[Перевод] Как принять закон или обработка данных в распределённых системах понятным языком |
|
|
Бесплатные билеты на In-Memory Computing Summit 2017 – Europe |

|
Метки: author Sibarit машинное обучение java big data .net блог компании gridgain apache ignite gridgain distributed computing data grid compute grid imc |
10 правил организации эффективной клиентской поддержки |

|
|
Белый список Роскомнадзора: выводы и убытки |



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Menaskop терминология it законодательство и it-бизнес роскомнадзор белый список роскомсвобода блокировка сайтов it- юрист |
[Из песочницы] Когда docker-compose не хватает |
Здесь периодически появляются посты, в которых авторы делятся своими подходами по использованию docker. Ну что же, вот вам еще один. Ниже я расскажу о нашем опыте использования docker-окружения, о неудобствах, с которыми мы столкнулись, как мы с ними боролись, и во что это вылилось. А также поделюсь небольшим, но столь полезным для нас, инструментом.

Для начала немного истории. Так сложилось, что по долгу службы, мы в той или иной степени разрабатываем и поддерживаем одновременно несколько проектов. Все они имеют разный возраст, требования и соответственно работают в разном окружении. В связи с этим при развертывании локальной копии возникали некоторые неудобства. Когда ты переключаешься на проект, с которым ранее не работал, приходится возиться с его настройкой, а также с настройкой рабочей среды. И если внутри команды это могло решиться довольно быстро, то с периодически подключаемыми внештатными разработчиками все сложнее. Было принято решение перенести разработку в docker-окружение. Здесь мы не стали ничего выдумывать, а пошли общепринятым путем. Каждый сервис поднимался в отдельном контейнере. Для связки использовали docker-compose.
Для параллельной работы над несколькими проектами требуется установка всех сервисов необходимых каждому из них. В первую очередь мы создали репозиторий, в котором располагался файл конфигурации для docker-compose, а также конфигурации требуемых для работы образов. Все довольно быстро заработало и на какое-то время это нас устроило. Как оказалось, в дальнейшем данный подход решал нашу проблему частично. По мере добавления проектов в новую экосистему этот репозиторий наполнялся файлами конфигураций и различными вспомогательными скриптами. Это привело к тому что при работе над одним единственным проектом разработчику приходилось либо тащить зависимости всех проектов, либо же править docker-compose.yml, отключая лишние сервисы. В первом случае приходилось ставить лишние контейнеры, что нам казалось не лучшим решением, а во втором нужно было знать какие контейнеры требуются для работы приложения. Хотелось иметь более гибкое решение, которое позволит устанавливать только необходимые компоненты, а также, если не исключит, то минимизирует ручную работу. И вот к чему мы пришли...
ddk (Docker Development Kit) — инструмент, призванный упростить настройку окружения и автоматизировать развертывание среды разработки для проектов, работающих в docker-окружении. Звучит, наверное, сильно. На деле же, ddk является некой оберткой над git и docker и предоставляет ряд дополнительных команд для удобного управления пакетами, файлами конфигураций и проектами. В некотором роде, это менеджер зависимостей окружения для проектов и сервисов docker-compose.
Изначально ddk — это набор python-скриптов, но конечный пользователь получает единственный исполняемый файл, с которым и работает. Теперь, помимо установки самого docker'а и docker-compose, разработчику необходимо проинициализоровать ddk, создав конфигурационный файл. Эта задача решается вызовом команды init.
cd /var/projects/ddk
ddk initПосле этого подключение к новому проекту выглядит следующим образом:
ddk project get my.project.ru
ddk compose --upТакже, при необходимости, перенаправляем новый домен на localhost.
echo 127.0.0.1 my.project.ddk >> /etc/hostsПервая команда клонирует проект и выполняет его инициализацию. Вторая генерирует конфигурацию для docker-compose и запускает необходимые сервисы. В процессе выполнения будут загружены все недостающие компоненты. По завершению сборки разработчик получает полностью рабочую локальную копию проекта, которая доступна по адресу my.project.ddk.
