Боремся с вирусами и инфраструктурой, или отключение SMB v1 |

В связи с недавной эпидемией шифровальщика WannaCry, эксплуатирующим уязвимость SMB v1, в сети снова появились советы по отключению этого протокола. Более того, Microsoft настоятельно рекомендовала отключить первую версию SMB еще в сентябре 2016 года. Но такое отключение может привести к неожиданным последствиям, вплоть до курьезов: лично сталкивался с компанией, где после борьбы с SMB перестали играть беспроводные колонки Sonos.
Специально для минимизации вероятности «выстрела в ногу» я хочу напомнить об особенностях SMB и подробно рассмотреть, чем грозит непродуманное отключение его старых версий.
SMB (Server Message Block) – сетевой протокол для удаленного доступа к файлам и принтерам. Именно он используется при подключении ресурсов через \servername\sharename. Протокол изначально работал поверх NetBIOS, используя порты UDP 137, 138 и TCP 137, 139. С выходом Windows 2000 стал работать напрямую, используя порт TCP 445. SMB используется также для входа в домен Active Directory и работы в нем.
Помимо удаленного доступа к ресурсам протокол используется еще и для межпроцессорного взаимодействия через «именованные потоки» – named pipes. Обращение к процессу производится по пути \.\pipe\name.
Первая версия протокола, также известная как CIFS (Common Internet File System), была создана еще в 1980-х годах, а вот вторая версия появилась только с Windows Vista, в 2006. Третья версия протокола вышла с Windows 8. Параллельно с Microsoft протокол создавался и обновлялся в его открытой имплементации Samba.
В каждой новой версии протокола добавлялись разного рода улучшения, направленные на увеличение быстродействия, безопасности и поддержки новых функций. Но при этом оставалась поддержка старых протоколов для совместимости. Разумеется, в старых версиях было и есть достаточно уязвимостей, одной из которых и пользуется WannaCry.
| Версия | Операционная система | Добавлено, по сравнению с предыдущей версией |
| SMB 2.0 | Windows Vista/2008 | Изменилось количество команд протокола со 100+ до 19 |
| Возможность «конвейерной» работы – отправки дополнительных запросов до получения ответа на предыдущий | ||
| Поддержка символьных ссылок | ||
| Подпись сообщений HMAC SHA256 вместо MD5 | ||
| Увеличение кэша и блоков записи\чтения | ||
| SMB 2.1 | Windows 7/2008R2 | Улучшение производительности |
| Поддержка большего значения MTU | ||
| Поддержка службы BranchCache – механизм, кэширующий запросы в глобальную сеть в локальной сети | ||
| SMB 3.0 | Windows 8/2012 | Возможность построения прозрачного отказоустойчивого кластера с распределением нагрузки |
| Поддержка прямого доступа к памяти (RDMA) | ||
| Управление посредством командлетов Powershell | ||
| Поддержка VSS | ||
| Подпись AES–CMAC | ||
| Шифрование AES–CCM | ||
| Возможность использовать сетевые папки для хранения виртуальных машин HyperV | ||
| Возможность использовать сетевые папки для хранения баз Microsoft SQL | ||
| SMB 3.02 | Windows 8.1/2012R2 | Улучшения безопасности и быстродействия |
| Автоматическая балансировка в кластере | ||
| SMB 3.1.1 | Windows 10/2016 | Поддержка шифрования AES–GCM |
| Проверка целостности до аутентификации с использованием хеша SHA512 | ||
| Обязательные безопасные «переговоры» при работе с клиентами SMB 2.x и выше |
Посмотреть используемую в текущий момент версию протокола довольно просто, используем для этого командлет Get–SmbConnection:

Вывод командлета при открытых сетевых ресурсах на серверах с разной версией Windows.
Из вывода видно, что клиент, поддерживающий все версии протокола, использует для подключения максимально возможную версию из поддерживаемых сервером. Разумеется, если клиент поддерживает только старую версию протокола, а на сервере она будет отключена – соединение установлено не будет. Включить или выключить поддержку старых версий в современных системах Windows можно при помощи командлета Set–SmbServerConfiguration, а посмотреть состояние так:
Get–SmbServerConfiguration | Select EnableSMB1Protocol, EnableSMB2Protocol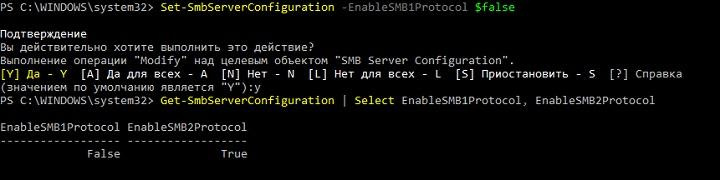
Выключаем SMBv1 на сервере с Windows 2012 R2.
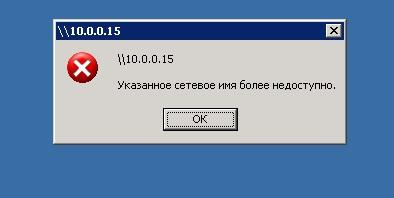
Результат при подключении с Windows 2003.
Таким образом, при отключении старого, уязвимого протокола можно лишиться работоспособности сети со старыми клиентами. При этом помимо Windows XP и 2003 SMB v1 используется и в ряде программных и аппаратных решений (например NAS на GNU\Linux, использующий старую версию samba).
| Производитель | Продукт | Комментарий |
| Barracuda | SSL VPN | |
| Web Security Gateway backups | ||
| Canon | Сканирование на сетевой ресурс | |
| Cisco | WSA/WSAv | |
| WAAS | Версии 5.0 и старше | |
| F5 | RDP client gateway | |
| Microsoft Exchange Proxy | ||
| Forcepoint (Raytheon) | «Некоторые продукты» | |
| HPE | ArcSight Legacy Unified Connector | Старые версии |
| IBM | NetServer | Версия V7R2 и старше |
| QRadar Vulnerability Manager | Версии 7.2.x и старше | |
| Lexmark | МФУ, сканирование на сетевой ресурс | Прошивки Firmware eSF 2.x и eSF 3.x |
| Linux Kernel | Клиент CIFS | С 2.5.42 до 3.5.x |
| McAfee | Web Gateway | |
| Microsoft | Windows | XP/2003 и старше |
| MYOB | Accountants | |
| NetApp | ONTAP | Версии до 9.1 |
| NetGear | ReadyNAS | |
| Oracle | Solaris | 11.3 и старше |
| Pulse Secure | PCS | 8.1R9/8.2R4 и старше |
| PPS | 5.1R9/5.3R4 и старше | |
| QNAP | Все устройства хранения | Прошивка старше 4.1 |
| RedHat | RHEL | Версии до 7.2 |
| Ricoh | МФУ, сканирование на сетевой ресурс | Кроме ряда моделей |
| RSA | Authentication Manager Server | |
| Samba | Samba | Старше 3.5 |
| Sonos | Беспроводные колонки | |
| Sophos | Sophos UTM | |
| Sophos XG firewall | ||
| Sophos Web Appliance | ||
| SUSE | SLES | 11 и старше |
| Synology | Diskstation Manager | Только управление |
| Thomson Reuters | CS Professional Suite | |
| Tintri | Tintri OS, Tintri Global Center | |
| VMware | Vcenter | |
| ESXi | Старше 6.0 | |
| Worldox | GX3 DMS | |
| Xerox | МФУ, сканирование на сетевой ресурс | Прошивки без ConnectKey Firmware |
Список взят с сайта Microsoft, где он регулярно пополняется.
Перечень продуктов, использующих старую версию протокола, достаточно велик – перед отключением SMB v1 обязательно нужно подумать о последствиях.
Если программ и устройств, использующих SMB v1 в сети нет, то, конечно, старый протокол лучше отключить. При этом если выключение на SMB сервере Windows 8/2012 производится при помощи командлета Powershell, то для Windows 7/2008 понадобится правка реестра. Это можно сделать тоже при помощи Powershell:
Set–ItemProperty –Path "HKLM:\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters" SMB1 –Type DWORD –Value 0 –Force
Или любым другим удобным способом. При этом для применения изменений понадобится перезагрузка.
Для отключения поддержки SMB v1 на клиенте достаточно остановить отвечающую за его работу службу и поправить зависимости службы lanmanworkstation. Это можно сделать следующими командами:
sc.exe config lanmanworkstation depend=bowser/mrxsmb20/nsi
sc.exe config mrxsmb10 start=disabled
Для удобства отключения протокола по всей сети удобно использовать групповые политики, в частности Group Policy Preferences. С помощью них можно удобно работать с реестром.

Создание элемента реестра через групповые политики.
Чтобы отключить протокол на сервере, достаточно создать следующий параметр:
путь: HKLM:\SYSTEM\CurrentControlSet\Services\LanmanServer\Parameters;
новый параметр: REG_DWORD c именем SMB1;
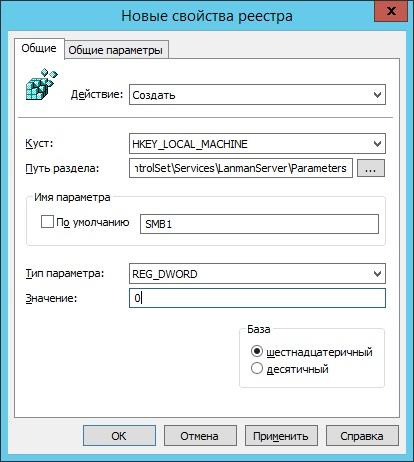
Создание параметра реестра для отключения SMB v1 на сервере через групповые политики.
Для отключения поддержки SMB v1 на клиентах понадобится изменить значение двух параметров.
Сначала отключим службу протокола SMB v1:
путь: HKLM:\SYSTEM\CurrentControlSet\services\mrxsmb10;
параметр: REG_DWORD c именем Start;

Обновляем один из параметров.
Потом поправим зависимость службы LanmanWorkstation, чтоб она не зависела от SMB v1:
путь: HKLM:\SYSTEM\CurrentControlSet\Services\LanmanWorkstation;
параметр: REG_MULTI_SZ с именем DependOnService;
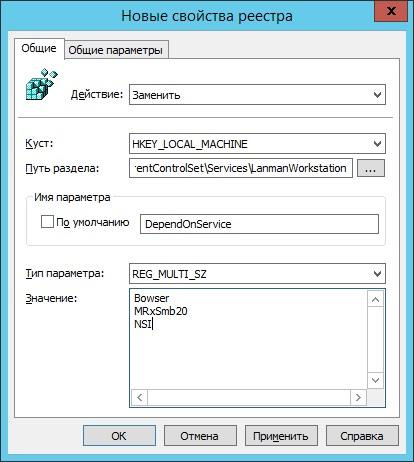
И заменяем другой.
После применения групповой политики необходимо перезагрузить компьютеры организации. После перезагрузки SMB v1 перестанет использоваться.
Как ни странно, эта старая заповедь не всегда полезна – в редко обновляемой инфраструктуре могут завестись шифровальщики и трояны. Тем не менее, неаккуратное отключение и обновление служб могут парализовать работу организации не хуже вирусов.
Расскажите, а вы уже отключили у себя SMB первой версии? Много было жертв?
|
Метки: author Tri-Edge системное администрирование серверное администрирование антивирусная защита it- инфраструктура блог компании сервер молл smb windows сетевые папки |
Размеры растровых изображений: пиксели, DPI, PPI, сантиметры — вы ничего не путаете? |

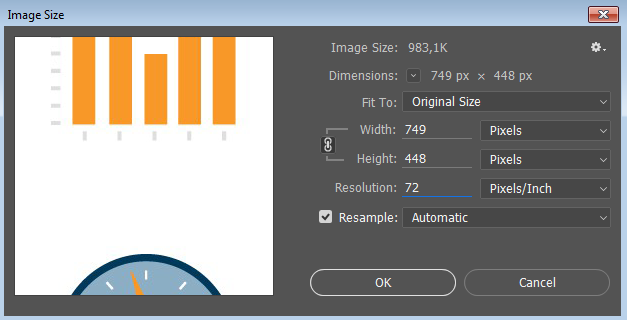
|
Метки: author Nickmob обработка изображений клиентская оптимизация css пиксели изображения оптимизация |
Усатый стрелок с полигональным пузом. Часть вторая |
Рассказ про разработку проекта похож на паутину: повсюду тянутся ниточки ассоциаций, истории про интересные идеи. А иногда нити повествования обвиваются коконом вокруг необычного бага. Вот и сейчас, материала накопилось столько, что приходится начинать работать над второй частью статьи до того, как первая опубликована.
А теперь, когда опубликована вторая часть, материала достаточно и для третьей части! :)
Сегодня в программе: смесь визуала и архитектуры проекта. Но сначала, ещё парочка деталей про тени.
Итак, поехали!
Как вы помните, тени уже генерируются на CPU с кучей оптимизаций. А вот их отрисовку нужно доработать. Пока я разбирался с генерацией, мне нужен был самый простой способ рендеринга, поэтому всё работает так:
Идея простая: вынести рендеринг теней в отдельный проход, добавив возможность отбрасывать тени любому количеству источников света (да-да, fps будет проседать).
Всего потребовалось несколько классов:
Код написан, шейдеры проверены, можно двигаться дальше. И тут начались проблемы.

