Тёмные паттерны — как зловредные интерфейсы пытаются атаковать и обманывать |
























|
Метки: author Milfgard интерфейсы блог компании мосигра темные паттерны dark pattern шаблоны ux |
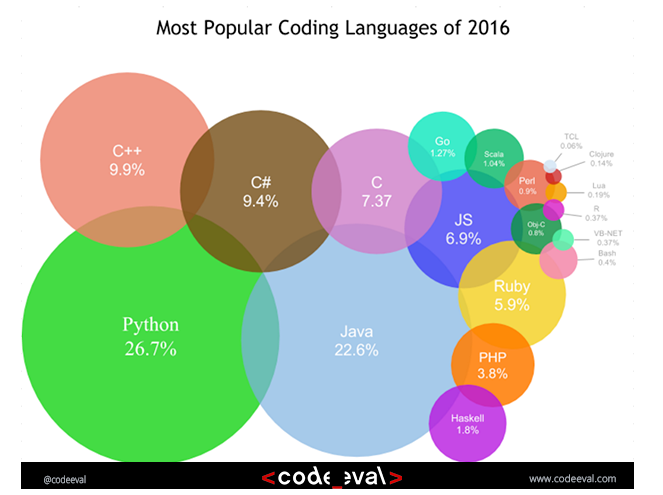
Разбираемся в джунглях программирования, или почему Маугли дружил с Python? |


|
Метки: author Dmitry21 программирование python блог компании отус otus.ru otus обучение |
Поддержка исследователей в области Deep Learning |

|
Метки: author a-pichugin обработка изображений машинное обучение data mining big data блог компании new professions lab deep learning gpu конкурс бесплатно без смс |
Советы начинающему скалисту (Часть 2) |
Часть 2. Обо всем и ни о чем
Сегодня мы обсудим ряд скалических идиом, которые не поместились в первую часть статьи. Мы рассмотрим вопросы интероперации языка с Java и, главное, неправильное использование объектно-ориентированных особенностей Scala.
Структура цикла
В Scala практически все является выражением, и даже если что-то возвращает Unit, вы всегда можете получить на выходе ваш (). После длительного программирования на языках, где превалируют операторы (statements), у многих из нас (и я не являюсь исключением) возникает желание запихнуть все вычисления в одно выражение, составив из них длинный-предлинный паровозик. Следующий пример я нагло утащил из Effective Scala. Допустим, у нас есть последовательность кортежей:
val votes = Seq(("scala", 1),
("java", 4),
("scala", 10),
("scala", 1),
("python", 10))Мы можем лихо её обработать (разбить на группы, просуммировать внутри групп, упорядочить по убыванию) единственным выражением:
val orderedVotes = votes
.groupBy(_._1)
.map { case (which, counts) =>
(which, counts.foldLeft(0)(_ + _._2))
}.toSeq
.sortBy(_._2)
.reverseЭтот код прост, понятен, выразителен? Возможно — для съевшего собаку скалиста. Однако, если мы разобьём выражение на именованные составляющие, легче станет всем:
val votesByLang =
votes groupBy { case (lang, _) => lang }
val sumByLang =
votesByLang map { case (lang, counts) =>
val countsOnly = counts map { case (_, count) => count }
(lang, countsOnly.sum)
}
val orderedVotes = sumByLang.toSeq
.sortBy { case (_, count) => count }
.reverseНаверное, этот пример недостаточно нагляден — чего уж, я даже поленился его сам придумать. Но поверьте, мне попадались очень длинные конструкции, которые их авторы даже не удосуживались переносить на несколько строк.
Очень часто в Scala приходят через Spark, а уж используя Spark так и хочется сцепить побольше «вагончиков»-преобразований в длинный и выразительный «поезд». Читать такие выражения сложно, их нить повествования теряется достаточно быстро.
Сверхдлинные выражения и operator notation
Надеюсь, всем известно, что 2 + 2 в Scala является синтаксическим сахаром для выражения 2.+(2). Этот вид записи именуется операторной нотацией (operator notation). Благодаря ей в языке нет операторов как таковых, а есть лишь методы, пусть и с небуквенными именами, а сама она — мощный инструмент, позволяющий создавать выразительные DSL (собственно, для этого символьная нотация и была добавлена в язык). Вы можете сколь угодно долго записывать вызовы методов без точек и скобочек: object fun arg fun1 arg1. Это безумно круто, если вы хотите сделать читаемый DSL:
myList should have length 10Но, в большинстве случаев, операторная нотация в сочетании с длинными выражениями приносит сплошные неудобства: да, операции над коллекциями без скобок выглядят круче, вот только понять их можно только тогда, когда они разбиты на именованные составляющие.
«Поезда» и postfix notation
Постфиксные операторы, при определенных условиях, способны вскружить голову несчастному парсеру, поэтому в последних версиях Scala эти выражения нужно импортировать явно:
import language.postfixOpsСтарайтесь не использовать эту возможность языка и проектировать ваши DSL так, чтобы и вашим пользователям не приходилось ее использовать. Это довольно просто сделать.
Scala поддерживает неинициализированные значения. Например, это может вам пригодиться при создании beans. Давайте посмотрим на следующий Java-класс:
class MyClass {
// По-умолчанию, любой наследник Object инциализируется в null.
// Примитивные типы инициализируются значениями по-умолчанию.
String uninitialized;
}Такого же поведения мы можем добиться и от Scala:
class {
// Синтаксис с нижним подчеркиванием говорит Scala, что
// данное поле не будет инциализировано.
var uninitialized: String = _
}Пожалуйста, не делайте этого бездумно. Инициализируйте значения везде, где можете. Используйте эту языковую конструкцию только если используемый вами фреймворк или библиотека яростно на этом настаивают. При неаккуратном использовании вы можете получить тонны NullPointerException. Однако знать об этой функции следует: однажды подобное знание сэкономит время. Если вы хотите отложить инициализацию, используйте ключевое слово lazy.
Nullable, которые могут прийти извне в Option.null: используйте Option, Either, Try и др.Иногда встречаются ситуации, когда null-значения являются частью модели. Возможно, эта ситуация возникла ещё задолго до вашего прихода в команду, а уж тем более задолго до внедрения Scala. Как говорится: если пьянку нельзя предотвратить, ее следует возглавить. И в этом вам поможет паттерн, именуемый Null Object. Зачастую это всего-лишь еще один case-класс в ADT:
sealed trait User
case class Admin extends User
case class SuperUser extends User
case class NullUser extends UserЧто мы получаем? Null, пользователя и типобезопасность.
Методы
В Scala существует возможность перегрузки конструкторов классов. И это — не лучший способ решить проблему. Скажу больше, это — не идиоматичный способ решения проблемы. Если говорить о практике, эта функция полезна, если вы используете Java-reflection и ваш Scala-код вызывается из Java или вам необходимо такое поведение (а почему бы в таком случае не сделать Builder)? В остальных случаях лучшая стратегия — создание объекта-компаньона и определение в нем нескольких методов apply.
Наиболее примечательны случаи перегрузки конструкторов из-за незнания о параметрах по-умолчанию (default parameters).
Совсем недавно, я стал свидетелем следующего безобразия:
// Все включено!
case class Monster (pos: Position, health: Int, weapon: Weapon) {
def this(pos: Position) = this(pos, 100, new Claws)
def this(pos: Position, weapon: Weapon) = this(pos, 100, weapon)
}Ларчик открывается проще:
case class Monster(
pos: Position,
health: Short = 100,
weapon: Weapon = new Claws
)Хотите наградить вашего монстра базукой? Да, не проблема:
val aMonster = Monster(Position(300, 300, 20), weapon = new Bazooka)Мы сделали мир лучше, монстра — миролюбивее, а заодно перестали перегружать все, что движется. Миролюбивее? Определенно. Ведь базука — это еще и музыкальный инструмент (Википедия об этом умалчивать не станет).
Сказанное относится не только к конструкторам: люди часто перегружают и обычные методы (там где этого можно было избежать).
Перегрузка операторов
Считается достаточно противоречивой фичей Scala. Когда я только-только погрузился в язык, перегрузка операторов использовалась повсюду, всеми и везде, где только можно. Сейчас эта фича стала менее популярна. Изначально перегрузка операторов была сделана, в первую очередь, для того, чтобы иметь возможность составлять DSL, как в Parboiled, или роутинг для akka-http.
Не перегружайте операторы без надобности, и если считаете, что эта надобность у вас есть, то все-равно не перегружайте.
А если перегружаете (вам нужен DSL или ваша библиотека делает нечто математическое (или трудновыразимое словами)), обязательно дублируйте оператор функцией с нормальным именем. И думайте о последствиях. Так, Благодаря scalaz оператор |@| (Applicative Builder) получил имя Maculay Culkin. А вот и фотография "виновника":

