Внедрение инструментов Lean в командe Сервис Деск |
 Любой сервис для конечных пользователей должен быть гибким, отражающим их текущие потребности. Бизнес развивается, качество сервиса тоже должно расти. Если этого не происходит, рано или поздно уровень услуг, заданных на старте проекта, перестает устраивать потребителей. Поэтому хочу поделиться с вами своим опытом внедрения новых методов работы в нашей команде Сервис Деск (SD).
Любой сервис для конечных пользователей должен быть гибким, отражающим их текущие потребности. Бизнес развивается, качество сервиса тоже должно расти. Если этого не происходит, рано или поздно уровень услуг, заданных на старте проекта, перестает устраивать потребителей. Поэтому хочу поделиться с вами своим опытом внедрения новых методов работы в нашей команде Сервис Деск (SD). 


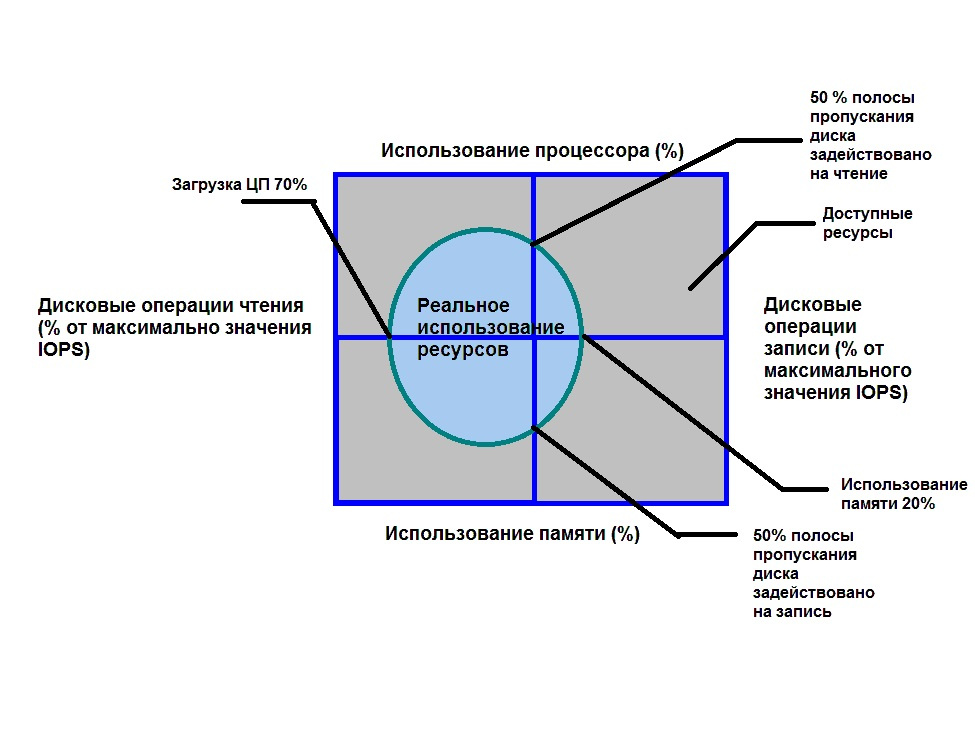
 «Sift»: мы провели анализ всех наших мест хранения проектной информации на предмет устаревших или неиспользуемых данных. Всю ненужную информацию переместили в соответствующую папку «Архив» на каждом ресурсе. Все инструкции, документация, хранящуюся на локальных компьютерах, были размещены в общем доступе команды и так же проанализирована. Это позволило оценить общий объем накопленных знаний на проекте. Информация, требующая уточнения, была помечена и постепенно прояснялась. На проекте используется 7 различных ресурсов, содержащих многогранную информацию.
«Sift»: мы провели анализ всех наших мест хранения проектной информации на предмет устаревших или неиспользуемых данных. Всю ненужную информацию переместили в соответствующую папку «Архив» на каждом ресурсе. Все инструкции, документация, хранящуюся на локальных компьютерах, были размещены в общем доступе команды и так же проанализирована. Это позволило оценить общий объем накопленных знаний на проекте. Информация, требующая уточнения, была помечена и постепенно прояснялась. На проекте используется 7 различных ресурсов, содержащих многогранную информацию. «Sort» запустил процесс перераспределения всей актуальной информации в соответствии с ее типом. Дубликаты файлов были удалены.
«Sort» запустил процесс перераспределения всей актуальной информации в соответствии с ее типом. Дубликаты файлов были удалены.  «Shine»: совместно с командой определили новую файловую структуру хранилищ, а так же ответственных за внесение и изменение информации.
«Shine»: совместно с командой определили новую файловую структуру хранилищ, а так же ответственных за внесение и изменение информации. «Standardise»: создали внутренний стандарт хранения и распределения входящей информации. Наименование файлов и папок, категории информации, периоды обязательной актуализации данных.
«Standardise»: создали внутренний стандарт хранения и распределения входящей информации. Наименование файлов и папок, категории информации, периоды обязательной актуализации данных. «Sustain»: примение разработанных стандартов и подходов в ходе предоставления сервиса. Проверка соответсвия новых стандартов выполняемым рабочим операциям. Это позволило нам сформировать новый подход к хранению, распределению, актуализации информации.
«Sustain»: примение разработанных стандартов и подходов в ходе предоставления сервиса. Проверка соответсвия новых стандартов выполняемым рабочим операциям. Это позволило нам сформировать новый подход к хранению, распределению, актуализации информации. |
Метки: author Bender251 управление проектами service desk блог компании icl services управление командой lean бережливое производство |
Global DevOps Bootcamp + подборка видео |

|
Метки: author maria_gore visual studio microsoft azure блог компании microsoft devops global devops bootcamp mvp microsoft |
Android-митап в офисе Badoo 17 июня |
Привет! 17 июня в нашем офисе пройдет первый (для нас) Android-митап. С докладами будут выступать разработчики из Avito, Яндекса, Одноклассников, из Badoo – я, Аркадий Гамза. Начало – в 12:00. Описание докладов – под катом.
11:00 – Начало регистрации (приходите, чтобы успеть выпить кофе и занять лучшие места)
12:00 – 12:40 – Филипп Уваров, Avito
12:40 – 12:55 – Вопросы
12:55 – 13:05 – Перерыв (вы успеете выпить по чашке кофе и задать еще пару вопросов спикеру)
13:10 – 13:50 – Аркадий Гамза, Badoo
13:50 – 14:05 – Вопросы
14:05 – 14:40 – Перерыв (обед)
14:40 – 15:20 – Андрей Сидоров, Яндекс.Браузер
15:20 – 15:35 – Вопросы
15:40 – 16:20 – Григорий Джанелидзе, OK.RU
16:20 – 16:35 – Вопросы
16:35 – 17:35 – Свободное общение

Тема: Компонентные тесты: как сделать жизнь вашего QA немного проще?
В докладе речь пойдёт о компонентных тестах, в том числе я поделюсь лучшими практиками, которые выработала наша команда, и расскажу, как они помогают нам делать более качественный продукт.
В частности поговорим о том:

Тема: Android Studio умеет больше, чем вы думаете
Мы обсудим полезные функции Android Studio – основного инструмента каждого Android-разработчика.
Я буду говорить:

Тема: Измерение энергопотребления мобильных и внедрение в Continuous Integration.
Во время выступления я буду говорить про:

Тема: Как перестать беспокоиться и начать запускать фичи
Запуск новых фич для любого продукта – довольно опасная штука, ведь столько всего может пойти не так: может вылезти огромное число разных багов (от device specific до багов в самой фиче), могут не выдержать сервера и в конце концов пользователям может просто не понравиться фича.
Я расскажу о том, как мы запускаем новые фичи, какие проблемы, связанные с запусками, у нас возникали и как это всё работает в Android-клиенте.
Тезисы:
Регистрироваться на митап – здесь (пишите ваши фамилии и имена кириллицей, пожалуйста).
Адрес: Москва, Цветной бульвар, 2, БЦ «Легенда Цветного», подъезд А. Метро: Трубная/Цветной бульвар. Захватите с собой какой-нибудь удостоверяющий личность документ.
|
Метки: author ArkadyGamza тестирование мобильных приложений разработка под android разработка мобильных приложений блог компании badoo android митап |
«Сломай голосовалку на РИТ++». Даёшь 1 000 000 RPS |

Прошёл второй день РИТ++, и по горячим следам мы хотим рассказать о том, как всем миром пытались сломать нашу голосовалку. Под катом — код, метрики, имена победителей и самых активных участников, и прочие грязные подробности.
Незадолго перед РИТ++ мы задумались, чем можно развлечь народ? Решили сделать голосовалку за самый крутой язык программирования. И чтобы результаты в реальном времени выводились на дашборд. Процедуру голосования сделали простой: можно было с любого устройства зайти на сайт ODN.PW, указать своё имя и e-mail, и проголосовать за какой-нибудь язык. Со списком языков не мудрили — взяли девять самых популярных по данным GitHub, десятым пунктом сделали язык “Other”. Цвета для плашек тоже взяли с GitHub.

