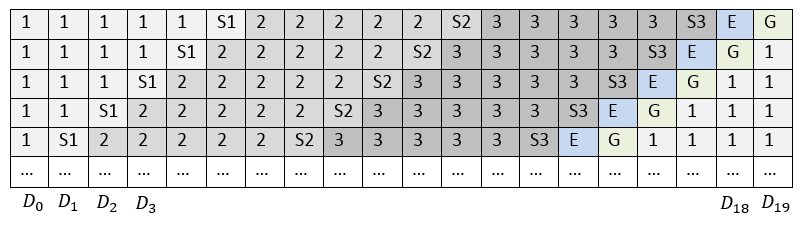
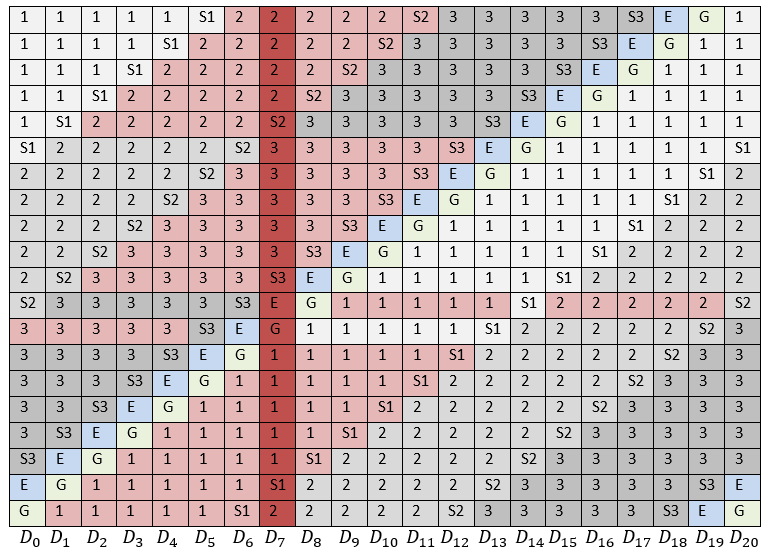
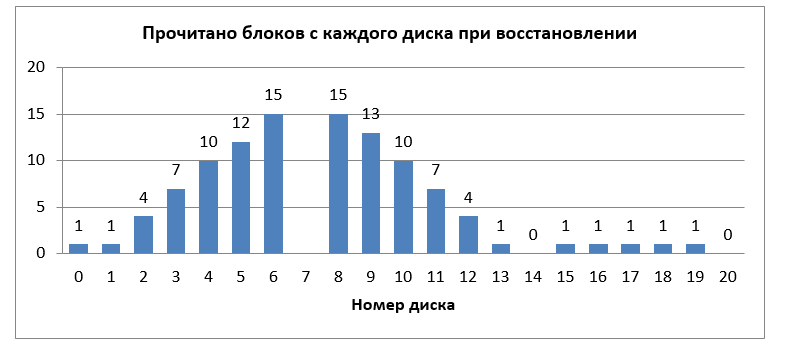
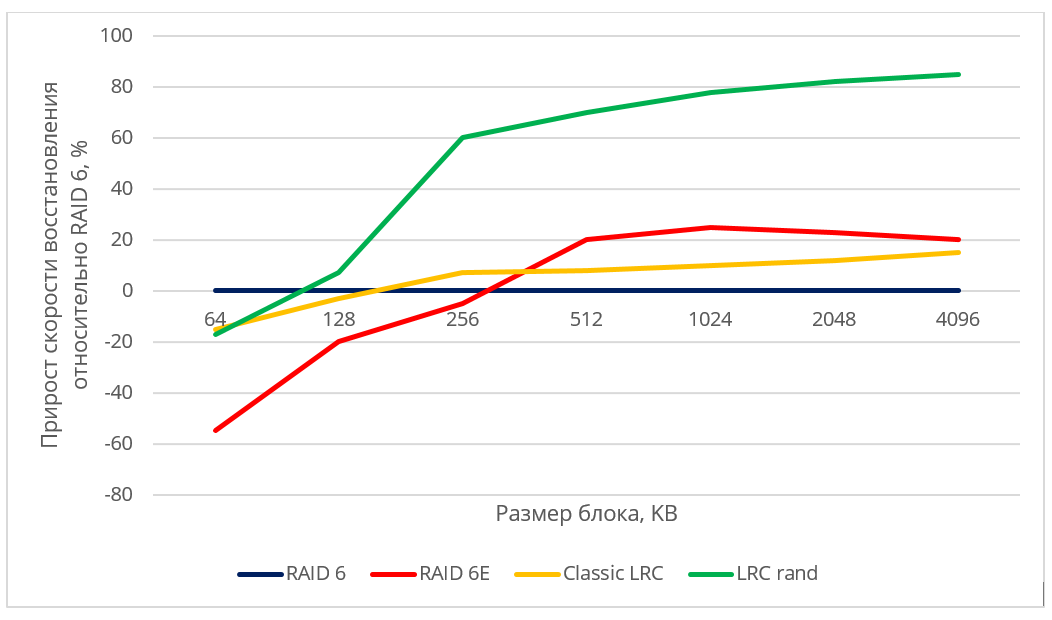
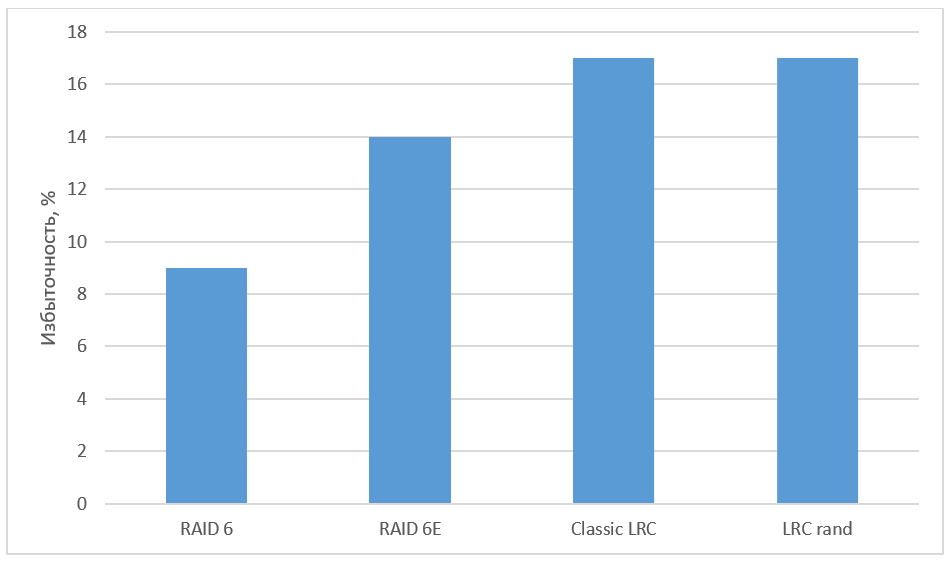
Быстрое восстановление данных. Чем нам помогут LRC? |

|
Метки: author raidixteam системное программирование математика алгоритмы блог компании raidix lrc xor восстановление данных raid6 доступность данных |
Как я участвовал в хакатоне Angular Attack, и что из этого вышло |





|
Метки: author stickytape разработка веб-сайтов программирование dart angularjs блог компании wrike angular2 angularattack хакатон front-end |
Интервью с Яковом Шуваевым про команду инженеров, мотивацию и собеседования |

Интересный факт. Не все знают, но физмат РУДН плотно обосновался в ЛАНИТ. Только в одном подразделении, в котором работает Яков, трудятся еще 5 выпускников физмата РУДН.


«У одного руководителя берут интервью.
— Скажите, вот у вас все сотрудники постоянно посещают разные конференции, получают сертификаты, ходят на разные тренинги и митапы в офисы других компаний… Вы не боитесь, что они за ваш счет всему научатся и уйдут от вас?
— Я боюсь, что они ничему не научатся и останутся».



|
Метки: author katjevl управление разработкой управление персоналом карьера в it-индустрии блог компании гк ланит работа в ит ланит инженерия devops интервью |
Новые продукты и сервисы на выставке Citrix Synergy |



|
Метки: author sergx71 сетевые технологии виртуализация it- инфраструктура citrix citrix synergy облачные технологии netscaler аналитика программно-определяемый |
[Из песочницы] Дополнение к анализу алгоритмов |

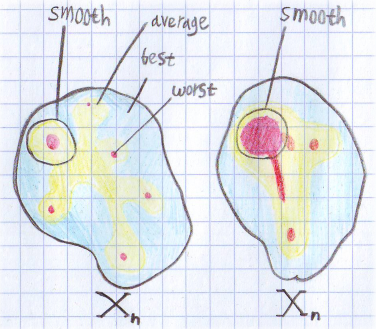 Тут нарисовано распределение времени по множеству входных данных для некоторого n. Красные области — худший случай, желтые — средний, а голубые — лучший. Для левого множества средняя и smoothed оценка будут примерно одинаковыми. А вот для правого smoothed оценка будет ближе к худшему случаю. Для обоих множеств smoothed оценка точнее описывает поведение алгоритма. Если представить, что оба рисунка соответствуют одной и той же задаче, но разным алгоритмам, получается интересная ситуация. Оценка лучшего, худшего и среднего случая у них одинаковая. Но на практике левый алгоритм будет работать по ощущениям лучше, т.к. на правый намного проще устроить алгоритмическую атаку.
Тут нарисовано распределение времени по множеству входных данных для некоторого n. Красные области — худший случай, желтые — средний, а голубые — лучший. Для левого множества средняя и smoothed оценка будут примерно одинаковыми. А вот для правого smoothed оценка будет ближе к худшему случаю. Для обоих множеств smoothed оценка точнее описывает поведение алгоритма. Если представить, что оба рисунка соответствуют одной и той же задаче, но разным алгоритмам, получается интересная ситуация. Оценка лучшего, худшего и среднего случая у них одинаковая. Но на практике левый алгоритм будет работать по ощущениям лучше, т.к. на правый намного проще устроить алгоритмическую атаку. |
Метки: author SharplEr математика асимптотика анализ алгоритмов |
Как «Пилот» модернизировал фискальный регистратор в ККТ Fujitsu |










|
Метки: author NoWE it- инфраструктура блог компании fujitsu fujitsu принтер ккт эклз пилот |
Объектное Реактивное Программирование |
Дмитрий Карловский из SAPRUN представляет… ммм...
Это — текстовая версия одноимённого выступления на FrontendConf'17. Вы можете читать её как статью, либо открыть в интерфейсе проведения презентаций.
| Надоело.. | Чем поможет ОРП? |
|---|---|
| … писать много, а делать мало? | Пиши мало, делай много! |
| … часами дебажить простую логику? | Реактивные правила обеспечат консистентность! |
| … асинхронщина? | Синхронный код тоже может быть неблокирующим! |
| … что всё по умолчанию тупит? | ОРП оптимизирует потоки данных автоматом! |
| … функциональные головоломки? | Объекты со свойствами — проще некуда! |
| … что приложение падает целиком? | Позволь упасть его части — само поднимется! |
| … жонглировать индикаторами ожидания? | Индикаторы ожидания пусть сами появляются, где надо! |
| … двустороннее связывание? | Двустороннее связывание нужно правильно готовить! |
| … пилить переиспользуемые компоненты? | Пусть компоненты будут переиспользуемыми по умолчанию! |
| … вечно догонять? | Вырывайся вперёд и лидируй! |

Всем привет, меня зовут Дмитрий Карловский. Я — руководитель группы веб-разработки компании САПРАН. Компания наша является крупнейшим интегратором САП-а в России, но в последнее время мы активно смотрим в сторону разработки собственных программных продуктов.
Один из них — кроссплатформенный open source веб фреймворк быстрого построения отзывчивых интерфейсов с говорящим названием "$mol". В нём мы по максимуму применяем возможности Объектного Реактивного Программирования, о которых я и расскажу далее...

Давайте представим, что мы решили открыть интернет-магазин по продаже игрушек. Причём сделать мы хотим всё не абы как, а стильно, модно, молодёжно, быстро, гибко и надёжно..
Игрушек у нас много, а начать продажи надо было ещё вчера. Поэтому мы хотим сделать всё как можно быстрее, но не про… теряв user experience.
Мы можем загрузить основные данные всех игрушек на клиентское устройство и позволить пользователю просматривать каталог быстро, без сетевых задержек.

