21 сентября 2017 года на встрече московского сообщества Java-разработчиков выступили Иван Пономарёв и Николай Поташников. Иван — с докладом «Скрытая сложность повседневной задачи: отображение табличных данных», совместный рассказ обоих докладчиков — про программные продукты Celesta и Flute, открытой платформы для создания бизнес-логики в Java-экосистеме.
/habrastorage.org/webt/59/d3/e0/59d3e08d3d4ca640484509.jpeg">" alt=«image»/>
Ближайший год с точки зрения новых технологий обещает быть захватывающим. Почему? Потому что технологии, которые ранее были специфичными для определенных секторов, станут мейнстримом. Итак, давайте посмотрим, какие новые вакансии будут возникать из-за этого, и где они могут существовать? Читать дальше ->
Привет, Хабрахабр!
Я продолжительное время учу английский и хочется достичь идеала, но этот процесс не быстрый. На данный момент уровень моего английского позволяет мне довольно таки неплохо распознавать разговорную речь, но фильмы, пока, я смотрю всё так же с субтитрами. Даже без них, я уверен, в видео могут попадаться слова, которых я не знаю и хоть общий смысл будет понятен, мне всё равно захочется узнать, что это за слово.
Таким образом при просмотре фильма получается такой порядок действий:
смотрим
встречаем незнакомое слово
переключаемся на браузер, вкладку lingualeo
ищем слово, выбираем перевод, добавляем
смотрим фильм дальше
Вроде бы достаточно неплохо, но утомляет. Хочется смотреть фильм беспрерывно, а если точно знаешь, что все слова будут знакомыми — отказаться от субтитров, слушать и заодно тренировать. Как я решил эту проблему, читайте дальше.
В веб-разработке нередки моменты, когда требуется отслеживать что именно видит на своём устройстве пользователь. В первую очередь это относится, конечно, к масштабу устройства.
Я работаю над встраиваемой мини-CRM и понятия не имею как будет выглядеть сайт. Внизу страницы плавает элемент управления, всегда занимающий комфортную для касания часть экрана. Вряд ли пользователь мобильного телефона будет увеличивать масштаб чтобы оценить эстетику шрифта нашем виджете, а вот чтобы разобрать текст неоптимизированного для мобильных устройств сайта — запросто. Поэтому, чтобы не перекрывать пользователю содержимое сайта, виджет прячется при масштабировании.
Сейчас задача определения масштаба решается, мягко говоря, непросто, и появление нормального API было бы весьма кстати. Читать дальше ->
Несколько примеров на синтетических данных со скрытыми линейными зависимостями.
Какие ещё скрытые зависимости могут содержаться в данных.
Автоматизация поиска зависимостей.
Число признаков меньше пороговой величины.
Число признаков превышает пороговую величину.
Постановка задачи
Нередко в машинном обучении встречаются ситуации, когда данные собираются априори, и лишь затем возникает необходимость разделить некоторую выборку по известным классам. Как следствие часто может возникнуть ситуация, когда имеющийся набор признаков плохо подходит для эффективной классификации. По крайней мере, при первом приближении.
В такой ситуации можно строить композиции слабо работающих по отдельности методов, а можно начать с обогащения данных путём выявления скрытых зависимостей между признаками. И затем строить на основе найденных зависимостей новые наборы признаков, некоторые из которых могут потенциально дать существенный прирост качества классификации.
Формальное описание задачи
Перед нами ставится задача классификации L объектов, заданных n вещественными числами. Мы будем рассматривать простой двухклассовый случай, когда метки классов — это -1 и +1. Наша цель — построить линейный классификатор, то есть такую функцию, которая возвращает -1 или + 1. При этом набор признаковых описаний таков, что для объектов противоположных классов, измеренных на данном множестве признаков, практически не работает гипотеза компактности, а разделяющая гиперплоскость строится крайне неэффективно.
