Иное применение блокчейнов: Смарт-контракты |
 / изображение Jason Benjamin PD
/ изображение Jason Benjamin PD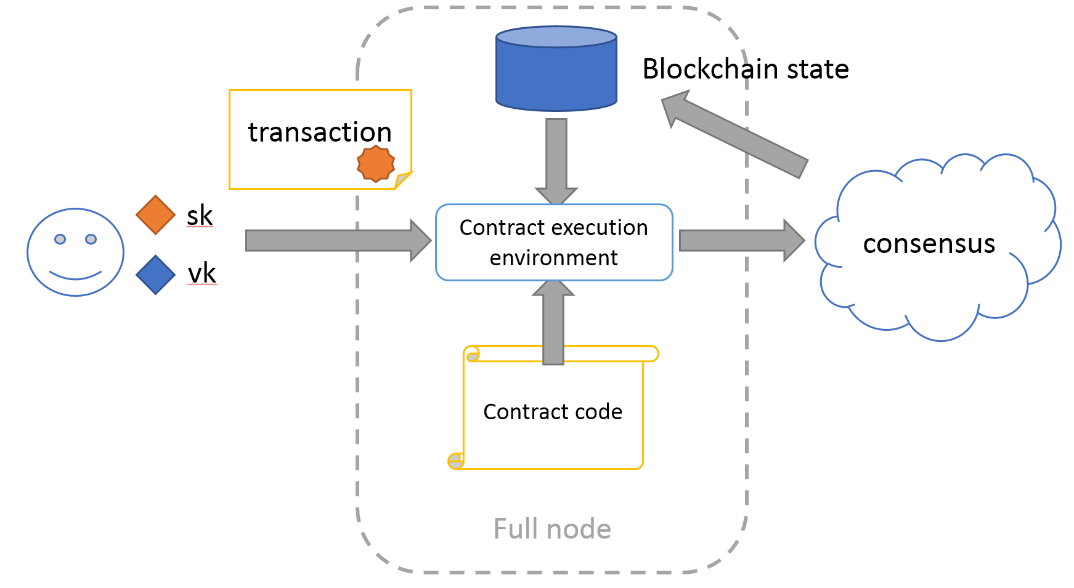
<Ключ> CHECKSIG
// 1. Инициализация
сценарий: <Подпись>
стек: пусто
// 2. Выполняется единственная инструкция отпирающего сценария
сценарий: пусто
стек: <Подпись>
// 3. Начинается запирающий сценарий
сценарий: <Ключ> CHECKSIG
стек: <Подпись>
// 4. Первая инструкция — добавить ключ в стек
сценарий: CHECKSIG
стек: <Подпись> <Ключ>
// 5. Вторая инструкция — проверить подпись
сценарий:
стек: <успех>
IF
// Требует любые 2 из 3 подписей от Алисы, Боба или арбитра.
2 <Ключ Алисы> <Ключ Боба> <Ключ арбитра> 3 CHECKMULTISIG
ELSE
// Проверяет, что со времени поступления средств на адрес депонирования
// прошло 7 дней.
// DROP — инструкция вытолкнуть из стека элемент; здесь она нужна
// для обратной совместимости — CHECKSEQUENCEVERIFY распознается
// не всеми версиями узлов биткойна
<7 дней в секундах> CHECKSEQUENCEVERIFY DROP
// Если предыдущая проверка успешна, то средства может забрать Алиса
<Ключ Алисы> CHECKSIG
ENDIF
// Перевод средств по согласию Алисы и Боба.
// Первый 0 необходим из-за бага в инструкции MULTISIG —
// она берет из стека на один элемент больше чем нужно.
// Последняя единица активирует ветку IF в запирающем сценарии.
0 <Подпись Алисы> <Подпись Боба> 1
// Арбитр согласился с Алисой
0 <Подпись Алисы> <Подпись арбитра> 1
// Арбитр согласился с Бобом
0 <Подпись Бобом> <Подпись арбитра> 1
// Возврат средств по тайм-ауту.
// 0 активирует ветку ELSE в запирающем сценарии.
// Этот сценарий не будет валидным, если тайм-аут еще не прошел.
<Подпись Алисы> 0
|
Метки: author alinatestova платежные системы блог компании bitfury group bitfury смарт-контракты блокчейн |
[Перевод] Хакер, хакни себя сам |
|
Метки: author nanton администрирование баз данных блог компании everyday tools атаки хакерские атаки информационная безопасность hashcat хэширование хэширование паролей |
[Из песочницы] 12 часов в шкуре Android разработчика глазами JS разработчика |




|
Метки: author ipgaero разработка под android разработка мобильных приложений javascript android development android studio android apps |
WWDC — на что Apple делает ставку в 2017 году? |






|
|
Обзор VR/AR новинок Google I/O 2017 |





|
Метки: author Developers_Relations разработка под ar и vr google api блог компании google google io tango ar\vr |
[Перевод] Внутренняя структура игры Contra |






|
Метки: author PatientZero реверс-инжиниринг разработка игр contra nes dendy обратная разработка гейм-дизайн |
Как заработать на API Яндекс.Денег |

С вас — идеи монетизации стриминга и реализация на API Яндекс.Денег, с нас — аудитория, реклама и деньги.
Шестой день рождения API переводов мы решили отпраздновать антихакатоном, на котором любой желающий может попробовать свои силы в борьбе за джекпот. Помимо денежного приза в 100 000 рублей мы поделимся с победителем прибылью от переводов через Яндекс.Деньги.
Приглашаем под кат всех индивидуальных разработчиков, предпринимателей и команды стартапов.
Как принять участие: нужно разработать готовое к использованию решение для сбора денег за стриминг в Сети.
Зачем это вообще нужно: количество сервисов с потоковой передачей платного контента стабильно растет, а удобного способа получения денег для них пока нет. По крайней мере такого, который был бы удобен не только владельцу сервиса, но и пользователям.
Насколько свободно творчество: в решении должны быть задействованы платежи через API Яндекс.Денег, все остальное — на ваше усмотрение. Жюри из экспертов компании выберет лучшее решение, а его авторы получат приз в 100 000 рублей и смогут забрать комиссию 0,5 % с каждой операции своего сервиса.
Когда будем подводить итоги: готовые прототипы и ваши анкеты мы принимаем до 1 августа 2017.
API позволяет выполнять следующие задачи:
запрашивать баланс;
просматривать историю операций;
переводить деньги между кошельками;
Чтобы вам было проще погрузиться в решение задачи, разберем на примерах популярные сценарии использования API.
Перед совершением каких-либо операций с кошельками в Яндекс.Деньгах (например, просмотр истории операций или состояния счета) разработчику нужно получить определенные права.
К слову, авторизация приложений в Яндекс.Деньгах соответствует следующим спецификациям:
Зарегистрируйте приложение и укажите его параметры. В качестве Redirect URI задайте адрес, на который Яндекс.Деньги будут отправлять пользователя после успешной OAuth-авторизации. После этого вы получаете свой уникальный идентификатор client_id.
Теперь можно запрашивать права на проведение необходимых нам действий с кошельками пользователей. Пример запроса авторизации с правом просмотра истории операций кошелька:
POST /oauth/authorize HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
Content-Length: 191
client_id=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ01&response_type=code&redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb&scope=account%2Dinfo%20operation%2DhistoryПо запросу авторизации пользователь перенаправляется на страницу аутентификации, где вводит логин-пароль и может подтвердить или отклонить перечень запрошенных прав:
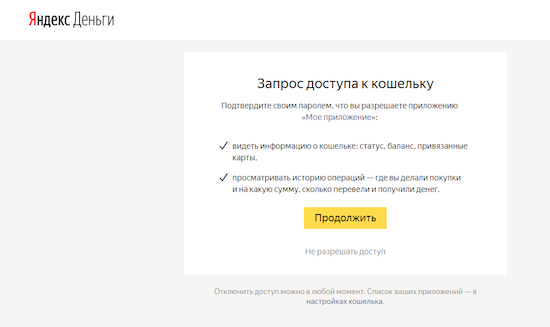
Интерфейс авторизации.
Результат авторизации возвращается как HTTP 302 Redirect – приложение перенаправит пользователя на адрес Redirect URI, который разработчик указал в параметрах запроса. Значение Redirect URI должно совпадать с настройками приложения, допуская возможность добавить в конце строки какие-либо дополнительные параметры. В адресе перенаправления с успешным результатом авторизации содержится параметр code — временный токен авторизации.
HTTP/1.1 302 Found
Location: https://client.example.com/cb?code=i1WsRn1uB1ehfbb37Последний шаг – получение токена, для которого назначен определенный набор прав. После этого приложение меняет временный токен на токен авторизации, который разработчик будет использовать для доступа к информации в кошельке:
POST /oauth/token HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
Content-Length: 421
code=0DF3343A8D9C7B005B1952D9B933DC56ACB7FED6D3F2590A6FD90EC6391050EDFFCC993D325B41B00F58E5383F37F6831E8F415696E1CF07676EE8D0A3655CDD7C667189DFB69BFDB7116C0329303AB2554290048BAF9B767B4C335BF0E85830AC017AD2F14D97F529893C202D3B2C27A61EE53DC4FB04DAE8E815DE2E3F865F&client_id=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ01&grant_type=authorization_code&redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2FcbА вот такой ответ придет при успешном обмене временного токена:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: 293
Cache-Control: no-store
{
"access_token":"410012345678901.0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ0123"
}Access_token является симметричным секретом, поэтому разработчику приложения стоит предпринять дополнительные меры по его защите: хранить токен в зашифрованном виде, предоставлять доступ только при успешном прохождении владельцем аутентификации.
Когда токен получен, разработчик может использовать его для авторизованных действий с кошельком. Напомню, что конкретно эта авторизация позволила просматривать историю в кошельке пользователя.
Самый простой пример из области краудфандинга в соцсетях: некое сообщество ВКонтакте, посвященное футболу, — подписчиков много и активность хорошая, но это сделанный на досуге проект, а не цель жизни. Одно время паблик проводил встречи подписчиков и через электронный кошелек администратора собирал на эту и прочие нужды деньги. Для большей прозрачности распределения поступивших денег администратор создал таблицу и подтянул туда данные об истории операций через API. Когда кто-то отправляет в кошелек деньги, то все видят детали операции, отправителя и цель перевода.
Для просмотра данных воспользуемся методом operation-history, позволяющим персонализировать запрос разработчика. На выходе получим, например, последние 10 транзакций, или операции за последние полгода, или только расходные операции. Все зависит от аппетита пользователей, для которых разработчик создает сервис.
В случае со стримерами полезно выводить информацию по дате и времени входящего пополнения, включая его сумму, никнейм и сообщение отправителя, используемый платежный метод. Данные чаще всего фильтруются по никнейму, что может быть полезно для стримера: например, можно выбрать лучшего донатера (подписчика) и поощрить его предложением выбрать любую игру, которая будет распространяться в ближайшее время.
Пример запроса на получение пяти последних входящих зачислений в кошелек выглядит так:
POST /api/operation-history HTTP/1.1
Host: money.yandex.ru
Authorization: Bearer 410012345678901.7EE34A50588723226C886A475AD1D415471BF687CCC2AFC7664BA12F4EC2BDBA1EB82625E49BC29D114A6C6AF12F87639A877E81A5B77B81F003A9DB4CCEB9BD80C6E70B157C18410E884465276AACBD58C2D7B6022CBDFD0004B80704E82D3F0E4039A29655EFAA44F037D6BF763B0B803329FE8A0E511057173B04341C4317
Content-Type: application/x-www-form-urlencoded
records=5&type=depositionВот что на это может ответить сервис Яндекс.Денег:
{
"next_record": "5",
"operations": [
{
"operation_id": "548936732440013012",
"title": "Перевод с банковской карты",
"amount": 1.96,
"direction": "in",
"datetime": "2017-05-24T10:25:32Z",
"label": "123007",
"status": "success",
"type": "deposition"
},
{
"pattern_id": "p2p",
"operation_id": "1097872036856016025",
"title": "Перевод от 410012345678902",
"amount": 0.99,
"direction": "in",
"datetime": "2017-05-24T10:13:38Z",
"status": "success",
"type": "incoming-transfer"
},
{
"operation_id": "548428048231013012",
"title": "Перевод с банковской карты",
"amount": 1.96,
"direction": "in",
"datetime": "2017-05-18T13:07:28Z",
"status": "success",
"type": "deposition"
},
{
"operation_id": "548427906481013012",
"title": "Перевод с банковской карты",
"amount": 1.96,
"direction": "in",
"datetime": "2017-05-18T13:05:06Z",
"status": "success",
"type": "deposition"
},
{
"pattern_id": "p2p",
"operation_id": "1096319740674326025",
"title": "Перевод от 410012345678903",
"amount": 0.01,
"direction": "in",
"datetime": "2017-05-15T10:37:50Z",
"status": "success",
"type": "incoming-transfer"
}
]
}Еще один пример сервиса на основе запроса к истории — коллективные закупки на форумах: люди договариваются скинуться и заказать что-то оптом по более низкой цене, а организатор собирает деньги на свой кошелек. Чтобы все видели, сколько участников в закупке и как расходуются деньги, можно использовать один из множества сервисов на базе API Яндекс.Денег. Сборщику достаточно авторизоваться кошельком в одном из таких сервисов.
Игровые стримеры часто работают с несколькими мониторами, поэтому команда Яндекс.Денег разработала виджет, в котором можно указать цель сбора денег, необходимую сумму – и отслеживать прогресс. Например, стример хочет купить новую PlayStation 4. Как только в кошельке наберется нужная сумма, Яндекс.Деньги пришлют в виджет уведомление, что пора делать заказ.

