[Из песочницы] Почему стоит полностью переходить на Ceylon или Kotlin (часть 1) |
В последнее время активную популярность набирает Kotlin. А что если попробовать выбрать более экзотические языки, и применить к ним те же аргументы? Статья написана по мотивам этой, практически повторяя все аргументы за Kotlin. Основная задача: показать, что Ceylon может практически тоже самое, что и Kotlin, применительно к Java. Но кроме этого у Ceylon есть кое-что еще, что будет описано в следующей статье.
Хочу рассказать о новом языке программирования, который называется Ceylon, и объяснить, почему вам стоит использовать его в своём следующем проекте. Раньше я писал на Java (много и долго, более 10 лет, начиная с Java 1.4 и заканчивая Java 8), и Java мне нравилась. Затем на меня большое впечатление произвела Scala, в результате чего Java как язык стал любить несколько меньше. Но судьба свела меня с языком Сeylon, и в последние полтора года мы пишем на Ceylon везде, где только можно. В реальных коммерческих проектах, правда внутренних. И в данный момент я не представляю себе ситуации, в которой лучше было бы выбрать Java, я не рассматриваю Java как язык, на котором стоит начинать новые проекты.
Ceylon разработан в Red Hat, автор языка — Gavin King, известный по такому фреймворку как Hibernate. Он создавался людьми, которые хорошо понимают недостатки Java, основная цель заключалась в решении сугубо прикладных задач, обеспечение максимально легкой читаемости кода, избегание любых неоднозначностей и подводных камней, во главу всего стала предсказуемость и структурная красота языка. Также большое внимание уделялось приемлемому времени компиляции. В настоящее время версия языка 1.3.2, непосредственно я познакомился с языком, когда вышла версия 1.2.0.
Хотя Ceylon компилируется в JavaScript, я сконцентрируюсь на его первичной среде — JVM.
Итак, несколько причин, почему вам следует полностью переходить на Ceylon (порядок совпадает с одноименными пунктами соответствующей Kotlin статьи):
0# Совместимость с Java
Также, как и Kotlin, как и Scala, Ceylon на 100 % совместим с Java. Вы можете в буквальном смысле продолжать работать над своим старым Java-проектом, но уже используя Ceylon. Все Java-фреймворки также будут доступны, и, в каком бы фреймворке вы ни писали, Ceylon будет легко принят упрямым любителем Java. Можно без проблем вызывать из Java Ceylon код, также без проблем вызывается Java код.
1# Знакомый синтаксис
Одна из основных особенностей языка Ceylon — максимально удобно читаемый для существующих разработчиков синтаксис. Если взять существующего Java разработчика, то с пониманием Ceylon синтаксиса у него не будет ни малейших проблем. Даже такие языки, как Scala и Kotlin будут менее похожи на Java. Ниже приведен код, показывающий значительное количество конструкций языка, аналогичный примеру на Kotlin:
class Foo(String a) {
String b= "b"; // unmodifiable
variable Integer i = 0; // variable means modifiable
void hello() {
value str = "Hello";
print("``str`` World");
}
Integer sum(Integer x, Integer y) {
return x + y;
}
Float maxOf(Float a, Float b) => if (a > b) then a else b
}Соответственно можно без проблем продолжать писать в Java стиле на Ceylon.
2# Интерполяция строк
Это как бы более умная и читабельная версия String.format() из Java, встроенная в язык:
value x = 4;
value y = 7;
print("sum of ``x`` and ``y`` is ``x + y``") ; // sum of 4 and 7 is 11ИМХО синтаксис здесь будет поприятнее, чем в Kotlin, с Java даже не хочется сравнивать.
3# Выведение типа
Ceylon будет выводить ваши типы, если вы посчитаете, что это улучшит читабельность:
value a = "abc"; // type inferred to String
value b = 4; // type inferred to Integer
Float c = 0.7; // type declared explicitly
List d = ArrayList(); // type declared explicitly 4# Умные приведения типов (Smart Casts)
Компилятор Ceylon отслеживает вашу логику и по мере возможности автоматически выполняет приведение типов, т. е. вам больше не нужны проверки instanceof после явных приведений:
if (is String obj) {
print(obj.uppercased) // obj is now known to be a String
}5# Интуитивные равенства (Intuitive Equals)
Можно больше не вызывать явно equals(), потому что оператор == теперь проверяет структурное равенство:
value john1 = Person("John"); //we override equals in Person
value john2 = Person("John");
print(john1 == john2); // true (structural equality)
print(john1 === john2); // false (referential equality)6# Аргументы по умолчанию
Больше не нужно определять несколько одинаковых методов с разными аргументами:
void build(String title, Integer width = 800, Integer height = 600) {
return Frame(title, width, height);
}7# Именованные аргументы
В сочетании с аргументами по умолчанию именованные аргументы избавляют от необходимости использовать Строителей:
build("PacMan", 400, 300) // equivalent
build {title = "PacMan"; width = 400; height = 300;} // equivalent
build {title = "PacMan"; height = 300;} // equivalent with default width8# Выражение switch
Оператор ветвления заменён гораздо более читабельным и гибким в применении выражением switch:
switch (obj)
case(1) { print("x is 1"); }
case(2) { print("x is 2"); }
case(3 | 4) { print("x is 3 or 4"); }
case(is String) { print ("x is String"); }
case([Integer a, Float b, String c]) {print ("x is tuple with Integer ``a``, Float ``b`` and String ``c``");}
else { print("x is out of range");}switch может работать как выражение, также результат switch может быть присвоен переменной:
Boolean|IllegalStateException res =
switch(obj)
case(null) false
case(is String) true
else IllegalStateException();Это не полноценный pattern matching, но для большинства случаев хватает и текущего функционала.
В отличие от Kotlin у Ceylon требуется, чтобы к switch все условия были disjoint, то есть не пересекались, что для switch гораздо более логично. Если требуется сопоставление по диапазону или условия могут пересекаться, то нужно использовать обычный if.
9# Свойства
Можно добавить публичным полям кастомное поведение set & get, т. е. перестать набивать код безумными геттерами и сеттерами.
class Frame() {
variable Integer width = 800;
variable Integer height = 600;
Integer pixels => width * height;
}10# Data Class
К сожалению данного функционала пока нет. Очень хотелось бы иметь иммутабельные классы, у которых автоматом переопределен toString(), equals(), hashCode() и copy(), но, в отличие от Java, не занимали 100 строк кода.
Но то, что этого пока нет в языке, не означает что это невозможно сделать. Приведу пример, как нужный функционал реализован у нас через библиотеки, средствами самого языка:
class Person(shared String name,
shared String email,
shared Integer age) extends DataObject() {}
value john = Person("John", "john@gmail.com", 112);
value johnAfterBirhstday = john.copy({`Person.age`->113;});
assertEquals(john, john.copy());
assertEquals(john.hash, john.copy().hash); То есть на уровне библиотек получилось переопределить toString, оставить класс иммутабельным, мы получили возможность создавать клоны и изменениями отдельных аттрибутов. К сожалению работает это не так быстро, как могло быть, если бы поддержка была в языке. И нет проверки типов во время компиляции = если мы склонируем с переопределениев возраста и в качестве значения укажем строку, получим ошибку в рантайме. То, что такого функционала пока нет — безусловно плохо. Но то, что нужный функционал при необъодимости можем написать самостоятельно на уровне библиотеки — это очень хорошо.
11# Перегрузка оператора (Operator Overloading)
Заранее определённый набор операторов, которые можно перегружать для улучшения читабельности:
class Vec(shared Float x, shared Float y) satisfies Summable {
shared actual Vec plus(Vec v) => Vec(x + v.x, y + v.y);
}
value v = Vec(2.0, 3.0) + Vec(4.0, 1.0); 12# Деструктурирующие объявления (Destructuring Declarations)
Некоторые объекты могут быть деструктурированы, что бывает полезно, к примеру, для итерирования map:
for ([key -> [val1, val2, val3]] in map) {
print("Key: ``key``");
print("Value: ``val1``, ``val2``, ``val3``");
}13# Диапазоны (Ranges)
Для улучшения читабельности:
for (i in 1..100) { ... }
for (i in 0 : 100) { ... }
for (i in (2..10).by(2)) { ... }
for (i in 10..2) { ... }
if (x in 1..10) { ... }В отличие от Kotlin обошлось без ключевого слова downTo.
14# Функции-расширения (Extension Functions)
Их нет. Возможно появится, в ранних спецификациях языка такая возможность рассматривалась. Но вместо функций расширений в принципе работают top level функции. Если мы, допустим, хотим добавить к классу String метод sayHello, то "world".sayHello() выглядит не намного лучше чем sayHello("world"). В будущем они могут появиться.
В принципе соответствующие функции, доступные для класса, позволяет находить сама IDE, иногда это работает.
15# Безопасность Null
Java следует называть почти статично типизированным языком. Внутри него переменная типа String не гарантированно ссылается на String — она может ссылаться на null. И хотя мы к этому привыкли, это снижает безопасность проверки на статичное типизирование, и в результате Java-разработчики вынуждены жить в постоянном страхе перед NPE.
В Ceylon эта проблема решена посредством разделения на типы, допускающие и не допускающие значение null. По умолчанию типы не допускают null, но их можно преобразовать в допускающие, если добавить ?:
variable String a = "abc";
a = null; // compile error
variable String? b = "xyz";
b = null; // no problemЗа счет функционала union types String? это просто синтаксический сахар для String|Null. Соответственно можно написать:
variable String|Null с = "xyz";
с = null; // no problemCeylon заставляет вас бороться с NPE, когда вы обращаетесь к типу, допускающему null:
value x = b.length // compile error: b might be nullВозможно, выглядит громоздко, но благодаря нескольким своим возможностям действительно полезно. У нас всё ещё есть умные приведения типов, когда типы, допускающие null, преобразуются в не допускающие:
if (!exists b) { return; }
value x = b.length // no problemТакже можно использовать безопасный вызов ?., он возвращает значение null вместо бросания NPE:
value x = b?.length; // type of x is nullable IntМожно объединять безопасные вызовы в цепочки, чтобы избегать вложенных проверок если-не-null, которые иногда мы пишем в других языках. А если нам по умолчанию нужно не null-значение, то воспользуемся elvis-оператором else
value name = ship?.captain?.name else "unknown";Если всё это вам не подходит и вам совершенно точно нужны NPE, то скажите об этом явно:
value x = b?.length else NullPointerException() // same as below
assert(!NullPointerException x);16# Улучшенные лямбды
Это хорошая система лямбд — идеальный баланс между читабельностью и лаконичностью благодаря нескольким толковым решениям. Синтаксис прост:
value sum = (Integer x, Integer y) => x + y; // type: Integer(Integer, Integer)
value res = sum(4,7) // res == 11Соответственно синтаксис может быть:
numbers.filter( (x) => x.isPrime() );
numbers.filter(isPrime)Это позволяет нам писать лаконичный функциональный код:
persons
.filter ( (it) => it.age >= 18)
.sort(byIncreasing(Person.name))
.map ( Person.email )
.each ( print );Система лямбд плюс синтаксические особенности языка, делает Ceylon неплохим инструментом для создания DSL. Пример DSL, похожего на Anko, в синтаксисе Ceylon:
VerticalLayout {
padding = dip(30); {
editText {
hint = "Name";
textSize = 24.0;
},
editText {
hint = "Password";
textSize = 24.0;
},
button {
"Login";
textSize = 45.0;
} }
};17# Поддержка IDE
Между прочим, она достаточно неплохая. Есть eclipse плагин, есть IDEA плагин. Да, по части фич и багов все несколько хуже, чем в Scala или Kotlin. Но в принципе работать можно и достаточно комфортно, проблемы IDE на скорости разработки практически не сказываются.
Итого, если брать сильные стороны Kotlin, Ceylon уступает Kotlin отсутствием функционала DataObject (который можно эмулировать самостоятельно средствами библиотек). В остальном он обеспечивает не меньшие возможности, но с более приятным для чтения синтаксисом.
Ну и так же, как и на Kotlin, на Ceylon можно писать для Android.
Прочитав вышесказанное, может сложиться впечатление — а зачем нам это? Тоже самое есть и в Kotlin, практически 1 в 1.
А то, что в Ceylon есть вещи, которых нет ни в Kotlin, ни в Scala, и за счет этих вещей сам язык во многом гораздо лучше, чем другие языки. Например union types, intersection types, enumerated types, более мощные generics, модульность, herd, аннотации и метамодель, кортежи, for comprehensions. Что реально меняет подход к программированию, позволяет писать гораздо более надежный, понятный и универсальный код. Но об этом в следующей части.
https://ceylon-lang.org/documentation/1.3/introduction/
https://ceylon-lang.org/documentation/1.3/faq/language-design/
https://dzone.com/articles/a-qa-with-gavin-king-on-ceylon
https://www.slant.co/versus/116/390/~scala_vs_ceylon
https://www.slant.co/versus/390/1543/~ceylon_vs_kotlin
https://dzone.com/articles/ceylon-enterprise-ready
http://tryge.com/2013/12/13/ceylon-and-kotlin/
|
Метки: author elmal программирование kotlin java ceylon |
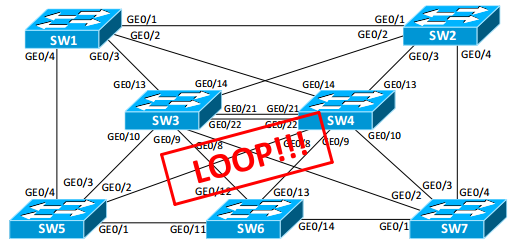
Rapid STP |




