Nuklear+ — миниатюрный кроссплатформенный GUI |
 Nuklear+ (читается как "Nuklear cross", значит "кроссплатформенный Nuklear") — это надстройка над GUI библиотекой Nuklear, которая позволяет абстрагироваться от драйвера вывода и взаимодействия с операционной системой. Нужно написать один простой код, а он потом уже сможет скомпилироваться под все поддерживаемые платформы.
Nuklear+ (читается как "Nuklear cross", значит "кроссплатформенный Nuklear") — это надстройка над GUI библиотекой Nuklear, которая позволяет абстрагироваться от драйвера вывода и взаимодействия с операционной системой. Нужно написать один простой код, а он потом уже сможет скомпилироваться под все поддерживаемые платформы.
Я уже писал на хабре статью "Nuklear — идеальный GUI для микро-проектов?". Тогда задача была простой — сделать маленькую кроссплатформенную утилиту с GUI, которая будет примерно одинаково выглядеть в Windows и Linux. Но с тех самых пор меня не отпускал вопрос, а можно ли на Nuklear сделать что-то более-менее сложное? Можно ли целиком на нём сделать какой-нибудь реальный проект, которым будут пользоваться?
Именно поэтому следующую свою игру, Wordlase, я делал на чистом Nuklear. И без всякого там OpenGL. Даже фоновые картинки у меня имеют тип nk_image. В конечном итоге это дало возможность выбора драйвера отрисовки, вплоть до чистого X11 или GDI+.
Ещё в прошлой своей статье я заложил основы Nuklear+ — библиотеки, призванной спрятать всю "грязь" от программиста и дать ему сфокусироваться на создании интерфейса. Библиотека умеет загружать шрифты, картинки, создавать окно операционной системы и контекст отрисовки.
Полный пример кода есть в Readme на GitHub. Там можно увидеть, что код получается довольно простой. Также я перенёс на Nuklear+ свои проекты dxBin2h и nuklear-webdemo. И сделать это было очень просто — вся инициализация заменяется на один вызов nkc_init, события обрабатываются nkc_poll_events, отрисовка функцией nkc_render, а в качестве деструктора вызывается nkc_shutdown.
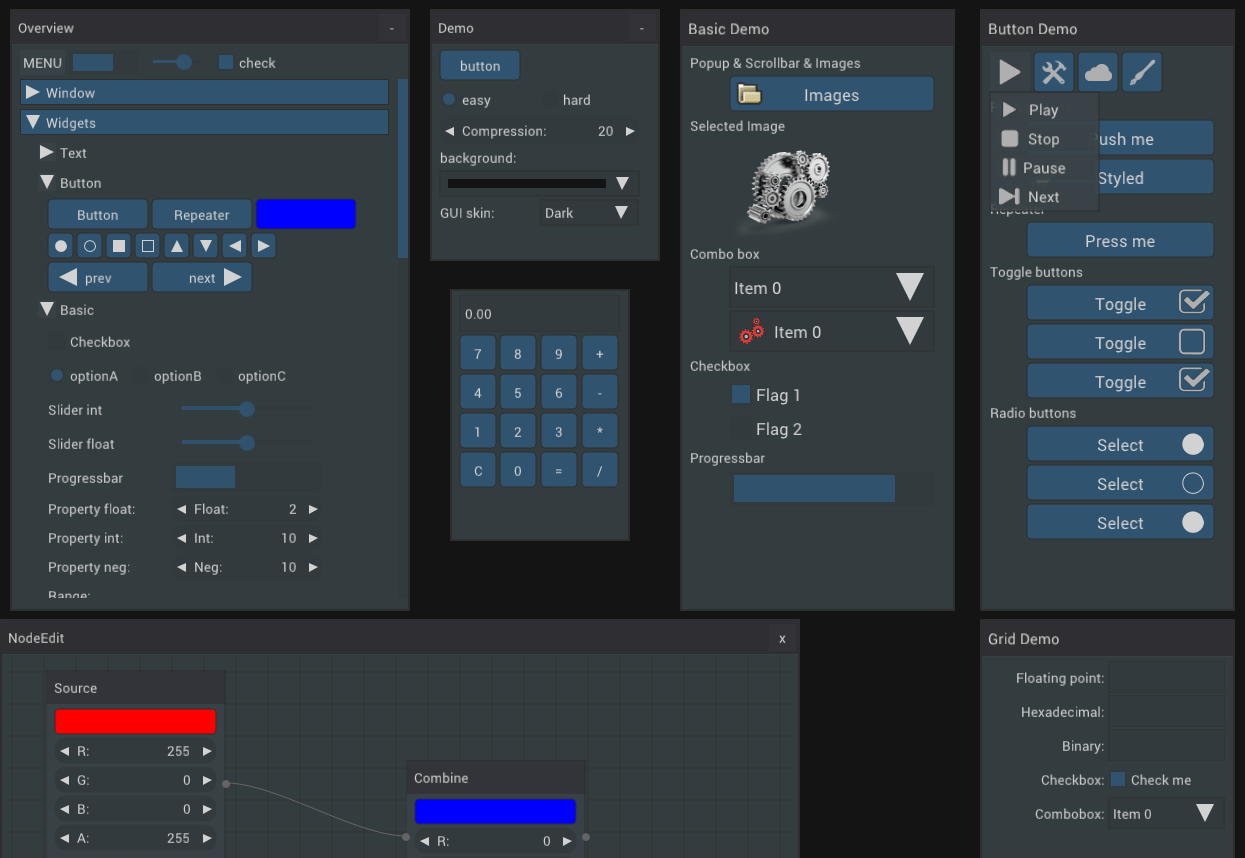
Но вернёмся к Wordlase, на примере которой и построена данная публикация. С недавних пор у игры есть веб-демо. Я не писал какого-то специфичного веб-кода для игры — это чистое С89 приложение, скомпилированное с помощью Emscripten. И если полностью следовать примеру из Readme Nuklear+ (а именно, использовать nkc_set_main_loop), то веб-версия приложения будет получена абсолютно на халяву, без особых лишних затрат.
Самой интересной частью Nuklear+ являются поддерживаемые фронтэнды и бэкэнды. В данном случае под фронтэндом понимается часть, ответственная за взаимодействие с ОС и отрисовку окна. Т.е. непосредственно то, что видит пользователь. Реализации лежат в папке nkc_frontend. Сейчас поддерживаются: SDL, GLFW, X11, GDI+. Они не равносильны. Например, GDI+ использует WinAPI даже для рендера шрифтов и загрузки изображений, т.е. получить ровно такую же картинку в других ОС будет проблематично. Реализация так же не везде одинакова. Например, реализация Х11 пока не умеет изменять разрешение экрана в полноэкранном режиме (буду рад видеть Pull Request)
Выбрать фронтэнд для своего приложения просто — нужно установить переменную препроцессора NKCD=NKC_x, где x это одно из: SDL, GLFW, XLIB, GDIP. Например: gcc -DNKCD=NKC_GLFW main.c
Бэкэнд в данном случае выполняет непосредственно отрисовку. Реализация в папке nuklear_drivers. Отрисовка средствами любой версии OpenGL выдаёт примерно одинаковую картинку на всех ОС и фронтэндах. Ведь для загрузки изображений там всегда используется stb_image, а шрифт рендерится стандартными средствами Nuklear (тоже основано на stb). В то же время чистый Х11 драйвер даже не умеет загружать шрифты. Так что не забывайте тестировать своё приложение для выбранной пары бэкэнд+фронтэнд.
Например: Wordlase, GLFW3, OpenGL 2, Windows

