[Из песочницы] Язык программирования SPL — пример решения задачи |
text = #.readtext("hamlet.txt")
words = #.split(text, " ", ".", ",", ";", "'", "!", "?", "-", "(", ")", "[", "]", #.crlf, #.quot)
> i, 1..#.size(words)
>> words[i] = ""
key = #.lower(words[i])
dict[key] += 1
total += 1
<
#.sortval(dict)
#.reverse(dict)
#.output(total, " слов; ", #.size(dict), " уникальных слов")
> i, 1..10
key = dict[i]
#.output(i, " : ", key, " = ", dict[key])
<
32885 слов; 4634 уникальных слов
1 : the = 1091
2 : and = 969
3 : to = 767
4 : of = 675
5 : i = 633
6 : a = 571
7 : you = 558
8 : my = 520
9 : in = 451
10 : it = 421text = #.readtext("hamlet.txt")words = #.split(text, " ", ".", ",", ";", "'", "!", "?", "-", "(", ")", "[", "]", #.crlf, #.quot)> i, 1..#.size(words)>> words[i] = ""key = #.lower(words[i])dict[key] += 1total += 1<#.sortval(dict)#.reverse(dict)#.output(total, " слов; ", #.size(dict), " уникальных слов")> i, 1..10key = dict[i]#.output(i, " : ", key, " = ", dict[key])<|
Метки: author Mr_Kibernetik программирование spl |
[Из песочницы] Клиент-сервер шаг — за — шагом, от однопоточного до многопоточного |
Цель публикации показать начинающим Java программистам все этапы создания многопоточного сервера. Для полного понимания данной темы основная информация содержится в комментариях моего кода и в выводимых в консоли сообщениях для лучшего понимания что именно происходит и в какой именно последовательности.
В начале будет рассмотрено создание элементарного клиент-сервера, для усвоения базовых знаний, на основе которых будет строиться многопоточная архитектура.
Понятия.
— Потоки: для того чтобы не перепутать что именно подразумевается под потоком я буду использовать существующий в профессиональной литературе синоним — нить, чтобы не путать Stream и Thread, всё таки более профессионально выражаться — нить, говоря про Thread.
— Сокеты(Sockets): данное понятие тоже не однозначно, поскольку в какой-то момент сервер выполняет — клиентские действия, а клиент — серверные. Поэтому я разделил понятие серверного сокета — (ServerSocket) и сокета (Socket) через который практически осуществляется общение, его будем называть сокет общения, чтобы было понятно о чём речь.
Кроме того сокетов общения создаётся по одному на каждом из обменивающихся данными приложении, поэтому сокет приложения которое имеет у себя объект - ServerSocket и первоначально открывает порт в ожидании подключения будем называть сокет общения на стороне сервера, а сокет который создаёт подключающееся к порту по известному адресу второе приложение будем называть сокетом общения на стороне клиента.Оглавление:
1) Однопоточный элементарный сервер.
2) Клиент.
3) Многопоточный сервер – сам по себе этот сервер не участвует в общении напрямую, а лишь является фабрикой однонитевых делигатов(делигированных для ведения диалога с клиентами серверов) для общения с вновь подключившимися клиентами, которые закрываются после окончания общения с клиентом.
4) Имитация множественного обращения клиентов к серверу.
Итак начнём с изучения структуры однопоточного сервер, который может принять только одного клиента для диалога. Код приводимый ниже необходимо запускать в своей IDE в этом идея всей статьи. Предлагаю все детали уяснить из подробно задокументированного кода ниже:
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class TestAsServer {
/**
*
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
// стартуем сервер на порту 3345
try (ServerSocket server= new ServerSocket(3345);){
// становимся в ожидание подключения к сокету под именем - "client" на серверной стороне
Socket client = server.accept();
// после хэндшейкинга сервер ассоциирует подключающегося клиента с этим сокетом-соединением
System.out.print("Connection accepted.");
// инициируем каналы для общения в сокете, для сервера
// канал чтения из сокета
DataInputStream in = new DataInputStream(client.getInputStream());
System.out.println("DataInputStream created");
// канал записи в сокет
DataOutputStream out = new DataOutputStream(client.getOutputStream());
System.out.println("DataOutputStream created");
// начинаем диалог с подключенным клиентом в цикле, пока сокет не закрыт
while(!client.isClosed()){
System.out.println("Server reading from channel");
// сервер ждёт в канале чтения (inputstream) получения данных клиента
String entry = in.readUTF();
// после получения данных считывает их
System.out.println("READ from client message - "+entry);
// и выводит в консоль
System.out.println("Server try writing to channel");
// инициализация проверки условия продолжения работы с клиентом по этому сокету по кодовому слову - quit
if(entry.equalsIgnoreCase("quit")){
System.out.println("Client initialize connections suicide ...");
out.writeUTF("Server reply - "+entry + " - OK");
Thread.sleep(3000);
break;
}
// если условие окончания работы не верно - продолжаем работу - отправляем эхо-ответ обратно клиенту
out.writeUTF("Server reply - "+entry + " - OK");
System.out.println("Server Wrote message to client.");
// освобождаем буфер сетевых сообщений (по умолчанию сообщение не сразу отправляется в сеть, а сначала накапливается в специальном буфере сообщений, размер которого определяется конкретными настройками в системе, а метод - flush() отправляет сообщение не дожидаясь наполнения буфера согласно настройкам системы
out.flush();
}
// если условие выхода - верно выключаем соединения
System.out.println("Client disconnected");
System.out.println("Closing connections & channels.");
// закрываем сначала каналы сокета !
in.close();
out.close();
// потом закрываем сам сокет общения на стороне сервера!
client.close();
// потом закрываем сокет сервера который создаёт сокеты общения
// хотя при многопоточном применении его закрывать не нужно
// для возможности поставить этот серверный сокет обратно в ожидание нового подключения
server.close();
System.out.println("Closing connections & channels - DONE.");
} catch (IOException e) {
e.printStackTrace();
}
}
}Сервер запущен и находится в блокирующем ожидании server.accept(); обращения к нему с запросом на подключение. Теперь можно подключаться клиенту, напишем код клиента и запустим его. Клиент работает когда пользователь вводит что-либо в его консоли (внимание! в данном случае сервер и клиент запускаются на одном компьютере с локальным адресом — localhost, поэтому при вводе строк, которые должен отправлять клиент не забудьте убедиться, что вы переключились в рабочую консоль клиента!). После ввода строки в консоль клиента и нажатия enter строка проверяется не ввёл ли клиент кодовое слово для окончания общения дальше отправляется серверу, где он читает её и то же проверяет на наличие кодового слова выхода. Оба и клиент и сервер получив кодовое слово закрывают ресурсы после предварительных приготовлений и завершают свою работу. Посмотрим как это выглядит в коде:
import java.io.BufferedReader;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.Socket;
import java.net.UnknownHostException;
public class TestASClient {
/**
*
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException {
// запускаем подключение сокета по известным координатам и нициализируем приём сообщений с консоли клиента
try(Socket socket = new Socket("localhost", 3345);
BufferedReader br =new BufferedReader(new InputStreamReader(System.in));
DataOutputStream oos = new DataOutputStream(socket.getOutputStream());
DataInputStream ois = new DataInputStream(socket.getInputStream()); )
{
System.out.println("Client connected to socket.");
System.out.println();
System.out.println("Client writing channel = oos & reading channel = ois initialized.");
// проверяем живой ли канал и работаем если тру
while(!socket.isOutputShutdown()){
// ждём консоли клиента на предмет появления в ней данных
if(br.ready()){
// данные появились - работаем
System.out.println("Client start writing in channel...");
Thread.sleep(1000);
String clientCommand = br.readLine();
// пишем данные с консоли в канал сокета для сервера
oos.writeUTF(clientCommand);
oos.flush();
System.out.println("Clien sent message " + clientCommand + " to server.");
Thread.sleep(1000);
// ждём чтобы сервер успел прочесть сообщение из сокета и ответить
// проверяем условие выхода из соединения
if(clientCommand.equalsIgnoreCase("quit")){
// если условие выхода достигнуто разъединяемся
System.out.println("Client kill connections");
Thread.sleep(2000);
// смотрим что нам ответил сервер на последок перед закрытием ресурсов
if(ois.available()!=0) {
System.out.println("reading...");
String in = ois.readUTF();
System.out.println(in);
}
// после предварительных приготовлений выходим из цикла записи чтения
break;
}
// если условие разъединения не достигнуто продолжаем работу
System.out.println("Client sent message & start waiting for data from server...");
Thread.sleep(2000);
// проверяем, что нам ответит сервер на сообщение(за предоставленное ему время в паузе он должен был успеть ответить)
if(ois.available()!=0) {
// если успел забираем ответ из канала сервера в сокете и сохраняем её в ois переменную, печатаем на свою клиентскую консоль
System.out.println("reading...");
String in = ois.readUTF();
System.out.println(in);
}
}
}
// на выходе из цикла общения закрываем свои ресурсы
System.out.println("Closing connections & channels on clentSide - DONE.");
} catch (UnknownHostException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}А что если к серверу хочет подключиться ещё один клиент!? Ведь описанный выше сервер либо находится в ожидании подключения одного клиента, либо общается с ним до завершения соединения, что делать остальным клиентам? Для такого случая нужно создать фабрику которая будет создавать описанных выше серверов при подключении к сокету новых клиентов и не дожидаясь пока делигированный подсервер закончит диалог с клиентом откроет accept() в ожидании следующего клиента. Но чтобы на серверной машине хватило ресурсов для общения со множеством клиентов нужно ограничить количество возможных подключений. Фабрика будет выдавать немного модифицированный вариант предыдущего сервера(модификация будет касаться того что класс сервера для фабрики будет имплементировать интерфейс — Runnable? для возможности его использования в пуле нитей — ExecuteServices). Давайте создадим такую серверную фабрику и ознакомимся с подробным описанием её работы в коде:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author mercenery
*
*/
public class MultiThreadServer {
static ExecutorService executeIt = Executors.newFixedThreadPool(2);
/**
* @param args
*/
public static void main(String[] args) {
// стартуем сервер на порту 3345 и инициализируем переменную для обработки консольных команд с самого сервера
try (ServerSocket server = new ServerSocket(3345);
BufferedReader br = new BufferedReader(new InputStreamReader(System.in))) {
System.out.println("Server socket created, command console reader for listen to server commands");
// стартуем цикл при условии что серверный сокет не закрыт
while (!server.isClosed()) {
// проверяем поступившие комманды из консоли сервера если такие
// были
if (br.ready()) {
System.out.println("Main Server found any messages in channel, let's look at them.");
// если команда - quit то инициализируем закрытие сервера и
// выход из цикла раздачии нитей монопоточных серверов
String serverCommand = br.readLine();
if (serverCommand.equalsIgnoreCase("quit")) {
System.out.println("Main Server initiate exiting...");
server.close();
break;
}
}
// если комманд от сервера нет то становимся в ожидание
// подключения к сокету общения под именем - "clientDialog" на
// серверной стороне
Socket client = server.accept();
// после получения запроса на подключение сервер создаёт сокет
// для общения с клиентом и отправляет его в отдельную нить
// в Runnable(при необходимости можно создать Callable)
// монопоточную нить = сервер - MonoThreadClientHandler и тот
// продолжает общение от лица сервера
executeIt.execute(new MonoThreadClientHandler(client));
System.out.print("Connection accepted.");
}
// закрытие пула нитей после завершения работы всех нитей
executeIt.shutdown();
} catch (IOException e) {
e.printStackTrace();
}
}
}import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.Socket;
public class MonoThreadClientHandler implements Runnable {
private static Socket clientDialog;
public MonoThreadClientHandler(Socket client) {
MonoThreadClientHandler.clientDialog = client;
}
@Override
public void run() {
try {
// инициируем каналы общения в сокете, для сервера
// канал чтения из сокета
DataInputStream in = new DataInputStream(clientDialog.getInputStream());
System.out.println("DataInputStream created");
// канал записи в сокет
DataOutputStream out = new DataOutputStream(clientDialog.getOutputStream());
System.out.println("DataOutputStream created");
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// основная рабочая часть //
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// начинаем диалог с подключенным клиентом в цикле, пока сокет не
// закрыт клиентом
while (!clientDialog.isClosed()) {
System.out.println("Server reading from channel");
// серверная нить ждёт в канале чтения (inputstream) получения
// данных клиента после получения данных считывает их
String entry = in.readUTF();
// и выводит в консоль
System.out.println("READ from clientDialog message - " + entry);
// инициализация проверки условия продолжения работы с клиентом
// по этому сокету по кодовому слову - quit в любом регистре
if (entry.equalsIgnoreCase("quit")) {
// если кодовое слово получено то инициализируется закрытие
// серверной нити
System.out.println("Client initialize connections suicide ...");
out.writeUTF("Server reply - " + entry + " - OK");
Thread.sleep(3000);
break;
}
// если условие окончания работы не верно - продолжаем работу -
// отправляем эхо обратно клиенту
System.out.println("Server try writing to channel");
out.writeUTF("Server reply - " + entry + " - OK");
System.out.println("Server Wrote message to clientDialog.");
// освобождаем буфер сетевых сообщений
out.flush();
// возвращаемся в началло для считывания нового сообщения
}
///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// основная рабочая часть //
//////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
// если условие выхода - верно выключаем соединения
System.out.println("Client disconnected");
System.out.println("Closing connections & channels.");
// закрываем сначала каналы сокета !
in.close();
out.close();
// потом закрываем сокет общения с клиентом в нити моносервера
clientDialog.close();
System.out.println("Closing connections & channels - DONE.");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Для имитации множественного обращения клиентов к серверу, создадим и запустим (после запуска серверной части) фабрику Runnable клиентов которые будут подключаться серверу и писать сообщения в цикле:
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
// private static ServerSocket server;
public static void main(String[] args) throws IOException, InterruptedException {
// запустим пул нитей в которых колличество возможных нитей ограничено -
// 10-ю.