|
Метки: author ksg222 системное администрирование сетевые технологии cisco блог компании cbs rstp mst stp pvst+ pvrst+ bpdu |
Huginn: простая интеграционная платформа |






docker run -it --name huginn \
-p 3000:3000 \
-e ADDITIONAL_GEMS="huginn_mysql2_agent(git: https://github.com/yubuylov/huginn_mysql2_agent.git),huginn_jsonapi_agent(git: https://github.com/yubuylov/huginn_jsonapi_agent.git)" \
huginn/huginn
http://localhost:3000/
Логин: admin, Пароль: password
|
Метки: author yubuylov программирование ruby on rails api блог компании carprice carprice карпрайс разработка продукт аукцион huginn zapier |
Задай вопрос разработчикам облачных сервисов Mail.Ru Group |

Благодаря Reddit становится популярен формат Ask Me Anything (AMA) — когда команда специалистов, ответственных за какой-то большой, популярный проект, предлагает всем желающим задавать им любые вопросы об их работе и о том, что у сервиса «под капотом», как всё устроено. Первыми формат AMA на Хабре использовали разработчики Badoo. Мы тоже решили попробовать. Надеемся, что другие компании последуют нашему примеру и начнут впускать читателей на свои внутренние кухни.
Стартовать AMA мы решили с командой Облака Mail.Ru. Это молодой, активно развивающийся проект, о котором нам всегда задают много вопросов. К тому же с момента запуска (с августа 2013 года) Облако разрослось в большую семью проектов.
Исторически Облако начиналось как B2C-продукт с веб-, десктопной и мобильными версиями. Однако B2B — это тоже очень перспективный рынок. Поэтому у нас появилась платформа Mail.Ru для бизнеса, объединяющая все B2B-сервисы компании Mail.Ru Group, в том числе Облако для архивов (Icebox), Облако для рабочих групп (Teambox) и Горячее хранилище (Hotbox).
Кто и как именно обеспечивает жизнедеятельность и процветание этого весёлого семейства, как достигается сохранность данных, за счёт чего мы добиваемся высокой скорости загрузки файлов и низкой latency — обо всём этом вы узнаете из статьи, а после сможете задать любые интересующие вас вопросы.
Когда мы начинали писать Облако, то взяли за основу единую кодовую базу, которая использовалась и в Почте, и в Моём Мире, и в контентных проектах. Эту кодовую базу мы называем Mpop. Она представляет собой кучу библиотек, написанных на Perl. И несколько лет назад на ней жили все портальные проекты Mail.Ru Group. Когда в каком-то из проектов что-то рефакторили в Mpop, это влияло и на остальные. Постепенно каждый проект переехал на свою версию Mpop, а затем мы начали от неё уходить. Почта, например, частично перешла на Go. Мы тоже изначально жили на Mpop, но потихонечку всё переписали на свой супербыстрый Perl-сервер. У нас полностью асинхронная архитектура, мы используем AnyEvent. И если вы знаете Perl, то приходите к нам, у нас очень весело и интересно!
Структурно Облако Mail.Ru состоит из нескольких команд:
Бэкенд Облака Mail.Ru написан на ANSI C, Perl, Lua и немного С++. На Perl решаются задачи, связанные с API. Например, редактирование документов. К слову, мы когда-то рассказывали на Хабре о том, как показываем видео в Облаке, серверная часть там написана на Perl + Lua.
С самого начала, когда ставилась задача создать Облако, одним из главных требований было отсутствие долгих поисков по БД, никаких seek по диску и хранения по принципу append only. На момент старта мы не нашли подходящей БД под древовидные данные, поэтому создали собственную для представления файловой системы.
Приведём немного чисел:
Изначально Облако писалось с фокусом на десктопные и мобильные клиенты. Затем стало ясно, что веб-то жжот, нужно переделывать. Облако полностью переписали асинхронно (вообще у нас вся кодовая база асинхронная, от ANSI C до AnyEvent в Perl), стало намного лучше и быстрее. Например, сейчас веб-версия Облака живёт на том же десятке серверов, что и три года назад, при том, что число пользователей существенно выросло. Только тогда они лежали в полке по ресурсам без какого-либо запаса. Другие наши новые продукты, например Hotbox, мы тоже пишем на Perl. Такие дела.
Для написания iOS-приложения Облака мы продолжаем использовать Objective-C. Swift пока не трогаем по ряду причин:
В качестве примеров применения динамизма Objective-C приведём следующие:
Другие архитектурные особенности iOS-приложения:

Главная архитектурная задача для iOS приложения на сегодняшний день — избавление от подвисаний приложения при работе с большими облаками. В качестве инструмента для решения данной проблемы мы видим паттерн Schedulable Architecture, о котором мы не так давно писали на Хабре. Чтобы по мере его внедрения немедленно видеть результаты и быть уверенными, что движемся в правильном направлении, мы сделали мониторинг подвисаний. Сейчас у нас уже есть график самых проблемных мест в виде списка классов, в которых чаще всего происходят зависания. Выглядит он так:
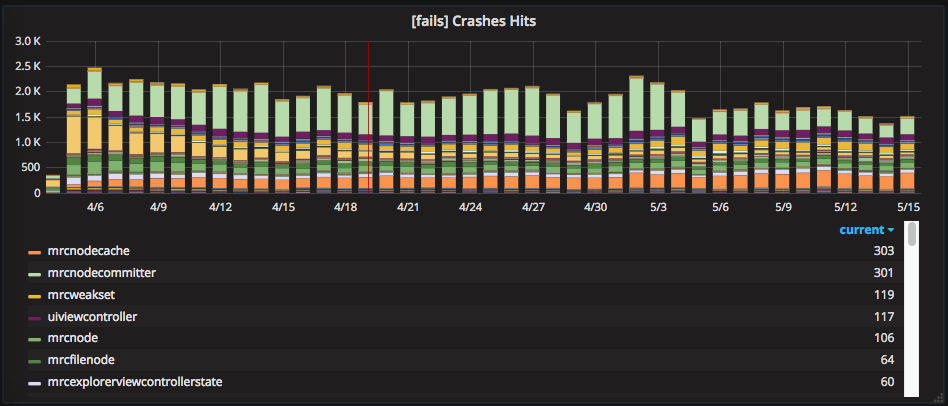
Благодаря плагину для HockeyApp у нас есть полная информация о каждом зависании — стек вызовов и логи.
Android-клиент Облака полностью разработан на Java (мы пока не нашли для себя выгоды в Kotlin’e). В принципе, в архитектуре нет ничего супермодного: MVP, весь сетевой слой в сервисе, для сети используем okhttp, данные храним в SQLite, за исключением галереи. Там может быть очень много данных, и их надо быстро поднимать из кеша. Поэтому для галереи мы применяем самописную сериализацию. Для коммуникации внутри приложения есть eventbus от green robot. Для эффективной работы в фоне на новых версиях андроида используем JobScheduler’ы, а для не очень новых — GcmNetworkManager.
Для выкатки фич на процент, A/B тестирования и части аналитики используем Firebase. Для отладки взаимодействия с сервером юзаем в дебажных сборках Stetho от Facebook. В последней версии почти перешли на векторную графику в приложении. Думаю, через пару версий полностью перейдём на неё. Тесты пишем на junit, uiautomator и espresso.
B2B-Облако — это три разных продукта:
B2B-Облако состоит из двух частей — фронтенда, который мы встроили в нашу Платформу для бизнеса, и бэкенда, который обеспечивает управление Облаком и его работу. Та часть бэкенда, которая отвечает за функционирование Облака, написана на Perl, поддержка управления — на Python.
Платформа для бизнеса biz.mail.ru обеспечивает доступ к управлению всех B2B-Облаков. Сама платформа — это общая административная панель для B2B-сервисов Mail.Ru: Почты для сайта, корпоративного Календаря, Агента, службы DNS и B2B-Облаков. Платформа предоставляет личный кабинет администраторов и реализована по принципу плагинов — есть общие элементы (авторизация, управление проектами и доменами, списком пользователей), есть отдельные разделы для подключаемых сервисов — Почты, Teambox, Hotbox, Icebox и других. У Платформы есть своё API и механизм проксирования запросов из бэкенда Платформы в бэкенды подключенных сервисов. Таким образом, у нас имеется общая инфраструктура, функционал которой разрабатывают разные команды программистов, а для пользователей всё управление собрано в одной административной панели.
По традиции надо обозначить время, когда мы будем отвечать на вопросы. И пусть это будут два дня, а не один: сегодня и завтра с 12.00 до 19.00 (по московскому времени). Но в случае особо ожесточённых дискуссий мы, конечно, не ограничимся этим интервалом. Задавайте вопросы про наш софт, про наши серверы, про наши команды, про наше API и так далее. Погнали!
|
Метки: author Croston разработка мобильных приложений разработка веб-сайтов высокая производительность анализ и проектирование систем блог компании mail.ru group mail.ru облако ama |
Особенности –webkit-box или как «подружить» flexbox со старыми Safari |
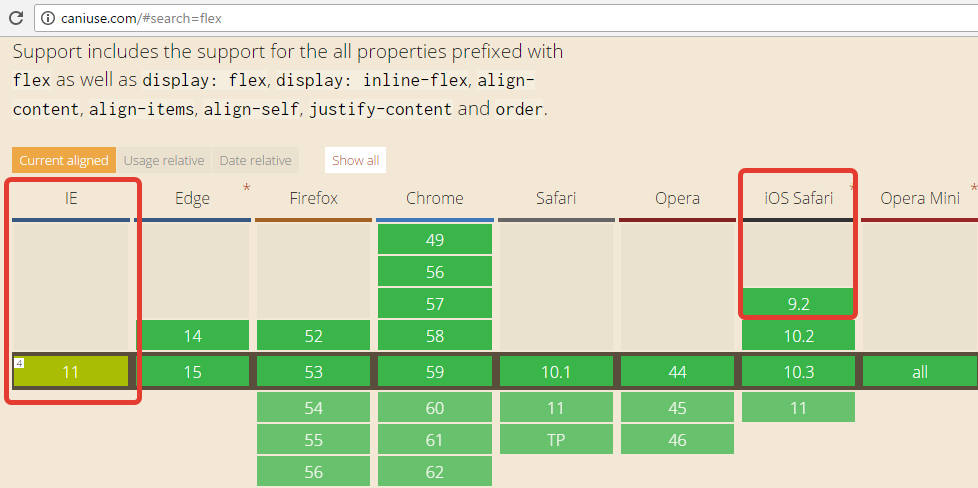