Виджет накопления.
Другой пример, когда стриминговому сервису нужен постоянный доступ к балансу — программа лояльности: в личном кабинете стримера, к примеру, можно разместить пиццерийный оффер со скидкой, по которому можно мгновенно заказать пиццу. Но перед этим сервис должен убедиться, что денег на счете достаточно для заказа.
Для просмотра баланса можно воспользоваться методом account-info:
POST /api/account-info HTTP/1.1
Host: money.yandex.ru
Authorization: Bearer 410012345678901.1578E01607EB3899853D2883E47841A195BC561F1F8CF479D593B662AD60B2D146EE49F02D750CB2972E51E0DF10369AE77FD930D82B7563AA0D65FA709A7C31EB59D4FFC1F2E85A14A817BDFB282C5A82FF1B79C65D2AE7B3BAE1C1C7D89CBE80477FF1C51A8F3DD9A032475BE629235949B7A2CA7823AC6AC06DB3176F9B54
Content-Type: application/x-www-form-urlencodedВ ответ сервер вернет следующее:
{
"account": "410012345678901",
"balance": 192.45,
"currency": "643",
"account_type": "professional",
"identified": true,
"account_status": "identified",
"cards_linked": [
{
"type": "MasterCard",
"id": "4005641800",
"pan_fragment": "532130******2227"
}
],
"balance_details": {
"total": 192.45,
"available": 192.45,
"blocked": 1
}
}В результате вы получите не только детализированную информацию по балансу, но и сведения о привязанных банковских картах: маскированный номер карты, тип, идентификатор привязанной карты.
Мой любимый пример — Дзен-мани. Это сервис, который помогает пользователям следить за своим бюджетом и планировать расходы на будущее. Разработчики Дзен-мани предложили пользователям привязать кошелек Яндекс.Денег к приложению, чтобы оно могло самостоятельно добавлять новые расходные операции и доходы. Разумеется, опция полезна только активным пользователям кошелька, которые оплачивают из него большинство покупок. И это действительно большое благо, так как в учете личных финансов сложнее всего не забывать отмечать расходы в программе. Почитать, как все это работает, можно в статье Дзен-мани на Geektimes.
С помощью API можно инициировать не только переводы из кошелька, но и с привязанной карты. Это удобно для мгновенных расчетов с людьми, которые не держат деньги на кошельке и используют его как прослойку, чтобы не светить карту в интернете. При этом за плательщиком по-прежнему остается контроль расходов, ведь даже автоматические списания с привязанной карты нужно авторизовать.
Как это работает:
После получения подтверждения от пользователя, API попробует списать из кошелька запрошенную сумму.
Если денег на балансе не хватает, сервис ответит not_enough_funds.
Стримеры могут мотивировать зрителей подписаться на регулярные переводы за публичную благодарность в эфире или соцсетях, подарки или право выбора следующей игры для стрима.
Подписка выглядит следующим образом:
Рядом с кнопкой «Поддержать» может стоять галка «Подписаться на ежемесячный платеж в пользу этого стримера».
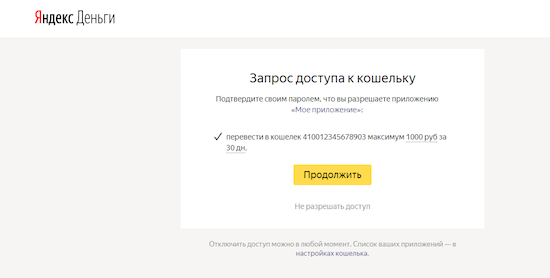
Поскольку речь идет об операции в кошельке, нужно запросить разрешение на ее проведение – запрос на предоставление доступа остается практически как в примере №1, но меняется набор прав (scope).
Набор запрашиваемых прав, который позволяет совершить единовременный перевод на сумму 1000 рублей в кошелек 410012345678901, выглядит следующим образом:
payment.to-account("410012345678901").limit(,1000)Если же отправитель подписался на регулярные платежи, авторизация может иметь следующее значение:
payment.to-account("410012345678901").limit(30,1000)Где 30 — период времени в сутках, 1000 — общая сумма платежей за период.
Пример запроса на регулярное списание:
POST /oauth/authorize HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
client_id=49414287408917F4BC735301F4731878533F409F3BA8EA055D0D441EE002F69B&redirect_uri=http%3A%2F%2Fexample.com%2Fapi%2Fredirect_uri.php&response_type=code&scope=payment.to-account(%22410012345678903%22).limit(30%2C1000)Отправитель же увидит красивую форму:
После получения токена разработчику нужно выполнить списание через методы request-payment и process-payment:
POST /api/request-payment HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
Authorization: Bearer 410012345678901.D2E0917C3E09DE474DD3BF6288DDCB6818D55B6BBC8A9386ABA2A983F3F4666102F9B7A2D370D7079891299907368389F3BA8E2BE04597DCFF4CF02F4E3423896776D1C5CCE30A09B5D2E73874C5FE33CAE19286EAB03D146B46A188939BEC1ADA93F3530ECBFACA2591715F686EDBC9F616A7BF912CF4DC9CFB689473328347
pattern_id=p2p&to=410012345678903&amount=10&comment=Transfer+to+Nuke73&message=Transfer+from+SuperManПример ответа:
{
"status": "success",
"request_id": "333235373335343733345f646366303562383436613661306133373130663766343166303137666131336262656637353539655f323537353532373836",
"recipient_identified": true,
"multiple_recipients_found": false,
"recipient_account_type": "professional",
"recipient_account_status": "identified",
"contract_amount": 10,
"money_source": {
"cards": {
"allowed": false
},
"wallet": {
"allowed": true
},
"card": {
"allowed": "false"
}
}
}К слову о переводах и комиссиях. В личном кабинете можно выбрать, кто платит комиссию за перевод – за это отвечают параметры amount и amount_due. Если в шаблоне платежа указан параметр amount_due, то именно эта сумма поступит в кошелек стримера (комиссию оплачивает зритель). Если же стример готов взять её на себя, то на входе указывается параметр amount. Таким образом, amount (сумма к переводу) равняется сумме комиссии и amount_due (сумма к получению).
Перевод выполняется после вызова метода process-payment уже без участия пользователя, который один раз при авторизации доступа подтвердил свои намерения. В качестве request_id используется идентификатор из ответа метода request-payment.
POST /api/process-payment HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
Authorization: Bearer 410012345678901.D2E0917C3E09DE474DD3BF6288DDCB6818D55B6BBC8A9386ABA2A983F3F4666102F9B7A2D370D7079891299907368389F3BA8E2BE04597DCFF4CF02F4E3423896776D1C5CCE30A09B5D2E73874C5FE33CAE19286EAB03D146B46A188939BEC1ADA93F3530ECBFACA2591715F686EDBC9F616A7BF912CF4DC9CFB689473328347
request_id=333235373335343733345f646366303562383436613661306133373130663766343166303137666131336262656637353539655f323537353532373836Пример ответа:
{
"status": "success",
"payer": "410012345678901",
"payee": "410012345678903",
"credit_amount": 9.95,
"payment_id": "549038975018120011"
}Отлично – списание с кошелька прошло успешно.
Перевод с банковской карты отличается от перевода из кошелька:
Во-первых, он не требует запроса на авторизацию. Чтобы идентифицировать приложение для оплаты картами, разработчик регистрирует в Яндекс.Деньгах его копию и получает instance_id с помощью одноименного метода;
Если перевод сформировался успешно, метод request-external-payment вернет следующее:
{
"status": "success",
"title": "Перевод на счет 410011498692222",
"contract_amount": 102.04,
"request_id": "333235373135303437315f36313764393332336462393164373433353264303465346432626262313465353933363763333133",
"money_source": {
"payment-card": {}
}
}После получения request_id – уникального идентификатора контекста платежа – можно инициировать платежную операцию и перенаправить пользователя на форму Яндекс.Денег. Для этого используется POST-запрос по адресу acs_uri с параметрами acs_params, где плательщику нужно указать данные банковской карты.
Пример запроса:
POST /api/process-external-payment HTTP/1.1
Host: money.yandex.ru
Content-Type: application/x-www-form-urlencoded
request_id=333235373135303437315f36313764393332336462393164373433353264303465346432626262313465353933363763333133&instance_id=hh2CVJWrU9uU7N2hpEh1LvjfyBAby8USyMUEF4DM8AS6w93o53M3xrlGHsMUiWTL&ext_auth_success_uri=http%3A%2F%2Fexample.com%2Fsuccess%2F&ext_auth_fail_uri=http%3A%2F%2Fexample.com%2Ffalse%2F&request_token=falseИ ответ:
{
"status": "ext_auth_required",
"acs_uri": "https://m.money.yandex.ru/internal/public-api/to-payment-type",
"acs_params": {
"cps_context_id": "333235373135303437315f36313764393332336462393164373433353264303465346432626262313465353933363763333133",
"paymentType": "FC"
}
}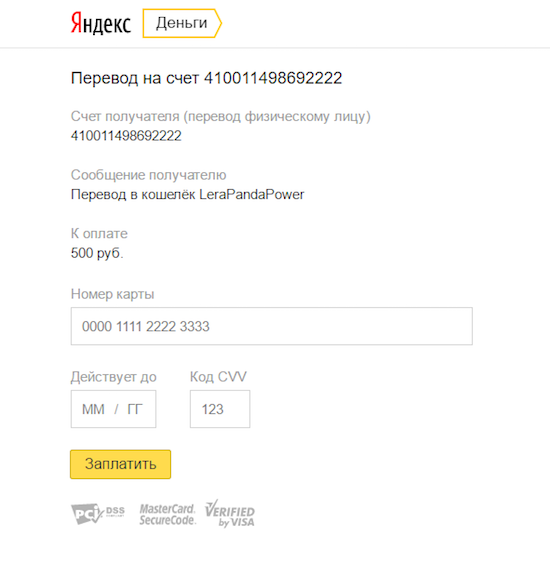
Карточная форма Яндекс.Денег.
Непосредственное проведение платежа ложится на плечи Яндекс.Денег. После указания реквизитов банковской карты и нажатия на кнопку «Заплатить» пользователь попадет на страницу 3-D Secure своего банка-эмитента и после ввода пароля возвращается к сервису разработчика: если 3-D Secure-аутентификация по банковской карте завершается успешно, он попадет на страницу с подтверждением платежа (ext_auth_success_uri). Если же банк-эмитент отказал в аутентификации, пользователь перенаправляется на страницу с ошибкой (ext_auth_fail_uri).
Адреса перенаправления разработчик может указать при вызове метода process-external-payment.
Когда плательщик переходит на страницу успеха после проверки 3-D Secure, нужно удостовериться что авторизация по банковской карте тоже прошла успешно. Для этого разработчик повторно вызывает process-external-payment с ранее полученным request_id.
Пример ответа:
{
"status": "success",
}Обычно авторизация карты происходит в промежутке 10-20 секунд после аутентификации. Если в момент повторного вызова process-external-payment мы не получили состояние авторизации от банка, разработчик об этом обязательно узнает.
Пример подобного ответа:
{
"status": "in_progress",
"next_retry": "5000"
}Next_retry — рекомендуемое время в миллисекундах, когда следует повторить запрос. Поле присутствует только при статусе in_progress.
Платежное решение с использованием API требует определенных усилий и сложного технологического взаимодействия. Более простой вариант заключается в использовании готовых настраиваемых форм Яндекс.Денег: в них информация о переводе разбита на параметры и передается методом POST на специальный адрес.
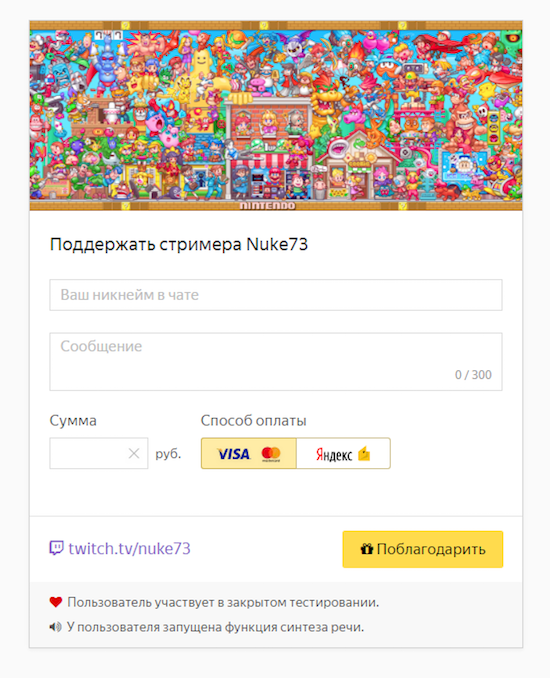
Пример интерфейса формы переводов в кошелек стримера на Яндексе.
Сценарий перевода с использованием кастомизированной формы выглядит так:
Отправитель выбирает, как перевести деньги — из электронного кошелька или с банковской карты.
Разработчик формирует строку из набора параметров Яндекс.Денег и передает их методом POST на адрес money.yandex.ru/quickpay/confirm.xml вместе с уникальной меткой платежа (label) для дальнейшей идентификации. Детали операции разработчик хранит в своей базе.
Плательщик переходит на страницу выбора способа оплаты и подтверждения перевода на стороне Яндекс.Денег, а сумма списывается и зачисляется на кошелек стримера. Разумеется, за вычетом комиссии.
Получатель узнает о поступлении средств через HTTP-уведомление, email, SMS, push. Адрес обработчика уведомлений получателю нужно заранее указать в настройках кошелька.
В этом сценарии есть один недостаток: для нормальной работы сервиса от стримера требуются лишние манипуляции с настройками HTTP-уведомлений внутри кошелька.
В отличии от API, формы и кнопки позволяют переводить деньги с привязанной банковской карты. Однако комиссия берется только с получателя.
Чтобы не требовать от стримера лишних манипуляций, достаточно научиться смотреть в его историю операций и сопоставлять уникальную метку перевода с данными из базы. Осталось только получить доступ к операциям стримера, для чего в самом начале статьи мы попросили стримера подтвердить доступ к правам account-info и operation-history. Первый метод поможет нам узнать номер кошелька стримера, второй — информацию по операциям.
Вот так выглядит ответ на запрос последних двух операций в кошельке стримера через API методом operation-history (перевод поступил через кастомизированную форму):
{
"next_record": "2",
"operations": [
{
"operation_id": "549575176734053012",
"title": "Перевод с банковской карты",
"amount": 49,
"direction": "in",
"datetime": "2017-05-31T19:46:16Z",
"label": "yadonate#1782",
"status": "success",
"type": "deposition"
},
{
"pattern_id": "p2p",
"operation_id": "1098088627442030025",
"title": "Перевод от 410011498790000",
"amount": 9.95,
"direction": "in",
"datetime": "2017-05-25T16:18:33Z",
"label": "testpayment",
"status": "success",
"type": "incoming-transfer"
}
]
}После проверки успешности перевода в кошелек стримера можно творить в видеопотоке любимую вами магию.
В этом посте мы рассмотрели только самые базовые идеи и сценарии использования API для стриминговых сервисов. Если что-то непонятно, смело спрашивайте в комментариях. А если среди читателей есть стримеры или их зрители — поделитесь мнением о том, как сделать донаты удобнее и веселее.
Зарегистрироваться для участия можно на Яндекс.Событиях. Прототипы и анкеты принимаем до 1 августа 2017.
От винта!
|
Метки: author Tuniyants управление проектами управление медиа терминология it развитие стартапа блог компании яндекс.деньги конкурс проектов хакатоны разработка под e-commerce |
Вот до чего бывают люди до чужого добра жадные, или еще одна ремарка про 44 50 49 |
Никто уже и не помнит, с чего все началось, но интересно куда это все движется.Возможно, кто-то уже изрек это до меня, но это не главное. Главное то, что существует болезнь, заразившись которой человек превращается в человека, который интеллектуально схож с бабушками, тяжело пережившими 90-е, и бездумно ругающие все, что есть сейчас происходит (и что в наше время… да колбаска… да по 25 копеек...)
Пункты ЗА:
Пункты ПРОТИВ:
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author qqwweerrttyy сетевые технологии dpi deep packet inspection tcpdump capture packet network |
[Перевод] Сказки, которые Вам расскажут облачные провайдеры |