Или: Wordlase, SDL2, OpenGL ES, Linux

В качестве бэкэнда по умолчанию выбран OpenGL2, если доступен. Можно задать NKC_USE_OPENGL=3 для OpenGL 3, и NKC_USE_OPENGL=NGL_ES2 для OpenGL ES 2.0. Для использования чистого Х11 отрисовщика константу NKC_USE_OPENGL указывать не надо. Также OpenGL опции не влияют на GDI+ — там отрисовка всегда идёт своими средствами.
Вот скриншот с GDI+: Wordlase, GDI+, без OpenGL, Windows

Этот бэкэнд полноценно поддерживает полупрозрачные изображения, картинка близка к оригиналу. Разница в шрифте: хинтинг, сглаживание, да даже размер (также буду рад Pull Request'у для автоматической подстройки размера GDI+ шрифта под размер stb_ttf).
И самый ужасный случай — чистый Х11 отрисовщик, который до моего pull request даже не умел загружать картинки. Wordlase, X11, без OpenGL, Linux:

Вот здесь уже довольно много отличий: логотип, солнечные лучи, более острый край девушки, шрифт. Почему? Фон в игре на лету собирается из нескольких полупрозрачных PNG. Но чистый Х11 поддерживает только битовую прозрачность, прямо как GIF. Также отрисовщик Х11 очень медленно работает на больших изображениях с прозрачностью. А если в движке отключить прозрачность, то картинка становится ещё хуже. Wordlase, X11, без OpenGL, без прозрачности:

Так зачем вообще нужны отрисовщики GDI+ и Х11, если они так уродливы? Потому, что они плохи только для больших изображений с прозрачностью. А если делать маленькую утилиту, где картинки используются только как иконки пользовательского интерфейса, то эти отрисовщики становятся вовсе неплохим вариантом, т.к. имеют минимальное количество зависимостей. Также я пользовался чистым Х11 отрисовщиком на слабых системах, где OpenGL только программный. В таком случае Х11 работает быстрее OpenGL. Подсказка: если вместо кучи полупрозрачных PNG использовать один большой JPEG, то Х11 будет работать быстро и корректно.
Пример хорошего использования чистого Х11 бэкэнда — главное игровое окно Wordlase. Больших картинок там почти нет, зато есть несколько интерфейсных иконок, которые вполне корректно отображаются:

Отлично, отрисовщик выбран, окно ОС создаётся. Теперь самое время заняться GUI!
Самым первым в Wordlase показывается экран выбора языка:

Здесь видны сразу 2 интересных техники: несколько картинок на фоне окна и центрирование виджетов.
Поместить картинку на фон окна достаточно просто:
nk_layout_space_push(ctx, nk_rect(x, y, width, height));
nk_image(ctx, img);x и y — позиция на экране, width и height — размеры изображения.
Центрирование является более сложной задачей, т.к. не поддерживается Nuklear напрямую. Нужно вычислять положение самостоятельно:
if ( nk_begin(ctx, WIN_TITLE,
nk_rect(0, 0, winWidth, winHeight), NK_WINDOW_NO_SCROLLBAR)
) {
int i;
/* 0.2 are a space skip on button's left and right, 0.6 - button */
static const float ratio[] = {0.2f, 0.6f, 0.2f}; /* 0.2+0.6+0.2=1 */
/* Just make vertical skip with calculated height of static row */
nk_layout_row_static(ctx,
(winHeight - (BUTTON_HEIGHT+VSPACE_SKIP)*langCount )/2, 15, 1
);
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 3, ratio);
for(i=0; i* skip 0.2 left */
if( nk_button_image_label(ctx, image, caption, NK_TEXT_CENTERED)
){
loadLang(nkcHandle, ctx, i);
}
nk_spacing(ctx, 1); /* skip 0.2 right */
}
}
nk_end(ctx);Следующая прикольная штучка — выбор темы оформления в настройках:

Реализуется тоже просто:
if (nk_combo_begin_color(ctx, themeColors[s.curTheme],
nk_vec2(nk_widget_width(ctx), (LINE_HEIGHT+5)*WTHEME_COUNT) )
){
int i;
nk_layout_row_dynamic(ctx, LINE_HEIGHT, 1);
for(i=0; icode>Здесь главное понимать, что всплывающее поле combo — это такое же окно, как и главное. И располагать там можно что угодно.
Самым сложно выглядящим окном является основное игровое окно:
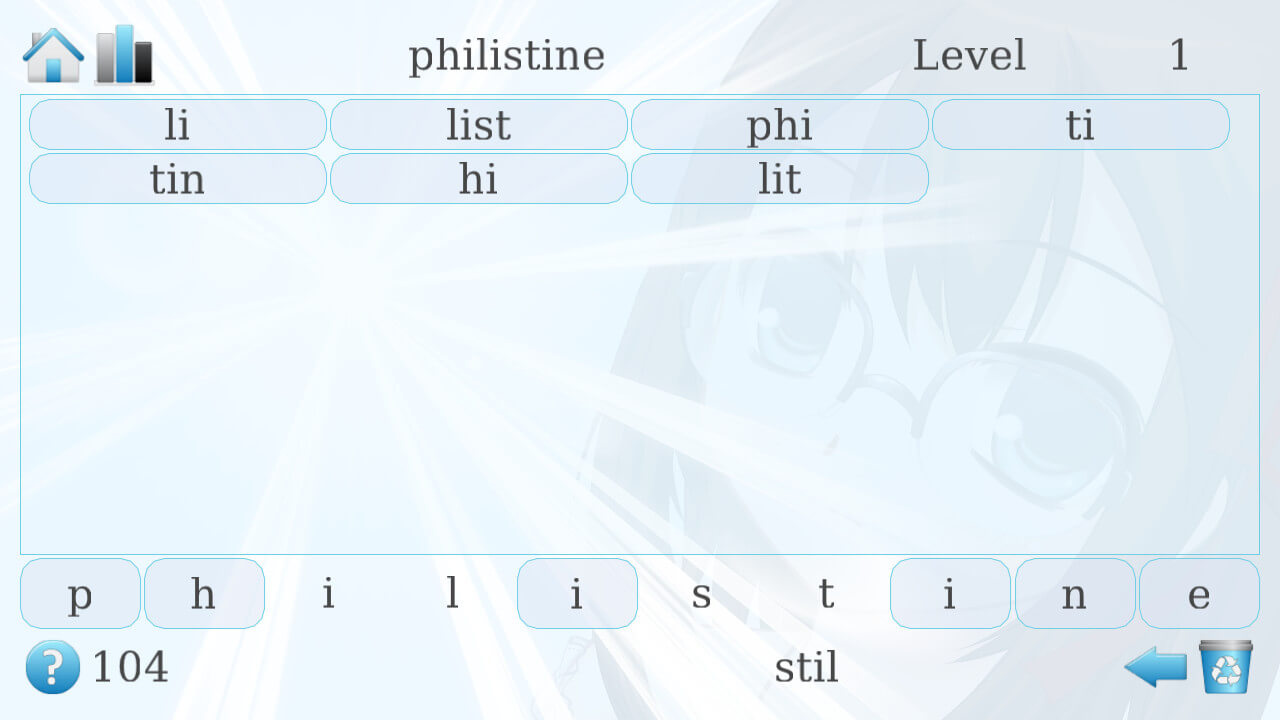
На самом деле, тут тоже нет ничего сложного. На экране всего 4 ряда:
nk_property_int)nk_group_scrolled)Единственный непонятный момент здесь — задание точных размеров элементам. Выполняется это с помощью соотношения ряда:
float ratio[] = {
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)BUTTON_HEIGHT/winWidth, /* square button */
(float)topWordSpace/winWidth,
(float)WORD_WIDTH/winWidth
};
nk_layout_row(ctx, NK_DYNAMIC, BUTTON_HEIGHT, 4, ratio);BUTTON_HEIGHT и WORD_WIDTH — константы, измеряются в пикселях; topWordSpace вычисляется как ширина экрана минус ширины всех остальных элементов.
И последнее сложно выглядящее окно — статистика:
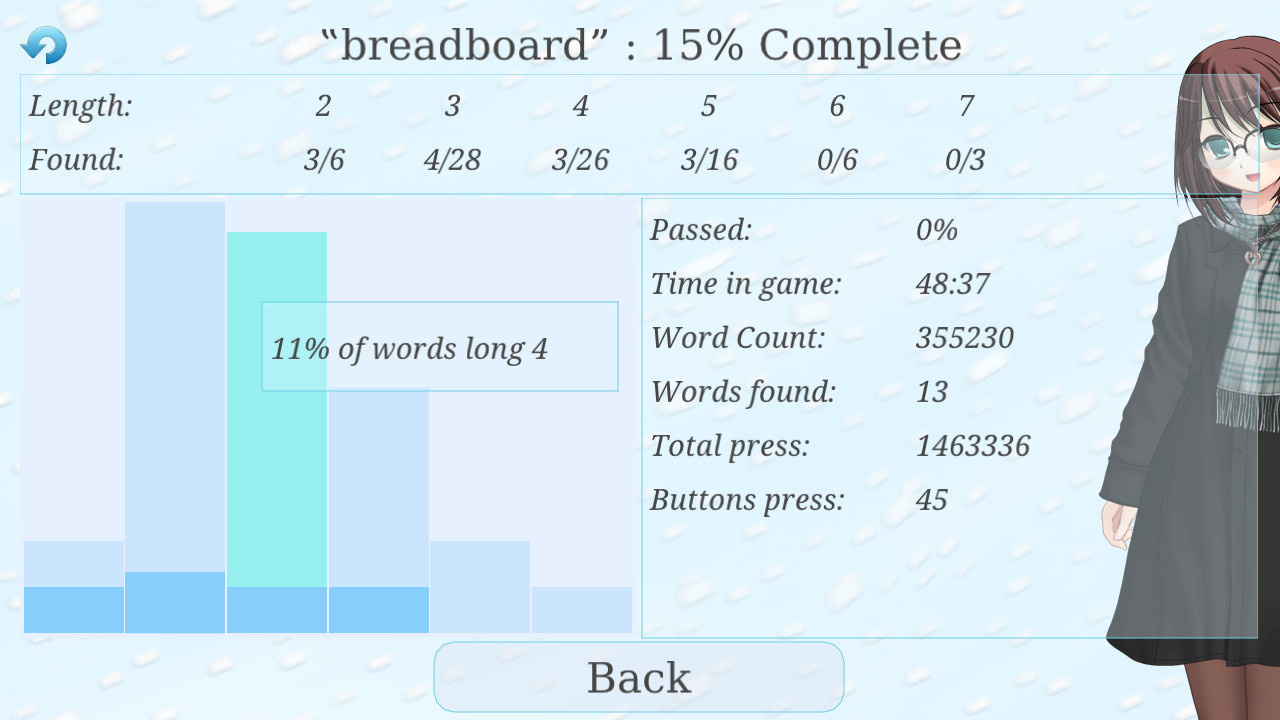
Расположение элементов регулируется с помощью группировки. Ведь всегда можно сказать Nuklear: "в этом ряду будет 2 виджета". Но группа тоже является виджетом. Т.е. можно просто создать группу с помощью nk_group_begin и nk_group_end, а дальше позиционироваться внутри неё как внутри обычного окна (nk_layout_row и пр.).
Nuklear уже готов даже для коммерческих игр и приложений. А Nuklear+ может сделать их создание более приятным.
|
|
[Перевод] PHP жив. PHP 7 на практике |
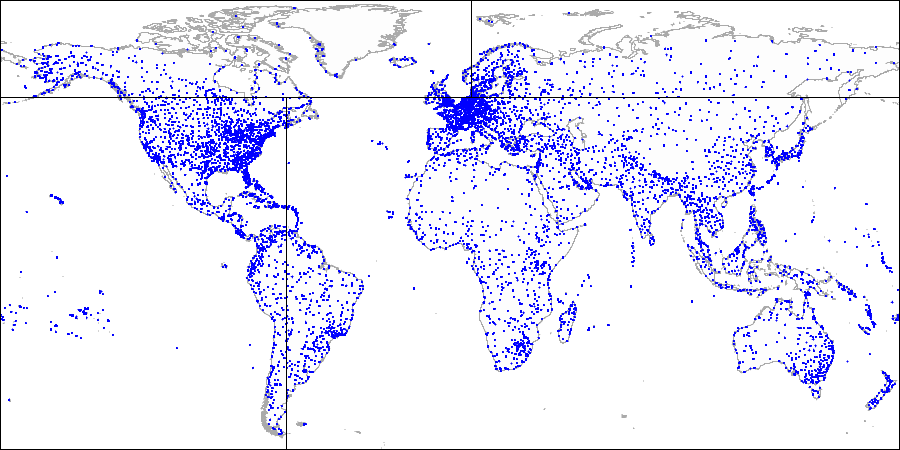
Недавно PHP-проекты Avito перешли на версию PHP 7.1. По этому случаю мы решили вспомнить, как происходил переход на PHP 7.0 у нас и наших коллег из OLX. Дела давно минувших дней, но остались красивые графики, которые хочется показать миру.
Первая часть рассказа основана на статье PHP’s not dead! PHP7 in practice, которую написал наш коллега из OLX Lukasz Szyma'nski (Лукаш Шиманьски): переход OLX на PHP 7. Во второй части — опыт перехода Avito на PHP 7.0 и PHP 7.1: процесс, трудности, результаты с графиками.