@media all and (-webkit-min-device-pixel-ratio:0) {
/*Всё, что вы сюда напишете, будет работать только с -webkit-*/
}|
Метки: author m1hasik разработка веб-сайтов safari html css css3 html- верстка |
[Перевод] Must-Have 3: игровые интерфейсы и ассеты для дизайнера и художника |































|
Метки: author Plarium интерфейсы дизайн мобильных приложений дизайн игр графический дизайн блог компании plarium дизайн gui ассеты наборы геймдев готовые решения |
Что такое Nimses? Интсаграм где вместо лайков деньги |



|
Метки: author zarytskiy развитие стартапа nimses криптовалюта |
[Из песочницы] Списки инициализации в C++: хороший, плохой, злой |

В этой статье я бы хотел рассказать о том, как работают списки инициализации (braced initializer lists) в C++, какие проблемы они были призваны решать, какие проблемы, в свою очередь, вызвали и как не попасть в просак.
Первым делом предлагаю почувствовать себя компилятором (или language lawyer-ом) и понять, компилируются ли следующие примеры, почему, и что они делают:
Классика:
std::vector v1{5};
std::vector v2(5);
std::vector v3({5});
std::vector v4{5};
std::vector v5 = 5; Современный C++ — безопасный язык, я никогда не выстрелю себе в ногу:
std::vector x( {"a", "b"} );
std::vector y{ {"a", "b"} };Больше скобочек богу скобочек!
// Почему их тут пять, скомпилируется ли программа и почему?
std::vector> v1{{{{{}}}}}; Если один конструктор не подходит, мы берем второй, правильно?
struct T{};
struct S {
S(std::initializer_list);
S(double, double);
S(T, T);
};
int main() {
S{T{}, T{}}; // Работает ли вот так?
S{1., 2.}; // а так?
} Almost Always Auto, говорили они. Это повышает читабельность, говорили они:
auto x = {0}; // какой тут тип у x?
auto y{0}; // а у y?
// вы уверены? попробуйте другую версию вашего компилятораПривет из древних времен:
struct S {
std::vector a, b;
};
struct T {
std::array a, b;
};
int main() {
T t1{{1, 2}, {3, 4}};
T t2{1, 2, 3, 4};
T t3{1, 2};
S s1{{1, 2}, {3, 4}};
S s2{1, 2, 3, 4};
S s3{1, 2};
} Все понятно? Или ничего не ясно? Добро пожаловать под кат.
{...} я буду называть braced-init-lists, тип из стандартной библиотеки — std::initializer_list, а вид инициализации, когда мы пишем как-то так: int x{5} — это list-init, также известная как uniform initialization syntax, или универсальный синтаксис инициализации.Первым делом обращу внимание на важное наблюдение. Даже если вы из всей статьи вынесете только его, а дальше читать станет лень, моя миссия здесь будет исполнена.
Итак, braced-init-lists (штуки с фигурными скобками, {1, 2, 3}, uniform initialization syntax) и std::initializer_list — разные вещи! Они сильно связаны, между ними происходят всякие тонкие взаимодействия, но любое из них вполне может существовать без другого.
Но сначала — немного предыстории.

В C++98 (и его bugfix-update, C++03) существовало достаточно проблем и непоследовательностей, связанных с инициализацией. Вот некоторые из них:
std::vector) из заранее известных элементов — в языке не было встроенной возможности для этого, а библиотечные решения (Boost.Assign) не отличались изящностью синтаксиса, были не бесплатны с точки зрения скорости работы и не слишком хорошо влияли на время компиляцииdouble в intПоэтому во время разработки C++11 родилась такая идея: давайте мы дадим возможность проинициализировать что угодно с помощью фигурных скобок:
Казалось бы, на этом можно и закончить: инициализация контейнеров должна получиться сама собой, ведь в C++11 появились еще и шаблоны с переменным числом параметров, так что если мы напишем variadic-конструктор… на самом деле, нет, так не получится:
std::vector-а будет все равно не идеальнаяДля решения этих проблем придумали std::initializer_list — "магический класс", который представляет собой очень легкую обертку для массива элементов известного размера, а так же умеет конструироваться от braced-init-list-а.
Почему же он "магический"? Как раз по описанным выше причинам его невозможно эффективно сконструировать в пользовательском коде, поэтому компилятор создает его специальным образом.
Зачем же он нужен? Главным образом, чтобы пользовательские классы могли сказать: "я хочу конструироваться от braced-init-list-а элементов такого-то типа", и им не требовался бы для этого шаблонный конструктор.
(Кстати, к этому моменту должно стать понятно, что std::initializer_list и braced-init-list это разные понятия)
Теперь-то все хорошо? Мы просто добавим в наш контейнер конструктор вида vector(std::initializer_list и все заработает? Почти.
Рассмотрим такую запись:
std::vector v{5}; Что имелось в виду, v(5) или v({5})? Другими словами, хотим ли мы сконструировать вектор из 5 элементов, или из одного элемента со значением 5?
Для решения этого конфликта разрешение перегрузок (overload resolution, выбор нужной функции по переданным аргументам) в случае list-initialization происходит в два этапа:
std::initializer_list (это один из главных моментов, когда компилятор таки генерирует std::initializer_list по содержимому фигурных скобочек). Разрешение перегрузок происходит между ними.Отметим, что конструктор, который проиграл на первом этапе, вполне может подойти на втором. Это объясняет пример с избытком скобочек для инициализации вектора из начала статьи. Для понятности удалим один из вложенных шаблонов, а также заменим std::vector на свой класс:
template struct vec {
vec(std::initializer_list);
};
int main() {
vec v1{{{}}};
} Под пункт 1 наш конструктор не подходит — {{{}}} не похож на std::initializer_list, потому что int нельзя проинициализировать с помощью {{}}. Однако {} — вполне себе zero-initialization, поэтому конструктор принимается на втором шаге.
Забавно, однако, что сужающее преобразование не является достаточным поводом для того, чтобы выкинуть конструктор — в следующем примере первый конструктор принимается на первом шаге разрешения перегрузок, и потом вызывает ошибку компилятора. Хорошо это или плохо — я не знаю, для меня это просто удивительно.
struct S {
S(std::initializer_list);
S(double, double);
};
int main() {
S{1., 2.};
} Похожая проблема с довольно страшным результатом получается и в примере с вектором строк из начала статьи. К несчастью, у std::string есть конструктор, который трактует два переданных указателя как начало и конец строки. Последствия такого поведения для строковых литералов, очевидно, плачевны, при этом синтаксически запись выглядит довольно похоже на корректный вариант и вполне может появиться, например, в обобщенном коде.
Ну теперь-то все? Не совсем. Старый синтаксис инициализации структур, доставшийся нам от C, никуда не делся, и можно делать так:
struct A { int i, j; };
struct B { A a1, a2; };
int main() {
B b1 = {{1, 2}, {3, 4}};
B b2 = {1, 2, 3, 4}; // brace elision
B b3 = {{1, 2}}; // clause omission
}Как видим, при иницализации агрегатов (грубо говоря, C-подобных структур, не путать с POD, POD — это про другое) можно и пропускать вложенные скобочки, и выкидывать часть инициализаторов. Все это поведение было аккуратно перенесено в C++.
Казалось бы, какой бред, зачем это в современном языке? Давайте хотя бы предупреждения компилятора будем на это выводить, подумали разработчики GCC и clang, и были бы правы, не будь std::array классом-агрегатом, содержащим внутри себя массив. Таким образом, предупреждение про выкидывание вложенных скобок по понятным причинам срабатывает на вот таком невинном коде:
int main() {
std::array a = {1,2,3};
}Проблему эту GCC "решил" выключением соответствующего предупреждения в режиме -Wall, в clang-е же уже три года все по-прежнему.
Кстати, тот факт, что std::array — агрегат, не прихоть безумных авторов стандарта или ленивых разработчиков стандартных библиотек: достичь требуемой семантики этого класса просто невозможно средствами языка, не теряя в эффективности. Еще один привет от C и его странных массивов.
Возможно, большая проблема с классами-агрегатами — это не самое удачное взаимодействие с обобщенными функциями (в том числе) из стандартной библиотеки. На данный момент функции, которые конструируют объект из переданных параметров (например, vector::emplace_back или make_unique), вызывают обычную инициализацию, не "универсальную". Вызвано это тем, что использование list-initialization не позволяет никаким нормальным способом вызвать "обычный" контруктор вместо принимающего std::initializer_list (примерно та же проблема, что и с инициализацией в не-шаблонном коде, только тут пользователь не может обойти ее вызовом другого конструктора). Работа в этом направлении ведется, но пока мы имеем то, что имеем.
Как же braced-init-list-ы ведут себя в сочетании с выводом типов? Что будет, если я напишу auto x = {0}; auto y = {1, 2};? Можно придумать несколько разумных стратегий:
int, а второй вариант запретитьstd::initializer_litsПоследний вариант нравится мне меньше всего (мало кому в реальной жизни заводить локальные переменные типа std::initializer_list), но в стандарт С++11 попал именно он. Постепенно стало выясняться, что это вызывает проблемы у программистов (кто бы мог подумать), поэтому в стандарт добавили патч http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2014/n3922.html, который реализует поведение №2… только в случае copy-list-initialization (auto x = {5}), а в случае direct-list-initialization (auto x{5}) оставляет все по-старому.

