[Из песочницы] Сумасшедший искусственный интеллект |
Почему все хотят создать здравомыслящий искусственный интеллект? Что если пойти другим путём, и попробовать создать сумасшедший искусственный интеллект? Случалось ли у вас такое такое, когда какая нибудь навязчивая мысль не давала вам покоя весь день, то и дело всплывая в сознании? Или что вы не могли вспомнить слово, хотя оно крутилось у вас на языке? Или вы пытались что-то вспомнить, но у вас ничего не выходило? А спустя несколько дней, а то и недель, эта информация вдруг всплывала в сознании...
В связи с этим сделаем предположение, что на самом деле мы не управляем мысленным процессом на прямую, а лишь отправляем задания на обработку. Есть задания, ответы на которые находятся на поверхности в быстром доступе. И есть задания, ответы на которые мозг отложил куда-то по дальше.
Тогда ситуацию, в которой мы ни как не можем что-то вспомнить, можно объяснить тем, что мозг взял задание в обработку, не нашел ответа в быстром доступе, и положил это задание в очередь заданий с низким приоритетом. Обработка очереди заданий с низким приоритетом происходит в фоновом режиме, и не гарантирует выполнение задания. Или ситуацию, когда у нас то и дело в сознании всплывает какая-то мысль можно объяснить тем, что мозг и не переставал эту мысль крутить в цикле. И иногда эта мысль попадала в наш фокус.
Наполнение словаря мыслесловами происходит путём анализа какого-либо текста (чем больше текста проанализировано, тем лучше). При анализе производятся следующие операции:
Давайте пока разберем только мыслеслово, мыслепредложение, эфир и мыслефункцию, которая на вход получает одно мыслеслово. Суть работы мыслефункции в следующем: если мы подадим на вход мыслефункции мыслеслово "лук", то в процессе обработки мыслеслова мыслефункция отберёт из словаря все мыслеслова, которые имеют мыслеассоциации со словом "лук", например "зеленый", "репчатый", "оружие", "овощ", "тетива", "стрела" и т.д. Затем она вызывает саму себя, отправляя на вход мыслеслово вес мыслеассоциации которого наибольший.
Получается, что мыслефункция порождает целый ряд вызовов мыслефункций, отправляя на вход очередное мыслеслово, тем самым мы получили цепочку из мыслеслов, т.е. мыслепредложение.
Весь этот процесс идёт непрерывно, тем самым создавая эфир.
Построим цепочку из трёх мыслефункций: На вход первой мы подаем мыслеслово "лук". Она, в свою очередь, вызывает вторую мыслефункцию подавая ей на вход мыслеслово "репчатый". Вторая мыслефункция вызывает третью, отправляя ей на вход мыслеслово "овощ" и т.д.
Таким образом мы получаем цепочку из мыслефункций, и если взять все мыслеслова этой цепочки, то получим мыслепредложение: "лук репчатый овощ".
С учётом того, что в фокусе сознания человек может держать, по моим наблюдениям, только одну мысль (для этого был придуман простой эксперимент, в ходе которого необходимо перечислить алфавит, произнося после каждой буквы цифру, т.е.: А1 Б2 В3 и т.д.), а все остальные мысли представим как непрерывный поток(эфир), из которого мы иногда ловим в фокусе одну из цепочек мыслей (мыслепредложение).
Изменяя веса мыслеассоциаций мы можем влиять на ход мыслеслов в мыслепредложениях. Это можно сравнить с тем, когда вы читаете статью, и после прочтения ещё долго обдумываете мысль, которой автор с вами поделился. Или же вы посмотрели фильм, и затем рассказываете о нём друзьям. Другой пример когда изменяются веса у мыслеассоциаций, это момент встречи с знакомым человеком, который вам что-то обещал, но вы про это забыли, а теперь увидев его снова вспомнили.
Если у нас получится создать подобный эфир, то поток мыслепредложений в этом эфире будет похож на мысли сумасшедшего человека, который повторяет одно и тоже. Одной из основных задач, решение которой необходимо будет добиться, это создание наибольшей длинны мыслепредложений. Тогда "спрашивая" систему о чём либо, она нам будет отвечать этими мыслепредложениями.
|
Метки: author PWRMind машинное обучение ai ии искусственный интеллект |
SQL Server Integration Services (SSIS) для начинающих – часть 2 |


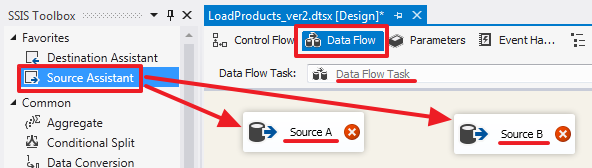

SELECT
ID SourceProductID,
Title,
Price
FROM Products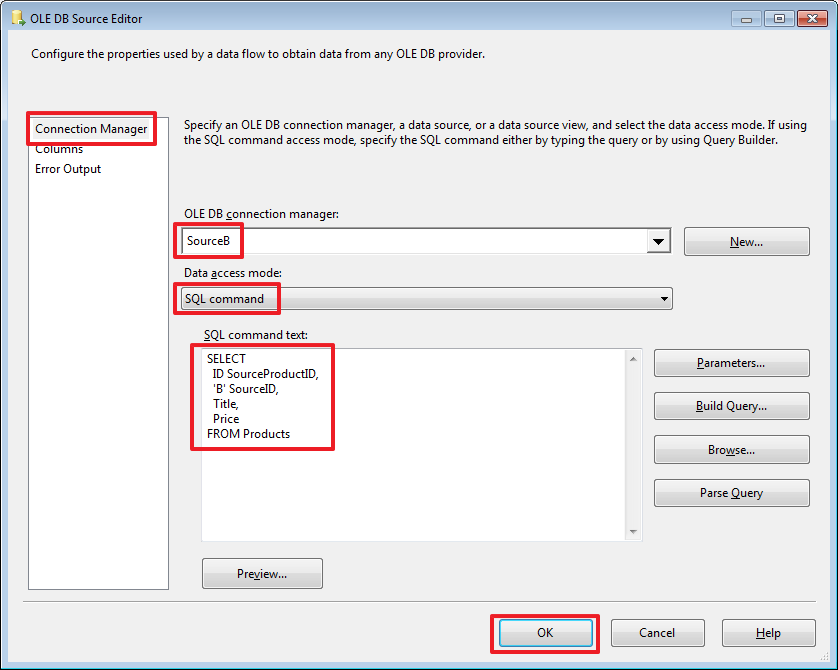
SELECT
ID SourceProductID,
'B' SourceID,
Title,
Price
FROM Products
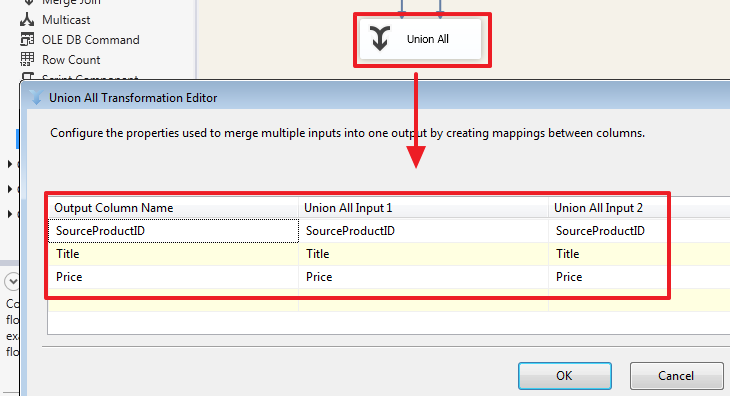
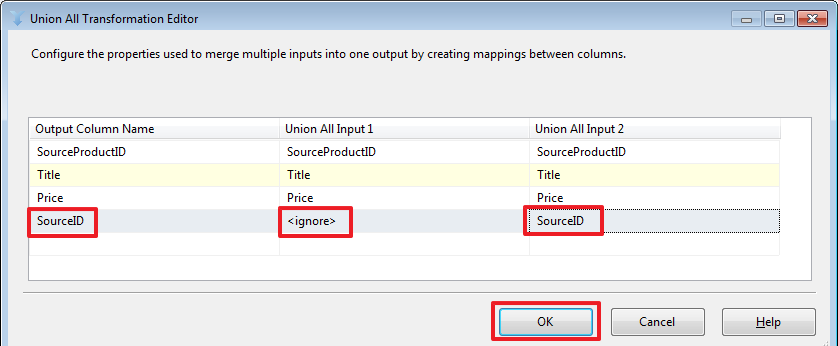
Объединение двух наборов в данном случае делается на стороне SSIS. Здесь стоит обратить внимание на то, что базы источники и принимающая база могут располагаться на разных серверах/экземплярах SQL Server, по этой причине мы не всегда сможем так просто написать SQL запрос используя в нем таблицы из разных баз с применением SQL-операции UNION или JOIN (который можно было использовать вместо Lookup описанного ниже).






Например, если выставить значение «Ignore failure», то в строках, для которых не нашлось сопоставления в поле TargetID (см. ниже) будет записано значение NULL и все строки будут возвращены через один набор «Lookup Match Output».
Если же выбрать «Partial cache» или «No cache», то на вкладке Advanced можно будет прописать запрос с параметрами, который будет выполняться для сопоставления каждой строки входящего набора. Для интереса можно поиграться с этим свойством и через SQL Server Profiler посмотреть какие будут формироваться запросы при выполнении пакета.

SELECT
SourceID,
SourceProductID,
ID TargetID
FROM Products









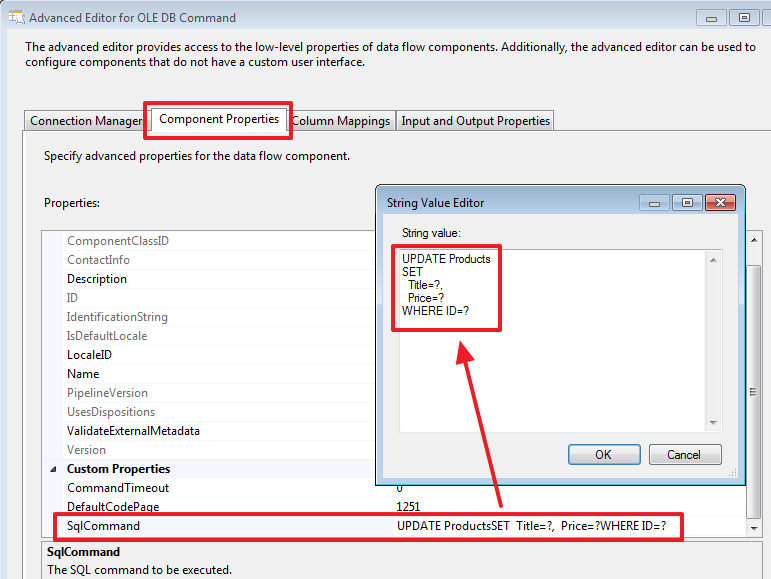
UPDATE Products
SET
Title=?,
Price=?
WHERE ID=?

USE DemoSSIS_SourceB
GO
-- добавим новых товаров
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(6,N'Точилка',NULL),
(7,N'Ластик',NULL),
(8,N'Карандаш простой',NULL)
SET IDENTITY_INSERT Products OFF
GO

USE DemoSSIS_Target
GO
ALTER TABLE Products ADD UpdatedOn datetime
GO

DECLARE @TargetID int=?
DECLARE @Title nvarchar(50)=?
DECLARE @Price money=?
IF(EXISTS(
SELECT Title,Price
FROM Products
WHERE ID=@TargetID
EXCEPT
SELECT @Title,@Price
)
)
BEGIN
UPDATE Products
SET
Title=@Title,
Price=@Price,
UpdatedOn=GETDATE()
WHERE ID=@TargetID
ENDТак же можно было бы все это оформить в виде хранимой процедуры, а здесь прописать ее через вызов «EXEC ProcName ?,?,?». Здесь, думаю, кому как удобнее, мне порой удобнее, чтобы все было прописано в одном месте, т.е. в SSIS-проекте. Но если использовать процедуру, то тоже получаем свои удобства, в этом случае можно, было бы просто изменить процедуру и избежать переделки и повторного развертывания SSIS-проекта.
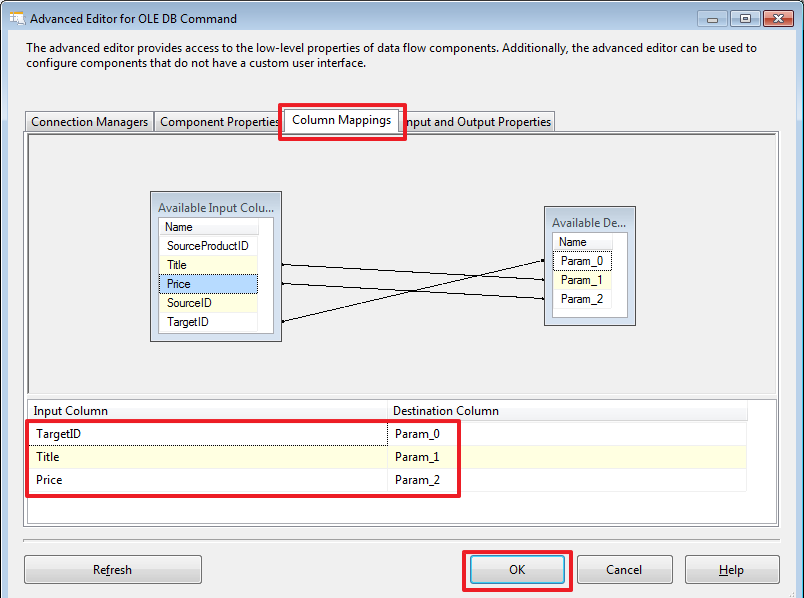
USE DemoSSIS_SourceA
GO
UPDATE Products
SET
Price=30
WHERE ID=2 -- Корректор

USE DemoSSIS_Target
GO
SELECT *
FROM Products
ORDER BY UpdatedOn DESC

USE DemoSSIS_Target
GO
CREATE TABLE LastAddedProducts(
SourceID char(1) NOT NULL, -- используется для идентификации источника
SourceProductID int NOT NULL, -- ID в источнике
Title nvarchar(50) NOT NULL,
Price money,
CONSTRAINT PK_LastAddedProducts PRIMARY KEY(SourceID,SourceProductID),
CONSTRAINT CK_LastAddedProducts_SourceID CHECK(SourceID IN('A','B'))
)
GO