Листать наш каталог, конечно, увлекательное занятие, но пользователь хотел бы ограничить выбор лишь теми игрушками, что особенно интересуют его в данный момент. Поэтому мы добавляем фильтрацию.
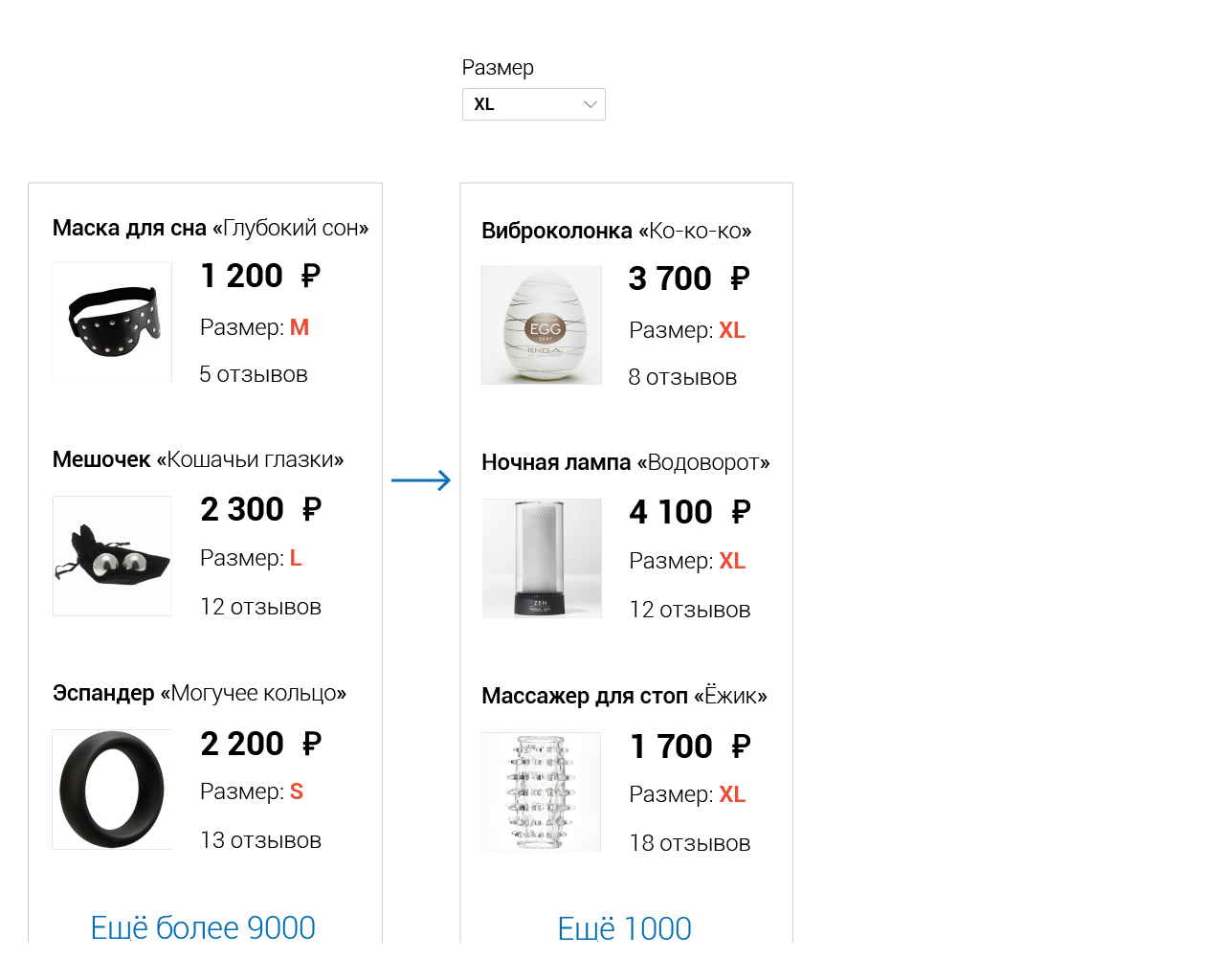
На больших объёмах данных сложный фильтр может накладываться продолжительное время, поэтому для обеспечения отзывчивости нам бы не хотелось, чтобы фильтрация повторялась лишний раз, когда в ней нет необходимости.
Например, если мы отфильтровали по размеру, то при изменении числа отзывов нет смысла выполнять повторную фильтрацию. А вот если отфильтровали по числу отзывов… ну вы поняли, да?
Нам важно знать от каких конкретно свойств каких конкретно товаров зависит результат фильтрации, чтобы перезапускать её при изменении лишь тех состояний, что реально влияют на результат.
Пользователь обычно хочет просматривать игрушки не в произвольном порядке, а в каком-то конкретном. Например: в порядке увеличения цены или в порядке уменьшения релевантности. Поэтому мы добавляем сортировку. Она опять же может затрагивать разные свойства товаров и быть довольно тяжёлой на больших объёмах данных.
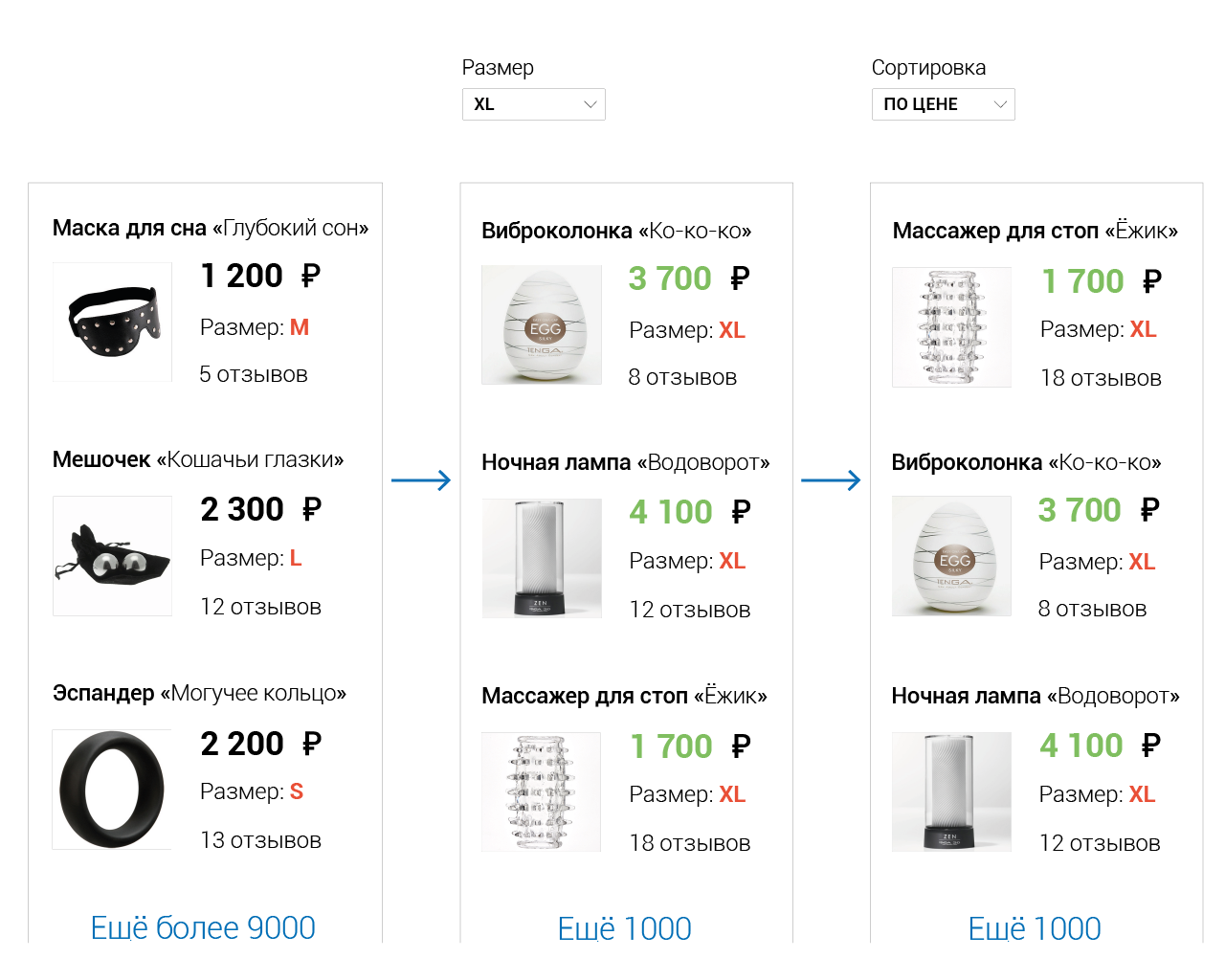
Очевидно, тут повторную сортировку нужно будет произвести лишь при изменении критерия сортировки… или тех свойств товаров, по которым мы сортировали. Но не любых товаров, а лишь тех, что соответствуют критерию фильтрации. И, соответственно, при изменении этого самого критерия. А также, при изменении свойств товаров, по которым мы фильтровали. И...
Если вы попытаетесь описать в коде все зависимости между всеми состояниями, то произойдёт комбинаторный взрыв и вам оторвёт руки.
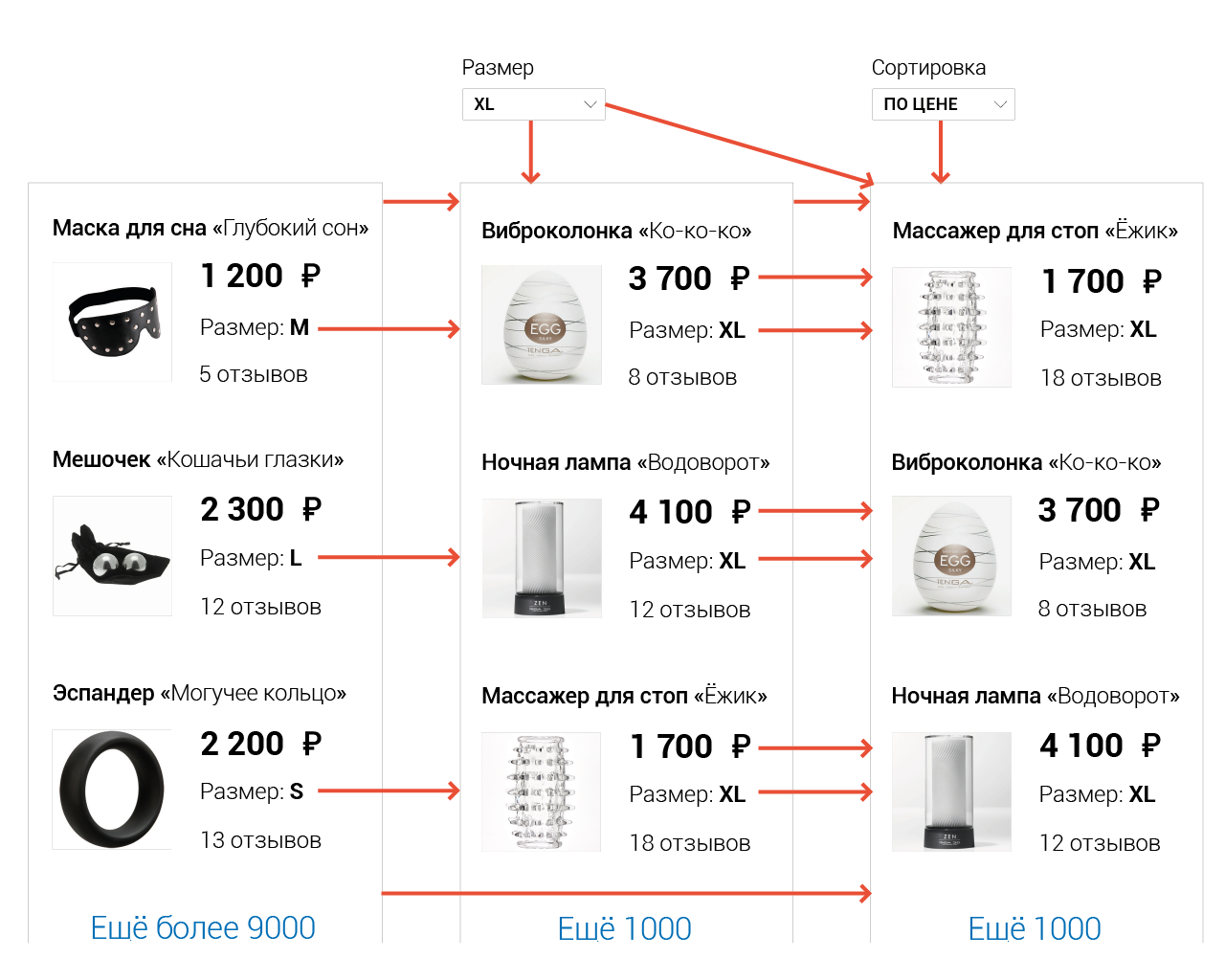
Тут мы описали лишь 2 шага преобразований, но в реальном приложении их может более десятка.
Чтобы обуздать эту экспоненциально растущую сложность, и было придумано Реактивное Программирование. Без него вы не сможете сделать сколь-нибудь сложное приложение быстрым, стабильным и компактным одновременно.
Если вы будете отображать все данные, что подготовили, то алгоритмическая сложность рендеринга будет пропорциональна объёму этих данных. 10 товаров рендерятся мгновенно, 1000 — с задержкой, а если 10000, то пользователь успеет сходить попить чайку.
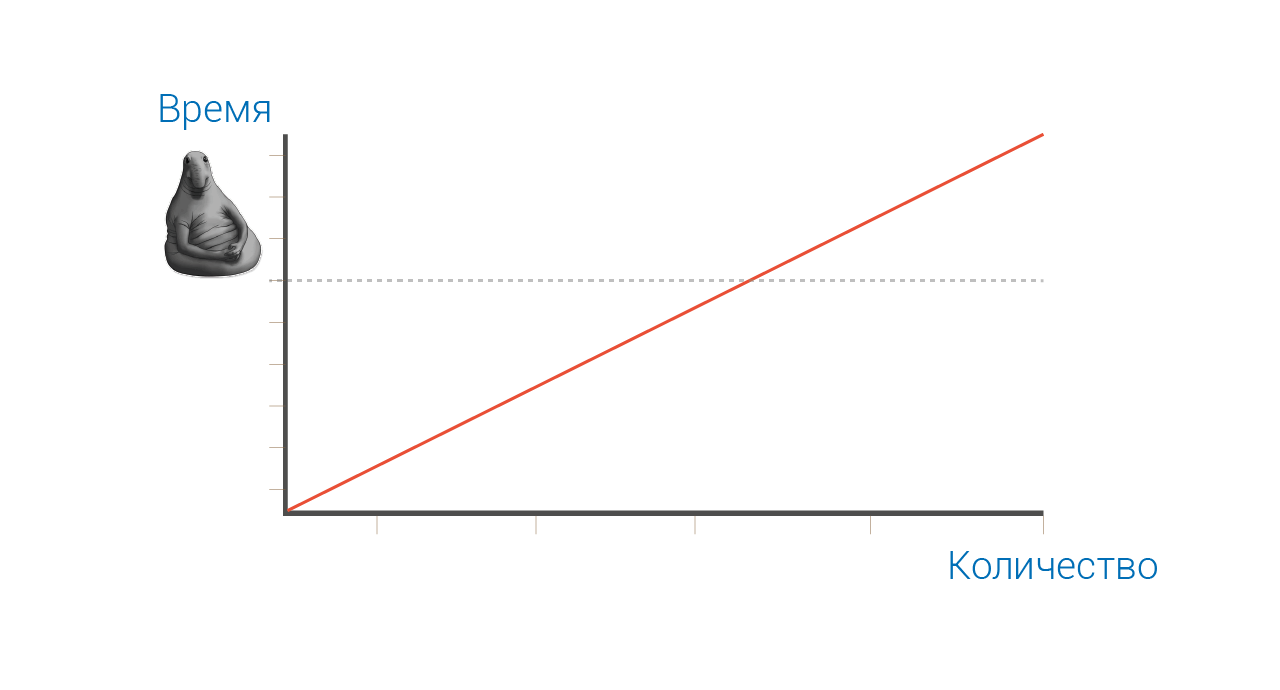
Если у пользователя такой экран, что одновременно в него влезает не более 10 товаров, то визуально для него не будет никакой разницы — будете ли вы рендерить всю 1000 или только 10 из них, а по мере скроллинга дорендеривать недостающее. Поэтому, каким бы быстрым ни был у васReactшаблонизатор, он всегда будет проигрывать по отзывчивости ленивой архитектуре, которая в гораздо меньшей мере зависит от объёмов данных.
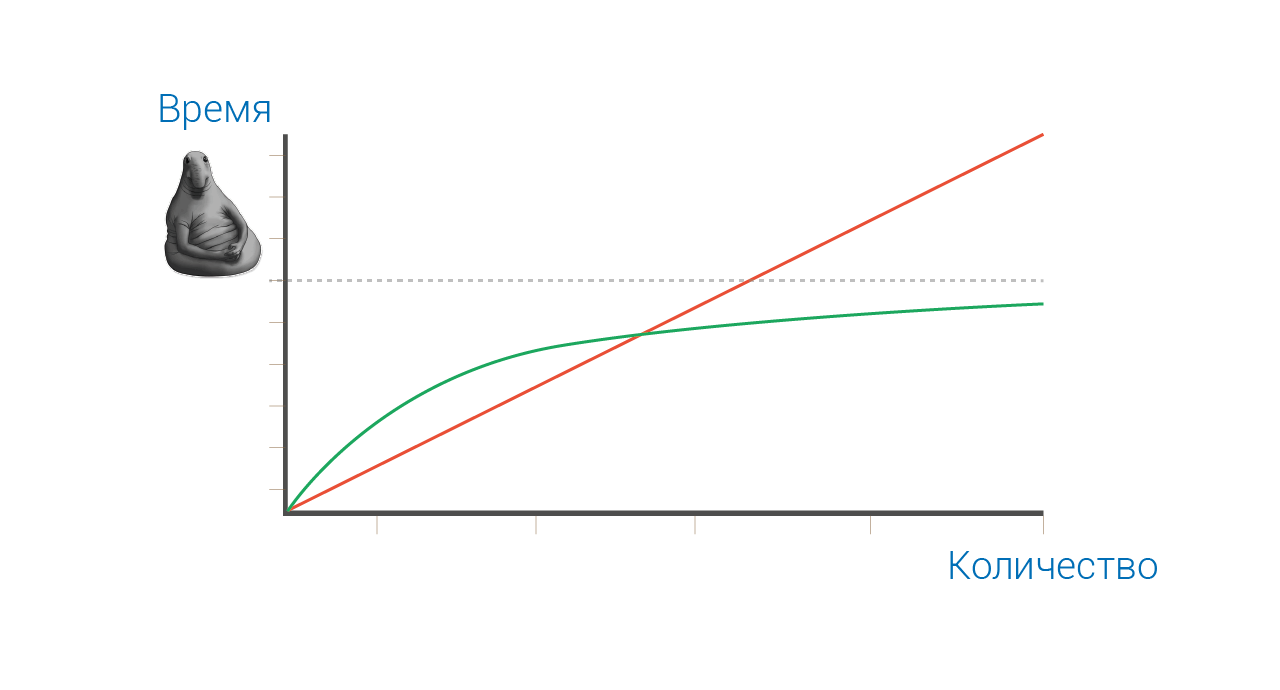
Если размеры карточек товаров нам примерно известны, то, зная высоту окна, легко понять какие товары точно не видны, а какие может хоть краешком, но влезают в видимую область.
Вырезать из огромного списка элементы с первого по десятый — плёвая операция. Но только, если этот список у нас хранится где-то в закешированном виде. Если же в каждом кадре мы будем получать его из исходных данных путём фильтрации и сортировки, то ни о какой плавности скроллинга не может идти и речи.
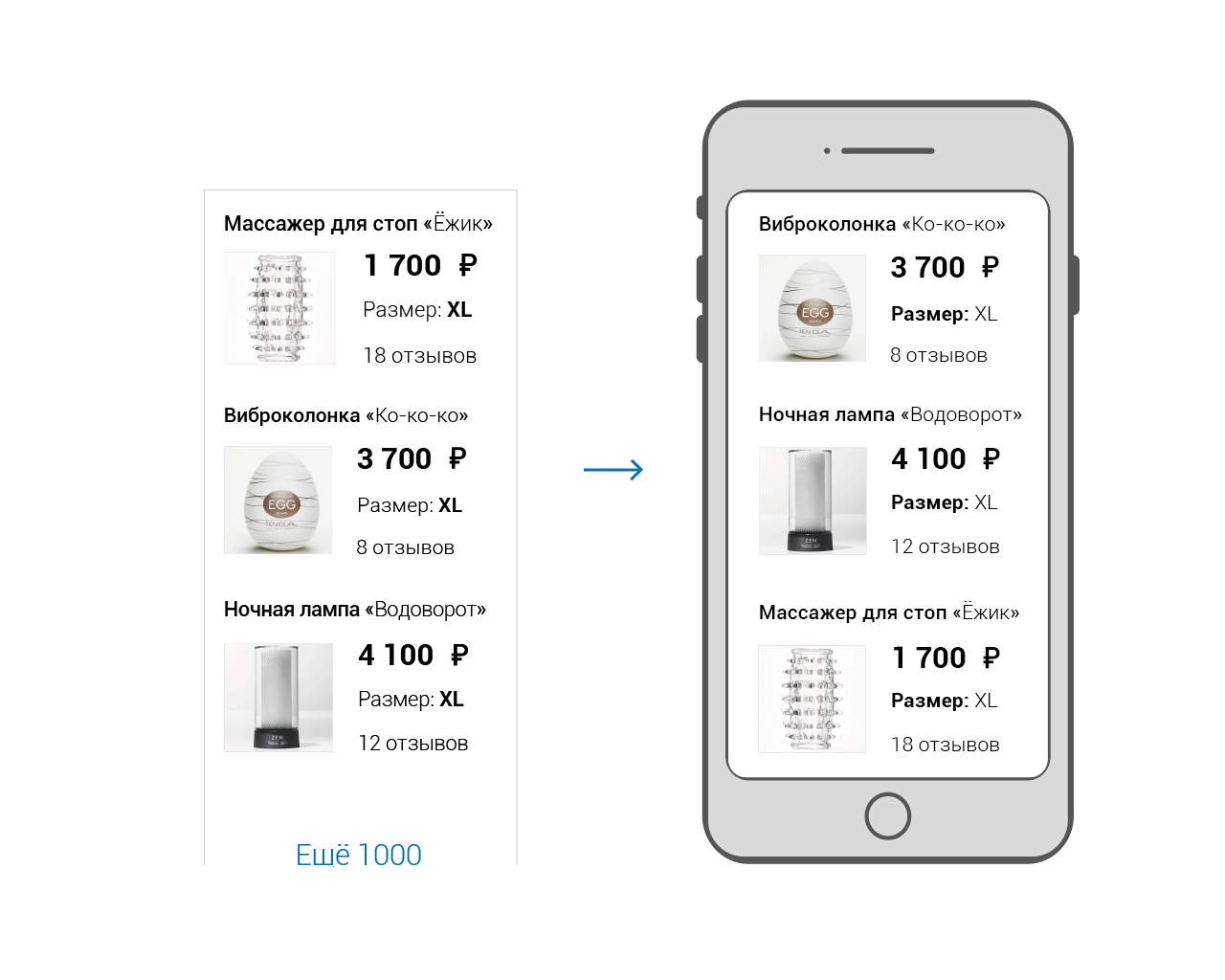
Ок, данные мы подготовили, осталось показать их пользователю. Решение в лоб — удалить старое DOM-дерево и вырастить новое. Именно так работают все HTML-шаблонизаторы.
Оно мало того, что медленное, так ещё и приводит к сбросу динамического состояния узлов. Например: позиция скроллинга и флаг открытости селекта. Некоторые из них потом можно восстановить программно, но далеко не все.
Короче говоря, реальность упорно не хочет быть чистой функцией. Чтобы приложение работало как следует, нужно по возможности изменять существующее состояние, а не просто создавать новое. А если не можешь победить — возглавь!
Как натянуть ужа на ежа? Правильно, давайте генерировать новое DOM дерево всего приложения, а потомReactспециальная библиотека будет сравнивать его новую и старую версию, и применять различия к тому DOM дереву, что реально видит пользователь.
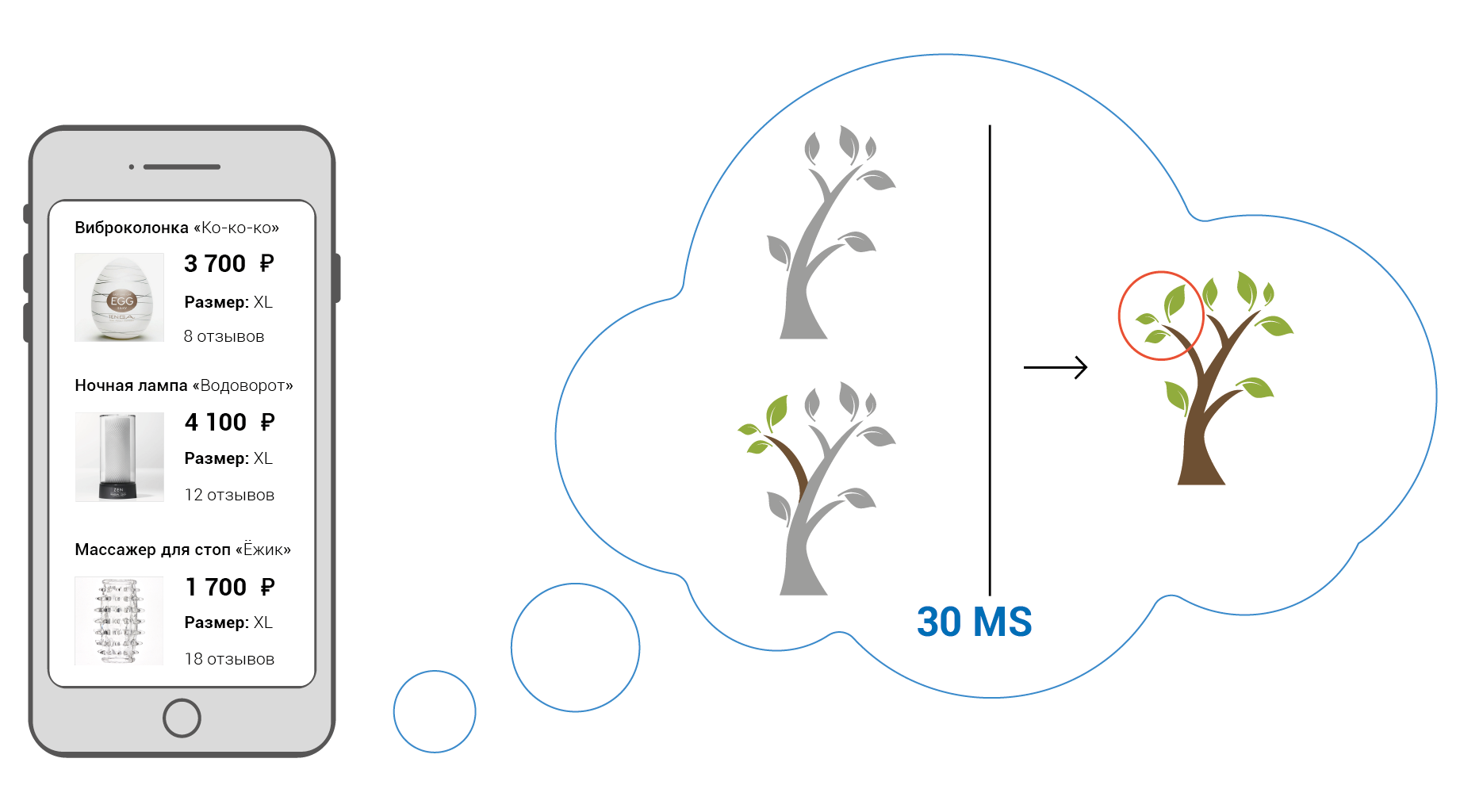
Звучит как костыль, не правда ли? Сколько работы приходится выполнять только лишь для того, чтобы, изменить значение текстового узла, когда в одной из моделей поменялось строковое свойство.
А как могла бы выглядеть работа наиболее эффективного решения?
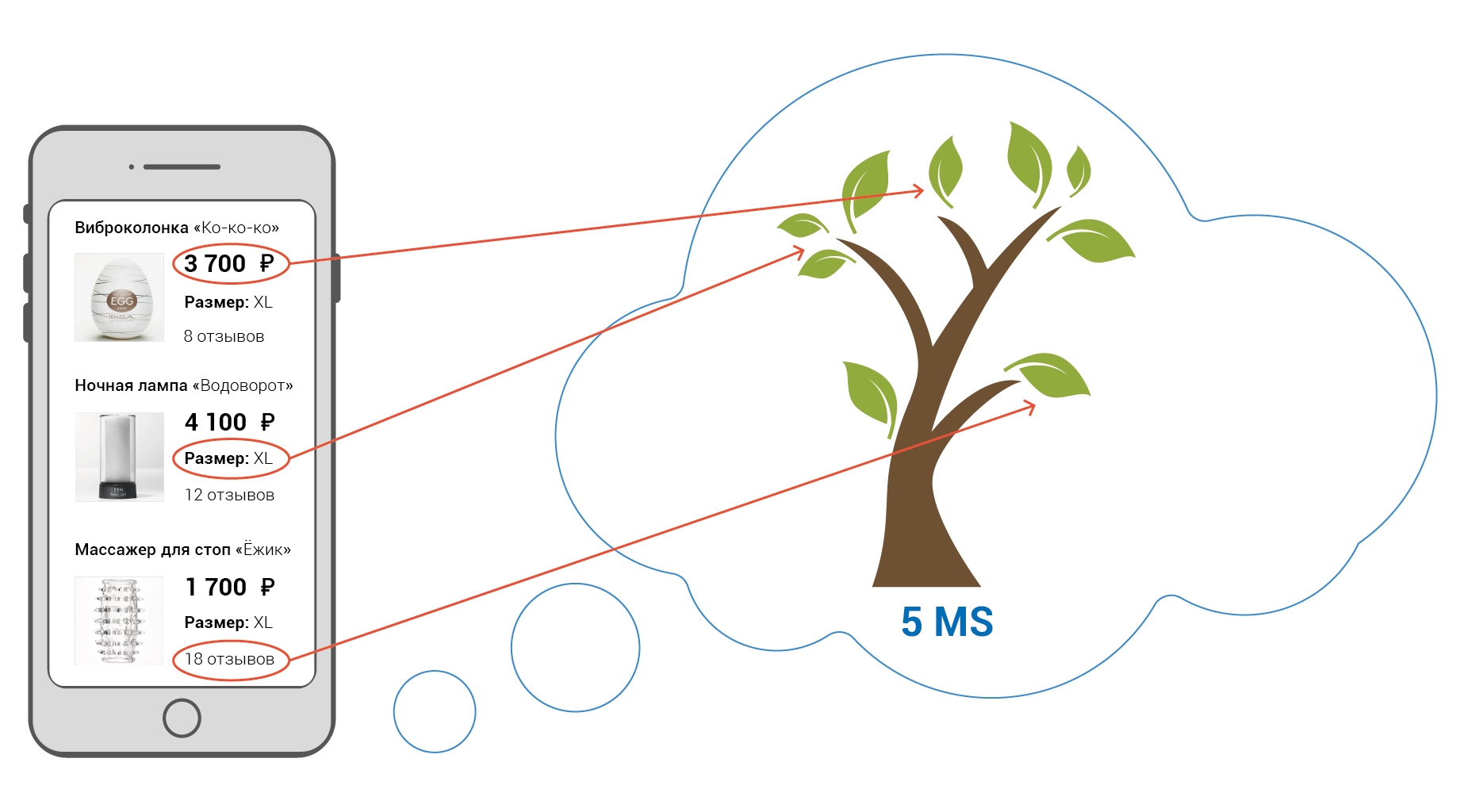
Всё просто — между исходными данными и их отображением устанавливаются прямые связи. При изменении одного состояния, изменяются лишь зависимые от него. Причём действует это не только между так называемыми "моделью" и "отображением", а между любыми зависимыми состояниями, начиная с записи в базе данных на сервере, через кучу промежуточных состояний и заканчивая дом-узлом в браузере. Именно в этом и заключается суть Реактивного Программирования, а не в шаблонизаторе с созвучным названием, который продают нам на каждой конференции.

