Swift Generics: cтили для UIView и не только #2 |
Данная публикация является продолжением выпуска, где была затронута тема декорирования объектов. Ознакомление с первой публикацией поможет лучше вникнуть в текущий в контекст, т.к. упомянутые ранее термины и решения буду описываться с упрощениями.
Подход получился весьма удачным и был многократно протестирован на реальных проектах. Кроме этого, появились дополнения к подходу и удобство его использования значительно возросло.
Напомню, что основным элементом представленного способа задания стилей является обобщенное замыкание:
typealias Decoration = (T) -> Void Использовать данное замыкание для придания свойств UIView можно следующим образом:
let decoration: Decoration = { (view: UIView) -> Void in
view.backgroundColor = .white
}
let view = UIView()
decoration(view) Используя оператор сложения и соблюдая порядок применения декораций можно получить механизм композиции декораций:
func +(lhs: @escaping Decoration, rhs: @escaping Decoration) -> Decoration {
return { (value: T) -> Void in
lhs(value)
rhs(value)
}
} Складывать можно не только замыкания, принимающие объекты одного класса. Однако, следует учесть, что класс объекта, передаваемого в одно из замыканий, должен быть подклассом объекта, передаваемого в другое замыкание:
Decoration + Decoration = Decoration
Decoration + Decoration = Decoration
Decoration + Decoration = нельзя Главным неудобством при создании декорации было написание кода самой конструкции декорации. Приходилось писать тип декорации, замыкание, тип класса внутри замыкания… Чаще всего это заканчивалось CTRL+C, CTRL+V.
Чтобы выйти из ситуации и генерировать замыкание через автокомплит была написана универсальная функция, которая принимала тип объекта:
func decor(_ type: T.Type, closure: @escaping Decoration) -> Decoration {
return closure
} Использовалось это следующим образом:
let decoration = decor(UIView.self) { (view) in
view.backgroundColor = .white
}Вот только self не автокомплитится и функцию нельзя было назвать decoration, т.к. чаще всего замыкание создавать с именем decoration и возникала ошибка:
error: variable used within its own initial value
let decoration = decoration(UIView.self) { (view) in
Более удачным решением стало создание универсальной static функции:
protocol Decorable: class {}
extension NSObject: Decorable {}
extension Decorable {
static func decoration(closure: @escaping Decoration) -> Decoration {
return closure
}
} Создавать декорирующее замыкание в итоге можно следующим образом:
let decoration = UIView.decoration { (view) in
view.backgroundColor = .white
}class MyView: UIView {
var isDisabled: Bool = false
var isFavorite: Bool = false
var isSelected: Bool = false
}Чаще всего сочетание подобных переменные применяется лишь для того, чтобы изменить стиль конкретного UIView.
Если попытаться описать состояние стиля UIView одной переменной, то можно использовать перечисления. Однако, еще лучше подойдет OptionSet, который позволяет предусмотреть сочетания.
struct MyViewState: OptionSet, Hashable {
let rawValue: Int
init(rawValue: Int) {
self.rawValue = rawValue
}
static let normal = TextPlaceholderState(rawValue: 1 << 0)
static let disabled = TextPlaceholderState(rawValue: 1 << 1)
static let favorite = TextPlaceholderState(rawValue: 1 << 2)
static let selected = TextPlaceholderState(rawValue: 1 << 3)
var hashValue: Int {
return rawValue
}
}Применять можно следующим образом:
class MyView: UIView {
var state: MyViewState = .normal
}
let view = MyView()
view.state = [.disabled, .favorite]
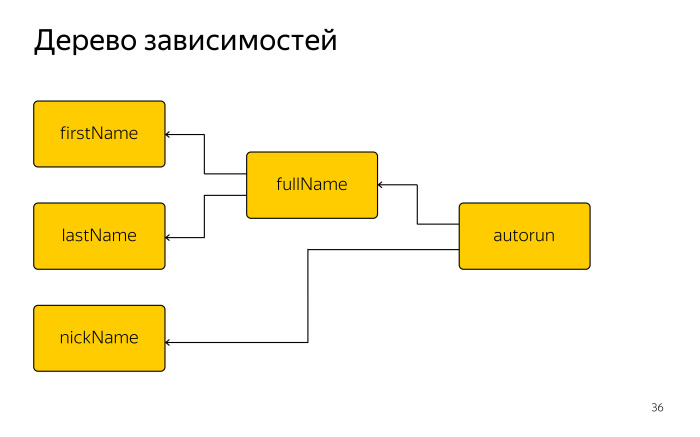
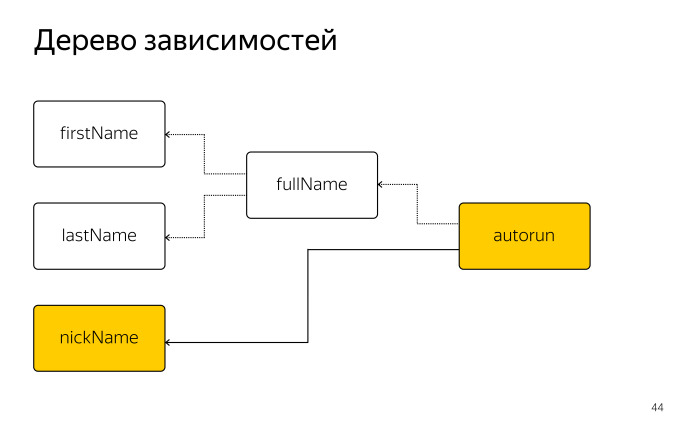
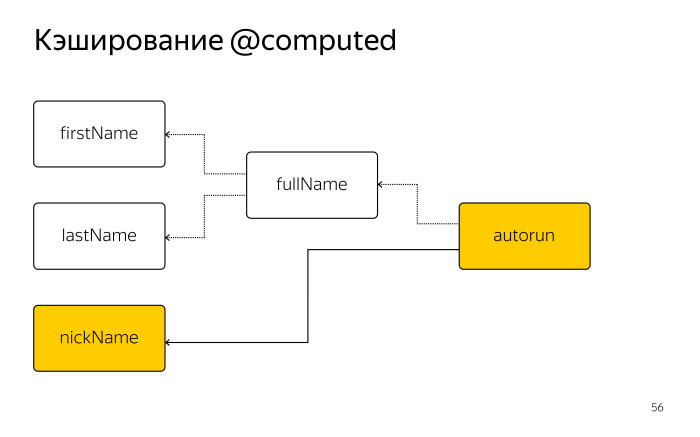
view.state = .selectedВ прошлой публикации была введена обобщенная структура, которая имеет указатель на экземпляр класса, к которому будут применяться декорации.
struct Style {
let object: T
} У обобщенной структуры Style введем дополнительную переменную, которая будет отвечать за состояние стиля.
extension Style where T: Decorable {
var state: AnyHashable? {
get {
//
}
set {
//
}
}
}Сохранять состояние объекта через обобщенную структуру стало возможным при использовании runtime функций ассоциации объектов. Введем класс, который будет ассоциирован объектом декорации и будет содержать нужные переменные.
class Holder {
var state = Optional.none
}
var KEY: UInt8 = 0
extension Decorable {
var holder: Holder {
get {
if let holder = objc_getAssociatedObject(self, &KEY) as? Holder {
return holder
} else {
let holder = Holder()
let policy = objc_AssociationPolicy.OBJC_ASSOCIATION_RETAIN_NONATOMIC
objc_setAssociatedObject(self, &KEY, holder, policy)
return holder
}
}
}
} Теперь обобщенная структура Style может сохранять состояние через ассоциированный с объектом Holder класс.
extension Style where T: Decorable {
var state: AnyHashable? {
get {
return object.holder.state
}
set(value) {
object.holder.state = value
}
}
}Если можно хранить состояние стиля, то точно так же можно хранить декорации для разных состояний. Это достигается путем создания словаря декораций [AnyHashable: Decoration, ассоциированного с объектом декорации.
class Holder {
var state = Optional.none
var states = [AnyHashable: Decoration]()
} Чтобы добавлять декорации в словарь введем функцию:
extension Style where T: Decorable {
func prepare(state: AnyHashable, decoration: @escaping Decoration) {
object.holder.states[state] = decoration
}
} Использовать можно следующим образом:
let view = MyView()
view.style.prepare(state: MyViewState.disabled) { (view) in
view.backgroundColor = .gray
}
view.style.prepare(state: MyViewState.favorite) { (view) in
view.backgroundColor = .yellow
}После наполнения словаря декораций, при изменении состояния стиля, следует применить соответствующую декорацию из словаря. Этого можно добиться немного изменив реализацию сеттера состояния стиля:
extension Style where T: Decorable {
var state: AnyHashable? {
get {
return object.holder.state
}
set(value) {
let holder = object.holder
if let key = value, let decoration = holder.states[key] {
object.style.apply(decoration)
}
holder.state = value
}
}
}Применяться декорация будет следующим образом:
let view = MyView()
// подготовка декораций
view.style.state = .selectedТак же стоит упомянуть случай, когда у объекта было установлено состояние стиля до того, как в словарь декораций попала соответствующая декорация. Для такой ситуации стоит доработать функцию подготовки декорации для состояния:
extension Style where T: Decorable {
func prepare(state: AnyHashable, decoration: @escaping Decoration) {
let holder = object.holder
holder.states[state] = decoration
if state == holder.state {
object.style.apply(decoration)
}
}
} Если внутри применяемой декорации содержится что-то, что можно анимировать,...
When positive, the background of the layer will be drawn with
rounded corners. Also effects the mask generated by the
'masksToBounds' property. Defaults to zero. Animatable.
open var cornerRadius: CGFloat
… то изменения стиля объекта внутри анимационного блока приведет к соответствующим анимациям:
UIView.animate(withDuration: 0.5) {
view.style.state = .selected
}Получен удобный инструмент создания, хранения, применения, переиспользования, композиции декораций. Полный код инструмента можно найти по ссылке. Как обычно есть возможно установить и опробовать через CocoaPods:
pod 'Style'
|
Метки: author iWheelBuy разработка под ios разработка мобильных приложений xcode swift generics ios uiview associatedtype typealias protocol |
160-терабитный трансатлантический кабель Marea закончен |

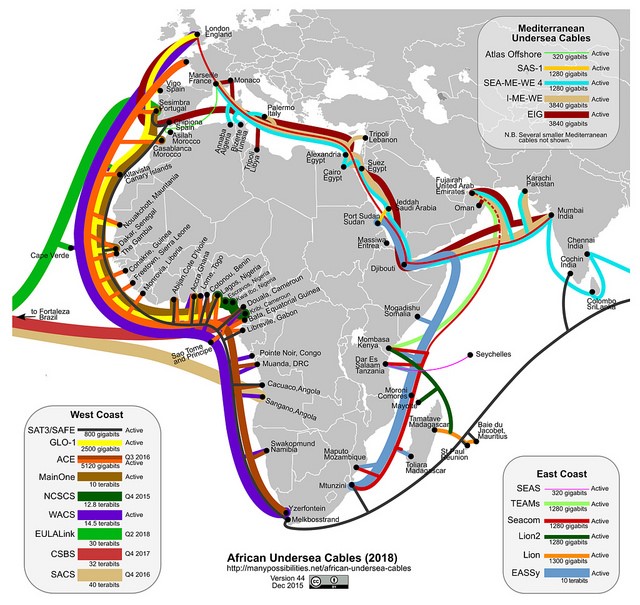
«Marea проложили вовремя. Через трансатлантические кабели проходит на 55% больше данных, чем через кабели Тихого океана. И на 40% больше, чем по кабелям, соединяющим США и Латинскую Америку.
Безусловно, поток данных через Атлантический океан будет расти, а Marea обеспечит необходимое качество соединения для США, Испании и других стран».
«Мы постоянно встречались с представителями Facebook на различных мероприятиях и поняли, что пытаемся решить одну и ту же проблему. Поэтому мы объединились и улучшили трансатлантическую сеть, спроектировав новый кабель», — рассказал Фрэнк Рей (Frank Ray), руководитель инфраструктурного направления облачных решений.
|
Метки: author it_man разработка систем передачи данных блог компании ит-град трансатлантический кабель marea |
Дайджест интересных материалов для мобильного разработчика #223 (25 сентября — 1 октября) |