Но мы понимали, что накрутки будут неизбежны, причём с применением «тяжёлой артиллерии» — все свои, аудитория продвинутая, это же не голосование на мамочкином форуме. Поэтому мы решили приветствовать накрутки всеми возможными способами. Более того, предложили попробовать сообществу положить нашу голосовалку большой нагрузкой. А чтобы участникам было ещё проще, выложили ссылку на API для накруток с помощью ботов. И заодно решили наградить поощрительными призами первых трёх участников с наибольшим количеством RPS. Отдельная номинация была заготовлена для того силача, который сможет поломать голосовалку в одиночку.
Голосовалку запустили почти с самого начала работы РИТ++, и работала она до 18 часов. Наше развлечение понравилось посетителям и докладчикам РИТ++. Специалисты по высокопроизводительным сервисам активно включились в гонку за RPS. Гости стенда живо обсуждали способы положить голосовалку. Стихийно возникали команды адептов того или иного языка, которые начинали придумывать стратегии продвижения. Кто-то тут же садился и начинал писать микросервисы или ботов для участия в голосовании.

Некоторые компании, участвующие в РИТ++ и предоставляющие услуги защищённых хостингов, тоже включились в наше соревнование. К самому концу дня совместными усилиями участники всё же смогли ненадолго положить систему. Ну как «положили» — сервис-то работал, просто мы упёрлись в потолок по количеству одновременно регистрируемых голосов. Поэтому к 18 часам мы приостановили голосование, иначе результаты были бы недостоверными.
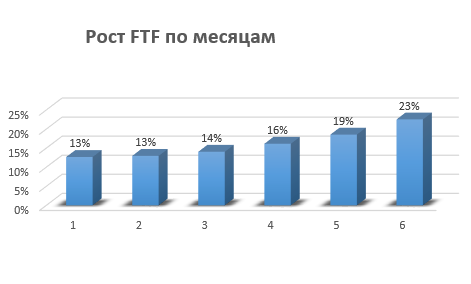
По результатам первого дня мы получили 160 млн голосов, а пиковая нагрузка достигала 20 000 RPS. Любопытно, что в этот день первое и второе места заняли активный участник РИТ++
Николай Мациевский (Айри) и спикер Елена Граховац из Openprovider.
Ночью мы подготовились к следующему дню, чтобы встретить его во всеоружии: оптимизировали общение с базой и поставили nginx перед Node.js-приложением на каждом воркере.
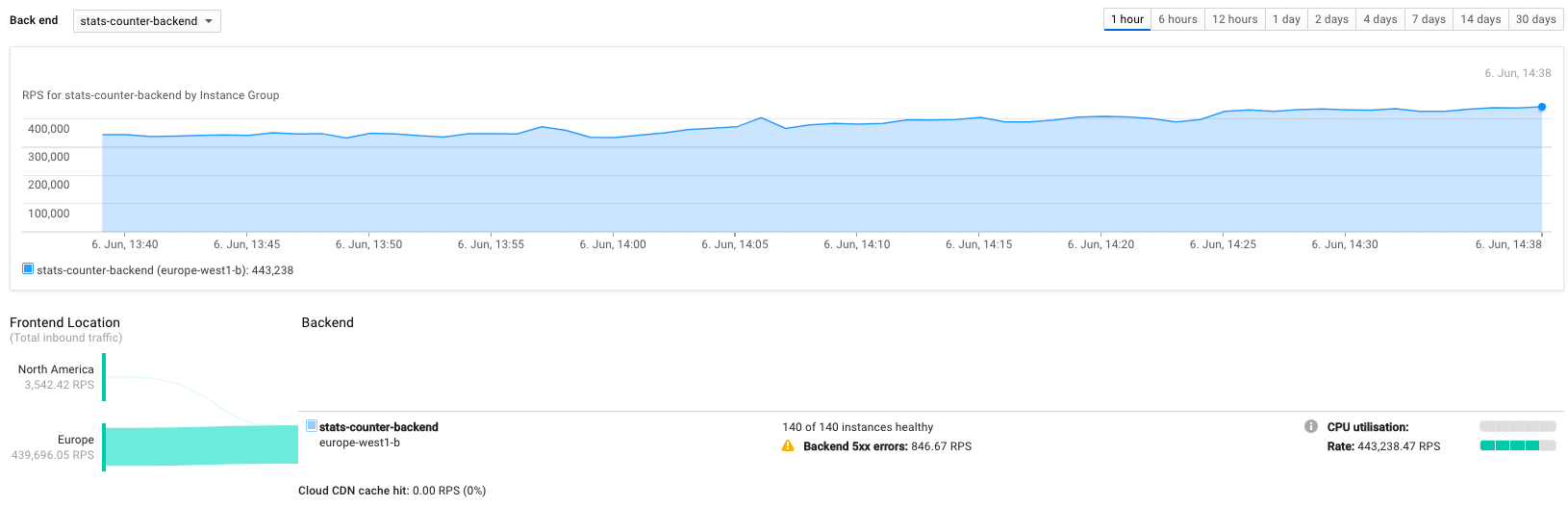
Многих заинтересовало наше предложение положить голосовалку, ведь гонка за RPS — задача увлекательная. Утром нас уже «ждали»: едва мы переключили DNS, как количество RPS взлетело до 100 000. И через полчаса нагрузка поднялась до 300 000 RPS.
Забавно, что когда мы только приступали к разработке голосовалки, то решили, что «неплохо было бы поддерживать 100 000 RPS». И на всякий случай заложили максимальную производительность в 1 млн RPS, но при этом даже всерьёз не рассматривали возможность приближения к такому показателю. А к середине второго дня уже практически делали ставки на то, пробьём ли потолок в миллион запросов в секунду. В результате мы достигли порядка 500 000 RPS.
Проект мы запилили втроём за 1,5 дня, перед самым РИТ++. Голосовалку разместили в облачном сервисе Google Cloud Platform. Архитектура трёхуровневая:
• Верхний уровень: балансировщик, выступающий в роли фронтенда, на который приходит поток запросов. Он раскидывает нагрузку по серверам.
• Средний уровень: бэкенд на Node.js 8.0. Количество задействованных машин масштабируется в зависимости от текущей нагрузки. Делается это экономно, а не с запасом, чтобы не переплачивать впустую. К слову, проектик обошёлся в 8000 рублей.
• Нижний уровень: кластеризованная MongoDB для хранения голосов, состоящая из трёх серверов (один master и два slave’а).
Все компоненты голосовалки — open source, доступны на Github:
• Backend: https://github.com/spukst3r/counter-store
• Frontend: https://github.com/weglov/treechart
Во время разработки бэкенда в воздухе витала идея кешировать каждый запрос на накрутку голосов и периодически отправлять их в базу. Но из-за нехватки времени, неуверенности в количестве участников и банальной лени было решено отложить эту идею и оставить отправку данных в базу на каждый запрос. Заодно и производительность MongoDB в таком режиме проверить.
Что ж, как показал первый день, прикрутить кеш надо было сразу. Каждый воркер Node.js выдавал не больше 3000 RPS на каждый POST на /poll, а мастер MongoDB тяжело кашлял с LA >100. Не очень помогла даже оптимизация агрегации запросов для получения статистики путём изменения read preference на использование slave'ов для чтения. Ну ничего, самое время реализовать кеш для накрутки счётчиков и для проверки валидности email'а (который был завёрнут в простой _.memoize, ведь мы никогда не удаляем пользователей). Также мы задействовали новый проект в Google Compute Engine, с бОльшими квотами.
После включения кеширования голосов MongoDB чувствовала себя превосходно, показывая LA <1 даже в пике загрузки. А производительность каждого воркера выросла на 50% — до 4500 RPS. Для периодической отправки данных мы использовали bulkWrite с отключённым параметром ordered, чтобы оставить на стороне базы очередность исполнения запросов для оптимизации скорости.
В первый день на каждом воркере работал Node.js-сервер, создающий через модуль cluster четыре дочерних процесса, каждый из которых слушал порт 3000. Для второго дня мы отказались от такого сервера и отдали обработку HTTP «профессионалам». Опыты показали, что nginx, взаимодействующий с приложением через unix-сокет, даёт примерно +500 RPS. Настройка достаточно стандартная для большого количества соединений: увеличенный worker_rlimit_nofile, достаточный worker_connections, включенный tcp_nopush и tcp_nodelay. Кстати, отключение алгоритма Нейгла помогло поднять RPS и в Node.js. В каждой виртуалке потребовалось увеличить лимит на количество открытых файлов и максимальный размер backlog'а.
За два дня ни одному участнику в одиночку не удалось положить наш сервис. Но в конце первого дня общими усилиями добились того, что система не успевала регистрировать все входящие запросы. На второй день мы поставили рекорд в нагрузке ~450 000 RPS. Различие в показаниях RPS на фронте (который высчитывал и усреднял RPS по фактическим записям в базе) и показания мониторинга Google пока остаётся для нас тайной.
И рады объявить победителей нашего маленького соревнования:
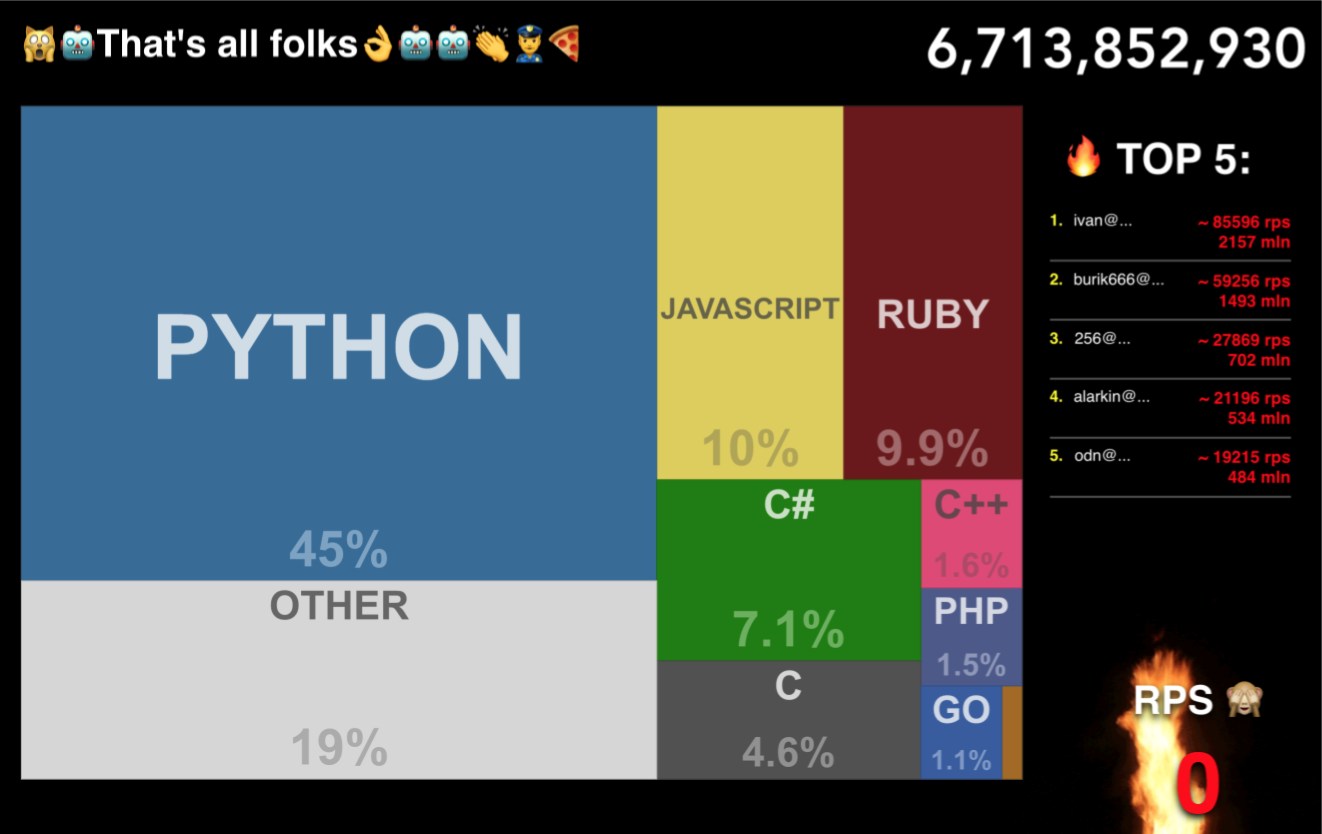
1 место — { "_id": "ivan@buymov.ru", "count": 2107126721 }
2 место — { "_id": "burik666@gmail.com", "count": 1453014107 }
3 место — { "_id": "256@flant.com", "count": 626160912 }
Для получения призов пишите kosheleva_ingram_micro!
|
|
Первыми закрываются компании где ставится много задач. Статистика использования системы управления проектами YouGile |






