Rich Notifications, utm-метки, webhook и другие нововведения PushAll |



{
"bigimage":"https:\/\/urlimage",
"actions":[
{
"title":"test",
"url":"https:\/\/url1"
},
{
"title":"test2",
"url":"https:\/\/url2"
}
]
}








|
Метки: author BupycNet расширения для браузеров api блог компании pushall pushall push уведомления android webhook push notifications webpush |
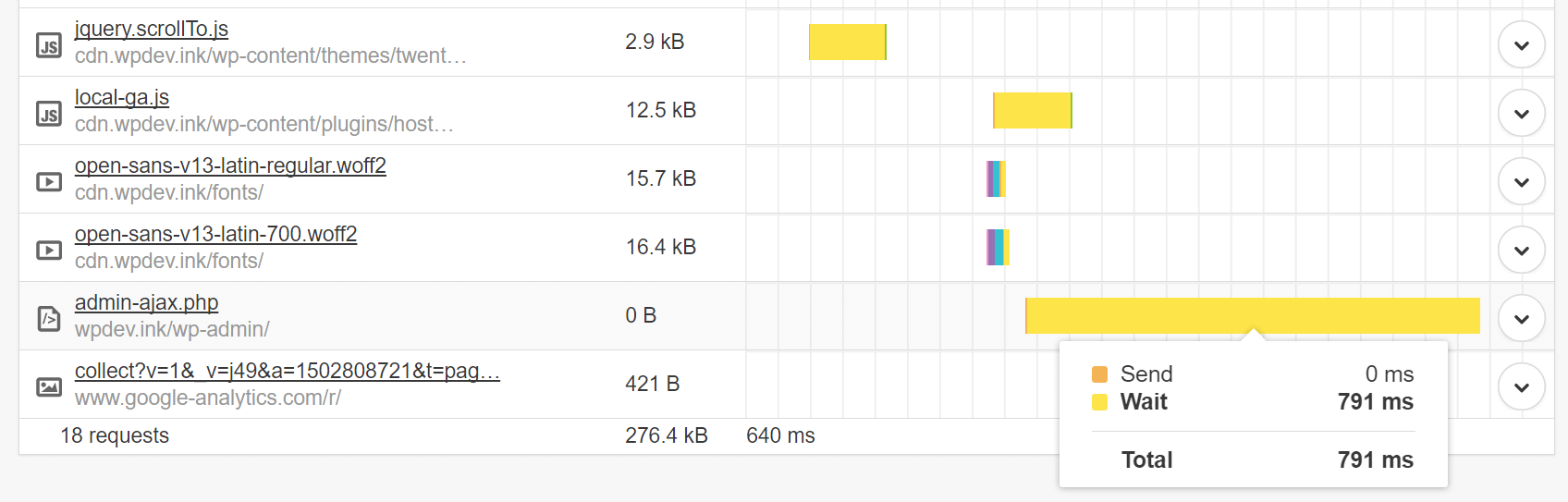
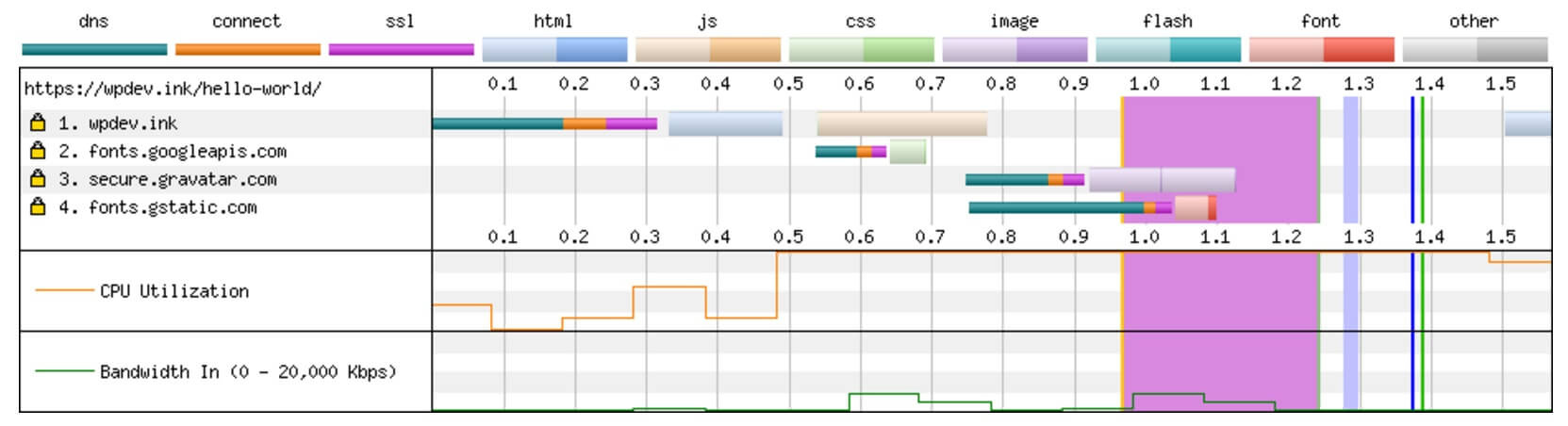
[Перевод] Создание быстрых и более оптимизированных сайтов на WordPress |

define('DISALLOW_FILE_EDIT', true);define('DISALLOW_FILE_MODS', true);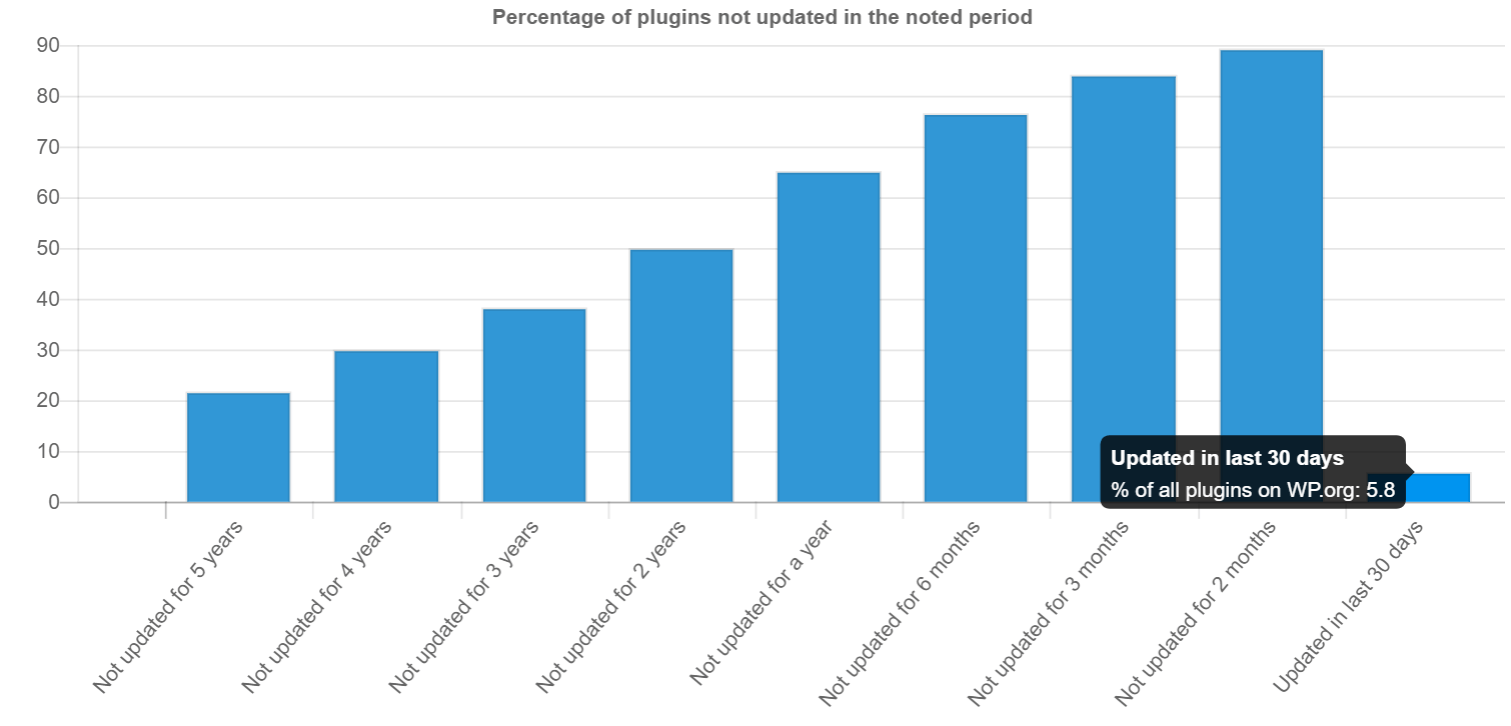