Компания OLX Europe управляет десятью сайтами, самый большой из которых — OLX.pl. Все наши сайты должны работать максимально эффективно, поэтому миграция на PHP 7 стала для нас основным приоритетом.
В этом посте расскажем, с какими проблемами пришлось столкнуться и чего удалось получить с переходом на PHP 7. Про переход было рассказано на конференции PHPers Summit 2016.
Вопреки нашим опасениям, миграция прошла гладко. За исключением стандартного списка необходимых изменений из официальной документации, пришлось внести лишь некоторые правки, связанные с нашей архитектурой.
Стоит упомянуть, что десять наших сайтов работают в разных странах. И изменения мы выкатываем последовательно: на один сайт за другим. Такой подход особенно важно применять при серьёзных изменениях.
Мы начали обновление версии с самого маленького сайта и переходили ко всё более крупным, поглядывая, чтобы тесты проходили успешно. Это позволило следить за возникновением неожиданных проблем и снизило потенциальный ущерб.
Отказ от поддержки Memcache в PHP 7 подтолкнул нас к переходу на Memcached. Пришлось поддержать две версии сайта: PHP 5 + Memcache и PHP 7 + Memcached.
Для решения задачи использовали простенькую обёртку. Она выбирает подходящий PHP-модуль для соединения с кэшом, исходя из информации о сервере, на котором выполняется код.
|
Метки: author pik4ez разработка веб-сайтов php блог компании avito php7 olx avito |
Набор полезных советов для эффективного использования FreeIPA |