|
Метки: author Superslon управление разработкой управление проектами развитие стартапа agile блог компании yougile yougile исследования пользователей стартапы |
Видео: инди-разработчики о провалах, успехе и монетизации |
|
|
По дороге с облаками. Реляционные базы данных в новом технологическом контексте |
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<пар0ль>';
CREATE DATABASE SCOPED CREDENTIAL FirstDBQueryCred -- Это имя учетной записи
WITH IDENTITY = '<ИмяПользователя>',
SECRET = '<пар0ль>';
CREATE EXTERNAL DATA SOURCE FirstDatabaseDataSource WITH
(
TYPE = RDBMS,
LOCATION = '.database.windows.net',
DATABASE_NAME = 'First',
CREDENTIAL = FirstDBQueryCred
)
CREATE EXTERNAL TABLE [dbo].[TableFromFirstDatabase]
( [KeyFieldID] [int] NOT NULL,
[DataField] [varchar](50) NOT NULL
)
WITH ( DATA_SOURCE = FirstDatabaseDataSource)
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author ph_piter профессиональная литература microsoft azure big data блог компании издательский дом «питер» базы данных azure sql cloud computing cloud storage книги |
[Перевод] Понимание событийной архитектуры Node.js |
|
Метки: author AloneCoder разработка веб-сайтов программирование node.js javascript блог компании mail.ru group никто не читает теги |
Катаем «смоляной шарик» или создание собственных правил сборки с помощью Qbs |
A product is the target of a build process, typically an application, library or maybe a tar ball
---product1.qbs---
Application {
name: "simpleApplication";
targetName: "appSimple"
files: ["main.cpp", "app.h", "app.cpp"]
Depends {name: "cpp"}
}
---product2.qbs---
Product {
type: "exampleArtefact"
name: "example"
targetName: "myArtefact"
Depends {name: "simpleApplication" }
Depends {name: "exampleModule" }
Group {
files: ["description.txt", "readme.txt"]
fileTags: ["txtFiles"]
}
Group {
files: ["imgA.png", "imgB.png", "imgC.png"]
fileTags: ["pngFiles"]
}
Group {
files: ["fontA.ttf", "fontB.ttf"]
fileTags: ["fontFiles"]
}
}
---exampleModule.qbs---
Module {
Rule {
inputs: ["pngFiles", "fontFiles"]
inputsFromDependencies: ["application"]
Artifact {
filePath: product.targetName + ".out"
fileTags: ["exampleArtefact"]
}
...
}
...
}
Artifact {
filePath: input.fileName + ".out"
fileTags: ["txt_output"]
}outputArtifacts: [{
var artifactNames = inputs["pngFiles"].map(function(file){
return "pictures/"+file.fileName;
});
artifactNames = artifactNames.concat(inputs["fontFiles"].map(function(file){
return "fonts/"+file.fileName;
}));
artifactNames = artifactNames.concat(inputs["application"].map(function(file){
return "app/"+file.fileName;
}));
var artifacts = artifactNames.map(function(art){
var a = {
filePath: art,
fileTags: ["exampleArtefact"]
}
return a;
});
return artifacts;
}]outputFileTags:
["exampleArtefact"]var myCommand = new Command("dir", ["/B", "/O", ">>", output.filePath]);var cmd = new JavaScriptCommand();
cmd.myFirstData = "This is 1 string";
cmd.mySecondData = "This is 2 string";
cmd.sourceCode = function() {
console.info("String from source code"); // -->> "String from source code"
console.info("Property 1: "+myFirstData); // -->> "Property 1: This is 1 string"
console.info("Property 2: "+mySecondData); // -->> "Property 2: This is 2 string"
}; qbs.buildVariant === "release" && qbs.targetOS.contains("windows") -- MyWindowsDeploy.qbs --
import qbs
import qbs.ModUtils
Module {
Rule {
condition: qbs.targetOS.contains("windows") //запускается только для windows
multiplex: true //обрабатываем все входные артефакты одним трансформером
alwaysRun: true //всегда выполнять правило
inputsFromDependencies: ["installable"] //брать устанавливаемые артефакты от зависимостей собираемого продукта
Artifact {
filePath: "Copied_qt_libs.txt";
fileTags: ["deployQt"];
}
prepare: {
var cmdQt = new JavaScriptCommand();
//определяем путь до windeployqt.exe
cmdQt.windeployqt = FileInfo.joinPaths(product.moduleProperty("Qt.core", "binPath"), "windeployqt.exe");
//задаем строку для вывода в консоли
cmdQt.description = "Copy Qt libs and generate text file: "+output.fileName;
//указываем развернутую информацию по выполняемой команде
cmdQt.extendedDescription = cmdQt.windeployqt + ".exe " +
["--json"].concat(args).concat(binaryFilePaths).join(" ");
//путь до папки, куда надо копировать qt библиотеки ("<папка установки>/QtLibs")
var deployDir = FileInfo.joinPaths(product.moduleProperty("qbs","installRoot"),
product.moduleProperty("qbs","installDir"));
deployDir = FileInfo.joinPaths(deployDir, "QtLibs");
cmdQt.qtLibsPath = deployDir;
//определяем аргументы запуска программы
cmdQt.args = [];
cmdQt.args.push("--libdir", deployDir);
cmdQt.args.push("--plugindir", deployDir);
cmdQt.args.push("--no-translations");
cmdQt.args.push("--release");
//полное имя файла для записи вывода.
cmdQt.outputFilePath = output.filePath;
//определяем список путей установки программ и библиотек, от которых зависит продукт
cmdQt.binaryFilePaths = inputs.installable.filter(function (artifact) {
return artifact.fileTags.contains("application")
|| artifact.fileTags.contains("dynamiclibrary");
}).map(function(a) { return ModUtils.artifactInstalledFilePath(a); });
cmdQt.sourceCode = function(){
var process;
var tf;
try {
//выводим значения параметров
console.info("windeployqtRule: outputFilePath: "+outputFilePath);
console.info("windeployqtRule: qtLibsPath: "+qtLibsPath);
console.info("windeployqtRule: windeployqt: "+windeployqt);
console.info("windeployqtRule: windeployqtArgs: "+windeployqtArgs.join(", "));
console.info("windeployqtRule: binaryFilePaths: "+binaryFilePaths.join(", "));
//создаем папку куда будут скопированы библиотеки Qt
File.makePath(qtLibsPath);
//создаем процесс
process = new Process();
//запускаем процесс
process.exec(windeployqt,
["--json"].concat(windeployqtArgs).concat(binaryFilePaths), true);
//читаем вывод программы
var out = process.readStdOut();
//парсим выходной JSON
var inputFilePaths = JSON.parse(out)["files"].map(function (obj) {
//определяем полный путь доя скопированной библиотеки
var fn = FileInfo.joinPaths(
FileInfo.fromWindowsSeparators(obj.target),
FileInfo.fileName(
FileInfo.fromWindowsSeparators(
obj.source)));
return fn;
});
//создаем файл
tf = new TextFile(outputFilePath, TextFile.WriteOnly);
//пишем заголовок
tf.writeLine("Copied Qt files:");
inputFilePaths.forEach(function(qtLib){
tf.writeLine(qtLib); //записываем в выходной файл полный путь до скопированной библиотеки
});
} finally {
if (process)
process.close();
if (tf)
tf.close();
}
}
return [cmdQt];
}
}
}
-- ProductDeploy.qbs --
import qbs
Product {
//продукт представляет собой результат деплоя Qt библиотек для продуктов от которых он
//зависит в виде скопированных библиотек и текстового файла
type: ["deployQt"]
// указываем зависимость от модуля в котором есть правило преобразования
Depends { name: "MyWindowsDeploy" }
// указываем зависимость от продуктов, для которых
// надо подготовить Qt библиотеки, плагины и пр.
Depends { name: "libratyA" }
Depends { name: "libratyB" }
Depends { name: "applicationA" }
Depends { name: "applicationB" }
Depends { name: "applicationC" }
condition: qbs.targetOS.contains("windows") // собирать только для windows
builtByDefault: false // собирать ли продукт при общей сборке проекта
qbs.install: true
qbs.installDir: "MyProject/qtDeploy"
}|
Метки: author hooligan системы сборки qt qbs |
[Из песочницы] Mikrotik. QoS для дома |