 |
Разработка прибыльной Android игры двумя школьниками + Продолжение |
 |
Процесс релиза iOS-приложений в Badoo |
 |
Как работает Android, часть 3 |
 iOS
iOS Первое React Native приложение: от «Hello World» до App Store Отладка Swift с LLDB Как уйти из колледжа и стать iOS-фрилансером Управление разными средами в Swift-проекте Руководство по ARKit для новичков Чистая Swift архитектура В Xcode 9 цвета можно добавлять в каталог ассетов Измерение времени компиляции в Xcode 9
Первое React Native приложение: от «Hello World» до App Store Отладка Swift с LLDB Как уйти из колледжа и стать iOS-фрилансером Управление разными средами в Swift-проекте Руководство по ARKit для новичков Чистая Swift архитектура В Xcode 9 цвета можно добавлять в каталог ассетов Измерение времени компиляции в Xcode 9 React Native Game Center: интеграция Game Center в React Native ButtonProgressBar: прогресс бар в кнопке Detect.Location: история посещения мест по фотографиям LifetimeTracker: отслеживание ключевых проблем прямо во время разработки
React Native Game Center: интеграция Game Center в React Native ButtonProgressBar: прогресс бар в кнопке Detect.Location: история посещения мест по фотографиям LifetimeTracker: отслеживание ключевых проблем прямо во время разработки Android
Android Android Dev Подкаст. Выпуск 43. Обзор Devfest Siberia 2017 RxJava: делаем креш-логи лучше Многопотоковый рендеринг на Android с Litho и Infer Flutter: от дизайна до приложения Использование шрифтов с Support Library 26 Android Architecture Components: тестирование ViewModel LiveData Наслаждение тулбаром Воссоздаем “Бутылочку” на Android Используем buildSrc для кастомной логики сборок Gradle
Android Dev Подкаст. Выпуск 43. Обзор Devfest Siberia 2017 RxJava: делаем креш-логи лучше Многопотоковый рендеринг на Android с Litho и Infer Flutter: от дизайна до приложения Использование шрифтов с Support Library 26 Android Architecture Components: тестирование ViewModel LiveData Наслаждение тулбаром Воссоздаем “Бутылочку” на Android Используем buildSrc для кастомной логики сборок Gradle Как улучшить быстродействие Android Studio на машине с малым объемом памяти Frames: готовое приложение с обоями Tutorial View: простая организация туториалов Croller: круглый контрол
Как улучшить быстродействие Android Studio на машине с малым объемом памяти Frames: готовое приложение с обоями Tutorial View: простая организация туториалов Croller: круглый контрол Разработка Mission-driven интерфейс Мобильная типографика Как получить работу в продуктовом или UX дизайне без портфолио Вопросы и ответы по Code Review Лучший кодинг через тестирование Понимаем Progressive Web App: стоят ли они всей шумихи? Как неинтуитивный пользовательский интерфейс может создать превосходный пользовательский опыт 19 альтернатив Parse в 2017 году
Разработка Mission-driven интерфейс Мобильная типографика Как получить работу в продуктовом или UX дизайне без портфолио Вопросы и ответы по Code Review Лучший кодинг через тестирование Понимаем Progressive Web App: стоят ли они всей шумихи? Как неинтуитивный пользовательский интерфейс может создать превосходный пользовательский опыт 19 альтернатив Parse в 2017 году Аналитика, маркетинг и монетизация Три стадии мобильного маркетинга Аналитика против атрибуции — Работа с несоответствием установок
Аналитика, маркетинг и монетизация Три стадии мобильного маркетинга Аналитика против атрибуции — Работа с несоответствием установок Устройства, IoT, AI Microsoft запускает новые инструменты машинного обучения
Устройства, IoT, AI Microsoft запускает новые инструменты машинного обучения|
|
[Из песочницы] Как легализовать торговлю игровыми предметами |

|
Метки: author Hyperevolution продвижение игр монетизация игр игры игровая индустрия внутриигровые покупки внутриигровая валюта |
[Из песочницы] Информационная безопасность в АСУ ТП: вектор атаки преобразователи интерфейсов |




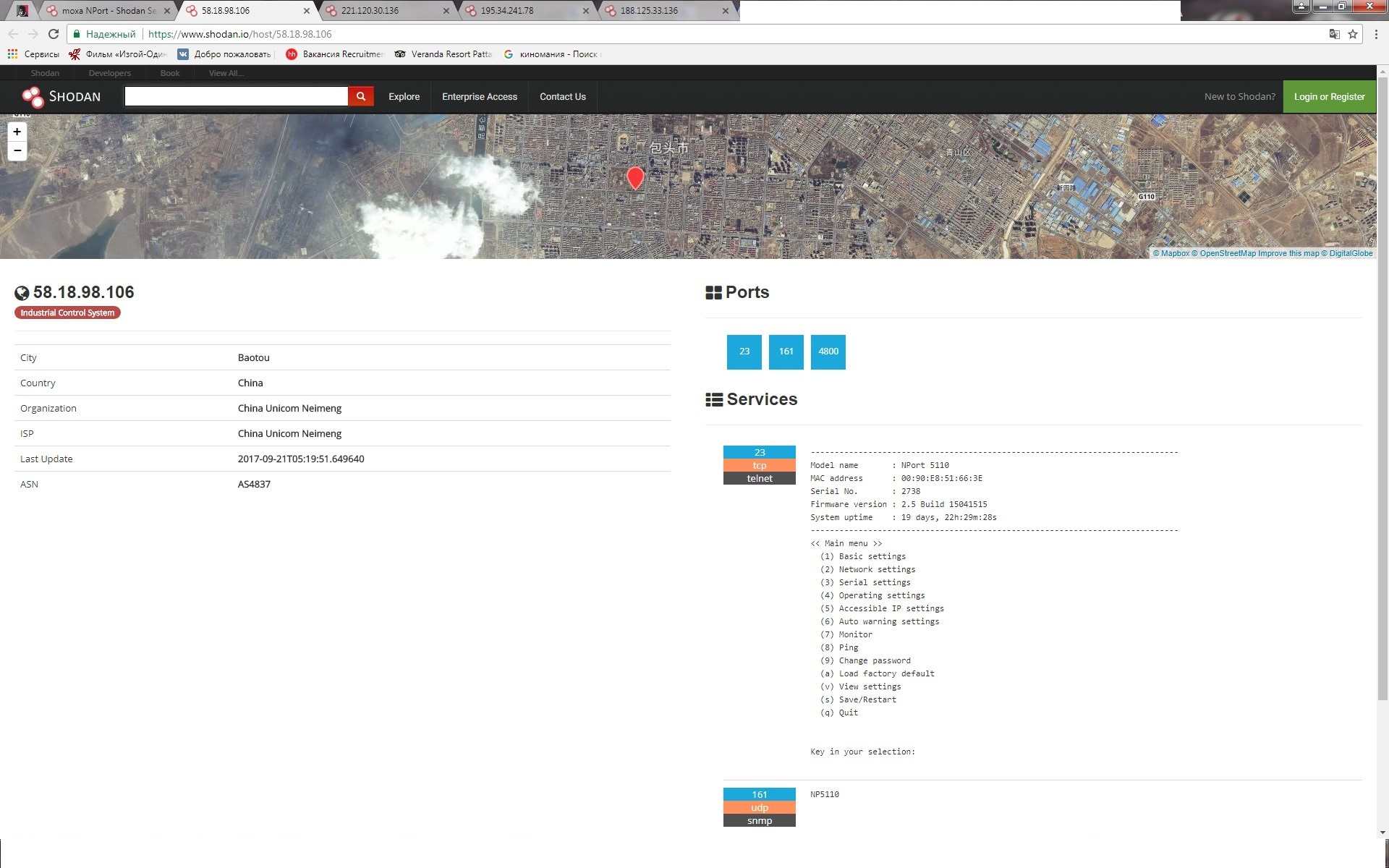
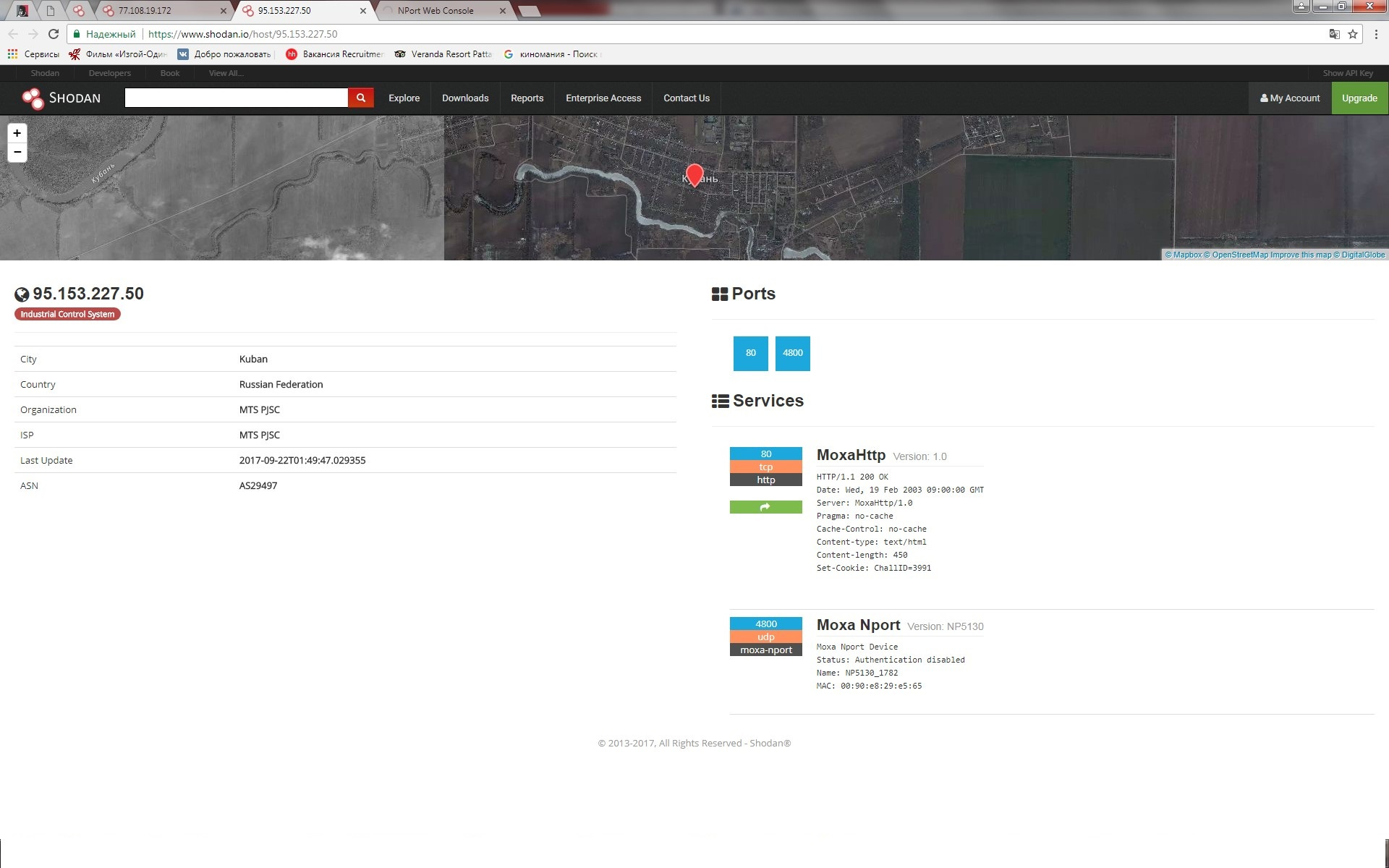