ExecutorService exec = Executors.newFixedThreadPool(10);
int j = 0;
// стартуем цикл в котором с паузой в 10 милисекунд стартуем Runnable
// клиентов,
// которые пишут какое-то количество сообщений
while (j < 10) {
j++;
exec.execute(new TestRunnableClientTester());
Thread.sleep(10);
}
// закрываем фабрику
exec.shutdown();
}
}Как видно из предыдущего кода фабрика запускает — TestRunnableClientTester() клиентов, напишем для них код и после этого запустим саму фабрику, чтобы ей было кого исполнять в своём пуле:
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import java.net.Socket;
public class TestRunnableClientTester implements Runnable {
static Socket socket;
public TestRunnableClientTester() {
try {
// создаём сокет общения на стороне клиента в конструкторе объекта
socket = new Socket("localhost", 3345);
System.out.println("Client connected to socket");
Thread.sleep(2000);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void run() {
try (
// создаём объект для записи строк в созданный скокет, для
// чтения строк из сокета
// в try-with-resources стиле
DataOutputStream oos = new DataOutputStream(socket.getOutputStream());
DataInputStream ois = new DataInputStream(socket.getInputStream())) {
System.out.println("Client oos & ois initialized");
int i = 0;
// создаём рабочий цикл
while (i < 5) {
// пишем сообщение автогенерируемое циклом клиента в канал
// сокета для сервера
oos.writeUTF("clientCommand " + i);
// проталкиваем сообщение из буфера сетевых сообщений в канал
oos.flush();
// ждём чтобы сервер успел прочесть сообщение из сокета и
// ответить
Thread.sleep(10);
System.out.println("Client wrote & start waiting for data from server...");
// забираем ответ из канала сервера в сокете
// клиента и сохраняемеё в ois переменную, печатаем на
// консоль
System.out.println("reading...");
String in = ois.readUTF();
System.out.println(in);
i++;
Thread.sleep(5000);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}Запускайте, вносите изменения в код, только так на самом деле можно понять работу этой структуры.
P.S. В последнем примере клиенты и серверы работают в бесконечном цикле, так что после окончания тестирования кода не забудьте завершить их работу.
Спасибо за внимание.
|
Метки: author OlegMercenery java многопоточность на java клиент-сервер чат java |
[recovery mode] Представляем 3CX Phone System V15.5 |

|
|
[Из песочницы] Делаем бота для дракончика в Google Chrome |


public static int x = 775;
public static int y = 250;
[DllImport("user32.dll")]
public static extern IntPtr GetDC(IntPtr hwnd);
[DllImport("user32.dll")]
public static extern int ReleaseDC(IntPtr hwnd, IntPtr hDC);
[DllImport("gdi32.dll")]
public static extern uint GetPixel(IntPtr hDC, int x, int y);
IntPtr hDC = GetDC(IntPtr.Zero);
while (true)
{
uint pixel = GetPixel(hDC, x, y);
if (pixel == 5460819)
{
SendKeys.SendWait("{UP}");
}
}
if (pixel == 5460819)SendKeys.SendWait("{UP}");using System.Diagnostics;
using System.Windows.Forms;using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.InteropServices;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.Windows.Forms;
namespace DragonChrome
{
class Program
{
#region VAR
public static int x = 775;
public static int y = 250;
#endregion
#region DLL
[DllImport("user32.dll")]
public static extern IntPtr GetDC(IntPtr hwnd);
[DllImport("user32.dll")]
public static extern int ReleaseDC(IntPtr hwnd, IntPtr hDC);
[DllImport("gdi32.dll")]
public static extern uint GetPixel(IntPtr hDC, int x, int y);
#endregion
static void Main(string[] args)
{
IntPtr hDC = GetDC(IntPtr.Zero);
while (true)
{
uint pixel = GetPixel(hDC, Convert.ToInt32(x), y);
if (pixel == 5460819)
{
SendKeys.SendWait("{UP}");
}
}
}
}
}|
|
[Из песочницы] Настройка Reverse Proxy Apache (Debian 8) с автоматической выдачей Let's Encrypt |
aptitude install -y build-essential
aptitude install -y libapache2-mod-proxy-html libxml2-dev
aptitude install -y apache2a2enmod proxy
a2enmod proxy_http
a2enmod proxy_ajp
a2enmod rewrite
a2enmod deflate
a2enmod headers
a2enmod proxy_balancer
a2enmod proxy_html
a2enmod proxy_ftp
a2enmod proxy_connect
a2enmod sslservice apache2 restartaptitude install apache2-prefork-dev libxml2 libxml2-dev apache2-dev
mkdir ~/modbuild/ && cd ~/modbuild/
wget http://apache.webthing.com/svn/apache/filters/mod_xml2enc.c
wget http://apache.webthing.com/svn/apache/filters/mod_xml2enc.h
apxs2 -aic -I/usr/include/libxml2 ./mod_xml2enc.c
cd ~
rm -rfd ~/modbuild/
service apache2 restartmkdir /etc/apache2/ssl
cd /etc/apache2/ssl
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout server.key -out server.crttouch /etc/apache2/sites-available/sambi4.conf
ServerName sambi4.ru
Redirect permanent / https://sambi4.ru/ #отвечает за перенаправление на https
SSLEngine On
SSLProxyEngine On
ProxyRequests Off
ProxyPreserveHost On
ProxyVia full
SSLCertificateFile /etc/apache2/ssl/server.crt #указываем путь к нашему самоподписанному сертификату
SSLCertificateKeyFile /etc/apache2/ssl/server.key #указываем путь к нашему самоподписанному ключу сертификата
ProxyHTMLInterp On
ProxyHTMLExtended On
Order deny,allow
Allow from all
ProxyPass / https://192.168.199.78/ #IP адрес публикуемого ресурса.
ProxyPassReverse / https://192.168.199.78/ #IP адрес публикуемого ресурса.
ServerName sambi4.ru
ServerAdmin sambi4@sambi4.ru #считается хорошим тоном указывать email админа
DocumentRoot "/var/www/html" #эта строка нужна для того чтобы апач запустился, без нее он не сможет опубликовать ваш ресурс.
a2ensite /etc/apache2/sites-available/sambi4.confservice apache2 restartecho 'deb http://ftp.debian.org/debian jessie-backports main' | tee /etc/apt/sources.list.d/backports.listaptitude updateaptitude install -y python-certbot-apache -t jessie-backportscertbot --apacheERROR:letsencrypt_apache.configurator:No vhost exists with servername or alias of: sambi4.ru. No vhost was selected. Please specify servernames in the Apache config
git clone https://github.com/certbot/certbot.git cd /usr/lib/python2.7/dist-packagescp /root/certbot/certbot /usr/lib/python2.7/dist-packages/
cp /root/certbot/acme/acme/ /usr/lib/python2.7/dist-packages/
cp /root/certbot/certbot-apache/certbot_apache/ /usr/lib/python2.7/dist-packages/certbot --apache30 2 * * 1 /usr/bin/certbot renew >> /var/log/le-renew.logcrontab -e|
Метки: author SAMbI4 apache *nix apache2 letsencrypt reverse proxy |
[Перевод] Советы по Postgres для Rails разработчиков |
В апреле на RailsConf в Фениксе мы обсудили огромное количество советов по использованию Postgres с Rails, и подумали, что будет полезно их записать и поделиться с более широкой аудиторией. Здесь вы найдете некоторые из них, касающиеся отладки и улучшения производительности базы данных вашего Rails приложения.
Долгие запросы могут оказывать все виды негативных воздействий на вашу базу данных. Независимо от того, работают ли запросы часами или всего несколько секунд, они могут держать блокировки, переполнять WAL, или просто потреблять огромное количество системных ресурсов. C Postgres легче добиться большей стабильности с помощью установки таймаута на запросы. Удобно, что можно установить значение по умолчанию, например, 5 секунд, как показано в примере ниже, и тогда любой запрос, длящийся дольше 5 секунд будет убит:
production:
url:
variables:
statement_timeout: 5000Если вам требуется, чтобы запрос выполнялся дольше в пределах сессии, можно задать таймаут, действительный только для текущего соединения:
class MyAnalyticsJob < ActiveJob::Base
queue_as :analytics
def perform
ActiveRecord::Base.connection.execute “SET statement_timeout = 600000” # 10 минут
# ...
ensure
ActiveRecord::Base.connection.execute “SET statement_timeout = 5000” # 5 секунд
end
end
Rails многое абстрагирует при взаимодействии с вашей базой данных. Это может быть как хорошо, так и плохо. Postgres сам позволяет отслеживать долгие запросы, но по мере роста вашего Rails приложения, этого может оказаться недостаточно. Чтобы узнать происхождение запроса, есть чрезвычайно удобный гем marginalia, который будет логировать, откуда именно пришел ваш запрос. Теперь, когда вы видите неправильный запрос, слишком медленный, или который просто можно убрать, вы точно знаете где в коде это поправить:
Account Load (0.3ms)
SELECT `accounts`.* FROM `accounts`
WHERE `accounts`.`queenbee_id` = 1234567890
LIMIT 1
/*application:BCX,controller:project_imports,action:show*/Внимание на комментарий — прим.пер.
Часто требуется общая картина того, что происходит в вашей базе данных. pg_stat_statements — это расширение Postgres, которое часто предустановленно в облачных средах, таких как Citus Cloud. Оно позволяет видеть, какие запросы выполнялись с момента последнего сброса статистики и как они себя вели.
Например, чтобы увидеть 10 наиболее долго выполняющихся запросов и их среднее время, выполните следующее:
SELECT query, total_time / calls AS avg_time
FROM pg_stat_statements
ORDER BY total_time DESC
LIMIT 10;Если включить «track_io_timing» в сборщике статистики Postgres, то можно понять что является узким местом — процессор или ввод-вывод. Можно узнать больше о pg_stat_statements здесь (или в другой статье okmeter.io на хабре — прим.пер.).
По умолчанию Rails использует файл «schema.rb» для хранения копии схемы базы данных, обычно используемой для инициализации базы данных перед запуском тестов. К сожалению, многие расширенные функции Postgres, такие как функциональные и частичные индексы, а также составные первичные ключи, не могут быть представлены в этом DSL.
Вместо этого имеет смысл перейти на генерируемый и используемый Rails файл «db/structure.sql», который можно сделать следующим образом:
# Use SQL instead of Active Record's schema dumper when creating the database.
# This is necessary if your schema can't be completely dumped by the schema dumper,
# like if you have constraints or database-specific column types
config.active_record.schema_format = :sqlВнутри используется формат Postgres «pg_dump», который иногда может быть чересчур подробным, но зато гарантирует получение полностью восстановленной структуры базы данных. Если вы столкнетесь с проблемой чрезмерно длинных diff-ов, можете взглянуть на activerecord-clean-db-structure.
