Проекции? Hет, спасибо |

gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config
sudo gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config install
CREATE EXTENSION pg_sphere;CREATE TABLE spoint_data (sp spoint);# --- gendata.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
printf ("(%14.10fd, %14.10fd)\n", lon, lat);
}./random 1000000 100000000 | gawk -f gendata.awk | sort > pgsphere.txtCOPY spoint_data (sp) FROM '/home/.../pgsphere.txt';CREATE INDEX sp_idx ON spoint_data USING gist (sp);gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config
sudo gmake USE_PGXS=1 PG_CONFIG=/usr/bin/pg_config install
create table test_points_3d (x integer,y integer, z integer);#--- gendata2.awk ------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
print ix"\t"iy"\t"iz;
}./random 1000000 100000000 | gawk -f gendata2.awk > zcurve.txtCOPY test_points_3d FROM '/home/.../zcurve.txt';create index zcurve_test_points_3d on test_points_3d(zcurve_num_from_xyz(x,y,z));#--- gentest.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
r2 = sqrt(x*x + y*y);
lat = atan2(z, r2) * rad;
lon = 180. + atan2(y, x) * rad;
# EXPLAIN (ANALYZE,BUFFERS)
printf ("select count(1) from spoint_data where sp @'<(%14.10fd,%14.10fd),.316d>'::scircle;\n", lon, lat);
}./random 1000000 100 1023 | gawk -f gentest.awk >tests1.sql#--- gentest2.awk -------
BEGIN{
pi=3.1415926535897932;
degra=pi/180.0;
rad=180.0/pi;
Grad = 1000000.;
}
{
x = $1; y = $2; z = $3;
r3 = sqrt(x*x + y*y + z*z);
x *= Grad / r3;
y *= Grad / r3;
z *= Grad / r3;
ix = int(x+0.5+Grad);
iy = int(y+0.5+Grad);
iz = int(z+0.5+Grad);
# EXPLAIN (ANALYZE,BUFFERS)
lrad = int(0.5 + Grad * sin(.316 * degra));
print "select count(1) from zcurve_3d_lookup_tidonly('zcurve_test_points_3d', "ix-lrad","iy-lrad","iz-lrad","ix+lrad","iy+lrad","iz+lrad");";
}./random 1000000 100 1023 | gawk -f gentest2.awk >tests2.sql| Radius | AVG NPoints | Nreq | Type | Time(ms) | Reads | Hits |
|---|---|---|---|---|---|---|
| .01° | 1.17 0.7631 (0.7615) |
10 000 | zcurve rtree |
.37 .46 |
1.4397 2.1165 |
9.5647 3.087 |
| .0316° | 11.6 7.6392 (7.6045) |
10 000 | zcurve rtree |
.39 .67 |
2.0466 3.0944 |
20.9707 2.7769 |
| .1° | 115.22 76.193 (76.15) |
1 000 | zcurve rtree |
.44 2.75 * |
4.4184 6.073 |
82.8572 2.469 |
| .316° | 1145.3 758.37 (760.45) |
1 000 | zcurve rtree |
.59 18.3 * |
15.2719 21.706 |
401.791 1.62 |
| 1.° | 11310 7602 (7615) |
100 | zcurve rtree |
7.2 94.5 * |
74.9544 132.15 |
1651.45 1.12 |
|
Метки: author zzeng геоинформационные сервисы алгоритмы postgresql open source spatial index r-tree zorder spi субд |
Тянем ролик с YouTube и раздаем по WebRTC в реалтайме |

curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dlchmod a+rx /usr/local/bin/youtube-dlyoutube-dl --list-formats https://www.youtube.com/watch?v=9cQT4urTlXM[youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[info] Available formats for 9cQT4urTlXM:
format code extension resolution note
171 webm audio only DASH audio 8k , vorbis@128k, 540.24KiB
249 webm audio only DASH audio 10k , opus @ 50k, 797.30KiB
250 webm audio only DASH audio 10k , opus @ 70k, 797.30KiB
251 webm audio only DASH audio 10k , opus @160k, 797.30KiB
139 m4a audio only DASH audio 53k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 10.36MiB
140 m4a audio only DASH audio 137k , m4a_dash container, mp4a.40.2@128k (44100Hz), 27.56MiB
278 webm 256x144 144p 41k , webm container, vp9, 30fps, video only, 6.54MiB
242 webm 426x240 240p 70k , vp9, 30fps, video only, 13.42MiB
243 webm 640x360 360p 101k , vp9, 30fps, video only, 20.55MiB
160 mp4 256x144 DASH video 123k , avc1.4d400c, 15fps, video only, 24.83MiB
134 mp4 640x360 DASH video 138k , avc1.4d401e, 30fps, video only, 28.07MiB
244 webm 854x480 480p 149k , vp9, 30fps, video only, 30.55MiB
135 mp4 854x480 DASH video 209k , avc1.4d401f, 30fps, video only, 42.42MiB
133 mp4 426x240 DASH video 274k , avc1.4d4015, 30fps, video only, 57.63MiB
247 webm 1280x720 720p 298k , vp9, 30fps, video only, 59.25MiB
136 mp4 1280x720 DASH video 307k , avc1.4d401f, 30fps, video only, 62.58MiB
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
43 webm 640x360 medium , vp8.0, vorbis@128k
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)wget http://ffmpeg.org/releases/ffmpeg-3.3.4.tar.bz2
tar -xvjf ffmpeg-3.3.4.tar.bz2
cd ffmpeg-3.3.4
./configure --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp
make
make installffmpeg -v#!/usr/bin/python
import subprocess
import sys
def show_help():
print 'Usage: '
print './streamer.py url streamName destination'
print './streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM streamName rtmp://192.168.88.59:1935/live'
return
def streamer() :
url = sys.argv[1]
if not url :
print 'Error: url is empty'
return
stream_id = sys.argv[2]
if not stream_id:
print 'Error: stream name is empty'
return
destination = sys.argv[3]
if not destination:
print 'Error: destination is empty'
return
_youtube_process = subprocess.Popen(('youtube-dl','-f','','--prefer-ffmpeg', '--no-color', '--no-cache-dir', '--no-progress','-o', '-', '-f', '22/18', url, '--reject-title', stream_id),stdout=subprocess.PIPE)
_ffmpeg_process = subprocess.Popen(('ffmpeg','-re','-i', '-','-preset', 'ultrafast','-vcodec', 'copy', '-acodec', 'copy','-threads','1', '-f', 'flv',destination + "/" + stream_id), stdin=_youtube_process.stdout)
return
if len(sys.argv) < 4:
show_help()
else:
streamer()python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://192.168.88.59:1935/live
rtmp://wcs5-eu.flashphoner.com:1935/livepython streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live# python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live
ffmpeg version 3.2.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.4.7 (GCC) 20120313 (Red Hat 4.4.7-11)
configuration: --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp --disable-yasm
libavutil 55. 34.101 / 55. 34.101
libavcodec 57. 64.101 / 57. 64.101
libavformat 57. 56.101 / 57. 56.101
libavdevice 57. 1.100 / 57. 1.100
libavfilter 6. 65.100 / 6. 65.100
libswscale 4. 2.100 / 4. 2.100
libswresample 2. 3.100 / 2. 3.100
libpostproc 54. 1.100 / 54. 1.100
]# [youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[download] Destination: -
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pipe:':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
creation_time : 2016-08-23T12:21:06.000000Z
Duration: 00:29:59.99, start: 0.000000, bitrate: N/A
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 288 kb/s, 30 fps, 30 tbr, 90k tbn, 60 tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Output #0, flv, to 'rtmp://192.168.88.59:1935/live/stream1':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
encoder : Lavf57.56.101
Stream #0:0(und): Video: h264 (Main) ([7][0][0][0] / 0x0007), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], q=2-31, 288 kb/s, 30 fps, 30 tbr, 1k tbn, 90k tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) ([10][0][0][0] / 0x000A), 44100 Hz, stereo, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream mapping:
Stream #0:0 -> #0:0 (copy)
Stream #0:1 -> #0:1 (copy)
frame= 383 fps= 30 q=-1.0 size= 654kB time=00:00:12.70 bitrate= 421.8kbits/s speed= 1x