src="example.js" asyncsrc="example.js" defer
ALTER TABLE wp_comments ENGINE=InnoDB;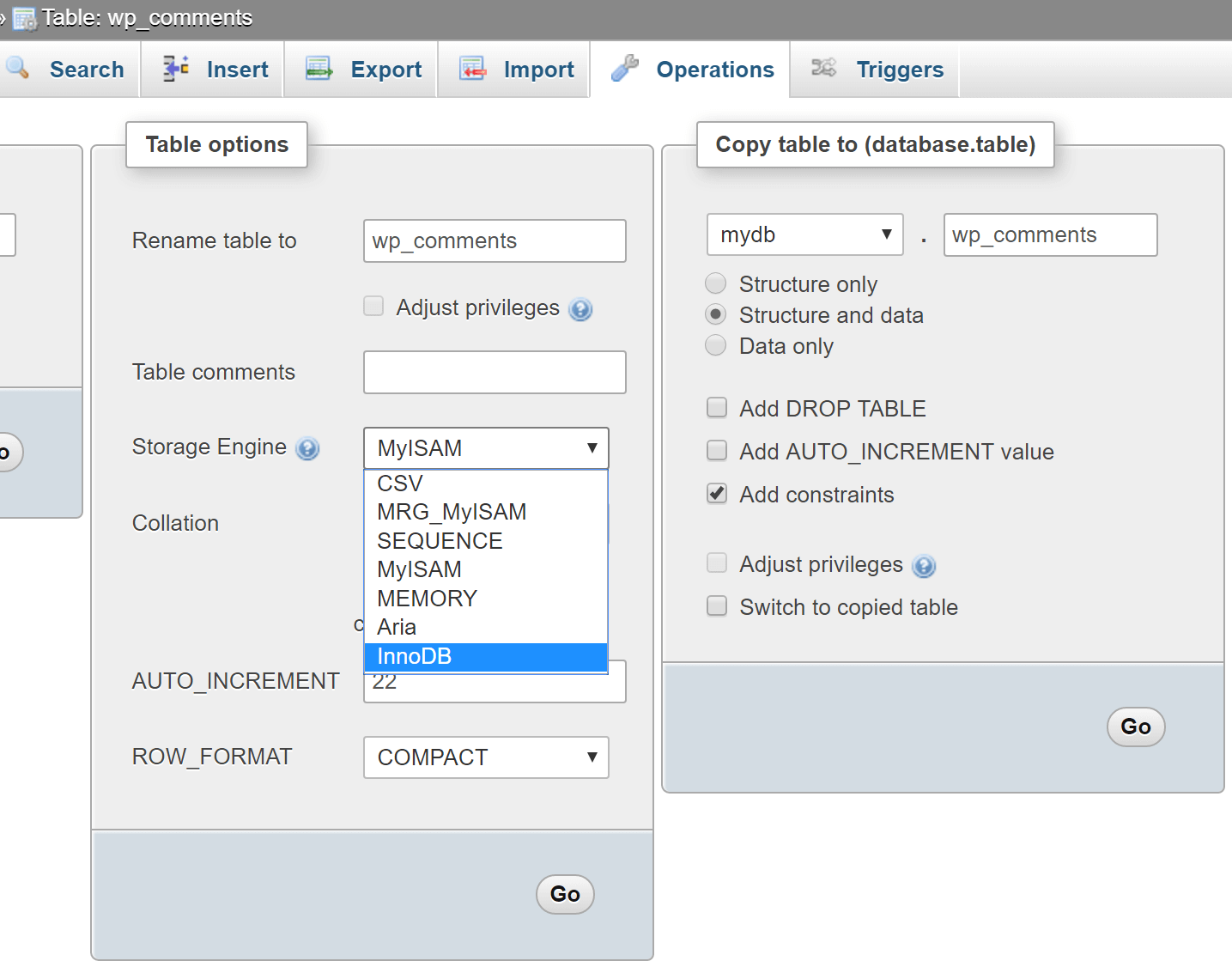
define('WP_POST_REVISIONS', false );define('WP_POST_REVISIONS', 3);DELETE FROM wp_posts WHERE post_type = "revision";
define( 'WP_DEBUG_LOG', true );define( 'WP_DEBUG_DISPLAY', true );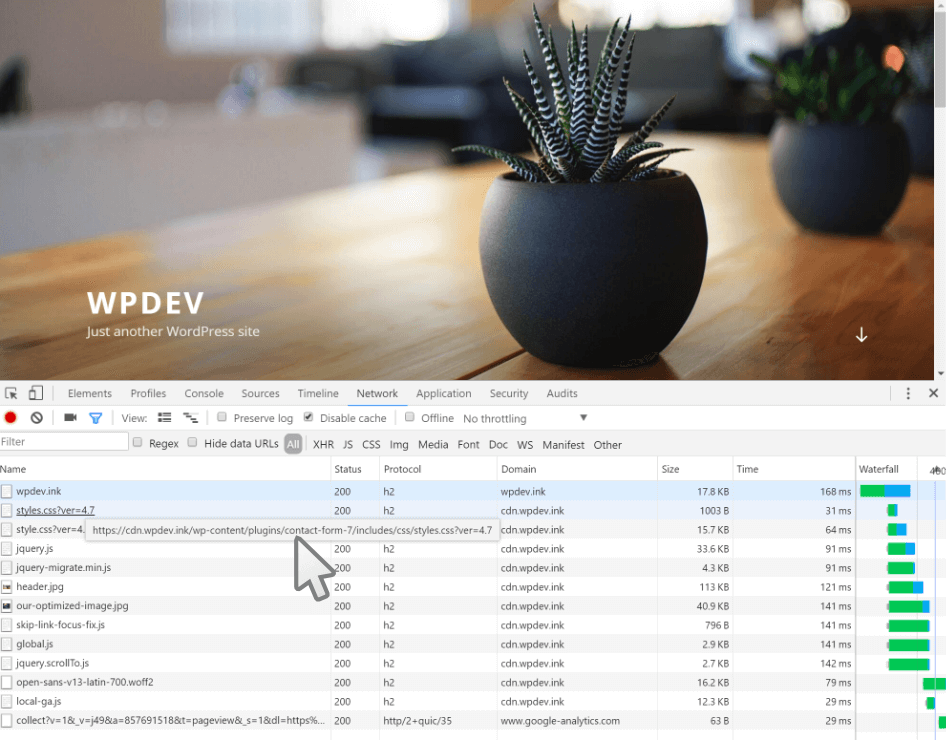
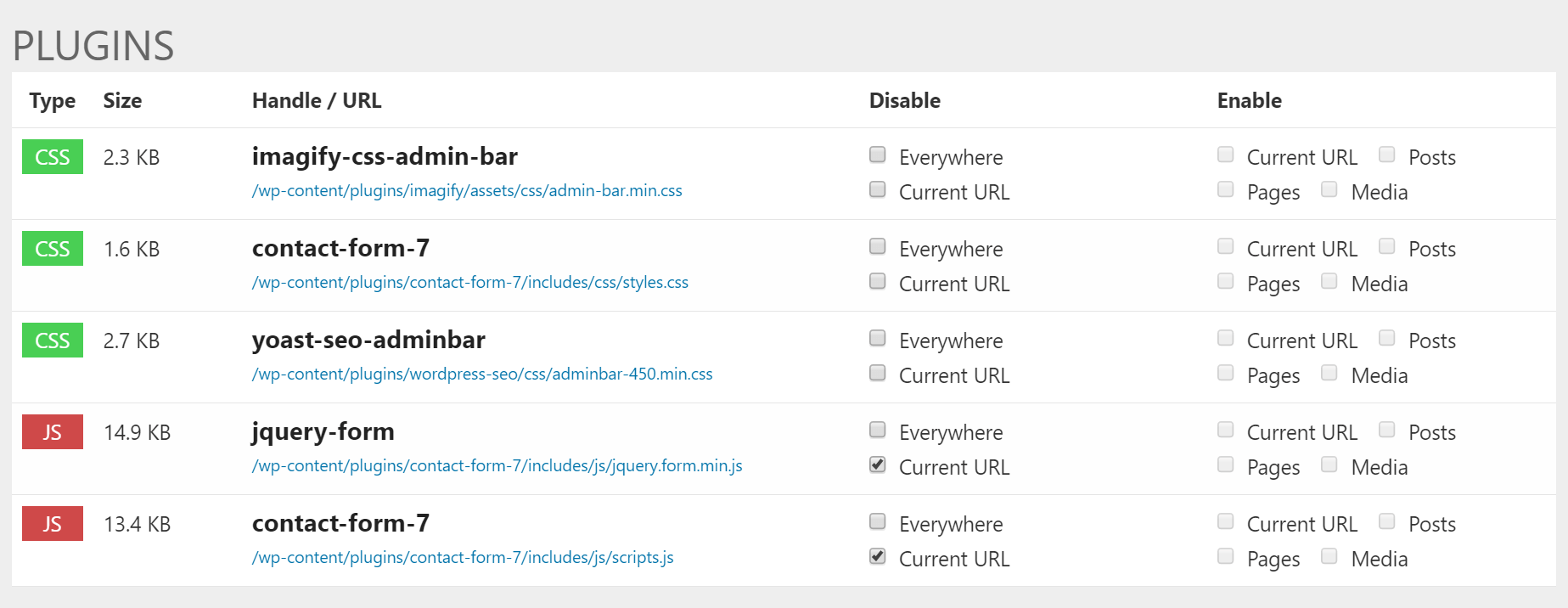
|
Метки: author ScarletFlash отладка высокая производительность wordpress перевод оптимизация mysql css javascript хостинг производительность скорость загрузка страница |
[Из песочницы] Динамическая таблица поверх Google Maps |
Вам когда-нибудь нужно было отображать крупные массивы данных с привязкой к карте? Мне на работе понадобилось отображать заказы сгруппированные по широте и долготе. И не просто статической таблицей, а динамической, с разной детализацией для разного приближения карты.
К сожалению (или к счастью?), готовых решений я не нашёл. Google Карты позволяют накладывать маркеры и фигуры на карты, но эти способы представляют слишком мало информации. С Яндекс картами оказалось не лучше. Но Карты Гугл имеют механизм пользовательских наложений с HTML-содержанием. И для инкапсуляции этой работы с картами и наложениями я создал JavaScript библиотеку GMapsTable. Возможно, кому-нибудь она окажется интересной или полезной. Рабочий пример.

Чтобы не возникло путаницы, параметр zoom будем называть приближением карты, а scale — масштабом. Первый относится к Google Maps API, а второй к описываемой библиотеке.
Итак, что у нас есть? Какой-нибудь источник данных (например, сервер с базой данных, обрабатывающий и посылающий данные в формате JSON) и веб-страничка с JavaScript, которая запрашивает данные и визуализирует их на Картах Гугл.
Данные имеют аккумулятивную природу (в моём случае каждой области можно поставить в соответствие: число заказов, клиентов и среднюю сумму). Поэтому данные могут и должны отображаться с разной детализацией для разных приближений.
Основное содержание HTML страницы для GMapsTable:
..в :
..в :
GMapsTable позволяет абстрагироваться от взаимодействия с GoogleMaps API. Вам нужно лишь предоставить подходящий объект с данными. Время перейти к JavaScript'y! Чтобы использовать GMapsTable, нужно получить объект DataContainer для Вашего div'a карты:
// Аргумент: ID div'а
// и словарь параметров GoogleMaps,
// это не обязательно
var container = new DataContainer("map", {
zoom: 9,
center: {lat: 55.7558, lng: 37.6173},
mapTypeId: 'roadmap'
});Затем нужно передать две функции:
container.dataLoader = function (scale, borders) {
... вызвать container.processData(some_data);
}
container.scaler = function (zoom) {
... return какое-нибудь число;
}Но что именно писать внутри функций?.. Для начала разберёмся, как работает GMapsTable.
DataContainer занимается отображением Ваших данных и заботится о том, когда оно должно быть обновлено. В самом начале и когда изменяются приближение и границы "камеры", он пробует использовать сохранённые данные, а если их нет, то вызывает функцию dataLoader. Вам нужно сгенерировать объект с данными и передать его функции DataContainer.processData. Структура объекта должна быть такая:
data: {
minLat: float,
difLat: float,
minLon: float,
difLon: float,
scale: int,
table: [
[value, value, ...],
[value, value, ...],
...
],
tocache: boolean
}Значением (value) может быть число, строка или любой объект, если вы укажите собственную функцию форматирования ячейки таблицы. Масштаб (sale) это целое число, говорящее, на сколько частей должны делиться единицы широты и долготы. Параметр tocache указывает, должны ли данные для текущего масштаба быть сохранены и более не запрашиваться.
data: {
minLat: 55.0,
difLat: 2.0,
minLon: 37.0,
difLon: 1.0,
scale: 2,
table: [
[1, 3, 0, 1],
[0, 1, 2, 0]
],
tocache: true
}Здесь данные покрывают область от 55.0, 37.0 до 57.0, 38.0 и делят каждую единицу широты и долготы на 2 части (получается, одна клетка широты-долготы делится на 4 части). Также здесь указано, что для данного масштаба это полные данные, и они должны быть сохранены для использования в дальнейшем.
Приближение (zoom) это параметр Google Maps API, целое число между 1 (карта мира) и 22 (улица). Запрашивать и хранить данные для каждой единицы приближения неудобно и нецелесообразно, поэтому GMapsTable переводит их в масштаб (scale) — число, указывающее, на сколько частей нужно делить единицу широты и долготы.
Чтобы отображение при изменении масштаба было моментальным, GMapsTable хранит наборы данных для некоторых (либо всех) масштабов. Например, у меня была база данных с координатами почти со всей России — около 42 тысяч ячеек для масштаба 10 (500 КБ, довольно легко хранится и обрабатывается у меня в десктопном браузере) и 17 миллионов для масштаба 200 (несколько МБ, вызывает значительные подвисания). Поэтому сервер оценивает число ячеек всех данных, и если их немного, отправляет данные из всей БД, иначе только для запрошенного региона. Получается такой алгоритм:

Границы (bounds) — это объект JavaScript с полями minlat, maxlat, minlon, maxlon — текущими границами Google Maps и хорошим отступом про запас.
В Вашей реализации dataLoader Вы можете смело игнорировать аргументы, если нет нужды использовать разную детализацию для разных масштабов или если Ваши данные не покрывают такой большой регион. Просто передайте данные и их границы по широте и долготе и scale, на сколько разбиваете единицы широты-долготы. Но для полноты картины я предлагаю такое поведение функции dataLoader (или сервера, к которому она обращается):

Вы можете указать такие параметры для DataContainer:
1) scaler(zoom) — переводит приближение из GoogleMaps в масштаб для GMapsTable. Оба целые числа.
2) dataLoader(scale, borders) — вызывается, когда нужны новые данные. Должен передать объект данных в DataContainer.processData(data).
Параметр borders это объект JavaScript с полями minlat, maxlat, minlon, maxlon — текущими границами Google Maps и хорошим отступом про запас.
3) tableBeforeInit(map, table, data) — вызывается перед тем, как таблица начинает заполняться ячейками. Аргумент map это объект Google Maps, table это HTML элемент таблицы, а data — предоставленный Вами объект данных для текущего масштаба.
4) cellFormatter(td, val) — вызывается для заполнения ячейки. td это HTML element, ячейка таблицы. val это данные из Вашего объекта данных.
5) boundsChangedListener(zoom) — вызывается, когда изменяются границы Google Maps.
6) minZoomLevel, maxZoomLevel — переменные для минимального и максимального приближения карты. Целые числа между 1 (карта мира) и 22 (улица).
Для успешной работы DataContainer необходимы только первые две функции.
Полный и хорошо прокомментированный пример использования: HTML-страничка и JS-код.
А также есть GMapsTable в GitHub.
|
Метки: author AivanF maps api javascript google maps визуализация данных |
Russian Minesweeper — мультиплеерная версия игры «Сапёр» |


Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author ParadoxFilm я пиарюсь swiper multiplayer сапер mineswiper мультиплеер asp.net c# websocket json |
Потенциально опасные алгоритмы |
|
Метки: author randall математика криптография информационная безопасность алгоритмы блог компании mail.ru group ошибки уравнение формулы разработка программирование |
Распределённые вычисления поверх Ceph RADOS и AsyncMessenger |
librados вызовы функций, доступные для большинства языком программирования, например, для C, C++, Python, PHP и Java. С этой целью вы сначала устанавливаете инструменты разработки. Например, для Debian- дистрибутивов: $ sudo apt-get install build-essential$ sudo apt-get install librados-devceph.conf для получения мониторовceph.conf для получения мониторовlibrados является организация приложений наблюдатель- уведомитель ( watch — notify). librados работает с объектами, хранящимися в распределённой системе хранения RADOS (Reliable Autonomic Distributed Object Store), в основе которого лежат демоны хранения объектов (OSD, Object Storage Daemon), каждый из которых обслуживает некое собственное хранилище (например, уже упоминавшееся BlueStore).RADOS. Это открывает широкие возможности революционного увеличения производительности распределённой обработки хранимых данных, поскольку избавляет вас от необходимости обмена самими данными для такой обработки.RADOS. Данный сценарий, как правило, в виде строк JSON (скажем, в программе с применением librados на Python) передаётся в имеющийся объект класса RADOS, где он и исполняется.RADOS, написанным, например, на C или C++. В Примере приложения вычисления MD5 объекта приводятся пошаговые инструкции построения такого решения, а также сопоставляются результаты времён его работы в сравнении с аналогичным приложением, исполняющимся на клиенте, находящимся не на узле OSD и вынужденном считывать данные с OSD и записывать в него результат расчёта. результат сравнения даёт преимущество в абсолютных затратах времени в два порядка.AsyncMessenger, судя по всему, разрабатывался в качестве расширения epoll, призванного полностью вытеснить SimpleMessenger, являющийся первоначальной системой обмена сообщений и лежащей в основе сетевого протокола Ceph. Такая потребность вызвана тем фактом, что для каждой пары участников однорангового взаимодействия (peering) в SimpleMessenger создаются 4 потока (по два с каждой стороны). С ростом числа участников это приводит к экспоненциальному росту общего числа потоков (thread) в узлах участников. AsyncMessenger участвуют сервер и клиент. Сервер выполняет инициализацию, привязывается к file descriptor (fd) и осуществляет ожидание уведомлений по нему (listen). В отличие от определённых POSIX методов select() и poll(), epoll предоставляет механизм обработки сообщений со сложностью O(1), в отличие от O(n) для SimpleMessenger, исключая перебор событий, не имеющих активных fd. AsyncMessenger применяет библиотеку libevent, предоставляемую средствами epoll. AsyncConnection. Статья Wei Jin акцентирует основные моменты данного типа взаимодействия.AsyncMessenger является развитие абстракции NetworkStack, которая позволяет осуществлять распределённую поддержку различных сетевых стеков (Posix/ DPDK/ RDMA), а также встроенной в BlueStore поддержки SPDK.ServerSocket и ConnectedSocket, причём первый ожидает поступления запросов, а второй собственно и осуществляет чтение и запись всех данных. Основные моменты реализации приложений с применением данных абстракций приводятся в статье Стек асинхронной системы сообщений Ceph того же Wei Jin.
|
|
Комиксы Даниэля Стори |

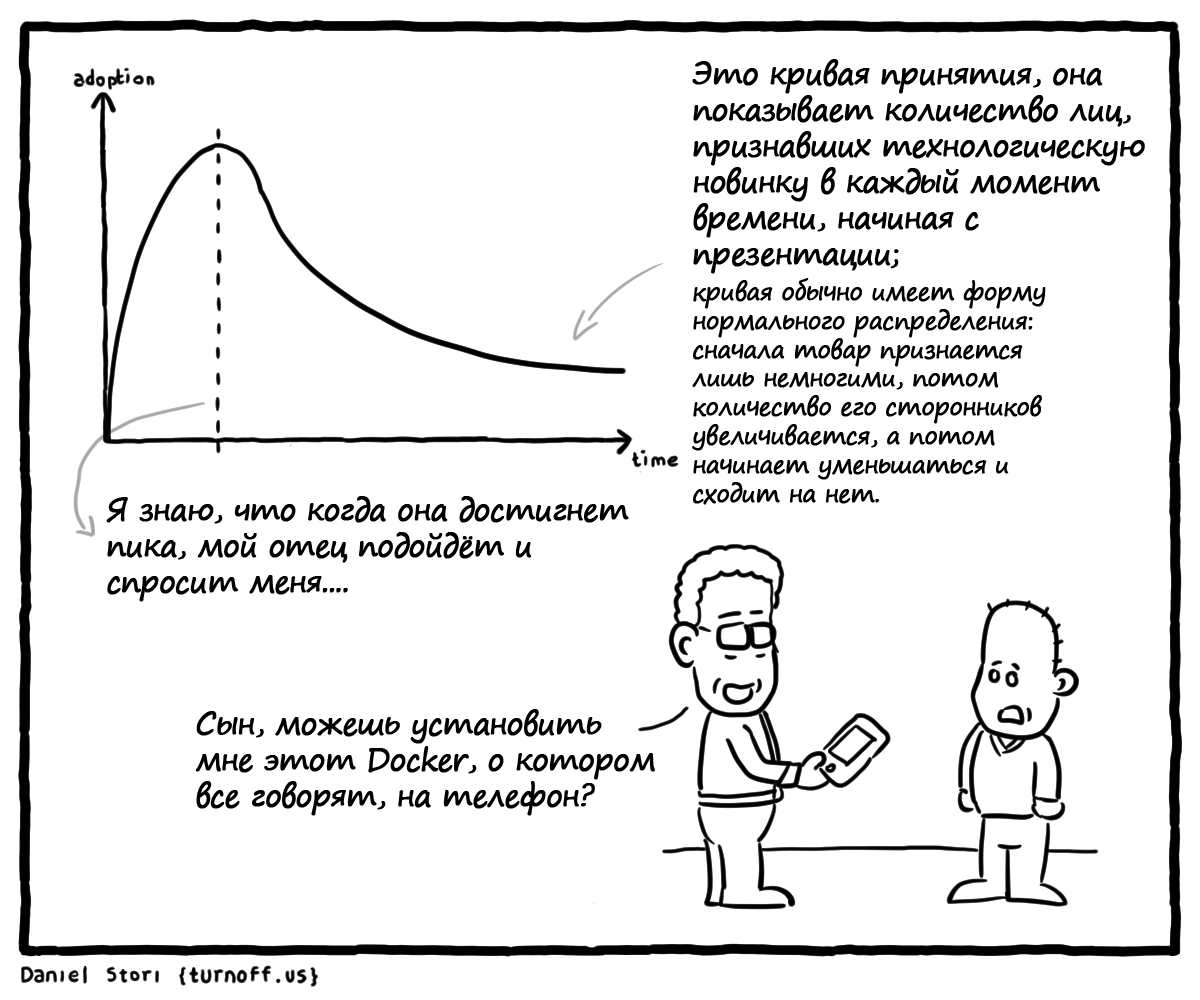



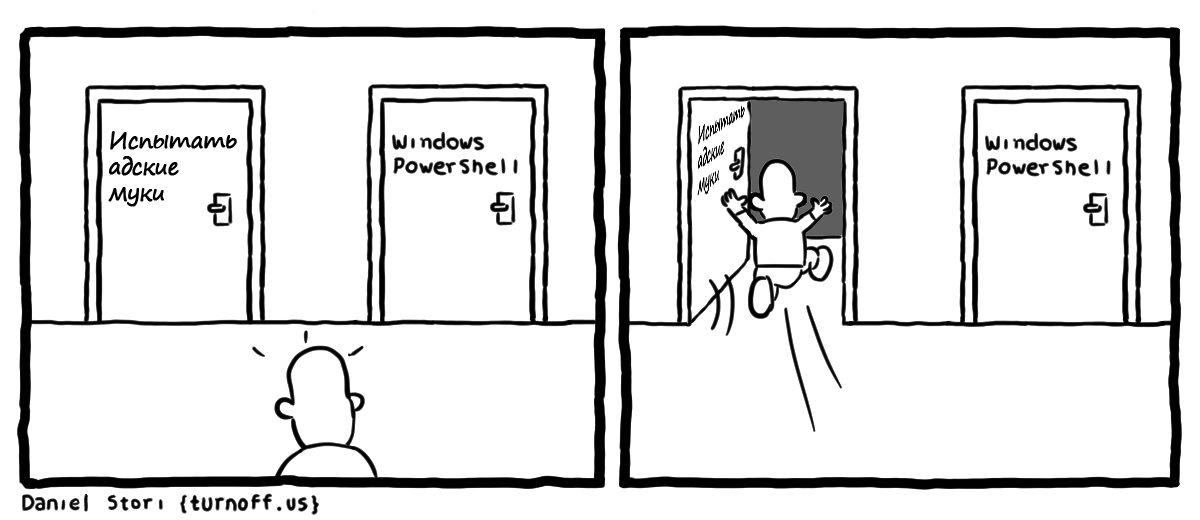















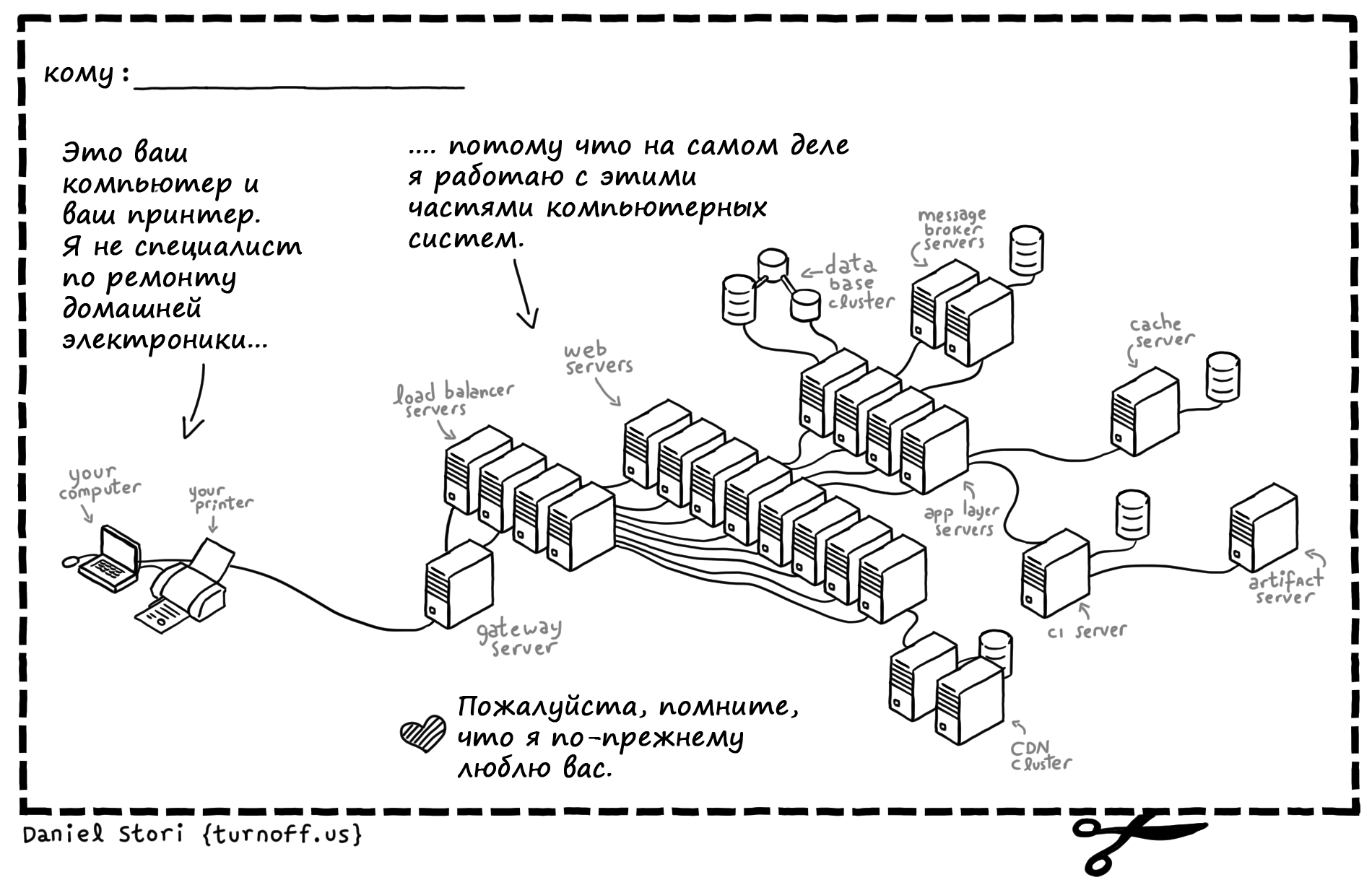
|
Метки: author Cloud4Y читальный зал блог компании cloud4y комиксы юмор bash linux cloud программисты шутят |
Сервис сбора статистики с Flussonic |
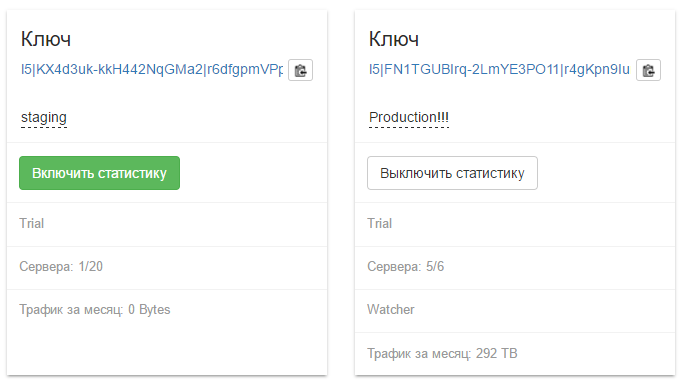