#Set bandwidth of the interface
:local interfaceBandwidth 100M
# address-lists
:for i from=1 to=10 do={/ip firewall address-list add list=WoT address=("login.p"."$i".".worldoftanks.net")}
#
/ip firewall mangle
# prio_1
add chain=prerouting action=mark-packet new-packet-mark=prio_1 protocol=icmp
add chain=prerouting action=mark-packet new-packet-mark=prio_1 protocol=tcp port=53
add chain=prerouting action=mark-packet new-packet-mark=prio_1 protocol=udp port=53
add chain=prerouting action=mark-packet new-packet-mark=prio_1 protocol=tcp tcp-flags=ack packet-size=0-123
# prio_2
add chain=prerouting action=mark-packet new-packet-mark=prio_2 dscp=40
add chain=prerouting action=mark-packet new-packet-mark=prio_2 dscp=46
add chain=prerouting action=mark-packet new-packet-mark=prio_2 protocol=udp port=5060,5061,10000-20000 src-address=192.168.100.110
add chain=prerouting action=mark-packet new-packet-mark=prio_2 protocol=udp port=5060,5061,10000-20000 dst-address=192.168.100.110
# prio_3
add chain=prerouting action=mark-packet new-packet-mark=prio_3 protocol=tcp port=22
add chain=prerouting action=mark-packet new-packet-mark=prio_3 address-list=WoT
# prio_4
add chain=prerouting action=mark-packet new-packet-mark=prio_4 protocol=tcp port=3389
add chain=prerouting action=mark-packet new-packet-mark=prio_4 protocol=tcp port=80,443
# prio_5
add chain=prerouting action=mark-packet new-packet-mark=prio_5queue tree add max-limit=$interfaceBandwidth name=QoS_global parent=global priority=1
:for indexA from=1 to=5 do={
/queue tree add \
name=( "prio_" . "$indexA" ) \
parent=QoS_global \
priority=($indexA) \
queue=ethernet-default \
packet-mark=("prio_" . $indexA) \
comment=("Priority " . $indexA . " traffic")
}/ip firewall mangle
# prio_1
add chain=prerouting action=set-priority new-priority=7 protocol=icmp
add chain=prerouting action=set-priority new-priority=7 protocol=tcp port=53
add chain=prerouting action=set-priority new-priority=7 protocol=udp port=53
add chain=prerouting action=set-priority new-priority=7 protocol=tcp tcp-flags=ack packet-size=0-123
# prio_2
add chain=prerouting action=set-priority new-priority=6 dscp=40
add chain=prerouting action=set-priority new-priority=6 dscp=46
add chain=prerouting action=set-priority new-priority=6 protocol=udp port=5060,5061,10000-20000 src-address=192.168.100.110
add chain=prerouting action=set-priority new-priority=6 protocol=udp port=5060,5061,10000-20000 dst-address=192.168.100.110
# prio_3
add chain=prerouting action=set-priority new-priority=5 protocol=tcp port=22
add chain=prerouting action=set-priority new-priority=4 address-list=WoT
# prio_4
add chain=prerouting action=set-priority new-priority=3 protocol=tcp port=3389:foreach i in=[/ip dns cache all find where (name~"youtube" || name~"facebook" || name~".googlevideo")]
do={:put [/ip dns cache get $i address]}:foreach i in=[/ip firewall nat find dynamic and comment~"Skype"]
do={:put [/ip firewall nat get $i dst-port]}|
Метки: author StraNNicK системное администрирование сетевые технологии mikrotik qos шейпинг трафика |
Браузеры на основе Chromium — теперь и в ReactOS |
--allow-no-sandbox-job —disable-preconnect —disable-translate —disable-accelerated-video —disable-gpu —disable-plugins —no-sandboxПри этом, вероятно, не все они жизненно необходимы, и от некоторых уже можно избавится, Напишите нам об итогах своих экспериментов.