ansible_virtualization_role == "guest" and ansible_virtualization_type == "lxc"get_sudorule_diff() takes exactly 2 arguments (3 given)diff = get_sudorule_diff(client, ipa_sudorule, module_sudorule)diff = get_sudorule_diff(ipa_sudorule, module_sudorule)1. Добавляем репозиторий
wget -qO - http://apt.numeezy.fr/numeezy.asc | apt-key add -
echo -e 'deb http://apt.numeezy.fr jessie main' >> /etc/apt/sources.list
2. Устанавливаем пакеты
apt-get update
apt-get install -y freeipa-client
3. Создаём директории
mkdir -p /etc/pki/nssdb
certutil -N -d /etc/pki/nssdb
mkdir -p /var/run/ipa
4. Убираем дефолтный конфиг
mv /etc/ipa/default.conf ~/
5. Устанавливаем и настраиваем клиент
ipa-client-install
6. Включаем создание директорий
echo 'session required pam_mkhomedir.so' >> /etc/pam.d/common-session
7. Проверяем, чтобы в /etc/nsswitch.conf был указан sss провайдер
passwd: files sss
group: files sss
shadow: files sss
8. Перезагружаем sssd
systemctl restart sssdip addr add $ADDR dev $IFaceip addr del $ADDR|
Метки: author Vrenskiy системное администрирование серверное администрирование *nix блог компании pixonic freeipa ansible |
Zabbix + RocksDB — миграция и первые впечатления |
CONSTRAINT FOREIGN KEY. Не умеет, и всё. И не планируется. NoSQL, однако. Казалось бы, на этом можно свернуть всю затею, но внимательный взгляд на схему данных zabbix-а показывает, что самые горячие таблицы — history_uint, history_text, history_log и history_str — куда, собственно, прилетают данные из всех grep -r 'history_uint' zabbix-3.2.5 приводит к выводу, что хоть zabbix и учиняет транзакции при добавлении значений, внутри этих транзакций он не трогает других таблиц (зачем бы ему, действительно?) — так что пролезаем.#!/usr/bin/perl
$tablename='';
$has_constraints=0;
while(<>) {
s/CHARACTER SET latin1//;
if(/CREATE TABLE `(.*)`/) {
$tablename=$1;
$has_constraints=0;
};
if(/CONSTRAINT/) {
$has_constraints=1;
};
if(/ENGINE=InnoDB/ and $has_constraints==0) {
s/ENGINE=InnoDB/ENGINE=ROCKSDB/;
s/CHARSET=([^ ^;]+)/CHARSET=$1 COLLATE=$1_bin/;
};
print $_;
};
apt-get update
apt-get install git g++ cmake libbz2-dev libaio-dev bison zlib1g-dev libsnappy-dev build-essential vim cmake perl bison ncurses-dev libssl-dev libncurses5-dev libgflags-dev libreadline6-dev libncurses5-dev libssl-dev liblz4-dev gdb smartmontools
apt-get install dpkg-dev devscripts chrpath dh-apparmor dh-systemd dpatch libboost-dev libcrack2-dev libjemalloc-dev libreadline-gplv2-dev libsystemd-dev libxml2-dev unixodbc-dev
apt-get install libjudy-dev libkrb5-dev libnuma-dev libpam0g-dev libpcre3-dev pkg-config libreadline-gplv2-dev uuid-dev
git clone https://github.com/MariaDB/server.git mariadb-10.2
cd mariadb-10.2
git checkout 10.2
git submodule init
git submodule update
./debian/autobake-deb.sh
wget http://releases.galeracluster.com/debian/pool/main/g/galera-3/galera-3_25.3.20-1jessie_amd64.deb
dpkg -i galera-3*.deb
apt-get install gawk libdbi-perl socat
dpkg -i mysql-common*.deb mariadb-server*.deb mariadb-plugin*.deb mariadb-client*.deb libm*.deb
version=368636fd94e484a5f4be5c0fcd205f507463412a
debian_version=net-snmp_5.7.2.1+dfsg-1.debian.tar.xz
unzip -q net-snmp-code-${version}.zip
cd net-snmp-code-${version}
tar -xvJf ../$debian_version
for i in 03_makefiles.patch 26_kfreebsd.patch 27_kfreebsd_bug625985.patch fix_spelling_error.patch fix_logging_option.patch fix_man_error.patch after_RFC5378 fix_manpage-has-errors_break_line.patch fix_manpage-has-errors-from-man.patch agentx-crash.patch TrapReceiver.patch ifmib.patch CVE-2014-3565.patch; do
rm debian/patches/$i
touch debian/patches/$i
done
cp ../rules debian/rules
dpkg-buildpackage -d -b
cd ..
dpkg -i *.deb
zabbixversion="3.2.7"
apt-get install libsnmp-dev libcurl4-openssl-dev python-requests
if [ ! -f zabbix-${zabbixversion}.tar.gz ]; then
wget https://downloads.sourceforge.net/project/zabbix/ZABBIX%20Latest%20Stable/${zabbixversion}/zabbix-${zabbixversion}.tar.gz
tar -xvzf zabbix-${zabbixversion}.tar.gz
fi
cd zabbix-${zabbixversion}
groupadd zabbix
useradd -g zabbix zabbix
sed -i 's/mariadbclient/mariadb/' configure
./configure --enable-proxy --enable-server --enable-agent --with-mysql --enable-ipv6 --with-net-snmp --with-libcurl --with-libxml2
make -j5
make install
|
Метки: author mickvav администрирование баз данных it- инфраструктура devops zabbix mysql rocksdb |
[Перевод] Знакомство с kube-spawn — утилитой для создания локальных Kubernetes-кластеров |
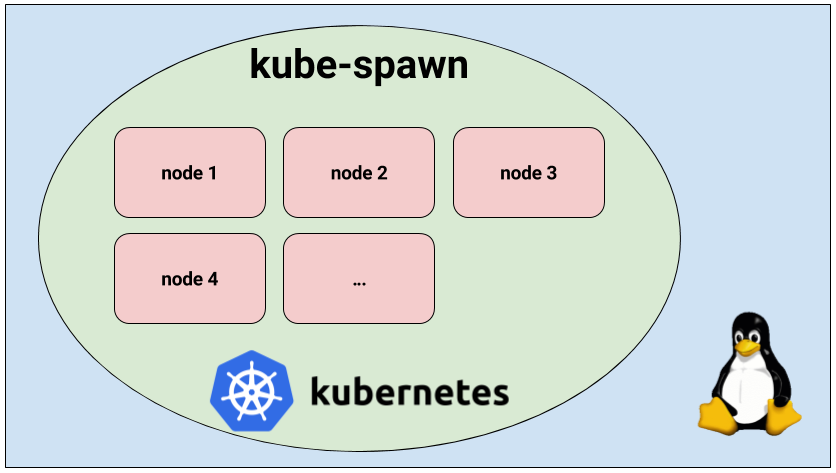
machinectl pull-raw и подкоманд kube-spawn setup и init. Однако подкоманда up сделает всё за нас:$ sudo GOPATH=$GOPATH CNI_PATH=$GOPATH/bin ./kube-spawn up --nodes=3$ export KUBECONFIG=$GOPATH/src/github.com/kinvolk/kube-spawn/.kube-spawn/default/kubeconfig
$ kubectl get nodes
NAME STATUS AGE VERSION
kube-spawn-0 Ready 1m v1.7.0
kube-spawn-1 Ready 1m v1.7.0
kube-spawn-2 Ready 1m v1.7.0microservices-demo и перейти в каталог deploy/kubernetes:$ cd ~/repos
$ git clone https://github.com/microservices-demo/microservices-demo.git sock-shop
$ cd sock-shop/deploy/kubernetes/sock-shop — в deployment предполагается его наличие:$ kubectl create namespace sock-shop
namespace "sock-shop" created$ kubectl create -f complete-demo.yaml
deployment "carts-db" created
service "carts-db" created
deployment "carts" created
service "carts" created
deployment "catalogue-db" created
service "catalogue-db" created
deployment "catalogue" created
service "catalogue" created
deployment "front-end" created
service "front-end" created
deployment "orders-db" created
service "orders-db" created
deployment "orders" created
service "orders" created
deployment "payment" created
service "payment" created
deployment "queue-master" created
service "queue-master" created
deployment "rabbitmq" created
service "rabbitmq" created
deployment "shipping" created
service "shipping" created
deployment "user-db" created
service "user-db" created
deployment "user" created
service "user" created$ watch kubectl -n sock-shop get pods
NAME READY STATUS RESTARTS AGE
carts-2469883122-nd0g1 1/1 Running 0 1m
carts-db-1721187500-392vt 1/1 Running 0 1m
catalogue-4293036822-d79cm 1/1 Running 0 1m
catalogue-db-1846494424-njq7h 1/1 Running 0 1m
front-end-2337481689-v8m2h 1/1 Running 0 1m
orders-733484335-mg0lh 1/1 Running 0 1m
orders-db-3728196820-9v07l 1/1 Running 0 1m
payment-3050936124-rgvjj 1/1 Running 0 1m
queue-master-2067646375-7xx9x 1/1 Running 0 1m
rabbitmq-241640118-8htht 1/1 Running 0 1m
shipping-2463450563-n47k7 1/1 Running 0 1m
user-1574605338-p1djk 1/1 Running 0 1m
user-db-3152184577-c8r1f 1/1 Running 0 1m$ kubectl -n sock-shop get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
carts 10.110.14.144 80/TCP 3m
carts-db 10.104.115.89 27017/TCP 3m
catalogue 10.110.157.8 80/TCP 3m
catalogue-db 10.99.103.79 3306/TCP 3m
front-end 10.105.224.192 80:30001/TCP 3m
orders 10.101.177.247 80/TCP 3m
orders-db 10.109.209.178 27017/TCP 3m
payment 10.107.53.203 80/TCP 3m
queue-master 10.111.63.76 80/TCP 3m
rabbitmq 10.110.136.97 5672/TCP 3m
shipping 10.96.117.56 80/TCP 3m
user 10.101.85.39 80/TCP 3m
user-db 10.107.82.6 27017/TCP 3m front-end) использует порт 30001 и внешний IP-адрес. Это означает, что мы можем достучаться до его служб через IP-адрес любого рабочего узла (worker) и порт 30001. Узнать IP-адреса всех узлов кластера можно через machinectl:$ machinectl
MACHINE CLASS SERVICE OS VERSION ADDRESSES
kube-spawn-0 container systemd-nspawn coreos 1492.1.0 10.22.0.137...
kube-spawn-1 container systemd-nspawn coreos 1492.1.0 10.22.0.138...
kube-spawn-2 container systemd-nspawn coreos 1492.1.0 10.22.0.139...10.22.0.138:30001 или 10.22.0.139:30001, где нас поприветствует магазин, продающий носки.$ sudo ./kube-spawn stop
2017/08/10 01:58:00 turning off machines [kube-spawn-0 kube-spawn-1 kube-spawn-2]...
2017/08/10 01:58:00 All nodes are stopped..kube-spawn, в котором вы найдёте несколько файлов и директорий в default. Чтобы не ограничиваться размером каждого OS Container, мы монтируем сюда /var/lib/docker каждого узла. Благодаря этому мы можем использовать дисковое пространство хостовой машины. Наконец, на данный момент у нас нет команды очистки (clean). Желающие полностью замести следы деятельности kube-spawn могут выполнить команду rm -rf .kube-spawn/.|
Метки: author shurup системное администрирование настройка linux devops блог компании флант kubernetes linux микросервисы |
[Перевод] Знакомство с kube-spawn — утилитой для создания локальных Kubernetes-кластеров |
machinectl pull-raw и подкоманд kube-spawn setup и init. Однако подкоманда up сделает всё за нас:$ sudo GOPATH=$GOPATH CNI_PATH=$GOPATH/bin ./kube-spawn up --nodes=3$ export KUBECONFIG=$GOPATH/src/github.com/kinvolk/kube-spawn/.kube-spawn/default/kubeconfig
$ kubectl get nodes
NAME STATUS AGE VERSION
kube-spawn-0 Ready 1m v1.7.0
kube-spawn-1 Ready 1m v1.7.0
kube-spawn-2 Ready 1m v1.7.0microservices-demo и перейти в каталог deploy/kubernetes:$ cd ~/repos
$ git clone https://github.com/microservices-demo/microservices-demo.git sock-shop
