SpaceX доставит суперкомпьютер HPE на МКС. Как это ускорит миссию на Марс? |


|
|
[Из песочницы] Подробное руководство по созданию и развертыванию чата на Tornado + Telegram |

pip install virtualenvvirtualenv --no-site-packages -p python3.4 chatsource chat/bin/activatepip install tornado==4.4.2 psycopg2==2.7.3 pyTelegramBotAPI==2.2.3
https://api.telegram.org/bot<токен_вашего_бота>/getUpdates{"id":555455667,"first_name":"Иван","last_name":"Иванович","username":"kamrus","language_code":"ru-RU"}
id и есть ваш chat_idsudo su - postgrespsqlCREATE DATABASE habr_chat ENCODING 'UNICODE';CREATE USER habr_user WITH PASSWORD '12345';GRANT ALL PRIVILEGES ON DATABASE habr_chat TO habr_user;\c habr_chat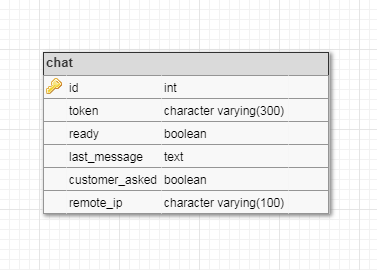
CREATE TABLE chat (
id SERIAL NOT NULL PRIMARY KEY,
token character varying(300) NOT NULL UNIQUE,
ready BOOLEAN NOT NULL DEFAULT True,
last_message TEXT,
customer_asked BOOLEAN NOT NULL DEFAULT False,
remote_ip character varying(100)
)GRANT ALL PRIVILEGES ON TABLE chat TO habr_user; INSERT INTO chat (token) VALUES ('your_bot_token');\qexitCHAT_ID = Вставить ваш chat_id
db = {
'db_name': 'habr_chat',
'user': 'habr_user',
'password': '12345',
'host': '',
'port': ''
}
from telebot import apihelper
from bot_settings import db
import psycopg2
import datetime
def get_updates(token, conn, cur, offset=None, limit=None, timeout=20):
''' Возвращает сообщение из телеграма '''
json_updates = apihelper.get_updates(token, offset, limit, timeout)
try:
answer = json_updates[-1]['message']['text']
except IndexError:
answer = ''
# если не проверять приходило ли сообщение от пользователя, то
# функция будет просто возвращать последнее сообщение от менеджера,
# которое в свою очередь могло предназначаться предыдущему клиенту
if is_customer_asked(conn, cur, token):
# необходимо проверять предыдущее сообщение, так как запрос к серверу
# повторяется через константное время и клиенту будет отправляться одно и тоже сообщение
if not is_last_message(conn, cur, token, answer):
# если сообщение прошло обе проверки то обновить это сообщение
# в базе данных
update_last_message(conn, cur, token, answer)
return answer
else:
# если пользователь еще ничего не спросил, то необходимо все равно обновить
# предыдущее сообщение менеджера, на случай если предыдущии пользовватель отключится,
# но менеджер все равно отправит сообщение
update_last_message(conn, cur, token, answer)
def send_message(token, chat_id, text):
'''Отправить сообщение менеджеру в телеграм'''
apihelper.send_message(token, chat_id, text)
def connect_postgres(**kwargs):
try:
conn = psycopg2.connect(dbname=db['db_name'],
user=db['user'],
password=db['password'],
host=db['host'],
port=db['port'])
except Exception as e:
print(e, 'Ошибка при подключении к posqgres')
raise e
cur = conn.cursor()
return conn, cur
def update_last_message(conn, cur, token, message, **kwargs):
''' Обновляет последнее сообщение, присланное менеджером '''
query = "UPDATE chat SET last_message = %s WHERE token = %s"
data = [message, token]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке обновить последнее сообщение на %s' %message)
raise e
def add_remote_ip(conn, cur, token, ip):
''' Функция добавляет ip адрес пользователя '''
query = "UPDATE chat SET remote_ip = %s WHERE token = %s"
data = [ip, token]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке добавить ip адрес')
raise e
def delete_remote_ip(conn, cur, token):
''' Удалить ip адрес у бота по переданному токену '''
query = "UPDATE chat SET remote_ip = %s WHERE token = %s"
data = ['', token]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке удалить ip адрес')
raise e
def is_last_message(conn, cur, token, message, **kwargs):
''' Проверить является ли переданное сообщение последним сообщением менеджера '''
query = "SELECT last_message FROM chat WHERE token = %s"
data = [token, ]
try:
cur.execute(query, data)
last_message = cur.fetchone()
if last_message:
if last_message[0] == message:
return True
return False
except Exception as e:
print(e, 'Ошибка при определении последнего сообщения')
raise e
def update_customer_asked(conn, cur, token, to_value):
''' Обновить статус ответа клиента '''
query = "UPDATE chat SET customer_asked = %s WHERE token = %s"
# to_value = True/False
data = [to_value, token]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке обновить "customer_asked" на %s' %to_value)
raise e
def is_customer_asked(conn, cur, token):
''' Если клиент уже написал сообщение, то функция вернет True '''
query = "SELECT customer_asked FROM chat WHERE token = %s"
data = [token, ]
try:
cur.execute(query, data)
customer_asked = cur.fetchone()
return customer_asked[0]
except Exception as e:
print(e, "Ошибка при попытке узнать написал ли пользователь сообщение или еще нет")
raise e
def get_bot(conn, cur):
'''
Функция берет из базы свободного бота, у которого ready = True.
Возвращает (id, token, ready, last_message, customer_asked) для свободного бота
'''
query = "SELECT * FROM chat WHERE ready = True"
try:
cur.execute(query)
bot = cur.fetchone()
if bot:
return bot
else:
return None
except Exception as e:
print(e, "Ошибка при попытке найти свободного бота")
raise e
def make_bot_busy(conn, cur, token):
''' Меняет значение ready на False, тем самым делая бота занятым '''
query = "UPDATE chat SET ready = False WHERE token = %s"
data = [token,]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке изменить значение "ready" на False')
raise e
def make_bot_free(conn, cur, token):
''' Меняет значение ready на False, тем самым делая бота свободным '''
update_customer_asked(conn, cur, token, False)
delete_remote_ip(conn, cur, token)
query = "UPDATE chat SET ready = True WHERE token = %s"
data = [token,]
try:
cur.execute(query, data)
conn.commit()
except Exception as e:
print(e, 'Ошибка при попытке изменить значение "ready" на True')
raise eimport tornado.ioloop
import tornado.web
import tornado.websocket
import core
from bot_settings import CHAT_ID
import datetime
class WSHandler(tornado.websocket.WebSocketHandler):
def __init__(self, application, request, **kwargs):
super(WSHandler, self).__init__(application, request, **kwargs)
# При создании нового подключения с пользователем подключимся к postgres
self.conn, self.cur = core.connect_postgres()
self.get_bot(self.conn, self.cur, request.remote_ip)
def get_bot(self, conn, cur, ip):
while True:
bot = core.get_bot(conn, cur)
if bot:
self.bot_token = bot[1]
self.customer_asked = bot[4]
# занять бота
core.make_bot_busy(self.conn, self.cur, self.bot_token)
# добавить боту ip адрес
core.add_remote_ip(self.conn, self.cur, self.bot_token, ip)
break
def check_origin(self, origin):
''' Дает возможность подключаться с различных адресов '''
return True
def bot_callback(self):
''' Функция вызывается PeriodicCallback и проверяет сервер Telegram на
наличие новых сообщений от менеджера
'''
ans_telegram = core.get_updates(self.bot_token, self.conn, self.cur)
if ans_telegram:
# если пришло сообщение от менеджера, то отправить его в браузер клиенту
self.write_message(ans_telegram)
def open(self):
''' Функция вызываемая при открытии сокета с клиентом '''
# Запускает опрос сервера Telegram каждые 3сек
self.telegram_loop = tornado.ioloop.PeriodicCallback(self.bot_callback, 3000)
self.telegram_loop.start()
def on_message(self, message):
''' Функция вызываемая, когда по сокету приходит сообщение '''
if not self.customer_asked:
self.customer_asked = True
# обновить значение в бд, что клиент задал вопрос
core.update_customer_asked(self.conn, self.cur, self.bot_token, True)
core.send_message(self.bot_token, CHAT_ID, message)
def on_close(self):
''' Функция вызываемая при закрытии соединения '''
core.send_message(self.bot_token, CHAT_ID, "Пользователь закрыл чат")
# остановить PeriodicCallback
self.telegram_loop.stop()
# освободить бота
core.make_bot_free(self.conn, self.cur, self.bot_token)
# WebSocket будет доступен по адресу ws://127.0.0.1:8080/ws
application = tornado.web.Application([
(r'/ws', WSHandler),
])
if __name__ == "__main__":
application.listen(8080)
tornado.ioloop.IOLoop.current().start()
.chatbox {
position: fixed;
bottom: 0;
right: 30px;
height: 400px;
background-color: #fff;
font-family: Arial, sans-serif;
-webkit-transition: all 600ms cubic-bezier(0.19, 1, 0.22, 1);
transition: all 600ms cubic-bezier(0.19, 1, 0.22, 1);
display: -webkit-flex;
display: flex;
-webkit-flex-direction: column;
flex-direction: column;
}
.chatbox-down {
bottom: -350px;
}
.chatbox--closed {
bottom: -400px;
}
.chatbox .form-control:focus {
border-color: #1f2836;
}
.chatbox__title,
.chatbox__body {
border-bottom: none;
}
.chatbox__title {
min-height: 50px;
padding-right: 10px;
background-color: #1f2836;
border-top-left-radius: 4px;
border-top-right-radius: 4px;
cursor: pointer;
display: -webkit-flex;
display: flex;
-webkit-align-items: center;
align-items: center;
}
.chatbox__title h5 {
height: 50px;
margin: 0 0 0 15px;
line-height: 50px;
position: relative;
padding-left: 20px;
-webkit-flex-grow: 1;
flex-grow: 1;
}
.chatbox__title h5 a {
color: #fff;
max-width: 195px;
display: inline-block;
text-decoration: none;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
.chatbox__title h5:before {
content: '';
display: block;
position: absolute;
top: 50%;
left: 0;
width: 12px;
height: 12px;
background: #4CAF50;
border-radius: 6px;
-webkit-transform: translateY(-50%);
transform: translateY(-50%);
}
.chatbox__title__tray,
.chatbox__title__close {
width: 24px;
height: 24px;
outline: 0;
border: none;
background-color: transparent;
opacity: 0.5;
cursor: pointer;
-webkit-transition: opacity 200ms;
transition: opacity 200ms;
}
.chatbox__title__tray:hover,
.chatbox__title__close:hover {
opacity: 1;
}
.chatbox__title__tray span {
width: 12px;
height: 12px;
display: inline-block;
border-bottom: 2px solid #fff
}
.chatbox__title__close svg {
vertical-align: middle;
stroke-linecap: round;
stroke-linejoin: round;
stroke-width: 1.2px;
}
.chatbox__body,
.chatbox__credentials {
padding: 15px;
border-top: 0;
background-color: #f5f5f5;
border-left: 1px solid #ddd;
border-right: 1px solid #ddd;
-webkit-flex-grow: 1;
flex-grow: 1;
}
.chatbox__credentials {
display: none;
}
.chatbox__credentials .form-control {
-webkit-box-shadow: none;
box-shadow: none;
}
.chatbox__body {
overflow-y: auto;
}
.chatbox__body__message {
position: relative;
}
.chatbox__body__message p {
padding: 15px;
border-radius: 4px;
font-size: 14px;
background-color: #fff;
-webkit-box-shadow: 1px 1px rgba(100, 100, 100, 0.1);
box-shadow: 1px 1px rgba(100, 100, 100, 0.1);
}
.chatbox__body__message img {
width: 40px;
height: 40px;
border-radius: 4px;
border: 2px solid #fcfcfc;
position: absolute;
top: 15px;
}
.chatbox__body__message--left p {
margin-left: 15px;
padding-left: 30px;
text-align: left;
}
.chatbox__body__message--left img {
left: -5px;
}
.chatbox__body__message--right p {
margin-right: 15px;
padding-right: 30px;
text-align: right;
}
.chatbox__body__message--right img {
right: -5px;
}
.chatbox__message {
padding: 15px;
min-height: 50px;
outline: 0;
resize: none;
border: none;
font-size: 12px;
border: 1px solid #ddd;
border-bottom: none;
background-color: #fefefe;
width: 100%;
}
.chatbox--empty {
height: 262px;
}
.chatbox--empty.chatbox-down {
bottom: -212px;
}
.chatbox--empty.chatbox--closed {
bottom: -262px;
}
.chatbox--empty .chatbox__body,
.chatbox--empty .chatbox__message {
display: none;
}
.chatbox--empty .chatbox__credentials {
display: block;
}
.description {
font-family: Arial, sans-serif;
font-size: 12px;
}
#start-ws {
margin-top: 30px;
}
.no-visible {
display: none;
}

(function($) {
$(document).ready(function() {
var $chatbox = $('.chatbox'),
$chatboxTitle = $('.chatbox__title'),
$chatboxTitleClose = $('.chatbox__title__close'),
$chatboxWs = $('#start-ws');
// Свернуть чат при нажатии на заголовок и наоборот
$chatboxTitle.on('click', function() {
$chatbox.toggleClass('chatbox-down');
});
// Закрыть чат
$chatboxTitleClose.on('click', function(e) {
e.stopPropagation();
$chatbox.addClass('chatbox--closed');
// Если на момент закрытия был открыт сокет, то
// следует закрыть его
if (window.sock) {
window.sock.close();
}
});
// Подключиться к сокету
$chatboxWs.on('click', function(e) {
e.preventDefault();
// сделать диалог видимым
$chatbox.removeClass('chatbox--empty');
// сделать кнопку начала чата невидимой
$chatboxWs.addClass('no-visible');
if (!("WebSocket" in window)) {
alert("Ваш браузер не поддерживает web sockets");
}
else {
alert("Начало соединения");
setup();
}
});
});
})(jQuery);
// Функция создания соединения по WebSocket
function setup(){
var host = "ws://62.109.2.175:8084/ws";
var socket = new WebSocket(host);
window.sock = socket;
var $txt = $("#message");
var $btnSend = $("#sendmessage");
// Отслеживать изменения в textarea
$txt.focus();
$btnSend.on('click',function(){
var text = $txt.val();
if(text == ""){return}
// отправить сообщение по сокету
socket.send(text);
// отобразить в дилоге сообщение
clientRequest(text);
$txt.val("");
// $('#send')
});
// отслеживать нажатие enter
$txt.keypress(function(evt){
// если был нажат enter
if(evt.which == 13){
$btnSend.click();
}
});
if(socket){
// действие на момент открытия сокета
socket.onopen = function(){
}
// действие на момент получения сообщения по сокету
socket.onmessage = function(msg){
// отобразить сообщение в диалоге
managerResponse(msg.data);
}
// действия на момент закрытия сокета
socket.onclose = function(){
webSocketClose("The connection has been closed.");
window.sock = false;
}
}else{
console.log("invalid socket");
}
}
function webSocketClose(txt){
var p = document.createElement('p');
p.innerHTML = txt;
document.getElementById('messages__box').appendChild(p);
}
//функция для ответов клиента
function clientRequest(txt) {
$("#messages__box").append(" " + txt + "
");
}
// Функция для ответов менеджера
function managerResponse(txt) {
$("#messages__box").append(" " + txt + "
");
}
sudo yum install postgresql-server postgresql-devel postgresql-contrib sudo postgresql-setup initdbsudo systemctl start postgresqlsudo systemctl enable postgresqlsudo yum install supervisor[unix_http_server]
file=/path/to/supervisor.sock ; (the path to the socket file)
[supervisord]
logfile=/var/log/supervisor/supervisord.log ; (main log file;default $CWD/supervisord.log)
logfile_maxbytes=50MB ; (max main logfile bytes b4 rotation;default 50MB)
logfile_backups=10 ; (num of main logfile rotation backups;default 10)
loglevel=error ; (log level;default info; others: debug,warn,trace)
pidfile=/path/to/supervisord.pid ; (supervisord pidfile;default supervisord.pid)
nodaemon=false ; (start in foreground if true;default false)
minfds=1024 ; (min. avail startup file descriptors;default 1024)
minprocs=200 ; (min. avail process descriptors;default 200)
user=root
childlogdir=/var/log/supervisord/ ; ('AUTO' child log dir, default $TEMP)
[rpcinterface:supervisor]
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl]
serverurl=unix:///path/to/supervisor.sock ; use a unix:// URL for a unix socket
[program:tornado-8004]
environment=PATH="/path/to/chat/bin"
command=/path/to/chat/bin/python3.4 /path/to/tornadino.py --port=8084
stopsignal=KILL
stderr_logfile=/var/log/supervisord/tornado-stderr.log
stdout_logfile=/var/log/supervisord/tornado-stdout.log
[include]
files = supervisord.d/*.inisudo supervisorctl start tornado-8004sudo supervisorctl statustornado-8004 RUNNING pid 32139, uptime 0:08:10var host = "ws://адресс_вашего_сервера:8084/ws";|
Метки: author Kamrus python tornado telegram websocket supervisor |
Что может чат-бот |
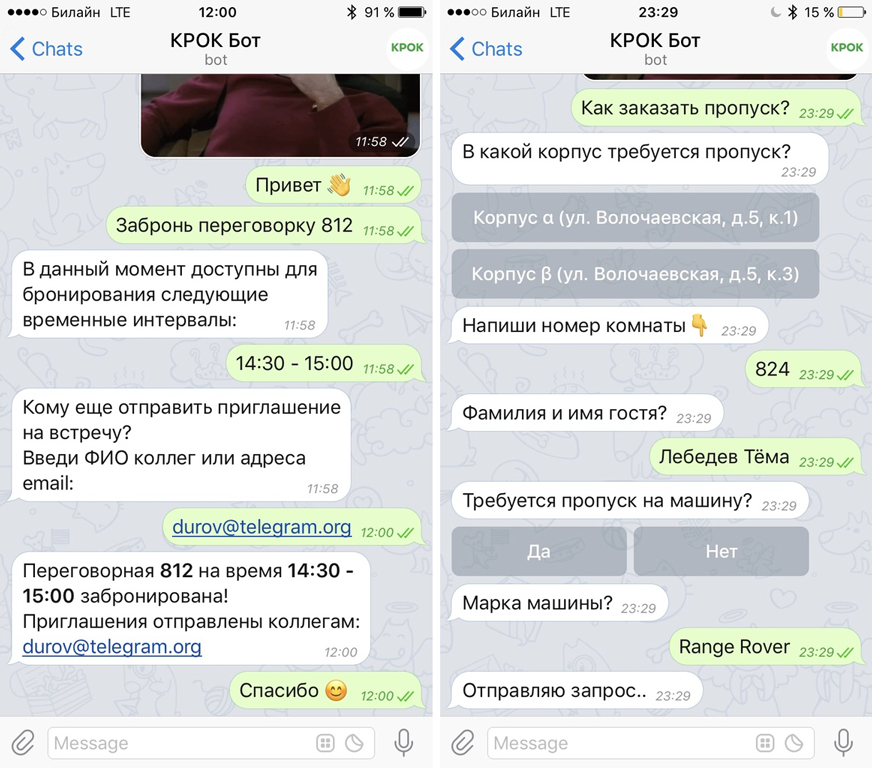