Вы можете сказать, что я сгущаю краски, а конкретно в вашем проекте никогда не будет столько данных, и тяжёлой их обработки, и запускать ваше приложение будут лишь на мощных рабочих станциях, а не на хилом китайском тапке в режиме энергосбережения.
Но на это у меня есть простое соображение. Чтобы выше приложение работало со скоростью в 60 кадров в секунду, то оно должно успевать выполнить все операции, начиная с подготовки данных и заканчивая их отрисовкой, всего за 16 миллисекунд. И превысить их очень легко даже в тривиальном приложении на мощном компьютере.
nin-jin.github.io/sierpinski/stack.html
Перед вами известное демо созданное ребятами из Facebook, показывающее как сильно тупят сложные приложения на Реакте. Они это сейчас пытаются решить размазыванием вычислений по нескольким кадрам, что даёт заветные 60 кадров в секунду, но приводит к визуальным артефактам. Фундаментальная же проблема у них остаётся неизменной — виртуальный DOM требует кучи лишних вычислений на каждый чих.
ОРП, напротив, позволяет минимизировать объём вычислений, автоматически оптимизируя потоки данных от их источника до их потребителя.
Как вы можете видеть, эквивалентная реализация с применением реактивного программирования показывает гораздо большую производительность, даже без размазывания вычислений по кадрам.
Давайте, наконец, добавим немного теории…
Что такое Объектное Программирование? Основной его чертой является объединение данных и функций для работы с ними в рамках одной абстракции с относительно простым интерфейсом — объекте.
А что такое Функциональное Программирование? Тут вся программа описывается в виде кучи чистых функций, которые не зависят от изменяемого состояния и сами не изменяют никаких состояний.
Наконец, что такое Реактивное Программирование? Здесь вы описываете правила получения одних состояний из других таким образом, что изменение одного состояния приводит к каскадному изменению зависимых.
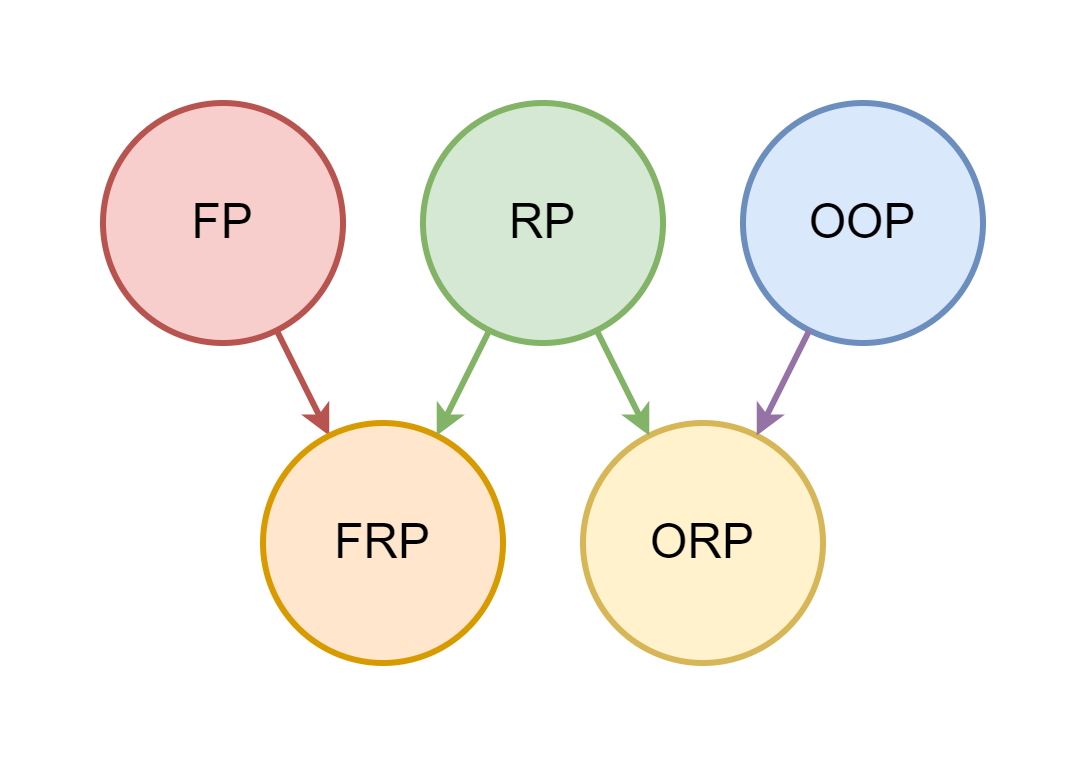
У многих Реактивное Программирование прочно ассоциируется с Функциональным, однако, оно куда ближе к Объектному, так как основные действующие лица в Реактивном Программировании — изменяемые состояния.
Есть два принципиально разных способа реализации реактивности.
Первый — это всякие беконы, RX-ы и прочий стрим-панк, так же известный как Функциональное Реактивное Программирование. Суть его в том, что вы явным образом получаете так называемые стримы, от которых зависит ваше состояние, добавляете к ним функцию вычисления нового значения. И полученное таким образом значение уже проталкивается во все зависимые стримы, а что с этим значением делать или не делать они уже решают сами.
const FilterSource = new Rx.BehaviorSubject( toy => toy.count > 0 )
const Filter = FilterSource.distinctUntilChanged().debounce( 0 )
const ToysSource = new Rx.BehaviorSubject( [] )
const Toys = ToysSource.distinctUntilChanged().debounce( 0 )
const ToysFiltered = Filter
.select( filter => {
if( !filter ) return Toys
return Toys.map( toys => toys.filter( filter ) )
} )
.switch()
.distinctUntilChanged()
.debounce( 0 )Посмотрите на этот ФРП-ребус и попробуйте сходу сказать, что и зачем он делает. А делает он простую штуку: создаёт стрим для товаров, стрим для критерия фильтрации и получает из них стрим отфильтрованного списка товаров.
Тут уже применено несколько типовых оптимизаций. Тем не менее работает этот код очень не эффективно: список игрушек перефильтровывается даже если в товаре поменялись те данные, от которых результат фильтрации не зависит. Чтобы побороть эту проблему, придётся ещё на порядок усложнить код, но мало кто это осилит.
Данный подход приводит к сложному, трудноподдерживаемому коду. Его трудно читать. Его сложно писать. Его лень писать правильно. И в нём легко допустить ошибку, если вы, конечно, не финалист специальной олимпиады по информатике.
Куда проще и эффективней использовать другой подход, где вычисления начинаются не от источника данных, а от их потребителя. Возьмём, например, самую продвинутую реализацию ОРП — $mol_mem.
class $my_toys {
@ $mol_mem()
filter( next ) {
if( next === undefined ) return toy => toy.count() > 0
return next
}
@ $mol_mem()
toys( next = [] ){ return next }
@ $mol_mem()
toys_filtered() {
if( !this.filter() ) return this.toys()
return this.toys().filter( this.filter() )
}
}Не правда ли ORP код куда проще, и понятнее? Это тот же код, который мы бы написали безо всякого реактивного программирования, но мы добавили специальный декоратор, который динамически отслеживает зависимости по факту обращения к ним, кеширует результат исполнения функции и сбрасывает кеш, когда зависимости изменяются.
Правильная реализация логики этих декораторов позволяет производить вычисления наиболее оптимальным образом, не перекладывая головную боль по контролю потоков данных на прикладного программиста.
Аналогичным образом мы можем добавить и отсортированный список товаров, зависящий от функции сортировки и отфильтрованного списка.
@ $mol_mem()
sorter( next ) {
if( next === undefined ) return ( a , b )=> b.price() - a.price()
return next
}
@ $mol_mem()
toys_sorted() {
if( !this.sorter() ) return this.toys_filtered()
return this.toys_filtered().slice().sort( this.sorter() )
}По умолчанию тут идёт сортировка по цене, а значит сортировка будет произведена вновь лишь при изменении цены какой-либо игрушки из отфильтрованного списка, самого этого отфильтрованного списка или критерия сортировки.
Ну и под конец, мы вырезаем лишь видимые сейчас на экране товары. При этом перемещение скроллинга будет приводить лишь к незначительному по времени повторному вырезанию видимых задач, без бессмысленных перефильтраций и пересоровок.
@ $mol_mem()
toys_visible() {
return this.toys_sorted().slice( ... this.view_window() )
}Сразу же введём свойство children, которое будет возвращать компоненты, которые мы хотим отрендерить внутри нашего. А рендерить мы хотим лишь попадающие в видимую область.children() {
return this.toys_visible()
}Простейший обобщённый рендеринг компонента может производиться в рамках вычисления свойства render, знакомого всем реактоводам.@ $mol_mem()
render() {
let node = document.getElementById( this.id() )
if( !node ) {
node = document.createElement( 'div' )
node.id = this.id()
}
/// Node updating here
return node
}Зная идентификатор компонента, мы ищем соответствующий узел в реальном DOM-дереве. А если не нашли, то создаём его. После этого актуализируем его состояние и возвращаем.
Обратите внимание на реактивныый кеширующий декоратор. Благодаря ему, рендеринг конкретно этого узла будет перезапущен лишь, когда изменится любое из свойств, к которому нам потребовалось обратиться в процессе обновления состояния нашего DOM-узла.
Часто исключения безвозвратно ломают приложение. Оно может начать глючить, недорисовывать страницу или вообще перестать реагировать на действия пользователя. Однако, исключение — такой же результат вычисления, как и собственно возвращаемое значение.
Если при рендеринге какого-то блока на странице произошло исключение, то именно этот блок и должен перестать работать, не затронув всё остальное приложение. Но устранение причины исключения в последующем должно восстанавливать работу этого блока, как если бы он и не падал.
Поэтому давайте завернём рендеринг DOM-узла в блок try-catch и в случае возникновения ошибки, записывать имя исключения в специальный атрибут. А если рендеринг пройдёт без эксцессов — стирать его.try {
/// Node updating here
node.removeAttribute( 'mol_view_error' )
} catch( error ) {
console.error( error )
node.setAttribute( 'mol_view_error' , error.name )
}Зачем нам этот атрибут? Да чтобы через CSS стилизовать сломанный блок, показывая пользователю, что он сейчас не работает. Например, мы можем сделать его полупрозрачным и запретить пользователю с ним взаимодействовать.
[mol_view_error] {
opacity: .5 !important;
pointer-events: none !important;
}Давайте сделаем шаг в сторону и поговорим о загрузке данных. Взгляните на пример кода, который вычисляет сообщение о числе тёзок текущего пользователя.
namesakes_message() {
/// Serial
const user = this.user()
const count = this.name_count( user.name )
return this.texts().namesakes_message
.replace( /\{count\}/g , count )
}Сначала мы загружаем информацию о текущем пользователе, потом получаем число пользователей с тем же именем, а под конец загружаем строковые константы подставляем туда число.
Код простой и понятный, не правда ли? Но тут есть одна беда: пока выполняется каждый из этих трёх запросов всё приложение встаёт колом, так как виртуальная машина javascript однопоточна, а эти запросы блокируют поток до своего завершения.
