[Перевод - recovery mode ] Angular vs. React vs. Vue: Сравнение 2017 |
Выбор JavaScript-фреймворка для вашего веб-приложения может быть невыносим. В настоящее время очень популярны Angular и React, и есть также выскочка, получающий много внимания в последнее время: VueJS. Кроме них, лишь эти несколько новичков.

Итак, как же нам выбрать? Список плюсов и минусов никогда не повредит. Проделаем это в стиле моей предыдущей статьи, “9 шагов: выбор технологического стэка для вашего веб-приложения”.
Сперва вы должны принять четкое решение, нужно ли вам одностраничное веб-приложение(SPA), или вы предпочли бы многостраничный подход. Больше на эту тему в моем посте “Одностраничные веб-приложения(SPA) против Многостраничных веб-приложений(MPA)”(скоро выйдет, следите за обновлениями в Twitter).
Сначала я хотел бы обсудить жизненный цикл и стратегические соображения. Затем мы перейдем к возможностям и идеям всех трех JavaScript-фреймворков. Наконец, мы придем к выводам.
Вопросы, которые мы сегодня рассмотрим:
На старт, внимание, марш!

React vs. Angular vs. Vue
Angular — это JavaScript-фреймворк, основанный на TypeScript. Разработанный и поддерживаемый Google, он описывается как “Супергеройский JavaScript MVW фреймворк”. Angular(известный также как “Angular 2+”, “Angular 2” или “ng2”) — переписанный, по большей части несовместимый преемник AngularJS(известный как “Angular.js” или “AngularJS 1.x”). Хотя AngularJS(старый) был впервые выпущен в октябре 2010-го, он до сих пор получает багфиксы и т.д. Новый Angular(без JS) был представлен как версия №2 в сентябре 2016. Последний мажорный релиз — версия 4, так как версию 3 пропустили. Angular используется Google, Wix, weather.com, healthcare.gov и Forbes(в соответствии с madewithangular, stackshare и libscore.com).
React характеризуется как “JavaScript-библиотека для создания пользовательских интерфейсов”. Впервые выпущенный в марте 2013-го, React разработан и поддерживается Facebook-ом, который использует React-компоненты на нескольких страницах(однако, не являясь одностраничным веб-приложением). В соответствии с этой статьей Криса Кордла, React в Facebook применяется значительно шире, чем Angular в Google. React также используют в Airbnb, Uber, Netflix, Twitter, Pinterest, Reddit, Udemy, Wix, Paypal, Imgur, Feedly, Stripe, Tumblr, Walmart и других(в соотв. с Facebook, stackshare и libscore.com).
В данный момент Facebook работает над выпуском React Fiber. Это изменит React под капотом — в результате, рендеринг должен значительно ускориться — но обратная совместимость сохранится после изменений. В Facebook рассказывали об этих изменениях на их конференции для разработчиков в апреле 2017-го, также была опубликована неофициальная статья о новой архитектуре. Предположительно, React Fiber будет выпущен вместе с React 16.
Vue — один из самых быстроразвивающихся JS-фреймворков в 2016-м. Vue описывает себя как “Интуитивный, Быстрый и Интегрируемый MVVM для создания интерактивных интерфейсов”. Впервые он был выпущен в феврале 2014-го бывшим сотрудником Google Эваном Ю(кстати, Эван тогда написал интересный пост про маркетинговую деятельность и цифры в первую неделю после старта). Это был неплохой успех, особенно учитывая, что Vue привлекает столько внимания будучи театром одного актера, без поддержки крупной компании. На данный момент, у Эвана есть команда из дюжины основных разработчиков. В 2016 была выпущена вторая версия. Vue используют Alibaba, Baidu, Expedia, Nintendo, GitLab. Список более мелких проектов можно найти на madewithvuejs.com.
И Angular, и Vue доступны под лицензией MIT, в то время как React — под BSD3-license. Есть много обсуждений по поводу патентного файла. Джеймс Аид(бывший инженер Facebook) объясняет причины и историю, лежащую за этим файлом: Патент Facebook касается распространения их кода при сохранении возможности защитить себя от патентных исков. Файл патента обновлялся единожды и некоторые люди утверждают, что React можно использовать, если ваша компания не собирается подавать в суд на Facebook. Можете ознакомиться с обсуждением вокруг этого Github issue. Я не являюсь адвокатом, поэтому вы сами должны решить, создает ли лицензия React проблемы для вас или вашей компании. Есть еще много статей на эту тему: Дэннис Уолш пишет, почему вам не стоит бояться. Рауль Крипалани предостерегает от использования в стартапах, у него также есть обзор в формате “изложение мыслей”. Также существует недавнее оригинальное заявление от Facebook на эту тему: “Разъяснение лицензии React”.
Как было отмечено ранее, Angular и React поддерживаются и используются крупными компаниями. Facebook, Instagram и Whatsapp используют их на своих страницах. Google использует их во многих своих проектах: например, новый пользовательский интерфейс Adwords был реализован с помощью Angular и Dart. Опять же, Vue разрабатывается группой лиц, чья работа поддерживается через Patreon и другие средства спонсирования. Решайте сами, хорошо это или плохо. Маттиас Гёцке считает, что небольшая команда Vue — это плюс, потому что это ведет к более чистому коду / API, и меньшему оверинженерингу.
Посмотрим на статистику: на странице команды Angular перечислено 36 человек, у Vue — 16 человек, у React страницы команды нет. На GitHub-е у Angular больше 25 000 звезд и 463 контрибьютора, у React — больше 70 000 звезд и 1000 контрибьюторов, и у Vue почти 60 000 звезд и лишь 120 контрибьюторов. Можете также проверить страничку “Github Stars History for Angular, React and Vue”. Опять же, Vue, похоже, очень хорошо развивается. В соответствии с bestof.js, за последние три месяца Angular 2 получал в среднем 31 звезду в день, React — 74 звезды, Vue — 107 звезд.
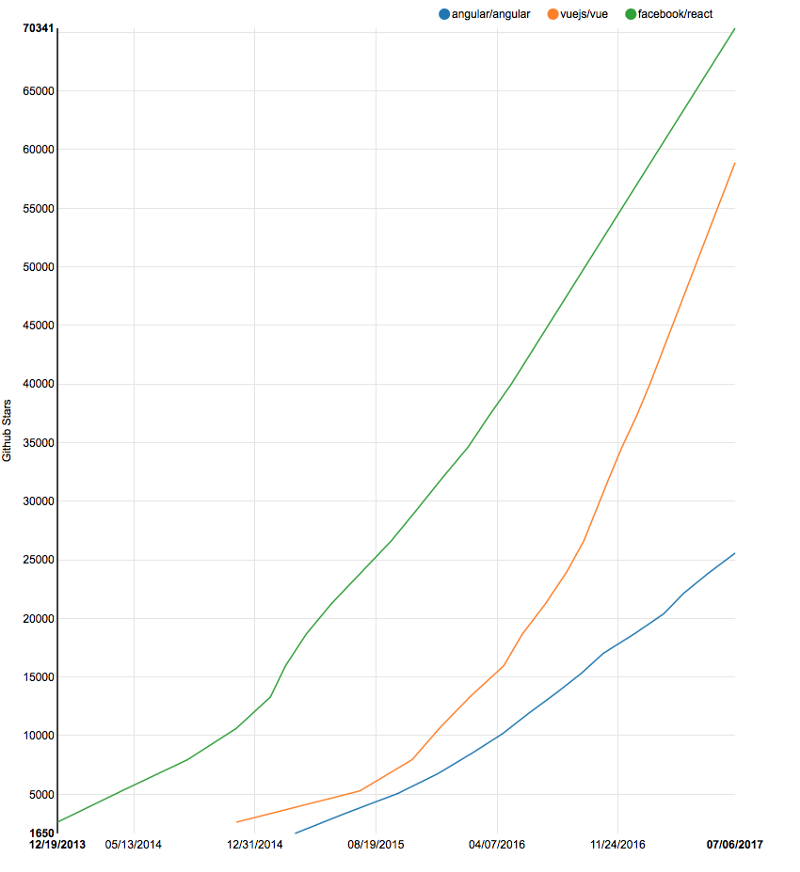
A Github Stars History для Angular, React и Vue (Источник)
Апдейт: Спасибо Полу Хеншелю за то, что указал на npm trends. Они показывают количество скачиваний для данных npm-пакетов и даже полезнее, как чистый взгляд на звезды GitHub.