|
Метки: author mary_guba хостинг облачные вычисления блог компании mclouds.ru cloud hosting ловушки продажи облачные сервисы |
Текстовый онлайн с фестиваля РИТ++ 2017. День второй |

|
Метки: author TM_content разработка мобильных приложений программирование высокая производительность блог компании конференции олега бунина (онтико) рит++ конференция фестиваль интернет-технологий |
WWDC 2017. Пошумим немножечко |





|
|
Дайджест продуктового дизайна, май 2017 |




 Jessica Enders — Designing UX: Forms
Jessica Enders — Designing UX: Forms

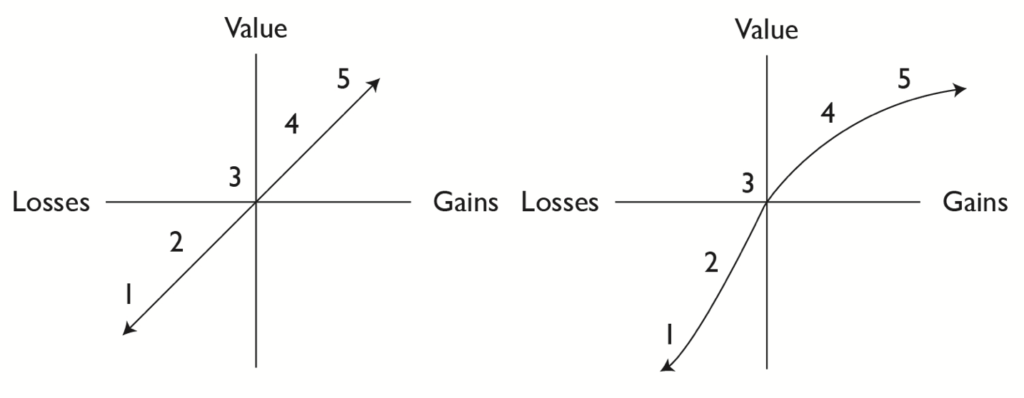

 Нир Эяль — На крючке
Нир Эяль — На крючке


 Джейк Кнапп — Спринт: Как разработать и протестировать новый продукт всего за пять дней
Джейк Кнапп — Спринт: Как разработать и протестировать новый продукт всего за пять дней
|
Метки: author jvetrau интерфейсы дизайн мобильных приложений веб-дизайн usability пользовательские интерфейсы продуктовый дизайн |
[Перевод] Развертывание Redmine с помощью Capistrano |

