[recovery mode] По щучьему велению… (язык программирования Pike) |
int main()
{
write("Hello world!\n");
return 0;
}
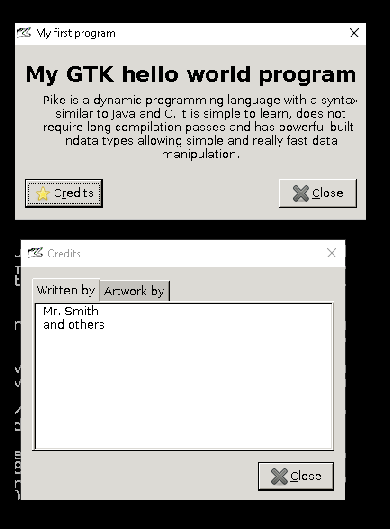
int main()
{
GTK.setup_gtk();
object w = GTK.AboutDialog();
w.set_program_name("My GTK hello world program");
w.signal_connect("destroy", lambda(){exit(0);});
w.set_title("My first program");
w.set_comments("Pike is a dynamic programming language with a syntax similar to Java and C. "+
"It is simple to learn, does not require long compilation passes and has powerful built-in" +
"data types allowing simple and really fast data manipulation.");
array(string) arr1=({"Mr. Smith", "and others"});
array(string) arr2=({"Mrs. Smith", "and others"});
w.set_authors(arr1);
w.set_artists(arr2);
w.show_now();
return -1;
}
int main()
{
array(string) arr1 = ({ "red", "green", "white" });
write(arr1);
write("\n");
array(string) arr2 = ({ "red", "green", "yellow" });
write(arr2);
write("\n");
write(arr2 + arr1); //просто все элементы двух массивов
write("\n");
write(arr2 & arr1); //пересечение
write("\n");
write(arr2 | arr1); //объединение множеств
write("\n");
write(arr2 ^ arr1); //xor - т.е. только те элементы которые не являются общими
write("\n");
write(arr2 - arr1); //разность
write("\n");
return 0;
}
int main()
{
mapping map2 = (["red":4, "white":42, "blue": 88]);
mapping map1 = (["red":4, "green":8, "white":15]);
print_map(map2 + map1);
print_map(map2 - map1);
print_map(map2 & map1);
print_map(map2 | map1);
print_map(map2 ^ map1);
return 0;
}
void print_map(mapping m){
array(string) arr;
arr = indices(m);
foreach(arr, string key){
write(key + ":" + m[key] + " ");
write("\n");
}
int main(){
multiset o = (< "", 1, 3.0, 1, "hi!" >);
print_multiset(o);
return 0;
}
void print_multiset(multiset m){
array(string) arr;
arr = indices(m);
foreach(arr, string key){
write(key + ":" + m[key] + " ");
};
write("\n");
}
class car {
public string color;
public string mark;
private string driver;
void create(string c, string m, string d){
color = c;
mark = m;
driver = d;
}
string who(){
return mark + " " + color + "\n";
}
}
int main(){
car car1 = car("red", "vaz", "Mike");
write(car1.who());
car car2 = car("green", "mers", "Nik");
write(car2.who());
write(car2.mark);
return 0;
}
int main()
{
float pi = Java.pkg.java.lang.Math.PI;
write("Pi = " + pi + "\n");
object syst = Java.pkg.java.lang.System;
write("time = " + syst.currentTimeMillis() + "\n");
object str = Java.pkg.java.lang.String("...Hello!...");
write((string)str.substring(3,str.length()-3) + "\n");
object map2 = Java.pkg.java.util.HashMap();
object key = Java.pkg.java.lang.String("oops");
object val = Java.pkg.java.lang.String("ha-ha");
map2.put(key, val);
write((string) map2.get("oops") + "\n");
object map = Java.JHashMap(([ "one":1, "two":2 ]));
write((string) map.get("two") + "\n");
return 0;
}
int main()
{
Protocols.HTTP.Query web_page;
web_page = Protocols.HTTP.get_url("https://pike.lysator.liu.se/about/");
string page_contents = web_page->data();
write(page_contents);
return 0;
}
int main(){
Geography.Countries.Country c = Geography.Countries.USSR;
write(c.name + "\n");
return 0;
}
|
Метки: author nemavasi программирование pike java |
[recovery mode] Без правок. Как стать самым счастливым дизайнером на планете |

|
Метки: author iskros прототипирование интерфейсы дизайн мобильных приложений графический дизайн веб-дизайн дизайн нетворкинг проектирование карьера |
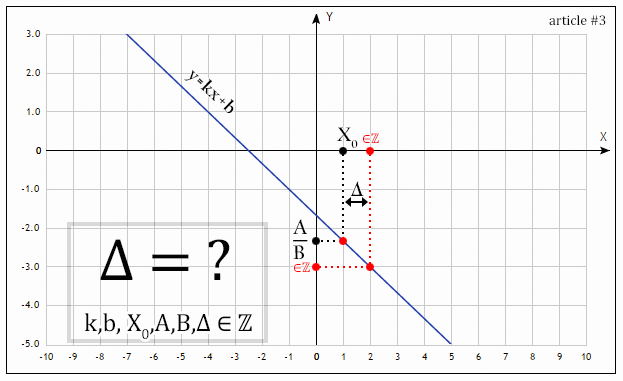
Решение линейных диофантовых уравнений с любым числом неизвестных |
|
Метки: author ParadoxFilm математика диофантовы уравнения целые числа уравнение полином решение |
Redux: попытка избавиться от потребности думать во время запросов к API, часть 2 |
Мы хотим создать пакет, который позволит нам избавиться от постоянного создания однотипных reducer'ов и action creator'ов для каждой модели, получаемой по API.
Первая часть — вот эта вот статья. В ней мы создали конфиг для нашего будущего пакета и выяснили, что он должен содержать action creator, middleware и reducer. Приступим к разработке!
Начнем мы с самого простого — action creator'а. Тут наш вклад будет минимальным — нам нужно просто написать традиционный action creator для redux-api-middleware с учетом нашего конфига.
Для получения юзеров он должен выглядеть приблизительно так:
import {CALL_API} from 'redux-api-middleware';
const get = () => ({
[CALL_API]: {
endpoint: 'mysite.com/api/users',
method: 'GET',
types: ['USERS_GET', 'USERS_SUCCESS', 'USERS_FAILURE']
}
});В action можно добавить еще headers, credentials. Если запрос успешен, то мы получаем USERS_SUCCESS, и у него в action.payload лежат полученные по API данные. Если произошла ошибка, — получаем USERS_FAILURE, у которого в action.errors лежат ошибки. Все это подробно описано в документации.
В дальнейшем, для простоты рассуждений, будем считать, что данные в payload уже нормализованы. Нас интересует, как можно модернизировать наш creator для получения всех сущностей. Все довольно просто: для того, чтоб возвращать нужные сущности, передаем в creator название этой сущности:
import {CALL_API} from 'redux-api-middleware';
const initGet = (api) => (entity) => ({
[CALL_API]: {
endpoint: api[entity].endpoint, // endpoint мы будем брать из конфига
method: 'GET',
types: api[entity].types // и actions мы будем брать из конфига
}
});Еще необходимо добавить фильтрацию ответа сервера по GET-параметрам, чтоб мы могли ходить только за нужными данными и не тащить ничего лишнего. Я предпочитаю передавать GET-параметры в качестве словаря и сериализовать их отдельным методом objectToQuery:
import {CALL_API} from 'redux-api-middleware';
const initGet = (api) => (entity, params) => ({
[CALL_API]: {
endpoint: `${api[entity].endpoint}${objectToQuery(params)}`,
method: 'GET',
types: api[entity].types
}
});Инициализируем сам creator:
const get = initGet(config.api);Теперь, вызывая с нужными аргументами метод get, мы отправим запрос о необходимых данных. Теперь надо позаботиться о том, как полученные данные хранить — напишем reducer.
Точнее, два. Один будет класть в store сущности, а другой — время их прихода. Хранить их в одном месте — плохая идея, ведь тогда мы будем смешивать чистые данные с локальным состоянием приложения на клиенте (ведь время прихода данных у каждого клиента свое).
Тут нам понадобятся те же successActionTypes и react-addons-update, который обеспечит иммутабельность store. Тут нам надо будет пройтись по каждой сущности из entities и сделать отдельный $merge, то есть, совместить ключи из defaultStore и receivedData.
const entitiesReducer = (entities = defaultStore, action) => {
if (action.type in successActionTypes) {
const processedData = {};
const receivedData = action.payload.entities || {};
for (let entity in receivedData) {
processedData[entity] = { $merge: receivedData[entity] };
}
return update(entities, processedData);
} else {
return entities;
}
};Аналогично для timestampReducer, но там мы будем устанавливать текущее время прибытия данных в store:
const now = Date.now();
for (let id in receivedData[entity]) {
entityData[id] = now;
}
processedData[entity] = { $merge: entityData };schema или lifetime, successActionTypes понадобятся нам при инициализации — аналогичный код мы писали в action creator'е.
Чтоб получить defaultState, сделаем так:
const defaultStore = {};
for (let key in schema) { // или lifetime, для второго reducer'а
defaultStore[key] = {};
}successActionTypes можно получить из конфига api:
const getSuccessActionTypes = (api) => {
let actionTypes = {};
for (let key in api) {
actionTypes[api[key].types[1]] = key;
}
return actionTypes;
};Это, конечно, задача простая, но один такой простой reducer сэкономит нам кучу времени на написании своего reducer'а для каждого типа данных.
Рутинная работа закончена — перейдем к основному компоненту нашего пакета, который и будет заботиться о том, чтоб ходить только за теми данными, которые реально нужны, и при этом не заставлять нас думать об этом.
Напомню, что мы считаем, что к нам приходят сразу нормализованные данные. Тогда в middleware мы должны пройтись по всем данным, полученным в entities, и собрать список id отсутствующих связанных сущностей, и сделать запрос к API за этими данными.
const middleware = store => next => action => {
if (action.type in successActionTypes) { // Если это action, в котором пришли данные
const entity = successActionTypes[action.type]; // Определяем тип данных
const receivedEntities = action.payload.entities || {};; // Достаем пришедшие сущности
const absentEntities = resolve(entity, store.getState(), receivedEntities); // Находим отсутствующие
for (let key in absentEntities) {
const ids = absentEntities[key]; // Получаем список id отсутствующих
if (ids instanceof Array && ids.length > 0) { // Если список не пустой
store.dispatch(get(key, {id: ids})); // Отправляем action, который идет за этими и только этими данными
}
}
}
return next(action);
}successActionTypes, resolve и get нужно передавать middleware при инициализации.
Осталось только реализовать метод resolve, который будет определять, каких данных не хватает. Это, пожалуй, самая интересная и важная часть.
Для простоты мы будем считать, что в store.entities хранятся наши данные. Можно и это вынести как отдельный пункт конфига, и присоединять туда reducer, но на данном этапе это неважно.
Мы должны вернуть abcentEntities — словарь такого вида:
const absentEntities = {users: [1, 2, 3], posts: [107, 6, 54]};Где в списках хранятся id отсутствующих данных. Чтоб определить, каких данные отсутствуют, нам и пригодятся наши schema и lifetime из конфига.
Вообще, по foreign key может лежать и список id, а не один id — никто не отменял many-to-many и one-to-many relations. Это нам надо будет учесть, проверив тип данных по foreign key, и, если что, сходить за всеми из списка.
const resolve = (type, state, receivedEntities) => {
let absentEntities = {};
for (let key in schema[type]) { // проходим по всем foreign key полученных
const keyType = schema[typeName][key]; // Получаем тип foreign key
absentEntities[keyType] = []; // Инициализируем будущий список отсутствующих
for (let id in receivedEntities[type]) { // Проходим по всем полученным сущностям
// Проверка на список
let keyIdList = receivedEntities[type][id][key];
if (!(keyIdList instanceof Array)) {
keyIdList = [keyIdList];
}
for (let keyId of keyIdList) {
// Проверяем, есть ли id в store
const present = state.entities.hasOwnProperty(keyType) && state.entities[keyType].hasOwnProperty(keyId);
// Проверяем, есть ли он в receivedEntities
const received = receivedEntities.hasOwnProperty(keyType) && receivedEntities[keyType].hasOwnProperty(keyId);
// Проверяем, не просрочены ли данные?
const relevant = present && !!lifetime ? state.timestamp[keyType][keyId] + lifetime[keyType] > Date.now() : true;
// Если он получен в данном action, или лежит в store и актуален, класть его в absent нет смысла
if (!(received || (present && relevant))) {
absentEntities[keyType].push(keyId);
}
}
}
};Вот и все — немного головоломной логики и рассмотрения всех случаев, и наша функция готова. При инициализации надо не забыть передать в нее schema и lifetime из конфига.
В целом, все уже работает, если мы примем такие допущения:
Все эти пункты (особенно первый!) необходимо тщательно проработать, и мы это сделаем в третьей части. Но это уже не так интересно, ведь почти весь код, выполняющий нашу цель, уже написан, поэтому для тех, кто захочет просто посмотреть и потестить самостоятельно, привожу ссылки:
|
Метки: author geoolekom разработка веб-сайтов reactjs javascript api es6 redux react |
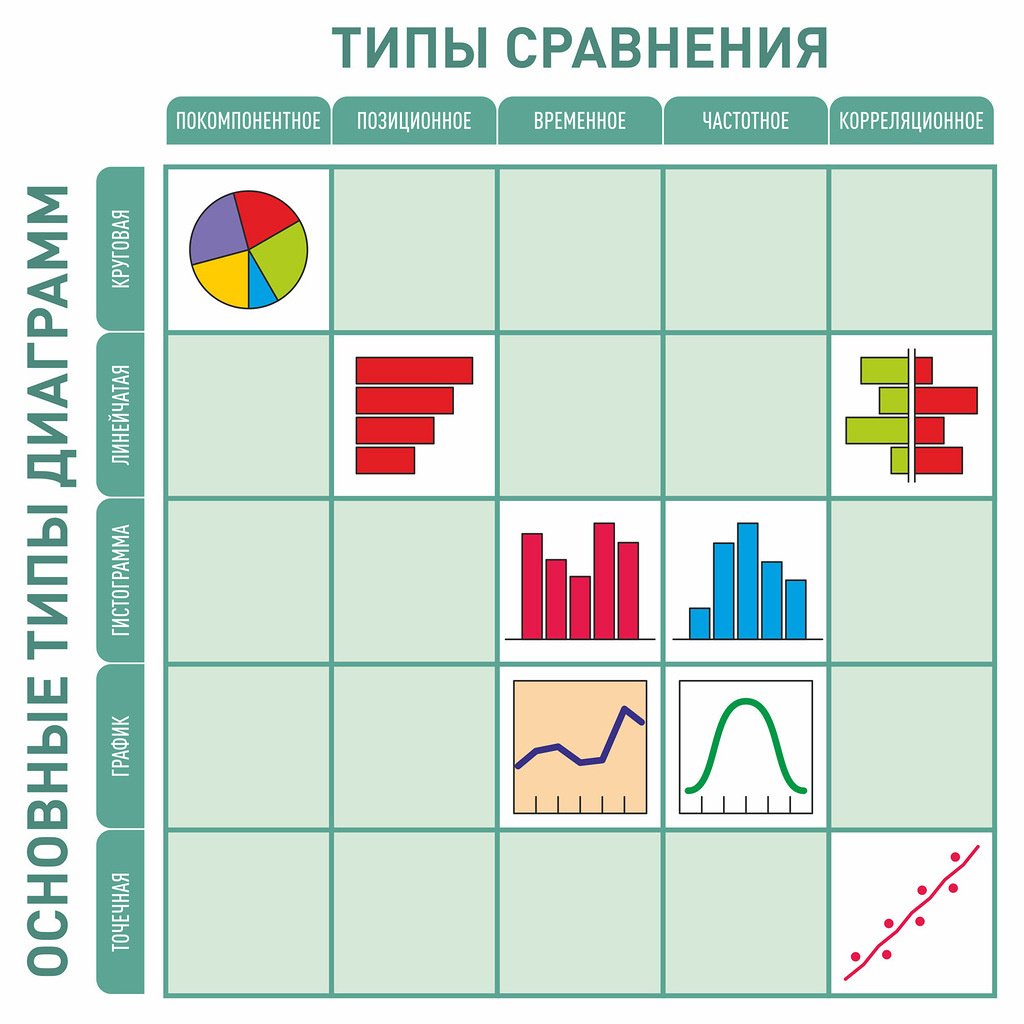
Наивно. Супер. Рецензия на книгу Джина Желязны «Говори на языке диаграмм» |