Иными словами, всё выглядит так, будто задача классификации на данном множестве объектов не может быть решена эффективно. Читать дальше →
Совсем недавно довелось наткнуться на весьма любопытную заморскую статью. Хотелось бы сопоставить изложенные там факты с российским опытом. Смело делитесь своими мыслями в коментариях. Спойлер: шеф, все пропало! Читать дальше ->
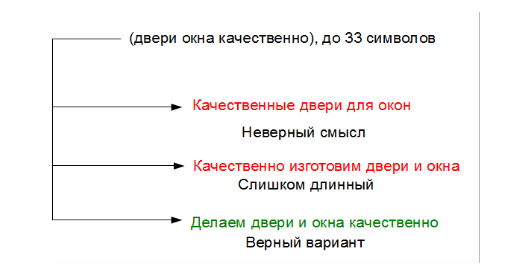
На практике нередко встречается задача не просто написать какой-то текст, а выполнить некоторые условия — например уложить максимум ключевых слов в заданную длину и/или использовать/не использовать определенные слова и словосочетания. Это бывает важно для бизнеса (при составление рекламных объявлений, в том числе, для контекстной рекламы, при SEO-оптимизации сайтов), для образовательных целей (автоматическое составление тестовых вопросов) и в ряде других случаев. Такие задачи оптимизации вызывают много головной боли, т. к. людям относительно легко сочинять тексты, но при этом не так просто написать что-то отвечающее тем или иным критериям «оптимальности». С другой стороны, компьютеры отлично справляются с задачами оптимизации в других областях, но плохо понимают естественный язык, и поэтому им трудно сочинять текст. В данной статье, рассмотрим известные подходы к решению этой задачи и немного поделимся собственным опытом.
В этой статье рассмотрим, как выжать все соки из Хромиума и максимально ускорить его или другой браузер на его движке (Chromium, Google Chrome, Opera, Vivaldi, Яндекс и др.). За счет включения многих экспериментальных возможностей по вынесу вычислений с процессора на видеокарту и включения использования находящихся в разработке программных алгоритмов. За счет этого наш любимый хромиум станет работать быстрее, может перестать тормозить или моргать экраном.
Не у каждого хватает смелости поменять освоенную профессию, в которой уже достиг каких-то вершин. Ведь это требует больших усилий, а положительный результат не гарантирован. Полтора года назад мы рассказывали, как один из наших тимлидов серверной разработки переквалифицировался в iOS-программиста. И сегодня мы хотим рассказать о ещё более «крутом повороте»: Алан Chetter2 Басишвили, занимавшийся frontend-разработкой, настолько увлёкся машинным обучением, что вскоре превратился в серьёзного специалиста, стал одним из ключевых разработчиков популярного проекта Artisto, а теперь занимается распознаванием лиц в Облаке Mail.Ru. Интервью с ним читайте под катом.
Приглашаем разработчиков, тимлидов и всех, кто так или иначе связан с разработкой на Elixir, принять участие в RamblerElixir Meetup, который состоится 19 октября в 19:00, в четверг, на уютной мансарде Rambler&Co. Читать дальше ->
В один из дней как обычно попивая кофе, мне приходит сообщение в Skype о том что нужно в кратчайшие сроки сделать приложение с нехитрым функционалом. Нужно было иметь таблицу с сортировкой и пагинацией, возможность фильтровать по слову, дате и.т.п. Так же иметь страницу с информацией о выбранном элементе из таблицы.
Имея на руках такое тз, было решено использовать последний Angular в связке с Ag-Grid, что бы не тратить драгоценное время. Читать дальше →
«Уж лучше я, тот, кто много раз испытал это все на себе, попытаюсь это как-нибудь разъяснить, чем вы будете слушать людей, которые сами никогда ничего значительного и творческого в своей жизни не делали.»
Так вот у Хэмминга есть целая книга, написанная по мотивам его выступлений. Давайте ее переведем, ведь мужик дело говорит.
Это книга не про ИТ, это книга про стиль мышления невероятно крутых людей.
Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Глава 25. Креативность
(за перевод спасибо Яне Щекотовой)
Креативность, оригинальность, новаторство, и прочие подобные слова воспринимаются как нечто «хорошее», и мы часто их путаем. И действительно, довольно сложно дать им определение. Конечно, особой необходимости в том, чтобы иметь три слова с одинаковым значением, нет, поэтому нужно попытаться как-то их различать на основе четко заданных определений. Важность определений подчеркивалась и раньше, а мы воспользуемся случаем, чтобы продемонстрировать подход к формулировке определений, но без ожиданий, что мы справимся с задачей идеально или даже хорошо. Читать дальше ->
Тема создания ботов для Telegram становится все более популярной, привлекая программистов попробовать свои силы на этом поприще. У каждого периодически возникают идеи и задачи, которые можно решить, написав тематического бота. Для меня, как программиста на JS, пример такой актуальной задачи — мониторинг рынка вакансий по соответствующей тематике.