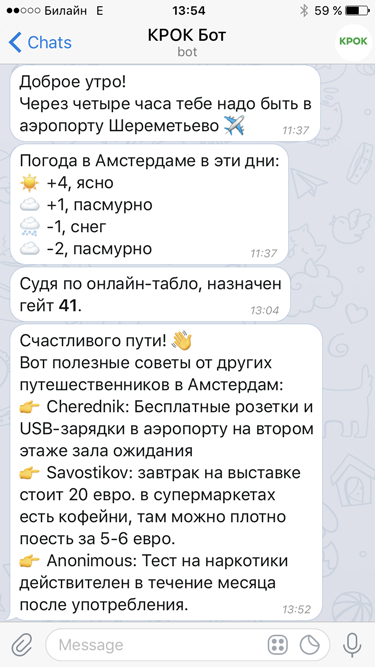
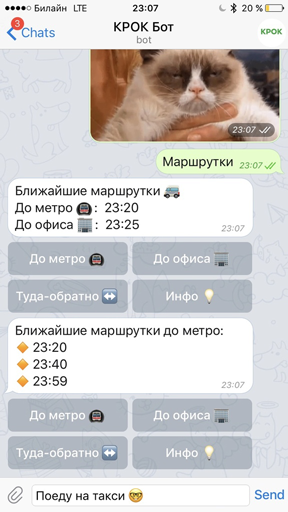
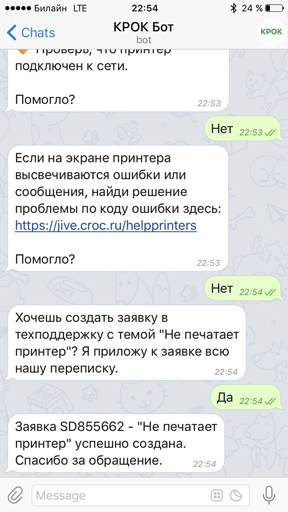
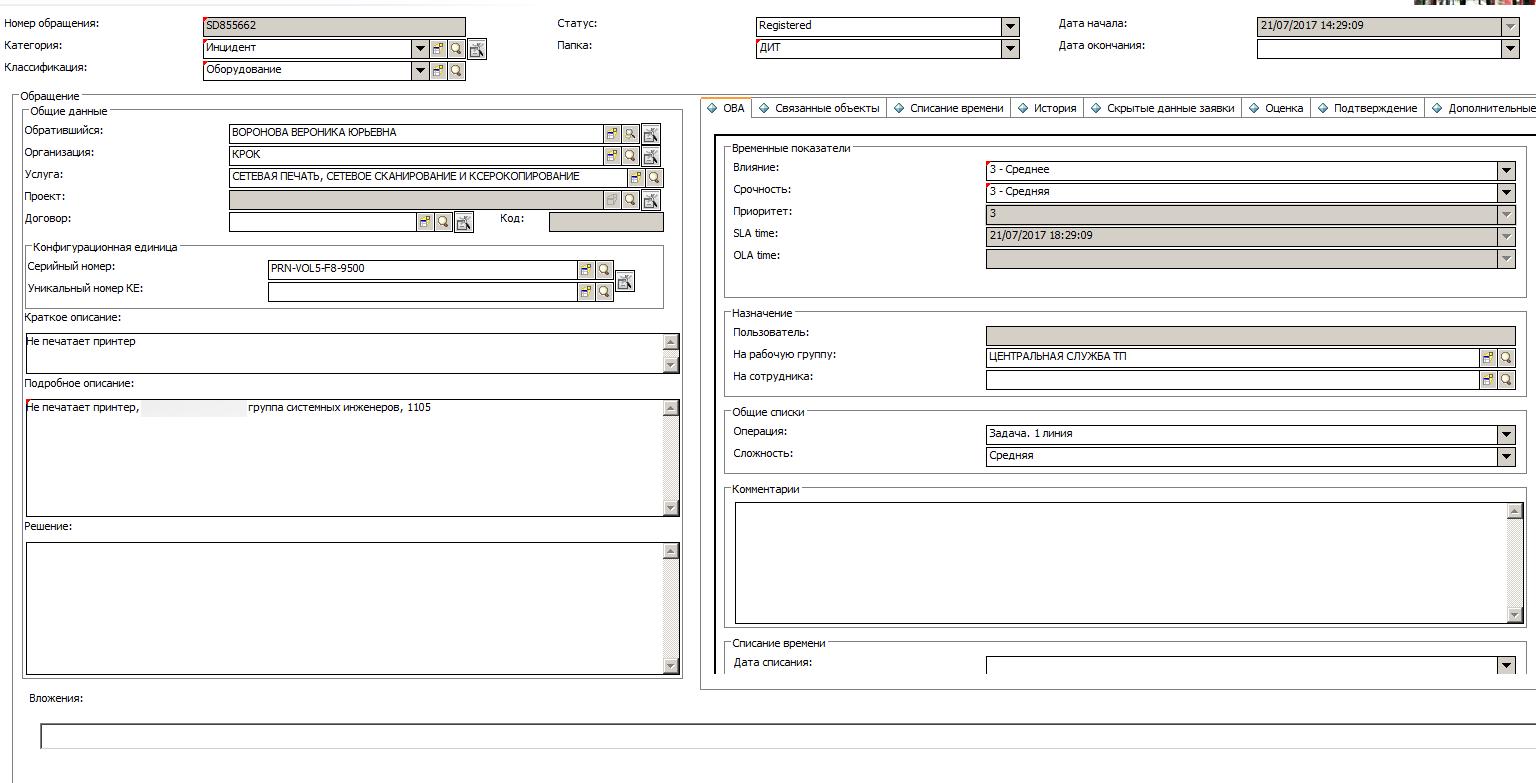

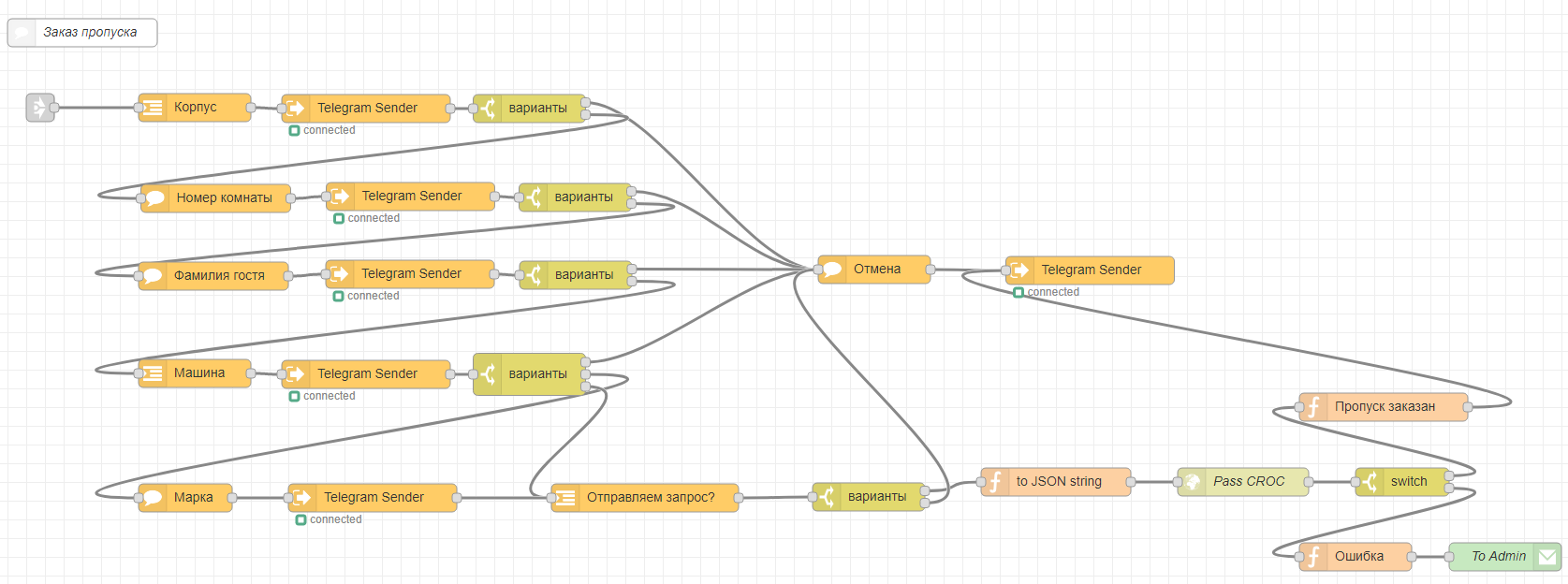
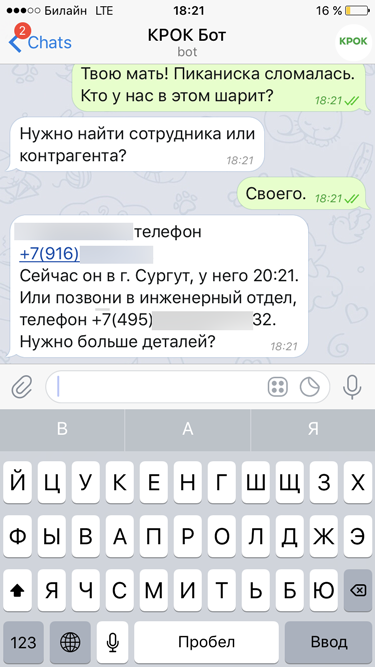
|
|
Зачем бэкап? У нас же RAID |