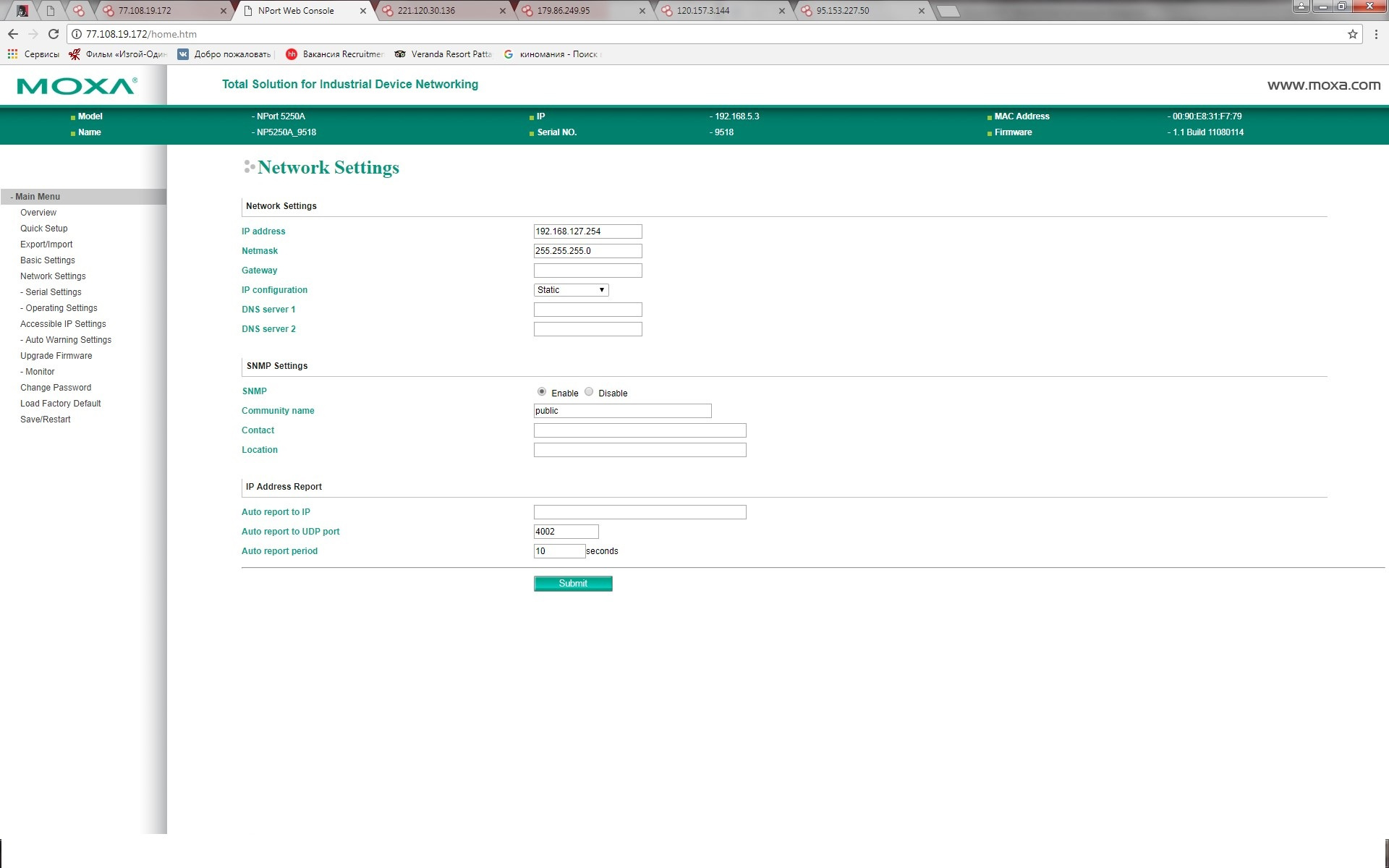
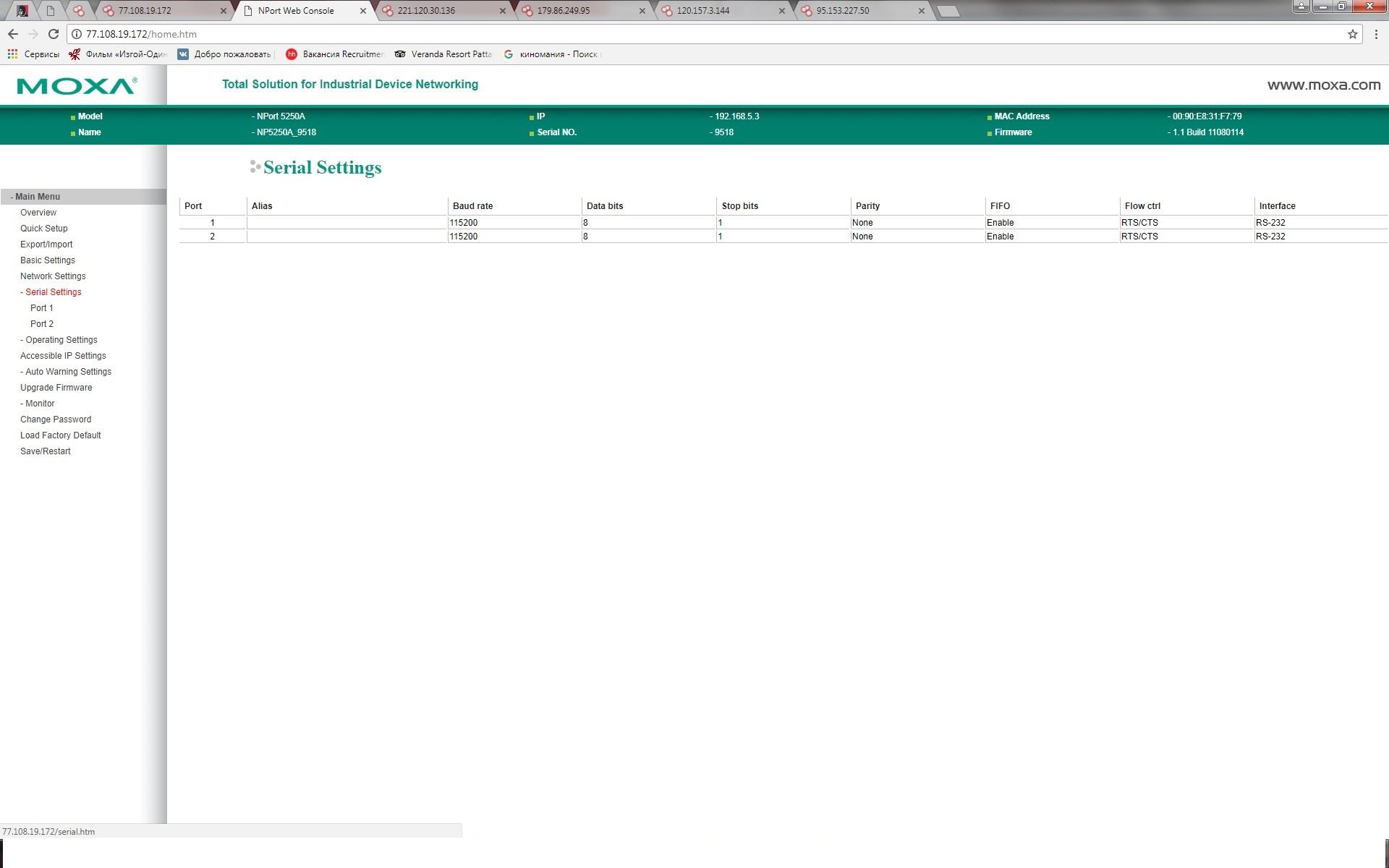
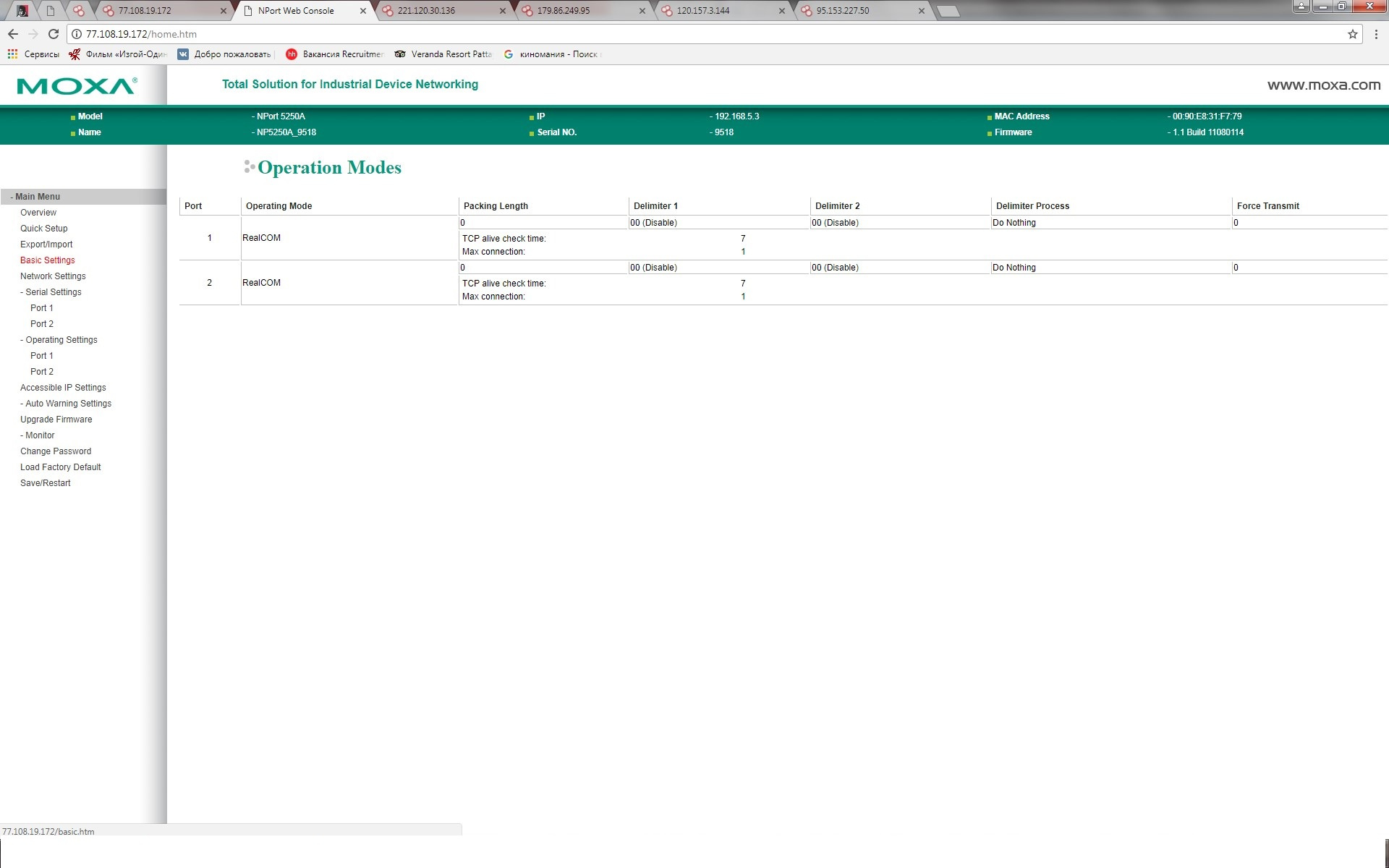
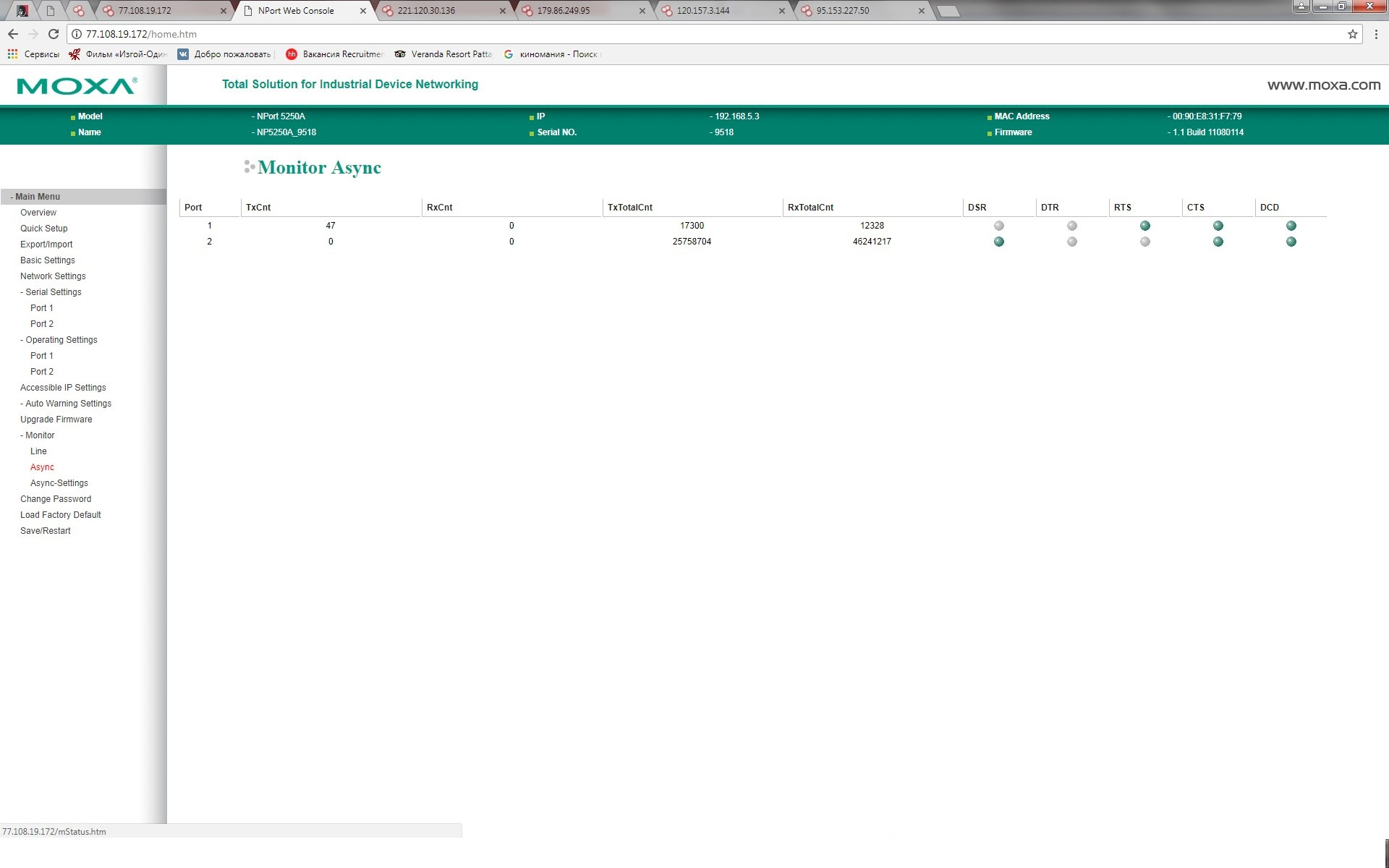