Чтобы решить эту проблему в яваскрипте принято писать код на колбэках.
namesakes_message() {
/// Parallel
return Promise.all([
/// Serial
this.user().then( user => this.name_count( user.name ) ,
this.texts() ,
])
.then( ([ count , texts ])=> {
return texts.namesakes_message.replace( /\{count\}/g , count )
} )
}Обратите внимание, что тут мы грузим информацию о числе пользователей и тексты параллельно, так как они не зависят друг от друга. Это ускоряет общую загрузку всех ресурсов, но код стал похож на тарелку макарошек.
Недавно в яваскрипте появились средства синхронизации, но действуют они лишь в пределах одной функции, а не всего стека вызовов.
/// Serial
async namesakes_count() {
const user = await this.user()
return await this.name_count( user.name )
}
async namesakes_message() {
/// Parallel
const [ count, texts ] = await Promise.all([
this.namesakes_count() ,
this.texts() ,
])
return texts.namesakes_message.replace( /\{count\}/g , count )
}Если мы пометили функцию как "асинхронную", то мы можем приостанавливать её до появления определённого события.
Как видно, это не сильно спасает, так как для распараллеливания запросов всё равно приходится кастовать специальные заклинания.
А что если я скажу вам, что следующий код не смотря на всю свою синхронность может быть не только неблокирующим, но и грузить информацию о пользователе и тексты параллельно?
@ $mol_mem()
namesakes_message() {
/// Parallel
const texts = this.texts()
const user = this.user()
/// Serial
const count = this.namesakes_count( user.name )
return texts.namesakes_message.replace( /\{count\}/g , count )
}Вся магия в адекватной обработке исключительных ситуаций. Когда мы синхронно запрашиваем данные, а их нет — это самая натуральная исключительная ситуация для синхронного кода. Поэтому, в этом случае кидается специальное исключение, которое останавливает текущий стек вызовов. Когда же данные придут, то благодаря реактивности исполнение будет перезапущено и на этот раз данные уже будут возвращены, как ни в чём ни бывало.
А чтобы добиться распараллеливания, реактивные свойства не пробрасывают исключение сразу, а возвращают прокси объект, который можно положить в переменную, куда-то передать, но при попытке доступа к его содержимому — будет брошено сохранённое исключение.
В данном примере, первое прерывание произойдёт лишь при доступе кuser.name, а значит загрузка текстов и информации о пользователе пойдёт параллельно.
@ $mol_mem()
namesakes_message() {
/// Parallel
const texts = this.texts()
const user = this.user()
/// Serial
const count = this.namesakes_count( user.name ) /// <-- first yield
return texts.namesakes_message.replace( /\{count\}/g , count )
}Давайте наконец добавим загрузку списка игрушек, вместо локального его хранения. Для этого нам потребуется изменить всего один метод.
/// Before
@ $mol_mem()
toys(){ return [] }
/// After
toys_data() {
return $mol_http.resource( '/toys.json' ).json()
}
@ $mol_mem()
toys() {
return Object.keys( this.toys_data() ).map( id => this.toy( id ) )
}Как видите, нам не потребовалось менять его интерфейс — мы просто взяли содержимое файла, как если бы оно было у нас локально, обработали его и вернули результат.
Остался последний штрих. Пока данные не загружены у нас бросается исключение, а имя исключения у нас автоматом прописывается в атрибуте DOM-элемента, который не смог отрендериться. А значит мы можем добавить этому блоку специальные стили, которые нарисуют для него анимированный индикатор ожидания. Что избавляет программиста и от этой назойливой ручной работы.
[mol_view_error="$mol_atom_wait"] {
animation: my_waiting .25s steps(6) infinite;
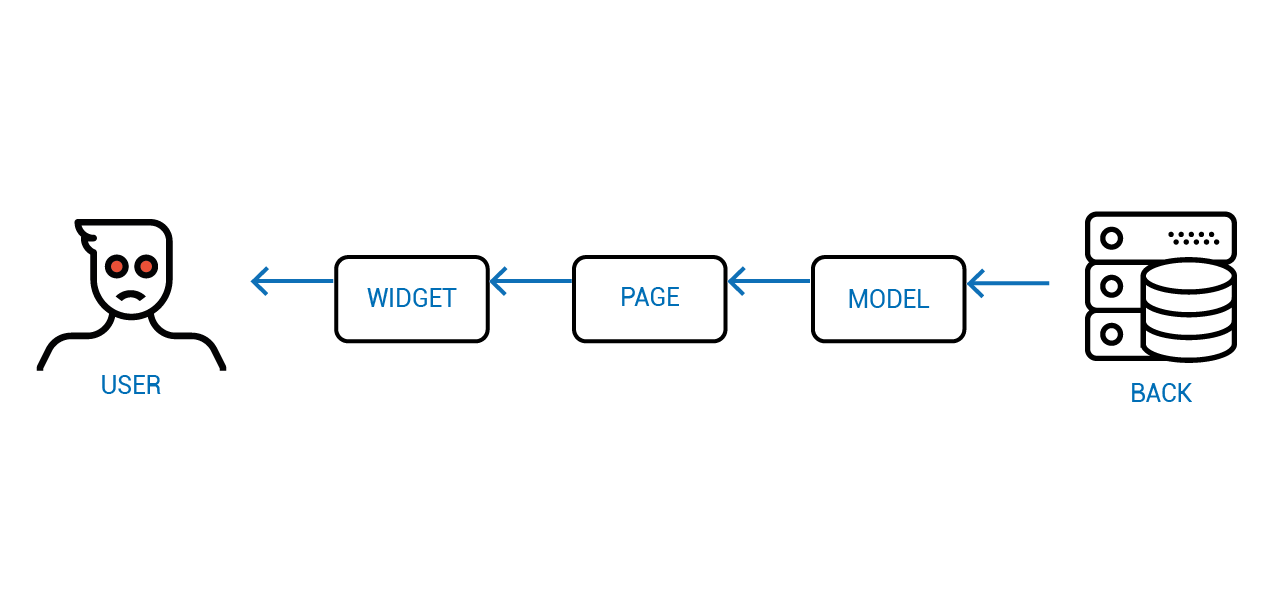
}Пока что мы говорили лишь про движение данных от сервера к пользователю. Однако, стоит обратить внимание и на обратный поток данных.
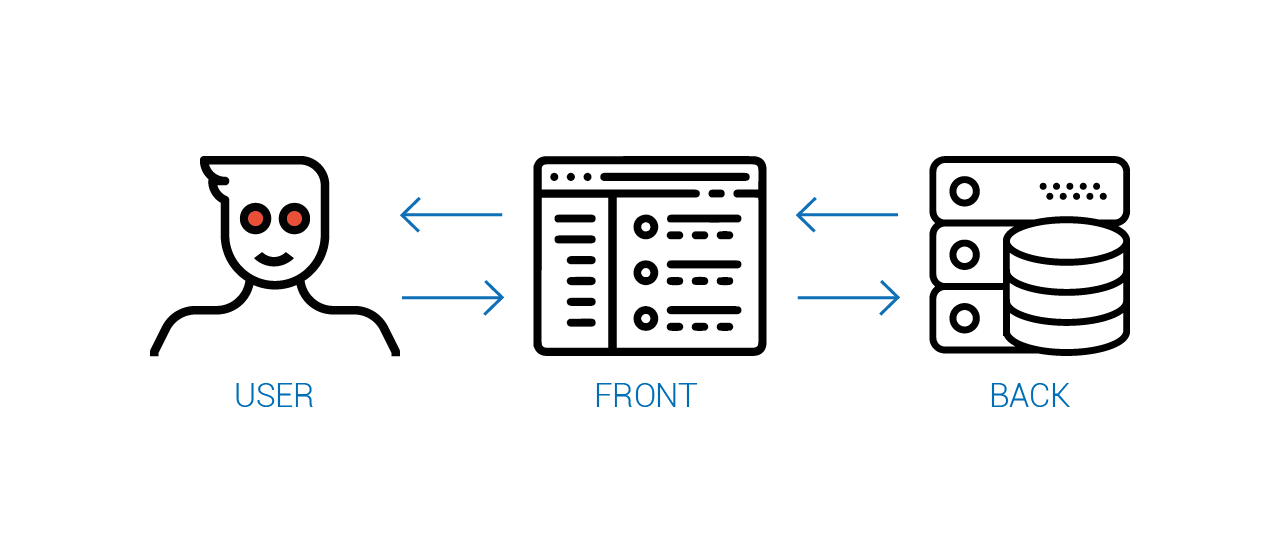
На диаграмме, каждое звено — некоторое состояние, выраженное в различных моделях. На бэкенде, например, дата у нас выражена числом в таблице. На фронтенде она уже представляется виджетом "календарик". Ну а в голове у пользователя это просто "тот день, когда я выступал на конференции".
Если опустить посредников, то можно заметить, что источником истины о том, что видит пользователь является бэкенд, а источником истины о том, что следует изменить на бэкенде, является пользователь.
Но самое интересное происходит, когда мы добавляем посредников. Например, пользовательский интерфейс, состояние которого зависит и от сервера и от пользователя. Как же реализовать его так, чтобы работал он чётко и предсказуемо?
Что если пользователь будет менять не исходные данные, а непосредственно то состояние, которое он видит в виджете, на который смотрит?
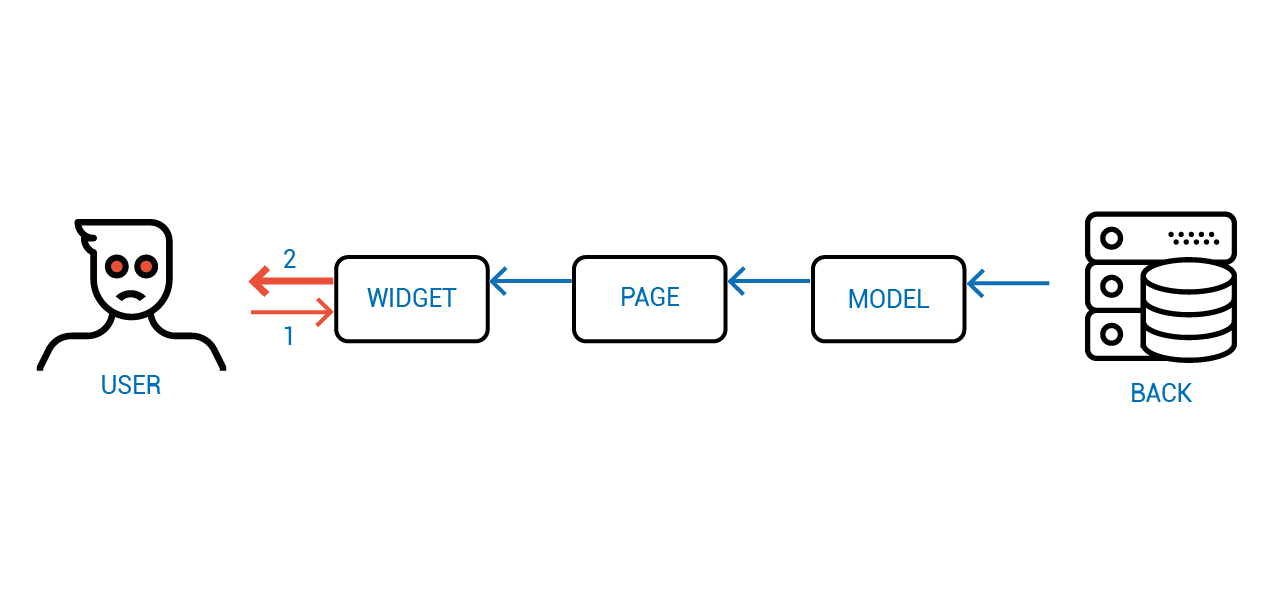
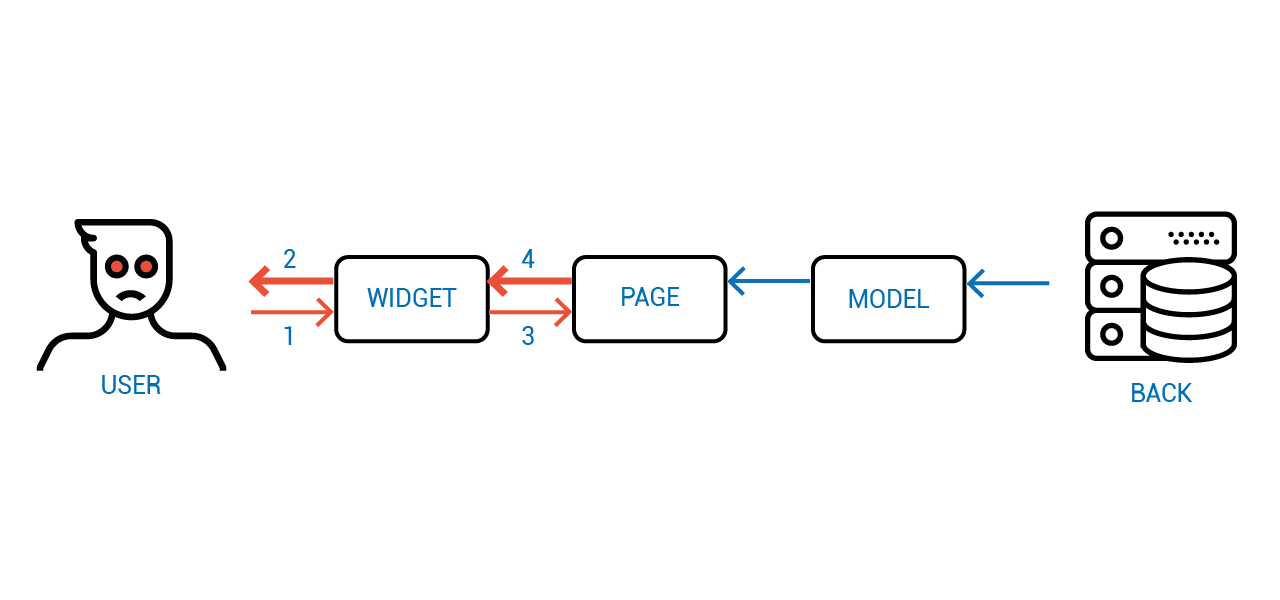
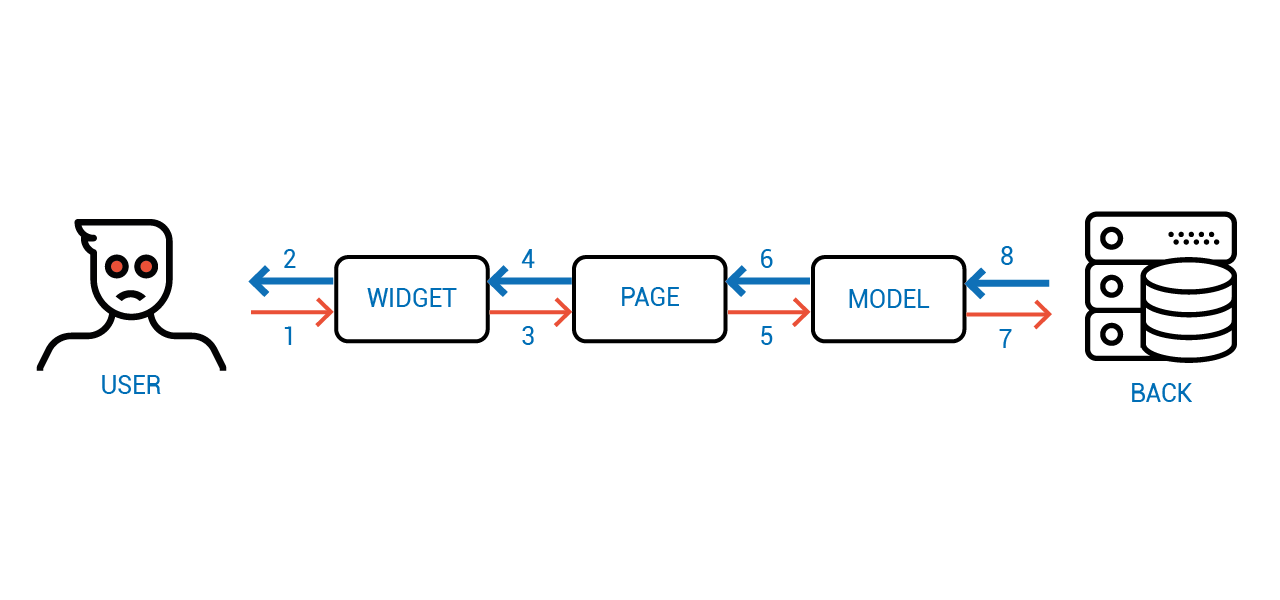
Как думаете, что за фреймворк тут использован?
Это типичное приложение на Angular. Когда пользователь меняет состояние, начинают срабатывать watcher-ы, которые итеративно синхонизируют состояния между собой, что приводит ко временной неконсистентности состояния клиент-серверной системы вцелом.
Эта логика работы мало того, что не эффективна, так ещё и требует очень аккуратного написания кода с точно подогнанными костылями вида "подождать пока всё синхронизируется, а потом вызвать обработчик".
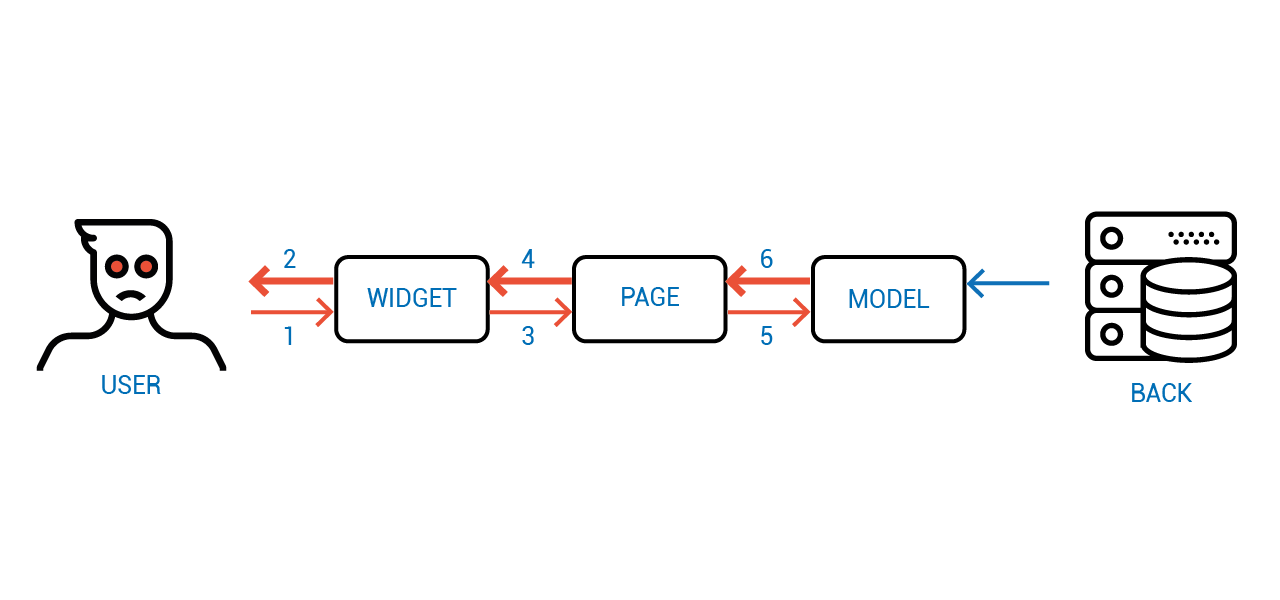
А как называется архитектура со следующей диаграммы?
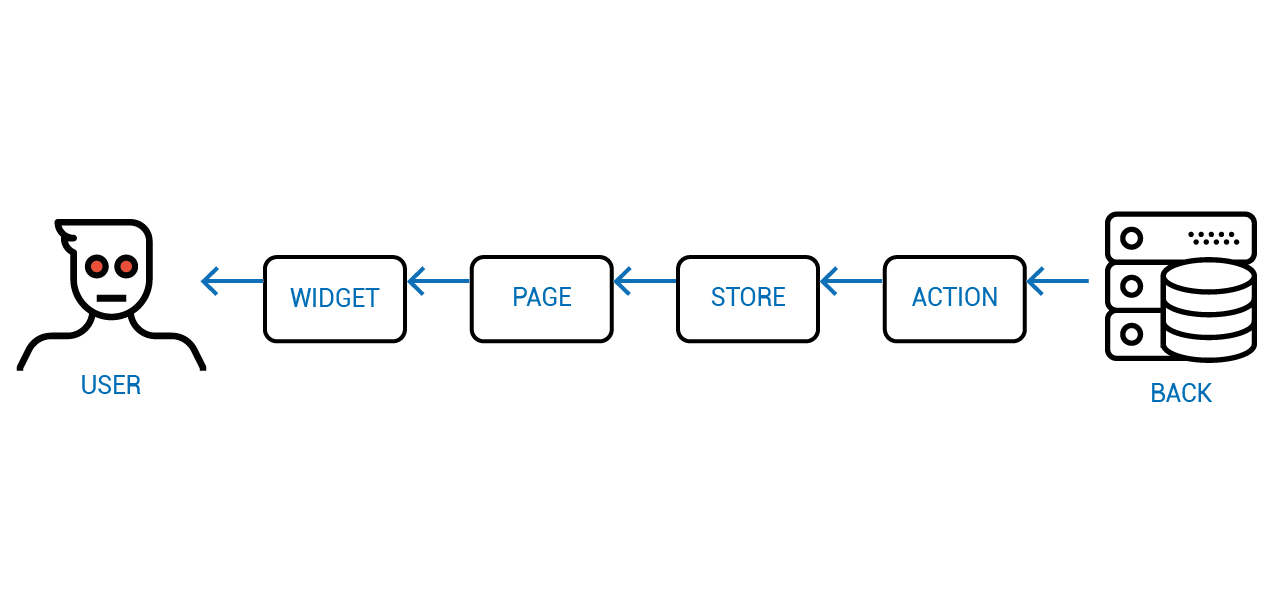
Facebook подумал-подумал и придумал FLUX, где поток от сервера к пользователю идёт через компоненты, а обратно — через глобальные процедуры — так называемые "Экшены".
Проблему с консистентностью мы побороли, но вылезла другая — компоненты взаимодействующие с пользователем получаются не переиспользуемыми. Вы не можете просто взять и использовать такой компонент, не реализовав для каждого места его использования набор отдельных глобальных процедур.
Пол века назад эта проблема уже была решена за счёт абстракции и инкапсуляции, но до сих пор мы ходим по одним и тем же граблям.
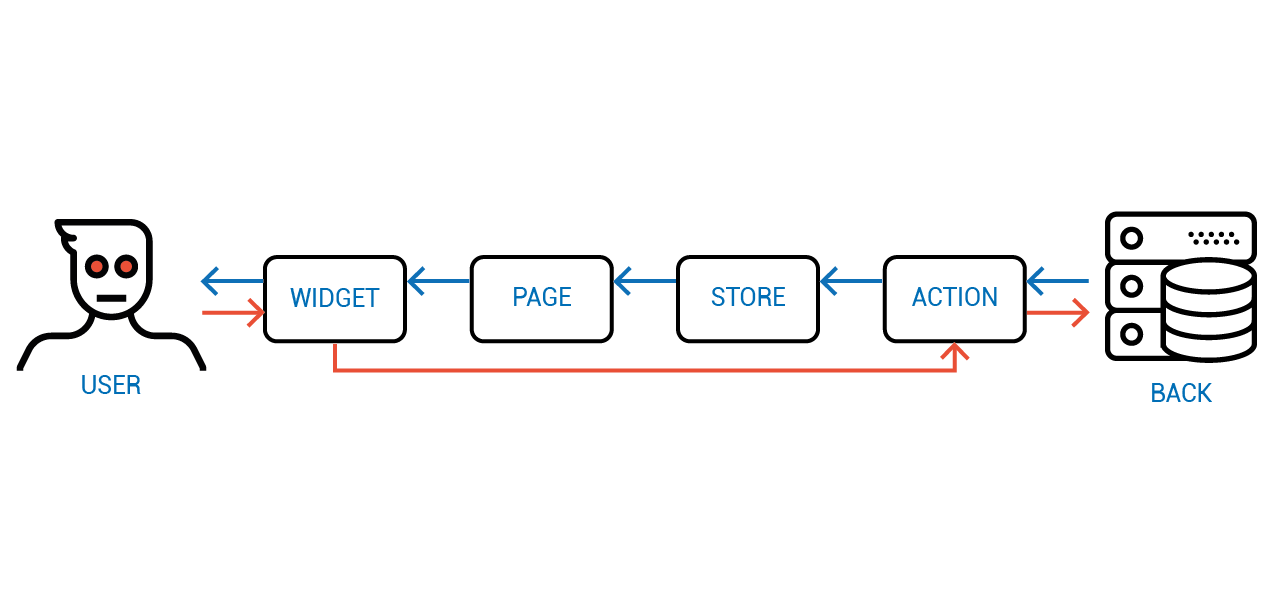
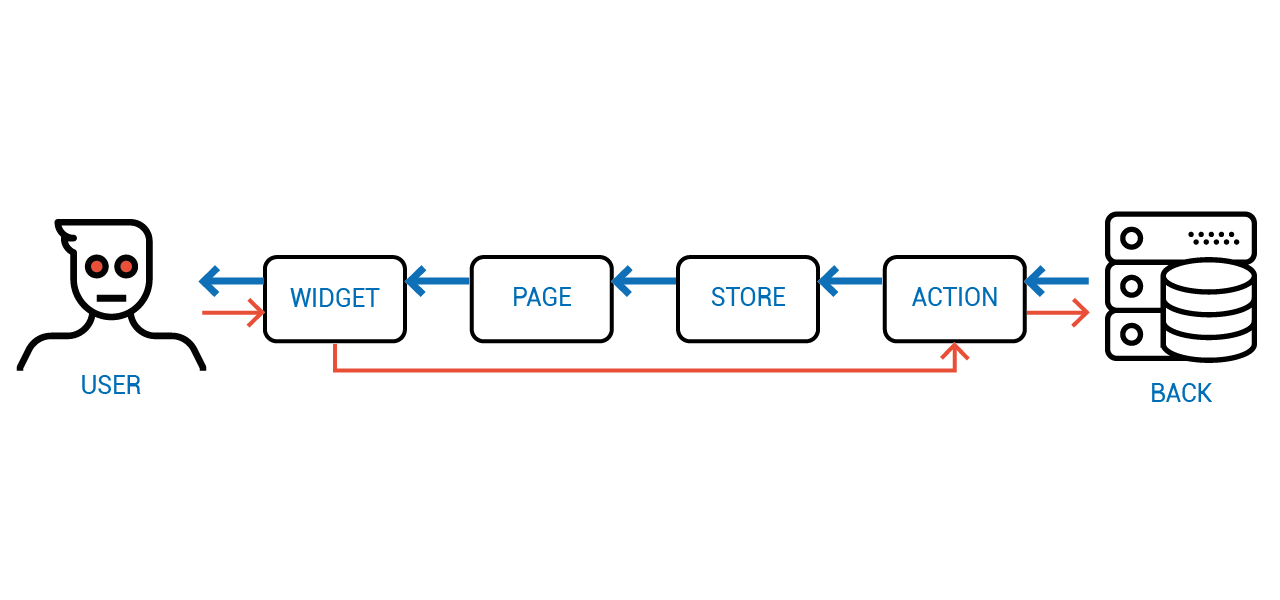
Проблема двустороннего связывания Ангуляра была не в том, что оно двустороннее, а в том, что состояние сначала изменялось, а потом отложенно синхронизировалось. Причём меняться оно могло как пользователем, так и сервером, что закономерно приводило к конфликтам состояний. Именно в этом был корень всех проблем. Как же его выкорчевать?
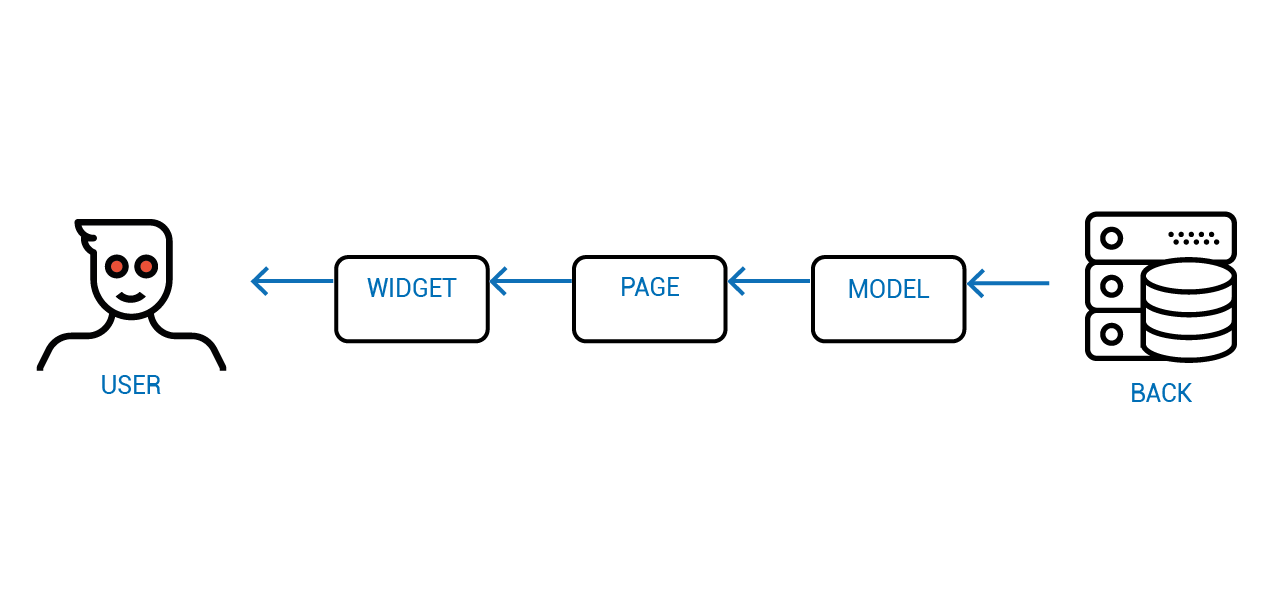
Решение в Объектном Программировании опять же существует не один десяток лет — не давать напрямую изменять состояние. Вместо этого доступ к состоянию реализуется через специальные функции — так называемые "акцессоры". Пользователь объекта может лишь изъявить желание поменять значение определённого свойства, а что с этим значением делать или не делать — объект уже решает сам.
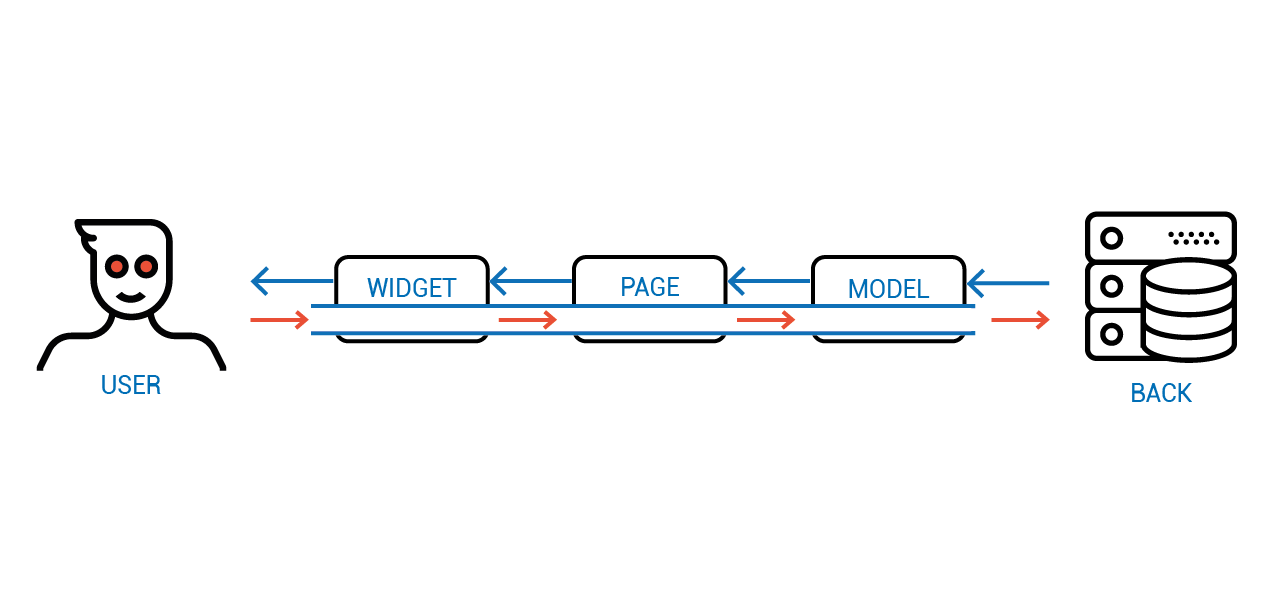
На диаграмме можно видеть, как новое значение передаётся от объекта к объекту не меняя их состояний.
И только когда приходит ответ от сервера с актуальным значением, оно спускается по иерархии компонент, меняя их состояние.
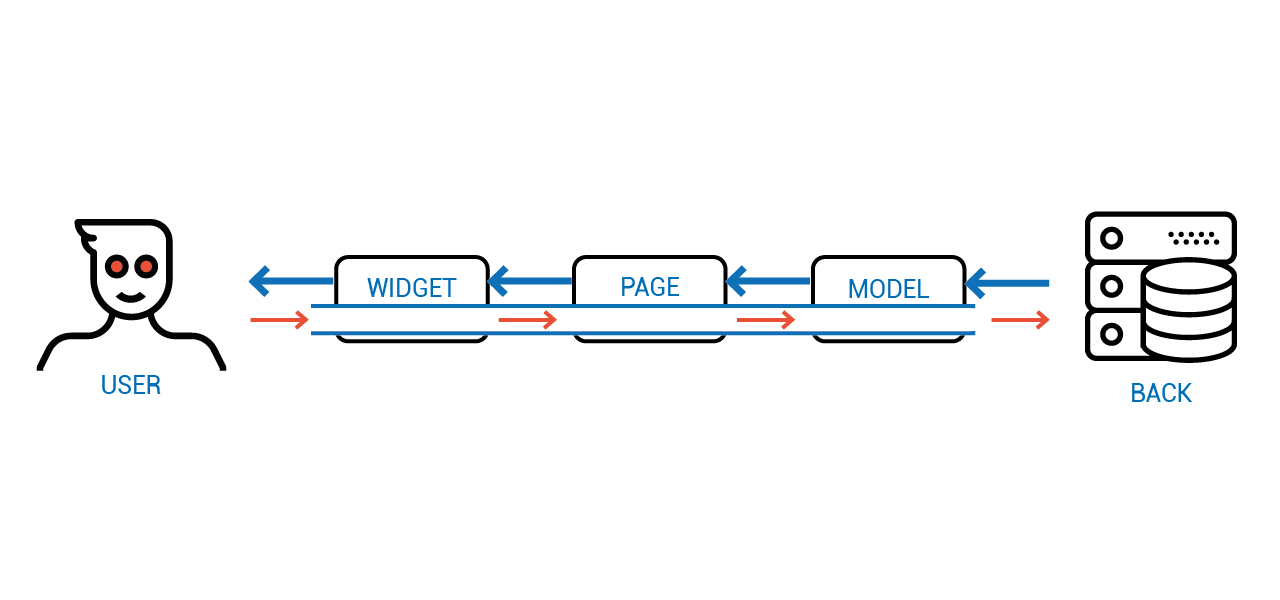
У этой архитектуры нет проблем Ангуляра с неконсистентностью, ведь прямой и обратный потоки данных не перемешиваются. Но нет и проблем FLUX-а, так как каждый компонент взаимодействует лишь со своим непосредственным владельцем и непосредственным имуществом.
class $mol_string {
hint() { return '' }
@ $mol_mem()
value( next = '' ) { return next }
// ...
}Данный пример — компонент строкового поля ввода. Для иллюстрации приведено два свойства:hint— это текст показываемый, если значение поля не задано; иvalue— это текущее значение. Когда пользователь вводит новое значение оно передаётся в value. А благодаря декоратору, результат работы метода кешируется в внутри объекта.
Чтобы настроить поведение компонента мы можем просто переопределить его свойства своими функциями. Например, можем сделать, чтобы hint возвращал известного персонажа комиксов.const Name = new $mol_string
Name.hint = ()=> 'Batman'Или можем попросить компонент в качестве value брать не своё локальное состояние, а нашу локальную переменную.let name = 'Jin'
Name.value = ( next = name )=> {
return name = next
}Тут мы просто говорим, что при затягивании изvalueнужно вернуть значение переменнойname, а при проталкивании — записывать вnameи возвращать актуальное значение.
Вам может показаться, что это дурнопахнущий код, так как мы берём и переопределяем любой метод стороннего объекта, и так делать нельзя.