Я не могу это комментирвать. По-моему, это один из очень редких случаев, когда здравый смысл временно покинул авторов языка. Если у вас есть, что сказать по этому поводу, сообщите мне об этом в комментариях.
Хотя универсальный синтаксис инициализации и std::initializer_list — возможности языка, добавленные из благих и правильных побуждений, мне кажется, что из-за извечной необходимости в обратной совместимости и не всегда дальновидных решениях на ранних этапах вся ситуация вокруг них на данный момент излишне сложная, вымученная и не самая приятная для всех вовлеченных сторон — авторов стандарта, компиляторов, библиотек и прикладных разработчиков. Хотели как лучше, а получилось, как в известном комиксе:

В качестве примера возьмем, например, историю с [over.best.ics]/4.5, который сначала добавили в стандарт, потом, не подумав, удалили, как избыточный, а потом добавили обратно в измененном виде — как описание крайнего случая с пятью (!) условиями.
Тем не менее, возможность полезная и облегчающая жизнь, поэтому здесь я приведу небольшой и не претендующий на объективность список того, как не выстрелить себе в ногу:
std::initializer_list, кроме как в параметре конструктораautostd::initializer_list — это разные концепции, весьма хитро взаимодействующие друг с другомТут я заканчиваю свое введение в существующее положение дел, и хочу вбросить помечтать, как все могло бы быть, если бы мы жили в идеальном мире.
Мне кажется, что переиспользовать фигурные скобки для создания std::initializer_list во время инициализации — ошибка дизайна языка. Я был бы очень рад, если бы вместо этого мы получили бы более явный и отдельный синтаксис (пусть и более уродливый, например, какие-нибудь странные скобки типа <$...$> или встроенный интринзик вроде std::of(...)). То есть инициализируем вектор как-то так: std::vector> x = std::of(std::of(1, 2), std::of(3, 4));
Что бы это дало? Новый способ инициализации (с защитой от most vexing parse и сужающих преобразований) оказался бы отвязан от std::initializer_list, не потребовалось бы вводить отдельный шаг для разрешения перегрузок, ушла бы проблема с конструктором vector или vector, новый синтаксис инициализации можно было бы использовать в обобщенном коде безо всяких проблем.
Конечно, недостатки у такого подхода довольно серьезные: более уродливый синтаксис в простейших случаях и уход от цели сделать синтаксис более унифицированным с инициализацией в стиле C (к такой унификации я отношусь довольно скептически, но это тема для отдельного разговора).
Еще я недолюбливаю классы-агрегаты. Если оставить за скобками проблему с std::array, я не вижу достойного обоснования для существования такой большой и особенной возможности языка. Проблему с тем, что программистам не хочется писать тривиальные конструкторы для простых классов, можно было бы решить менее инвазивными способами, например, дать возможность генерировать конструктор, который бы инициализировал все поля по очереди:
struct S {
int a, b;
S(...) = aggregate;
};Напоследок повторюсь еще раз, что я не претендую на 100% корректность или на истину в последней инстанции. Добро пожаловать в комментарии, если что-то осталось непонятным, или если есть что сказать по этой довольно специфической теме.
|
Метки: author dkozh c++ с++ c++11 initialization braces |
[Из песочницы] Типизированные компоненты в Vue.js, или как подружить Vue, TypeScript и Webpack |

{
"name": "vuejs-webpack-ts",
"version": "1.0.0",
"description": "Sample project of Webpack+TS+Vue.js ",
"main": "webpack.config.js",
"scripts": {
"start": "webpack-dev-server --hot --inline --history-api-fallback"
},
"repository": "https://github.com/StepanZharychev/vue-ts-webpack.git",
"author": "Stepan Zharychev",
"license": "ISC",
"dependencies": {
"babel-core": "^6.24.0",
"babel-loader": "^6.4.1",
"css-loader": "^0.27.3",
"style-loader": "^0.16.0",
"ts-loader": "^2.0.3",
"typescript": "^2.2.1",
"webpack": "^2.3.2",
"vue": "^2.3.3",
"vue-class-component": "^5.0.1",
"vue-loader": "^12.1.0",
"vue-property-decorator": "^5.0.1",
"vue-template-compiler": "^2.3.3",
"webpack-dev-server": "^2.4.2"
}
}module.exports = {
entry: './app/init.ts',
output: {
filename: 'dist/bundle.js',
path: __dirname,
publicPath: '/static/'
},
module: {
loaders: [
{
test: /\.tsx?$/,
loader: 'ts-loader',
options: {
configFileName: 'tsconfig.json',
appendTsSuffixTo: [/\.vue$/]
}
},
{
test: /\.js/,
loaders: ['babel-loader']
},
{
test: /\.vue$/,
loader: 'vue-loader',
options: {
loaders: {
ts: 'ts-loader'
},
esModule: true
}
},
{
test: /\.css/,
loaders: ['style-loader', 'css-loader']
}
]
},
devServer: {
compress: true,
port: 8001
},
resolve: {
extensions: ['.tsx', '.ts', '.js']
},
devtool: 'source-map'
}
import Vue from 'vue'
import Component from 'vue-class-component'
import HelloComponent from '../hello/hello.vue'
@Component({
components: {
hello: HelloComponent
}
})
export default class MainComponent extends Vue {
public message = 'Hello there, Vue works!'
}
import MainComponent from './components/main/main.vue'declare module '*.vue' {
import Vue from 'vue'
export default Vue
}
import Vue from 'vue'
import MainComponent from './components/main/main.vue'
class AppCore {
private instance: Vue;
private init() {
this.instance = new Vue({
el: '#appContainer',
render: h => h(MainComponent),
})
}
constructor() {
this.init();
}
}
new AppCore();|
Метки: author StepanZharychev системы сборки программирование javascript vue.js webpack 2 typescript components |
Awless — мощная альтернативная CLI-утилита для работы с сервисами AWS |

awless completion).$ awless create instance subnet=subnet-356d517f image=ami-70edb016 type=t2.microawless log);awless revert с идентификатором операции из журнала);awless ssh);awless sync для локального хранения данных).$ curl https://raw.githubusercontent.com/wallix/awless/master/getawless.sh | bash$ go get -u github.com/wallix/awless$ awless list instances --sort uptime$ awless show jsmith$ awless create instance name=my_machine image=ami-3f1bd150 keypair={keypair.name} \
subnet={main.subnet} securitygroup={securitygroup} \
userdata=https://gist.github.com/simcap/360dffae4c6d76ab0e89621dd824a244$ awless attach policy user=jsmith arn=arn:aws:iam::aws:policy/AmazonEC2FullAccess$ awless create s3object bucket=my-existing-bucket file=./todolist.txt$ awless run repo:instance_ssh
Please specify (Ctrl+C to quit):
instance.name ? my-new-instance-name
instance.subnet ? @my-existing-subnet
instance.vpc ? @my-existing-vpc
keypair.name ? my-new-keyname
$ awless ssh my-new-instance-name-h (например, awless create instance -h).
|
Метки: author shurup open source amazon web services блог компании флант aws cloud cli утилиты devops |
Интеграция телефонии с CRM: на что опираться при самостоятельной настройке |