|
|
Тянем ролик с YouTube и раздаем по WebRTC в реалтайме |
curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dlchmod a+rx /usr/local/bin/youtube-dlyoutube-dl --list-formats https://www.youtube.com/watch?v=9cQT4urTlXM[youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[info] Available formats for 9cQT4urTlXM:
format code extension resolution note
171 webm audio only DASH audio 8k , vorbis@128k, 540.24KiB
249 webm audio only DASH audio 10k , opus @ 50k, 797.30KiB
250 webm audio only DASH audio 10k , opus @ 70k, 797.30KiB
251 webm audio only DASH audio 10k , opus @160k, 797.30KiB
139 m4a audio only DASH audio 53k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 10.36MiB
140 m4a audio only DASH audio 137k , m4a_dash container, mp4a.40.2@128k (44100Hz), 27.56MiB
278 webm 256x144 144p 41k , webm container, vp9, 30fps, video only, 6.54MiB
242 webm 426x240 240p 70k , vp9, 30fps, video only, 13.42MiB
243 webm 640x360 360p 101k , vp9, 30fps, video only, 20.55MiB
160 mp4 256x144 DASH video 123k , avc1.4d400c, 15fps, video only, 24.83MiB
134 mp4 640x360 DASH video 138k , avc1.4d401e, 30fps, video only, 28.07MiB
244 webm 854x480 480p 149k , vp9, 30fps, video only, 30.55MiB
135 mp4 854x480 DASH video 209k , avc1.4d401f, 30fps, video only, 42.42MiB
133 mp4 426x240 DASH video 274k , avc1.4d4015, 30fps, video only, 57.63MiB
247 webm 1280x720 720p 298k , vp9, 30fps, video only, 59.25MiB
136 mp4 1280x720 DASH video 307k , avc1.4d401f, 30fps, video only, 62.58MiB
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
43 webm 640x360 medium , vp8.0, vorbis@128k
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)wget http://ffmpeg.org/releases/ffmpeg-3.3.4.tar.bz2
tar -xvjf ffmpeg-3.3.4.tar.bz2
cd ffmpeg-3.3.4
./configure --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp
make
make installffmpeg -v#!/usr/bin/python
import subprocess
import sys
def show_help():
print 'Usage: '
print './streamer.py url streamName destination'
print './streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM streamName rtmp://192.168.88.59:1935/live'
return
def streamer() :
url = sys.argv[1]
if not url :
print 'Error: url is empty'
return
stream_id = sys.argv[2]
if not stream_id:
print 'Error: stream name is empty'
return
destination = sys.argv[3]
if not destination:
print 'Error: destination is empty'
return
_youtube_process = subprocess.Popen(('youtube-dl','-f','','--prefer-ffmpeg', '--no-color', '--no-cache-dir', '--no-progress','-o', '-', '-f', '22/18', url, '--reject-title', stream_id),stdout=subprocess.PIPE)
_ffmpeg_process = subprocess.Popen(('ffmpeg','-re','-i', '-','-preset', 'ultrafast','-vcodec', 'copy', '-acodec', 'copy','-threads','1', '-f', 'flv',destination + "/" + stream_id), stdin=_youtube_process.stdout)
return
if len(sys.argv) < 4:
show_help()
else:
streamer()python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://192.168.88.59:1935/livertmp://wcs5-eu.flashphoner.com:1935/livepython streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live# python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live
ffmpeg version 3.2.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.4.7 (GCC) 20120313 (Red Hat 4.4.7-11)
configuration: --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp --disable-yasm
libavutil 55. 34.101 / 55. 34.101
libavcodec 57. 64.101 / 57. 64.101
libavformat 57. 56.101 / 57. 56.101
libavdevice 57. 1.100 / 57. 1.100
libavfilter 6. 65.100 / 6. 65.100
libswscale 4. 2.100 / 4. 2.100
libswresample 2. 3.100 / 2. 3.100
libpostproc 54. 1.100 / 54. 1.100
]# [youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[download] Destination: -
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pipe:':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
creation_time : 2016-08-23T12:21:06.000000Z
Duration: 00:29:59.99, start: 0.000000, bitrate: N/A
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 288 kb/s, 30 fps, 30 tbr, 90k tbn, 60 tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Output #0, flv, to 'rtmp://192.168.88.59:1935/live/stream1':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
encoder : Lavf57.56.101
Stream #0:0(und): Video: h264 (Main) ([7][0][0][0] / 0x0007), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], q=2-31, 288 kb/s, 30 fps, 30 tbr, 1k tbn, 90k tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) ([10][0][0][0] / 0x000A), 44100 Hz, stereo, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream mapping:
Stream #0:0 -> #0:0 (copy)
Stream #0:1 -> #0:1 (copy)
frame= 383 fps= 30 q=-1.0 size= 654kB time=00:00:12.70 bitrate= 421.8kbits/s speed= 1x|
|
Тянем ролик с YouTube и раздаем по WebRTC в реалтайме |
curl -L https://yt-dl.org/downloads/latest/youtube-dl -o /usr/local/bin/youtube-dlchmod a+rx /usr/local/bin/youtube-dlyoutube-dl --list-formats https://www.youtube.com/watch?v=9cQT4urTlXM[youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[info] Available formats for 9cQT4urTlXM:
format code extension resolution note
171 webm audio only DASH audio 8k , vorbis@128k, 540.24KiB
249 webm audio only DASH audio 10k , opus @ 50k, 797.30KiB
250 webm audio only DASH audio 10k , opus @ 70k, 797.30KiB
251 webm audio only DASH audio 10k , opus @160k, 797.30KiB
139 m4a audio only DASH audio 53k , m4a_dash container, mp4a.40.5@ 48k (22050Hz), 10.36MiB
140 m4a audio only DASH audio 137k , m4a_dash container, mp4a.40.2@128k (44100Hz), 27.56MiB
278 webm 256x144 144p 41k , webm container, vp9, 30fps, video only, 6.54MiB
242 webm 426x240 240p 70k , vp9, 30fps, video only, 13.42MiB
243 webm 640x360 360p 101k , vp9, 30fps, video only, 20.55MiB
160 mp4 256x144 DASH video 123k , avc1.4d400c, 15fps, video only, 24.83MiB
134 mp4 640x360 DASH video 138k , avc1.4d401e, 30fps, video only, 28.07MiB
244 webm 854x480 480p 149k , vp9, 30fps, video only, 30.55MiB
135 mp4 854x480 DASH video 209k , avc1.4d401f, 30fps, video only, 42.42MiB
133 mp4 426x240 DASH video 274k , avc1.4d4015, 30fps, video only, 57.63MiB
247 webm 1280x720 720p 298k , vp9, 30fps, video only, 59.25MiB
136 mp4 1280x720 DASH video 307k , avc1.4d401f, 30fps, video only, 62.58MiB
17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k
36 3gp 320x180 small , mp4v.20.3, mp4a.40.2
43 webm 640x360 medium , vp8.0, vorbis@128k
18 mp4 640x360 medium , avc1.42001E, mp4a.40.2@ 96k
22 mp4 1280x720 hd720 , avc1.64001F, mp4a.40.2@192k (best)wget http://ffmpeg.org/releases/ffmpeg-3.3.4.tar.bz2
tar -xvjf ffmpeg-3.3.4.tar.bz2
cd ffmpeg-3.3.4
./configure --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp
make
make installffmpeg -v#!/usr/bin/python
import subprocess
import sys
def show_help():
print 'Usage: '
print './streamer.py url streamName destination'
print './streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM streamName rtmp://192.168.88.59:1935/live'
return
def streamer() :
url = sys.argv[1]
if not url :
print 'Error: url is empty'
return
stream_id = sys.argv[2]
if not stream_id:
print 'Error: stream name is empty'
return
destination = sys.argv[3]
if not destination:
print 'Error: destination is empty'
return
_youtube_process = subprocess.Popen(('youtube-dl','-f','','--prefer-ffmpeg', '--no-color', '--no-cache-dir', '--no-progress','-o', '-', '-f', '22/18', url, '--reject-title', stream_id),stdout=subprocess.PIPE)
_ffmpeg_process = subprocess.Popen(('ffmpeg','-re','-i', '-','-preset', 'ultrafast','-vcodec', 'copy', '-acodec', 'copy','-threads','1', '-f', 'flv',destination + "/" + stream_id), stdin=_youtube_process.stdout)
return
if len(sys.argv) < 4:
show_help()
else:
streamer()python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://192.168.88.59:1935/livertmp://wcs5-eu.flashphoner.com:1935/livepython streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live# python streamer.py https://www.youtube.com/watch?v=9cQT4urTlXM stream1 rtmp://wcs5-eu.flashphoner.com:1935/live
ffmpeg version 3.2.3 Copyright (c) 2000-2017 the FFmpeg developers
built with gcc 4.4.7 (GCC) 20120313 (Red Hat 4.4.7-11)
configuration: --enable-shared --disable-logging --enable-gpl --enable-pthreads --enable-libx264 --enable-librtmp --disable-yasm
libavutil 55. 34.101 / 55. 34.101
libavcodec 57. 64.101 / 57. 64.101
libavformat 57. 56.101 / 57. 56.101
libavdevice 57. 1.100 / 57. 1.100
libavfilter 6. 65.100 / 6. 65.100
libswscale 4. 2.100 / 4. 2.100
libswresample 2. 3.100 / 2. 3.100
libpostproc 54. 1.100 / 54. 1.100
]# [youtube] 9cQT4urTlXM: Downloading webpage
[youtube] 9cQT4urTlXM: Downloading video info webpage
[youtube] 9cQT4urTlXM: Extracting video information
[youtube] 9cQT4urTlXM: Downloading MPD manifest
[download] Destination: -
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'pipe:':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
creation_time : 2016-08-23T12:21:06.000000Z
Duration: 00:29:59.99, start: 0.000000, bitrate: N/A
Stream #0:0(und): Video: h264 (Main) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 288 kb/s, 30 fps, 30 tbr, 90k tbn, 60 tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Output #0, flv, to 'rtmp://192.168.88.59:1935/live/stream1':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
encoder : Lavf57.56.101
Stream #0:0(und): Video: h264 (Main) ([7][0][0][0] / 0x0007), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], q=2-31, 288 kb/s, 30 fps, 30 tbr, 1k tbn, 90k tbc (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream #0:1(und): Audio: aac (LC) ([10][0][0][0] / 0x000A), 44100 Hz, stereo, 125 kb/s (default)
Metadata:
creation_time : 2016-08-23T12:21:06.000000Z
handler_name : ISO Media file produced by Google Inc.
Stream mapping:
Stream #0:0 -> #0:0 (copy)
Stream #0:1 -> #0:1 (copy)
frame= 383 fps= 30 q=-1.0 size= 654kB time=00:00:12.70 bitrate= 421.8kbits/s speed= 1x|
|
Легкая работа со списками — RendererRecyclerViewAdapter (часть 2) |
...
final MyDiffCallback diffCallback = new MyDiffCallback(getOldItems(), getNewItems());
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mRecyclerViewAdapter.setItems(getNewItems());
diffResult.dispatchUpdatesTo(mRecyclerViewAdapter);
...
public class MyDiffCallback extends DiffUtil.Callback {
private final List mOldList;
private final List mNewList;
public MyDiffCallback(List oldList, List newList) {
mOldList = oldList;
mNewList = newList;
}
@Override
public int getOldListSize() {
return mOldList.size();
}
@Override
public int getNewListSize() {
return mNewList.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return mOldList.get(oldItemPosition).getID() == mNewList.get(
newItemPosition).getID();
}
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
BaseItemModel oldItem = mOldList.get(oldItemPosition);
BaseItemModel newItem = mNewList.get(newItemPosition);
return oldItem.equals(newItem);
}
@Nullable
@Override
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
return super.getChangePayload(oldItemPosition, newItemPosition);
}
}
public interface BaseItemModel extends ItemModel {
int getID();
}
public abstract static class DiffCallback extends DiffUtil.Callback {
private final List mOldItems = new ArrayList<>();
private final List mNewItems = new ArrayList<>();
void setItems(List oldItems, List newItems) {
mOldItems.clear();
mOldItems.addAll(oldItems);
mNewItems.clear();
mNewItems.addAll(newItems);
}
@Override
public int getOldListSize() {
return mOldItems.size();
}
@Override
public int getNewListSize() {
return mNewItems.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return areItemsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areItemsTheSame(BM oldItem, BM newItem);
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
return areContentsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areContentsTheSame(BM oldItem, BM newItem);
...
}
public void setItems(List items, DiffCallback diffCallback) {
diffCallback.setItems(mItems, items);
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mItems.clear();
mItems.addAll(items);
diffResult.dispatchUpdatesTo(this);
}
public interface CompositeItemModel extends ItemModel {
List getItems();
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
public CompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public CompositeViewRenderer(int viewType, Context context, ViewRenderer... renderers) {
super(viewType, context);
Collections.addAll(mRenderers, renderers);
}
public CompositeViewRenderer registerRenderer(ViewRenderer renderer) {
mRenderers.add(renderer);
return this;
}
public void bindView(M model, VH holder) {}
public VH createViewHolder(ViewGroup parent) { return ...; }
...
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
private RendererRecyclerViewAdapter mAdapter;
...
public void bindView(M model, VH holder) {
mAdapter.setItems(model.getItems());
mAdapter.notifyDataSetChanged();
}
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
return ???;
}
...
}
public abstract class CompositeViewHolder extends RecyclerView.ViewHolder {
public RecyclerView mRecyclerView;
public CompositeViewHolder(View itemView) {
super(itemView);
}
}
public abstract class CompositeViewRenderer extends ViewRenderer {
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
VH viewHolder = createCompositeViewHolder(parent);
viewHolder.mRecyclerView.setLayoutManager(createLayoutManager());
viewHolder.mRecyclerView.setAdapter(mAdapter);
return viewHolder;
}
public abstract VH createCompositeViewHolder(ViewGroup parent);
protected RecyclerView.LayoutManager createLayoutManager() {
return new LinearLayoutManager(getContext(), LinearLayoutManager.HORIZONTAL, false);
}
...
}
public class SomeCompositeItemModel implements CompositeItemModel {
public static final int TYPE = 999;
private int mID;
