[Из песочницы] Идея черно-белого кино, правильных пчел и безоружных ниндзя в оптимизации сайта |

|
Метки: author konkin_ivan интернет-маркетинг веб-аналитика сео оптимизация сайтов |
[Перевод] Показатели работы digital-агентства / продакшна (примеры с Запада) |
Любой бизнес, какой бы «простой» моделью он ни обладал, является сплавом из многих элементов, выражающихся в конкретных показателях. И digital — не исключение. Любое его направление можно и нужно измерять. Поэтому сегодняшняя статья — о цифрах.
Примечание: большая часть данных взята из исследования HubSpot на основе опроса 500+ западных агентств (большинство из которых с небольшим штатом до 10 человек и оборотом до $500,000 в год).
Читать дальше ->|
Метки: author zarutskiy_k исследования и прогнозы в it веб-студии digital- агентства |
Красочный код: как цвет помогает в работе с кодом |
|
Метки: author xbitstream семантика разработка под ios разработка под windows разработка под android код программирование swift kotlin java c# |
[Перевод] Точность через неточность: Улучшаем Time-объекты |
При создании value-объекта для хранения времени, я рекомендую выбирать вместе с экспертами в предметной области и вокруг нее с какой точностью он будет храниться.
Моделируя работу с числами считается хорошим тоном указывать точность. Неважно о чем идет речь — о деньгах, размере или весе; округляйте до заданного десятичного знака. Наличие округления делает данные предсказуемее для обработки и хранения, даже если это число только для отображения пользователю.
К сожалению, так делают не часто, и, когда приходит момент, проблема дает о себе знать. Рассмотрим следующий код:
$estimatedDeliveryDate = new DateTimeImmutable('2017-06-21');
// представим, что сегодня ТАКЖЕ 2017-06-21
$now = new DateTimeImmutable('now');
if ($now > $estimatedDeliveryDate) {
echo 'Package is late!';
} else {
echo 'Package is on the way.';
}Ожидаемо что, что 21 июня этот код выведет Package is on the way., ведь день еще не закончился и пакет, например, доставят ближе к вечеру.
Несмотря на это код так не делает. Так как не указана часть со временем, PHP заботливо подставляет нулевые значения и приводит $estimatedDeliveryDate к 2017-06-21 00:00:00.
С другой стороны $now вычисляется как… сейчас. Now включает в себя текущий момент времени, который, скорее всего, не полночь, так что получится 2017-06-21 15:33:34 или вроде того, что будет позднее, чем 2017-06-21 00:00:00.
|
Метки: author iGusev разработка веб-сайтов проектирование и рефакторинг программирование php php7 datetime time value object object timestamp date |
Будущее контакт-центров: омниканальность и клиентский опыт |

|
|
[Перевод] Что за черт, Javascript |

Этот пост — список забавных и хитрых примеров на JavaScript. Это отличный язык. У него простой синтаксис, большая экосистема и, что гораздо важнее, огромное сообщество.
В то же время мы все знаем, что JavaScript довольно забавный язык, в котором есть хитрые вещи. Некоторые из них быстро превращают нашу повседневную работу в ад, а некоторые заставляют хохотать. В этом посте рассмотрим некоторые из них.
Читать дальше ->|
Метки: author AloneCoder разработка веб-сайтов ненормальное программирование javascript it- стандарты блог компании mail.ru group wtf никто не читает теги |
Редизайн Хабрахабра и Гиктаймс. Финишная прямая |

|
Метки: author habrahabr типографика графический дизайн веб-дизайн usability блог компании тechmedia хабрахабр дизайн редизайн |
[Из песочницы] Отладка Xamarin проектов из VirtualBox на эмуляторе Android |
|
Метки: author Yuribtr разработка под android visual studio c# xamarin.forms android virtualbox android studio xamarin отладка эмулятор |
Новые возможности Veeam Agent for Microsoft Windows 2.0 (в бесплатной и платных версиях) |

|
|
Книга «Теория и практика языков программирования. Учебник для вузов. 2-е изд. Стандарт 3-го поколения» |
 Учебник посвящен систематическому изложению теории и практики языков программирования. Он отражает классическое содержание учебной дисциплины по языкам программирования. Все сложные вопросы поясняются законченными примерами. Кроме того, здесь предлагается полный комплекс задач и упражнений по узловым вопросам. Учебник охватывает базисные разделы следующих дисциплин: теория формальных языков, теория автоматов и формальных языков, языки программирования, программирование, объектно-ориентированное программирование, логическое и функциональное программирование, теория вычислительных процессов.
Учебник посвящен систематическому изложению теории и практики языков программирования. Он отражает классическое содержание учебной дисциплины по языкам программирования. Все сложные вопросы поясняются законченными примерами. Кроме того, здесь предлагается полный комплекс задач и упражнений по узловым вопросам. Учебник охватывает базисные разделы следующих дисциплин: теория формальных языков, теория автоматов и формальных языков, языки программирования, программирование, объектно-ориентированное программирование, логическое и функциональное программирование, теория вычислительных процессов.|
Метки: author ph_piter профессиональная литература блог компании издательский дом «питер» книги |
Как узнать баланс чужой банковской карты, зная её номер? |

|
Метки: author Gorodnya платежные системы информационная безопасность банк баланс карты банки мошенничество вишинг ivr |
Intel Optane SSD: возможности и преимущества |