Rails любит помещать всё в транзакции, особенно при использовании хуков «before_save» и многоуровневых связей между моделями. Существует одно важное предостережение, которое следует учитывать при транзакциях, которые могут создавать проблемы при масштабировании. Например, в такой транзакции:
BEGIN;
UPDATE organizations SET updated_at = ‘2017-04-27 11:31:03 -0700’ WHERE id = 123;
SELECT * FROM products WHERE store_id = 456;
--- еще всякие statement’ы тут
COMMIT; Первый оператор UPDATE будет удерживать блокировку на строку "organizations" с id "123", с самого начала и до COMMIT’а транзакции.
Представьте другой запрос к той же самой "organization", пришедший, например, от другого пользователя, и выполняющий аналогичную транзакцию. Как правило, чтобы выполниться, этому другому запросу придется ждать комита первой транзакции, что увеличит время ответа. Чтобы исправить это, можно переупорядочить транзакцию, чтобы UPDATE выполнялся ближе к концу, а также рассмотреть возможность сгруппировать обновления полей временных меток вне транзакции после выполнения основной работы.
Чтобы обнаруживать подобные проблемы зарание, вы можете установить «log_lock_waits = on» в PostgreSQL.
Rails по умолчанию поддерживает пул подключений к базе данных. Когда приходит новый запрос, он берет одно соединение из пула и передает его в приложение. По мере масштабирования вашего Rails приложения это может привести к сотням открытых подключений к базе данных, хотя на самом деле только часть из них выполняет работу. Ключом к этому является использование менеджера соединений для уменьшения активных подключений к базе данных, например, такого как pgBouncer. Менеджер соединений будет открывать соединения, когда транзакции активны, и не пропускать простаивающие соединения, которые не выполняют никакой работы.
От переводчика — а еще вы можете использовать наш мониторинг, который отследит количество соединений к Постгресу и к pgBouncer и много всего другого и поможет предупредить и разрешить проблемные ситуации.
|
Метки: author tru_pablo ruby on rails postgresql блог компании okmeter.io active record postgres activerecord |
Самодельный эмулятор дисковода для Amiga |

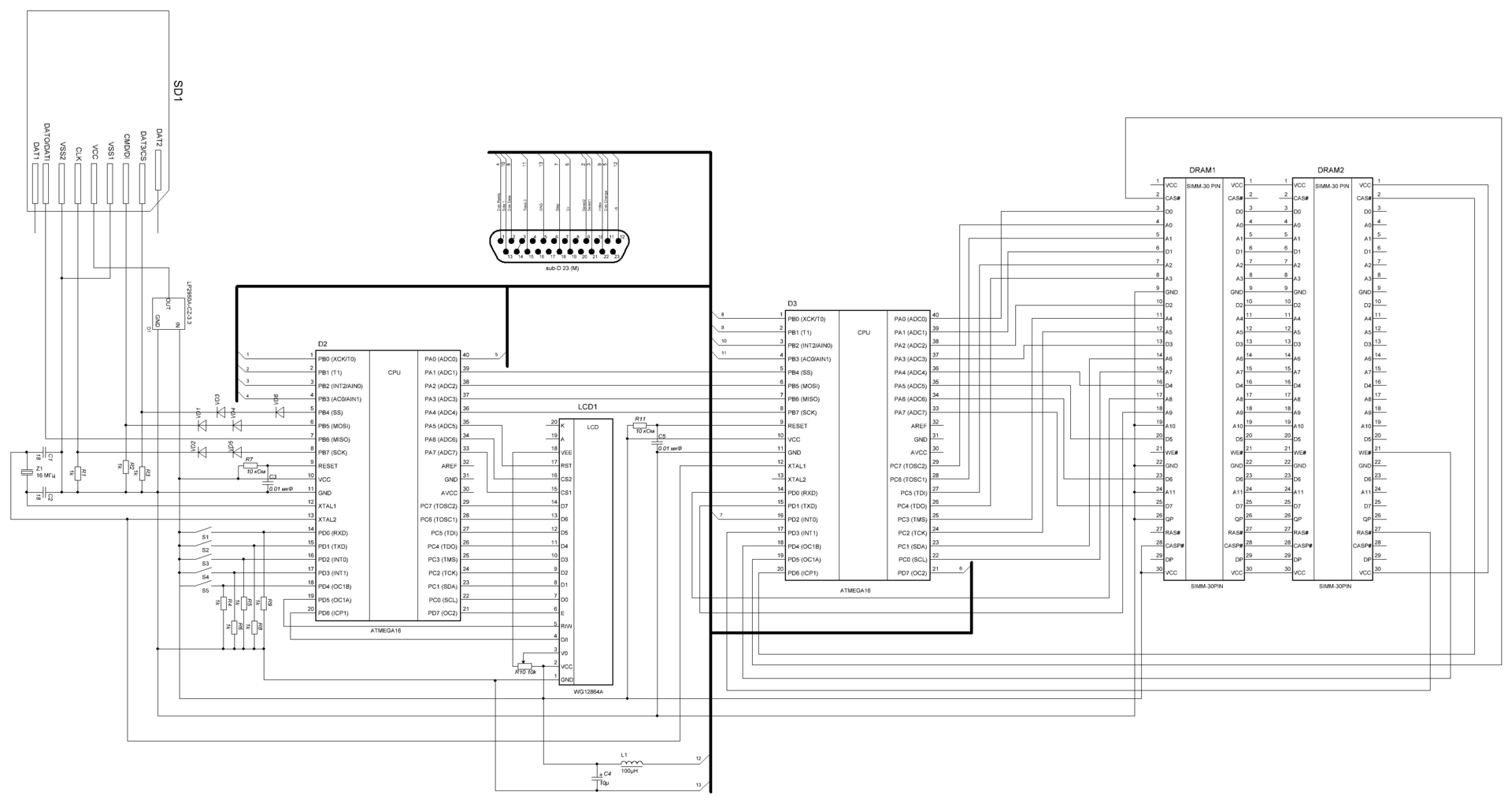 Схема эмулятора (в архиве она есть в полном качестве).
Схема эмулятора (в архиве она есть в полном качестве).



|
Метки: author da-nie программирование микроконтроллеров assembler amiga avr эмулятор дисковода |
Интернет на магнитах 5 — Маяки и сообщения (личные, публичные и обновления) |
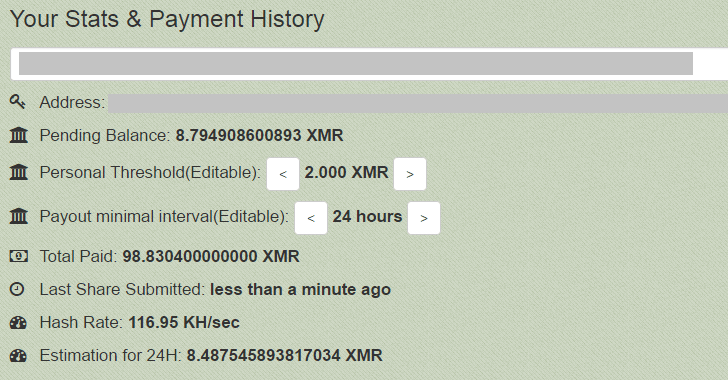
![]() Я вспомнил что не рассказал важную часть для обеспечения возможности общения и обновления контента в P2P сетях.
Я вспомнил что не рассказал важную часть для обеспечения возможности общения и обновления контента в P2P сетях.
Не все P2P сети имеют возможность отправки и приёма личных сообщений. Также не всегда сообщение можно оставить в оффлайн. Мы исправим этот недостаток используя три возможности P2P сетей: поиск файла, просмотр шары(списка опубликованных файлов) или комментарии к файлу.
Шаблон маяка создаётся однократно и используется для создания маяков для связи с автором.
Наше сообщение и маяк свободно могут копировать другие участники сети. Так как оно зашифровано они не смогут его прочитать но помогут его держать онлайн пока его не получит адресат.
Это файл из которого формируется маяк.
Шаблон маяка формирует тот кто желает получать сообщения (адресат) и публикует у себя в шаре либо комментарием с магнитом к другому маяку. Шаблон должен включать в себя
Инструкции шаблона должны позволить генерировать файлы с одинаковыми хешами(маяки) каждый час либо другой выбранный период времени.
Файл: lighthouse_template_f43b4866b4f47e8e27bfafa56f4c4f2384a3135d.asc
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA256
- -----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v2
mQENBFk6ZDMBCADE/yoNEOosw16n3P2ZSjH+quYlSbZePBudHnAlNZ/e4KSxEnXx
B/44vKJX98y0X6TjCk0TVrAfJQhOrwg9/X6IMkeii1Nzt+NhrygojuVmEJS0kHvi
QoJLrotBXdYWbUtfVE8zGS/qVmtFi6ns/ouV1yqLnRSA+dVfLNa/7k5glo+7TEDt
g/CkSQ5CKJowPnBYnCxF4aQQQi8ydDIMXIFVyuApPRHLNsqIeA4CFlpb2Xb3ksEN
/tse4zjBRgNS3nc6SLYfv6KKb8O6oHxWzz+mXlrvL4G1dszUE7Yg4FND9t9P+bMQ
d+7OqDgO00/eEBooTcOptuHXTLxftu3z9S2VABEBAAG0Iml2YW4zODYgPG1hZ25l
dEBpdmFuMzg2LmdpdGh1Yi5pbz6JAT8EEwEIACkFAlk6ZDMCGyMFCQEOQt0HCwkI
BwMCAQYVCAIJCgsEFgIDAQIeAQIXgAAKCRBvTE8jhKMTXUA7B/93TSAcSQW5Nvgw
CpgsJHTRbUsWT2heovl1CeME39H3iKxlNVMl2N5l5kFNUryLMo63ZXp5tm9C7UKx
o2X6+3TJg/Td+WxC2vhXyLeSWc6KkV98a7Sg6kgdBBDXA1x4TfLNT8dijYBqNNgU
OVJ3gOyOCXa7Is9gPYobtwFvTTzsKqfz3JkAZf54Y7EulLYo+esty2nDqIhyC+7Q
a5izjxhGME1gAWjPT4Yr/QytmL1D1WD8tmmVrvFtBwUo3iyZhf2TCVkkJ41mOAq+
Vr2tfZPnxUxSaLMU4cm0rUoZ79NK3FX70xJjy4IgQtj/NDuQwv1KgqSClxCKkpI/
BJSvjxzguQENBFk6ZDMBCAD6DTPWTkG7Zqqhz/5oaM4zFG9ncTtnVXiR0rRPzuyn
aXz1/Kn3odEEG4kyEQbHS/lLfnLsqAkSMjUHiBsC6R0h1bTqSDnHEhPqpuLm526N
6j+o5/oIC8ANlGH5fFGDMNXy5MrRuFGMv/tHDuSW56rb6Kh9jPoU+1HCAGpv4zd9
iXB/nOYHlLl3NZ4+883wd0BgIKslSpvOU8sTjqcEwcIFFHr8SBUM6x1nKSq1Ad+C
bEQPBA7EKdIeV/N5CZ9s6fnvUvc1bNMOO8YdJ4wCWfDSGWu7ZdPyj+Yh+9/R7EIW
bEAHX5v/IcAu1u0U53goehGvEu9K4lNjibYRu8hDU02fABEBAAGJASUEGAEIAA8F
Alk6ZDMCGwwFCQEOQt0ACgkQb0xPI4SjE11j5Af9EBukKcDSQfSFBgsRRxLzfk3l
B4Qa7Kb2JKPdf8p+rlC8n7b7nS1WnDsh/ADnRO1+njP4oHo4eV3P09ao9PNagM5k
YldAG2oAOj9RhVSMI4Jt+/Tf7NZixLPjMCakrGA47wQwC9bp+AmV/ST8I6/r2t3W
4uXDLUKzvZxpBUVqEG9x0olnQiBgMicyUlW1WmyMKiorVET6rSnCv3yv33lMRQRG
5txSw/z0jXhhK6ENn0mHMGeiBqGITTwjQM7uQTkw2GmNJfHpg+jThnJQran+cGDZ
tvKsoBc4BFnM4eTxZfeyYPquG2QWZ59kcqm4JRyJfHYKT+CIPQXmEmD4uyp5/Q==
=QxOi
- -----END PGP PUBLIC KEY BLOCK-----
yyyy - год полностью по UTC±0:00
mm - месяц по времени UTC±0:00 (дополняется нулём если меньше 10)
dd - день по времени UTC±0:00 (дополняется нулём если меньше 10)
hh - час в 24 часовом формате по времени UTC±0:00 (дополняется нулём если меньше 10)
Шаблон имени файла маяка (важно для сети BitTorrent):
lighthouse_yyyy-mm-ddThhZ_f43b4866b4f47e8e27bfafa56f4c4f2384a3135d.asc
Для формирования маяка добавьте в конце файла дату и время в формате:
yyyy-mm-ddThhZ
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2
iQEcBAEBCAAGBQJZOr9iAAoJEG9MTyOEoxNd8RIIALQUa9BuMgh+uET4wse7sBDG
19RvKbUq+9HCOaxL+Qfz+C5VO1XVIxC/Vi2iP1RVwBjkKtTANXdxcf9jR/S2ZHpL
0ohDsJ8O8EPf0sTEr5nvGE27KobEhvAb9TbxrOLuZlWtqWh09CvgyEZPVnnMa7v1
WL6xVln2BjZOkndn60ToqPcVUYQpwIEfHBz7S8WYdRFumN8sUCfJYaXGFElSLKiA
2Y+fTayhPIKcwBTzRuIU6fQWWCUA7egZ3JsWWiBP68parRcsDDOia3UiddFRr0jW
lmGrsOJiZ2Vq2xfXNqY+BfcSdT8AXnt9yUYCdaH2w2oI3uEXlw8eF8JyxO60w8k=
=FJOw
-----END PGP SIGNATURE-----
Маяк формируется из шаблона маяка по инструкциям указанным в нём. Сначала идёт сам шаблон в неизменном виде а далее идут данные которые сформированы по инструкциям из шаблона.