Немного о том, как это работает.
При использовании ddk рабочей считается та директория, в которой расположен конфигурационный файл, сгенерированный командой init. Сам же исполняемый файл может располагаться в любом удобном месте. Поиск конфигурации осуществляется, начиная с текущей директории, а затем ddk поднимается по дереву каталогов пока не обнаружит искомый файл или не достигнет корня файловой системы. Схожим образом работают git и docker-compose. После того, как файл конфигурации найден, ddk формирует некоторые каталоги для хранения пакетов и исходного кода проектов, разрешает и устанавливает зависимости. Установка компонентов осуществляется простым клонированием git-репозитория, адрес которого определяется путем конкатенации имени компонента и префикса из конфигурационного файла.
# "project-repo-prefix": ["git@github.com/vendor-name/"]
ddk project get my.project.ru
git clone git@github.com/vendor-name/my.project.ru.gitСамо собой, ddk не является простым шорткатом для git clone, и имеет дополнительные функциональные возможности, из-за которых он и задумывался. О том, как, зачем и почему — чуть ниже, а здесь добавлю лишь то, что в итоге сформируется директория, в которой будут собраны все проекты, а также необходимые для их работы конфигурационные файлы. Данная директория может быть без проблем перемещена в другой каталог или на другую машину.
Первое чего хотелось добиться — сделать все окружение максимально модульным. Мы выделили описание каждого сервиса в отдельные конфигурационные файлы и вынесли их в самостоятельные репозитории. Коллега назвал их пакетами. Эти самые пакеты и легли в основу работы нашего инструмента. При сборке docker-compose.yml ddk проходит по всем требуемым пакетам и генерирует на их основе итоговый конфигурационный файл.
Как правило, нет необходимости устанавливать отдельные пакеты самостоятельно, так как при сборке автоматически подгружаются все недостающие компоненты. Тем не менее имеется возможность для их установки и обновления.
ddk package install package-name
ddk package updateТеперь о содержимом. В корне всегда находится конфигурационный файл ddk.json, в котором указываются имя контейнера и используемый docker-образ. Ниже приведен пример пакета с минимальной конфигурацией.
{
"container_name": "memcached.ddk",
"image": "memcached:latest"
}Как вы, наверное, заметили, фактически, это часть конфигурации из docker-compose.yml представленная в формате JSON. Такой подход дает возможность установить любые параметры, поддерживаемые docker-compose. Вот пример более сложного пакета, который использует отдельный Dockerfile и монтирует директории.
{
"build": "${PACKAGE_PATH}",
"container_name": "nginx.ddk",
"volumes": [
"${SHARE_PATH}/var/www:/var/www",
"${PACKAGE_PATH}/storage/etc/nginx/conf.d:/etc/nginx/conf.d:ro",
"${PACKAGE_PATH}/storage/etc/nginx/nginx.conf:/etc/nginx/nginx.conf:ro",
"${PACKAGE_PATH}/storage/var/log/nginx:/var/log/nginx"
]
}Листинг директории пакета:
storage/
etc/
nginx/
conf.d/
site.ddk.sample
nginx.conf
ddk.json
DockerfileКлючи, имеющие префикс "ddk-" используются для указания специальных директив. На данный момент единственным поддерживаемым ключом является "ddk-post-install", который хранит список команд, выполняющихся после установки и обновления пакета.
{
"ddk-post-install": [
"echo 'Done'"
]
}Один из вариантов использования данной опции приведен в разделе "Соглашения"
Теперь рассмотрим, как использовать ddk на примере конкретного проекта. Для того, чтобы развернуть существующий проект достаточно вызвать команду get.
ddk project get project-idДанная команда клонирует проект в директорию share/var/www, после чего производится поиск конфигурационного файла (по умолчанию в корне проекта), и запускаются все необходимые команды из секции on-init. На этом этапе выполняется настройка индивидуальных параметров проекта (генерация .env, установка прав на файлы, конфигурация базы данных и т.п.).
Помимо команд для инициализации, файл ddk.json содержит список пакетов, от которых зависит работа проекта. Если какой-то из пакетов отсутствует, он будет автоматически установлен. Ниже приведен пример конфигурации проекта.