private final List mItems;
public SomeCompositeItemModel(final int ID, List items) {
mID = ID;
mItems = items;
}
public int getID() {
return mID;
}
public int getType() {
return TYPE;
}
public List getItems() {
return mItems;
}
}
public class SomeCompositeViewHolder extends CompositeViewHolder {
public SomeCompositeViewHolder(View view) {
super(view);
mRecyclerView = (RecyclerView) view.findViewById(R.id.composite_recycler_view);
}
}
public class SomeCompositeViewRenderer extends CompositeViewRenderer {
public SomeCompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public SomeCompositeViewHolder createCompositeViewHolder(ViewGroup parent) {
return new SomeCompositeViewHolder(inflate(R.layout.item_composite, parent));
}
}
public class SomeActivity extends AppCompatActivity {
protected void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
SomeCompositeViewRenderer composite = new SomeCompositeViewRenderer(
SomeCompositeItemModel.TYPE,
this,
new SomeViewRenderer(SomeModel.TYPE, this, mListener)
);
mRecyclerViewAdapter.registerRenderer(composite);
...
}
...
}
public class SomeViewRenderer extends ViewRenderer {
private final Listener mListener;
public SomeViewRenderer(int type, Context context, Listener listener) {
super(type, context);
mListener = listener;
}
public void bindView(SomeModel model, SomeViewHolder holder) {
...
holder.itemView.setOnClickListener(new View.OnClickListener() {
public void onClick(final View view) {
mListener.onSomeItemClicked(model);
}
});
}
...
public interface Listener {
void onSomeItemClicked(SomeModel model);
}
}
|
Метки: author vivchar разработка под android разработка мобильных приложений android android development recyclerview adapter composite nested recyclerview |
Легкая работа со списками — RendererRecyclerViewAdapter (часть 2) |
...
final MyDiffCallback diffCallback = new MyDiffCallback(getOldItems(), getNewItems());
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mRecyclerViewAdapter.setItems(getNewItems());
diffResult.dispatchUpdatesTo(mRecyclerViewAdapter);
...
public class MyDiffCallback extends DiffUtil.Callback {
private final List mOldList;
private final List mNewList;
public MyDiffCallback(List oldList, List newList) {
mOldList = oldList;
mNewList = newList;
}
@Override
public int getOldListSize() {
return mOldList.size();
}
@Override
public int getNewListSize() {
return mNewList.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return mOldList.get(oldItemPosition).getID() == mNewList.get(
newItemPosition).getID();
}
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
BaseItemModel oldItem = mOldList.get(oldItemPosition);
BaseItemModel newItem = mNewList.get(newItemPosition);
return oldItem.equals(newItem);
}
@Nullable
@Override
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
return super.getChangePayload(oldItemPosition, newItemPosition);
}
}
public interface BaseItemModel extends ItemModel {
int getID();
}
public abstract static class DiffCallback extends DiffUtil.Callback {
private final List mOldItems = new ArrayList<>();
private final List mNewItems = new ArrayList<>();
void setItems(List oldItems, List newItems) {
mOldItems.clear();
mOldItems.addAll(oldItems);
mNewItems.clear();
mNewItems.addAll(newItems);
}
@Override
public int getOldListSize() {
return mOldItems.size();
}
@Override
public int getNewListSize() {
return mNewItems.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return areItemsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areItemsTheSame(BM oldItem, BM newItem);
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
return areContentsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areContentsTheSame(BM oldItem, BM newItem);
...
}
public void setItems(List items, DiffCallback diffCallback) {
diffCallback.setItems(mItems, items);
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mItems.clear();
mItems.addAll(items);
diffResult.dispatchUpdatesTo(this);
}
public interface CompositeItemModel extends ItemModel {
List getItems();
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
public CompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public CompositeViewRenderer(int viewType, Context context, ViewRenderer... renderers) {
super(viewType, context);
Collections.addAll(mRenderers, renderers);
}
public CompositeViewRenderer registerRenderer(ViewRenderer renderer) {
mRenderers.add(renderer);
return this;
}
public void bindView(M model, VH holder) {}
public VH createViewHolder(ViewGroup parent) { return ...; }
...
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
private RendererRecyclerViewAdapter mAdapter;
...
public void bindView(M model, VH holder) {
mAdapter.setItems(model.getItems());
mAdapter.notifyDataSetChanged();
}
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
return ???;
}
...
}
public abstract class CompositeViewHolder extends RecyclerView.ViewHolder {
public RecyclerView mRecyclerView;
public CompositeViewHolder(View itemView) {
super(itemView);
}
}
public abstract class CompositeViewRenderer extends ViewRenderer {
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
VH viewHolder = createCompositeViewHolder(parent);
viewHolder.mRecyclerView.setLayoutManager(createLayoutManager());
viewHolder.mRecyclerView.setAdapter(mAdapter);
return viewHolder;
}
public abstract VH createCompositeViewHolder(ViewGroup parent);
protected RecyclerView.LayoutManager createLayoutManager() {
return new LinearLayoutManager(getContext(), LinearLayoutManager.HORIZONTAL, false);
}
...
}
public class SomeCompositeItemModel implements CompositeItemModel {
public static final int TYPE = 999;
private int mID;
private final List mItems;
public SomeCompositeItemModel(final int ID, List items) {
mID = ID;
mItems = items;
}
public int getID() {
return mID;
}
public int getType() {
return TYPE;
}
public List getItems() {
return mItems;
}
}
public class SomeCompositeViewHolder extends CompositeViewHolder {
public SomeCompositeViewHolder(View view) {
super(view);
mRecyclerView = (RecyclerView) view.findViewById(R.id.composite_recycler_view);
}
}
public class SomeCompositeViewRenderer extends CompositeViewRenderer {
public SomeCompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public SomeCompositeViewHolder createCompositeViewHolder(ViewGroup parent) {
return new SomeCompositeViewHolder(inflate(R.layout.item_composite, parent));
}
}
public class SomeActivity extends AppCompatActivity {
protected void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
SomeCompositeViewRenderer composite = new SomeCompositeViewRenderer(
SomeCompositeItemModel.TYPE,
this,
new SomeViewRenderer(SomeModel.TYPE, this, mListener)
);
mRecyclerViewAdapter.registerRenderer(composite);
...
}
...
}
public class SomeViewRenderer extends ViewRenderer {
private final Listener mListener;
public SomeViewRenderer(int type, Context context, Listener listener) {
super(type, context);
mListener = listener;
}
public void bindView(SomeModel model, SomeViewHolder holder) {
...
holder.itemView.setOnClickListener(new View.OnClickListener() {
public void onClick(final View view) {
mListener.onSomeItemClicked(model);
}
});
}
...
public interface Listener {
void onSomeItemClicked(SomeModel model);
}
}
|
Метки: author vivchar разработка под android разработка мобильных приложений android android development recyclerview adapter composite nested recyclerview |
Легкая работа со списками — RendererRecyclerViewAdapter (часть 2) |
...
final MyDiffCallback diffCallback = new MyDiffCallback(getOldItems(), getNewItems());
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mRecyclerViewAdapter.setItems(getNewItems());
diffResult.dispatchUpdatesTo(mRecyclerViewAdapter);
...
public class MyDiffCallback extends DiffUtil.Callback {
private final List mOldList;
private final List mNewList;
public MyDiffCallback(List oldList, List newList) {
mOldList = oldList;
mNewList = newList;
}
@Override
public int getOldListSize() {
return mOldList.size();
}
@Override
public int getNewListSize() {
return mNewList.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return mOldList.get(oldItemPosition).getID() == mNewList.get(
newItemPosition).getID();
}
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
BaseItemModel oldItem = mOldList.get(oldItemPosition);
BaseItemModel newItem = mNewList.get(newItemPosition);
return oldItem.equals(newItem);
}
@Nullable
@Override
public Object getChangePayload(int oldItemPosition, int newItemPosition) {
return super.getChangePayload(oldItemPosition, newItemPosition);
}
}
public interface BaseItemModel extends ItemModel {
int getID();
}
public abstract static class DiffCallback extends DiffUtil.Callback {
private final List mOldItems = new ArrayList<>();
private final List mNewItems = new ArrayList<>();
void setItems(List oldItems, List newItems) {
mOldItems.clear();
mOldItems.addAll(oldItems);
mNewItems.clear();
mNewItems.addAll(newItems);
}
@Override
public int getOldListSize() {
return mOldItems.size();
}
@Override
public int getNewListSize() {
return mNewItems.size();
}
@Override
public boolean areItemsTheSame(int oldItemPosition, int newItemPosition) {
return areItemsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areItemsTheSame(BM oldItem, BM newItem);
@Override
public boolean areContentsTheSame(int oldItemPosition, int newItemPosition) {
return areContentsTheSame(
mOldItems.get(oldItemPosition),
mNewItems.get(newItemPosition)
);
}
public abstract boolean areContentsTheSame(BM oldItem, BM newItem);
...
}
public void setItems(List items, DiffCallback diffCallback) {
diffCallback.setItems(mItems, items);
final DiffUtil.DiffResult diffResult = DiffUtil.calculateDiff(diffCallback);
mItems.clear();
mItems.addAll(items);
diffResult.dispatchUpdatesTo(this);
}
public interface CompositeItemModel extends ItemModel {
List getItems();
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
public CompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public CompositeViewRenderer(int viewType, Context context, ViewRenderer... renderers) {
super(viewType, context);
Collections.addAll(mRenderers, renderers);
}
public CompositeViewRenderer registerRenderer(ViewRenderer renderer) {
mRenderers.add(renderer);
return this;
}
public void bindView(M model, VH holder) {}
public VH createViewHolder(ViewGroup parent) { return ...; }
...
}
public abstract class CompositeViewRenderer extends ViewRenderer {
private final ArrayList mRenderers = new ArrayList<>();
private RendererRecyclerViewAdapter mAdapter;
...
public void bindView(M model, VH holder) {
mAdapter.setItems(model.getItems());
mAdapter.notifyDataSetChanged();
}
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
return ???;
}
...
}
public abstract class CompositeViewHolder extends RecyclerView.ViewHolder {
public RecyclerView mRecyclerView;
public CompositeViewHolder(View itemView) {
super(itemView);
}
}
public abstract class CompositeViewRenderer extends ViewRenderer {
public VH createViewHolder(ViewGroup parent) {
mAdapter = new RendererRecyclerViewAdapter();
for (final ViewRenderer renderer : mRenderers) {
mAdapter.registerRenderer(renderer);
}
VH viewHolder = createCompositeViewHolder(parent);
viewHolder.mRecyclerView.setLayoutManager(createLayoutManager());
viewHolder.mRecyclerView.setAdapter(mAdapter);
return viewHolder;
}
public abstract VH createCompositeViewHolder(ViewGroup parent);
protected RecyclerView.LayoutManager createLayoutManager() {
return new LinearLayoutManager(getContext(), LinearLayoutManager.HORIZONTAL, false);
}
...
}
public class SomeCompositeItemModel implements CompositeItemModel {
public static final int TYPE = 999;
private int mID;
private final List mItems;
public SomeCompositeItemModel(final int ID, List items) {
mID = ID;
mItems = items;
}
public int getID() {
return mID;
}
public int getType() {
return TYPE;
}
public List getItems() {
return mItems;
}
}
public class SomeCompositeViewHolder extends CompositeViewHolder {
public SomeCompositeViewHolder(View view) {
super(view);
mRecyclerView = (RecyclerView) view.findViewById(R.id.composite_recycler_view);
}
}
public class SomeCompositeViewRenderer extends CompositeViewRenderer {
public SomeCompositeViewRenderer(int viewType, Context context) {
super(viewType, context);
}
public SomeCompositeViewHolder createCompositeViewHolder(ViewGroup parent) {
return new SomeCompositeViewHolder(inflate(R.layout.item_composite, parent));
}
}
public class SomeActivity extends AppCompatActivity {
protected void onCreate(final Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
SomeCompositeViewRenderer composite = new SomeCompositeViewRenderer(
SomeCompositeItemModel.TYPE,
this,
new SomeViewRenderer(SomeModel.TYPE, this, mListener)
);
mRecyclerViewAdapter.registerRenderer(composite);
...
}
...
}
public class SomeViewRenderer extends ViewRenderer {
private final Listener mListener;
public SomeViewRenderer(int type, Context context, Listener listener) {
super(type, context);
mListener = listener;
}
public void bindView(SomeModel model, SomeViewHolder holder) {
...
holder.itemView.setOnClickListener(new View.OnClickListener() {
public void onClick(final View view) {
mListener.onSomeItemClicked(model);
}
});
}
...
public interface Listener {
void onSomeItemClicked(SomeModel model);
}
}
|
Метки: author vivchar разработка под android разработка мобильных приложений android android development recyclerview adapter composite nested recyclerview |
5 правил работы с суммами |
|
Метки: author sergey-b разработка под e-commerce платежные системы java c# currency decimal double |
[Перевод] «Паттерны» функционального программирования |