«Работа над любой презентацией начинается с определения того, что вы хотите сказать. И лишь потом — выбор формы диаграммы и рисунка».К этой мысли автор возвращает читателя на протяжении всей книги. Этим фактом объясняется успех книги: несмотря на то, что она написана очень давно и технологии визуализации данных шагнули далеко вперед, подход и способы остаются актуальными. Желязны признается:
«Не всегда было так, как сейчас. Я пришел в сферу визуальных коммуникаций в 1961 году до нашей эры. То есть до эры компьютеров, вычислительных и копировальных машин».В оригинале используется игра слов: «It wasn’t always like that. I entered the field of visual communications in the year 1961 B.C. That’s Before Computers, Before Calculators, Before Copiers». B.C. = Before Christ = до рождества Христова, то есть до н.э. Before Computers, Before Calculators, Before Copiers.
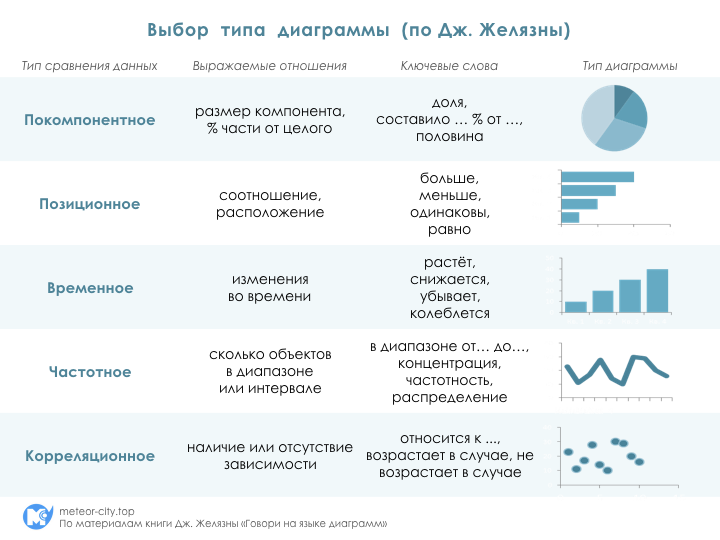
«Тип диаграммы определяют вовсе не данные (доллары или проценты) и не те или иные параметры (прибыль, рентабельность или зарплата), а ваша идея — то, что вы хотите в диаграмму вложить».
«диаграммы — это наглядные пособия, вспомогательные материалы, а отнюдь не замена письменному и устному слову. Используйте их умело, и они сослужат вам хорошую службу».
«Необязательно хвататься за первую понравившуюся вам идею. Продолжайте искать, играйте с диаграммами и, в конце концов, вы найдете идеально подходящее визуальное решение».
«Отсутствие шкал не должно мешать пониманию взаимосвязей. Убрав шкалы, вы можете с успехом проверить, наглядно ли составлены диаграммы, чётко ли они передают основную идею».



