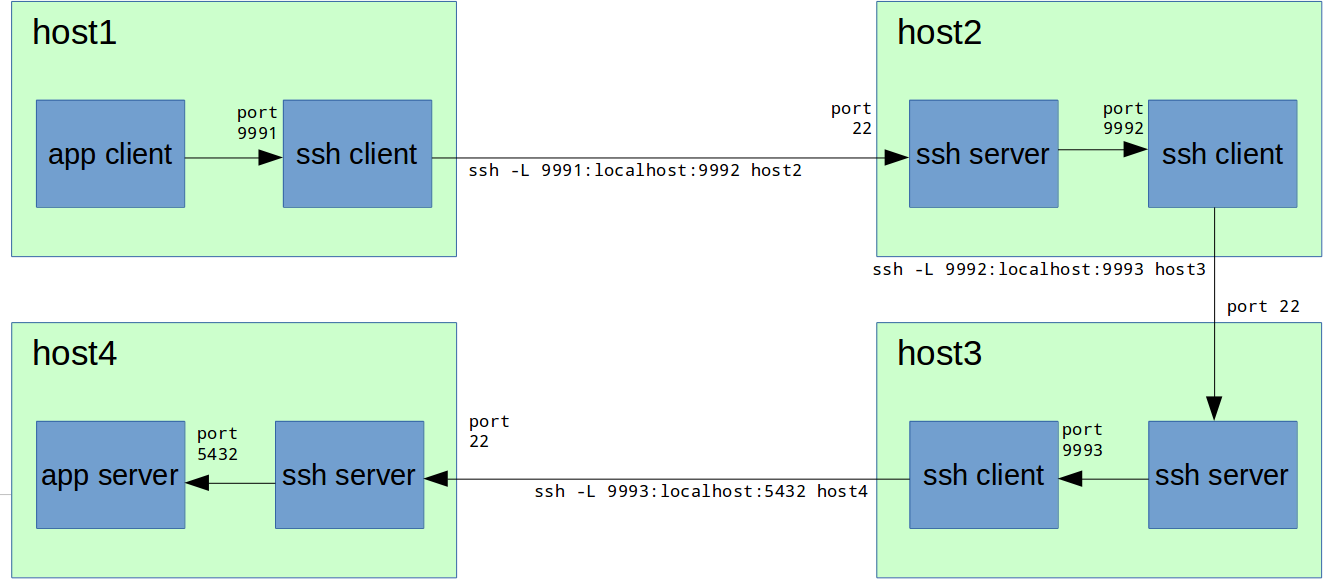
host1# ssh -L 9991:localhost:9992 host2
host2# ssh -L 9992:localhost:9993 host3
host3# ssh -L 9993:localhost:5432 host4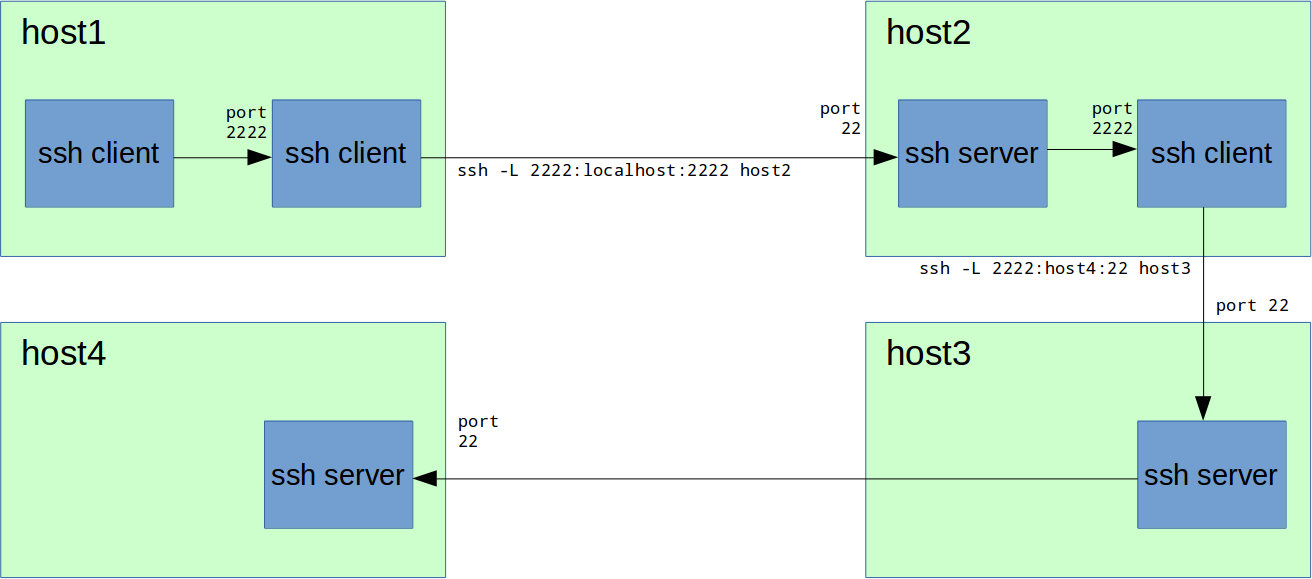
host1# ssh -L 2222:localhost:2222 host2
host2# ssh -L 2222:host4:22 host3host1# ssh -p 2222 localhost
host4# echo hello host4# копируем файл на host4
host1# scp -P 2222 /local/path/to/some/file localhost:/path/on/host4
# копируем файл с host4
host1# scp -P 2222 localhost:/path/on/host4 /local/path/to/some/file
# делаем еще один замечательный TCP forwarding на host4
host1# ssh -p 2222 -L 9999:localhost:5432 localhost
host1# psql -h localhost -p 9999 -U postgres
# обратите внимание, что порт для команды ssh задается ключем -p в нижнем регистре,
# а для команды scp -P в верхнем регистреPermitTunnel yesPermitTunnel point-to-pointPermitRootLogin without-passwordsudo service sshd restart # centos/etc/init.d/ssh restart # (debian/ubuntu)host1# sudo ssh -w 5:5 root@host2host1# ifconfig tun5
tun5 Link encap:UNSPEC HWaddr 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00
POINTOPOINT NOARP MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)host1# sudo ifconfig tun5 192.168.150.101/24 pointopoint 192.168.150.102
host2# sudo ifconfig tun5 192.168.150.102/24 pointopoint 192.168.150.101host1# # сохраняем исходные правила файрвола
host1# sudo iptables-save > /tmp/iptables.rules.orig
host1# sudo iptables -I INPUT 1 -i tun5 -j ACCEPT