| Свойство | PCM | EERPROM | NOR | NAND | DRAM |
|---|---|---|---|---|---|
| Энергонезависимость | да | да | да | да | нет |
| Минимальные размер элемента, нм | <10 | ~4x | ~3x | ~1x | ~2x |
| Побитовое изменение данных | да | да | нет | нет | да |
| Требуется цикл стирания | нет | нет | да | да | нет |
| Скорость записи | ~100 МБ/с | ~30 КБ/с | ~1 МБ/с | ~20 МБ/с | ~1ГБ/с |
| Скорость чтения | 50 … 100 нс | ~200 нс | 70 … 100 нс | 15… 50 мкс | 20 ..80 нс |
| Количество циклов перезаписи | 106… 108 | 105… 106 | 105 | 104… 105 | не ограничено |

|
Метки: author AndreiYemelianov san блог компании селектел intel optane ssd 3d x-point хранение данных память новые технологии кэширование selectel селектел |
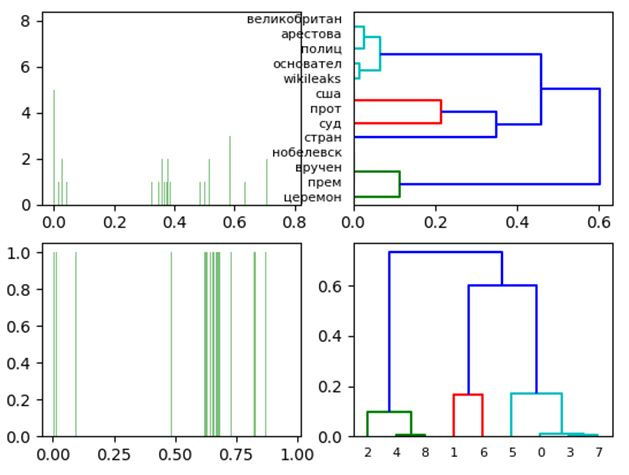
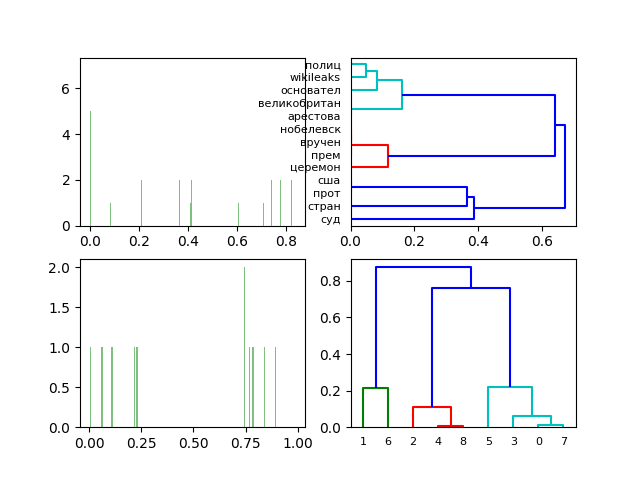
Визуализация результатов латентно-семантического анализа средствами Python |
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy
from numpy import *
import nltk
import scipy
from nltk.corpus import brown
from nltk.stem import SnowballStemmer
from scipy.spatial.distance import pdist
from scipy.cluster import hierarchy
import matplotlib.pyplot as plt
stemmer = SnowballStemmer('russian')
stopwords=nltk.corpus.stopwords.words('russian')
#Тестовый набор документов из коротких новостей
docs =[
"Британская полиция знает о местонахождении основателя WikiLeaks",# Документ № 0
"В суде США начинается процесс против россиянина, рассылавшего спам",# Документ №1
"Церемонию вручения Нобелевской премии мира бойкотируют 19 стран",# Документ №2
"В Великобритании основатель арестован основатель сайта Wikileaks Джулиан Ассандж",# Документ №3
"Украина игнорирует церемонию вручения Нобелевской премии",# Документ №4
"Шведский суд отказался рассматривать апелляцию основателя Wikileaks",# Документ №5
"НАТО и США разработали планы обороны стран Балтии против России",# Документ №6
"Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала",# Документ №7
"В Стокгольме и Осло сегодня состоится вручение Нобелевских премий"# Документ №8
]
word=nltk.word_tokenize((' ').join(docs))# Разбиение всего текста на слова
n=[stemmer.stem(w).lower() for w in word if len(w) >1 and w.isalpha()]#Стемминг всех слов с исключением символов
stopword=[stemmer.stem(w).lower() for w in stopwords]#Стемминг стоп-слов
fdist=nltk.FreqDist(n)
t=fdist.hapaxes()#Слова которые встречаются один раз в тексте
#Построение частотной матрицы А
d={};c=[]
for i in range(0,len(docs)):
word=nltk.word_tokenize(docs[i])
word_stem=[stemmer.stem(w).lower() for w in word if len(w)>1 and w.isalpha()]
word_stop=[ w for w in word_stem if w not in stopword]
words=[ w for w in word_stop if w not in t]
for w in words:
if w not in c:
c.append(w)
d[w]= [i]
elif w in c:
d[w]= d[w]+[i]
a=len(c); b=len(docs)
A = numpy.zeros([a,b])
c.sort()
for i, k in enumerate(c):
for j in d[k]:
A[i,j] += 1
# TF-IDF нормализация матрицы А
wpd = sum(A, axis=0)
dpw= sum(asarray(A > 0,'i'), axis=1)
rows, cols = A.shape
for i in range(rows):
for j in range(cols):
m=float(A[i,j])/wpd[j]
n=log(float(cols) /dpw[i])
A[i,j] =round(n*m,2)
#Сингулярное разложение нормализованной матрицы А
U, S,Vt = numpy.linalg.svd(A)
rows, cols = U.shape
for j in range(0,cols):
for i in range(0,rows):
U[i,j]=round(U[i,j],4)
print('Первые 2 столбца ортогональной матрицы U слов')
for i, row in enumerate(U):
print(c[i], row[0:2])
res1=-1*U[:,0:1]; res2=-1*U[:,1:2]
data_word=[]
for i in range(0,len(c)):# Подготовка исходных данных в виде вложенных списков координат
data_word.append([res1[i][0],res2[i][0]])
plt.figure()
plt.subplot(221)
dist = pdist(data_word, 'euclidean')# Вычисляется евклидово расстояние (по умолчанию)
plt.hist(dist, 500, color='green', alpha=0.5)# Диаграмма евклидовых расстояний
Z = hierarchy.linkage(dist, method='average')# Выделение кластеров
plt.subplot(222)
hierarchy.dendrogram(Z, labels=c, color_threshold=.25, leaf_font_size=8, count_sort=True,orientation='right')
print('Первые 2 строки ортогональной матрицы Vt документов')
rows, cols = Vt.shape
for j in range(0,cols):
for i in range(0,rows):
Vt[i,j]=round(Vt[i,j],4)
print(-1*Vt[0:2, :])
res3=(-1*Vt[0:1, :]);res4=(-1*Vt[1:2, :])
data_docs=[];name_docs=[]
for i in range(0,len(docs)):
name_docs.append(str(i))
data_docs.append([res3[0][i],res4[0][i]])
plt.subplot(223)
dist = pdist(data_docs, 'euclidean')
plt.hist(dist, 500, color='green', alpha=0.5)
Z = hierarchy.linkage(dist, method='average')
plt.subplot(224)
hierarchy.dendrogram(Z, labels=name_docs, color_threshold=.25, leaf_font_size=8, count_sort=True)
#plt.show()
print('Первые 3 столбца ортогональной матрицы U слов')
for i, row in enumerate(U):
print(c[i], row[0:3])
res1=-1*U[:,0:1]; res2=-1*U[:,1:2];res3=-1*U[:,2:3]
data_word_xyz=[]
for i in range(0,len(c)):
data_word_xyz.append([res1[i][0],res2[i][0],res3[i][0]])
plt.figure()
plt.subplot(221)
dist = pdist(data_word_xyz, 'euclidean')# Вычисляется евклидово расстояние (по умолчанию)
plt.hist(dist, 500, color='green', alpha=0.5)#Диаграмма евклидовых растояний
Z = hierarchy.linkage(dist, method='average')# Выделение кластеров
plt.subplot(222)
hierarchy.dendrogram(Z, labels=c, color_threshold=.25, leaf_font_size=8, count_sort=True,orientation='right')
print('Первые 3 строки ортогональной матрицы Vt документов')
rows, cols = Vt.shape
for j in range(0,cols):
for i in range(0,rows):
Vt[i,j]=round(Vt[i,j],4)
print(-1*Vt[0:3, :])
res3=(-1*Vt[0:1, :]);res4=(-1*Vt[1:2, :]);res5=(-1*Vt[2:3, :])
data_docs_xyz=[];name_docs_xyz=[]
for i in range(0,len(docs)):
name_docs_xyz.append(str(i))
data_docs_xyz.append([res3[0][i],res4[0][i],res5[0][i]])
plt.subplot(223)
dist = pdist(data_docs_xyz, 'euclidean')
plt.hist(dist, 500, color='green', alpha=0.5)
Z = hierarchy.linkage(dist, method='average')
plt.subplot(224)
hierarchy.dendrogram(Z, labels=name_docs_xyz, color_threshold=.25, leaf_font_size=8, count_sort=True)
plt.show()
|
Метки: author Scorobey разработка под windows математика python латентно семантический анализ кластерный анализ дендрограмма сингулярное разложение |
Coco Framework — блокчейн по-крупному |