Забагованные тени.
На изображении выше целых две проблемы.
Во-первых, тени слишком длинные и иногда неправильно перекрывают объекты. Такое может быть, если тени рендерятся поверх пустого z-buffer'а (другие объекты могут перекрывать тень, но сами тени в z-buffer ничего не пишут).
Во-вторых, тени в каком-то странном шуме. Такое бывает, если работать с неочищенным буфером.
Итак, проблема в том, что z-buffer, с которым я работаю, судя по всему, не использовался камерой. Рендеринг кадра сейчас работает так:
Когда работаешь с постэффектами зачастую нужно с помощью какого-то шейдера преобразовать текстуру. В Unity3D для этого есть метод Graphics.Blit. Мы передаём в него исходную текстуру, указываем target — куда отрисовывать, материал и даже проход шейдера.
По сути, мы работаем минимум с тремя различными буферами:
И в методе Graphics.Blit целевой color buffer и depth buffer неразделимы. Т.е., если нам нужно, например, читать глубину геометрии сцены из исходной текстуры, а записывать пиксели в целевую — облом.
Или если мы сделали рендеринг сцены в текстуру, при этом часть шейдеров записала данные в стенсил, а теперь хотим получить новую текстуру, воспользовавшись этими данными (и сохранив исходную текстуру!) — тоже облом.
Выход есть и в документации Unity3D об этом прямо сказано:
Note that if you want to use depth or stencil buffer that is part of the source (Render)texture, you'll have to do equivalent of Blit functionality manually — i.e. Graphics.SetRenderTarget with destination color buffer and source depth buffer, setup orthographic projection (GL.LoadOrtho), setup material pass (Material.SetPass) and draw a quad (GL.Begin).
В общем, модифицированная версия Blit, позволяющая разделить передачу буферов:
static void Blit(RenderBuffer colorBuffer, RenderBuffer depthBuffer, Material material) {
Graphics.SetRenderTarget(colorBuffer, depthBuffer);
GL.PushMatrix();
GL.LoadOrtho();
for (int i = 0, passCount = material.passCount; i < passCount; ++i) {
material.SetPass(i);
GL.Begin(GL.QUADS);
GL.TexCoord(new Vector3(0, 0, 0));
GL.Vertex3(0, 0, 0);
GL.TexCoord(new Vector3(0, 1, 0));
GL.Vertex3(0, 1, 0);
GL.TexCoord(new Vector3(1, 1, 0));
GL.Vertex3(1, 1, 0);
GL.TexCoord(new Vector3(1, 0, 0));
GL.Vertex3(1, 0, 0);
GL.End();
}
GL.PopMatrix();
Graphics.SetRenderTarget(null);
}Использование в коде:
void RenderShadowEffect(RenderTexture source, RenderTexture target, LightSource light) {
shadowEffect.SetColor("_ShadowColor", light.ShadowColor);
shadowEffect.SetColor("_LightColor", light.LightColor);
shadowEffect.SetTexture("_WorldTexture", source);
shadowEffect.SetTexture("_ShadowedTexture", target);
Blit(target.colorBuffer, source.depthBuffer, shadowEffect);
}Итак, в чем же дело? Почему моя RenderTexture, в которую я рендерю камеру на выходе совершенно пуста (и даже не очищена от мусора)?
Выключаю тени и смотрю, что показывает frame debug:


Странные рендер-текстуры.
Любопытно. Судя по всему, постэффект антиалиасинга принудительно переводит камеру на рендеринг в свою текстуру. При этом доступа до этой текстуры у меня нет: при дебаге в Camera.аctiveTexture пустая.
Ах, так, антиалиасинг! Лезешь в мою последовательность отрисовки? Тогда я залезу в твой код!
Постэффекты работают через метод MonoBehaviour.OnRenderImage, а я через MonoBehaviour.OnRenderImage и
MonoBehaviour.OnPostRender. Делаю грязный хак: переименовываю OnRenderImage в Apply и вызываю его руками, после рендеринга теней, с моими renderTexture. Теперь антиалиасинг не мешает теням.
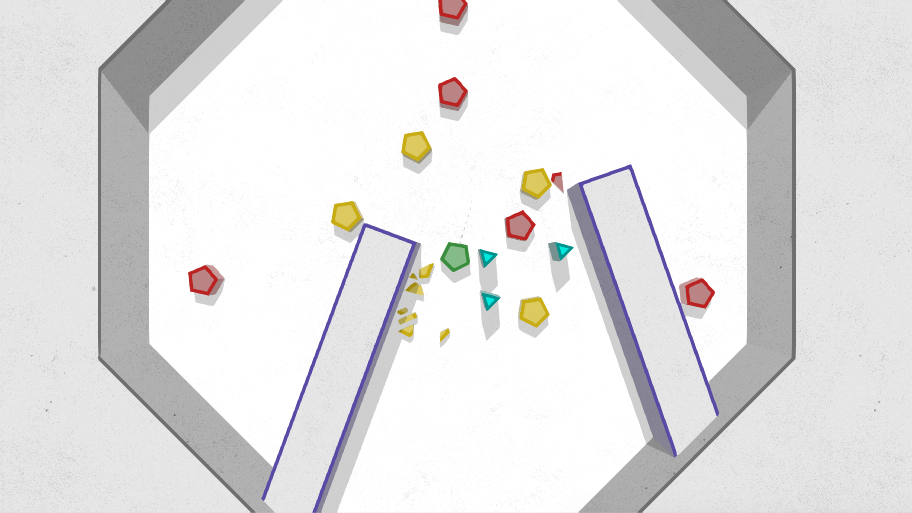
Новые тени позволяют делать смешные, но не очень нужные штуки вроде хроматической aберрации или гладких теней.

Сотня обычных бледных теней с небольшим смещением.
Три цветных тени.
Пока тени притормаживают на мобилках (съедают примерно 10 — 15 лишних fps). Если все будет грустно, переведу под конец все в однопроходную отрисовку, а пока не буду налегать на источники света.
Хинт: импровизируйте в отладке графики! Отлаживать вертексные шейдеры бывает больно, поэтому визуализируйте все данные, которые сможете: вытягивайте вертексы вдоль нормалей, добавляйте цвет и прозрачность и т.д.
Дебажная визуализация через шейдеры и гизмо.
Оказалось, что добавлять новые классы стало тяжелее из-за некоторых неудачных проектных решений.
Todo: почистить архитектуру и код проекта.
Как вы помните, я развиваю проект с прототипа. Но тянуть все прототипную архитектуру (знаете, какая архитектура в прототипах, написанных за 2 часа?) не хочется, значит, нужен рефакторинг.
Итак:
Для начала выношу как можно больше данных из MonoBehaviour в ScriptableObject. Это всяческие стили, настройки, библиотека префабов;
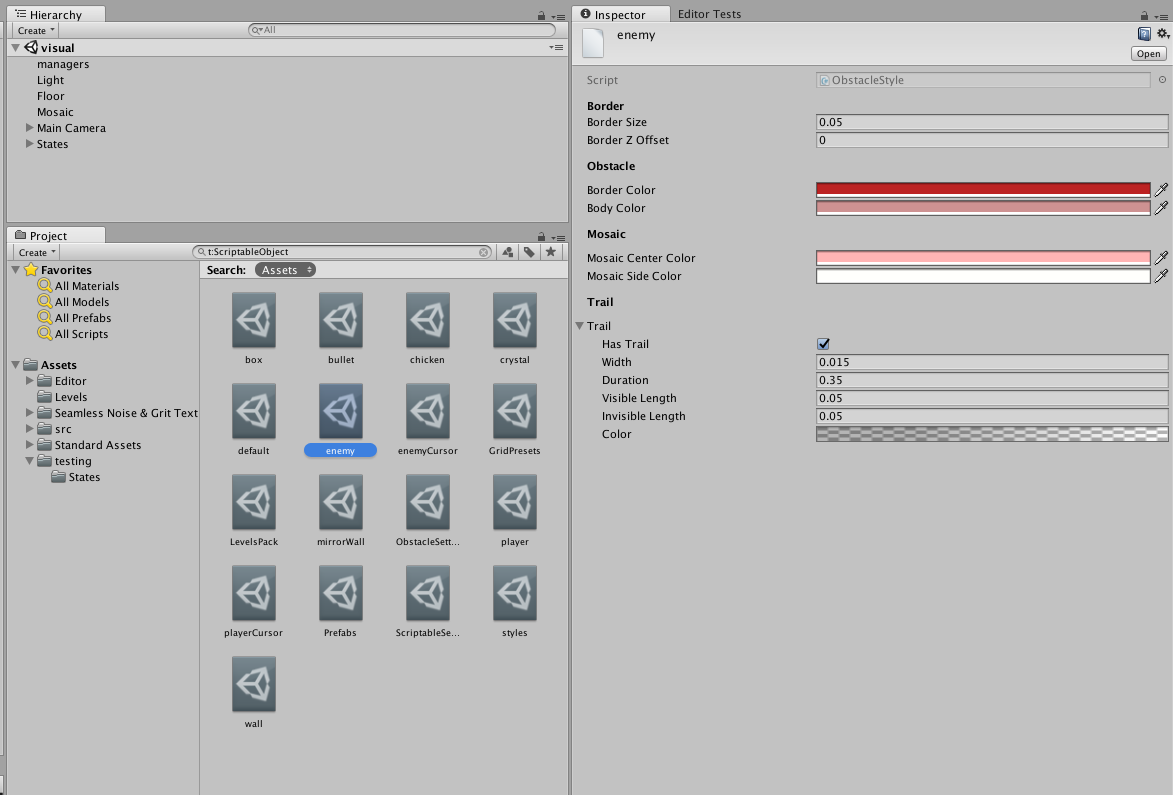
Настройки проекта.
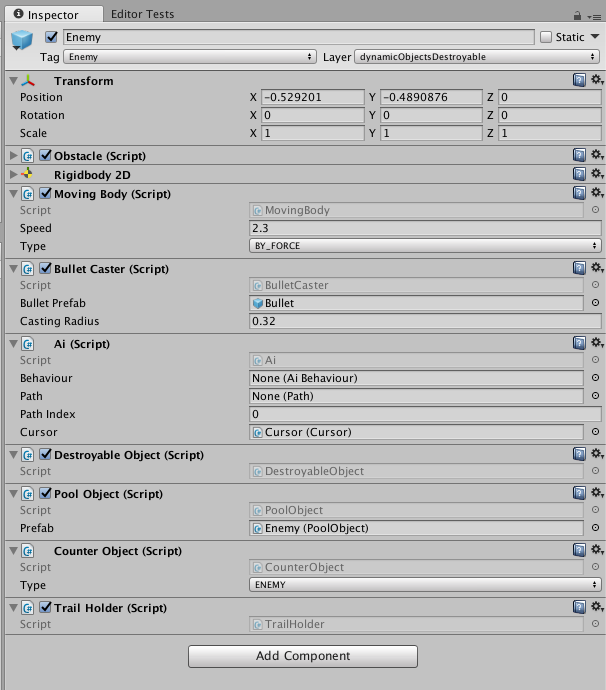
Разбиваю всю логику на маленькие классы, например, BulletCaster или MovableObject. Каждый из них содержит в себе нужные настройки и преследует только одну цель.
public class BulletCaster : MonoBehaviour {
public void CastBullet(Vector2 direction);
}
public class MovingBody : MonoBehaviour {
public Vector2 Direction {get; set;}
public bool IsStopped {get; set;}
}
Из микроклассов можно собрать сложную логику.
Убираю прямые зависимости от синглтонов (Clock, ShadowManager и т.д.) и реализую паттерн service locator (несколько спорная вещь, но куда аккуратнее, чем россыпь синглтонов).
Реализую обработку столкновений через слои, оптимизирую их, явно убирая невозможные столкновения (например, статика <-> статика).
Оптимизирую создание объектов, написав глобальный pool. Думаю, это очередной велосипед, но мне хотелось написать его своими руками. Пул умеет создавать объекты по ключу-префабу, инициализировать их после создания, уведомлять объекты о создании/удалении.
У моих пуль есть ограничение по времени жизни (примерно 10 секунд "незамороженного" времени). Как то раз появился странный баг: часть пуль исчезала прямо в воздухе, словно кулдаун наступал раньше срока и пуля исчезала по таймеру.
Отловить было сложно: не все пули исчезали, а дебажить каждую, надеясь, что хоть одна исчезнет — очень утомительно.
Впрочем, удалось выяснить два странных факта:
Самое важное правило в очередной раз не подвело:
Чем страннее кажется баг, тем глупее его причины.
Итак, наслаждайтесь:
Конечно, такая ошибка могла быть и без старых стен, при сложных коллизиях. Поэтому я добавил проверки на активность объекта при столкновениях и, конечно, начал удалять старые стены.
Вспоминаю про проблему с неудобным тачем и реализую TouchManager. Он запоминает последнее прикосновение и трекает только его. Он сохраняет N последних движений, игнорируя слишком короткие (дрожание пальца). В момент, когда палец или мышь перестали касаться экрана, менеджер рассчитывает направление и длину жеста. Если жест слишком короткий — менеджер игнорирует его: игрок передумал, не выбрав чёткого направления.
Теперь код стал более читаемым, добавлять новые классы стало проще, а ощущение, что архитектура проекта развалится при добавлении самой последней фичи перед релизом, исчезло.
Можно вернуться к арту и игровой логике. По правде говоря, и в логике игры не мешало бы провести чистку.
Todo: подумать над геймплейными элементами, понятностью и простотой геймплея для игрока.
Когда я обдумывал геймплейные фичи, я был заворожён огромным количеством возможностей. Судите сами, все объекты могут обладать четырьмя ортогональными характеристиками:
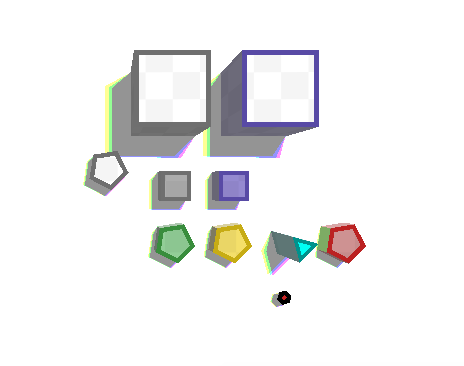
Все эти характеристики можно скомбинировать и даже менять на лету. Но как показать это игроку? Сначала мой список объектов выглядел так:

Все доступные объекты.
У меня явно будут проблемы с понятной визуализацией всей этой красоты. Когда я начинал работать над low-poly версией, я планировал использовать простое цветовое кодирование:
Например, серая кромка означает, что объект поглотит пулю, фиолетовая — отразит. Но получается, что цвет кромки должен кодировать очень много свойств. Слишком сложно. Нахожу типы объектов с очевидными проблемами:
Итого, остаётся:

Всё хорошо кодируется цветом, объектов стало мало, но есть простор для левелдизайна.
Теперь, когда я определился с игровыми сущностями и почистил код от мусора, можно довести графику до финального состояния. Это и эффекты и физика, и всякие интерфейсные элементы. Короче говоря, работы много.
Todo: начать разработку релизных эффектов.
Точный, выверенный жест и ход сделан. Пуля летит, отражается от стены, проходит в считанных пикселях от игрока, задевает кромку другого отражателя и вновь меняет направление. Теперь она нацелена в последнего противника на карте. Ход закончен. Новый ход, в ожидании победы. Направление уже не важно: прошлая пуля сделает своё дело. Итак, законы геометрии неумолимы и снаряд находит свою цель. Пуля касается врага… И враг просто исчезает. Вот облом.
Да, хочется какого-то фана при попадании пули. Чтобы игра визуально говорила:
Но сейчас при попадании пули элементы просто исчезают. Пробую сделать плавное погружение объектов сквозь пол. Выглядит медленно и неестественно, а ещё, непонятно, что объект уже уничтожен и с ним нельзя взаимодействовать.
Ладно, что требуется от эффекта гибели?
Осколки! Пусть пуля разбивает противников на кусочки! Хм, а это не сложно? Неа, все объекты выпуклые, а резать выпуклые многоугольники — одно удовольствие.
На самом деле, просто разрезать противника пополам я не могу. Он состоит из нескольких мешей:

Части объекта, которые нужно разрезать отдельно.
В результате алгоритм получается такой:
При каждом разрезании я делю объекты на две части, поэтому при трёх разрезаниях получается 8 осколков. Можно было бы немного "играть" с глубиной, но и так красиво.
Модифицирую код создания меша, коллайдера и тени многоугольника, чтобы он мог создавать ещё и осколки по заданным точкам.
Получаю примерно такие осколки.
Сначала я планировал сделать кешированные разбиения и использовать только их, но оказалось, что разбиение в реалтайме не вызывает тормозов, а выглядит эффектнее.
Осколки выявили неприятный баг с тенями: я неправильно искал силуэтные точки на многоугольниках. Именно из-за этого на предыдущем видео часть осколков отбрасывают тени лишь частично. Исправления уже доступны в предыдущей статье.
Итак, теперь при попадании пули в объект я подменяю последний на осколки. Объект убирается в пул, а осколки загружаются из пула и обновляют свои меши/коллайдеры согласно своей новой форме. Скорости для rigidBody рассчитываются исходя из скорости разрушенного элемента и направления пули. У осколков выключен флаг isBullet, они взаимодействуют только со стенами и друг с другом. У каждого осколка есть специальный класс FloorHider, он опускает объект по координате z сквозь пол, а после его полного исчезновения — удаляет (перемещает в пул.)
Небольшая ретроспектива:
Осколки!
Разлетающиеся на куски враги — весьма эффектный штрих, но он подпорчен тем, что осколки исчезают без всяких следов. Есть и ещё несколько причин, кроме эффектности, почему мне бы эти следы добавить.
Todo: реализовать эффект следов от осколков.
Когда я думал над визуалом, у меня в голове крутилась идея "пятен крови", которые бы появлялись при гибели игрока или npc. На длинных уровнях такие пятна станут удобными метками для навигации. А в случае проигрыша помогут оценить начальное положение врагов и обдумать тактику повторного прохождения.
Итак, пятна. Вариант с декалями и отрисованными текстурами отбрасываю: мне кажется, так я выбьюсь из стиля. Пробую отобразить след от осколков или места их исчезновения. Смотрится плохо:


Разные варианты пятен.
Думаю над полноценной заливкой, среди вариантов прототипирую такой:
Просто создание кучи треугольников.
Да, этот вариант мне понравился больше. Но создавать множество треугольников с диким overdraw'ом — плохая идея. Впрочем, результат похож на мозаику, так что думаю в сторону диаграммы Вороного.
Вот только генерировать её на лету, особенно с последующей релаксацией Ллойда (релаксация делает ячейки схожими по размеру) на мобильных устройствах будет слишком больно. Нужен предрассчет. И отсюда очередная проблема: пятна могут быть на любом расстоянии друг от друга, и я, очевидно, не могу предрассчитать бесконечно большую диаграмму. Знаете, что такое тайлинг? :)
Для начала, нахожу подходящую библиотеку для генерации диаграммы Вороного.
Теперь разбираюсь с тайлингом. Построить диаграмму прямо на торе было бы идеальным решением, но лезть в дебри библиотеки или даже писать свою очень не хочется. Поэтому придумываю следующий алгоритм:
В результате получается тайл с полигонами, у которого левая сторона идеально подходит к правой, верхняя — к нижней (с диагоналями — аналогично). На самом деле, не всё так гладко.
Идея в том, что диаграмма Вороного — очень локальная штука, поэтому можно эмулировать тор, сделав несколько копий исходных точек во все стороны. Но вот релаксация Ллойда уж точно локальной не является, и чем больше количество итераций, тем больше нужно делать копий (увеличивать значение tiles).
Да и координаты центров не всегда получается корректно проверить, все-таки, плавающая запятая. Поэтому иногда, очень редко, на краешке мозаики не хватает какого-нибудь элемента.

Найдёте повторения?

Итак, получается примерно такой кусочек мозаики:

Мозаика отрендерена на текстуре средствами библиотеки.
Делаю небольшой ScriptableObject, хранящий массив рассчитанных тайлов и редактор с большой кнопкой "recalculate tiles".
Проблемы с редкими дырами из-за float'а в проверках на попадание полигона в тайл я решил перегенерированием некорректных тайлов. Т.к. я делаю предрассчет один раз, руками в редакторе, могу себе такое позволить. :)
Теперь бы выводить эти тайлы на экран!
Todo: генерировать треугольники тайлов мозаики.
Допустим, что пятно будет идеально круглое и мне известны его координаты и радиус. Нужно как-то получить все полигоны, которые находятся внутри этого пятна. Кроме того, пятно может появится в любых координатах, так что мозаику нужно "виртуально" тайлить.
Для проверки алгоритма создал вот такую "мозаику", с ней проще будет найти проблемы:

Поддельная мозаика
Допустим, у меня мозаика генерируется из 512 точек. Значит, на выходе получится 512 полигонов и проверять каждый на пересечение с окружностью — слишком дорого. Поэтому храню мозаику в виде небольших прямоугольных блоков:

Визуализация разделения на блоки.
Зная площадь мозаики и количество полигонов, можно получить оптимальное количество блоков, при котором скорость поиска будет максимальна.
Итак, логика поиска такая:
Дана окружность с координатами center и радиусом radius. Нужно найти все полигоны, попадающие в окружность.
var rectSize = size / (float)rows;
int minX = Mathf.FloorToInt((center.x - radius) / rectSize);
int minY = Mathf.FloorToInt((center.y - radius) / rectSize);
int maxX = Mathf.CeilToInt((center.x + radius) / rectSize);
int maxY = Mathf.CeilToInt((center.y + radius) / rectSize);int innerX = ((x + rows) % rows + rows) % rows;
int innerY = ((y + rows) % rows + rows) % rows;Итак, теперь можно одним запросом получить данные обо всех полигонах, попадающих в заданную окружность:

Запрос полигонов. Тестовая мозаика изменена на более наглядную
Все полигоны диаграммы Вороного выпуклы по определению, поэтому триангулировать их и добавить в меш — проще простого. Делаю первый тест рендеринга:
Выглядит, мягко говоря, скучно. Более того, если два пятна создаются с примерно на расстоянии одного тайла, например, {0, 0} и {1, 1}, бывают заметны повторения.
Спасибо любимой, она предложила хорошую модификацию этого алгоритма:
А теперь в картинках:
Пусть у нас есть вот такая мозаика:

Points = 500, Relax = 5
В ней бывают видны повторы, а ещё она очень однообразна.
Убираем релаксацию Ллойда:

Points = 500, Relax = 0
А теперь смешиваем все карты: считаем полигоном не многоугольник, сгенерированные в диаграмме Вороного, а треугольники, получаемые триангуляцией для рендеринга:

Triangles, Points = 500, Relax = 0
Теперь избавляемся от видимых паттернов. Полигоны, полученные из диаграммы Вороного, фактически, однонаправленны: нулевая вершина сверху, следующие вершины идут по часовой стрелке. Из-за этого чётко прослеживается "направление", как будто бумагу скомкали по диагонали и получилась мятая поверхность со складками, вытянутыми в одну сторону:

Выделены нулевые треугольники в каждом полигоне диаграммы.
Всё, что требуется — создавать треугольники начиная со случайной вершины полигона. Дополнительным плюсом становится то, что после триангуляции исчезают все повторы: в каждом тайле полигон триангулируется по-разному:

Паттерны перестали быть заметны.
Резюмирую: теперь у меня есть бесконечная мозаика, в которой не видно повторов. Я могу делать запрос на получение треугольников этой мозаики в определённом радиусе. Судя по всему, основа для пятен "крови" готова.
Todo: придумать конкретную геометрию пятен и замостить её мозаикой.
Проект развивается, и обрастает эффектами. Я отрезаю лишнее на уровне прототипа и пытаюсь упрощать всё донельзя — как геймплей, так и визуальную часть. Тем не менее, остается еще несколько эффектов (и их полировка), без которых игра смотрится незаконченной.
Итак, ещё несколько выводов:
В следующей статье я планирую закончить рассказ про рендеринг пятен, описать эффект следов, особенности редактора карт и загрузки уровней.
Спасибо за внимание, жду ваших комментариев и feedback'a!
|
|
[Перевод] Как создаются визуальные эффекты для игр |
|
Метки: author PatientZero разработка игр unreal engine unreal engine 4 визуальные эффекты частицы освещение |
[Перевод] Разработка нового сервиса в Android 7 | Кастомизация строки навигации |