Это вторая часть моего руководства о том, как самостоятельно администрировать Redmine в долгосрочной перспективе. Первая часть была посвящена управлению собственной версией Redmine с помощью Git (ссылка на перевод).
Имея собственный репозиторий Redmine, пришло время ...
Серьезно. Не пытайтесь развернуть старомодным способом, копируя всё вручную.
Автоматизация развертывания — это однократное вложение, окупающееся сэкономленным временем и усилиями каждый раз, когда нужно (ну, или приходится) обновить Redmine. Цель автоматизации — сделать последующие развертывания максимально легкими. Даже самое незначительное исправление или улучшение может быть выполнено мгновенно, потому что автоматизированная процедура обновления быстра, надежна и может быть запущена одной командой.
Я прошу вас научиться тому, как «профи» (то есть люди, которые зарабатывают на жизнь тем, что разрабатывают и запускают Rails-приложения, развертывают свои системы. И неважно, кто вы — локальный администратор сервера или разработчик Python, которому поручено поддерживать Redmine в организации. За прошедшие годы много умных людей потратили кучу времени на разработку набора инструментов, который после установки одним легким нажатием клавиши сокращает время простоя Rails-приложений до нуля. Такие инструменты существуют, ими просто нужно воспользоваться. И вполне возможно, вы узнаете пару новых фокусов, которые пригодятся вне контекста Redmine.
Capistrano — удаленный многосерверный инструмент автоматизации — идеальный выбор, когда дело доходит до автоматизации развертывания. Он внедрен в Ruby, но не ограничен развертыванием Ruby- или Rails-приложений. С помощью Capistrano реально автоматизировать все действия, производящиеся в SSH. И это можно осуществить на любом количестве серверов параллельно. Как Chef предназначен для развертывания серверов, Capistrano предназначен для развертывания систем, но им гораздо проще пользоваться.
Я привожу очень краткое введение в специфику Redmine, прочитать подробнее можно на capistranorb.com. Readme для этого — хорошая отправная точка.
В ветке Redmine local/x.y-stable создайте файл с именем Gemfile.local. Это позволит удержать любые gems локальными по отношению к частной установке Redmine.
Gemfile.local
group :development do
# uncomment if you're using modern (and secure!) ed25519 ssh keys
# gem 'net-ssh', '4.0.0.alpha2'
gem 'capistrano', '~> 3.4.0'
gem 'capistrano-rails', require: false
endПосле создания этого файла запустите команду bundle install и добавьте/зафиксируйте как файл Gemfile.local, так и появившийся Gemfile.lock.
Теперь запустите команду bundle exec cap install чтобы настроить Capistrano. Это добавит несколько новых файлов: config/deploy.rb и два файла в каталоге config/deploy/, которые соответствуют двум целевым установкам (или "stages" — "стадиям") по умолчанию. Если у вас есть отдельная установка Redmine для тестирования, например, новых плагинов, то это будет ваша "staging target", в то время как живая (рабочая) stage — это производство. Основная идея состоит в том, что всё общее идет в deploy.rb, а отличающееся для разных stage— в соответствующие файлы в каталоге config/deploy. Чаще всего здесь указывается только целевой хост и, возможно, настраивается другая ветвь git или имя пользователя для развертывания.
Вот как может выглядеть минимальная конфигурация Capistrano:
config/deploy.rb
# config valid only for current version of Capistrano
lock '3.4.0'
set :application, 'redmine'
set :scm, :git
set :repo_url, 'git@code.yourcompany.com:redmine.git'
# Target directory in the server.
# Should exist and the user account you're using for deployment should
# have write access.
set :deploy_to, '/srv/webapps/redmine'
set :pty, true
set :log_level, :info
# Linked files are expected to exist below /srv/webapps/redmine/shared and will be
# symlinked into the deployed # code. Create them either manually or through an
# automation tool like chef. The reason for doing so is to not keep database
# credentials and server secrets in your git repository.
set :linked_files, fetch(:linked_files, []).push('config/database.yml',
'config/secrets.yml')
# Directories with contents you want to keep across deployments are declared here.
# Most important is files where Redmine stores any uploaded files.
set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp',
'vendor/bundle', 'files')
# keep the last 5 deployed versions on the server.
# Useful in case you have to revert to an older version.
set :keep_releases, 5
namespace :deploy do
# Declares a task to be executed once the new code is on the server.
after :updated, :plugin_assets do
on roles(:app) do
within release_path do
with rails_env: fetch(:rails_env) do
# Copy over plugin assets
execute :rake, 'redmine:plugins:assets'
# Run plugin migrations
execute :rake, 'redmine:plugins:migrate'
end
end
end
end
# This will run after the deployment finished and is used to reload
# the application. You most probably have to change that depending on
# your server setup.
after :published, :restart do
on roles(:app) do
sudo "/etc/init.d/unicorn reload redmine"
end
end
# cleans up old versions on the server (keeping the number of releases
# configured above)
after :finished, 'deploy:cleanup'
endОстается только настроить сервер, на который вы собираетесь развертывать, пользователя Capistrano для входа на этот сервер и ветвь для развертывания:
config/deploy/production.rb
set :branch, 'local/3.2-stable'
server 'redmine.yourcompany.com', user: 'deploy', roles: %w{web app db}Если вы используете одну и ту же машину для тестирования и производства, просто перенесите параметр deploy_to в файлы конфигурации stage, чтобы иметь возможность установить отдельный каталог для каждого stage. Не забудьте добавить и зафиксировать Gemfile.local, Gemfile.lock и конфигурацию Capistrano, которую вы только что настроили. Эти файлы — часть кастомного Redmine и должны быть сохранены вместе с ним в системе управления версиями.
Если вы используете подмодули Git для добавления плагинов или тем для Redmine, обратите внимание на стратегию субмодулей Git для Capistrano, чтобы автоматически разворачивать и их.
Capistrano использует SSH и полагается на правильно настроенную аутентификацию на основе ключей. Это также очень удобно при использовании какого-либо агента SSH или перенаправления агентов для доступа к репозиторию git через сервер развертывания со своим локальным ключом.
Обязательно прочтите главу «Аутентификация и авторизация» в руководстве по Capistrano.
Теперь, когда всё на месте, пришло время для первого развертывания:
$ bundle exec cap production deployЕсли вы настроили все правильно, эта команда совершит развертывание Redmine за вас. Обычно неудачи случаются из-за проблем с разрешениями или аутентификацией, но в большинстве случаев их легко исправить.
|
Метки: author olemskoi ruby on rails ruby git блог компании southbridge redmine capistrano devops deploy |
Добавляем в jsx циклы и условия |
React.createElement, но с jsx получится гораздо лаконичнее, что повышает читаемость. И всё замечательно до появления первой необходимости вывести данные в цикле. В jsx циклы не предусмотрены. Зато предусмотрена вставка js-кода. И тут вновь возникает вопрос читаемости, но теперь она значительно ухудшается. Возникает ситуация, когда в js-коде пишется html, в котором пишется js-код с html. Конечно, можно выделить html в отдельную функцию. Но тогда html будет появляться в коде то тут, то там. А хотелось бы локализовать всё в одном месте. К счастью, в современном javascript почти для любой проблемы, есть решение в виде библиотеки или плагина. Выше обозначенную проблему легко решает плагин для babel transform-react-statements.
const MyComponent = props =>
-
{item.text}
var _this = this;
const MyComponent = props =>
{Array.prototype.map.call(props.items, function (item, index) {
return -
{item.text}
;
}, _this)}
;
For. В первую очередь атрибут in. Это обязательный атрибут, в котором обозначается способ получения итерируемого объекта (например, переменная). Значение должно быть выражением, т.е. заключено в фигурные скобки.
Атрибут each задает имя переменной для каждого элемента массива. Он не является обязательным. В случае его отсутствия, элементы массива будут передаваться в качестве spread-атрибута.
Преобразуется в:
{Array.prototype.map.call(items, function (value, index) {
return
Также, как видно из примеров выше, в цикле доступен номер элемента в переменной index. Переменную можно переименовать с помощью атрибута counter:
{ cell.content }
Атрибут key
Для корректной работы React, каждый элемент в массивах должен иметь атрибут key. Его можно указать очевидно, как в примере выше. Другой способ - использовать атрибут key-is. Это может немного улучшить читаемость. Также можно указать keyIs в параметрах плагина. Тогда key не нужно будет писать в шаблоне - логика его получения уходит в бизнес-логику.
.babelrc
{
plugins: [["transform-react-statements", { keyIs: "id" }]]
}
{ item.value }
{ item.value }
{ item.value }
Будет преобразовано в:
{Array.prototype.map.call(array, function (item) {
// key берется из параметров плагина
return {item.value};
}, this)}
{Array.prototype.map.call(array, function (item) {
// key - из атрибута
Условие If
Это просто альтернатива для синтаксиса:
{ condition &&
Основная задача сделать всё в едином, html-подобном стиле. Есть два атрибута: либо true, либо false, проверяющие условие на истинность или ложность соответственно. Для нескольких дочерних элементов, условие будет применяться к каждому из них:
Текст 1
Текст 2
Преобразуется в:
{ !someCondition && Текст 1 }
{ !someCondition && Текст 2 }
Switch..Case..Default
Switch ведёт себя также, как и в javascript. У компонента Switch есть атрибут value, значение которого должно быть выражением в фигурных скобках, и дочерние компоненты Case, со своими атрибутами value. Если значение не соответствует ни одному из значений Case, выводится блок Default. Если блок Default отсутствует, возвращается null.
Text 1
Text 2
Text 3
Default text
Component
Довольно специфическое выражение. Превращает содержимое в стрелочную функцию:
text
Преобразуется в
props => text ;
Соответственно, внутри props, которую можно переопределить через атрибут props:
На выходе получим:
item => ;
Автоматическое обертывание
Предположим, есть такой компонент:
class MyComponent extends React.Component {
render() {
return
{item.text}
}
}
For будет преобразован в выражение, возвращающее массив. Однако метод render должен вернуть React-элемент. Для того, чтобы использовать такой компонент, цикл нужно обернуть в элемент. Например так:
class MyComponent extends React.Component {
render() {
return
{item.text}
}
}
Но делать это не обязательно. Так как плагин сам обернёт массив в react-элемент. По умолчанию, это wrapper в настройках плагина:
{
plugins: [["transform-react-statements", { wrapper: '' }]]
}
Также можно отключить автоматическое обёртывание, используя значение параметра no-wrap:
{
plugins: [["transform-react-statements", { wrapper: "no-wrap" }]]
}
Отключение и переименование выражений
Допустим, что в проекте уже есть компонент disabled:
{
plugins: [["transform-react-statements", { disabled: ["If"]}]]
}
Или можно переименовать выражение, чтобы в jsx использовать другое имя, например, IfStatement:
{
plugins: [["transform-react-statements", { rename: { "If": "IfStatement" } }]]
}
Код пишется для людей, поэтому так важна его читаемость. И читаемость является главной проблемой jsx, а конкретно - перемешивание двух языков. Как видно, эта проблема решается, и решается она благодаря гибкости jsx в возможности вставлять javascript-код.
P.S. Автору было бы приятно получить звездочек на github, в качестве благодарности за работу.|
Метки: author PavelDymkov reactjs javascript jsx |
Советы для инженеров от менеджера Google |
|
Метки: author Larrr управление проектами управление продуктом управление персоналом карьера в it-индустрии карьера продуктивность |
Анонс RamblerElixir #3 |

 Лингвистическая относительность – Станислав Герман (Rambler&Co)
Лингвистическая относительность – Станислав Герман (Rambler&Co)У каждого языка есть принципы, на которых он основан. Для Erlang — «Let it crash and let someone else deal with it», для Ruby — «less astonishing» и «programmer happiness», в Python такие принципы как «Explicit is better than implicit», сформулированы в «Zen of Python». В то время, как одни взгляды нам близки, а другие мы не принимаем, они формируют не только дизайн языка и архитектуру библиотек и систем, которые разрабатываются на этом языке, но и сообщество разработчиков вокруг этого языка. В своем докладе я рассмотрю какие принципы заложены в Elixir, чем знание этих принципов полезно разработчику, и как они влияют на код, который мы пишем и используем в своей работе.
 Трюки с ETS – Алексей Никитин (Bookmate)
Трюки с ETS – Алексей Никитин (Bookmate)У меня сложилось впечатление, что в Elixir-сообществе незаслуженно подзабыли про такую штуку как ETS. Про этот мощный инструмент, который предоставляет платформа. Я расскажу несколько хитростей, которые сделают работу с ETS более удобной и как решить некоторые проблемы, которые возникают при работе с ним. Доклад будет интересен в основном новичкам. Но, возможно, и опытные разработчики смогут узнать что-то новое.
Нейронные сети набирают всё большую популярность в ИТ-индустрии, во многом благодаря применению графических сопроцессоров. Существует множество библиотек для реализации нейронных сетей, большинство из которых написано на Python или C. Вместе с тем платформа Erlang OTP позволяет без лишних усилий реализовать отказоустойчивое приложение с высокой степенью распараллеливания вычислений, и, на наш взгляд, идеально подходит для реализации высоко интегрированного решения для обработки потокового видео с помощью нейронных сетей. Также в библиотеке реализован медиа-сервер для приёма потокового видео. Таким образом пользователь может сосредоточиться на конфигурации нейронной сети, не отвлекаясь на технические детали обработки видео.
|
Метки: author SanDark7 ruby on rails ruby erlang/otp elixir/phoenix блог компании rambler co elixir erlang phoenix |
Swift Playgrounds 1.5. Программируем Sphero и многое другое |




|
Метки: author Snusmumrick97 swift apple playgrounds |
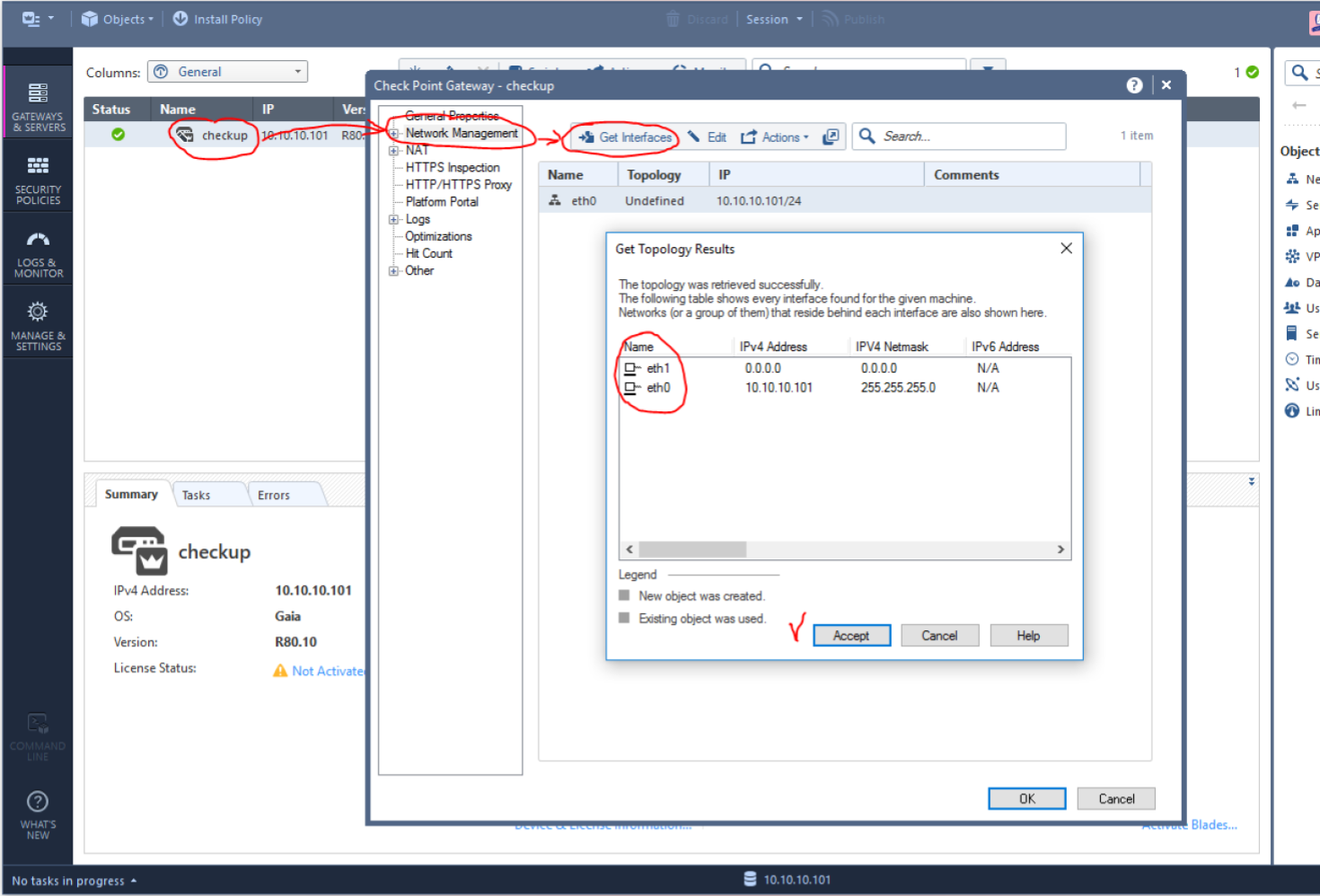
Check Point Security CheckUP — R80.10. Часть 3 |


