Автопилот своими рукам. Добавляем электронное управление steer-by-wire на обычный автомобиль |
Всем привет. Любому автопилоту, очевидно, нужно не только принимать решения по управлению, но и заставлять автомобиль этим решениям подчиняться. Сегодня увидим, как весьма доступными средствами доработать обычный автомобиль полностью электронным рулевым управлением (steer-by-wire). Оказывается, сам авто для разработки не очень и нужен, а большинство функционала можно с комфортом отлаживать дома или в офисе. В главных ролях всем известные компоненты из хобби-магазинов электроники.

Задумаемся на секунду, что нужно для системы электронного управления? Сервопривод, который может поворачивать колёса, и контроллер, чтобы сервоприводом управлять. Внезапно, всё это в большинстве современных автомобилей уже есть, и называется "усилитель рулевого управления". Традиционные чисто механические (как правило, гидравлические) усилители стремительно исчезают с рынка, уступая место узлам с электронным блоком управления (ЭБУ). А значит, задача сразу упрощается: нам остается только "уговорить" имеющийся ЭБУ усилителя выдать нужные команды на сервопривод.
Очень удобным для доработки оказался KIA Cee'd начиная с 2015 модельного года (скорее всего аналогично и его соплатформенники от KIA/Hyundai). Сошлись одновременно несколько факторов:
Итак, получена в распоряжение рулевая колонка в сборе:

Будем заставлять её крутиться. Для этого нужно создать у блока управления впечатление, что
Пойдем по порядку.
Нужно понять интерфейс между электронным блоком управления (ЭБУ) усилителя и остальным автомобилем. Нагуглив электрическую схему видим картинку:

Из схемы видно, что физически интерфейс очень прост:
Внешний вид и распиновки разъемов находим на том же сайте.
С питанием и зажиганием всё просто, берем 12V с обычного компьютерного блока питания. Но если просто подать питание и зажигание, усилитель полноценно не включится, и усиливать не будет. Дополнительно нужна информация от других блоков автомобиля: работает ли двигатель (чтобы не тратить энергию аккумулятора при выключенном), текущая скорость (чтобы делать руль "тяжелее" на скорости), наверняка что-то ещё.
Обмен данными между электронными блоками в современных автомобилях организован по шинам CAN (Controller Area Network). Это широковещательная (у пакетов нет адресов назначения) локальная сеть на витой паре, где каждый блок может публиковать свои данные. У каждого типа данных свой идентификатор. Например, в нашем случае усилитель руля рассылает значения угла поворота руля с ID 0x2B0. Часто бывает несколько физически разделенных шин, чтобы второстепенные блоки типа контроллеров стеклоподъемников не мешались обмену между критически важными компонентами. В Cee'd используется две шины: C-CAN и B-CAN (схема здесь, в части "Информация о канале передачи данных"). На C-CAN "висят" почти все блоки с ней и будем работать.
Первым делом понадобится CAN интерфейс для компьютера. Детальный обзор возможных решений есть например здесь, цены варьируются от десятков до сотен долларов. По устройствам у нас относительно доступны:
Софта разного тоже много (за обзором опять сюда). Самый простой вариант — Linux c can-utils из SocketCAN, за который спасибо инженерам Volkswagen. Большой плюс SocketCAN в стандартизации — любое USB устройство с поддержкой протокола LAWICEL (pdf) видится системой как обычный сетевой интерфейс. Таким образом избегаем привязки к вендор-специфическому софту конкретного устройства. У текущей версии CANHacker есть небольшая несовместимость со стоковыми can-utils по работе с USB, поэтому берём патченную версию отсюда. Raspberry Pi с CAN шилдом работает со стоковым пакетом can-utils из Raspbian OS без проблем.
С подключением к индивидуальному узлу на стенде всё просто: соединяем контакт CAN-High адаптера с CAN-High автомобильного узла, CAN-Low — c CAN-Low. По стандарту между CAN-High и CAN-Low должно быть 2 замыкающих резистора по 120 Ом, на практике обычно всё работает на довольно широком интервале сопротивлений, у меня например одно на 110 Ом.
На автомобиле замыкающий резистор не нужен (они там уже стоят, чтобы шина сама по себе работала). В зависимости от модели авто, возможно придется повозиться с физическим доступом к проводке шины. Самый удобный вариант — разъём OBD-II (on-board diagnostic), он обязателен на всех легковых автомобилях, выпущенных в Европе с начиная 2001-2004 года и находится не дальше 60 см от рулевого колеса. На Cee'd разъём слева под рулём, за пластмасовой крышкой блока предохранителей.

Распиновка OBD-II стандартизована и включает шину CAN (CANH на 6 контакте, CANL на 14). Нам повезло, корейцы пошли по пути наименьшего сопротивления и вывели C-CAN, на которой висят все важные узлы, прямо на диагностический разъём:

В результате на Cee'd можно прослушать весь внутренний трафик, ничего в авто не разбирая. Когда машина не твоя, а знакомые пустили повозиться — большой плюс. Но такая халява не везде. У Volkswagen например служебная CAN изолирована от OBD шлюзом, поэтому подключаться пришлось бы примерно так:

Подключив все контакты, поднимаем сетевой интерфейс:
$ sudo slcand -o -c -s6 -S 115200 ttyACM0 slcan0 && sleep 1 && sudo ifconfig slcan0 upПроверяем, что сеть работает и данные принимаются (включив зажигание):
$ cansniffer slcan0И наконец, если всё нормально, можно записывать лог:
$ candump -L slcan0 > real-car-can-log.txtЗдесь нужно запустить двигатель, т.к. усилитель руля включается на собственно усиление только при работающем двигателе, а нам на стенде надо, чтобы он усиливал.
С записанным логом с авто можно возвращаться на стенд и приступать к обману нашего одинокого усилителя. Первым делом вспомним, что в автомобиле стоит свой собственный усилитель, он тоже шлёт данные в CAN шину, и эти пакеты есть и в нашем логе. Отфильтруем их, чтобы избежать конфликтов. Подключаемся к усилителю на стенде, смотрим, что он выдает:
$ $ candump slcan0
slcan0 2B0 [5] 00 00 00 00 00
slcan0 2B0 [5] FF 7F FF 06 F1
slcan0 2B0 [5] FF 7F FF 06 C2
slcan0 2B0 [5] FF 7F FF 06 D3
slcan0 2B0 [5] FF 7F FF 06 A4
slcan0 2B0 [5] FF 7F FF 06 B5
slcan0 2B0 [5] FF 7F FF 06 86
slcan0 2B0 [5] FF 7F FF 06 97
slcan0 2B0 [5] FF 7F FF 06 68
slcan0 5E4 [3] 00 00 00
slcan0 2B0 [5] FF 7F FF 06 79
slcan0 2B0 [5] FF 7F FF 06 4A
....Видим, что рассылаются пакеты 2B0 (текущий угол поворота руля) и, реже, 5E4 (какой-то общий статус усилителя). Отфильтровываем их из общего лога:
$ cat real-car-can-log.txt | grep -v ' 2B0' | grep -v ' 5E4 ' > can-log-no-steering.txtФильтрованный лог можно подавать на воспроизведение:
% sudo ifconfig slcan0 txqueuelen 1000
$ canplayer -I can-log-no-steering.txtЕсли всё сработало успешно, усилитель заработает, крутить рукой рулевой вал станет гораздо легче. Итак, работать в штатном режиме мы узел заставили, можно переходить к симуляции усилий на руле.
Крутящий момент на рулевом валу и угол поворота измеряются встроенным блоком датчиков, от которого идет жгут проводов к блоку управления усилителем:

Блок управления обрабатывает сигналы датчиков и выдаёт команды сервоприводу на создание дополнительного усилия на поворот рулевого вала.
По информации PolySync, на Soul, у которого с Cee'd общая платформа, два аналоговых датчика крутящего момента. Cигнал каждого — отклонение уровня постоянного напряжения от базовых 2.5V, провода в жгуте — зеленый и синий. Проверим, что у нас то же самое:

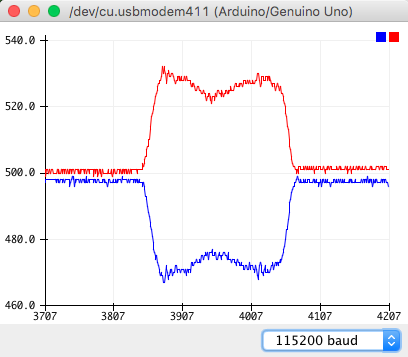
Переходим к эмуляции сигнала датчиков. Для этого поставим свой модуль в разрыв цепи между датиком и ЭБУ, будем транслировать настоящий сигнал с датчика и по команде сдвигать его на фиксированный уровень (изображая приложенное к рулевой колонке усилие). Силами одной arduino это не получится: там нет полноценного цифро-аналогового преобразователя, который мог бы выдавать постоянное напряжение. Аналоговые входы arduino нам тоже не очень подходят — хотя пинов для них целых 6, канал АЦП в контроллере только один, и его переключение между пинами занимает заметное время.
Нужно добавить к arduino внешние ЦАП/АЦП. Мне попались модули YL-40 (описание в pdf) на основе чипа PCF8591 — на каждой по 4 канала 8-бит АЦП и 1 8-бит ЦАП. Модуль может общаться с arduino по протоколу I2C. Потребуется небольшое допиливание (в буквальном смысле): китайские товарищи поставили на плату светодиод индикации напряжения на выходе ЦАП — его обязательно надо отсоединить. Иначе утекающий через диод ток не даст ЦАП поднять напряжение на выходе больше 4.2V (вместо штатных 5V). Диод отсоединяем, отковыривая резистор R4 с обратной стороны платы.

Также на входы распаяны игрушечные нагрузки (терморезистор, фоторезистор, ещё что-то), отсоединяем их, убирая перемычки, чтобы не мешались.

С интерфейсом к arduino есть нюанс — нам нужно 2 канала ЦАП, соотвественно 2 модуля, но у них одинаковые адреса I2C (зашиты в чип). Хотя чип позволяет менять свой I2C адрес, замыкая определенные ноги на +5V вместо земли, на плате эти перемычки не разведены. Вместо перепайки возьмем костыль — две разные библиотеки I2C на arduino (стандартная Wire и SoftI2CMaster), каждая на свою пару пинов. Получаем модули на разных шинах, конфликт пропадает.
Остальное прямолинейно — ставим модули в разрыв цепи от датчиков, соединяем с arduino, загружаем скетч. Подробности по распиновке подключения есть в комментариях в скетче. Остается включить всё в сборе, здесь важна последовательность:
l и r через Serial Monitor усилитель будет поворачивать рулевой вал. Объявляется победа. На сегодня всё, на очереди доработка софта (интеграция с CAN шиной, чтение оттуда текущего угла поворота и динамическое управление крутящим усилием, чтобы внешний контроллер мог задать фиксированный угол поворота руля и система его выдерживала), отработка на автомобиле (на стенде не смоделируешь сопротивление от колёс). Возможно замена 8-битных ЦАП/АЦП на 10 или 12 бит (взял первое, что под руку попалось). Рулящая нейросеть тоже в процессе, надеюсь скоро сделать пост.
Спасибо Artemka86 за ценные консультации по работе с CAN и помощь с оборудованием.
Прежде всего, внимание, CAN шилд и raspberry pi нельзя соединять напрямую, они не совместимы по напряжению. На Arduino UNO-совместимых платах напряжение логики 5V, а на raspberry pi только 3.3V, поэтому прямое соединение только сожжет задействованные пины.
Нам понадобятся:
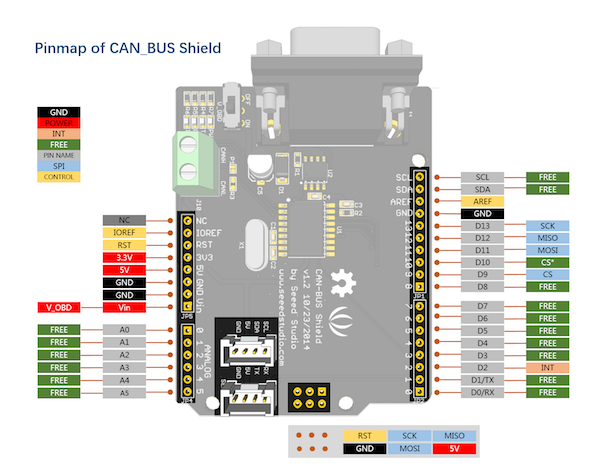
Нужно завести на CAN шилд питание (5V), соединения интерфейса данных SPI (4 пина: MOSI, MISO, SCLK, CS) и 1 пин сигнала прерывания. Всё, кроме питания, идет через преобразователь уровня, который в свою очередь тоже надо запитать.
На схемах ищем нужные пины.
Raspberry Pi:

CAN шилд:
Получаем результат:
Соединяем через преобразователь, заводим нужные напряжения питания на каждую сторону преобразователя, получается такая лапша:

Всё, кроме 5V питания и земли на шилд идёт через преобразователь:

Переходим к настройке софта (стандартный Raspbian).
Включаем поддержку SPI и CAN модуля. В /boot/config.txt добавляем
dtparam=spi=on
dtoverlay=mcp2515-can0,oscillator=16000000,interrupt=25,spimaxfrequency=1000000
dtoverlay=spi0-hw-csЗдесь interrupt=25 указывает пин, на который заведено прерывание с шилда. Индексация идёт по GPIO пинам, поэтому interrupt=25 это GPIO 25, он же пин 22 по сквозной индексации всех пинов. Также важно указать частоту интерфейса SPI spimaxfrequency, т.к. значение по умолчанию — 10 МГц — слишком высокое для шилда, он просто не соединится.
Перезагружаем raspberry pi, проверяем соединение с шилдом:
$ dmesg
...
[ 12.985754] CAN device driver interface
[ 13.014774] mcp251x spi0.0 can0: MCP2515 successfully initialized.
...Устанавливаем can-utils:
$ sudo apt install can-utilsЗапускаем виртуальный сетевой интерфейс:
$ sudo /sbin/ip link set can0 up type can bitrate 500000
$ sudo ifconfig can0 txqueuelen 1000Вторая команда важна при воспроизведении большого количества данных с raspberry pi, то есть когда записанный на автомобиле полный лог CAN шины воспоизводим для изолированного узла на стенде. Без увеличения буфера он скорее всего переполнится, когда в логе встретится несколько CAN пакетов с маленькими интервалами, и тогда соединение зависнет.
candump, cansniffer и всем остальным из can-utils.|
Метки: author waiwnf разработка робототехники программирование микроконтроллеров self-driving-car steer-by-wire |
Промо в чеке: Как без больших затрат построить программу лояльности для магазина |









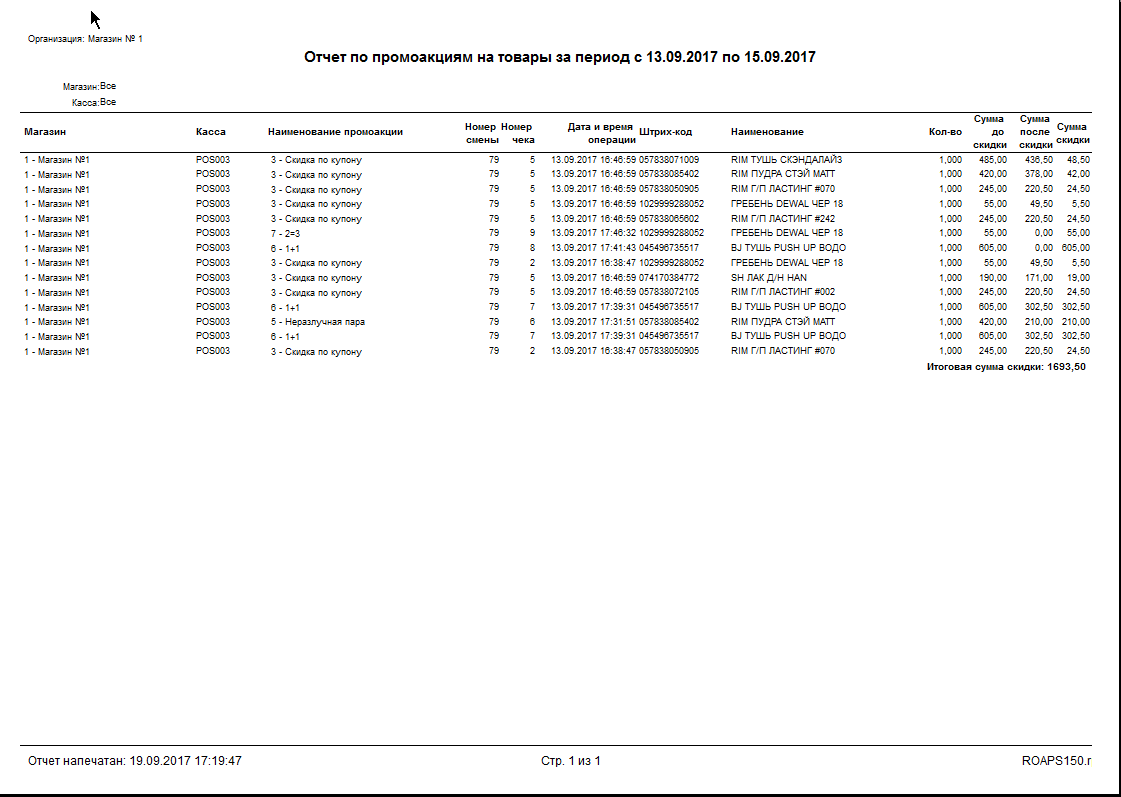
|
|
Промо в чеке: Как без больших затрат построить программу лояльности для магазина |
|
|
Фьючерсы, индексы и IPO: как на самом деле устроены биржи и зачем они нужны |