Но на практике это всё отлично работает и не доставляет проблем.
Мы не можем записать левый метод или изменить сигнатуру существующего, иначе тайпчекер настучит нам по башке.
Есть только два ограничения, которых очень просто придерживаться: переопределять методы можно лишь один раз при создании объекта и конструктор не должен обращаться к свойствам объекта так как они могут быть переопределены в дальнейшем.
Лучше, конечно, не создавать объекты в воздухе и не разбрасываться локальными переменными, а хранить все объекты в свойствах других объектов. Например, мы можем создать локальную фабрику, которая единожды создаёт и настраивает объект.
@ $mol_mem()
Name() {
const Name = new $mol_string
/// Setup ```Name``` here
return Name
}А благодаря реактивному декоратору, этот объект кешируется, пока он кому-нибудь нужен, после чего будет автоматически уничтожен. Что обеспечивает своевременное освобождение занятых им ресурсов.
Для настройки вложенного мы просто связываем его свойства с нашими таким образом, что оба объекта начинают работать с одним и тем же состоянием, что избавляет от необходимости синхронизировать состояния, как это делает Ангуляр.
/// Setup ```Name```:
/// One way binding
Name.hint = ()=> this.name_hint()
/// Two way binding
Name.value = ( next )=> this.name( next )Такая простая, но мощная концепция позволяет создавать самодостаточные компоненты, которые знают о внешнем мире чуть менее, чем ничего. Но владелец нескольких компонент, через свои собственные свойства, может провязать их друг с другом так, чтобы они работали сообща.
Реактивное программирование — каскадное изменение состояний по нашим правилам.
ОРП провоцирует простой, понятный, но эффективный код.
Ленивая архитектура минимизирует объём вычислений.
Потока данных всегда два и они не должны пересекаться.
Синхронный код — добро.
Ручное управление потоками данных — зло.
Напоследок хотелось бы дать совет: не гонитесь за хайпом. Мода переменчива и часто тащит нас в болото. Если ваш единственный аргумент — число разработчиков "знающих" технологию, то готовьтесь к тому, что через пару лет никто из них уже не захочет с ней связываться, а ещё через пару — вы не найдёте никого, кто смог бы разобраться в коде проекта.
Разумеется большой компанией выбираться из жопы интересней. Но если вы хотите вырваться вперёд, пока остальные буксуют, нужно трезво и рационально выбирать технологии, которые позволят писать простой, ясный и эффективный код. Которые возьмут на себя как можно больше рутины, позволяя программисту сконцентрироваться на бизнес логике. Именно такой технологией и является Объектное Реактивное Программирование.
На этом у меня всё. Если у вас возникли какие-либо вопросы, я с радостью на них отвечу.
Реализации ОРП: $mol_mem, VueJS, MobX, CellX, KnockOut
Получившийся магазин: toys.hyoo.ru
Исходники магазина: github.com/nin-jin/toys.hyoo.ru
Эти слайды: nin-jin.github.io/slides/orp
Треугольники Серпинского: github.com/nin-jin/sierpinski
|
Метки: author vintage программирование javascript $mol $mol_mem reactive programming components asynchronous i/o lazy evaluation frontendconf ritfest |
Зачем хакеры воруют торговые алгоритмы хедж-фондов и HFT-компаний |