(apple -> banana).let z = 1
let add = x + y // int -> int ->int
(apple -> banana), а другая бананы в вишни (banana -> cherry), объединив их мы получим функции преобразования яблок в вишни (apple -> cherry). С точки зрения программиста нет разницы получена эта функция с помощью композиции или написана вручную, главное – ее сигнатура.httpRequest -> httpResponse. Конечно это возможно только для синхронных операций, но для асинхронных есть реактивное функциональное программирование, позволяющее сделать тоже самое.
Шаблон компоновщик (Composite) в ООП тоже можно представлять себе «фракталом», но компоновщик работает со структурами данных, а не преобразованиями.
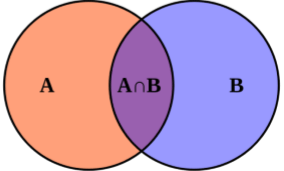 У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП.
У системы типов в ФП больше общего с теорией множеств, чем с классами из ООП. int – это тип. Но тип не обязательно должен быть примитивом. Customer – это тоже тип. Функции могут принимать на вход и возвращать функции. int -> int – тоже тип. Так что «тип» — это название для некоторого множества.type Birthday = Person * Datetype PaymentMethod =
| Cash
| Cheque of ChequeNumber
| Card of CardType * CardNumberОднажды нам пригодились «объединения» для моделирования предметной модели.
Entity Framework умеет работать с такими типами из коробки, нужно лишь добавить id.