|
Метки: author saul анализ и проектирование систем open source блог компании intel coco framework |
Как мы участвовали в первом Лигалтех хакатоне СНГ и почему решили делать ещё один в Москве |






|
Метки: author mobilz законодательство и it-бизнес хакатон лигалтех юристы amp;a legaltech |
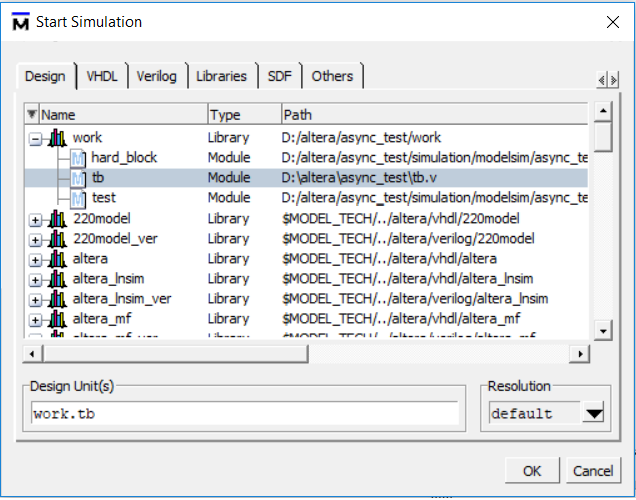
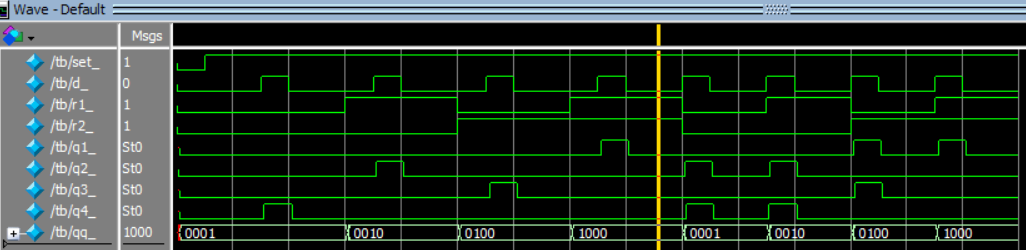
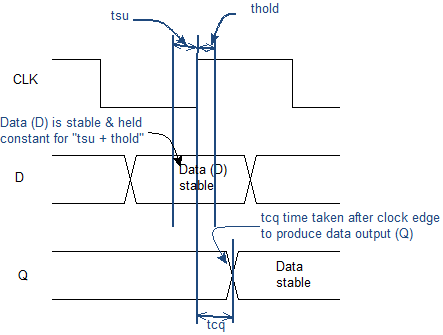
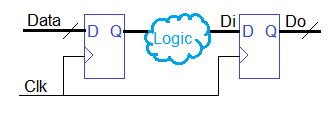
Исследование асинхронной схемы в ModelSim |
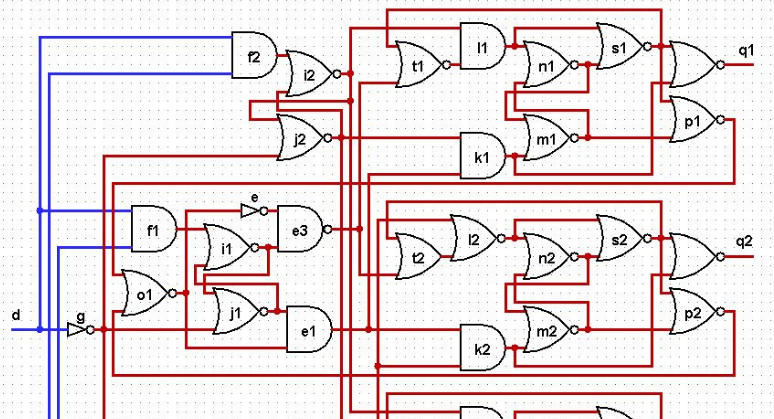
Выходные сигналы:
q1 — переключается если r1=1 и r2=1;
q2 — переключается если r1=1 и r2=0;
q3 — переключается если r1=0 и r2=1;
q4 — переключается если r1=0 и r2=0.
e=NOT(o1); e1=AND(o1,j1); e2=AND(o2,h1); e3=NAND(e,i1);
e4=OR(o2,h1); f1=AND(d,r1); f2=AND(d,r2); g=NOT(d);
h1=NOR(g,r1); h2=NOR(g,r2); i1=NOR(f1,j1); i2=NOR(f2,j2);
j1=NOR(g,i1); j2=NOR(g,i2); k1=AND(e1,j2); k2=AND(e1,h2);
k3=AND(e2,j2); k4=AND(e2,h2); l1=AND(t1,i2); l2=NOR(t2,h2);
l3=AND(t3,i2); l4=NOR(t4,h2); m1=NOR(k1,n1); m2=NOR(k2,n2);
m3=NOR(k3,n3); m4=NOR(k4,n4); n1=NOR(l1,m1); n2=NOR(l2,m2);
n3=NOR(l3,m3); n4=NOR(l4,m4); o1=NOR(p1,p2); o2=NOR(p3,p4);
p1=NOR(m1,s1); p2=NOR(m2,s2); p3=NOR(m3,s3); p4=NOR(m4,s4);
s1=NOR(n1,l1); s2=NOR(n2,l2); s3=NOR(n3,l3); s4=NOR(n4,l4);
t1=NOR(e3,s1); t2=OR(e3,s2); t3=NOR(e4,s3); t4=OR(e4,s4);
q1=NOR(s1,k1); q2=NOR(s2,k2); q3=NOR(s3,k3); q4=NOR(s4,k4).module test(
input wire d,
input wire r1,
input wire r2,
input wire set0,
output wire q1,
output wire q2,
output wire q3,
output wire q4,
output wire [3:0]qq
);
wire e, e1, e2, e3, e4;
wire f1, f2;
wire g;
wire i1, i2;
wire j1, j2;
wire h1, h2;
wire k1, k2, k3, k4;
wire l1, l2, l3, l4;
wire m1, m2, m3, m4;
wire n1, n2, n3, n4;
wire o1, o2;
wire p1, p2, p3, p4;
wire s1, s2, s3, s4;
wire t1, t2, t3, t4;
function NOT;
input s;
begin
NOT=~s;
end
endfunction
function AND;
input s1,s2;
begin
AND=s1&s2;
end
endfunction
function NAND;
input s1,s2;
begin
NAND=~(s1&s2);
end
endfunction
function OR;
input s1,s2;
begin
OR=s1|s2;
end
endfunction
function NOR;
input s1,s2;
begin