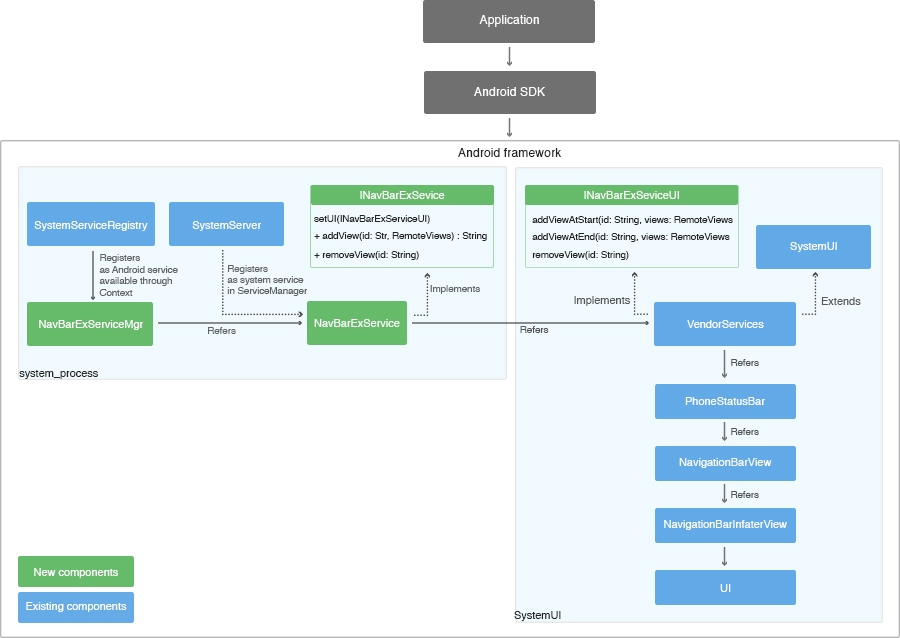
package android.os;
/**
* /framework/base/core/java/android/os/NavBarExServiceMgr.java
* It will be available in framework through import android.os.NavBarExServiceMgr;
*/
import android.content.Context;
import android.widget.RemoteViews;
public class NavBarExServiceMgr
{
private static final String TAG = "NavBarExServiceMgr";
private final Context context;
private final INavBarExService navBarExService;
public static NavBarExServiceMgr getInstance(Context context)
{
return (NavBarExServiceMgr) context.getSystemService(Context.NAVBAREX_SERVICE);
}
/**
* Creates a new instance.
*
* @param context The current context in which to operate.
* @param service The backing system service.
* @hide
*/
public NavBarExServiceMgr(Context context, INavBarExService service)
{
this.context = context;
if (service == null) throw new IllegalArgumentException("service is null");
this.navBarExService = service;
}
/**
* Sets the UI component
*
* @param ui - ui component
* @throws RemoteException
* @hide
*/
public void setUI(INavBarExServiceUI ui) throws RemoteException
{
navBarExService.setUI(ui);
}
public String addView(int priority, RemoteViews remoteViews)
{
try { return navBarExService.addView(priority, remoteViews); }
catch (RemoteException ignored) {}
return null;
}
public boolean removeView(String id)
{
try { return navBarExService.removeView(id); }
catch (RemoteException ignored) {}
return false;
}
public boolean replaceView(String id, RemoteViews remoteViews)
{
try { return navBarExService.replaceView(id, remoteViews); }
catch (RemoteException e) {}
return false;
}
public boolean viewExist(String id)
{
try { return navBarExService.viewExist(id); }
catch (RemoteException e) {}
return false;
}
}
registerService(Context.NAVBAREX_SERVICE, NavBarExServiceMgr.class,
new CachedServiceFetcher() {
@Override
public NavBarExServiceMgr createService(ContextImpl ctx) {
IBinder b = ServiceManager.getService(Context.NAVBAREX_SERVICE);
INavBarExService service = INavBarExService.Stub.asInterface(b);
if (service == null) {
Log.wtf(TAG, "Failed to get INavBarExService service.");
return null;
}
return new NavBarExServiceMgr(ctx, service);
}});
NavBarExServiceMgr navBarExServiceMgr = (NavBarExServiceMgr) getSystemService(Context.NAVBAREX_SERVICE);
// TODO
/*
* aidl file :
* frameworks/base/core/java/android/os/INavBarExService.aidl
* This file contains definitions of functions which are
* exposed by service.
*/
package android.os;
import android.os.INavBarExServiceUI;
import android.widget.RemoteViews;
/** */
interface INavBarExService
{
/**
* @hide
*/
void setUI(INavBarExServiceUI ui);
String addView(in int priority, in RemoteViews remoteViews);
boolean removeView(in String id);
boolean replaceView(in String id, in RemoteViews remoteViews);
boolean viewExist(in String id);
}
public class NavBarExService extends INavBarExService.Stub
…
@Override
public void setUI(INavBarExServiceUI ui)
{
Log.d(TAG, "setUI");
this.ui = ui;
if (ui != null)
{
try
{
for (Pair entry : remoteViewsList.getList())
{
ui.navBarExAddViewAtEnd(entry.first, entry.second);
}
}
catch (Exception e)
{
Log.e(TAG, "Failed to configure UI", e);
}
}
}
@Override
public String addView(int priority, RemoteViews remoteViews) throws RemoteException
{
String id = UUID.randomUUID().toString();
int pos = remoteViewsList.add(priority, id, remoteViews);
if (ui != null)
{
if (pos == 0)
ui.navBarExAddViewAtStart(id, remoteViews);
else if (pos == remoteViewsList.size() - 1)
ui.navBarExAddViewAtEnd(id, remoteViews);
else
{
// find previous element ID
Pair prevElPair = remoteViewsList.getAt(pos - 1);
ui.navBarExAddViewAfter(prevElPair.first, id, remoteViews);
}
}
return id;
}
try {
traceBeginAndSlog("StartNavBarExService");
ServiceManager.addService(Context.NAVBAREX_SERVICE, new NavBarExService(context));
Slog.i(TAG, "NavBarExService Started");
} catch (Throwable e) {
reportWtf("Failure starting NavBarExService Service", e);
}
Trace.traceEnd(Trace.TRACE_TAG_SYSTEM_SERVER);
type navbarex_service, app_api_service, system_server_service, service_manager_type;navbarex u:object_r:navbarex_service:s0
/**
* Use with {@link #getSystemService} to retrieve a
* {@link android.os.NavBarExServiceMgr} for using NavBarExService
*
* @see #getSystemService
*/
public static final String NAVBAREX_SERVICE = "navbarex";
/*
* aidl file :
* frameworks/base/core/java/android/os/INavBarExServiceUI.aidl
* This file contains definitions of functions which are provided by UI.
*/
package android.os;
import android.widget.RemoteViews;
/** @hide */
oneway interface INavBarExServiceUI
{
void navBarExAddViewAtStart(in String id, in RemoteViews remoteViews);
void navBarExAddViewAtEnd(in String id, in RemoteViews remoteViews);
void navBarExAddViewBefore(in String targetId, in String id, in RemoteViews remoteViews);
void navBarExAddViewAfter(in String targetId, in String id, in RemoteViews remoteViews);
void navBarExRemoveView(in String id);
void navBarExReplaceView(in String id, in RemoteViews remoteViews);
}
public class VendorServices extends SystemUI
{
private final Handler handler = new Handler();
private NavBarExServiceMgr navBarExServiceMgr;
private volatile PhoneStatusBar statusBar;
private INavBarExServiceUI.Stub navBarExServiceUI = new INavBarExServiceUI.Stub()
{
@Override
public void navBarExAddViewAtStart(final String id, final RemoteViews remoteViews)
{
if (!initStatusBar()) return;
handler.post(new Runnable()
{
@Override
public void run()
{
statusBar.navBarExAddViewAtStart(id, remoteViews);
}
});
}
//…
}
@Override
protected void onBootCompleted()
{
super.onBootCompleted();
navBarExServiceMgr = (NavBarExServiceMgr) mContext.getSystemService(Context.NAVBAREX_SERVICE);
if (navBarExServiceMgr == null)
{
Log.e(TAG, "navBarExServiceMgr=null");
return;
}
try
{
navBarExServiceMgr.setUI(navBarExServiceUI);
}
catch (Exception e)
{
Log.e(TAG, "setUI exception: " + e);
}
}
}
private boolean initStatusBar()
{
if (statusBar == null)
{
synchronized (initLock)
{
if (statusBar == null)
{
statusBar = getComponent(PhoneStatusBar.class);
if (statusBar == null)
{
Log.e(TAG, "statusBar = null");
return false;
}
Log.d(TAG, "statusBar initialized");
}
}
}
return true;
}
public void navBarExAddViewAtStart(String id, RemoteViews remoteViews) {
if ((mRot0 == null) || (mRot90 == null)) return;
ViewGroup ends0 = (ViewGroup) mRot0.findViewById(R.id.ends_group);
ViewGroup ends90 = (ViewGroup) mRot90.findViewById(R.id.ends_group);
if ((ends0 == null) || (ends90 == null)) return;
navBarExAddView(0, id, remoteViews, ends0);
navBarExAddView(0, id, remoteViews, ends90);
}
private void navBarExAddView(int index, String id, RemoteViews remoteViews, ViewGroup parent) {
View view = remoteViews.apply(mContext, parent);
view.setTag(navBarExFormatTag(id));
TransitionManager.beginDelayedTransition(parent);
parent.addView(view, index);
}
LOCAL_SRC_FILES += \
core/java/android/os/INavBarExService.aidl \
core/java/android/os/INavBarExServiceUI.aidl \
...
aidl_files := \
frameworks/base/core/java/android/os/INavBarExService.aidl \
...
. build/envsetup.sh
lunch sdk_x86-eng
make sdk -j16
. build/envsetup.sh
lunch aosp_flounder-userdebug
make otapackage -j16
fastboot -w flashall
|
Метки: author r_ii разработка под android open source android android development aosp customization |
У нас не только путь в сеньоры, но и путь развития для тех, кто уже таковыми стал |

«Был интересный доклад про дженерики. Там, типа, пазлеры с дженериками. Я после этого тоже, ну, не прямо по итогам доклада, но, типа, заинтересовался тоже темой этой более-менее и кое-что переписал в своем проекте».
«Сложно вспомнить, но совершенно точно Joker сильно расширяет кругозор. И даже если из тех докладов, которые прослушали, никаких практических выводов не делаем прямо в момент прослушивания, в любом случае это откладывается в голове. Когда мы встречаемся с какой-то проблемой, то вспоминаем, что да, что-то такое мы слышали. И во-вторых, мы расширяем кругозор в том смысле, что видим происходящее в индустрии и куда всё движется — это даже видно по темам докладов. У нас компания небольшая, нет специального отдела, следящего за тенденциями. Поэтому мы ездим сами. Вообще, мы занимаемся разработкой софта на заказ на Java уже 8 лет. Мы стараемся присутствовать и на JPoint, и на Joker — конечно, всю команду привезти не можем, но я как директор каждый раз езжу.
… Поскольку у нас много проектов на Enterprise Edition, то в каждом проекте встречаются, безусловно, задачи пакетной обработки. Мы раньше всегда их решали вручную. Сейчас это стало частью стандарта, но мы не обратили на это внимание, а после доклада стало понятно, что будем эту технологию использовать. Эффективность этой технологии в том, что она содержит в себе все вещи, которые обычно в ходе реализации пакетной обработки появляются потихоньку. То есть вам надо файл в 100 000 строк переместить — вы пишете одну строчку. Потом вы понимаете, что вам нужны чекпоинты, что нужно делать что-то с дефектными данными, нужна транзакционность, мониторинг. Всё это пишется вручную. Сейчас появился стандартизированный способ, есть поддержка контейнера для таких задач, и мы это будем использовать. Хотя это, конечно, немного не в стиле Joker, но этот доклад будет применен — не прямо завтра, но через несколько недель точно».
«Как Шипилёв говорил в кейноуте, “нужно с умом подходить к этому делу”. Не просто так, мол, “а увидел крутую вещь — буду запиливать”. Всё пригодится на практике, просто не сразу».