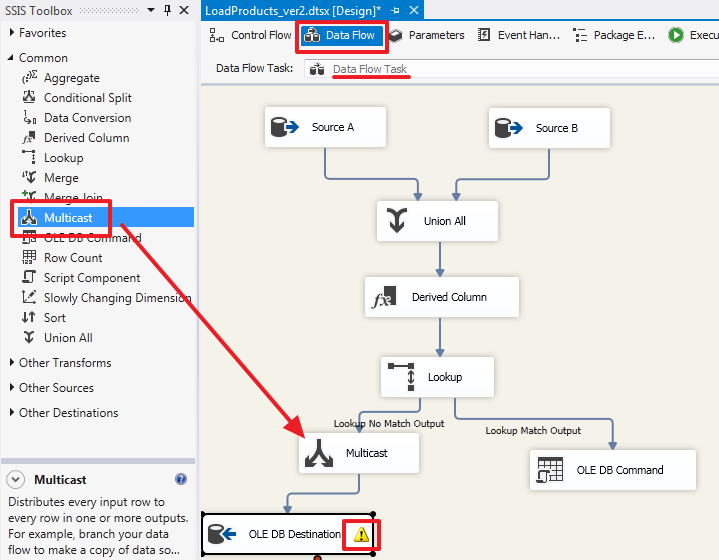


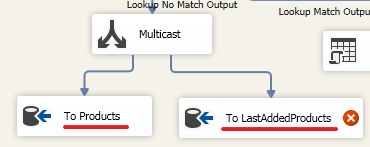
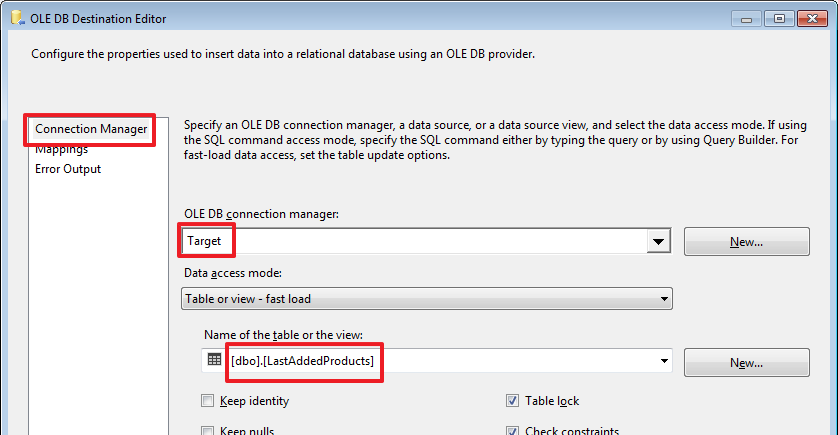
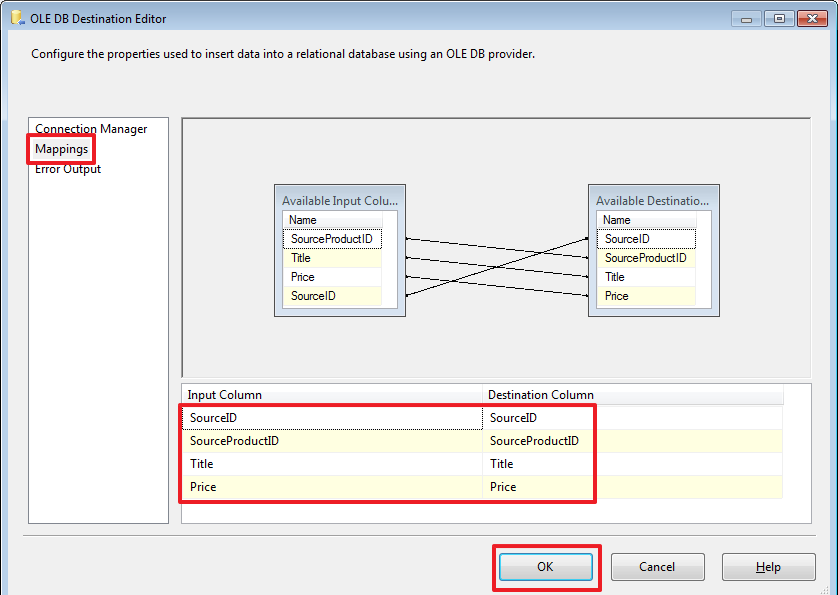
USE DemoSSIS_Target
GO
DELETE Products
WHERE SourceID='B'
AND SourceProductID>=6
Чтобы не нарушать ссылочную целостность, иногда запись в принимающей таблице удаляется логически, для этого, например, можно в эту таблицу добавить поле Deleted типа bit (флаг логического удаления) или DeletedOn типа datetime (дата/время логического удаления).
Порой на сервере, на котором располагается база Target делается вспомогательная промежуточная база (обычно ее называют Staging) и первым делом «сырые» данные из Source загружаются в нее. Так как теперь Target и Staging находятся на одном сервере, то вторым шагом мы можем легко написать SQL-запрос (например, используя SQL-конструкцию MERGE или запрос с применение конструкции JOIN), который оперирует с наборами обеих этих баз.
|
Метки: author Leran2002 sql microsoft sql server ssis integration services sql server etl |
Дайджест интересных материалов для мобильного разработчика #206 (05-12 июня) |

 |
Побеждаем Android Camera2 API с помощью RxJava2 (часть 1) |
 |
12 часов в шкуре Android разработчика глазами JS разработчика |
 |
Новый опрос Developer Economics 2017 |
 iOS
iOS Нативное машинное обучение и компьютерное зрение в iOS 11 iOS 11: Важные дополнения UIKit Дождь или снег при помощи CAEmitterLayer Множественный выбор в Table View Уроки из 3 миллионов загрузок Core ML и Vision: Руководство по Machine Learning в iOS 11
Нативное машинное обучение и компьютерное зрение в iOS 11 iOS 11: Важные дополнения UIKit Дождь или снег при помощи CAEmitterLayer Множественный выбор в Table View Уроки из 3 миллионов загрузок Core ML и Vision: Руководство по Machine Learning в iOS 11  Android
Android Android Dev Подкаст. Выпуск 35. Безопасность, фрагментация, новые тренды и старые проблемы Задачи по расписанию и умные работы в Android Как разместить файлы разметки в подпапки Гильотинная анимация меню в Android Топ-5 библиотек июня Барьеры ConstraintLayout Учимся создавать Paint для Android Keddit: Учите Kotlin, разрабатывая приложение Как я сделал умный звонок с помощью Android Things Apdroid O API финализированы Как сделать свайп-кнопку Graywater для Android Адаптивные иконки и больше Как ускорить медленные сборки Gradle
Android Dev Подкаст. Выпуск 35. Безопасность, фрагментация, новые тренды и старые проблемы Задачи по расписанию и умные работы в Android Как разместить файлы разметки в подпапки Гильотинная анимация меню в Android Топ-5 библиотек июня Барьеры ConstraintLayout Учимся создавать Paint для Android Keddit: Учите Kotlin, разрабатывая приложение Как я сделал умный звонок с помощью Android Things Apdroid O API финализированы Как сделать свайп-кнопку Graywater для Android Адаптивные иконки и больше Как ускорить медленные сборки Gradle Aesthetic: движок для внедрения тем Karchitec: RSS ридер на компонентах Google
Aesthetic: движок для внедрения тем Karchitec: RSS ридер на компонентах Google Windows
Windows Разработка
Разработка Аналитика, маркетинг и монетизация Сколько следует тратить на мобильный маркетинг? 21 метрика для измерения успеха
Аналитика, маркетинг и монетизация Сколько следует тратить на мобильный маркетинг? 21 метрика для измерения успеха Устройства, IoT, AI
Устройства, IoT, AI|
|
[recovery mode] Готовим git reset правильно |
|
Метки: author SbWereWolf git admin |
Реформа SQL-ориентированного подхода в DAO |
public class Client {
private Long id;
private String name;
private ClientState state;
private Date regTime;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public ClientState getState() {
return state;
}
public void setState(ClientState state) {
this.state = state;
}
public Date getRegTime() {
return regTime;
}
public void setRegTime(Date regTime) {
this.regTime = regTime;
}
}
enum ClientState {
ACTIVE(1),
BLOCKED(2),
DELETED(3);
private int state;
ClientState(int state) {
this.state = state;
}
@TargetMethod
public int getState() {
return state;
}
@TargetMethod
public static ClientState getClientState(int state) {
return values()[state - 1]; // только для краткости
}
}public interface IClientDao {
@TargetQuery(query =
"SELECT id, name, state " +
" FROM clients " +
" WHERE id = ?", type = QT_SELECT)
Client findClient(long clientId);
}-- Таблица клиентов
CREATE TABLE clients (
id bigint NOT NULL,
name character varying(127) NOT NULL,
state int NULL,
reg_time timestamp NOT NULL,
CONSTRAINT pk_clients PRIMARY KEY (id)
);IClientDao clientDao = com.reforms.orm.OrmDao.createDao(connection, IClientDao.class);
Client client = clientDao.findClient(1L);
// где-то в DAO
private String makeRegTimeFilter(Date beginDate, Date endDate) {
StringBuilder filter = new StringBuilder();
if (beginDate != null) {
filter.append(" reg_time >= ?");
}
if (endDate != null) {
if (filter.length() != 0) {
filter.append(" AND");
}
filter.append(" reg_time < ?");
}
return filter.length() == 0 ? null : filter.toString();
}
public interface IClientDao {
@TargetQuery(query =
"SELECT id, name, state " +
" FROM clients " +
" WHERE regTime >= ::begin_date AND " +
" regTime < ::end_date", type = QT_SELECT)
List findClients(@TargetFilter("begin_date") Date beginDate,
@TargetFilter("end_date") Date endDate);
}
SELECT id, name, state FROM clients WHERE regTime < ?// Бойлерплейт get/set код вырезал. В своем файле.
public class ClientFilter {
private Date beginDate;
private Date endDate;
}
public interface IClientDao {
@TargetQuery(query =
"SELECT id, name, state " +
" FROM clients " +
" WHERE regTime >= ::begin_date AND " +
" regTime < ::end_date", type = QT_SELECT)
List findClients(@TargetFilter ClientFilter period);
}
public interface IClientDao {
@TargetQuery(query =
"SELECT id, name, state " +
" FROM clients " +
" WHERE state = :state", type = QT_SELECT)
List findClients(@TargetFilter("state") ClientState state);
}
public class Client {
private long clientId;
private String clientName;
private ClientState clientState;
private Address address;
private Date regTime;
// ниже как обычно...
}
enum ClientState {
ACTIVE(1),
BLOCKED(2),
DELETED(3);
private int state;
ClientState(int state) {
this.state = state;
}
@TargetMethod
public int getState() {
return state;
}
@TargetMethod
public static ClientState getClientState(int state) {
return values()[state - 1]; // для примера сойдет
}
}
public class Address {
private long addressId;
private String refCity;
private String refStreet;
}
public interface IClientDao {
@TargetQuery(query =
"SELECT cl.id AS client_id, " + // underscore_case -> camelCase преобразование
" cl.name AS clientName, " + // можно сразу в camelCase
" cl.state AS client_state, " + // any_type to enum преобразование автоматически поддерживается, если в enum имеется аннотация @TargetMethod
" cl.regDate AS t#regTime, " + // t# - это директива, что нам нужна и дата и время java.sql.Timestamp -> java.util.Date
" addr.addressId AS address.addressId, " + // обращение к вложенному объекту через точку, а как еще?
" addr.city AS address.refCity, " +
" addr.street AS address.refStreet " +
" FROM clients cl, addresses addr" +
" WHERE id = :client_id", // допускается указание именованного параметра для простого фильтра
type = QT_SELECT)
Client findClient(long clientId);
}
public interface IClientDao {
// этот метод уже видели
@TargetQuery(query =
"SELECT id, name, state " +
" FROM clients " +
" WHERE id = ?", type = QT_SELECT)
Client findClient(long clientId);
// получить дао внутри другого дао доступно из коробки
IAddressDao getAddressDao();
// метод с бизнес логикой
default Client findClientAndCheck(long clientId, long addressId) throws Exception {
Client client = findClient(clientId);
if (client == null) {
throw new Exception("Клиент с id '" + clientId + "' не найден");
}
// Здесь код может быть сколь угодно сложным, если нужно
IAddressDao addressDao = getAddressDao();
client.setAddress(addressDao.loadAddress(addressId));
return client;
}
}
|
Метки: author reforms программирование java reforms sql ориентированный интерфейсное программирование dao |
«Ближе к народу»: Как сделать IaaS доступнее |