NOR=~(s1|s2);
end
endfunction
assign e=NOT(o1); assign e1=AND(o1,j1); assign e2=AND(o2,h1); assign e3=NAND(e,i1);
assign e4=OR(o2,h1); assign f1=AND(d,r1); assign f2=AND(d,r2); assign g=NOT(d);
assign h1=NOR(g,r1); assign h2=NOR(g,r2); assign i1=NOR(f1,j1); assign i2=NOR(f2,j2);
assign j1=NOR(g,i1); assign j2=NOR(g,i2); assign k1=AND(e1,j2); assign k2=AND(e1,h2);
assign k3=AND(e2,j2); assign k4=AND(e2,h2); assign l1=AND(t1,i2); assign l2=NOR(t2,h2);
assign l3=AND(t3,i2); assign l4=NOR(t4,h2);
assign m1=NAND( set0, OR(k1,n1)); /* NOR(k1,n1); */
assign m2=NAND( set0, OR(k2,n2)); /* NOR(k2,n2); */
assign m3=NAND( set0, OR(k3,n3)); /* NOR(k3,n3); */
assign m4=NAND( set0, OR(k4,n4)); /* NOR(k4,n4); */
assign n1=NOR(l1,m1); assign n2=NOR(l2,m2);
assign n3=NOR(l3,m3); assign n4=NOR(l4,m4); assign o1=NOR(p1,p2); assign o2=NOR(p3,p4);
assign p1=NOR(m1,s1); assign p2=NOR(m2,s2); assign p3=NOR(m3,s3); assign p4=NOR(m4,s4);
assign s1=NOR(n1,l1); assign s2=NOR(n2,l2); assign s3=NOR(n3,l3); assign s4=NOR(n4,l4);
assign t1=NOR(e3,s1); assign t2=OR(e3,s2); assign t3=NOR(e4,s3); assign t4=OR(e4,s4);
assign q1=NOR(s1,k1); assign q2=NOR(s2,k2); assign q3=NOR(s3,k3); assign q4=NOR(s4,k4);
assign qq = 1 << {r2,r1};
endmodule
`timescale 1ns / 1ns
module tb();
reg r1_;
reg r2_;
reg d_;
reg set_;
wire q1_,q2_,q3_,q4_;
wire [3:0]qq_;
test test_inst(
.d(d_),
.r1(r1_),
.r2(r2_),
.set0(set_),
.q1(q1_),
.q2(q2_),
.q3(q3_),
.q4(q4_),
.qq(qq_)
);
initial
begin
$dumpfile("out.vcd");
$dumpvars(0,tb);
//reset m1-m4 signals using "set_"
r1_=0;
r2_=0;
d_=0;
set_=0;
#100;
set_=1;
#100;
//check addr 00
r1_=0;
r2_=0;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 01
r1_=1;
r2_=0;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 10
r1_=0;
r2_=1;
#100;
d_=1;
#100;
d_=0;
#200;
//check addr 11
r1_=1;
r2_=1;
#100;
d_=1;
#100;
d_=0;
#200;
//--------------------
//check addr 00
r1_=0;
r2_=0;
d_=1;
#100;
d_=0;
#200;
//check addr 01
r1_=1;
r2_=0;
d_=1;
#100;
d_=0;
#200;
//check addr 10
r1_=0;
r2_=1;
d_=1;
#100;
d_=0;
#200;
//check addr 11
r1_=1;
r2_=1;
d_=1;
#100;
d_=0;
#200;
end
endmodule