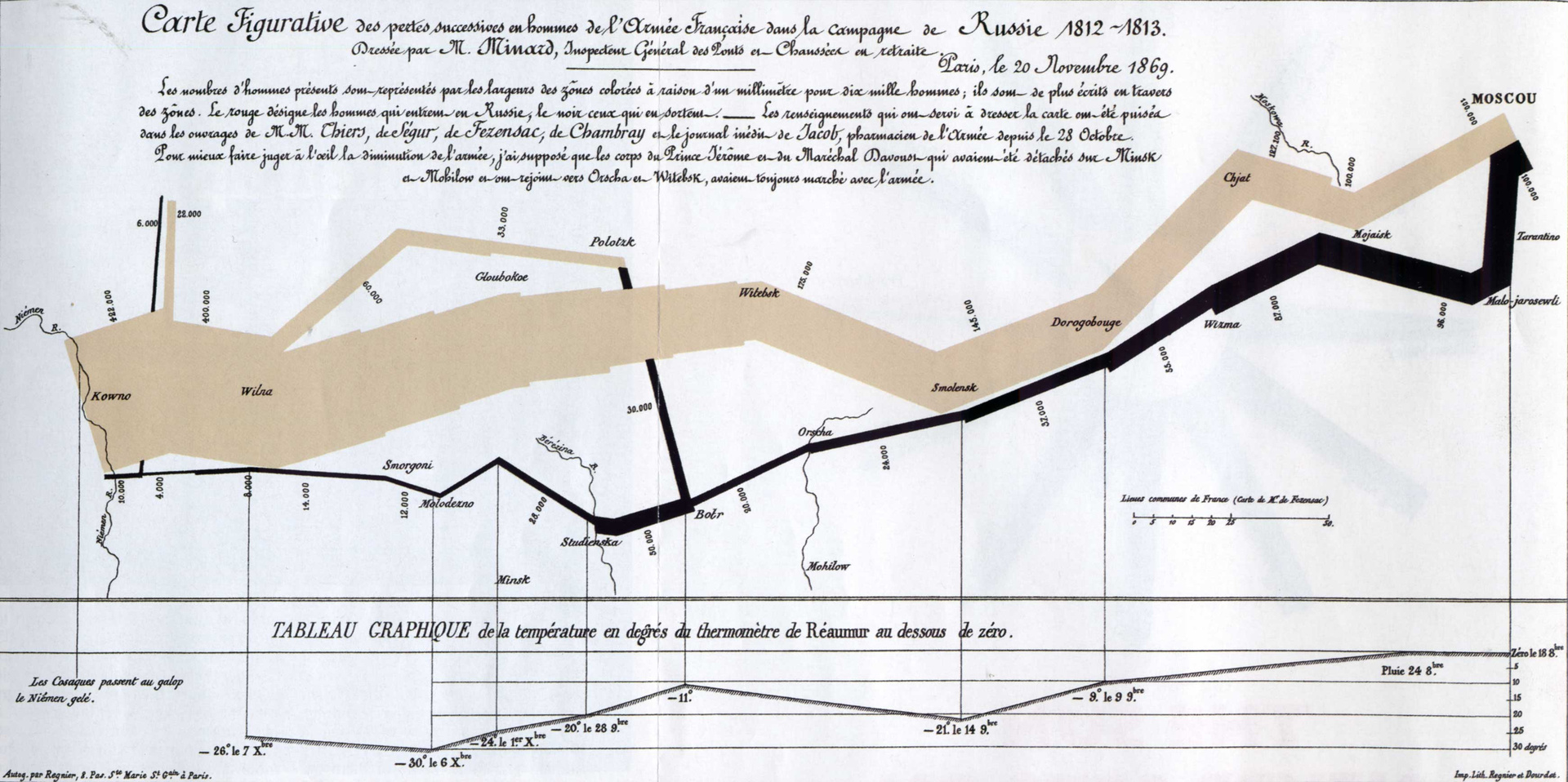
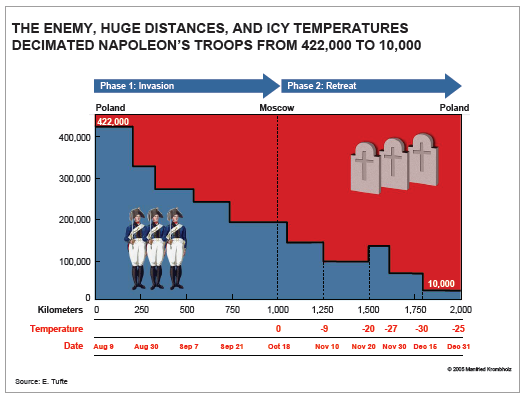
«Думаю, что все вы знаете о жарких спорах экспертов бизнес-коммуникации вокруг PowerPoint. Наверное, нет другого такого софта, вокруг которого было бы столько эмоций. Иногда даже кажется, что противники застрелят друг друга пунктами списков (bullet points — «пули пункты»). Громче всех, конечно, «выстрелы» критиков. Один из главных, профессор Университета Йеля Эдвард Тафти, утверждает, что PowerPoint провоцирует людей на создание пошлого, тривиального контента и сильно «засоряет» серьёзную коммуникацию. «Совещания должны фокусироваться на кратких письменных отчетах на бумаге, а не на тезисах или обрывочных пунктах списка, проецируемых на стену», — считает Тафти в своей работе «Когнитивный стиль PowerPoint».Далее Желязны доказывает пользу самой популярной программы для создания презентаций, приводя свой вариант визуализации карты похода Наполеона на Москву (Charles Joseph Minard (1781–1840)) — той самой карты, которую Тафти называет одним из лучших примеров информационной графики, — сделанные в PowerPoint.
«Если бы вы были восьмилетним ребёнком и видели, что ваших друзей куда-то забирают нацисты, то вы бы подумали, что Париж — это плохое место пребывания в 1942 году. Если бы вы носили Звезду Давида, то так оно и было. Переход от измученной Европы к энергичной, трепещущей Америке также не всегда воспринимался легко. Школа в Бронксе (на уличный манер «Da Bronx»), колледж, служба в ВВС и, наконец, корпоративная Америка — мир крупного бизнеса. Большие шаги и отсутствие матери, которая могла бы вести тебя. Для начала Жанно стал Джином, автором этих сверкающих, разоблачающих, дерзких, тонких, мудрых, острых, терпимых, любопытных, гениальных, грустных и веселых, хитрых и прямолинейных эссе без границ. Джин, мы готовы развлекаться и удивляться всему тому, что ты должен сказать, и неизменно восхищаться твоими идеями».


|
Метки: author meteor-city графический дизайн информационный дизайн презентация диаграммы визуализация рецензия на книгу джин желязны |
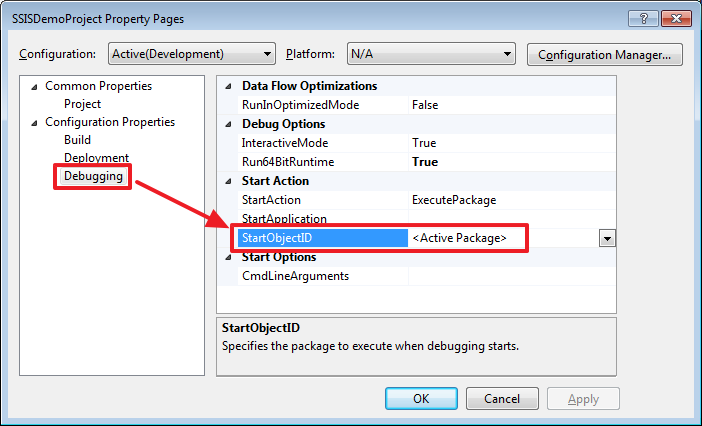
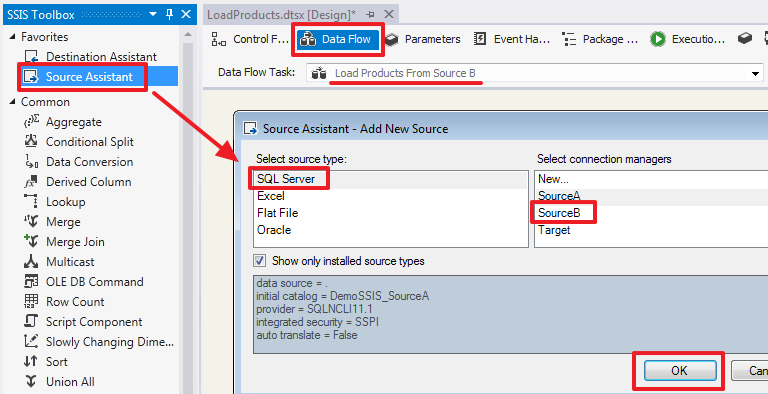
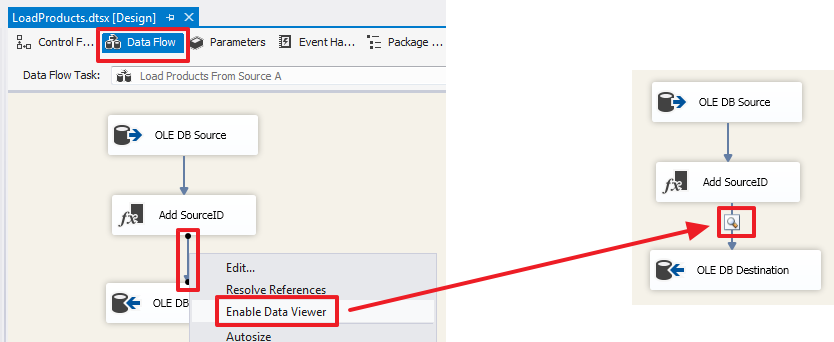
SQL Server Integration Services (SSIS) для начинающих – часть 1 |


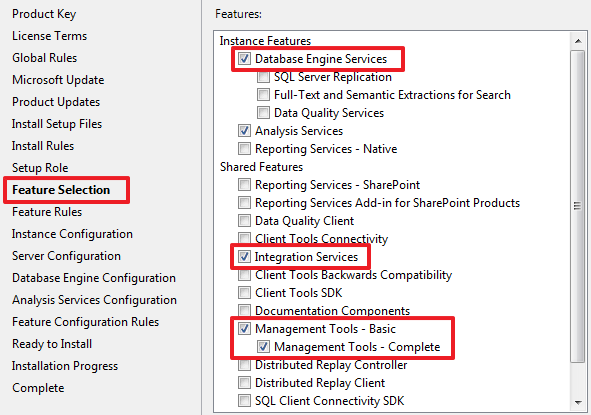


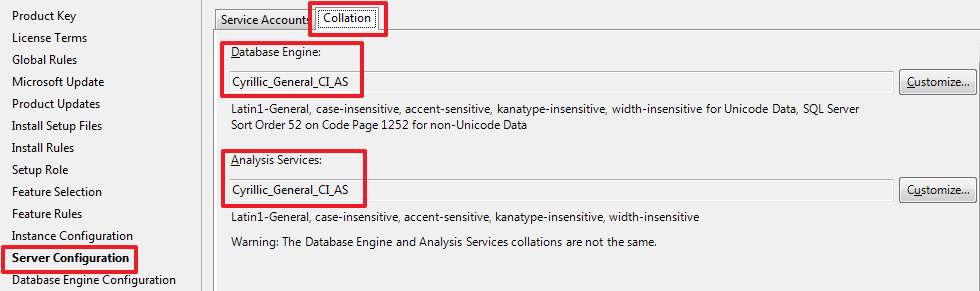



-- первая БД выступающая в роли источника данных
CREATE DATABASE DemoSSIS_SourceA
GO
ALTER DATABASE DemoSSIS_SourceA SET RECOVERY SIMPLE
GO
-- вторая БД выступающая в роли источника данных
CREATE DATABASE DemoSSIS_SourceB
GO
ALTER DATABASE DemoSSIS_SourceB SET RECOVERY SIMPLE
GO
-- БД выступающая в роли получателя данных
CREATE DATABASE DemoSSIS_Target
GO
ALTER DATABASE DemoSSIS_Target SET RECOVERY SIMPLE
GO
USE DemoSSIS_SourceA
GO
-- продукты из источника A
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar(50) NOT NULL,
Price money,
CONSTRAINT PK_Products PRIMARY KEY(ID)
)
GO
-- наполняем таблицу тестовыми данными
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(1,N'Клей',20),
(2,N'Корректор',NULL),
(3,N'Скотч',100),
(4,N'Стикеры',80),
(5,N'Скрепки',25)
SET IDENTITY_INSERT Products OFF
GO
USE DemoSSIS_SourceB
GO
-- продукты из источника B
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar(50) NOT NULL,
Price money,
CONSTRAINT PK_Products PRIMARY KEY(ID)
)
GO
-- наполняем таблицу тестовыми данными
SET IDENTITY_INSERT Products ON
INSERT Products(ID,Title,Price)VALUES
(1,N'Ножницы',200),
(2,N'Нож канцелярский',70),
(3,N'Дырокол',220),
(4,N'Степлер',150),
(5,N'Шариковая ручка',15)
SET IDENTITY_INSERT Products OFF
GO
USE DemoSSIS_Target
GO
-- принимающая таблица
CREATE TABLE Products(
ID int NOT NULL IDENTITY,
Title nvarchar(50) NOT NULL,
Price money,
SourceID char(1) NOT NULL, -- используется для идентификации источника
SourceProductID int NOT NULL, -- ID в источнике
CONSTRAINT PK_Products PRIMARY KEY(ID),
CONSTRAINT UK_Products UNIQUE(SourceID,SourceProductID),
CONSTRAINT CK_Products_SourceID CHECK(SourceID IN('A','B'))
)
GO













