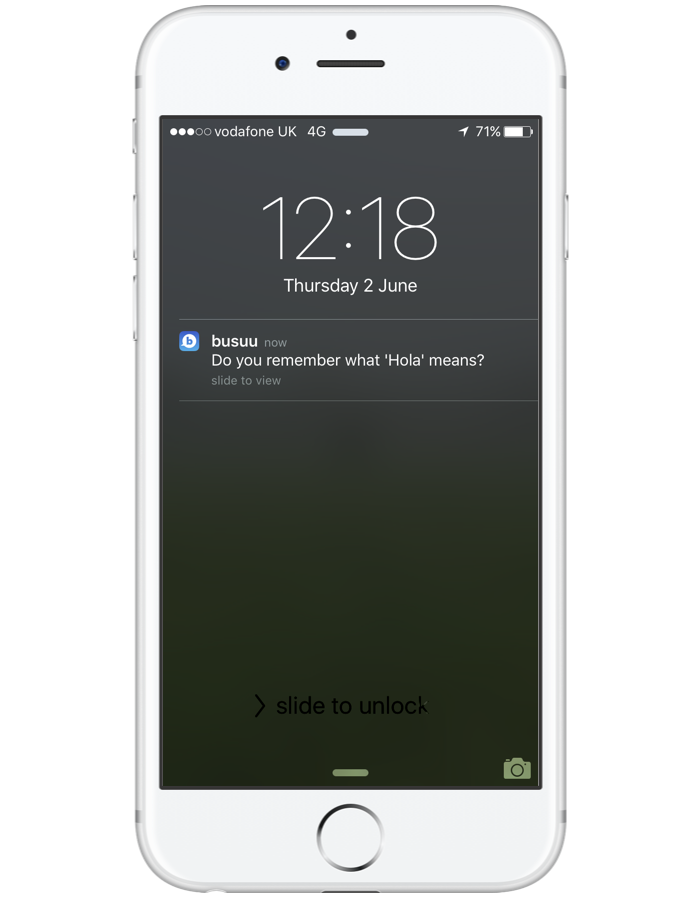
«Я не могу просто ходить с флагом «Postgres – наше всё». Нужно руками доказывать, что это работает» – Алексей Лустин |
 PG Day: Алексей, расскажите о себе. Кто вы, чем занимаетесь, как пришли к своей специализации?
PG Day: Алексей, расскажите о себе. Кто вы, чем занимаетесь, как пришли к своей специализации?|
Метки: author rdruzyagin блог компании pg day'17 russia postgresql 1c interview интервью vagrant |
Ставим Selenium Grid на колеса Apache Mesos |




$ java
-jar selenium-server-standalone.jar
-role hub$ java \
-jar selenium-server-standalone.jar \
-role node \
-hub http://host1:4444/grid/register/opt/selenium/generate_config > /opt/selenium/config.json $ /opt/selenium$ ls
chromedriver-2.29
selenium-server-standalone.jar
config.json
$ java ${JAVA_OPTS} -jar /opt/selenium/selenium-server-standalone.jar \
-role node \
-hub http://$HUB_HOST:$HUB_PORT/grid/register \
-nodeConfig /opt/selenium/config.json \
${SE_OPTS} &
$ ansible-playbook -i inventory play-site.yml \
-e test_id=mytest \
-e nodes_type=chrome \
-e nodes_count=4test_id: уникальный идентификатор проекта с тестами
nodes_count: количество нод
nodes_type: тип браузера [chrome|firefox]
$ ansible-playbook -i inventory play-site.yml \
-e test_id=mytest \
-e clean=true export grid_name=testproject
export nodes_count=$(find tests -name "*feature" \
| grep -v build | grep -v classes | grep features | wc -l)
cd ansible
ansible-playbook -i inventory play-site.yml \
-e test_id=$grid_name \
-e nodes_type=chrome \
-e nodes_count=$nodes_count
export hub_url=$(cat hub.url)
currentdir=$(pwd)
cd ../tests
./gradlew clean generateCucumberReport \
-i -Pbrowser=$browser -PremoteHub=$hub_url
$ docker run -d -p 6666:5555 selenium/node-chrome

$ docker run -d -p |
Метки: author Travieso тестирование веб-сервисов тестирование it-систем блог компании «альфа-банк» selenium grid selenium mesos инфраструктура apache mesos |
Как написать максимально хреновый бэкенд для мобильного приложения |

Известно, что практически ни одно мобильное приложение не обходится без бэкенда.
Если вы мобильный разработчик, то наверняка сталкивались с такими бородатыми дядями, которые меланхолично тянут логику на перле и вечно что-то пишут в консоли. Или может это был сутулый анимешник с длинными волосами, всосавший php с молоком матери.
Так или иначе, большинство из них ни разу не сталкивалось с мобильной разработкой, а кое-кто считает себя при этом гуру.
Специально для таких случаев, я подготовил список вредных советов о том как угробить бэкенд вашего приложения.
Приятного чтения.
Итак, если вы серверный разработчик:

Когда показывал эту статью коллегам, то многие бэкенд разработчики тоже решили поделиться парой наболевших моментов:

Вместе посмеяться над знакомыми ситуациями — это здорово, но кроме этого хотелось бы поделиться еще действенными практиками, которые мы используем у себя. Даже когда приходится работать с внешними мобильными разработчиками, они всегда благодарят нас за исключительно удобное API и профессионализм.
Все дальнейшие советы относятся к бэкенду, но если вы мобильный разработчик, то вам тоже будет интересно и полезно это прочитать. Ведь в первую очередь именно вы заинтересованы в изменениях.
Это интерфейс для мобильного разработчика. Она должна быть не просто информативна, но еще легко читаться и быть приятной глазу. Звучит странно, но чем легче воспринимается документ, тем быстрее и проще с ним работать, и тем меньше возникает к вам вопросов в процессе.
Самый простой и удобный вариант — это использовать Swagger.
Хоть его изначальный внешний вид и оставляет желать лучшего:
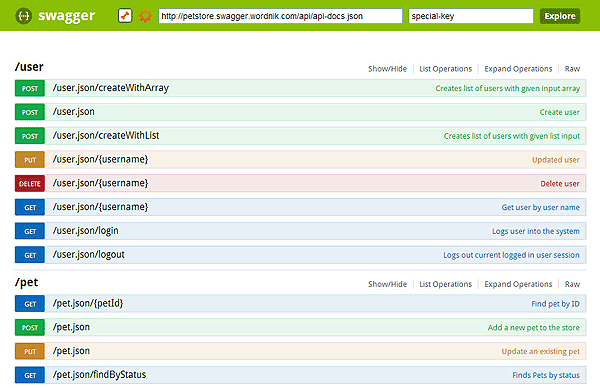
Но его можно без проблем облагородить с помощью форматтера:
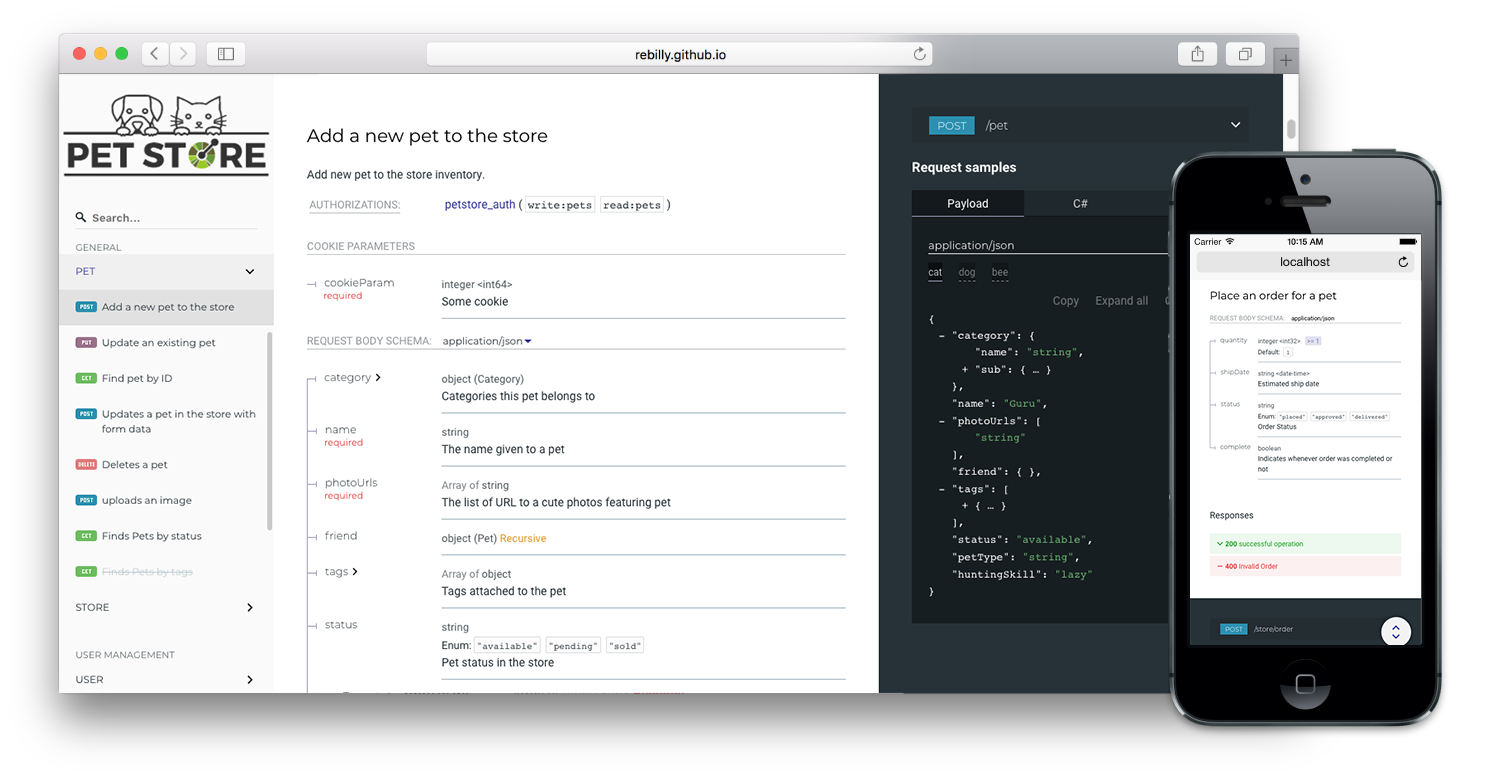
Получается симпатично и удобно. В качестве альтернатив можно использовать Apiary, но придется разделять код и документацию, что нежелательно, либо заморачиваться с рендерингом.
В мобильной разработке есть сложность — многие решения и фреймворки крайне неповоротливы. Нельзя просто взять и поменять формат для какого-то одного конкретного запроса, либо это предельно сложно. Как и нельзя изменить название определенного поля только для определенного случая: бедный девелопер будет орать в голосину, пытаясь воткнуть под это костыль.
Все должно быть целостно: везде одинаковые названия, один формат взаимодействия (предпочтительно JSON), и тп.
Особенно хорошо, если названия параметров в запросе и ответе идеально совпадают с полями соответствующих классов в мобильном приложении. Звучит странно, но это настолько упрощает жизнь разработчикам, что они будут вам за это шоколадки таскать из магазина.
В некоторых местах упрощение доходит до абсурда: например, сохранение в Realm (мобильная база данных) может быть произведено практически сразу из json. Если будет интересно, то отдельно расскажу о том, как мы избавлялись от middleware в мобильном приложении.
Пример кода по сохранению любых пришедших объектов на iOS:

Один generic метод на любую запись в базу с сервера. Классно, правда?
Тоже самое касается и изображений. Лучше всего, когда на картинку сразу приходит ссылка, которую не нужно 'доделывать'. И по тому же правилу — название ссылки должно быть везде одинаковым.
У нас был случай, когда нужно было искать изображения в гугле для определенных информационных блоков в мобильном приложении. В итоге мы просто сделали псевдо-ссылку на картинку, к которой приложение обращается, а внутри сервак ищет подходящее изображение в гугле и делает на нее редирект. А для приложения это выглядит как самая обыкновенная пикча, которая просто немного дольше соображает.
Когда работаешь над сервером, то привычно, что все находится в едином scope запроса, где достаточно просто открыть транзакцию на запись и в нее последовательно протолкнуть данные. Все изолированно, предсказуемо и линейно.
В мобильном приложении такого нет. Все крутится асинхронно, а если требуется соблюсти целостность данных из разных запросов, то это выливается в сложнейшие манипуляции с многопоточностью, злющими критическими секциями и распределением приоритетов, чтобы не было и намека на тормоза. Не зря вопрос про синхронизацию потоков в собеседовании на мобильного разработчика задают одним из первых.
Теперь понимаете, почему мобильные девелоперы стараются, чтобы все приходило в едином запросе? От этого зависит, уйдут они сегодня домой или нет)
И конечно, если какие-то данные нужно загрузить асинхронно, то не надо их пихать в общую кучу, это надо понимать.
В конце концов, не поленитесь открыть дизайн приложения и посмотреть из чего состоит экран для которого вы делаете API. Посоветуйтесь с вашими мобильными коллегами, определите как лучше вам отдавать им данные и какие последующие запросы будут от них зависеть. Может быть, в данном конкретном запросе нужно выдать чуть больше информации, чем кажется достаточным. Но зато это сделает последующую работу удобнее и приятнее на клиенте. Помогая в таких мелочах, вас потом будут вспоминать с теплотой всю профессиональную жизнь.
В этот же пункт хочется отнести отладочную информацию. Если вы сделали запрос для получения списка комментариев, то озаботьтесь, чтобы эти комментарии там были. Вам накопипастить однотипных данных — дело одной минуты, а для напарника из мобильного отдела — это целый выдох облегчения.
Просто архиважный пункт на который хочется отдельно обратить внимание. Всегда проверяйте свое API, а еще лучше — пусть тесты делают это за вас. Каждый баг на бэкенде равен десяти на клиенте. Ведь между сервером и пользователем находится множество уровней абстракций, которые надо исключить перед тем, как винить сервер.
Каждый баг тратит время пользователя, тестировщика, мобильного разработчика и только потом — вас. На вас возложена наибольшая ответственность, и ваши ошибки обходятся компании дороже всего.
В качестве бонуса хочется добавить, что здорово, когда есть pretty print, хотя бы на время разработки. Бывает, что надо разобраться с тем, что пришло от сервера, не заглядывая в документацию.
А что приятнее читать, такое:
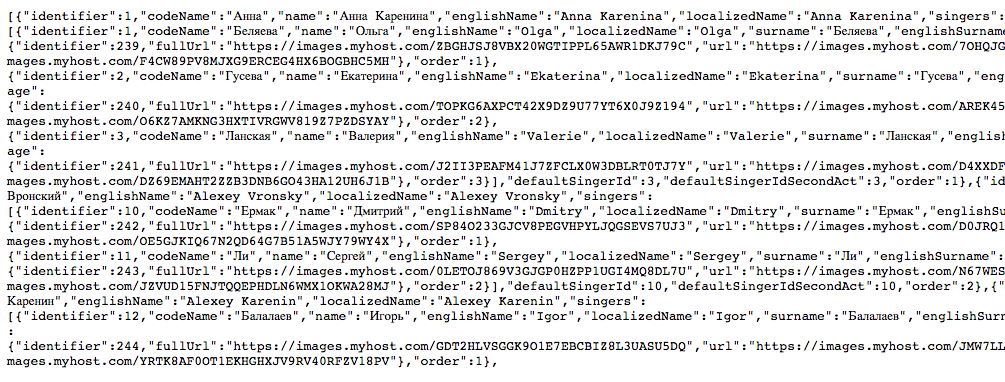
Или такое:

Разница, мне кажется, на лицо.
Главное, не забудьте отключить Pretty Print на боевом сервере, поскольку ресурсов он жрет как не в себя.
Хочется всем просто сказать, что правило на самом деле одно и довольно простое — не заставляйте коллег скрежетать зубами от вашей работы.
В следующий раз планирую рассказать о том, как мы переезжали на Go и избавились от огромного куска бизнес логики на клиенте, сократив бинарник приложения больше, чем на треть.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Mehdzor разработка под ios разработка под android разработка мобильных приложений api backend ios android |
[Из песочницы] Ненормальный GraphQL в Electron или как я писал десктопный клиент для Tinder |
Привет, Хабр. В начале зимы 2016 года я снова стал одинок. Спустя какое-то время я решил завести себе профиль в Tinder. Всё бы ничего, но постепенно стала накапливаться усталость из-за невозможности нормально печатать на физической клавиатуре. Мне виделось несколько решений этой проблемы:
Первый вариант меня не устраивал из-за принципиального превосходства реальной клавиатуры над экранной. Второй вариант не подходил из-за того, что всё-таки это было бы приложение, не оптимизированное под десктоп. Третий вариант был всем хорош кроме дизайна, багов, и малой активности в репозитории. Позже Tinder++ получил письмо от юристов Tinder и проект был и вовсе свёрнут. Таким образом, лично для меня выбор был очевиден.

Прежде всего стоит отметить, что у Tinder нет открытого API, однако оно было вскрыто в 2014 году при помощи MITM. Этого оказалось вполне достаточно для написания клиента.
Пожалуй, единственным, что почти не претерпело изменений во время нелёгкой судьбы проекта, был Electron.
Мне не терпелось поиграться с React, поэтому была выбрана стандартная связка react + redux + redux-saga + immutable. К маю была написана первая версия, но возникли проблемы с моими кривыми руками архитектурой. Выяснилось, что для того, чтобы сделать redux быстрым требуется много ручной работы: мемоизация, shouldComponentUpdate, фабрики селекторов и тому подобное.
Также, пожалуй, не стоило каждый раз запрашивать всю историю и сливать её с существующим store при помощи Immutable.Map.mergeDeep
В любом случае, многословность redux и redux-saga стала утомлять меня. Моим постоянным впечатлением было, что библиотека борется со мной вместо того, чтобы помогать.
Я не хочу сказать, что redux — плохая библиотека. С эстетической точки зрения она очень элегантна. И если она позволяет вам писать хороший код, то это самое главное. Однако нельзя отрицать, что обычно с ней требуется попутно создавать очень много вспомогательного кода даже для простых вещей.
Итак, стиль redux не устраивал меня, а в лагах я винил его и react. Мне оставалось только одно.