До этого момента я писал про отдельные локальные задачки на базе API, которые наши пользователи могут делать самостоятельно — получение уведомлений о потерянных звонках в мессенджеры и т.п.
Сейчас мы основательно обновляем более масштабный блок API — по управлению данными (Data API). Типовой кейс c его использованием — это, например, самостоятельная интеграция телефонии с CRM с расширенными возможностями контроля передаваемых между системами данных.
Давайте посмотрим, как сделать интеграцию телефонии с CRM с поддержкой базового функционала на примере retailCRM. При этом оговоримся, что под базовым функционалом мы понимаем:
Конкретно в схеме интеграции UIS с retailCRM мы реализовали еще несколько полезных функций (например, синхронизацию статусов сотрудников в сервисах и т.п.). Однако, думается, что они все-таки выходят за рамки базового функционала подобных интеграций, так что подробно на них в этом материале я останавливаться не буду.
В рамках статьи также подразумевается, что для работы интеграции необходим сервер-коннектор, который обеспечивает взаимодействие облачной АТС и CRM.
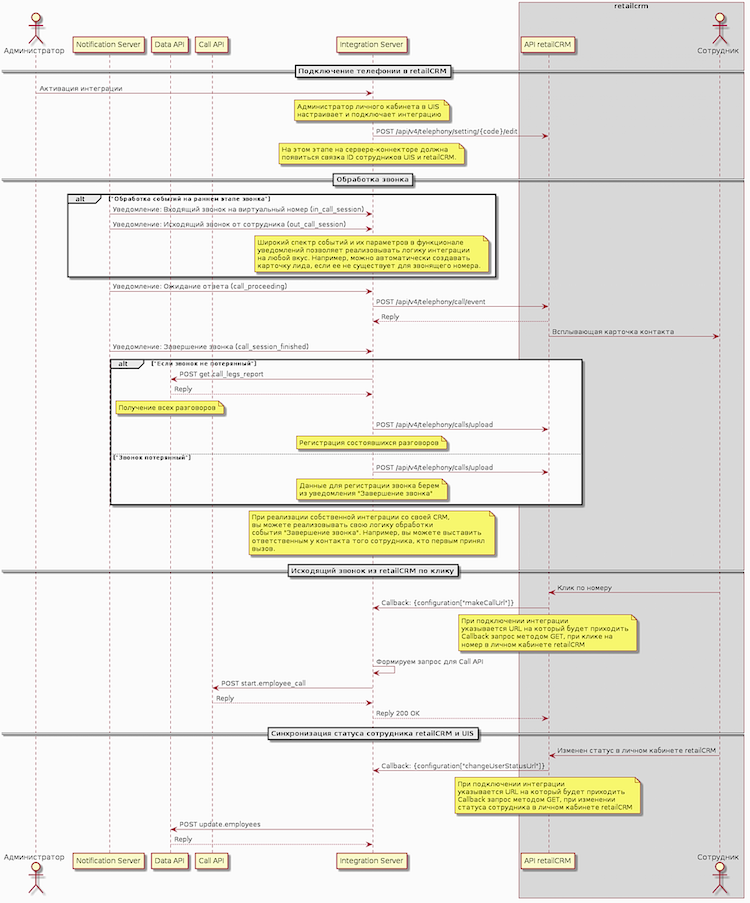
Кликайте на схему, чтобы посмотреть в полном размере.
Телефония в retailCRM активируется запросом к /api/v4/telephony/setting/{code}/edit. Cреди прочих, в запросе указываются следующие параметры:
Всплывающая карточка контакта в retailCRM осуществляется простым запросом к API /api/v4/telephony/call/event, триггером будет сработавшее уведомление на событие «Ожидание ответа», когда у сотрудника уже звонит телефон.
Пропущен звонок или успешен, можно определить по параметру is_lost в уведомлении о завершении звонка. И если звонок пропущен, то статус звонка будет загружен запросом API /api/v4/telephony/calls/upload, поля которого можно заполнить параметрами из уведомления.
Чтобы загрузить успешный звонок в retailCRM, предварительно нужно получить дополнительную информацию по этому вызову, с чем и поможет справиться Data API.
Немного о компоновке запроса:
{
"jsonrpc": "2.0",
"id": 1122,
"method": "get.call_legs_report",
"date_from": "2017-06-01 14:34:00",
"date_till": "2017-06-01 14:36:52",
"params": {
"access_token": "N2dw2Rf33fn23fknkmdfeJmcP",
"filter": {
"filters": [
{
"field": "call_session_id",
"operator": "=",
"value": 31451224
},
{
"field": "is_talked",
"operator": "=",
"value": true
}
],
"condition": "and"
},
"fields": [
"id",
"call_seesion_id",
"call_records",
"release_cause_code",
"direction",
"start_time",
"employee_id",
"called_phone_number",
"contact_phone_number",
"total_duration",
"duration"
]
}
}Полученную информацию необходимо загрузить в retailCRM запросом API /api/v4/telephony/calls/upload. Если требуется расширить набор загружаемых параметров, их можно взять из параметров уведомления «Завершение звонка».
При попытке сотрудника позвонить по клику на номер контакта из интерфейса CRM, retailCRM будет присылать вам запрос на URL, указанный при активации телефонии. Теперь необходимо этот запрос перенаправить в сервис телефонии для совершения звонка. Для этого можно использовать наш Call API.
{
"jsonrpc": "2.0",
"method": "start.employee_call",
"id": "number",
"params": {
"access_token": "N2dw2Rf33fn23fknkmdfeJmcP",
"first_call": "employee",
"early_switching": true,
"switch_at_once": true,
"show_virtual_phone_number": false,
"virtual_phone_number": "88002000600",
"direction": "out",
"contact": "72131231111",
"employee": {
"id": 13421
}
}
}При получении уведомления о смене статуса сотрудника от retailCRM, необходимо сгенерировать запрос к Data API, чтобы изменить настройки этого сотрудника в соответствии с новым статусом.
{
"jsonrpc": "2.0",
"id": "number",
"method": "update.employees",
"params": {
"access_token": "N2dw2Rf33fn23fknkmdfeJmcP",
"id": 13421,
"calls_available": false
}
}А сейчас, как обещал, расскажу о ключевых функциях по контролю передаваемых между телефонией и CRM данных, которые мы предусмотрели в обновленном API UIS.
Публичный запуск функционала мы запланировали на июль, но я готов рассказать больше, если вы хотите реализовать свою схему интеграции, подобную описанной выше, и нужны детали уже сейчас (писать мне лучше сюда).
P.S. Кстати говоря, если вы представитель CRM-системы, которой не хватает интеграции с телефонией, то тоже буду рад сотрудничать. Вы поможете нам проработать схему готовых партнерских интеграций в один клик из Личного кабинета UIS, а мы вам — сделать интеграцию наших сервисов для ваших пользователей.
|
|
[Перевод] Нативные EcmaScript модули: новые возможности и отличия перед webpack |

В предыдущей статье Нативные ECMAScript модули — первый обзор я рассказал историю JavaScript модулей и текущее состояние дел реализации нативных EcmaScript модулей.
Сейчас доступны две реализации, которые мы попробуем сравнить с бандлерами модулей.
Основные мысли:
|
Метки: author nialvi разработка веб-сайтов программирование браузеры javascript блог компании туту.ру frontend babel стандарты будущее webpack |
Notepad++: проверка кода пять лет спустя |