{
"packages": [
"mysql5.5",
"memcached",
"apache-php5.5"
],
"on-init": [
"${PROJECT_PATH}/init.sh ${PACKAGES_PATH} ${PROJECT_DIR}"
]
}Несмотря на то, что секция on-init позволяет передать несколько команд мы, как правило, указываем лишь одну. В примере выше вы можете видеть, что при инициализации проекта запустится скрипт развертывания, который и выполнит основную конфигурацию. Такой подход оказался удобнее, так как дает большую гибкость и позволяет добавить интерактив в процесс инициализации проекта.
При необходимости расширить конфигурацию какого-либо пакета, можно сделать это, указав его в виде объекта. Данный объект должен иметь атрибут name, содержащий название пакета. Все остальные атрибуты будут восприняты как конфигурация.
{
"packages": [
{
"name": "nginx",
"depends_on": [
"php-fpm7.1"
],
"environment": [
"SOME_VAR=Hello"
]
}
]
}Таким образом мы имеем возможность влиять на работу сервисов, не меняя оригинальную конфигурацию пакета.
В процессе работы в docker-окружении мы выработали несколько соглашений, которых и стараемся придерживаться.
Во-первых, при монтировании каких-либо файлов и директорий пакета либо проекта, их структура должна совпадать со структурой внутри контейнера. Т.е. package-name/storage соответствует корневой директории контейнера package-name. Директория share также соответствует корневой директории контейнеров. Именно поэтому все проекты располагаются в share/var/www. Данное правило прослеживается и в приведенных выше примерах.
Следующий пункт заключается в том, что при установке пакетов, в контейнерах которых предполагается модификация файловой системы, создается специальный пользователь, учетные данные которого соответствуют данным пользователя хост-системы. Другими словами, мы мапим логин, идентификатор пользователя и идентификатор группы с хост-системы в контейнер. В дальнейшем все команды в контейнере рекомендуется выполнять, используя эти данные. Такой подход позволяет избежать проблем с правами доступа при обращении к файлам вне контейнера. Если хотя бы один из проектов сконфигурирован подобным образом, будет создана директория share/home/, которая монтируется в контейнер и используется в качестве домашнего каталога. Ниже пример того, как мы это реализовали.
{
"container_name": "php71-fpm.ddk",
"command": "map-user.sh",
"env_file": [
"${PACKAGE_PATH}/env/user.env"
],
"ddk-post-install": [
"mkdir -p ${PACKAGE_PATH}/env",
"echo USER_NAME=`whoami` > ${PACKAGE_PATH}/env/user.env",
"echo USER_ID=`id -u` >> ${PACKAGE_PATH}/env/user.env",
"echo GROUP_ID=`id -g` >> ${PACKAGE_PATH}/env/user.env"
]
}Как вы видите, после установки пакета генерируется файл с данными пользователя. При старте контейнера скрипт map-user.sh проверяет и при необходимости создает учетную запись, используя полученные данные.
Последнее, что требуется сделать это запустить все необходимые сервисы, используя обычный docker-compose. Для генерации параметров запуска предназначена команда compose. При ее вызове, ddk проходит по всем активным проектам, собирает данные о пакетах и их параметрах, объединяет всю полученную информацию с конфигурациями самих пакетов и на основе этих данных генерирует итоговый docker-compose.yml. Данный файл и используется при запуске.
ddk compose
docker-compose up -dЕсли при формировании конфигурации указать соответствующую опцию, можно обойтись одной командой.
ddk compose --upЖелающие увидеть ddk в действии могут развернуть демо-проект.
Качаем последнюю сборку:
wget https://github.com/simbigo/ddk/raw/master/dist/ddk
chmod +x ddkНастраиваем будущий домен:
echo 127.0.0.1 hello.ddk >> /etc/hostsРазворачиваем проект:
./ddk init
./ddk project get hello
./ddk compose --upПосле успешной сборки всех образов, проект доступен по адресу http://hello.ddk
Чего добились:
Над чем стоит поработать:
Для тех, у кого возникнет непреодолимое желание посмотреть, сделать лучше или просто покритиковать код, прилагаю ссылку на github. Будем рады, если инструмент окажется полезным еще кому-то, кроме нас.
|
Метки: author Simbigo разработка веб-сайтов программирование ddk docker docker-compose |
Polybius Bank: самое значительное событие года в мире криптовалют |