int -> int и это ложь! Если мы подадим на вход 0, функция выбросит исключение. Вместо этого мы можем заменить сигнатуру на NonZeroInteger -> int или на int -> int option.


let printList anAction aList =
for i in aList do
anAction ipublic static int Product(int n)
{
int product = 1; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
product *= i; // действие
}
return product; // возвращаемое значение
}
public static int Sum(int n)
{
int sum = 0; // инициализация
for (int i = 1; i <= n; i++) // цикл
{
sum += i;
}
return sum; // возвращаемое значение
} let product n =
let initialValue = 1
let action productSoFar x = productSoFar * x
[1..n] |> List.fold action initialValue
let sum n =
let initialValue = 0
let action sumSoFar x = sumSoFar+x
[1..n] |> List.fold action initialValueAggregate, который делает тоже самое! Поздравляю, LINQ написан в функциональном стиле :)Рекомендую цикл статей Эрика Липперта о монадах в C#. С десятой части начинается объяснение «монадической» природы SelectManyinterface IBunchOfStuff
{
int DoSomething(int x);
string DoSomethingElse(int x); // один интерфейс - одно дело
void DoAThirdThing(string x); // нужно разделить
}
interface IBunchOfStuff
{
int DoSomething(int x);
}
int -> int. В F# не нужно объявлять интерфейс, чтобы сделать функции взаимозаменяемыми, они взаимозаменяемы «из коробки» просто по своей сигнатуре. Таким образом паттерн «стратегия» реализуется простой передачей функции в качестве аргумента другой функции:let DoSomethingWithStuff strategy x =
strategy x
let isEvenWithLogging = log >> isEven >> log // int -> boolЗдесь автор для простоты изложения опускает вопросы семантики. При моделировании реальных предметных моделей одной сигнатуры функции не всегда достаточно.

int -> int -> int не содержит скобок не случайно. Можно воспринимать сложение, как функцию от двух аргументов типа int, возвращающую значение типа int или как функцию от одного аргумента, возвращающую функциональный тип int -> int. Возвращаемая функция будет называться сумматор по основанию n, где n — число переданное аргументом в первую функцию. Повторив эту операцию рекурсивно можно функцию от любого числа аргументов преобразовать в функции от одного аргумента.Такие преобразования возможны не только для компилируемых функций в программировании, но и для математических функций. Возможность такого преобразования впервые отмечена в трудах Готтлоба Фреге, систематически изучена Моисеем Шейнфинкелем в 1920-е годы, а наименование получило по имени Хаскелла Карри — разработчика комбинаторной логики, в которой сведение к функциям одного аргумента носит основополагающий характер.
let three = 1 + 2
let three = (+) 1 2
let three = ((+) 1) 2
let add1 = (+) 1
let three = add1 2 // эта функция требует зависимость
let getCustomerFromDatabase connection (customerId:CustomerId) =
from connection
select customer
where customerId = customerId
// а эта уже нет
let getCustomer1 = getCustomerFromDatabase myConnection int Divide(int top, int bottom)
{
if (bottom == 0)
{
// кто решил, что нужно выбросить исключение?
throw new InvalidOperationException("div by 0");
}
else
{
return top/bottom;
}
}
void Divide(int top, int bottom, Action ifZero, Action ifSuccess)
{
if (bottom == 0)
{
ifZero();
}
else
{
ifSuccess( top/bottom );
}
}

let ifSomeDo f opt =
if opt.IsSome then
f opt.Value
else
Nonelet example input =
doSomething input
|> ifSomeDo doSomethingElse
|> ifSomeDo doAThirdThing
|> ifSomeDo (fun z -> Some z)


bind
let bind nextFunction optionInput =
match optionInput with
// передаем результат выполнения предыдущей функции в случае успеха
| Some s -> nextFunction s
// или просто пробрасываем значение None дальше
| None -> None
bind// было
let example input =
let x = doSomething input
if x.IsSome then
let y = doSomethingElse (x.Value)
if y.IsSome then
let z = doAThirdThing (y.Value)
if z.IsSome then
let result = z.Value
Some result
else
None
else
None
else
None
// стало
let bind f opt =
match opt with
| Some v -> f v
| None -> None
let example input =
doSomething input
|> bind doSomethingElse
|> bind doAThirdThing
|> bind (fun z -> Some z)
Если у вас появилось смутное ощущение, что дальше идет описание монады Either, так оно и естьstring UpdateCustomerWithErrorHandling()
{
var request = receiveRequest();
validateRequest(request);
canonicalizeEmail(request);
db.updateDbFromRequest(request);
smtpServer.sendEmail(request.Email)
return "OK";
} string UpdateCustomerWithErrorHandling()
{
var request = receiveRequest();
var isValidated = validateRequest(request);
if (!isValidated)
{
return "Request is not valid"
}
canonicalizeEmail(request);
try
{
var result = db.updateDbFromRequest(request);
if (!result)
{
return "Customer record not found"
}
}
catch
{
return "DB error: Customer record not updated"
}
if (!smtpServer.sendEmail(request.Email))
{
log.Error "Customer email not sent"
}
return "OK";
} bind можно абстрагировать логику обработки ошибок. Вот так будет выглядеть метод без обработки ошибок, если его переписать на F#:

Мне не очень понравилось описание функторов у Скотта. Прочитайте лучше статью «Функторы, аппликативные функторы и монады в картинках»

За более строгим определением обратитесь к википедии. В рамках статьи обсуждается лишь несколько примеров применения моноидов на практике.
1 * 2 * 3 * 4
[ 1; 2; 3; 4 ] |> List.reduce (*)1 + 2 + 3 + 4. Мы можем вычислить 1 + 2 на первом ядре, а 3 + 4 — на втором, а результат сложить. Больше последовательных вычислений — больше ядер.reduce есть несколько проблем: что делать с пустыми списками? Что делать, если у нас нечетное количество элементов? Правильно, добавить в список нейтральный элемент.Кстати, в математике часто встречается определение моноида как полугруппы с нейтральным элементом. Если нейтральный элемент отсутствует, то можно попробовать его доопределить, чтобы воспользоваться преимуществами моноида.
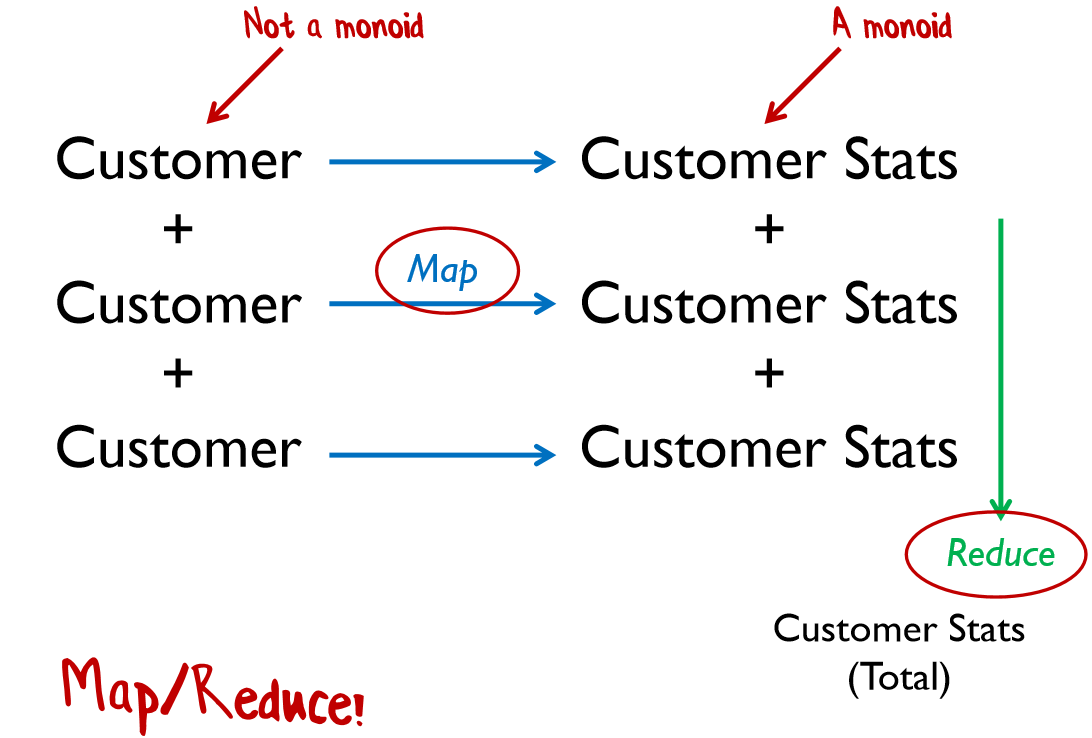
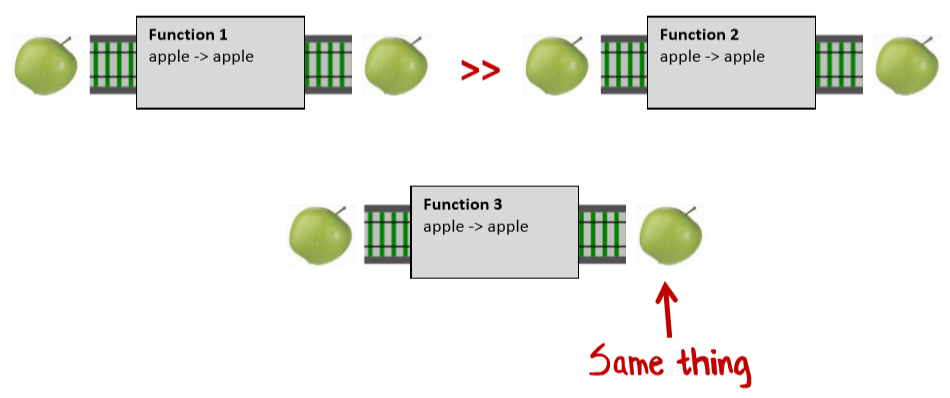 Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.
Функции с одинаковым типом входного и выходного значения являются моноидами и имеют специальное название — «эндоморфизмы» (название заимствовано из теории категорий). Что более важно, функции, содержащие эндоморфизмы могут быть преобразованы к эндоморфизмам с помощью частичного применения.Грег Янг открыто заявляет, что Event Sourcing — это просто функциональный код. Flux и unidirectional data flow, кстати тоже.
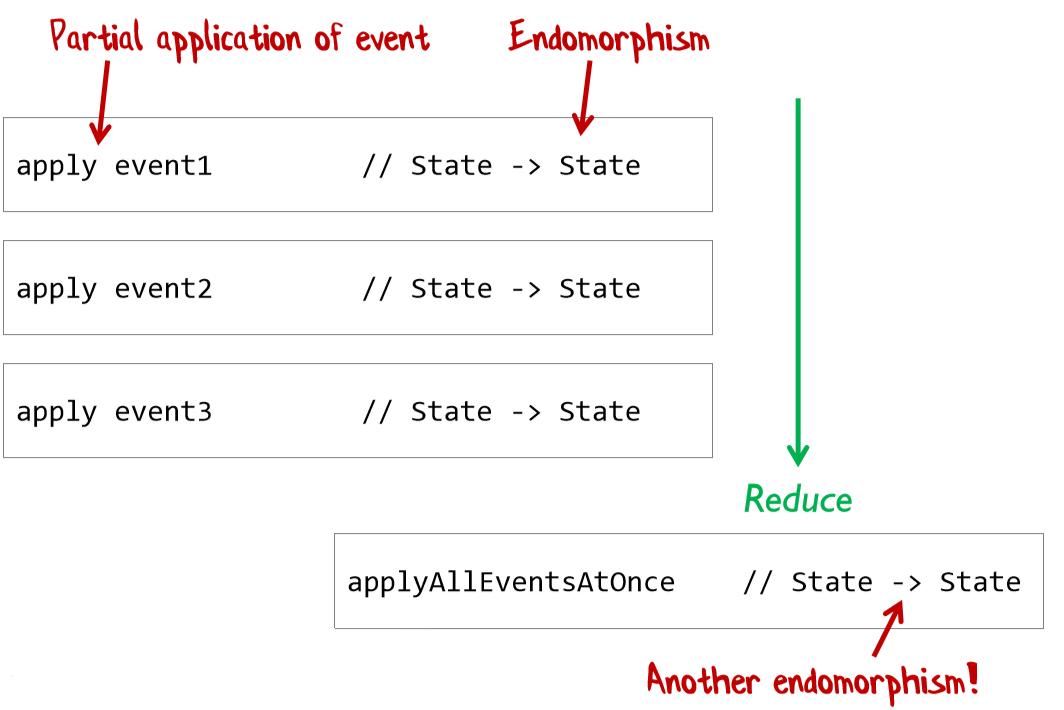
Кстати, бастион ООП — GOF тоже содержит монады. Паттерн «интерпретатор» — это так называемая свободная монада.
|
Метки: author marshinov функциональное программирование проектирование и рефакторинг анализ и проектирование систем c# .net f# ref#actoring patterns functional programming |
Дайджест свежих материалов из мира фронтенда за последнюю неделю №280 (11 — 17 сентября 2017) |
|
|
Что в черном ящике: из чего складываются затраты на виртуальную и физическую инфраструктуру |