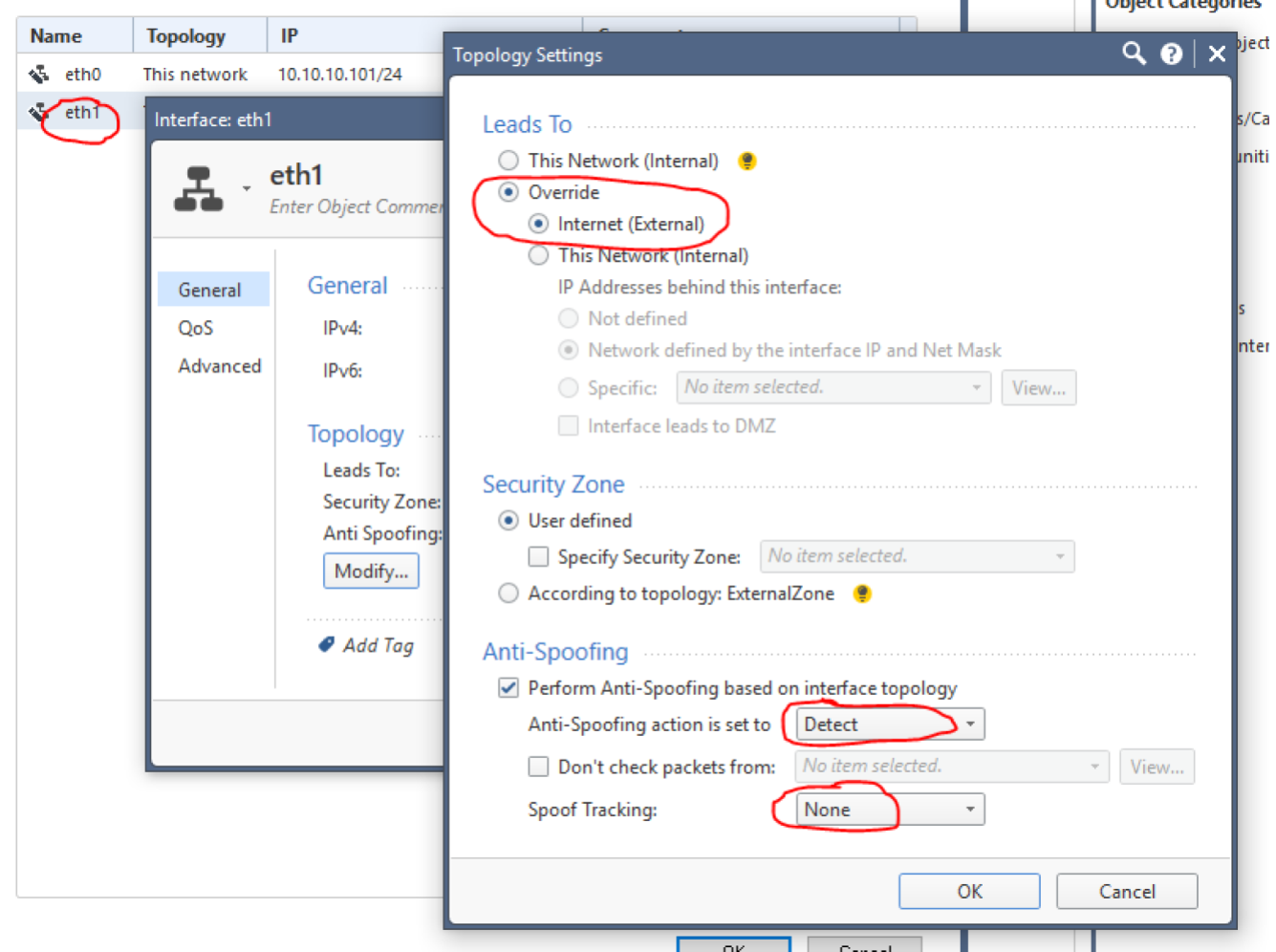

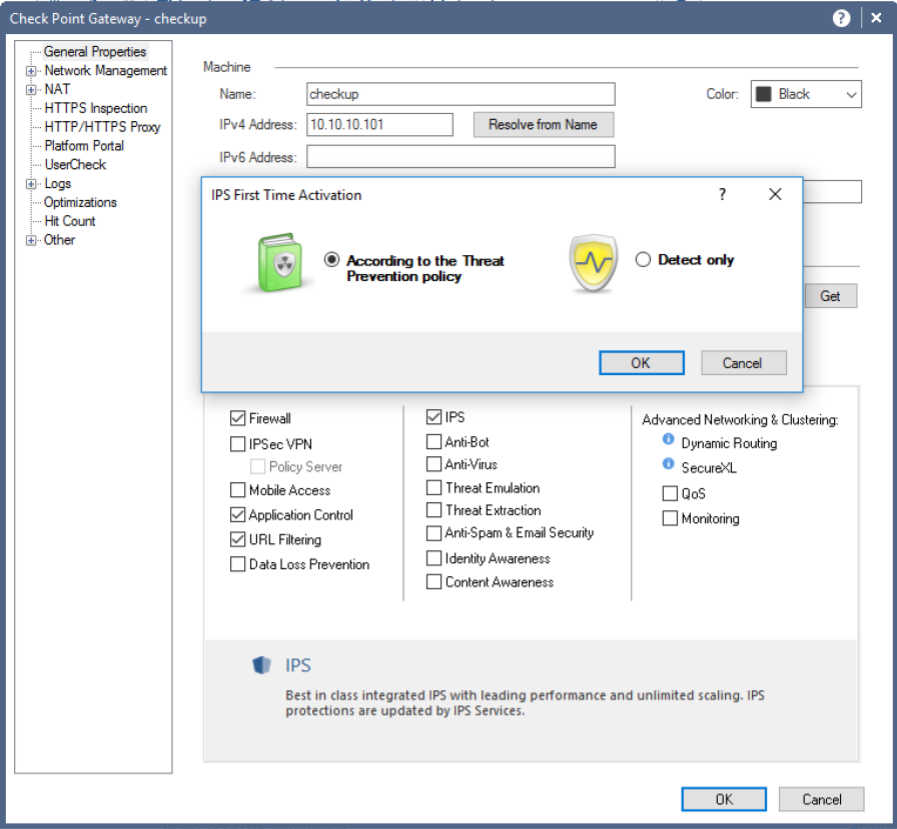
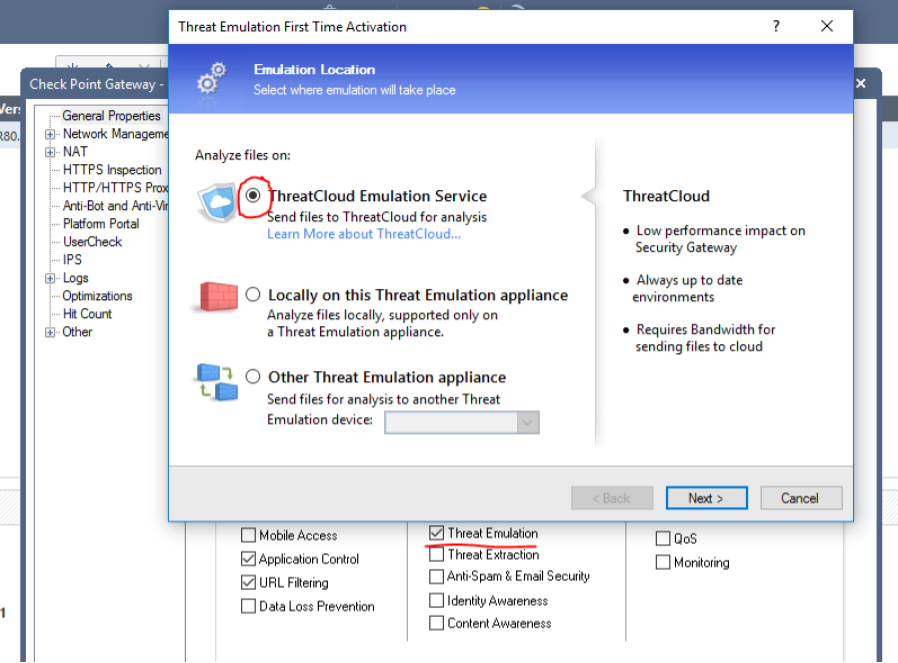
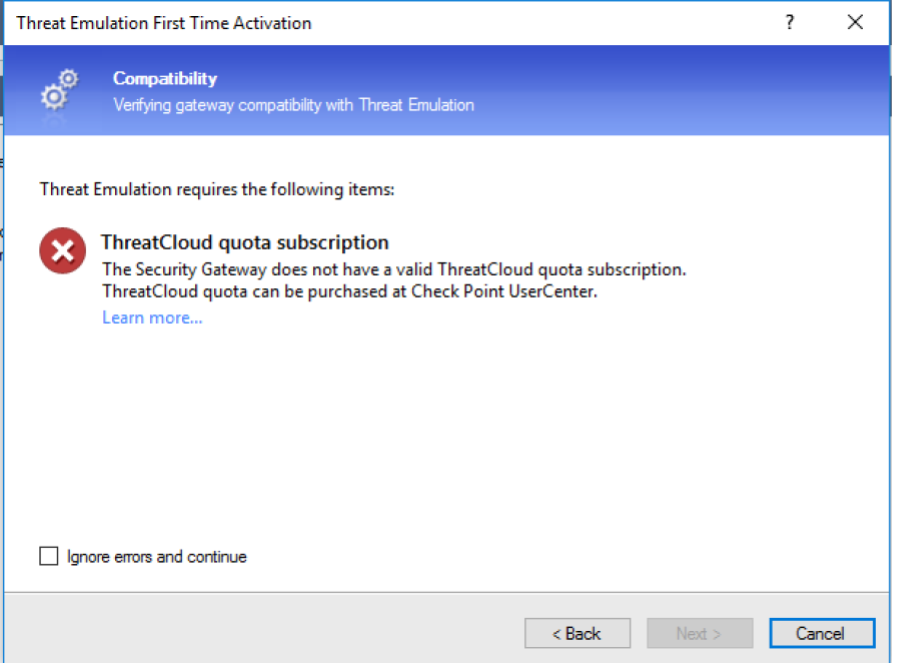
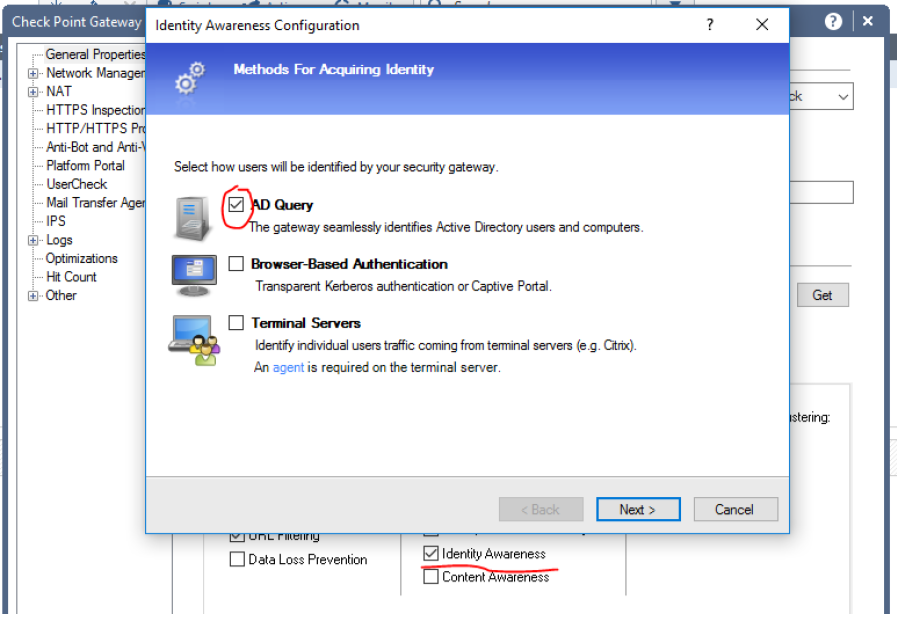
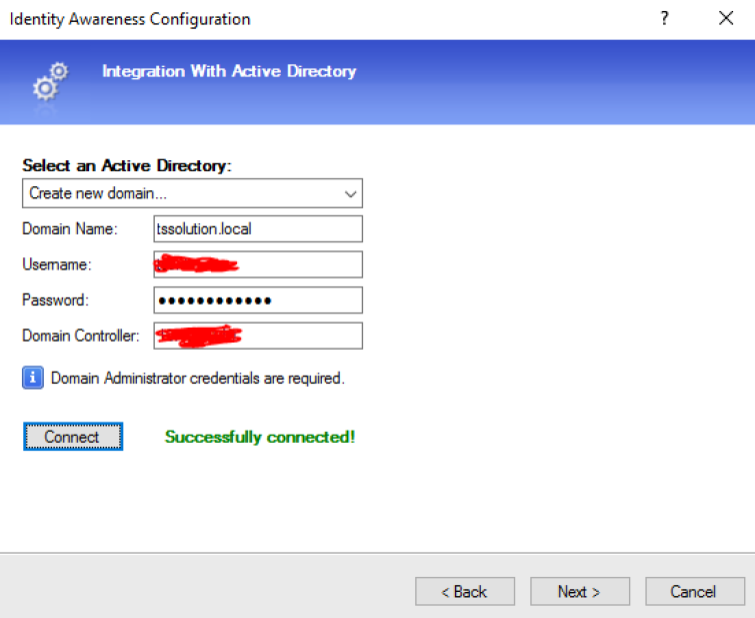