Количество скачиваний для заданных npm-пакетов в течение двух лет
Angular, React и Vue сложно сравнить в Google Trends из-за их разнообразных имен и версий. Одним из способов получить приблизительные значения может быть поиск в категории “Internet & technologies”. Вот результат:
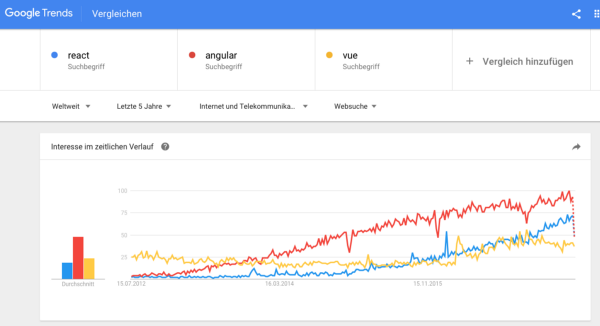
Ну, что ж. Vue до 2014 года не существовало — значит, тут что-то не так. La Vue по-французски — “вид”, “взгляд”, или “мнение”. Может быть, дело в этом. Сравнение “VueJS” с “Angular” или “React” несправедливо, так как у VueJS почти нет результатов, которые можно сравнить с остальными.
В таком случае, попробуем кое-что другое. Technology Radar от ThoughtWorks дает хорошее представление о том, как технологии эволюционируют в течение времени. Redux находится на стадии принятия(принятия в проектах!) и он был бесценен на ряде проектов ThoughtWorks. Vue.js на стадии испытаний(испытайте!). Его описывают, как легковесную и гибкую альтернативу Angular с более низкой кривой обучения. Angular 2 находится на стадии оценки — он успешно используется командами ThoughtWorks, но пока не имеет настоятельных рекомендаций.
В соответствии с последним опросом StackOverflow 2017, React любят 67% опрошенных разработчиков, а AngularJS — 52%. “Отсутствие интересу к продолжению разработки” регистрирует большие значения для AngularJS(48%) в сравнении с React(33%). Vue не входит в первую десятку ни в одном из случаев. Далее, есть опрос statejs.com, сравнивающий “front-end фреймворки”. Самые интересные факты: React и Angular обладают 100%-й известностью, Vue незнаком 23%-м опрошенных людей. Касательно “удовлетворенности”, React набрал 92% для варианта “использовал бы снова”, Vue — 89%, Angular 2 — только 65%.
Как насчет другого опроса об удовлетворенности пользователей? Эрик Элиотт запустил один в октябре 2016-го, чтобы оценить Angular 2 и React. Лишь 38% опрошенных людей использовали бы Angular 2 снова, в то время как 84% использовали бы снова React.
API React-а достаточно стабилен, как заявляет об этом Facebook в своих принципах проектирования. Существуют также скрипты, помогающие мигрировать с вашего текущего API на новый: попробуйте react-codemod. Миграции достаточно просты и здесь нет такой вещи(и необходимости в ней), как LTS версии. В этом посте на Reddit люди отмечают, что апгрейд на самом деле никогда не был проблемой. Команда React написала пост об их схеме версионирования. Когда они добавляют предупреждение об устаревании, они оставляют его для остальной части текущей релизной версии до того момента, пока поведение не будет изменено в следующей мажорной версии. Планов выпустить новую мажорную версию нет — v14 выпущена в октябре 2015-го, v15 опубликована в апреле 2016-го, а у v16 пока нет даты релиза. Обновление не должно стать проблемой, как недавно заметил один из основных разработчиков React.
Что касается Angular, есть пост о версионировании и релизах Angular начиная с релиза v2. Будет одно мажорное обновление каждые шесть месяцев и период устаревания(deprecation period), как минимум шесть месяцев(два мажорных релиза). Существуют экспериментальные API, помеченные в документации более коротким периодом устаревания. Официального анонса нет, но в соответствии с этой статьей, команда Angular анонсировала LTS версии начиная с Angular 4. Они будут поддерживаться как минимум год после следующего мажорного релиза. Это значит, что Angular 4 будет поддерживаться багфиксами и важными патчами как минимум до сентября 2018-го. В большинстве случаев, обновление со второй до четвертой версии Angular также просто, как обновление зависимостей Angular. Angular также предоставляет руководство с информацией о том, какие понадобятся изменения в дальнейшем.
Процесс обновления с Vue 1.x до 2.0 должен быть простым для небольшого приложения — команда разработчиков утверждает, что 90% API осталось без изменений. Имеется приятный инструмент для диагностики обновления и помощи во время миграции, работающий из консоли. Один из разработчиков отметил, что обновление с v1 до v2 до сих пор не приносит особого удовольствия на больших приложениях. К сожалению, roadmap-а для следующего мажорного релиза или информации о планах создания LTS версий нет.
Еще кое-что: Angular — это цельный фреймворк, предлагающий кучу вещей в комплекте. React гибче, чем Angular, и вы, вероятно, столкнетесь с использованием более независимых, неустаканенных, быстроразвивающихся библиотек — это означает, что вам придется самостоятельно заботиться о соответствующих обновлениях и миграциях. Это может нанести вред, если определенные пакеты больше не поддерживаются или если какой-то другой пакет в определенный момент становится стандартом де-факто.
Если у вас есть HTML-разработчики, которые не хотят углубляться в JavaScript, вам лучше выбрать Angular или Vue. React повлечет за собой увеличение количества JavaScript-а(позже мы поговорим об этом).
У вас есть дизайнеры, работающие в непосредственной близости с кодом? Пользователь “pier25” отмечает в своем Reddit-посте, что выбирать React имеет смысл, если вы работаете в Facebook, где каждый разработчик — супергерой. В реальном мире, вы не всегда найдете дизайнера, способного модифицировать JSX — по существу, работать с HTML-шаблонами будет намного проще.
Хорошая новость относительно Angular это то, что новый Angular 2-разработчик из другой компании сможет быстро ознакомиться со всеми необходимыми соглашениями. Каждый проект на React отличается в плане архитектурных решений и разработчикам нужно будет знакомиться с настройками конкретного проекта.
Angular также хорош, если у вас есть разработчики с ООП-бэкграундом или те, кто не любят JavaScript. Чтобы заострить на этом внимание, цитата Манеша Чанда:
“Я не JavaScript-девелопер. Мой бэкграунд — создание крупномасштабных корпоративных систем с использованием “настоящих” платформ для разработки ПО. Я начинал в 1997-м, разрабатывая приложения на C, C++, Pascal, Ada и Fortran. (...) Я могу точно сказать, что JavaScript для меня просто белиберда. Будучи MVP в Microsoft и экспертом, я хорошо понимаю TypeScript. Я также не рассматриваю Facebook, как компанию-разработчика ПО. Однако, Google и Microsoft уже крупнейшие инноваторы в этой сфере. Я чувствую себя более комфортно, работая с продуктом, у которого есть хорошая поддержка от Google или Microsoft. Также (...) с моим бэкграундом, я знаю, что у Microsoft даже большие планы для TypeScript”
Ну… Видимо, я должен упомянуть, что Манеш Чанд является региональным директором в Microsoft.
Все обсуждаемые фреймворки основаны на компонентах. Компонент получает что-то на вход и после внутренних вычислений возвращает отрендеренный шаблон UI(область входа / выхода с сайта или элемент списка to-do) на выходе. Определенные компоненты должно быть легко переиспользовать на веб-странице или в других компонентах. Например, у вас мог бы быть компонент сетки(состоящий из шапки и нескольких компонентов для рядов) с разнообразными свойствами(колонки, информация о шапке, data rows, и т.д.) и возможностью переиспользования этого компонента с разными данными на другой странице. Вот всеобъемлющая статья о компонентах на тот случай, если вам захочется изучить их получше.
И React, и Vue превосходно подходят для работы с “тупыми” компонентами: небольшие функции, не имеющие состояния, которые получают что-то на вход и возвращают элементы на выходе.
React фокусируется на использовании JavaScript ES6. Vue использует JavaScript ES5 либо ES6.
Angular зависит от TypeScript. Это дает большую консистентность в примерах и в опенсорсных проектах(примеры React можно найти в ES5 или в ES6). Это также вводит такие понятия, как декораторы или статическая типизация. Статическая типизация полезна для инструментов для анализа кода, типа автоматического рефакторинга, перехода к определению и т.д. — они должны уменьшить количество багов в приложении, хотя консенсус по поводу их использования, определенно, не достигнут. Эрик Элиот не согласен с этим в своей статье “Шокирующий секрет статических типов”. Дэниэл С Вонг говорит, что использование статических типов не вредит и что хорошо иметь разработку через тестирование(TDD) и статическую типизацию одновременно.
Вам, вероятно, следует знать о том, что вы можете использовать Flow, чтобы включить проверку типов в React. Это инструмент для статической проверки типов, разработанный Facebook для JavaScript. Flow также можно интегрировать в VueJS.
Если вы пишете код на TypeScript, вы уже не пишете стандартный JavaScript. Несмотря на рост, у TypeScript до сих пор крошечное число пользователей, по сравнению со всем языком JavaScript. Один из рисков может заключаться в том, что вы будете двигаться в неверном направлении, поскольку TypeScript может — хотя и вряд ли — исчезнуть со временем. Помимо того, TypeScript создает приличный оверхед на проектах(на обучение) — можете больше почитать об этом в Сравнении Angular 2 и React от Эрика Элиотта.
Апдейт: Джеймс Рейвенскрофт написал к этой статье комментарий о том, что у TypeScript первоклассная поддержка JSX — компоненты можно легко проверить на соответствие типу. Так что, если вам нравится TypeScript и вы хотите использовать React, это не должно быть проблемой.
React нарушает устоявшиеся best practices. Десятилетиями разработчики пытались разделить шаблоны и встроенную джаваскриптовую логику, но в JSX они опять перемешаны. Может быть, это звучит ужасно, но вам следует послушать речь Питера Ханта “React: Переосмысление best practices”(от октября 2013-го). Он указывает на то, что разделение шаблонов и логики — это просто разделение технологий, а не ответственности. Вы должны создавать компоненты вместо шаблонов. Компоненты переиспользуемы, интегрируемы и удобны для unit-тестирования.
JSX — это опциональный препроцессор с HTML-подобным синтаксисом, который затем компилируется в JavaScript. Отсюда некоторые странности — например, вам нужно использовать className вместо class, потому что последний является в JavaScript зарезервированным ключевым словом. JSX — большое преимущество для разработки, так как у вас все будет в одном и том же месте, а также быстрее будут работать автокомплит и проверки на стадии компиляции. Когда вы допускаете ошибку в JSX, React не компилирует код и выводит номер строки, в которой допущена ошибка. Angular 2 тихо падает в рантайме(возможно, этот аргумент некорректен, если вы пользуетесь AOT с Angular).
JSX подразумевает, что все в React = JavaScript — он используется и для JSX-шаблонов, и для логики. Кори Хаус указывает в своей статье от января 2016-го: “Angular 2 продолжает внедрять ‘JS’ в HTML. React внедряет ‘HTML’ в JS”. Это хорошо, потому что JavaScript мощнее, чем HTML.
Шаблоны в Angular представляют собой усовершенствованный HTML со специальным языком Angular(штуки, вроде ngIf или ngFor). В то время, как React требует знания JavaScript, Angular заставляет вас учить специфичный для Angular синтаксис.
Vue предлагает “однофайловые компоненты”. Это похоже на компромисс относительно разделения ответственности — шаблоны, скрипты и стили в одном файле, но в трех различных, упорядоченных секциях. Это значит, что вы получаете подсветку синтаксиса, поддержку CSS и возможность легко использовать препроцессоры типа Jade или SCSS. Я прочитал в других статьях, что JSX проще дебажить, потому что Vue не показывает синтаксические ошибки в HTML. Это не так, поскольку Vue конвертирует HTML в render-функции — поэтому ошибки показываются без проблем(Спасибо Винициусу Рейзу за комментарий и поправки!).
Примечание: Если вам нравится задумка с JSX и вам хочется использовать его в Vue, вы можете использовать babel-plugin-transform-vue-jsx.
Angular — больше фреймворк, чем библиотека, так как предоставляет убедительные предложения о том, как ваше приложение должно быть структурировано, а также имеет больше функционала из коробки. Angular — это “цельное решение” — включены “батарейки” и вам предоставляется возможность удобного старта. Вам не нужно проводить анализ библиотек, решать вопрос с роутингом и т.п. — вы можете просто начать работать.
React и Vue, с другой стороны, универсально гибки. Их библиотеки можно совмещать с любого рода пакетами(их достаточно много для React в npm, но у Vue пакетов меньше, так как он еще достаточно молод). Используя React, вы можете даже заменить саму библиотеку на ее API-совместимую альтернативу, такую как Inferno. С большей гибкостью, однако, появляется большая ответственность — для React не существует правил и и ограничительных рекомендаций. Каждый проект требует принятия решения относительно его архитектуры, и все может легко пойти не так, как планировалось.
С другой стороны, Angular поставляется с запутанным клубком систем для сборки, бойлерплейтов, линтеров и других пожирателей времени, с которыми придется иметь дело. Это верно и для React в случае использования стартер-китов или бойлерплейтов. Конечно, они очень полезны, React работает из коробки, и это, может быть для вас способ его изучить. Иногда разнообразие инструментов, необходимых для работы в JavaScript-окружении называют “усталостью от JavaScript”. Вот статья Эрика Клеммонса, который сказал следующее:
По-прежнему существует множество инструментов, к которым вы не привыкли, в момент когда вы начинаете работать с фреймворком. Они генерируются, но возможно многие разработчики не понимают, что происходит у них под капотом, либо требуется много времени, чтобы это понять.
Vue кажется самым чистым и легким из трех фреймворков. У GitLab есть пост о принятии решения в пользу Vue.js(октябрь 2016-го):
Vue.js прекрасно поставляется отлично сбалансированным в плане того, что он может сделать для вас и того, что вам нужно делать самостоятельно. (...) Vue.js всегда находится в пределах досягаемости; прочная, но гибкая сетка готова помочь сохранить эффективность вашего программирования и свести связанные с DOM страдания к минимуму.
Им нравится простота и легкость использования — исходный код очень читабелен и документация или внешние библиотеки не нужны. Все достаточно просто. Vue.js “не делает далекоидущих предположений о большей части чего-либо”. Имеется также подкаст о решении GitLab.
Другой пост о переходе на Vue от Pixeljets. React “был большим шагом вперед для мира JS в плане state-awareness, и он показал множеству людей реальное функциональное программирование хорошим, практичным способом”. Одним из серьезных минусов React по сравнению с Vue является проблема разбиения компонентов на более мелкие компоненты из-за ограничений JSX. Вот цитата из статьи:
Для меня и моей команды важна читабельность кода, но также крайне важно то, чтобы написание кода приносило удовольствие. Нет ничего приятного в том, чтобы создать 6 компонентов, если вы разрабатываете простенький виджет-калькулятор. Во многих ситуациях это также плохо в плане поддержки, модификаций или визуальной переработки какого-то виджета, так как вам надо перемещаться по множеству файлов/функций и по-отдельности проверять каждый маленький кусочек HTML. Опять же, я не предлагаю писать монолиты — я предлагаю использовать в повседневной разработке компоненты вместо микрокомпонентов.
На Hacker news и Reddit есть интересные дискуссии об этом посте — в наличии аргументы от недовольных и дальнейших сторонников Vue.
Разрабатывать UI сложно, так как состояния присутствуют везде — данные меняются с течением времени, что влечет за собой увеличение сложности. Определенные способы работы с состоянием оказывают большую помощь, когда приложение разрастается и становится более сложным. Для небольших приложений это может быть перебор, и что-то типа Vanilla JS было бы достаточно.
Как это работает? Компоненты описывают UI в определенный момент времени. Когда данные изменяются, фреймворк перерисовывает UI-компонент целиком — отображаемые данные всегда актуальны. Мы может назвать эту идею “UI как функция”.
React часто работает в паре с Redux. Redux описывает себя в трех фундаментальных принципах:
Другими словами: состояние приложения целиком находится в дереве объектов внутри единого хранилища. Это помогает отлаживать приложение и кое-какая функциональность становится проще для реализации. Состояние в read-only режиме и может быть изменено только через “экшены”, чтобы избежать состояния гонки(также полезно для отладки). “Редьюсеры” пишутся, чтобы указать, как “экшены” могут трансформировать состояние.
Большая часть туториалов и бойлерплейтов включают в себя Redux, но вы можете использовать React без него(или вам может быть вообще не нужен Redux в вашем проекте). Redux добавляет сложность и достаточно серьезные ограничения для вашего кода. Если вы изучаете React, вам стоит подумать об изучении чистого React перед тем, как вы перейдете к Redux. Вам определенно стоит прочесть “Вам может быть не нужен Redux” Дэна Абрамова.
Некоторые разработчики предлагают использовать Mobx вместо Redux. Можете думать о нем, как о “автоматическом Redux”, который упрощает использование и понимание с самого начала. Если хотите посмотреть, вам стоит начать с введения. Вы можете также почитать это полезное сравнение Redux и MobX от Робина. Тот же автор также предлагает информацию о переходе с Redux на MobX. Этот список полезен, если вы хотите проверить другие Flux-библиотеки. И, если вы пришли из мира MVC, вы захотите прочесть статью “Философия Redux (если вы уже знаете MVC)” Михаила Левковского.
Vue можно использовать с Redux, но он предлагает Vuex как свое собственное решение.
Большое отличие между React и Angular — одно- или двустороннее связывание. Двустороннее связывание в Angular меняет модель состояния, когда элемент пользовательского интерфейса(к примеру, поле ввода) обновляется. React идет только одним путем: сначала обновляет модель и затем отрисовывает элемент. Подход Angular чище в коде и проще для реализации разработчиком. Подход React позволяет получить лучшее понимание о том, что происходит с данными, потому что поток данных течет лишь в одном направлении(это делает отладку проще).
Оба подхода имеют плюсы и минусы. Вам нужно понять эти идеи и определить, влияют ли они на ваше решение о выборе фреймворка. И статья “Двустороннее связывание: Angular 2 и React”, и этот вопрос на StackOverflow предоставляют хорошие объяснения. Здесь вы можете найти интерактивные примеры кода(возрастом в 3 года, только для Angular 1 и React). Последнее, но тем не менее важное: Vue поддерживает и одностороннее, и двустороннее связывание(одностороннее по-умолчанию).
Если хотите почитать больше, имеется длинная статья о различных типах состояния и управлении состоянием в Angular-приложениях(от Виктора Савкина).
Angular включает в себя dependency injection, паттерн, в котором один объект(сервис) предоставляет зависимости другому объекту(клиенту). Это дает большую гибкость и более чистый код. Статья “Понять dependency injection” в деталях объясняет эту идею.
Паттерн Модель-Вид-Контроллер(MVC) делит проект на три части — модель, вид и контроллер. У Angular, как у MVC-фреймворка, имеется поддержка MVC из коробки. У React есть лишь V — что будет M и C нужно решить вам самим.
Вы можете работать с React или Vue просто добавляя JavaScript-библиотеку к исходникам. Это невозможно с Angular, потому что он использует TypeScript.
Мы все больше движемся в сторону микросервисов и микроприложений. React и Vue предоставляют вам полный контроль над размером приложения, позволяя включить только те вещи, которые действительно нужны. Они дают больше гибкости при переходе от SPA к микросервисам, используя части бывшего приложения. Angular лучше подходит для SPA, так как для использования в микросервисах он, вероятно, слишком раздут.
Как отмечает Кори Хаус:
JavaScript быстро развивается, и React позволяет вам заменять небольшие фрагменты вашего приложения более подходящими библиотеками вместо того, чтобы ждать и надеяться на то, что ваш фреймворк обновят. Философия маленьких, интегрируемых, узкоспециализированных инструментов никогда не выйдет из моды.
Некоторые люди также используют React для не-SPA вебсайтов(например, для сложных форм или мастеров). Даже Facebook использует React не для главной страницы, а, скорее, для определенных страниц и возможностей.
Обратная сторона функциональности: Angular довольно-таки раздут. Размер сжатого gzip-ом файла — 143кб, по сравнению с 23кб Vue и 43кб React.
И у React, и у Vue есть Virtual DOM, который должен увеличивать производительность. Если вам интересно, можете почитать об отличиях между Virtual DOM и DOM, а также о реальных преимуществах Virtual DOM в React. Один из авторов Virtual DOM также отвечает на вопросы, связанные с производительностью на StackOverflow.
Чтобы проверить производительность, я посмотрел великолепный js-framework-benchmark. Вы можете сами скачать и запустить его или посмотреть на интерактивную таблицу с результатами. Перед тем, как проверить результаты, вам нужно знать, что фреймворки обманывают бенчмарки — такие замеры производительности не должны быть основой принятия решений.