Конечно, заголовок слегка провокационный. На самом деле подошёл период защиты диплома, сессия, сбор документов для магистратуры, военные сборы, и переезд в другую страну. Но как только всё слегка устаканилось, я перешёл к следующему пункту.
Новый стек включал в себя Inferno и MobX. Обе эти библиотеки обещали хорошую производительность при минимуме работы руками (как позже выяснилось, не совсем). В целом с ними было приятно работать, благодаря MobX код стал гораздо лаконичнее, но параллельно росли три проблемы.
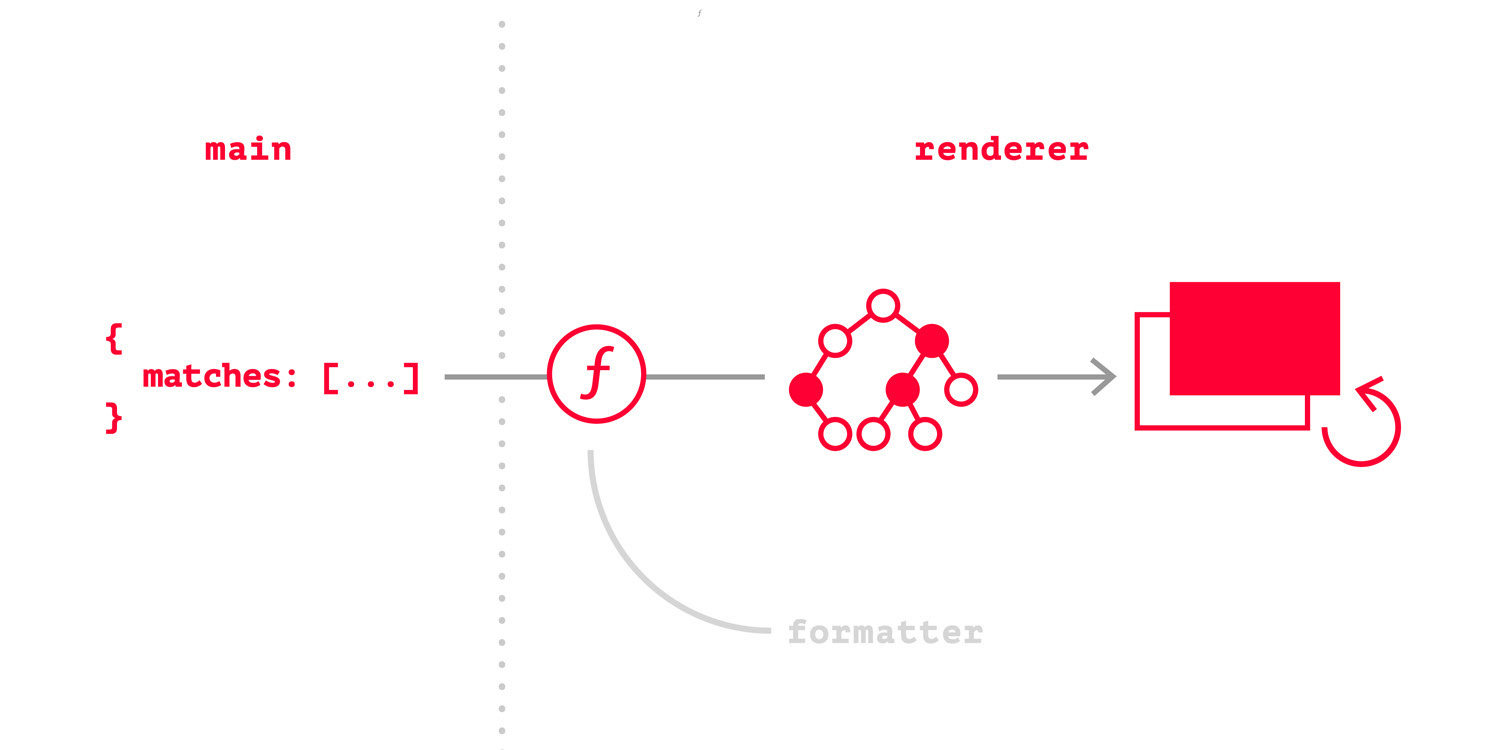
Первым очевидным решением было использования localStorage. Для этого я использовал замечательную библиотеку localForage. Однако JSON.stringify и JSON.parse при каждом сохранении и извлечении истории (а история сохранялась каждый раз заново целиком при каждом обновлении) не добавлял радости. Даже то, что теперь я запрашивал лишь обновления с сервера и сливал их с историей, не позволяло добиться желаемой производительности.
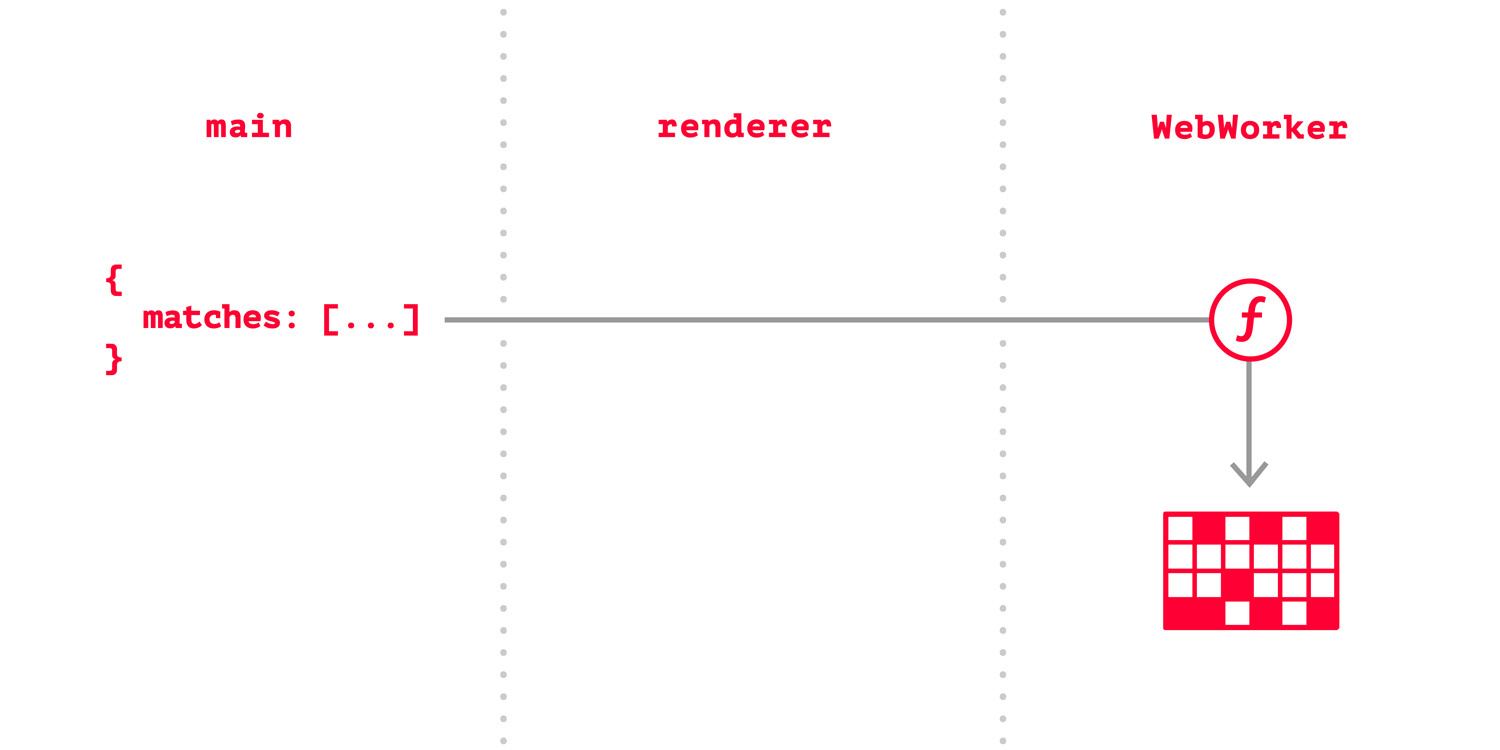
Следующим решением было использование IndexedDB, а для максимальной производительности была выбрана библиотека Dexie.js. Быстро выяснилось, что обновление лишь изменившихся данных существенно добавляет скорости, но лаги интерфейса всё ещё были заметны. Тогда я вынес всю работу с IndexedDB в WebWorker и вроде бы всё наладилось.
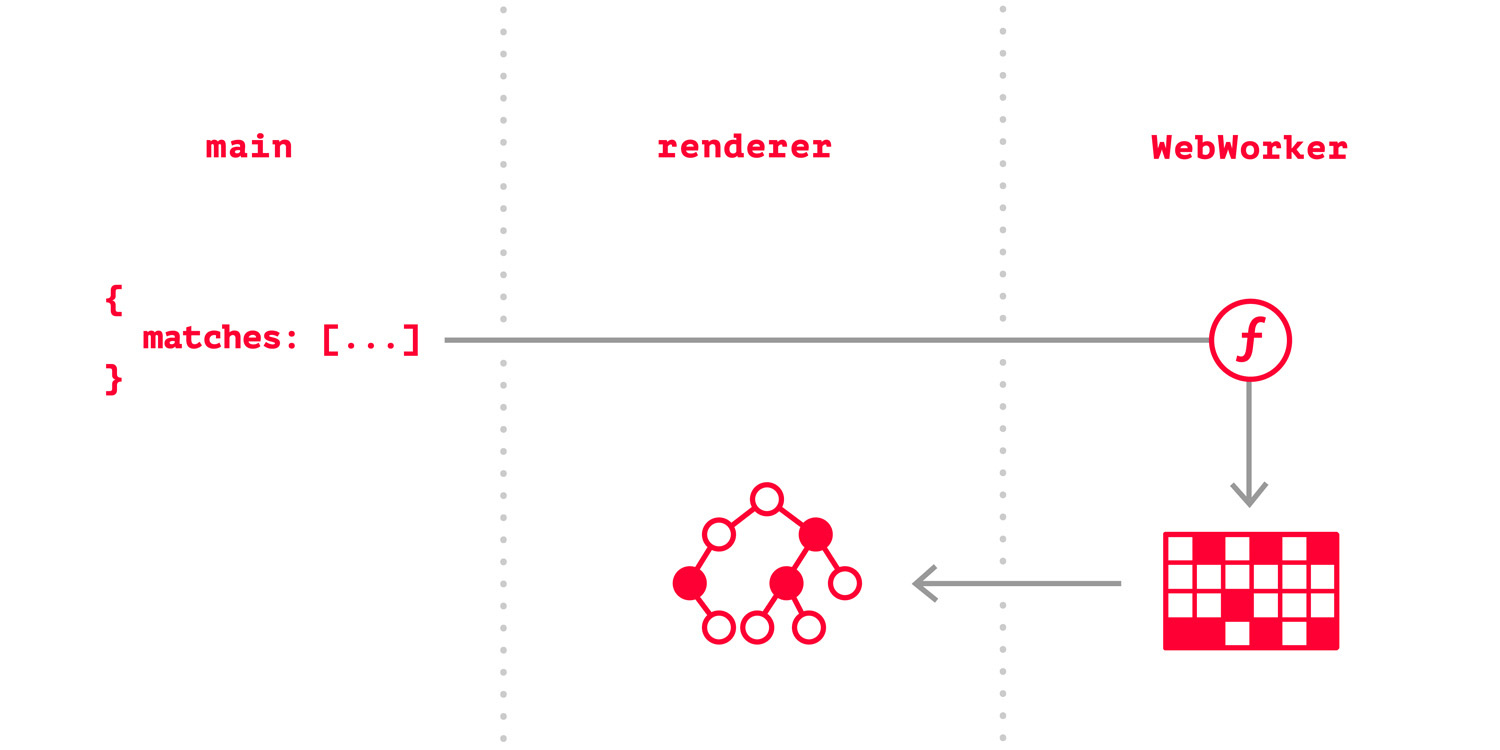
Для запроса к API Tinder необходимо устанавливать специальные заголовки для мимикрии под их Android-клиент. Из соображений безопасности браузерный JS не поддерживает такие трюки, так что все запросы выполнялись из main процесса Electron.
Таким образом, данные проходили следующий путь:
Это позволило добиться приемлемой производительности, но stores разрослись и каждый раз аккуратно сливать данные в IndexedDB, а затем и в MobX означало делать одну и ту же работу дважды руками. Кроме того, была и третья проблема.
Inferno побеждает конкурентов по скорости почти во всех бенчмарках, но производительность разработчика не менее важна. Несмотря на существование inferno-compat, многие React-библиотеки всё равно не работали. С трудом получалось запустить material-ui, не подгружалась react-vistualized.
Конечно, большая часть отсутствующих вещей была довольна простой и легко писалась самостоятельно. Кое-где получалось завести React-библиотеки при помощи пары грязных хаков. Но в целом эта ситуация стала утомлять меня, как и ручная синхронизация базы данных и реактивного хранилища. Я старался вносить вклад в репозиторий Inferno, но надолго меня не хватило. Три процесса для такого простого приложения тоже казались перебором. Мне хотелось чего-нибудь декларативного и не требующего кучи кода для поддержки.
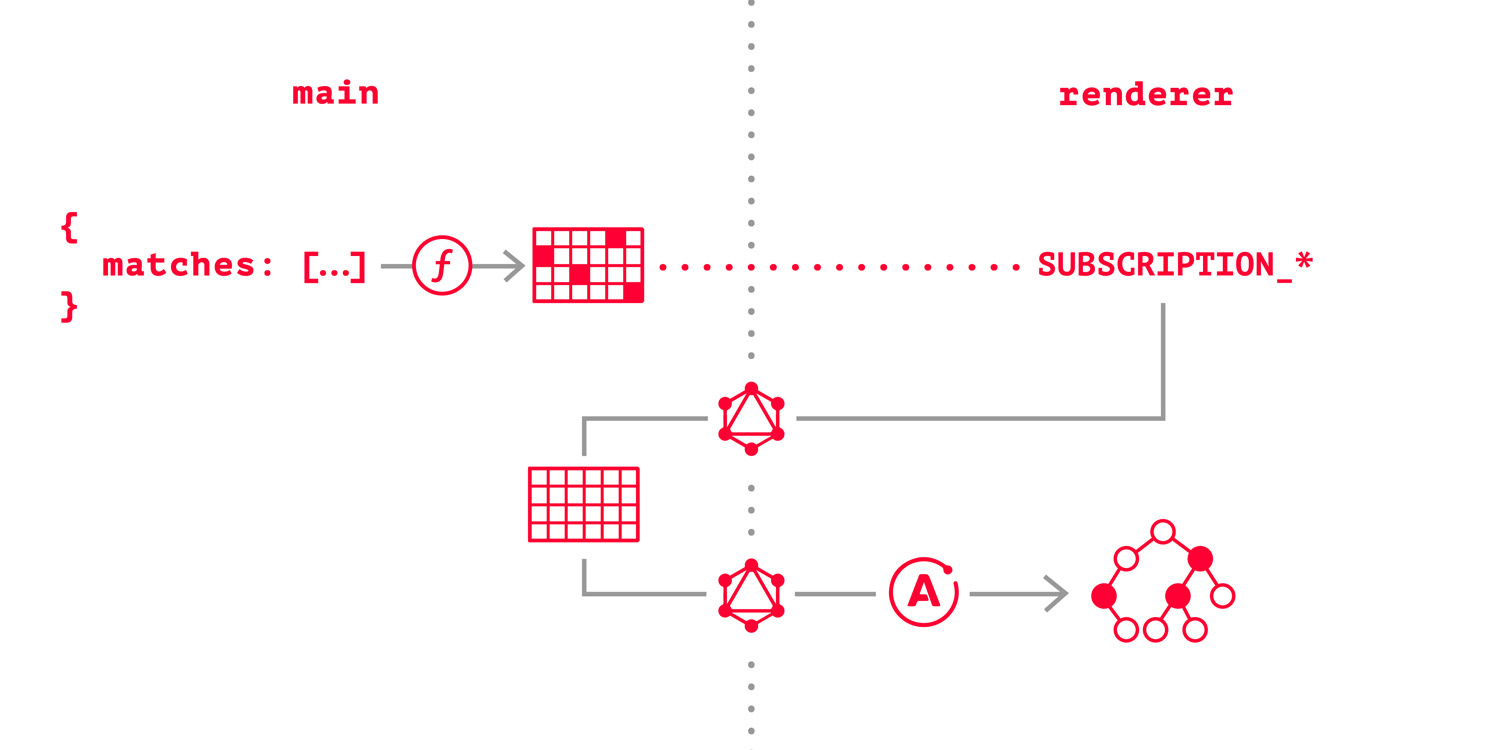
На этот раз решение было более взвешенным. Нужна совместимость с React — просто используем React, подобные бенчмарки важны лишь если отображать тысячи элементов. Не нравится слишком много процессов — значит данные нужно хранить там же, откуда они и приходят, в main процессе. В целом нравится MobX и его преимущества, но с большими хранилищами становится не очень удобно работать — следовательно MobX остаётся в качестве менеджера локального состояния компонентов, а для глобальных данных используется что-то ещё.
Если вы прочитали заголовок статьи, то что-то ещё будет для вас очевидным. Разумеется, это GraphQL. В качестве клиента используется Apollo. Сперва решение покажется необычным, но призадумавшись, вы обнаружите много плюсов:
Разумеется, в Apollo по умолчанию нет поддержки IPC, однако есть возможность создать свой сетевой интерфейс. Это очень просто:
import { ipcRenderer } from 'electron'
import { GRAPHQL } from 'shared/constants'
import uuid from 'uuid'
import { print } from 'graphql/language/printer'
export class ElectronInterface {
ipc
listeners = new Map()
constructor(ipc = ipcRenderer) {
this.ipc = ipc
this.ipc.on(GRAPHQL, this.listener)
}
listener = (event, args) => {
const { id, payload } = args
if (!id) {
throw new Error('Listener ID is not present!')
}
const resolve = this.listeners.get(id)
if (!resolve) {
throw new Error(`Listener with id ${id} does not exist!`)
}
resolve(payload)
this.listeners.delete(id)
}
printRequest(request) {
return {
...request,
query: print(request.query)
}
}
generateMessage(id, request) {
return {
id,
payload: this.printRequest(request)
}
}
setListener(request, resolve) {
const id = uuid.v1()
this.listeners.set(id, resolve)
const message = this.generateMessage(id, request)
this.ipc.send(GRAPHQL, message)
}
query = request => {
return new Promise(this.setListener.bind(this, request))
}
}Далее приведён код обработки запросов в main процессе. Все фабрики создают методы класса ServerAPI.
Код для выполнения GraphQL запроса:
// @flow
import { ServerAPI } from './ServerAPI'
import { graphql } from 'graphql'
export default function callGraphQLFactory(instance: ServerAPI) {
return function callGraphQL(payload: any) {
const { query, variables, operationName } = payload
return graphql(
instance.schema,
query,
null,
instance,
variables,
operationName
)
}
}
Код для создания ответного сообщения:
// @flow
export default function generateMessage(id: string, res: any) {
return {
id,
payload: res
}
}Код, обрабатывающий запрос и возвращающий данные:
// @flow
import { ServerAPI } from './ServerAPI'
import { GRAPHQL } from 'shared/constants'
type RequestArguments = {
id: string,
payload: any
}
export default function processRequestFactory(instance: ServerAPI) {
return async function processRequest(event: Event, args: RequestArguments) {
const { id, payload } = args
const res = await instance.callGraphQL(payload)
const message = instance.generateMessage(id, res)
if (instance.app.window !== null) {
instance.app.window.webContents.send(GRAPHQL, message)
}
}
}И, наконец, в конструкторе создаём подписчик на сообщение:
import { ipcMain } from 'electron'
ipcMain.on(GRAPHQL, instance.processRequest)Теперь при получении каждого обновлении оно записывается в базу данных NeDB, затем main процесс при помощи IPC шлёт в renderer процесс сообщение о необходимости перезапросить актуальные данные.
Я очень долго не хотел использовать react-router. Дело в том, что я застал их масштабное переписывание API и не горел желанием наступать на те же грабли в очередной раз. Поэтому сперва я подключил router5 + самописное middleware, синхронизирующее состояние в MobX. Внутри Electron де-факто нет URL в привычном смысле, так что идея хранить состояние навигации в реактивном хранилище была отличной. Однако несмотря на то, что такая связка даёт вам полный контроль над навигацией, порой она требует слишком много лишнего кода.
Переход на react-router@v4 я совместил с частичным переходом с Flexbox на CSS Grid. Эти вещи будто созданы друг для друга. Похоже, что в этот раз у команды react-router действительно получилось!
Сперва я использовал webpack и electron-packager, но во время последнего крупного изменения перешёл на electron-forge. Насколько я понимаю, в будущем этот пакет станет стандартным решением для сборки и распространения приложений на Electron. Он включает в себя electron-packager для сборки и electron-compile, позволяющий транспилировать JS/TS, компилировать другие форматы (Less, Stylus, SCSS), и многое другое практически без конфигурации.