|
Метки: author nckma fpga асинхронные схемы modelsim verilog |
Чат-бот своими руками: история одного велосипеда |

|
Метки: author Trympyrym программирование анализ и проектирование систем java блог компании headhunter headhunter development обучение |
Избранное: ссылки по reverse engineering |

Всем привет!
Сегодня мы хотели бы поделиться своим списком материалов по тематике reverse engineering (RE). Перечень этот очень обширный, ведь наш исследовательский отдел в первую очередь занимается задачами RE. На наш взгляд, подборка материалов по теме хороша для старта, при этом она может быть актуальной в течение продолжительного времени.
Данный список ссылок, ресурсов, книг мы уже лет пять рассылаем людям, которые хотели бы попасть в наш исследовательский отдел, но не проходят пока по уровню знаний или только начинают свой путь в сфере информационной безопасности. Естественно, этому перечню, как и большинству материалов/подборок, через некоторая время потребуется обновление и актуализация.
Забавный факт: нам показывали, как некоторые компании рассылают наш список материалов от себя, но только в очень старой редакции. И вот после этой публикации они, наконец, смогут использовать его обновленную версию с чистой совестью ;)
Итак, перейдем к списку материалов!
В данном разделе мы рассмотрим основные направления применения RE. Начнем непосредственно с самого процесса обратной разработки, перейдем к поиску уязвимостей и разработке эксплоитов, и, конечно, доберемся до анализа вредоносных программ.
Ниже представлены популярные инструменты, применяемые при RE.
Без знания принципов работы отладчика и умения им пользоваться тоже не обойтись. Ниже мы рассмотрим отладчики для ОС Windows, а в следующем пункте уделим внимание знаменитому GDB. Итак, поехали:
Программируемая отладка — это сегодня неотъемлемый подход в арсенале любого реверсера. И DBI — один из инструментов. Подробнее:
Что такое SMT-решатель? Если кратко, SMT-решатель — это программа, которая может решать логические формулы.
Основная идея применения SMT в области безопасности ПО заключается в том, чтобы перевести программный код или алгоритм в логическую формулу, а затем с помощью SMT-решателя проверить то или иное свойство этого кода.
Другими словами, SMT предоставляет математический аппарат для семантического анализа кода.
SMT-решатели уже довольно давно применяются в нашей сфере. Они неплохо зарекомендовали себя для решения следующих задач:
За это время SMT потеряла ореол таинственности, появились более-менее работающие инструменты для "простых" людей.
Ниже приведены источники, которые помогут погрузиться в тему:
Сегодня без знаний основ языка Python будет очень сложно, потому что этот язык программирования считается самым популярном средством для автоматизации различных задач в сфере ИБ (и не только). К тому же, он используется в различных утилитах (к примеру, все указанные выше утилиты позволяют дополнять функционал с помощью этого ЯП):
Для немного более продвинутых мы рекомендуем обратить внимание на целые фреймворки, которые в своем составе используют ранее упомянутые механизмы и средства анализа для решения более сложных задач. Итак, вот они:
Несколько интересных фреймворков/инструментов:
Мы рассмотрим только несколько популярных архитектур. В конце статьи в разделе с дополнительными материалами вы найдете информацию по многим другим (MIPS, PowerPC и т.д.).
Знание принципов работы популярных Операционных Систем.
В этом разделе представлены ссылки, разъесняющие подробности популярных форматов исполняемых файлов.
Известный исследователь corkami делает очень полезные и интересные "постеры" со схемой различных форматов файлов, в том числе, упомянутых выше. Советуем использовать их как шпаргалку.
Один наш знакомый как-то сказал, что хороший реверсер это на 80% хороший программист. Умение программировать и понимание того, что и зачем делается, упрощает процесс исследования чужой программы. Поэтому без программирования в реверсе никуда. Ну и конечно автоматизация рутинной задачи, как вы уже наверняка поняли, — очень полезная вещь ;)
В этой секции представлены ссылки на виртуальные машины и online-ресурсы, позволяющие попрактиковаться.
Ну и напоследок несколько ссылок с большим количеством материалов по вышеуказанным темам:
|
Метки: author dukebarman реверс-инжиниринг информационная безопасность блог компании «digital security» reverse engineering ссылки хакинг |
[Перевод] 10 шагов по решению задач в программировании |

