ФСТЭК даёт «добро» |





|
Метки: author ru_vds хостинг сетевые технологии it- инфраструктура блог компании ruvds.com ruvds фстэк сертификация |
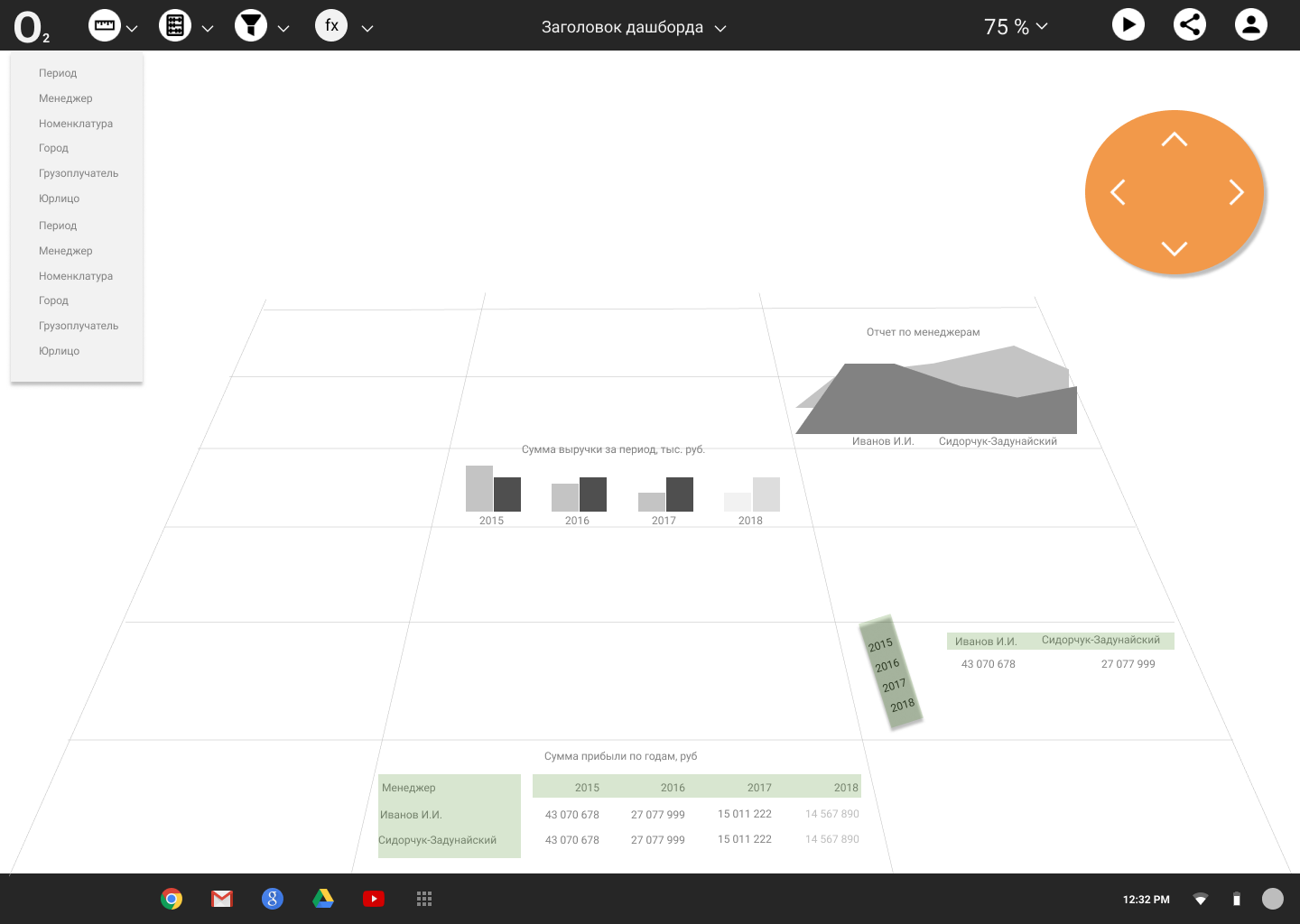
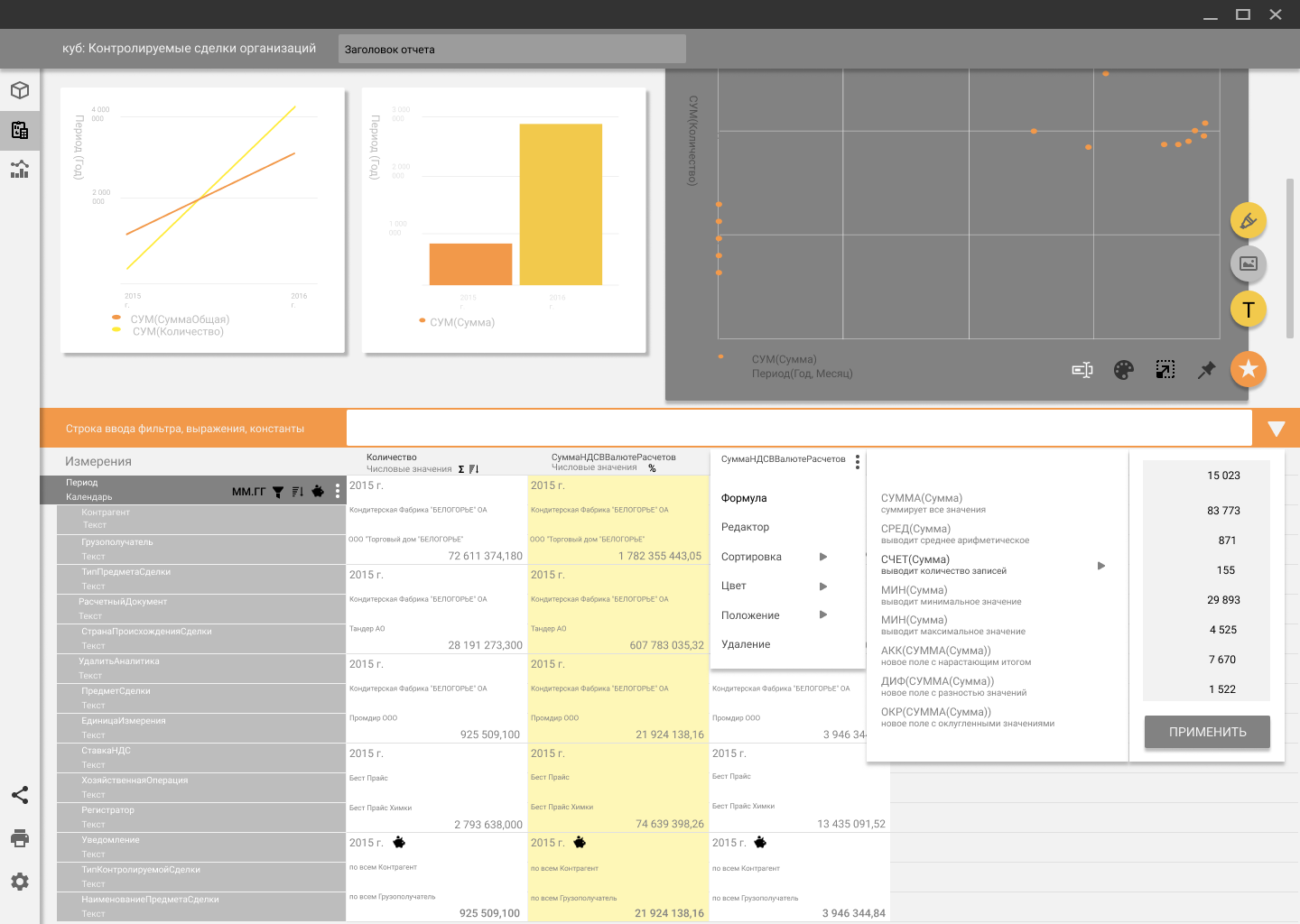
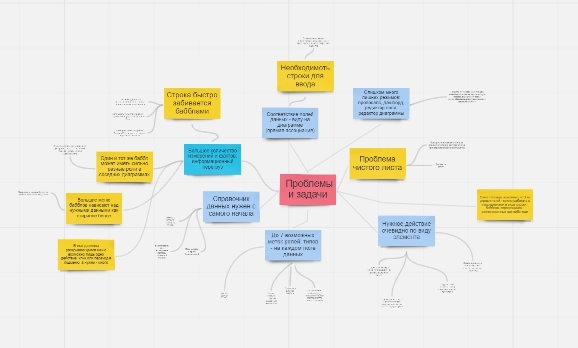
Дизайн интерфейса корпоративного инструмента BI для data mining |




Смотришь прямо — видишь таблицу, чуть наклонил рабочую панель, как вдруг из цифр выросли цветные столбцы или линейные диаграммы, превращая набор таблиц — в визуально красивый дашбоард.





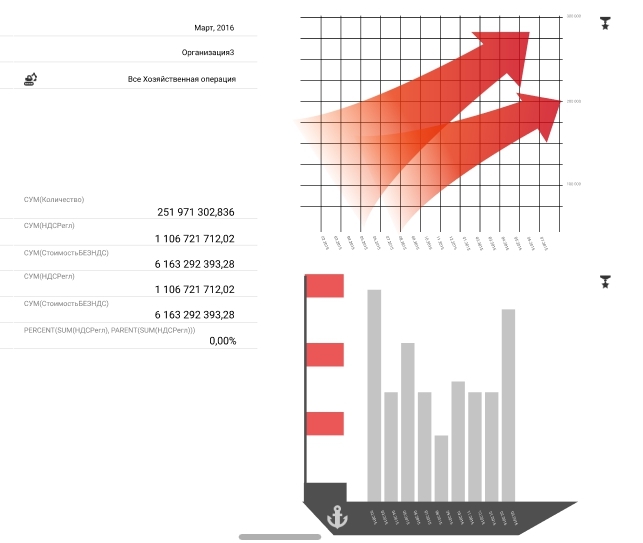

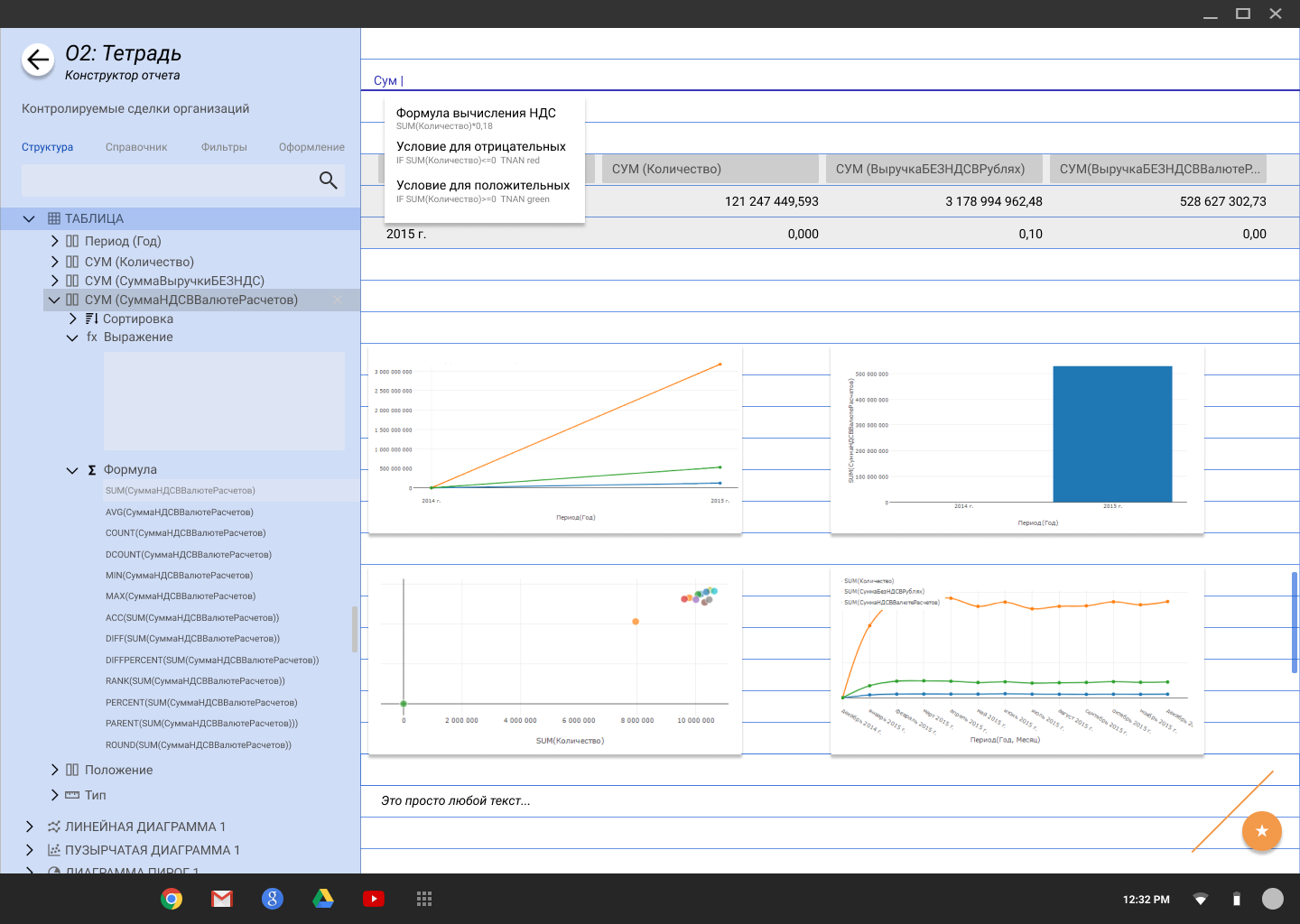

|
Метки: author sanemerov интерфейсы веб-дизайн usability data mining data science business intelligence business analysis полиматика |
Сохранить данные и веру в человечество: большая миграция кластера ElasticSearch |