|
Метки: author itinvest информационная безопасность блог компании itinvest хакеры взломы биржа |
Интеграция Cordova в нативный iOS проект |

sudo port install npm4sudo npm install -g cordovasudo npm install -g cordova-ioscordova-ios/bin/createcordova createcordova create cordova_full
cd cordova_full/
cordova platform add iossudo npm install -g plugmanplugman install --platform ios --project . --plugin cordova-plugin-console
plugman install --platform ios --project . --plugin cordova-plugin-statusbar"$(TARGET_BUILD_DIR)/usr/local/lib/include"
"$(OBJROOT)/UninstalledProducts/include"
"$(OBJROOT)/UninstalledProducts/$(PLATFORM_NAME)/include"
"$(BUILT_PRODUCTS_DIR)"#ifndef Bridging_Header_h
#define Bridging_Header_h
#import "CDVViewController.h"
#endif /* Bridging_Header_h */CordovaEmbedded/Libraries/Bridging-Header.hCordovaEmbedded[31857:638683] Received Event: deviceready
pod initpod 'Cordova' # Cordova framework and plugins
pod 'CordovaPlugin-console'
pod 'cordova-plugin-camera'
pod 'cordova-plugin-contacts'
pod 'cordova-plugin-device'
pod 'cordova-plugin-device-orientation'
pod 'cordova-plugin-device-motion'
pod 'cordova-plugin-globalization'
pod 'cordova-plugin-geolocation'
pod 'cordova-plugin-file'
pod 'cordova-plugin-media-capture'
pod 'cordova-plugin-network-information'
pod 'cordova-plugin-splashscreen'
pod 'cordova-plugin-inappbrowser'
pod 'cordova-plugin-file-transfer'
pod 'cordova-plugin-statusbar'
pod 'cordova-plugin-vibration'
pod 'cordova-plugin-wkwebview-engine'
pod 'phonegap-ios-template' # Cordova template pod install"${PODS_ROOT}"|
Метки: author comhot разработка под ios разработка мобильных приложений ios development webview cordova cordova/phonegap swift 3 гибридные приложения |
Экосистема: больше участников — больше прибыль! Зачем Skyeng открывает API |

 Говоря об экосистеме, важно не уходить от целого к частностям — к конкретным предлагаемым продуктам и сервисам, а то можно не увидеть леса за деревьями. Давайте поговорим не о конкретных сервисах, а о неких «сферических продуктах в вакууме».
Говоря об экосистеме, важно не уходить от целого к частностям — к конкретным предлагаемым продуктам и сервисам, а то можно не увидеть леса за деревьями. Давайте поговорим не о конкретных сервисах, а о неких «сферических продуктах в вакууме».

|
Метки: author Ontaelio расширения для браузеров разработка мобильных приложений api блог компании skyeng конкурс экосистема идея для стартапа словарь лексический анализ переводчик |
Dagaz: Забегая вперёд |
 Сто тринадцать раз в секунду оно тянется, и достает все дальше. Если бы пришло подтверждение, сигнал — оно могло бы остановиться, и оно не останавливается. Оно тянется и находит всё новые способы. Оно импровизирует, оно изучает. Оно не сознает, что делает…
Сто тринадцать раз в секунду оно тянется, и достает все дальше. Если бы пришло подтверждение, сигнал — оно могло бы остановиться, и оно не останавливается. Оно тянется и находит всё новые способы. Оно импровизирует, оно изучает. Оно не сознает, что делает…CarefulAi.prototype.getMove = function(ctx) {
var result = [];
// Генерируем все ходы из текущей позиции
_.chain(Dagaz.AI.generate(ctx, ctx.board))
// Просто проверка наличия действий внутри хода, на всякий случай
.filter(function(move) {
return move.actions.length > 0;
})
// Для каждого хода
.each(function(move) {
// Применяем ход к текущей позиции, получая новую позицию
var b = ctx.board.apply(move);
// Если цель противника не достигнута
if (b.checkGoals(ctx.design, ctx.board.player) >= 0) {
// Добавляем ход к списку безопасных ходов
result.push(move);
}
}, this);
if (result.length > 0) {
// Выбираем любой случайный ход из списка безопасных
var ix = this.params.rand(0, result.length - 1);
return {
done: true,
move: result[ix],
ai: "careful"
};
}
// Если нет безопасных ходов
if (this.parent) {
// Обращаемся к Рандому
return this.parent.getMove(ctx);
}
}
var x = [];
var queue = [ ctx.board ];
var timestamp = Date.now();
while ((Date.now() - timestamp < this.params.AI_FRAME) && queue.length > 0) {
var board = queue.shift();
var moves = cache(x, board);
if (board.checkGoals(Dagaz.Model.getDesign(), board.player) != 0) {
return {
done: true,
move: traceMove(ctx, board),
ai: "win"
};
}
for (var i = 1; i < moves.length; i++) {
var b = board.apply(moves[i]);
var k = getKey(b);
if (_.isUndefined(x.cache[k]) && !isLoop(ctx, b)) {
queue.push(b);
}
}
}
...
Dagaz.AI.heuristic = function(ai, design, board, move) {
var r = 1;
if (move.actions.length > 0) {
var pos = move.actions[0][1][0];
if (board.getPiece(pos) !== null) {
r += 9;
}
}
return r;
}
Dagaz.AI.heuristic = function(ai, design, board, move) {
var r = 1;
for (var i = 0; i < move.actions.length; i++) {
if ((move.actions[i][0] !== null) && (move.actions[i][1] !== null)) {
var d = move.actions[i][1][0] - move.actions[i][0][0];
if ((board.player == 1) && (d < -1)) {
r += 10;
}
if ((board.player == 2) && (d == 1)) {
r += 10;
}
}
if ((move.actions[i][0] !== null) && (move.actions[i][1] === null)) {
r += 5;
}
}
return r;
}
function UctAi(params) {
this.params = params;
...
if (_.isUndefined(this.params.UCT_COEFF)) {
this.params.UCT_COEFF = Math.sqrt(2);
}
}
UctAi.prototype.getMove = function(ctx) {
this.generate(ctx, ctx.board);
...
var mx = null;
for (var i = 0; i < ctx.childs.length; i++) {
var u = 0;
if (ctx.childs[i].win > 0) {
u = ctx.childs[i].win / ctx.childs[i].all;
}
var h = this.heuristic(ctx.design, ctx.board, ctx.childs[i].move);
var w = this.params.UCT_WEIGHT * u + (1 - this.params.UCT_WEIGHT) * h;
if ((mx === null) || (w > mx)) {
mx = w;
ctx.result = ctx.childs[i].move;
}
console.log("Weight: " + w + "; Win = " + ctx.childs[i].win + "; All = " + ctx.childs[i].all + "; Move = " + ctx.childs[i].move.toString());
}
...
}
|
Метки: author GlukKazan разработка игр алгоритмы javascript настольные игры uct монте-карло |
Распределенные структуры данных (часть 2, как это сделано) |
В предыдущей статье — часть 1, обзорная — я рассказал о том, зачем нужны распределенные структуры данных (далее — РСД) и разобрал несколько вариантов, предлагаемых распределенным кешем Apache Ignite.
Сегодня же я хочу рассказать о подробностях реализации конкретных РСД, а также провести небольшой ликбез по распределенным кешам.
Итак:

Начнем с того, что, как минимум в случае с Apache Ignite, РСД не реализованы с нуля, а являются надстройкой над распределенным кешем.
Распределенный кеш — система хранения данных, в которой информация хранится более чем на одном сервере, но при этом обеспечивается доступ ко всему объему данных сразу.
Основным преимуществом подобного рода систем является возможность впихнуть невпихуемое хранить огромные объемы данных без разбиения их на куски, ограниченные объемами конкретных накопителей или даже целых серверов.
Чаще всего такие системы позволяют динамически наращивать объемы хранения посредством добавления новых серверов в систему распределенного хранения.
Чтобы иметь возможность изменять топологию кластера (добавлять и удалять серверы), а также балансировать данные, используется принцип партиционирования (секционирования) данных.
При создании распределенного кеша указывается число партиций, на которые будут разделены данные, например, 1024. При добавлении данных выбирается партиция, ответственная за их хранение, например по хешу ключа. Каждая партиция может храниться на одном или нескольких серверах, в зависимости от конфигурации кеша. Для каждой конкретной топологии (набора серверов), сервер, где будет храниться партиция, вычисляется по заранее заданному алгоритму.
Например, при старте кеша укажем что:
Запустим четыре data node [JVM 1-4] (ответственные за хранение данных) и одну client node [Client JVM] (ответственную только за предоставление доступа к данным).
Каждая из четырёх data node может быть использована как client node (то есть предоставлять доступ ко всем данным). Например, JVM 1 смогла получить данные по партициям A,C,D, хотя, локально, располагает только A (Primary) и D (Backup).
Любая data node распределенного кеша для конкретной партиции может являться Primary или Backup, либо вообще не содержать партицию.
Primary node отличается от Backup тем, что именно она обрабатывает запросы в рамках партиции и, по необходимости, реплицирует результаты на Backup node.
В случае выхода Primary node из строя, одна из Backup node становится Primary.
В случае выхода Primary node из строя, при отсутствии Backup node, партиция считается утерянной.
Некоторые распределенные кеши предоставляют возможность локально кешировать данные, расположенные на других node. Например Client JVM локально закешировала партицию B и не будет запрашивать дополнительные данные, пока они не изменятся.
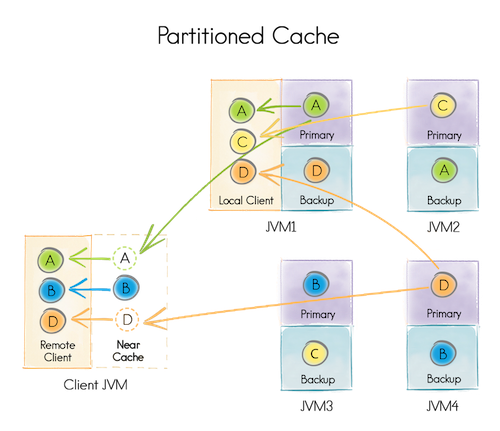
Рапределенные кеши разделяют на Partitioned и Replicated.
Разница состоит в том, что Partitioned-кеш хранит один (или один + N бекапов) экзепляр партиции в рамках кластера, а Replicated хранит по одному экземпляру партиции на каждой data node.