Безусловно, после того, как вы многократно перегрузите конструкторы, вам для довершения картины захочется налепить геттеров и сеттеров.
Scala предоставляет отличное взаимодействие с Java. Она также способна облегчить вам жизнь при дизайне так называемых Beans. Если вы не знакомы с Java или концепцией Beans, возможно, вам следует с ней ознакомиться.
Слышали ли вы о Project Lombok? В стандартной библиотеке Scala имеется схожий механизм. Он именуется BeanProperty. Все, что вам нужно, — создать bean и добавить аннотацию BeanProperty к каждому полю, для которого хотите создать getter или setter.
Для того чтобы получить имя видаisPropertyдля переменных булева типа, следует добавитьscala.beans.BooleanBeanPropertyв вашу область видимости.
Аннотацию @BeanProperty можно так же использовать и для полей класса:
import scala.beans.{BooleanBeanProperty, BeanProperty}
class MotherInLaw {
// По закону, она может сменить имя:
@BeanProperty var name = "Megaera"
// А эти ребята имеют свойство плодиться.
@BeanProperty var numberOfCatsSheHas = 0
// Но некоторые вещи неизменны.
@BooleanBeanProperty val jealous = true
}Для case class-ов тоже работает:
import scala.beans.BeanProperty
case class Dino(@BeanProperty name: String,
@BeanProperty var age: Int)Поиграем с нашим динозавром:
// Начнем с того, что он не так стар как вы думаете
val barney = Dino("Barney", 29)
barney.setAge(30)
barney.getAge
// res4: Int = 30
barney.getName
// res14: String = BarneyВ виду того, что мы не сделали name переменной, при попытке использовать сеттер, мы получим следующее:
barney.setName
:15: error: value setName is not a member of Dino
barney.setName Появление case-классов — это прорыв для JVM-платформы. В чем же их основное преимущество? Правильно, в их неизменяемости (immutability), а также наличию готовых equals, toString и hashCode. Однако, зачастую и в них можно встретить подобное:
// Внимание на var.
case class Person(var name: String, var age: Int)Иногда case-классы приходится-таки делать изменяемыми: например, если вы, имитируете beans, как в примере выше.
Но зачастую подобное случается тогда, когда глубокий джуниор не понимает, что такое имутабельность. С разработчиками уровнем повыше бывает не менее интересно, ведь они прекрасно осознают что делают:
case class Person (name: String, age: Int) {
def updatedAge(newAge: Int) = Person(name, newAge)
def updatedName(newName: String) = Person(newName, age)
}Однако про метод copy знают не все. Это норма. Подобное мне доводилось наблюдать не раз, чего уж там, в свое время я сам так хулиганил. Работает copy аналогично своему тезке, который определен для кортежей:
// Обновили возраст, получили новый инстанс.
person.copy(age = 32)Иногда case-классы имеют свойство раздуваться до 15–20 полей. До появления Scala 2.11 этот процесс хоть как-то ограничивался 22 элементами. Но сейчас ваши руки развязаны:
case class AlphabetStat (
a: Int, b: Int,
c: Int, d: Int,
e: Int, f: Int,
g: Int, h: Int,
i: Int, j: Int,
k: Int, l: Int,
m: Int, n: Int,
o: Int, p: Int,
q: Int, r: Int,
s: Int, t: Int,
u: Int, v: Int,
w: Int, x: Int,
y: Int, z: Int
)Хорошо, я вам наврал: руки, конечно, стали свободнее, однако ограничения JVM никто не отменял.
Большие case-классы это плохо. Это очень плохо. Бывают ситуации, когда этому есть оправдание: предметная область, в которой вы работаете, не допускает агрегации, и структура представляется плоской; вы работаете с API, спроектированным глубокими идиотами, которые сидят на сильнодействующих транквилизаторах.
И знаете, чаще всего приходится иметь дело со вторым вариантом. Хочется, чтобы case-классы легко и непринужденно укладывались на API. И я вас пойму, если так.
Но я перечислил только уважительные оправдания монструозности ваших case-классов. Есть и наиболее очевидная: для того, чтобы обновить поле, глубоко запрятанного вглубь вложенных классов, приходится очень сильно помучиться. Каждый case-класс надо старательно разобрать, подменить значение и собрать. И от этого недуга есть средство: вы можете использовать линзы (lenses).
Почему линзы называются линзами? Потому что они способны сфокусироваться на главном. Вы фокусируете линзу на определенную часть структуры, и получаете ее, вместе с возможностью ее (структуру) обновить. Для начала объявим наши case-классы:
case class Address(street: String,
city: String,
postcode: String)
case class Person(name: String, age: Int, address: Address)А теперь заполним их данными:
val person = Person("Joe Grey", 37,
Address("Southover Street",
"Brighton", "BN2 9UA"))Создаем линзу для улицы (предположим что наш персонаж захотел переехать):
import shapeless._
val streetLens = lens[Person].address.streetЧитаем поле (прошу заметить что строковый тип будет выведен автоматически):
val street = streetLens.get(person)
// "Southover Street"Обновляем значение поля:
val person1 = streetLens.set(person)("Montpelier Road")
// person1.address.street == "Montpelier Road"Пример был нагло украден «из отсюда»
Аналогичную операцию вы можете совершить и над адресом. Как видите, это достаточно просто. К сожалению, а может быть и к счастью, Scala не имеет встроенных линз. Поэтому вам придется использовать стороннюю библиотеку. Я бы рекомендовал вам использовать shapeless. Собственно, приведенный выше пример, был написан с помощью этой весьма доступной для начинающего скалиста библиотеки.
Существует множество других реализаций линз, если хотите, вы можете
использовать scalaz, monocle. Последняя предоставляет более продвинутые механизмы использования оптики, и я бы рекомендовал ее к дальнейшему использованию.
К сожалению, для того, чтобы описать и объяснить механизм действия линз, может потребоваться отдельная статья, поэтому считаю, что вышеизложенной информации достаточно для того, чтобы начать собственное исследование оптических систем.
Берем опытного Java-разработчика и заставляем его писать на Scala. Не проходит и пары дней, как он отчаянно начинает искать enum'ы. Не находит их и расстраивается: в Scala нет ключевого слова enum или, хотя бы, enumeration. Далее есть два варианта событий: или он нагуглит идиоматичное решение, или начнет изобретать свои перечисления. Часто лень побеждает, и в результате мы видем вот это:
object Weekdays {
val MONDAY = 0
// догадайтесь что будет дальше...
}А дальше то что? А вот что:
if (weekday == Weekdays.Friday) {
stop(wearing, Tie)
}Что не так? В Scala есть идиоматичный способ создания перечислений, именуется он ADT (Algebraic Data Types), по-русски алгебраические типы данных. Используется, например в Haskell. Вот как он выглядит:
sealed trait TrafficLight
case object Green extends TrafficLight
case object Yellow extends TrafficLight
case object Red extends TrafficLight
case object Broken extends TrafficLightМногословно, самодельное перечисление, конечно, было короче. Зачем столько писать? Давайте объявим следующую функцию:
def tellWhatTheLightIs(tl: TrafficLight): Unit = tl match {
case Red => println("No cars go!")
case Green => println("Don't stop me now!")
case Yellow => println("Ooohhh you better stop!")
}И получим:
warning: match may not be exhaustive.
It would fail on the following input: Broken
def tellWhatTheLightIs(tl: TrafficLight): Unit = tl match {
^
tellWhatTheLightIs: (tl: TrafficLight)UnitМы получаем перечисление, свободное от привязки к каким либо константам, а также проверку на полноту сопоставления с образцом. И да, если вы используете «enum для бедных», как их обозвал один мой небезызвестный коллега, используйте сопоставление с образцом. Это наиболее идиоматичный способ. Стоит заметить, об этом упоминается в начале книги Programming in Scala. Не каждая птица долетит до середины Днепра, так же как и не каждый скалист прочтет Magnum Opus.
Неплохо про алгебраические типы данных рассказано, как ни странно, в Википедии. Касательно Scala, есть достаточно доступный пост и презентация, которая, возможно, покажется вам интересной.
Признайтесь, вы писали методы, которые в качестве аргумента принимают Boolean? В случае с Java ситуация вообще катастрофичная:
PrettyPrinter.print(text, 1, true)Что может означать 1? Доверимся интуиции и предположим что это количество копий. А за что отвечает true? Это может быть что угодно. Ладно, сдаюсь, схожу в исходники и посмотрю, что это.
В Scala вы можете использовать ADT:
def print(text: String, copies: Int, wrapWords: WordWrap)Даже если вам достался в наследство код, требующий логических аргументов, вы можете использовать параметры по умолчанию.
// К интам тоже применимо,
// а вдруг это не количество копий, а отступы?
PrettyPrinter.print(text, copies = 1, WordWrap.Enabled)Хвостовая рекурсия работает быстрее, чем большинство циклов. Если она, конечно, хвостовая. Для уверенности используйте аннотацию @tailrec. Ситуации бывают разными, не всегда рекурсивное решение оказывается простым доступным и понятным, тогда используйте while. В этом нет ничего зазорного. Более того, вся библиотека коллекций написана на простых циклах с предусловиями.
Главное, что вам следует знать про генераторы списков, или, как их еще Называют, «for comprehensions», — это то, что основное их предназначение — не в реализации циклов.
Более того, использование этой конструкции для итерации по индексам будет достаточно дорогостоящей процедурой. Цикл while или использование хвостовой рекурсии — намного дешевле. И нагляднее.
«For comprehension» представляет собой синтаксический сахар для методов map, flatMap и withFilter. Ключевое слово yield используется для последующей агрегации значений в результирующей структуре. Используя «for comprehension» вы, на самом деле, используете те же комбинаторы, просто в завуалированой форме. Используйте их напрямую:
// хорошо
1 to 10 foreach println
// плохо
for (i <- 1 to 10) println(i)Помимо того, что вы вызвали тот же код, вы еще и добавили некую переменную i, которой совершенно здесь не место. Если вам нужна скорость, используйте цикл while.
Об именах переменных
Занимательная история имен переменных в формате вопрос-ответ:
Вопрос: Откуда вообще взялись i, j, k в качестве параметров циклов?
Ответ: Из математики. А в программирование они попали благодаря фортрану, в котором тип переменной определяется ее именем: если первая буква имени начинается с I, J, K, L, M, или N, это автоматически означает, что переменная принадлежит к целочисленному типу. В противном случае, переменная будет считаться вещественной (можно использовать директиву IMPLICIT для того, чтобы изменить тип, устанавливаемый по умолчанию).
И этот кошмар живет с нами вот уже почти 60 лет. Если вы не перемножаете матрицы, то использованию i, j и k даже в Java нет оправдания. Используйте index, row, column — все что угодно. А вот если вы пишете на Scala, старайтесь вообще избегать итерации с переменными внутри for. От лукваого это.
Дополнением к этому разделу будет видео, в котором подробно рассказывается все, что вы хотели знать про генераторы списков.
В Scala почти все является выражением. Исключение составляет return, который не следует использовать ни при каких обстоятельствах. Это не опциональное слово, как думают многие. Это конструкция которая меняет семантику программы. Подробнее об этом можете прочитать здесь
Представьте себе, в Scala есть метки. И я понятия не имею, зачем они туда были добавлены. До выхода Scala 2.8 по данному адресу располагалась еще и метка continue, позже она была устранена.
К счастью, метки не являются частью языка, а реализованы при помощи выбрасывания и отлова исключений (о том, что делать с исключениями, мы поговорим далее в этой статье).
В своей практике я не встречал еще ни единого случая, когда подобное поведение могло хоть как-то быть оправдано. Большая часть примеров, которые я нахожу в сети, притянуты за уши и высосаны из пальца. Нет, ну вы посмотрите:
Этот пример взят отсюда:
breakable {
for (i <- 1 to 10) {
println(i)
if (i > 4) break // выскочить из цикла.
}
}Это исключительная тема заслуживает большой и отдельной статьи. Возможно, даже серии статей. Рассказывать об этом можно долго. Во-первых, потому, что Scala поддерживает несколько принципиально разных подходов к обработке исключений. В зависимости от ситуации, вы можете выбрать тот, который подходит лучше всего.
В Scala нет checked exceptions. Так что если где-то у нас исключения и могут возникнуть — обязательно их обрабатывайте. И самое главное, не бросайтесь исключениями. Да, есть ситуации когда зеленые монстры вынуждают вас это делать. И более того, у зеленых монстров и их почитателей это вообще является нормой. Во всех остальных случаях — не бросайтесь исключениями. То, что в свое время Джоэл Спольски писал применительно к C++ и Java, к Scala применимо даже в большей степени. И в первую очередь именно из-за ее функциональной природы. Метки и goto недопустимы в функциональном программировании. Исключения ведут себя схожим образом. Бросив исключение, вы прерываете flow. Но, как уже было сказано выше, ситуации бывают разными, и если ваш фреймворк этого требует — Scala дает такую возможность.
Вместо того, чтобы возбуждать исключения, вы можете использовать Validation из scalaz, scala.util.Try, Either. Можно использовать и Option, если вам не жалко людей, которые будут поддерживать ваш код. И это будет все-равно лучше, чем бросаться исключениями.
Просто не используйте их. Даже если ваши руки к ним тянутся, вам, скорее всего, они не нужны. Во-первых, структурные типы работают через рефлексию, что достаточно дорого с точки зрения производительности, во вторых — вы их не контролируете. Интересные мысли изложены на этот счет здесь.
Знаете что не так с этим кодом:
object Main extends App {
Console.println("Hello World: " + (args mkString ", "))
}Конкретно с этим примером «все так». Все будет хорошо и прекрасно работать, пока вы не усложните код достаточно, чтобы встретиться с непредсказуемым поведением. И виной тому один трейт из стандартной библиотеки. Он называется DelayedInit. Прочитать о нем вы можете здесь. Трейт App, который вам предлагается расширить в большинстве руководств, расширяет трейт DelayedInit. Подробнее об App в документации.
It should be noted that this trait is implemented using the DelayedInit functionality, which means that fields of the object will not have been initialized before the main method has been executed.
По-русски:
Следует учесть, что данный трейт реализован с использованием функциональности DelayedInit, что означает то, что поля объекта не будут проинициализированны до выполнения метода main.
В будущем это обещают исправить:
Future versions of this trait will no longer extend DelayedInit.
Плохо ли использовать App? В сложных многопоточных приложениях я бы не стал этого делать. А если вы пишете «Hello world»? Почему бы нет. Я стараюсь лишний раз не связываться и использую традиционный метод main.
Очень часто в коде можно увидеть эмуляцию функций стандартной библиотеки Scala. Приведу простой пример:
tvs.filter(tv => tv.displaySize == 50.inches).headOptionТоже самое, только короче:
tvs.find(tv => tv.displaySize == 50.inches)Подобные «антипаттерны» не редкость:
list.size = 0 // плохо
list.isEmpty // ok
!list.empty // плохо
list.nonEmpty // ok
tvs.filter(tv => !tv.supportsSkype) // плохо
tvs.filterNot(tv => tv.supportsSkype) // okКонечно, если вы используете IntelliJ IDEA, она вам обязательно подскажет наиболее эффективную комбинацию методов. Scala IDE, насколько мне известно, так не умеет.
О неэффективном использовании библиотеки коллекций Scala можно рассказывать сколь угодно долго. И это уже очень не плохо сделал Павел Фатин в своей статье Scala collections Tips and Tricks, с которой я вам очень рекомендую ознакомиться. И да, старайтесь не вызывать элементы коллекций по индексам. Нехорошо это.
В заключении этой статьи я бы хотел порекомендовать материалы, которые я нахожу полезными для изучения.
Книга, которую должен прочесть каждый Scala-разработчик. К сожалению, терпения хватает не всем, однако она стоит затраченных усилий.
Автор хотел бы выразить свою признательность
typedef в первой части статьи,Отдельное спасибо EDU-отделу DataArt и всем тем, кто, проходя наши курсы по Scala, подталкивал меня к написанию этой статьи. Спасибо вам, уважаемые читатели, за то, что дочитали (или хотя бы промотали) до конца.
|
Метки: author ppopoff функциональное программирование программирование scala начинающим начинающему чистый код стиль кодирования |
[Перевод] Декораторы в JavaScript |
|
Метки: author ru_vds javascript блог компании ruvds.com декоратор программирование |
LXC aka Linux Container: простота и надёжность |

Аббревиатура расшифровывается просто Linux Container. Это контейнерная система виртуализации, которая действует в пределах операционной системы Linux. Что это значит? С LXC можно запустить несколько полностью изолированных и независимых друг от друга экземпляров ОС Linux на одном компьютере. Помимо этого есть возможность создать надежный кластер из нескольких десятков серверов, когда один и тот же экземляпр контейнера выполняется сразу на нескольких физических машинах и в случае выхода из строя одного сервера работа контейнера не приостанавливается ни на минуту. Так же данные контейнера находятся сразу на нескольких хранилищах, реализуется это различными методами (ceph ). Что позволяет помимо живой миграции контейнера между нодами кластера так же еще больше повысить надежность хранения данных, гибко увеличивать дисковую подсистему контейнера в пределах … ну пределы практически неограничены –настолько насколько хватит хранилища, а хранилища могут быть очень большие, например, в нашем случае мы сейчас строим хранилище в несколько петабайт информации.
В чем разница между виртуальными машинами и контейнерами? традиционные типы виртуализации, например, KVM тратят ресурсы сервера на обcлуживание самой виртуальной среды, в случае же контейнера до 95% мощности отдается непосредственно в контейнер и он работает по сути на уровне хостовой машины. Замеры производительности контейнеров мы приведем ниже в этой статье.
| LXC | KVM |
|---|---|
| Изменение размера диска – в случае контейнера LXC увеличение или уменьшение диска происходит очень быстро практически на «лету» | Так как KVM это полноценно изолированный контейнер измение размера диска требует перезагрузки виртуальной машины, все как на физическом сервере |
| Расщирение RAM, ядер CPU, диска etc. Не требует перезагрузки, если требуется непрерывная работа виртуальной машины то выбор очевиден | При любых изменениях в параметрах VPS требуется перезагрузка |
| Быстрая перезагрузка контейнера | Как писали выше – KVM требует столько же времени на рестарт как и обычный сервер |
| Быстрая установка любого образа как операционной системы так и готовых шаблонов (OpenVPN, TorrenServer,OpenLDAP,MediaServer, OwnCloud у нас больше 100 различных шаблонов на все случаи жизни) | Возможность установки различных версий Windows и FreeBSD как из шаблонов так и из собственного ISO |
| Создание собственной внутренней сети между контейнерами | Создание собственной внутренней сети между контейнерами |
По сути, LXC и не является полноценной системой виртуализации. Виртуального аппаратного окружения как такового нет, зато создаётся безопасное изолированное пространство. LXC отличается высокой функциональностью, компактностью и гибкостью в отношении ресурсов, необыкновенной результативностью, простотой использования. С этим механизмом вы сможете создать дата-центр состоящий из нескольких контейнеров для различных целей. Как пример один контейнер мы настраиваем как роутер и firewall за ним распологаем в сегменте DMZ –web, почтовый и file сервера.