Ликвидность – это возможность быстро и без существенных накладных расходов продать или купить ценную бумагу.
Маркетмейкер – это участник торгов, который по соглашению с биржей обязан поддерживать разницу цен покупки-продажи в определенных пределах. За это он получает от биржи определенные льготы – например возможность совершать операции с ценными бумагами, которые поддерживает маркетмейкер с уменьшенными комиссиями или вовсе без них.
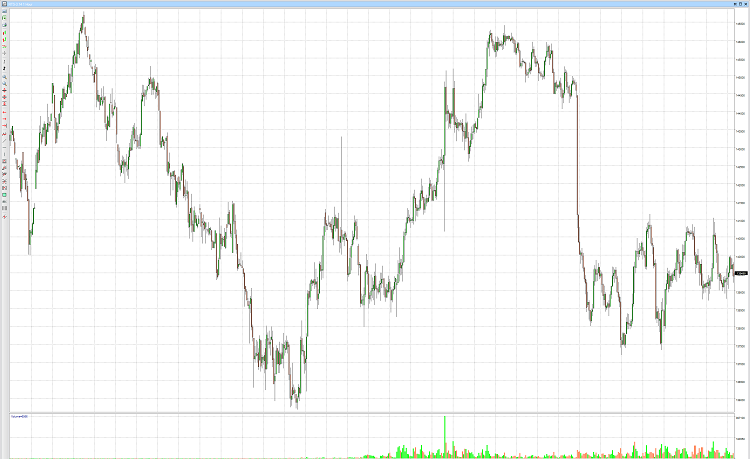
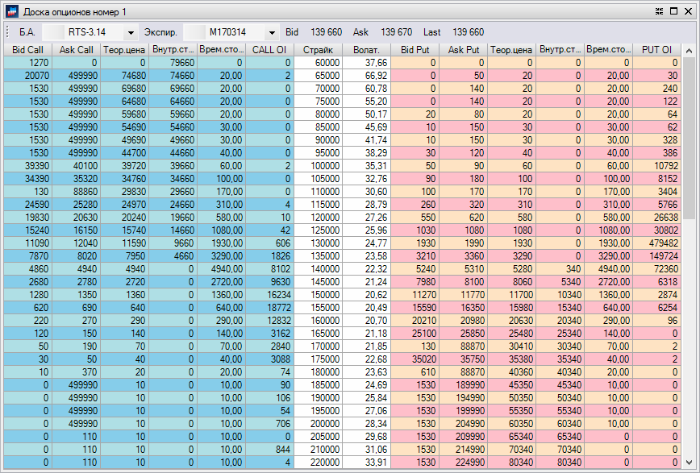
|
Метки: author itinvest финансы в it блог компании itinvest биржи фондовый рынок опционы |
Фьючерсы, индексы и IPO: как на самом деле устроены биржи и зачем они нужны |
Ликвидность – это возможность быстро и без существенных накладных расходов продать или купить ценную бумагу.
Маркетмейкер – это участник торгов, который по соглашению с биржей обязан поддерживать разницу цен покупки-продажи в определенных пределах. За это он получает от биржи определенные льготы – например возможность совершать операции с ценными бумагами, которые поддерживает маркетмейкер с уменьшенными комиссиями или вовсе без них.
|
Метки: author itinvest финансы в it блог компании itinvest биржи фондовый рынок опционы |
Safari 11 и WebRTC: подводные камни видеозвонков |
 Итак, это свершилось. Кроме iPhone 8, который устарел ровно через полчаса после анонса iPhone 10, Apple обновила свой десктопный и мобильный браузер Safari. Среди прочих улучшений — реализация WebRTC (ходят слухи, что частично позаимствованная у Chromium. «Plan B» на это тоже намекает). Что это значит для разработчиков? Можно звонить через браузер как на десктопе, так и на айфонах. Голосом и видео. Я уже писал про обновленные инструменты разработчика в браузере, а сейчас хочу поделиться, как это все работает в релизе. Мы уже обновили SDK Voximplant, проверили, как Safari звонит в Microsoft Edge, и вот что я хочу рассказать…
Итак, это свершилось. Кроме iPhone 8, который устарел ровно через полчаса после анонса iPhone 10, Apple обновила свой десктопный и мобильный браузер Safari. Среди прочих улучшений — реализация WebRTC (ходят слухи, что частично позаимствованная у Chromium. «Plan B» на это тоже намекает). Что это значит для разработчиков? Можно звонить через браузер как на десктопе, так и на айфонах. Голосом и видео. Я уже писал про обновленные инструменты разработчика в браузере, а сейчас хочу поделиться, как это все работает в релизе. Мы уже обновили SDK Voximplant, проверили, как Safari звонит в Microsoft Edge, и вот что я хочу рассказать…|
Метки: author eyeofhell разработка веб-сайтов программирование safari javascript блог компании voximplant voximplant webrtc |
Safari 11 и WebRTC: подводные камни видеозвонков |
Итак, это свершилось. Кроме iPhone 8, который устарел ровно через полчаса после анонса iPhone 10, Apple обновила свой десктопный и мобильный браузер Safari. Среди прочих улучшений — реализация WebRTC (ходят слухи, что частично позаимствованная у Chromium. «Plan B» на это тоже намекает). Что это значит для разработчиков? Можно звонить через браузер как на десктопе, так и на айфонах. Голосом и видео. Я уже писал про обновленные инструменты разработчика в браузере, а сейчас хочу поделиться, как это все работает в релизе. Мы уже обновили SDK Voximplant, проверили, как Safari звонит в Microsoft Edge, и вот что я хочу рассказать…|
Метки: author eyeofhell разработка веб-сайтов программирование safari javascript блог компании voximplant voximplant webrtc |
ФРИИ: опыт акселлерации компаний участников ISDEF |

|
Метки: author Spbwriter монетизация веб-сервисов монетизация it-систем конференции growth hacking блог компании ассоциация isdef isdef фрии софт стартап software бизнес |
ФРИИ: опыт акселлерации компаний участников ISDEF |
|
Метки: author Spbwriter монетизация веб-сервисов монетизация it-систем конференции growth hacking блог компании ассоциация isdef isdef фрии софт стартап software бизнес |
Дизайн-система Acronis. Часть первая. Единая библиотека компонентов |

Меня зовут Сергей, я работаю старшим дизайнером в компании Acronis. В отделе дизайна продуктов для бизнеса я отвечаю за разработку и внедрение единой библиотеки компонентов.
Так как у нас много продуктов и сервисов, а дизайн в этих продуктах и сервисах сильно отличается, мы решили его унифицировать и привести к единому UI. Зачем? Все просто: такой подход дает возможность оптимизировать работу отдела, сосредоточить дизайнеров на UX, ускорить процесс разработки и запуск новых продуктов, снизить нагрузку на отделы тестирования и значительно сократить количество багов на стороне front-end. В этой статье я расскажу о нашем опыте, остановлюсь на инструментах и покажу, как устроена библиотека изнутри.
Долгое время роль библиотеки играл собранный в Иллюстраторе PDF файл с палитрой цветов, скудным набором элементов и большими планами на будущее в виде 70-ти пустых страниц. Для того, чтобы найти какой-нибудь уже существующий элемент, приходилось постоянно дергать других дизайнеров или лопатить чужие исходники, а потом сверять актуальность с реализованным элементом на одном из тестовых стендов. Пик отчаяния наступал в тот момент, когда на тестовом стенде искомый элемент выглядел несколько иначе и вел себя не совсем так, как было запланировано в макетах. Получалась достаточно стандартная ситуация: дизайнеры тянули одеяло в свою сторону, мотивируя свои решения авторитетным «Хочу, чтобы так!», а разработчики пытались прикрываться мало значимым «Но ведь технические ограничения?!». Такой подход, закономерно, приводил к не самым лучшим результатам по обе стороны баррикад и его нужно было менять. Забегая вперед, скажу, что сейчас большинство сложных UI решений мы принимаем коллегиально и стараемся искать компромисс между красотой и технологичностью. Итак:
Первое, что предстояло сделать, это найти инструменты, которые закроют большую часть потребностей отдела. После длительного изучения различных подходов к формированию библиотек и дизайн-систем, после вороха статей на Medium и тестирования огромного количества приложений и сервисов, мы выстроили следующую схему:

Abstract отвечает за контроль версий и историю изменений мастер-файла библиотеки. Craft используется как библиотека для палитры цветов и замена нативному color инспектору. Lingo отвечает за хранение, подключение и обновление компонентов библиотеки в Sketch файлах.
Такая схема уже сейчас позволяет легко поддерживать библиотеку в актуальном состоянии, контролировать изменения и, что наиболее важно, быстро доставлять обновления дизайнерам. При этом, доступ к мастер-файлу библиотеки имеет только Owner, а остальные участники процесса получают элементы в виде символов и составных компонентов из Lingo. Для доступа к Angular компонентам мы подняли на каждой машине песочницу, чтобы дизайнеры с помощью «npm start» в консоли могли быстро запустить node server и работать с кодом.
Еще раз забегая вперед скажу, что одна из наших основных, долгосрочных и амбициозных задач — перенести большую часть работы над дизайном из графического редактора в браузер.

Десктопное приложение позволяющее контролировать историю изменений, откатываться к прошлым версиям и держать один, всегда актуальный, мастер-файл, доступ к которому есть у каждого члена команды. Для начала работы с Abstract достаточно добавить в приложение уже существующий проект или создать новый. Изменения идут в одной или нескольких параллельных ветках с последующим добавлением утвержденных кусков в мастер-файл.

Так как Abstract не дает создать новую ветку или слить ветку с мастер-файлом без комментария, история изменений появляется сама собой. Благодаря таким комментариям, значительно снижается вероятность случайных или неконтролируемых изменений. К тому же, удобно через какое-то время открыть проект и прочитать историю, посмотреть, как и зачем менялись элементы.