При помощи GraphQL я избавился от большого количества моего кода (значит и от моих багов). Добавлять новые возможности в код стало гораздо проще. Я и приложение стали работать быстрее.
Я надеюсь, что этот подход поможет кому-нибудь в создании его приложений на Electron. Я планирую выделить реализацию GraphQL-over-IPC в отдельный npm пакет, чтобы её можно было удобно использовать.
К версии 2.0 мне хотелось бы
Спасибо Юле Курди за замечательные иллюстрации!
|
Метки: author wasd171 reactjs node.js javascript web react electron redux mobx graphql разработка приложений никто не читает теги |
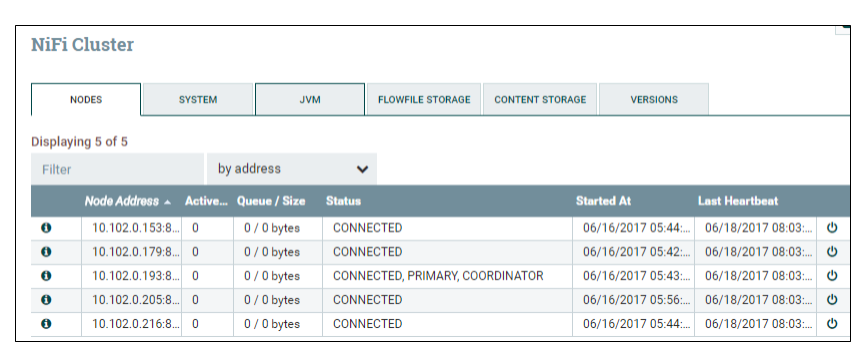
Динамическое создание кластера Apache NiFi |
 Рис. 1. GUI Apache NiFi.
Рис. 1. GUI Apache NiFi.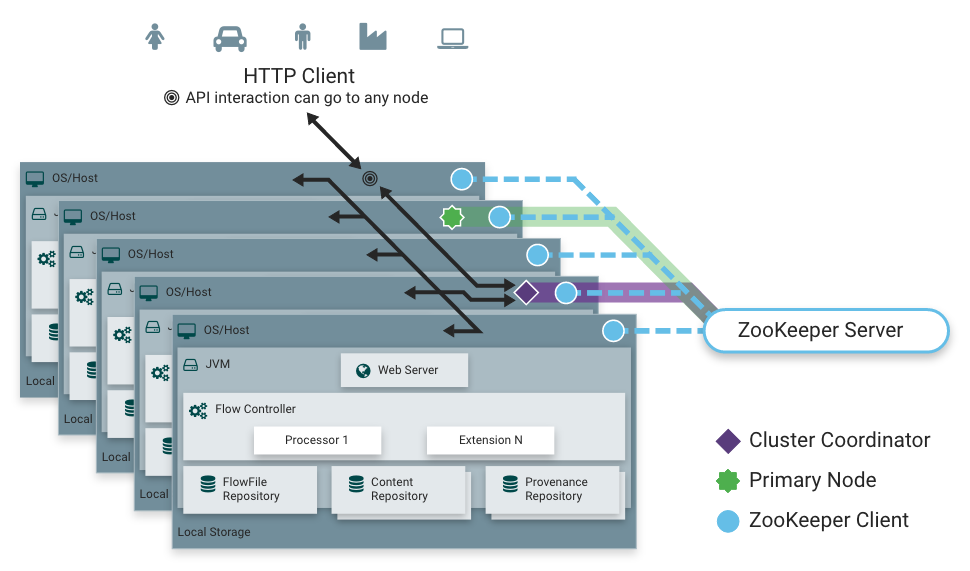 Рис. 2. Схема кластера Apache NiFi
Рис. 2. Схема кластера Apache NiFi 1. Задать в nifi.properties:
nifi.cluster.is.node=true
nifi.cluster.node.address=
nifi.cluster.node.protocol.port=3030
nifi.state.management.embedded.zookeeper.start=true
nifi.remote.input.host=
nifi.web.http.host=
nifi.zookeeper.connect.string=
connect-string список серверов с zk через запятую.
Например: nifi01:2181,nifi02:21818,nifi03:2181
2. В zookeeper.properties прописать сервера кластера:
server.1=:2888:3888
server.2=:2888:3888
server.3=:2888:3888
initLimit=5
syncLimit=2
3. Задать id в файле ./state/zookeeper/myid, если локальный узел является частью Zookeeper кластера.
4. Прописать в файле state-management.xml строку подключения к кластеру
bin/nifi.sh startvagrant upjava -cp cluster-joiner-0.0.1-jar-with-dependencies.jar ru.itis.suc.NodeAgent /home/user/nifi/nifi-1.2.0 8085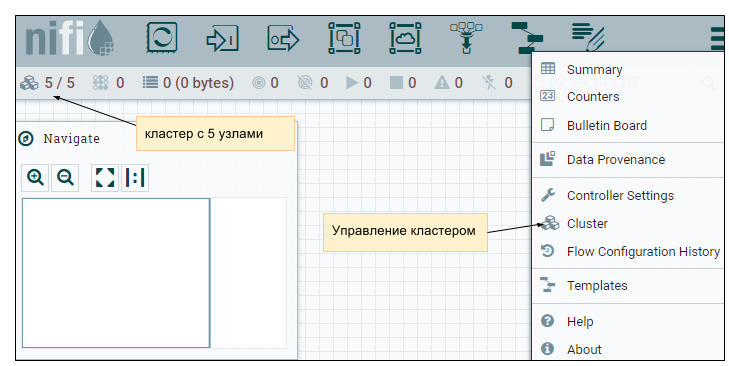
|
Метки: author DeFacto разработка для интернета вещей big data nifi flow-based programming |
[Из песочницы] Эффект Медичи или можно ли скрестить персик и дыню или Windows и iOs |

Последовательность площадей квадратов, где каждый следующий квадрат получается соединением середин сторон предыдущего — бесконечная геометрическая прогрессия со знаменателем.



«Нельзя скрещивать концентрированные (или горячие) растворы кислот и щелочей. Это важное правило техники безопасности, нарушение которого грозит химику, ну или просто криворукому экспериментатору серьезными неприятностями»(с) Alex Sol. Также, как и
«нельзя скрещивать атомные ядра одних частиц с другими ядрами или элементарными частицами. Последствием взаимодействия может стать деление ядра и испускание новых элементарных частиц. Кинетическая энергия вновь образованных частиц может быть гораздо выше первоначальной»(с) Andrey Alekseev.
|
Метки: author IlyaVv читальный зал разработка девеломпент стартапы финансирование идеи для стартапов |
Финал конкурса SAP Кодер 2017 пройдёт в прямом эфире |

Прямая трансляция финала конкурса SAP Кодер 2017 состоится 28 июня с 10:00 до 14:00 (по московскому времени).
Чтобы не пропустить прямую трансляцию, добавьте мероприятие в свой календарь.
Расписание:
10:00 — На что SAP потратит 2,2 млрд. долларов в ближайшие 5 лет? Куда направить взгляд, Рольф Шуманн, вице-президент по платформе и инновациям SAP SE
11:00 — Взгляд клиента: промышленная разработка приложений на платформе SAP Cloud Platform, Сорен Лоингер, директор по продажам и инновациям в сфере обслуживания, Aesculap/B. Braun, Germany
11:30 — Перерыв
11:45 — Выступление финалистов конкурса
13:30 — Награждение победителей конкурса
|
Метки: author SAP разработка для интернета вещей программирование блог компании sap sap кодер 2017 sap cloud platform |
[Перевод] SIP: этот рост не остановить |