В этом материале я продолжаю делиться полевым опытом работы с системой сбора логов на базе Heka и ElasticSearch.
На этот раз рассказ пойдет про миграцию данных между двумя кластерами ElasticSearch 2.2 и 5.2.2, которая стоила немалых нервов лично мне. Как-никак, предстояло перевезти 24 миллиарда записей, не сломав уже работающую систему.
Прошлая статья закончилась на том, что система работает, логи поступают и складываются в кластер ElasticSearch, доступен их просмотр в реальном времени через Kibana. Но кластер изначально был собран со значительным запасом по памяти как раз на вырост.
Если обратиться к официальной документации ElasticSearch (далее просто ES), то в первую очередь вы увидите строгое предупреждение «Don't cross 32 gb». Превышение грозит проседанием производительности вплоть до моментов полной остановки, пока garbage collector выполняет пересборку в духе «stop the world». Рекомендация производителя по памяти на сервере: 32 ГБ под heap (xms/xmx) и еще 32 ГБ свободного места под кэш. Итого 64 ГБ физической памяти на одну дата-ноду.
Но что делать, если памяти больше? Официальный ответ все в той же документации – ставить несколько экземпляров ES на один хост. Но мне такой подход показался не совсем правильным, так как штатных средств для этого не предусмотрено. Дублировать init-скрипты – это прошлый век, поэтому более интересной выглядела виртуализация кластера с размещением нод в LXD-контейнерах.
LXD (Linux Container Daemon) – так называемый «контейнерный легковизор». В отличии от «тяжелых» гипервизоров не содержит эмуляции аппаратуры, что позволяет сократить накладные расходы на виртуализацию. К тому же имеет продвинутый REST API, гибкую настройку используемых ресурсов, возможности переноса контейнеров между хостами и другие возможности, более характерные для классических систем виртуализации.

Вот такая вырисовывалась структура будущего кластера.
К началу работ под рукой было следующее железо:
Четыре работающих дата-ноды ES в составе старого кластера: Intel Xeon 2x E5-2640 v3; 512 ГБ ОЗУ, 3x16 ТБ RAID-10.
По задумке, на каждом физическом сервере будет две дата-ноды ES, мастер-нода и клиентская нода. Кроме того, на сервере разместится контейнер-приёмник логов с установленными HAProxy и пулом Heka для обслуживания дата-нод этого физического сервера.
В первую очередь нужно освободить одну из дата-нод – этот сервер сразу уходит в новый кластер. Нагрузка на оставшиеся три возрастет на 30%, но они справятся, что подтверждает статистика загрузки за последний месяц. Тем более это ненадолго. Далее привожу свою последовательность действий для штатного вывода дата-ноды из кластера.
Снимем с четвертой дата-ноды нагрузку, запретив размещение на ней новых индексов:
{
"transient": {
"cluster.routing.allocation.exclude._host": "log-data4"
}
}Теперь выключаем автоматическую ребалансировку кластера на время миграции, чтобы не создавать лишней нагрузки на оставшиеся дата-ноды:
{
"transient": {
"cluster.routing.rebalance.enable": "none"
}
}Собираем список индексов с освобождаемой дата-ноды, делим его на три равные части и запускаем перемещение шардов на оставшиеся дата-ноды следующим образом (по каждому индексу и шарду):
PUT _cluster/reroute
{
"commands" : [ {
"move" :
{
"index" : "service-log-2017.04.25", "shard" : 0,
"from_node" : "log-data4", "to_node" : "log-data1"
}
}
}Когда перенос завершится, выключаем освободившуюся ноду и не забываем вернуть ребалансировку обратно:
{
"transient": {
"cluster.routing.rebalance.enable": "all"
}
}Если позволяют сеть и нагрузка на кластер, то для ускорения процесса можно увеличить очередь одновременно перемещаемых шардов (по умолчанию это количество равно двум)
{
"transient": {
"cluster": {
"routing": {
"allocation": {
"cluster_concurrent_rebalance": "10"
}
}
}
}
}Пока старый кластер постепенно приходит в себя, собираем на трёх имеющихся серверах новый на базе ElasticSearch 5.2.2, с отдельными LXD-контейнерами под каждую ноду. Дело это простое и хорошо описанное в документации, поэтому опущу подробности. Если что – спрашивайте в комментариях, расскажу детально.
В ходе настройки нового кластера я распределил память следующим образом:
Мастер-ноды: 4 ГБ
Клиентские ноды: 8 ГБ
Дата-ноды: 32 ГБ
Такое распределение родилось после осмысления документации, просмотра статистики работы старого кластера и применения здравого смысла.
Итак, у нас есть два кластера:
Старый – три дата-ноды, каждая на железном сервере.
Первое, что делаем, – включаем зеркалирование трафика в оба кластера. На приемных пулах Heka (за подробным описанием отсылаю к предыдущей статье цикла) добавляем ещё одну секцию Output для каждого обрабатываемого сервиса:
[Service1Output_Mirror]
type = "ElasticSearchOutput"
message_matcher = "Logger == 'money-service1''"
server = "http://newcluster.receiver:9200"
encoder = "Service1Encoder"
use_buffering = trueПосле этого трафик пойдет параллельно в оба кластера. Учитывая, что мы храним индексы с оперативными логами компонент не более 21 дня, на этом можно было бы и остановиться. Через 21 день в кластерах будут одинаковые данные, а старый можно отключить и разобрать. Но долго и скучно столько ждать. Поэтому переходим к последнему и самому интересному этапу – миграции данных между кластерами.
Так как официальной процедуры миграции данных между кластерами ES на момент выполнения проекта не существует, а изобретать «костыли» не хочется – используем Logstash. В отличии от Heka он умеет не только писать данные в ES, но и читать их оттуда.
Судя по комментариям к прошлой статье, у многих сформировалось мнение, что я почему-то не люблю Logstash. Но ведь каждый инструмент предназначен для своих задач, и для миграции между кластерами именно Logstash подошёл как нельзя лучше.
На время миграции полезно увеличить размер буфера памяти под индексы с 10% по умолчанию до 40%, которые выбраны по среднему количеству свободной памяти на работающих дата-нодах ES. Также нужно выключить обновление индексов на каждой дата-ноде, для чего добавляем в конфигурацию дата-нод следующие параметры:
memory.index_buffer_size: 40%
index.refresh_interval: -1По-умолчанию индекс обновляется каждую секунду и создает тем самым лишнюю нагрузку. Поэтому, пока в новый кластер никто из пользователей не смотрит, обновление можно отключить. Заодно я создал шаблон по умолчанию для нового кластера, который будет использоваться при формировании новых индексов:
{
"default": {
"order": 0,
"template": "*",
"settings": {
"index": {
"number_of_shards": "6",
"number_of_replicas": "0"
}
}
}
}С помощью шаблона выключаем на время миграции репликацию, тем самым снизив нагрузку на дисковую систему.
Для Logstash получилась следующая конфигурация:
input {
elasticsearch {
hosts => [ "localhost:9200" ]
index => "index_name"
size => 5000
docinfo => true
query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'}
}
output {
elasticsearch { hosts => [ "log-new-data1:9200" ]
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"}}
}В секции input описываем источник получения данных, указываем системе, что данные нужно забирать пачками (bulk) по 5000 записей, и выбираем все записи, отсортированные по timestamp.
В output нужно указать назначение для пересылки полученных данных. Обратите внимание на описания следующих полей, которые можно получить из старых индексов:
document_type – тип (mapping) документа, который лучше указать при переезде, чтобы имена создаваемых mappings в новом кластере совпадали с именами в старом – они используются в сохранённых запросах и дашбордах.
Параметры запуска Logstash:
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8Ключевыми параметрами, влияющими на скорость миграции, являются размер пачек, которые Logstash будет отправлять в ES, и количество одновременно запускаемых процессов (pipeline.workers) для обработки. Строгих правил, которые определяли бы выбор этих значений, нет – они выбирались экспериментальным путем по следующей методике:
Выбираем небольшой индекс: для тестов использовался индекс с 1 млн многострочных (это важно) записей.
Запускаем миграцию этого индекса с помощью Logstash.
Смотрим на thread_pool на приёмной дата-ноде, обращая внимание на количество «rejected» записей. Рост этого значения однозначно говорит о том, что ES не успевает проиндексировать поступающие данные – тогда количество параллельных процессов Logstash стоит уменьшить.
После того как всё было подготовлено, составлены списки индексов на переезд, написаны конфигурации, а также разосланы предупреждения о предстоящих нагрузках в отделы сетевой инфраструктуры и мониторинга, я запустил процесс.
Чтобы не сидеть и не перезапускать процесс logstash, после завершения миграции очередного индекса я сделал с новым файлом конфигурации следующее:
Список индексов на переезд разделил на три примерно равные части.
В /etc/logstash/conf.d/migrate.conf оставил только статическую часть конфигурации:
input {
elasticsearch {
hosts => [ "localhost:9200" ]
size => 5000
docinfo => true
query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'}
}
output {
elasticsearch { hosts => [ "log-new-data1:9200" ]
index => "%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"}}
}Собрал скрипт, который читает имена индексов из файла и вызывает процесс logstash, динамически подставляя имя индекса и адрес ноды для миграции.
Код одного из экземпляров скрипта:
cat /tmp/indices_to_move.0.txt | while read line
do
echo $line > /tmp/0.txt && /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8 --config.string "input {elasticsearch { index => \"$line\" }} output { elasticsearch { hosts => [ \"log-new-data1:9200\" ] }}"
done;Для просмотра статуса миграции пришлось «на коленке» собрать ещё один скрипт, и запустить в отдельном процессе screen (через watch -d -n 60):
#!/bin/bash
regex=$(cat /tmp/?.txt)
regex="(($regex))"
regex=$(echo $regex | sed 's/ /)|(/g')
curl -s localhost:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P $regex |sort > /tmp/indices.local
curl -s log-new-data1:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P$regex | sort > /tmp/indices.remote
echo -e "index\t\t\tcount.source\tcount.dest\tremaining\tdeleted\tsource.gb\tdest.gb"
diff --side-by-side --suppress-common-lines /tmp/indices.local /tmp/indices.remote | awk '{print $1"\t"$2"\t"$7"\t"$2-$7"\t"$8"\t"$4"\t\t"$9}'Процесс миграции занял около недели. И честно скажу – спалось мне эту неделю неспокойно.
После переноса индексов осталось сделать совсем немного. В одну прекрасную субботнюю ночь старый кластер был выключен и изменены записи в DNS. Поэтому все пришедшие на работу в понедельник увидели новый розово-голубой интерфейс пятой Kibana. Пока сотрудники привыкали к обновленной цветовой гамме и изучали новые возможности, я продолжил работу.
Из старого кластера взял еще один освободившийся сервер и поставил на него два контейнера с дата-нодами ES под кластер новый. Все остальное железо отправилось в резерв.
Итоговая структура получилась точно такой, какой планировалась на первой схеме:
Три мастер-ноды.
Две клиентские ноды.
Восемь дата-нод (по две на сервер).
Переводим кластер в production режим – возвращаем параметры буферов и интервалы обновления индексов:
memory.index_buffer_size: 10%
index.refresh_interval: 1sКворум кластера (учитывая три мастер-ноды) выставляем равным двум:
discovery.zen.minimum_master_nodes: 2Далее нужно вернуть значения шард, принимая во внимание, что дата-нод у нас уже восемь:
{
"default": {
"order": 0,
"template": "*",
"settings": {
"index": {
"number_of_shards": "8",
"number_of_replicas": "1"
}
}
}
}Наконец, выбираем удачный момент (все сотрудники разошлись по домам) и перезапускаем кластер.
В этом разделе я хочу обратить особое внимание на снижение общей надёжности системы, которое возникает при размещении нескольких дата-нод ES в одном железном сервере, да и вообще при любой виртуализации.
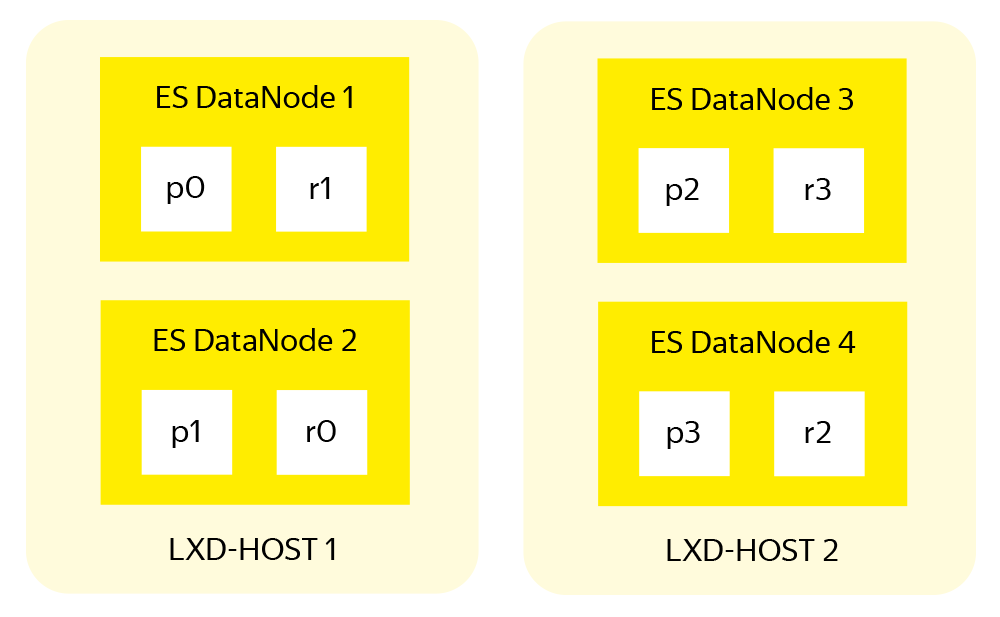
С точки зрения ES кластера – всё хорошо: индекс разбит на шарды по количеству дата-нод, каждый шард имеет реплику, primary и replica шарды хранятся на разных нодах.
Система шардирования и репликации в ES повышают как скорость работы, так и надёжность хранения данных. Но эта система проектировалась с учётом размещения одной ноды ES на одном сервере, когда в случае проблем с оборудованием теряется лишь одна дата-нода ES. В случае с нашим кластером упадут две. Даже с учетом равного разделения индексов между всеми нодами и наличия реплики для каждого шарда, не исключена ситуация когда primary и replica одного и того же шарда оказываются на двух смежных дата-нодах одного физического сервера.
Поэтому разработчики ES предложили инструмент для управления размещением шард в пределах одного кластера – Shard Allocation Awareness (SAA). Этот инструмент позволяет при размещении шард оперировать не дата-нодами, а более глобальными структурами вроде серверов с LXD-контейнерами.
В настройки каждой дата-ноды нужно поместить ES атрибут, описывающий физический сервер, на котором она находится:
node.attr.rack_id: log-lxd-host-NТеперь нужно перезагрузить ноды для применения новых атрибутов, и добавить в конфигурацию кластера следующий код:
{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"awareness": {
"attributes": "rack_id"
}
}
}
}
}
}Причем только в таком порядке, ведь после включения SAA кластер не будет размещать шарды на нодах без указанного атрибута.
Кстати, аналогичный механизм можно использовать для нескольких атрибутов. Например, если кластер расположен в нескольких дата-центрах и вы не хотите туда-сюда перемещать шарды между ними. В этом случае уже знакомые настройки будут выглядеть так:
node.attr.rack_id: log-lxd-hostN
node.attr.dc_id: datacentre_name{
"persistent": {
"cluster": {
"routing": {
"allocation": {
"awareness": {
"attributes": "rack_id, dc_id"
}
}
}
}
}
}Казалось бы, все в этом разделе очевидно. Но именно очевидное и вылетает из головы в первую очередь, так что отдельно проверьте – тогда после переезда не будет мучительно больно.
Следующая статья цикла будет посвящена двум моим самым любимым темам – мониторингу и тюнингу уже построенной системы. Обязательно пишите в комментариях, если что-то из уже написанного или запланированного особенно интересно и вызывает вопросы.
|
Метки: author adel-s системное администрирование серверная оптимизация it- инфраструктура devops блог компании яндекс.деньги elasticsearch kibana lxd логи |
Mониторинг Nginx Plus в Zabbix |
|
Метки: author StraNNicK nginx devops nginx plus zabbix |
Некоммерческий сертификат официального сайта Кубка конфедераций |