|
Метки: author 1cloud управление e-commerce блог компании 1cloud.ru 1cloud iaas |
NNCP: лечение online- и цензуро- зависимости store-and-forward методом |
alice% nncp-cfgnew | tee alice.yaml
self:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
exchprv: 3URFZQXMZQD6IMCSAZXFI4YFTSYZMKQKGIVJIY7MGHV3WKZXMQ7Q
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
signprv: TEXUCVA4T6PGWS73TKRLKF5GILPTPIU4OHCMEXJQYEUCYLZVR7KB7P2LRKNSUXMTPVK36X5NZSAGJ632KKGCNODPRZBRFIQFJARDEKY
noiseprv: 7AHI3X5KI7BE3J74BW4BSLFW5ZDEPASPTDLRI6XRTYSHEFZPGVAQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
neigh:
self:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
sendmail:
- /usr/sbin/sendmail
spool: /var/spool/nncp/alice
log: /var/spool/nncp/alice/log
alice% cat bob.yaml
self:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
exchprv: HXDO6IG275S7JNXFDRGX6ZSHHBBN4I7DQ3UGLOZKDY7LIBU65LPA
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
signprv: TT2F5TIWJIQYCXUBC2F2A5KKND5LDGIHDQ3P2P3HTZUNDVAH7QUPO6L7GFDTZKXFNVAIEQY7GDO2NNESVZXX6JL3BXRF7JVYQGYU3IA
noiseprv: NKMWTKQVUMS3M45R3XHGCZIWOWH2FOZF6SJJMZ3M7YYQZBYPMG7A
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
neigh:
self:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q
signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA
noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA
sendmail:
- /usr/sbin/sendmail
alice:
id: ZY3VTECZP3T5W6MTD627H472RELRHNBTFEWQCPEGAIRLTHFDZARQ
exchpub: F73FW5FKURRA6V5LOWXABWMHLSRPUO5YW42L2I2K7EDH7SWRDAWQ
signpub: D67UXCU3FJOZG7KVX5P23TEAMT5XUUUME24G7DSDCKRAKSBCGIVQ
noisepub: 56NKDPWRQ26XT5VZKCJBI5PZQBLMH4FAMYAYE5ZHQCQFCKTQ5NKA
spool: /var/spool/nncp/bob
log: /var/spool/nncp/bob/log
bob% nncp-file -cfg bob.yaml ifmaps.tar.xz alice: 2017-06-11T15:33:20Z File ifmaps.tar.xz (350 KiB) transfer to alice:ifmaps.tar.xz: sent
bob% export NNCPCFG=/path/to/bob.yaml bob% zfs send zroot@backup | xz -0 | nncp-file - alice:bobnode-$(date "+%Y%m%d").zfs.xz 2017-06-11T15:44:20Z File - (1.1 GiB) transfer to alice:bobnode-20170611.zfs.xz: sent
bob% nncp-stat
self
alice
nice: 196 | Rx: 0 B, 0 pkts | Tx: 1.1 GiB, 2 pkts
bob% nncp-xfer -mkdir /mnt/media 2017-06-11T18:23:28Z Packet transfer, sent to node alice (1.1 GiB) 2017-06-11T18:23:28Z Packet transfer, sent to node alice (350 KiB)
alice% nncp-xfer /mnt/media
2017-06-11T18:41:29Z Packet transfer, received from node bob (1.1 GiB)
2017-06-11T18:41:29Z Packet transfer, received from node bob (350 KiB)
alice% nncp-stat
self
bob
nice: 196 | Rx: 1.1 GiB, 2 pkts | Tx: 0 B, 0 pkts
bob: id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA incoming: /home/alice/bob/incoming
alice% nncp-toss 2017-06-11T18:49:21Z Got file ifmaps.tar.xz (350 KiB) from bob 2017-06-11T18:50:34Z Got file bobnode-20170611.zfs.xz (1.1 GiB) from bob
bob: id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA incoming: /home/alice/nncp/bob/incoming freq: /home/alice/nncp/bob/pub
bob% nncp-freq alice:pulp_fiction.avi PulpFiction.avi 2017-06-11T18:55:32Z File request from alice:pulp_fiction.avi to pulp_fiction.avi: sent bob% nncp-xfer -node alice /mnt/media
alice% nncp-toss 2017-06-11T18:59:14Z File /home/alice/nncp/bob/pub/pulp_fiction.avi (650 MiB) transfer to bob:PulpFiction.avi: sent 2017-06-11T18:59:14Z Got file request pulp_fiction.avi to bob
bob: id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA eve: self: id: URVEPJR5XMJBDHBDXFL3KCQTY3AT54SHE3KYUYPL263JBZ4XZK2A exchpub: QI7L34EUPXQNE6WLY5NDHENWADORKRMD5EWHZUVHQNE52CTCIEXQ signpub: KIRJIZMT3PZB5PNYUXJQXZYKLNG6FTXEJTKXXCKN3JCWGJNP7PTQ noisepub: RHNYP4J3AWLIFHG4XE7ETADT4UGHS47MWSAOBQCIQIBXM745FB6A via: [bob]
notify:
file:
from: nncp@bobnode
to: bob+file@example.com
freq:
from: nncp@bobnode
to: bob+freq@example.com
bob: id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ exchpub: GQ5UPYX44T7YK5EJX7R73652J5J7UPOKCGLKYNLJTI4EBSNX4M2Q signpub: 654X6MKHHSVOK3KAQJBR6MG5U22JFLTPP4SXWDPCL6TLRANRJWQA noisepub: M5V35L5HOFXH5FCRRV24ZDGBVVHMAT3S63AGPULND4FR2GIPPFJA sendmail: [/usr/sbin/sendmail, "-v"]
% nncp-daemon -nice 128 -bind [::]:5400
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
...
addrs:
lan: "[fe80::be5f:f4ff:fedd:2752%igb0]:5400"
pub: "bob.example.com:5400"
% nncp-call bob % nncp-call bob:lan % nncp-call bob:main % nncp-call bob forced.bob.example.com:1234
bob:
id: FG5U7XHVJ342GRR6LN4ZG6SMAU7RROBL6CSU5US42GQ75HEWM7AQ
...
calls:
-
cron: "*/10 9-21 * * MON-FRI"
nice: 128
addr: pub
xx: rx
-
cron: "*/1 21-23,0-9 * * MON-FRI"
onlinedeadline: 3600
addr: lan
-
cron: "*/1 * * * SAT,SUN"
onlinedeadline: 3600
addr: lan
|
Метки: author stargrave2 децентрализованные сети fidonet цензура javascript броузеры слежка интернет mesh сеть diaspora uucp |
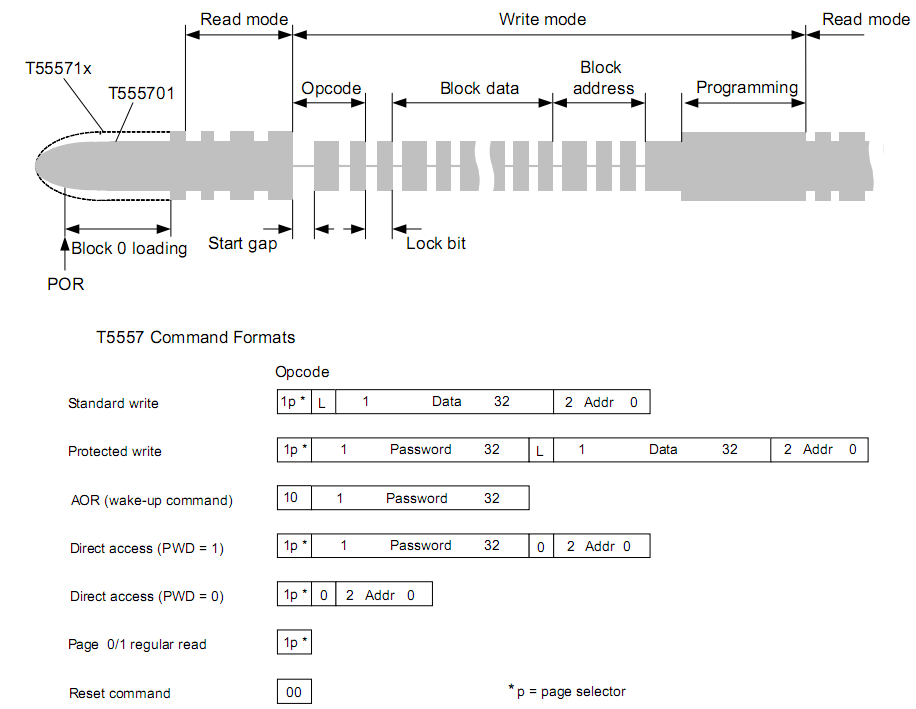
Копировщик RFID-меток стандарта EM-Marin |
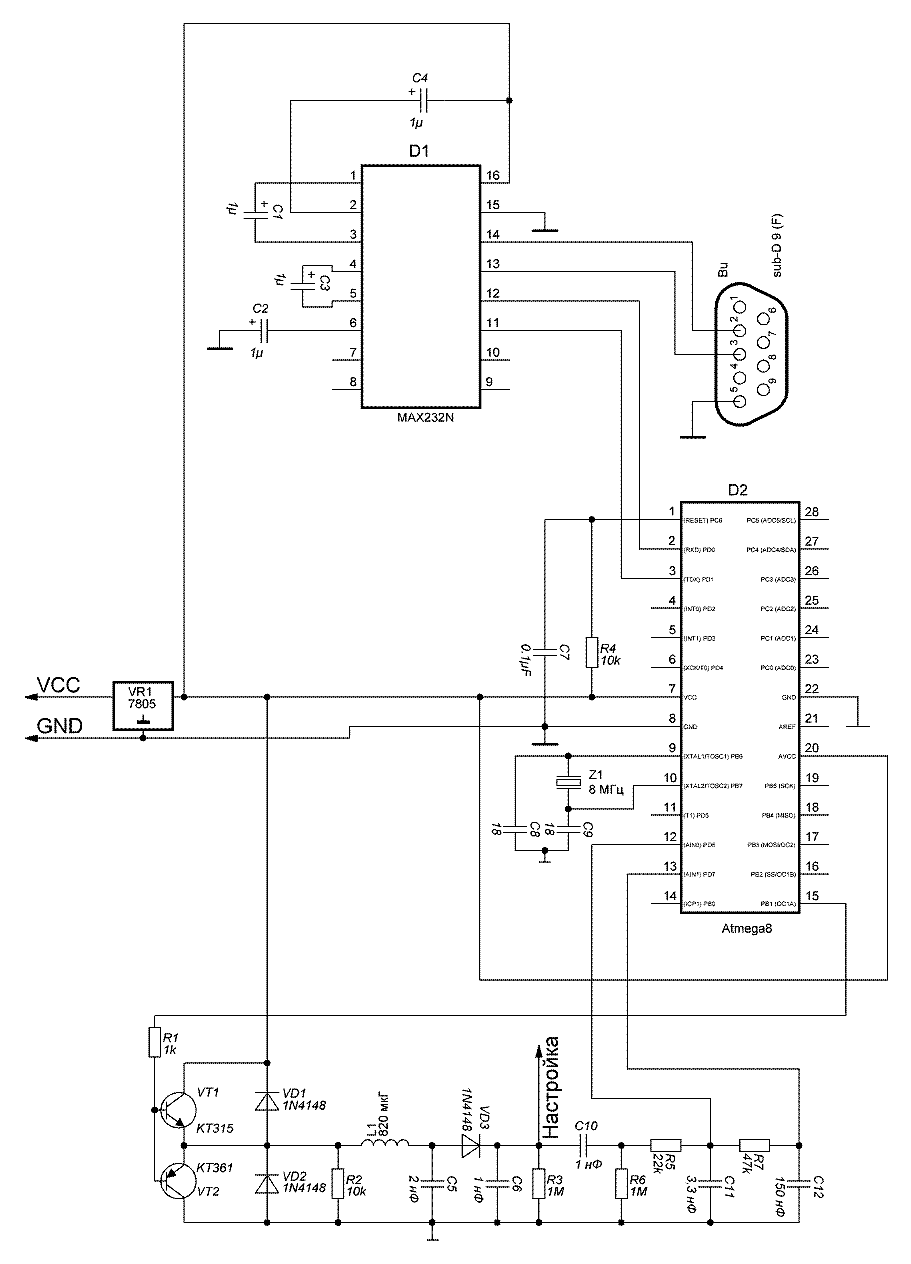
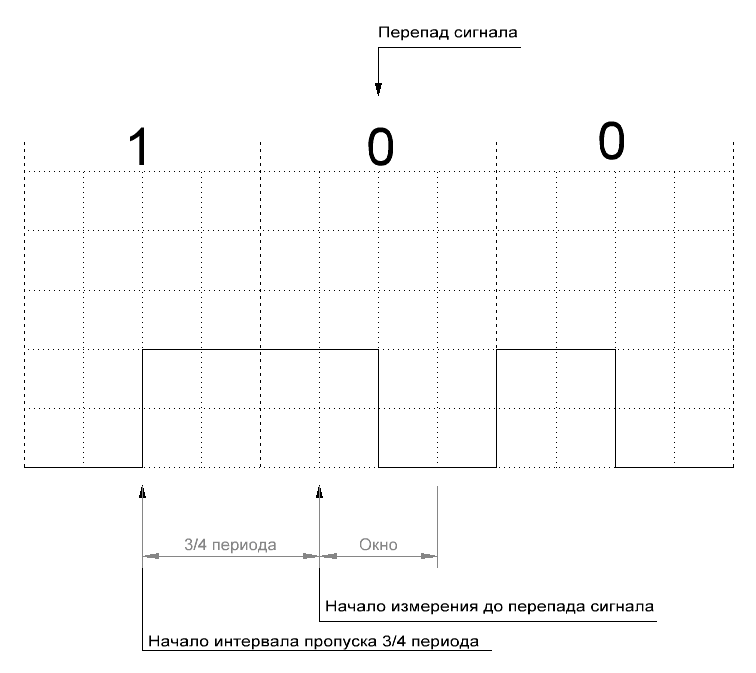
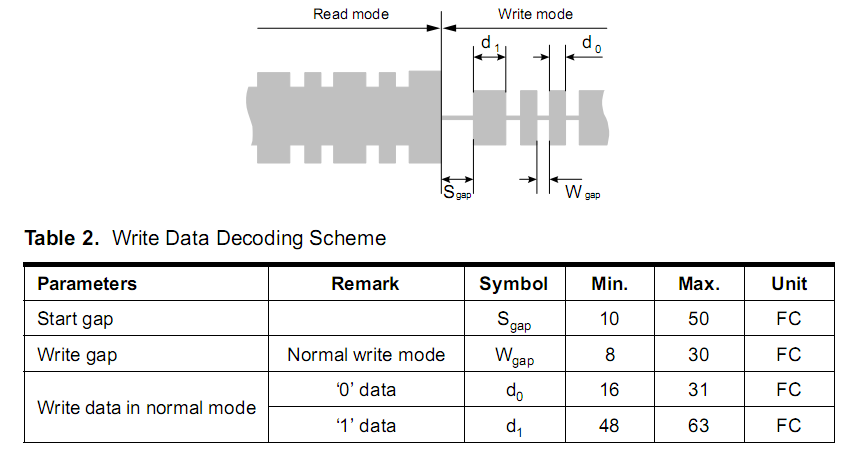
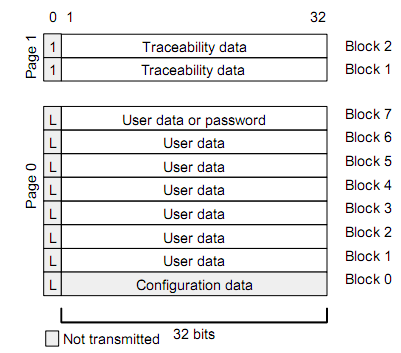





|
Метки: author da-nie программирование микроконтроллеров assembler rfid копировщик rfid em4305 t5557 t5577 |
[Перевод] Вы — не Google |
Дело в том, что в мире сейчас есть где-то 5 компаний, обрабатывающие данные подобных объёмов. Все остальные гоняют все эти данные туда-сюда, добиваясь отказоустойчивости, которая им на самом деле не нужна. Люди страдают гигантоманией и гугломанией где-то с середины 2000-ых годов: «мы сделаем всё так, как делает Google, ведь мы же строим один из крупнейших (в будущем) сервисов по обработке данных в мире!»
 Сколько этажей в вашем датацентре? Google сейчас строит четырёхэтажные, как вот этот в Оклахоме.
Сколько этажей в вашем датацентре? Google сейчас строит четырёхэтажные, как вот этот в Оклахоме.


 Вот этот зал вмещает 7000 людей. А у Амазона было 7800, когда понадобился переход на SOA.
Вот этот зал вмещает 7000 людей. А у Амазона было 7800, когда понадобился переход на SOA.
Глупо пытаться найти ответ на вопрос, которого ты не знаешь. Грустно работать над тем, что не решает твою проблему.
|
Метки: author tangro проектирование и рефакторинг высокая производительность анализ и проектирование систем google cloud platform блог компании инфопульс украина архитектура приложений |
[Перевод] Отзывчивые столбчатые диаграммы с Bokeh, Flask и Python 3 |
Недавно наткнулся в python digest на туториал по Flask+Bokeh. Туториал ориентирован на новичков, не требуется даже знать синтаксис Python и HTML. Примеры работают под Ubuntu 16.04, на Windows немного отличается работа с виртуальными окружениями.
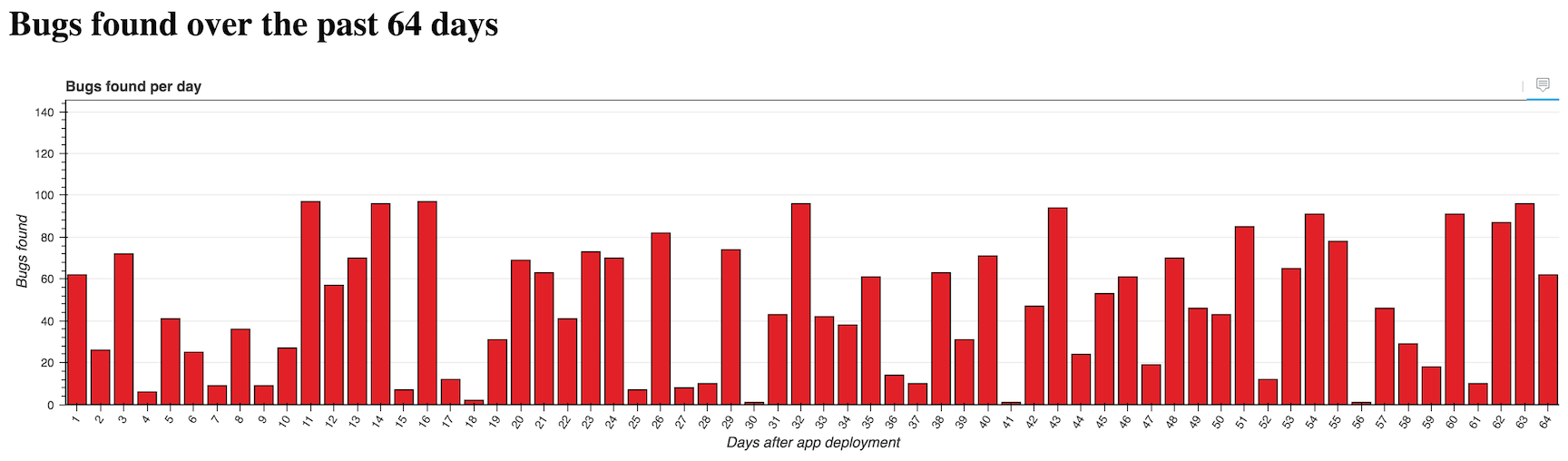
Bokeh — это мощная библиотека с открытым исходным кодом, которая позволяет визуализировать данные для веб-приложений, не написав ни строчки на javascript. Изучение библиотек для визуализации вроде d3.js может оказаться полезным, но гораздо легче написать несколько строк кода на Python, чтобы решить задачу.
С Bokeh мы можем создавать поразительно детальные интерактивные визуализации или же более простые вещи, вроде столбчатых диаграмм.
Давайте разберёмся, как можно использовать Flask и Bokeh для визуализации данных в веб-приложении.
Всё, что описано далее, работает как на Python 2, так и на Python 3, однако, рекомендуется использовать Python 3 для новых приложений. Я использовал Python 3.6.1 на момент написания этой статьи. Помимо самого Python, нам потребуются следующие зависимости:
Если вам нужны дополнительные сведения по настройке окружения разработки, можете обратиться к руководству.
Весь код примеров доступен по лицензии MIT на GitHub.
Создайте чистое виртуальное окружение для проекта. Как правило, я запускаю эту команду в отдельной папке venvs, где которой находятся все мои виртуальные окружения.
python3 -m venv barchartАктивируйте виртуальное окружение.
source barchart/bin/activateПосле активации виртуального окружения изменится приглашение командной строки:

Не забывайте, что вам понадобится активировать виртуальное окружение в каждом новом окне терминала, из которого вы захотите запустить своё приложение.
Теперь можно установить Bokeh и Flask в созданное виртуальное окружение. Выполните эту команду, чтобы установить Bokeh и Flask подходящих версий.
pip install bokeh==0.12.5 flask==0.12.2 pandas==0.20.1После загрузки и установки необходимые библиотеки будут доступны в виртуальном окружении. Проверьте вывод, чтобы удостовериться, что всё установилось.
Installing collected packages: six, requests, PyYAML, python-dateutil, MarkupSafe, Jinja2, numpy, tornado, bokeh, Werkzeug, itsdangerous, click, flask, pytz, pandas
Running setup.py install for PyYAML ... done
Running setup.py install for MarkupSafe ... done
Running setup.py install for tornado ... done
Running setup.py install for bokeh ... done
Running setup.py install for itsdangerous ... done
Successfully installed Jinja2-2.9.6 MarkupSafe-1.0 PyYAML-3.12 Werkzeug-0.12.2 bokeh-0.12.5 click-6.7 flask-0.12.2 itsdangerous-0.24 numpy-1.12.1 pandas-0.20.1 python-dateutil-2.6.0 pytz-2017.2 requests-2.14.2 six-1.10.0 tornado-4.5.1Теперь мы можем перейти непосредственно к нашему приложению.
Мы напишем простое Flask-приложение и добавим столбчатую диаграмму на страницу.
Создайте папку для своего прокта с файлом app.py с таким содержанием:
from flask import Flask, render_template
app = Flask(__name__)
@app.route("//")
def chart(bars_count):
if bars_count <= 0:
bars_count = 1
return render_template("chart.html", bars_count=bars_count)
if __name__ == "__main__":
app.run(debug=True)Это простое Flask-приложение, в котором есть функция chart. chart принимает целое число, которое позже будет использоваться для определения количества данных для отрисовки. Функция render_template внутри chart будет использовать шаблонизатор Jinja2 для генерации HTML.
Последние 2 строки позволяют нам запустить приложение из консоли на 5000 порту в режиме отладки. Никогда не используйте режим отладки в продакшене, для этого существуют WSGI-серверы проде Gunicorn.
Создайте папку templates внутри папки проекта. Внутри неё создайте файл chart.html. Он нужен функции chart из app.py, поэтому без него приложение не будет работать правильно. Заполните chart.html Jinja2-разметкой.
Bugs found over the past {{ bars_count }} days
Заготовка chart.html будет показывать количество столбцов, переданное в функцию chart через URL.
Сообщение внутри тега h1 отвечает теме нашего приложения. Мы будем строить график количества багов, найденных систимой автоматического тестирования за каждый день.
Теперь мы можем протестировать наше приложение.
Убедитесь, что виртуальное окружение всё ещё активно и вы находитесь в папке с app.py. Запустите app.py с помощью команды python.
$(barchart) python app.pyПерейдите на localhost:5000/16/. Вы должны увидеть большое сообщение, которой меняется, когда вы меняете URL.