«Был доклад парня из Дойче-банка, я не помню, как его звали. Он рассказывал про мониторинг производительности. Мы этим воспользовались… Ну, там он снимал дампы и проводил статистический анализ этих треддампов. И на основе их смотрел, что у него тормозит. Мы этим потом воспользовались, когда решали проблему производительности наших приложений. Также в 2015 году был доклад Андрея Паньгина. Тоже там он рассказывал про java agent, мы этим периодически пользуемся, особенно если у нас application… Ну, проблема не в нашем коде, а в application server'е. Чего-нибудь залезть там, подхачить. В прошлом году мы, например, заказали онлайн-трансляцию. И сделали у нас на corporate, и сделали типа JPoint’а, но у нас, локальный, в офисе. Это для джуниоров хорошо, такой был этот. В этом году решили сами приехать, ещё раз посмотреть. Не стали заказывать. И уже пожалели, что ребят не подтянули».
«Начали внимательно следить за версиями драйвера Postgres’а, потому что товарищ рассказывал, как он там достаточно стрёмные вещи чинил в этом самом драйвере, локи довольно жёсткие. И посмотрели на Кассандру, ну, чуть более пристально, она не пошла. Но посмотрели».
«Мы уже давно ходим на конференции. У части докладов всегда был прикладной интерес. Сейчас я успел побывать на трёх (докладах), и все так или иначе для меня релевантные, даже Шипилёвский кейноут. Каждый раз открываешь для себя что-то либо изучаешь более подробно. Не знаю, что конкретно выделить. Каждый раз получаешь то, что ожидаешь получить. И нельзя рассматривать это напрямую, мол, вот я научился чему-то и сейчас пойду это запиливать. Это, скорее, толчок для дальнейшего подробного изучения и просмотра. Потому что мы уже матёрые ребята, нас сложно чем-то удивить. Конференция — это место пообщаться и некоторый способ нарушить изоляцию своего коллектива. Посмотреть, что в тренде, что народ делает. Посмотреть, насколько твоя команда актуальна сейчас. Ещё момент с точки зрения практической пользы — общение с докладчиками. В прошлый раз я с ними болтал просто так. Был спикер Venkat Subramaniam — я его книжки читаю, часто на YouTube смотрю. Было интересно с ним поговорить вживую, задать конкретные вопросы. А что касается дискуссионных зон… Вот видишь Шипилёва и думаешь, что бы у него такого спросить, и ничего в голову не приходит».
«И эти хардкорные вещи… Их обычно просто так не ищешь ради развлечения вечером. И потом, когда узнаешь о них, задумываешься: а может, так попробовать, а может, сяк? Второе — это разнообразие. Ты сидишь на работе, каждый день плюс-минус одно и то же. А конференция — это такая возможность заново окунуться в новый мир. Это сильно мотивирует. Смотришь, что народ делает, и думаешь: “А я вроде тоже не хуже! Вечером приду и тоже что-нибудь посмотрю”. И конференция действует как перезарядка. Вот, долго работаешь, всё бесит, а потом приходишь, узнаёшь кучу всего, общаешься, и уже как новый глоток воздуха».
«Виктор Лаврентьев, брейнсторменное clean pragmatic architecture, это был очень практический доклад, который опять-таки очень помогает при создании фреймворков. Я бы отметил еще Калеолу, первый самый доклад. Просто открывает глаза на то, когда, в какие моменты жизни проекта какие оптимизации стоит применять, а когда надо опустить. Просто такой подход к ведению всего проекта».

«В прошлом Джокере был Барух, который рассказывал про Мавен и Грейдл. Интересный был доклад. После него потянуло поковыряться в Грейдле, посмотреть, как с ним можно взаимодействовать. Сегодня тоже доклад про Мавен и Грейдл, который послушал, — буду разбираться дальше. Доклады про Stream API и Java 8 тоже слушаю, тоже применимы в работе. Плюс на конференции до фига знакомых».
«Потому что понравились в прошлом году — как доклады, так обстановка. Мне удалось случайно встретиться со многими людьми, которых не видел десяток лет, и это очень круто. Из полезного — в том году был доклад, который получилось принять на практике, про мутационное тестирование (спикер — Николас Франкель).
Сегодня меня интересуют две темы: микробенчмарки и проблемы микросервисов и распределённого логирования. Общаюсь с людьми, узнаю, как можно это сделать, получаю для себя полезную инфу и решения».
«На первом Joker было много полезного. Практическое применение — я знаю, куда рыть, чтобы интересные вещи для себя изучить более подробно. Сложно назвать что-то конкретное, потому что это по крупицам собирается из разных мест и потом применяется в работе. Ну, и плюс общение со знакомыми старыми. Так ни с кем не знакомлюсь».
 Не секрет, что компании стараются на таких конференциях познакомиться с потенциальными жертвами хедхантинга, а разработчики иногда ездят, чтобы таковыми стать. «Прямых сделок» и передачи оферов почти не происходит, но все с радостью пользуются возможностью прощупать почву у коллег. Ключевые моменты — узнать, кто и сколько получает (и за что именно), у кого какие подводные камни в работе чисто в процессе. А ещё многие наши гости отмечают, что конференции — это социализация (насколько это возможно в сообществе разработчиков), то есть знакомства и связи между компаниями. Плюс разработчик может посмотреть возможности работы у компаний-спонсоров, которые чаще всего — международные холдинги со спектром хороших и интересных проектов.
Не секрет, что компании стараются на таких конференциях познакомиться с потенциальными жертвами хедхантинга, а разработчики иногда ездят, чтобы таковыми стать. «Прямых сделок» и передачи оферов почти не происходит, но все с радостью пользуются возможностью прощупать почву у коллег. Ключевые моменты — узнать, кто и сколько получает (и за что именно), у кого какие подводные камни в работе чисто в процессе. А ещё многие наши гости отмечают, что конференции — это социализация (насколько это возможно в сообществе разработчиков), то есть знакомства и связи между компаниями. Плюс разработчик может посмотреть возможности работы у компаний-спонсоров, которые чаще всего — международные холдинги со спектром хороших и интересных проектов.«Ну, такой наиболее яркий пример — это, например, доклад Романа Елизарова «Ожидай своего счастья без блокировок». То есть после его доклада я начал экспериментировать с его информацией, которую он дал. Через полгода у меня было решение, которое внезапно пригодилось на работе. То есть очень сильно продакшн удалось разгрузить. Много чего у Алексея Шипилёва: всякие нюансы, которые помогают более тонко осознавать, что я вижу при профайлинге. На всяких метриках с продакшна. Вот сегодня я уже три полезняшки успел снять, которые я, как приеду, буду смотреть, как это применяется… Инструмент для поиска deadlock'ов превентивный. Это профайлер от Куксенко, который тоже не есть код, который обычно профайлер не берёт, и я не мог понять, чего с этим делать. Теперь я хотя бы знаю, куда я смогу копать… Я просто фотографирую, записываю по ходу дела. Ну, и плюс «Разбор Полетов» узнал оттуда же. В результате я сейчас постоянно вишу в их чате, и там опять-таки со специалистами можно обсудить, с тем же Алексеем (не далее как во вторник он мне подсказал вещь, которую мне срочно надо было, чтобы понять, что у меня на продакшне творится). И в принципе просто кругозор расширяется. То есть сначала я сам съездил, потом стал каждый раз кого-то из сотрудников притаскивать. В этот раз уже организация поняла, что польза есть, польза большая. Выделили большую квоту, и даже этой квоты не хватило, и кое-кто из наших приехал уже даже за свой счёт. То есть у нас тут сейчас целая шайка. И это, наверно, самый ценный источник информации, которую больше достать негде».
|
Метки: author ARG89 программирование java блог компании jug.ru group конференция карьера обучение |
Знакомство с методологией ITIL в ITSM |
 / фото rawpixel CC
/ фото rawpixel CC / фото Witizia CC
/ фото Witizia CC|
Метки: author it-guild it- стандарты блог компании ит гильдия ит гильдия itil itsm |
Умный замок на Android Things и Raspberry Pi3 |
В декабре 2016 года Google анонсировал выход первой Developer Preview версии Android Things. С тех пор проект сильно изменился. Все еще доступна только preview-версия, но с каждым шагом у платформы появляются новые возможности и растет число поддерживаемых устройств.
С каждым днем появляются новые примеры использования IoT устройств в реальном мире, а сама платформа становится все более привлекательной. Мы в Live Typing решили тоже погрузиться в интереснейший мир Интернет Вещей и рассказать о своем опыте. Эта статья для тех, кто слышал об Android Things, но боялся попробовать. А также о том, как мы реализовали свой «умный замок» и пользуемся им в собственном офисе.
Проблема №1: Наша компания снимает офис с системой электронных пропусков и стеклянными дверями. Часто сотрудники забывают свои карточки дома или просто выходят на улицу без них, а потом стучатся или звонят коллегам, чтобы попасть обратно. Карточку нужно прикладывать к магнитному замку и внутри, и снаружи офиса. Если внутри мы просто привязали карточку на веревочку, то попасть в офис без ключа снаружи — это проблема, которую мы бы хотели решить.
Проблема №2: По выходным в нашем офисе проводятся разного рода митапы. Основная часть присутствующих не является нашими коллегами. Их количество варьируется, но сколько бы их ни было, дать ключ постороннему человеку мы не можем, как и держать дверь все время открытой — это небезопасно для нашего имущества. Поэтому сейчас приходится назначать специального «человека-швейцара» или подпирать дверь чем придётся.
Отключить, убрать или модернизировать проходную систему мы не имеем права, но на то, чтобы подключить что-то снаружи, ограничения не распространяются. Мы решили оборудовать дверь сервоприводом, который будет поворачивать прикреплённую карточку к считывающему датчику при успешном распознавании лица. Фотографию лица предоставляет камера. Таким образом получаем этакий умный дверной замок.
С таким замком у нас появляется своя идентификационная система с блэкджеком и широкими возможностями. (Например смешные фотографий сотрудников, из которых можно делать стикеры для внутреннего шутливого использования). Если говорить о второй проблеме, то замок позволяет сделать регистрацию и пропуск по фотографиям участников встречи. Awesome, не правда ли?
Дальше идея обрастала сопутствующими нюансами и вопросами. Когда начинать и заканчивать фотографировать? Как часто и долго делать фотографии? Стоит отключать систему в нерабочие часы и темное время суток? Как визуализировать работу системы? Но обо всем этом далее и по отдельности. За основу проекта мы взяли пример Doorbell с официальной страницы Android Things. Оригинальный пример называется «звонок», однако мы хотели, чтобы пользователь системы отпирал дверь с минимальными усилиями, а посторонние люди внутрь не попали. Поэтому мы посчитали более правильным назвать его «умный замок».
Сначала у нас не было ничего. Ни самого Raspberry, ни комплектующих, ни опыта работы с ними — только теоретические знания, полученные из статей и документации. Первый раз попробовать поиграться c Android Things удалось на CodeLab проводимом в нашей IT-столице Сибири, городе Омск, ребятами из Mobilatorium. Мы быстро завели проект, где вместо Google Cloud Vision имплементировали свою реализацию FindFace на Tensor Flow. Если вам интересно, как устроен back-end, то можете ознакомиться с отличной статьей «Ищем знакомые лица», где автор очень подробно описал принципы и алгоритмы работы с распознаванием лиц. Если нет, то можете воспользоваться связкой Google Cloud Vision + Firebase Realtime Database, как это сделано в приведённом выше CodeLab.
Когда мы вернулись в офис, оказалось что у нашего сотрудника Миши есть все необходимые компоненты и даже сам Raspberry Pi3, которые он недавно приобрёл, желая побаловаться чем-то эдаким. Также остались компоненты от ребят, проводивших [летнюю школу] (https://vk.com/mobilatorium?w=wall-130802553_81%2Fall) с изучением Arduino. Огромное им спасибо за предоставленные железяки.
Для реализации умного замка нам понадобились:
Все комплектующие легко найти и недорого заказать на китайских сайтах, и мы специально оставили их названия на английском для удобства поиска. Стоит лишь упомянуть, что комплект обойдётся вам примерно в 100-125$. Самыми дорогими компонентами являются камера и сам Raspberry Pi3.
Для лучшего понимания мы разобьём описание реализации на отдельные шаги. Соединяя схему по частям, удобней восстановить картину на любом шаге. Кода мало, и если вы написали хотя бы одно приложение под Android, то проблем у вас не возникнет, на мой взгляд. Для разработки будем использовать привычную Android Studio. Вы даже сможете использовать свои любимые библиотеки и фреймворки, такие как Dagger, RxJava, Retrofit, OkHttp, Timber и т.п.
Перед началом работ стоит ознакомиться с кратким введением в Android Things, а также с пинами на Raspberry Pi3. А эта цветная картинка с распиновкой является отличным наглядным гайдом и пригодится вам ещё не один раз.
Raspberry Pi поддерживает разный набор интерфейсов оборудования. Но нас главным образом интересуют GPIO (General-purpose input/output) и PWM (Pulse Width Modulation). Они будут основными способами взаимодействия между платой и датчиками при реализации нашего проекта.
Библиотеки для различных периферийных устройств уже написаны до нас, а многие из них доступны даже сразу из коробки. Поэтому, когда начнёте интегрировать новый датчик, сначала ознакомтесь с этим и этим репозиториями. Здесь собрано множество драйверов. Скорее всего, вы найдете нужный. Если нет, то Google предоставили специальный концепт User Drivers, который расширяет возможности Android Framework Services. Он перенаправляет происходящие в железе во фреймворк и позволяет обработать их стандартными средствами Android API и таким образом создать свой драйвер. Коротко работу с любым драйвером можно разбить на следующие этапы:
Устанавливаем самый свежий образ Android Things на Raspberry Pi3. Там же приведены ссылки на инструкции по установке образа для различных операционных систем.
Убедиться, что всё успешно установлено, можно, подключив к Raspberry какой-нибудь дисплей через HDMI-кабель. Если все окей, то вы увидите на экране анимацию загрузки Android Things.