Partitioned-кеш имеет смысл использовать для хранения данных, чьи объемы превышают возможности отдельных серверов, а Replicated — для хранения одних и тех же данных «везде».
Хорошим примером для понимания является связка Сотрудник — Организация. Сотрудников много, и они довольно часто меняются, так что лучше хранить их в Partitioned-кеше. Организаций же мало, и меняются они редко, значит имеет смысл хранить их в Replicated-кеше, чтение из него гораздо быстрее.
Итак, перейдем к подробностям реализации.
Хочу еще раз обозначить, что речь идет о реализации в рамках исходного кода Apache Ignite, в других распределенных кешах реализация может отличаться.
Для обеспечения работы РСД используются два кеша: один Replicated и один Partitioned.
Replicated-кеш — в данном случае это системный кеш, (ignite-sys-cache) отвечающий, в том числе, за хранение информации об РСД, зарегистрированных в системе.
Partitioned-кеш (ignite-atomics-sys-cache) хранит данные, необходимые для работы РСД, и их состояние.
Итак, большинство РСД создается следующим образом:
ignite-sys-cache, по ключу DATA_STRUCTURES_KEY, берется Map<Имя_РСД, DataStructureInfo> (при необходимости создается), и в нее добавляется новый элемент с описанием, например, IgniteAtomicReference.ignite-atomics-sys-cache, по ключу из добавленного ранее DataStructureInfo добавляется элемент, отвечающий за состояние РСД.При первом запросе на создание РСД создается новый экземпляр, а последующие запросы получают уже ранее созданный.
Третий шаг инициализации для обоих типов сводится к добавлению в ignite-atomics-sys-cache объекта типа GridCacheAtomicReferenceValue или GridCacheAtomicLongValue.
Оба класса содержат одно единственное поле val.
Соответственно, любое изменение IgniteAtomicReference:
// Изменим значение, если текущее соответствует ожидаемому.
ref.compareAndSet(expVal, newVal);… это запуск EntryProcessor со следующим кодом метода process:
EntryProcessor — это функция, позволяющая атомарно выполнять сложные операции над объектами в кеше.
Метод process принимает MutableEntry (объект в кеше) и может изменить его значение.
EntryProcessor, по сути, является альтернативой транзакции по одному ключу (иногда даже реализуется как транзакция).
Как следствие, гарантируется, что над одним объектом в кеше будет выполняться только один EntryProcessor в единицу времени.
Boolean process(MutableEntry> e, Object... args) {
GridCacheAtomicReferenceValue val = e.getValue();
T curVal = val.get();
// Переменные expVal и newVal — параметры метода
// ref.compareAndSet(expVal, newVal);
if (F.eq(expVal, curVal)) {
e.setValue(new GridCacheAtomicReferenceValue(newVal));
return true;
}
return false;
} IgniteAtomicLong является дефакто расширением IgniteAtomicReference, поэтому и его метод compareAndSet реализован аналогичным образом.
Метод incrementAndGet не имеет проверок на ожидаемое значение, а просто добавляет единицу.
Long process(MutableEntry e, Object... args) {
GridCacheAtomicLongValue val = e.getValue();
long newVal = val.get() + 1;
e.setValue(new GridCacheAtomicLongValue(newVal));
return newVal;
}При создании каждого экземпляра IgniteAtomicSequence...
// Создадим или получим ранее созданный IgniteAtomicSequence.
final IgniteAtomicSequence seq = ignite.atomicSequence("seqName", 0, true);… ему выделяется пул идентификаторов.
// Начинаем транзакцию
try (GridNearTxLocal tx = CU.txStartInternal(ctx, seqView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheAtomicSequenceValue seqVal = cast(dsView.get(key), GridCacheAtomicSequenceValue.class);
// Нижняя граница локального пула идентификаторов
locCntr = seqVal.get();
// Верхняя граница
upBound = locCntr + off;
seqVal.set(upBound + 1);
// Обновляем экземпляр GridCacheAtomicSequenceValue в кеше
dsView.put(key, seqVal);
// Завершаем транзакцию
tx.commit();Соответственно, вызов...
seq.incrementAndGet(); … просто инкрементирует локальный счетчик до достижения верхней границы пула значений.
При достижении границы происходит выделение нового пула идентификаторов, аналогично тому, как это происходит при создании нового экземпляра IgniteAtomicSequence.
Декремент счетчика:
latch.countDown();… реализуется следующим образом:
// Начинаем транзакцию
try (GridNearTxLocal tx = CU.txStartInternal(ctx, latchView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheCountDownLatchValue latchVal = latchView.get(key);
int retVal;
if (val > 0) {
// Декрементируем значение
retVal = latchVal.get() - val;
if (retVal < 0)
retVal = 0;
}
else
retVal = 0;
latchVal.set(retVal);
// Сохраняем значение
latchView.put(key, latchVal);
// Завершаем транзакцию
tx.commit();
return retVal;
}Ожидание декрементации счетчика до 0...
latch.await();… реализуется через механизм Continuous Queries, то есть при каждом изменении GridCacheCountDownLatchValue в кеше все экземпляры IgniteCountDownLatch уведомляются об этих изменениях.
Каждый экземпляр IgniteCountDownLatch имеет локальный:
/** Internal latch (transient). */
private CountDownLatch internalLatch;Каждое уведомление декрементирует internalLatch до актуального значения. Поэтому latch.await() реализуется очень просто:
if (internalLatch.getCount() > 0)
internalLatch.await();Получение разрешения...
semaphore.acquire();… происходит следующим образом:
// Пока разрешение не будет получено
for (;;) {
int expVal = getState();
int newVal = expVal - acquires;
try (GridNearTxLocal tx = CU.txStartInternal(ctx, semView, PESSIMISTIC, REPEATABLE_READ)) {
GridCacheSemaphoreState val = semView.get(key);
boolean retVal = val.getCount() == expVal;
if (retVal) {
// Сохраняем информацию о получивших разрешения.
// В случае выхода из строя какой-либо node,
// захваченные ею разрешения будут возвращены.
{
UUID nodeID = ctx.localNodeId();
Map map = val.getWaiters();
int waitingCnt = expVal - newVal;
if (map.containsKey(nodeID))
waitingCnt += map.get(nodeID);
map.put(nodeID, waitingCnt);
val.setWaiters(map);
}
// Устанавливаем новое значение
val.setCount(newVal);
semView.put(key, val);
tx.commit();
}
return retVal;
}
}
Возврат разрешения...
semaphore.release();… происходит аналогичным образом, за исключением того, что новое значение больше текущего.
int newVal = cur + releases;В отличие от остальных РСД, IgniteQueue не использует ignite-atomics-sys-cache. Используемый кеш описывается через параметр colCfg.
// Создадим или получим ранее созданный IgniteQueue.
IgniteQueue queue = ignite.queue("queueName", 0, colCfg); В зависимости от указанного Atomicity Mode (TRANSACTIONAL, ATOMIC) можно получить разные варианты IgniteQueue.
queue = new GridCacheQueueProxy(cctx, cctx.atomic() ?
new GridAtomicCacheQueueImpl<>(name, hdr, cctx) :
new GridTransactionalCacheQueueImpl<>(name, hdr, cctx));В обоих случаях состояние IgniteQueue контролируется с помощью:
class GridCacheQueueHeader{
private long head;
private long tail;
private int cap;
... Для добавления элемента используется AddProcessor...
Long process(MutableEntry e, Object... args) {
GridCacheQueueHeader hdr = e.getValue();
boolean rmvd = queueRemoved(hdr, id);
if (rmvd || !spaceAvailable(hdr, size))
return rmvd ? QUEUE_REMOVED_IDX : null;
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(),
hdr.capacity(),
hdr.collocated(),
hdr.head(),
hdr.tail() + size, // Выделяем место под элемент
hdr.removedIndexes());
e.setValue(newHdr);
return hdr.tail();
}… который, по сути, просто перемещает указатель на хвост очереди.
После этого...
// По ключу, сформированному на основе
// нового hdr.tail()
QueueItemKey key = itemKey(idx);… в очередь добавляется новый элемент:
cache.getAndPut(key, item);Удаление элемента происходит аналогично, но указатель меняется не на tail, а на head...
GridCacheQueueHeader newHdr = new GridCacheQueueHeader(hdr.id(),
hdr.capacity(),
hdr.collocated(),
hdr.head() + 1, // Двигаем указатель на голову
hdr.tail(),
null);… и элемент удаляется.
Long idx = transformHeader(new PollProcessor(id));
QueueItemKey key = itemKey(idx);
T data = (T)cache.getAndRemove(key);Разница между GridAtomicCacheQueueImpl и GridTransactionalCacheQueueImpl состоит в том, что:
GridAtomicCacheQueueImpl при добавлении элемента сначала атомарно инкрементирует hdr.tail(), а потом уже добавляет по полученному индексу элемент в кеш.
GridTransactionalCacheQueueImpl делает оба действия в рамках одной транзакции. Как следствие, GridAtomicCacheQueueImpl работает быстрее, но может возникнуть проблема консистентности данных: если информация о размере очереди и сами данные сохраняются не одновременно, то и вычитаться они могут не одновременно.
Вполне вероятна ситуация, когда внутри метода poll видно, что очередь содержит новые элементы, но самих элементов еще нет. Такое крайне редко, но всё же возможно.
Эта проблема решается таймаутом ожидания значения.
long stop = U.currentTimeMillis() + RETRY_TIMEOUT;
while (U.currentTimeMillis() < stop) {
data = (T)cache.getAndRemove(key);
if (data != null)
return data;
}Бывали реальные случаи, когда не хватало и пятисекундного таймаута, что приводило к потерям данных в очереди.
Я хотел бы еще раз отметить, что распределенный кеш — это, по сути, ConcurrentHashMap в рамках множества компьютеров, объединенных в кластер.
Распределенный кеш может быть использован для реализации множества важных, сложных, но надежных систем.
Частным случаем реализации являются распределенные структуры данных, а в целом они применяются для хранения и обработки колоссальных объемов данных в реальном времени, с возможностью увеличения объемов или скорости обработки простым добавлением новых узлов.
|
Метки: author randoom программирование java big data блог компании gridgain распределенные системы распределенные вычисления apache ignite |
[Из песочницы] awless.io, могучий CLI для AWS |
|
Метки: author buddha_pinmask devops amazon web services go |
Путешествие внутрь Avito: платформа |


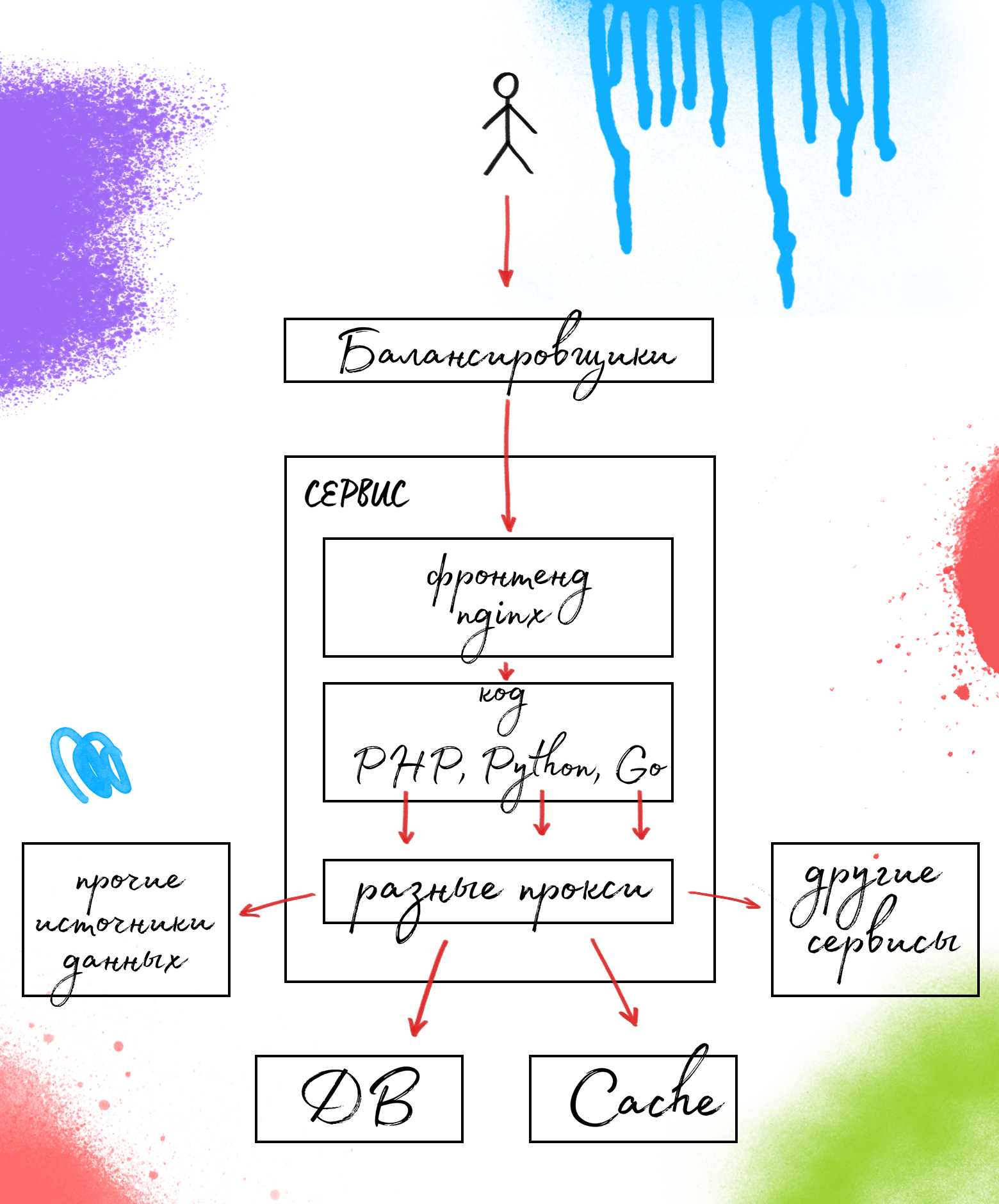
|
Метки: author tiandrey хранение данных виртуализация it- инфраструктура блог компании avito docker архитектура платформа серверы сеть kubernetes микросервисы |
Ethernet-коммутаторы Brocade |




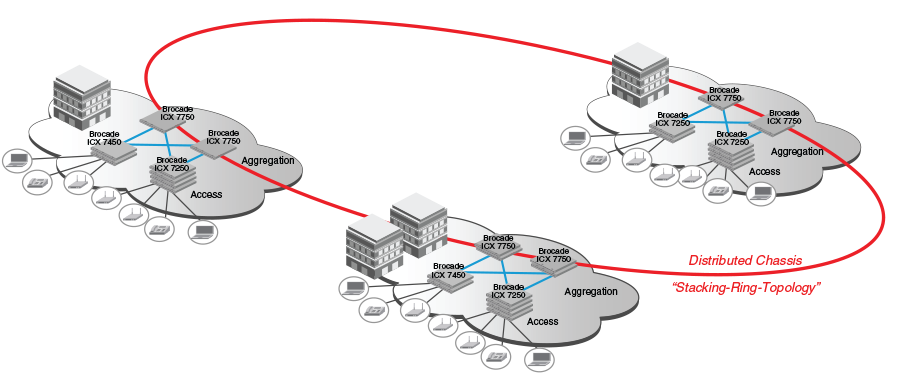

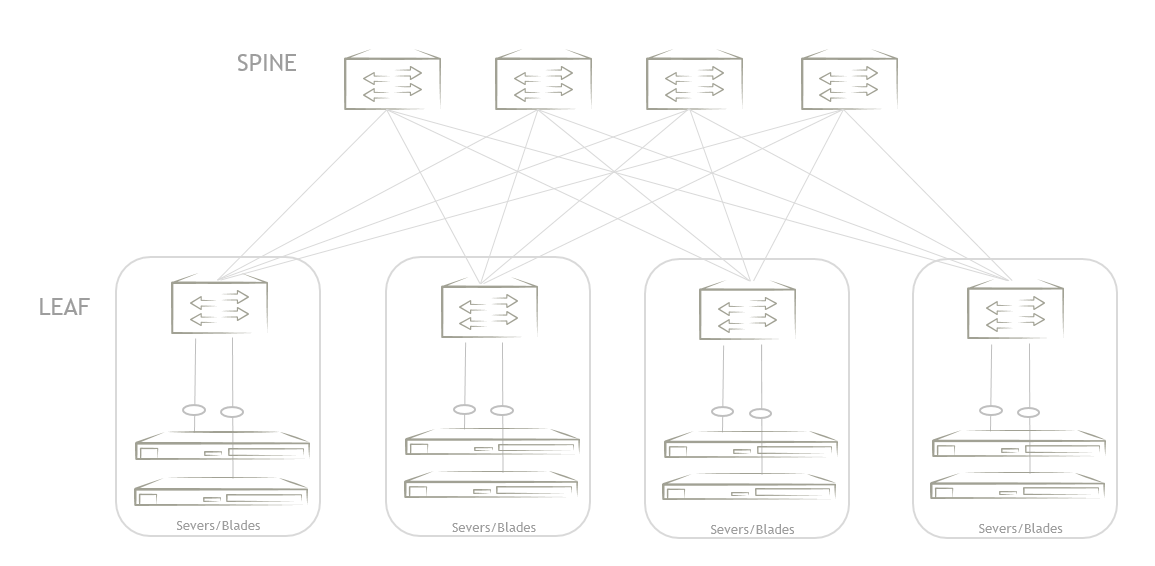



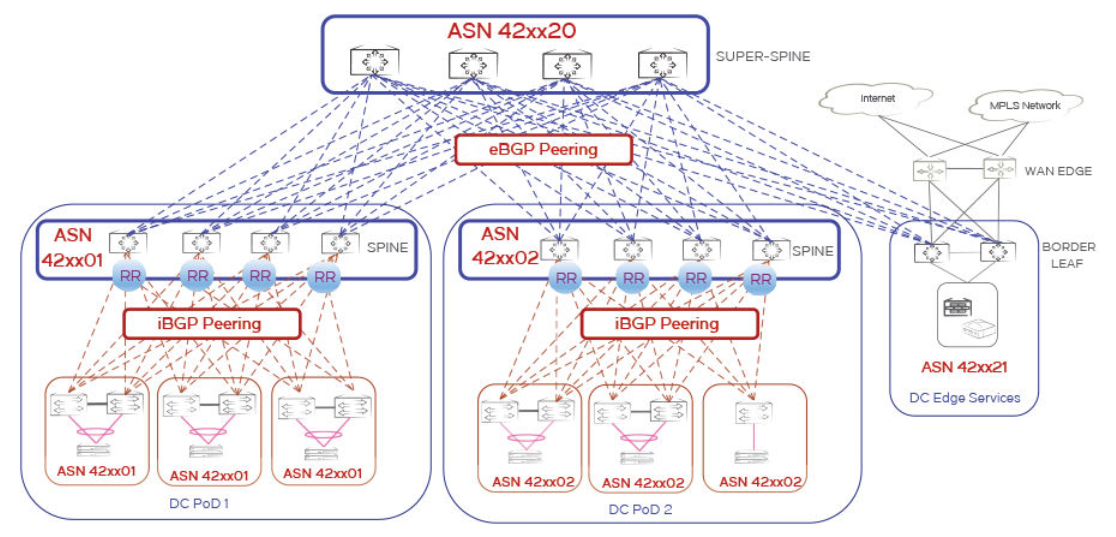


|
Метки: author WirelessMAN сетевые технологии блог компании comptek brocade коммутатор сетевое оборудование icx сети |
Firebase на I/O 2017: новые возможности |





npm -g install firebase-toolsfirebase loginfirebase init functionsconst admin = require('firebase-admin');
admin.initializeApp(functions.config().firebase);
exports.addWelcomeMessages = functions.auth.user().onCreate(event => {
const user = event.data;
console.log('A new user signed in for the first time.');
const fullName = user.displayName || 'Anonymous';
// В базу данных будет положено сообщение от файрбез бота о добавлении нового пользователя
return admin.database().ref('messages').push({
name: 'Firebase Bot',
photoUrl: 'https://image.ibb.co/b7A7Sa/firebase_logo.png', // Firebase logo выгружен на первый попавшийся image hosting
text: '${fullName} signed in for the first time! Welcome!'
});
});
firebase deploy --only functions

jcenter() classpath 'com.google.firebase:firebase-plugins:1.1.0'compile 'com.google.firebase:firebase-perf:10.2.6'apply plugin: 'com.google.firebase.firebase-perf'Trace myTrace = FirebasePerformance.getInstance().newTrace("test_trace");
myTrace.start();
myTrace.stop();myTrace.incrementCounter("storage_load");




|
Метки: author Developers_Relations разработка под ios разработка под android разработка мобильных приложений google api блог компании google google io firebase |
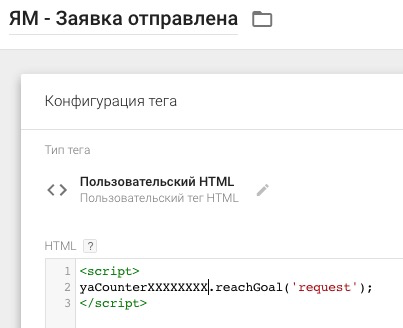
[recovery mode] Отслеживание отправки форм с помощью GTM |