Наше приложение уже запускается, но пока не впечатляет. Пришло время добавить график.
Нам нужно всего лишь добавить немного кода, который будет использовать Bokeh.
Откройте app.py и добавьте в него строки сверху.
import random
from bokeh.models import (HoverTool, FactorRange, Plot, LinearAxis, Grid,
Range1d)
from bokeh.models.glyphs import VBar
from bokeh.plotting import figure
from bokeh.charts import Bar
from bokeh.embed import components
from bokeh.models.sources import ColumnDataSource
from flask import Flask, render_templateОстальная часть файла будет использовать Bokeh вместе с модулем random для генерации данных и столбчатой диаграммы.
Данные для диаграммы будут генерироваться заново при каждой перезагрузке страницы. В реальном приложении используйте более надёжный и полезный источник данных!
Продолжайте изменять app.py. Код после импортов должен выглядеть следующим образом.
app = Flask(__name__)
@app.route("//")
def chart(bars_count):
if bars_count <= 0:
bars_count = 1
data = {"days": [], "bugs": [], "costs": []}
for i in range(1, bars_count + 1):
data['days'].append(i)
data['bugs'].append(random.randint(1,100))
data['costs'].append(random.uniform(1.00, 1000.00))
hover = create_hover_tool()
plot = create_bar_chart(data, "Bugs found per day", "days",
"bugs", hover)
script, div = components(plot)
return render_template("chart.html", bars_count=bars_count,
the_div=div, the_script=script)Функция chart сгенерирует списки с данными с помощью встроенного модуля random.
chart вызывает 2 функции: create_hover_tool и create_bar_chart. Мы пока не написали эти функции, поэтому продолжим добавлять код после функции chart:
def create_hover_tool():
# эту функцию мы напишем чуть позже
return None
def create_bar_chart(data, title, x_name, y_name, hover_tool=None,
width=1200, height=300):
"""Создаёт столбчатую диаграмму.
Принимает данные в виде словаря, подпись для графика,
названия осей и шаблон подсказки при наведении.
"""
source = ColumnDataSource(data)
xdr = FactorRange(factors=data[x_name])
ydr = Range1d(start=0,end=max(data[y_name])*1.5)
tools = []
if hover_tool:
tools = [hover_tool,]
plot = figure(title=title, x_range=xdr, y_range=ydr, plot_width=width,
plot_height=height, h_symmetry=False, v_symmetry=False,
min_border=0, toolbar_location="above", tools=tools,
responsive=True, outline_line_color="#666666")
glyph = VBar(x=x_name, top=y_name, bottom=0, width=.8,
fill_color="#e12127")
plot.add_glyph(source, glyph)
xaxis = LinearAxis()
yaxis = LinearAxis()
plot.add_layout(Grid(dimension=0, ticker=xaxis.ticker))
plot.add_layout(Grid(dimension=1, ticker=yaxis.ticker))
plot.toolbar.logo = None
plot.min_border_top = 0
plot.xgrid.grid_line_color = None
plot.ygrid.grid_line_color = "#999999"
plot.yaxis.axis_label = "Bugs found"
plot.ygrid.grid_line_alpha = 0.1
plot.xaxis.axis_label = "Days after app deployment"
plot.xaxis.major_label_orientation = 1
return plotЗдесь много кода, с которым нужно разобраться. Функция create_hover_tool пока только возвращает None, потому что пока нам не нужно отображать подсказки при наведении.
Внутри функции create_bar_chart мы преобразуем сгенерированные данные в объект типа ColumnDataSource, который мы можем передать на вход функциям Bokeh для построения графика. Мы задаём диапазоны осей x и y.
Пока у нас не настроены подсказки при наведении, список tools пуст. Вся магия происходит в вызове функции figure. Мы передаём ей всё необходимое для построения графика: размер, панель инструментов, границы, настройки поведения графика при изменении размера окна браузера.
Мы создаём вертикальные столбцы с помощью класса VBar и добавляем их на график с помощью функции add_glyph, которая задаёт правила, по которым данные превращаются в столбцы.
Последние 2 строки изменяют оформление графика. Для примера я убрал логотип Bokeh при помощи plot.toolbar.logo = None и добавил подписи к обеим осям. Я рекомендую держать документацию bokeh.plotting перед глазами, чтобы знать, как можно кастомизировать визуализацию.
Нам нужно сделать всего пару изменений в файле templates/chart.html, чтобы отобразить график. Откройте файл и замените его содержимое следующим.
Bugs found over the past {{ bars_count }} days
{{ the_div|safe }}
{{ the_script|safe }}
2 из 6 добавленных строк нужны для загрузки CSS-файлов Bokeh, ещё 2 для загрузки его скриптов, и ещё 2 — для генерации графика.
Всё готово, давайте проверим наше приложение. Flask должен автоматически перезгрузить приложение, когда вы сохраните изменения в app.py. Если вы остановили веб-сервер, вы можете снова его запустить командой python app.py.
Откройте в браузере localhost:5000/4/.
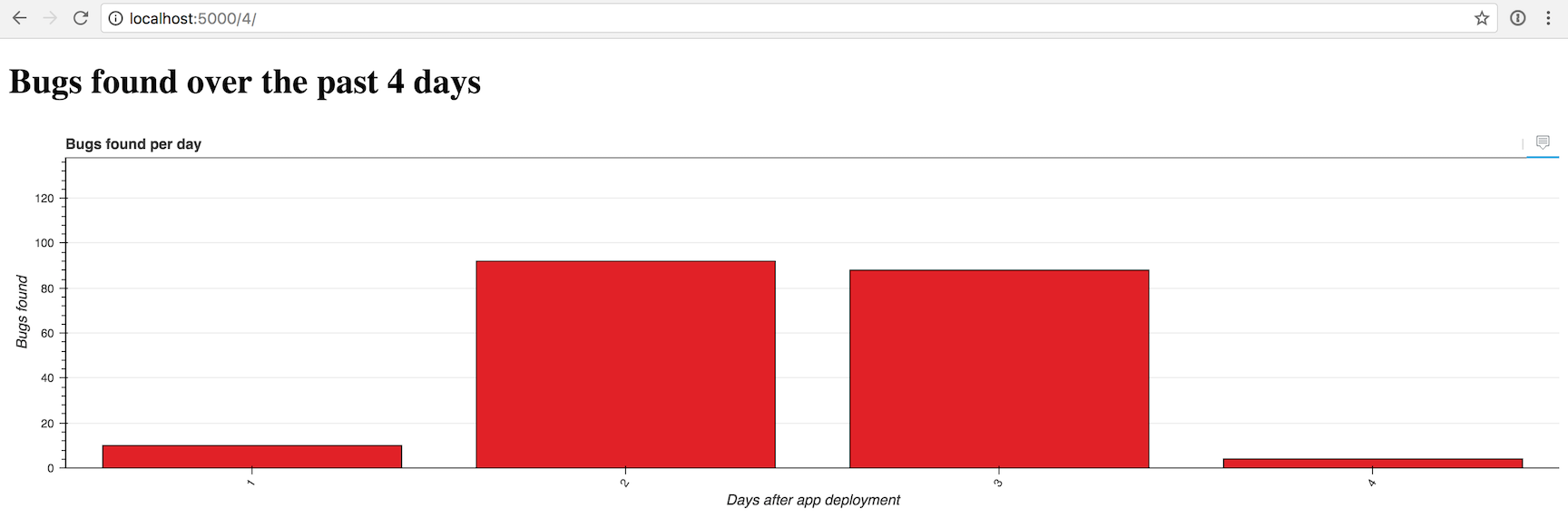
Выглядит немного пусто, но мы можем изменить количество столбцов на 16, если перейдём на /localhost:5000/16/.
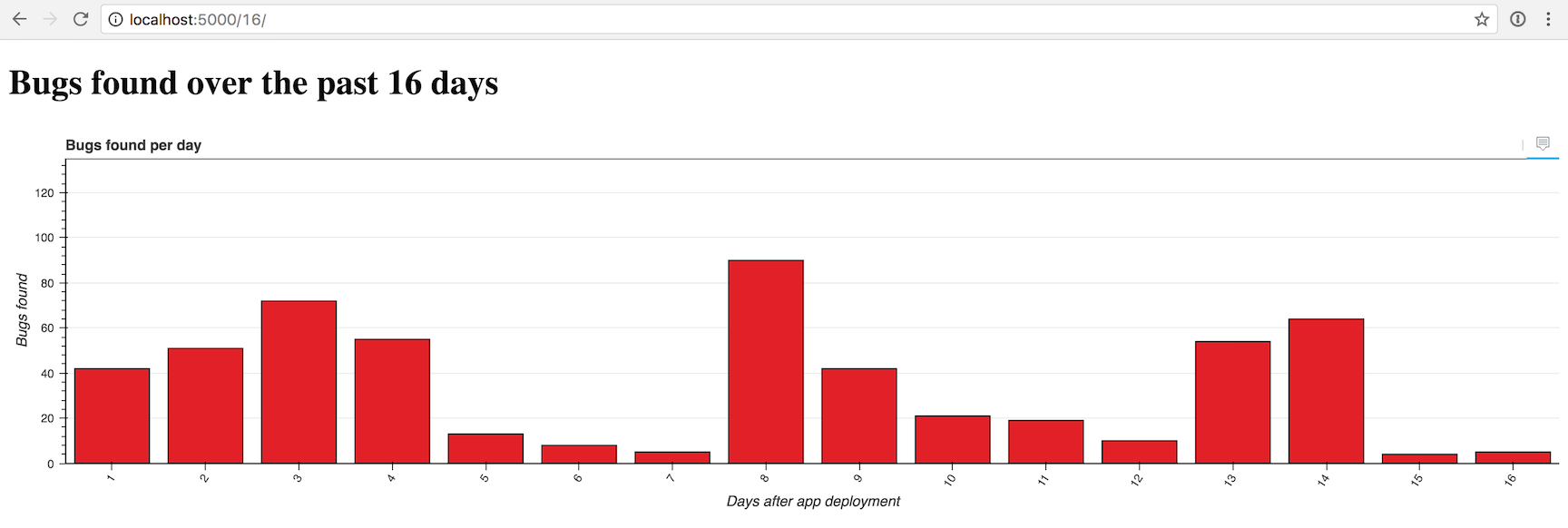
Ещё в 4 раза больше...
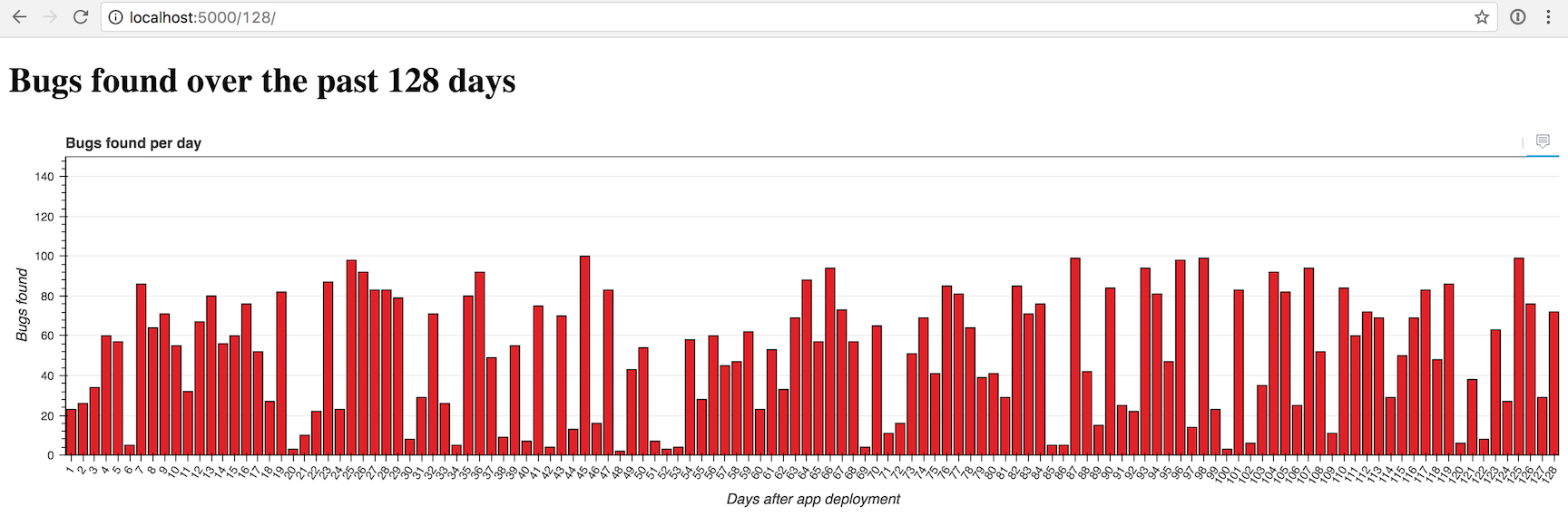
Выглядит довольно неплохо. Но что, если мы добавим подсказки при наведении, чтобы можно было подробно изучить каждый столбец? Чтобы добавить подсказки, нам нужно поменять функцию create_hover_tool.
Внутри app.py измените функцию create_hover_tool
def create_hover_tool():
"""Generates the HTML for the Bokeh's hover data tool on our graph."""
hover_html = """
$x
@bugs bugs
$@costs{0.00}
"""
return HoverTool(tooltips=hover_html)Встраивание HTML в приложение на Python может показаться довольно странным, но именно так мы определяем вид подсказки. Мы используем $x, чтобы показать x-координату столбца, @bugs, чтобы показать поле "bugs" источника данных и $@costs{0.00}, чтобы показать поле "costs" как числ с 2 знаками после запятой.
Убедитесь, что вы заменили return None на return HoverTool(tooltips=hover_html).
Вернитесь в браузер и перезагрузить страницу localhost:5000/128/.
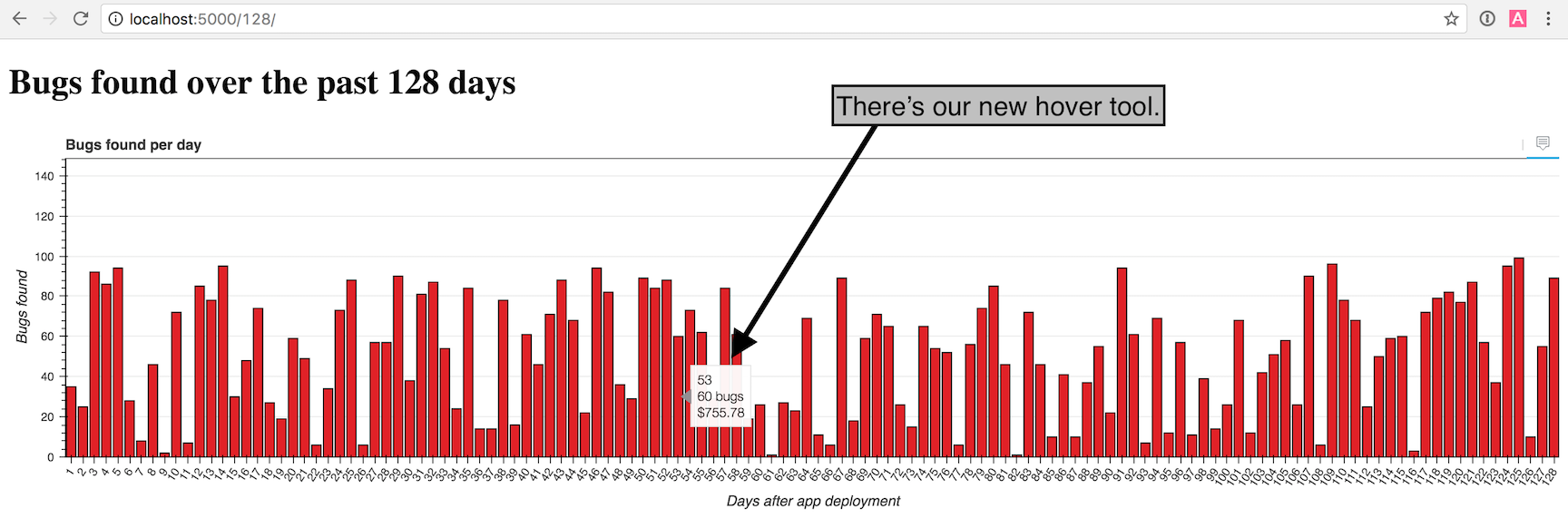
Отличная работа! Попробуйте поиграть с количеством столбцов в URL и посмотрите как график будет выглядеть.
График выглядит заполненным примерно при 100 столбцах, но вы можете попробовать задать любое значение. На 50,000 получается грустная картина:
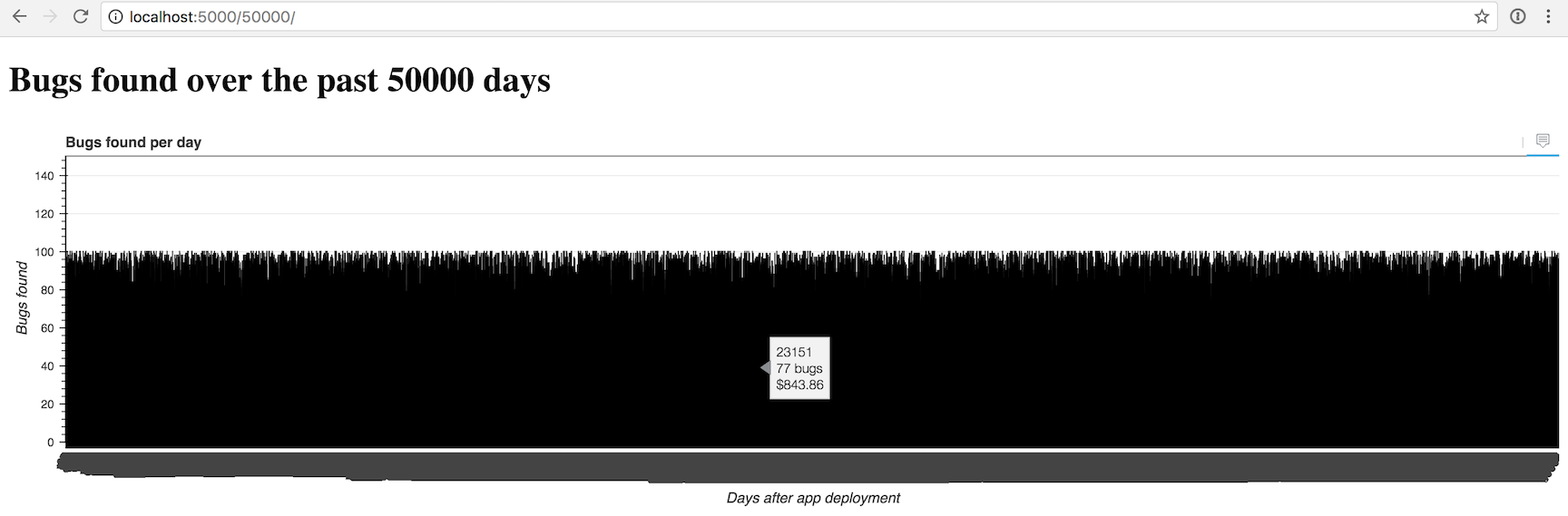
Да уж, похоже, нам нужно сделать ещё что-то, чтобы можно было отображать больше пары сотен столбцов за раз.
Мы создали отличный график на Bokeh. Далее вы можете изменить цветовую схему, подключить другой источник данных, попробовать другие типы графиков или придумать, как отображать огромные объёмы данных.
С помощью Bokeh можно делать гораздо больше, так что стоит посмотреть официальную документацию, репозиторий на GitHub, страничку Bokeh на Full Stack Python.
Есть вопросы? Задайте мне из через GitHub либо через Twitter @fullstackpython или @mattmakai.
|
Метки: author gsedometov визуализация данных python bokeh flask virtualenv |
[Из песочницы] Создаем свой кастомный плагин Style – Темизация Views в Drupal 8 |
namespace Drupal\demo\Plugin\views\style;
use Drupal\Core\Form\FormStateInterface;
use Drupal\views\Plugin\views\style\StylePluginBase;
/**
* Views стиль, который передает разметку для Bootstrap вкладок.
*
* @ingroup views_style_plugins
*
* @ViewsStyle(
* id = "bootstrap_tabs",
* title = @Translation("Bootstrap Tabs"),
* help = @Translation("Uses the Bootstrap Tabs component."),
* theme = "demo_bootstrap_tabs",
* display_types = {"normal"}
* )
*/
class BootstrapTabs extends StylePluginBase {
/**
* Разрешает ли этот Style плагин Row плагины?
*
* @var bool
*/
protected $usesRowPlugin = TRUE;
/**
* Поддерживает ли Style плагин группировку строк?
*
* @var bool
*/
protected $usesGrouping = FALSE;
/**
* {@inheritdoc}
*/
protected function defineOptions() {
$options = parent::defineOptions();
$options['tab_nav_field'] = array('default' => '');
return $options;
}
/**
* {@inheritdoc}
*/
public function buildOptionsForm(&$form, FormStateInterface $form_state) {
parent::buildOptionsForm($form, $form_state);
$options = $this->displayHandler->getFieldLabels(TRUE);
$form['tab_nav_field'] = array(
'#title' => $this->t('The tab navigation field'),
'#description' => $this->t('Select the field that will be used as the tab navigation. The rest of the fields will show up in the tab content.'),
'#type' => 'select',
'#default_value' => $this->options['tab_nav_field'],
'#options' => $options,
);
}
}
/**
* Implements hook_theme().
*/
function demo_theme($existing, $type, $theme, $path) {
return array(
'demo_bootstrap_tabs' => array(
'variables' => array('view' => NULL, 'rows' => NULL),
'path' => drupal_get_path('module', 'demo') . '/templates',
),
);
}/**
* Подготовка переменных для шаблона представления demo_bootstrap_tabs.
*
* Шаблон: demo-bootstrap-tabs.html.twig.
*
* @param array $variables
* Ассоциативный массив содержит:
* - view: объект view.
* - row: массив пунктов rows. Каждый row – это массив из контента.
*/
function template_preprocess_demo_bootstrap_tabs(&$variables) {
$view = $variables['view'];
$rows = $variables['rows'];
$variables['nav'] = array();
// Подготовка навигации вкладок.
$field = $view->style_plugin->options['tab_nav_field'];
if (!$field || !isset($view->field[$field])) {
template_preprocess_views_view_unformatted($variables);
return;
}
$nav = array();
foreach ($rows as $id => $row) {
$nav[$id] = array(
'#theme' => 'views_view_field',
'#view' => $view,
'#field' => $view->field[$field],
'#row' => $row['#row'],
);
}
template_preprocess_views_view_unformatted($variables);
$variables['nav'] = $nav;
}
{% for tab in nav %}
{% set active = '' %}
{% if loop.index0 == 0 %}
{% set active = 'active' %}
{% endif %}
- {{ tab }}
{% endfor %}
{% for row in rows %}
{% set active = '' %}
{% if loop.index0 == 0 %}
{% set active = 'active' %}
{% endif %}
{{ row.content }}
{% endfor %}
|
Метки: author helender php drupal views theming style module drupal 8 |
Теория и практика unattended upgrades в Ubuntu |
unattended-upgrades и конфигурационного файла /etc/apt/apt.conf.d/50unattended-upgrades, а настроен на обновления пакетов только из security-репозитория, куда попадают, например, критичные исправления для пакета libssl, которые выходят в результате очередного пополнения базы уязвимостей CVE.
.dpkg-new, в которых оказывается новый конфиг для пакета (если контрольная сумма конфига в устанавливаемой пакете отличается от контрольной суммы конфига в системе). Это обстоятельство стоит учитывать, потому что иначе можно получить новую версию софта, которая больше не работает с опцией, добавленной вами в конфиг, и после установки пакета сервис/приложение просто не запустится. Собирая или заимствуя пакет в свой репозиторий, помните, что установка такого пакета не обновит конфиги сама, поэтому, например, если конфиги версий не совместимы, может получиться очень неприятная ситуация, когда все давно уже спят, а ваш пакет выкатился на куче серверов и «Всё сломалось, шеф!»./etc/cron.daily/apt. Файл запускается из /etc/crontab, в котором по умолчанию задано раннее утро (06:25)./etc/apt/apt.conf.d/51unattended-upgrades-custom, в котором будут всего три строки:Unattended-Upgrade::Allowed-Origins {
"Origin:Suite";
};Origin и Suite должны как минимум вызывать ассоциации из разряда «Где-то я уже это видел…». Подскажу, что такие параметры можно увидеть у репозитория на самой машине, где должен обновляться пакет, в файле *_InRelease. Иллюстрация для хорошо известной ppa:nginx/stable:$ head -10 /var/lib/apt/lists/ppa.launchpad.net_nginx_stable_ubuntu_dists_trusty_InRelease
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA512
Origin: LP-PPA-nginx-stable
Label: NGINX Stable
Suite: trusty
Version: 14.04
Codename: trusty
Date: Sat, 11 Feb 2017 21:55:33 UTC
Architectures: amd64 arm64 armhf i386 powerpc ppc64elOrigin — «происхождение» репозитория, что может указывать на имя мейнтейнера или самого репозитория;Suite — ветка дистрибутива; например, stable, testing для Debian или trusty, xenial для Ubuntu.nginx/stable конфигурация, разрешающая unattended upgrades для всех пакетов из него, будет выглядеть следующим образом:Unattended-Upgrade::Allowed-Origins {
"LP-PPA-nginx-stable:trusty";
};$ unattended-upgrade -v --dry-run-v — быть более многословным, а --dry-run — не применять изменения. При пробном запуске мы сразу увидим, что у этого решения могут быть обратные стороны:Package-Blacklist ниже./etc/apt/apt.conf.d/50unattended-upgrades можно увидеть, что ещё умеют unattended upgrades. Настроек не так много, но некоторые из них полезны:Package-Blacklist — список пакетов, которые запрещено обновлять подобным способом. Тут же нам в примере сразу предлагают это сделать для libc, а выше описан другой пример — с PostgreSQL. Но помните, что на другой чаше весов: откладывая критичные исправления, вы рискуете безопасностью.AutoFixInterruptedDpkg — если последний процесс установки/обновления не смог завершиться по каким-либо причинам, вероятно, вам приходилось исправлять ситуацию вручную. То же самое делает и эта опция, т.е. вызывает dpkg --force-confold --configure -a. Обратите внимание, что здесь указана опция --force-confold — она означает, что будут сохранены старые версии конфигов, если возникнут конфликты.MinimalSteps — выполнять обновления минимально возможными частями. Позволяет прервать обновление отправкой SIGUSR1 процессу unattended-upgrade. InstallOnShutdown — устанавливать обновления перед выключением компьютера. Лично мне кажется плохой идеей, т.к. не хотелось бы получить труп после плановой перезагрузки сервера.Mail и MailOnlyOnError — кому отправлять письма об обновлениях и/или проблемах с ними. Письма отправляются через стандартный MTA sendmail (используется переменная окружения SENDMAIL_BINARY). К сожалению, только письма, а выполнять curl к какому-то API здесь нельзя.Automatic-Reboot — перезагружать автоматически после окончания установки, если есть файл /var/run/reboot-required. Сам файл появляется, например, после установки пакета ядра Linux, когда срабатывает правило /etc/kernel/postinst.d/update-notifier. В общем, ещё одна опция из набора «грязного Гарри».Automatic-Reboot-Time — если вы хотите сделать свои тёмные дела ночью, пока никто не видит… задаёт конкретное время автоматической перезагрузки.Acquire::http::Dl-Limit — это уже из общего набора параметров apt. Ограничивает скорость загрузки обновлений, чтобы не забить канал.|
|
PHP-Дайджест № 110 – свежие новости, материалы и инструменты (28 мая – 11 июня 2017) |

Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.2.0 Alpha 1, свежие предложения из PHP Internals, Symfony 3.3.0, Yii 1.1.19 и 2.0.12, нововведния Laravel 5.5, спор о Visual Debt и многое другое.
Приятного чтения!
$x ~> $x + 1;, а также ^($x) => $x + $y. На данный момент рассматриваются следующие возможные варианты:fn(params) => expr
function(params) => expr
(params) ==> expr
(params) => expr
[](params) => expr
 ЧПУ (SEF URLs) в Symfony 3 — автогенерация slug, настройка и маршрутизация История одного лендинга Методы работы с «тяжёлыми» XML Тестирование с Сodeception для чайников: 3 вида тестов Как выбрать тот самый PHP-фреймворк. Сравнительное тестирование Как получить оффер в Badoo в день собеседования. Часть вторая, для PHP-разработчика
ЧПУ (SEF URLs) в Symfony 3 — автогенерация slug, настройка и маршрутизация История одного лендинга Методы работы с «тяжёлыми» XML Тестирование с Сodeception для чайников: 3 вида тестов Как выбрать тот самый PHP-фреймворк. Сравнительное тестирование Как получить оффер в Badoo в день собеседования. Часть вторая, для PHP-разработчикаСпасибо за внимание!
Если вы заметили ошибку или неточность — сообщите, пожалуйста, в личку.
Вопросы и предложения пишите на почту или в твиттер.
Прислать ссылку
Быстрый поиск по всем дайджестам
<- Предыдущий выпуск: PHP-Дайджест № 109
|
Метки: author pronskiy разработка веб-сайтов php блог компании zfort group дайджест php- ссылки symfony yii laravel zend hhvm |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №266 (5 — 11 июня 2017) |