Производительность Angular, React и Vue (Источник)

Выделение памяти в Мб (Источник)
Чтобы подытожить: у Vue прекрасная производительность и лучшее распределение памяти, но все фреймворки действительно довольно рядом друг с другом, по сравнению с особенно медленными или особенно быстрыми фреймворками(типа Inferno). Еще раз: тесты производительности следует рассматривать как побочные данные, не для вынесения вердикта.
Facebook использует Jest, чтобы тестировать свой код на React. Здесь есть сравнение Jest и Mocha, и есть статья о том, как использовать Enzyme с Mocha. Enzyme — библиотека для тестирования, написанная на JavaScript, используемая Airbnb(в сочетании с Jest, Karma и другими тест-раннерами). Если вы хотите почитать побольше, имеются старые статьи про тестирование в React(здесь и здесь).
Далее, существует Jasmine, как тестовый фреймворк для Angular 2. В статье Эрика Элиотта говорится о том, что Jasmine “приводит к миллионам способов написания тестов и утверждений, нуждающихся в тщательном прочтении каждого из них, чтобы понять, что он делает”. Вывод также раздут и труден для чтения. Есть несколько информативных статей про интеграцию Angular 2 с Karma и Mocha. Также есть старое видео(от 2015-го) о тестовых стратегиях в Angular 2.
У Vue есть недостатки в тестировании, но Эван написал в своем превью от 2017-го, что команда планирует поработать над этим. Они рекомендуют использовать Karma. Vue работает с Jest, также есть тестовая утилита avoriaz.
Универсальные приложения внедряются в веб, на десктопы, а также в мир нативных приложений.
И React, и Angular поддерживают нативную разработку. У Angular есть NativeScript(при поддержке Telerik) для нативных приложений и Ionic Framework для гибридных приложений. С React вы можете попробовать react-native-renderer, чтобы разрабатывать кроссплатформенные приложения для iOS или Android, или react-native для нативных приложений. Большое число приложений(включая Facebook; за подробностями на Showcase) сделаны с помощью react-native.
JavaScript-фреймворки рендерят страницы на клиенте. Это плохо для воспринимаемой производительности, пользовательского опыта в целом и SEO. Серверный рендеринг — это плюс. У всех трет фреймворков имеются библиотеки, чтобы помочь с этим. Для React это next.js, у Vue есть nuxt.js, и у Angular есть… Angular Universal.
У Angular, определенно, крутая кривая обучения. Он обладает всеобъемлющей документацией, но иногда это может вас расстраивать, потому что ряд вещей сложнее, чем кажется. Даже если вы глубоко понимаете JavaScript, вам нужно изучить, что происходит под капотом фреймворка. Вначале установка магическая, предлагает большое число встроенных пакетов и кода. Это можно рассматривать, как минус из-за большой, сразу существующей экосистемы, которую вам нужно со временем изучить. С другой стороны, это может и хорошо в определенных ситуациях, поскольку многие решения уже приняты. С React вам, скорее всего, придется принять множество внушительных решений относительно использования third-party библиотек. Существует 16 различных flux-пакетов для управления состоянием, которые можно выбрать для React.
Vue довольно прост для изучения. Компании переходят на Vue из-за того, что он кажется значительно более простым для начинающих разработчиков. Тут вы сможете почитать, как некто описывает переезд своей команды с Angular на Vue. По информации от другого пользователя, приложение на React в его компании было таким сложным, что новый разработчик не идти в ногу с кодом. С Vue разрыв между младшим и старшим разработчиком сокращается, и они могут взаимодействовать проще и с меньшим количеством багов, проблем и времени на разработку.
Некоторые люди утверждают, что то, что они сделали на React было бы написано лучше с использованием Vue. Если вы — неопытный JavaScript разработчик — или в последние 10 лет работали в основном с jQuery — вам стоит подумать об использовании Vue. Сдвиг парадигмы более выражен при переходе на React. Vue выглядит больше как чистый JavaScript в тоже время привнося некоторые новые идеи: компоненты, событийная модель и однонаправленный data-flow. Также у него небольшой размер.
Тем временем, у Angular и React свой собственный подход к вещам. Они могут мешать вам, потому что вам нужно приспосабливаться под них, чтобы заставить их работать. Это может быть вредно из-за меньшей гибкости и крутой кривой обучения. Это также может быть и полезно, поскольку вас заставляют изучать правильные подходы в процессе изучения технологии. С Vue вы можете работать в стиле старомодного JavaScript. Это может быть проще вначале, но может стать проблемой в долгосрочной перспективе, если все сделать не верно.
Когда речь заходит об отладке, плюс React и Vue в меньшем количестве магии. Охота на баги проще, потому что есть лишь несколько мест, куда нужно смотреть, и у стектрейсов лучше видны отличия между собственным кодом и исходниками библиотеки. Работающие с React сообщают, что им никогда не требовалось читать исходный код библиотеки. Однако, отлаживая ваш код вашего приложения на Angular, вам часто нужно отлаживать внутренности Angular, чтобы понять лежащую в его основе модель. С другой стороны, сообщения об ошибках должны стать более чистыми и информативными начиная с Angular 4.
Хотите проверить исходники самостоятельно? Хотите увидеть, как все складывается?
Возможно, вам стоит сначала проверить вот эти GitHub-репозитории: React(github.com/facebook/react), Angular(github.com/angular/angular) и Vue(github.com/vuejs/vue).
Как выглядит синтаксис? ValueCoders сравнивают синтаксис Angular, React и Vue.
Хорошо бы также увидеть все на продакшене — вместе с исходным кодом, на котором все основано. На TodoMVC есть список из десятков вариантов одного и того же Todo-приложения, написанного на различных JavaScript-фреймворках — можете сравнить решения на Angular, React и Vue. RealWorld разрабатывает реальное приложение(клон Medium) и у них есть готовые решения для Angular(4+) и React(с Redux). Для Vue работа в процессе.
Также есть некоторые реальные приложения, на которые вы можете посмотреть. Решения на базе React:
Приложения на Angular:
А также решения на Vue:
И React, и Angular, и Vue достаточно круты, и никого из них нельзя поставить сильно выше остальных. Доверьтесь своему нутру. Эта последний кусочек развлекательного цинизма может помочь вам принять решение:
Грязный маленький секрет — “современная JavaScript-разработка” не имеет ничего общего с созданием веб-сайтов — это создание пакетов, которые могут использоваться людьми, создающими библиотеки, которые могут использоваться людьми, создающими фреймворки, которым люди, пишущие туториалы и ведущие курсы могут обучать. Не уверен, что кто-то действительно что-то создает для настоящих пользователей.
Это преувеличение, конечно, но в нем возможно есть доля правды. Да, в экосистеме JavaScript есть много лишнего шума. Может быть, вы найдете множество более привлекательных альтернатив во время ваших поисков — постарайтесь не быть ослепленным новейшим блестящим фреймворком.

Дааа, вы его приняли!
Отлично! Читайте о том, как начать разрабатывать с Angular, React или Vue (скоро, подписывайтесь на меня в Twitter для обновлений).
React JS, Angular & Vue JS — Quickstart & Comparison (восьмичасовое введение и сравнение трех фреймворков)
Angular vs. React (vs. Vue) — the DEAL breaker (короткое, но превосходное сравнение от Доминика Т)
Angular 2 vs. React — the ultimate dance off (неплохое сравнение от Эрика Элиотта)
React vs. Angular vs. Ember vs. Vue.js (сравнение трех фреймворков в форме заметок от Гекана Сари)
React vs. Angular (понятное сравнение двух фреймворков)
Can Vue fight for the Throne with React? (приятное сравнение с большим количеством примеров кода)
10 reasons, why I moved from Angular to React (еще одно неплохое сравнение от Робина Вируча)
All JavaScript frameworks are terrible (большая заметка обо всех основных фреймворках от Мэтта Берджесса)
|
Метки: author Synoptic reactjs javascript angularjs framework react.js angular vue comparison |
Постъядерный караван в 35 килобайт |

this.view = {}; // объект для хранения элементов DOM
this.view.crew = document.getElementById('game-stat-crew'); // находим элемент при запуске игры
// ...
this.view.crew.innerHTML = world.crew; // записываем число людей в караване как обычный html
function WorldState(stats) {
this.day = 0; // текущий день, с десятичными долям
this.crew = stats.crew; // количество людей
this.oxen = stats.oxen; // количество быков
this.food = stats.food; // запасы еды
this.firepower = stats.firepower; // единиц оружия
this.cargo = stats.cargo; // товаров для торговли
this.money = stats.money; //деньги
// лог событий, содержит день, описание и характеристику
// { day: 1, message: "Хорошо покушали", goodness: Goodness.positive}
this.log = [];
// координаты каравана, пункта отправления и назначения
this.caravan = { x: 0, y: 0};
this.from = {x: 0, y: 0};
this.to = {x: 0, y: 0};
this.distance = 0; // сколько всего пройдено
this.gameover = false; // gameover
this.stop = false; // маркер для обозначения того, что караван стоит
this.uiLock = false; // маркер для блокировки интерфейса
}
Game = {
plugins: [], // генераторы событий,
};
Game.init = function () {
// создаем мир по стартовому состоянию которое хранится в отдельном файле
// в объекте StartWorldState в директории data
this.world = new WorldState(StartWorldState);
var i;
for (i = 0; i < this.plugins.length; i++) {
this.plugins[i].init(this.world);
}
};
// добавление плагинов
Game.addPlugin = function (plugin) {
this.plugins.push(plugin);
};
// игровой цикл
Game.update = function () {
if (this.world.gameover) return; // никаких действий
var i;
for (i = 0; i < this.plugins.length; i++) {
this.plugins[i].update();
}
};
Game.resume = function () {
this.interval = setInterval(this.update.bind(this), GameConstants.STEP_IN_MS);
};
Game.stop = function () {
clearInterval(this.interval);
};
Game.restart = function () {
this.init();
this.resume();
};
CorePlugin = {};
CorePlugin.init = function (world) {
this.world = world; // запоминаем world
this.time = 0; // общее время с начала игры, в миллисекундах
this.dayDelta = GameConstants.STEP_IN_MS / GameConstants.DAY_IN_MS; // сколько дней в одном шаге игру
this.lastDay = -1; // отслеживаем наступление нового дня
this.speedDelta = Caravan.FULL_SPEED - Caravan.SLOW_SPEED; // разница между полной и минимальной скоростью
};
CorePlugin.update = function () {
if (this.world.stop) return; // если стоим - никаких изменений
this.time += GameConstants.STEP_IN_MS; // увеличение времени
this.world.day = Math.ceil(this.time / GameConstants.DAY_IN_MS); // текущий день, целый
// Движение каравана в зависимости от того, сколько дней прошло
this.updateDistance(this.dayDelta, this.world);
// события связанные с наступлением нового дня
if (this.lastDay < this.world.day) {
this.consumeFood(this.world);
this.lastDay = this.world.day;
}
};
// еда выдается один раз в день
CorePlugin.consumeFood = function (world) {
world.food -= world.crew * Caravan.FOOD_PER_PERSON;
if (world.food < 0) {
world.food = 0;
}
};
// обновить пройденный путь в зависимости от потраченного времени в днях
CorePlugin.updateDistance = function (dayDelta, world) {
var maxWeight = getCaravanMaxWeight(world);
var weight = getCaravanWeight(world);
// при перевесе - Caravan.SLOW_SPEED
// при 0 весе - Caravan.FULL_SPEED
var speed = Caravan.SLOW_SPEED + (this.speedDelta) * Math.max(0, 1 - weight/maxWeight);
// расстояние, которое может пройти караван при такой скорости
var distanceDelta = speed * dayDelta;
// вычисляем расстояние до цели
var dx = world.to.x - world.caravan.x;
var dy = world.to.y - world.caravan.y;
// если мы находимся около цели - останавливаемся
if(areNearPoints(world.caravan, world.to, Caravan.TOUCH_DISTANCE)){
world.stop = true;
return;
}
// до цели еще далеко - рассчитываем угол перемещения
// и получаем смещение по координатам
var angle = Math.atan2(dy, dx);
world.caravan.x += Math.cos(angle) * distanceDelta;
world.caravan.y += Math.sin(angle) * distanceDelta;
world.distance += distanceDelta;
};
// регистрируем плагин в игре
Game.addPlugin(CorePlugin);
var RandomEvents = [
{
goodness: Goodness.negative,
stat: 'crew',
value: -4,
text: 'На караван напал смертокогть! Людей: -$1'
},
{
goodness: Goodness.negative,
stat: 'food',
value: -10,
text: 'Кротокрысы на привале сожрали часть еды. Пропало пищи: -$1'
},
{
goodness: Goodness.positive,
stat: 'money',
value: 15,
text: 'У дороги найден мертвый путешественник. На теле найдены монеты. Денег: +$1'
},
{
goodness: Goodness.positive,
stat: 'crew',
value: 2,
text: 'Вы встретили одиноких путников, которые с радостью хотят присоединиться к вам. Людей: +$1'
},