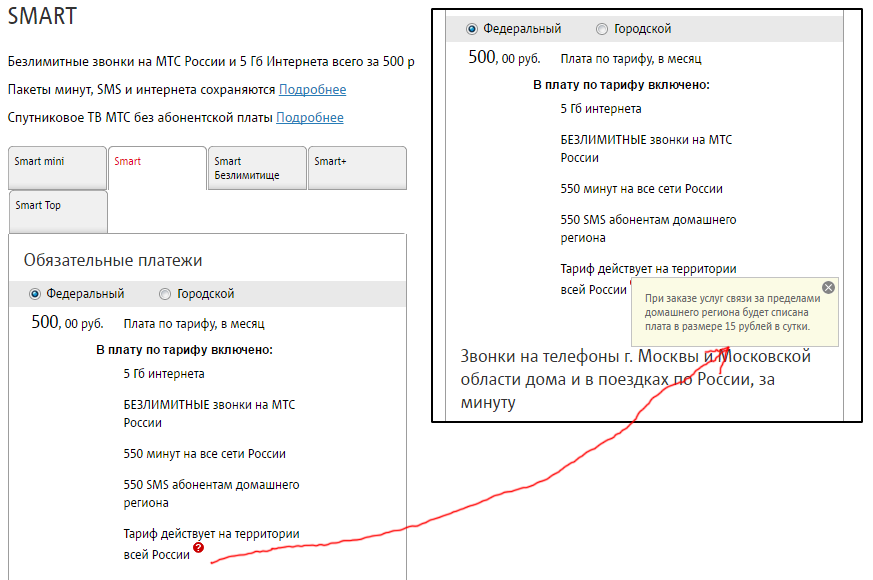
Итак приступим к заказу (ссылка на корзину) – выбираем имя хоста, пароль для root, параметры CPU, RAM и диска, далее переходим к выбору шаблона для контейнера и жмем «Далее», для тестов мы сделали промо-код HelloHabr, который позволит месяц тестировать совершенно бесплатно. Далее регистрируемся в билинге и если что-то пошло не так создаем запрос в сапорт. Заходим в клиентский кабинет выбираем свежесозданный контейнер и приступаем к тестам. Какие же возможности по доступу нам предлагают в личном кабинете – самое простое это noVNC консоль которая позволяет управлять контейнером непосредственно из браузера 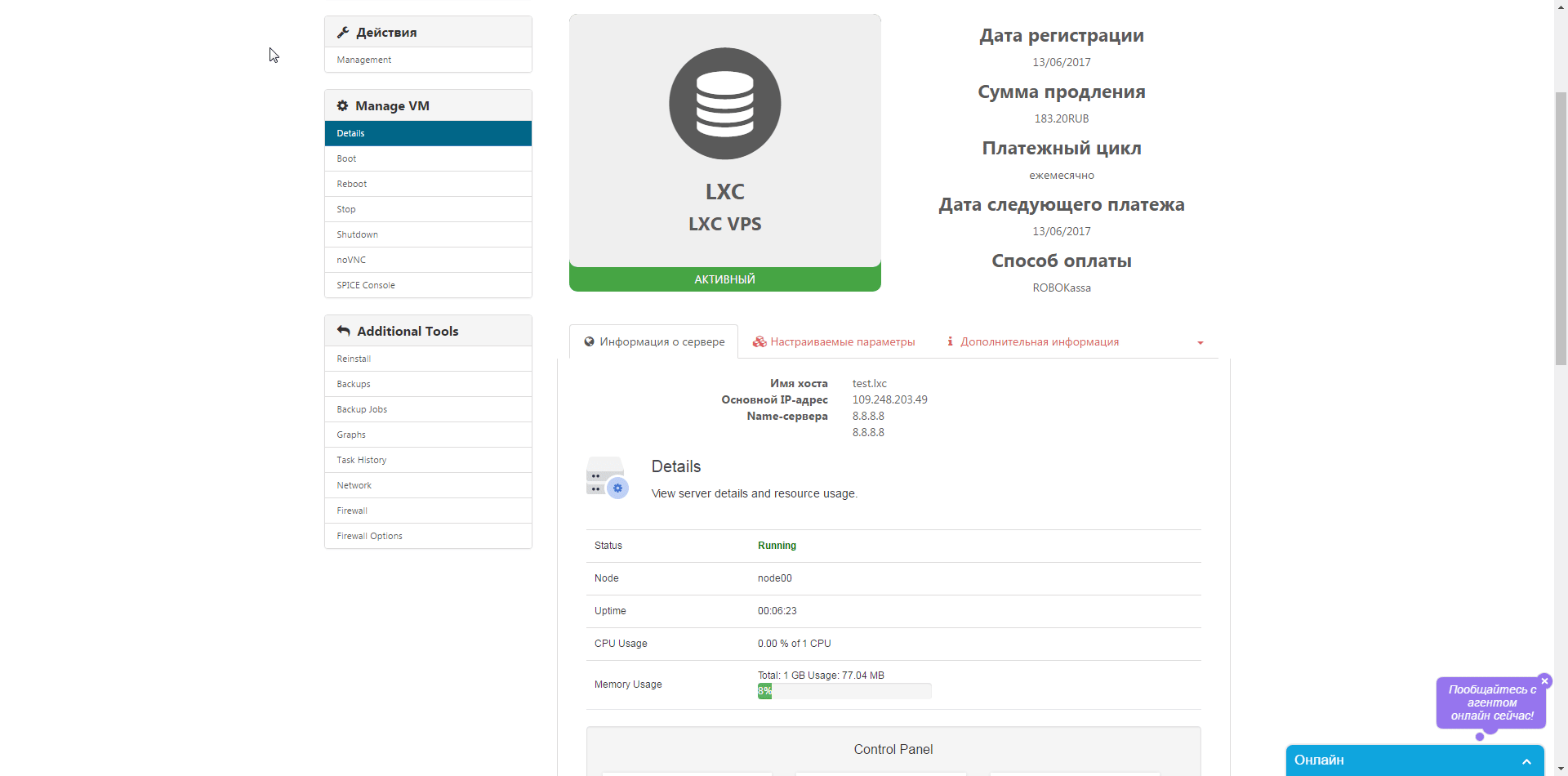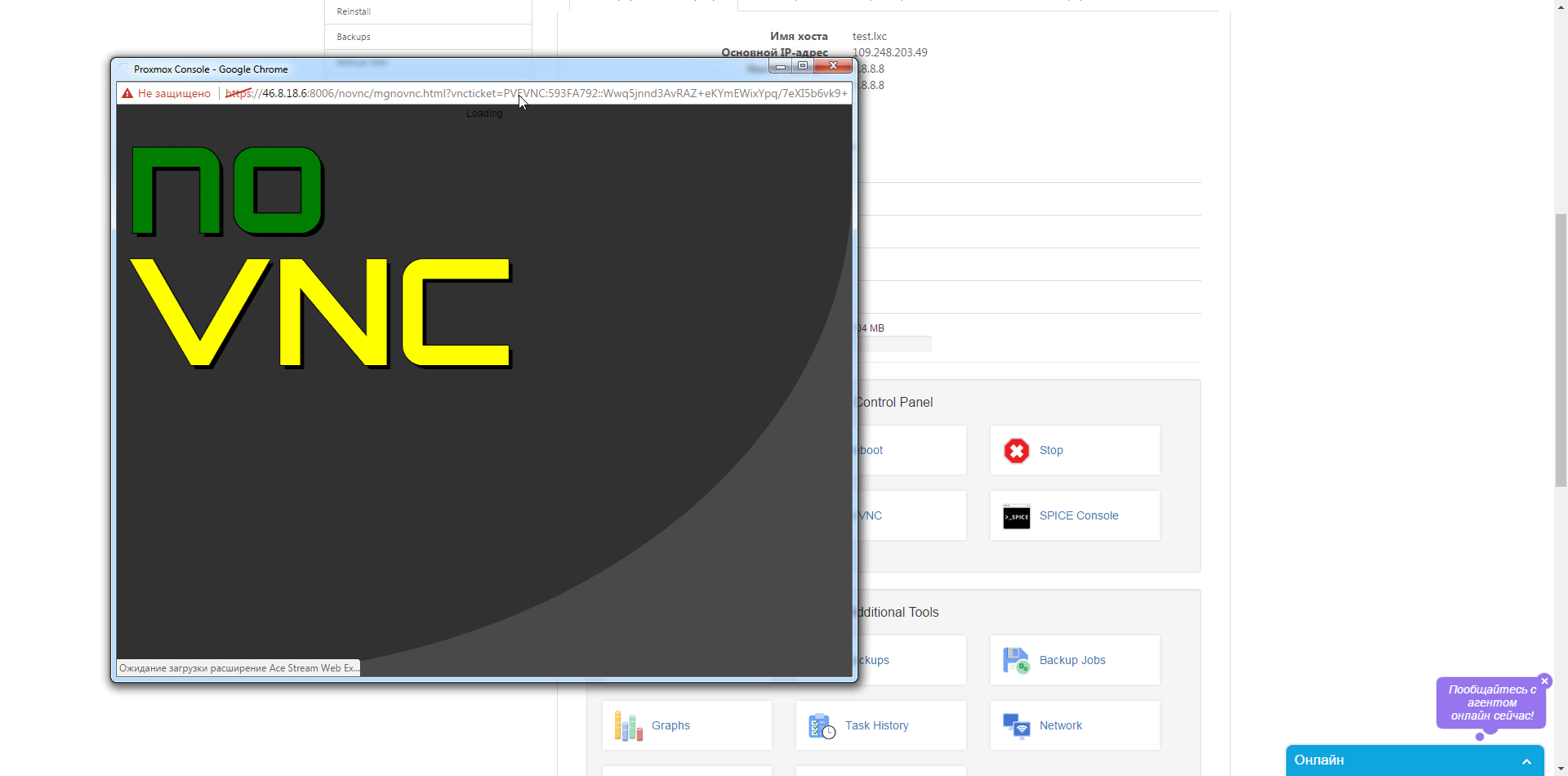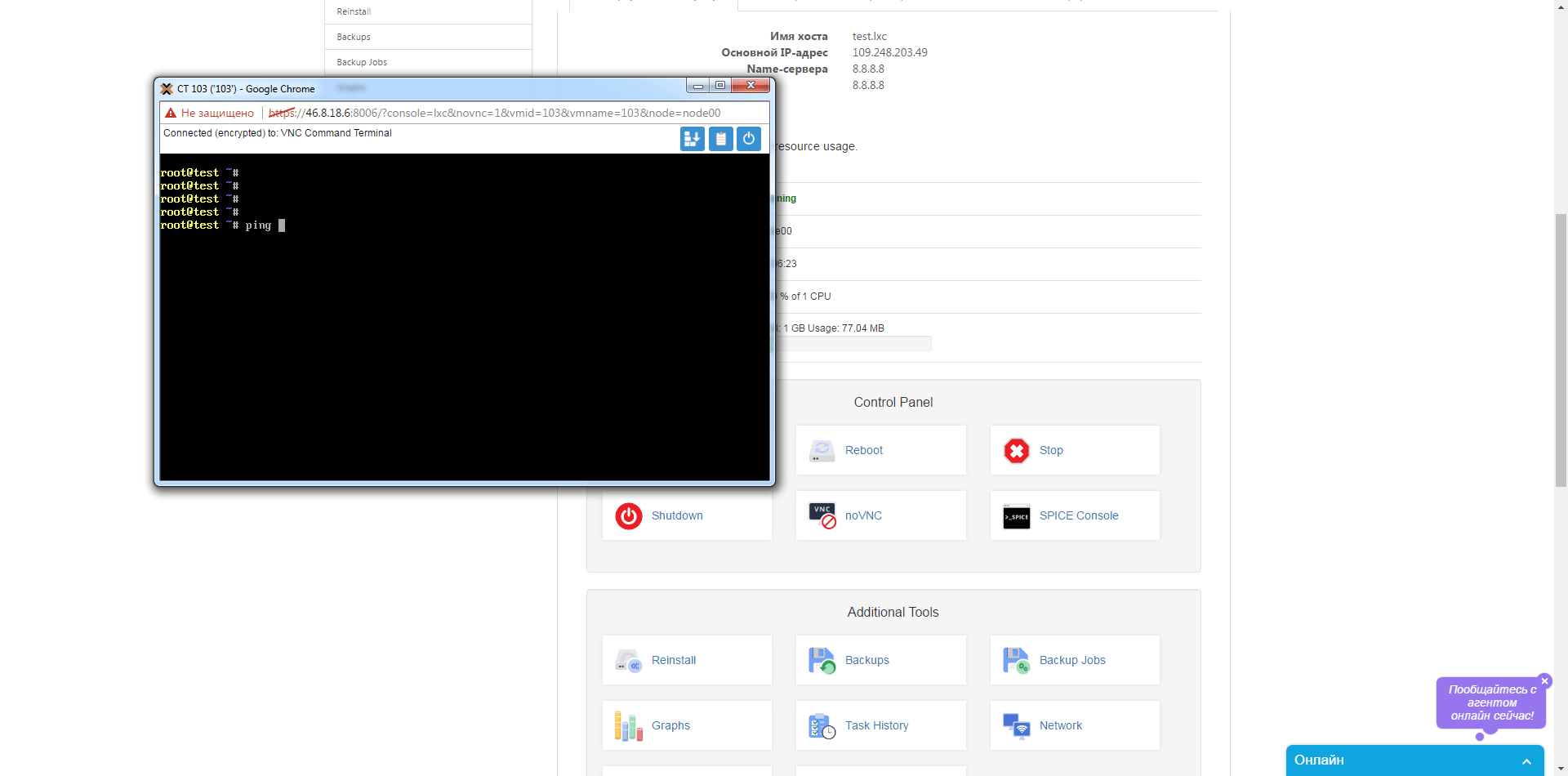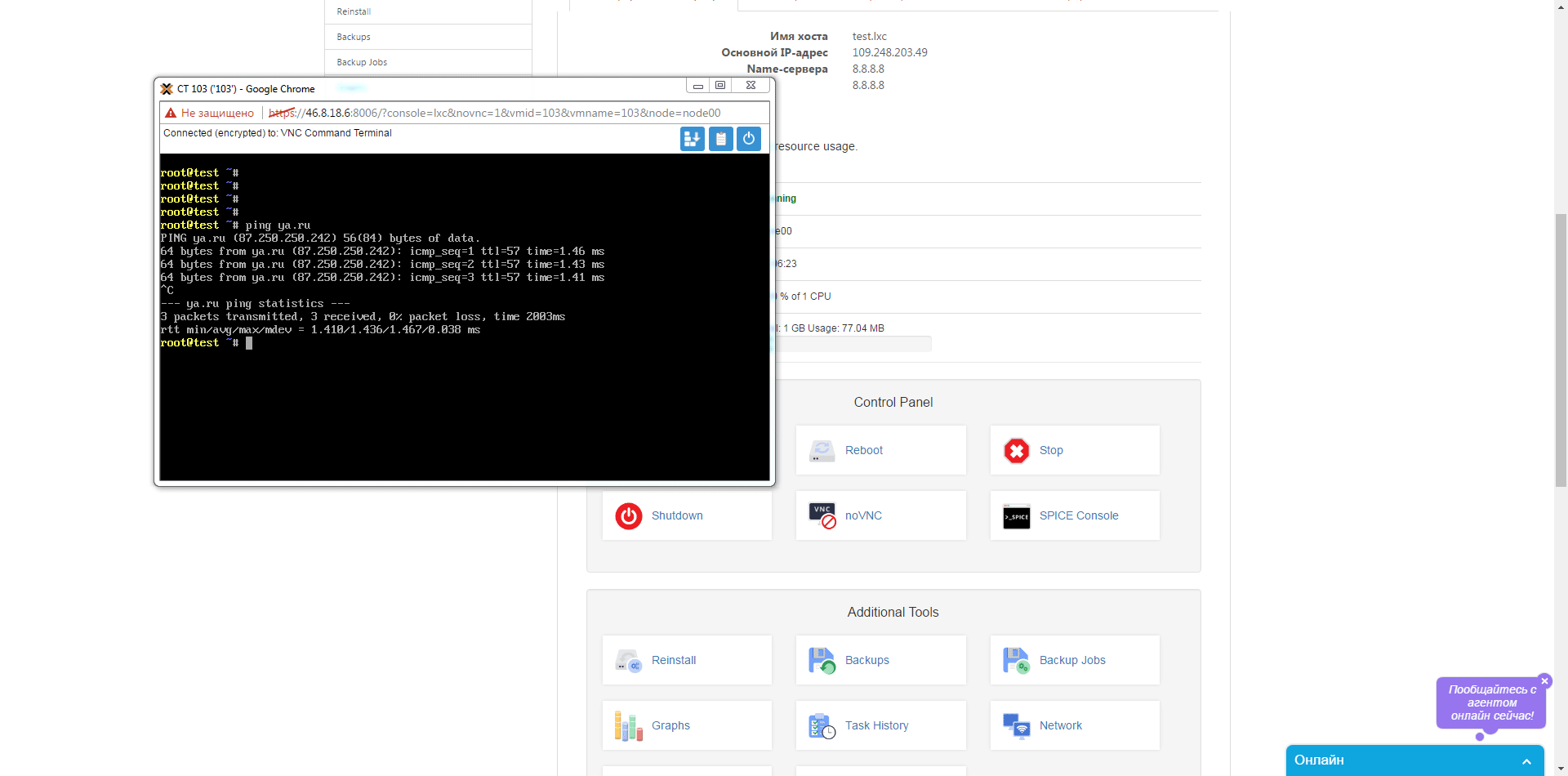 , далее SPICE консоль — представляет собой систему отображения (рендеринга) удаленного дисплея, построенную для виртуальной среды, которая позволяет вам просматривать виртуальный «рабочий стол» вычислительной среды не только на машине, на которой он запущен, но и откуда угодно через Интернет(из wiki), так же в разделе Backup мы можем сделать как мгновенный снимок контейнера, так и полное резервное копирование виртуально машины, есть возможность выбрать как тип архива, так и вид копии.
, далее SPICE консоль — представляет собой систему отображения (рендеринга) удаленного дисплея, построенную для виртуальной среды, которая позволяет вам просматривать виртуальный «рабочий стол» вычислительной среды не только на машине, на которой он запущен, но и откуда угодно через Интернет(из wiki), так же в разделе Backup мы можем сделать как мгновенный снимок контейнера, так и полное резервное копирование виртуально машины, есть возможность выбрать как тип архива, так и вид копии. 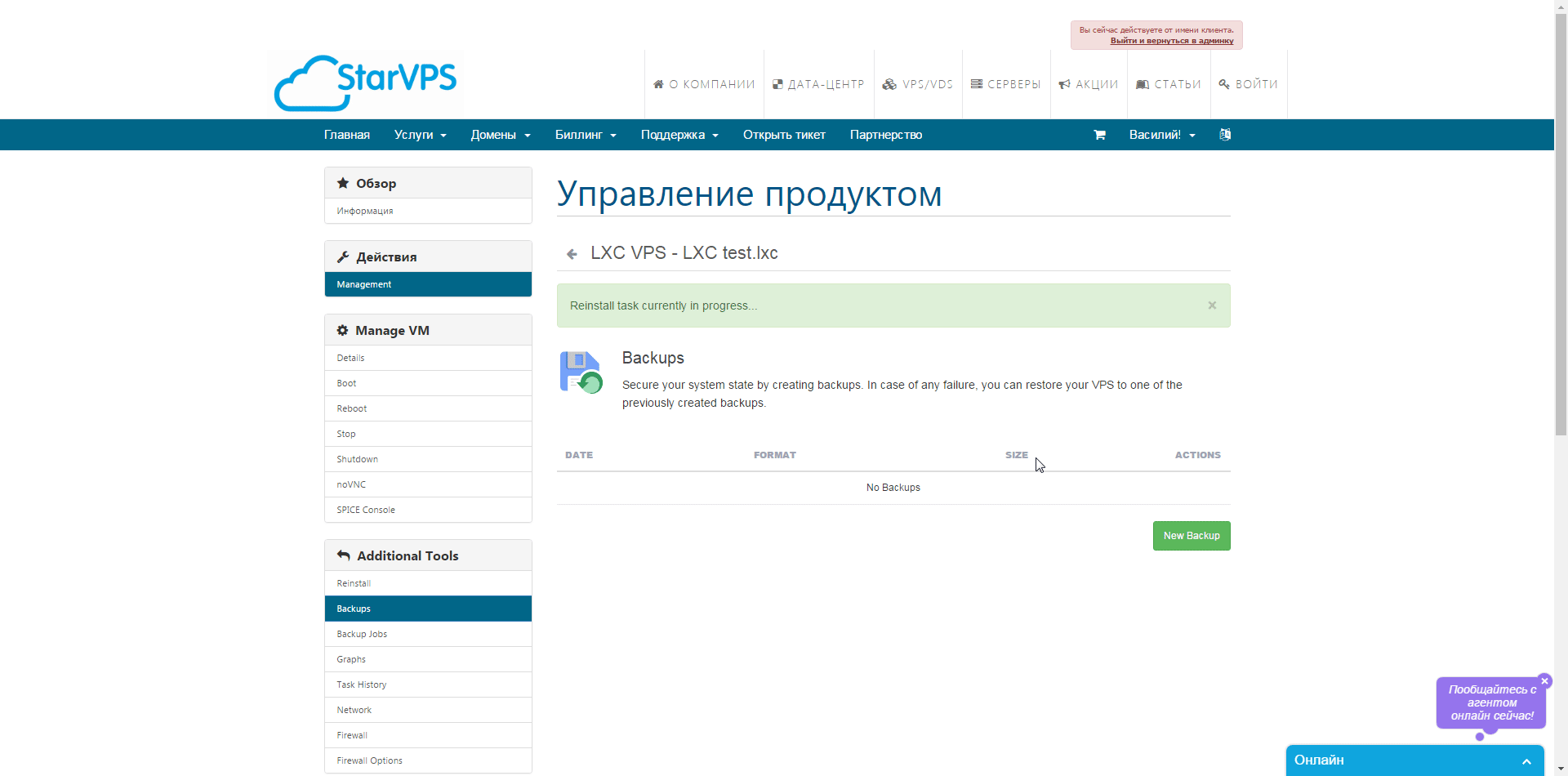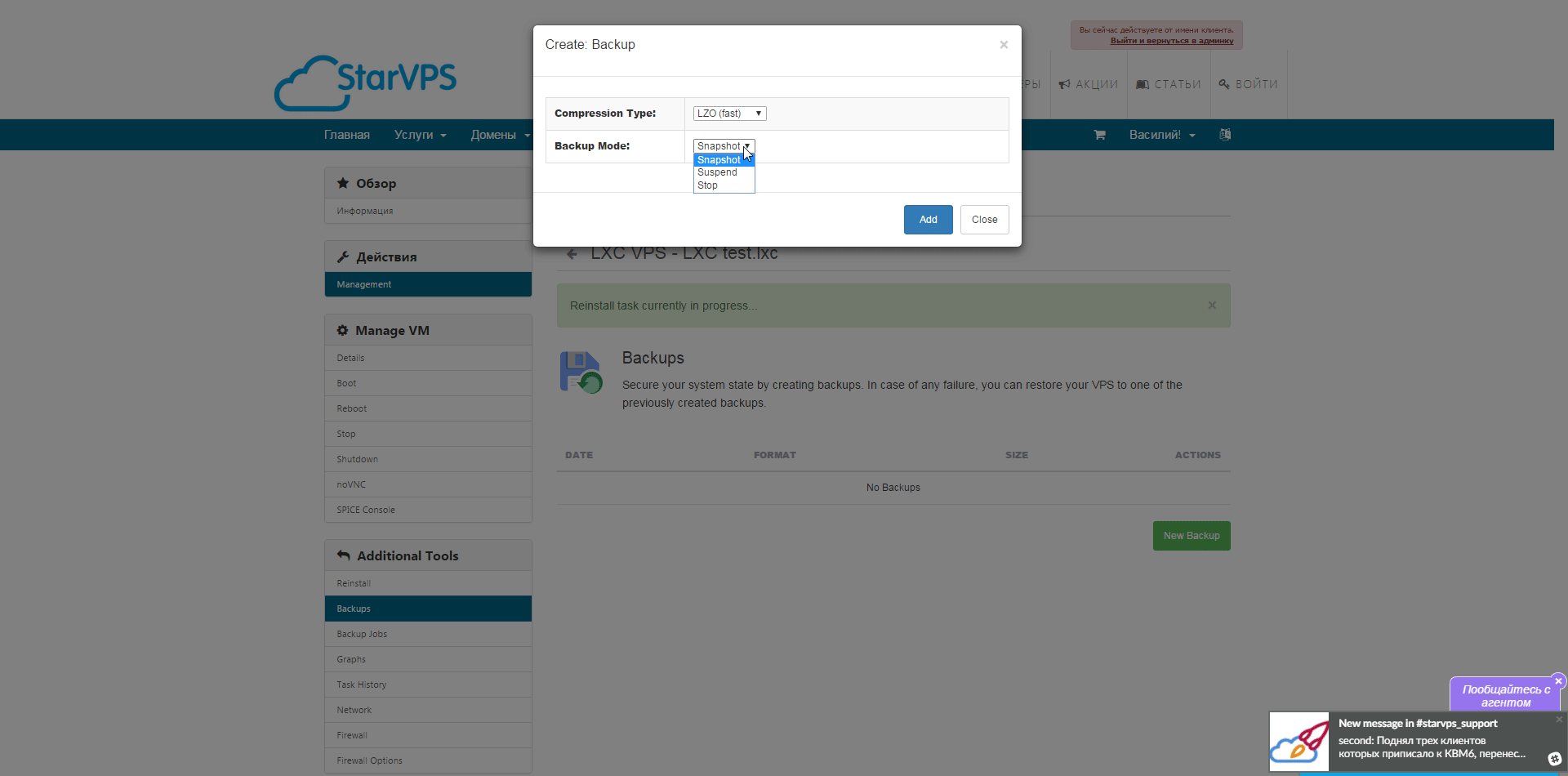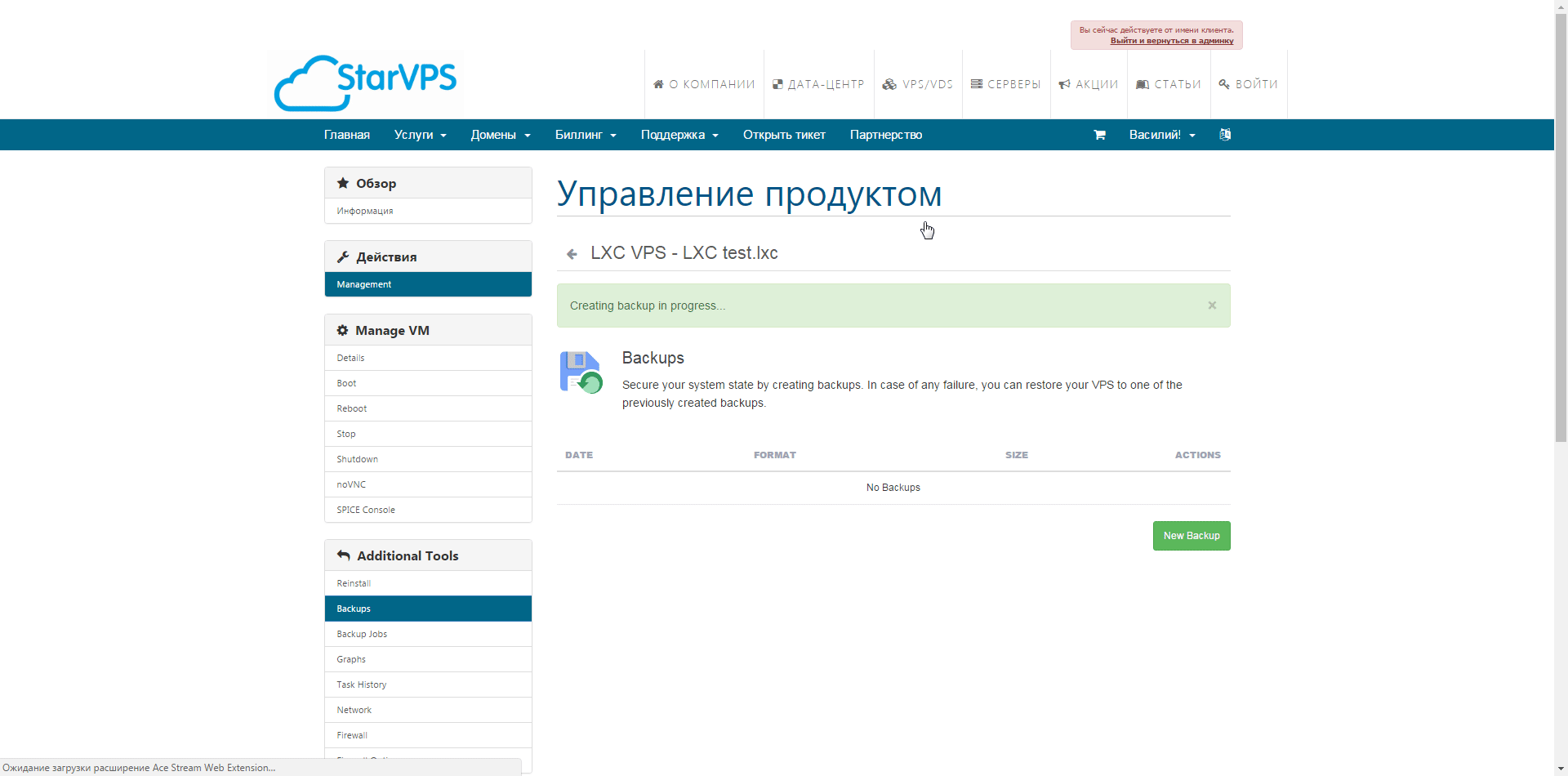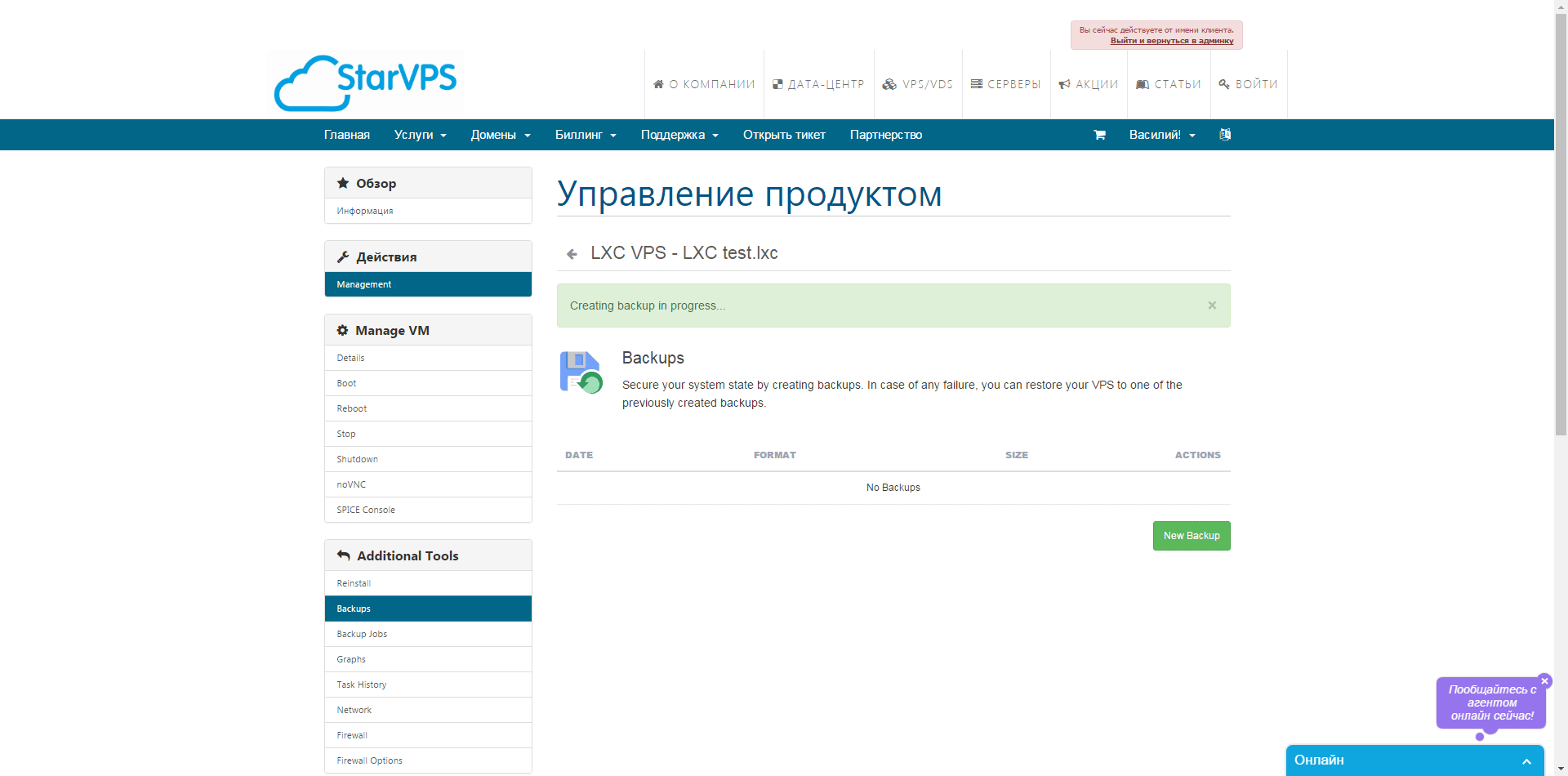 Так же мы можем настроить задания для Backup которые будут выполнятся по определенному расписанию с оповещением на емейл.
Так же мы можем настроить задания для Backup которые будут выполнятся по определенному расписанию с оповещением на емейл.