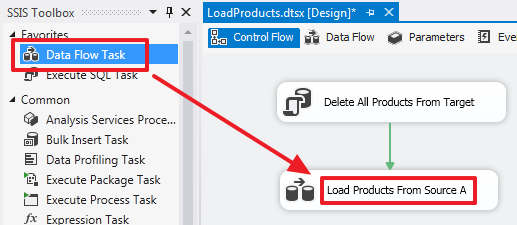








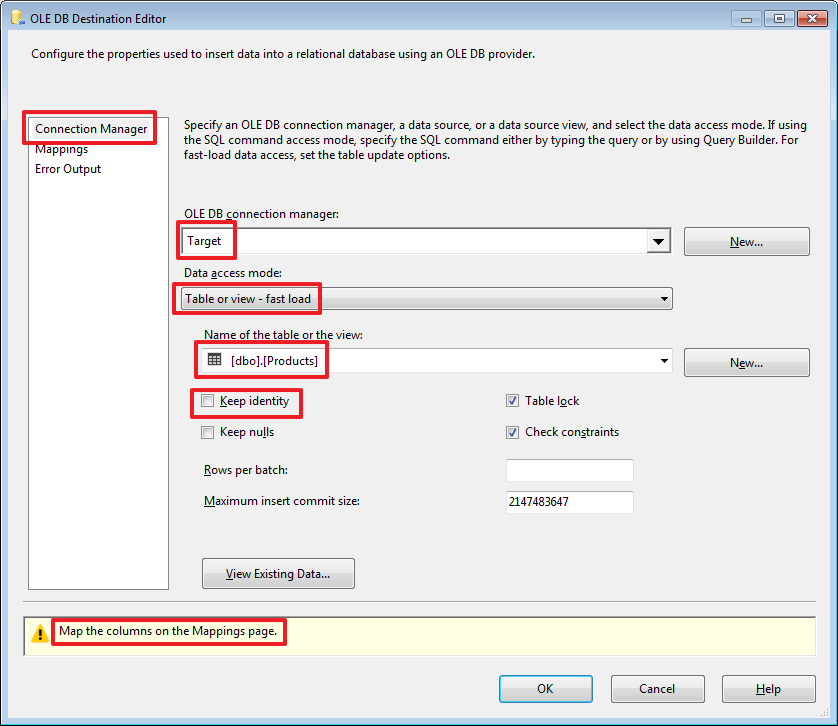
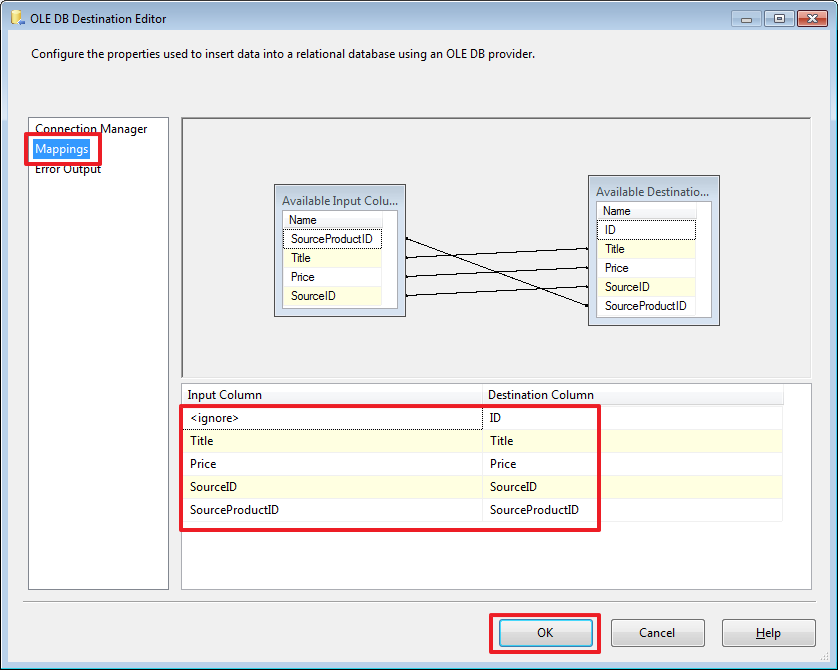
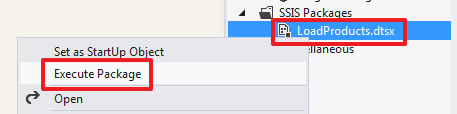


USE DemoSSIS_Target
GO
SELECT *
FROM Products


SELECT
ID SourceProductID,
'B' SourceID,
Title,
Price
FROM Products




USE DemoSSIS_Target
GO
SELECT *
FROM Products


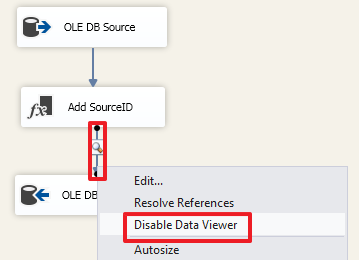
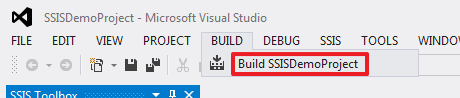
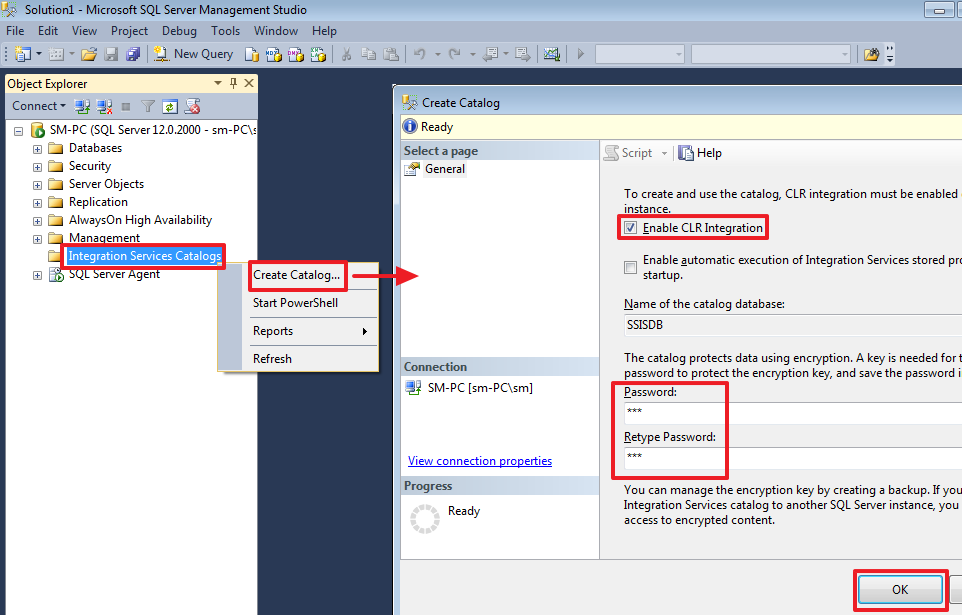








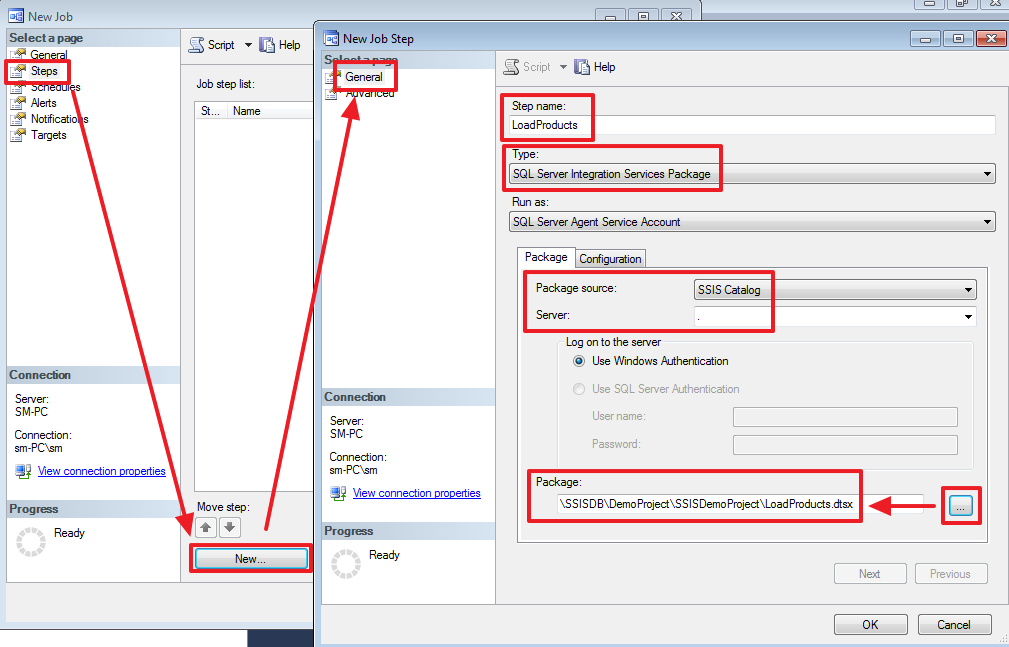









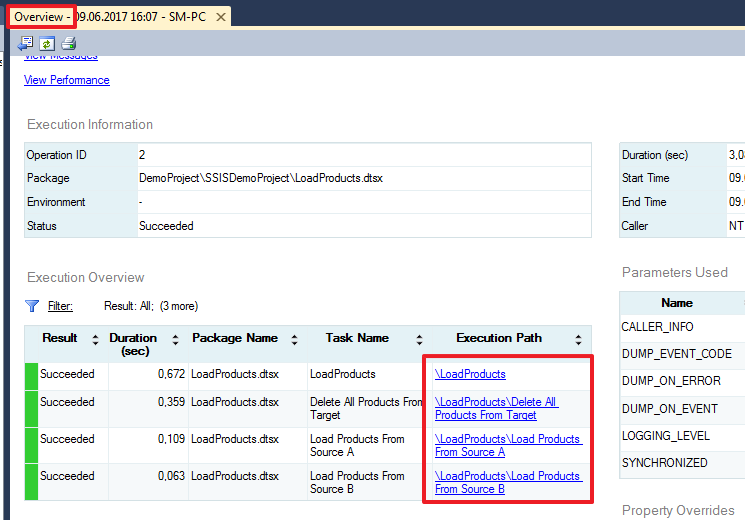
|
Метки: author Leran2002 sql microsoft sql server ssis integration services sql server etl |
Security Week 23: EternalBlue портировали на Win10, ЦРУ атакует с файлсерверов, маркетологи незаметно заразили весь мир |
 Приключения EternalBlue продолжаются: теперь исследователи из RiskSense портировали его на Windows 10. На первый взгляд это деструктивное достижение, однако же, именно в этом состоит немалая часть работы исследователя-безопасника. Чтобы защититься от будущей угрозы, сначала надо эту угрозу создать и испытать, причем крайне желательно сделать это раньше «черных шляп».
Приключения EternalBlue продолжаются: теперь исследователи из RiskSense портировали его на Windows 10. На первый взгляд это деструктивное достижение, однако же, именно в этом состоит немалая часть работы исследователя-безопасника. Чтобы защититься от будущей угрозы, сначала надо эту угрозу создать и испытать, причем крайне желательно сделать это раньше «черных шляп». 
 Новость. Исследование. Пекинское маркетинговое агентство Rafotech продемонстрировало блестящий пример беспощадного китайского маркетинга. Не само – ему помогли ребята из CheckPoint, вскрывшие нехилую кампанию Fireball. Современный маркетинг не может без биг даты – клиента надо знать лучше, чем его мама. Поэтому бигдату нужно собирать, как можно быстрее и больше.
Новость. Исследование. Пекинское маркетинговое агентство Rafotech продемонстрировало блестящий пример беспощадного китайского маркетинга. Не само – ему помогли ребята из CheckPoint, вскрывшие нехилую кампанию Fireball. Современный маркетинг не может без биг даты – клиента надо знать лучше, чем его мама. Поэтому бигдату нужно собирать, как можно быстрее и больше.