«Сонь, на «прогнившем западе» уже через 3 года умрет TDM, а у нас только лет через 50», — утирая слезы зависти, говорит мне SvyatoslavVasiliev. Мы с ним обсуждаем статью коллег из GetVoIP о мировых трендах развития VoIP, вытесняющего традиционные технологии из ТфОП/PSTN (телефонные сети общего пользования). Под катом — ее перевод. Слово автору, Matt Grech.
SIP- и VoIP-технологии существенно развились с момента возникновения. Фактически, на их долю сегодня приходится почти половина трафика корпоративных коммуникаций — как малого, так и крупного бизнеса. И все же большая часть трафика последних все-таки еще идет мимо IP-каналов, поскольку крупные компании традиционно медленно адаптируются к изменениям.
Ожидается, что SIP-технологии продолжат стремительно расти в течение ближайших нескольких лет и уже к концу этого года корпоративный IP-трафик обгонит по своим объемам бизнес-коммуникации, проходящие через ТфОП с использованием традиционных для этой сети технологий. Возможно, это случится даже быстрее с учетом того, что крупные провайдеры вообще собираются отключить старую схему работы ТфОП. Eastern Management Group провела исследование участия IT-специалистов компаний в формировании глобальных SIP-технологий в период до 2020 года и пришла к интересным результатам.
Можно прямо сходу ответить, что дела у SIP обстоят просто прекрасно. Даже с учетом того, что уже сложилась инфраструктура сервисов, предоставляющих услуги по SIP-транкингу и SIP-телефонии, золотые дни SIP-протокола, лежащего в основе решений по IP-коммуникациям, все еще впереди.
Исследование Eastern Management Group показывает, что в настоящий момент более 60% компаний уже используют технологии SIP в коммуникациях, хотя уровень ее проникновения в бизнес разнится в зависимости от его масштабов. Благодаря большому размеру выборки, исследователям удалось учесть данные по IT-подразделениям компаний всего рыночного спектра.
«Исследование Eastern Management Group было проведено среди 3 500 IT-специалистов в январе 2017. Оно показывает, что мировой рынок SIP (включая SIP-транки, SIP-телефонию, SBC, аудио- и видеоприложения) растет. И в течение следующих 5 лет статья расходов на SIP будет расти быстрее темпов роста IT-бюджетов в целом».
Данные по компаниям с разным размером бизнеса:

Мы можем видеть, что как в маленьких компаниях, так и в больших корпорациях ожидается стремительный рост проникновения SIP. Только в SMB-сегменте мы видим скачок по приросту трафика c 55% (а это уже большая его доля) до 59% всего за один год. Но что более интересно — к 2020 году SIP-трафик в SMB сравняется с объемами аналогичного трафика в крупном бизнесе (его доля в обоих сегментах составит 71%).
Вполне естественно, что крупный бизнес медленно адаптируется к технологиям, имея сложную и разветвленную структуру представительств, в том числе, международных. Такая структура требует времени для реконфигурации. При этом потребность в экономии расходов на связь, являясь важной, может быть не столь экстренной для крупного бизнеса, как, скажем, для стартапа с командой из десяти человек.
Хотя уже даже в 2017 году мы увидим, как крупный бизнес достигнет отметки в 51% по объемам использования SIP-коммуникаций, что является весьма существенным скачком по сравнению с 44% в предыдущем году. Это логично: корпорации видят, что IP-решения начинают все больше затачиваться под их структуру, при этом осознавая, что преимущества SIP — это нечто гораздо большее, чем способ сэкономить ресурсы на связь.
Существует целый ряд преимуществ SIP по сравнению с традиционными технологиями проводной телефонии. Я разговаривал с Джоном Малоуном, президентом и CEO Eastern Management Group, и он был решительно убежден в том, насколько SIP-технологии лучше — особенно для малого бизнеса.
«Если у вас малый бизнес, то вы просто спятили, если еще не сделали все возможное для того, чтобы использовать SIP».
Я и сам не очень понимаю, зачем малому бизнесу хотеть тратить лишние деньги на традиционные технологии — одна только экономия ресурсов за счет внедрения виртуальной АТС покроет все, не говоря уже о внедрении системы Unified Communications в целом. Как мы знаем, ТфОП, основанная на традиционной технологии, умеет только это — совершать телефонные звонки. На основе же SIP в рамках ТфОП могут быть выстроены решения по организации командного общения и взаимодействия, автоматическому определению статуса сотрудников в телефонии, видеоконференциям. Тот же SIP лежит в основе концепции BYoD (прим.: bring your own device — концепция, предусматривающая возможность использования сотрудниками собственных мобильных устройств для решения рабочих задач) и вообще мобильности бизнеса, на которой выстраивается сегодня командная работа.
Возможно, BYoD пока не самая предпочтительная политика IT-команд в крупных корпорациях, но не так трудно разработать достаточно защищенные решения в этой области и для этого сегмента. Тем не менее, трудно спорить с тем, что, по сути, все эти преимущества SIP по сравнению с традиционными технологиями — это и не преимущества вовсе, а скорее вещи другого порядка, с которыми в принципе невозможно конкурировать.

Одни только видеоконференции — яркий пример того, как SIP прокачивает командное взаимодействие. То же самое соединение, которое используется для передачи голоса лежит в основе организации видеосвязи. Для этого существует множество решений — от бесплатных провайдеров до сервиса Chime от Amazon, так что любой бизнес не только может, но и должен ими пользоваться. SIP — драйвер корпоративных видеорешений, а они, в свою очередь — драйвер увеличения продуктивности бизнеса.
Звучавшие некоторое время назад жалобы на качество связи на основе SIP больше не актуальны. Из разговора с Джоном я узнал, что большая часть провайдеров IP-телефонии находится в рейтингах на одном уровне с операторами традиционной телефонии. И, как мы уже говорили, операторы даже собираются отказаться от поддержки традиционных технологий в рамках ТфОП и организовать ее в структуру из связанных IP-сетей по всему миру.
Итак, классические технологии ТфОП исчезнут в ближайшие несколько лет — это уже точно известно. Ускоренные темпы принятия SIP-технологий бизнесом только способствуют такому исходу. Согласно исследованию, большая часть компаний уже переключается или собирается переключиться на SIP в самое ближайшее время.
«Согласно отчету Eastern Management Group, быстрое развитие SIP и его принятие директорами по IT по всему миру приближает конец традиционных технологий ТфОП и прекращение их поддержки операторами связи в США, Великобритании, Германии, Японии и других странах. Это вдохновляющие новости для SIP-провайдеров, виртуальных АТС, решений SBC и других сервисов в этой области».
В ходе исследования были также определены ключевые даты по прекращению поддержки традиционных технологий в рамках национальных ТфОП. Большая часть провайдеров по всему миру собирается сделать это до 2020 года, причем некоторые уже в текущем или следующем году.
Подготовка к прекращению поддержки традиционных каналов ТфОП в США, как мы помним, началась в 2014 году, когда FCC (Federal Communications Commission) разрешила AT&T приступить к процессу конвертирования традиционных сетей в широкополосную IP-инфраструктуру, придерживаясь при этом существующих нормативов функционирования ТфОП. Вот как AT&T прокомментировал решение FCC в своем пресс-релизе:
«Рабочая группа, работающая над Национальной стратегией по переходу на широкополосную сеть, и TAC (Technical Advisory Committee) единодушно признали, что создание возможностей для операторов по прекращению поддержки устаревших технологий ТфОП было необходимым шагом для обеспечения единой широкополосной сети связи на территории США. В частности, все понимают, что расходы на обслуживание традиционной инфраструктуры с ее быстро уменьшающейся абонентской базой становятся неокупаемыми и отнимают значительную часть инвестиций, выделяемых на создание широкополосной сети».
Развитие SIP — не единственный фактор, ведущий к отключению старых технологий ТфОП, но рост этого рынка как нельзя кстати ложится в логику происходящего. Ну а в 2020 году у бизнеса не останется выбора, компаниям придется массово перейти к какой-то форме IP-коммуникаций, и SIP возглавит список главенствующих в этой области технологий.
SIP как таковой — это гораздо больше, чем SIP-транкинг, который так привлек большой бизнес, поскольку дал жизнь множеству новых решений и каналов IP-коммуникаций. В действительности, облачные АТС — это только один из кусочков пазла, остальные части которого держатся вместе с помощью «клея» SIP.
Как объясняет исследование, развитие SIP и ответственно за возникновение сервисов виртуальных АТС, и одновременно подстегивается ростом их популярности. Поскольку «за прошедшие несколько лет рынок виртуальных АТС вырос на 500%, SIP-телефония и SIP-транкинг также существенно прирастали по объемам продаж».
Делая SIP технологической основой в своих штаб-квартирах, компании распространяют их на свои региональные или даже международные представительства посредством сервисов виртуальных АТС. Собственно, виртуальные АТС тоже переживают устойчивый рост в последние пять или около того лет. И сейчас доля облачных АТС на рынке решений в сфере телефонии почти достигла 20%.
Вы можете запросить подробный отчет по исследованию в Eastern Management Group.
|
Метки: author sophie стандарты связи it- инфраструктура блог компании uis sip исследования тенденции телефонные сети тфоп pstn |
«Гоночки» на SVG |




{i: size_i, j: size_j, size: indent_in_cell}

{i: size_i, j: size_j, width: width_in_cels}
{
s: racer.speed,
r: racer.root,
i: racer.coord.i,
j: racer.coord.j,
wait: 0,
}
time: this.timer,
human_time: racer.human_time,
start_i: racer.start.i,
start_j: racer.start.j,
road: settings.road,
name: racer.name,
color: racer.fill,
|
Метки: author Arteben разработка игр javascript raphael.js playground.js svg |
Стагнация неизбежна. CRM принимает бой |



Клиентский сервис в графиках — несколько исследованийМы выбрали несколько свежих графиков из разных исследований, посвящённых сервису, перевели и перерисовали их. Так, Tech News World опросил 500 организаций, которые внедряют CRM-системы и выяснил, что предприниматели ожидают получить от автоматизации взаимоотношений с клиентами. 74% опрошенных рассчитывают прежде всего улучшить клиентский сервис, а 66% — увеличить удовлетворенность клиентов. Кстати, другие цели также совпали с нашим видением того, как и для чего можно использовать CRM-систему.
Компания ClickFox выяснила, как компании могут удержать клиентов у самих клиентов. Так, 33% предпочитают получить исключительный сервис 24/7. Для нас, если честно, удивительно, что 12% добровольно согласились на эксклюзивные предложения и 11% — на персонализированные продукты. Кстати, исследование Inside CRM показало, что более 75% эффекта от улучшения сервиса приходится на увеличение продаж и рост количества клиентов.
Но в том же опросе выяснилось, что с клиентами шутки плохи — новости о вашем негодном сервисе активно распространятся. У социальных сетей в опросе всего 16%, но нам думается, что в России эта цифра явно выше.
Исследование The Rockefeller Corporation показало, что основной причиной ухода клиентов является невнимание к ним.
В общем, сервис чрезвычайно важен и стоит избегать ухода клиента — хотя бы по вашей вине, поскольку с рядом других причин бороться сложнее.