Задача маяка в том чтоб один и тот же маяк(с одинаковым хешем) могли сформировать и отправитель и получатель и по хешу найти друг друга или посредника который хранит сообщение.
Маяк на 09 июня 2017 года 18:33 Москвы будет выглядеть так.
Файл: lighthouse_2017-06-09T15Z_f43b4866b4f47e8e27bfafa56f4c4f2384a3135d.asc
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA256
- -----BEGIN PGP PUBLIC KEY BLOCK-----
Version: GnuPG v2
mQENBFk6ZDMBCADE/yoNEOosw16n3P2ZSjH+quYlSbZePBudHnAlNZ/e4KSxEnXx
B/44vKJX98y0X6TjCk0TVrAfJQhOrwg9/X6IMkeii1Nzt+NhrygojuVmEJS0kHvi
QoJLrotBXdYWbUtfVE8zGS/qVmtFi6ns/ouV1yqLnRSA+dVfLNa/7k5glo+7TEDt
g/CkSQ5CKJowPnBYnCxF4aQQQi8ydDIMXIFVyuApPRHLNsqIeA4CFlpb2Xb3ksEN
/tse4zjBRgNS3nc6SLYfv6KKb8O6oHxWzz+mXlrvL4G1dszUE7Yg4FND9t9P+bMQ
d+7OqDgO00/eEBooTcOptuHXTLxftu3z9S2VABEBAAG0Iml2YW4zODYgPG1hZ25l
dEBpdmFuMzg2LmdpdGh1Yi5pbz6JAT8EEwEIACkFAlk6ZDMCGyMFCQEOQt0HCwkI
BwMCAQYVCAIJCgsEFgIDAQIeAQIXgAAKCRBvTE8jhKMTXUA7B/93TSAcSQW5Nvgw
CpgsJHTRbUsWT2heovl1CeME39H3iKxlNVMl2N5l5kFNUryLMo63ZXp5tm9C7UKx
o2X6+3TJg/Td+WxC2vhXyLeSWc6KkV98a7Sg6kgdBBDXA1x4TfLNT8dijYBqNNgU
OVJ3gOyOCXa7Is9gPYobtwFvTTzsKqfz3JkAZf54Y7EulLYo+esty2nDqIhyC+7Q
a5izjxhGME1gAWjPT4Yr/QytmL1D1WD8tmmVrvFtBwUo3iyZhf2TCVkkJ41mOAq+
Vr2tfZPnxUxSaLMU4cm0rUoZ79NK3FX70xJjy4IgQtj/NDuQwv1KgqSClxCKkpI/
BJSvjxzguQENBFk6ZDMBCAD6DTPWTkG7Zqqhz/5oaM4zFG9ncTtnVXiR0rRPzuyn
aXz1/Kn3odEEG4kyEQbHS/lLfnLsqAkSMjUHiBsC6R0h1bTqSDnHEhPqpuLm526N
6j+o5/oIC8ANlGH5fFGDMNXy5MrRuFGMv/tHDuSW56rb6Kh9jPoU+1HCAGpv4zd9
iXB/nOYHlLl3NZ4+883wd0BgIKslSpvOU8sTjqcEwcIFFHr8SBUM6x1nKSq1Ad+C
bEQPBA7EKdIeV/N5CZ9s6fnvUvc1bNMOO8YdJ4wCWfDSGWu7ZdPyj+Yh+9/R7EIW
bEAHX5v/IcAu1u0U53goehGvEu9K4lNjibYRu8hDU02fABEBAAGJASUEGAEIAA8F
Alk6ZDMCGwwFCQEOQt0ACgkQb0xPI4SjE11j5Af9EBukKcDSQfSFBgsRRxLzfk3l
B4Qa7Kb2JKPdf8p+rlC8n7b7nS1WnDsh/ADnRO1+njP4oHo4eV3P09ao9PNagM5k
YldAG2oAOj9RhVSMI4Jt+/Tf7NZixLPjMCakrGA47wQwC9bp+AmV/ST8I6/r2t3W
4uXDLUKzvZxpBUVqEG9x0olnQiBgMicyUlW1WmyMKiorVET6rSnCv3yv33lMRQRG
5txSw/z0jXhhK6ENn0mHMGeiBqGITTwjQM7uQTkw2GmNJfHpg+jThnJQran+cGDZ
tvKsoBc4BFnM4eTxZfeyYPquG2QWZ59kcqm4JRyJfHYKT+CIPQXmEmD4uyp5/Q==
=QxOi
- -----END PGP PUBLIC KEY BLOCK-----
yyyy - год полностью по UTC±0:00
mm - месяц по времени UTC±0:00 (дополняется нулём если меньше 10)
dd - день по времени UTC±0:00 (дополняется нулём если меньше 10)
hh - час в 24 часовом формате по времени UTC±0:00 (дополняется нулём если меньше 10)
Шаблон имени файла маяка (важно для сети BitTorrent):
lighthouse_yyyy-mm-ddThhZ_f43b4866b4f47e8e27bfafa56f4c4f2384a3135d.asc
Для формирования маяка добавьте в конце файла дату и время в формате:
yyyy-mm-ddThhZ
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v2
iQEcBAEBCAAGBQJZOr9iAAoJEG9MTyOEoxNd8RIIALQUa9BuMgh+uET4wse7sBDG
19RvKbUq+9HCOaxL+Qfz+C5VO1XVIxC/Vi2iP1RVwBjkKtTANXdxcf9jR/S2ZHpL
0ohDsJ8O8EPf0sTEr5nvGE27KobEhvAb9TbxrOLuZlWtqWh09CvgyEZPVnnMa7v1
WL6xVln2BjZOkndn60ToqPcVUYQpwIEfHBz7S8WYdRFumN8sUCfJYaXGFElSLKiA
2Y+fTayhPIKcwBTzRuIU6fQWWCUA7egZ3JsWWiBP68parRcsDDOia3UiddFRr0jW
lmGrsOJiZ2Vq2xfXNqY+BfcSdT8AXnt9yUYCdaH2w2oI3uEXlw8eF8JyxO60w8k=
=FJOw
-----END PGP SIGNATURE-----
2017-06-09T15ZХеши этого маяка (urn:[название]:[хеш или мультихеш или CIDv1])
urn:sha1:mthkta2fsilqxpoox6vessac37674gl3
urn:tree:tiger:abrmyjcyckt7lccz5jjqebazmt3tkuordfetana
urn:btih:i7mif67cu6r2jkxw23qwyanlx7tqqtoy
urn:ed2k:7f9112c53d5ae16377d54c6bdc34d4f7
urn:sha256:ad300aeb8b4ab6db19b640883d19d0900841c25689ed97e0ec0490cd23a7bd71
urn:ipfs:zb2rhiJLDNbWfS1z6yKcTGzQcazmumkcttkXc4FFq3hfeGn8YСоответственно каждый час создаётся новый маяк.
В каждой P2P сети используется соответствующий ей хеш.
Поиск фалов по хешу маяка позволяет передать открытое сообщение в имени файла маяка. (Gnutella2, DirectConnect, Edonkey2000, IPFS)
Поиск используя хеш как часть имени файла позволит передать файл. Это может быть зашифрованное публичным ключём из маяка приватное сообщение. (Gnutella2, DirectConnect, Edonkey2000, IPFS)
Комментарии к файлу маяка также могут использоваться. В них может быть сообщение либо магнит на файл с сообщением приватным. (Gnutella2)
Для сети IPFS необходимо найти источники маяка и получить связанные с источниками файлы/каталоги по публичным ключам источников. Далее в списке найти сам маяк или файл/каталог с хешем маяка в имени.
Получаем список пиров с маяком:
ipfs dht findprovs [мультихеш маяка]Результатом будут мультихеши публичных ключей пиров с маяком
Получаем мультихеш шары:
ipfs name resolve [мультихеш публичного ключа]Результат /ipfs/ путь с мультихешом связанного файла или каталога
Ищем маяк и файл с хешом маяка в имени:
ipfs refs -r --format=" " [мультихеш шары]| grep "[мультихеш маяка]" В результате получаем сообщения:
[мультихеш маяка] [Сообщение в имени файла маяка]
[мультихеш файла] [Имя файла которое содержит в себе мультихеш маяка]Во втором случае сообщением является содержимое файла. Его можно загрузить командой:
ipfs get [мультихеш файла]Эти сети позволяют поиск по хешу и по имени файла. Так что достаточно хеш использовать как имя либо искать сам маяк по хешу и смотреть шару источников.
В этой сети возможно комментирование источниками файла. В таком случае достаточно искать маяк по хешу и смотреть комментарии к результатам. Или можно также искать используя хеш как часть имени файла.
Пока не придумал. Возможность комментирования раздачи убрали из uTorrent.
Есть идея по генерации большого маяка и путём затирания частей формировать штрихкод из которого можно получить хеш нового сообщения.
Второй вариант создание множества маяков и тогда присутствие на раздаче будет 1 а отсутствие 0. Часть маяков будут кодировать хеш а другая часть контрольную сумму.
Как то так.
CID (Content IDentifier)
multihash
Commands | IPFS Docs
Интернет на магнитах 1 — Магнит
Интернет на магнитах 2 — Гипертекст
Интернет на магнитах 3 — P2P Сайт и Форум
Интернет на магнитах 4 — Делим магнит на части
|
Метки: author ivan386 децентрализованные сети peer-to-peer lighthouse gnupg |
[Из песочницы] Дело было вечером. автомасштабируемый веб-сервис с балансировкой нагрузки на примере Bitrix в Google Cloud Platform |



sudo wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64
sudo mv cloud_sql_proxy.linux.amd64 cloud_sql_proxy
sudo chmod +x cloud_sql_proxy
sudo ./cloud_sql_proxy -instances==tcp:3306 &
sudo apt-get update
sudo apt-get upgradesudo apt-get install mysql-clientsudo apt-get install apache2sudo apt-get install php5 libapache2-mod-php5 php5-mysqlsudo systemctl restart apache2mysql -u root -p --host 127.0.0.1mysql>Wget https://www.1c-bitrix.ru/download/start_encode_php5.tar.gz


sudo ./cloud_sql_proxy -instances==tcp:3306 &


|
|
[Из песочницы] Подходы к версионированию изменений БД |
Намного лучше дисциплинарные ограничения убирать инструментарным расширением
Автор статьи
При разработке информационной системы, то есть программы, нацеленной на хранение, работу с данными, обработку, анализ и визуализацию какой-то базы данных, одним из краеугольных камней стоит задача разработки БД. Когда я только начинал задаваться этим вопросом, казалось – что ни сделай, все равно будет криво.