|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw eternalblue wikileaks fireball rafotech цру |
О новых интересных законах или «Тварь ли я дрожащая или всё-таки сообщество» |

Всех программистов, помогающих этой «содомии» «банить» — не брать на работу за то, что работал в соответствующих местах и помогал «насаждать». Составлять чёрные списки, распространять информацию и т.п.
|
Метки: author prohodil_mimo управление персоналом карьера в it-индустрии законодательство и it-бизнес vpn tor torrent it законодательство и ит |
[Из песочницы] Русскоязычная спецификация языка Java |
switch (choice) {
case 1:
. . . .
break;
case 2:
. . . .
break;
case 3:
. . . .
break;
case 4:
. . . .
break;
default:
//неверный ввод
break;
}
Выполнение начинается с метки ветви case, соответствующей значению 1 переменной choice, и продолжается до очередного оператора break или конца оператора switch.. Лично меня формулировка
соответствующей значению 1 переменной choiceвводит в ступор, хотя, конечно, догадаться можно. Но не это главное. Тут продемонстрирована устоявшаяся традиция перевода термина statement словом «оператор», вносящая некоторую сумятицу по отношению к его англоязычному собрату. Что же касается поставленного вопроса, то вот как его трактует спецификация:
|
Метки: author vitaliy4us java |
Приглашаем на официальный мастер-класс по UE4 от Epic Games |
 Во вторник, 13 июня, в Санкт-Петербруге, в Университете ИТМО пройдет мастер-класс по разработке игр на Unreal Engine 4, где экспертом выступит евангелист Epic Games — Шьорд де Йонг. Посетителям на выбор будет предложена одна из двух тем, которые Шьорд подготовил для выступления. В зале Шьорду будут помогать опытные разработчики на UE4.
Во вторник, 13 июня, в Санкт-Петербруге, в Университете ИТМО пройдет мастер-класс по разработке игр на Unreal Engine 4, где экспертом выступит евангелист Epic Games — Шьорд де Йонг. Посетителям на выбор будет предложена одна из двух тем, которые Шьорд подготовил для выступления. В зале Шьорду будут помогать опытные разработчики на UE4.|
|
Гейзенбаг 2.0: как прошла в Петербурге конференция по тестированию |


А Илари говорят ненастоящий - бороды то нет. Ну почти нет :) @ilarihenrik, where is your beard?#heisenbug pic.twitter.com/YCWQET07Bk
— Maxim Shulga (@maxbeard12) June 4, 2017







Что может сделать профессионал в безопасности (@paradoxengine) с системой управления лифтом за 5 секунд #heisenbug pic.twitter.com/gAzyNnge4H
— SQA underhood (@sqaunderhood) June 4, 2017
|
|
[Из песочницы] Xenoblade Chronicles — разбор игровых данных |

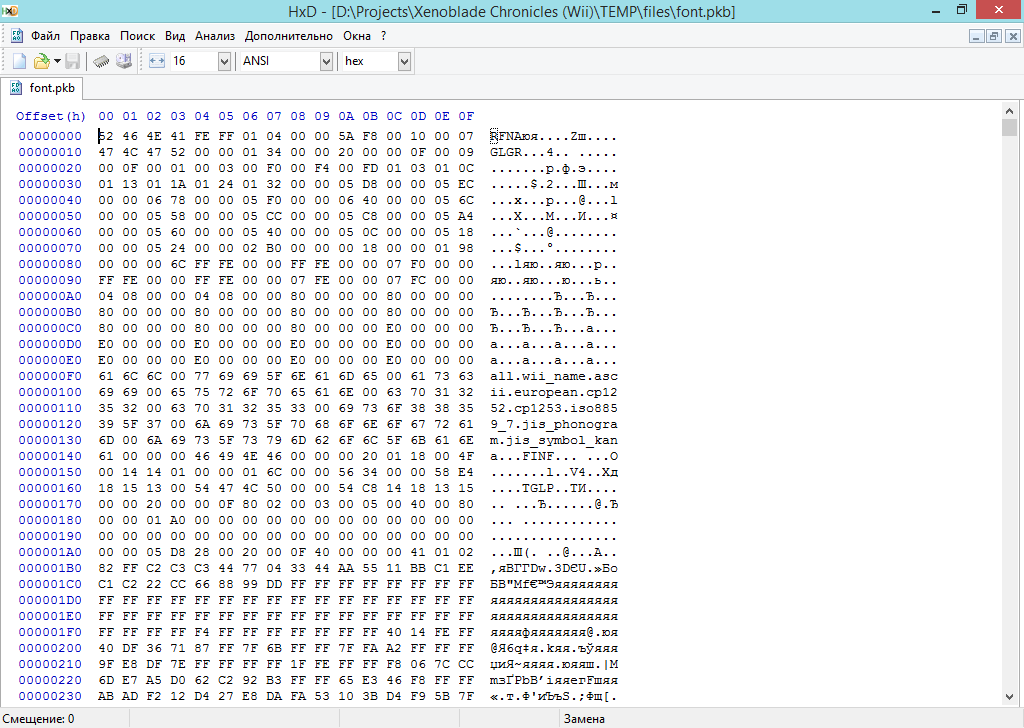
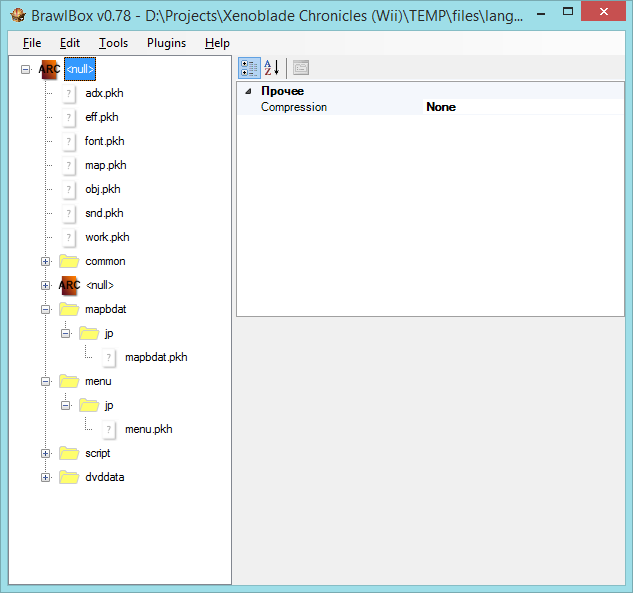
public class pkhModuleEntry
{
public uint ID;
public uint unk;
public ushort sizeFile;
public uint offsetFile;
public pkhModuleEntry()
{
ID = unk = offsetFile = sizeFile = 0;
}
}
public class pkhModule
{
uint Magic;
uint version;
uint tableOffset;
uint pkhSize;
uint countFiles;
pkhModuleEntry[] entry;
string[] extensions;
...
}
for (int i = 0; i < countFiles; i++)
{
entry[i] = new pkhModuleEntry();
entry[i].ID = mainPkhSfa.ReadUInt32();
entry[i].unk = mainPkhSfa.ReadUInt32();
}
for (int i = 0; i < countFiles; i++)
entry[i].sizeFile = mainPkhSfa.ReadUInt16();
for (int i = 0; i < countFiles; i++)
entry[i].offsetFile = mainPkhSfa.ReadUInt32();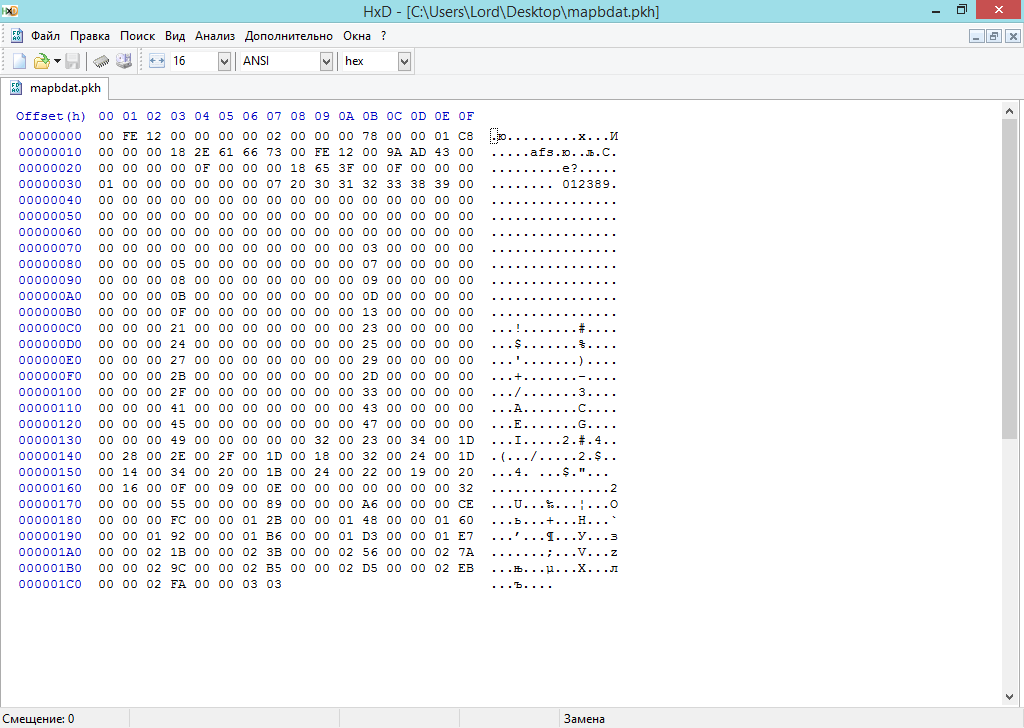