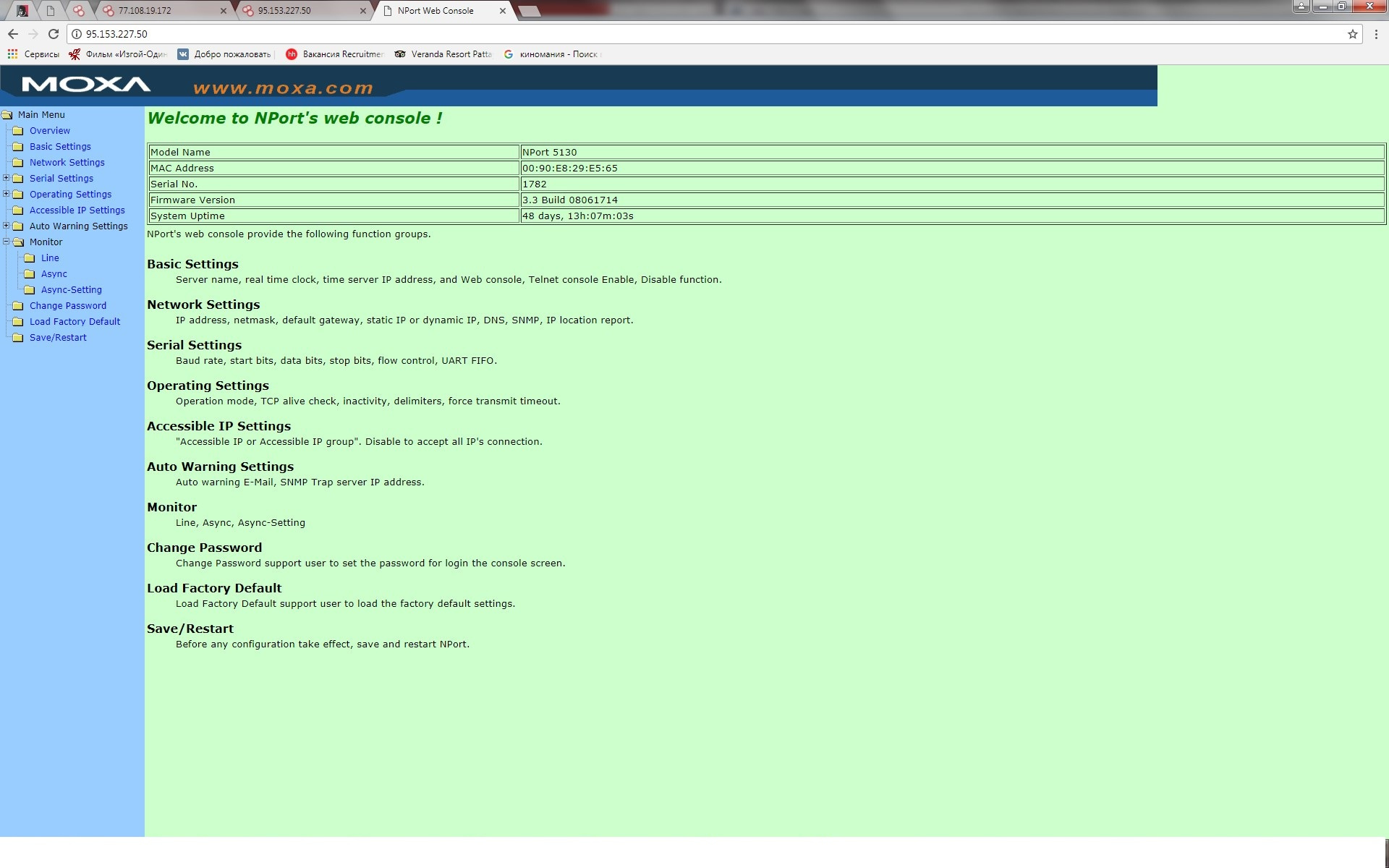
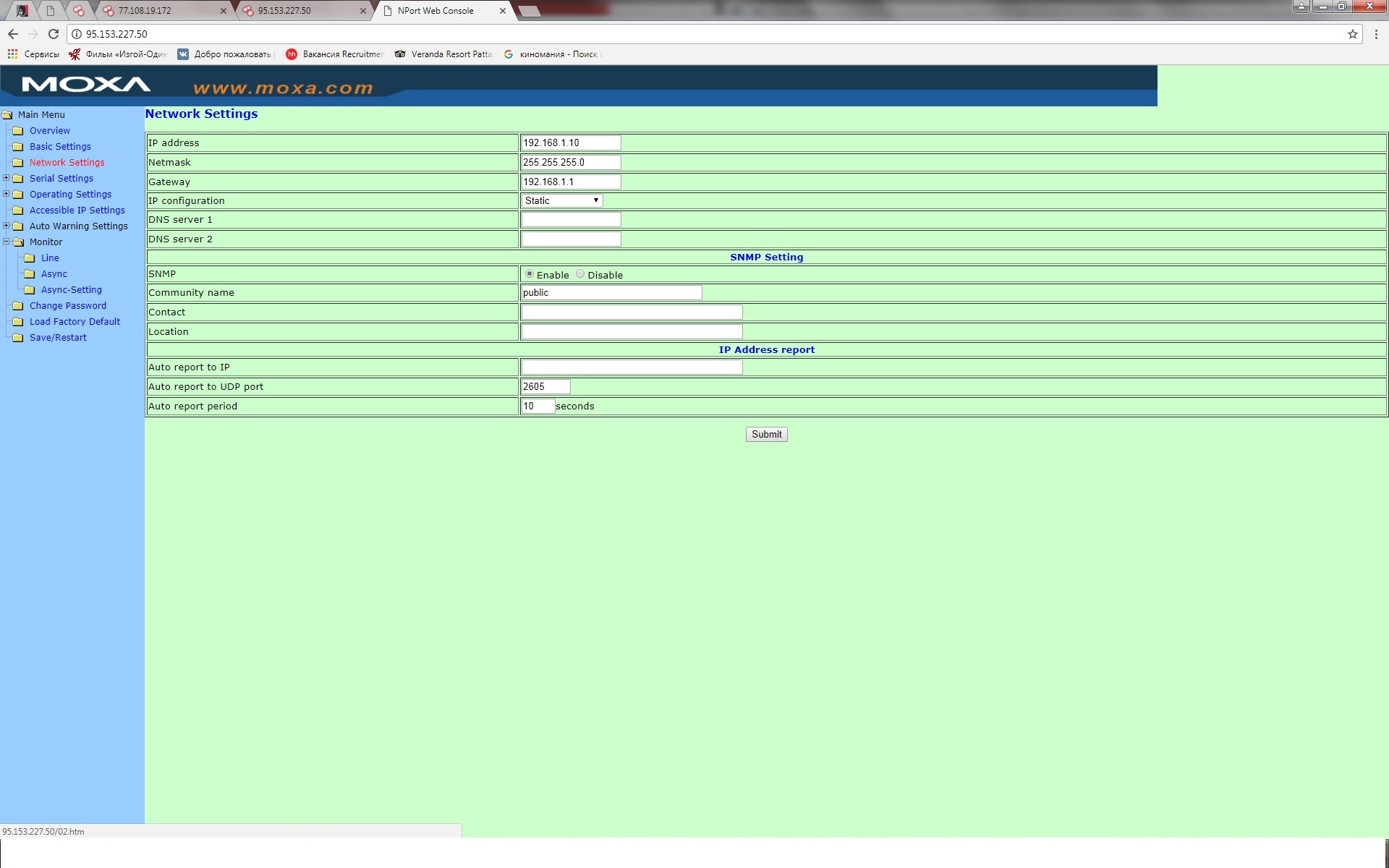




|
Метки: author 2younda исследования и прогнозы в it хабрахабр взлом информационная безопасность асу тп |
MobX — управление состоянием без боли. Лекция в Яндексе |