|
Метки: author JetHabr системное администрирование резервное копирование восстановление данных it- инфраструктура блог компании инфосистемы джет бэкап raid |
Визуализация данных Московской Биржи с помощью InterSystems DeepSee. Часть I |
В стеке технологий InterSystems есть технология для разработки аналитических решений DeepSee. Это встраиваемая аналитическая технология и набор инструментов для создания систем поддержки принятия эффективных решений, в том числе, и с применением прогнозных моделей. DeepSee работает со структурированными и неструктурированными данными. Она предназначена для создания OLAP-решений для баз данных Cach'e и любых реляционных СУБД. InterSystems DeepSee предоставляет разработчикам средства для внедрения в свои приложения аналитической OLAP-функциональности, которая способна работать на оперативных базах данных приложений без создания отдельной инфраструктуры для решения аналитических задач.
В статье рассматривается пример создания в OLAP-куба, работа со средствами аналитики и построение пользовательского интерфейса на примере анализа котировок акций торгуемых на Московской Бирже.
Для визуализации данных о котировках акций необходимо их сначала загрузить. У Московской Биржи есть публичное задокументированное API, которое предоставляет информацию о торговле акциями в форматах HTML, XML, JSON, CSV.
Вот, к примеру, XML данные за 27 мая 2013 года. Создадим XML-Enabled класс Ticker.Data в платформе InterSystems:
Class Ticker.Data Extends (%Persistent, %XML.Adaptor)
{
/// Дата торгов
Property Date As %Date(FORMAT = 3, XMLNAME = "TRADEDATE", XMLPROJECTION = "attribute");
/// Краткое название компании
Property Name As %String(XMLNAME = "SHORTNAME", XMLPROJECTION = "attribute");
/// Тикер
Property Ticker As %String(XMLNAME = "SECID", XMLPROJECTION = "attribute");
/// Количество сделок
Property Trades As %Integer(XMLNAME = "NUMTRADES", XMLPROJECTION = "attribute");
/// Общая сумма сделок
Property Value As %Decimal(XMLNAME = "VALUE", XMLPROJECTION = "attribute");
/// Цена открытия
Property Open As %Decimal(XMLNAME = "OPEN", XMLPROJECTION = "attribute");
/// Цена закрытия
Property Close As %Decimal(XMLNAME = "CLOSE", XMLPROJECTION = "attribute");
/// Цена закрытия официальная
Property CloseLegal As %Decimal(XMLNAME = "LEGALCLOSEPRICE", XMLPROJECTION = "attribute");
/// Минимальная цена акции
Property Low As %Decimal(XMLNAME = "LOW", XMLPROJECTION = "attribute");
/// Максимальная цена акции
Property High As %Decimal(XMLNAME = "HIGH", XMLPROJECTION = "attribute");
/// Средневзвешенная цена акции http://www.moex.com/s1194
/// Может считаться как за день так и не за период.
Property Average As %Decimal(XMLNAME = "WAPRICE", XMLPROJECTION = "attribute");
/// Количество акций участвовавших в сделках
Property Volume As %Integer(XMLNAME = "VOLUME", XMLPROJECTION = "attribute");
}И напишем загрузчик данных в формате XML. Так как класс у нас XML-Enabled то конвертация из XML в объекты класса Ticker.Data происходит автоматически. Аналогичного поведения можно достичь для данных в форматах JSON (через динамические объекты) и CSV (используя %SQL.Util.Procedures). Так как API отдаёт данные за определённую дату (день) то нам надо итерировать по дням и сохранять поступающие данные. Кроме того данные о котировках акций приходят страницами по 100 записей. Загрузчик может выглядеть так:
/// Загрузить информацию об акциях начиная с From и заканчивая To. Purge - удалить все записи перед началом загрузки
/// Формат From, To - YYYY-MM-DD
/// Write $System.Status.GetErrorText(##class(Ticker.Loader).Populate())
ClassMethod Populate(From As %Date(DISPLAY=3) = "2013-03-25", To As %Date(DISPLAY=3) = {$ZDate($Horolog,3)}, Purge As %Boolean = {$$$YES})
{
#Dim Status As %Status = $$$OK
// Переводим даты во внутренний формат для простоты итерации
Set FromH = $ZDateH(From, 3)
Set ToH = $ZDateH(To, 3)
Do:Purge ..Purge()
For DateH = FromH:1:ToH {
Write $c(13), "Populating ", $ZDate(DateH, 3)
Set Status = ..PopulateDay(DateH)
Quit:$$$ISERR(Status)
}
Quit Status
}
/// Загрузить данные за день. Данные загружаются страницами по 100 записей.
/// Write $System.Status.GetErrorText(##class(Ticker.Loader).PopulateDay($Horolog))
ClassMethod PopulateDay(DateH As %Date) As %Status
{
#Dim Status As %Status = $$$OK
Set Reader = ##class(%XML.Reader).%New()
Set Date = $ZDate(DateH, 3) // Преобразовать дату из внутреннего формата в YYYY-MM-DD
Set Count = 0 // Число загруженных записей
While Count '= $G(CountOld) {
Set CountOld = Count
Set Status = Reader.OpenURL(..GetURL(Date, Count)) // Получаем следующую страницу данных
Quit:$$$ISERR(Status)
// Устанавливаем соответствие нода row == объект класса Ticker.Data
Do Reader.Correlate("row", "Ticker.Data")
// Десериализуем каждую ноду row в объект класса Ticker.Data
While Reader.Next(.Object, .Status) {
#Dim Object As Ticker.Data
// Сохраняем объект
If Object.Ticker '="" {
Set Status = Object.%Save()
Quit:$$$ISERR(Status)
Set Count = Count + 1
}
}
Quit:(Count-CountOld)<100 // На текущей странице меньше 100 записей => эта страница - последняя
}
Quit Status
}
/// Получить URL с информацией о котировках акций за дату Date, пропустить первые Start записей
ClassMethod GetURL(Date, Start As %Integer = 0) [ CodeMode = expression ]
{
$$$FormatText("http://iss.moex.com/iss/history/engines/stock/markets/shares/boards/tqbr/securities.xml?date=%1&start=%2", Date, Start)
}
Теперь загрузим данные командой: Write $System.Status.GetErrorText(##class(Ticker.Loader).Populate())
Весь код доступен в репозитории.