| Веб-разработка |
| CSS |
| Javascript |
| Браузеры |
| Занимательное |
 Веб-разработка
Веб-разработка Favicon сегодня: форматы, поддержка, автоматизация Будущее MDN — фокус на Web Docs
Favicon сегодня: форматы, поддержка, автоматизация Будущее MDN — фокус на Web Docs Зачем нужны заголовки — HTML Шорты Записи докладов с потока Frontend на Codefest 2017
Зачем нужны заголовки — HTML Шорты Записи докладов с потока Frontend на Codefest 2017  Чеклист для запуска сайта Большой список советов по работе с Progressive Web Apps Подробное введение в веб-компоненты с теорией и примерами. И выдрами. SVGI — CLI инструмент для инспектирования контента SVG файлов JPG, PNG и SVG в вебе: руководство для новичков World Wide Web, небогатый западный веб (часть 1). Bruce Lawson о нюансах использования интернета в Азии и Африке Креативные идеи эффектного интерактива для букв в заголовках WebAssembly 101: первые шаги разработчиков Как 17 строчек кода улучшили загрузку Shopify.com на 50% Оптимизация изображений: основные ошибки и решения Мрачные мысли по поводу AMP Как создавать страницы AMP в wordpress Принципы доступности. Как люди с ограниченными возможностями используют веб. Обновленная официальная документация W3C WAI Чеклист доступности: 10 критических элементов для оценки доступности сайта Аудит доступности — это забавно Как сделать сайт доступным для людей, пользующихся Screen Magnifier Как работать с доступностью цвета
Чеклист для запуска сайта Большой список советов по работе с Progressive Web Apps Подробное введение в веб-компоненты с теорией и примерами. И выдрами. SVGI — CLI инструмент для инспектирования контента SVG файлов JPG, PNG и SVG в вебе: руководство для новичков World Wide Web, небогатый западный веб (часть 1). Bruce Lawson о нюансах использования интернета в Азии и Африке Креативные идеи эффектного интерактива для букв в заголовках WebAssembly 101: первые шаги разработчиков Как 17 строчек кода улучшили загрузку Shopify.com на 50% Оптимизация изображений: основные ошибки и решения Мрачные мысли по поводу AMP Как создавать страницы AMP в wordpress Принципы доступности. Как люди с ограниченными возможностями используют веб. Обновленная официальная документация W3C WAI Чеклист доступности: 10 критических элементов для оценки доступности сайта Аудит доступности — это забавно Как сделать сайт доступным для людей, пользующихся Screen Magnifier Как работать с доступностью цвета CSS «Цена пропущенного фрейма». Доклад на производительной анимации от Дмитрия Шуранова Текстовая визуализация Template Areas в CSS Grid Локальные CSS переменные: что, как и зачем Awesome CSS in JS: коллекция полезных ссылок на тему техник CSS in JS 70% повторений в таблицах стилей: информация о том, как мы фейлим оптимизацию CSS CSS Shapes, clipping и masking – и как их использовать Masking vs. Clipping: когда их использовать Равносторонний треугольник идеального параграфа. Если хочется поиграться со шрифтами OOCSS – будущее написания CSS в качестве инструмента тестирования / проверки доступности Как долго нужно работать с css, чтобы быть в нем хорошим? Обсуждение на reddit/r/css Забавы с единицами вьюпорта
CSS «Цена пропущенного фрейма». Доклад на производительной анимации от Дмитрия Шуранова Текстовая визуализация Template Areas в CSS Grid Локальные CSS переменные: что, как и зачем Awesome CSS in JS: коллекция полезных ссылок на тему техник CSS in JS 70% повторений в таблицах стилей: информация о том, как мы фейлим оптимизацию CSS CSS Shapes, clipping и masking – и как их использовать Masking vs. Clipping: когда их использовать Равносторонний треугольник идеального параграфа. Если хочется поиграться со шрифтами OOCSS – будущее написания CSS в качестве инструмента тестирования / проверки доступности Как долго нужно работать с css, чтобы быть в нем хорошим? Обсуждение на reddit/r/css Забавы с единицами вьюпорта JavaScript Нативные EcmaScript модули: новые возможности и отличия от webpack От «нового числового формата» до «кода как UI»: как прошла HolyJS 2017 Piter Внушительный список современного JavaScript инструментария ES.next: object rest и свойства распространения Рассматриваем ES2017 декораторы в JavaScript Коллбэки в JavaScript Классы, сложность, и функциональное программирование Сравнение Flow и TypeScript JavaScript: что такое немедленно вызываемые функции? Функциональные миксины Как получить максимальную отдачу от консоли JavaScript Апгрейдим Node 6 до Node 8: сравнение производительности в реальном мире Полное руководство по Angular Material Themes Angular 2 vs React: очередное сравнение Angular2: советы и хитрости разработки Пример приложения задачника на React-е с объяснением Начало работы с PreactJS — пошаговое руководство Типизированные компоненты в Vue.js, или как подружить Vue, TypeScript и Webpack Введение в серверный рендеринг приложений Vue.js с помощью Nuxt Создание приложения для поиска учебников на Vue Впечатления от VueJs & ReactJS. Что думают люди… Может ли Vue бороться за трон с React? synt — находит похожие функции и классы в JavaScript/TypeScript коде flubber — инструмент для плавной анимации между 2-D фигурами getlibs — Встроенный загрузчик модулей, настроенный на получение внешних зависимостей непосредственно от CDN. Включает babel/typescript billboard.js — леграя интерфейсная JavaScript библиотека для графиков, основанная на D3 v4+ Новые функции Microsoft Edge: поддержка CSS object-fit/object-position, position: sticky, улучшенная консоль и многое другое Стал доступен Safari Technology Preview 32, с WebRTC, WebAssembly и улучшениями Auto-Play Кроссбраузерные расширения теперь доступны в Firefox
JavaScript Нативные EcmaScript модули: новые возможности и отличия от webpack От «нового числового формата» до «кода как UI»: как прошла HolyJS 2017 Piter Внушительный список современного JavaScript инструментария ES.next: object rest и свойства распространения Рассматриваем ES2017 декораторы в JavaScript Коллбэки в JavaScript Классы, сложность, и функциональное программирование Сравнение Flow и TypeScript JavaScript: что такое немедленно вызываемые функции? Функциональные миксины Как получить максимальную отдачу от консоли JavaScript Апгрейдим Node 6 до Node 8: сравнение производительности в реальном мире Полное руководство по Angular Material Themes Angular 2 vs React: очередное сравнение Angular2: советы и хитрости разработки Пример приложения задачника на React-е с объяснением Начало работы с PreactJS — пошаговое руководство Типизированные компоненты в Vue.js, или как подружить Vue, TypeScript и Webpack Введение в серверный рендеринг приложений Vue.js с помощью Nuxt Создание приложения для поиска учебников на Vue Впечатления от VueJs & ReactJS. Что думают люди… Может ли Vue бороться за трон с React? synt — находит похожие функции и классы в JavaScript/TypeScript коде flubber — инструмент для плавной анимации между 2-D фигурами getlibs — Встроенный загрузчик модулей, настроенный на получение внешних зависимостей непосредственно от CDN. Включает babel/typescript billboard.js — леграя интерфейсная JavaScript библиотека для графиков, основанная на D3 v4+ Новые функции Microsoft Edge: поддержка CSS object-fit/object-position, position: sticky, улучшенная консоль и многое другое Стал доступен Safari Technology Preview 32, с WebRTC, WebAssembly и улучшениями Auto-Play Кроссбраузерные расширения теперь доступны в Firefox Занимательное WWDC 2017 за 14 минут на русском
Занимательное WWDC 2017 за 14 минут на русскомПросим прощения за возможные опечатки или неработающие/дублирующиеся ссылки. Если вы заметили проблему — напишите пожалуйста в личку, мы стараемся оперативно их исправлять.
|
|
[Перевод] Идиоматичный Redux: Дао Redux'а, Часть 1 — Реализация и Замысел |
Мысли о том, какие требования выдвигает Redux, как задумано использование Redux и что возможно с Redux.
Я потратил много времени, обсуждая онлайн паттерны использования Redux, была ли это помощь тем, кто изучает Redux в Reactiflux каналах, дискуссии о возможных изменениях в API библиотеки Redux на Github'е, или обсуждение различных аспектов Redux'а в комментариях к тредам на Reddit'е или HN (HackerNews). С течением времени, я выработал свое собственное мнение о том, что представляет собой хороший, идиоматичный Redux код, и я хотел бы поделиться некоторыми из этих мыслей. Несмотря на мой статус мейнтейнера Redux'а, это всего лишь мнения, но я предпочитаю думать, что они являются достаточно хорошими подходами :)
Redux, в своей сути, невероятно простой паттерн. Он сохраняет значение, выполняет одну функцию для обновления значения когда это необходимо, и уведомляет любых подписчиков о том, что что-то изменилось.
Несмотря на эту простоту, или, возможно, вследствие ее, существует широкий спектр походов, мнений и взглядов о том, как использовать Redux. Многие из этих подходов широко расходятся с концепциями и примерами из документации.
В то же время, продолжаются жалобы на то, как Redux «заставляет» вас делать вещи определенными способами. Многие из этих жалоб на самом деле включают концепции связанные с тем, как Redux обычно используется, а не фактическими ограничениями наложенными самой библиотекой Redux. (Например, только в одном недавнем HN треде я видел жалобы: «слишком много шаблонного кода», «константы action'ов и action creator'ы не нужны», «я вынужден редактировать слишком много файлов чтобы добавить одну фичу», «почему я должен переключаться между файлами чтобы добраться до своей логики?», «термины и названия слишком сложны для изучения или запутанны», и слишком много других.)
По мере того, как я исследовал, читал, обсуждал и изучал разнообразие способов использования Redux'а и идей, разделяемых в сообществе, я пришел к выводу, что важно различать то, как Redux на самом деле работает, задуманные способы его концептуального использования, и почти бесконечное количество способов возможного использования Redux. Я хотел бы затронуть несколько аспектов использования Redux и обсудить, как они вписываются в эти категории. В целом, я надеюсь объяснить, почему существуют конкретные паттерны и практики использования Redux, философию и замысел Redux'а, и то, что я считаю «идиоматичным» и «неидиоматичным» использованием Redux.
Этот пост будет разделен на две части. В «Часть 1 — Реализация и Замысел» мы рассмотрим фактическую реализацию Redux, какие конкретные ограничения он накладывает, и почему эти ограничения существуют. Затем, мы рассмотрим первоначальный замысел и проектные цели для Redux, основываясь на обсуждениях и заявлениях авторов (особенно на ранней стадии процесса разработки).
В «Часть 2 — Практика и Философия» мы исследуем распространенные практики, широко используемые в приложениях Redux, и опишем почему эти практики существуют в первую очередь. Наконец, мы рассмотрим ряд «альтернативных» подходов к использованию Redux и обсудим, почему многие их них возможны, но не обязательно «идиоматичны».
Начнем со взгляда на теперь известные Три Принципа Redux'а
В самом прямом смысле, каждое из этих заявлений — ложь! (или, заимствуя классическую реплику из «Возвращение джежая» — «они верны… с определенной точки зрения.»)
Но если эти заявления не полностью правдивы, зачем вообще они нужны? Эти принципы не фиксированные правила или буквальные заявления о реализации Redux'а. Скорее они формируют заявление о замысле того, как Redux следует использовать.
Эта тема будет продолжаться в остальной части текущей дискуссии. Из-за того, что Redux такая минимальная библиотека с точки зрения реализации, он так мало требует или навязывает на техническом уровне. Это поднимает ценную побочную дискуссию, на которую стоит взглянуть.
В своей речи на ReactConf 2017 «Приручение Мета-языка» Ченг Лу описывает, что только исходный код является «языком», а все остальное, наподобие комментариев, тестов, документации, туториалов, блог постов, и конференций, является «мета-языком». Другими словами, исходный код сам по себе может передать только определенную часть информации. Много дополнительных слоев передачи информации на уровне человека требуется, чтобы люди понимали «язык».
Далее Ченг Лу продолжает обсуждать, как смещение дополнительных концепций в сам язык, позволяет выразить больше информации через медиум исходного кода, не прибегая к использованию «мета-языка» для передачи идей. С этой точки зрения, Redux — крошечный «язык» и почти вся информация о том, как его следует использовать является на самом деле «мета-языком».
«Язык» (в этом случае основная библиотека Redux) имеет минимальную экспрессивность, и следовательно концепции, нормы и идеи, окружающие Redux, все находятся на уровне «мета-языка». (Фактически, пост Понимание «Приручения Мета-языка», который раскладывает по полочкам идеи из выступления Ченга Лу, называет Redux конкретным примером этих идей.) В конечном счете, это означает, что понимание того, почему определенные практики существуют вокруг Redux'а, и решения о том, что является и не является «идиоматичным» будут включать мнения и обсуждения, а не просто определение, основанное на исходном коде.
Прежде чем мы сильно углубимся в философскую сторону вещей, важно понимать какие технические ожидания у Redux'а действительно есть. Взгляд на внутренности и реализацию будет информативен.
Функция createStore центральная часть функциональности Redux'а. Если мы отсечем комментарии, проверку ошибок, и код для пары продвинутых возможностей, таких как store enhancers (усилители хранилища — функции, расширяющие возможности store — примечание переводчика) и observables, вот как выглядит createStore (пример кода позаимствован из «построй-мини-Redux» туториала под названием «Взламывая Redux»):
function createStore(reducer) {
var state;
var listeners = []
function getState() {
return state
}
function subscribe(listener) {
listeners.push(listener)
return unsubscribe() {
var index = listeners.indexOf(listener)
listeners.splice(index, 1)
}
}
function dispatch(action) {
state = reducer(state, action)
listeners.forEach(listener => listener())
}
dispatch({})
return { dispatch, subscribe, getState }
}
Это примерно 25 строк кода, но все же они включают ключевую функциональность. Код отслеживает текущее значение состояния и множество подписчиков, обновляет значение и уведомляет подписчиков когда action диспатчится, и предоставляет API для store.
Взгляните на все те вещи которые этот фрагмент не включает:
В этом ключе стоит процитировать pull-request Дэна Абрамова для примера «классический счетчик»:
Новый пример «классический счетчик» направлен на то, чтобы развеять миф о том, что Redux требует Webpack, React, горячую перезагрузку, саги, action creator'ы, константы, Babel, npm, CSS модули, декораторы, отличное знание латыни, подписки на Egghead, научную степень, или степень С.О.В. Нет, это всего лишь HTML, некоторые кустарные скрипт-тэги и старые добрые манипуляции с DOM. Наслаждайтесь!
Функция dispatch внутри createStore просто вызывает функцию-reducer и сохраняет любое возвращаемое значение. И все же, несмотря на это, элементы в том списке идей широко расцениваются, как концепции, о которых должно заботиться хорошее приложение на Redux.
Изложив все те вещи до которых createStore нет дела, важно отметить, что на самом деле эта функция требует. Настоящая функция createStore навязывает два конкретных ограничения: action'ы, которые доходят до store, обязаны быть простыми объектами, и action'ы обязаны иметь поле «type» не равное undefined.
Оба этих ограничения происходят от оригинальной концепции «Flux архитектуры». Цитируя секцию Flux Action'ы и Диспатчер из документации Flux:
Когда новые данные попадают в систему, как через человека, взаимодействующего с приложением, так и через web api вызов, эти данные упаковываются в action — объект, содержащий новые поля данных и конкретный action тип. Мы зачастую создаем библиотеку вспомогательных методов называемых ActionCreators которые не только создают объект action, но и передают action диспатчеру. Различные действия идентифицируются аттрибутом «type». Когда все store получают action, они обычно используют этот аттрибут для определения, следует ли им реагировать на него и каким образом. В приложении Flux, stor'ы и view контролируют сами себя; на них не воздействуют внешние объекты. Action'ы поступают в stor'ы через функции обратного вызова которые они определяют и регистрируют, а не методами установки (сеттерами).
Изначально Redux не требовал специальное поле «type», но позже была добавлена проверка валидности, чтобы помочь отловить возможные опечатки или неправильный импорт констант action'ов, и для избежания бесполезных споров о базовой структуре объектов.
Здесь мы начинаем наблюдать некоторые ограничения, знакомые большему количеству людей. combineReducers ожидает, что каждый reducer среза, переданный в него, будет «корректно» реагировать на неизвестный action, возвращая свое состояние по-умолчанию и никогда не вернет undefined. Она также ожидает, что значением текущего состояния является простой JS объект, и что имеется точное соответствие между ключами в объекте текущего состояния и в объекте функции-reducer'а. И наконец, combineReducers выполняет проверку на равенство по ссылке, для определения все ли срез-reducer'ы вернули свое предыдущее значение. Если все вернувшиеся значения выглядят как предыдущие значения, combineReducers полагает, что ничего нигде не изменилось и, в качестве оптимизации, возвращает исходный корневой объект состояния.
Инструменты разработчика Redux состоят из двух основных частей: enhancer'а (усилителя) для store который реализует перемещение во времени путем отслеживания диспатченных action'ов, и пользовательского интерфейса, позволяющего просматривать и управлять историей. Сам по себе store enhancer не заботится о содержимом action'ов или состояния, он просто хранит action'ы в памяти. Изначально интерфейс инструментов разработчика нужно было рендерить внутри дерева компонентов вашего приложения, и он также не заботился о содержимом action'ов или состояния. Тем не менее, расширение Redux DevTools работает в отдельном процессе (по крайней мере в Chrome), и, следовательно, требует сериализуемости всех action'ов и состояния, для того, чтобы все возможности перемещения во времени работали корректно и быстро. Возможность импорта и экспорта состояния и action'ов также требует чтобы они были сериализуемыми.
Другое полу-требование для отладки с помощью перемещения во времени — иммутабельность и чистые функции. Если функция-reducer мутирует состояние, тогда переход между acton'ами в отладчике приведет к неконсистентным значениям. Если у reducer'а есть побочные эффекты, тогда эти побочные эффекты будут проявляться каждый раз когда DevTools повторяет action. В обоих случаях, отладка путем перемещения во времени не будет работать полностью как ожидается.
Настоящей проблемой мутация становится в функции connect из React-Redux. Оберточные компоненты, сгенерированные connect, реализуют множество оптимизаций для обеспечения того, чтобы обернутые компоненты ререндерились только тогда, когда на самом деле необходимо. Эти оптимизации вращаются вокруг проверок на ссылочное равенство, для определения того, изменились ли данные.