var DeathDialogs = {
"start": {
icon: "images/pic_death.jpg", // ссылка на url картинки
title: "Погибший в пустоши", // заголовок диалога
desc: "", // статический текст диалога
desc_action: function (world, rule) { // функция для создания вычисляемого текста диалога
var desc = " Причина смерти: "+rule.text+". Вы сумели пройти "+Math.floor(world.distance) + " миль и накопить "+Math.floor(world.money) + " денег";
desc += "Может быть, следующим караванщикам повезет больше?"
return desc;
},
choices:[ // массив выборов
{
text: 'Начать новую игру', // текст на кнопке
action: function () { return "stop"; } // функция, возвращающая тег следующего диалога
}
]
},
};
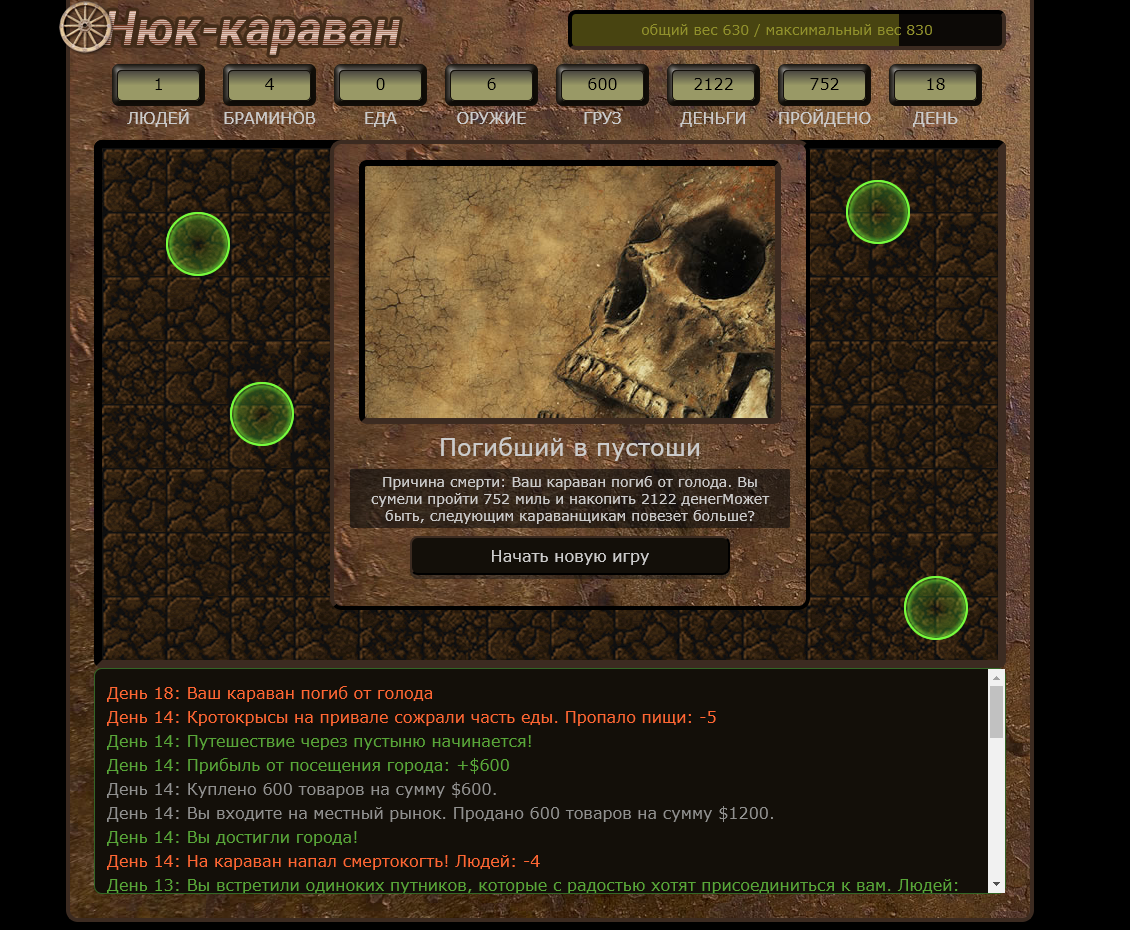
// ... где-то в недрах update у объекта-плагина
// останавливаем караван, аналог паузы
world.stop = true;
// просим показать диалог с набором развилок из DeathDialogs
// в развилки будут передаваться аргументы world и rule
DialogWindow.show(DeathDialogs, world, rule, this);
DeathCheck.onDialogClose = function () {
Game.restart();
};
|
Метки: author Zoolander разработка игр javascript html html5 текстовые игры fallout игровая механика игростроение |
Постъядерный караван в 35 килобайт |
this.view = {}; // объект для хранения элементов DOM
this.view.crew = document.getElementById('game-stat-crew'); // находим элемент при запуске игры
// ...
this.view.crew.innerHTML = world.crew; // записываем число людей в караване как обычный html
function WorldState(stats) {
this.day = 0; // текущий день, с десятичными долям
this.crew = stats.crew; // количество людей
this.oxen = stats.oxen; // количество быков
this.food = stats.food; // запасы еды
this.firepower = stats.firepower; // единиц оружия
this.cargo = stats.cargo; // товаров для торговли
this.money = stats.money; //деньги
// лог событий, содержит день, описание и характеристику
// { day: 1, message: "Хорошо покушали", goodness: Goodness.positive}
this.log = [];
// координаты каравана, пункта отправления и назначения
this.caravan = { x: 0, y: 0};
this.from = {x: 0, y: 0};
this.to = {x: 0, y: 0};
this.distance = 0; // сколько всего пройдено
this.gameover = false; // gameover
this.stop = false; // маркер для обозначения того, что караван стоит
this.uiLock = false; // маркер для блокировки интерфейса
}
Game = {
plugins: [], // генераторы событий,
};
Game.init = function () {
// создаем мир по стартовому состоянию которое хранится в отдельном файле
// в объекте StartWorldState в директории data
this.world = new WorldState(StartWorldState);
var i;
for (i = 0; i < this.plugins.length; i++) {
this.plugins[i].init(this.world);
}
};
// добавление плагинов
Game.addPlugin = function (plugin) {
this.plugins.push(plugin);
};
// игровой цикл
Game.update = function () {
if (this.world.gameover) return; // никаких действий
var i;
for (i = 0; i < this.plugins.length; i++) {
this.plugins[i].update();
}
};
Game.resume = function () {
this.interval = setInterval(this.update.bind(this), GameConstants.STEP_IN_MS);
};
Game.stop = function () {
clearInterval(this.interval);
};
Game.restart = function () {
this.init();
this.resume();
};
CorePlugin = {};
CorePlugin.init = function (world) {
this.world = world; // запоминаем world
this.time = 0; // общее время с начала игры, в миллисекундах
this.dayDelta = GameConstants.STEP_IN_MS / GameConstants.DAY_IN_MS; // сколько дней в одном шаге игру
this.lastDay = -1; // отслеживаем наступление нового дня
this.speedDelta = Caravan.FULL_SPEED - Caravan.SLOW_SPEED; // разница между полной и минимальной скоростью
};
CorePlugin.update = function () {
if (this.world.stop) return; // если стоим - никаких изменений
this.time += GameConstants.STEP_IN_MS; // увеличение времени
this.world.day = Math.ceil(this.time / GameConstants.DAY_IN_MS); // текущий день, целый
// Движение каравана в зависимости от того, сколько дней прошло
this.updateDistance(this.dayDelta, this.world);
// события связанные с наступлением нового дня
if (this.lastDay < this.world.day) {
this.consumeFood(this.world);
this.lastDay = this.world.day;
}
};
// еда выдается один раз в день
CorePlugin.consumeFood = function (world) {
world.food -= world.crew * Caravan.FOOD_PER_PERSON;
if (world.food < 0) {
world.food = 0;
}
};
// обновить пройденный путь в зависимости от потраченного времени в днях
CorePlugin.updateDistance = function (dayDelta, world) {
var maxWeight = getCaravanMaxWeight(world);
var weight = getCaravanWeight(world);
// при перевесе - Caravan.SLOW_SPEED
// при 0 весе - Caravan.FULL_SPEED
var speed = Caravan.SLOW_SPEED + (this.speedDelta) * Math.max(0, 1 - weight/maxWeight);
// расстояние, которое может пройти караван при такой скорости
var distanceDelta = speed * dayDelta;
// вычисляем расстояние до цели
var dx = world.to.x - world.caravan.x;
var dy = world.to.y - world.caravan.y;
// если мы находимся около цели - останавливаемся
if(areNearPoints(world.caravan, world.to, Caravan.TOUCH_DISTANCE)){
world.stop = true;
return;
}
// до цели еще далеко - рассчитываем угол перемещения
// и получаем смещение по координатам
var angle = Math.atan2(dy, dx);
world.caravan.x += Math.cos(angle) * distanceDelta;
world.caravan.y += Math.sin(angle) * distanceDelta;
world.distance += distanceDelta;
};
// регистрируем плагин в игре
Game.addPlugin(CorePlugin);
var RandomEvents = [
{
goodness: Goodness.negative,
stat: 'crew',
value: -4,
text: 'На караван напал смертокогть! Людей: -$1'
},
{
goodness: Goodness.negative,
stat: 'food',
value: -10,
text: 'Кротокрысы на привале сожрали часть еды. Пропало пищи: -$1'
},
{
goodness: Goodness.positive,
stat: 'money',
value: 15,
text: 'У дороги найден мертвый путешественник. На теле найдены монеты. Денег: +$1'
},
{
goodness: Goodness.positive,
stat: 'crew',
value: 2,
text: 'Вы встретили одиноких путников, которые с радостью хотят присоединиться к вам. Людей: +$1'
},
var DeathDialogs = {
"start": {
icon: "images/pic_death.jpg", // ссылка на url картинки
title: "Погибший в пустоши", // заголовок диалога
desc: "", // статический текст диалога
desc_action: function (world, rule) { // функция для создания вычисляемого текста диалога
var desc = " Причина смерти: "+rule.text+". Вы сумели пройти "+Math.floor(world.distance) + " миль и накопить "+Math.floor(world.money) + " денег";
desc += "Может быть, следующим караванщикам повезет больше?"
return desc;
},
choices:[ // массив выборов
{
text: 'Начать новую игру', // текст на кнопке
action: function () { return "stop"; } // функция, возвращающая тег следующего диалога
}
]
},
};
// ... где-то в недрах update у объекта-плагина
// останавливаем караван, аналог паузы
world.stop = true;
// просим показать диалог с набором развилок из DeathDialogs
// в развилки будут передаваться аргументы world и rule
DialogWindow.show(DeathDialogs, world, rule, this);
DeathCheck.onDialogClose = function () {
Game.restart();
};
|
Метки: author Zoolander разработка игр javascript html html5 текстовые игры fallout игровая механика игростроение |
GeekUniversity открывает набор на факультет разработки игр |

|
Метки: author mary_arti разработка игр блог компании mail.ru group mail.ru обучение программированию geekuniversity |
GeekUniversity открывает набор на факультет разработки игр |
|
Метки: author mary_arti разработка игр блог компании mail.ru group mail.ru обучение программированию geekuniversity |
[Из песочницы] Что такое dinghy или как ускорить docker |



cat ~/.dinghy/preferences.yml
:preferences:
:proxy_disabled: false
:fsevents_disabled: false
:create:
provider: virtualbox
disk: 30000
export DOCKER_MACHINE_NAME=dinghy и пр.), то использование обычных докер машин параллельно с динги может принести много хлопот.169b86af85da codekitchen/dinghy-http-proxy:2.5 "/app/docker-entry..." 4 hours ago Up 4 hours 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp, 19322/tcp, 0.0.0.0:19322->19322/udp dinghy_http_proxy
hostname в этом файле. Далее, при обращении на данный хост, динги найдёт нужную запись и перенаправит на нужный контейнер. Профит.|
Метки: author jesprider разработка веб-сайтов docker dinghy docker for mac docker toolbox docker-machine docker-osx-dev |
[Из песочницы] Что такое dinghy или как ускорить docker |
cat ~/.dinghy/preferences.yml
:preferences:
:proxy_disabled: false
:fsevents_disabled: false
:create:
provider: virtualbox
disk: 30000
export DOCKER_MACHINE_NAME=dinghy и пр.), то использование обычных докер машин параллельно с динги может принести много хлопот.169b86af85da codekitchen/dinghy-http-proxy:2.5 "/app/docker-entry..." 4 hours ago Up 4 hours 0.0.0.0:80->80/tcp, 0.0.0.0:443->443/tcp, 19322/tcp, 0.0.0.0:19322->19322/udp dinghy_http_proxy
hostname в этом файле. Далее, при обращении на данный хост, динги найдёт нужную запись и перенаправит на нужный контейнер. Профит.|
Метки: author jesprider разработка веб-сайтов docker dinghy docker for mac docker toolbox docker-machine docker-osx-dev |
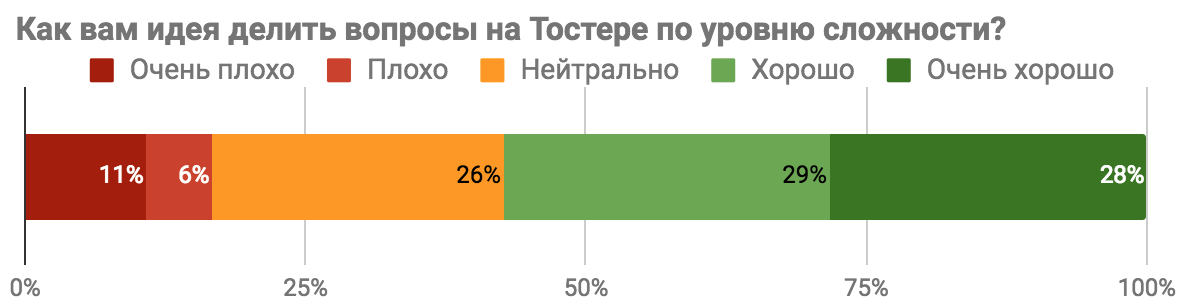
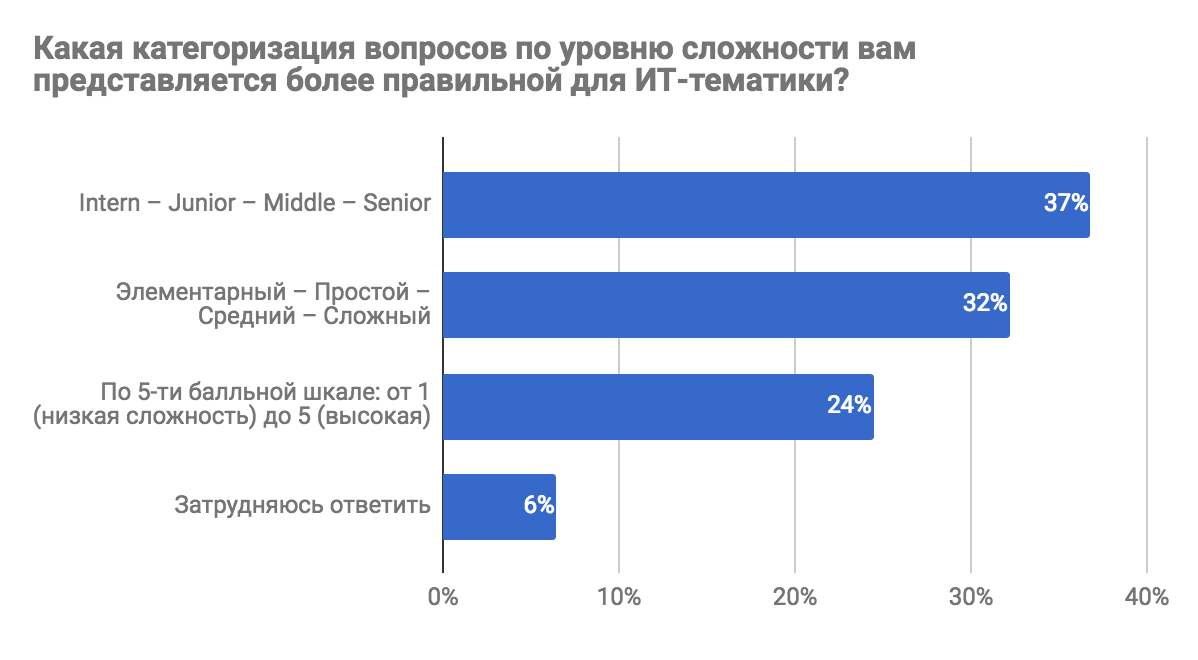
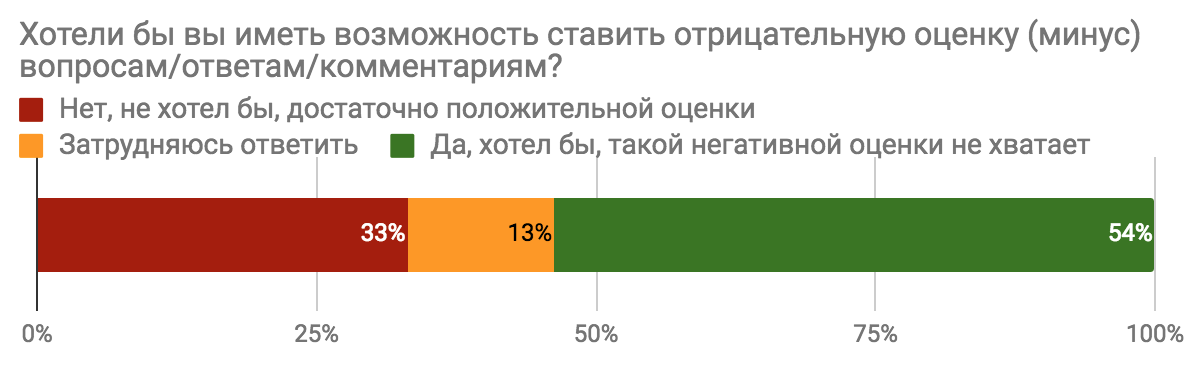
Результаты опроса «Каким бы вы хотели видеть Toster.ru?» |





|
Метки: author toster управление сообществом блог компании тостер тостер toster.ru amp;a вопросы и ответы it опрос |
Результаты опроса «Каким бы вы хотели видеть Toster.ru?» |
|
Метки: author toster управление сообществом блог компании тостер тостер toster.ru amp;a вопросы и ответы it опрос |
Эксперимент: действительно ли все разбираются в дизайне? |



