«Самый большой конкурент — это те, кто делают все самостоятельно» — Петр Зайцев о создании и развитии компании Percona |

|
Метки: author rdruzyagin развитие стартапа карьера в it-индустрии бизнес-модели блог компании pg day'17 russia mysql percona interview интервью |
Zabbix: LLD-мониторинг IPMI датчиков |

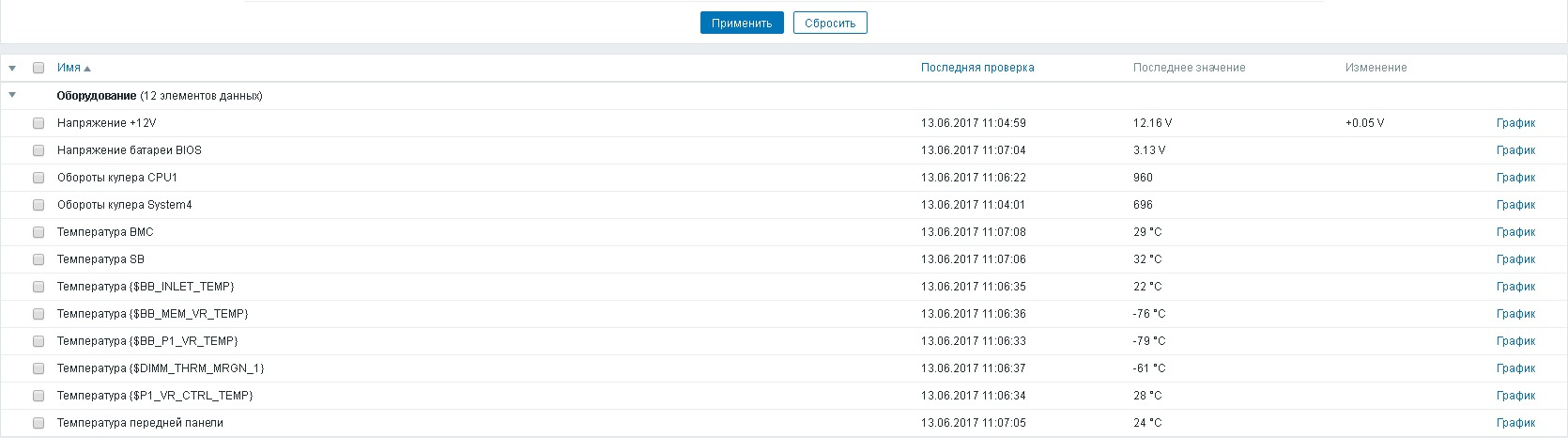
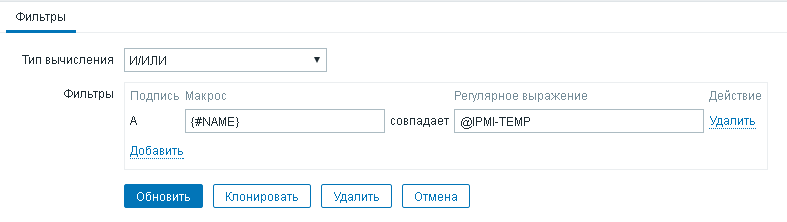

|
Метки: author AcidVenom системное администрирование серверное администрирование zabbix мониторинг ipmi bash |
Полное погружение в виртуальную реальность: настоящее и будущее |





|
Метки: author viacheslavnu разработка под ar и vr vr виртуальная реальность teslasuit костюм виртуальной реальности полное погружение тактильная связь haptic |
Пишем Guard |

Привет, хабр!
Есть несколько способов проверять аргументы на правильность. Например, для проверки на null можно использовать:
В статье я рассмотрю только третий вариант (все примеры кода — для C#, однако некоторые из них будут полезны и в Java).
Чаще всего в проекте, для устранения копирования одинакового кода, кто-то создает статический класс, в котором можно проверить поле на null, больше нуля и т.д.
Однако в этом случае забывается, что одна и так же проверка может быть крайне полезна и для валидации аргументов (в этом случае дополнительным параметром передается имя аргумента), и для проверок внутри метода (в этом случае бросается другое исключение).
Итак, для начала лучше всего заранее договориться об именованиях обоих случаев. Например, Guard.IsNotNull для тела метода и Guard.ArgumentIsNotNull для аргументов
Сразу примеры ошибочного кода:
Guard.IsNotNull(connection, $"Unable to setup connection with host {host} and port {port}")
Guard.IsNotNull(connection, string.Format("Unable to setup connection with host {0} and port {1}", host, port)) // это просто развернутая строчка вышеОба примера выше генерят строку на каждую проверку (в теории, все Guard не бросают исключений на боевом сервере, то есть мы генерим немало строк просто для того, чтобы их потом съел сборщик мусора).
Исправленный вариант:
public static class Guard
{
public static void IsNotNull(object value, string format, params object[] formattingArgs) // тут мы сконструируем строку в самый последний момент, когда выделение небольшого куска памяти уже не будет ударять по производительности
}На самом деле вариант выше тоже плохой. В нем уже не создается строка, однако на каждый вызов метода создается новый массив formattingArgs. Конечно, для него выделяется меньше памяти, однако такие методы всё равно будут нагружать на сборщик мусора.
Самое обидное, что программа будет тормозить, однако простой профайлинг не подстветит проблему. У вас просто программа будет чаще останавливаться для очистки памяти (я исправил такую ошибку в одной из программ, сборка мусора стала занимать вместо прежних 15% всего лишь 5%).
Итак, поступаем так же, как сделано в string.Format: нагенерим побольше методов для разного числа аргументов.
public static class Guard
{
public static void IsNotNull(object value, string errorMessage)
public static void IsNotNull(object value, string errorMessageFormat, object arg1)
public static void IsNotNull(object value, string errorMessageFormat, object arg1, object arg2)
public static void IsNotNull(object value, string errorMessageFormat, object arg1, object arg2, object arg3)
}Итак, теперь массив выделяться не будет. Однако, мы автоматом получили новую проблему — Boxing.
Рассмотрим вызов метода: Guard.IsNotNull(connection, "Unable to setup connection with host {0} and port {1}", host, port). Переменная port имеет тип int (чаще всего по крайней мере). Получается, что для того, чтобы передать переменную по значению, .Net каждый раз будет создавать int в куче, чтобы передать его как object. Эта ситуация будет встречаться намного реже, но всё же будет.
И другая проблема — если изначальный проверяемый объект — это value type (например, мы проверяем на null в generic методе, который не имеет ограничений на тип).
Исправить это можно увеличением созданием Generic методов для проверок:
public static class Guard
{
public static void IsNotNull(TObject value, string errorMessage)
public static void IsNotNull(TObject value, string errorMessageFormat, TArg1 arg1)
public static void IsNotNull(TObject value, string errorMessageFormat, TArg1 arg1, TArg2 arg2)
public static void IsNotNull(TObject value, string errorMessageFormat, TArg1 arg1, TArg2 arg2, TArg3 arg3)
} Как видно выше, для того, чтобы удобно проверять значения на null нам надо:
Без кодогенерации относительно сложно добавлять новые функции, а уж тем более менять их.
Пункты ниже не ускорят вашу программу, а просто незначительно улучшат читаемость
Часто ReSharper ругается, что значение может быть null, хотя его вроде бы проверили с помощью Guard'а. В этом случае можно либо начать постепенно забивать на предупреждения в коде (что может быть чревато), либо объяснить проверяющим, что всё нормально. Полный список аттрибутов можно просмотреть здесь, однако вот полезные для нас:
В теории, число исключений из наших функций на боевых серверах должно быть наименьшим. А следовательно, любое их срабатывание должно нести в себе максимум информации: что же произошло на самом деле (ведь ситуация-то редкая). Как минимум, лучше всего включать в текст:
Надеюсь, эта статья поможет сравнительно просто улучшить проверки в вашем коде.
Немного ранее я реализовал все наработки в библиотеке (исходный код под MIT лицензией) — так что можете просто использовать её (или скопировать код к себе и т.д.)
|
|
Цена ошибки: кто и сколько платит за промахи программистов? |
Современные программисты живут в интересное время, когда программное обеспечение проникает буквально во все сферы жизни человека и начинает существовать в бесчисленном количестве устройств, плотно вошедших в наш обиход. Сейчас уже никого не удивишь программами в холодильниках, часах и кофе-машинах. Однако, параллельно с торжеством удобства растет и зависимость людей от умной техники. Неизбежное последствие: на первый план выходит надежность программного обеспечения. Сложно кого-то напугать взбесившейся кофеваркой, хотя и она может натворить много бед (литры кипящего кофе стекают по вашей белоснежной мраморной столешнице...). Но мысль о растущих требованиях к качеству ПО важна, поэтому поговорим об ошибках в коде, которые повлекли за собой существенные траты времени и денег.