Если говорить о недостатках, то ключевым для некоторых команд может стать отсутствие возможности решать конфликты на уровне слоев в одном артборде, из-за чего параллельная работа над одним экраном невозможна, всегда будет конфликт версий и предложение выбрать один из двух вариантов. В нашей команде такой проблемы нет, так как мы одновременно не работаем над одним артбордом. Остальные мелкие неровности и шероховатости нивелируются полным контролем над происходящим; больше никаких папок по датам, никаких md. файлов с описанием изменений и кучи исходников на внутреннем хранилище.
На данный момент мы используем Craft как библиотеку для цветовой палитры и замену нативному color инспектору. Под рукой не только все цвета, но и названия переменных. Благодаря такому подходу удалось решить еще одну важную проблему. Дизайнеры перестали “пипетить”, а разработчики перестали резонно негодовать, почему в двух макетах у одного и того же элемента отличаются значения цвета. Кто работает в Sketch и использует несколько мониторов знает, что на каждом подключенном мониторе один и тот же цвет взятый пипеткой, в большинстве случаев, будет иметь разный HEX.
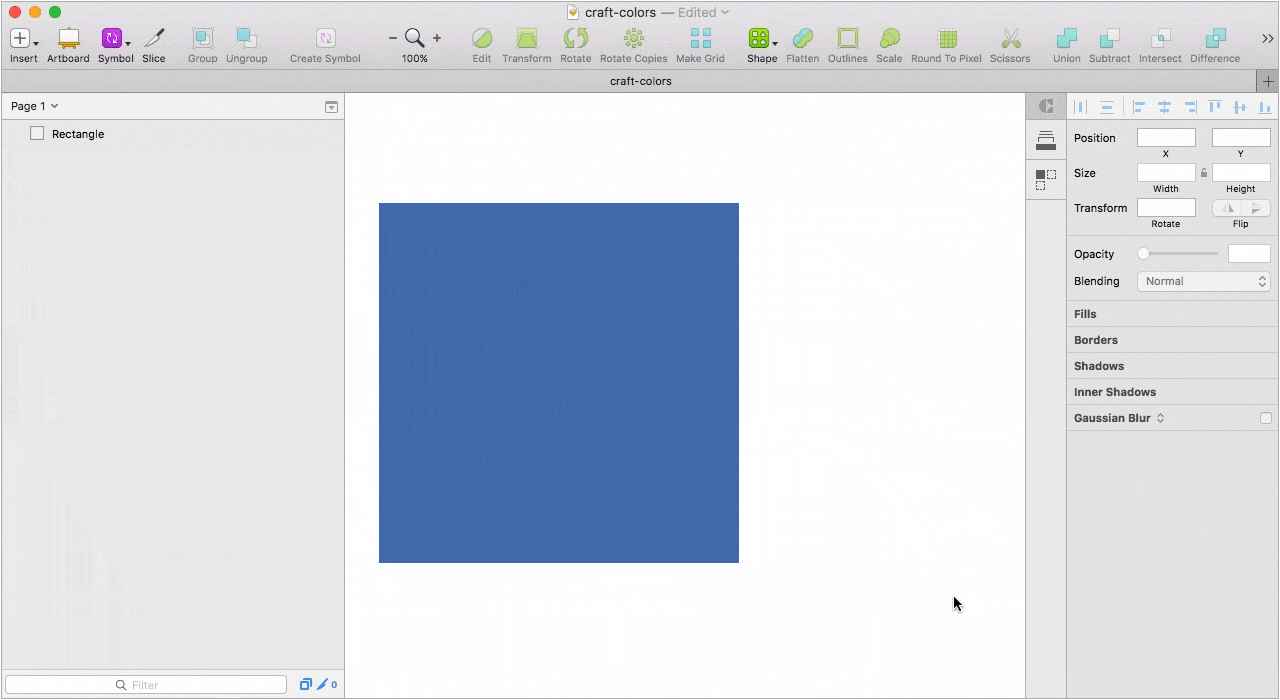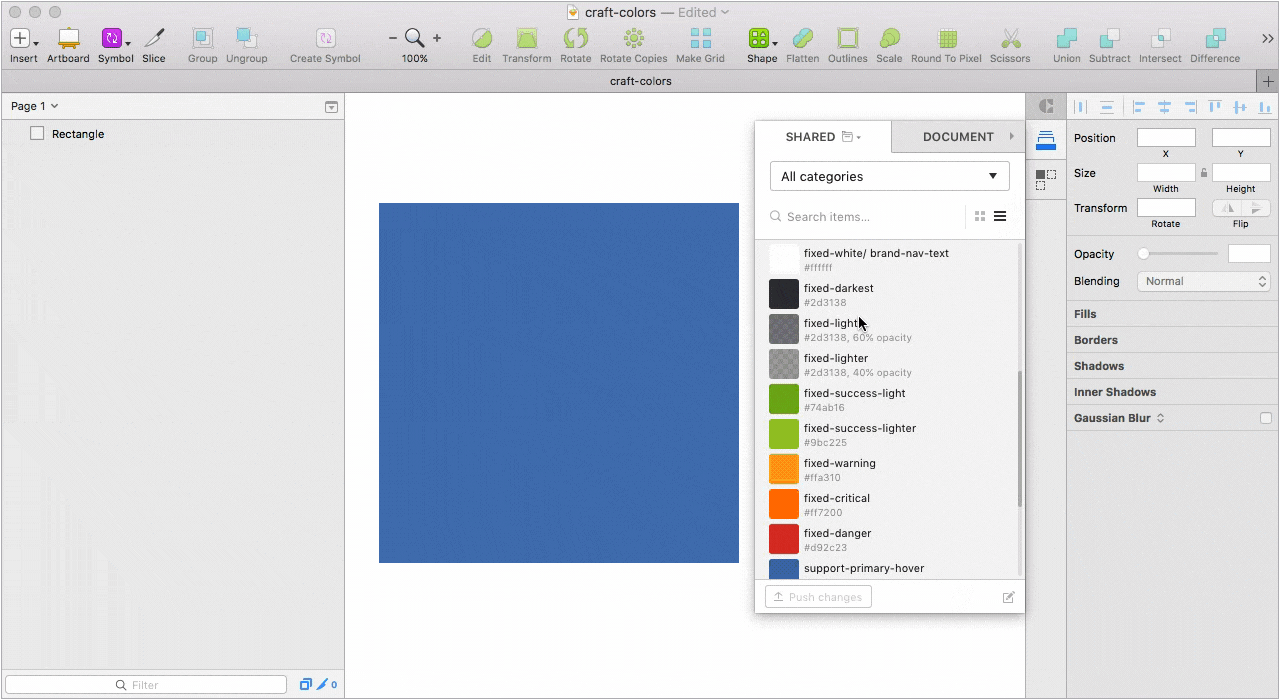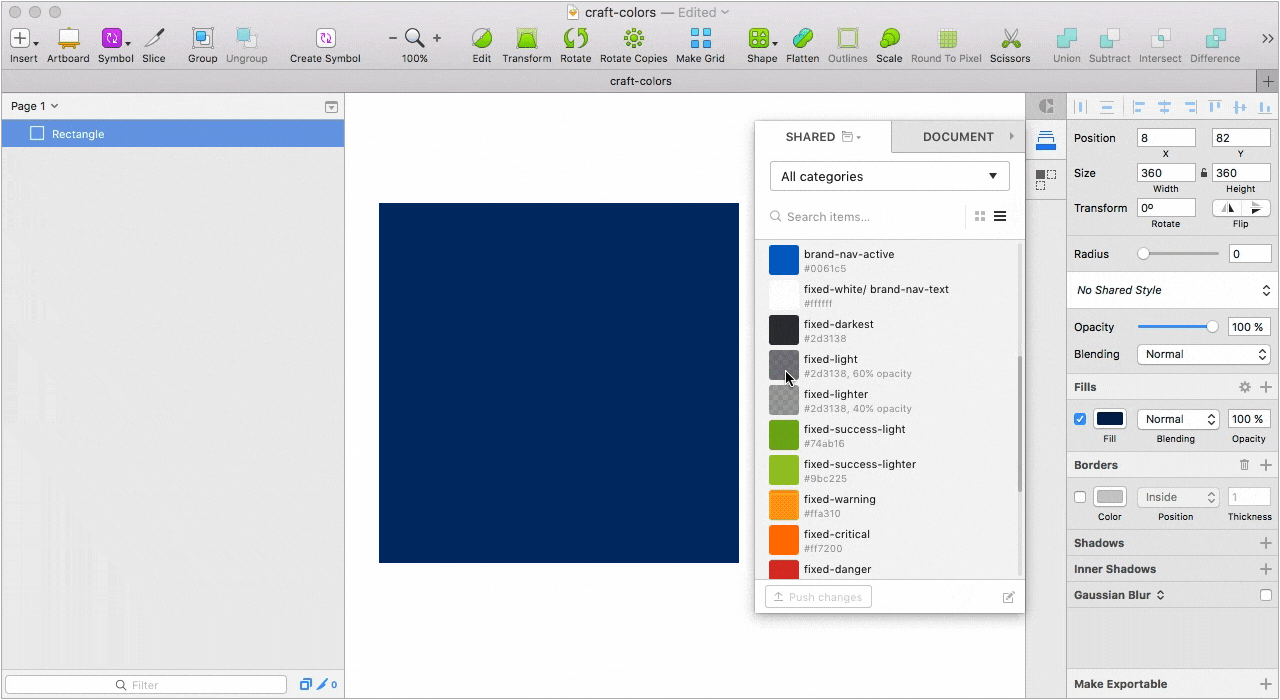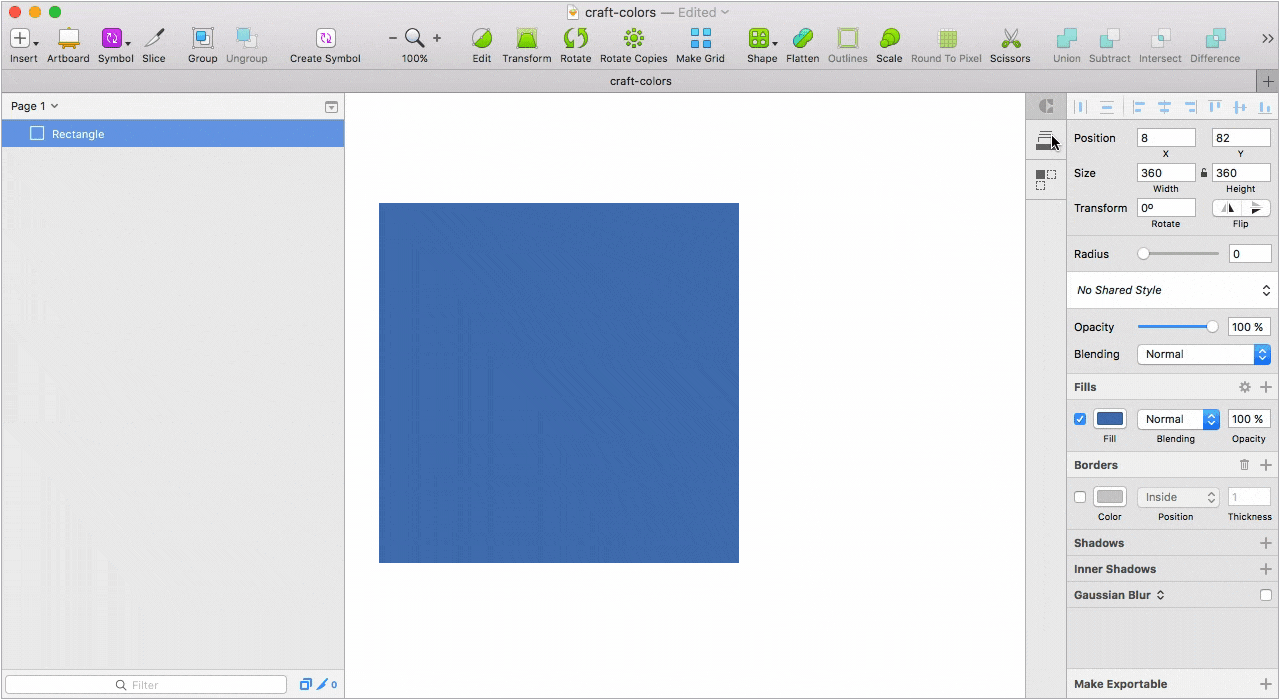
Десктопное приложение, с помощью которого мы решили все проблемы связанные с подключением актуальной библиотеки к новым файлам и обновлением компонентов в уже подключенных проектах.
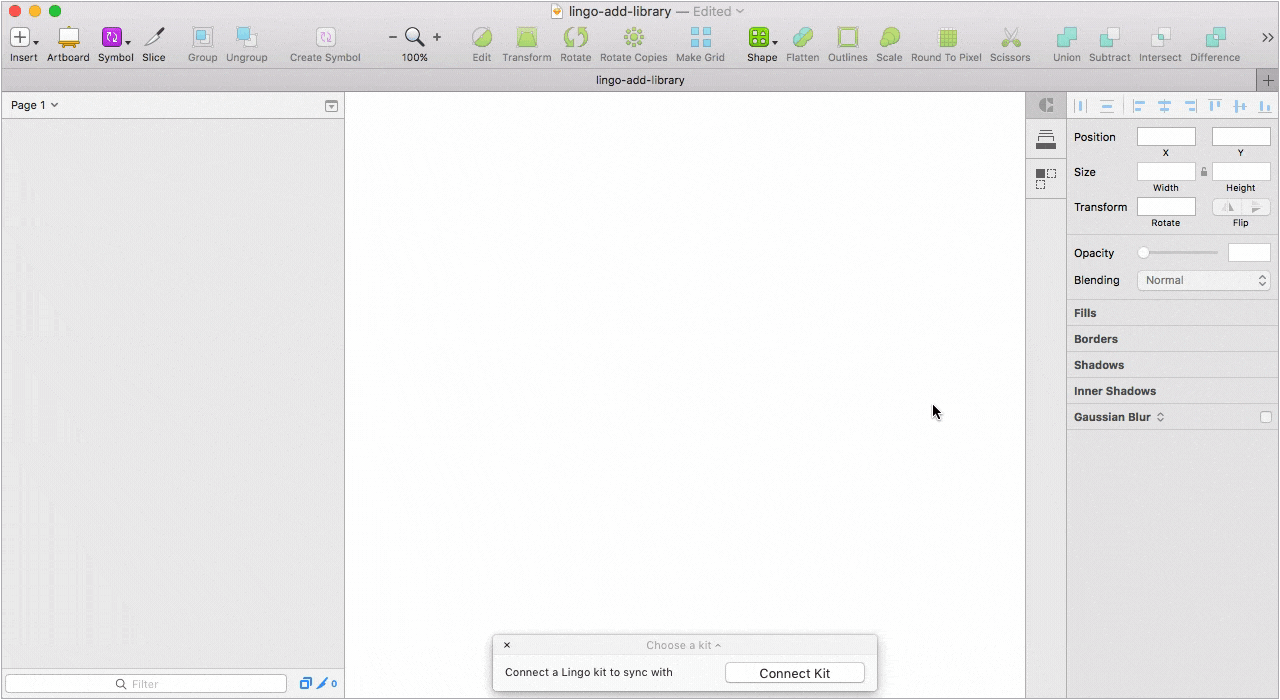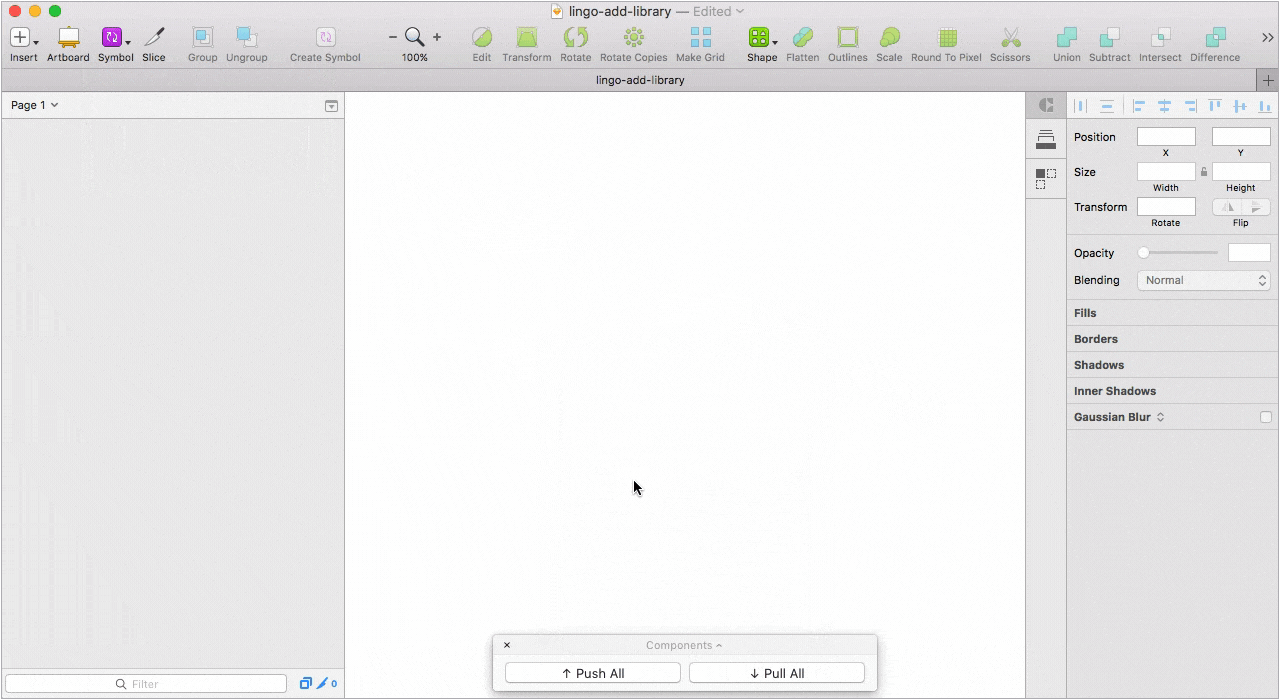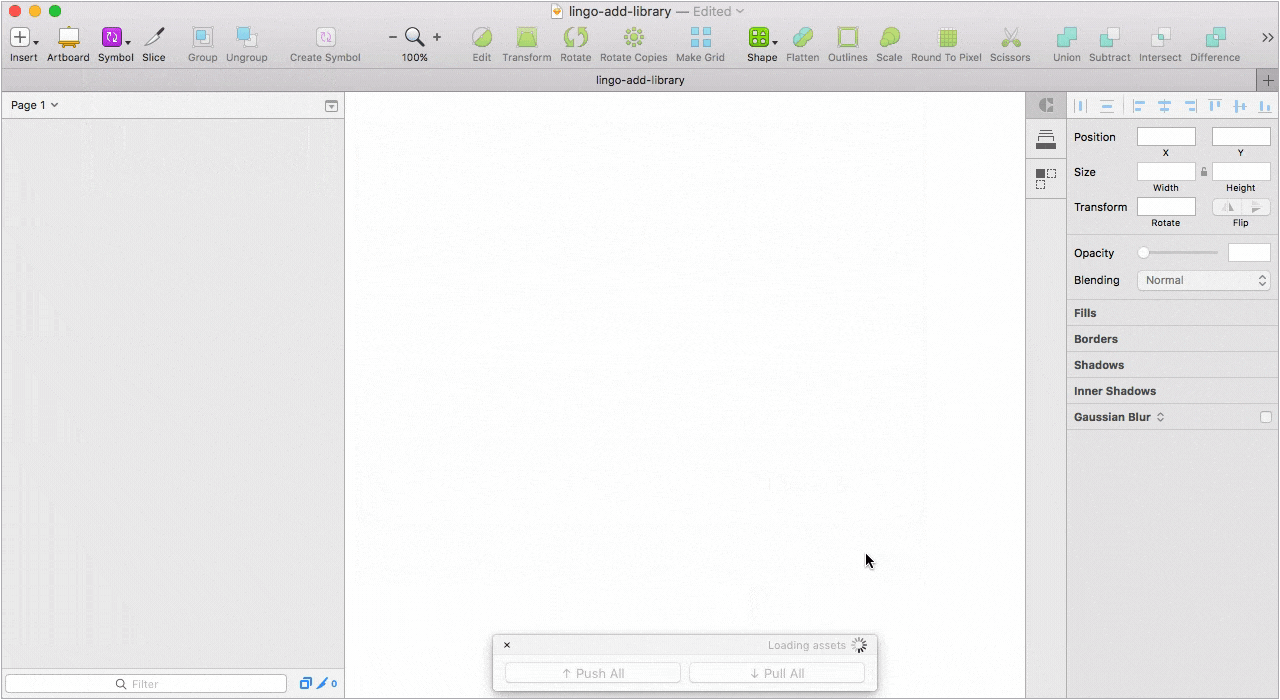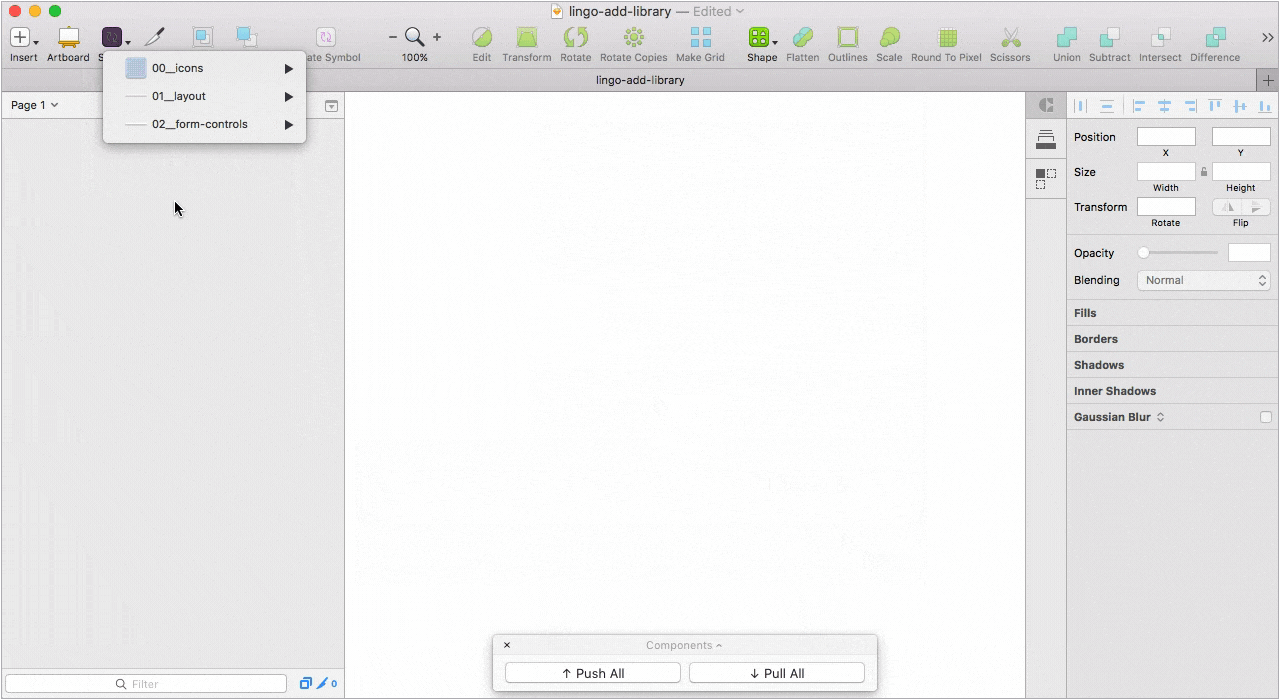
Можно создать несколько библиотек, разбить библиотеку на категории, проставить теги для каждого элемента, а при импорте элементов выбрать какой элемент добавить, а какой нет. При обновлении существующего компонента в библиотеке, Lingo предложит его заменить, сделать дубликат или отказаться от изменений.
Так же, в Lingo можно хранить составные компоненты в виде папок со слоями или артборды целиком. Для нас эта возможность особенно актуальна, так как мы сознательно не делаем компоненты с большим количеством оверрайдов из-за сложностей в поддержке и кастомизации.
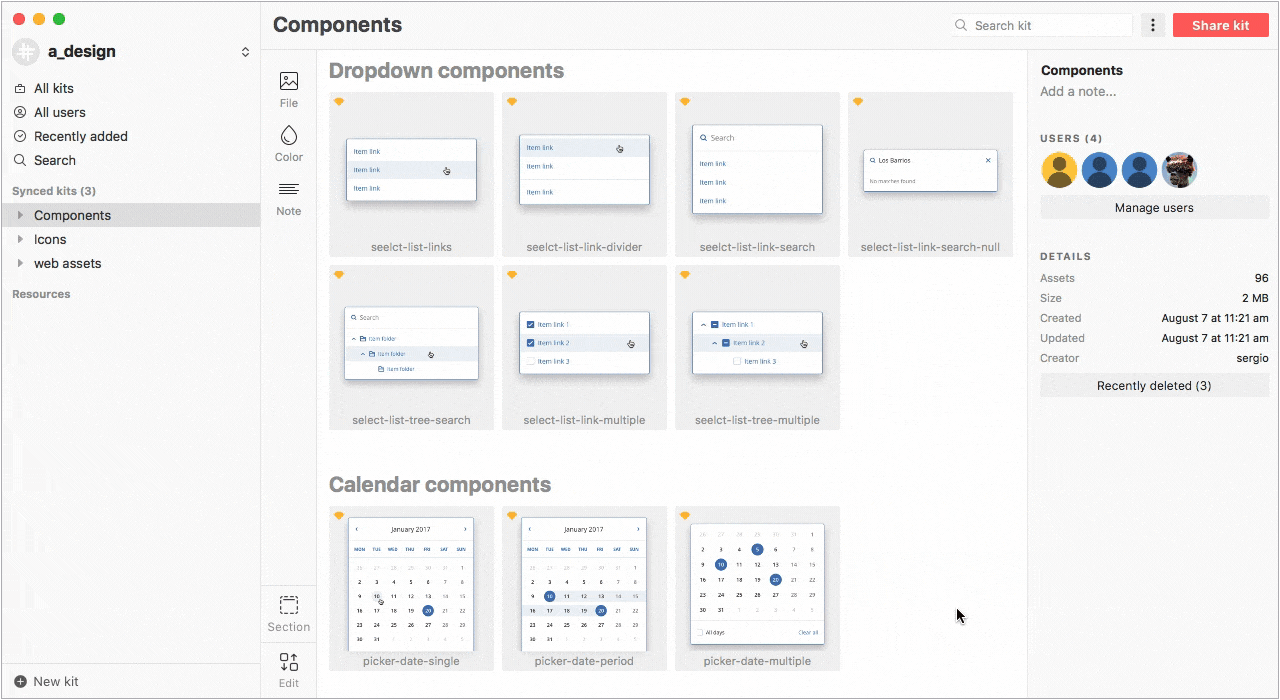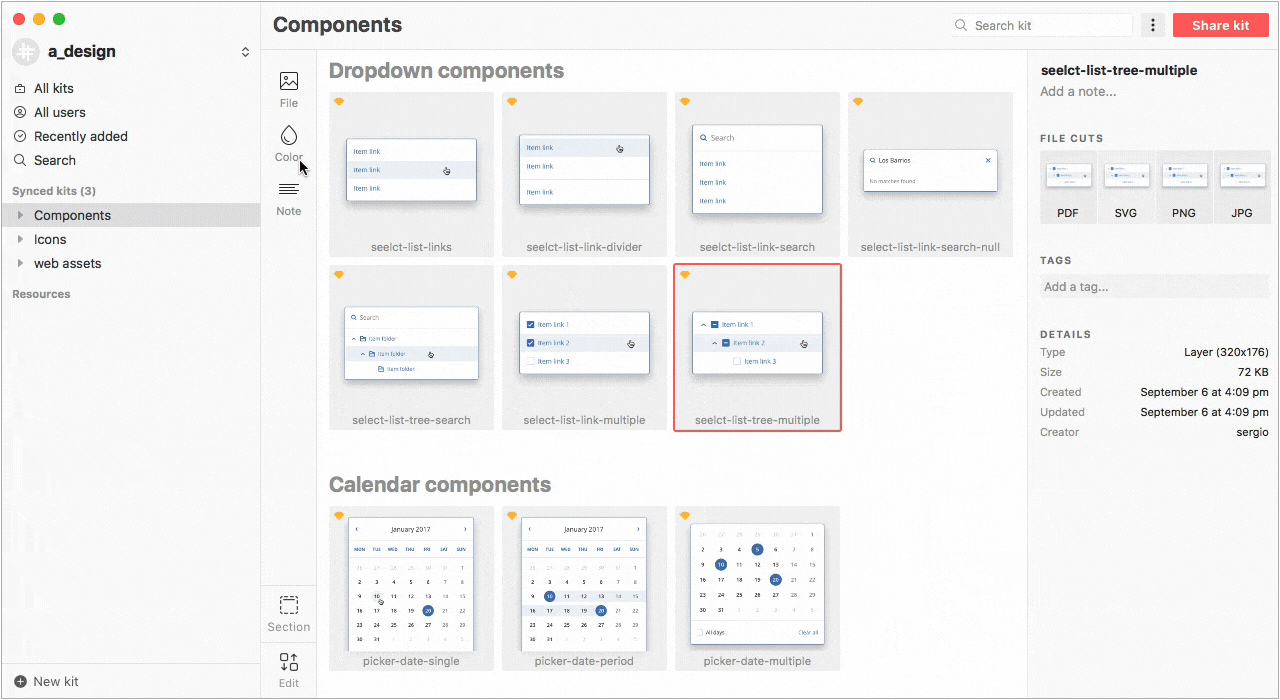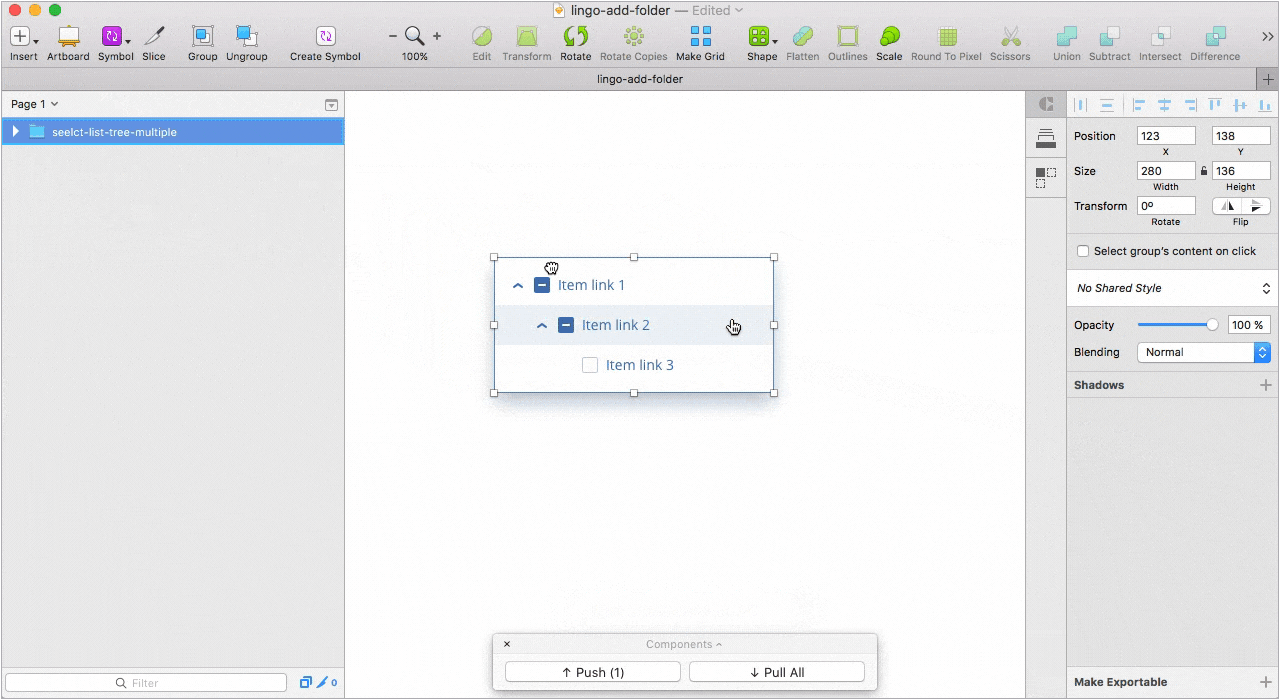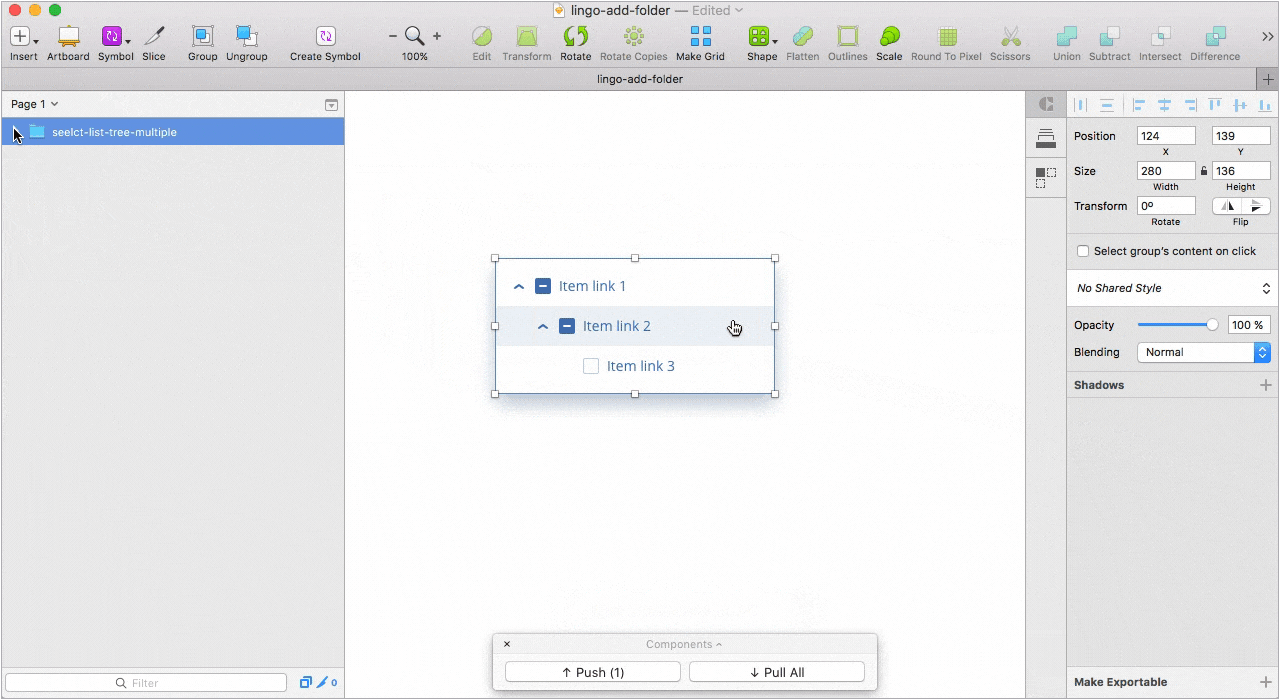
Несмотря на то, что в Sketch 47 будут библиотеки символов которые уже доступны в бета-версии (работают, кстати, круто), мы не спешим уходить с Lingo из-за его возможностей и большей гибкости в работе.
Централизованно мы используем три плагина:
Первый — Shared Text Styles для работы с текстовыми стилями. Позволяет экспортить текстовые стили в JSON, добавлять стили в новый Sketch документ и апдейтить уже подгруженные.