|
|
[Перевод] 40 необычных вопросов, задаваемых на собеседовании в Apple |

|
Метки: author zarytskiy карьера в it-индустрии собеседование вопросы apple |
Два года с Dart: о том, как мы пишем на языке, который ежегодно «хоронят» (часть 1) |



|
Метки: author Wriketeam разработка веб-сайтов программирование javascript dart блог компании wrike wrike wriketechclub dartium ddc angular2 angularjs |
«Когда с базами данных происходит критическая авария, это всегда случается несколько эпически» — Илья Космодемьянский |

|
Метки: author rdruzyagin администрирование баз данных блог компании pg day'17 russia postgresql data egret postgresql consulting interview интервью |
Совет по открытым данным: раскрытие транспортных данных |

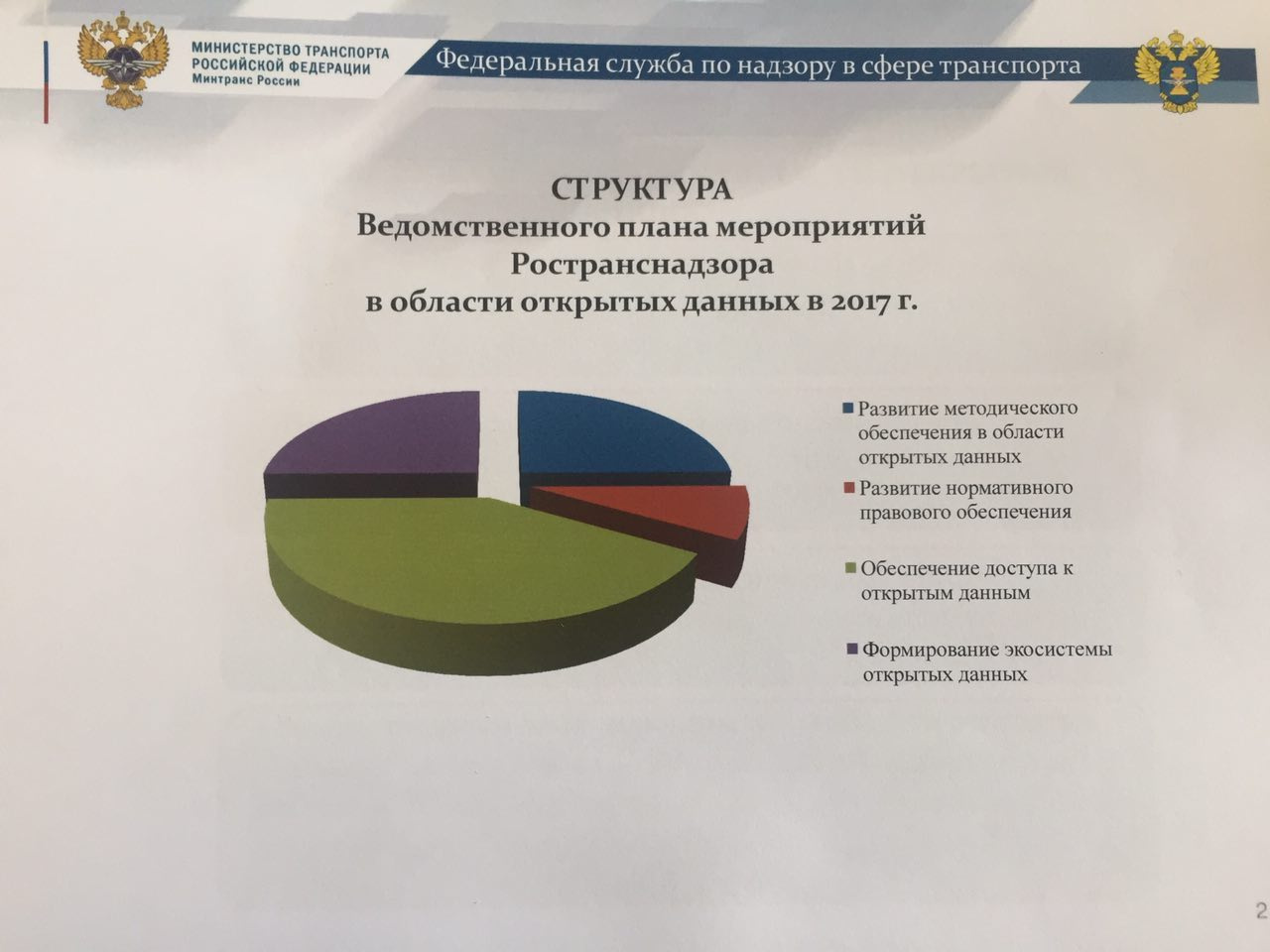
|
Метки: author k0shk открытые данные геоинформационные сервисы блог компании «информационная культура» совет по открытым данным транспортные данные |
Cloud Expo Asia Hong Kong – отчет с крупнейшей в Азии выставки ИТ-технологий |
|
Метки: author SolarSecurity конференции блог компании solar security отчет мероприятия выставка cloud expo asia hong kong |
Банковские отделения будущего и кому они нужны |

|
Метки: author GemaltoRussia блог компании gemalto russia банки банковские технологии |
Оптическое распознавание символов на микроконтроллере |
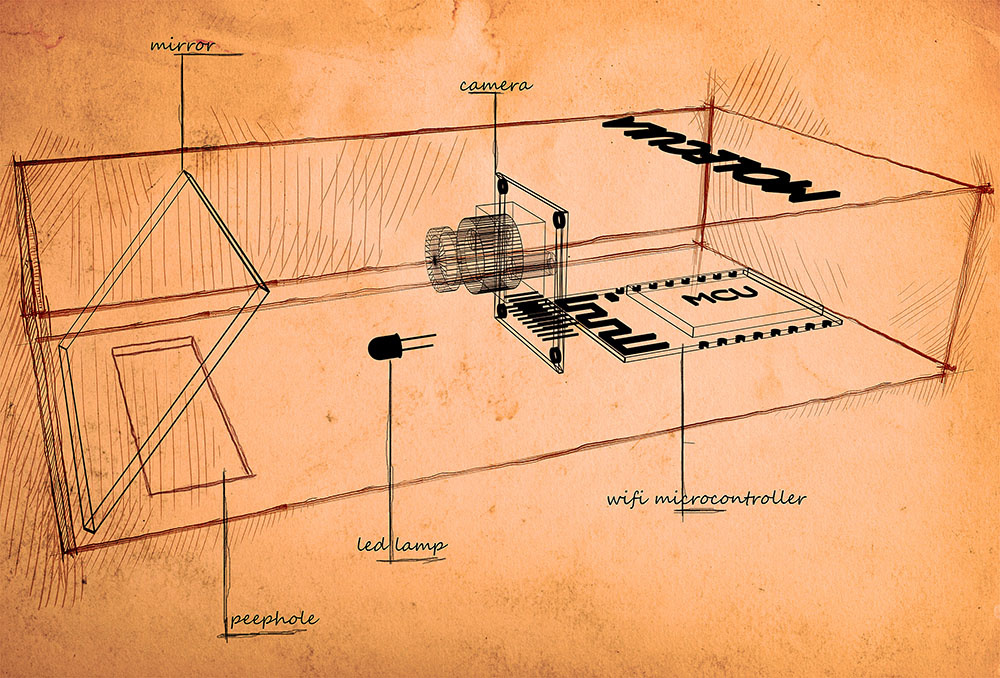