Цель повествования — борьба с идеей, что к дефектам в программах можно относиться так же пренебрежительно, как и раньше. Теперь ошибки в программах — это не только неправильно нарисованный юнит в игре, сейчас от кода зависит сохранность имущества и здоровье людей. В этой статье я хочу привести несколько новых примеров необходимости трепетного отношения к коду.
Нельзя отрицать, что сложные программы все активнее входят в нашу жизнь: управляемая со смартфона бытовая техника, гаджеты, наделенные таким функционалом, о котором еще 10 лет назад не приходилось и мечтать и, конечно, более сложное ПО на заводах, в автомобилях и т.д. Любая программа создается человеком и, чем она умнее, тем опаснее ее сбой.
Поговорим о деньгах, потерянных из-за ошибок в программном обеспечении, и росте нашей зависимости от программного кода. Тема неоднократно обсуждаемая (в том числе моим коллегой — Андреем Карповым — "Большой Калькулятор выходит из-под контроля"), и каждый новый пример доказывает: качество кода — не то, чем можно пренебрегать.

Спутник Mariner 1 в 1962 году должен был отправиться к Венере. Стартовав с мыса Канаверал, ракета практически сразу сильно отклонилась от курса, что создало серьезную угрозу падения на землю. Для предотвращения возможной катастрофы NASA было принято решение запустить систему самоуничтожения ракеты. Спустя 293 секунды с момента старта, Mariner 1 был ликвидирован.

Ревизионная комиссия провела расследование, в ходе которого было выявлено: причиной аварии послужила программная ошибка, из-за которой поступали неверные управляющие сигналы.
Программист неправильно перевел написанную формулу в компьютерный код, пропустив макрон или надчёркивание (что значит "n-ое сглаживание значения производной радиуса R по времени").
Программа даже незначительные изменения скорости воспринимала как весьма существенные и проводила корректировку курса (источник).
Цена "пропущенного дефиса" — 18 млн долларов (на тот момент).
Ярким примером того, как из-за программной ошибки могут быть потеряны миллионы, является относительно недавний случай. Казалось бы, в 21 веке есть все необходимое для написания надёжных программ, особенно, если речь идет о космической отрасли. Опытные специалисты с отличным образованием, хорошее финансирование, возможность использования лучших инструментов для проверки программного обеспечения. Все это не помогло. 5 декабря 2010 года ракета-носитель "Протон-М" с тремя спутниками "Глонасс-М" — российский аналог GPS, упала в Тихий океан.

Причину аварии, после завершения расследования, озвучил официальный представитель Генпрокуратуры РФ Александр Куренной: "Установлено, что причиной аварии стало применение неверной формулы, в результате чего масса заправленного в бак окислителя разгонного блока жидкого кислорода на 1582 кг превысила максимально допустимую величину, что повлекло выведение ракеты-носителя на незамкнутую орбиту и его падение в акваторию Тихого океана" (источник).
Интересный момент в этой истории — документ о необходимости корректировки формулы был, но его списали как исполненный. Руководство же не удосужилось проверить выполнение своих указаний. Все причастные к аварии лица были привлечены к уголовной ответственности и крупным штрафам. Но это не компенсирует потери, составившие 138 миллионов долларов.
Еще в 2009 году профессор информатики в Техническом университете Мюнхена, эксперт по программному обеспечению в автомобилях Манфред Бра, сказал: "Программное обеспечение автомобиля премиум-класса содержит около 100 миллионов строк кода" (источник). С того момента прошло уже восемь лет, и совсем не обязательно быть поклонником передачи Top Gear, чтобы заметить: современные автомобили — это настоящие интеллектуальные машины.
По заявлению все того же эксперта, стоимость программного обеспечения и электроники в автомобиле составляет порядка 40% от его цены на рынке. И это касается бензиновых моторов, что же говорить о гибридах и электрокарах, где это значение равно примерно 70%!
Когда электронная начинка становится сложнее механической, то возрастает ответственность разработчиков программного обеспечения. Баг в одной из ключевых систем, например, торможения, представляет гораздо большую опасность, чем порвавшийся тормозной шланг.
Садиться за руль современных комфортных и "умных" авто или ездить на олдскульных, но понятных машинах? Решать вам, я же предлагаю небольшую подборку багов в программном обеспечении автомобилей.
Японские автомобили Toyota имеют положительную репутацию, но периодически в СМИ попадает информация об отзыве некоторого количества машин. В нашем блоге уже есть статья о программной ошибке в Toyota — "Toyota: 81 514 нарушений в коде", но этот случай, к сожалению, не единичный.

В 2005 году было отозвано 160 тыс. гибридов Toyota Prius 2004 года выпуска и начала 2005. Проблема заключалась в том, что машина могла в любой момент остановиться и заглохнуть. На устранение бага было затрачено около 90 минут на одно транспортное средство или около 240 тыс. человеко-часов.
В мае 2008 года Chrysler отозвал 24535 автомобилей Jeep Commanders 2006 года выпуска. Причина — программная ошибка в модуле управления автоматической трансмиссией. Сбой приводил к неконтролируемой остановке двигателя.
В июне того же года Volkswagen отзывает около 4000 Passat и 2500 Tiguans. Здесь ошибка в программном обеспечении оказывала воздействие на увеличение оборотов двигателя. Показания тахометра начинали ползти вверх при включенном кондиционере.
Стоит ли говорить о том, что процесс отзыва автомобилей связан с огромными финансовыми затратами. Но для таких крупных компаний-производителей гораздо страшнее не денежные потери, а упадок доверия потребителей. При огромной конкуренции на автомобильном рынке, одна такая оплошность может обернуться очень и очень негативными последствиями. Восстановление репутации надежного производителя — дело нелегкое.
Выше речь шла об обычных автомобилях, причем не самых последних годов выпуска. Как видите, даже в них возможны программные ошибки, что уж говорить об активно популяризируемых экологически безопасных электрокарах.
Поговорим, конечно же, о Tesla Model S. 7 мая 2016 Джошуа Браун, прославившийся благодаря своим роликам на YouTube, посвященным восхвалениям электромобиля, попал в автокатастрофу. Он находился за рулем Tesla Model S. Будучи на 100% уверенным в интеллекте машины, он доверился автопилоту. Результат доверия трагичный — от полученных травм Джошуа скончался на месте.
Катастрофа получила широкую огласку. Началось расследование. Удалось установить, что, по всей видимости, Браун самостоятельно не следил за дорогой, а автопилот столкнулся с ситуацией, которая не нашла отражение в его программном коде. Перед Tesla Джошуа двигался грузовик с прицепом. Автомобиль планировал выполнить маневр — левый поворот, соответственно, требовалось сбавить скорость. Но Tesla, едущий позади, не начал тормозить, т.к. системы автопилота не распознали находящийся впереди объект.
Произошло это, скорее всего, из-за яркого солнца. Лучи отражались от прицепа и автопилот воспринял грузовик единым целым с небом. В официальном докладе это объяснялось следующим образом: "Системы автоматического торможения Теслы являются технологией избегания столкновения в редких случаях и не спроектированы для надежного выполнения во всех режимах аварии, включая столкновения в результате пересечения путей" (источник). Полный отчет об аварии находится в свободном доступе.
Иными словами, автопилот призван помогать водителю (более совершенный круиз-контроль, грубо говоря), а не заменять его функции. Конечно, репутацию Tesla такое оправдание не сильно спасло. Работы над совершенствованием программного обеспечения продолжились, но Tesla Model S с дорог отозваны не были.