$ cd sock-shop/deploy/kubernetes/sock-shop — в deployment предполагается его наличие:$ kubectl create namespace sock-shop
namespace "sock-shop" created$ kubectl create -f complete-demo.yaml
deployment "carts-db" created
service "carts-db" created
deployment "carts" created
service "carts" created
deployment "catalogue-db" created
service "catalogue-db" created
deployment "catalogue" created
service "catalogue" created
deployment "front-end" created
service "front-end" created
deployment "orders-db" created
service "orders-db" created
deployment "orders" created
service "orders" created
deployment "payment" created
service "payment" created
deployment "queue-master" created
service "queue-master" created
deployment "rabbitmq" created
service "rabbitmq" created
deployment "shipping" created
service "shipping" created
deployment "user-db" created
service "user-db" created
deployment "user" created
service "user" created$ watch kubectl -n sock-shop get pods
NAME READY STATUS RESTARTS AGE
carts-2469883122-nd0g1 1/1 Running 0 1m
carts-db-1721187500-392vt 1/1 Running 0 1m
catalogue-4293036822-d79cm 1/1 Running 0 1m
catalogue-db-1846494424-njq7h 1/1 Running 0 1m
front-end-2337481689-v8m2h 1/1 Running 0 1m
orders-733484335-mg0lh 1/1 Running 0 1m
orders-db-3728196820-9v07l 1/1 Running 0 1m
payment-3050936124-rgvjj 1/1 Running 0 1m
queue-master-2067646375-7xx9x 1/1 Running 0 1m
rabbitmq-241640118-8htht 1/1 Running 0 1m
shipping-2463450563-n47k7 1/1 Running 0 1m
user-1574605338-p1djk 1/1 Running 0 1m
user-db-3152184577-c8r1f 1/1 Running 0 1m$ kubectl -n sock-shop get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
carts 10.110.14.144 80/TCP 3m
carts-db 10.104.115.89 27017/TCP 3m
catalogue 10.110.157.8 80/TCP 3m
catalogue-db 10.99.103.79 3306/TCP 3m
front-end 10.105.224.192 80:30001/TCP 3m
orders 10.101.177.247 80/TCP 3m
orders-db 10.109.209.178 27017/TCP 3m
payment 10.107.53.203 80/TCP 3m
queue-master 10.111.63.76 80/TCP 3m
rabbitmq 10.110.136.97 5672/TCP 3m
shipping 10.96.117.56 80/TCP 3m
user 10.101.85.39 80/TCP 3m
user-db 10.107.82.6 27017/TCP 3m front-end) использует порт 30001 и внешний IP-адрес. Это означает, что мы можем достучаться до его служб через IP-адрес любого рабочего узла (worker) и порт 30001. Узнать IP-адреса всех узлов кластера можно через machinectl:$ machinectl
MACHINE CLASS SERVICE OS VERSION ADDRESSES
kube-spawn-0 container systemd-nspawn coreos 1492.1.0 10.22.0.137...
kube-spawn-1 container systemd-nspawn coreos 1492.1.0 10.22.0.138...
kube-spawn-2 container systemd-nspawn coreos 1492.1.0 10.22.0.139...10.22.0.138:30001 или 10.22.0.139:30001, где нас поприветствует магазин, продающий носки.$ sudo ./kube-spawn stop
2017/08/10 01:58:00 turning off machines [kube-spawn-0 kube-spawn-1 kube-spawn-2]...
2017/08/10 01:58:00 All nodes are stopped..kube-spawn, в котором вы найдёте несколько файлов и директорий в default. Чтобы не ограничиваться размером каждого OS Container, мы монтируем сюда /var/lib/docker каждого узла. Благодаря этому мы можем использовать дисковое пространство хостовой машины. Наконец, на данный момент у нас нет команды очистки (clean). Желающие полностью замести следы деятельности kube-spawn могут выполнить команду rm -rf .kube-spawn/.|
Метки: author shurup системное администрирование настройка linux devops блог компании флант kubernetes linux микросервисы |
[Перевод] Знакомство с kube-spawn — утилитой для создания локальных Kubernetes-кластеров |
machinectl pull-raw и подкоманд kube-spawn setup и init. Однако подкоманда up сделает всё за нас:$ sudo GOPATH=$GOPATH CNI_PATH=$GOPATH/bin ./kube-spawn up --nodes=3$ export KUBECONFIG=$GOPATH/src/github.com/kinvolk/kube-spawn/.kube-spawn/default/kubeconfig
$ kubectl get nodes
NAME STATUS AGE VERSION
kube-spawn-0 Ready 1m v1.7.0
kube-spawn-1 Ready 1m v1.7.0
kube-spawn-2 Ready 1m v1.7.0microservices-demo и перейти в каталог deploy/kubernetes:$ cd ~/repos
$ git clone https://github.com/microservices-demo/microservices-demo.git sock-shop
$ cd sock-shop/deploy/kubernetes/sock-shop — в deployment предполагается его наличие:$ kubectl create namespace sock-shop
namespace "sock-shop" created$ kubectl create -f complete-demo.yaml
deployment "carts-db" created
service "carts-db" created
deployment "carts" created
service "carts" created
deployment "catalogue-db" created
service "catalogue-db" created
deployment "catalogue" created
service "catalogue" created
deployment "front-end" created
service "front-end" created
deployment "orders-db" created
service "orders-db" created
deployment "orders" created
service "orders" created
deployment "payment" created
service "payment" created
deployment "queue-master" created
service "queue-master" created
deployment "rabbitmq" created
service "rabbitmq" created
deployment "shipping" created
service "shipping" created
deployment "user-db" created
service "user-db" created
deployment "user" created
service "user" created$ watch kubectl -n sock-shop get pods
NAME READY STATUS RESTARTS AGE
carts-2469883122-nd0g1 1/1 Running 0 1m
carts-db-1721187500-392vt 1/1 Running 0 1m
catalogue-4293036822-d79cm 1/1 Running 0 1m
catalogue-db-1846494424-njq7h 1/1 Running 0 1m
front-end-2337481689-v8m2h 1/1 Running 0 1m
orders-733484335-mg0lh 1/1 Running 0 1m
orders-db-3728196820-9v07l 1/1 Running 0 1m
payment-3050936124-rgvjj 1/1 Running 0 1m
queue-master-2067646375-7xx9x 1/1 Running 0 1m
rabbitmq-241640118-8htht 1/1 Running 0 1m
shipping-2463450563-n47k7 1/1 Running 0 1m
user-1574605338-p1djk 1/1 Running 0 1m
user-db-3152184577-c8r1f 1/1 Running 0 1m$ kubectl -n sock-shop get svc
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
carts 10.110.14.144 80/TCP 3m
carts-db 10.104.115.89 27017/TCP 3m
catalogue 10.110.157.8 80/TCP 3m
catalogue-db 10.99.103.79 3306/TCP 3m
front-end 10.105.224.192 80:30001/TCP 3m
orders 10.101.177.247 80/TCP 3m
orders-db 10.109.209.178 27017/TCP 3m
payment 10.107.53.203 80/TCP 3m
queue-master 10.111.63.76 80/TCP 3m
rabbitmq 10.110.136.97 5672/TCP 3m
shipping 10.96.117.56 80/TCP 3m
user 10.101.85.39 80/TCP 3m
user-db 10.107.82.6 27017/TCP 3m front-end) использует порт 30001 и внешний IP-адрес. Это означает, что мы можем достучаться до его служб через IP-адрес любого рабочего узла (worker) и порт 30001. Узнать IP-адреса всех узлов кластера можно через machinectl:$ machinectl
MACHINE CLASS SERVICE OS VERSION ADDRESSES
kube-spawn-0 container systemd-nspawn coreos 1492.1.0 10.22.0.137...
kube-spawn-1 container systemd-nspawn coreos 1492.1.0 10.22.0.138...
kube-spawn-2 container systemd-nspawn coreos 1492.1.0 10.22.0.139...10.22.0.138:30001 или 10.22.0.139:30001, где нас поприветствует магазин, продающий носки.$ sudo ./kube-spawn stop
2017/08/10 01:58:00 turning off machines [kube-spawn-0 kube-spawn-1 kube-spawn-2]...
2017/08/10 01:58:00 All nodes are stopped..kube-spawn, в котором вы найдёте несколько файлов и директорий в default. Чтобы не ограничиваться размером каждого OS Container, мы монтируем сюда /var/lib/docker каждого узла. Благодаря этому мы можем использовать дисковое пространство хостовой машины. Наконец, на данный момент у нас нет команды очистки (clean). Желающие полностью замести следы деятельности kube-spawn могут выполнить команду rm -rf .kube-spawn/.|
Метки: author shurup системное администрирование настройка linux devops блог компании флант kubernetes linux микросервисы |
[Перевод] OO VS FP |
Мой перевод, как и оригинальный доклад вызвали неоднозначную реакцию в комментариях. Поэтому я решил перевести статью-ответ дяди Боба на оригинальный материал.
Думаю, здесь дядя Боб ругает ORM за то они часто подталкивают к анемичной модели, а не к богатой.
f(o), o.f() и (f o)? Что, вся разница в синтаксисе. Так в чем же настоящие различия между ООП и ФП? Что есть в ООП, чего нет в ФП и наоборот?|
Метки: author marshinov функциональное программирование программирование анализ и проектирование систем .net oop fp patterns design |
[Перевод] OO VS FP |
Мой перевод, как и оригинальный доклад вызвали неоднозначную реакцию в комментариях. Поэтому я решил перевести статью-ответ дяди Боба на оригинальный материал.
Думаю, здесь дядя Боб ругает ORM за то они часто подталкивают к анемичной модели, а не к богатой.
f(o), o.f() и (f o)? Что, вся разница в синтаксисе. Так в чем же настоящие различия между ООП и ФП? Что есть в ООП, чего нет в ФП и наоборот?|
Метки: author marshinov функциональное программирование программирование анализ и проектирование систем .net oop fp patterns design |
[Перевод] OO VS FP |
Мой перевод, как и оригинальный доклад вызвали неоднозначную реакцию в комментариях. Поэтому я решил перевести статью-ответ дяди Боба на оригинальный материал.
Думаю, здесь дядя Боб ругает ORM за то они часто подталкивают к анемичной модели, а не к богатой.
f(o), o.f() и (f o)? Что, вся разница в синтаксисе. Так в чем же настоящие различия между ООП и ФП? Что есть в ООП, чего нет в ФП и наоборот?|
Метки: author marshinov функциональное программирование программирование анализ и проектирование систем .net oop fp patterns design |
Wi-Fi сети в ритейле: типовые сценарии и подбор оборудования |