На протяжении 5 лет разработки нескольких корпоративных ИС, я ставил и пытался решать вопросы, как тот или иной аспект разработки БД сделать удобным. Искал инструменты, помогающие что-то делать с БД, методологии. На удивление в этой области мало наработок. И в каждом подходе сразу видно – вот это нельзя, вот тут будет неудобно, тут слишком много дисциплинарных правил (см эпиграф)… В этой статье я попытался собрать те походы, которые считаю наиболее эффективными, и один, в добавление к собранным, представлю как венец моих исканий, который считаю наиболее «бронебойным».
Приведу пример, как может задача разработки БД стать проблемой и эволюционировать. Если интересна сразу глобальная постановка задачи со всеми фичами, этот параграф можно пропустить.
Какие-то из пунктов этой эволюции могут показаться излишними и вообще придумыванием себе проблем, но при их решении удобным инструментом разработка БД станет почти такой же простой и безболезненной, как и разработка обычного кода приложения.
Собрав в одну кучу все возможные проблемы, связанные с разработкой БД, которые увидел при разработке информационных систем, я пришел к глобальной формулировке постановки задачи в моем видении.
Задачи и проблемы, которые могут вставать при разработке БД:
По каждому объекту БД нужно иметь возможность увидеть историю его изменений.
A. Для контроля нужно иметь возможность увидеть, какие изменения будут накатаны, в конкретных SQL-скриптах («накопительные скрипты»).
B. Очень желательна возможность code review. Причем явный оператор alter предпочтительнее сравнения операторов create table (на основе которых делается diff и впоследствии накатывается), поскольку лучше контролировать действия с БД, а не декларации. А для процедур и подобных объектов надо иметь возможность видеть diff тела.
В моей практике я руководствовался пунктами:
Так что я считаю обязательными все пункты, кроме 3b и 4.
Я пришел к выводу, что целесообразно выделить подходы:
В этом списке подходы отсортированы по увеличению полезности.
В целом к идеи автоматизации наката скриптов по коммиту я бы отнесся крайне настороженно – иногда бывает, что коммиты делаются неготовыми или неполными. Дисциплинарное правило «коммить в мастер только готовый код» на практике работает очень плохо. Лучше его избегать улучшением инструментария – для этого существует класс инструментов continuous integration (например, TeamCity от JetBrains или совсем бесплатный Jenkins). Я за то, чтобы накат скриптов на БД происходил исключительно осознанно человеком-программистом и только в нужные моменты времени – которые никак не должны быть связаны с коммитом.
Redgate SQL Compare. Еще есть http://compalex.net/, но он работает только с php. Есть и другие инструменты сравнения схем БД.
Кроме БД prod – она целевая БД – делается БД dev – она БД-источник.
Каким-либо образом делаются изменения в БД-источнике. Причем эта БД-источник получается не тестовая в общепринятом смысле, потому что с ней нельзя делать все, что угодно – подразумевается, что все изменения (по крайней мере, изменения схемы БД) должны перенестись на целевую БД. Далее эти изменения могут скриптоваться, но эти скрипты впоследствии никак не используются – потому что, если их использовать и накатывать каким-либо образом, то вся суть подхода исчезает, сравнение схем становится бессмысленным. Эти скрипты могут лишь играть роль истории изменений. Но которая может отличаться от реальности, поскольку можно что-то визуально в Management Studio (или другом GUI для БД) поменять и забыть это заскриптовать. Или заскриптовать неправильно. Потом, в момент деплоя на целевую БД, делается (с помощью инструмента) diff-скрипт, который накатывается, приводя целевую БД в состояние равной схемы с источником.
Я не знаю, какой инструмент мог бы сравнить две схемы БД не по самим базам, а по скриптам. Поэтому этот подход теоретический. Но, если найти или сделать такой инструмент, кажется, подход стал бы неплохим. Особенно, если этот инструмент мог бы сравнивать и данные.
Роль БД-источника тут играл бы каталог с скриптами, полностью создающими БД – и схему, и версионируемые данные (справочники, персистентные справочники). То есть программист вносит изменения в эти скрипты, запускает инструмент, который сравнивает весь каталог с целевой БД и делает diff-скрипт, который либо сохраняется для code review, либо сразу накатывается.
Так как инструмента нет, то можно лишь фантазировать о том, как этот инструмент мог бы сравнивать данные и настройки БД и SQL Server’а.
flyway db. Возможно, есть альтернативы (https://github.com/lecaillon/Evolve – я не готов рассказать об этом инструменте, но, похоже, делает что-то похожее).
Методология подхода наиболее проста. Зачаровывающе проста. По мере необходимости пишутся sql-скрипты изменений – произвольные, как на изменение схемы, так и на изменение данных. Не имеет значения, какие скрипты. Файлики нумеруются, складываются в папочку. В нужное время запускается инструмент, который в порядке нумерации накатывает новые, то есть еще не исполненные файлы скриптов на выбранную БД. Накатанные запоминает в специальной табличке, то есть повторно скрипт не исполнится.
Так работает компания Qiwi. Или работала, когда я там участвовал в разработке платежной системы. Но там без инструментов, инструмент заменяют дисциплинарные правила. Есть несколько QA-сотрудников, которые следят за специальным репозитарием git и накатывают новые скрипты, сначала на тестовую БД – смотрят, не сломалось ли чего, потом, если все хорошо, на prod.
liquibase. Возможно, есть альтернативы (redgate SQL Source Control, https://www.quora.com/What-are-the-alternatives-to-LiquiBase – но я не вполне хорошо знаю, как они работают).
Для создания и изменения схемы на каждый объект БД создаем по файлику, в котором будет скрипт, отвечающий за этот объект – таким образом при версионировании файлов получаем историю изменений на каждый объект. Эти файлики кладем в папочки, повторяющие структуру БД. Так как последовательность исполнения скриптов важна, вводим управляющие файлы, содержащие последовательность наката скриптов, а инструмент делает написание этих управляющих файлов достаточно простым и решает, какое изменение накатывать нужно, а какое нет – если оно уже было накатано ранее или отфильтровано. Кроме того, если нужно различие в чем-то в различных инстансах БД, вводим значения переменных, которые инструмент использует, модифицируя нужным образом скрипты для каждого инстанса. Кроме того, можно ввести фильтры на скрипты, и, в зависимости от контекста («только изменение схемы», «только импорт справочников», «создать/обновить только такой-то кусок схемы») отфильтровать скрипты.
Для изменения таблицы нужно в файлик с ее create’ом дописать скриптик (changeset) с оператором alter или create index или каким-то другим. Или можно изменить существующий соответствующий changeset, если возможно сделать его повторнонакатываемым.
Для изменения процедуры/функции/триггера/вью надо поменять код в файлике, соответствующем этому объекту. Чтобы этот скрипт был повторнонакатываемым, нужно в первом changeset’е сделать создание этого объекта с пустым телом, а во втором – оператор alter с нужным телом (жаль, у SQL Server’а нет оператора create or alter). Тогда первый changeset будет исполняться только один раз, а второй – при изменении.
Ну а для непосредственно deploy’я делаем bat-файл(-ы), запускающие инструмент с нужным контекстом и настройками. Таким образом нужный deploy будет запускаться посредством запуска соответствующего bat’ника.
Можно настроить, чтобы логи запусков (какие changeset’ы исполнялись и сколько времени) сохранялись. Добавив их в .gitignore.
Делаем следующую структуру папок:
— <Имя БД>
Clipboard.SetText("0x" + string.Join(“”, File.ReadAllBytes(path).Select(b => b.ToString("x2"))) ) — core
Тут будет сам инструмент и его настроечные файлы.
Как видно, идея этих папок в повторении схемы БД и соответствии каждого объекта своему одному файлу.
В головной папке <Имя БД> будут файлы:
Заметим, что для создания/изменения хранимых процедур, триггеров, функций и типов последовательность не важна. Поэтому достаточно команды includeAll инструмента, накатывающего их в алфавитном порядке.
Для каждого варианта использования нужно создать bat-файл, запускающий инструмент с соответствующим контекстом – например, deploy_local_scheme.bat, deploy_local_full.bat, deploy_prod_scheme.bat, deploy_prod_full.bat, deploy_
Кроме контекста, bat-файл в себе должен содержать connection string и имя команды инструмента.
Возможные команды:
Я еще для удобства просмотра логов исполнения сделал вывод их в текстовый файлик:
> %outputfilename% 2>&1
Changeset’ы могут быть помечены атрибутами:
=true указывает инструменту накатить changeset при его изменении (если написать =false, то после изменения changeset'а будет ошибка вида «накатанный changeset был изменен»); В случае, когда нужно изменить схему так, что сломаются какие-то скрипты изменения данных, то есть миграционные скрипты (например, если нужно изменить название таблицы, колонки, удаление чего-то), то нужно написать соответствующий alter или sp_rename в файлик, соответствующий данной таблице, и соответствующим образом изменить нужные скрипты. Далее, для одноразовых скриптов из них нужно сделать так, чтобы инструмент не выдавал ошибку, что накатанный changeset изменился. Это достигается двумя путями – либо команда changelogSync, либо вручную изменить соответствующую строку в таблице инструмента, обновив там md5-сумму – значение ее подскажет сам инструмент.
Только необязательный в моем видении п3b. Победа.
|
Метки: author breezemaster системы управления версиями sql microsoft sql server git версионирование баз данных версионная миграция бд версионирование версионная миграция |
[Перевод] Внимание! Хакеры начали использовать уязвимость «SambaCry» для взлома Linux-систем |

|
|
[Перевод] Интеграция React и DataTables — не так тяжело, как рекламируют |
Несколько месяцев назад я искал React-компонент для отображения таблицы данных в одном из наших веб-приложений в Undertone. В предыдущем проекте, который не был основан на высокоуровневой библиотеке, такой как React, мы использовали jQuery-плагин DataTables, и мы были очень довольны той гибкостью, которую он предлагает. Теперь я искал нечто похожее, которое можно легко интегрировать как React-компонент в наше новое приложение.
Проведя довольно обширные исследования, я узнал две вещи. Во-первых, это то, что не рекомендуется использовать DataTables вместе с React, потому что обе библиотеки управляют DOM. Во-вторых, не было библиотеки, которая обеспечивала гибкость, необходимую для нашего веб-приложения (с момента моего исследования). Крайний срок для сдачи проекта приближался, и мне нужно было что-то выбрать. Я решил пойти по непопулярному пути и интегрировать DataTables в свой проект. Результат получился намного лучше, чем я ожидал, и весь процесс интеграции на самом деле был довольно плавным. В следующих разделах я опишу схему проекта, в котором работает интеграция React + DataTables.
Мы будем использовать Create-React-App (CRA) для строительных лесов нашего проекта. Если вы не знакомы с CRA, это в основном инструмент для создания приложений React без конфигурации. Первое, что нам нужно сделать, это установить CRA (если вы его еще не установили) и инициализировать новый проект с помощью команды create-react-app (см. документацию по CRA для получения подробных сведений о том, как инициализировать и запустить проект).
Мы завершаем нашу установку, добавляя модули jQuery и Datatables в качестве dev-dependencies.
$ npm i --save-dev datatables.net jquery После завершения установки модулей мы удаляем ненужные файлы, автоматически генерируемые CRA из репозитория. Окончательный результат проекта, который мы создаем здесь в этой статье, можно найти в репозитории react-datatables на GitHub.
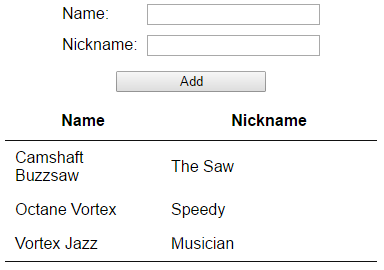
Мы реализуем очень простой интерфейс. У пользователей есть область ввода, где они могут вводить имя и псевдоним в соответствующие текстовые поля. Когда нажимается кнопка «Добавить», данные, введенные в текстовые поля, добавляются в таблицу данных. Имя является уникальным «ключом» для каждой записи — если пользователь набирает имя, которое уже существует, новая пара имен-ников не создается, и только псевдоним существующей пары обновляется в таблице.