| Имя состояния,номер | Описание состояния | Сигнал к переходу в другое состояние |
| camoff,0 | камера не готова к работе |
vzz (vsync=1,href=0,pclk=0) |
| frapause, 1 | пауза между кадрами. ожидание начала кадра. |
zzz (vsync=0,href=0,pclk=0) |
| framebeg, 2 | чтение кадра. ожидание начала строки в кадре. |
zhz (vsync=0,href=1,pclk=0) |
| framebeg, 2 | чтение кадра. ожидание конца кадра после чтения последнего пикселя |
vzz (vsync=1,href=0,pclk=0) |
| fbyteread, 3 | яркостный байт прочитан. ожидание начала паузы перед цветоразностным байтом. |
zhz (vsync=0,href=1,pclk=0) |
| fpause, 4 | пауза перед цветоразностным байтом. ожидание начала чтения цветоразностного байта. |
zhp (vsync=0,href=1,pclk=1) |
| sbyteread, 5 | цветоразностный байт прочитан. ожидание начала паузы перед яркостным байтом. |
zhz (vsync=0,href=1,pclk=0) |
| spause, 6 | пауза перед яркостным байтом. ожидание окончания строки. |
zzz (vsync=0,href=0,pclk=0) |
| spause, 6 | пауза перед яркостным байтом. ожидание начала чтения яркостного байта. |
zhp (vsync=0,href=1,pclk=1) |
#include "ets_sys.h"
#include "osapi.h"
#include "os_type.h"
#include
#include "driver/uart_register.h"
#include "user_config.h"
#include "user_interface.h"
#include "driver/uart.h"
#include "readCam.h"
#define DELAY 5000 /* milliseconds */
LOCAL os_timer_t cam_timer;
uint16_t frN;
extern uint8_t pixVal;
uint8_t rN[10];
LOCAL void ICACHE_FLASH_ATTR getNFrame(void *arg){
uint16_t sig, sV,sH,sP;
uint16_t pVal;
uint16_t d7,d6,d5,d4,d3,d2;
stateMashine camSM;
ets_uart_printf("getNFrame...\r\n");
initSMcm(&camSM);
while(frN<20){
system_soft_wdt_feed();
pVal= *GPIO_IN;
sV=((pVal&(1UL<>VSYNC);
sH=((pVal&(1UL<>HREF);
sP=((pVal&(1UL<>PCLK);
sig=4*sV+2*sH+sP*sH;
d7=((pVal&(1UL<>D7);
d6=((pVal&(1UL<>D6);
d5=((pVal&(1UL<>D5);
d4=((pVal&(1UL<>D4);
d3=((pVal&(1UL<>D3);
d2=((pVal&(1UL<>D2);
pixVal=128*d7+64*d6+32*d5+16*d4+8*d3+4*d2;
exCAM(&camSM,sig,&frN,rN);
}
}
uint32 ICACHE_FLASH_ATTR user_rf_cal_sector_set(void)
{
enum flash_size_map size_map = system_get_flash_size_map();
uint32 rf_cal_sec = 0;
switch (size_map) {
case FLASH_SIZE_4M_MAP_256_256:
rf_cal_sec = 128 - 8;
break;
case FLASH_SIZE_8M_MAP_512_512:
rf_cal_sec = 256 - 5;
break;
case FLASH_SIZE_16M_MAP_512_512:
case FLASH_SIZE_16M_MAP_1024_1024:
rf_cal_sec = 512 - 5;
break;
case FLASH_SIZE_32M_MAP_512_512:
case FLASH_SIZE_32M_MAP_1024_1024:
rf_cal_sec = 1024 - 5;
break;
default:
rf_cal_sec = 0;
break;
}
return rf_cal_sec;
}
void ICACHE_FLASH_ATTR user_init(void){
void (*cbGetFrame)(void *arg);
cbGetFrame=(void*)getNFrame;
UARTInit(BIT_RATE_921600);
user_gpio_init();
os_timer_disarm(&cam_timer);
os_timer_setfn(&cam_timer, (os_timer_func_t *)cbGetFrame, NULL);
os_timer_arm(&cam_timer, DELAY, 0);
}
#ifndef INCLUDE_READCAM_H_
#define INCLUDE_READCAM_H_
#define GPIO_IN ((volatile uint32_t*) 0x60000318)
#define WP 320
#define HP 240
#define PIXTYP 0
//image __________________________________________
#define IMAGEY0 60
#define IMAGEH HP/3
//____________________pins_____________________
#define VSYNC 15
#define HREF 13
#define PCLK 3
#define D7 4
#define D6 12
#define D5 0
#define D4 14
#define D3 2
#define D2 5
//*************signals OV7670*****************
#define ZZZ 0
#define VZZ 4
#define ZHZ 2
#define ZHP 3
//*************states OV7670*******************
#define CAMOFF 0
#define FRAPAUSE 1
#define FRAMEBEG 2
#define FBYTEREAD 3
#define FPAUSE 4
#define SBYTEREAD 5
#define SPAUSE 6
#define SSCC 40//max state_signal_condition count
#define STATE_L 5
#define STATE_V 0x1F
#define SIG_L 8
#define SIG_V 0xFF
typedef struct {
uint8 pix[WP] ;
}linePixel;
typedef struct gen{
uint8_t state;
uint8_t sig;
uint8_t stateX;
void *fp;
}gen;
typedef struct stateMashine{
uint8_t count;
uint16_t ssc[SSCC];
uint8_t stateX[SSCC];
void *fPoint[SSCC];
void *fpd;
}stateMashine;
#endif /* INCLUDE_READCAM_H_ */
#include "ets_sys.h"
#include "osapi.h"
#include "os_type.h"
#include
#include "driver/uart_register.h"
#include "user_config.h"
#include "user_interface.h"
#include "driver/uart.h"
#include "readCam.h"
void sendLine(uint16_t lN);
void ICACHE_FLASH_ATTR sendFramMark(void);
void ICACHE_FLASH_ATTR sendCtr3Byte(uint8_t typ,uint16_t len);
void user_gpio_init(void);
void sendByte(uint8_t bt);
void ICACHE_FLASH_ATTR initSMcm(stateMashine *psm);
void exCAM( stateMashine *psm,uint8_t sig,uint16_t *frameN,uint8_t *rN);
int indexOf(stateMashine *psm,uint16_t ssc);
linePixel lp;
uint8_t pixVal;
void exCAM( stateMashine *psm,uint8_t sig,uint16_t *frameN,uint8_t *rN){
int16_t ind;
uint16_t lN;
uint16_t pN;
static uint8_t state=CAMOFF,stateX=CAMOFF;
static void (*pfun)()=NULL;
uint16_t stateSigCond=0;
stateSigCond|=((state&STATE_V)<<(16-STATE_L))|((sig&SIG_V)<<(16-STATE_L-SIG_L));
ind=indexOf(psm,stateSigCond);
if(ind>-1) stateX=(*psm).stateX[ind];
if(ind>-1) pfun=(*psm).fPoint[ind];
else pfun=(*psm).fpd;
pfun(frameN,&lN,&pN,rN);
state=stateX;
}
void _cm0(){}
void _cm1(uint16_t *fN,uint16_t *lN,uint16_t *pN){//new frame
sendFramMark();
sendCtr3Byte(PIXTYP,0);
(*lN)=0;
}
void _cm2(uint16_t *fN,uint16_t *lN,uint16_t *pN){//frame end
if(*lN==HP-1)(*fN)++;
}
void _cm3(uint16_t *fN,uint16_t *lN,uint16_t *pN){//new line
uint16_t pixN;
(*pN)=0;
// pixN=(*pN);//right image
pixN=WP-1-(*pN);//revers image
(lp).pix[pixN]=pixVal;
(*pN)++;
}
void _cm4(uint16_t *fN,uint16_t *lN,uint16_t *pN){// first byte
uint16_t pixN;
// pixN=(*pN);//right image
pixN=WP-1-(*pN);//reverse image
(lp).pix[pixN]=pixVal;
// if(pixN/right image
if(pixN)(*pN)++;//reverse image
}
void _cm5(uint16_t *fN,uint16_t *lN,uint16_t *pN,uint8_t *rN){//end line
uint16_t lineN;
lineN=(*lN);
sendLine(lineN);
if((*lN)/0#1
{FRAPAUSE,ZZZ,FRAMEBEG,_cm1},//1#2
{FRAMEBEG,VZZ,FRAPAUSE,_cm2},//2#1
{FRAMEBEG,ZHZ,FBYTEREAD,_cm3},//2#3
{FBYTEREAD,ZHP,FPAUSE,_cm0},//3#4
{FPAUSE,ZHZ,SBYTEREAD,_cm0},//4#5
{SBYTEREAD,ZHP,SPAUSE,_cm0},//5#6
{SPAUSE,ZHZ,FBYTEREAD,_cm4},//6#3
{SPAUSE,ZZZ,FRAMEBEG,_cm5},//6#2
{FPAUSE,ZZZ,FRAMEBEG,_cm5},//5#2
};
(*psm).count=count;
for(i=0;i>UART_TXFIFO_CNT_S)
& UART_TXFIFO_CNT;
}
buf[lenBuff] =bt;
uart0_tx_buffer(buf, lenBuff + 1);
}
void sendLine(uint16_t lN){
uint16_t j;
uint8_t sByt;
for(j=0;j(IMAGEY0+IMAGEH))sByt=0xFF;
sendByte(sByt);
}
}
void ICACHE_FLASH_ATTR user_gpio_init(void) {
ets_uart_printf("GPIO initialisation...\r\n");
PIN_FUNC_SELECT(PERIPHS_IO_MUX_GPIO0_U, FUNC_GPIO0);
gpio_output_set(0, 0, 0, BIT0); // Set GPIO0 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_GPIO2_U, FUNC_GPIO2);
gpio_output_set(0, 0, 0, BIT2); // Set GPIO2 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_U0RXD_U, FUNC_GPIO3);
gpio_output_set(0, 0, 0, BIT3); // Set GPIO3 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_GPIO4_U, FUNC_GPIO4);
gpio_output_set(0, 0, 0, BIT4); // Set GPIO4 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_GPIO5_U, FUNC_GPIO5);
gpio_output_set(0, 0, 0, BIT5); // Set GPIO5 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_MTDI_U, FUNC_GPIO12);
gpio_output_set(0, 0, 0, BIT1); // Set GPIO13 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_MTMS_U, FUNC_GPIO14);
gpio_output_set(0, 0, 0, BIT14); // Set GPIO14 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_MTCK_U, FUNC_GPIO13); // Set GPIO13 function
gpio_output_set(0, 0, 0, BIT13); // Set GPIO13 as input
PIN_FUNC_SELECT(PERIPHS_IO_MUX_MTDO_U, FUNC_GPIO15);
gpio_output_set(0, 0, 0, BIT15); // Set GPIO15 as input
ets_uart_printf("...init done!\r\n");
}
void ICACHE_FLASH_ATTR sendFramMark(void){
sendByte(42);
sendByte(42);
}
void ICACHE_FLASH_ATTR sendCtr3Byte(uint8_t typ,uint16_t len){
uint8_t lLen,hLen;
sendByte(typ);
lLen=len&0xFF;
hLen=(len&(0xFF<<8))>>8;
sendByte(lLen);
sendByte(hLen);
}