|
Метки: author 1cloud управление разработкой блог компании 1cloud.ru 1cloud it- инфраструктура затраты облако |
Дайджест интересных материалов для мобильного разработчика #221 (11-17 сентября) |
 |
Быстрый рендеринг океанских волн на мобильных устройствах |
 iOS
iOS Используем SpriteKit для создания анимации загрузки watchOS Как сделать компас на Swift Три важные вещи для разработчиков из мероприятия Apple Как пофиксить Webview для iOS 11
Используем SpriteKit для создания анимации загрузки watchOS Как сделать компас на Swift Три важные вещи для разработчиков из мероприятия Apple Как пофиксить Webview для iOS 11 Android
Android Android Dev Подкаст. Android Things (английский) Улучшаем Android-приложение с помощью Remixer от Google Оптимизируем RecyclerView Инструменты, помогающие справляться с Android-разработкой Создание реактивного уровня данных с Realm и RxJava2 Как использовать AsyncListUtil ViewModels и LiveData: Patterns + AntiPatterns Понимание Activity.runOnUiThread() MapMe: адаптер карт для Android Как использовать share() в RxJava 6 самых важных нетехнических навыков для Android-разработчика Google Assistant, контролирующий устройства Android Things
Android Dev Подкаст. Android Things (английский) Улучшаем Android-приложение с помощью Remixer от Google Оптимизируем RecyclerView Инструменты, помогающие справляться с Android-разработкой Создание реактивного уровня данных с Realm и RxJava2 Как использовать AsyncListUtil ViewModels и LiveData: Patterns + AntiPatterns Понимание Activity.runOnUiThread() MapMe: адаптер карт для Android Как использовать share() в RxJava 6 самых важных нетехнических навыков для Android-разработчика Google Assistant, контролирующий устройства Android Things  Bubbble: клиент для Dribbble с использованием Clean Architecture + MVP
Bubbble: клиент для Dribbble с использованием Clean Architecture + MVP Разработка Чему я научился, проходя практику дизайнера в Tesla и Uber Плоский UI привлекает меньше внимание и вызывает неопределенность Введение в TensorFlow Datasets и Estimators Инженерное руководство о том, как не испортить приложение Почему PWA это то, что нужно Microsoft Прием платежей в React Native приложении Анимация пузыря в React Native Сколько стоит сделать приложение вроде Periscope
Разработка Чему я научился, проходя практику дизайнера в Tesla и Uber Плоский UI привлекает меньше внимание и вызывает неопределенность Введение в TensorFlow Datasets и Estimators Инженерное руководство о том, как не испортить приложение Почему PWA это то, что нужно Microsoft Прием платежей в React Native приложении Анимация пузыря в React Native Сколько стоит сделать приложение вроде Periscope Аналитика, маркетинг и монетизация
Аналитика, маркетинг и монетизация Устройства, IoT, AI
Устройства, IoT, AI|
|
Анализ работы MS SQL Server, для тех кто видит его впервые (часть 2) |

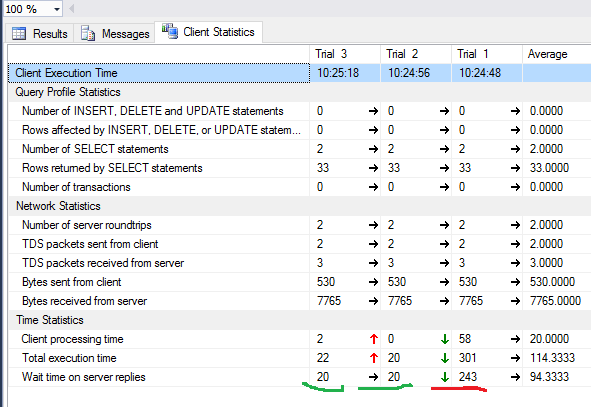
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductID
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 16 мс, истекшее время = 89 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
(32 row(s) affected)
Таблица «ProductProductPhoto». Число просмотров 32, логических чтений 96, физических чтений 5, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «Product». Число просмотров 0, логических чтений 64, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «ProductDocument». Число просмотров 1, логических чтений 3, физических чтений 1, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Время работы SQL Server:
Время ЦП = 15 мс, затраченное время = 35 мс.
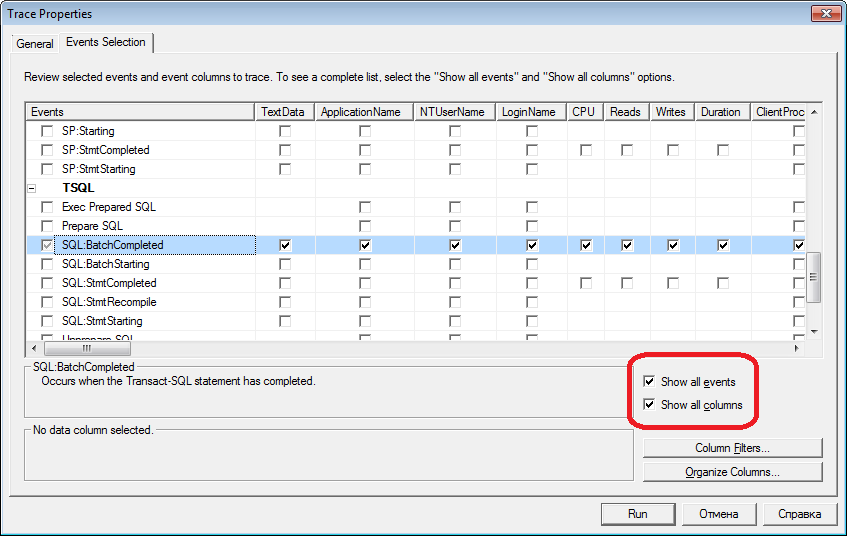

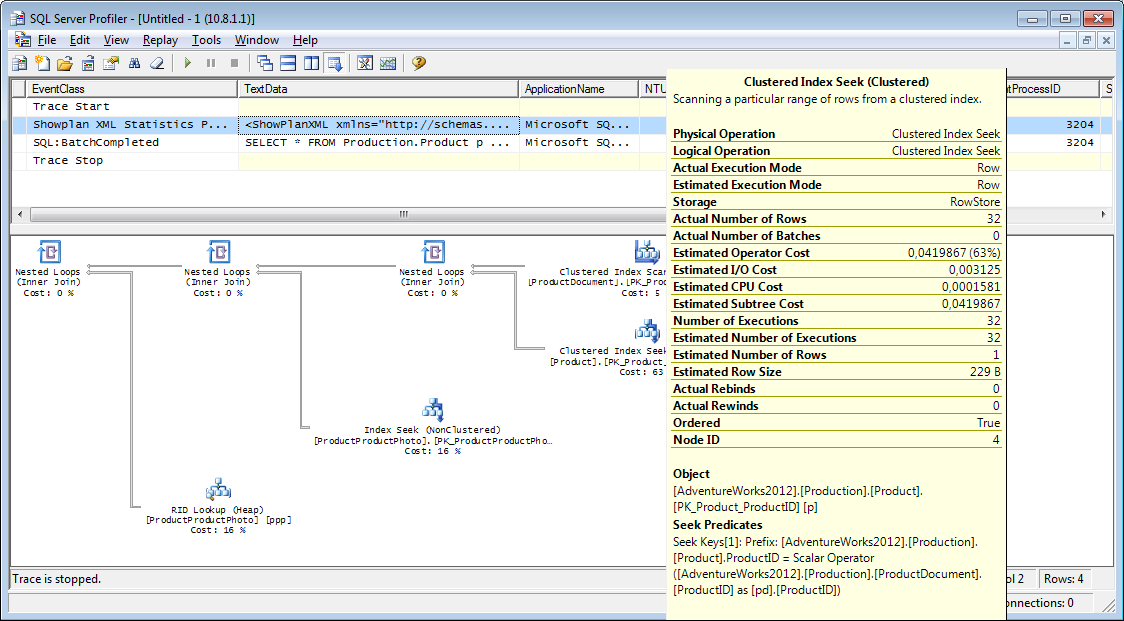
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'ждем секунду для накопления статистики при первом запуске'
-- при последующих запусках не ждем, т.к. сравниваем с результатом предыдущего запуска
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [интервал времени, мс]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id