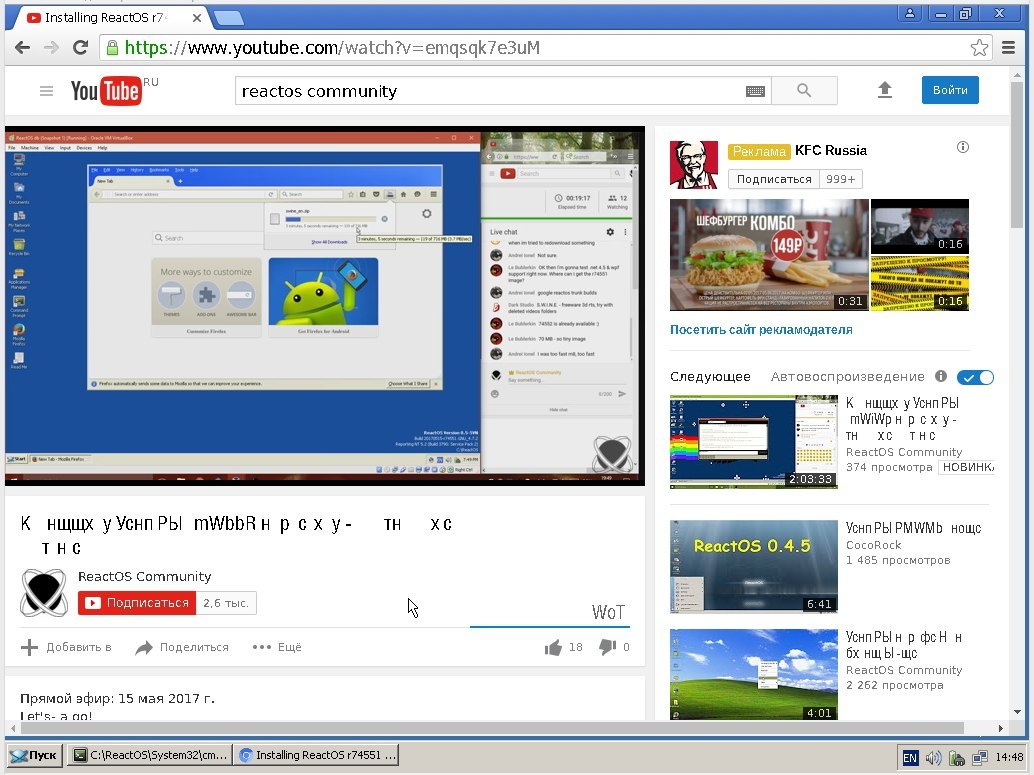
Reading a file from an UDF volume in @reactos (yes, it's something like the MS-PSDK setup DVD) pic.twitter.com/6iYEiOWOFI
— Pierre Schweitzer (@HeisSpiter) June 3, 2017
|
Метки: author Jeditobe реверс-инжиниринг open source блог компании фонд reactos chromium reactos файловая система udf шг |
Предоставляем анализатор PVS-Studio экспертам безопасности |
 Неожиданно для самих себя мы поняли, что можем взаимовыгодно сотрудничать с экспертами в сфере информационной безопасности. Те из них, кто занимается поиском уязвимостей в коде приложений, могут воспользоваться бесплатной версией анализатора PVS-Studio для своих исследований. В свою очередь, если будут найдены уязвимости, наш анализатор приобретёт большую популярность. PVS-Studio может быть использован для исследований проектов, написанных на языке C и C++.
Неожиданно для самих себя мы поняли, что можем взаимовыгодно сотрудничать с экспертами в сфере информационной безопасности. Те из них, кто занимается поиском уязвимостей в коде приложений, могут воспользоваться бесплатной версией анализатора PVS-Studio для своих исследований. В свою очередь, если будут найдены уязвимости, наш анализатор приобретёт большую популярность. PVS-Studio может быть использован для исследований проектов, написанных на языке C и C++.|
Метки: author Andrey2008 блог компании pvs-studio pvs-studio информационная безопасность статический анализ кода ошибки в коде эксперт tizen c/c++ уязвимости уязвимость |
[Перевод] Пять шагов к спасению Linux-сервера, который рухнул |

$ sudo ethtool eth0$ sudo dmidecode --type memorydmidecode память всё ещё остаётся под подозрением — пришло время воспользоваться Memtest86. Это отличная программа для проверки памяти, но работает она медленно. Если вы запустите её на сервере, не рассчитывайте на возможность использовать эту машину для чего-нибудь другого до завершения проверки.$ sudo modprobe edac_core$ sudo grep "[0-9]" /sys/devices/system/edac/mc/mc*/csrow*/ch*_ce_countcsrow). Эти сведения, если сопоставить их с с данными dmidecode о каналах памяти, слотах и заводских номерах компонентов, помогут выявить сбойную планку памяти.$ sudo ps -ef | grep apache2
$ sudo netstat -plunt | grep apache2$ sudo service apache2 starttop. Она позволяет узнать среднюю нагрузку на сервер, использование файла подкачки, выяснить, какие ресурсы системы используют процессы. Эта утилита показывает общие сведения о системе и выводит данные по всем выполняющимся процессам на Linux-сервере. Вот подробное описание данных, которые выводит эта команда. Тут можно найти массу информации, которая способна помочь в поиске проблем с сервером. Вот несколько полезных способов работы с top, позволяющих найти проблемные места.M. Для того, чтобы выяснить приложение, потребляющее больше всего ресурсов процессора, отсортируйте список, введя P. Для сортировки процессов по времени активности, введите с клавиатуры T. Для того, чтобы лучше видеть колонку, по которой производится сортировка, нажмите клавишу b.O или o. Появится следующее приглашение, где предлагается добавить фильтр:add filter #1 (ignoring case) as: [!]FLD?VALCOMMAND=apache, программа будет выводить только сведения о процессах Apache.top заключается в выводе полного пути процесса и аргументов запуска. Для того, чтобы просмотреть эти данные, воспользуйтесь клавишей c.top активируется вводом символа V. Она позволяет переключиться в режим иерархического вывода сведений о процессах.u или U, или скрыть процессы, не потребляющих ресурсы процессора, нажав клавишу i.top долго была самой популярной интерактивной утилитой Linux для просмотра текущей ситуации в системе, у неё есть и альтернативы. Например, существует программа htop обладает расширенным набором возможностей, которая отличается более простым и удобным графическим интерфейсом Ncurses. Работая с htop, можно пользоваться мышью и прокручивать список процессов по вертикали и по горизонтали для того, чтобы просмотреть их полный список и полные командные строки.top сообщит мне — в чём проблема. Скорее, я использую этот инструмент для того, чтобы найти нечто, что заставит подумать: «А это уже интересно», и вдохновит меня на дальнейшие исследования. Основываясь на данных от top, я знаю, например, на какие логи стоит взглянуть в первую очередь. Логи я просматриваю, используя комбинации команд less, grep и tail -f.df используют двумя способами.$ sudo df -h$ sudo df -idf — T. Он позволяет вывести данные о типах файловых систем хранилищ. Например, команда вида $ sudo df -hT показывает и объём занятого пространства диска, и данные о его файловой системе.$ iostat -xz 1top для того, чтобы выяснить, нагружает ли сервер MySQL (или какая-нибудь ещё работающая на нём СУБД). Если подобных приложений найти не удалось, значит есть вероятность, что с диском что-то не так.%util, где выводятся сведения об использовании устройства. Этот показатель указывает на то, как напряжённо работает устройство. Значения, превышающие 60% указывают на низкую производительность дисковой подсистемы. Если значение близко к 100%, это означает, что диск работает на пределе возможностей./var/log, в отдельных папках для различных сервисов.$ dmesg | tailtail с ключом -f. Выглядит это так:$ dmesg | tail -f /var/log/syslogsyslog, и когда в него попадают сведения о новых событиях, выводит их на экран.$ sudo find /var/log -type f -mtime -1 -exec tail -Fn0 {} +journald. В отличие от других логов Linux, journald хранит данные в двоичном, а не в текстовом формате.journald так, чтобы он сохранял логи после перезагрузки системы. Сделать это можно, воспользовавшись такой командой:$ sudo mkdir -p /var/log/journal/etc/systemd/journald.conf, включив в него следующее:[Journal] Storage=persistentjournalctl -b$ journalctl -b -1journalctl.grep, awk, и других, полезно бывает задействовать специальные программы для просмотра логов.|
Метки: author ru_vds сетевые технологии серверное администрирование настройка linux блог компании ruvds.com linux администрирование диагностика |
Мониторинг Linksys SPA8000 через Zabbix |