|
Метки: author EShumilov финансы в it блог компании emercoin polybius блокчейн криптовалюты |
[recovery mode] Кто владеет Nimses? |

Администрация — NIMSES INC, 1209 N ORANGE ST, WILMINGTON, DE 19801, USA, Tel (650) 288- 1989



Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author lawboot исследования и прогнозы в it nimses lawboot юристы для it юрист it lawyer it стартап оффшорные компании |
Дзен не позвонит |


Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author firstpasha reactjs javascript redux redux-sucks react |
Дешевый full flash – выдумка или реальность? |





|
|
[Перевод] Интеллектуальность — новый виток в развитии систем локализации |

|
Метки: author alconost управление проектами локализация продуктов gtd блог компании alconost alconost локализация автоматизация перевод переводчики |
История одного лендинга |
 Здравствуйте, дорогие хабравчане! В этом посте я хочу рассказать о том, как и в какую цену я заказывал сайт у фрилансеров, в какие сроки я получил результат и что из этого сделал сам. Задача была создать “лендинг-магазин”: одностраничный сайт для двух товаров, с возможностью сразу же сделать заказ через полнофункциональную корзину.
Здравствуйте, дорогие хабравчане! В этом посте я хочу рассказать о том, как и в какую цену я заказывал сайт у фрилансеров, в какие сроки я получил результат и что из этого сделал сам. Задача была создать “лендинг-магазин”: одностраничный сайт для двух товаров, с возможностью сразу же сделать заказ через полнофункциональную корзину. |
Метки: author Treg разработка веб-сайтов php javascript лендинг дизайн верстка техническое задание фриланс |
[Из песочницы] Как создать язык программирования |
a = true
if a
console.log('Hello, lexer')[IDENTIFIER:"a"]
[ASSIGN:"="]
[BOOLEAN:"true"]
[NEWLINE:"\n"]
[NEWLINE:"\n"]
[KEYWORD:"if"]
[IDENTIFIER:"a"]
[NEWLINE:"\n"]
[INDENT:" "]
[IDENTIFIER:"console"]
[DOT:"."]
[IDENTIFIER:"log"]
[ROUND_BRAKET_START:"("]
[STRING:"'Hello, lexer'"]
[ROUND_BRAKET_END:")"]
[NEWLINE:"\n"]
[OUTDENT:""]
[EOF:"EOF"]def lexer(code):
code = code.split(";") # Токенезация
code = code[0:-1] # Т.к. есть баг, что последний элемент пустой
return parse(code, number=0) # "Отсылаем" это все парсеруprintf Test; exit;["printf Test", "exit"]number = 0
if code[number].startswith("printf"):
print(code[number][7:-0]
number += 1number = 0
if code[number].startswith("printf"):
print(code[number][7:-1]
number += 1number = 0
if code[number].startswith("printf"):
l = len(code[number])
print(code[number][7:l]
number += 1if code[number][7] == " ":
l = len(code[number])
print(code[number][8:l]
else:
l = len(code[number])
print(code[number][7:l]
l = len(code[number]) # Получаем длину
if code[number][6] == " ": # Если 6-ой символ это пробел
print(code[number][7:l]) # Печатаем все с 7-го символа
else: # Иначе
print(code[number][8:l]) #def parse(code, number=0):
try:
# Print function #
if code[number].startswith("printf") or code[number].startswith(" printf"):
# Get len
l = len(code[number])
# If text starts with space
if code[number][6] == " ":
print(code[number][7:l])
# Else
else:
print(code[number][8:l])
number += 1
parse(code, number)
# Input function #
if code[number].startswith("input") or code[number].startswith(" input"):
# Get len
l = len(code[number])
# If text starts with space
if code[number][6] == " ":
input(code[number][7:l])
# Else
else:
input(code[number][8:l])
number += 1
parse(code, number)
# Exit function #
elif code[number].startswith("exit") or code[number].startswith(" exit"):
input("\nPress \"Enter\" to exit.")
exit()
else:
cl = len(code[number])
command = code[number]
command = command[1:cl]
print("\n", "=" * 10)
print("Error!")
print("Undefined command " + '"' + command + '"' + ".")
print("=" * 10)
input("Press \"Enter\" to exit...")
exit()
except IndexError:
input("\n[!] Press \"Enter\" to exit.")
exit()
def lexer(code):
code = code.split(";")
code = code[0:-1]
return parse(code, number=0)
code = input()
lexer(code)|
Метки: author isisTance программирование python язык программирования |
Найти дизайнера: миссия (почти) выполнима |