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author erlyvideo визуализация данных reactjs erlang/otp блог компании эрливидео статистика flussonic сервис статистики |
Спикеры #ITsubbotnik – о том, как технологии изменят мир через пять лет |





|
Метки: author AliceMir исследования и прогнозы в it блог компании epam мероприятие будущее epam systems конференция информационные технологии |
Юмор для IT-специалистов |







|
|
[Из песочницы] Современный CMake: 10 советов по улучшению скриптов сборки |
CMake — это система сборки для C/C++, которая с каждым годом становится всё популярнее. Он практически стал решением по умолчанию для новых проектов. Однако, множество примеров выполнения какой-либо задачи на CMake содержат архаичные, ненадёжные, раздутые действия. Мы выясним, как писать скрипты сборки на CMake лаконичнее.
Если вы хотите опробовать советы в деле, возьмите пример на github и исследуйте его по мере чтения статьи: https://github.com/sergey-shambir/modern-cmake-sample
Совет не относится к тем, кто пишет публичные библиотеки, поскольку для них важна совместимость со старым окружением разработки. А если вы пишете проект с закрытым кодом либо узкоспециальное опенсорсное ПО, то можно потребовать от всех разработчиков поставить последнюю версию CMake. Без этого многие советы статьи работать не будут! На момент написания статьи мы имеем CMake 3.8.
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)Современный CMake умеет сам вызывать систему сборки. В документации CMake такой режим называется Build Tool Mode.
# Переходим из каталога myproj в myproj-build
mkdir ../myproj-build && cd ../myproj-build
# Конфигурируем для сборки из исходников в ../myproj
cmake -DCMAKE_BUILD_TYPE=Release ../myproj
# Запускаем сборку в текущем каталоге
cmake --build .
# Запускаем сборку, передаём ключ '-j4' низлежащей системе сборки.
cmake --build . -- -j4Если вы генерируете проект Visual Studio, вы также можете собрать его из командной строки, в том числе можно собрать конкретный проект в конкретной конфигурации:
cmake --build . \
--target myapp \
--config Release \
--clean-firstНа Linux не используйте make install, иначе вы засорите свою систему. Об этом есть отдельная статья Хочется взять и расстрелять, или ликбез о том, почему не стоит использовать make install
Вложенность CMakeLists.txt — это нормально. Если ваш проект разделён на 3 библиотеки, 3 набора тестов и 2 приложения, то почему бы не добавить CMakeLists.txt для каждого из них? Тогда вам потребуется создать ещё один центральный CMakeLists.txt, и в нём выполнить add_subdirectory. Так может выглядеть центральный CMakeLists:
cmake_minimum_required(VERSION 3.8 FATAL_ERROR)
project(opengl-samples)
# Лайфхак: объявленные в старшем CMakeLists функции
# будут видны в подпроектах, включённых через add_subdirectory
include(scripts/functions.cmake)
add_subdirectory(libs/libmath)
add_subdirectory(libs/libplatform)
add_subdirectory(libs/libshade)
# Инструкция enable_testing неявно объявляет опцию BUILD_TESTING,
# по умолчанию BUILD_TESTING=ON.
# Вызывайте `cmake -DBUILD_TESTING=OFF projectdir` из командной строки,
# если не хотите собирать тесты.
enable_testing()
if(BUILD_TESTING)
add_subdirectory(tests)
endif()
# ..остальные цели..Не заводите глобальных переменных без крайней необходимости. Не используйте link_directories(), include_directories(), add_definitions(), add_compile_options() и другие подобные инструкции.
# Добавляем цель-библиотеку
add_library(mylibrary \
ColorDialog.h ColorDialog.cpp \
ColorPanel.h ColorPanel.cpp)
# ! Осторожно - непереносимый код !
# Добавляем к цели путь поиска заголовков /usr/include/wx-3.0
# Лучше использовать find_package для получения пути к заголовкам.
target_include_directories(mylibrary /usr/include/wx-3.0)Стоит заметить, чтоtarget_link_librariesможет добавить пути поиска заголовков библиотеки, если библиотека находится в вашем проекте и к ней были прикреплены пути поиска заголовков через конструкциюtarget_include_directories(libfoo PUBLIC ...).
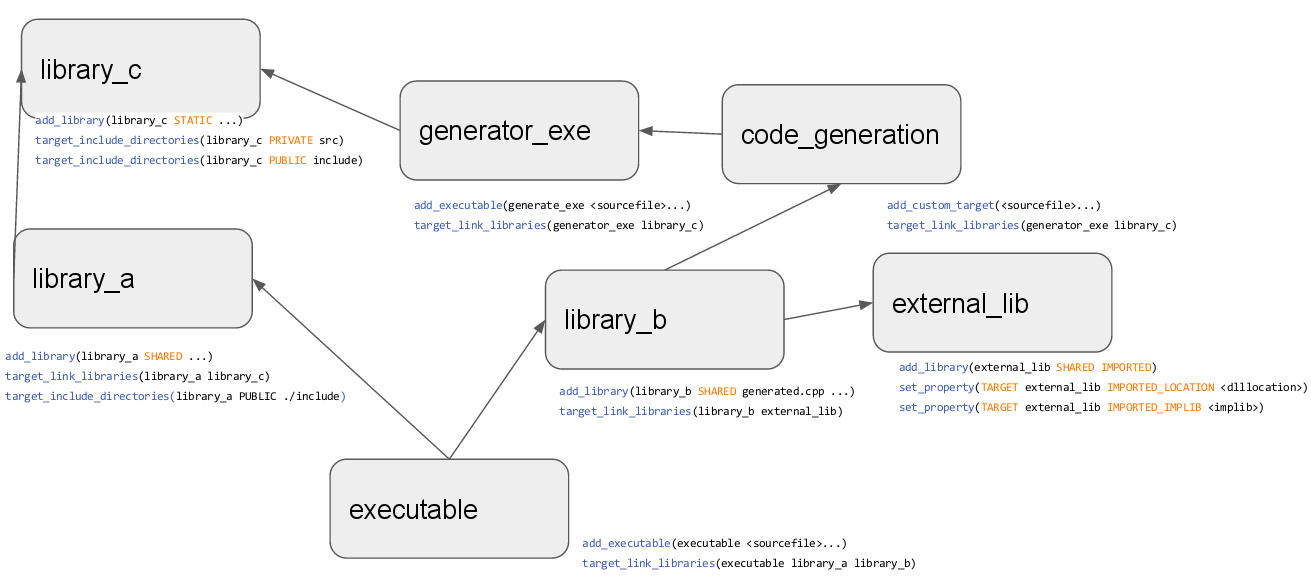
Есть пример схемы зависимостей, взятый из презентации Modern CMake / an Introduction за авторством Tobias Becker:
В последние годы стандарт C++ обновляется часто: мы получили потрясающие изменения в C++11, C++14, C++17. Старайтесь по возможности отказаться от старых компиляторов. Например, для Linux ничто не мешает установить последнюю версию Clang и libc++ и начать собирать все проекты со статической компоновкой C++ runtime.
Лучший способ включить C++17 без игры с флагами компиляции — явно сказать CMake, что он вам нужен.
# Способ первый: затребовать от компилятора фичу cxx_std_17
target_compile_features(${TARGET} PUBLIC cxx_std_17)
# Способ второй: указать компилятору на стандарт
set_target_properties(${TARGET} PROPERTIES
CXX_STANDARD 17
CXX_STANDARD_REQUIRED YES
CXX_EXTENSIONS NO
)С помощью target_compile_features вы можете требовать не C++17 или C++14, а определённых фич со стороны компилятора. Полный список известных CMake фич компиляторов можно посмотреть в документации.
В CMake можно объявлять свои функциональные макросы и свои функции. Есть лишь одно различие между ними: переменные, установленные внутри функции, являются локальными.
Удобно писать функции, чтобы решать текущие проблемы кастомизации сборки либо упрощать добавление множества целей сборки. Пример ниже был написан для более корректного включения C++17 из-за того, что
/std:c++latest для включения C++17std::experimental::filesystem в Clang/libc++ нужно указать компоновщику, что проект надо линковать с libc++experimental.a, поскольку в libc++.a модуля filesystem пока ещё нет; также нужно линковать с pthread, поскольку реализация thread/mutex и т.п. опирается на pthread# В текущей версии CMake не может включить режим C++17 в некоторых компиляторах.
# Функция использует обходной манёвр.
function(custom_enable_cxx17 TARGET)
# Включаем C++17 везде, где CMake может.
target_compile_features(${TARGET} PUBLIC cxx_std_17)
# Включаем режим C++latest в Visual Studio
if (CMAKE_CXX_COMPILER_ID STREQUAL "MSVC")
set_target_properties(${TARGET} PROPERTIES COMPILE_FLAGS "/std:c++latest")
# Включаем компоновку с libc++, libc++experimental и pthread для Clang
elseif (CMAKE_CXX_COMPILER_ID MATCHES "Clang")
set_target_properties(${TARGET} PROPERTIES COMPILE_FLAGS "-stdlib=libc++ -pthread")
target_link_libraries(${TARGET} c++experimental pthread)
endif()
endfunction(custom_enable_cxx17)Каждая функция — это по сути хак, созданный для переопределения языка CMake или его поведения. Для других разработчиков смысл этого хака неясен. Поэтому старайтесь к каждой инструкции в функции добавлять комментарий, объясняющий её цель и смысл.
В крупных открытых проектах, например в KDE, применение своих функций может быть дурным тоном. Вы можете рассмотреть иные варианты: писать скрипт сборки явно по принципу "Explicit is better then implicit", либо даже предложить добавить свою функцию в upstream проекта CMake.
Мой коллега разрабатывает вне работы маленький 3D движок для рендеринга сцены с моделями и анимациями через OpenGL, GLES, DirectX и Vulkan. Однажды мы с ним обсуждали этот проект, и оказалось, что для сборки под все платформы (Windows, Linux, Android) он использует Visual Studio! Он недоволен тем, что Microsoft редко обновляет Android NDK, но не хочет отказываться от сборки через MSBuild по одной простой причине.
Ему не хочется сопровождать список файлов для сборки в двух системах сборки.
Когда-то я вёл портирование игры с iOS на Android, и мы поддерживали две системы сборки с помощью скрипта, который читал проект XCode и автоматически дополнял список файлов в Android.mk. Если вы используете CMake, то вам даже скрипт не нужно писать.
В CMake есть функция aux_source_directory, но она имеет недостаток: заголовки не добавляются в список и не появляются в любом сгенерированном проекте для IDE.
file(GLOB ...), сканирующий файлы по маскеcustom_add_executable_from_dir(name)CMAKE_CURRENT_SOURCE_DIRfunction(custom_add_executable_from_dir TARGET)
# Собираем файлы с текущего каталога
file(GLOB TARGET_SRC "CMAKE_CURRENT_SOURCE_DIR/*.cpp"
# Добавляем исполняемый файл
add_executable(${TARGET} ${TARGET_SRC})
endfunction()Вы можете добавить функцию custom_add_library_from_dir для целей-библиотек аналогичным путём.
Если же вы — фанат ручной работы или создаёте публичную библиотеку, тогда, возможно, вам лучше добавлять файлы по одному. В этом случае используйте target_sources для добавления платформо-специфичных файлов:
add_library(libfoo Foo.h Foo_common.cpp)
if(WIN32)
target_sources(libfoo Foo_win32.cpp)
endif(WIN32)Наверняка вам хотелось ради автоматизации вызвать из cmake команду Bash, чтобы создать каталог, распаковать архив или подсчитать md5 сумму. Но вызов утилит командной строки может лишить проект кроссплатформенности. Более переносимый метод — вызывать cmake -E команда, пользуясь Command-Line Tool Mode.
Совет относится к вам, если вы пишете публично доступные библиотеки. В этом случае вам стоит упрощать следующие сценарии:
CMakeLists.txt через add_subdirectoryДобавляя библиотеку, создавайте ещё и уникальный синоним:
# Добавляем цель-библиотеку
add_library(foo ${FOO_SRC})
# Добавляем синоним, содержащий имя выпускающей библиотеку организации
add_library(MyOrg::foo ALIAS foo)Оставляйте пользователям библиотеки право использования опции BUILD_SHARED_LIBS для выбора между сборкой статической и динамической версий библиотеки.
При установке настроек компоновки, поиска заголовков и флагов компиляции для библиотек используйте ключевые слова PUBLIC, PRIVATE, INTERFACE, чтобы позволить целям, зависящим от вашей библиотеки, наследовать необходимые настройки:
target_link_libraries(foobarapp
PUBLIC MyOrg::libfoo
PRIVATE MyOrg::libbar
)Подсистема CTest не заставляет вас использовать какие-то особые библиотеки для тестирования вместо привычных Boost.Test, Catch или Google Tests. Она всего лишь регистрирует автотесты так, чтобы CMake мог запустить все тесты или выбранные тесты одной командой ctest.
Чтобы включить поддержку CTest по всему проекту, есть инструкция enable_testing
# Инструкция enable_testing неявно объявляет опцию BUILD_TESTING,
# по умолчанию BUILD_TESTING=ON.
# Вызывайте `cmake -DBUILD_TESTING=OFF projectdir` из командной строки,
# если не хотите собирать тесты.
enable_testing()
if(BUILD_TESTING)
add_subdirectory(tests/libhellotest)
add_subdirectory(tests/libgoodbyetest)
endif()Чтобы исполняемый файл с тестом был зарегистирован в CTest, нужно вызвать инструкцию add_test.
# Исполняемый файл теста - это обычная исполняемая цель сборки
add_executable(${TARGET} ${TARGET_SRC})
# Регистрируем исполняемый файл в CMake как набор тестов.
# можно назначить тесту особое имя, но проще использовать имя исполняемого файла теста.
add_test(${TARGET} ${TARGET})Перед созданием статьи были прочитаны, опробованы и переосмыслены несколько англоязычных источников:
Некоторые советы из этих источников никак не отражены в статье. Поэтому после их прочтения вы определённо станете глубже разбираться в CMake.
|
Метки: author sergey_shambir c++ c++17 cmake |
[Перевод статьи] Лучшие IT-конференции для участия в Июне — Августе 2017 |