Представители компании привели следующую дорожную статистику: "На каждые 90 млн. миль пройденного пути умирает один человек. В противоположность, люди проезжали 130 млн. миль на автопилоте Тесла перед тем, как была подтверждена первая смерть. Сейчас эта цифра поднялась до 200 млн." (источник)
С одной стороны, такая статистика свидетельствует о том, что электрокар безопаснее, но готовы ли вы доверить свою жизнь, жизнь пассажиров и других участников дорожного движения программе?
И это не риторический вопрос. Судя по новостям биржи, вопреки нашумевшей аварии, акции Tesla выросли на 50% с начала 2017 года. Способствуют этому два значимых фактора: популярность движений, выступающих за улучшение экологии в мире, и высокий личный рейтинг главы Tesla — Илона Маска.
Не могла не привести в завершении статьи этот пример. Подробно о Беде 2038 года вы можете прочитать в статье "2038: остался всего 21 год", я же остановлю внимание на одном важном моменте.
Оборудование для заводов: всевозможные станки, конвейеры; бытовая техника и другие сложные агрегаты, оснащенные специализированным программным обеспечением, имеют достаточно продолжительный срок службы. Вероятность того, что выпущенный в 2017 году станок будет функционировать и в 2038 очень и очень велика. Отсюда логично сделать вывод: проблема, когда 32-битные значения типа time_t больше не смогут корректно отображать даты, уже актуальна!
Если сейчас разработчики программного обеспечения не будут брать ее в расчет, то что же ждет программистов в 2038 году?! Есть все шансы на то, что ПО для встроенных систем устроит немало сюрпризов. Но, думаю, мы будем тому свидетелями.
Возможно, приведенные в статье примеры покажутся слишком эпичными. Безусловно, широкую огласку получают только трагические случаи. Но я уверена, что в каждой компании, занимающейся разработкой программного обеспечения, есть история о том, как всего одна ошибка повлекла за собой множество проблем, пусть и в локальном масштабе.
Можно ли найти виновного? Иногда да, иногда — нет. Но смысл не в том, чтобы найти крайнего и каким-то образом покарать его. Идея в другом — программы усложняются, они все больше входят в нашу жизнь, а значит и требования к надежности кода растут. Увеличивается цена типовых ошибок, ответственность за качество кода тяжелой ношей ложится на плечи разработчиков.
Какой же выход? Модернизировать процесс разработки. Дать программистам помощников — специальные программы для выявления и устранения ошибок. Комплексное использование современных методик существенно снижает вероятность того, что баг в коде не будет обнаружен на этапе разработки.
Желаю вам не допускать промахов, а вашим проектам никогда не попасть в подборку, аналогичную той, что приведена в этой статье.
|
|
Операция “Миграция”: если ваша почта где-то там, а надо, чтобы была здесь |


|
|
Как мы собрали 400 человек на конференцию с нулевым рекламным бюджетом |

|
|
Как масштабировать биткойн-блокчейн |
 / изображение Susana Fernandez CC
/ изображение Susana Fernandez CC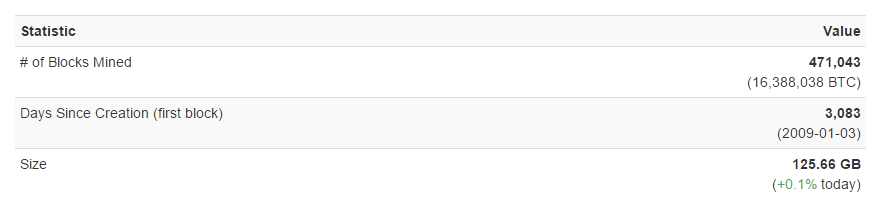

"scriptPubKey": {
"asm": "0 07389b37ea077e9431a2e64530649f8a61befa54",
"hex": "001407389b37ea077e9431a2e64530649f8a61befa54",
"type": "witness_v0_keyhash"
}|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury биткойн блокчейн segregated witness lightning network |
[Перевод] Создание VR-игры от третьего лица |
Theseus — это наша первая VR-игра, в которой мы столкнулись с совершенно новыми вопросами. В этом посте я расскажу о проблемах, с которыми мы встретились при создании дизайна игры и UI.









|
Метки: author PatientZero разработка под ar и vr разработка игр vr virtual reality vr games amp; experiences |
Цепочка вызовов append(x).append(y) в StringBuilder работает быстрее чем типичные sb.append(x); sb.append(y) |
@BenchmarkMode(Mode.Throughput)
@Fork(1)
@State(Scope.Thread)
@Warmup(iterations = 10, time = 1, batchSize = 1000)
@Measurement(iterations = 40, time = 1, batchSize = 1000)
public class Chaining {
private String a1 = "111111111111111111111111";
private String a2 = "222222222222222222222222";
private String a3 = "333333333333333333333333";
@Benchmark
public String typicalChaining() {
return new StringBuilder().append(a1).append(a2).append(a3).toString();
}
@Benchmark
public String noChaining() {
StringBuilder sb = new StringBuilder();
sb.append(a1);
sb.append(a2);
sb.append(a3);
return sb.toString();
}
}
Benchmark Mode Cnt Score Error Units
Chaining.noChaining thrpt 40 8408.703 ± 214.582 ops/s
Chaining.typicalChaining thrpt 40 35830.907 ± 1277.455 ops/ssb.append().append() в 4 раза быстрее… Автор из статьи выше утверждает, что разница связана с тем, что в случае цепочки вызовов генерируется меньше байткода и, соответственно, он выполняется быстрее. public class UriBuilder {
private String schema;
private String host;
private String path;
public UriBuilder setSchema(String schema) {
this.schema = schema;
return this;
}
...
@Override
public String toString() {
return schema + "://" + host + path;
}
}
@BenchmarkMode(Mode.Throughput)
@Fork(1)
@State(Scope.Thread)
@Warmup(iterations = 10, time = 1, batchSize = 1000)
@Measurement(iterations = 40, time = 1, batchSize = 1000)
public class UriBuilderChaining {
private String host = "host";
private String schema = "http";
private String path = "/123/123/123";
@Benchmark
public String chaining() {
return new UriBuilder().setSchema(schema).setHost(host).setPath(path).toString();
}
@Benchmark
public String noChaining() {
UriBuilder uriBuilder = new UriBuilder();
uriBuilder.setSchema(schema);
uriBuilder.setHost(host);
uriBuilder.setPath(path);
return uriBuilder.toString();
}
}Benchmark Mode Cnt Score Error Units
UriBuilderChaining.chaining thrpt 40 35797.519 ± 2051.165 ops/s
UriBuilderChaining.noChaining thrpt 40 36080.534 ± 1962.470 ops/s
StringBuilder и append(), то наверное это как-то связано с известной JVM опцией +XX:OptimizeStringConcat. Давайте проверим. Повторим самый первый тест, но с отключенной опцией. @Fork(value = 1, jvmArgsAppend = "-XX:-OptimizeStringConcat")Benchmark Mode Cnt Score Error Units
Chaining.noChaining thrpt 40 7598.743 ± 554.192 ops/s
Chaining.typicalChaining thrpt 40 7946.422 ± 313.967 ops/sx + y довольно частая операция в любом приложении — Hotspot JVM находит new StringBuilder().append(x).append(y).toString() паттерны в байткоде и заменяет их на оптимизированный машинний код, обходясь без создания промежуточных объектов. sb.append(x); sb.append(y);. Разница на больших строках может быть на порядок.StringBuilder это поможет JIT заоптимизировать конкатенацию строк. Во-вторых, так генерируется меньше байт кода и это действительно может помочь заинлайнить Ваш метод в некоторых случаях.|
Метки: author doom369 java stringbuilder method chaining performance optimizestringconcat |
Эмулятор магнитофона для ZX-Spectrum |


|
Метки: author da-nie программирование микроконтроллеров zx-spectrum эмулятор магнитофона |
Как при помощи токена сделать Windows домен безопаснее? Часть 2 |