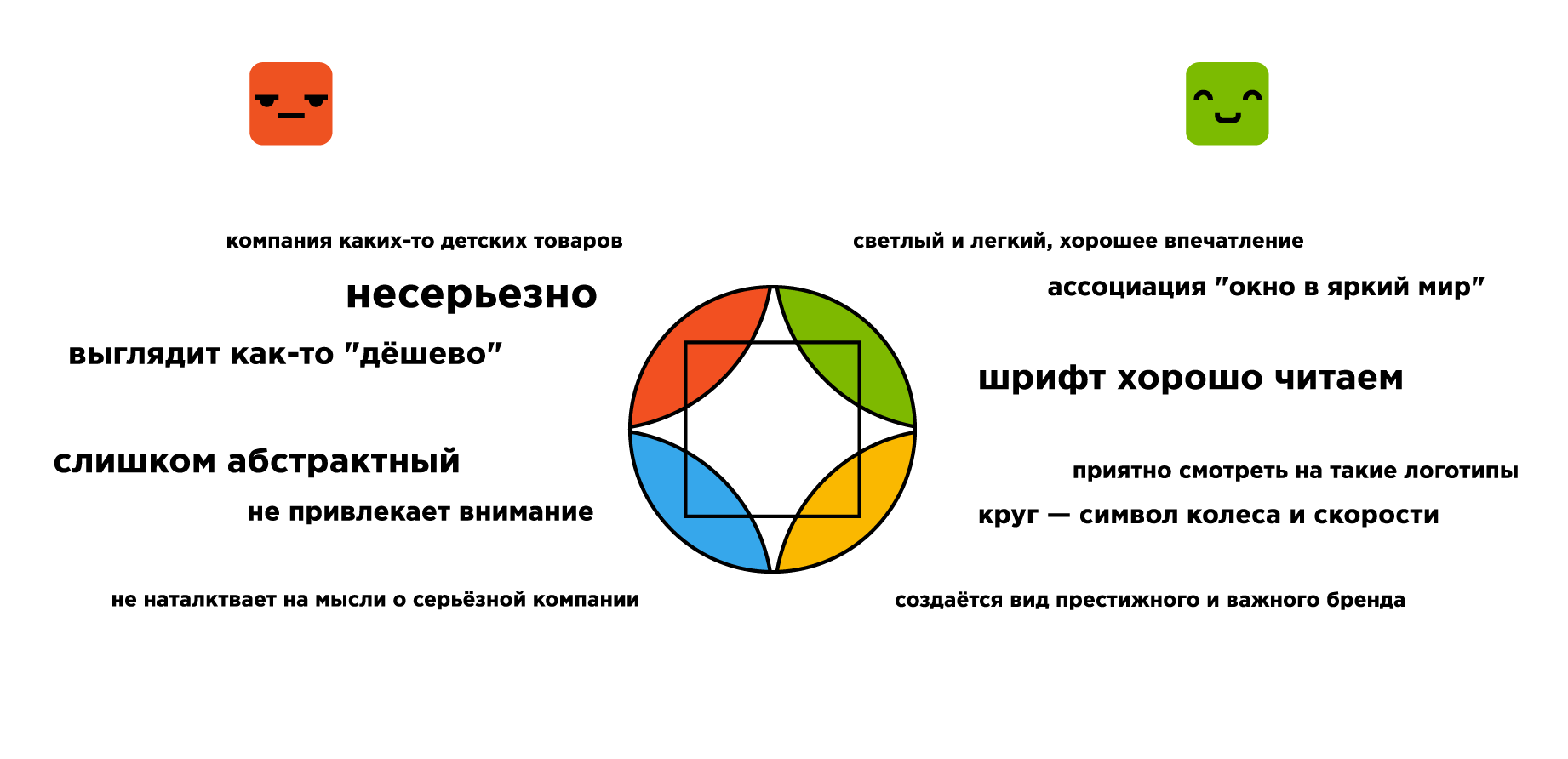
«Яркие цвета и простые формы обеспечили легкость восприятия и просмотра логотипа, округлость притянула взгляд и внимание своей совершенной, без изъянов и излишеств формой. Просто, увлекательно и с намеком на совершенство». [М, 17, маркетолог-программист]Это очень приятно, особенно если учесть, что этот логотип сделал лично я за пару минут. А ведь я даже не дизайнер! Тем не менее 57% опрошенных связали успех моей вымышленной фирмы «Polska Moto» именно с логотипом. Они искали причины в сочетании цветов, похожести на Майкрософт, простоте и нестандартности:
«Возможно, повлияла идея гармоничного сочетания разных элементов — четырех основных цветов, круга и квадрата, при этом логотип остался мягким и скругленным, глаз ни за что не цепляется». [Ж, 23, интернет-маркетинг]


Логотип не отражает сущности компании, он безлик и похож на сотни других. Первая ассоциация с ним — Microsoft, а не мотоиндустрия. [Ж, 26, фрилансер]
Цвета логотипа слишком заезжены. Вызывают сильную ассоциацию с Microsoft или Google. [М, 18 лет, —]… или все-таки хорошо?
Минималистичность, геометрия, цветовая гамма соответствует корпорации Майкрософт, что изначально внушает уверенность. [Ж, 17, маркетолог]
Ассоциация с Windows / Google (цвета и геометрия) [Ж, 22, юрист ]Группы по-разному восприняли факт «несоответствия сфере»:
Скучный лого, никак не намекают на связь с мотопроизводством. Цвета не соответствуют специализации (слишком ярко).
Не понятно чем занимается компания. Это скорее похоже на сферу развлечений. [Ж, 23, графический дизайнер]
Яркий логотип, не построенный на стереотипных идеях о мотоциклах. При этом внешне создаётся вид престижного и важного бренда. [М, 24, дизайнер-фрилансер]
… логотип не заезженный и не похож на другие логотипы производителей авто-механики или авто. [Ж, 16, программист]Мнения разошлись и насчет цветовой гаммы логотипа:
Слишком несерьёзно выглядит сочетание цветов [М, 22, —]
Я считаю, что все детали помешали успеху компании. Форма и цвета больше подходят логотипу цирка [Ж, 30, дизайн]
Логотип напоминает калейдоскоп и вызывает этим приятные воспоминая из детства. Этим располагает к себе. [Ж, 30, техник строитель / домохозяйка]
Простота логотипа и его броскость (яркость) легко запоминались пользователями и угадывались [М, 25, инженер-программист]
… Меня крайне смущает квадрат в центре. [Ж, 24, дизайн]
Мне кажется, этот контур квадрата здесь абсолютно лишний… [Ж, 19, студент издательского дела]Однако группа с «успешной компанией» нашла в квадрате глубинный смысл:
Из-за квадрата [Ж, 32, дизайн]
В интернете ходит картинка с тремя кругами: дорого, долго, качественно. И на пересечении их результат. Я думаю в квадрате они тоже выделили что у них все и сразу :) [М, 21, разработчик]
…4 стихии мира (кружок — сам логотип) и многогранность этого мира, так как внутри квадрат. Для мототехники это важно. [Ж, 21, логист и переводчик]Опрашиваемые даже не смогли определиться, простой это логотип или сложный:
… он визуально сложный [М, 24, Веб]
Перегруженность деталями и цветами [М, 20, студент-программист]
Лого создан на основе простых форм и цветов [Ж, 25, дизайнер полиграфии]
Простой, яркий, запоминающийся логотип [Ж, 23, педагог]