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
[Перевод] Создаем нормальные push-уведомления |


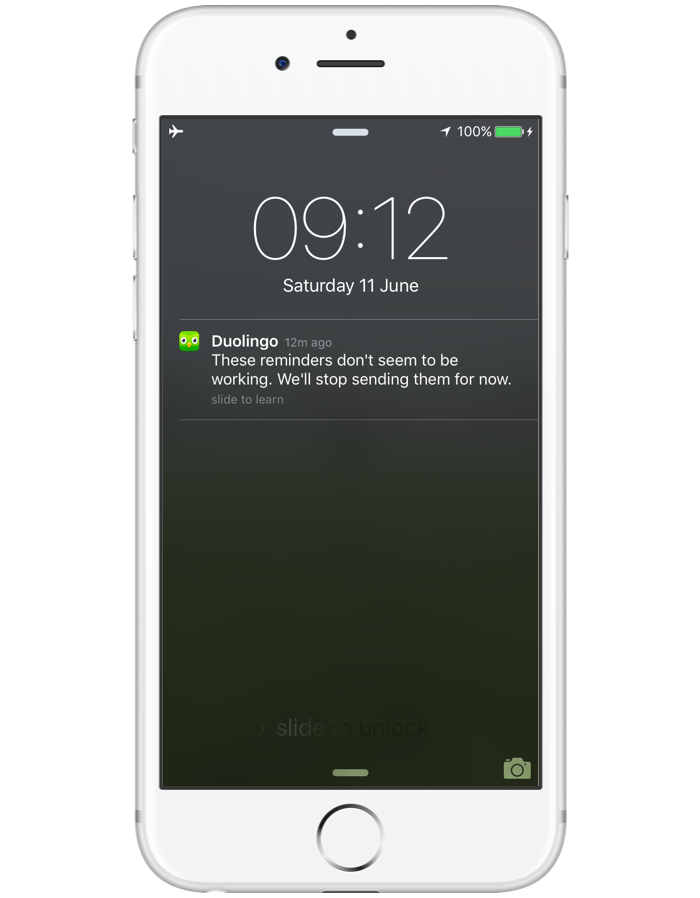

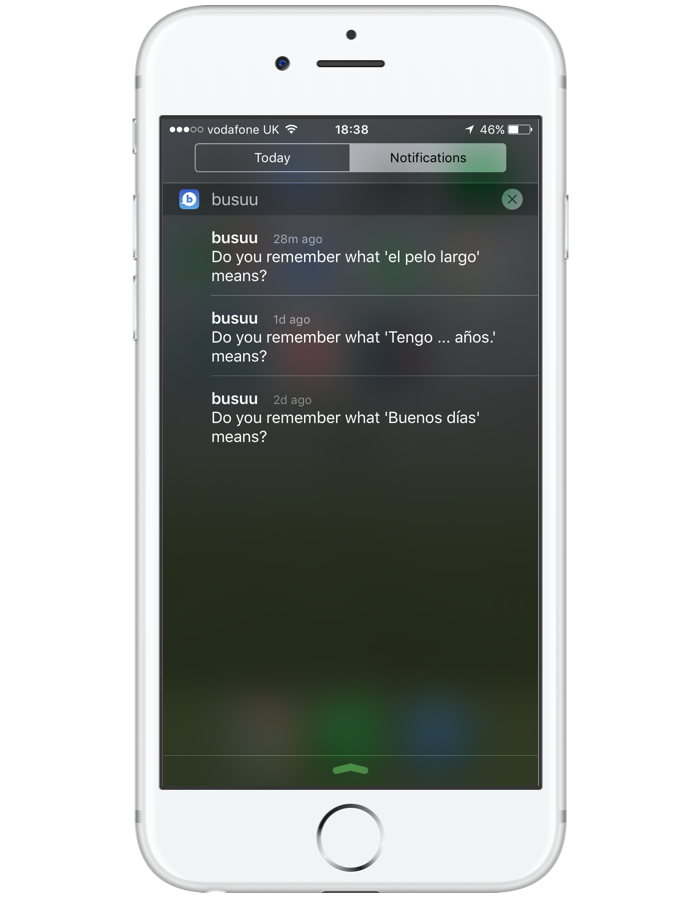
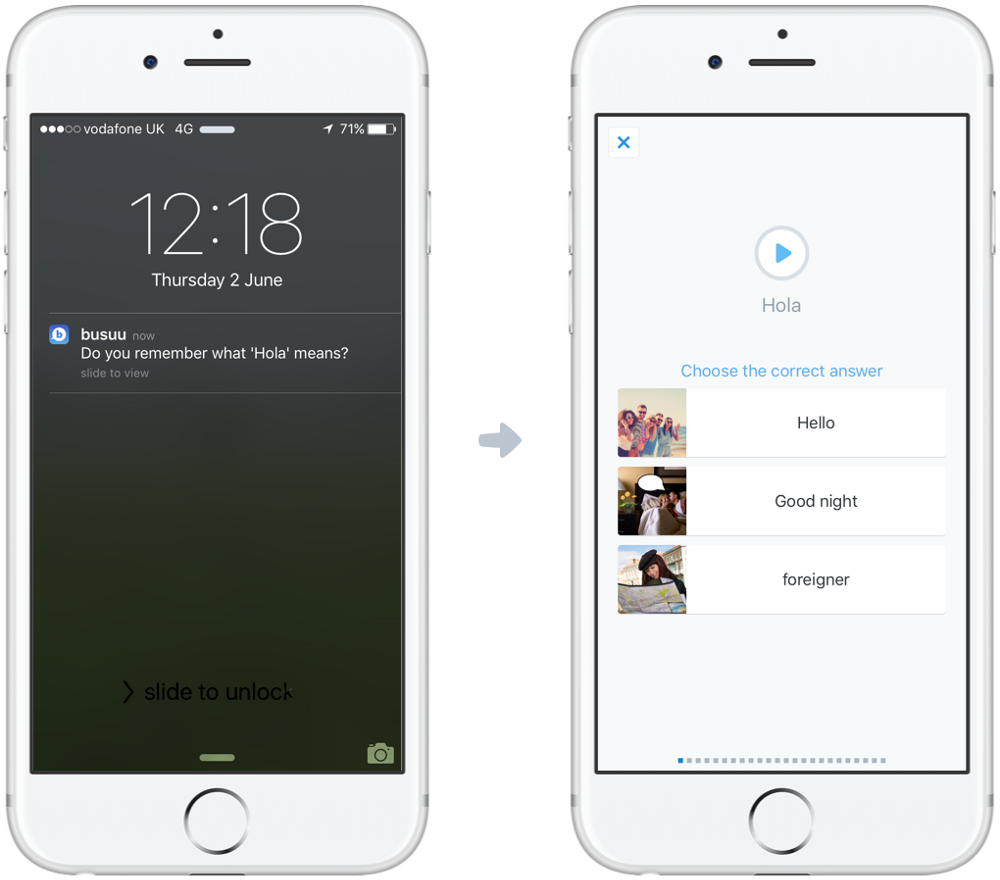
«Постарайтесь понять, что именно пользователи ценят в вашем продукте, и подгоняйте сообщения под их индивидуальные нужды и интересы. Увидите: число интеракций с уведомлениями сразу пойдет в гору, а пользователи превратятся в ярых приверженцев».
«Толика любопытства многое может сделать для того, чтобы подтолкнуть пользователя совершить определенное целевое действие.
Триггеры лучше всего побуждают людей провести по экрану и узнать подробности, когда уведомление содержит в себе некую загадку: что они найдут внутри?
Timehop, к примеру, рассылает нахальные уведомления с текстом: «С ума сойти, это правда ты?», тем самым подталкивая людей зайти в приложение. Чтобы увидеть фото, о котором идет речь, достаточно просто провести по экрану. Здесь помогает и то, что сообщения Timehop написаны в легком, забавном стиле, что выделяет их на общем фоне».


|
Метки: author nanton повышение конверсии контент-маркетинг блог компании everyday tools push notifications push- уведомления реактивация клиентов |
Запускаем GSM сеть у себя дома |








apt-get install build-essential libtool libtalloc-dev shtool autoconf automake git-core pkg-config make gcc libpcsclite-dev
git clone git://git.osmocom.org/libosmocore.git
cd libosmocore/
autoreconf -i
./configure
make
make install
ldconfig -i
git clone https://github.com/axilirator/gnu-arm-installer.git
cd gnu-arm-installer
apt-get install libgmp3-dev libmpfr-dev libx11-6 libx11-dev flex bison libncurses5 libncurses5-dbg libncurses5-dev libncursesw5 libncursesw5-dbg libncursesw5-dev zlibc zlib1g-dev libmpfr4 libmpc-dev texinfo
./download.sh
./build.sh
vi /etc/bash.bashrc
add in the end
export PATH=$PATH:/root/osmocom/gnu-arm-installer/install/bin
CFLAGS += -DCONFIG_TX_ENABLE
git clone git://git.osmocom.org/osmocom-bb.git osmocombb
cd osmocombb/src
make
wget http://www.fftw.org/fftw-3.3.6-pl2.tar.gz
tar -xvzf fftw-3.3.6-pl2.tar.gz
cd fftw-3.3.6-pl2
./configure --enable-threads --enable-float
make
make install
ldconfig
git clone git://git.osmocom.org/libosmo-dsp.git
cd libosmo-dsp/
autoreconf -i
./configure
make
make install
ldconfig
git clone git://git.osmocom.org/osmocom-bb.git trx
cd trx/
git checkout jolly/testing
cd src/
CFLAGS += -DCONFIG_TX_ENABLE
make HOST_layer23_CONFARGS=--enable-transceiver
apt-get install sqlite3 libsqlite3-dev libsctp-dev
tar -xvzf libdbi-0.8.3.tar.gz
cd libdbi-0.8.3
autogen.sh
./configure --disable-docs
make
make install
ldconfig
cd ..
tar -xvzf libdbi-drivers-0.8.3.tar.gz
cd libdbi-drivers-0.8.3
vi drivers/sqlite3/dbd_sqlite3.c
_dbi_internal_error_handler_dbd_internal_error_handler
./autogen.sh
./configure --disable-docs --with-sqlite3 --with-sqlite3-dir=/usr/bin --with-dbi-incdir=/usr/local/include
make
make install
ldconfig
wget http://download.savannah.gnu.org/releases/linphone/ortp/sources/ortp-0.22.0.tar.gz
tar -xvf ortp-0.22.0.tar.gz
cd ortp-0.22.0/
./autogen.sh
./configure
make
make install
ldconfig
git clone git://git.osmocom.org/libosmo-abis.git
cd libosmo-abis
autoreconf -i
./configure
make
make install
ldconfig
git clone git://git.osmocom.org/libosmo-netif.git
cd libosmo-netif
autoreconf -i
./configure
make
make install
ldconfig
apt-get install libssl0.9.8 libssl-dev
ldconfig
git clone git://git.osmocom.org/openbsc.git
cd openbsc/openbsc/
autoreconf -i
./configure
make
make install
git clone git://git.osmocom.org/osmo-bts.git
cd osmo-bts
autoreconf -i
./configure --enable-trx
make
make install
mkdir /root/.osmocom;cd /root/.osmocom
touch ~/.osmocom/osmo-bts.cfg
touch ~/.osmocom/open-bsc.cfg
ls -l /dev/ttyUSB*
cd /root/osmocom/trx/src
host/osmocon/osmocon -m c123xor -p /dev/ttyUSB0 -s /tmp/osmocom_l2 -c target/firmware/board/compal_e88/trx.highram.bin -r 99
cd /root/osmocom/trx/src
host/osmocon/osmocon -m c123xor -p /dev/ttyUSB1 -s /tmp/osmocom_l2.2 -c target/firmware/board/compal_e88/trx.highram.bin -r 99
cd /root/osmocom/trx/src/host/layer23/src/transceiver/
./transceiver -a ARFCN -2 -r 99
cd /root/.osmocom
osmo-nitb -c ~/.osmocom/open-bsc.cfg -l ~/.osmocom/hlr.sqlite3 -P -C --debug=DRLL:DCC:DMM:DRR:DRSL:DNM
cd /root/.osmocom
osmo-bts-trx --debug DRSL:DOML:DLAPDM -r 99
telnet localhost 4242
telnet localhost 4241
|
Метки: author antgorka разработка систем передачи данных информационная безопасность open source osmocom infosec |
Приглашаем на Science Slam Digital 7 июля |