selectEvenNumbers, которая берёт массив чисел и возвращает массив evenNumbers с одними лишь чётными числами. Если чётных чисел в исходном массиве нет, то массив evenNumbers возвращается пустым.function selectEvenNumbers() {
// здесь ваш код
}Предельно допустимые случаи: проблема или ситуация, возникающая за пределами нормальных параметров функционирования. Например, когда одновременно несколько переменных или состояний среды имеют экстремальные значения, даже если каждый из параметров находится в своём специфическом диапазоне.
Крайние случаи: проблемы или ситуации, возникающие только при экстремальных (минимальных или максимальных) значениях параметров функционирования.
[1][1].[1, 2][1, 2]1.2.evenNumbers и добавляем в него 2.[2].[1] отличается от алгоритма для [1, 2]. Поэтому рекомендуется проходить по нескольким наборам данных. Например, с единственным элементом; смесь целых и нецелых чисел; многоразрядные числа; наборы с отрицательными числами.selectEvenNumbers.evenNumbers для хранения чётных чисел.[1, 2].evenNumbers.n = 1, n = 2, ...n = k.n = k + 1.
filter, но ради простоты примера воспользуемся простым циклом for (однако при последующем рефакторинге мы ещё столкнёмся с filter).function selectEvenNumbers
создаём массив evenNumbers и делаем его эквивалентным пустому массиву
для каждого элемента в этом массиве
смотрим, является ли элемент чётным
если чётный (при делении на 2 результат получается нецелым)
добавляем его к массиву evenNumbers
return evenNumbersfunction selectEvenNumbers
evenNumbers = []
for i = 0 to i = length of evenNumbers
if (element % 2 === 0)
добавляем его к массиву evenNumbers
return evenNumbersselectEvenNumbers([1])
selectEvenNumbers([1, 2])
selectEvenNumbers([1, 2, 3, 4, 5, 6])
selectEvenNumbers([-200.25])
selectEvenNumbers([-800.1, 2000, 3.1, -1000.25, 42, 600])console.log(). Это поможет проверить, ведут ли себя значения и код так, как ожидается, прежде чем двигаться дальше. Таким образом вы выловите любые проблемы, не зайдя слишком далеко. Вот пример того, какие значения можно проверить при начале работы.function selectEvenNumbers(arrayofNumbers) {
let evenNumbers = []
console.log(evenNumbers) // Удаляем после проверки выходных данных
console.log(arrayofNumbers) // Удаляем после проверки выходных данных
}// обозначают строки из псевдокода. Жирным выделен реальный код на JavaScript.// function selectEvenNumbers
function selectEvenNumbers(arrayofNumbers) {
// evenNumbers = []
let evenNumbers = []
// for i = 0 to i = length of evenNumbers
for (var i = 0; i < arrayofNumbers.length; i++) {
// if (element % 2 === 0)
if (arrayofNumbers[i] % 2 === 0) {
// добавляем его к массиву evenNumbers
evenNumbers.push(arrayofNumbers[i])
}
}
// return evenNumbers
return evenNumbers
}function selectEvenNumbers(arrayofNumbers) {
let evenNumbers = []
for (var i = 0; i < arrayofNumbers.length; i++) {
if (arrayofNumbers[i] % 2 === 0) {
evenNumbers.push(arrayofNumbers[i])
}
}
return evenNumbers
}
«Простота — предпосылка надёжности».
filter. В этом случае нам не нужно определять переменную evenNumbers, потому что filter вернёт новый массив с копиями элементов, которые соответствуют фильтру. При этом исходный массив не изменится. Также нам не нужно использовать цикл for. filter пройдёт по каждому элементу, и если вернёт true, то элемент попадёт в массив, а если false, то будет пропущен.function selectEvenNumbers(arrayofNumbers) {
let evenNumbers = arrayofNumbers.filter(n => n % 2 === 0)
return evenNumbers
}«Программы должны быть написаны так, чтобы люди их читали, и лишь во вторую очередь — чтобы машины их исполняли».
«Самый эффективный инструмент отладки — тщательное продумывание в сочетании с разумно размещёнными командами вывода на экран».
// Это массив. Итерируем его.// Это переменная.«Неважно, насколько медленно вы пишете чистый код, вы всегда будете тратить больше времени, если пишете грязный код».
«Гордитесь тем, сколько вы прошли. Верьте в то, что пройдёте ещё больше. Но не забывайте наслаждаться путешествием».
|
Метки: author NIX_Solutions функциональное программирование программирование ооп анализ и проектирование систем блог компании nix solutions советы новичкам |
Как провести неидеальное собеседование тестировщика и почему идеальных не бывает |