|
Метки: author Danya_Baranov работа с векторной графикой графический дизайн блог компании логомашина бизнес эксперимент интересное полезно |
Эксперимент: действительно ли все разбираются в дизайне? |
«Яркие цвета и простые формы обеспечили легкость восприятия и просмотра логотипа, округлость притянула взгляд и внимание своей совершенной, без изъянов и излишеств формой. Просто, увлекательно и с намеком на совершенство». [М, 17, маркетолог-программист]Это очень приятно, особенно если учесть, что этот логотип сделал лично я за пару минут. А ведь я даже не дизайнер! Тем не менее 57% опрошенных связали успех моей вымышленной фирмы «Polska Moto» именно с логотипом. Они искали причины в сочетании цветов, похожести на Майкрософт, простоте и нестандартности:
«Возможно, повлияла идея гармоничного сочетания разных элементов — четырех основных цветов, круга и квадрата, при этом логотип остался мягким и скругленным, глаз ни за что не цепляется». [Ж, 23, интернет-маркетинг]
Логотип не отражает сущности компании, он безлик и похож на сотни других. Первая ассоциация с ним — Microsoft, а не мотоиндустрия. [Ж, 26, фрилансер]
Цвета логотипа слишком заезжены. Вызывают сильную ассоциацию с Microsoft или Google. [М, 18 лет, —]… или все-таки хорошо?
Минималистичность, геометрия, цветовая гамма соответствует корпорации Майкрософт, что изначально внушает уверенность. [Ж, 17, маркетолог]
Ассоциация с Windows / Google (цвета и геометрия) [Ж, 22, юрист ]Группы по-разному восприняли факт «несоответствия сфере»:
Скучный лого, никак не намекают на связь с мотопроизводством. Цвета не соответствуют специализации (слишком ярко).
Не понятно чем занимается компания. Это скорее похоже на сферу развлечений. [Ж, 23, графический дизайнер]
Яркий логотип, не построенный на стереотипных идеях о мотоциклах. При этом внешне создаётся вид престижного и важного бренда. [М, 24, дизайнер-фрилансер]
… логотип не заезженный и не похож на другие логотипы производителей авто-механики или авто. [Ж, 16, программист]Мнения разошлись и насчет цветовой гаммы логотипа:
Слишком несерьёзно выглядит сочетание цветов [М, 22, —]
Я считаю, что все детали помешали успеху компании. Форма и цвета больше подходят логотипу цирка [Ж, 30, дизайн]
Логотип напоминает калейдоскоп и вызывает этим приятные воспоминая из детства. Этим располагает к себе. [Ж, 30, техник строитель / домохозяйка]
Простота логотипа и его броскость (яркость) легко запоминались пользователями и угадывались [М, 25, инженер-программист]
… Меня крайне смущает квадрат в центре. [Ж, 24, дизайн]
Мне кажется, этот контур квадрата здесь абсолютно лишний… [Ж, 19, студент издательского дела]Однако группа с «успешной компанией» нашла в квадрате глубинный смысл:
Из-за квадрата [Ж, 32, дизайн]
В интернете ходит картинка с тремя кругами: дорого, долго, качественно. И на пересечении их результат. Я думаю в квадрате они тоже выделили что у них все и сразу :) [М, 21, разработчик]
…4 стихии мира (кружок — сам логотип) и многогранность этого мира, так как внутри квадрат. Для мототехники это важно. [Ж, 21, логист и переводчик]Опрашиваемые даже не смогли определиться, простой это логотип или сложный:
… он визуально сложный [М, 24, Веб]
Перегруженность деталями и цветами [М, 20, студент-программист]
Лого создан на основе простых форм и цветов [Ж, 25, дизайнер полиграфии]
Простой, яркий, запоминающийся логотип [Ж, 23, педагог]
|
Метки: author Danya_Baranov работа с векторной графикой графический дизайн блог компании логомашина бизнес эксперимент интересное полезно |
[Из песочницы] Генерация родословного дерева на основе данных Wikipedia |
@BeforeClass
public static void Start() {
driver = DriverHelper.getDriver();
}
@Test
public void testGetDriver() {
driver.navigate().to("https://ru.wikipedia.org/wiki/%D0%A0%D1%8E%D1%80%D0%B8%D0%BA");
assertTrue(driver.getTitle().equals("Рюрик — Википедия"));
}
@AfterClass
public static void Stop() {
driver.quit();
}
public final class DriverHelper{
private static final int TIMEOUT = 30;
public static WebDriver getDriver() {
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(TIMEOUT, TimeUnit.SECONDS);
return driver;
}
}
@Test
public void testGetPerson() throws Exception {
PersonPage page = new PersonPage(driver);
Person person = page.getPerson("https://ru.wikipedia.org/wiki/Владимир_Александрович");
assertTrue(person.getName().equals("Владимир Александрович"));
assertTrue(person.getUrl().equals(
"https://ru.wikipedia.org/wiki/
%D0%92%D0%BB%D0%B0%D0%B4%D0%B8%D0%BC%D0%B8%D1%80_
%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%B2%D0%B8%D1%87"));
}
public Person getPerson(String url) throws MalformedURLException {
driver.navigate().to(url);
String name = getName();
Person person = new Person(driver.getCurrentUrl());
person.setName(name);
return person;
}
private String getName() throws MalformedURLException {
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
return namePage;
}
@Test
public void testGetChildrenUrl() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
Person person = children.get(0);
assertTrue(person.getUrl().equals("https://ru.wikipedia.org/wiki/
%D0%98%D0%B3%D0%BE%D1%80%D1%8C_
%D0%A0%D1%8E%D1%80%D0%B8%D0%BA%D0%BE%D0%B2%D0%B8%D1%87"));
}
public List getChildrenUrl() throws MalformedURLException {
List childrenLinks = driver.findElements(
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]//a"));
List children = new ArrayList();
for (WebElement link : childrenLinks) {
Person person = new Person(link.getAttribute("href"));
children.add(person);
}
return children;
}
@Test
public void testChildrenSize() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 16);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Ярославич_(князь_галицкий)");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Мария_Добронега");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
public void setChild(int childId) {
if (!children.contains(childId)) {
children.add(childId);
}
}
public final class GenerateGenealogicalTree {
public static void main(String[] args) throws Exception {
String url = getUrl(args);
GenealogicalTree tree = getGenealogicalTreeByUrl(url);
saveResultAndQuit(tree);
}
public static GenealogicalTree getGenealogicalTreeByUrl(String url) throws MalformedURLException {
WebDriver driver = DriverHelper.getDriver();
Person person = new Person(url);
GenealogicalTree tree = new GenealogicalTree(person);
PersonPage page = new PersonPage(driver);
while (tree.hasUnvisitingPerson()) {
String currentUrl = tree.getCurrentUrl();
Person currentPerson = page.getPerson(currentUrl);
tree.setCurrentPerson(currentPerson);
if (!tree.isCurrentPersonDeleted()) {
List children = page.getChildrenUrl();
tree.setChildren(children);
}
tree.updatingCurrentPerson();
}
driver.quit();
return tree;
}
}
public final class GenealogicalTree {
private List allPersons;
private int indexCurrentUnvisitedPerson;
private boolean isCurrentPersonDeleted;
}
public GenealogicalTree(Person person) {
if (person == null) {
throw new IllegalArgumentException("Укажите непустого основателя династии");
}
allPersons = new ArrayList();
allPersons.add(person);
indexCurrentUnvisitedPerson = 0;
isCurrentPersonDeleted = false;
}
public boolean hasUnvisitingPerson() {
return indexCurrentUnvisitedPerson < allPersons.size();
}
public String getCurrentUrl() {
return allPersons.get(indexCurrentUnvisitedPerson).getUrl();
}
public void setCurrentPerson(Person currentPerson) {
int indexDuplicate = allPersons.indexOf(currentPerson);
if ((0 <= indexDuplicate) && (indexDuplicate < indexCurrentUnvisitedPerson)) {
removePerson(indexDuplicate);
} else {
allPersons.get(indexCurrentUnvisitedPerson).copyMainData(currentPerson);
isCurrentPersonDeleted = false;
}
}
@Override
public boolean equals(Object object) {
if ((object == null) || (!(object instanceof Person))) {
return false;
}
Person person = (Person) object;
return this.url.equals(person.url);
}
@Override
public int hashCode() {
return this.url.hashCode();
}
private void removePerson(int indexDuplicate) {
int idRemovedPerson = allPersons.get(indexCurrentUnvisitedPerson).getId();
int idDuplicate = allPersons.get(indexDuplicate).getId();
for (int i = 0; i < indexCurrentUnvisitedPerson; i++) {
Person person = allPersons.get(i);
person.replaceChild(idRemovedPerson, idDuplicate);
}
allPersons.remove(indexCurrentUnvisitedPerson);
isCurrentPersonDeleted = true;
}
public void replaceChild(int oldId, int newId) {
if (oldId == newId) {
return;
}
if (!children.contains(oldId)) {
return;
}
children.remove((Object) oldId);
setChild(newId);
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) {
id = allPersons.get(index).getId();
} else {
allPersons.add(person);
id = person.getId();
}
allPersons.get(indexCurrentUnvisitedPerson).setChild(id);
}
}
public void updatingCurrentPerson() {
if (isCurrentPersonDeleted) {
isCurrentPersonDeleted = false;
} else {
indexCurrentUnvisitedPerson++;
}
}
public class MySqlHelper {
private static final String url = "jdbc:mysql://localhost:3306/genealogicaltree"
+ "?serverTimezone=UTC&useUnicode=yes&characterEncoding=UTF-8";
private static final String user = "root";
private static final String password = "";
private static Connection connection;
private static Statement statement;
private static ResultSet resultSet;
public static void saveTree(String tableName, List tree) throws MalformedURLException {
try {
connection = DriverManager.getConnection(url, user, password);
statement = connection.createStatement();
String table = createTable(tableName);
statement.executeUpdate(table);
for (Person person : tree) {
String insert = insertPerson(tableName, person);
statement.executeUpdate(insert);
}
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
} finally {
try {
connection.close();
} catch (SQLException se) {
}
try {
statement.close();
} catch (SQLException se) {
}
}
}
private static String createTable(String tableName) {
StringBuilder sql = new StringBuilder();
sql.append("CREATE TABLE " + tableName + " (");
sql.append("id INTEGER not NULL, ");
sql.append("name VARCHAR(255), ");
sql.append("url VARCHAR(2048), ");
sql.append("children VARCHAR(255), ");
sql.append("PRIMARY KEY ( id ))");
return sql.toString();
}
private static String insertPerson(String tableName, Person person) {
StringBuilder sql = new StringBuilder();
sql.append("INSERT INTO genealogicaltree." + tableName);
sql.append("(id, name, url, nameUrl, children, parents, numberGeneration) \n VALUES (");
sql.append(person.getId() + ",");
sql.append("'" + person.getName() + "',");
sql.append("'" + person.getUrl() + "',");
sql.append("'" + person.getChildren() + "',");
sql.append(");");
return sql.toString();
}
}
private static void saveResultAndQuit(GenealogicalTree tree) throws Exception {
Timestamp timestamp = new Timestamp(System.currentTimeMillis());
String tableName = "generate" + timestamp.getTime();
MySqlHelper.saveTree(tableName, tree.getGenealogicalTree());
}
driver.navigate().to("https://ru.wikipedia.org/wiki/Ярослав_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 3);
driver.navigate().to("https://ru.wikipedia.org/wiki/Людовик_VII");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to("https://ru.wikipedia.org/wiki/Галеран_IV_де_Бомон,_граф_де_Мёлан");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Юрий_Ярославич_(князь_туровский)");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
public List getChildrenUrl() throws MalformedURLException {
waitLoadPage();
List childrenLinks = getChildrenLinks();
List children = new ArrayList();
for (WebElement link : childrenLinks) {
if (DriverHelper.isSup(link)) {
continue;
}
Person person = new Person(link.getAttribute("href"));
person.setNameUrl(link.getText());
if (person.isCorrectNameUrl()) {
children.add(person);
}
}
return children;
}
private List getChildrenLinks() {
List childrenLinks = DriverHelper.getElements(driver,
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]" +
"//a[not(@class='new' or @class='extiw')]"));
return childrenLinks;
}
private void waitLoadPage() {
this.driver.findElement(By.cssSelector("#firstHeading"));
}
public final class DriverHelper {
/**
* Возвращает список элементов без ожидания их появления.
* По умолчанию установлено неявное ожидание - это значит, что если на
* странице нет заданных элементов, то пустой результат будет выведен не
* сразу, а через таймаут, что приведет к потере времени. Чтобы не терять
* время создан этот метод, где неявное ожидание обнуляется, а после поиска
* восстанавливается.
*/
public static List getElements(WebDriver driver, By by) {
driver.manage().timeouts().implicitlyWait(0, TimeUnit.SECONDS);
List result = driver.findElements(by);
driver.manage().timeouts().implicitlyWait(DriverHelper.TIMEOUT, TimeUnit.SECONDS);
return result;
}
public static boolean isSup(WebElement element) {
String parentTagName = element.findElement(By.xpath(".//..")).getTagName();
return parentTagName.equals("sup");
}
}
public class Person {
private String nameUrl;
public boolean isCorrectNameUrl() {
Pattern p = Pattern.compile("^[\\D]+.+");
Matcher m = p.matcher(nameUrl);
return m.matches();
}
}
public List getChildrenUrl() {
waitLoadPage();
if (DriverHelper.hasAnchor(driver)) {
return new ArrayList();
}
...
}
public final class DriverHelper {
...
public static boolean hasAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef() != null;
}
...
}
@Test
public void testEmptyChildrenInPersonWithAnchor() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Александрович");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to(
"https://ru.wikipedia.org/wiki/Владимир_Александрович#.D0.A1.D0.B5.D0.BC.D1.8C.D1.8F");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
private String getName() throws MalformedURLException {
waitLoadPage();
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
if (!DriverHelper.hasAnchor(driver)) {
return namePage;
}
String anchor = DriverHelper.getAnchor(driver);
List list = DriverHelper.getElements(driver, By.id(anchor));
if (list.size() == 0) {
return namePage;
}
String name = list.get(0).getText().trim();
return name.isEmpty() ? namePage : name;
}
public final class DriverHelper {
...
public static String getAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef();
}
...
}
| id | name | children | url | urlName |
|---|---|---|---|---|
| 8 | Пелагея | [] | ссылка | Пелагея |
| 9 | Марфа | [] | ссылка | Марфа |
| 10 | Софья | [] | ссылка | Софья |
| 15 | Анна | [] | ссылка | Анна |
| 23 | Евдокия (младшая) | [] | ссылка | Евдокия |
| 26 | Феодора | [] | ссылка | Феодора |
| 28 | Мария | [] | ссылка | Мария |
| 29 | Феодосия | [] | ссылка | Феодосия |
| 36 | Дети Петра I | [] | ссылка | Наталья |
| 133 | Семья | [] | ссылка | Александр |
| 360 | Брак и дети | [] | ссылка | Луана Оранско-Нассауская |
private List parents = new ArrayList();
private int numberGeneration = 0;
public void setParent(int parent) {
parents.add(parent);
}
public void setNumberGeneration(int numberGeneration) {
if (this.numberGeneration == 0) {
this.numberGeneration = numberGeneration;
}
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
Person currentPerson = allPersons.get(indexCurrentUnvisitedPerson);
int numberGeneration = currentPerson.getNumberGeneration();
numberGeneration++;
int idParent = currentPerson.getId();
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) { // Непервый родитель, номер поколения не трогаем
allPersons.get(index).setParent(idParent);
id = allPersons.get(index).getId();
} else { // Первый родитель
person.setNumberGeneration(numberGeneration);
person.setParent(idParent);
allPersons.add(person);
id = person.getId();
}
currentPerson.setChild(id);
}
}
|
Метки: author fonkost тестирование веб-сервисов открытые данные алгоритмы selenium seleniumwebdriver java wikipedia.org |
[Из песочницы] Генерация родословного дерева на основе данных Wikipedia |
@BeforeClass
public static void Start() {
driver = DriverHelper.getDriver();
}
@Test
public void testGetDriver() {
driver.navigate().to("https://ru.wikipedia.org/wiki/%D0%A0%D1%8E%D1%80%D0%B8%D0%BA");
assertTrue(driver.getTitle().equals("Рюрик — Википедия"));
}
@AfterClass
public static void Stop() {
driver.quit();
}
public final class DriverHelper{
private static final int TIMEOUT = 30;
public static WebDriver getDriver() {
WebDriver driver = new ChromeDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(TIMEOUT, TimeUnit.SECONDS);
return driver;
}
}
@Test
public void testGetPerson() throws Exception {
PersonPage page = new PersonPage(driver);
Person person = page.getPerson("https://ru.wikipedia.org/wiki/Владимир_Александрович");
assertTrue(person.getName().equals("Владимир Александрович"));
assertTrue(person.getUrl().equals(
"https://ru.wikipedia.org/wiki/
%D0%92%D0%BB%D0%B0%D0%B4%D0%B8%D0%BC%D0%B8%D1%80_
%D0%90%D0%BB%D0%B5%D0%BA%D1%81%D0%B0%D0%BD%D0%B4%D1%80%D0%BE%D0%B2%D0%B8%D1%87"));
}
public Person getPerson(String url) throws MalformedURLException {
driver.navigate().to(url);
String name = getName();
Person person = new Person(driver.getCurrentUrl());
person.setName(name);
return person;
}
private String getName() throws MalformedURLException {
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
return namePage;
}
@Test
public void testGetChildrenUrl() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
Person person = children.get(0);
assertTrue(person.getUrl().equals("https://ru.wikipedia.org/wiki/
%D0%98%D0%B3%D0%BE%D1%80%D1%8C_
%D0%A0%D1%8E%D1%80%D0%B8%D0%BA%D0%BE%D0%B2%D0%B8%D1%87"));
}
public List getChildrenUrl() throws MalformedURLException {
List childrenLinks = driver.findElements(
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]//a"));
List children = new ArrayList();
for (WebElement link : childrenLinks) {
Person person = new Person(link.getAttribute("href"));
children.add(person);
}
return children;
}
@Test
public void testChildrenSize() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Рюрик");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 1);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 16);
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Ярославич_(князь_галицкий)");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Мария_Добронега");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
public void setChild(int childId) {
if (!children.contains(childId)) {
children.add(childId);
}
}
public final class GenerateGenealogicalTree {
public static void main(String[] args) throws Exception {
String url = getUrl(args);
GenealogicalTree tree = getGenealogicalTreeByUrl(url);
saveResultAndQuit(tree);
}
public static GenealogicalTree getGenealogicalTreeByUrl(String url) throws MalformedURLException {
WebDriver driver = DriverHelper.getDriver();
Person person = new Person(url);
GenealogicalTree tree = new GenealogicalTree(person);
PersonPage page = new PersonPage(driver);
while (tree.hasUnvisitingPerson()) {
String currentUrl = tree.getCurrentUrl();
Person currentPerson = page.getPerson(currentUrl);
tree.setCurrentPerson(currentPerson);
if (!tree.isCurrentPersonDeleted()) {
List children = page.getChildrenUrl();
tree.setChildren(children);
}
tree.updatingCurrentPerson();
}
driver.quit();
return tree;
}
}
public final class GenealogicalTree {
private List allPersons;
private int indexCurrentUnvisitedPerson;
private boolean isCurrentPersonDeleted;
}
public GenealogicalTree(Person person) {
if (person == null) {
throw new IllegalArgumentException("Укажите непустого основателя династии");
}
allPersons = new ArrayList();
allPersons.add(person);
indexCurrentUnvisitedPerson = 0;
isCurrentPersonDeleted = false;
}
public boolean hasUnvisitingPerson() {
return indexCurrentUnvisitedPerson < allPersons.size();
}
public String getCurrentUrl() {
return allPersons.get(indexCurrentUnvisitedPerson).getUrl();
}
public void setCurrentPerson(Person currentPerson) {
int indexDuplicate = allPersons.indexOf(currentPerson);
if ((0 <= indexDuplicate) && (indexDuplicate < indexCurrentUnvisitedPerson)) {
removePerson(indexDuplicate);
} else {
allPersons.get(indexCurrentUnvisitedPerson).copyMainData(currentPerson);
isCurrentPersonDeleted = false;
}
}
@Override
public boolean equals(Object object) {
if ((object == null) || (!(object instanceof Person))) {
return false;
}
Person person = (Person) object;
return this.url.equals(person.url);
}
@Override
public int hashCode() {
return this.url.hashCode();
}
private void removePerson(int indexDuplicate) {
int idRemovedPerson = allPersons.get(indexCurrentUnvisitedPerson).getId();
int idDuplicate = allPersons.get(indexDuplicate).getId();
for (int i = 0; i < indexCurrentUnvisitedPerson; i++) {
Person person = allPersons.get(i);
person.replaceChild(idRemovedPerson, idDuplicate);
}
allPersons.remove(indexCurrentUnvisitedPerson);
isCurrentPersonDeleted = true;
}
public void replaceChild(int oldId, int newId) {
if (oldId == newId) {
return;
}
if (!children.contains(oldId)) {
return;
}
children.remove((Object) oldId);
setChild(newId);
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) {
id = allPersons.get(index).getId();
} else {
allPersons.add(person);
id = person.getId();
}
allPersons.get(indexCurrentUnvisitedPerson).setChild(id);
}
}
public void updatingCurrentPerson() {
if (isCurrentPersonDeleted) {
isCurrentPersonDeleted = false;
} else {
indexCurrentUnvisitedPerson++;
}
}
public class MySqlHelper {
private static final String url = "jdbc:mysql://localhost:3306/genealogicaltree"
+ "?serverTimezone=UTC&useUnicode=yes&characterEncoding=UTF-8";
private static final String user = "root";
private static final String password = "";
private static Connection connection;
private static Statement statement;
private static ResultSet resultSet;
public static void saveTree(String tableName, List tree) throws MalformedURLException {
try {
connection = DriverManager.getConnection(url, user, password);
statement = connection.createStatement();
String table = createTable(tableName);
statement.executeUpdate(table);
for (Person person : tree) {
String insert = insertPerson(tableName, person);
statement.executeUpdate(insert);
}
} catch (SQLException sqlEx) {
sqlEx.printStackTrace();
} finally {
try {
connection.close();
} catch (SQLException se) {
}
try {
statement.close();
} catch (SQLException se) {
}
}
}
private static String createTable(String tableName) {
StringBuilder sql = new StringBuilder();
sql.append("CREATE TABLE " + tableName + " (");
sql.append("id INTEGER not NULL, ");
sql.append("name VARCHAR(255), ");
sql.append("url VARCHAR(2048), ");
sql.append("children VARCHAR(255), ");
sql.append("PRIMARY KEY ( id ))");
return sql.toString();
}
private static String insertPerson(String tableName, Person person) {
StringBuilder sql = new StringBuilder();
sql.append("INSERT INTO genealogicaltree." + tableName);
sql.append("(id, name, url, nameUrl, children, parents, numberGeneration) \n VALUES (");
sql.append(person.getId() + ",");
sql.append("'" + person.getName() + "',");
sql.append("'" + person.getUrl() + "',");
sql.append("'" + person.getChildren() + "',");
sql.append(");");
return sql.toString();
}
}
private static void saveResultAndQuit(GenealogicalTree tree) throws Exception {
Timestamp timestamp = new Timestamp(System.currentTimeMillis());
String tableName = "generate" + timestamp.getTime();
MySqlHelper.saveTree(tableName, tree.getGenealogicalTree());
}
driver.navigate().to("https://ru.wikipedia.org/wiki/Ярослав_Святославич");
children = page.getChildrenUrl();
assertTrue(children.size() == 3);
driver.navigate().to("https://ru.wikipedia.org/wiki/Людовик_VII");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to("https://ru.wikipedia.org/wiki/Галеран_IV_де_Бомон,_граф_де_Мёлан");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
driver.navigate().to("https://ru.wikipedia.org/wiki/Юрий_Ярославич_(князь_туровский)");
children = page.getChildrenUrl();
assertTrue(children.size() == 5);
public List getChildrenUrl() throws MalformedURLException {
waitLoadPage();
List childrenLinks = getChildrenLinks();
List children = new ArrayList();
for (WebElement link : childrenLinks) {
if (DriverHelper.isSup(link)) {
continue;
}
Person person = new Person(link.getAttribute("href"));
person.setNameUrl(link.getText());
if (person.isCorrectNameUrl()) {
children.add(person);
}
}
return children;
}
private List getChildrenLinks() {
List childrenLinks = DriverHelper.getElements(driver,
By.xpath("//table[contains(@class, 'infobox')]//tr[th[.='Дети:']]" +
"//a[not(@class='new' or @class='extiw')]"));
return childrenLinks;
}
private void waitLoadPage() {
this.driver.findElement(By.cssSelector("#firstHeading"));
}
public final class DriverHelper {
/**
* Возвращает список элементов без ожидания их появления.
* По умолчанию установлено неявное ожидание - это значит, что если на
* странице нет заданных элементов, то пустой результат будет выведен не
* сразу, а через таймаут, что приведет к потере времени. Чтобы не терять
* время создан этот метод, где неявное ожидание обнуляется, а после поиска
* восстанавливается.
*/
public static List getElements(WebDriver driver, By by) {
driver.manage().timeouts().implicitlyWait(0, TimeUnit.SECONDS);
List result = driver.findElements(by);
driver.manage().timeouts().implicitlyWait(DriverHelper.TIMEOUT, TimeUnit.SECONDS);
return result;
}
public static boolean isSup(WebElement element) {
String parentTagName = element.findElement(By.xpath(".//..")).getTagName();
return parentTagName.equals("sup");
}
}
public class Person {
private String nameUrl;
public boolean isCorrectNameUrl() {
Pattern p = Pattern.compile("^[\\D]+.+");
Matcher m = p.matcher(nameUrl);
return m.matches();
}
}
public List getChildrenUrl() {
waitLoadPage();
if (DriverHelper.hasAnchor(driver)) {
return new ArrayList();
}
...
}
public final class DriverHelper {
...
public static boolean hasAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef() != null;
}
...
}
@Test
public void testEmptyChildrenInPersonWithAnchor() throws Exception {
driver.navigate().to("https://ru.wikipedia.org/wiki/Владимир_Александрович");
PersonPage page = new PersonPage(driver);
List children = page.getChildrenUrl();
assertTrue(children.size() == 5);
driver.navigate().to(
"https://ru.wikipedia.org/wiki/Владимир_Александрович#.D0.A1.D0.B5.D0.BC.D1.8C.D1.8F");
children = page.getChildrenUrl();
assertTrue(children.size() == 0);
}
private String getName() throws MalformedURLException {
waitLoadPage();
String namePage = driver.findElement(By.cssSelector("#firstHeading")).getText();
if (!DriverHelper.hasAnchor(driver)) {
return namePage;
}
String anchor = DriverHelper.getAnchor(driver);
List list = DriverHelper.getElements(driver, By.id(anchor));
if (list.size() == 0) {
return namePage;
}
String name = list.get(0).getText().trim();
return name.isEmpty() ? namePage : name;
}
public final class DriverHelper {
...
public static String getAnchor(WebDriver driver) throws MalformedURLException {
URL url = new URL(driver.getCurrentUrl());
return url.getRef();
}
...
}
| id | name | children | url | urlName |
|---|---|---|---|---|
| 8 | Пелагея | [] | ссылка | Пелагея |
| 9 | Марфа | [] | ссылка | Марфа |
| 10 | Софья | [] | ссылка | Софья |
| 15 | Анна | [] | ссылка | Анна |
| 23 | Евдокия (младшая) | [] | ссылка | Евдокия |
| 26 | Феодора | [] | ссылка | Феодора |
| 28 | Мария | [] | ссылка | Мария |
| 29 | Феодосия | [] | ссылка | Феодосия |
| 36 | Дети Петра I | [] | ссылка | Наталья |
| 133 | Семья | [] | ссылка | Александр |
| 360 | Брак и дети | [] | ссылка | Луана Оранско-Нассауская |
private List parents = new ArrayList();
private int numberGeneration = 0;
public void setParent(int parent) {
parents.add(parent);
}
public void setNumberGeneration(int numberGeneration) {
if (this.numberGeneration == 0) {
this.numberGeneration = numberGeneration;
}
}
public void setChildren(List children) {
if (isCurrentPersonDeleted) {
throw new IllegalArgumentException(
"Нельзя установить детей удаленной персоне. Текущая персона уже другая");
}
Person currentPerson = allPersons.get(indexCurrentUnvisitedPerson);
int numberGeneration = currentPerson.getNumberGeneration();
numberGeneration++;
int idParent = currentPerson.getId();
for (Person person : children) {
int index = allPersons.indexOf(person);
int id;
if (index >= 0) { // Непервый родитель, номер поколения не трогаем
allPersons.get(index).setParent(idParent);
id = allPersons.get(index).getId();
} else { // Первый родитель
person.setNumberGeneration(numberGeneration);
person.setParent(idParent);
allPersons.add(person);
id = person.getId();
}
currentPerson.setChild(id);
}
}
|
Метки: author fonkost тестирование веб-сервисов открытые данные алгоритмы selenium seleniumwebdriver java wikipedia.org |
Контроль опасных кассовых операций: интеграция видеонаблюдения с 1С |
|
Метки: author randall управление продажами erp- системы ecm/ сэд блог компании ivideon с:предприятие интеграция видеонаблюдение касса ivideon |
Контроль опасных кассовых операций: интеграция видеонаблюдения с 1С |
|
Метки: author randall управление продажами erp- системы ecm/ сэд блог компании ivideon с:предприятие интеграция видеонаблюдение касса ivideon |
Социнжиниринг в военной пропаганде |