Для более комфортного взаимодействия с устройством в документации советуют настроить подключение по WiFi. После этого внизу экрана под заставкой Android Things появится IP-адрес девайса в вашей WiFi сети.

Если в вашей сети только одно такое устройство, то можно не запоминать адрес и не проверять его всякий раз при изменении, а воспользоваться зарезервированным Raspberry именем хоста и подключаться через adb командой.
$ adb connect Android.localСоздаём новое приложение через Android Studio. Можно визуализировать работу своей программы стандартными Android виджетами, разместив их экране, хотя это не обязательно. Ознакомьтесь с полной инструкцией создания первого Android Things приложения на официальном сайте, а мы разберём только основные моменты.
Минимальные требования:
Добавим в app/build.gradle зависимость Android Things support library, которая даст нам доступ к нужному API, не являющемся частью стандартного Android SDK.
dependencies {
...
provided 'com.google.android.things:androidthings:0.4-devpreview'
...
}Каждое приложение связывается с используемой по умолчанию библиотекой Android, в которой имеются базовые пакеты для построения приложений (со стандартными классами, например Activity, Service, Intent, View, Button, Application, ContentProvider и так далее).
Однако некоторые пакеты находятся в собственных библиотеках. Если ваше приложение использует код из одного из таких пакетов, оно должно в явном виде потребовать, чтобы его связали с этим пакетом. Это делается через отдельный элемент .
...
...
Android Things позволяет одновременно устанавливать только одно приложение, а больше нам и не надо. Благодаря этому ограничению появляется возможность декларировать для Activity, как IOT_LAUCHER в AndroidManifest приложения, что позволяет запускать это Activity по-умолчанию сразу же при старте девайса. Также оставим стандартный чтобы Android Studio смогла запустить наше приложение после сборки и деплоя.
...
Начнём с подключения тактовой кнопки, при нажатии на которую камера сделает один снимок. Это простой механизм: толкатель нажимается — цепь замыкается. Кнопка с четырьмя контактами представляет собой две пары соединительных рельс. При замыкании и размыкании между пластинами кнопки возникают микроискры, провоцирующие многократные переключения за крайне малый промежуток времени. Такое явление называется дребезгом. Подробней о кнопке.

Кнопка подключается через макетную плату с использованием резистора на 1 кОм. Чтобы не запутаться в резисторах обратите, внимание на их цветовую кодировку. Не будем подробно расписывать процесс подключения. Просто сопоставьте представленную схему с распиновкой Raspberry, данной чуть выше.
Для интеграции кнопки используем готовый драйвер, который уже учитывает эффект дребезга. Добавим зависимость
dependencies {
...
compile 'com.google.android.things.contrib:driver-button:0.3'
...
}Напишем класс-обёртку для работы с кнопкой. Возможно, реализация через обёртку покажется немного излишней, но таких образом мы сможем инкапсулировать работу с кодом драйвера кнопки и создать собственный интерфейс взаимодействия.
import com.google.android.things.contrib.driver.button.Button;
public class ButtonWrapper {
private @Nullable Button mButton;
private @Nullable OnButtonClickListener mOnButtonClickListener;
public ButtonWrapper(final String gpioPin) {
try {
mButton = new Button(gpioPin, Button.LogicState.PRESSED_WHEN_HIGH);
mButton.setOnButtonEventListener(new Button.OnButtonEventListener() {
@Override
public void onButtonEvent(Button button, boolean pressed) {
if (pressed && mOnButtonClickListener != null) {
mOnButtonClickListener.onClick();
}
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
public void setOnButtonClickListener(@Nullable final OnButtonClickListener listener) {
mOnButtonClickListener = listener;
}
public void onDestroy() {
if (mButton == null) {
return;
}
try {
mButton.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
mButton = null;
}
}
public interface OnButtonClickListener {
public void onClick();
}
}Воспользуемся этой обёрткой в нашем Activity. Просто передадим в конструктор объекта кнопки название GPIO порта ("BCM4") на Raspberry Pi3, к которому она подключена на схеме.
public class MainActivity extends Activity {
private static final String GPIO_PIN_BUTTON = "BCM4";
private ButtonWrapper mButtonWrapper;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
mButtonWrapper = new ButtonWrapper(GPIO_PIN_BUTTON);
mButtonWrapper.setOnButtonClickListener(new ButtonWrapper.OnButtonClickListener() {
@Override
public void onClick() {
Timber.d("BUTTON WAS CLICKED");
startTakingImage();
}
});
...
}
@Override
protected void onDestroy() {
super.onDestroy();
...
mButtonWrapper.onDestroy();
...
}
private void startTakingImage() {
// TODO take photo
...
}
}Мы использовали камеру NoIR Camera V2. Примерно за 45$ вы получите характеристики, достаточные для нашего проекта:
Камера подключается к управляющей плате шлейфом через видеовход CSI (Camera Serial Interface). Такой способ снижает нагрузку на центральный процессор по сравнению с подключением аналогичных камер по USB.
Добавляем в манифест разрешение на использование камеры и требования, что устройство должно ею обладать. Добавление разрешений обязательно, однако согласие на все Permissions, в том числе и на Dangerous Permissions, получается автоматически при установке приложения (существует известная проблема, что при добавлении нового пермишена после переустановки приложения требуется полностью перезагрузить устройство).
Для дальнейшего подключения камеры требуется написать большие по меркам этой статьи куски кода. Пожалуйста, ознакомьтесь с ними самостоятельно по этой ссылке на официальном сайте. В коде устанавливаются настройки камеры. Мы не стали использовать всю её мощь и выбрали разрешение 480х320.
Светодиод — вид диода, который светится, когда через него проходит ток. Его собственное сопротивление после насыщения очень мало. При подключении потребуется резистор, который будет ограничивать ток, проходящий через светодиод, иначе последний просто перегорит. Подробней о светодиодах
Мы будем использовать три светодиода разных цветов:
BCM20) — индикатор начала работы, которая продолжается указанный разработчиком интервал времени;BCM21) — программа успешно распознала лицо из базы данных;BCM16) — программа не распознала лицо в течении указанного интервала времениМожно использовать один трехцветный светодиод вместо трёх одноцветных. Мы пользовались тем, что было под рукой. Используя резисторы в 1 кОм, поочередно подключаем наши светодиоды через макетную плату в соответствии с приведенной схемой.

При реализации обёртки для работы со светодиодом воспользуемся PeripheralManagerService, сервисом, который дает доступ к GPIO интерфейсу. Открываем соединение и конфигурируем его для передачи сигнала. К сожалению, если заглянуть в реализацию абстрактного класса com.google.android.things.pio.Gpio, то можно увидеть, что вызов почти каждого метода способен генерировать java.io.IOException. Для простоты скроем все try-catch выражения в нашей обертке.
public class LedWrapper {
private @Nullable Gpio mGpio;
public LedWrapper(String gpioPin) {
try {
PeripheralManagerService service = new PeripheralManagerService();
mGpio = service.openGpio(gpioPin);
mGpio.setDirection(Gpio.DIRECTION_OUT_INITIALLY_LOW);
} catch (IOException e) {
e.printStackTrace();
}
}
public void turnOn() {
if (mGpio == null) {
return;
}
try {
mGpio.setValue(true);
} catch (IOException e) {
e.printStackTrace();
}
}
public void turnOff() {
if (mGpio == null) {
return;
}
try {
mGpio.setValue(false);
} catch (IOException e) {
e.printStackTrace();
}
}
public void onDestroy() {
try {
mGpio.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
mGpio = null;
}
}
}Имплементируем его в наше Activity для каждого светодиода по отдельности.
public class MainActivity extends Activity {
private final static String GPIO_PIN_LED_GREEN = “BCM21”;
private LedWrapper mLedWrapper;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
mLedWrapper = new LedWrapper(GPIO_PIN_LED_GREEN);
mLedWrapper.turnOff();
...
}
private void turnOn() {
mLedWrapper.turnOn();
}
@Override
protected void onDestroy() {
super.onDestroy();
...
mLedWrapper.onDestroy();
...
}
}Каждый раз подходить к двери и жать на кнопку, словно это дверной звонок, скучно. Мы хотели избавить гостя нашего офиса от лишних действий или даже вовсе открывать дверь, пока человек только подходит к двери. Поэтому мы решили использовать датчик движения как основной триггер для начала работы всей системы. На всякий случай оставим кнопку с дублирующей функциональностью как есть. Подробней о датчике движения.
Подключаем датчик движения через BCM6 пин по схеме, приведенной ниже.

public class MotionWrapper {
private @Nullable Gpio mGpio;
private @Nullable MotionEventListener mMotionEventListener;
public MotionWrapper(String gpioPin) {
try {
mGpio = new PeripheralManagerService().openGpio(gpioPin);
} catch (IOException e) {
e.printStackTrace();
}
}
public void setMotionEventListener(@Nullable final MotionEventListener listener) {
mMotionEventListener = listener;
}
public void startup() {
try {
mGpio.setDirection(Gpio.DIRECTION_IN);
mGpio.setActiveType(Gpio.ACTIVE_HIGH);
mGpio.setEdgeTriggerType(Gpio.EDGE_RISING);
mGpio.registerGpioCallback(mCallback);
} catch (IOException e) {
e.printStackTrace();
}
}
public void shutdown() {
if (mGpio == null) {
return;
}
try {
mGpio.unregisterGpioCallback(mCallback);
mGpio.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public void onDestroy() {
try {
mGpio.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
mGpio = null;
}
}
private final GpioCallback mCallback = new GpioCallback() {
@Override
public boolean onGpioEdge(Gpio gpio) {
if (mMotionEventListener != null) {
mMotionEventListener.onMovement();
}
return true;
}
};
public interface MotionEventListener {
void onMovement();
}
}public class MainActivity extends Activity {
private static final String GPIO_PIN_MOTION_SENSOR = "BCM6";
private MotionWrapper mMotionWrapper;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
mMotionWrapper = new MotionWrapper(GPIO_PIN_MOTION_SENSOR);
mMotionWrapper.setMotionEventListener(new MotionWrapper.MotionEventListener() {
@Override
public void onMovement() {
startTakingPhotos();
}
});
mMotionWrapper.startup();
...}
@Override
protected void onDestroy() {
super.onDestroy();
...
mMotionWrapper.shutdown();
mMotionWrapper.onDestroy();
...
}
private void startTakingPhotos() {
...
}}
Сервопривод совершает основную механическую работу в нашем девайсе. Именно он поворотом выходного вала на 180 градусов подносит карточку к считывающему устройству. Подробней про сервоприводы.
Мы снова используем уже существующий драйвер, над которым напишем свою обёртку. Добавляем в app/build.gradle зависимость.
dependencies {
...
compile 'com.google.android.things.contrib:driver-pwmservo:0.2'
...
}Подключим привод через интерфейс широтно-импульсной модуляции PWM1 в соответствии со схемой приведенной ниже. Использование PWMинтерфейса обусловлено тем, что, в отличии от предыдущих случаев, требуется передать конкретное значение через управляющий сигнал, а не просто бинарный импульс. Управляющий сигнал — импульсы постоянной частоты и переменной ширины. Сервопривод использует широтно-импульсный входящий PWM-сигнал, преобразуя его в конкретный угол поворота выходного вала.

public class ServoWrapper {
private static final float ANGLE_CLOSE = 0f;
private static final float ANGLE_OPEN = 180f;
private Servo mServo;
private Handler mHandler = new Handler();
public ServoWrapper(final String gpioPin) {
try {
mServo = new Servo(gpioPin);
mServo.setAngleRange(ANGLE_CLOSE, ANGLE_OPEN);
mServo.setEnabled(true);
} catch (IOException e) {
e.printStackTrace();
}
}
public void open(final long delayMillis) {
try {
mServo.setAngle(ANGLE_OPEN);
} catch (IOException e) {
e.printStackTrace();
}
mHandler.removeCallbacks(mMoveServoRunnable);
if (delayMillis > 0) {
mHandler.postDelayed(mMoveServoRunnable, delayMillis);
}
}
public void close() {
if (mServo == null) {
return;
}
try {
mServo.setAngle(ANGLE_CLOSE);
} catch (IOException e) {
e.printStackTrace();
}
}
public void onDestroy() {
mHandler.removeCallbacks(mMoveServoRunnable);
mMoveServoRunnable = null;
if (mServo != null) {
try {
mServo.close();
} catch (IOException e) {
e.printStackTrace();
} finally {
mServo = null;
}
}
}
private Runnable mMoveServoRunnable = new Runnable() {
@Override
public void run() {
mHandler.removeCallbacks(this);
close();
}
};
}public class MainActivity extends Activity {
private static final String GPIO_PIN_SERVO = "PWM1";
private ServoWrapper mServoWrapper;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
mServoWrapper = new ServoWrapper(GPIO_PIN_SERVO);
...}
private void openDoor() {
...
mServoWrapper.open(DELAY_SERVO_MS);
...
}
@Override
protected void onDestroy() {
super.onDestroy();
...
mServoWrapper.onDestroy();
...
}}
В тёмное время суток работа замка бессмысленна, потому что по полученным фотографиям сложнее распознать лица. Значит, систему можно временно отключать. Для этого в качестве датчика света используем фоторезистор — Light Dependent Resistors (LDR). Подробней о фоторезисторе.
Для работы с фоторезистором подходит драйвер кнопки, описанный ранее. Это логично, ведь суть и механика работы действительно совпадают. В app/build.gradle уже должна быть подключена библиотека.
dependencies {
...
compile 'com.google.android.things.contrib:driver-button:0.3'
...
}Схема подключения к макетной плате аналогична схеме подключения кнопки. Отличие лишь в использовании резистор в 10 кОм. Используем порт BCM25.