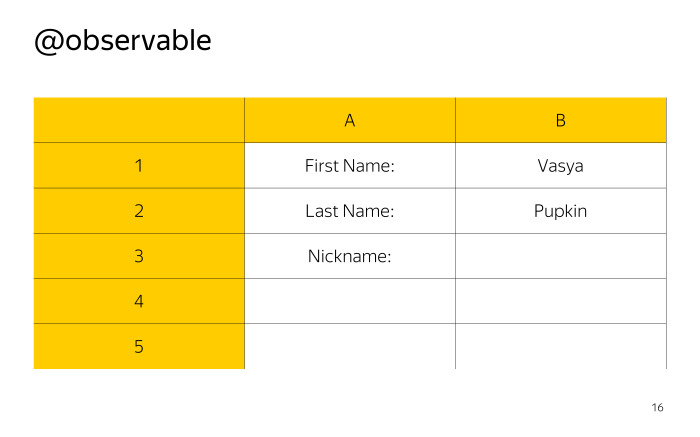

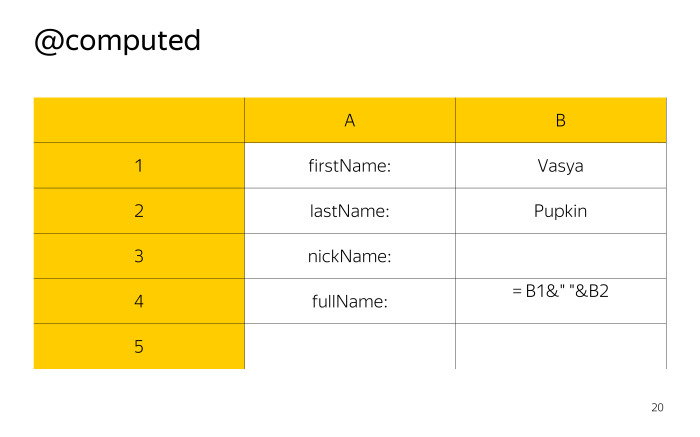



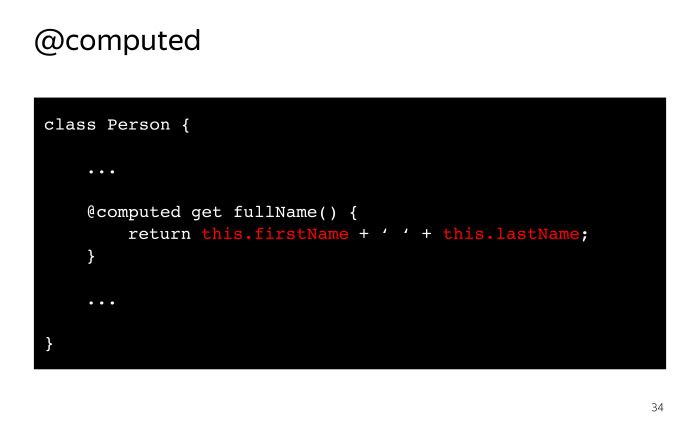


























|
Метки: author Leono разработка веб-сайтов reactjs блог компании яндекс state react react.js mobx mobx-state-tree веб-приложения |
Чтение на выходных: 17 независимых блогов по математике, алгоритмам и языкам программирования |
 / Flickr / home thods / CC BY
/ Flickr / home thods / CC BY
|
Метки: author it_man профессиональная литература блог компании ит-град ит-град блоги подборка математика языки программирования |
DevOps приходит к нам домой? Домашний Minecraft server в Azure с применением современных DevOps практик |
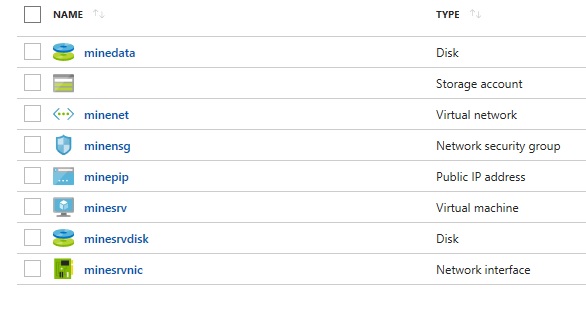
все артефакты, которые требуются для разворачивания приложения, должны быть опубликованы в подконтрольный сторадж с высокой доступностью.
az configure --defaults location=$LOCATION group=$GROUP
echo "create new group"
az group create -n $GROUP
echo "create storage account"
az storage account create -n $STORAGE_ACCOUNT --sku Standard_LRS
STORAGE_CS=$(az storage account show-connection-string -n $STORAGE_ACCOUNT)
export AZURE_STORAGE_CONNECTION_STRING="$STORAGE_CS"
echo "create storage container"
az storage container create -n $STORAGE_CONTAINER --public-access blobmkdir $DISTR_DIR
cd $DISTR_DIR
echo "download minecraft server from official site"
curl -Os https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.$MVERSION.jar
echo "copy jre from this machine"
cp -r "$JRE" ./jre
echo "create ititial world folder"
mkdir initial_world
cd initial_world
echo "download initial map"
curl -Os https://dl01.mcworldmap.com/user/1821/world2.zip
unzip -q world2.zip
cp -r StarWars/* .
rm -r -f StarWars
rm world2.zip
cd ../
echo "create archive (zip utility -> https://ranxing.wordpress.com/2016/12/13/add-zip-into-git-bash-on-windows/)"
cd ../
zip -r -q $DISTR_ZIP $DISTR_DIR
rm -r -f $DISTR_DIR
Все зависимости должны быть точно определены и ресолвиться всегда однозначно
echo "prepare server configuration"
curl -s -L -o configuration/xPSDesiredStateConfiguration.zip "https://www.powershellgallery.com/api/v2/package/xPSDesiredStateConfiguration/7.0.0.0"
curl -s -L -o configuration/xNetworking.zip "https://www.powershellgallery.com/api/v2/package/xNetworking/5.1.0.0"
curl -s -L -o configuration/xStorage.zip "https://www.powershellgallery.com/api/v2/package/xStorage/3.2.0.0"
cd configuration
unzip -q xPSDesiredStateConfiguration.zip -d xPSDesiredStateConfiguration
rm -r xPSDesiredStateConfiguration.zip
unzip -q xNetworking.zip -d xNetworking
rm -r xNetworking.zip
unzip -q xStorage.zip -d xStorage
rm -r xStorage.zip
zip -r -q ../$CONFIG_ZIP . *
rm -r -f xPSDesiredStateConfiguration
rm -r -f xNetworking
rm -r -f xStorage
cd ../
echo "create network security group and rules"
az network nsg create -n $NSG
az network nsg rule create --nsg-name $NSG -n AllowMinecraft --destination-port-ranges 25556 --protocol Tcp --priority 100
az network nsg rule create --nsg-name $NSG -n AllowRDP --destination-port-ranges 3389 --protocol Tcp --priority 110
echo "create vnet, nic and pip"
NIC_NAME=minesrvnic
PIP_NAME=minepip
SUBNET_NAME=servers
az network vnet create -n $VNET --subnet-name $SUBNET_NAME
az network public-ip create -n $PIP_NAME --dns-name $DNS --allocation-method Static
az network nic create --vnet-name $VNET --subnet $SUBNET_NAME --public-ip-address $PIP_NAME -n $NIC_NAME
echo "create data disk"
DISK_NAME=minedata
az disk create -n $DISK_NAME --size-gb 10 --sku Standard_LRS
echo "create server vm"
az vm create -n $VM_NAME --size $VM_SIZE --image $VM_IMAGE \
--nics $NIC_NAME \
--admin-username $VM_ADMIN_LOGIN --admin-password $VM_ADMIN_PASSWORD \
--os-disk-name ${VM_NAME}disk --attach-data-disk $DISK_NAME echo "prepare dsc extension settings"
cat MinecraftServerDSCSettings.json | envsubst > ThisMinecraftServerDSCSettings.json
echo "configure vm"
az vm extension set \
--name DSC \
--publisher Microsoft.Powershell \
--version 2.7 \
--vm-name $VM_NAME \
--resource-group $GROUP \
--settings ThisMinecraftServerDSCSettings.json
rm -f ThisMinecraftServerDSCSettings.jsonxRemoteFile DistrCopy
{
Uri = "https://$accountName.blob.core.windows.net/$containerName/mineserver.$minecraftVersion.zip"
DestinationPath = "$mineHome.zip"
MatchSource = $true
}
Archive UnzipServer
{
Ensure = "Present"
Path = "$mineHome.zip"
Destination = $mineHomeRoot
DependsOn = "[xRemoteFile]DistrCopy"
Validate = $true
Force = $true
}
File CheckProperties
{
DestinationPath = "$mineHome\server.properties"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "....."
}
File CheckEULA
{
DestinationPath = "$mineHome\eula.txt"
Type = "File"
Ensure = "Present"
Force = $true
Contents = "..."
DependsOn = "[File]CheckProperties"
}
xWaitForDisk WaitWorldDisk
{
DiskIdType = "Number"
DiskId = "2"
RetryIntervalSec = 60
RetryCount = 5
DependsOn = "[File]CheckEULA"
}
xDisk PrepareWorldDisk
{
DependsOn = "[xWaitForDisk]WaitWorldDisk"
DiskIdType = "Number"
DiskId = "2"
DriveLetter = "F"
AllowDestructive = $false
}
xWaitForVolume WaitForF
{
DriveLetter = 'F'
RetryIntervalSec = 5
RetryCount = 10
DependsOn = "[xDisk]PrepareWorldDisk"
}
File WorldDirectoryExists
{
Ensure = "Present"
Type = "Directory"
Recurse = $true
DestinationPath = "F:\world"
SourcePath = "$mineHome\initial_world"
MatchSource = $false
DependsOn = "[xWaitForVolume]WaitForF"
}
Script LinkWorldDirectory
{
DependsOn="[File]WorldDirectoryExists"
GetScript=
{
@{ Result = (Test-Path "$using:mineHome\World") }
}
SetScript=
{
New-Item -ItemType SymbolicLink -Path "$using:mineHome\World" -Confirm -Force -Value "F:\world"
}
TestScript=
{
return (Test-Path "$using:mineHome\World")
}
}
Script EnsureServerStart
{
DependsOn="[Script]LinkWorldDirectory"
GetScript=
{
@{ Result = (Get-Process -Name java -ErrorAction SilentlyContinue) }
}
SetScript=
{
Start-Process -FilePath "$using:mineHome\jre\bin\java" -WorkingDirectory "$using:mineHome" -ArgumentList "-Xms512M -Xmx512M -jar `"$using:mineHome\minecraft_server.$using:minecraftVersion.jar`" nogui"
}
TestScript=
{
return (Get-Process -Name java -ErrorAction SilentlyContinue) -ne $null
}
}
xFirewall FirewallIn
{
Name = "Minecraft-in"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Inbound'
}
xFirewall FirewallOut
{
Name = "Minecraft-out"
Action = "Allow"
LocalPort = ('25565')
Protocol = 'TCP'
Direction = 'Outbound'
}git clone https://github.com/AndreyPoturaev/minecraft-in-azure
cd minecraft-in-azure
git checkout v1.0.0
export MINESERVER_PASSWORD=
export MINESERVER_DNS=
export MINESERVER_STORAGE_ACCOUNT=
az login
. rollout.sh

|
Метки: author Dronopotamus microsoft azure azure automation minecraft server |
История создания синхронизатора часов DCF77 |
|
Метки: author assad77 программирование микроконтроллеров microcontroller radio |
Как довести первый проект до конца. Часть 2. Мифы, ошибки и провалы |