var btn = document.getElementById('com');
var gui = require("nw.gui");
var select_com = document.getElementById('select_com');
var bdr = document.getElementById('bdr');
var canvas = document.getElementById('canvas');
var dev = document.getElementById('dev');
var ctx = canvas.getContext('2d');
var width = 320,
height = 240;
var byteCount = (width * height)/3;
var lastStr=byteCount-width;
var dataArr;
var dataStr;
var indArr = 0;
var dataArrLen = 0;
var byteCounter = 0;
var newStr = 0;
var sendTyp=0;
document.addEventListener('DOMContentLoaded', function() {
btn.addEventListener('click', function() {
connectCom(function(vector) {
drawImg(vector);
});
});
dev.addEventListener('click', function(){
var win = gui.Window.get();
win.showDevTools();
});
});
function drawImg(imgArr) {
var imgData = ctx.createImageData(width, height);
var ind;
for (var i = 0; i < imgArr.length; i++) {
imgData.data[4 * i] = imgArr[i];
imgData.data[4 * i + 1] = imgArr[i];
imgData.data[4 * i + 2] = imgArr[i];
imgData.data[4 * i + 3] = 255;
if(ilastStr){ //red line
imgData.data[4 * i] = 255;
imgData.data[4 * i + 1] = 0;
imgData.data[4 * i + 2] = 0;
imgData.data[4 * i + 3] = 255;
}
if(i<2*byteCount&&i>byteCount+lastStr){ //green line
imgData.data[4 * i] = 0;
imgData.data[4 * i + 1] = 255;
imgData.data[4 * i + 2] = 0;
imgData.data[4 * i + 3] = 255;
}
if(i<3*byteCount&&i>2*byteCount+lastStr){ //blue line
imgData.data[4 * i] = 0;
imgData.data[4 * i + 1] = 0;
imgData.data[4 * i + 2] = 255;
imgData.data[4 * i + 3] = 255;
}
}
ctx.putImageData(imgData, 0, 0);
imgArr.length=0;
}
function connectCom(callback) {
const PIXTYPE=0,BINTYPE=1,FIGTYPE=2;
var imgTyp=PIXTYPE;
var serialport = require('serialport');
var imgArr = [];
var framCount=0,strNum,colNum;
var pix=false;
var comm = 'COM' + select_com.value;
var boudrate = +bdr.value;
var SerialPort = serialport.SerialPort;
var port = new SerialPort(comm, {
baudRate: boudrate,
dataBits: 8,
stopBits: 1,
parity: "none",
bufferSize: 65536,
parser: SerialPort.parsers.byteLength(1)
});
port.on('open', function() {
console.log('Port ' + comm + ' Open');
});
port.on('data', function(data) {
if(imgTyp==PIXTYPE||imgTyp==BINTYPE){
if (data[0] == 42 && newStr == 0) {
newStr = 1;
data[0]=255;
}
if (newStr == 1 && data[0] == 42) {
newStr = 2;
}
if (newStr == 2 && byteCounter <2*byteCount) {
colNum=byteCounter%width;
strNum=(byteCounter-colNum)/width;
if(strNum%2==0){
imgArr[(strNum/2)*width+colNum]=data[0];
}
if(strNum%2==1){
imgArr[((strNum-1)/2)*width+byteCount+colNum]=data[0];
}
byteCounter++;
}
if (newStr == 2 && byteCounter == 2*byteCount) {
newStr = 0;
byteCounter = 0;
framCount++;
console.log('Frame Num ', framCount);
imgTyp=FIGTYPE;
}
}
if(imgTyp==FIGTYPE){
if (data[0] == 42 && newStr == 0) {
newStr = 1;
data[0]=255;
}
if (newStr == 1 && data[0] == 42) {
newStr = 2;
}
if (newStr == 2 && byteCounter < byteCount) {
imgArr[byteCounter+2*byteCount] = data[0];
byteCounter++;
}
if (newStr == 2 && byteCounter == byteCount) {
newStr = 0;
byteCounter = 0;
framCount++;
console.log('Frame Num ', framCount);
imgTyp=PIXTYPE;
callback(imgArr);
}
}
});
port.on('error', function() {
alert('Ошибка подключения к порту СОМ');
});
}
|
|
В MIT разработали фотонный чип для глубокого обучения |
 / фото Bill Benzon CC
/ фото Bill Benzon CC
|
Метки: author it_man высокая производительность блог компании ит-град ит-град глубокое обучение mit |
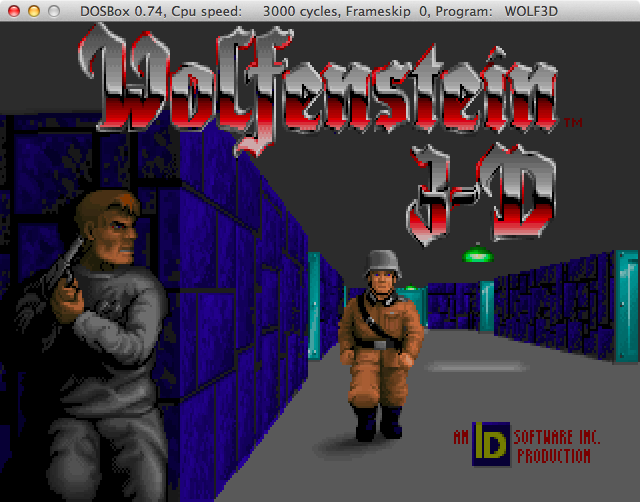
[Перевод] Компилируем, как будто на дворе 1992 год |
cd ~
mkdir system
cd system
mkdir c
mkdir a
cd ~system/a.system/csystem/c (в конце статьи я объясню, зачем это нужно). cd system/a
curl -O http://fabiensanglard.net/Compile_Like_Its_1992/tools/BCPP31.zip
cd ../c
curl -O http://fabiensanglard.net/Compile_Like_Its_1992/tools/wolfsrc.zip
curl -O http://fabiensanglard.net/Compile_Like_Its_1992/tools/vgafiles.zip cd ..
find ~/system /Users/fabiensanglard/system
/Users/fabiensanglard/system/a
/Users/fabiensanglard/system/a/BCPP31.zip
/Users/fabiensanglard/system/c
/Users/fabiensanglard/system/c/vgafiles.zip
/Users/fabiensanglard/system/c/wolfsrc.zip cd ~/system/a
unzip BCPP31.zip
cd ~/system/c
unzip vgafiles.zip
unzip wolfsrc.zip
Z:/> mount c ~/system/c
Z:/> mount a ~/system/a Z:\> a:
A:\> cd BCPP31
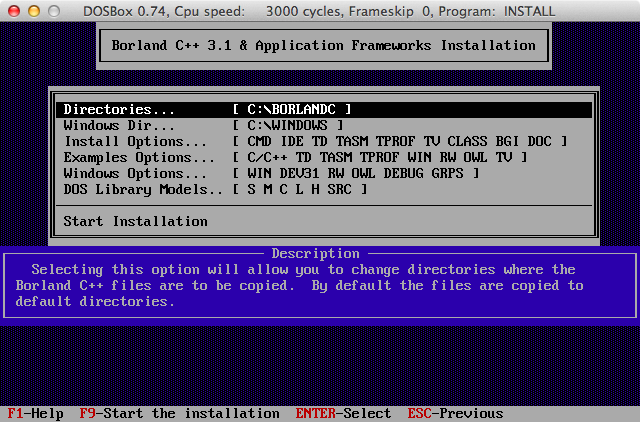
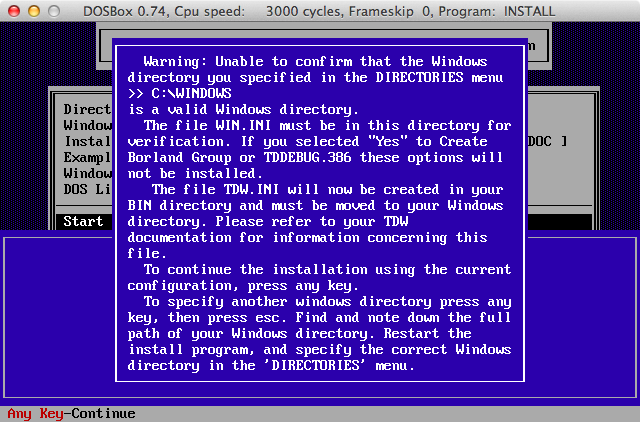
A:\> install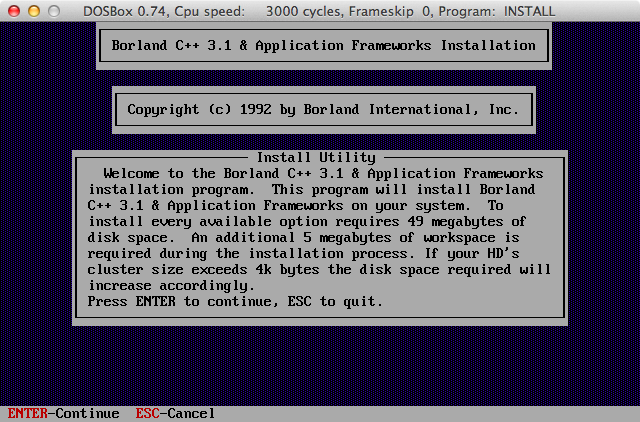

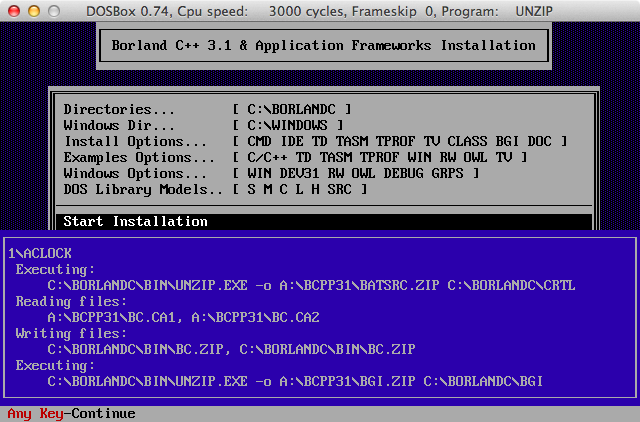
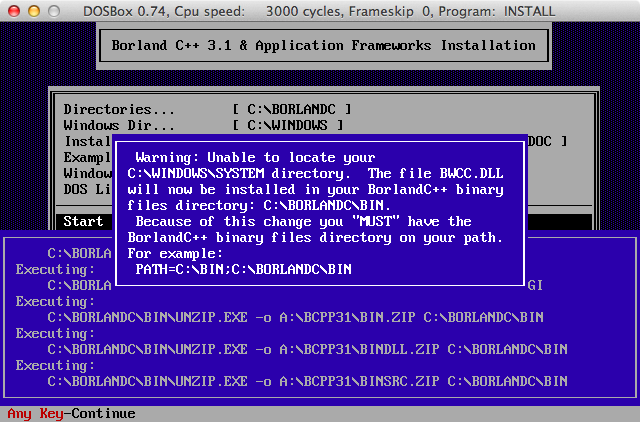
A:\> c:
C:\> cd\
C:\> install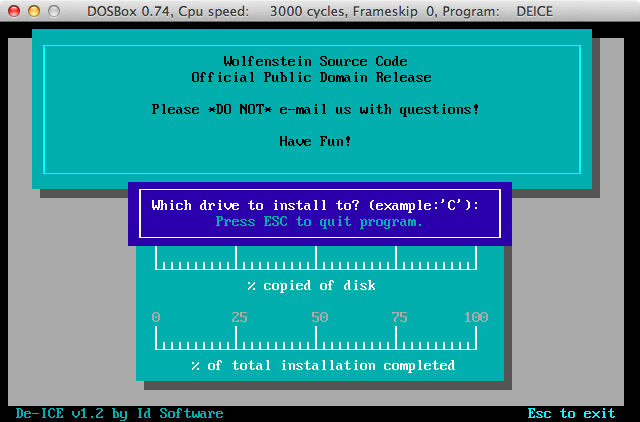

\WOLFSRC
C:\> cd\
C:\> cd borlandc
C:\> cd bin
C:\> bc.exe
..\..\WOLFSRC\WOLF3D.PRJ:
Include Directories: C:\BORLANDC\INCLUDE
Library Directories: C:\BORLANDC\LIB
Ouptput Directories: OBJ
Source Directories: C:\WOLFSRC
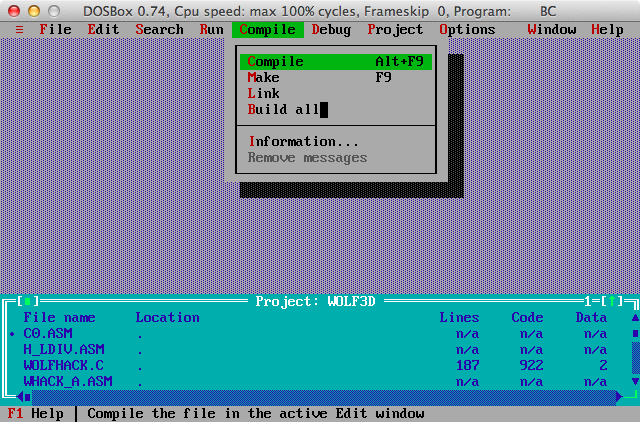
C:\> CD ..
C:\> PATH=C:\BORLANDC\BIN
C:\> BC.EXE
C:\SOURCE\WOLF\: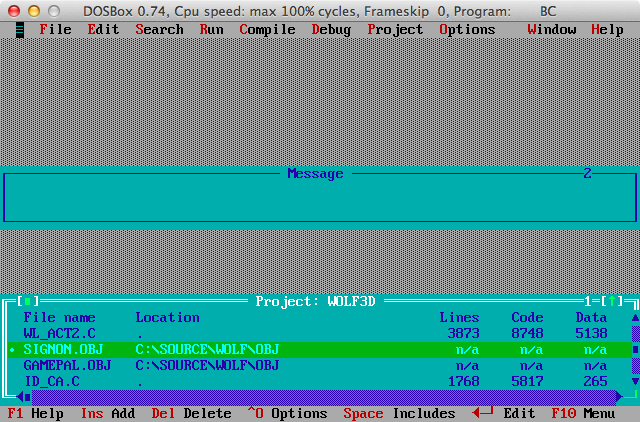
WOLFSRC\OBJ\SIGNON.OBJ и WOLFSRC\OBJ\GAMEPAL.OBJ
cd ~/system/c
curl -O http://fabiensanglard.net/Compile_Like_Its_1992/tools/1wolf14.zip
unzip 1wolf14.zipC:\WOLF3D. C:\> c:
C:\> cd \
C:\> cd 1wolf14
C:\1WOLF14> install C:\> c:
C:\> cd wolf3d
C:\WOLF3D> copy WOLF3D.EXE WOLF3D.OLD
C:\WOLF3D> copy ../WOLRSRC/WOLF.EXE C:\> cd wolf3d
C:\WOLF3D> copy WOLF3D.EXE WOLF3D.OLD
C:\WOLF3D> copy ../WOLRSRC/OBJ/WOLF3D.EXE .
C:\WOLF3D> WOLF3D.EXE