# Hostname шлюза. Его же надо как-то называть.
spa8000.name = SPA8000
# Серийный номер. Это больше для инвентаризации.
spa8000.serial = CFH01N704858
# Версия ПО.
spa8000.software = 6.1.12(XU)
# Версия платы, насколько я понимаю.
spa8000.hardware = 1.0.0
# MAC-адрес сетевого интерфейса. Без него никуда.
spa8000.mac = D0C789784BE4
# Есть ли сертификат.
spa8000.cert = Installed
# Открыт ли шлюз для изменения конфигурации.
spa8000.customization = Open
# Время и аптайм. Не забывайте про NTP, товарищи.
spa8000.time = 1/12/2003 14:15:42
spa8000.system.uptime = 11 days and 02:15:42
# Средства для рисования красивых графиков, разнообразные счетчики
# сообщений, пакетов и байт.
spa8000.rtp.packets.sent = 3463097
spa8000.rtp.bytes.sent = 646834968
spa8000.rtp.packets.recv = 3435569
spa8000.rtp.bytes.recv = 641524220
spa8000.sip.msg.sent = 76279
spa8000.sip.bytes.sent = 36830167
spa8000.sip.msg.recv = 73969
spa8000.sip.bytes.recv = 30078139
# Autodiscovery линии.
# Статус линии.
spa8000.line{#LINE}.hook.state = On
# Статус регистрации линии.
spa8000.line{#LINE}.reg.state = Registered
# Дата и время последней регистрации.
spa8000.line{#LINE}.reg.time = 1/12/2003 14:08:01
# Количество секунд до перерегистрации.
spa8000.line{#LINE}.reg.next = 1321 s
# Состояние уведомления о голосовой почте.
spa8000.line{#LINE}.mvi = No
# Состояние уведомления о callback.
spa8000.line{#LINE}.callback = No
# Последний номер, на который звонили с этой линии.
spa8000.line{#LINE}.last.called = 8965ХХХХХХХ
# Последний номер с которого звонили на линию.
spa8000.line{#LINE}.last.caller = +7911ХХХХХХХ
"info","SPA8000","CFH01N704858","6.1.12(XU)","1.0.0","D0C789784BE4","Installed","Open","1/12/2003 14:15:42","11 days and 02:15:42",3463097,646834968,3435569,641524220,76279,36830167,73969,30078139
"line1","On","Registered","1/12/2003 14:08:01",1321,"No","No","8965ХХХХХХХ","+7911ХХХХХХХ"
"line2",
. . .
#!/usr/bin/python
# Get Cisco SPA status for Zabbix.
# codecs импортируется, если происходит отладка скрипта с открытием локального Файла.
#import codecs
import csv
import datetime
import os.path
import re
import sys
import tempfile
import time
import urllib
# Ссылка на интерфейс.
url = 'http:///voice/'
# Путь до файла кэша.
temp = tempfile.gettempdir()
base = temp + '/spa.csv'
# Генератор кэша.
# Если файл кэша не существует или старее 30 секунд, то получаем данные из web-интерфейса.
# Кэш проверяется и создается всегда самым первым, потому что все данные возвращаются
# на основе выборок из файла кэша, то есть напрямую со страницы данные читаются только
# в кэш.
if(not(os.path.exists(base)) or ((int(time.time()) - os.path.getmtime(base)) > 30)):
# Читаем HTML страницу.
html = urllib.urlopen(url).read()
# Отладочная секция - читает файл с диска.
#f = codecs.open("text.html", 'r', "utf-8")
#html = f.read()
#f.close()
# Нормализуем и парсим HTML.
# Приводим текст к одной строке.
html = re.sub(r"\n+", " ", html)
# Убираем пробелы между тегами.
html = re.sub(r">\s+<", "><", html)
# Страница очень длинная - там все вкладки интерфейса. Чтобы уменьшить вероятность
# выборки не того отрезаем нужный нам кусок страницы.
html = re.search(r".+?Trunk", html).group(0)
# Получаем количество линий.
count = len(re.findall(r"]+>]+>Line\s(\d+)\sStatus",html))
# Извлекаем все данные вперемешку. Так как в HTML формат всех полей с данными
# одинаковый, то просто ищем все совпавшие кусочки данных и считаем их по
# умолчанию значениями. дальше разберутся.
data = re.findall(r"([^<:>]+):.+?]+>([^<]*)",html)
# Создаем CSV файл.
number = 0
rows = []
# Создаем заголовки строк.
rows.append(['info'])
count += 1
for i in range (1, count):
rows.append(['line' + str(i)])
count -= 1
# Заполняем строки. Выбираем из собранных данных все по одному и внимательно
# присматриваемся. Так как данные лежат в массиве в том порядке, в котором
# они отображаются на странице, то можем считать, что все значения до определенного
# относятся к общей информации, а все что дальше, относится к линиям. Так все и устроено
# первое значение каждой линии - это Hook State. Все что находится до первого такого значения
# относится к общей информации, все что после - к линиям.
# Цикл по извлеченным данным.
for entry in data:
# Значение, по которому разделяются данные общей информации и линий.
if(entry[0] == 'Hook State'):
number += 1
# Обрабатываем все нужные данные, кроме всяких Call 1 Forward и иже с ними.
if(not(re.match(r'Call\s\d+\s', entry[0]))):
value = entry[1]
# Преобразуем время в соответствующих полях. В Zabbix время уходит в виде unixtime.
if(((entry[0] == 'Current Time') or (entry[0] == 'Last Registration At')) and (value)): # 1/13/2003 14:03:52
if(value != '0/0/0 00:00:00'):
value = int(time.mktime(datetime.datetime.strptime(entry[1], "%m/%d/%Y %H:%M:%S").timetuple()))
else:
value = 0
# Извлекаем количество секунд.
if((entry[0] == 'Next Registration In') and (value)): # 1263 s
value = int(entry[1].split()[0])
# Сохраняем значение в соответствующей строке массива.
rows[number].extend([value])
# Сохраняем кэш.
with open(base, 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(rows)
csvfile.close()
# Ну вот, кэш сохранен, можно теперь его использовать для вывода данных. Проверяем
# наличие параметров. Если они переданы, значит мы хотим чего-то конкретного.
if(len(sys.argv) > 1):
# Открываем файл кэша и ищем строку, которую мы запрашиваем первым параметром.
with open(base, 'rb') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# TODO: Прерывание цикла, если строка нашлась.
if(row[0] == sys.argv[1]):
line = row
csvfile.close()
# Проверяем, что запрошенная строка вообще есть в кэше.
if('line' in locals()):
# Определяем, что у нас спрашивают вторым параметром, и что вообще возвращать.
# Блок общей информации.
if(line[0] == 'info'):
try:
print({
'name': line[1],
'serial': line[2],
'software': line[3],
'hardware': line[4],
'mac': line[5],
'cert': line[6],
'customization': line[7],
'time': line[8],
'uptime': line[9],
'rtp.packets.sent': line[10],
'rtp.bytes.sent': line[11],
'rtp.packets.recv': line[12],
'rtp.bytes.recv': line[13],
'sip.msg.sent': line[14],
'sip.bytes.sent': line[15],
'sip.msg.recv': line[16],
'sip.bytes.recv': line[17]
}.get(sys.argv[2]))
# Если запрошенного поля не нашлось, так и говорим.
except IndexError as e:
print('ZBX_UNSUPPORTED')
# Блок линий.
else:
try:
print({
'hook.state': line[1],
'reg.state': line[2],
'reg.time': line[3],
'reg.next': line[4],
'mvi': line[5],
'callback': line[6],
'last.called': line[7],
'last.caller': line[8],
}.get(sys.argv[2]))
except IndexError as e:
print('ZBX_UNSUPPORTED')
# Если запрашиваемая строка не нашлась в кэше, то тоже возвращаем ошибку.
# Это позволяет не смущать Zabbix пустым результатом.
else:
print('ZBX_UNSUPPORTED')
else:
# Получаем autodiscovery для линий.
# Выходная строка.
s = ""
# Открываем файл кэша и читаем его, формируя выходную строку.
with open(base, 'rb') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
# Проставляем разделители.
if(len(s) > 0):
s = s + ","
# Формируем JSON строку вручную.
if(row[0] != 'info'):
s = s + '{"{#LINE}":"' + str(row[0]) + '"}'
csvfile.close()
# Выводим сформированную строку.
print('{"data":[' + s + ']}')
# Завершаем работу скрипта.
quit()
sudo chmod +x /share/zabbix/externalscripts/zabbix_spa8000.py
/share/zabbix/externalscripts/zabbix_spa8000.py
{"data":[{"{#LINE}":"line1"},{"{#LINE}":"line2"},{"{#LINE}":"line3"},{"{#LINE}":"line4"},{"{#LINE}":"line5"},{"{#LINE}":"line6"},{"{#LINE}":"line7"},{"{#LINE}":"line8"}]}
/share/zabbix/externalscripts/zabbix_spa8000.py info serial
CFH01N704858
/etc/zabbix_agentd.conf.d/spa8000.conf
UserParameter=spa[],/share/zabbix/externalscripts/zabbix_spa.py $1 $2
UserParameter=spa.lines,/share/zabbix/externalscripts/zabbix_spa.py
sudo service zabbix-agent restart
zabbix_agentd -t spa.lines
spa.lines [t|{"data":[{"{#LINE}":"line1"},{"{#LINE}":"line2"},{"{#LINE}":"line3"},{"{#LINE}":"line4"},{"{#LINE}":"line5"},{"{#LINE}":"line6"},{"{#LINE}":"line7"},{"{#LINE}":"line8"}]}]
zabbix_agentd -t spa[info,serial]
spa[info,serial] [t|CFH01N70
4858]
3.0
2016-09-09T11:04:05Z
Шаблоны общие
Template_Cisco_Linksys_SPA
Template Cisco(Linksys) SPA
Шаблон мониторинга Cisco(Linksys) SPA.
Шаблоны общие
RTP
SIP
Информация
Линии
-
Сертификат
0
0
spa[info,cert]
3600
10
0
0
4
0
0
0
0
1
0
Наличие сертификата SPA.
0
Информация
-
Блокировка
0
0
spa[info,customization]
3600
10
0
0
4
0
0
0
0
1
0
Блокировка конфигурации SPA от изменения.
0
Информация
-
Аппаратное обеспечение
0
0
spa[info,hardware]
3600
10
0
0
4
0
0
0
0
1
0
Версия аппаратного обеспечения SPA.
0
Информация
-
MAC-адрес
0
0
spa[info,mac]
3600
10
0
0
4
0
0
0
0
1
0
МАС-адрес SPA.
0
Информация
-
Имя
0
0
spa[info,name]
3600
10
0
0
4
0
0
0
0
1
0
Hostname SPA.
0
Информация
-
Получено байт RTP
0
0
spa[info,rtp.bytes.recv]
30
30
60
0
3
B
0
0
0
0
1
0
Количество полученных байт RTP.
0
RTP
-
Отправлено байт RTP
0
0
spa[info,rtp.bytes.sent]
30
30
60
0
3
B
0
0
0
0
1
0
Количество отправленных байт RTP.
0
RTP
-
Получено пакетов RTP
0
0
spa[info,rtp.packets.recv]
30
30
60
0
3
0
0
0
0
1
0
Количество полученных пакетов RTP.
0
RTP
-
Отправлено пакетов RTP
0
0
spa[info,rtp.packets.sent]
30
30
60
0
3
0
0
0
0
1
0
Количество отправленных пакетов RTP.
0
RTP
-
Серийный номер
0
0
spa[info,serial]
3600
10
0
0
4
0
0
0
0
1
0
Серийный номер SPA.
0
Информация
-
Получено байт SIP
0
0
spa[info,sip.bytes.recv]
30
30
60
0
3
B
0
0
0
0
1
0
Количество полученных байт SIP.
0
SIP
-
Отправлено байт SIP
0
0
spa[info,sip.bytes.sent]
30
30
60
0
3
B
0
0
0
0
1
0
Количество отправленных байт SIP.
0
SIP
-
Получено сообщений SIP
0
0
spa[info,sip.msg.recv]
30
30
60
0
3
0
0
0
0
1
0
Количество полученных сообщений SIP.
0
SIP
-
Отправлено сообщений SIP
0
0
spa[info,sip.msg.sent]
30
30
60
0
3
0
0
0
0
1
0
Количество отправленных сообщений SIP.
0
SIP
-
Программное обеспечение
0
0
spa[info,software]
3600
10
0
0
4
0
0
0
0
1
0
Версия программного обеспечения SPA.
0
Информация
-
Локальное время
0
0
spa[info,time]
60
30
60
0
3
unixtime
0
0
0
0
1
0
Локальное время SPA.
0
Информация
-
Аптайм
0
0
spa[info,uptime]
60
30
60
0
3
uptime
0
0
0
0
1
0
Время непрерывной работы SPA.
0
Информация
Линии
0
spa.lines
3600
0
0
0
0
0
0
30
Линии SPA.
Статус callback линии {#LINE}
0
0
spa[{#LINE},callback]
30
10
0
0
4
0
0
0
0
1
0
Статус callback линии {#LINE}.
0
Линии
Статус Hook линии {#LINE}
0
0
spa[{#LINE},hook.state]
30
10
0
0
4
0
0
0
0
1
0
Статус Hook линии {#LINE}.
0
Линии
Последний исходящий с линии {#LINE}
0
0
spa[{#LINE},last.called]
30
5
0
0
4
0
0
0
0
1
0
Последний исходящий с линии {#LINE}.
0
Линии
Последний входящий на линию {#LINE}
0
0
spa[{#LINE},last.caller]
30
5
0
0
4
0
0
0
0
1
0
Последний входящий на линию {#LINE}.
0
Линии
Статус MVI линии {#LINE}
0
0
spa[{#LINE},mvi]
30
10
0
0
4
0
0
0
0
1
0
Статус MVI линии {#LINE}.
0
Линии
Интервал регистрации линии {#LINE}
0
0
spa[{#LINE},reg.next]
30
30
60
0
3
uptime
0
0
0
0
1
0
Время до следующей регистрации линии {#LINE}.
0
Линии
Статус регистрации линии {#LINE}
0
0
spa[{#LINE},reg.state]
30
10
0
0
4
0
0
0
0
1
0
Статус регистрации линии {#LINE}.
0
Линии
Локальное время регистрации линии {#LINE}
0
0
spa[{#LINE},reg.time]
30
30
60
0
3
unixtime
0
0
0
0
1
0
Локальное время регистрации линии {#LINE}.
0
Линии
{Template_Cisco_Linksys_SPA:spa[{#LINE},reg.state].count(#2,Registered,eq,0)}<2
Ошибка регистрации линии {#LINE}
0
4
Линия {#LINE} не может зарегистрироваться в течение 1 минуты.
0
{Template_Cisco_Linksys_SPA:spa[info,uptime].last()}<180
SPA перезагружен
0
2
Время работы SPA менее 3 минут.
0
|
Метки: author binfini системное администрирование серверное администрирование cisco блог компании business infinity group zabbix monitoring cisco spa8000 linksys |
Без заголовка |

