|
Метки: author waytostart_ru управление персоналом управление медиа развитие стартапа карьера в it-индустрии дизайнер веб-дизайн дизайн студия дизайн дизайн сайтов веб-студия |
Совместная безопасность в облаке по версии RUVDS, HUAWEI и «Лаборатории Касперского» |















|
Метки: author ru_vds хостинг сетевые технологии it- инфраструктура блог компании ruvds.com ruvds касперский безопасность |
Поездка на Google I/O: как, зачем и сколько стоит |







|
|
Предварительная программа PyConRu-2017: выступят докладчики из Disney, Facebook, Яндекса, JetBrains, Тинькофф Банка |

 Inside the Hat: Python @ Walt Disney Animation Studios
Inside the Hat: Python @ Walt Disney Animation Studios Gradual Typing of Production Applications
Gradual Typing of Production Applications Elegant Solutions for Everyday Python Problems
Elegant Solutions for Everyday Python Problems Python на острие бритвы: PyPy project
Python на острие бритвы: PyPy project Отладка в Python 3.6: быстрее, выше, сильнее
Отладка в Python 3.6: быстрее, выше, сильнее Python of Things
Python of Things Тотальный контроль производительности
Тотальный контроль производительности Write once run anywhere — почём опиум для народа?
Write once run anywhere — почём опиум для народа? Микросервисы наносят ответный удар!
Микросервисы наносят ответный удар! Как написать свой debugger
Как написать свой debugger (Без)опасный Python
(Без)опасный Python Gevent — быть или не быть?
Gevent — быть или не быть? 