Научные конференции — это нужное и важное дело, но зачастую они проходят в слишком академической атмосфере. Поэтому мы приглашаем студентов IT-специальностей, профессионалов в сфере IT и просто любителей высоких технологий на Science Slam Digital. Это сражение цифровых и технологических умов: молодые ученые и профессионалы в живой форме рассказывают о своих проектах. Только в нашем случае это будут сотрудники компании, которые расскажут о том, с какими технологиями они работают или какие создают ежедневно. То есть их задача — не просто рассказать о чём-то интересном, но и сделать это увлекательно. Победители в каждом поединке определяются аплодисментами зрителей и голосами тех, кто будет смотреть интернет-трансляцию через VK-Live. По результатам будут объявлены два победителя. Программу Science Slam Digital смотрите под катом.
19:00. Сбор гостей
19:30. Начало интернет-трансляции.
20:00. Открытие.
20:05. Выступление Дмитрия Гришина — председателя совета директоров и сооснователь Mail.Ru Group.
20:15. 1 слемер. Выступление Яна Романихина — руководителя команды машинного обучения Почты.
20:30. 2 слемер. Выступление Бориса Реброва — руководителя разработки клиентской части в группе frontend-разработки медиапроектов.
20:45. 3 слемер. Выступление Вячеслава Шебанова — старшего программиста-разработчик отдела разработки ВКонтакте.
21:00. Музыкальная пауза.
21:05. 4 слемер. Выступление Виталия Худобахшова — разработчика отдела дата-майнинга Одноклассников.
21:20. 5 слемер. Выступление Дмитрия Суконовалова — руководителя направления аналитики бюзнес-юнита Почта и Портал.
21:35. 6 слэмер. Выступление Алексея Петрова — директора по качеству в отделе тестирования Почты.
21:50. Музыкальная пауза.
21:55. Выбор и награждение двух лучших слемеров.
Партнерами проекта являются ВКонтакте, организующий трансляцию, и Delivery Club, предоставляющий специальные купоны для участников мероприятия.
Вход свободный, количество мест ограничено, необходимо зарегистрироваться. Вход для гостей откроется в 19:00. Адрес: офис Mail.Ru Group, Ленинградский проспект, д. 39 стр. 79, 1 этаж.
|
Метки: author pkruglov программирование блог компании mail.ru group mail.ru science slam digital |
Семинар «Пустячок, а приятно: 20 мелочей, которые сделают работу в серверной по-настоящему комфортной», 4 июля, Москва |

|
Метки: author 5000shazams it- инфраструктура блог компании dataline эксплуатация цод дата-центр цод dataline даталайн |
Как семантические технологии улучшают онлайн-образование: проект ученых Университета ИТМО |
 / Фото Craig Sunter / CC
/ Фото Craig Sunter / CC

|
Метки: author itmo учебный процесс в it блог компании университет итмо университет итмо семантика онлайн-курсы |
[Из песочницы] Как создавать компактный и эффективный javascript используя RollupJS |
npm. (У вас его нет? Установите Node.js здесь.)Rollup — это инструмент следующего поколение для пакетной обработки JavaScript-модулей. Создайте свое приложение или библиотеку с помощью модулей ES2015, затем объедините их в один файл для эффективного использования в браузерах и Node.js. Это похоже на использование Browserify и webpack. Вы можете также назвать Rollup инструментом построения, который стоит на одном ряду с такими инструментами как Grunt и Gulp. Тем не менее, важно отметить, что, хотя вы можете использовать Grunt и Gulp для решения задач пакетной обработки JavaScript, эти инструменты будут использовать подобный функционал Rollup, Browserify или webpack.
learn-rollup/
+-- build/
| +-- index.html
+-- src/
| +-- scripts/
| | +-- modules/
| | | +-- mod1.js
| | | +-- mod2.js
| | +-- main.js
| +-- styles/
| +-- main.css
+-- package.json# Move to the folder where you keep your dev projects.
cd /path/to/your/projects
# Clone the starter branch of the app from GitHub.
git clone -b step-0 --single-branch https://github.com/jlengstorf/learn-rollup.git
# The files are downloaded to /path/to/your/projects/learn-rollup/build/index.html в свой собственный код. В этом руководстве HTML не рассматривается.npm install --save-dev rolluprollup.config.js в папке learn-rollup. В него добавьте следующее.export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
};./node_modules/.bin/rollup -cbuild в вашем проекте с подпапкой js, которая будет содержать наш сгенерированный файл main.min.js.build/index.html в нашем браузере: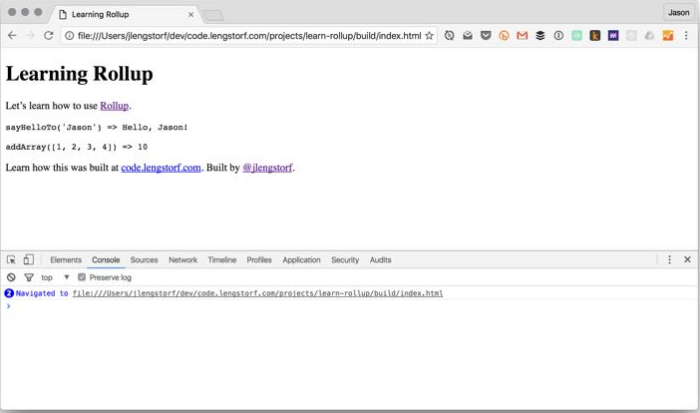
src/scripts/modules/mod1.js есть функция sayGoodbyeTo (), которая не используется в нашем приложении — и поскольку она никогда не используется, Rollup не включает ее в итоговый пакет:
(function () {
'use strict';
/**
* Says hello.
* @param {String} name a name
* @return {String} a greeting for `name`
*/
function sayHelloTo( name ) {
const toSay = `Hello, ${name}!`;
return toSay;
}
/**
* Adds all the values in an array.
* @param {Array} arr an array of numbers
* @return {Number} the sum of all the array values
*/
const addArray = arr => {
const result = arr.reduce((a, b) => a + b, 0);
return result;
};
sayGoodbyeTo (), и полученный в результате пакет более чем в два раза превышает размер, который генерирует Rollup.# Install Rollup’s Babel plugin.
npm install --save-dev rollup-plugin-babel
# Install the Babel preset for transpiling ES2015.
npm install --save-dev babel-preset-es2015
# Install Babel’s external helpers for module support.
npm install --save-dev babel-plugin-external-helpers.babelrc..babelrc в корневом каталоге проекта (learn-rollup/). Внутри добавьте следующий JSON:{
"presets": [
[
"es2015",
{
"modules": false
}
]
],
"plugins": [
"external-helpers"
]
}
es2015-rollup. Если вы не можете обновить npm, см. эту проблему для альтернативной конфигурации .babelrc..babelrc использует устаревшую конфигурацию. См. этот pull request для изменения конфигурации, и этот для изменений в package.json.rollup.config.js.
// Rollup plugins
import babel from 'rollup-plugin-babel';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
babel({
exclude: 'node_modules/**',
}),
],
};
exclude для игнорирования каталога node_modules../node_modules/.bin/rollup -c addArray ():
var addArray = function addArray(arr) {
var result = arr.reduce(function (a, b) {
return a + b;
}, 0);
return result;
};
(arr.reduce ((a, b) => a + b, 0)) в обычную функцию. Array.prototype.reduce () доступными в IE8 и более раних версиях.npm install --save-dev rollup-plugin-eslint.eslintrc.json.
$ ./node_modules/.bin/eslint --init
? How would you like to configure ESLint? Answer questions about your style
? Are you using ECMAScript 6 features? Yes
? Are you using ES6 modules? Yes
? Where will your code run? Browser
? Do you use CommonJS? No
? Do you use JSX? No
? What style of indentation do you use? Spaces
? What quotes do you use for strings? Single
? What line endings do you use? Unix
? Do you require semicolons? Yes
? What format do you want your config file to be in? JSON
Successfully created .eslintrc.json file in /Users/jlengstorf/dev/code.lengstorf.com/projects/learn-rollup
.eslintrc.json:{
"env": {
"browser": true,
"es6": true
},
"extends": "eslint:recommended",
"parserOptions": {
"sourceType": "module"
},
"rules": {
"indent": [
"error",
4
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"always"
]
}
}
.eslintrc.jsonENV, поэтому нам нужно занести ее в белый список..eslintrc.json — свойство globals и настройку свойства indent:{
"env": {
"browser": true,
"es6": true
},
"globals": {
"ENV": true
},
"extends": "eslint:recommended",
"parserOptions": {
"sourceType": "module"
},
"rules": {
"indent": [
"error",
2
],
"linebreak-style": [
"error",
"unix"
],
"quotes": [
"error",
"single"
],
"semi": [
"error",
"always"
]
}
}
rollup.config.js
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
],
};
./node_modules/.bin/rollup -c, похоже, ничего не происходит. Дело в том, что код приложения в его нынешнем виде проходит linter без проблем.
$ ./node_modules/.bin/rollup -c
/Users/jlengstorf/dev/code.lengstorf.com/projects/learn-rollup/src/scripts/main.js
12:64 error Missing semicolon semi
1 problem (1 error, 0 warnings)
require.debug. Начните с его установки:
npm install --save debug
src/scripts/main.js, давайте добавим простой логинг:
// Import a couple modules for testing.
import { sayHelloTo } from './modules/mod1';
import addArray from './modules/mod2';
// Import a logger for easier debugging.
import debug from 'debug';
const log = debug('app:log');
// Enable the logger.
debug.enable('*');
log('Logging is enabled!');
// Run some functions from our imported modules.
const result1 = sayHelloTo('Jason');
const result2 = addArray([1, 2, 3, 4]);
// Print the results on the page.
const printTarget = document.getElementsByClassName('debug__output')[0];
printTarget.innerText = `sayHelloTo('Jason') => ${result1}\n\n`;
printTarget.innerText += `addArray([1, 2, 3, 4]) => ${result2}`;
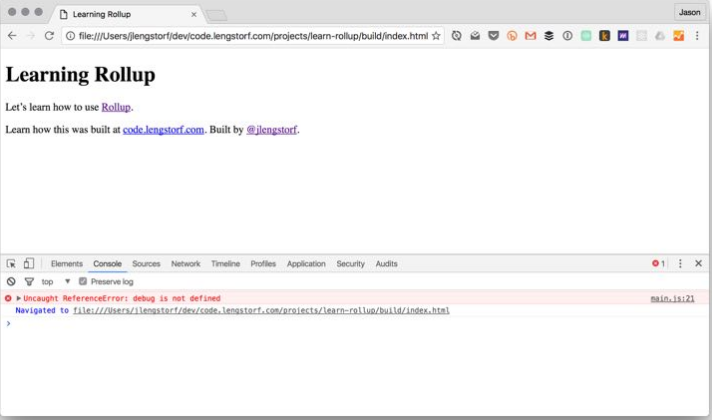
$ ./node_modules/.bin/rollup -c
Treating 'debug' as external dependency
No name was provided for external module 'debug' in options.globals – guessing 'debug'
rollup-plugin-node-resolve, что позволяет загружать сторонние модули из node_modules.rollup-plugin-commonjs, который обеспечивает поддержку подключения CommonJS-модулей.npm install --save-dev rollup-plugin-node-resolve rollup-plugin-commonjs
rollup.config.js
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
],
};
jsnext обеспечивает простое мигрирование ES2015-модулей для Node-пакетов. Свойства main и browser помогают плагину решать, какие файлы следует использовать для пакета../node_modules/.bin/rollup -c, затем снова проверьте браузер, чтобы увидеть результат: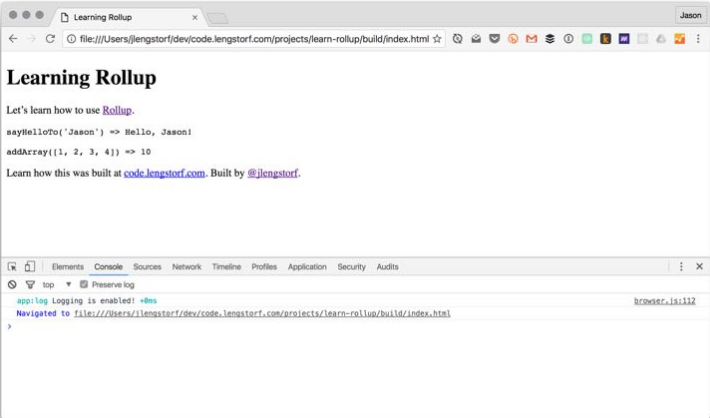
ENV В main.jssrc/scripts/main.js, изменим способ инициализации нашего log():
// Import a logger for easier debugging.
import debug from 'debug';
const log = debug('app:log');
// The logger should only be disabled if we’re not in production.
if (ENV !== 'production') {
// Enable the logger.
debug.enable('*');
log('Logging is enabled!');
} else {
debug.disable();
}
(./node_modules/.bin/rollup -c) и посмотрим браузер, мы увидим, что это дает нам ReferenceError для ENV.ENV = production ./node_modules/.bin/rollup -c, он все равно не сработает. Это связано с тем, что установка переменной среды таким образом делает ее доступной только для Rollup, а не к пакету, созданному с помощью Rollup.rollup-plugin-replace, которая по существу является просто утилитой find-and-replace. Он может делать много вещей, но для наших целей мы просто найдем появление переменной среды и заменим ее фактическим значением (например, все вхождения ENV будут заменены на «production» в сборке).npm install --save-dev rollup-plugin-replace
rollup.config.jsrollup.config.js импортируем его и добавим в наш список плагинов.
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import replace from 'rollup-plugin-replace';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
replace({
exclude: 'node_modules/**',
ENV: JSON.stringify(process.env.NODE_ENV || 'development'),
}),
],
};
NODE_ENV=production ./node_modules/.bin/rollup -c
SET NODE_ENV = production ./node_modules/.bin/rollup -c, чтобы избежать ошибок при работе с переменными среды. Если у вас есть проблемы с этой командой, см. эту проблему для получения дополнительной информации.
rollup-plugin-uglify.npm install --save-dev rollup-plugin-uglify
rollup.config.js
// Rollup plugins
import babel from 'rollup-plugin-babel';
import eslint from 'rollup-plugin-eslint';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import replace from 'rollup-plugin-replace';
import uglify from 'rollup-plugin-uglify';
export default {
entry: 'src/scripts/main.js',
dest: 'build/js/main.min.js',
format: 'iife',
sourceMap: 'inline',
plugins: [
resolve({
jsnext: true,
main: true,
browser: true,
}),
commonjs(),
eslint({
exclude: [
'src/styles/**',
]
}),
babel({
exclude: 'node_modules/**',
}),
replace({
ENV: JSON.stringify(process.env.NODE_ENV || 'development'),
}),
(process.env.NODE_ENV === 'production' && uglify()),
],
};
uglify (), когда NODE_ENV имеет значение «production».NODE_ENV=production ./node_modules/.bin/rollup -c
build/js/main.min.js:
|
Метки: author kolesoffac javascript rollup bundler bundling webpack gulp guide browserify grunt |
Как внедрить процессы управления конфигурацией |
 Изображение Kenny Louie CC
Изображение Kenny Louie CC