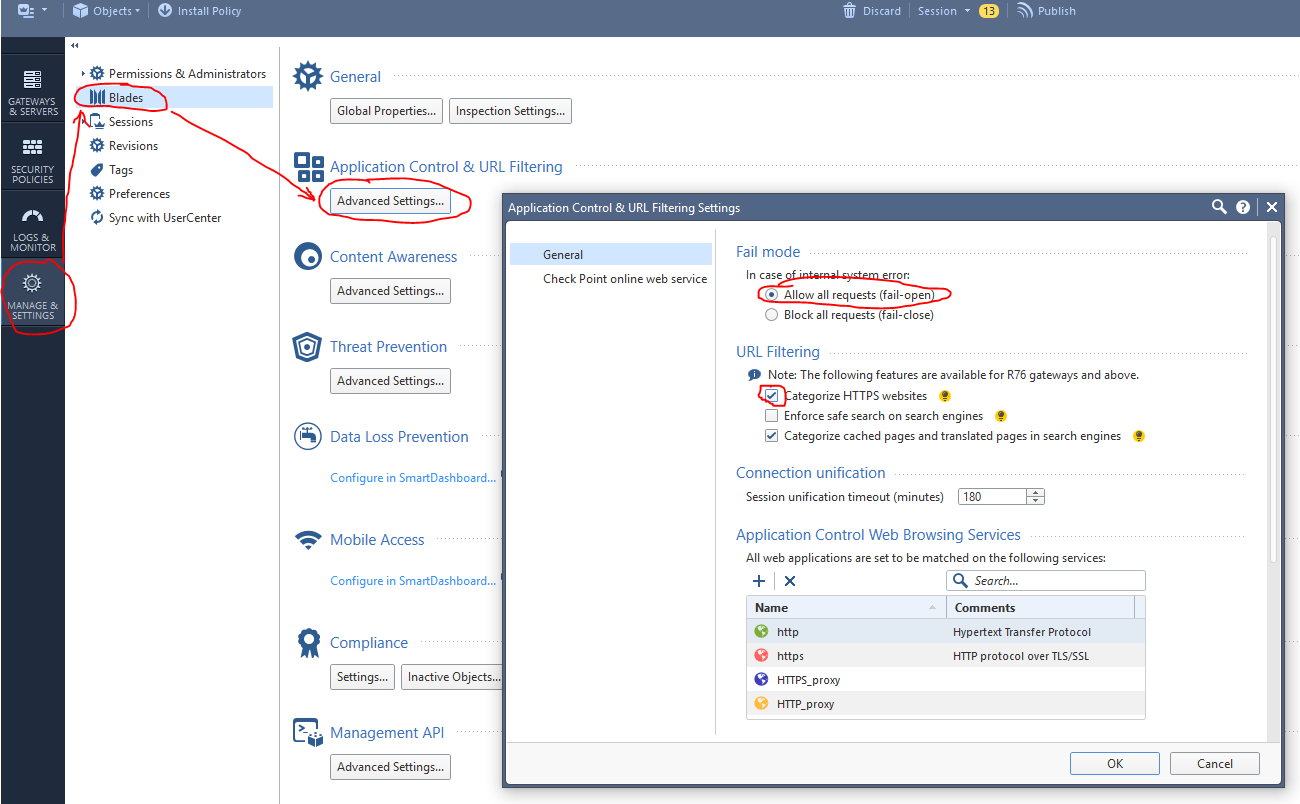



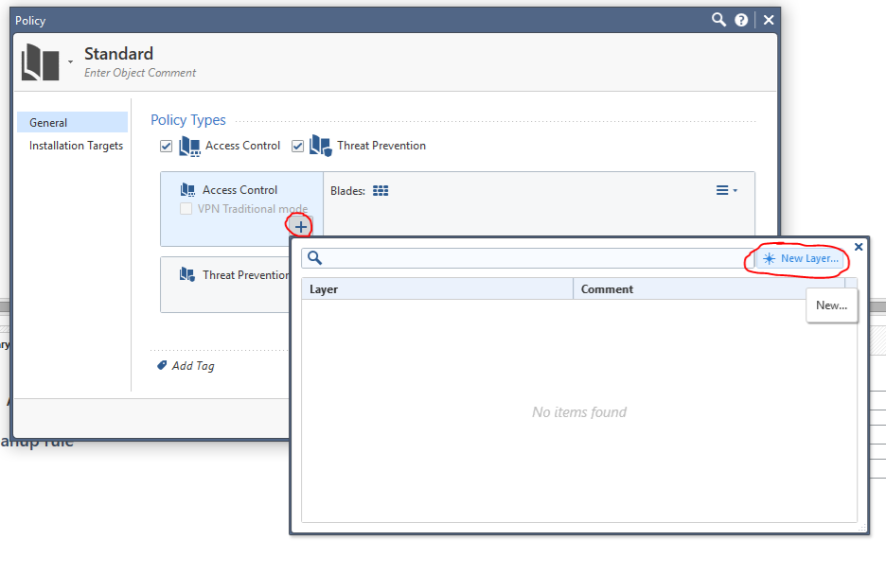




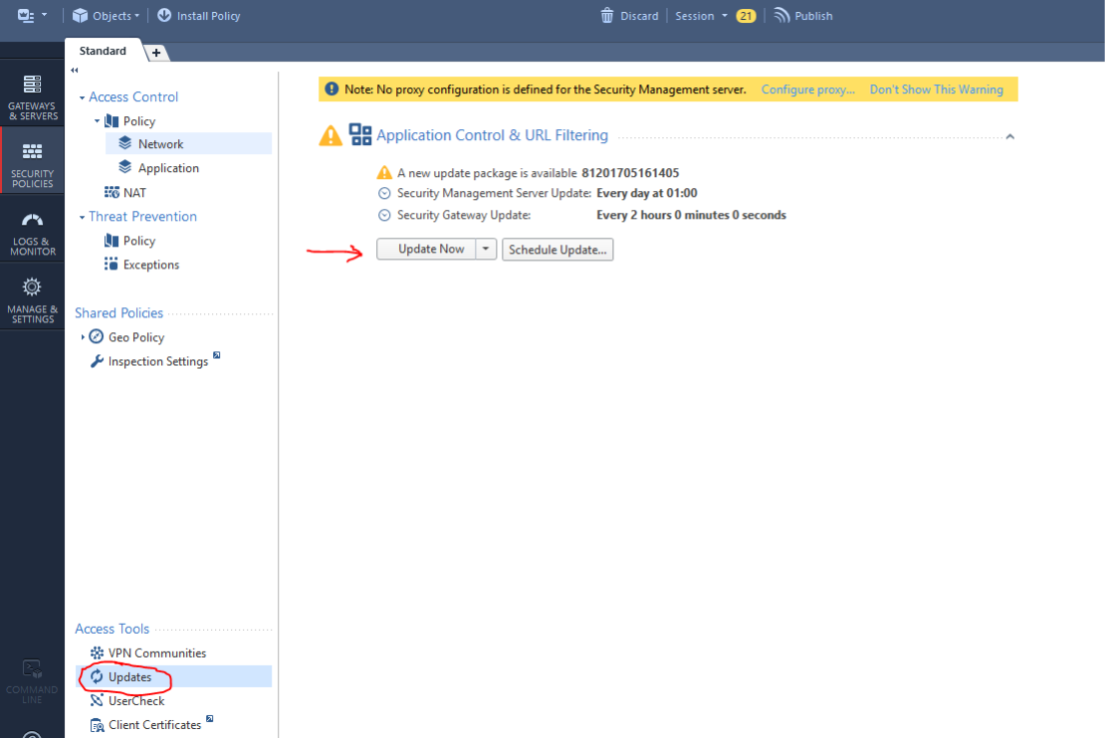







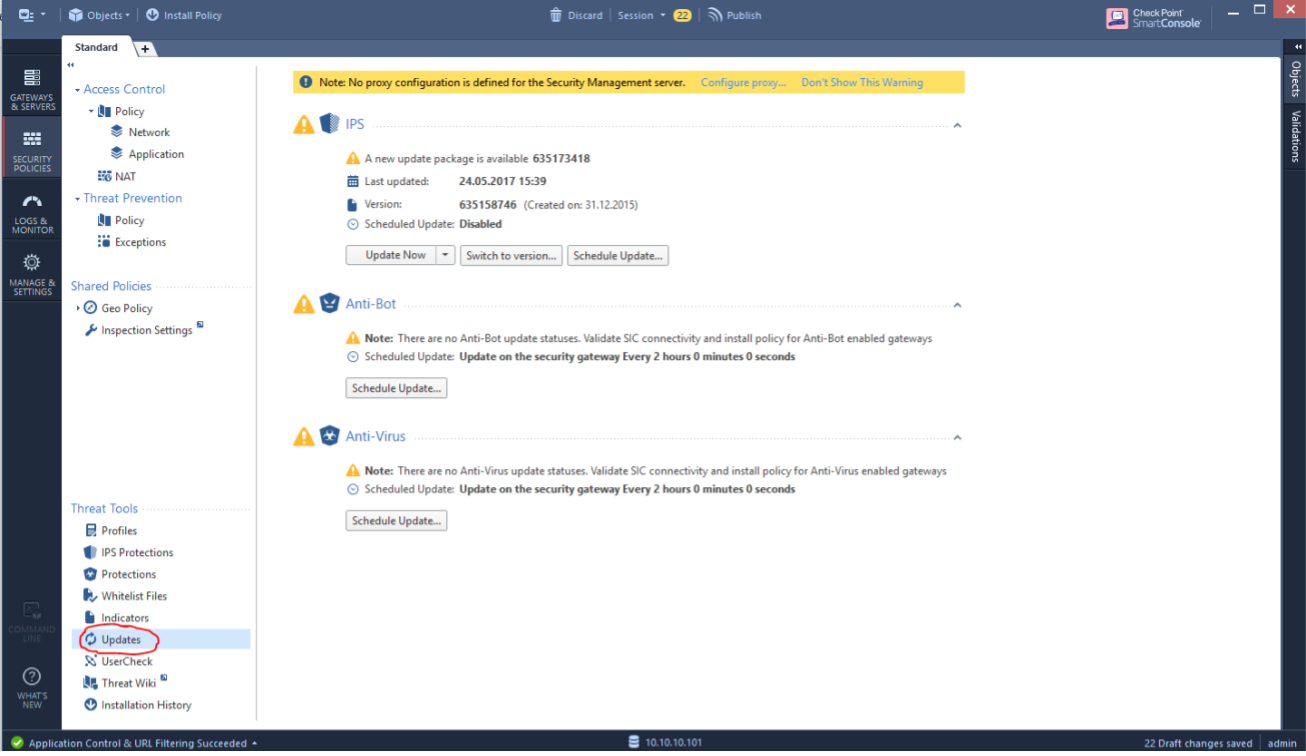
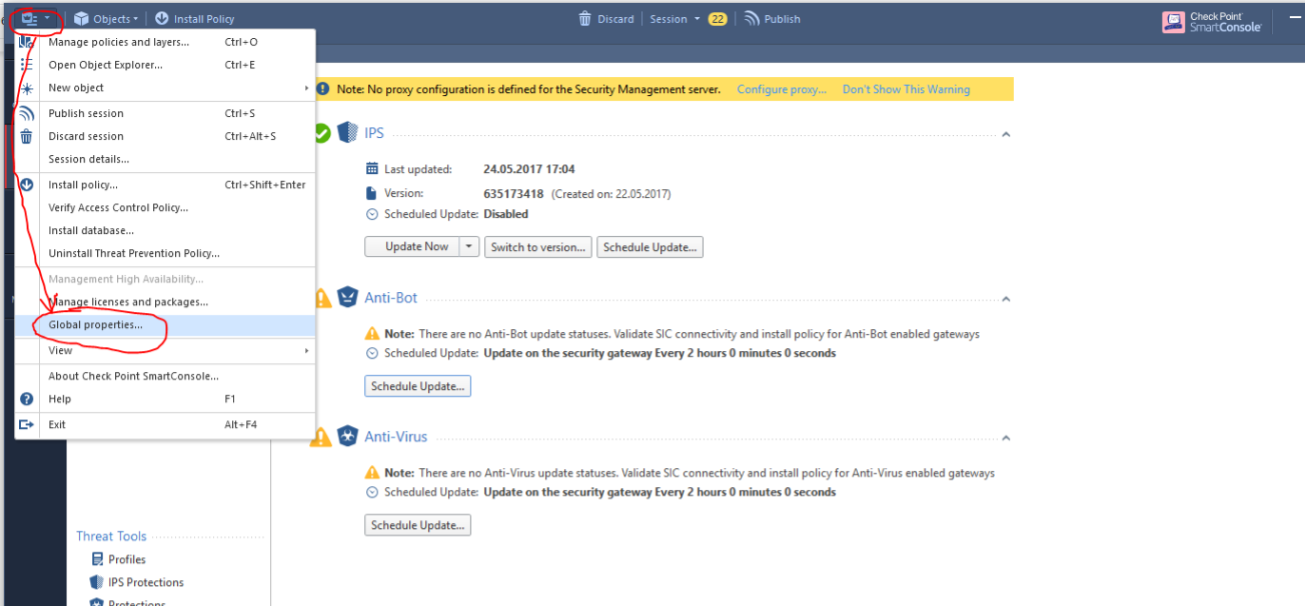
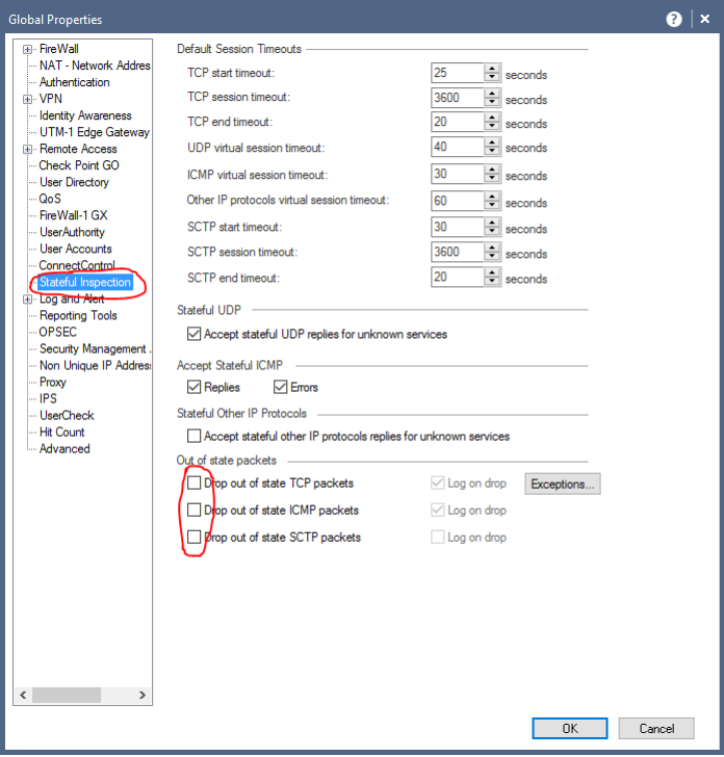


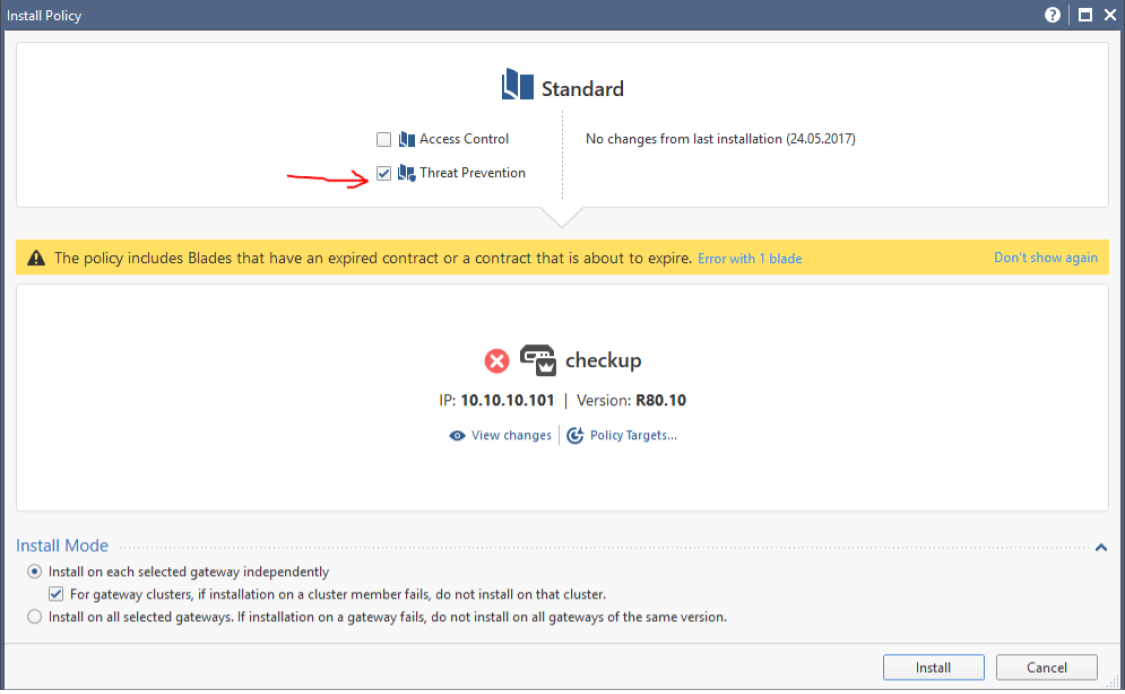



|
|
Пеленгатор на дополненной реальности |

Когда я только начинал инженерную деятельность разработкой пеленгаторов, в головах опытных товарищей, называемых нами, молодыми, за глаза "дедами", бродила мечта о “пеленгаторе на пупке”. “Это — говорили они — такой маленький пеленгатор, который можно носить с собой и пеленговать украдкой. Вот, дескать, нам приходится таскать на себе такие тяжести на крышу и обратно (хотя таскала, конечно, молодежь), а они, молодежь, никак не разработают такую вещь”. Смотря на стоящие на столе огромные железяки, мы считали их немного не в себе.
Со временем техника уменьшалась в размерах, конечно не настолько, чтобы можно было носить за пазухой. Но несколькими годами позднее, познав немного проектирование антенной техники, я уже не относился к этим мечтам старших товарищей, как к бредням.
Затем буря экзистенциального кризиса вынесла меня из уютного офиса прославленной в узких кругах организации в жестокий океан народного хозяйства. Но молодость не отпускает, она въедается в наш мозг и я обнаружил — что бы я ни взялся делать, у меня почти всегда выходил пеленгатор. По крайней мере, так говорят мои товарищи.
Ужасный рок! Но я осмотрелся и увидел, что пеленгаторы могут быть нужны обычным людям. Это давало надежду!
Сначала укажу на интерес сугубо мирных организаций к пеленгаторам (Direction Finders). В организации Bluetooth есть рабочая группа по внедрению возможности определения угла прихода волны в радио-средства Bluetooth стандарта номер 5. Они прорабатывают изменения в физическом уровне, которые позволят строить пеленгаторы источников излучения Bluetooth. Целью разработки, скорее всего, является улучшение позиционирования мобильных устройств пользователя и Bluetooth-радиометок (маяков). Они бывают персональные, которые можно носить с собой или вешать на вещи, и инфраструктурные, которые крепят на стены. Сейчас их в любом случае почти всегда позиционируют по уровню сигнала. Это такие вот штуки (все на свете их уже видели):

И действительно, давайте представим себе будущий мир, напичканный устройствами Интернета Вещей (IoT — Internet of Things). В одной с вами комнате будут излучать несколько десятков IoT-устройств: лампочки, колонки, датчики внешней среды, нательные гаджеты, смартфоны, планшеты, маячки на детях, собачках, котиках, wifi-роутеры, чайники, кофеварки, стиральные машины и другие взрослые игрушки). И хорошо, если вы уже бывали в этом месте и ваш гаджет запомнил соответствие идентификатора устройства конкретной физической вещи. А если вы здесь впервые, а вам обязательно надо приглушить свет или звук вот в этой части комнаты (ужас! неужели это правда будет кто-то делать). И вы ни за что не захотите свайпить длинный список устройств, а захотите просто перевести свое внимание — навести свой гаджет — на нужный предмет и управлять им. Вот тогда будет очень нужно знать, какой идентификатор устройства в фокусе вашего внимания.