— Мы обращаемся к вам, командир подводной лодки «U-507» капитан-лейтенант Блюм. С вашей стороны было очень опрометчиво оставить свою жену в Бремене, где в настоящее время проводит свой отпуск ваш друг капитан-лейтенант Гроссберг. Их уже, минимум, трижды видели вместе в ресторане, а ваша соседка фрау Моглер утверждает: ваши дети отправлены к матери в Мекленбург…
Цитата из «Операция «Гроза» — И. Бунич
«Военные власти проверили 20000 женщин. Свыше 80 процентов из них оказались больными венерическими заболеваниями. Среди проверенных женщин только 21 процент – проститутки. Остальные 79 процентов распределяются так: 61 процент – замужние женщины, вступившие в случайную связь, 18 процентов – девушки, знакомые военнослужащих (при этом 17 процентов в возрасте до 20 лет). Обе группы женщин оказались в большинстве своем членами быстрорастущего общества женщин „V“ (»Победа"), которые заявили о своем патриотическом стремлении утешать войска. А твоя девушка тоже среди них?".
Цитата из книги Крысько В. Г. — Секреты психологической войны (цели, задачи, методы, формы, опыт). Советую, там прямо весь опыт в методологии.
«Ежедневное меню объединенных сил:
Завтрак: яйцо, хлеб с маслом, 2 фрукта, фруктовый сок, молоко, кофе, чай. Обед: мясо, фасоль или картошка, бутерброд с сыром, сладости, фруктовый сок. Ужин: мясо, хлеб с маслом, зелень (овощи), яйцо, молоко, фрукты и фруктовый сок, кофе, чай. Пленные питаются так же, как солдаты объединенных сил».


«К лету 1940 г. германские передачи велись уже более чем на 30 языках. Один из руководителей нацистского иновещания сравнивал немецкие коротковолновые станции с дальнобойными орудиями, стреляющими через все границы. Чтобы пресечь влияние зарубежного иновещания на германское население, нацисты с 1 сентября 1939 г. запретили прослушивание иностранных радиопередач на территории Германии, была введена смертная казнь за распространение почерпнутых из них сведений.
После вступления Великобритании в войну в сентябре 1939 г. в структуре Би-Би-Си была создана Европейская служба, на которую возлагались задачи информационно-пропагандистской поддержки военных действий стран антигитлеровской коалиции на европейском театре военных действий. Передачи на европейскую аудиторию велись как на английском, так и на немецком, французском, португальском, испанском и других языках народов Европы. Стартовавшее еще в феврале 1938 г. немецкоязычное вещание Би-Би-Си быстро наращивало объем передач, совершенствовалось их содержание. Стремясь нейтрализовать воздействие британского вещания, государства нацистского блока организовали глушение радиопередач Би-Би-Си. В свою очередь, британские власти, убедившиеся в малой эффективности гитлеровской радиопропаганды, отказались от ответного глушения передач германского радио на Англию».
Беспалова А.Г., Корнилов Е.А., Короченский А.П.,
Лучинский Ю.В., Станько А.И.
ИСТОРИЯ МИРОВОЙ ЖУРНАЛИСТИКИ.
«Радиослушатели начали повторять эти звуки всеми возможными способами в знак поддержки движения сопротивления, — пишет Уэлч. — По всей оккупированной территории Европы люди чертили букву V и выстукивали ее „морзянкой“, демонстрируя свою солидарность… .19 июля 1941 года Уинстон Черчилль одобрительно отозвался о ней в своей речи и с тех пор стал изображать знак V пальцами».
Психологические приемы, которые помогли победить во Второй мировой войне
Фиона Макдоналд
BBC Culture

«One Saturday a big football match was to be played between Celtic and Rangers. At the same time we believed the Germans were to launch a bombing raid on Clydeside. The game was to be broadcast on the radio ,the commentator was R.E, Kingsley (REX). In the late morning however, a blanket of fog descended upon Clydeside so the match had to be abandoned. But, of course the Germans couldn't be allowed to find out about the fog as they would cancel their raid. So, REX Kingsley actually did a complete broadcast of a non existent game ,with all the goals and sound effects such as cheering and chanting. He even announced that it was a gloriously sunny day without a cloud in the sky. It was so life like it actually fooled the German Luftwaffe.»
|
Метки: author Milfgard информационная безопасность блог компании мосигра пропаганда реклама контент-маркетинг история социнжиниринг |
Первый в России OpenHack от Microsoft (то есть от нас) |

|
|
Kaggle: как наши сеточки считали морских львов на Алеутских островах |

Привет, Коллеги!
27 июня закончилось соревнование на Kaggle по подсчёту морских львов (сивучей) на аэрофотоснимках NOAA Fisheries Steller Sea Lions Population Count. В нем состязались 385 команд. Хочу поделиться с вами историей нашего участия в челлендже и (почти) победой в нём.
Как многие уже знают, Kaggle – это платформа для проведения онлайн соревнований по Data Science. И в последнее время там стало появляться всё больше и больше задач из области компьютерного зрения. Для меня этот тип задач наиболее увлекателен. И соревнование Steller Sea Lions Population Count — одно из них. Я буду повествовать с расчётом на читателя, который знает основы глубокого обучения применительно к картинкам, поэтому многие вещи я не буду детально объяснять.
Пару слов о себе. Я учусь в аспирантуре в университете города Хайдельберг в Германии. Занимаюсь исследованиями в области глубокого обучения и компьютерного зрения. Страничка нашей группы CompVis.
Захотелось поучаствовать в рейтинговом соревновании на Kaggle с призами. На это дело мной был также подбит Дмитрий Котовенко , который в это время проходил учебную практику в нашей научной группе. Было решено участвовать в соревновании по компьютерному зрению.
На тот момент у меня был некий опыт участия в соревнованиях на Kaggle, но только в нерейтинговых, за которые не дают ни медалей, ни очков опыта (Ranking Points). Но у меня был довольно обширный опыт работы с изображениями с помощью глубокого обучения. У Димы же был опыт на Kaggle в рейтинговых соревнованиях, и была 1 бронзовая медаль, но работать с компьютерным зрением он только начинал.
Перед нами встал нелёгкий выбор из 3 соревнований: предсказание рака матки на медицинских изображениях, классификация спутниковых изображений из лесов Амазонии и подсчёт сивучей на аэрофотоснимках. Первое было отброшено из-за визуально не очень приятных картинок, а между вторым и третьим было выбрано третье из-за более раннего дедлайна.
В связи со значительным уменьшением популяции сивучей на западных Алеутских островах (принадлежащих США) за последние 30 лет ученые из NOAA Fisheries Alaska Fisheries Science Center ведут постоянный учет количества особей с помощью аэрофотоснимков с дронов. До этого времени подсчет особей производился на фотоснимках вручную. Биологам требовалось до 4 месяцев, чтобы посчитать количество сивучей на тысячах фотографий, получаемых NOAA Fisheries каждый год. Задача этого соревнования — разработать алгоритм для автоматического подсчета сивучей на аэрофотоснимках.
Все сивучи разделены на 5 классов:
 ),
), ),
), ),
), ),
), ).
).Дано 948 тренировочных картинок, для каждой из которых известно Ground Truth число особей каждого класса. Требуется предсказать число особей по классам на каждой из 18641 тестовых картинок. Вот пример некоторых частей из датасета.

Картинки разных разрешений: 4608x3456 до 5760x3840. Качество и масштаб очень разнообразный, как видно из примера выше.
Положение на лидерборде определяется ошибкой RMSE, усредненной по всем тестовым изображениям и по классам.
Как бонус организаторы предоставили копии тренировочных изображений с сивучами, помеченными точками разного цвета. Каждый цвет соответствовал определенному классу. Все эти точки были кем-то размечены вручную (я надеюсь, биологами), и они не всегда находились чётко в центре животного. То есть, по факту, мы имеем грубую позицию каждой особи, заданную одной точкой. Выглядит это так.