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Viktor_D разработка под ios разработка под android unity3d magento google chrome события конференции события в мире события it профессионалов |
GeekUniversity открывает набор студентов на факультет Java-разработки |


|
Метки: author Sadovnikova разработка под android разработка мобильных приложений java блог компании mail.ru group mail.ru обучение программированию geekuniversity |
Найдена новая уязвимость в Intel AMT, связанная с режимом Serial-over-LAN |
 / фото Andi Weiland CC
/ фото Andi Weiland CC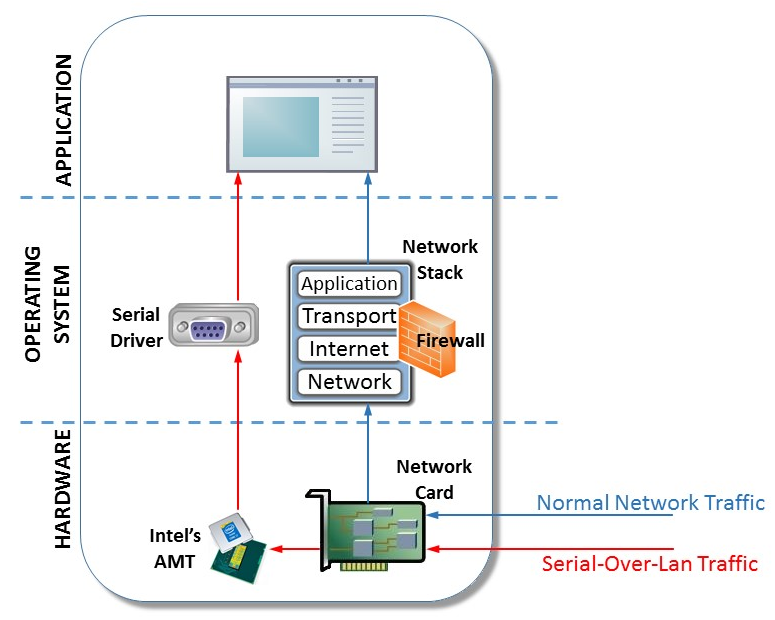
|
Метки: author it_man информационная безопасность блог компании ит-град ит-град intel amt |
SQL Server Integration Services (SSIS) для начинающих – часть 3 |

USE DemoSSIS_SourceA
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
USE DemoSSIS_SourceB
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
USE DemoSSIS_Target
GO
CREATE TABLE ProductResidues(
ResidueDate date NOT NULL,
ProductID int NOT NULL,
ResidueAmount decimal(10,2) NOT NULL,
CONSTRAINT PK_ProductResidues PRIMARY KEY(ResidueDate,ProductID),
CONSTRAINT FK_ProductResidues_ProductID FOREIGN KEY(ProductID) REFERENCES Products(ID)
)
GO
USE DemoSSIS_SourceA
--USE DemoSSIS_SourceB
GO
DECLARE @MinDate date=DATEADD(MONTH,-2,GETDATE())
DECLARE @MaxDate date=GETDATE()
;WITH dayCTE AS(
SELECT CAST(@MinDate AS date) ResidueDate,10000 ResidueAmount
UNION ALL
SELECT DATEADD(DAY,1,ResidueDate),ResidueAmount-1
FROM dayCTE
WHERE ResidueDate<@MaxDate
)
INSERT ProductResidues(ResidueDate,ProductID,ResidueAmount)
SELECT
d.ResidueDate,
p.ID,
d.ResidueAmount
FROM dayCTE d
CROSS JOIN Products p
OPTION(MAXRECURSION 0)


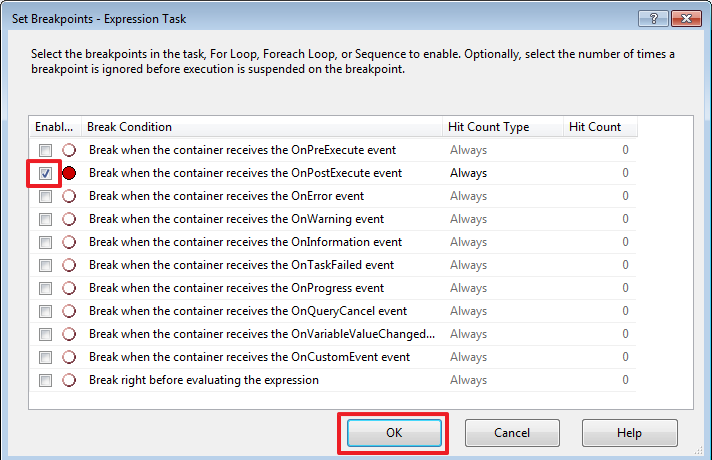
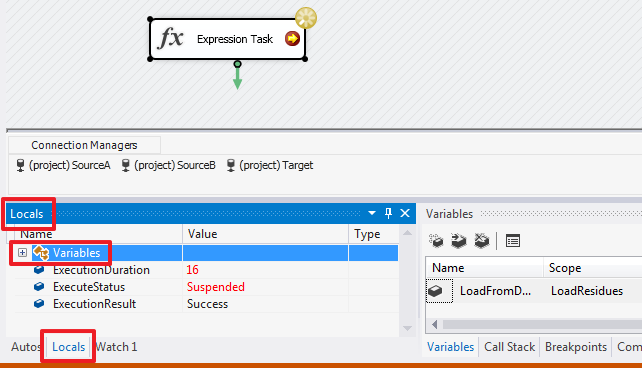
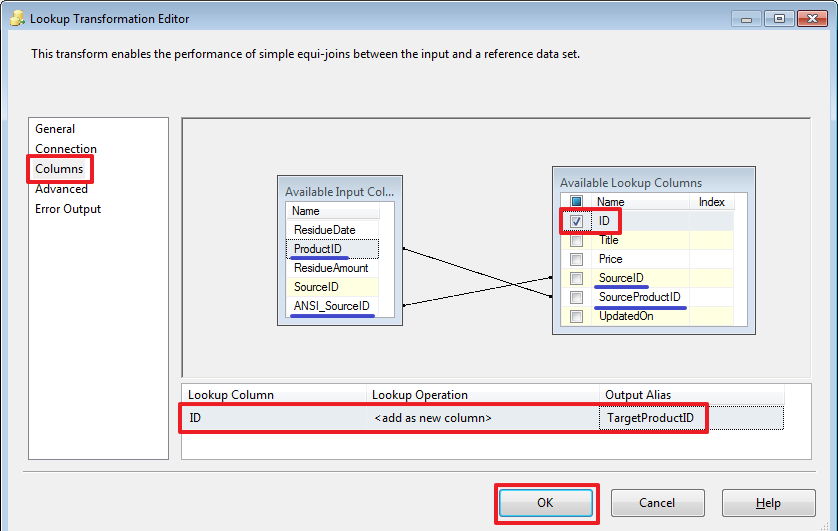
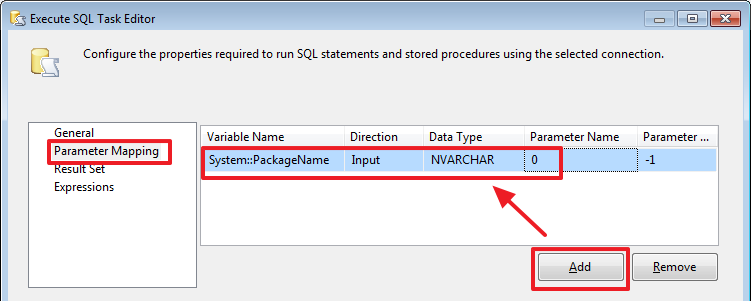
Так же стоит обратить внимание на Expression – если прописать в этом поле выражение, то переменная будет работать как формула и мы не сможем изменять ее значение при помощи присваивания. При каждом обращении к такой переменной ее значение будет рассчитываться согласно указанному выражению.


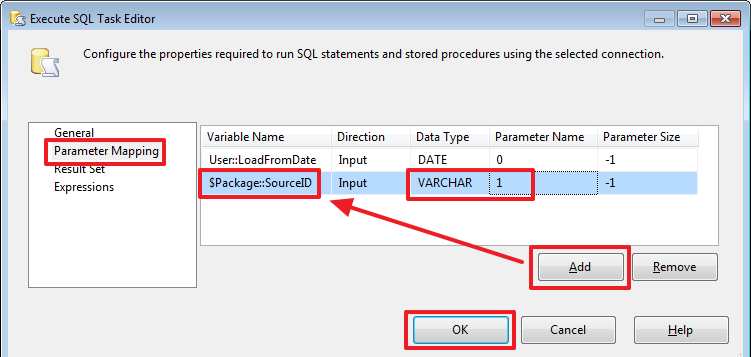
@[User::LoadFromDate] = (DT_DATE) (DT_DBDATE) GETDATE()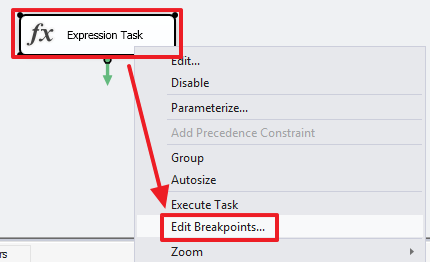

@[User::LoadFromDate] = (DT_DATE) (DT_DBDATE) DATEADD("DAY", -7, GETDATE())


В отличие от переменных значение параметров при помощи «Expression Task» менять нельзя.
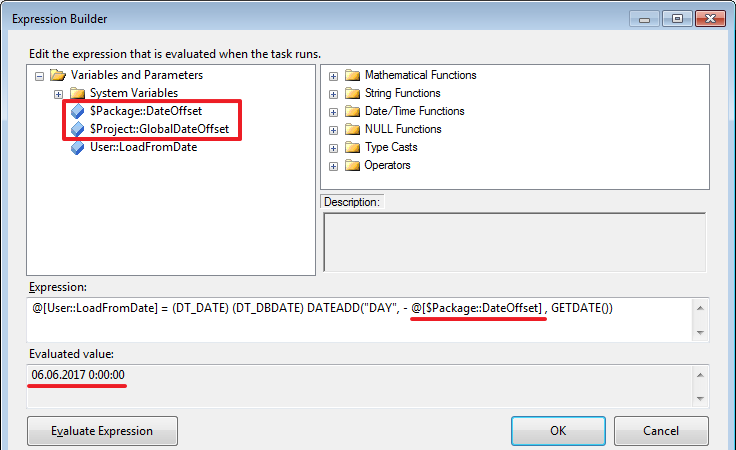
@[User::LoadFromDate] = (DT_DATE) (DT_DBDATE) DATEADD("DAY", - @[$Package::DateOffset] , GETDATE())