(Бред, но хоть что-то! Хоть какой-то смысл в каждодневных усилиях одинокого инженера!)
Сначала я пошел по проторенной дороге — стал делать фазовый пеленгатор. Но вскоре увидел, что это уже сделано. Есть финская фирма Quoppa, как я думаю, осколок от объединения с Microsoft какого-то подразделения Nokia. Они внедряют свои пеленгаторы в системы позиционирования в помещениях. Их штука подвешивается к потолку и показывает вектор в направлении Bluetooth-маяка, которым уже сегодня может быть все что угодно.
Вообще, Nokia была главным застрельщиков в этом вопросе. Вот статья черте-какого года, в которой они рассказывают про пеленгатор Bluetooth на мобильном устройстве. Тогда даже название Интернет Вещей еще было не на слуху.
Осознав, что существующий уровень техники не позволяет мне создать малогабаритный фазовый пеленгатор, я начал пробовать амплитудный. Хотя электроника для нахождения угла прихода волны двигалась вперед. Фирмы Broadcom и Marvel анонсировали чипсеты с поддержкой Bluetooth 5 с функцией пеленгования (AoA — angle of arrival). Но получить доступ даже просто к документации не получилось. А их ребята на конференция бодро рассказывали (про позиционирование Bluetooth 5 устройств сразу смотрите с 12-й минуты 25-й секунды), как скоро пользователи мобильных устройств будут направлять смартфон на Bluetooth устройство и получать информацию. То есть, это получается дополненная реальность в интернете вещей. Концепция!

Так вот, амплитудный пеленгатор. Естественно хотелось сделать что-то маленькое. Обычная направленная антенна не подходит. Размеры ее зависят от направленности, на стандартную частоту 2.4 ГГц ничего хорошего в размерах планшета не получить. Тут всплыло давно забытое старое решение — моноимпульсный амплитудный пеленгатор. В те времена, когда приемники были дорогие и громоздкие, а пеленговать было нужно, инженеры пользовались не "положительной", а “отрицательной” направленностью. Грубо говоря, ловили не на максимум сигнала, а на минимум, на ноль. Так работает и рамочная антенна на коротковолновых пеленгаторах, знакомых неискушенному читателю, например, по фильму о Штирлице. Так же работает и пеленгатор в “охоте на лис”. И еще во многих хороших и не очень пеленгаторах.

Характерной особенностью таких пеленгаторов является необходимость двигаться для получения точного пеленга. Нет, можно и стоять на месте, но тогда отсчет будет неточный. Точность в таком пеленгаторе живет возле нуля диаграммы направленности.
Первый блин вышел таким.