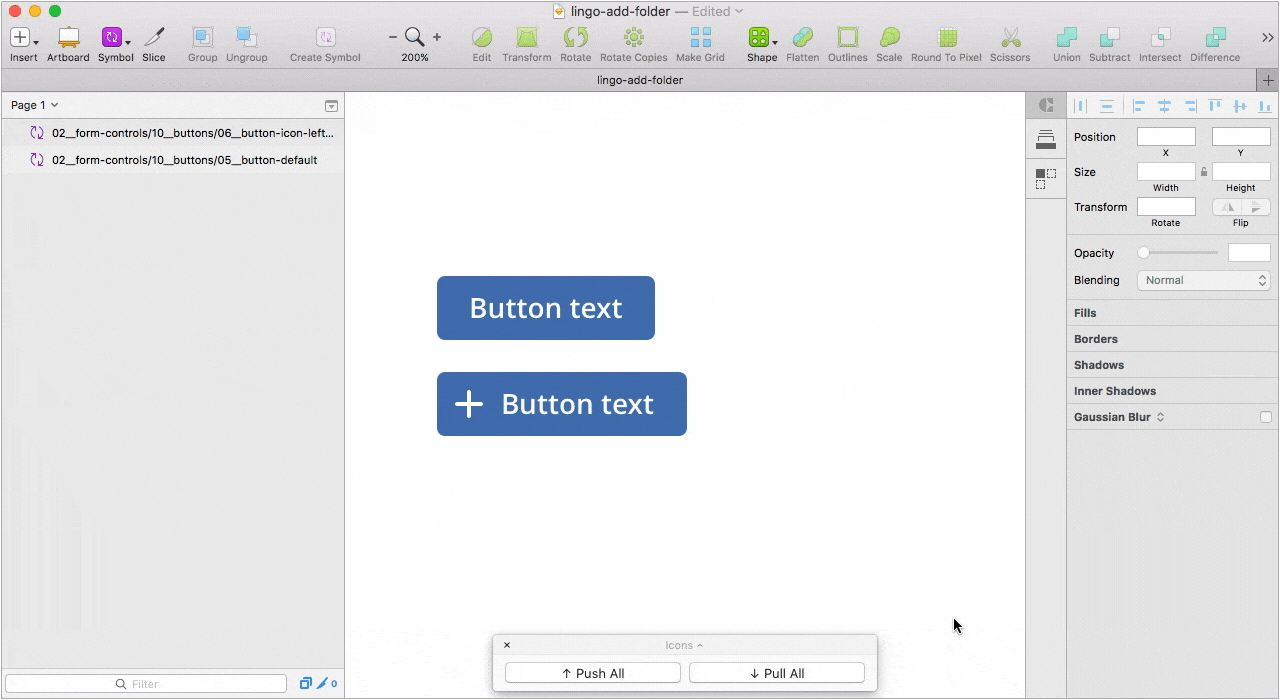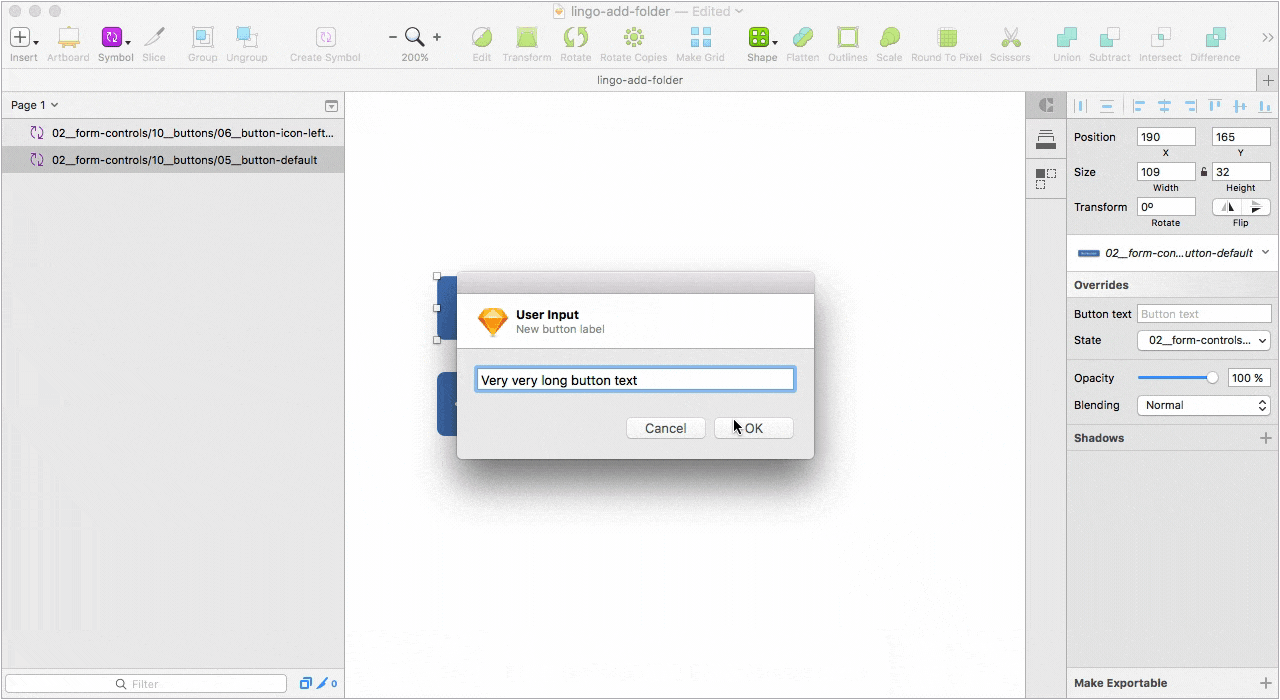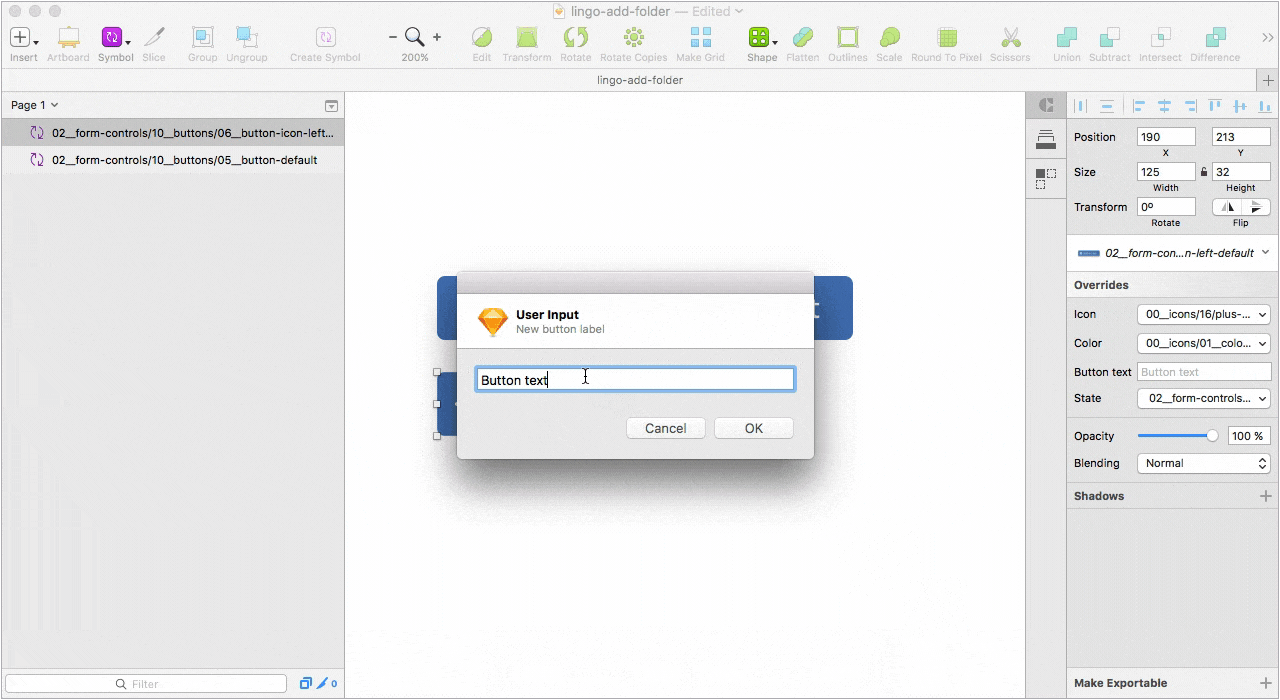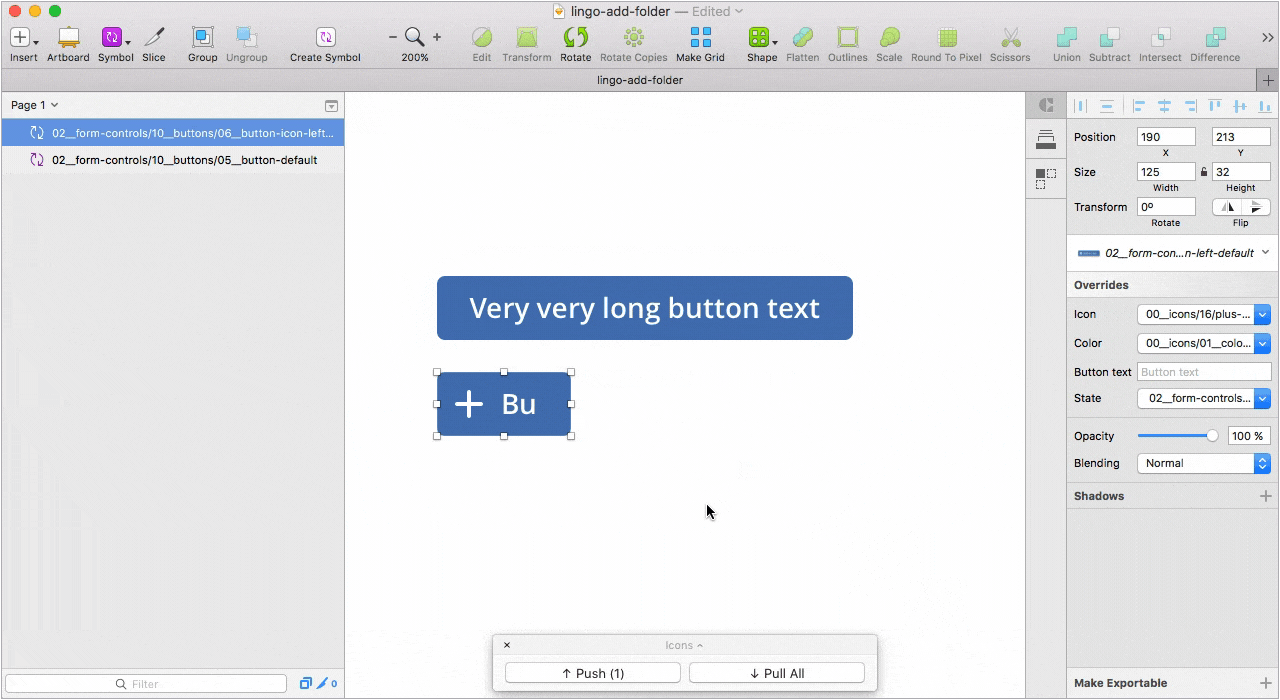
Второй — Relabel button для работы с кнопками. Одна из лучших реализаций плагинов такого рода, на мой взгляд. Достаточно правильно настроить привязки элементов внутри символа.
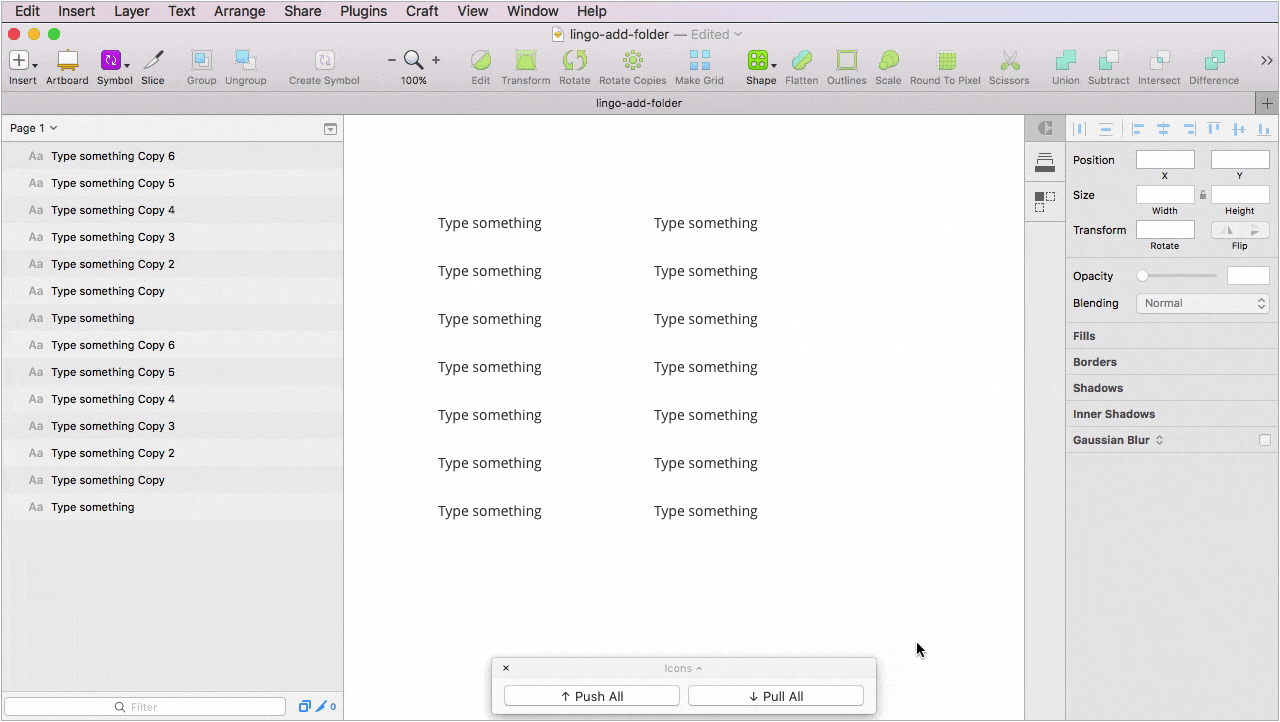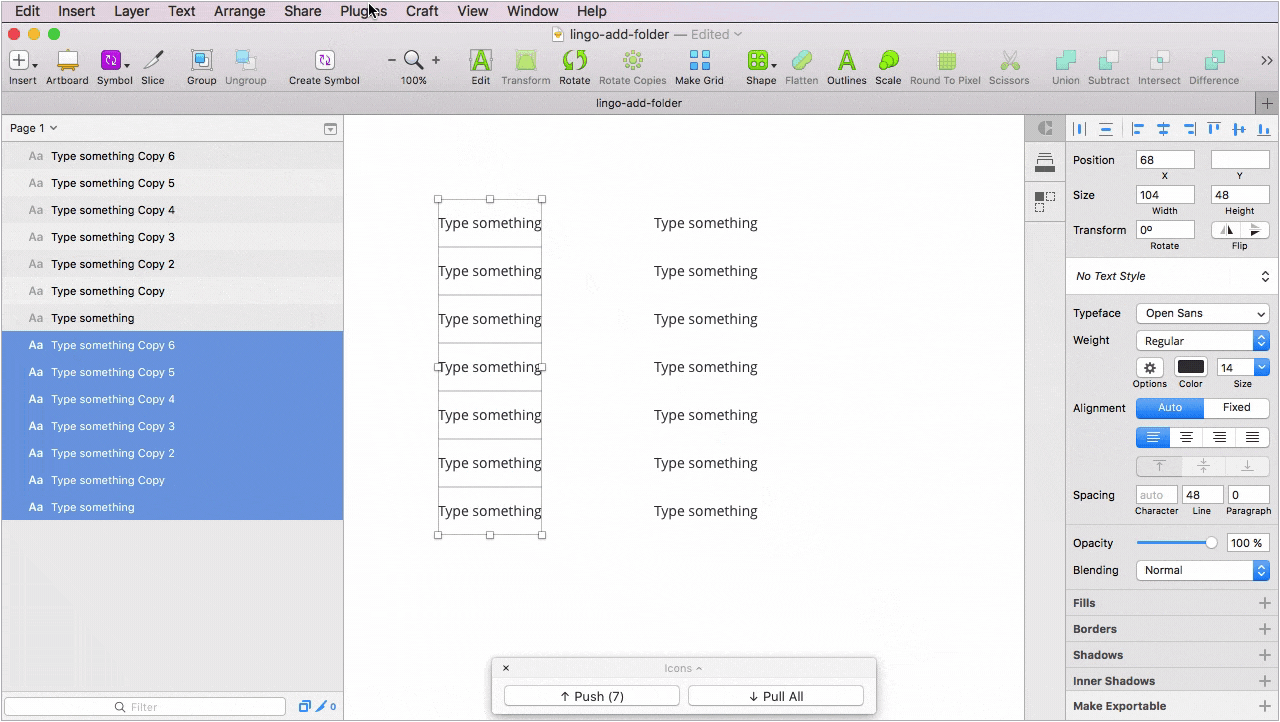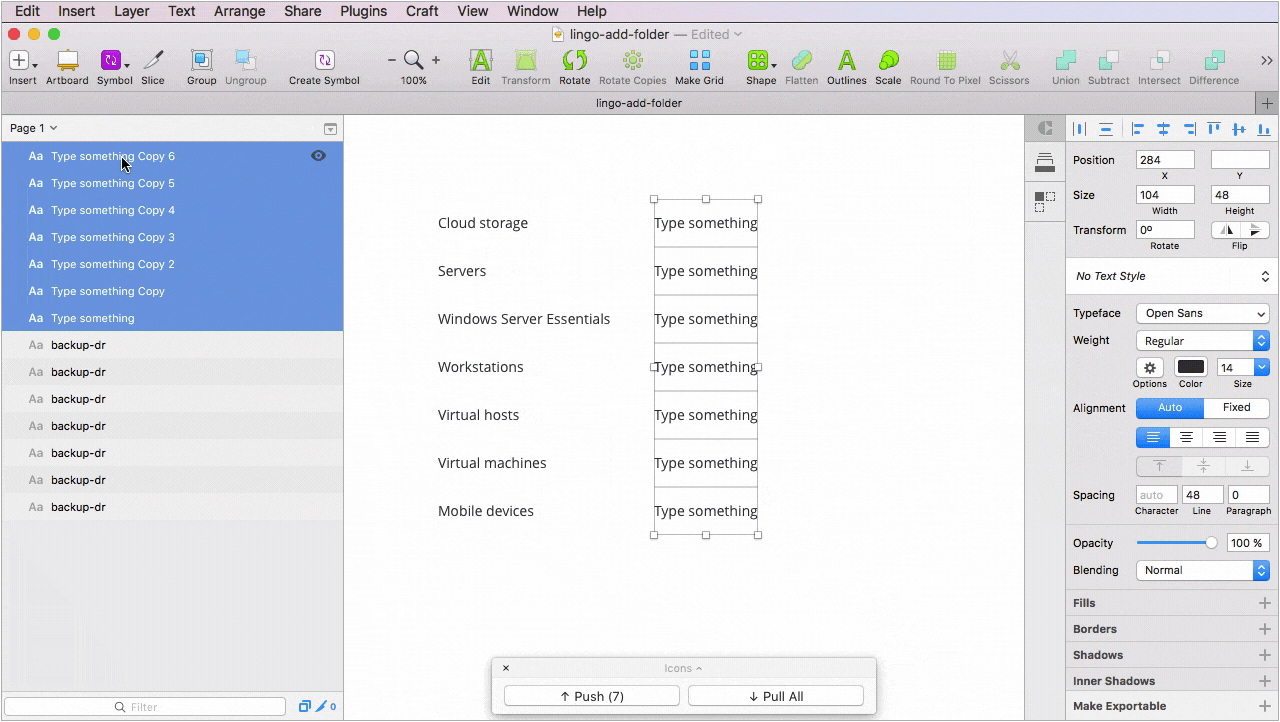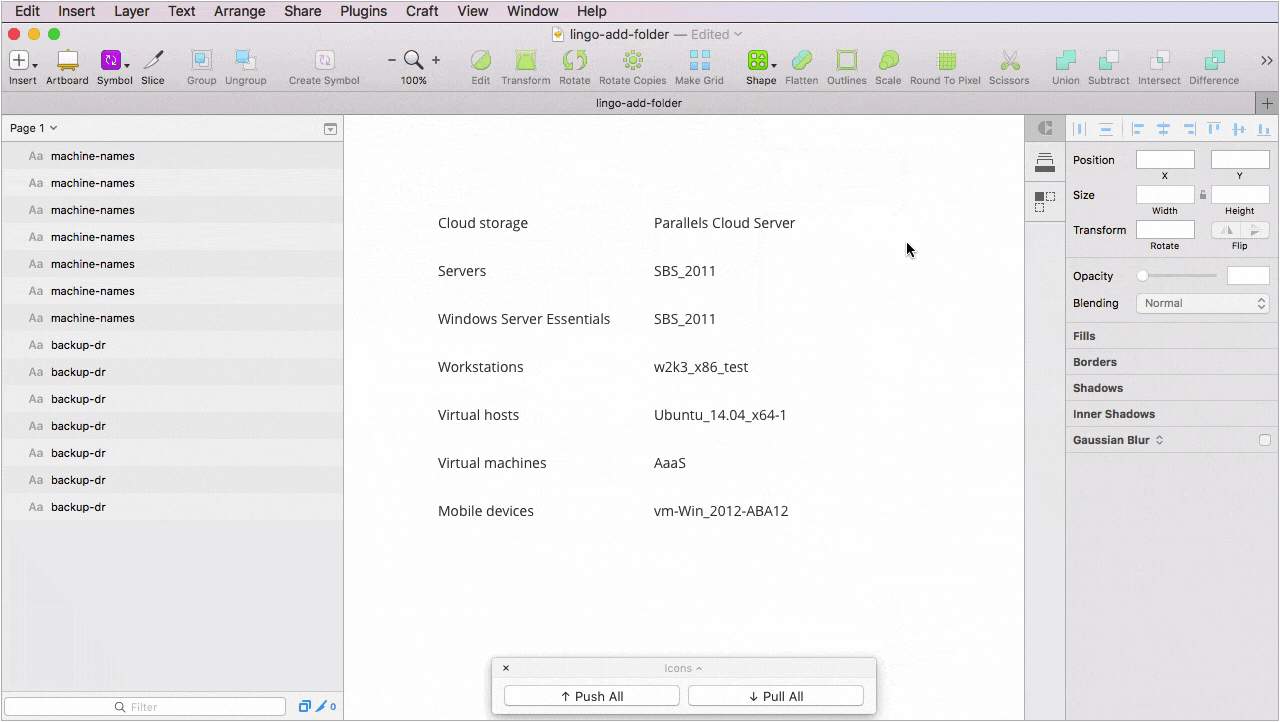
Третий — Acronis data. Так как мы достаточно много работаем с таблицами и большими массивами данных, я собрал плагин, который генерирует специализированные значения для этих таблиц (offering items, agents name, schedule options, machines и т.д.). Плагин работает на основе dummy data и подтягивает значения из JSON. Перед тем, как собирать кастомное решение, была неудачная попытка подружить единый JSON с Craft, но увы. Как оказалось, Craft не умеет в исходную разметку документа и показывает поля не по порядку.
Рано или поздно перед каждым дизайнером, работающим в Sketch, встает проблема повторного использования символа иконки с другим цветом. В частных случаях можно отвязать иконку от символа или держать несколько символов с разными цветами, что не очень актуально, когда иконок много. Я решил проблему следующим образом: прямоугольники с необходимыми цветами собрал в отдельные символы, а потом эти символы в виде масок добавил к иконкам, у которых может быть несколько цветов. Таким образом изменение цвета становится доступно через overrides.
Несмотря на удобство, у этого способа есть существенный минус. При экспорте SVG в коде будет присутствовать маска. Если на стороне разработки нет способа автоматизировать процесс удаления масок, придется держать отдельную библиотеку чистых иконок.
Неважно, насколько прокачана и удобна библиотека пока она существует исключительно в виде Sketch файла. Если в браузере компонент выглядит не так, как в макетах, библиотека уже неактуальна, а исходники устарели и не соответствуют действительности. Благодаря Сергею Сабурову, Кириллу Севёлову и всей команде мониторинга, наши компоненты плавно перетекают в код и работают именно так, как запланировано. Несмотря на то, что часть новых продуктов и сервисов мы уже начали собирать с помощью текущих компонентов, еще не все front-end команды готовы внедрять и использовать эти компоненты у себя. Где-то фронт написан на Ext JS, где-то используется Vue и быстрый переход с одного фреймворка или библиотеки на другой технически невозможен по ряду причин. О том, почему в компании выбрали именно Angular, подробно поговорим в следующей статье. А пока давайте вернемся к библиотеке и посмотрим, как устроены компоненты.
У каждого компонента есть набор свойств. Свойства позволяют управлять состоянием компонента, его внешним видом и функциональностью. Так выглядит стандартный инпут в Sketch библиотеке:

А вот так в коде:

Чтобы изменить размер и внешний вид инпута достаточно в свойствах указать
[size] = "'sm'"Теперь давайте посмотрим на более сложный пример:

Два типа дропдаунов. В первом случае — это список из значений, во втором к списку значений добавляется строка поиска. Переключимся на код:

С помощью #selectChild получаем вложенный компонент для активного значения поля, через (select) подписываемся на событие текущего компонента, а с помощью директивы *ngFor проходим по массиву из значений и выводим их в выпадающем списке. Чтобы включить строку поиска и возможность искать по списку, во втором примере включаем свойство [search]. Как я говорил выше, более подробно об Angular и работе компонентов на front-end стороне мы расскажем в следующей статье. Stay tuned!
Одна из наших амбициозных и долгосрочных задач — перенести дизайн из Sketch в браузер, чтобы дизайнер мог передавать в разработку не статичные исходники или прототипы, собранные в сторонних приложениях, а готовый код. До того момента, как появились Angular компоненты, для сложных прототипов я продвигал Framer, каждую неделю готовил лекции, рассказывал о принципах и тонкостях работы с Coffee Script. Несмотря на потраченные усилия Framer не прижился по нескольким причинам:
От Framer мы полностью не отказались и изредка собираем в нем шоты для Dribbble. Забиваем гвозди микроскопом, да.
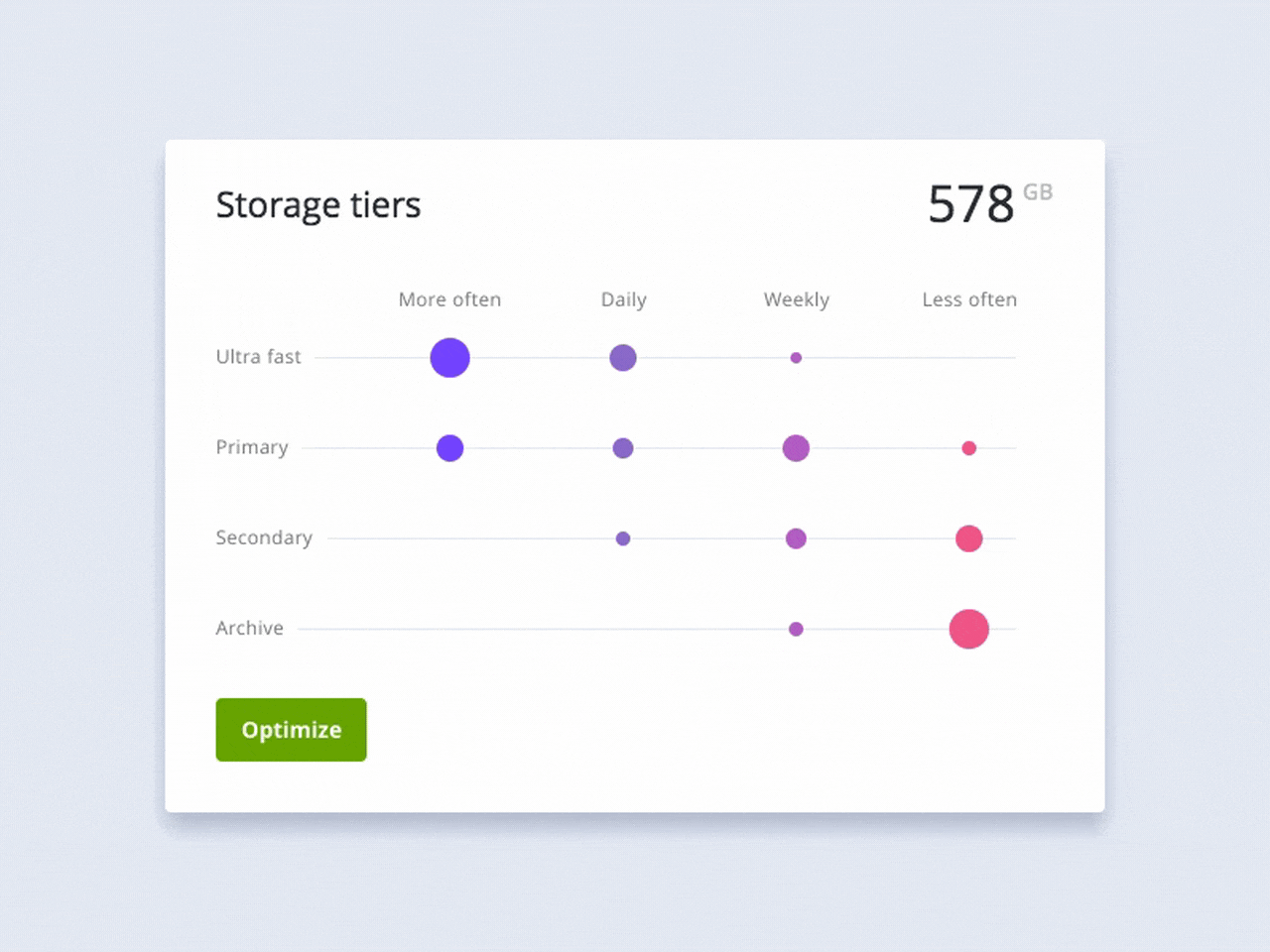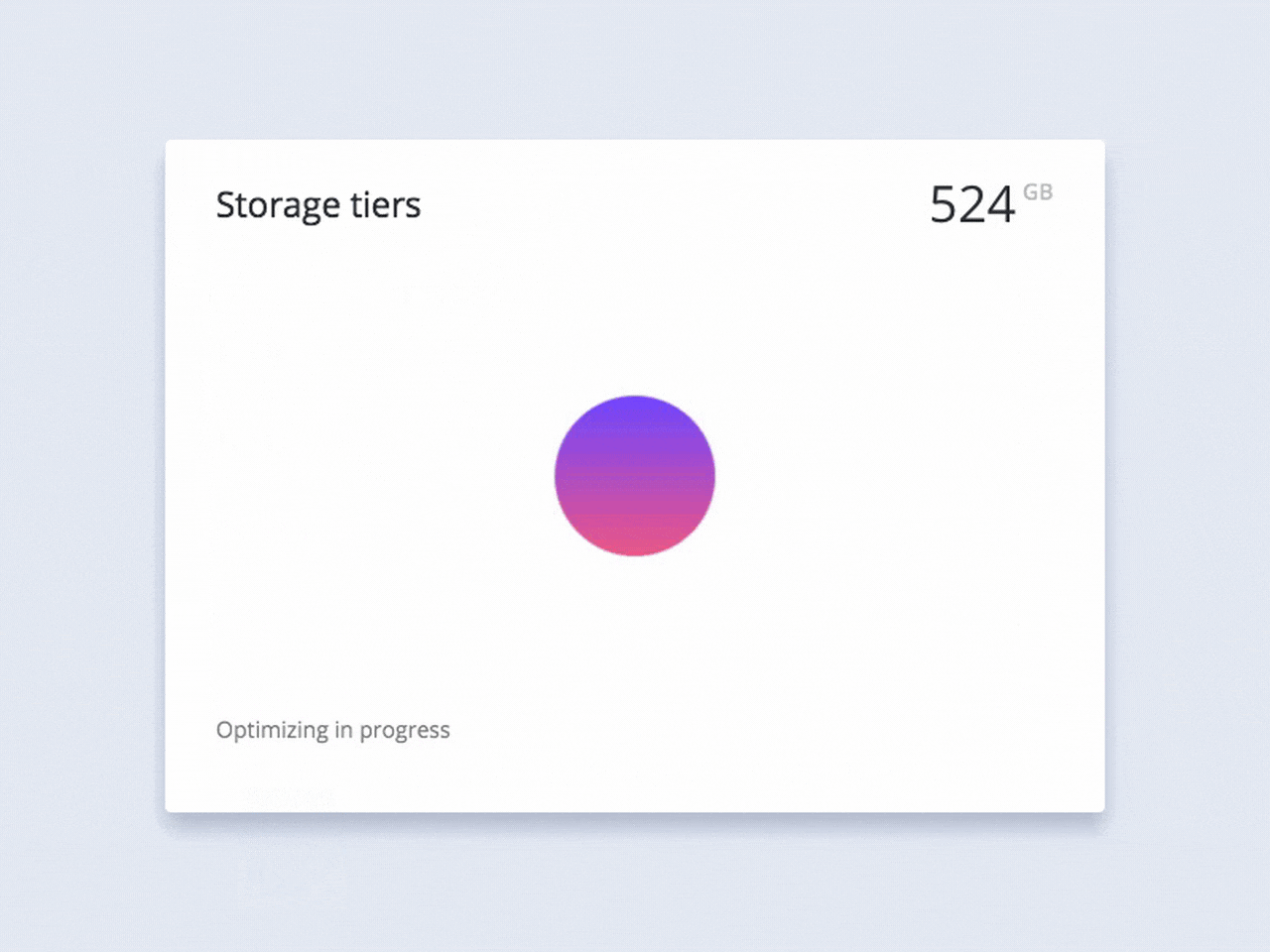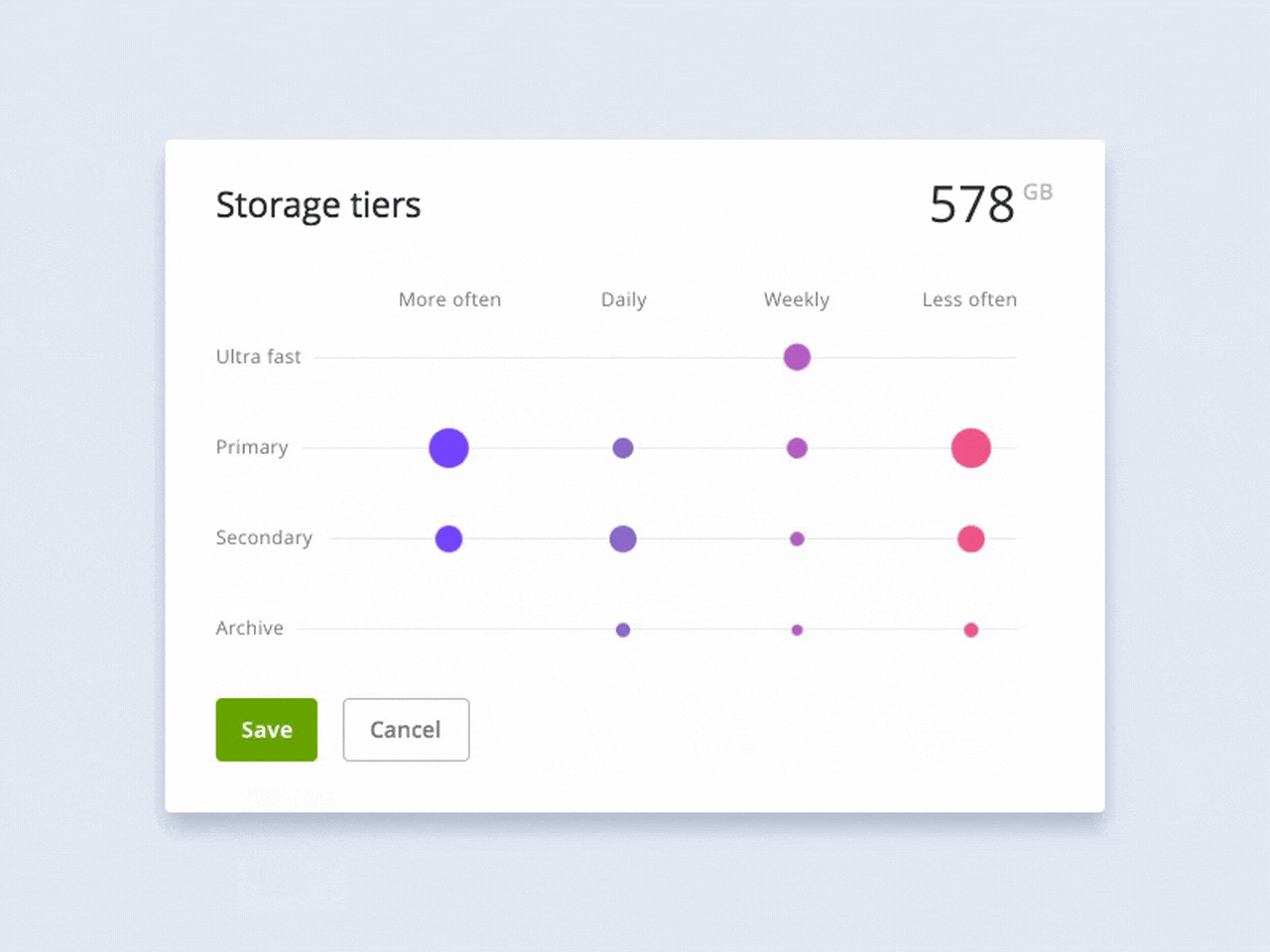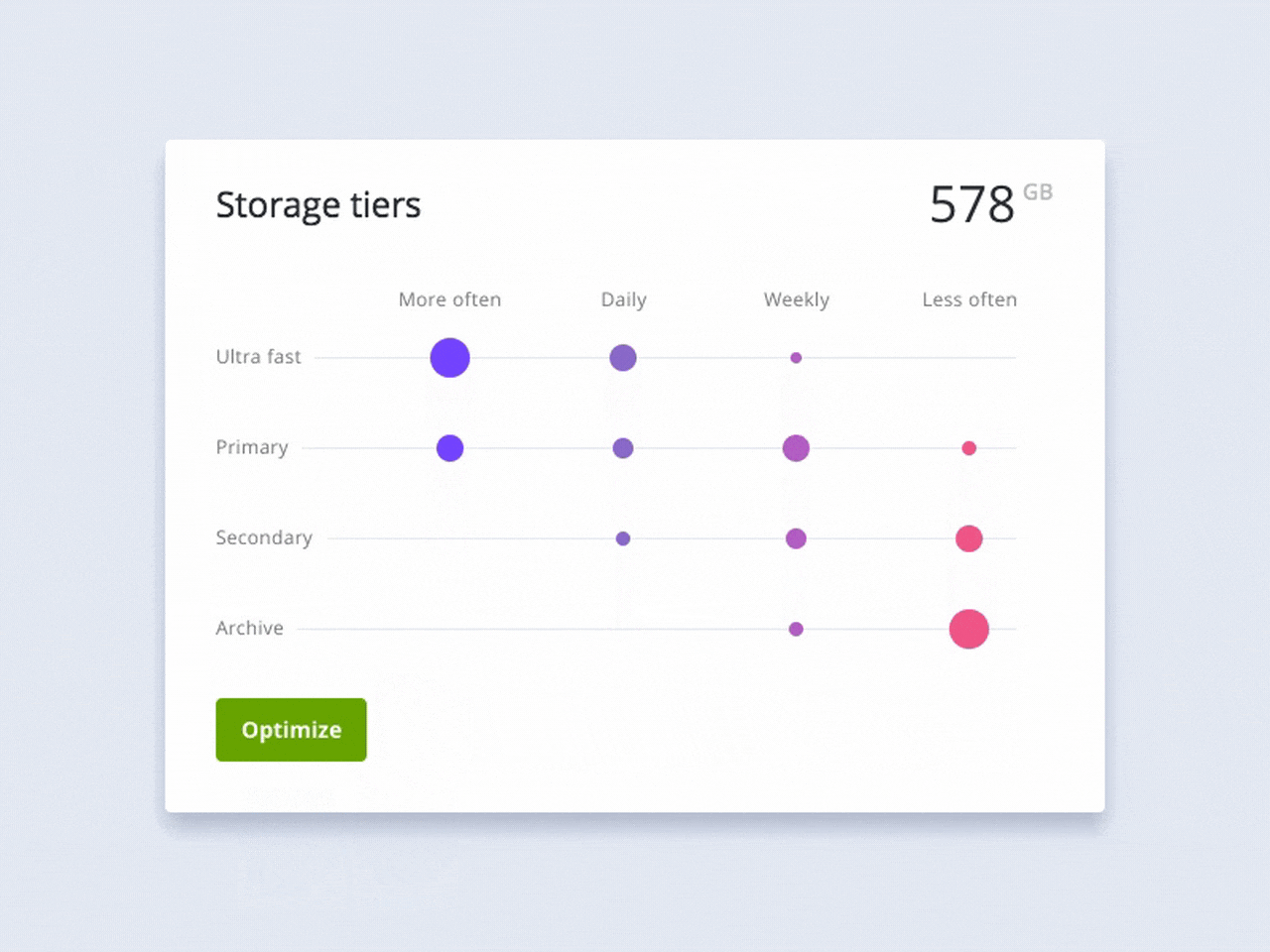
Сейчас, в отделе, мы только начинаем делать первые шаги к коду и не заставляем дизайнеров верстать или учить JS, но даем такую возможность. Возможность расти и развиваться, лучше понимать разработчиков и говорить с ними на одном языке.
Конечно мы только в начале пути, но первые результаты не заставили себя долго ждать. Помимо внедрения новых инструментов, оптимизации процессов и ускорения работы удалось оздоровить коммуникацию не только внутри отдела, но и между командами. Мы стали чаще договариваться, обсуждать и принимать совместные решения, получили прозрачный и понятный workflow который легко масштабировать и добавили еще один вектор развития для дизайнеров в виде работы с кодом. Несмотря на первые успехи и маленькие победы, задач и проблем которые нужно решить еще очень много. Мы ежедневно тестируем заложенные решения, описываем правила и закладываем базовые принципы, чтобы сделать процесс работы еще более прозрачным и комфортным.
Кстати, мы всегда рады опытным дизайнерам. Если вы такой, напишите мне на почту: sergey.nikishkin@acronis.com
|
Метки: author Nikishkin интерфейсы веб-дизайн блог компании acronis inc acronis ui ux product design design system components angular 4 library |
[Перевод] Взбираясь на непокорённую гору: сложности создания игры в одиночку |