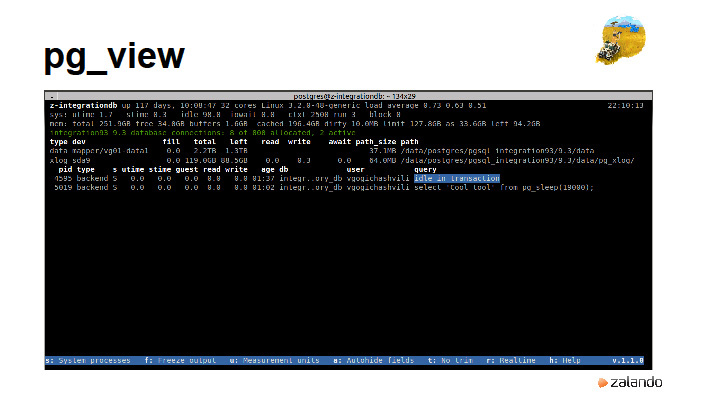









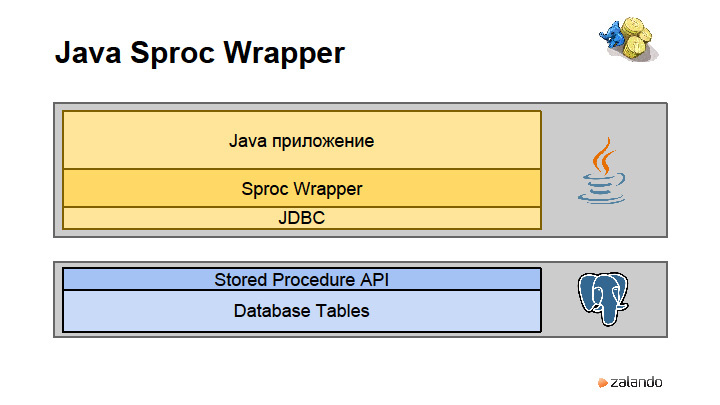






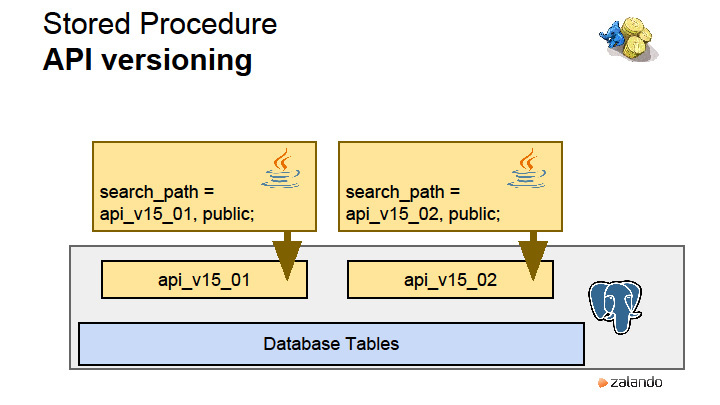
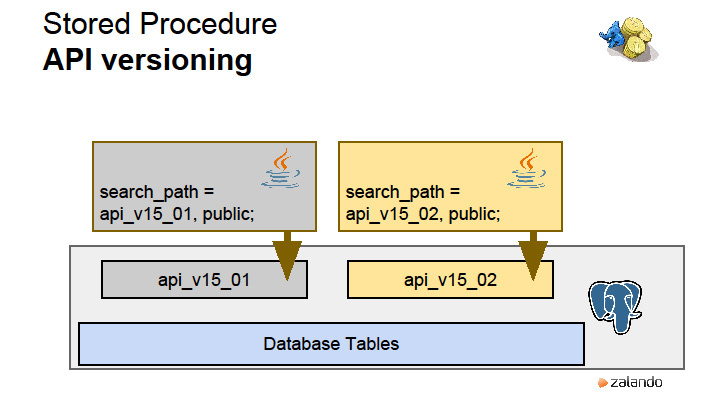