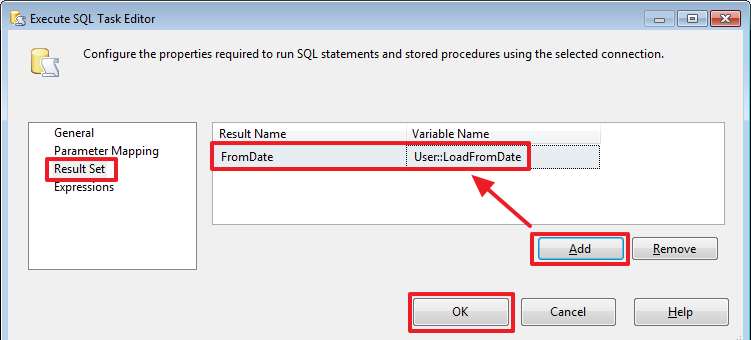
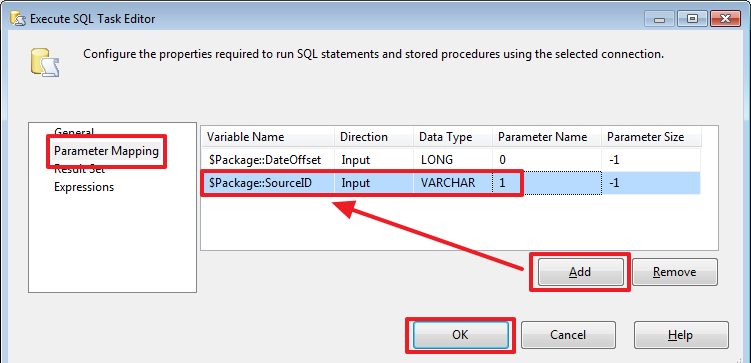
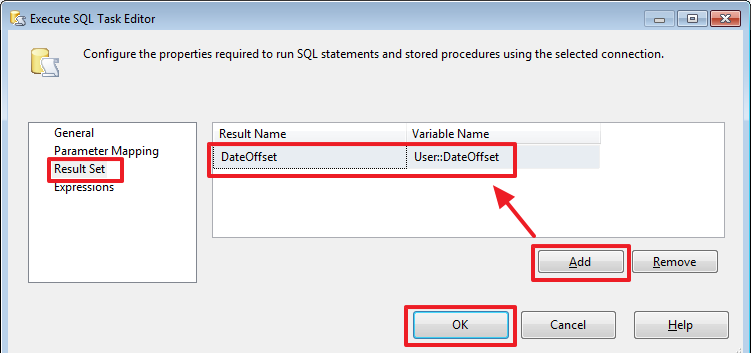
SELECT ISNULL(DATEADD(DAY,-?,MAX(ResidueDate)),'19000101') FromDate
FROM ProductResidues

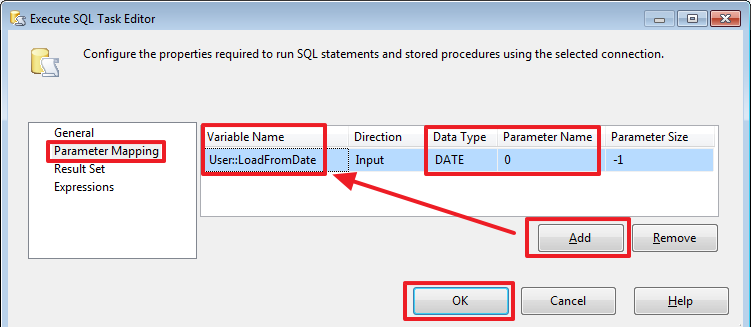
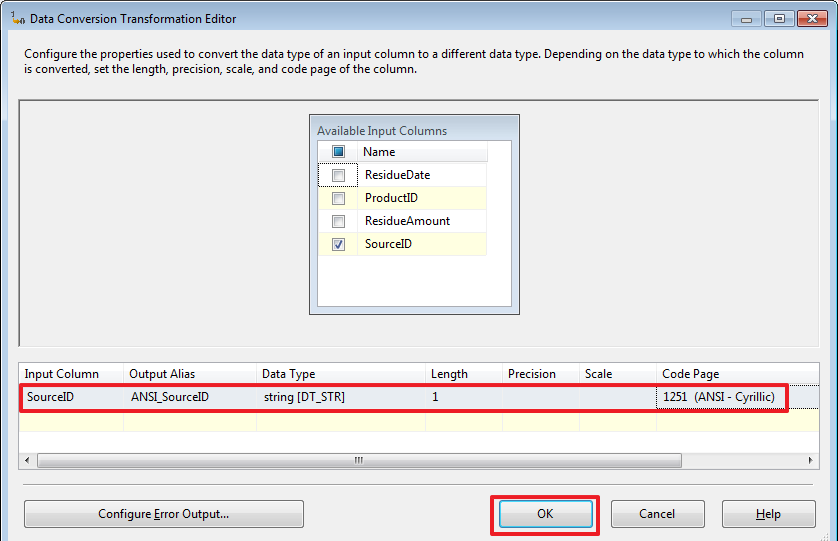
Стоит отметить, что если при создании соединения воспользоваться другим видом провайдера, например, «ADO» или «ADO.Net», то вместо вопросов мы сможем использовать именованные параметры типа @ParamName и в качестве «Parameter Name» тоже могли бы указывать @ParamName, а не его номер. Но увы типом соединения с другим провайдером мы сможем воспользоваться не во всех случаях.



DELETE ProductResidues
WHERE ResidueDate>=?











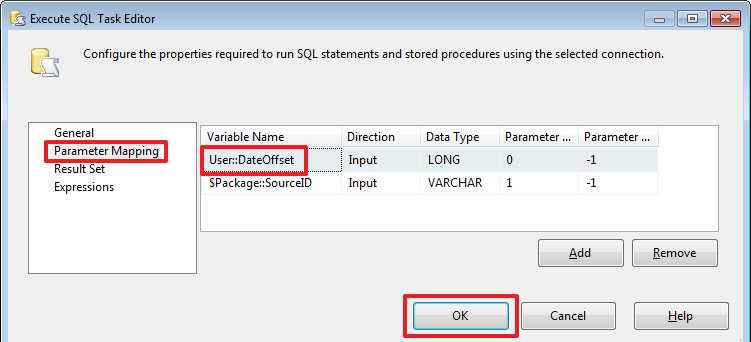
SELECT ISNULL(DATEADD(DAY,-?,MAX(res.ResidueDate)),'19000101') FromDate
FROM ProductResidues res
JOIN Products prod ON res.ProductID=prod.ID
WHERE prod.SourceID=?

DELETE res
FROM ProductResidues res
JOIN Products prod ON res.ProductID=prod.ID
WHERE ResidueDate>=?
AND prod.SourceID=?






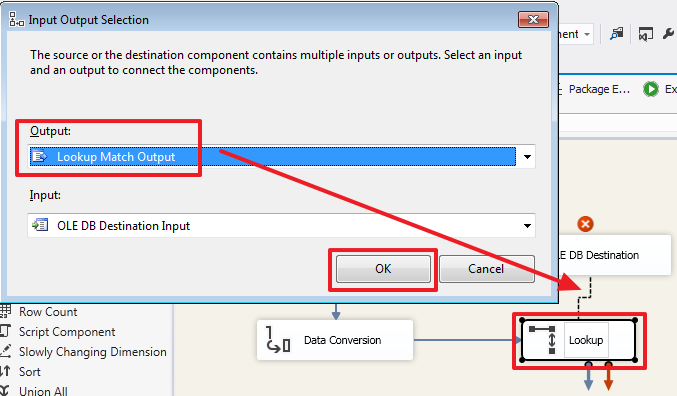

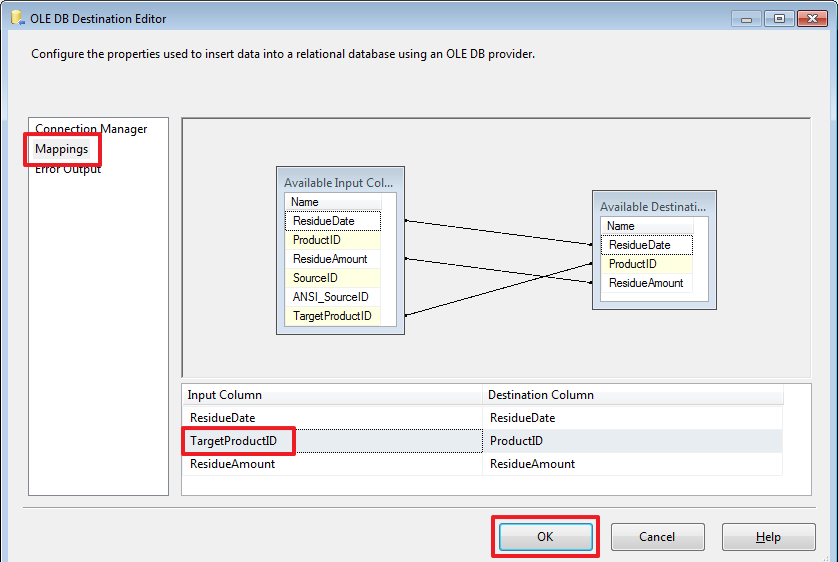
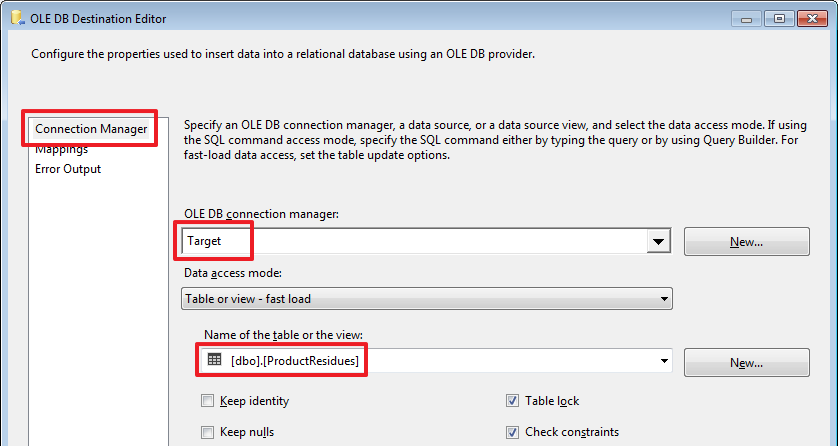
TRUNCATE TABLE DemoSSIS_Target.dbo.ProductResidues






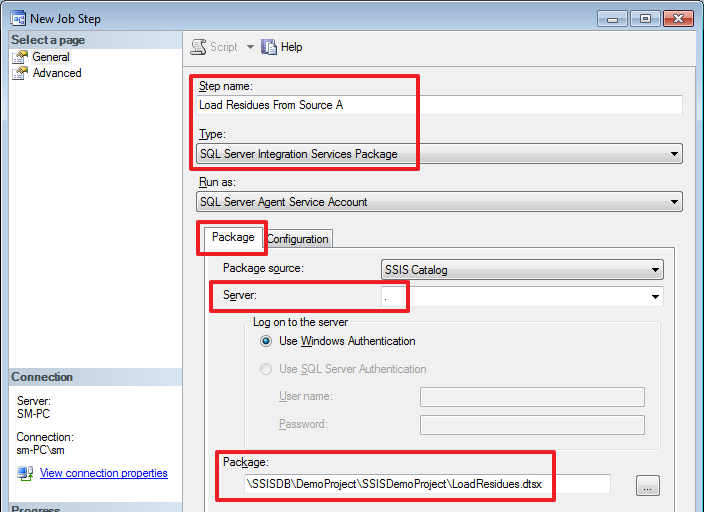





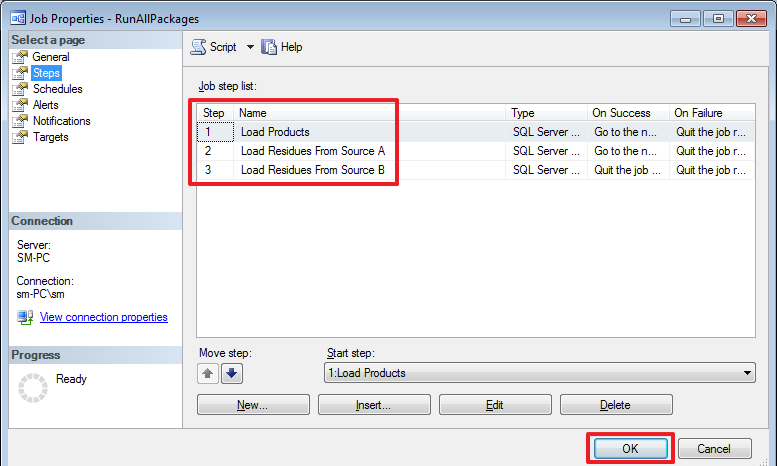

USE DemoSSIS_Target
GO
SELECT prod.SourceID,COUNT(*)
FROM ProductResidues res
JOIN Products prod ON res.ProductID=prod.ID
GROUP BY prod.SourceID



DECLARE @SourceID char(1)=?
IF(@SourceID='A') USE DemoSSIS_SourceA
ELSE USE DemoSSIS_SourceB
SELECT
ResidueDate,
ProductID,
ResidueAmount
FROM ProductResidues
WHERE ResidueDate>=?