|
Метки: author AllSoliton разработка игр unity3d |
[CppCon 2017] Бьёрн Страуструп: Изучение и преподавание современного C++ |
Сейчас проходит конференция CppCon 2017, и на их youtube-канале уже стали появляться видео оттуда. И я подумал, почему бы не попробовать сделать конспекты интересных лекций. Конечно, не очень уверен, надолго ли меня хватит, зависит от того насколько вам это понравится.
Это первое вступительное видео. Оно не такое интересное для меня, но пропустить тоже не мог, это же Страуструп. Далее, текст от его лица. Заголовки взяты из слайдов.
Disclaimer: весь дальнейший текст — достаточно краткий пересказ, являющийся результом работы моего восприятия, и то, что я посчитал "водой" и проигнорировал, могло оказаться важным для вас. Иногда выступление было таким: "(важная мысль 1)(минута воды)(важная мысль 2)". Эти две мысли плавно перетекали друг в друга, а у меня получались довольно резкие скачки. Где можно сгладил, но посчитал нецелесообразным полностью причесывать текст, на это бы потребовалось много времени.
Когда меня попросили выступить на открытии конференции, я задумался, о чем же я могу рассказать такого, что важно для вас, и чего вы не слышали миллион раз. И я решил рассказать про обучение языку C++.
Зададимся вопросом кого мы учим, чему, зачем и как. Нужно делать это лучше. Я не критикую кого-то в частности, но чувствую, что мы должны делать это лучше. Не все из нас преподаватели, но тем не менее постоянно возникают случаи, когда мы занимаемся обучением. Например, рассказываем коллегам о последних фичах или даем советы. Общаемся на StackOverflow, Reddit, ведем блоги и т.д. Но нужно давать хорошие советы. Советы, которые двигают мир вперед.
Есть одна вещь, которая сильно беспокоит меня — зачастую у людей бывают очень странные представления о том, что собой представляет C++. Чуть позже я вернусь к этой проблеме.
Когда учите, задумайтесь, чего вы хотите достичь. И от от этого и начинайте. Не отталкивайтесь от "что мы уже сделали" и "что проще, чтобы начать", а если вы преподаватель, то от "что проще проверить".
Не нужно фокусироваться на языковых фичах. Например, вы встречали примеры в которых объясняется проблема приведения signed short к unsigned int [рассказывается о преподавании языка в общем, а не об особенностях C++]. Это неинтересно и можно увидеть в отладчике или прочитать в руководстве. Учите так, чтобы такая проблема не появлялась.
Не пытайтесь учить всему, вы не сможете. Внимательно выберите подмножество языка.
Одна из встечающихся проблем обучения C++ — то что язык изучается сам по себе, отдельно от библиотек. Вектор на 697 странице, sort через 100 страниц. Это учит, что stl скучная, сложная фигня. И в то же время: свой Linked List или Hash table это круто, круче чем stl.
[в выступлении автор использует слово clever с негативным оттенком, что-то вроде человека, который пытается казаться быть умным]
Люди которые хотят и требуют "самое последнее" часто не знают основ. Пересмотрите основы.
Будьте проще. Не бросайтесь в самое сложное и изощренное. Не используйте самый продвинутый алгоритм, который только можно найти. Я бы не выбрал пузырьковую сортировку, но также не выбрал бы и "полный общий алгоритм для всего". Предлагайте самый простой пример, который иллюстрирует технику или фичу.
Фокусируйтесь на общих случаях. Будьте рациональными. Не говорите ученикам "Делай только так, это правильно, это закаляет характер. И можете получить пятерку, если ответите именно так". Нужно объяснить, почему нужно следовать правилам, дать ученикам хорошие идеалы, идеи, техники.
Конечно, обучая, очень заманчиво, стоять перед коллегами, группой людей и всем своим видом показывать: "Смотрите, эта сложная вещь, которую вы не поняли. Это означает, что я умный". Это не очень хорошее обучение.
Если изучать только сам язык, то попав в реальность можно просто "утонуть".
Используйте различные инструменты. Не только компилятор и учебник, но и IDE, отладчики, системы контроля версий, профилировщики, модульное тестирорвание, статические анализаторы, онлайн компиляторы. Интрументы должны быть современными (иногда получаю вопросы по Turbo C++ 4.0 :( )
Нужно изучать принципы и закреплять на практике. Используйте графику, сети, интернет, Raspberry Pi, робототехнику и т.д. Это очевидно для вас, но не очевидно для университетов. Не говорите что это просто и быстро. И помните, что никто не умеет делать все.
Как мы часто учим? Объясняем язык плюс немного стандартную библиотеку. Без всякой графики, пользовательского интерфейса, веба, электронной почты, баз данных… И многие ученики считают, что C++ скучный бесполезный язык. Но это же не так, ведь такие вещи как браузеры, СУБД, САПР и прочие пишутся на C++. Перед началом лекции потратьте 5 минут о практическом применении.
Нам, сообществу C++, очень важно упростить начало работы, возможность пользоваться "прямо сейчас".
Как пользователи в различных отраслях разделяются на группы? Приведем пример с фотографией. Результат зависит от оборудования и от пользователя. Лично я новичок в фотографии. Большинство возможностей профессиональной фотокамеры будут для меня бесполезными. Она много весит, дорого стоит. Для нее существует множество аксессуаров в которых можно утонуть. Но с ее помощью можно делать превосходные фотографии, если потратить много времени на обучение. Аналогично существует много людей, которые не могут использовать разнообразные фичи языка и библиотеки.
С другой стороны, у нас есть устройства, которыми можно пользоваться сразу. Такое устройство дешевое, простое, "милое". Прощает ошибки, не требует много усилий для освоения. Является "вещью в себе". Мало расширений и дополнений, если таковые вообще есть. Отсуствуют взаимозаменяемые части.
Как-то во время преподавания мне было нужно, чтобы у студентов была установлена библиотека GUI. Оказалось, что установить одну и ту же библиотеку на студенческие Mac, Linux, Windows, весьма болезненно.
Каждый произвожитель фототехнии предлагает "систему", которая предполагает, что вы можете постепенно обновлять оборудование и переходить на следующий уровень по мере обучения.
Не обязательно давать новичку профессиональную камеру со всеми наворотами. В этом случае у него будут трудности и результат вероятно будет хуже, чем если бы он использовал "мыльницу". Поэтому какое-то одно решение не будет подходящим для всех.
Язык должен быть представлен тремя дистрибутивами. Для новичков, любителей и профессионалов.
База:
import bundle.entry_level; //Для новичков
import bundle.enthusiast_level; //Для продвинутых
import bundle.professional_level; //Для профессионаловРасширения (которые не входят в базу):
import grahics.2d;
import grahics.3d;
import professional.graphics.3d;
import physlib.linear_algebra;
import boost.XML;
import 3rd_party.image_filtering;Как ученик на вторую неделю после начала обучения может установить библиотеку графического интерфейса и работы с базами данных? Различные библиотеки и системы собираются по разному. Различные библиотеки могут быть плохо совместимыми. Десяток несовметимых пакетных менеджеров — это не решение. Нужно сделать простым выполнение простых задач
> download gui_xyz
> install gui_xyzИли эквивалетным способом, например в IDE:
import gui_xyz; //в кодеМое видение современного C++ (как обычно):
Современный C++ это не C, Java, C++98 и не тот язык, на которым вы программировали 10 лет назад. Инерция — враг хорошего кода. Преподаватели, оправдывая неиспользование современных стандартов, говорят, что "мы так не делаем", "это не вставить в мою учебную программу", "может быть через 5 лет". У студентов появляется большее доверие к интернету, чем к преподавателям. Некоторые считают, что они умнее преподавателей, и иногда они правы. У меня стабильно каждый год на курсе были студенты, абсолютно убежденные, что они умнее меня в программировании. В этих частных случаях, я обоснованно уверен, что оне не правы [смех в зале].
Для реализации этого 2 года назад был открыт проект C++ Core Guidelines. Он дает конкретные ответы на вопросы. У него много много участников, включая Microsoft и Red Hat.
Не отделяйте примеры от объяснения. 5 страниц голой теории это лишняя трата. Давайте примеры и объяснения к ним. Без объяснения люди не обобщают. Они просто копипастят и сами изобретают трактовку, причем иногда очень странную.
Всегда объясняйте причины. Например:
//1
int max = v.size();
for(int i = 0; i < max; ++i)
//2
for (auto x : v)Почему 2 лучше чем 1? Пример 2 явно показывает намерение, v может быть изменен без переписывания цикла, и менее подвержен ошибкам. Следует заметить, что 1 предоставляет более гибкие возможности. Но ведь goto еще более универсален, и поэтому мы избегаем его.
[I.4 означает пункт из Core Guidelines]
void blink_led1(int time_to_blink) //Плохо - неясный тип
void blink_led2(milliseconds time_to_blink) //Хорошо
void use()
{
blink_led2(1500); //Ошибка: какая единица измерения?
blink_led2(1500ms);
blink_led2(1500s); //Ошибка: неверная единица измерения
}[Здесь milliseconds какой-то простой тип не из библиотеки Chrono, поэтому последняя строчка приводит к ошибке. Ниже по тексту описано обобщение типа для единицы измерения, взятого из Chrono. Если интересно, можете почитать мое описание этой библиотеки]
template
void blink_led(duration time_to_blink)
{
auto ms_to_blink = duration_cast(time_to_blink);
}
void use()
{
blink_led(2s);
blink_led(1500ms);
} Error_code err; //неинициализировано: потенциальная проблема
//...
Channel ch = Channel::open(s, &err); //out-параметр: потенциальная проблема
if(err) { ... }
Лучше:
auto [ch, err] = Channel::open(s) //structured binding
if(err) ...А должен ли этот код использовать возврат двух параметров?
auto ch = Channel::open(s);Лучше? Да, если неуспешное открытие было предусмотрено в программе.
Слово "умный" в контексте использования C++ — ругательное. Найдите баг:
istream& init_io()
{
if(argc > 1)
return *new istream { argv[1], "r" };
else
return cin;
}//Плохо
auto x = m * v1 + vv //Перемножение m с v1 и прибавление vv
//Хорошо
void stable_sort(Sortable& c)
//cортирует "c" согласно порядку, задаваемым "<"
//сохраняет исходный порядок равных элементов (определяемыми "==")
{
//...несколько строк нетривиального кода
}Я рекомендую вам отправиться на github и почитать раздел Philosophy rules, содержащий основные концепции.
Моя цель очень проста. Мы можем писать типо- и ресурсобезопасный код без утечек, повреждения памяти, сборщика мусора, ограничений в выразительности, ухудшения производительности.
Сейчас разрабатываются 2 открытых проекта: анализатор, для проверки провил Core Guidelines, и библиотека GSL — guidelines support library (реализация от Microsoft).

Нет, я расказал далеко не все про обучение. Лишь едва царапнул поверхность.
[У Страуструпа есть сверхспособность отвечать по 5 минут на простые вопросы, поэтому я очень сильно сократил его ответы да и сами вопросы тоже]
Core Guidelines слишком всеобъемлющие. как учить?
Не нужно читать всё. Прочитать введение, затем раздел с философией. Не нужно искать правило, правило само найдет вас.
Нужны ли стандартной библиотеке нужны простые функции? Например random [я полагаю, что имеется в виду функция без необходимости установки начального значения и возможностью задания закона распределения]?
Да, нужны.
Вы говорили про 3 дистрибутива C++. Кто должен этим заниматься?
Вряд этим будет заниматься комитет, поэтому, я думаю, это нужно делать силами сообщества. Это будет проще с развитием единого пакетного менеджера и модулей
Моя дочь учится в колледже и мы вместе делали проект термостата. Так вот, для того, чтобы получить температуру и отобразить на экране, потребовался целый семестр изучения C++. Что вы думаете по этому поводу?
Да, есть такая проблема. С модулями будет лучше.
Нужно ли преподавать программирование как общий предмет, так же как математику
Я не компетентен в этом вопросе.
mmatrosov: вы говорили о том, что в обучении нужно пользоваться билиотеками. Не будет ли такого, что новое поколение программистов не будет знать основ?
Зависит от цели. Я учу студентов как реализовать вектор, они должны знать об указателях, но не каждому нужно реализовывать lock-free код.
|
Метки: author Fil c++ c++17 cppcon изучение программирования страуструп |
Продолжение поста от школьников. Как Хабрахабр смог изменить нашу судьбу? |


|
Метки: author Noobariouse разработка под android разработка мобильных приложений разработка игр программирование java android google play indie издание игр |
[Из песочницы] Необразованная молодёжь |