Так же хотел бы отметить еще одну удобную опцию – настройка firewall непосрдественно из бразуера, что очень удобно для тех кто не владеет тонкими настройками firewall в Linux. Все очень удобно как для опытных администраторов, так и совсем начинающих. 
Я для тестов взял самую начальную конфигурацию и теперь хочу посмотреть насколько ее хватает для простых задач, тестировать производительность я буду с помощью пакета unixbench сначала добавим недостающие пакеты
apt-get install build-essential libx11-dev libgl1-mesa-dev libxext-devдалее скачиваем сам unixbench и приступаем к тестированию —
cd /tmp/
wget https://github.com/kdlucas/byte-unixbench/archive/master.zip
unzip master.zipи запускаем
./RunЖдем пока unixbench потестирует контейнер и любуемся результатом
BYTE UNIX Benchmarks (Version 5.1.3)
System: test: GNU/Linux
OS: GNU/Linux -- 4.4.59-1-pve -- #1 SMP PVE 4.4.59-87 (Tue, 25 Apr 2017 09:01:58 +0200)
Machine: x86_64 (unknown)
Language: en_US.utf8 (charmap="ANSI_X3.4-1968", collate="ANSI_X3.4-1968")
CPU 0: Intel(R) Xeon(R) CPU E5649 @ 2.53GHz (5076.7 bogomips)
Hyper-Threading, x86-64, MMX, Physical Address Ext, SYSENTER/SYSEXIT, SYSCALL/SYSRET, Intel virtualization
09:14:27 up 33 min, 2 users, load average: 0.23, 0.06, 0.06; runlevel Jun
------------------------------------------------------------------------
Benchmark Run: Tue Jun 13 2017 09:14:28 - 09:42:27
24 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 29175436.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 3707.9 MWIPS (8.9 s, 7 samples)
Execl Throughput 4656.0 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 874980.2 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 243115.0 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1778945.2 KBps (30.0 s, 2 samples)
Pipe Throughput 1587733.6 lps (10.0 s, 7 samples)
Pipe-based Context Switching 273143.4 lps (10.0 s, 7 samples)
Process Creation 11873.0 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 5665.4 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 1061.0 lpm (60.0 s, 2 samples)
System Call Overhead 1897076.6 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 29175436.4 2500.0
Double-Precision Whetstone 55.0 3707.9 674.2
Execl Throughput 43.0 4656.0 1082.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 874980.2 2209.5
File Copy 256 bufsize 500 maxblocks 1655.0 243115.0 1469.0
File Copy 4096 bufsize 8000 maxblocks 5800.0 1778945.2 3067.1