host2# # сохраняем исходные правила файрвола
host2# sudo iptables-save > /tmp/iptables.rules.orig
host2# sudo iptables -I INPUT 1 -i tun5 -j ACCEPThost1# ping 192.168.150.102
host2# ping 192.168.150.101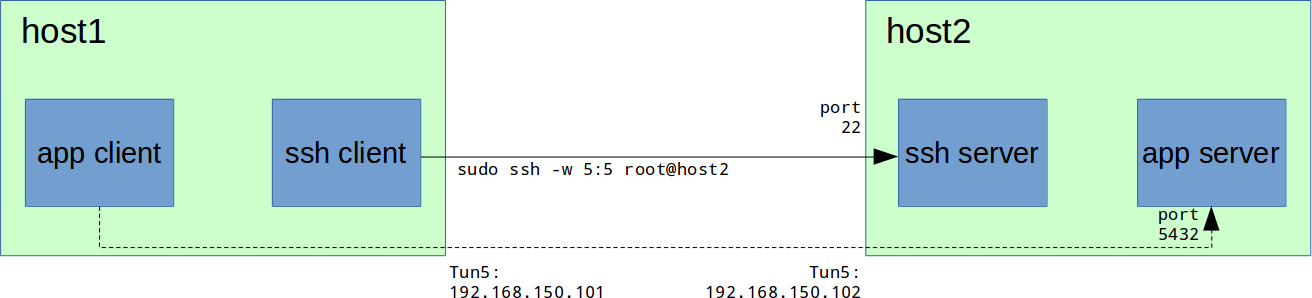
host1# psql -h 192.168.150.102 -U postgreshost2# # разрешаем IP forwarding
host2# sudo sysctl -w net.ipv4.ip_forward=1
host2# # разрешаем IP forwarding с host1
host2# sudo iptables -I FORWARD 1 -s 192.168.150.101 -j ACCEPT
host2# # разрешаем IP forwarding на host1
host2# sudo iptables -I FORWARD 1 -d 192.168.150.101 -j ACCEPT
host2# # маскируем IP адрес host1
host2# sudo iptables -t nat -A POSTROUTING -s 192.168.150.101 -j MASQUERADEhost1# # Предположим, у host2 есть доступ к сети 192.168.2.x, куда нам нужно попасть с host1
host1# # Прописываем host2 как шлюз в сеть 192.168.2.x
host1# sudo ip route add 192.168.2.0/24 via 192.168.150.2
host1# # Наслаждаемся доступом в сеть с host1
host1# ping 192.168.2.1host1# sudo iptables-restore < /tmp/iptables.rules.orig
host2# sudo iptables-restore < /tmp/iptables.rules.orighost1# ssh -L 2222:localhost:2222 host2
host2# ssh -L 2222:host4:22 host3host1# sudo ssh -p 2222 -w 5:5 root@localhost
host1# # или если host4 доступен сразу: sudo ssh -w 5:5 root@host4
host1# sudo ifconfig tun5 192.168.150.101/24 pointopoint 192.168.150.102
host4# sudo ifconfig tun5 192.168.150.102/24 pointopoint 192.168.150.101host4# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.150.0 0.0.0.0 255.255.255.0 U 0 0 0 tun5