public static void BDAT_DecryptPart(int offset, int size, ushort key, MemoryStream data)
{
data.Position = offset;
int endOffset = offset + size;
if (endOffset > data.Length)
endOffset = (int)data.Length;
bool reg = true;
byte _r0 = (byte)(0xFF - (key & 0xFF));
byte _r5 = (byte)(0xFF - (key >> 8 & 0xFF));
byte inByte = 0;
while (offset < endOffset)
{
inByte = data.GetBuffer()[offset];
if (reg)
{
data.GetBuffer()[offset] = (byte)(inByte ^ _r5);
_r5 = (byte)((_r5 + inByte) & 0xFF);
reg = false;
}
else
{
data.GetBuffer()[offset] = (byte)(inByte ^ _r0);
_r0 = (byte)((_r0 + inByte) & 0xFF);
reg = true;
}
offset += 1;
}
}
class header
{
public uint magic;
public byte mode;
public byte unk;
public ushort offsetToNameBlock;
public ushort sizeTableStruct;
public ushort unkTableOffset;
public ushort unk2;
public ushort offsetToMainData;
public ushort countEntryMain;
public ushort unk3; public ushort unk4;
public ushort cryptKey;
public uint offsetToStringBlock;
public uint sizeStringBlock;
...
}
class typeStruct
{
public byte unk;
public byte type;
public ushort idx;
...
}
class nameBlock
{
public string bdatName;
public nameBlockEntry[] nameEntry;
public nameBlock(StreamFunctionAdd sfa, int countName)
{
bdatName = sfa.ReadAnsiStringStopByte();
sfa.SeekValue(2);
nameEntry = new nameBlockEntry[countName];
for (int i = 0; i < countName; i++)
{
nameEntry[i] = new nameBlockEntry(sfa);
}
}
}
class nameBlockEntry
{
public ushort offsetToStructType;
public ushort unk;
public string name;
public typeStruct type;
public nameBlockEntry(StreamFunctionAdd sfa)
{
offsetToStructType = sfa.ReadUInt16();
unk = sfa.ReadUInt16();
name = sfa.ReadAnsiStringStopByte();
type = new typeStruct(sfa, offsetToStructType);
sfa.SeekValue(2);
}
}
|
Метки: author TTEMMA реверс-инжиниринг разработка игр xenoblade chonicles russian studio video 7 перевод xenoblade chronicles |
Кодировка символов и Console |
system("chcp 1251");|
Метки: author Boctopr разработка под windows разработка под linux программирование кодировка операционная система отображение коды символы одиночество тоска никто не читает теги |
Третья IT-конференция GeekDay — три дня бесплатных мастер-классов по программированию |

Новость для тех, кто мечтает получить IT-профессию: с 22 по 24 июня пройдёт онлайн-IT-конференция GeekDay #3. За это время вы сможете прослушать 20 бесплатных мастер-классов по различным сферам программирования и разработки.
Что вас ждёт на третьем GeekDay?
Спикеры конференции:
После записи на участие в GeekDay вы сможете пройти бесплатные подготовительные мастер-классы, чтобы уверенно себя чувствовать в течение трёх дней самой конференции.
Зарегистрироваться для участия в конференции или просмотра трансляции можно на сайте конференции. Ждем вас!
|
Метки: author Sadovnikova разработка мобильных приложений разработка веб-сайтов программирование блог компании mail.ru group geekday mail.ru |
Набор на курс Python: почему мы думаем, что Python 2.7. — это серьезно, а Python 3 — модно |
|
Метки: author Dmitry21 программирование python блог компании отус otus.ru обучение обучение программированию python3 python 2.7 |
Собеседуй меня полностью. Или как избавиться от холодных рук на собеседовании |

|
Метки: author ildarchegg читальный зал собеседования интервью рынок труда |
[Перевод] Пишем софт, который будут ненавидеть |







|
Метки: author ru_vds программирование блог компании ruvds.com разработка стартап архитектура по пятничный пост |
[Перевод] Ansible v.s. Salt (SaltStack) v.s. StackStorm |

За последний месяц я слушал интервью с разработчиками на всех трех продуктах и слышал утверждение «считайте [Ansible / Salt / StackStorm] клеем». А теперь я, как самоделкин-любитель, с удовольствием скажу, что у меня в гараже отнюдь не единственный горшок с клеем. У меня 6 разных типов клея для разного применения, различных склеиваемых материалов и условий среды. Все эти 3 продукта находятся в одном и том же лагере, и каждый может быть с успехом использован для достижения совершенно разных целей. Недавно произошел большой перехлест функционала, состоящий в том, что все они проникают в область сетевой автоматизации. Мнения, приведенные ниже, принадлежат мне, а не моему работодателю (который продает продуктов сетевой инфраструктуры и развертывания на миллиарды долларов).
Я пользовался всеми тремя продуктами, в развитие двух из них (Salt и StackStorm) внес значительный вклад и частично способствовал развитию Ansible. Говоря откровенно, продукт, с которым я менее всего знаком, — это Ansible, но я беседовал с коллегами и собирал информацию, чтобы заполнить пробелы.
Если вы собираетесь пролистать текст до конца и узнать, какой продукт я объявил победителем, вы будете разочарованы. Обдумайте свои требования и попробуйте более одного продукта.

Использовать под присмотром взрослых
Задайте себе несколько вопросов:
Уделите этому внимание, это действительно важно. В этой статье я собираюсь сосредоточиться на вопросах автоматизации устройств и их оркестрации. Этими устройствами могут быть маршрутизаторы, коммутаторы, межсетевые экраны, излучающие электромагнитные волны следующего поколения циркулятроны — не имеет значения. Что действительно важно — в их операционной системе не будет установлен агент. У Ansible было совместимое решение — использование SSH в качестве транспорта, поэтому он хорошо вписывается в мир конфигураций конечных устройств, для которых SSH является наименьшим общим знаменателем. SaltStack создавался как шина для высокоскоростного и безопасного миньона (агента), управляющего коммуникацией, но он также имеет режим использования без агента. StackStorm вышел на игровое поле последним и по своей архитектуре не отдает предпочтения какой-либо из работ. Он поддерживает инструменты на основе агентов посредством пакетов для Chef, Puppet, Salt, а также собственные SSH-средства дистанционного управления и встроенную поддержку для вызова сборников сценариев — плейбуков Ansible.
Другое ключевое отличие — API:
Ansible — детище Майкла ДеХаана. Продукт был разработан для автоматизации однообразных задач администрирования серверов в крупных средах. Майкл был в новообразованной технологической группе RedHat, где основал разные проекты (такие как Cobbler), а после ухода из RedHat основал Ansible (хотя теперь Ansible и принадлежит RedHat). Выдержка из блога Майкла, посвященного основам Ansible, объясняющая цель проекта:
«Мы хотели создать еще один очень демократичный проект для решения новых проблем с открытым исходным кодом в Red Hat, в который мог быть вовлечен широкий круг разработчиков. Мы вспомнили о busrpc. Этот проект существовал для заполнения пробелов между Cobbler и Puppet. Cobbler может подготовить систему, а Puppet может сложить файлы конфигурации. Но, поскольку Puppet слишком описательный, его невозможно использовать для выполнения таких операций, как перезагрузка серверов или выполнение в промежуточное время всех задач «по требованию».
Эти задачи «по требованию» эволюционировали в плейбуки Ansible, а затем появилась и начала свое развитие экосистема модулей Ansible.
Ansible прост, что является его главным качеством (это сразу станет ясным, если посмотреть на другие 2 качества). В нем нет ни демонов, ни баз данных, а требования для установки минимальны. Ansible просто устанавливается на Linux-машине и всё. Можно определить целевые серверы в статическом файле, сгруппировать их в содержательные разделы или использовать некий динамический модуль обнаружения хостов (такой как Amazon EC2 или OpenStack) для поиска виртуальных машин на основе вызова API. После того как была проведена инвентаризация, можно выделить специфичные для хоста или группы переменные для использования в плейбуках. Они, опять же, хранятся в статических текстовых файлах.
Затем Ansible подключится к выбранному хосту или группе и запустит плейбук. Сборник сценариев (плейбук) представляет собой последовательность модулей Ansible для выполнения на удаленных хостах, написанных на YAML.
Подключение к удаленному хосту немного похоже на хорошо спланированные военные учения: вошел, сделал свою работу и вышел.
Ansible работает по следующему алгоритму: подключение к серверу по SSH (или WS-Man/WinRM для Windows), копирование кода на языке Python, исполнение и удаление самого себя.
Архитектура Ansible прямолинейна: существует приложение, выполняющееся на локальном компьютере, и выполняемые на удаленном хосте задачи, которые поддерживают между собой связь по SSH и через файлы, передаваемые по SCP/SFTP. У Ansible нет архитектуры «сервер-клиент», в отличие от двух других продуктов, поэтому распараллеливание задач происходит на локальной машине, но не масштабируется на несколько серверов (если не использовать Tower).
Ansible при управлении удаленными машинами не оставляет на них своего кода, поэтому вопрос, как обновить Ansible при переходе на новую версию, в действительности не стоит.
Модули в Ansible действительно просты в разработке, как, впрочем, и в остальных двух продуктах. Прочтите стайл гайд, если позже решите попробовать смерджить свое решение в репозиторий продукта с открытым исходным кодом вместо его повторного рефакторинга.
#!/usr/bin/python
import datetime
import json
date = str(datetime.datetime.now())
print json.dumps({
"time" : date
})ansible/hacking/test-module -m ./timetest.pyВы должны увидеть примерно следующий результат:
{"time": "2012-03-14 22:13:48.539183"}В модулях можно определить свой код для формирования «фактов» об удаленном хосте на стадии «сбора», которые могут быть использованы собственными или сторонними модулями. Это может быть реализовано в виде просмотра как установленных файлов, так и конфигурации для определения способа настройки сервиса.
Ansible Tower — это корпоративная версия (Enterprise), которая превращает командную строку Ansible в сервис с веб-интерфейсом, планировщиком и системой уведомлений.