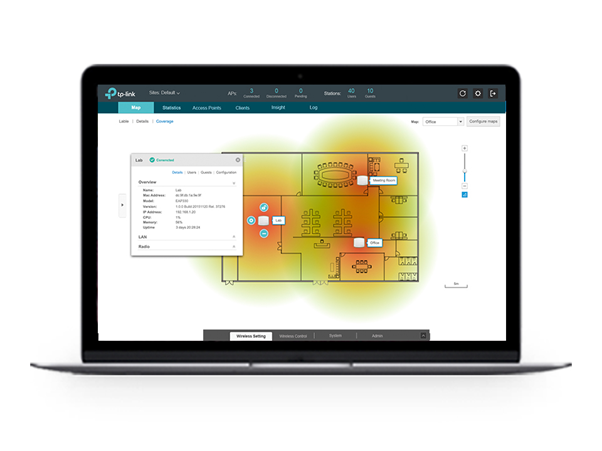


|
Метки: author TP-Link системное администрирование сетевые технологии беспроводные технологии it- инфраструктура блог компании tp-link tp-link оборудование связь ритейл |
Wi-Fi сети в ритейле: типовые сценарии и подбор оборудования |
|
Метки: author TP-Link системное администрирование сетевые технологии беспроводные технологии it- инфраструктура блог компании tp-link tp-link оборудование связь ритейл |
Wi-Fi сети в ритейле: типовые сценарии и подбор оборудования |
|
Метки: author TP-Link системное администрирование сетевые технологии беспроводные технологии it- инфраструктура блог компании tp-link tp-link оборудование связь ритейл |
Индексы в PostgreSQL — 6 |

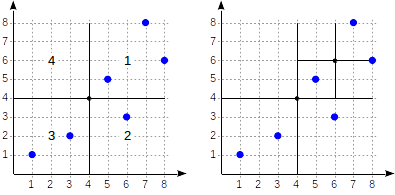
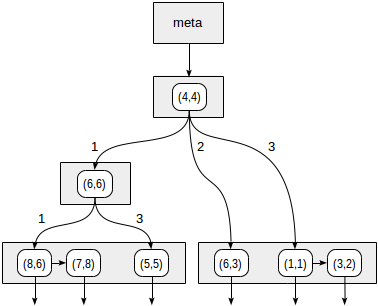
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 строго слева
>>(point,point) | 5 строго справа
~=(point,point) | 6 совпадает
<^(point,point) | 10 строго сверху
>^(point,point) | 11 строго снизу
<@(point,box) | 8 содержится в прямоугольнике
(6 rows)
select * from points where p >^ point '(2,7)' (найти все точки, лежащие выше заданной).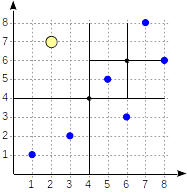
>^ эта функция сравнивает точку (2,7) с центральной точкой узла (4,4) и выбирает квадранты, в которых могут находиться искомые точки — в данном случае первый и четвертый.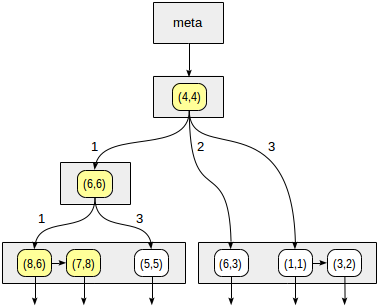
postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...

postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
CREATE INDEX
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
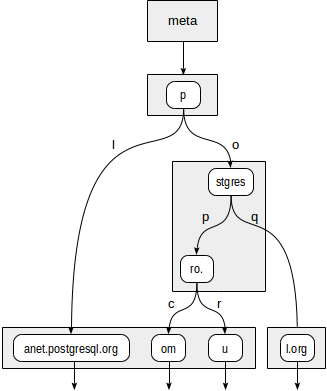
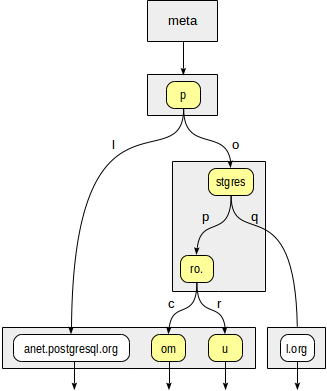
postgres=# create table sites(url text);
CREATE TABLE
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
select * from sites where url like 'postgresp%ru'. Он может быть выполнен с помощью индекса:postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- тип префикса
node_label smallint, -- тип метки
leaf_value text -- тип листового значения
)
order by tid, n;
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
|
Метки: author erogov sql postgresql блог компании postgres professional postgres index indexing |
Индексы в PostgreSQL — 6 |
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 строго слева
>>(point,point) | 5 строго справа
~=(point,point) | 6 совпадает
<^(point,point) | 10 строго сверху
>^(point,point) | 11 строго снизу
<@(point,box) | 8 содержится в прямоугольнике
(6 rows)
select * from points where p >^ point '(2,7)' (найти все точки, лежащие выше заданной).>^ эта функция сравнивает точку (2,7) с центральной точкой узла (4,4) и выбирает квадранты, в которых могут находиться искомые точки — в данном случае первый и четвертый.postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
CREATE INDEX
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
postgres=# create table sites(url text);
CREATE TABLE
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
select * from sites where url like 'postgresp%ru'. Он может быть выполнен с помощью индекса:postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- тип префикса
node_label smallint, -- тип метки
leaf_value text -- тип листового значения
)
order by tid, n;
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
|
Метки: author erogov sql postgresql блог компании postgres professional postgres index indexing |
Индексы в PostgreSQL — 6 |
postgres=# create table points(p point);
CREATE TABLE
postgres=# insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
INSERT 0 6
postgres=# create index points_quad_idx on points using spgist(p);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 строго слева
>>(point,point) | 5 строго справа
~=(point,point) | 6 совпадает
<^(point,point) | 10 строго сверху
>^(point,point) | 11 строго снизу
<@(point,box) | 8 содержится в прямоугольнике
(6 rows)
select * from points where p >^ point '(2,7)' (найти все точки, лежащие выше заданной).>^ эта функция сравнивает точку (2,7) с центральной точкой узла (4,4) и выбирает квадранты, в которых могут находиться искомые точки — в данном случае первый и четвертый.postgres=# set enable_seqscan = off;
SET
postgres=# explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
demo=# create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
CREATE INDEX
demo=# select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
postgres=# create index points_kd_idx on points using spgist(p kd_point_ops);
CREATE INDEX
demo=# select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- тип префикса
node_label int, -- тип метки (в данном случае не используется)
leaf_value point -- тип листового значения
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
postgres=# create table sites(url text);
CREATE TABLE
postgres=# insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
INSERT 0 4
postgres=# create index on sites using spgist(url);
CREATE INDEX
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
select * from sites where url like 'postgresp%ru'. Он может быть выполнен с помощью индекса:postgres=# explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
postgres=# select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- тип префикса
node_label smallint, -- тип метки
leaf_value text -- тип листового значения
)
order by tid, n;
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
postgres=# explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
|
Метки: author erogov sql postgresql блог компании postgres professional postgres index indexing |
Мой опыт съемки панорамы 360o на фотопленку |
|
Метки: author BorodinKO обработка изображений фотография 360 панорамное фото пленка старое железо панорама canon vr 3d forfun |
Мой опыт съемки панорамы 360o на фотопленку |
|
Метки: author BorodinKO обработка изображений фотография 360 панорамное фото пленка старое железо панорама canon vr 3d forfun |
Мой опыт съемки панорамы 360o на фотопленку |
|
Метки: author BorodinKO обработка изображений фотография 360 панорамное фото пленка старое железо панорама canon vr 3d forfun |
Проекции? Hет, спасибо |

gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config
sudo gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config install
CREATE EXTENSION pg_sphere;CREATE TABLE spoint_data (sp spoint);# --- gendata.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
printf ("(%14.10fd, %14.10fd)\n", lon, lat);
}./random 1000000 100000000 | gawk -f gendata.awk | sort > pgsphere.txtCOPY spoint_data (sp) FROM '/home/.../pgsphere.txt';CREATE INDEX sp_idx ON spoint_data USING gist (sp);gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config
sudo gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config install
create table test_points_3d (x integer,y integer, z integer);#--- gendata2.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
print ix"\t"iy"\t"iz;
}./random 1000000 100000000 | gawk -f gendata2.awk > zcurve.txtCOPY test_points_3d FROM '/home/.../zcurve.txt';create index zcurve_test_points_3d on test_points_3d(zcurve_num_from_xyz(x,y,z));#--- gentest.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
# EXPLAIN (ANALYZE,BUFFERS)
printf ("select count(1) from spoint_data where sp @'<(%14.10fd,%14.10fd),.316d>'::scircle;\n", lon, lat);
}./random 1000000 100 1023 | gawk -f gentest.awk >tests1.sql#--- gentest2.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
# EXPLAIN (ANALYZE,BUFFERS)
lrad = int(0.5 + Grad * sin(.316 * degra));
print "select count(1) from zcurve_3d_lookup_tidonly('zcurve_test_points_3d', "ix-lrad","iy-lrad","iz-lrad","ix+lrad","iy+lrad","iz+lrad");";
}./random 1000000 100 1023 | gawk -f gentest2.awk >tests2.sql| Radius | AVG NPoints | Nreq | Type | Time(ms) | Reads | Hits |
|---|---|---|---|---|---|---|
| .01° | 1.17 0.7631 (0.7615) |
10 000 | zcurve rtree |
.37 .46 |
1.4397 2.1165 |
9.5647 3.087 |
| .0316° | 11.6 7.6392 (7.6045) |
10 000 | zcurve rtree |
.39 .67 |
2.0466 3.0944 |
20.9707 2.7769 |
| .1° | 115.22 76.193 (76.15) |
1 000 | zcurve rtree |
.44 2.75 * |
4.4184 6.073 |
82.8572 2.469 |
| .316° | 1145.3 758.37 (760.45) |
1 000 | zcurve rtree |
.59 18.3 * |
15.2719 21.706 |
401.791 1.62 |
| 1.° | 11310 7602 (7615) |
100 | zcurve rtree |
7.2 94.5 * |
74.9544 132.15 |
1651.45 1.12 |
|
Метки: author zzeng геоинформационные сервисы алгоритмы postgresql open source spatial index r-tree zorder spi субд |