.H и .EQU? Если вкратце, то они позволяют получать доступ по имени. Когда IGRABed собирает все файлы, он также создаёт перечисление (enum) с соответствующими индексами: enum{
H_WOLFLOGOPIC
GETPSYCHEDPIC
L_GUYPIC
.
.
} graphicnums H_WOLFLOGOPIC = 0
GETPSYCHEDPIC = 1
L_GUYPIC = 2 C:\> copy C:\vgafiles\VGADICT.WL6 C:\WOLF3D\VGADICT.WL1
C:\> copy C:\vgafiles\VGAGRAPH.WL6 C:\WOLF3D\VGAGRAPH.WL1
C:\> copy C:\vgafiles\VGAHEAD.WL6 C:\WOLF3D\VGAHEAD.WL1 C:\WOLF3D> WOLF3D.EXE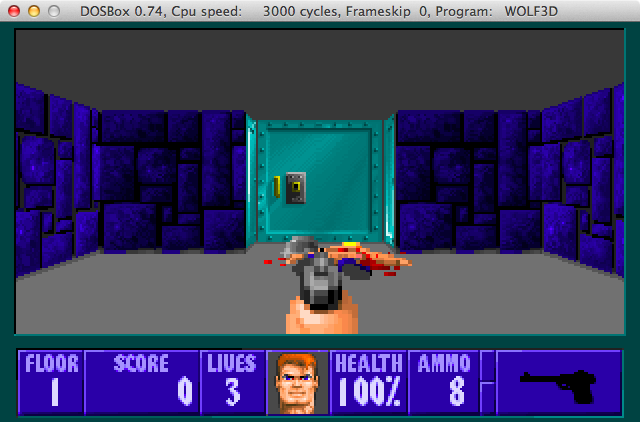
vi ~/Library/Preferences/DOSBox\ 0.74\ Preferences
[render]
# frameskip: количество кадров, пропускаемых DOSBox при отрисовке кадра.
# aspect: выполнять коррекцию соотношения сторон. Если способ вывода не поддерживает масштабирование, то это может привести к замедлению работы!
# scaler: используется для расширения/улучшения режимов низкого разрешения.
# Если использована опция 'forced', то scaler используется, даже когда результат может оказаться неправильным.
# Возможные значения: none, normal2x, normal3x, advmame2x, advmame3x, advinterp2x, advinterp3x, ...
frameskip=0
aspect=false
scaler=normal2x C:\WOLF3D> WOLF3D.EXE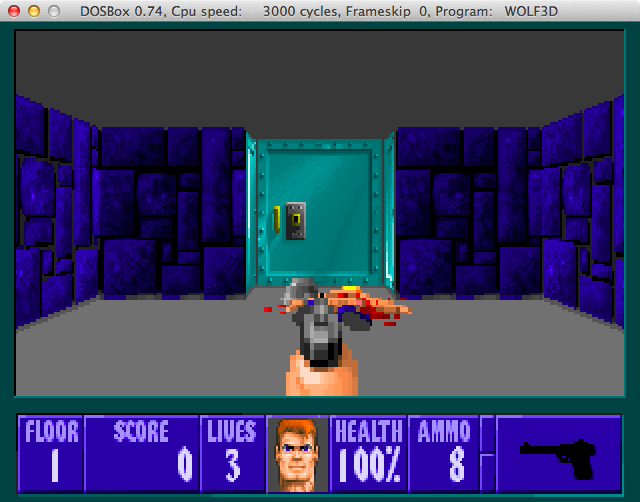
|
Метки: author PatientZero разработка игр компиляторы wolfenstein 3d borland c++ dosbox игры ретрогейминг |
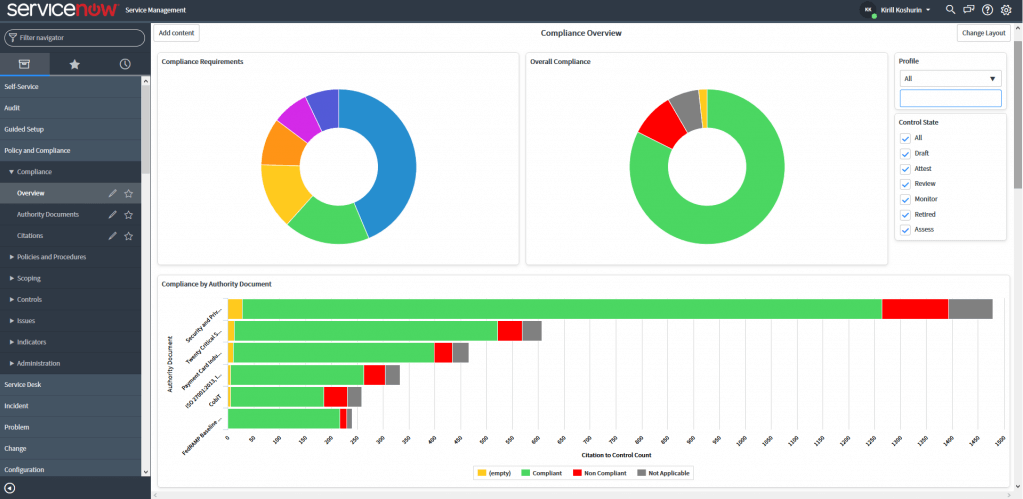
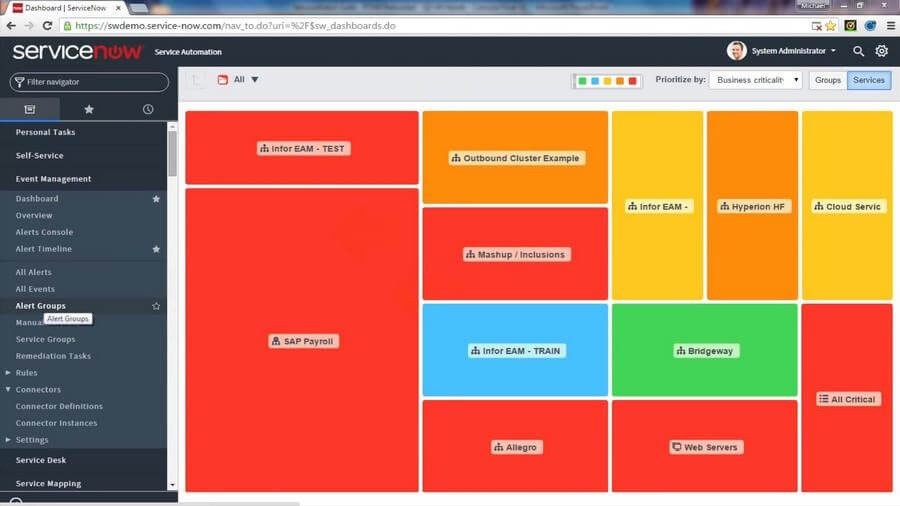
«Управление в ИТ»: Что такое ITSM и платформа ServiceNow |
 Marco Verch / CC / Flickr
Marco Verch / CC / Flickr
|
Метки: author it-guild help desk software блог компании ит гильдия ит-гильдия servicenow itsm |
Hard Reverse или особенности реверса файлов для архитектуры PowerPC Big-Endian |
 Задания на reverse engineering — обязательная часть любых CTF, и NeoQUEST в этом плане не исключение. В каждое задание мы добавляем «изюминку», которая, с одной стороны, несколько затрудняет участникам прохождение задания, а с другой — позволяет на практике разобраться с тем, с чем еще не приходилось работать.
Задания на reverse engineering — обязательная часть любых CTF, и NeoQUEST в этом плане не исключение. В каждое задание мы добавляем «изюминку», которая, с одной стороны, несколько затрудняет участникам прохождение задания, а с другой — позволяет на практике разобраться с тем, с чем еще не приходилось работать.



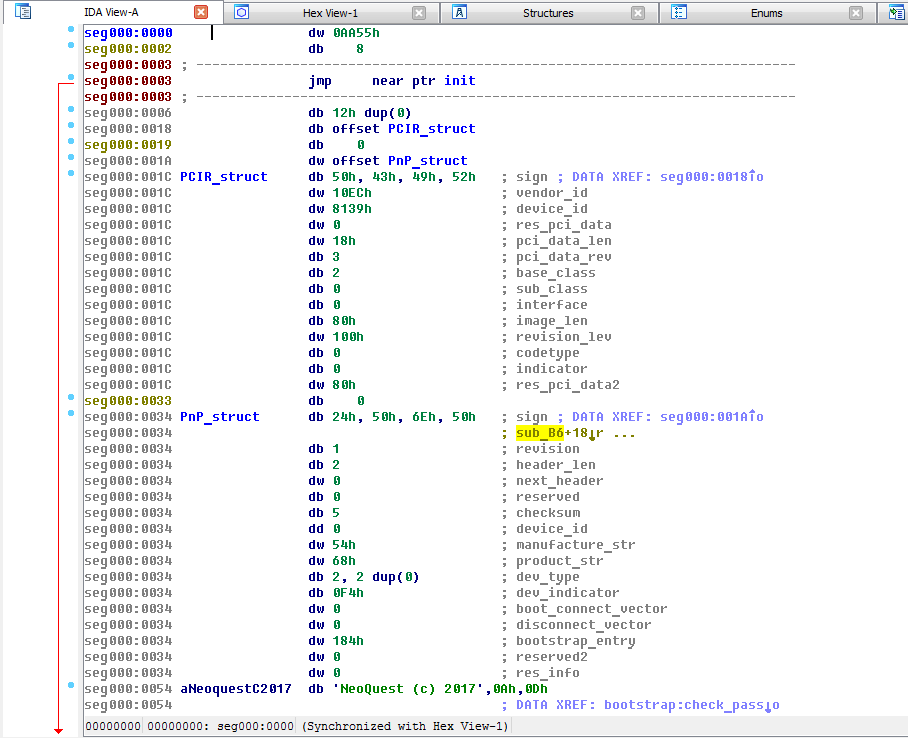
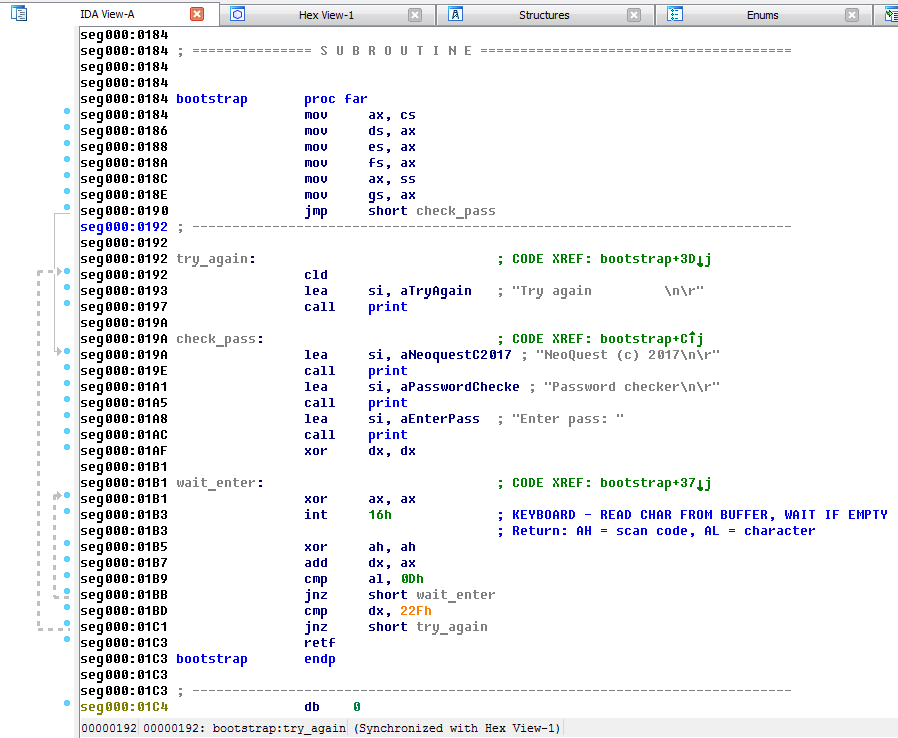