Несмотря на всю похожесть, напишем для него отдельную обёртку.
public class BrightrWrapper {
private @Nullable Button mLightDetector;
private @Nullable OnLightStateChangeListener mOnLightStateChangeListener;
public BrightrWrapper(final String gpioPin) {
try {
mLightDetector = new Button(gpioPin, Button.LogicState.PRESSED_WHEN_HIGH);
mLightDetector.setOnButtonEventListener(new Button.OnButtonEventListener() {
@Override
public void onButtonEvent(Button button, boolean isLighted) {
if (mOnLightStateChangeListener != null) {
mOnLightStateChangeListener.onLightStateChange(isLighted);
}
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
public void setOnLightStateListener(@Nullable final OnLightStateChangeListener listener) {
mOnLightStateChangeListener = listener;
}
public void onDestroy() {
if (mLightDetector == null) {
return;
}
try {
mLightDetector.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public interface OnLightStateChangeListener {
public void onLightStateChange(boolean isLighted);
}
}public class MainActivity extends Activity {
private static final String GPIO_PIN_LIGHT_DETECTOR = "BCM25";
private BrightrWrapper mBrightrWrapper;
private boolean mIsTakePhotoAllowed = true;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
...
mBrightrWrapper = new BrightrWrapper(GPIO_PIN_LIGHT_DETECTOR);
mBrightrWrapper.setOnLightStateListener(new BrightrWrapper.OnLightStateChangeListener() {
@Override
public void onLightStateChange(final boolean isLighted) {
mIsTakePhotoAllowed = isLighted;
handleLightState();
}
});
...
}
private void handleLightState() {
if (mIsTakePhotoAllowed) {
...
} else {
...
}
}
@Override
protected void onDestroy() {
super.onDestroy();
...
mBrightrWrapper.onDestroy();
...
}
}Пересмотрев все выпуски телепередачи «Очумелые ручки», мы искусно упаковали нашего «монстра» в коробочку из-под старого телефона. В разобранном виде это выглядит так

Видео-демонстрация
Плохое качество датчиков и сенсоров. Срабатывают или не срабатывают, когда надо и когда не надо. Сервопривод потрескивает в режиме ожидания.
Если вы ознакомились с принципом работы датчика движения, то могли понять, что через стекло он не срабатывает. Поэтому пришлось выводить его наружу.
Разместив нашу конструкцию изнутри на тройной стеклопакет все фотографии оказались сильно засвечены. Быстро сообразив, что проблема заключается в отражении света от белой поверхности коробочки и его многократном преломлении через стеклопакет, мы просто наклеили чёрный лист бумаги вокруг камеры, чтобы он поглощал часть света.
Нет защиты от распечатанных фотографий.
Пример кода на Github.
Интересно, захватывающе, модно, молодежно. Это был интересный проект, и идеи для его развития еще есть. Например, изнутри дверь также открывается по карточке. Можно решить и эту проблему — открывать дверь каждому, кто подходит к ней изнутри. Пожалуйста, предложите в комментариях свои варианты доработки нашего умного замка. Если они нам понравятся, то мы обязательно их реализуем.
Какие варианты монетизации разработок под IoT знаете вы? Делитесь своим опытом в комментариях.
Не на правах рекламы хочу поделиться отличной статьей, где автор придумал и реализовал самодельную читалку новостей шрифтом Брайля BrailleBox для слабо видящих на Android Things. Выглядит и реализовано так же круто, как и звучит. Отличный, воодушевляющий проект.
|
Метки: author cosic разработка под android android things raspberry pi doorbell doorunlocker tutorial |
Четыре вопроса для выбора облачного решения аутентификации |

|
Метки: author GemaltoRussia блог компании gemalto russia безопасность безопасность в сети аутентификация аутентификация пользователей облачные сервисы |
Как магазин в торговом центре узнаёт вас по Wi-Fi (точнее, по MAC-адресу) — на базе обычных хотспотов |
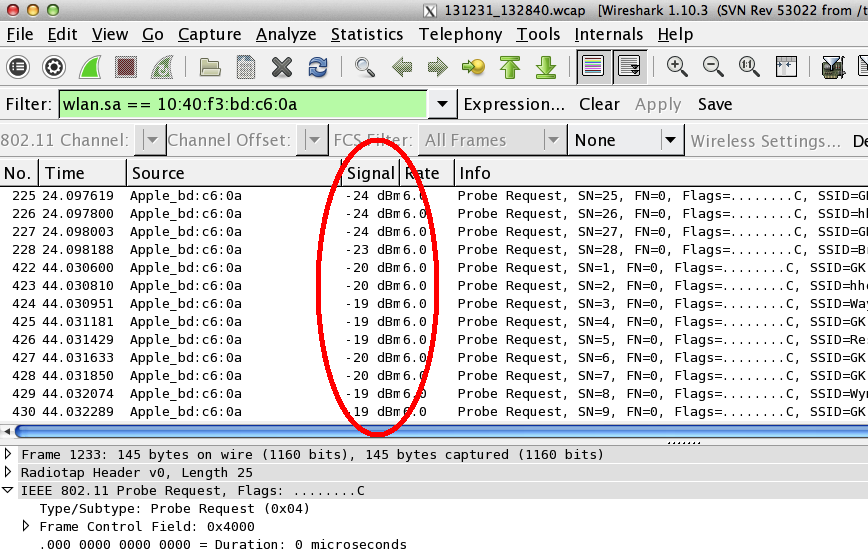
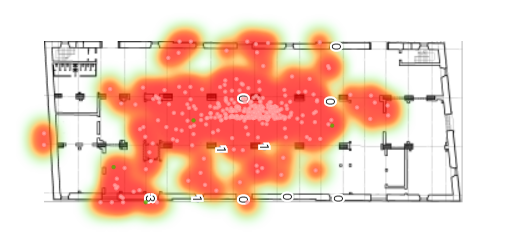


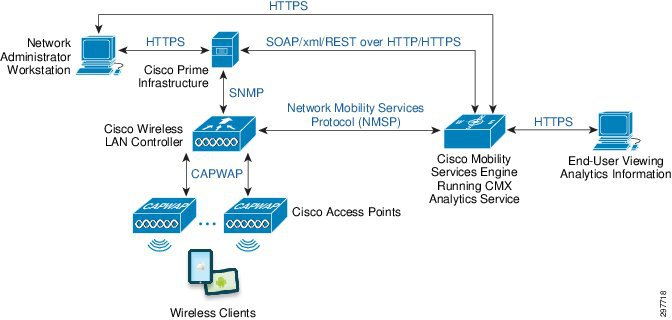
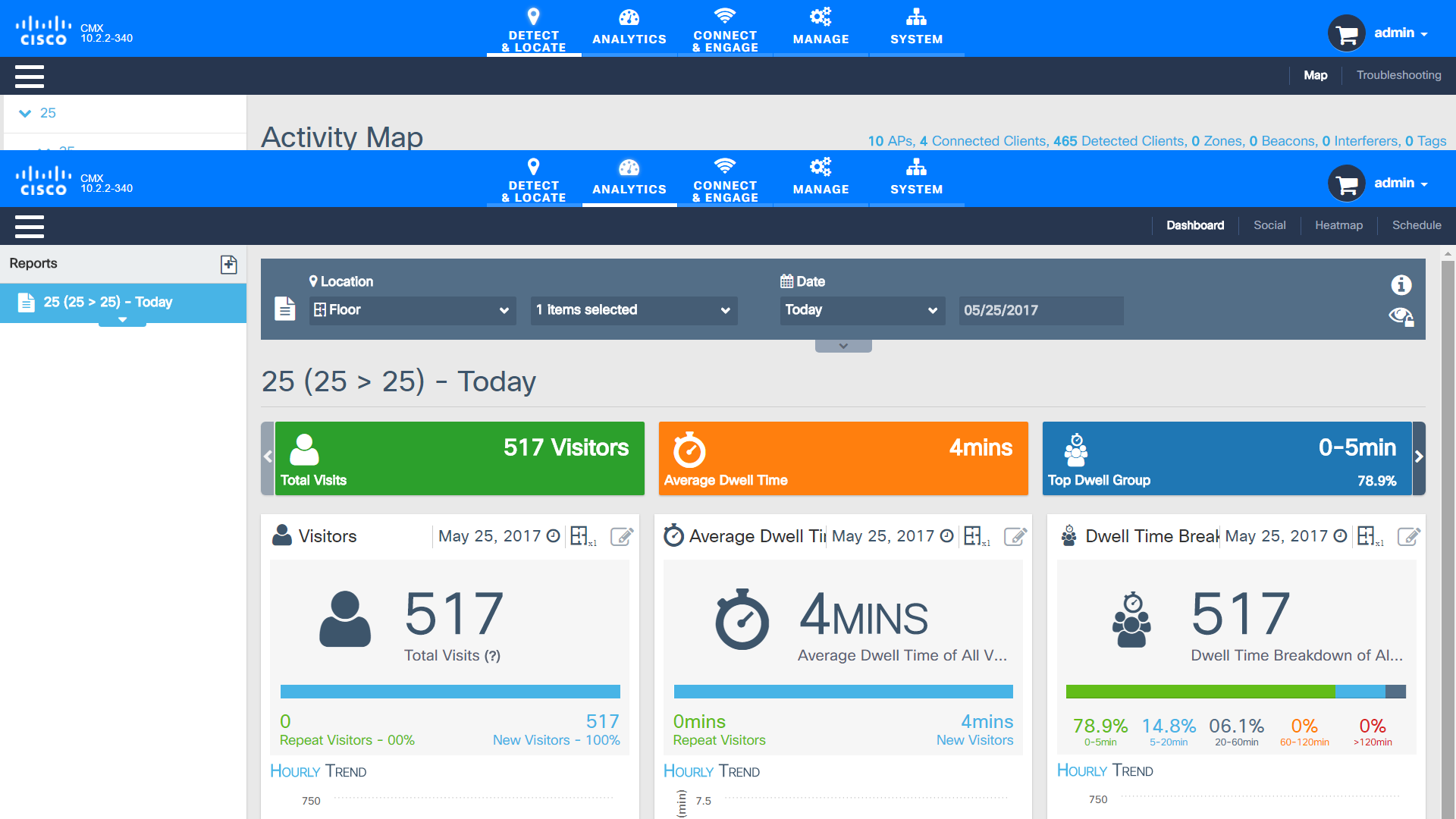
|
Метки: author SVrublevskaya сетевые технологии беспроводные технологии it- инфраструктура блог компании крок wi-fi хотспоты точки доступа статистика аналитика |
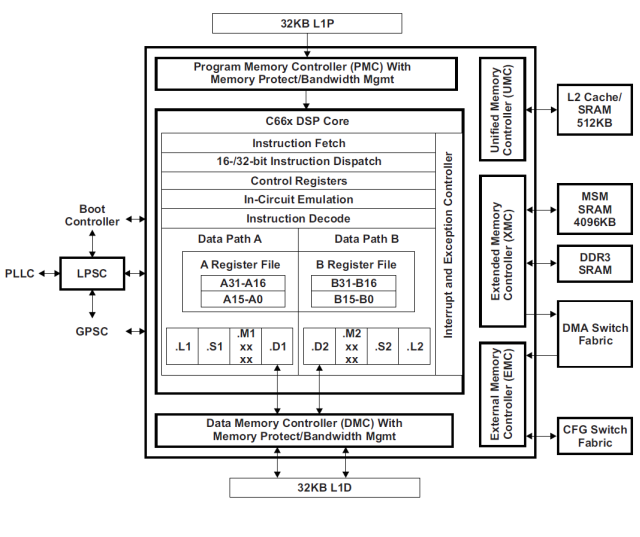
Многоядерный DSP TMS320C6678. Операционные ядра: вычислительные ресурсы процессора |