Pipe Throughput 12440.0 1587733.6 1276.3
Pipe-based Context Switching 4000.0 273143.4 682.9
Process Creation 126.0 11873.0 942.3
Shell Scripts (1 concurrent) 42.4 5665.4 1336.2
Shell Scripts (8 concurrent) 6.0 1061.0 1768.3
System Call Overhead 15000.0 1897076.6 1264.7
========
System Benchmarks Index Score 1372.3
------------------------------------------------------------------------
Benchmark Run: Tue Jun 13 2017 09:42:27 - 10:10:50
24 CPUs in system; running 24 parallel copies of tests
Dhrystone 2 using register variables 28791897.2 lps (10.1 s, 7 samples)
Double-Precision Whetstone 3650.7 MWIPS (9.0 s, 7 samples)
Execl Throughput 4573.6 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 899496.3 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 243438.3 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 1960457.7 KBps (30.0 s, 2 samples)
Pipe Throughput 1588441.9 lps (10.1 s, 7 samples)
Pipe-based Context Switching 221247.7 lps (10.0 s, 7 samples)
Process Creation 10910.9 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 8683.0 lpm (60.1 s, 2 samples)
Shell Scripts (8 concurrent) 1088.9 lpm (60.8 s, 2 samples)
System Call Overhead 1899698.1 lps (10.1 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 28791897.2 2467.2
Double-Precision Whetstone 55.0 3650.7 663.8
Execl Throughput 43.0 4573.6 1063.6
File Copy 1024 bufsize 2000 maxblocks 3960.0 899496.3 2271.5
File Copy 256 bufsize 500 maxblocks 1655.0 243438.3 1470.9
File Copy 4096 bufsize 8000 maxblocks 5800.0 1960457.7 3380.1
Pipe Throughput 12440.0 1588441.9 1276.9
Pipe-based Context Switching 4000.0 221247.7 553.1
Process Creation 126.0 10910.9 865.9
Shell Scripts (1 concurrent) 42.4 8683.0 2047.9
Shell Scripts (8 concurrent) 6.0 1088.9 1814.9
System Call Overhead 15000.0 1899698.1 1266.5
========
System Benchmarks Index Score 1399.9
Немного рекламы
Так же хотел бы напомнить про наши выделенные сервера с защитой от ДДОС атак
Сейчас вы можете заказать 2x Intel Xeon E5540 с 32Gb ECC DDR3 RAM с полной защитой и SSD диском на 240Gb всего за 3127 руб
Так же всегда в наличии Intel Core i7-7700 от 3769 руб
За дополнительными скидками велкам в личку
|
Метки: author ondys devops *nix блог компании контел хостинг |
ГИС и распределенные вычисления |
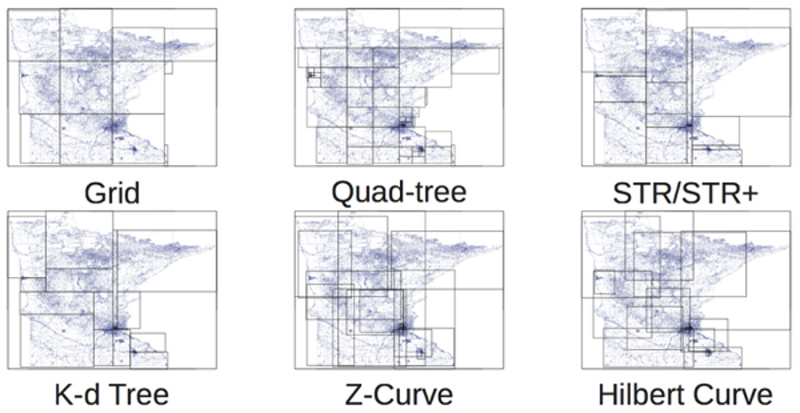