Электронная почта является сегодня не просто способом доставки сообщений. Ее смело можно назвать важнейшим средством коммуникации, распределения информации и управления различными процессами в бизнесе. Но всегда ли мы можем быть уверены в корректности и безопасности ее работы?
На самом деле уязвимость электронной почты — это большая проблема.
Электронная почта — один из старейших сетевых сервисов. Появилась она в 1982 году, а ведь в то время вопросы безопасности в Интернете стояли не так остро, как сейчас. Если верить исследованиям компании Mimecast, около 94% опрошенных компаний полностью бессильны в борьбе с утечкой информации через электронную почту.
Новостные ленты регулярно пестрят сообщениями о взломанных электронных почтах политиков, спортсменов, артистов и других публичных людей. Подобных ситуаций можно было бы избежать, для этого всего лишь надо знать о возможности шифровать электронные письма.
Ведь стоит это недорого, а работает надежно.
В прошлой статье «Как при помощи токена сделать Windows домен безопаснее? Часть 1» мы рассказали, как настроить безопасный вход в домен. Напомнили, что такое двухфакторная аутентификация и каковы ее преимущества.
В этой статье мы поговорим о защите электронной почты.
Стандартные почтовые протоколы не включают очевидных механизмов защиты, которые гарантировали бы авторство писем и обеспечивали простую и легкую проверку. Такая ситуация с защитой почтовых систем дает возможность злоумышленникам создавать письма с фальшивыми адресами. Поэтому нельзя быть на 100% уверенным в том, что человек, данные которого указаны в поле «От кого», действительно является автором письма. Также тело электронного письма легко изменить, т. к. нет средств проверки целостности и при передаче через множество серверов письмо может быть прочитано и изменено.
Один из способов обеспечить конфиденциальность переписки — шифрование сообщений, а один из способов проверить целостность письма и установить авторство — подписание его электронной подписью.
Зашифрованное сообщение будет доступно для прочтения только тем получателям, у которых имеется закрытый ключ, соответствующий открытому, при помощи которого было зашифровано сообщение. Любой другой получатель не сможет даже открыть письмо.
Протокол S/MIME (Secure/Multipurpose Internet Mail Extensions) обеспечивает аутентификацию, целостность сообщения, сохранение авторства и безопасность данных.
S/MIME идентифицирует обладателя открытого ключа с помощью сертификата X.509.
S/MIME обеспечивает защиту от трех типов нарушений безопасности:
Для защиты от искажения почтового сообщения или фальсификации в S/MIME используется цифровая подпись. Наличие цифровой подписи гарантирует нам то, что сообщение не было изменено в процессе передачи. Кроме того, не позволяет отправителю сообщения отказаться от своего авторства.
Однако цифровая подпись сама по себе не гарантирует передачу сообщений с обеспечением конфиденциальности. В S/MIME эту функцию выполняет шифрование. Грубо говоря, оно осуществляется с помощью асимметричного криптографического алгоритма.
Спецификация S/MIME определяет два типа файлов в формате MIME: один для цифровых подписей, другой для шифрования сообщений. Оба типа базируются на синтаксисе криптографических сообщений стандарта PKCS#7.
Если сообщение должно быть зашифровано, а шифртексту должны быть присвоены некоторые атрибуты, то используются вложенные конверты. Внешний и внутренний конверты предназначаются для защиты цифровой подписи, а промежуточный конверт — для защиты шифртекста.
При работе с S/MIME необходимо иметь два ключа — открытый и закрытый. Ключи сопровождает сертификат, то есть информация о пользователе, позволяющая определить, что он — именно тот, за кого себя выдает. Сертификат можно сравнить с неким электронным паспортом, своеобразным удостоверением личности.
Для отправки зашифрованного сообщения необходимо получить открытый ключ получателя сообщения и, грубо говоря, зашифровать сообщение с его использованием.
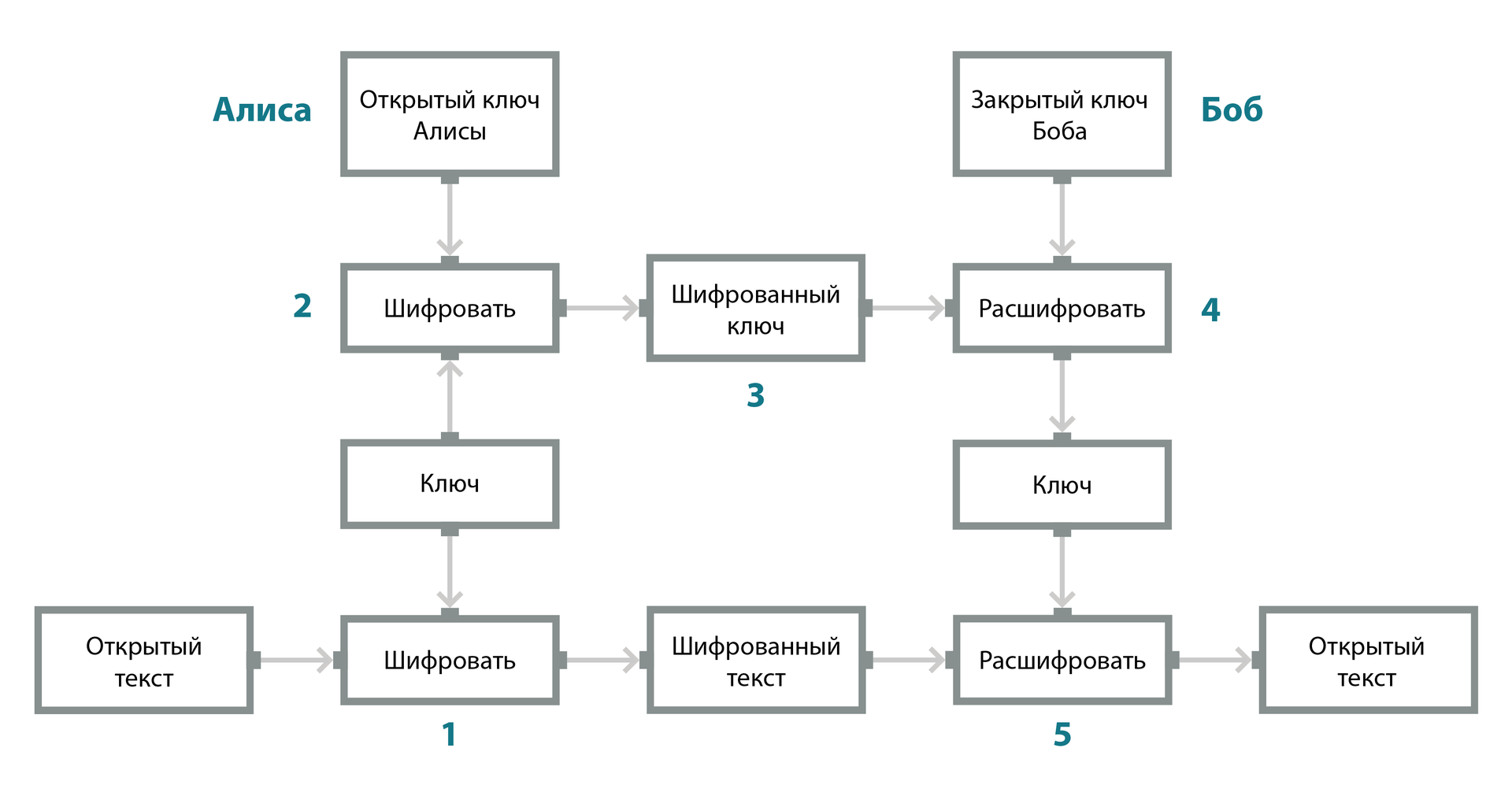
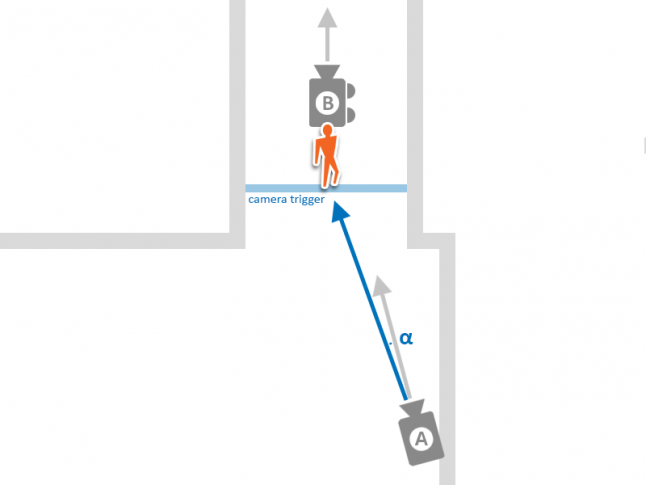
На рисунке показаны этапы шифрования сообщения электронной почты в S/MIME:
Шифрование не защищает сообщение от подделки и изменения содержания в процессе передачи. Поэтому вместе с шифрованием для защиты электронного письма необходимо использовать электронную подпись.
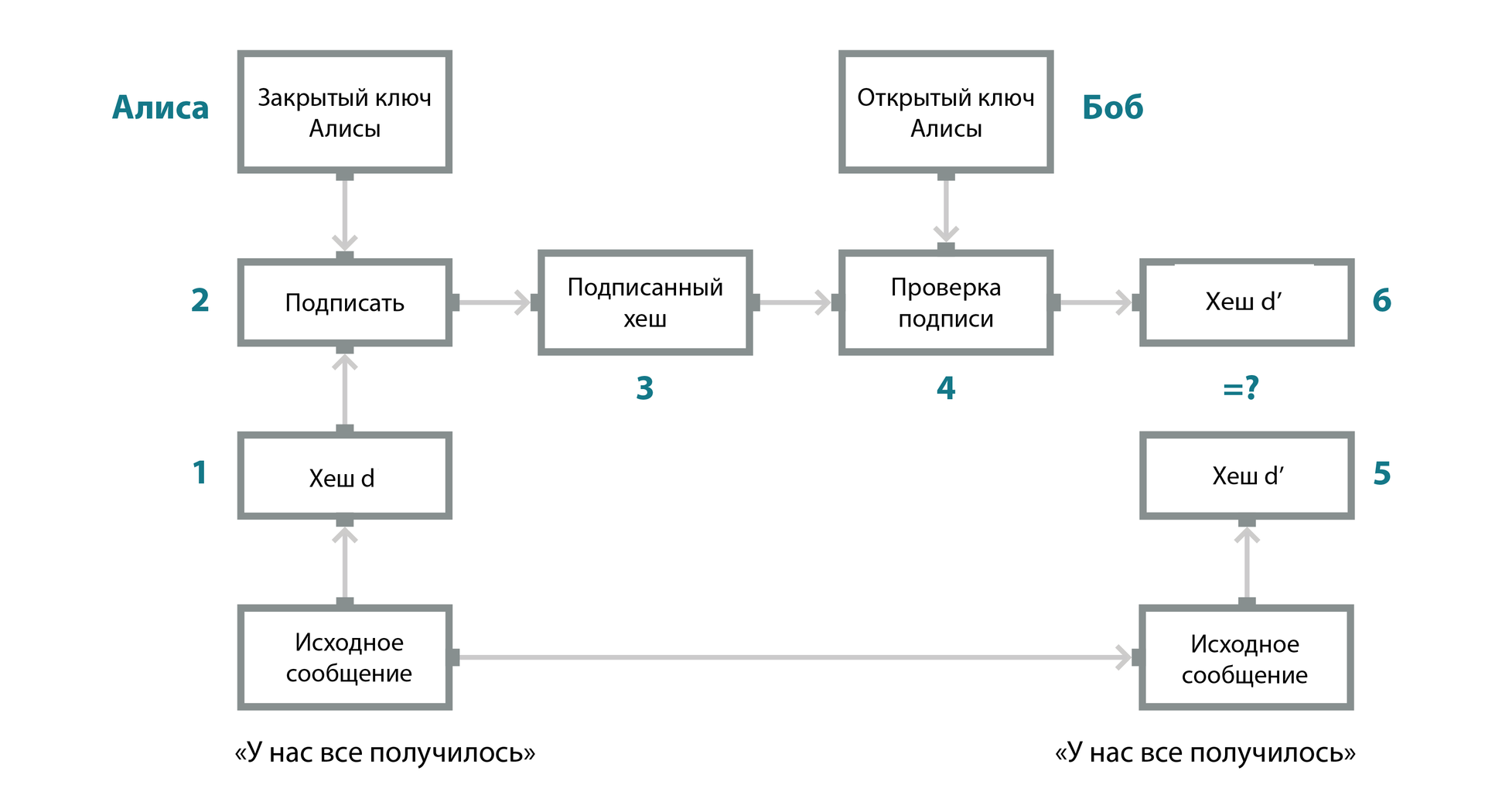
На рисунке показаны этапы аутентификации и обнаружения подделки сообщения с использованием электронной подписи:
Microsoft Outlook и другие почтовые клиенты для шифрования и подписания электронных писем используют протокол S/MIME. Если получатель и отправитель зашифрованного электронного письма используют разные почтовые клиенты, то это не означает, что они не смогут читать зашифрованные письма друг друга. Мы для примера рассмотрим процесс настройки почтового клиента Microsoft Outlook, как наиболее распространенного в корпоративной среде. Другие почтовые клиенты тоже можно использовать для шифрования и подписи сообщений. Их настройка в целом похожа, но могут быть нюансы.
А теперь за дело. Настроим шифрование и подписание писем.
Для примера я буду использовать устройство для безопасного хранения ключей и сертификатов Рутокен ЭЦП PKI .