У нас уже есть исходные файлы с пустым контентом, созданным CRA. Мы создаем новый файл, содержащий наш компонент Table — этот компонент отвечает за визуализацию и управление таблицей. Сначала мы импортируем как jQuery, так и DataTables и связываем их так, чтобы DataTables имел доступ к функциям jQuerey. Это можно сделать с помощью следующих двух строк:
const $ = require('jquery');
$.DataTable = require('datatables.net');Мы определяем два столбца, которые извлекают соответствующие значения из пары имя-ник, которую мы собираемся предоставить таблице:
const columns = [
{
title: 'Name',
width: 120,
data: 'name'
},
{
title: 'Nickname',
width: 180,
data: 'nickname'
},
];Наконец, само определение компонента:
class Table extends Component {
componentDidMount() {
$(this.refs.main).DataTable({
dom: '<"data-table-wrapper"t>',
data: this.props.names,
columns,
ordering: false,
})
}
componentWillUnmount() {
$('.data-table-wrapper')
.find('table')
.DataTable()
.destroy(true)
}
shouldComponentUpdate(nextProps) {
if (nextProps.names.length !== this.props.names.length) {
reloadTableData(nextProps.names)
} else {
updateTable(nextProps.names)
}
return false
}
render() {
return (
)
}
}Несколько замечаний. В функции render мы создаем один HTML-элемент таблицы. Это требование DataTables, поскольку для заполнения DOM нужен элемент таблицы. React никогда не узнает, что внутри элемента таблицы будет больше DOM. Мы гарантируем, что никаких повторных попыток со стороны React не произойдет, всегда возвращая false из метода shouldComponentUpdate. Сама инициализация таблицы должна произойти только один раз, когда наш компонент монтируется, потому что мы хотим оставить все внутренние манипуляции DOM в DataTables. Наконец, нам нужно уничтожить таблицу, когда компонент должен быть размонтирован. Это делается в методе componentWillUnmount с соответствующим вызовом API DataTables.
В настоящее время наш компонент Table берет свои данные через props.names, но мы не реализовали способ добавления или обновления имен. Мы сделаем это в следующем разделе.
Существует два способа изменения массива пар имя-ник. Во-первых, добавив на него новую пару имя-ник. Во-вторых, заменив существующую пару имя-ник новой парой с таким же именем и другим ником. Это делается в другом компоненте, внешнем по отношению к компоненту Table. (Я не буду вдаваться в подробности о том, как распространяются эти обновления — более подробную информацию см. в репозитории проекта на GitHub.) Здесь мы рассмотрим два типа обновлений с помощью двух разных методов.
1) Когда добавляется новая пара имя-ник, мы перезагружаем всю таблицу:
function reloadTableData(names) {
const table = $('.data-table-wrapper').find('table').DataTable()
table.clear()
table.rows.add(names)
table.draw()
}Мы используем стандартный селектор jQuery, чтобы найти экземпляр таблицы, используя класс, который мы предоставили в componentDidMount (data-table-wrapper). Затем мы удаляем все предыдущие данные и загружаем новые данные (для краткости я не добавлял новую пару имя-ник — это также работает, если вы удаляете одну пару или несколько пар).
2) Когда пара обновляется, мы хотим найти эту пару и изменить конкретную часть данных, которые были изменены (поле ника в нашем примере):
function updateTable(names) {
const table = $('.data-table-wrapper').find('table').DataTable()
let dataChanged = false
table.rows().every(function() {
const oldNameData = this.data()
const newNameData = names.find(nameData => {
return nameData.name === oldNameData.name
})
if (oldNameData.nickname !== newNameData.nickname) {
dataChanged = true
this.data(newNameData)
}
return true
})
if (dataChanged) {
table.draw()
}
}Мы должны не забыть перерисовывать таблицу с помощью API-метода draw, если какие-либо данные были изменены или изменения не будут видны пользователю.
Остается только различать два случая и вызывать соответствующий метод, когда компонент таблицы отображается в React. Мы делаем это в коде shouldComponentUpdate, чтобы проверить тип изменения и выполнить соответствующий метод.
shouldComponentUpdate(nextProps) {
if (nextProps.names.length !== this.props.names.length) {
reloadTableData(nextProps.names)
} else {
updateTable(nextProps.names)
}
return false
}Теперь, каждый раз, когда количество пар в файлах props.names изменяется, мы повторно отображаем всю таблицу или обновляем соответствующие элементы. Обратите внимание, что в реальном приложении содержимое всего массива может измениться, а количество элементов может оставаться неизменным — случай, который не может произойти в нашем примере.
Это определенно возможно и даже довольно просто интегрировать React и DataTables, если вы ограждаете React от манипуляций DataTables в DOM. Вариант использования, который мы реализовали в этой статье, довольно прост, но он обеспечивает все строительные блоки, необходимые для интеграции работы в реальном проекте.
Пожалуйста, поделитесь опытом — какие используете React-компоненты для реализации функционала таблиц с сортировкой и пагинацией для манипуляции большими объемами данных?
|
Метки: author comerc разработка веб-сайтов reactjs вискас |
[Из песочницы] Диалектика нейронного машинного перевода |
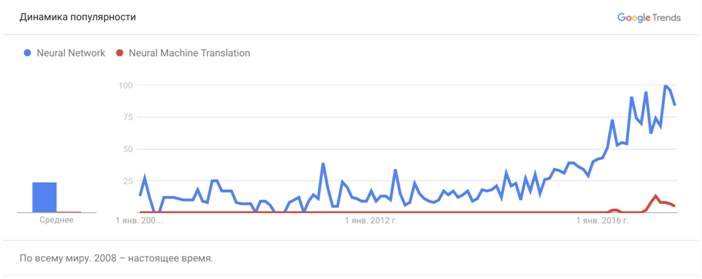
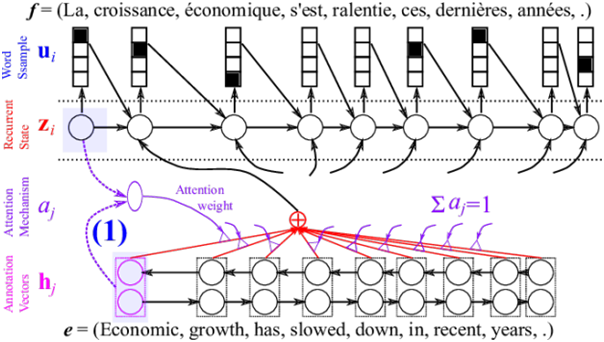
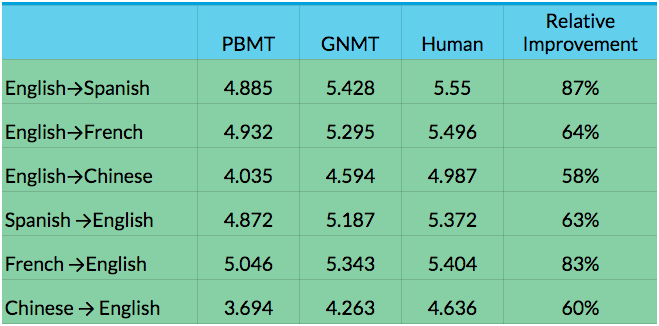
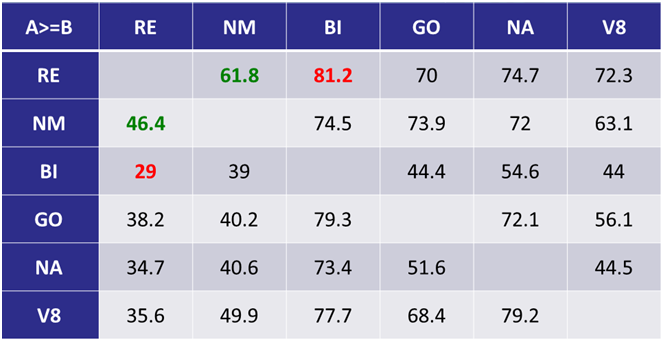
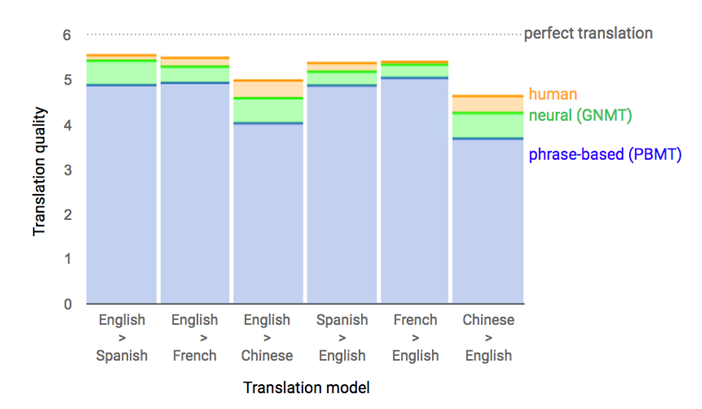
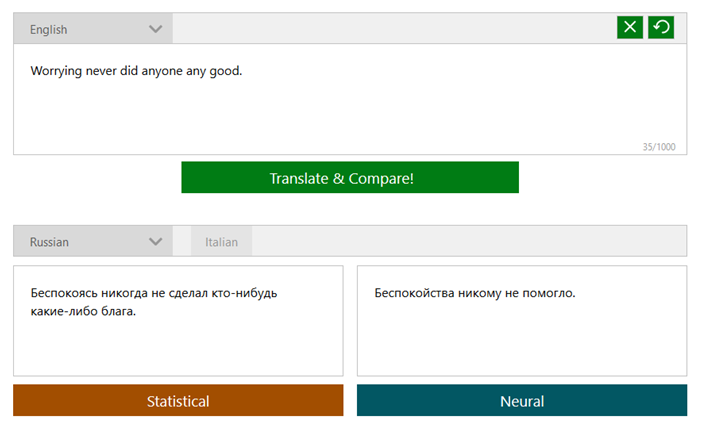
|
Метки: author boris_tikhomirov машинное обучение анализ и проектирование систем big data машинный перевод нейронные сети |
Как найти работу и переехать в Дубай |
|
|
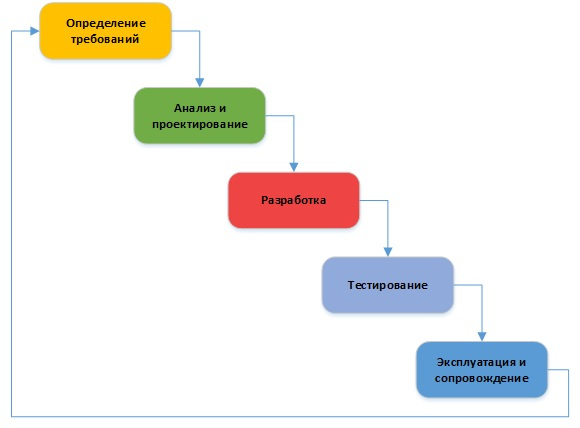
Опыт перехода с Waterfall на методологию RUP для реализации больших ИТ проектов |


Главная задача при разработке корпоративной ИС обеспечить непрерывность поддерживаемого бизнес-процесса. Когда ткань бизнес-процесса рвется, то встают все следующие за ним этапы в производственной цепочке, а порой и весь бизнес объемом в десятки миллиардов рублей.пример остановки торгов Московской биржейПоэтому в основе разработки корпоративной ИС лежит проектирование нового бизнес-процесса на основе её использования, чтобы заменить один процесс на другой и сотни людей с определенного дня начали работать по другому чем привыкли до этого. В этом главное и основное отличие разработки корпоративной ИС от других видов программного обеспечения.На фондовом, валютном и срочном рынках Московской биржи нештатная ситуация … Последний раз биржа приостанавливала торги 1 сентября, но это коснулось только секции «Основной рынок». Этот сбой стал четвертым за последние четыре месяца. — Lenta.ru
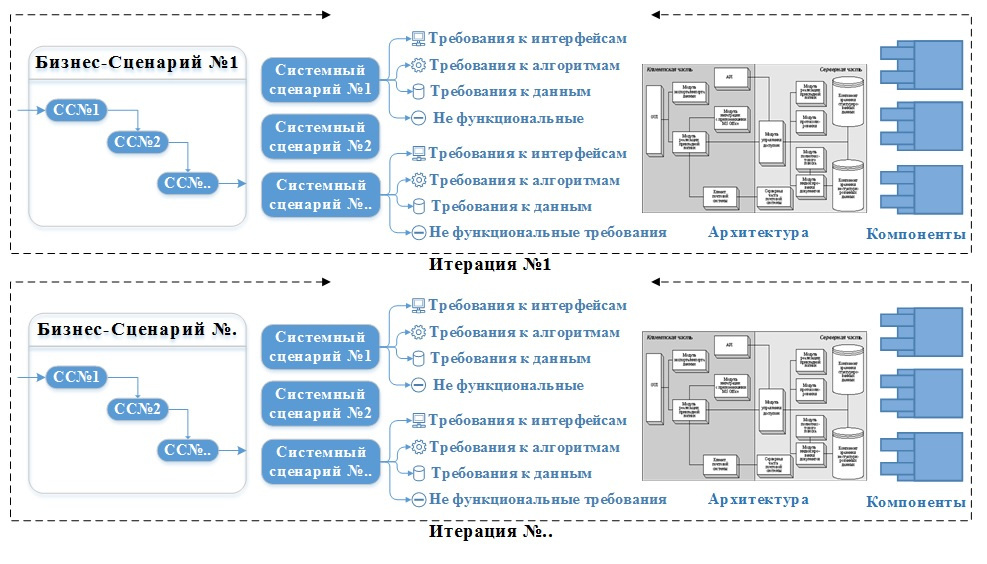
Наличие отдельных компонент позволяет их переиспользовать и заменять одни на другие. Чем больше компоненты используются совместно тем выше вероятность сломать соседний бизнес-сценарий при внесении изменений в компоненту. Также наличие общих компонент ограничивает скорость и масштаб последующих работ по развитию системы. Если одна команда занимается тем, что меняет какую-то общую компоненту, то другая не может начать работы по её изменению до тех пор пока первая не закончит работы и не отладит свой бизнес-сценарий использования.