|
Метки: author shulyndina разработка веб-сайтов программирование python django блог компании it-people конференция |
[Из песочницы] Redux: попытка избавиться от потребности думать во время запросов к API |
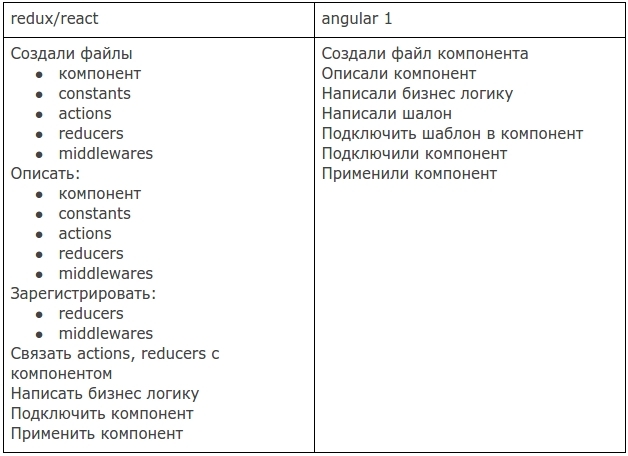
Я начал изучать React и Redux не так давно, но он уже успел изрядно потрепать мне нервы. Буквально над каждым действием приходится задумываться — почти никакие изменения в коде невозможны без того, чтоб что-то оторвать. Чтоб просто получить список постов по API и вывести их, надо, пожалуй, написать не меньше сотни строк кода — создать корневой контейнер, создать store, добавить action для запроса к API, для успешного результата запроса, для неудачного результата запроса, создать action-creators, сматчить action-creators и props, сматчить dispatch и props, написать reducer на каждый action… Ух, продолжать не хочется. И все это мы должны делать заново для каждого веб-приложения — крайне нерациональная трата сил программиста.
Да, можно сказать новичку: "Смотри, тут десяток пакетов, которые могут сделать каждое действие из этого списка вместо тебя. Выбирай и пользуйся!" Но проблема в том, что надо разобраться в настройке и воспользоваться десятком пакетов, позаботившись о том, чтоб они совпадали с версией, которая описана в документации и не вступали друг с другом в конфликты… Слишком сложно. Хочется чего-то проще, такого же простого, как в мире Django, из которого я пришел. Какой-то один пакет, после установки которого в store сами по волшебству складываются все нужные данные — бери и пользуйся.
Ну, я и решил — если такого решения нет, напишу-ка я его сам.
Убирая всю лирику из первого абзаца, получаю задачу — нам нужно создать инструмент, который будет:
По описанию выходит, что состоять пакет будет из action creator'а, middleware и reducer'а.
К счастью, как было сказано в первом абзаце, очень многие вещи на JS уже давно написаны, и писать их заново не придется. Например, ходить в API мы будем с помощью redux-api-middleware, следить за неизменяемостью данных будем с помощью react-addons-update, а нормализовать данные (куда же без этого?) будем с помощью normalizr.
Самое главное в этом пакете — простота настройки. Для того, чтоб просто описать модель данных, точки входа в API и инвалидацию старых данных, нам нужен конфиг. С его помощью мы и будем придумывать архитектуру приложения. Может, архитектурно это и не очень правильно, но мое мнение таково — плясать в первую очередь нужно от удобства разработчика, даже если это накладывает трудности на техническую реализацию кода.
1. Опишем схему данных со связанными сущностями на примере постов и юзеров:
const schema = {
users: {},
posts: {
author: "users"
}
};Что-то напоминает, правда? Похоже на schema.Entity из normalizr. да, можно было использовать сразу классы из normalizr, но я считаю, что это пойдет во вред удобству конфига. В normalizr ключ должен ссылаться не просто на строку, как в нашем конфиге, а на объект entity, и конфиг превратился бы в это:
import {schema} from 'normalizr';
const user = new schema.Entity("users", {});
const post = new schema.Entity("posts", {author: user});
const normalizrSchema = {
users: user,
posts: post,
}И это намного менее красиво и удобно, чем первый вариант.
2. Точки входа и actions для API.
Тут мы будем следовать обратной логике — если есть удобный способ конфигурации, написанный ком-то до нас, зачем его менять? Сформируем конфиг с параметрами, которые передаются в action в redux-api-middleware, и получится довольно удобно:
const api = {
users: {
endpoint: "mysite.com/api/users/",
types: ['USERS_GET', 'USERS_SUCCESS', 'USERS_FAILURE'],
},
posts: {
endpoint: "mysite.com/api/posts/",
types: ['POSTS_GET', 'POSTS_SUCCESS', 'POSTS_FAILURE'],
}
};Конечно, все типы action можно объявить отдельными переменными, а не строками — тут это сделано исключительно для простоты. Реализуем мы только GET-запросы, поэтому нет нужды в поле method.
3. "Время жизни" данных в store.
Конечно, рано или поздно данные на клиенте теряют актуальность — нам нельзя слепо полагаться на данные, которые когда-то давно к нам пришли с сервера. Поэтому надо предусмотреть механизм инвалидации старых данных и записать "время жизни" каждого типа данных в конфиг.
const lifetime = {
users: 20000,
posts: 100000
};Соберем все части конфига воедино:
const config = {schema, api, lifetime};Таким образом, все довольно просто — юзеры "живут" в store 20 секунд, а посты — 100 секунд. Как только время жизни выйдет, мы должны будем идти за данными, даже если они уже хранятся в store, значит, нужно будет запоминать время прихода данных. И это нас подводит к следующему пункту — планированию store.
В этом пункте все довольно просто — нам нужно хранить данные и время их прихода. Заведем два ключа в store — entities и timestamp. Для уже знакомых с normalizr сразу становится понятно — в entities мы будем хранить наши сущности, и выглядеть он будет как-то так:
const entities = {
posts: {1: {id: 1, content: "content", author: 1}, 2: {id: 2, content: "not content", author: 2}},
users: {1: {id: 1, username: "one"}, 2: {id: 2, username: "two"}}
};То есть, это словарь с ключами-сущностями, каждая из которых, в свою очередь, словарь с ключами-id моделей.
timestamp же будет выглядеть очень похоже, но по id мы будем получать не данные, а момент доставки данных клиенту — Date.now().
const timestamp = {
posts: {1: 1496618924981, 2: 1496618924981},
users: {1: 1496618924983, 2: 1496618924983}
};На этом, в общем-то, пока все. В следующей части будет описан процесс разработки самих компонентов.
|
Метки: author geoolekom разработка веб-сайтов reactjs javascript api redux react npm middleware es6 |
Выстраиваем процесс разработки и CI pipeline, или Как разработчику стать DevOps для QA |