Планировщик задач
Он также имеет пользовательский интерфейс для плейбуков, посредством которого можно автоматизировать развертывание облачной инфраструктуры, а затем автоматически добавить виртуальные машины в перечень.
Стоит отметить, что планировщик задач, облачные развертывания и сервер — это функции бесплатных версий как Salt, так и StackStorm.
Раздел о поддержке сетей в Ansible — наиболее полный среди всех трех продуктов и охватывает всех основных вендоров сетевого оборудования и платформы. В Ansible возможно:
Ansible поддерживает Arista, Cisco (все программируемые платформы), F5, Juniper и других производителей. Только в Ansible поддержка в основном предоставляется и осуществляется вендорами, а не сообществом. На данный момент это лучшие интерфейсы API, наибольшая функциональность и работа с самыми последними платформами (поскольку поддерживаются более новые версии).
Я пользовался StackStorm начиная с версии v0.11 (ранняя предварительная бета-версия) вплоть до последней версии v2.2. Это сложная платформа широкого применения, как и Salt. Хотя рассказ о ней требует времени, но все же часто у слушателя создается неправильное впечатление о системе. Я вижу в этом и силу, и слабость. Слабость, потому что сложность системы может заставить отказаться от развертывания совсем или использовать более простое, но неправильное решение там, где StackStorm была бы хорошей альтернативой (часто в таких случаях даже пишется собственное решение «с нуля»). Сила в том, что, как только станет понятно, как использовать сильные стороны, система становится действительно гибкой.
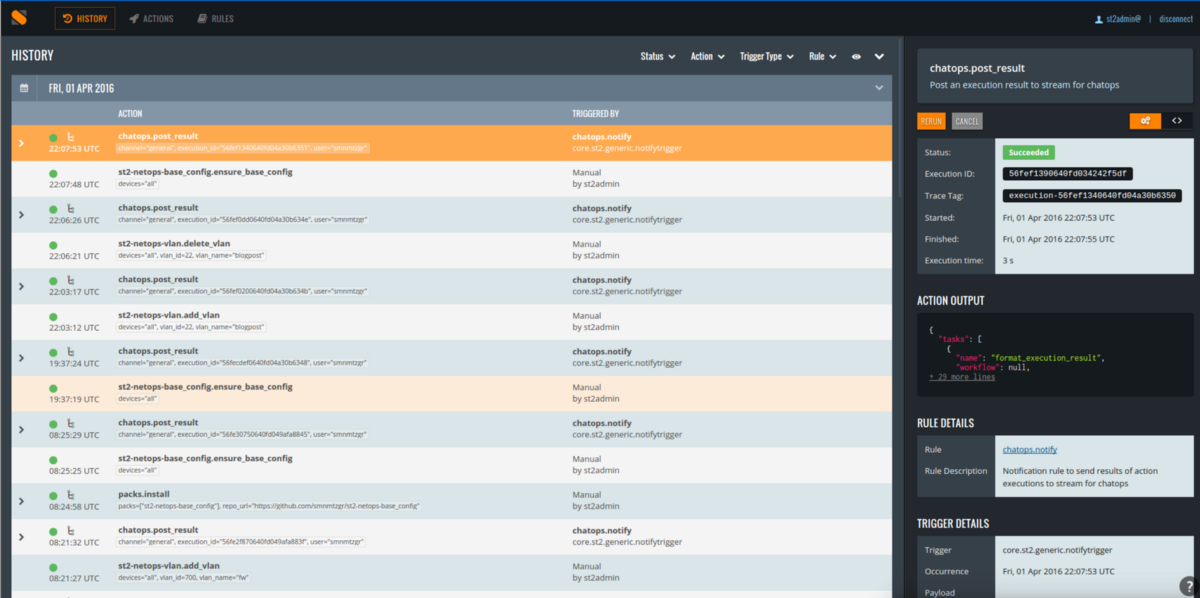
Интерфейс StackStorm
Ядром StackStorm является исполняемый движок с подключаемыми правилами, спроектированный как глубоко настраиваемая служба IFTTT (if-this-then-that, «если это, тогда то»). Можно настроить StackStorm реагировать на произошедшие события запуском простого «действия» (команды) или сложного рабочего процесса. Рабочие процессы доступны в двух вариантах: в виде ActionChain — цепочки действий (проприетарный рабочий процесс DSL) или в виде рабочего процесса на OpenStack Mistral, движок которого основан на YAML.
StackStorm также включает службу для «chatops», с помощью которой можно инициировать рабочие процессы из событий или сообщений платформы чата (например, Slack).
Перечень основных составляющих StackStorm:
StackStorm состоит из ряда сервисов, использующих очередь сообщений (rabbit) и хранилище данных (mongo) для сохранения своего состояния и обмена данными между собой. StackStorm также имеет web-интерфейс (да, даже в бесплатной версии!), который позволяет настраивать правила, выполнять действия «по требованию» и проверять журнал аудита.
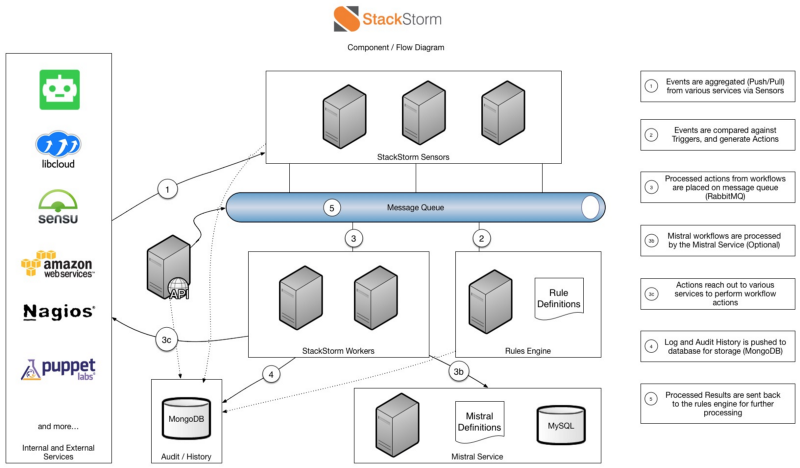
В отличие от Ansible и Salt, StackStorm не был предназначен для настройки рабочих станций или коммуникаций. StackStorm включает пакеты для Salt, Chef, Puppet и Ansible, поэтому при необходимости использования Chef для системы управления агентами и конфигурациями воспользуйтесь StackStorm для вызова сервисов на базе API, таких как Sensu или Kubernetes. Это является легко достижимым и очевидным решением. В Salt все еще существует концепция выполнения на конечной машине или на мастере (на выбор). Если требуется вызвать API Kubernetes, то вопрос о том, какой компьютер вызвал API, становится спорным. То же самое касается конфигурации сетевых устройств.
MongoDB можно масштабировать, используя хорошо документированные шаблоны, то же касается и RabbitMQ. Сами службы разрабатывались с API HTTP/RESTful и могут использовать балансировку нагрузки для масштабирования. Роли могут быть развернуты на одном сервере или распределены по нескольким серверам в зависимости от потребностей.
Мне действительно нравится расширяемость StackStorm, это определенно ключевое преимущество над другими двумя продуктами. Точки расширения StackStorm называются пакетами. Они являются автономными, могут храниться в Git и управляют своими зависимостями через виртуальные среды уровня пакета на языке Python. При установке пакета указывается URL-адрес Git или URL-адрес HTTP, (необязательные) учетные данные, а StackStorm уже загружает, настраивает и устанавливает пакет.
Если бы StackStorm был языком программирования, он был бы сильно типизирован. Для действий указываются типы всех входных данных, для триггеров указываются поля и типы. Это позволяет легко предугадать, что будет возвращено сторонним расширением, и является уникальной особенностью StackStorm.
В отличие от Salt и Ansible, StackStorm не содержит никаких расширений при поставке, все они должны устанавливаться индивидуально. Это облегчает развертывание и упрощает зависимости.
При разработке механизма интеграции для StackStorm можно создавать сенсоры, действия и рабочие процессы в одном определении. Модули Salt и Ansible являются автономными. Таким образом, если расширение (например, Salt) включает Beacons, «Модули исполнения» и «Модули состояния», то у них нет ничего общего, за исключением названия и автора. Это может создать проблемы при управлении зависимостями pip.
Решение этой проблемы в StackStorm заключается в том, что каждый пакет имеет как свой файл requirements.txt, так и файл YAML, описывающий назначение, требования и версию пакета. Можно обновить пакет линейно и при этом сохранить существующую конфигурацию. Пакеты также содержат шаблонную конфигурацию, в отличие от Ansible и Salt, в которых формат конфигурации модулей хранится только в документации, делая их более подверженными ошибкам пользователя. Кроме того, часто приходится просматривать код модуля, если разработчик не удосужился задокументировать параметры конфигурации должным образом.
Еще одной уникальной особенностью является то, что «ChatOps-псевдонимы» (команды чата) встроены в пакеты. Поэтому при установке, например, пакета NAPALM установятся также все команды чата для NAPALM.
StackStorm — это продукт с открытым исходным кодом по лицензии Apache-2, размещенный на GitHub. StackStorm принадлежит компании Brocade (которая недавно распродала часть активов, и часть StackStorm теперь принадлежит Extreme Networks).
При лицензировании StackStorm покупается продукт под названием «Brocade Workflow Composer», и владелец лицензии получает дополнительный функционал, а также Enterprise-level-поддержку. Развернутая в производственной среде система, с которой я работал, была лицензирована, и их группа поддержки оставила у меня впечатление отзывчивой и знающей. Вы также получаете RBAC, в котором можете указать для каждого уровня действий, у кого и к каким действиям есть доступ.
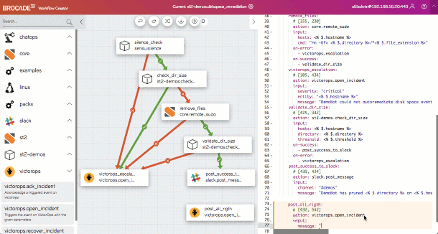
Brocade Workflow Composer
Вам повезло, если вы используете Brocade VLX или SDX, так как они хорошо поддерживаются, чего и следовало ожидать.
В апреле 2017 года они объединили поддержку библиотеки NAPALM и кроссплатформенного пакета абстракции Python для Cisco, Juniper, Arista и других вендоров. Теперь можно использовать функционал NAPALM в части маршрутизации, интерфейсов, пиринга BGP и некоторых других отличных возможностей. Мэтт Освальт (соавтор книги O'Reilly по сетевой автоматизации) написал хороший блог о прогрессе в этом направлении.
Демонстрация NAPALM для StackStorm
Прежде всего Salt — это продукт, SaltStack — это компания. Поэтому, когда я говорю о Salt, я говорю о Salt Open — версии с открытым исходным кодом.
Salt имеет массивный перечень составляющих, поначалу (и когда я говорю «поначалу», я имею в виду «первый год»), это может быть действительно потрясающим. Salt выполняет множество функций, поэтому, как правило, сравнивая Salt с Ansible, Salt-фанаты говорят «да, но он делает намноооооого больше». Как и в случае со StackStorm, это работает и за, и против Salt. Если бы я просто сказал вам принести grains (кристаллы) из шахты, вы бы подумали, что я имею в виду роман Толкиена, но как только вы узнаете, что такое Salt mine (соляная шахта) в терминологии Salt, все станет очевидным.
Salt родилась как распределенная система для удаленного исполнения команд и данных запросов на удаленных узлах или «миньонах». Удаленное исполнение возможно либо на отдельных узлах, либо на группах по произвольным критериям выбора — «таргетинг».
Salt была расширена до системы управления конфигурациями, способной поддерживать удаленные узлы в заданных состояниях (например, гарантируя, что на них установлены определенные пакеты и запущены определенные службы). В Salt есть множество компонентов, и я попросту уверен, что пропустил что-то!
Движки — они же Salt Engines (солевые двигатели) — это внешние процессы, исполняемые в течение продолжительного времени, которые работают с Salt.
Миньоны (прокси или обычные) могут быть адресованы с использованием grains (крупинки, кристаллы), pillars (столбов, колонн) или идентификаторов. Существуют и другие плагины для таргетинга, а также возможность создавать собственные, основанные на чем-то вроде SQL-запроса или KVP-хранилища.
Grains — Salt содержит интерфейс для получения информации о нижерасположенной системе. Он называется интерфейс «крупинок», потому что представляет собой «соль», состоящую из «крупинок» информации. Grains собираются для операционной системы, имени домена, IP-адреса, ядра, типа ОС, памяти и многих других свойств системы. Интерфейс grains доступен для модулей и компонентов Salt, так что нужные команды миньонов автоматически становятся доступными в соответствующих системах.
Для извлечения данных можно также использовать данные от миньонов и хранить их в Salt mine (соляной шахте). В дальнейшем эти данные можно использовать в других задачах, таких как конфигурация состояний на основе шаблонов. В отличие от Ansible (который поддерживает только YAML), это может быть реализовано в разных форматах.