Как известно, для построения OLAP-куба в первую очередь необходимо сформировать таблицу фактов: таблицу операций, записи которой требуется группировать и фильтровать. Таблица фактов может быть связана с другими таблицами по схеме звезда или снежинка.
Таблица фактов для куба обычно является результатом работы аналитиков и разработчиков по процессу, который называется ETL (extract, transform, load). Т.е. из данных предметной области делается “выжимка” необходимых для анализа данных, и переносится в удобную для хранилища структуру "звезда"/"снежинка": факты и справочники фактов.
В нашем случае этап ETL пропустим т.к. наш класс Ticker.Data уже находятся во вполне удобном для создания куба состоянии.
DeepSee Architect — это веб-приложение для создания OLAP-куба. Для перехода к DeepSee Architect откроем Портал Управления Системой -> DeepSee -> Выбор области -> Architect. Открывается рабочее окно Архитектора.
Возможно нужно будет выбрать область, которая поддерживает DeepSee. В том случае если вы не видите вашей области в списке областей DeepSee перейдите в Портал Управления Системой -> Меню -> Управление веб-приложениями -> /csp/область, и там в поле Включен поставьте галочку DeepSee и нажмите кнопку сохранить. После этого выбранная область должна появиться в списке областей DeepSee.
Нажав на кнопку "Создать" попадаем на экран создания нового куба, там необходимо установить следующие параметры:
Вот как выглядит наш новый куб:
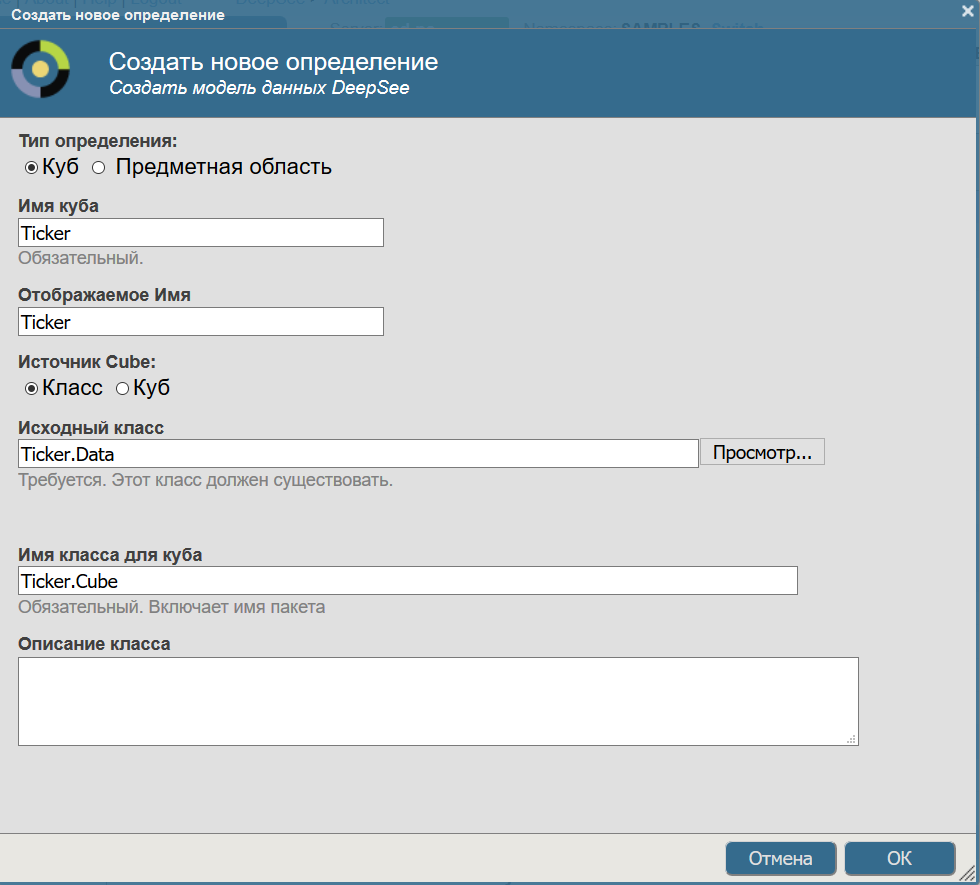
После нажатия кнопки OK будет создан новый куб:
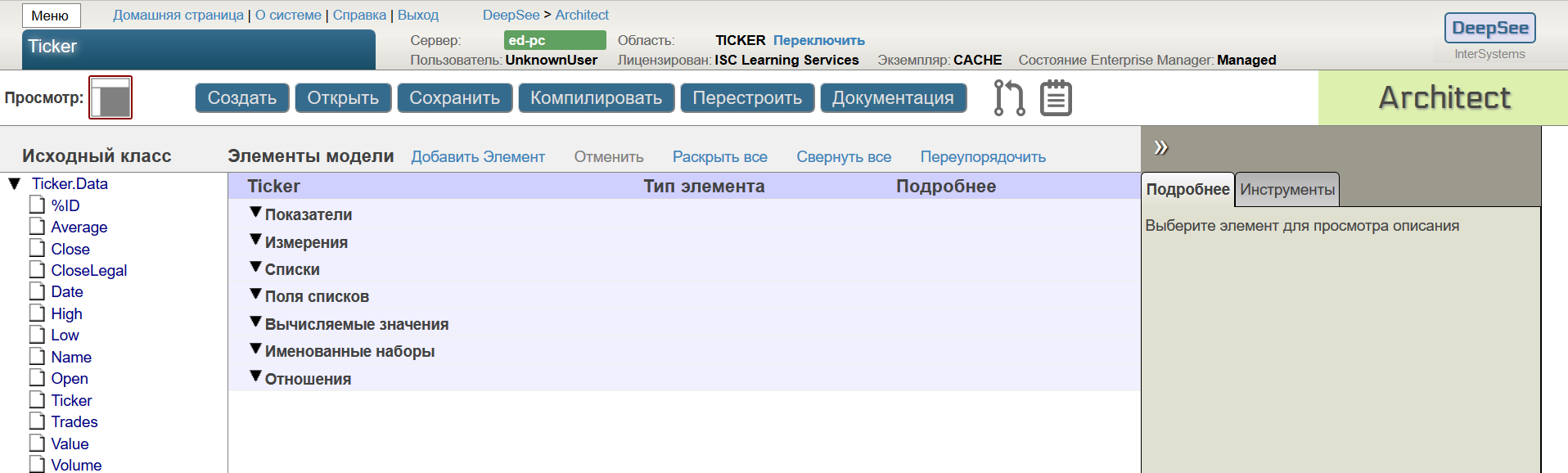
Слева выводятся свойства базового и связанных с ним по “снежинке” классов, которые можно использовать при построении куба.
Центральная часть экрана — это скелет куба. Его можно наполнить свойствами класса с помощью drag-n-drop из области базового класса, либо добавляя элементы вручную. Основными элементами куба являются измерения, показатели и списки.
Измерения — это элементы куба, которые группируют записи таблицы фактов. В измерения обычно относят “качественные” атрибуты базового класса, которые разбивают все записи таблицы фактов по тем или иным срезам. Например нам бы хотелось группировать все факты по названиям инструментов и по датам.
Для разбиения фактов по тикерам прекрасно подойдет свойство Ticker.
Перетянем Ticker на область измерений — в результате Архитектор добавит в куб измерение Ticker с одной иерархией H1 и одним уровнем Ticker. Укажем отображаемые названия в подписях к измерению и уровню.
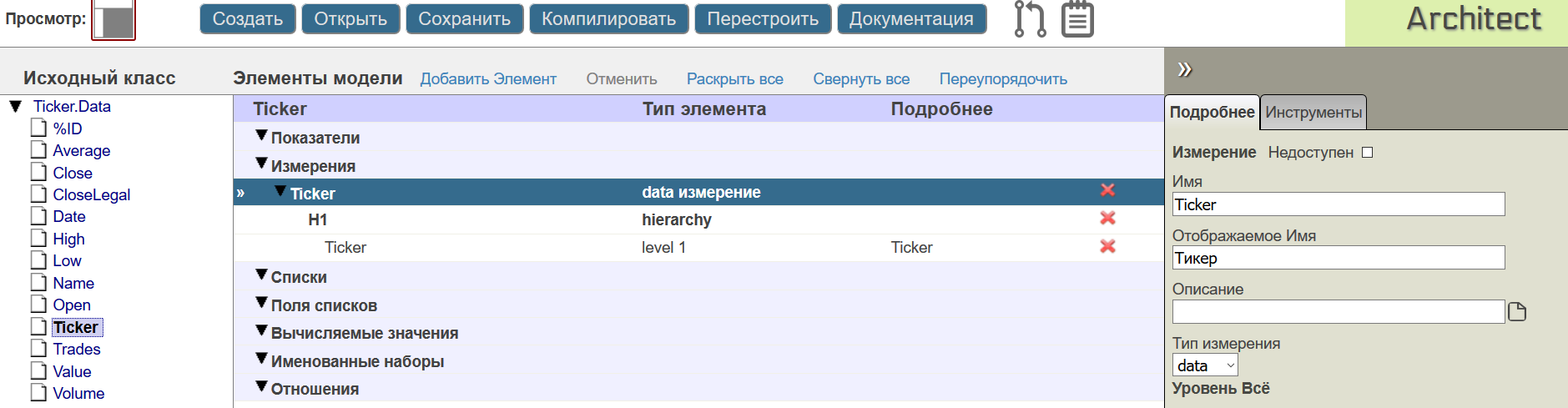
Измерения помимо группировки позволяют строить иерархии вложенности фактов от общего к частному. Типичным примером является измерение по дате, которое обычно часто требуется представить в виде иерархии Год-Месяц-День.
Для свойств типа дата(например как у свойства Date тип %Date) в DeepSee есть специальный тип измерения time, в котором уже предусмотрены часто используемые функции для создания иерархий по дате. Воспользуемся этим и построим трехуровневую иерархию Год-месяц-день с помощью свойства Date.
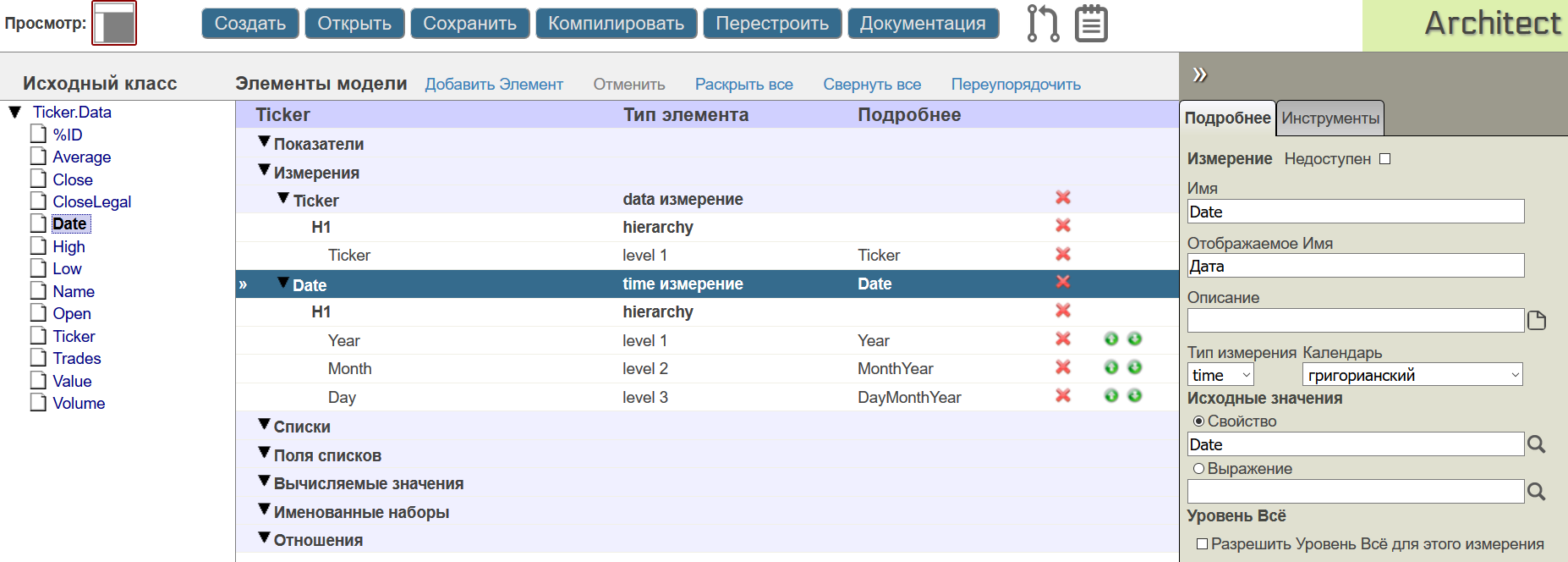
Заметим, что в измерении есть элементы: собственно измерение, иерархия и уровни этой иерархии (Level). Любое измерение куба состоит как минимум из одной иерархии в котором в простейшем случае всего один уровень.
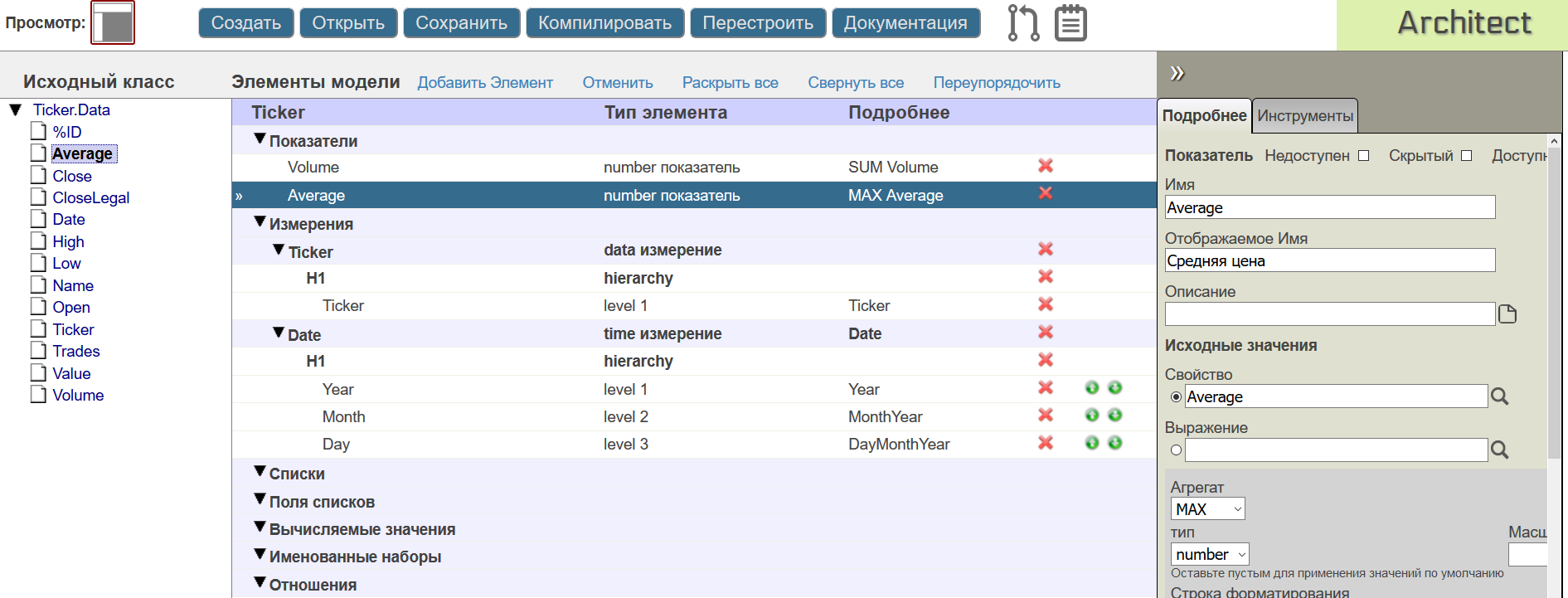
Показатели или метрики это такие элементы куба, куда относят какие-либо "количественные" данные, которые необходимо посчитать для "качественных" измерений куба (Dimensions).
Например в таблице фактов такими показателями могут быть свойства Volume (количество акций) и Average (Средняя цена). Перетянем свойство Volume на область показателей и создадим показатель "Количество" с функцией SUM, которая будет считать общее количество акций в текущем срезе.
Добавим также в показатели свойство Average и укажем в качестве функции расчета MAX — расчет максимального значения. С целью использования цены для визуализации изменения максимальной цены акции во времени.
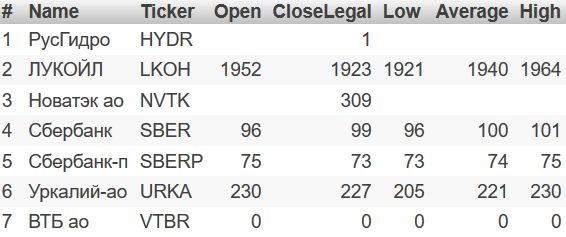
Списки — это элементы куба, описывающие способ доступа к исходным данным куба, позволяя перейти от агрегированных к исходным данным куба. Как правило при работе с кубом, аналитик просматривает агрегированную информацию в различных срезах. Однако, часто возникает необходимость посмотреть на исходные факты, которые вошли в текущий срез. Для этого и создаются листинги — они перечисляют набор полей таблицы фактов, который нужно отобразить при переходе к просмотру фактов Drillthrough. Создадим простой листинг нажав кнопку "Добавить элемент":
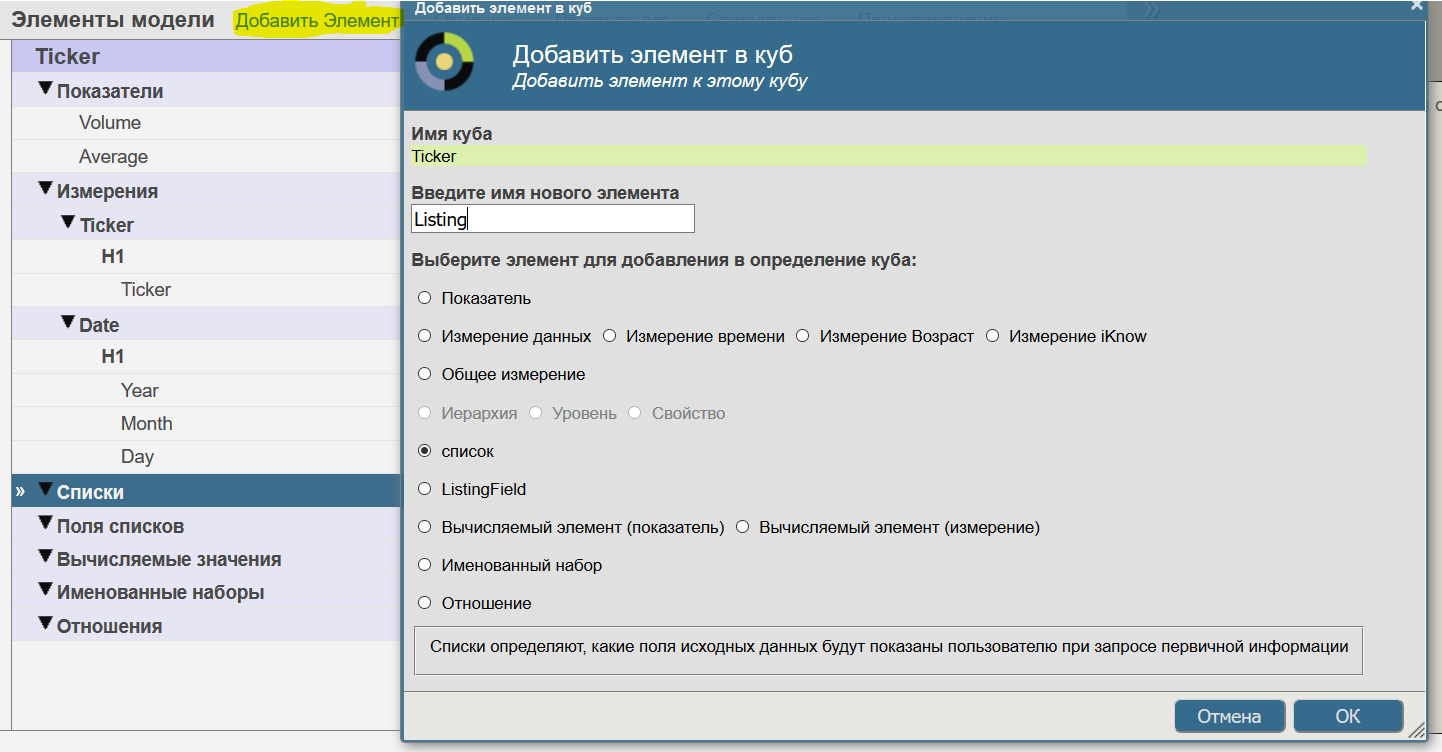
Теперь зададим поля таблицы фактов, которые надо выводить. Например выведем информацию о тикерах и колебаних их цены за день (Name, Ticker, "Open", CloseLegal, Low, Average, High):
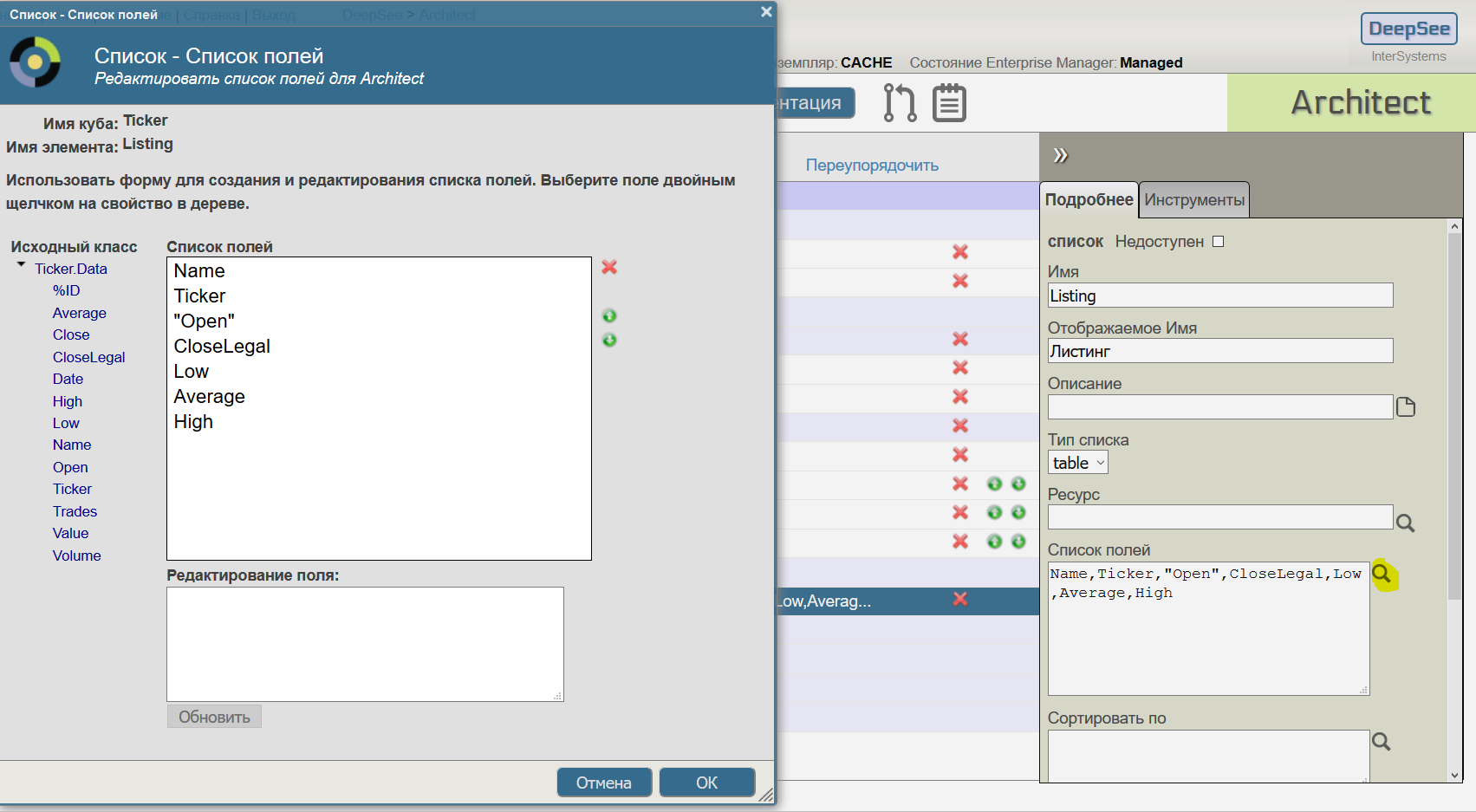
Итак мы добавили в куб два показателя, два измерения и один листинг — этого вполне достаточно и уже можно посмотреть, что получилось.
Скомпилируем класс куба (Кнопка "Компилировать"). Если ошибок компиляции нет, значит куб создан правильно и можно наполнить его данными.
Для этого нужно нажать "Построить куб" — в результате DeepSee загрузит данные из таблицы фактов в хранилище данных куба.
Для работы с данными куба нам пригодится другое веб-приложение — DeepSee Analyzer.
DeepSee Analyzer — визуальное средство для непосредственного анализа данных кубов и подготовки источников данных для дальнейшей визуализации. Для перехода к DeepSee Analyzer откроем Портал Управления Системой -> DeepSee -> Выбор области -> Analyzer. Открывается рабочее окно Аналайзера.
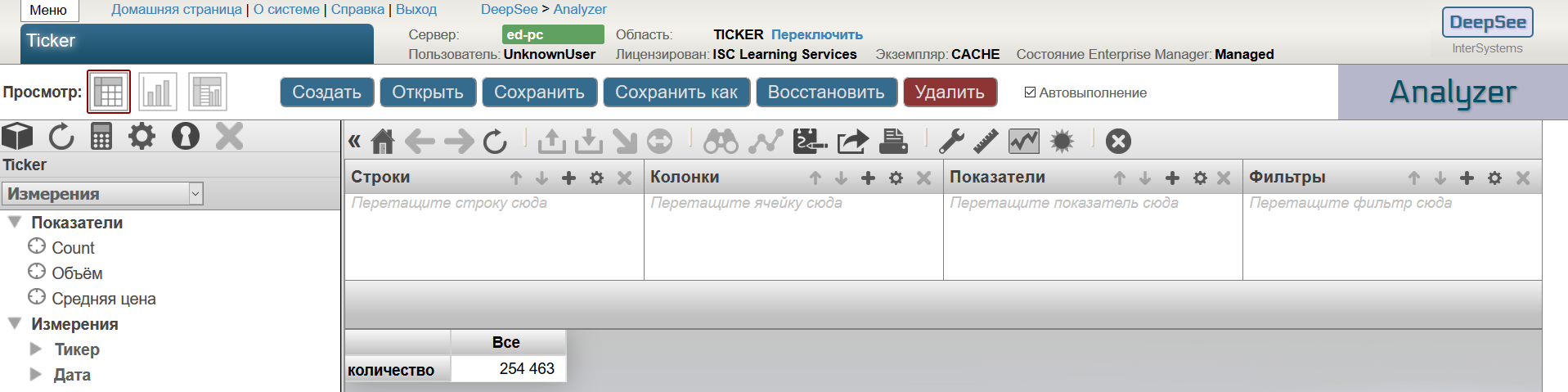