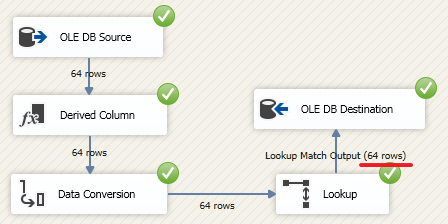

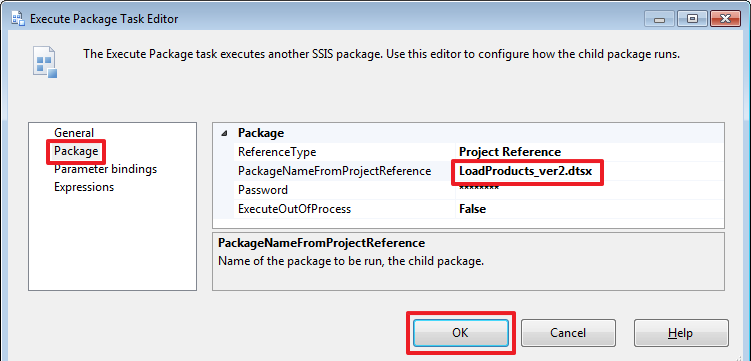

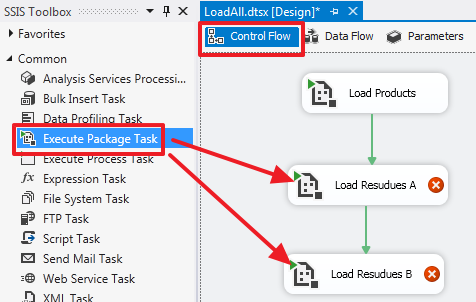


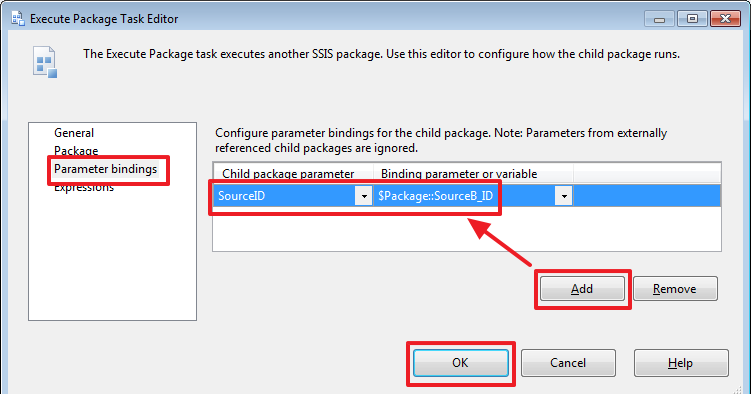

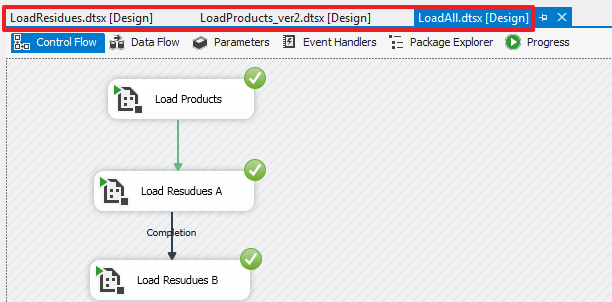
USE DemoSSIS_Target
GO
CREATE TABLE IntegrationPackageParams(
PackageName nvarchar(128) NOT NULL,
DateOffset int NOT NULL,
CONSTRAINT PK_IntegrationPackageParams PRIMARY KEY(PackageName)
)
GO
INSERT IntegrationPackageParams(PackageName,DateOffset)VALUES
(N'LoadResidues',7)
GO



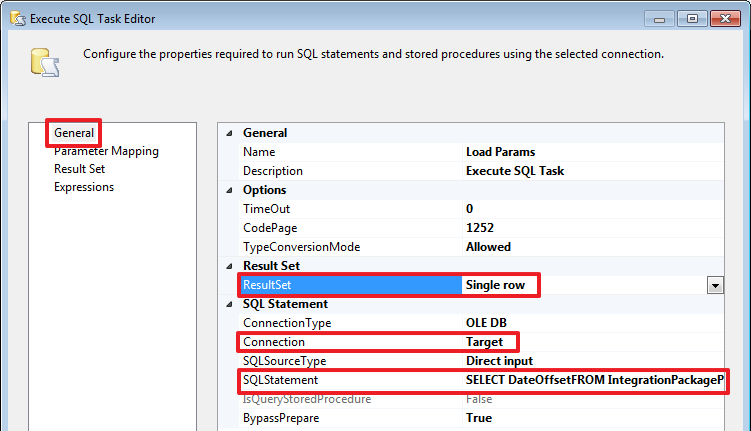
SELECT DateOffset
FROM IntegrationPackageParams
WHERE PackageName=?

|
Метки: author Leran2002 sql microsoft sql server ssis integration services sql server etl |
5 возможностей LESS, о которых вы могли не знать |
|
Метки: author belyan html css блог компании netcracker less css3 |
[Перевод] Коллбэк в JavaScript… Что за зверь? |

function first(){
console.log(1);
}
function second(){
console.log(2);
}
first();
second();first() выполняется первой, а функция second() — второй. Запуск этого кода приводит к тому, что в консоль будет выведено следующее:// 1
// 2first() содержит код, который нельзя выполнить немедленно? Например, там есть обращение к некоему API, причём, сначала нужно отправить запрос, а потом дождаться ответа? Для того, чтобы это сымитировать, воспользуемся функцией setTimeout(), которая применяется в JavaScript для вызова других функций с заданной задержкой. Мы собираемся отложить вызов функции на 500 миллисекунд.function first(){
// Имитируем задержку
setTimeout( function(){
console.log(1);
}, 500 );
}
function second(){
console.log(2);
}
first();
second();setTimeout() сейчас неважны. Главное — обратите внимание на то, что вызов console.log(1) будет выполнен с задержкой.// 2
// 1first() была вызвана первой, сначала в лог попало то, что выводит функция second().second(), не дожидаясь ответа от функции first().Ctrl + Shift + J в Windows, или Cmd + Option + J в Mac) и введите следующее:function doHomework(subject) {
alert(`Starting my ${subject} homework.`);
}doHomework(). Эта функция принимает одну переменную — название предмета, по которому некто делает домашнюю работу. Вызовите функцию, введя в консоли следующее:doHomework('math');
// Выводит сообщение: Starting my math homework.doHomework(), параметр callback, который будем использовать для того, чтобы передать doHomework() функцию обратного вызова. Теперь код будет выглядеть так:function doHomework(subject, callback) {
alert(`Starting my ${subject} homework.`);
callback();
}doHomework('math', function() {
alert('Finished my homework');
});Starting my math homework., потом — с текстом Finished my homework.function doHomework(subject, callback) {
alert(`Starting my ${subject} homework.`);
callback();
}
function alertFinished(){
alert('Finished my homework');
}
doHomework('math', alertFinished);doHomework() всё будет выглядеть точно так же, как в предыдущем примере. Различия заключаются лишь в том, как мы работаем с функцией обратного вызова. doHomework(), использовано имя функции alertFinished().T.get('search/tweets', params, function(err, data, response) {
if(!err){
// Именно здесь можно работать с тем, что вернёт нам Twitter
} else {
console.log(err);
}
})
T.get()'search/tweets', представляет собой маршрут запроса. Здесь мы собираемся выполнить поиск по твитам. Второй аргумент — params — это параметры поиска. Третий аргумент — анонимная функция, которая и является функцией обратного вызова.search/tweet с помощью get-запроса, приходится ждать. Как только Twitter ответит на запрос, будет выполнена функция обратного вызова. Если что-то пошло не так, в ней мы получим объект ошибок (err). Если запрос обработан нормально, в аргументе err будет значение, эквивалентное false, а значит, во-первых, будет исполнена ветвь if условного оператора, а во-вторых — можно будет рассчитывать на то, что в объекте response окажутся некие полезные данные, с которыми уже можно что-то делать.|
Метки: author ru_vds javascript блог компании ruvds.com программирование функция обратного вызова коллбэк |
Искусственный интеллект захватывает Уолл-стрит: как это скажется на сфере финансов и не только |

|
Метки: author itinvest финансы в it исследования и прогнозы в it блог компании itinvest искусственный интеллект онлайн-трейдинг |
[Из песочницы] Дневник одной разработки, или Xamarin как он есть |