Дрейк и не знал, насколько был близок к подбору правильного тестировщика.
Рано или поздно может настать момент, когда к вам придут с просьбой найти тестировщика. Можно, конечно, почитать какую-нибудь литературу про тестирование – например, «тестирование .net» Романа Савина. Да только, вполне возможно, кандидаты её тоже читали.
Поэтому я хочу поделиться своим взглядом на то, какие вопросы задавать и на какие качества обращать внимание при собеседовании вашего первого тестировщика.
Последние 5 лет я работаю в Яндекс.Деньгах руководителем отдела тестирования и регулярно собеседую людей на позиции тестировщиков. Приходилось проводить собеседования как по хорошо знакомым продуктам, так и по тем, про которые самому пришлось узнать за пару минут до интервью. Со временем я составил оптимальный для себя путь прохождения квеста, которым и хочу поделиться в статье.
Наверное, в деле собеседований самое важное – идти без мысли «скорее всего, это наш человек». В моей практике не раз встречались идеальные резюме, как будто специально написанные под нашу вакансию. Во-первых, они действительно могут быть просто под вас написаны, а во-вторых, в реальном общении человек может оказаться тяжелым или просто необщительным. Поэтому, если кандидат не подойдет, предварительный настрой на найм именно его будет психологически тяжело изменить.
Есть даже расхожее название псевдо-идеальных резюме – «письма к Санте». К ним стоит в начале добавлять: «Дорогой Санта, сделай так, чтобы в следующем году я знал: ...» А в конце: «Best regards, Tommy».
Справедлив и вариант от обратного, когда вы заранее негативно настроены к человеку из-за слабого резюме – о собеседовании уже договорились и отменять как-то некрасиво. Если договорились пообщаться, то будьте беспристрастны.
К слову об общительности и опрятном виде – для тестировщика это важные, близкие к необходимым качества. Какой бы баг он ни обнаружил, приходится объяснять разработчикам, почему это ошибка и как ее воспроизвести – по понятным причинам делать все это нужно в благожелательном тоне. Без навыков общения тут не обойтись, потому что на резкую критику по поводу найденных багов легко получить негатив в ответ.
Это может показаться неоднозначным, но я рекомендую не заострять внимание на небольшом опоздании кандидата на собеседование, особенно если он позвонил и предупредил. Пунктуальность у инженеров не самое распространенное качество. К тому же с секундомером утром на входе все равно никто не стоит и найти офис с первого раза новому человеку не всегда просто.
Еще я не люблю популярные в наши дни стрессовые собеседования, особенно на инженерные позиции. Вы ведь не менеджера по урегулированию конфликтов ищете, а специалиста по QA. В его работе стресс связан не с конфликтами, а с уровнем ответственности за пропущенные ошибки. Поэтому в нашем деле лучше обойтись без криков на собеседовании и нарочно пролитого кофе – пусть этим занимается кто-нибудь из сферы биржевой торговли.
Когда нанимаешь человека на новую для себя и компании должность, непонятно, о чем вообще его спрашивать. Тут часто возникают две крайности:
%candidacy_name% должен уметь все, включая администрирование и навыки моделирования ракетных двигателей. На всякий случай.
Оба варианта одинаково ужасны и порождают массу странных и ненужных вопросов, создавая собеседующему неприглядный имидж в глазах кандидата. Проще идти от реальных обязанностей человека. Если тестировщик будет проверять новые сборки продукта и искать в них ошибки – предложите кандидату сделать именно это.
Предварительно составьте описание продукта или сервиса. Если продукт слишком большой, возьмите ту его часть, которой и будет заниматься потенциальный идеальный кандидат. Желательно при этом не подниматься до такого уровня абстракции, где будет два больших квадрата – фронтэнд или бэкенд, – дайте больше конкретики по вашей системе. Совсем замечательно, если спросите про что-то, что и сами не понимаете, как тестировать. В конце концов, не зазорно быть немного меркантильным.
Например, мы просим протестировать наш небольшой сервис под названием «Напоминатель» – письменные напоминания о том, что какой-то платеж нужно будет вот-вот совершить. Удобен он тем, что не очень понятно, как его тестировать: как получить напоминание, которое должно прийти через месяц, как проверить, что если напоминание поставлено на 31 число месяца, то в условном феврале оно придет 28, а не 29-ого.
Каждый тестировщик должен быть хоть немного и аналитиком. Поэтому на собеседованиях мы часто просим людей рассказать, как бы они сами создали продукт или сервис, который им предлагается протестировать. С тем же напоминателем просим описать, где бы хранились его записи (после этого даже самые недогадливые понимают, что там, где хранятся напоминатели, хранится и дата следующего события), какой бы механизм выбрасывал оповещения. Если вам нужен не monkey clicker, а осознающий свои поступки человек, то это хороший способ проверить его на тот самый «аналитический склад ума».
Надеюсь, что вы не будете указывать «аналитический склад ума» в требованиях к кандидату. А если указали, то не продолжайте чтение, пока не поправите объявление.