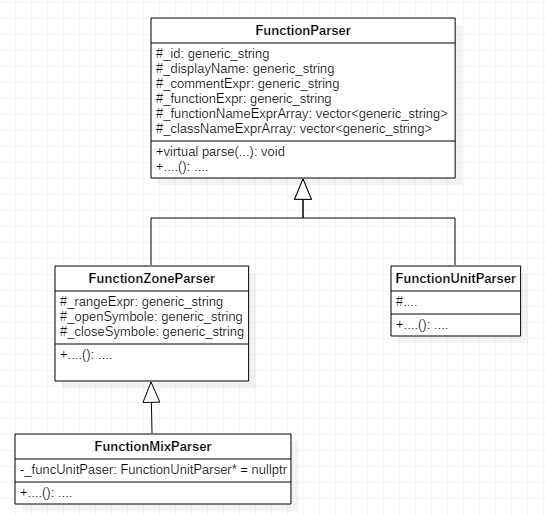
class FunctionParser
{
friend class FunctionParsersManager;
public:
FunctionParser(....): ....{};
virtual void parse(....) = 0;
void funcParse(....);
bool isInZones(....);
protected:
generic_string _id;
generic_string _displayName;
generic_string _commentExpr;
generic_string _functionExpr;
std::vector _functionNameExprArray;
std::vector _classNameExprArray;
void getCommentZones(....);
void getInvertZones(....);
generic_string parseSubLevel(....);
};
std::vector _parsers;
FunctionParsersManager::~FunctionParsersManager()
{
for (size_t i = 0, len = _parsers.size(); i < len; ++i)
{
delete _parsers[i]; // <=
}
if (_pXmlFuncListDoc)
delete _pXmlFuncListDoc;
} class FunctionZoneParser : public FunctionParser
{
public:
FunctionZoneParser(....): FunctionParser(....) {};
void parse(....);
protected:
void classParse(....);
private:
generic_string _rangeExpr;
generic_string _openSymbole;
generic_string _closeSymbole;
size_t getBodyClosePos(....);
};
class FunctionUnitParser : public FunctionParser
{
public:
FunctionUnitParser(....): FunctionParser(....) {}
void parse(....);
};
class FunctionMixParser : public FunctionZoneParser
{
public:
FunctionMixParser(....): FunctionZoneParser(....), ....{};
~FunctionMixParser()
{
delete _funcUnitPaser;
}
void parse(....);
private:
FunctionUnitParser* _funcUnitPaser = nullptr;
};
class Window
{
....
virtual void display(bool toShow = true) const
{
::ShowWindow(_hSelf, toShow ? SW_SHOW : SW_HIDE);
}
virtual void redraw(bool forceUpdate = false) const
{
::InvalidateRect(_hSelf, nullptr, TRUE);
if (forceUpdate)
::UpdateWindow(_hSelf);
}
....
}
class SplitterContainer : public Window
{
....
virtual void display(bool toShow = true) const; // <= good
virtual void redraw() const; // <= error
....
}
bool ProjectPanel::openWorkSpace(const TCHAR *projectFileName)
{
TiXmlDocument *pXmlDocProject = new TiXmlDocument(....);
bool loadOkay = pXmlDocProject->LoadFile();
if (!loadOkay)
return false; // <=
TiXmlNode *root = pXmlDocProject->FirstChild(TEXT("Note...."));
if (!root)
return false; // <=
TiXmlNode *childNode = root->FirstChildElement(TEXT("Pr...."));
if (!childNode)
return false; // <=
if (!::PathFileExists(projectFileName))
return false; // <=
....
delete pXmlDocProject; // <= free pointer
return loadOkay;
}bool FindReplaceDlg::processReplace(....)
{
....
TCHAR *pTextFind = new TCHAR[stringSizeFind + 1];
TCHAR *pTextReplace = new TCHAR[stringSizeReplace + 1];
lstrcpy(pTextFind, txt2find);
lstrcpy(pTextReplace, txt2replace);
....
}
LRESULT CALLBACK ScintillaEditView::scintillaStatic_Proc(....)
{
ScintillaEditView *pScint = (ScintillaEditView *)(....);
if (Message == WM_MOUSEWHEEL || Message == WM_MOUSEHWHEEL)
{
....
if (isSynpnatic || makeTouchPadCompetible)
return (pScint->scintillaNew_Proc(....); // <=
....
}
if (pScint)
return (pScint->scintillaNew_Proc(....));
else
return ::DefWindowProc(hwnd, Message, wParam, lParam);
}Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ((_langList[i]->_langID == langID) || (!_langList[i]))
return _langList[i];
}
return nullptr;
}Lang * getLangFromID(LangType langID) const
{
for (int i = 0 ; i < _nbLang ; ++i)
{
if ( !_langList[i] && _langList[i]->_langID == langID )
return _langList[i];
}
return nullptr;
}
bool VerifySignedLibrary(...., const wstring& cert_subject, ....)
{
wstring subject;
....
if ( status && !cert_subject.empty() && subject != subject)
{
status = false;
OutputDebugString(
TEXT("VerifyLibrary: Invalid certificate subject\n"));
}
....
}subject != subjectif ( status && !cert_subject.empty() && cert_subject != subject)
{
....
}TCHAR GetASCII(WPARAM wParam, LPARAM lParam)
{
int returnvalue;
TCHAR mbuffer[100];
int result;
BYTE keys[256];
WORD dwReturnedValue;
GetKeyboardState(keys);
result = ToAscii(static_cast(wParam),
(lParam >> 16) && 0xff, keys, &dwReturnedValue, 0); // <=
returnvalue = (TCHAR) dwReturnedValue;
if(returnvalue < 0){returnvalue = 0;}
wsprintf(mbuffer, TEXT("return value = %d"), returnvalue);
if(result!=1){returnvalue = 0;}
return (TCHAR)returnvalue;
} (lParam >> 16) & 0xffTCHAR* FileDialog::doOpenSingleFileDlg()
{
....
try {
fn = ::GetOpenFileName(&_ofn)?_fileName:NULL;
if (params->getNppGUI()._openSaveDir == dir_last)
{
::GetCurrentDirectory(MAX_PATH, dir);
params->setWorkingDir(dir);
}
} catch(std::exception e) { // <=
::MessageBoxA(NULL, e.what(), "Exception", MB_OK);
} catch(...) {
::MessageBox(NULL, TEXT("....!!!"), TEXT(""), MB_OK);
}
::SetCurrentDirectory(dir);
return (fn);
}LRESULT CALLBACK GridProc(HWND hWnd, UINT message,
WPARAM wParam, LPARAM lParam)
{
....
case WM_CREATE:
lpcs = &cs;
lpcs = (LPCREATESTRUCT)lParam;
....
}typedef std::basic_string generic_string;
generic_string TreeView::getItemDisplayName(....) const
{
if (not Item2Set)
return false; // <=
TCHAR textBuffer[MAX_PATH];
TVITEM tvItem;
tvItem.hItem = Item2Set;
tvItem.mask = TVIF_TEXT;
tvItem.pszText = textBuffer;
tvItem.cchTextMax = MAX_PATH;
SendMessage(...., reinterpret_cast(&tvItem));
return tvItem.pszText;
} 
void Notepad_plus::wsTabConvert(spaceTab whichWay)
{
....
char * source = new char[docLength];
if (source == NULL)
return;
....
}bool Notepad_plus::doBlockComment(comment_mode currCommentMode)
{
....
if ((!commentLineSymbol) || // <=
(!commentLineSymbol[0]) ||
(commentLineSymbol == NULL)) // <= WTF?
{ .... }
....
}INT_PTR CALLBACK PluginsAdminDlg::run_dlgProc(UINT message, ....)
{
switch (message)
{
case WM_INITDIALOG :
{
return TRUE;
}
....
case IDC_PLUGINADM_RESEARCH_NEXT:
searchInPlugins(true);
return true;
case IDC_PLUGINADM_INSTALL:
installPlugins();
return true;
....
}
....
}void Notepad_plus::notifyBufferChanged(Buffer * buffer, int mask)
{
// To avoid to crash while MS-DOS style is set as default
// language,
// Checking the validity of current instance is necessary.
if (!this) return;
....
}
|
|
«Искусство в мире развлечений»: Чем занимаются художники в игровой индустрии |
 Photo by Inventain
Photo by Inventain
|
Метки: author dmitrykabanov я пиарюсь дизайн игр inventain |
Вышло обновление Apache Hadoop впервые за два года |
 / фото Jermaine Janszen CC
/ фото Jermaine Janszen CC|
Метки: author it_man big data блог компании ит-град ит-град hadoop apache |
Netflix выходит из «битвы» за сетевой нейтралитет |
 Mark Bonica / Flickr / CC
Mark Bonica / Flickr / CC|
Метки: author VASExperts законодательство и it-бизнес блог компании vas experts vas experts netflix net neutrality |
MySQL 8, Postgres NoSQL, Tarantool Винил, CockroachDB, ClickHouse, и все-же, почему Uber ушел от Postgresql? |
 17 июня в Москве, Измайлово пройдет конференция Devconf::Storage
17 июня в Москве, Измайлово пройдет конференция Devconf::StorageТолько зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author ConfGuru анализ и проектирование систем postgresql nosql mysql блог компании devconf mariadb tarantool cockroachdb базы данных |
[recovery mode] Несколько слов про «наш» микроконтроллер |