В рабочем окне Аналайзера слева мы видим элементы созданного куба: показатели и измерения. Комбинируя их мы строим запросы к кубу на языке MDX — аналоге языка SQL для многомерных OLAP кубов.
Рассмотрим интерфейс Аналайзера. Справа — поле сводной таблицы. В поле сводной таблицы Аналайзера всегда показывается результат выполнения MDX-запроса. Посмотреть текущий MDX-запрос можно если нажать кнопку  . При первом открытии куба в поле сводной таблицы по умолчанию показывается количество записей в таблице фактов — в нашем случае это количество записей в классе Ticker.Data. Этому соответствует MDX:
. При первом открытии куба в поле сводной таблицы по умолчанию показывается количество записей в таблице фактов — в нашем случае это количество записей в классе Ticker.Data. Этому соответствует MDX: SELECT FROM [TICKER].
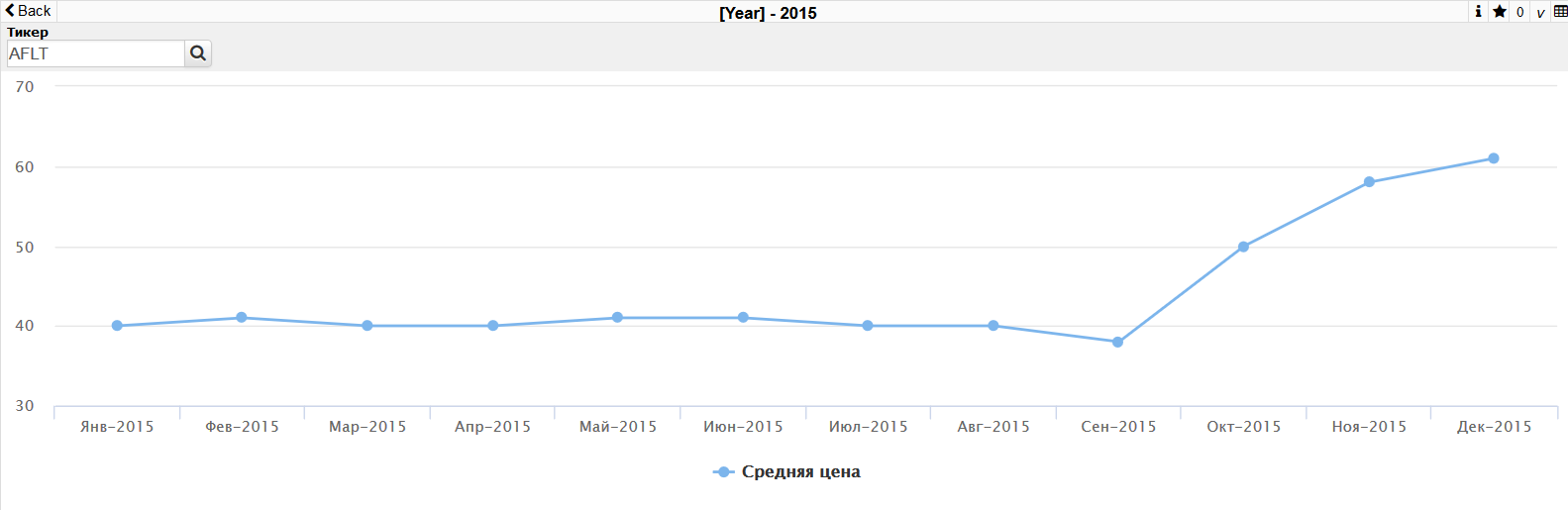
Чтобы создать сводную таблицу перетянем в поле колонок измерение “Год”. Показателем выберем "Объём". В результате получим таблицу количества проданных акций по годам.
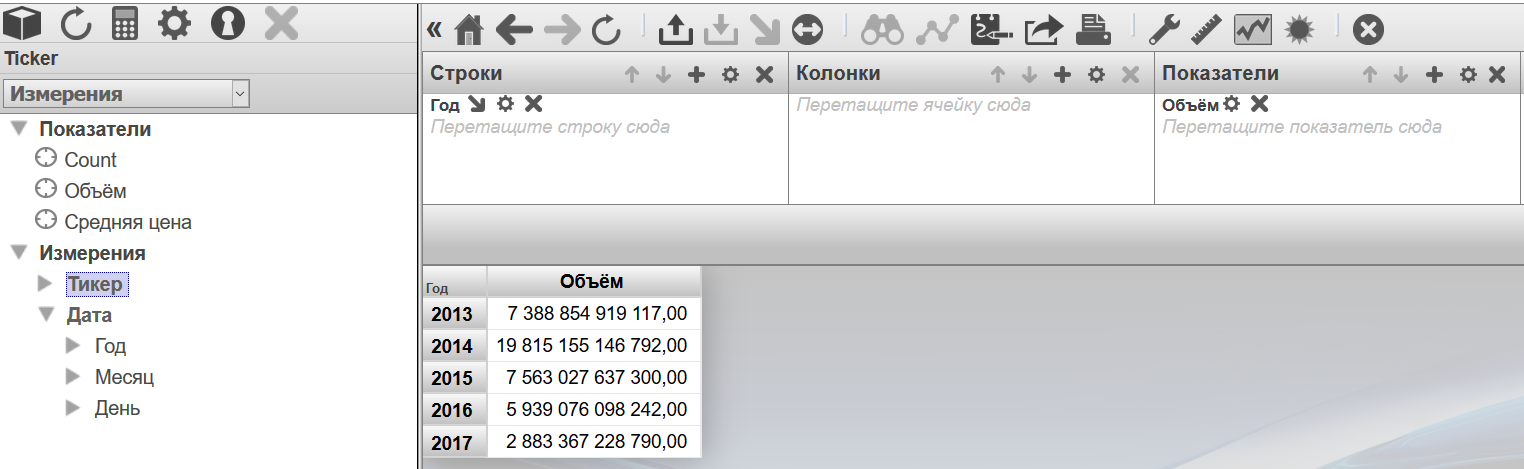
Далее перетянем измерение “Тикер” в поле колонок и получим уже сводную таблицу количества акций по инструментам, с разбиением по годам:
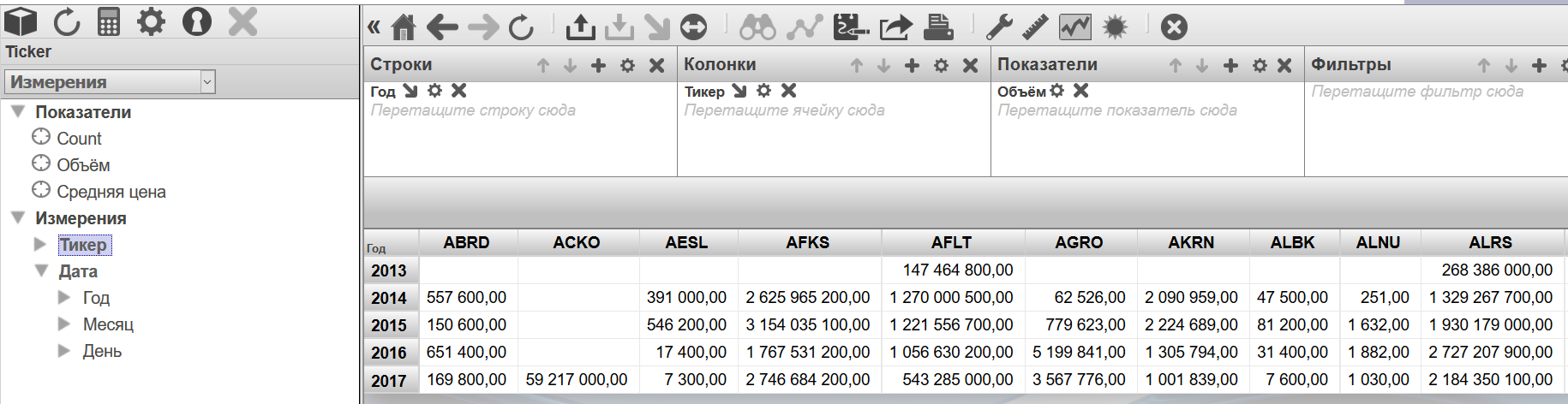
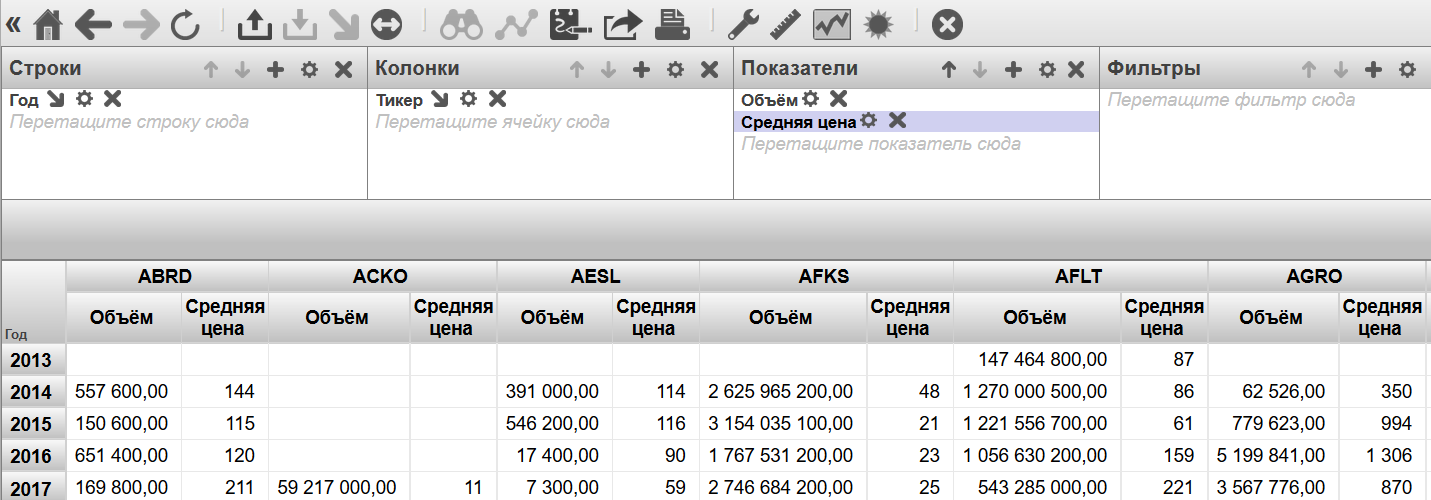
Сейчас для каждой ячейки полученной таблицы рассчитывается одна величина — суммарное количество акций участвовавших в сделках (в случае если не выбран ни один показатель, считается количество фактов — в данном случае это можно интерпретировать как количество дней торговли инструмента). Это можно изменить. Добавим показатель "Средняя цена". В результате можно видеть уже более интересную картину: сводная таблица отображает среднюю максимум цены по каждому инструменту за год.
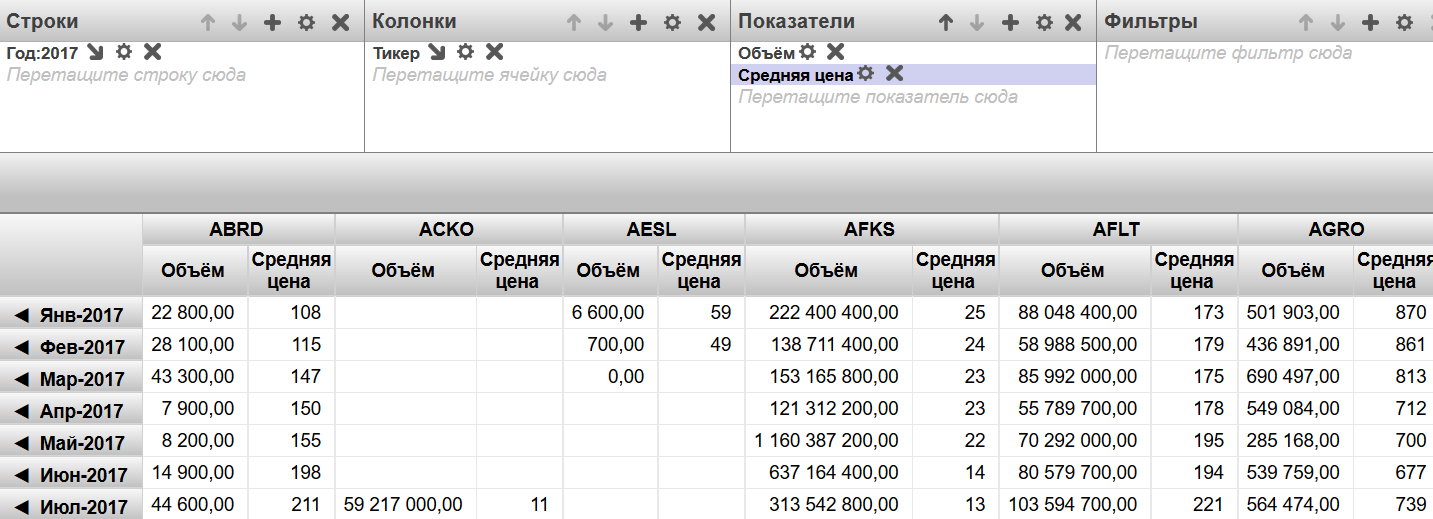
Как мы помним, в определении куба у нас заложена иерархия по датам. Это значит что по измерению Дата возможна операция DrillDown (переход по иерархии измерения от общего к частному). В Аналайзере двойной щелчок по заголовку измерения приводит переходу к следующему по иерархии измерению (DrillDown). В данном случае двойной клик по году приведет к переходу к месяцам этого года, а двойной клик на месяце — к переходу на уровень дней. В итоге можно посмотреть как менялась средняя цена акции для дней или месяцев.
На предыдущем этапе мы создали листинг — инструмент перехода от агрегированных данных к исходным фактам. Выберем любую строку сводной таблицы и нажмём кнопку  для перехода к листингу:
для перехода к листингу:
Следующий этап — визуализация. Перед сохранением упростим сводную таблицу и сохраним её под именем TickersByYears.
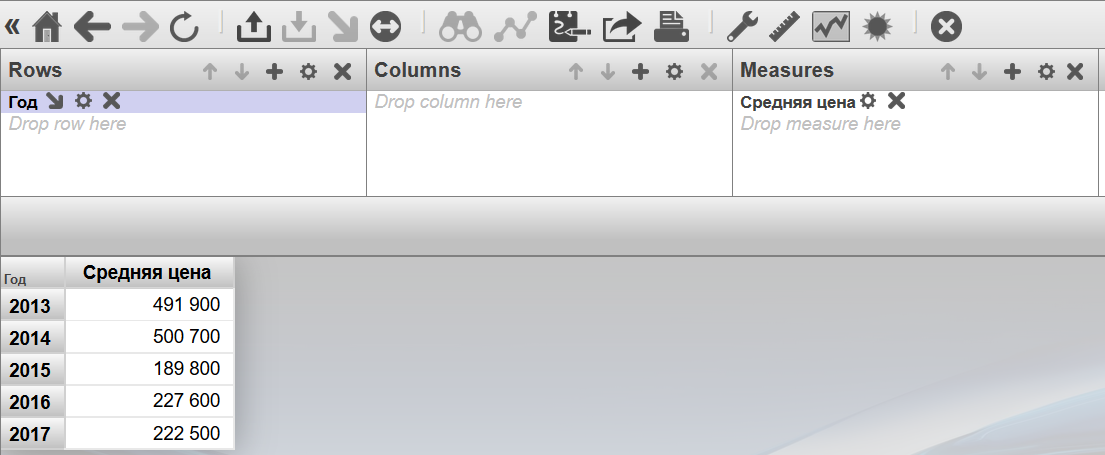
Портал Пользователя — это веб-приложение для создания и использования дашбордов (панелей индикаторов). Дашборды содержат виждеты: таблицы, графики и карты на основе сводных таблиц, созданных аналитиками в Аналайзере.
Для перехода к Порталу Пользователя DeepSee откроем Портал Управления Системой -> DeepSee -> Выбор области -> Портал Пользователя.
Создадим новый дашборд нажав на стрелку справа -> добавить -> Добавить индикаторную панель
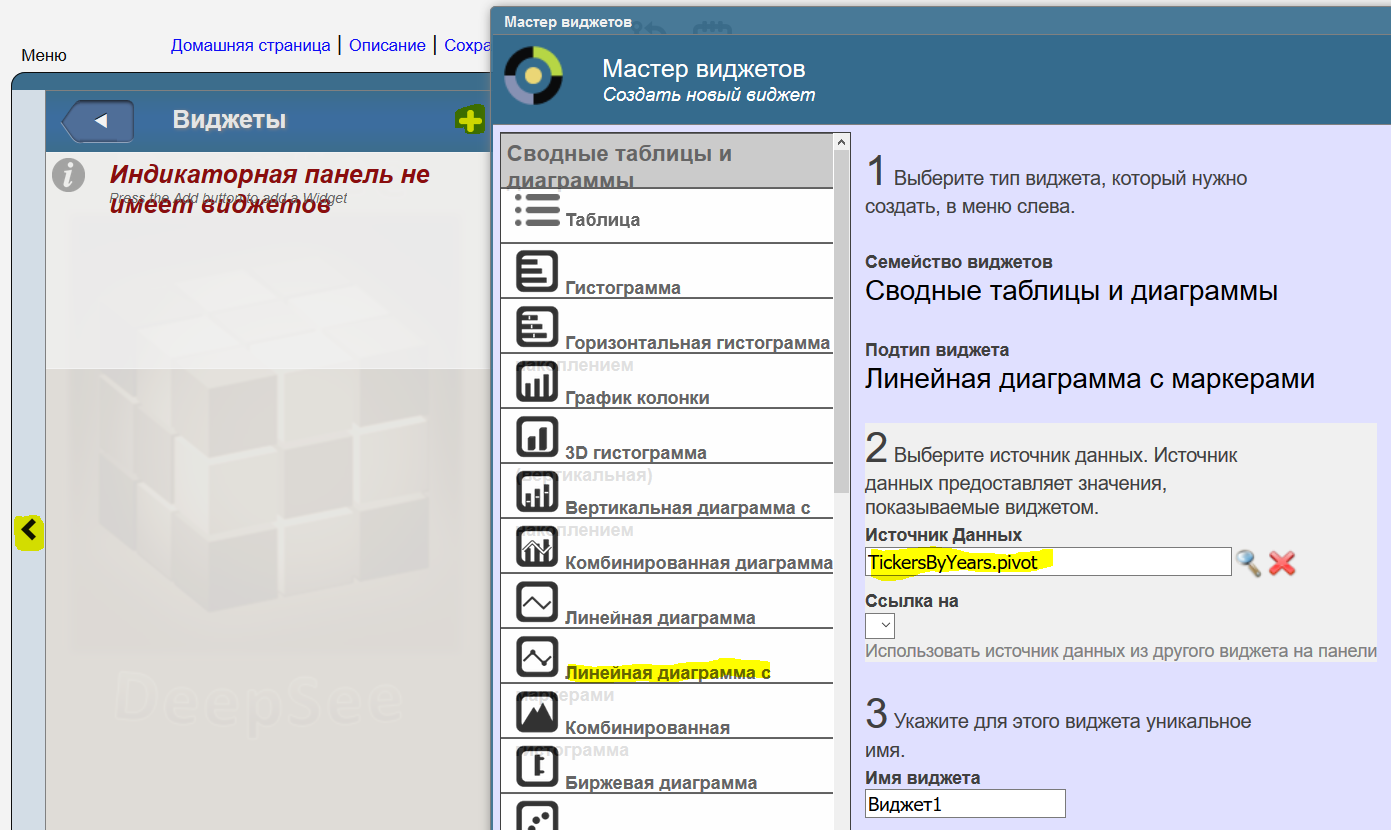
Создадим виджет нажав на стрелку справа -> Виджеты -> "+" -> Линейная диаграмма с маркерами. В качестве источника данных выберем TickersByYears:
Однако читатель возразит — это же средняя температура по больнице. И будет прав. Добавим фильтрацию по инструменту. Для этого нажмём стрелку справа -> Виджеты -> Виджет 1 -> Элементы управления -> "+". Форма создания нового фильтра выглядит следующим образом:
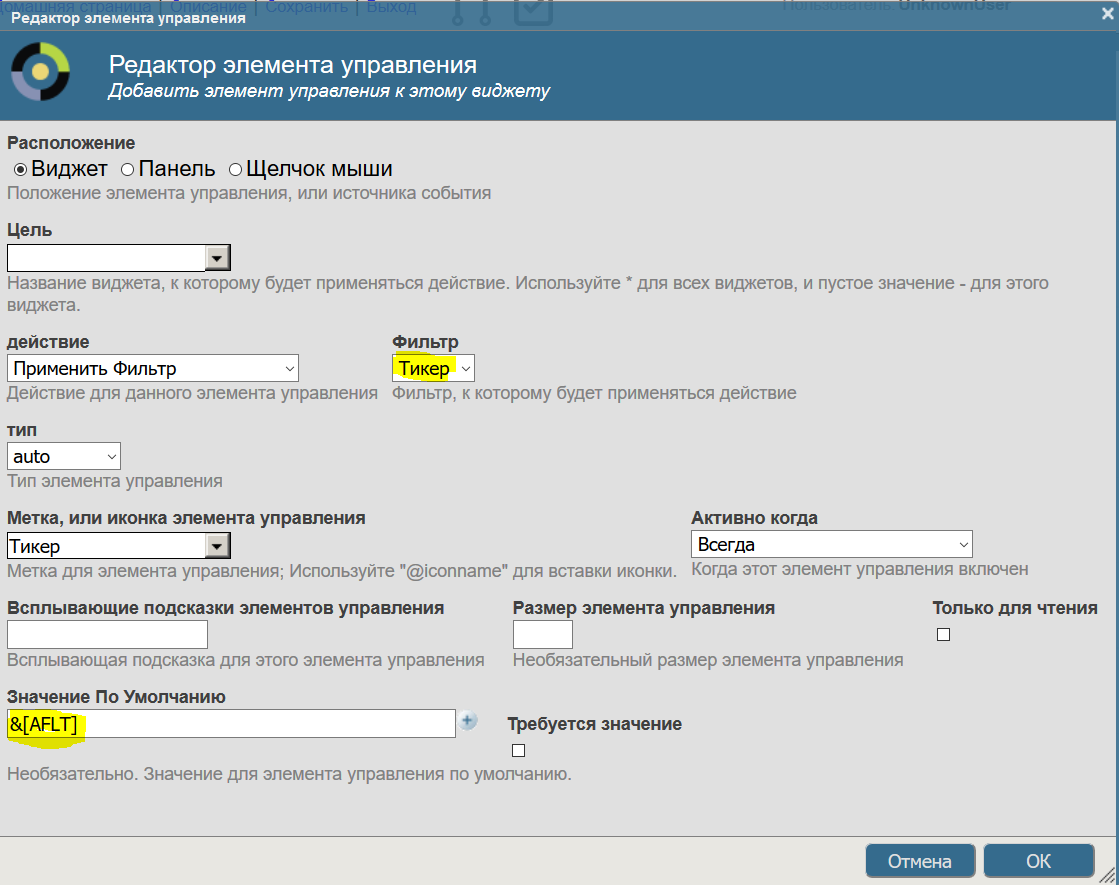
А вот так выглядит наш виджет с фильтром. Пользователь может изменить значение фильтра на любое другое.
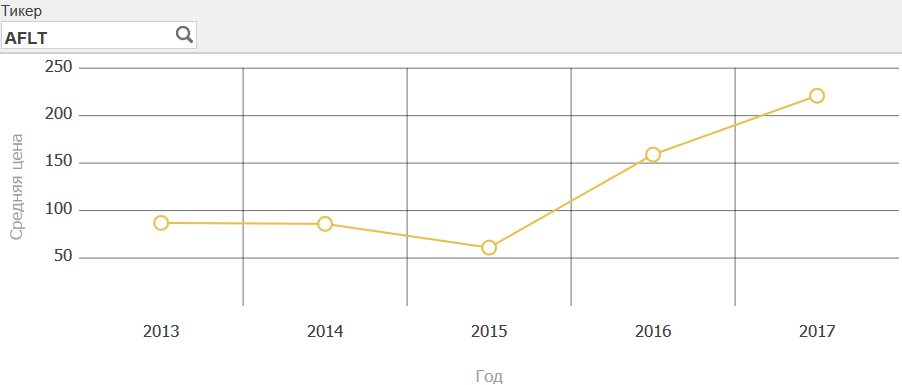
После этого сохраним дашборд.
Для визуализации созданного дашборда можно использовать следующие OpenSource решения:
Для установки MDX2JSON надо:
Do $System.OBJ.Load(file).Do ##class(MDX2JSON.Installer).setup()Для проверки установки надо открыть в браузере страницу http://server:port/MDX2JSON/Test?Debug. Возможно потребуется ввести логин и пароль (в зависимости от настроек безопасности сервера). Должна открыться страница с информацией о сервере. В случае получения ошибки, можно почитать на Readme и Wiki.
Для установки DeepSeeWeb надо:
Do $System.OBJ.Load(file).Do ##class(DSW.Installer).setup()Для проверки установки надо открыть в браузере страницу http://server:port/dsw/index.html. Должна открыться станица авторизации. В области SAMPLES представлено множество уже готовых дашбордов и все они автоматически отображаются в DeepSeeWeb.
Откроем http://server:port/dsw/index.html и авторизируемся, также нужно указать область с кубом. Откроется список дашбордов, в нашем случае есть только один созданный дашборд "Акции". Откроем его:
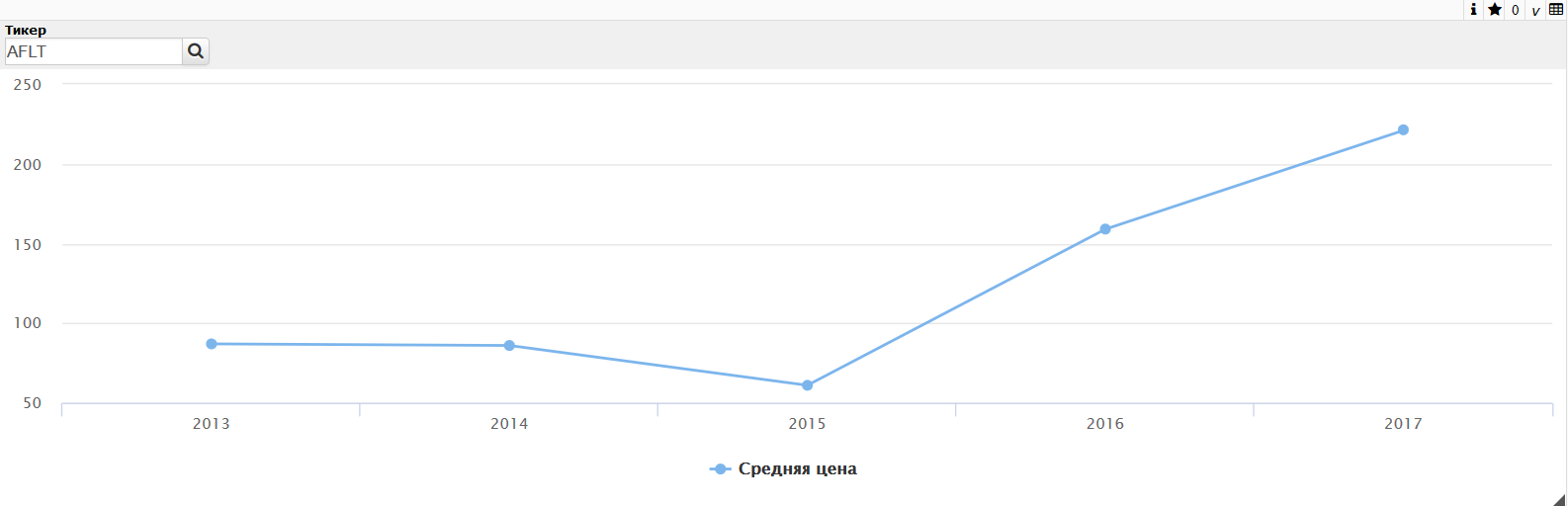
Отображается наш созданный виджет. Для него поддерживается Drilldown и фильтр созданный в Портале Пользователя DeepSee:
InterSystems DeepSee является мощным инструментом создания OLAP-решений, предоставляя разработчикам средства для создания и внедрения в свои приложения аналитической OLAP-функциональности, которая способна работать на оперативных базах данных приложений без создания отдельной инфраструктуры для решения аналитических задач. В следующий части я расскажу про различные варианты визуализации данных.
|
Метки: author eduard93 визуализация данных блог компании intersystems intersystems intersystems cache deepsee биржа котировки |
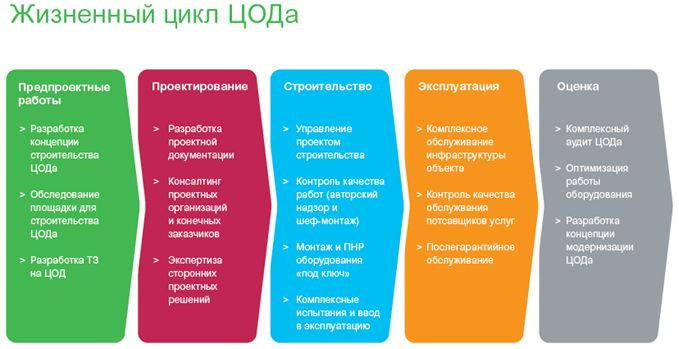
ЦОД: этапы большой жизни |