Как на токене появились ключи и сертификаты, мы подробно объяснять не будем. Вы можете получить их в удостоверяющем центре или создать самостоятельно, как описано в одной из наших прошлых статей.
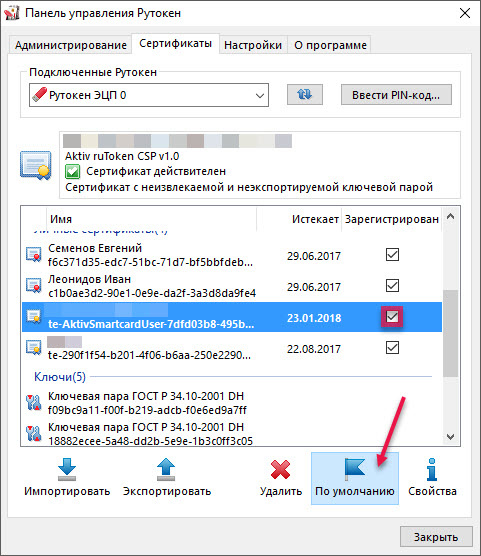
Для начала, используя панель Рутокен, сохраните сертификат в локальном хранилище и установите для него параметр «по умолчанию».
На вкладке «Сертификаты» щелкните по названию необходимого сертификата, нажмите «По умолчанию». Также установите флажок в строке с этим сертификатов, в столбце «Зарегистрирован».
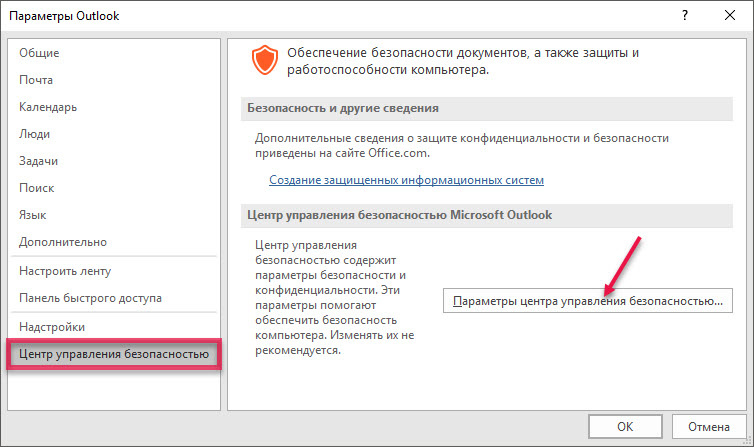
В Microsoft Outlook выберите пункт меню «Файл» и подпункт «Параметры».
Выберите пункт «Центр управления безопасностью» и нажмите «Параметры центра управления безопасностью...».
Выберите пункт «Защита электронных писем» и установите необходимые флажки.
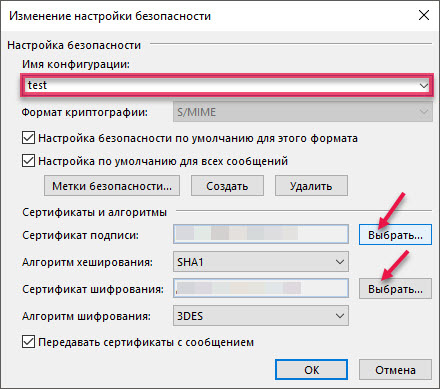
Нажмите «Параметры».
Измените имя конфигурации, выберите сертификаты для подписи и шифрования.
После этого все письма, отправленные с помощью MS Outlook, будут автоматически зашифрованы и подписаны.
Для начала обмена электронными письмами необходимо отправить сертификат получателю зашифрованного письма. Для этого можно отправить ему письмо с файлом сертификата или письмо, подписанное электронной подписью.
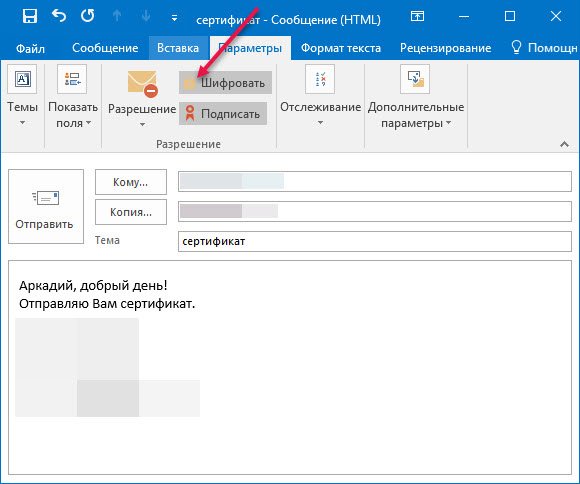
Мы отправим подписанное письмо.
Для подписания письма электронной подписью перейдите на вкладку «Параметры» и нажмите «Шифрование» (чтобы письмо было только подписано). Все просто!
Получателю необходимо добавить вас в контакты Outlook и ответить на ваше письмо зашифрованным и подписанным письмом. После этого вы сможете обмениваться с получателем зашифрованными письмами, и никто кроме вас двоих прочитать их не сможет.
Иногда необходимо подписать только файл, приложенный к письму. Это можно сделать, подписав сам файл в одном из популярных приложений Microsoft Word или Microsoft Excel.
Мы рассмотрим процесс подписания файла в приложении Microsoft Word.
Защитить файл от изменений можно с помощью электронной подписи.
Открытый ключ автора документа должен быть распространен среди всех пользователей,
которые будут работать с подписанным документом. Обычно это реализуется с помощью рассылки сертификата открытого ключа всем пользователям из списка контактов.
Есть документ, который необходимо подписать. С помощью специального ПО из содержания документа и закрытого ключа создается уникальная символьная последовательность. Эта последовательность и является электронной подписью. Она всегда уникальна для данного пользователя и данного документа.
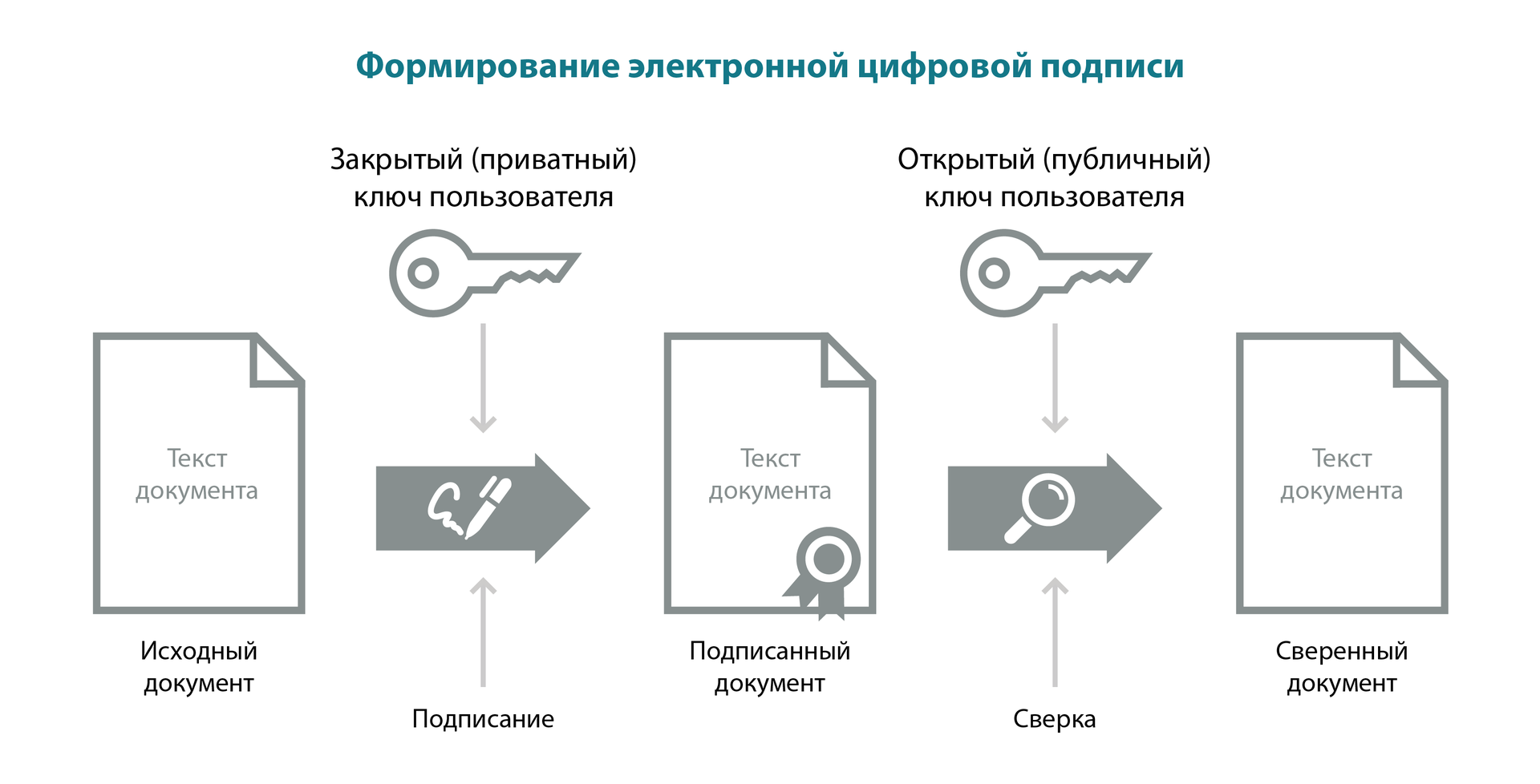
Электронная подпись — это реквизит документа, который позволяет установить факт искажения информации в электронном документе с момента формирования электронной подписи и подтвердить принадлежность ее владельцу.
Электронная подпись может быть равносильна собственноручной подписи на бумажном документе, поэтому очень важно, чтобы вашу электронную подпись не смог поставить злоумышленник.
Чтобы обезопасить свою электронную подпись, закрытый ключ электронной подписи необходимо хранить на токене или смарт-карте. Тогда ваша электронная подпись будет защищена PIN-кодом и даже в случае кражи токена или смарт-карты, злоумышленник не сможет ей воспользоваться.
Давайте для примера подпишем любой документ в формате DOCX.
Я буду использовать приложение Microsoft Word 2016.
Вам потребуется токен или смарт-карта. Я для примера буду использовать Рутокен ЭЦП 2.0.