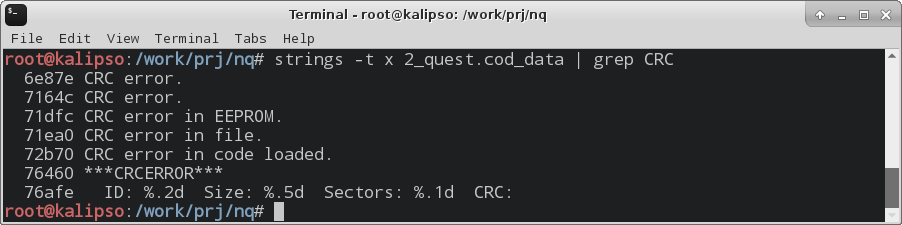
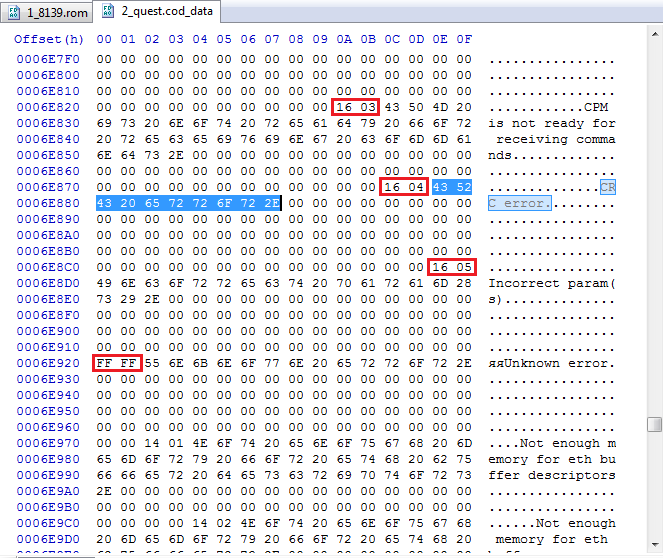
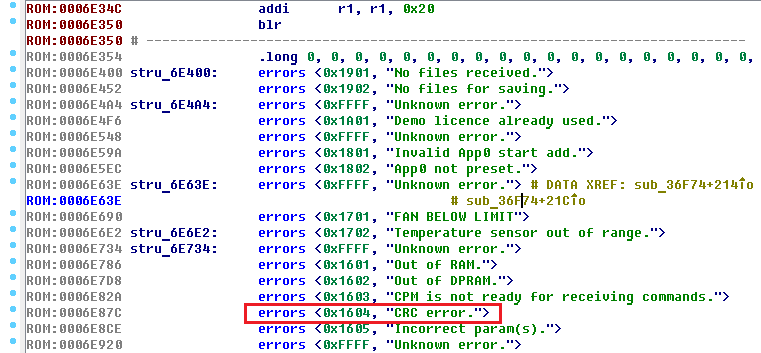
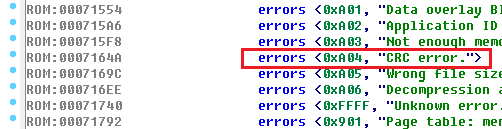






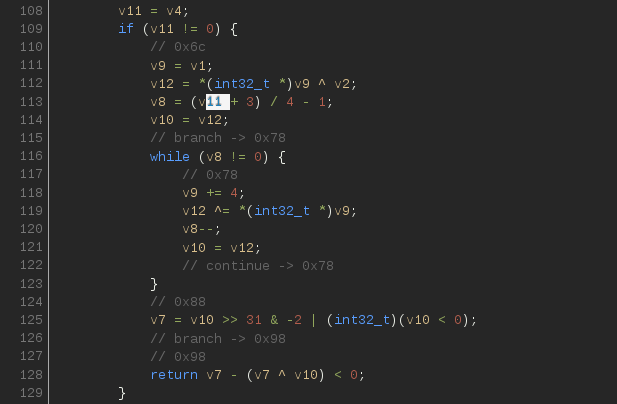

|
|
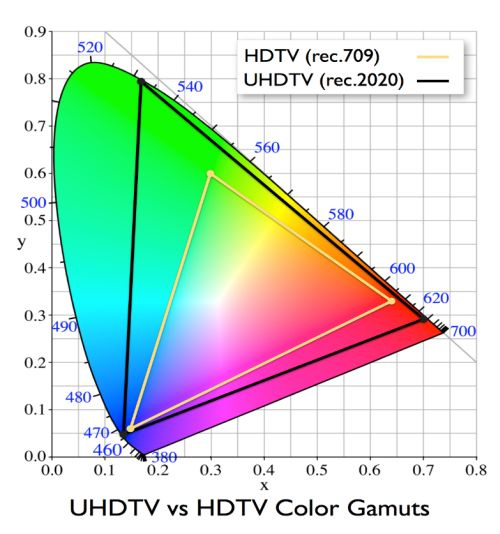
[Перевод] Наслаждайтесь миллиардами цветов с 10-битным HEVC |

| Глубина канала | Оттенков на канал на пиксель | Общее количество возможных оттенков |
|---|---|---|
| 8-бит | 256 | 16.78 миллионов |
| 10-бит | 1024 | 1.07 миллиарда |
| 12-бит | 4096 | 68.68 миллиардов |

sample_decode.exe h265 -p010 -i input.h265 -o raw_farmes.yuv -hwsample_encode.exe h265 -i raw_frames.yuv -o output.265 -w 3840 -h 2160 -p010 -hw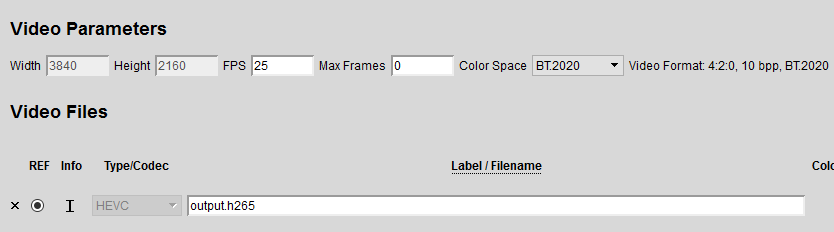
|
Метки: author saul программирование обработка изображений блог компании intel 10-bit color depth hevc |
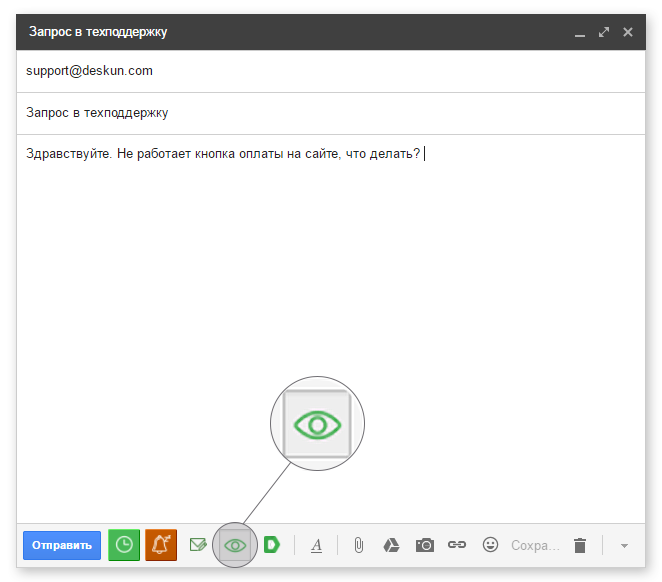
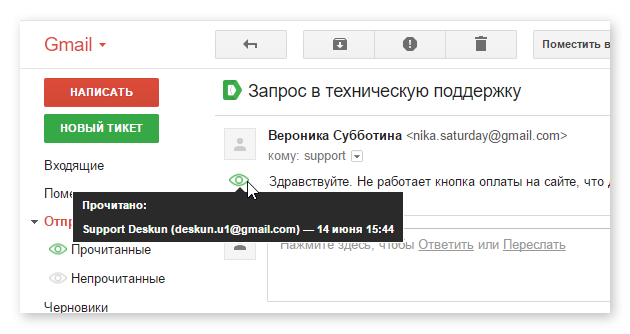
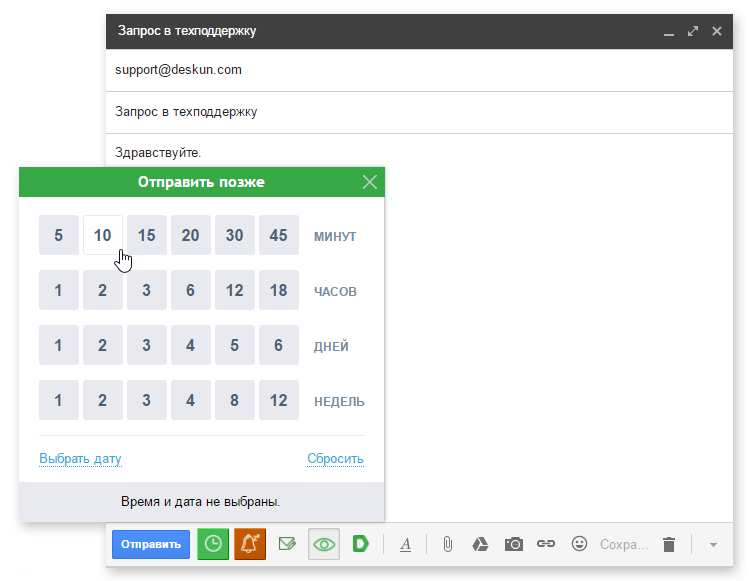
Чего не хватает Gmail. 4 бесплатные возможности Deskun |