|
Метки: author PatientZero разработка игр игры инди-разработка создание игр в одиночку |
Из эскулапов в сисадмины: есть ли жизнь в IT после Клятвы Гиппократа? |
|
Метки: author Shaltay учебный процесс в it медицина смена работы врачи |
Go быстрее Rust, Mail.Ru Group сделала замеры |
Эти тесты показывают, как ведут себя голые серверы, без «прочих нюансов» которые зависят от рук программистов.
При тестировании выяснилось, что все претенденты работают примерно с одинаковой производительностью в такой постановке — все упиралось в производительность V8. Однако реализация задания не была лишней — разработка на каждом из языков позволила составить значительную часть субъективных оценок, которые так или иначе могли бы повлиять на окончательный выбор.
GET / HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello World!GET /greeting/user HTTP/1.1
Host: service.host
HTTP/1.1 200 OK
Hello, uservar cluster = require('cluster');
var numCPUs = require('os').cpus().length;
var http = require("http");
var debug = require("debug")("lite");
var workers = [];
var server;
cluster.on('fork', function(worker) {
workers.push(worker);
worker.on('online', function() {
debug("worker %d is online!", worker.process.pid);
});
worker.on('exit', function(code, signal) {
debug("worker %d died", worker.process.pid);
});
worker.on('error', function(err) {
debug("worker %d error: %s", worker.process.pid, err);
});
worker.on('disconnect', function() {
workers.splice(workers.indexOf(worker), 1);
debug("worker %d disconnected", worker.process.pid);
});
});
if (cluster.isMaster) {
debug("Starting pure node.js cluster");
['SIGINT', 'SIGTERM'].forEach(function(signal) {
process.on(signal, function() {
debug("master got signal %s", signal);
process.exit(1);
});
});
for (var i = 0; i < numCPUs; i++) {
cluster.fork();
}
} else {
server = http.createServer();
server.on('listening', function() {
debug("Listening %o", server._connectionKey);
});
var greetingRe = new RegExp("^\/greeting\/([a-z]+)$", "i");
server.on('request', function(req, res) {
var match;
switch (req.url) {
case "/": {
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello World!");
break;
}
default: {
match = greetingRe.exec(req.url);
res.statusCode = 200;
res.statusMessage = 'OK';
res.write("Hello, " + match[1]);
}
}
res.end();
});
server.listen(8080, "127.0.0.1");
}package main
import (
"fmt"
"net/http"
"regexp"
)
func main() {
reg := regexp.MustCompile("^/greeting/([a-z]+)$")
http.ListenAndServe(":8080", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
switch r.URL.Path {
case "/":
fmt.Fprint(w, "Hello World!")
default:
fmt.Fprintf(w, "Hello, %s", reg.FindStringSubmatch(r.URL.Path)[1])
}
}))
}extern crate hyper;
extern crate regex;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
let greeting_re = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
_ => {
greet(&req, res, greeting_re.captures(path).unwrap());
}
},
_ => {
not_found(&req, res);
}
};
}
fn hello(_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write_all(format!("Hello, {}", cap.at(1).unwrap()).as_bytes()).unwrap();
r.end().unwrap();
}
fn not_found(_: &Request, mut res: Response) {
*res.status_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write_all(b"Not Found\n").unwrap();
}
fn main() {
let _ = Server::http("127.0.0.1:8080").unwrap().handle(handler);
} package lite
import akka.actor.{ActorSystem, Props}
import akka.io.IO
import spray.can.Http
import akka.pattern.ask
import akka.util.Timeout
import scala.concurrent.duration._
import akka.actor.Actor
import spray.routing._
import spray.http._
import MediaTypes._
import org.json4s.JsonAST._
object Boot extends App {
implicit val system = ActorSystem("on-spray-can")
val service = system.actorOf(Props[LiteActor], "demo-service")
implicit val timeout = Timeout(5.seconds)
IO(Http) ? Http.Bind(service, interface = "localhost", port = 8080)
}
class LiteActor extends Actor with LiteService {
def actorRefFactory = context
def receive = runRoute(route)
}
trait LiteService extends HttpService {
val route =
path("greeting" / Segment) { user =>
get {
respondWithMediaType(`text/html`) {
complete("Hello, " + user)
}
}
} ~
path("") {
get {
respondWithMediaType(`text/html`) {
complete("Hello World!")
}
}
}
}Example: Avoid compiling the same regex in a loop
It is an anti-pattern to compile the same regular expression in a loop since compilation is typically expensive. (It takes anywhere from a few microseconds to a few milliseconds depending on the size of the regex.) Not only is compilation itself expensive, but this also prevents optimizations that reuse allocations internally to the matching engines.
In Rust, it can sometimes be a pain to pass regular expressions around if they're used from inside a helper function. Instead, we recommend using the lazy_static crate to ensure that regular expressions are compiled exactly once.
For example:
#[macro_use] extern crate lazy_static; extern crate regex; use regex::Regex; fn some_helper_function(text: &str) -> bool { lazy_static! { static ref RE: Regex = Regex::new("...").unwrap(); } RE.is_match(text) } fn main() {}
Specifically, in this example, the regex will be compiled when it is used for the first time. On subsequent uses, it will reuse the previous compilation.
But you should avoid the repeated compilation of a regular expression in a loop for performance reasons.
Спасибо! Я тоже думал было переписать на split во всех примерах, но потом показалось, что с regexp будет более жизненно. При оказии попробую прогнать wrk со split.
extern crate hyper;
extern crate regex;
#[macro_use] extern crate lazy_static;
use std::io::Write;
use regex::{Regex, Captures};
use hyper::Server;
use hyper::server::{Request, Response};
use hyper::net::Fresh;
use hyper::uri::RequestUri::{AbsolutePath};
fn handler(req: Request, res: Response) {
lazy_static! {
static ref GREETING_RE: Regex = Regex::new(r"^/greeting/([a-z]+)$").unwrap();
}
match req.uri {
AbsolutePath(ref path) => match (&req.method, &path[..]) {
(&hyper::Get, "/") => {
hello(&req, res);
},
_ => {
greet(&req, res, GREETING_RE.captures(path).unwrap());
}
},
_ => {
not_found(&req, res);
}
};
}
fn hello(_: &Request, res: Response) {
let mut r = res.start().unwrap();
r.write_all(b"Hello World!").unwrap();
r.end().unwrap();
}
fn greet(_: &Request, res: Response, cap: Captures) {
let mut r = res.start().unwrap();
r.write_all(format!("Hello, {}", cap.at(1).unwrap()).as_bytes()).unwrap();
r.end().unwrap();
}
fn not_found(_: &Request, mut res: Response) {
*res.status_mut() = hyper::NotFound;
let mut r = res.start().unwrap();
r.write_all(b"Not Found\n").unwrap();
}
fn main() {
let _ = Server::http("127.0.0.1:3000").unwrap().handle(handler);
}
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 11.729 | 21825.65 |
| Go | 13.992 | 18296.71 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 11.982 | 21365.36 |
| Go | 14.589 | 17547.04 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 8.987 | 28485.53 |
| Go | 9.839 | 26020.16 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 9.148 | 27984.13 |
| Go | 9.689 | 26420.82 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 5.601 | 45708.98 |
| Go | 6.770 | 37815.62 |
ab -n50000 -c256 -t10 "http://127.0.0.1:3000/greeting/hello"| Label | Time per request, ms | Request, #/sec |
|---|---|---|
| Rust | 5.736 | 44627.28 |
| Go | 6.451 | 39682.85 |

|
Метки: author humbug тестирование веб-сервисов программирование высокая производительность rust go benchmark rust is faster than go |
[Перевод] Padding Oracle Attack: криптография по-прежнему пугает |
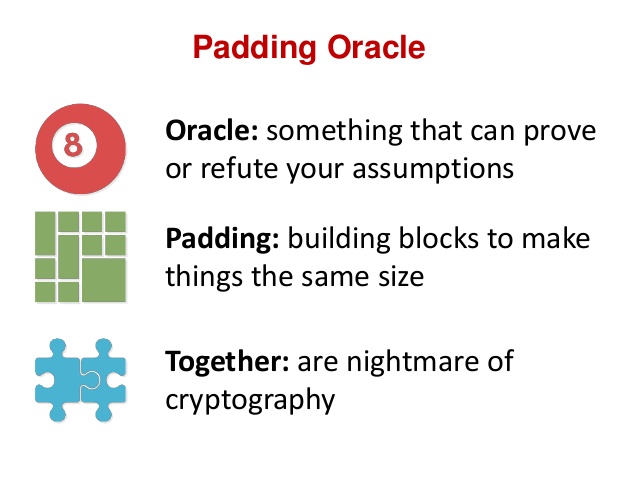

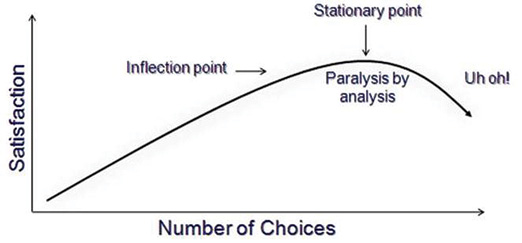
(0) или (1,1) или (2,2,2) или т.п.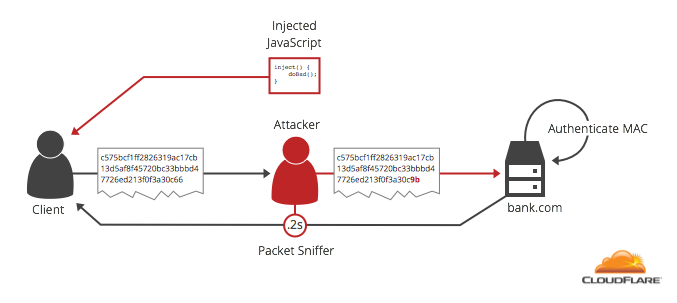


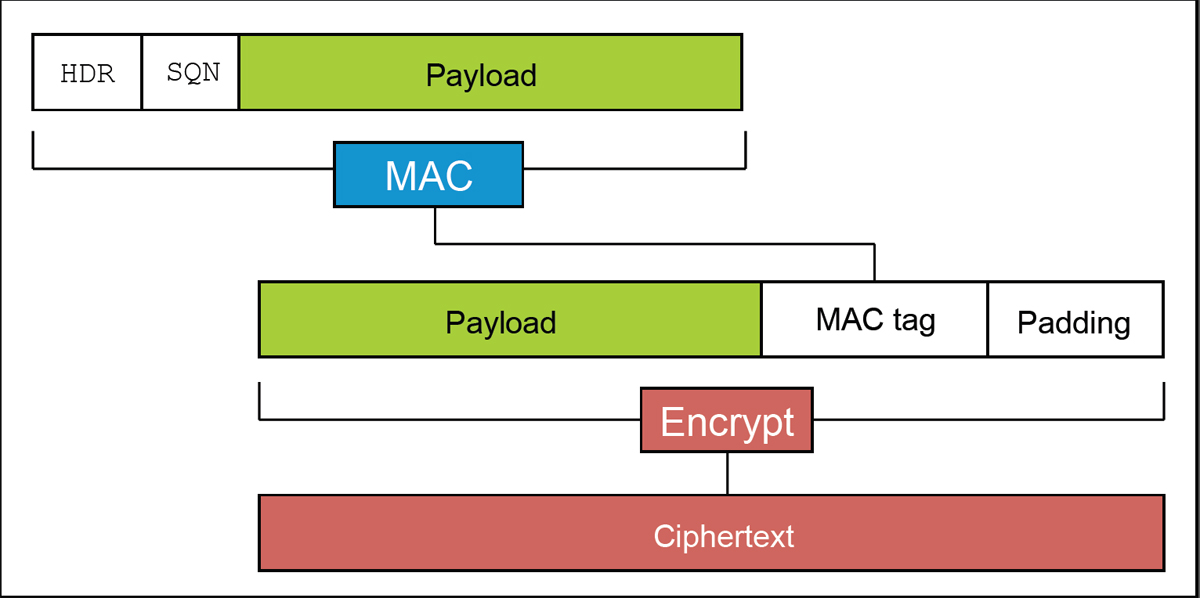
Своё название эта атака получила из-за того, что размер заголовка, хешируемого перед «полезной нагрузкой», ограничил перебор вариантов набивки двухбайтными последовательностями. Будь этот заголовок 14-байтным или длинее, скачок во времени отклика сервера пришёлся бы на более короткие куски открытого текста, и перебирать бы приходилось в сотни раз больше вариантов набивки. С другой стороны, будь этот заголовок 11-байтным, скачок бы пришёлся на переход между 8 и 9 блоками открытого текста, и атака была бы совершенно невозможна. Ну а самое счастливое число — конечно же, 12: с такой длиной заголовка для атаки было бы достаточно перебирать значения последнего байта самого по себе, как и в атаке Воденэ.
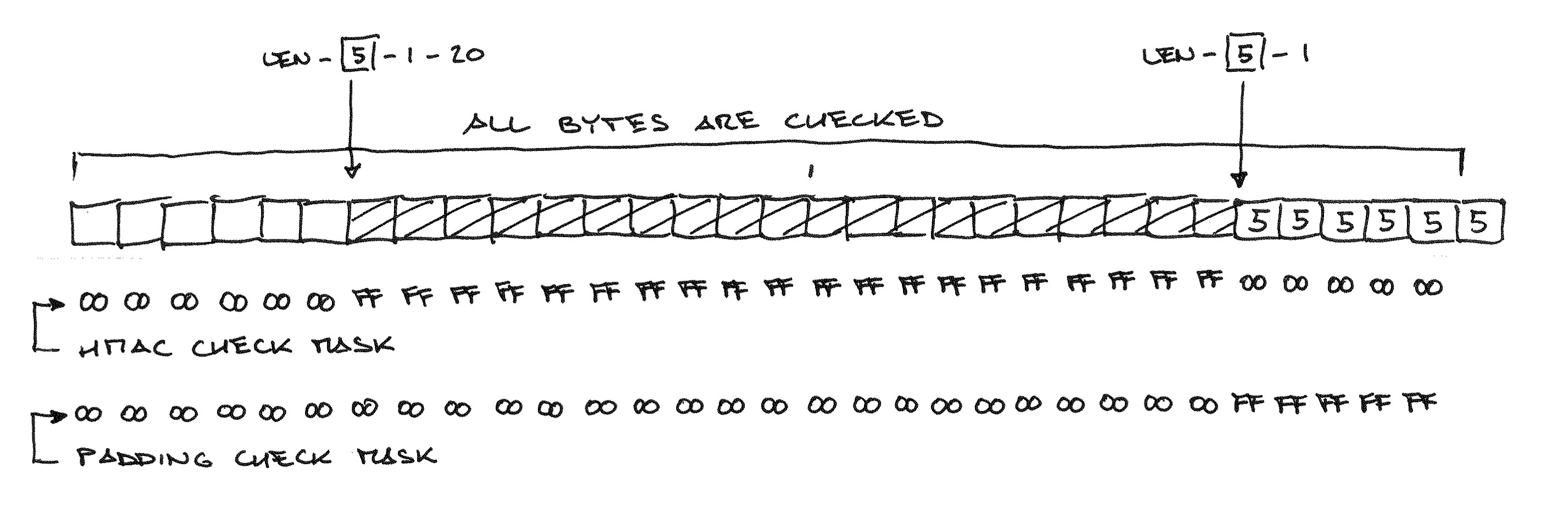