Эта штука состоит из двух антенн. Первая имеет плавную диаграмму направленности, а вторая — резко меняющуюся.
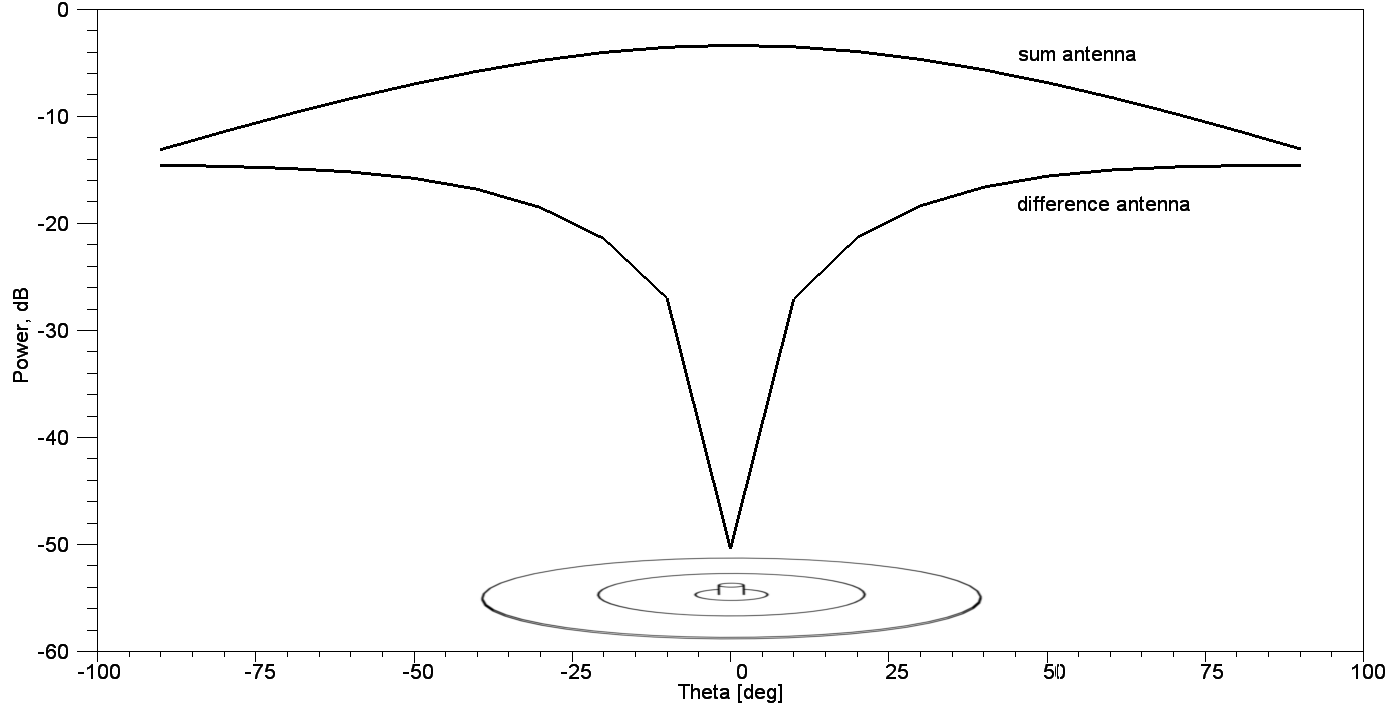
По разнице уровней с двух антенн можно определить насколько близко по углу источник волны находится в нормали к плоскости устройства. Чем больше разница, тем ближе источник к нормали к плоскости устройства или, другими словами, к фокусу камеры планшета или смартфона, если устройство закреплено с его тыльной стороны.
Первый такой пеленгатор был сделан для Bluetooth-маяков. Вот ролик с демонстрацией его работы.
Хотя устройство получилось маленьким, у него была большая зависимость от поляризации падающей волны. При падении на такой пеленгатор волны с вектором поляризации преимущественно параллельным к плоскости устройства пеленгационная характеристика вырождалась. Грубо говоря, он просто переставал работать. На ролике видно, что надо было немного вращать устройство вокруг оси, перпендикулярной его плоскости.
Таким образом, надо было сделать штырь с круговой поляризацией. Эта задача в исходных размерах пока не решена, но если увеличить пеленгатор раза в два, то можно предложить конструкцию типа расфазированной антенной решетки. Это решетка из четырех элементов, фазы которых повернуты друг относительно друга. У нее будет ноль по нормали и круговая поляризация. Как показывают графики, разница между диаграммами направленности для горизонтальной и вертикальной поляризаций незначительна.
Это измеренные характеристики реальной модели:
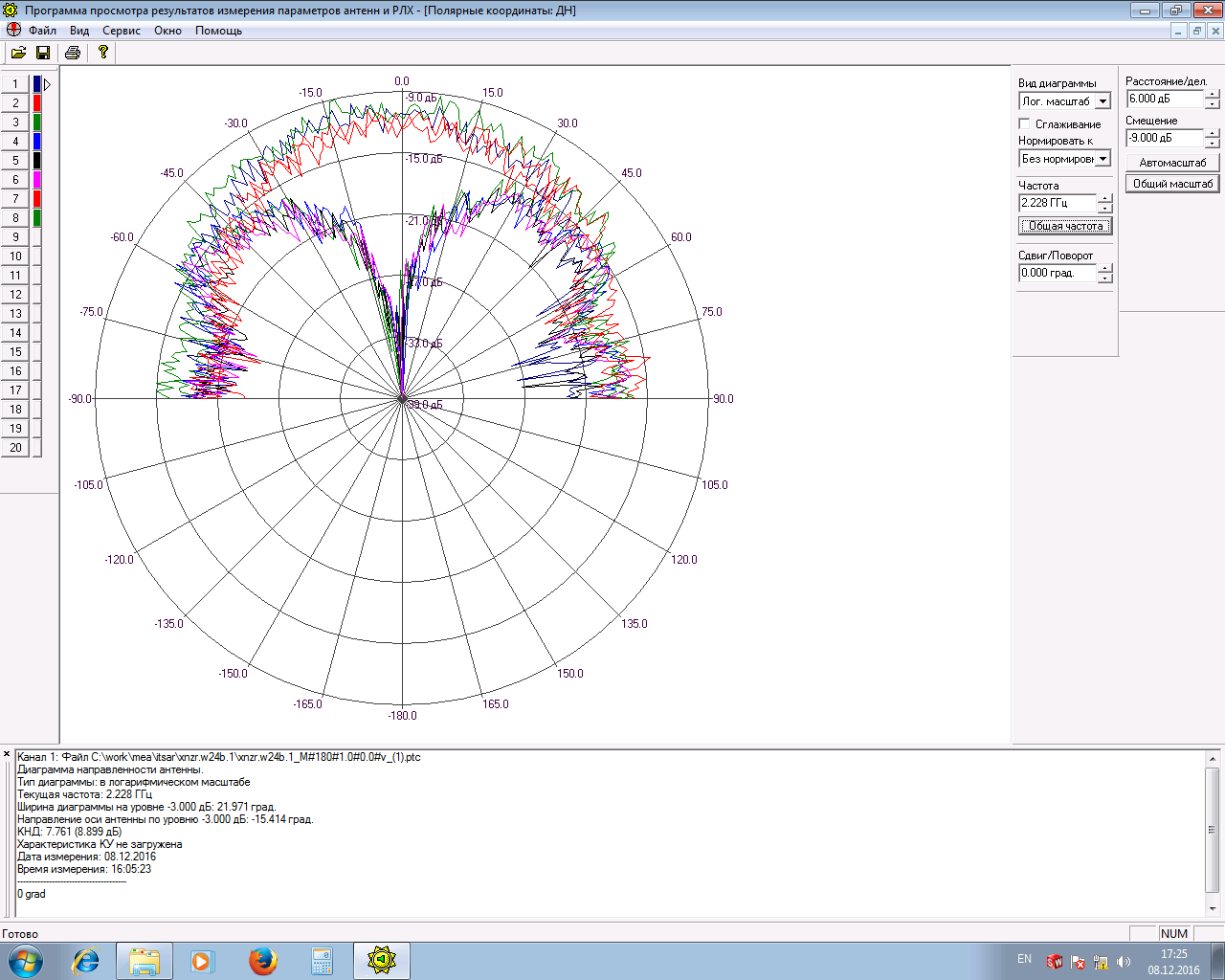
Размеры пеленгатора стали вдвое больше, сильно возросла сложность антенны, но поляризационное вырождение пропало.
Теперь пеленгатор работает так. И выглядит так:

Собственно приемник может быть построен на любом Bluetooth или WiFi-модуле или чипе. Например, на ESP8266, как сделано сейчас. Устройство соединяется с мобильным девайсом по USB. Разница уровней инвертируется и показывается на фоне реального видео как размер окружности. Чем дальше фокус камеры от направления на источник, тем больше диаметр, чем ближе — тем меньше. Что вполне естественно, при наведении на источник круг сжимается.
Исходники приложения на Андроид доступны на GitHub.
Следует упомянуть две базовые проблемы. Во-первых, чувствительность такого пеленгатора заведомо намного хуже фазового, так как она определяется усилением антенны в минимуме диаграммы направленности. Во-вторых, на такой пеленгатор влияет многолучевость, как и на все другие, но встроенной возможности справляться с ней у пеленгатора нет. В условия интерференции нужно двигаться, чтобы обнаружить местоположение источника. Нужна некоторая тренировка, чтобы научиться делать это быстро.
Но на счет этой сложности есть кое-какие соображения. Если они подтвердятся, то я обязательно здесь об этом напишу.
Попытка внедрения пеленгатора в народное хозяйство оказалась провальной. Поэтому мне очень важно услышать ваше мнение о том, кому могло бы пригодиться такое устройство и для чего.
|
|
Как настроить простую систему автотестов без Java и Selenium |

This is the end — https://t.co/GVmimAyRB5 #phantomjs 2.5 will not be released. Sorry, guys!
— Vitaly Slobodin (@Vitalliumm) April 13, 2017
sudo apt-get install chromium-browsernpm install chromedrivernpm install nightwatch -> Chromedriver ->
-> Chromedriver -> 
{
"src_folders": ["tests"], // путь к папке с тестами
"output_folder": "reports",
"custom_commands_path": "",
"custom_assertions_path": "",
"page_objects_path": "",
"globals_path": "globals.js", // путь к файлу, в котором задаётся глобальный контекст для всех тестов
"selenium": {
"start_process": false // отменяем запуск Селениума, т.к. будем обращаться к Chromedriver напрямую
},
"test_settings": {
"default": {
"selenium_port": 9515, // номер порта Chromedriver по умолчанию ("selenium_" в имени поля — это пережиток прошлого)
"selenium_host": "localhost",
"default_path_prefix" : "",
"desiredCapabilities": {
"browserName": "chrome",
"chromeOptions" : {
"args" : ["--no-sandbox", "--headless", "--disable-gpu"], // специальные флаги для работы Хрома в headless-режиме
"binary" : "/usr/bin/chromium-browser" // путь к исполняемому файлу Хрома
},
"acceptSslCerts": true
}
}
}
}const chromedriver = require('chromedriver');
module.exports = {
before: function(done) {
chromedriver.start();
done();
},
after: function(done) {
chromedriver.stop();
done();
}
};module.exports = {
'Test ya.ru': function(browser) {
const firstResultSelector = '.serp-list .organic__subtitle b';
browser
.url('http://ya.ru', () => {
console.log('Loading ya.ru...');
})
.waitForElementVisible('#text', 5000)
.execute(function() {
document.getElementById('text').value = 'Привет, Хабр!';
})
.submitForm('form')
.waitForElementVisible(firstResultSelector, 5000)
.getText(firstResultSelector, result => {
browser.assert.equal(result.value, 'm.habrahabr.ru');
})
.end();
}
};$ nightwatch --test tests/ya.js
[Ya] Test Suite
===================
Running: Test ya.ru
Loading ya.ru...
Element <#text> was visible after 70 milliseconds.
Warn: WaitForElement found 10 elements for selector ".serp-list .organic__subtitle b". Only the first one will be checked.
Element <.serp-list .organic__subtitle b> was visible after 1706 milliseconds.
Passed [equal]: m.habrahabr.ru == m.habrahabr.ru
OK. 3 assertions passed. (4.992s)|
Метки: author Aralot тестирование веб-сервисов программирование node.js javascript тестирование qa selenium nightwatch headless browser phantomjs |