|
Метки: author fall_out_bug геоинформационные сервисы big data блог компании техносерв гис распределенные вычисления |
FabricPool — технология экономии для All Flash хранилищ |
|
|
LTS Webinar — Топ-5 интересных уязвимостей или как Вас могли взломать за последний год |

|
Метки: author Evgenia_s5 информационная безопасность java блог компании luxoft безопасность веб-приложений тестирование application security |
Сервис будущего: возможности и риски |
|
Метки: author ceesaxp читальный зал финансы в it блог компании райффайзенбанк i/o 2017 google будущее уже здесь конференция raiffeisenbank |
Win32/Industroyer: новая угроза для промышленных систем управления |



GetCurrentHwProfile
ImagePath на путь к новому бинарному файлу бэкдора.
THREAD_PRIORITY_HIGHEST, что означает, что они получают более высокую долю ресурсов центрального процессора. haslo.dat. Ожидаемые командные строки имеют вид:%LAUNCHER%.exe %WORKING_DIRECTORY% %PAYLOAD%.dll %CONFIGURATION%.ini%LAUNCHER%.exe – имя файла компонента запуска%WORKING_DIRECTORY% – каталог, в котором хранится вредоносная DLL и конфигурация%PAYLOAD%.dll – имя файла вредоносной DLL %CONFIGURATION%.ini – файл, в котором хранятся данные конфигурации конкретной полезной нагрузки. Путь к этому файлу передается вредоносной DLL компонентом запуска Crash как показано на рис. 5.
Crash101.dll и экспортированной функцией Crash.101.dll названа в честь международного стандарта IEC 101 (он же IEC 60870-5-101), который описывает протокол мониторинга и управления электроэнергетическими системами. Протокол обеспечивает коммуникацию между промышленными системами управления и удаленными терминальными блоками (Remote Terminal Units – RTUs). Обмен данными осуществляется через последовательное соединение. 
CreateFile, WriteFile и ReadFile. Первый СОМ-порт из файла конфигурации используется для фактической связи, два остальных – открыты, чтобы предотвратить обращение других процессов. Таким образом, компонент 101 может взять на себя управление устройством RTU.C_SC_NA_1) и двухпозиционной командой (C_DC_NA_1) и отправляет на устройство RTU. Основная цель компонента – изменить значение выключателя On/Off для однопозиционного и двухпозиционного командного типа IOA. Так, на первом этапе компонент пытается переключить IOA в состояние Off, на второй – On, на заключительном этапе – вернуть в значение Off.
104.dll названа в честь стандарта IEC 104 (IEC 60870-5-104). Протокол IEC 104 дополняет IEC 101 так, чтобы передавать данные по TCP/IP. Благодаря гибко изменяемой конфигурации, компонент может быть настроен атакующими под различное оборудование. Рис. 8 показывает, как может выглядеть файл конфигурации.
STATION, за которым следуют свойства, определяющие работу компонента 104. Конфигурация может содержать множество записей STATION.
STATION, по одному на каждый. В каждом таком процессе компонент 104 попытается связаться с указанным адресом IP при помощи протокола, описанного в стандарте IEC 104. До установления соединения он попытается завершить легитимный процесс, который должен отвечать за обмен данными с устройством. Это происходит только в том случае, если свойство stop_comm_service прописано в конфигурации. По умолчанию компонент 104 завершает процесс с именем D2MultiCommService.exe, либо с тем именем, которое прописано в его конфигурации.operation, чтобы указать, как будут опрошены IOA адреса однопозиционного типа.operation — range. Хакеры используют его для обнаружения возможных IOA в интересующем устройстве. Им приходится применять данный подход, потому что протокол, описанный в стандарте IEC 104, не дает определенного метода получения этой информации.range работает в два этапа. Во время первого, после получения диапазона IOA из файла конфигурации, компонент 104 подключается к целевому адресу IP и выполняет опрос указанных IOA. На каждый из этих IOA компонент 104 передает пакеты команд выбора и исполнения для изменения состояния и проверки, относится ли данный IOA к однопозиционному командному типу.
range. Если возможность записи в логи включена, компонент запишет в него Starting only success. Остальная часть второго этапа состоит в бесконечном цикле использования ранее обнаруженных IOA однопозиционного типа. В цикле компонент непрерывно передает пакеты команд выбора и исполнения. Вдобавок, если опция change определена, компонент переключает состояние On/Off между этапами цикла.change была включена, так что между циклами компонент переключал значение выключателя с On на Off и писал это в лог.
operation — shift. Он очень похож на режим range. Атакующий определяет в файле конфигурации диапазон IOA и изменяемые значения. После активации компонента 104 все происходит точно так же, как и в режиме range; однако, как только все IOA в определенном диапазоне будут опрошены, он начинает опрос нового диапазона. Новый диапазон высчитывается путем сложения дефолтного диапазона и значений сдвига.operation — sequence. Может применяться хакерами после того, как они узнают значения всех IOA однопозиционного типа команд, поддерживаемых подключенным устройством. Этот компонент незамедлительно начнет исполнение бесконечного цикла, передавая пакеты выбора и исполнения на IOA, указанные в файле конфигурации.
61850.exe и DLL 61850.dll. Назван в честь стандарта IEC 61850. Этот стандарт описывает протокол, используемый для обмена данными между устройствами различных производителей, которые выполняют функции защиты, автоматизации, измерения, мониторинга и управления систем автоматики электрических подстанций. Это сложный и надежный протокол, но компонент 61850 использует только небольшой ряд его параметров, чтобы привести к разрушительным последствиям.i.ini. Ожидается, что файл конфигурации содержит список IP-адресов устройств, которые имеют возможность обмена данными по протоколу, описанному в стандарте IEC 61850. 
InitiateRequest при помощи Спецификации производственных сообщений (MMS). Если ожидаемый ответ получен, он передает MMS запрос getNameList. Таким образом, компонент составляет список имен объектов в виртуальном производственном устройстве (VMD). getNameList с каждым именем объекта. Таким образом, компонент нумерует названные переменные в определенном домене. 
getNameList в Wireshark.Read. Для некоторых из этих переменных компонент также может передать MMS запрос Write, который изменит их текущее состояние.OPC.exe и DLL, который использует функционал и 61850, и OPC DA компонентов. Внутреннее название DLL в экспортированной таблице PE OPCClientDemo.dll, что дает основание предположить, что этот компонент может быть основан на проекте с открытым исходным кодом OPC Client.
ICatInformation::EnumClassesOfCategories с идентификатором категории CATID_OPCDAServer20 и IOPCServer::GetStatus для определения тех, которые запущены.IOPCBrowseServerAddressSpace для нумерации всех серверных элементов OPC. Особым образом он ищет элементы, содержащие следующие последовательности в имени:
Abdul при добавлении новой группы OPC. Возможно эта строка используется атакующими в качестве сленгового названия решений ABB.
Abdul. IOPCSyncIO, прописывая значение 0x01 дважды. 
IOPCSyncIO.haslo.dat или haslo.exe, он может быть исполнен компонентом запуска, либо использоваться в качестве отдельного вредоносного инструмента.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\ServicesImagePath с пустой строкой в каждой обнаруженной записи. Это приведет к тому, что операционная система перестанет загружаться.Windows в названии.
SYS_BASCON.COM используется решениями ABB для хранения информации с конфигурацией, а файлы с расширением .paf (Product Authorization File) – для хранения информации по лицензиям для продуктов ABB MicroSCADA.

F6C21F8189CED6AE150F9EF2E82A3A57843B587D
CCCCE62996D578B984984426A024D9B250237533
8E39ECA1E48240C01EE570631AE8F0C9A9637187
2CB8230281B86FA944D3043AE906016C8B5984D9
79CA89711CDAEDB16B0CCCCFDCFBD6AA7E57120A
94488F214B165512D2FC0438A581F5C9E3BD4D4C
5A5FAFBC3FEC8D36FD57B075EBF34119BA3BFF04
B92149F046F00BB69DE329B8457D32C24726EE00
B335163E6EB854DF5E08E85026B2C3518891EDA8195.16.88[.]6
46.28.200[.]132
188.42.253[.]43
5.39.218[.]152
93.115.27[.]57
|
Метки: author esetnod32 антивирусная защита блог компании eset nod32 industroyer malware blackenergy |
Интернатура в геймдеве: быть или не быть? Первый опыт краснодарской студии Plarium |




|
Метки: author Plarium управление персоналом карьера в it-индустрии блог компании plarium геймдев интернатура интерны интерн обучение |
[Из песочницы] Симметричное и асимметричное шифрование. Разбор алгоритма передачи шифрованных данных между серверами |
$encrypted_data = urlencode(base64_encode(mcrypt_encrypt(MCRYPT_RIJNDAEL_256, $sinc_key, $notice_text, MCRYPT_MODE_ECB)));
$test_decrypted = trim(mcrypt_decrypt(MCRYPT_RIJNDAEL_256,$sinc_key, base64_decode(urldecode($encrypted_data)),MCRYPT_MODE_ECB));
|
Метки: author var_null криптография информационная безопасность алгоритмы симметричное шифрование ассиметричное шифрование php |
[recovery mode] Релиз chrome, исправляющий уязвимостей на 23,500$ |
На прошлой неделе Chrome обновился до 59 версии. Кроме изменений в сторону материал дизайна, было закрыто 30 ошибок безопасности. Общий размер вознаграждений за которые превысил 23k$, что еще раз доказывает работоспособность bugs bounty.