Конечно, какие-то полезные знания они дали, но по эффективности знания/время — в глубоком дне.— понравившийся комментарий.
|
Метки: author aleshqqa1337 учебный процесс в it обучение обучение программистов молодые специалисты вуз колледжи |
[Перевод] Как создавали систему чувств ИИ в Thief: The Dark Project |
|
Метки: author PatientZero разработка игр система чувств искусственный интеллект конечные автоматы thief half-life |
Security Week 39: Вечер восхитительных историй о том, как бизнесу наплевать на безопасность |
 В этот раз новости из нашего дайджеста содержат самоочевидную мораль: многим компаниям плевать на безопасность их клиентов, пока это не наносит прямой финансовый ущерб. К счастью, это касается не всех компаний, но эта неделя выдалась особенно богатой на подобные постыдные истории.
В этот раз новости из нашего дайджеста содержат самоочевидную мораль: многим компаниям плевать на безопасность их клиентов, пока это не наносит прямой финансовый ущерб. К счастью, это касается не всех компаний, но эта неделя выдалась особенно богатой на подобные постыдные истории. Соответственно, мобильных приложений для трейдинга выпущено очень много. Понятно, что их вендоры должны тщательно выстраивать систему безопасности, даже в ущерб удобству – деньги на кону большие. Но вот на поверку все оказалось не так. Исследователи из IOActive взяли 21 приложение из топа (как для iOS, так и для Android) и нашли там много веселых дыр. Очень много. Вплоть до хранения паролей открытым текстом и передачи данных по HTTP.
Соответственно, мобильных приложений для трейдинга выпущено очень много. Понятно, что их вендоры должны тщательно выстраивать систему безопасности, даже в ущерб удобству – деньги на кону большие. Но вот на поверку все оказалось не так. Исследователи из IOActive взяли 21 приложение из топа (как для iOS, так и для Android) и нашли там много веселых дыр. Очень много. Вплоть до хранения паролей открытым текстом и передачи данных по HTTP. По данным Guardian, контору взломали еще осенью 2016 года, а обнаружили это только в марте. Скорее всего, атака шла через учетные данные админа почтового сервера. Никакой двухфакторной аутентификации не было – пароль то ли отбрутфорсили, то ли выманили из админа каким-либо методом социальной инженерии.
По данным Guardian, контору взломали еще осенью 2016 года, а обнаружили это только в марте. Скорее всего, атака шла через учетные данные админа почтового сервера. Никакой двухфакторной аутентификации не было – пароль то ли отбрутфорсили, то ли выманили из админа каким-либо методом социальной инженерии. 
|
Метки: author Kaspersky_Lab информационная безопасность блог компании «лаборатория касперского» klsw deloitte macos high sierra keychain |
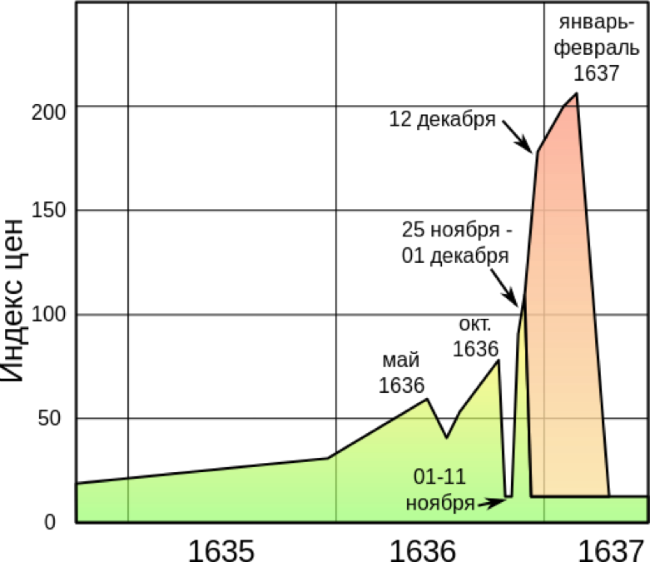
[Перевод] «Тюльпаномания»: биржевой пузырь, которого не было |


|
Метки: author itinvest блог компании itinvest тюльпаномания финансы история биржа фондовый рынок спекуляции |
Интернет там, где его нет, или Стационарная связь на базе 3G-LTE |

Задумал я сделать интернет у себя на даче, в глуши. И наконец возможность срослась с желанием! Проблем в моей глуши две: дураки частые перебои с электроэнергией (в зависимости от погоды может ещё отключиться АТС) и плохая мобильная связь. Сигнал ловится не везде, а где ловится, там нестабилен. Добавляет сложности и оцинкованная крыша дома, экранирующая радиоволны. Возможности современного оборудования и корректировка запросов сужали и улучшали подходящие свойства, что привело меня к мысли создать максимально работоспособный узел сети. Я расскажу о том, как пытался поймать LTE-сигнал, с описанием оборудования и возможными проблемами.
В моей глуши нормально ловится только МТС, в связи с чем был выбран именно этот оператор. Качество покрытия я определял с помощью https://4g-faq.ru/karty-pokrytiya/. На этой карте удобно выбирать режимы сети, а также хорошо видно ориентировочное расположение вышек стандартов 3G и LTE.
Направление установки антенн выбиралось примерно так:

Коэффициент усиления антенны я выбирал в зависимости от расстояния до населённых пунктов. Подходящее направление сигнала — с помощью мобильного приложения Netmonitor. Для этого пришлось поездить к ближайшим вышкам. Netmonitor — приложение бесплатное, самое удобное и простое в управлении, аналоги меня не впечатлили. Также в нём сохраняются истории замеров, поэтому, когда я вернулся на «площадку», было удобно выбирать направление.

Для начала необходимо понять, какой режим сети вас интересует. Диапазон частот у 3G и LTE разный, и, чтобы принимать их сигналы, необходимо выбрать антенны или облучатели, в зависимости от конфигурации, с соответствующей частотностью. Конечно, можно взять антенны с частотным диапазоном, который захватывает оба стандарта, но в таком случае выходной сигнал будет немного хуже (опять же, в зависимости от количества переходников, длины кабелей и их свойств; эти характеристики влияют на все конфигурации данной системы, в том числе это касается и затухания сигнала).
Необходимо заранее проверить на площадке уровни сигналов мобильных сетей. Как уже говорил, я выбрал МТС, потому что здесь он ловится всегда и у МТС довольно много вышек (по сравнению с другими операторами) с разными режимами сетей, в том числе и LTE, который, надеюсь, в будущем проапгрейдят до 5G. Так что своё оборудование я подобрал «на вырост».
Лишний раз переплачивать мне не хотелось. И система с легко заменяемыми компонентами выходила дешевле, чем спутниковый интернет и предложения от фирм, которые делают готовые наборы. Вариант со «свистком» отпал на первый день подбора оборудования: такая система крайне нестабильна. Ещё я планировал поставить систему на долгосрочную работу, но этот вариант тоже не подходил, поскольку компоненты корпуса при длительной работе перегревались и выводили «свисток» из строя до его остывания. В большинстве случаев данная проблема решалась пришаманенным кулером, но нестабильность подключения и потери пакетов не склонили меня к этому варианту. По той же причине я отказался от мысли о тандеме «свисток» + роутер (с поддержкой «свистка»).
Изначально я планировал использовать «восьмёрку», она же антенна Харченко, но, учитывая зону покрытия и расстояние до ближайших населённых пунктов, есть возможность успешно ловить 3G-LTE на дистанциях, превышающих возможности «восьмёрки». Такой диапазон частот соответствует этим сетям и взят на случай непогоды, когда осадки существенно ухудшают качество сигнала. Меня удивил тот факт, что 4G-LTE работают в трёх диапазонах: около 800, около 1600 и около 2500.
Частотные диапазоны LTE-сетей у различных провайдеров:
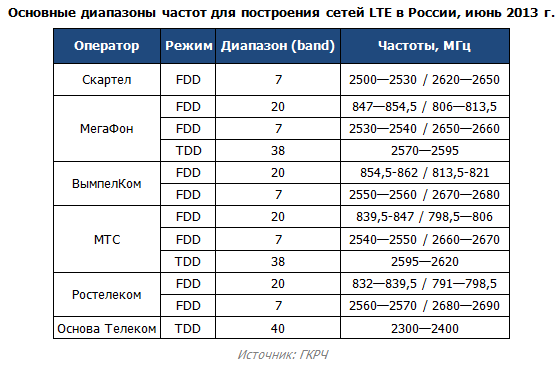
Здесь разобраны частотные диапазоны 3G-сетей:
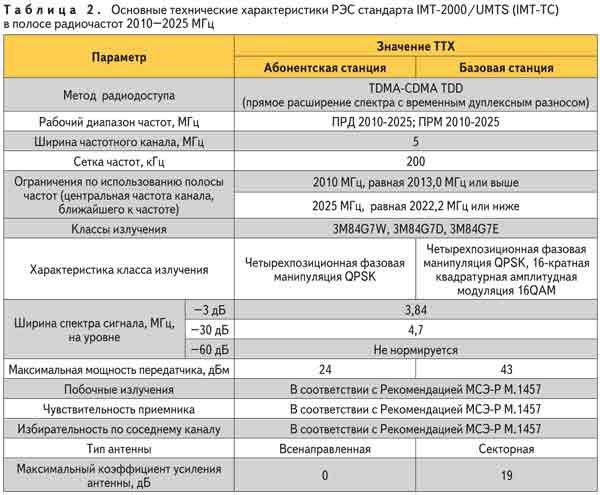
Офсет, как мне кажется, гораздо лучше, так что я сделал неправильный выбор, особенно учитывая свои возможности: но LTE я ловил на «волнушку», и проблема заключается в высоте. Для начала я долго и усердно выбирал оборудование и возможные связки, в том числе и различные типы антенн. В итоге мне понравились два варианта:
Коэффициент усиления у обоих наборов — от 24 до 28 dbi. Остановился я на втором: у него гораздо меньше проблем с ловлей сигнала от телефонных вышек. Кабель взял с пониженными потерями и затуханиями, чтобы сигнал на приём был стабильнее.
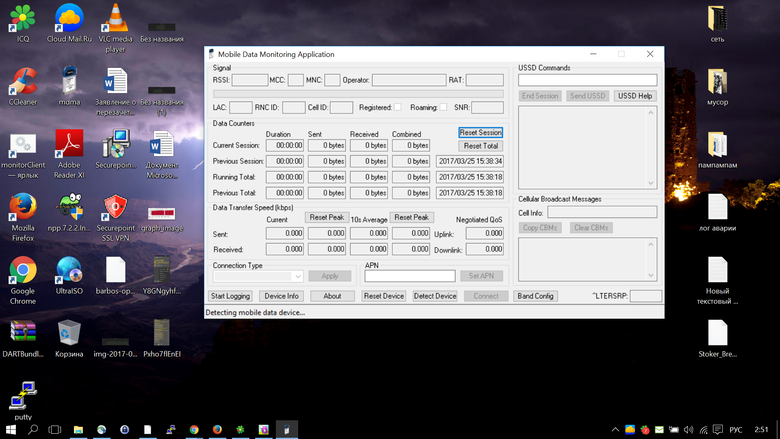
На месте я выставлял антенну с помощью Google Maps и программы MDMA. Настольная версия MDMA позволяет проверить уровень сигнала на принимающем устройстве (модуль модема в роутере). С этой программой обращаться не так просто, но если вы разобрались с Netmonitor, то у вас она вряд ли вызовет затруднения. В конце концов, есть очень неплохие рекомендации и понятные инструкции. Обратите внимание, что нужно подключение через USB «папа-папа».
Для проверки направления антенны достаточно собрать всю систему, то есть подключить антенну к роутеру, а роутер — к компьютеру, но только через USB-переходник. После чего запускаем MDMA и выбираем направление антенны.
MDMA:
Выбор конкретной модели роутера был обусловлен вышеперечисленными требованиями, но список был ограничен этими моделями:
Разброс цен — от 4 до 9 тысяч рублей за единицу. Я выбрал Huawei B315S из-за дешевизны и возможности создания IP-телефонии и подключения до 32 устройств. А ещё он может ловить LTE.
Роутер B315s-22:




Huawei B315S изначально был привязан к Yota, но я выполнил отвязку
Поскольку, кроме МТС, у меня ничего не ловилось, то и смысла усиливать то, что не ловится, не было. Но ситуация сложилась так, что мне пришлось купить роутер Yota, привязанный к сим-картам одноименного оператора (другие не подходили, проверял). Для отвязки каждого роутера свой способ, информацию легко найти в интернете, в том числе и на 4pda.ru. Полное название модели по классификации — Huawei LTE CPE B315s-22, так что, если вам необходимы технические характеристики, ищите по названию в интернете.
Оборудование подключается почти так же, как и обычный роутер. Разница в том, что необходимо подключить внешние антенны, которые будут ловить сигнал. Чтобы у вас появился интернет, не требуется никакого стороннего ПО, но, как я уже указывал, оно необходимо для определения направления антенны. На рынке тысячи вариантов разъёмов и коннекторов, и вам нужны те, которые подходят непосредственно для вашего оборудования. В моем случае это коннекторы на кабелях SMA со стороны роутера и TS9 со стороны антенн. К счастью, оборудование я подобрал таким образом, что можно прямо из коробки провести первичную настройку и начать пользоваться интернетом. Никаких танцев с бубнами не потребовалось, только в настройках через веб-интерфейс поменял пароли и режим рабочего сигнала.
Две антенны работают в тандеме по технологии MIMO, волновой канал с 24—28 dbi. Два кабеля с пониженными потерями длиной 10 метров, стандарт 5D-FB. Соответственно, придётся либо заказать переходники, либо заменить разъёмы подходящими, с одной стороны — для антенн, с другой — для подключения роутера.
Результат трудов:

Сразу хочу дать рекомендации на основании своего опыта:
Считаю, что я молодец: всё работает, скорости хватает на комфортный онлайн-просмотр фильмов. Ещё есть куда расти: на основе этой системы я планирую создать зачатки умного дома. Сейчас интернет ловится только на 3G, поэтому нужно кое-что доделать: увеличить высоту мачты, перепрошить модуль модема для возможности подключения безлимитного интернета, купить тариф для планшетов типа «Безлимитище» или аналог.
Тем, кто пойдёт по моим стопам, рекомендую сразу брать безлимитный тариф, потому что у меня всего 30 Гб трафика. Сети 4G хоть и ловятся оборудованием, но очень плохо. Гипотез две: либо я не принял в расчёт рельеф, либо нашёл антенны, которые не подходят по диапазону рабочих частот. Полагаю, что виноваты антенны: продавец заявляет, что на них написан ошибочный частотный диапазон, но, скорее всего, это ложь, потому что сети 3G ловятся идеально, а именно их диапазон указан на антеннах.
|
Метки: author asterrios стандарты связи беспроводные технологии блог компании mail.ru group мобильный интернет lte |
Страницы 404 |




































|
Метки: author MagisterLudi интерфейсы графический дизайн веб-дизайн usability блог компании edison 404 error |
Чеклист: как выбрать модель системы управления правами доступа и не прогадать |
|
Метки: author SolarSecurity информационная безопасность блог компании solar security idm iga itsm права доступа |
[Перевод] Selenium и Node.js: пишем надёжные браузерные тесты |

driver.sleep — худший враг разработчика тестов. Однако, несмотря на это, его используют повсюду. Возможно, это так из-за краткости документации для Node-версии Selenium, и из-за того, что она покрывает лишь синтаксис API. Ей недостаёт примеров из реальной жизни.driver.sleep, рассмотрим пример. Предположим, у нас есть анимированная панель, которая, в ходе появления на экране, меняет размеры и положение. Взглянем на неё.
Close меняется вместе с панелью: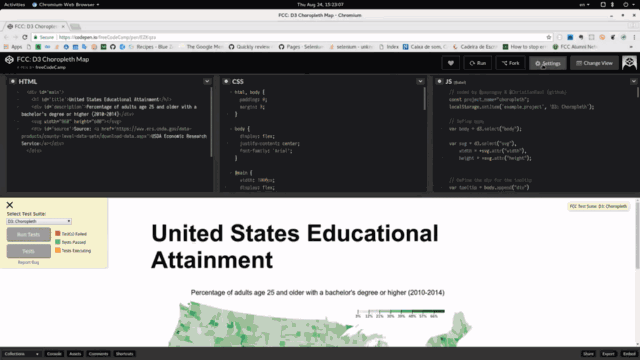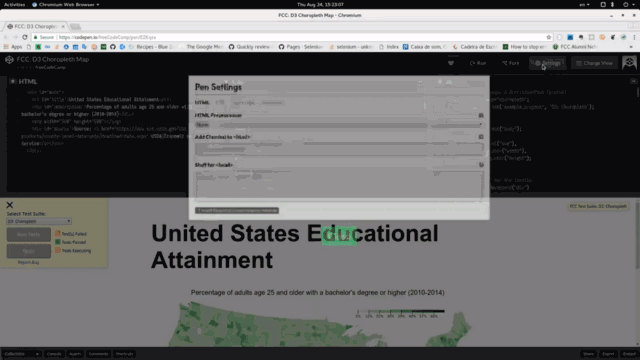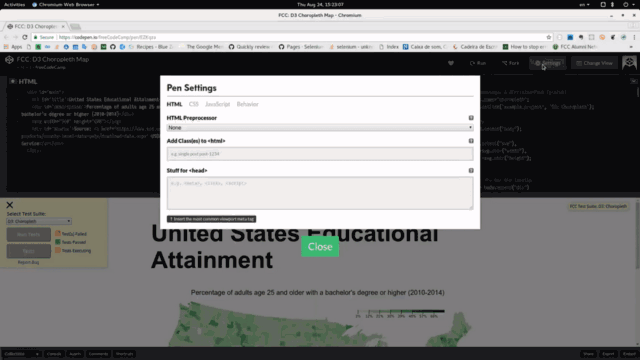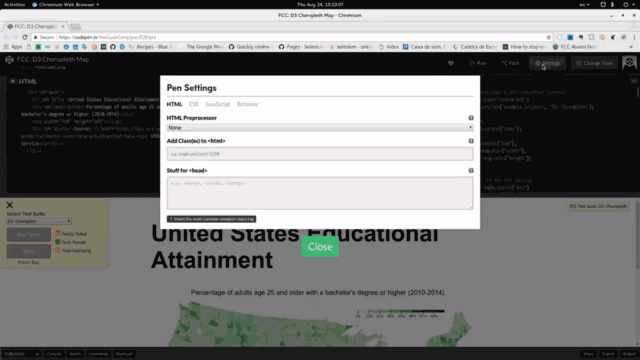
Close в процессе анимации, вы, вполне возможно, просто по ней не попадёте.System.InvalidOperationException : Element is not clickable at point (326, 792.5)driver.sleep(1000) для того, чтобы панель пришла в нормальное состояние». Похоже, задача решена? Однако, не всё так просто.driver.sleep(1000) выполняет именно то, чего от неё можно ожидать. Она останавливает выполнение теста на 1000 миллисекунд и позволяет браузеру продолжать работать: загружать страницы, размещать на них фрагменты документов, анимировать или плавно выводить на экран элементы, или делать что угодно другое.driver.sleep(1000) обычно помогает достичь того, ради чего её вызывают. Итак, почему бы ей не воспользоваться?driver.sleep не всегда работоспособны? Другими словами, почему это недетерминированный механизм?driver.sleep(1000) даст сбой.driver.sleep. Затем, полагаясь на удачу, программист будет надеяться, что это улучшение сработает во всех возможных сценариях тестирования, что оно поможет справиться с различными нагрузками на систему, сгладит отличия в системах визуализации различных браузеров, и так далее. Но перед нами всё ещё недетерминированный подход. Поэтому так поступать нельзя.driver.sleep — это, во многих ситуациях, вредная команда, подумайте вот о чём. Без driver.sleep тесты будут работать гораздо быстрее. Например, мы надеемся, что анимация из нашего примера займёт всего 800 миллисекунд. В реальном тестовом наборе подобное предположение приведёт к использованию чего-то вроде driver.sleep(2000), опять же, в надежде на то, что 2-х секунд хватит на то, чтобы анимация успешно завершилась, какими бы ни были дополнительные факторы, влияющие на браузер и страницу.driver.sleep, теперь выполняется меньше пятнадцати секунд.driver.sleep и преобразования тестов в надёжные, полностью детерминированные конструкции.my-button был добавлен в DOM после загрузки страницы:// Код инициализации Selenium опущен для ясности
// Загрузка страницы.
driver.get('https:/foobar.baz');
// Найти элемент.
const button = driver.findElement(By.id('my-button'));
button.click();driver.findElement ожидает, что элемент уже присутствует в DOM. Он выдаст ошибку, если элемент невозможно немедленно найти. В данном случае «немедленно», из-за вызова driver.get, означает: «после того, как завершится загрузка страницы».driver.findElement может быть удобен, если вы уверены, что элемент уже имеется в DOM.driver.get('https:/foobar.baz');
// Страница загружается, засыпаем на несколько секунд
driver.sleep(3000);
// Надеемся, что три секунды достаточно для того, чтобы по прошествии этого времени элемент можно было бы найти на странице.
const button = driver.findElement(By.id('my-button'));
button.click();driver.wait для того, чтобы ожидать того момента, когда элемент появится в DOM, не более двадцати секунд.const button = driver.wait(
until.elementLocated(By.id('my-button')),
20000
);
button.click();driver.wait завершит работу за одну секунду. Он не будет ждать все двадцать секунд, которые ему отведены.driver.sleep, который всегда будет ждать всё заданное время.const button = driver.wait(
until.elementLocated(By.id('my-button')),
20000
)
.then(element => {
return driver.wait(
until.elementIsVisible(element),
20000
);
});
button.click();driver.sleep. Рассмотрим ещё несколько примеров, которые помогут обойтись без driver.sleep в более сложных обстоятельствах.until JavaScript API для Selenium уже имеет некоторое количество вспомогательных методов, которые можно использовать с driver.wait. Кроме того, можно организовать ожидание до тех пор, пока элемент не будет больше существовать, ожидать появления элемента, содержащего конкретный текст, ожидать показа уведомления, или использовать много других условий.driver.wait можно предоставить функцию, которая возвращает true или false.opacity некоего элемента стало бы равным единице:// Получить элемент.
const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
);
// driver.wait всего лишь нужна функция, которая возвращает true или false.
driver.wait(() => {
return element.getCssValue('opacity')
.then(opacity => opacity === '1');
});const waitForOpacity = function(element) {
return driver.wait(element => element.getCssValue('opacity')
.then(opacity => opacity === '1');
);
};driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);
// Вот незадача. Переменная element может быть true или false, это не элемент, у которого есть метод click().
element.click();const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity)
.then(element => {
// Так тоже не пойдёт, element и здесь является логическим значением.
element.click();
}); const waitForOpacity = function(element) {
return driver.wait(element => element.getCssValue('opacity')
.then(opacity => {
if (opacity === '1') {
return element;
} else {
return false;
});
);
};false. Такой шаблон подходит для повторного использования, его можно задействовать при написании собственных условий.driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity)
.then(element => element.click());const element = driver.wait(
until.elementLocated(By.id('some-id')),
20000
)
.then(waitForOpacity);
element.click();until, вы могли заметить методы вроде elementIsNotVisible или elementIsDisabled или на не столь очевидный метод stalenessOf.// Элемент уже добавлен в DOM, отсюда сразу же произойдёт возврат.
const desiredElement = driver.wait(
until.elementLocated(By.id('some-id')),
20000
);
// Но с элементом нельзя взаимодействовать до тех пор, пока панель с индикатором загрузки
// не исчезнет.
driver.wait(
until.elementIsNotVisible(By.id('loading-panel')),
20000
);
// Панель с информацией о загрузке больше не видна, с элементом теперь можно взаимодействовать, не опасаясь ошибок.
desiredElement.click();stalenessOf особенно полезен. Он ожидает, пока элемент не будет удалён из DOM, что, кроме прочих причин, может произойти из-за обновления страницы.iframe для продолжения работы:let iframeElem = driver.wait(
until.elementLocated(By.className('result-iframe')),
20000
);
// Выполняем некое действие, которое приводит к обновлению iframe.
someElement.click();
// Ожидаем пока предыдущий iframe перестанет существовать:
driver.wait(
until.stalenessOf(iframeElem),
20000
);
// Переключаемся на новый iframe.
driver.wait(
until.ableToSwitchToFrame(By.className('result-iframe')),
20000
);
// Всё, что будет написано здесь, относится уже к новому iframe.sleep. Полагаться на метод sleep — значит основываться на произвольных предположениях. А это, рано или поздно, приводит к сбоям.|
Метки: author ru_vds node.js javascript блог компании ruvds.com selenium тестирование |