|
Метки: author Andrey_SE блог компании schneider electric цод инфраструктура дата-центр ит-инфраструктура дата-центры |
[Перевод] Kubernetes на голом железе за 10 минут |

Kubernetes — это предназначенный для контейнерной оркестровки фреймворк с открытым исходным кодом. Он был создан с учетом богатейшего опыта Google в области создания сред управления контейнерами и позволяет выполнять контейнеризованные приложения в готовом к промышленной эксплуатации кластере. В механизме Kubernetes много движущихся частей и способов их настройки — это различные системные компоненты, драйверы сетевого транспорта, утилиты командной строки, не говоря уже о приложениях и рабочих нагрузках.
По ходу этой статьи мы установим Kubernetes 1.6 на реальную (не виртуальную) машину под управлением Ubuntu 16.04 примерно за 10 минут. В результате у вас появится возможность начать изучать взаимодействие с Kubernetes посредством его CLI kubectl.Обзор Kubernetes:
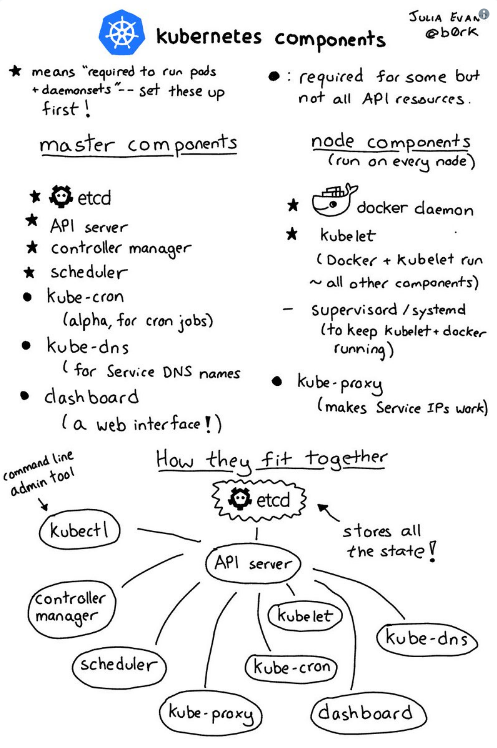
Компоненты Kubernetes, автор Julia Evans
Для развертывания кластера я предлагаю использовать физическую машину от сервиса Packet. Вы также можете проделать описанные мною шаги в виртуальной машине или на домашнем компьютере, если на них в качестве операционной системы установлена Ubuntu 16.04.
Зайдите на Packet.net и создайте новый проект. Для целей этой статьи нам хватит хоста Type 0 (4 ядра Atom и 8GB RAM за 0,05$/час).
При настройке хоста не забудьте выбрать в качестве ОС Ubuntu 16.04. В отличие от Docker Swarm Kubernetes лучше работает с проверенными временем релизами Docker. К счастью, репозиторий Ubuntu apt содержит Docker 1.12.6.
$ apt-get update && apt-get install -qy docker.ioНе обновляйте Docker на этом хосте. Использовать более свежие версии для сборки образов можно в инструментарии CI или на ноутбуке.
$ apt-get update && apt-get install -y apt-transport-https
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
OK
$ cat </etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF Теперь обновите список пакетов командой apt-get update.
kubelet, kubeadm и kubernetes-cni.kubelet отвечает за выполнение контейнеров на хостах кластера. kubeadm является удобной утилитой для настройки различных компонентов, составляющих кластер, а kubernetes-cni нужен для работы с сетевыми компонентами.
CNI расшифровывается как Container Networking Interface и представляет из себя спецификацию, определяющую взаимодействие сетевых драйверов с Kubernetes.
$ apt-get update
$ apt-get install -y kubelet kubeadm kubernetes-cnikubeadm.Из документации:
kubeadm предназначен для создания сразу «из коробки» безопасного кластера с помощью таких механизмов, как RBAC.
В Docker Swarm по умолчанию есть драйвер оверлейной сети, но с kubeadm решение остается за нами. Команда все еще работает над обновлением инструкций, поэтому я покажу, как использовать драйвер, наиболее похожий на докеровский, — flannel от CoreOS.
Flannel
Flannel позволяет организовать программно определяемую сеть (Software Defined Network, SDN), используя для этого модули ядра Linux overlay и ipvlan.
В Packet машина подключается к двум сетям: первая — это сеть дата-центра, которая соединяет хосты, входящие в определенный регион и проект, а вторая — это выход в Интернет. Брандмауэр по умолчанию не настроен, поэтому при желании ограничить сетевую активность придется настроить iptables или ufw вручную.
Внутренний IP-адрес можно выяснить с помощью ifconfig:
root@kubeadm:~# ifconfig bond0:0
bond0:0 Link encap:Ethernet HWaddr 0c:c4:7a:e5:48:d4
inet addr:10.80.75.9 Bcast:255.255.255.255 Mask:255.255.255.254
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1Воспользуемся этим внутренним IP-адресом для трансляции Kubernetes API.
$ kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=10.80.75.9 --skip-preflight-checks --kubernetes-version stable-1.6--pod-network-cidr необходим драйверу flannel и определяет адресное пространство для контейнеров.--apiserver-advertise-address определяет IP-адрес, который Kubernetes будет афишировать в качестве своего API-сервера.--skip-preflight-checks позволяет kubeadm не проверять ядро хоста на наличие требуемых функций. Это нужно из-за отсутствия метаданных ядра на хостах Packet.--kubernetes-version stable-1.6 жестко определяет версию кластера (в данном случае 1.6); при желании использовать, например, Kubernetes 1.7 пропустите этот флаг.Вот что мы должны получить на выходе:
[init] Using Kubernetes version: v1.6.6
[init] Using Authorization mode: RBAC
[preflight] Skipping pre-flight checks
[certificates] Generated CA certificate and key.
[certificates] Generated API server certificate and key.
[certificates] API Server serving cert is signed for DNS names [kubeadm kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.80.75.9]
[certificates] Generated API server kubelet client certificate and key.
[certificates] Generated service account token signing key and public key.
[certificates] Generated front-proxy CA certificate and key.
[certificates] Generated front-proxy client certificate and key.
[certificates] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/scheduler.conf"
[kubeconfig] Wrote KubeConfig file to disk: "/etc/kubernetes/admin.conf"
[apiclient] Created API client, waiting for the control plane to become ready
[apiclient] All control plane components are healthy after 36.795038 seconds
[apiclient] Waiting for at least one node to register
[apiclient] First node has registered after 3.508700 seconds
[token] Using token: 02d204.3998037a42ac8108
[apiconfig] Created RBAC rules
[addons] Created essential addon: kube-proxy
[addons] Created essential addon: kube-dns
Your Kubernetes master has initialized successfully!
To start using your cluster, you need to run (as a regular user):
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
http://kubernetes.io/docs/admin/addons/
You can now join any number of machines by running the following on each node
as root:
kubeadm join --token 02d204.3998037a42ac8108 10.80.75.9:6443В установке Ubuntu от Packet нет обычного пользователя, поэтому давайте создадим его.
# useradd packet -G sudo -m -s /bin/bash
# passwd packetТеперь, используя приведенное выше сообщение о создании кластера, можно настроить переменные окружения.
Войдите под учетной записью нового пользователя: sudo su packet.
$ cd $HOME
$ sudo whoami
$ sudo cp /etc/kubernetes/admin.conf $HOME/
$ sudo chown $(id -u):$(id -g) $HOME/admin.conf
$ export KUBECONFIG=$HOME/admin.conf
$ echo "export KUBECONFIG=$HOME/admin.conf" | tee -a ~/.bashrcТеперь с помощью kubectl и двух записей из документации flannel мы применим к кластеру конфигурацию сети:
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel-rbac.yml
clusterrole "flannel" created
clusterrolebinding "flannel" created
$ kubectl create -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
serviceaccount "flannel" created
configmap "kube-flannel-cfg" created
daemonset "kube-flannel-ds" created Сеть для подов сконфигурирована.
Обычно в кластер Kubernetes входит несколько хостов, поэтому по умолчанию контейнеры не могут быть запущены на мастере. Но поскольку у нас только одна нода, разрешим на ней запуск контейнеров с помощью операции taint.
$ kubectl taint nodes --all node-role.kubernetes.io/master-В качестве альтернативы можно было бы добавить в кластер вторую машину, используяjoin tokenиз выводаkubeadm.
Многие компоненты Kubernetes выполняются в виде контейнеров кластера в скрытом пространстве имен kube-system. Вывести информацию о них можно следующим образом:
$ kubectl get all --namespace=kube-system
NAME READY STATUS RESTARTS AGE
po/etcd-kubeadm 1/1 Running 0 12m
po/kube-apiserver-kubeadm 1/1 Running 0 12m
po/kube-controller-manager-kubeadm 1/1 Running 0 13m
po/kube-dns-692378583-kqvdd 3/3 Running 0 13m
po/kube-flannel-ds-w9xvp 2/2 Running 0 1m
po/kube-proxy-4vgwp 1/1 Running 0 13m
po/kube-scheduler-kubeadm 1/1 Running 0 13m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kube-dns 10.96.0.10 53/UDP,53/TCP 14m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kube-dns 1 1 1 1 14m
NAME DESIRED CURRENT READY AGE
rs/kube-dns-692378583 1 1 1 13m Как видно из листинга, все сервисы находятся в состоянии Running, значит, с кластером все в порядке. Если эти компоненты находятся в состоянии загрузки из Интернет, они могут быть еще не запущены.
Теперь в кластере можно запустить контейнер. В Kubernetes контейнеры организованы в поды (Pods), которые используют общий IP-адрес, привязаны к одной и той же ноде (хосту) и могут использовать общие тома.
Проверьте, что сейчас у вас нет запущенных подов (контейнеров):
$ kubectl get podsТеперь с помощью kubectl run запустите контейнер. Мы развернем Node.js- и Express.js-микросервис, генерирующий идентификаторы GUID по HTTP.
Этот код был изначально написан для руководства по Docker Swarm. Соответствующие исходники можно найти по этой ссылке: Scale a real microservice with Docker 1.12 Swarm Mode
$ kubectl run guids --image=alexellis2/guid-service:latest --port 9000
deployment "guids" created Теперь в колонке Name можно увидеть, какое имя было назначено новому поду и когда он был запущен:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
guids-2617315942-lzwdh 0/1 Pending 0 11s Используйте Name для проверки состояния пода:
$ kubectl describe pod guids-2617315942-lzwdh
...
Pulling pulling image "alexellis2/guid-service:latest"
...Раз у нас есть работающей контейнер, можно взять его IP-адрес и получать сгенерированные идентификаторы с помощью curl:
$ kubectl describe pod guids-2617315942-lzwdh | grep IP:
IP: 10.244.0.3
$ curl http://10.244.0.3:9000/guid ; echo
{"guid":"4659819e-cf00-4b45-99d1a9f81bdcf6ae","container":"guids-2617315942-lzwdh"}
$ curl http://10.244.0.3:9000/guid ; echo
{"guid":"1604b4cb-88d2-49e2-bd38-73b589da0469","container":"guids-2617315942-lzwdh"}Для просмотра логов пода можно использовать следующую команду:
$ kubectl logs guids-2617315942-lzwdh
listening on port 9000 Очень полезной функцией для отладки контейнеров является возможность подключаться к их консоли и выполнять там различные команды:
$ kubectl exec -t -i guids-2617315942-lzwdh sh
/ # head -n3 /etc/os-release
NAME="Alpine Linux"
ID=alpine
VERSION_ID=3.5.2
/ # exitПанель инструментов Kubernetes также устанавливается в качестве пода, к которому мы потом сможем обратиться на локальной машине. Поскольку мы не открывали Kubernetes выход в Интернет, для доступа к панели инструментов воспользуемся SSH-туннелем.
$ kubectl create -f https://git.io/kube-dashboard
$ kubectl proxy
Starting to serve on 127.0.0.1:8001 Теперь создадим туннель на хост Packet и откроем в веб-браузере страницу http://localhost:8001/ui/.
$ ssh -L 8001:127.0.0.1:8001 -N
Более подробную информацию можно получить здесь: Dashboard check it out on Github.
Вы создали кластер Kubernetes и запустили свой первый микросервис. Теперь вы можете начать изучать компоненты кластера, используя в работе интерфейс командной строки kubectl.
Руководство Kubernetes by Example, созданное Michael Hausenblas, показалось мне детальным и доступным.
Состоящий из одной ноды кластер у нас теперь есть, можно начинать добавлять еще ноды Type 0, используя join token, полученный от kubeadm.
Docker Swarm — это встроенный в Docker CE и EE инструмент оркестровки. Кластер Docker Swarm может быть поднят одной командой. Более подробную информацию можно почерпнуть из моих уроков по Docker Swarm.
Благодарности:
Спасибо @mhausenblas, @_errm и @kubernetesonarm за обратную связь и советы по настройке кластера Kubernetes.
Ссылки:
|
Метки: author olemskoi системное администрирование серверное администрирование devops блог компании southbridge docker kubernetes k8s orchestration |
Возвращение в строй маршрутизатора Cisco с нерабочей CF или mini-flash картой |