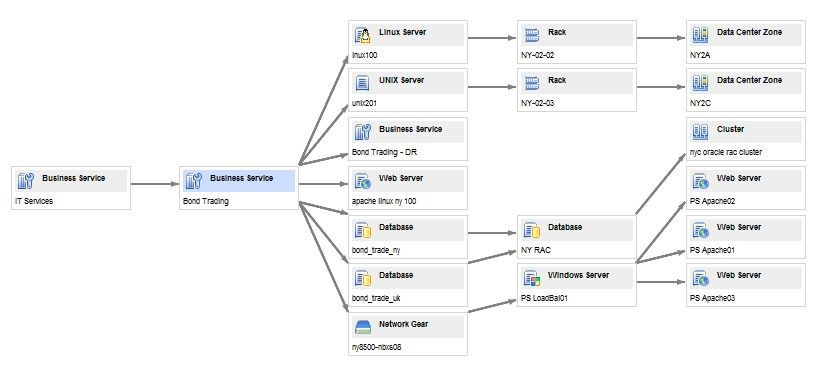
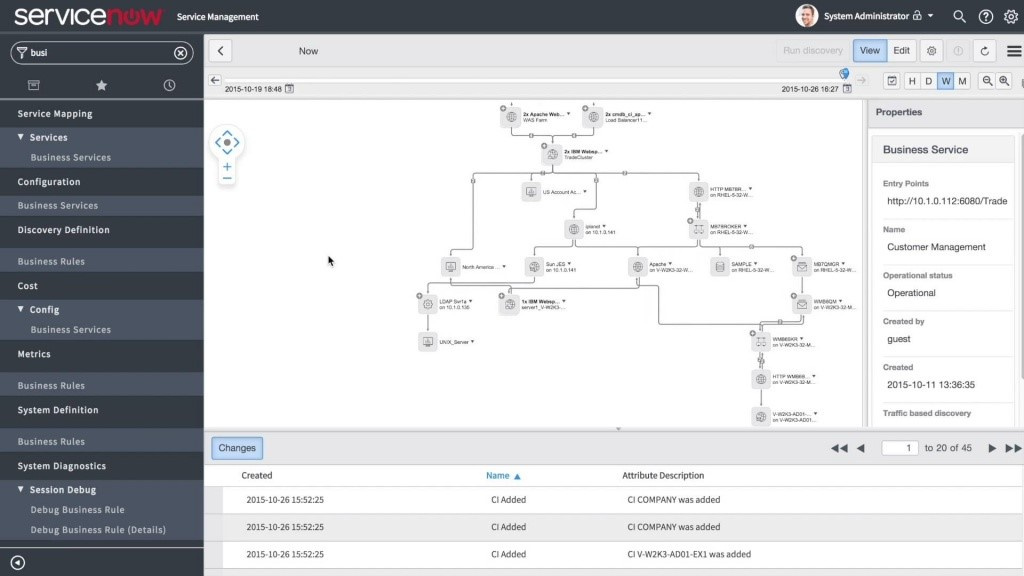
|
Метки: author it-guild service desk блог компании ит гильдия ит гильдия cms управление конфигурацией |
Добавляем реактивность в строковые шаблонизаторы |
model.justText('time')1498115282970var model = {};
model.key1 = 1;
$("#time1").html(model.justText('key1'))
model = {key1:2};
<~ this.data.itemslist>
-
<~>
- с фильтрацией
- без фильтрации
|
Метки: author Levhav разработка веб-сайтов jquery javascript html templates css just |
Сайт бухгалтерских услуг – боль клиента |
 Навеяно статьей на Хабре «бухгалтерские тонкости для технологического (и другого) бизнеса». Один из посылов статьи: «Это что-то очень скучное и очень страшное.»
Навеяно статьей на Хабре «бухгалтерские тонкости для технологического (и другого) бизнеса». Один из посылов статьи: «Это что-то очень скучное и очень страшное.»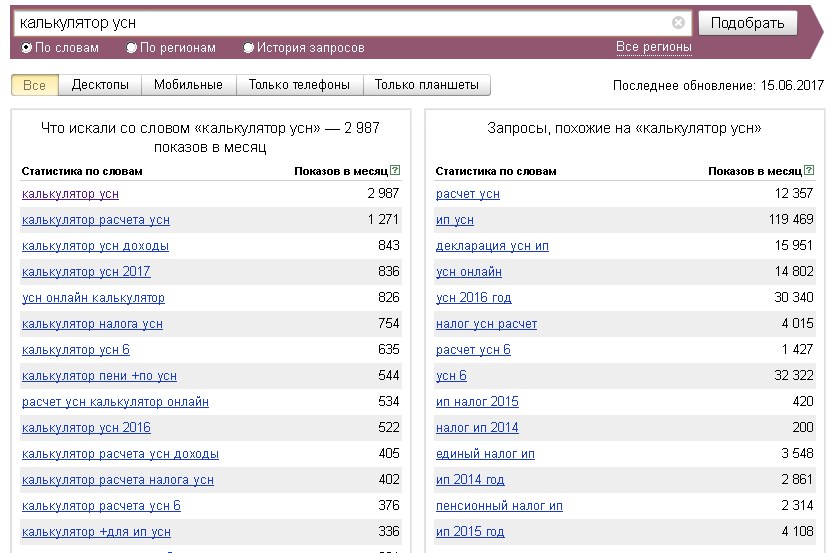
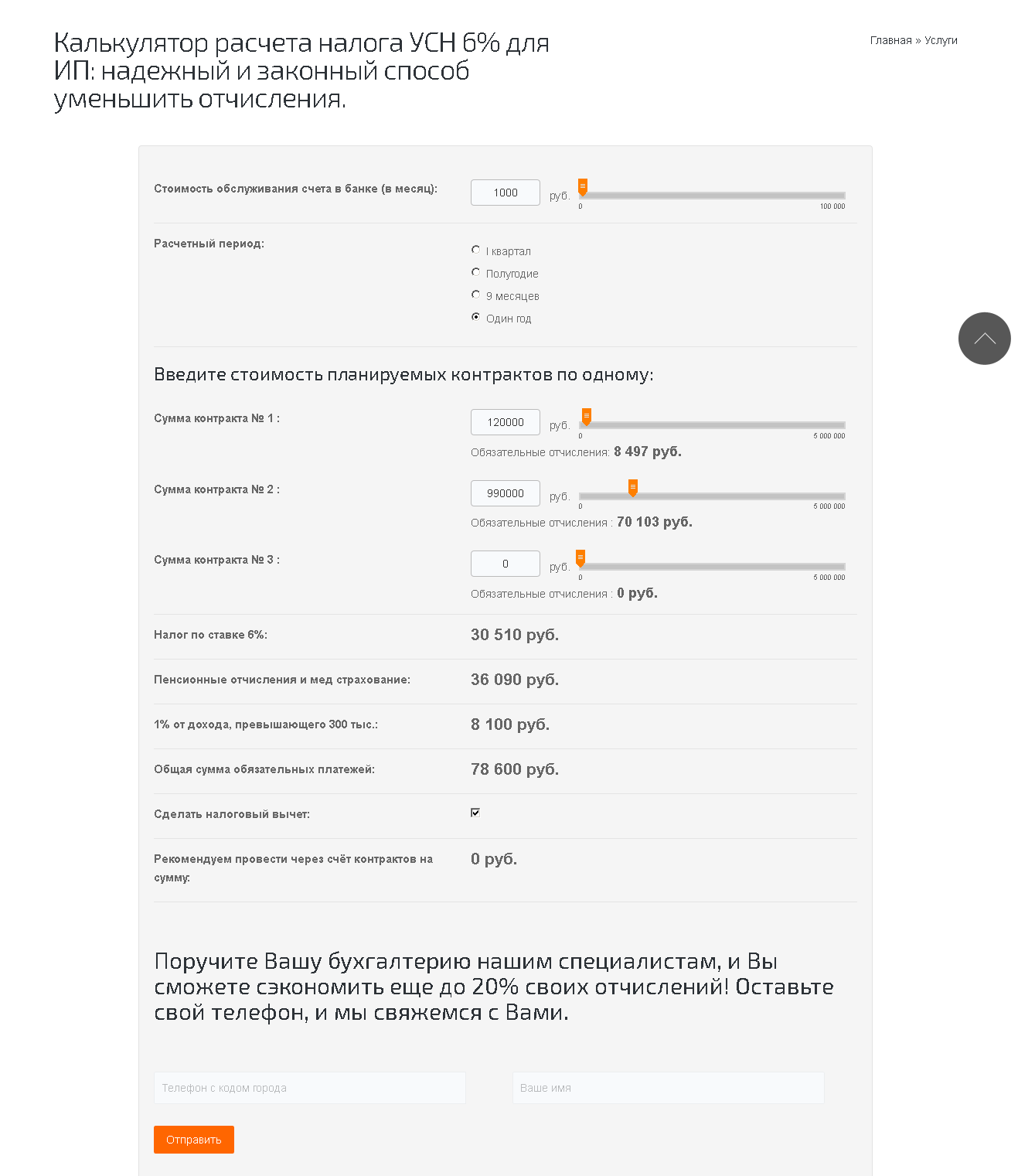
|
Метки: author wilelf чулан бухгалтерия разработка сайтов |
Что было в прошлом году: №1 по ИТ-услугам в стране, 2000+ проектов, много инженерных историй |

|
Метки: author VTantzorov it- инфраструктура блог компании крок ит-инфраструктура проекты 2016 |