Для начала откройте документ, который необходимо подписать.
Выберите пункт «Файл» и нажмите «Защита документа».
Выберите пункт «Добавить цифровую подпись».
Откроется окно подписи. Оно позволяет добавить личные сертификаты, которые будут использоваться при формировании подписи. Один из сертификатов выбран автоматически.
В раскрывающемся списке выберите тип подтверждения и при необходимости внесите цель подписания документа.
Нажмите «Изменить» и выберите необходимый сертификат.
После выбора сертификата нажмите «Подписать» и укажите PIN-код токена. Подпись сохранится в документе. В строке состояния отобразится значок, свидетельствующий о том, что данный документ создан с подписью.
Теперь, если кто-то изменит документ, то ему придется подписать его заново. А это значит, что вы всегда будете знать, кто является автором последней версии документа. И будете понимать, была ли изменена ваша версия документа.
Это, в свою очередь, позволит сделать обмен документами более безопасным и «прозрачным».
В результате произведенных настроек вы можете отправлять сообщения которые будут:
В следующей статье мы расскажем, что такое Bitlocker, как он может защитить вашу информацию от злоумышленников и как его настроить.
|
Метки: author Nastya_d криптография информационная безопасность рутокен outlook word электронная подпись |
Junior, который в первый день работы удалил базу данных с production |