В частности, каждый раз, когда action диспатчится и подписчики уведомляются, connect проверяет, изменился ли корневой объект состояния. Если нет, connect предполагает что ничего в состоянии не изменилось, и пропускает дальнейшую работу по рендерингу (Вот почему combineReducers пытается, по мере возможности, вернуть тот же самый корневой объект состояния). Если же корневой объект состояния изменился, connect вызовет предоставленную функцию mapStateToProps, и выполнит неглубокую проверку на равенство между текущим результатом и предыдущим, для выявления изменились ли props, рассчитанные от данных store. Опять же, если содержимое данных выглядит одинаково, connect не будет ререндерить обернутый компонент. Эти проверки на равенство в connect'е являются причиной того, почему случайные мутации состояния не приводят к ререндерингу компонентов, это из-за того, что connect предполагает, что данные не изменились и ререндеринг не нужен.
Иммутабельность также имеет значение и в других библиотеках, зачастую использующихся совместо с Redux. Библиотека Reselect создает запоминающие функции-селекторы, обычно используемые для извлечения данных из дерева состояния Redux. Запоминание значений, как правило, полагается на проверку ссылочного равенства, для определения того, совпадают ли входные параметры с ранее использованными.
Также, хотя React'овский компонент может реализовать shouldComponentUpdate, используя любую логику какую захочет, самая распространенная реализация полагается на неглубокие проверки равенства текущих props и новых входящих props, например:
return !shallowEqual(this.props, nextProps)В любом случае, мутация данных обычно приводит к нежелательному поведению. Запоминающие функции-селекторы не вернут правильные значения, и оптимизированные компоненты React'а не будут ререндерится когда должны.
Центральная функция Redux'а createStore сама по себе накладывает только два ограничения на то, как вы должны писать свой код: action'ы должны быть простыми объектами, и должны содержать определенный type. Ее не заботит иммутабельность, сериализуемость, побочные эффекты или какое на самом деле принимает значение поле type.
С учетом вышесказанного, широко используемые части вокруг этого ядра, включая Redux DevTools, React-Redux, React и Reselect, действительно полагаются на правильное использование иммутабельности, сериализуемости action'ов/состояния и чистых функций-reducer'ов. Основная логика приложения может работать нормально если эти ожидания проигнорированы, но, с большой долей вероятности, отладка перемещением во времени и ререндеринг компонентов сломаются. Они также повлияют и на любые другие случаи использования, связанные с постоянством.
Важно отметить, что иммутабельность, сериализуемость и чистые функции никаким образом не навязываются Redux'ом. Функция-reducer вполне может мутировать свое состояние или выполнять AJAX-вызов. Любая другая часть приложения вполне может вызывать getState() и модифицировать содержимое дерева состояния напрямую. Полностью возможно помещать промисы, функции, Символы, инстансы класса или другие не сериализуемые значения в action'ы или дерево состояний. Вам не следует делать ничего из этого, но это возможно.
Помня про эти технические ограничения, мы можем обратить внимание на то, как задумано использование Redux'а. Чтобы лучше понять эту мысль, полезно оглянуться на идеи, которые привели к начальной разработке Redux'а.
Раздел «Введение» в документации Redux содержит несколько основных идей, повлиявших на разработку и концепции Redux, в темах Мотивация, Ключевые концепции и Предшественники. В качестве краткого итога:
Также стоит взглянуть на заявленные проектные цели в ранней версии README Redux'a.
Философия и проектные цели
- Вам не нужна книга по функциональному программированию для того, чтобы использовать Redux.
- Всё (Stores, Action Creator'ы, конфигурация) способно на «горячую» перезагрузку.
- Сохраняет преимущества Flux'а, но добавляет другие полезные свойства благодаря своей функциональной природе.
- Предотвращает некоторые анти-паттерны распространенные в коде Flux.
- Отлично работает в изоморфных приложениях, потому что не использует синглтоны, и данные могут быть «увлажнены».
- Не имеет значения как вы храните ваши данные: вы можете использовать JS объекты, массивы, ImmutableJS и т.д.
- Под капотом, Redux держит все ваши данные в виде дерева, но вам не нужно об этом думать.
- Позволяет эффективно подписываться на меньшие обновления, чем обновления индивидуальных Stor'ов.
- Предоставляет зацепки для реализации мощных инструментов разработчика (например, переходы по времени, запись/проигрывание) без обязательной их установки
- Предоставляет точки расширения, чтобы можно было легко поддержать промисы или генерировать константы вне ядра Redux.
- Никаких оберточных вызовов в ваших stor'ах и action'ах. Ваши вещи — это ваши вещи.
- Невероятно просто тестировать в изоляции без моков (mocks).
- Можно использовать «плоские» Stor'ы, или композировать и переиспользовать Stor'ы также как композируются компоненты.
- Поверхность API минимальна.
- Я уже упоминал «горячую» перезагрузку?
Прочитывая документацию Redux, ранние issue-треды, и многие другие комментарии Дэна Абрамова и Эндрю Кларка, можно заметить несколько конкретных тем касательно задуманного использования Redux.
Redux изначально задумывался «всего лишь» как еще одна библиотека реализующая архитектуру Flux. В результате она уследовала многие коцепции от Flux: идею «отправки (dispatching) action'ов», то что action'ы — это простые объекты с полем type, использование «функций создания» action'ов (action creators), то, что «логика обновления» должна быть отделена от остальной части приложения и централизована, и многое другое.
Я часто вижу вопросы «Почему Redux делает ТАК», и на многие из подобных вопросов ответ: «Потому что Архитектура Flux'а и конкретные библиотеки Flux делали ТАК».
Почти каждый аспект Redux'а, призван помочь разработчику понять когда, почему и как изменилась конкретная часть состояния. Это включает как фактическую реализацию, так и поощряемое использование.
Это значит, что разработчик должен иметь возможность посмотреть отправленный action, увидеть какие изменения состояния получились в результате, и вернуться к местам в кодовой базе, где этот action был диспатчен (особенно в зависимости от его типа). Если в store неверные данные, должно быть возможно отследить, какой диспатченный action привел к неправильному состоянию, и отмотать оттуда назад.
Упор на «горячую перезагрузку» и «отладку с переходом во времени» также нацелен на производительность и удобство разработчиков, поскольку обе возможности позволяют разработчику выполнять быстрые итерации и лучше понимать что происходит в системе.
Хотя ядро Redux'а не заботит какие конкретные значения содержатся в поле type ваших action'ов, довольно очевидно, что типы action'ов должны нести некоторый смысл и информацию. Redux DevTools и другие утилиты логирования отображают поле type для каждого диспатченного action'а, так что важно иметь значения, понятные с беглого взгляда.
Это значит, что строки полезнее Символов или чисел, с точки зрения передачи информации. Это также означает, что формулировка action типа должна быть ясной и понятной. Как правило, это означает, что наличие различных action типов будет понятнее разработчику, чем наличие только одного или двух action типов. Если во всей кодовой базе используется только один action тип (например, SET_DATA), то будет сложнее отслеживать откуда конкретный action был диспатчен, а жрунал истории действий будет менее читабельным.
Redux явно замыслен для использования с концепциями функционального программирования, и для того, чтобы помочь представить эти концепции как новым, так и опытным разработчикам. Эти концепции включают основы ФП, такие как: иммутабельность и чистые функции, а также идеи, наподобие композиции функций для решения большей задачи.
В то же время, Redux призван помочь обеспечить реальную ценность для разработчиков, пытающихся решать проблемы и создавать приложения, не подавляя при этом большим количеством абстрактных концепций ФП, и не увязая в спорах о терминах ФП, таких как «монады» или «эндофункторы». (Нужно признать, количество терминов и концепций вокруг Redux'а выросло с течением времени, и многие из них путают новичков, но цели: использования преимуществ ФП и введение в ФП для начинающих — явно были частью оригинального дизайна и философии.)
Наличие reducer'ов в качестве чистых функций позволяет выполнять отладку с переходом во времени, и также означает, что функция-reducer может легко быть протестирована в изоляции. Тестирование reducer'а должно требовать только его вызова с конкретными аргументами и проверки вывода — нет необходимости создавать моки для таких вещей как AJAX вызовы.
AJAX вызовы и другие побочные эффекты по-прежнему должны находится где-то в приложении, и тестирующий код, который их использует, может по-прежнему работать. Тем не менее, упор на чистые функции в значительной части кодовой базы снижает общую сложность тестирования.
Redux берет концепт индивидуальных «хранилищ» из архитектуры Flux и объединяет их в единственный store. Самым прямолинейным соответствием между Flux и Redux является создание отдельного ключа верхнего уровня или «среза» в дереве состояний для каждого Flux хранилища. Если Flux приложение имеет раздельные UsersStore, PostsStore и CommentsStore, эквивалент в Redux будет иметь корневое дерево состояний, выглядящее так: { users, posts, comments }.
Можно ограничиться единственной функцией, содержащей всю логику по обновлению всех срезов состояния, но любое осмысленное приложение захочет разбить такую функцию на более мелкие функции для облегчения сопровождения. Самым очевидным способом это сделать является раздление логики в зависимости от того, какой срез состояния должен быть обновлен. Это значит, что каждый «reducer среза» должен заботиться только о своем срезе состояния, и, насколько ему известно, этот срез может быть всем состоянием. Этот паттерн «композиции reducer'ов» можно многократно повторяться для обработки обновлений иерархической структуры состояния. И утилита combineReducers включена в состав Redux'а специально для упрощения использования этого паттерна.
Если каждую функцию-reducer среза можно вызывать отдельно и предоставлять ей только собственный срез состояния в качестве параметра, то это означает, что с одним и тем же action'ом можно вызывать несколько reducer'ов среза, и каждый из них может обновлять свой срез состояния независимо от других. Основываясь на заявлениях Дэна и Эндрю, возможность одного action'а привести к обновлениям нескольких reducer'ов среза, является ключевой особенностью Redux'а. Про это часто говорят: «action'ы имеют отношение 1-ко-многим с reducer'ами.»
Redux не содержит никакой «магии». Некоторые аспекты его реализации (такие как applyMiddleware и store enhancers) чуть сложнее понять сразу, если вы не знакомы с более продвинутыми принципами ФП, но в остальном все должно быть явным, ясным и отслеживаемым с минимальным количеством абстракций.
Redux на самом деле даже не реализует саму логику обновления состояния. Он просто полагается на любую корневую функцию-reducer, которую вы предоставите. Он имеет утилиту combineReducers, чтобы помочь в распространненом случае — независимом управлении состояниями reducer'ами среза. Но вас полностью поощряют на написание собственной логики reducer'а для удовлетворения ваших потребностей. Также это означает, что ваша логика reducer'а может быть простой или сложной, абстрактной или многословной — все зависит от того, как вы хотите ее написать.
В оригинальном диспатчере Flux'а, Stor'ам нужно было событие waitFor(), которое могло быть использовано для задания цепочек зависимостей. Если CommentsStore нуждался в данных от PostsStore для того, чтобы правильно обновить себя, он мог вызвать PostsStore.waitFor(), чтобы гарантировать, что он выполнится после того как PostsStore обновится. К сожалению, такую цепочку зависимостей было нелегко визуализировать. Тем не менее, с Redux такая последовательность операций может быть достигнута явным вызовом конкретных функций-reducer'ов в нужной последовательности.
Вот в качестве примера некоторые (немного модифицированные) цитаты и сниппеты из Дэновского гиста «Combining Stateless Stores»
В этом случае, commentsReducer не зависит полностью от состояния и action'а. Он также зависит и от hasCommentReallyBeenAdded (былЛиКомментарийДействительноДобавлен). Мы добавляем этот параметр к его API. Да, его теперь нельзя использовать «как есть», но в этом весь смысл: reducer теперь имеет явную зависимость от других данных. Он не store верхнего уровня. То, что управляет им, обязано каким-то образом предоставить ему эти данные.
export default function commentsReducer(state = initialState, action, hasPostReallyBeenAdded) {}
// в другом месте
export default function rootReducer(state = initialState, action) {
const postState = postsReducer(state.post, action);
const {hasPostReallyBeenAdded} = postState;
const commentState = commentsReducer(state.comments, action, hasPostReallyBeenAdded);
return { post : postState, comments : commentState };
}
Это также применимо к идее «reducer'ов высшего порядка». Отдельный reducer среза может быть обернут другими reducer'ами, чтобы получить такие способности как отмена/повтор или пагинация.
Эта цель повторялась снова и снова Дэном и Эндрю на протяжении разработки Redux'а. Проще всего процитировать некоторые из их комментариев:
Зачастую лучший API — это отсутствие API. Текущие предложения для middleware и stor'ов высшего порядка обладают огромным преимуществом в том, что они не требуют особого отношения со стороны ядра Redux — они просто обертки вокруг dispatch() и createStore() соответственно. Вы даже можете использовать их сегодня, до релиза 1.0. Это огромная победа для расширяемости и быстрых инноваций. Мы должны поддерживать паттерны и соглашения вместо жестких, привилегированных API.
Вот почему я решил написать Redux вместо использования NuclearJS:
- Я не хочу жесткую зависимость от ImmutableJS
- Я хочу настолько малый API насколько возможно
- Я хочу сделать так, чтобы можно было легко спрыгнуть с Redux когда появиться что-то получше
С Redux я могу использовать простые объекты, массивы и что угодно для состояния.
Я изо всех сил старался избегать API наподобие createStore, потому что они привязывают вас к конкретной реализации. Вместо этого, для каждой сущности (Reducer, Action Creator) я попытался найти минимальный способ взаимодействия с ней без какой-либо зависимости от Redux. Единственный код, импортирующий Redux и действительно жестко зависимый от него, будет в вашем корневом компоненте и компонентах, подписанных на него.
Это связано с целью «минимального API». Некоторые библиотеки Flux, такие как Flummox Эндрю, имели некую форму асинхронного поведения, встроенную непосредственно в библиотеку (например, START/SUCCESS/FAILURE action'ы для промисов). И хотя наличие чего-то встроенного в ядро означало, что оно всегда доступно, это также ограничивало гибкость.
Снова проще всего процитировать комментарии из обсуждений и Hashnode AMA (вопросы/ответы) с Дэном и Эндрю:
Для продолжения поддержки асинхронных action'ов и для предоставления точки расширения для внешних плагинов и инструментов, мы можем предоставить некий общий action middleware, вспомогательную функцию для композиции middlewar'ов, и документацию для авторов расширений о том, как легко создавать свои собственные.
Я согласен, что это естественная возможность, которую наверняка захотят большинство Redux приложений, но как только мы встроим ее в ядро, все сразу начнут бессмысленные споры о том, как именно она должна работать, что собственно и случилось со мной и Flummox. Мы пытаемся держать ядро настолько малым и гибким насколько возможно, чтобы мы могли выполнять короткие итерации и позволять другим строить поверх него.Как однажды сказал Дэн (не помню где… возможно в Slack) мы нацелены быть Koа для Flux библиотек. В конечном счете, когда сообщество повзрослеет, мы планируем поддерживать коллекцию «благословленных» плагинов и расширений, возможно в рамках reduxjs организации на Github'е.
Мы не хотели прописывать что-то подобное в самом Redux'е, потому что знаем, что многие люди не готовы изучать Rx операторы для выполнения базовых асинхронных операций. Они полезны, когда у вас сложная асинхронная логика, но мы не хотели вынуждать каждого пользователя Redux изучать Rx, так что мы намеренно поддержали гибкость middlewar'ов.
Причина, по которой middleware API вообще существует, в том, что мы совершенно не хотели останавливаться на конкретном решении для асинхронности. Моя предыдущая библиотека Flux — Flummox — имела, по сути, встроенный промис-middleware. Для кого-то это было удобно, но из-за того, что она была встроенной, вы не могли изменить ее поведение или отказаться от нее. С Redux мы знали, что сообщество придумает множество лучших асинхронных решений, чем то, что мы бы могли сделать самостоятельно. Redux Thunk рекламируется в документации потому, что это абсолютно минимальное решение. Мы были уверены, что сообщество придумает нечто другое и/или лучшее. Мы были правы!
Я потратил много времени на исследование для этих двух постов. Было невероятно интересно прочитать ранние дискуссии и комментарии, и увидеть как Redux эволюционировал в то, что мы знаем теперь. Как видно из процитированного ранее README, видение Redux'а было ясным с самого начала, и было несколько конкретных идей и концептуальных скачков, которые привели к окончательному API и реализации. Надеюсь, этот взгляд на внутренности и историю Redux поможет пролить свет на то, как Redux работает на самом деле, и почему он был построен таким образом.
Обязательно ознакомьтесь с Дао Redux'а, Часть 2 — Практика и Философия, где мы взглянем на то, почему существует множество паттернов использования Redux, и я поделюсь своими мыслями о плюсах и минусах многих «вариаций» того, как можно использовать Redux.
Источник: blog.isquaredsoftware.com/2017/05/idiomatic-redux-tao-of-redux-part-1
У меня ушло достаточно много времени на перевод этого поста, пишите в комментариях если понравилось и есть желание прочитать перевод второй части, буду рад услышать ваше мнение.
|
Метки: author Checkmatez функциональное программирование разработка веб-сайтов reactjs open source javascript redux dan abramov mvc immutability |
Об оптимизации комбинаторных алгоритмов |
$a=array_merge(array_reverse(array_slice($a, 0, $i)),array_slice($a, $i));
$c=$a;
$z=0;
for ($i-=1; $i > -1; $i--) $a[$z++]=$c[$i]; #include
#include
int main() {
char b[] = "1234";
char a[] = "4321";
char d[8];
int fact = 24;
int i;
int j;
char c;
int z;
int y=0;
while (y != fact) {
printf("%s\n", a);
i=1;
while(a[i] > a[i-1]) {
i++;
}
j=0;
while(a[j] < a[i]) {
j++;
}
c=a[j];
a[j]=a[i];
a[i]=c;
strcpy(d, a);
z=0;
for (i-=1; i > -1; i--) a[z++]=d[i];
y++;
}
}
|
Метки: author dcc0 алгоритмы оптимизация алгоритмов |
[Из песочницы] Туториал: Создание простейшей 2D игры на андроид |