await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
await grid.RotateYTo(grid.RotationY + rotation, 125);
await grid.RotateYTo(grid.RotationY + rotation, 125);
longTapGrid.IsVisible = true;
await Task.Run(async () => await grid.RotateYTo(grid.RotationY + rotation, 125));
|
Метки: author SmartSmall разработка мобильных приложений c# .net xamarin xamarin.forms юмор |
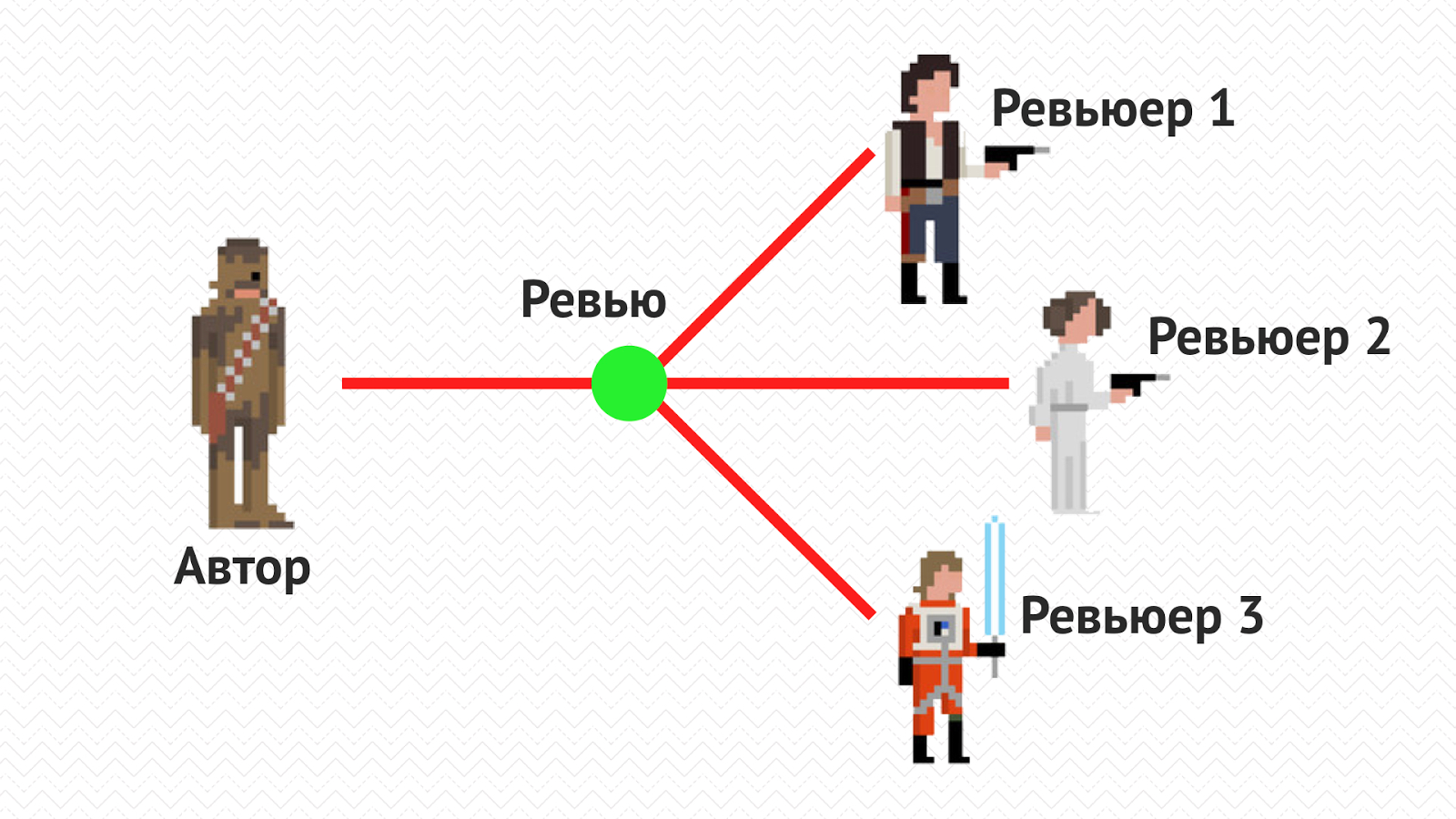
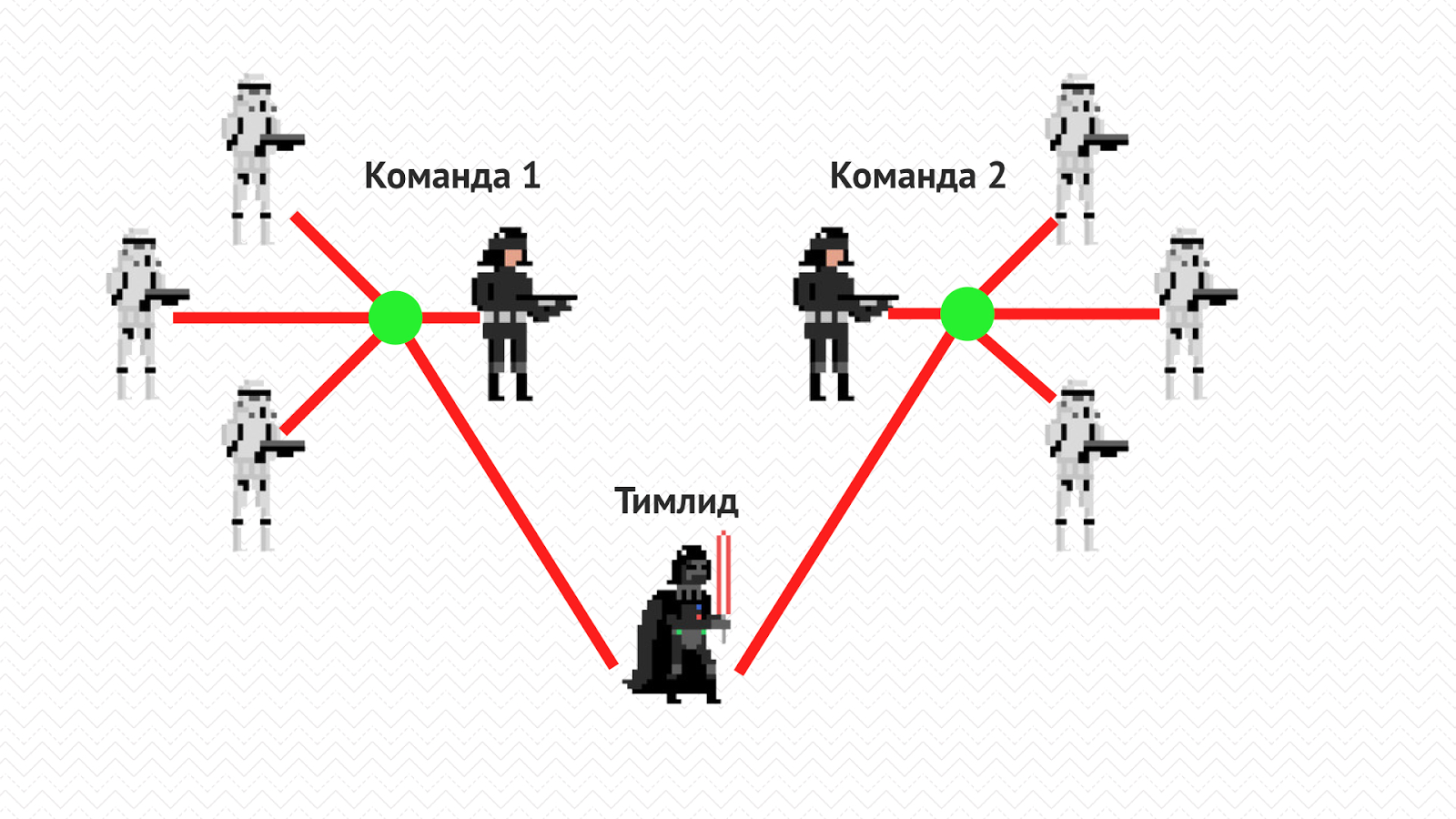
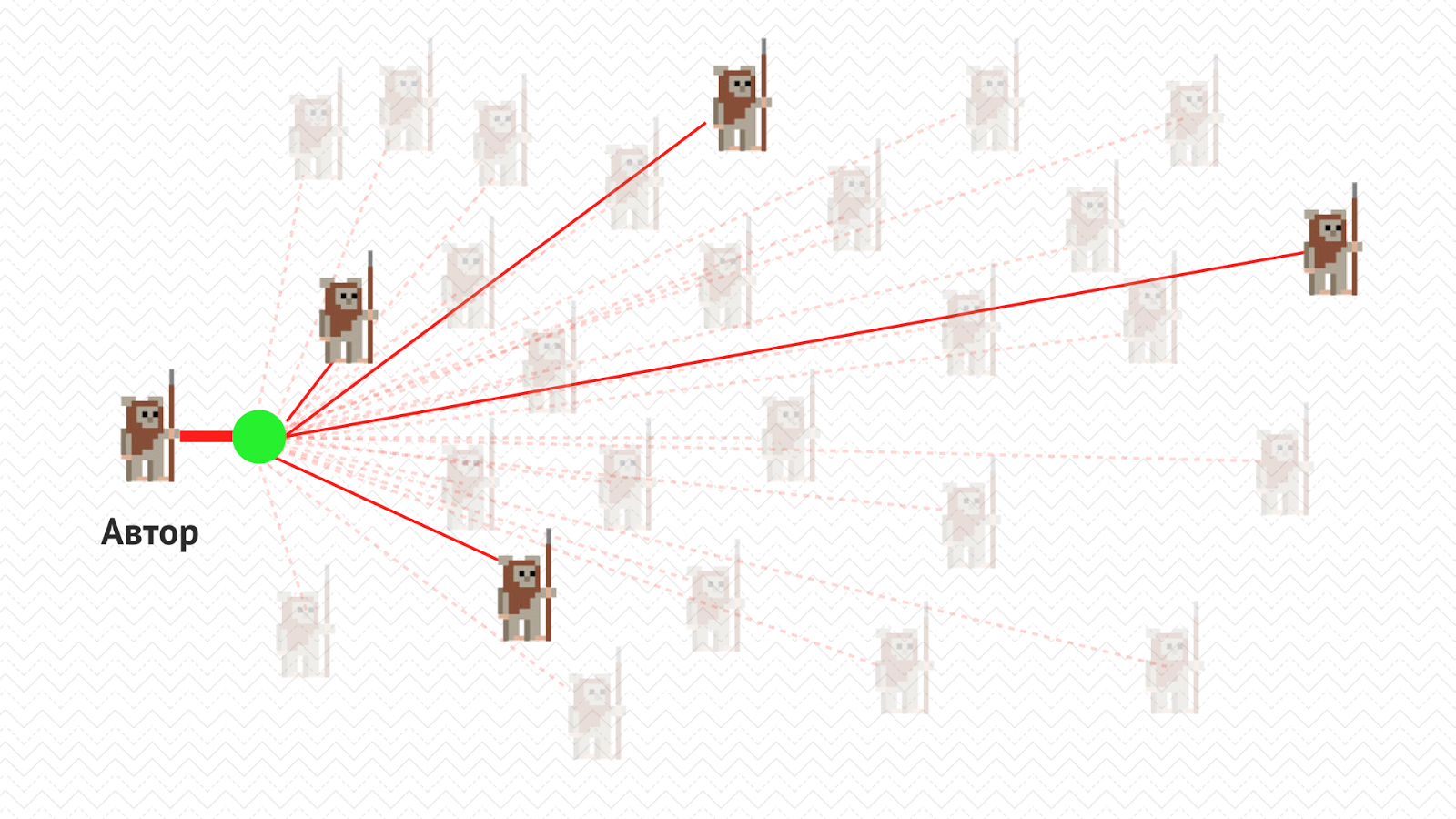
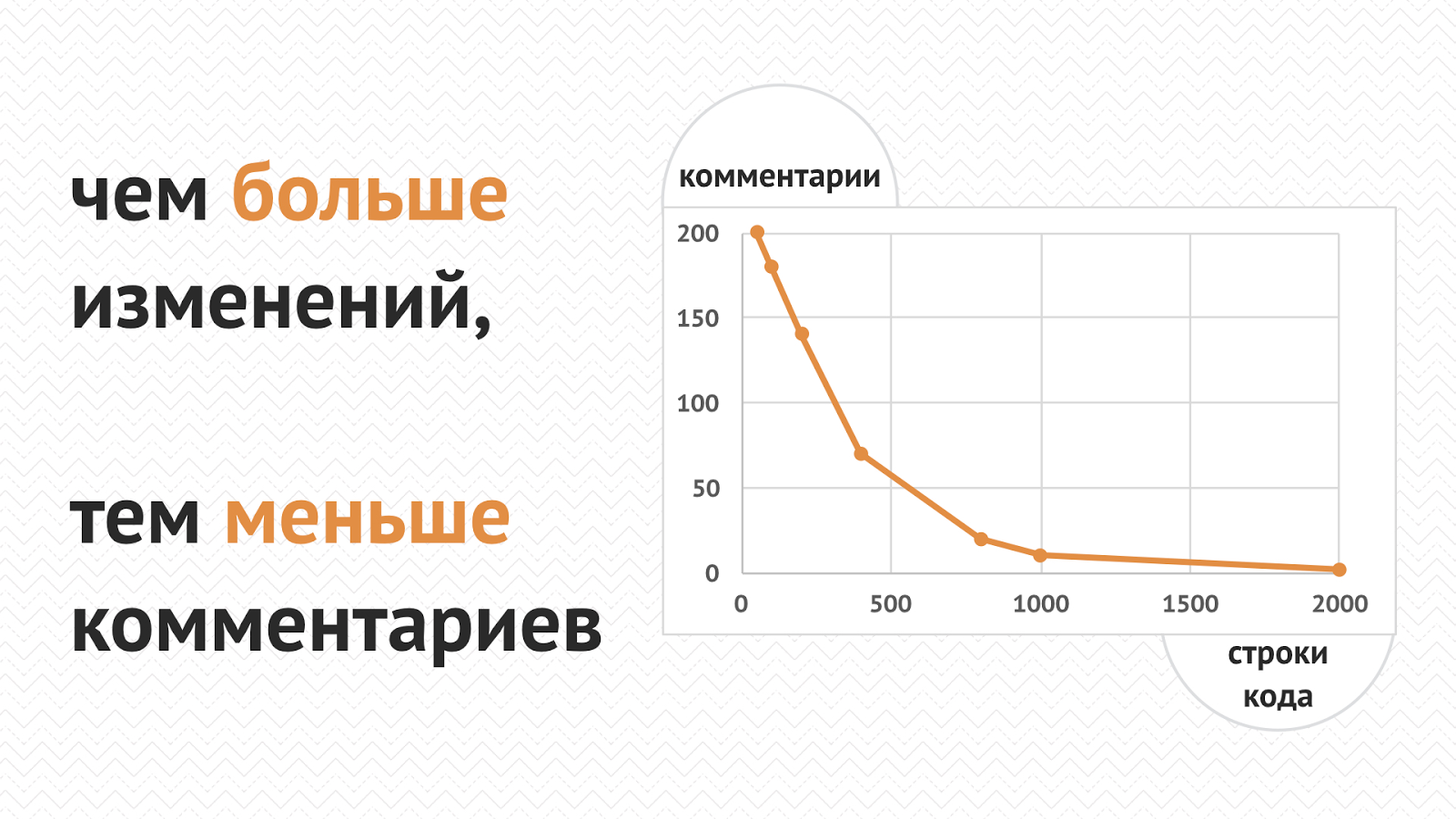
May the Code Review be with you |



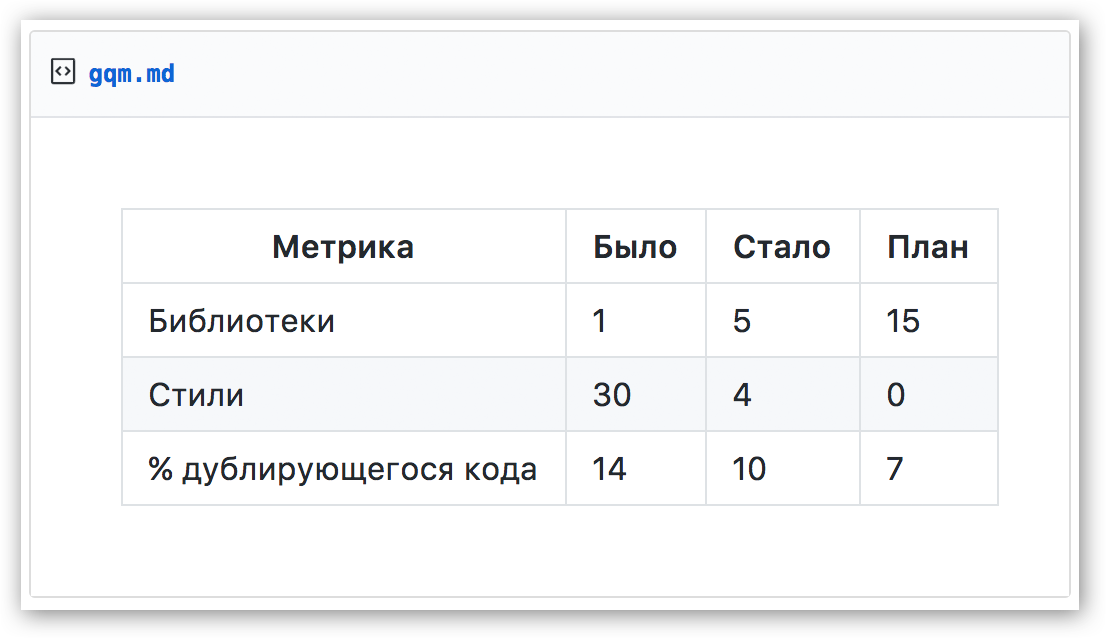

|
Метки: author YourDestiny совершенный код разработка под ios программирование отладка блог компании avito code review код ревью ревью кода |