192.168.56.0 0.0.0.0 255.255.255.0 U 1 0 0 eth0
0.0.0.0 192.168.56.254 0.0.0.0 UG 0 0 0 eth0host4# route -n > routes.orighost1# # разрешаем IP forwarding
host1# sudo sysctl -w net.ipv4.ip_forward=1
host1# # сохраняем исходные правила файрвола
host1# sudo iptables-save > /tmp/iptables.rules.orig
host1# # разрешаем IP forwarding с host4
host1# sudo iptables -I FORWARD 1 -s 192.168.150.102 -j ACCEPT
host1# # разрешаем IP forwarding на host4
host1# sudo iptables -I FORWARD 1 -d 192.168.150.102 -j ACCEPT
host1# # маскируем IP адрес host4
host1# sudo iptables -t nat -A POSTROUTING -s 192.168.150.102 -j MASQUERADEhost4# sudo ip route replace default via 192.168.150.101
host4# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.150.0 0.0.0.0 255.255.255.0 U 0 0 0 tun5
192.168.56.0 0.0.0.0 255.255.255.0 U 1 0 0 eth0
0.0.0.0 192.168.150.101 0.0.0.0 UG 0 0 0 tun5host4# ping 8.8.8.8nameserver 8.8.8.8
nameserver 8.8.4.4host4# ping ya.ruhost1# # восстанавливаем правила файрвола на host1
host1# sudo iptables-restore < /tmp/iptables.rules.orig
host1# # не забудьте восстановить также значение net.ipv4.ip_forwardhost2# # восстановите маршрут по-умолчанию на host4:
host2# sudo ip route replace default via 192.168.56.254
host2# # и уберите добавленные ранее DNS-сервера из /etc/resolv.confclient1# ssh-keygen -t rsassh-copy-id user@sshserverssh user@sshserverPasswordAuthentication noPubkeyAuthentication yesGSSAPIAuthentication no