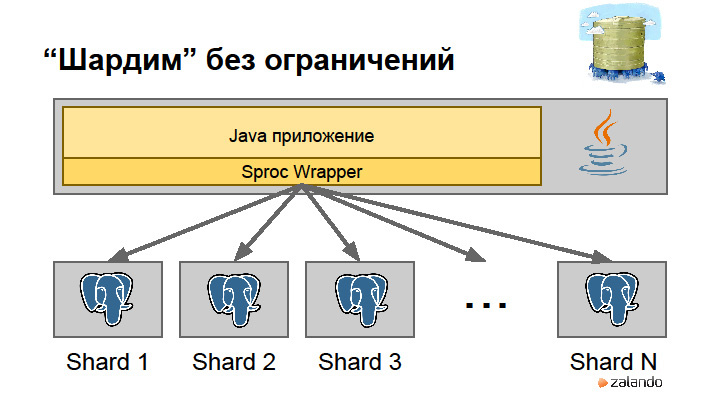



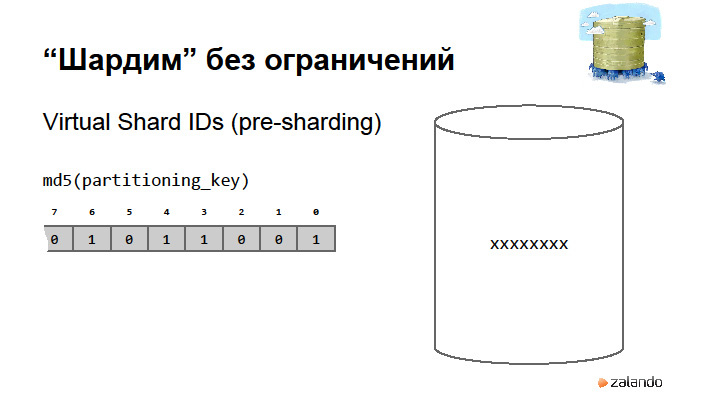
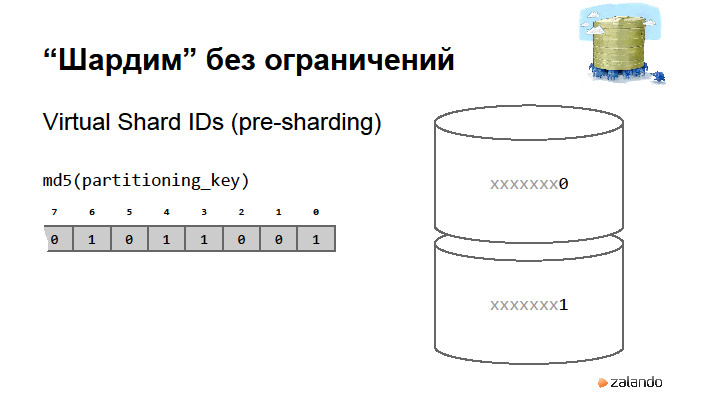
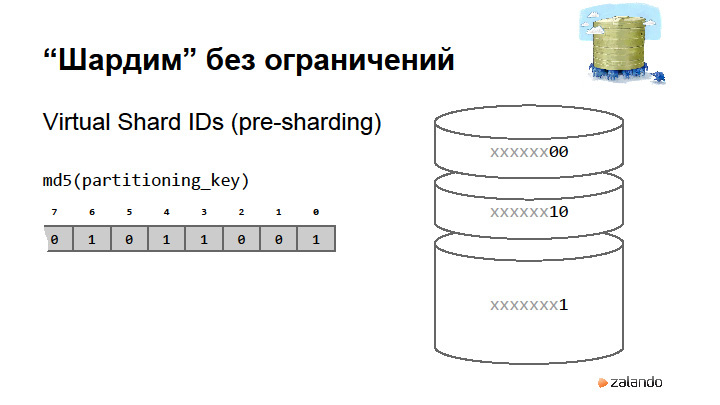
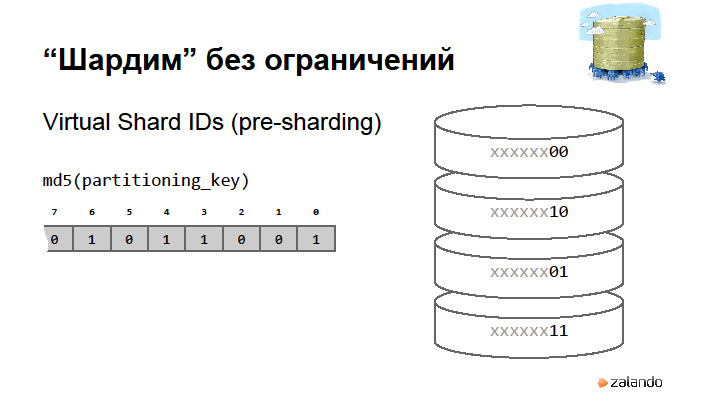




|
Метки: author rdruzyagin sql postgresql блог компании pg day'17 russia locks constraints sharding |
[Перевод] Эволюционные стратегии как масштабируемая альтернатива обучению с подкреплением |
 Изложение статьи от том, что давно известные эволюционные стратегии оптимизации могут превзойти алгоритмы обучения с подкреплением.
Изложение статьи от том, что давно известные эволюционные стратегии оптимизации могут превзойти алгоритмы обучения с подкреплением.
# simple example: minimize a quadratic around some solution point
import numpy as np
solution = np.array([0.5, 0.1, -0.3])
def f(w): return -np.sum((w - solution)**2)
npop = 50 # population size
sigma = 0.1 # noise standard deviation
alpha = 0.001 # learning rate
w = np.random.randn(3) # initial guess
for i in range(300):
N = np.random.randn(npop, 3)
R = np.zeros(npop)
for j in range(npop):
w_try = w + sigma*N[j]
R[j] = f(w_try)
A = (R - np.mean(R)) / np.std(R)
w = w + alpha/(npop*sigma) * np.dot(N.T, A)
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
|
Метки: author sergeypid обработка изображений машинное обучение алгоритмы reinforcement learning обучение с подкреплением эволюционный алгоритм оптимизация |
Как не дать алгоритму продать банк |

|
Метки: author volnnik алгоритмы блог компании технологический центр дойче банка разработка |
Телефония в офис за палку колбасы |






|
|
15 лучших рецептов для Умного Дома с ioBroker |

|
|
Yii 2.0.12 |
Вышла версия 2.0.12 PHP фреймворка Yii. Инструкции по установке и обновлению ищите на странице
http://www.yiiframework.com/download/.

Версия 2.0.12 является минорным релизом Yii 2.0. Она включает в себя более сотни улучшений и исправлений.
В релиз вошли несколько изменений, которые могут повлиять на существующие приложения. Эти изменений описаны в UPGRADE.md file.
Спасибо сообществу Yii за поддержку проекта!
За разработкой фреймворка можно следить поставив звёздочку на GitHub. Также можно подписаться на Twitter и Facebook.
Данный релиз задержался так как команда была занятна дргими вещами. Например, мы работаем над новым сайтом и YiiConf
— конференции по Yii, которая пройдёт совсем скоро в Москве.
Так как Yii 2.1 уже разрабатывается, убедитесь, что версия в вашем composer.jsonпрописана как ~2.0.12, а не >= или *. Так при релизе 2.1 ваш проект точно не сломается.
Ниже мы рассмотрим самые интересные изменения релиза. Полный список можно посмотреть в CHANGELOG.
Покрытие тестами очень важно для своевременного обнаружения проблем.
К релизу @vladis84, @boboldehampsink, @Kolyunya и
другие члены сообщества Yii помогли нам расширить покрытие кода.
@schmunk42 настроил дополнительное тестирование на базе docker и развернул его в GitLab. Некоторые тесты там всё ещё падают. Главным образом из за отличий в данных для интернационализации. Это будет исправлено немного позже.
Слой работы с базами получил несколько улучшений в работе с выражениями. Теперь из можно использовать в \yii\db\QueryTrait::limit(), \yii\db\QueryTrait::offset() и \yii\data\Sort.
Поддержка MSSQL существенно улучшилась. Значительно возросла скорость чтения схемы и был реализован метод yii\db\mssql\QueryBuilder::resetSequence().
yii\base\Security::hkdf() был улушен. Теперь, если это возможно, используется hash_hkdf() из PHP >= 7.1.2.yii\captcha\CaptchaAction теперь используется mt_rand() вместо rand() .Шаблон миграций теперь по умолчанию использует safeUp() и safeDown(). В том случае, когда изменения схемы в транзакции не поддерживаются (например, MySQL), изменения применяются без транзакций.
Различные компоненты фреймворка обзавелись значениями по умолчанию:
\yii\data\SqlDataProvider теперь считаем записи самостоятельно в том случае, когда totalCount не указан.yii\grid\DataColumn автоматически генерится как выпадающий список в том случае, если format выставлен в boolean.Команда yii cache начала предупреждать о том, что она не может очистить кеш APC из консоли.
yii\filters\AccessRule теперь позволяет передать параметры в функцию проверки роли.
yii\web\UrlManager добавлена поддержка кеширования вызовов yii\web\UrlRule::createUrl() в случае использования правил с умолчаниями.yii\data\ActiveDataProvider не делает запросы в том случае, когда количество моделей равно нулю.StringHelper научился работать с URL-безопасным base64 через методы encode()/decode(). Это может быть полезно для различных токенов.
yii\helpers\Html::img() теперь позволяет указать srcset:
[php]
echo Html::img('/base-url', [
'srcset' => [
'100w' => '/example-100w',
'500w' => '/example-500w',
'1500w' => '/example-1500w',
],
]);У yii\widgets\LinkPager можно рендерить кнопку текущей страницы как disabled. Для этого необходимо выставить disableCurrentPageButton в true.
Контроль доступа и валидаторы стали требовать меньше зависимостей:
yii\filters\AccessControl теперь может использоваться без компонента user.Yii::$app.|
Метки: author SamDark yii php framework mvc |