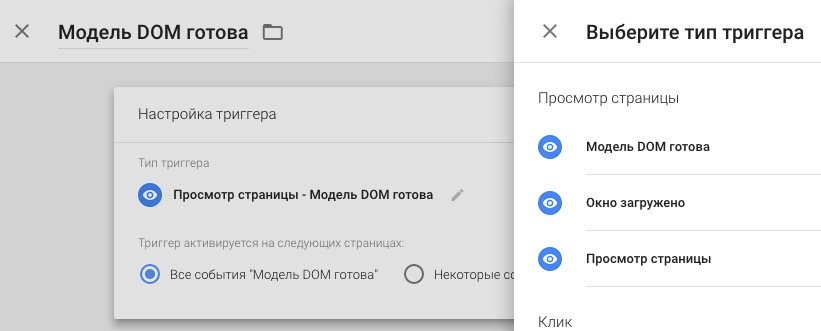
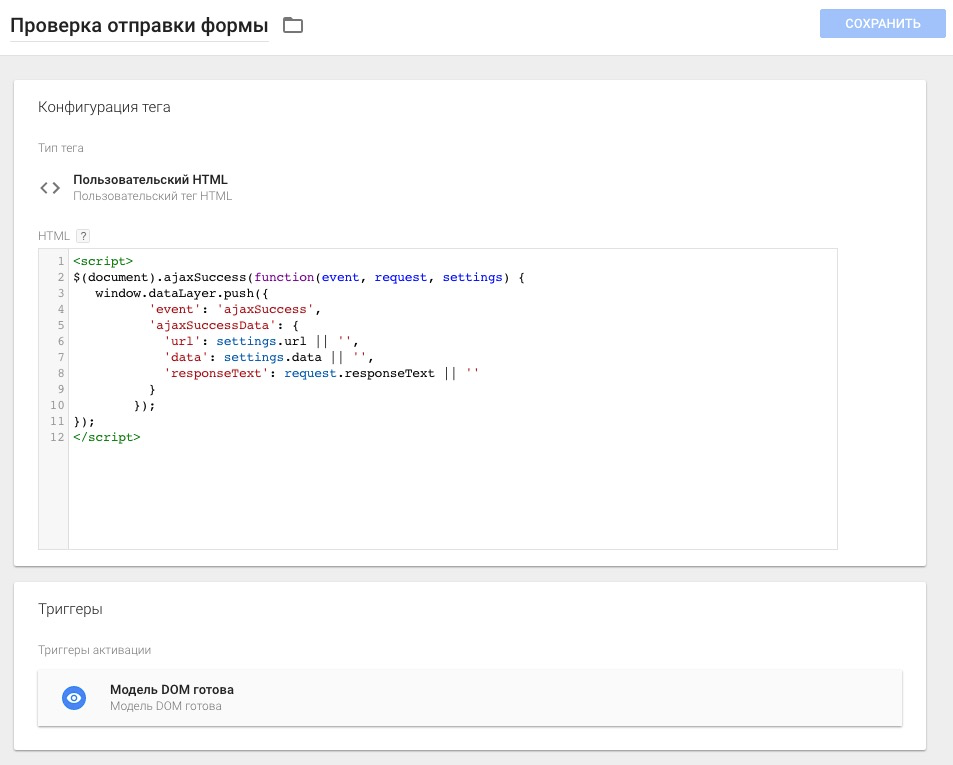


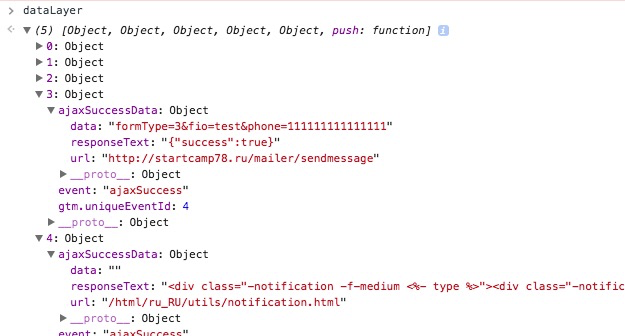

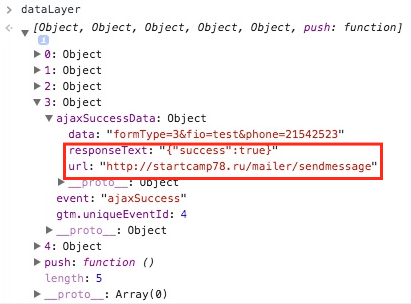
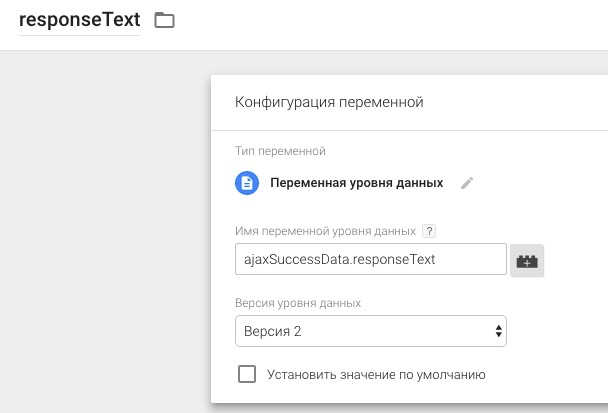
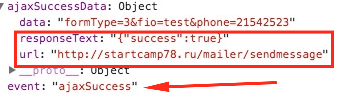
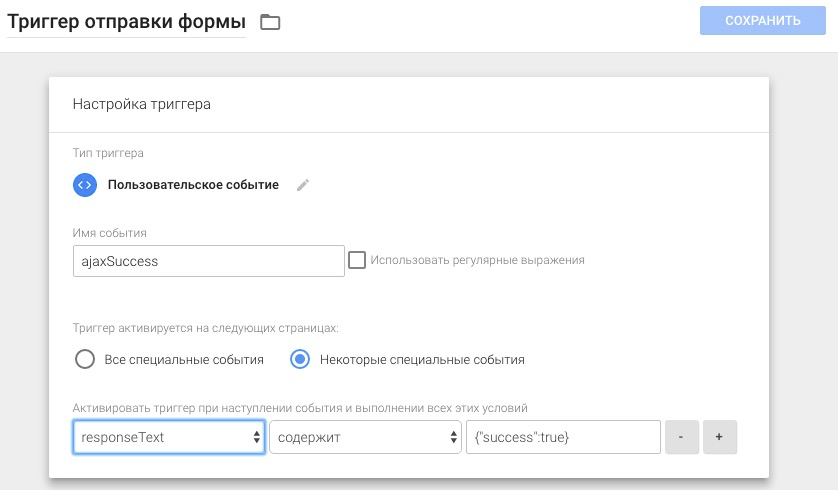
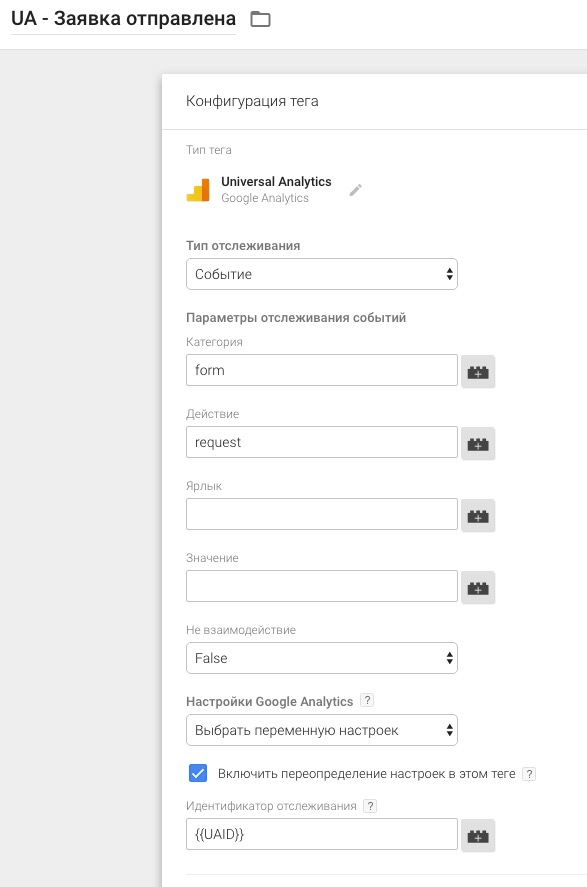
|
|
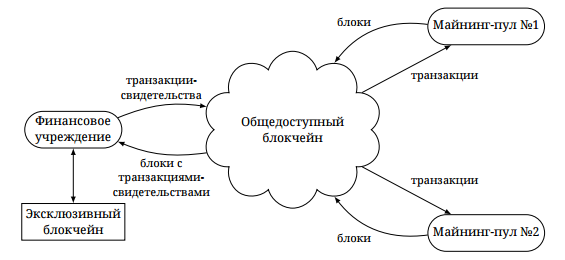
«Корпоративный сектор»: Что такое эксклюзивные блокчейны |
 / изображение Adam Bailey CC
/ изображение Adam Bailey CC«Закрытые блокчейны предоставляют компаниям интересную возможность использовать бездоверительность и прозрачность [блокчейнов] во внутренних и межкорпоративных сценариях», — говорит Дэн Василюк (Dan Wasyluk), руководитель команды Syscoin.
|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury эксклюзивные блокчейны |
Пишем пасьянс «Косынка» |
//масти
enum CARD_SUIT
{
//пики
CARD_SUIT_SPADES,
//червы
CARD_SUIT_HEARTS,
//трефы
CARD_SUIT_CLUBS,
//буби
CARD_SUIT_DIAMONDS
};
struct SCard
{
CARD_SUIT Suit;//масть
long Value;//значение карты от двойки до туза
bool Visible;//true-карта видима
} sCard_Box[13][53];//тринадцать ящиков по 52 карты в каждой максимум

//----------------------------------------------------------------------------------------------------
//переместить карту из ящика s в ячейку d
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::MoveCard(long s,long d)
{
long n;
long s_end=0;
long d_end=0;
//ищем первые свободные места в ящиках
for(n=0;n<52;n++)
{
s_end=n;
if (sCard_Box[s][n].Value<0) break;
}
for(n=0;n<52;n++)
{
d_end=n;
if (sCard_Box[d][n].Value<0) break;
}
if (s_end==0) return(false);//начальный ящик пуст
//иначе переносим карты
sCard_Box[d][d_end]=sCard_Box[s][s_end-1];
sCard_Box[s][s_end-1].Value=-1;//карты там больше нет
return(true);
}
//----------------------------------------------------------------------------------------------------
//перемещение карт внутри колоды
//----------------------------------------------------------------------------------------------------
void CWnd_Main::RotatePool(void)
{
bool r=MoveCard(0,1);//перемещаем карты из нулевого ящика в первый
if (r==false)//карт нет
{
//перемещаем обратно
while(MoveCard(1,0)==true);
}
}
//----------------------------------------------------------------------------------------------------
//инициализировать расклад
//----------------------------------------------------------------------------------------------------
void CWnd_Main::InitGame(void)
{
TimerMode=TIMER_MODE_NONE;
long value=sCursor.Number[0]+10*sCursor.Number[1]+100*sCursor.Number[2]+1000*sCursor.Number[3]+10000*sCursor.Number[4];
srand(value);
long n,m,s;
//выставляем все отделения ящиков в исходное положение
for(s=0;s<13;s++)
for(n=0;n<53;n++) sCard_Box[s][n].Value=-1;
//помещаем в исходный ящик карты
long index=0;
CARD_SUIT suit[4]={CARD_SUIT_SPADES,CARD_SUIT_HEARTS,CARD_SUIT_CLUBS,CARD_SUIT_DIAMONDS};
for(s=0;s<4;s++)
{
for(n=0;n<13;n++,index++)
{
sCard_Box[0][index].Value=n;//ставим карты
sCard_Box[0][index].Suit=suit[s];
sCard_Box[0][index].Visible=true;
}
}
//теперь разбрасываем карты по ящикам
for(n=0;n<7;n++)
{
for(m=0;m<=n;m++)
{
long change=RND(100);
for(s=0;s<=change;s++) RotatePool();//пропускаем карты
//перемещаем карту
if (MoveCard(0,n+2)==false)//если пусто в ящике 0 - делаем заново
{
m--;
continue;
}
long amount=GetCardInBox(n+2);
if (amount>0) sCard_Box[n+2][amount-1].Visible=false;//карты невидимы
}
}
//приводим магазин в исходное состояние
while(1)
{
if (GetCardInBox(1)==0) break;//если пусто в ящике 1
RotatePool();//пропускаем карты
}
}
//----------------------------------------------------------------------------------------------------
//получить количество карт в ящике
//----------------------------------------------------------------------------------------------------
long CWnd_Main::GetCardInBox(long box)
{
long n;
long amount=0;
for(n=0;n<53;n++)
{
if (sCard_Box[box][n].Value<0) break;
amount++;
}
return(amount);
}
//----------------------------------------------------------------------------------------------------
//сделать нижние карты всех рядов видимыми
//----------------------------------------------------------------------------------------------------
void CWnd_Main::OnVisibleCard(void)
{
long n;
for(n=2;n<9;n++)
{
long amount=GetCardInBox(n);
if (amount>0) sCard_Box[n][amount-1].Visible=true;
}
}
//----------------------------------------------------------------------------------------------------
//переместить карты из одного ящика в другой
//----------------------------------------------------------------------------------------------------
void CWnd_Main::ChangeBox(long s_box,long s_index,long d_box)
{
long n;
long d_end=0;
//ищем первое свободное место в ящике назначения
for(n=0;n<52;n++)
{
d_end=n;
if (sCard_Box[d_box][n].Value<0) break;
}
//перемещаем туда карты из начального ящика
for(n=s_index;n<52;n++,d_end++)
{
if (sCard_Box[s_box][n].Value<0) break;
sCard_Box[d_box][d_end]=sCard_Box[s_box][n];
sCard_Box[s_box][n].Value=-1;//карты там больше нет
}
}
//----------------------------------------------------------------------------------------------------
//переместить карты с учётом правил
//----------------------------------------------------------------------------------------------------
void CWnd_Main::ChangeCard(long s_box,long s_index,long d_box,long d_index)
{
if (d_box>=2 && d_box<9)//если ящик на игровом поле
{
//если он пуст, то класть туда можно только короля
if (d_index<0)
{
if (sCard_Box[s_box][s_index].Value==12) ChangeBox(s_box,s_index,d_box);//наша карта - король, перемещаем её
return;
}
//иначе, класть можно в порядке убывания и разных цветовых мастей
if (sCard_Box[d_box][d_index].Value<=sCard_Box[s_box][s_index].Value) return;//значение карты больше, чем та, что есть в ячейке ящика
if (sCard_Box[d_box][d_index].Value>sCard_Box[s_box][s_index].Value+1) return;//можно класть только карты, отличающиеся по значению на 1
CARD_SUIT md=sCard_Box[d_box][d_index].Suit;
CARD_SUIT ms=sCard_Box[s_box][s_index].Suit;
if ((md==CARD_SUIT_SPADES || md==CARD_SUIT_CLUBS) && (ms==CARD_SUIT_SPADES || ms==CARD_SUIT_CLUBS)) return;//цвета масти совпадают
if ((md==CARD_SUIT_HEARTS || md==CARD_SUIT_DIAMONDS) && (ms==CARD_SUIT_HEARTS || ms==CARD_SUIT_DIAMONDS)) return;//цвета масти совпадают
ChangeBox(s_box,s_index,d_box);//копируем карты
return;
}
if (d_box>=9 && d_box<13)//если ящик на поле сборки
{
//если выбрано несколько карт, то так перемещать карты нельзя - только по одной
if (GetCardInBox(s_box)>s_index+1) return;
//если ящик пуст, то класть туда можно только туза
if (d_index<0)
{
if (sCard_Box[s_box][s_index].Value==0)//наша карта - туз, перемещаем её
{
DrawMoveCard(s_box,s_index,d_box);
}
return;
}
//иначе, класть можно в порядке возрастания и одинаковых цветовых мастей
if (sCard_Box[d_box][d_index].Value>sCard_Box[s_box][s_index].Value) return;//значение карты меньше, чем та, что есть в ячейке ящика
if (sCard_Box[d_box][d_index].Value+1/можно класть только карты, отличающиеся по значению на 1
CARD_SUIT md=sCard_Box[d_box][d_index].Suit;
CARD_SUIT ms=sCard_Box[s_box][s_index].Suit;
if (ms!=md) return;//масти не совпадают
DrawMoveCard(s_box,s_index,d_box);
return;
}
}//----------------------------------------------------------------------------------------------------
//проверить на собранность пасьянс
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::CheckFinish(void)
{
long n;
for(n=9;n<13;n++)
{
if (GetCardInBox(n)!=13) return(false);
}
return(true);
}
//координаты расположения ячеек карт
long BoxXPos[13][53];
long BoxYPos[13][53];
//размер поля по X
#define BOX_WIDTH 30
//положение ящиков 0 и 2 по X и Y
#define BOX_0_1_OFFSET_X 5
#define BOX_0_1_OFFSET_Y 5
//положение ящиков с 2 по 8 по X и Y
#define BOX_2_8_OFFSET_X 5
#define BOX_2_8_OFFSET_Y 45
//положение ящиков с 9 по 12 по X и Y
#define BOX_9_12_OFFSET_X 95
#define BOX_9_12_OFFSET_Y 5
//смещение каждой следующей карты вниз
#define CARD_DX_OFFSET 10
//масштабный коэффициент относительно размеров карт на PSP
#define SIZE_SCALE 2
for(n=0;n<13;n++)
{
long xl=0;
long yl=0;
long dx=0;
long dy=0;
if (n<2)
{
xl=BOX_0_1_OFFSET_X+BOX_WIDTH*n;
yl=BOX_0_1_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=0;
}
if (n>=2 && n<9)
{
xl=BOX_2_8_OFFSET_X+BOX_WIDTH*(n-2);
yl=BOX_2_8_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=CARD_DX_OFFSET*SIZE_SCALE;
}
if (n>=9 && n<13)
{
xl=BOX_9_12_OFFSET_X+(n-9)*BOX_WIDTH;
yl=BOX_9_12_OFFSET_Y;
xl*=SIZE_SCALE;
yl*=SIZE_SCALE;
dx=0;
dy=0;
}
for(m=0;m<53;m++)
{
BoxXPos[n][m]=xl+dx*m;
BoxYPos[n][m]=yl+dy*m;
}
}
//размер карты по X
#define CARD_WIDTH 27
//размер карты по Y
#define CARD_HEIGHT 37
//----------------------------------------------------------------------------------------------------
//определение что за ящик и номер ячейки в данной позиции экрана
//----------------------------------------------------------------------------------------------------
bool CWnd_Main::GetSelectBoxParam(long x,long y,long *box,long *index)
{
*box=-1;
*index=-1;
long n,m;
//проходим по ячейкам "магазина"
for(n=0;n<13;n++)
{
long amount;
amount=GetCardInBox(n);
for(m=0;m<=amount;m++)//ради m<=amount сделана 53-я ячейка (чтобы щёлкать на пустых ячейках)
{
long xl=BoxXPos[n][m];
long yl=BoxYPos[n][m];
long xr=xl+CARD_WIDTH*SIZE_SCALE;
long yr=yl+CARD_HEIGHT*SIZE_SCALE;
if (x>=xl && x<=xr && y>=yl && y<=yr)
{
*box=n;
if (mcode>|
Метки: author da-nie разработка игр программирование пасьянс косынка |
PHDays 2017: как это было |












|
Метки: author haumea информационная безопасность блог компании mclouds.ru phdays доклады форум |