Сегодня был мой первый день на работе в роли младшего разработчика программного обеспечения (Junior Software Developer) и моя первая позиция после университета, не являющаяся стажировкой. К сожалению, я сильно напортачил.
Мне дали документ с информацией о том, как настроить локальное окружение для разработки. Инструкции включают запуск маленького скрипта для создания личной копии БД с тестовыми данными. После запуска определённой команды я должен был скопировать URL/пароль/юзера базы данных из её вывода и настроить dev-окружение, указав там эту базу. К сожалению, вместо копирования данных нужной команды я по какой-то причине использовал значения из самого документа.
К несчастью, оказалось, что указанные там значения — от базы данных в production (не знаю, почему они задокументированы в инструкции по настройке dev-окружения). Далее, как понимаю, тесты добавили ненастоящие данные и очистили существующие, то есть между запусками тестов все данные из БД в production были удалены. Честное слово, не имел представления, что я сделал, а чтобы это выяснить/осознать, кому-то из коллег потребовалось даже не полчаса.
Когда начало проясняться, что же на самом деле произошло, технический директор сказал мне покинуть работу и больше не возвращаться. Он также сообщил, что из-за важности потерянных данных к делу подключат юристов. Я просил и умолял позволить мне как-то помочь реабилитироваться, однако ответом мне было, что я «полностью всё про***л».

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author shurup управление проектами управление персоналом блог компании флант epic fail истории неуспеха истории из жизни разработка бэкапы |
[Перевод] Как создать современную CI/CD-цепочку с помощью бесплатных облачных сервисов |
|
|
DevConf::BackEnd уже на этой неделе 17 июня в субботу, программа сформирована |

|
|
[recovery mode] Принципы тестирования программного обеспечения. Личный перевод из книги «Искусство тестирования» Г. Майерса |

|
Метки: author RockMachine тестирование мобильных приложений тестирование веб-сервисов тестирование it-систем тестирование по психология тестирования фундаментализм |
Один урок программирования |
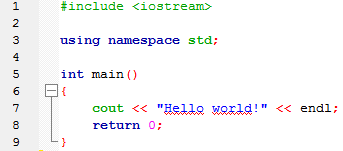
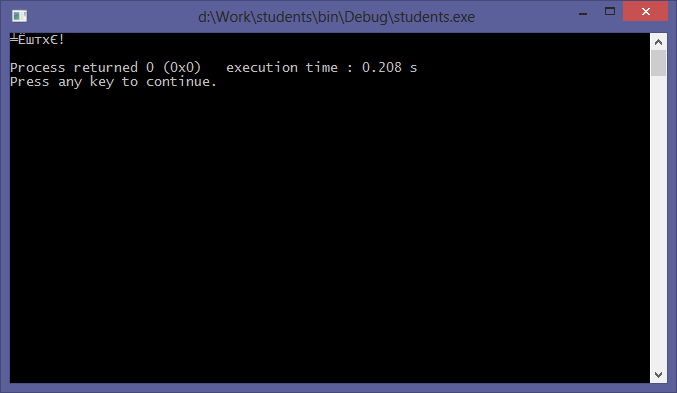
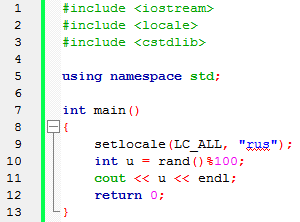
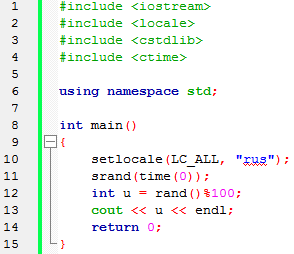



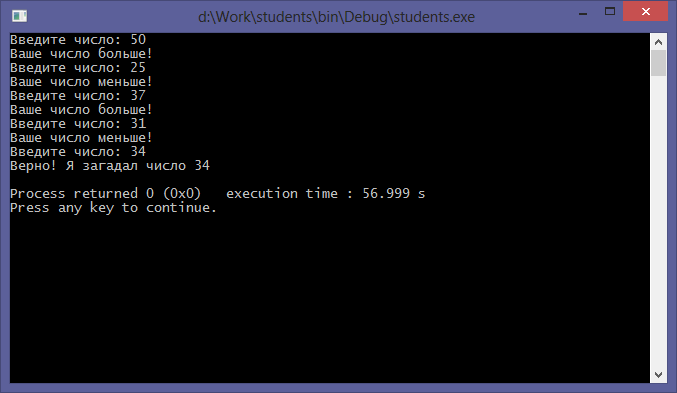
|
Метки: author Albom учебный процесс в it школа информатика программирование c++ |
Очень грубый подход к определению языка человека (ли как понять язык человека по обычной корпоративной базе) |


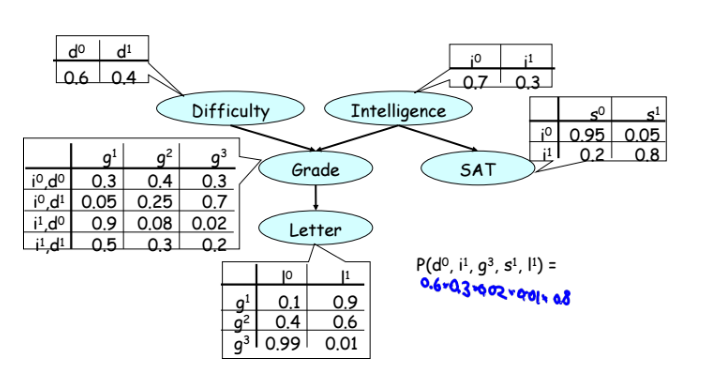
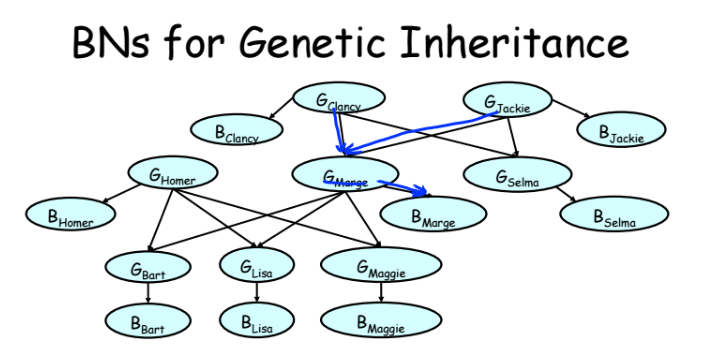
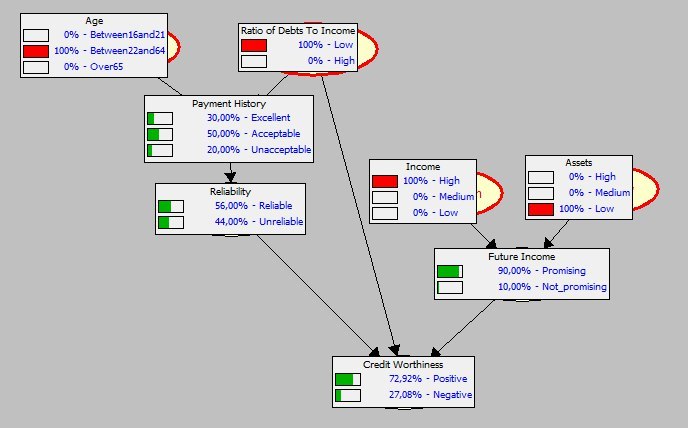

















|
Метки: author snakers4 повышение конверсии интернет-маркетинг веб-аналитика growth hacking email- маркетинг рассылки анализ данных байесовский подход определение языка |
Нейрокурятник: часть 4 — итоговая модель и код на прод |
|
|
Нейрокурятник часть 3. Про разметку кур |