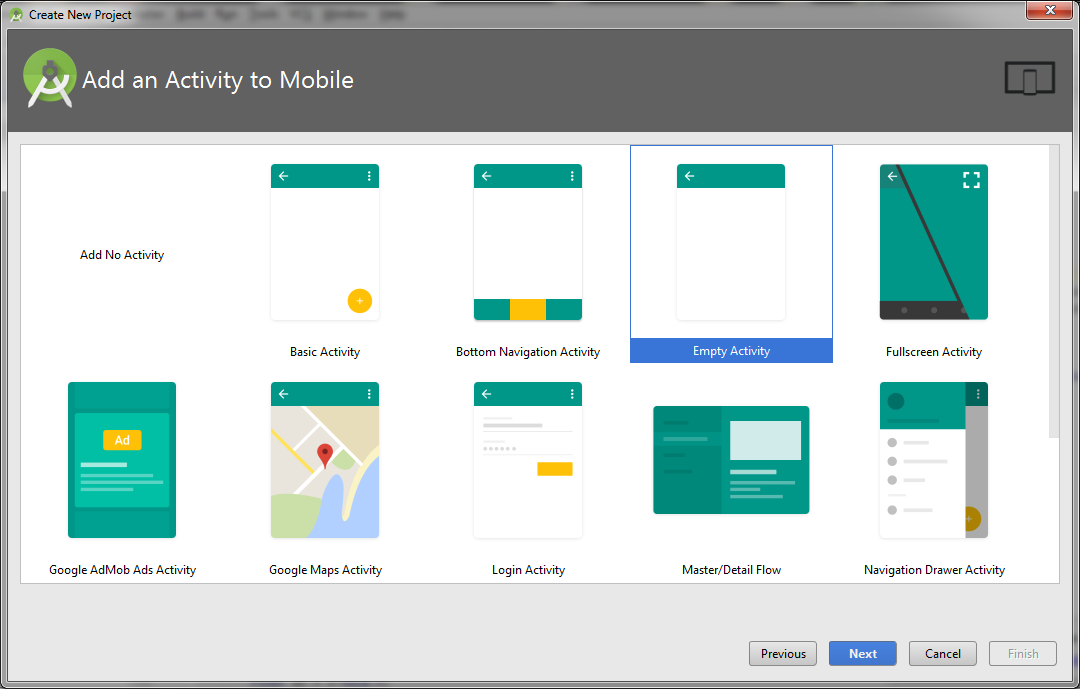


public class MainActivity extends AppCompatActivity implements View.OnTouchListener {public static boolean isLeftPressed = false; // нажата левая кнопка
public static boolean isRightPressed = false; // нажата правая кнопкаGameView gameView = new GameView(this); // создаём gameView
LinearLayout gameLayout = (LinearLayout) findViewById(R.id.gameLayout); // находим gameLayout
gameLayout.addView(gameView); // и добавляем в него gameView
Button leftButton = (Button) findViewById(R.id.leftButton); // находим кнопки
Button rightButton = (Button) findViewById(R.id.rightButton);
leftButton.setOnTouchListener(this); // и добавляем этот класс как слушателя (при нажатии сработает onTouch)
rightButton.setOnTouchListener(this);public boolean onTouch(View button, MotionEvent motion) {
switch(button.getId()) { // определяем какая кнопка
case R.id.leftButton:
switch (motion.getAction()) { // определяем нажата или отпущена
case MotionEvent.ACTION_DOWN:
isLeftPressed = true;
break;
case MotionEvent.ACTION_UP:
isLeftPressed = false;
break;
}
break;
case R.id.rightButton:
switch (motion.getAction()) { // определяем нажата или отпущена
case MotionEvent.ACTION_DOWN:
isRightPressed = true;
break;
case MotionEvent.ACTION_UP:
isRightPressed = false;
break;
}
break;
}
return true;
}package com.spaceavoider.spaceavoider;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.MotionEvent;
import android.view.View;
import android.widget.Button;
import android.widget.LinearLayout;
public class MainActivity extends AppCompatActivity implements View.OnTouchListener {
public static boolean isLeftPressed = false; // нажата левая кнопка
public static boolean isRightPressed = false; // нажата правая кнопка
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
GameView gameView = new GameView(this); // создаём gameView
LinearLayout gameLayout = (LinearLayout) findViewById(R.id.gameLayout); // находим gameLayout
gameLayout.addView(gameView); // и добавляем в него gameView
Button leftButton = (Button) findViewById(R.id.leftButton); // находим кнопки
Button rightButton = (Button) findViewById(R.id.rightButton);
leftButton.setOnTouchListener(this); // и добавляем этот класс как слушателя (при нажатии сработает onTouch)
rightButton.setOnTouchListener(this);
}
public boolean onTouch(View button, MotionEvent motion) {
switch(button.getId()) { // определяем какая кнопка
case R.id.leftButton:
switch (motion.getAction()) { // определяем нажата или отпущена
case MotionEvent.ACTION_DOWN:
isLeftPressed = true;
break;
case MotionEvent.ACTION_UP:
isLeftPressed = false;
break;
}
break;
case R.id.rightButton:
switch (motion.getAction()) { // определяем нажата или отпущена
case MotionEvent.ACTION_DOWN:
isRightPressed = true;
break;
case MotionEvent.ACTION_UP:
isRightPressed = false;
break;
}
break;
}
return true;
}
}public static int maxX = 20; // размер по горизонтали
public static int maxY = 28; // размер по вертикали
public static float unitW = 0; // пикселей в юните по горизонтали
public static float unitH = 0; // пикселей в юните по вертикалиprivate boolean firstTime = true;
private boolean gameRunning = true;
private Ship ship;
private Thread gameThread = null;
private Paint paint;
private Canvas canvas;
private SurfaceHolder surfaceHolder;public GameView(Context context) {
super(context);
//инициализируем обьекты для рисования
surfaceHolder = getHolder();
paint = new Paint();
// инициализируем поток
gameThread = new Thread(this);
gameThread.start();
}@Override
public void run() {
while (gameRunning) {
update();
draw();
control();
}
}
private void update() {
if(!firstTime) {
ship.update();
}
}
private void draw() {
if (surfaceHolder.getSurface().isValid()) { //проверяем валидный ли surface
if(firstTime){ // инициализация при первом запуске
firstTime = false;
unitW = surfaceHolder.getSurfaceFrame().width()/maxX; // вычисляем число пикселей в юните
unitH = surfaceHolder.getSurfaceFrame().height()/maxY;
ship = new Ship(getContext()); // добавляем корабль
}
canvas = surfaceHolder.lockCanvas(); // закрываем canvas
canvas.drawColor(Color.BLACK); // заполняем фон чёрным
ship.drow(paint, canvas); // рисуем корабль
surfaceHolder.unlockCanvasAndPost(canvas); // открываем canvas
}
}
private void control() { // пауза на 17 миллисекунд
try {
gameThread.sleep(17);
} catch (InterruptedException e) {
e.printStackTrace();
}
}protected float x; // координаты
protected float y;
protected float size; // размер
protected float speed; // скорость
protected int bitmapId; // id картинки
protected Bitmap bitmap; // картинкаvoid init(Context context) { // сжимаем картинку до нужных размеров
Bitmap cBitmap = BitmapFactory.decodeResource(context.getResources(), bitmapId);
bitmap = Bitmap.createScaledBitmap(
cBitmap, (int)(size * GameView.unitW), (int)(size * GameView.unitH), false);
cBitmap.recycle();
}
void update(){ // тут будут вычисляться новые координаты
}
void drow(Paint paint, Canvas canvas){ // рисуем картинку
canvas.drawBitmap(bitmap, x*GameView.unitW, y*GameView.unitH, paint);
}public Ship(Context context) {
bitmapId = R.drawable.ship; // определяем начальные параметры
size = 5;
x=7;
y=GameView.maxY - size - 1;
speed = (float) 0.2;
init(context); // инициализируем корабль
}@Override
public void update() { // перемещаем корабль в зависимости от нажатой кнопки
if(MainActivity.isLeftPressed && x >= 0){
x -= speed;
}
if(MainActivity.isRightPressed && x <= GameView.maxX - 5){
x += speed;
}
}private int radius = 2; // радиус
private float minSpeed = (float) 0.1; // минимальная скорость
private float maxSpeed = (float) 0.5; // максимальная скоростьpublic Asteroid(Context context) {
Random random = new Random();
bitmapId = R.drawable.asteroid;
y=0;
x = random.nextInt(GameView.maxX) - radius;
size = radius*2;
speed = minSpeed + (maxSpeed - minSpeed) * random.nextFloat();
init(context);
}@Override
public void update() {
y += speed;
}public boolean isCollision(float shipX, float shipY, float shipSize) {
return !(((x+size) < shipX)||(x > (shipX+shipSize))||((y+size) < shipY)||(y > (shipY+shipSize)));
}private ArrayList asteroids = new ArrayList<>(); // тут будут харанится астероиды
private final int ASTEROID_INTERVAL = 50; // время через которое появляются астероиды (в итерациях)
private int currentTime = 0; private void checkCollision(){ // перебираем все астероиды и проверяем не касается ли один из них корабля
for (Asteroid asteroid : asteroids) {
if(asteroid.isCollision(ship.x, ship.y, ship.size)){
// игрок проиграл
gameRunning = false; // останавливаем игру
// TODO добавить анимацию взрыва
}
}
}
private void checkIfNewAsteroid(){ // каждые 50 итераций добавляем новый астероид
if(currentTime >= ASTEROID_INTERVAL){
Asteroid asteroid = new Asteroid(getContext());
asteroids.add(asteroid);
currentTime = 0;
}else{
currentTime ++;
}
}@Override
public void run() {
while (gameRunning) {
update();
draw();
checkCollision();
checkIfNewAsteroid();
control();
}
}private void update() {
if(!firstTime) {
ship.update();
for (Asteroid asteroid : asteroids) {
asteroid.update();
}
}
}private void draw() {
if (surfaceHolder.getSurface().isValid()) { //проверяем валидный ли surface
if(firstTime){ // инициализация при первом запуске
firstTime = false;
unitW = surfaceHolder.getSurfaceFrame().width()/maxX; // вычисляем число пикселей в юните
unitH = surfaceHolder.getSurfaceFrame().height()/maxY;
ship = new Ship(getContext()); // добавляем корабль
}
canvas = surfaceHolder.lockCanvas(); // закрываем canvas
canvas.drawColor(Color.BLACK); // заполняем фон чёрным
ship.drow(paint, canvas); // рисуем корабль
for(Asteroid asteroid: asteroids){ // рисуем астероиды
asteroid.drow(paint, canvas);
}
surfaceHolder.unlockCanvasAndPost(canvas); // открываем canvas
}
}|
Метки: author Andrey_139 разработка под android разработка игр tutorial android game 2d туториал андроид |
Создаём динамическую обложку ВКонтакте |
{
"type": "group_join",
"object": {
"user_id": XXXXXXXX,
"join_type": "join"
},
"group_id": XXXXXXXX
}https://api.vk.com/method/users.get?user_ids=XXXXXXXX&fields=photo_max_orig&v=5.65{
"response": [
{
"id": XXXXXXXX,
"first_name": "имя",
"last_name": "фамилия",
"photo_max_orig": "https:\/\/pp.userapi.com\/\/..."
}
]
}// Фоновое изображение и аватар пользователя
BufferedImage background_image = ImageIO.read(new File("/some/folder/bg.png")),
user_avatar = ImageIO.read(new URL("https://..."));
// Результат - отдельное изображение
BufferedImage result = new BufferedImage(background_image.getWidth(), background_image.getHeight(), BufferedImage.TYPE_INT_ARGB);
// В качестве "холста" берём наше новое изображение
Graphics2D g = (Graphics2D) result.getGraphics();
// Рисуем фон
g.drawImage(background_image, 0, 0, null);
// Рисуем аватар подписчика
g.drawImage(user_avatar, x_avatar, y_avatar, width, height, null);
// Подписываем имя подписчика
g.drawString(user_name, x_name, y_name);
// Записываем результат на диск
ImageIO.write(result, "PNG", new File("some/folder/result.png"));https://api.vk.com/method/photos.getOwnerCoverPhotoUploadServer?group_id=XXXXXXXX&crop_x=0&crop_y=0&crop_x2=1590&crop_y2=400&access_token=ACCESS_TOKEN&v=5.64{
"response": {
"upload_url": "https://..."
}
}{
"hash": "...",
"photo": "..."
}https://api.vk.com/method/photos.saveOwnerCoverPhoto?hash=HASH&photo=HASH&access_token=ACCESS_TOKEN&v=5.65while (true) {
// Спим минуту
Thread.sleep(1000*60);
// Берём текущее время в формате "20:25"
String current_tine = new SimpleDateFormat("H:m").format(new Date());
// Рисуем!
BufferedImage result = ImageIO.read(new File("some/folder/result.png"));
Graphics2D g = (Graphics2D) result.getGraphics();
g.drawString(current_tine, x_time, y_time);
// Можно перезаписать изображение, или сразу его загружать
// Или делать что душе угодно
ImageIO.write(result, "PNG", new File("some/folder/result.png");
}|
Метки: author PeterSamokhin программирование обработка изображений вконтакте api java vkontakte api вконтакте |
Применение национальных языков в программировании на SPL |
|
Метки: author Mr_Kibernetik программирование spl |
Оценка параметров старения с помощью носимой электроники. Лекция в Яндексе |


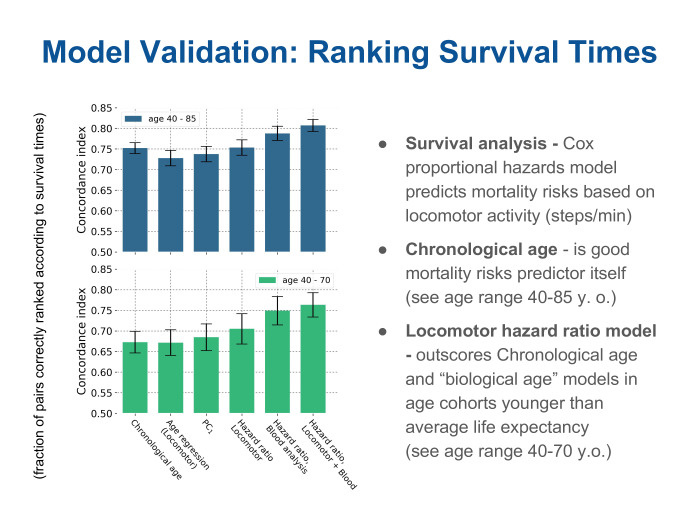
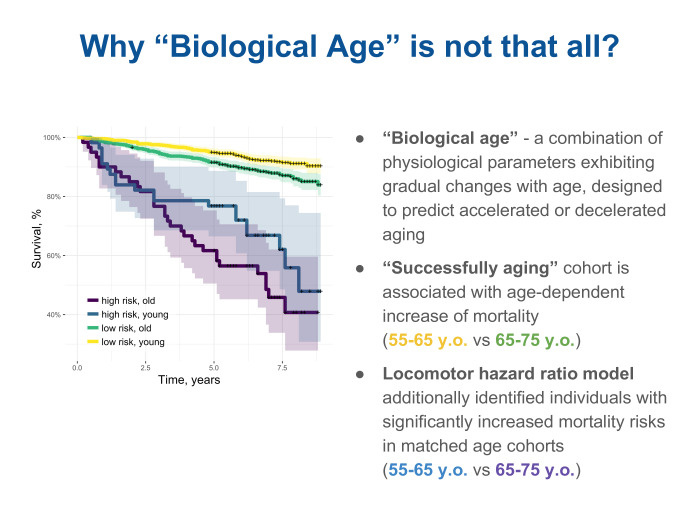
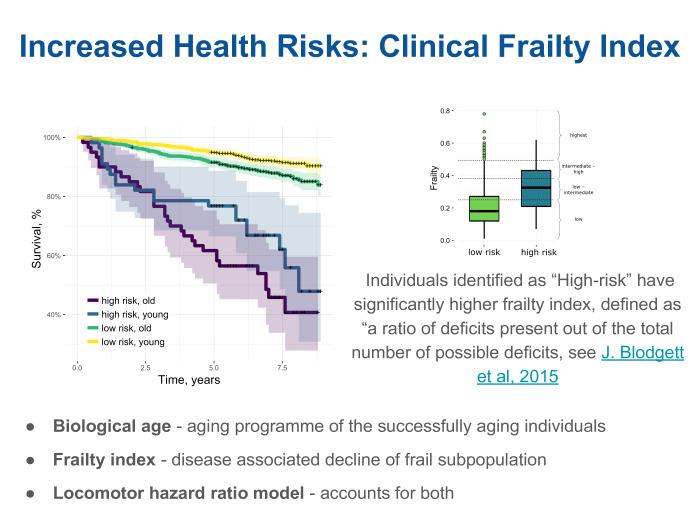



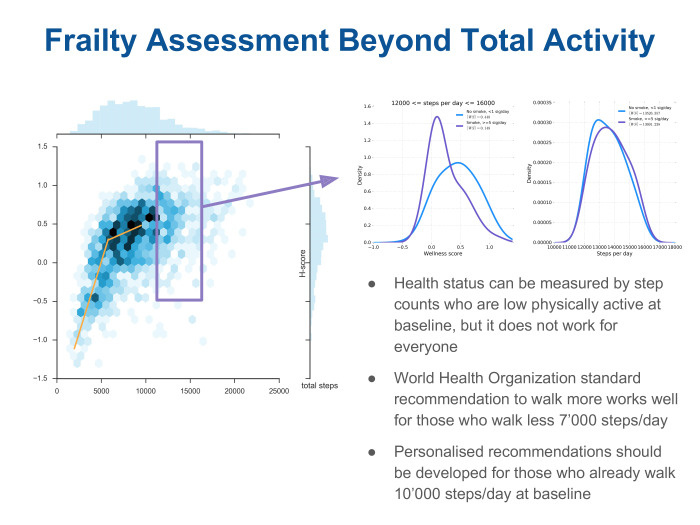

|
|