Наиболее серьезная брешь была обнаружена Чжао Цюйшуном (Zhao Qixun), также известным как S0rryMybad. Затрагивает эта уязвимость движок JavaScript V8 (CVE-2017-5070), эксперт получил за нее 7500 долларов. В апреле двое других экспертов сообщили разработчикам Chrome о недостатках, связанных с выполнением кода вне пределов памяти (CVE-2017-5071) и спуфингом омнибокс-адресов (CVE-2017-5071). За каждую из этих уязвимостей исследователи заработали 3000 долларов США.
Подробности о большинстве ошибок не раскрываются, пока большинство пользователей не установит обновления или если проблема была в сторонней библиотеке
[$7500] High CVE-2017-5070: Type confusion in V8. Reported by Zhao Qixun(@S0rryMybad) of Qihoo 360 Vulcan Team on 2017-05-16
[$3000] High CVE-2017-5071: Out of bounds read in V8. Reported by Choongwoo Han on 2017-04-26
[$3000] High CVE-2017-5072: Address spoofing in Omnibox. Reported by Rayyan Bijoora on 2017-04-07
[$2000] High CVE-2017-5073: Use after free in print preview. Reported by Khalil Zhani on 2017-04-28
[$1000] High CVE-2017-5074: Use after free in Apps Bluetooth. Reported by anonymous on 2017-03-09
[$2000] Medium CVE-2017-5075: Information leak in CSP reporting. Reported by Emmanuel Gil Peyrot on 2017-01-05
[$1000] Medium CVE-2017-5086: Address spoofing in Omnibox. Reported by Rayyan Bijoora on 2017-05-16
[$1000] Medium CVE-2017-5076: Address spoofing in Omnibox. Reported by Samuel Erb on 2017-05-06
[$1000] Medium CVE-2017-5077: Heap buffer overflow in Skia. Reported by Sweetchip on 2017-04-28
[$1000] Medium CVE-2017-5078: Possible command injection in mailto handling. Reported by Jose Carlos Exposito Bueno on 2017-04-12
[$500] Medium CVE-2017-5079: UI spoofing in Blink. Reported by Khalil Zhani on 2017-04-20
[$500] Medium CVE-2017-5080: Use after free in credit card autofill. Reported by Khalil Zhani on 2017-04-05
[$N/A] Medium CVE-2017-5081: Extension verification bypass. Reported by Andrey Kovalev (@L1kvID) Yandex Security Team on 2016-12-07
[$N/A] Low CVE-2017-5082: Insufficient hardening in credit card editor. Reported by Nightwatch Cybersecurity Research on 2017-05-11
[$N/A] Low CVE-2017-5083: UI spoofing in Blink. Reported by Khalil Zhani on 2017-04-24
[$N/A] Low CVE-2017-5085: Inappropriate javascript execution on WebUI pages. Reported by Zhiyang Zeng of Tencent security platform department on 2017-02-15
Кроме этих ошибок, команда Хрома пользуется и постоянно исправляет то, что находят известные сканеры — AddressSanitizer, MemorySanitizer, Control Flow Integrity, и libFuzzer.
|
Метки: author alexZzZzZzZ информационная безопасность google chrome |
[Перевод] Теория современного Go |
tl;dr магия это плохо; глобальные состояние это магия -> глобальные переменные в пакетах это плохо; функция init() не нужна
Самое главное и лучшее свойство Go это то, что он, по-сути, антимагический. Не считая пары исключений, простое чтение Go кода не оставляет двусмысленности в определениях, зависимостях или поведении рантайма. Это делает Go относительно легким для чтения, что, в свою очередь, делает его легким для поддерживания, что является самым главным свойством в индустриальном программировании.
Но всё же есть пару мест, где магия может просочиться. Один из, к сожалению, распространённых путей это использование глобального состояния. Объекты, определенные в глобальном пространстве пакета могут хранить состояние или поведение, которое спрятано от внешнего наблюдателя. Код, который зависит от этих глобальных объектов может иметь неприятные побочные эффекты, которые разрушают способность читателя понимать и строить ментальную модель прогреты.
Функции (включая методы) по сути являются единственным механизмом, который есть в Go, чтобы строить абстракции. Давайте посмотрим на следующее определение функции:
fund NewObject(n int) (*Object, error)По соглашению, мы ожидаем, что функции в форме NewXXX это конструкторы типов. Это ожидание подтверждается, когда мы видим, что функция возвращает указатель на Object и ошибку. Из этого мы можем вывести, что конструктор может не сработать, и в этом случае он вернёт ошибку, в которой объяснена причина. Также мы видим, что функция принимает на вход единственный целочисленный параметр, который, как мы полагаем, контролирует какой-то аспект или свойство объекта, который будет возвращён. Вероятно, есть какие-то допустимые значения n, которые, будучи нарушенными, приведут к ошибке. Но, поскольку, функция больше не принимает других параметров, мы ожидаем, что функция больше никаких побочных эффектов нет, кроме (вероятно) выделения памяти.
Просто прочитав сигнатуру функции, мы могли сделать все эти выводы и построить ментальную модель функции. Этот процесс, будучи умноженным и повторенным много раз рекурсивно начиная с первой строки функции main — это то, как мы читаем и понимаем программы.
Теперь, давайте посмотрим на тело функции:
func NewObject(n int) (*Object, error) {
row := dbconn.QueryRow("SELECT ... FROM ... WHERE ...")
var id string
if err := row.Scan(&id); err != nil {
logger.Log("during row scan: %v", err)
id = "default"
}
resource, err := pool.Request(n)
if err != nil {
return nil, err
}
return &Object{
id: id,
res: resource,
}, nil
}Функция использует глобальный объект из пакета sql — database/sql.Conn, чтобы произвести запрос к какой-то непонятной базе данных; затем глобальный для пакета логгер, чтобы записать строку в непонятном формате в непонятно куда; и глобальный объект пула запросов, чтобы запросить какой-то ресурс. Все эти операции имеют побочные эффекты, которые абсолютно невидимы при чтении сигнатуры функции. У программиста, читающего её, нет способа предсказать ни одно из этих действий, кроме как чтения тела функции и заглатывания в определения глобальных переменных.
Давайте попробуем такой вариант сигнатуры:
func NewObject(db *sql.DB, pool *resource.Pool, n int, logger log.Logger) (*Object, error)Просто подняв все эти зависимости как параметры, мы позволили программисту достаточно аккуратно смоделировать зависимости и поведение функции. Теперь знает точно, в чем функция нуждается, чтобы выполнить свою работу, и может предоставить всё необходимое.
Если бы мы разрабатывали публичное API для этого пакета, мы бы могли пойти даже дальше:
// RowQueryer models part of a database/sql.DB.
type RowQueryer interface {
QueryRow(string, ...interface{}) *sql.Row
}
// Requestor models the requesting side of a resource.Pool.
type Requestor interface {
Request(n int) (*resource.Value, error)
}
func NewObject(q RowQueryer, r Requestor, logger log.Logger) (*Object, error) {
// ...
}Смоделировав каждый конкретный объект как интерфейс, содержащий только методы, которые нам нужны, мы позволили вызывающему коду легко переключаться между реализациями. Это уменьшает связанность между пакетами, и позволяет нам легко мокать (mock) конкретные зависимости в тестах. Тестирование же оригинальной версии кода, с конкретными глобальными переменными, включает утомительное и склонне к ошибкам подмену компонентов.
Если бы все наши конструкторы и функции принимали зависимости явно, нам бы не нужны были глобальные переменные вообще. Взамен, мы бы могли создавать все наши соединения с базами данных, логгеры и пулы ресурсов, в функции main, давая возможность будущим читателям кода очень четко понимать граф компонентов. И мы можем очень явно передавать все наши зависимости, убирая вредную для понимания магию глобальных переменных. Также, заметьте, что если у нас нет глобальных переменных, нам больше не нужна функция init, чья единственная функция это создавать или изменять глобальное состояние пакета. Мы можем затем посмотреть на все случаи использования функций int со справедливым подозрением: что, собственно, это код вообще делает? Если он не в функции main, зачем он?
И это не просто возможно, но и очень просто, и, на самом деле, очень освежающе, писать Go программы, в которых практически нет глобального состояния. Из моего опыта, программирование таким способом ничуть не медленнее и не скучнее, чем использование глобальных переменных для уменьшения определений функций. Даже наоборот: когда сигнатура функции надежно и полноценно описывает её поведение, мы можем аргументировать, рефакторить и поддерживать код в больших кодовых базах гораздо более эффективно. Go kit был написан именно в таком стиле с самого начала, и только выиграл от этого.
--
И на этом моменте я могу сформулировать теорию современного Go. Отталкиваясь от слов Дейва Чини, я предлагаю следующие правила:
Конечно, есть исключения. Но следуя этим правилам, остальные практики появляются естественным образом.
|
Метки: author divan0 go global state |
Пошаговая настройка Apache с выбором версий php + Nginx как reverse proxy (с mod_pagespeed) на ubuntu 16.0.4 |
sudo -i
apt install -y apache2
-y apt install apache2 apt install -y php libapache2-mod-php apt updateapt install -y make \
git autoconf \
lynx \
wget \
build-essential \
libxml2-dev \
libssl-dev \
libbz2-dev \
libcurl4-openssl-dev \
libpng12-dev \
libfreetype6-dev \
libxpm-dev \
libmcrypt-dev \
libmhash-dev \
libmysqlclient-dev \
libjpeg62-dev \
freetds-dev \
libjson-c-dev \
re2c \
zlib1g-dev \
libpcre3 \
libpcre3-dev \
unzip \
libxslt1-devmkdir -p /opt/source/php
mkdir -p /opt/php/
cd /opt/source/php
wget -c http://php.net/get/php-5.6.18.tar.bz2/from/this/mirror -O php-5.6.18.tar.bz2
tar xvjf php-5.6.18.tar.bz2
cd /opt/source/php/php-5.6.18
./configure --enable-cli \
--prefix=/opt/php/php-5.6.18 \
--disable-rpath \
--enable-calendar \
--enable-discard-path \
--enable-fastcgi \
--enable-force-cgi-redirect \
--enable-fpm \
--enable-ftp \
--enable-gd-native-ttf \
--enable-inline-optimization \
--enable-mbregex \
--enable-mbstring \
--enable-pcntl \
--enable-soap \
--enable-sockets \
--enable-sysvsem \
--enable-sysvshm \
--enable-zip \
--with-bz2 \
--with-curl \
--with-curl \
--with-freetype-dir \
--with-gd \
--with-gd \
--with-gettext \
--with-jpeg-dir \
--with-jpeg-dir=/usr/lib/ \
--with-libdir=/lib/x86_64-linux-gnu \
--with-libxml-dir=/usr \
--with-mcrypt \
--with-mhash \
--with-mysql \
--with-mysql \
--with-mysqli \
--with-mysqli \
--with-openssl \
--with-pcre-regex \
--with-pdo-mysql \
--with-png-dir=/usr \
--with-zlib \
--with-zlib-dir
make
make install
/opt/php/php-5.6.18/bin/php -v
apt install libapache2-mod-fcgid
a2enmod cgi fcgid actions
service apache2 restart
mkdir -p /opt/php/php-5.6.18/fcgi-bin
#!/opt/php/php-5.6.18/bin/php-cginano /opt/php/php-5.6.18/fcgi-bin/php
chmod +x /opt/php/php-5.6.18/fcgi-bin/php
ServerAdmin webmaster@localhost
DocumentRoot /var/www/html
IPCCommTimeout 7200
FcgidConnectTimeout 320
MaxRequestLen 25728640
FcgidMaxRequestsPerProcess 0
FcgidBusyTimeout 3600
FcgidOutputBufferSize 0
SetHandler fcgid-script
FCGIWrapper /opt/php/php-5.6.18/fcgi-bin/php
ErrorLog /var/www/html/error.log
CustomLog /var/www/html/access.log combined
service apache2 reload
apt install apache2-suexec-custom
a2enmod suexec
|--/var/www/ - Корневая папка, права 751 владелец root
|----/php-bin - Папка храннения дефолтных настроек для php
|------/php-5.6.18 - Папка храннения дефолтных настроек для php-5.6.18
|--------php - Исполняемый файл для php-5.6.18
|--------php.ini - Дефольный файл настроке
|--------php.ini - Дефольный файл настроке
|----/apache-cert - папка хранения сертификатов для apache
mkdir -p /var/www/users/admin
mkdir -p /var/www/users/admin/domain.ru
mkdir -p /var/www/users/admin/apache-log
mkdir -p /var/www/users/admin/php-bin
mkdir -p /var/www/users/admin/temp
mkdir -p /var/www/users/admin/temp/php-session
cp /opt/php/php-5.6.18/fcgi-bin/php /var/www/users/admin/php-bin/php
cp /opt/php/php-5.6.18/fcgi-bin/php.ini /var/www/users/admin/php-bin/php.ini
useradd -m -s /bin/bash admin
passwd admin
chown admin:admin -R /var/www/users/admin
usermod -d /var/www/users/admin admin
ServerAdmin webmaster@localhost
DocumentRoot /var/www/users/admin/domain.ru
SuexecUserGroup admin admin
RemoteIPHeader X-Forwarded-For
RemoteIPHeader X-Real-IP
RemoteIPInternalProxy 127.0.0.1
RewriteEngine On
RewriteRule .* - [E=REMOTE_USER:%{HTTP:Authorization}]
IPCCommTimeout 7200
FcgidConnectTimeout 320
MaxRequestLen 25728640
FcgidMaxRequestsPerProcess 0
FcgidBusyTimeout 3600
FcgidOutputBufferSize 0
SetHandler fcgid-script
FCGIWrapper /var/www/users/admin/php-bin/php
ErrorLog /var/www/users/admin/apache-log/error.log
CustomLog /var/www/users/admin/apache-log/access.log combined
session.save_path = /var/www/users/admin/temp/php-sessionservice apache2 restart
/etc/apache2/ports.conf
+ Ваши созданные виртуальные хосты
service apache2 restart
apt-get install nginx
apt install -y build-essential zlib1g-dev libpcre3 libpcre3-dev unzip libxslt1-dev libgd-dev libgeoip-dev
mkdir -p /opt/source/nginx
cd /opt/source/nginx
wget https://github.com/pagespeed/ngx_pagespeed/archive/v1.11.33.4-beta.zip
unzip v1.11.33.4-beta.zip
cd ngx_pagespeed-1.11.33.4-beta
wget https://dl.google.com/dl/page-speed/psol/1.11.33.4.tar.gz
tar -xzvf 1.11.33.4.tar.gz
cd /opt/source/nginxnginx -Vwget https://nginx.ru/download/nginx-1.10.0.tar.gz
tar -xvzf nginx-1.10.0.tar.gz
cd /opt/source/nginx/nginx-1.10.0
./configure \
--with-cc-opt='-g -O2 -fPIE -fstack-protector-strong -Wformat -Werror=format-security -Wdate-time -D_FORTIFY_SOURCE=2' --with-ld-opt='-Wl,-Bsymbolic-functions -fPIE -pie -Wl,-z,relro -Wl,-z,now' --prefix=/usr/share/nginx --conf-path=/etc/nginx/nginx.conf --http-log-path=/var/log/nginx/access.log --error-log-path=/var/log/nginx/error.log --lock-path=/var/lock/nginx.lock --pid-path=/run/nginx.pid --http-client-body-temp-path=/var/lib/nginx/body --http-fastcgi-temp-path=/var/lib/nginx/fastcgi --http-proxy-temp-path=/var/lib/nginx/proxy --http-scgi-temp-path=/var/lib/nginx/scgi --http-uwsgi-temp-path=/var/lib/nginx/uwsgi --with-debug --with-pcre-jit --with-ipv6 --with-http_ssl_module --with-http_stub_status_module --with-http_realip_module --with-http_auth_request_module --with-http_addition_module --with-http_dav_module --with-http_geoip_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_image_filter_module --with-http_v2_module --with-http_sub_module --with-http_xslt_module --with-stream --with-stream_ssl_module --with-mail --with-mail_ssl_module --with-threads \
--add-module=/opt/source/nginx/ngx_pagespeed-1.11.33.4-beta \
--with-http_mp4_module
make
make install
service nginx stop
mv /usr/sbin/nginx /usr/sbin/nginx_backup
mv /opt/source/nginx/nginx-1.10.0/objs/nginx /usr/sbin/nginx
service nginx start
/var/www/temp/
/var/www/temp/page-speed/
pagespeed on;
pagespeed FileCachePath "/var/www/temp/page-speed/";
pagespeed EnableFilters combine_css,combine_javascript,rewrite_images,rewrite_css,rewrite_javascript,inline_images,recompress_jpeg,recompress_png,resize_images;
pagespeed JpegRecompressionQuality 85;
pagespeed ImageRecompressionQuality 85;
pagespeed ImageInlineMaxBytes 2048;
pagespeed LowercaseHtmlNames on;
server {
listen 80;
server_name domain.ru;
access_log /var/log/nginx.access_log;
location ~* \.(jpg|jpeg|gif|png|css|zip|tgz|gz|rar|bz2|doc|xls|exe|pdf|ppt|tar|wav|bmp|rtf|swf|ico|flv|txt|xml|docx|xlsx)$ {
root /var/www/users/admin/domain.ru;
index index.html index.php;
access_log off;
expires 30d;
error_page 404 = @prox;
}
location @prox{
proxy_pass 127.0.0.1:8880;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-for $remote_addr;
proxy_set_header Host $host;
proxy_connect_timeout 60;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_redirect off;
proxy_set_header Connection close;
proxy_pass_header Content-Type;
proxy_pass_header Content-Disposition;
proxy_pass_header Content-Length;
}
location ~ /\.ht {
deny all;
}
location / {
proxy_pass 127.0.0.1:8880;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-for $remote_addr;
proxy_set_header Host $host;
proxy_connect_timeout 60;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_redirect off;
proxy_set_header Connection close;
proxy_pass_header Content-Type;
proxy_pass_header Content-Disposition;
proxy_pass_header Content-Length;
}
}
|
Метки: author pan-alexey хостинг nginx apache администрирование linux-систем apache2 suexec php fastcgi pagespeed insights |
Багфикс человека: как фиксить баги, которые мешают работать |
Почему у людей не получается взять — и выполнить задачу? Откуда берутся заминки, неправильные оценки и прокрастинация? Почему люди не понимают друг друга, хотя вроде бы не дураки и общаются на одном языке?
Как оказалось, причина у всего этого одна — когнитивные искажения. Вот про них и поговорим.