Однако одним из наиболее популярных языков и технологий в сфере создания ботов является Python, предлагающий программисту огромное количество хороших библиотек для обработки и парсинга различных источников информации в виде текста. Мне же захотелось сделать это именно на JavaScript — одном из моих любимых языков. Читать дальше ->
Напоминаем, что уже полным ходом идёт чемпионат «RAIF-Challenge 2017», который финиширует 25 октября. В Чемпионате могут испытать свои силы разработчики в сфере ML/AI и им сочувствующие! На момент старта участникам были доступны две номинации — «AI в страховании» и «AI в банках». С понедельника компания «М.Видео» также предоставила свои исходные бизнес-данные для номинации «AI в ритейле».
Хочу предложить Хабру свою версию нерекурсивного алгоритма генерации всех разбиений целого числа в лексикографическом порядке.
Толчком послужила майская заметка habrahabr.ru/post/329948.
В предлагаемом алгоритме также идея переноса крайне правого элемента.
Причины по которым захотелось предложить свой вариант алгоритма в том, что во всех увиденных мной алгоритмах на каждом шагу есть поиск по массиву. Мне показалось это несколько избыточным. Сам алгоритм будем рассматривать как описание перестановки единичных кубиков (квадратиков) на плоскости ( справа налево) и их периодическое рассыпание по горизонтальной оси.
Подробности ниже. Читать дальше ->
Мы продолжаем говорить о криптовалютах. И сегодня речь пойдет уже не просто о перспективных ICO, а о сервисах, которые позволяют снизить издержки и, наоборот, больше заработать при использовании биткоина. Читать дальше ->
Привет, Хабр! Сейчас мы расскажем кое-что интересное.
C 14 по 18 августа 2017 года в Кёльне (Германия) проходил второй в истории Хакфест по ReactOS. Хотим в этом посте поделится кратким дайджестом об итогах этого мероприятия и приоткрыть завесу тайны над происходившими там событиями.
В этот раз в Хакфесте очно участвовало на 2 человека меньше, чем в прошлый раз, что конечно немного грустно. Но это было более чем скомпенсировано тем фактом, что такие разрабочики как Вадим Галянт, Herm`es B'elusca-Ma"ito, David Quintana, принимали участие активное участие в заочном формате, а в тестировании разработок Вадима были задействованы все активные пользователи группы ReactOS в VK. Читать дальше ->
Похоже, сегодня ИТ-специалисту в России стало легче найти работу. Последние впечатления от российского рынка труда: предложения с уровнем зарплаты существенно выше среднего получают специалисты самых разных профилей и не обязательно высокой квалификации. Более того, похоже, что в кои-то веки ИТ-профессионалы получили возможность выбирать из конкурентных предложений! Кандидаты без специального образования и довольно посредственно, на уровне любителя, разбирающиеся в профильных технологиях, с гордостью публикуют в соцсетях свои новые должности — разработчиков, специалистов по технической поддержке, внедренцев…
К тому же, в прессе все чаще появляются истории о низкоквалифицированных разработчиках, которые тем не менее успешно проходили интервью, и уже в ходе работы наносили огромной финансовый ущерб компании. Так, Uber в 2015 случайно опубликовал паспортные данные своих водителей, а Google в 2010 году понес убытки в $100 млн долларов и проиграл суд компании Oracle за использование без разрешения 11 строк кода. И уже не из жизни гигантов: когда работодатель не понимает, что делает разработчик, а сам сотрудник пользуется этим и завышает как сложность своей работы, так и ее стоимость, а впоследствии и пренебрегает добросовестностью исполнения служебных заданий.
Наш интерес к этим вещам далеко не праздный, ведь для агентства AGIMA ИТ-профессионалы — главный производственный актив. Поэтому HR-отдел агентства попросил наших аналитиков отложить в сторону Google Analytics, сплит-тестирования, карточные сортировки и разобраться в этих вопросах. В ходе эксперимента ни один аналитик и текущий проект компании не пострадали.





 Привет, Хабр.
Привет, Хабр.