Нелишне спросить все то же самое, но про тот продукт, который тестировщик уже проверял раньше. Спросите про архитектуру, как была устроена система. В процессе задайте пару вопросов формата «а зачем вы так сделали?», чтобы человек описал хотя бы общими словами, почему он принял именно такое решение. Главное, чтобы он не пожимал плечами со словами: «я-то откуда знаю – я простой тестировщик».
Представьте, что вас забросили на парашюте в центр Китая. Без денег и телефона, без знания языка. То же самое произойдет, если вы в свою команду приведете умного и всячески приятного в общении человека. Он и команда разработчиков просто не будут понимать друг друга, и вам придется нанимать кого-нибудь вроде героини Эми Адамс из «Прибытия», чтобы она научила нового специалиста этому непонятному птичьему языку. Ведь, помимо умения составлять правильные алгоритмы тестов, тестировщик должен общаться с разработкой и продуктовой командой на одном языке.
К такому собеседованию как раз удобно привлекать разработчиков из своей команды – разумеется, они легко «завалят» кандидата, но вы сможете оценить кругозор нового человека и его общее понимание, где он оказался. Например, банальные фразы про JIRA, Bitbucket, сертификаты и IDE могут быть наскальной азбукой для совсем новичков в профессии.
Если разработчиков почему-то не привлечь, то спросите в лоб: что такое интернет? Что мне только не отвечали на эту банальность: от «ну это сайты» и до «это то, что позволяет общаться между собой». Часто люди просто уходили глубоко в себя, а после встречи бурно возмущались, что им задают такие глупые и бесполезные вопросы.
Важно также предложить кандидату составить не особенно сложный алгоритм для какого-то действия или теста. Так вы убедитесь, что ему это не впервой и с алгоритмами он знаком. К этому навыку я еще добавляю умение быстро считать в уме. Конечно, это спорный момент, но для плодотворной работы полезно уметь посчитать выражения из кода в уме – без предварительной сборки проекта и калькулятора.
Согласен, что тестовое задание сродни практике – позволяет лучше оценить знания. Но обычно кандидаты не горят желанием их выполнять, потому что это долго, муторно и непонятно, стоит ли игра свеч. Да и проверяющие не всегда добросовестно относятся к тесту. Например, они могут отложить проверку результатов на несколько дней (а кандидат торопился, делал) или проверять «по трафарету». Если решение вылезает за границы идеального трафарета – кандидат бракуется, что не правильно. Вы ведь помните про ход мысли и его приоритет над правильным решением?
На мой взгляд, тестовое задание в большинстве случаев не нужно, но, надо признать, есть ряд оправданных исключений:
Вы ищете не junior тестировщика, а автоматизатора, то есть уже состоявшегося специалиста со своим карьерным путем. В таком случае может оказаться проще оценить заявленное владение технологиями и проверить опыт работы.
У вас в компании высокая степень формализма при написании многочисленной документации, и нужно быть точно уверенным, что кандидат способен письменно излагать свои мысли и не страдает дислексией. Но вообще это можно проверить, дав кандидату ноутбук и попросив завести описание какого-нибудь бага.
По одной такой задаче нам как-то пришло полторы тысячи писем. На второй сотне сообщений о багах вы впадаете в дзен и перестаете реагировать на внешние раздражители. Заодно можно быстро, без регистрации и СМС научиться медитации.
Любопытное наблюдение я сделал после работы в нескольких крупных компаниях – тестировщики часто развивают свою карьеру не в сторону разработки, а в сторону проектного управления. В сущности, это неудивительно, так как в основе обеих профессий лежит навык общения с людьми. Тестировщику тоже важнее сохранять корректность и нейтралитет, чем знать пару дополнительных языков программирования.
Спросите кандидата, как он будет справляться с относительно невозможными ситуациями. Относительно – потому что не стоит спрашивать у него, что он будет делать, когда вогоны сносят его планету, и почему у него нет с собой полотенца.
Примеры подходящих вопросов:
- «Два ПМа приходят к тебе и просят быстро протестировать их проект, который нужно релизить вечером. Что ты будешь делать?»
- «ПМ укатил в отпуск и не сказал, должна ли стоять по умолчанию галочка в пункте «да, я хочу получать ежесекундные напоминания о трансфере Неймара», а разработчик говорит, что в гробу он его видел и галочка стоять не должна. Стоит ли заводить баг или нет?»
Если ранжировать качества кандидатов, то на первое место я с особой помпой поставлю ум, а на второе – остроумие. Поэтому всегда спрашиваю, какие книги читал кандидат. Причем это не обязательно должны быть книги по тестированию.
Один из наших старших тестировщиков устроился в Яндекс.Деньги после письма, которое начиналось со слов: «Я ничего не знаю о тестировании, но очень хочу у вас работать». Это было три года назад, и с тех пор он сначала избавился от приставки «младший», а потом получил «старшего». Леша, привет!
|
Метки: author embriodead управление персоналом терминология it развитие стартапа карьера в it-индустрии блог компании яндекс.деньги тестирование найм персонала тестировщики |