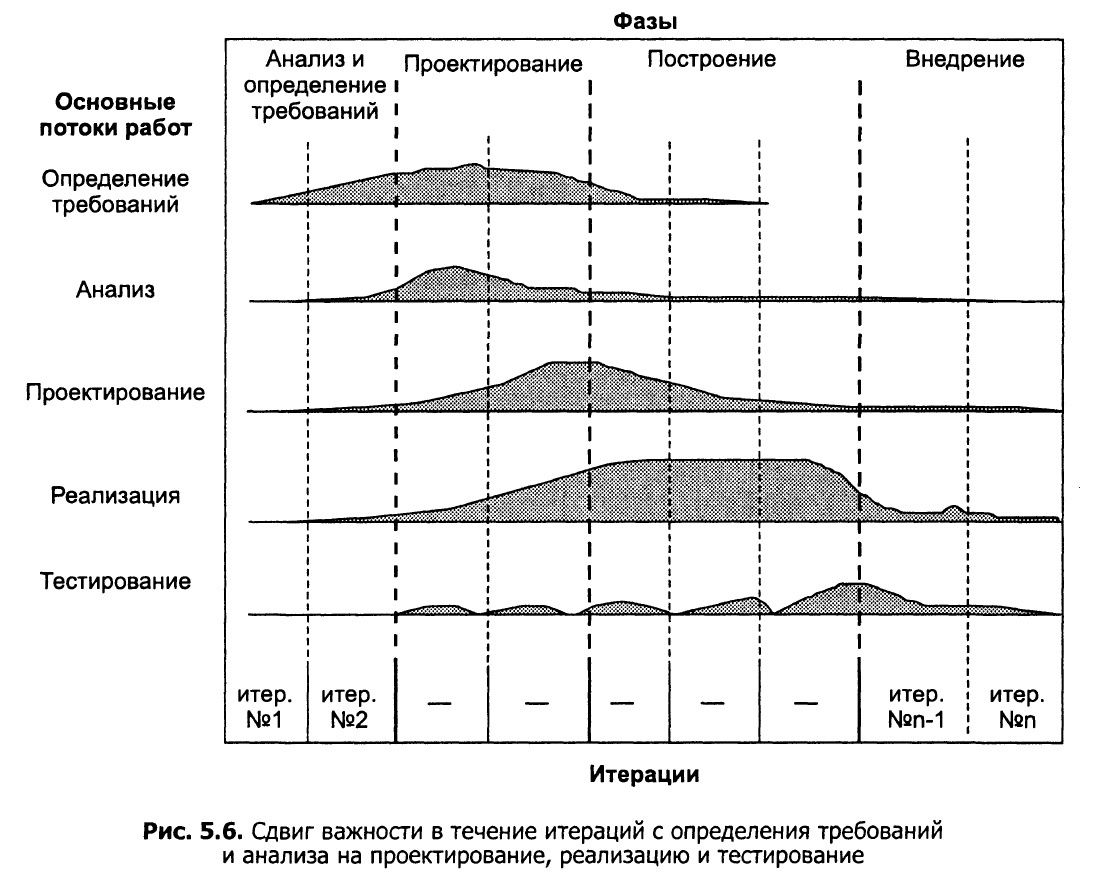
В Waterfall от того нет итераций, так как порой невероятно сложно разделить функциональные требования на самодостаточные блоки и реализовывать их итерациями. Я не говорю, что этого нельзя сделать, можно, но чаще всего результатом этого будет не работающий прототип ИТ-решения, а какая-то часть будущей программы. От этого бизнесу не становится легче, работающий прототип он так и получит через год, наличие итераций здесь помогает, но не сильно.
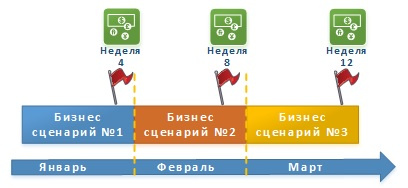

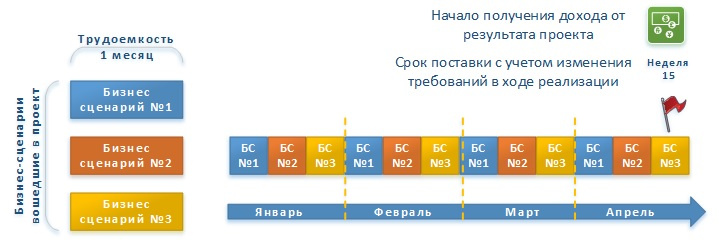
Компания-Заказчик — это Банк. Он решает, что хочет начать предоставлять своим клиентам услугу по удаленной выдаче наличных при помощи банкоматов, установленных в офисах клиентов и на станциях метро.
Для оказания данной услуги, нужно разработать и доработать имеющееся у банка программное обеспечение. В ходе сбора требований и их анализа было выделено три крупных процедуры в бизнес-сценарии услуги:
- Загрузка наличных в банкомат Сотрудниками банка.
- Выдача наличных Клиенту по его запросу со счёта в банке.
- Учет количества загруженных и выданных купюр.
В ходе второй итерации были выявлены две дополнительные процедуры к основному бизнес-сценарию:
Для обеспечения доступности услуги выдачи наличных в режиме 24/7.
- Мониторинг и нотификация, направляемая банкоматом в банк, об окончании в нём наличных.
- Мониторинг и нотификация о работоспособности банкомата или наличия на нем проблем/ошибок в работе.
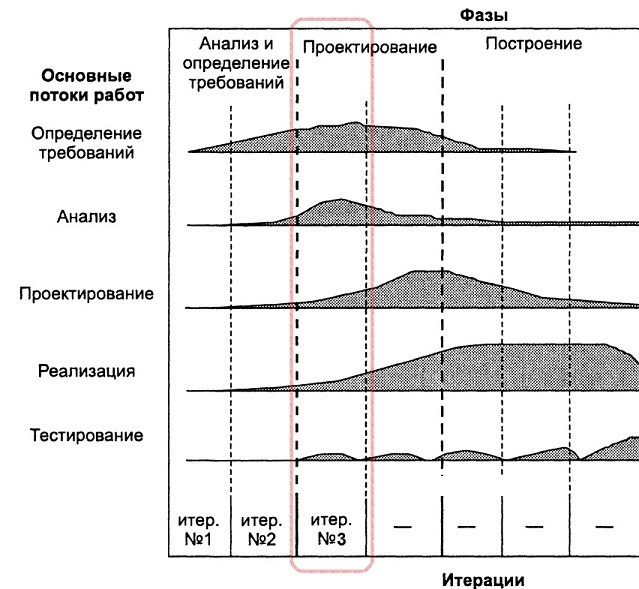
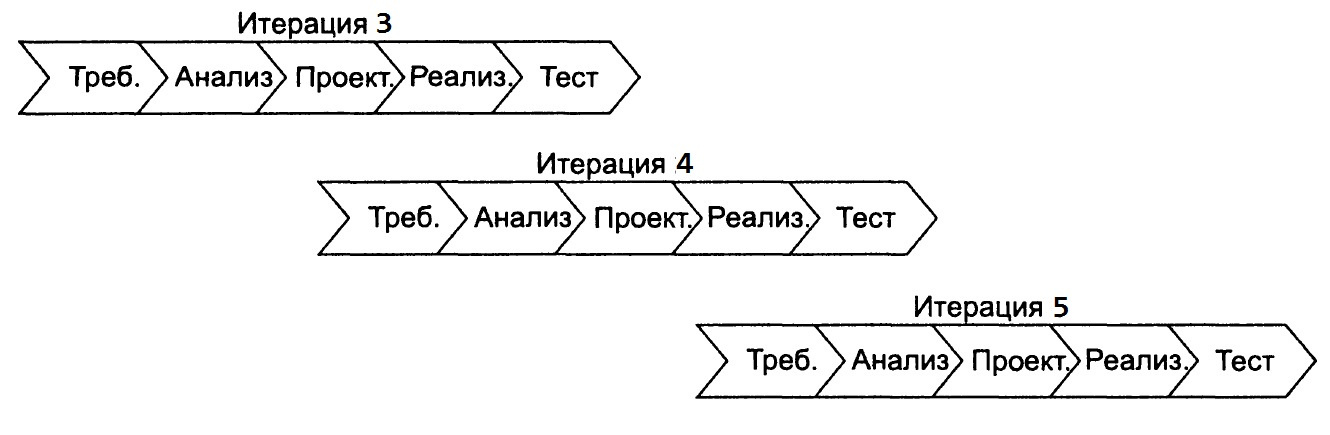
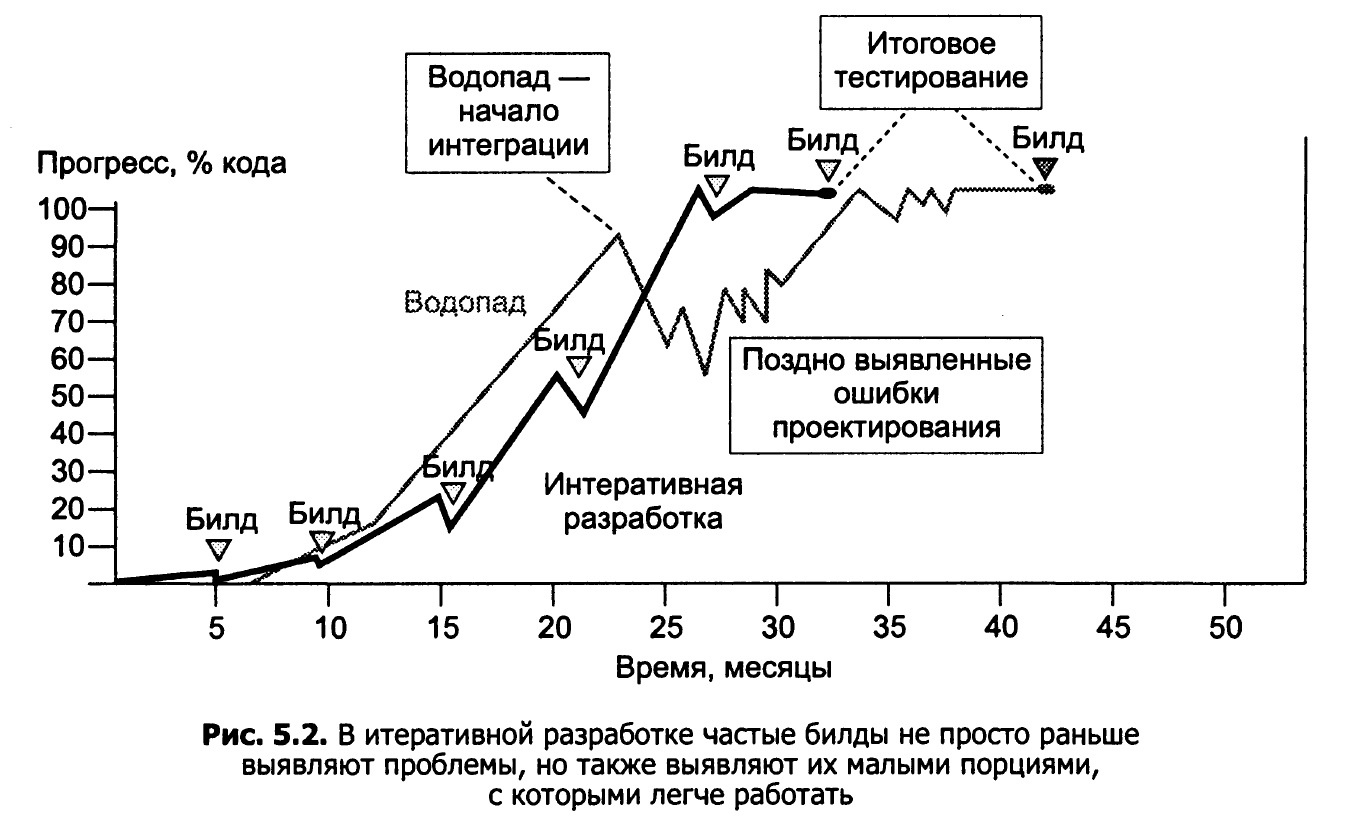
|
|
[Перевод] Ruby on Rails соглашение. Часть 4 |

|
Метки: author dmitriy-strukov ruby on rails ruby dhh |
Решение задач линейного программирования с использованием Python |

from pulp import *
import time
start = time.time()
x1 = pulp.LpVariable("x1", lowBound=0)
x2 = pulp.LpVariable("x2", lowBound=0)
problem = pulp.LpProblem('0',pulp.LpMaximize)
problem += 30*x1 +x2, "Функция цели"
problem += 90*x1+ 5*x2 <= 10000, "1"
problem +=x2 ==3*x1, "2"
problem.solve()
print ("Результат:")
for variable in problem.variables():
print (variable.name, "=", variable.varValue)
print ("Прибыль:")
print (value(problem.objective))
stop = time.time()
print ("Время :")
print(stop - start)
from cvxopt.modeling import variable, op
import time
start = time.time()
x = variable(2, 'x')
z=-(30*x[0] +1*x[1])#Функция цели
mass1 = (90*x[0] + 5*x[1] <= 10000) #"1"
mass2 = (3*x[0] -x[1] == 0) # "2"
x_non_negative = (x >= 0) #"3"
problem =op(z,[mass1,mass2,x_non_negative])
problem.solve(solver='glpk')
problem.status
print ("Прибыль:")
print(abs(problem.objective.value()[0]))
print ("Результат:")
print(x.value)
stop = time.time()
print ("Время :")
print(stop - start)
from scipy.optimize import linprog
import time
start = time.time()
c = [-30,-1] #Функция цели
A_ub = [[90,5]] #'1'
b_ub = [10000]#'1'
A_eq = [[3,-1]] #'2'
b_eq = [0] #'2'
print (linprog(c, A_ub, b_ub, A_eq, b_eq))
stop = time.time()
print ("Время :")
print(stop - start)
from pulp import *
import time
start = time.time()
x1 = pulp.LpVariable("x1", lowBound=0)
x2 = pulp.LpVariable("x2", lowBound=0)
x3 = pulp.LpVariable("x3", lowBound=0)
x4 = pulp.LpVariable("x4", lowBound=0)
x5 = pulp.LpVariable("x5", lowBound=0)
x6 = pulp.LpVariable("x6", lowBound=0)
x7 = pulp.LpVariable("x7", lowBound=0)
x8 = pulp.LpVariable("x8", lowBound=0)
x9 = pulp.LpVariable("x9", lowBound=0)
problem = pulp.LpProblem('0',pulp.LpMaximize)
problem += -7*x1 - 3*x2 - 6* x3 - 4*x4 - 8*x5 -2* x6-1*x7- 5*x8-9* x9, "Функция цели"
problem +=x1 + x2 +x3<= 74,"1"
problem +=x4 + x5 +x6 <= 40, "2"