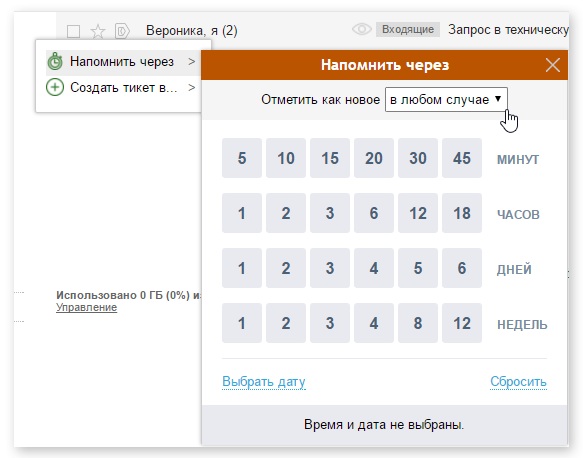
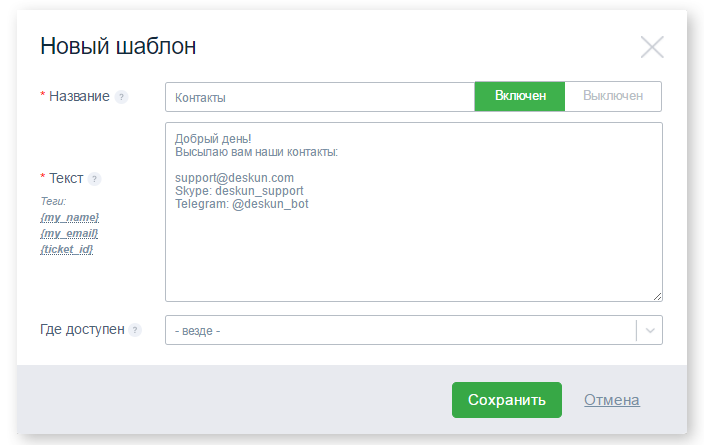
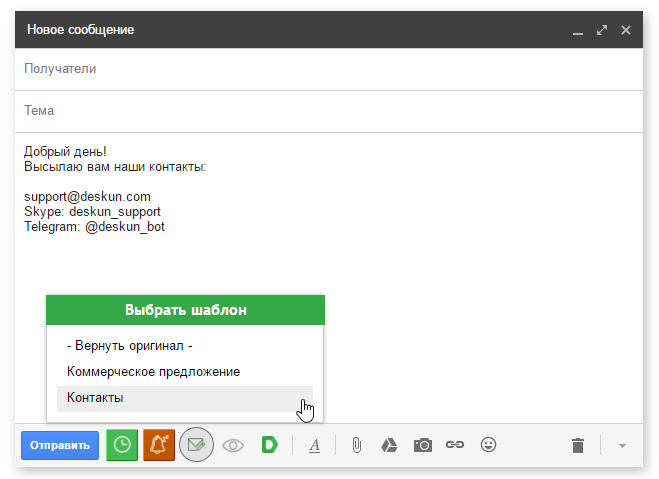
|
Метки: author ChiPer управление персоналом service desk help desk software блог компании deskun gmail расширения chrome google chrome extensions google chrome helpdesk |
Java: автоматически формируем SQL-запросы |
public static class Person {
public String firstName;
public String lastName;
public int age;
}
System.out.println(MySQLQueryGenerator.generateCreateTableQuery(Person.class));
CREATE TABLE `Person_table` (
`firstName` VARCHAR(256),
`lastName` VARCHAR(256),
`age` INT);
@IfNotExists // Добавлять в CREATE-запрос IF NOT EXISTS
@TableName("persons") // Произвольное имя таблицы
public static class Person {
@AutoIncrement // Добавить модификатор AUTO_INCREMENT
@PrimaryKey // Создать на основе этого поля PRIMARY KEY
public int id;
@NotNull // Добавить модификатор NOT NULL
public long createTime;
@NotNull
public String firstName;
@NotNull
public String lastName;
@Default("21") // Значение по умолчанию
public Integer age;
@Default("")
@MaxLength(1024) // Длина VARCHAR
public String address;
@ColumnName("letter") // Произвольное имя поля
public Character someLetter;
}
CREATE TABLE IF NOT EXISTS `persons` (
`id` INT AUTO_INCREMENT,
`createTime` BIGINT NOT NULL,
`firstName` VARCHAR(256) NOT NULL,
`lastName` VARCHAR(256) NOT NULL,
`age` INT DEFAULT '21',
`address` VARCHAR(1024) DEFAULT '',
`letter` VARCHAR(1),
PRIMARY KEY (`id`));
MySQLClient client = new MySQLClient("login", "password", "dbName");
client.connect(); // Подключаемся к БД
client.createTable(PersonV1.class); // Создаем таблицу
client.alterTable(PersonV1.class, PersonV2.class); // Изменяем таблицу
PersonV2 person = new PersonV2();
person.createTime = new Date().getTime();
person.firstName = "Ivan";
person.lastName = "Ivanov";
client.insert(person); // Добавляем запись в таблицу
person.age = 28;
person.createTime = new Date().getTime();
person.address = "Zimbabve";
client.insert(person);
person.createTime = new Date().getTime();
person.firstName = "John";
person.lastName = "Johnson";
person.someLetter = 'i';
client.insert(person);
List selected = client.select(PersonV2.class); // Извлекаем из таблицы все данные
System.out.println("Rows: " + selected.size());
for (Object obj: selected) {
System.out.println(obj);
}
client.disconnect(); // Отключаемся от БД
public static String generateCreateTableQuery(Class clazz) throws MoreThanOnePrimaryKeyException {
List columnList = new ArrayList<>();
Field[] fields = clazz.getFields(); // получаем массив полей класса
for (Field field: fields) {
int modifiers = field.getModifiers();
if (Modifier.isPublic(modifiers) && !Modifier.isStatic(modifiers)) { // если public и не static
Column column = Column.fromField(field); // преобразуем Field в Column
if (column!=null) columnList.add(column);
}
}
/* из полученных Column генерируем запрос */
}
/***************************/
public static Column fromField(Field field) {
Class fieldType = field.getType(); // получаем тип поля класса
ColumnType columnType;
if (fieldType == boolean.class || fieldType == Boolean.class) {
columnType = ColumnType.BOOL;
} /* перебор остальных типов данных */ {
} else if (fieldType==String.class) {
columnType = ColumnType.VARCHAR;
} else { // Если тип данных не поддерживается фреймворком
return null;
}
Column column = new Column();
column.columnType = columnType;
column.name = field.getName();
column.isAutoIncrement = field.isAnnotationPresent(AutoIncrement.class);
/* перебор остальных аннотаций */
if (field.isAnnotationPresent(ColumnName.class)) { // если установлено произвольное имя таблицы
ColumnName columnName = (ColumnName)field.getAnnotation(ColumnName.class);
String name = columnName.value();
if (!name.trim().isEmpty()) column.name = name;
}
return column;
}
Column column = Column.fromField(field);
if (column!=null) {
if (column.isAutoIncrement) continue;
Object value = field.get(obj);
if (value==null && column.hasDefaultValue) continue; // есть один нюанс: для корректной работы значений по умолчанию предпочтительно использовать объектные типы вместо примитивных
if (column.isNotNull && value==null) {
throw new NotNullColumnHasNullValueException();
}
String valueString = value!=null ? "'" + value.toString().replace("'","\'") + "'" : "NULL";
String setValueString = "`"+column.name+"`="+valueString;
valueStringList.add(setValueString);
}
|
Метки: author jatx sql mysql java java annotation java reflection api |
И грянет страшный русский firewall |
После статьи ValdikSS о блокировке сайтов по тухлым доменам РКН мне не давала покоя мысль о том, что произойдёт, если реестр начнёт резольвится в очень большое число IPv4-адресов. Проводить полноценные "учения" мне кажется сомнительным делом, т.к. они могут случайно обернуться умышленным нарушением связности рунета. Поэтому я ограничился поиском ответов на два вопроса:
Я нагрепал и зарегистрировал несколько свободных доменов из списка, поднял DNS сервер и поставил писаться трафик в pcap...
Домены для регистрации были выбраны следующим образом: два домена присутствующие в выгрузке с https-ссылками, два домена с http ссылками и два "голых" домена без ссылок. Сделано это для проверки гипотезы о равенстве всех доменов перед фильтром. IPv4 адреса, на которые указывают эти домены, были выбраны из существующих в реестре, чтоб не повышать нагрузку на фильтры. Адреса отсутствующие в реестре выделены в настоящий момент моим виртуальным машинам, поэтому DoS-атаки в данном эксперименте не содержится.
Можно пойти по открытым спискам Looking Glass разных провайдеров и посмотреть, какие из крупных около-российских провайдеров имеют на своих маршрутизаторах маршруты с маской /32 на адреса из реестра, т.к. эти провайдеры имеют риск пострадать от атаки на переполнение таблицы маршрутизации. Таких провайдеров находится не так уж мало: Эквант aka GIN aka Orange Business Services, Beeline, Ростелеком, Транстелеком, Obit и, что немного забавно, Федеральная университетская компьютерная сеть России (шутка про академическую свободу и независимость университетов).
Проверим, что IP-адрес, который мы планируем внести "под блок" не присутствуют в таблицах маршрутизации на этих же LG: 1, 2, 3, 4, 5, 6. Если кто-то будет воспроизводить этот эксперимент предельно чисто, то стоит также проверить все IPv4 и IP адреса, которые планируется добавить в таблицу. Я предполагаю, что с ними ситуация аналогичная.
14 июня в 15:00 по Москве я добавил адреса некоторых из своих серверов в файлы DNS-зон и стал наблюдать, что происходит в pcap-файлах, пока резольверы обновляли записи.
Всего в логи за 16 часов попали запросы резольверов из полутора тысяч автономных систем. В них наблюдается довольно большое разнообразие вариантов поведения с точки зрения резолва доменов.
Из сети с abuse-контактом на netup.ru резольвятся только те домены, которые в списке указаны с URLом, при этом домен с 2048 записями получает запросов примерно в 5 раз больше. AS ФГУП Электросвязь с тем же контактом исправно ходит в DNS для всех "маленьких" доменов раз в 8 минут, но почему-то не присылает ни одного запроса на "большие" домены, ровно как и ижевский РадиоЛинк. Tele2 резольвит https и "безурловый" dns, но не резольвит http, предположительно весь http там завёрнут на proxy. Железногорский Сигнал и екатеринбургский Miralogic наоборот — резольвят только http. SPNet из Сергиевого Посада — URLы не резольвит вообще, только "голые" домены. Московский citytelecom — наоборот, только https и, как ФГУП Электросвязь, даже не пытается порезольвить "большие" домены, что позволяет предположить наличие альтернативного способа распространения чёрных списков с пред-резолвленными адресами.
| HTTPS | HTTP | Domain-only
asn | tiny | 2k/udp | 2k/tcp | tiny | 2k/udp | 2k/tcp | tiny | 2k/udp | 2k/tcp
------+------+--------+--------+------+--------+--------+------+--------+-------
50317 | 903 | 1416 | 1030 | 285 | 1295 | 1012 | 0 | 0 | 0
57835 | 207 | 0 | 0 | 200 | 0 | 0 | 200 | 0 | 0
38959 | 29 | 0 | 0 | 56 | 0 | 0 | 39 | 0 | 0
39475 | 155 | 217 | 217 | 0 | 0 | 0 | 151 | 209 | 209
42514 | 0 | 0 | 0 | 120 | 136 | 13 | 0 | 0 | 0
12668 | 0 | 0 | 0 | 95 | 103 | 18 | 0 | 0 | 0
43826 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 33 | 12
56705 | 415 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0Полное содержание статистики числа запросов за первые 16 часов можно увидеть в gist, обращаю внимание, что не все ASN принадлежат российским провайдерам.
В pcap-ах практически не обнаружено запросов с опцией EDNS Client Subnet, таких запросов меньше 1%. Это не очень удивительно, т.к. google (практически единственный "поставщик" подобных запросов) раскрывает адреса клиентов только тем DNS-серверам, которые явно анонсируют поддержку данной опции, а мой DNS-сервер этого не делал. Указанный небольшой процент запросов — это, полагаю, и есть те попытки автоматического определения поддержки EDNS Client Subnet: каждый четвёртый запрос из AS гугла приходил с этой опцией.
Помимо гугла с Client Subnet пришло 4 запроса из Бразилии с резольвера, использующего "хак" с bit 0x20:
ts | src | query | client4
---------------------------+---------------+----------------------+--------------
2017-06-14 04:47:41.231796 | 187.1.128.119 | udp A zenitbET66.CoM | 200.248.248.0
2017-06-14 04:47:41.748585 | 187.1.128.119 | tcp A ZenItbET66.cOm | 200.248.248.0
2017-06-14 04:47:42.274296 | 187.1.128.119 | udp A zEnItbET66.coM | 200.248.248.0
2017-06-14 04:47:42.798544 | 187.1.128.119 | tcp A zeNitBET66.com | 200.248.248.0Хак с битом 0x20 относительно популярен – с ним приходит порядка 5% запросов от 2.5% резольверов (если считать уникальные резольверы по ASN).
Другой интересной опцией EDNS является EDNS UDP payload size, анонсирующая максимальный размер DNS-пакета, который клиент готов принять. Помимо четверти запросов, которые не анонсируют поддержку EDNS и 55% запросов установивших эту опцию в 4096 байта, есть несколько других интересных значений.
2% запросов говорят, что UDP-пакеты увеличенного размера им ни к чему и используют минимальное допустимое значение 512. Примером такого резольвера может служить irc.kristel.ru из Минусинска, который изменяет эту опцию после первого "большого" ответа, который пришлось получать по TCP. Аналогичное поведение наблюдается и на некоторых других резольверах, включая сброс размера обратно в 512 байт через некоторое время.
ts | proto | qtype | qname | udpsz
---------------------------+-------+-------+--------------------+------
2017-06-14 12:41:59.678401 | udp | A | zenitbet66.com | 512
2017-06-14 12:41:59.898596 | tcp | A | zenitbet66.com | 512
2017-06-14 12:42:32.14485 | udp | A | m.zenitbet66.com | 4096
2017-06-14 12:44:40.532815 | udp | A | www.kisa54.com | 4096
2017-06-14 12:56:54.083849 | udp | A | diplom-lipetsk.com | 4096
2017-06-14 12:56:54.311013 | tcp | A | diplom-lipetsk.com | 4096
2017-06-14 13:06:38.524876 | udp | A | www.cool-sino.com | 4096Также в логи попали пара сканеров, которые могли искать DNS amplification, т.к. выставили клиентский размер в 65527 байта, что является максимальным значением. Интересно, что "большие" ответы powerdns отправляет без каких-либо ответных resource records, ставя флаг truncated в заголовке, что вынуждает резольвер перейти на TCP. Так powerdns избегает DNS amplification при работе с большими ответами по UDP.
Я был немного удивлён, что ни одного DNS-запроса по TCP не пришло с использованием TCP Fast Open. Конечно, отсутствие этой фичи можно объяснить тем, что если беспокоиться о скорости, то прежде всего не следует отдавать большие DNS ответы, вынуждающие резольвер переходить на TCP.
За 10 часов на вышеперечисленных looking glass не появилось /32 маршрута ни на один из "добавленных" в DNS IPv4 адресов. Но, если провести измерения с помощью RIPE Atlas, то можно найти некоторое количество транзитных провайдеров, которые, вероятно, выполняют резольвинг и заносят маршруты на фильтр, получив 2049 A записей в ответ:
Список неполный, т.к. был составлен методом пристального всматривания. Наличие крупных провайдеров в списке говорит о том, что вопрос о потенциальной уязвимости критической инфраструктуры к данной атаке не закрыт. Также остаются открытыми вопросы:
sortlist или непосредственно ручной геренации ответа в LUA кодеЕсли кто-то хочет посмотреть на данные самостоятельно, то в RIPE Atlas это измерения 8844224, 8844225, 8844226, 8844227, 8844228, 8844229, 8844230, 8844231, 8844232, 8844233, 8844234, 8844235. Запросы за первые 16 часов эксперимента доступны в виде дампа postgres:9.6. Гигабайты pcap-ов могу отгрузить по отдельному запросу.
|
|