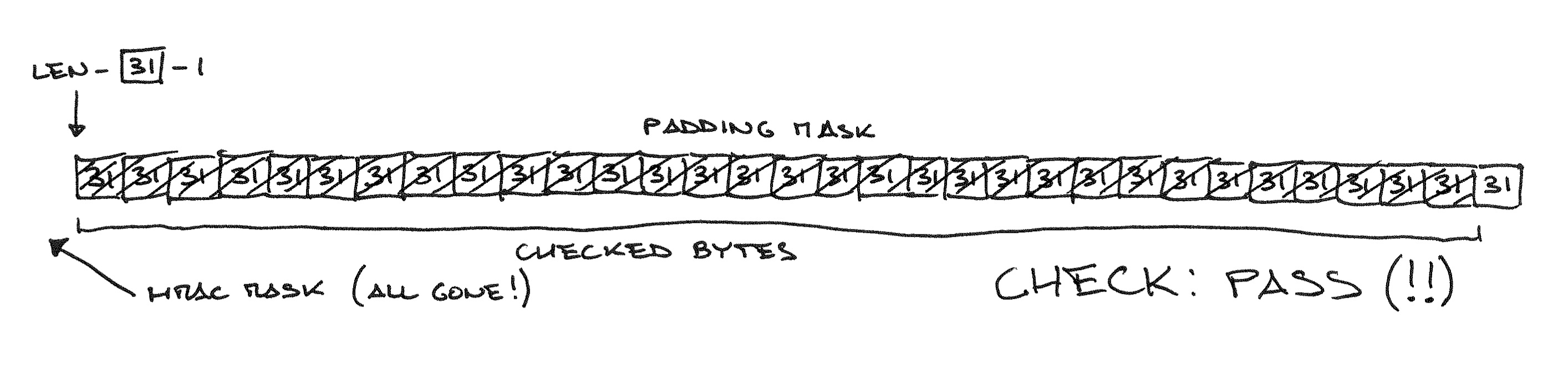

Техническое замечание: даже если POST-запрос оканчивается на последовательность из байтов 31, перед CBC-шифрованием он будет дополнен MAC и набивкой, так что в описанном виде атака не сработает. Подготовительный этап атаки — варьируя запрашиваемый путь, подобрать такую длину POST-запроса, чтобы MAC и настоящая набивка заняли последние два CBC-блока целиком; затем в ходе атаки эти последние два блока будут отбрасываться, а использоваться будут блоки от пятого до третьего с конца. Наладив такую координацию действий между скриптом, генерирующим HTTPS-запросы, и MitM-сервером, злоумышленник может обеспечить, что результат CBC-расшифровки будет оканчиваться на 31 байт со значением 31.
|
|
Глобальные тренды геймдева: о чем расскажут на «4C: Санкт-Петербург»? |
|
Метки: author megapost тестирование игр монетизация игр продвижение игр разработка игр wargaming |
4 распространенные ошибки в дизайне, которые легко исправить |


















|
Метки: author Logomachine работа с векторной графикой графический дизайн блог компании логомашина бизнес логотип фирменный стиль помощь советы |
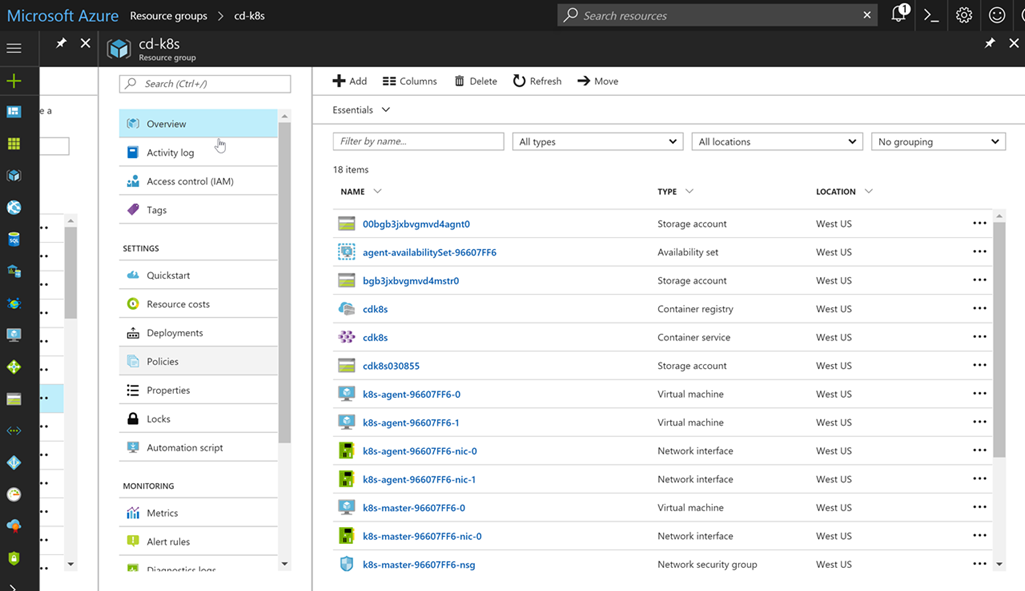
[Перевод] DevOps с Kubernetes и VSTS. Часть 2: Облачная история |

# set some variables
export RG="cd-k8s"
export clusterName="cdk8s"
export location="westus"
# create a folder for the cluster ssh-keys
mkdir cdk8s
# login and create a resource group
az login
az group create --location $location --name $RG
# create an ACS k8s cluster
az acs create --orchestrator-type=kubernetes --resource-group $RG --name=$ClusterName --dns-prefix=$ClusterName --generate-ssh-keys --ssh-key-value ~/cdk8s/id_rsa.pub --location $location --agent-vm-size Standard_DS1_v2 --agent-count 2
# create an Azure Container Registry
az acr create --resource-group $RG --name $ClusterName --location $location --sku Basic --admin-enabled
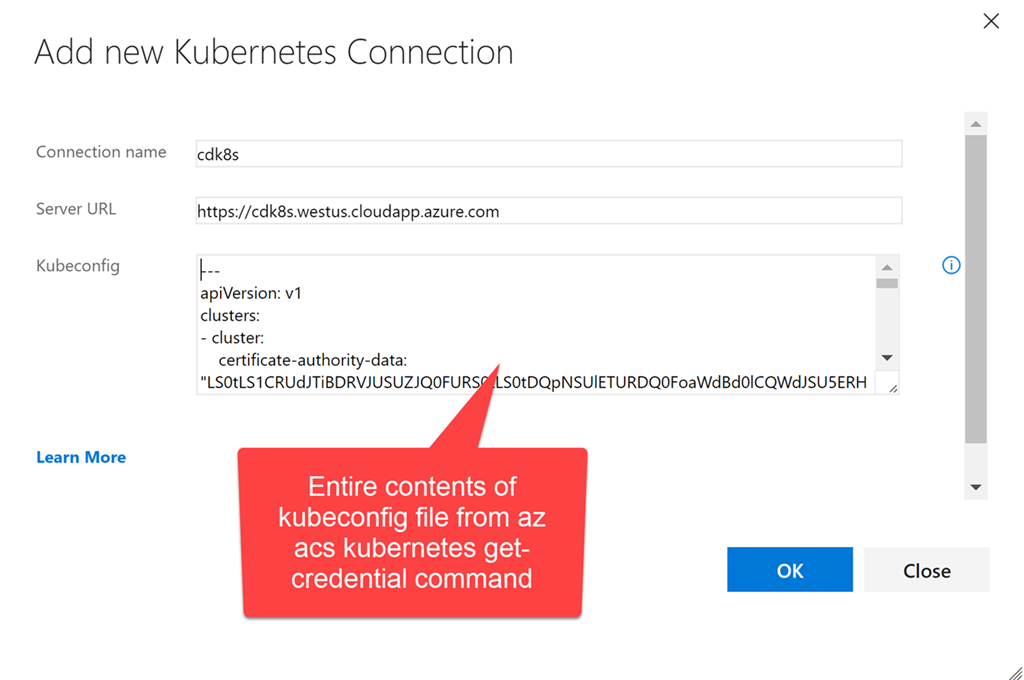
# configure kubectl
az acs kubernetes get-credentials --name $ClusterName --resource-group $RG --file ~/cdk8s/kubeconfig --ssh-key-file ~/cdk8s/id_rsa
export KUBECONFIG="~/cdk8s/kubeconfig"
# test connection
kubectl get nodes
NAME STATUS AGE VERSION
k8s-agent-96607ff6-0 Ready 17m v1.6.6
k8s-agent-96607ff6-1 Ready 17m v1.6.6
k8s-master-96607ff6-0 Ready,SchedulingDisabled 17m v1.6.6
apiVersion: v1
kind: Namespace
metadata:
name: dev
---
apiVersion: v1
kind: Namespace
metadata:
name: prod
kubectl apply -f namespaces.yml
namespace "dev" created
namespace "prod" created
kubectl get namespaces
NAME STATUS AGE
default Active 27m
dev Active 20s
kube-public Active 27m
kube-system Active 27m
prod Active 20s
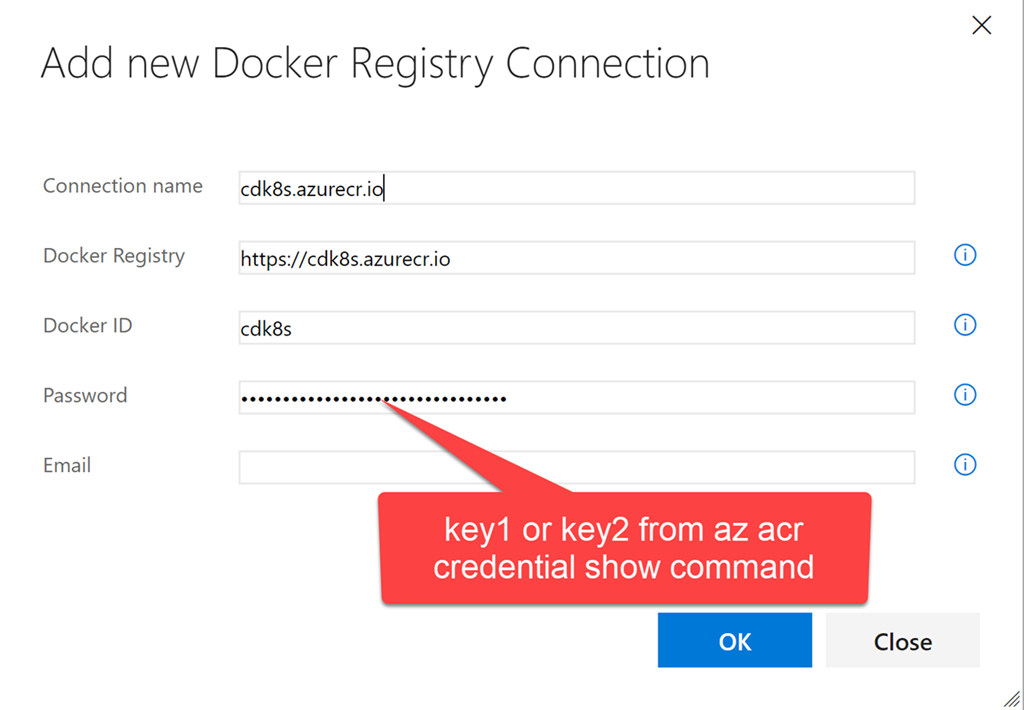
az acr credential show --name $ClusterName --output table
USERNAME PASSWORD PASSWORD2
---------- -------------------------------- --------------------------------
cdk8s some-long-key-1 some-long-key-2
kubectl create secret docker-registry regsecret --docker-server=$ClusterName.azurecr.io --docker-username=$ClusterName --docker-password= --docker-email=admin@azurecr.io
secret "regsecret" created