Архитектура Salt основана на принципе ступицы колеса и спицы (веерная структура). В некоторых очень больших развертываниях используется несколько мастеров, но это случается довольно редко. Мастера можно легко масштабировать до многих тысяч узлов отчасти из-за облегченной шины сообщений ZeroMQ. Другие модели развертывания:
Мастер содержит файлы состояния, которые обычно помещаются в общий том хранения. Они настроены в виде дерева для возможности использования таргетинга, чтобы определять группы серверов для настройки и сред/приложений для развертывания.
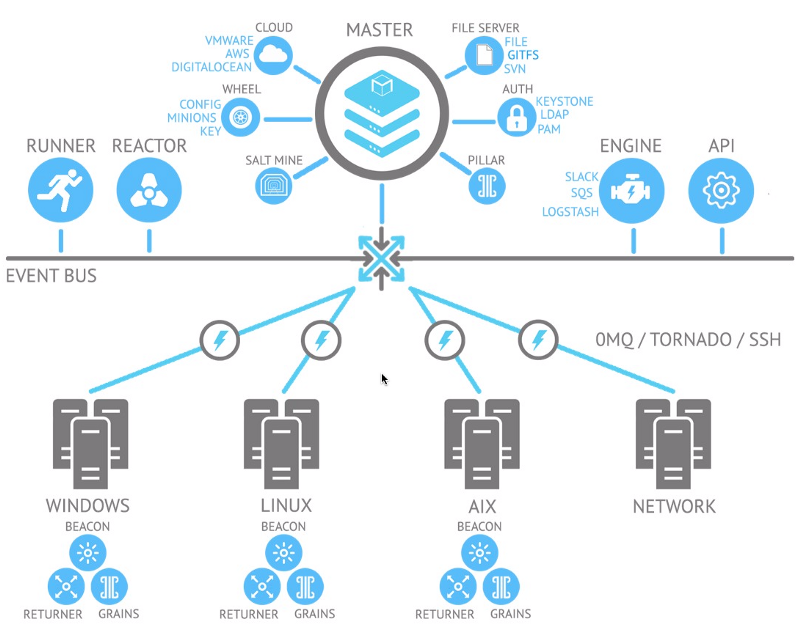
Основанная на событиях система Salt использует маяки (beacons). Подобно системе сенсоров и триггеров StackStorm, маяки Salt запускают события в шину сообщений, которые затем могут быть обработаны в реакторе (на мастере). Механизм правил в реакторе довольно сырой по сравнению со StackStorm, поскольку обычно команда состояния или выполнения активируется позади маяка, запускающего событие. Тем не менее, маяки работают на миньонах, поэтому, если события обнаруживаются на серверах, все предельно ясно. Поскольку StackStorm и Ansible не имеют агентов, это будет уникальной функцией Salt.
Thorium (торий) — комплексный реактор для Salt, был включен в прошлый релиз в качестве эксперимента и, может быть, будет поддерживаться в будущих выпусках. Thorium добавляет поддержку более сложных правил и сбора событий.
Все в Salt является расширяемым, вплоть до модулей, отображающих результаты выполнения в CLI. Это большой плюс Salt, так как можно легко внедрять собственные изменения без необходимости поддерживать параллельный fork в главном проекте. Каждая функция в Salt также является подключаемой.
Наиболее распространенными сценариями для расширения могут быть разработка модуля состояния (для описания того, как должна быть сконфигурирована часть программного обеспечения или службы) или модуля исполнения (код для взаимодействия с API или системой). Оба типа модулей могут быть написаны по относительно небольшому шаблону, оба хорошо задокументированы и могут быть проверены с помощью неплохой встроенной тестовой среды. Выполнить узловую проверку модулей можно c помощью PyTest, даже не находясь на мастере или совсем без работающего мастера. Для тестирования интеграций требуется система Linux, хотя с небольшими навыками хакера модули можно запустить и на OSX (о Windows не может идти и речи, как и в случае StackStorm с Ansible).
Возможно либо поддерживать свой автономный пакет, либо вносить непосредственный вклад в проект Salt на GitHub. Самым большим недостатком при внесении кода в основной проект является то, что пользователям для легкой установки ваших модулей может потребоваться подождать целый цикл обновлений. Это занимает примерно 3-5 месяцев при их текущем темпе работы, поэтому, хотя система Salt и «поставляется с батарейками», она имеет недостатки.
У Salt также есть менеджер пакетов, SPM, который в основном нацелен на группировку формул управления конфигурацией (state files). Его можно использовать для упаковки модулей, чтобы обойти медленный цикл релизов, о котором я упомяну в слабых сторонах (хотя это и не очень хорошо задокументировано).
Salt развивается очень быстро в течение последних нескольких лет и претерпела некоторые большие изменения. Из-за этого может наблюдаться несовместимость между разработанными сообществом модулями. Я также считаю (хотя это и не уникально для Salt), что модули, представленные сообществом, плохо тестируются.
«Salt Open» — это версия системы с открытым исходным кодом, но можно лицензировать и "Salt Enterprise", которая поставляется с некоторыми приятными функциями, такими как:
Поскольку Salt полагается на шину сообщений, а ZeroMQ имеет ряд зависимостей, для которых обычно требуется полная настройка сети на уровне ОС, то управление сетевыми устройствами не является очевидным при использовании Salt. В последнем релизе Salt значительно улучшена поддержка «прокси миньонов». Прокси-миньоны — виртуальные миньоны — это процесс, который может где угодно работать для удаленного управления устройствами по SSH, HTTP или с помощью другого транспортного механизма. Он использует ту же функциональность, что и обычный миньон, но у него есть и некоторые особенности. Чтобы избежать путаницы с прокси в Puppet (прокси там является центральной машиной, через которую проходят все запросы), скажу, что это всего лишь процесс, связанный с устройством, к которому вы обращаетесь. Таким образом, это отдельный процесс на каждом миньоне. Он обычно легкий и потребляет около 40 МБ ОЗУ. Можно создавать прокси-миньоны, разрабатывая модули Python, которые могут выполняться на миньоне. Команда Salt демонстрировала это в прошлые годы на SaltConf.
Поддерживаемые в настоящее время сетевые платформы:
Поддержка NAPALM в демонстрации Salt
salt-ssh).Это самое большое различие между этими тремя продуктами. Salt и StackStorm имеют такой функционал. StackStorm имеет службы, которые можно написать (сенсоры), и строго типизированные события, которые могут быть вызваны, как и сложный механизм правил. Salt имеет маяки — службы, которые могут быть запущены как на агентах, так на центральном мастере для обнаружения событий на локальных машинах. Это уникальная возможность. Версия Ansible с открытым исходным кодом не позволяет (и не пытается) реагировать на события.
Я видел, что производители сетей специально разрабатывали модули для Ansible, тогда как в случае с другими платформами (за исключением Brocade для StackStorm) модули были внесены сообществом. Несомненно, Ansible имеет самую широкую поддержку сетевых платформ. Хотя с внедрением NAPALM и NSO как в StackStorm, так и в Salt это меняет ситуацию, поскольку обе системы поддерживают Arista, JunOS (Juniper), Cisco APIC-EM, NXOS и т.д.
Сила Ansible — это минимальное количество настроек (их, в принципе, нет). Популярность в сетевых задачах может быть обусловлена простотой и знакомством сетевых администраторов с CLI для управления удаленными устройствами без необходимости развертывания каких-либо дополнительных серверов для запуска программного обеспечения. Если у вас много небольших изолированных сайтов (например, коммерческих филиалов), следует подумать, не разделить ли архитектуру. Мой работодатель управляет сетями передачи данных в некоторых крупных сетевых супермаркетах, и я бы не решился иметь мастера в центре, в то время как магазины в сельских районах могут иметь ненадежную связь.
Salt уникальна тем, что ее ключевые хранилища подключаемы. Если вы хотите хранить пароли или ключи из Hashicorp Vault, это как два пальца. Если вы хотите хранить крупицы данных в базе SQL, все, опять же, работает «из коробки». Подумайте, каким другим системам и платформам могут потребоваться для доступа или ввода данные, которые вы таргетируете.
Если сравнивать Ansible и Salt, Salt имеет собственное хранилище ключей для связи с агентами, а Ansible использует SSH для транспорта. Плохо управляемая среда Ansible, как правило, представляет собой набор закрытых ключей, хранящихся на ноутбуке администраторов (пожалуйста, не делайте этого). Salt предлагает уникальную функцию для защиты данных. Шаблоны, состояния или grains могут быть сохранены во внешнем безопасном хранилище данных. StackStorm хранит данные в MongoDB, которые ваша группа информационной безопасности, безусловно, должна проверить перед тем, как выпускать систему в производственную среду.
Если вы не хотите быть единственным специалистом, поддерживающим эту платформу, нужно будет обучить некоторых коллег. Salt и Ansible имеют опубликованные подробные книги, StackStorm — нет. Salt и (RedHat) Ansible предлагают решения для обучения почти исключительно в США, StackStorm — нет (пока). Salt и Ansible имеют курсы по PluralSight, но они действительно базовые.
И Salt, и StackStorm имеют лицензию Apache-2, Ansible — GPLv3. Если вы не слишком хорошо знакомы с лицензированием OSS, я рекомендую веб-сайт «TLDR Legal». Salt в качестве примера была использована SuSE для создания продукта системного управления (отчасти из-за гибкости их лицензии OSS).
Анекдотично (я очень внимательно слежу за этим), но Ansible пользуется вниманием сетевых администраторов и инженеров DevOps по всему миру. Вы наверняка убедитесь, что нанять инженера Ansible намного проще, чем Salt или StackStorm. Но инженеры DevOps так же редки, как и зубы у куриц, поэтому вы будете платить много долларов независимо от платформы.
Пожалуйста, попробуйте хотя бы две платформы и примите обоснованное решение. Я уже писал об этом ранее, но, работая с инструментами DevOps, люди могут открыть чудо автоматизации, а изучив инструмент, затем просто религиозно придерживаться его.
Вы не должны как ребенок, который впервые попробовал шоколад, запросто верить, что краткий миг радости — это заслуга Кэдберри.

Благодарность: спасибо за отзывы и вклад в развитие от Salt, StackStorm, Ansible и членов сообщества.
Директор группы по инновациям и техническому развитию Dimension Data, отец, христианин, фанат Python, решает проблемы с opensource, идеями и людьми.
|
Метки: author olemskoi системное администрирование серверное администрирование devops блог компании southbridge ansible saltstack salt stackstorm networking napalm |
Информационная безопасность: не ждите «жареного петуха» — он сам придет |


Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
|
Город цифрового солнца. Путевые заметки из Иннополиса |
|
Метки: author megapost карьера в it-индустрии иннополис город будущего |