BRP, PRSEG, SEG1, SEG2, Fosc). Сама формула и зависимость параметров от значений бит в регистрах разнесены страниц на пятнадцать. В итоге, проще сделать скрин с таблицей значений регистров и открывать его в пэинте, пока разбираешься с формулой.BRP=1, PRSEG=1, SEG1=5, SEG2=5). В общем, ошибка в несколько % так или иначе будет присутствовать. Я уже писал выше — пока ещё я не дофига спец в данном протоколе, возможно он и с такой ошибкой заработает на низких скоростях — в конце концов у данной шины весьма большой запас по надёжности передачи данных."Программа защищена. По вопросам приобретения обратитесь в компанию МИЛАНДР."#include int по умолчанию у данного компилятора имеет размер 8 бит, а не 16, как принято в том же XC8 для PIC.TXSTA1 = ((CSRC & 0x01) << 7) | ((TX9 & 0x01) << 6) |((TXEN & 0x01) << 5) |((SYNC & 0x01) << 4);
"Unable to generate code."temp0 = ((CSRC & 0x01) << 7);
temp1 = ((TX9 & 0x01) << 6);
temp2 = ((TXEN & 0x01) << 5);
temp3 = ((SYNC & 0x01) << 4);
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author Psychosynthesis программирование микроконтроллеров программирование миландр микроконтроллеры 1886 ве5у |
Генерируем произвольные последовательности на выводах платы Raspberry Pi |

|
|
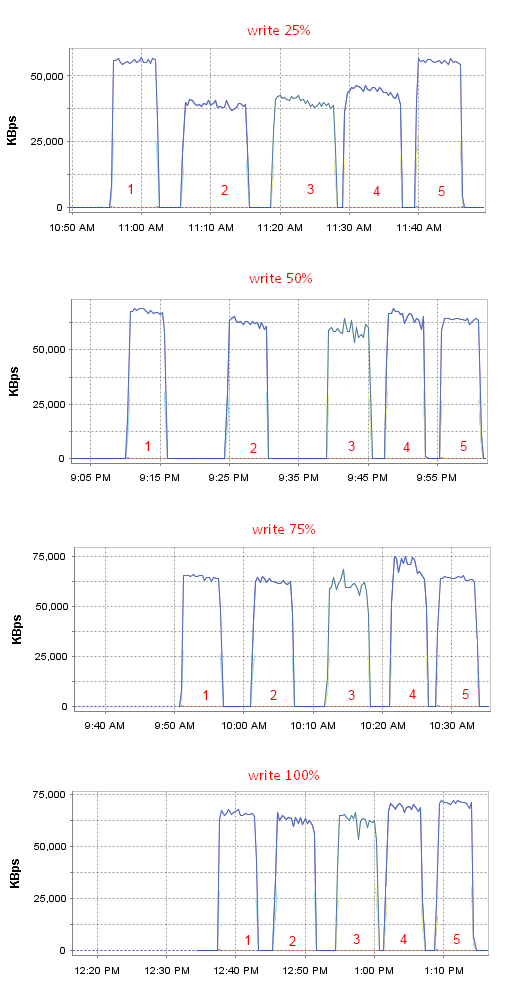
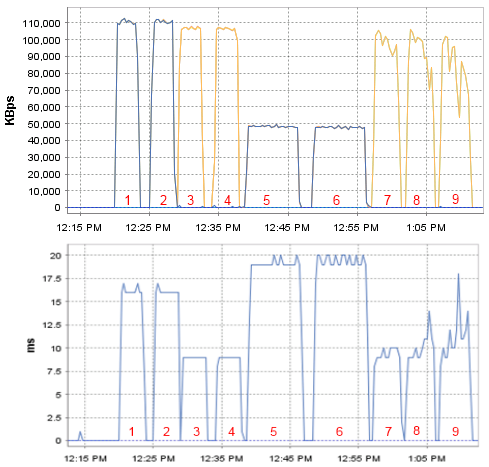
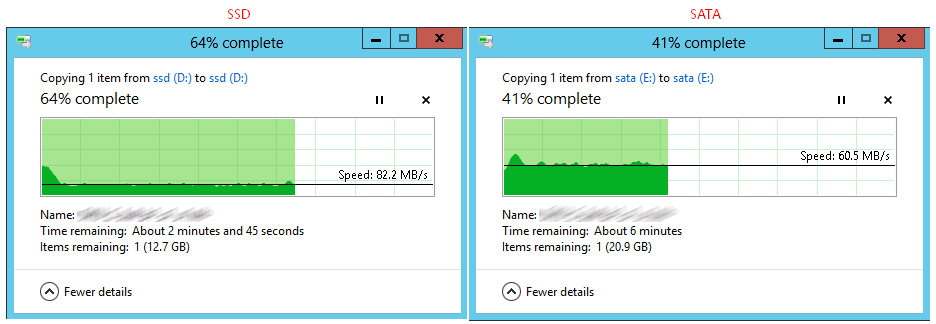
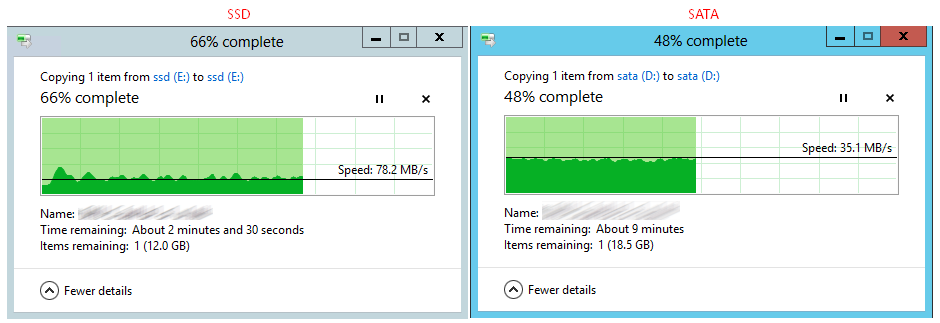
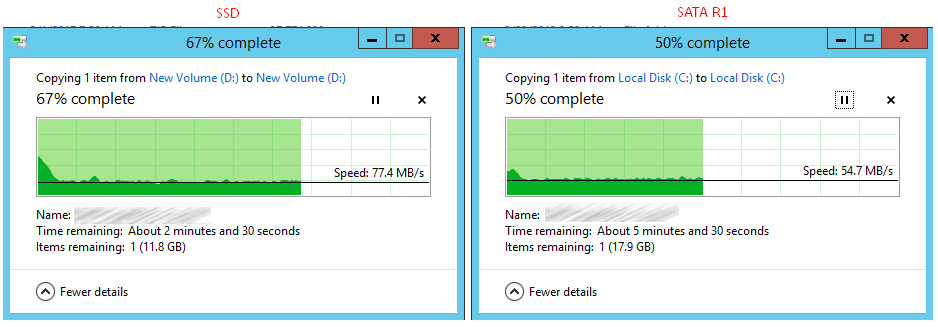
HP DL120 G7 — вторая жизнь сервера |

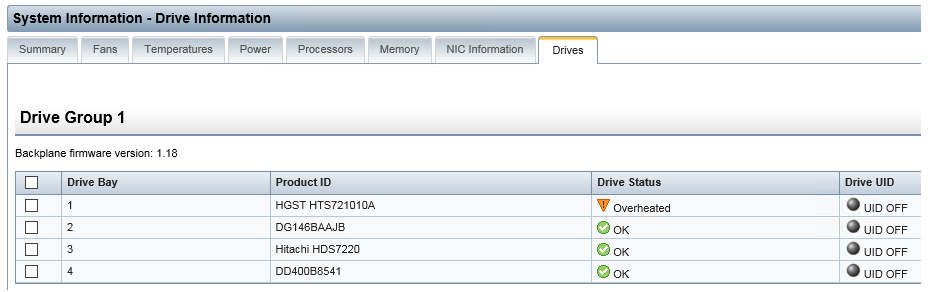










|
|