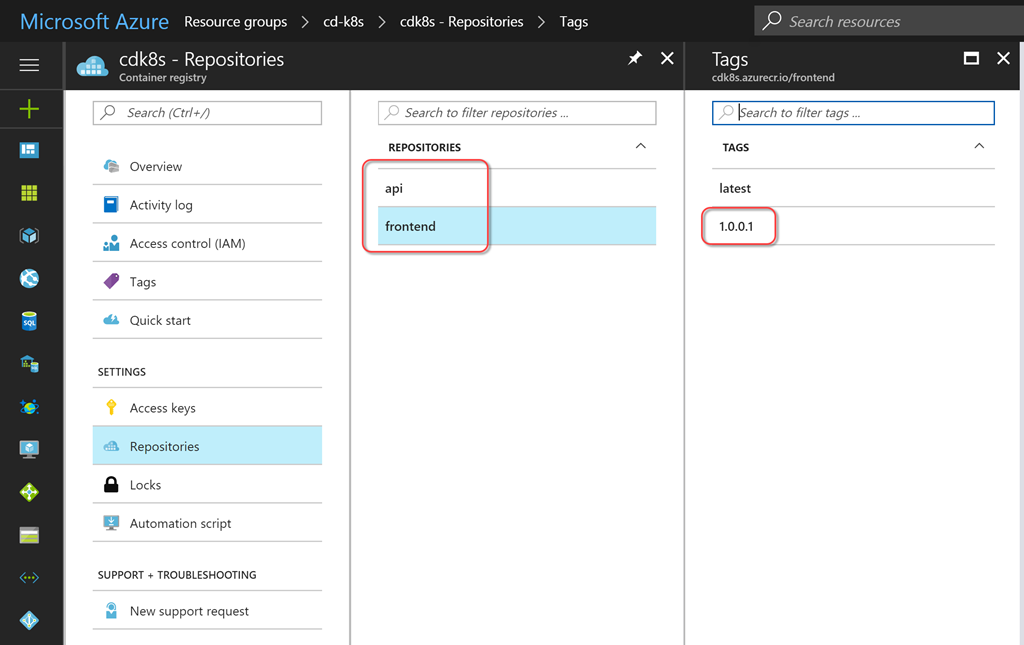

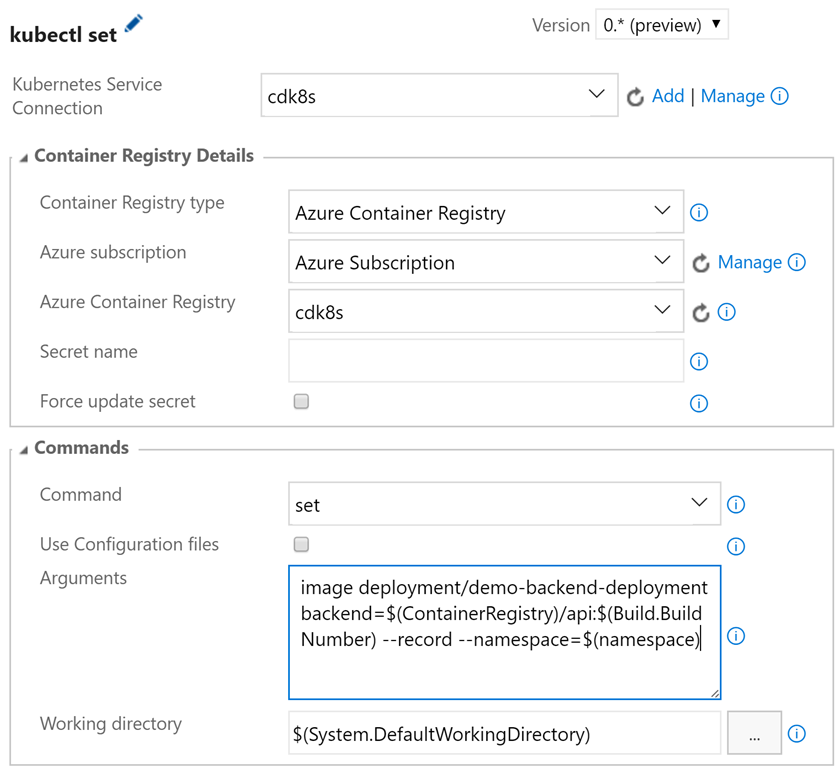
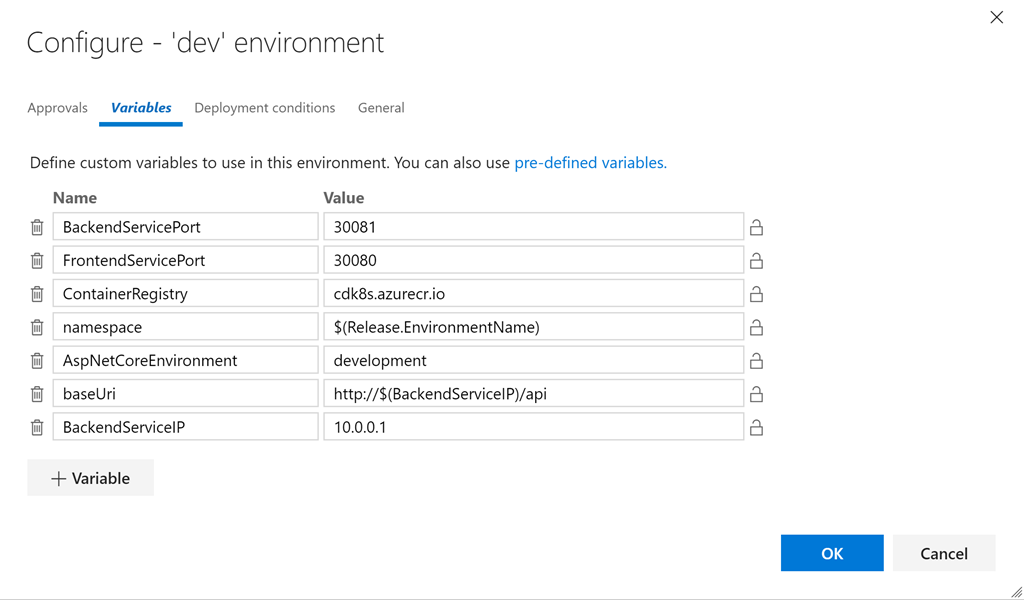
apiVersion: v1
kind: Service
metadata:
name: demo-frontend-service
labels:
app: demo
spec:
selector:
app: demo
tier: frontend
ports:
- protocol: TCP
port: 80
nodePort: __FrontendServicePort__
type: LoadBalancer
---
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: demo-frontend-deployment
spec:
replicas: 2
template:
metadata:
labels:
app: demo
tier: frontend
spec:
containers:
- name: frontend
image: __ContainerRegistry__/frontend
ports:
- containerPort: 80
env:
- name: "ASPNETCORE_ENVIRONMENT"
value: "__AspNetCoreEnvironment__"
volumeMounts:
- name: config-volume
mountPath: /app/wwwroot/config/
imagePullPolicy: Always
volumes:
- name: config-volume
configMap:
name: demo-app-frontend-config
imagePullSecrets:
- name: regsecret
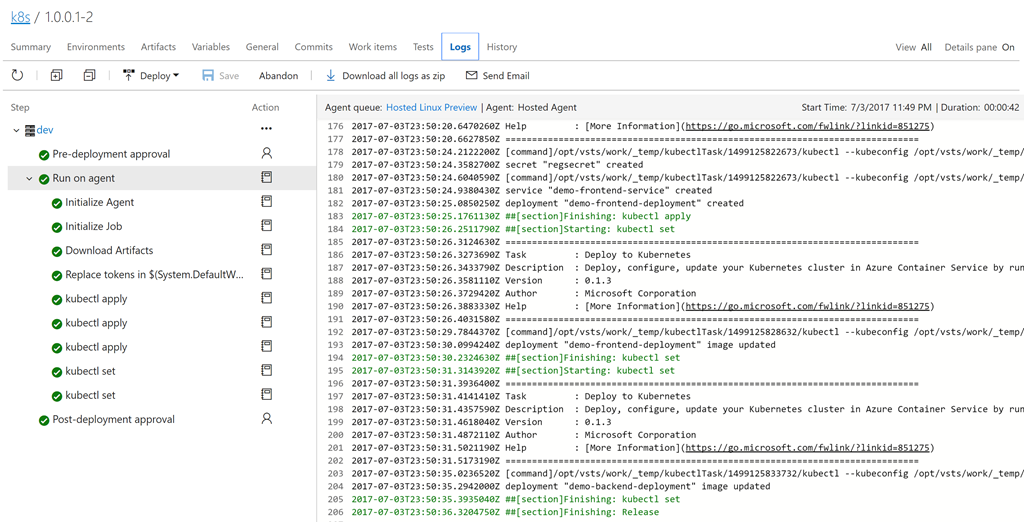
az acs kubernetes browse -n $ClusterName -g $RG --ssh-key-file ~/cdk8s/id_rsa
Proxy running on 127.0.0.1:8001/ui
Press CTRL+C to close the tunnel...
Starting to serve on 127.0.0.1:8001
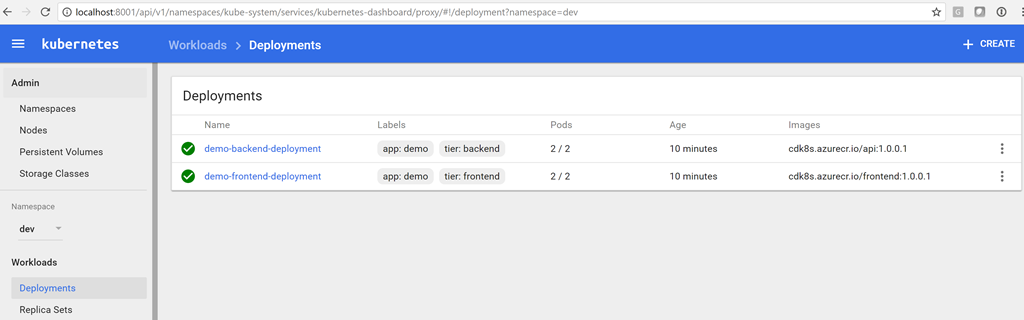
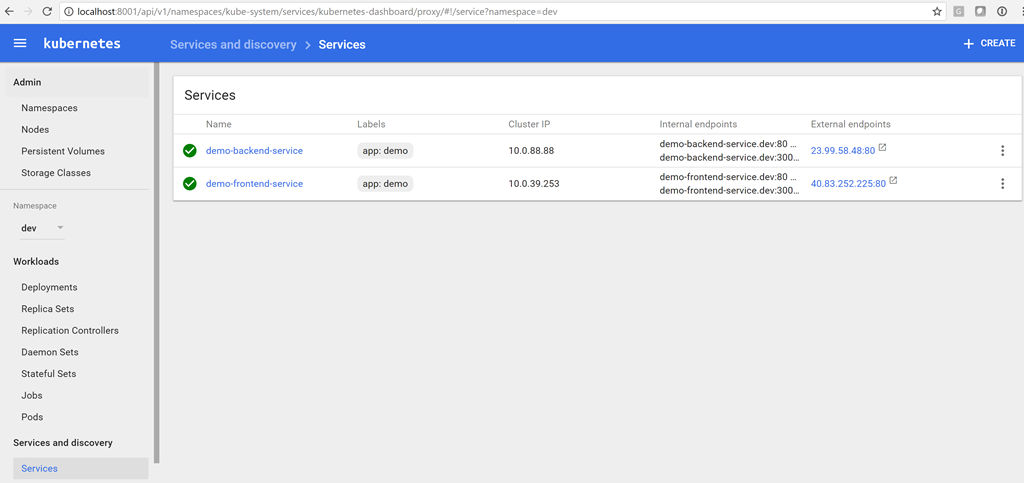
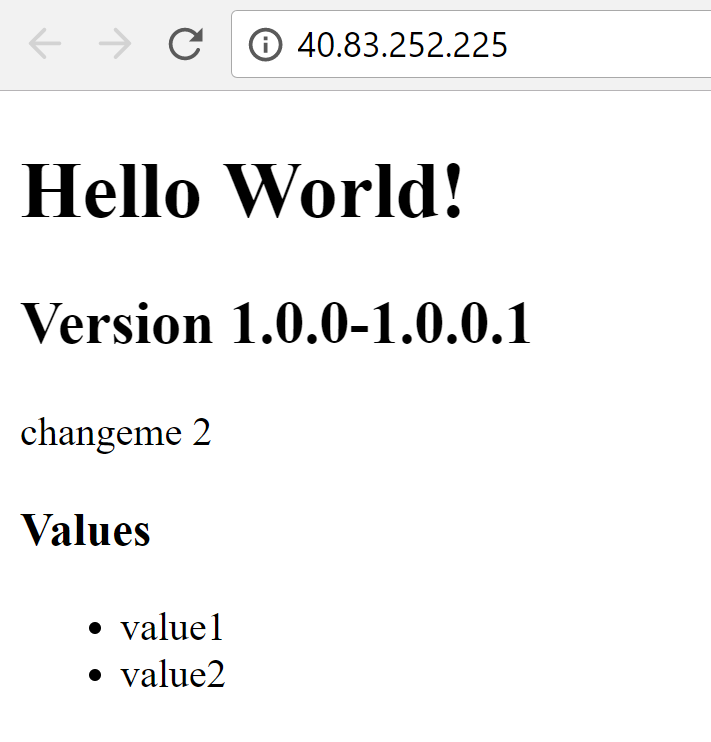
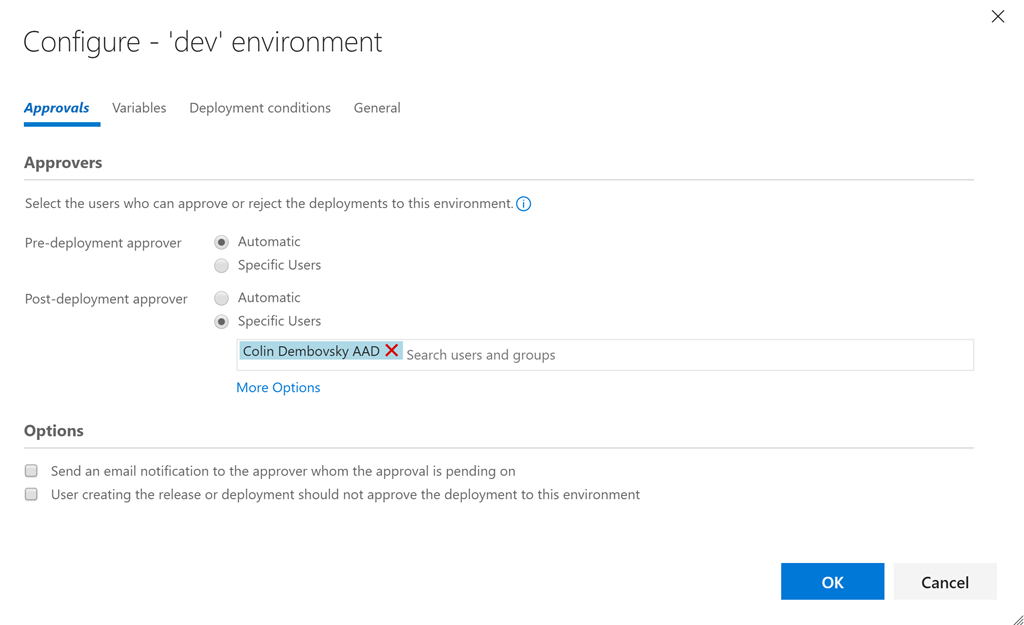
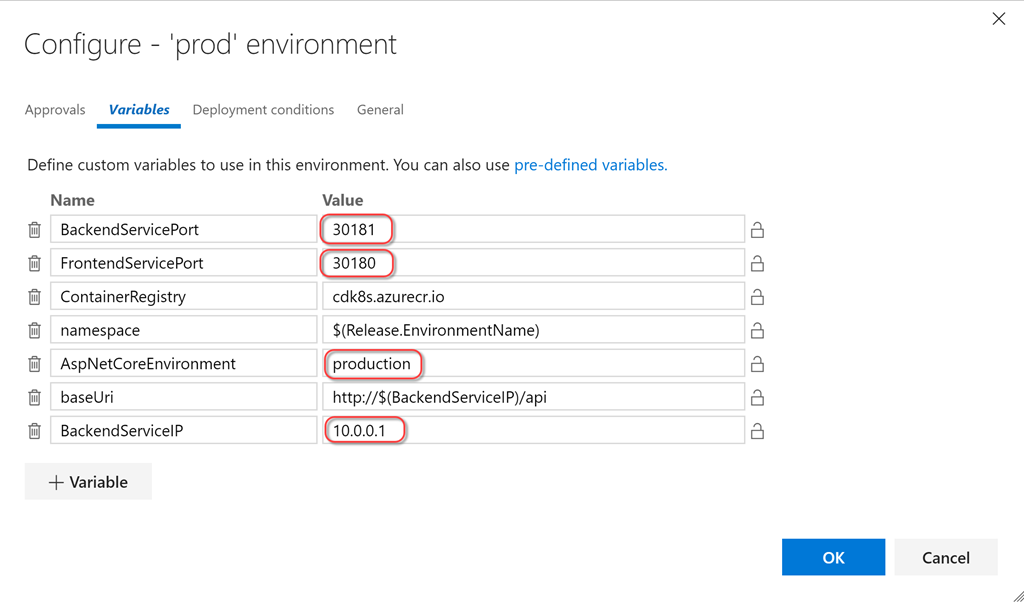
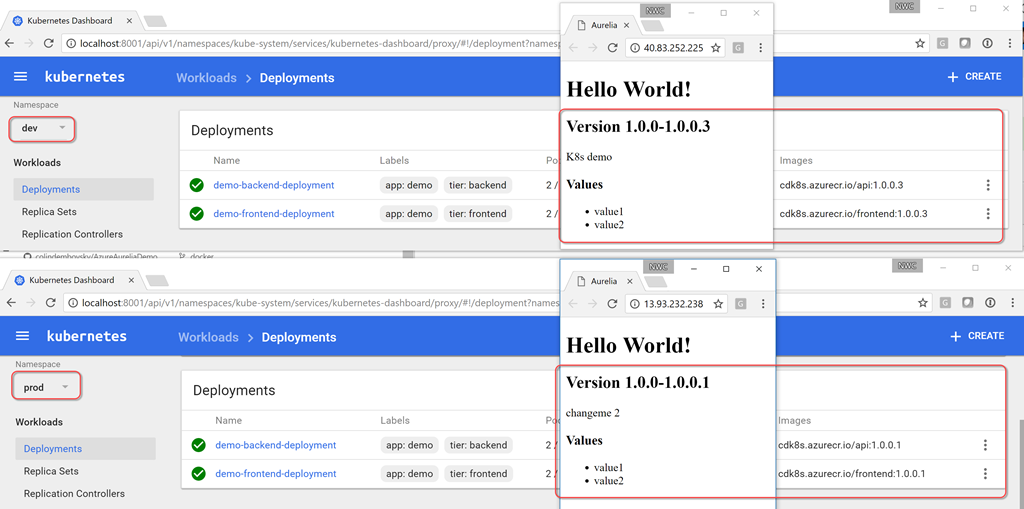
|
Метки: author stasus программирование visual studio microsoft azure блог компании microsoft kubernetes k8s vsts devops acs kubectl microsoft |
[Из песочницы] Пишем для UEFI BIOS в Visual Studio. Часть 1 — разворачивание среды разработки, компиляция и запуск на отладку |
git clone https://github.com/ProgrammingInUEFI/FW
TOOL_CHAIN_TAG = VS2010x86


set NASM_PREFIX=C:\FW\NASM\
call c:\FW\edk2\edksetup.bat --nt32
build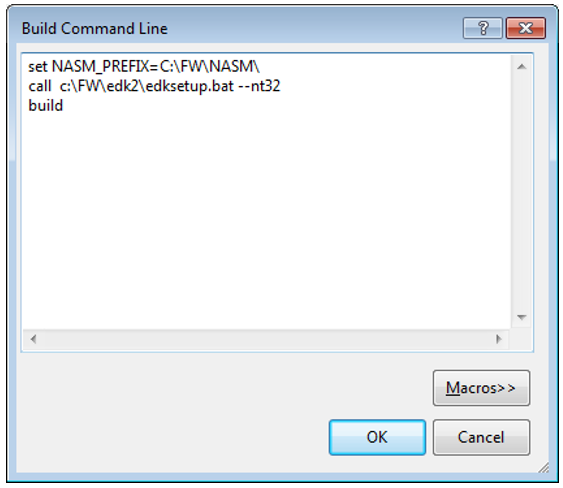
set NASM_PREFIX=C:\FW\NASM\
call c:\FW\edk2\edksetup.bat --nt32
build clean
buildset NASM_PREFIX=C:\FW\NASM\
call c:\FW\edk2\edksetup.bat --nt32
build clean
C:\FW\edk2\Build\NT32IA32\DEBUG_VS2010x86\IA32\SecMain.exeC:\FW\edk2\Build\NT32IA32\DEBUG_VS2010x86\IA32\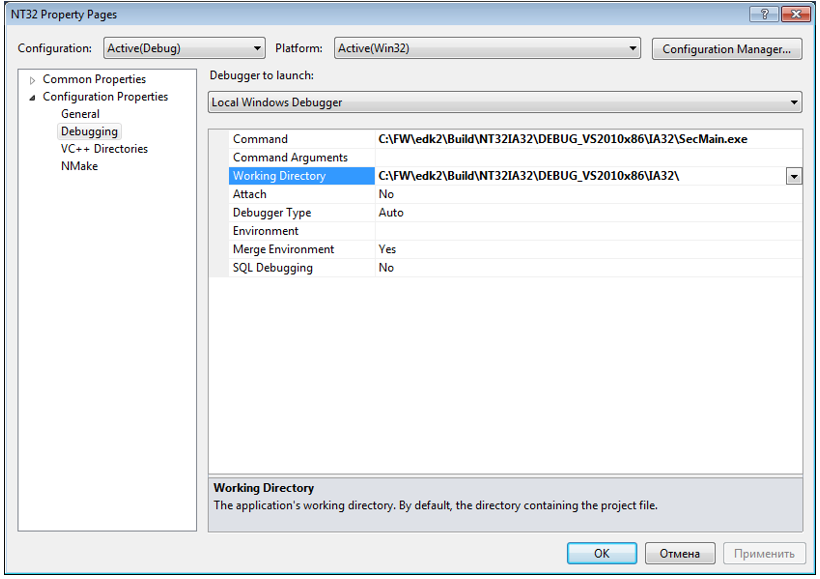
========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========LINK : fatal error LNK1123: failure during conversion to COFF: file invalid or corrupt
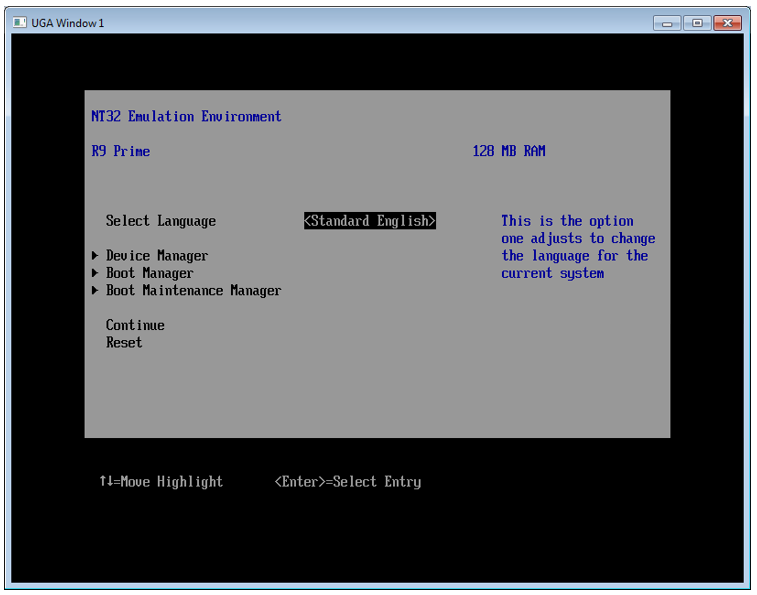
C:\FW\edk2\MdeModulePkg\Application\HelloWorld\HelloWorld.cPrint (L"I did it in UEFI!\r\n");
|
Метки: author DarkTiger системное программирование uefi bios |
Платформа ServiceNow: тематическая подборка материалов для начинающих |
 / Flickr / Dean Hochman / CC
/ Flickr / Dean Hochman / CC|
Метки: author it-guild управление e-commerce service desk блог компании ит гильдия ит гильдия servicenow |
[Из песочницы] learnopengl. Урок 2.6 — Несколько источников освещения |

out vec4 FragColor;
void main()
{
// устанавливаем значение нашего выходного цвета
vec3 output = vec3(0.0);
// добавляем значение, полученное из направленного источника освещения
output += someFunctionToCalculateDirectionalLight();
// делаем тоже самое и с точечным источником
for(int i = 0; i < nr_of_point_lights; i++)
output += someFunctionToCalculatePointLight();
// и добавляем остальные значения так же
output += someFunctionToCalculateSpotLight();
FragColor = vec4(output, 1.0);
}struct DirLight {
vec3 direction;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
uniform DirLight dirLight;vec3 CalcDirLight(DirLight light, vec3 normal, vec3 viewDir);Также как в C и C++, если мы хотим вызвать функцию (в нашем случае внутри функции main) функция должна быть объявлена где-нибудь до того момента, где мы её вызываем. В нашем случае, мы объявим прототип над функцией main, а опишем её где нибудь ниже.Вы можете видеть, что функция требует DirLight структуру и 2 вектора. Если вы успешно завершили предыдущие уроки, тогда код этой функции не должен вызывать для вас вопросов:
vec3 CalcDirLight(DirLight light, vec3 normal, vec3 viewDir)
{
vec3 lightDir = normalize(-light.direction);
// диффузное освещение
float diff = max(dot(normal, lightDir), 0.0);
// освещение зеркальных бликов
vec3 reflectDir = reflect(-lightDir, normal);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
// комбинируем результаты
vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
vec3 specular = light.specular * spec * vec3(texture(material.specular, TexCoords));
return (ambient + diffuse + specular);
} struct PointLight {
vec3 position;
float constant;
float linear;
float quadratic;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
#define NR_POINT_LIGHTS 4
uniform PointLight pointLights[NR_POINT_LIGHTS];Мы могли также создать одну большую структуру, которая включала бы все нужные переменные для всех разных типов освещения, и использовали бы её для каждой функции, игнорируя переменные в которых бы мы не нуждались. Хотя, я лично нахожу нынешний подход более лучшим, т.к. не всем типам освещения будут нужны все переменные.Прототип функции точечного источника:
vec3 CalcPointLight(PointLight light, vec3 normal, vec3 fragPos, vec3 viewDir);vec3 CalcPointLight(PointLight light, vec3 normal, vec3 fragPos, vec3 viewDir)
{
vec3 lightDir = normalize(light.position - fragPos);
// диффузное освещение
float diff = max(dot(normal, lightDir), 0.0);
// освещение зеркальных бликов
vec3 reflectDir = reflect(-lightDir, normal);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
// затухание
float distance = length(light.position - fragPos);
float attenuation = 1.0 / (light.constant + light.linear * distance +
light.quadratic * (distance * distance));
// комбинируем результаты
vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
vec3 specular = light.specular * spec * vec3(texture(material.specular, TexCoords));
ambient *= attenuation;
diffuse *= attenuation;
specular *= attenuation;
return (ambient + diffuse + specular);
} void main()
{
// свойства
vec3 norm = normalize(Normal);
vec3 viewDir = normalize(viewPos - FragPos);
// фаза 1: Направленный источник освещения
vec3 result = CalcDirLight(dirLight, norm, viewDir);
// фаза 2: Точечные источники
for(int i = 0; i < NR_POINT_LIGHTS; i++)
result += CalcPointLight(pointLights[i], norm, FragPos, viewDir);
// фаза 3: фонарик
//result += CalcSpotLight(spotLight, norm, FragPos, viewDir);
FragColor = vec4(result, 1.0);
}lightingShader.setFloat("pointLights[0].constant", 1.0f);glm::vec3 pointLightPositions[] = {
glm::vec3( 0.7f, 0.2f, 2.0f),
glm::vec3( 2.3f, -3.3f, -4.0f),
glm::vec3(-4.0f, 2.0f, -12.0f),
glm::vec3( 0.0f, 0.0f, -3.0f)
}; 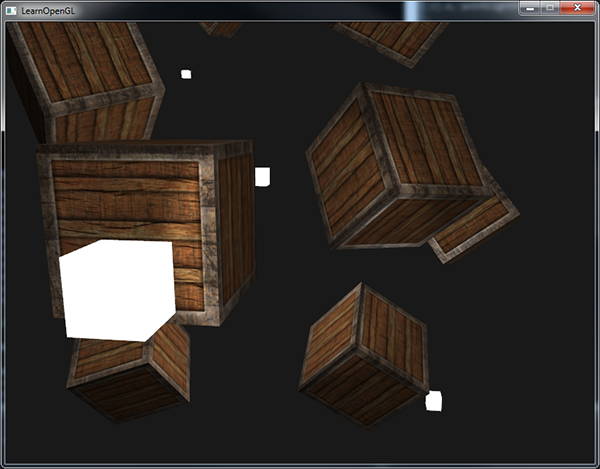

|
Метки: author dima19972525 разработка игр c++ перевод glsl opengl opengl 3 light casters shading |