| C674x | C66x | |
|---|---|---|
| Число умножений с накоплением за такт в формате 16х16 бит с фиксированной точкой | 8 | 32 |
| Число умножений с накоплением за такт в формате 32х32 бит с фиксированной точкой | 2 | 8 |
| Число умножений с накоплением за такт в формате обычной точности с плавающей точкой | 2 | 8 |
| Число общих операций в формате с плавающей точкой за такт | 6 | 16 |
| Пропускная способность каналов чтения/записи между ядром и памятью | 2x64 бита | 2x64 бита |
| Размерность векторных операндов (возможности SIMD-обработки) |
32 бита (2х16 бит, 4х8 бит) |
128 бит (4х32 бита, 4х16 бит, 4х8 бит) |
|
Метки: author vsv630 программирование микроконтроллеров dsp сигнальные процессоры tms320c66x цифровые сигнальные процессоры многоядерные процессоры многоядерные dsp |
[Из песочницы] PSEFABRIC — новый подход в менеджменте и автоматизации сетей |
addresses dc1-vlan111 ipv4-prefix 10.101.1.0/24 structure dc DC1 zone none device dc1_sw1 interface e0/0 vlan 111 vrf VRF1
addresses dc1-vlan112 ipv4-prefix 10.101.2.0/24 structure dc DC1 zone none device dc1_sw1 interface e0/0 vlan 112 vrf VRF1
addresses dc2-vlan221 ipv4-prefix 10.202.1.0/24 structure dc DC2 zone none device dc2_sw1 interface e0/1 vlan 221 vrf TRUSTaddress-sets dc1-vlan111-set addresses dc1-vlan111
address-sets dc1-vlan112-set addresses dc1-vlan112
address-sets dc2-vlan221-set addresses dc2-vlan221applications http-app prot 6 ports destination-port-range lower-port 80 upper-port 80
applications https-app prot 6 ports destination-port-range lower-port 443 upper-port 443
applications icmp-app prot 1application-sets web-app-set applications [ http-app https-app ]
application-sets icmp-app-set applications [ icmp-app ]policies test match source-address-sets [ dc1-vlan111-set dc1-vlan112-set ] destination-address-sets dc2-vlan221-set application-sets [ icmp-app-set web-app-set ]conf t
structure data-centers [ none DC1 DC2 DC3 ]
structure equipment [ none dc1_sw1 dc1_fw1 dc3_r1 dc3_sw1 dc2_fw1 dc2_sw1 ]
structure vrf [ none DMZ TRUST VRF1 VRF2 VRF3 ]
structure zone [ none ]
structure interface [ none e0/0 e0/1 e0/2 e0/3 ]
structure vlans none vlan-number 0
structure vlans Vlan111 vlan-number 111
structure vlans Vlan112 vlan-number 112
structure vlans Vlan121 vlan-number 121
structure vlans Vlan122 vlan-number 122|
Метки: author nihole сетевые технологии it- инфраструктура devops psefabric network automation network management iaas naas |
5 этапов разработки микросервиса |

Деплой осуществляется через свой костыльный питон-деплояторВ параметрах деплоя, в зависимости от окружения, указывается в какой кластер деплоить (у нас их на данный момент 4), количество реплик, лимиты процессора, памяти и т. д.
|
Метки: author akimserg программирование анализ и проектирование систем go bamboo docker |
CoreDNS — DNS-сервер для мира cloud native и Service Discovery для Kubernetes |

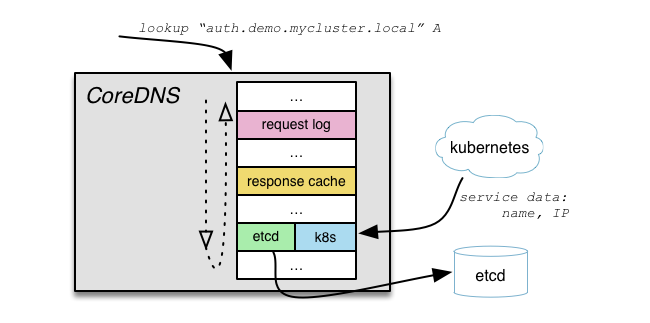
Существует множество различных DNS-серверов, существуют даже другие решения для обнаружения сервисов, основанные на DNS. Но одним из главных достоинств CoreDNS является то, насколько это решение расширяемое и гибкое. Это позволяет легко адаптировать его под динамичный, часто изменяющийся мир cloud-native.
Наша цель — сделать CoreDNS DNS-сервером и решением service discovery для cloud-native. CNCF как организация сосредоточена на совершенствовании архитектур для cloud-native. Таким образом, для нас это прекрасное совпадение [преследуемых целей]. Обнаружение сервисов — ключевой компонент в родном облачном пространстве CNCF, и CoreDNS первенствует в этой роли.
ConfigMap и Deployment) и даже Bash-скрипт deploy.sh для быстрого деплоя. Они позаботились и о примере, как этим пользоваться (все дальнейшие листинги взяты из него):$ ./deploy.sh 10.3.0.0/24 cluster.local10.3.0.0/24 — CIDRs сервисов;cluster.local (указывается опционально) — доменное имя кластера.apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
log stdout
health
kubernetes cluster.local {
cidrs 10.3.0.0/24
}
proxy . /etc/resolv.conf
cache 30
}
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: coredns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "CoreDNS"
spec:
replicas: 1
selector:
matchLabels:
k8s-app: coredns
template:
metadata:
labels:
k8s-app: coredns
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
scheduler.alpha.kubernetes.io/tolerations: '[{"key":"CriticalAddonsOnly", "operator":"Exists"}]'
spec:
containers:
- name: coredns
image: coredns/coredns:latest
imagePullPolicy: Always
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: coredns
kubernetes.io/cluster-service: "true"
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: coredns
clusterIP: 10.3.0.10
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCPCorefile) директива cidrs 10.3.0.0/24 сообщает в Kubernetes middleware из CoreDNS, что необходимо обслуживать PTR-запросы для обратной зоны 0.3.10.in-addr.arpa.$ ./deploy.sh 10.3.0.0/24 | kubectl apply -f -
configmap "coredns" created
deployment "coredns" created
service "kube-dns" configured$ kubectl run -it --rm --restart=Never --image=infoblox/dnstools:latest dnstools
Waiting for pod default/dnstools to be running, status is Pending, pod ready: false
If you don't see a command prompt, try pressing enter.
# host kubernetes
kubernetes.default.svc.cluster.local has address 10.3.0.1
# host kube-dns.kube-system
kube-dns.kube-system.svc.cluster.local has address 10.3.0.10
# host 10.3.0.1
1.0.3.10.in-addr.arpa domain name pointer kubernetes.default.svc.cluster.local.
# host 10.3.0.10
10.0.3.10.in-addr.arpa domain name pointer kube-dns.kube-system.svc.cluster.local.# найдем поды со службой CoreDNS
$ kubectl get --namespace kube-system pods
NAME READY STATUS RESTARTS AGE
coredns-3558181428-0zhnh 1/1 Running 0 2m
coredns-3558181428-xri9i 1/1 Running 0 2m
heapster-v1.2.0-4088228293-a8gkc 2/2 Running 0 126d
kube-apiserver-10.222.243.77 1/1 Running 2 126d
kube-controller-manager-10.222.243.77 1/1 Running 2 126d
kube-proxy-10.222.243.77 1/1 Running 2 126d
kube-proxy-10.222.243.78 1/1 Running 0 126d
kube-scheduler-10.222.243.77 1/1 Running 2 126d
kubernetes-dashboard-v1.4.1-gi2xr 1/1 Running 0 24d
tiller-deploy-3299276078-e8phb 1/1 Running 0 24d
# посмотрим на логи первого
$ kubectl logs --namespace kube-system coredns-3558181428-0zhnh
2017/02/23 14:48:29 [INFO] Kubernetes middleware configured without a label selector. No label-based filtering will be performed.
.:53
2017/02/23 14:48:29 [INFO] CoreDNS-005
CoreDNS-005
10.2.6.127 - [23/Feb/2017:14:49:44 +0000] "AAAA IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR 107 544.128µs
10.2.6.127 - [23/Feb/2017:14:49:44 +0000] "MX IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR 107 7.576897ms
10.2.6.127 - [23/Feb/2017:14:49:52 +0000] "A IN kube-dns.kube-system.default.svc.cluster.local. udp 64 false 512" NXDOMAIN 117 471.176µs
23/Feb/2017:14:49:52 +0000 [ERROR 0 kube-dns.kube-system.default.svc.cluster.local. A] no items found
10.2.6.127 - [23/Feb/2017:14:50:00 +0000] "PTR IN 10.0.3.10.in-addr.arpa. udp 40 false 512" NOERROR 92 752.956µs
# посмотрим на логи второго
$ kubectl logs --namespace kube-system coredns-3558181428-xri9i
2017/02/23 14:48:29 [INFO] Kubernetes middleware configured without a label selector. No label-based filtering will be performed.
.:53
2017/02/23 14:48:29 [INFO] CoreDNS-005
CoreDNS-005
10.2.6.127 - [23/Feb/2017:14:49:44 +0000] "A IN kubernetes.default.svc.cluster.local. udp 54 false 512" NOERROR 70 1.10732ms
10.2.6.127 - [23/Feb/2017:14:49:52 +0000] "A IN kube-dns.kube-system.svc.cluster.local. udp 56 false 512" NOERROR 72 409.74µs
10.2.6.127 - [23/Feb/2017:14:49:52 +0000] "AAAA IN kube-dns.kube-system.svc.cluster.local. udp 56 false 512" NOERROR 109 210.817µs
10.2.6.127 - [23/Feb/2017:14:49:52 +0000] "MX IN kube-dns.kube-system.svc.cluster.local. udp 56 false 512" NOERROR 109 796.703µs
10.2.6.127 - [23/Feb/2017:14:49:56 +0000] "PTR IN 1.0.3.10.in-addr.arpa. udp 39 false 512" NOERROR 89 694.649µslog stdout из Corefile.$ minikube addons list
- dashboard: enabled
- default-storageclass: enabled
- kube-dns: enabled
- heapster: disabled
- ingress: disabled
- registry-creds: disabled
- addon-manager: enabled
$ minikube addons disable kube-dns
kube-dns was successfully disabled
$ minikube addons list
- heapster: disabled
- ingress: disabled
- registry-creds: disabled
- addon-manager: enabled
- dashboard: enabled
- default-storageclass: enabled
- kube-dns: disabledkubectl apply -f из примера выше). А после применения этой конфигурации потребуется ещё удалить ReplicationController из kube-dns, поскольку отключение дополнения не делает этого автоматически:$ kubectl get -n kube-system pods
NAME READY STATUS RESTARTS AGE
coredns-980047985-g2748 1/1 Running 1 36m
kube-addon-manager-minikube 1/1 Running 0 9d
kube-dns-v20-qzvr2 3/3 Running 0 1m
kubernetes-dashboard-ks1jp 1/1 Running 0 9d
$ kubectl delete -n kube-system rc kube-dns-v20
replicationcontroller "kube-dns-v20" deleted|
|
Как NVIDIA и AMD зарабатывают на росте популярности криптовалют |
|
Метки: author me76 финансы в it исследования и прогнозы в it amd nvidia bitcoin перевод |
Отчет об инциденте: «GoldenEye/Petya» |




|
Метки: author PandaSecurityRus системное администрирование антивирусная защита блог компании panda security в россии шифровальщик goldeneye petya информационная безопасность pandalabs |
GUI на Grafana для mgstat — утилиты мониторинга системы на InterSystems Cach'e, Ensemble или HealthShare |
|
Метки: author myardyas администрирование баз данных блог компании intersystems |
Как запутать аналитика. Часть первая |
|
Метки: author maxstroy семантика ооп математика анализ и проектирование систем it- стандарты аналитика owl типизация атрибуты |
[Питер] Встреча JUG.ru c легендой параллельного программирования Maurice Herlihy — Transactional Memory and Beyond |
HTM — довольно модная штука. Процессоры Intel начиная с Haswell имеют HTM на борту. На самом деле, все не так просто — в Haswell года три назад нашли баг, связанный с HTM, поэтому HTM в Haswell принудительно пришлось отключать через апдейты микрокода. В последних Intel-ах HTM вроде снова починили, так что обладатели новейших процессоров уже могут поиграть с этой технологией.

|
|
Шифровальщик, которому не нужны деньги |
 / фото Adam Foster CC
/ фото Adam Foster CC|
Метки: author it_man бизнес-модели блог компании ит-град ит-град шифровальщик petya |