rommon 1 > Значит маршрутизатор не смог найти или загрузить прошивку. К этому мы оказались не готовы и полезли искать подходящую, а вот копия конфигурации маршрутизатора нашлась.IP_ADDRESS=192.168.1.200
IP_SUBNET_MASK=255.255.255.0
DEFAULT_GATEWAY=192.168.1.1
TFTP_SERVER=192.168.1.2
TFTP_FILE=c870-advipservicesk9-mz.124-24.T8.bin
tftpdnld -r (ключ -r важен в том случае, если карта памяти не работает Router#copy tftp: running-config|
Метки: author yaanyk cisco карта памяти прошивка |
Система управления складом с использованием CQRS и Event Sourcing. Service Layer |
|
|
Тестируем новый механизм синхронизации настроек JetBrains IDEs |


|
Метки: author andreycheptsov блог компании jetbrains intellij idea intellij phpstorm rubymine clion appcode rider |
[Из песочницы] Стоимость недвижимости на тепловых картах |
В статье рассказано о процессе создания тепловой карты цен по продаже недвижимости для Москвы и Санкт-Петербурга.
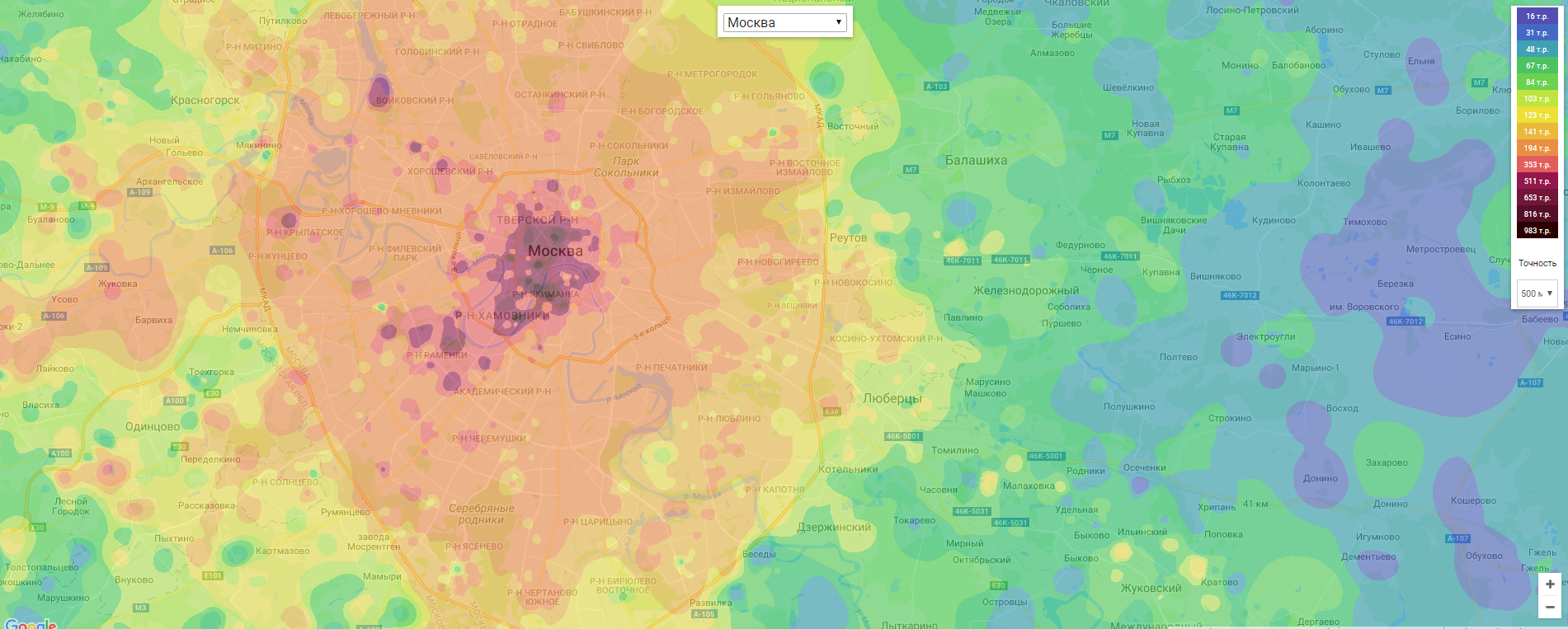
Меня зовут Дмитрий, я программист из Санкт-Петербурга и у меня есть хобби — это портал по недвижимости которым я занимаюсь в свободное от работы время вот уже почти 5 лет. Сайт авторский, и это дает достаточный уровень свободы для экспериментирования и реализации любых идей на нем. И одной из давних идей было создание тепловой карты цен.
Если лень читать статью, то потрогать готовый результат можно здесь.
При обилии сайтов посвященных недвижимости, в рунете нет нормальной карты цен. Есть какие-то не очень внятные карты где районы покрашены в разный цвет, но это все не то. Средняя цена по району мало о чем говорит, есть районы в которых цены различаются на порядок, а то и больше. Идея сделать тепловую карту посещала меня давно, но предвидя сложности браться за это не хотелось — не хватало вдохновения что-ли.
Как водится, я случайно наткнулся на статью про статистику цен на недвижимость Саратова. Автор описывает именно то что хотел сделать я: карту какой я ее себе представлял. Собственно это меня и вдохновило.
В статье есть ссылка на исходники, но я не понимаю в Пайтоне (или в питоне), и цели изучать новый язык у меня не было, так что решил искать если не готовый компонент, то хотя бы что-то что я смогу самостоятельно переписать под .Net.
В качестве первого компонента для генерации изображения я попробовал то что предлагает Гугл.
Это оказалось совсем не то что нужно. Тут скорее карты интенсивности — они бы подошли для визуализации плотности объектов на карте, но не для отображения цен. Кроме того, при масштабировании карты точки сливаются становясь более интенсивными — это уж совсем никуда не годится.

Есть один белорусский сайт где с помощью данного способа реализована карта цен. Можно посмотреть здесь.

Глядя на эту карту кто может сказать, где дороже, а где дешевле? Я не могу. В общем такое… три из десяти.
Поиски продолжились, и я нагуглил в итоге на стэке вот что: человек задает именно тот вопрос который интересовал меня, а именно, как сделать тепловую карту а не карту интенсивности. И в ответах есть ссылка на JS-библиотеку которая делает то что надо. Для расчетов используется Inverse Distance Weighting. JS — это конечно не шарп, но уже ближе, так что я был очень рад. Особенно после того как “пощупал” все это на jsfiddle и убедился в годности результата. Через несколько часов у меня уже был работающий код на C# (который впоследствии был сильно доработан). Вот ссылка на Гитхаб, если кому надо.
За время работы портала у меня накопилось более 20 миллионов объектов по всей России (архивные объекты сохраняются навсегда).
Как обработать сырые данные — вопрос не очевидный. Для начала фильтры: объекты по продаже, новостройки и вторичка, причем только квартиры и дома, потому что по ним можно точно рассчитать стоимость квадратного метра, а я собирался именно стоимость метра показывать на карте, как наиболее объективный показатель. Я не люблю аренду, потому что там много мусора. Цены сильно искажены, множество фиктивных объявлений, и т.д. В продаже тоже это все есть, но в меньших масштабах. Кроме того, цены на аренду напрямую зависят от стоимости продажи квартир, так что итоговая карта вполне подходит для визуализации общей картины, если не привязываться к значениям в легенде.
Всякую коммерцию, участки и паркинги пришлось исключить, но по каждой из этих категорий тоже было бы интересно посмотреть результат, но это как-нибудь потом. Плюс ко всему, наверное не имеет смысла включать туда старые объекты, цены-то меняются. Было решено что за полгода и объем будет нормальный и цены актуальны. Получилось примерно 40 000 объектов для Москвы и 30 000 для Питера.
Я так и не смог определиться с оптимальным шагом для компоновки объектов в исходную точку на карте. Пробовал разные варианты от 100 метров до 5 км. Решил оставить на усмотрение пользователей три наиболее интересных варианта: 250, 500 и 1000 метров.
Точки генерируются следующим образом: область рекурсивно делится на 4 прямоугольные секции до тех пор пока размер секции не будет совпадать или чуть-чуть превышать минимальный, либо до тех пор пока в области не останется объектов меньше чем минимально-допустимое количество (например 3). Для секций в которых меньше трех объектов итоговая точка не создается — они искажают общую картину и создают излишнюю “дырявость”, так как часто такие одинокие объекты отличаются по цене от окружающих.

Внутри каждой получившейся секции считается средняя цена по объектам и устанавливается итоговая точка. Координаты устанавливаются не на центр секции а высчитывается среднее значение по координатам всех объектов.
Для каждого из шагов (250, 500, 1000) генерируется свой набор точек. Для каждой точки запоминается список использованных объектов для отображения по клику на карте.
Координаты точек в БД хранятся в виде географических данных, поэтому прежде чем передать их в работу, координаты надо привести к мировым, а потом к пиксельным на итоговом битмапе. Что такое мировые координаты можно почитать здесь. Если в двух словах, то географические координаты подразумевают размещение на сфере, и чтобы их отобразить на плоскости их нужно сконвертировать определенным образом. Вот отсюда я взял код для получения мировых и пиксельных коордиат.
Я решил что ограничу зум на карте от 8 до 14, потому как учитывая минимальный шаг сетки со значениями в 250 метров, ближе нет смысла рассматривать.
Я поначалу думал что лучше сделать один большой битмап, а потом разбить его на маленькие фрагменты. Но, в итоге, сделал наоборот — генерируются маленькие фрагменты — тайлы (tile), после чего компонуются для каждого из зумов.
Теперь чтобы отобразить все на карте надо привязать их к соответствующим координатам. Первое что я нашел в поиске — Ground Overlays.
После нескольких часов работы я получил вполне себе наглядный результат, но с одной проблемой — жуткие тормоза при навигации по карте. Очевидно работа с большим количеством фрагментов — это не то для чего нужен данный механизм.
Стал гуглить дальше и нашел Tile Overlays — это оказалось в итоге то что нужно. Суть такова: для каждого из уровней приближения карты (zoom index) итоговое изображение компонуется из плиток 256 на 256 пикселей, для каждой из которых можно наложить поверх свое изображение. При навигации по карте подгружаются только те тайлы которые попадают в видимую область и соответствуют значению zoom index.
Сами координаты границ регионов у меня всегда были, так что это немного облегчило работу. При генерации каждого из тайлов проверяется не нужно ли его обрезать, и если нужно — то обрезаю, делая непопадающую область прозрачной.
Увидев результат я подумал что пользователей мало интересуют официальные границы, и, возможно им было бы полезнее видеть и близлежащие области тоже. Пришлось нарисовать свои границы для карт захватывающие как непосредственно города (Москву и Питер) так и ближайшие области. Количество объектов выросло в несколько раз. Теперь их стало около 140 и 50 тысяч для Москвы и СПб соответственно.
Москва:

Санкт-Петербург:

Для рисования границ и получения их координат я использовал чей-то готовый код в codepen.io с небольшими изменениями. Вот ссылка для Москвы и Питера. После изменения какой-нибудь из точек на карте в окошко снизу вставляется список географических координат в виде удобном для вставки в БД.
Позже обнаружилась такая проблема: бывают ситуации когда области с разными ценовыми категориями расположены настолько близко что попадают в один сегмент и для них считается средняя цена. Например в Питере есть Каменный и Крестовский острова, где продается только элитная недвижимость, а через реку шириной в 300 метров — обычный район с хрущевками. Разница в цене — более чем на порядок (98 т.р. против 1200 т.р.).
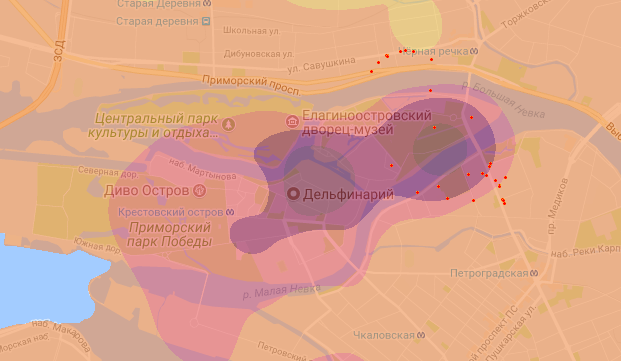
На рисунке Каменный остров, и красными точками обозначены объекты с двух сторон от него попавшими в итоговую секцию при шаге в 1000 метров. Это сильно влияет на среднюю цену в позиции и искажает общую картину.
Решение было такое: выделить некоторые секции и при компоновке объектов, попавшие в секцию объекты не должны смешиваться с объектами непопавшими, либо попавшими в другую секцию. Для Питера я выделил также острова.
Точность тут не важна. Главное — чтобы не было пересечений между областями.
Я сделал настраиваемым процесс генерации тепловой карты так чтобы можно было выбирать цвета, настраивать количество уровней, и т.д.
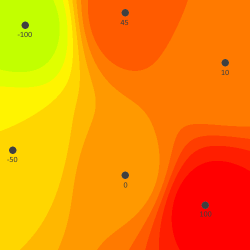
Например для области в 500 на 500 пикселей с установленными 6 точками со значениями от -100 до 100 можно получить такие варианты.
Тестовые точки со значениями:

Те же данные на карте с уровнями:
Без ограничения по цветам и с разбивкой по уровням:

С ограничением по цветами и без уровней:
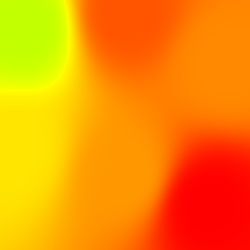
С заданными вручную цветами:

После долгих и мучительных экспериментов предпочтение было отдано собственному набору цветов (позаимствовал здесь) которые захардкодил в класс как дефолтный набор.
Результат при шаге в 500 метров выглядит так:
Чтобы сгенерировать карту только для Москвы при параллельных 6 потоках (на восьмиядерном сервере 3,2 GHz) требовалось более суток. Это совсем неприемлемо, потому что в перспективе регионов будет больше и запуск должен происходить по расписанию, как минимум раз в неделю.
Узкое место в алгоритме — высчитывание цвета для каждого пикселя в тайле. Нужно отсортировать все точки по расстоянию от данного пикселя. То есть массив из 6000 точек приходилось сортировать 256х256 раз. Бессмысленная трата ресурсов. Очевидно, что все точки не нужны, и можно ограничиться ближайшими. Самое простое решение взять, например топ 100 точек отсортированных по расстоянию от центра тайла. Но тут может быть ситуация когда ближайшие 100 точек находятся в группе, например с одной только стороны. Т.е. нужны не просто 100 ближайших, а так чтобы они еще и были расположены вокруг. Вот что я сделал: из середины тайла во все стороны с шагом в 10 градусов распространяются лучи каждый длиной в треть всей карты. Каждый луч растет до тех пор пока в нем не будет как минимум 5 точек, либо он не достигнет предела по длине. Таким образом, гарантированно в итоговом списке будет примерно 150 точек со всех сторон.
Выглядит это так (зеленые точки — которые попали в выборку, красные — все остальные. Красный квадратик в середине — это непосредственно тайл):

Красиво, интересно и залипательно, но абсолютно бесполезно. Велосипед, в классическом его проявлении. Я потратил целый выходной день экспериментируя с параметрами: количеством лучей, их длиной, количеством точек в каждом луче, и т.д. И всегда я получал ошибки на карте.
Выглядят они так:

Это угловатости на областях границы которых должны быть всегда округлыми. Ошибки эти появляются всегда в местах с низкой концентрацией данных.
В итоге, весь этот механизм пришлось выкинуть. Лучше всего работает самый простой и очевидный способ — 100 ближайших точек без учета тех которые в самом тайле. Хоть ошибки и остались на карте, но они в местах которые, я надеюсь, мало интересны людям, ибо там почти ничего не продается.
Скорость работы выросла в разы. На Москву уходит около 3 часов, из них около часа только на обработку данных, остальное непосредственно на рисование.
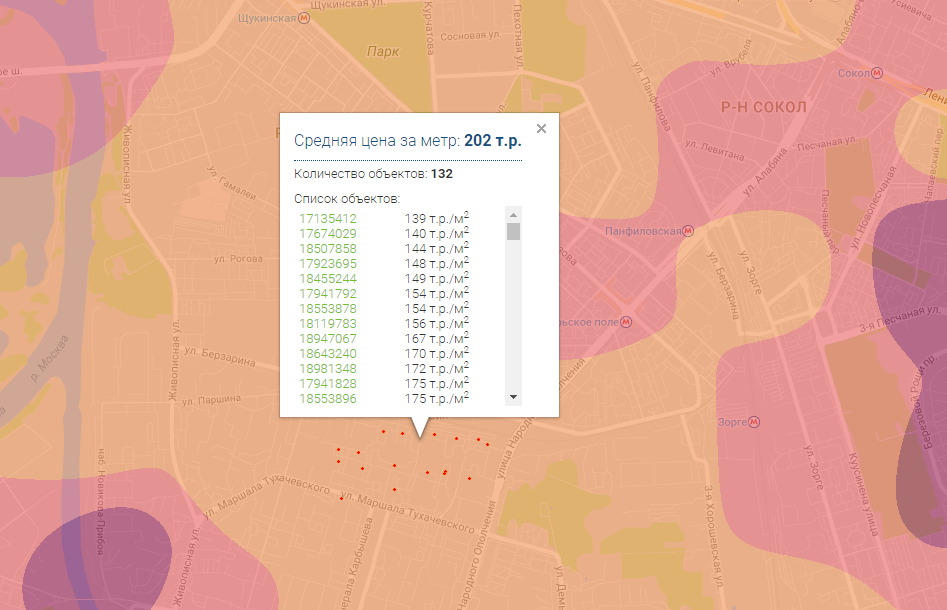
При клике по карте выбирается ближайшая к месту клика точка, и для нее отображается сводная информация: средняя цена за метр и список объектов использованных для расчета. Также, красными точками на карте отображены координаты этих объектов. По ссылке можно зайти в карточку каждого для более подробной информации. Многие объекты являются архивными, так что для них могут не отображаться фотографии и контакты продавца, а в остальном — вся информация соответствует изначальной.
В ближайшее время я планирую увеличить количество объектов на карте, потому что большая часть их в БД не имеет географических координат. Для этого надо сделать модуль геолокации который будет ежедневно проходить по таким объектам получая для них координаты по адресу через сервисы Гугл или Яндекс.
Также я планирую дополнить карту некоторой статистической информацией в виде табличных данных. Разбивка по ценовым категориям, средние цены и т.д.
На всякий случай дублирую ссылки здесь в том же порядке в каком они указаны в статье.
https://habrahabr.ru/post/324596/
https://developers.google.com/maps/documentation/javascript/examples/layer-heatmap
https://resta.by/karta-cen
https://stackoverflow.com/questions/30073977/create-custom-temperature-map-with-front-end-javascript
https://github.com/optimisme/javascript-temperatureMap
https://en.wikipedia.org/wiki/Inverse_distance_weighting
https://jsfiddle.net/mertk/y9gcuf65/
https://github.com/d-sky/HeatMap
https://developers.google.com/maps/documentation/javascript/maptypes?hl=ru#MapCoordinates
https://developers.google.com/maps/documentation/javascript/examples/map-coordinates
https://developers.google.com/maps/documentation/javascript/examples/groundoverlay-simple
https://developers.google.com/maps/documentation/android-api/tileoverlay
https://codepen.io/d-sky/pen/JJqpYe
https://codepen.io/d-sky/pen/PKJzoO
https://www.ventusky.com/?p=9;71;1&l=temperature
https://квартиры-домики.рф/карта-цен
При навигации по карте сейчас примерно раз в 10-15 секунд происходит небольшое зависание, это не у меня на сайте баг, так ведет себя новый Вебвизор Метрики. В Яндекс я уже написал — они сказали что им нужно время чтобы разобраться. Так что, в скором времени, надеюсь починят.
|
Метки: author d-sky геоинформационные сервисы .net тепловые карты недвижимость недвижимость и цены цены карта цен |
[Из песочницы] Размещение иконок на странице сайта. Делать проще, поддерживать легче |
Все должно быть изложено так просто, как только возможно, но не проще.А. Эйнштейн
menu
.bl_button__wrapp{
width: 100%;
margin: 5% auto;
font-size: 30px;
line-height: 34px;
color: blue
}
.bl_button{
position: relative;
width: 150px;
padding: 10px;
margin: 0 auto;
text-align: center;
border: 1px solid #00f;
cursor:pointer;
}
.fa-bars{
position: absolute;
left: 10px;
font-size: 34px;
}
.bl_button__text{
display: inline-block;
}

See the Pen bad button by Andry Zirka (@BlackStar1991) on CodePen.
Это стандартная форма описания кнопки. Я сам долгое время примерно так писал свой код. Данное написание особо практикуется теми, кто использует готовые иконочные шрифты на подобии FontAwesome
Небольшие трудности возникают если текст должен быть по центру, а иконка несколько смещена относительно текста. Но всё это прекрасно решаемо через свойство position:absolute; задаваемое иконке. Также бывают проблемы с позиционированием данной иконки при адаптивности кнопки, но это другая история.
Теперь я хотел бы описать свой метод оформления иконок в тексте страници (на примере всё того же FontAwesome).
HTML
.button_menu{
width: 280px;
margin-top: 5%;
margin-left: 4%;
font-size: 4em;
color: blue;
border: 1px solid #00f;
outline:none; /* Убираем если вас это смущает по дизайну*/
background:none; /* Убираем если вас это смущает по дизайну*/
}
.button_menu__text{
position:relative;
width: 100%;
display: inline-block;
text-align: center;
margin: 0 auto;
padding: 10px;
}
.button_icon__menu:before{
content: "\f0c9";
font-family: FontAwesome;
position: absolute;
left: 0px;
top: 14px;
}
See the Pen good button by Andry Zirka (@BlackStar1991) on CodePen.
button довольно часто приходится сбрасывать или переопределять стили, иначе выглядит не очень. outline:none;
background:none;
border:none; 
|
Метки: author BlackStar1991 разработка веб-сайтов клиентская оптимизация html css css3 html5 icons refactoring |
Emercoin снизит комиссии на транзакции в 100 раз |

|
Метки: author EShumilov блог компании emercoin блокчейн блокчейн технологии эмеркоин |
Ой, у меня задержка |
|
Метки: author erlyvideo блог компании эрливидео video streaming low latency |
[recovery mode] Вызов управляемого кода из неуправляемого |
 С задачей вызова неуправляемого кода из управляемого мы сталкиваемся довольно часто, и эта задача имеет простое решение в виде одного атрибута [DllImport] и небольшого набора дополнительных правил, которые хорошо изложены в MSDN. Обратная же задача встречается гораздо реже. В данной статье мы и рассмотрим небольшой пример, как это можно сделать. Его не стоит рассматривать как исчерпывающий, скорее лишь, как направление хода мыслей и концепцию. Итак, начнем.
С задачей вызова неуправляемого кода из управляемого мы сталкиваемся довольно часто, и эта задача имеет простое решение в виде одного атрибута [DllImport] и небольшого набора дополнительных правил, которые хорошо изложены в MSDN. Обратная же задача встречается гораздо реже. В данной статье мы и рассмотрим небольшой пример, как это можно сделать. Его не стоит рассматривать как исчерпывающий, скорее лишь, как направление хода мыслей и концепцию. Итак, начнем. 
public class Service
{
public void Add(Int32 a, Int32 b)
{
Console.WriteLine("Hello from Managed Code!");
Console.WriteLine(String.Format("Result: {0}", a + b));
}
}// Директивы препроцессора нужны, чтобы компилятор сгенерировал записи
// об экспорте класса из библиотеки
#ifdef INSIDE_MANAGED_CODE
# define DECLSPECIFIER __declspec(dllexport)
# define EXPIMP_TEMPLATE
#else
# define DECLSPECIFIER __declspec(dllimport)
# define EXPIMP_TEMPLATE extern
#endif
namespace MixedLibrary
{
class DECLSPECIFIER CppService
{
public:
CppService();
virtual ~CppService();
public:
void Add(int a, int b);
private:
void * m_impl;
};
}
#include "CppService.h"
using namespace System;
using namespace System::Runtime::InteropServices;
using namespace SimpleLibrary;
namespace MixedLibrary
{
CppService::CppService()
{
Service^ service = gcnew Service();
m_impl = GCHandle::ToIntPtr(GCHandle::Alloc(service)).ToPointer();
}
CppService::~CppService()
{
GCHandle handle = GCHandle::FromIntPtr(IntPtr(m_impl));
handle.Free();
}
void CppService::Add(int a, int b)
{
GCHandle handle = GCHandle::FromIntPtr(IntPtr(m_impl));
Service^ service = safe_cast(handle.Target);
service->Add(a, b);
}
}

#include "stdafx.h"
#pragma comment(lib, "../Debug/MixedLibrary.lib")
#include
#include "../MixedLibrary/CppService.h"
using namespace std;
using namespace MixedLibrary;
int main()
{
CppService* service = new CppService();
service->Add(5, 6);
cout << "press any key..." << endl;
getchar();
}

|
Метки: author ICLServices системное программирование разработка под windows c++ c# блог компании icl services cli неуправляемый код msdn программирование |
[Из песочницы] World Machine + UE4: Полный рабочий процесс |















|
Метки: author Darell_Ldark разработка игр перевод с английского перевод ue4 unreal engine 4 world machine туториал урок |
В разрезе: новостной агрегатор на Android с бэкендом. Система контроля конфигураций (Puppet) |
class apache (String $version = 'latest') {
package {'httpd':
ensure => $version, # Using the class parameter from above
before => File['/etc/httpd.conf'],
}
file {'/etc/httpd.conf':
ensure => file,
owner => 'httpd',
content => template('apache/httpd.conf.erb'), # Template from a module
}
service {'httpd':
ensure => running,
enable => true,
subscribe => File['/etc/httpd.conf'],
}
}
node 'www1.example.com', 'www2.example.com', 'www3.example.com' {
include common
include apache, squid
}
node /^(foo|bar)\.example\.com$/ {
include common
}#!/bin/sh
PUPPET_BIN='/opt/puppetlabs/bin/puppet'
# Ставим необходимые пакеты для старта
apt-get update && apt-get -y install git mc htop apt-transport-https nano wget lsb-release apt-utils curl python
# Первоначально осуществляем установку `puppet-agent`
if [ ! -d /etc/puppetlabs ]; then
rm *.deb.* *.deb # possible trash
wget https://apt.puppetlabs.com/puppetlabs-release-pc1-xenial.deb && dpkg -i puppetlabs-release-pc1-xenial.deb
apt-get update && apt-get -y install puppet-agent
fi
# Определяем тип `environment`
/opt/puppetlabs/bin/puppet config set environment $PUPPET_ENV
if [ ! -d /etc/puppetlabs/code/environments/$PUPPET_ENV ]; then
cp -r /etc/puppetlabs/code/environments/production /etc/puppetlabs/code/environments/$PUPPET_ENV
fi
# Install puppet modules
$PUPPET_BIN module install puppetlabs-ntp
$PUPPET_BIN module install aco-oracle_java
$PUPPET_BIN module install puppetlabs-firewall
$PUPPET_BIN module install saz-ssh
$PUPPET_BIN module install saz-sudo
$PUPPET_BIN module install saz-limits
$PUPPET_BIN module install thias-sysctl
$PUPPET_BIN module install yo61-logrotate
$PUPPET_BIN module install puppetlabs-apt
$PUPPET_BIN module install puppet-archive
# git pull "deployment" project and go in it only if POVISION_NO_GIT_CLONE set to "true"
if [ ${POVISION_NO_GIT_CLONE:-"false"} = "true" ];
then
echo "do nothing"
else
LOCAL_REV=""
if [ -f local_latest.sha1 ]; then
LOCAL_REV=`cat local_latest.sha1`
fi
REMOTE_REV=`git ls-remote --tags | grep "latest" | awk '{print $1}'`
if [ $LOCAL_REV = $REMOTE_REV ]; then
exit 0
fi
git fetch --all --tags --prune
git checkout -f tags/latest
fi
# replace puppet configs
cp puppet_config/hiera.yaml /etc/puppetlabs/code/environments/$PUPPET_ENV/
# replace hiera db
rm /etc/puppetlabs/code/environments/$PUPPET_ENV/hieradata/*
cp -r $PUPPET_ENV/hieradata/* /etc/puppetlabs/code/environments/$PUPPET_ENV/hieradata
# replace storyline_* modules
rm -r /etc/puppetlabs/code/environments/$PUPPET_ENV/modules/storyline_*
cp -r modules/* /etc/puppetlabs/code/environments/$PUPPET_ENV/modules
# copy site.pp
cp $PUPPET_ENV/site.pp /etc/puppetlabs/code/environments/$PUPPET_ENV/manifests/site.pp
#echo "hostname:"
#hostname
$PUPPET_BIN apply /etc/puppetlabs/code/environments/$PUPPET_ENV/manifests/site.pp
echo $REMOTE_REV > local_latest.sha1|
Метки: author fedor_malyshkin тестирование it-систем отладка java puppet scm |
[Перевод] Охота на вредоносные npm-пакеты |
|
Метки: author ru_vds node.js javascript блог компании ruvds.com npm безопасность |
Социальный Организм — как форма эффективного взаимодействия команды. Часть 2 |
Примешь синюю таблетку — и сказке конец.
Ты проснешься в своей постели и поверишь, что это был сон.
Примешь красную таблетку — войдешь в страну чудес.
Я покажу тебе, насколько глубока кроличья нора.
Морфеус (Фильм «Матрица»)
|
Метки: author ARadzishevskiy управление сообществом управление проектами управление персоналом развитие стартапа формирование команды команда стартапа формирование требований |
[Из песочницы] Отсутствие полноценной многоязычности в 1С-Битрикс — неумение или плохое управление проектом? |

|
|