problem +=x7 + x8+ x9 <= 36, "3"
problem +=x1+ x4+ x7 == 20, "4"
problem +=x2+x5+ x8 == 45, "5"
problem +=x3 + x6+x9 == 30, "6"
problem.solve()
print ("Результат:")
for variable in problem.variables():
print (variable.name, "=", variable.varValue)
print ("Стоимость доставки:")
print (abs(value(problem.objective)))
stop = time.time()
print ("Время :")
print(stop - start)
from cvxopt.modeling import variable, op
import time
start = time.time()
x = variable(9, 'x')
z=(7*x[0] + 3*x[1] +6* x[2] +4*x[3] + 8*x[4] +2* x[5]+x[6] + 5*x[7] +9* x[8])
mass1 = (x[0] + x[1] +x[2] <= 74)
mass2 = (x[3] + x[4] +x[5] <= 40)
mass3 = (x[6] + x[7] + x[8] <= 36)
mass4 = (x[0] + x[3] + x[6] == 20)
mass5 = (x[1] +x[4] + x[7] == 45)
mass6 = (x[2] + x[5] + x[8] == 30)
x_non_negative = (x >= 0)
problem =op(z,[mass1,mass2,mass3,mass4 ,mass5,mass6, x_non_negative])
problem.solve(solver='glpk')
problem.status
print("Результат:")
print(x.value)
print("Стоимость доставки:")
print(problem.objective.value()[0])
stop = time.time()
print ("Время :")
print(stop - start)
from scipy.optimize import linprog
import time
start = time.time()
c = [7, 3, 6,4,8,2,1,5,9]
A_ub = [[1,1,1,0,0,0,0,0,0],
[0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,1,1,1]]
b_ub = [74,40,36]
A_eq = [[1,0,0,1,0,0,1,0,0],
[0,1,0,0,1,0,0,1,0],
[0,0,1,0,0,1,0,0,1]]
b_eq = [20,45,30]
print(linprog(c, A_ub, b_ub, A_eq, b_eq))
stop = time.time()
print ("Время :")
print(stop - start)
import numpy as np
from scipy.optimize import linprog
b_ub = [74,40,36]
b_eq = [20,45,30]
A=np.array([[7, 3,6],[4,8,2],[1,5,9]])
m, n = A.shape
c=list(np.reshape(A,n*m))# Преобразование матрицы A в список c.
A_ub= np.zeros([m,m*n])
for i in np.arange(0,m,1):# Заполнение матрицы условий –неравенств.
for j in np.arange(0,n*m,1):
if i*n<=j<=n+i*n-1:
A_ub [i,j]=1
A_eq= np.zeros([m,m*n])
for i in np.arange(0,m,1):# Заполнение матрицы условий –равенств.
k=0
for j in np.arange(0,n*m,1):
if j==k*n+i:
A_eq [i,j]=1
k=k+1
print(linprog(c, A_ub, b_ub, A_eq, b_eq))
|
Метки: author Scorobey python линейное программирование scipy optimize |
[Из песочницы] Поворот экрана во время выполнения долговременной операции |
android:name="net.mabramyan.asmyk.core.AsmykApplicationContext"
...
void onProgress(final Object progressObj)void onFail(final Object errorObj) void onSuccess(final Object successObj)void onSuccess(final Object successObj)void doInBackground(final AsmykApplicationContext ctx)void fireProgress(AsmykApplicationContext ctx, final Object progressObj) — данный метод впоследствии вызовет onProgress у вашей AsmykPleaseWaitActivity. По завершении задачи вызовите метод fireSuccess или fireFailed в зависимости от результата выполнения операции.
pleaseWaitTask.start((AsmykApplicationContext) MainActivity.this.getApplicationContext());
Intent intent = new Intent(MainActivity.this, PleaseWaitActivity.class);
startActivity(intent);
|
Метки: author mabramyan разработка под android android development asynchronous howto |
Красно-черные деревья: коротко и ясно |
Девушка: Нарисуй дерево.
Программист: (рисует бинарное дерево)
Девушка: Нет, другое.
Программист: Я и красно-черное дерево могу нарисовать.
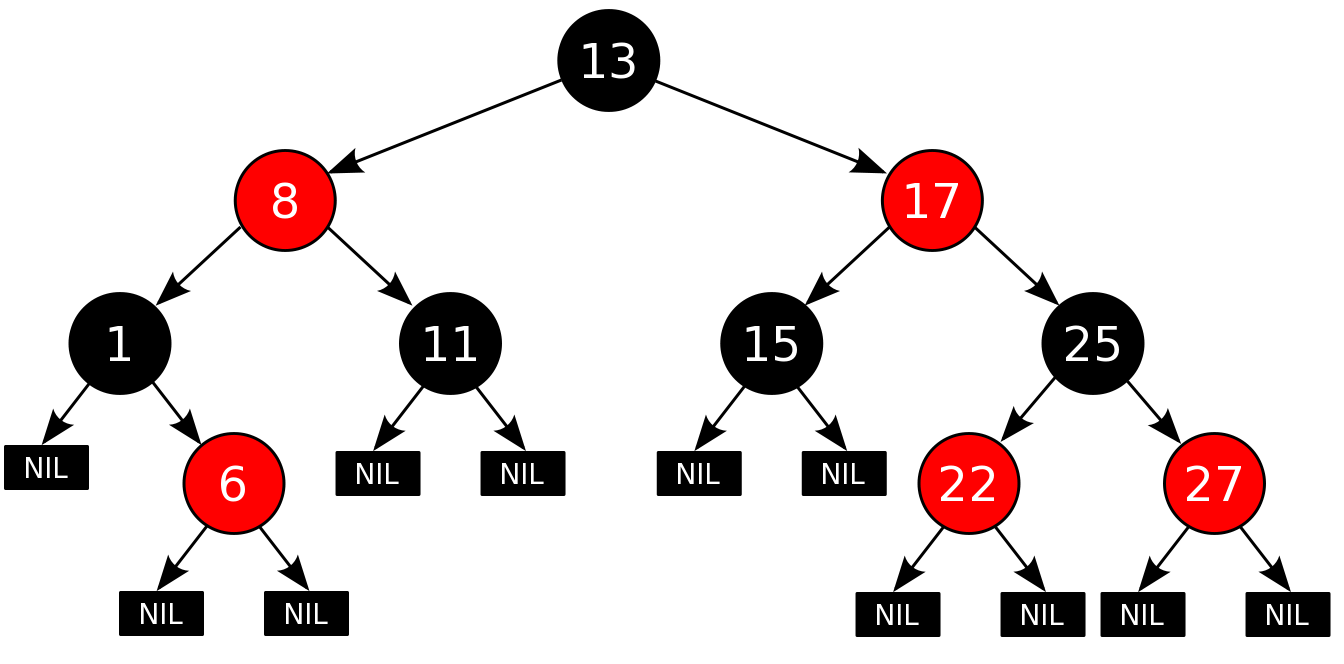
|
Метки: author AnROm алгоритмы структуры данных красно-черное дерево |
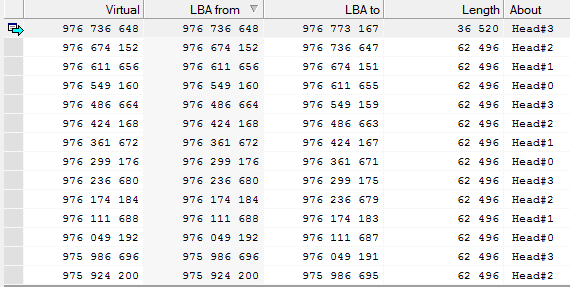
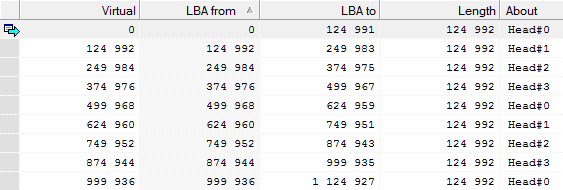
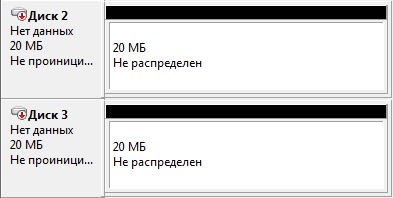
Всегда ли надежно шифрование или восстановление данных с внешнего жесткого диска Prestigio Data Safe II |







|
Метки: author hddmasters хранение данных восстановление данных hdd жесткий диск винчестер шифрование |