Когнитивные искажения — баги в психике человека, которые мешают объективно воспринимать реальность. Их много и они водятся в каждом — на странице Википедии в списке когнитивных искажений под 130 пунктов, и 129 вы, скорее всего, обнаружите у себя. К ним относится сила первого впечатления, желание оправдываться и даже причина, почему мы не можем дать адекватную оценку по задаче.
Когнитивные искажения — как вредные привычки. Жить можно, но лучше бы с ними покончить. И тут с вредными привычками даже проще: мы хотя бы знаем, что курить или точить пиццу под покровом ночи — грешновато, и надо бы в один прекрасный день это прекратить. А когнитивные искажения если в лицо не знаешь — то даже не представляешь, с чем бороться. Сам мозг против этого (но об этом ниже).
Так как когнитивные искажения мешают работать, понимать друг друга и, по итогу, выполнять задачи, от них нужно избавляться. Это касается менеджеров, разработчиков, дизайнеров, аналитиков, копирайтеров — всех. В идеальном мире каждый сам отлавливает и фиксит свои искажения, но в реальности, как мы знаем, без тестировщиков (взгляда со стороны) такое редко случается. Так что будьте готовы: если вы не фиксите свой баг — однажды окружающие придут на помощь и заставят вас это сделать. А я расскажу, как именно :) Не буду рассматривать все 130 искажений — пройдусь только по тем, которые были пойманы в нашей студии и которые часто встречаются у работников ИТ-сферы.

Генерализация частных случаев — когнитивное искажение, из-за которого человек расширяет поставленную задачу. При этом он даже не осознает, что её можно выполнить проще и быстрее. Чаще всего встречается у программистов и редко фиксится самостоятельно. Чтобы вправить это когнитивное искажение, нужна помощь менеджера. Как минимум один раз ему придётся включить режим варан-менеджмента.
Есть такая байка, что варан кусает жертву, при этом отравляет её. Яд действует не сразу, поэтому после варан ходит за покусанным и ждёт, когда тот сдохнет. И уже тогда съедает.
Так же пристально, как варан за своим будущим обедом, менеджер должен следить за работой разработчика или дизайнера. В отличие от зверей из дикой природы, они не помирают от этого, но — о чудо! — дело делается, а варан остается голодным :) Кстати, программистам это только поначалу неприятно (ну и неприятна сама идея, что с ними так поступят). Дальше, как ни странно — человек втягивается и выравнивается.
Этот метод гарантированно ставит мозги на место и снижает прокрастинацию — и в итоге оказывается, что вместо недели задачу можно без особого напряга решить за один день. Или час. Или 20 минут. Ну вы поняли.

Среди когнитивных искажений можно выделить целую группу тех, которые мешают приступить к выполнению задачи. Они тоже чаще встречаются у программистов и дизайнеров, хотя иногда проскакивают и у менеджеров в ответах на хотелки клиентов. И обычно выражаются категоричным: «Это невозможно!».
У такой реакции несколько причин:
Этот баг уже легче отловить самому. Просто нужно помнить и верить, что не бывает невыполнимых задач. Вспомнили — и думайте, какие ресурсы нужны, чтобы выполнить задание.
Если вы словили это когнитивное искажение у коллеги — задайте ему тот же вопрос, какой задали бы себе: «Скажи, пожалуйста, что тебе потребуется, чтобы сделать эту задачу?». И повторяйте его, пока коллега не поймёт, что ему не верят, да и действительно задача не так уж и невыполнима.
Ну и в будущем, если ситуация повторится, на «Это невозможно!» у вас будет кейс, как человек задачу с таким же диагнозом решил за N минут. Напомните ему этот случай пару раз — и дальше он уже научится сам фиксить этот баг.

Проклятие знания — ситуация, когда человек более информированный не может рассмотреть проблему с точки зрения человека, который знает меньше. Отсюда, кстати, столько непонятых гениев. Среди менеджеров даже больше, чем среди программистов или дизайнеров. В основном этот багуля встречается у неопытных менеджеров — которым кажется, что сделать ВОТ ТАК было очевидным решением, которое даже проговаривать не обязательно (чего, естественно, и не было сделано и не сформулировано в задаче). А то, что программист/дизайнер/аналитик этого не понял — его косяк. Конечно, такое нужно фиксить.
Проклятие знания устраняется самодрессировкой. Нужно отлавливать своё нелогичное поведение и наступать себе на хвост. Пытаться выстроить конструктивный диалог, даже если очень не хочется. А то всю жизнь можно прожить, думая, что все вокруг глупые, а ты один в пальто стоишь красивый. А на деле окажется, что всё совсем наоборот.

Следующее когнитивное искажение — когда критика результата воспринимается как личное оскорбление тем, чью работу критикуют.
Это искажение часто встречается у личностей творческих. Особенно если они не выспались и в плохом настроении. За человека говорят эмоции, поэтому он редко может себя контролировать, обижается и сыпет возражениями. Чтобы вырулить такую ситуацию в конструктив и никого не обидеть, нужно действовать по следующему алгоритму.

Отдаю должное: не все когнитивные искажения — причина проблем и непонимания. Бывают и полезные. Например, «эффект генерации». Благодаря этому искажению человек лучше запоминает информацию, когда воспроизводит её сам, а не воспринимает извне. Поэтому если вы сомневаетесь, что правильно поняли задачу, или боитесь забыть — просто повторите её вслух.
Нечто похожее есть в авиационных регламентах. Когда диспетчер на земле передает какую-то информацию, пилот в самолете должен всю её повторить. В такой ситуации высока цена ошибки, поэтому повторение необходимо, во-первых, чтобы исключить помехи и другие лажи со связью. Во-вторых, чтобы пилот успел выставить нужные параметры, пока слушает, и просто считал их с приборов, когда отвечает. И, в-третьих, чтобы закрепить полученную информацию эффектом генерации — бонусом.
Поэтому не бойтесь и не стесняйтесь повторять постановки — это реальный рабочий приём, проверенный пилотами.

Это как раз то, о чем я упоминал в начале статьи — мозг не хочет замечать свои несовершенства. Поэтому существует слепое пятно в отношении когнитивных искажений. Даже если человек знает о них, то вряд ли согласится, что они влияют на его поведение. А последствия спишет на обстоятельства и на глупость окружающих. И, соответственно, не сделает ничего, чтобы пофиксить свои когнитивные искажения.
Поэтому если вы замечаете, что задачи делаются с сучками и задоринками, и хотите это изменить — попробуйте оценить объективно, может, причина тому — когнитивные искажения? Если вам кажется, что конечно нет — лучше на всякий случай спросите коллег. Слепое пятно не действует в отношении чужих багов :)
Теперь, когда вы знаете про когнитивные искажения, и даже понимаете, в каких именно местах они выпирают и мешают работать, вы сможете с ними бороться. Конечно, будет трудно поначалу, да ещё и слепое пятно будет мешаться. Но со временем оно уменьшится. И тогда и вам, и вашим коллегам станет проще жить и работать — в процессах станет меньше необъяснимых лаж и больше конструктива, мира, дружбы и жвачки.
То, что описано в этой статье — верхушка айсберга когнитивных искажений и аномалий в работе нашего мозга. Если тема вас зацепила и хочется ещё — рекомендую почитать эти книги:
|
Метки: author zevvssibirix управление сообществом управление персоналом управление людьми баги психология психология влияния |
[Перевод] Выпуск Rust 1.18 |
Команда Rust рада представить выпуск Rust 1.18.0. Rust — это системный язык программирования, нацеленный на безопасность, скорость и параллельное выполнение кода.
Если у вас установлена предыдущая версия Rust, то для обновления достаточно выполнить:
$ rustup update stableЕсли у вас ещё не установлен Rust, вы можете установить rustup c соответствующей страницы нашего веб-сайта и ознакомиться с подробным примечанием к выпуску 1.18.0 на GitHub.
Как и всегда, Rust 1.18.0 собрал в себе множество улучшений и новых возможностей.
Одно из крупнейших и самых ожидаемых изменений: члены команды Carol Nichols и Steve Klabnik пишут новую редакцию "Язык программирования Rust", официальной книги о Rust. Она пишется открыто на GitHub, и уже более ста человек внесли в нее свой вклад. Этот выпуск включает первый черновой вариант второго издания в нашей онлайн документации. 19 из 20 глав уже написаны, черновой вариант 20 главы будет добавлен в выпуске Rust 1.19. Когда книга будет завершена, версия для печати будет доступна через No Starch Press, если вы предпочитаете бумажную копию. Мы все еще работаем совместно с редакторами No Startch, чтобы улучшить текст, но мы бы хотели представить книгу широкой аудитории уже сейчас.
Новое издание написано полностью с нуля, используя знания, полученные нами за последние два года обучения людей Rust. Вы найдете совершенно новые объяснения множества ключевых концепций Rust, новые проекты для обучения, и много других интересных и полезных вещей. Пожалуйста, взгляните и сообщите нам, что думаете!
Что касается самого языка, старые функции получили новые возможности: ключевое слово pub было немного расширено. Опытные программисты Rust знают, что в Rust все элементы приватны по умолчанию, и вы должны использовать ключевое слово pub, чтобы сделать их публичными. В Rust 1.18.0 pub получило новую форму:
pub(crate) bar;Выражение внутри () является 'ограничением', уточняющим область видимости. Использование ключевого слова crate в примере выше означает, что bar будет публичным для всего контейнера (crate), но не вне него. Это упрощает создание API, которые "публичны для вашего контейнера", но не доступны вашим пользователям. Это было возможно с существующей системой модулей, но очень часто выглядело неудобно.
Вы также можете указать путь, например:
pub(in a::b::c) foo;Это означает "foo публично внутри иерархии a::b::c, но нигде больше". Эта особенность была определена в RFC 1422 и описана в документации.
Для пользователей Windows, Rust 1.18.0 имеет новый атрибут, #![windows_subsystem]. Это работает так:
#![windows_subsystem = "console"]
#![windows_subsystem = "windows"]Эти выражения контролируют флаг /SUBSYSTEM компоновщика. В настоящий момент, доступны только console и windows.
Когда это может быть полезным? В простейшем случае, если вы разрабатываете графическое приложение, и не указали windows, окно консоли будет появляться при старте вашего приложения. С этим флагом, этого не произойдет.
Наконец, кортежи, перечисления и структуры (без #[repr]) всегда имели неопределенное размещение в памяти. Мы включили автоматическое переупорядочивание, что может привести к меньшим размерам структур.
Представьте следующую структуру:
struct Suboptimal(u8, u16, u8);В предыдущих версиях Rust на платформе x86_64, эта структура будет занимать в памяти шесть байт. Но смотря на код, вы ожидаете только 4. Дополнительные два байта появляются из-за выравнивания: так как наибольший тип в структуре u16, она должна быть выравнена по два байта. Но в этом случае u16 расположено в памяти со смещением в один байт. Чтобы разместить его со смещением в два байта, нужно добавить еще один байт выравнивания после первого u8. Добавив еще один байт после второго u8, получаем
1 + 1 (выравнивание) + 2 + 1 + 1 (выравнивание) = 6 байт.
Но что, если наша структура выглядит так?
struct Optimal(u8, u8, u16);Эта структура выровнена оптимально; u16 лежит с выравниванием в два байта, как и вся структура в целом. Никакого выравнивания не требуется. Это дает нам 1 + 1 + 2 = 4 байт.
Проектируя Rust, мы оставили детали размещения в памяти неопределенными именно по этой причине. Не придерживаясь определенной политики, мы можем вносить оптимизации, например, как в этом случае, когда компилятор может оптимизировать Suboptimal в Optimal автоматически. И если вы проверите размеры Suboptimal и Optimal в Rust 1.18.0, вы увидите, что они обе имеют размер 4 байта.
Мы планировали это изменение в течение длительного времени; предыдущие версии Rust включали эту оптимизацию в ночных (nightly) сборках, но некоторые люди писали небезопасный код, который требовал точных данных о размещении в памяти. Мы откатили это изменение и исправили все подобные случаи, о которых знали. Но если вы найдете какой-нибудь код, который работает неправильно, сообщите нам, чтобы мы смогли его исправить!
Мы планировали перенести rustdoc на Markdown-совместимый парсер CommonMark в течение долгого времени. Однако, простой переход может привести к проблемам, так как спецификация CommonMark отличается от нашего текущего парсера, Hoedown. Как часть нашего плана перехода, новый флаг был добавлен в rustdoc,
--enable-commonmark. Этот флаг включает использование нового парсера вместо старого. Пожалуйста попробуйте его! Насколько мы знаем, оба парсера производят одинаковые результаты, но мы хотим знать, если вы найдете сценарий, при котором их результаты отличаются!
Наконец, компиляция самого rustc теперь на 15%-20% быстрее. Сообщения коммитов в этом PR содержат некоторые детали; существовало множество неэффективных мест, но теперь все они исправлены.
Смотрите подробные заметки о выпуске для подробностей.
Семь новых API были стабилизированы в этом выпуске:
Child::try_wait, неблокирующая версия Child::wait.HashMap::retain и HashSet::retain добавляют retain из API Vec для этих двух хранилищ.PeekMut::pop позволяет вам вытащить верхний элемент из BinaryHeap после того как вы уже прочитали его без необходимости упорядочивать кучу второй раз.TcpStream::peek, UdpSocket::peek, UdpSocket::peek_from позволяют вам просматривать поток или сокет.Смотрите подробные заметки о выпуске для подробностей.
В Cargo появилась поддержка для Pijul VCS, написанной на Rust.
cargo new my-awesome-project --vcs=pijul включает ее!
В дополнение к флагу --all, Cargo теперь имеет несколько новых флагов, например --bins, --examples, --tests и --benches, которые позволяют вам собирать все программы заданного типа.
Наконец, Cargo теперь поддерживает Haiku и Android!
Смотрите подробные заметки о выпуске для подробностей.
Множество людей участвовало в создании Rust 1.18. Мы не смогли бы этого добиться без помощи каждого из вас. Спасибо!
От переводчика
Благодарю Gordon-F и ozkriff за помощь в переводе.
Если вы заинтересовались Rust и у вас есть вопросы, присоединяйтесь!
|
Метки: author vitvakatu программирование rust релиз новости перевод |
[Из песочницы] Автоматизация тестирования OpenStack |







|
Метки: author Ilusa тестирование it-систем open source openstack testing automated testing itis |
Тест на знание мобильной рекламы в Facebook |

|
|