UseDNS noservice sshd restart>
или
/etc/init.d/ssh restart
7) Спасибо (ссылки)
help.ubuntu.com/community/SSH_VPN
habrahabr.ru/post/87197
blog.backslasher.net/ssh-openvpn-tunneling.html|
Метки: author nitro2005 системное администрирование серверное администрирование настройка linux *nix ssh ssh tunnel ssh-2 vpn port forwarding |
Как грамотно развернуть Wi-Fi в отеле: типовые вопросы и решения |

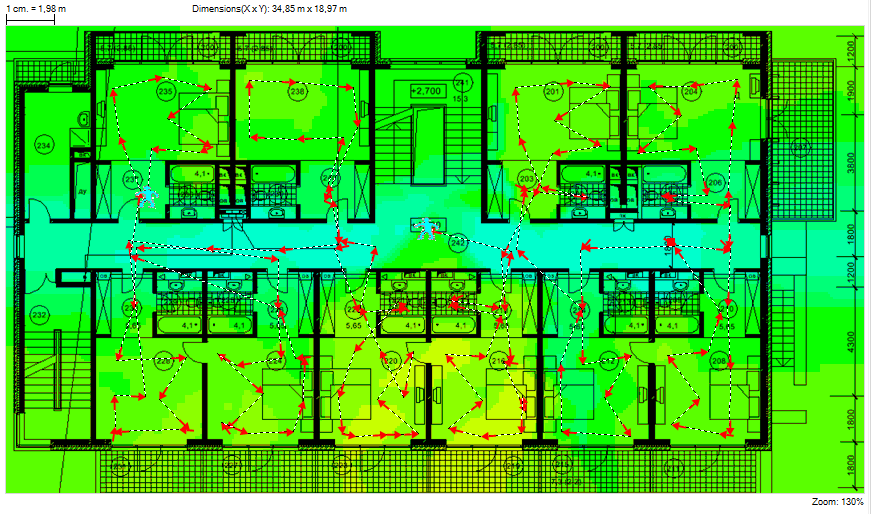

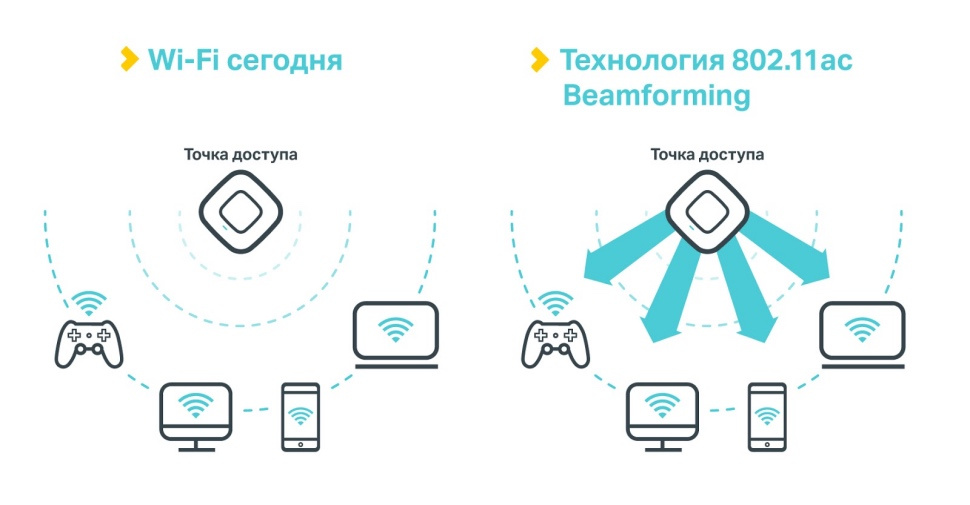
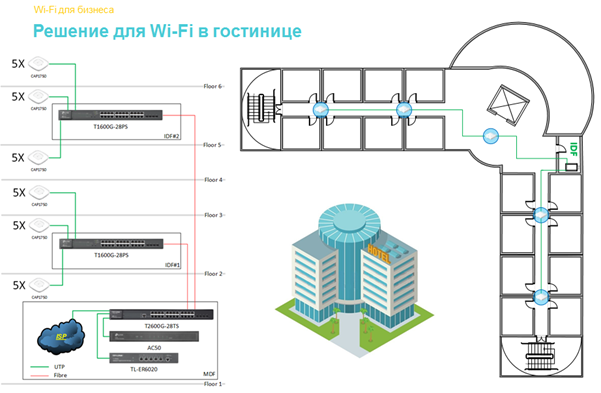
| Наименование |
Описание |
Количество |
Стоимость за единицу, у.е. |
Общая цена, у.е. |
| Шлюз |
|
|
|
|
| TL-ER6020 |
SafeStream гигабитный VPN-маршрутизатор с 2мя WAN-портами |
1 |
147 |
147 |
| Коммутаторы |
|
|
|
|
| T2600G-28TS |
JetStream 24-портовый гигабитный управляемый коммутатор 2 уровня с 4 SFP-слотами |
1 |
270 |
270 |
| T1600G-28PS |
JetStream 24-портовый гигабитный Smart коммутатор PoE+ с 4 SFP-слотами |
2 |
400 |
800 |
| Точки доступа |
|
|
|
|
| CAP1750 |
AC1750 Wi-Fi двухдиапазонная гигабитная потолочная точка доступа |
30 |
153 |
4590 |
| AC50 |
Wi-Fi контроллер точек доступа |
1 |
48 |
48 |
| Итого |
|
|
|
5855 |





|
|
Об ИТ простыми словами — проект Интеллекции |



|
Метки: author vovaekb90 учебный процесс в it мероприятия лекции популяризация ит-индустрия информационные технологии |