DECLARE @sql_handle varbinary(64)
DECLARE @plan_handle varbinary(64)
DECLARE @sid INT
Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT
-- для инфы по конкретному юзеру - указываем номер сессии
SELECT @sid=182
-- получаем переменные состояния для дальнейшей обработки
IF @sid IS NOT NULL
SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id
FROM sys.dm_exec_requests der WHERE der.session_id=@sid
--печатаем текст выполняемого запроса
DECLARE @txt VARCHAR(max)
IF @sql_handle IS NOT NULL
SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle)
PRINT @txt
-- выводим план выполняемого батча/процы
IF @plan_handle IS NOT NULL
select * from sys.dm_exec_query_plan(@plan_handle)
-- и план выполняемого запроса в рамках батча/процы
IF @plan_handle IS NOT NULL
SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml
from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)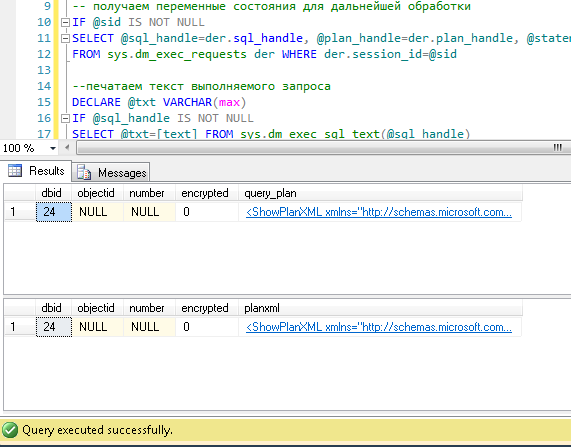

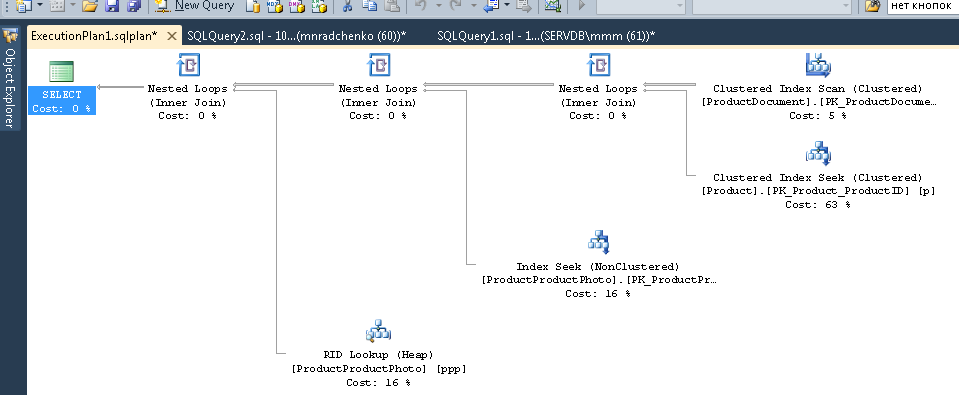
-- статистика по плану
IF @sql_handle IS NOT NULL
SELECT * FROM sys.dm_exec_query_stats QS WHERE QS.sql_handle=@sql_handle
-- получаем список всех текущих запросов
SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt
--,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat
,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, *
from sys.dm_exec_requests der
left join sys.dm_exec_sessions s ON s.session_id = der.session_id
WHERE der.session_id<>@@SPID
-- AND der.session_id>50
|
Метки: author 71rmn администрирование баз данных ms sql server для чайников программирование баз данных |
Анализ работы MS SQL Server, для тех кто видит его впервые (часть 2) |
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductID
Время синтаксического анализа и компиляции SQL Server:
время ЦП = 16 мс, истекшее время = 89 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
Время работы SQL Server:
Время ЦП = 0 мс, затраченное время = 0 мс.
(32 row(s) affected)
Таблица «ProductProductPhoto». Число просмотров 32, логических чтений 96, физических чтений 5, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «Product». Число просмотров 0, логических чтений 64, физических чтений 0, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Таблица «ProductDocument». Число просмотров 1, логических чтений 3, физических чтений 1, упреждающих чтений 0, lob логических чтений 0, lob физических чтений 0, lob упреждающих чтений 0.
Время работы SQL Server:
Время ЦП = 15 мс, затраченное время = 35 мс.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'ждем секунду для накопления статистики при первом запуске'
-- при последующих запусках не ждем, т.к. сравниваем с результатом предыдущего запуска
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [интервал времени, мс]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_idDECLARE @sql_handle varbinary(64)
DECLARE @plan_handle varbinary(64)
DECLARE @sid INT
Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT
-- для инфы по конкретному юзеру - указываем номер сессии
SELECT @sid=182
-- получаем переменные состояния для дальнейшей обработки
IF @sid IS NOT NULL
SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id
FROM sys.dm_exec_requests der WHERE der.session_id=@sid
--печатаем текст выполняемого запроса
DECLARE @txt VARCHAR(max)
IF @sql_handle IS NOT NULL
SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle)
PRINT @txt
-- выводим план выполняемого батча/процы
IF @plan_handle IS NOT NULL
select * from sys.dm_exec_query_plan(@plan_handle)
-- и план выполняемого запроса в рамках батча/процы
IF @plan_handle IS NOT NULL
SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml
from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)-- статистика по плану
IF @sql_handle IS NOT NULL
SELECT * FROM sys.dm_exec_query_stats QS WHERE QS.sql_handle=@sql_handle
-- получаем список всех текущих запросов
SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt
--,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat
,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, *
from sys.dm_exec_requests der
left join sys.dm_exec_sessions s ON s.session_id = der.session_id
WHERE der.session_id<>@@SPID
-- AND der.session_id>50
|
Метки: author 71rmn администрирование баз данных ms sql server для чайников программирование баз данных |
Как я проходил собеседования на позицию Junior .Net Developer |
|
Метки: author JosefDzeranov алгоритмы c# .net собеседование вопросы с# net |
Как я проходил собеседования на позицию Junior .Net Developer |
|
Метки: author JosefDzeranov алгоритмы c# .net собеседование вопросы с# net |
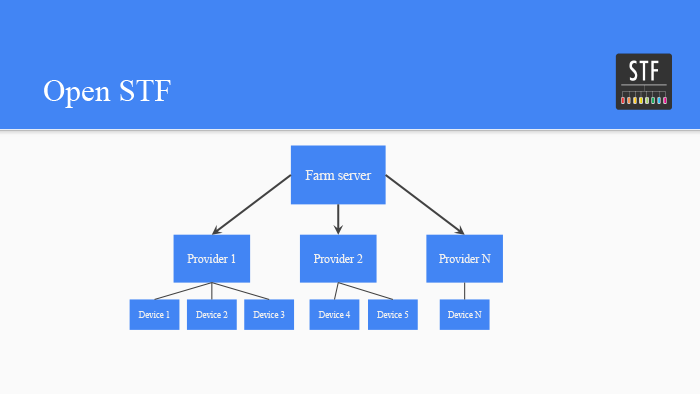
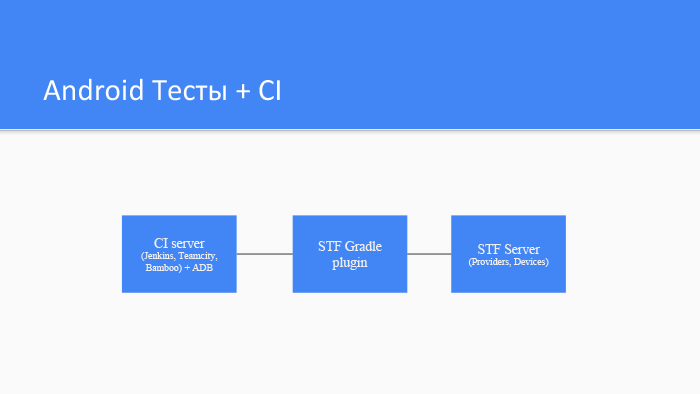
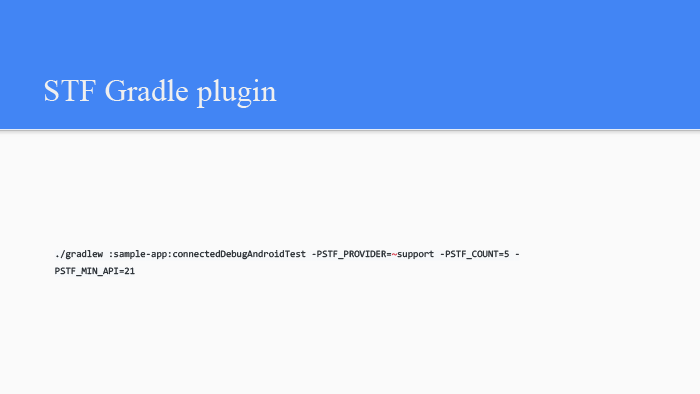
Управление фермой Android-устройств. Лекция в Яндексе |














|
|
Управление фермой Android-устройств. Лекция в Яндексе |
|
|