Одна не сильно впечатляющая статья про разметку изображений кур.
Прошло 1,5 месяца, мы окончательно смирились с тем, что камеру нельзя повесить лучше, удалили ненужные фотографии с сервера и поняли, что они все копятся и копятся. И даже уже я не проверяю, что происходит в курятнике (а иногда там вырубают электричество и бот просто молчит). И пора бы уже размечать.
Сначала мы понадеялись на то, что существуют тулзы для разметки по типу drag and drop, которые упростят жизнь. Они существуют, да. Но адекватные либо сложно установить, либо в последний раз обновлялись много лет назад, другие не поддерживают нужные форматы и не позволяют добавить метаданные, третьи слишком продвинуты (попиксельная разметка, маски), что нам не нужно, четвертые являются специфическим плагином.
По сути нам нужно просто разнести картинки по классам, не нужно даже выделять объект на фотографии — он все равно присутствует или нет. Разметку в итоге я делаю так:
Что такое идентификатор объекта?
Объект — это курица, отсутствие чего-либо вообще, две курицы, яйцо, два яйца, отсутсвие света или что-то совсем нерелевантное (чья-то рука, ворующая яйца динозавров, привидения, кошка) и т.д. Идентификатор объекта — просто уникальный номер в базе. Например, 14 — это курица psycho, -1 — отсутствие света, 0 -отсутсвие чего-либо, 10 — восемь яиц в гнезде. У объектов есть атрибуты, например, пестрота спинки и воротничка, основной цвет. У атрибутов есть выраженность.
У объекта есть тип (курица, яйцо и др.). Я на всякий случай разбила куриные яйца на классы и типы по количеству, при желании можно будет объединить. У типа есть еще и атрибут количество.
Сначала я засела за pgAdmin и честно делала все через sql, что не сильно отличается от сидения в консоли бд, поэтому в какой-то момент я все-таки поставила себе вайн и открыла навикат. Все-таки так удобнее и быстрее, хотя бывает нужно добавить забытый sequence или constraint или удалить лишний, придется все равно открывать доку и писать запрос). И csv-шки потом проще заливать. Хотя можно составить формулами в excel запросы на инсерт, так я тоже делаю, да =)
Все это вылилось в малюсенькую er-диаграмму:

Мило, прекрасно, потом легко выгрузить в нужном формате, хоть json, хоть xml, хоть csv, и в общем, при отсутствии нужного формата и присутсвии желания, конкатенация сделает что угодно почти.
Главная таблица в схеме — chicoopfiles. Это соотнесение файла и объекта. Так как файлу соответсвует всего один объект, я заношу объекты в таблицу с файлами сразу.
Если кого-то заинтересовало, почему курица psycho, то история такая: это была самая обычная пестрая курица, но с ней что-то произошло. Теперь периодически она трясет головой и делает несколько шагов назад (обычно, тряски головой у кур бывают из-за того, что они замерзают зимой, но этим чаще страдает петух из-за большого гребня: его проще отморозить). По этой причине мама подозревала, что она не собо-то и несется, но оказалось, что несется она лучше всех. Курица определенно поехавшая, но несется и несется хорошо!

У мамы недавно завелись новые куры — совсем молодые, белые, уже несут мелкие белые яйца. В отличие от степенных старых птиц, у этих полно ребяческой энергии, они все время носятся, любопытничают, лазят в гнездо, иногда зачем-то в нем сидят, спят, потом их выгоняет какая-нибудь старушка. Таких размечать нет смысла, так как они, как правило, в гнезде не затем, чтобы снести яйцо (хотя изредка бывает, но вообще они выбрали себе другое гнездо). Так как они не сильно различаются, я разметила их как одну белую курицу.
Новые куры очень смешные. Мама заметила, что они очень плохо несутся, но если закрыть их в небольшом помещении без тайников, то несутся они хорошо. Очевидно, куры недокладывают в гнездо. И да, отец недавно обнаружил их тайник под бревнами, куда они навалили 22 яйца...
На фотографиях заметно, что птицы постепенно приобретают цвет — кожа на голове и гребень наливаются красным, куры перестают быть синюшно-белыми фабричными птицами. Еще они перестают бояться людей и кучковаться в углу, о чем камера уже не расскажет.

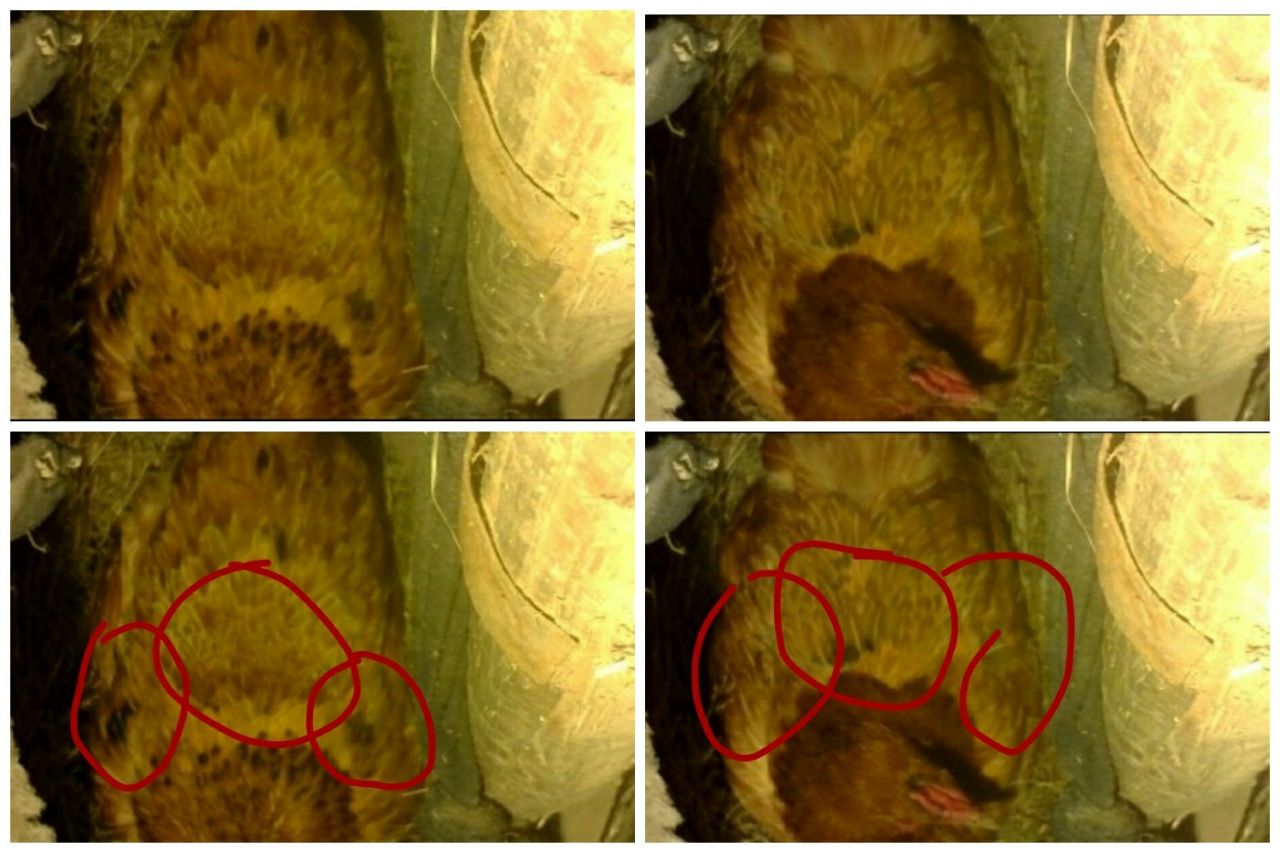
По поводу того, как различать кур, которые очень похожи. Вообще, лучше всего кур различать по «лицу» — форме глаз, гребню, складкам кожи. Да, это возможно, и куры сами друг друга различают и запоминают (иначе они не могли бы построить сложную иерархию доминирования одной особи над другой с транзитивными свойствами: курица А доминирует над Б, курица Б доминирует над В, тогда А доминирует над В). Но у нас камера висит так, что это просто невозможно. Приходится опираться на окраску.
В таком случае получаем иногда трудноразличимых кур. У нас это куры red star и red twin. Это две красные курицы, одна из которых получила прозвище Звезда Интернета, потому что некоторое время я использовала ее фото в качестве аватарки, родителей это позабавило и теперь курица носит такое прозвище. Вторая просто очень на нее похожа. На фотографиях их можно различить по темным пятнам. У Звезды более пестрый воротник и темные пятна на плечах, у ее подруги более темное пятно на спине у воротника.
Ну и немного про ручных наглых кур и как они чуть не сожрали меня.
|
Метки: author snakers4 машинное обучение data mining разметка изображений image annotation data science |