tail -f, отыскивает грепом изменения нужного вида, и потом дёргает уже REST API TC. Не самый логичный подход, и некоторые билды начали задваиваться, но что поделаешь, некогда.-Dcatalina.base путь к копии директории $TOMCAT_PATH/conf, и запускает WAR не единым куском, а в exploded виде, то есть, разархивированным, — чтобы на лету можно было файлы с байткодом подменять.#####.dev.стартап.ком/путь/до/REST/endpoint на localhost:#####/путь/до/REST/endpoint и обратно. ##### — это уже конкретный номер порта, который конфигурируется в томкэтовых конфигах. Да, нечего пытаться даже запустить все фич-бранчи под одним томкэтом, вместо этого, для каждого из них будем заводить отдельную директорию $TOMCAT_PATH/conf, и запускать свой томкэт. Это в разы проще и надёжнее, и проблем с параллельностью нет.feature-#####-что-нибудь или bugfix-#####-что-нибудь. Вот последние три цифры номера и будут входить в номер порта. А ещё это красиво.-Dcatalina.base=/deployments/d###, и готово./deployments/d###. Пройти по поддиректориям, выплюнуть для каждой ссылки на старт/стоп, например.list.dev.стартап.ком (доступен будет только из внутренней сети стартапа, как и все экземпляры)… Иногда хочется чего-нибудь не только полезного, но и слегка ненормального. Такого, как минимальный обработчик HTTP-запросов на bash.list.dev.стартап.ком/refresh?start=d### при помощи регулярок bash и никсовых утилит всё же не очень удобно. Но это уже я сам виноват — придумал глобальные слэш-команды и знак-вопроса-действия для экземпляров. Да, и вызывались внешние утилиты там для 60 поддиректорий много сотен раз, отчего консолька работала небыстро.mysql -e "SHOW DATABASES" не отходя от кассы, и сунуть это в стандартный вывод, слегка подредактировав седом или авком для читаемости. Для диагностики очень хорошо, удобно.killall -9 java (иногда хочется начать неделю с чистого листа), uptime, и несколько других полезностей. Самая главная — это возможность удалить экземпляр приложения вместе с базой. По крону, конечно, директория /deployments через две недели почистится (изначально было предусмотрено), но иногда хочется задеплоенную копию билда реджектнутого лидом PR убрать с глаз долой, чтобы не мозолила./deployments/s### (другая буква префикса, чтобы у экземпляров и снимков были разные пространства имён). Деплоим примерно тем же скриптом, что и с тимсити, только базу копируем не из дампа, а существующую.
|
|
[recovery mode] Создание простого аудиоредактора |

|
Метки: author elder_cat разработка под windows c# блог компании everyday tools uwp windows store windows аудио |