(image credits to bestfitting)
Самые частые классы сивучей — это самки (), подростки () и детеныши ().
Здесь я кратко перечислю, какие были проблемы с данными, да и с задачей в целом.
В Германии, как и в России, в этом году выпали большие выходные на 1 Мая. Свободные дни с субботы по понедельник оказались как никогда кстати для того, чтобы начать погружаться в задачу. Соревнование длилось уже больше месяца. Всё началось с того, что мы с Димой Котовенко в субботу прочитали условие.
Первое впечатление было противоречивым. Много данных, нету устоявшегося способа, как решать такие задачи. Но это подогревало интерес. Не всё ж "стакать xgboost-ы”. Цель я поставил себе довольно скромную — просто попасть в топ-100 и получить бронзовую медальку. Хотя потом цели поменялись.
Первых 3 дня ушло на обработку данных и написание первой версии пайплайна. Один добрый человек, Radu Stoicescu, выложил кернел, который преобразовывал точки на тренировочных изображениях в координаты и класс сивуча. Здорово, что на это не пришлось тратить своё время. Первый сабмит я сделал только через неделю после начала.
Очевидно, решать эту задачу в лоб с помощью semantic segmentation нельзя, так как нет Ground Truth масок. Нужно либо генерить грубые маски самому либо обучать в духе weak supervision. Хотелось начать с чего-то попроще.
Задача подсчёта числа объектов/людей не является новой, и мы начали искать похожие статьи. Было найдено несколько релевантных работ, но все про подсчёт людей CrowdNet, Fully Convolutional Crowd Counting, Cross-scene Crowd Counting via Deep Convolutional Neural Networks. Все они имели одну общую идею, основанную на Fully Convolutional Networks и регрессии. Я начал с чего-то похожего.
Хотим научиться предсказывать хитмапы (2D матрицы) для каждого класса, да такие, что бы можно было просуммировать значения в каждом из них и получить число объектов класса.
Для этого генерируем Grount Truth хитмапы следующим образом: в центре каждого объекта рисуем гауссиану. Это удобно, потому что интеграл гауссианы равен 1. Получаем 5 хитмапов (по одному на каждый из 5 классов) для каждой картинки из тренировочной выборки. Выглядит это так.

Увеличить
Среднеквадратичное отклонение гауссиан для разных классов выставил на глазок. Для самцов – побольше, для детенышей – поменьше. Нейронная сеть (тут и далее по тексту я имею в виду сверточную нейронную сеть) принимает на вход изображения, нарезанные на куски (тайлы) по 256x256 пикселей, и выплёвывает 5 хитмапов для каждого тайла. Функция потерь – норма Фробениуса разности предсказанных хитмапов и Ground Truth хитмапов, что эквивалентно L2 норме вектора, полученного векторизацией разности хитмапов. Такой подход иногда называют Density Map Regression. Чтобы получить итоговое число особей в каждом классе, мы суммируем значения в каждом хитмапе на выходе.
| Метод | Public Leaderboard RMSE |
|---|---|
| Baseline 1: предсказать везде 0 | 29.08704 |
| Baseline 2: предсказать везде среднее по train | 26.83658 |
| Мой Density Map Regression | 25.51889 |
Моё решение, основанное на Density Map Regression, было немного лучше бейзлайна и давало 25.5. Вышло как-то не очень.

В задачах на зрение, бывает очень полезно посмотреть глазами на то, что породила ваша сеть, случаются откровения. Я так и сделал. Посмотрел на предсказания сети — они вырождаются в нуль по всем классам, кроме одного. Общее число животных предсказывалось ещё куда ни шло, но все сивучи относились сетью к одному классу.
Оригинальная задача, которая решалась в статьях — это подсчет количества людей в толпе, т. е. был только один класс объектов. Вероятно, Density Map Regression не очень хороший выбор для задачи с несколькими классами. Да и всё усугубляет огромная вариация плотности и масштаба объектов. Пробовал менять L2 на L1 функцию потерь и взвешивать классы, всё это не сильно влияло на результат.
Было ощущение, что L2 и L1 функции потерь делают что-то не так в случае взаимоисключающих классов, и что попиксельная cross-entropy функция потерь может работать лучше. Это натолкнуло меня на идею натренировать сеть сегментировать особей с попиксельной cross-entropy функцией потерь. В качестве Ground Truth масок я нарисовал квадратики с центром в ранее полученных координатах объектов.
Но тут появилась новая проблема. Как получить количество особей из сегментации? В чатике ODS Константин Лопухин признался, что использует xgboost для регрессии числа сивучей по набору фич, посчитанных по маскам. Мы же хотели придумать как сделать всё end-to-end с помощью нейронных сетей.
Тем временем, пока я занимался crowd counting и сегментацией, у Димы заработал простой как апельсин подход. Он взял VGG-19, натренированную на классификации Imagenet, и зафайнтьюнил ее предсказывать количество сивучей по тайлу. Он использовал обычную L2 функцию потерь. Получилось как всегда — чем проще метод, тем лучше результат.
Итак, стало понятно, что обычная регрессия делает свое дело и делает хорошо. Идея с сегментацией была радостно отложена до лучших времен. Я решил обучить VGG-16 на регрессию. Присобачил в конце выходной слой для регрессии на 5 классов сивучей. Каждый выходной нейрон предсказывал количество особей соответствующего класса.
Я резко вышел в топ-20 c RMSE 20.5 на паблик лидерборде.

К этому моменту целеполагание претерпело небольшие изменения. Стало понятно, что целиться имеет смысл не в топ-100, а как минимум в топ-10. Это уже не казалось чем-то недостижимым.
Выяснилось, что на test выборке многие снимки были другого масштаба, сивучи на них выглядели крупнее, чем на train. Костя Лопухин (отдельное ему за это спасибо) написал в слаке ODS, что уменьшение тестовых картинок по каждой размерности в 2 раза давало существенный прирост на паблик лидерборде.
Но Дима тоже не лыком шит, он подкрутил что-то в своей VGG-19, уменьшил картинки и вышел на 2-e место со скором ~16.

(image credits to Konstantin Lopuhin)
С функцией потерь у нас всё понятно. Время начинать экспериментировать с более глубокими сетями. В ход пошли VGG-19, ResnetV2-101, ResnetV2-121, ResnetV2-152 и тяжелая артиллерия — Inception-Resnet-V2.
Inception-Resnet-V2 — это архитектура придуманная Google, которая представляет собой комбинацию трюков от Inception архитектур (inception блоки) и от ResNet архитектур (residual соединения). Эта сеть изрядно глубже предыдущих и выглядит этот монстр вот так.
(image from research.googleblog.com)
В статье "Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning" ребята из Google показывают, что эта архитектура давала на тот момент state of the art на Imagenet без использования ансамблей.
Кроме самих архитектур мне пришлось перебрать:
Лучшей комбинацией оказались: Inception-Resnet-V2-BASE + average-pooling + FC-слой на 256 нейронов + Dropout + финальный FC-слой на 5 нейронов. Inception-Resnet-V2-BASE обозначает часть оригинальной сети от первого до последнего сверточного слоя.
Лучшим размером входного тайла оказался 299x299 пикселей.
Для тренировочных картинок мы делали типичный набор аугментаций для задач из CV.
К каждому тайлу применялись:
Test time augmentation мы не делали. Потому что предсказание на всех тестовых картинках и так занимало полдня.
В какой-то момент, пока я перебирал гиперпараметры и архитектуры сетей, мы объединились в команду с Димой Котовенко. Я в тот момент был 2-м месте, Дима на 3-м. Для отвода китайцев в ложном направлении команду назвали "DL Sucks".

Объединились, потому что было бы нечестно у кого-то забирать медальку, ведь с Димой мы активно обсуждали наши решения и обменивались идеями. Этому событию очень порадовался Костя, мы освободили ему призовое место. С 4-го он попал на 3-е.
Последние 3-4 недели соревнования мы плотно держались на 2-м месте на паблик лидерборде, по одной десятой, по одной тысячной улучшая скор перебором гиперпараметров и стакая модели.
Нам казалось, что уменьшение в 2 раза всех тестовых изображений — это пошло и грубо. Хотелось сделать всё красиво, чтобы сеть предсказала как нужно отмасштабировать каждое из изображений. Дима инвестировал в эту идею довольно много времени. Если вкратце, то он пытался по картинке предсказать масштаб сивучей, что равносильно предсказанию высоты полета дрона во время съемки. К сожалению, из-за недостатка времени и ряда проблем, с которыми мы столкнулись, это не было доведено до конца. Например, многие картинки содержат только одного сивуча и большая часть пространства — это море и камни. Поэтому, не всегда, глядя только на скалы или море, возможно понять с какой высоты был сделан снимок.
За пару дней до дедлайна мы собрали все лучшие модели и сделали ансамбль из 24 нейронных сетей. Все модели имели лучшую архитектуру Inception-Resnet-V2, которую я описал ранее. Отличались модели только тем, насколько агрессивно мы аугментировали картинки, на каком масштабе тестовых изображений делались предсказания. Выходы с разных сетей усреднялись.
Команда "DL Sucks" закончила соревнование на 2-м месте на паблик лидерборде, что не могло не радовать, так как мы были "в деньгах". Мы понимали, что на прайвэт лидерборде всё может поменяться и нас вообще может выкинуть из первой десятки. У нас был приличный разрыв с 4-м и 5-м местом, и это добавляло нам уверенности. Вот так выглядело положение на лидерборде:
1-е место 10.98445 outrunner (Китаец 1)
2-е место 13.29065 Мы (DL Sucks)
3-е место 13.36938 Костя Лопухин
4-е место 14.03458 bestfitting (Китаец 2)
5-е место 14.47301 LeiLei-WeiWei (Команда из двух китайцев)
Оставалось дождаться финальных результатов…
И что бы вы думали? Китаец нас обошел! Мы были сдвинуты со 2-го на 4-ое место. Ну ничего, зато получили по золотой медали ;)
Первое место, как оказалось, занял другой китаец, альфа-гусь outrunner. И решение у него было почти как у нас. Обучил VGG-16 c дополнительным полносвязным слоем на 1024 нейрона предсказывать количество особей по классам. Что вывело его на первое место, так это ad-hoc увеличение количества подростков на 50% и уменьшение количества самок на такое же число, умножение количества детёнышей на 1.2. Такой трюк поднял бы нас на несколько позиций выше.
Финальное положение мест:
1-е место 10.85644 outrunner (Китаец 1)
2-е место 12.50888 Костя Лопухин
3-е место 13.03257 (Китаец 2)
4-е место 13.18968 Мы (DL Sucks)
5-е место 14.47301 Дмитро Поплавский (тоже в слаке ODS) в команде с 2 другими
Резонный вопрос — а нельзя ли натренировать детектор и посчитать потом баундинг боксы каждого класса? Ответ — можно. Некоторые парни так и сделали. Александр Буслаев (13-ое место) натренировал SSD, а Владимир Игловиков (49-ое место) — Faster RCNN.
Пример предсказания Владимира:

(image credits to Vladimir Iglovikov)
Минус такого подхода состоит в том, что он сильно ошибается, когда сивучи на фотографии очень плотно лежат друг к другу. А наличие нескольких различных классов еще и усугубляет ситуацию.
Решение, основанное на сегментации с помощью UNet, тоже имеет место быть и вывело Константина на 2 место. Он предсказывал маленькие квадратики, которые он нарисовал внутри каждого сивуча. Далее — танцы с бубном. По предсказанным хитмапам Костя вычислял различные фичи (площади выше заданных порогов, количество и вероятности блобов) и скармливал их в xgboost для предсказания числа особей.

(image credits to Konstantin Lopuhin)
Подробнее про его решение можно посмотреть на youtube.
У 3-го места (bestfitting) тоже решение основано на UNet. Опишу его в двух словах. Парень разметил вручную сегментационные маски для 3 изображений, обучил UNet и предсказал маски на еще 100 изображениях. Поправил маски этих 100 изображений руками и заново обучил на них сеть. С его слов, это дало очень хороший результат. Вот пример его предсказания.

(image credits to bestfitting)
Для получения числа особей по маскам он использовал морфологические операции и детектор блобов.
Итак, начальная цель была попасть хотя бы в топ-100. Цель мы выполнили и даже перевыполнили. Было перепробовано много всяких подходов, архитектур и аугментаций. Оказалось, проще метод – лучше. А для сетей, как ни странно, глубже — лучше. Inception-Resnet-V2 после допиливания, обученная предсказывать количество особей по классам, давала наилучший результат.
В любом случае это был полезный опыт создания хорошего решения новой задачи в сжатые сроки.
В аспирантуре я исследую в основном Unsupervised Learning и Similarity Learning. И мне, хоть я и занимаюсь компьютерным зрением каждый день, было интересно поработать с какой-то новой задачей, не связанной с моим основным направлением. Kaggle дает возможность получше изучить разные Deep Learning фреймворки и попробовать их на практике, а также поимплементировать известные алгоритмы, посмотреть как они работают на других задачах. Мешает ли Kaggle ресерчу? Вряд ли он мешает, скорее помогает, расширяет кругозор. Хотя времени он отнимает достаточно. Могу сказать, что проводил за этим соревнованием по 40 часов в неделю (прямо как вторая работа), занимаясь каждый день по вечерам и на выходных. Но оно того стоило.
Кто дочитал, тому спасибо за внимание и успехов в будущих соревнованиях!
Мой профиль на Kaggle: Artem.Sanakoev
Краткое техническое описание нашего решения на Kaggle: ссылка
Код решения на github: ссылка
|
|
[Перевод] Как работает JS: управление памятью, четыре вида утечек памяти и борьба с ними |
|
Метки: author ru_vds разработка веб-сайтов javascript блог компании ruvds.com разработка обучение управление памятью сборка мусора |
Компьютерное зрение. Задайте вопрос эксперту Intel |
 Далеко не все ответы можно найти в Интернет. Особенно если вопрос ваш относится к достаточно узкой или новой области — тут необходима консультация гуру, Владельца Тайного Знания. В традициях блога Intel — проведение блого-семинаров, построенных на вопросах читателей. На эти вопросы отвечают эксперты Intel, принимавшие непосредственное участие в создании технологий и продуктов — кому, как не им знать все детали?
Далеко не все ответы можно найти в Интернет. Особенно если вопрос ваш относится к достаточно узкой или новой области — тут необходима консультация гуру, Владельца Тайного Знания. В традициях блога Intel — проведение блого-семинаров, построенных на вопросах читателей. На эти вопросы отвечают эксперты Intel, принимавшие непосредственное участие в создании технологий и продуктов — кому, как не им знать все детали? Анатолий Бакшеев, руководитель команды Computer Vision for Retail в Intel. Занимается компьютерным зрением и машинным обучением вот уже более 11 лет, в том числе последние несколько лет Deep Learning’ом. Начал свою карьеру в компании Itseez и проработал там более 10 лет до тех пор, пока компания не была приобретена Intel. За это время в его портфолио накопилось множество выполненных проектов, спроектированных и оптимизированных алгоритмов, большое количество кода, выложенного в библиотеку OpenCV, а также ее оптимизация под NVIDIA GPU.
Анатолий Бакшеев, руководитель команды Computer Vision for Retail в Intel. Занимается компьютерным зрением и машинным обучением вот уже более 11 лет, в том числе последние несколько лет Deep Learning’ом. Начал свою карьеру в компании Itseez и проработал там более 10 лет до тех пор, пока компания не была приобретена Intel. За это время в его портфолио накопилось множество выполненных проектов, спроектированных и оптимизированных алгоритмов, большое количество кода, выложенного в библиотеку OpenCV, а также ее оптимизация под NVIDIA GPU. Вадим Писаревский, бессменный руководитель команды OpenCV, начиная с 2000 года.
Вадим Писаревский, бессменный руководитель команды OpenCV, начиная с 2000 года.|
Метки: author saul разработка робототехники обработка изображений блог компании intel opencv машинное зрение распознавание образов вопросы экспертам |






